Artifacts
W&B Artifacts の概要、その仕組み、およびそれらの使用を開始する方法について説明します。
W&B Artifacts を使用して、W&B Runs の入力および出力としてデータを追跡およびバージョン管理します。たとえば、モデルトレーニング run は、データセットを入力として受け取り、トレーニング済みのモデルを出力として生成する場合があります。ハイパー パラメーター、メタデータ、およびメトリクスを run に記録できます。また、artifact を使用して、モデルのトレーニングに使用されるデータセットを入力として、結果のモデル チェックポイントを別の artifact として、ログ記録、追跡、およびバージョン管理できます。
ユースケース
Artifact は、runs の入力および出力として、ML ワークフロー全体で使用できます。データセット、モデル、またはその他の artifact を、処理の入力として使用できます。

| ユースケース |
入力 |
出力 |
| モデルトレーニング |
データセット (トレーニングおよび検証データ) |
トレーニング済みモデル |
| データセットの前処理 |
データセット (未加工データ) |
データセット (前処理済みデータ) |
| モデルの評価 |
モデル + データセット (テストデータ) |
W&B Table |
| モデルの最適化 |
モデル |
最適化されたモデル |
以降のコード スニペットは、順番に実行することを目的としています。
artifact を作成する
4 行のコードで artifact を作成します。
- W&B run を作成します。
wandb.Artifact API を使用して、artifact オブジェクトを作成します。- モデル ファイルやデータセットなど、1 つ以上のファイルを artifact オブジェクトに追加します。
- artifact を W&B に記録します。
たとえば、次のコード スニペットは、dataset.h5 というファイルを example_artifact という artifact に記録する方法を示しています。
import wandb
run = wandb.init(project="artifacts-example", job_type="add-dataset")
artifact = wandb.Artifact(name="example_artifact", type="dataset")
artifact.add_file(local_path="./dataset.h5", name="training_dataset")
artifact.save()
# artifact バージョン "my_data" を dataset.h5 のデータを持つデータセットとして記録します
Amazon S3 バケットなどの外部オブジェクト ストレージに保存されているファイルまたはディレクトリーへの参照を追加する方法については、
外部ファイルの追跡 ページを参照してください。
artifact をダウンロードする
use_artifact メソッドを使用して、run への入力としてマークする artifact を示します。
上記のコード スニペットに従って、次のコード ブロックは training_dataset artifact の使用方法を示しています。
artifact = run.use_artifact(
"training_dataset:latest"
) # "my_data" artifact を使用して run オブジェクトを返します
これにより、artifact オブジェクトが返されます。
次に、返されたオブジェクトを使用して、artifact のすべてのコンテンツをダウンロードします。
datadir = (
artifact.download()
) # `my_data` artifact 全体をデフォルトのディレクトリーにダウンロードします。
次のステップ
- artifact をバージョン管理および更新する方法を学びます。
- オートメーションを使用して、artifact の変更に応じてダウンストリーム ワークフローをトリガーしたり、Slack channel に通知したりする方法を学びます。
- トレーニング済みモデルを格納するスペースであるレジストリについて学びます。
- Python SDK および CLI リファレンス ガイドをご覧ください。
1 - Create an artifact
W&B の Artifact を作成、構築します。1 つまたは複数のファイル、または URI 参照を Artifact に追加する方法を学びます。
W&B Python SDK を使用して、W&B Runs から Artifacts を構築します。ファイル、ディレクトリー、URI、および並列 run からのファイルを Artifacts に追加できます。ファイルを Artifacts に追加したら、Artifacts を W&B サーバーまたは独自のプライベートサーバーに保存します。
Amazon S3 に保存されているファイルなど、外部ファイルを追跡する方法については、外部ファイルを追跡のページを参照してください。
Artifacts を構築する方法
W&B Artifactは、次の3つのステップで構築します。
1. wandb.Artifact() で Artifacts Python オブジェクトを作成する
wandb.Artifact() クラスを初期化して、Artifacts オブジェクトを作成します。次の パラメータ を指定します。
- Name: Artifacts の名前を指定します。名前は、一意で記述的で、覚えやすいものにする必要があります。Artifacts 名を使用して、W&B App UI で Artifacts を識別したり、その Artifacts を使用する場合に使用したりします。
- Type: タイプを指定します。タイプは、シンプルで記述的で、機械学習 パイプライン の単一のステップに対応している必要があります。一般的な Artifacts タイプには、
'dataset' または 'model' があります。
指定する「name」と「type」は、有向非巡回グラフの作成に使用されます。つまり、W&B App で Artifacts の リネージ を表示できます。
詳細については、Artifacts グラフを探索およびトラバースを参照してください。
タイプ パラメータ に別のタイプを指定した場合でも、Artifacts は同じ名前にすることはできません。つまり、タイプ dataset の cats という名前の Artifacts と、タイプ model の同じ名前の別の Artifacts を作成することはできません。
Artifacts オブジェクトを初期化するときに、オプションで説明と メタデータ を指定できます。利用可能な属性と パラメータ の詳細については、Python SDK リファレンス ガイドの wandb.Artifact クラス定義を参照してください。
次の例は、データセット Artifacts を作成する方法を示しています。
import wandb
artifact = wandb.Artifact(name="<replace>", type="<replace>")
上記の コードスニペット の文字列 引数 を、自分の名前とタイプに置き換えます。
2. 1つ以上のファイルを Artifacts に追加する
Artifacts メソッド を使用して、ファイル、ディレクトリー、外部 URI 参照 (Amazon S3 など) などを追加します。たとえば、単一のテキスト ファイルを追加するには、add_file メソッド を使用します。
artifact.add_file(local_path="hello_world.txt", name="optional-name")
add_dir メソッド を使用して、複数のファイルを追加することもできます。ファイルを追加する方法の詳細については、Artifacts を更新を参照してください。
3. Artifacts を W&B サーバー に保存する
最後に、Artifacts を W&B サーバー に保存します。Artifacts は run に関連付けられています。したがって、run オブジェクト の log_artifact() メソッド を使用して、Artifacts を保存します。
# W&B Run を作成します。'job-type' を置き換えます。
run = wandb.init(project="artifacts-example", job_type="job-type")
run.log_artifact(artifact)
オプションで、W&B run の外部で Artifacts を構築できます。詳細については、外部ファイルを追跡を参照してください。
log_artifact の呼び出しは、パフォーマンスの高いアップロードのために非同期的に実行されます。これにより、ループで Artifacts を ログ 記録するときに、予期しない 振る舞い が発生する可能性があります。次に例を示します。
for i in range(10):
a = wandb.Artifact(
"race",
type="dataset",
metadata={
"index": i,
},
)
# ... Artifacts a にファイルを追加 ...
run.log_artifact(a)
Artifacts バージョン v0 は、Artifacts が任意の順序で ログ 記録される可能性があるため、 メタデータ に 0 のインデックスを持つことは保証されません。
Artifacts にファイルを追加する
次のセクションでは、さまざまなファイル タイプ と並列 run から Artifacts を構築する方法について説明します。
次の例では、複数のファイルとディレクトリー構造を持つ プロジェクト ディレクトリー があると仮定します。
project-directory
|-- images
| |-- cat.png
| +-- dog.png
|-- checkpoints
| +-- model.h5
+-- model.h5
単一のファイルを追加する
上記の コードスニペット は、単一のローカル ファイルを Artifacts に追加する方法を示しています。
# 単一のファイルを追加
artifact.add_file(local_path="path/file.format")
たとえば、作業ローカル ディレクトリー に 'file.txt' という名前のファイルがあるとします。
artifact.add_file("path/file.txt") # `file.txt' として追加されました
Artifacts には、次のコンテンツが含まれるようになりました。
file.txt
オプションで、name パラメータ に Artifacts 内の目的の パス を渡します。
artifact.add_file(local_path="path/file.format", name="new/path/file.format")
Artifacts は次のように保存されます。
new/path/file.txt
| API 呼び出し |
結果の Artifacts |
artifact.add_file('model.h5') |
model.h5 |
artifact.add_file('checkpoints/model.h5') |
model.h5 |
artifact.add_file('model.h5', name='models/mymodel.h5') |
models/mymodel.h5 |
複数のファイルを追加する
上記の コードスニペット は、ローカル ディレクトリー 全体を Artifacts に追加する方法を示しています。
# ディレクトリー を再帰的に追加
artifact.add_dir(local_path="path/file.format", name="optional-prefix")
上記の API 呼び出しは、上記の Artifacts コンテンツを生成します。
| API 呼び出し |
結果の Artifacts |
artifact.add_dir('images') |
cat.png
dog.png
|
artifact.add_dir('images', name='images') |
images/cat.png
images/dog.png
|
artifact.new_file('hello.txt') |
hello.txt |
URI 参照を追加する
Artifacts は、W&B ライブラリ が処理する方法を知っている スキーム を URI が持つ場合、再現性のために チェックサム やその他の情報を追跡します。
add_reference メソッド を使用して、外部 URI 参照を Artifacts に追加します。'uri' 文字列を自分の URI に置き換えます。オプションで、name パラメータ に Artifacts 内の目的の パス を渡します。
# URI 参照を追加
artifact.add_reference(uri="uri", name="optional-name")
Artifacts は現在、次の URI スキーム をサポートしています。
http(s)://: HTTP 経由でアクセス可能なファイルへの パス 。Artifacts は、HTTP サーバー が ETag および Content-Length レスポンス ヘッダー をサポートしている場合、etag および サイズ メタデータ の形式で チェックサム を追跡します。s3://: S3 内の オブジェクト または オブジェクト プレフィックス への パス 。Artifacts は、参照されている オブジェクト の チェックサム および バージョン 管理情報 ( バケット で オブジェクト の バージョン 管理が有効になっている場合) を追跡します。オブジェクト プレフィックス は、プレフィックス の下の オブジェクト を含むように拡張され、最大 10,000 個の オブジェクト が含まれます。gs://: GCS 内の オブジェクト または オブジェクト プレフィックス への パス 。Artifacts は、参照されている オブジェクト の チェックサム および バージョン 管理情報 ( バケット で オブジェクト の バージョン 管理が有効になっている場合) を追跡します。オブジェクト プレフィックス は、プレフィックス の下の オブジェクト を含むように拡張され、最大 10,000 個の オブジェクト が含まれます。
上記の API 呼び出しは、上記の Artifacts を生成します。
| API 呼び出し |
結果の Artifacts コンテンツ |
artifact.add_reference('s3://my-bucket/model.h5') |
model.h5 |
artifact.add_reference('s3://my-bucket/checkpoints/model.h5') |
model.h5 |
artifact.add_reference('s3://my-bucket/model.h5', name='models/mymodel.h5') |
models/mymodel.h5 |
artifact.add_reference('s3://my-bucket/images') |
cat.png
dog.png
|
artifact.add_reference('s3://my-bucket/images', name='images') |
images/cat.png
images/dog.png
|
並列 run から Artifacts にファイルを追加する
大規模な データセット または分散 トレーニング の場合、複数の並列 run が単一の Artifacts に貢献する必要がある場合があります。
import wandb
import time
# デモ の目的で、ray を使用して並列で run を 起動 します。
# ただし、並列 run は、どのように編成してもかまいません。
import ray
ray.init()
artifact_type = "dataset"
artifact_name = "parallel-artifact"
table_name = "distributed_table"
parts_path = "parts"
num_parallel = 5
# 並列 ライター の各 バッチ には、独自の
# 一意の グループ 名が必要です。
group_name = "writer-group-{}".format(round(time.time()))
@ray.remote
def train(i):
"""
ライター ジョブ 。各 ライター は、1つの画像を Artifacts に追加します。
"""
with wandb.init(group=group_name) as run:
artifact = wandb.Artifact(name=artifact_name, type=artifact_type)
# データを wandb テーブル に追加します。この場合、サンプル データ を使用します
table = wandb.Table(columns=["a", "b", "c"], data=[[i, i * 2, 2**i]])
# テーブル を Artifacts 内の フォルダ に追加します
artifact.add(table, "{}/table_{}".format(parts_path, i))
# Artifacts を アップサート すると、Artifacts のデータ が作成または追加されます
run.upsert_artifact(artifact)
# 並列で run を 起動 します
result_ids = [train.remote(i) for i in range(num_parallel)]
# すべての ライター に 参加 して、ファイル が
# Artifacts を終了する前に追加されていることを確認します。
ray.get(result_ids)
# すべての ライター が終了したら、Artifacts を終了して、
# 準備完了にします。
with wandb.init(group=group_name) as run:
artifact = wandb.Artifact(artifact_name, type=artifact_type)
# テーブル の フォルダ を指す "PartitionTable" を作成します
# Artifacts に追加します。
artifact.add(wandb.data_types.PartitionedTable(parts_path), table_name)
# Finish artifact は Artifacts を確定し、この バージョン への将来の "upsert" を許可しません
run.finish_artifact(artifact)
2 - Download and use artifacts
複数のプロジェクトから Artifacts をダウンロードして使用します。
W&B サーバーにすでに保存されている Artifacts をダウンロードして使用するか、必要に応じて重複排除のために Artifacts オブジェクトを構築して渡します。
表示専用のシートを持つチームメンバーは、Artifacts をダウンロードできません。
W&B に保存されている Artifacts のダウンロードと使用
W&B Run の内部または外部で、W&B に保存されている Artifacts をダウンロードして使用します。Public API (wandb.Api) を使用して、W&B にすでに保存されているデータをエクスポート (または更新) します。詳細については、W&B のPublic API Reference guideを参照してください。
まず、W&B Python SDK をインポートします。次に、W&B Runを作成します。
import wandb
run = wandb.init(project="<example>", job_type="<job-type>")
use_artifact メソッドを使用して、使用する Artifacts を指定します。これにより、run オブジェクトが返されます。次のコードスニペットでは、エイリアス 'latest' を持つ 'bike-dataset' という Artifacts を指定します。
artifact = run.use_artifact("bike-dataset:latest")
返されたオブジェクトを使用して、Artifacts のすべてのコンテンツをダウンロードします。
datadir = artifact.download()
オプションで、ルートパラメータにパスを渡して、Artifacts のコンテンツを特定のディレクトリーにダウンロードできます。詳細については、Python SDK Reference Guideを参照してください。
get_path メソッドを使用して、ファイルのサブセットのみをダウンロードします。
path = artifact.get_path(name)
これは、パス name にあるファイルのみをフェッチします。これは、次のメソッドを持つ Entry オブジェクトを返します。
Entry.download: パス name にある Artifacts からファイルをダウンロードしますEntry.ref: add_reference がエントリをリファレンスとして保存した場合、URI を返します
W&B が処理する方法を知っているスキームを持つリファレンスは、Artifacts ファイルとまったく同じようにダウンロードされます。詳細については、Track external filesを参照してください。
まず、W&B SDK をインポートします。次に、Public API クラスから Artifacts を作成します。その Artifacts に関連付けられたエンティティ、プロジェクト、Artifacts、エイリアスを指定します。
import wandb
api = wandb.Api()
artifact = api.artifact("entity/project/artifact:alias")
返されたオブジェクトを使用して、Artifacts のコンテンツをダウンロードします。
オプションで、root パラメータにパスを渡して、Artifacts のコンテンツを特定のディレクトリーにダウンロードできます。詳細については、API Reference Guideを参照してください。
wandb artifact get コマンドを使用して、W&B サーバーから Artifacts をダウンロードします。
$ wandb artifact get project/artifact:alias --root mnist/
Artifacts の部分的なダウンロード
オプションで、プレフィックスに基づいて Artifacts の一部をダウンロードできます。path_prefix パラメータを使用すると、単一のファイルまたはサブフォルダーのコンテンツをダウンロードできます。
artifact = run.use_artifact("bike-dataset:latest")
artifact.download(path_prefix="bike.png") # bike.png のみをダウンロードします
または、特定のディレクトリーからファイルをダウンロードすることもできます。
artifact.download(path_prefix="images/bikes/") # images/bikes ディレクトリー内のファイルをダウンロードします
別のプロジェクトの Artifacts の使用
Artifacts の名前をプロジェクト名とともに指定して、Artifacts を参照します。エンティティ名とともに Artifacts の名前を指定することで、エンティティ間で Artifacts を参照することもできます。
次のコード例は、別のプロジェクトから Artifacts をクエリして、現在の W&B run への入力として使用する方法を示しています。
import wandb
run = wandb.init(project="<example>", job_type="<job-type>")
# 別のプロジェクトから Artifacts の W&B をクエリして、それをマークします
# この run への入力として。
artifact = run.use_artifact("my-project/artifact:alias")
# 別のエンティティからの Artifacts を使用して、入力としてマークします
# この run に。
artifact = run.use_artifact("my-entity/my-project/artifact:alias")
Artifacts の同時構築と使用
Artifacts を同時に構築して使用します。Artifacts オブジェクトを作成し、それを use_artifact に渡します。これにより、Artifacts がまだ存在しない場合は W&B に作成されます。use_artifact API はべき等であるため、必要な回数だけ呼び出すことができます。
import wandb
artifact = wandb.Artifact("reference model")
artifact.add_file("model.h5")
run.use_artifact(artifact)
Artifacts の構築の詳細については、Construct an artifactを参照してください。
3 - Update an artifact
W&B Run の内外で既存の Artifact を更新します。
Artifact の description、metadata、および alias を更新するために希望する value を渡します。W&B サーバー上の Artifact を更新するには、save() メソッドを呼び出します。W&B の Run 中または Run の外部で Artifact を更新できます。
Run の外部で Artifact を更新するには、W&B Public API(wandb.Api)を使用します。Run 中に Artifact を更新するには、Artifact API(wandb.Artifact)を使用します。
モデルレジストリ内のモデルにリンクされている Artifact の エイリアス を更新することはできません。
次のコード例は、wandb.Artifact API を使用して、Artifact の description を更新する方法を示しています。
import wandb
run = wandb.init(project="<example>")
artifact = run.use_artifact("<artifact-name>:<alias>")
artifact.description = "<description>"
artifact.save()
次のコード例は、wandb.Api API を使用して、Artifact の description を更新する方法を示しています。
import wandb
api = wandb.Api()
artifact = api.artifact("entity/project/artifact:alias")
# description を更新
artifact.description = "My new description"
# 選択的に metadata の キー を更新
artifact.metadata["oldKey"] = "new value"
# metadata を完全に置き換え
artifact.metadata = {"newKey": "new value"}
# エイリアス を追加
artifact.aliases.append("best")
# エイリアス を削除
artifact.aliases.remove("latest")
# エイリアス を完全に置き換え
artifact.aliases = ["replaced"]
# すべての Artifact の変更を永続化
artifact.save()
詳細については、Weights and Biases Artifact API を参照してください。
単一の Artifact と同じ方法で、Artifact のコレクションを更新することもできます。
import wandb
run = wandb.init(project="<example>")
api = wandb.Api()
artifact = api.artifact_collection(type="<type-name>", collection="<collection-name>")
artifact.name = "<new-collection-name>"
artifact.description = "<This is where you'd describe the purpose of your collection.>"
artifact.save()
詳細については、Artifacts Collection のリファレンスを参照してください。
