Tutorial: Use custom charts
3 minute read
커스텀 차트를 사용하여 패널에 로드하는 데이터와 시각화를 제어할 수 있습니다.
1. W&B에 데이터 기록
먼저 스크립트에 데이터를 기록합니다. 트레이닝 시작 시 설정된 단일 포인트 (예: 하이퍼파라미터)에는 wandb.config를 사용합니다. 시간에 따른 여러 포인트에는 wandb.log()를 사용하고, wandb.Table()을 사용하여 커스텀 2D 배열을 기록합니다. 기록된 키당 최대 10,000개의 데이터 포인트를 기록하는 것이 좋습니다.
# 커스텀 데이터 테이블 기록
my_custom_data = [[x1, y1, z1], [x2, y2, z2]]
wandb.log(
{"custom_data_table": wandb.Table(data=my_custom_data, columns=["x", "y", "z"])}
)
데이터 테이블을 기록하려면 간단한 예제 노트북을 사용해 보고, 다음 단계에서 커스텀 차트를 설정합니다. 라이브 리포트에서 결과 차트가 어떻게 보이는지 확인하세요.
2. 쿼리 만들기
시각화할 데이터를 기록했으면 프로젝트 페이지로 이동하여 + 버튼을 클릭하여 새 패널을 추가한 다음 Custom Chart를 선택합니다. 이 워크스페이스에서 따라 할 수 있습니다.

쿼리 추가
summary를 클릭하고historyTable을 선택하여 run 기록에서 데이터를 가져오는 새 쿼리를 설정합니다.wandb.Table()을 기록한 키를 입력합니다. 위의 코드 조각에서는my_custom_table입니다. 예제 노트북에서 키는pr_curve및roc_curve입니다.
Vega 필드 설정
이제 쿼리가 이러한 열을 로드하므로 Vega 필드 드롭다운 메뉴에서 선택할 수 있는 옵션으로 사용할 수 있습니다.
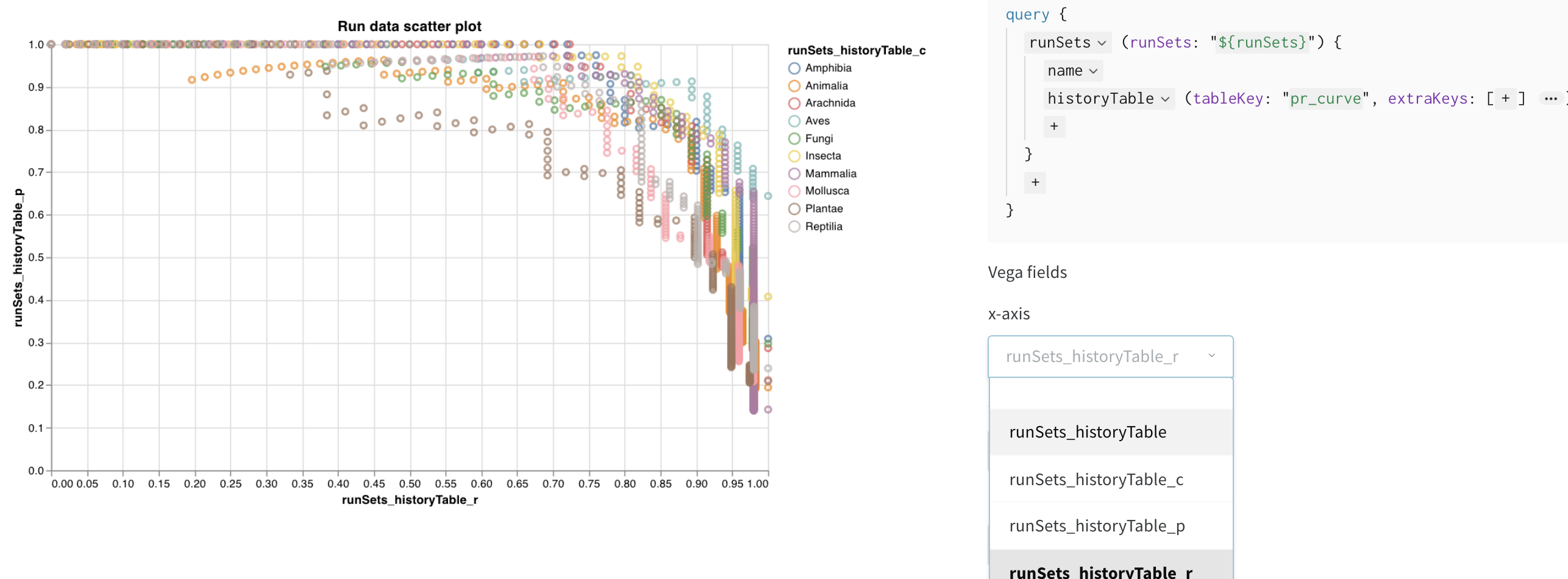
- x-axis: runSets_historyTable_r (recall)
