これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
Launch
- 1: Tutorial: W&B Launch basics
- 2: Launch terms and concepts
- 3: Set up Launch
- 3.1: Configure launch queue
- 3.2: Set up launch agent
- 3.3: Tutorial: Set up W&B Launch on Kubernetes
- 3.4: Tutorial: Set up W&B Launch on SageMaker
- 3.5: Tutorial: Set up W&B Launch on Vertex AI
- 3.6: Tutorial: Set up W&B Launch with Docker
- 4: Create and deploy jobs
- 4.1: Add job to queue
- 4.2: Create a launch job
- 4.3: Manage job inputs
- 4.4: Monitor launch queue
- 4.5: View launch jobs
- 5: Create sweeps with W&B Launch
- 6: Launch FAQ
- 6.1: Are there best practices for using Launch effectively?
- 6.2: Can I specify a Dockerfile and let W&B build a Docker image for me?
- 6.3: Can Launch automatically provision (and spin down) compute resources for me in the target environment?
- 6.4: Can you specify secrets for jobs/automations? For instance, an API key which you do not wish to be directly visible to users?
- 6.5: Does Launch support parallelization? How can I limit the resources consumed by a job?
- 6.6: How can admins restrict which users have modify access?
- 6.7: How do I control who can push to a queue?
- 6.8: How do I fix a "permission denied" error in Launch?
- 6.9: How do I make W&B Launch work with Tensorflow on GPU?
- 6.10: How does W&B Launch build images?
- 6.11: I do not like clicking- can I use Launch without going through the UI?
- 6.12: I do not want W&B to build a container for me, can I still use Launch?
- 6.13: Is `wandb launch -d` or `wandb job create image` uploading a whole docker artifact and not pulling from a registry?
- 6.14: What permissions does the agent require in Kubernetes?
- 6.15: What requirements does the accelerator base image have?
- 6.16: When multiple jobs in a Docker queue download the same artifact, is any caching used, or is it re-downloaded every run?
- 7: Launch integration guides
1 - Tutorial: W&B Launch basics
Launch とは?
W&B Launch を使用すると、デスクトップから Amazon SageMaker や Kubernetes などのコンピューティングリソースまで、トレーニング runs を簡単に拡張できます。 W&B Launch を設定すると、数回クリックしてコマンドを実行するだけで、トレーニング スクリプト、モデル 評価スイートの実行、本番環境での推論に向けたモデルの準備などをすばやく行うことができます。
仕組み
Launch は、launch jobs 、queues 、agents の 3 つの基本的なコンポーネントで構成されています。
launch job は、 ML ワークフローでタスクを構成および実行するための設計図です。 launch job を作成したら、それを launch queue に追加できます。 launch queue は、先入れ先出し (FIFO) キューであり、Amazon SageMaker や Kubernetes クラスターなどの特定のコンピューティング ターゲット リソースにジョブを構成して送信できます。
ジョブが queue に追加されると、launch agents はその queue をポーリングし、 queue をターゲットとするシステムでジョブを実行します。
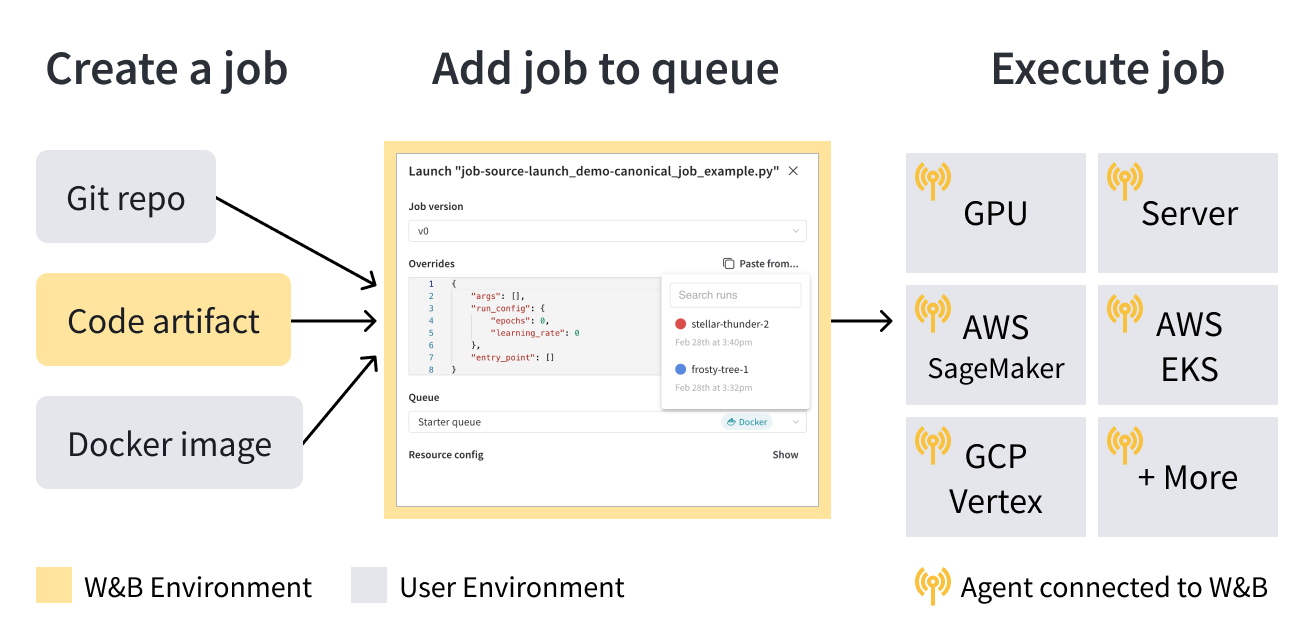
ユースケースに基づいて、ユーザー (またはチームの誰か) が、選択した コンピューティング リソース ターゲット (たとえば、Amazon SageMaker) に従って launch queue を構成し、独自のインフラストラクチャに launch agent をデプロイします。
launch jobs 、 queue の仕組み、 launch agents 、および W&B Launch の仕組みに関する追加情報については、用語と概念 ページを参照してください。
開始方法
ユースケースに応じて、次のリソースを参照して W&B Launch を開始してください。
- W&B Launch を初めて使用する場合は、チュートリアル ガイドを参照することをお勧めします。
- W&B Launch の設定方法について説明します。
- launch job を作成します。
- W&B Launch のパブリック jobs GitHub リポジトリで、Triton へのデプロイ、LLM の評価 などの一般的なタスクのテンプレートを確認してください。
- このリポジトリから作成された launch jobs は、このパブリック
wandb/jobsproject W&B プロジェクトで表示します。
- このリポジトリから作成された launch jobs は、このパブリック
チュートリアル
このページでは、W&B Launch ワークフローの基本について説明します。
前提条件
開始する前に、次の前提条件を満たしていることを確認してください。
- https://wandb.ai/site でアカウントにサインアップし、W&B アカウントにログインします。
- このチュートリアルでは、動作する Docker CLI およびエンジンを備えたマシンへの ターミナル アクセスが必要です。 詳しくは、Docker インストール ガイドをご覧ください。
- W&B Python SDK バージョン
0.17.1以上をインストールします。
pip install wandb>=0.17.1
- ターミナル 内で
wandb loginを実行するか、WANDB_API_KEY環境変数を設定して W&B で認証します。
ターミナル 内で以下を実行します。
```bash
wandb login
```
```bash
WANDB_API_KEY=<your-api-key>
```
`<your-api-key>` を W&B APIキーに置き換えます。
launch job の作成
次の 3 つの方法のいずれかで launch job を作成します。Docker イメージを使用、git リポジトリから、またはローカル ソース コードから。
W&B にメッセージを記録する既製のコンテナを実行するには、 ターミナル を開き、次のコマンドを実行します。
wandb launch --docker-image wandb/job_hello_world:main --project launch-quickstart
上記のコマンドは、コンテナ イメージ wandb/job_hello_world:main をダウンロードして実行します。
Launch は、wandb で記録されたすべての内容を launch-quickstart project に報告するようにコンテナを構成します。 コンテナはメッセージを W&B に記録し、新しく作成された run へのリンクを W&B に表示します。 リンクをクリックして、W&B UI で run を表示します。
W&B Launch jobs リポジトリ のソース コードから同じ hello-world ジョブを起動するには、次のコマンドを実行します。
wandb launch --uri https://github.com/wandb/launch-jobs.git \\
--job-name hello-world-git --project launch-quickstart \\
--build-context jobs/hello_world --dockerfile Dockerfile.wandb \\
--entry-point "python job.py"
このコマンドは次のことを行います。
- W&B Launch jobs リポジトリを一時ディレクトリーにクローンします。
- hello project に hello-world-git という名前のジョブを作成します。 このジョブは、コードの実行に使用される正確なソース コードと設定を追跡します。
jobs/hello_worldディレクトリーとDockerfile.wandbからコンテナ イメージを構築します。- コンテナを起動し、
job.pyPython スクリプトを実行します。
コンソール出力に、イメージの構築と実行が表示されます。 コンテナの出力は、前の例とほぼ同じであるはずです。
git リポジトリでバージョン管理されていないコードは、--uri 引数にローカル ディレクトリー パスを指定することで起動できます。
空のディレクトリーを作成し、次の内容で train.py という名前の Python スクリプトを追加します。
import wandb
with wandb.init() as run:
run.log({"hello": "world"})
次の内容で requirements.txt ファイルを追加します。
wandb>=0.17.1
ディレクトリー内から、次のコマンドを実行します。
wandb launch --uri . --job-name hello-world-code --project launch-quickstart --entry-point "python train.py"
このコマンドは次のことを行います。
- 現在のディレクトリーの内容をコード Artifacts として W&B に記録します。
- launch-quickstart project に hello-world-code という名前のジョブを作成します。
train.pyとrequirements.txtをベース イメージにコピーし、要件をpip installしてコンテナ イメージを構築します。- コンテナを起動し、
python train.pyを実行します。
queue の作成
Launch は、チームが共有コンピューティングを中心にワークフローを構築するのに役立つように設計されています。 これまでの例では、wandb launch コマンドはローカル マシンでコンテナを同期的に実行していました。 Launch queues と agents により、共有リソースでのジョブの非同期実行と、優先順位付けやハイパーパラメーター最適化などの高度な機能が実現します。 基本的な queue を作成するには、次の手順に従います。
- wandb.ai/launch に移動し、queue の作成ボタンをクリックします。
- queue に関連付ける Entity を選択します。
- queue 名を入力します。
- リソースとして Docker を選択します。
- 構成は、今のところ空白のままにします。
- queue の作成 :rocket: をクリックします
ボタンをクリックすると、ブラウザは queue ビューの Agents タブにリダイレクトされます。 agent がポーリングを開始するまで、 queue は 非アクティブ 状態のままです。
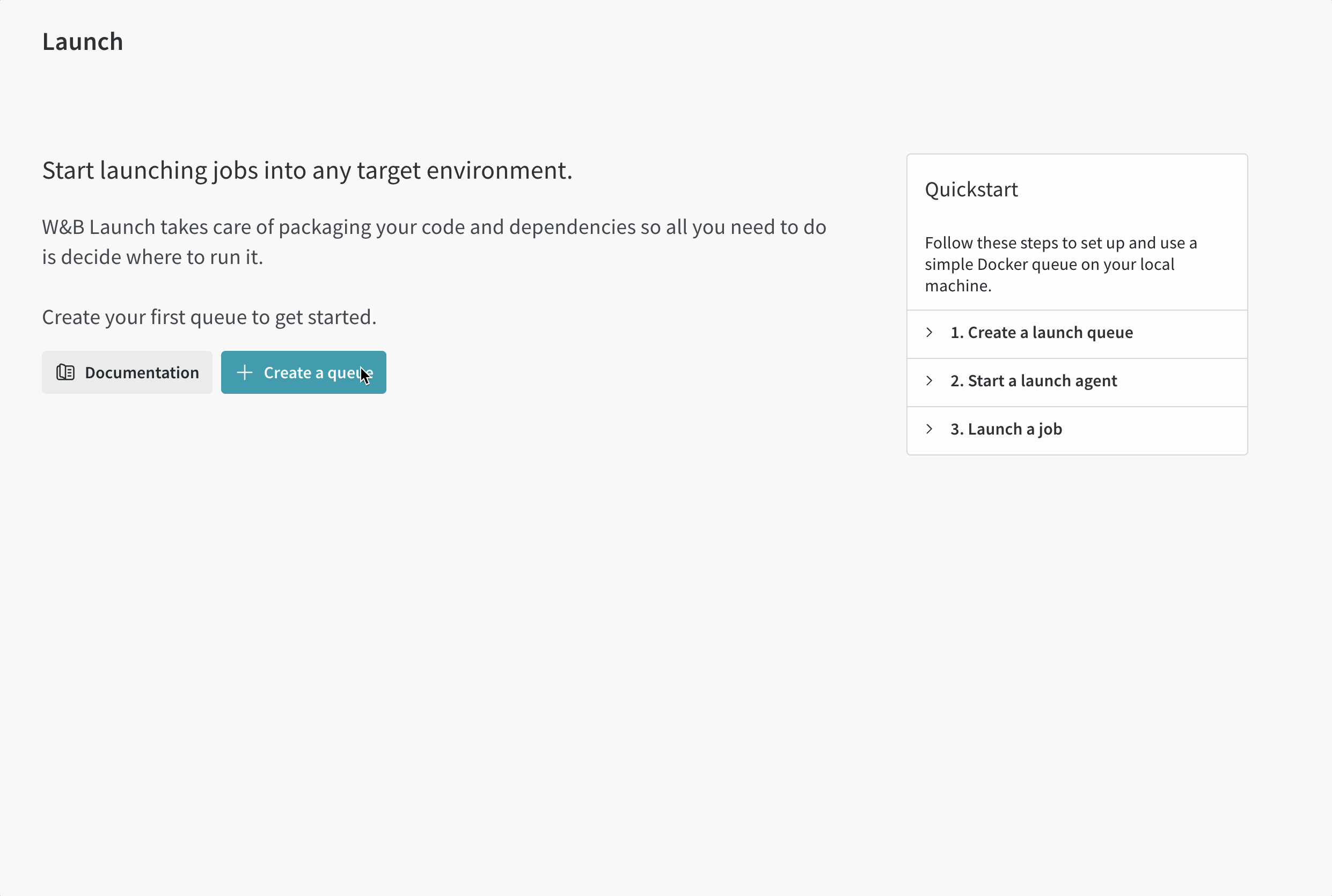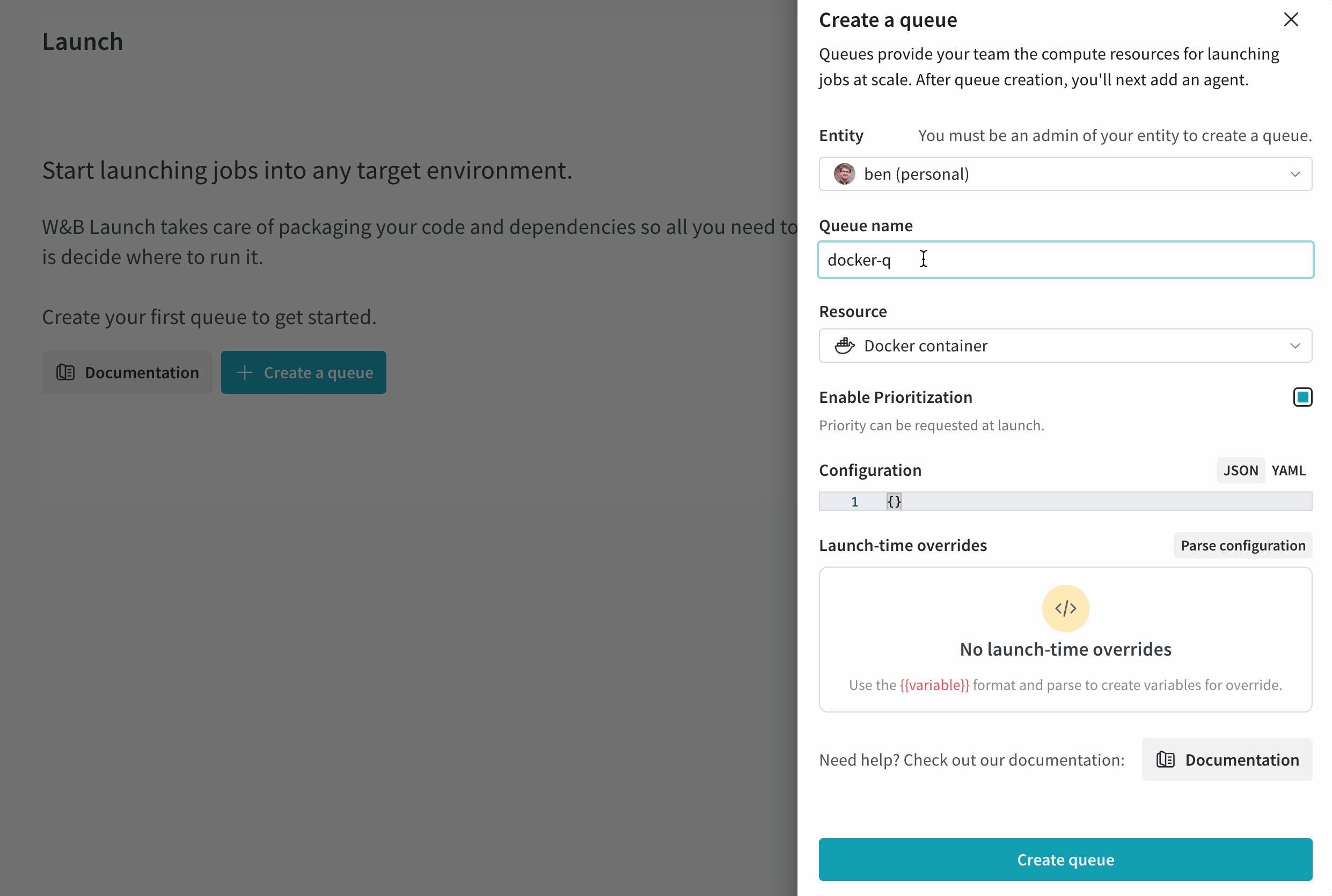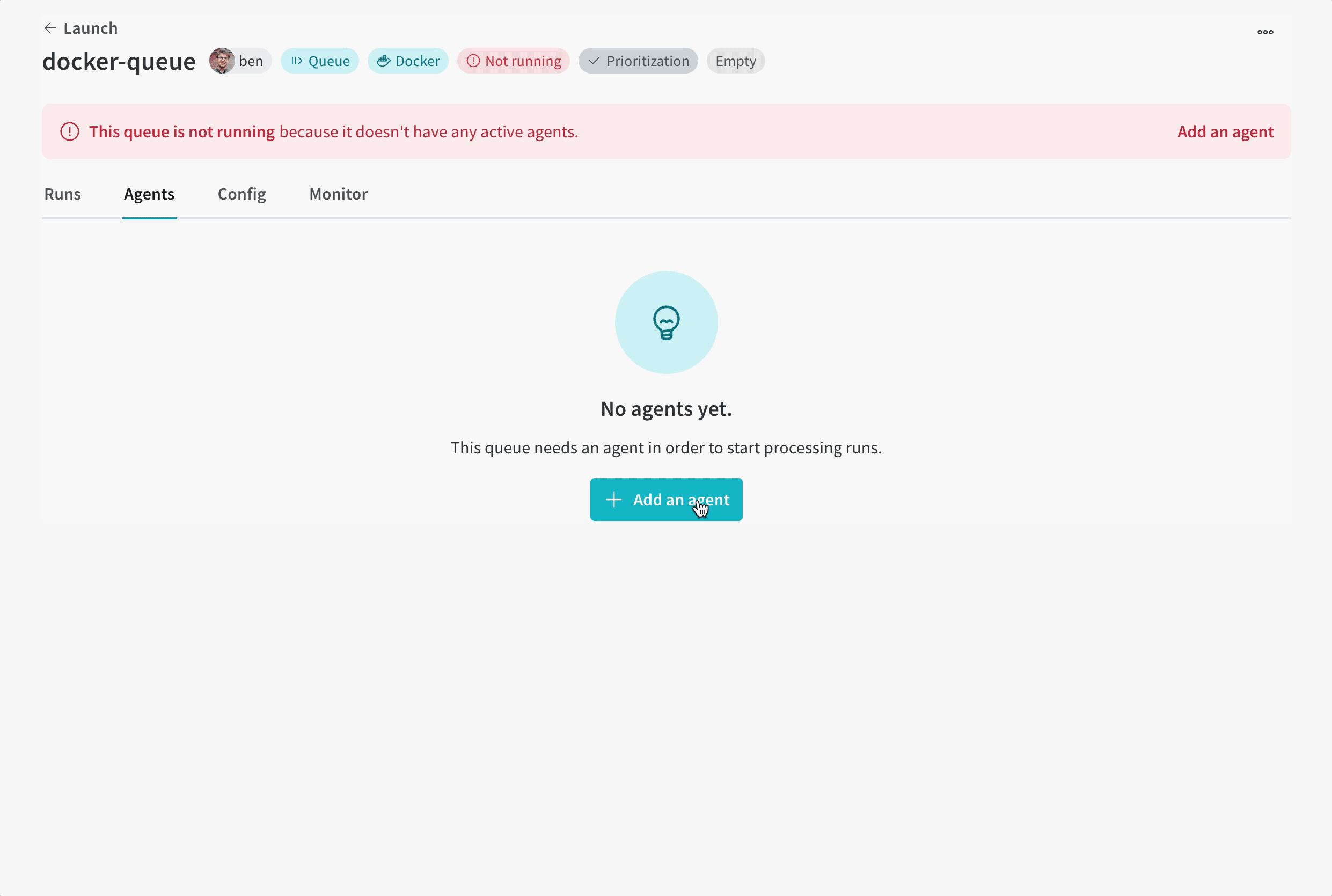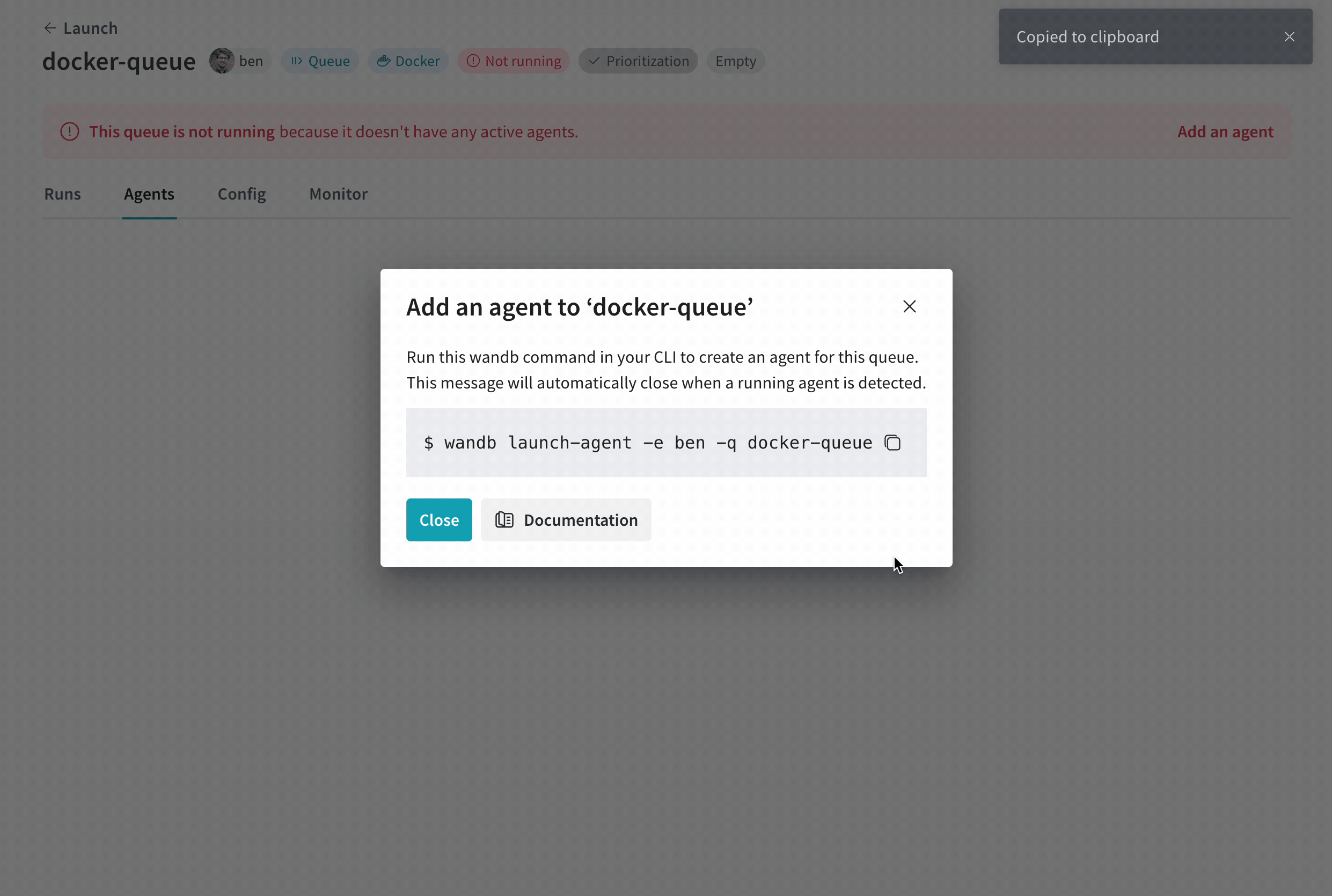
高度な queue 構成オプションについては、高度な queue セットアップ ページ を参照してください。
agent を queue に接続する
queue にポーリング agent がない場合、 queue ビューの画面上部の赤いバナーに agent の追加ボタンが表示されます。 ボタンをクリックして、agent を実行するコマンドをコピーして表示します。 コマンドは次のようになります。
wandb launch-agent --queue <queue-name> --entity <entity-name>
ターミナル でコマンドを実行して、agent を起動します。 agent は、実行するジョブについて、指定された queue をポーリングします。 受信すると、agent はジョブのコンテナ イメージをダウンロードまたは構築してから実行します。これは、wandb launch コマンドがローカルで実行された場合と同様です。
Launch ページ に戻り、 queue が アクティブ と表示されることを確認します。
ジョブを queue に送信する
W&B アカウントで新しい launch-quickstart project に移動し、画面左側のナビゲーションから [Jobs] タブを開きます。
[Jobs] ページには、以前に実行された runs から作成された W&B Jobs のリストが表示されます。 launch job をクリックして、ソース コード、依存関係、およびジョブから作成された runs を表示します。 このチュートリアルを完了すると、リストに 3 つのジョブが表示されます。
新しいジョブの 1 つを選択し、次の手順に従って queue に送信します。
- [Launch] ボタンをクリックして、ジョブを queue に送信します。 Launch ドロワーが表示されます。
- 以前に作成した queue を選択し、[Launch] をクリックします。
これにより、ジョブが queue に送信されます。 この queue をポーリングする agent は、ジョブを取得して実行します。 ジョブの進捗状況は、W&B UI から監視するか、 ターミナル で agent の出力を検査することで監視できます。
wandb launch コマンドは、--queue 引数を指定することで、ジョブを queue に直接プッシュできます。 たとえば、hello-world コンテナ ジョブを queue に送信するには、次のコマンドを実行します。
wandb launch --docker-image wandb/job_hello_world:main --project launch-quickstart --queue <queue-name>
2 - Launch terms and concepts
W&B Launch を使用すると、ジョブをキューにエンキューして run を作成できます。ジョブは、W&B で計測された Python スクリプトです。キューは、ターゲットリソースで実行するジョブのリストを保持します。エージェントは、キューからジョブをプルし、ターゲットリソースでジョブを実行します。W&B は、W&B がrunを追跡するのと同様に、Launch ジョブを追跡します。
Launch ジョブ
Launch ジョブは、完了するタスクを表す特定のタイプの W&B Artifactです。たとえば、一般的な Launch ジョブには、モデルのトレーニングやモデルの評価のトリガーなどがあります。ジョブの定義には以下が含まれます。
- 少なくとも1つの実行可能なエントリポイントを含む、Python コードおよびその他のファイルアセット。
- 入力 (config パラメータ) と出力 (記録されたメトリクス) に関する情報。
- 環境に関する情報 (例:
requirements.txt、ベースDockerfile)。
ジョブの定義には、主に次の3種類があります。
| ジョブタイプ | 定義 | このジョブタイプの実行方法 |
|---|---|---|
| Artifact ベース (またはコードベース) のジョブ | コードおよびその他のアセットは、W&B artifact として保存されます。 | artifact ベースのジョブを実行するには、Launch エージェントをビルダーで構成する必要があります。 |
| Git ベースのジョブ | コードおよびその他のアセットは、git リポジトリ内の特定のコミット、ブランチ、またはタグから複製されます。 | git ベースのジョブを実行するには、Launch エージェントをビルダーおよび git リポジトリの認証情報で構成する必要があります。 |
| イメージベースのジョブ | コードおよびその他のアセットは、Docker イメージにベイクされます。 | イメージベースのジョブを実行するには、Launch エージェントをイメージリポジトリの認証情報で構成する必要がある場合があります。 |
wandb.init を呼び出す必要があります。これにより、W&B ワークスペースで追跡するための run が作成されます。作成したジョブは、W&B アプリのプロジェクト ワークスペースの [Jobs] タブにあります。そこから、ジョブを構成して Launch キューに送信し、さまざまなターゲットリソースで実行できます。
Launch キュー
Launch キュー は、特定のターゲットリソースで実行するジョブの順序付きリストです。Launch キューは先入れ先出し (FIFO) です。キューの数に実用的な制限はありませんが、適切なガイドラインはターゲットリソースごとに1つのキューです。ジョブは、W&B アプリ UI、W&B CLI、または Python SDK でエンキューできます。次に、1つ以上の Launch エージェントを構成して、キューからアイテムをプルし、キューのターゲットリソースで実行できます。
ターゲットリソース
Launch キューがジョブの実行を構成するように設定されているコンピューティング環境は、ターゲットリソース と呼ばれます。
W&B Launch は、次のターゲットリソースをサポートしています。
各ターゲットリソースは、リソース構成 と呼ばれる異なる設定パラメータのセットを受け入れます。リソース構成は、各 Launch キューによって定義されたデフォルト値を採用しますが、各ジョブによって個別に上書きできます。詳細については、各ターゲットリソースのドキュメントを参照してください。
Launch エージェント
Launch エージェントは、Launch キューで実行するジョブを定期的にチェックする、軽量で永続的なプログラムです。Launch エージェントがジョブを受信すると、最初にジョブ定義からイメージを構築またはプルし、ターゲットリソースで実行します。
1つのエージェントが複数のキューをポーリングする場合がありますが、エージェントは、ポーリングする各キューのバッキングターゲットリソースをすべてサポートするように適切に構成する必要があります。
Launch エージェント環境
エージェント環境は、Launch エージェントがジョブをポーリングして実行されている環境です。
3 - Set up Launch
このページでは、W&B Launch を設定するために必要な大まかな手順について説明します。
- キューの設定: キューは FIFO であり、キュー設定を備えています。キューの設定は、ターゲットリソース上でジョブがどこでどのように実行されるかを制御します。
- エージェントの設定: エージェントは、ユーザーのマシン/インフラストラクチャー上で実行され、Launch ジョブの 1 つ以上のキューをポーリングします。ジョブがプルされると、エージェントはイメージが構築され、利用可能であることを確認します。その後、エージェントはジョブをターゲットリソースに送信します。
キューの設定
Launch キューは、特定ターゲットリソースと、そのリソースに固有の追加設定を指すように設定する必要があります。たとえば、Kubernetes クラスターを指す Launch キューには、環境変数を含めたり、Launch キュー設定のカスタム名前空間を設定したりできます。キューを作成する際には、使用するターゲットリソースと、そのリソースが使用する設定の両方を指定します。
エージェントがキューからジョブを受信すると、キュー設定も受信します。エージェントがジョブをターゲットリソースに送信する際、ジョブ自体のオーバーライドとともにキュー設定が含まれます。たとえば、ジョブ設定を使用して、そのジョブインスタンスのみの Amazon SageMaker インスタンスタイプを指定できます。この場合、キュー設定テンプレートをエンドユーザーインターフェイスとして使用するのが一般的です。
キューの作成
- wandb.ai/launch で Launch アプリケーションに移動します。
- 画面右上の create queue ボタンをクリックします。
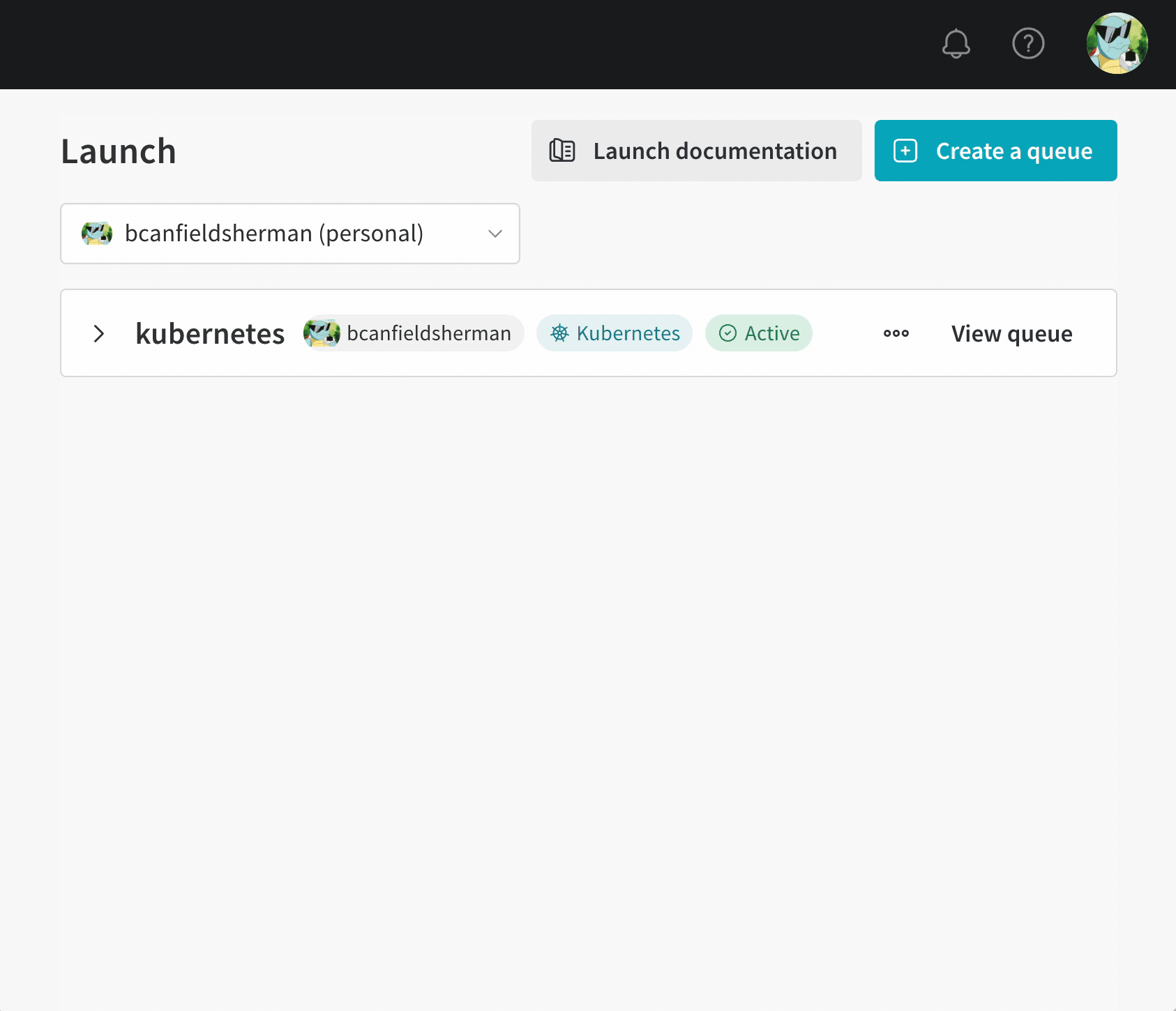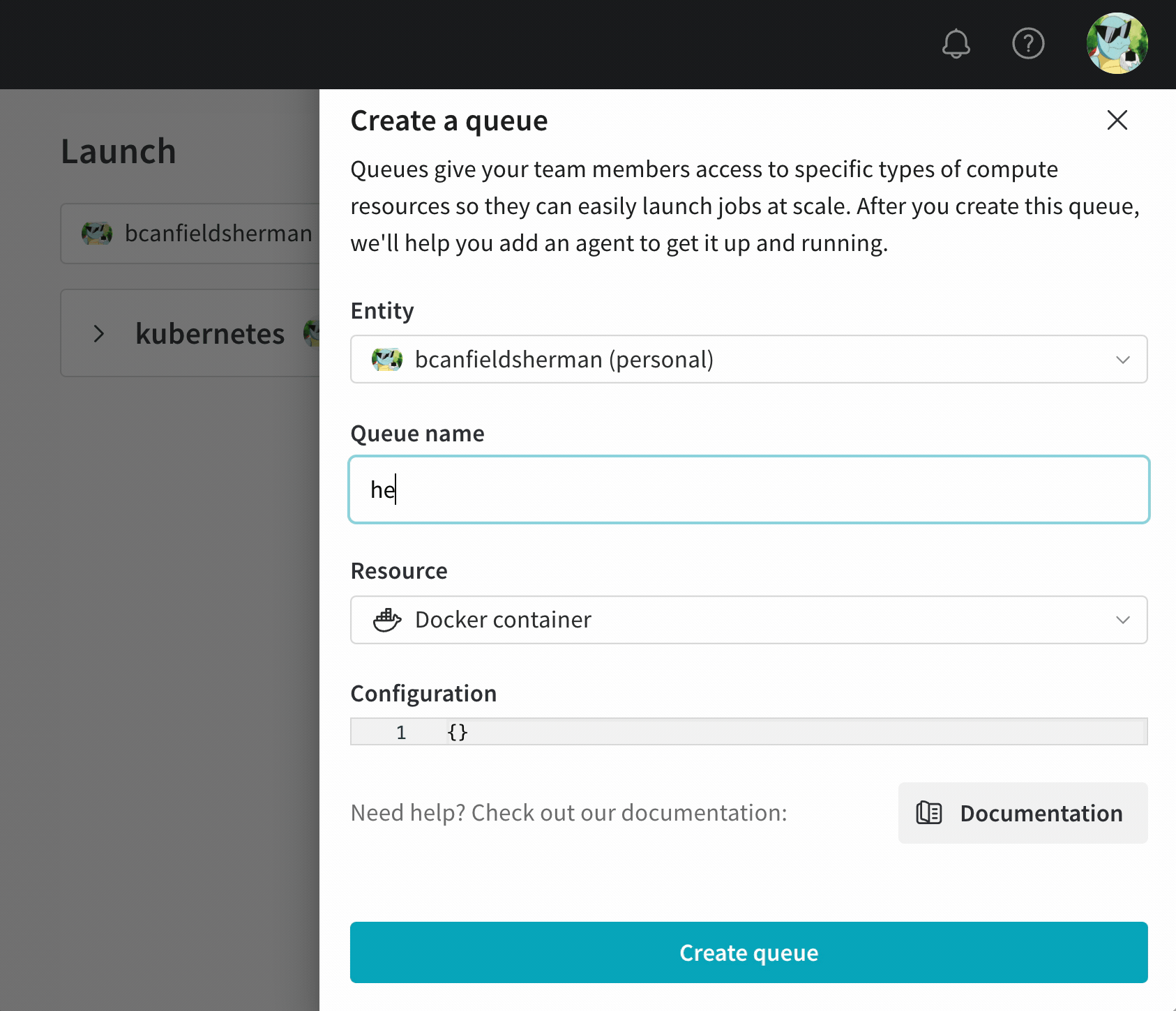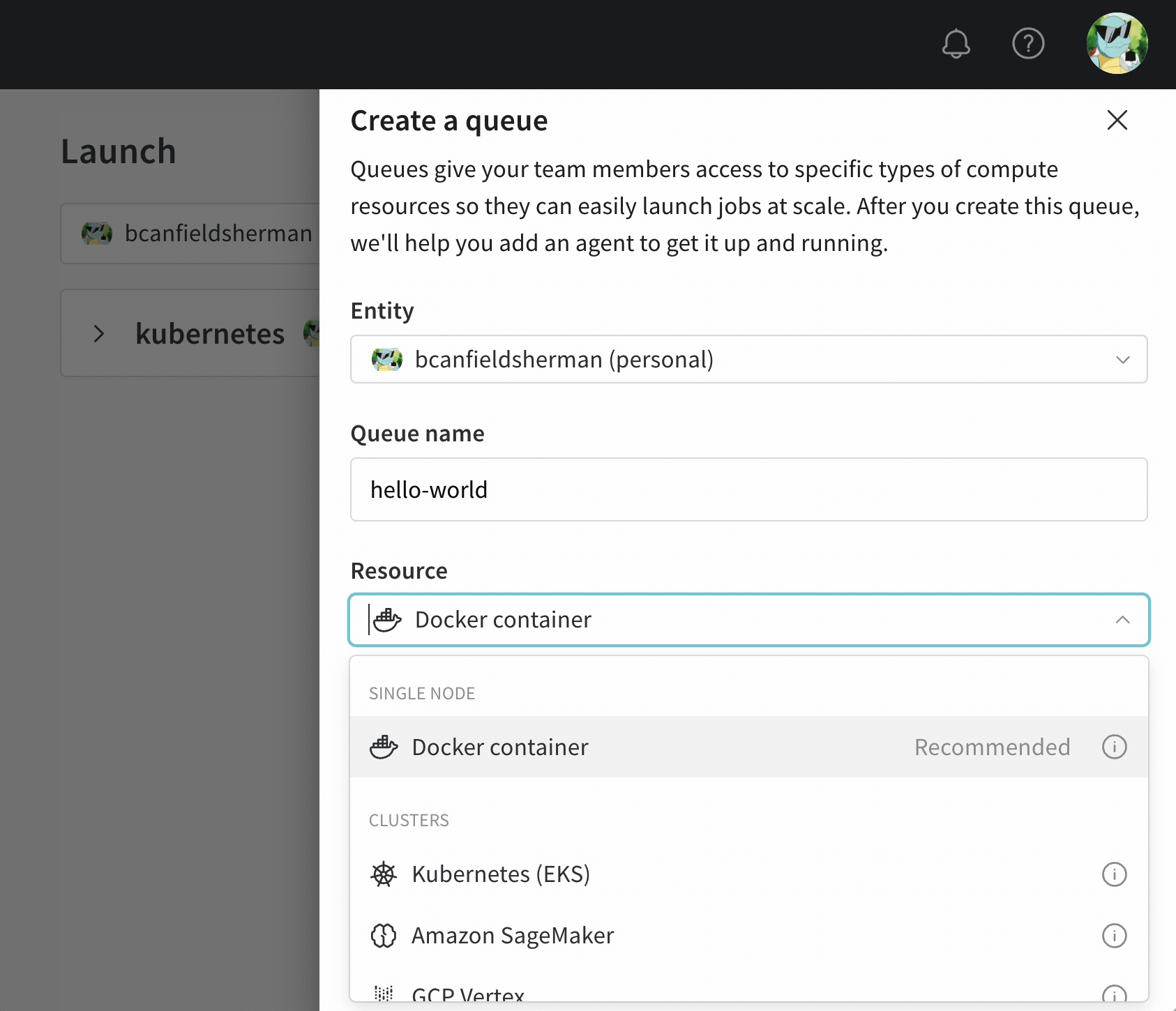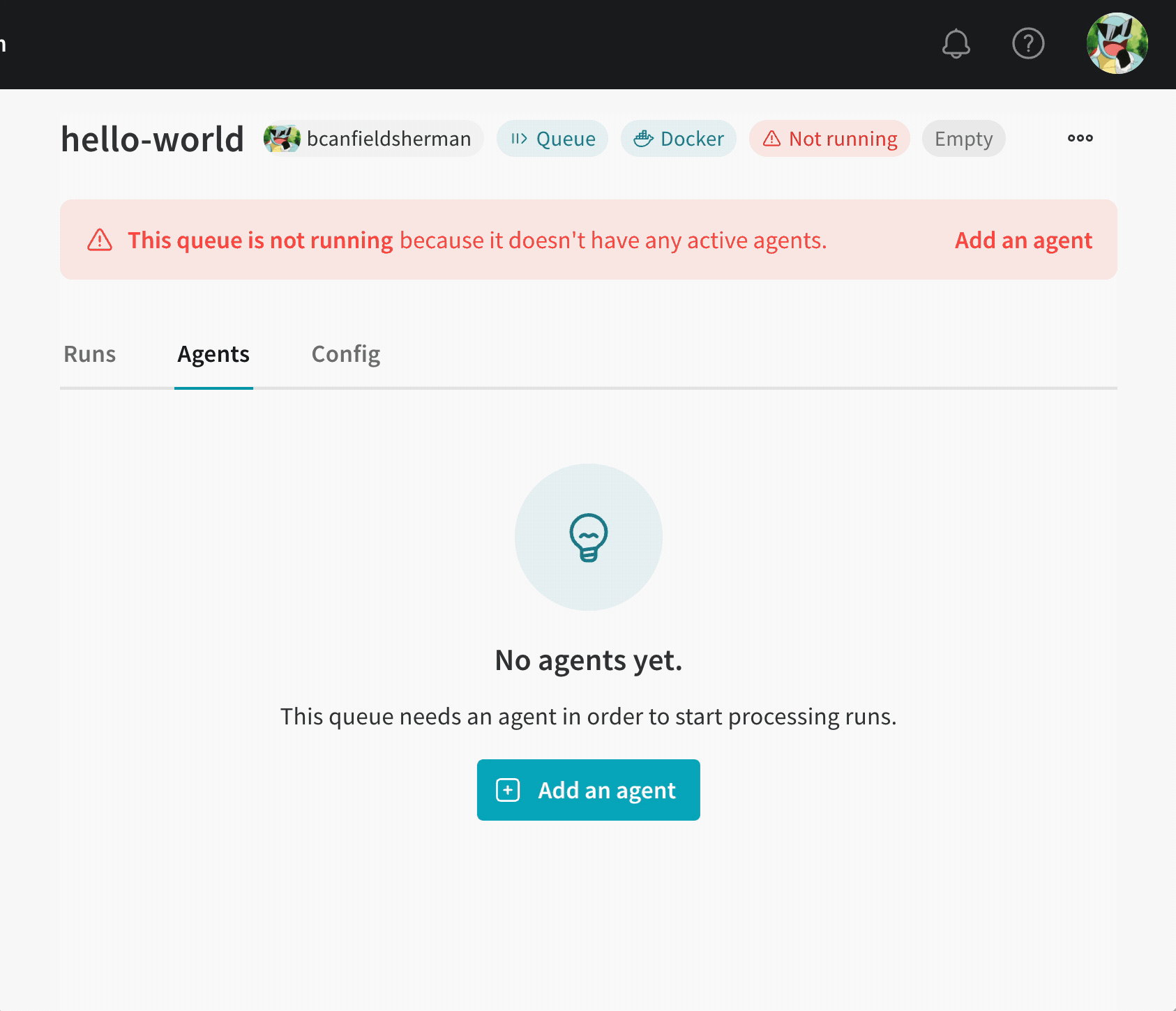
- Entity ドロップダウンメニューから、キューが属するエンティティを選択します。
- Queue フィールドにキューの名前を入力します。
- Resource ドロップダウンから、このキューに追加されたジョブで使用するコンピュートリソースを選択します。
- このキューの Prioritization を許可するかどうかを選択します。優先順位付けが有効になっている場合、チームのユーザーは、エンキュー時に Launch ジョブの優先順位を定義できます。優先度の高いジョブは、優先度の低いジョブよりも先に実行されます。
- Configuration フィールドに、JSON または YAML 形式でリソース設定を入力します。設定ドキュメントの構造とセマンティクスは、キューが指すリソースタイプによって異なります。詳細については、ターゲットリソースの専用設定ページを参照してください。
Launch エージェントの設定
Launch エージェントは、ジョブのために 1 つ以上の Launch キューをポーリングする、長時間実行されるプロセスです。Launch エージェントは、先入れ先出し(FIFO)順、またはプル元のキューに応じて優先順位順にジョブをデキューします。エージェントがキューからジョブをデキューすると、オプションでそのジョブのイメージを構築します。その後、エージェントはジョブをターゲットリソースに、キュー設定で指定された設定オプションとともに送信します。
W&B では、特定ユーザーの API キーではなく、サービスアカウントの API キーでエージェントを開始することをお勧めします。サービスアカウントの API キーを使用することには、次の 2 つの利点があります。
- エージェントは、個々のユーザーに依存しません。
- Launch を介して作成された run に関連付けられた作成者は、エージェントに関連付けられたユーザーではなく、Launch ジョブを送信したユーザーとして Launch によって認識されます。
エージェントの設定
launch-config.yaml という YAML ファイルで Launch エージェントを設定します。デフォルトでは、W&B は ~/.config/wandb/launch-config.yaml にある設定ファイルを確認します。Launch エージェントをアクティブ化するときに、別のディレクトリーをオプションで指定できます。
Launch エージェントの設定ファイルの内容は、Launch エージェントの環境、Launch キューのターゲットリソース、Docker ビルダーの要件、クラウドリポジトリの要件などによって異なります。
ユースケースに関係なく、Launch エージェントには、設定可能な主要オプションがあります。
max_jobs: エージェントが並行して実行できるジョブの最大数entity: キューが属するエンティティqueues: エージェントが監視する 1 つ以上のキューの名前
wandb launch-agent コマンドを参照してください。次の YAML コードスニペットは、主要な Launch エージェント設定キーを指定する方法を示しています。
# 実行する同時runsの最大数。 -1 = 無制限
max_jobs: -1
entity: <entity-name>
# ポーリングするキューのリスト。
queues:
- <queue-name>
コンテナビルダーの設定
Launch エージェントは、イメージを構築するように構成できます。git リポジトリまたはコード Artifacts から作成された Launch ジョブを使用する場合は、コンテナビルダーを使用するようにエージェントを設定する必要があります。 Launch ジョブの作成方法の詳細については、Launch ジョブの作成を参照してください。