4 - Create an artifact alias
W&B Artifacts のカスタムエイリアスを作成します。
エイリアス を使用して、特定の バージョン へのポインタとして使用します。デフォルトでは、Run.log_artifact はログに記録された バージョン に latest エイリアス を追加します。
アーティファクト の バージョン v0 は、初めて アーティファクト を ログ に記録する際に作成され、 アーティファクト にアタッチされます。W&B は、同じ アーティファクト に再度 ログ を記録する際に、コンテンツの チェックサム を計算します。アーティファクト が変更された場合、W&B は新しい バージョン v1 を保存します。
たとえば、 トレーニング スクリプト で データセット の最新 バージョン を取得したい場合は、その アーティファクト を使用する際に latest を指定します。次の コード 例は、latest という エイリアス を持つ bike-dataset という名前の最新の データセット アーティファクト をダウンロードする方法を示しています。
import wandb
run = wandb.init(project="<example-project>")
artifact = run.use_artifact("bike-dataset:latest")
artifact.download()
カスタム エイリアス を アーティファクト バージョン に適用することもできます。たとえば、 モデル の チェックポイント が メトリック AP-50 で最高であることを示したい場合は、 モデル アーティファクト を ログ に記録する際に、'best-ap50' という 文字列を エイリアス として追加できます。
artifact = wandb.Artifact("run-3nq3ctyy-bike-model", type="model")
artifact.add_file("model.h5")
run.log_artifact(artifact, aliases=["latest", "best-ap50"])
5 - Create an artifact version
単一の run 、または分散された プロセス から新しい アーティファクト の バージョン を作成します。
単一の run で、または分散されたrunと共同で、新しいアーティファクトのバージョンを作成します。オプションで、インクリメンタルアーティファクト として知られる、以前のバージョンから新しいアーティファクトのバージョンを作成できます。
元のアーティファクトのサイズが著しく大きい場合に、アーティファクト内のファイルのサブセットに変更を適用する必要がある場合は、インクリメンタルアーティファクトを作成することをお勧めします。
新しいアーティファクトのバージョンをゼロから作成する
新しいアーティファクトのバージョンを作成する方法は2つあります。単一のrunから作成する方法と、分散されたrunから作成する方法です。それらは次のように定義されます。
- 単一のrun: 単一のrunは、新しいバージョンのすべてのデータを提供します。これは最も一般的なケースであり、runが必要なデータを完全に再作成する場合に最適です。例:分析のために保存されたモデルまたはモデルの予測をテーブルに出力するなど。
- 分散されたrun: runのセットが集合的に新しいバージョンのすべてのデータを提供します。これは、多くの場合並行してデータを生成する複数のrunを持つ分散ジョブに最適です。例:分散方式でモデルを評価し、予測を出力するなど。
W&B は、プロジェクトに存在しない名前を wandb.Artifact API に渡すと、新しいアーティファクトを作成し、v0 エイリアスを割り当てます。同じアーティファクトに再度ログを記録すると、W&B はコンテンツのチェックサムを計算します。アーティファクトが変更された場合、W&B は新しいバージョン v1 を保存します。
wandb.Artifact API に名前とアーティファクトのタイプを渡し、それがプロジェクト内の既存のアーティファクトと一致する場合、W&B は既存のアーティファクトを取得します。取得されたアーティファクトのバージョンは1より大きくなります。
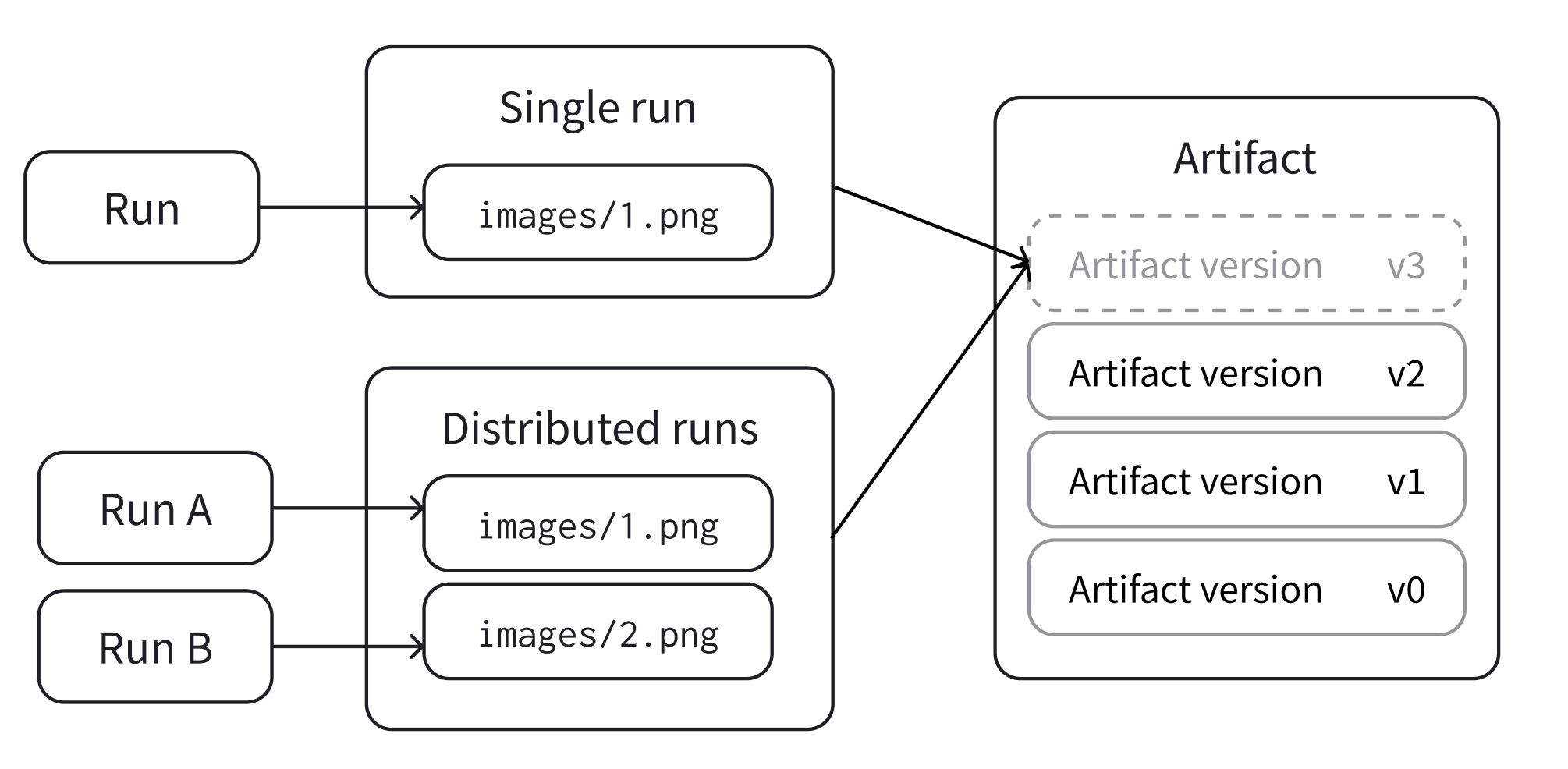
単一のrun
アーティファクト内のすべてのファイルを生成する単一のrunで、Artifactの新しいバージョンをログに記録します。このケースは、単一のrunがアーティファクト内のすべてのファイルを生成する場合に発生します。
ユースケースに基づいて、以下のタブのいずれかを選択して、runの内側または外側に新しいアーティファクトのバージョンを作成します。
W&B run内でアーティファクトのバージョンを作成します。
wandb.init でrunを作成します。wandb.Artifact で新しいアーティファクトを作成するか、既存のアーティファクトを取得します。.add_file でアーティファクトにファイルを追加します。.log_artifact でアーティファクトをrunにログ記録します。
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`、`.add_file`、`.add_dir`、および `.add_reference` を使用して、
# ファイルとアセットをアーティファクトに追加します
artifact.add_file("image1.png")
run.log_artifact(artifact)
W&B runの外側でアーティファクトのバージョンを作成します。
wanb.Artifact で新しいアーティファクトを作成するか、既存のアーティファクトを取得します。.add_file でアーティファクトにファイルを追加します。.save でアーティファクトを保存します。
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`、`.add_file`、`.add_dir`、および `.add_reference` を使用して、
# ファイルとアセットをアーティファクトに追加します
artifact.add_file("image1.png")
artifact.save()
分散されたrun
コミットする前に、runのコレクションがバージョンで共同作業できるようにします。これは、1つのrunが新しいバージョンのすべてのデータを提供する上記の単一runモードとは対照的です。
- コレクション内の各runは、同じバージョンで共同作業するために、同じ一意のID(
distributed_id と呼ばれます)を認識している必要があります。デフォルトでは、存在する場合、W&B は wandb.init(group=GROUP) によって設定されたrunの group を distributed_id として使用します。
- バージョンの状態を永続的にロックする、バージョンを「コミット」する最終的なrunが必要です。
- 共同アーティファクトに追加するには
upsert_artifact を使用し、コミットを完了するには finish_artifact を使用します。
次の例を検討してください。異なるrun(以下では Run 1、Run 2、および Run 3 としてラベル付け)は、upsert_artifact で同じアーティファクトに異なる画像ファイルを追加します。
Run 1:
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`、`.add_file`、`.add_dir`、および `.add_reference` を使用して、
# ファイルとアセットをアーティファクトに追加します
artifact.add_file("image1.png")
run.upsert_artifact(artifact, distributed_id="my_dist_artifact")
Run 2:
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`、`.add_file`、`.add_dir`、および `.add_reference` を使用して、
# ファイルとアセットをアーティファクトに追加します
artifact.add_file("image2.png")
run.upsert_artifact(artifact, distributed_id="my_dist_artifact")
Run 3
Run 1とRun 2が完了した後に実行する必要があります。finish_artifact を呼び出すRunはアーティファクトにファイルを含めることができますが、必須ではありません。
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# ファイルとアセットをアーティファクトに追加します
# `.add`、`.add_file`、`.add_dir`、および `.add_reference`
artifact.add_file("image3.png")
run.finish_artifact(artifact, distributed_id="my_dist_artifact")
既存のバージョンから新しいアーティファクトのバージョンを作成する
変更されていないファイルを再インデックスする必要なく、以前のアーティファクトのバージョンからファイルのサブセットを追加、変更、または削除します。以前のアーティファクトのバージョンからファイルのサブセットを追加、変更、または削除すると、インクリメンタルアーティファクトとして知られる新しいアーティファクトのバージョンが作成されます。
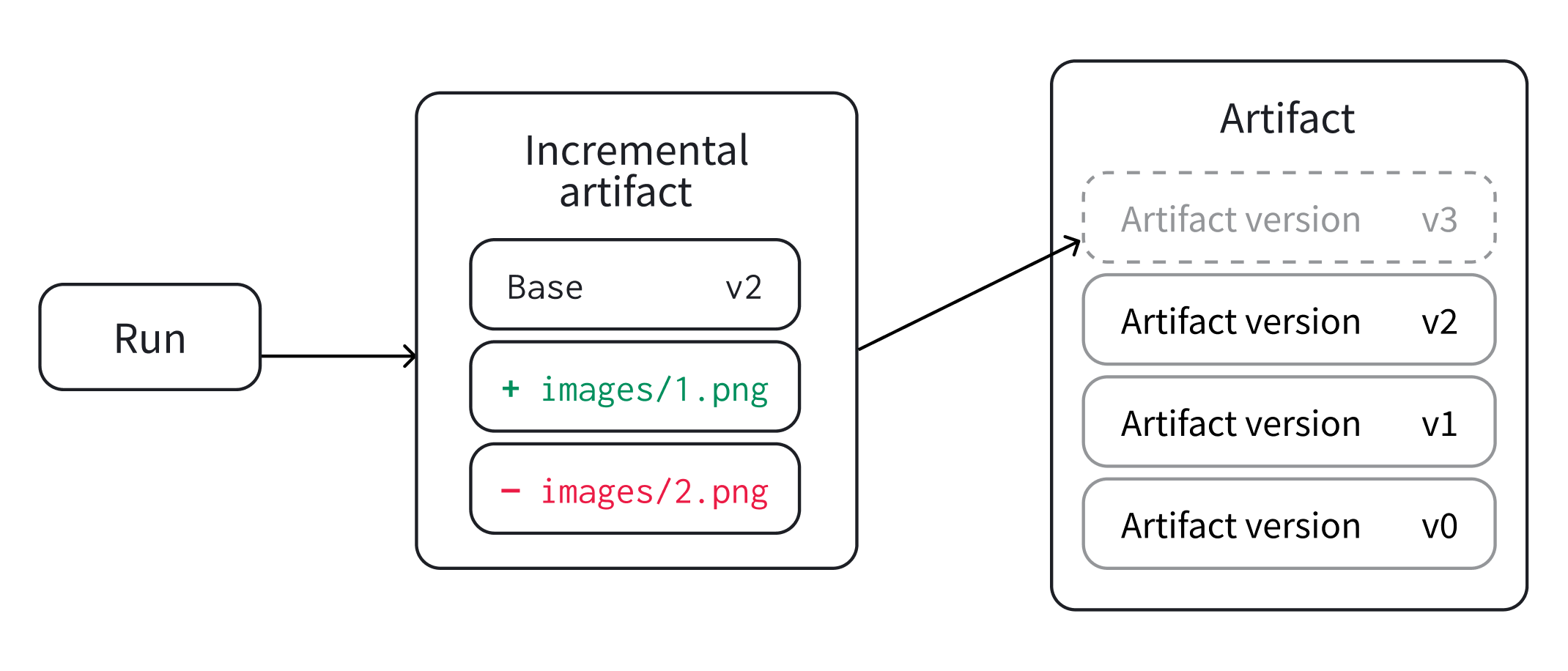
発生する可能性のあるインクリメンタルな変更のタイプごとのシナリオを次に示します。
- add: 新しいバッチを収集した後、データセットに新しいファイルのサブセットを定期的に追加します。
- remove: 複数の重複ファイルを発見し、アーティファクトから削除したいとします。
- update: ファイルのサブセットのアノテーションを修正し、古いファイルを正しいファイルに置き換えたいとします。
インクリメンタルアーティファクトと同じ機能を実行するために、アーティファクトをゼロから作成できます。ただし、アーティファクトをゼロから作成する場合、アーティファクトのすべてのコンテンツをローカルディスクに用意する必要があります。インクリメンタルな変更を行う場合、以前のアーティファクトのバージョンからファイルを変更せずに、単一のファイルを追加、削除、または変更できます。
インクリメンタルアーティファクトは、単一のrun内またはrunのセット(分散モード)で作成できます。
以下の手順に従って、アーティファクトをインクリメンタルに変更します。
- インクリメンタルな変更を実行するアーティファクトのバージョンを取得します。
saved_artifact = run.use_artifact("my_artifact:latest")
client = wandb.Api()
saved_artifact = client.artifact("my_artifact:latest")
- 次を使用してドラフトを作成します。
draft_artifact = saved_artifact.new_draft()
- 次のバージョンで表示したいインクリメンタルな変更を実行します。既存のエントリを追加、削除、または変更できます。
これらの変更を実行する方法の例については、以下のタブのいずれかを選択してください。
add_file メソッドを使用して、既存のアーティファクトのバージョンにファイルを追加します。
draft_artifact.add_file("file_to_add.txt")
add_dir メソッドを使用してディレクトリーを追加することで、複数のファイルを追加することもできます。
remove メソッドを使用して、既存のアーティファクトのバージョンからファイルを削除します。
draft_artifact.remove("file_to_remove.txt")
ディレクトリーパスを渡すことで、remove メソッドを使用して複数のファイルを削除することもできます。
ドラフトから古いコンテンツを削除し、新しいコンテンツを再度追加して、コンテンツを変更または置き換えます。
draft_artifact.remove("modified_file.txt")
draft_artifact.add_file("modified_file.txt")
- 最後に、変更をログに記録または保存します。以下のタブは、W&B runの内側と外側で変更を保存する方法を示しています。ユースケースに合ったタブを選択してください。
run.log_artifact(draft_artifact)
まとめると、上記のコード例は次のようになります。
with wandb.init(job_type="データセットの変更") as run:
saved_artifact = run.use_artifact(
"my_artifact:latest"
) # アーティファクトをフェッチしてrunに入力します
draft_artifact = saved_artifact.new_draft() # ドラフトバージョンを作成します
# ドラフトバージョン内のファイルのサブセットを変更します
draft_artifact.add_file("file_to_add.txt")
draft_artifact.remove("dir_to_remove/")
run.log_artifact(
artifact
) # 変更をログに記録して新しいバージョンを作成し、runへの出力としてマークします
client = wandb.Api()
saved_artifact = client.artifact("my_artifact:latest") # アーティファクトをロードします
draft_artifact = saved_artifact.new_draft() # ドラフトバージョンを作成します
# ドラフトバージョン内のファイルのサブセットを変更します
draft_artifact.remove("deleted_file.txt")
draft_artifact.add_file("modified_file.txt")
draft_artifact.save() # ドラフトへの変更をコミットします
6 - Track external files
W&B の外部に保存されたファイル (Amazon S3 バケット 、GCS バケット 、HTTP ファイル サーバー 、NFS 共有など) を追跡します。
参照 Artifacts を使用して、W&Bシステム外に保存されたファイル(例えば、Amazon S3 バケット、GCS バケット、Azure Blob、HTTP ファイルサーバー、あるいは NFS 共有など)を追跡します。W&B CLIを使用し、W&B Runの外で Artifacts をログ記録します。
run の外で Artifacts をログ記録する
run の外で Artifact をログ記録すると、W&B は run を作成します。各 Artifact は run に属し、その run は プロジェクト に属します。Artifact(バージョン)はコレクションにも属し、タイプを持ちます。
wandb artifact put コマンドを使用すると、W&B run の外で Artifact を W&B サーバーにアップロードできます。Artifact が属する プロジェクト の名前と Artifact の名前(project/artifact_name)を指定します。オプションで、タイプ(TYPE)を指定します。以下のコードスニペットの PATH を、アップロードする Artifact のファイルパスに置き換えます。
$ wandb artifact put --name project/artifact_name --type TYPE PATH
指定した プロジェクト が存在しない場合、W&B は新しい プロジェクト を作成します。Artifact のダウンロード方法については、Artifacts のダウンロードと使用を参照してください。
W&B の外で Artifacts を追跡する
W&B Artifacts を使用して、データセット の バージョン管理 と モデルリネージ を行い、参照 Artifacts を使用して W&B サーバーの外に保存されたファイルを追跡します。このモードでは、Artifact は URL、サイズ、チェックサムなどのファイルに関する メタデータ のみを保存します。基になる データ がシステムから離れることはありません。ファイルを W&B サーバーに保存する方法については、クイックスタートを参照してください。
以下では、参照 Artifacts を構築する方法と、ワークフロー に組み込む最適な方法について説明します。
Amazon S3 / GCS / Azure Blob Storage 参照
W&B Artifacts を使用して、データセット と モデル の バージョン管理 を行い、クラウド ストレージ バケット内の参照を追跡します。Artifact の参照を使用すると、既存のストレージ レイアウトを変更することなく、シームレスに追跡を バケット の上に重ねることができます。
Artifacts は、基盤となるクラウド ストレージ ベンダー(AWS、GCP、Azure など)を抽象化します。以下のセクションで説明する情報は、Amazon S3、Google Cloud Storage、Azure Blob Storage に均一に適用されます。
W&B Artifacts は、MinIO を含む、Amazon S3 互換のインターフェースをサポートします。AWS_S3_ENDPOINT_URL 環境変数 を MinIO サーバーを指すように設定すると、以下の スクリプト はそのまま動作します。
次の構造の バケット があると仮定します。
s3://my-bucket
+-- datasets/
| +-- mnist/
+-- models/
+-- cnn/
mnist/ の下には、画像のコレクションである データセット があります。これを Artifact で追跡してみましょう。
import wandb
run = wandb.init()
artifact = wandb.Artifact("mnist", type="dataset")
artifact.add_reference("s3://my-bucket/datasets/mnist")
run.log_artifact(artifact)
デフォルトでは、W&B はオブジェクト プレフィックス を追加する際に 10,000 オブジェクト の制限を課します。この制限は、add_reference の呼び出しで max_objects= を指定することで調整できます。
新しい参照 Artifact mnist:latest は、通常の Artifact と同様に見え、動作します。唯一の違いは、Artifact が S3/GCS/Azure オブジェクト に関する メタデータ (ETag、サイズ、オブジェクト の バージョン管理 が バケット で有効になっている場合は バージョン ID など)のみで構成されていることです。
W&B は、使用している クラウド プロバイダー に基づいて、認証情報 を検索するためのデフォルトのメカニズムを使用します。使用する認証情報 の詳細については、 クラウド プロバイダー の ドキュメント を参照してください。
AWS の場合、 バケット が設定された ユーザー のデフォルト リージョン にない場合は、AWS_REGION 環境変数 を バケット リージョン と一致するように設定する必要があります。
この Artifact は、通常の Artifact と同様に操作します。App UI では、ファイル ブラウザー を使用して参照 Artifact のコンテンツ を調べたり、完全な依存関係グラフ を調べたり、Artifact の バージョン管理 された履歴をスキャンしたりできます。
画像、オーディオ、ビデオ、ポイント クラウド などのリッチ メディア は、 バケット の CORS 設定によっては、App UI で レンダリング されない場合があります。 バケット の CORS 設定で app.wandb.ai のリストを許可すると、App UI でそのようなリッチ メディア を適切に レンダリング できます。
会社の VPN がある場合、プライベート バケット の パネル が App UI で レンダリング されない場合があります。VPN 内の IP を ホワイトリスト に登録するように バケット の アクセス ポリシー を更新できます。
参照 Artifact をダウンロードする
import wandb
run = wandb.init()
artifact = run.use_artifact("mnist:latest", type="dataset")
artifact_dir = artifact.download()
W&B は、参照 Artifact をダウンロードする際に、Artifact がログ記録されたときに記録された メタデータ を使用して、基盤となる バケット からファイル を取得します。 バケット で オブジェクト の バージョン管理 が有効になっている場合、W&B は Artifact がログ記録された時点でのファイルの 状態 に対応する オブジェクト バージョン を取得します。これは、 バケット のコンテンツ を進化させても、特定の モデル がトレーニング された データの 正確な イテレーション を指すことができることを意味します。Artifact は トレーニング 時の バケット の スナップショット として機能するためです。
ワークフロー の一部としてファイルを上書きする場合は、ストレージ バケット で「オブジェクト の バージョン管理 」を有効にすることをお勧めします。 バケット で バージョン管理 が有効になっている場合、上書きされたファイルへの参照を持つ Artifacts は、古い オブジェクト バージョン が保持されるため、そのまま残ります。
ユースケース に基づいて、オブジェクト の バージョン管理 を有効にする 手順 を読んでください:AWS, GCP, Azure.
統合する
次のコード例は、Amazon S3、GCS、または Azure で データセット を追跡するために使用できる簡単な ワークフロー を示しています。
import wandb
run = wandb.init()
artifact = wandb.Artifact("mnist", type="dataset")
artifact.add_reference("s3://my-bucket/datasets/mnist")
# Artifact を追跡し、この run への入力としてマークします。
# バケット 内のファイル が変更された場合にのみ、新しい Artifact バージョン がログ記録されます。
run.use_artifact(artifact)
artifact_dir = artifact.download()
# ここで トレーニング を実行します...
モデル を追跡するために、 トレーニング スクリプト が モデル ファイル を バケット にアップロードした後、 モデル Artifact をログ記録できます。
import boto3
import wandb
run = wandb.init()
# トレーニング はこちら...
s3_client = boto3.client("s3")
s3_client.upload_file("my_model.h5", "my-bucket", "models/cnn/my_model.h5")
model_artifact = wandb.Artifact("cnn", type="model")
model_artifact.add_reference("s3://my-bucket/models/cnn/")
run.log_artifact(model_artifact)
GCP または Azure の参照によって Artifacts を追跡する方法のエンドツーエンド の チュートリアル については、次の レポート を参照してください。
ファイルシステム 参照
データセット に 高速 に アクセス するためのもう 1 つの一般的なパターンは、すべての トレーニング ジョブ を実行しているマシンでリモート ファイルシステム に NFS マウント ポイント を公開することです。トレーニング スクリプト の観点から見ると、ファイル がローカル ファイルシステム にあるように見えるため、これは クラウド ストレージ バケット よりもさらに簡単なソリューションになる可能性があります。幸いなことに、その使いやすさは、ファイルシステム への参照を追跡するために Artifacts を使用することにも拡張されます(マウントされているかどうかに関係なく)。
次の構造のファイルシステム が /mount にマウントされていると仮定します。
mount
+-- datasets/
| +-- mnist/
+-- models/
+-- cnn/
mnist/ の下には、画像のコレクションである データセット があります。これを Artifact で追跡してみましょう。
import wandb
run = wandb.init()
artifact = wandb.Artifact("mnist", type="dataset")
artifact.add_reference("file:///mount/datasets/mnist/")
run.log_artifact(artifact)
デフォルトでは、W&B は ディレクトリー への参照を追加する際に 10,000 ファイル の制限を課します。この制限は、add_reference の呼び出しで max_objects= を指定することで調整できます。
URL には 3 つのスラッシュ があることに注意してください。最初のコンポーネント は、ファイルシステム 参照の使用を示す file:// プレフィックス です。2 番目のコンポーネント は、 データセット へのパス /mount/datasets/mnist/ です。
結果として得られる Artifact mnist:latest は、通常の Artifact と同じように見え、動作します。唯一の違いは、Artifact がファイル に関する メタデータ (サイズ や MD5 チェックサム など)のみで構成されていることです。ファイル 自体がシステムから離れることはありません。
この Artifact は、通常の Artifact と同じように操作できます。UI では、ファイル ブラウザー を使用して参照 Artifact のコンテンツ を参照したり、完全な依存関係グラフ を調べたり、Artifact の バージョン管理 された履歴をスキャンしたりできます。ただし、 データ 自体が Artifact に含まれていないため、UI は画像 やオーディオ などのリッチ メディア を レンダリング できません。
参照 Artifact のダウンロードは簡単です。
import wandb
run = wandb.init()
artifact = run.use_artifact("entity/project/mnist:latest", type="dataset")
artifact_dir = artifact.download()
ファイルシステム 参照の場合、download() 操作は参照されたパスからファイルをコピーして Artifact ディレクトリー を構築します。上記の例では、/mount/datasets/mnist のコンテンツ が ディレクトリー artifacts/mnist:v0/ にコピーされます。Artifact に上書きされたファイル への参照が含まれている場合、Artifact を再構築できなくなるため、download() は エラー をスローします。
すべてをまとめると、マウントされたファイルシステム の下にある データセット を追跡するために使用できる簡単な ワークフロー を次に示します。
import wandb
run = wandb.init()
artifact = wandb.Artifact("mnist", type="dataset")
artifact.add_reference("file:///mount/datasets/mnist/")
# Artifact を追跡し、この run への入力としてマークします。
# ディレクトリー の下のファイル が変更された場合にのみ、新しい Artifact バージョン がログ記録されます。
run.use_artifact(artifact)
artifact_dir = artifact.download()
# ここで トレーニング を実行します...
モデル を追跡するために、 トレーニング スクリプト が モデル ファイル をマウント ポイント に書き込んだ後、 モデル Artifact をログ記録できます。
import wandb
run = wandb.init()
