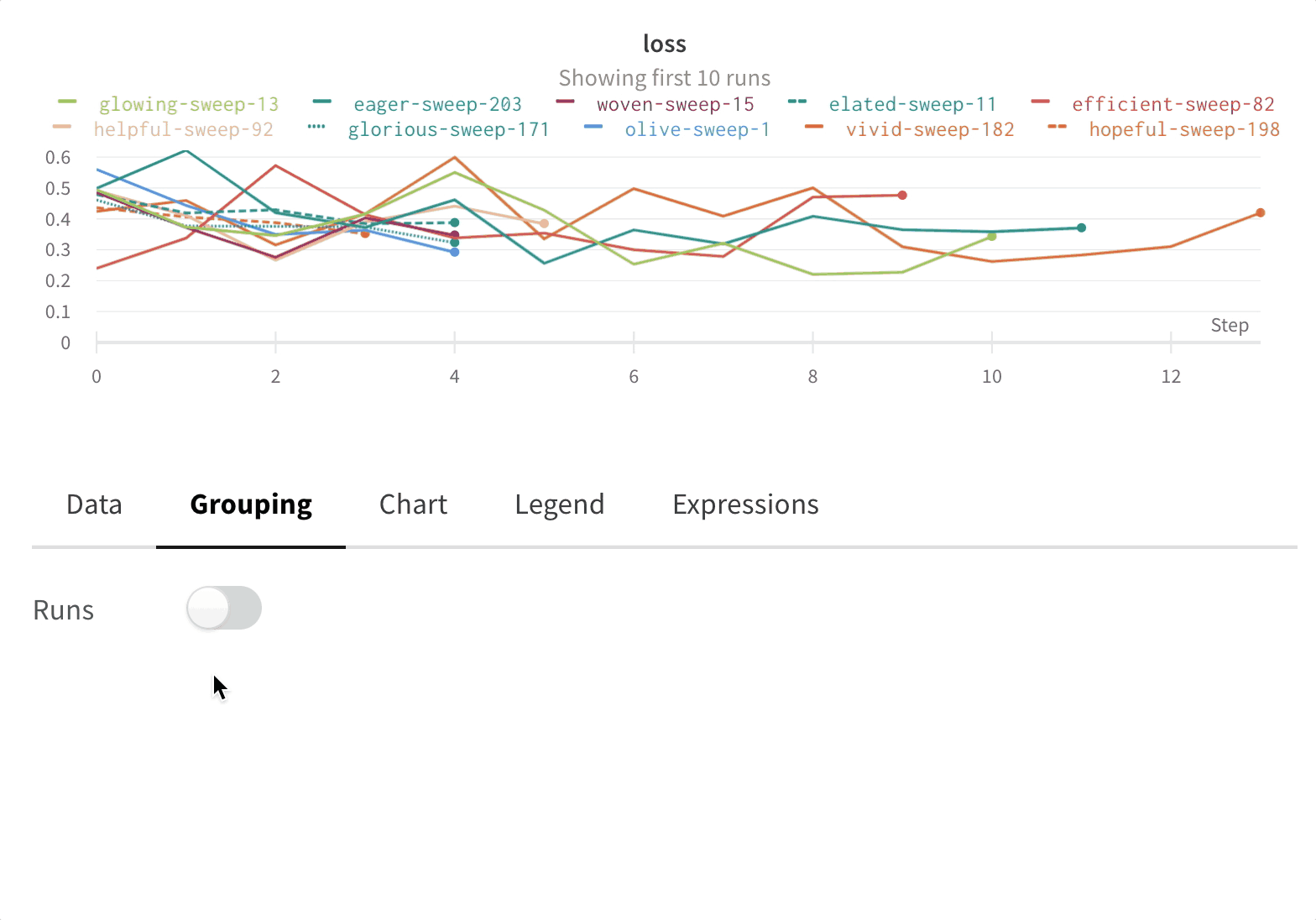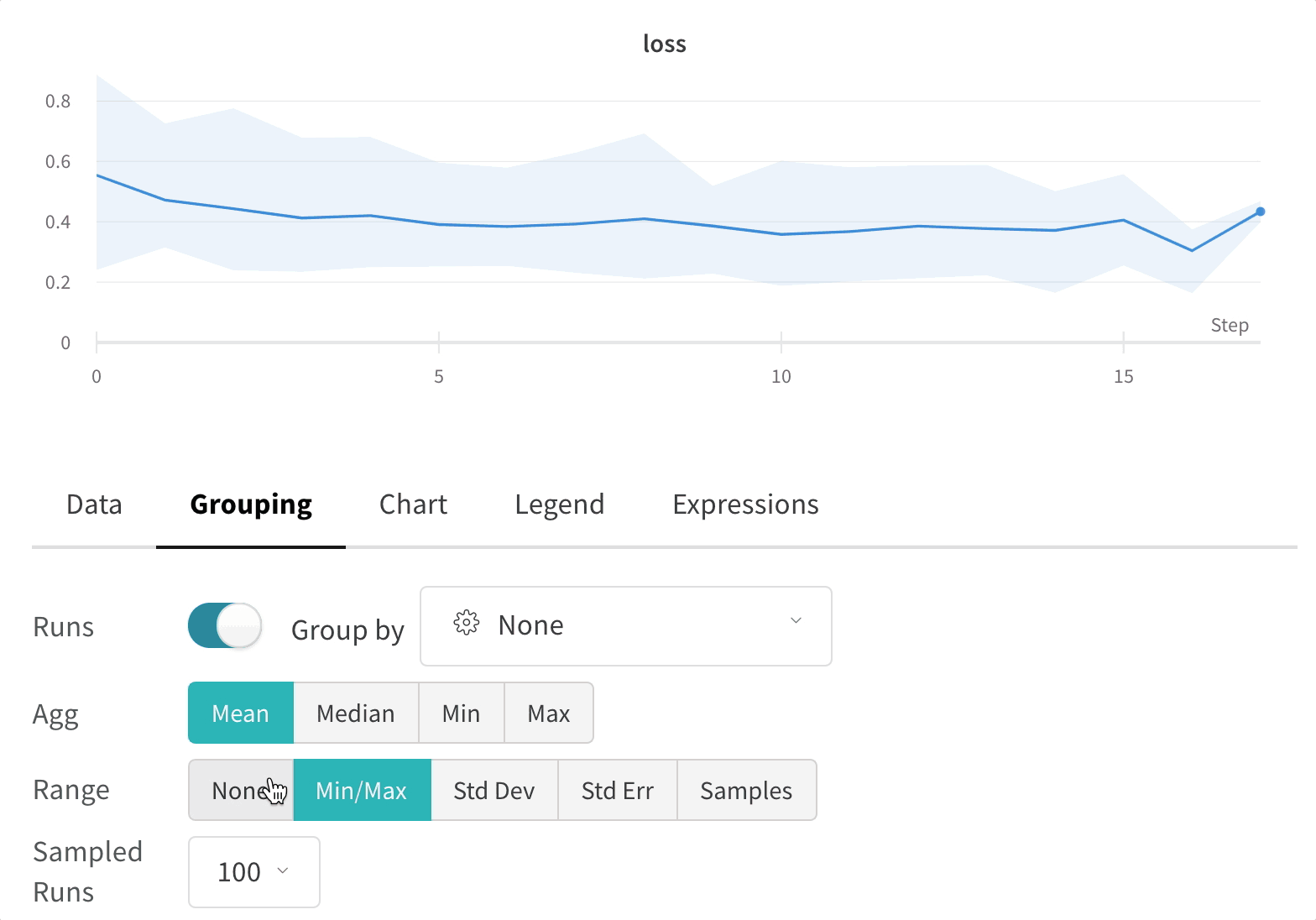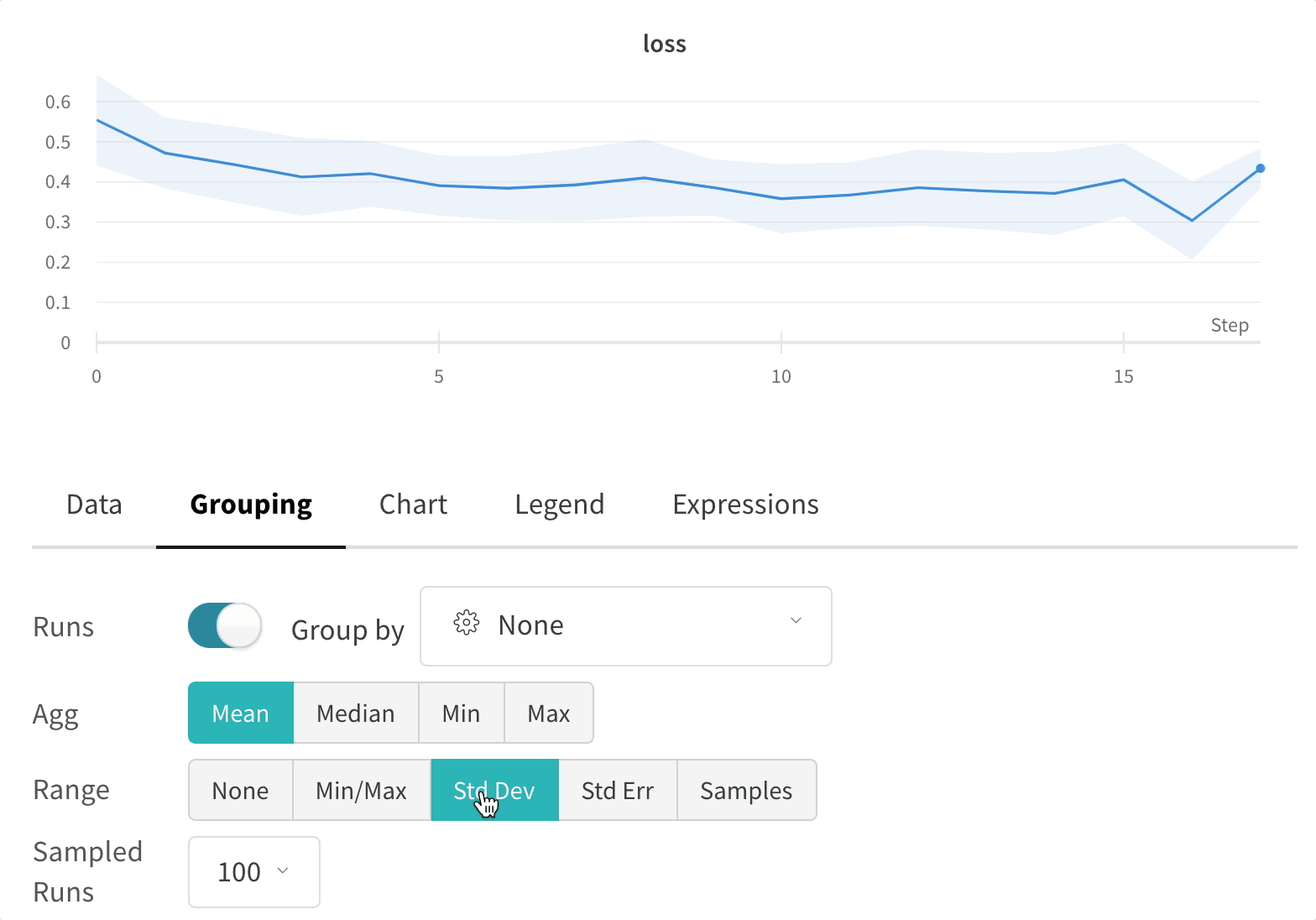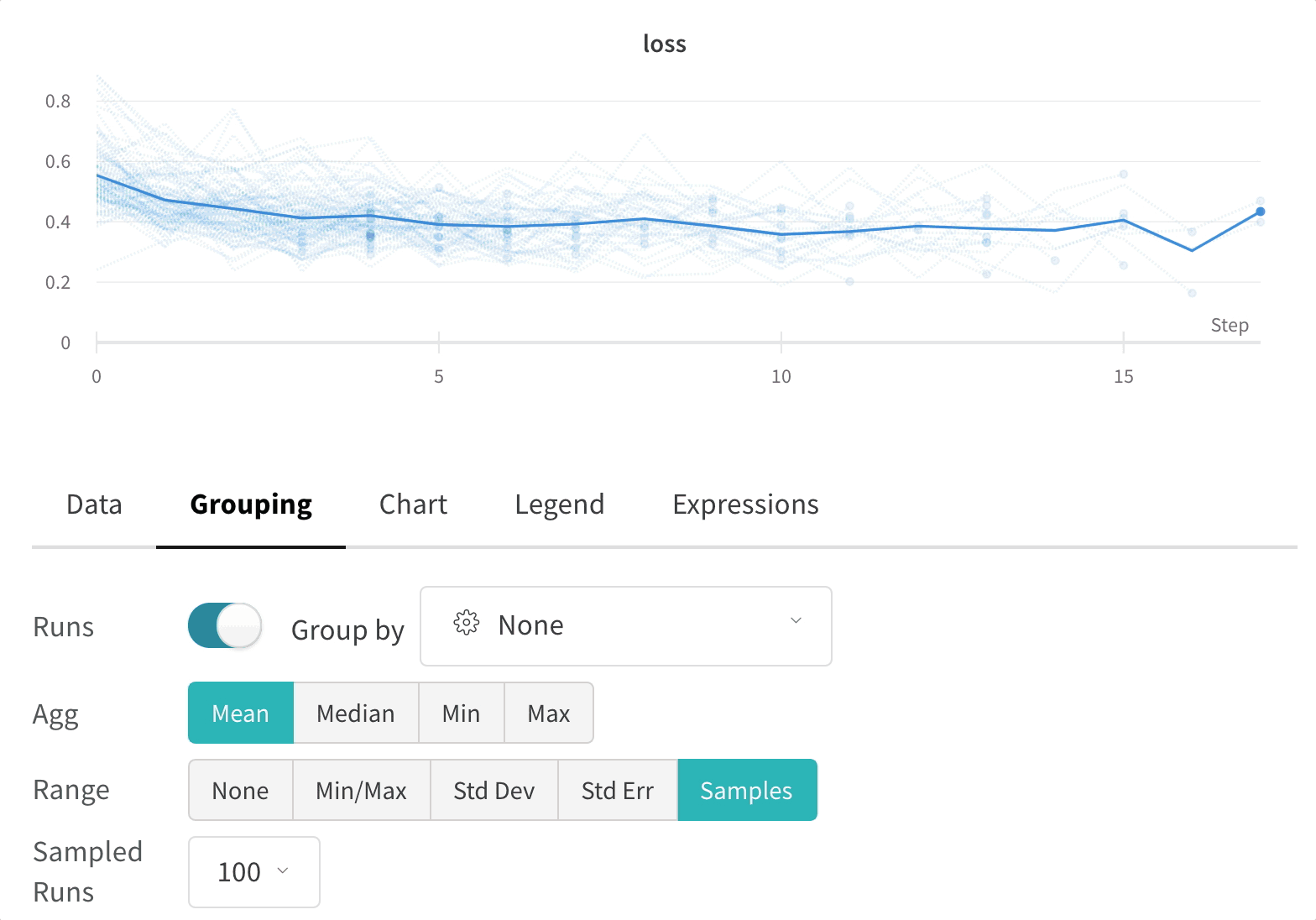
Experiments
W&B で 機械学習 の 実験 を トラックします。
数行のコードで 機械学習 の 実験 を追跡します。次に、インタラクティブ ダッシュボード で 結果 を確認するか、Public API を使用して、プログラムで アクセス できるように データ を Python にエクスポートできます。
PyTorch , Keras , or Scikit のような一般的な フレームワーク を使用する場合は、W&B インテグレーション を活用してください。インテグレーション の完全なリストと、W&B を コード に追加する方法については、インテグレーション ガイド を参照してください。
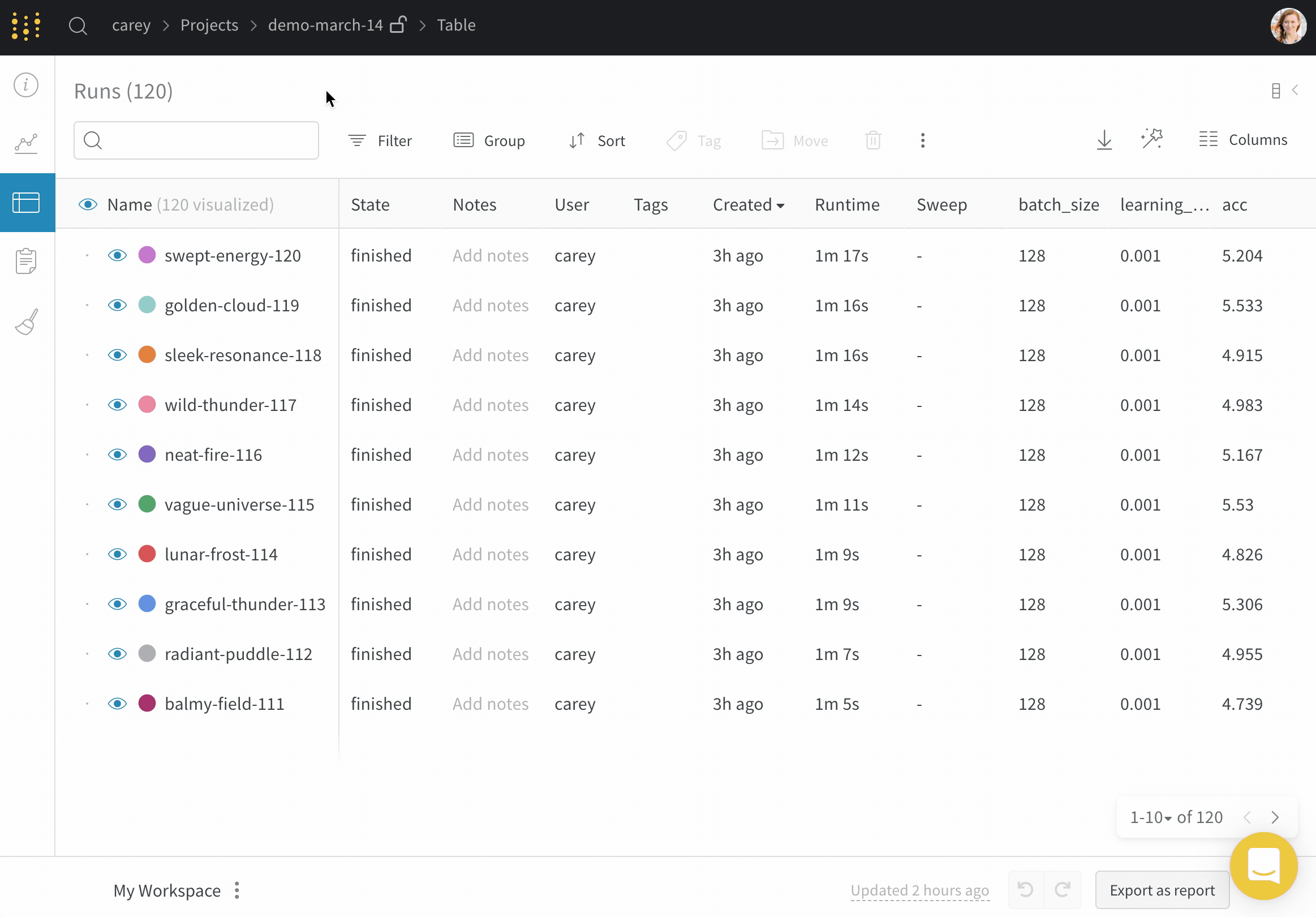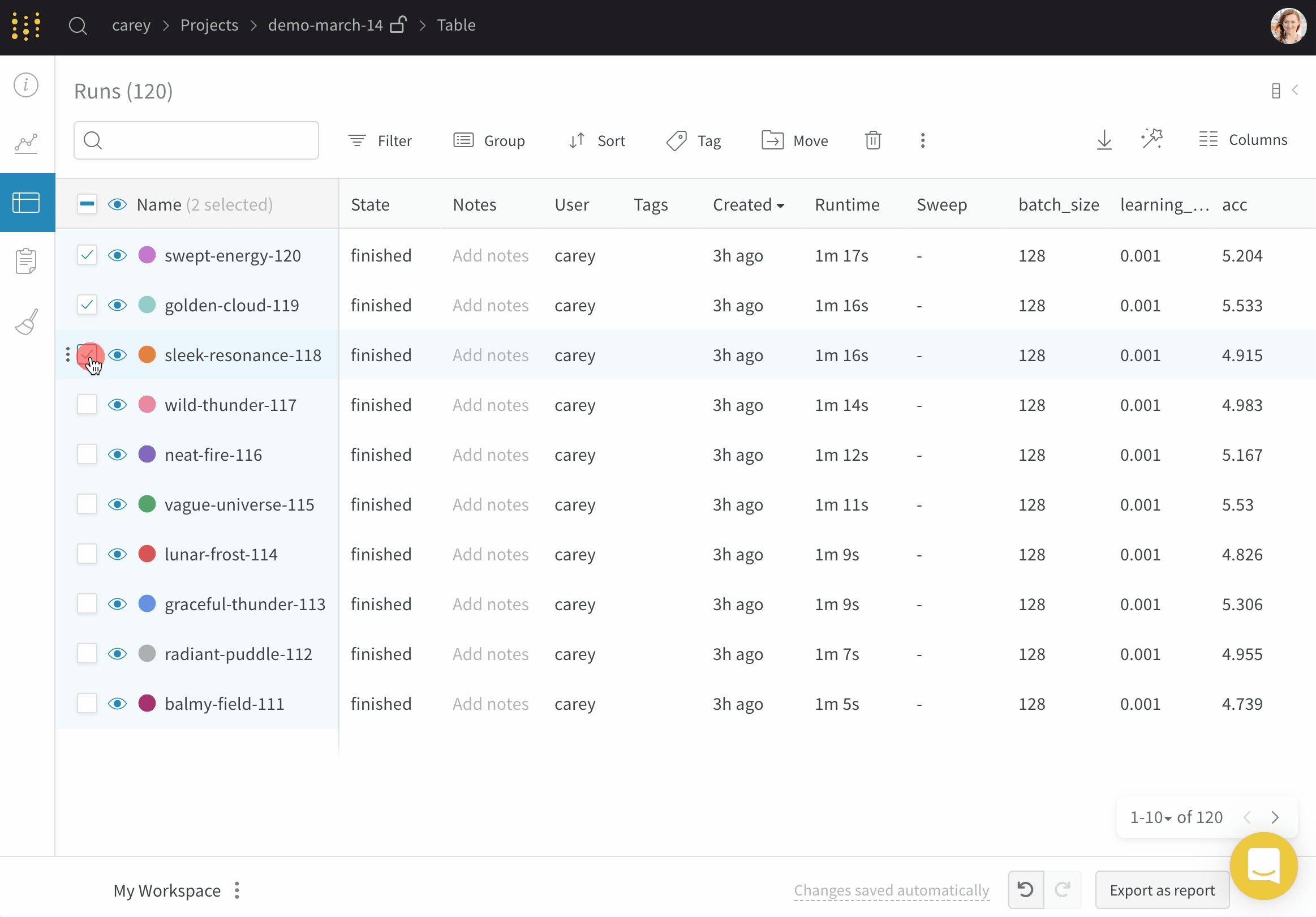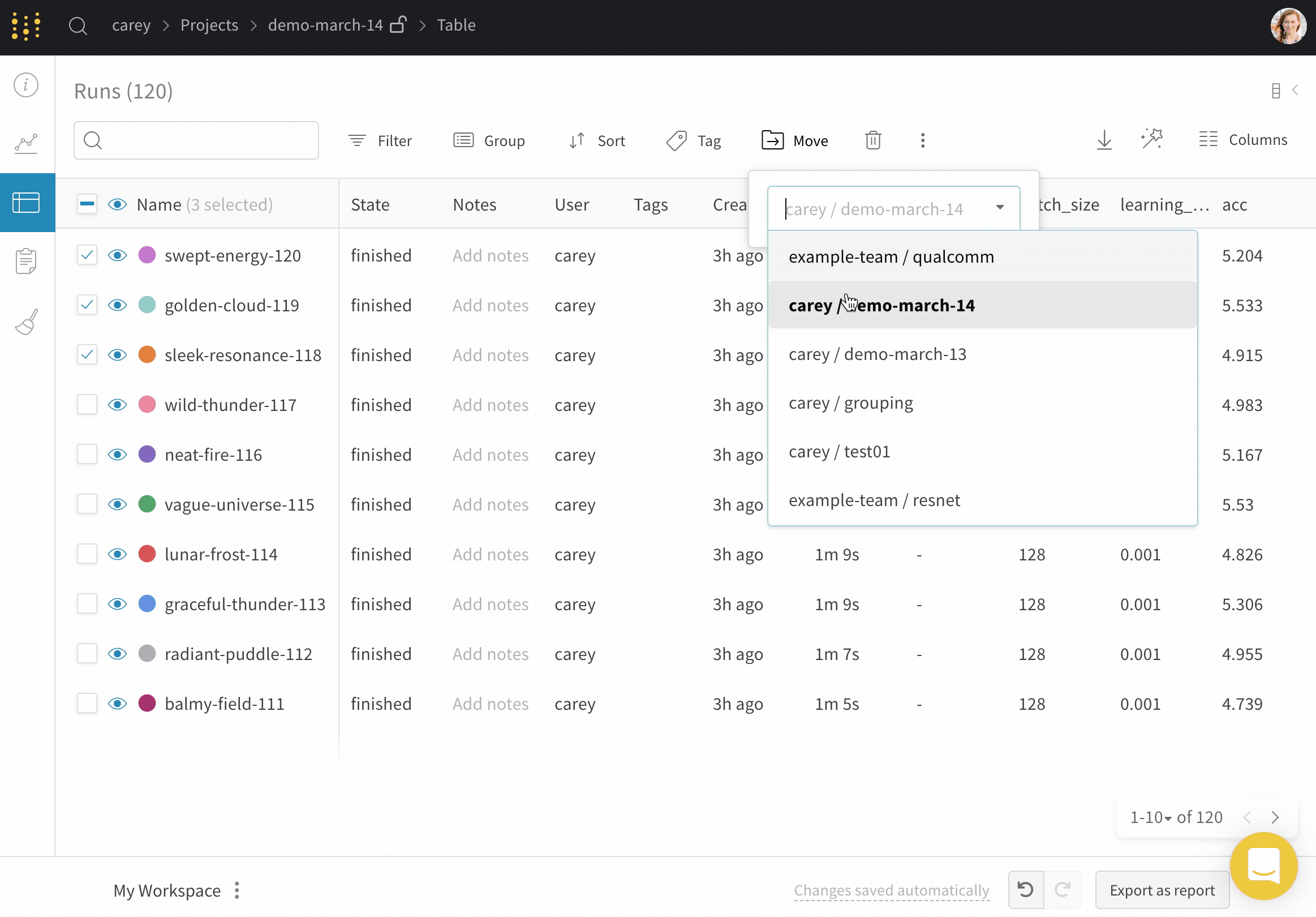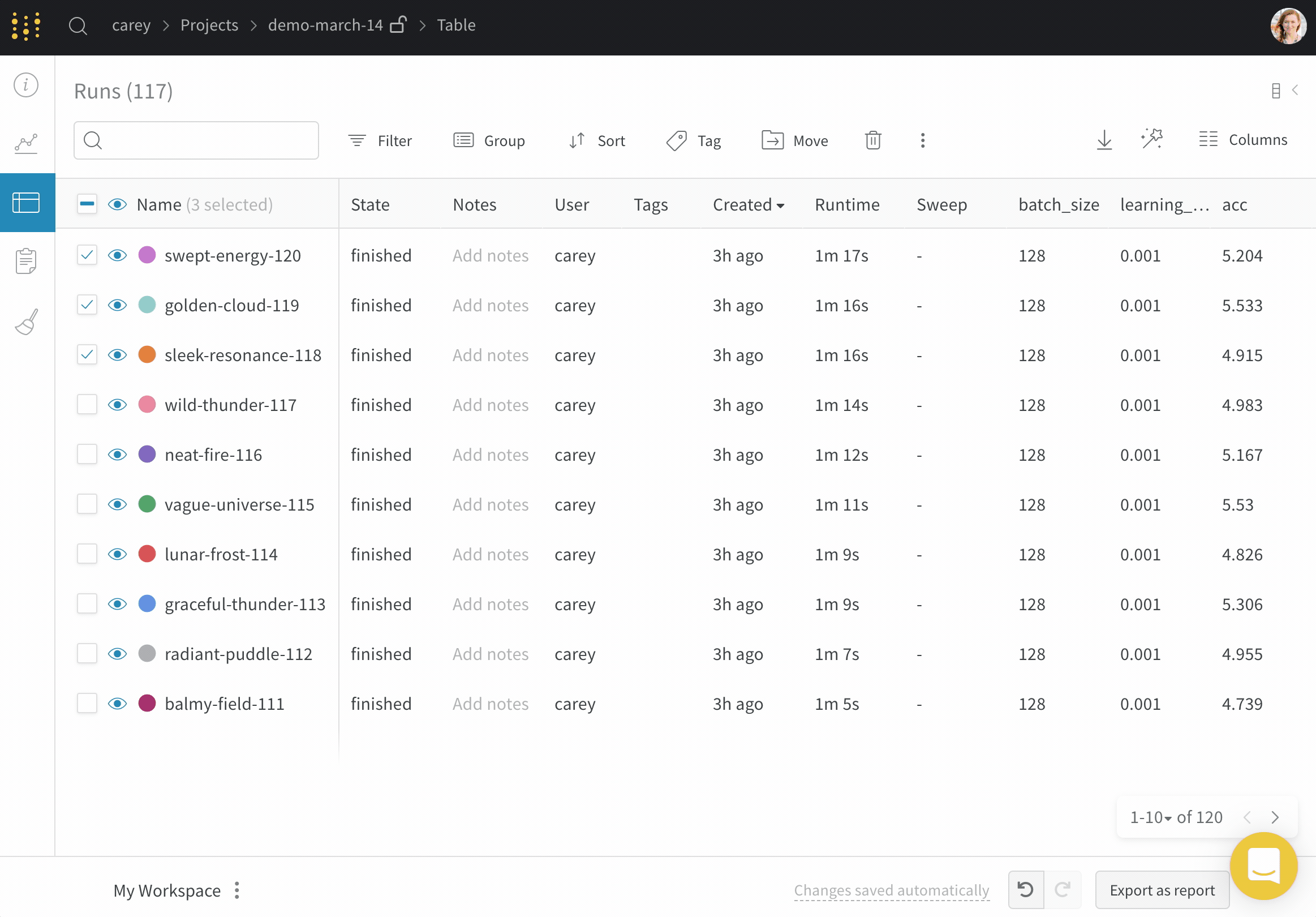
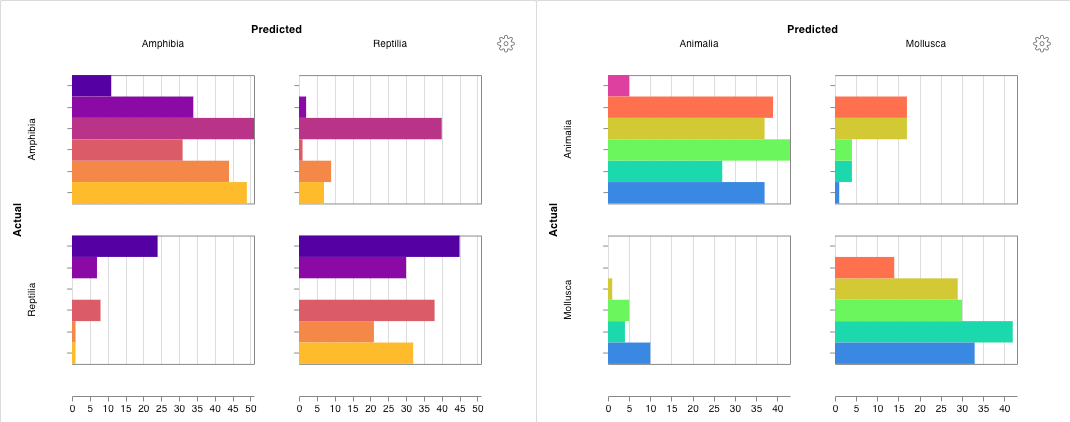
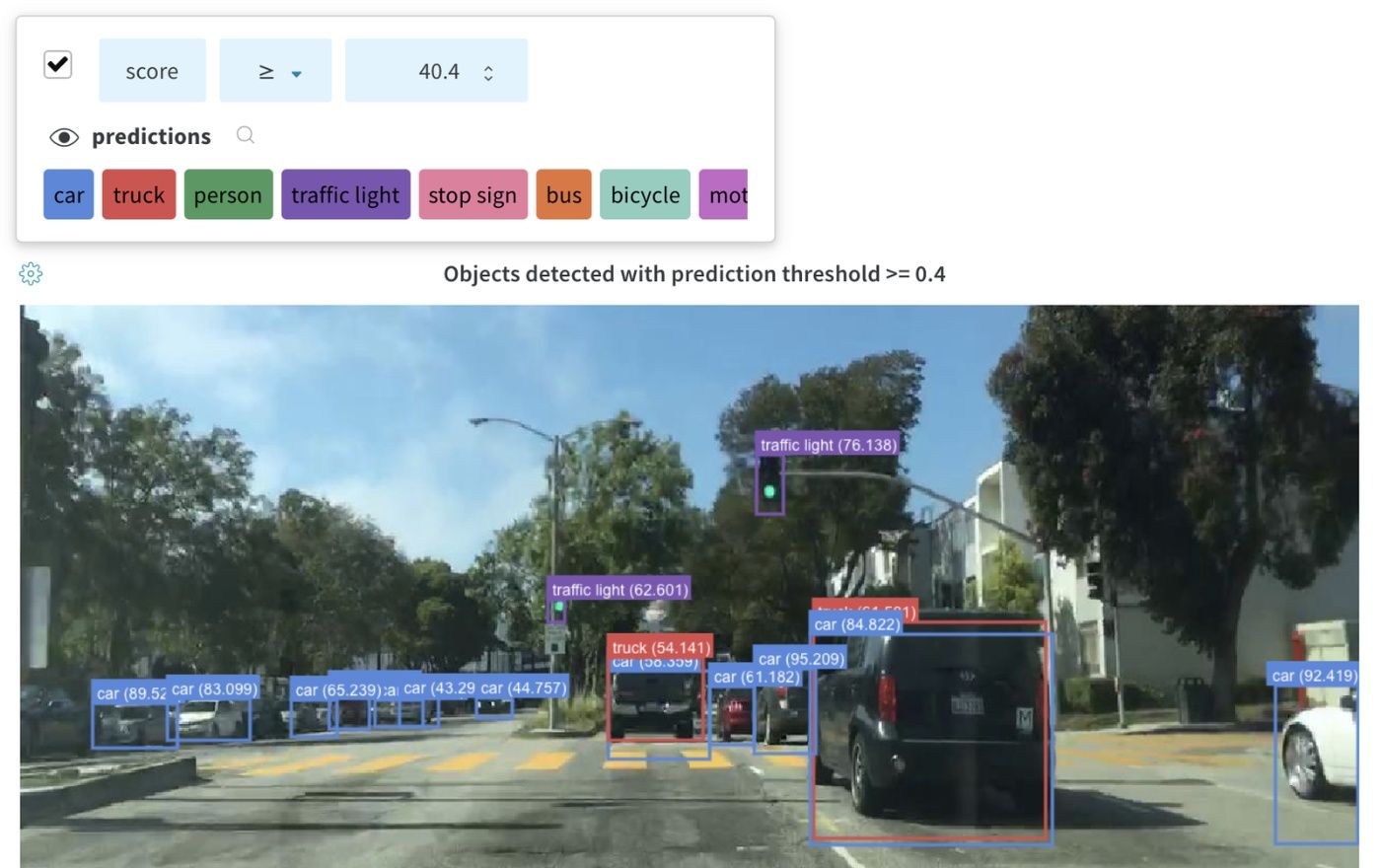
上の図は、複数の runs にわたって メトリクス を表示および比較できる ダッシュボード の例を示しています。
仕組み
数行の コード で 機械学習 の 実験 を追跡します。
W&B run を作成します。学習率や モデル タイプなどの ハイパーパラメーター の 辞書 を 設定 (run.config
トレーニング ループで、精度や 損失 などの メトリクス (run.log()
モデル の 重みや 予測 の テーブル など、run の 出力 を保存します。