W&B Launch は、次の 3 つのビルダーオプションをサポートしています。
- Docker: Docker ビルダーは、ローカル Docker デーモンを使用してイメージを構築します。
- Kaniko: Kaniko は、Docker デーモンが利用できない環境でイメージを構築できる Google プロジェクトです。
- Noop: エージェントはジョブの構築を試行せず、代わりに構築済みのイメージのみをプルします。
エージェントが Docker デーモンが利用できない環境(Kubernetes クラスターなど)でポーリングしている場合は、Kaniko ビルダーを使用してください。
Kaniko ビルダーの詳細については、Kubernetes の設定を参照してください。
イメージビルダーを指定するには、エージェント設定に builder キーを含めます。たとえば、次のコードスニペットは、Docker または Kaniko を使用するように指定する Launch 設定(launch-config.yaml)の一部を示しています。
builder:
type: docker | kaniko | noop
コンテナレジストリの設定
場合によっては、Launch エージェントをクラウドリポジトリに接続する必要があるかもしれません。Launch エージェントをクラウドリポジトリに接続する一般的なシナリオとしては、次のようなものがあります。
- 強力なワークステーションやクラスターなど、イメージを構築したのとは別の環境でジョブを実行する場合。
- エージェントを使用してイメージを構築し、これらのイメージを Amazon SageMaker または VertexAI で実行する場合。
- Launch エージェントに、イメージリポジトリからプルするための認証情報を提供させる場合。
コンテナレジストリとやり取りするようにエージェントを設定する方法の詳細については、エージェントの詳細設定ページを参照してください。
Launch エージェントのアクティブ化
launch-agent W&B CLI コマンドで Launch エージェントをアクティブ化します。
wandb launch-agent -q <queue-1> -q <queue-2> --max-jobs 5
一部のユースケースでは、Kubernetes クラスター内から Launch エージェントにキューをポーリングさせたい場合があります。詳細については、キューの詳細設定ページを参照してください。
3.1 - Configure launch queue
以下のページでは、 ローンチ キューのオプションを設定する方法について説明します。
キュー設定テンプレートの設定
キュー設定テンプレートを使用して、コンピュート消費に関するガードレールを管理します。メモリ消費量、 GPU 、ランタイム時間などのフィールドのデフォルト値、最小値、および最大値を設定します。
設定テンプレートでキューを設定すると、チームのメンバーは、定義した範囲内でのみ、定義したフィールドを変更できます。
キューテンプレートの設定
既存のキューでキューテンプレートを設定するか、新しいキューを作成できます。
- https://wandb.ai/launch の ローンチ アプリに移動します。
- テンプレートを追加するキューの名前の横にある View queue を選択します。
- Config タブを選択します。これにより、キューが作成された時期、キューの設定、既存の ローンチ 時のオーバーライドなど、キューに関する情報が表示されます。
- Queue config セクションに移動します。
- テンプレートを作成する設定の キー の 値 を特定します。
- 設定内の 値 をテンプレートフィールドに置き換えます。テンプレートフィールドは
{{variable-name}}の形式を取ります。 - Parse configuration ボタンをクリックします。設定を解析すると、作成した各テンプレートのタイルが自動的にキュー設定の下に作成されます。
- 生成された各タイルについて、最初にキュー設定で許可する データ 型(文字列、整数、または浮動小数点)を指定する必要があります。これを行うには、Type ドロップダウンメニューから データ 型を選択します。
- データ 型に基づいて、各タイル内に表示されるフィールドに入力します。
- Save config をクリックします。
たとえば、チームが使用できる AWS インスタンスを制限するテンプレートを作成するとします。テンプレートフィールドを追加する前は、キュー設定は次のようになります。
RoleArn: arn:aws:iam:region:account-id:resource-type/resource-id
ResourceConfig:
InstanceType: ml.m4.xlarge
InstanceCount: 1
VolumeSizeInGB: 2
OutputDataConfig:
S3OutputPath: s3://bucketname
StoppingCondition:
MaxRuntimeInSeconds: 3600
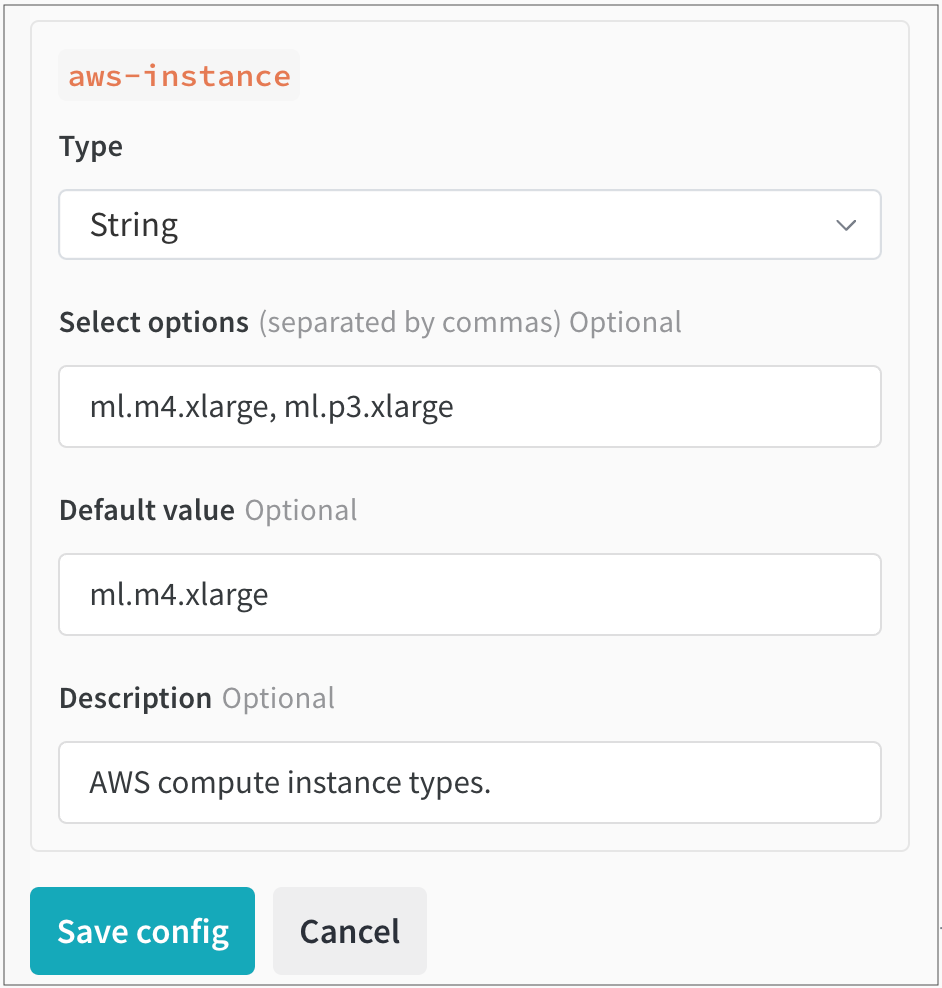
InstanceType のテンプレートフィールドを追加すると、設定は次のようになります。
RoleArn: arn:aws:iam:region:account-id:resource-type/resource-id
ResourceConfig:
InstanceType: "{{aws_instance}}"
InstanceCount: 1
VolumeSizeInGB: 2
OutputDataConfig:
S3OutputPath: s3://bucketname
StoppingCondition:
MaxRuntimeInSeconds: 3600
次に、Parse configuration をクリックします。aws-instance というラベルの新しいタイルが Queue config の下に表示されます。
そこから、Type ドロップダウンから String を データ 型として選択します。これにより、 ユーザー が選択できる 値 を指定できるフィールドが入力されます。たとえば、次の図では、チームの管理者が ユーザー が選択できる2つの異なる AWS インスタンスタイプ(ml.m4.xlarge と ml.p3.xlarge)を設定しています。
ローンチ ジョブの動的な設定
キュー設定は、 エージェント がキューからジョブをデキューするときに評価されるマクロを使用して動的に設定できます。次のマクロを設定できます。
| Macro | Description |
|---|---|
${project_name} |
run が ローンチ されている プロジェクト の名前。 |
${entity_name} |
run が ローンチ されている プロジェクト の所有者。 |
${run_id} |
ローンチ されている run の ID。 |
${run_name} |
ローンチ されている run の名前。 |
${image_uri} |
この run のコンテナ イメージの URI。 |
${MY_ENV_VAR} など)は、 エージェント の 環境 から 環境 変数に置き換えられます。ローンチ エージェント を使用して、アクセラレータ( GPU )で実行されるイメージを構築する
アクセラレータ 環境 で実行されるイメージを構築するために ローンチ を使用する場合は、アクセラレータ ベース イメージを指定する必要がある場合があります。
このアクセラレータ ベース イメージは、次の要件を満たしている必要があります。
- Debian の互換性( ローンチ Dockerfile は apt-get を使用して python をフェッチします)
- CPU と GPU のハードウェア命令セットの互換性(使用する予定の GPU で CUDA バージョンがサポートされていることを確認してください)
- 提供するアクセラレータ バージョンと ML アルゴリズムにインストールされているパッケージとの互換性
- ハードウェアとの互換性を設定するために追加の手順が必要なインストール済みパッケージ
TensorFlow で GPU を使用する方法
TensorFlow が GPU を適切に利用していることを確認します。これを実現するには、キュー リソース 設定で builder.accelerator.base_image キーの Docker イメージとそのイメージ タグを指定します。
たとえば、tensorflow/tensorflow:latest-gpu ベース イメージは、TensorFlow が GPU を適切に使用することを保証します。これは、キュー内のリソース設定を使用して構成できます。
次の JSON スニペットは、キュー設定で TensorFlow ベース イメージを指定する方法を示しています。
{
"builder": {
"accelerator": {
"base_image": "tensorflow/tensorflow:latest-gpu"
}
}
}
3.2 - Set up launch agent
高度なエージェントの設定
このガイドでは、さまざまな環境でコンテナイメージを構築するために W&B Launch エージェントをセットアップする方法について説明します。
ビルドは、git および コード Artifacts ジョブでのみ必要です。イメージジョブはビルドを必要としません。
ジョブタイプに関する詳細については、Launch ジョブの作成を参照してください。
ビルダー
Launch エージェントは、Docker または Kaniko を使用してイメージを構築できます。
- Kaniko: 特権コンテナとしてビルドを実行せずに、Kubernetes でコンテナイメージを構築します。
- Docker:
docker buildコマンドをローカルで実行して、コンテナイメージを構築します。
ビルダータイプは、Launch エージェント設定の builder.type キーで制御でき、ビルドをオフにするには docker、kaniko、または noop のいずれかに設定します。デフォルトでは、エージェント Helm チャートは builder.type を noop に設定します。builder セクションの追加キーは、ビルドプロセスを設定するために使用されます。
エージェント設定でビルダーが指定されておらず、動作する docker CLI が見つかった場合、エージェントはデフォルトで Docker を使用します。Docker が利用できない場合、エージェントはデフォルトで noop になります。
コンテナレジストリへのプッシュ
Launch エージェントは、構築するすべてのイメージに一意のソースハッシュでタグを付けます。エージェントは、builder.destination キーで指定されたレジストリにイメージをプッシュします。
たとえば、builder.destination キーが my-registry.example.com/my-repository に設定されている場合、エージェントはイメージに my-registry.example.com/my-repository:<source-hash> というタグを付けてプッシュします。イメージがレジストリに存在する場合、ビルドはスキップされます。
エージェントの設定
Helm チャートを介してエージェントをデプロイする場合、エージェント設定は values.yaml ファイルの agentConfig キーで指定する必要があります。
wandb launch-agent でエージェントを自分で呼び出す場合は、--config フラグを使用して、エージェント設定を YAML ファイルへのパスとして指定できます。デフォルトでは、設定は ~/.config/wandb/launch-config.yaml からロードされます。
Launch エージェント設定(launch-config.yaml)内で、ターゲットリソース環境の名前と、environment および registry キーのコンテナレジストリの名前を指定します。
次のタブは、環境とレジストリに基づいて Launch エージェントを設定する方法を示しています。
AWS 環境設定には、region キーが必要です。region は、エージェントが実行される AWS リージョンである必要があります。
environment:
type: aws
region: <aws-region>
builder:
type: <kaniko|docker>
# エージェントがイメージを保存する ECR リポジトリの URI。
# リージョンが環境で設定したものと一致していることを確認してください。
destination: <account-id>.ecr.<aws-region>.amazonaws.com/<repository-name>
# Kaniko を使用する場合は、エージェントがビルドコンテキストを保存する S3 バケットを指定します。
build-context-store: s3://<bucket-name>/<path>
エージェントは boto3 を使用してデフォルトの AWS 認証情報をロードします。デフォルトの AWS 認証情報を設定する方法の詳細については、boto3 のドキュメント を参照してください。
Google Cloud 環境には、region および project キーが必要です。region をエージェントが実行されるリージョンに設定します。project をエージェントが実行される Google Cloud プロジェクトに設定します。エージェントは、Python で google.auth.default() を使用して、デフォルトの認証情報をロードします。
environment:
type: gcp
region: <gcp-region>
project: <gcp-project-id>
builder:
type: <kaniko|docker>
# エージェントがイメージを保存する Artifact Registry リポジトリとイメージ名の URI。
# リージョンとプロジェクトが、環境で設定したものと一致していることを確認してください。
uri: <region>-docker.pkg.dev/<project-id>/<repository-name>/<image-name>
# Kaniko を使用する場合は、エージェントがビルドコンテキストを保存する GCS バケットを指定します。
build-context-store: gs://<bucket-name>/<path>
エージェントが利用できるように、デフォルトの GCP 認証情報を設定する方法の詳細については、google-auth ドキュメント を参照してください。
Azure 環境は、追加のキーを必要としません。エージェントは起動時に azure.identity.DefaultAzureCredential() を使用して、デフォルトの Azure 認証情報をロードします。
environment:
type: azure
builder:
type: <kaniko|docker>
# エージェントがイメージを保存する Azure Container Registry リポジトリの URI。
destination: https://<registry-name>.azurecr.io/<repository-name>
# Kaniko を使用する場合は、エージェントがビルドコンテキストを保存する Azure Blob Storage コンテナーを指定します。
build-context-store: https://<storage-account-name>.blob.core.windows.net/<container-name>
デフォルトの Azure 認証情報を設定する方法の詳細については、azure-identity ドキュメント を参照してください。
エージェントの権限
必要なエージェントの権限は、ユースケースによって異なります。
クラウドレジストリの権限
以下は、Launch エージェントがクラウドレジストリとやり取りするために一般的に必要な権限です。
{
'Version': '2012-10-17',
'Statement':
[
{
'Effect': 'Allow',
'Action':
[
'ecr:CreateRepository',
'ecr:UploadLayerPart',
'ecr:PutImage',
'ecr:CompleteLayerUpload',
'ecr:InitiateLayerUpload',
'ecr:DescribeRepositories',
'ecr:DescribeImages',
'ecr:BatchCheckLayerAvailability',
'ecr:BatchDeleteImage',
],
'Resource': 'arn:aws:ecr:<region>:<account-id>:repository/<repository>',
},
{
'Effect': 'Allow',
'Action': 'ecr:GetAuthorizationToken',
'Resource': '*',
},
],
}
artifactregistry.dockerimages.list;
artifactregistry.repositories.downloadArtifacts;
artifactregistry.repositories.list;
artifactregistry.repositories.uploadArtifacts;
Kaniko ビルダーを使用する場合は、AcrPush ロール を追加します。
Kaniko のストレージ権限
エージェントが Kaniko ビルダーを使用する場合、Launch エージェントはクラウドストレージにプッシュする権限が必要です。Kaniko は、ビルドジョブを実行しているポッドの外部にあるコンテキストストアを使用します。
AWS での Kaniko ビルダーの推奨コンテキストストアは Amazon S3 です。次のポリシーを使用して、エージェントに S3 バケットへのアクセス権を付与できます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ListObjectsInBucket",
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::<BUCKET-NAME>"]
},
{
"Sid": "AllObjectActions",
"Effect": "Allow",
"Action": "s3:*Object",
"Resource": ["arn:aws:s3:::<BUCKET-NAME>/*"]
}
]
}
GCP では、エージェントがビルドコンテキストを GCS にアップロードするために、次の IAM 権限が必要です。
storage.buckets.get;
storage.objects.create;
storage.objects.delete;
storage.objects.get;
エージェントがビルドコンテキストを Azure Blob Storage にアップロードするには、ストレージ BLOB データ共同作成者 ロールが必要です。
Kaniko ビルドのカスタマイズ
エージェント設定の builder.kaniko-config キーで、Kaniko ジョブが使用する Kubernetes ジョブスペックを指定します。次に例を示します。
builder:
type: kaniko
build-context-store: <my-build-context-store>
destination: <my-image-destination>
build-job-name: wandb-image-build
kaniko-config:
spec:
template:
spec:
containers:
- args:
- "--cache=false" # Args は "key=value" 形式である必要があります
env:
- name: "MY_ENV_VAR"
value: "my-env-var-value"
CoreWeave への Launch エージェントのデプロイ
オプションで、W&B Launch エージェントを CoreWeave Cloud インフラストラクチャにデプロイします。CoreWeave は、GPU アクセラレーションされたワークロード用に構築されたクラウドインフラストラクチャです。
Launch エージェントを CoreWeave にデプロイする方法については、CoreWeave ドキュメント を参照してください。
3.3 - Tutorial: Set up W&B Launch on Kubernetes
W&B Launch を使用して、ML ワークロードを Kubernetes クラスターにプッシュできます。これにより、ML エンジニアは、Kubernetes で既に管理しているリソースを使用するために、W&B 内でシンプルなインターフェースを利用できます。
W&B は、W&B が管理する 公式 Launch agent イメージ を保持しており、Helm chart を使用してクラスターにデプロイできます。
W&B は Kaniko ビルダーを使用して、Launch エージェントが Kubernetes クラスターで Docker イメージを構築できるようにします。Launch エージェント用に Kaniko をセットアップする方法、またはジョブの構築をオフにして、事前構築済みの Docker イメージのみを使用する方法の詳細については、エージェントの詳細設定 を参照してください。
kubectl アクセス権がクラスターに必要です。通常、cluster-admin または同等の権限を持つカスタムロールを持つユーザーが必要です。Kubernetes のキューを設定する
Kubernetes ターゲットリソースの Launch キュー設定は、Kubernetes Job spec または Kubernetes Custom Resource spec のいずれかに類似します。
Launch キューを作成するときに、Kubernetes ワークロードリソース spec のあらゆる側面を制御できます。
spec:
template:
spec:
containers:
- env:
- name: MY_ENV_VAR
value: some-value
resources:
requests:
cpu: 1000m
memory: 1Gi
metadata:
labels:
queue: k8s-test
namespace: wandb
ユースケースによっては、CustomResource 定義を使用したい場合があります。たとえば、マルチノード分散トレーニングを実行する場合、CustomResource 定義が役立ちます。Volcano を使用したマルチノードジョブで Launch を使用するチュートリアルで、アプリケーションの例を参照してください。別のユースケースとして、W&B Launch を Kubeflow で使用したい場合もあります。
次の YAML スニペットは、Kubeflow を使用するサンプル Launch キュー設定を示しています。
kubernetes:
kind: PyTorchJob
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
template:
spec:
containers:
- name: pytorch
image: '${image_uri}'
imagePullPolicy: Always
restartPolicy: Never
Worker:
replicas: 2
template:
spec:
containers:
- name: pytorch
image: '${image_uri}'
imagePullPolicy: Always
restartPolicy: Never
ttlSecondsAfterFinished: 600
metadata:
name: '${run_id}-pytorch-job'
apiVersion: kubeflow.org/v1
セキュリティ上の理由から、W&B は、指定されていない場合、次のリソースを Launch キューに挿入します。
securityContextbackOffLimitttlSecondsAfterFinished
次の YAML スニペットは、これらの値が Launch キューにどのように表示されるかを示しています。
spec:
template:
`backOffLimit`: 0
ttlSecondsAfterFinished: 60
securityContext:
allowPrivilegeEscalation: False,
capabilities:
drop:
- ALL,
seccompProfile:
type: "RuntimeDefault"
キューを作成する
Kubernetes をコンピューティングリソースとして使用するキューを W&B アプリケーションで作成します。
- Launch ページ に移動します。
- [キューを作成] ボタンをクリックします。
- キューを作成する Entity を選択します。
- [名前] フィールドにキューの名前を入力します。
- [リソース] として Kubernetes を選択します。
- [設定] フィールドで、前のセクションで設定した Kubernetes Job ワークフロー spec または Custom Resource spec を指定します。
Helm で Launch エージェントを設定する
W&B が提供する Helm chart を使用して、Launch エージェントを Kubernetes クラスターにデプロイします。values.yaml ファイル で Launch エージェントの振る舞いを制御します。
通常は Launch エージェント設定ファイル (~/.config/wandb/launch-config.yaml) で定義される内容を、values.yaml ファイルの launchConfig キー内に指定します。
たとえば、Kaniko Docker イメージビルダーを使用する EKS で Launch エージェントを実行できるようにする Launch エージェント設定があるとします。
queues:
- <queue name>
