これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
W&B App UI Reference
- 1: Panels
- 1.1: Line plots
- 1.1.1: Line plot reference
- 1.1.2: Point aggregation
- 1.1.3: Smooth line plots
- 1.2: Bar plots
- 1.3: Parallel coordinates
- 1.4: Scatter plots
- 1.5: Save and diff code
- 1.6: Parameter importance
- 1.7: Compare run metrics
- 1.8: Query panels
- 1.8.1: Embed objects
- 2: Custom charts
- 3: Manage workspace, section, and panel settings
- 4: Settings
- 4.1: Manage user settings
- 4.2: Manage billing settings
- 4.3: Manage team settings
- 4.4: Manage email settings
- 4.5: Manage teams
- 4.6: Manage storage
- 4.7: System metrics
- 4.8: Anonymous mode
1 - Panels
ワークスペース パネルの 可視化 を使用して、ログに記録された データ を キー ごとに探索し、 ハイパーパラメータ と出力 メトリクス の関係を 可視化 することができます。
ワークスペース のモード
W&B の プロジェクト は、2つの異なる ワークスペース モードをサポートしています。 ワークスペース 名の横にあるアイコンは、そのモードを示しています。
| アイコン | ワークスペース モード |
|---|---|
 |
自動 ワークスペース は、 プロジェクト で ログ されたすべての キー に対して パネル を自動的に生成します。 自動 ワークスペース を選択する:
|
 |
手動 ワークスペース は、空白の状態から始まり、 ユーザー が意図的に追加した パネル のみを表示します。 手動 ワークスペース を選択する:
|
ワークスペース での パネル の生成方法を変更するには、ワークスペース をリセットします。
ワークスペース への変更を元に戻す
ワークスペース への変更を元に戻すには、[元に戻す] ボタン (左を指す矢印) をクリックするか、CMD + Z (macOS) または CTRL + Z (Windows / Linux) を入力します。ワークスペース のリセット
ワークスペース をリセットするには:
- ワークスペース の上部にあるアクション メニュー
...をクリックします。 - ワークスペース をリセット をクリックします。
ワークスペース のレイアウトを 設定
ワークスペース のレイアウトを 設定 するには、 ワークスペース の上部にある Settings をクリックし、次に Workspace layout をクリックします。
- 検索中に空のセクションを非表示にする (デフォルトでオン)
- パネル をアルファベット順に並べ替える (デフォルトでオフ)
- セクション構成 (デフォルトでは最初の プレフィックス でグループ化)。 この 設定 を変更するには:
- 南京錠アイコンをクリックします。
- セクション内の パネル をグループ化する方法を選択します。
ワークスペース の折れ線 プロット のデフォルトを 設定 するには、折れ線 プロット を参照してください。
セクションのレイアウトを 設定 する
セクションのレイアウトを 設定 するには、歯車アイコンをクリックし、次に Display preferences をクリックします。
- ツールチップ で色付きの run 名をオンまたはオフにする (デフォルトでオン)
- コンパニオン チャート のツールチップにハイライトされた run のみを表示する (デフォルトでオフ)
- ツールチップ に表示される run の数 (単一の run 、すべての run 、または Default)
- プライマリ チャート のツールチップ に完全な run 名を表示する (デフォルトでオフ)
パネル をフルスクリーン モード で表示する
フルスクリーン モード では、 run セレクター が表示され、 パネル は、通常 1000 バケットではなく、10,000 バケットの高精度サンプリング モード プロット を使用します。
パネル をフルスクリーン モード で表示するには:
- パネル の上にマウスを置きます。
- パネル のアクション メニュー
...をクリックし、次にファインダーまたは正方形の4つの角を示すアウトラインのようなフルスクリーン ボタンをクリックします。
- フルスクリーン モード で表示中に パネル を共有すると、表示されるリンクは自動的にフルスクリーン モード で開きます。
フルスクリーン モード から パネル の ワークスペース に戻るには、 ページ の上部にある左向きの矢印をクリックします。
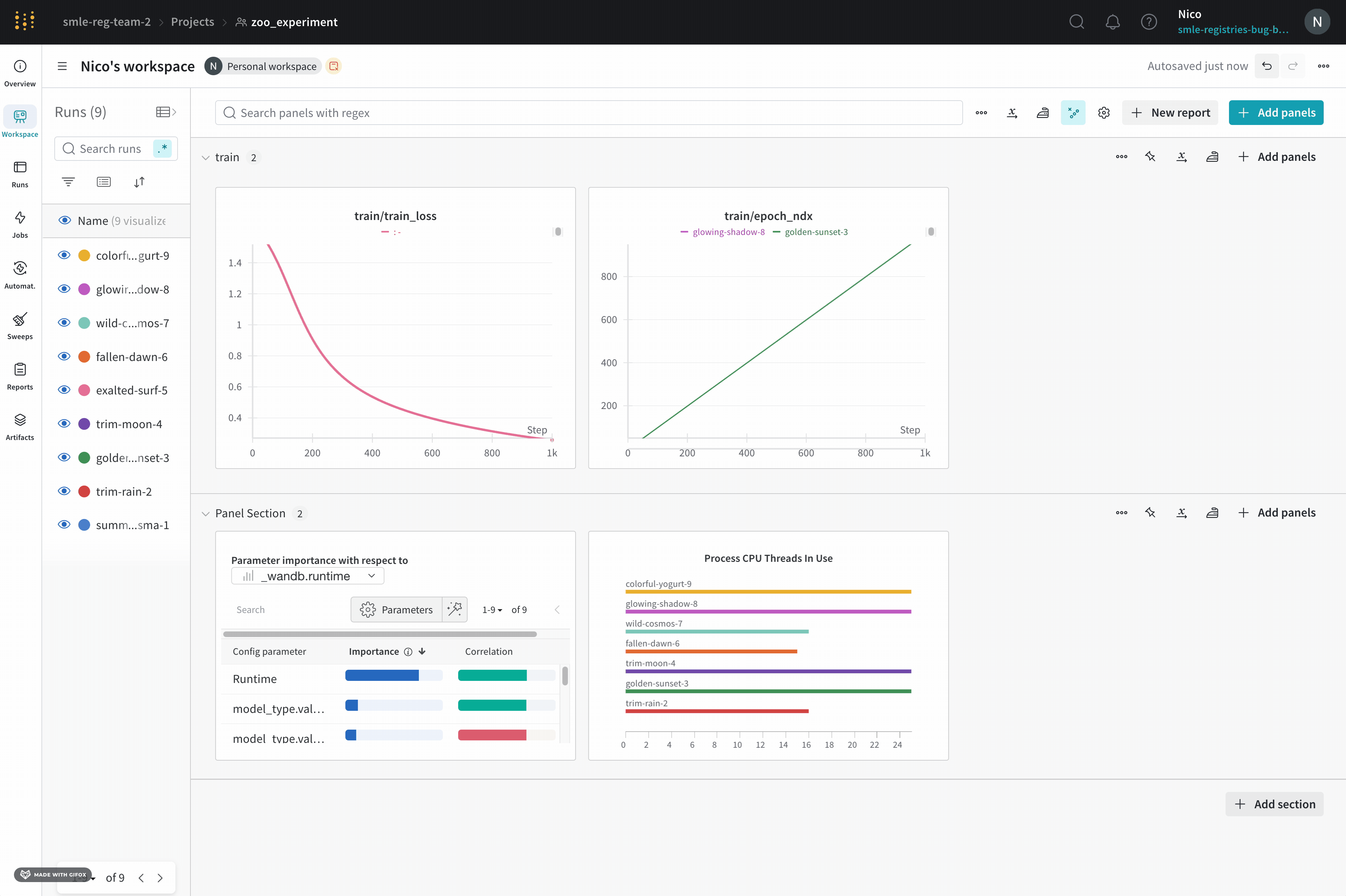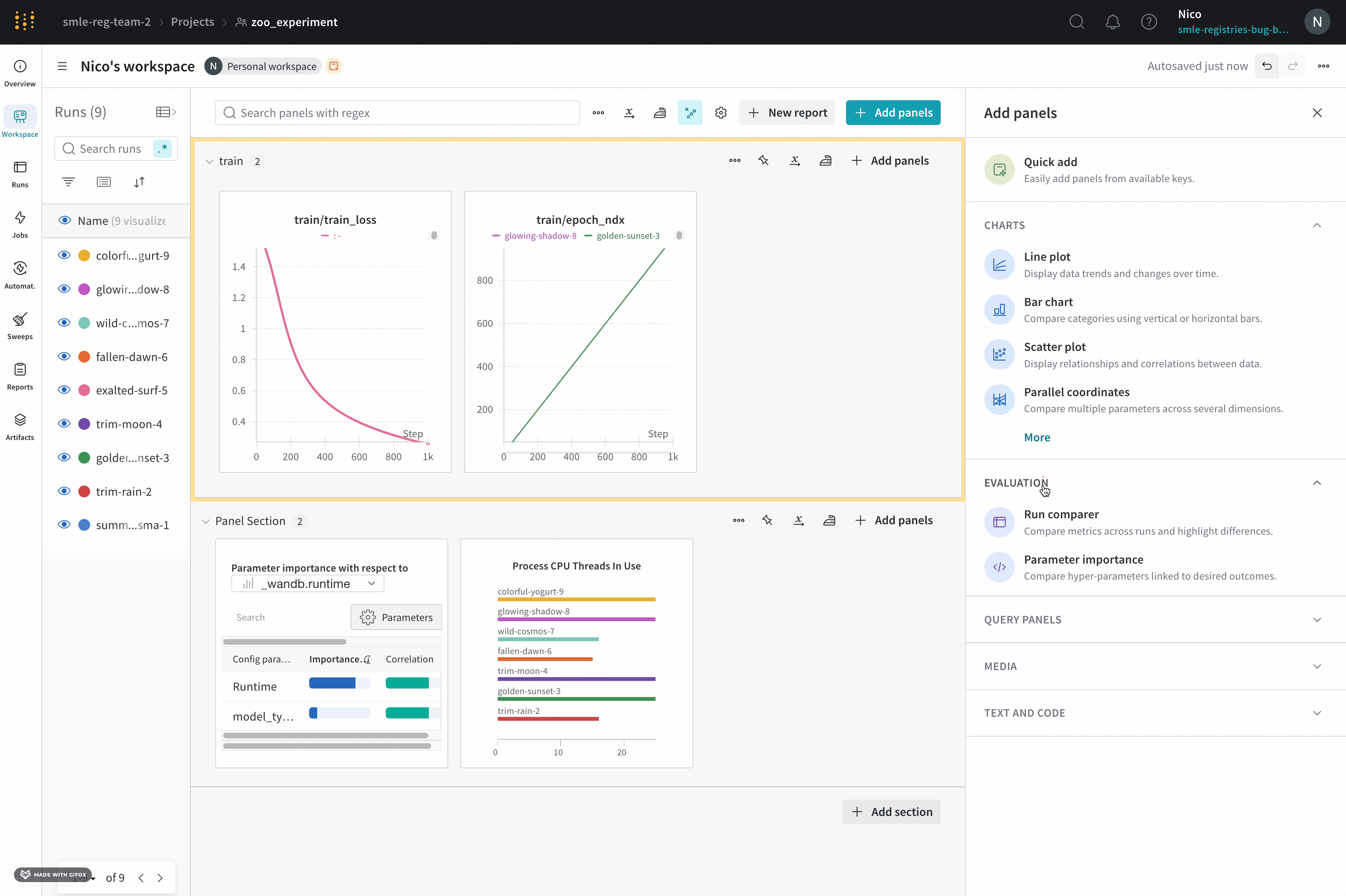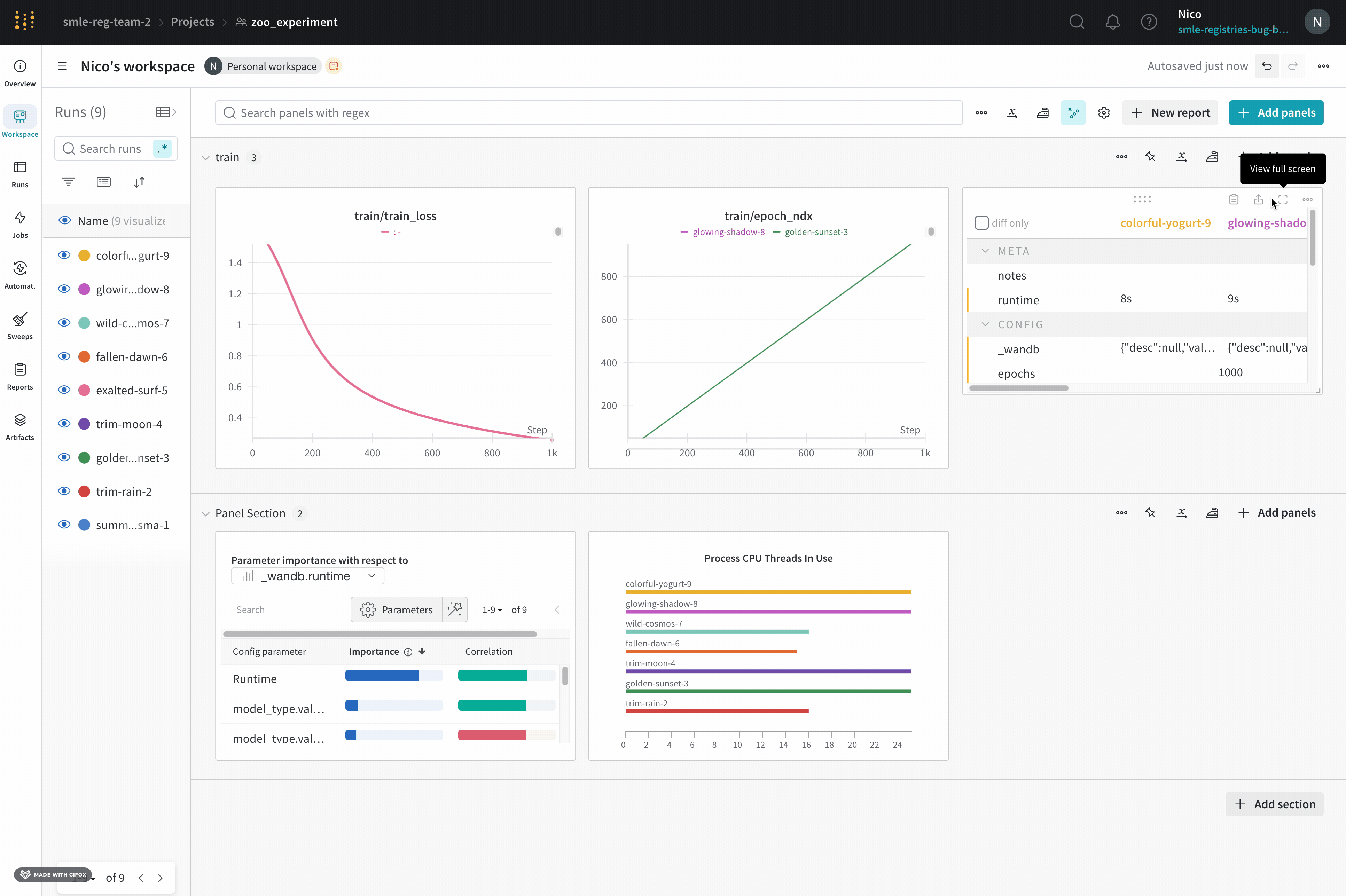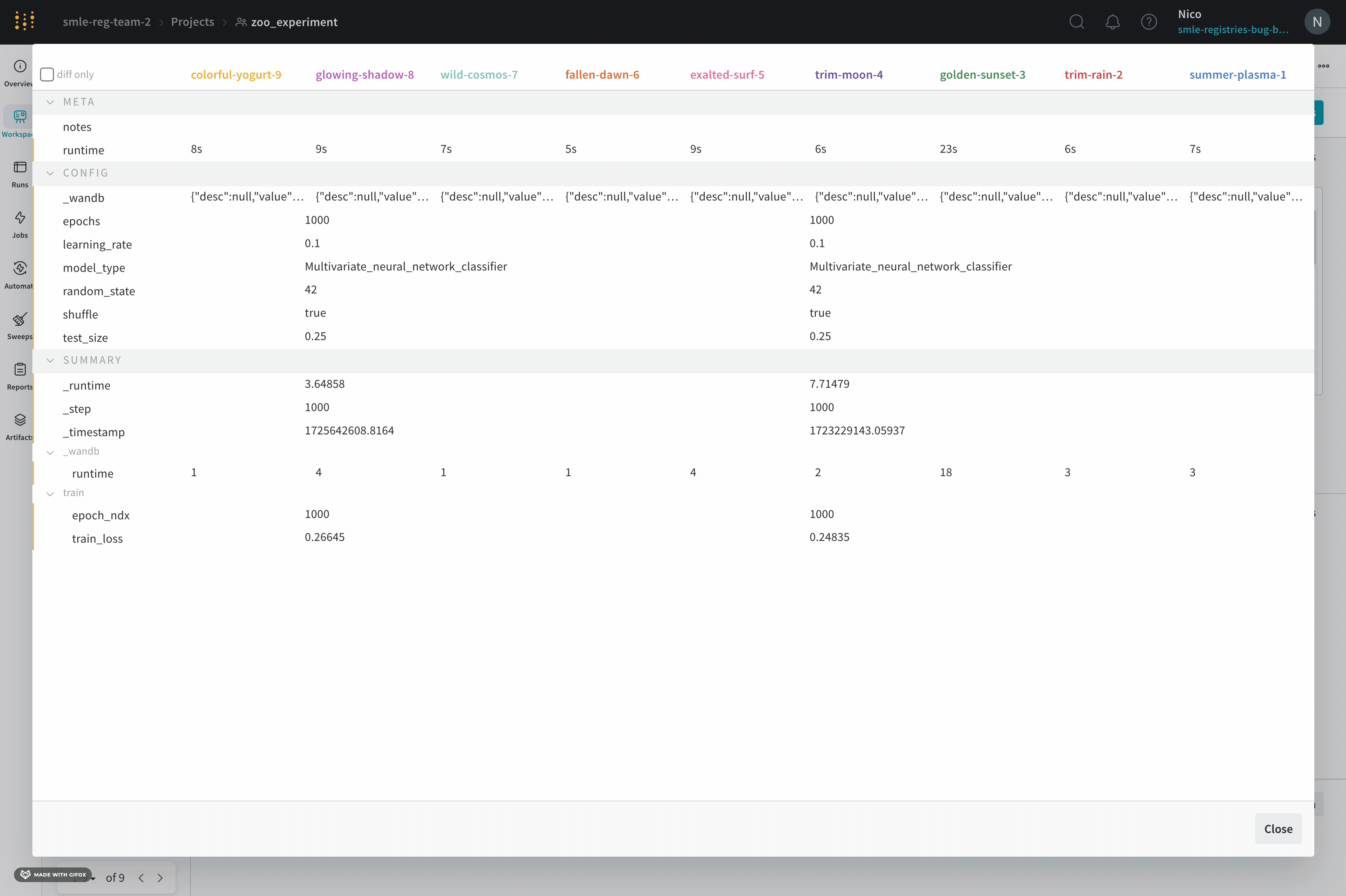
パネル の追加
このセクションでは、 ワークスペース に パネル を追加するさまざまな方法を示します。
パネル を手動で追加する
グローバル またはセクション レベルで、 ワークスペース に パネル を1つずつ追加します。
- パネル をグローバルに追加するには、 パネル 検索フィールドの近くにあるコントロール バーの Add panels をクリックします。
- 代わりに パネル をセクションに直接追加するには、セクションのアクション
...メニューをクリックし、次に + Add panels をクリックします。 - チャート など、追加する パネル のタイプを選択します。 パネル の 設定 詳細が表示され、デフォルトが選択されています。
- 必要に応じて、 パネル とその表示 設定 をカスタマイズします。 設定 オプションは、選択する パネル のタイプによって異なります。 各タイプの パネル のオプションの詳細については、以下の関連セクション (たとえば、折れ線 プロット または棒グラフ) を参照してください。
- Apply をクリックします。
パネル をクイック追加する
Quick add を使用して、選択した キー ごとに パネル をグローバル またはセクション レベルで自動的に追加します。
- Quick add を使用して パネル をグローバルに追加するには、 パネル 検索フィールドの近くにあるコントロール バーの Add panels をクリックし、次に Quick add をクリックします。
- Quick add を使用して パネル をセクションに直接追加するには、セクションのアクション
...メニューをクリックし、Add panels をクリックして、次に Quick add をクリックします。 - パネル のリストが表示されます。 チェックマークが付いている各 パネル は、すでに ワークスペース に含まれています。
- 利用可能なすべての パネル を追加するには、リストの上部にある Add
panels ボタンをクリックします。 Quick Add リストが閉じ、新しい パネル が ワークスペース に表示されます。 - リストから個々の パネル を追加するには、 パネル の行の上にマウスを置き、次に Add をクリックします。 追加する パネル ごとにこの手順を繰り返し、右上にある X をクリックして Quick Add リストを閉じます。 新しい パネル が ワークスペース に表示されます。
- 利用可能なすべての パネル を追加するには、リストの上部にある Add
- 必要に応じて、 パネル の 設定 をカスタマイズします。
パネル の共有
このセクションでは、リンクを使用して パネル を共有する方法を示します。
リンクを使用して パネル を共有するには、次のいずれかを実行します。
- パネル をフルスクリーン モード で表示しているときに、ブラウザから URL をコピーします。
- アクション メニュー
...をクリックし、Copy panel URL を選択します。
リンクを ユーザー または チーム と共有します。 ユーザー がリンクに アクセス すると、 パネル がフルスクリーン モード で開きます。
フルスクリーン モード から パネル の ワークスペース に戻るには、 ページ の上部にある左向きの矢印をクリックします。
プログラムで パネル のフルスクリーン リンクを作成する
オートメーション の作成など、特定の状況では、 パネル のフルスクリーン URL を含めると便利な場合があります。 このセクションでは、 パネル のフルスクリーン URL の形式を示します。 以下の例では、エンティティ 、 プロジェクト 、 パネル 、およびセクション名を角かっこで囲んで置き換えます。
https://wandb.ai/<ENTITY_NAME>/<PROJECT_NAME>?panelDisplayName=<PANEL_NAME>&panelSectionName=<SECTON_NAME>
同じセクション内の複数の パネル が同じ名前を持つ場合、この URL はその名前の最初の パネル を開きます。
ソーシャル メディア で パネル を埋め込むか共有する
Webサイトに パネル を埋め込んだり、ソーシャル メディア で共有したりするには、リンクを知っている人なら誰でも パネル を表示できる必要があります。 プロジェクト がプライベートの場合、 プロジェクト の メンバー のみ パネル を表示できます。 プロジェクト がパブリックの場合、リンクを知っている人なら誰でも パネル を表示できます。
ソーシャル メディア で パネル を埋め込んだり共有したりするための コード を取得するには:
- ワークスペース から、 パネル の上にマウスを置き、次にアクション メニュー
...をクリックします。 - Share タブをクリックします。
- Only those who are invited have access を Anyone with the link can view に変更します。 そうしないと、次の手順の選択肢は使用できません。
- Share on Twitter 、 Share on Reddit 、 Share on LinkedIn 、または Copy embed link を選択します。
パネル レポート をメールで送信する
スタンドアロン レポート として単一の パネル をメールで送信するには:
- パネル の上にマウスを置き、次に パネル のアクション メニュー
...をクリックします。 - Share panel in report をクリックします。
- Invite タブを選択します。
- メール アドレス または ユーザー 名を入力します。
- 必要に応じて、can view を can edit に変更します。
- Invite をクリックします。 W&B は、共有している パネル のみを含む レポート へのクリック可能なリンクを記載したメールを ユーザー に送信します。
パネル を共有する場合とは異なり、受信者はこの レポート から ワークスペース にアクセスできません。
パネル の管理
パネル の編集
パネル を編集するには:
- 鉛筆アイコンをクリックします。
- パネル の 設定 を変更します。
- パネル を別のタイプに変更するには、タイプを選択してから 設定 を 設定 します。
- Apply をクリックします。
パネル の移動
パネル を別のセクションに移動するには、 パネル のドラッグ ハンドルを使用できます。 代わりに、リストから新しいセクションを選択するには:
- 必要に応じて、最後のセクションの後に Add section をクリックして、新しいセクションを作成します。
- パネル のアクション
...メニューをクリックします。 - Move をクリックし、次に新しいセクションを選択します。
ドラッグ ハンドルを使用して、セクション内の パネル を再配置することもできます。
パネル の複製
パネル を複製するには:
- パネル の上部にあるアクション
...メニューをクリックします。 - Duplicate をクリックします。
必要に応じて、複製された パネル をカスタマイズまたは移動できます。
パネル の削除
パネル を削除するには:
- パネル の上にマウスを置きます。
- アクション
...メニューを選択します。 - Delete をクリックします。
手動 ワークスペース からすべての パネル を削除するには、アクション ... メニューをクリックし、次に Clear all panels をクリックします。
自動または手動 ワークスペース からすべての パネル を削除するには、ワークスペース をリセットできます。 デフォルトの パネル セットで開始するには Automatic を選択し、 パネル のない空の ワークスペース で開始するには Manual を選択します。
セクションの管理
デフォルトでは、 ワークスペース のセクションには、 キー の ログ 階層が反映されます。 ただし、手動 ワークスペース では、セクションは パネル の追加を開始した後にのみ表示されます。
セクションの追加
セクションを追加するには、最後のセクションの後に Add section をクリックします。
既存のセクションの前または後に新しいセクションを追加するには、代わりにセクションのアクション ... メニューをクリックし、次に New section below または New section above をクリックします。
セクションの パネル の管理
多数の パネル を含むセクションは、Standard grid レイアウトを使用している場合、デフォルトで ページ 分割されます。 ページ 上の パネル のデフォルトの数は、 パネル の 設定 とセクション内の パネル のサイズによって異なります。
- セクションで使用されているレイアウトを確認するには、セクションのアクション
...メニューをクリックします。 セクションのレイアウトを変更するには、Layout grid セクションで Standard grid または Custom grid を選択します。 - パネル のサイズを変更するには、 パネル の上にマウスを置き、ドラッグ ハンドルをクリックしてドラッグし、 パネル のサイズを調整します。
- セクションで Standard grid が使用されている場合、1つの パネル のサイズを変更すると、セクション内のすべての パネル のサイズが変更されます。
- セクションで Custom grid が使用されている場合、各 パネル のサイズを個別にカスタマイズできます。
- セクションが ページ 分割されている場合は、 ページ に表示する パネル の数をカスタマイズできます。
- セクションの上部にある 1 to
of をクリックします。ここで、<X>は表示されている パネル の数、<Y>は パネル の合計数です。 - ページ ごとに表示する パネル の数 (最大100) を選択します。
- 多数の パネル がある場合にすべての パネル を表示するには、Custom grid レイアウトを使用するように パネル を 設定 します。 セクションのアクション
...メニューをクリックし、次に Layout grid セクションで Custom grid を選択します - セクションから パネル を削除するには:
- パネル の上にマウスを置き、次にアクション
...メニューをクリックします。 - Delete をクリックします。
ワークスペース を自動 ワークスペース にリセットすると、削除されたすべての パネル が再び表示されます。
セクションの名前を変更する
セクションの名前を変更するには、アクション ... メニューをクリックし、次に Rename section をクリックします。
セクションの削除
セクションを削除するには、... メニューをクリックし、次に Delete section をクリックします。 これにより、セクションとその パネル が削除されます。
1.1 - Line plots
折れ線グラフは、wandb.log() で時間の経過とともにメトリクスをプロットすると、デフォルトで表示されます。チャートの設定をカスタマイズして、同じプロット上に複数の線を比較したり、カスタム軸を計算したり、ラベルの名前を変更したりできます。
折れ線グラフの設定を編集する
このセクションでは、個々の折れ線グラフ パネル、セクション内のすべての折れ線グラフ パネル、またはワークスペース内のすべての折れ線グラフ パネルの設定を編集する方法について説明します。
wandb.log() の呼び出しでログに記録されていることを確認してください。個々の折れ線グラフ
折れ線グラフの個々の設定は、セクションまたはワークスペースの折れ線グラフの設定よりも優先されます。折れ線グラフをカスタマイズするには:
- マウスをパネルの上に置き、歯車アイコンをクリックします。
- 表示されるモーダル内で、タブを選択して 設定 を編集します。
- 適用 をクリックします。
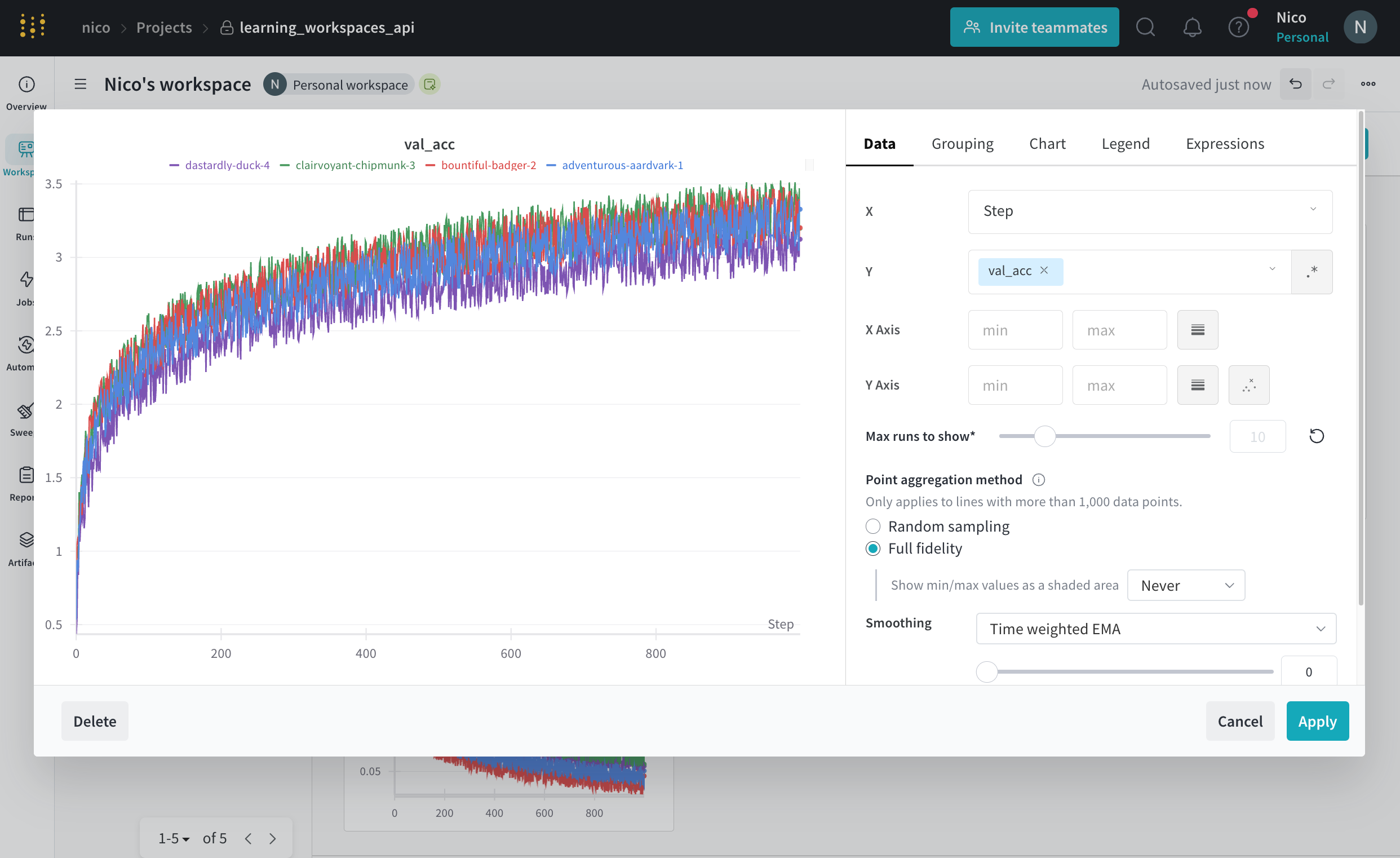
折れ線グラフの設定
折れ線グラフでは、次の設定を構成できます。
日付: プロットのデータの表示に関する詳細を構成します。
- X: X 軸に使用する値を選択します (デフォルトは ステップ)。X 軸を 相対時間 に変更するか、W&B でログに記録した値に基づいてカスタム軸を選択できます。
- 相対時間 (Wall) は、プロセスが開始してからのクロック時間です。したがって、run を開始して 1 日後に再開し、何かをログに記録した場合、24 時間後にプロットされます。
- 相対時間 (プロセス) は、実行中のプロセス内の時間です。したがって、run を開始して 10 秒間実行し、1 日後に再開した場合、そのポイントは 10 秒でプロットされます。
- Wall Time は、グラフ上の最初の run の開始からの経過時間 (分) です。
- ステップ は、デフォルトで
wandb.log()が呼び出されるたびに増分され、モデルからログに記録したトレーニング ステップの数を反映することになっています。