次の コード は、一般的な W&B の 実験 管理 ワークフロー を示しています。
# Start a run.
#
# When this block exits, it waits for logged data to finish uploading.
# If an exception is raised, the run is marked failed.
with wandb. init(entity= "" , project= "my-project-name" ) as run:
# Save mode inputs and hyperparameters.
run. config. learning_rate = 0.01
# Run your experiment code.
for epoch in range(num_epochs):
# Do some training...
# Log metrics over time to visualize model performance.
run. log({"loss" : loss})
# Upload model outputs as artifacts.
run. log_artifact(model)
はじめに
ユースケース に応じて、次の リソース を調べて W&B Experiments を開始してください。
ベストプラクティス と ヒント
実験 と ログ の ベストプラクティス と ヒント については、Best Practices: Experiments and Logging を参照してください。
1 - Create an experiment
W&B の 実験 を作成します。
W&B Python SDK を使用して、 機械学習 の 実験 を追跡します。次に、インタラクティブな ダッシュボード で 結果 を確認するか、W&B Public API でプログラムから アクセス できるように データ を Python にエクスポートできます。
この ガイド では、W&B の構成要素を使用して W&B の 実験 を作成する方法について説明します。
W&B の 実験 を作成する方法
W&B の 実験 は、次の 4 つの ステップ で作成します。
W&B Run の初期化 ハイパーパラメーター の 辞書 をキャプチャ トレーニング ループ 内で メトリクス を ログ 記録 W&B に アーティファクト を ログ 記録
W&B run の初期化
wandb.init()
次の コードスニペット は、この run を識別するために、説明が “My first experiment” である “cat-classification” という名前の W&B の プロジェクト で run を作成します。タグ “baseline” および “paper1” は、この run が将来の論文出版を目的とした ベースライン 実験 であることを思い出させるために含まれています。
import wandb
with wandb. init(
project= "cat-classification" ,
notes= "My first experiment" ,
tags= ["baseline" , "paper1" ],
) as run:
...
wandb.init() は、Run オブジェクト を返します。
注意:run は、wandb.init() を呼び出すときに プロジェクト が既に存在する場合、既存の プロジェクト に追加されます。たとえば、“cat-classification” という プロジェクト が既にある場合、その プロジェクト は引き続き存在し、削除されません。代わりに、新しい run がその プロジェクト に追加されます。
ハイパーパラメーター の 辞書 をキャプチャ
学習率や モデル タイプなどの ハイパーパラメーター の 辞書 を保存します。config でキャプチャする モデル の 設定 は、 後で 結果 を整理してクエリするのに役立ちます。
with wandb. init(
... ,
config= {"epochs" : 100 , "learning_rate" : 0.001 , "batch_size" : 128 },
) as run:
...