# トレーニング はこちら...
# モデル を ディスク に書き込みます
model_artifact = wandb.Artifact("cnn", type="model")
model_artifact.add_reference("file:///mount/cnn/my_model.h5")
run.log_artifact(model_artifact)
7 - Manage data
7.1 - Delete an artifact
App UI を使用してインタラクティブに、または W&B SDK を使用してプログラム的に Artifacts を削除します。
App UIまたは W&B SDK を使用して、アーティファクトをインタラクティブに、またはプログラムで削除できます。アーティファクトを削除すると、W&B はそのアーティファクトを 論理削除 としてマークします。つまり、アーティファクトは削除対象としてマークされますが、ファイルはストレージからすぐに削除されるわけではありません。
アーティファクトの内容は、論理削除、つまり削除保留状態のままとなり、定期的に実行されるガベージコレクション プロセスが、削除対象としてマークされたすべてのアーティファクトを確認します。ガベージコレクション プロセスは、アーティファクトとその関連ファイルが、以前または以降のアーティファクト バージョンで使用されていない場合、ストレージから関連ファイルを削除します。
このページのセクションでは、特定のアーティファクト バージョンを削除する方法、アーティファクト コレクションを削除する方法、エイリアスを使用または使用せずにアーティファクトを削除する方法などについて説明します。アーティファクトが W&B から削除されるタイミングは、TTL ポリシーでスケジュールできます。詳細については、アーティファクト TTL ポリシーによるデータ保持の管理 を参照してください。
TTL ポリシーで削除がスケジュールされているアーティファクト、W&B SDK で削除されたアーティファクト、または W&B App UI で削除されたアーティファクトは、最初に論理削除されます。論理削除されたアーティファクトは、完全に削除される前にガベージコレクションの対象となります。
アーティファクト バージョンを削除する
アーティファクト バージョンを削除するには:
- アーティファクトの名前を選択します。これにより、アーティファクト ビューが展開され、そのアーティファクトに関連付けられているすべてのアーティファクト バージョンが一覧表示されます。
- アーティファクトのリストから、削除するアーティファクト バージョンを選択します。
- ワークスペースの右側にあるケバブ ドロップダウンを選択します。
- 削除を選択します。
アーティファクト バージョンは、delete() メソッドを使用してプログラムで削除することもできます。以下の例を参照してください。
エイリアスを持つ複数のアーティファクト バージョンを削除する
次のコード例は、エイリアスが関連付けられているアーティファクトを削除する方法を示しています。アーティファクトを作成したエンティティ、プロジェクト名、run ID を指定します。
import wandb
run = api.run("entity/project/run_id")
for artifact in run.logged_artifacts():
artifact.delete()
アーティファクトに1つ以上のエイリアスがある場合にエイリアスを削除するには、delete_aliases パラメータをブール値 True に設定します。
import wandb
run = api.run("entity/project/run_id")
for artifact in run.logged_artifacts():
# 1つ以上エイリアスを持つ
# アーティファクトを削除するには
# delete_aliases=True を設定します
artifact.delete(delete_aliases=True)
特定のエイリアスを持つ複数のアーティファクト バージョンを削除する
次のコードは、特定のエイリアスを持つ複数のアーティファクト バージョンを削除する方法を示しています。アーティファクトを作成したエンティティ、プロジェクト名、run ID を指定します。削除ロジックを独自のものに置き換えます。
import wandb
runs = api.run("entity/project_name/run_id")
# エイリアス 'v3' と 'v4' を持つアーティファクトを削除します
for artifact_version in runs.logged_artifacts():
# 独自の削除ロジックに置き換えます。
if artifact_version.name[-2:] == "v3" or artifact_version.name[-2:] == "v4":
artifact.delete(delete_aliases=True)
エイリアスを持たないアーティファクトのすべてのバージョンを削除する
次のコードスニペットは、エイリアスを持たないアーティファクトのすべてのバージョンを削除する方法を示しています。wandb.Api の project および entity キーに、プロジェクトとエンティティの名前をそれぞれ指定します。<> をアーティファクトの名前に置き換えます。
import wandb
# wandb.Api メソッドを使用する場合は、
# エンティティとプロジェクト名を指定してください。
api = wandb.Api(overrides={"project": "project", "entity": "entity"})
artifact_type, artifact_name = "<>" # タイプと名前を指定
for v in api.artifact_versions(artifact_type, artifact_name):
# 'latest' などのエイリアスを持たないバージョンをクリーンアップします。
# 注: ここには、必要な削除ロジックを入れることができます。
if len(v.aliases) == 0:
v.delete()
アーティファクト コレクションを削除する