- Y: メトリクスや時間の経過とともに変化するハイパーパラメーターなど、ログに記録された値から 1 つ以上の Y 軸を選択します。
- X 軸 および Y 軸 の最小値と最大値 (オプション)。
- ポイント集計メソッド。ランダム サンプリング (デフォルト) または フル フィデリティ。 サンプリング を参照してください。
- スムージング: 折れ線グラフのスムージングを変更します。デフォルトは 時間加重 EMA です。その他の値には、スムージングなし、移動平均、および ガウス があります。
- 外れ値: デフォルトのプロットの最小スケールと最大スケールから外れ値を排除するようにリスケールします。
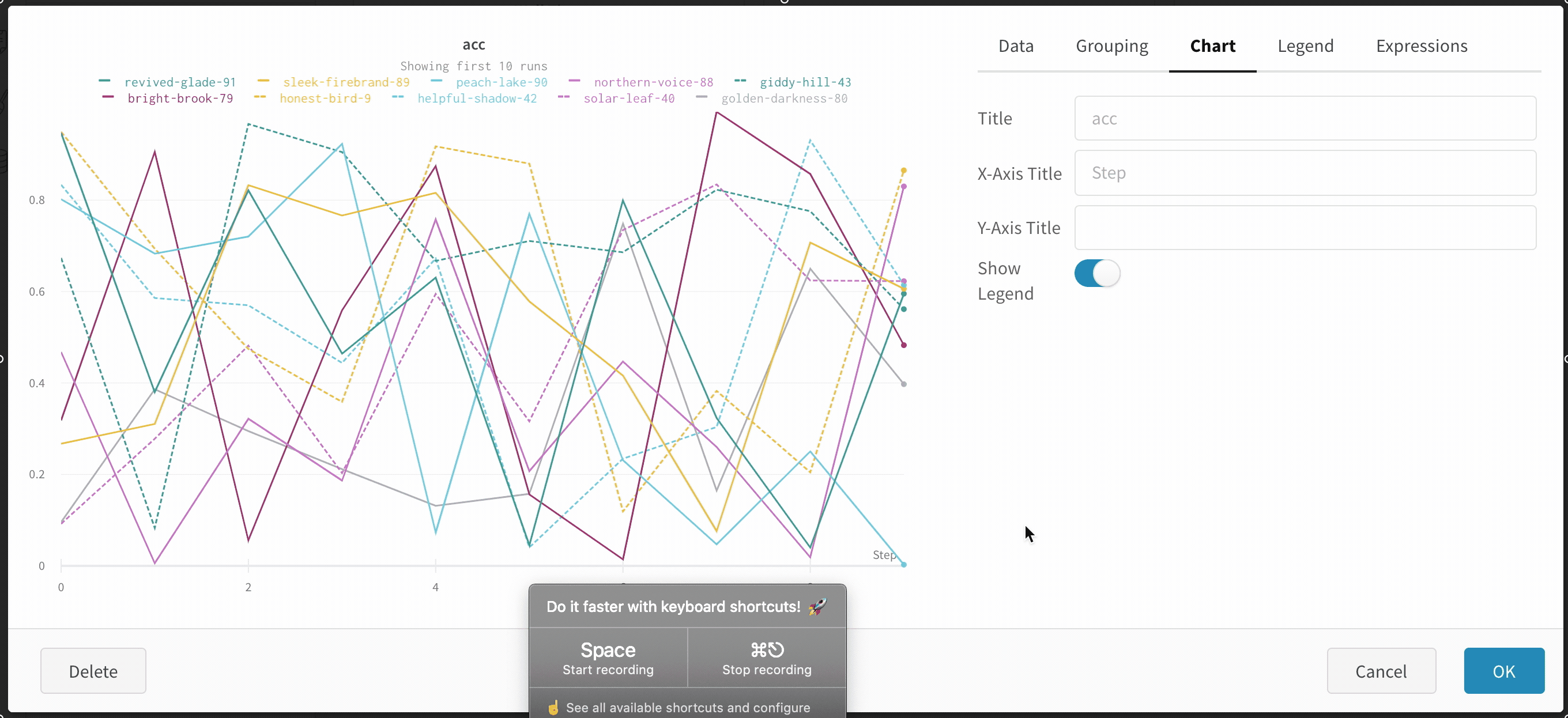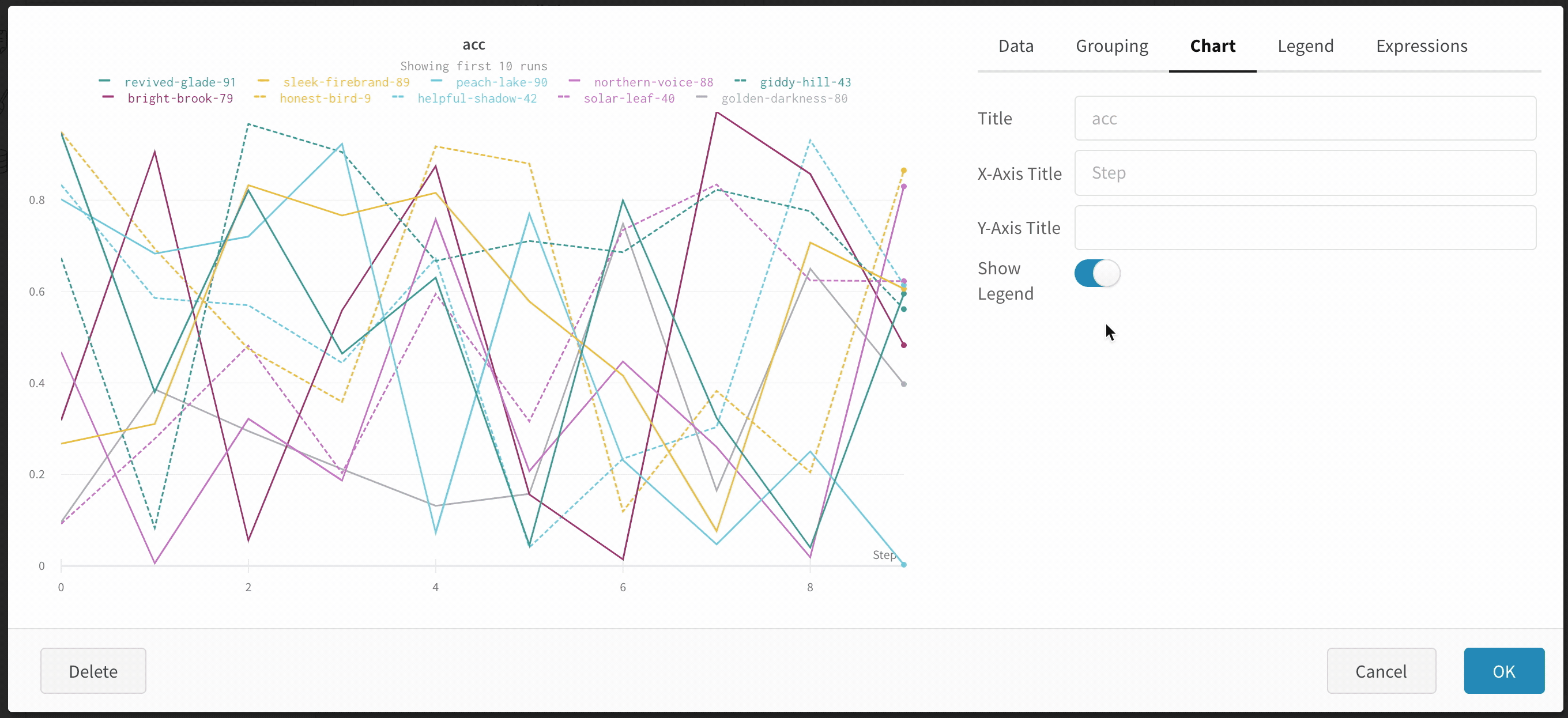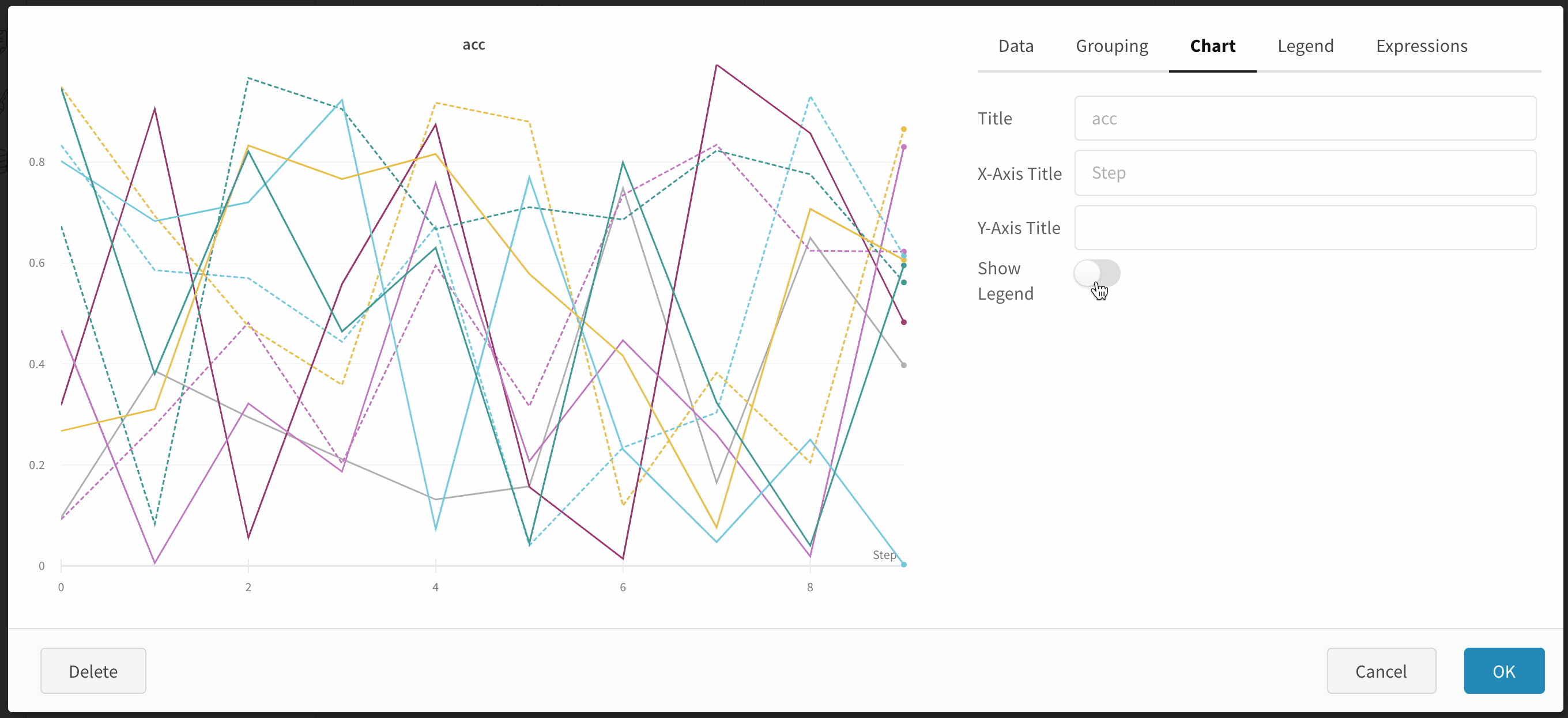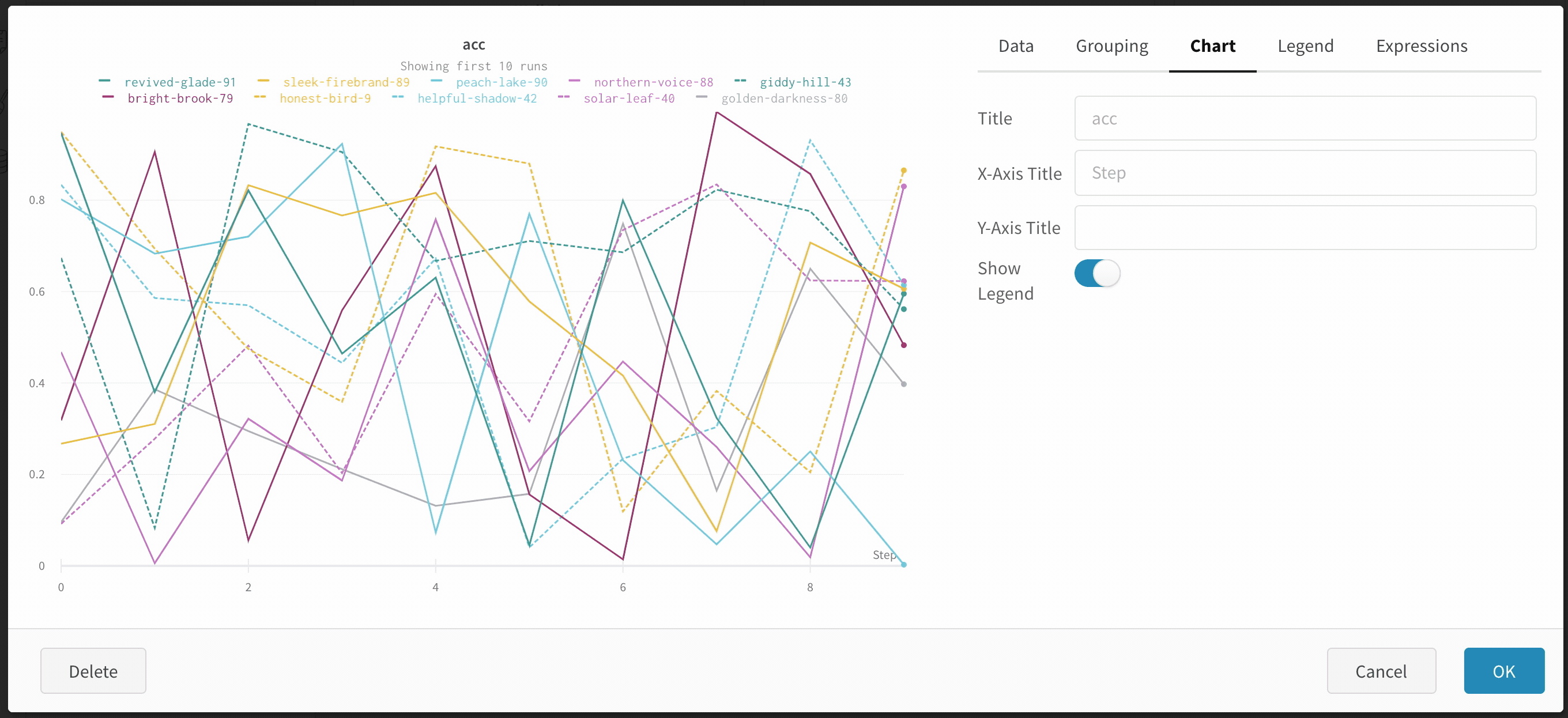
- run またはグループの最大数: この数を増やすことで、折れ線グラフに一度に表示される線を増やします。デフォルトは 10 runs です。利用可能な run が 10 よりも多いが、グラフが表示数を制限している場合、チャートの上部に「最初の 10 runs を表示」というメッセージが表示されます。
- チャートの種類: 折れ線グラフ、面グラフ、およびパーセンテージ面グラフを切り替えます。
グループ化: プロットで run をグループ化および集計するかどうか、またその方法を構成します。
- グループ化: 列を選択すると、その列に同じ値を持つすべての run がグループ化されます。
- 集計: 集計—グラフ上の線の値。オプションは、グループの平均、中央値、最小値、および最大値です。
チャート: パネル、X 軸、Y 軸、および -軸のタイトルを指定し、凡例の表示/非表示を切り替え、その位置を構成します。
凡例: パネルの凡例の外観をカスタマイズします (有効になっている場合)。
- 凡例: プロットの凡例の各線の凡例のフィールド。
- 凡例テンプレート: 凡例の完全にカスタマイズ可能なテンプレートを定義します。線のプロットの上部にあるテンプレートに表示するテキストと変数、およびマウスをプロットの上に置いたときに表示される凡例を正確に指定します。
式: カスタム計算式をパネルに追加します。
- Y 軸式: 計算されたメトリクスをグラフに追加します。ログに記録されたメトリクスのいずれか、およびハイパーパラメーターなどの設定値を使用して、カスタム線を計算できます。
- X 軸式: カスタム式を使用して計算された値を使用するように X 軸をリスケールします。役立つ変数には、デフォルトの X 軸の **_step** が含まれ、要約値を参照するための構文は
${summary:value}です。
セクション内のすべての折れ線グラフ
セクション内のすべての折れ線グラフのデフォルト設定をカスタマイズするには、折れ線グラフのワークスペース設定をオーバーライドします。
- セクションの歯車アイコンをクリックして、その設定を開きます。
- 表示されるモーダル内で、データ または 表示設定 タブを選択して、セクションのデフォルト設定を構成します。各 データ 設定の詳細については、前のセクション 個々の折れ線グラフ を参照してください。各表示設定の詳細については、セクション レイアウトの構成 を参照してください。
ワークスペース内のすべての折れ線グラフ
ワークスペース内のすべての折れ線グラフのデフォルト設定をカスタマイズするには:
- ワークスペースの設定をクリックします。これには、設定 というラベルの付いた歯車が付いています。
- 折れ線グラフ をクリックします。
- 表示されるモーダル内で、データ または 表示設定 タブを選択して、ワークスペースのデフォルト設定を構成します。
-
各 データ 設定の詳細については、前のセクション 個々の折れ線グラフ を参照してください。
-
各 表示設定 セクションの詳細については、ワークスペースの表示設定 を参照してください。ワークスペース レベルでは、折れ線グラフのデフォルトの ズーム の振る舞いを構成できます。この設定は、一致する X 軸キーを持つ折れ線グラフ間でズームを同期するかどうかを制御します。デフォルトでは無効になっています。
-
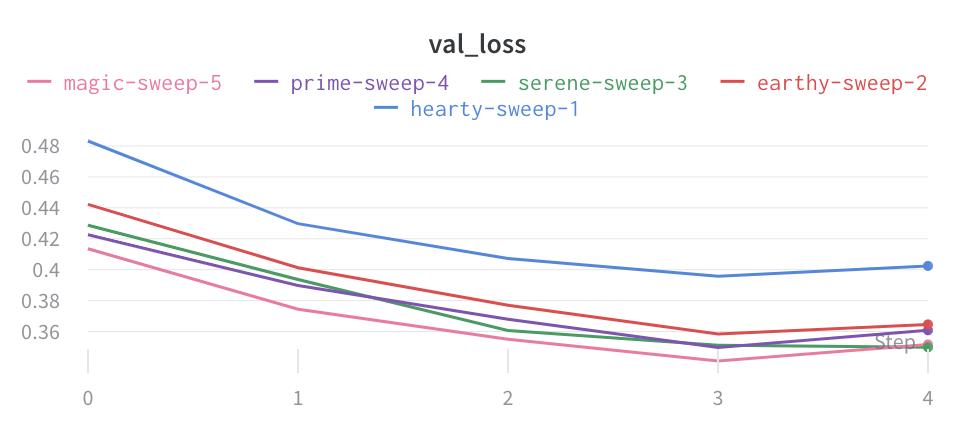
プロット上の平均値を可視化する
いくつかの異なる Experiments があり、プロット上の値の平均を表示する場合は、テーブルのグループ化機能を使用できます。run テーブルの上にある [グループ] をクリックし、[すべて] を選択して、グラフに平均値を表示します。
平均化する前のグラフは次のようになります。
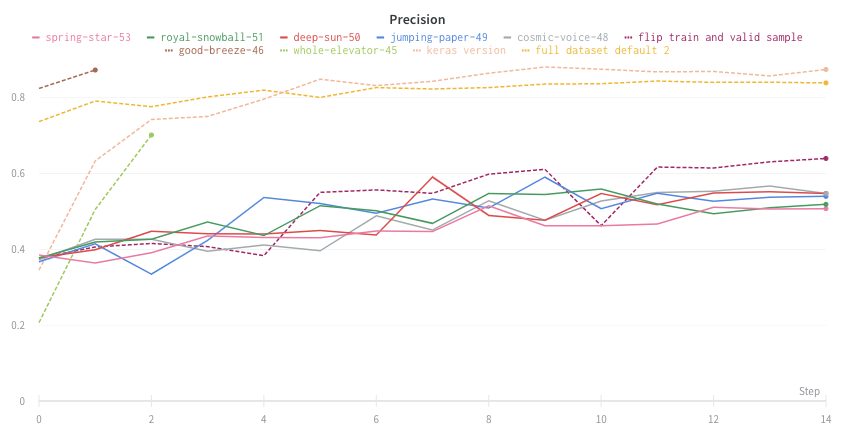
次の画像は、グループ化された線を使用して runs 全体の平均値を表すグラフを示しています。
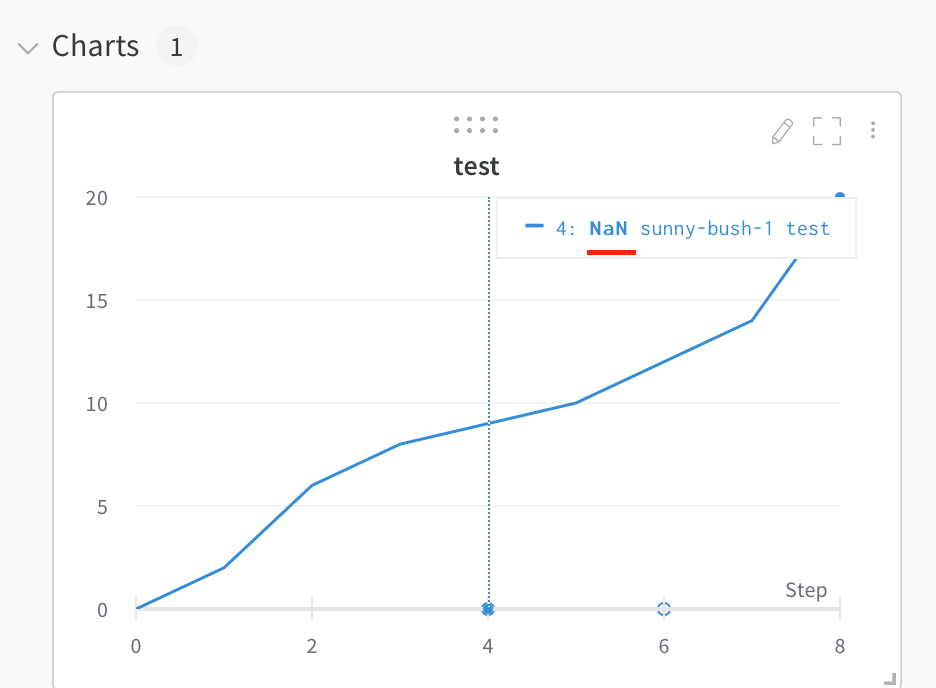
プロット上の NaN 値を可視化する
wandb.log を使用して、PyTorch テンソルを含む NaN 値を折れ線グラフにプロットすることもできます。例:
wandb.log({"test": [..., float("nan"), ...]})
1 つのチャートで 2 つのメトリクスを比較する
- ページの右上隅にある パネルを追加 ボタンを選択します。
- 表示される左側のパネルから、[評価] ドロップダウンを展開します。
- Run comparer を選択します。
折れ線グラフの色を変更する
runs のデフォルトの色が比較に役立たない場合があります。これを克服するために、wandb には、手動で色を変更できる 2 つのインスタンスが用意されています。
各 run には、初期化時にデフォルトでランダムな色が割り当てられます。

いずれかの色をクリックすると、カラー パレットが表示され、そこから必要な色を手動で選択できます。
- 設定を編集するパネルの上にマウスを置きます。
- 表示される鉛筆アイコンを選択します。
- [凡例] タブを選択します。
異なる X 軸で可視化する
実験にかかった絶対時間を確認したり、実験が実行された曜日を確認したりする場合は、X 軸を切り替えることができます。ステップから相対時間、そして Wall Time に切り替える例を次に示します。
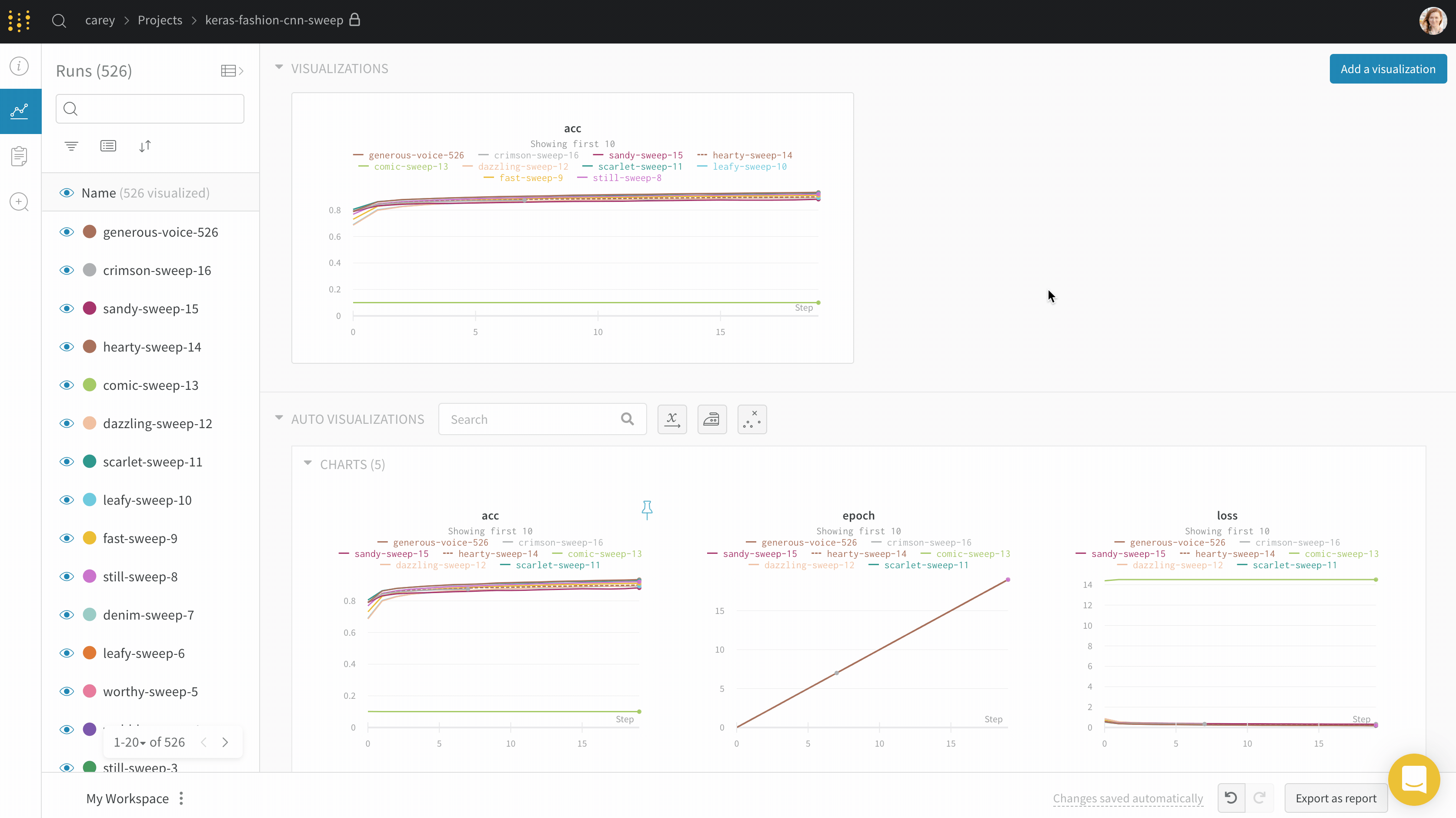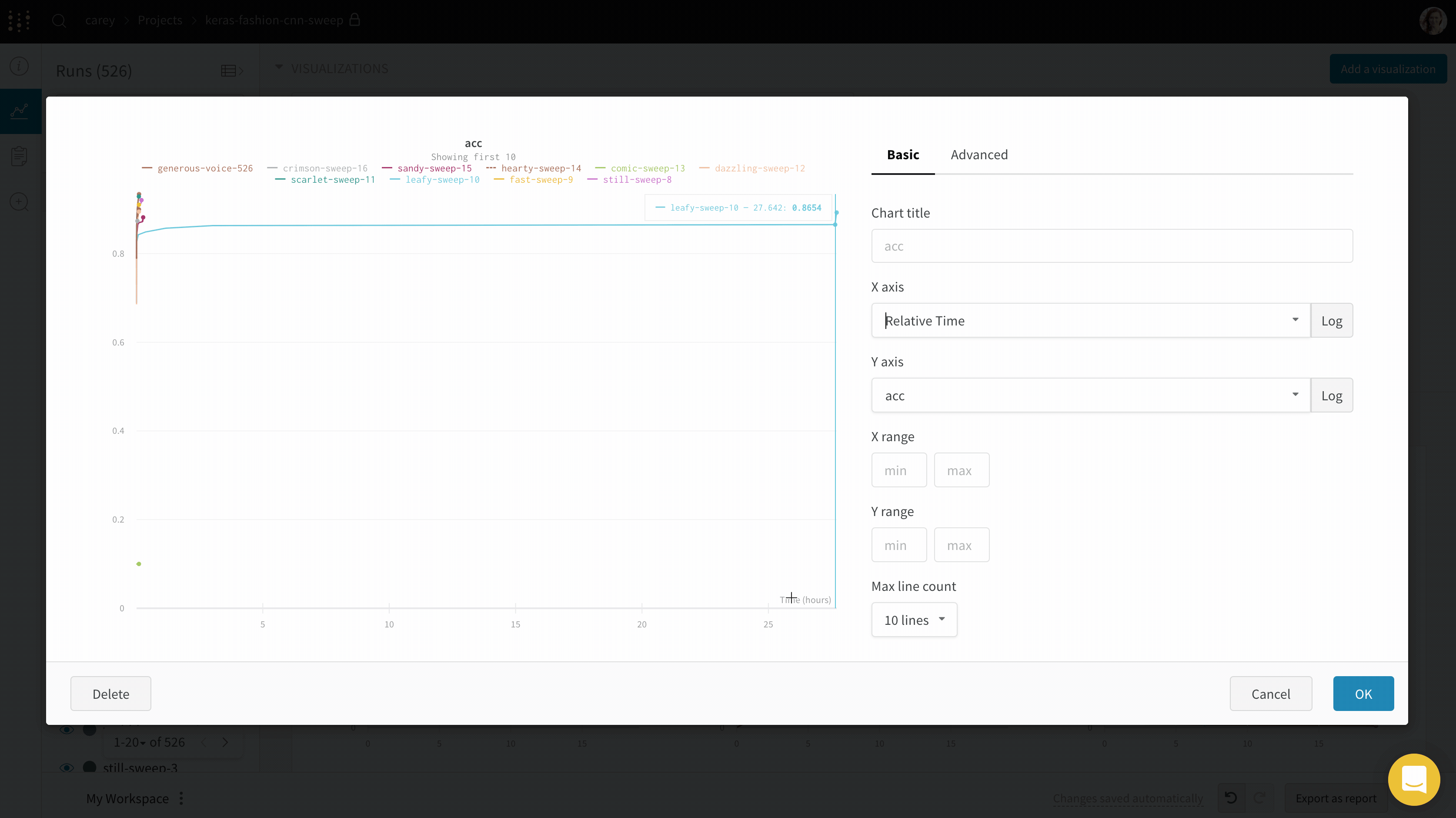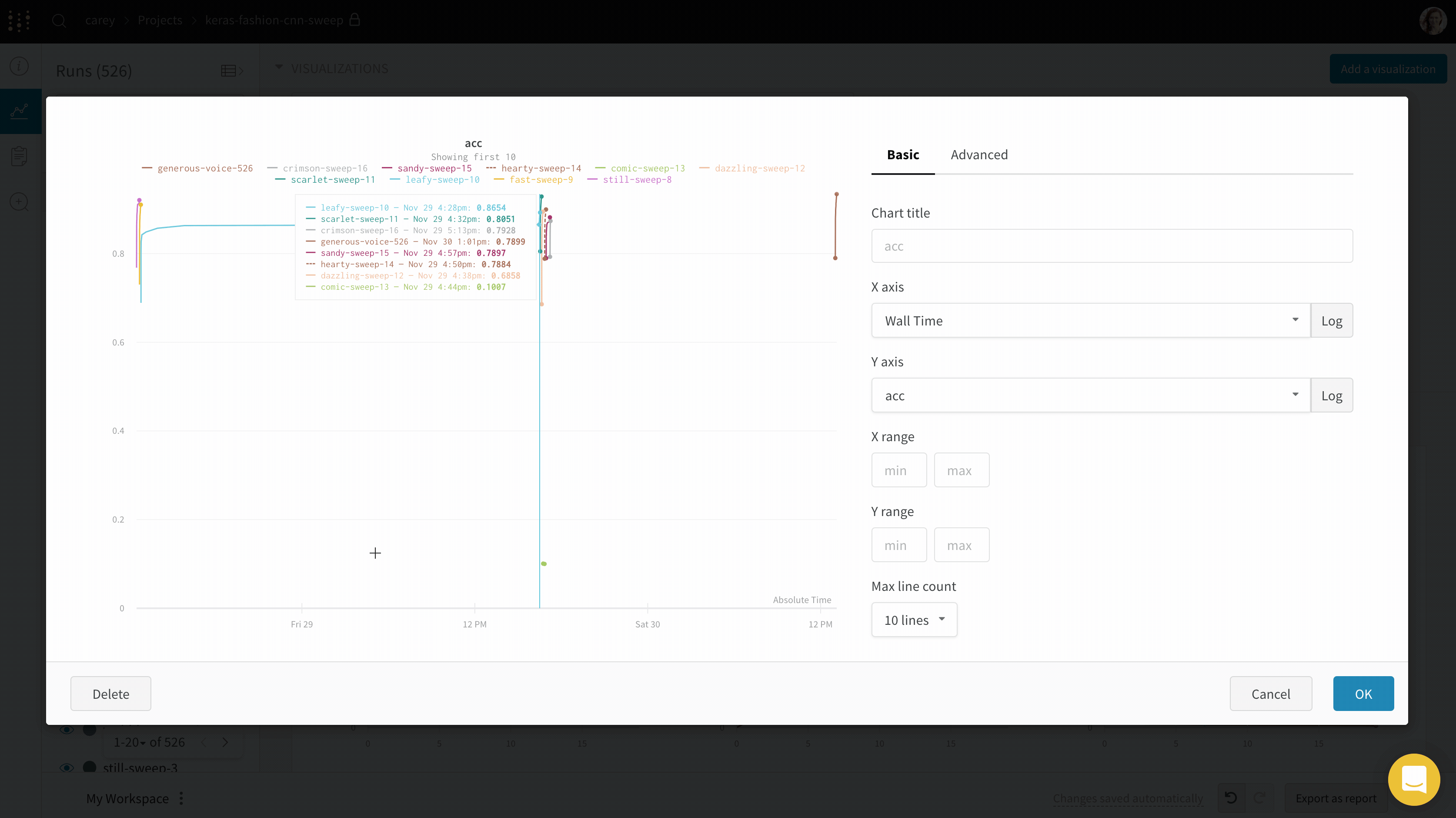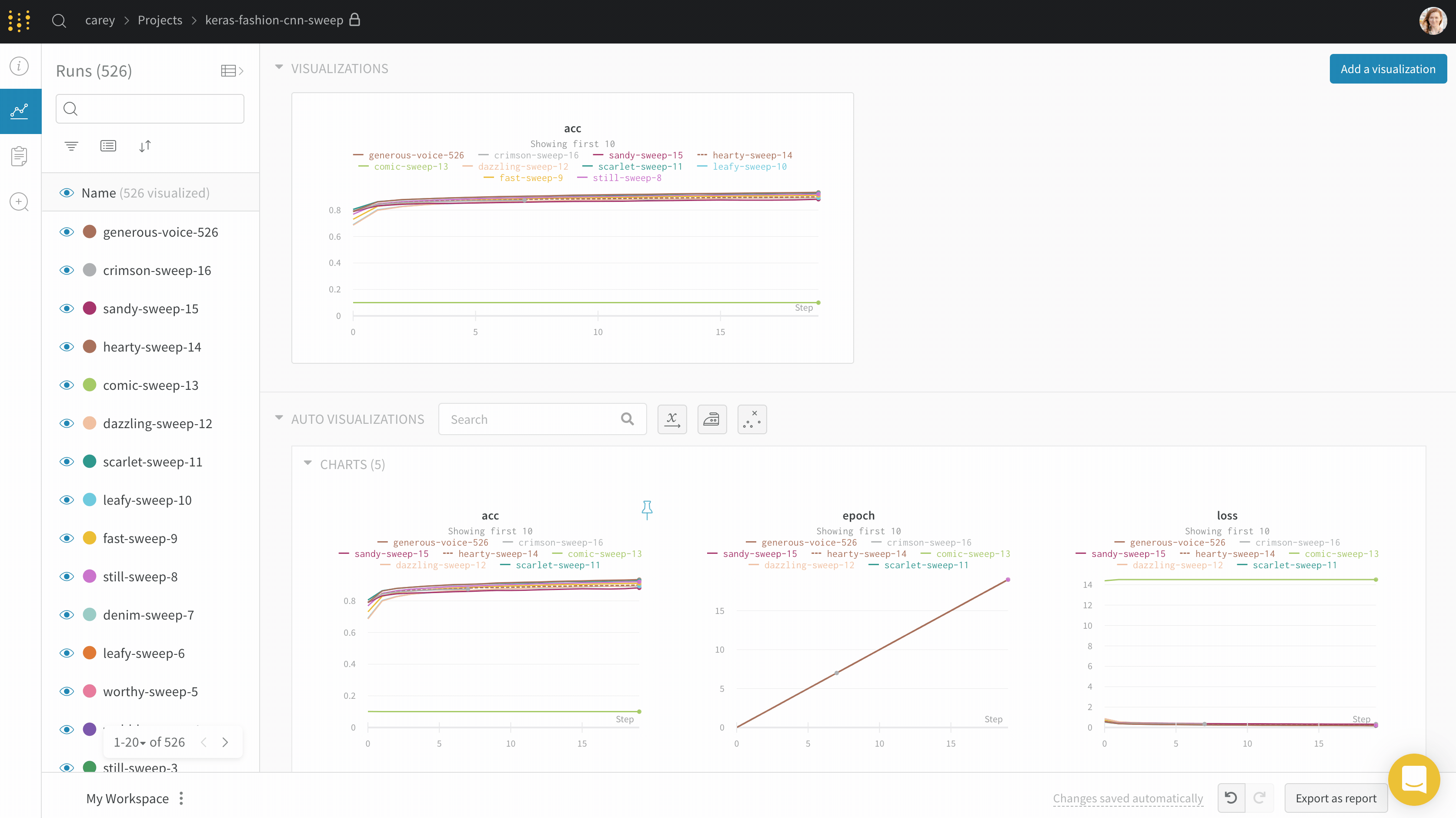
面グラフ
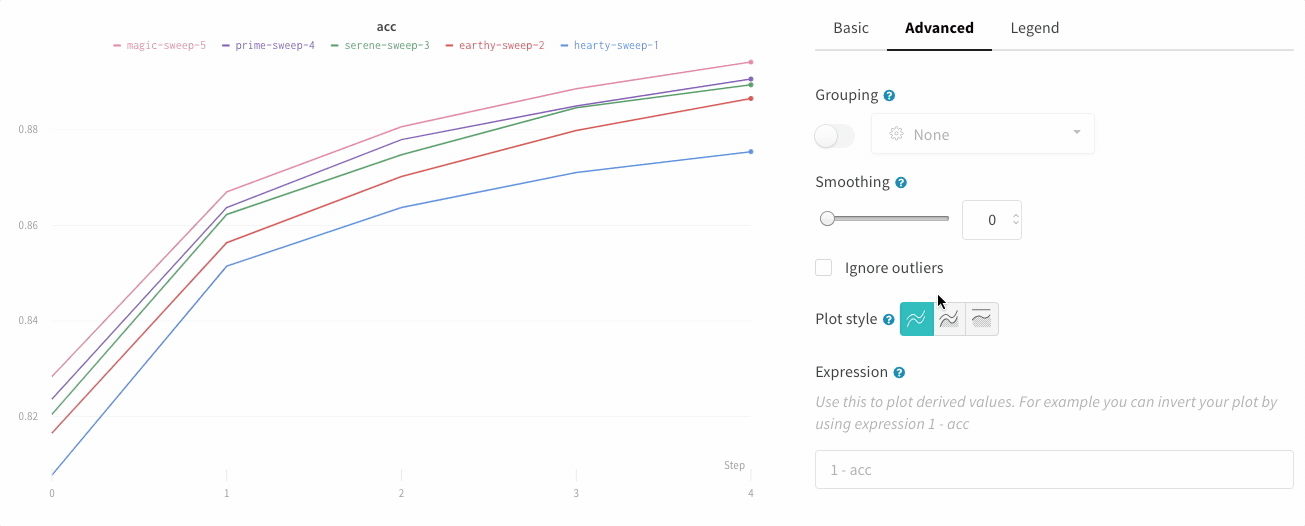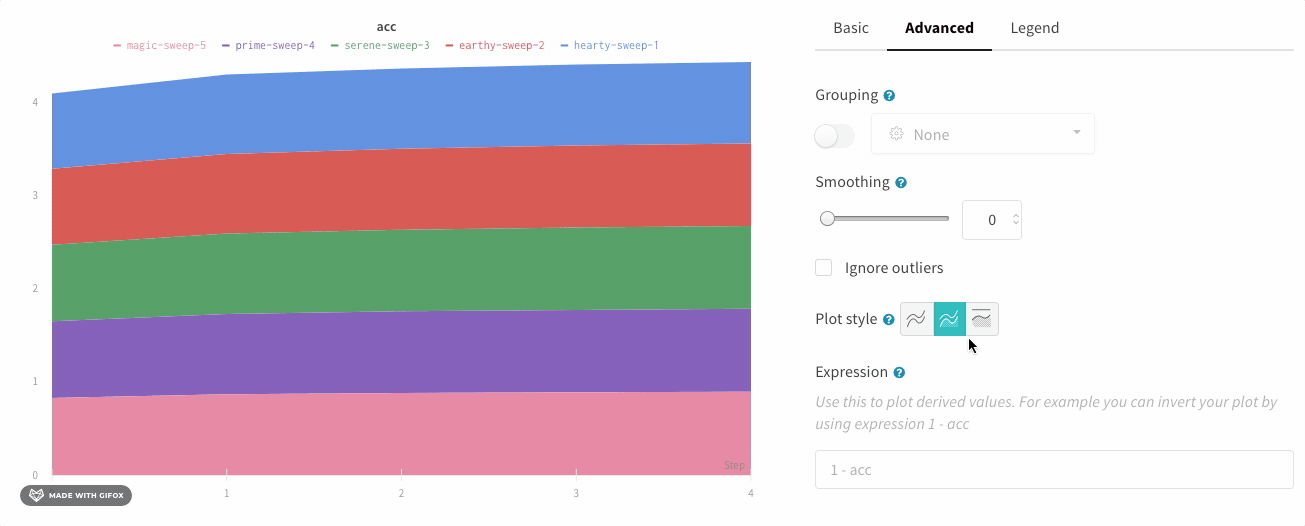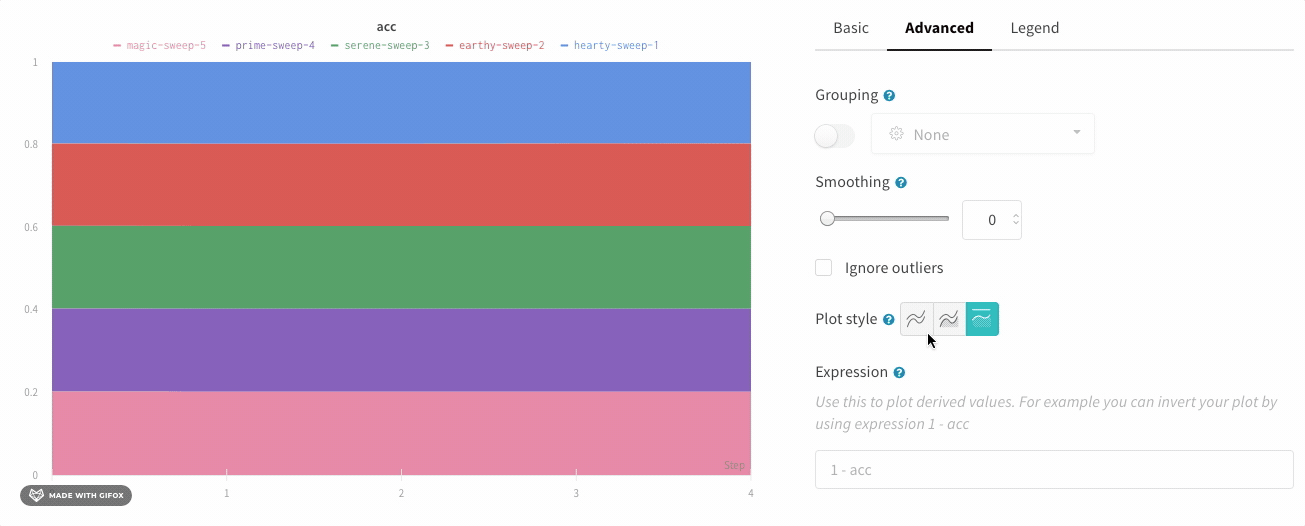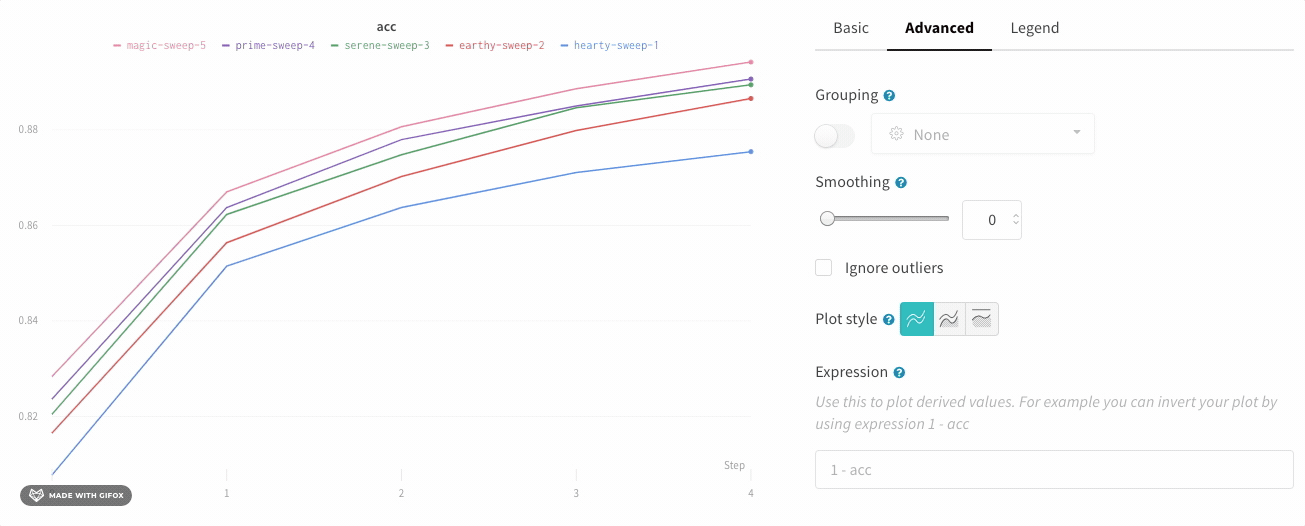
折れ線グラフの設定の [詳細設定] タブで、異なるプロット スタイルをクリックして、面グラフまたはパーセンテージ面グラフを取得します。
ズーム
長方形をクリックしてドラッグし、垂直方向と水平方向に同時にズームします。これにより、X 軸と Y 軸のズームが変更されます。
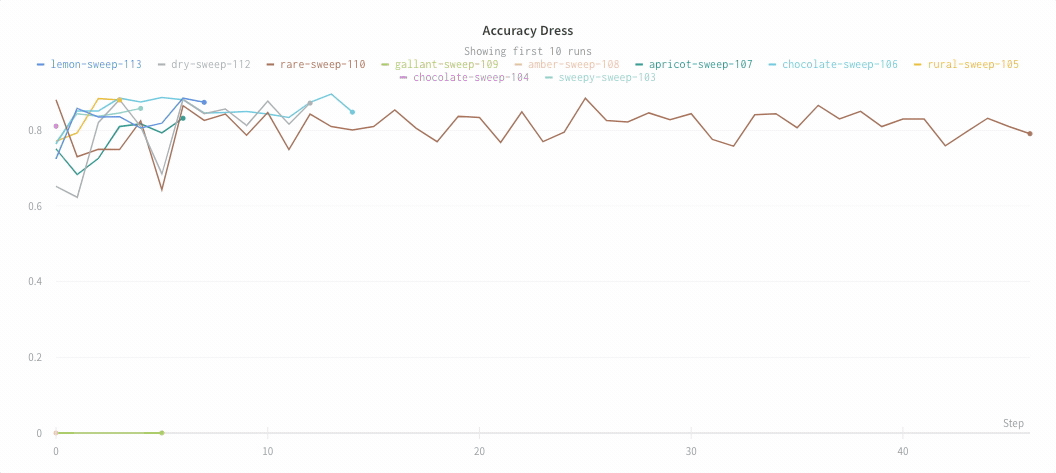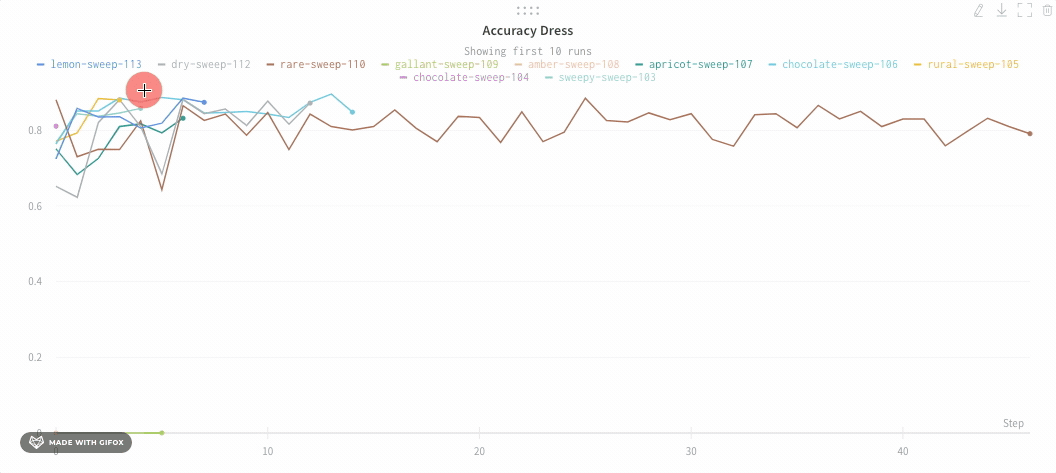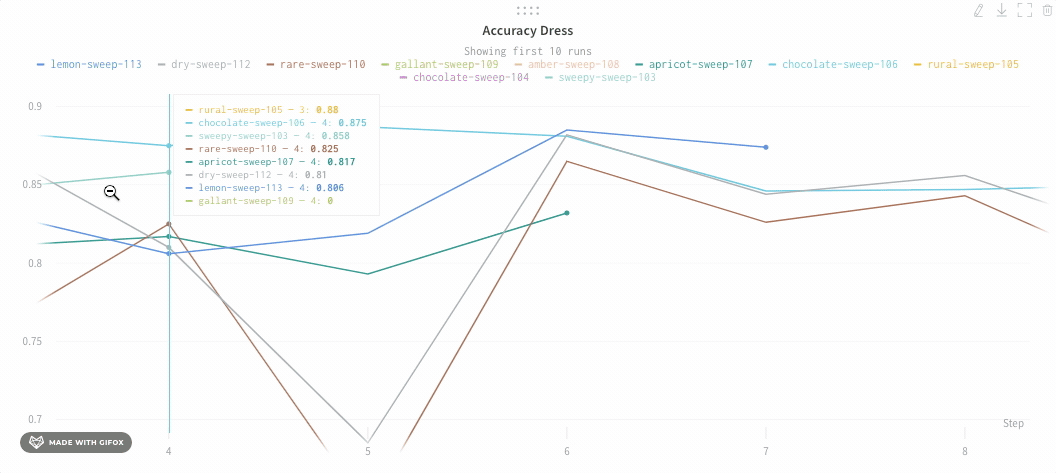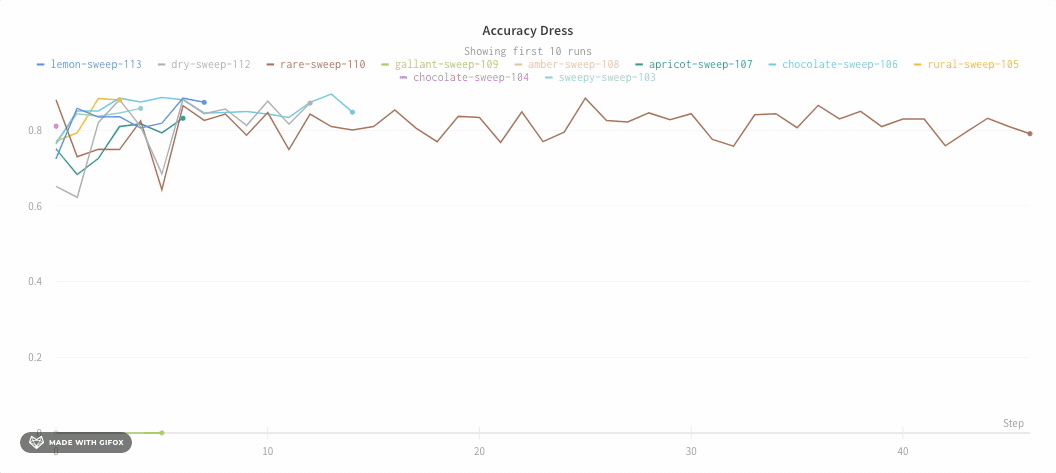
チャートの凡例を非表示にする
この単純なトグルを使用して、折れ線グラフの凡例をオフにします。
1.1.1 - Line plot reference
X軸
折れ線グラフのX軸には、W&B.log でログに記録した値を設定できます。ただし、常に数値としてログに記録されている必要があります。
Y軸の変数
Y軸の変数には、wandb.log でログに記録した値を設定できます。ただし、数値、数値の配列、または数値のヒストグラムをログに記録している必要があります。変数のポイント数が1500を超える場合、W&B は1500ポイントまでサンプルダウンします。
X範囲とY範囲
プロットのXとYの最大値と最小値を変更できます。
X範囲のデフォルトは、X軸の最小値から最大値までです。
Y範囲のデフォルトは、メトリクスの最小値とゼロからメトリクスの最大値までです。
最大 run /グループ数
デフォルトでは、10個の run または run のグループのみがプロットされます。run は run テーブルまたは run セットの上部から取得されるため、run テーブルまたは run セットをソートすると、表示される run を変更できます。
凡例
チャートの凡例を制御して、ログに記録した任意の run の任意の設定値と、作成時間や run を作成した ユーザー など、run からのメタデータを表示できます。
例:
${run:displayName} - ${config:dropout} は、各 run の凡例名を royal-sweep - 0.5 のようにします。ここで、royal-sweep は run 名で、0.5 は dropout という名前の設定 パラメータ です。
[[ ]] 内に値を設定すると、チャートにカーソルを合わせたときに、ポイント固有の値をクロスヘアに表示できます。たとえば、\[\[ $x: $y ($original) ]] は “2: 3 (2.9)” のように表示されます。
[[ ]] 内でサポートされている値は次のとおりです。
| 値 | 意味 |
|---|---|
${x} |
X値 |
${y} |
Y値(平滑化調整を含む) |
${original} |
Y値(平滑化調整を含まない) |
${mean} |
グループ化された run の平均 |
${stddev} |
グループ化された run の標準偏差 |
${min} |
グループ化された run の最小 |
${max} |
グループ化された run の最大 |
${percent} |
合計のパーセント(積み上げ面グラフの場合) |
グルーピング
グルーピングをオンにしてすべての run を集計したり、個々の変数でグループ化したりできます。テーブル内でグループ化してグルーピングをオンにすることもできます。グループは自動的にグラフに表示されます。
平滑化
平滑化係数を0から1の間に設定できます。0は平滑化なし、1は最大平滑化です。
外れ値を無視する
デフォルトのプロットの最小スケールと最大スケールから外れ値を排除するようにプロットをリスケールします。プロットに対する設定の影響は、プロットのサンプリングモードによって異なります。
- ランダムサンプリングモードを使用するプロットの場合、[外れ値を無視する]を有効にすると、5%から95%のポイントのみが表示されます。外れ値が表示されても、他のポイントとは異なる形式にはなりません。
- フルフィデリティモードを使用するプロットの場合、すべてのポイントが常に表示され、各バケットの最後の値に凝縮されます。[外れ値を無視する]が有効になっている場合、各バケットの最小境界と最大境界が網掛け表示されます。それ以外の場合、領域は網掛け表示されません。
式
式を使用すると、1-精度などの メトリクス から派生した値をプロットできます。現在、単一の メトリクス をプロットしている場合にのみ機能します。単純な算術式(+、-、*、/、%)、および累乗の場合は ** を実行できます。
プロットスタイル
折れ線グラフのスタイルを選択します。
折れ線グラフ:
面グラフ:
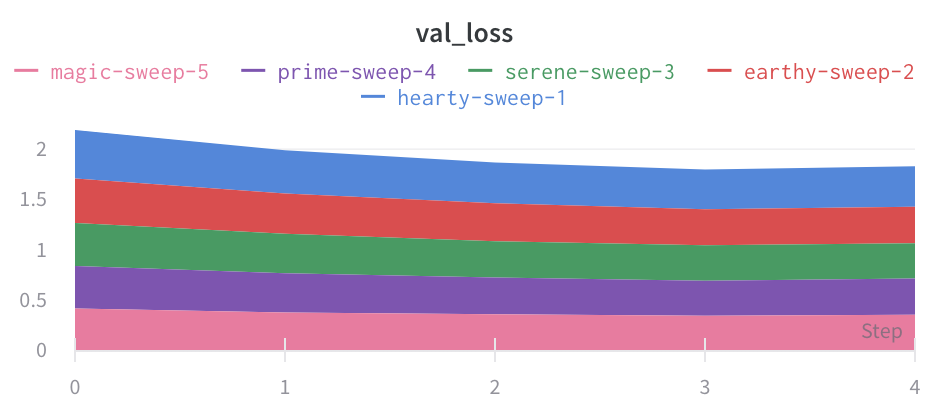
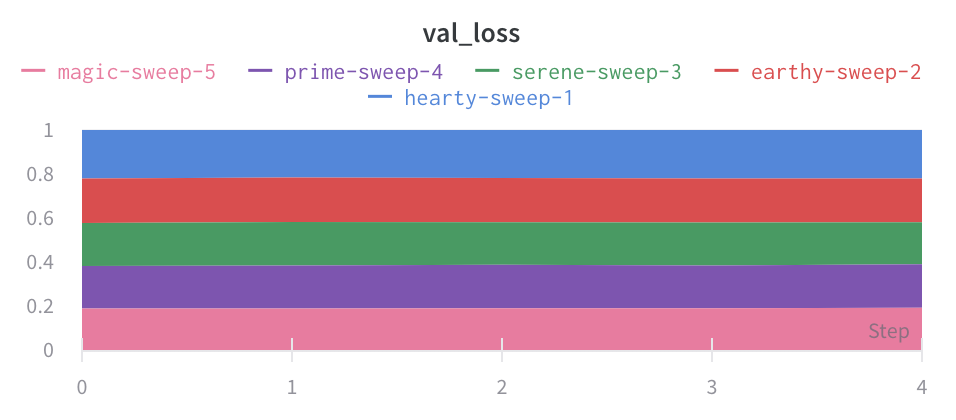
パーセンテージ面グラフ:
1.1.2 - Point aggregation
Data Visualization の精度とパフォーマンスを向上させるために、折れ線グラフ内でポイント集約メソッドを使用します。ポイント集約モードには、full fidelity(完全精度) と random sampling(ランダムサンプリング) の2種類があります。W&B はデフォルトで完全精度モードを使用します。
Full fidelity
完全精度モードを使用すると、W&B はデータポイントの数に基づいて、x軸を動的なバケットに分割します。次に、各バケット内の最小値、最大値、平均値を計算し、折れ線グラフのポイント集約をレンダリングします。
ポイント集約に完全精度モードを使用する主な利点は3つあります。
- 極端な値とスパイクを保持する: データ内の極端な値とスパイクを保持します。
- 最小点と最大点のレンダリング方法を設定する: W&B App を使用して、極端な(最小/最大)値を影付きの領域として表示するかどうかをインタラクティブに決定します。
- データ忠実度を損なわずにデータを探索する: W&B は、特定のデータポイントにズームインすると、x軸のバケットサイズを再計算します。これにより、精度を損なわずにデータを探索できます。キャッシュを使用して、以前に計算された集約を保存し、ロード時間を短縮します。これは、大規模なデータセットをナビゲートする場合に特に役立ちます。
最小点と最大点のレンダリング方法を設定する
折れ線グラフの周りの影付き領域で最小値と最大値を表示または非表示にします。
次の画像は、青い折れ線グラフを示しています。水色の影付き領域は、各バケットの最小値と最大値を表しています。
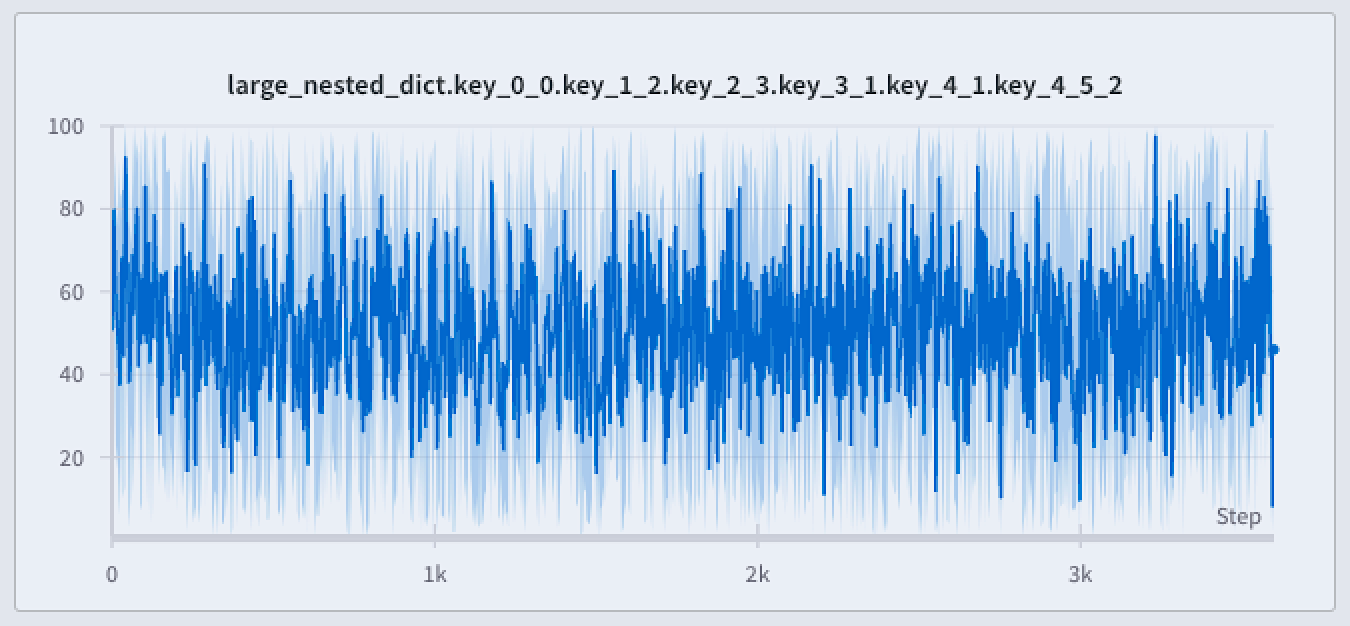
折れ線グラフで最小値と最大値をレンダリングするには、次の3つの方法があります。
- Never: 最小/最大値は影付きの領域として表示されません。x軸バケット全体の集約された線のみを表示します。
- On hover: 最小/最大値の影付き領域は、チャートにカーソルを合わせると動的に表示されます。このオプションを使用すると、ビューがすっきりした状態に保たれ、範囲をインタラクティブに検査できます。
- Always: 最小/最大影付き領域は、チャート内のすべてのバケットに対して常に表示され、常に値の全範囲を視覚化できます。チャートで多くの Runs が可視化されている場合、これは視覚的なノイズになる可能性があります。
デフォルトでは、最小値と最大値は影付き領域として表示されません。影付き領域オプションのいずれかを表示するには、次の手順に従います。
- W&B の Projects に移動します。
- 左側のタブで Workspace アイコンを選択します。
- 画面の右上隅にある歯車アイコンを、Add panels ボタンの左側の横にあるアイコンを選択します。
- 表示される UI スライダーから、Line plots を選択します。
- Point aggregation セクション内で、Show min/max values as a shaded area ドロップダウンメニューから On over または Always を選択します。
- W&B の Projects に移動します。
- 左側のタブで Workspace アイコンを選択します。
- 完全精度モードを有効にする折れ線グラフ パネルを選択します。
- 表示されるモーダル内で、Show min/max values as a shaded area ドロップダウンメニューから On hover または Always を選択します。
データ忠実度を損なわずにデータを探索する
極端な値やスパイクなどの重要なポイントを見逃すことなく、データセットの特定領域を分析します。折れ線グラフをズームインすると、W&B は各バケット内の最小値、最大値、平均値を計算するために使用されるバケットサイズを調整します。
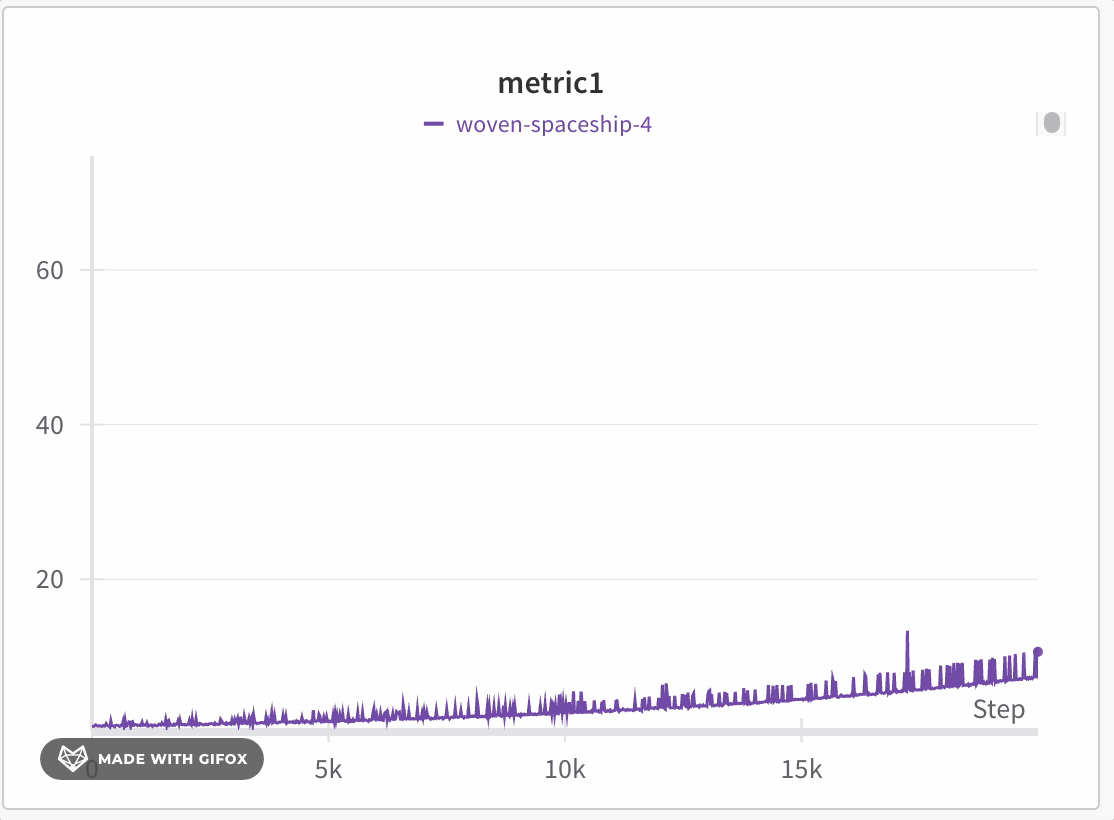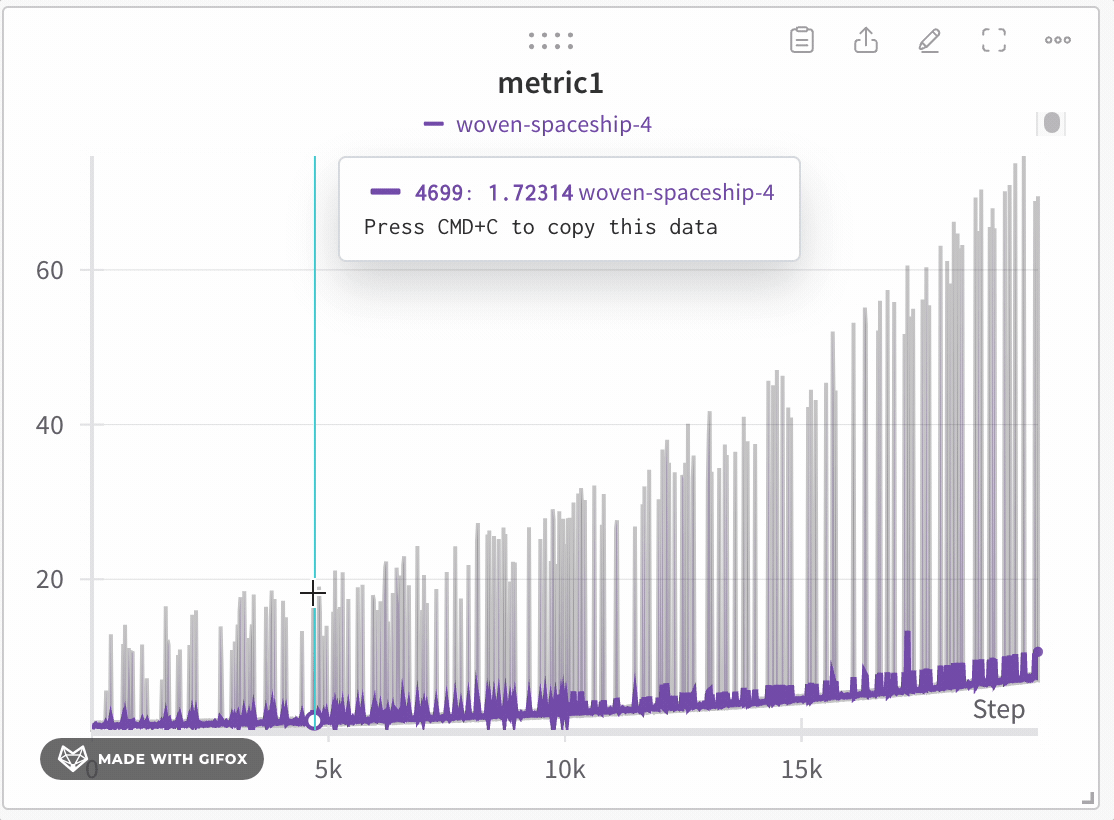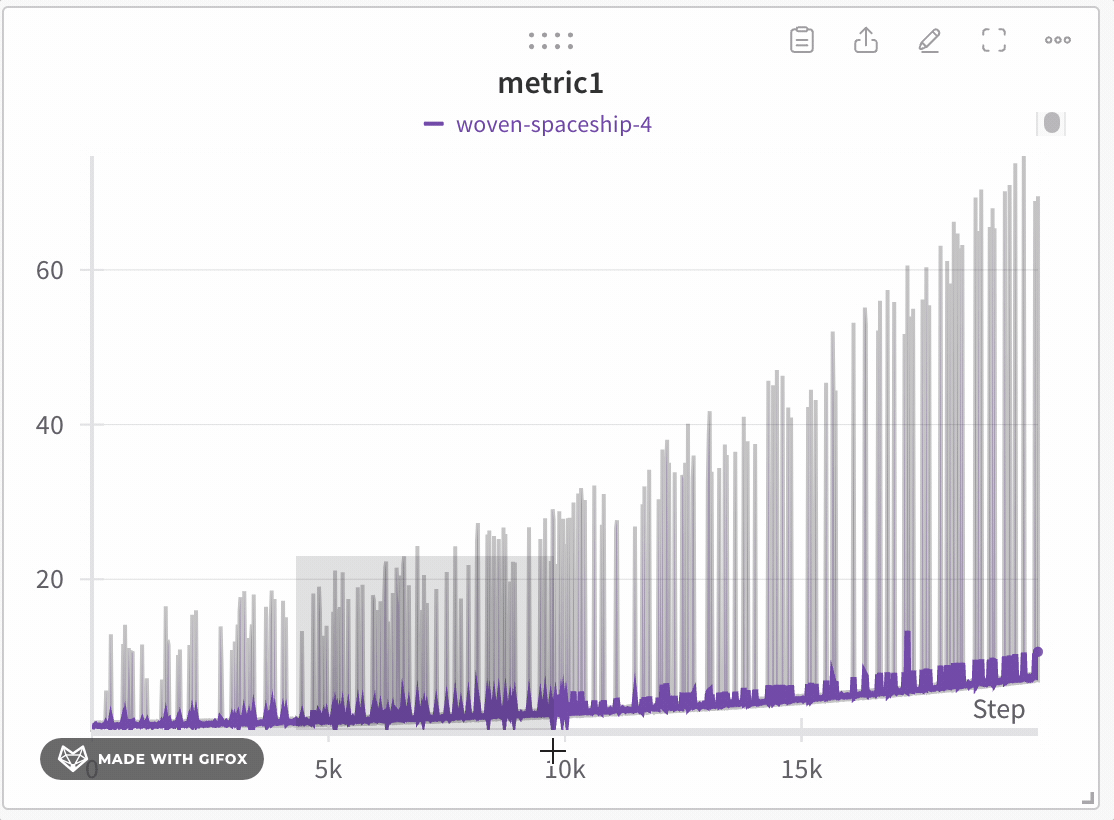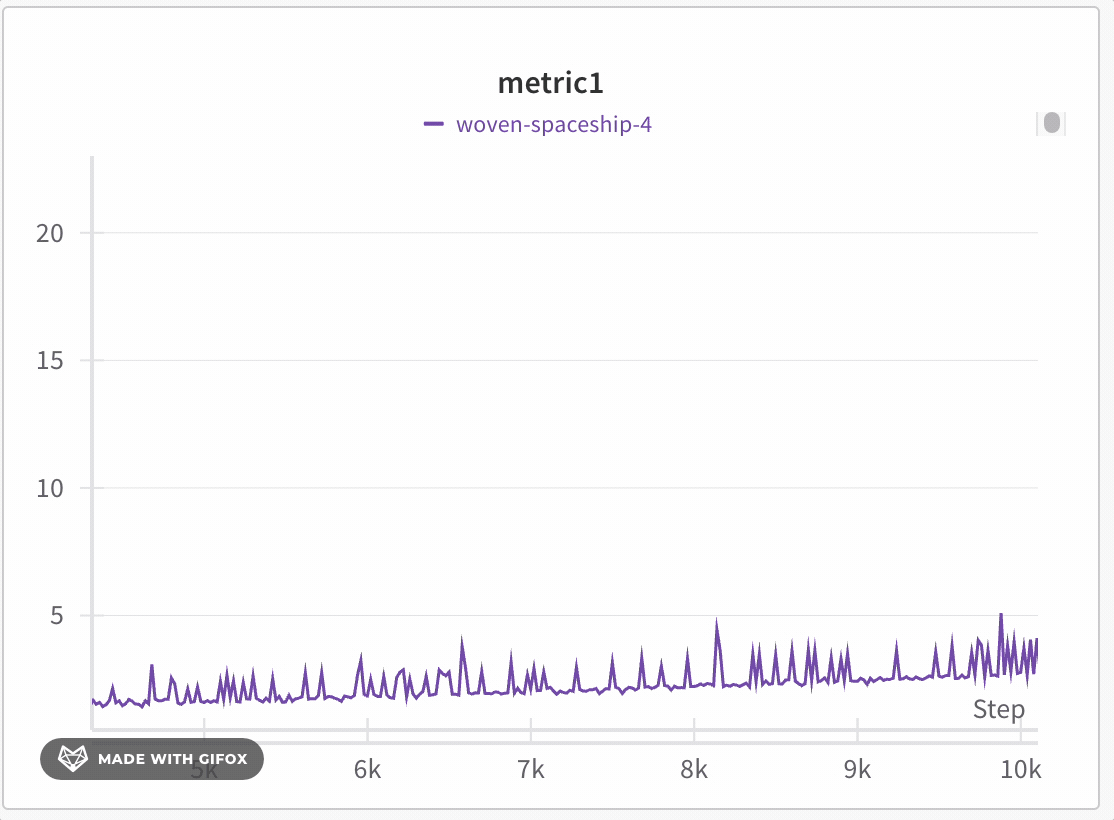
W&B は x軸をデフォルトで1000個のバケットに動的に分割します。各バケットについて、W&B は次の値を計算します。
- Minimum: そのバケット内の最小値。
- Maximum: そのバケット内の最大値。
- Average: そのバケット内のすべてのポイントの平均値。
W&B は、完全なデータ表現を保持し、すべてのプロットに極端な値を含める方法でバケット内の値をプロットします。1,000ポイント以下にズームインすると、完全精度モードは追加の集約なしですべてのデータポイントをレンダリングします。
折れ線グラフをズームインするには、次の手順に従います。
- W&B の Projects に移動します。
- 左側のタブで Workspace アイコンを選択します。
- オプションで、折れ線グラフ パネルを ワークスペース に追加するか、既存の折れ線グラフ パネルに移動します。
- クリックしてドラッグし、ズームインする特定の領域を選択します。
折れ線グラフのグループ化と式
折れ線グラフのグループ化を使用すると、W&B は選択したモードに基づいて以下を適用します。
- 非ウィンドウ サンプリング (グループ化): x軸上の Runs 全体でポイントを整列させます。複数のポイントが同じ x 値を共有する場合、平均が計算されます。それ以外の場合は、個別のポイントとして表示されます。
- ウィンドウ サンプリング (グループ化と式): x軸を 250 個のバケットまたは最長線のポイント数 (いずれか小さい方) に分割します。W&B は各バケット内のポイントの平均を取ります。
- Full fidelity (グループ化と式): 非ウィンドウ サンプリングと同様ですが、パフォーマンスと詳細のバランスを取るために、Run ごとに最大 500 ポイントを取得します。
Random sampling
ランダムサンプリングは、1500個のランダムにサンプリングされたポイントを使用して折れ線グラフをレンダリングします。ランダムサンプリングは、多数のデータポイントがある場合にパフォーマンス上の理由で役立ちます。
ランダムサンプリングを有効にする
デフォルトでは、W&B は完全精度モードを使用します。ランダムサンプリングを有効にするには、次の手順に従います。
- W&B の Projects に移動します。