実験 の構成方法の詳細については、実験 の構成 を参照してください。
トレーニング ループ 内で メトリクス を ログ 記録
run.log()
model, dataloader = get_model(), get_data()
for epoch in range(run. config. epochs):
for batch in dataloader:
loss, accuracy = model. training_step()
run. log({"accuracy" : accuracy, "loss" : loss})
W&B で ログ 記録できるさまざまな データ タイプ の詳細については、実験 中の データ の ログ 記録 を参照してください。
W&B に アーティファクト を ログ 記録
オプションで、W&B Artifact を ログ 記録します。Artifacts を使用すると、 データセット と モデル を簡単に バージョン管理 できます。
# You can save any file or even a directory. In this example, we pretend
# the model has a save() method that outputs an ONNX file.
model. save("path_to_model.onnx" )
run. log_artifact("path_to_model.onnx" , name= "trained-model" , type= "model" )
Artifacts または Registry での モデル の バージョン管理 について詳しく学びましょう。
まとめ
上記の コードスニペット を使用した完全な スクリプト は、以下にあります。
import wandb
with wandb. init(
project= "cat-classification" ,
notes= "" ,
tags= ["baseline" , "paper1" ],
# Record the run's hyperparameters.
config= {"epochs" : 100 , "learning_rate" : 0.001 , "batch_size" : 128 },
) as run:
# Set up model and data.
model, dataloader = get_model(), get_data()
# Run your training while logging metrics to visualize model performance.
for epoch in range(run. config["epochs" ]):
for batch in dataloader:
loss, accuracy = model. training_step()
run. log({"accuracy" : accuracy, "loss" : loss})
# Upload the trained model as an artifact.
model. save("path_to_model.onnx" )
run. log_artifact("path_to_model.onnx" , name= "trained-model" , type= "model" )
次の ステップ : 実験 を視覚化する
W&B ダッシュボード を、 機械学習 モデル からの 結果 を整理して視覚化するための一元的な場所として使用します。数回クリックするだけで、パラレル座標図 、パラメータ の重要性分析 などの豊富な インタラクティブ な グラフ を構築できます。その他 もあります。
実験 と特定の run の表示方法の詳細については、実験 からの 結果 の視覚化 を参照してください。
ベストプラクティス
以下は、 実験 を作成する際に考慮すべき推奨 ガイドライン です。
run を完了させる : wandb.init() を with ステートメント で使用して、 コード が完了するか 例外 が発生したときに、run が自動的に完了としてマークされるようにします。
Config : ハイパーパラメーター 、 architecture 、 データセット 、 モデル を再現するために使用したいその他のものを追跡します。これらは列に表示されます。 config 列を使用して、アプリ で run を動的にグループ化、並べ替え、フィルター処理します。Project : プロジェクト は、一緒に比較できる 実験 の セット です。各 プロジェクト には専用の ダッシュボード ページがあり、さまざまな モデル バージョン を比較するために、さまざまな run のグループを簡単にオン/オフにできます。Notes : スクリプト から直接クイック コミット メッセージ を設定します。W&B App の run の 概要 セクション で ノート を編集して アクセス します。Tags : ベースライン run とお気に入りの run を識別します。タグ を使用して run をフィルター処理できます。W&B App の プロジェクト の ダッシュボード の 概要 セクション で、 後で タグ を編集できます。複数の run セット を作成して 実験 を比較する : 実験 を比較するときは、 メトリクス を簡単に比較できるように複数の run セット を作成します。同じ グラフ または グラフ のグループで run セット のオン/オフを切り替えることができます。
次の コードスニペット は、上記の ベストプラクティス を使用して W&B の 実験 を定義する方法を示しています。
import wandb
config = {
"learning_rate" : 0.01 ,
"momentum" : 0.2 ,
"architecture" : "CNN" ,
"dataset_id" : "cats-0192" ,
}
with wandb. init(
project= "detect-cats" ,
notes= "tweak baseline" ,
tags= ["baseline" , "paper1" ],
config= config,
) as run:
...
W&B の 実験 を定義する際に使用できる パラメータ の詳細については、API Reference Guide の wandb.init
2 - Configure experiments
実験 の 設定 を保存するには、 辞書 のような オブジェクト を使用します
config プロパティを使用すると、トレーニングの設定を保存できます。
ハイパーパラメータ
データセット名やモデルタイプなどの入力設定
実験のその他の独立変数
run.config プロパティを使用すると、実験の分析や将来の作業の再現が容易になります。W&B App で設定値ごとにグループ化したり、異なる W&B の run の設定を比較したり、各トレーニング設定がアウトプットに与える影響を評価したりできます。config プロパティは、複数の辞書のようなオブジェクトから構成できる辞書のようなオブジェクトです。
損失や精度などの出力メトリクスや従属変数を保存するには、run.config の代わりに run.log を使用してください。
実験設定の構成
通常、設定はトレーニングスクリプトの最初に定義されます。ただし、機械学習のワークフローは異なる場合があるため、トレーニングスクリプトの最初に設定を定義する必要はありません。
config 変数名では、ピリオド(.)の代わりにダッシュ(-)またはアンダースコア(_)を使用してください。
スクリプトがルートより下の run.config キーにアクセスする場合は、属性アクセス構文 config.key.value の代わりに辞書アクセス構文 ["key"]["value"] を使用してください。
以下のセクションでは、実験設定を定義するさまざまな一般的なシナリオについて概説します。
初期化時に設定を構成する
W&B Run としてデータを同期およびログ記録するためのバックグラウンド プロセスを生成するために、wandb.init() API を呼び出すときに、スクリプトの先頭で辞書を渡します。
次のコードスニペットは、設定値を持つ Python 辞書を定義する方法と、W&B Run を初期化するときにその辞書を引数として渡す方法を示しています。
import wandb
# config 辞書オブジェクトを定義します
config = {
"hidden_layer_sizes" : [32 , 64 ],
"kernel_sizes" : [3 ],
"activation" : "ReLU" ,
"pool_sizes" : [2 ],
"dropout" : 0.5 ,
"num_classes" : 10 ,
}
# W&B を初期化するときに config 辞書を渡します
with wandb. init(project= "config_example" , config= config) as run:
...
config としてネストされた辞書を渡すと、W&B はドットを使用して名前をフラット化します。
Python の他の辞書にアクセスするのと同じように、辞書から値にアクセスします。
# インデックス値としてキーを使用して値にアクセスします
hidden_layer_sizes = run. config["hidden_layer_sizes" ]
kernel_sizes = run. config["kernel_sizes" ]
activation = run. config["activation" ]
# Python 辞書 get() メソッド
hidden_layer_sizes = run. config. get("hidden_layer_sizes" )
kernel_sizes = run. config. get("kernel_sizes" )
activation = run. config. get("activation" )
開発者ガイドと例全体を通して、設定値を個別の変数にコピーしています。このステップはオプションです。これは、読みやすさのために行われています。
argparse で設定を構成する
argparse オブジェクトで設定を構成できます。argparse (引数パーサーの略)は、Python 3.2 以降の標準ライブラリモジュールであり、コマンドライン引数のすべての柔軟性と機能を活用するスクリプトを簡単に作成できます。
これは、コマンドラインから起動されたスクリプトの結果を追跡するのに役立ちます。
次の Python スクリプトは、パーサーオブジェクトを定義して実験設定を定義および設定する方法を示しています。関数 train_one_epoch および evaluate_one_epoch は、このデモンストレーションの目的でトレーニングループをシミュレートするために提供されています。
# config_experiment.py
import argparse
import random
import numpy as np
import wandb
# トレーニングと評価のデモコード
def train_one_epoch (epoch, lr, bs):
acc = 0.25 + ((epoch / 30 ) + (random. random() / 10 ))
loss = 0.2 + (1 - ((epoch - 1 ) / 10 + random. random() / 5 ))
return acc, loss
def evaluate_one_epoch (epoch):
acc = 0.1 + ((epoch / 20 ) + (random. random() / 10 ))
loss = 0.25 + (1 - ((epoch - 1 ) / 10 + random. random() / 6 ))
return acc, loss
def main (args):
# W&B Run を開始します
with wandb. init(project= "config_example" , config= args) as run:
# config 辞書から値にアクセスし、読みやすくするために変数に格納します
lr = run. config["learning_rate" ]
bs = run. config["batch_size" ]
epochs = run. config["epochs" ]
# トレーニングをシミュレートし、値を W&B に記録します
for epoch in np. arange(1 , epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
run. log(
{
"epoch" : epoch,
"train_acc" : train_acc,
"train_loss" : train_loss,
"val_acc" : val_acc,
"val_loss" : val_loss,
}
)
if __name__ == "__main__" :
parser = argparse. ArgumentParser(
formatter_class= argparse. ArgumentDefaultsHelpFormatter
)
parser. add_argument("-b" , "--batch_size" , type= int, default= 32 , help= "バッチサイズ" )
parser. add_argument(
"-e" , "--epochs" , type= int, default= 50 , help= "トレーニングエポック数"
)
parser. add_argument(
"-lr" , "--learning_rate" , type= int, default= 0.001 , help= "学習率"
)
args = parser. parse_args()
main(args)
スクリプト全体で設定を構成する
スクリプト全体で config オブジェクトにパラメーターを追加できます。次のコードスニペットは、新しいキーと値のペアを config オブジェクトに追加する方法を示しています。
import wandb
# config 辞書オブジェクトを定義します
config = {
"hidden_layer_sizes" : [32 , 64 ],
"kernel_sizes" : [3 ],
"activation" : "ReLU" ,
"pool_sizes" : [2 ],
"dropout" : 0.5 ,
"num_classes" : 10 ,
}
# W&B を初期化するときに config 辞書を渡します
with wandb. init(project= "config_example" , config= config) as run:
# W&B を初期化した後に config を更新します
run. config["dropout" ] = 0.2
run. config. epochs = 4
run. config["batch_size" ] = 32
一度に複数の値を更新できます。
run. config. update({"lr" : 0.1 , "channels" : 16 })
Run の完了後に設定を構成する
W&B Public API を使用して、完了した Run の config を更新します。
API には、エンティティ、プロジェクト名、および Run の ID を指定する必要があります。これらの詳細は、Run オブジェクトまたは W&B App UI で確認できます。
with wandb. init() as run:
...
# 現在のスクリプトまたはノートブックから開始された場合は、Run オブジェクトから次の値を見つけるか、W&B App UI からコピーできます。
username = run. entity
project = run. project
run_id = run. id
# api.run() は wandb.init() とは異なる型のオブジェクトを返すことに注意してください。
api = wandb. Api()
api_run = api. run(f " { username} / { project} / { run_id} " )
api_run. config["bar" ] = 32
api_run. update()
absl.FLAGSabsl フラグ
flags. DEFINE_string("model" , None , "実行するモデル" ) # name, default, help
run. config. update(flags. FLAGS) # absl フラグを config に追加します
ファイルベースの Configs
config-defaults.yaml という名前のファイルを Run スクリプトと同じディレクトリーに配置すると、Run はファイルで定義されたキーと値のペアを自動的に取得し、run.config に渡します。
次のコードスニペットは、サンプルの config-defaults.yaml YAML ファイルを示しています。
batch_size :
desc : 各ミニバッチのサイズ
value : 32
config-defaults.yaml から自動的にロードされたデフォルト値をオーバーライドするには、wandb.init の config 引数で更新された値を設定します。次に例を示します。
import wandb
# カスタム値を渡して config-defaults.yaml をオーバーライドします
with wandb. init(config= {"epochs" : 200 , "batch_size" : 64 }) as run:
...
config-defaults.yaml 以外の構成ファイルをロードするには、--configs コマンドライン 引数を使用し、ファイルへのパスを指定します。
python train.py --configs other-config.yaml
ファイルベースの Configs のユースケース例
Run のメタデータを含む YAML ファイルと、Python スクリプトにハイパーパラメーターの辞書があるとします。ネストされた config オブジェクトに両方を保存できます。
hyperparameter_defaults = dict(
dropout= 0.5 ,
batch_size= 100 ,
learning_rate= 0.001 ,
)
config_dictionary = dict(
yaml= my_yaml_file,
params= hyperparameter_defaults,
)
with wandb. init(config= config_dictionary) as run:
...