max_jobs: <n concurrent jobs>
environment:
type: aws
region: us-east-1
registry:
type: ecr
uri: <my-registry-uri>
builder:
type: kaniko
build-context-store: <s3-bucket-uri>
values.yaml ファイル内では、次のようになります。
agent:
labels: {}
# W&B API key.
apiKey: ''
# Container image to use for the agent.
image: wandb/launch-agent:latest
# Image pull policy for agent image.
imagePullPolicy: Always
# Resources block for the agent spec.
resources:
limits:
cpu: 1000m
memory: 1Gi
# Namespace to deploy launch agent into
namespace: wandb
# W&B api url (Set yours here)
baseUrl: https://api.wandb.ai
# Additional target namespaces that the launch agent can deploy into
additionalTargetNamespaces:
- default
- wandb
# This should be set to the literal contents of your launch agent config.
launchConfig: |
queues:
- <queue name>
max_jobs: <n concurrent jobs>
environment:
type: aws
region: <aws-region>
registry:
type: ecr
uri: <my-registry-uri>
builder:
type: kaniko
build-context-store: <s3-bucket-uri>
# The contents of a git credentials file. This will be stored in a k8s secret
# and mounted into the agent container. Set this if you want to clone private
# repos.
gitCreds: |
# Annotations for the wandb service account. Useful when setting up workload identity on gcp.
serviceAccount:
annotations:
iam.gke.io/gcp-service-account:
azure.workload.identity/client-id:
# Set to access key for azure storage if using kaniko with azure.
azureStorageAccessKey: ''
レジストリ、環境、および必要なエージェント権限の詳細については、エージェントの詳細設定 を参照してください。
3.4 - Tutorial: Set up W&B Launch on SageMaker
W&B の Launch を使用すると、提供された、またはカスタムのアルゴリズムを使用して、Amazon SageMaker に Launch ジョブを送信し、SageMaker プラットフォームで機械学習 モデルをトレーニングできます。SageMaker は、コンピューティングリソースの起動と解放を行うため、EKS クラスターを持たない Teams にとって良い選択肢となります。
Amazon SageMaker に接続された W&B Launch キューに送信された Launch ジョブは、CreateTrainingJob API を使用して SageMaker Training ジョブとして実行されます。Launch キューの設定を使用して、CreateTrainingJob API に送信される引数を制御します。
Amazon SageMaker は、Docker イメージを使用して Training ジョブを実行します。SageMaker によってプルされるイメージは、Amazon Elastic Container Registry (ECR) に保存する必要があります。これは、トレーニングに使用するイメージが ECR に保存されている必要があることを意味します。
前提条件
開始する前に、次の前提条件を満たしていることを確認してください。
- Launch エージェント に Docker イメージを構築させるかどうかを決定します。
- AWS リソースをセットアップし、S3、ECR、および Sagemaker IAM ロールに関する情報を収集します。
- Launch エージェント の IAM ロールを作成します。
Launch エージェント に Docker イメージを構築させるかどうかを決定します。
W&B Launch エージェント に Docker イメージを構築させるかどうかを決定します。次の 2 つのオプションから選択できます。
- Launch エージェント が Docker イメージを構築し、イメージを Amazon ECR にプッシュして、SageMaker Training ジョブを送信できるようにします。このオプションは、機械学習 エンジニアがトレーニング コードを迅速に反復処理する際に、ある程度の簡素化をもたらすことができます。
- Launch エージェント は、トレーニング スクリプトまたは推論スクリプトを含む既存の Docker イメージを使用します。このオプションは、既存の CI システムとうまく連携します。このオプションを選択した場合は、Docker イメージを Amazon ECR のコンテナー レジストリに手動でアップロードする必要があります。
AWS リソースのセットアップ
優先する AWS リージョンで次の AWS リソースが構成されていることを確認してください。
- コンテナー イメージを保存する ECR リポジトリ。
- SageMaker Training ジョブの入出力を保存する 1 つ以上の S3 バケット。
- SageMaker が Training ジョブを実行し、Amazon ECR および Amazon S3 とやり取りすることを許可する Amazon SageMaker の IAM ロール。
これらのリソースの ARN をメモしておきます。Launch キューの設定を定義する際に、ARN が必要になります。
Launch エージェント の IAM ポリシーを作成する
- AWS の IAM 画面から、新しいポリシーを作成します。
- JSON ポリシー エディターに切り替え、ユースケースに基づいて次のポリシーを貼り付けます。
<>で囲まれた値を独自の値に置き換えます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams",
"SageMaker:AddTags",
"SageMaker:CreateTrainingJob",
"SageMaker:DescribeTrainingJob"
],
"Resource": "arn:aws:sagemaker:<region>:<account-id>:*"
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<account-id>:role/<RoleArn-from-queue-config>"
},
{
"Effect": "Allow",
"Action": "kms:CreateGrant",
"Resource": "<ARN-OF-KMS-KEY>",
"Condition": {
"StringEquals": {
"kms:ViaService": "SageMaker.<region>.amazonaws.com",
"kms:GrantIsForAWSResource": "true"
}
}
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams",
"SageMaker:AddTags",
"SageMaker:CreateTrainingJob",
"SageMaker:DescribeTrainingJob"
],
"Resource": "arn:aws:sagemaker:<region>:<account-id>:*"
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<account-id>:role/<RoleArn-from-queue-config>"
},
{
"Effect": "Allow",
"Action": [
"ecr:CreateRepository",
"ecr:UploadLayerPart",
"ecr:PutImage",
"ecr:CompleteLayerUpload",
"ecr:InitiateLayerUpload",
"ecr:DescribeRepositories",
"ecr:DescribeImages",
"ecr:BatchCheckLayerAvailability",
"ecr:BatchDeleteImage"
],
"Resource": "arn:aws:ecr:<region>:<account-id>:repository/<repository>"
},
{
"Effect": "Allow",
"Action": "ecr:GetAuthorizationToken",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "kms:CreateGrant",
"Resource": "<ARN-OF-KMS-KEY>",
"Condition": {
"StringEquals": {
"kms:ViaService": "SageMaker.<region>.amazonaws.com",
"kms:GrantIsForAWSResource": "true"
}
}
}
]
}
- [Next] をクリックします。
- ポリシーに名前と説明を付けます。
- [Create policy] をクリックします。
Launch エージェント の IAM ロールを作成する
Launch エージェント に Amazon SageMaker Training ジョブを作成する権限が必要です。次の手順に従って、IAM ロールを作成します。
- AWS の IAM 画面から、新しいロールを作成します。
- [Trusted Entity] で、[AWS Account] (または組織のポリシーに適した別のオプション) を選択します。
- 権限画面をスクロールして、上記で作成したポリシー名を選択します。
- ロールに名前と説明を付けます。
- [Create role] を選択します。
- ロールの ARN をメモします。Launch エージェント を設定する際に、ARN を指定します。
IAM ロールの作成方法の詳細については、AWS Identity and Access Management のドキュメントを参照してください。
- Launch エージェント にイメージを構築させる場合は、追加で必要な権限について、エージェント の高度な設定を参照してください。
- SageMaker キューの
kms:CreateGrant権限は、関連付けられた ResourceConfig に VolumeKmsKeyId が指定されていて、関連付けられたロールにこのアクションを許可するポリシーがない場合にのみ必要です。
SageMaker の Launch キューを設定する
次に、SageMaker をコンピューティング リソースとして使用するキューを W&B アプリ で作成します。
- Launch アプリに移動します。
- [Create Queue] ボタンをクリックします。
- キューを作成する [Entity] を選択します。
- [Name] フィールドにキューの名前を入力します。
- [Resource] として [SageMaker] を選択します。
- [Configuration] フィールド内で、SageMaker ジョブに関する情報を提供します。デフォルトでは、W&B は YAML および JSON の
CreateTrainingJobリクエスト本文を生成します。
{
"RoleArn": "<必須>",
"ResourceConfig": {
"InstanceType": "ml.m4.xlarge",
"InstanceCount": 1,
"VolumeSizeInGB": 2
},
"OutputDataConfig": {
"S3OutputPath": "<必須>"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 3600
}
}
少なくとも以下を指定する必要があります。
RoleArn: SageMaker 実行 IAM ロールの ARN (前提条件を参照)。Launch エージェント IAM ロールと混同しないようにしてください。OutputDataConfig.S3OutputPath: SageMaker の出力が保存される Amazon S3 URI。ResourceConfig: リソース設定に必要な仕様。リソース設定のオプションはこちらに概説されています。StoppingCondition: Training ジョブの停止条件に必要な仕様。オプションはこちらに概説されています。
- [Create Queue] ボタンをクリックします。
Launch エージェント を設定する
次のセクションでは、エージェント をデプロイできる場所と、デプロイ場所に基づいて エージェント を構成する方法について説明します。
Amazon SageMaker の Launch エージェント をデプロイする方法には、いくつかのオプションがあります。ローカル マシン、EC2 インスタンス、または EKS クラスターです。エージェント をデプロイする場所に基づいて、Launch エージェント を適切に構成します。
Launch エージェント を実行する場所を決定する
本番環境のワークロードや、既に EKS クラスターをお持ちのお客様には、この Helm チャートを使用して、Launch エージェント を EKS クラスターにデプロイすることをお勧めします。
現在の EKS クラスターを使用しない本番環境のワークロードの場合、EC2 インスタンスは優れたオプションです。Launch エージェント インスタンスは常に実行され続けますが、エージェント には t2.micro サイズの EC2 インスタンス以上のものは必要ありません。これは比較的安価です。
実験的なユースケースや個人のユースケースの場合、ローカル マシンで Launch エージェント を実行すると、すばやく開始できます。
ユースケースに基づいて、次のタブに記載されている手順に従って、Launch エージェント を適切に構成してください。
W&B は、W&B 管理の Helm チャートを使用して、EKS クラスターに エージェント をインストールすることを強くお勧めします。
Amazon EC2 ダッシュボードに移動し、次の手順を実行します。
- [Launch instance] をクリックします。
- [Name] フィールドに名前を入力します。必要に応じて、タグを追加します。
- [Instance type] で、EC2 コンテナーのインスタンス タイプを選択します。1 vCPU と 1 GiB のメモリを超えるものは必要ありません (たとえば、t2.micro)。
- [Key pair (login)] フィールド内で、組織のキー ペアを作成します。このキー ペアを使用して、後の手順で SSH クライアントを使用してEC2 インスタンスに接続します。
- [Network settings] 内で、組織に適したセキュリティ グループを選択します。
- [Advanced details] を展開します。[IAM instance profile] で、上記で作成した Launch エージェント IAM ロールを選択します。
- [Summary] フィールドを確認します。正しい場合は、[Launch instance] を選択します。
AWS の EC2 ダッシュボードの左側のパネルにある [Instances] に移動します。作成した EC2 インスタンスが実行されていることを確認します ([Instance state] 列を参照)。EC2 インスタンスが実行されていることを確認したら、ローカル マシンのターミナルに移動して、次の手順を実行します。
- [Connect] を選択します。
- [SSH client] タブを選択し、概要が示されている手順に従って EC2 インスタンスに接続します。
- EC2 インスタンス内で、次のパッケージをインストールします。
sudo yum install python311 -y && python3 -m ensurepip --upgrade && pip3 install wandb && pip3 install wandb[launch]
- 次に、EC2 インスタンス内で Docker をインストールして起動します。
sudo yum update -y && sudo yum install -y docker python3 && sudo systemctl start docker && sudo systemctl enable docker && sudo usermod -a -G docker ec2-user
newgrp docker
これで、Launch エージェント の構成に進むことができます。
~/.aws/config および ~/.aws/credentials にある AWS 構成ファイルを使用して、ローカル マシンでポーリングする エージェント にロールを関連付けます。前の手順で Launch エージェント 用に作成した IAM ロール ARN を指定します。
[profile SageMaker-agent]
role_arn = arn:aws:iam::<account-id>:role/<agent-role-name>
source_profile = default
[default]
aws_access_key_id=<access-key-id>
aws_secret_access_key=<secret-access-key>
aws_session_token=<session-token>
セッション トークンには、関連付けられているプリンシパルに応じて、最大長が 1 時間または 3 日であることに注意してください。
Launch エージェント を構成する
YAML 構成ファイル launch-config.yaml を使用して Launch エージェント を構成します。
デフォルトでは、W&B は ~/.config/wandb/launch-config.yaml で構成ファイルを確認します。必要に応じて、-c フラグを使用して Launch エージェント をアクティブ化するときに、別のディレクトリーを指定できます。
次の YAML スニペットは、コア構成 エージェント オプションを指定する方法を示しています。
max_jobs: -1
queues:
- <queue-name>
environment:
type: aws
region: <your-region>
registry:
type: ecr
uri: <ecr-repo-arn>
builder:
type: docker
次に、wandb launch-agent で エージェント を開始します。
(オプション) Launch ジョブ Docker イメージを Amazon ECR にプッシュする
Launch ジョブを含む Docker イメージを Amazon ECR リポジトリにアップロードします。イメージベースのジョブを使用している場合は、新しい Launch ジョブを送信する前に、Docker イメージが ECR レジストリに存在する必要があります。
3.5 - Tutorial: Set up W&B Launch on Vertex AI
W&B Launch を使用して、 Vertex AI トレーニングジョブとして実行するジョブを送信できます。Vertex AI トレーニングジョブを使用すると、Vertex AI プラットフォーム上で、提供されたアルゴリズムまたはカスタム アルゴリズムを使用して、機械学習モデルをトレーニングできます。Launch ジョブが開始されると、Vertex AI は基盤となるインフラストラクチャー、スケーリング、およびオーケストレーションを管理します。
W&B Launch は、google-cloud-aiplatform SDK の CustomJob クラスを通じて Vertex AI と連携します。CustomJob のパラメータは、launch キュー設定で制御できます。Vertex AI は、GCP 外部のプライベートレジストリからイメージをプルするように構成できません。つまり、W&B Launch で Vertex AI を使用する場合は、コンテナイメージを GCP またはパブリックレジストリに保存する必要があります。コンテナイメージを Vertex ジョブからアクセスできるようにする方法については、Vertex AI のドキュメントを参照してください。
前提条件
- Vertex AI API が有効になっている GCP プロジェクトを作成またはアクセスします。 API の有効化の詳細については、GCP API Console のドキュメントを参照してください。
- Vertex で実行するイメージを保存するための GCP Artifact Registry リポジトリを作成します。 詳細については、GCP Artifact Registry のドキュメントを参照してください。
- Vertex AI がそのメタデータを保存するためのステージング GCS バケットを作成します。 このバケットは、ステージングバケットとして使用するには、Vertex AI ワークロードと同じリージョンにある必要があることに注意してください。同じバケットをステージングおよびビルドコンテキストに使用できます。
- Vertex AI ジョブをスピンアップするために必要な権限を持つサービスアカウントを作成します。 サービスアカウントへの権限の割り当ての詳細については、GCP IAM ドキュメントを参照してください。
- Vertex ジョブを管理する権限をサービスアカウントに付与します
| 権限 | リソーススコープ | 説明 |
|---|---|---|
aiplatform.customJobs.create |
指定された GCP プロジェクト | プロジェクト内で新しい機械学習ジョブを作成できます。 |
aiplatform.customJobs.list |
指定された GCP プロジェクト | プロジェクト内の機械学習ジョブを一覧表示できます。 |
aiplatform.customJobs.get |
指定された GCP プロジェクト | プロジェクト内の特定の機械学習ジョブに関する情報を取得できます。 |
spec.service_account フィールドを使用して、W&B Runs のカスタムサービスアカウントを選択できます。Vertex AI のキューを設定する
Vertex AI リソースのキュー設定では、Vertex AI Python SDK の CustomJob コンストラクタと、CustomJob の run メソッドへの入力を指定します。リソース設定は、spec キーと run キーに格納されます。
specキーには、Vertex AI Python SDK のCustomJobコンストラクタ の名前付き引数の値が含まれています。runキーには、Vertex AI Python SDK のCustomJobクラスのrunメソッドの名前付き引数の値が含まれています。
実行環境のカスタマイズは、主に spec.worker_pool_specs リストで行われます。ワーカープールのスペックは、ジョブを実行するワーカーのグループを定義します。デフォルト設定のワーカーのスペックは、アクセラレータなしの単一の n1-standard-4 マシンを要求します。ニーズに合わせて、マシンの種類、アクセラレータの種類、および数を変更できます。
利用可能なマシンの種類とアクセラレータの種類について詳しくは、Vertex AI のドキュメントをご覧ください。
キューを作成する
Vertex AI をコンピューティングリソースとして使用するキューを W&B App で作成します。
- Launch ページに移動します。
- キューを作成 ボタンをクリックします。
- キューを作成する Entity を選択します。
- 名前 フィールドにキューの名前を入力します。
- リソース として GCP Vertex を選択します。
- 設定 フィールド内で、前のセクションで定義した Vertex AI
CustomJobに関する情報を提供します。デフォルトでは、W&B は次のような YAML および JSON リクエスト本文を生成します。
spec:
worker_pool_specs:
- machine_spec:
machine_type: n1-standard-4
accelerator_type: ACCELERATOR_TYPE_UNSPECIFIED
accelerator_count: 0
replica_count: 1
container_spec:
image_uri: ${image_uri}
staging_bucket: <REQUIRED>
run:
restart_job_on_worker_restart: false
- キューを設定したら、キューを作成 ボタンをクリックします。
少なくとも、以下を指定する必要があります。
spec.worker_pool_specs: ワーカープールの仕様の空でないリスト。spec.staging_bucket: Vertex AI のアセットとメタデータのステージングに使用される GCS バケット。
