W&B Sweeps 를 사용하여 하이퍼파라미터 검색을 자동화하고 풍부하고 인터랙티브한 experiment 추적을 시각화하세요. Bayesian, 그리드 검색 및 random과 같은 인기 있는 검색 방법 중에서 선택하여 하이퍼파라미터 공간을 검색합니다. 하나 이상의 시스템에서 스윕을 확장하고 병렬화합니다.
터미널에서 Ctrl+C를 눌러 현재 run을 중지합니다. 다시 누르면 에이전트가 종료됩니다.
2 - Add W&B (wandb) to your code
Python 코드 스크립트 또는 Jupyter 노트북 에 W&B를 추가하세요.
스크립트 또는 Jupyter Notebook에 W&B Python SDK를 추가하는 방법은 다양합니다. 아래에는 W&B Python SDK를 사용자 정의 코드에 통합하는 “모범 사례” 예제가 나와 있습니다.
원본 트레이닝 스크립트
다음 코드가 Python 스크립트에 있다고 가정합니다. 일반적인 트레이닝 루프를 모방하는 main이라는 함수를 정의합니다. 각 에포크마다 트레이닝 및 검증 데이터 세트에서 정확도와 손실이 계산됩니다. 이 예제의 목적을 위해 해당 값은 임의로 생성됩니다.
하이퍼파라미터 값을 저장하는 config라는 사전을 정의했습니다. 셀의 끝에서 main 함수를 호출하여 모의 트레이닝 코드를 실행합니다.
import random
import numpy as np
deftrain_one_epoch(epoch, lr, bs):
acc =0.25+ ((epoch /30) + (random.random() /10))
loss =0.2+ (1- ((epoch -1) /10+ random.random() /5))
return acc, loss
defevaluate_one_epoch(epoch):
acc =0.1+ ((epoch /20) + (random.random() /10))
loss =0.25+ (1- ((epoch -1) /10+ random.random() /6))
return acc, loss
# config 변수, 하이퍼파라미터 값 포함config = {"lr": 0.0001, "bs": 16, "epochs": 5}
defmain():
# 하드 코딩된 값을 정의하는 대신# `wandb.config`에서 값을 정의합니다. lr = config["lr"]
bs = config["bs"]
epochs = config["epochs"]
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
print("epoch: ", epoch)
print("training accuracy:", train_acc, "training loss:", train_loss)
print("validation accuracy:", val_acc, "training loss:", val_loss)
W&B Python SDK를 사용한 트레이닝 스크립트
다음 코드 예제에서는 W&B Python SDK를 코드에 추가하는 방법을 보여줍니다. CLI에서 W&B Sweep 작업을 시작하는 경우 CLI 탭을 살펴보십시오. Jupyter Notebook 또는 Python 스크립트 내에서 W&B Sweep 작업을 시작하는 경우 Python SDK 탭을 살펴보십시오.
W&B Sweep을 생성하기 위해 코드 예제에 다음을 추가했습니다.
Weights & Biases Python SDK를 가져옵니다.
키-값 쌍이 스윕 구성을 정의하는 사전 오브젝트를 생성합니다. 다음 예제에서는 각 스윕 중에 배치 크기(batch_size), 에포크(epochs) 및 학습률(lr) 하이퍼파라미터가 다양합니다. 스윕 구성을 생성하는 방법에 대한 자세한 내용은 스윕 구성 정의를 참조하십시오.
스윕 구성 사전을 wandb.sweep에 전달합니다. 그러면 스윕이 초기화됩니다. 스윕 ID(sweep_id)가 반환됩니다. 스윕을 초기화하는 방법에 대한 자세한 내용은 스윕 초기화를 참조하십시오.
(선택 사항) 하드 코딩된 값을 정의하는 대신 wandb.config에서 값을 정의합니다.
wandb.log를 사용하여 최적화하려는 메트릭을 기록합니다. 구성에 정의된 메트릭을 기록해야 합니다. 구성 사전(이 예제에서는 sweep_configuration) 내에서 val_acc 값을 최대화하도록 스윕을 정의했습니다.
wandb.agent API 호출로 스윕을 시작합니다. 스윕 ID, 스윕이 실행할 함수의 이름(function=main)을 제공하고 시도할 최대 run 수를 4개(count=4)로 설정합니다. W&B Sweep 시작 방법에 대한 자세한 내용은 스윕 에이전트 시작을 참조하십시오.
import wandb
import numpy as np
import random
# 스윕 구성 정의sweep_configuration = {
"method": "random",
"name": "sweep",
"metric": {"goal": "maximize", "name": "val_acc"},
"parameters": {
"batch_size": {"values": [16, 32, 64]},
"epochs": {"values": [5, 10, 15]},
"lr": {"max": 0.1, "min": 0.0001},
},
}
# 구성을 전달하여 스윕을 초기화합니다.# (선택 사항) 프로젝트 이름을 제공합니다.sweep_id = wandb.sweep(sweep=sweep_configuration, project="my-first-sweep")
# `wandb.config`에서 하이퍼파라미터# 값을 가져와서 모델을 트레이닝하고# 메트릭을 반환하는 트레이닝 함수를 정의합니다.deftrain_one_epoch(epoch, lr, bs):
acc =0.25+ ((epoch /30) + (random.random() /10))
loss =0.2+ (1- ((epoch -1) /10+ random.random() /5))
return acc, loss
defevaluate_one_epoch(epoch):
acc =0.1+ ((epoch /20) + (random.random() /10))
loss =0.25+ (1- ((epoch -1) /10+ random.random() /6))
return acc, loss
defmain():
run = wandb.init()
# 하드 코딩된 값을 정의하는 대신# `wandb.config`에서 값을 정의합니다. lr = wandb.config.lr
bs = wandb.config.batch_size
epochs = wandb.config.epochs
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb.log(
{
"epoch": epoch,
"train_acc": train_acc,
"train_loss": train_loss,
"val_acc": val_acc,
"val_loss": val_loss,
}
)
# 스윕 작업을 시작합니다.wandb.agent(sweep_id, function=main, count=4)
W&B Sweep을 생성하려면 먼저 YAML 구성 파일을 생성합니다. 구성 파일에는 스윕이 탐색할 하이퍼파라미터가 포함되어 있습니다. 다음 예제에서는 각 스윕 중에 배치 크기(batch_size), 에포크(epochs) 및 학습률(lr) 하이퍼파라미터가 다양합니다.
최상위 parameters 키 내에는 learning_rate, batch_size, epoch 및 optimizer 키가 중첩되어 있습니다. 중첩된 각 키에 대해 하나 이상의 값, 분포, 확률 등을 제공할 수 있습니다. 자세한 내용은 스윕 구성 옵션의 파라미터 섹션을 참조하십시오.
이중 중첩 파라미터
스윕 구성은 중첩된 파라미터를 지원합니다. 중첩된 파라미터를 구분하려면 최상위 파라미터 이름 아래에 추가 parameters 키를 사용하십시오. 스윕 구성은 다단계 중첩을 지원합니다.
베이지안 또는 랜덤 하이퍼파라미터 검색을 사용하는 경우 랜덤 변수에 대한 확률 분포를 지정하십시오. 각 하이퍼파라미터에 대해:
스윕 구성에 최상위 parameters 키를 만듭니다.
parameters 키 내에서 다음을 중첩합니다.
최적화하려는 하이퍼파라미터의 이름을 지정합니다.
distribution 키에 사용할 분포를 지정합니다. 하이퍼파라미터 이름 아래에 distribution 키-값 쌍을 중첩합니다.
탐색할 하나 이상의 값을 지정합니다. 값은 분포 키와 일치해야 합니다.
(선택 사항) 최상위 파라미터 이름 아래에 추가 parameters 키를 사용하여 중첩된 파라미터를 구분합니다.
스윕 구성에 정의된 중첩된 파라미터는 W&B run 구성에 지정된 키를 덮어씁니다.
예를 들어, train.py Python 스크립트에서 다음 구성으로 W&B run을 초기화한다고 가정합니다 (1-2행 참조). 다음으로 sweep_configuration이라는 dictionary에 스윕 구성을 정의합니다 (4-13행 참조). 그런 다음 스윕 구성 dictionary를 wandb.sweep에 전달하여 스윕 구성을 초기화합니다 (16행 참조).
metric 최상위 스윕 구성 키를 사용하여 최적화할 이름, 목표 및 대상 메트릭을 지정합니다.