- 左側のタブで Workspace アイコンを選択します。
- 画面の右上隅にある歯車アイコンを、Add panels ボタンの左側の横にあるアイコンを選択します。
- 表示される UI スライダーから、Line plots を選択します。
- Point aggregation セクションから Random sampling を選択します。
- W&B の Projects に移動します。
- 左側のタブで Workspace アイコンを選択します。
- ランダムサンプリングを有効にする折れ線グラフ パネルを選択します。
- 表示されるモーダル内で、Point aggregation method セクションから Random sampling を選択します。
サンプリングされていないデータへのアクセス
W&B Run API を使用して、Run 中にログに記録された メトリクス の完全な履歴にアクセスできます。次の例は、特定の Run から損失値を取得して処理する方法を示しています。
# W&B API を初期化します
run = api.run("l2k2/examples-numpy-boston/i0wt6xua")
# 'Loss' メトリクスの履歴を取得します
history = run.scan_history(keys=["Loss"])
# 履歴から損失値を抽出します
losses = [row["Loss"] for row in history]
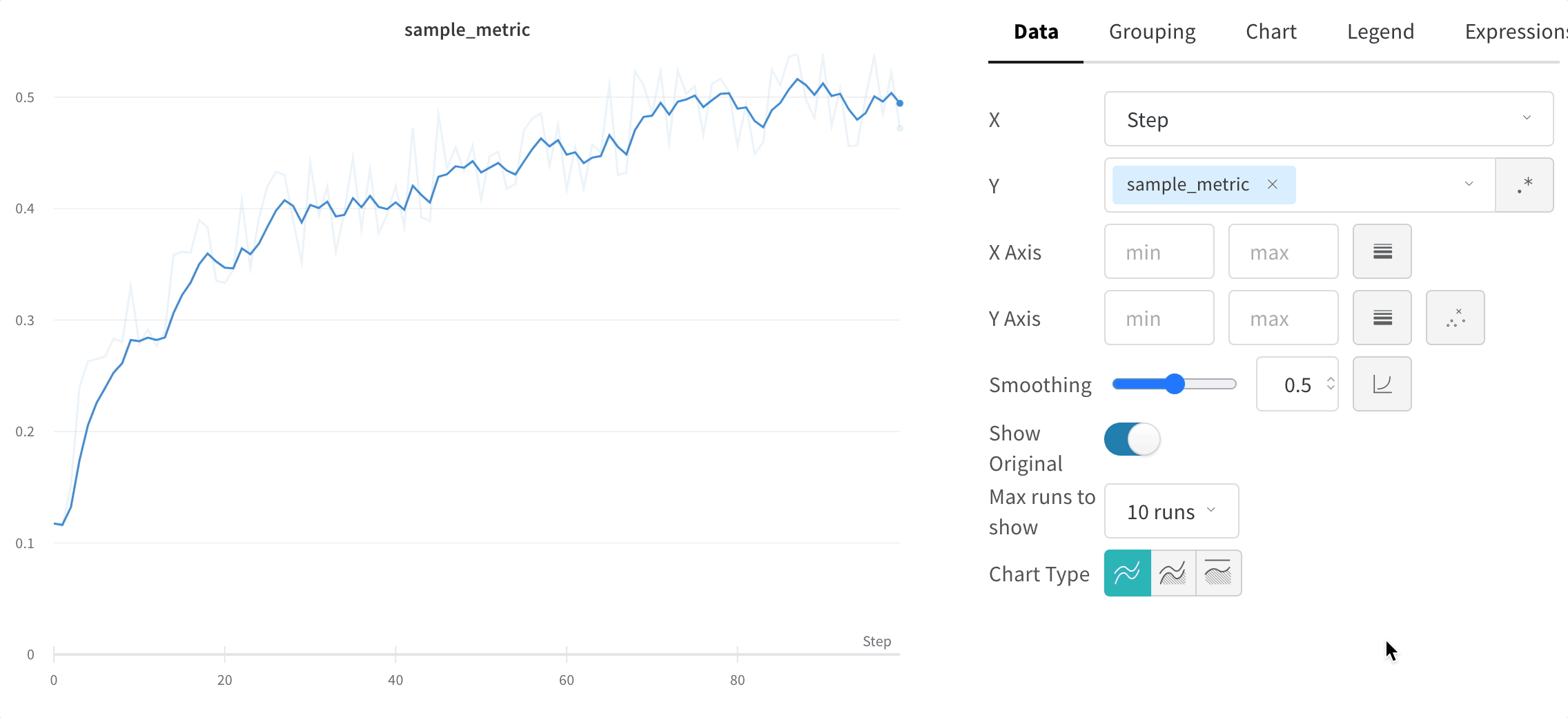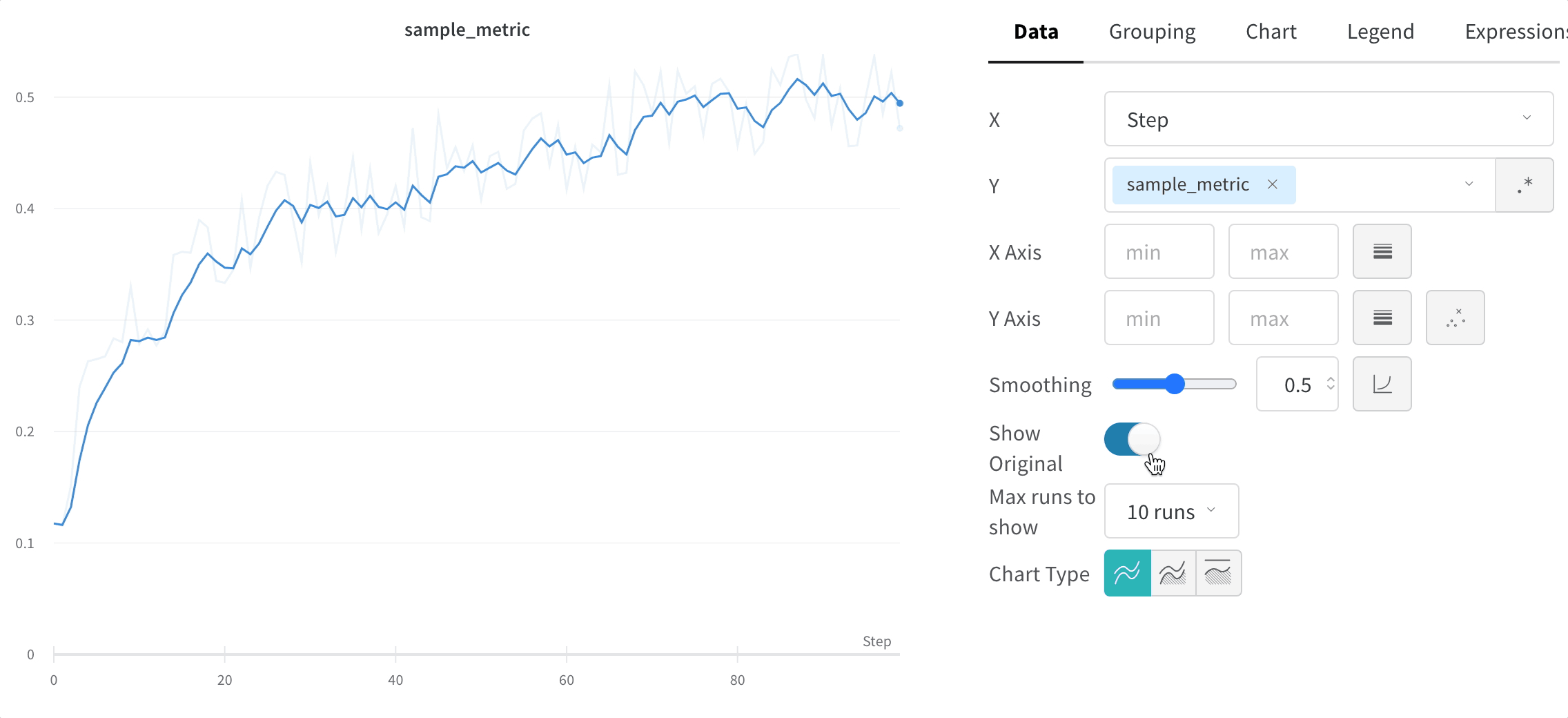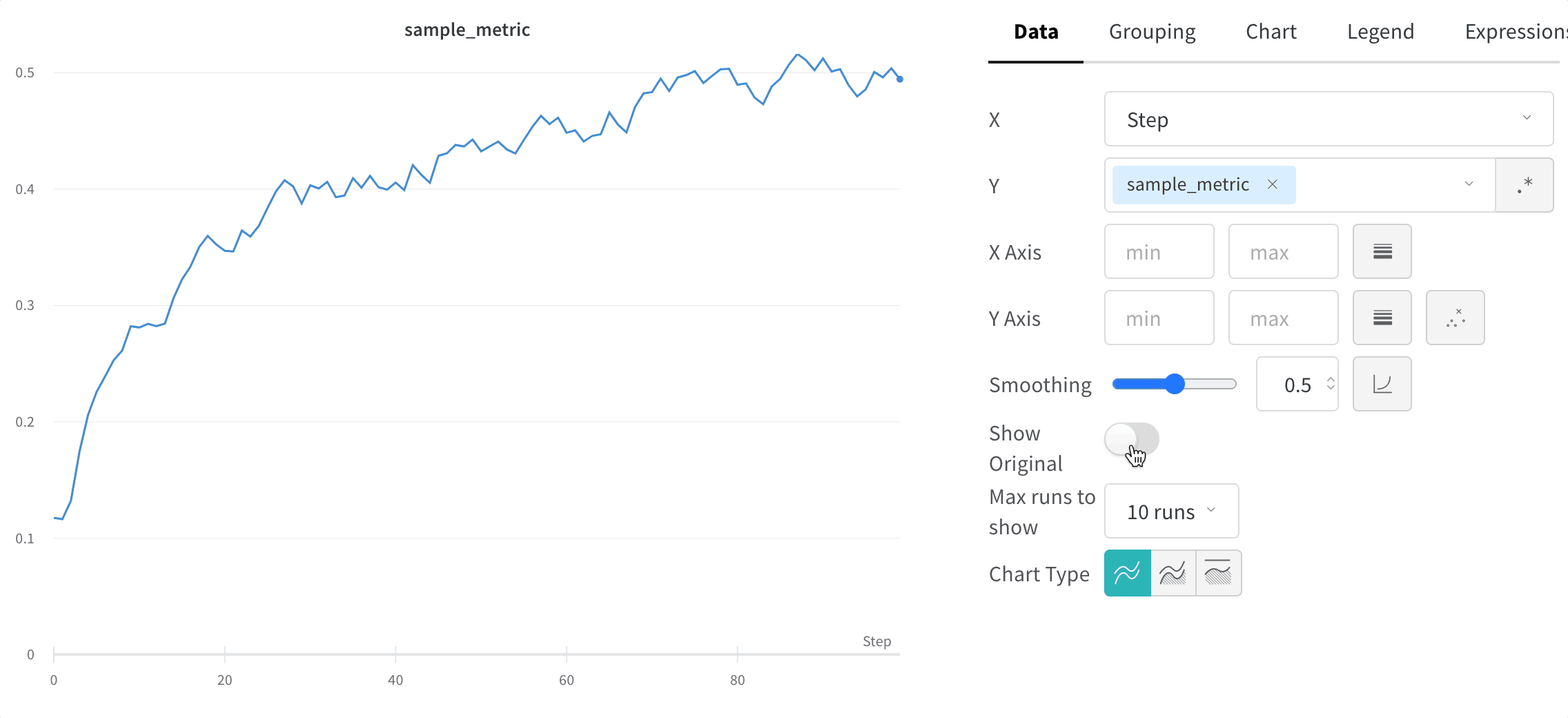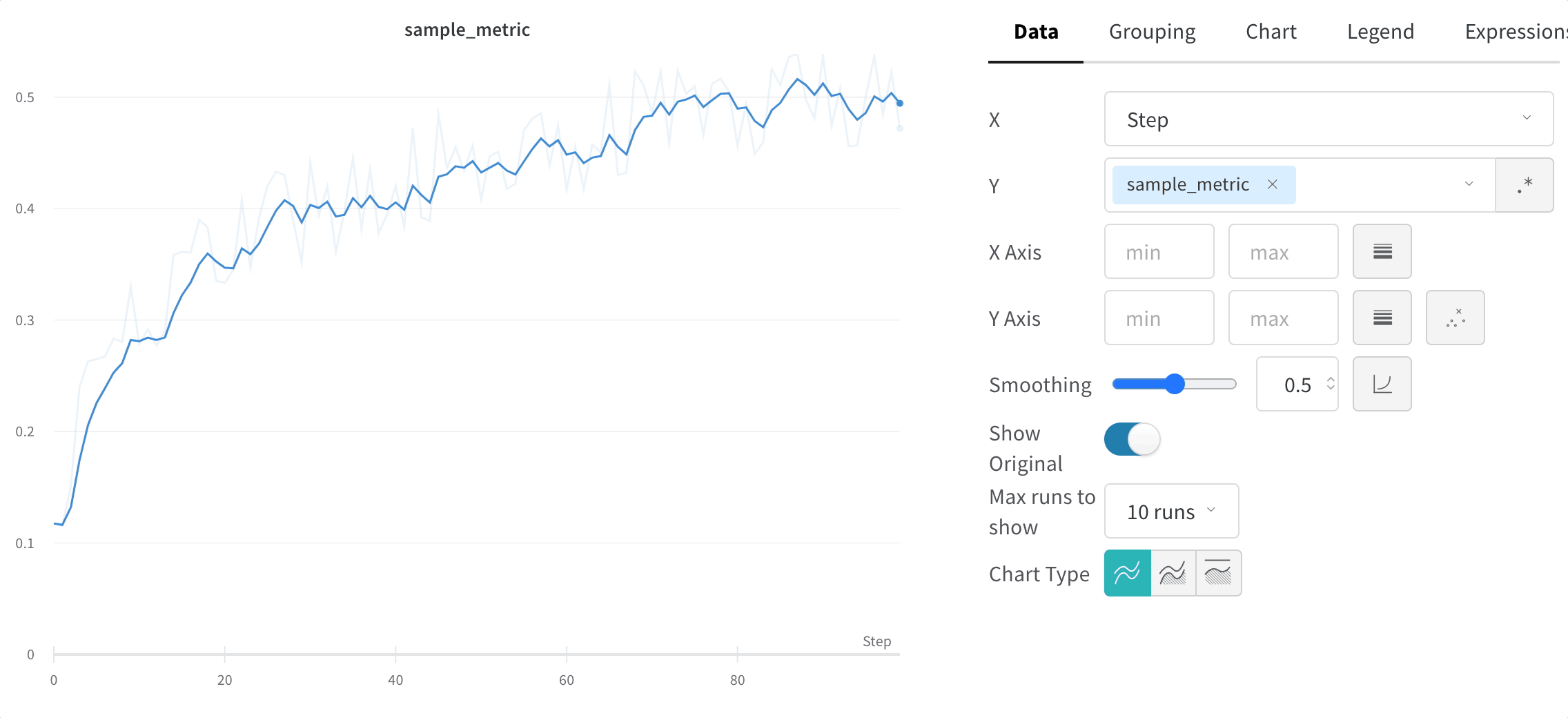
1.1.3 - Smooth line plots
W&B は3種類の平滑化をサポートしています。
- 指数移動平均 (デフォルト)
- ガウシアン平滑化
- 移動平均
- 指数移動平均 - Tensorboard (非推奨)
これらの機能を インタラクティブな W&B レポート でライブで確認できます。
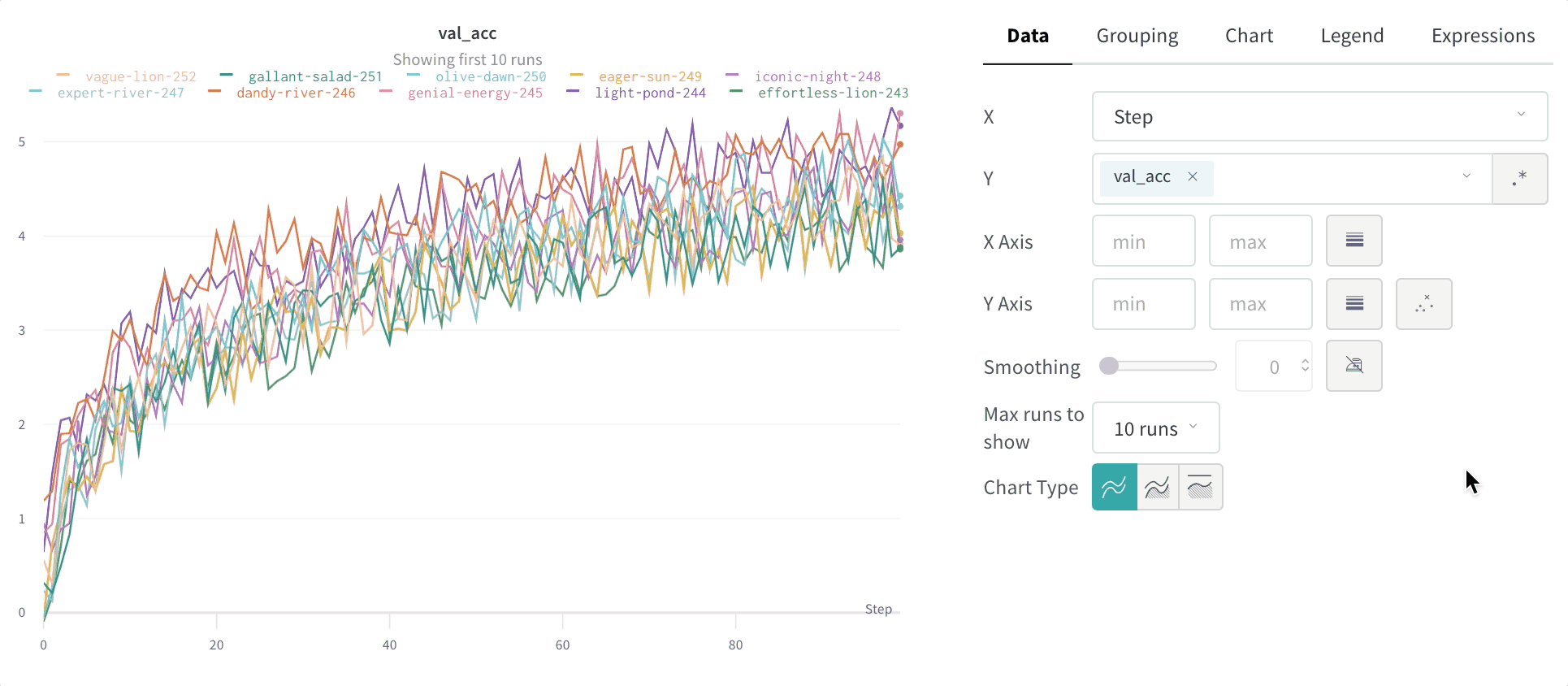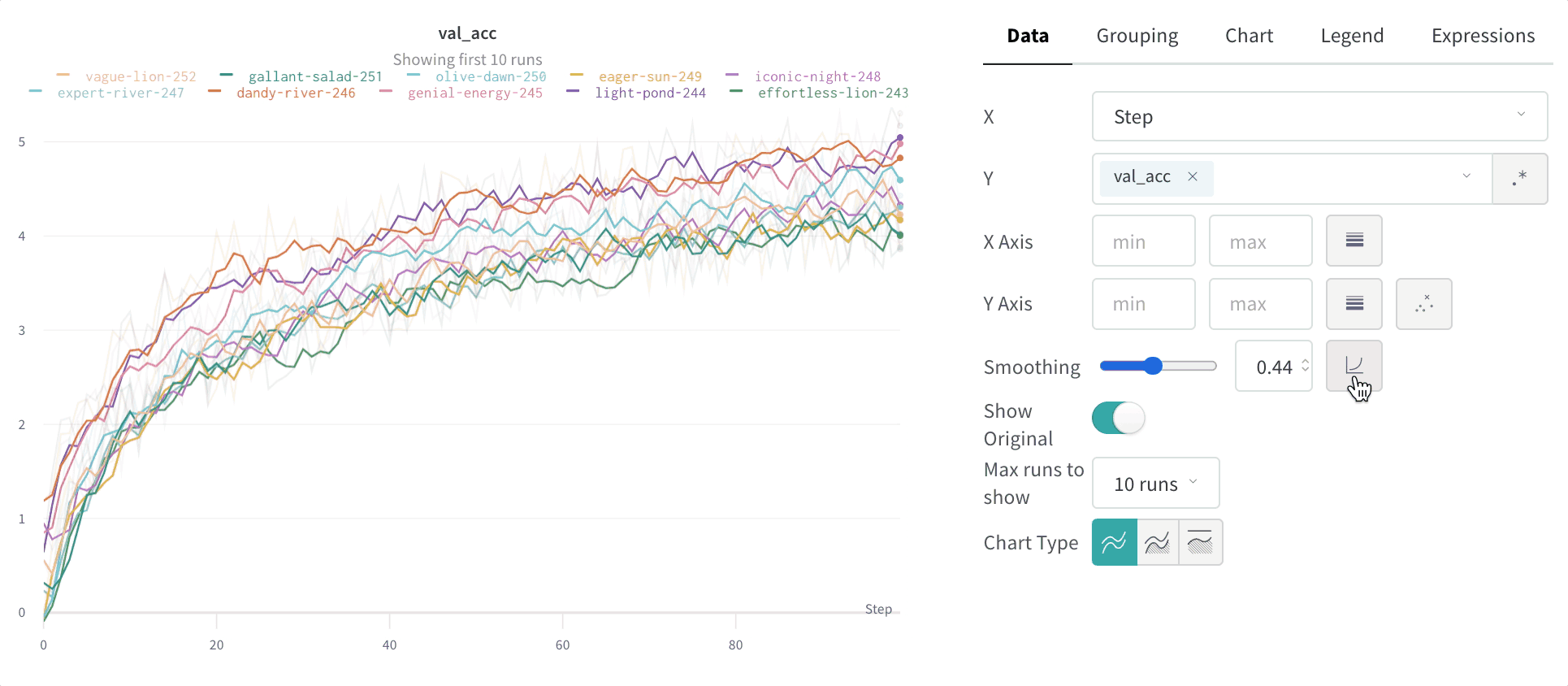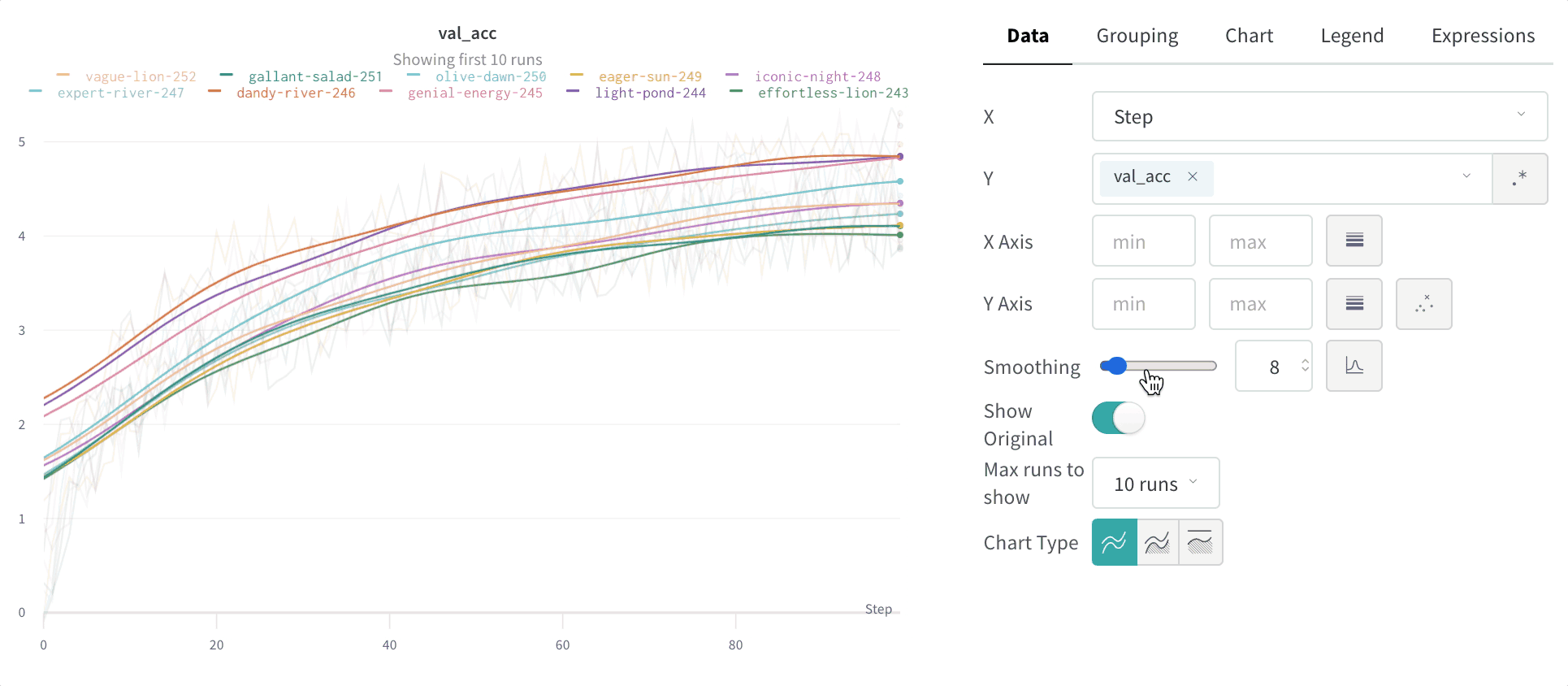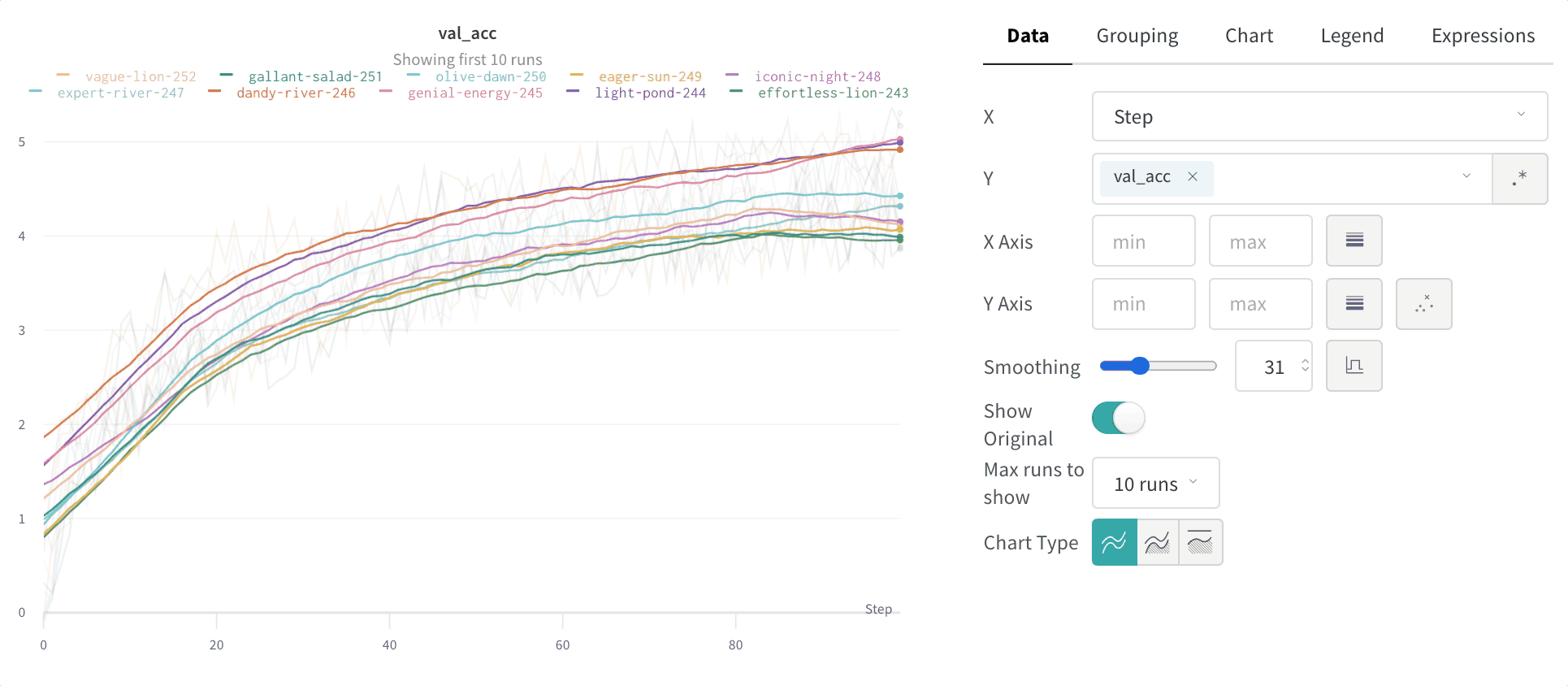
指数移動平均 (デフォルト)
指数平滑化は、過去の点の重みを指数関数的に減衰させることで、 時系列 データを平滑化する手法です。範囲は0から1です。背景については、指数平滑化を参照してください。時系列の初期の値がゼロに偏らないように、バイアス除去項が追加されています。
EMAアルゴリズムは、線上の点の密度 (x軸の範囲の単位あたりの y 値の数) を考慮します。これにより、異なる特性を持つ複数の線を同時に表示する際に、一貫した平滑化が可能になります。
以下は、この仕組みの内部動作を示すサンプル コードです。
const smoothingWeight = Math.min(Math.sqrt(smoothingParam || 0), 0.999);
let lastY = yValues.length > 0 ? 0 : NaN;
let debiasWeight = 0;
return yValues.map((yPoint, index) => {
const prevX = index > 0 ? index - 1 : 0;
// VIEWPORT_SCALEは、結果をチャートのx軸範囲にスケールします
const changeInX =
((xValues[index] - xValues[prevX]) / rangeOfX) * VIEWPORT_SCALE;
const smoothingWeightAdj = Math.pow(smoothingWeight, changeInX);
lastY = lastY * smoothingWeightAdj + yPoint;
debiasWeight = debiasWeight * smoothingWeightAdj + 1;
return lastY / debiasWeight;
});
これは アプリ内 では次のようになります。
ガウシアン平滑化
ガウシアン平滑化 (またはガウシアン カーネル平滑化) は、点の加重平均を計算します。ここで、重みは平滑化 パラメータ として指定された標準偏差を持つガウス分布に対応します。を参照してください。平滑化された 値 は、すべての入力x 値 に対して計算されます。
TensorBoard の 振る舞い と一致させることを気にしない場合は、ガウシアン平滑化は平滑化に適した標準的な選択肢です。指数移動平均とは異なり、値の前後に発生する点に基づいて点が平滑化されます。
これは アプリ内 では次のようになります。
移動平均
移動平均は、指定されたx 値 の前後のウィンドウ内の点の平均で点を置き換える平滑化アルゴリズムです。https://en.wikipedia.org/wiki/Moving_average の「Boxcar Filter」を参照してください。移動平均に選択された パラメータ は、Weights and Biases に移動平均で考慮する点の数を伝えます。
点 がx軸上で不均等に配置されている場合は、ガウシアン平滑化の使用を検討してください。
次の画像は、実行中のアプリが アプリ内 でどのように見えるかを示しています。
指数移動平均 (非推奨)
TensorBoard EMAアルゴリズムは、一貫した点密度 (x軸の単位あたりにプロットされる点の数) を持たない同じチャート上の複数の線を正確に平滑化できないため、非推奨になりました。
指数移動平均は、TensorBoard の平滑化アルゴリズムと一致するように実装されています。範囲は0から1です。背景については、指数平滑化を参照してください。時系列の初期の値がゼロに偏らないように、バイアス除去項が追加されています。
以下は、この仕組みの内部動作を示すサンプル コードです。
data.forEach(d => {
const nextVal = d;
last = last * smoothingWeight + (1 - smoothingWeight) * nextVal;
numAccum++;
debiasWeight = 1.0 - Math.pow(smoothingWeight, numAccum);
smoothedData.push(last / debiasWeight);
これは アプリ内 では次のようになります。
実装の詳細
すべての平滑化アルゴリズムはサンプリングされた データ で実行されます。つまり、1500を超える点を ログ に記録すると、平滑化アルゴリズムは サーバー から点がダウンロードされた 後 に実行されます。平滑化アルゴリズムの目的は、 データ 内のパターンをすばやく見つけるのに役立つことです。多数の ログ に記録された点 を持つ メトリクス で正確な平滑化された 値 が必要な場合は、API を介して メトリクス をダウンロードし、独自の平滑化 メソッド を実行する方が良い場合があります。
元のデータを非表示にする
デフォルトでは、元の平滑化されていない データ が背景に薄い線として表示されます。これをオフにするには、[元のデータを表示] トグルをクリックします。
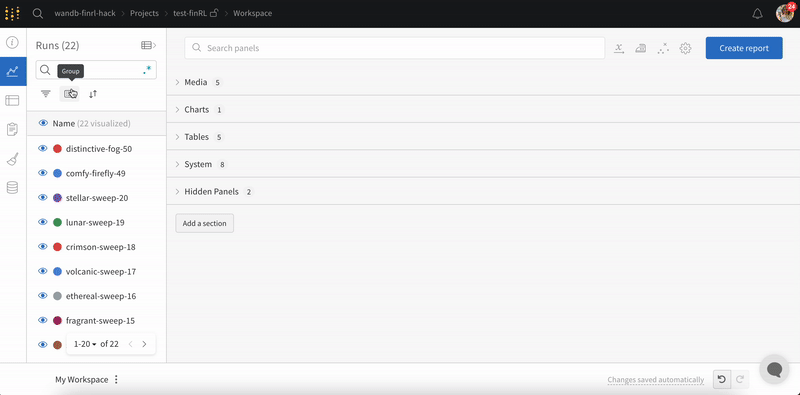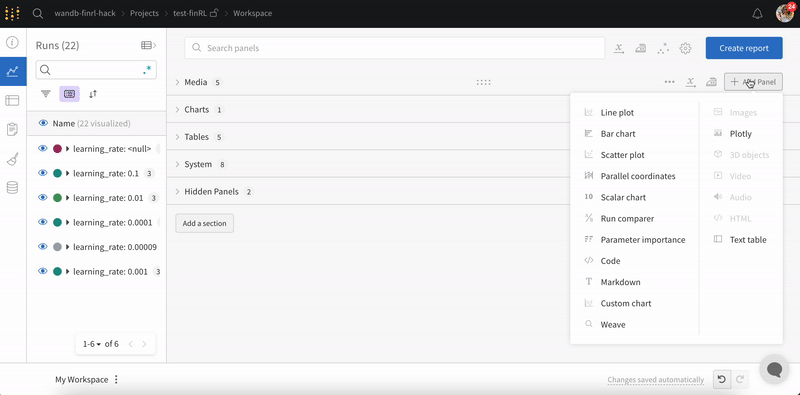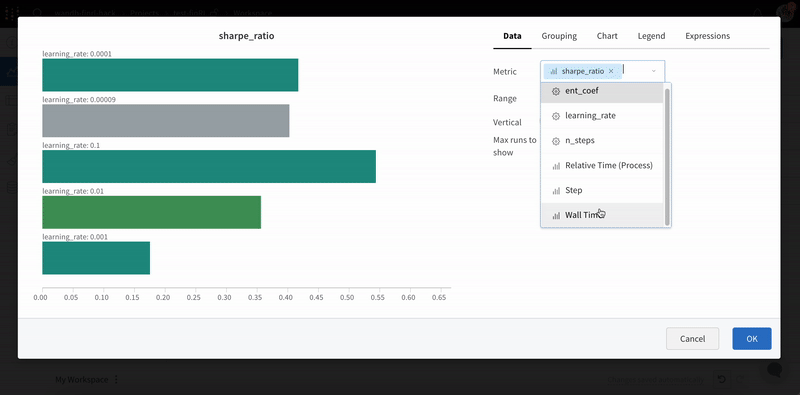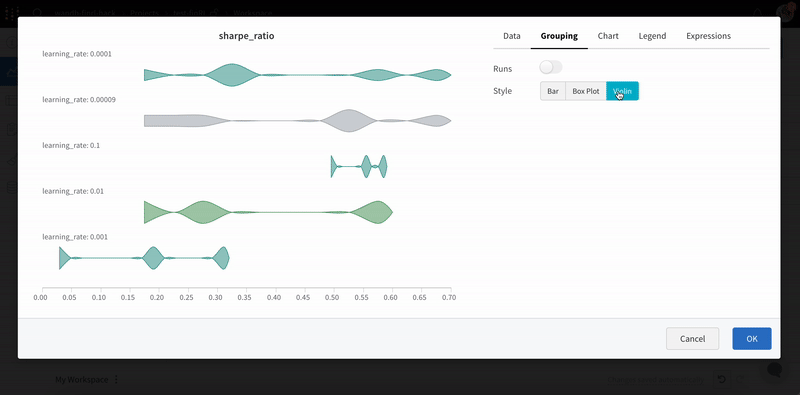
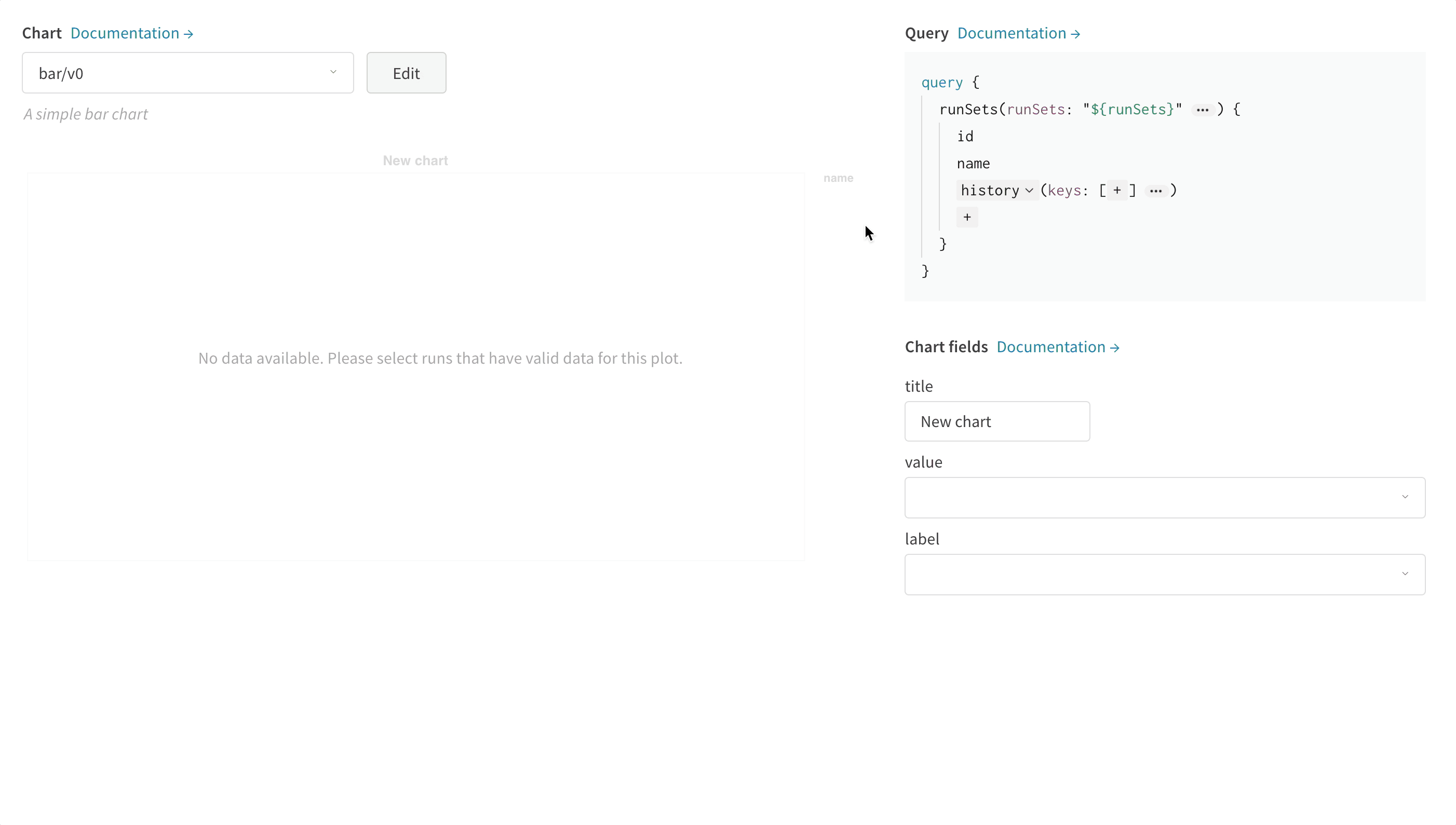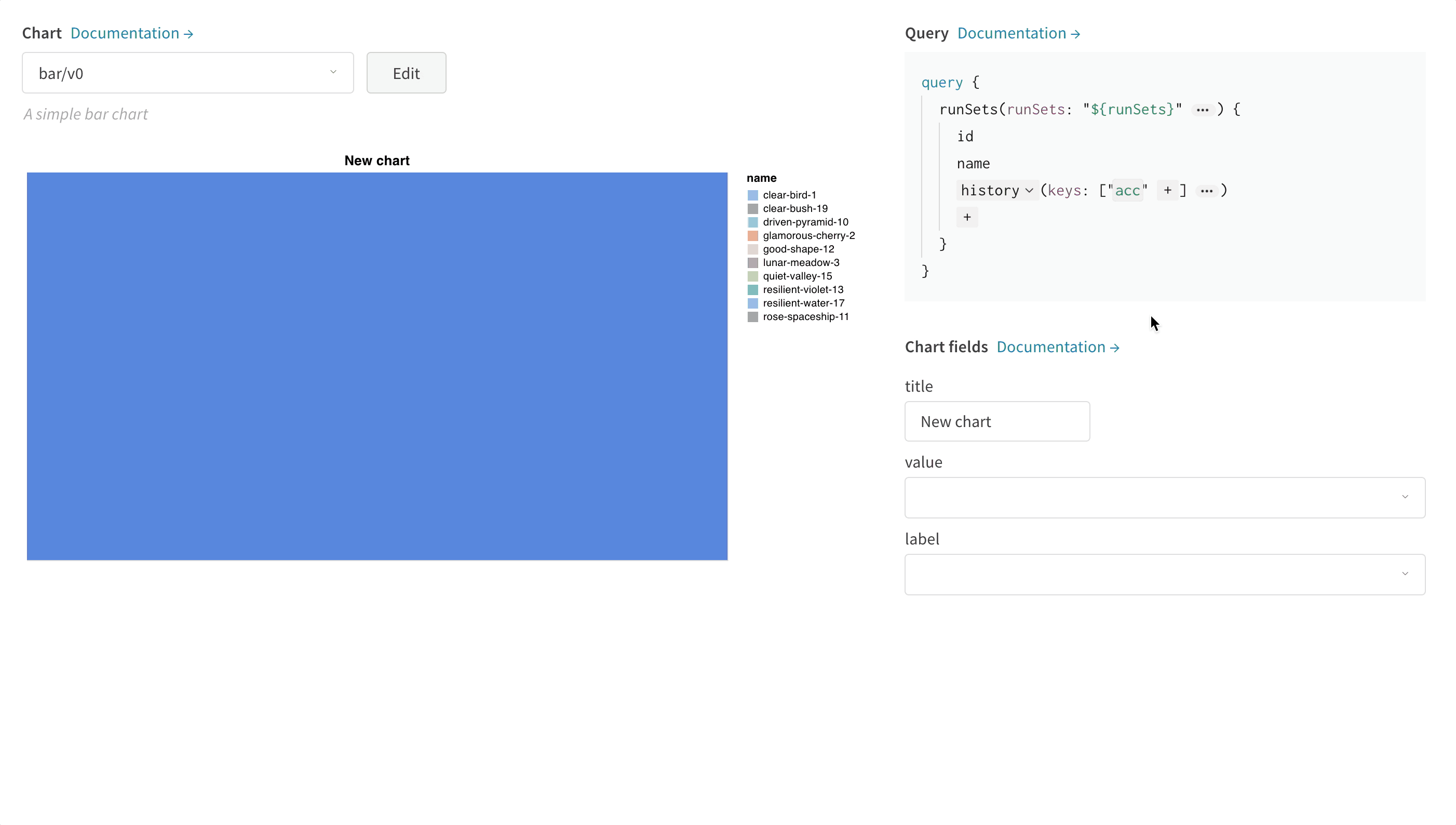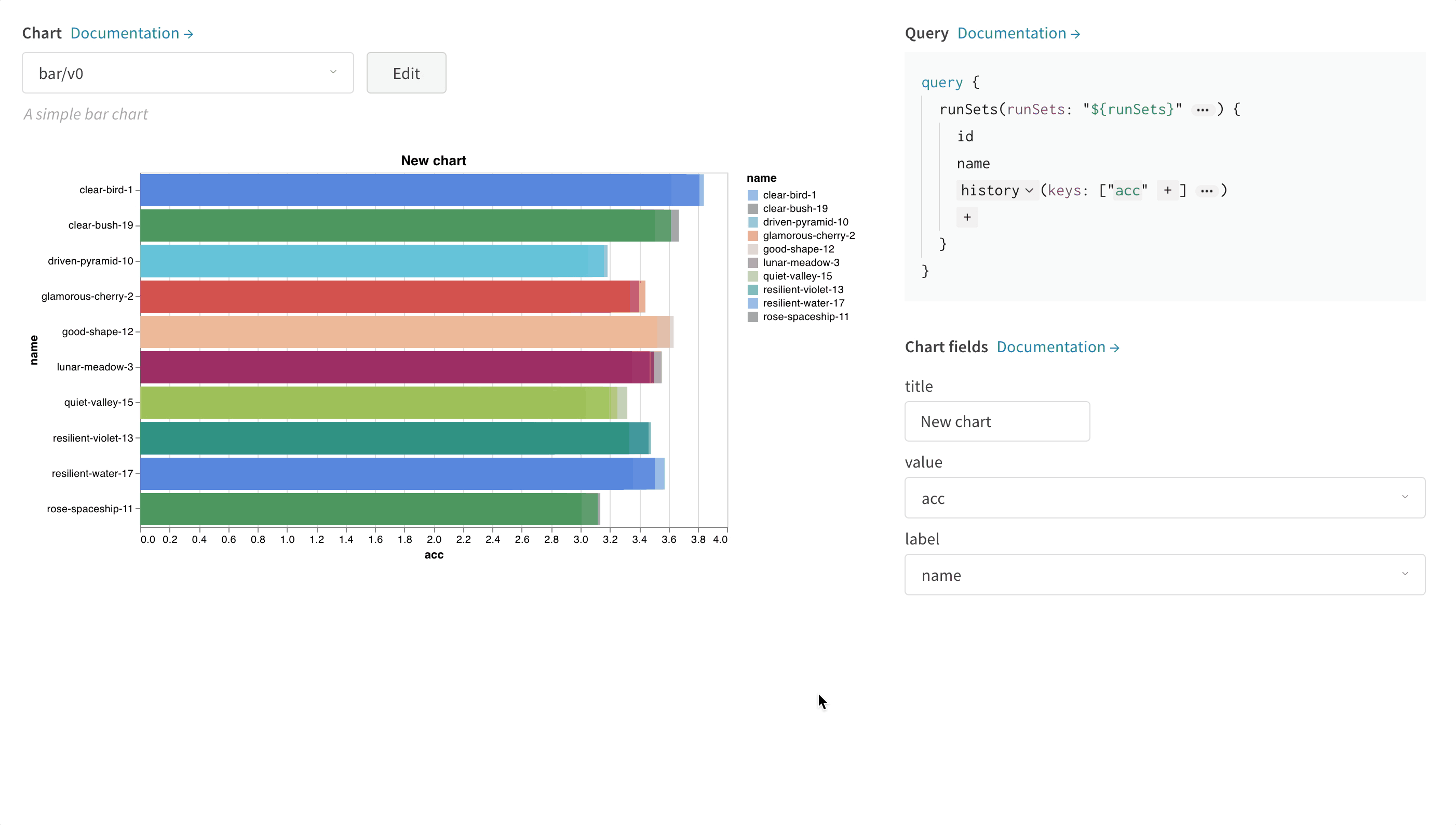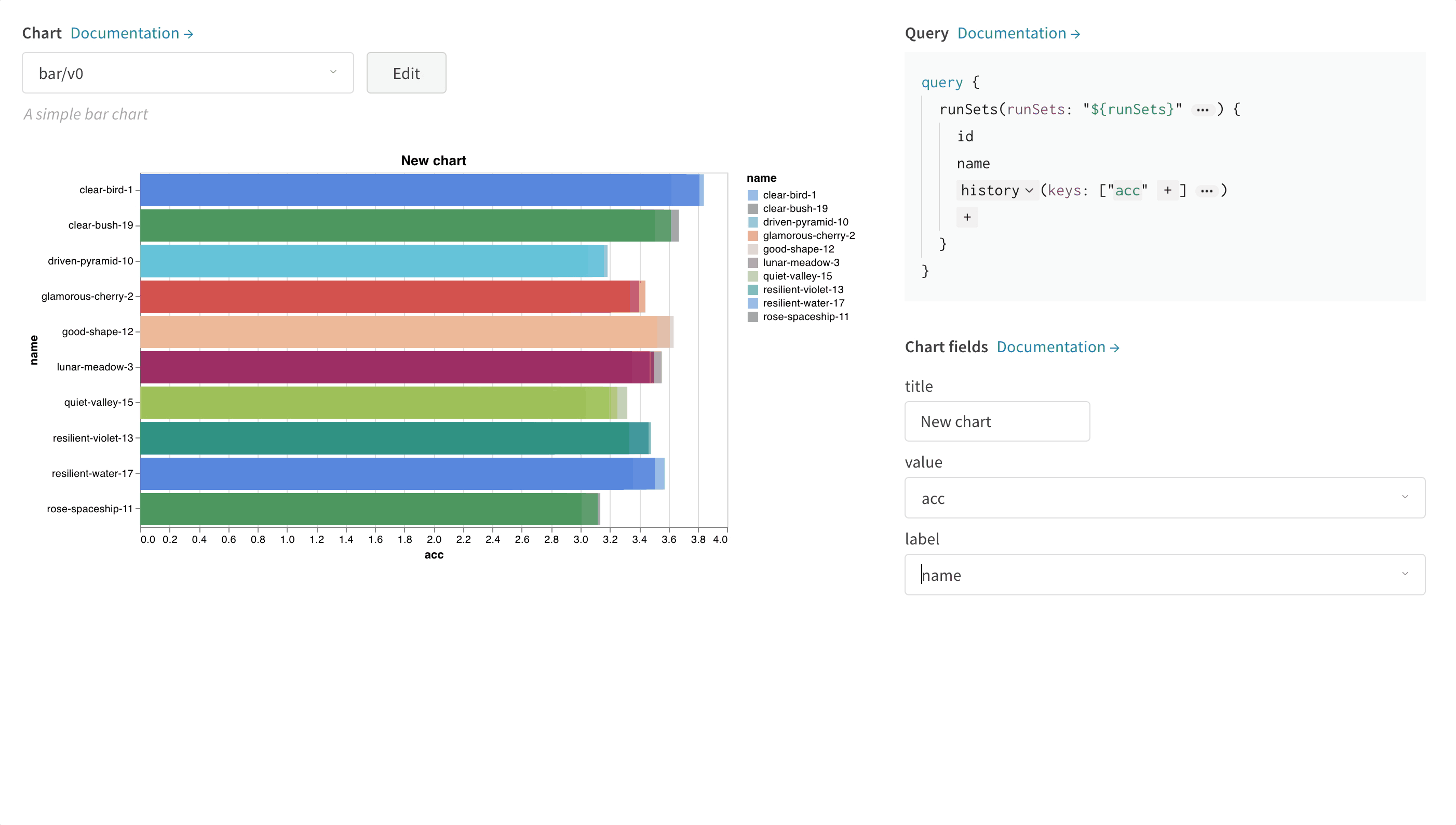
1.2 - Bar plots
棒グラフは、カテゴリカルデータを長方形の棒で表示し、垂直または水平にプロットできます。棒グラフは、すべてのログに記録された値の長さが1の場合、デフォルトで wandb.log() で表示されます。
チャートの設定で、表示する最大 run 数を制限したり、configで run をグループ化したり、ラベルの名前を変更したりできます。
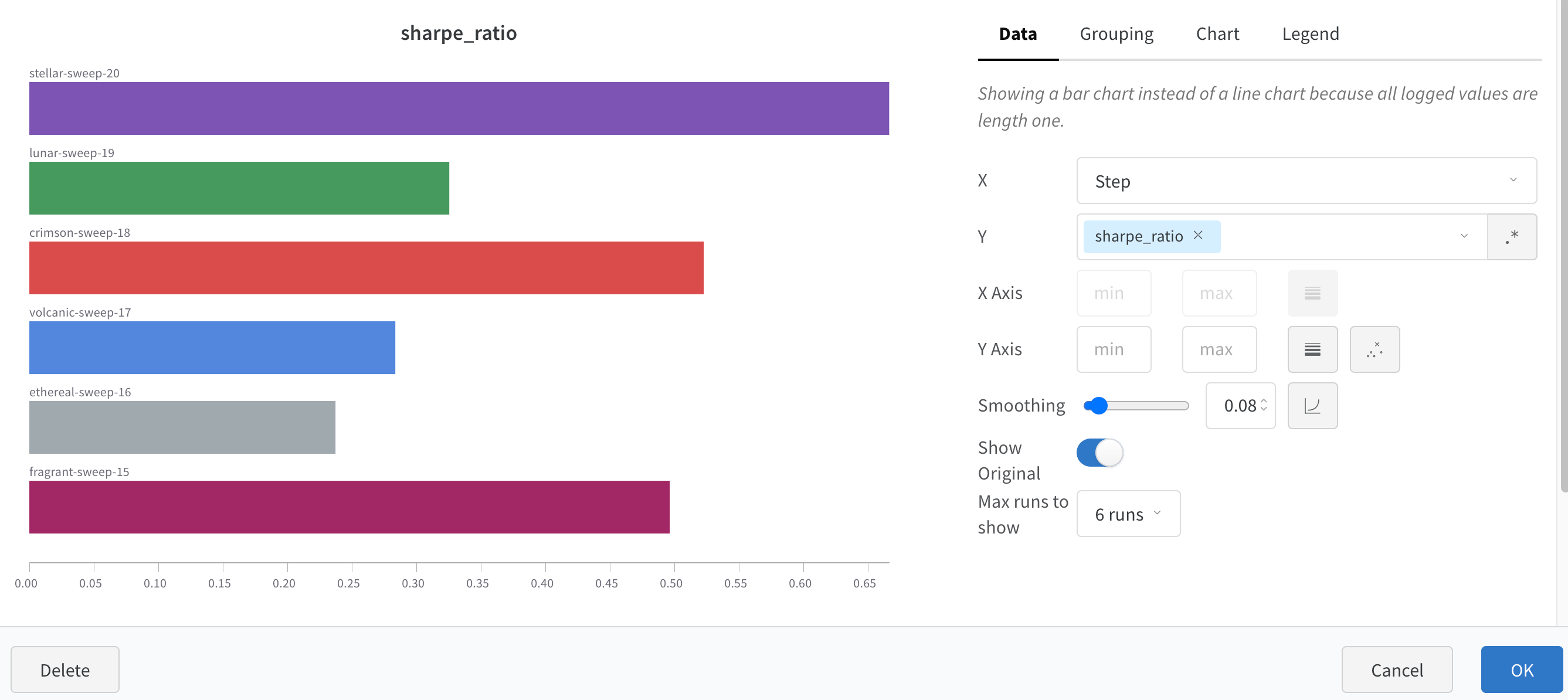
棒グラフのカスタマイズ
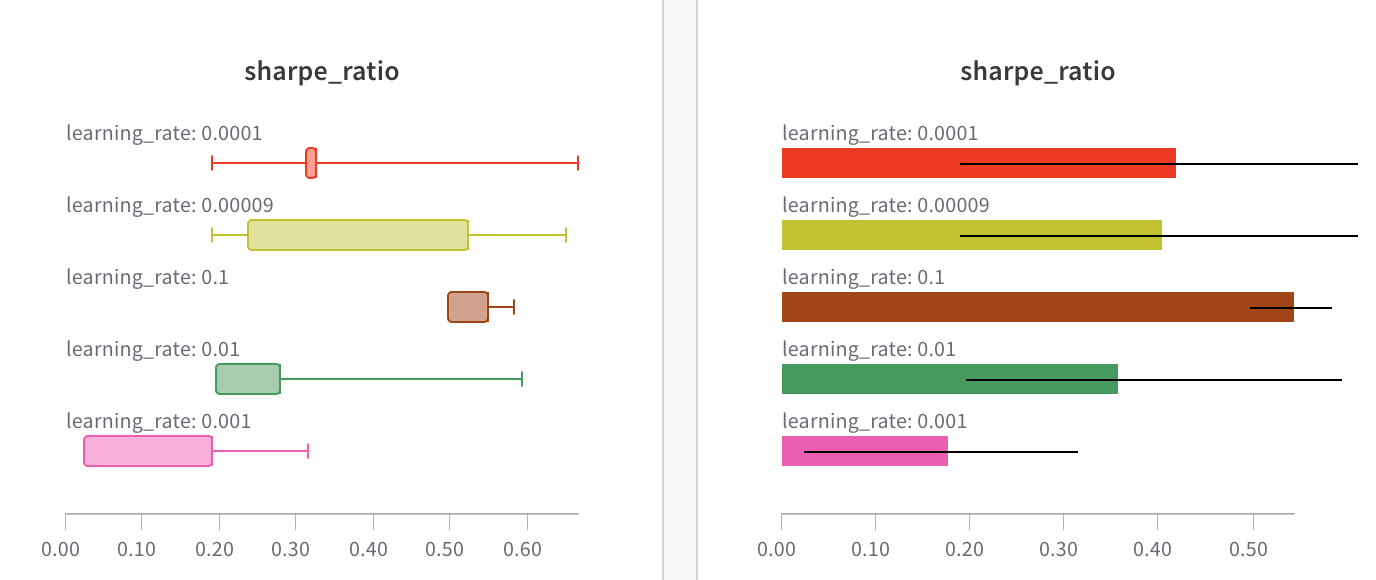
また、Box プロットまたは Violin プロットを作成して、多くの要約統計量を1つのチャートタイプにまとめることもできます。
- run テーブルで run をグループ化します。
- ワークスペース で「パネルを追加」をクリックします。
- 標準の「棒グラフ」を追加し、プロットするメトリックを選択します。
- 「グループ化」タブで、「箱ひげ図」または「バイオリン」などを選択して、これらのスタイルをプロットします。
1.3 - Parallel coordinates
並列座標チャートは、多数のハイパーパラメータとモデル の メトリクス の関係を一目で把握できるようにまとめたものです。
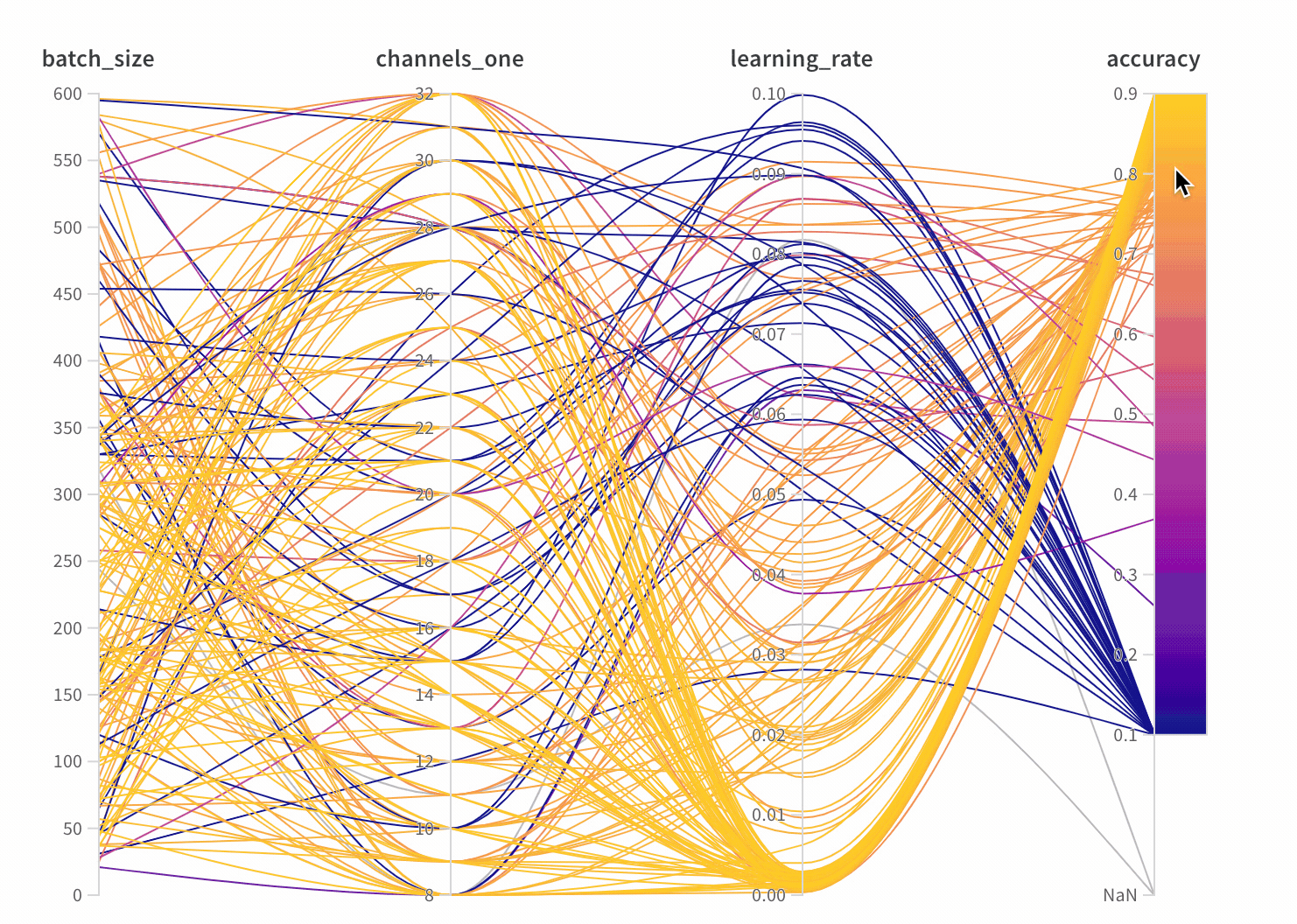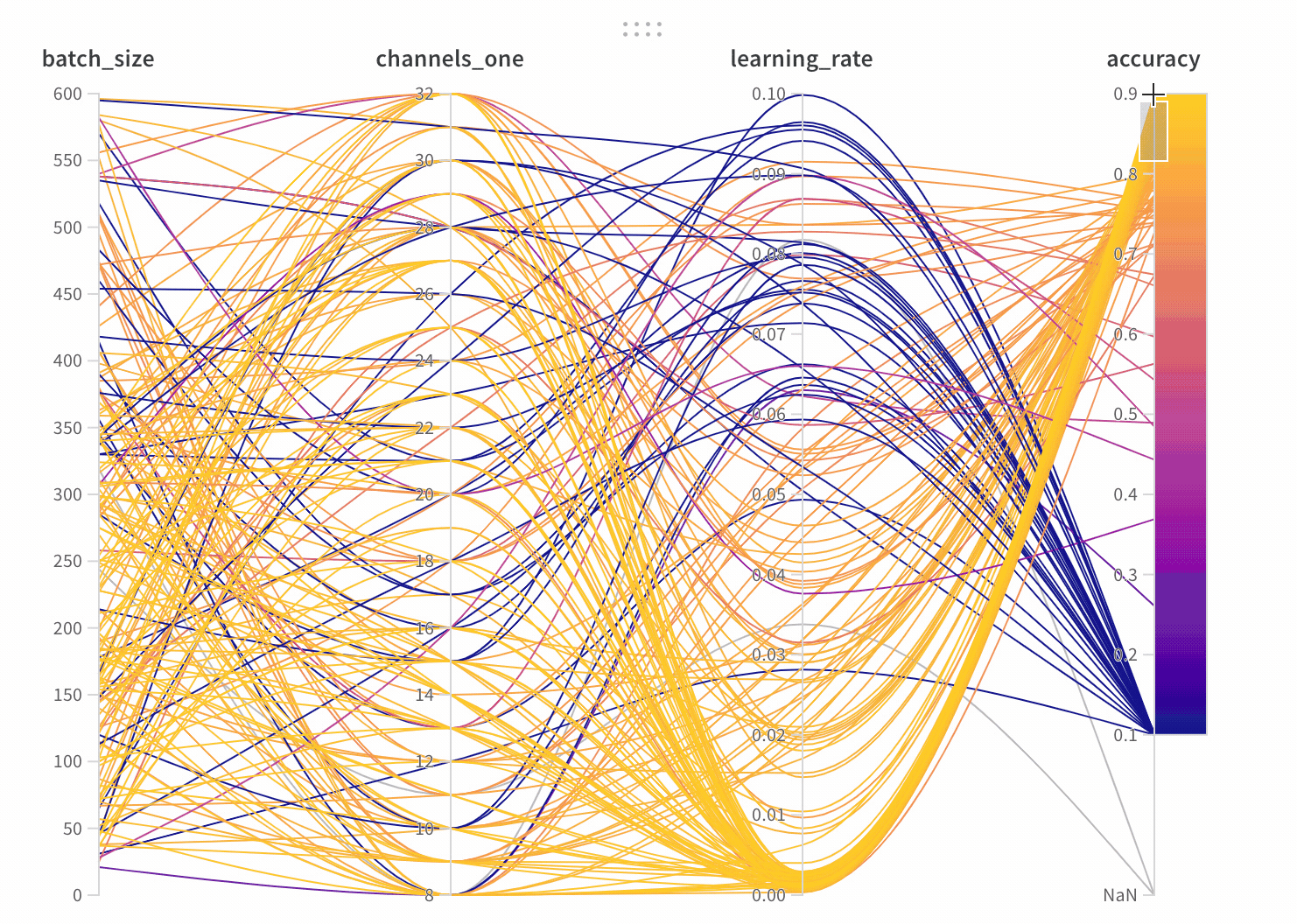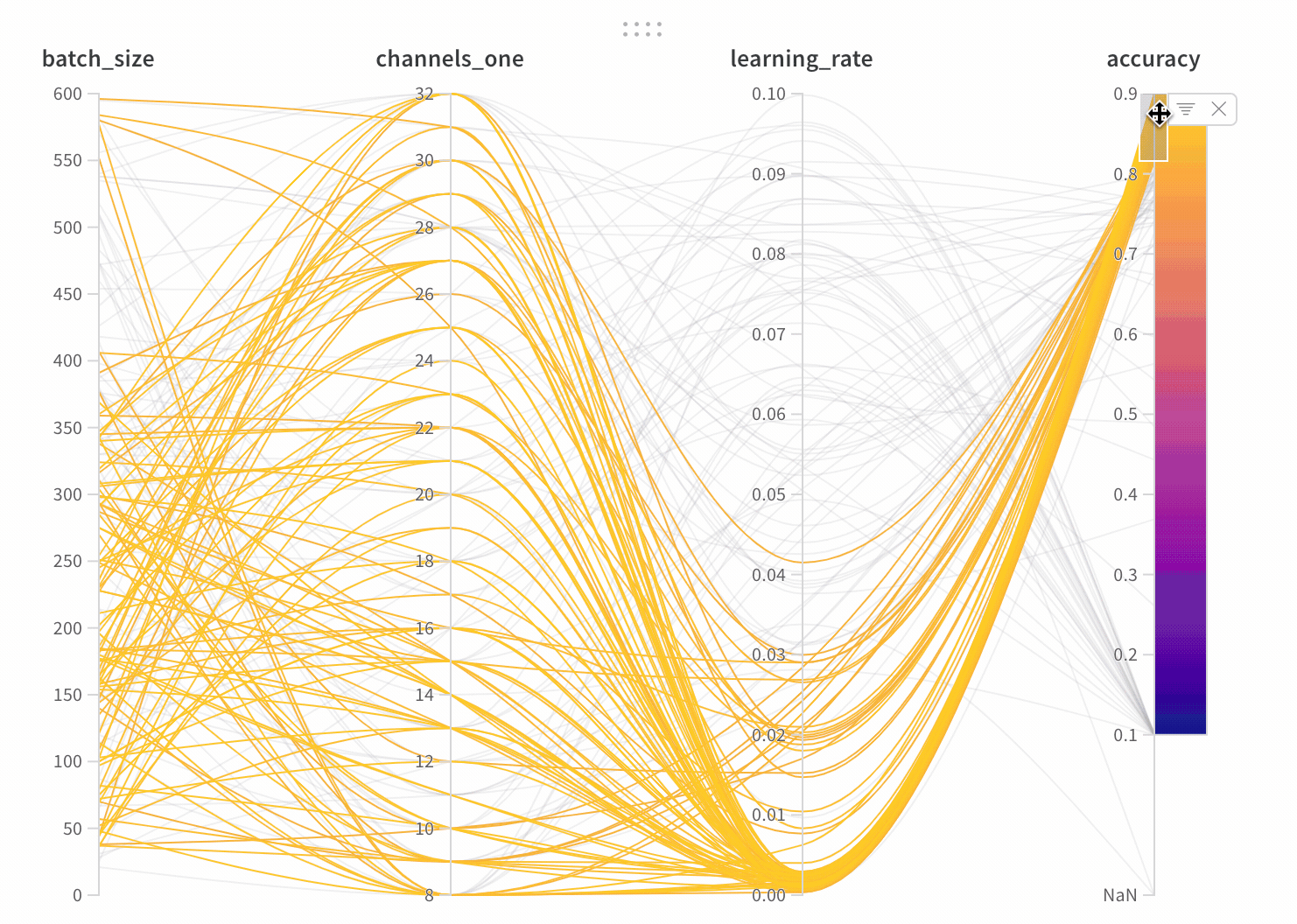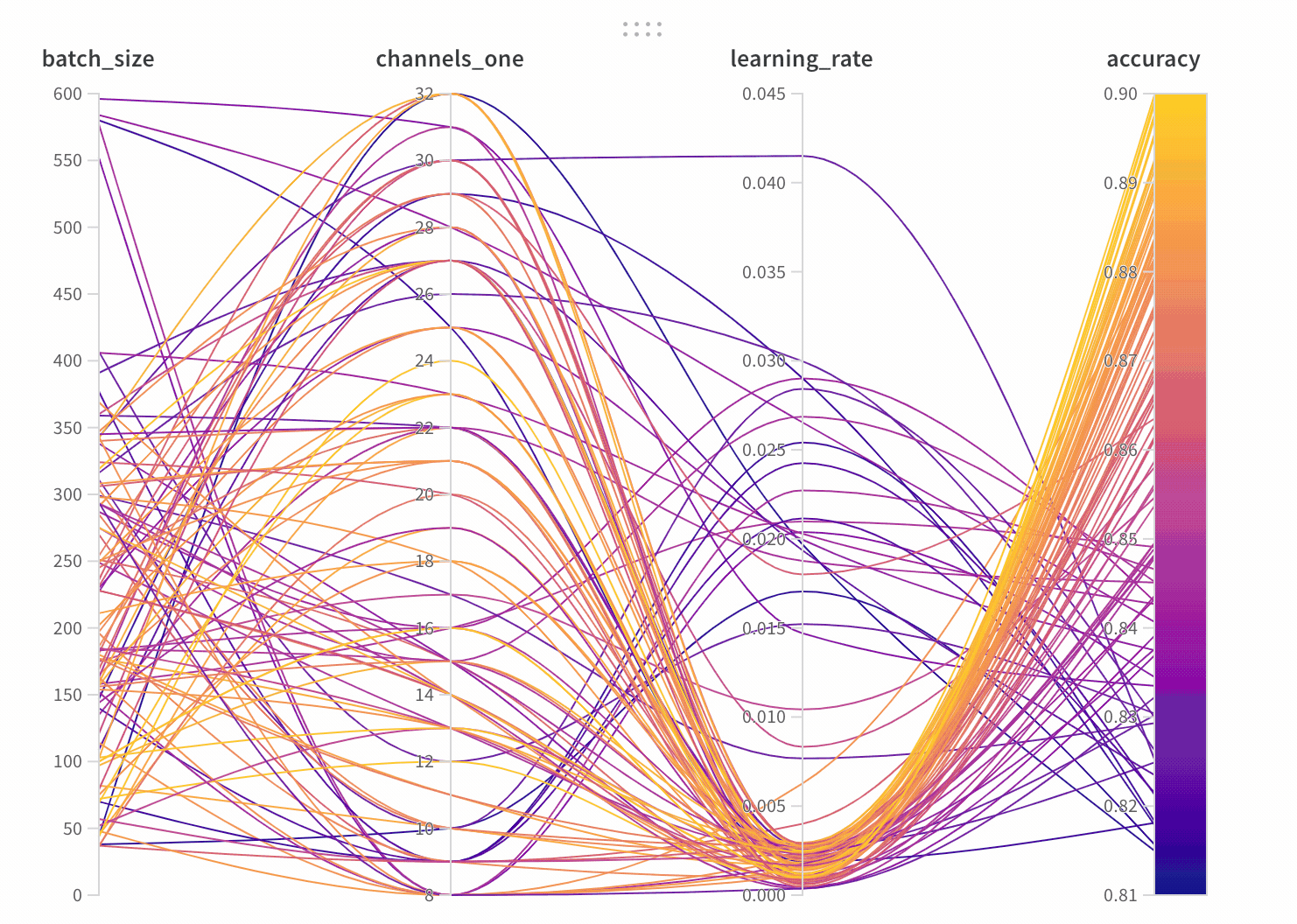
- 軸:
wandb.configのさまざまなハイパーパラメータと、wandb.logのメトリクス。 - 線: 各線は単一の run を表します。線にマウスオーバーすると、run に関する詳細がツールチップに表示されます。現在のフィルタに一致するすべての線が表示されますが、目のアイコンをオフにすると、線はグレー表示になります。
並列座標パネルの作成
- ワークスペース のランディングページに移動します
- パネルを追加 をクリックします
- 並列座標 を選択します
パネル の 設定
パネル を構成するには、パネル の右上隅にある編集ボタンをクリックします。
- ツールチップ: マウスオーバーすると、各 run の情報を示す凡例が表示されます
- タイトル: 軸のタイトルを編集して、より読みやすくします
- 勾配: 好みの色範囲に合わせて 勾配 をカスタマイズします
- 対数スケール: 各軸は、対数スケールで個別に表示するように設定できます
- 軸の反転: 軸の方向を切り替えます。これは、精度と損失の両方を列として持つ場合に便利です
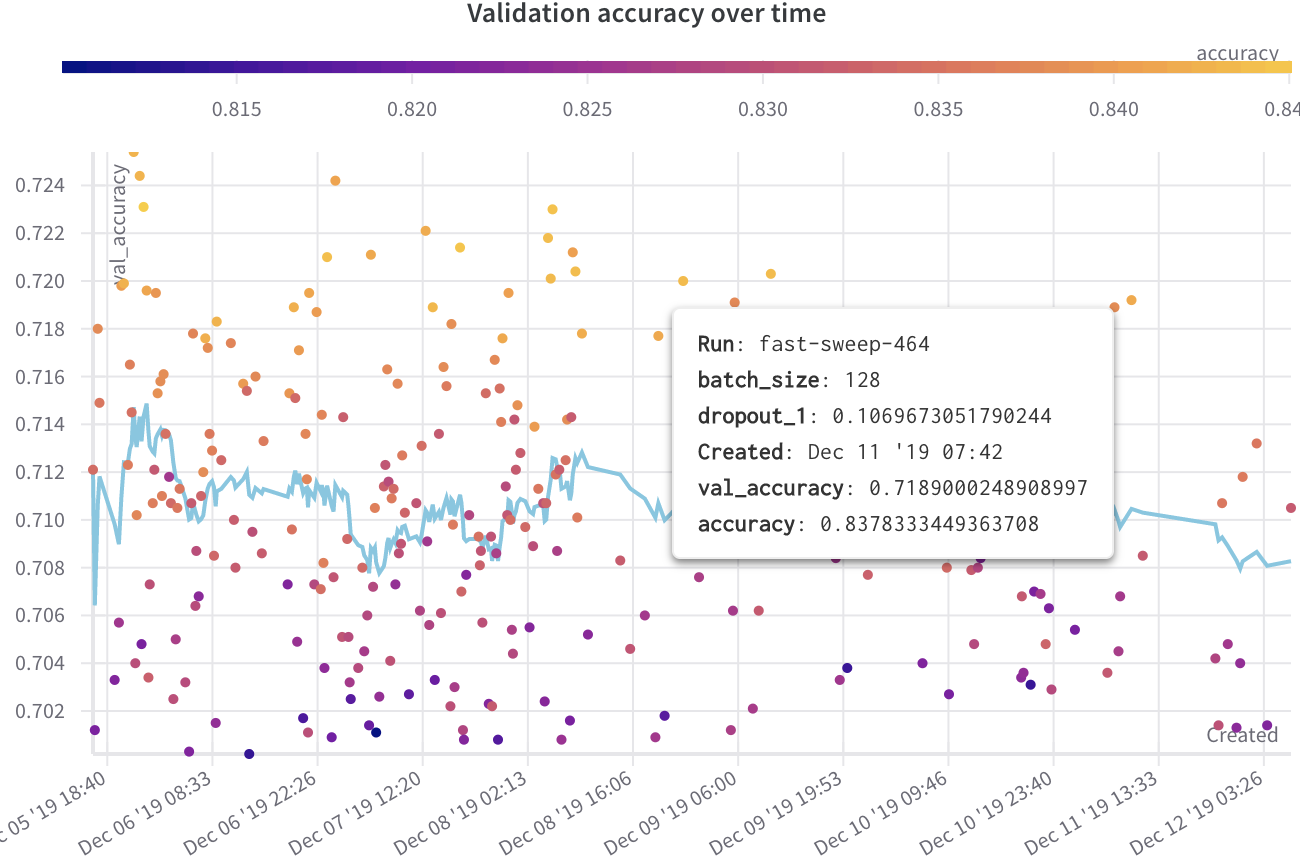
1.4 - Scatter plots
このページでは、W&B で散布図を使用する方法について説明します。
ユースケース
散布図を使用して、複数の run を比較し、実験のパフォーマンスを可視化します。
- 最小値、最大値、および平均値の線を描画します。
- メタデータツールチップをカスタマイズします。
- 点の色を制御します。
- 軸の範囲を調整します。
- 軸にログスケールを使用します。
例
次の例は、数週間の実験におけるさまざまな model の検証精度を表示する散布図を示しています。ツールチップには、バッチサイズ、ドロップアウト、および軸の値が含まれています。線は、検証精度の移動平均も示しています。
散布図の作成
W&B UI で散布図を作成するには:
- [Workspaces] タブに移動します。
- [Charts] パネルで、アクションメニュー
...をクリックします。 - ポップアップメニューから、[Add panels] を選択します。
- [Add panels] メニューで、[Scatter plot] を選択します。
- 表示するデータのプロットするために、
x軸とy軸を設定します。オプションで、軸の最大範囲と最小範囲を設定するか、z軸を追加します。 - [Apply] をクリックして、散布図を作成します。
- [Charts] パネルで新しい散布図を表示します。
1.5 - Save and diff code
デフォルトでは、W&B は最新の git コミットハッシュのみを保存します。より多くのコード機能を有効にすると、UI で Experiments 間のコードを動的に比較できます。
wandb バージョン 0.8.28 以降、W&B は wandb.init() を呼び出すメインのトレーニングファイルからコードを保存できます。
ライブラリコードを保存する
コードの保存を有効にすると、W&B は wandb.init() を呼び出したファイルからコードを保存します。追加のライブラリコードを保存するには、次の 3 つのオプションがあります。
wandb.init() を呼び出した後、wandb.run.log_code(".") を呼び出す
import wandb
wandb.init()
wandb.run.log_code(".")
code_dir を設定して、設定オブジェクトを wandb.init に渡す
import wandb
wandb.init(settings=wandb.Settings(code_dir="."))
これにより、現在のディレクトリーとそのすべてのサブディレクトリーにあるすべての Python ソースコードファイルが Artifacts としてキャプチャされます。保存されるソースコードファイルの種類と場所をより詳細に制御するには、リファレンスドキュメント を参照してください。
UI でコードの保存を設定する
プログラムでコードの保存を設定するだけでなく、W&B アカウントの Settings でこの機能を切り替えることもできます。これにより、アカウントに関連付けられているすべての Teams に対してコードの保存が有効になることに注意してください。
デフォルトでは、W&B はすべての Teams に対してコードの保存を無効にします。
- W&B アカウントにログインします。
- Settings > Privacy に移動します。
- Project and content security で、Disable default code saving をオンにします。
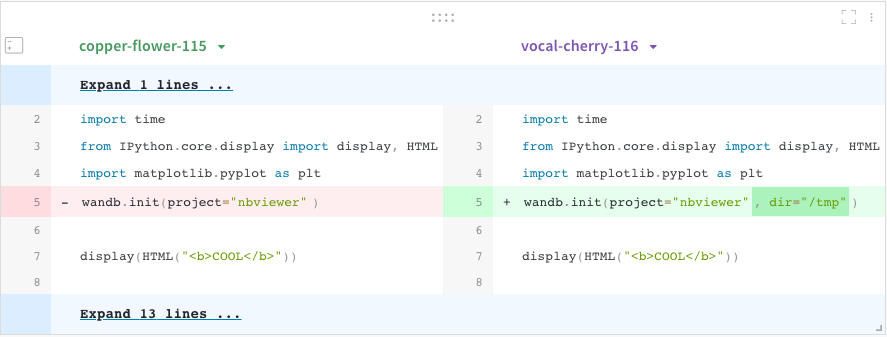
コード比較ツール
異なる W&B の Runs で使用されるコードを比較します。
- ページの右上隅にある Add panels ボタンを選択します。
- TEXT AND CODE ドロップダウンを展開し、Code を選択します。
Jupyter セッション履歴
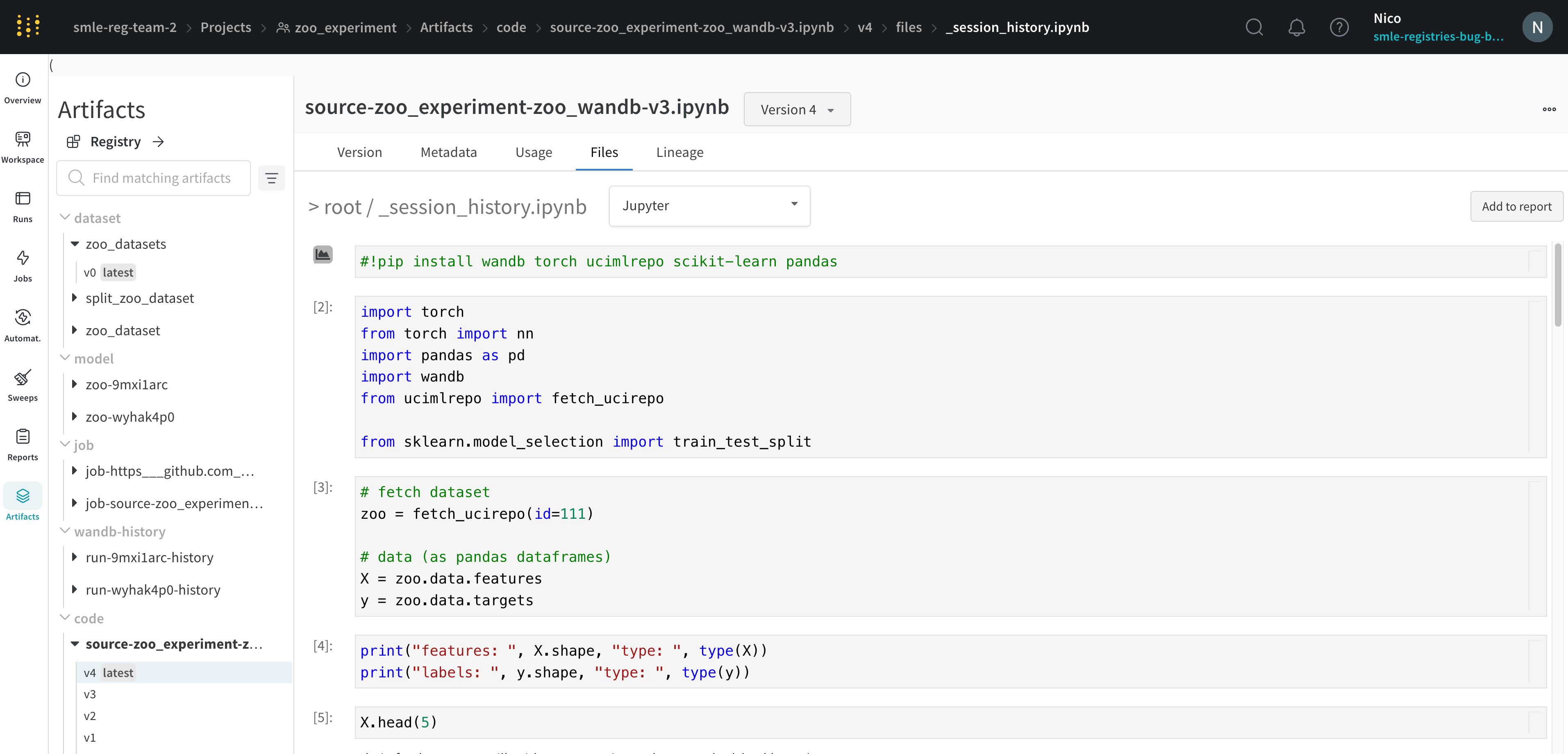
W&B は、Jupyter ノートブックセッションで実行されたコードの履歴を保存します。Jupyter 内で wandb.init() を呼び出すと、W&B は現在のセッションで実行されたコードの履歴を含む Jupyter ノートブックを自動的に保存する hook を追加します。
- コードを含む project のワークスペースに移動します。
- 左側のナビゲーションバーで Artifacts タブを選択します。
- code artifact を展開します。
- Files タブを選択します。
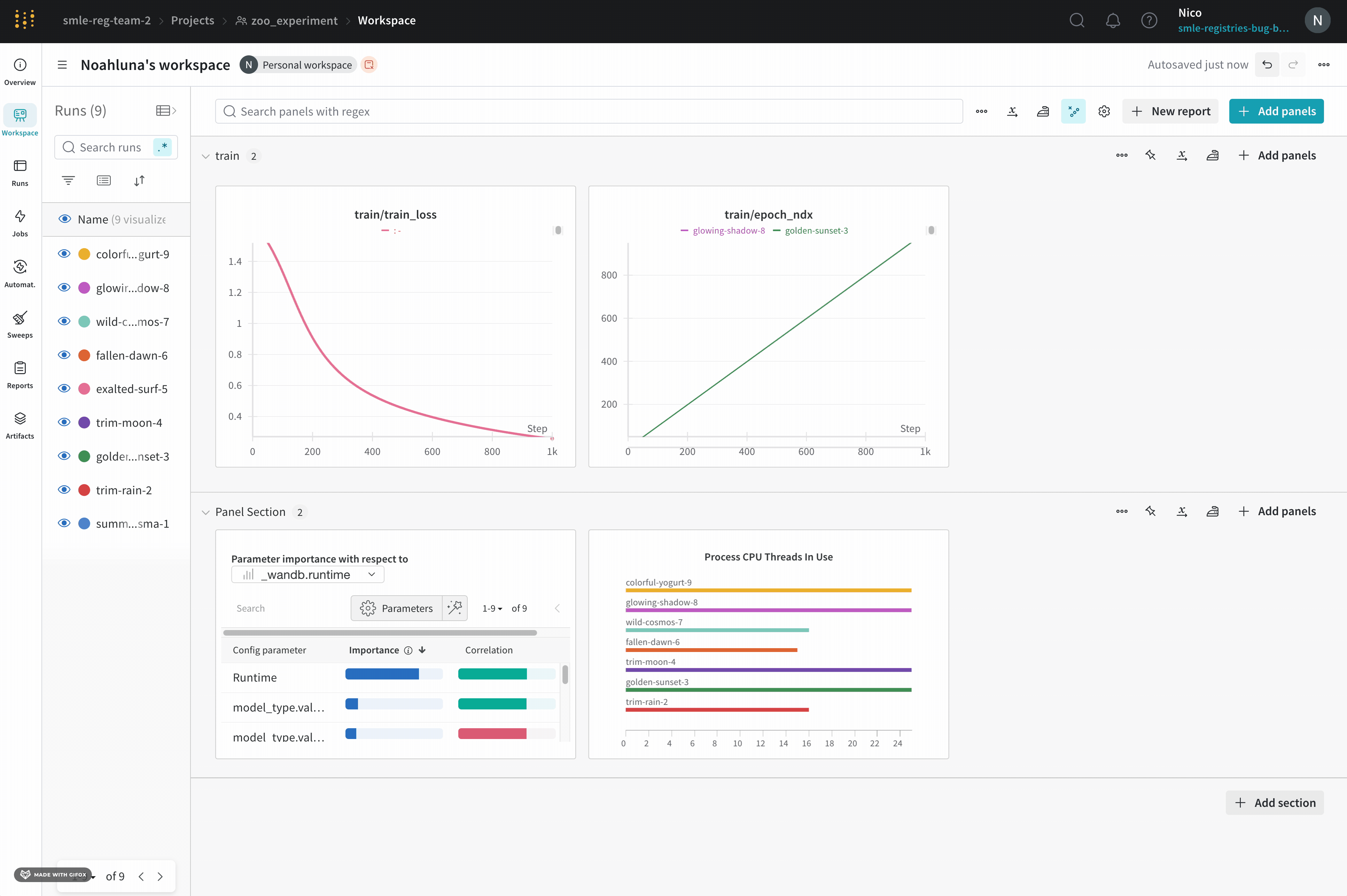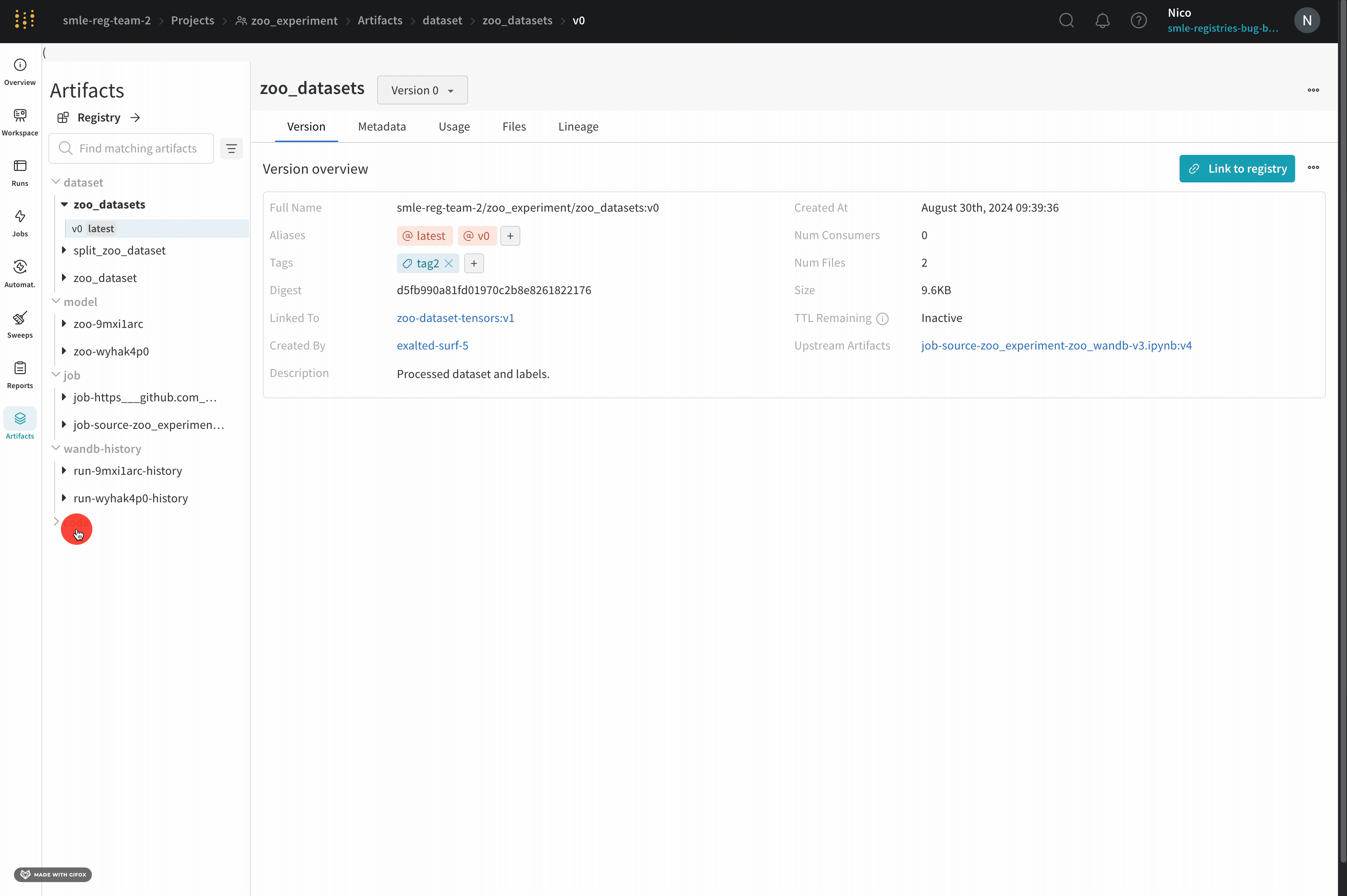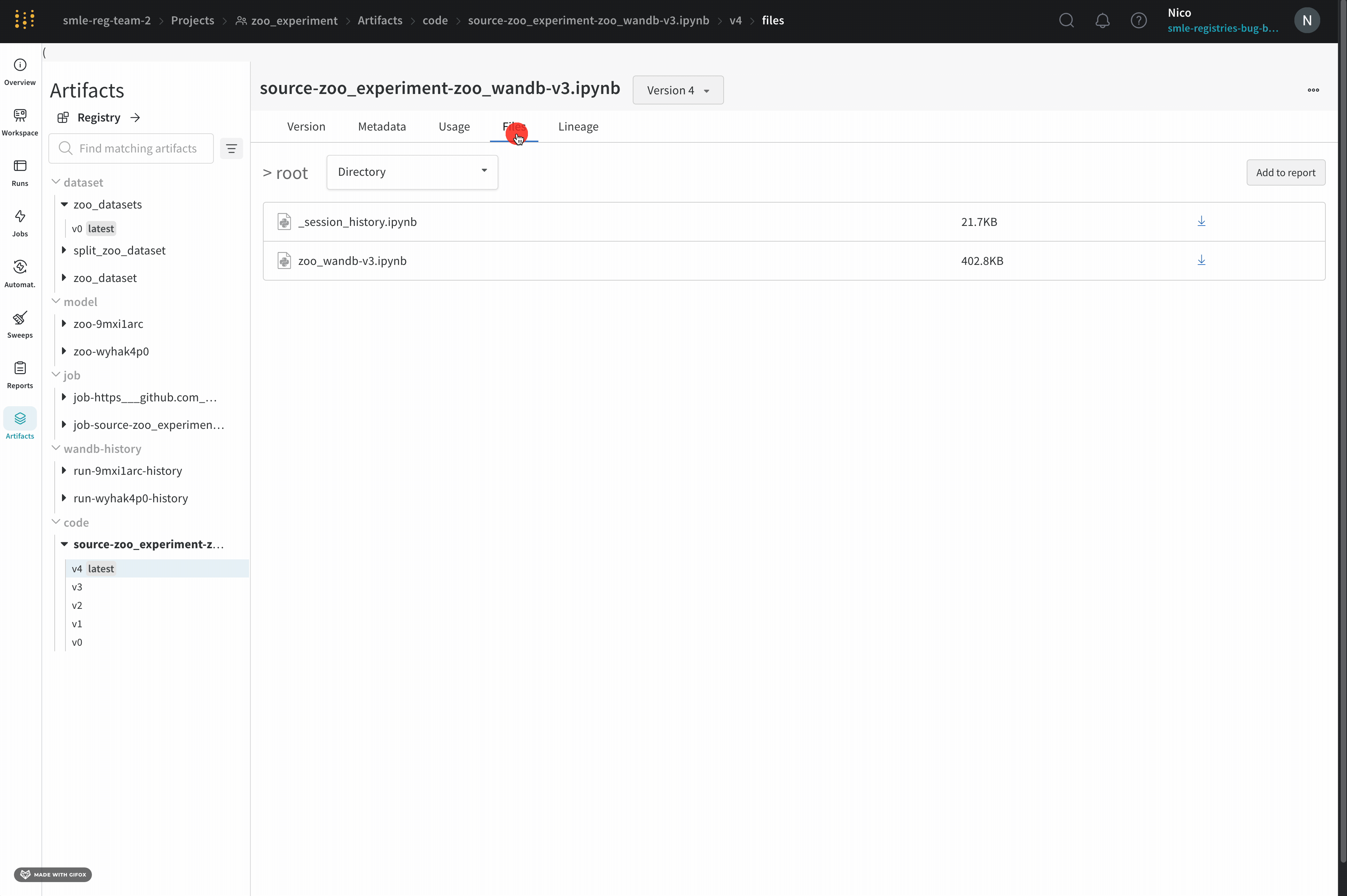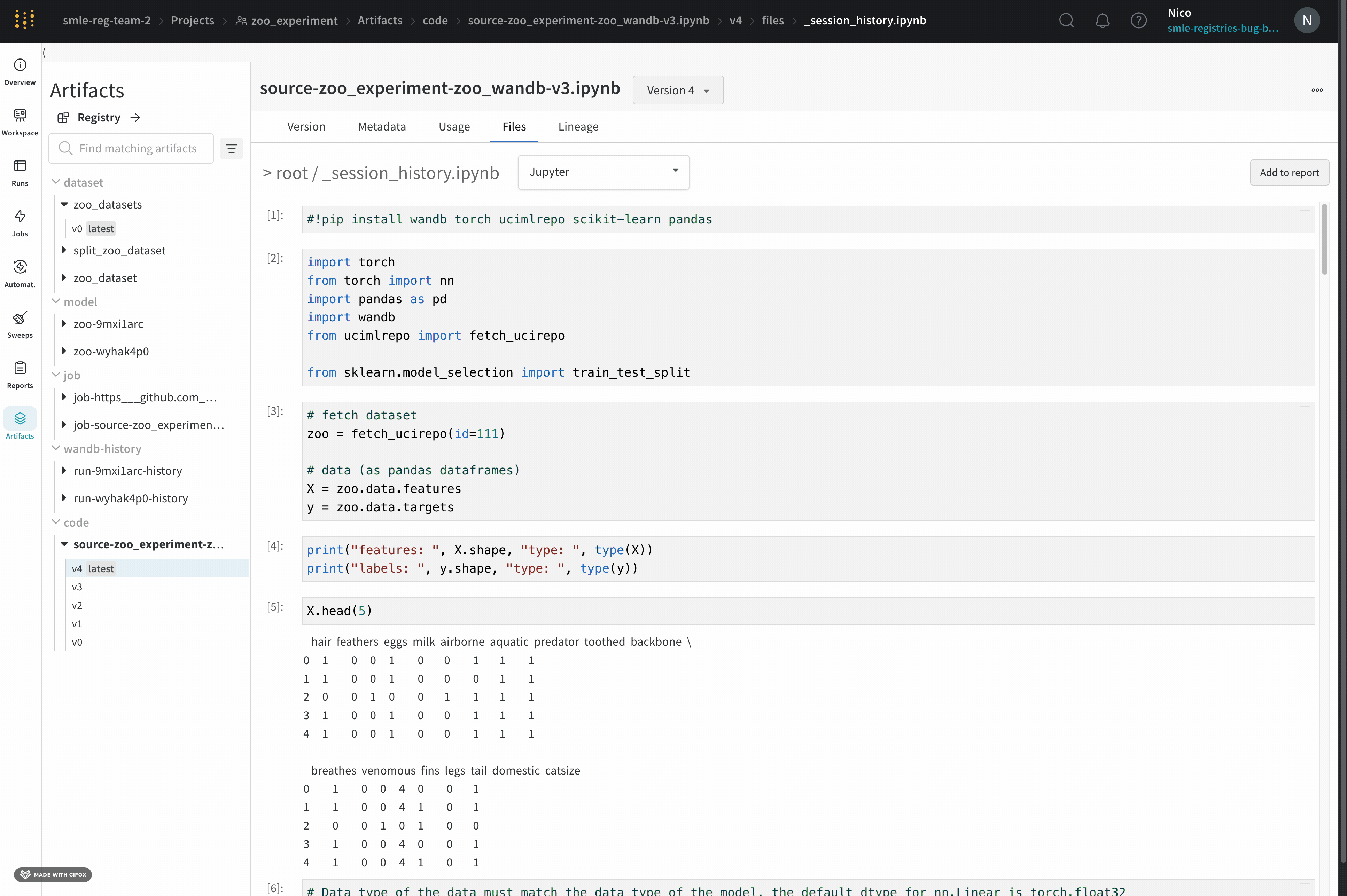
これにより、セッションで実行されたセルと、iPython の display メソッドを呼び出すことによって作成された出力が表示されます。これにより、特定の run で Jupyter 内で実行されたコードを正確に確認できます。可能な場合、W&B はコードディレクトリーにある最新バージョンのノートブックも保存します。
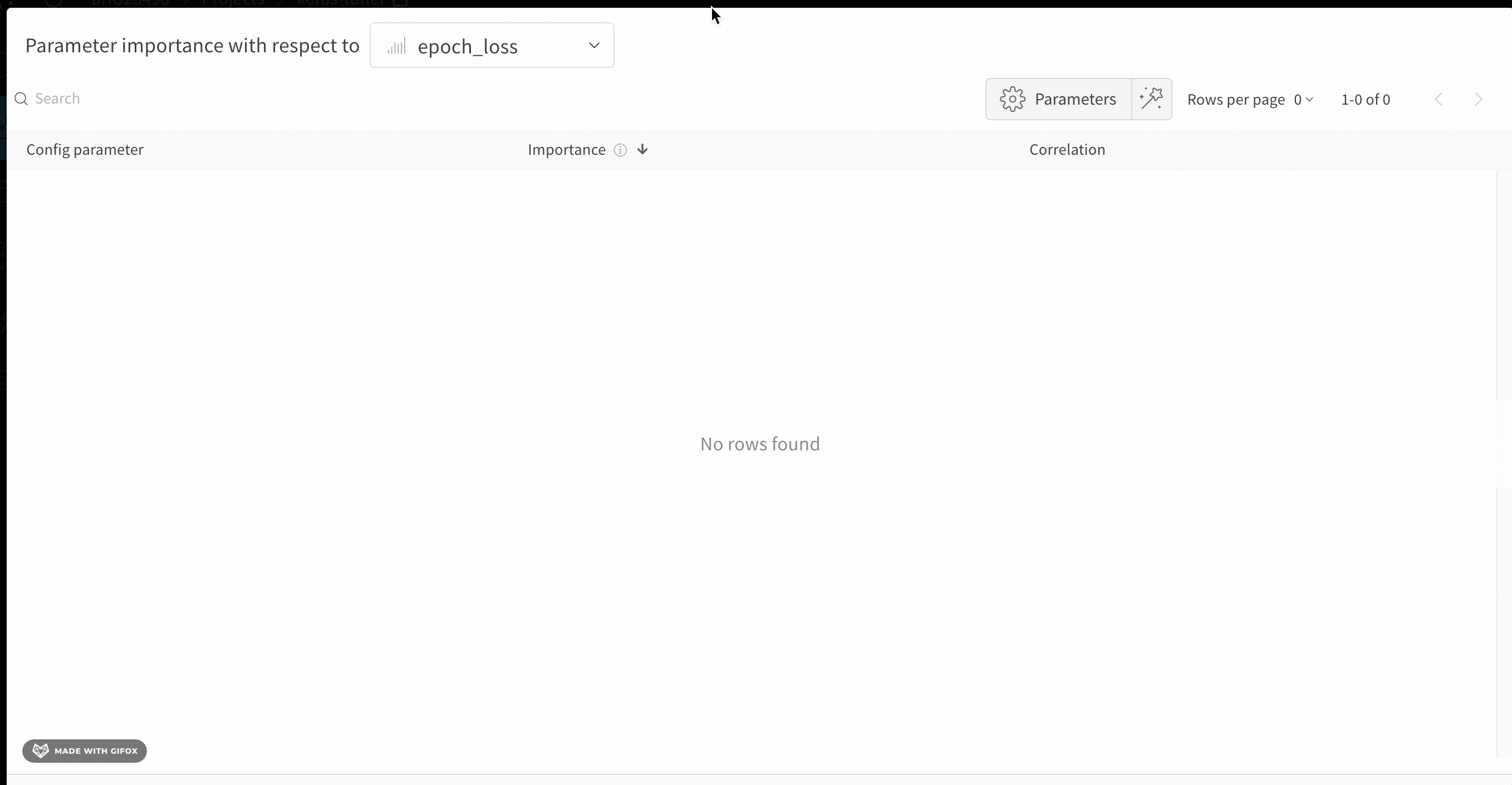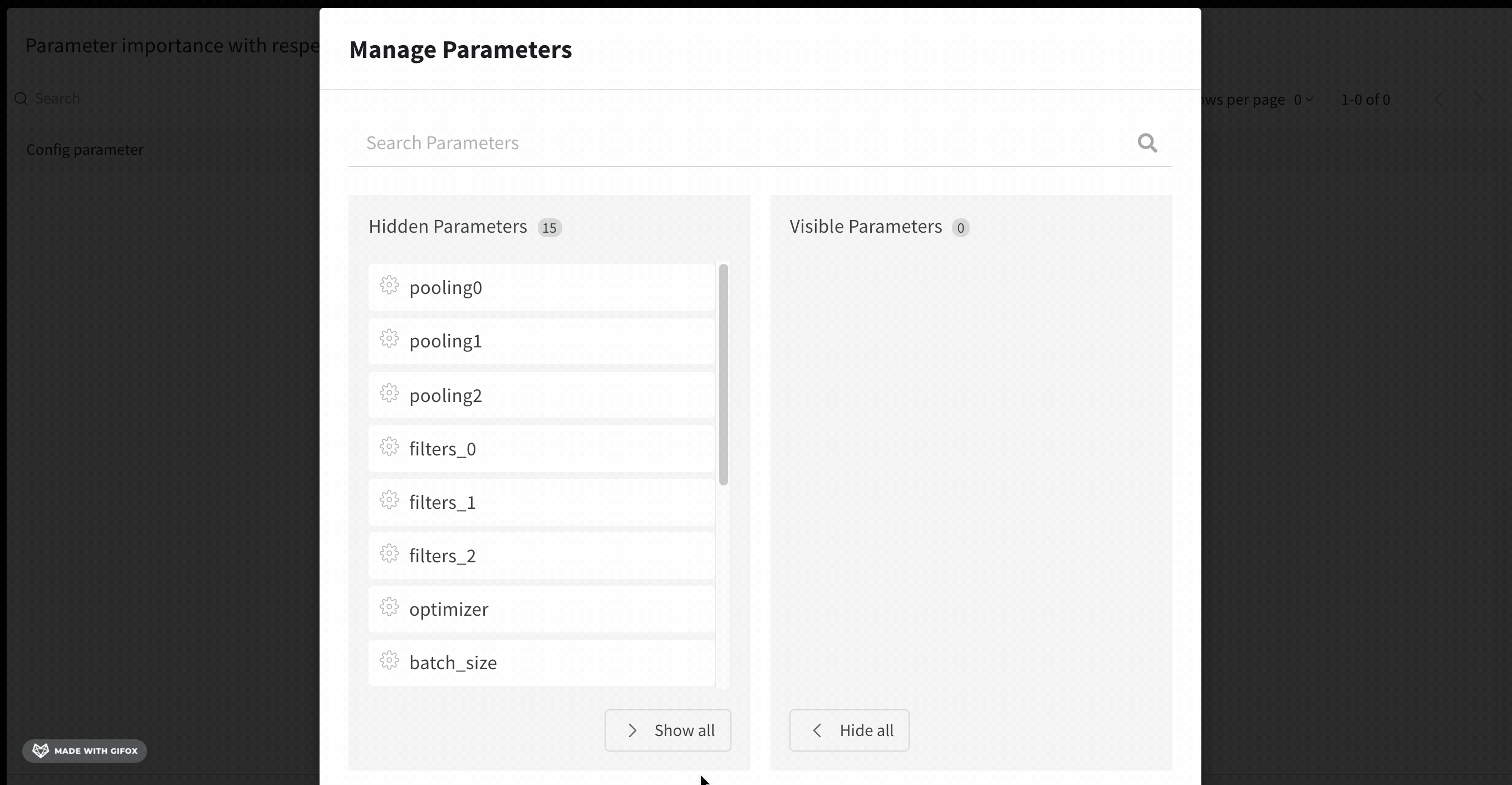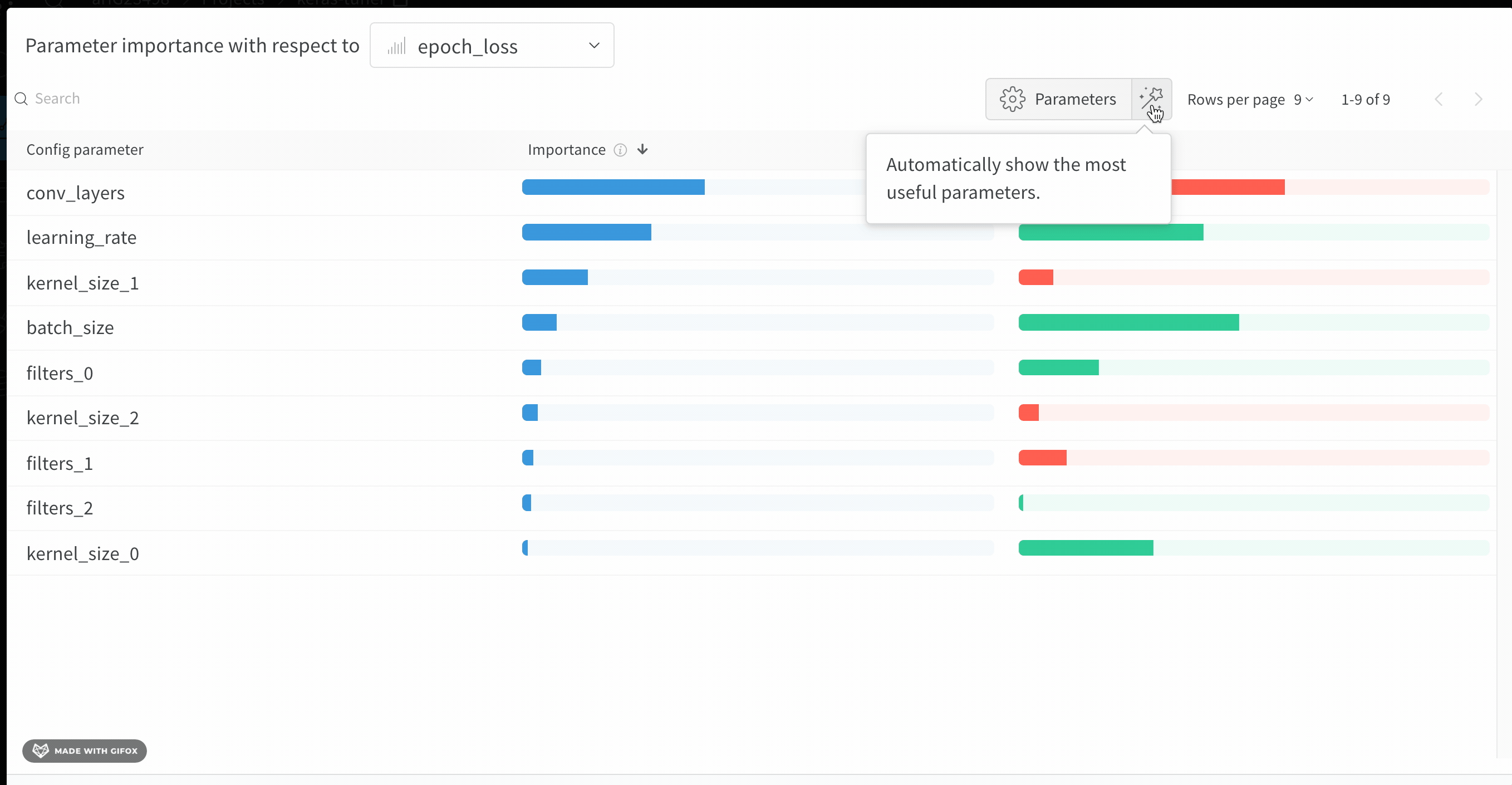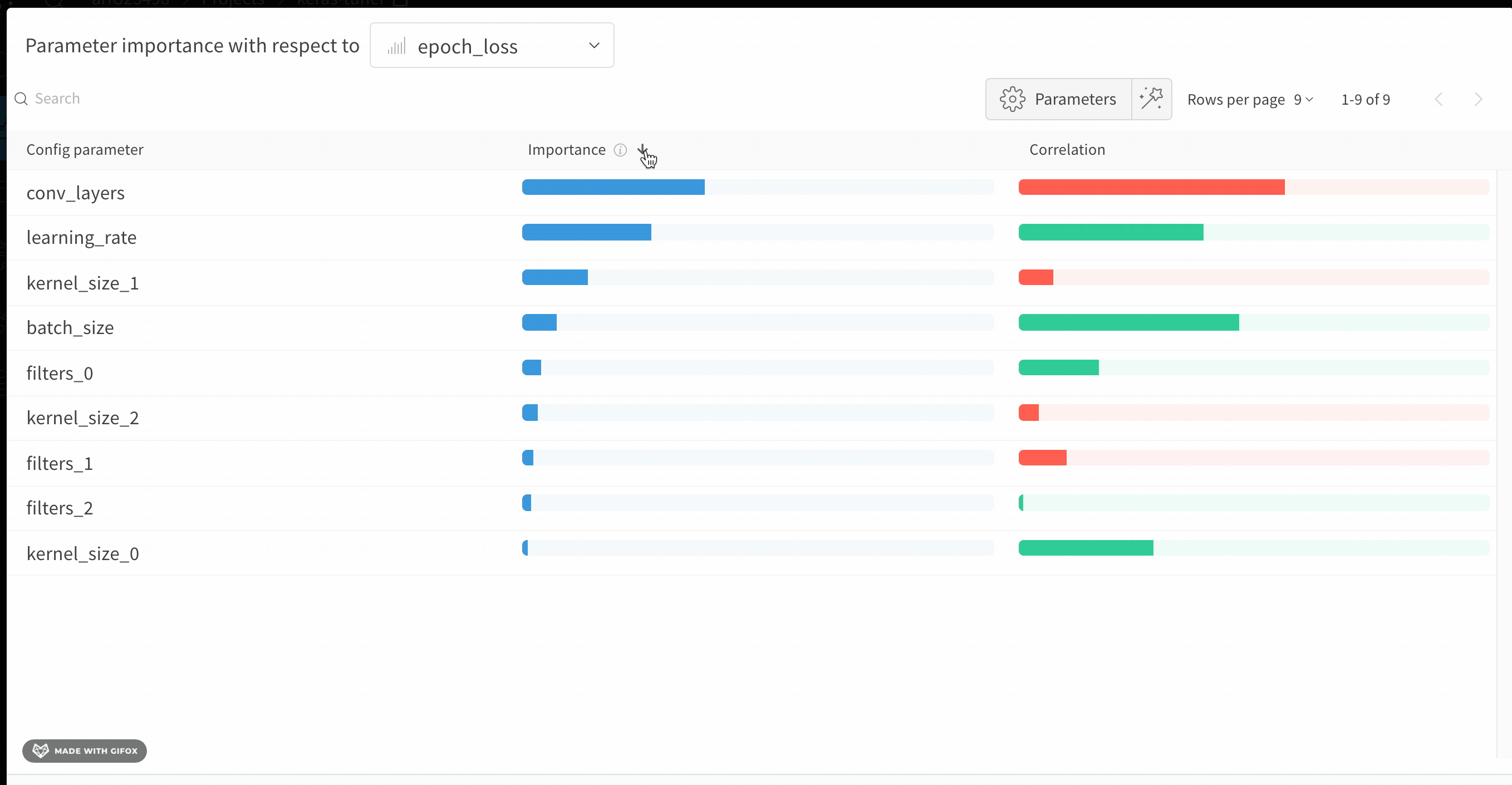
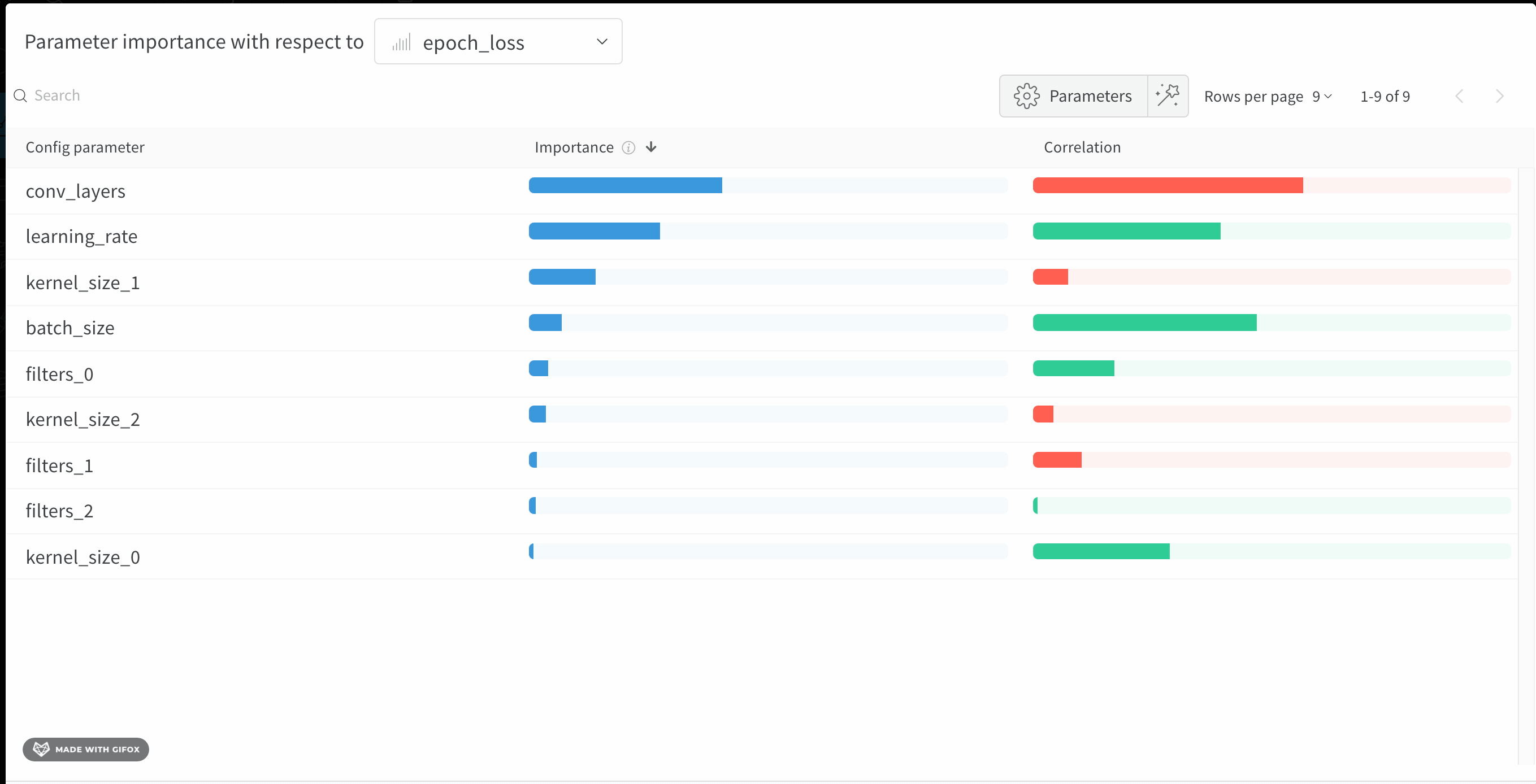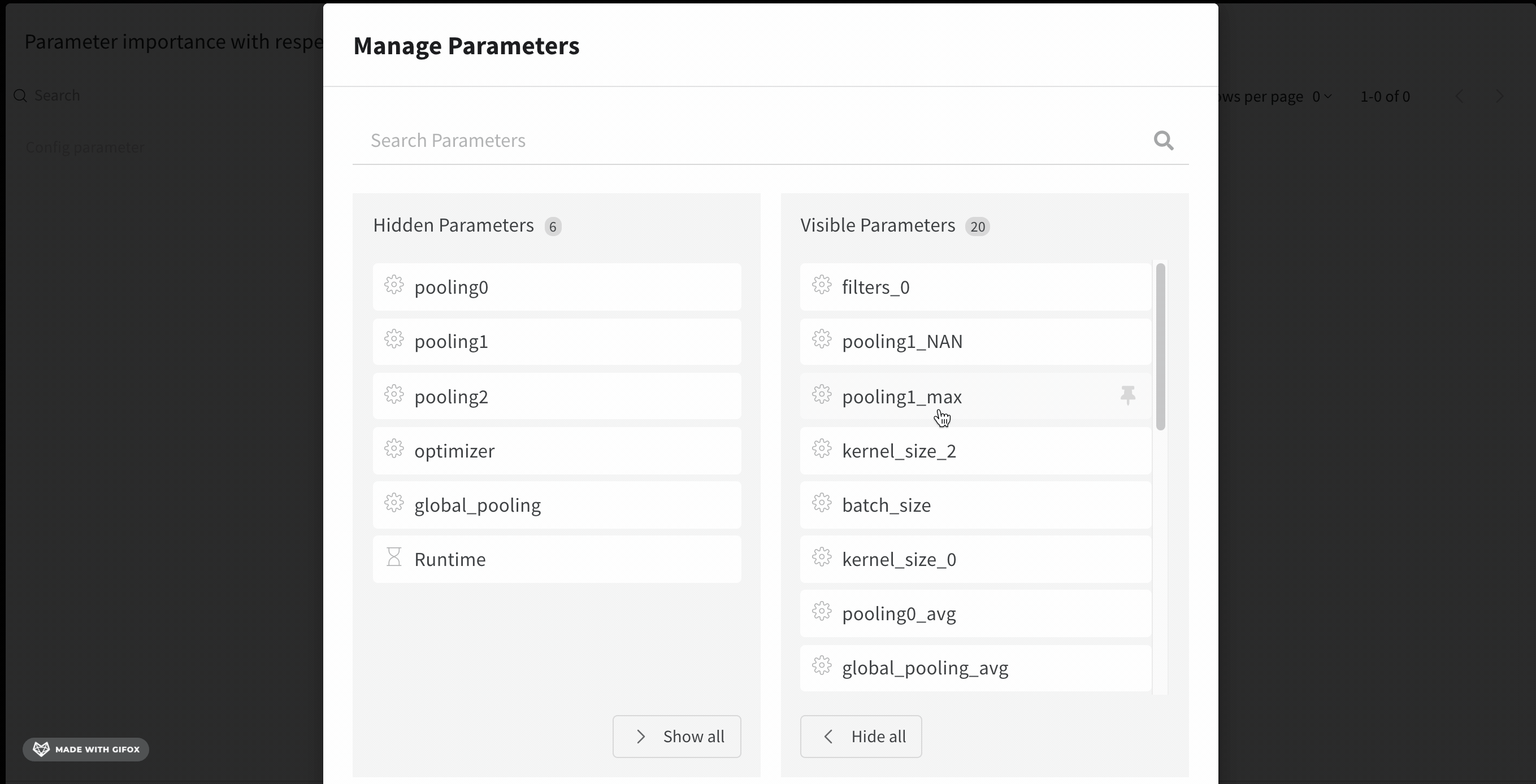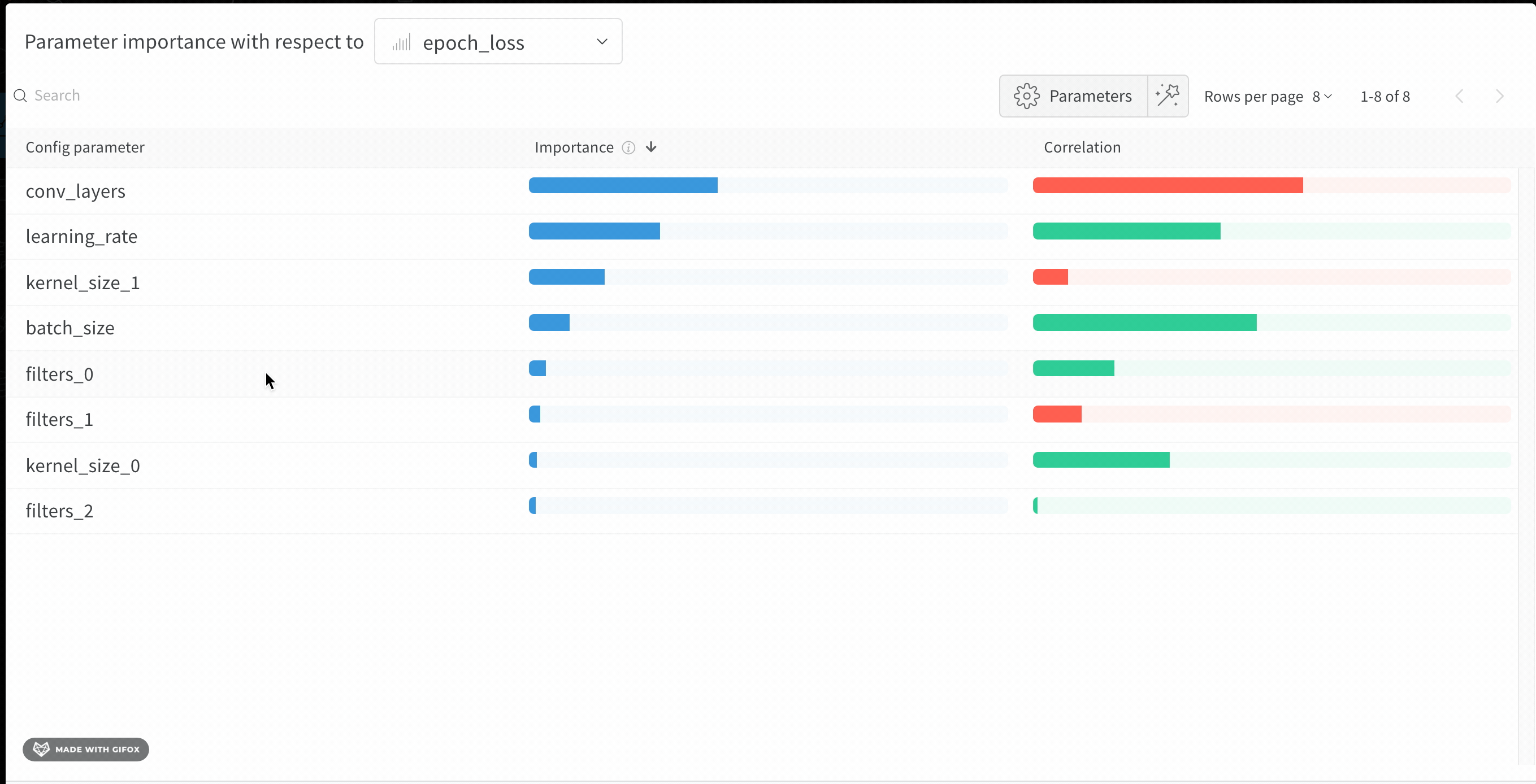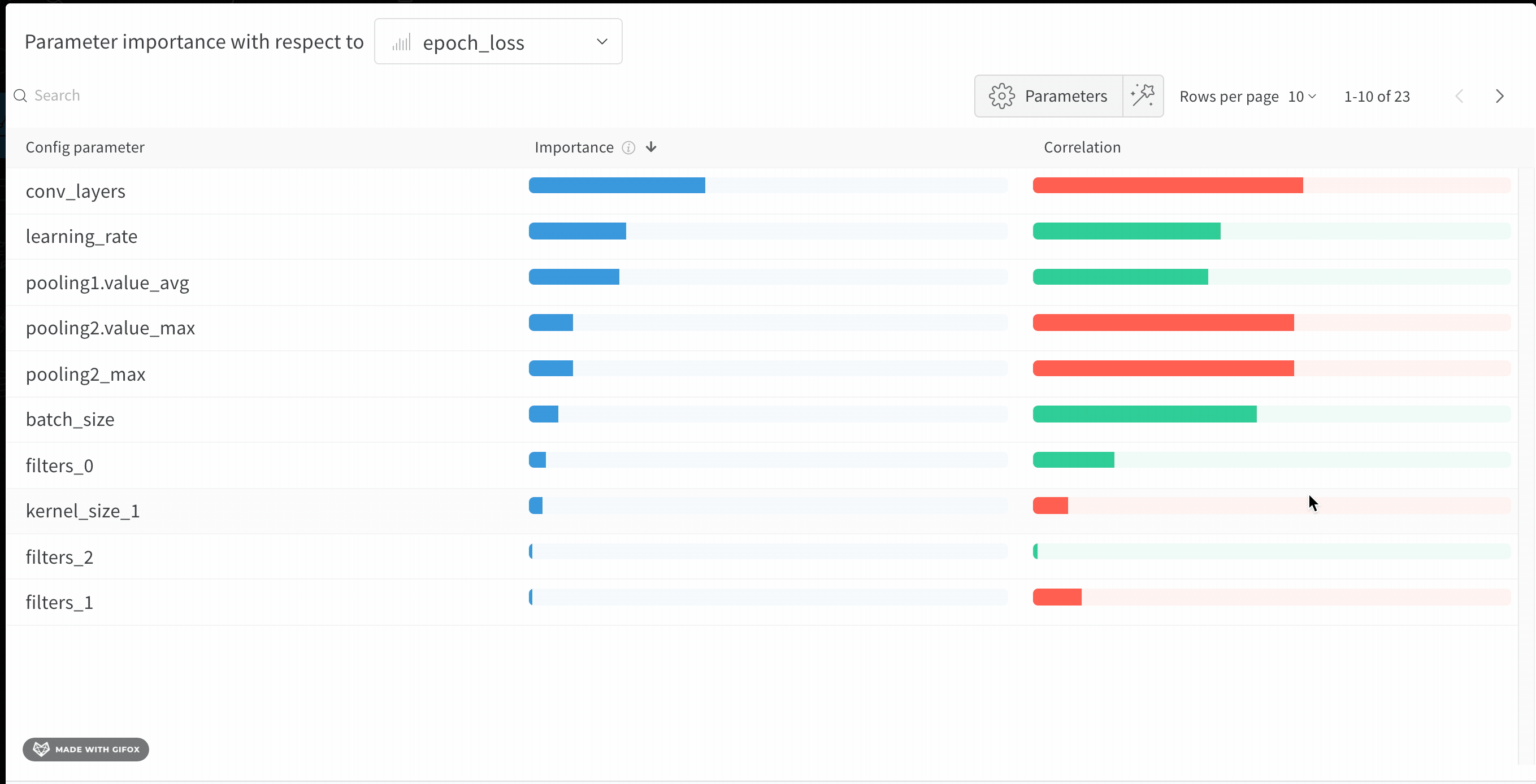
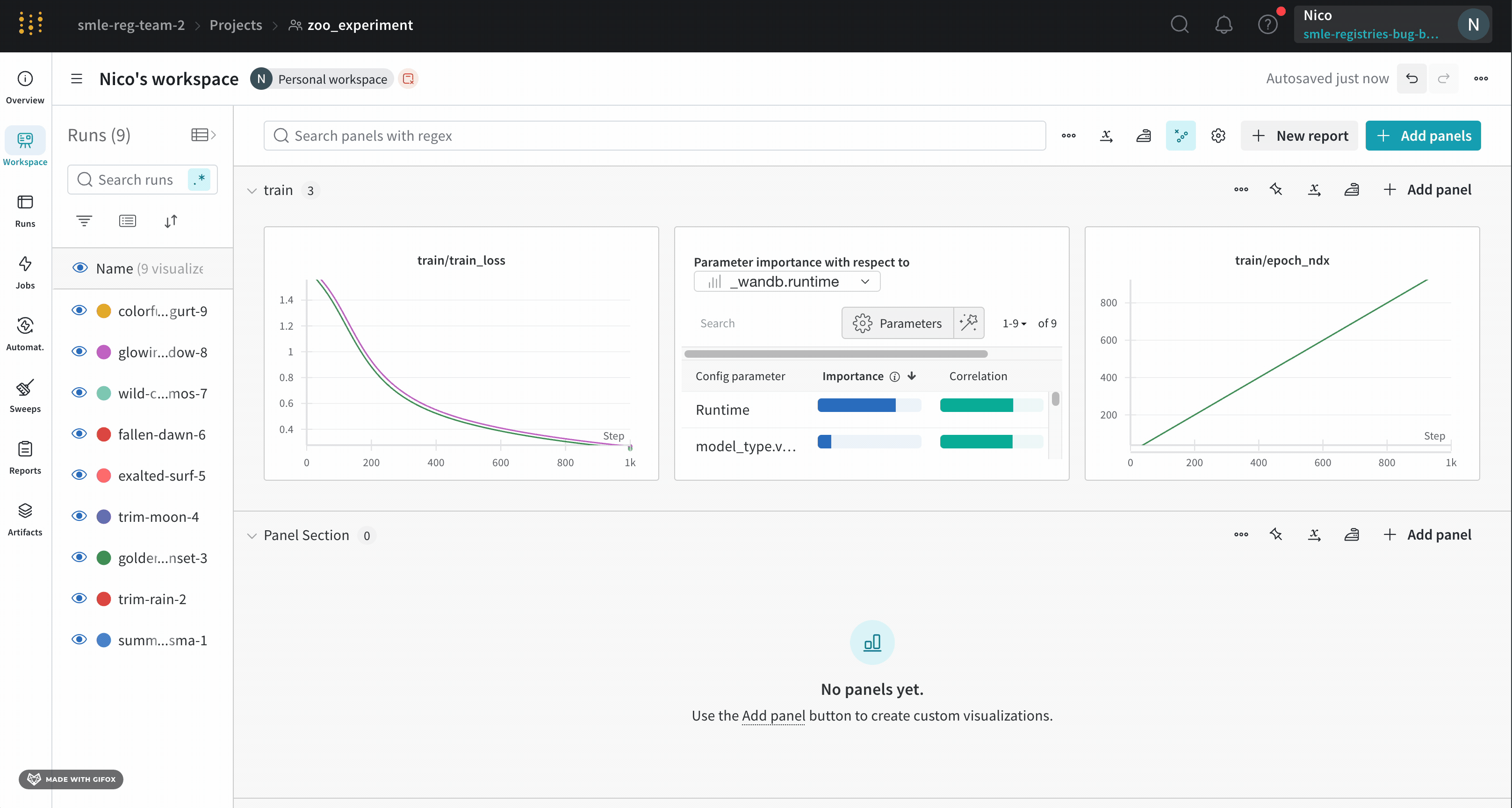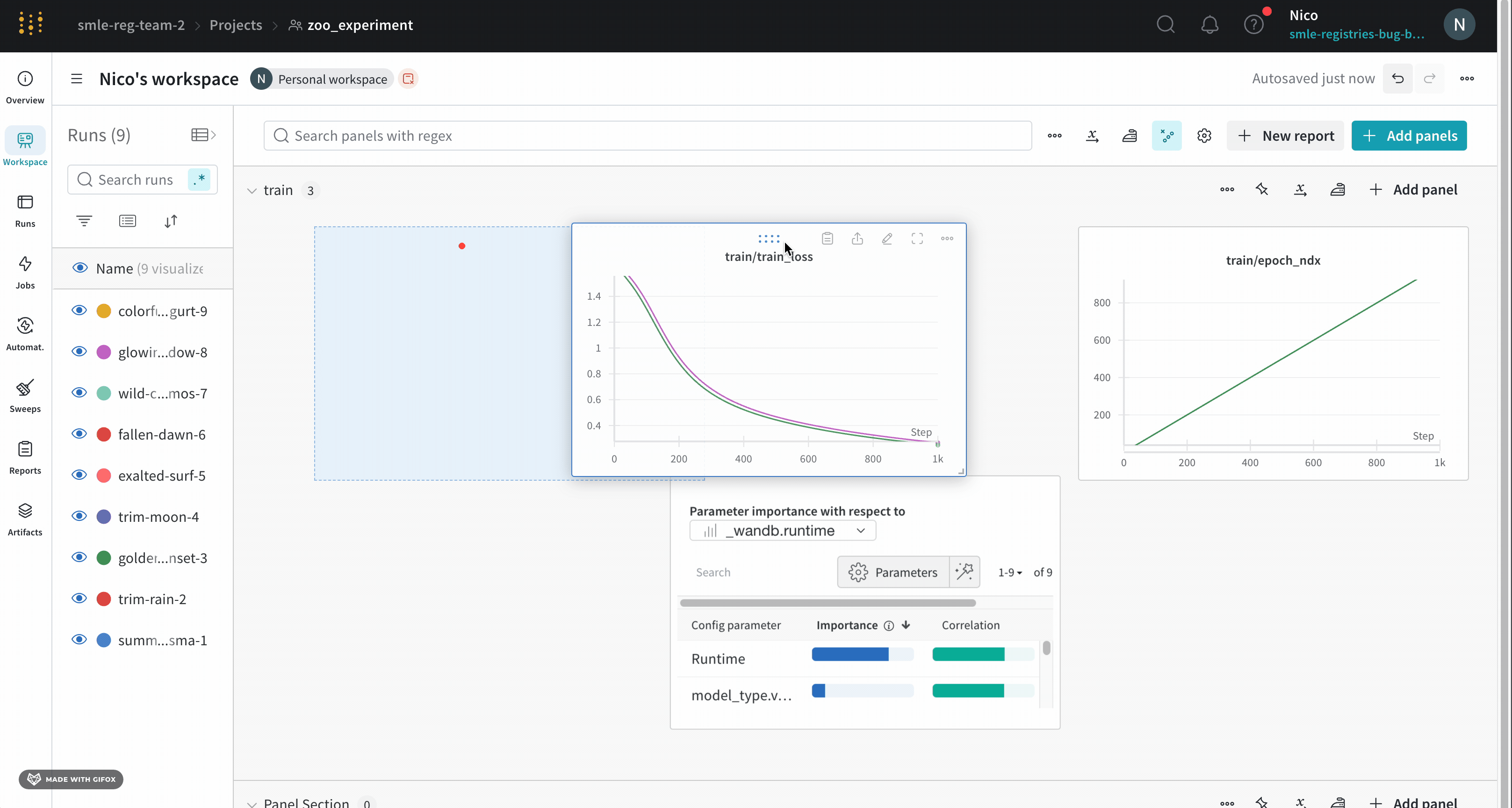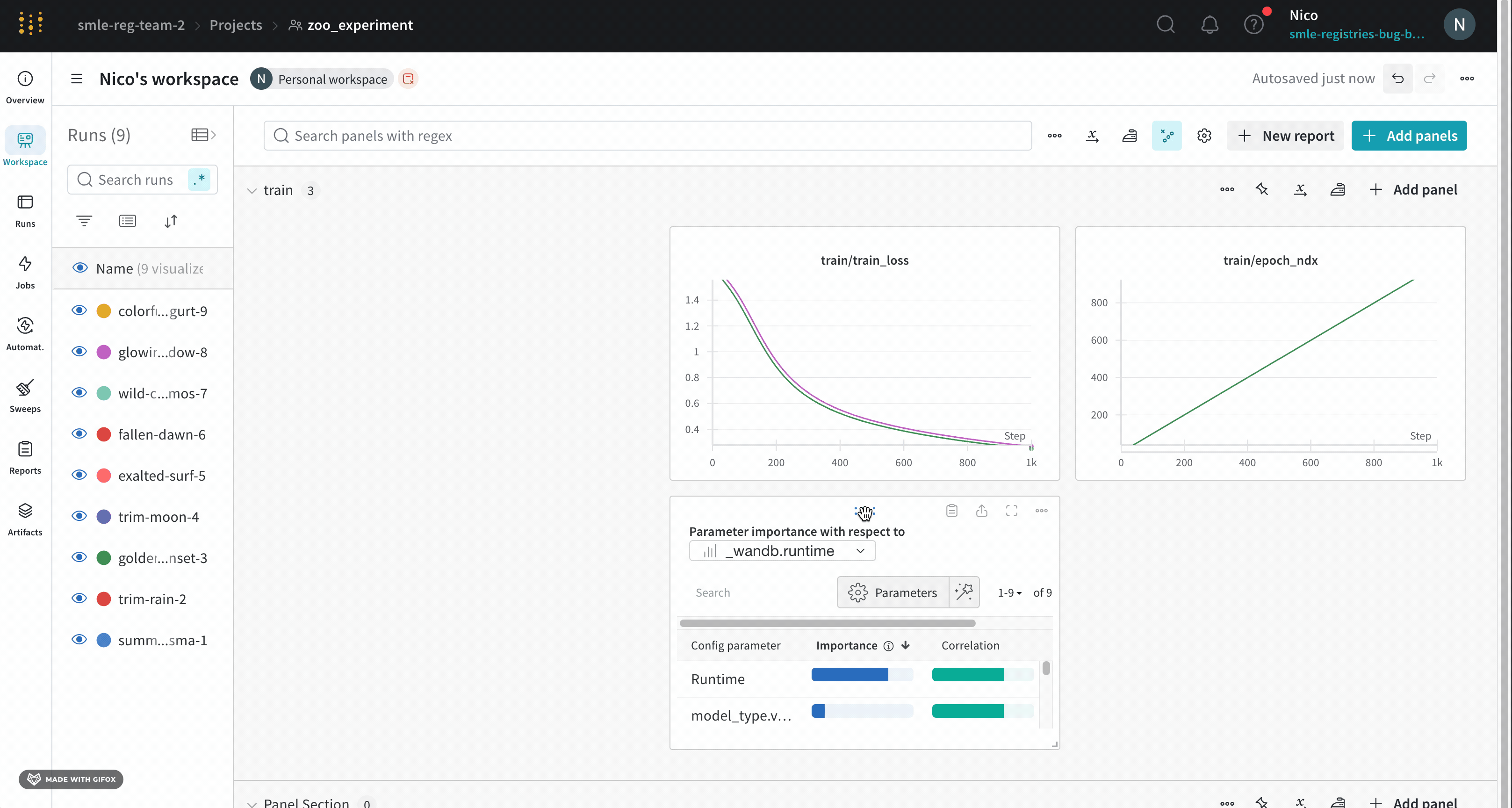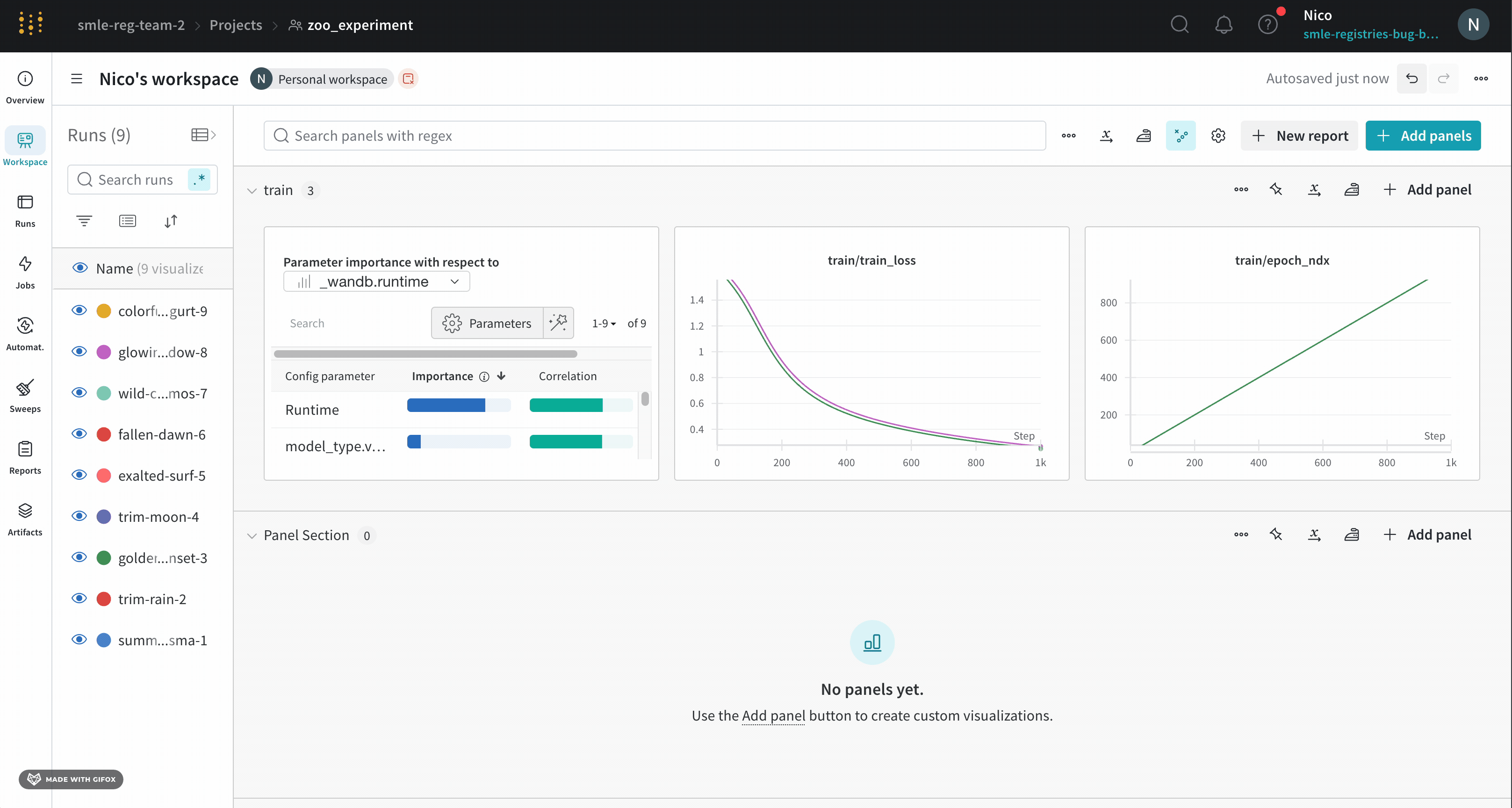
1.6 - Parameter importance
どのハイパーパラメータが最も優れた予測因子であり、メトリクスの望ましい値と高度に相関しているかを調べます。
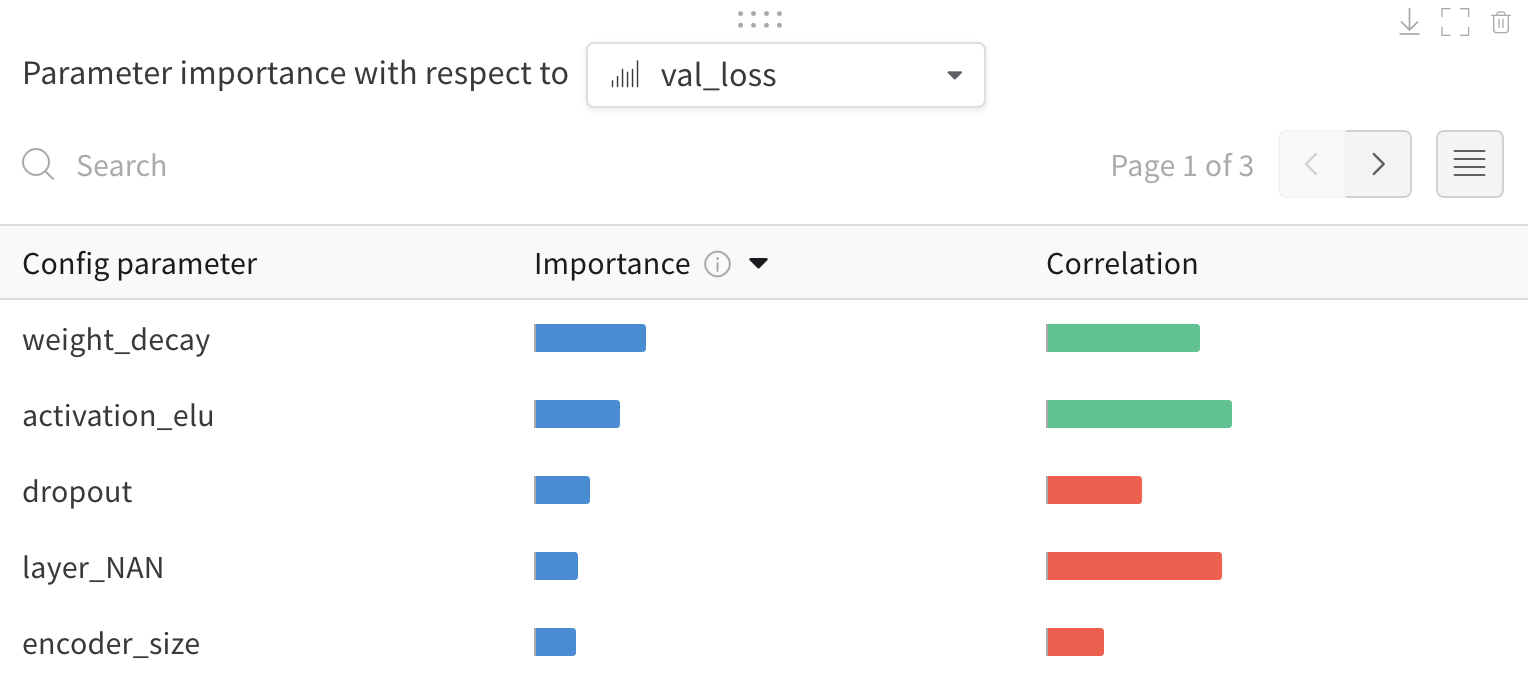
相関 は、ハイパーパラメータと選択したメトリクス(この場合は val_loss)の間の線形相関です。したがって、高い相関は、ハイパーパラメータが高い値を持つ場合、メトリクスも高い値を持つことを意味し、その逆もまた同様です。相関は見るべき優れたメトリクスですが、入力間の二次的な相互作用を捉えることができず、大きく異なる範囲の入力を比較するのが面倒になる可能性があります。
したがって、W&B は 重要度 メトリクスも計算します。W&B は、ハイパーパラメータを入力として、メトリクスをターゲット出力としてランダムフォレストをトレーニングし、ランダムフォレストのフィーチャーの重要度の値をレポートします。
この手法のアイデアは、Jeremy Howard との会話に触発されました。彼は、Fast.ai でハイパーパラメータ空間を調査するために、ランダムフォレストのフィーチャーの重要度の使用を開拓しました。W&B は、この 講義 (およびこれらの ノート)をチェックして、この分析の背後にある動機について詳しく学ぶことを強くお勧めします。