Vertex AI のドキュメントの一部には、すべてのキーがキャメルケース (たとえば、 workerPoolSpecs) のワーカープールの仕様が示されています。Vertex AI Python SDK は、これらのキーにスネークケース (たとえば、worker_pool_specs) を使用します。
Launch キュー設定のすべてのキーは、スネークケースを使用する必要があります。
Launch エージェントを設定する
Launch エージェントは、デフォルトで ~/.config/wandb/launch-config.yaml にある構成ファイルを使用して設定できます。
max_jobs: <n-concurrent-jobs>
queues:
- <queue-name>
Launch エージェントに Vertex AI で実行されるイメージを構築させる場合は、エージェントの詳細設定を参照してください。
エージェントの権限を設定する
このサービスアカウントとして認証するには、複数の方法があります。これは、Workload Identity、ダウンロードされたサービスアカウント JSON、環境変数、Google Cloud Platform コマンドライン ツール、またはこれらの方法の組み合わせによって実現できます。
3.6 - Tutorial: Set up W&B Launch with Docker
以下のガイドでは、 W&B Launch を設定して、 ローンチ エージェント環境とキューのターゲットリソースの両方でローカルマシン上の Docker を使用する方法について説明します。
ジョブの実行に Docker を使用すること、および同じローカルマシン上で ローンチ エージェントの環境として使用することは、お使いのコンピューティングが (Kubernetes などの) クラスター 管理システムを持たないマシンにインストールされている場合に特に役立ちます。
また、 Docker キューを使用して、強力なワークステーションでワークロードを実行することもできます。
W&B Launch で Docker を使用すると、W&B は最初にイメージを構築し、次にそのイメージからコンテナを構築して実行します。イメージは、Docker docker run <image-uri> コマンドで構築されます。キュー構成は、 docker run コマンドに渡される追加の 引数 として解釈されます。
Docker キューの構成
(Docker ターゲットリソースの) ローンチ キュー構成は、 docker run CLI コマンドで定義されているものと同じオプションを受け入れます。
エージェント は、キュー構成で定義されたオプションを受け取ります。次に、 エージェント は、受信したオプションを ローンチ ジョブの構成からのオーバーライドとマージして、ターゲットリソース (この場合はローカルマシン) で実行される最終的な docker run コマンドを生成します。
次の 2 つの構文変換が行われます。
- 繰り返されるオプションは、キュー構成でリストとして定義されます。
- フラグオプションは、キュー構成で値が
trueのブール値として定義されます。
たとえば、次のキュー構成があるとします。
{
"env": ["MY_ENV_VAR=value", "MY_EXISTING_ENV_VAR"],
"volume": "/mnt/datasets:/mnt/datasets",
"rm": true,
"gpus": "all"
}
次の docker run コマンドになります。
docker run \
--env MY_ENV_VAR=value \
--env MY_EXISTING_ENV_VAR \
--volume "/mnt/datasets:/mnt/datasets" \
--rm <image-uri> \
--gpus all
ボリュームは、文字列のリストまたは単一の文字列として指定できます。複数のボリュームを指定する場合は、リストを使用します。
Docker は、値が割り当てられていない 環境 変数を ローンチ エージェント環境から自動的に渡します。つまり、 ローンチ エージェントに 環境 変数 MY_EXISTING_ENV_VAR がある場合、その 環境 変数はコンテナで使用できます。これは、キュー構成で公開せずに他の構成 キー を使用する場合に役立ちます。
docker run コマンドの --gpus フラグを使用すると、Docker コンテナで使用できる GPU を指定できます。 gpus フラグの使用方法の詳細については、 Docker のドキュメント を参照してください。
-
Docker コンテナ内で GPU を使用するには、 NVIDIA Container Toolkit をインストールします。
-
コードまたは Artifacts ソースのジョブからイメージを構築する場合、 エージェント で使用されるベースイメージをオーバーライドして、NVIDIA Container Toolkit を含めることができます。 たとえば、 ローンチ キュー内で、ベースイメージを
tensorflow/tensorflow:latest-gpuにオーバーライドできます。{ "builder": { "accelerator": { "base_image": "tensorflow/tensorflow:latest-gpu" } } }
キューの作成
W&B CLI を使用して、Docker をコンピューティングリソースとして使用するキューを作成します。
- Launch pageに移動します。
- [Create Queue] ボタンをクリックします。
- キューを作成する Entities を選択します。
- [Name] フィールドにキューの名前を入力します。
- [Resource] として Docker を選択します。
- [Configuration] フィールドで Docker キュー構成を定義します。
- [Create Queue] ボタンをクリックしてキューを作成します。
ローカルマシンでの ローンチ エージェント の構成
launch-config.yaml という名前の YAML 構成ファイルを使用して、 ローンチ エージェント を構成します。デフォルトでは、W&B は ~/.config/wandb/launch-config.yaml で構成ファイルを確認します。オプションで、 ローンチ エージェント をアクティブ化するときに別の ディレクトリー を指定できます。
wandb launch-agent コマンドを参照してください。コア エージェント 構成オプション
次のタブは、W&B CLI および YAML 構成ファイルを使用して、コア構成 エージェント オプションを指定する方法を示しています。
wandb launch-agent -q <queue-name> --max-jobs <n>
max_jobs: <n concurrent jobs>
queues:
- <queue-name>
Docker イメージビルダー
マシン上の ローンチ エージェント は、Docker イメージを構築するように構成できます。デフォルトでは、これらのイメージはマシンのローカルイメージリポジトリーに保存されます。 ローンチ エージェント が Docker イメージを構築できるようにするには、 ローンチ エージェント 構成の builder キー を docker に設定します。
builder:
type: docker
エージェント に Docker イメージを構築させたくない場合は、代わりにレジストリーから事前に構築されたイメージを使用し、 ローンチ エージェント 構成の builder キー を noop に設定します。
builder:
type: noop
コンテナレジストリ
Launch は、 Dockerhub、Google Container Registry、Azure Container Registry、Amazon ECR などの外部コンテナレジストリを使用します。 ジョブを構築した環境とは異なる環境でジョブを実行する場合は、コンテナレジストリからプルできるように エージェント を構成します。
ローンチ エージェント を クラウド レジストリに接続する方法の詳細については、 高度な エージェント のセットアップ ページを参照してください。
4 - Create and deploy jobs
4.1 - Add job to queue
次のページでは、Launch キューに Launch ジョブを追加する方法について説明します。
キューにジョブを追加する
W&B App を使用してインタラクティブに、または W&B CLI を使用してプログラムで、ジョブをキューに追加します。
W&B App を使用して、プログラムでジョブをキューに追加します。
- W&B の Project ページに移動します。
- 左側のパネルで、Jobs アイコンを選択します。
- Jobs ページには、以前に実行された W&B の run から作成された W&B の Launch ジョブのリストが表示されます。
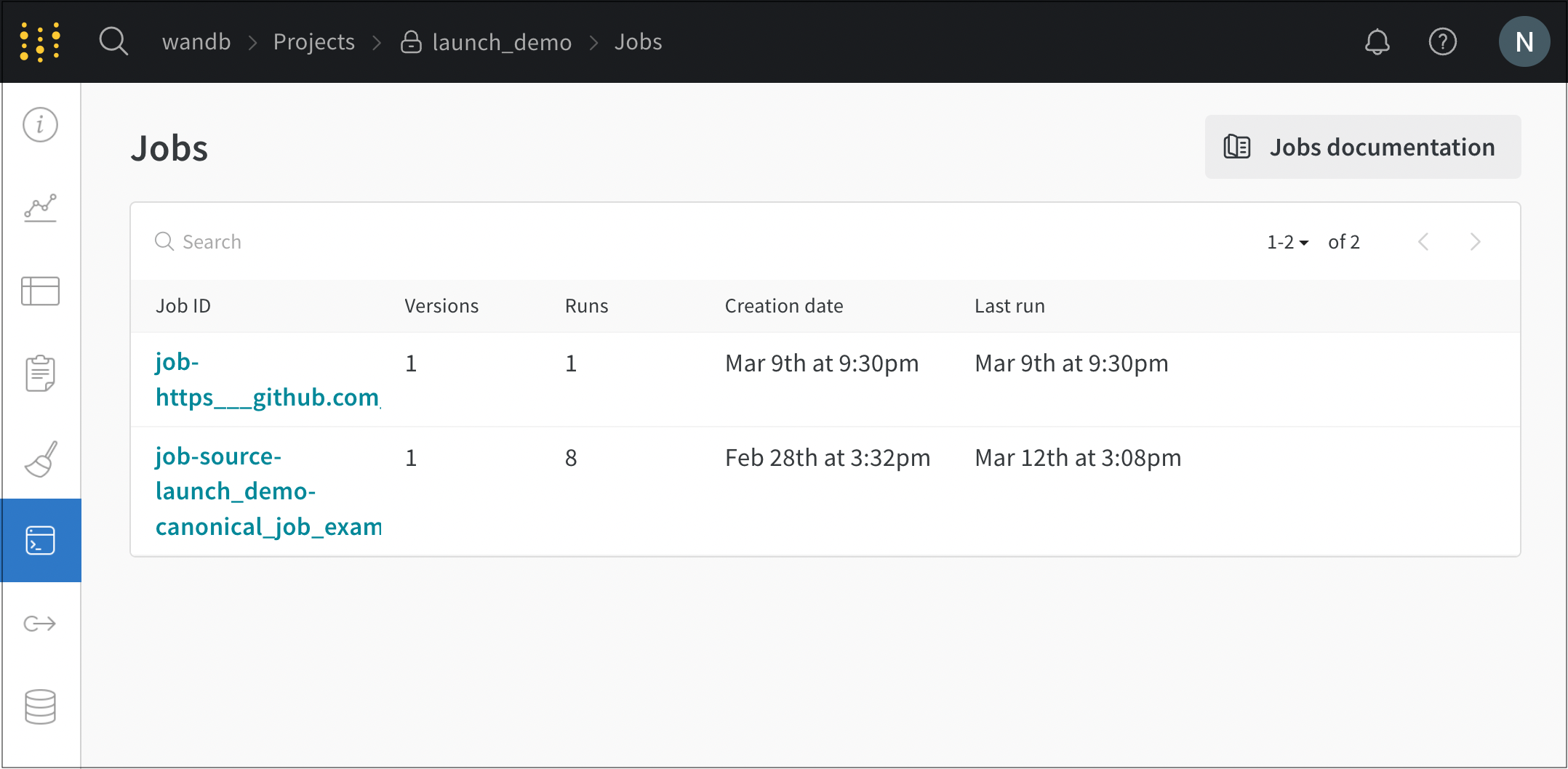
- ジョブ名の横にある Launch ボタンを選択します。モーダルがページの右側に表示されます。
- Job version ドロップダウンから、使用する Launch ジョブのバージョンを選択します。Launch ジョブは、他の W&B Artifact と同様にバージョン管理されています。ジョブの実行に使用されるソフトウェアの依存関係またはソースコードを変更すると、同じ Launch ジョブの異なるバージョンが作成されます。
- Overrides セクション内で、Launch ジョブに設定されているすべての入力に新しい値を指定します。一般的なオーバーライドには、新しいエントリポイントコマンド、引数、または新しい W&B の run の
wandb.configの値が含まれます。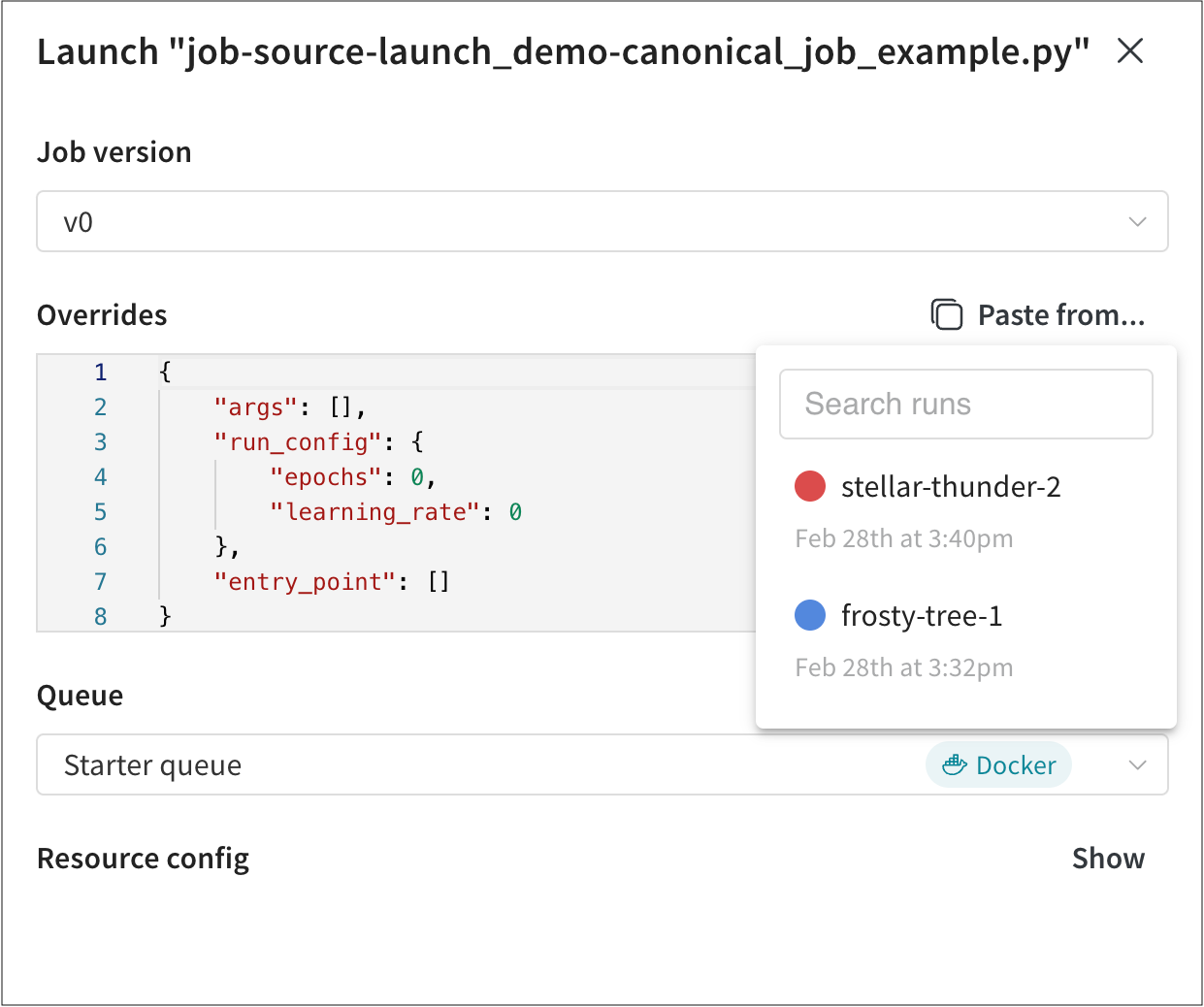 Paste from… ボタンをクリックして、Launch ジョブを使用した他の W&B の run から値をコピーして貼り付けることができます。
Paste from… ボタンをクリックして、Launch ジョブを使用した他の W&B の run から値をコピーして貼り付けることができます。 - Queue ドロップダウンから、Launch ジョブを追加する Launch キューの名前を選択します。
- Job Priority ドロップダウンを使用して、Launch ジョブの優先度を指定します。Launch キューが優先順位付けをサポートしていない場合、Launch ジョブの優先度は「Medium」に設定されます。
- (オプション)チーム管理者がキュー構成テンプレートを作成した場合にのみ、この手順に従ってください
Queue Configurations フィールド内で、チームの管理者によって作成された構成オプションの値を指定します。
たとえば、次の例では、チーム管理者はチームが使用できる AWS インスタンスタイプを構成しました。この場合、チームメンバーは
ml.m4.xlargeまたはml.p3.xlargeコンピュートインスタンスタイプのいずれかを選択して、モデルをトレーニングできます。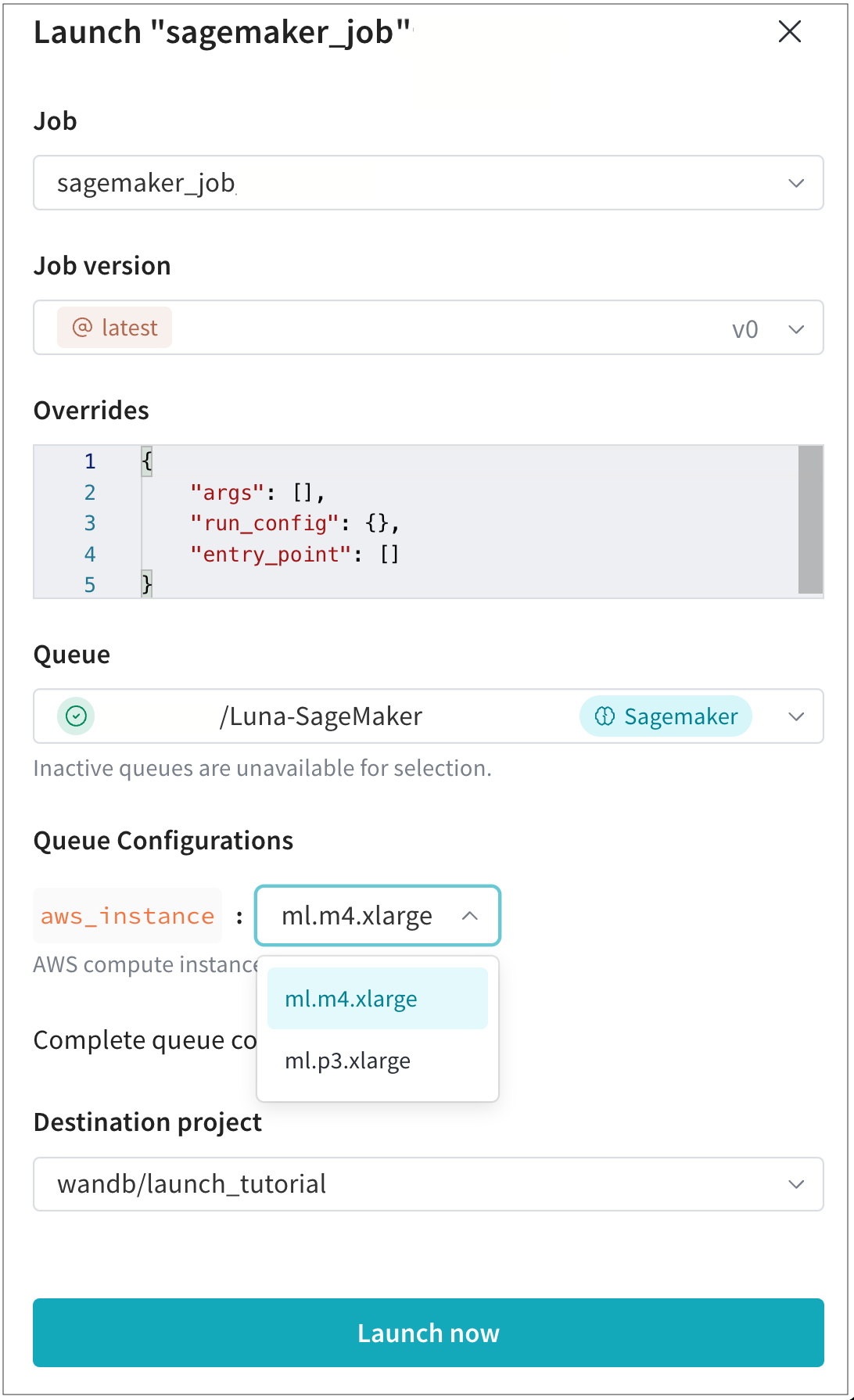
- 結果の run が表示される Destination project を選択します。この Project は、キューと同じエンティティに属している必要があります。
- Launch now ボタンを選択します。
wandb launch コマンドを使用して、ジョブをキューに追加します。ハイパー パラメーターのオーバーライドを含む JSON 構成を作成します。たとえば、クイックスタート ガイドのスクリプトを使用して、次のオーバーライドを含む JSON ファイルを作成します。
{
"overrides": {
"args": [],
"run_config": {
"learning_rate": 0,
"epochs": 0
},
"entry_point": []
}
}
キュー構成をオーバーライドする場合、または Launch キューに構成リソースが定義されていない場合は、config.json ファイルで resource_args キーを指定できます。たとえば、上記の例に続いて、config.json ファイルは次のようになります。
{
"overrides": {
"args": [],
"run_config": {
"learning_rate": 0,
"epochs": 0
},
"entry_point": []
},
"resource_args": {
"<resource-type>" : {
"<key>": "<value>"
}
}
}
<> 内の値を独自の値に置き換えます。
queue(-q) フラグのキューの名前、job(-j) フラグのジョブの名前、および config(-c) フラグの構成ファイルへのパスを指定します。
wandb launch -j <job> -q <queue-name> \
-e <entity-name> -c path/to/config.json
W&B の Teams で作業する場合は、キューが使用するエンティティを示すために entity フラグ (-e) を指定することをお勧めします。
4.2 - Create a launch job
Launch jobsは、W&B runを再現するための設計図です。Jobsは、ワークロードを実行するために必要なソース コード、依存関係、および入力をキャプチャするW&B Artifactsです。
wandb launch コマンドでjobsを作成および実行します。
wandb job create コマンドを使用します。詳細については、コマンドリファレンスドキュメントを参照してください。Git jobs
W&B Launchを使用して、コードやその他の追跡対象アセットがリモートgitリポジトリの特定のコミット、ブランチ、またはタグからクローンされるGitベースのjobを作成できます。コードを含むURIを指定するには、--uriまたは-uフラグを使用し、必要に応じてサブディレクトリーを指定するには、--build-contextフラグを使用します。
次のコマンドを使用して、gitリポジトリから「hello world」jobを実行します。
wandb launch --uri "https://github.com/wandb/launch-jobs.git" --build-context jobs/hello_world --dockerfile Dockerfile.wandb --project "hello-world" --job-name "hello-world" --entry-point "python job.py"
このコマンドは次のことを行います。
- W&B Launch jobs repositoryを一時ディレクトリーにクローンします。
- hello プロジェクトにhello-world-gitという名前のjobを作成します。このjobは、リポジトリのデフォルトブランチの先頭にあるコミットに関連付けられています。
jobs/hello_worldディレクトリーとDockerfile.wandbからコンテナーイメージを構築します。- コンテナーを起動し、
python job.pyを実行します。
特定のブランチまたはコミットハッシュからjobを構築するには、-g、--git-hash引数を追加します。引数の完全なリストについては、wandb launch --helpを実行してください。
リモートURLの形式
Launch jobに関連付けられたgitリモートは、HTTPSまたはSSH URLのいずれかになります。URLタイプは、jobソース コードの取得に使用されるプロトコルを決定します。
| リモートURLタイプ | URL形式 | アクセスと認証の要件 |
|---|---|---|
| https | https://github.com/organization/repository.git |
gitリモートで認証するためのユーザー名とパスワード |
| ssh | git@github.com:organization/repository.git |
gitリモートで認証するためのsshキー |
正確なURL形式は、ホスティングプロバイダーによって異なることに注意してください。wandb launch --uriで作成されたjobsは、指定された--uriで指定された転送プロトコルを使用します。
Code artifact jobs
Jobsは、W&B Artifactに保存されている任意のソース コードから作成できます。--uriまたは-u引数を持つローカルディレクトリーを使用して、新しいcode artifactとjobを作成します。
まず、空のディレクトリーを作成し、次のコンテンツを含むmain.pyという名前のPythonスクリプトを追加します。
import wandb
with wandb.init() as run:
run.log({"metric": 0.5})
次のコンテンツを含むrequirements.txtファイルを追加します。
wandb>=0.17.1
ディレクトリーをcode artifactとして記録し、次のコマンドでjobを起動します。
wandb launch --uri . --job-name hello-world-code --project launch-quickstart --entry-point "python main.py"
上記のコマンドは次のことを行います。
- 現在のディレクトリーを
hello-world-codeという名前のcode artifactとして記録します。 launch-quickstartプロジェクトにhello-world-codeという名前のjobを作成します。- 現在のディレクトリーとLaunchのデフォルトのDockerfileからコンテナーイメージを構築します。デフォルトのDockerfileは、
requirements.txtファイルをインストールし、エントリポイントをpython main.pyに設定します。
Image jobs
または、既製のDockerイメージからjobsを構築することもできます。これは、MLコード用の確立された構築システムがすでに存在する場合、またはjobのコードまたは要件を調整する予定はないが、ハイパーパラメーターまたはさまざまなインフラストラクチャースケールを試したい場合に役立ちます。
イメージはDockerレジストリからプルされ、指定されたエントリポイント、またはエントリポイントが指定されていない場合はデフォルトのエントリポイントで実行されます。--docker-imageオプションに完全なイメージタグを渡して、Dockerイメージからjobを作成および実行します。
既製のイメージから単純なjobを実行するには、次のコマンドを使用します。
wandb launch --docker-image "wandb/job_hello_world:main" --project "hello-world"
Automatic job creation
W&Bは、追跡されたソース コードを含むrunに対してjobを自動的に作成および追跡します。これは、Launchでrunが作成されなかった場合でも同様です。Runは、次の3つの条件のいずれかが満たされた場合に、追跡されたソース コードを持っていると見なされます。
- Runに関連付けられたgitリモートとコミットハッシュがある
- Runがcode artifactを記録した(詳細については、
Run.log_codeを参照してください) - Runが、イメージタグに設定された
WANDB_DOCKER環境変数を持つDockerコンテナーで実行された
Launch jobがW&B runによって自動的に作成された場合、GitリモートURLはローカルgitリポジトリから推測されます。
Launch job names
デフォルトでは、W&Bはjob名を自動的に生成します。名前は、jobの作成方法(GitHub、code artifact、またはDockerイメージ)に応じて生成されます。または、環境変数またはW&B Python SDKを使用してLaunch jobの名前を定義することもできます。
次の表は、jobソースに基づいてデフォルトで使用されるjob命名規則を示しています。
| ソース | 命名規則 |
|---|---|
| GitHub | job-<git-remote-url>-<path-to-script> |
| Code artifact | job-<code-artifact-name> |
| Docker image | job-<image-name> |
W&B環境変数またはW&B Python SDKを使用してjobに名前を付けます。
WANDB_JOB_NAME環境変数を優先job名に設定します。次に例を示します。
WANDB_JOB_NAME=awesome-job-name
wandb.Settingsを使用してjobの名前を定義します。次に、wandb.initでW&Bを初期化するときに、このオブジェクトを渡します。次に例を示します。
settings = wandb.Settings(job_name="my-job-name")
wandb.init(settings=settings)
Containerization
Jobsはコンテナー内で実行されます。Image jobsは既製のDockerイメージを使用しますが、Gitおよびcode artifact jobsはコンテナー構築手順を必要とします。
Jobのコンテナー化は、wandb launchへの引数とjobソース コード内のファイルを使用してカスタマイズできます。
Build context
構築コンテキストという用語は、コンテナーイメージを構築するためにDockerデーモンに送信されるファイルとディレクトリーのツリーを指します。デフォルトでは、Launchはjobソース コードのルートを構築コンテキストとして使用します。サブディレクトリーを構築コンテキストとして指定するには、jobの作成および起動時にwandb launchの--build-context引数を使用します。
--build-context引数は、複数のプロジェクトを含むモノレポを指すGit jobsを操作する場合に特に役立ちます。サブディレクトリーを構築コンテキストとして指定することで、モノレポ内の特定のプロジェクトのコンテナーイメージを構築できます。
--build-context引数を公式のW&B Launch jobsリポジトリで使用する方法のデモについては、上記の例を参照してください。
Dockerfile
Dockerfileは、Dockerイメージを構築するための命令を含むテキストファイルです。デフォルトでは、Launchはrequirements.txtファイルをインストールするデフォルトのDockerfileを使用します。カスタムDockerfileを使用するには、wandb launchの--dockerfile引数を使用してファイルへのパスを指定します。
Dockerfileパスは、構築コンテキストを基準にして指定されます。たとえば、構築コンテキストがjobs/hello_worldで、Dockerfileがjobs/hello_worldディレクトリーにある場合、--dockerfile引数はDockerfile.wandbに設定する必要があります。--dockerfile引数を公式のW&B Launch jobsリポジトリで使用する方法のデモについては、上記の例を参照してください。
Requirements file
カスタムDockerfileが提供されていない場合、LaunchはインストールするPython依存関係の構築コンテキストを検索します。requirements.txtファイルが構築コンテキストのルートに見つかった場合、Launchはそのファイルにリストされている依存関係をインストールします。それ以外の場合、pyproject.tomlファイルが見つかった場合、Launchはproject.dependenciesセクションから依存関係をインストールします。
4.3 - Manage job inputs
Launch のコアな体験は、ハイパーパラメーターやデータセットのような様々なジョブ入力を容易に実験し、これらのジョブを適切なハードウェアにルーティングすることです。ジョブが作成されると、最初の作成者以外の ユーザー は、W&B GUIまたはCLIを介してこれらの入力を調整できます。CLIまたはUIから起動する際にジョブ入力を設定する方法については、ジョブをエンキューする ガイド を参照してください。
このセクションでは、ジョブで調整できる入力をプログラムで制御する方法について説明します。
デフォルトでは、W&B ジョブ は Run.config 全体をジョブへの入力としてキャプチャしますが、 Launch SDK は、run config 内の選択した キー を制御したり、JSONまたはYAMLファイルを 入力 として指定したりする機能を提供します。
wandb-core が必要です。詳細については、wandb-core README を参照してください。Run オブジェクト の再構成
ジョブ内の wandb.init によって返される Run オブジェクト は、デフォルトで再構成できます。 Launch SDK は、ジョブの起動時に Run.config オブジェクト のどの部分を再構成できるかをカスタマイズする方法を提供します。
import wandb
from wandb.sdk import launch
# Required for launch sdk use.
wandb.require("core")
config = {
"trainer": {
"learning_rate": 0.01,
"batch_size": 32,
"model": "resnet",
"dataset": "cifar10",
"private": {
"key": "value",
},
},
"seed": 42,
}
with wandb.init(config=config):
launch.manage_wandb_config(
include=["trainer"],
exclude=["trainer.private"],
)