키
설명
name
최적화할 메트릭의 이름입니다.
goal
minimize 또는 maximize (기본값은 minimize)입니다.
target
최적화하려는 메트릭의 목표 값입니다. 스윕은 run이 지정한 목표 값에 도달하면 새 run을 만들지 않습니다. run을 실행 중인 활성 에이전트는 (run이 목표에 도달하면) 에이전트가 새 run 생성을 중단하기 전에 run이 완료될 때까지 기다립니다.
parameters
YAML 파일 또는 Python 스크립트에서 parameters를 최상위 키로 지정합니다. parameters 키 내에서 최적화하려는 하이퍼파라미터의 이름을 제공합니다. 일반적인 하이퍼파라미터에는 학습률, 배치 크기, 에포크, 옵티마이저 등이 있습니다. 스윕 구성에서 정의하는 각 하이퍼파라미터에 대해 하나 이상의 검색 제약 조건을 지정합니다.
다음 표는 지원되는 하이퍼파라미터 검색 제약 조건을 보여줍니다. 하이퍼파라미터 및 유스 케이스에 따라 아래 검색 제약 조건 중 하나를 사용하여 스윕 에이전트에게 검색하거나 사용할 위치 (분포의 경우) 또는 내용 (value, values 등)을 알려줍니다.
검색 제약 조건
설명
values
이 하이퍼파라미터에 대한 모든 유효한 값을 지정합니다. grid와 호환됩니다.
value
이 하이퍼파라미터에 대한 단일 유효한 값을 지정합니다. grid와 호환됩니다.
distribution
확률 분포를 지정합니다. 기본값에 대한 정보는 이 표 다음에 나오는 참고 사항을 참조하십시오.
probabilities
random을 사용할 때 values의 각 요소를 선택할 확률을 지정합니다.
min, max
(int 또는 float) 최대값 및 최소값입니다. int인 경우 int_uniform 분포된 하이퍼파라미터에 사용됩니다. float인 경우 uniform 분포된 하이퍼파라미터에 사용됩니다.
mu
(float) normal 또는 lognormal 분포된 하이퍼파라미터에 대한 평균 파라미터입니다.
sigma
(float) normal 또는 lognormal 분포된 하이퍼파라미터에 대한 표준 편차 파라미터입니다.
method 키를 사용하여 하이퍼파라미터 검색 전략을 지정합니다. 선택할 수 있는 세 가지 하이퍼파라미터 검색 전략이 있습니다: 그리드, 랜덤, 베이지안 탐색.
그리드 검색
하이퍼파라미터 값의 모든 조합을 반복합니다. 그리드 검색은 각 반복에서 사용할 하이퍼파라미터 값 집합에 대해 정보에 입각하지 않은 결정을 내립니다. 그리드 검색은 계산 비용이 많이 들 수 있습니다.
그리드 검색은 연속 검색 공간 내에서 검색하는 경우 영원히 실행됩니다.
랜덤 검색
각 반복에서 분포에 따라 임의의, 정보에 입각하지 않은 하이퍼파라미터 값 집합을 선택합니다. 랜덤 검색은 커맨드라인, Python 스크립트 또는 W&B 앱 UI 내에서 프로세스를 중지하지 않는 한 영원히 실행됩니다.
랜덤 (method: random) 검색을 선택하는 경우 메트릭 키를 사용하여 분포 공간을 지정합니다.
베이지안 탐색
랜덤 및 그리드 검색과 달리 베이지안 모델은 정보에 입각한 결정을 내립니다. 베이지안 최적화는 확률 모델을 사용하여 목적 함수를 평가하기 전에 대리 함수에서 값을 테스트하는 반복적인 프로세스를 통해 사용할 값을 결정합니다. 베이지안 탐색은 작은 수의 연속 파라미터에 적합하지만 확장성이 떨어집니다. 베이지안 탐색에 대한 자세한 내용은 Bayesian Optimization Primer 논문을 참조하십시오.
베이지안 탐색은 커맨드라인, Python 스크립트 또는 W&B 앱 UI 내에서 프로세스를 중지하지 않는 한 영원히 실행됩니다.
랜덤 및 베이지안 탐색을 위한 분포 옵션
parameter 키 내에서 하이퍼파라미터의 이름을 중첩합니다. 다음으로 distribution 키를 지정하고 값에 대한 분포를 지정합니다.
다음 표는 W&B가 지원하는 분포를 나열합니다.
distribution 키 값
설명
constant
상수 분포. 사용할 상수 값 (value)을 지정해야 합니다.
categorical
범주형 분포. 이 하이퍼파라미터에 대한 모든 유효한 값 (values)을 지정해야 합니다.
int_uniform
정수에 대한 이산 균등 분포. max 및 min을 정수로 지정해야 합니다.
uniform
연속 균등 분포. max 및 min을 부동 소수점으로 지정해야 합니다.
q_uniform
양자화된 균등 분포. round(X / q) * q를 반환합니다. 여기서 X는 균등 분포입니다. q의 기본값은 1입니다.
log_uniform
로그 균등 분포. exp(min)과 exp(max) 사이의 값 X를 반환합니다. 여기서 자연 로그는 min과 max 사이에서 균등하게 분포됩니다.
log_uniform_values
로그 균등 분포. min과 max 사이의 값 X를 반환합니다. 여기서 log(X)는 log(min)과 log(max) 사이에서 균등하게 분포됩니다.
q_log_uniform
양자화된 로그 균등 분포. round(X / q) * q를 반환합니다. 여기서 X는 log_uniform입니다. q의 기본값은 1입니다.
q_log_uniform_values
양자화된 로그 균등 분포. round(X / q) * q를 반환합니다. 여기서 X는 log_uniform_values입니다. q의 기본값은 1입니다.
inv_log_uniform
역 로그 균등 분포. X를 반환합니다. 여기서 log(1/X)는 min과 max 사이에서 균등하게 분포됩니다.
inv_log_uniform_values
역 로그 균등 분포. X를 반환합니다. 여기서 log(1/X)는 log(1/max)와 log(1/min) 사이에서 균등하게 분포됩니다.
normal
정규 분포. 평균 mu (기본값 0) 및 표준 편차 sigma (기본값 1)로 정규 분포된 값을 반환합니다.
q_normal
양자화된 정규 분포. round(X / q) * q를 반환합니다. 여기서 X는 normal입니다. Q의 기본값은 1입니다.
log_normal
로그 정규 분포. 자연 로그 log(X)가 평균 mu (기본값 0) 및 표준 편차 sigma (기본값 1)로 정규 분포된 값 X를 반환합니다.
q_log_normal
양자화된 로그 정규 분포. round(X / q) * q를 반환합니다. 여기서 X는 log_normal입니다. q의 기본값은 1입니다.
early_terminate
조기 종료 (early_terminate)를 사용하여 성능이 낮은 run을 중지합니다. 조기 종료가 발생하면 W&B는 새 하이퍼파라미터 값 집합으로 새 run을 만들기 전에 현재 run을 중지합니다.
early_terminate를 사용하는 경우 중지 알고리즘을 지정해야 합니다. 스윕 구성 내에서 early_terminate 내에 type 키를 중첩합니다.
Hyperband 하이퍼파라미터 최적화는 프로그램을 중지해야 하는지 또는 사전 설정된 하나 이상의 반복 횟수 ( brackets 라고 함)에서 계속해야 하는지 평가합니다.
W&B run이 bracket에 도달하면 스윕은 해당 run의 메트릭을 이전에 보고된 모든 메트릭 값과 비교합니다. 스윕은 run의 메트릭 값이 너무 높으면 (목표가 최소화인 경우) 또는 run의 메트릭 값이 너무 낮으면 (목표가 최대화인 경우) run을 종료합니다.
Brackets는 기록된 반복 횟수를 기반으로 합니다. brackets 수는 최적화하는 메트릭을 기록하는 횟수에 해당합니다. 반복은 단계, 에포크 또는 그 사이의 무언가에 해당할 수 있습니다. 단계 카운터의 숫자 값은 bracket 계산에 사용되지 않습니다.
bracket 일정을 만들려면 min_iter 또는 max_iter를 지정합니다.
키
설명
min_iter
첫 번째 bracket에 대한 반복을 지정합니다.
max_iter
최대 반복 횟수를 지정합니다.
s
총 bracket 수를 지정합니다 (max_iter에 필요).
eta
bracket 승수 일정을 지정합니다 (기본값: 3).
strict
원본 Hyperband 논문을 더 면밀히 따르면서 실행을 적극적으로 정리하는 ‘엄격’ 모드를 활성화합니다. 기본값은 false입니다.
Hyperband는 몇 분마다 종료할 W&B run을 확인합니다. run 또는 반복이 짧으면 종료 run 타임스탬프가 지정된 brackets와 다를 수 있습니다.
command
command 키 내에서 중첩된 값으로 형식과 내용을 수정합니다. 파일 이름과 같은 고정된 구성 요소를 직접 포함할 수 있습니다.
Unix 시스템에서 /usr/bin/env는 OS가 환경에 따라 올바른 Python 인터프리터를 선택하도록 합니다.