アーティファクト コレクションを削除するには:
- 削除するアーティファクト コレクションに移動し、その上にカーソルを置きます。
- アーティファクト コレクション名の横にあるケバブ ドロップダウンを選択します。
- 削除を選択します。
delete() メソッドを使用して、プログラムでアーティファクト コレクションを削除することもできます。wandb.Api の project および entity キーに、プロジェクトとエンティティの名前をそれぞれ指定します。
import wandb
# wandb.Api メソッドを使用する場合は、
# エンティティとプロジェクト名を指定してください。
api = wandb.Api(overrides={"project": "project", "entity": "entity"})
collection = api.artifact_collection(
"<artifact_type>", "entity/project/artifact_collection_name"
)
collection.delete()
W&B のホスト方法に基づいてガベージコレクションを有効にする方法
W&B の共有クラウドを使用している場合、ガベージコレクションはデフォルトで有効になっています。W&B のホスト方法によっては、ガベージコレクションを有効にするために追加の手順が必要になる場合があります。これには以下が含まれます。
次の表は、デプロイメントの種類に基づいてガベージコレクションを有効にするための要件を満たす方法を示しています。
X は、要件を満たす必要があることを示します。
note
セキュア ストレージ コネクタは、現在 Google Cloud Platform および Amazon Web Services でのみ利用可能です。
7.2 - Manage artifact data retention
Time to live ポリシー (TTL)
W&B Artifact time-to-live(TTL)ポリシーを使用して、Artifacts が W&B から削除されるタイミングをスケジュールします。アーティファクトを削除すると、W&B はそのアーティファクトを ソフト削除 としてマークします。つまり、アーティファクトは削除対象としてマークされますが、ファイルはストレージからすぐに削除されるわけではありません。W&B が Artifacts を削除する方法の詳細については、Artifacts の削除 ページを参照してください。
W&B アプリで Artifacts TTL を使用してデータ保持を管理する方法については、こちらのビデオチュートリアルをご覧ください。
W&B は、モデルレジストリにリンクされたモデル Artifacts の TTL ポリシーを設定するオプションを無効にします。これは、リンクされたモデルがプロダクションワークフローで使用されている場合に誤って期限切れにならないようにするためです。
- チーム管理者のみが チームの設定を表示し、(1)TTL ポリシーを設定または編集できるユーザーを許可するか、(2)チームのデフォルト TTL を設定するなど、チームレベルの TTL 設定にアクセスできます。
- W&B アプリ UI のアーティファクトの詳細で TTL ポリシーを設定または編集するオプションが表示されない場合、またはプログラムで TTL を設定してもアーティファクトの TTL プロパティが正常に変更されない場合は、チーム管理者がそのための権限を付与していません。
自動生成された Artifacts
ユーザーが生成した Artifacts のみ、TTL ポリシーを使用できます。W&B によって自動生成された Artifacts は、TTL ポリシーを設定できません。
次の Artifact の種類は、自動生成された Artifact を示します。
run_tablecodejobwandb-* で始まる任意の Artifact の種類
W&B プラットフォームで、またはプログラムで Artifact の種類を確認できます。
import wandb
run = wandb.init(project="<my-project-name>")
artifact = run.use_artifact(artifact_or_name="<my-artifact-name>")
print(artifact.type)
<> で囲まれた値を独自の値に置き換えます。
TTL ポリシーを編集および設定できるユーザーを定義する
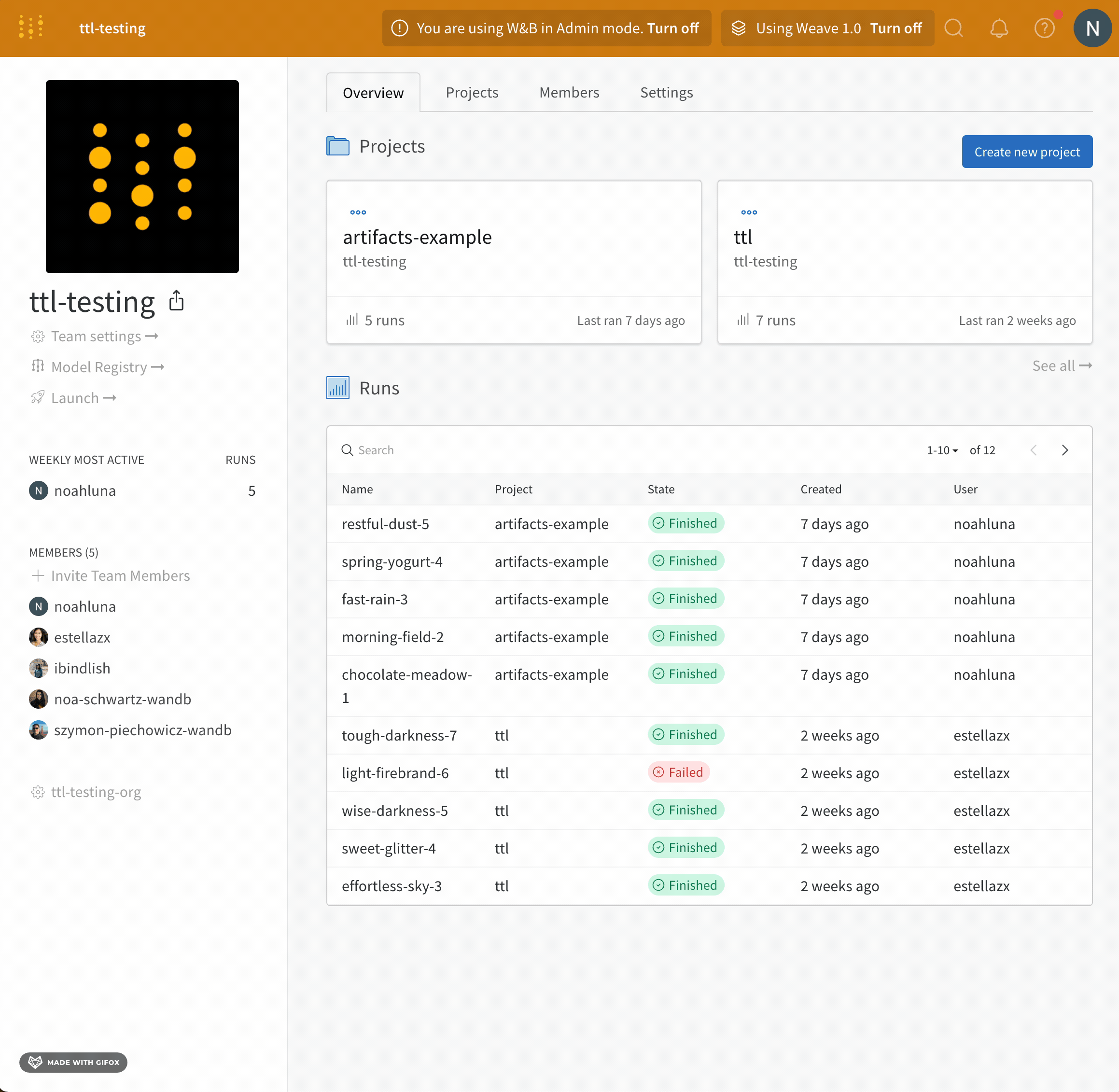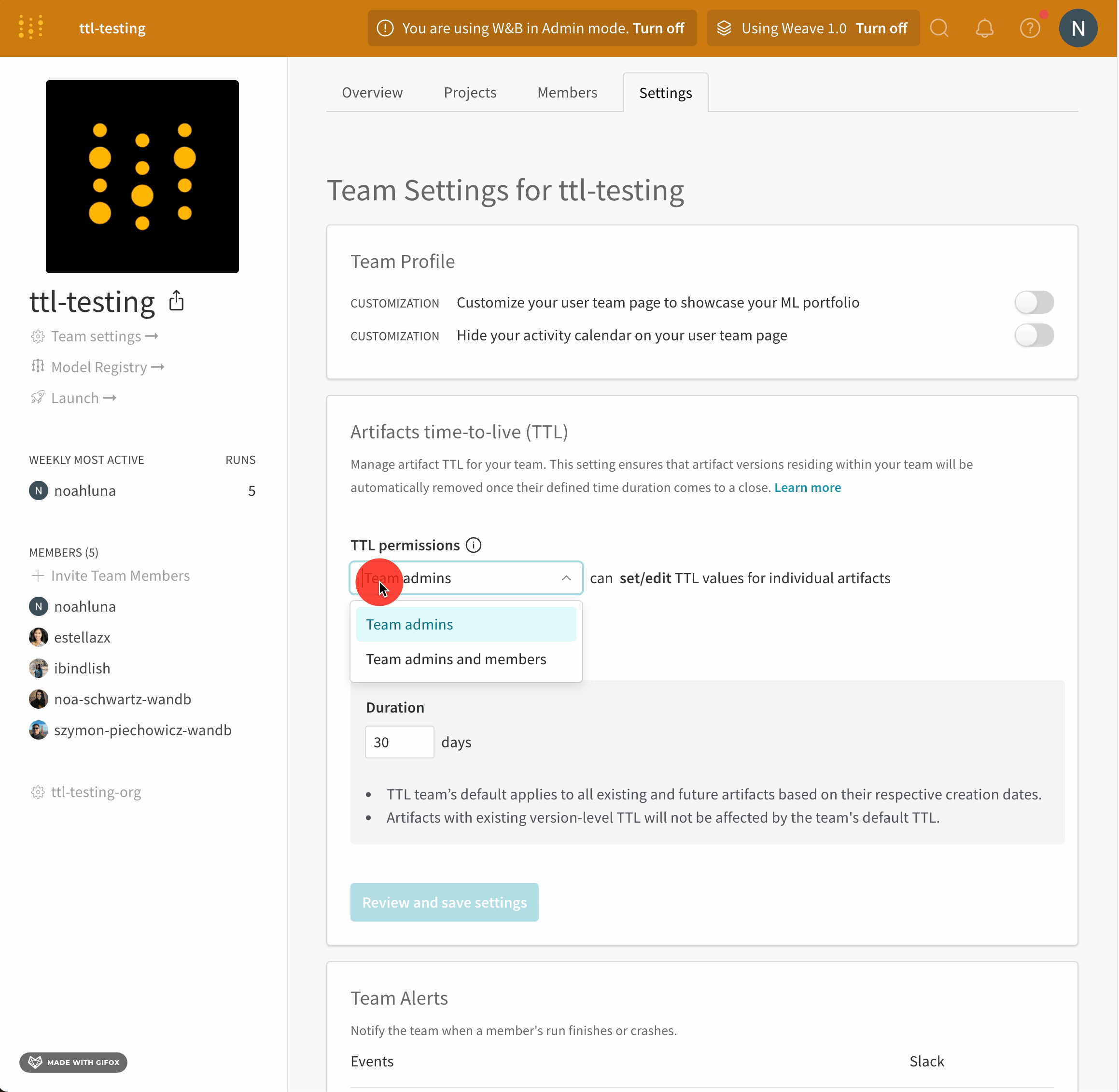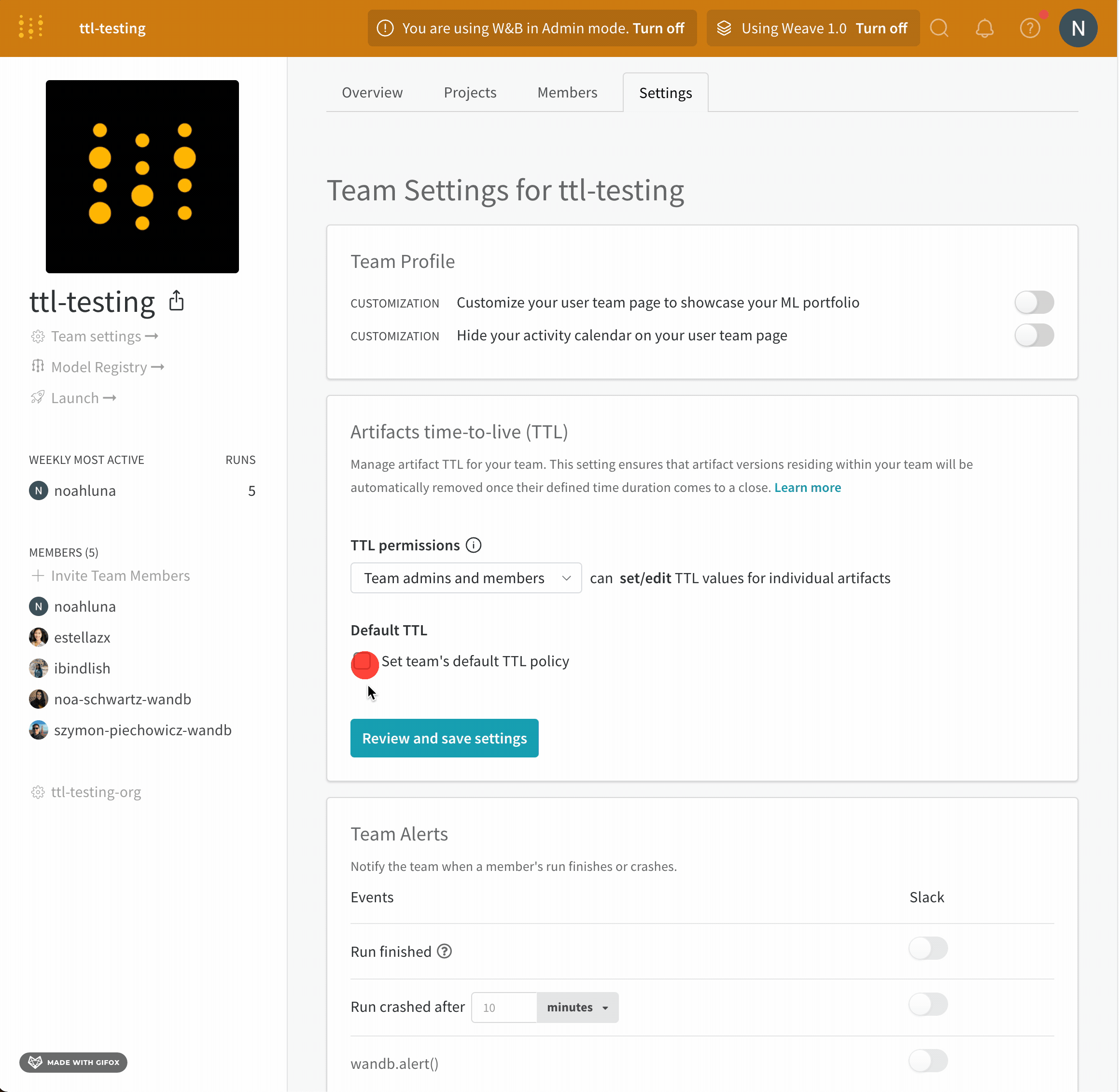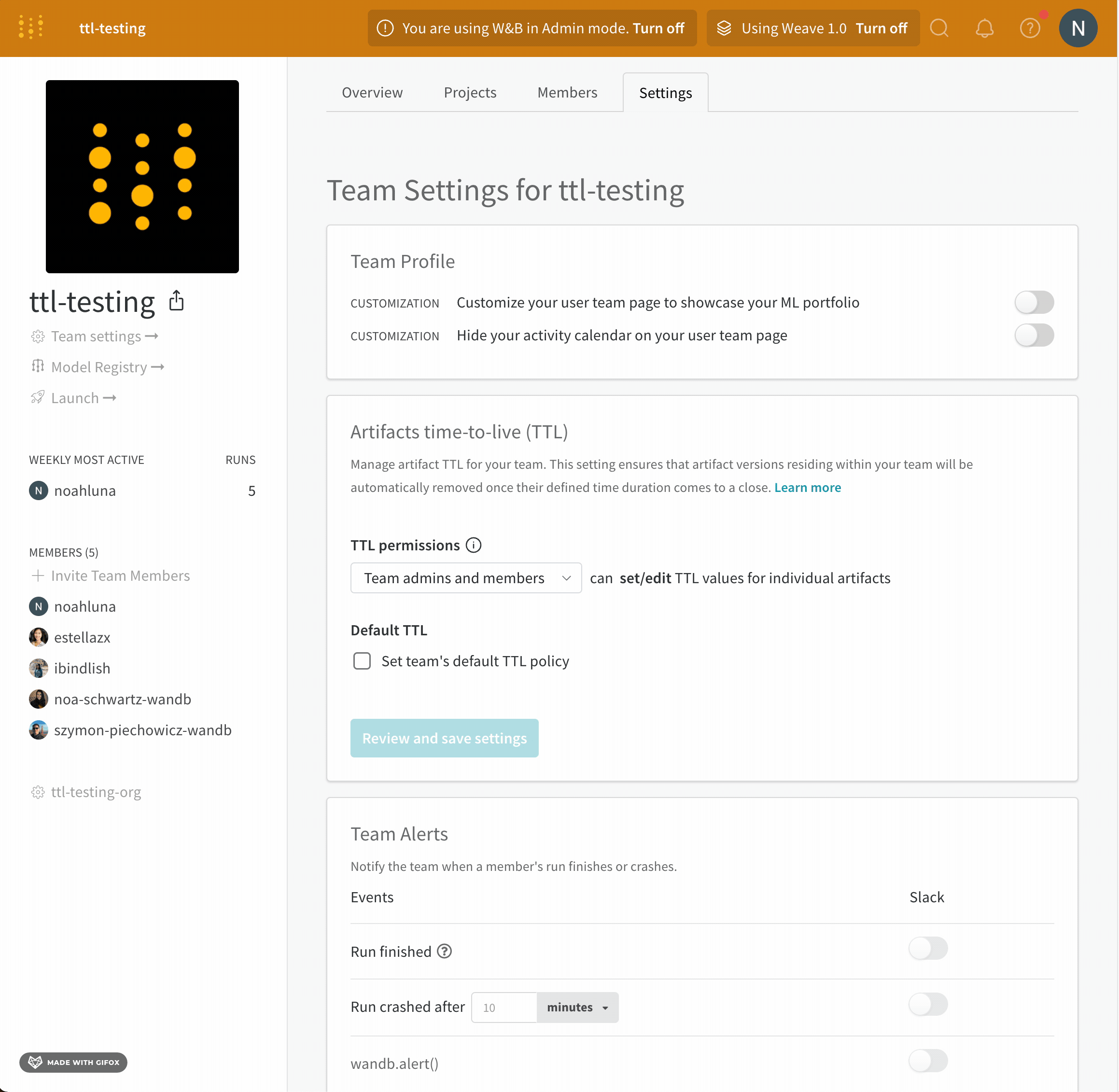
チーム内で TTL ポリシーを設定および編集できるユーザーを定義します。TTL 権限をチーム管理者のみに付与するか、チーム管理者とチームメンバーの両方に TTL 権限を付与できます。
チーム管理者のみが、TTL ポリシーを設定または編集できるユーザーを定義できます。
- チームのプロファイルページに移動します。
- [設定] タブを選択します。
- [Artifacts time-to-live (TTL) section] に移動します。
- [TTL permissions dropdown] で、TTL ポリシーを設定および編集できるユーザーを選択します。
- [Review and save settings] をクリックします。
- 変更を確認し、[Save settings] を選択します。
TTL ポリシーを作成する
アーティファクトを作成するとき、またはアーティファクトの作成後に遡及的に、アーティファクトの TTL ポリシーを設定します。
以下のすべてのコードスニペットについて、<> で囲まれたコンテンツを自分の情報に置き換えて、コードスニペットを使用します。
アーティファクトを作成するときに TTL ポリシーを設定する
W&B Python SDK を使用して、アーティファクトを作成するときに TTL ポリシーを定義します。TTL ポリシーは通常、日数で定義されます。
アーティファクトを作成するときに TTL ポリシーを定義することは、通常