# Etc.
関数 launch.manage_wandb_config は、Run.config オブジェクト の入力値を 受け入れる ようにジョブを構成します。オプションの include および exclude オプションは、ネストされた config オブジェクト 内のパスのプレフィックスを受け取ります。これは、たとえば、ジョブがエンド ユーザー に公開したくないオプションを持つ ライブラリ を使用する場合に役立ちます。
include プレフィックス が指定されている場合、include プレフィックス に一致する config 内のパスのみが入力値を 受け入れます。exclude プレフィックス が指定されている場合、exclude リスト に一致するパスは入力値から除外されません。パスが include と exclude の両方のプレフィックス に一致する場合、exclude プレフィックス が優先されます。
上記の例では、パス ["trainer.private"] は private キー を trainer オブジェクト から除外し、パス ["trainer"] は trainer オブジェクト にないすべての キー を除外します。
\ でエスケープされた . を使用して、名前に . が付いた キー を除外します。
たとえば、r"trainer\.private" は、trainer オブジェクト の下の private キー ではなく、trainer.private キー を除外します。
上記の r プレフィックス は、raw 文字列 を表すことに注意してください。
上記の コード がパッケージ化され、ジョブとして実行される場合、ジョブの入力 タイプ は次のようになります。
{
"trainer": {
"learning_rate": "float",
"batch_size": "int",
"model": "str",
"dataset": "str",
},
}
W&B CLI または UI からジョブを起動すると、 ユーザー は4つの trainer パラメータ のみをオーバーライドできます。
run config 入力 へのアクセス
run config 入力 で起動されたジョブは、Run.config を介して入力値に アクセス できます。ジョブ コード の wandb.init によって返される Run には、入力値が自動的に設定されます。ジョブ コード の任意の場所で run config 入力 値をロードするには、
from wandb.sdk import launch
run_config_overrides = launch.load_wandb_config()
を使用します。
ファイル の再構成
Launch SDK は、ジョブ コード の config ファイル に保存されている入力値を管理する方法も提供します。これは、この torchtune の例やこの Axolotl config のように、多くの ディープラーニング および大規模言語 モデル の ユースケース で一般的なパターンです。
Run.config オブジェクト を介して制御する必要があります。launch.manage_config_file 関数 を使用すると、config ファイル を Launch ジョブ への入力として追加できるため、ジョブの起動時に config ファイル 内の値を編集できます。
デフォルトでは、launch.manage_config_file が使用されている場合、run config 入力 はキャプチャされません。launch.manage_wandb_config を呼び出すと、この 振る舞い がオーバーライドされます。
次の例を考えてみましょう。
import yaml
import wandb
from wandb.sdk import launch
# Required for launch sdk use.
wandb.require("core")
launch.manage_config_file("config.yaml")
with open("config.yaml", "r") as f:
config = yaml.safe_load(f)
with wandb.init(config=config):
# Etc.
pass
コード が隣接するファイル config.yaml で実行されると想像してください。
learning_rate: 0.01
batch_size: 32
model: resnet
dataset: cifar10
launch.manage_config_file の呼び出しは、config.yaml ファイル をジョブへの入力として追加し、W&B CLI または UI から起動するときに再構成できるようにします。
include および exclude キーワード arg は、launch.manage_wandb_config と同じ方法で、config ファイル の許容される入力 キー をフィルタリングするために使用できます。
config ファイル 入力 へのアクセス
Launch によって作成された run で launch.manage_config_file が呼び出されると、launch は config ファイル の内容を入力値でパッチします。パッチされた config ファイル は、ジョブ 環境 で使用できます。
launch.manage_config_file を呼び出してください。ジョブ の Launch ドロワー UI のカスタマイズ
ジョブ の入力 の スキーマ を定義すると、ジョブ を起動するためのカスタム UI を作成できます。ジョブ の スキーマ を定義するには、launch.manage_wandb_config または launch.manage_config_file の呼び出しに含めます。スキーマ は、JSON Schema の形式の python 辞書 、または Pydantic モデル クラス のいずれかになります。
次の例は、次の プロパティ を持つ スキーマ を示しています。
seed、整数trainer、いくつかの キー が指定された 辞書 :trainer.learning_rate、ゼロより大きい floattrainer.batch_size、16、64、または256のいずれかである必要がある整数trainer.dataset、cifar10またはcifar100のいずれかである必要がある 文字列
schema = {
"type": "object",
"properties": {
"seed": {
"type": "integer"
}
"trainer": {
"type": "object",
"properties": {
"learning_rate": {
"type": "number",
"description": "Learning rate of the model",
"exclusiveMinimum": 0,
},
"batch_size": {
"type": "integer",
"description": "Number of samples per batch",
"enum": [16, 64, 256]
},
"dataset": {
"type": "string",
"description": "Name of the dataset to use",
"enum": ["cifar10", "cifar100"]
}
}
}
}
}
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=schema,
)
一般に、次の JSON Schema 属性 がサポートされています。
| 属性 | 必須 | 注記 |
|---|---|---|
type |
はい | number 、 integer 、 string 、または object のいずれかである必要があります。 |
title |
いいえ | プロパティ の表示名をオーバーライドします |
description |
いいえ | プロパティ ヘルパー テキスト を指定します |
enum |
いいえ | フリーフォーム テキスト 入力 の代わりに ドロップダウン 選択 を作成します |
minimum |
いいえ | type が number または integer の場合にのみ許可されます |
maximum |
いいえ | type が number または integer の場合にのみ許可されます |
exclusiveMinimum |
いいえ | type が number または integer の場合にのみ許可されます |
exclusiveMaximum |
いいえ | type が number または integer の場合にのみ許可されます |
properties |
いいえ | type が object の場合、ネストされた 構成 を定義するために使用されます |
次の例は、次の プロパティ を持つ スキーマ を示しています。
seed、整数trainer、いくつかのサブ 属性 が指定された スキーマ :trainer.learning_rate、ゼロより大きい floattrainer.batch_size、1〜256(両端を含む)の範囲の整数trainer.dataset、cifar10またはcifar100のいずれかである必要がある 文字列
class DatasetEnum(str, Enum):
cifar10 = "cifar10"
cifar100 = "cifar100"
class Trainer(BaseModel):
learning_rate: float = Field(gt=0, description="Learning rate of the model")
batch_size: int = Field(ge=1, le=256, description="Number of samples per batch")
dataset: DatasetEnum = Field(title="Dataset", description="Name of the dataset to use")
class Schema(BaseModel):
seed: int
trainer: Trainer
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=Schema,
)
クラス の インスタンス を使用することもできます。
t = Trainer(learning_rate=0.01, batch_size=32, dataset=DatasetEnum.cifar10)
s = Schema(seed=42, trainer=t)
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
input_schema=s,
)
ジョブ 入力 スキーマ を追加すると、 Launch ドロワー に構造化されたフォームが作成され、ジョブ の起動が容易になります。
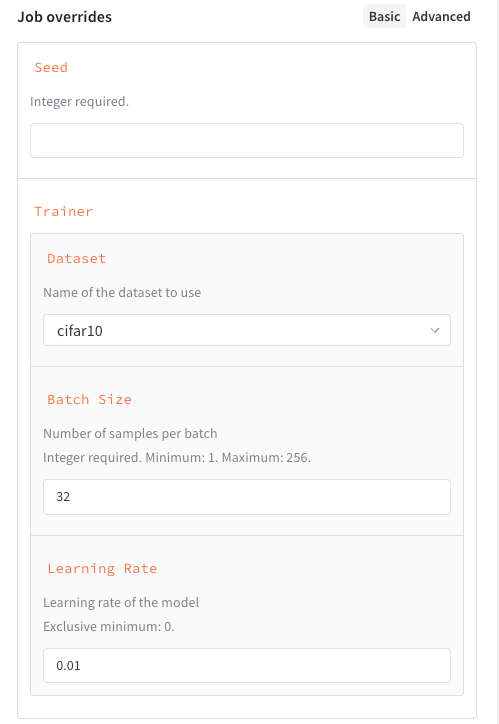
4.4 - Monitor launch queue
インタラクティブな Queue monitoring dashboard を使用して、 Launch キューの使用率が高いかアイドル状態かを確認したり、実行中のワークロードを視覚化したり、非効率なジョブを見つけたりできます。 Launch キューダッシュボードは、コンピューティングハードウェアまたはクラウド リソースを効果的に使用しているかどうかを判断する場合に特に役立ちます。
より詳細な 分析を行うために、このページから W&B の 実験管理 ワークスペースや、Datadog、NVIDIA Base Command、クラウドコンソールなどの外部 インフラストラクチャー 監視プロバイダーにリンクできます。
ダッシュボードとプロット
Monitor タブを使用すると、過去7日間に発生したキューのアクティビティを表示できます。左側の パネル を使用して、時間範囲、グループ化、フィルターを制御します。
ダッシュボードには、パフォーマンスと効率に関する よくある質問 に答える多くのプロットが含まれています。以下のセクションでは、キューダッシュボードのUI要素について説明します。
ジョブステータス
Job status プロットは、各時間間隔で実行中、保留中、キューイング中、または完了したジョブの数を示します。 Job status プロットを使用して、キュー内のアイドル期間を特定します。
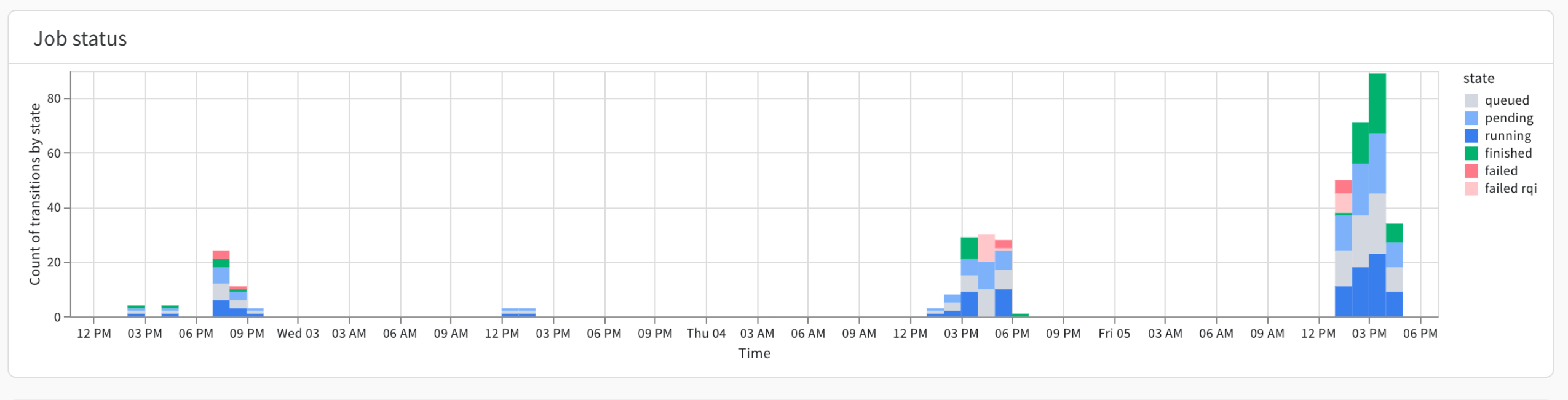
たとえば、固定リソース(DGX BasePodなど)があるとします。固定リソースでアイドルキューが観察された場合、これは スイープ などの優先度の低いプリエンプティブ Launch ジョブを実行する機会があることを示唆している可能性があります。
一方、クラウド リソースを使用していて、アクティビティが定期的に発生しているとします。アクティビティが定期的に発生する場合は、特定の時間帯にリソースを予約することでコストを節約できる可能性があります。
プロットの右側には、 Launch ジョブの [ステータス] (/ja/guides/launch/launch-view-jobs/#check-the-status-of-a-job)を示すキーがあります。
Queued アイテムは、ワークロードを他のキューにシフトする機会を示している可能性があります。失敗の急増は、 Launch ジョブのセットアップでサポートが必要な ユーザー を特定するのに役立ちます。キューイング時間
Queued time プロットは、 Launch ジョブが特定の日付または時間範囲のキューにあった時間(秒単位)を示します。
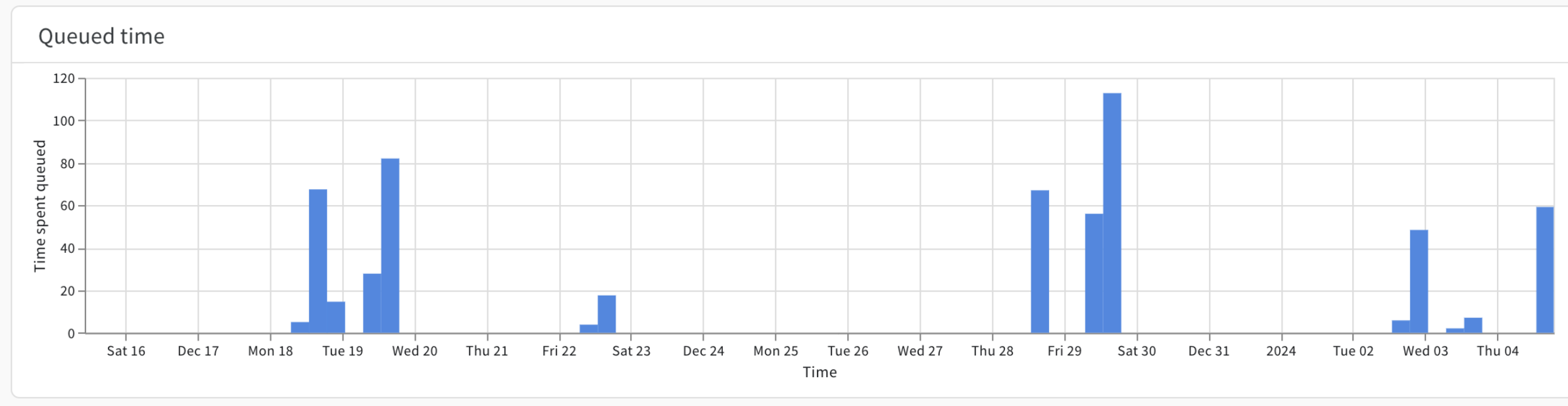
x軸は指定した時間枠を示し、y軸は Launch ジョブが Launch キューにあった時間(秒単位)を示します。たとえば、特定の日にある Launch ジョブが10個キューイングされているとします。これらの10個の Launch ジョブが平均60秒ずつ待機する場合、 Queue time プロットは600秒を示します。
左側のバーにある Grouping コントロールを使用して、各ジョブの色をカスタマイズします。
これにより、どの ユーザー とジョブがキュー容量の不足による影響を受けているかを特定するのに特に役立ちます。
ジョブのrun
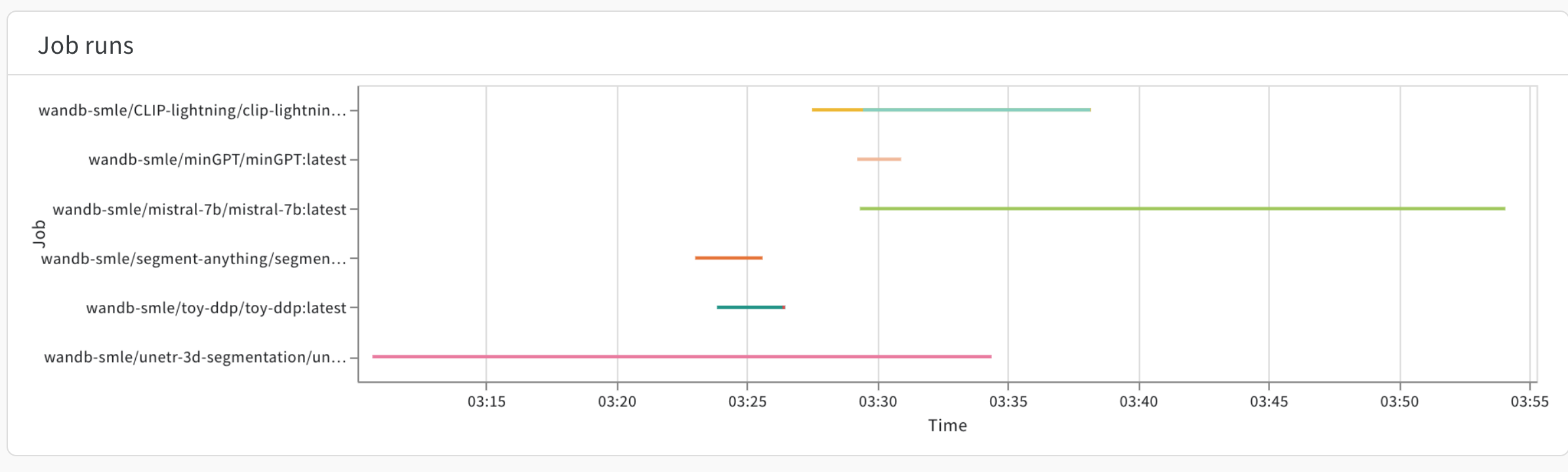
このプロットは、特定の期間に実行されたすべてのジョブの開始と終了を示し、runごとに異なる色で表示されます。これにより、特定の時点でキューが処理していたワークロードを一目で簡単に確認できます。
パネル の右下にある選択 ツール を使用してジョブをブラッシングし、下のテーブルに詳細を入力します。
CPU と GPU の使用率
GPU use by a job 、 CPU use by a job 、 GPU memory by job 、 System memory by job を使用して、 Launch ジョブの効率を表示します。
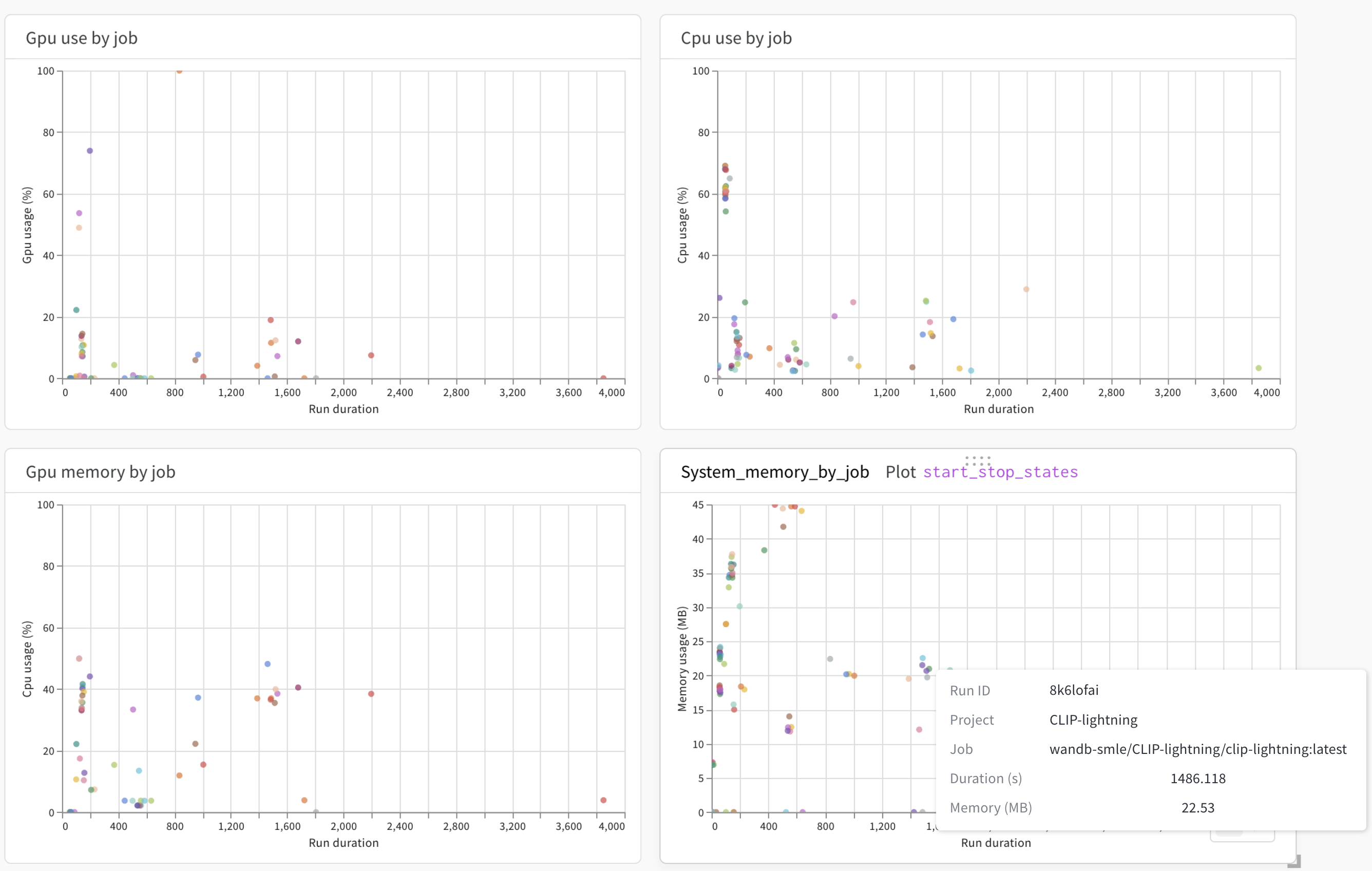
たとえば、 GPU memory by job を使用して、W&B の run が完了するまでに長い時間がかかったかどうか、CPUコアの使用率が低いかどうかを確認できます。
各プロットのx軸は、 Launch ジョブによって作成されたW&B の run の継続時間(秒単位)を示します。データポイントにマウスを合わせると、run ID、runが属する プロジェクト 、W&B の run を作成した Launch ジョブなど、W&B の run に関する情報が表示されます。
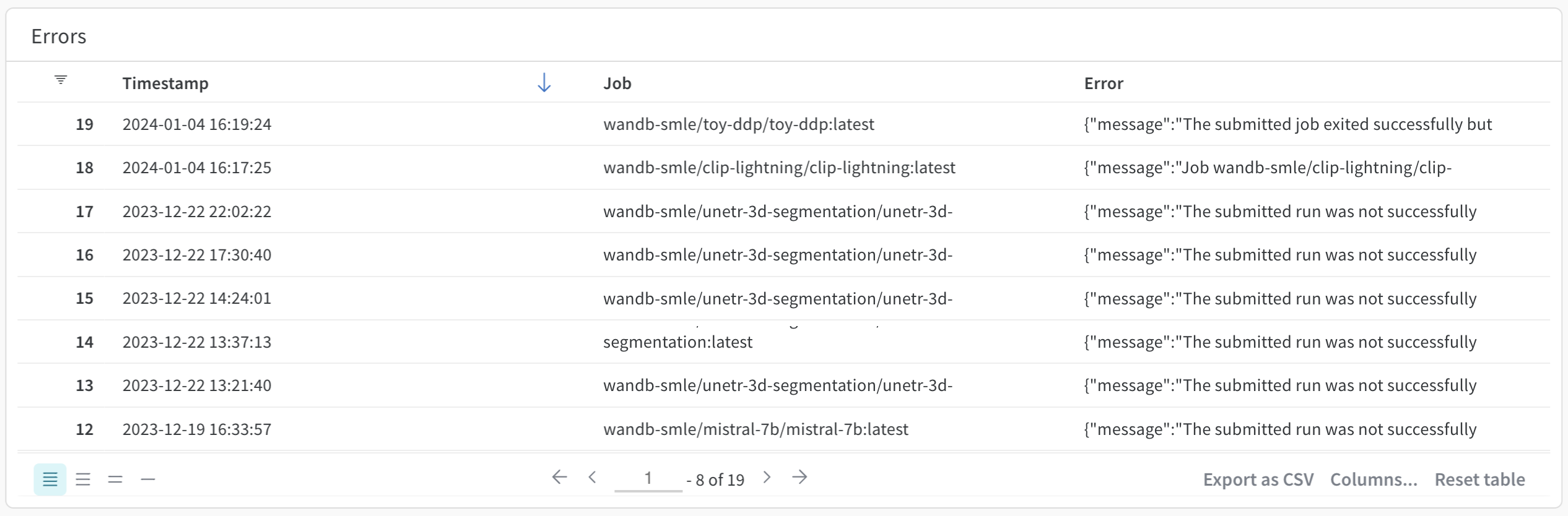
エラー
Errors パネルには、特定の Launch キューで発生したエラーが表示されます。具体的には、Errors パネルには、エラーが発生したときのタイムスタンプ、エラーが発生した Launch ジョブの名前、および作成されたエラーメッセージが表示されます。デフォルトでは、エラーは最新のものから古いものの順に並べられています。
Errors パネルを使用して、 ユーザー を特定してブロックを解除します。
外部リンク
キューの可観測性ダッシュボードのビューは、すべてのキュータイプで一貫性がありますが、多くの場合、 環境 固有のモニターに直接ジャンプすると役立ちます。これを実現するには、キューの可観測性ダッシュボードからコンソールへのリンクを直接追加します。
ページ の下部にある Manage Links をクリックして パネル を開きます。必要な ページ の完全なURLを追加します。次に、ラベルを追加します。追加したリンクは、 External Links セクションに表示されます。
4.5 - View launch jobs
以下のページでは、キューに追加された Launch ジョブに関する情報を表示する方法について説明します。
ジョブの表示
W&B アプリでキューに追加されたジョブを表示します。
- W&B アプリ (https://wandb.ai/home) に移動します。
- 左側のサイドバーの [Applications] セクションで [Launch] を選択します。
- [All entities] ドロップダウンを選択し、Launch ジョブが属するエンティティを選択します。
- Launch アプリケーションページから折りたたみ可能なUIを展開して、その特定のキューに追加されたジョブのリストを表示します。
たとえば、次の図は、job-source-launch_demo-canonical というジョブから作成された2つの run を示しています。このジョブは Start queue というキューに追加されました。キューにリストされている最初の run は resilient-snowball と呼ばれ、2番目の run は earthy-energy-165 と呼ばれます。
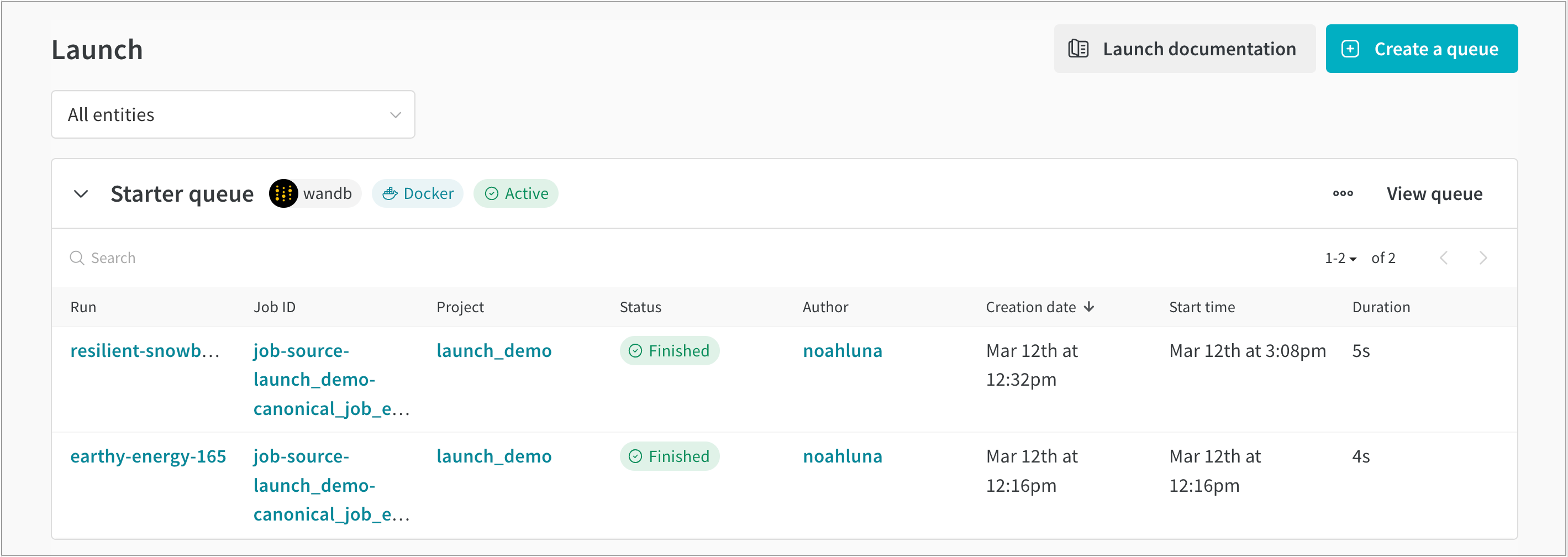
W&B アプリのUI内では、Launch ジョブから作成された run に関する追加情報を見つけることができます。
- Run: そのジョブに割り当てられた W&B の run の名前。
- Job ID: ジョブの名前。
- Project: run が属する project の名前。
- Status: キューに入れられた run のステータス。
- Author: run を作成した W&B エンティティ。
- Creation date: キューが作成されたときのタイムスタンプ。
- Start time: ジョブが開始されたときのタイムスタンプ。
- Duration: ジョブの run が完了するまでにかかった時間(秒単位)。
ジョブのリスト表示
W&B CLI を使用して、project 内に存在するジョブのリストを表示します。W&B job list コマンドを使用し、Launch ジョブが属する project とエンティティの名前をそれぞれ --project および --entity フラグで指定します。
wandb job list --entity your-entity --project project-name
ジョブのステータスを確認する
次の表は、キューに入れられた run が持つことができるステータスを定義しています。
| Status | Description |
|---|---|
| Idle | run はアクティブなエージェントのないキューにあります。 |
| Queued | run はエージェントが処理するのを待機しているキューにあります。 |
| Pending | run はエージェントによって取得されましたが、まだ開始されていません。これは、 cluster でリソースが利用できないことが原因である可能性があります。 |
| Running | run は現在実行中です。 |
| Killed | ジョブは user によって強制終了されました。 |
| Crashed | run はデータの送信を停止したか、正常に開始されませんでした。 |
| Failed | run がゼロ以外の終了コードで終了したか、run の開始に失敗しました。 |
| Finished | ジョブは正常に完了しました。 |
5 - Create sweeps with W&B Launch
W&B Launch でハイパーパラメータチューニングジョブ ( Sweeps ) を作成します。 Launch で Sweeps を行うと、sweep スケジューラは、sweep するために指定されたハイパーパラメータとともに Launch Queue にプッシュされます。 sweep スケジューラは、エージェントによって選択されると開始され、選択されたハイパーパラメータを使用して sweep の run を同じキューに起動します。 これは、sweep が終了または停止するまで継続されます。
デフォルトの W&B Sweep スケジューリングエンジンを使用するか、独自のカスタムスケジューラを実装できます。
- 標準 sweep スケジューラ: W&B Sweeps を制御するデフォルトの W&B Sweep スケジューリングエンジンを使用します。 使い慣れた
bayes、grid、およびrandomの method を使用できます。 - カスタム sweep スケジューラ: sweep スケジューラをジョブとして実行するように設定します。 このオプションを使用すると、完全にカスタマイズできます。 標準の sweep スケジューラを拡張して、より多くのログを含める方法の例を以下のセクションに示します。
W&B 標準スケジューラで sweep を作成する
Launch で W&B Sweeps を作成します。 W&B App でインタラクティブに sweep を作成するか、W&B CLI でプログラムで作成できます。 スケジューラのカスタマイズ機能など、Launch Sweeps の高度な設定を行うには、CLI を使用します。
W&B App でインタラクティブに sweep を作成します。
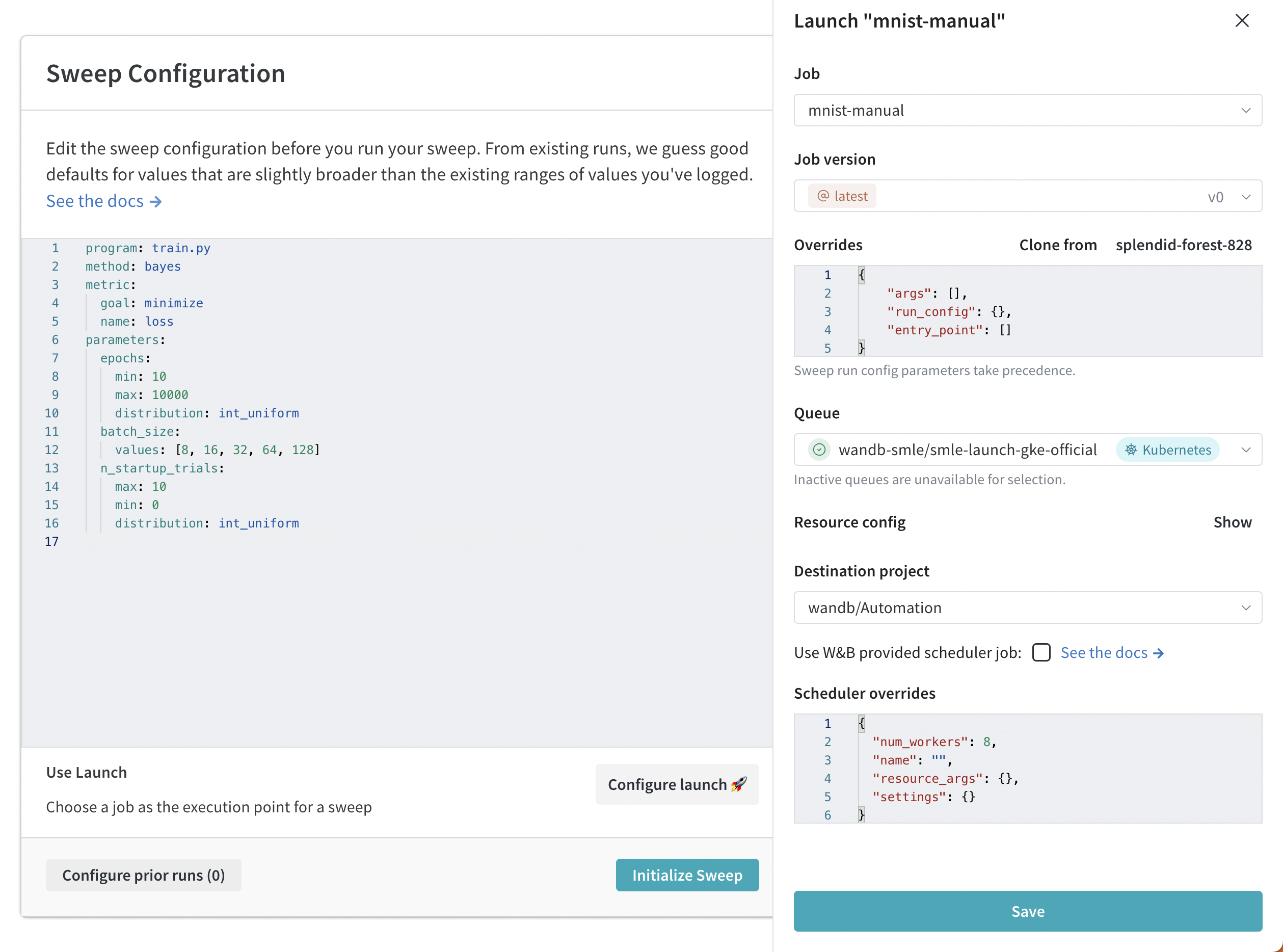
- W&B App で W&B プロジェクトに移動します。
- 左側のパネルにある sweeps アイコン (ほうきの画像) を選択します。
- 次に、Sweep の作成 ボタンを選択します。
- Launch の設定🚀 ボタンをクリックします。
- ジョブ ドロップダウンメニューから、ジョブの名前と sweep の作成元となるジョブの バージョンを選択します。
- キュー ドロップダウンメニューを使用して、sweep を実行するキューを選択します。
- ジョブの優先度 ドロップダウンを使用して、Launch ジョブの優先度を指定します。 Launch キューが優先順位付けをサポートしていない場合、Launch ジョブの優先度は「中」に設定されます。
- (オプション) run または sweep スケジューラのオーバーライド arg を設定します。 たとえば、スケジューラのオーバーライドを使用して、
num_workersを使用してスケジューラが管理する同時実行 run の数を設定します。 - (オプション) 宛先プロジェクト ドロップダウンメニューを使用して、sweep を保存するプロジェクトを選択します。
- 保存 をクリックします。
- Sweep の起動 を選択します。
W&B CLI を使用して、プログラムで Launch で W&B Sweep を作成します。
- Sweep 設定を作成します。
- sweep 設定内でジョブの完全な名前を指定します。
- sweep agent を初期化します。
たとえば、次の コードスニペット では、ジョブの値に 'wandb/jobs/Hello World 2:latest' を指定します。
# launch-sweep-config.yaml
job: 'wandb/jobs/Hello World 2:latest'
description: launch jobs を使用した sweep の例
method: bayes
metric:
goal: minimize
name: loss_metric
parameters:
learning_rate:
max: 0.02
min: 0
distribution: uniform
epochs:
max: 20
min: 0
distribution: int_uniform
# Optional scheduler parameters:
# scheduler:
# num_workers: 1 # concurrent sweep runs
# docker_image: <base image for the scheduler>
# resource: <ie. local-container...>
# resource_args: # resource arguments passed to runs
# env:
# - WANDB_API_KEY
# Optional Launch Params
# launch:
# registry: <registry for image pulling>
sweep 設定の作成方法については、sweep 設定の定義 ページを参照してください。
- 次に、sweep を初期化します。 設定ファイルへのパス、ジョブキューの名前、W&B エンティティ、およびプロジェクトの名前を指定します。
wandb launch-sweep <path/to/yaml/file> --queue <queue_name> --entity <your_entity> --project <project_name>
W&B Sweeps の詳細については、ハイパーパラメータの チューニング のチャプターを参照してください。
カスタム sweep スケジューラを作成する
W&B スケジューラまたはカスタムスケジューラのいずれかを使用して、カスタム sweep スケジューラを作成します。
0.15.4 が必要です。W&B sweep スケジューリングロジックをジョブとして使用して、Launch sweep を作成します。
- パブリック wandb/sweep-jobs プロジェクトで Wandb スケジューラジョブを識別するか、ジョブ名を使用します。
'wandb/sweep-jobs/job-wandb-sweep-scheduler:latest' - この名前を指す
jobキーを含む追加のschedulerブロックを使用して、構成 yaml を作成します。以下の例を参照してください。 - 新しい設定で
wandb launch-sweepコマンドを使用します。
構成例:
# launch-sweep-config.yaml
description: スケジューラジョブを使用した Launch sweep 構成
scheduler:
job: wandb/sweep-jobs/job-wandb-sweep-scheduler:latest
num_workers: 8 # 8 つの同時 sweep run を許可します
# sweep runs が実行するトレーニング/チューニングジョブ
job: wandb/sweep-jobs/job-fashion-MNIST-train:latest
method: grid
parameters:
learning_rate:
min: 0.0001
max: 0.1
カスタムスケジューラは、スケジューラジョブを作成することで作成できます。 このガイドの目的のために、ログをより多く提供するために WandbScheduler を変更します。
wandb/launch-jobsリポジトリ (具体的にはwandb/launch-jobs/jobs/sweep_schedulers) を複製します。- これで、
wandb_scheduler.pyを変更して、必要なログの増加を実現できます。 例: 関数_pollにログを追加します。 これは、新しい sweep run を起動する前に、ポーリングサイクルごとに 1 回 (設定可能なタイミング) 呼び出されます。 - 変更したファイルを実行してジョブを作成します。
python wandb_scheduler.py --project <project> --entity <entity> --name CustomWandbScheduler - UI または前の呼び出しの出力で、作成されたジョブの名前を特定します。これは、コードアーティファクトジョブになります (特に指定されていない場合)。
- 次に、スケジューラが新しいジョブを指す sweep 構成を作成します。
...