W&B는 코맨드의 가변 구성 요소에 대해 다음 매크로를 지원합니다.
코맨드 매크로
설명
${env}
Unix 시스템의 경우 /usr/bin/env, Windows에서는 생략됩니다.
${interpreter}
python으로 확장됩니다.
${program}
스윕 구성 program 키로 지정된 트레이닝 스크립트 파일 이름입니다.
${args}
--param1=value1 --param2=value2 형식의 하이퍼파라미터 및 해당 값입니다.
${args_no_boolean_flags}
--param1=value1 형식의 하이퍼파라미터 및 해당 값입니다. 단, 부울 파라미터는 True이면 --boolean_flag_param 형식이고 False이면 생략됩니다.
${args_no_hyphens}
param1=value1 param2=value2 형식의 하이퍼파라미터 및 해당 값입니다.
${args_json}
JSON으로 인코딩된 하이퍼파라미터 및 해당 값입니다.
${args_json_file}
JSON으로 인코딩된 하이퍼파라미터 및 해당 값이 포함된 파일의 경로입니다.
${envvar}
환경 변수를 전달하는 방법입니다. ${envvar:MYENVVAR}은 MYENVVAR 환경 변수의 값으로 확장됩니다.
4 - Initialize a sweep
W&B 스윕 초기화
W&B는 클라우드 (표준), 로컬 (local) 환경에서 하나 이상의 머신에서 Sweeps 를 관리하기 위해 Sweep Controller 를 사용합니다. Run이 완료되면, 스윕 컨트롤러는 실행할 새로운 Run을 설명하는 새로운 명령어 세트를 발행합니다. 이 명령어는 실제로 Run을 수행하는 에이전트 에 의해 선택됩니다. 일반적인 W&B 스윕에서 컨트롤러는 W&B 서버에 존재합니다. 에이전트는 사용자 의 머신에 존재합니다.
다음 코드 조각은 CLI 및 Jupyter Notebook 또는 Python 스크립트 내에서 스윕을 초기화하는 방법을 보여줍니다.
스윕을 초기화하기 전에 YAML 파일 또는 스크립트의 중첩된 Python dictionary 오브젝트에 스윕 구성이 정의되어 있는지 확인하세요. 자세한 내용은 스윕 구성 정의를 참조하세요.
W&B Sweep 과 W&B Run 은 동일한 Projects 에 있어야 합니다. 따라서 W&B를 초기화할 때 제공하는 이름(wandb.init)은 W&B Sweep 을 초기화할 때 제공하는 Projects 이름(wandb.sweep)과 일치해야 합니다.
W&B SDK를 사용하여 스윕을 초기화합니다. 스윕 구성 dictionary 를 sweep 파라미터에 전달합니다. 선택적으로 W&B Run 의 출력을 저장할 Projects 파라미터 (project)에 대한 프로젝트 이름을 제공합니다. 프로젝트가 지정되지 않은 경우 Run은 “Uncategorized” 프로젝트에 배치됩니다.
멀티 코어 또는 멀티 GPU 머신에서 W&B 스윕 에이전트를 병렬화하세요. 시작하기 전에 W&B 스윕을 초기화했는지 확인하세요. W&B 스윕을 초기화하는 방법에 대한 자세한 내용은 스윕 초기화를 참조하세요.
멀티 CPU 머신에서 병렬화
유스 케이스에 따라 다음 탭을 살펴보고 CLI 또는 Jupyter Notebook 내에서 W&B 스윕 에이전트를 병렬화하는 방법을 알아보세요.
wandb agent 코맨드를 사용하여 터미널에서 여러 CPU에 걸쳐 W&B 스윕 에이전트를 병렬화하세요. 스윕을 초기화할 때 반환된 스윕 ID를 제공하세요.
로컬 머신에서 둘 이상의 터미널 창을 여세요.
아래 코드 조각을 복사하여 붙여넣고 sweep_id를 스윕 ID로 바꾸세요.
wandb agent sweep_id
W&B Python SDK 라이브러리를 사용하여 Jupyter Notebook 내에서 여러 CPU에 걸쳐 W&B 스윕 에이전트를 병렬화하세요. 스윕을 초기화할 때 반환된 스윕 ID가 있는지 확인하세요. 또한 스윕이 실행할 함수의 이름을 function 파라미터에 제공하세요.
둘 이상의 Jupyter Notebook을 여세요.
여러 Jupyter Notebook에 W&B 스윕 ID를 복사하여 붙여넣어 W&B 스윕을 병렬화하세요. 예를 들어, 스윕 ID가 sweep_id라는 변수에 저장되어 있고 함수의 이름이 function_name인 경우 다음 코드 조각을 여러 Jupyter Notebook에 붙여넣어 스윕을 병렬화할 수 있습니다.
CUDA 툴킷을 사용하여 터미널에서 여러 GPU에 걸쳐 W&B 스윕 에이전트를 병렬화하려면 다음 절차를 따르세요.
로컬 머신에서 둘 이상의 터미널 창을 여세요.
W&B 스윕 작업을 시작할 때 CUDA_VISIBLE_DEVICES를 사용하여 사용할 GPU 인스턴스를 지정하세요(wandb agent). 사용할 GPU 인스턴스에 해당하는 정수 값을 CUDA_VISIBLE_DEVICES에 할당하세요.
예를 들어, 로컬 머신에 두 개의 NVIDIA GPU가 있다고 가정해 보겠습니다. 터미널 창을 열고 CUDA_VISIBLE_DEVICES를 0으로 설정하세요(CUDA_VISIBLE_DEVICES=0). 다음 예제에서 sweep_ID를 W&B 스윕을 초기화할 때 반환되는 W&B 스윕 ID로 바꾸세요.
터미널 1
CUDA_VISIBLE_DEVICES=0 wandb agent sweep_ID
두 번째 터미널 창을 여세요. CUDA_VISIBLE_DEVICES를 1로 설정하세요(CUDA_VISIBLE_DEVICES=1). 이전 코드 조각에 언급된 sweep_ID에 대해 동일한 W&B 스윕 ID를 붙여넣으세요.
터미널 2
CUDA_VISIBLE_DEVICES=1 wandb agent sweep_ID
7 - Visualize sweep results
W&B App UI를 사용하여 W&B Sweeps의 결과를 시각화하세요.
W&B App UI를 사용하여 W&B Sweeps 의 결과를 시각화합니다. https://wandb.ai/home에서 W&B App UI로 이동합니다. W&B Sweep을 초기화할 때 지정한 project를 선택합니다. project workspace로 리디렉션됩니다. 왼쪽 panel에서 Sweep 아이콘(빗자루 아이콘)을 선택합니다. Sweep UI에서 목록에서 Sweep 이름을 선택합니다.