ハイパーパラメータの重要度パネルは、高度に相関するハイパーパラメータ間の複雑な相互作用を解きほぐします。そうすることで、モデルのパフォーマンスを予測するという点で、どのハイパーパラメータが最も重要であるかを示すことにより、ハイパーパラメータの検索を微調整するのに役立ちます。
ハイパーパラメータの重要度パネルの作成
- W&B の Projects に移動します。
- Add panels ボタンを選択します。
- CHARTS ドロップダウンを展開し、ドロップダウンから Parallel coordinates を選択します。
パラメータマネージャーを使用すると、表示および非表示のパラメータを手動で設定できます。
ハイパーパラメータの重要度パネルの解釈
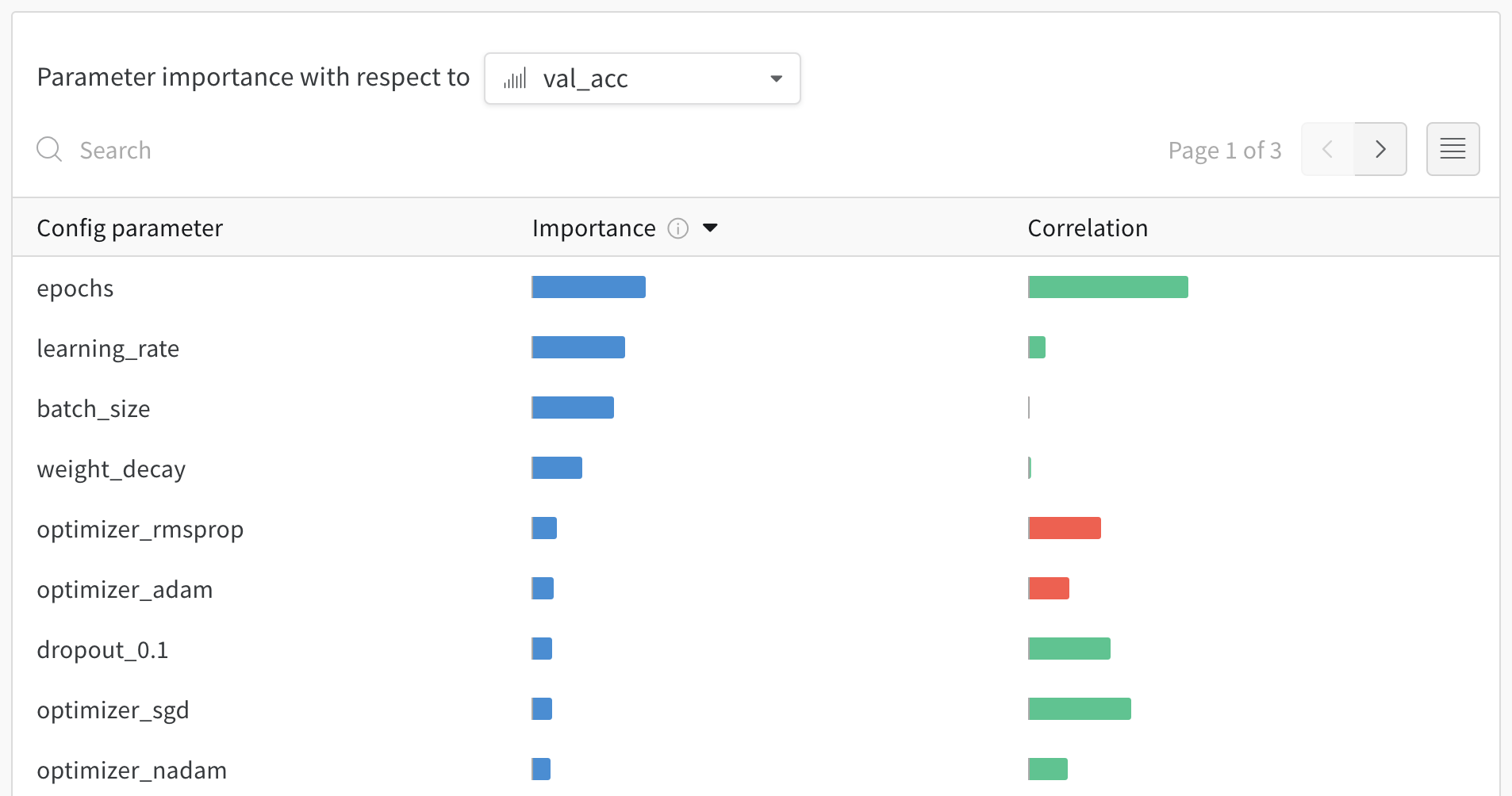
この panel には、トレーニングスクリプトの wandb.config オブジェクトに渡されたすべてのパラメータが表示されます。次に、これらの config パラメータのフィーチャーの重要度と相関関係が、選択したモデルメトリクス(この場合は val_loss)に関して表示されます。
重要度
重要度の列には、選択したメトリクスの予測に各ハイパーパラメータがどの程度役立ったかが表示されます。多数のハイパーパラメータのチューニングを開始し、このプロットを使用して、さらに調査する価値のあるハイパーパラメータを絞り込むシナリオを想像してください。後続の Sweeps は、最も重要なハイパーパラメータに限定できるため、より優れたモデルをより迅速かつ安価に見つけることができます。
前の画像では、epochs, learning_rate, batch_size および weight_decay が非常に重要であることがわかります。
相関
相関は、個々のハイパーパラメータとメトリクスの値の間の線形関係を捉えます。SGD オプティマイザーなどのハイパーパラメータの使用と val_loss の間に有意な関係があるかどうかという質問に答えます(この場合の答えはイエスです)。相関値の範囲は -1 から 1 で、正の値は正の線形相関を表し、負の値は負の線形相関を表し、0 の値は相関がないことを表します。一般に、どちらかの方向に 0.7 より大きい値は強い相関を表します。
このグラフを使用して、メトリクスとの相関が高い値をさらに調べたり(この場合は、確率的勾配降下法または adam を rmsprop または nadam よりも選択したり)、より多くのエポックでトレーニングしたりできます。
- 相関は、必ずしも因果関係ではなく、関連性の証拠を示しています。
- 相関は外れ値に敏感です。特に試行されたハイパーパラメータのサンプルサイズが小さい場合、強い関係を中程度の関係に変える可能性があります。
- そして最後に、相関はハイパーパラメータとメトリクスの間の線形関係のみを捉えます。強い多項式関係がある場合、相関によって捉えられません。
重要度と相関の間の格差は、重要度がハイパーパラメータ間の相互作用を考慮するのに対し、相関は個々のハイパーパラメータがメトリクスの値に与える影響のみを測定するという事実に起因します。次に、相関は線形関係のみを捉え、重要度はより複雑な関係を捉えることができます。
ご覧のとおり、重要度と相関はどちらも、ハイパーパラメータがモデルのパフォーマンスにどのように影響するかを理解するための強力な Tool です。
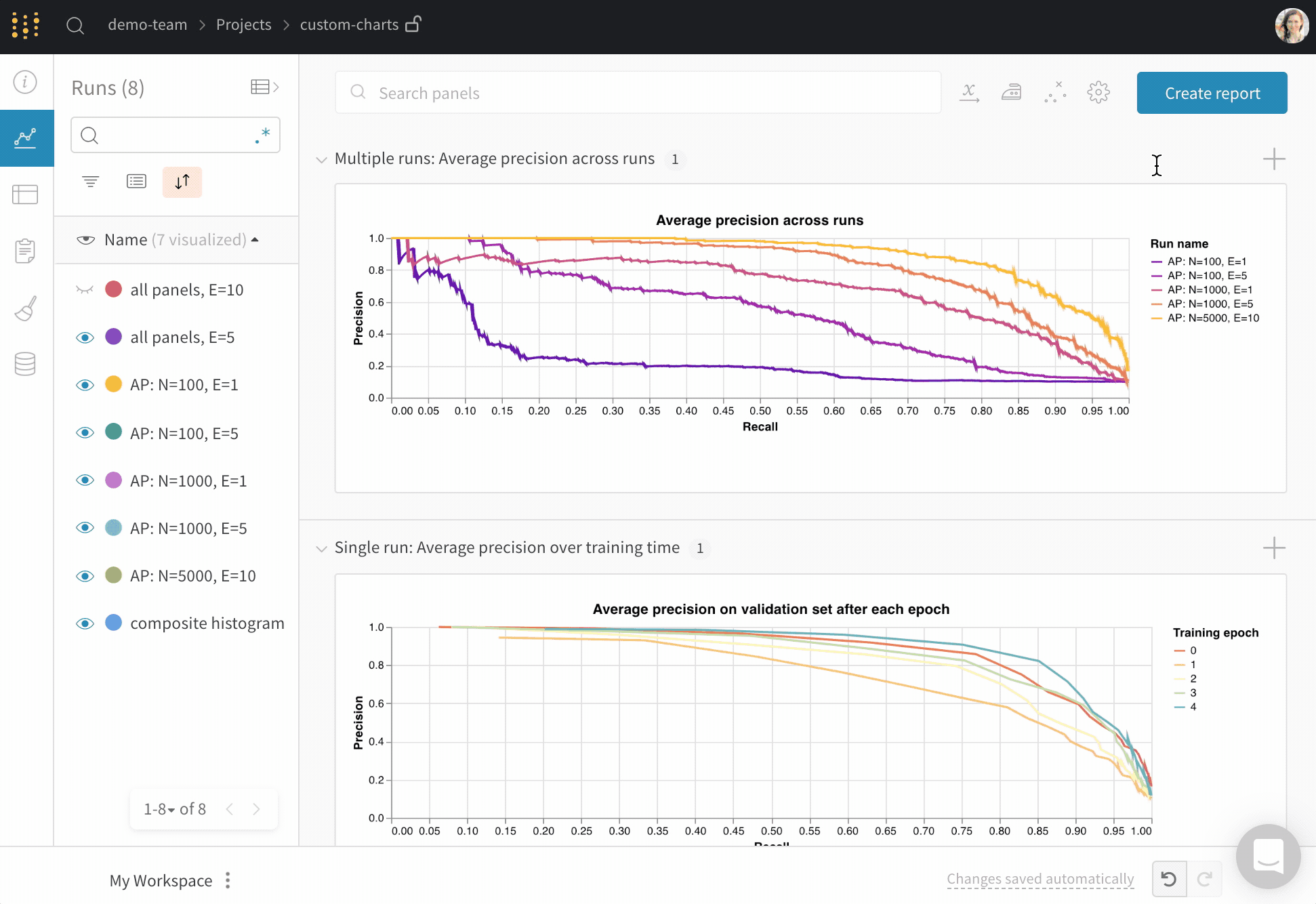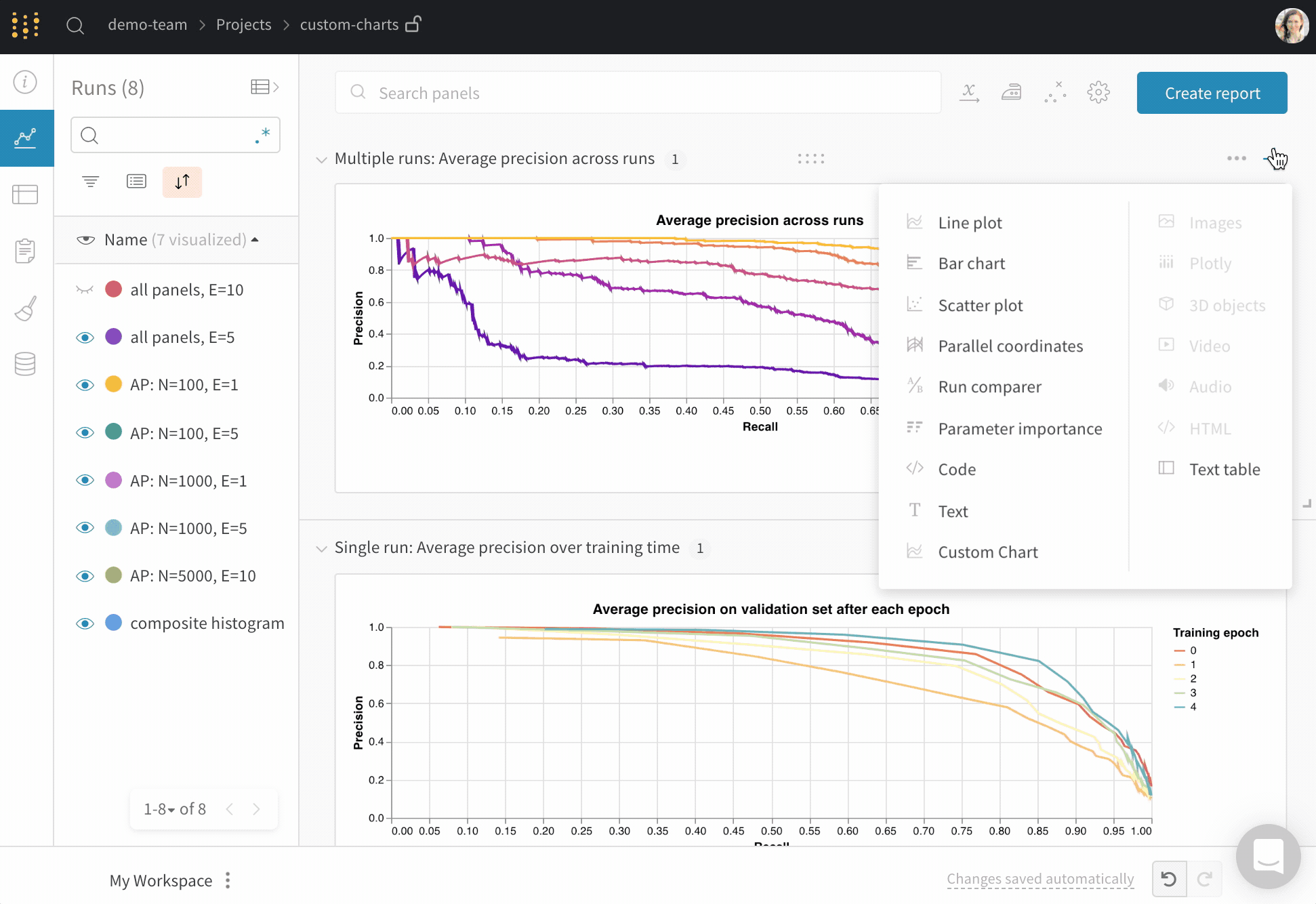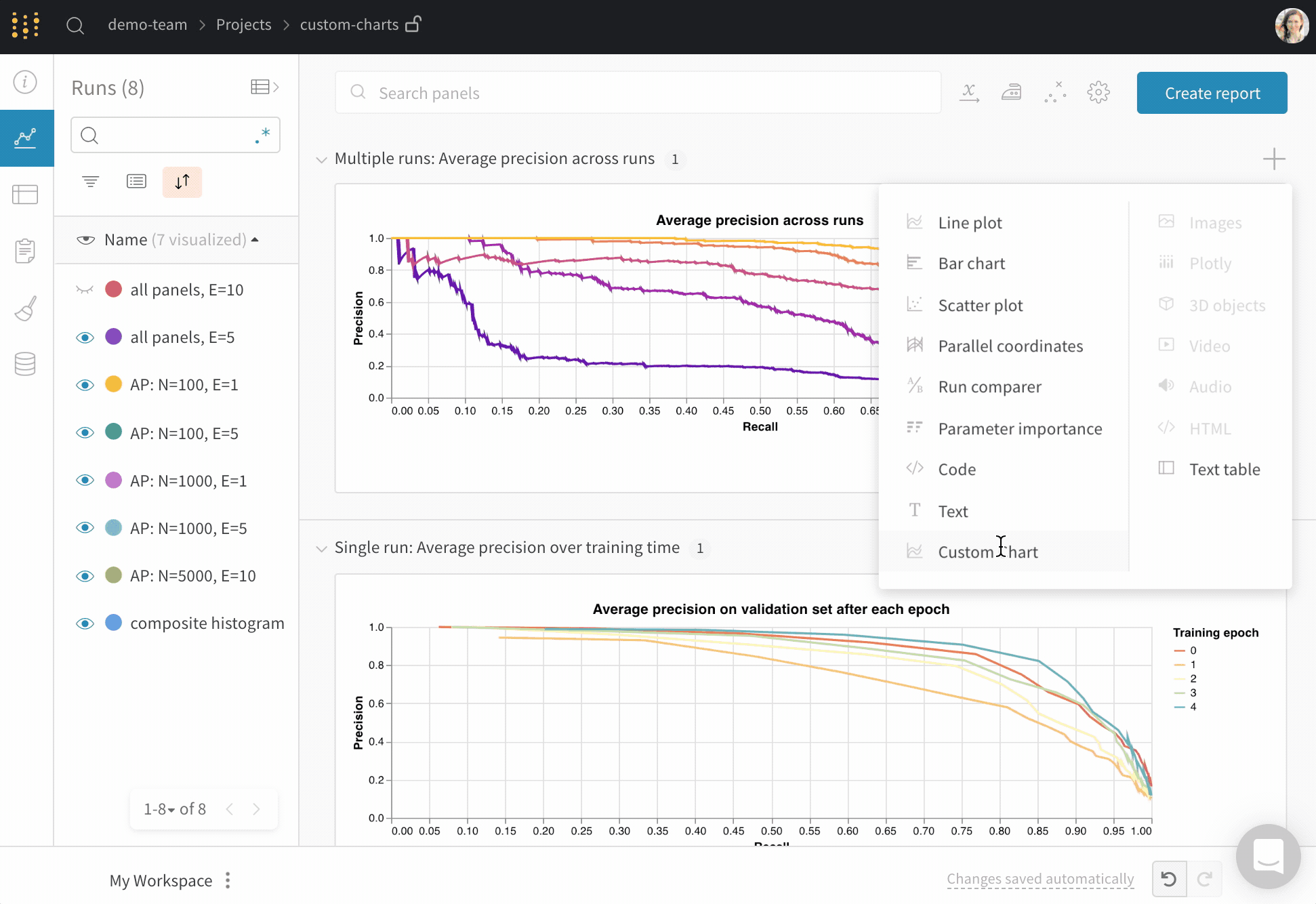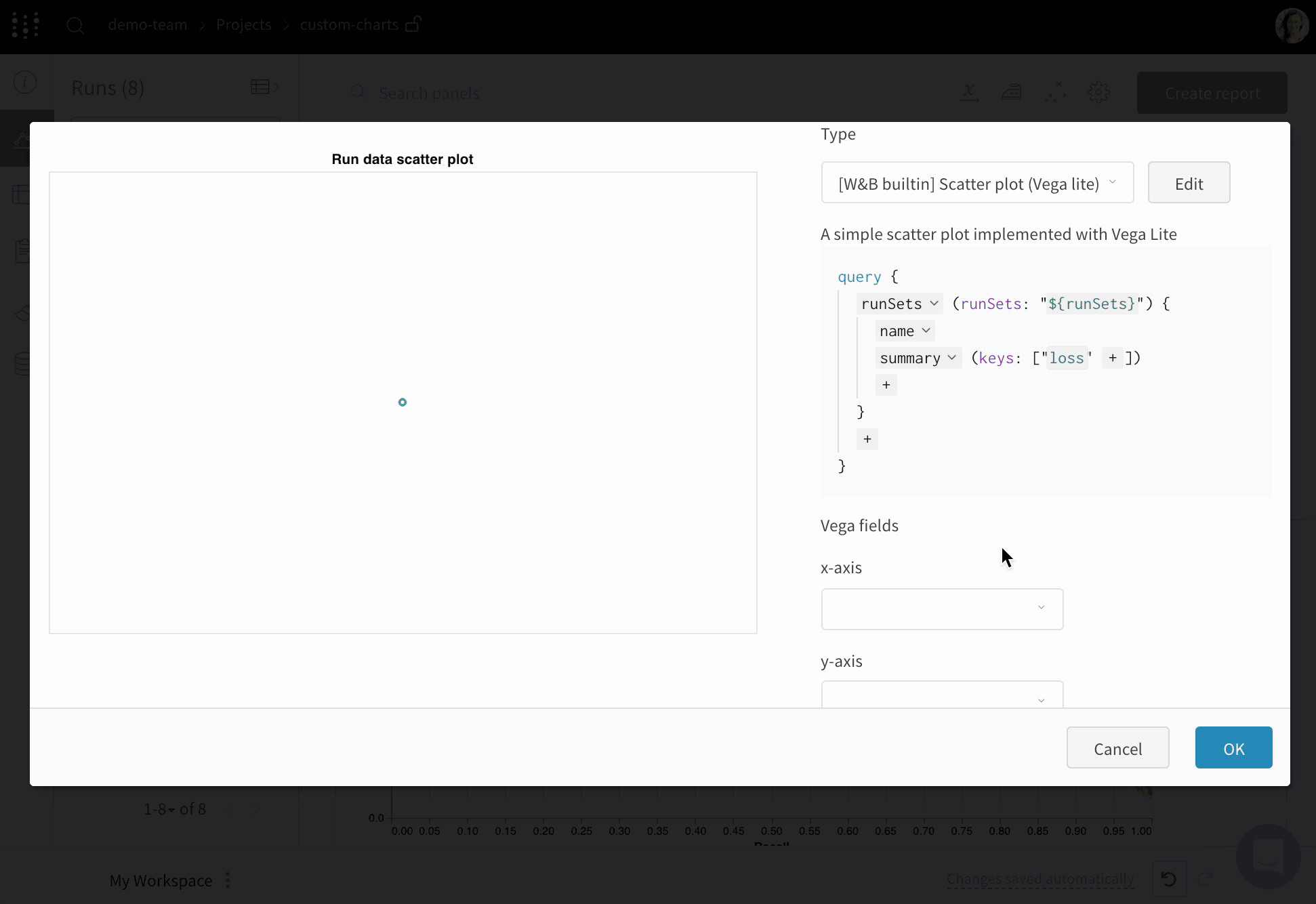
1.7 - Compare run metrics
Run Comparer を使用して、run間で異なるメトリクスを確認できます。
- ページの右上隅にある [Add panels] ボタンを選択します。
- 表示される左側のパネルで、[Evaluation] ドロップダウンを展開します。
- [Run comparer] を選択します。
diff only オプションを切り替えて、run間で値が同じ行を非表示にします。
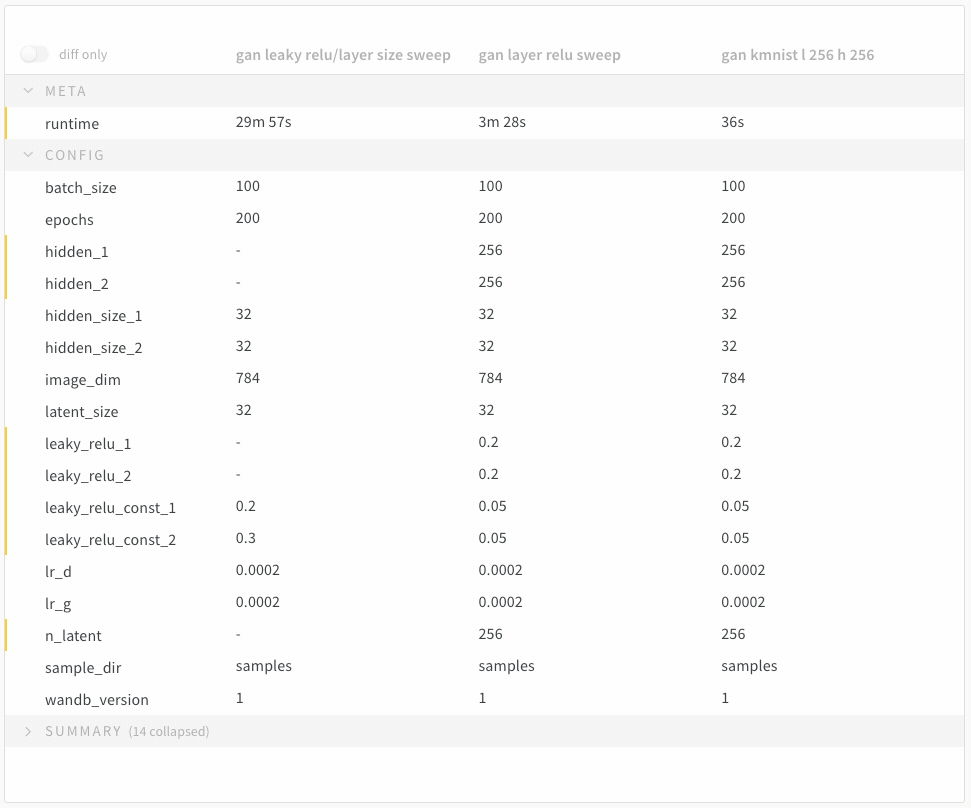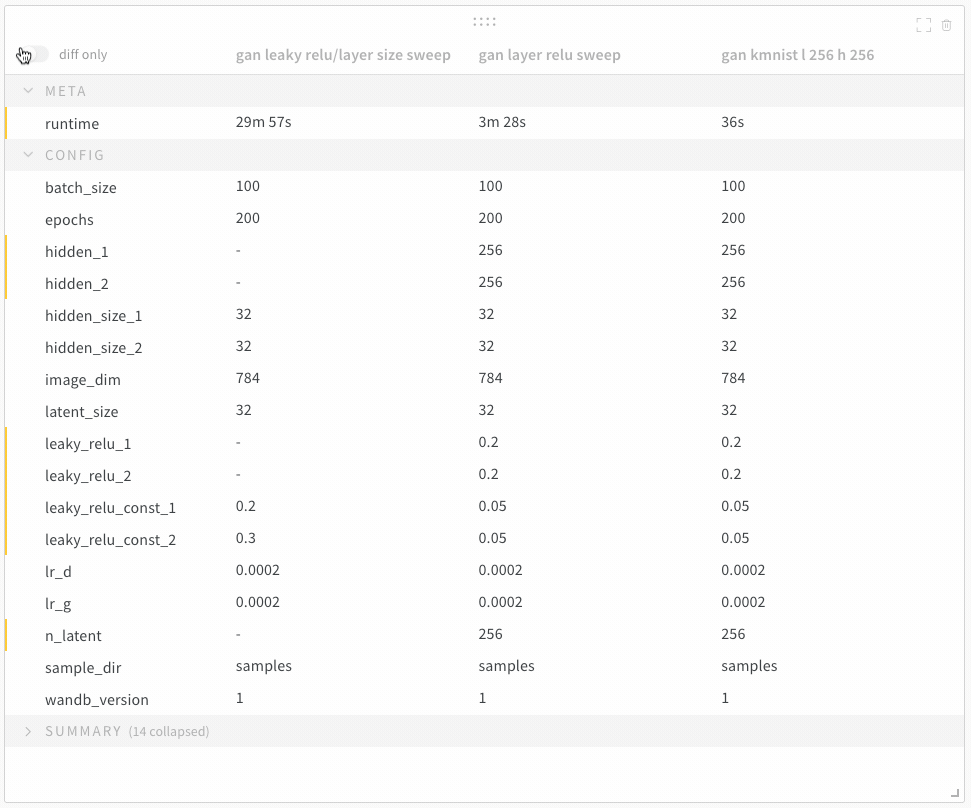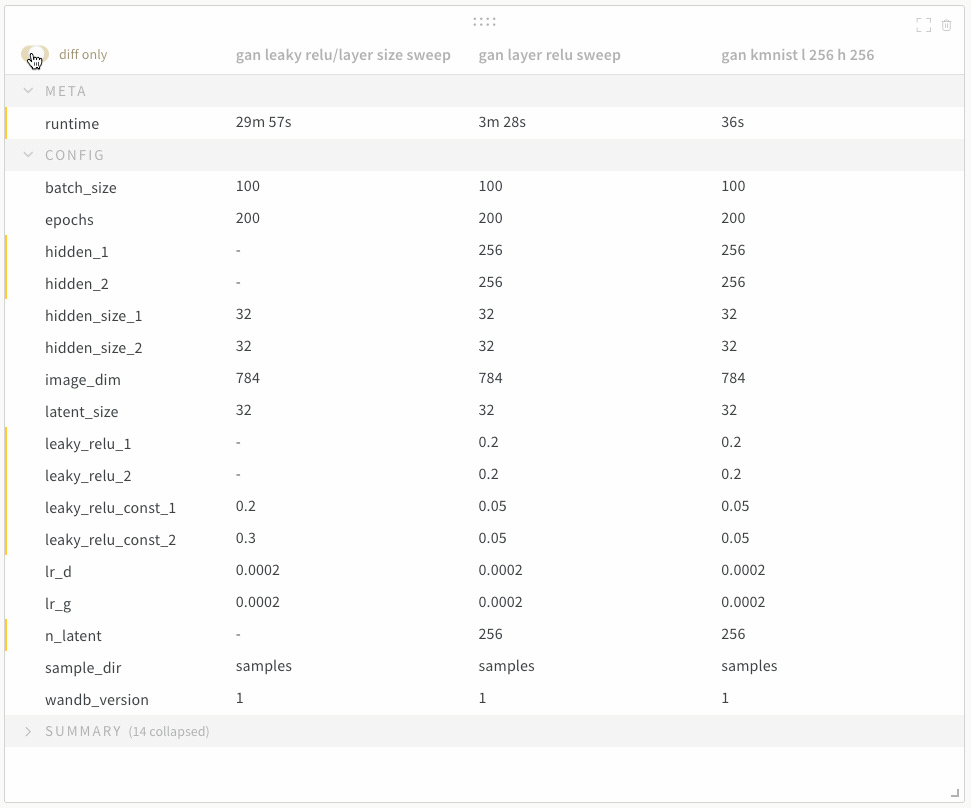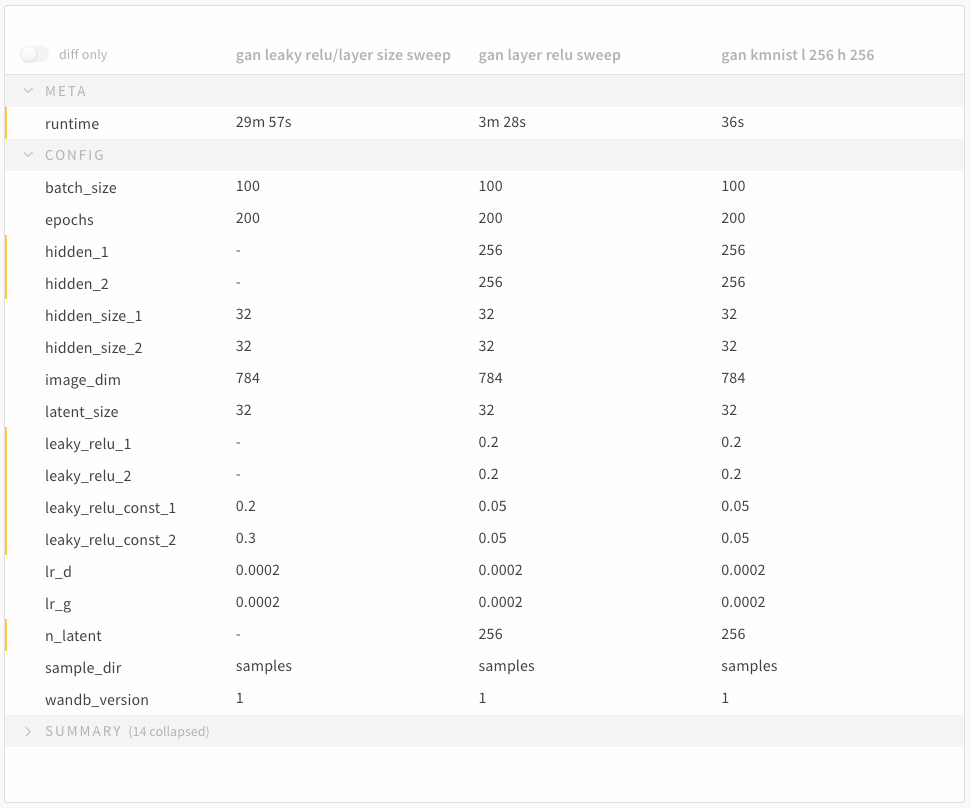
1.8 - Query panels
weave-plot を追加してください。クエリー パネルを使用して、データをクエリーし、インタラクティブに視覚化します。
クエリー パネルの作成
ワークスペースまたは レポート 内にクエリーを追加します。
- プロジェクト の ワークスペース に移動します。
- 右上隅にある「Add panel( パネル を追加)」をクリックします。
- ドロップダウンから「Query panel(クエリー パネル )」を選択します。
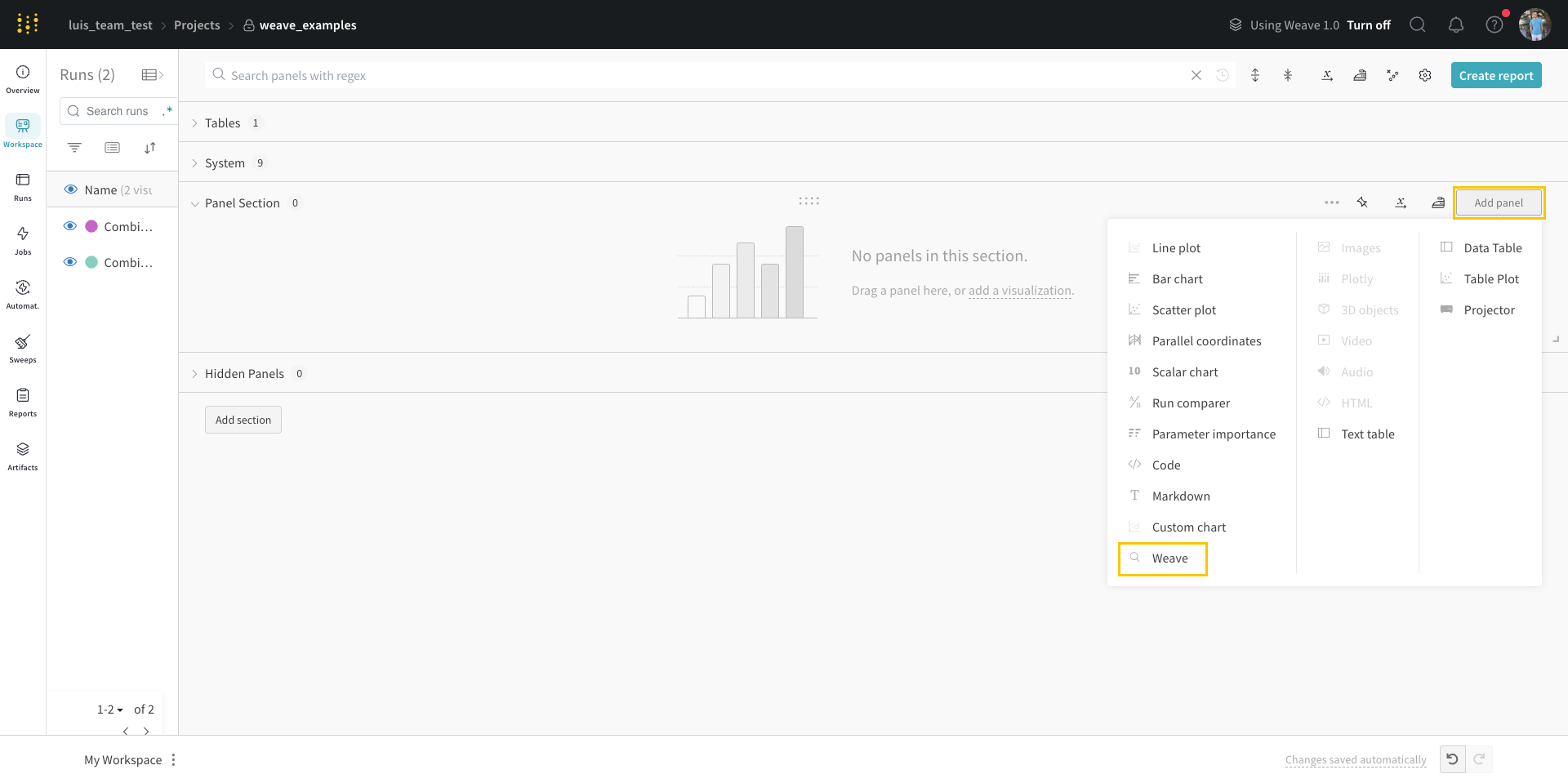
「/Query panel(/クエリー パネル )」と入力して選択します。
または、クエリーを 一連の Runs に関連付けることもできます。
- レポート 内で、「/Panel grid(/ パネル グリッド)」と入力して選択します。
- 「Add panel( パネル を追加)」ボタンをクリックします。
- ドロップダウンから「Query panel(クエリー パネル )」を選択します。
クエリーのコンポーネント
式
クエリー式を使用して、Runs、Artifacts、Models、Tables など、W&B に保存されているデータをクエリーします。
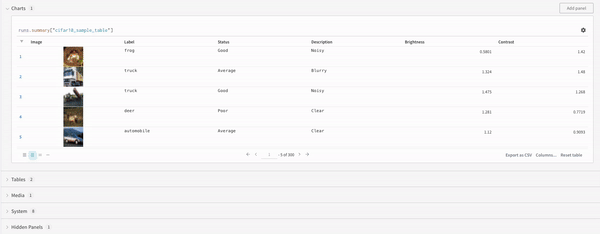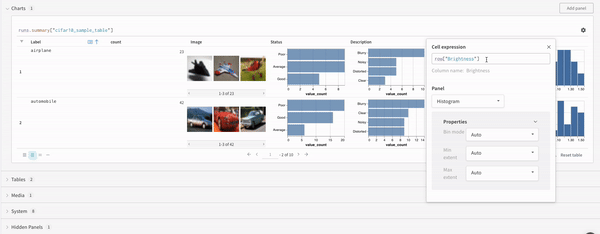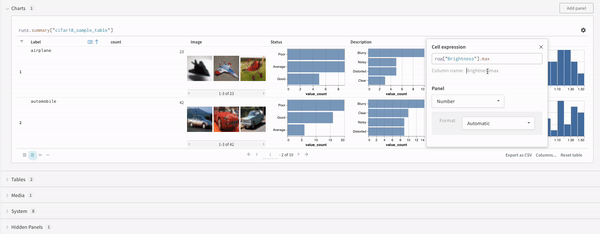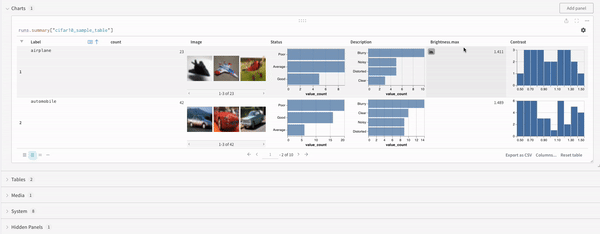
例: テーブル のクエリー
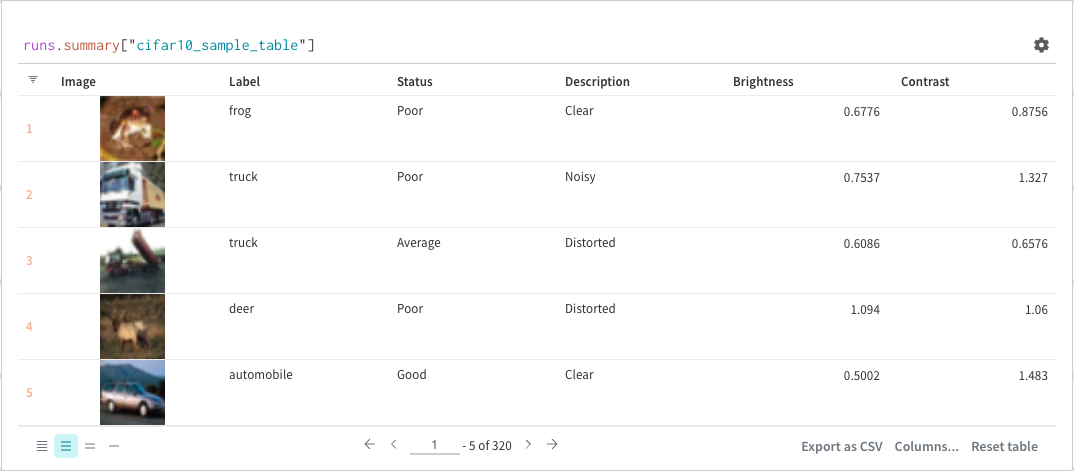
W&B Table をクエリーするとします。 トレーニング コード で、"cifar10_sample_table"というテーブルを ログ に記録します。
import wandb
wandb.log({"cifar10_sample_table":<MY_TABLE>})
クエリー パネル 内では、次のコードでテーブルをクエリーできます。
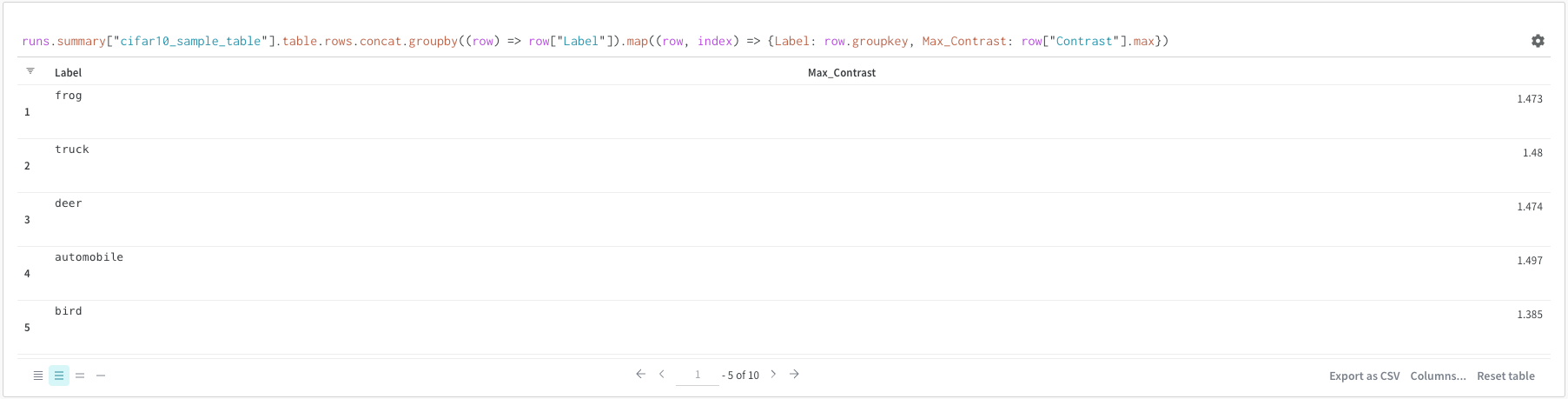
runs.summary["cifar10_sample_table"]

これを分解すると次のようになります。
runsは、クエリー パネル が ワークスペース にある場合、クエリー パネル 式に自動的に挿入される変数です。 その「値」は、特定の ワークスペース で表示できる Runs のリストです。 run で使用できるさまざまな属性については、こちらをお読みください。summaryは、Run の Summary オブジェクトを返す op です。 Op は mapped です。つまり、この op はリスト内の各 Run に適用され、Summary オブジェクトのリストが生成されます。["cifar10_sample_table"]は、predictionsという パラメータ を持つ Pick op(角かっこで示されます)です。 Summary オブジェクトは ディクショナリー または マップ のように動作するため、この操作は各 Summary オブジェクトからpredictionsフィールドを選択します。
独自のクエリーをインタラクティブに作成する方法については、この レポート を参照してください。
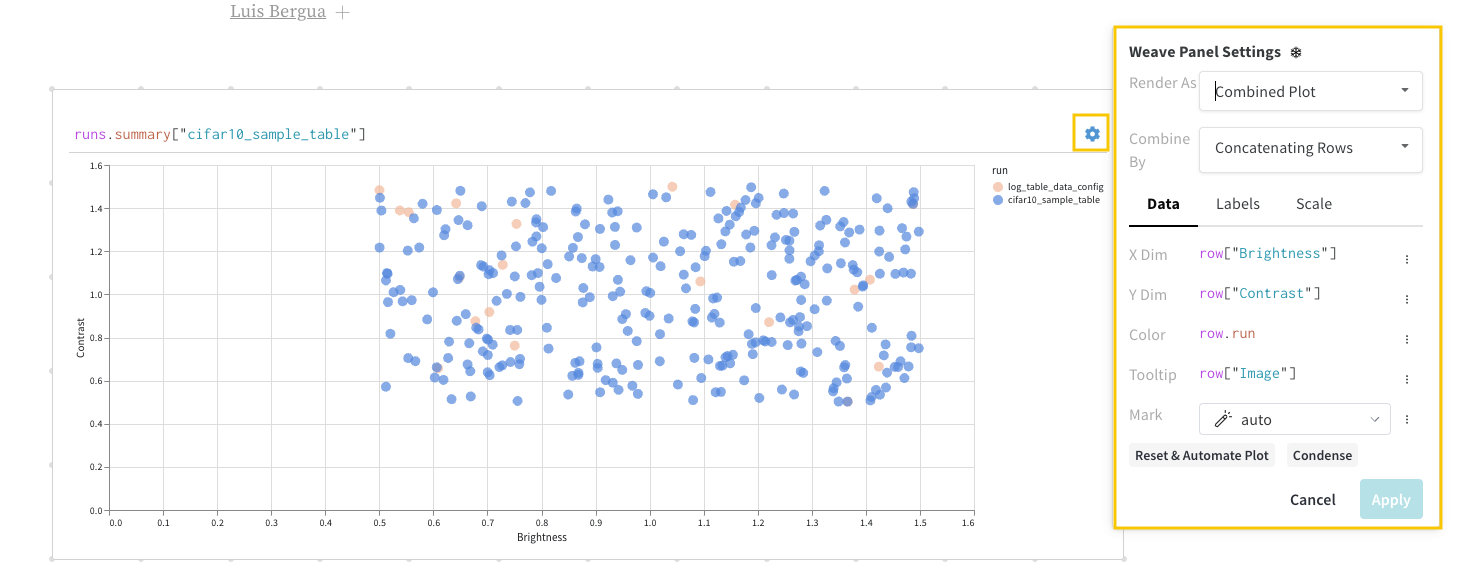
設定
パネル の左上隅にある歯車アイコンを選択して、クエリー 設定 を展開します。 これにより、 ユーザー は パネル のタイプと、結果 パネル の パラメータ を 設定 できます。
結果 パネル
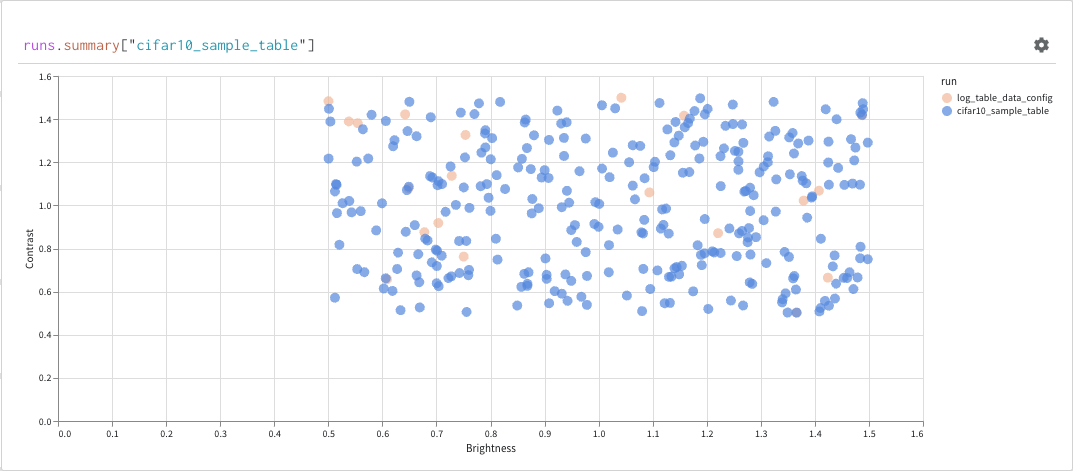
最後に、クエリー結果 パネル は、選択したクエリー パネル を使用して、クエリー式の結果をレンダリングし、データ をインタラクティブな形式で表示するように 設定 によって 設定 されます。 次の画像は、同じデータの Table とプロットを示しています。
基本操作
クエリー パネル 内で実行できる一般的な操作を次に示します。
並べ替え
列オプションから並べ替えを行います。
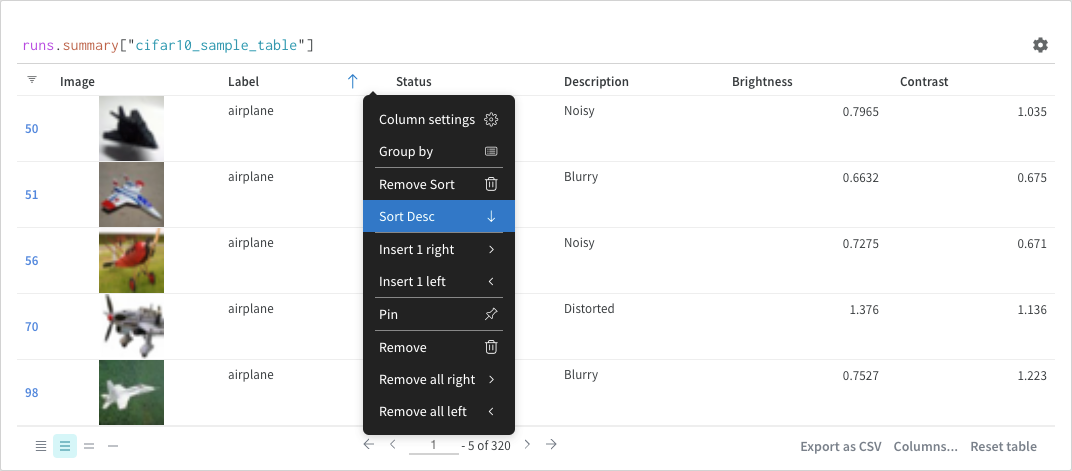
フィルター
クエリーで直接 フィルター するか、左上隅にある フィルター ボタンを使用できます(2 番目の画像)。
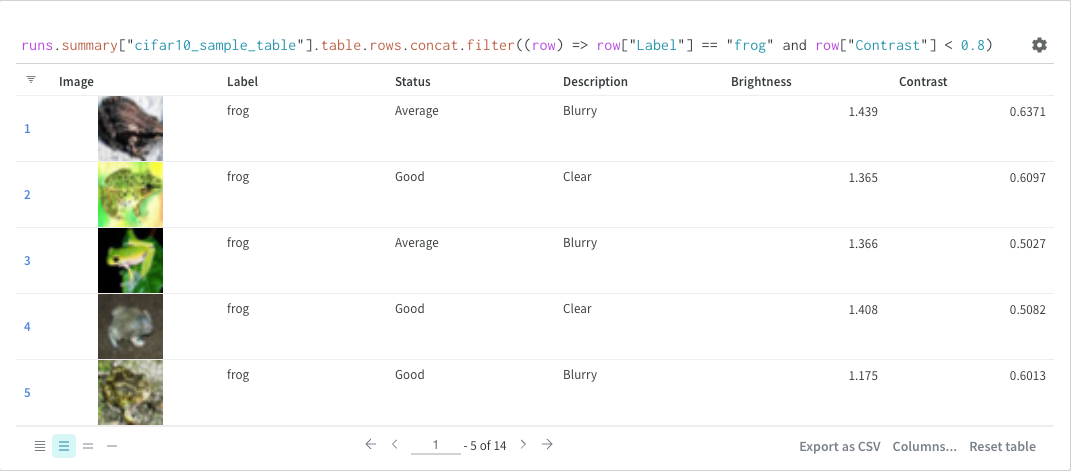
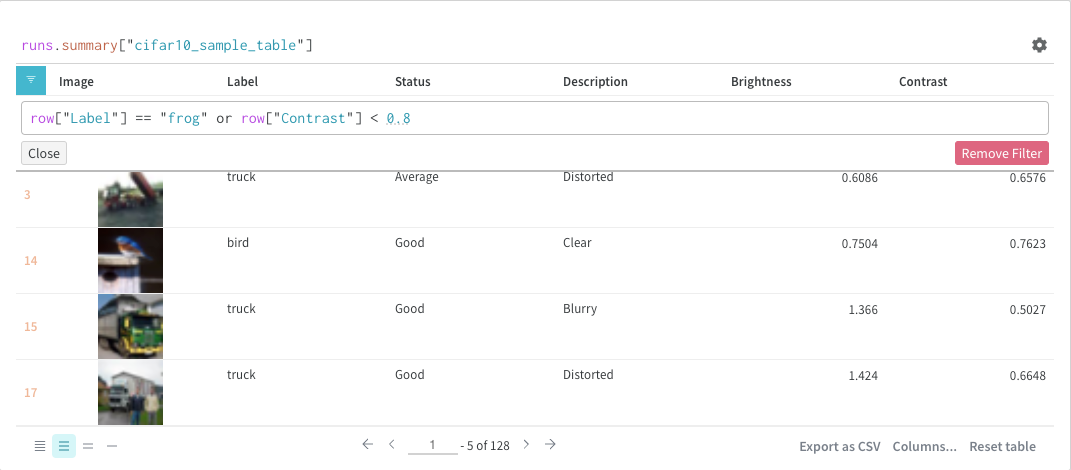
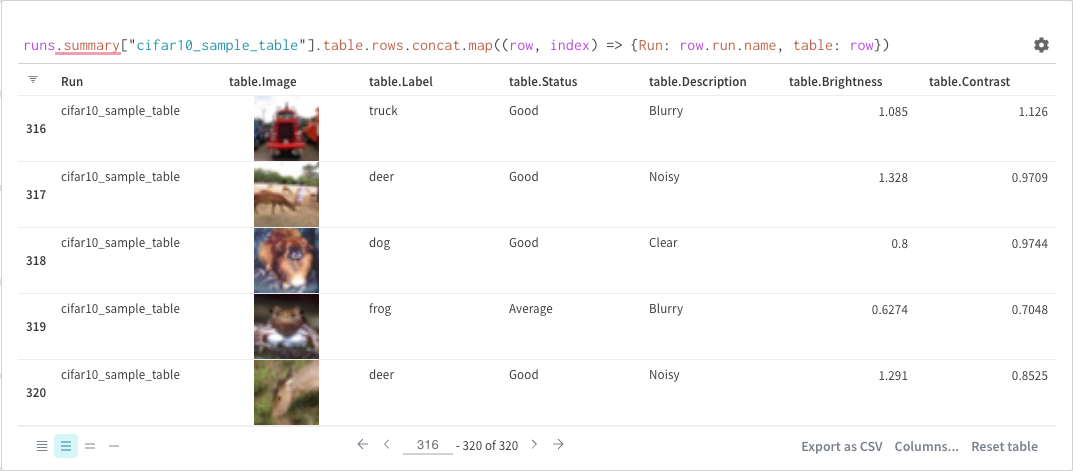
マップ
マップ 操作はリストを反復処理し、データ 内の各要素に関数を適用します。 これは、 パネル クエリー で直接行うか、列オプションから新しい列を挿入して行うことができます。

グループ化
クエリーまたは列オプションを使用してグループ化できます。
連結
連結操作を使用すると、2 つのテーブルを連結し、 パネル 設定 から連結または結合できます。
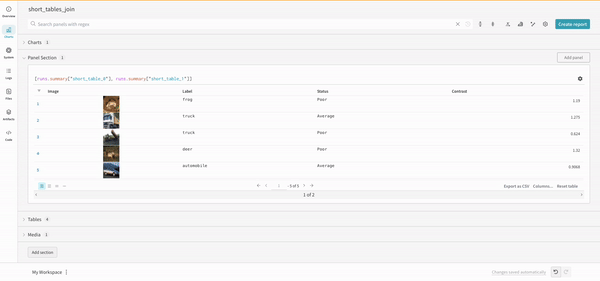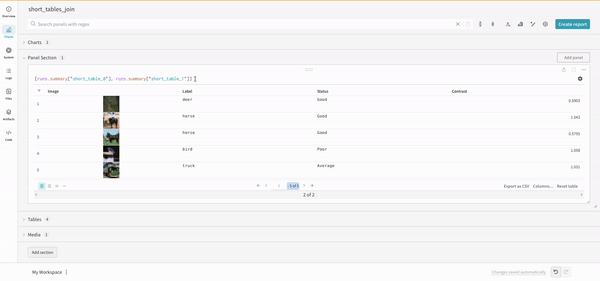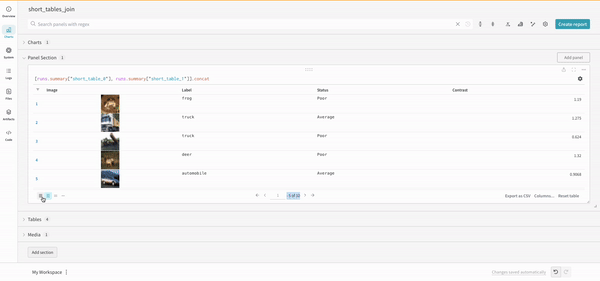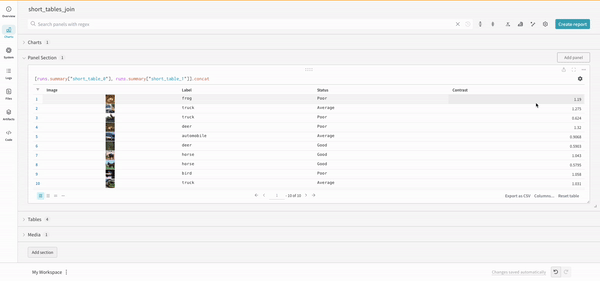
結合
クエリーでテーブルを直接結合することも可能です。 次のクエリー式を検討してください。
project("luis_team_test", "weave_example_queries").runs.summary["short_table_0"].table.rows.concat.join(\
project("luis_team_test", "weave_example_queries").runs.summary["short_table_1"].table.rows.concat,\
(row) => row["Label"],(row) => row["Label"], "Table1", "Table2",\
"false", "false")
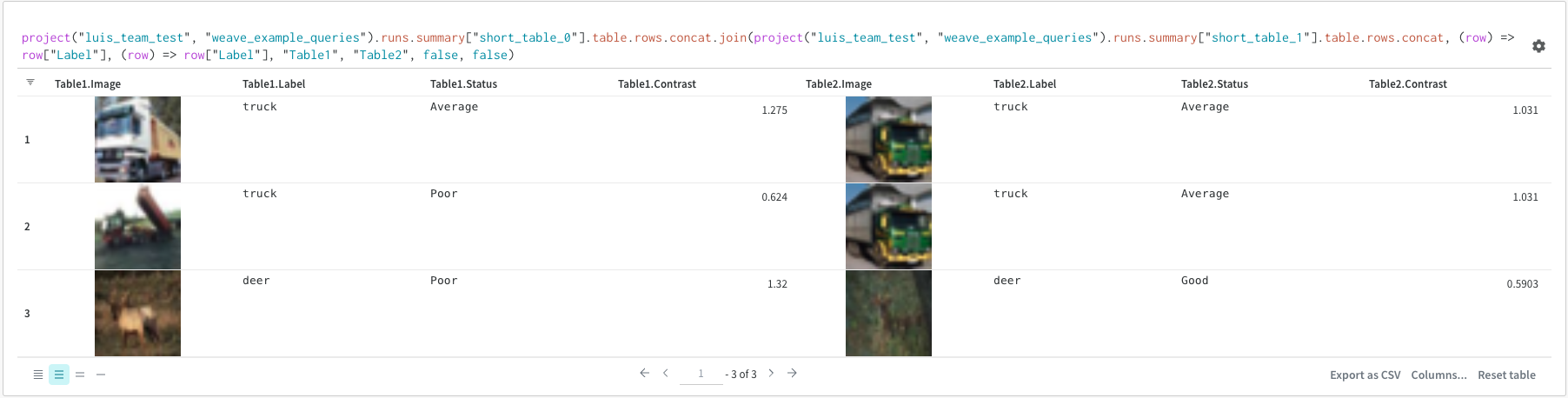
左側のテーブルは、次のように生成されます。
project("luis_team_test", "weave_example_queries").\
runs.summary["short_table_0"].table.rows.concat.join
右側のテーブルは、次のように生成されます。
project("luis_team_test", "weave_example_queries").\
runs.summary["short_table_1"].table.rows.concat
説明:
(row) => row["Label"]は各テーブルのセレクターであり、結合する列を決定します"Table1"と"Table2"は、結合時の各テーブルの名前ですtrueとfalseは、左側の内部/外部結合 設定 用です
Runs オブジェクト
クエリー パネル を使用して runs オブジェクトにアクセスします。 Run オブジェクトは、 Experiments のレコードを保存します。 詳細については、 レポート のこのセクションを参照してください。簡単にまとめると、runs オブジェクトには次のものが含まれます。
summary: Run の結果をまとめた情報の ディクショナリー 。 これは、精度や損失などのスカラー、または大きなファイルにすることができます。 デフォルトでは、wandb.log()は Summary を ログ に記録された 時系列 の最終値に 設定 します。 Summary の内容を直接 設定 できます。 Summary を Run の出力として考えてください。history: 損失など、モデル の トレーニング 中に変化する値を保存するための ディクショナリー のリスト。 コマンドwandb.log()はこの オブジェクト に追加されます。config: トレーニング Run の ハイパー パラメータ ーや、データセット Artifact を作成する Run の 前処理 メソッド など、Run の 設定 情報の ディクショナリー 。 これらを Run の「入力」と考えてください。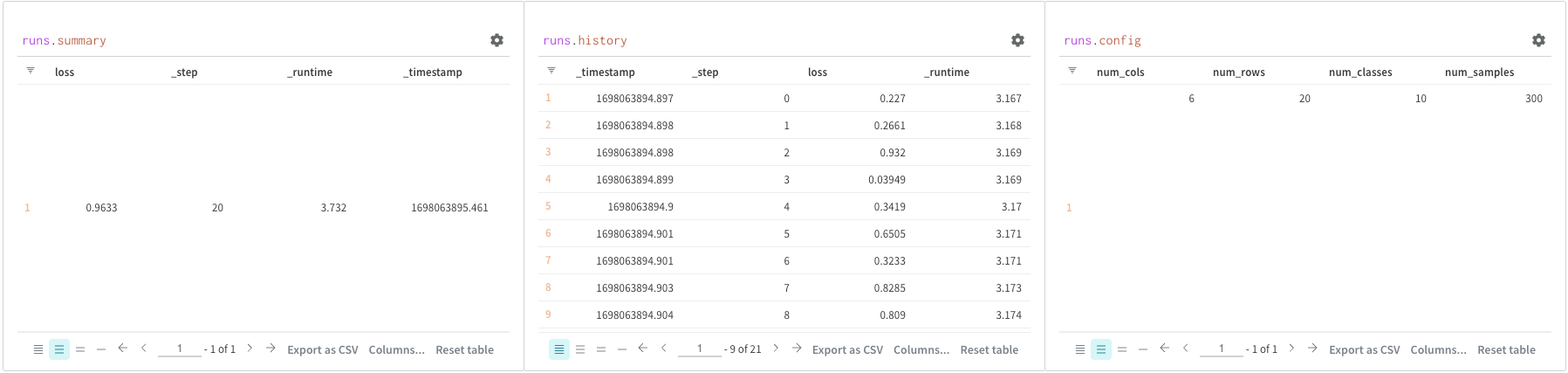
Artifacts へのアクセス
Artifacts は W&B の 中核となる概念です。 これらは、 バージョン 管理された名前付きのファイルと ディレクトリー のコレクションです。 Artifacts を使用して、モデル の重み、データセット 、およびその他のファイルまたは ディレクトリー を追跡します。 Artifacts は W&B に保存され、ダウンロードしたり、他の Runs で使用したりできます。 詳細と例については、 レポート のこのセクションを参照してください。 Artifacts には通常、project オブジェクト からアクセスします。
project.artifactVersion(): プロジェクト 内の指定された名前と バージョン の特定の Artifact バージョン を返します。project.artifact(""): プロジェクト 内の指定された名前の Artifact を返します。 次に、.versionsを使用して、この Artifact のすべての バージョン のリストを取得できます。project.artifactType(): プロジェクト 内の指定された名前のartifactTypeを返します。 次に、.artifactsを使用して、このタイプのすべての Artifacts のリストを取得できます。project.artifactTypes: プロジェクト 下にあるすべての Artifact タイプ のリストを返します。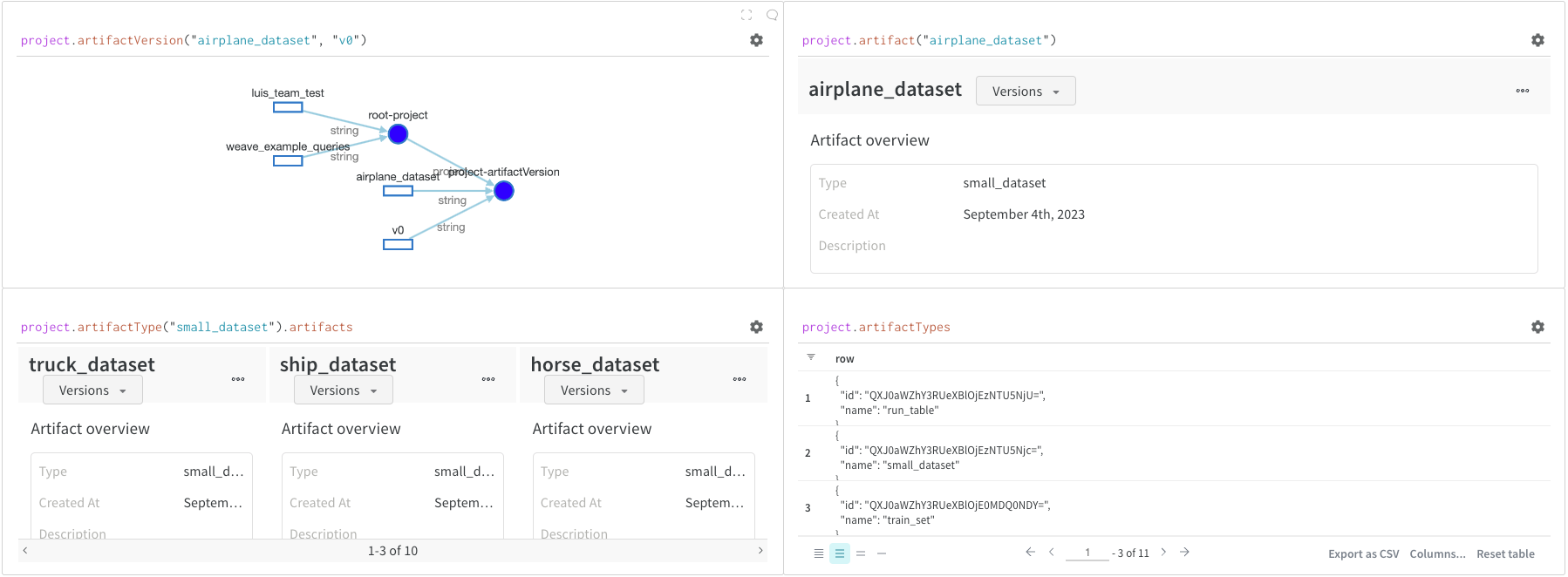
1.8.1 - Embed objects
埋め込み は、オブジェクト(人、画像、投稿、単語など)を数値のリスト、つまり ベクトル で表現するために使用されます。 機械学習とデータサイエンスのユースケースでは、埋め込みは、さまざまなアプリケーションでさまざまなアプローチを使用して生成できます。このページでは、読者が埋め込みについてよく理解しており、W&B 内で視覚的に分析することに関心があることを前提としています。
埋め込みの例
Hello World
W&B を使用すると、wandb.Table クラスを使用して埋め込みをログに記録できます。それぞれが 5 次元で構成される 3 つの埋め込みの次の例を考えてみましょう。
import wandb
wandb.init(project="embedding_tutorial")
embeddings = [
# D1 D2 D3 D4 D5
[0.2, 0.4, 0.1, 0.7, 0.5], # 埋め込み 1
[0.3, 0.1, 0.9, 0.2, 0.7], # 埋め込み 2
[0.4, 0.5, 0.2, 0.2, 0.1], # 埋め込み 3
]
wandb.log(
{"embeddings": wandb.Table(columns=["D1", "D2", "D3", "D4", "D5"], data=embeddings)}
)
wandb.finish()
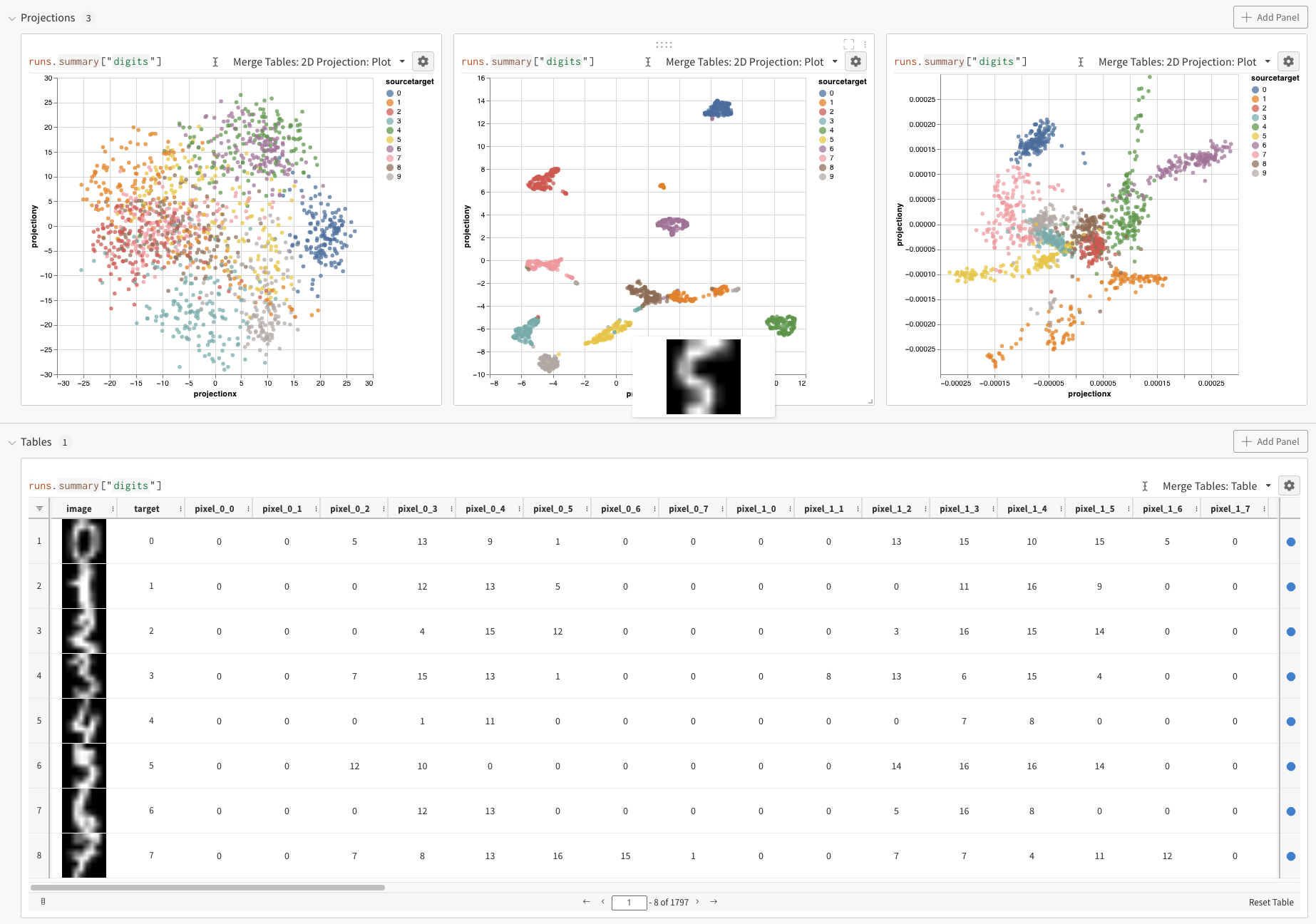
上記のコードを実行すると、W&B ダッシュボードにデータを含む新しい Table が表示されます。 右上のパネルセレクターから [2D Projection] を選択して、埋め込みを 2 次元でプロットできます。 スマートデフォルトが自動的に選択されます。これは、歯車アイコンをクリックしてアクセスできる設定メニューで簡単にオーバーライドできます。 この例では、利用可能な 5 つの数値次元すべてを自動的に使用します。
Digits MNIST
上記の例は、埋め込みをログに記録する基本的なメカニズムを示していますが、通常はより多くの次元とサンプルを扱っています。 MNIST Digits データセット(UCI ML 手書き数字データセットs) について考えてみましょう。SciKit-Learn 経由で利用できます。 このデータセットには 1797 件のレコードがあり、それぞれに 64 の次元があります。 この問題は、10 クラス分類のユースケースです。 入力データを画像に変換して、可視化することもできます。
import wandb
from sklearn.datasets import load_digits
wandb.init(project="embedding_tutorial")
# データセットをロードする
ds = load_digits(as_frame=True)
df = ds.data
# 「target」列を作成する
df["target"] = ds.target.astype(str)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
# 「image」列を作成する
df["image"] = df.apply(
lambda row: wandb.Image(row[1:].values.reshape(8, 8) / 16.0), axis=1
)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
wandb.log({"digits": df})
wandb.finish()