scheduler:
job: '<entity>/<project>/job-CustomWandbScheduler:latest'
...
Optuna は、特定のモデルに最適なハイパーパラメータを見つけるためにさまざまなアルゴリズムを使用するハイパーパラメータ最適化 フレームワーク です (W&B と同様)。 Optuna は、サンプリングアルゴリズムに加えて、パフォーマンスの低い run を早期に終了するために使用できるさまざまな枝刈りアルゴリズムも提供します。 これは、多数の run を実行する場合に特に役立ちます。時間とリソースを節約できるためです。 クラスは高度に設定可能で、設定ファイルの scheduler.settings.pruner/sampler.args ブロックに必要なパラメータを渡すだけです。
Optuna のスケジューリングロジックをジョブで使用して、Launch sweep を作成します。
-
まず、独自のジョブを作成するか、事前構築済みの Optuna スケジューライメージジョブを使用します。
- 独自のジョブを作成する方法の例については、
wandb/launch-jobsリポジトリを参照してください。 - 事前構築済みの Optuna イメージを使用するには、
wandb/sweep-jobsプロジェクトのjob-optuna-sweep-schedulerに移動するか、ジョブ名wandb/sweep-jobs/job-optuna-sweep-scheduler:latestを使用できます。
- 独自のジョブを作成する方法の例については、
-
ジョブを作成したら、sweep を作成できます。 Optuna スケジューラジョブを指す
jobキーを持つschedulerブロックを含む sweep 構成を作成します (以下の例)。
# optuna_config_basic.yaml
description: 基本的な Optuna スケジューラ
job: wandb/sweep-jobs/job-fashion-MNIST-train:latest
run_cap: 5
metric:
name: epoch/val_loss
goal: minimize
scheduler:
job: wandb/sweep-jobs/job-optuna-sweep-scheduler:latest
resource: local-container # イメージから取得したスケジューラジョブに必要
num_workers: 2
# optuna 固有の設定
settings:
pruner:
type: PercentilePruner
args:
percentile: 25.0 # run の 75% を強制終了
n_warmup_steps: 10 # 最初の x ステップでは枝刈りはオフ
parameters:
learning_rate:
min: 0.0001
max: 0.1
- 最後に、launch-sweep コマンドを使用して、アクティブなキューに sweep を起動します。
wandb launch-sweep <config.yaml> -q <queue> -p <project> -e <entity>
Optuna sweep スケジューラジョブの正確な実装については、wandb/launch-jobs を参照してください。 Optuna スケジューラで可能なことのより多くの例については、wandb/examples を確認してください。
カスタム sweep スケジューラジョブで可能なことの例は、jobs/sweep_schedulers の wandb/launch-jobs リポジトリにあります。 このガイドでは、一般公開されている Wandb スケジューラジョブ の使用方法と、カスタム sweep スケジューラジョブを作成するプロセスについて説明します。
Launch で sweep を再開する方法
以前に Launch された sweep から Launch sweep を再開することも可能です。 ハイパーパラメータとトレーニングジョブは変更できませんが、スケジューラ固有のパラメータとプッシュ先のキューは変更できます。
- 以前に実行された Launch sweep の sweep 名/ID を特定します。 sweep ID は 8 文字の文字列 (たとえば、
hhd16935) で、W&B App のプロジェクトにあります。 - スケジューラのパラメータを変更する場合は、更新された構成ファイルを作成します。
- ターミナルで、次のコマンドを実行します。
<および>で囲まれたコンテンツを情報に置き換えます。
wandb launch-sweep <optional config.yaml> --resume_id <sweep id> --queue <queue_name>
6 - Launch FAQ
6.1 - Are there best practices for using Launch effectively?
-
簡単な 設定 を可能にするために、 エージェント を開始する前に キュー を作成してください。これに失敗すると、 キュー が追加されるまで エージェント が機能しなくなるエラーが発生します。
-
個人 の ユーザー アカウント にリンクされていないことを確認して、 エージェント を開始するために W&B サービス アカウント を作成します。
-
wandb.configを使用して ハイパーパラメーター を管理し、ジョブ の再実行中に 上書きできるようにします。argparse の使用に関する詳細については、この ガイドを参照してください。
6.2 - Can I specify a Dockerfile and let W&B build a Docker image for me?
この機能は、要件は安定しているものの、コードベースが頻繁に変更される プロジェクトに適しています。
Dockerfile を構成した後、W&B に次の 3 つの方法のいずれかで指定します。
- Dockerfile.wandb を使用する
- W&B CLI を使用する
- W&B App を使用する
W&B run のエントリポイントと同じ ディレクトリーに Dockerfile.wandb ファイルを含めます。W&B は、組み込みの Dockerfile の代わりにこのファイルを利用します。
ジョブをキューに入れるには、wandb Launch コマンドで --dockerfile フラグを使用します。
wandb launch --dockerfile path/to/Dockerfile
W&B App でジョブをキューに追加するときに、オーバーライド セクションで Dockerfile のパスを指定します。キーと 値 のペアとして、"dockerfile" を キー として、Dockerfile へのパスを 値 として入力します。
次の JSON は、ローカル ディレクトリーに Dockerfile を含める方法を示しています。
{
"args": [],
"run_config": {
"lr": 0,
"batch_size": 0,
"epochs": 0
},
"entrypoint": [],
"dockerfile": "./Dockerfile"
}
6.3 - Can Launch automatically provision (and spin down) compute resources for me in the target environment?
このプロセス は 環境 に依存します。Amazon SageMaker と Vertex でプロビジョニングされたリソース。Kubernetes では、オートスケーラーが需要に応じてリソースを自動的に調整します。W&B のソリューションアーキテクトは、再試行、オートスケーリング、スポットインスタンスノードプールの使用を可能にするために、Kubernetes の インフラストラクチャー の構成を支援します。サポートが必要な場合は、support@wandb.com にお問い合わせいただくか、共有の Slack チャンネル をご利用ください。
6.4 - Can you specify secrets for jobs/automations? For instance, an API key which you do not wish to be directly visible to users?
はい。以下の手順に従ってください。
-
次のコマンドを使用して、 run 用の指定された名前空間に Kubernetes シークレットを作成します。
kubectl create secret -n <namespace> generic <secret_name> <secret_value> -
シークレットを作成したら、 run 開始時にシークレットを注入するようにキューを設定します。クラスター管理者のみがシークレットを表示でき、エンド ユーザー は表示できません。
6.5 - Does Launch support parallelization? How can I limit the resources consumed by a job?
Launch は、複数の GPU とノードにまたがるジョブのスケーリングをサポートしています。詳細については、こちらのガイドを参照してください。
各 Launch エージェント は、実行できる同時ジョブの最大数を決定する max_jobs パラメータ で設定されています。複数の エージェント は、適切な起動 インフラストラクチャ に接続している限り、単一のキューを指すことができます。
リソース設定では、CPU、GPU、メモリ、およびその他のリソースの制限を、キューまたはジョブ run レベルで設定できます。Kubernetes でリソース制限付きのキューを設定する方法については、こちらのガイドを参照してください。
Sweeps の場合、同時 run の数を制限するには、次のブロックをキュー設定に含めます。
scheduler:
num_workers: 4
6.6 - How can admins restrict which users have modify access?
キュー設定テンプレート を使用して、チーム管理者ではない ユーザー が特定のキューフィールドへの アクセス を制御できます。チーム管理者は、管理者以外の ユーザー が表示できるフィールドを定義し、編集制限を設定します。チーム管理者のみが、キューを作成または編集する権限を持ちます。
6.7 - How do I control who can push to a queue?
キューは、特定のユーザー の Teams に固有のものです。キューの作成時に、所有 Entity を定義します。アクセスを制限するには、Teams のメンバーシップを変更します。
6.8 - How do I fix a "permission denied" error in Launch?
Launch Error: Permission denied というエラーメッセージが表示された場合、これは目的の プロジェクト にログを記録するための権限が不十分であることを示しています。考えられる原因は次のとおりです。
- このマシンにログインしていません。 コマンドライン で
wandb loginを実行してください。 - 指定された Entity が存在しません。 Entity は、 ユーザー 名または既存の Team 名である必要があります。必要に応じて、Subscriptions page で Team を作成してください。
- プロジェクト の権限がありません。 プロジェクト の作成者にプライバシー設定を Open に変更して、 run を プロジェクト に記録できるように依頼してください。
6.9 - How do I make W&B Launch work with Tensorflow on GPU?
GPU を使用する TensorFlow ジョブの場合、コンテナを構築するためのカスタムベースイメージを指定します。これにより、run 中の適切な GPU 使用率が保証されます。リソース設定の builder.accelerator.base_image キーの下にイメージタグを追加します。以下に例を示します。
{
"gpus": "all",
"builder": {
"accelerator": {
"base_image": "tensorflow/tensorflow:latest-gpu"
}
}
}
W&B 0.15.6 より前のバージョンでは、base_image の親キーとして accelerator の代わりに cuda を使用します。
6.10 - How does W&B Launch build images?
イメージを構築する手順は、ジョブのソースと、リソース設定で指定されたアクセラレータのベースイメージによって異なります。
キューを設定したり、ジョブを送信する際は、キューまたはジョブリソース設定にベースアクセラレータイメージを含めてください。
{
"builder": {
"accelerator": {
"base_image": "image-name"
}
}
}
構築プロセスには、ジョブタイプと指定されたアクセラレータのベースイメージに基づいて、次のアクションが含まれます。
| | aptを使用してPythonをインストール | Pythonパッケージをインストール | ユーザーとワークディレクトリを作成 | コードをイメージにコピー | エントリーポイントを設定 | |
6.11 - I do not like clicking- can I use Launch without going through the UI?
はい。標準の wandb CLI には、ジョブを ローンチ するための launch サブ コマンド が含まれています。詳細については、以下を実行してください。
wandb launch --help
6.12 - I do not want W&B to build a container for me, can I still use Launch?
事前に構築されたDockerイメージをローンチするには、次のコマンドを実行します。< >内のプレースホルダーを、お客様固有の情報に置き換えてください。
wandb launch -d <docker-image-uri> -q <queue-name> -E <entrypoint>
このコマンドは、ジョブを作成し、runを開始します。
イメージからジョブを作成するには、次のコマンドを使用します。
wandb job create image <image-name> -p <project> -e <entity>
6.13 - Is `wandb launch -d` or `wandb job create image` uploading a whole docker artifact and not pulling from a registry?
いいえ、wandb Launch -d コマンドはイメージをレジストリにアップロードしません。イメージは別途レジストリにアップロードしてください。以下の手順に従ってください。
- イメージを構築します。
- イメージをレジストリにプッシュします。
ワークフローは次のとおりです。
docker build -t <repo-url>:<tag> .
docker push <repo-url>:<tag>
wandb launch -d <repo-url>:<tag>
次に、Launch エージェントが、指定されたコンテナを指すジョブを起動します。コンテナレジストリからイメージをプルするためのエージェントのアクセスを設定する例については、高度なエージェントの設定を参照してください。
Kubernetes の場合、Kubernetes クラスターの Pod がイメージのプッシュ先のレジストリにアクセスできることを確認してください。
6.14 - What permissions does the agent require in Kubernetes?
以下の Kubernetes マニフェストは、wandb 名前空間に wandb-launch-agent という名前のロールを作成します。このロールにより、エージェントは wandb 名前空間に Pod、configmap、secret を作成し、Pod の ログ に アクセス できるようになります。wandb-cluster-role を使用すると、エージェントは Pod の作成、Pod の ログ への アクセス 、secret、ジョブの作成、および指定された名前空間全体のジョブステータスの確認を行うことができます。
6.15 - What requirements does the accelerator base image have?
アクセラレーターを利用するジョブの場合、必要なアクセラレーターコンポーネントを含むベースイメージを指定してください。アクセラレーターイメージには、以下の要件を満たすようにしてください。
- Debian との互換性 ( Launch の Dockerfile は、apt-get を使用して Python をインストールします)
- サポートされている CPU および GPU ハードウェア命令セット (目的の GPU との CUDA バージョンの互換性を確認してください)
- 提供されるアクセラレーターバージョンと機械学習アルゴリズムのパッケージとの互換性
- ハードウェア互換性のため追加の手順が必要なパッケージのインストール
6.16 - When multiple jobs in a Docker queue download the same artifact, is any caching used, or is it re-downloaded every run?
キャッシュは存在しません。各 Launch ジョブは独立して動作します。キューまたは エージェント を設定して、キューの設定で Docker の 引数 を使用して共有キャッシュをマウントします。
さらに、特定の ユースケース では、W&B Artifacts キャッシュを永続ボリュームとしてマウントします。
7 - Launch integration guides
7.1 - Dagster
Dagster と W&B (Weights & Biases) を使用して、MLOps パイプラインを編成し、ML アセットを維持します。W&B との統合により、Dagster 内で次のことが容易になります。
- W&B Artifacts の使用と作成。
- W&B Registry で Registered Models の使用と作成。
- W&B Launch を使用した、専用コンピューティングでのトレーニングジョブの実行。
- ops およびアセットでの wandb クライアントの使用。
W&B Dagster インテグレーションは、W&B 固有の Dagster リソースと IO Manager を提供します。
wandb_resource: W&B API に対して認証および通信するために使用される Dagster リソース。wandb_artifacts_io_manager: W&B Artifacts の消費に使用される Dagster IO Manager。
次のガイドでは、Dagster で W&B を使用するための前提条件を満たす方法、ops およびアセットで W&B Artifacts を作成および使用する方法、W&B Launch の使用方法、推奨されるベストプラクティスについて説明します。
始める前に
Weights & Biases 内で Dagster を使用するには、次のリソースが必要です。
- W&B APIキー。
- W&B entity (ユーザーまたは Team): エンティティとは、W&B Runs と Artifacts を送信するユーザー名または Team 名です。run を記録する前に、W&B App UI でアカウントまたは Team エンティティを作成してください。エンティティを指定しない場合、run はデフォルトのエンティティ (通常はユーザー名) に送信されます。Project Defaults の設定でデフォルトのエンティティを変更します。
- W&B project: W&B Runs が保存される Project の名前。
W&B App でユーザーまたは Team のプロフィールページを確認して、W&B エンティティを見つけてください。既存の W&B Project を使用することも、新しい Project を作成することもできます。新しい Project は、W&B App のホームページまたはユーザー/Team のプロフィールページで作成できます。Project が存在しない場合、最初に使用するときに自動的に作成されます。以下の手順では、APIキーを取得する方法について説明します。
APIキーを取得する方法
- W&B にログイン します。注: W&B Server を使用している場合は、インスタンスのホスト名について管理者に問い合わせてください。
- 認証ページ またはユーザー/Team の設定に移動して、APIキーを収集します。本番環境では、サービスアカウント を使用してそのキーを所有することをお勧めします。
- その APIキーの環境変数を設定します。
export WANDB_API_KEY=YOUR_KEY.