アーティファクトを作成する方法と似ています。ただし、アーティファクトの
ttl 属性に時間デルタを渡す点が異なります。
手順は次のとおりです。
- アーティファクトを作成します。
- ファイル、ディレクトリー、参照など、アーティファクトにコンテンツを追加します。
- Python の標準ライブラリの一部である
datetime.timedelta データ型を使用して、TTL 制限時間を定義します。
- アーティファクトをログに記録します。
次のコードスニペットは、アーティファクトを作成し、TTL ポリシーを設定する方法を示しています。
import wandb
from datetime import timedelta
run = wandb.init(project="<my-project-name>", entity="<my-entity>")
artifact = wandb.Artifact(name="<artifact-name>", type="<type>")
artifact.add_file("<my_file>")
artifact.ttl = timedelta(days=30) # TTL ポリシーを設定
run.log_artifact(artifact)
上記のコードスニペットは、アーティファクトの TTL ポリシーを 30 日に設定します。つまり、W&B は 30 日後にアーティファクトを削除します。
アーティファクトを作成した後で TTL ポリシーを設定または編集する
W&B アプリ UI または W&B Python SDK を使用して、既に存在するアーティファクトの TTL ポリシーを定義します。
アーティファクトの TTL を変更すると、アーティファクトが期限切れになるまでの時間は、アーティファクトの createdAt タイムスタンプを使用して計算されます。
- アーティファクトを取得します。
- 時間デルタをアーティファクトの
ttl 属性に渡します。
saveメソッドを使用してアーティファクトを更新します。
次のコードスニペットは、アーティファクトの TTL ポリシーを設定する方法を示しています。
import wandb
from datetime import timedelta
artifact = run.use_artifact("<my-entity/my-project/my-artifact:alias>")
artifact.ttl = timedelta(days=365 * 2) # 2 年後に削除
artifact.save()
上記のコード例では、TTL ポリシーを 2 年に設定しています。
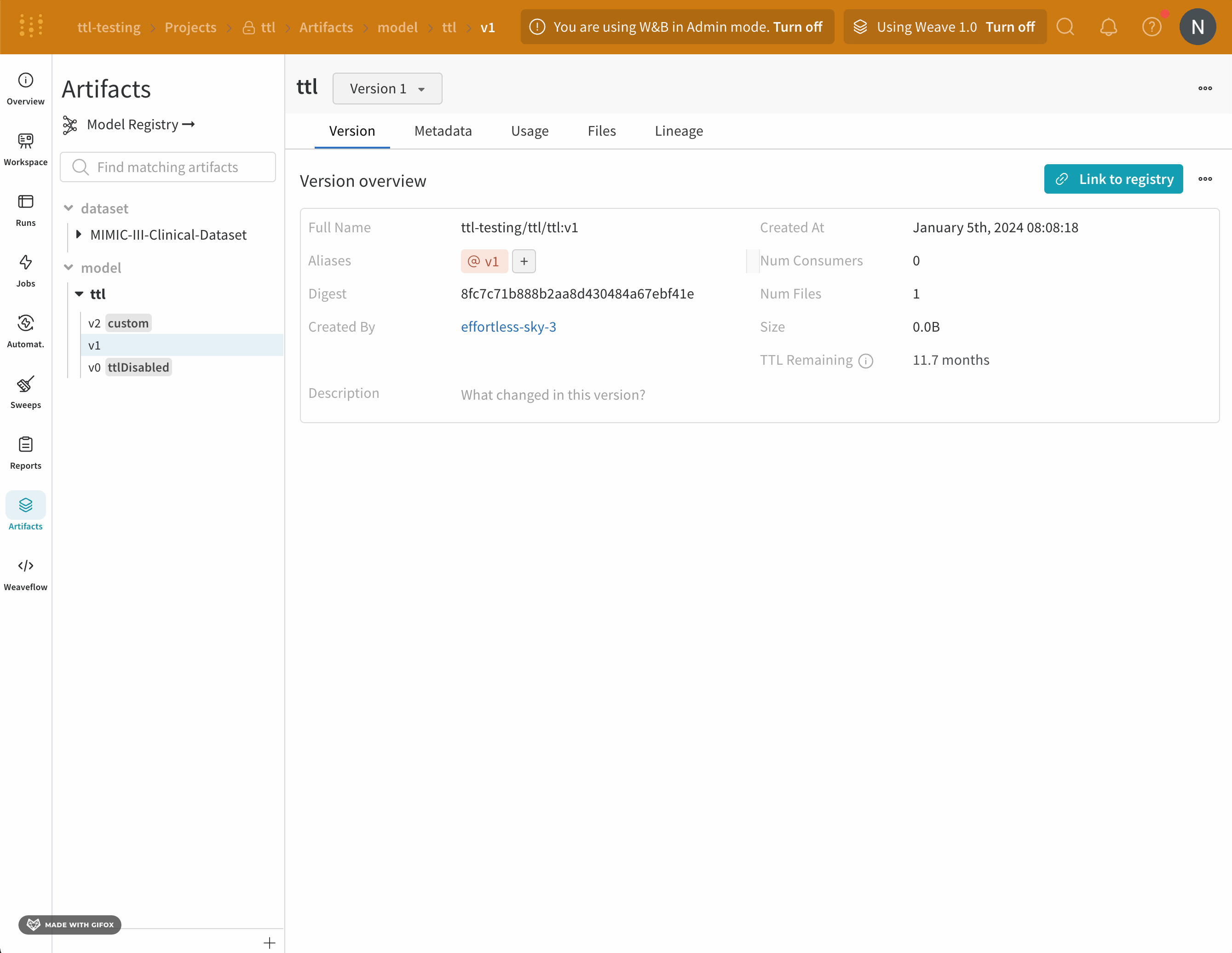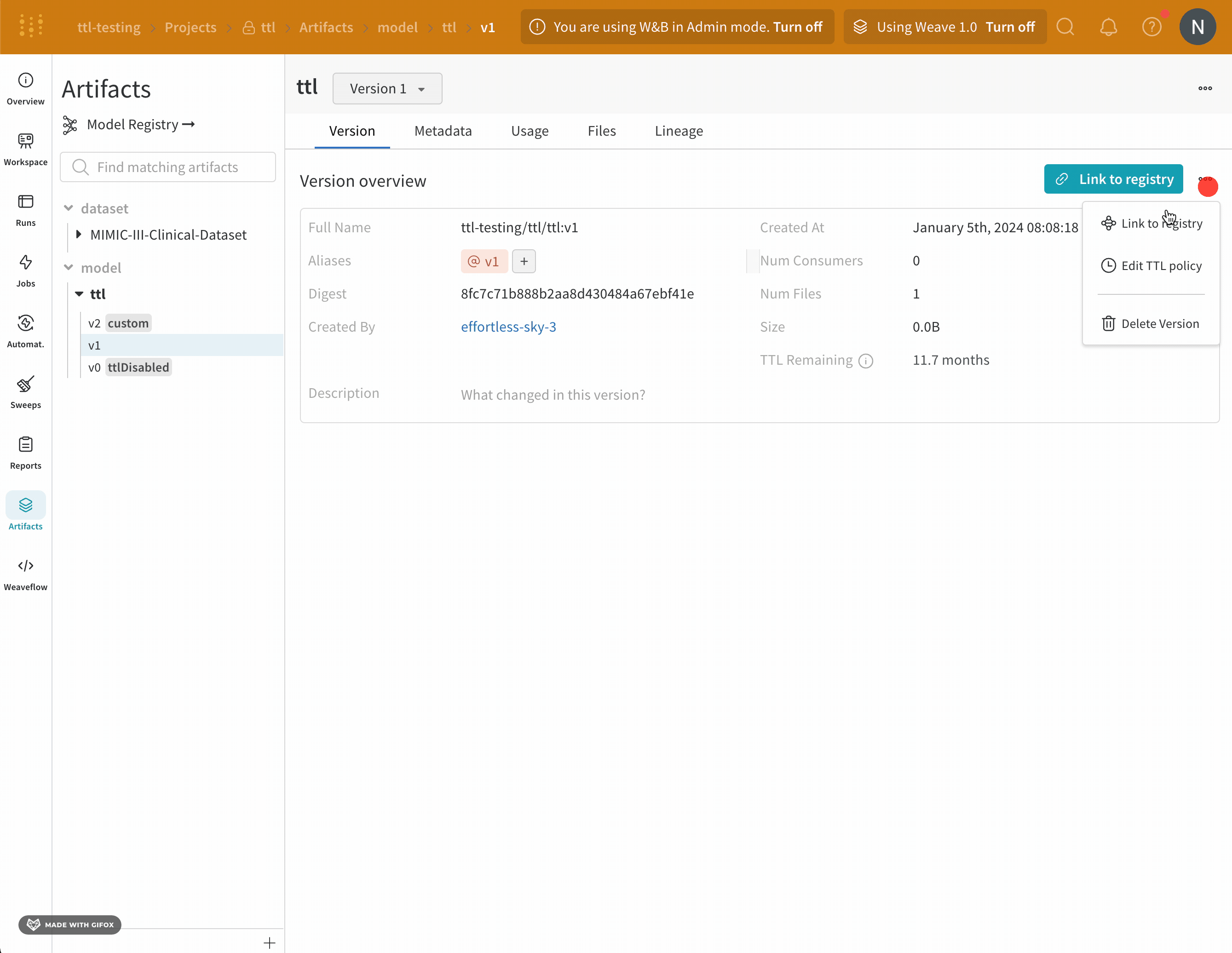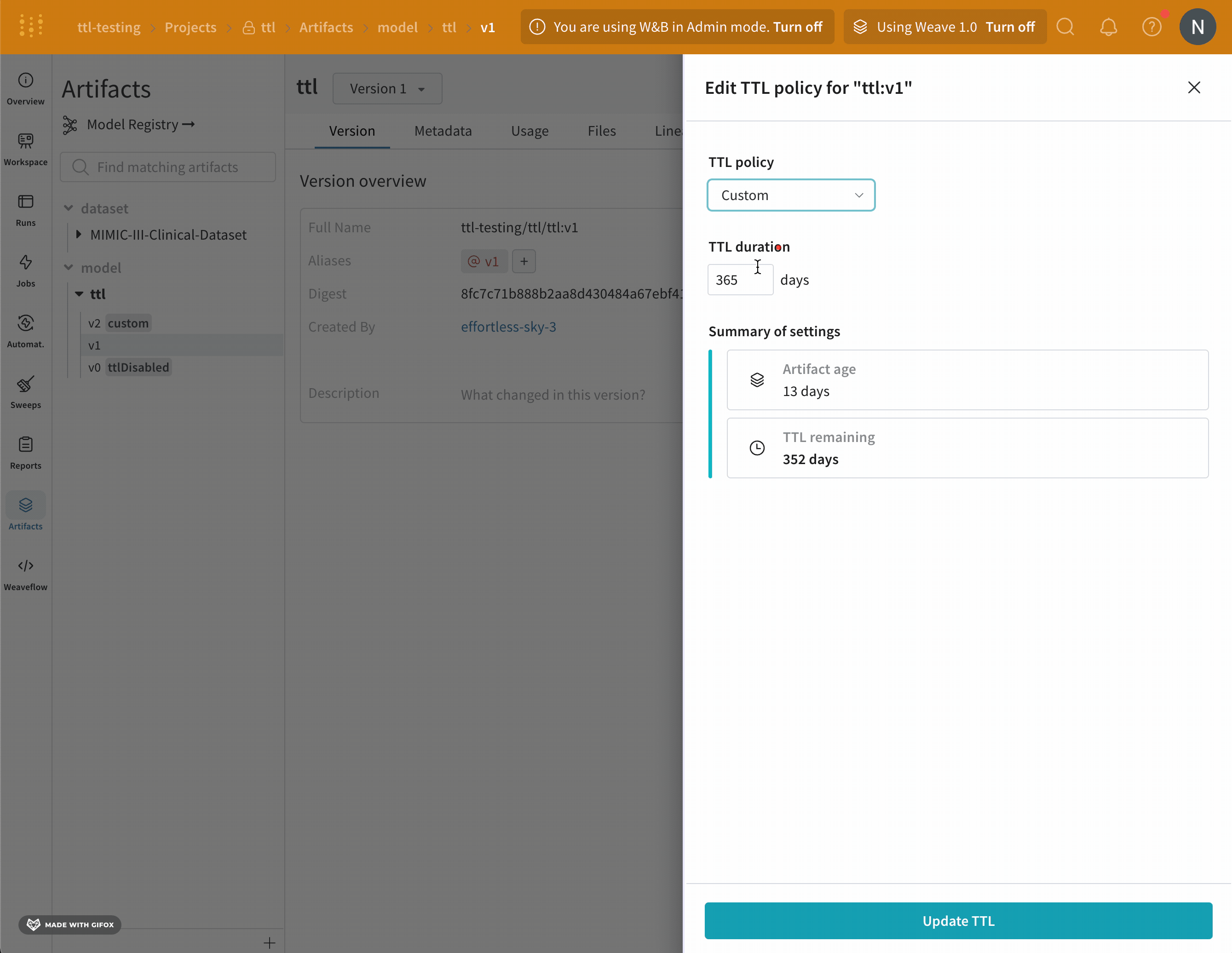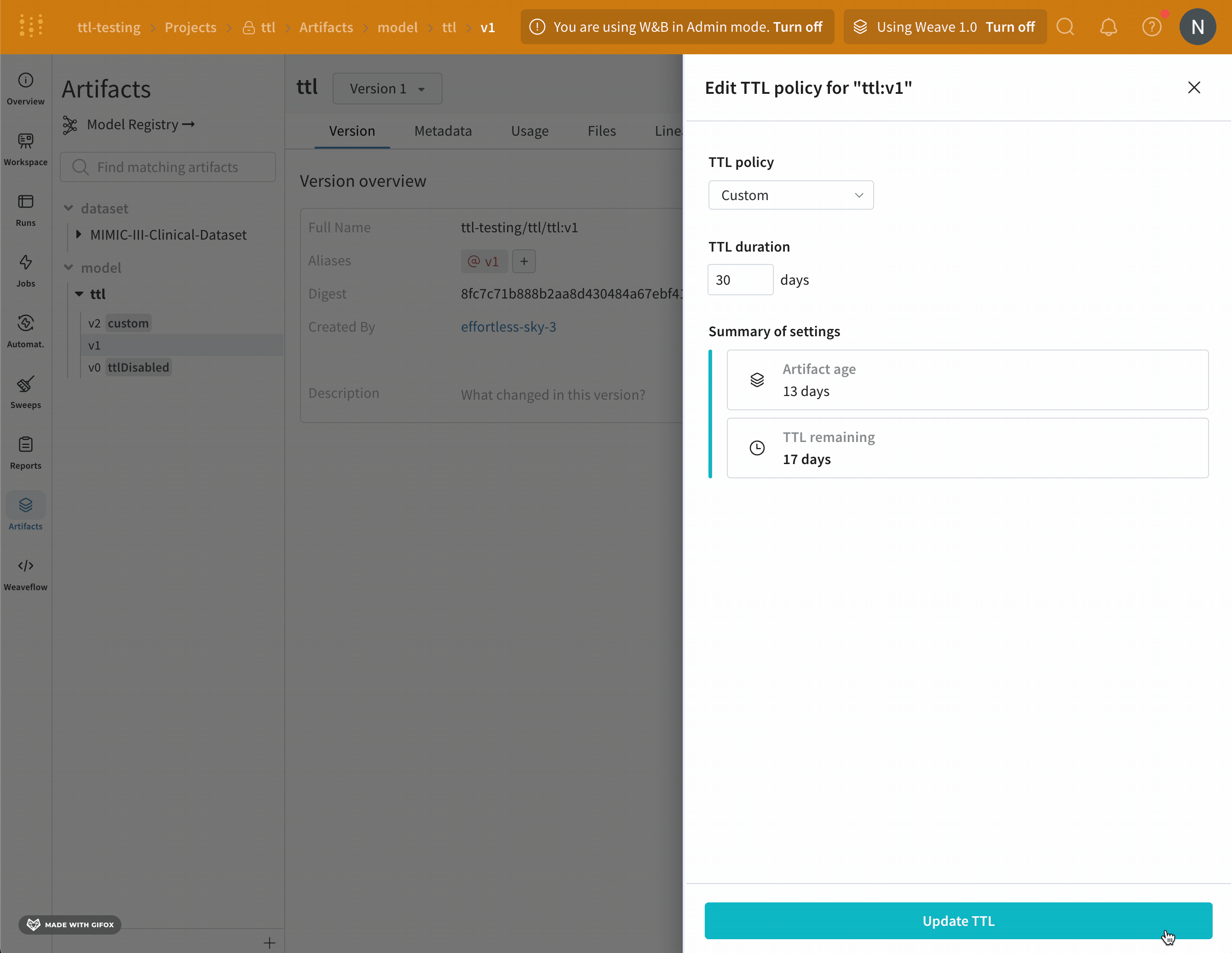
- W&B アプリ UI で W&B プロジェクトに移動します。
- 左側のパネルでアーティファクトアイコンを選択します。
- アーティファクトのリストから、TTL ポリシーを編集するアーティファクトの種類を展開します。
- TTL ポリシーを編集するアーティファクトバージョンを選択します。
- [バージョン] タブをクリックします。
- ドロップダウンから [TTL ポリシーの編集] を選択します。
- 表示されるモーダル内で、TTL ポリシードロップダウンから [カスタム] を選択します。
- [TTL 期間] フィールドに、TTL ポリシーを日数単位で設定します。
- [TTL の更新] ボタンを選択して、変更を保存します。
チームのデフォルト TTL ポリシーを設定する
チーム管理者のみが、チームのデフォルト TTL ポリシーを設定できます。
チームのデフォルト TTL ポリシーを設定します。デフォルト TTL ポリシーは、それぞれの作成日に基づいて、既存および将来のすべてのアーティファクトに適用されます。既存のバージョンレベルの TTL ポリシーを持つアーティファクトは、チームのデフォルト TTL の影響を受けません。
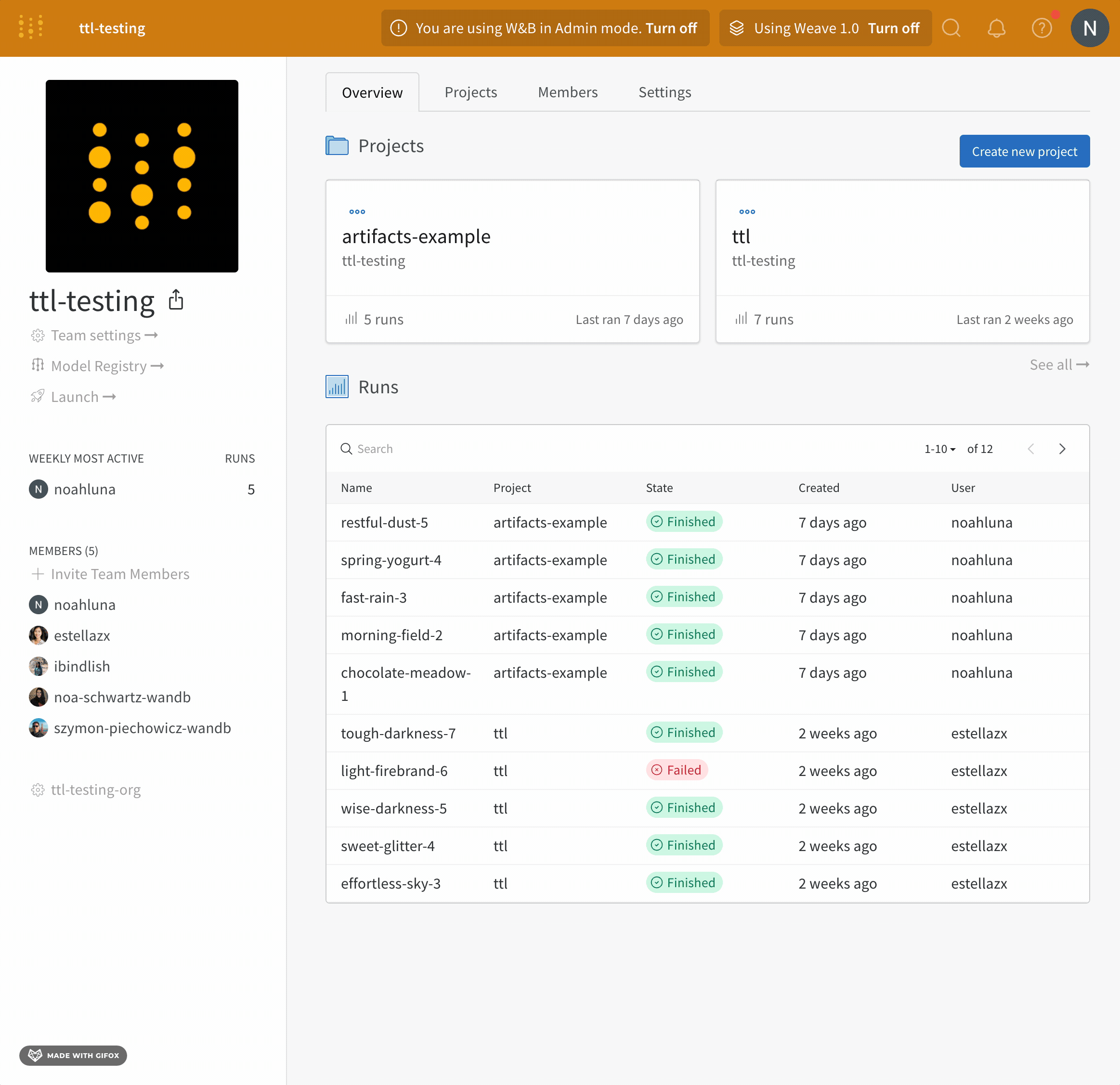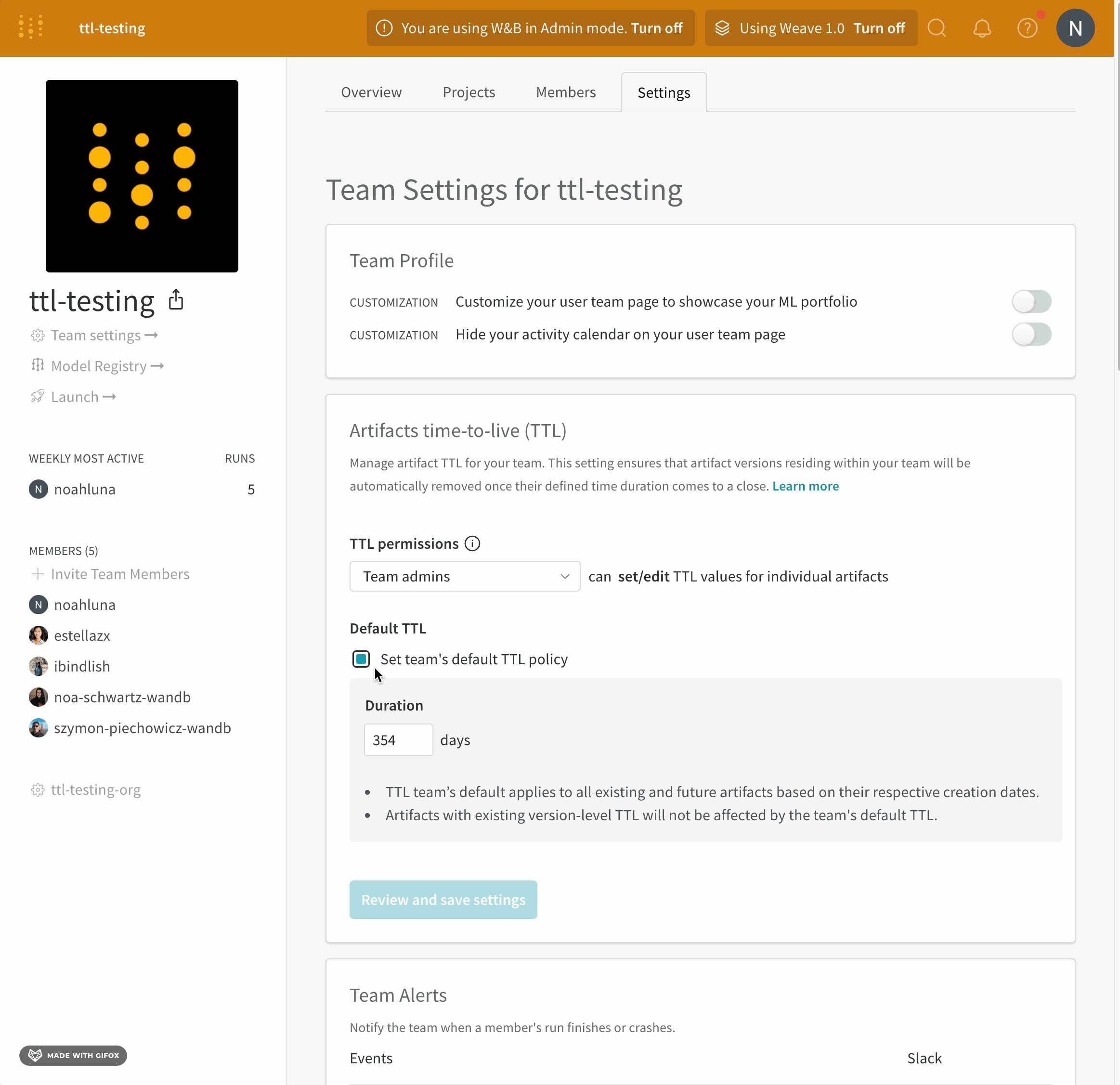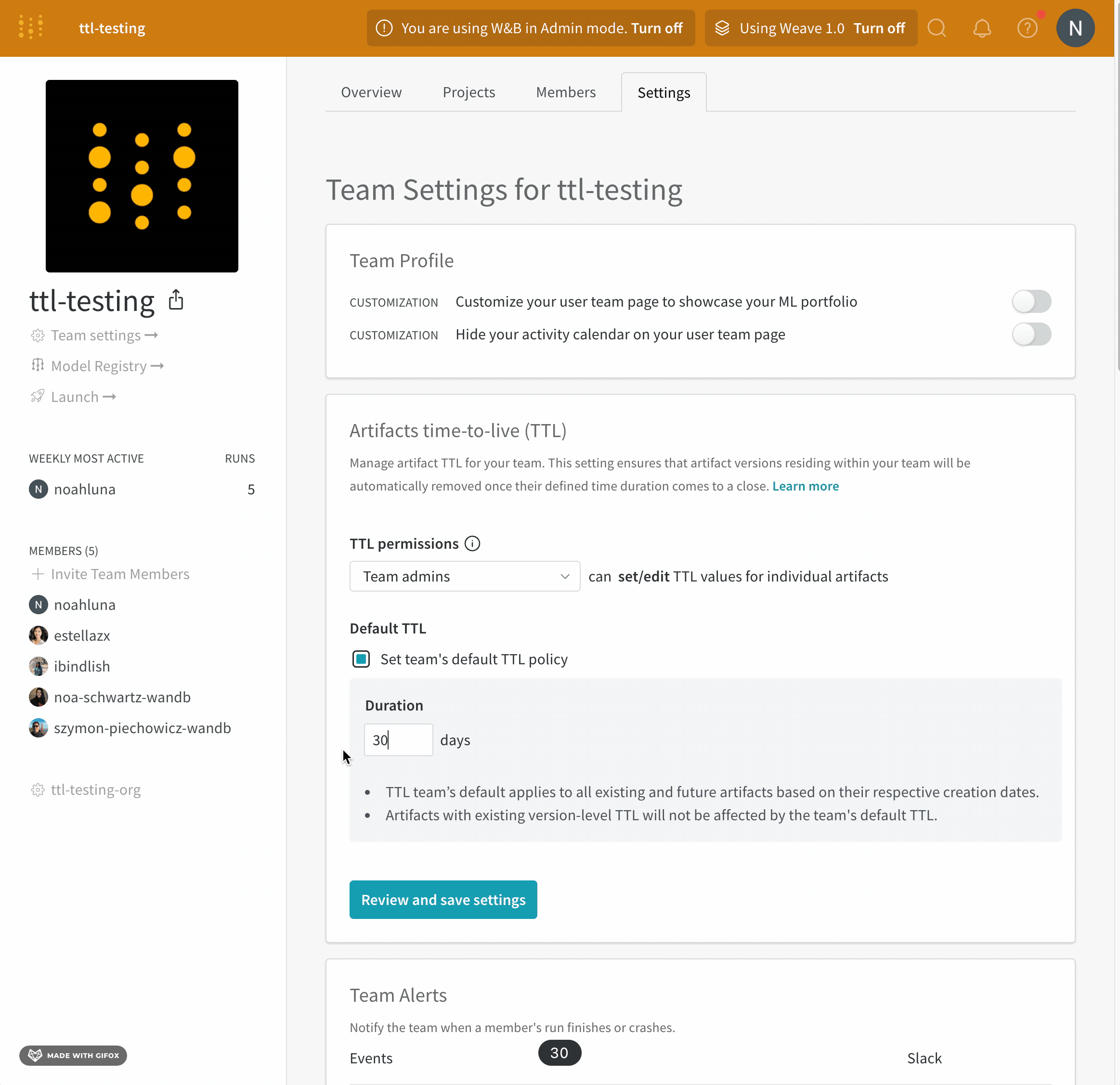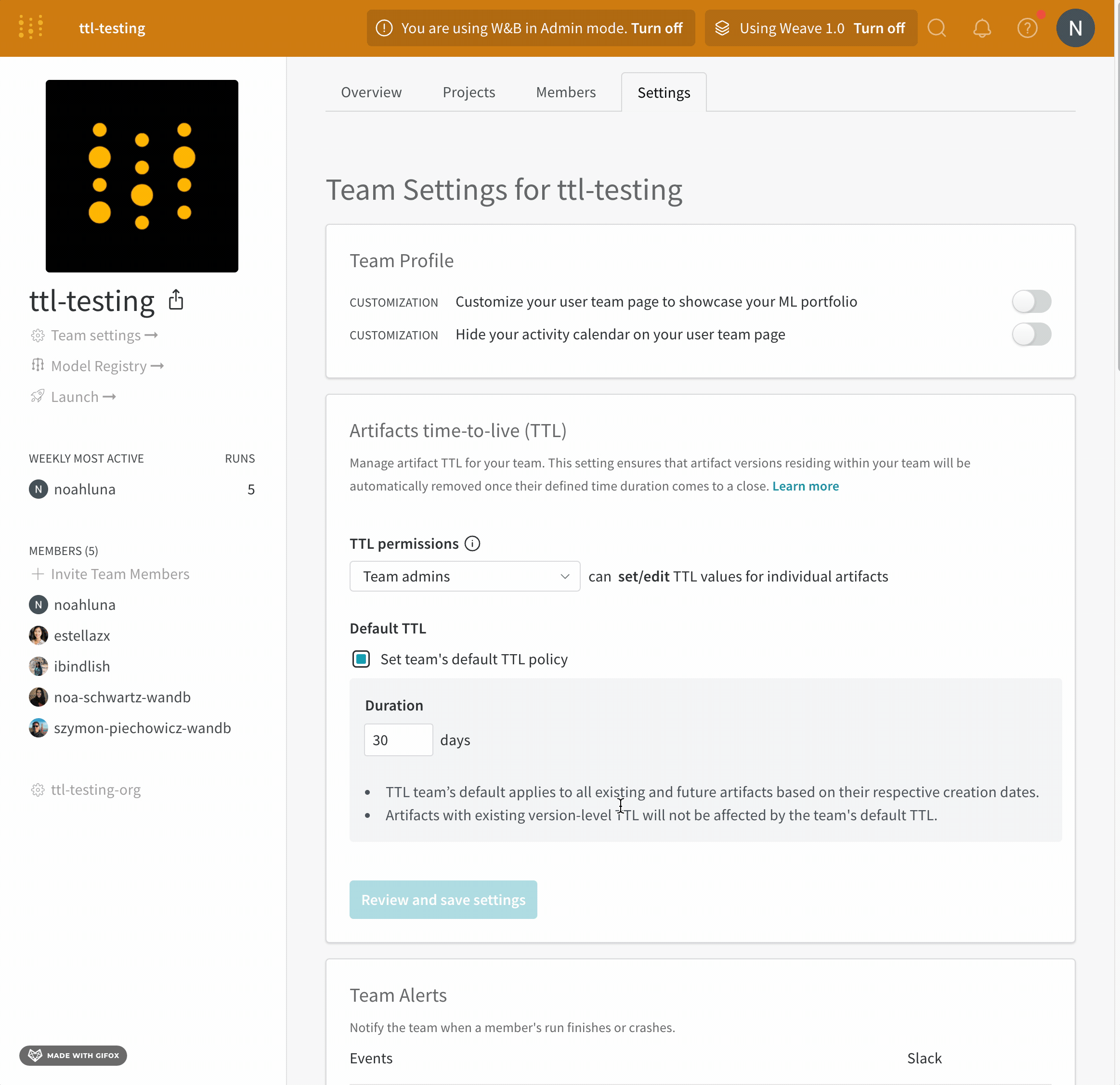
- チームのプロファイルページに移動します。
- [設定] タブを選択します。
- [Artifacts time-to-live (TTL) section] に移動します。
- [チームのデフォルト TTL ポリシーを設定] をクリックします。
- [期間] フィールドに、TTL ポリシーを日数単位で設定します。
- [Review and save settings] をクリックします。
- 変更を確認し、[Save settings] を選択します。
run の外部で TTL ポリシーを設定する
パブリック API を使用して、run を取得せずにアーティファクトを取得し、TTL ポリシーを設定します。TTL ポリシーは通常、日数で定義されます。
次のコードサンプルは、パブリック API を使用してアーティファクトを取得し、TTL ポリシーを設定する方法を示しています。
api = wandb.Api()
artifact = api.artifact("entity/project/artifact:alias")
artifact.ttl = timedelta(days=365) # 1 年後に削除
artifact.save()
TTL ポリシーを無効化する
W&B Python SDK または W&B アプリ UI を使用して、特定のアーティファクトバージョンの TTL ポリシーを無効化します。
- アーティファクトを取得します。
- アーティファクトの
ttl 属性を None に設定します。
saveメソッドを使用してアーティファクトを更新します。
次のコードスニペットは、アーティファクトの TTL ポリシーをオフにする方法を示しています。