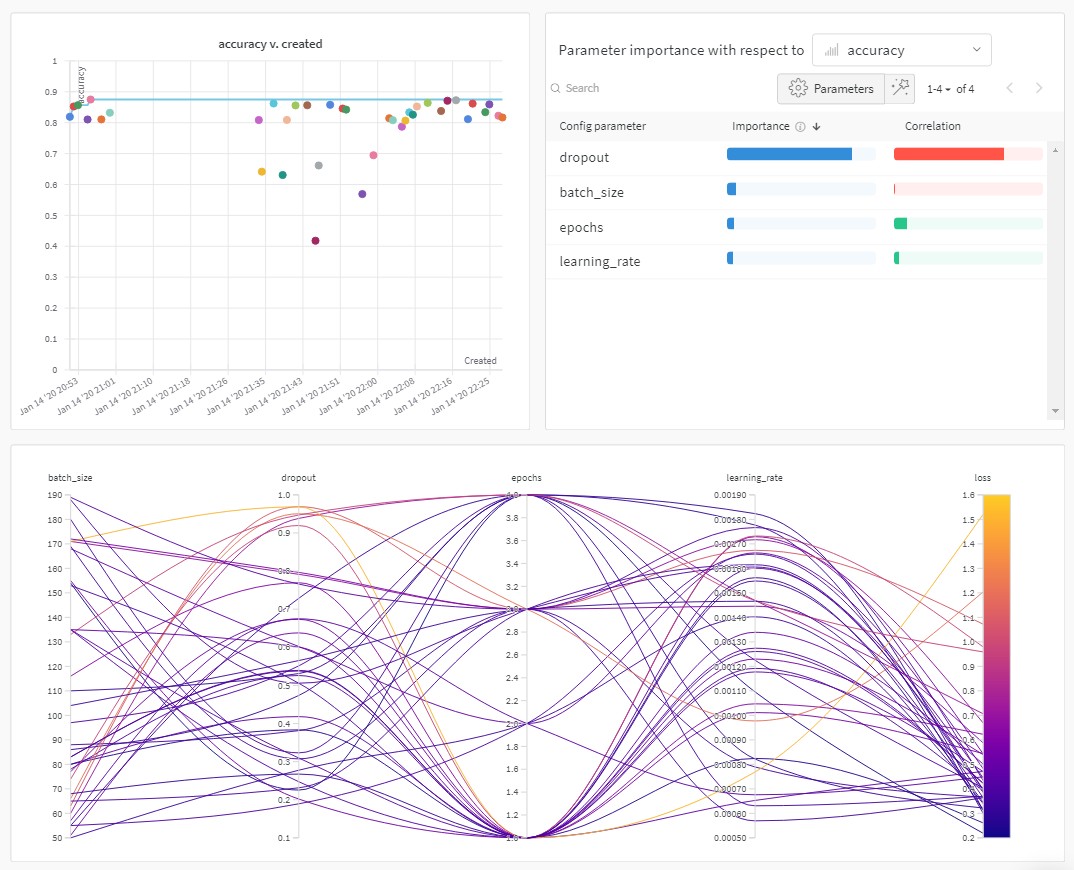
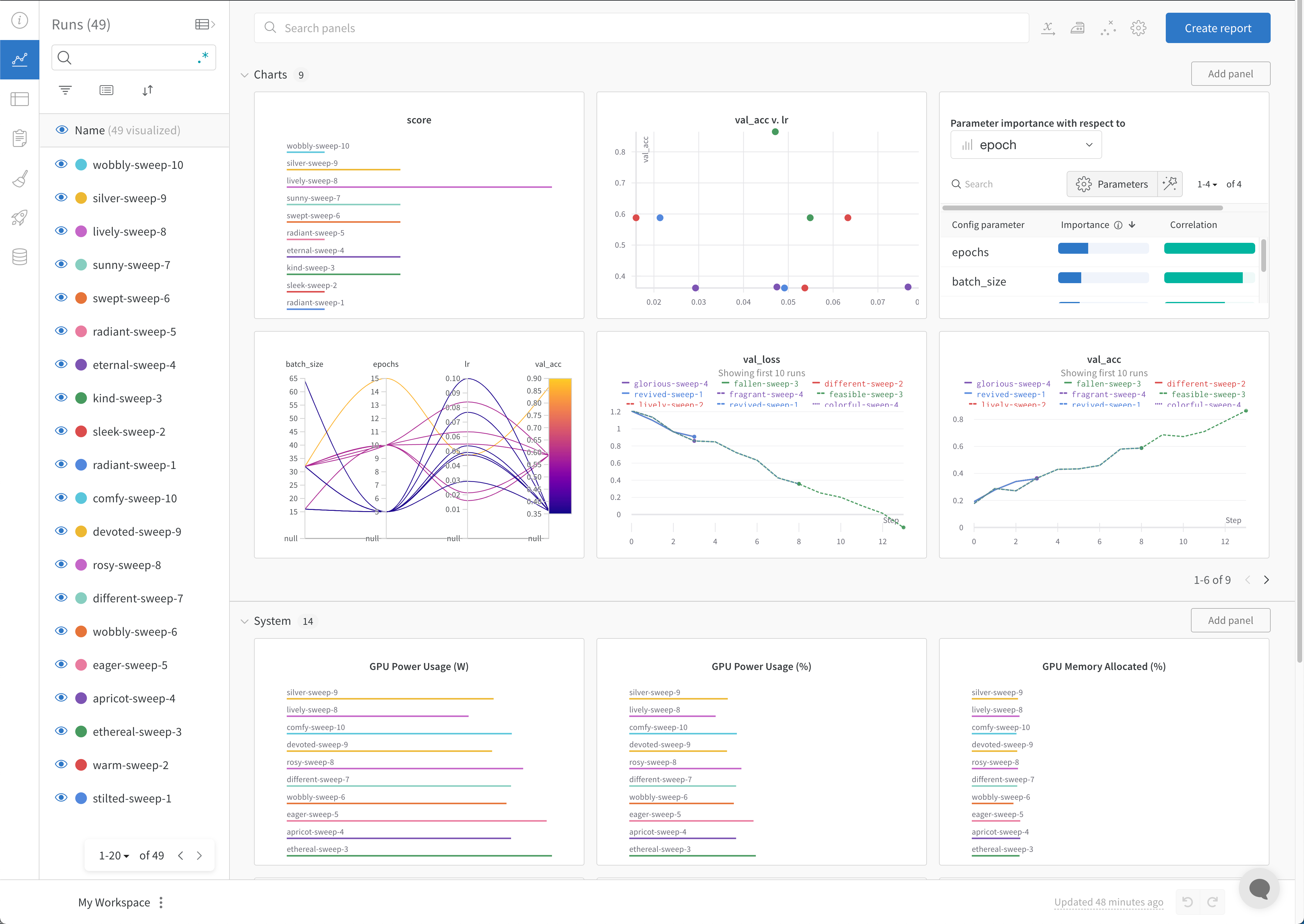
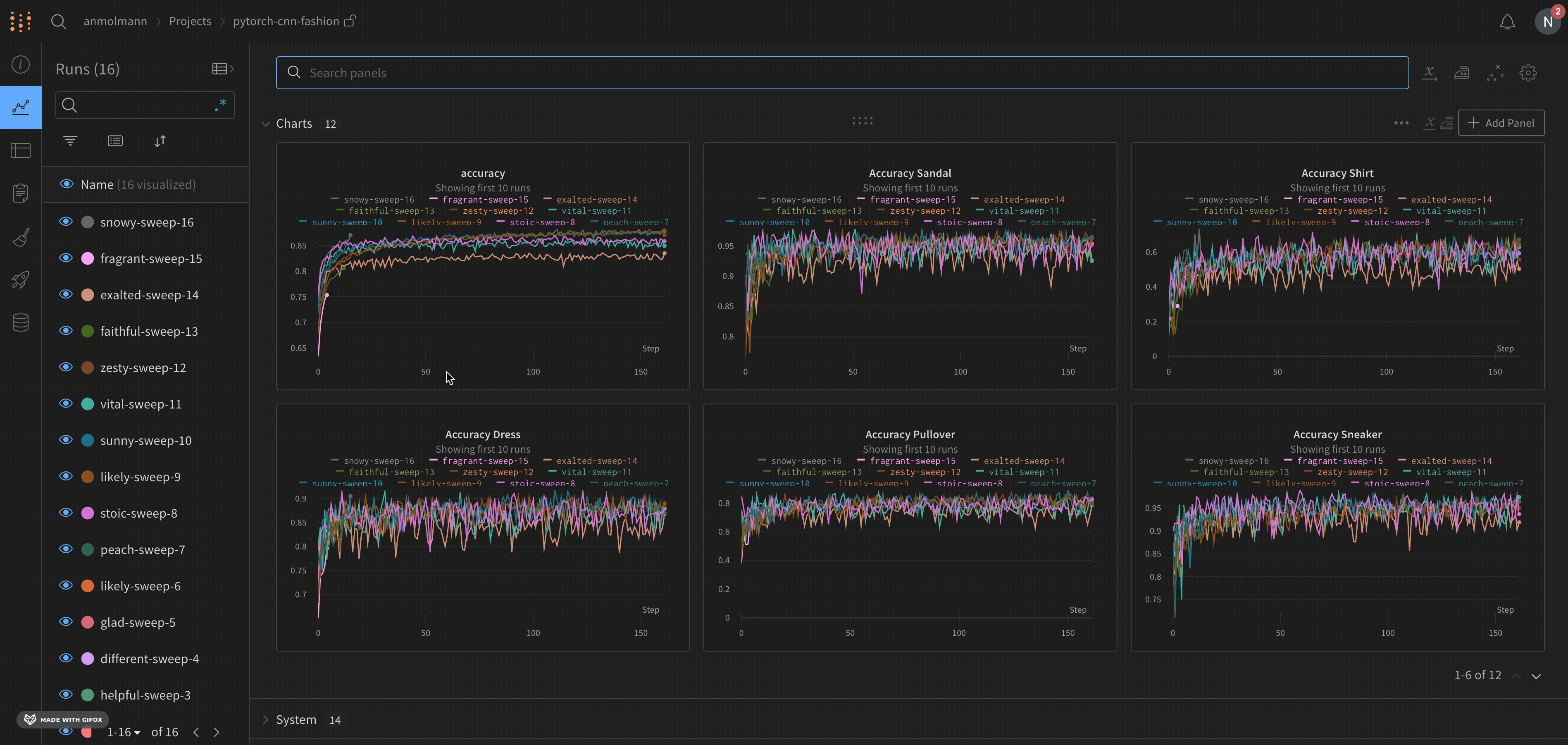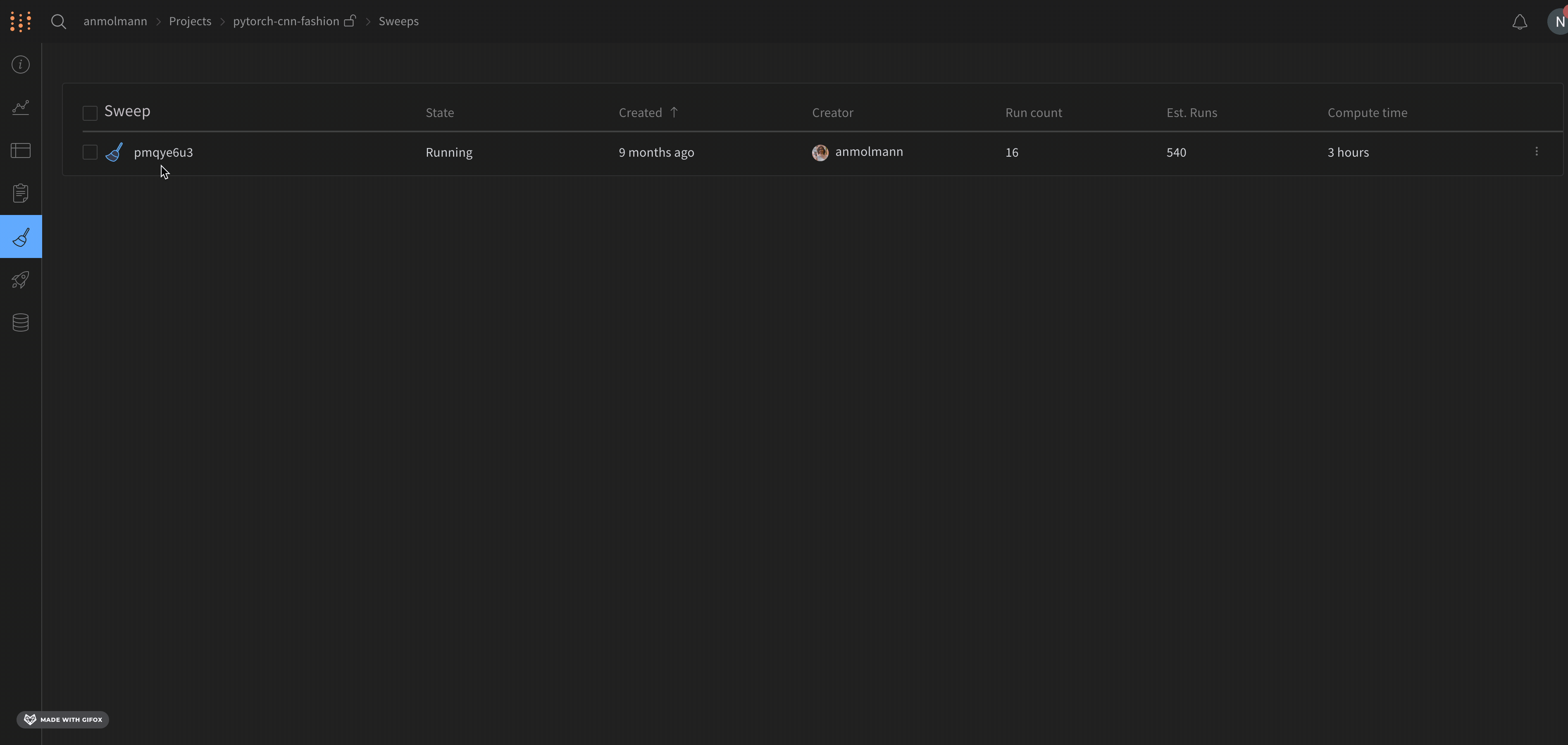