上記のコードを実行すると、再び UI に Table が表示されます。 [2D Projection] を選択すると、埋め込みの定義、色付け、アルゴリズム (PCA、UMAP、t-SNE)、アルゴリズムのパラメータ、さらにはオーバーレイ (この場合は、ポイントにカーソルを合わせると画像が表示されます) を設定できます。 この特定のケースでは、これらはすべて「スマートデフォルト」であり、[2D Projection] を 1 回クリックすると、非常によく似たものが表示されます。 (ここをクリックして操作この例を参照してください)。
ログ記録のオプション
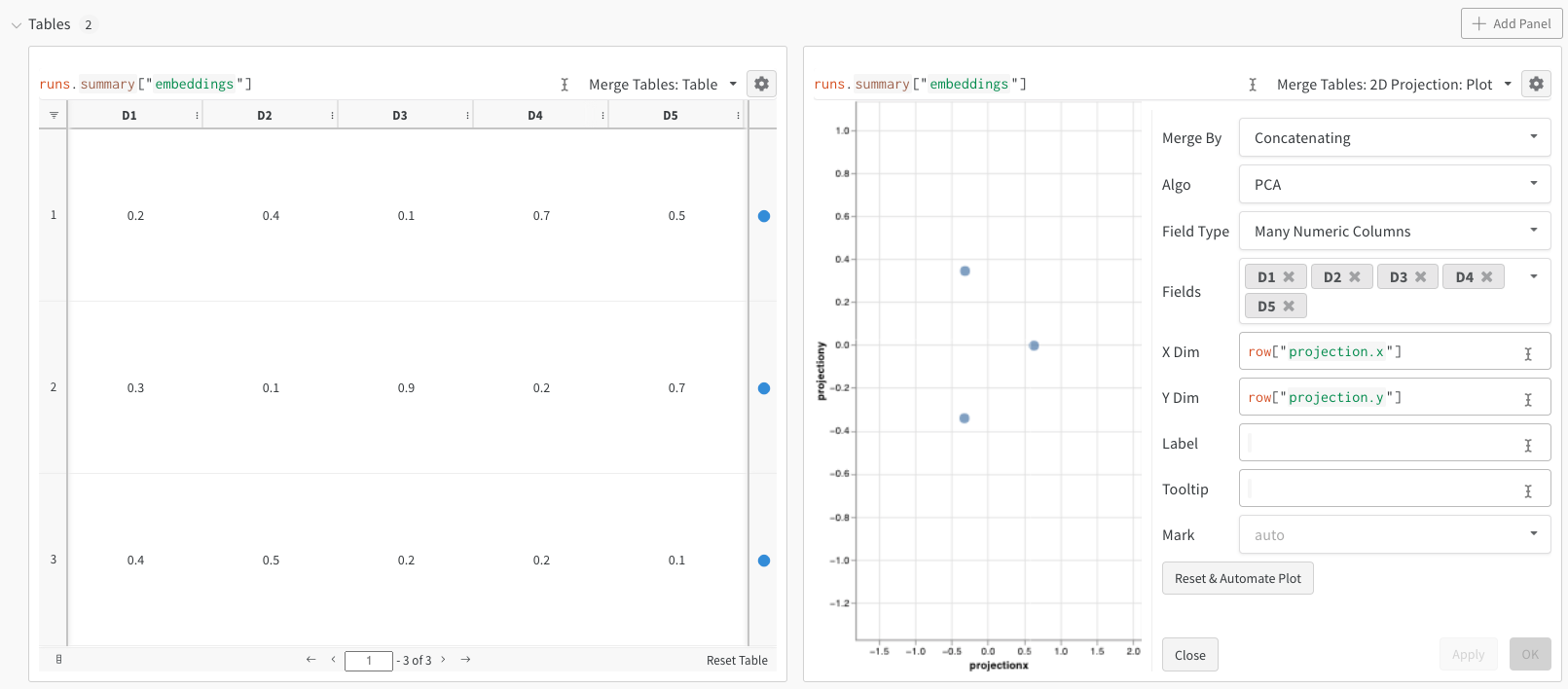
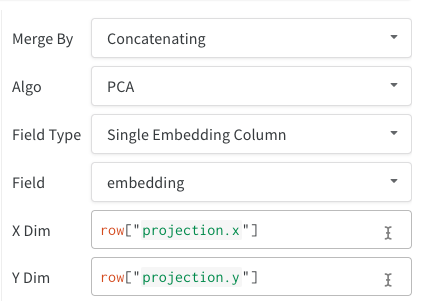
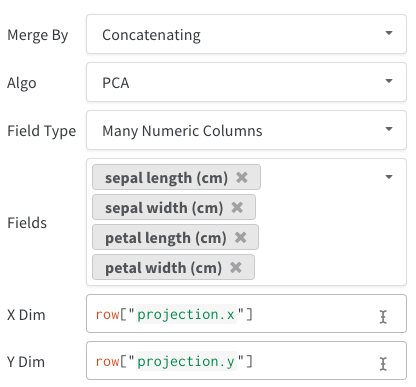
埋め込みは、さまざまな形式でログに記録できます。
- 単一の埋め込み列: 多くの場合、データはすでに「マトリックス」のような形式になっています。 この場合、単一の埋め込み列を作成できます。ここで、セル値のデータ型は
list[int]、list[float]、またはnp.ndarrayになります。 - 複数の数値列: 上記の 2 つの例では、このアプローチを使用し、次元ごとに列を作成します。 現在、セルには python
intまたはfloatを使用できます。
さらに、すべてのテーブルと同様に、テーブルの構築方法に関して多くのオプションがあります。
wandb.Table(dataframe=df)を使用して dataframe から直接wandb.Table(data=[...], columns=[...])を使用して データのリスト から直接- テーブルを 行ごとに (コードにループがある場合に最適) 段階的に構築 します。
table.add_data(...)を使用してテーブルに行を追加します - テーブルに 埋め込み列 を追加します (埋め込み形式の予測のリストがある場合に最適)。
table.add_col("col_name", ...) - 計算された列 を追加します (テーブルにマップする関数または model がある場合に最適)。
table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
プロットオプション
[2D Projection] を選択した後、歯車アイコンをクリックしてレンダリング設定を編集できます。 目的の列を選択することに加えて (上記を参照)、目的のアルゴリズム (および目的のパラメータ) を選択できます。 以下に、それぞれ UMAP と t-SNE のパラメータを示します。
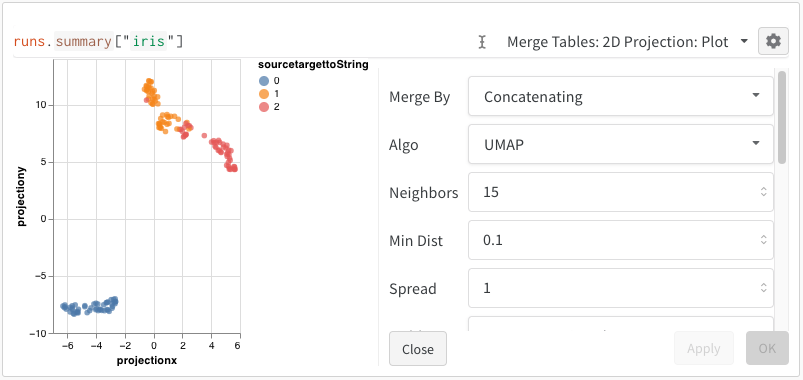
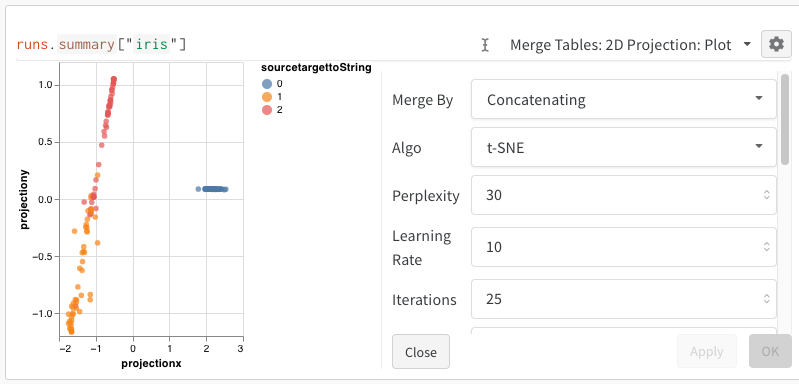
2 - Custom charts
W&B のプロジェクトでカスタムグラフを作成できます。任意のデータのテーブルを記録し、必要な方法で正確に可視化します。Vega の機能を使用して、フォント、色、ツールチップの詳細を制御します。
- コード: Colab Colabノートブック の例をお試しください。
- 動画: 解説動画 をご覧ください。
- 例: KerasとSklearnのデモ notebook
仕組み
- データ の ログ: スクリプトから、config とサマリーデータを記録します。
- グラフのカスタマイズ: GraphQL クエリでログに記録されたデータを取得します。強力な可視化文法である Vega を使用して、クエリの結果を可視化します。
- グラフのログ:
wandb.plot_table()を使用して、スクリプトから独自のプリセットを呼び出します。
期待されるデータが表示されない場合は、探している列が選択された runs に記録されていない可能性があります。グラフを保存し、runs テーブルに戻り、目 のアイコンを使用して選択した runs を確認します。
スクリプトからグラフをログ
組み込みプリセット
W&B には、スクリプトから直接ログに記録できる多数の組み込みグラフプリセットがあります。これには、折れ線グラフ、散布図、棒グラフ、ヒストグラム、PR曲線、ROC曲線が含まれます。
wandb.plot.line()
任意の軸 x と y 上の接続された順序付けられた点 (x,y) のリストであるカスタム折れ線グラフをログに記録します。
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb.Table(data=data, columns=["x", "y"])
wandb.log(
{
"my_custom_plot_id": wandb.plot.line(
table, "x", "y", title="Custom Y vs X Line Plot"
)
}
)
折れ線グラフは、任意の2つの次元で曲線をログに記録します。2つの値のリストを互いにプロットする場合、リスト内の値の数は完全に一致する必要があります (たとえば、各ポイントには x と y が必要です)。
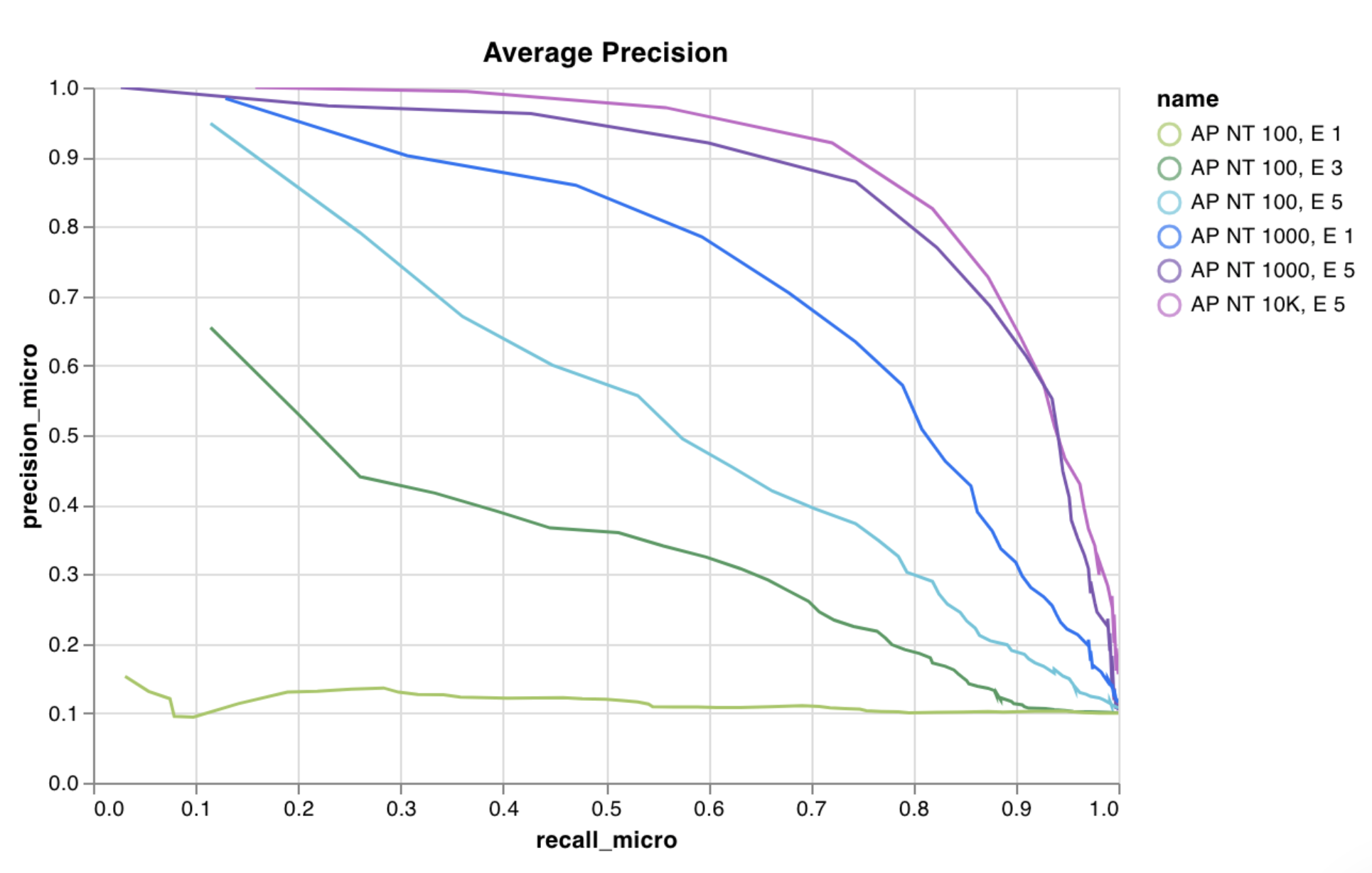
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.scatter()
カスタム散布図 (任意の軸 x と y のペア上の点のリスト (x, y)) をログに記録します。
data = [[x, y] for (x, y) in zip(class_x_prediction_scores, class_y_prediction_scores)]
table = wandb.Table(data=data, columns=["class_x", "class_y"])
wandb.log({"my_custom_id": wandb.plot.scatter(table, "class_x", "class_y")})
これを使用して、任意の2つの次元で散布点をログに記録できます。2つの値のリストを互いにプロットする場合、リスト内の値の数は完全に一致する必要があることに注意してください (たとえば、各ポイントには x と y が必要です)。
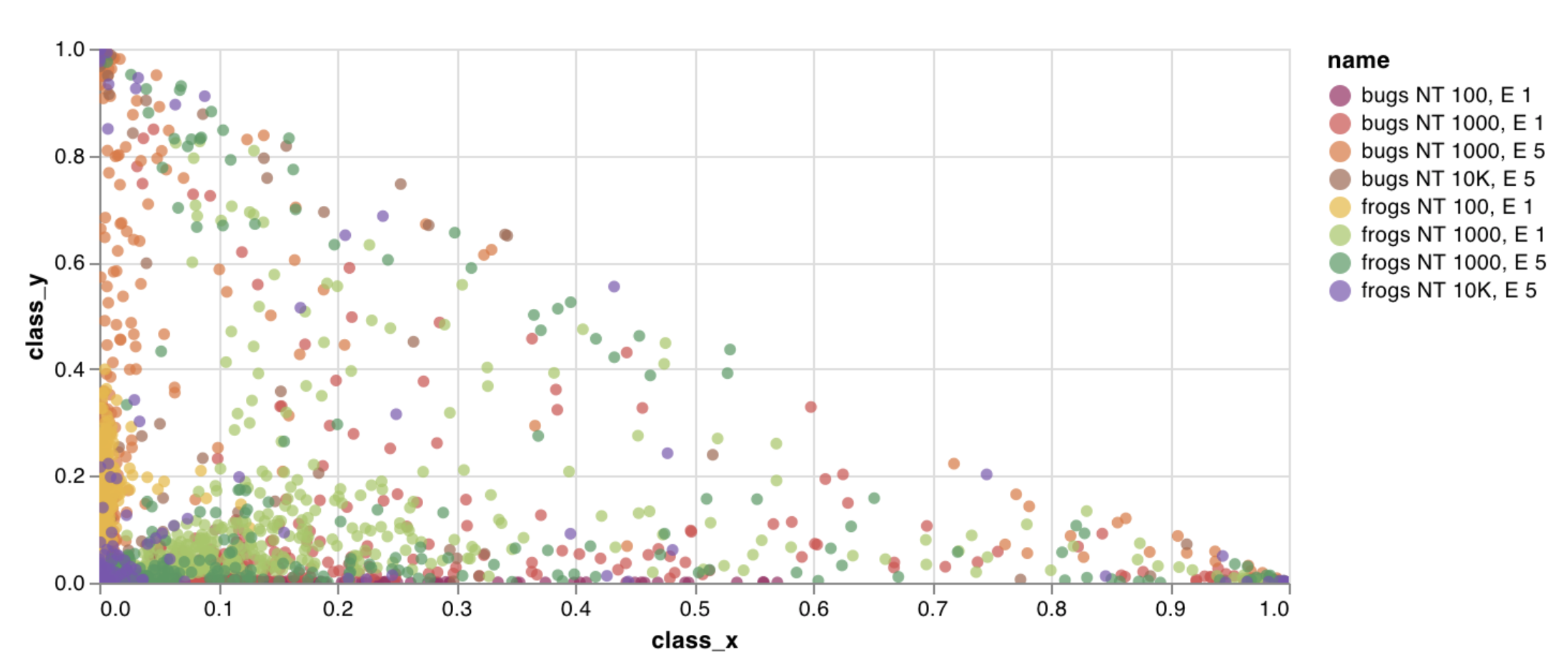
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.bar()
カスタム棒グラフ (ラベル付きの値のリストを棒として) を数行でネイティブにログに記録します。
data = [[label, val] for (label, val) in zip(labels, values)]
table = wandb.Table(data=data, columns=["label", "value"])
wandb.log(
{
"my_bar_chart_id": wandb.plot.bar(
table, "label", "value", title="Custom Bar Chart"
)
}
)
これを使用して、任意の棒グラフをログに記録できます。リスト内のラベルと値の数は完全に一致する必要があることに注意してください (たとえば、各データポイントには両方が必要です)。
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.histogram()
カスタムヒストグラム (値のソートされたリストを、発生のカウント/頻度でビンに分類) を数行でネイティブにログに記録します。予測信頼度スコア (scores) のリストがあり、その分布を可視化するとします。
data = [[s] for s in scores]
table = wandb.Table(data=data, columns=["scores"])
wandb.log({"my_histogram": wandb.plot.histogram(table, "scores", title=None)})
これを使用して、任意のヒストグラムをログに記録できます。data はリストのリストであり、行と列の2D配列をサポートすることを目的としています。
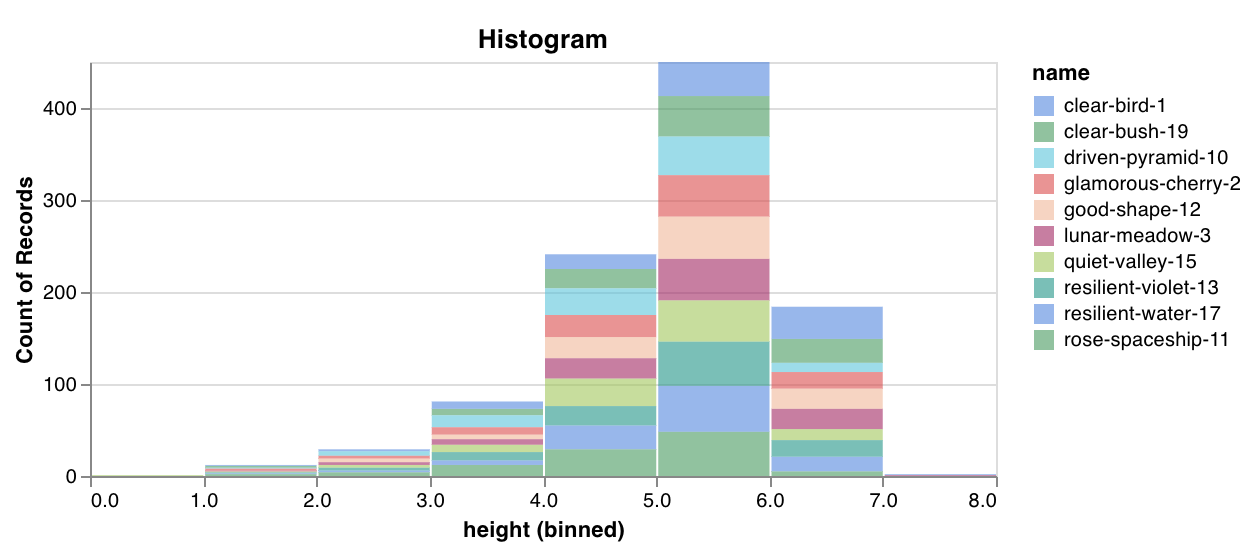
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
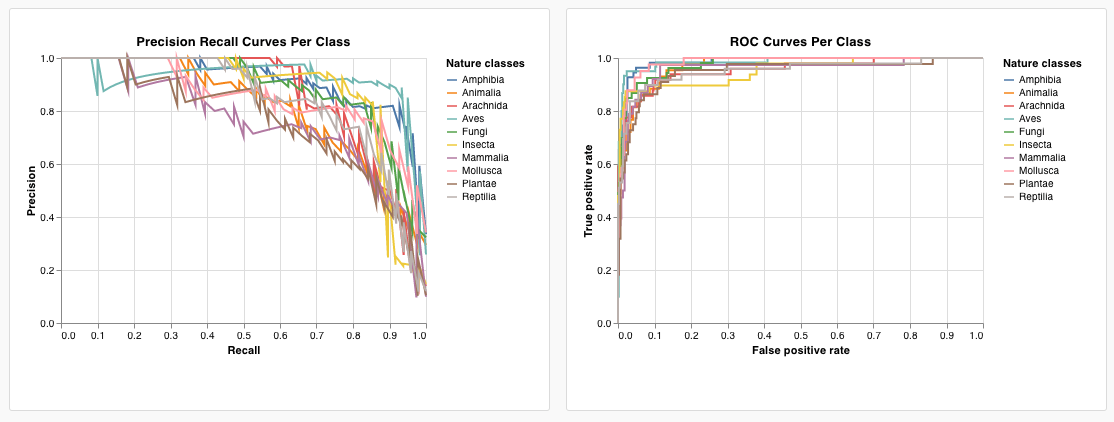
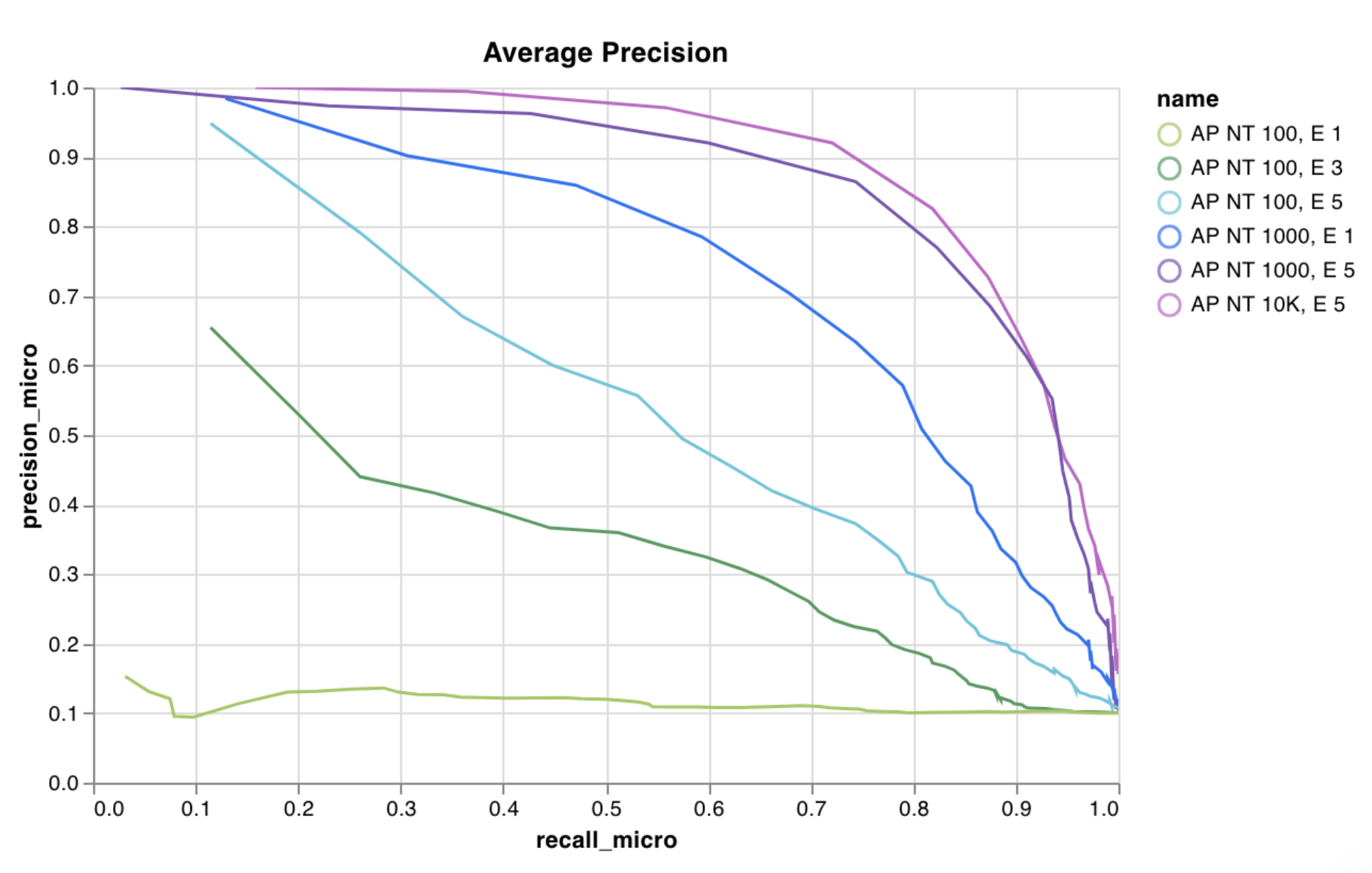
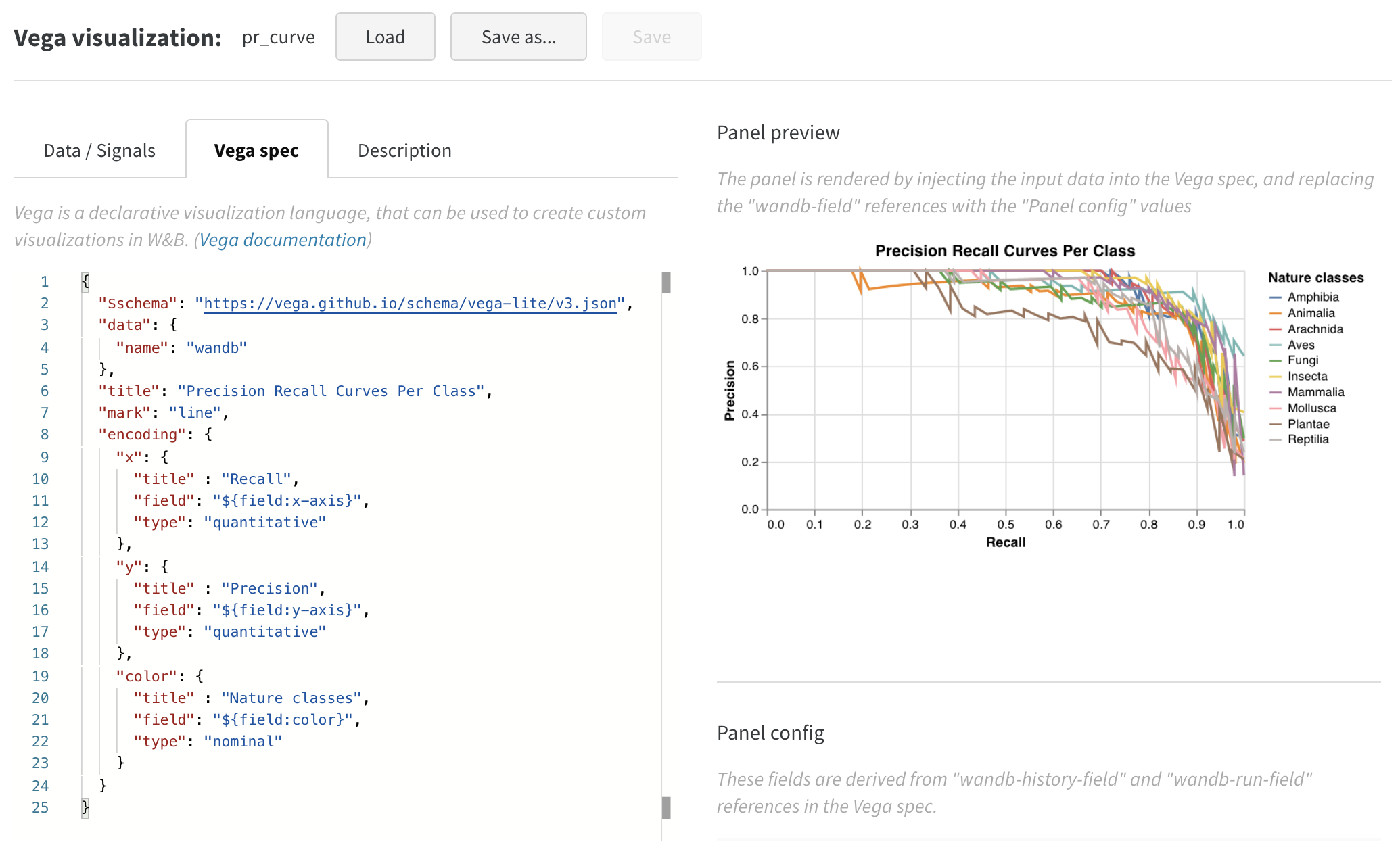
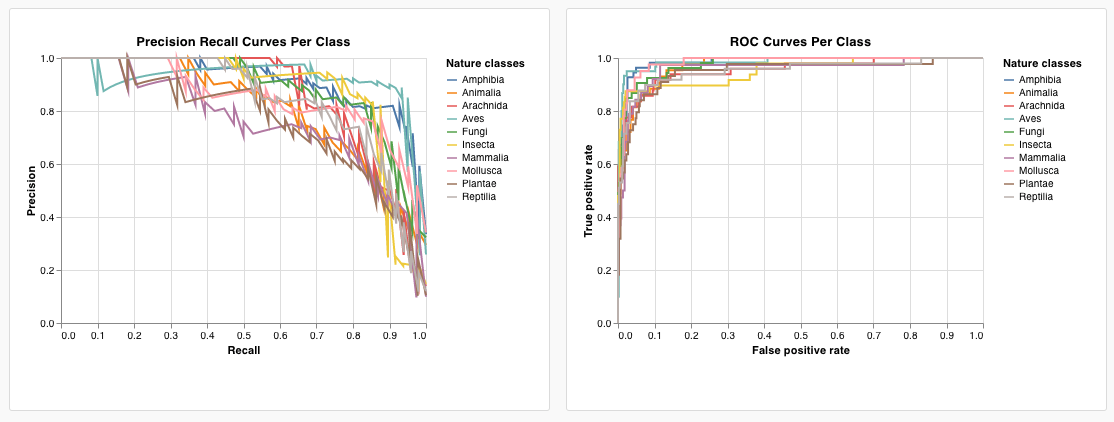
wandb.plot.pr_curve()
適合率-再現率曲線 を1行で作成します。
plot = wandb.plot.pr_curve(ground_truth, predictions, labels=None, classes_to_plot=None)
wandb.log({"pr": plot})
コードが以下にアクセスできる場合は、いつでもこれをログに記録できます。
- 例のセットに対するモデルの予測スコア (
predictions) - これらの例に対応する正解ラベル (
ground_truth) - (オプション) ラベル/クラス名のリスト (
labels=["cat", "dog", "bird"...](ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合)) - (オプション) プロットで可視化するラベルのサブセット (リスト形式のまま)
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.roc_curve()
ROC曲線 を1行で作成します。
plot = wandb.plot.roc_curve(
ground_truth, predictions, labels=None, classes_to_plot=None
)
wandb.log({"roc": plot})
コードが以下にアクセスできる場合は、いつでもこれをログに記録できます。
- 例のセットに対するモデルの予測スコア (
predictions) - これらの例に対応する正解ラベル (
ground_truth) - (オプション) ラベル/クラス名のリスト (
labels=["cat", "dog", "bird"...](ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合)) - (オプション) プロットで可視化するこれらのラベルのサブセット (リスト形式のまま)
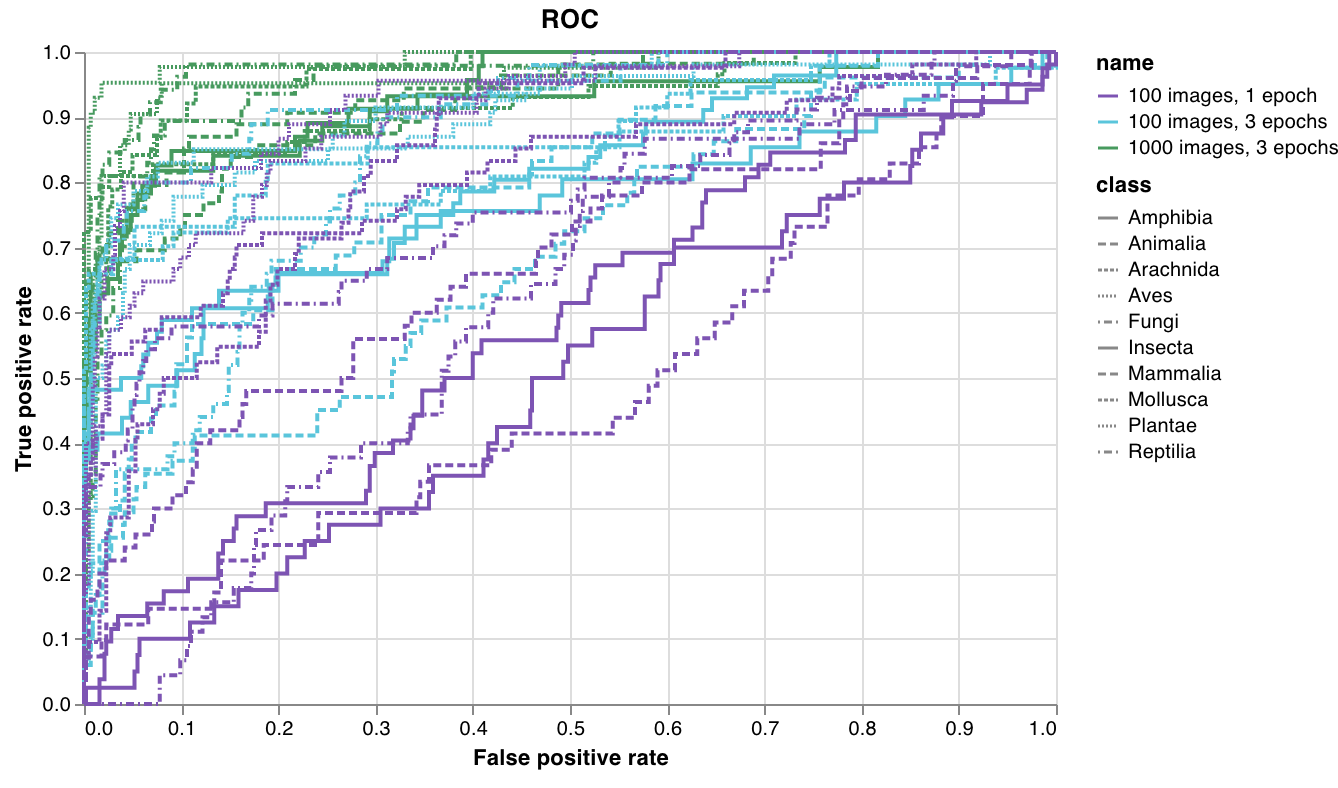
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
カスタムプリセット
組み込みプリセットを調整するか、新しいプリセットを作成して、グラフを保存します。グラフIDを使用して、スクリプトからそのカスタムプリセットに直接データをログに記録します。Google Colabノートブックの例 をお試しください。
# プロットする列を含むテーブルを作成します
table = wandb.Table(data=data, columns=["step", "height"])
# テーブルの列からグラフのフィールドへのマッピング
fields = {"x": "step", "value": "height"}
# テーブルを使用して、新しいカスタムグラフプリセットを作成します
# 独自の保存されたグラフプリセットを使用するには、vega_spec_name を変更します
my_custom_chart = wandb.plot_table(
vega_spec_name="carey/new_chart",
data_table=table,
fields=fields,
)
データの ログ
スクリプトから次のデータ型をログに記録し、カスタムグラフで使用できます。
- Config: experiment の初期設定 (独立変数)。これには、トレーニングの開始時に
wandb.configのキーとしてログに記録した名前付きフィールドが含まれます。例:wandb.config.learning_rate = 0.0001 - サマリー: トレーニング中にログに記録された単一の値 (結果または従属変数)。例:
wandb.log({"val_acc" : 0.8})。wandb.log()を介してトレーニング中にこのキーに複数回書き込むと、サマリーはそのキーの最終値に設定されます。 - 履歴: ログに記録されたスカラーの完全な時系列は、
historyフィールドを介してクエリで使用できます - summaryTable: 複数の値のリストをログに記録する必要がある場合は、
wandb.Table()を使用してそのデータを保存し、カスタム パネルでクエリを実行します。 - historyTable: 履歴データを確認する必要がある場合は、カスタムグラフ パネルで
historyTableをクエリします。wandb.Table()を呼び出すか、カスタムグラフをログに記録するたびに、そのステップの履歴に新しいテーブルが作成されます。
カスタムテーブルをログする方法
wandb.Table() を使用して、データを2D配列としてログに記録します。通常、このテーブルの各行は1つのデータポイントを表し、各列はプロットする各データポイントの関連フィールド/次元を示します。カスタム パネルを構成すると、テーブル全体が wandb.log() (custom_data_table below) に渡される名前付きキーを介してアクセスできるようになり、個々のフィールドは列名 (x、y、および z) を介してアクセスできるようになります。 experiment 全体で複数のタイムステップでテーブルをログに記録できます。各テーブルの最大サイズは10,000行です。Google Colab の例 をお試しください。
# データのカスタムテーブルをログ
my_custom_data = [[x1, y1, z1], [x2, y2, z2]]
wandb.log(
{"custom_data_table": wandb.Table(data=my_custom_data, columns=["x", "y", "z"])}
)
グラフのカスタマイズ
新しいカスタムグラフを追加して開始し、クエリを編集して表示されている runs からデータを選択します。クエリは GraphQL を使用して、runs の config、サマリー、および履歴フィールドからデータをフェッチします。
カスタム可視化
右上隅の グラフ を選択して、デフォルトのプリセットから開始します。次に、グラフフィールド を選択して、クエリから取得しているデータをグラフの対応するフィールドにマッピングします。
次の画像は、メトリクスを選択し、それを下の棒グラフフィールドにマッピングする方法の例を示しています。
Vega を編集する方法
パネルの上部にある 編集 をクリックして、Vega 編集モードに移動します。ここでは、UI でインタラクティブなグラフを作成する Vega 仕様 を定義できます。グラフのあらゆる側面を変更できます。たとえば、タイトルを変更したり、別の配色を選択したり、曲線を接続された線としてではなく一連の点として表示したりできます。また、Vega 変換を使用して値の配列をヒストグラムにビン化するなど、データ自体に変更を加えることもできます。パネルプレビューはインタラクティブに更新されるため、Vega 仕様またはクエリを編集するときの変更の効果を確認できます。Vega のドキュメントとチュートリアル を参照してください。
フィールド参照
W&B からグラフにデータをプルするには、Vega 仕様の任意の場所に "${field:<field-name>}" 形式のテンプレート文字列を追加します。これにより、右側の グラフフィールド 領域にドロップダウンが作成され、ユーザーはクエリ結果の列を選択して Vega にマッピングできます。
フィールドのデフォルト値を設定するには、次の構文を使用します: "${field:<field-name>:<placeholder text>}"
グラフプリセットの保存
モーダルの下部にあるボタンを使用して、特定の可視化パネルに変更を適用します。または、Vega 仕様を保存して、プロジェクトの他の場所で使用することもできます。再利用可能なグラフ定義を保存するには、Vega エディターの上部にある 名前を付けて保存 をクリックし、プリセットに名前を付けます。
記事とガイド
一般的なユースケース
- エラーバー付きのカスタム棒グラフ
- カスタム x-y 座標を必要とするモデル検証メトリクスを表示する (適合率-再現率曲線など)
- 2つの異なるモデル/ experiment からのデータ分布をヒストグラムとしてオーバーレイする
- トレーニング中の複数のポイントでのスナップショットを介してメトリクスの変化を表示する
- W&B でまだ利用できない独自の可視化を作成する (そして、うまくいけばそれを世界と共有する)
2.1 - Tutorial: Use custom charts
カスタムチャートを使用すると、パネルにロードするデータとその可視化を制御できます。
1. データを W&B にログ記録する
まず、スクリプトにデータをログ記録します。トレーニングの開始時に設定された単一のポイント(ハイパーパラメータなど)には、wandb.config を使用します。時間の経過に伴う複数のポイントには、wandb.log() を使用し、wandb.Table() を使用してカスタム 2D 配列をログ記録します。ログに記録されるキーごとに最大 10,000 個のデータポイントをログに記録することをお勧めします。
# データのカスタムテーブルをログ記録する
my_custom_data = [[x1, y1, z1], [x2, y2, z2]]
wandb.log(
{"custom_data_table": wandb.Table(data=my_custom_data, columns=["x", "y", "z"])}
)
クイックなサンプルノートブックを試してデータテーブルをログに記録してください。次のステップでは、カスタムチャートを設定します。結果として得られるチャートがライブ Reportでどのように見えるかを確認してください。
2. クエリを作成する
可視化するデータをログに記録したら、プロジェクトページに移動し、**+**ボタンをクリックして新しいパネルを追加し、カスタムチャートを選択します。この Workspaceで一緒に操作できます。

クエリを追加する