- y-axis: runSets_historyTable_p (precision)
- color: runSets_historyTable_c (class label)
3. 차트 사용자 정의
이제 보기에 좋지만 산점도에서 선 플롯으로 전환하고 싶습니다. Edit를 클릭하여 이 내장 차트에 대한 Vega 사양을 변경합니다. 이 워크스페이스에서 따라 하세요.

시각화를 사용자 정의하기 위해 Vega 사양을 업데이트했습니다.
- 플롯, 범례, x축 및 y축에 대한 제목 추가 (각 필드에 대해 “title” 설정)
- “mark” 값을 “point"에서 “line"으로 변경
- 사용되지 않는 “size” 필드 제거
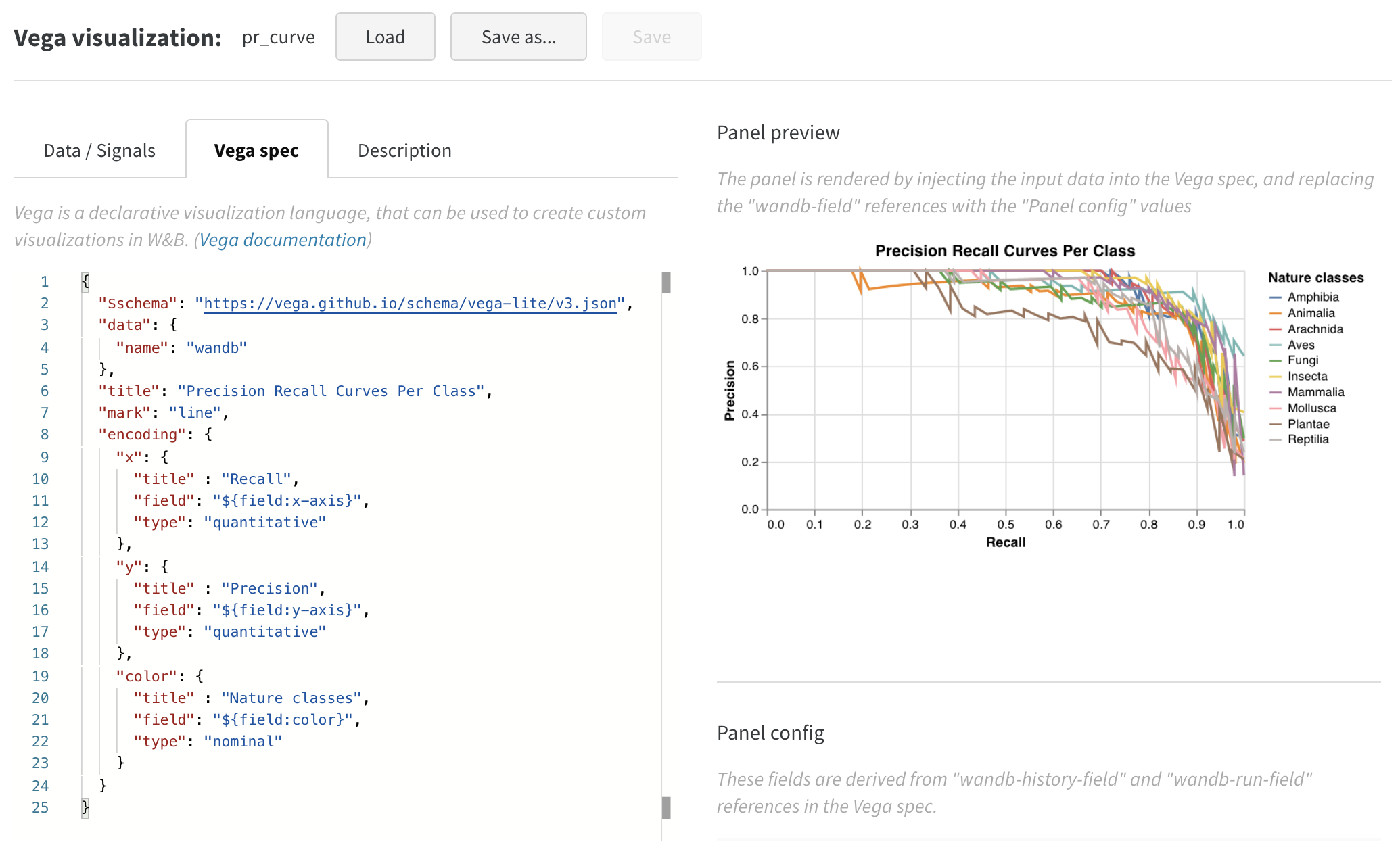
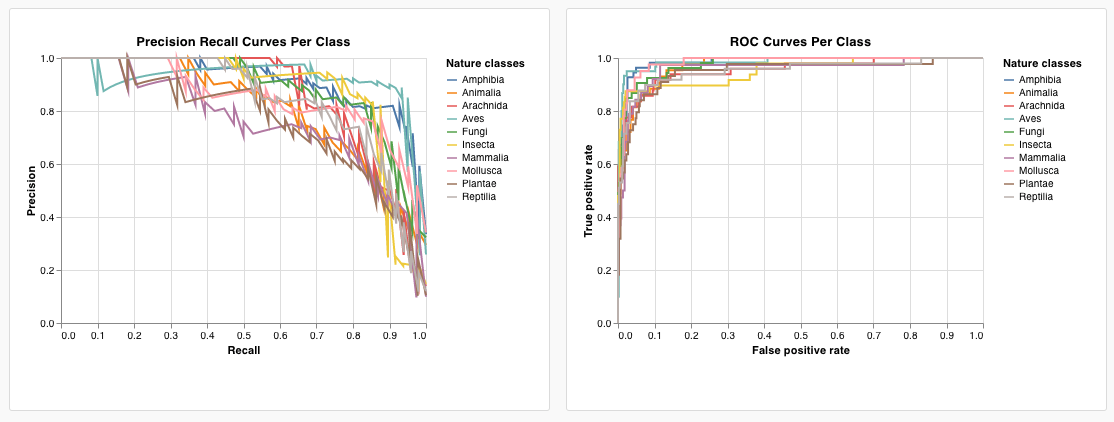
이것을 이 프로젝트의 다른 곳에서 사용할 수 있는 사전 설정으로 저장하려면 페이지 상단의 Save as를 클릭합니다. 결과는 ROC 곡선과 함께 다음과 같습니다.