TensorFlow v1 フラグ
TensorFlow フラグを wandb.config オブジェクトに直接渡すことができます。
with wandb. init() as run:
run. config. epochs = 4
flags = tf. app. flags
flags. DEFINE_string("data_dir" , "/tmp/data" )
flags. DEFINE_integer("batch_size" , 128 , "バッチサイズ" )
run. config. update(flags. FLAGS) # tensorflow フラグを config として追加します
3 - Projects
モデルのバージョンを比較し、スクラッチ ワークスペース で結果を調査し、 学び をレポートにエクスポートして、メモと 可視化 を保存します。
project は、結果の可視化、実験の比較、Artifactsの表示とダウンロード、オートメーションの作成などを行う中心的な場所です。
各projectには、誰がそれにアクセスできるかを決定する可視性の設定があります。誰が project にアクセスできるかの詳細については、
Project visibility を参照してください。
各 project には、サイドバーからアクセスできる次のものが含まれています。
Overview Workspace Runs Automations : project で構成されたオートメーションSweeps Reports Artifacts
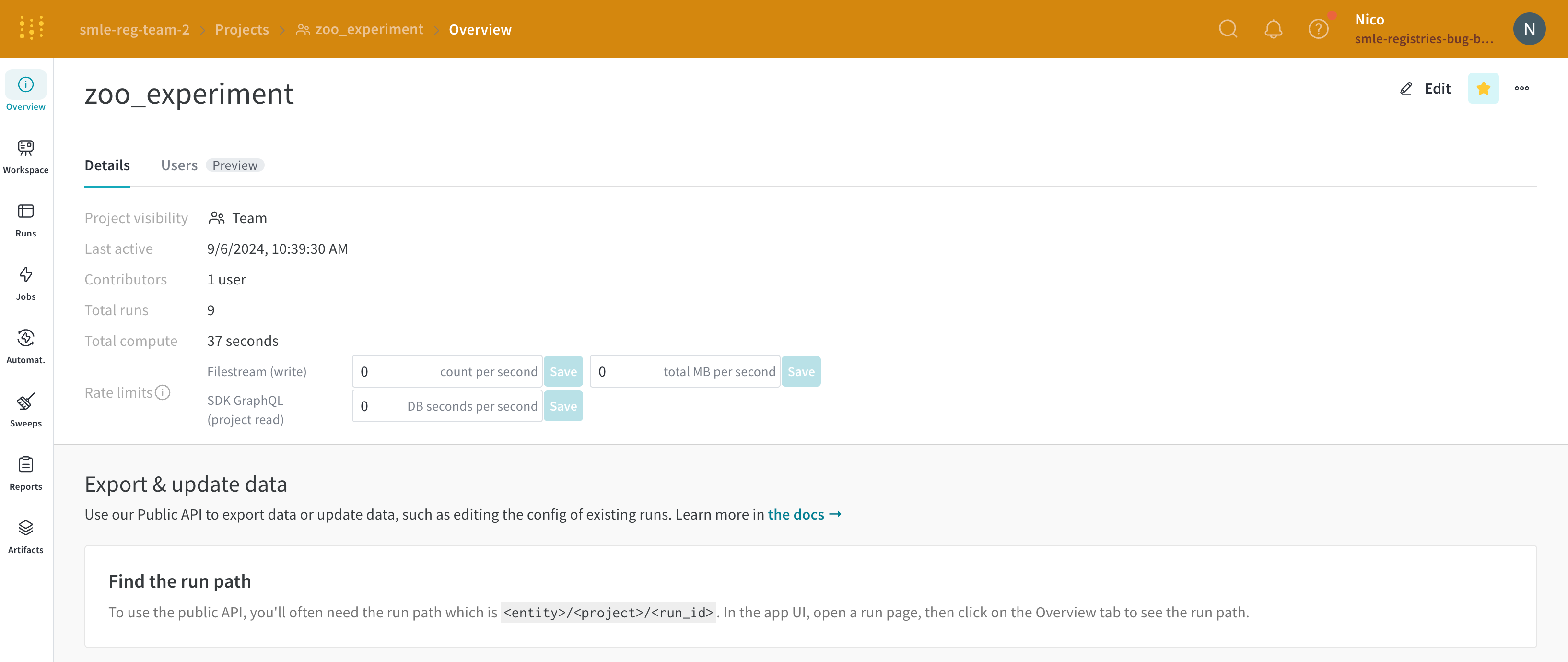
Overview タブ
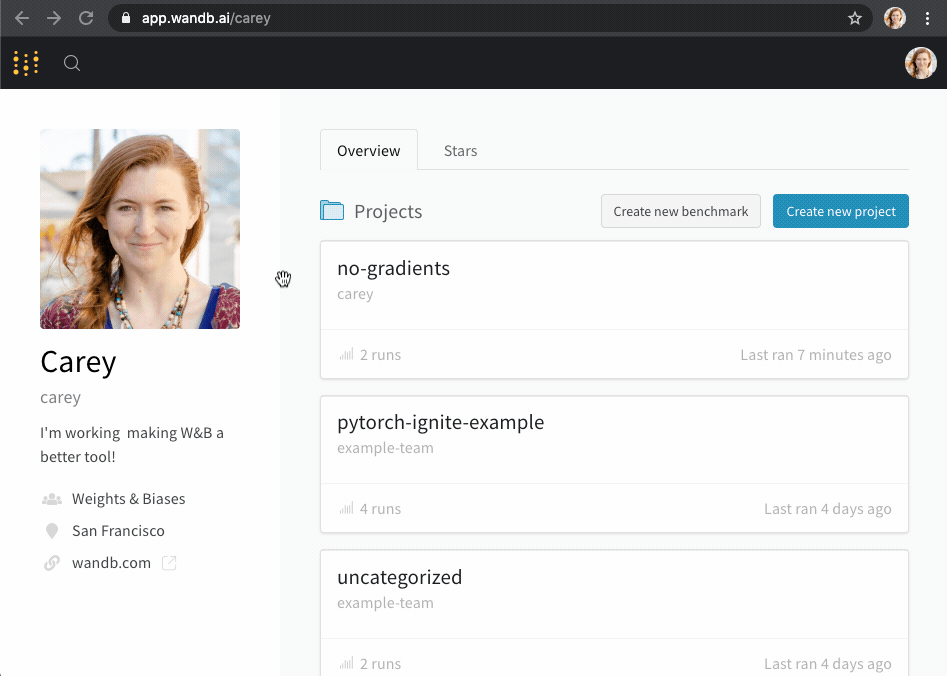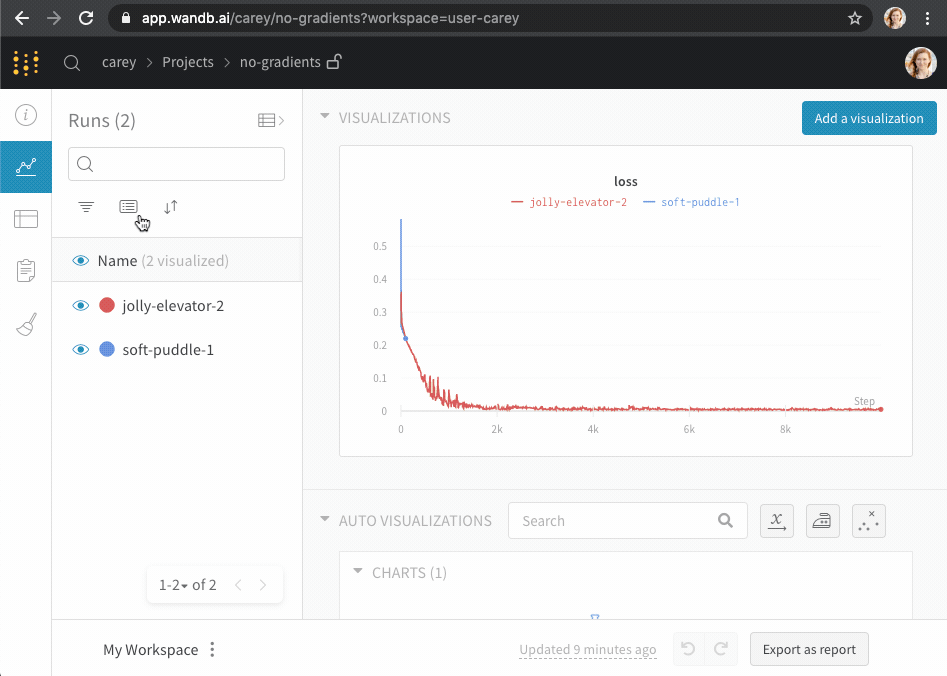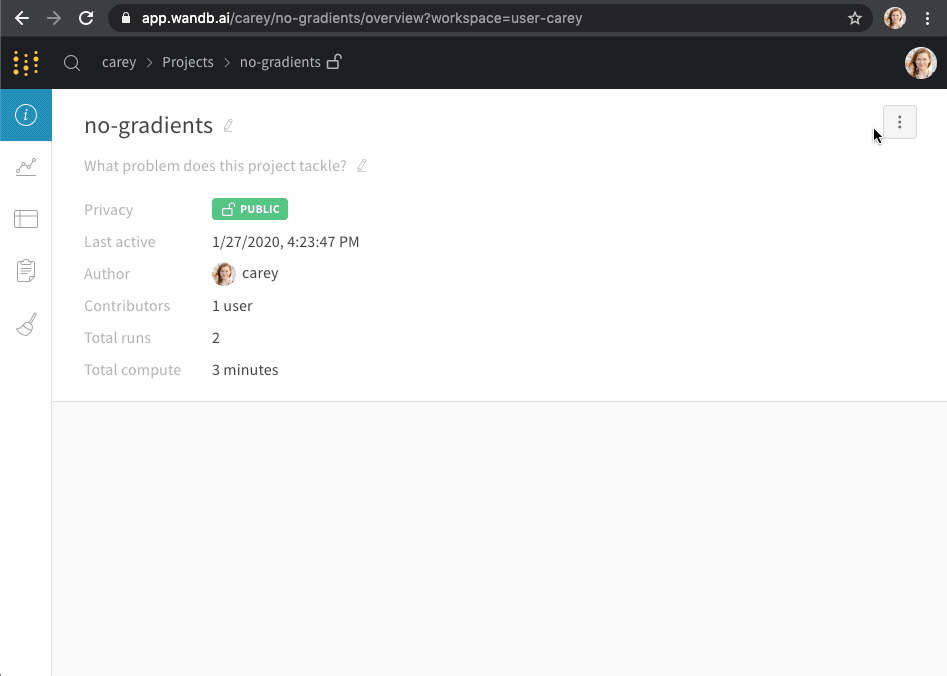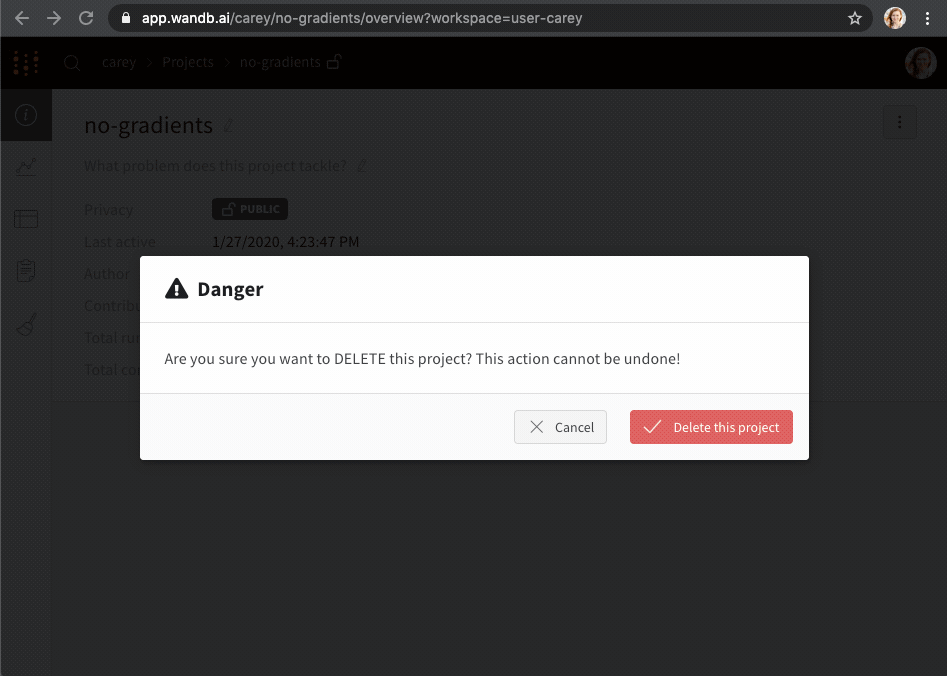
Project name : project の名前。W&B は、project フィールドに指定した名前で run を初期化すると、project を作成します。project の名前は、右上隅にある Edit ボタンを選択すると、いつでも変更できます。Description : project の説明。