- 「summary」をクリックし、「historyTable」を選択して、run の履歴からデータを取得する新しいクエリを設定します。
wandb.Table()をログに記録したキーを入力します。上記のコードスニペットでは、my_custom_tableでした。サンプルノートブックでは、キーはpr_curveとroc_curveです。
Vega フィールドを設定する
クエリがこれらの列をロードするようになったので、Vega フィールドのドロップダウンメニューで選択するオプションとして使用できます。
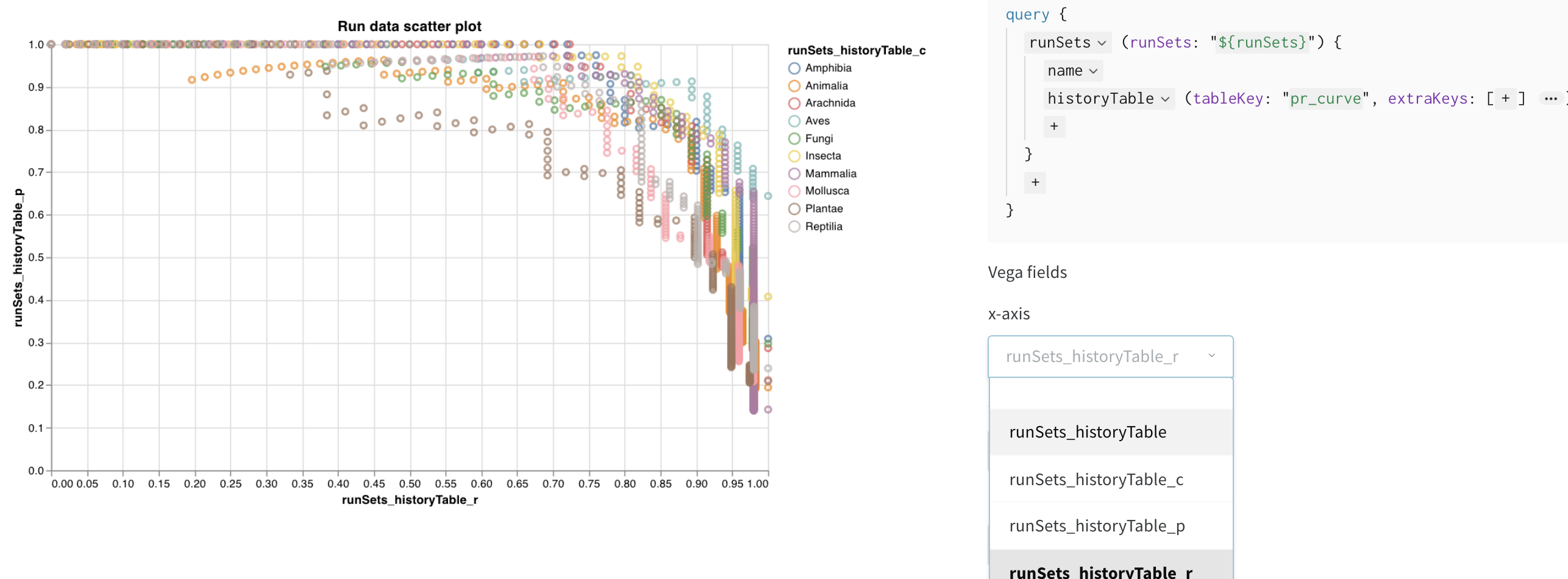
- x 軸: runSets_historyTable_r (再現率)
- y 軸: runSets_historyTable_p (精度)
- 色: runSets_historyTable_c (クラスラベル)
3. チャートをカスタマイズする
見た目はかなり良いですが、散布図から折れ線グラフに切り替えたいと思います。「編集」をクリックして、この組み込みチャートの Vega 仕様を変更します。この Workspaceで一緒に操作できます。

Vega 仕様を更新して、可視化をカスタマイズしました。
- プロット、凡例、x 軸、および y 軸のタイトルを追加します(各フィールドの「title」を設定します)。
- 「mark」の値を「point」から「line」に変更します。
- 使用されていない「size」フィールドを削除します。
これをプリセットとして保存して、このプロジェクトの他の場所で使用できるようにするには、ページの上部にある「名前を付けて保存」をクリックします。結果は次のようになり、ROC 曲線が表示されます。
ボーナス: 複合ヒストグラム
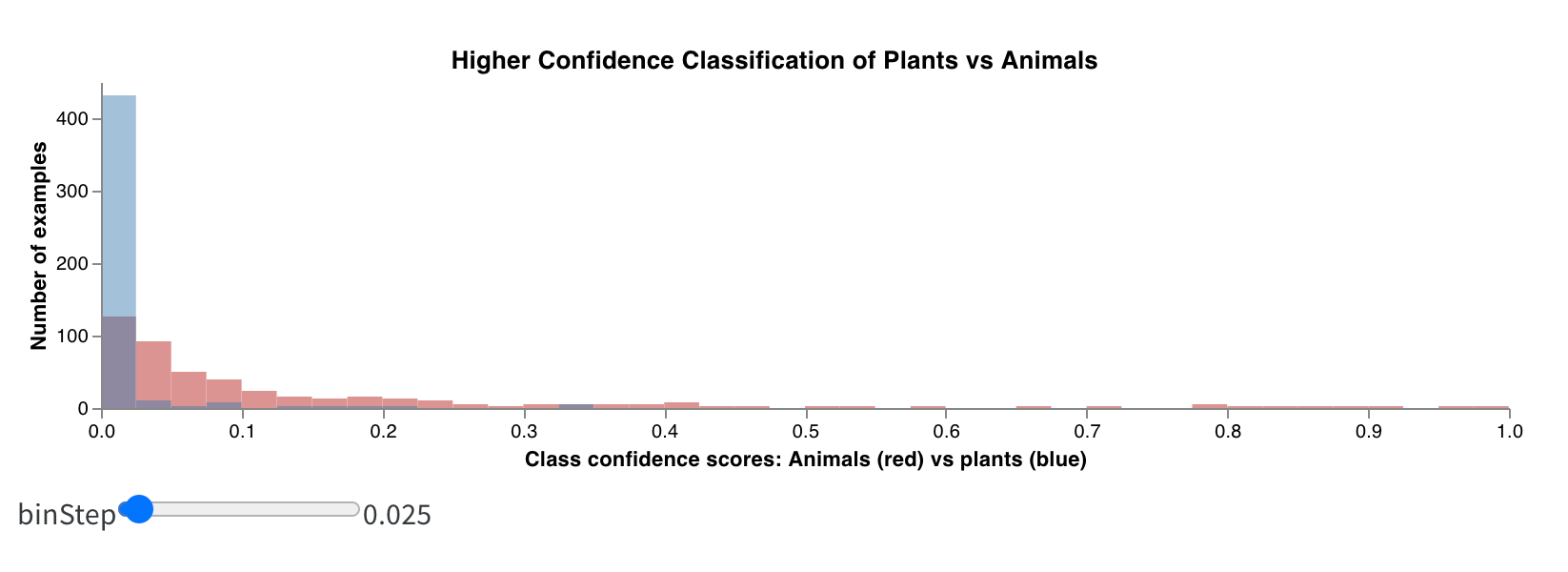
ヒストグラムは、数値分布を可視化して、より大きなデータセットを理解するのに役立ちます。複合ヒストグラムは、同じビンに複数の分布を表示し、異なるモデル間、またはモデル内の異なるクラス間で、2 つ以上のメトリクスを比較できます。運転シーンでオブジェクトを検出するセマンティックセグメンテーションモデルの場合、精度と intersection over union (IOU) の最適化の効果を比較したり、異なるモデルが車(データ内の大きく一般的な領域)と交通標識(はるかに小さく、一般的でない領域)をどの程度検出できるかを知りたい場合があります。デモ Colabでは、10 種類の生物のクラスのうち 2 つの信頼度スコアを比較できます。
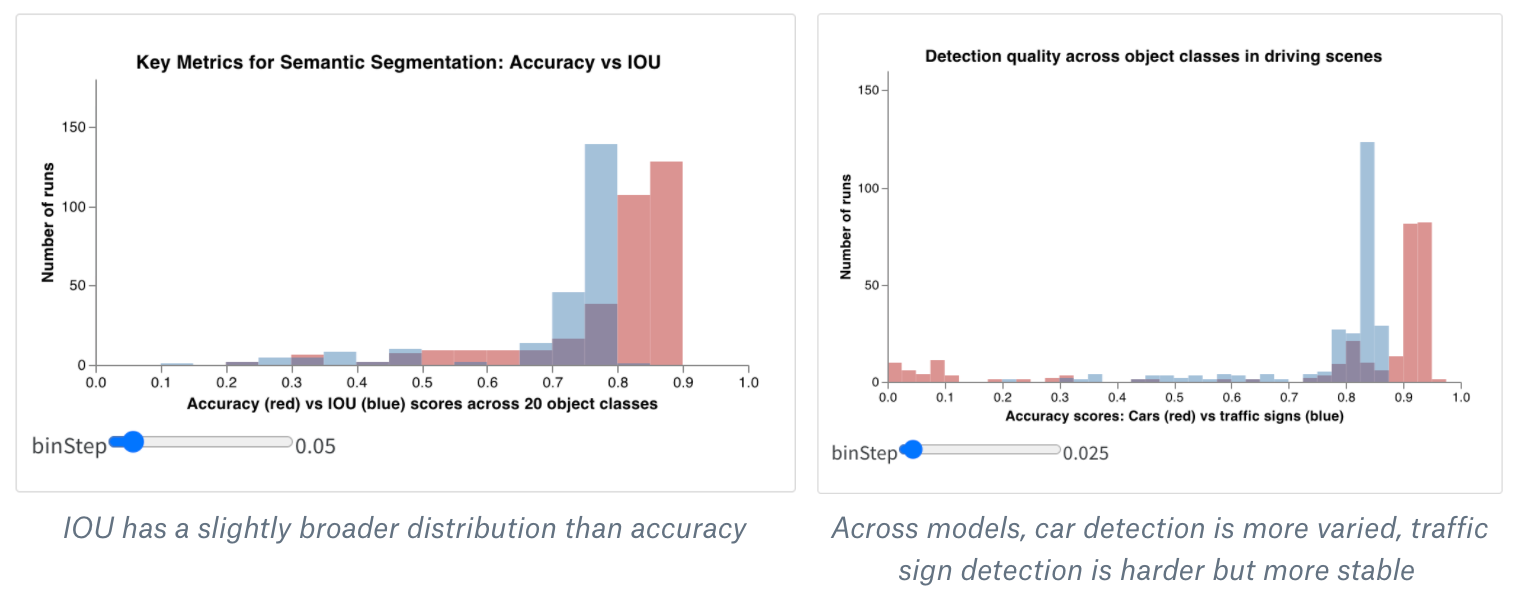
カスタム複合ヒストグラムパネルの独自のバージョンを作成するには:
- Workspace または Report で新しいカスタムチャートパネルを作成します(「カスタムチャート」可視化を追加することによって)。右上にある「編集」ボタンをクリックして、組み込みのパネルタイプから Vega 仕様を変更します。
- その組み込みの Vega 仕様を、Vega の複合ヒストグラムの MVP コードに置き換えます。メインタイトル、軸タイトル、入力ドメイン、およびその他の詳細を、この Vega 仕様で直接Vega 構文を使用して変更できます(色を変更したり、3 番目のヒストグラムを追加したりすることもできます:)
- 右側のクエリを変更して、wandb ログから正しいデータをロードします。フィールド
summaryTableを追加し、対応するtableKeyをclass_scoresに設定して、run によってログに記録されたwandb.Tableをフェッチします。これにより、class_scoresとしてログに記録されたwandb.Tableの列を使用して、ドロップダウンメニューから 2 つのヒストグラムビンセット(red_binsとblue_bins)を設定できます。私の例では、赤いビンの動物クラスの予測スコアと、青いビンの植物の予測スコアを選択しました。 - プレビューレンダリングに表示されるプロットに満足するまで、Vega 仕様とクエリの変更を続けることができます。完了したら、上部の「名前を付けて保存」をクリックし、カスタムプロットに名前を付けて再利用できるようにします。次に、「パネルライブラリから適用」をクリックして、プロットを完了します。
これは、非常に簡単な実験からの結果がどのように見えるかです。1 エポックでわずか 1000 個のサンプルでトレーニングすると、ほとんどの画像が植物ではないと非常に確信しており、どの画像が動物である可能性があるかについては非常に不確かなモデルが生成されます。
3 - Manage workspace, section, and panel settings
特定の ワークスペース ページ内には、ワークスペース、セクション、パネルという3つの異なる設定レベルがあります。ワークスペース の 設定 は、ワークスペース 全体に適用されます。セクション の 設定 は、セクション内のすべてのパネルに適用されます。パネル の 設定 は、個々のパネルに適用されます。
ワークスペース の 設定
ワークスペース の 設定は、すべてのセクションと、それらのセクション内のすべてのパネルに適用されます。編集できるワークスペース の 設定には、ワークスペース の レイアウト と 折れ線グラフ の2種類があります。ワークスペース の レイアウト は ワークスペース の構造を決定し、折れ線グラフ の 設定は ワークスペース 内の折れ線グラフのデフォルト設定を制御します。
この ワークスペース の全体的な構造に適用される設定を編集するには:
- プロジェクト の ワークスペース に移動します。
- New report ボタンの横にある歯車アイコンをクリックして、ワークスペース の 設定を表示します。
- ワークスペース のレイアウトを変更するには Workspace layout を選択し、ワークスペース 内の折れ線グラフのデフォルト設定を構成するには Line plots を選択します。
ワークスペース の レイアウト オプション
ワークスペース のレイアウトを構成して、ワークスペース の全体的な構造を定義します。これには、セクション分割ロジックとパネルの構成が含まれます。
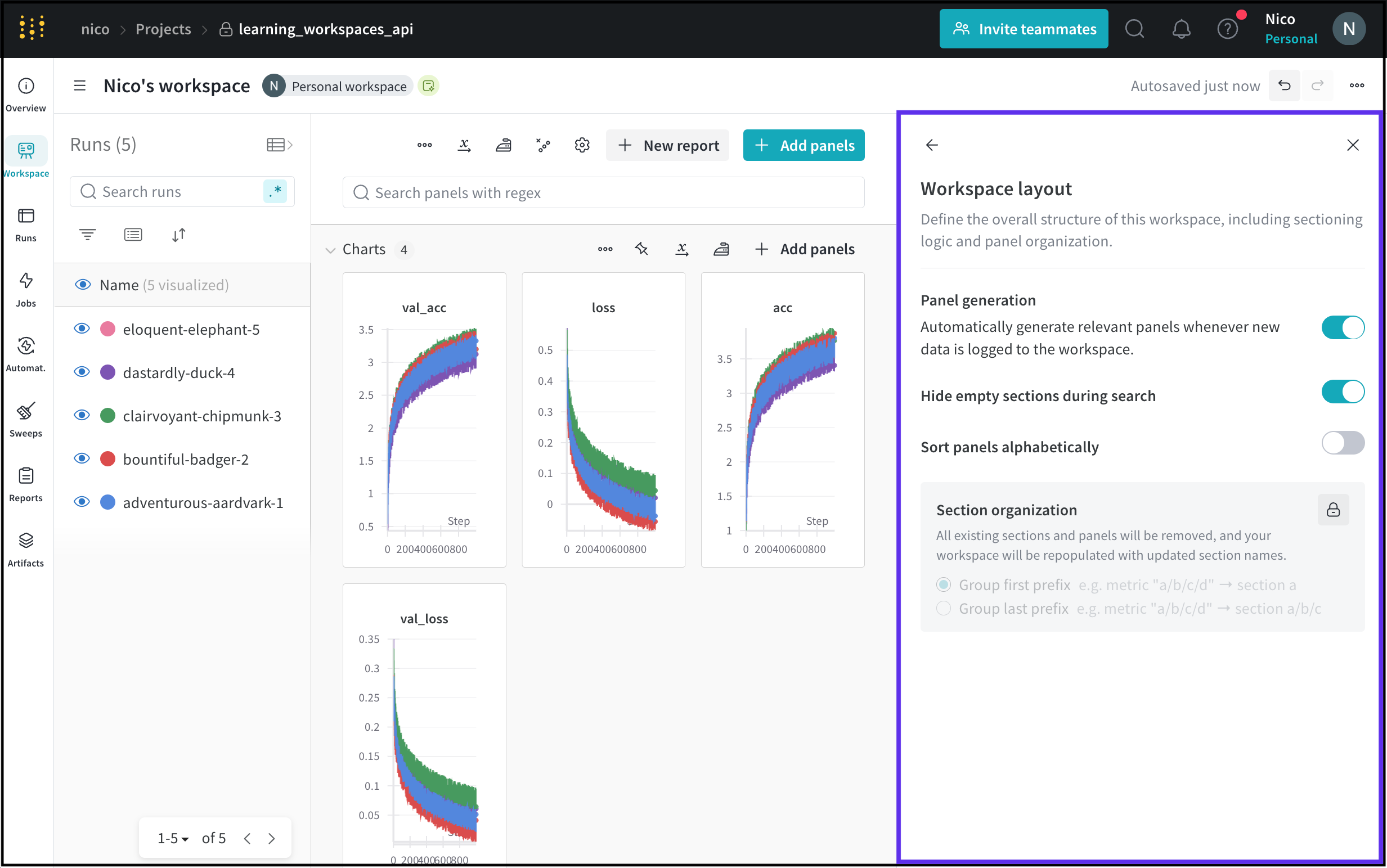
ワークスペース のレイアウト オプション ページには、ワークスペース がパネルを自動的に生成するか、手動で生成するかが表示されます。ワークスペース のパネル生成モードを調整するには、Panels を参照してください。
次の表は、各ワークスペース のレイアウト オプションについて説明したものです。
| ワークスペース の 設定 | 説明 |
|---|---|
| 検索時に空のセクションを非表示にする | パネルを検索するときに、パネルを含まないセクションを非表示にします。 |
| パネルをアルファベット順に並べ替える | ワークスペース 内のパネルをアルファベット順に並べ替えます。 |
| セクション の 構成 | 既存のすべてのセクションとパネルを削除し、新しいセクション名で再作成します。新しく作成されたセクションを、最初のプレフィックスまたは最後のプレフィックスでグループ化します。 |
折れ線グラフ の オプション
Line plots ワークスペース の 設定を変更して、ワークスペース 内の折れ線グラフのグローバルなデフォルトとカスタムルールを設定します。
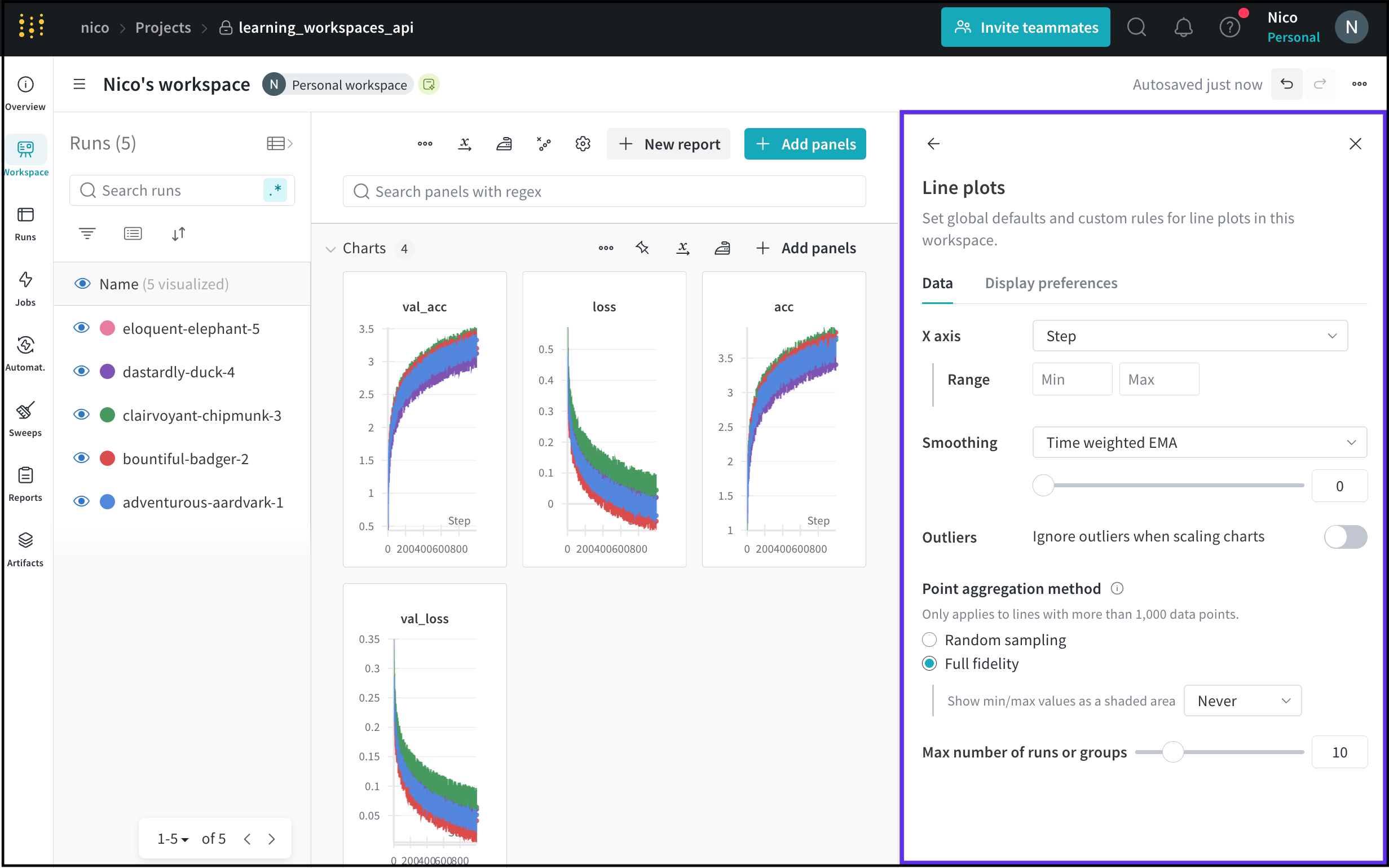
Line plots の 設定では、Data と Display preferences という2つのメイン設定を編集できます。Data タブには、次の設定が含まれています。
| 折れ線グラフ の 設定 | 説明 |
|---|---|
| X軸 | 折れ線グラフのX軸のスケール。X軸はデフォルトで Step に設定されています。X軸のオプションのリストについては、次の表を参照してください。 |
| 範囲 | X軸に表示する最小値と最大値の設定。 |
| Smoothing | 折れ線グラフの Smoothing を変更します。Smoothing の詳細については、Smooth line plots を参照してください。 |
| Outliers | デフォルトのプロットの最小スケールと最大スケールから外れ値を排除するためにリスケールします。 |
| Point aggregation method | Data Visualization の精度とパフォーマンスを向上させます。詳細については、Point aggregation を参照してください。 |
| Max number of runs or groups | 折れ線グラフに表示される Runs またはグループの数を制限します。 |
Step に加えて、X軸には次のオプションがあります。
| X軸 オプション | 説明 |
|---|---|
| 相対時間 (Wall) | プロセス の開始からのタイムスタンプ。たとえば、run を開始し、翌日にその run を再開するとします。その後、何かを log に記録すると、記録されたポイントは24時間になります。 |
| 相対時間 (Process) | 実行中のプロセス内のタイムスタンプ。たとえば、run を開始して10秒間続行するとします。翌日にその run を再開します。ポイントは10秒として記録されます。 |
| Wall Time | グラフ上の最初の run の開始からの経過時間 (分)。 |
| Step | wandb.log() を呼び出すたびに増分します。 |
Display preferences タブでは、次の設定を切り替えることができます。
| 表示設定 | 説明 |
|---|---|
| Remove legends from all panels | パネルの凡例を削除します |
| Display colored run names in tooltips | ツールチップ内に Runs を色付きのテキストとして表示します |
| Only show highlighted run in companion chart tooltip | チャートのツールチップに強調表示された Runs のみを表示します |
| Number of runs shown in tooltips | ツールチップに Runs の数を表示します |
| Display full run names on the primary chart tooltip | チャートのツールチップに run のフルネームを表示します |
セクション の 設定
セクション の 設定は、そのセクション内のすべてのパネルに適用されます。ワークスペース の セクション 内では、パネルの並べ替え、パネルの再配置、セクション名の変更を行うことができます。
セクション の 設定を変更するには、セクション の右上隅にある3つの水平ドット (…) を選択します。
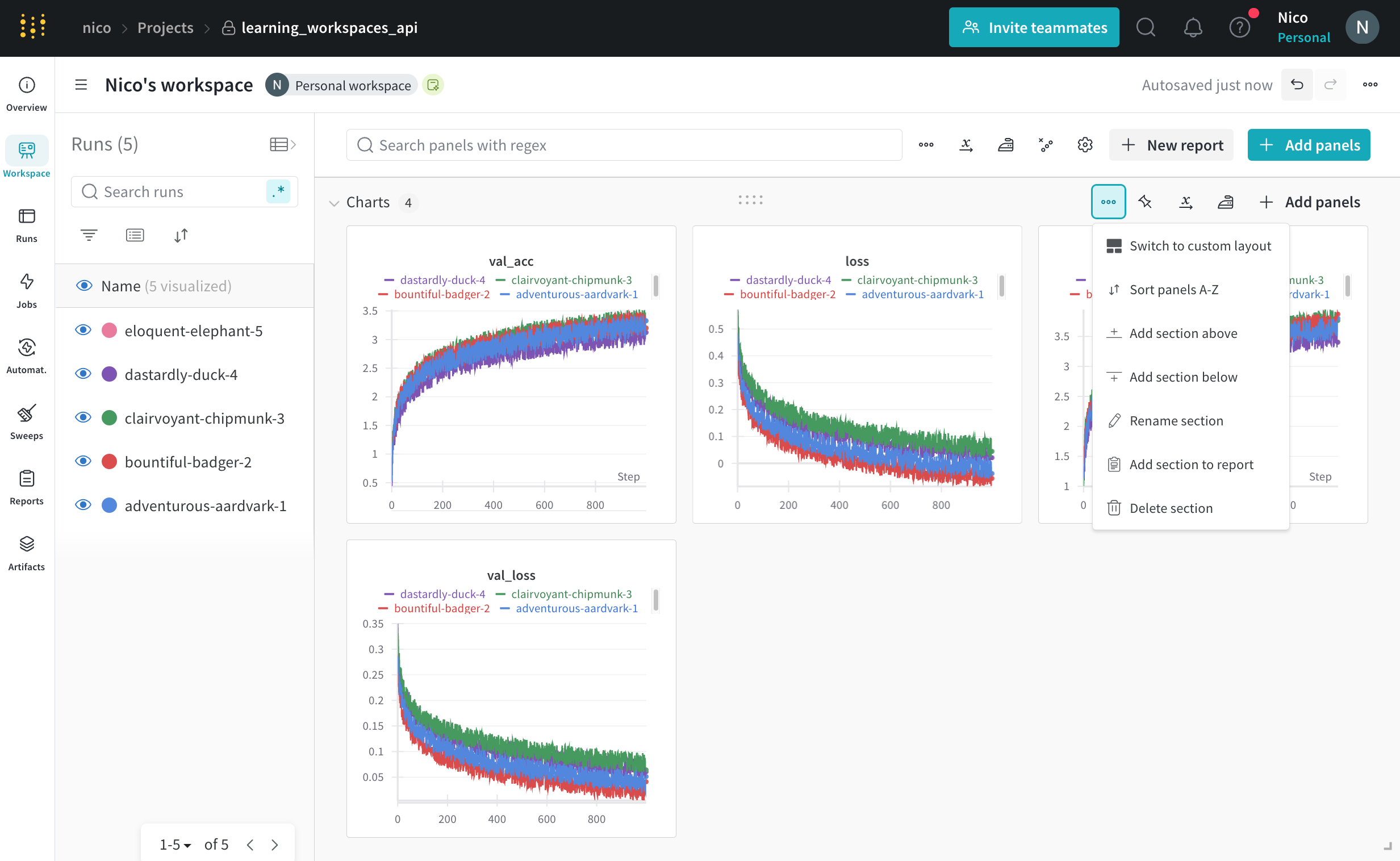
ドロップダウンから、セクション全体に適用される次の設定を編集できます。
| セクション の 設定 | 説明 |
|---|---|
| Rename a section | セクションの名前を変更します |
| Sort panels A-Z | セクション内のパネルをアルファベット順に並べ替えます |
| Rearrange panels | セクション内のパネルを選択してドラッグし、パネルを手動で並べ替えます |
次のアニメーションは、セクション内のパネルを再配置する方法を示しています。
パネル の 設定
個々のパネルの 設定をカスタマイズして、同じプロット上に複数の線を比較したり、カスタム軸を計算したり、ラベルの名前を変更したりできます。パネルの 設定を編集するには:
- 編集するパネルにマウスを合わせます。
- 表示される鉛筆アイコンを選択します。
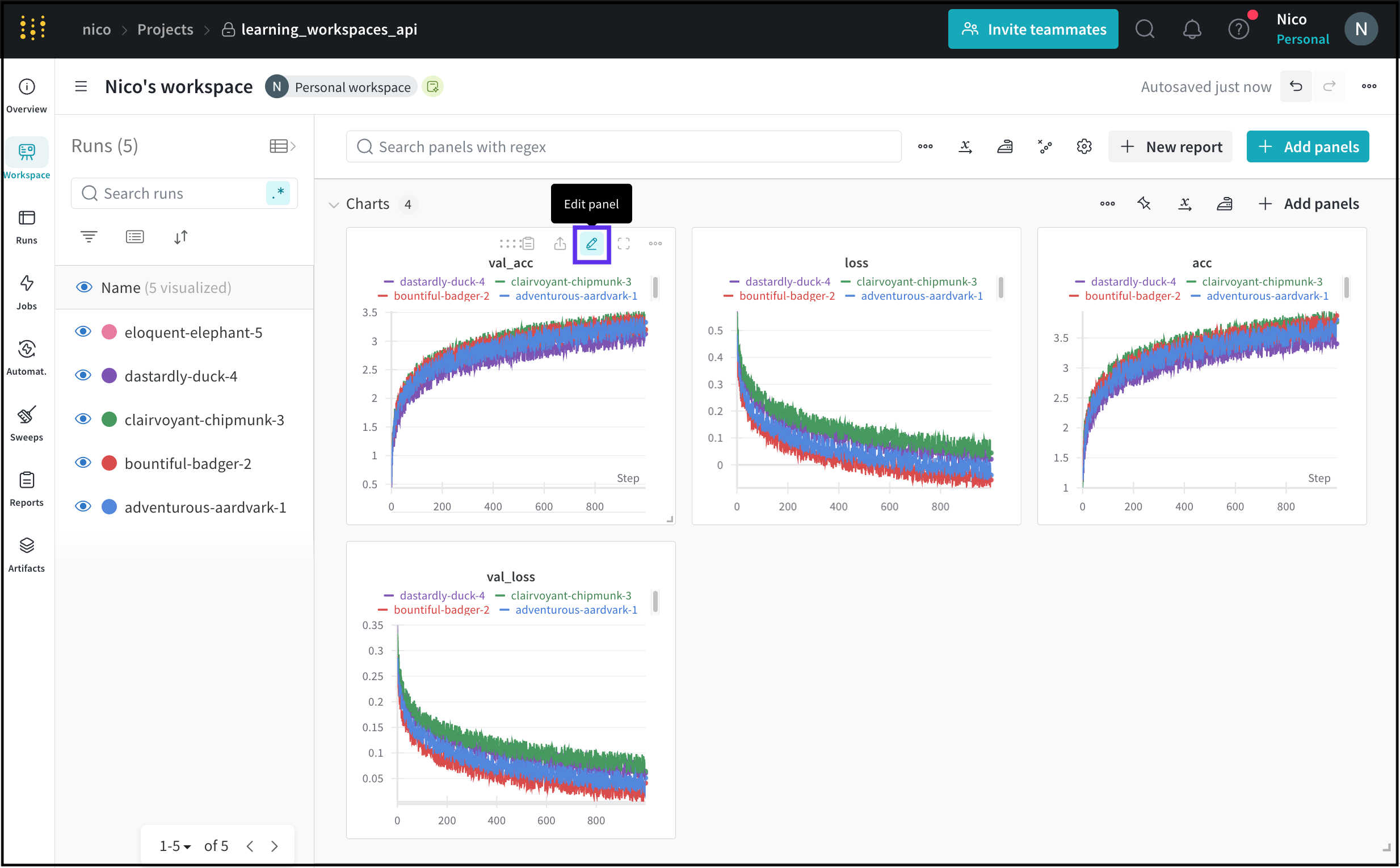
- 表示されるモーダル内で、パネルの データ、表示設定などに関連する設定を編集できます。
パネルに適用できる設定の完全なリストについては、Edit line panel settings を参照してください。
4 - Settings
個々の ユーザー アカウント内では、プロフィール画像、表示名、地理的な場所、自己紹介情報、アカウントに関連付けられたメールアドレスを編集したり、runs のアラートを管理したりできます。設定 ページを使用して、GitHub リポジトリをリンクしたり、アカウントを削除したりすることもできます。詳細については、ユーザー settings を参照してください。
Team settings ページを使用して、新しいメンバーを Team に招待または削除したり、Team runs のアラートを管理したり、プライバシー 設定を変更したり、ストレージの使用状況を表示および管理したりできます。Team settings の詳細については、Team settings を参照してください。
4.1 - Manage user settings
ユーザープロファイルページに移動し、右上隅にあるユーザーアイコンを選択します。ドロップダウンから、設定 を選択します。
プロフィール
プロフィール セクションでは、アカウント名と所属機関を管理および変更できます。オプションで、略歴、場所、個人または所属機関のウェブサイトへのリンクを追加したり、プロフィール画像をアップロードしたりできます。
イントロダクションを編集する
イントロダクションを編集するには、プロフィールの最上部にある 編集 をクリックします。開く WYSIWYG エディターは Markdown をサポートしています。
- 行を編集するには、それをクリックします。時間を節約するために、
/と入力し、リストから Markdown を選択できます。 - 項目のドラッグハンドルを使用して、移動します。
- ブロックを削除するには、ドラッグハンドルをクリックし、削除 をクリックします。
- 変更を保存するには、保存 をクリックします。
ソーシャルバッジを追加する
X で @weights_biases アカウントのフォローバッジを追加するには、バッジ画像を指す HTML <img> タグを含む Markdown スタイルのリンクを追加できます。
[<img src="https://img.shields.io/twitter/follow/weights_biases?style=social" alt="X: @weights_biases" >](https://x.com/intent/follow?screen_name=weights_biases)
<img> タグでは、width、height、またはその両方を指定できます。いずれか一方のみを指定した場合、画像のプロポーションは維持されます。
Teams
Team セクションで新しい team を作成します。新しい team を作成するには、新しい team ボタンを選択し、以下を入力します。
- Team 名 - team の名前。team 名は一意である必要があります。Team 名は変更できません。
- Team タイプ - 仕事 または 学術 ボタンを選択します。
- 会社/組織 - team の会社または組織の名前を入力します。ドロップダウンメニューを選択して、会社または組織を選択します。オプションで、新しい組織を入力できます。
ベータ機能
ベータ機能 セクションでは、オプションで楽しいアドオンや開発中の新製品の先行プレビューを有効にできます。有効にするベータ機能の横にあるトグルスイッチを選択します。
アラート
wandb.alert() で、run がクラッシュまたは終了した場合、またはカスタムアラートを設定した場合に通知を受け取ります。メールまたは Slack で通知を受信します。アラートを受信するイベントタイプの横にあるスイッチを切り替えます。
- Runs finished: Weights and Biases の run が正常に終了したかどうか。
- Run crashed: run が完了しなかった場合に通知します。
アラートの設定と管理方法の詳細については、wandb.alert でアラートを送信 を参照してください。
個人の GitHub integration
個人の Github アカウントを接続します。Github アカウントを接続するには:
- Github に接続 ボタンを選択します。これにより、オープン認証 (OAuth) ページにリダイレクトされます。
- 組織アクセス セクションで、アクセスを許可する組織を選択します。
- wandb を認証 します。
アカウントを削除する
アカウントを削除 ボタンを選択して、アカウントを削除します。
ストレージ
ストレージ セクションでは、アカウントが Weights and Biases サーバーで使用した総メモリ使用量を説明します。デフォルトのストレージプランは 100GB です。ストレージと価格の詳細については、価格 ページを参照してください。
4.2 - Manage billing settings
ユーザープロフィールページに移動し、右上隅にあるユーザーアイコンを選択します。ドロップダウンから、Billing を選択するか、Settings を選択し、Billing タブを選択します。
プラン詳細
Plan details セクションでは、組織の現在のプラン、料金、制限、使用状況の概要が示されます。
- ユーザーの詳細とリストを表示するには、Manage users をクリックします。
- 使用状況の詳細を表示するには、View usage をクリックします。
- 組織が使用するストレージの量(無料と有料の両方)。ここから、追加のストレージを購入したり、現在使用中のストレージを管理したりできます。ストレージの設定 の詳細をご覧ください。
ここから、プランを比較したり、営業担当者と話をしたりできます。
プランの使用状況
このセクションでは、現在の使用状況を視覚的にまとめ、今後の使用料金を表示します。月ごとの使用状況の詳細な分析情報を得るには、個々のタイルで View usage をクリックします。カレンダー月、Team、または Project ごとに使用状況をエクスポートするには、Export CSV をクリックします。
使用状況アラート
有料プランをご利用の組織の場合、管理者は、特定のしきい値に達すると、1 回の請求期間につき 1 回、メールでアラートを受信します。また、請求管理者 の場合は、組織の制限を増やす方法、それ以外の場合は、請求管理者に連絡する方法の詳細も記載されています。Pro plan では、請求管理者のみが使用状況アラートを受信します。
これらのアラートは構成できず、次の場合に送信されます。