artifact = run.use_artifact("<my-entity/my-project/my-artifact:alias>")
artifact.ttl = None
artifact.save()
- W&B アプリ UI で W&B プロジェクトに移動します。
- 左側のパネルでアーティファクトアイコンを選択します。
- アーティファクトのリストから、TTL ポリシーを編集するアーティファクトの種類を展開します。
- TTL ポリシーを編集するアーティファクトバージョンを選択します。
- [バージョン] タブをクリックします。
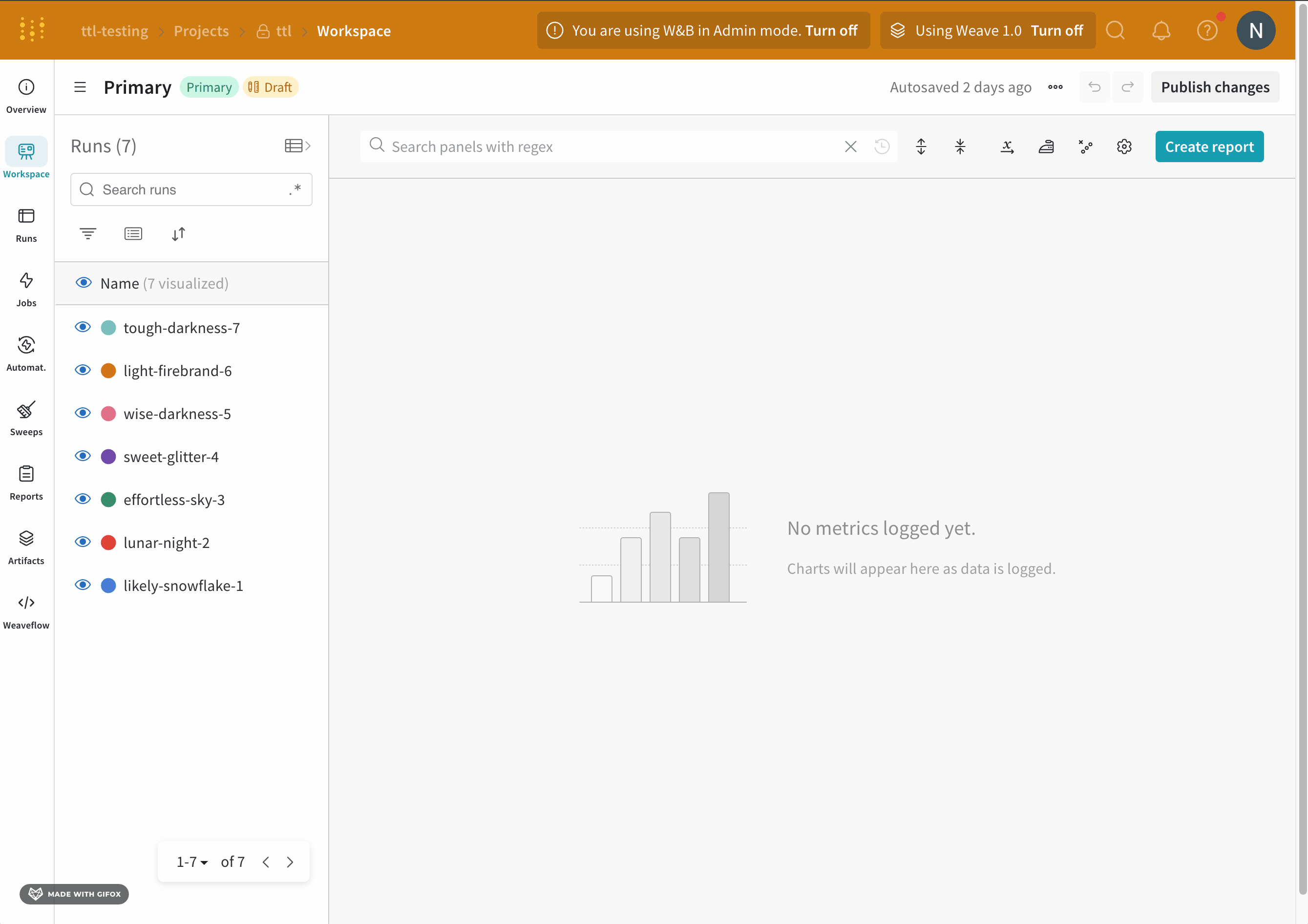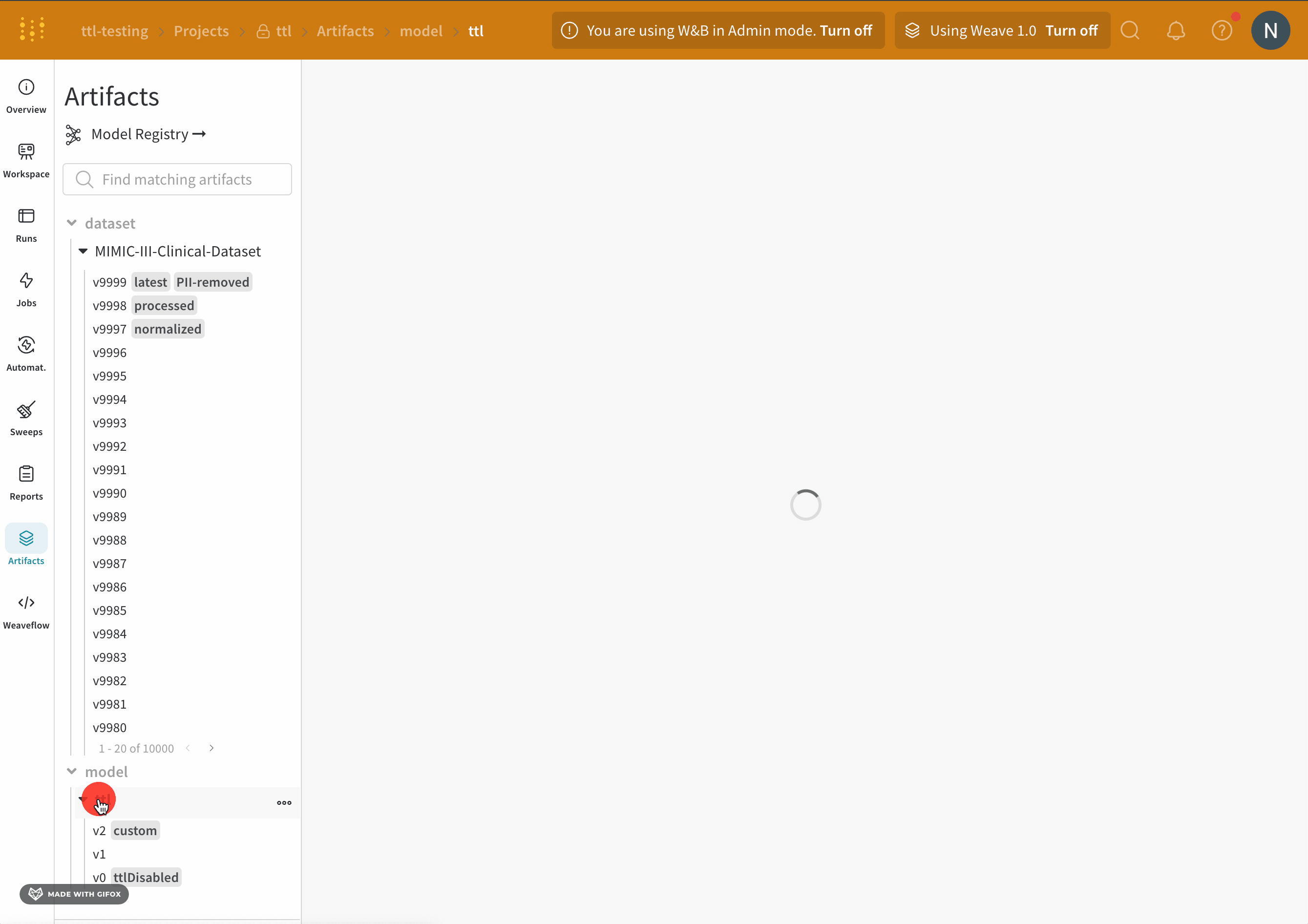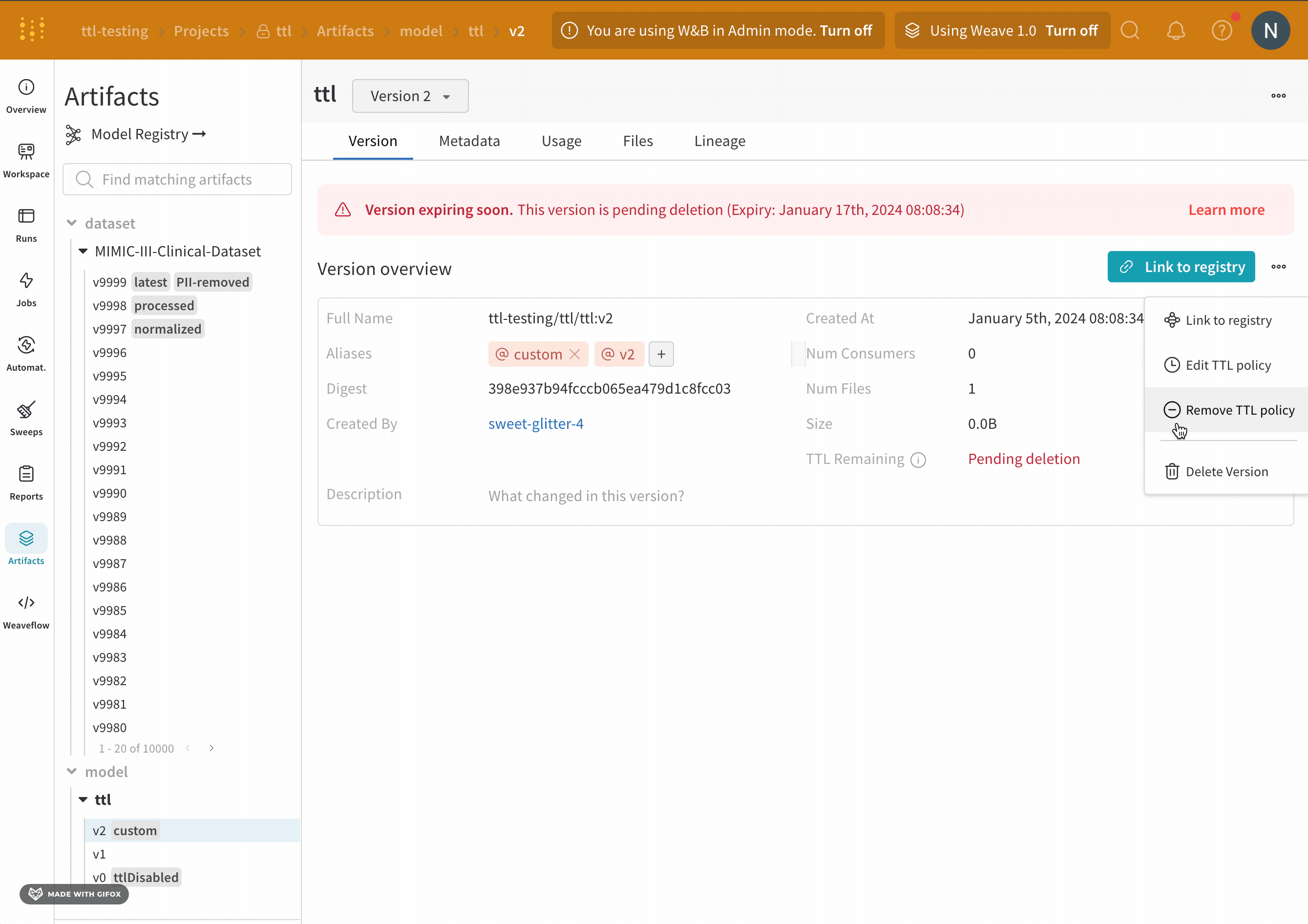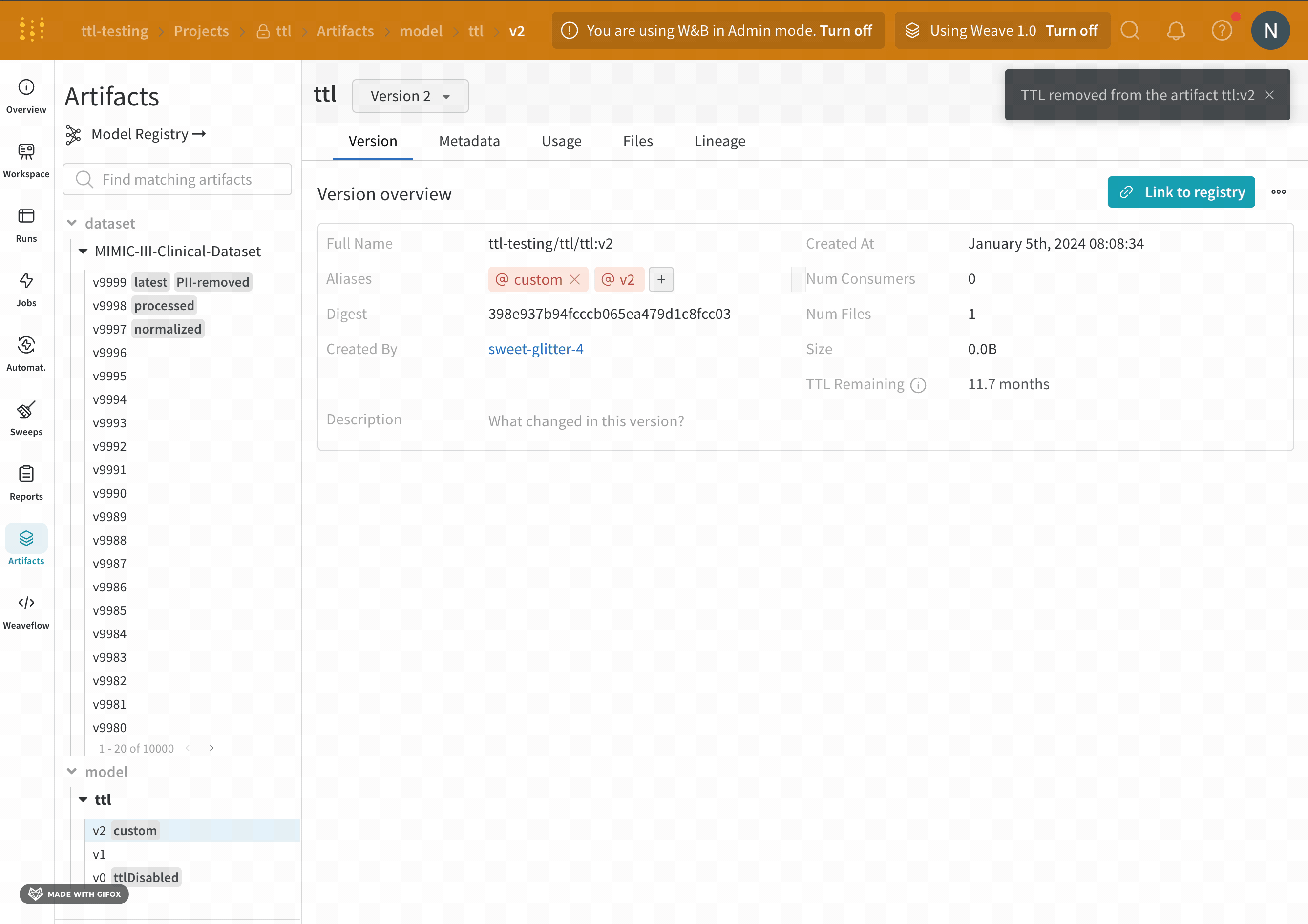
- [レジストリへのリンク] ボタンの横にあるミートボール UI アイコンをクリックします。
- ドロップダウンから [TTL ポリシーの編集] を選択します。
- 表示されるモーダル内で、TTL ポリシードロップダウンから [非アクティブ化] を選択します。
- [TTL の更新] ボタンを選択して、変更を保存します。
TTL ポリシーを表示する
Python SDK または W&B アプリ UI でアーティファクトの TTL ポリシーを表示します。
print ステートメントを使用して、アーティファクトの TTL ポリシーを表示します。次の例は、アーティファクトを取得し、その TTL ポリシーを表示する方法を示しています。
artifact = run.use_artifact("<my-entity/my-project/my-artifact:alias>")
print(artifact.ttl)
W&B アプリ UI でアーティファクトの TTL ポリシーを表示します。
- https://wandb.ai で W&B アプリに移動します。
- W&B プロジェクトに移動します。
- プロジェクト内で、左側のサイドバーにある [Artifacts] タブを選択します。
- コレクションをクリックします。
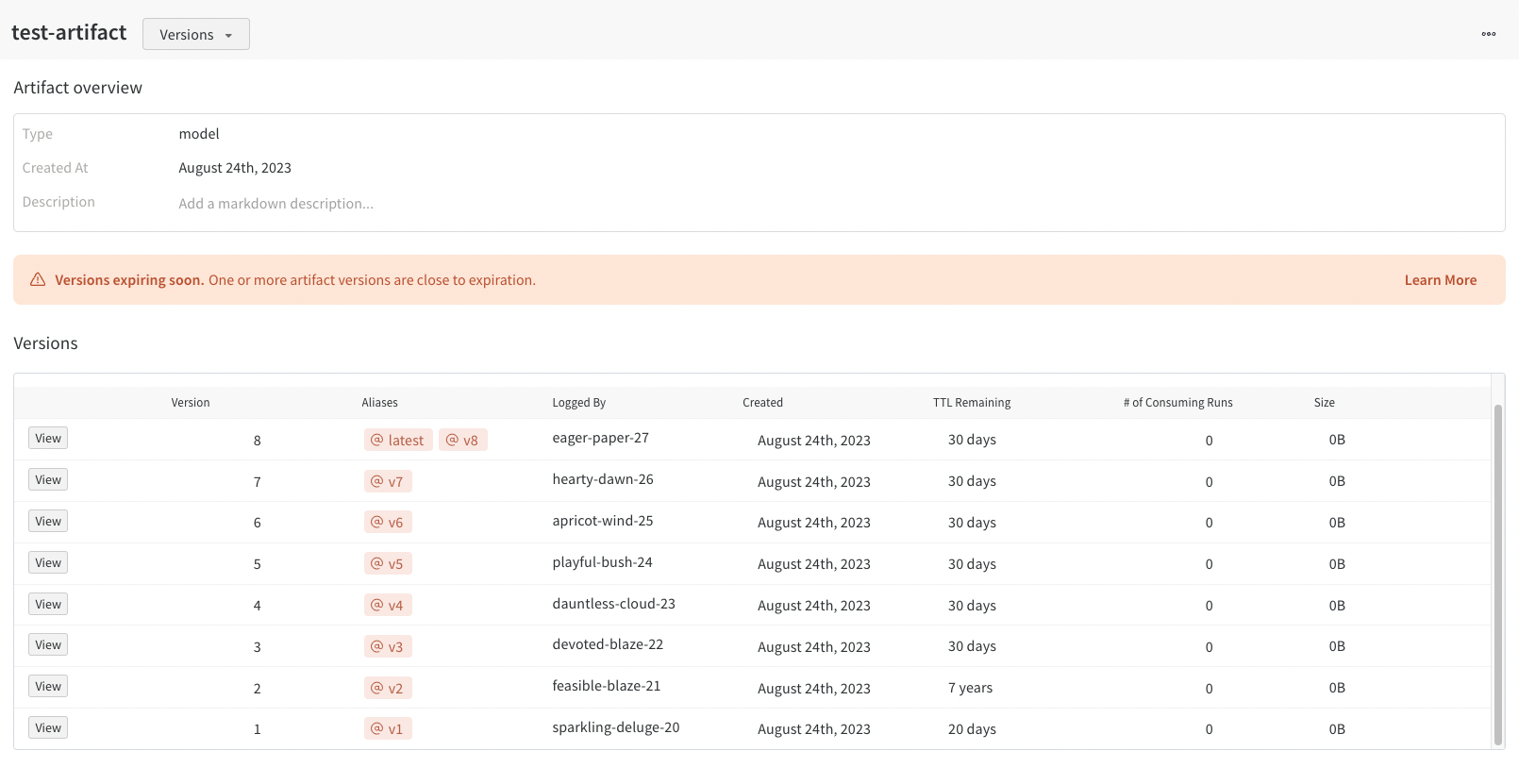
コレクションビュー内では、選択したコレクション内のすべてのアーティファクトを表示できます。[Time to Live] 列には、そのアーティファクトに割り当てられた TTL ポリシーが表示されます。
7.3 - Manage artifact storage and memory allocation
W&B Artifacts のストレージ、メモリアロケーションを管理します。
W&B は artifact ファイルを、デフォルトで米国にあるプライベートな Google Cloud Storage バケットに保存します。すべてのファイルは、保存時および転送時に暗号化されます。
機密性の高いファイルについては、Private Hosting をセットアップするか、reference artifacts を使用することをお勧めします。
トレーニング中、W&B はログ、アーティファクト、および設定ファイルを次のローカルディレクトリーにローカルに保存します。
| ファイル |
デフォルトの場所 |
デフォルトの場所を変更するには、以下を設定します: |
| ログ |
./wandb |
wandb.init の dir 、または WANDB_DIR 環境変数を設定 |
| artifacts |
~/.cache/wandb |
WANDB_CACHE_DIR 環境変数 |
| configs |
~/.config/wandb |
WANDB_CONFIG_DIR 環境変数 |
| アップロード用に artifacts をステージング |
~/.cache/wandb-data/ |
WANDB_DATA_DIR 環境変数 |
| ダウンロードされた artifacts |
./artifacts |
WANDB_ARTIFACT_DIR 環境変数 |
環境変数を使用して W&B を構成するための完全なガイドについては、環境変数のリファレンスを参照してください。
wandb が初期化されるマシンによっては、これらのデフォルトフォルダーがファイルシステムの書き込み可能な場所に配置されていない場合があります。これにより、エラーが発生する可能性があります。
ローカル artifact キャッシュのクリーンアップ
W&B は artifact ファイルをキャッシュして、ファイルを共有する バージョン 間でのダウンロードを高速化します。時間の経過とともに、このキャッシュディレクトリーが大きくなる可能性があります。wandb artifact cache cleanup コマンドを実行して、キャッシュを削除し、最近使用されていないファイルを削除します。
次のコードスニペットは、キャッシュのサイズを 1GB に制限する方法を示しています。コードスニペットをコピーして ターミナル に貼り付けます。
$ wandb artifact cache cleanup 1GB
8 - Explore artifact graphs
自動的に作成された有向非巡回 W&B Artifact グラフをトラバースします。
W&B は、特定の run が ログに記録した Artifacts と、特定の run が使用する Artifacts を自動的に追跡します。これらの Artifacts には、データセット、モデル、評価結果などが含まれます。Artifacts のリネージを調べることで、機械学習のライフサイクル全体で生成されるさまざまな Artifacts を追跡および管理できます。
リネージ
Artifacts のリネージを追跡することには、いくつかの重要な利点があります。
-
再現性: すべての Artifacts のリネージを追跡することで、チームは Experiments、モデル、および結果を再現できます。これは、デバッグ、実験、および機械学習モデルの検証に不可欠です。
-
バージョン管理: Artifacts のリネージには、Artifacts のバージョン管理と、時間の経過に伴う変更の追跡が含まれます。これにより、チームは必要に応じてデータまたはモデルの以前のバージョンにロールバックできます。