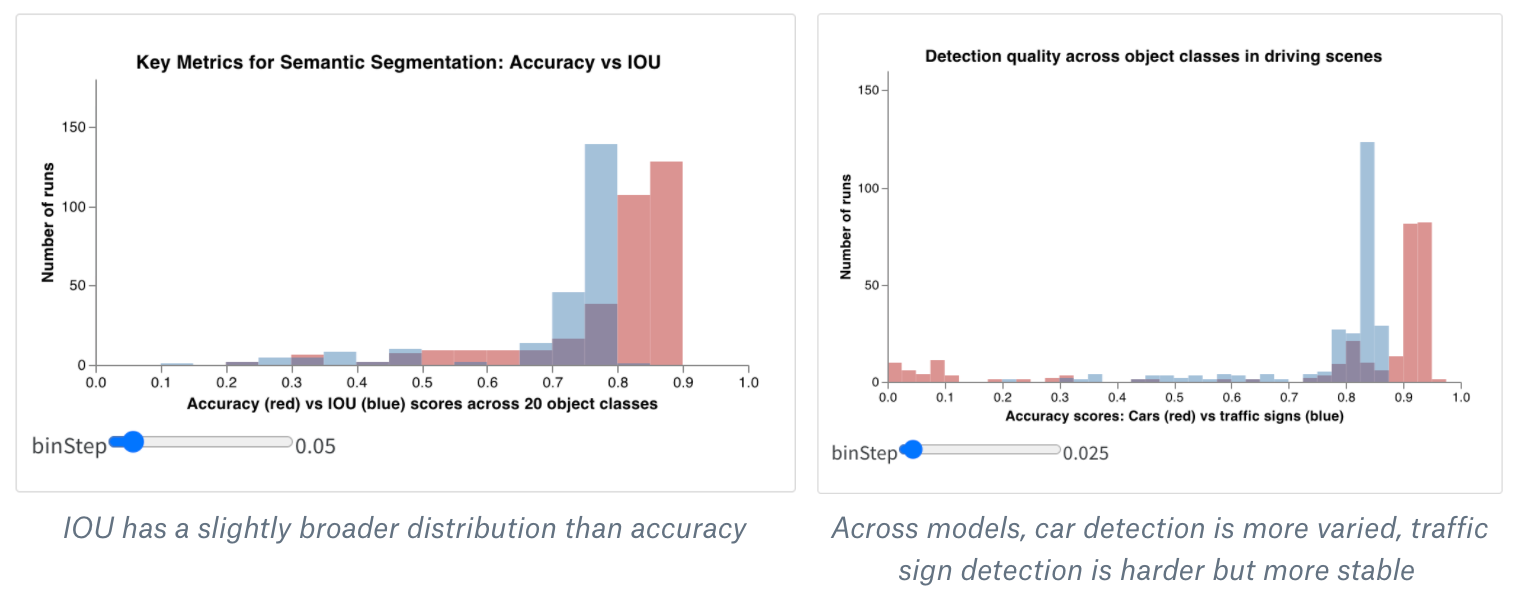
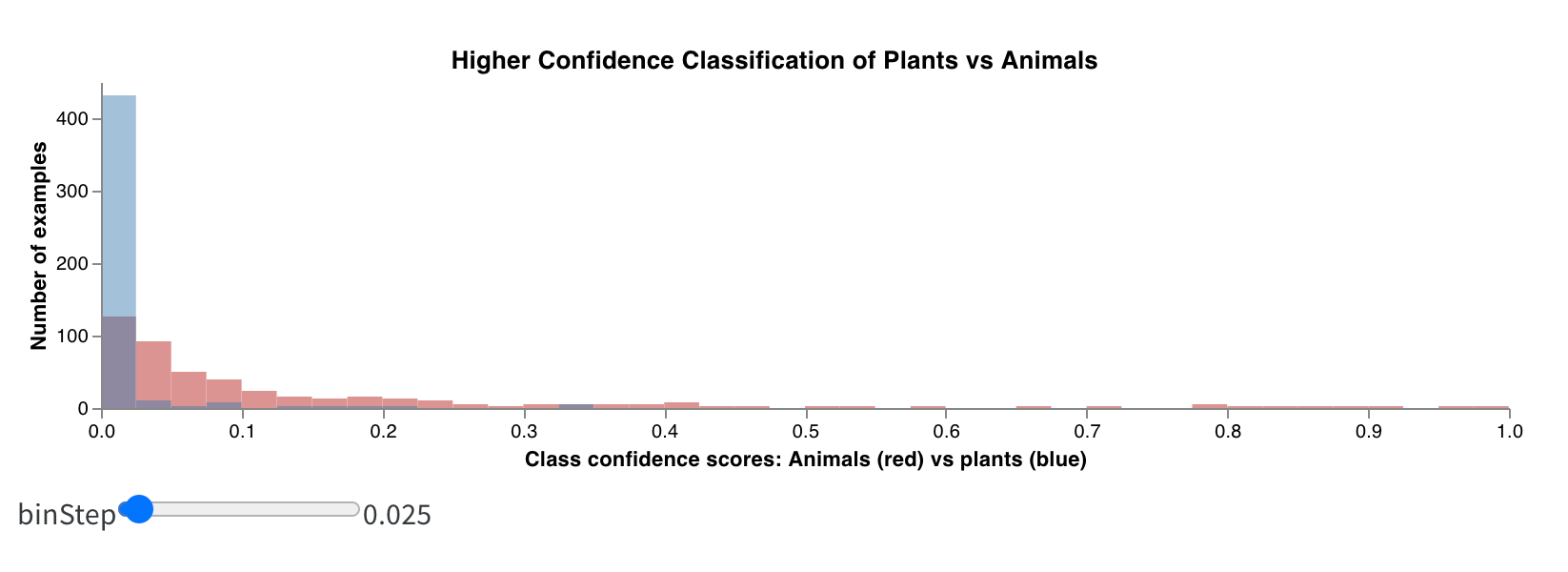
보너스: 합성 히스토그램
히스토그램은 숫자 분포를 시각화하여 더 큰 데이터셋을 이해하는 데 도움을 줄 수 있습니다. 합성 히스토그램은 동일한 bin에서 여러 분포를 보여주어 서로 다른 모델 간 또는 모델 내의 서로 다른 클래스 간에 두 개 이상의 메트릭을 비교할 수 있습니다. 운전 장면에서 오브젝트를 감지하는 시멘틱 세그멘테이션 모델의 경우 정확도 대 IOU (intersection over union)에 대해 최적화하는 효과를 비교하거나 서로 다른 모델이 자동차 (데이터에서 크고 일반적인 영역) 대 교통 표지판 (훨씬 작고 덜 일반적인 영역)을 얼마나 잘 감지하는지 알고 싶을 수 있습니다. 데모 Colab에서는 10가지 생물 클래스 중 2가지에 대한 신뢰도 점수를 비교할 수 있습니다.