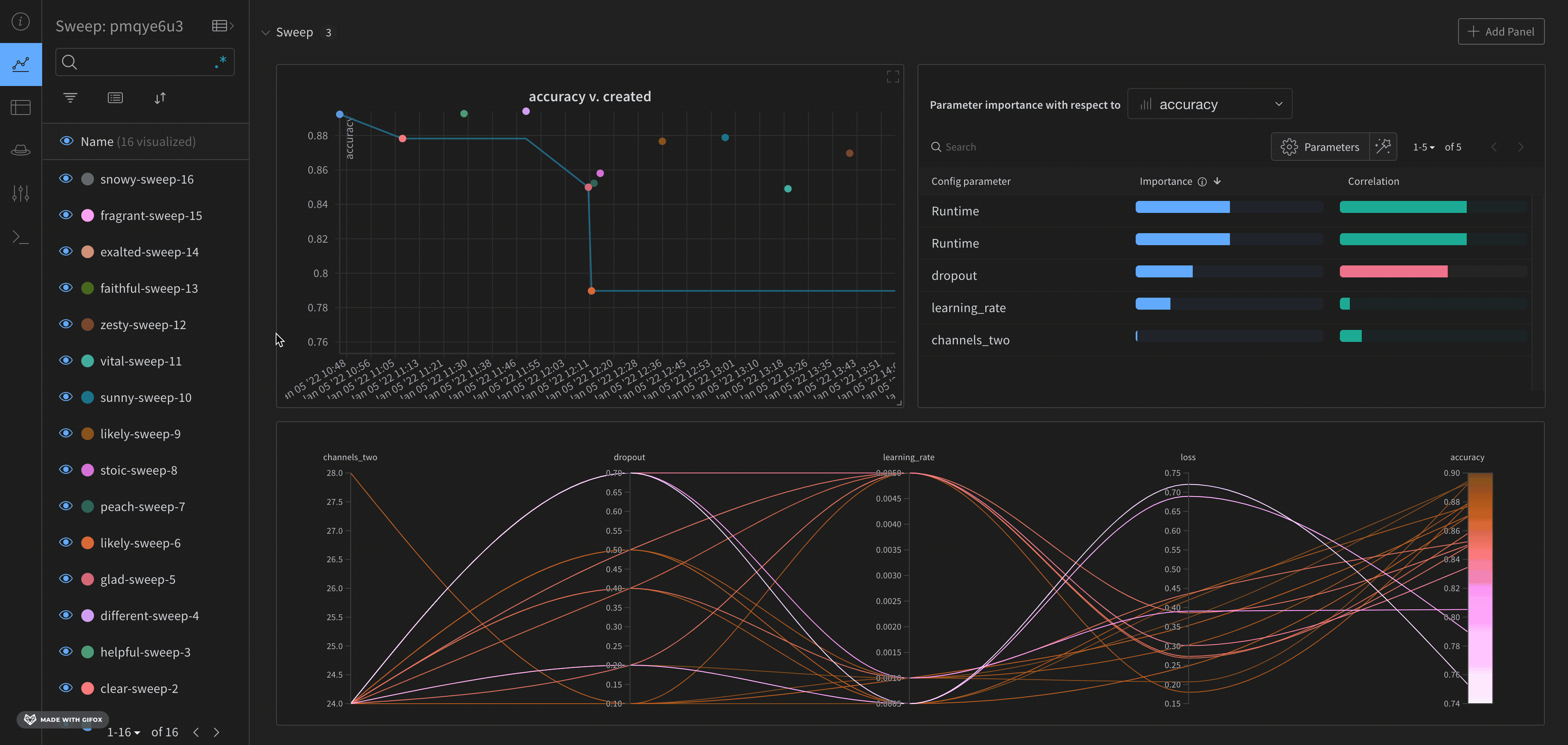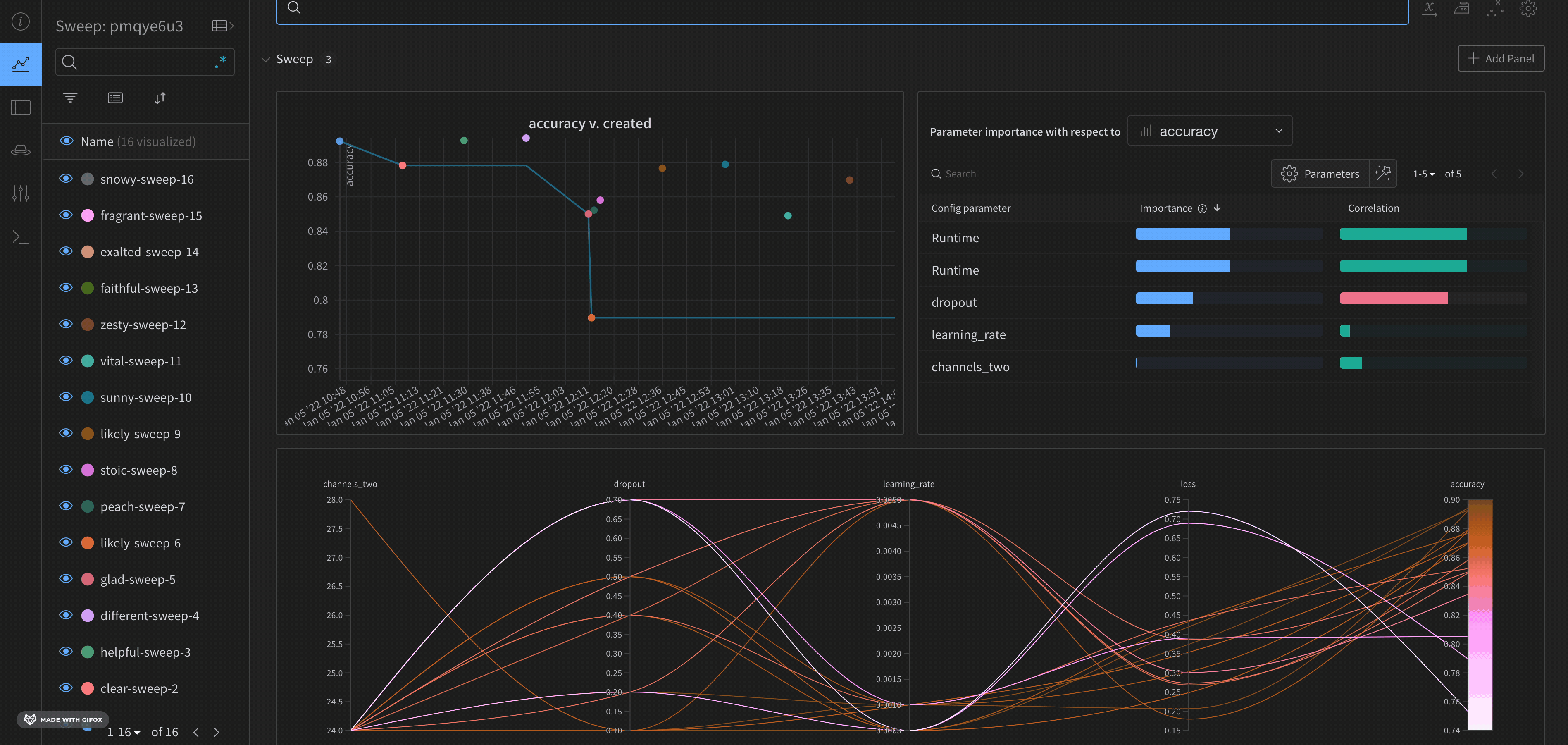
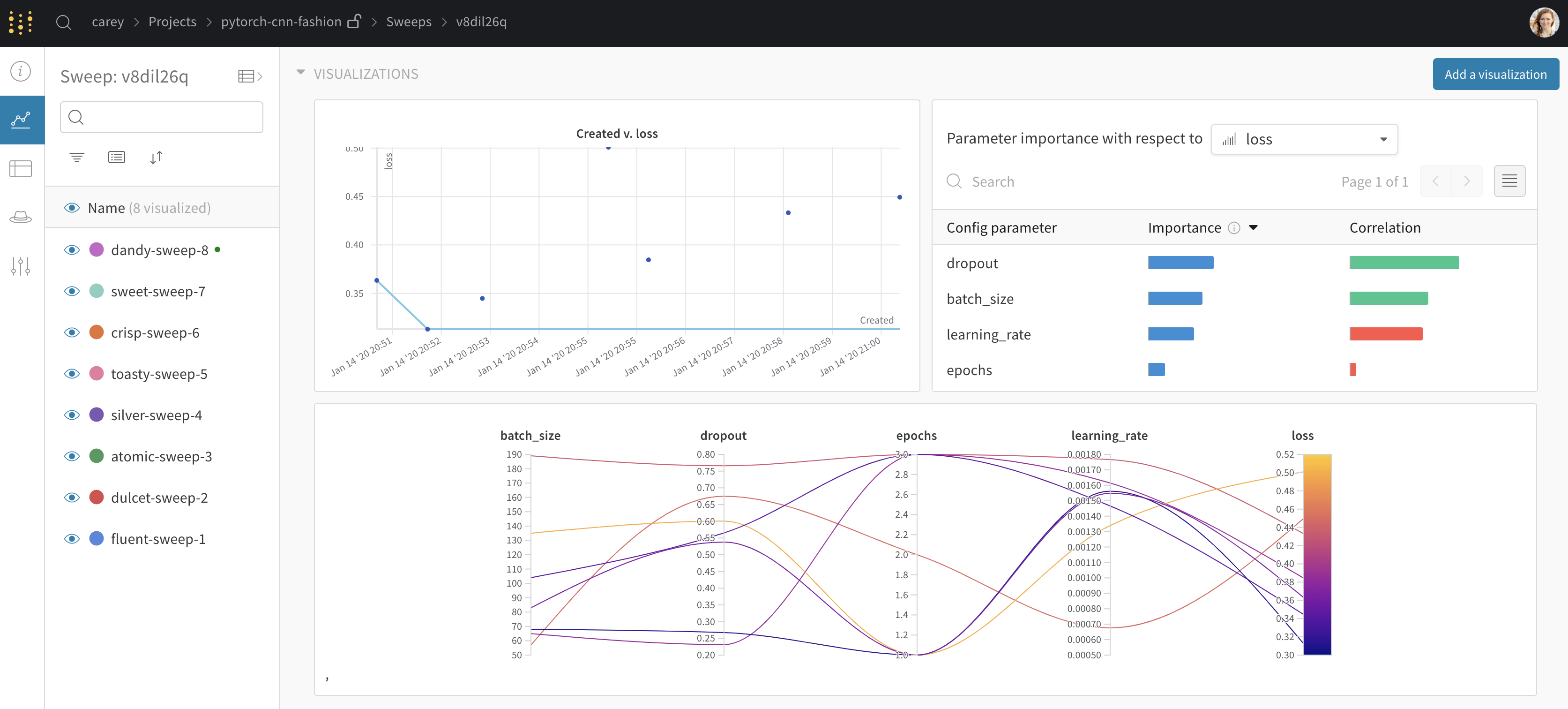
기본적으로 W&B는 W&B Sweep 작업을 시작할 때 평행 좌표 플롯, 파라미터 중요도 플롯 및 산점도를 자동으로 생성합니다.
평행 좌표 차트는 많은 수의 하이퍼파라미터 와 model metrics 간의 관계를 한눈에 요약합니다. 평행 좌표 플롯에 대한 자세한 내용은 평행 좌표를 참조하십시오.