-
監査: Artifacts とその変換の詳細な履歴を持つことで、組織は規制およびガバナンスの要件を遵守できます。
-
コラボレーションと知識の共有: Artifacts のリネージは、試行錯誤の明確な記録を提供することにより、チームメンバー間のより良いコラボレーションを促進します。これは、努力の重複を回避し、開発プロセスを加速するのに役立ちます。
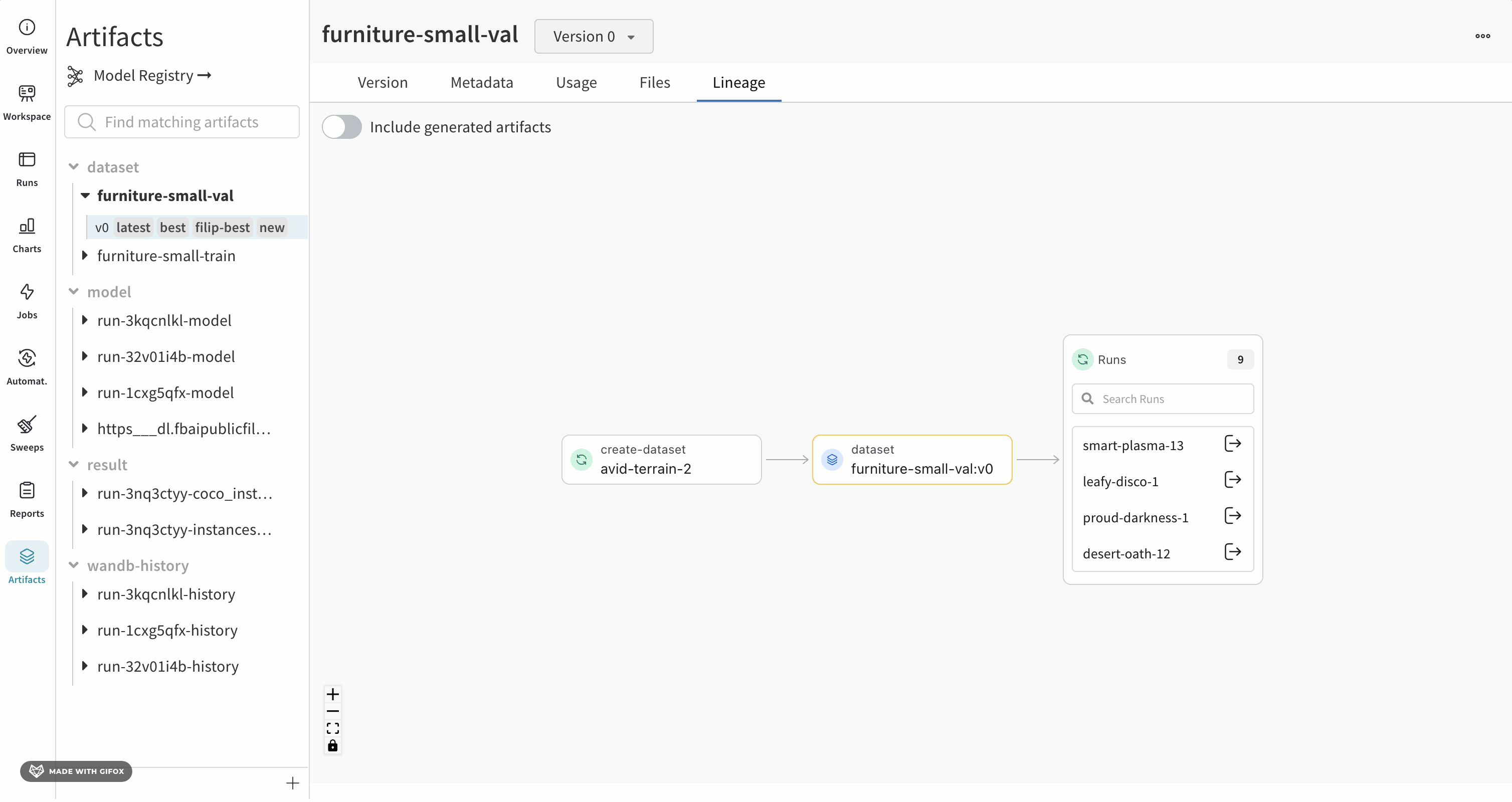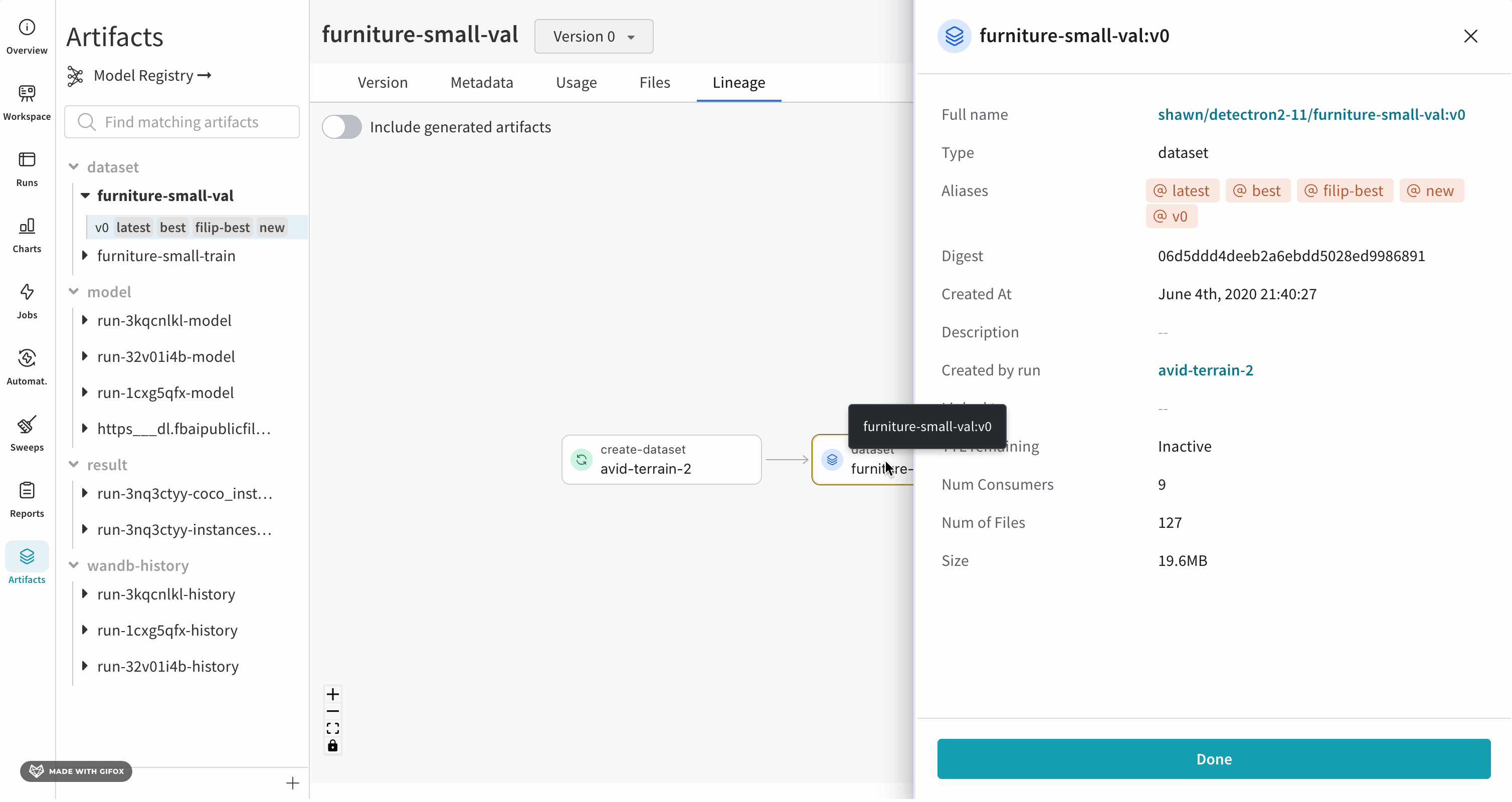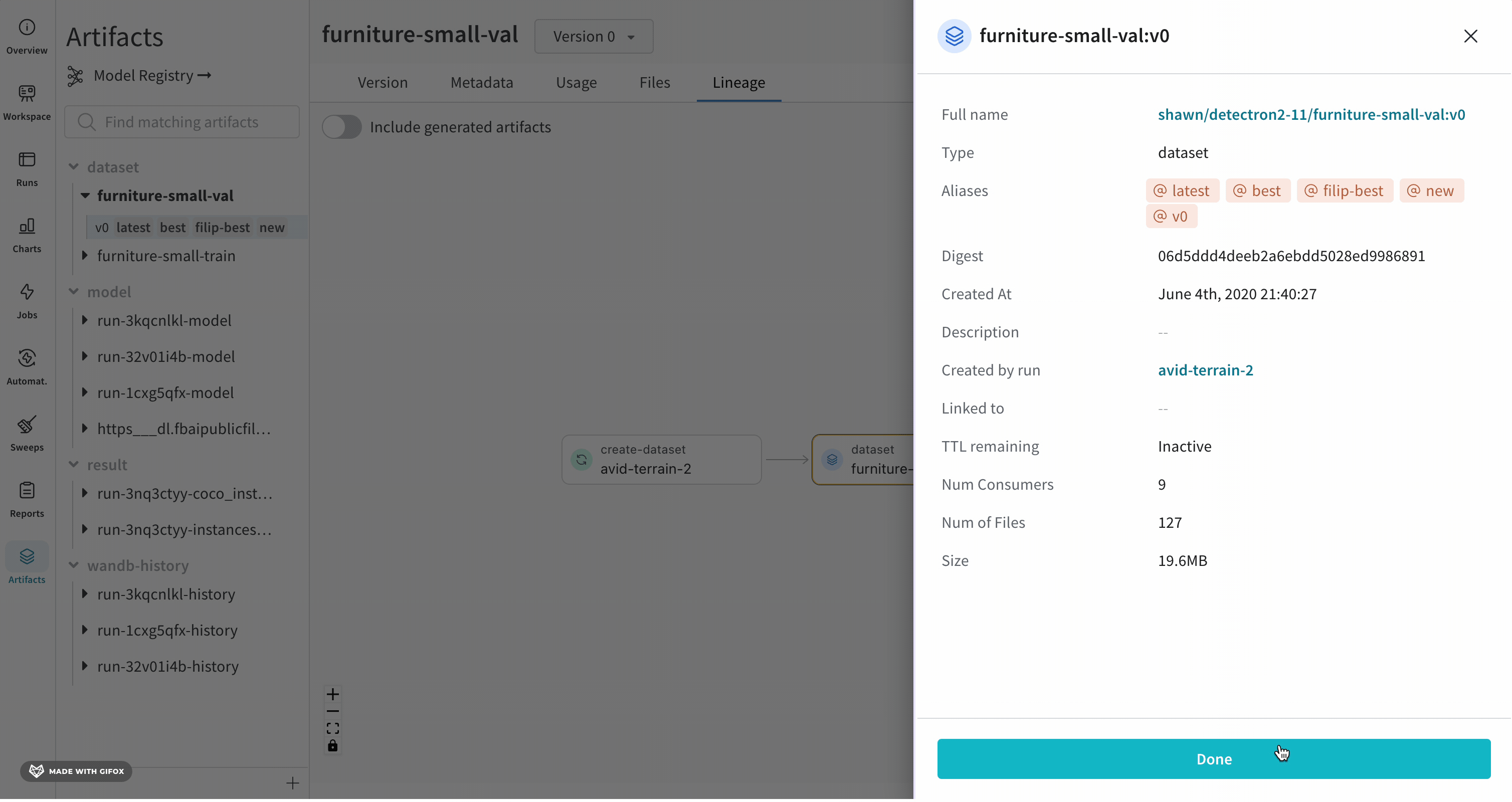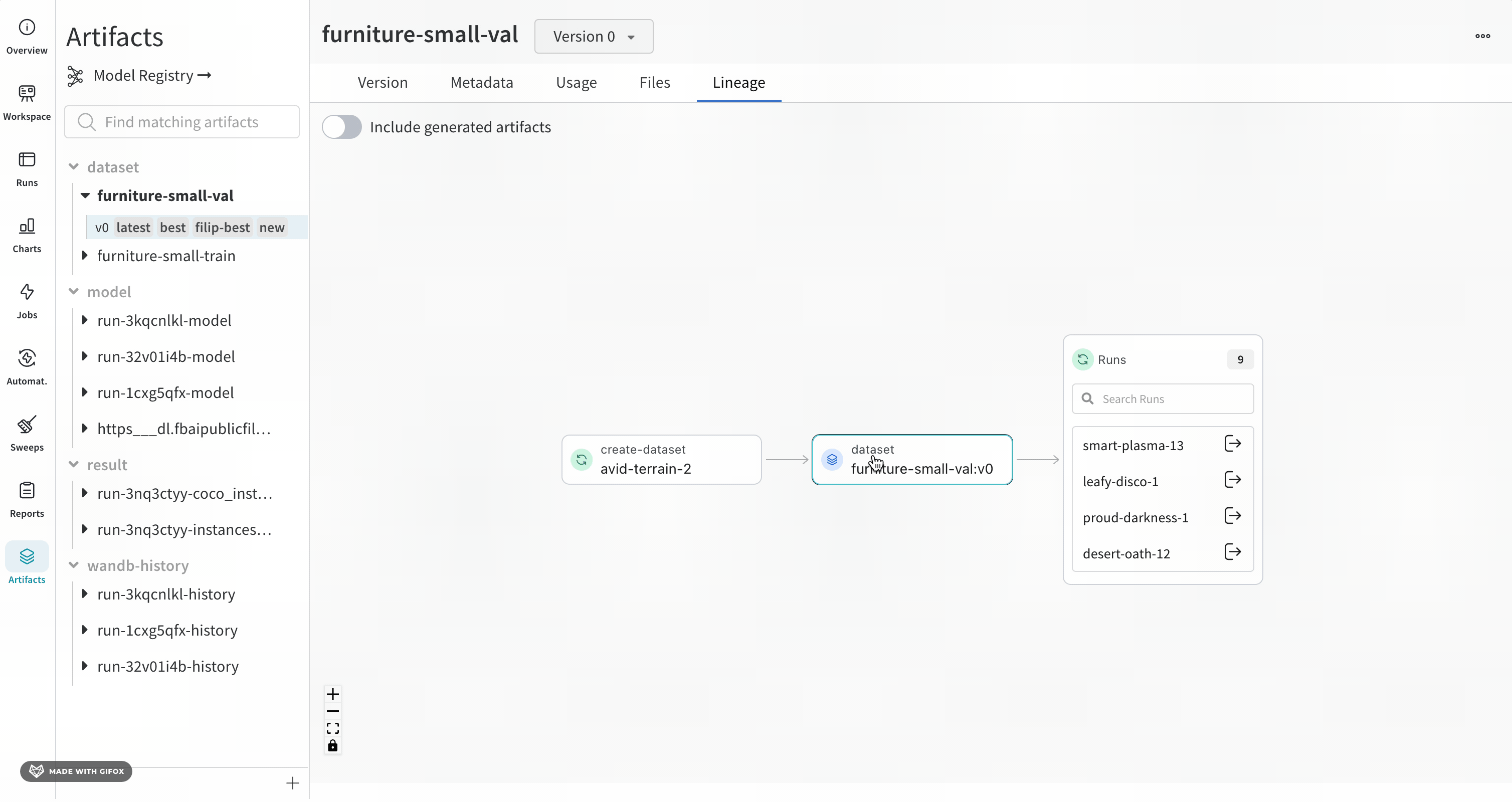
Artifacts のリネージの検索
[Artifacts] タブで Artifacts を選択すると、Artifacts のリネージを確認できます。このグラフビューには、パイプラインの概要が表示されます。
Artifacts グラフを表示するには:
- W&B App UI で プロジェクト に移動します。
- 左側の パネル で Artifacts アイコンを選択します。
- [Lineage] を選択します。
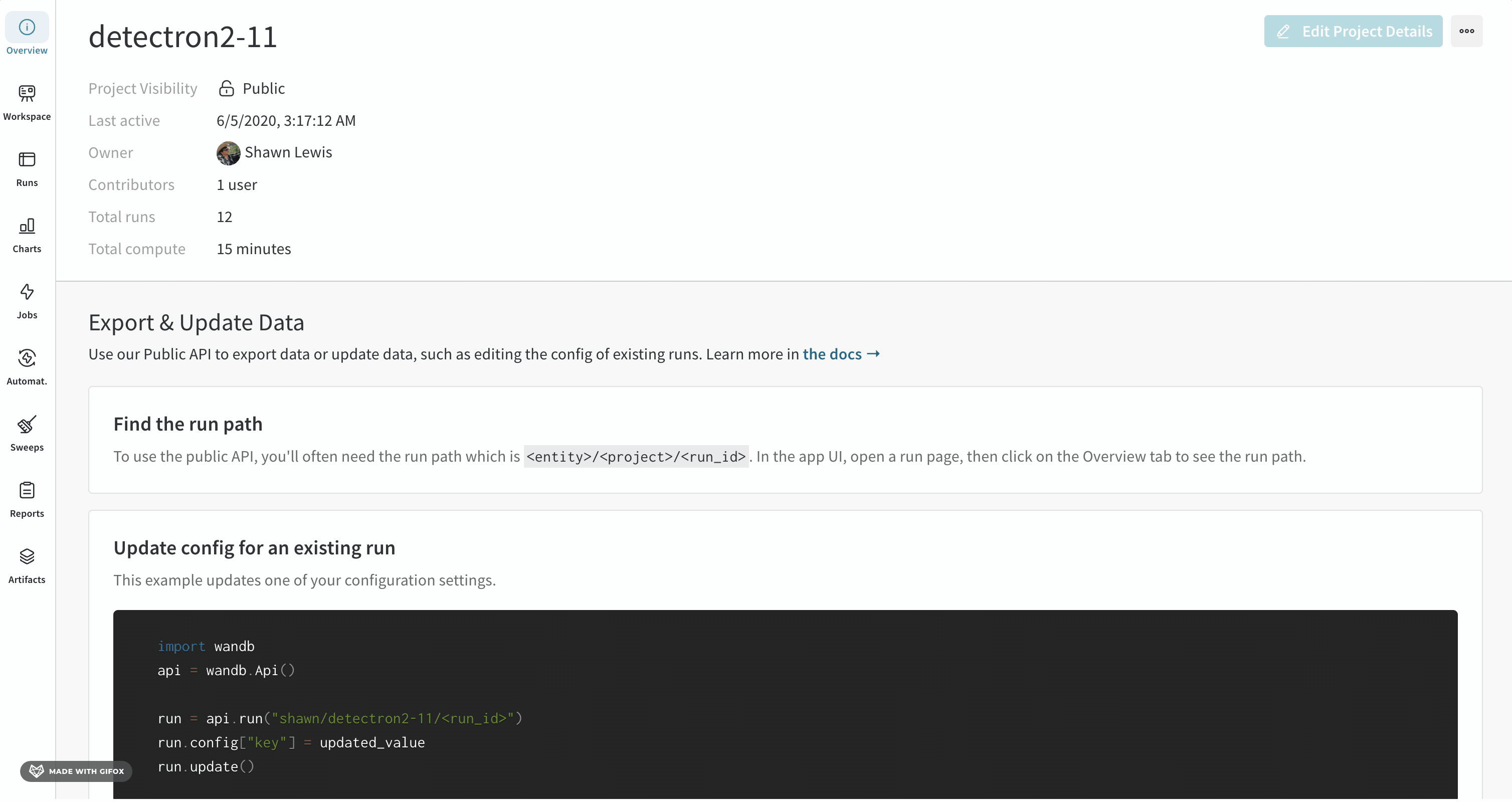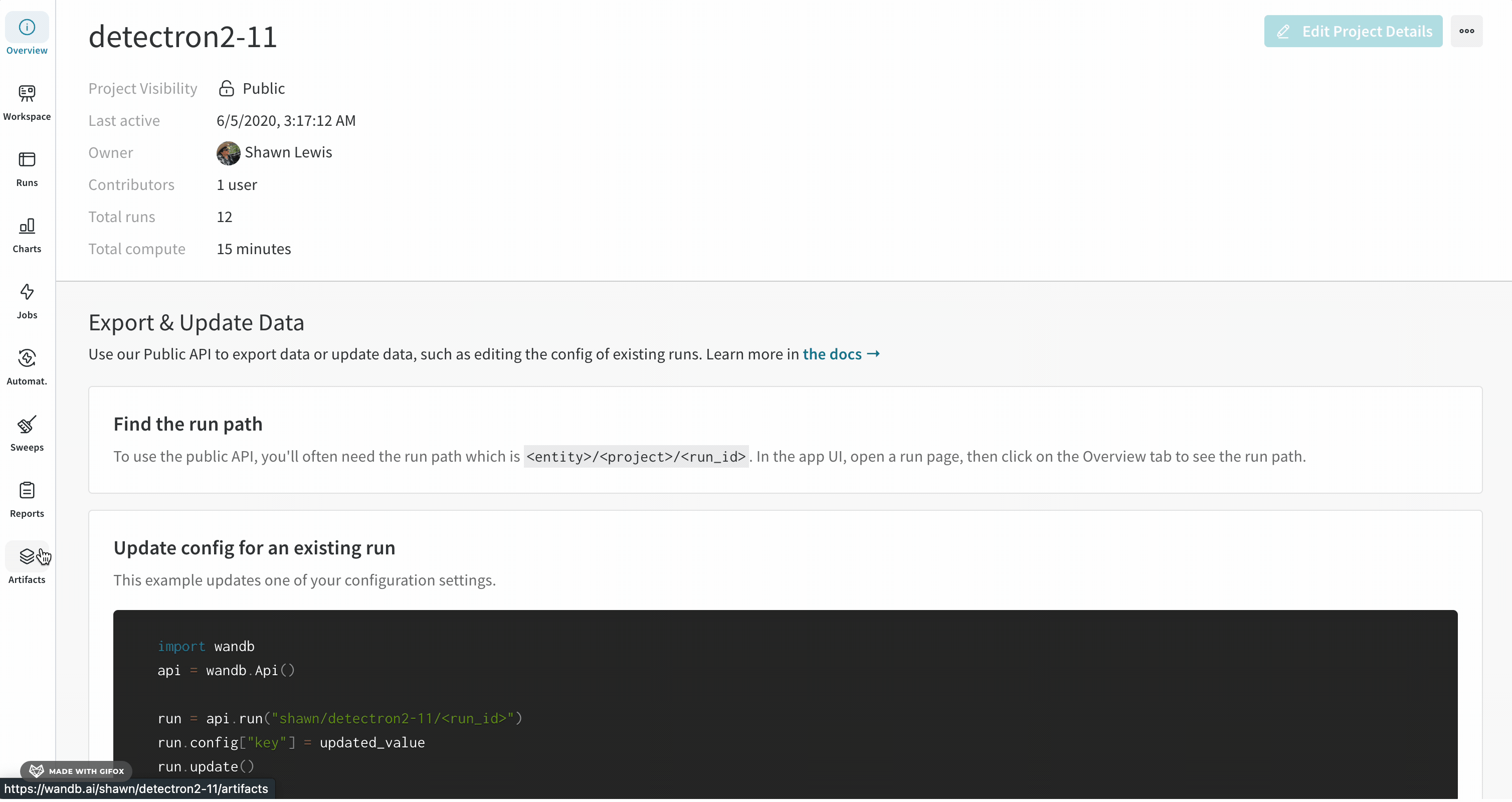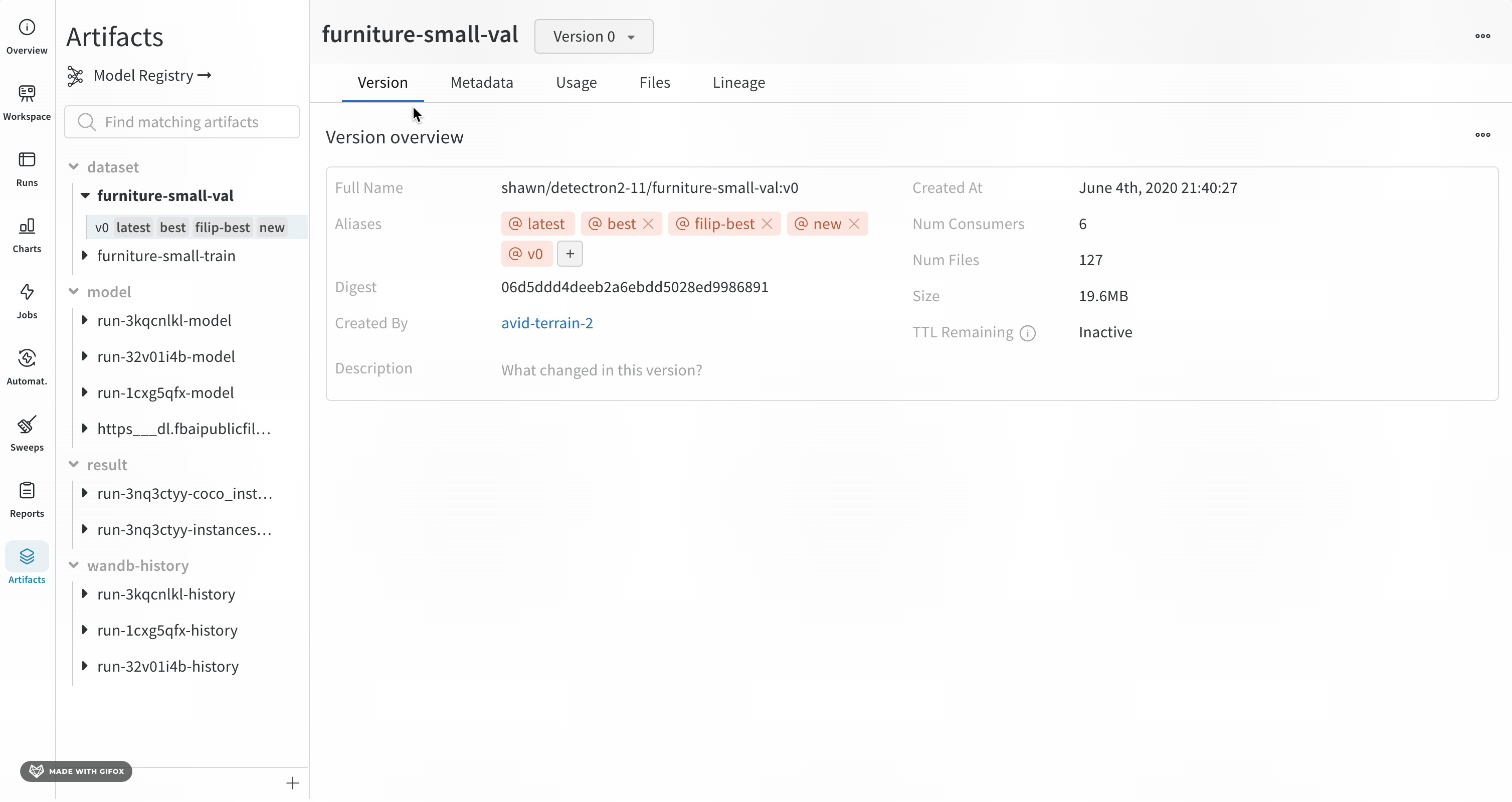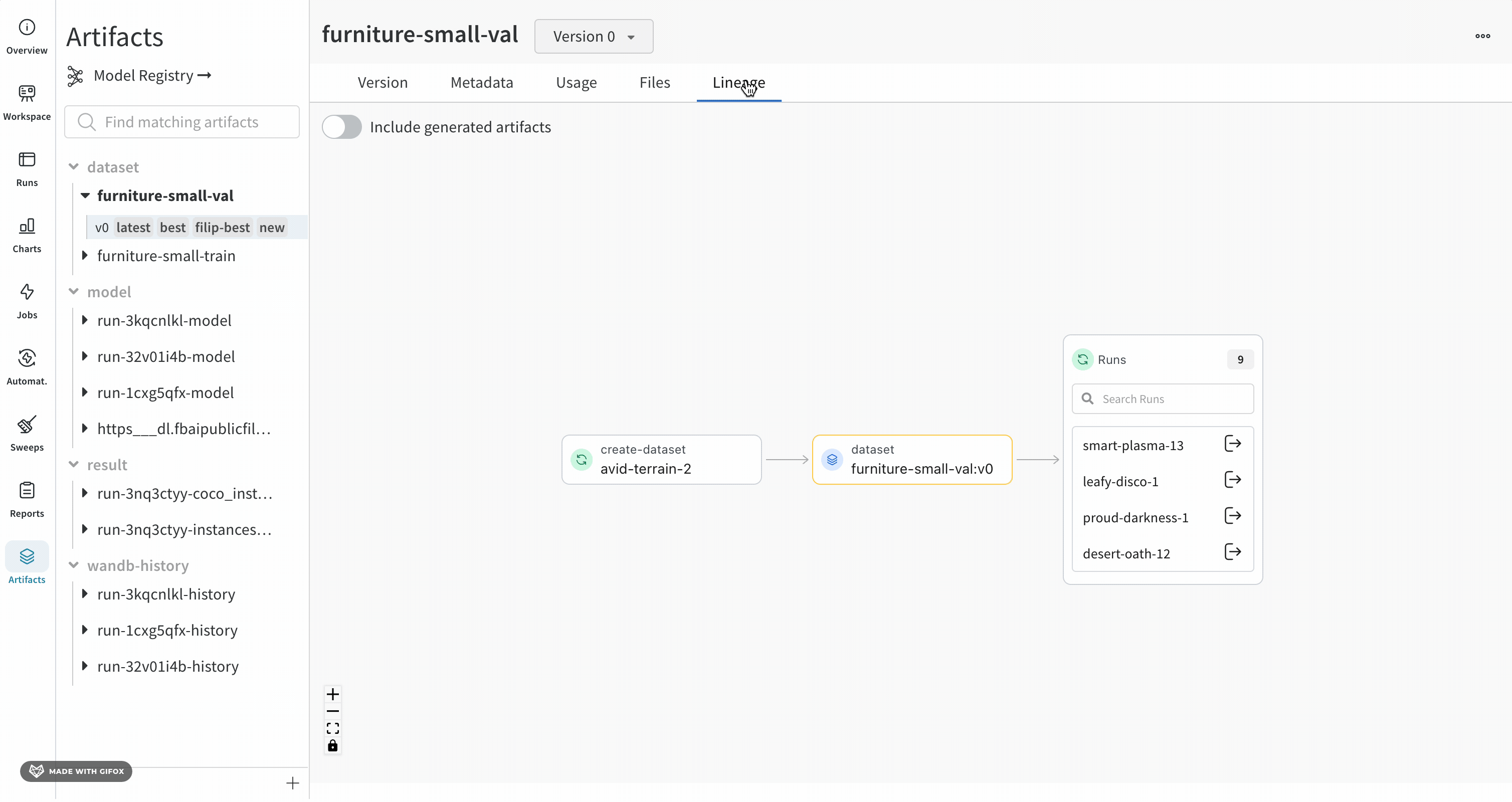
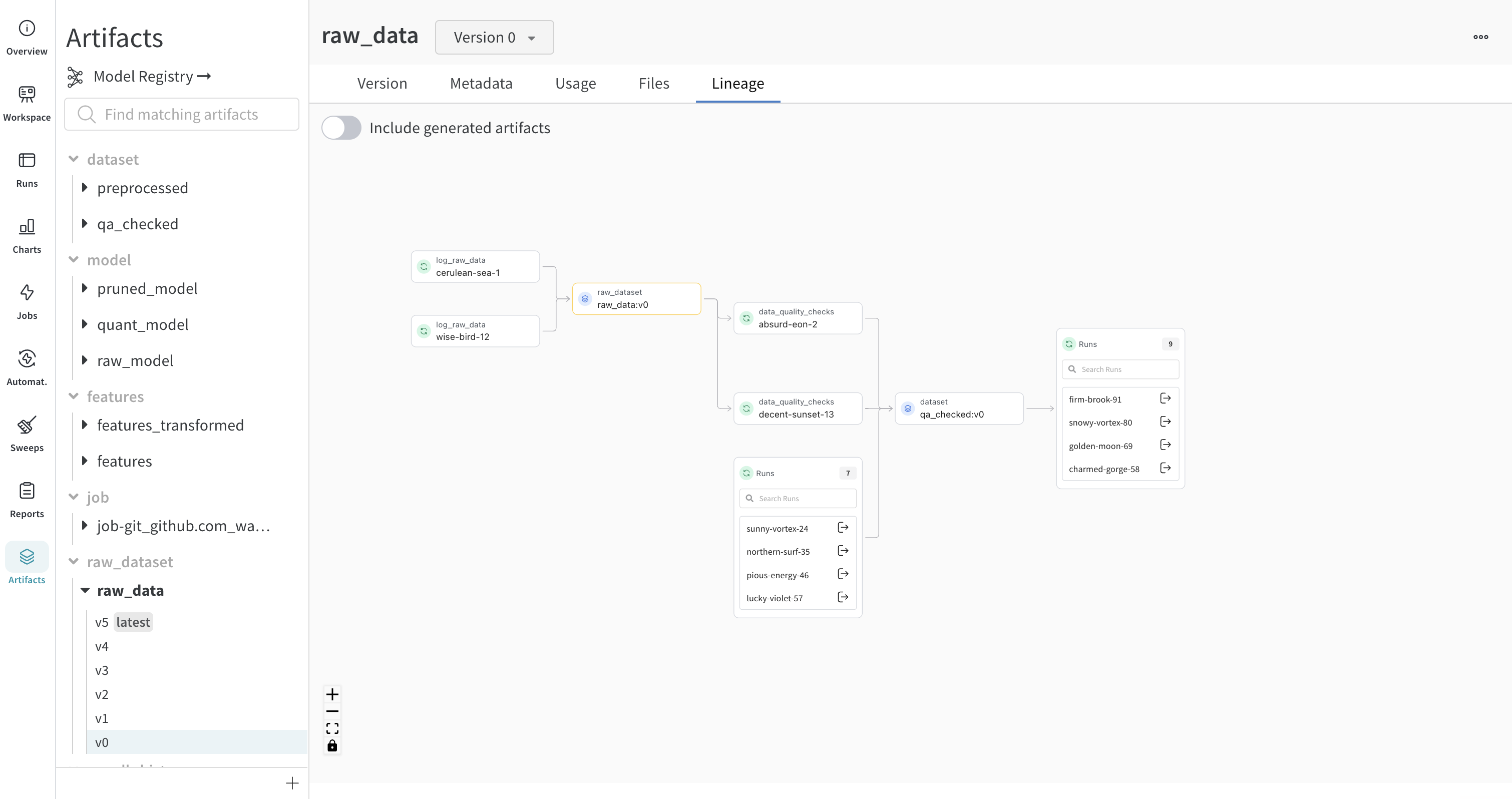
リネージグラフのナビゲート
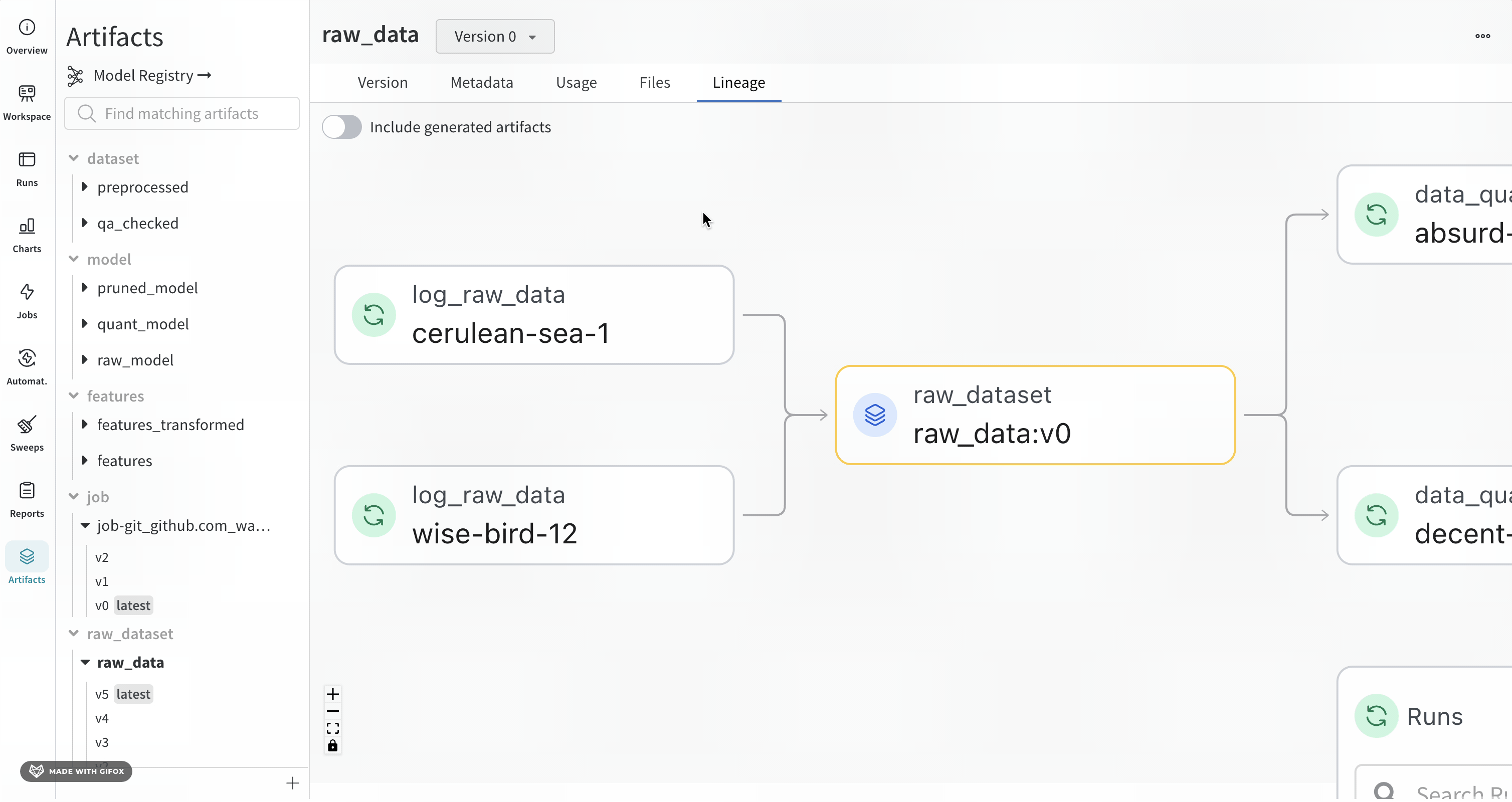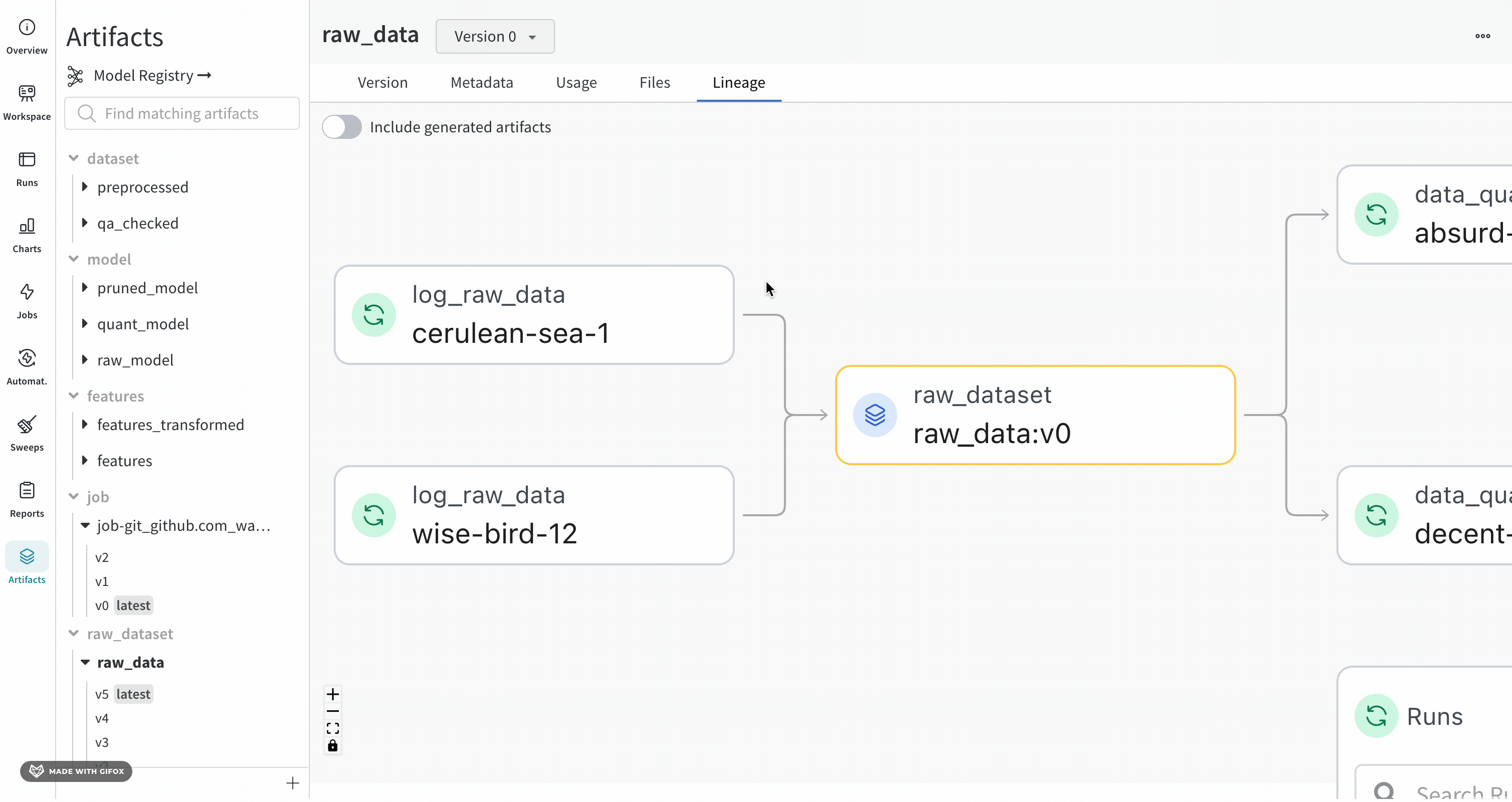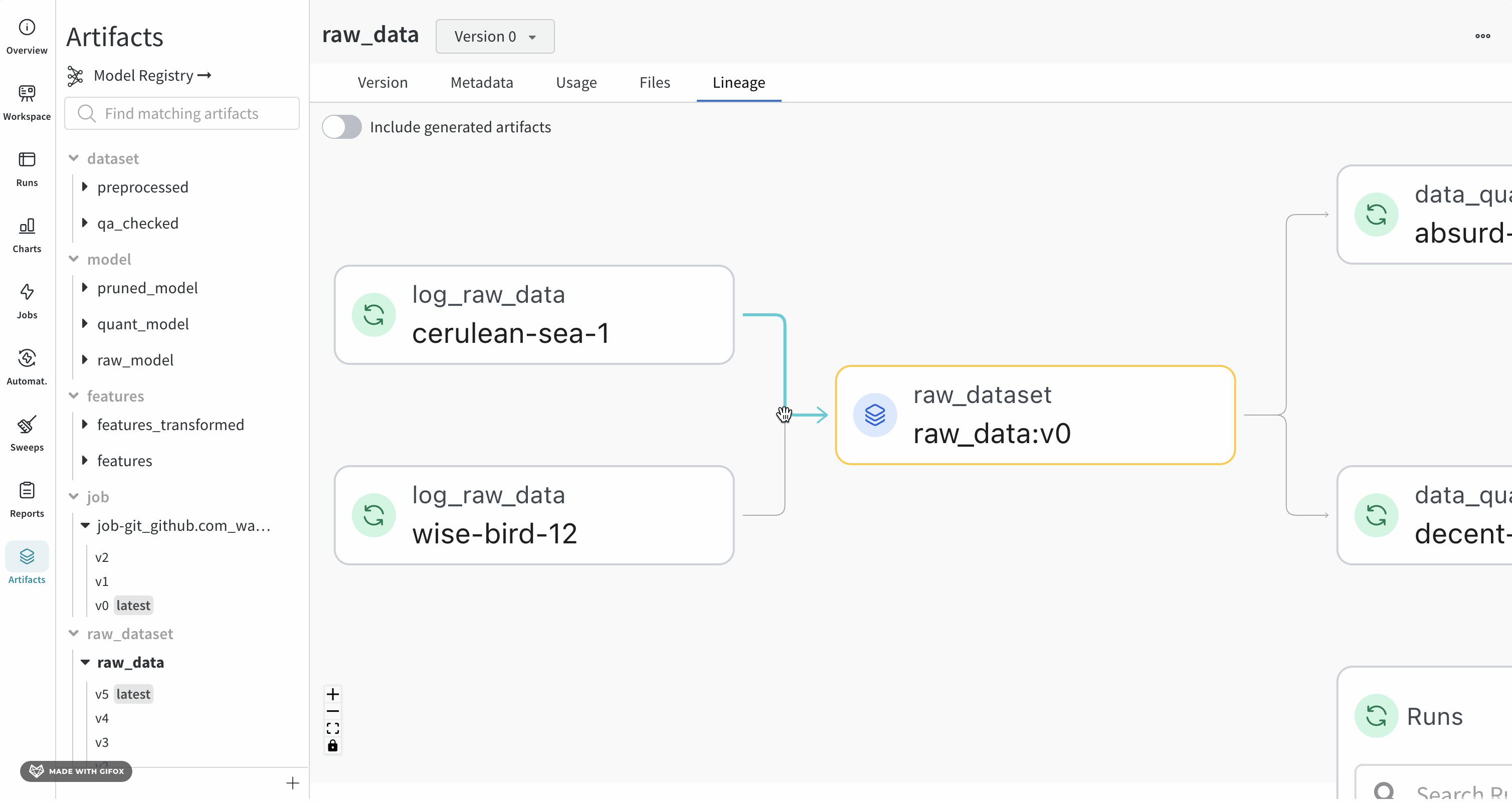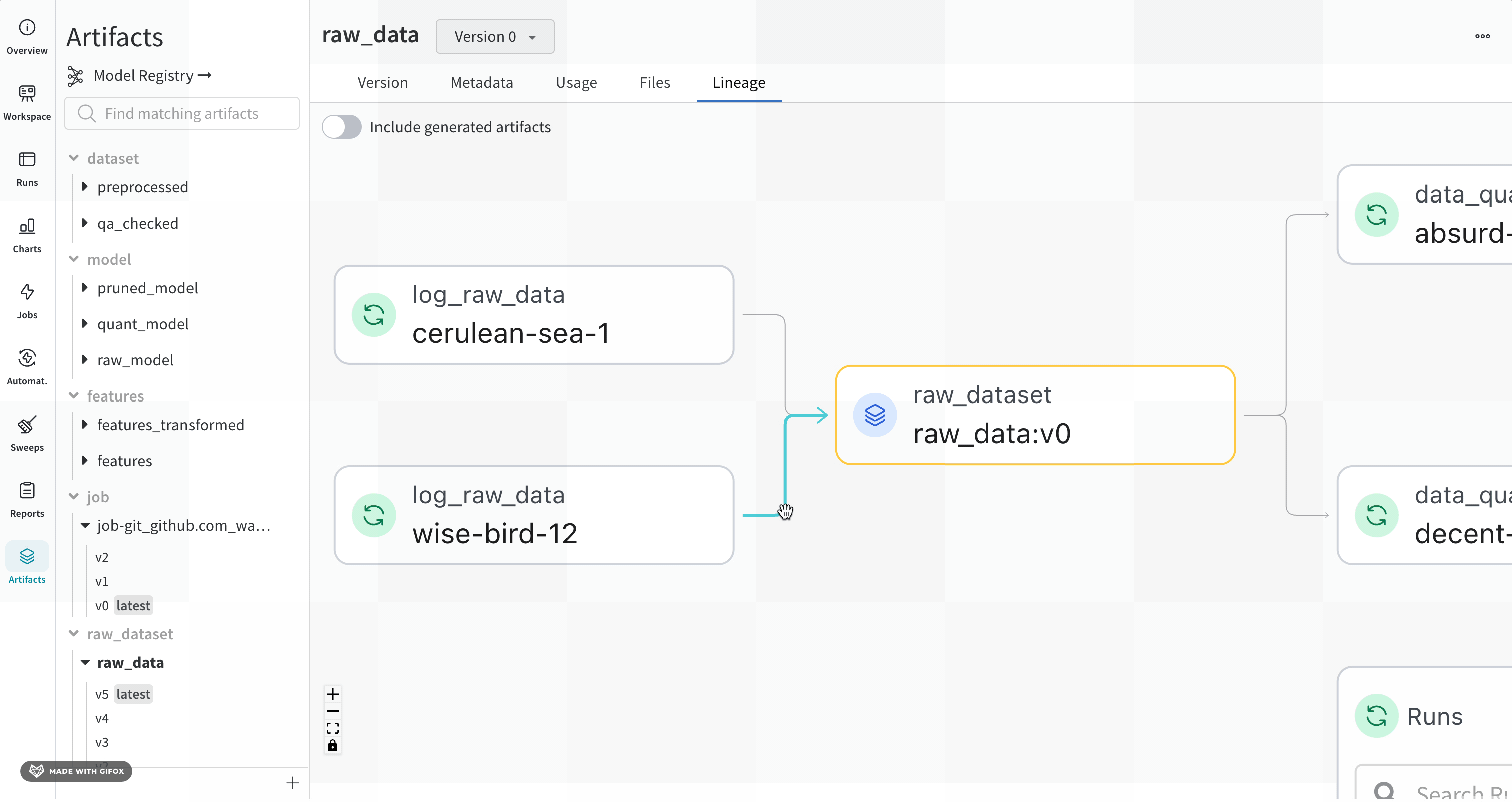
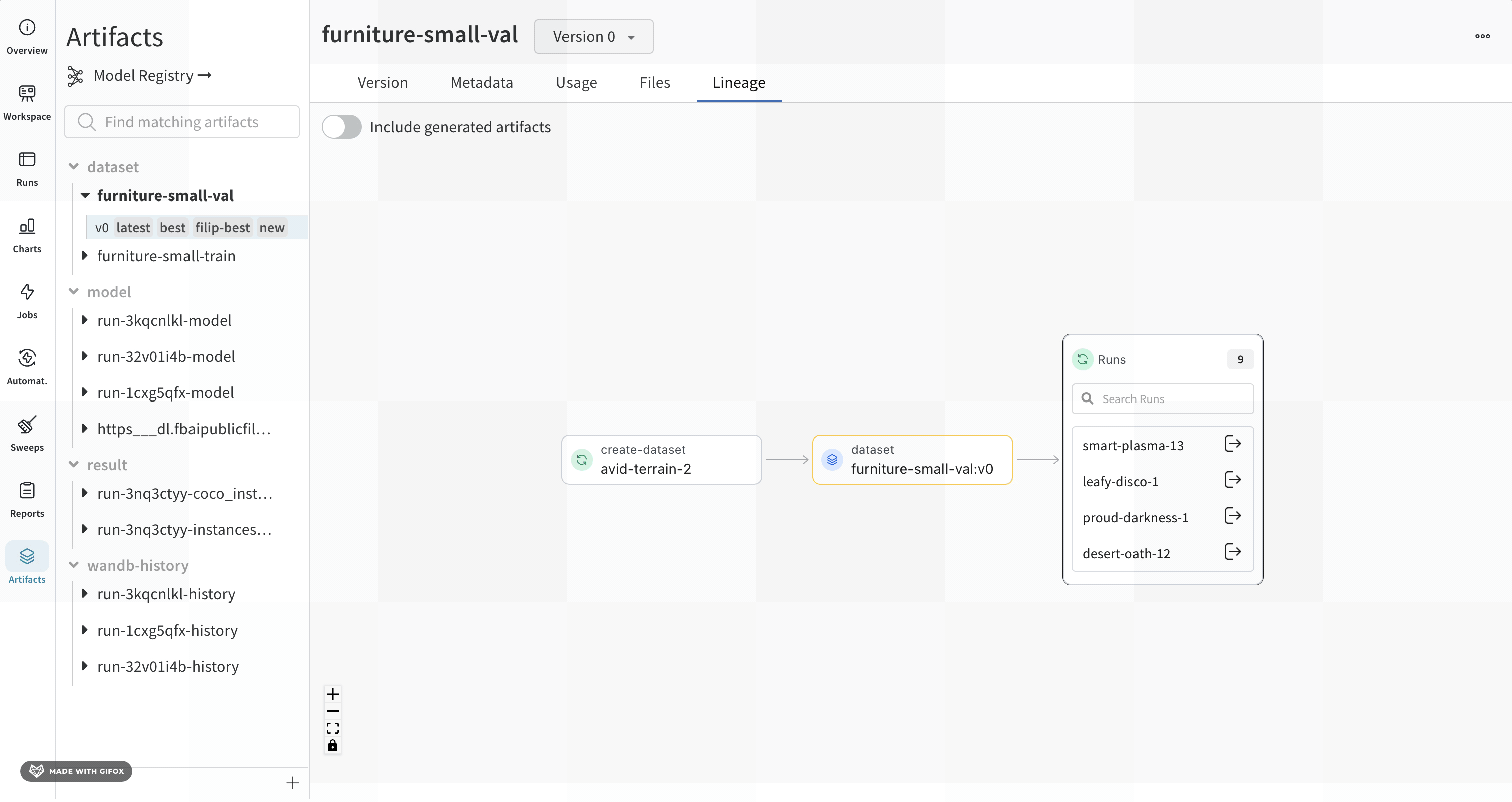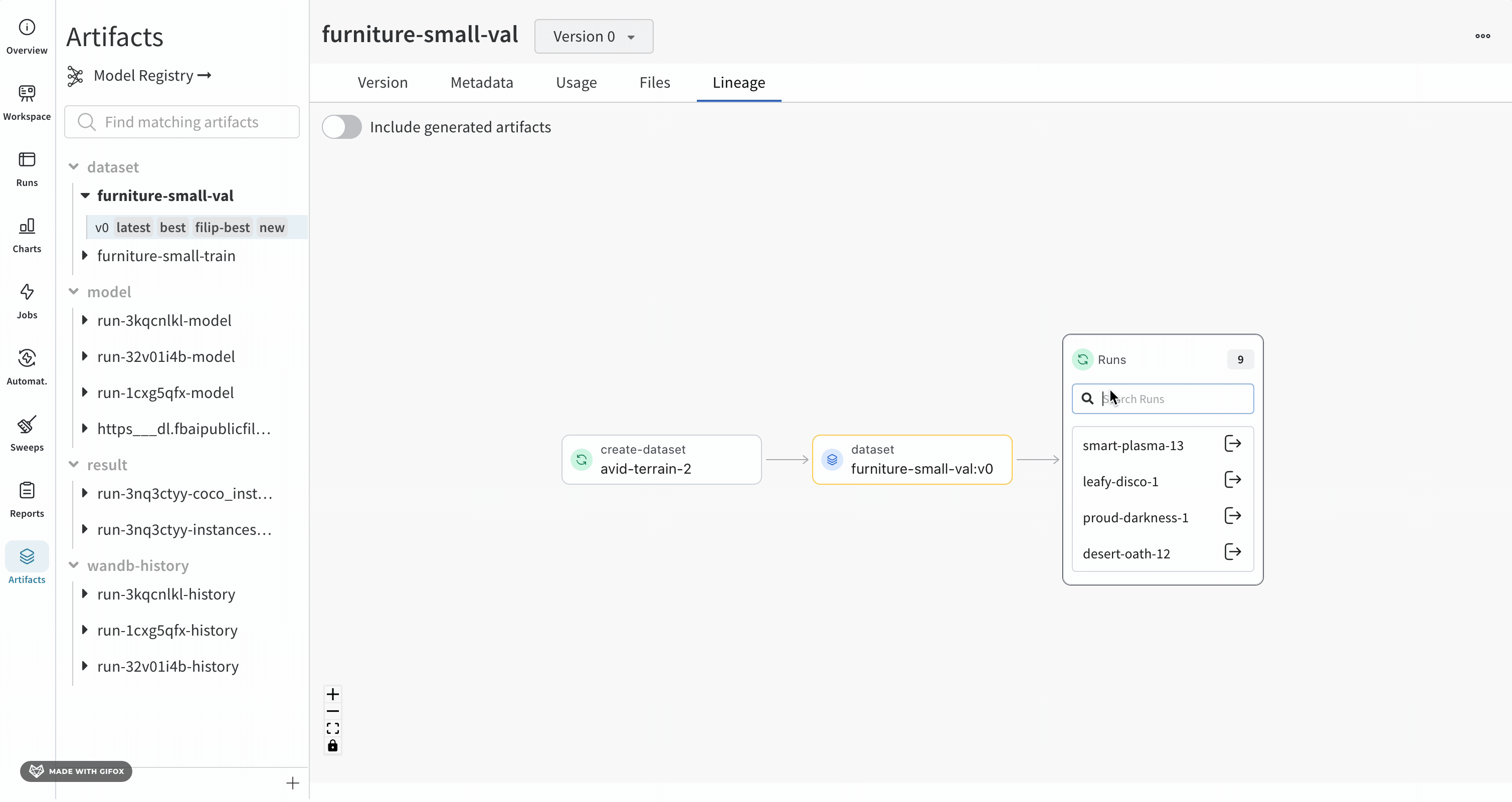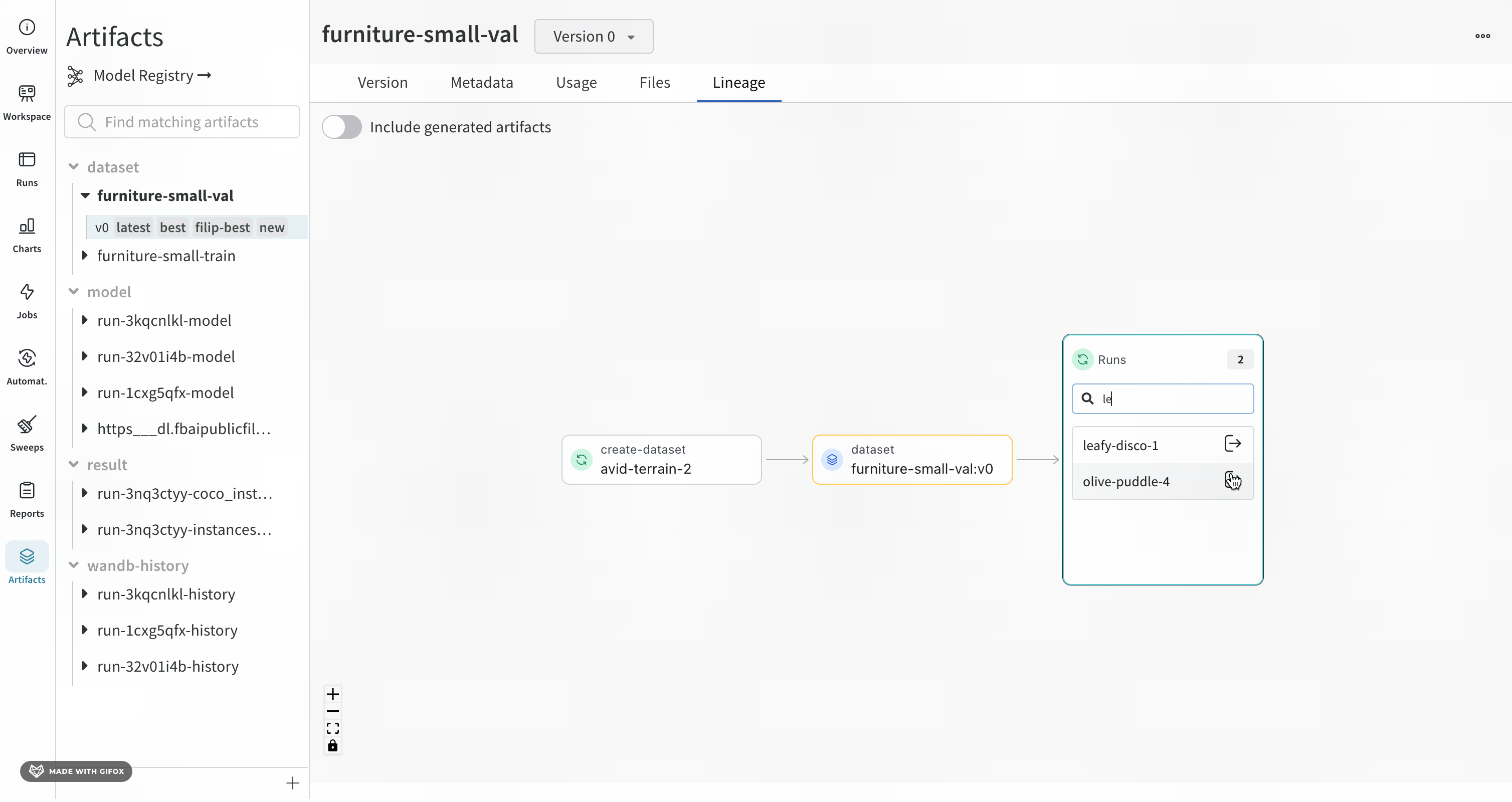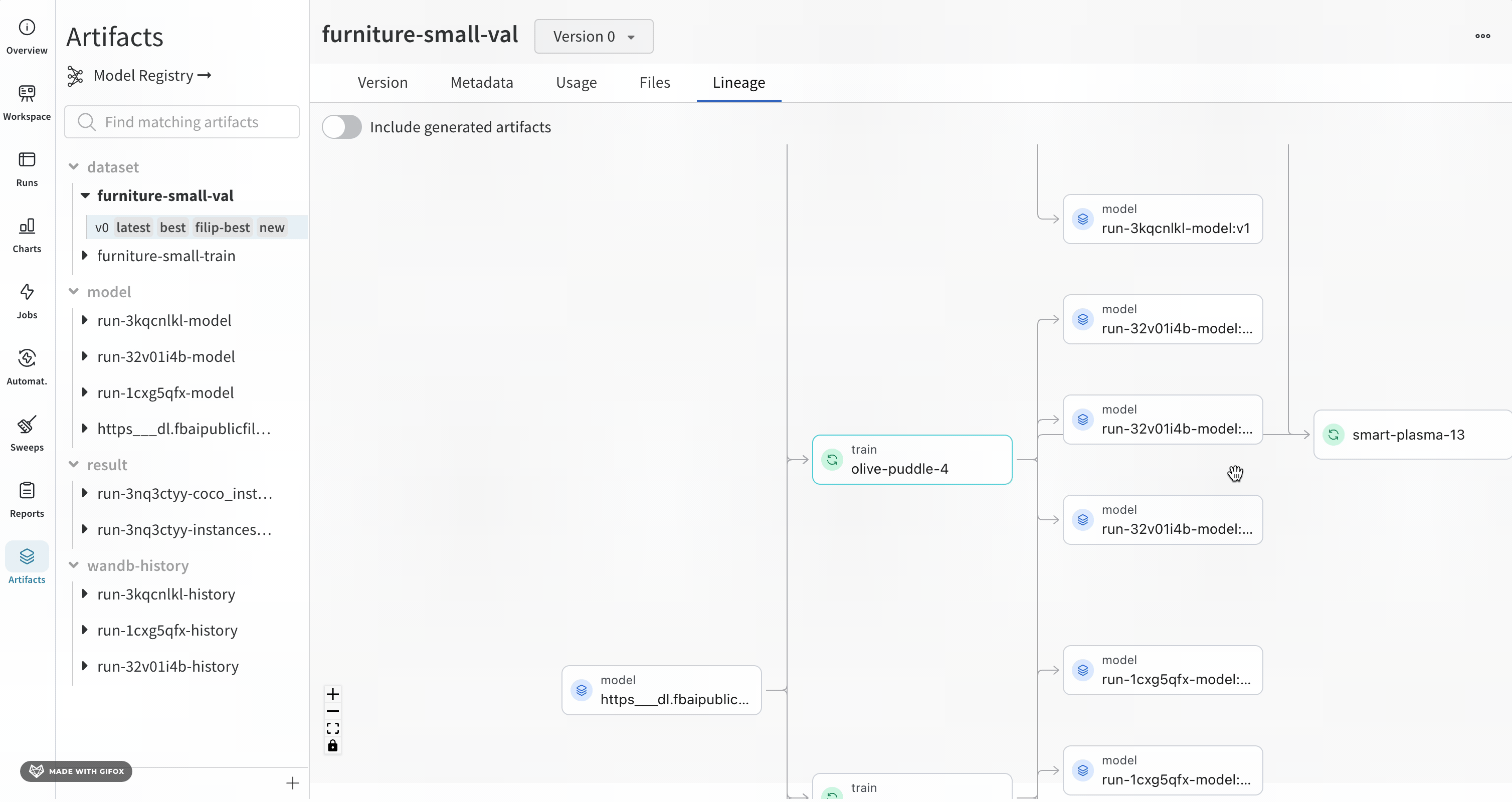
指定した Artifacts またはジョブタイプが名前の前に表示され、Artifacts は青いアイコンで、runs は緑のアイコンで表示されます。矢印は、グラフ上の run または Artifacts の入出力を詳細に示します。
Artifacts のタイプと名前は、左側のサイドバーと [Lineage] タブの両方で確認できます。
より詳細なビューを表示するには、個々の Artifacts または run をクリックして、特定のオブジェクトに関する詳細情報を取得します。
Artifacts クラスター
グラフのレベルに 5 つ以上の runs または Artifacts がある場合、クラスターが作成されます。クラスターには、runs または Artifacts の特定の バージョン を検索するための検索バーがあり、クラスターから個々のノードをプルして、クラスター内のノードのリネージの調査を続行します。
ノードをクリックすると、ノードの概要を示すプレビューが開きます。矢印をクリックすると、個々の run または Artifacts が抽出され、抽出されたノードのリネージを調べることができます。
API を使用してリネージを追跡する
W&B APIを使用してグラフをナビゲートすることもできます。
Artifacts を作成します。まず、wandb.init で run を作成します。次に、wandb.Artifact で新しい Artifacts を作成するか、既存の Artifacts を取得します。次に、.add_file で Artifacts にファイルを追加します。最後に、.log_artifact で Artifacts を run に ログ します。完成した コード は次のようになります。
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# Add Files and Assets to the artifact using
# `.add`, `.add_file`, `.add_dir`, and `.add_reference`
artifact.add_file("image1.png")
run.log_artifact(artifact)
Artifacts オブジェクトの logged_by メソッドと used_by メソッドを使用して、Artifacts からグラフをたどります。
# Walk up and down the graph from an artifact:
producer_run = artifact.logged_by()
consumer_runs = artifact.used_by()
次のステップ
9 - Artifact data privacy and compliance
W&B のファイルがデフォルトでどこに保存されるかについて学びましょう。機密情報の保存、保存方法について説明します。
ファイルを Artifacts としてログに記録すると、ファイルは W&B が管理する Google Cloud バケットにアップロードされます。バケットの内容は、保存時も転送時も暗号化されます。Artifact ファイルは、対応する プロジェクト への アクセス権 を持つ ユーザー のみに表示されます。
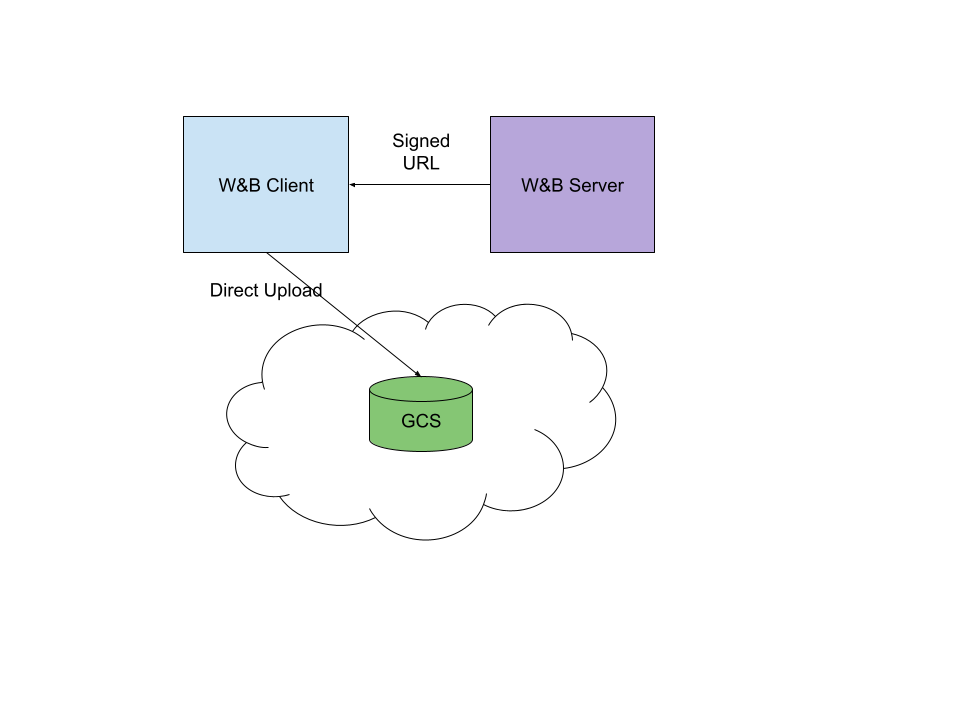
Artifact の バージョン を削除すると、 データベース 内でソフト削除としてマークされ、ストレージコストから削除されます。Artifact 全体を削除すると、 完全に削除されるようにキューに入れられ、そのすべてのコンテンツが W&B バケット から削除されます。ファイルの削除に関して特別なニーズがある場合は、カスタマーサポートまでご連絡ください。