以下の例では、Dagster コードで APIキーを指定する場所を示しています。wandb_config ネストされた辞書内でエンティティと Project 名を必ず指定してください。異なる W&B Project を使用する場合は、異なる wandb_config 値を異なる ops/アセットに渡すことができます。渡すことができるキーの詳細については、以下の構成セクションを参照してください。
例: @job の構成
# add this to your config.yaml
# alternatively you can set the config in Dagit's Launchpad or JobDefinition.execute_in_process
# Reference: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # replace this with your W&B entity
project: my_project # replace this with your W&B project
@job(
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
"io_manager": wandb_artifacts_io_manager,
}
)
def simple_job_example():
my_op()
例: アセットを使用した @repository の構成
from dagster_wandb import wandb_artifacts_io_manager, wandb_resource
from dagster import (
load_assets_from_package_module,
make_values_resource,
repository,
with_resources,
)
from . import assets
@repository
def my_repository():
return [
*with_resources(
load_assets_from_package_module(assets),
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
"wandb_artifacts_manager": wandb_artifacts_io_manager.configured(
{"cache_duration_in_minutes": 60} # only cache files for one hour
),
},
resource_config_by_key={
"wandb_config": {
"config": {
"entity": "my_entity", # replace this with your W&B entity
"project": "my_project", # replace this with your W&B project
}
}
},
),
]
@job の例とは対照的に、この例では IO Manager のキャッシュ期間を構成していることに注意してください。
構成
以下の構成オプションは、インテグレーションによって提供される W&B 固有の Dagster リソースおよび IO Manager の設定として使用されます。
wandb_resource: W&B API との通信に使用される Dagster リソース。提供された APIキーを使用して自動的に認証します。プロパティ:api_key: (str, 必須): W&B API との通信に必要な W&B APIキー。host: (str, オプション): 使用する API ホストサーバー。W&B Server を使用している場合にのみ必要です。デフォルトはパブリッククラウドホストhttps://api.wandb.aiです。
wandb_artifacts_io_manager: W&B Artifacts を消費するための Dagster IO Manager。プロパティ:base_dir: (int, オプション) ローカルストレージとキャッシュに使用されるベースディレクトリー。W&B Artifacts と W&B Run のログは、そのディレクトリーから書き込まれ、読み取られます。デフォルトでは、DAGSTER_HOMEディレクトリーを使用しています。cache_duration_in_minutes: (int, オプション) W&B Artifacts と W&B Run ログをローカルストレージに保持する時間を定義します。その時間の間、開かれなかったファイルとディレクトリーのみがキャッシュから削除されます。キャッシュのパージは、IO Manager の実行の最後に発生します。キャッシュを完全にオフにする場合は、0 に設定できます。キャッシュを使用すると、同じマシンで実行されているジョブ間で Artifact が再利用される場合に速度が向上します。デフォルトは 30 日です。run_id: (str, オプション): 再開に使用されるこの Run の一意の ID。Project 内で一意である必要があり、Run を削除した場合は ID を再利用できません。UI での識別に役立つ短い説明名には name フィールドを使用し、Run 全体でハイパーパラメーターを比較するために保存するには config を使用します。ID には、次の特殊文字を含めることはできません:/\#?%:..IO Manager が Run を再開できるようにするには、Dagster 内で実験管理を行うときに Run ID を設定する必要があります。デフォルトでは、Dagster Run ID (例:7e4df022-1bf2-44b5-a383-bb852df4077e) に設定されています。run_name: (str, オプション) UI でこの Run を識別するのに役立つ、この Run の短い表示名。デフォルトでは、dagster-run-[Dagster Run ID の最初の 8 文字]という形式の文字列です。たとえば、dagster-run-7e4df022です。run_tags: (list[str], オプション): UI でこの Run のタグのリストを設定する文字列のリスト。タグは、Run をまとめて編成したり、baselineやproductionなどの一時的なラベルを適用したりするのに役立ちます。UI でタグを簡単に追加および削除したり、特定のタグを持つ Run のみに絞り込んだりできます。インテグレーションで使用される W&B Run には、dagster_wandbタグが付けられます。
W&B Artifacts を使用する
W&B Artifact との統合は、Dagster IO Manager に依存しています。
IO Manager は、アセットまたは op の出力を保存し、ダウンストリームのアセットまたは op の入力としてロードする役割を担う、ユーザーが提供するオブジェクトです。たとえば、IO Manager はファイルシステムのファイルからオブジェクトを保存およびロードできます。
この統合は、W&B Artifacts の IO Manager を提供します。これにより、Dagster の @op または @asset は、W&B Artifacts をネイティブに作成および消費できます。以下は、Python リストを含むデータセット型の W&B Artifact を生成する @asset の簡単な例です。
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3] # this will be stored in an Artifact
Artifact を書き込むには、@op、@asset、および @multi_asset にメタデータ構成をアノテーションできます。同様に、Dagster の外部で作成された場合でも、W&B Artifacts を消費することもできます。
W&B Artifacts を書き込む
続行する前に、W&B Artifacts の使用方法を十分に理解しておくことをお勧めします。Artifacts に関するガイド を参照してください。
W&B Artifact を書き込むには、Python 関数からオブジェクトを返します。W&B では、次のオブジェクトがサポートされています。
- Python オブジェクト (int、dict、list…)
- W&B オブジェクト (Table, Image, Graph…)
- W&B Artifact オブジェクト
以下の例では、Dagster アセット (@asset) で W&B Artifacts を書き込む方法を示しています。
pickle モジュールでシリアル化できるものはすべて、インテグレーションによって作成された Artifact に pickle 化されて追加されます。コンテンツは、Dagster 内でその Artifact を読み取るときに unpickle 化されます (アーティファクトの読み取り を参照して詳細を確認してください)。
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3]
W&B は、複数の Pickle ベースのシリアル化モジュール (pickle、dill、cloudpickle、joblib) をサポートしています。ONNX や PMML などのより高度なシリアル化を使用することもできます。詳細については、シリアル化 セクションを参照してください。
ネイティブの W&B オブジェクト (例: Table、Image、または Graph) は、インテグレーションによって作成された Artifact に追加されます。以下は、Table を使用した例です。
import wandb
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset_in_table():
return wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
複雑なユースケースでは、独自の Artifact オブジェクトを構築する必要がある場合があります。インテグレーションは、インテグレーションの両側でメタデータを拡張するなど、役立つ追加機能も提供します。
import wandb
MY_ASSET = "my_asset"
@asset(
name=MY_ASSET,
io_manager_key="wandb_artifacts_manager",
)
def create_artifact():
artifact = wandb.Artifact(MY_ASSET, "dataset")
table = wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
artifact.add(table, "my_table")
return artifact
構成
wandb_artifact_configuration と呼ばれる構成ディクショナリは、@op、@asset、および @multi_asset で設定できます。このディクショナリは、メタデータとしてデコレーター引数で渡す必要があります。この構成は、W&B Artifacts の IO Manager の読み取りと書き込みを制御するために必要です。
@op の場合、Out メタデータ引数を介して出力メタデータに配置されます。
@asset の場合、アセットのメタデータ引数に配置されます。
@multi_asset の場合、AssetOut メタデータ引数を介して各出力メタデータに配置されます。
以下のコード例では、@op、@asset、および @multi_asset 計算でディクショナリを構成する方法を示しています。
@op の例:
@op(
out=Out(
metadata={
"wandb_artifact_configuration": {
"name": "my_artifact",
"type": "dataset",
}
}
)
)
def create_dataset():
return [1, 2, 3]
@asset の例:
@asset(
name="my_artifact",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3]
@asset にはすでに名前があるため、構成を介して名前を渡す必要はありません。インテグレーションは、Artifact 名をアセット名として設定します。
@multi_asset の例:
@multi_asset(
name="create_datasets",
outs={
"first_table": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "training_dataset",
}
},
io_manager_key="wandb_artifacts_manager",
),
"second_table": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "validation_dataset",
}
},
io_manager_key="wandb_artifacts_manager",
),
},
group_name="my_multi_asset_group",
)
def create_datasets():
first_table = wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
second_table = wandb.Table(columns=["d", "e"], data=[[4, 5]])
return first_table, second_table
サポートされているプロパティ:
name: (str) この Artifact の人間が判読できる名前。これは、UI でこの Artifact を識別したり、use_artifact 呼び出しで参照したりする方法です。名前には、文字、数字、アンダースコア、ハイフン、およびドットを含めることができます。名前は、Project 全体で一意である必要があります。@opに必須。type: (str) Artifact のタイプ。Artifact を編成および区別するために使用されます。一般的なタイプにはデータセットまたはモデルがありますが、文字、数字、アンダースコア、ハイフン、およびドットを含む任意の文字列を使用できます。出力が Artifact でない場合は必須。description: (str) Artifact の説明を提供する自由形式のテキスト。説明は UI で Markdown レンダリングされるため、テーブルやリンクなどを配置するのに適しています。aliases: (list[str]) Artifact に適用する 1 つ以上のエイリアスを含む配列。インテグレーションは、設定されているかどうかに関係なく、「latest」タグもそのリストに追加します。これは、モデルとデータセットのバージョン管理を管理するための効果的な方法です。add_dirs: (list[dict[str, Any]]): Artifact に含めるローカルディレクトリーごとの構成を含む配列。SDK の同名メソッドと同じ引数をサポートしています。add_files: (list[dict[str, Any]]): Artifact に含めるローカルファイルごとの構成を含む配列。SDK の同名メソッドと同じ引数をサポートしています。add_references: (list[dict[str, Any]]): Artifact に含める外部参照ごとの構成を含む配列。SDK の同名メソッドと同じ引数をサポートしています。serialization_module: (dict) 使用するシリアル化モジュールの構成。詳細については、シリアル化セクションを参照してください。name: (str) シリアル化モジュールの名前。受け入れられる値:pickle、dill、cloudpickle、joblib。モジュールはローカルで利用可能である必要があります。parameters: (dict[str, Any]) シリアル化関数に渡されるオプションの引数。そのモジュールのダンプメソッドと同じパラメーターを受け入れます。たとえば、{"compress": 3, "protocol": 4}です。
高度な例:
@asset(
name="my_advanced_artifact",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
"description": "My *Markdown* description",
"aliases": ["my_first_alias", "my_second_alias"],
"add_dirs": [
{
"name": "My directory",
"local_path": "path/to/directory",
}
],
"add_files": [
{
"name": "validation_dataset",
"local_path": "path/to/data.json",
},
{
"is_tmp": True,
"local_path": "path/to/temp",
},
],
"add_references": [
{
"uri": "https://picsum.photos/200/300",
"name": "External HTTP reference to an image",
},
{
"uri": "s3://my-bucket/datasets/mnist",
"name": "External S3 reference",
},
],
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_advanced_artifact():
return [1, 2, 3]
アセットは、インテグレーションの両側で役立つメタデータを使用して具体化されます。
- W&B 側: ソースインテグレーションの名前とバージョン、使用された Python バージョン、pickle プロトコルバージョンなど。
- Dagster 側:
- Dagster Run ID
- W&B Run: ID、名前、パス、URL
- W&B Artifact: ID、名前、タイプ、バージョン、サイズ、URL
- W&B Entity
- W&B Project
以下の画像は、Dagster アセットに追加された W&B からのメタデータを示しています。この情報は、インテグレーションなしでは利用できません。
次の画像は、提供された構成が W&B Artifact 上の役立つメタデータでどのようにエンリッチされたかを示しています。この情報は、再現性とメンテナンスに役立ちます。この情報は、インテグレーションなしでは利用できません。
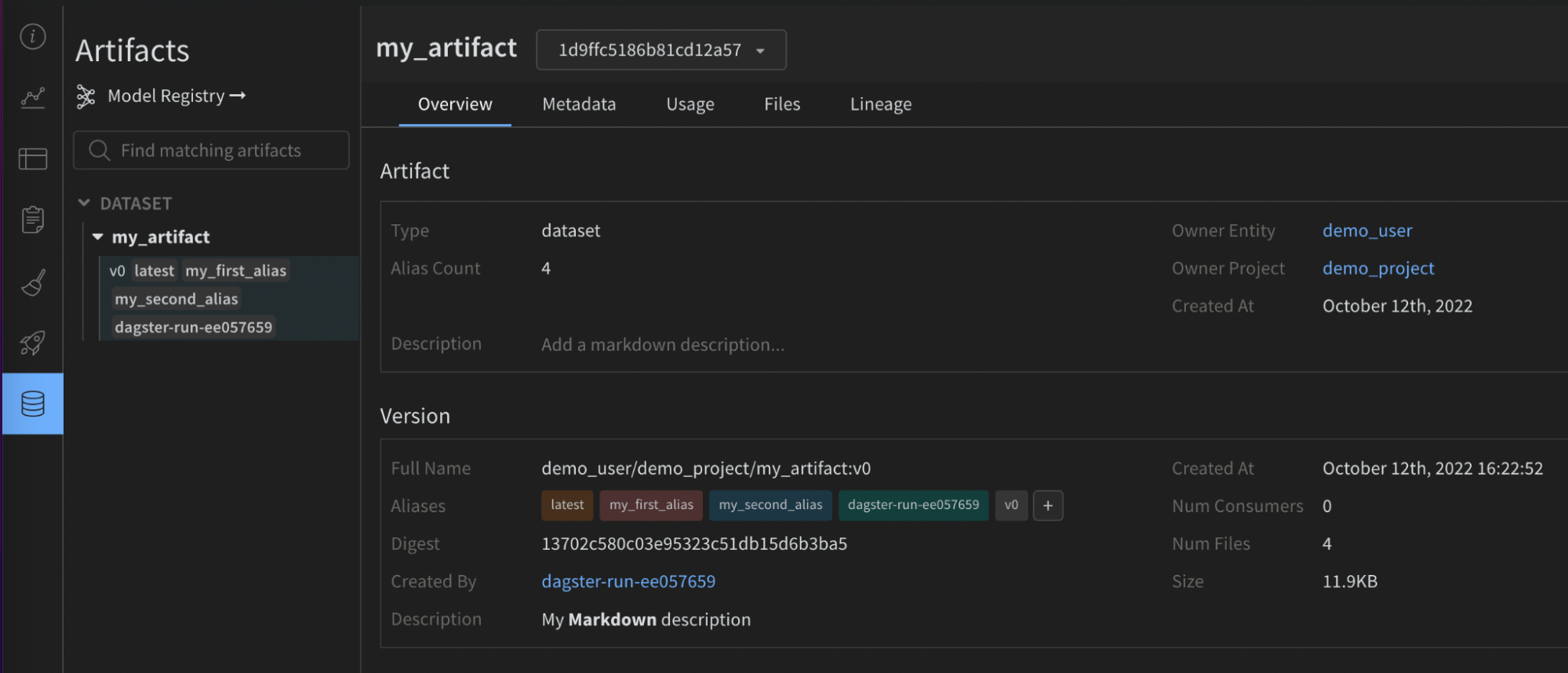
mypy のような静的型チェッカーを使用する場合は、次のものを使用して構成型定義オブジェクトをインポートします。
from dagster_wandb import WandbArtifactConfiguration
パーティションの使用
このインテグレーションは、Dagster パーティション をネイティブにサポートしています。
以下は、DailyPartitionsDefinition を使用してパーティション化された例です。
@asset(
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01", end_date="2023-02-01"),
name="my_daily_partitioned_asset",
compute_kind="wandb",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
}
},
)
def create_my_daily_partitioned_asset(context):
partition_key = context.asset_partition_key_for_output()
context.log.info(f"Creating partitioned asset for {partition_key}")
return random.randint(0, 100)
このコードは、パーティションごとに 1 つの W&B Artifact を生成します。パーティションキーが追加されたアセット名の下の Artifact パネル (UI) で Artifact を表示します。たとえば、my_daily_partitioned_asset.2023-01-01、my_daily_partitioned_asset.2023-01-02、または my_daily_partitioned_asset.2023-01-03 です。複数のディメンションにわたってパーティション化されたアセットは、ドット区切りの形式で各ディメンションを示します。たとえば、my_asset.car.blue です。
このインテグレーションでは、1 つの Run 内で複数のパーティションを具体化することはできません。アセットを具体化するには、複数の Run を実行する必要があります。これは、アセットを具体化するときに Dagit で実行できます。
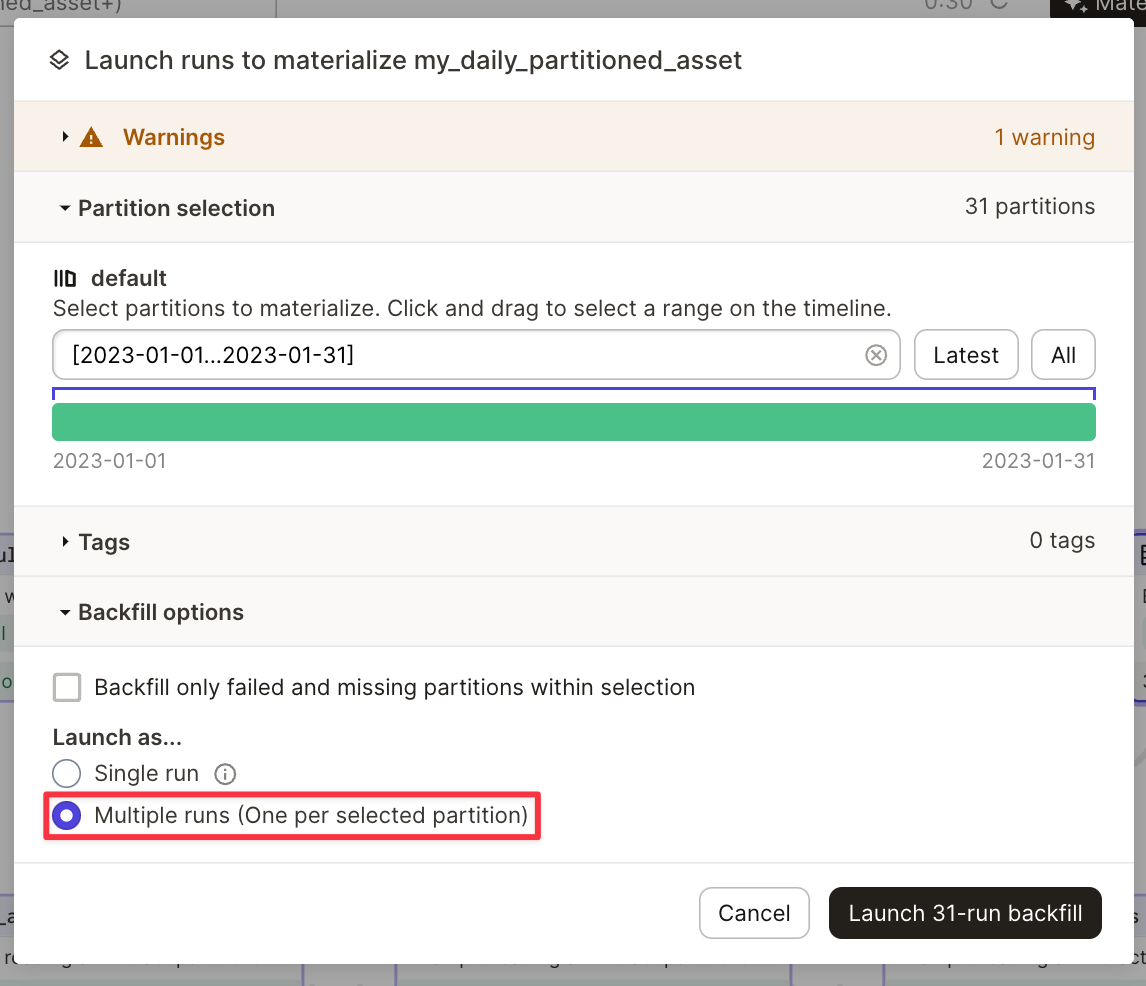
高度な使用法
W&B Artifacts を読み取る
W&B Artifacts の読み取りは、書き込みに似ています。wandb_artifact_configuration と呼ばれる構成ディクショナリは、@op または @asset で設定できます。唯一の違いは、出力ではなく入力で構成を設定する必要があることです。
@op の場合、In メタデータ引数を介して入力メタデータに配置されます。Artifact の名前を明示的に渡す必要があります。
@asset の場合、Asset In メタデータ引数を介して入力メタデータに配置されます。親アセットの名前と一致する必要があるため、Artifact 名を渡さないでください。
インテグレーションの外部で作成された Artifact に依存関係を持たせたい場合は、SourceAsset を使用する必要があります。常にそのアセットの最新バージョンを読み取ります。
次の例では、さまざまな ops から Artifact を読み取る方法を示しています。
@op からの Artifact の読み取り
@op(
ins={
"artifact": In(
metadata={
"wandb_artifact_configuration": {
"name": "my_artifact",
}
}
)
},
io_manager_key="wandb_artifacts_manager"
)
def read_artifact(context, artifact):
context.log.info(artifact)
別の @asset によって作成された Artifact の読み取り
@asset(
name="my_asset",
ins={
"artifact": AssetIn(
# if you don't want to rename the input argument you can remove 'key'
key="parent_dagster_asset_name",
input_manager_key="wandb_artifacts_manager",
)
},
)
def read_artifact(context, artifact):
context.log.info(artifact)
Dagster の外部で作成された Artifact の読み取り:
my_artifact = SourceAsset(
key=AssetKey("my_artifact"), # the name of the W&B Artifact
description="Artifact created outside Dagster",
io_manager_key="wandb_artifacts_manager",
)
@asset
def read_artifact(context, my_artifact):
context.log.info(my_artifact)
構成
以下の構成は、IO Manager が収集し、装飾された関数への入力として提供する内容を示すために使用されます。次の読み取りパターンがサポートされています。
- Artifact 内に含まれる名前付きオブジェクトを取得するには、get を使用します。
@asset(
ins={
"table": AssetIn(
key="my_artifact_with_table",
metadata={
"wandb_artifact_configuration": {
"get": "my_table",
}
},
input_manager_key="wandb_artifacts_manager",
)
}
)
def get_table(context, table):
context.log.info(table.get_column("a"))
- Artifact 内に含まれるダウンロードされたファイルのローカルパスを取得するには、get_path を使用します。
@asset(
ins={
"path": AssetIn(
key="my_artifact_with_file",
metadata={
"wandb_artifact_configuration": {
"get_path": "name_of_file",
}
},
input_manager_key="wandb_artifacts_manager",
)
}
)
def get_path(context, path):
context.log.info(path)
- Artifact オブジェクト全体を取得するには (コンテンツをローカルにダウンロードした場合):
@asset(
ins={
"artifact": AssetIn(
key="my_artifact",
input_manager_key="wandb_artifacts_manager",
)
},
)
def get_artifact(context, artifact):
context.log.info(artifact.name)
サポートされているプロパティ
get: (str) Artifact の相対名にある W&B オブジェクトを取得します。get_path: (str) Artifact の相対名にあるファイルのパスを取得します。
シリアル化構成
デフォルトでは、インテグレーションは標準の pickle モジュールを使用しますが、一部のオブジェクトはそれと互換性がありません。たとえば、yield を使用する関数は、pickle 化しようとするとエラーが発生します。
より多くの Pickle ベースのシリアル化モジュール (dill、cloudpickle、joblib) をサポートしています。ONNX や PMML などのより高度なシリアル化を使用することもできます。シリアル化された文字列を返すか、Artifact を直接作成することで、それらを使用できます。適切な選択はユースケースによって異なります。この件に関する利用可能な文献を参照してください。
Pickle ベースのシリアル化モジュール
wandb_artifact_configuration の serialization_module ディクショナリを使用して、使用するシリアル化を構成できます。モジュールが Dagster を実行しているマシンで使用できることを確認してください。
インテグレーションは、その Artifact を読み取るときに使用するシリアル化モジュールを自動的に認識します。
現在サポートされているモジュールは、pickle、dill、cloudpickle、および joblib です。
以下は、joblib でシリアル化された「モデル」を作成し、それを推論に使用する簡単な例です。
@asset(
name="my_joblib_serialized_model",
compute_kind="Python",
metadata={
"wandb_artifact_configuration": {
"type": "model",
"serialization_module": {
"name": "joblib"
},
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_model_serialized_with_joblib():
# This is not a real ML model but this would not be possible with the pickle module
return lambda x, y: x + y
@asset(
name="inference_result_from_joblib_serialized_model",
compute_kind="Python",
ins={
"my_joblib_serialized_model": AssetIn(
input_manager_key="wandb_artifacts_manager",
)
},
metadata={
"wandb_artifact_configuration": {
"type": "results",
}
},
io_manager_key="wandb_artifacts_manager",
)
def use_model_serialized_with_joblib(
context: OpExecutionContext, my_joblib_serialized_model
):
inference_result = my_joblib_serialized_model(1, 2)
context.log.info(inference_result) # Prints: 3
return inference_result
高度なシリアル化形式 (ONNX、PMML)
ONNX や PMML のような交換ファイル形式を使用するのが一般的です。インテグレーションはこれらの形式をサポートしていますが、Pickle ベースのシリアル化よりも少し手間がかかります。
これらの形式を使用するには、2 つの異なる方法があります。
- モデルを選択した形式に変換し、その形式の文字列表現を通常の Python オブジェクトであるかのように返します。インテグレーションはその文字列を pickle 化します。次に、その文字列を使用してモデルを再構築できます。
- シリアル化されたモデルを使用して新しいローカルファイルを作成し、add_file 構成を使用してそのファイルでカスタム Artifact を構築します。
以下は、ONNX を使用してシリアル化される Scikit-learn モデルの例です。
import numpy
import onnxruntime as rt
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from dagster import AssetIn, AssetOut, asset, multi_asset
@multi_asset(
compute_kind="Python",
outs={
"my_onnx_model": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "model",
}
},
io_manager_key="wandb_artifacts_manager",
),
"my_test_set": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "test_set",
}
},
io_manager_key="wandb_artifacts_manager",
),
},
group_name="onnx_example",
)
def create_onnx_model():
# Inspired from https://onnx.ai/sklearn-onnx/
# Train a model.
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
clr = RandomForestClassifier()
clr.fit(X_train, y_train)
# Convert into ONNX format
initial_type = [("float_input", FloatTensorType([None, 4]))]
onx = convert_sklearn(clr, initial_types=initial_type)
# Write artifacts (model + test_set)
return onx.SerializeToString(), {"X_test": X_test, "y_test": y_test}
@asset(
name="experiment_results",
compute_kind="Python",
ins={
"my_onnx_model": AssetIn(
input_manager_key="wandb_artifacts_manager",
),
"my_test_set": AssetIn(
input_manager_key="wandb_artifacts_manager",
),
},
group_name="onnx_example",
)
def use_onnx_model(context, my_onnx_model, my_test_set):
# Inspired from https://onnx.ai/sklearn-onnx/
# Compute the prediction with ONNX Runtime
sess = rt.InferenceSession(my_onnx_model)
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onx = sess.run(
[label_name], {input_name: my_test_set["X_test"].astype(numpy.float32)}
)[0]
context.log.info(pred_onx)
return pred_onx
パーティションの使用
このインテグレーションは、Dagster パーティション をネイティブにサポートしています。
アセットの 1 つ、複数、またはすべてのパーティションを選択的に読み取ることができます。
すべてのパーティションは辞書で提供され、キーと値はそれぞれパーティションキーと Artifact コンテンツを表します。
アップストリーム @asset のすべてのパーティションを読み取ります。これらは辞書として提供されます。この辞書では、キーと値はそれぞれパーティションキーと Artifact コンテンツに対応しています。
@asset(
compute_kind="wandb",
ins={"my_daily_partitioned_asset": AssetIn()},
output_required=False,
)
def read_all_partitions(context, my_daily_partitioned_asset):
for partition, content in my_daily_partitioned_asset.items():
context.log.info(f"partition={partition}, content={content}")
AssetIn の partition_mapping 構成を使用すると、特定のパーティションを選択できます。この場合、TimeWindowPartitionMapping を採用しています。
@asset(
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01", end_date="2023-02-01"),
compute_kind="wandb",
ins={
"my_daily_partitioned_asset": AssetIn(
partition_mapping=TimeWindowPartitionMapping(start_offset=-1)
)
},
output_required=False,
)
def read_specific_partitions(context, my_daily_partitioned_asset):
for partition, content in my_daily_partitioned_asset.items():
context.log.info(f"partition={partition}, content={content}")
構成オブジェクト metadata は、Weights & Biases (wandb) が Project 内のさまざまな Artifact パーティションとどのように対話するかを構成するために使用されます。
オブジェクト metadata には、wandb_artifact_configuration という名前のキーが含まれており、さらにネストされたオブジェクト partitions が含まれています。
partitions オブジェクトは、各パーティションの名前をその構成にマップします。各パーティションの構成では、そこからデータを取得する方法を指定できます。これらの構成には、各パーティションの要件に応じて、get、version、および alias という異なるキーを含めることができます。
構成キー
get:getキーは、データをフェッチする W&B オブジェクト (Table, Image…) の名前を指定します。version:versionキーは、Artifact の特定のバージョンをフェッチする場合に使用されます。alias:aliasキーを使用すると、エイリアスで Artifact を取得できます。
ワイルドカード構成
ワイルドカード "*" は、構成されていないすべてのパーティションを表します。これにより、partitions オブジェクトで明示的に言及されていないパーティションにデフォルト構成が提供されます。
たとえば、
"*": {
"get": "default_table_name",
},
この構成は、明示的に構成されていないすべてのパーティションについて、データが default_table_name という名前のテーブルからフェッチされることを意味します。
特定のパーティション構成
キーを使用して特定の構成を提供することで、特定のパーティションのワイルドカード構成をオーバーライドできます。
たとえば、
"yellow": {
"get": "custom_table_name",
},
この構成は、yellow という名前のパーティションの場合、データが custom_table_name という名前のテーブルからフェッチされ、ワイルドカード構成がオーバーライドされることを意味します。
バージョン管理とエイリアス
バージョン管理とエイリアスの目的で、構成に特定の version および alias キーを指定できます。
バージョンについては、
"orange": {
"version": "v0",
},
この構成は、orange Artifact パーティションのバージョン v0 からデータをフェッチします。
エイリアスについては、
"blue": {
"alias": "special_alias",
},
この構成は、エイリアス special_alias (構成では blue と呼ばれる) を持つ Artifact パーティションのテーブル default_table_name からデータをフェッチします。
高度な使用法
インテグレーションの高度な使用法を表示するには、次の完全なコード例を参照してください。
W&B Launch の使用
続行する前に、W&B Launch の使用方法を十分に理解しておくことをお勧めします。Launch に関するガイド: /guides/launch を参照してください。
Dagster インテグレーションは、以下に役立ちます。
- Dagster インスタンスで 1 つまたは複数の Launch エージェントを実行します。
- Dagster インスタンス内でローカル Launch ジョブを実行します。
- オンプレミスまたはクラウドでリモート Launch ジョブを実行します。
Launch エージェント
このインテグレーションは、run_launch_agent と呼ばれるインポート可能な @op を提供します。これは、Launch エージェントを起動し、手動で停止するまで長時間実行されるプロセスとして実行します。
エージェントは、Launch キューをポーリングし、ジョブを実行 (または外部サービスにディスパッチして実行) するプロセスです。
構成については、リファレンスドキュメント を参照してください。
また、Launchpad ですべてのプロパティの役立つ説明を表示することもできます。
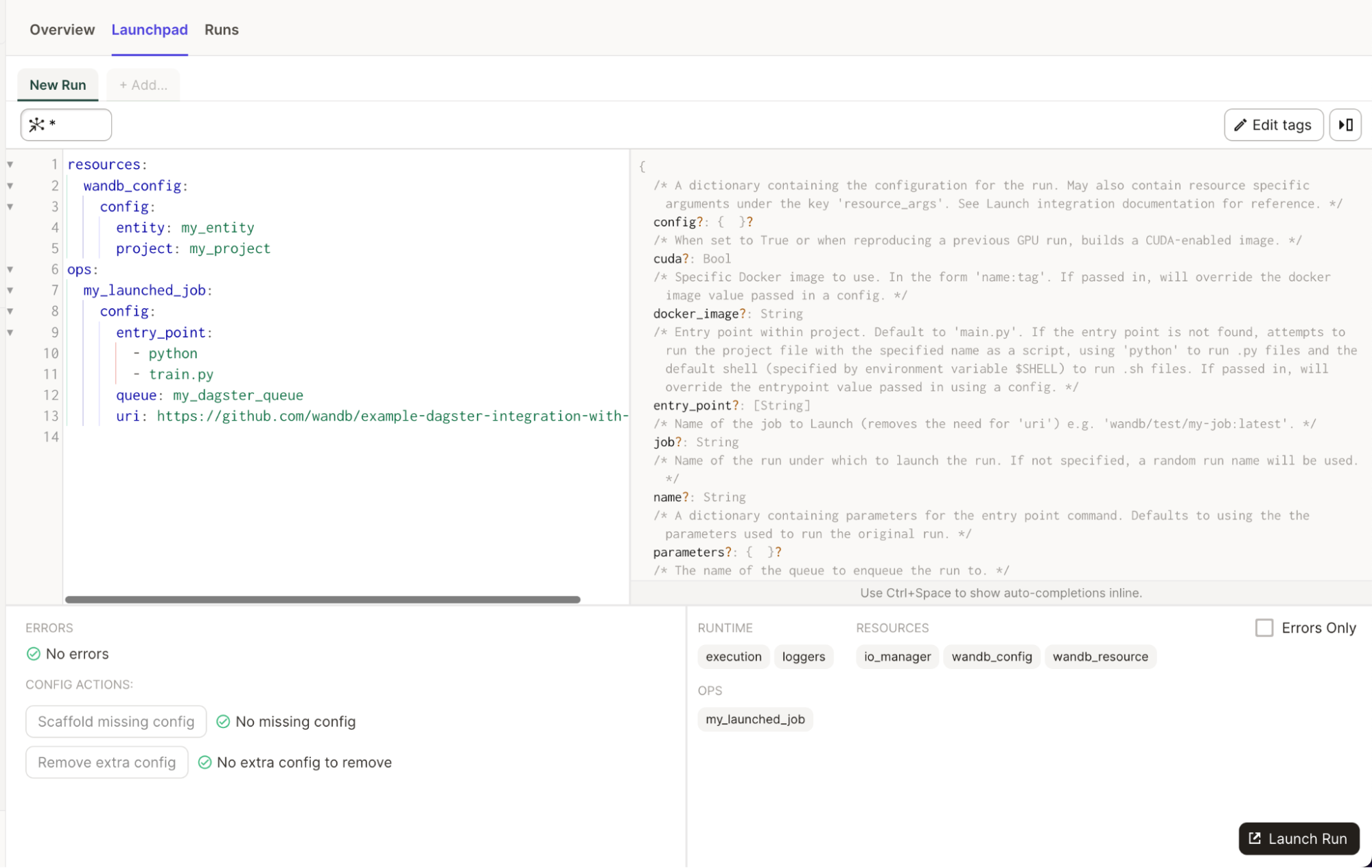
簡単な例
# add this to your config.yaml
# alternatively you can set the config in Dagit's Launchpad or JobDefinition.execute_in_process
# Reference: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # replace this with your W&B entity
project: my_project # replace this with your W&B project
ops:
run_launch_agent:
config:
max_jobs: -1
queues:
- my_dagster_queue
from dagster_wandb.launch.ops import run_launch_agent
from dagster_wandb.resources import wandb_resource
from dagster import job, make_values_resource
@job(
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
},
)
def run_launch_agent_example():
run_launch_agent()
Launch ジョブ
このインテグレーションは、run_launch_job と呼ばれるインポート可能な @op を提供します。Launch ジョブを実行します。
Launch ジョブは、実行されるためにキューに割り当てられます。キューを作成するか、デフォルトのキューを使用できます。そのキューをリッスンするアクティブなエージェントがあることを確認してください。Dagster インスタンス内でエージェントを実行できますが、Kubernetes でデプロイ可能なエージェントを使用することも検討できます。
構成については、リファレンスドキュメント を参照してください。
また、Launchpad ですべてのプロパティの役立つ説明を表示することもできます。
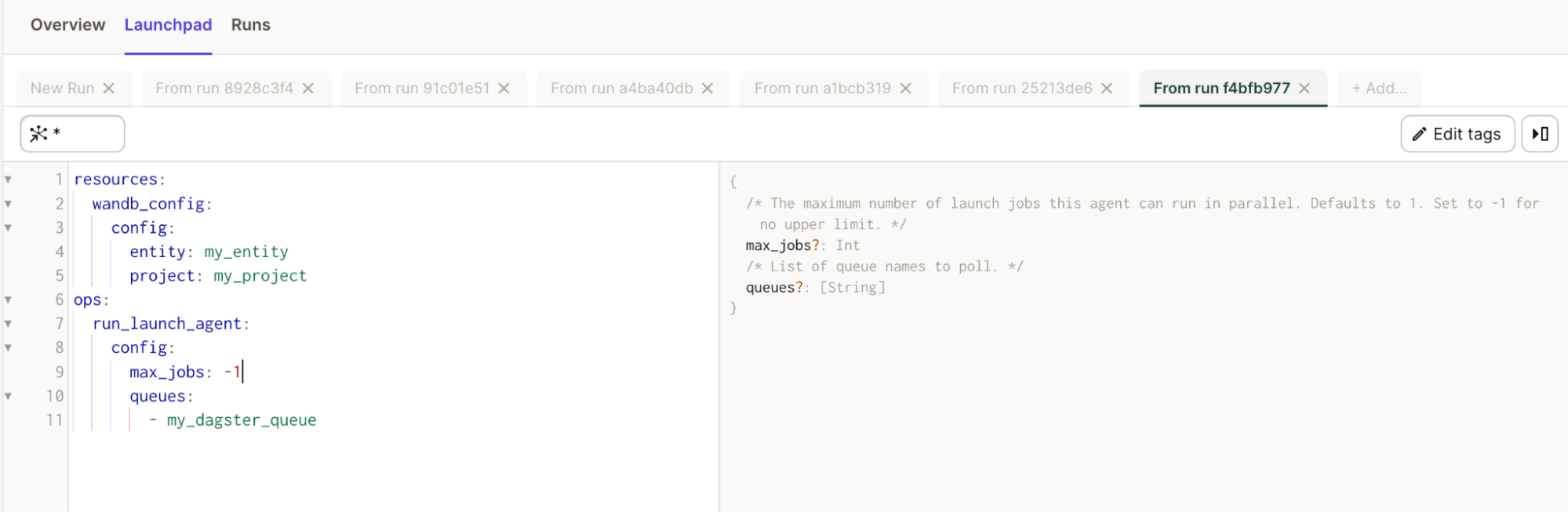
簡単な例
# add this to your config.yaml
# alternatively you can set the config in Dagit's Launchpad or JobDefinition.execute_in_process
# Reference: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # replace this with your W&B entity
project: my_project # replace this with your W&B project
ops:
my_launched_job:
config:
entry_point:
- python
- train.py
queue: my_dagster_queue
uri: https://github.com/wandb/example-dagster-integration-with-launch
from dagster_wandb.launch.ops import run_launch_job
from dagster_wandb.resources import wandb_resource
from dagster import job, make_values_resource
@job(resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
},
)
def run_launch_job_example():
run_launch_job.alias("my_launched_job")() # we rename the job with an alias
ベストプラクティス
-
IO Manager を使用して Artifacts を読み書きします。
Artifact.download()またはRun.log_artifact()を直接使用する必要はありません。これらのメソッドは、インテグレーションによって処理されます。Artifact に保存するデータを返すだけで、残りはインテグレーションに任せます。これにより、W&B での Artifact のリネージが向上します。 -
複雑なユースケースでのみ Artifact オブジェクトを自分で構築します。 Python オブジェクトと W&B オブジェクトは、ops/アセットから返される必要があります。インテグレーションは、Artifact のバンドルを処理します。 複雑なユースケースでは、Dagster ジョブで Artifact を直接構築できます。ソースインテグレーションの名前とバージョン、使用された Python バージョン、pickle プロトコルバージョンなどのメタデータエンリッチメントのために、Artifact オブジェクトをインテグレーションに渡すことをお勧めします。
-
メタデータを介してファイル、ディレクトリー、および外部参照を Artifacts に追加します。 インテグレーション
wandb_artifact_configurationオブジェクトを使用して、ファイル、ディレクトリー、または外部参照 (Amazon S3、GCS、HTTP…) を追加します。詳細については、Artifact 構成セクション の高度な例を参照してください。 -
Artifact が生成される場合は、@op の代わりに @asset を使用します。 Artifacts はアセットです。Dagster がそのアセットを維持する場合は、アセットを使用することをお勧めします。これにより、Dagit Asset Catalog での可観測性が向上します。
-
SourceAsset を使用して、Dagster の外部で作成された Artifact を消費します。 これにより、インテグレーションを利用して外部で作成された Artifact を読み取ることができます。それ以外の場合は、インテグレーションによって作成された Artifact のみを使用できます。
-
W&B Launch を使用して、大規模モデルの専用コンピューティングでのトレーニングを編成します。 Dagster クラスター内で小さなモデルをトレーニングでき、GPU ノードを備えた Kubernetes クラスターで Dagster を実行できます。大規模なモデルトレーニングには、W&B Launch を使用することをお勧めします。これにより、インスタンスの過負荷を防ぎ、より適切なコンピューティングへのアクセスを提供できます。
-
Dagster 内で実験管理を行う場合は、W&B Run ID を Dagster Run ID の値に設定します。 Run を再開可能 にし、W&B Run ID を Dagster Run ID または選択した文字列に設定することをお勧めします。この推奨事項に従うと、Dagster 内でモデルをトレーニングするときに、W&B メトリクスと W&B Artifacts が同じ W&B Run に保存されるようになります。
W&B Run ID を Dagster Run ID に設定します。
wandb.init(
id=context.run_id,
resume="allow",
...