- 組織が、プランに応じた使用量のカテゴリの月間制限に近づいている場合(使用時間の 85%)および制限の 100% に達した場合。
- 組織の請求期間の累積平均料金が、200 ドル、450 ドル、700 ドル、および 1000 ドルのしきい値を超えた場合。これらの超過料金は、組織が追跡時間、ストレージ、または Weave data ingestion に対して、プランに含まれる量よりも多くの使用量を累積した場合に発生します。
使用状況または請求に関するご質問は、アカウントTeamまたはサポートにお問い合わせください。
支払い方法
このセクションには、組織に登録されている支払い方法が表示されます。支払い方法を追加していない場合は、プランをアップグレードするか、有料ストレージを追加するときに、追加するように求められます。
請求管理者
このセクションには、現在の請求管理者が表示されます。請求管理者は組織の管理者であり、請求関連のすべてのメールを受信し、支払い方法を表示および管理できます。
請求管理者を変更するか、ロールを追加のユーザーに割り当てるには、次の手順に従います。
- Manage roles をクリックします。
- ユーザーを検索します。
- そのユーザーの行にある Billing admin フィールドをクリックします。
- 概要を読んでから、Change billing user をクリックします。
請求書
クレジットカードで支払う場合、このセクションでは毎月の請求書を表示できます。
- 銀行振込で支払う Enterprise アカウントの場合、このセクションは空白です。ご不明な点がございましたら、アカウントTeamにお問い合わせください。
- 組織が料金を発生させない場合、請求書は生成されません。
4.3 - Manage team settings
チーム設定
チームのメンバー、アバター、アラート、プライバシー、利用状況などの設定を変更します。Organization の管理者と チーム の管理者は、チーム の設定を表示および編集できます。
メンバー
「メンバー」セクションには、保留中の招待と、チームへの参加招待を承認したメンバーのリストが表示されます。リストに表示される各メンバーには、メンバーの名前、ユーザー名、メールアドレス、チームの役割、および Models と Weave へのアクセス権限が表示されます。これらは Organization から継承されます。標準のチームの役割 Admin 、 Member 、および View-only から選択できます。Organization がカスタムロールを作成している場合は、代わりにカスタムロールを割り当てることができます。
チームの作成方法、チームの管理方法、チームのメンバーシップと役割の管理方法については、チームの追加と管理を参照してください。誰が新しいメンバーを招待できるかを設定し、チームのその他のプライバシー設定を構成するには、プライバシーを参照してください。
アバター
アバターセクションに移動し、画像をアップロードしてアバターを設定します。
- アバターを更新を選択して、ファイルダイアログを表示します。
- ファイルダイアログから、使用する画像を選択します。
アラート
run がクラッシュ、完了、またはカスタムアラートを設定したときに、チームに通知します。チームは、メールまたは Slack でアラートを受信できます。
アラートを受信するイベントタイプの横にあるスイッチを切り替えます。Weights and Biases は、デフォルトで次のイベントタイプのオプションを提供します。
- Runs finished: Weights and Biases の run が正常に完了したかどうか。
- Run crashed: run が完了しなかった場合。
アラートの設定と管理方法の詳細については、wandb.alert でアラートを送信を参照してください。
Slack 通知
チームの Automations が、新しい Artifact が作成されたときや、run メトリクスが定義されたしきい値を満たしたときなど、Registry または プロジェクト でイベントが発生したときに通知を送信できる Slack の送信先を設定します。Slack オートメーションの作成を参照してください。
This feature is available for all Enterprise licenses.
Webhook
チームの Automations が、新しい Artifact が作成されたときや、run メトリクスが定義されたしきい値を満たしたときなど、Registry または プロジェクト でイベントが発生したときに実行できる Webhook を設定します。Webhook オートメーションの作成を参照してください。
This feature is available for all Enterprise licenses.
プライバシー
プライバシーセクションに移動して、プライバシー設定を変更します。プライバシー設定を変更できるのは、Organization の管理者のみです。
- 将来の プロジェクト を公開したり、 Reports を公開共有したりする機能をオフにします。
- チーム管理者だけでなく、チームメンバーが他のメンバーを招待できるようにします。
- コードの保存をデフォルトでオンにするかどうかを管理します。
利用状況
利用状況セクションでは、チームが Weights and Biases サーバーで使用した総メモリ使用量について説明します。デフォルトのストレージプランは 100GB です。ストレージと価格の詳細については、価格ページを参照してください。
ストレージ
ストレージセクションでは、チームの データ に使用されている クラウド ストレージ バケットの設定について説明します。詳細については、セキュアストレージコネクタを参照するか、セルフホスティングの場合は W&B Server のドキュメントを確認してください。
4.4 - Manage email settings
W&B プロフィールの 設定 ページで、メールの種類やプライマリ メール アドレスの追加、削除、管理ができます。W&B ダッシュボード の右上にあるプロフィール アイコンを選択します。ドロップダウンから、設定 を選択します。設定 ページ内で、Emails ダッシュボード までスクロールします。
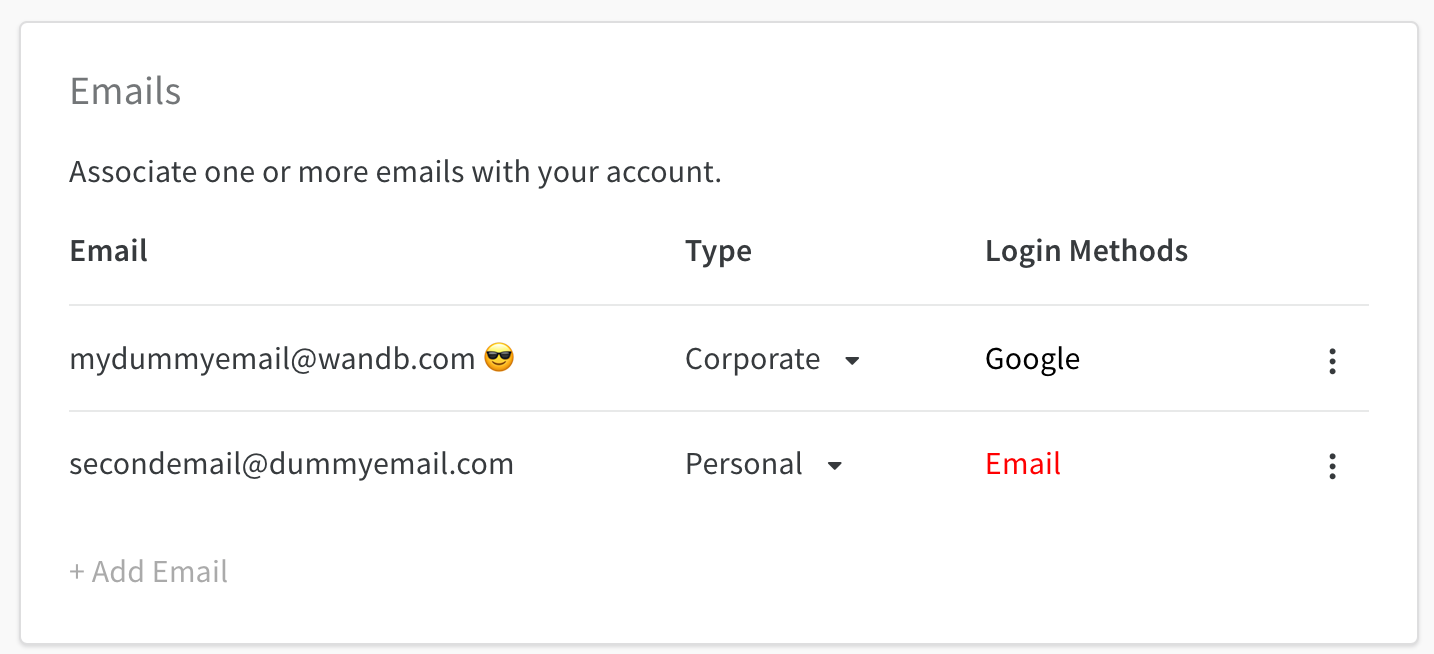
プライマリ メール の管理
プライマリ メール は 😎 の絵文字でマークされています。プライマリ メール は、W&B アカウント を作成した際に提供したメール アドレスで自動的に定義されます。
ケバブ ドロップダウンを選択して、Weights And Biases アカウント に関連付けられたプライマリ メール を変更します。
メール の追加
+ Add Email を選択して、メール を追加します。これにより、Auth0 ページに移動します。新しいメール の認証情報を入力するか、シングル サインオン (SSO) を使用して接続できます。
メール の削除
ケバブ ドロップダウンを選択し、Delete Emails を選択して、W&B アカウント に登録されているメール を削除します。
ログイン 方法
[ログイン 方法] 列には、アカウント に関連付けられているログイン 方法が表示されます。
W&B アカウント を作成すると、確認メール がメール アカウント に送信されます。メール アカウント は、メール アドレス を確認するまで検証されていないと見なされます。未検証のメール は赤で表示されます。
メール アドレス で再度ログインして、メール アカウント に送信された最初の確認メール が既になくても、2 通目の確認メール を取得してみてください。
アカウント ログイン の問題については、support@wandb.com までお問い合わせください。
4.5 - Manage teams
W&B Teams を、より優れたモデルをより迅速に構築するための ML チーム用の一元的なワークスペースとして使用します。
- チームが試したすべての実験を追跡し 、作業の重複をなくします。
- 以前にトレーニングしたモデルを保存して再現します。
- 上司や共同研究者と進捗状況や結果を共有します。
- 回帰を検出し、パフォーマンスが低下した場合に直ちに警告を受けます。
- モデルのパフォーマンスを評価し、モデルのバージョンを比較します。
コラボレーションチームを作成する
- 無料の W&B アカウントにサインアップまたはログインします。
- ナビゲーションバーの [Invite Team(チームを招待)] をクリックします。
- チームを作成し、共同研究者を招待します。
- チームの設定については、チームの設定を管理を参照してください。
チームプロファイルを作成する
チームのプロファイルページをカスタマイズして、イントロダクションを表示したり、一般公開またはチームメンバーに公開されている Reports と Projects を紹介したりできます。 Reports 、 Projects 、および外部リンクを提示します。
- 最高の公開 Reports を紹介して、最高の research を訪問者にアピールします
- 最もアクティブな Projects を紹介して、チームメイトが見つけやすくします
- 会社や research ラボのウェブサイト、および公開した論文への外部リンクを追加して、共同研究者を見つけます
チームメンバーを削除する
チーム管理者は、チームの設定ページを開き、退職するメンバーの名前の横にある削除ボタンをクリックできます。 run は、ユーザーが退席した後もチームに記録されたままになります。
チームの役割と権限を管理する
同僚をチームに招待するときに、チームの役割を選択します。次のチームの役割オプションがあります。
- 管理者:チーム管理者は、他の管理者またはチームメンバーを追加および削除できます。すべての Projects を変更する権限と、完全な削除権限を持っています。これには、 Runs 、 Projects 、 Artifacts 、および Sweeps の削除が含まれますが、これらに限定されません。
- メンバー:チームの通常のメンバー。デフォルトでは、管理者のみがチームメンバーを招待できます。この振る舞いを変更するには、チームの設定を管理を参照してください。
チームメンバーは、自分が作成した run のみ削除できます。メンバー A と B がいるとします。メンバー B は、 run をチーム B の Project からメンバー A が所有する別の Project に移動します。メンバー A は、メンバー B がメンバー A の Project に移動した run を削除できません。管理者は、チームメンバーが作成した Runs と Sweep Runs を管理できます。
- 表示のみ(エンタープライズ限定機能):表示のみのメンバーは、 Runs 、 Reports 、 Workspace など、チーム内のアセットを表示できます。 Reports をフォローしてコメントできますが、 Project の概要、 Reports 、 Runs を作成、編集、または削除することはできません。
- カスタムロール(エンタープライズ限定機能):カスタムロールを使用すると、組織管理者は、表示のみまたはメンバーロールのいずれかに基づいて、追加の権限を付与して、きめ細かいアクセス制御を実現する新しいロールを作成できます。次に、チーム管理者は、これらのカスタムロールをそれぞれのチームのユーザーに割り当てることができます。詳細については、W&B Teams のカスタムロールの紹介を参照してください。
- サービスアカウント(エンタープライズ限定機能):サービスアカウントを使用してワークフローを自動化するを参照してください。
チームの設定
チーム設定を使用すると、チームとそのメンバーの設定を管理できます。これらの権限を使用すると、W&B 内でチームを効果的に監督および整理できます。
| 権限 | 表示のみ | チームメンバー | チーム管理者 |
|---|---|---|---|
| チームメンバーを追加する | X | ||
| チームメンバーを削除する | X | ||
| チーム設定を管理する | X |
レジストリ
次の表に、特定のチームのすべての Projects に適用される権限を示します。
| 権限 | 表示のみ | チームメンバー | レジストリ管理者 | チーム管理者 |
|---|---|---|---|---|
| エイリアスを追加する | X | X | X | |
| モデルをレジストリに追加する | X | X | X | |
| レジストリでモデルを表示する | X | X | X | X |
| モデルをダウンロードする | X | X | X | X |
| レジストリ管理者を追加または削除する | X | X | ||
| 保護されたエイリアスを追加または削除する | X |
保護されたエイリアスの詳細については、レジストリアクセス制御を参照してください。
Reports
Report 権限は、 Reports を作成、表示、および編集するためのアクセスを許可します。次の表に、特定のチームのすべての Reports に適用される権限を示します。
| 権限 | 表示のみ | チームメンバー | チーム管理者 |
|---|---|---|---|
| Reports を表示する | X | X | X |
| Reports を作成する | X | X | |
| Reports を編集する | X (チームメンバーは自分の Reports のみ編集できます) | X | |
| Reports を削除する | X (チームメンバーは自分の Reports のみ編集できます) | X |
実験管理
次の表に、特定のチームのすべての実験管理に適用される権限を示します。
| 権限 | 表示のみ | チームメンバー | チーム管理者 |
|---|---|---|---|
| 実験管理メタデータ(履歴メトリクス、システムメトリクス、ファイル、ログを含む)を表示する | X | X | X |
| 実験管理パネルとワークスペースを編集する | X | X | |
| 実験管理をログに記録する | X | X | |
| 実験管理を削除する | X (チームメンバーは自分が作成した実験管理のみ削除できます) | X | |
| 実験管理を停止する | X (チームメンバーは自分が作成した実験管理のみ停止できます) | X |
Artifacts
次の表に、特定のチームのすべての Artifacts に適用される権限を示します。
| 権限 | 表示のみ | チームメンバー | チーム管理者 |
|---|---|---|---|
| Artifacts を表示する | X | X | X |
| Artifacts を作成する | X | X | |
| Artifacts を削除する | X | X | |
| メタデータを編集する | X | X | |
| エイリアスを編集する | X | X | |
| エイリアスを削除する | X | X | |
| Artifacts をダウンロードする | X | X |
システム設定(W&B Server のみ)
システム権限を使用して、チームとそのメンバーを作成および管理し、システム設定を調整します。これらの権限により、W&B インスタンスを効果的に管理および保守できます。
| 権限 | 表示のみ | チームメンバー | チーム管理者 | システム管理者 |
|---|---|---|---|---|
| システム設定を構成する | X | |||
| チームを作成/削除する | X |
チームサービスアカウントの振る舞い
- トレーニング環境でチームを構成する場合、そのチームのサービスアカウントを使用して、そのチーム内のプライベートまたはパブリック Projects で Runs を記録できます。さらに、環境に WANDB_USERNAME または WANDB_USER_EMAIL 変数が存在し、参照されているユーザーがそのチームに属している場合、それらの Runs をユーザーに帰属させることができます。
- トレーニング環境でチームを構成しない場合にサービスアカウントを使用すると、 Runs はそのサービスアカウントの親チーム内の名前付き Project に記録されます。この場合も同様に、環境に WANDB_USERNAME または WANDB_USER_EMAIL 変数が存在し、参照されているユーザーがサービスアカウントの親チームに属している場合、 Runs をユーザーに帰属させることができます。
- サービスアカウントは、親チームとは異なるチームのプライベート Project に Runs を記録できません。サービスアカウントは、 Project が
OpenProject の可視性に設定されている場合にのみ、 Runs を Project に記録できます。
チームトライアル
W&B のプランの詳細については、価格ページを参照してください。ダッシュボード UI またはエクスポート APIを使用して、いつでもすべてのデータをダウンロードできます。
プライバシー設定
チーム設定ページで、すべてのチーム Project のプライバシー設定を確認できます。
app.wandb.ai/teams/your-team-name
高度な設定
セキュアストレージコネクタ
チームレベルのセキュアストレージコネクタを使用すると、チームは W&B で独自のクラウドストレージバケットを使用できます。これにより、機密性の高いデータや厳格なコンプライアンス要件を持つチームに対して、より優れたデータアクセス制御とデータ分離が提供されます。詳細については、セキュアストレージコネクタを参照してください。
4.6 - Manage storage
ストレージ制限に近づいている、または超過している場合、データを管理するための複数の方法があります。最適な方法は、アカウントの種類と現在のプロジェクトの設定によって異なります。
ストレージ消費量の管理
W&B は、ストレージ消費量を最適化するためのさまざまなメソッドを提供しています。
- 参照 Artifacts を使用して、W&B ストレージにアップロードする代わりに、W&B システムの外部に保存されたファイルを追跡します。
- ストレージに外部クラウドストレージバケットを使用します。 (エンタープライズのみ)
データを削除する
ストレージ制限内に収まるように、データを削除することもできます。これを行うには、いくつかの方法があります。
- アプリ UI を使用してインタラクティブにデータを削除します。
- Artifacts に TTL ポリシーを設定 して、自動的に削除されるようにします。
4.7 - System metrics