커스텀 합성 히스토그램 패널의 자체 버전을 만들려면:
- 워크스페이스 또는 리포트에서 새 Custom Chart 패널을 만듭니다 (“Custom Chart” 시각화를 추가하여). 오른쪽 상단의 “Edit” 버튼을 눌러 내장 패널 유형부터 시작하여 Vega 사양을 수정합니다.
- 해당 내장 Vega 사양을 Vega의 합성 히스토그램에 대한 MVP 코드로 바꿉니다. Vega 구문 Vega syntax를 사용하여 이 Vega 사양에서 메인 제목, 축 제목, 입력 도메인 및 기타 세부 정보를 직접 수정할 수 있습니다 (색상을 변경하거나 세 번째 히스토그램을 추가할 수도 있습니다 :)
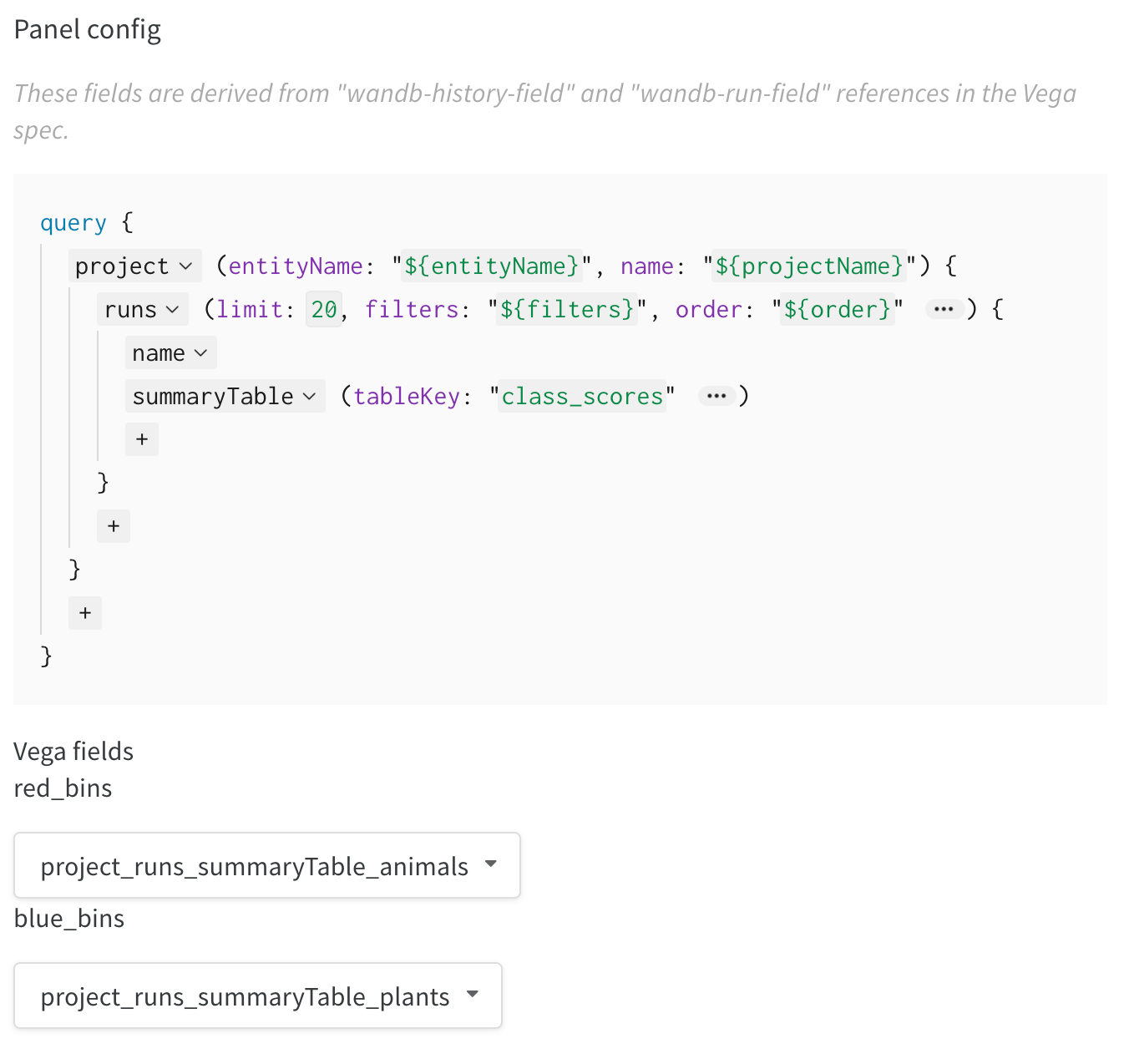
- 오른쪽 쿼리를 수정하여 wandb 로그에서 올바른 데이터를 로드합니다. 필드
summaryTable을 추가하고 해당tableKey를class_scores로 설정하여 run에서 기록한wandb.Table을 가져옵니다. 이렇게 하면 드롭다운 메뉴를 통해wandb.Table이class_scores로 기록된 열과 함께 두 개의 히스토그램 bin 세트 (red_bins및blue_bins)를 채울 수 있습니다. 내 예제에서는 빨간색 bin에 대한animal클래스 예측 점수와 파란색 bin에 대한plant를 선택했습니다. - 미리 보기 렌더링에서 보이는 플롯이 마음에 들 때까지 Vega 사양과 쿼리를 계속 변경할 수 있습니다. 완료되면 상단의 Save as를 클릭하고 나중에 재사용할 수 있도록 커스텀 플롯 이름을 지정합니다. 그런 다음 Apply from panel library를 클릭하여 플롯을 완료합니다.
다음은 매우 간단한 실험에서 얻은 결과입니다. 에포크에 대해 1000개의 예제만으로 트레이닝하면 대부분의 이미지가 식물이 아니고 어떤 이미지가 동물일 수 있는지 매우 불확실한 모델이 생성됩니다.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.