)
または、独自の W&B Run ID を選択して、IO Manager 構成に渡します。
wandb.init(
id="my_resumable_run_id",
resume="allow",
...
)
@job(
resource_defs={
"io_manager": wandb_artifacts_io_manager.configured(
{"wandb_run_id": "my_resumable_run_id"}
),
}
)
-
大規模な W&B Artifacts の場合は、get または get_path で必要なデータのみを収集します。 デフォルトでは、インテグレーションは Artifact 全体をダウンロードします。非常に大きな Artifact を使用している場合は、必要な特定のファイルまたはオブジェクトのみを収集する必要があります。これにより、速度とリソースの使用率が向上します。
-
Python オブジェクトの場合は、ユースケースに合わせて pickle モジュールを調整します。 デフォルトでは、W&B インテグレーションは標準の pickle モジュールを使用します。ただし、一部のオブジェクトはそれと互換性がありません。たとえば、yield を使用する関数は、pickle 化しようとするとエラーが発生します。W&B は、他の Pickle ベースのシリアル化モジュール (dill、cloudpickle、joblib) をサポートしています。
シリアル化された文字列を返すか、Artifact を直接作成することで、ONNX や PMML などのより高度なシリアル化を使用することもできます。適切な選択はユースケースによって異なります。この件に関する利用可能な文献を参照してください。
7.2 - Launch multinode jobs with Volcano
このチュートリアルでは、Kubernetes 上で W&B と Volcano を使用して、マルチノードのトレーニングジョブを起動するプロセスを説明します。
概要
このチュートリアルでは、W&B Launch を使用して Kubernetes 上でマルチノードジョブを実行する方法を学びます。手順は次のとおりです。
- Weights & Biases のアカウントと Kubernetes クラスターがあることを確認します。
- volcano ジョブの Launch キューを作成します。
- Launch エージェントを Kubernetes クラスターにデプロイします。
- 分散トレーニングジョブを作成します。
- 分散トレーニングを Launch します。
前提条件
始める前に、以下が必要です。
- Weights & Biases アカウント
- Kubernetes クラスター
Launch キューを作成する
最初のステップは、Launch キューを作成することです。wandb.ai/launch にアクセスし、画面の右上隅にある青い キューを作成 ボタンをクリックします。キューの作成ドロワーが画面の右側からスライドして表示されます。エンティティを選択し、名前を入力して、キューのタイプとして Kubernetes を選択します。
設定セクションでは、volcano job テンプレートを入力します。このキューから Launch された Run は、このジョブ仕様を使用して作成されるため、必要に応じてこの設定を変更してジョブをカスタマイズできます。
この設定ブロックは、Kubernetes ジョブ仕様、volcano ジョブ仕様、または Launch したいその他のカスタムリソース定義(CRD)を受け入れることができます。設定ブロックでマクロを使用 して、この仕様の内容を動的に設定できます。
このチュートリアルでは、Volcano の pytorch プラグイン を使用するマルチノード pytorch トレーニングの設定を使用します。次の設定を YAML または JSON としてコピーして貼り付けることができます。
kind: Job
spec:
tasks:
- name: master
policies:
- event: TaskCompleted
action: CompleteJob
replicas: 1
template:
spec:
containers:
- name: master
image: ${image_uri}
imagePullPolicy: IfNotPresent
restartPolicy: OnFailure
- name: worker
replicas: 1
template:
spec:
containers:
- name: worker
image: ${image_uri}
workingDir: /home
imagePullPolicy: IfNotPresent
restartPolicy: OnFailure
plugins:
pytorch:
- --master=master
- --worker=worker
- --port=23456
minAvailable: 1
schedulerName: volcano
metadata:
name: wandb-job-${run_id}
labels:
wandb_entity: ${entity_name}
wandb_project: ${project_name}
namespace: wandb
apiVersion: batch.volcano.sh/v1alpha1
{
"kind": "Job",
"spec": {
"tasks": [
{
"name": "master",
"policies": [
{
"event": "TaskCompleted",
"action": "CompleteJob"
}
],
"replicas": 1,
"template": {
"spec": {
"containers": [
{
"name": "master",
"image": "${image_uri}",
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "OnFailure"
}
}
},
{
"name": "worker",
"replicas": 1,
"template": {
"spec": {
"containers": [
{
"name": "worker",
"image": "${image_uri}",
"workingDir": "/home",
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "OnFailure"
}
}
}
],
"plugins": {
"pytorch": [
"--master=master",
"--worker=worker",
"--port=23456"
]
},
"minAvailable": 1,
"schedulerName": "volcano"
},
"metadata": {
"name": "wandb-job-${run_id}",
"labels": {
"wandb_entity": "${entity_name}",
"wandb_project": "${project_name}"
},
"namespace": "wandb"
},
"apiVersion": "batch.volcano.sh/v1alpha1"
}
ドロワーの下部にある キューを作成 ボタンをクリックして、キューの作成を完了します。
Volcano をインストールする
Kubernetes クラスターに Volcano をインストールするには、公式インストールガイド に従ってください。
Launch エージェントをデプロイする
キューを作成したので、キューからジョブをプルして実行するために Launch エージェントをデプロイする必要があります。これを行う最も簡単な方法は、W&B の公式 helm-charts リポジトリの launch-agent チャート を使用することです。README の指示に従ってチャートを Kubernetes クラスターにインストールし、必ず前に作成したキューをポーリングするようにエージェントを設定してください。
トレーニングジョブを作成する
Volcano の pytorch プラグインは、pytorch コードが DDP を正しく使用している限り、MASTER_ADDR、RANK、WORLD_SIZE など、pytorch DPP が機能するために必要な環境変数を自動的に構成します。カスタム python コードで DDP を使用する方法の詳細については、pytorch のドキュメント を参照してください。
Trainer を介したマルチノードトレーニング とも互換性があります。Launch 🚀
キューとクラスターがセットアップされたので、分散トレーニングを Launch する時間です。まず、Volcano の pytorch プラグインを使用して、ランダムデータで単純な多層パーセプトロンをトレーニングする ジョブ を使用します。ジョブのソースコードはこちらにあります。
このジョブを Launch するには、ジョブのページ にアクセスし、画面の右上隅にある Launch ボタンをクリックします。ジョブを Launch するキューを選択するように求められます。
- ジョブのパラメータを任意に設定します。
- 先ほど作成したキューを選択します。
- リソース設定 セクションで volcano ジョブを変更して、ジョブのパラメータを変更します。たとえば、
workerタスクのreplicasフィールドを変更することで、worker の数を変更できます。 - Launch 🚀 をクリックします
W&B UI からジョブの進行状況を監視し、必要に応じてジョブを停止できます。
7.3 - NVIDIA NeMo Inference Microservice Deploy Job
W&B から NVIDIA NeMo Inference Microservice にモデル Artifact をデプロイするには、W&B Launch を使用します。W&B Launch は、モデル Artifact を NVIDIA NeMo Model に変換し、実行中の NIM/Triton サーバーにデプロイします。
W&B Launch は現在、以下の互換性のあるモデルタイプを受け入れています。
a2-ultragpu-1g で約 1 分かかります。クイックスタート
-
まだ Launch キューを作成 していない場合は作成します。以下のキュー構成の例を参照してください。
net: host gpus: all # 特定の GPU のセット、またはすべてを使用する場合は `all` runtime: nvidia # nvidia container runtime も必要 volume: - model-store:/model-store/
-
プロジェクト でこのジョブを作成します。
wandb job create -n "deploy-to-nvidia-nemo-inference-microservice" \ -e $ENTITY \ -p $PROJECT \ -E jobs/deploy_to_nvidia_nemo_inference_microservice/job.py \ -g andrew/nim-updates \ git https://github.com/wandb/launch-jobs -
GPU マシンで エージェント を起動します。
wandb launch-agent -e $ENTITY -p $PROJECT -q $QUEUE -
Launch UI から、必要な構成でデプロイメント Launch ジョブを送信します。
- CLI から送信することもできます。
wandb launch -d gcr.io/playground-111/deploy-to-nemo:latest \ -e $ENTITY \ -p $PROJECT \ -q $QUEUE \ -c $CONFIG_JSON_FNAME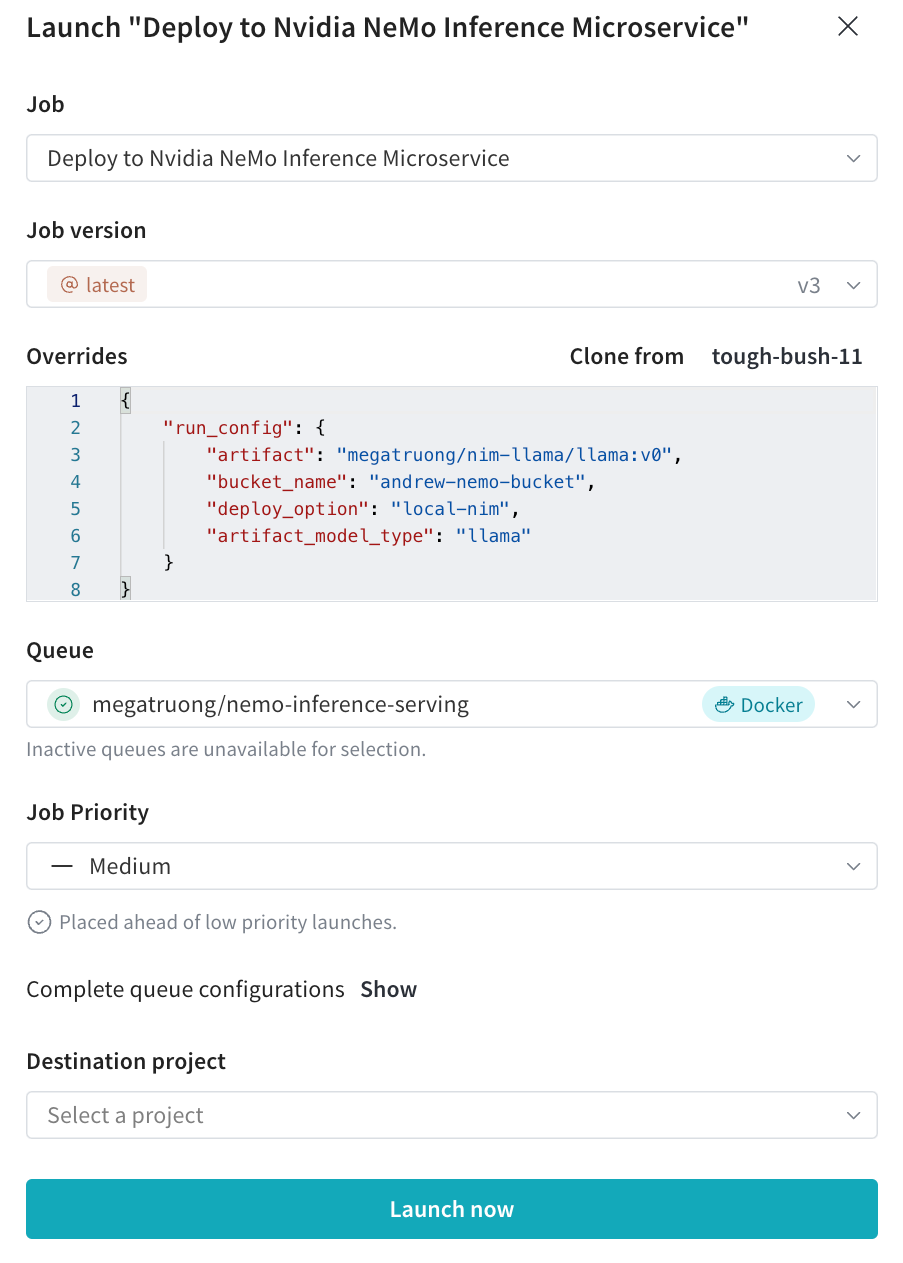
- CLI から送信することもできます。
-
デプロイメント プロセス を Launch UI で追跡できます。
-
完了したら、すぐにエンドポイントを curl してモデルをテストできます。モデル名は常に
ensembleです。#!/bin/bash curl -X POST "http://0.0.0.0:9999/v1/completions" \ -H "accept: application/json" \ -H "Content-Type: application/json" \ -d '{ "model": "ensemble", "prompt": "Tell me a joke", "max_tokens": 256, "temperature": 0.5, "n": 1, "stream": false, "stop": "string", "frequency_penalty": 0.0 }'
7.4 - Spin up a single node GPU cluster with Minikube
GPU ワークロードをスケジュールおよび実行できる Minikube クラスターで W&B Launch をセットアップします。
このチュートリアルは、複数の GPU を搭載したマシンに直接アクセスできるユーザーを対象としています。クラウドマシンをレンタルしているユーザーは対象としていません。
クラウドマシンに minikube クラスターをセットアップする場合は、クラウドプロバイダーが提供する GPU をサポートする Kubernetes クラスターを作成することをお勧めします。たとえば、AWS、GCP、Azure、Coreweave などのクラウドプロバイダーには、GPU をサポートする Kubernetes クラスターを作成するツールがあります。
単一の GPU を搭載したマシンで GPU のスケジューリングを行うために minikube クラスターをセットアップする場合は、Launch Docker queue を使用することをお勧めします。チュートリアルは、楽しみのために実行することもできますが、GPU のスケジューリングはあまり役に立ちません。
背景
Nvidia container toolkit により、Docker で GPU 対応の ワークフローを簡単に実行できるようになりました。1 つの制限は、ボリュームによる GPU のスケジューリングに対するネイティブサポートがないことです。docker run コマンドで GPU を使用する場合は、ID または存在するすべての GPU で特定の GPU を要求する必要があります。これにより、多くの分散 GPU 対応ワークロードが非現実的になります。Kubernetes はボリュームリクエストによるスケジューリングをサポートしていますが、GPU スケジューリングを備えたローカル Kubernetes クラスターのセットアップには、最近までかなりの時間と労力がかかりました。シングルノード Kubernetes クラスターを実行するための最も一般的なツールの 1 つである Minikube は、最近 GPU スケジューリングのサポート をリリースしました 🎉 このチュートリアルでは、マルチ GPU マシンに Minikube クラスターを作成し、W&B Launch 🚀 を使用して同時 Stable Diffusion 推論ジョブをクラスターに Launch します。
前提条件
開始する前に、以下が必要です。
- W&B アカウント。
- 以下がインストールされ、実行されている Linux マシン:
- Docker ランタイム
- 使用する GPU のドライバー
- Nvidia container toolkit
n1-standard-16 Google Cloud Compute Engine インスタンスを使用しました。Launch ジョブのキューを作成する
まず、Launch ジョブの Launch キューを作成します。
- wandb.ai/launch(または、プライベート W&B サーバーを使用している場合は
<your-wandb-url>/launch)に移動します。 - 画面の右上隅にある青色の Create a queue ボタンをクリックします。キュー作成ドロワーが画面の右側からスライドして表示されます。
- エンティティを選択し、名前を入力して、キューのタイプとして Kubernetes を選択します。
- ドロワーの Config セクションでは、Launch キューの Kubernetes ジョブ仕様 を入力します。このキューから Launch された Run は、このジョブ仕様を使用して作成されるため、必要に応じてこの設定を変更してジョブをカスタマイズできます。このチュートリアルでは、以下のサンプル設定を YAML または JSON としてキュー設定にコピーして貼り付けることができます。
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: '{{gpus}}'
restartPolicy: Never
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
}
}
}
],
"restartPolicy": "Never"
}
},
"backoffLimit": 0
}
}
キュー構成の詳細については、Set up Launch on Kubernetes および Advanced queue setup guide を参照してください。
${image_uri} および {{gpus}} 文字列は、キュー構成で使用できる 2 種類の変数テンプレートの例です。${image_uri} テンプレートは、エージェントによって Launch しているジョブのイメージ URI に置き換えられます。{{gpus}} テンプレートは、ジョブの送信時に Launch UI、CLI、または SDK からオーバーライドできるテンプレート変数を作成するために使用されます。これらの値はジョブ仕様に配置され、ジョブで使用されるイメージと GPU リソースを制御するために正しいフィールドを変更します。
- Parse configuration ボタンをクリックして、
gpusテンプレート変数のカスタマイズを開始します。 - Type を
Integerに設定し、Default、Min、および Max を選択した値に設定します。 テンプレート変数の制約に違反するこのキューに Run を送信しようとすると、拒否されます。
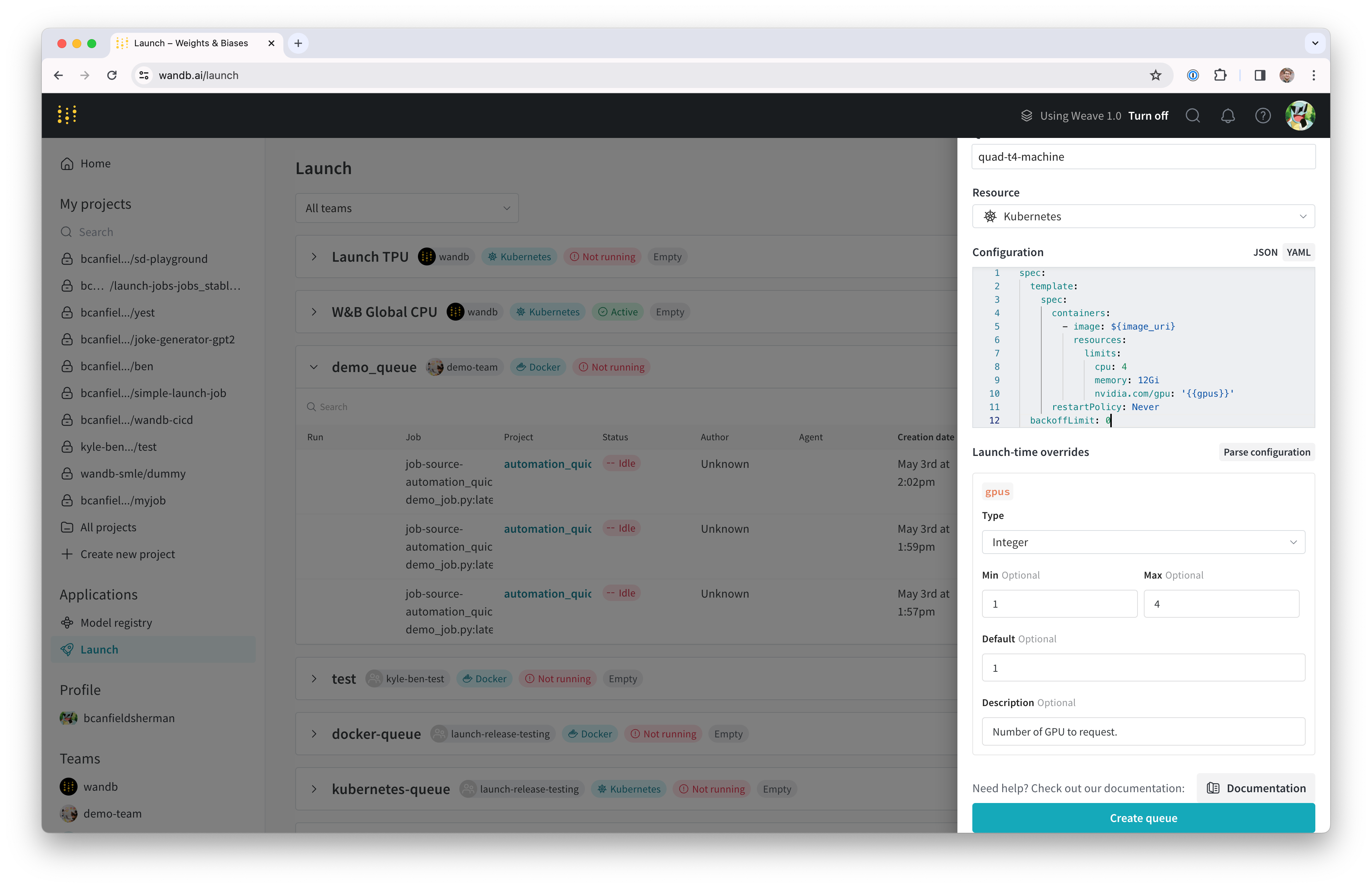
- Create queue をクリックしてキューを作成します。新しいキューのキューページにリダイレクトされます。
次のセクションでは、作成したキューからジョブをプルして実行できるエージェントをセットアップします。
Docker + NVIDIA CTK のセットアップ
Docker と Nvidia container toolkit がマシンに既にセットアップされている場合は、このセクションをスキップできます。
システムでの Docker container エンジンのセットアップ手順については、Docker のドキュメント を参照してください。
Docker をインストールしたら、Nvidia のドキュメントの手順に従って Nvidia container toolkit をインストールします。
コンテナランタイムが GPU にアクセスできることを検証するには、以下を実行します。
docker run --gpus all ubuntu nvidia-smi
マシンに接続されている GPU を記述する nvidia-smi 出力が表示されます。たとえば、セットアップでの出力は次のようになります。
Wed Nov 8 23:25:53 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 Tesla T4 Off | 00000000:00:06.0 Off | 0 |
| N/A 40C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 Tesla T4 Off | 00000000:00:07.0 Off | 0 |
| N/A 39C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Minikube のセットアップ
Minikube の GPU サポートには、バージョン v1.32.0 以降が必要です。最新のインストールヘルプについては、Minikube のインストールドキュメント を参照してください。このチュートリアルでは、次のコマンドを使用して最新の Minikube リリースをインストールしました。
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
次のステップでは、GPU を使用して minikube クラスターを起動します。マシンで、以下を実行します。
minikube start --gpus all
上記のコマンドの出力は、クラスターが正常に作成されたかどうかを示します。
Launch エージェントの起動
新しいクラスターの Launch エージェントは、wandb launch-agent を直接呼び出すか、W&B が管理する helm チャート を使用して Launch エージェントをデプロイすることで起動できます。
このチュートリアルでは、エージェントをホストマシン上で直接実行します。
エージェントをローカルで実行するには、デフォルトの Kubernetes API コンテキストが Minikube クラスターを参照していることを確認してください。次に、以下を実行します。
pip install "wandb[launch]"
エージェントの依存関係をインストールします。エージェントの認証をセットアップするには、wandb login を実行するか、WANDB_API_KEY 環境変数を設定します。
エージェントを起動するには、次のコマンドを実行します。
wandb launch-agent -j <max-number-concurrent-jobs> -q <queue-name> -e <queue-entity>
ターミナル内で、Launch エージェントがポーリングメッセージの出力を開始するのを確認できます。
おめでとうございます。Launch キューをポーリングする Launch エージェントができました。ジョブがキューに追加されると、エージェントがそれを取得し、Minikube クラスターで実行するようにスケジュールします。
ジョブの Launch
エージェントにジョブを送信しましょう。W&B アカウントにログインしているターミナルから、次のコマンドで簡単な「hello world」を Launch できます。
wandb launch -d wandb/job_hello_world:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
任意のジョブまたはイメージでテストできますが、クラスターがイメージをプルできることを確認してください。詳細については、Minikube のドキュメント を参照してください。パブリックジョブのいずれかを使用してテスト することもできます。
(オプション) NFS を使用したモデルとデータのキャッシュ
ML ワークロードの場合、多くの場合、複数のジョブが同じデータにアクセスできるようにする必要があります。たとえば、データセットやモデルの重みなどの大きなアセットを繰り返しダウンロードするのを避けるために、共有キャッシュを用意することができます。Kubernetes は、Persistent Volumes と Persistent Volume Claims を通じてこれをサポートします。Persistent Volumes を使用して、Kubernetes ワークロードに volumeMounts を作成し、共有キャッシュへの直接ファイルシステムアクセスを提供できます。
このステップでは、モデルの重みの共有キャッシュとして使用できるネットワークファイルシステム (NFS) サーバーをセットアップします。最初のステップは、NFS をインストールして構成することです。このプロセスはオペレーティングシステムによって異なります。VM は Ubuntu を実行しているため、nfs-kernel-server をインストールし、/srv/nfs/kubedata にエクスポートを構成しました。
sudo apt-get install nfs-kernel-server
sudo mkdir -p /srv/nfs/kubedata
sudo chown nobody:nogroup /srv/nfs/kubedata
sudo sh -c 'echo "/srv/nfs/kubedata *(rw,sync,no_subtree_check,no_root_squash,no_all_squash,insecure)" >> /etc/exports'
sudo exportfs -ra
sudo systemctl restart nfs-kernel-server
ホストファイルシステム内のサーバーのエクスポート場所と、NFS サーバーのローカル IP アドレスをメモしておきます。次のステップでこの情報が必要になります。
次に、この NFS の Persistent Volume と Persistent Volume Claim を作成する必要があります。Persistent Volumes は高度にカスタマイズ可能ですが、ここでは簡単にするために簡単な構成を使用します。
以下の yaml を nfs-persistent-volume.yaml というファイルにコピーし、必要なボリューム容量とクレームリクエストを必ず入力してください。PersistentVolume.spec.capcity.storage フィールドは、基になるボリュームの最大サイズを制御します。PersistentVolumeClaim.spec.resources.requests.stroage を使用して、特定のクレームに割り当てられたボリューム容量を制限できます。ユースケースでは、それぞれに同じ値を使用するのが理にかなっています。
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 100Gi # Set this to your desired capacity.
accessModes:
- ReadWriteMany
nfs:
server: <your-nfs-server-ip> # TODO: Fill this in.
path: '/srv/nfs/kubedata' # Or your custom path
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi # Set this to your desired capacity.
storageClassName: ''
volumeName: nfs-pv
次のコマンドを使用して、クラスター内にリソースを作成します。
kubectl apply -f nfs-persistent-volume.yaml
Run がこのキャッシュを利用できるようにするには、Launch キュー構成に volumes と volumeMounts を追加する必要があります。Launch 構成を編集するには、wandb.ai/launch(または wandb サーバーのユーザーの場合は <your-wandb-url>/launch)に戻り、キューを見つけてキューページをクリックし、Edit config タブをクリックします。元の構成は次のように変更できます。
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: "{{gpus}}"
volumeMounts:
- name: nfs-storage
mountPath: /root/.cache
restartPolicy: Never
volumes:
- name: nfs-storage
persistentVolumeClaim:
claimName: nfs-pvc
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
},
"volumeMounts": [
{
"name": "nfs-storage",
"mountPath": "/root/.cache"
}
]
}
}
],
"restartPolicy": "Never",
"volumes": [
{
"name": "nfs-storage",
"persistentVolumeClaim": {
"claimName": "nfs-pvc"
}
}
]
}
},
"backoffLimit": 0
}
}
これで、NFS はジョブを実行しているコンテナ内の /root/.cache にマウントされます。コンテナが root 以外のユーザーとして実行されている場合、マウントパスを調整する必要があります。Huggingface のライブラリと W&B Artifacts はどちらもデフォルトで $HOME/.cache/ を使用するため、ダウンロードは 1 回だけ行う必要があります。
Stable Diffusion を使用する
新しいシステムをテストするために、Stable Diffusion の推論パラメーターを試してみます。 デフォルトのプロンプトと適切なパラメーターを使用して、単純な Stable Diffusion 推論ジョブを実行するには、以下を実行します。
wandb launch -d wandb/job_stable_diffusion_inference:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
上記のコマンドは、コンテナイメージ wandb/job_stable_diffusion_inference:main をキューに送信します。
エージェントがジョブを取得してクラスターで実行するようにスケジュールすると、
接続によっては、イメージのプルに時間がかかる場合があります。
wandb.ai/launch(または wandb サーバーのユーザーの場合は <your-wandb-url>/launch)のキューページでジョブのステータスを確認できます。
Run が完了すると、指定したプロジェクトにジョブ Artifact が作成されます。
プロジェクトのジョブページ(<project-url>/jobs)を確認して、ジョブ Artifact を見つけることができます。そのデフォルト名は job-wandb_job_stable_diffusion_inference である必要がありますが、ジョブの名前の横にある鉛筆アイコンをクリックして、ジョブのページで好きな名前に変更できます。
これで、このジョブを使用して、クラスターでより多くの Stable Diffusion 推論を実行できます。 ジョブページから、右上隅にある Launch ボタンをクリックして、 新しい推論ジョブを構成し、キューに送信できます。ジョブ構成ページには、元の Run のパラメーターがあらかじめ入力されていますが、Launch ドロワーの Overrides セクションで値を変更することで、好きなように変更できます。