マルチテナント 環境 に存在できない機密性の高い データセット の場合、 クラウド バケット に接続された プライベート W&B サーバー 、または reference artifacts を使用できます。Reference artifacts は、ファイルの内容を W&B に送信せずに、 プライベート バケット への参照を追跡します。Reference artifacts は、 バケット または サーバー 上のファイルへのリンクを保持します。つまり、W&B はファイル自体ではなく、ファイルに関連付けられた メタデータ のみを追跡します。
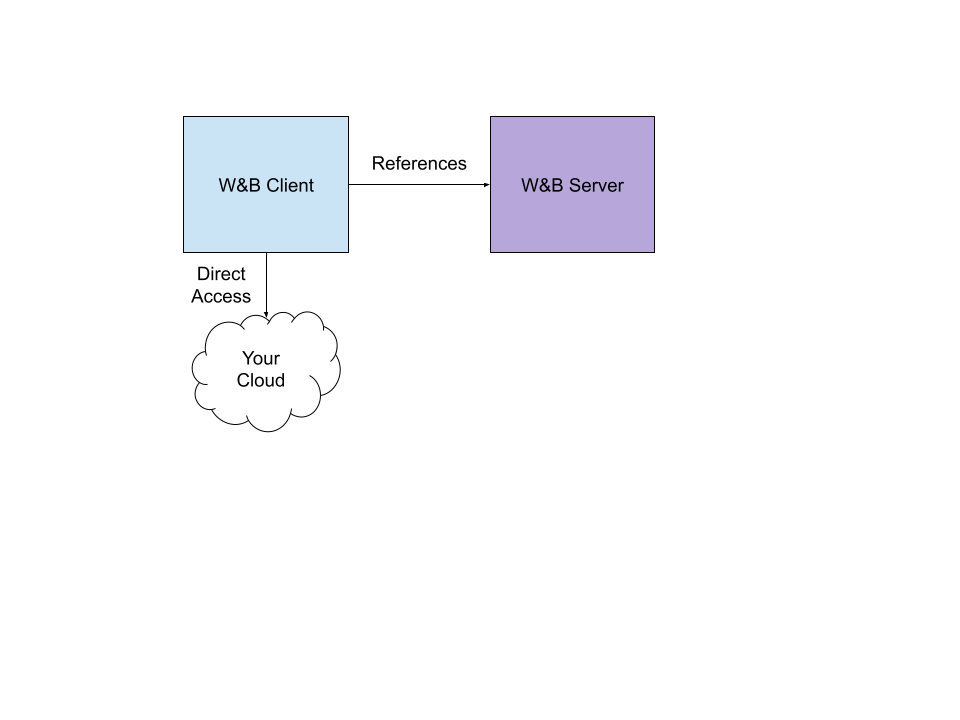
Reference artifact は、非 Reference artifact を作成するのと同じように作成します。
import wandb
run = wandb.init()
artifact = wandb.Artifact("animals", type="dataset")
artifact.add_reference("s3://my-bucket/animals")
代替案については、contact@wandb.com までお問い合わせいただき、 プライベートクラウド および オンプレミス のインストールについてご相談ください。
10 - Tutorial: Create, track, and use a dataset artifact
Artifacts クイックスタート では、W&B で データセット artifact を作成、追跡、使用する方法を紹介します。
このチュートリアルでは、W&B Runsからデータセット Artifactsを作成、追跡、および使用する方法を示します。
1. W&Bにログイン
W&Bライブラリをインポートし、W&Bにログインします。まだお持ちでない場合は、無料のW&Bアカウントにサインアップする必要があります。
import wandb
wandb.login()
2. runを初期化
wandb.init() APIを使用して、W&B Runとしてデータを同期および記録するためのバックグラウンド プロセスを生成します。 project名とジョブタイプを指定します。
# W&B Runを作成します。この例では、データセット Artifactsの作成方法を示すため、ジョブタイプとして「dataset」を指定します。
run = wandb.init(project="artifacts-example", job_type="upload-dataset")
3. artifact オブジェクトを作成
wandb.Artifact() APIを使用して、artifact オブジェクトを作成します。 artifactの名前とファイルタイプの記述を、それぞれname パラメータと type パラメータに指定します。
たとえば、次のコードスニペットは、‘bicycle-dataset’ という名前で ‘dataset’ というラベルの artifact を作成する方法を示しています。
artifact = wandb.Artifact(name="bicycle-dataset", type="dataset")
artifact の構成方法の詳細については、Artifactsの構築を参照してください。
データセットを artifact に追加
artifact にファイルを追加します。一般的なファイルタイプには、Models や Datasets などがあります。次の例では、マシンにローカルに保存されている dataset.h5 という名前のデータセットを artifact に追加します。
# ファイルをartifactのコンテンツに追加します。
artifact.add_file(local_path="dataset.h5")
上記のコードスニペットのファイル名 dataset.h5 を、artifact に追加するファイルへのパスに置き換えます。
4. データセットをログに記録
W&B run オブジェクトの log_artifact() メソッドを使用して、artifact のバージョンを保存し、artifact を run の出力として宣言します。
# artifact のバージョンを W&B に保存し、この run の出力としてマークします。
run.log_artifact(artifact)
artifact をログに記録すると、デフォルトで 'latest' エイリアスが作成されます。 artifact のエイリアスとバージョンの詳細については、カスタムエイリアスを作成すると新しい artifact バージョンを作成するをそれぞれ参照してください。
5. artifact をダウンロードして使用する
次のコード例は、W&B サーバーにログして保存した artifact を使用するために実行できる手順を示しています。
- まず、
wandb.init() を使用して新しい run オブジェクトを初期化します。
- 次に、run オブジェクトの
use_artifact() メソッドを使用して、使用する artifact を W&B に指示します。 これにより、artifact オブジェクトが返されます。
- 3 番目に、artifact の
download() メソッドを使用して、artifact のコンテンツをダウンロードします。
# W&B Runを作成します。ここでは、この run をトレーニングの追跡に使用するため、'type' に 'training' を指定します。
run = wandb.init(project="artifacts-example", job_type="training")
# W&B に artifact を照会し、この run への入力としてマークします。
artifact = run.use_artifact("bicycle-dataset:latest")
# artifact のコンテンツをダウンロードします
artifact_dir = artifact.download()
または、パブリック API(wandb.Api)を使用して、Run の外部にある W&B にすでに保存されているデータをエクスポート(または更新)できます。 詳細については、外部ファイルを追跡するを参照してください。