Create an experiment
4 minute read
W&B Python SDK를 사용하여 기계 학습 Experiments를 추적합니다. 그런 다음 인터랙티브 대시보드에서 결과를 검토하거나 W&B Public API를 사용하여 프로그래밍 방식으로 Python으로 데이터를 내보낼 수 있습니다.
이 가이드에서는 W&B 빌딩 블록을 사용하여 W&B Experiment를 만드는 방법을 설명합니다.
W&B Experiment를 만드는 방법
W&B Experiment를 만드는 4단계:
W&B run 초기화
wandb.init()를 사용하여 W&B Run을 만듭니다.
다음 코드 조각은 이 run을 식별하는 데 도움이 되도록 설명이 “My first experiment” 인 “cat-classification”이라는 W&B project에서 run을 만듭니다. 태그 “baseline” 및 “paper1”은 이 run이 향후 논문 출판을 위한 베이스라인 experiment임을 알려줍니다.
import wandb
with wandb.init(
project="cat-classification",
notes="My first experiment",
tags=["baseline", "paper1"],
) as run:
...
wandb.init()는 Run 오브젝트를 반환합니다.
wandb.init()를 호출할 때 해당 project가 이미 존재하는 경우 Run은 기존 project에 추가됩니다. 예를 들어 “cat-classification”이라는 project가 이미 있는 경우 해당 project는 계속 존재하며 삭제되지 않습니다. 대신 새 run이 해당 project에 추가됩니다.하이퍼파라미터 dictionary 캡처
학습률 또는 모델 유형과 같은 하이퍼파라미터 dictionary를 저장합니다. config에서 캡처하는 모델 설정은 나중에 결과를 구성하고 쿼리하는 데 유용합니다.
with wandb.init(
...,
config={"epochs": 100, "learning_rate": 0.001, "batch_size": 128},
) as run:
...
experiment를 구성하는 방법에 대한 자세한 내용은 Experiments 구성을 참조하십시오.
트레이닝 루프 내에서 메트릭 기록
run.log()를 호출하여 정확도 및 손실과 같은 각 트레이닝 단계에 대한 메트릭을 기록합니다.
model, dataloader = get_model(), get_data()
for epoch in range(run.config.epochs):
for batch in dataloader:
loss, accuracy = model.training_step()
run.log({"accuracy": accuracy, "loss": loss})
W&B로 기록할 수 있는 다양한 데이터 유형에 대한 자세한 내용은 Experiments 중 데이터 기록을 참조하십시오.
W&B에 아티팩트 기록
선택적으로 W&B Artifact를 기록합니다. Artifact를 사용하면 데이터셋과 Models를 쉽게 버전 관리할 수 있습니다.
# 모든 파일 또는 디렉토리를 저장할 수 있습니다. 이 예에서는 모델에 ONNX 파일을 출력하는
# save() 메소드가 있다고 가정합니다.
model.save("path_to_model.onnx")
run.log_artifact("path_to_model.onnx", name="trained-model", type="model")
Artifacts 또는 Registry에서 Models 버전 관리에 대해 자세히 알아보십시오.
모두 함께 놓기
이전 코드 조각이 포함된 전체 스크립트는 아래에서 찾을 수 있습니다.
import wandb
with wandb.init(
project="cat-classification",
notes="",
tags=["baseline", "paper1"],
# run의 하이퍼파라미터를 기록합니다.
config={"epochs": 100, "learning_rate": 0.001, "batch_size": 128},
) as run:
# 모델 및 데이터를 설정합니다.
model, dataloader = get_model(), get_data()
# 모델 성능을 시각화하기 위해 메트릭을 기록하면서 트레이닝을 실행합니다.
for epoch in range(run.config["epochs"]):
for batch in dataloader:
loss, accuracy = model.training_step()
run.log({"accuracy": accuracy, "loss": loss})
# 트레이닝된 모델을 아티팩트로 업로드합니다.
model.save("path_to_model.onnx")
run.log_artifact("path_to_model.onnx", name="trained-model", type="model")
다음 단계: experiment 시각화
W&B Dashboard를 기계 학습 모델의 결과를 구성하고 시각화하는 중앙 장소로 사용하십시오. 몇 번의 클릭만으로 평행 좌표 플롯, 파라미터 중요도 분석 및 기타와 같은 풍부한 인터랙티브 차트를 구성합니다.