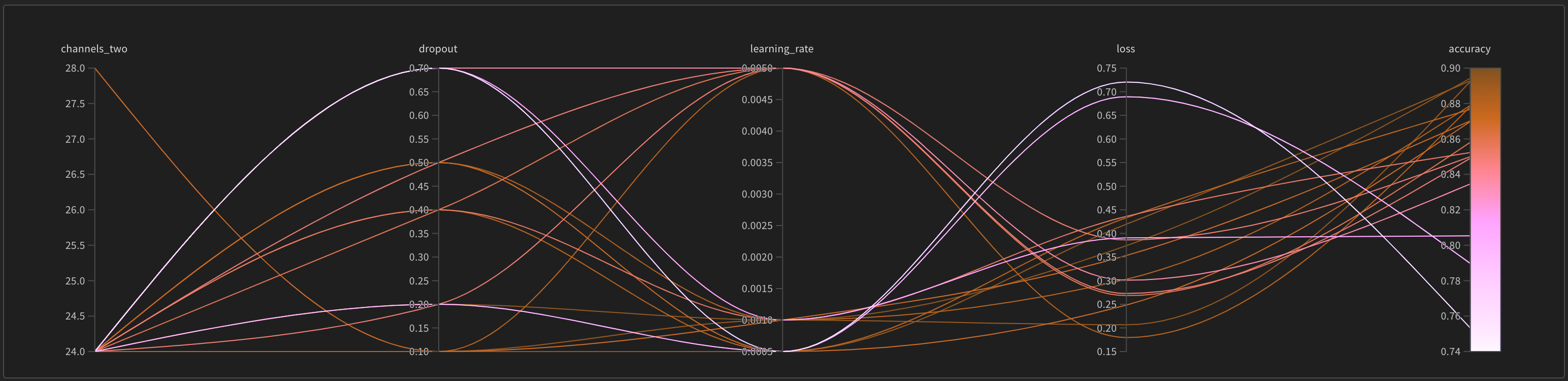
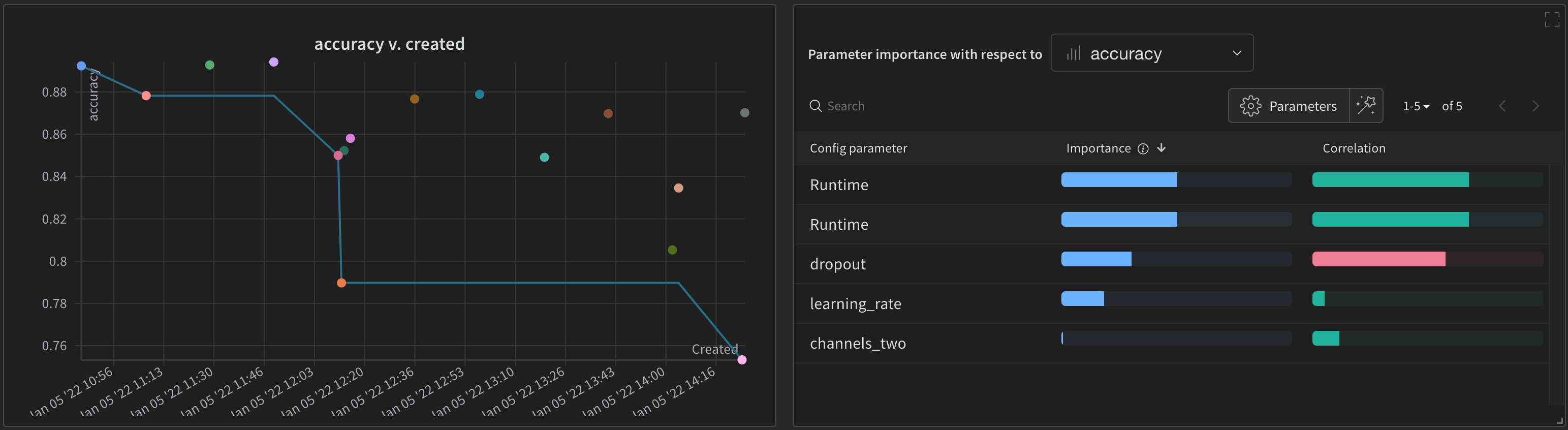
산점도(왼쪽)는 Sweep 중에 생성된 W&B Runs 을 비교합니다. 산점도에 대한 자세한 내용은 산점도를 참조하십시오.
파라미터 중요도 플롯(오른쪽)은 metrics 의 바람직한 value 와 가장 잘 예측하고 높은 상관 관계가 있는 하이퍼파라미터 를 나열합니다. 자세한 내용은 파라미터 중요도 플롯은 파라미터 중요도를 참조하십시오.
자동으로 사용되는 종속 및 독립 value (x 및 y 축)를 변경할 수 있습니다. 각 panel 에는 Edit panel 이라는 연필 아이콘이 있습니다. Edit panel 을 선택합니다. model 이 나타납니다. 모달 내에서 그래프의 행동을 변경할 수 있습니다.
모든 기본 W&B visualization 옵션에 대한 자세한 내용은 Panels를 참조하십시오. W&B Sweep의 일부가 아닌 W&B Runs 에서 플롯을 만드는 방법에 대한 자세한 내용은 Data Visualization docs를 참조하십시오.
8 - Manage sweeps with the CLI
CLI를 사용하여 W&B 스윕을 일시 중지, 재개 및 취소합니다.
CLI를 사용하여 W&B 스윕을 일시 중지, 재개 및 취소합니다. W&B 스윕을 일시 중지하면 스윕이 재개될 때까지 새로운 W&B Runs이 실행되지 않도록 W&B 에이전트에 알립니다. 스윕을 재개하면 에이전트가 새로운 W&B Runs을 계속 실행합니다. W&B 스윕을 중지하면 W&B 스윕 에이전트가 새로운 W&B Runs의 생성 또는 실행을 중지합니다. W&B 스윕을 취소하면 스윕 에이전트가 현재 실행 중인 W&B Runs을 중단하고 새로운 Runs 실행을 중지합니다.
각각의 경우, W&B 스윕을 초기화할 때 생성된 W&B 스윕 ID를 제공합니다. 선택적으로 새 터미널 창을 열어 다음 명령을 실행합니다. 새 터미널 창은 W&B 스윕이 현재 터미널 창에 출력문을 인쇄하는 경우 명령을 더 쉽게 실행할 수 있도록 합니다.
다음 지침에 따라 스윕을 일시 중지, 재개 및 취소합니다.
스윕 일시 중지
새로운 W&B Runs 실행을 일시적으로 중단하도록 W&B 스윕을 일시 중지합니다. wandb sweep --pause 코맨드를 사용하여 W&B 스윕을 일시 중지합니다. 일시 중지할 W&B 스윕 ID를 제공합니다.
하이퍼파라미터 컨트롤러는 기본적으로 Weights & Biases에서 클라우드 서비스로 호스팅됩니다. W&B 에이전트는 컨트롤러와 통신하여 트레이닝에 사용할 다음 파라미터 세트를 결정합니다. 또한 컨트롤러는 조기 중단 알고리즘을 실행하여 중단할 수 있는 run을 결정합니다.
로컬 컨트롤러 기능을 사용하면 사용자가 로컬에서 검색 및 중단 알고리즘을 시작할 수 있습니다. 로컬 컨트롤러는 사용자에게 문제를 디버그하고 클라우드 서비스에 통합할 수 있는 새로운 기능을 개발하기 위해 코드를 검사하고 계측할 수 있는 기능을 제공합니다.
이 기능은 Sweeps 툴에 대한 새로운 알고리즘의 더 빠른 개발 및 디버깅을 지원하기 위해 제공됩니다. 실제 하이퍼파라미터 최적화 워크로드에는 적합하지 않습니다.
시작하기 전에 W&B SDK(wandb)를 설치해야 합니다. 커맨드라인에 다음 코드 조각을 입력하세요.
pip install wandb sweeps
다음 예제에서는 이미 구성 파일과 트레이닝 루프가 Python 스크립트 또는 Jupyter Notebook에 정의되어 있다고 가정합니다. 구성 파일을 정의하는 방법에 대한 자세한 내용은 스윕 구성 정의를 참조하세요.
커맨드라인에서 로컬 컨트롤러 실행
W&B에서 클라우드 서비스로 호스팅하는 하이퍼파라미터 컨트롤러를 사용할 때와 유사하게 스윕을 초기화합니다. 컨트롤러 플래그(controller)를 지정하여 W&B 스윕 작업에 로컬 컨트롤러를 사용하려는 의사를 나타냅니다.
반환된 W&B Sweep ID를 기록해 둡니다. 다음으로, Python SDK(wandb.agent) 대신 CLI를 사용하여 wandb agent로 Sweep 작업을 시작합니다. 아래 코드 조각에서 sweep_ID를 이전 단계에서 반환된 Sweep ID로 바꿉니다.
wandb agent sweep_ID
anaconda 400 error
다음 오류는 일반적으로 최적화하려는 메트릭을 로깅하지 않을 때 발생합니다.
wandb: ERROR Error while calling W&B API: anaconda 400 error:
{"code": 400, "message": "TypeError: bad operand type for unary -: 'NoneType'"}
YAML 파일 또는 중첩된 사전 내에서 최적화할 “metric"이라는 키를 지정합니다. 이 메트릭을 반드시 로깅(wandb.log)해야 합니다. 또한 Python 스크립트 또는 Jupyter Notebook 내에서 스윕을 최적화하도록 정의한 정확한 메트릭 이름을 사용해야 합니다. 구성 파일에 대한 자세한 내용은 스윕 구성 정의를 참조하세요.
12 - Sweeps UI
Sweeps UI의 다양한 구성 요소에 대해 설명합니다.
상태 (State), 생성 시간 (Created), 스윕을 시작한 엔티티 (Creator), 완료된 run 수 (Run count) 및 스윕을 계산하는 데 걸린 시간 (Compute time)이 Sweeps UI에 표시됩니다. 스윕이 생성할 것으로 예상되는 run 수 (Est. Runs)는 이산 검색 공간에서 그리드 검색을 수행할 때 제공됩니다. 인터페이스에서 스윕을 클릭하여 스윕을 일시 중지, 재개, 중지 또는 중단할 수도 있습니다.
프로젝트 페이지에서 사이드바의 Sweep tab을 열고 Create Sweep을 선택합니다.