このページでは、W&B SDK によって追跡されるシステム メトリクスの詳細な情報を提供します。
wandb は、システム メトリクスを15秒ごとに自動的にログに記録します。CPU
プロセスの CPU 使用率 (%) (CPU)
利用可能な CPU 数で正規化された、プロセスによる CPU 使用率の割合。
W&B は、このメトリクスに cpu タグを割り当てます。
プロセスの CPU スレッド数
プロセスで使用されるスレッドの数。
W&B は、このメトリクスに proc.cpu.threads タグを割り当てます。
Disk
デフォルトでは、使用状況メトリクスは / パスに対して収集されます。監視するパスを構成するには、次の設定を使用します。
run = wandb.init(
settings=wandb.Settings(
x_stats_disk_paths=("/System/Volumes/Data", "/home", "/mnt/data"),
),
)
ディスク使用率 (%)
指定されたパスの合計システムディスク使用量をパーセンテージで表します。
W&B は、このメトリクスに disk.{path}.usagePercent タグを割り当てます。
ディスク使用量
指定されたパスの合計システムディスク使用量をギガバイト (GB) で表します。 アクセス可能なパスがサンプリングされ、各パスのディスク使用量 (GB 単位) がサンプルに追加されます。
W&B は、このメトリクスに disk.{path}.usageGB タグを割り当てます。
Disk In
合計システムディスクの読み取り量をメガバイト (MB) で示します。 最初のサンプルが取得されると、最初のディスク読み取りバイト数が記録されます。後続のサンプルでは、現在の読み取りバイト数と初期値の差が計算されます。
W&B は、このメトリクスに disk.in タグを割り当てます。
Disk Out
合計システムディスクの書き込み量をメガバイト (MB) で表します。 Disk In と同様に、最初のサンプルが取得されると、最初のディスク書き込みバイト数が記録されます。後続のサンプルでは、現在の書き込みバイト数と初期値の差が計算されます。
W&B は、このメトリクスに disk.out タグを割り当てます。
Memory
プロセスのメモリ RSS
プロセスのメモリ常駐セットサイズ (RSS) をメガバイト (MB) で表します。RSS は、メインメモリ (RAM) に保持されているプロセスによって占有されているメモリの部分です。
W&B は、このメトリクスに proc.memory.rssMB タグを割り当てます。
プロセスのメモリ使用率 (%)
利用可能な合計メモリに対するプロセスのメモリ使用量をパーセンテージで示します。
W&B は、このメトリクスに proc.memory.percent タグを割り当てます。
メモリ使用率 (%)
利用可能な合計メモリに対する合計システムメモリ使用量をパーセンテージで表します。
W&B は、このメトリクスに memory_percent タグを割り当てます。
利用可能なメモリ
利用可能な合計システムメモリをメガバイト (MB) で示します。
W&B は、このメトリクスに proc.memory.availableMB タグを割り当てます。
Network
ネットワーク送信
ネットワーク経由で送信された合計バイト数を表します。 最初のバイト送信は、メトリクスが最初に初期化されたときに記録されます。後続のサンプルでは、現在のバイト送信数と初期値の差が計算されます。
W&B は、このメトリクスに network.sent タグを割り当てます。
ネットワーク受信
ネットワーク経由で受信した合計バイト数を示します。 ネットワーク送信 と同様に、最初のバイト受信は、メトリクスが最初に初期化されたときに記録されます。後続のサンプルでは、現在のバイト受信数と初期値の差が計算されます。
W&B は、このメトリクスに network.recv タグを割り当てます。
NVIDIA GPU
以下に説明するメトリクスに加えて、プロセスまたはその子孫が特定の GPU を使用する場合、W&B は対応するメトリクスを gpu.process.{gpu_index}.{metric_name} としてキャプチャします。
GPU メモリ使用率
各 GPU の GPU メモリ使用率をパーセントで表します。
W&B は、このメトリクスに gpu.{gpu_index}.memory タグを割り当てます。
GPU 割り当て済みメモリ
各 GPU の利用可能な合計メモリに対する GPU 割り当て済みメモリをパーセンテージで示します。
W&B は、このメトリクスに gpu.{gpu_index}.memoryAllocated タグを割り当てます。
GPU 割り当て済みメモリ (バイト単位)
各 GPU の GPU 割り当て済みメモリをバイト単位で指定します。
W&B は、このメトリクスに gpu.{gpu_index}.memoryAllocatedBytes タグを割り当てます。
GPU 使用率
各 GPU の GPU 使用率をパーセントで反映します。
W&B は、このメトリクスに gpu.{gpu_index}.gpu タグを割り当てます。
GPU 温度
各 GPU の GPU 温度を摂氏で示します。
W&B は、このメトリクスに gpu.{gpu_index}.temp タグを割り当てます。
GPU 消費電力 (ワット単位)
各 GPU の GPU 消費電力をワット単位で示します。
W&B は、このメトリクスに gpu.{gpu_index}.powerWatts タグを割り当てます。
GPU 消費電力 (%)
各 GPU の電力容量に対する GPU 消費電力をパーセンテージで反映します。
W&B は、このメトリクスに gpu.{gpu_index}.powerPercent タグを割り当てます。
GPU SM クロック速度
GPU 上のストリーミングマルチプロセッサ (SM) のクロック速度を MHz で表します。このメトリクスは、計算タスクを担当する GPU コア内の処理速度を示します。
W&B は、このメトリクスに gpu.{gpu_index}.smClock タグを割り当てます。
GPU メモリクロック速度
GPU メモリのクロック速度を MHz で表します。これは、GPU メモリとプロセッシングコア間のデータ転送速度に影響します。
W&B は、このメトリクスに gpu.{gpu_index}.memoryClock タグを割り当てます。
GPU グラフィックスクロック速度
GPU 上のグラフィックスレンダリング操作のベースクロック速度を MHz で表します。このメトリクスは、可視化またはレンダリングタスク中のパフォーマンスを反映することがよくあります。
W&B は、このメトリクスに gpu.{gpu_index}.graphicsClock タグを割り当てます。
GPU 修正済みメモリ エラー
W&B がエラーチェックプロトコルによって自動的に修正する GPU 上のメモリ エラーの数を追跡します。これは、回復可能なハードウェアの問題を示します。
W&B は、このメトリクスに gpu.{gpu_index}.correctedMemoryErrors タグを割り当てます。
GPU 未修正メモリ エラー
W&B が修正しなかった GPU 上のメモリ エラーの数を追跡します。これは、処理の信頼性に影響を与える可能性のある回復不能なエラーを示します。
W&B は、このメトリクスに gpu.{gpu_index}.unCorrectedMemoryErrors タグを割り当てます。
GPU エンコーダー使用率
GPU のビデオエンコーダーの使用率をパーセンテージで表します。これは、エンコードタスク (ビデオレンダリングなど) の実行時にエンコーダーの負荷を示します。
W&B は、このメトリクスに gpu.{gpu_index}.encoderUtilization タグを割り当てます。
AMD GPU
W&B は、AMD が提供する rocm-smi ツール (rocm-smi -a --json) の出力からメトリクスを抽出します。
ROCm 6.x (最新) および 5.x 形式がサポートされています。ROCm 形式の詳細については、AMD ROCm ドキュメント を参照してください。新しい形式には、より詳細な情報が含まれています。
AMD GPU 使用率
各 AMD GPU デバイスの GPU 使用率をパーセントで表します。
W&B は、このメトリクスに gpu.{gpu_index}.gpu タグを割り当てます。
AMD GPU 割り当て済みメモリ
各 AMD GPU デバイスの利用可能な合計メモリに対する GPU 割り当て済みメモリをパーセンテージで示します。
W&B は、このメトリクスに gpu.{gpu_index}.memoryAllocated タグを割り当てます。
AMD GPU 温度
各 AMD GPU デバイスの GPU 温度を摂氏で示します。
W&B は、このメトリクスに gpu.{gpu_index}.temp タグを割り当てます。
AMD GPU 消費電力 (ワット単位)
各 AMD GPU デバイスの GPU 消費電力をワット単位で示します。
W&B は、このメトリクスに gpu.{gpu_index}.powerWatts タグを割り当てます。
AMD GPU 消費電力 (%)
各 AMD GPU デバイスの電力容量に対する GPU 消費電力をパーセンテージで反映します。
W&B は、このメトリクスに gpu.{gpu_index}.powerPercent タグを割り当てます。
Apple ARM Mac GPU
Apple GPU 使用率
特に ARM Mac 上の Apple GPU デバイスの GPU 使用率をパーセントで示します。
W&B は、このメトリクスに gpu.0.gpu タグを割り当てます。
Apple GPU 割り当て済みメモリ
ARM Mac 上の Apple GPU デバイスの利用可能な合計メモリに対する GPU 割り当て済みメモリをパーセンテージで示します。
W&B は、このメトリクスに gpu.0.memoryAllocated タグを割り当てます。
Apple GPU 温度
ARM Mac 上の Apple GPU デバイスの GPU 温度を摂氏で示します。
W&B は、このメトリクスに gpu.0.temp タグを割り当てます。
Apple GPU 消費電力 (ワット単位)
ARM Mac 上の Apple GPU デバイスの GPU 消費電力をワット単位で示します。
W&B は、このメトリクスに gpu.0.powerWatts タグを割り当てます。
Apple GPU 消費電力 (%)
ARM Mac 上の Apple GPU デバイスの電力容量に対する GPU 消費電力をパーセンテージで示します。
W&B は、このメトリクスに gpu.0.powerPercent タグを割り当てます。
Graphcore IPU
Graphcore IPU (Intelligence Processing Units) は、機械学習タスク専用に設計された独自のハードウェアアクセラレータです。
IPU デバイスメトリクス
これらのメトリクスは、特定の IPU デバイスのさまざまな統計を表します。各メトリクスには、デバイス ID (device_id) と、それを識別するためのメトリックキー (metric_key) があります。W&B は、このメトリクスに ipu.{device_id}.{metric_key} タグを割り当てます。
メトリクスは、Graphcore の gcipuinfo バイナリと対話する独自の gcipuinfo ライブラリを使用して抽出されます。sample メソッドは、プロセス ID (pid) に関連付けられた各 IPU デバイスのこれらのメトリクスを取得します。時間の経過とともに変化するメトリクス、またはデバイスのメトリクスが初めて取得された場合にのみ、冗長なデータのログ記録を回避するためにログに記録されます。
各メトリクスについて、メソッド parse_metric が使用されて、メトリクスの値をその生の文字列表現から抽出します。次に、メトリクスは aggregate メソッドを使用して複数のサンプルに集約されます。
以下に、利用可能なメトリクスとその単位を示します。
- ボードの平均温度 (
average board temp (C)): IPU ボードの温度 (摂氏)。 - ダイの平均温度 (
average die temp (C)): IPU ダイの温度 (摂氏)。 - クロック速度 (
clock (MHz)): IPU のクロック速度 (MHz)。 - IPU 電力 (
ipu power (W)): IPU の消費電力 (ワット)。 - IPU 使用率 (
ipu utilisation (%)): IPU 使用率 (パーセント)。 - IPU セッション使用率 (
ipu utilisation (session) (%)): 現在のセッションに固有の IPU 使用率 (パーセント)。 - データリンク速度 (
speed (GT/s)): データ伝送速度 (ギガ転送/秒)。
Google Cloud TPU
Tensor Processing Units (TPU) は、機械学習ワークロードを高速化するために使用される Google 独自のカスタム開発 ASIC (特定用途向け集積回路) です。
TPU メモリ使用量
TPU コアあたりの現在の高帯域幅メモリ使用量 (バイト単位)。
W&B は、このメトリクスに tpu.{tpu_index}.memoryUsageBytes タグを割り当てます。
TPU メモリ使用量 (%)
TPU コアあたりの現在の高帯域幅メモリ使用量 (パーセント)。
W&B は、このメトリクスに tpu.{tpu_index}.memoryUsageBytes タグを割り当てます。
TPU デューティサイクル
TPU デバイスあたりの TensorCore デューティサイクル (%)。アクセラレータ TensorCore がアクティブに処理していたサンプル期間中の時間の割合を追跡します。値が大きいほど、TensorCore の使用率が高いことを意味します。
W&B は、このメトリクスに tpu.{tpu_index}.dutyCycle タグを割り当てます。
AWS Trainium
AWS Trainium は、AWS が提供する特殊なハードウェアプラットフォームで、機械学習ワークロードの高速化に重点を置いています。AWS の neuron-monitor ツールは、AWS Trainium メトリクスをキャプチャするために使用されます。
Trainium Neuron Core 使用率
NeuronCore ごとの使用率 (%) (コアごとに報告)。
W&B は、このメトリクスに trn.{core_index}.neuroncore_utilization タグを割り当てます。
Trainium ホストメモリ使用量、合計
ホスト上の合計メモリ消費量 (バイト単位)。
W&B は、このメトリクスに trn.host_total_memory_usage タグを割り当てます。
Trainium Neuron デバイスの合計メモリ使用量
Neuron デバイス上の合計メモリ使用量 (バイト単位)。
W&B は、このメトリクスに trn.neuron_device_total_memory_usage) タグを割り当てます。
Trainium ホストメモリ使用量の内訳:
以下は、ホスト上のメモリ使用量の内訳です。
- アプリケーションメモリ (
trn.host_total_memory_usage.application_memory): アプリケーションで使用されるメモリ。 - 定数 (
trn.host_total_memory_usage.constants): 定数に使用されるメモリ。 - DMA バッファ (
trn.host_total_memory_usage.dma_buffers): ダイレクトメモリアクセスバッファに使用されるメモリ。 - テンソル (
trn.host_total_memory_usage.tensors): テンソルに使用されるメモリ。
Trainium Neuron Core メモリ使用量の内訳
NeuronCore ごとの詳細なメモリ使用量情報:
- 定数 (
trn.{core_index}.neuroncore_memory_usage.constants) - モデルコード (
trn.{core_index}.neuroncore_memory_usage.model_code) - モデル共有スクラッチパッド (
trn.{core_index}.neuroncore_memory_usage.model_shared_scratchpad) - ランタイムメモリ (
trn.{core_index}.neuroncore_memory_usage.runtime_memory) - テンソル (
trn.{core_index}.neuroncore_memory_usage.tensors)
OpenMetrics
OpenMetrics / Prometheus 互換のデータを公開する外部エンドポイントからメトリクスをキャプチャしてログに記録します。消費されるエンドポイントに適用されるカスタム正規表現ベースのメトリクスフィルタをサポートします。
このレポート を参照して、NVIDIA DCGM-Exporter を使用して GPU クラスターのパフォーマンスを監視する特定のケースで、この機能を使用する方法の詳細な例を確認してください。
4.8 - Anonymous mode
誰でも簡単に実行できるようにしたいコードを公開していますか? 匿名モードを使用すると、W&B のアカウントを最初に作成しなくても、誰でもあなたのコードを実行し、W&B のダッシュボードを確認し、結果を可視化できます。
匿名モードで結果を記録できるようにするには、以下のようにします。
import wandb
wandb.init(anonymous="allow")
たとえば、次のコードスニペットは、W&B で Artifacts を作成およびログに記録する方法を示しています。
import wandb
run = wandb.init(anonymous="allow")
artifact = wandb.Artifact(name="art1", type="foo")
artifact.add_file(local_path="path/to/file")
run.log_artifact(artifact)
run.finish()
ノートブックの例を試して、匿名モードの動作を確認してください。