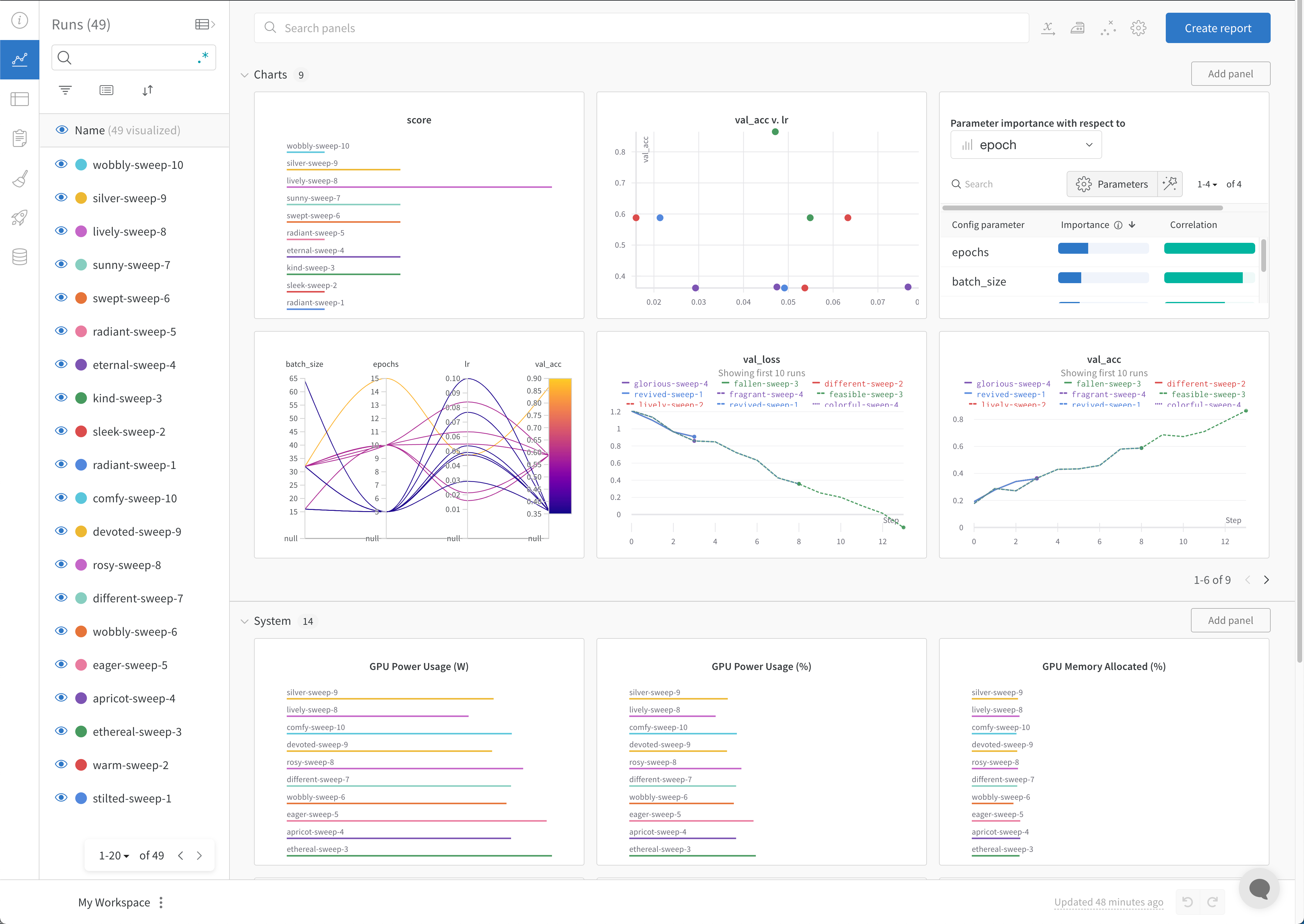
Experiments 및 특정 runs를 보는 방법에 대한 자세한 내용은 Experiments 결과 시각화를 참조하십시오.
모범 사례
다음은 Experiments를 만들 때 고려해야 할 몇 가지 제안된 지침입니다.
- Runs 완료: 코드가 완료되거나 예외가 발생하면 자동으로 run을 완료된 것으로 표시하려면
with문에서wandb.init()를 사용합니다.-
Jupyter 노트북에서는 Run 오브젝트를 직접 관리하는 것이 더 편리할 수 있습니다. 이 경우 Run 오브젝트에서
finish()를 명시적으로 호출하여 완료된 것으로 표시할 수 있습니다.# 노트북 셀에서: run = wandb.init() # 다른 셀에서: run.finish()
-
- Config: 하이퍼파라미터, 아키텍처, 데이터셋 및 모델을 재현하는 데 사용하려는 모든 항목을 추적합니다. 이러한 항목은 열에 표시됩니다. config 열을 사용하여 앱에서 runs를 동적으로 그룹화, 정렬 및 필터링합니다.
- Project: project는 함께 비교할 수 있는 experiment 집합입니다. 각 project에는 전용 대시보드 페이지가 제공되며, 다양한 모델 버전을 비교하기 위해 다양한 run 그룹을 쉽게 켜거나 끌 수 있습니다.
- Notes: 스크립트에서 직접 빠른 커밋 메시지를 설정합니다. W&B App에서 run의 개요 섹션에서 노트를 편집하고 엑세스합니다.
- Tags: 베이스라인 runs 및 즐겨찾는 runs를 식별합니다. 태그를 사용하여 runs를 필터링할 수 있습니다. W&B App의 project 대시보드의 개요 섹션에서 나중에 태그를 편집할 수 있습니다.
- Experiments를 비교하기 위해 여러 run 집합 만들기: Experiments를 비교할 때 메트릭을 쉽게 비교할 수 있도록 여러 run 집합을 만듭니다. 동일한 차트 또는 차트 그룹에서 run 집합을 켜거나 끌 수 있습니다.
다음 코드 조각은 위에 나열된 모범 사례를 사용하여 W&B Experiment를 정의하는 방법을 보여줍니다.
import wandb
config = {
"learning_rate": 0.01,
"momentum": 0.2,
"architecture": "CNN",
"dataset_id": "cats-0192",
}
with wandb.init(
project="detect-cats",
notes="tweak baseline",
tags=["baseline", "paper1"],
config=config,
) as run:
...
W&B Experiment를 정의할 때 사용할 수 있는 파라미터에 대한 자세한 내용은 API Reference Guide의 wandb.init API 문서를 참조하십시오.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.