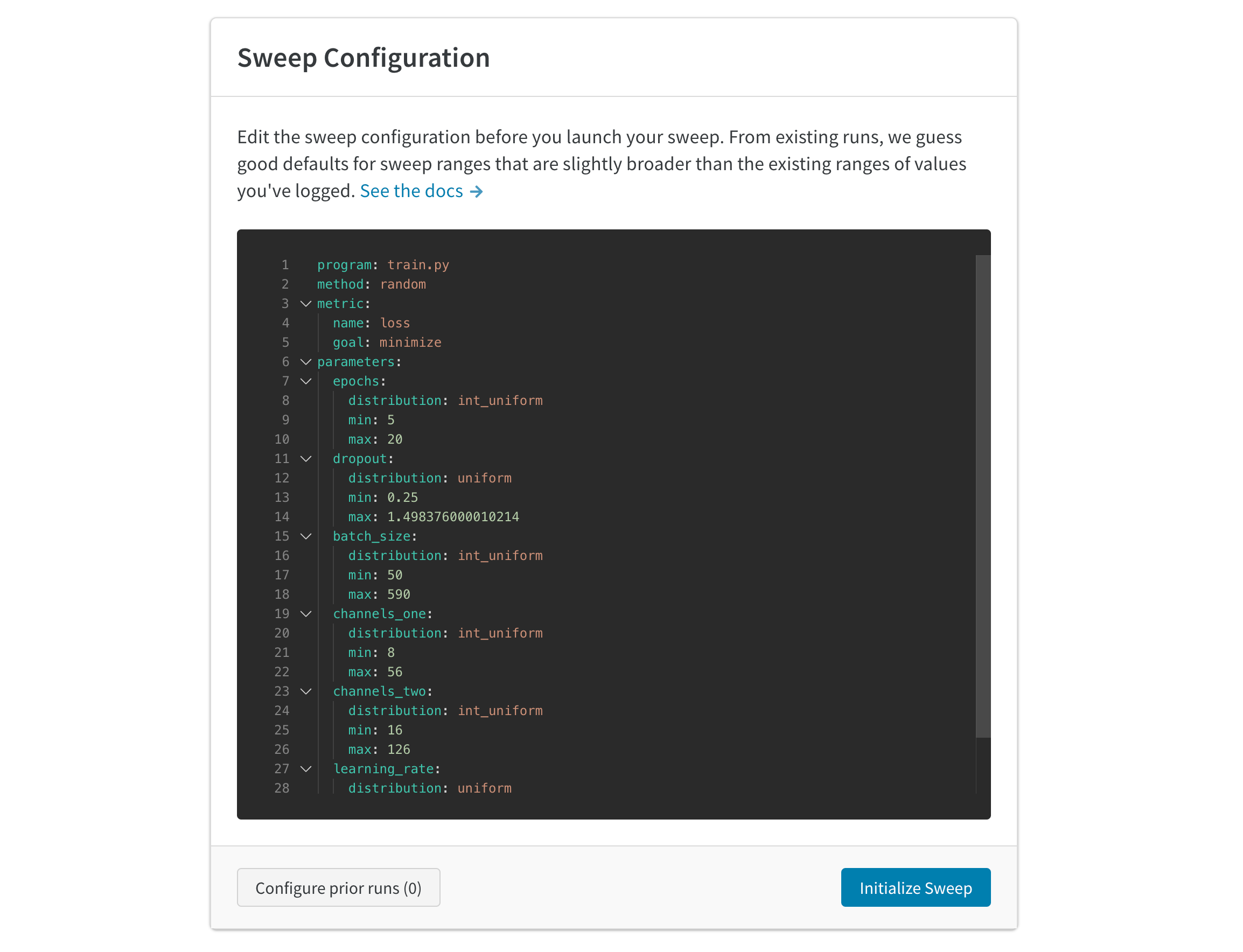
자동 생성된 설정은 완료한 run을 기반으로 스윕할 값을 추측합니다. 시도할 하이퍼파라미터 범위를 지정하도록 설정을 편집합니다. 스윕을 시작하면 호스팅된 W&B 스윕 서버에서 새 프로세스가 시작됩니다. 이 중앙 집중식 서비스는 트레이닝 작업을 실행하는 머신인 에이전트를 조정합니다.
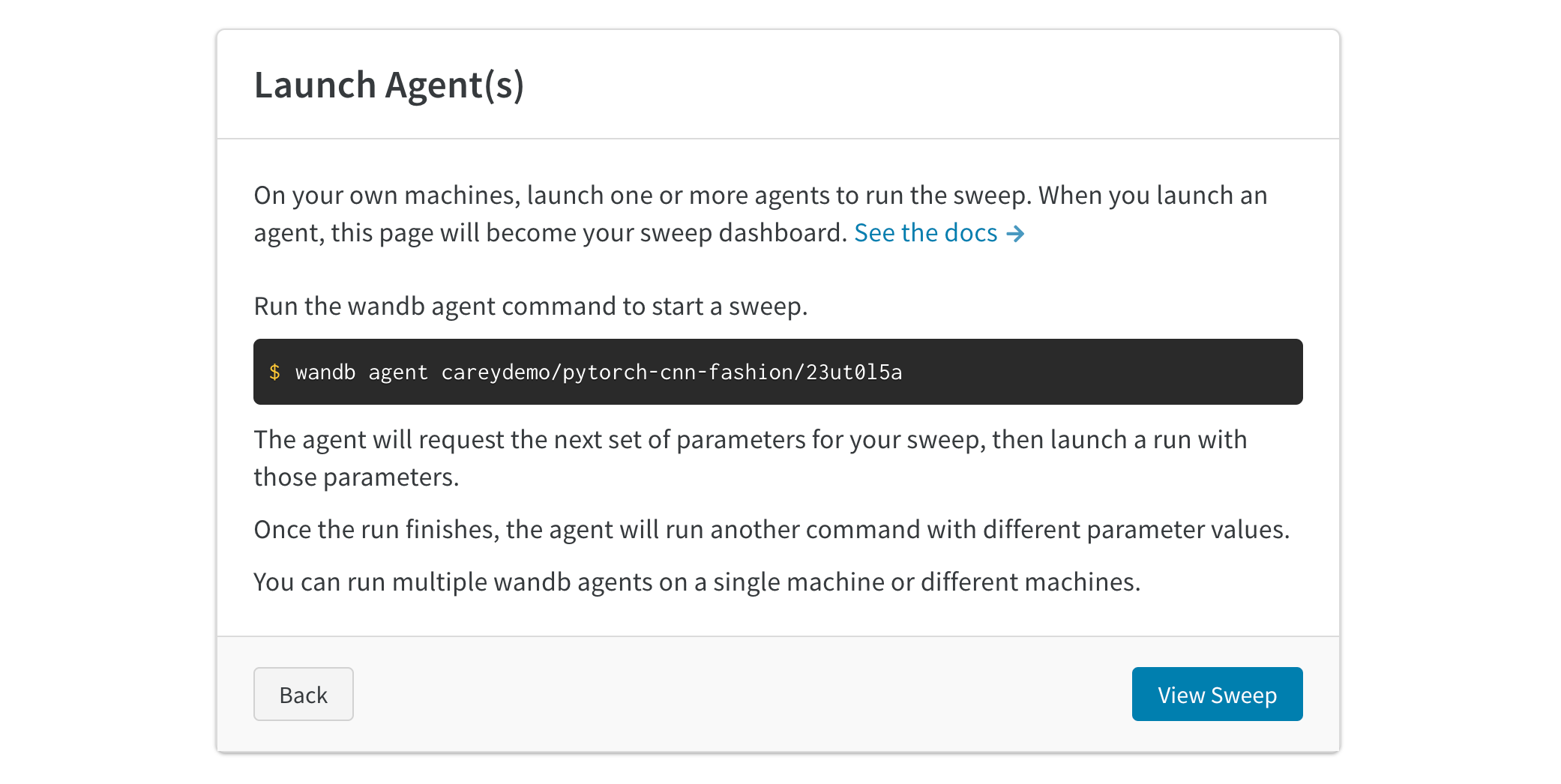
3. 에이전트 시작
다음으로, 로컬에서 에이전트를 시작합니다. 작업을 분산하고 스윕 작업을 더 빨리 완료하려면 최대 20개의 에이전트를 서로 다른 머신에서 병렬로 시작할 수 있습니다. 에이전트는 다음에 시도할 파라미터 세트를 출력합니다.
이제 스윕을 실행하고 있습니다. 다음 이미지는 예제 스윕 작업이 실행되는 동안 대시보드가 어떻게 보이는지 보여줍니다. 예제 프로젝트 페이지 보기 →
기존 run으로 새 스윕 시드하기
이전에 기록한 기존 run을 사용하여 새 스윕을 시작합니다.
프로젝트 테이블을 엽니다.
테이블 왼쪽에서 확인란을 사용하여 사용할 run을 선택합니다.
드롭다운을 클릭하여 새 스윕을 만듭니다.
이제 스윕이 서버에 설정됩니다. run 실행을 시작하려면 하나 이상의 에이전트를 시작하기만 하면 됩니다.