Project visibility : project の可視性。誰がアクセスできるかを決定する可視性設定。詳細については、Project visibility を参照してください。Last active : この project に最後にデータが記録されたときのタイムスタンプOwner : この project のエンティティContributors : この project に貢献する ユーザー の数Total runs : この project 内の run の総数Total compute : この合計を取得するために、project 内のすべての run 時間を合計します。Undelete runs : ドロップダウン メニューをクリックし、[Undelete all runs] をクリックして、project 内で削除された run を復元します。Delete project : 右隅にあるドット メニューをクリックして、project を削除します。
ライブの例を見る
Workspace タブ
project の workspace は、実験を比較するための個人的なサンドボックスを提供します。異なるアーキテクチャ、ハイパーパラメーター、データセット、プロセッシングなどで同じ問題に取り組んでいる、比較できる Models を整理するために project を使用します。
Runs Sidebar : project 内のすべての run のリスト。
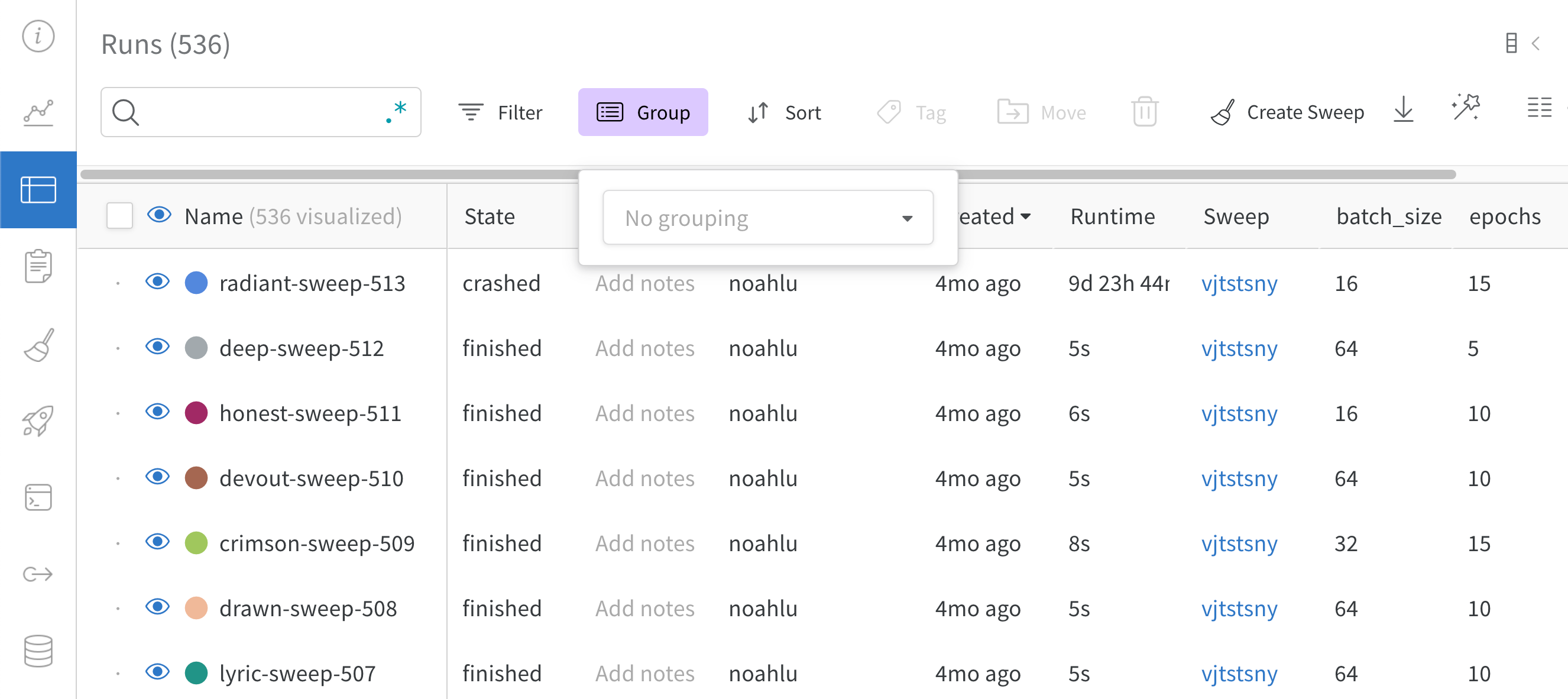
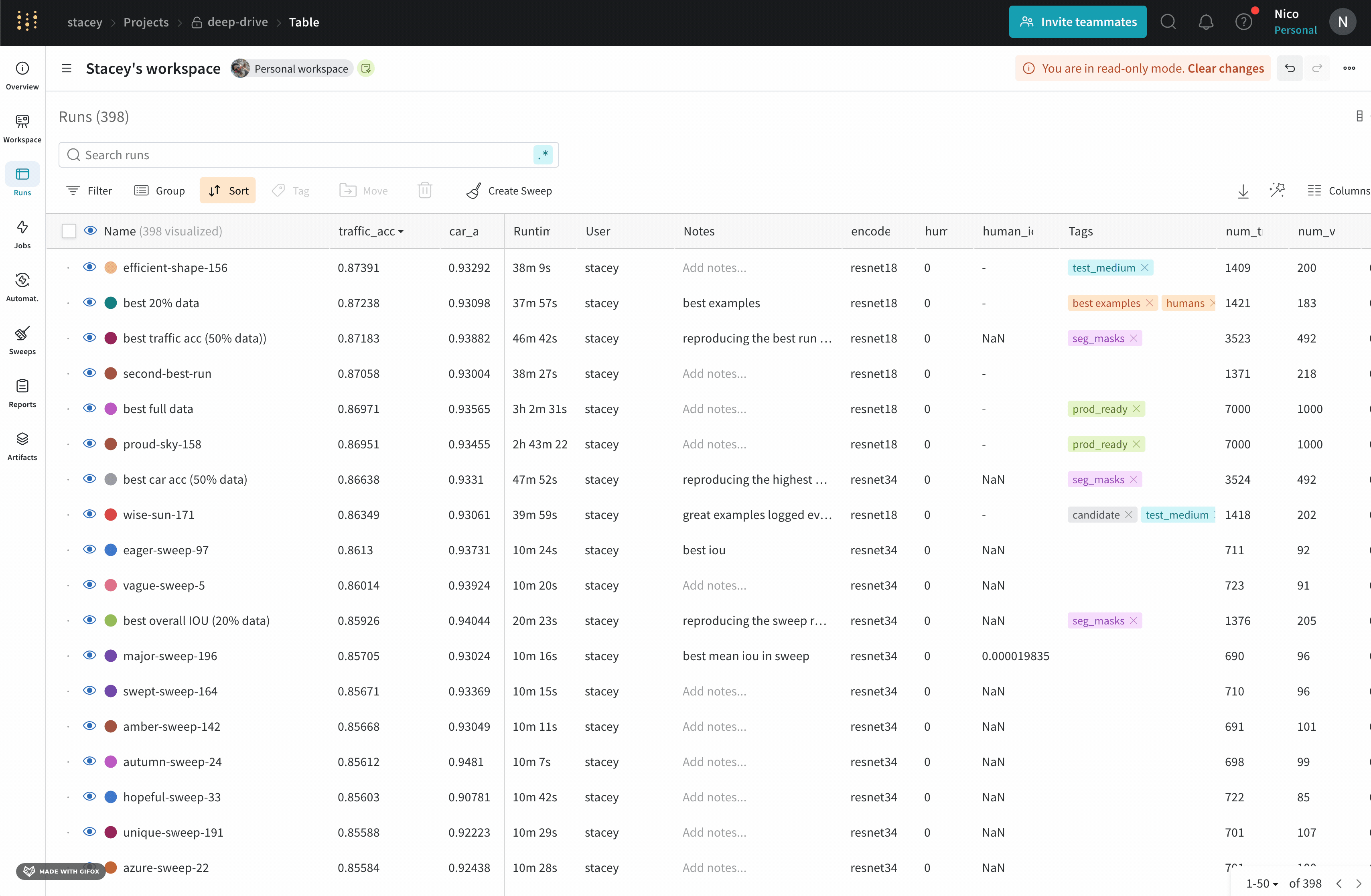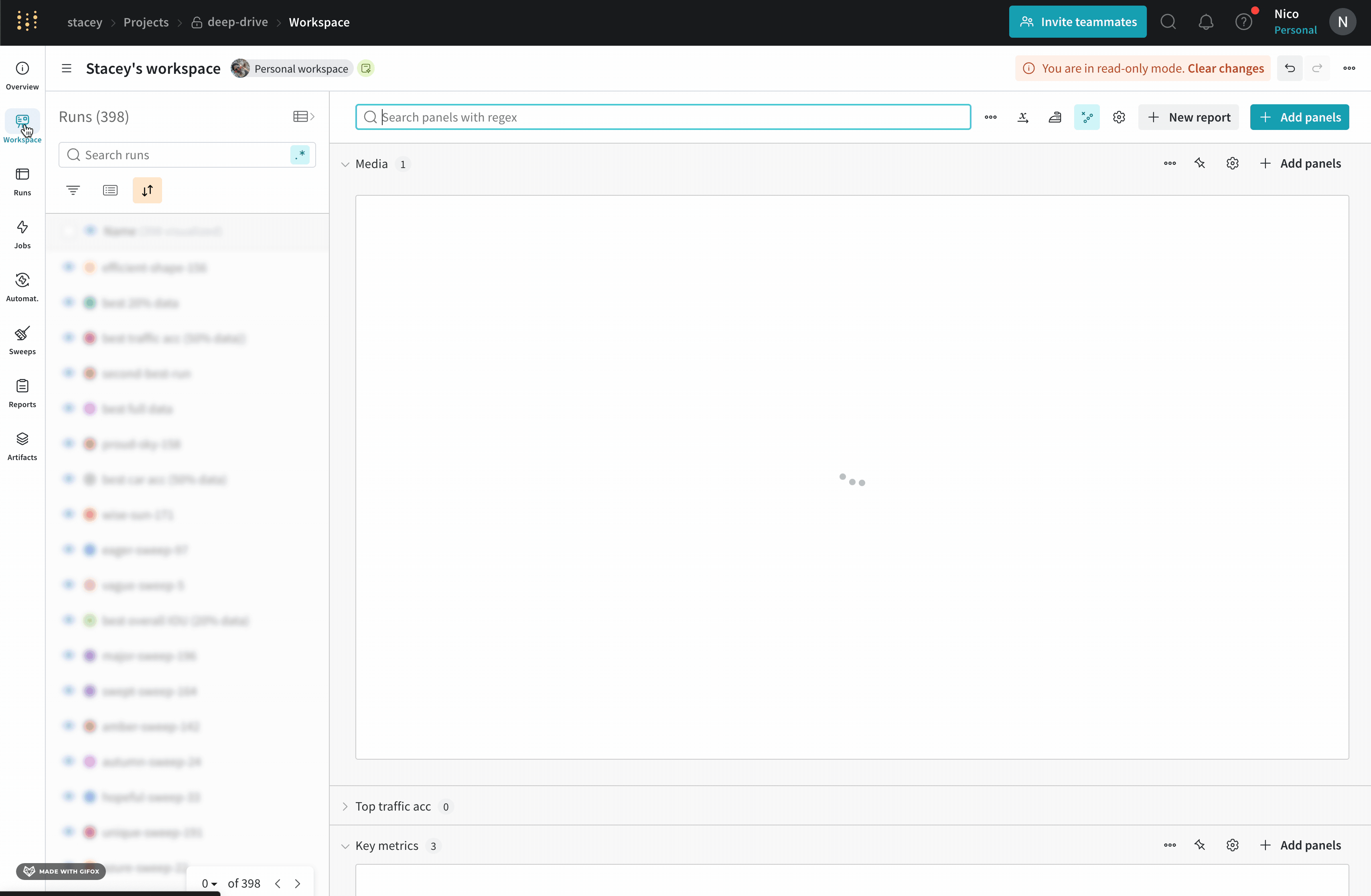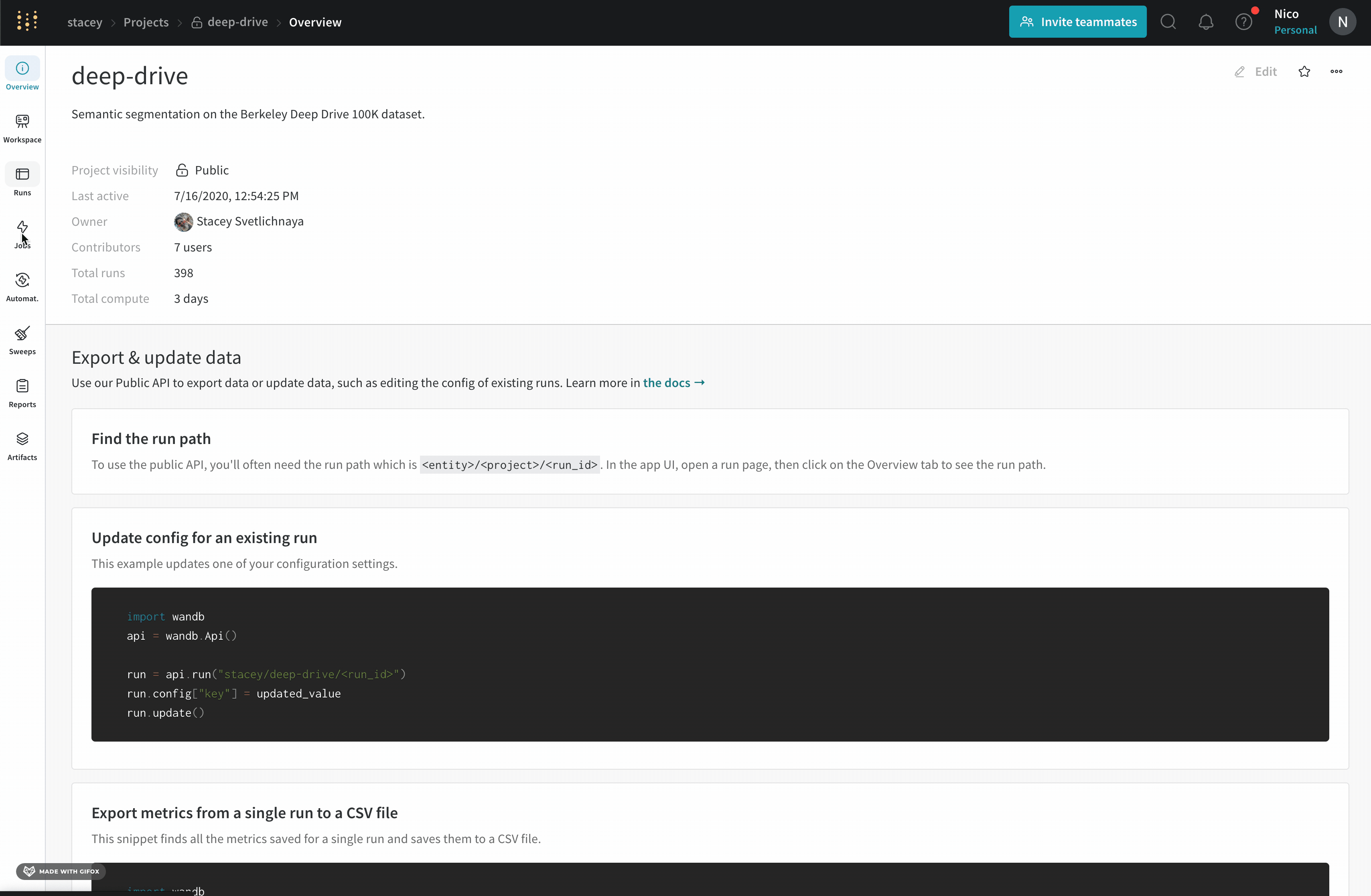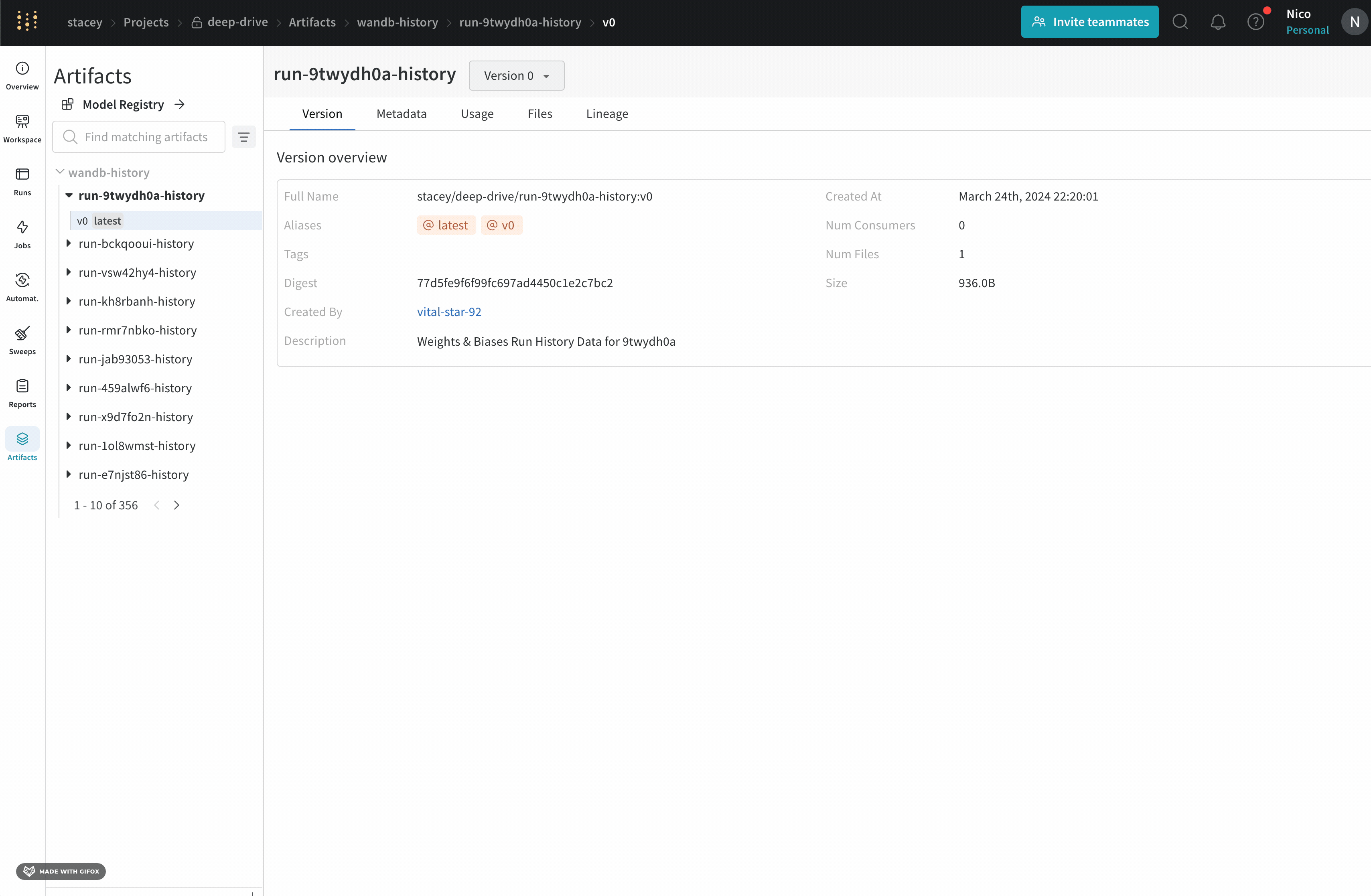
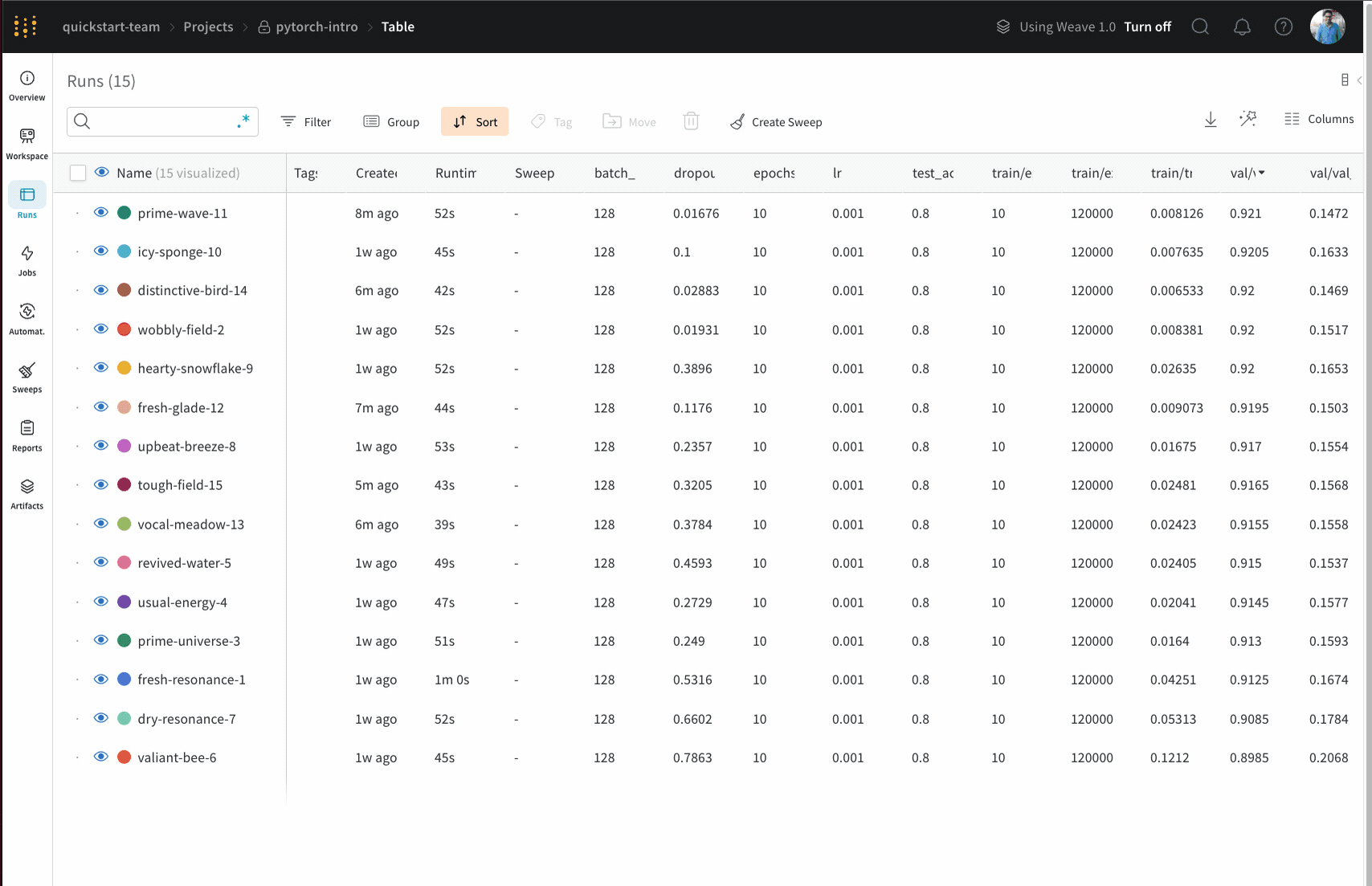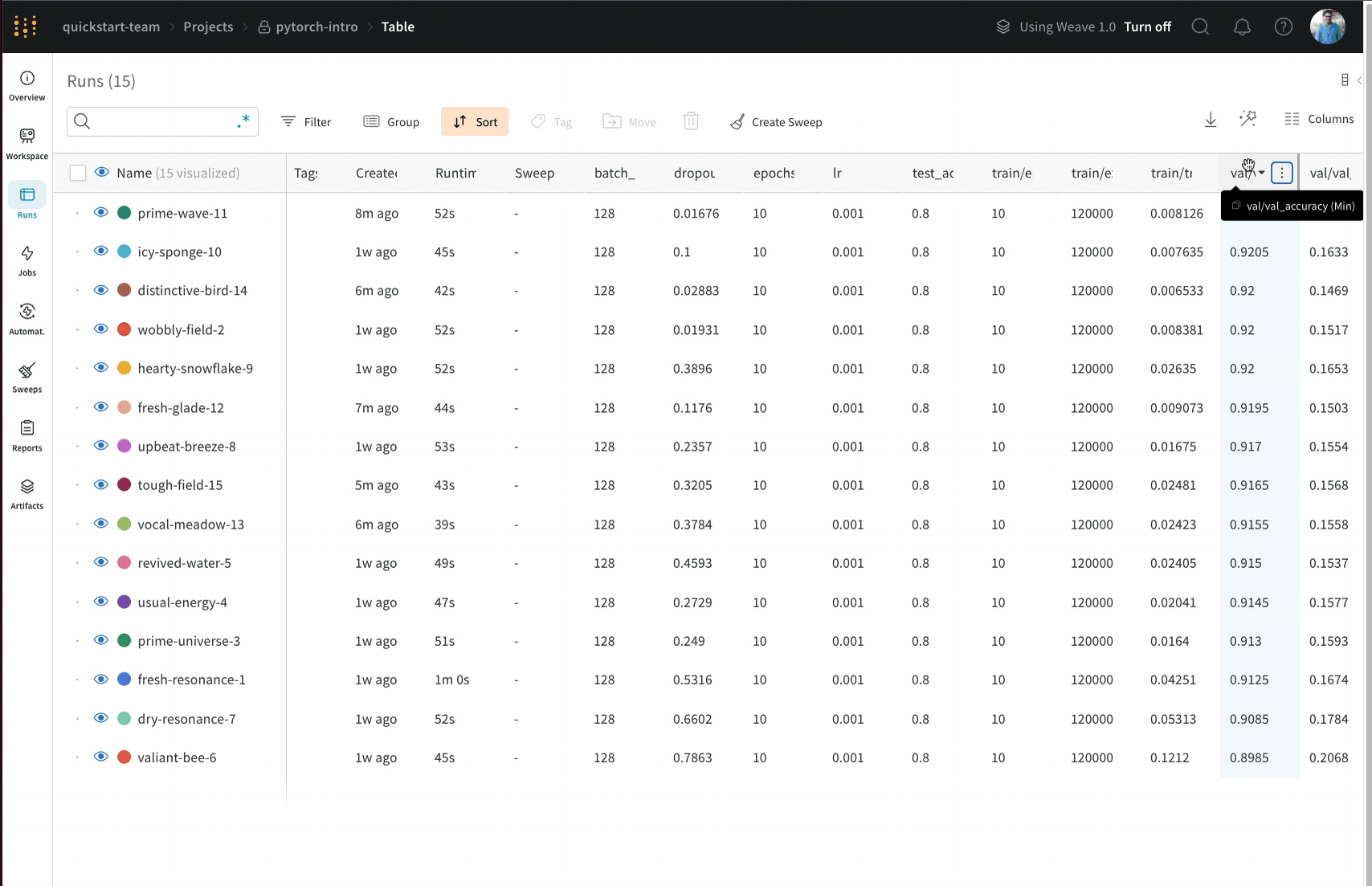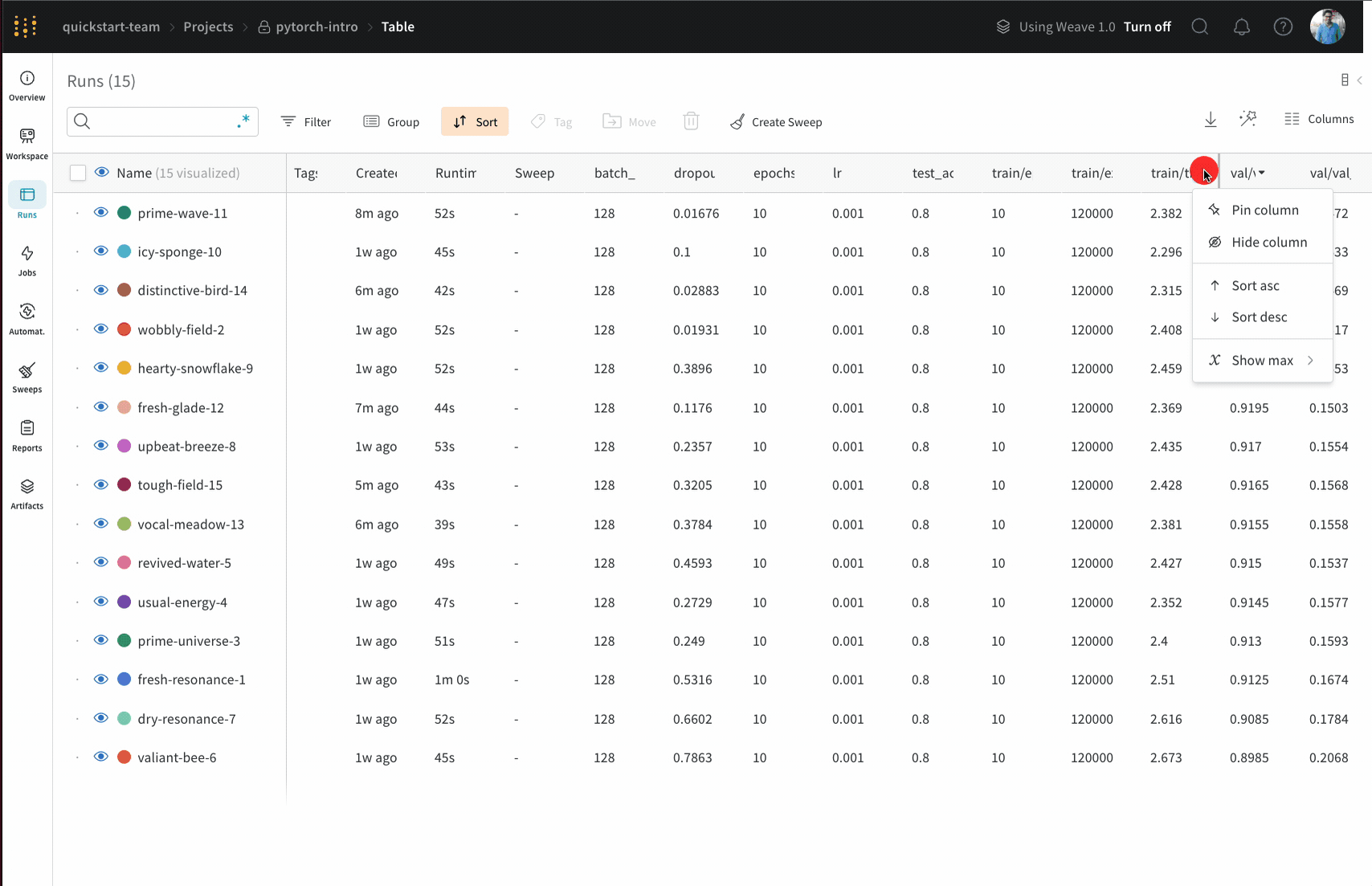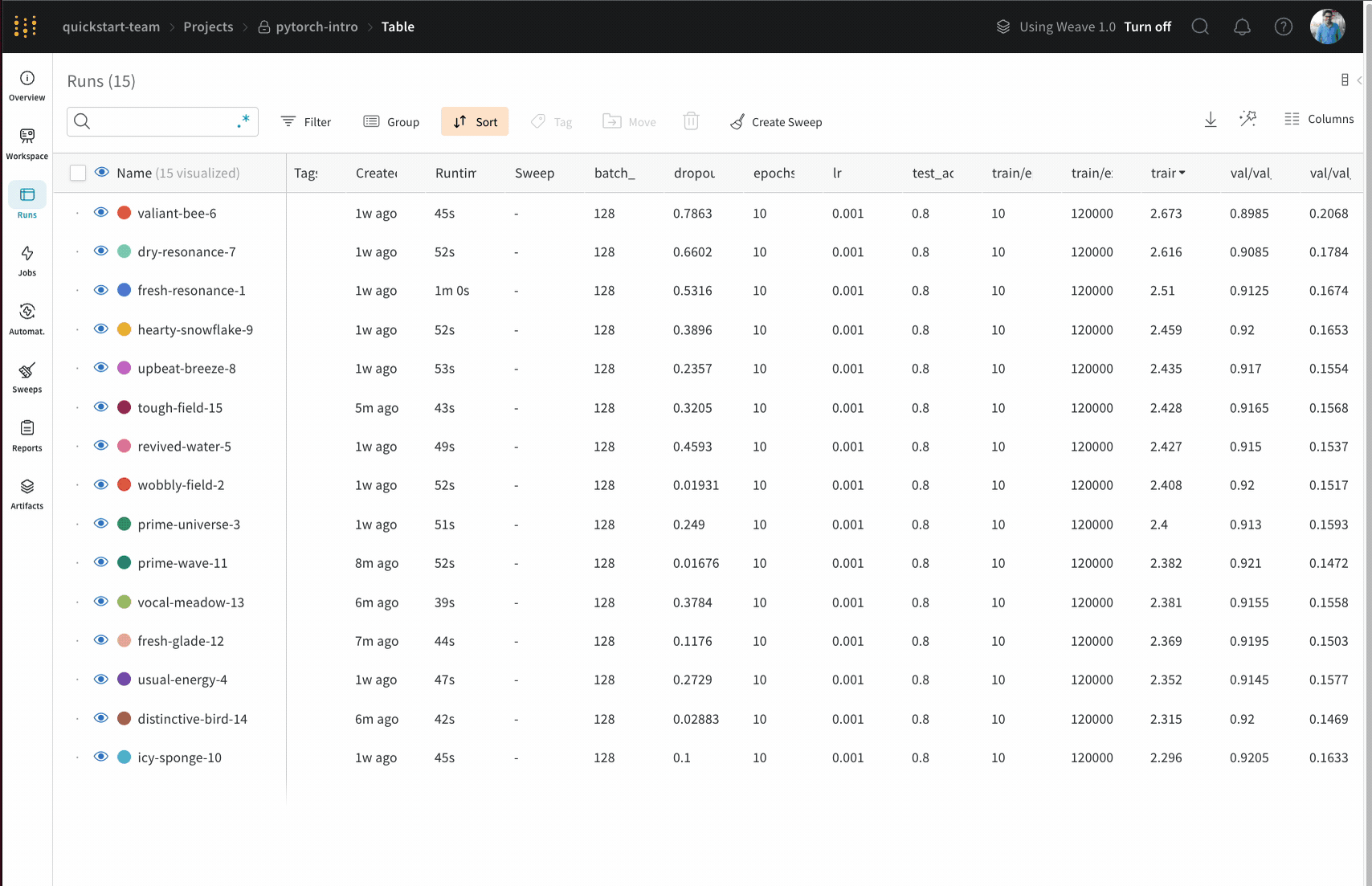
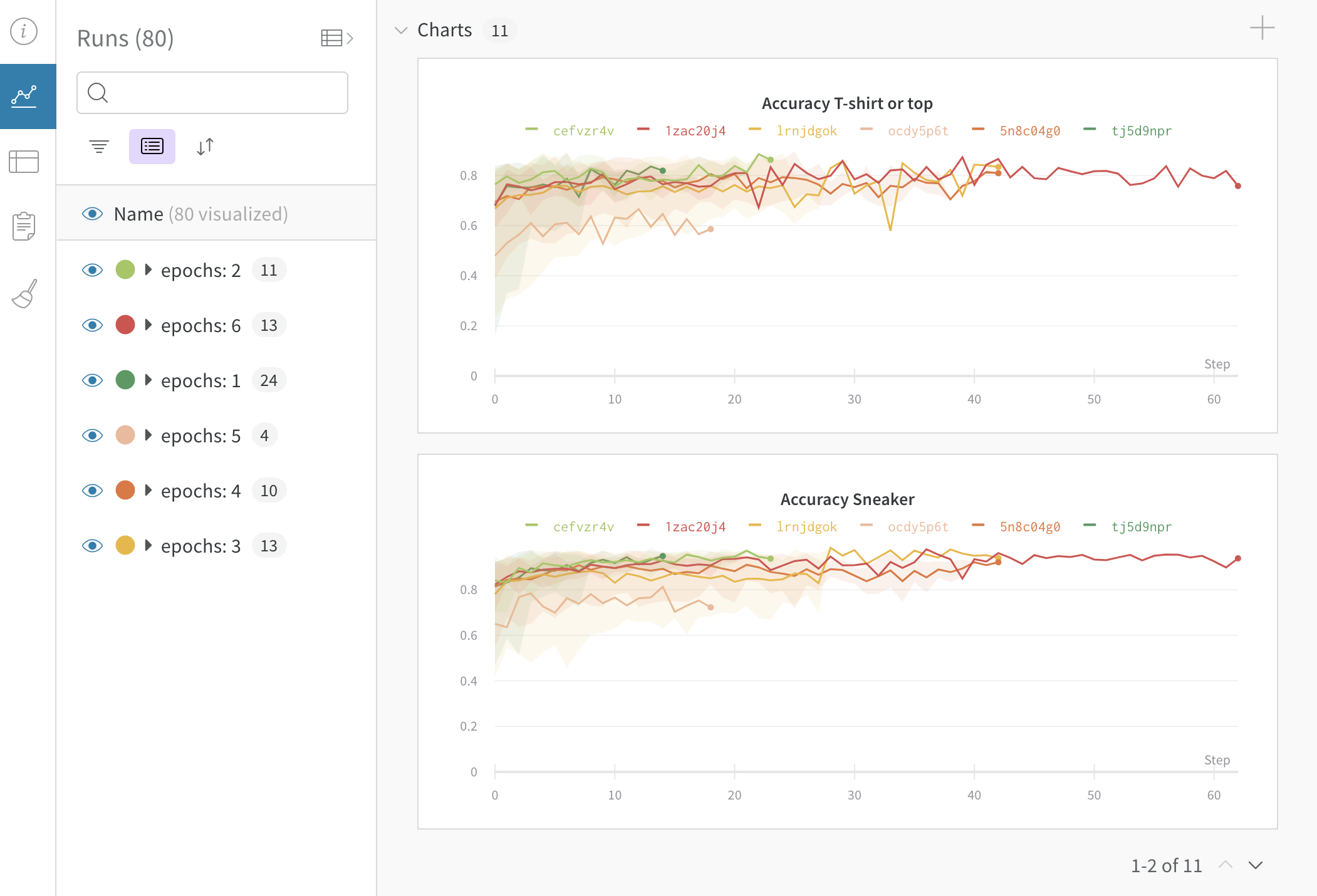
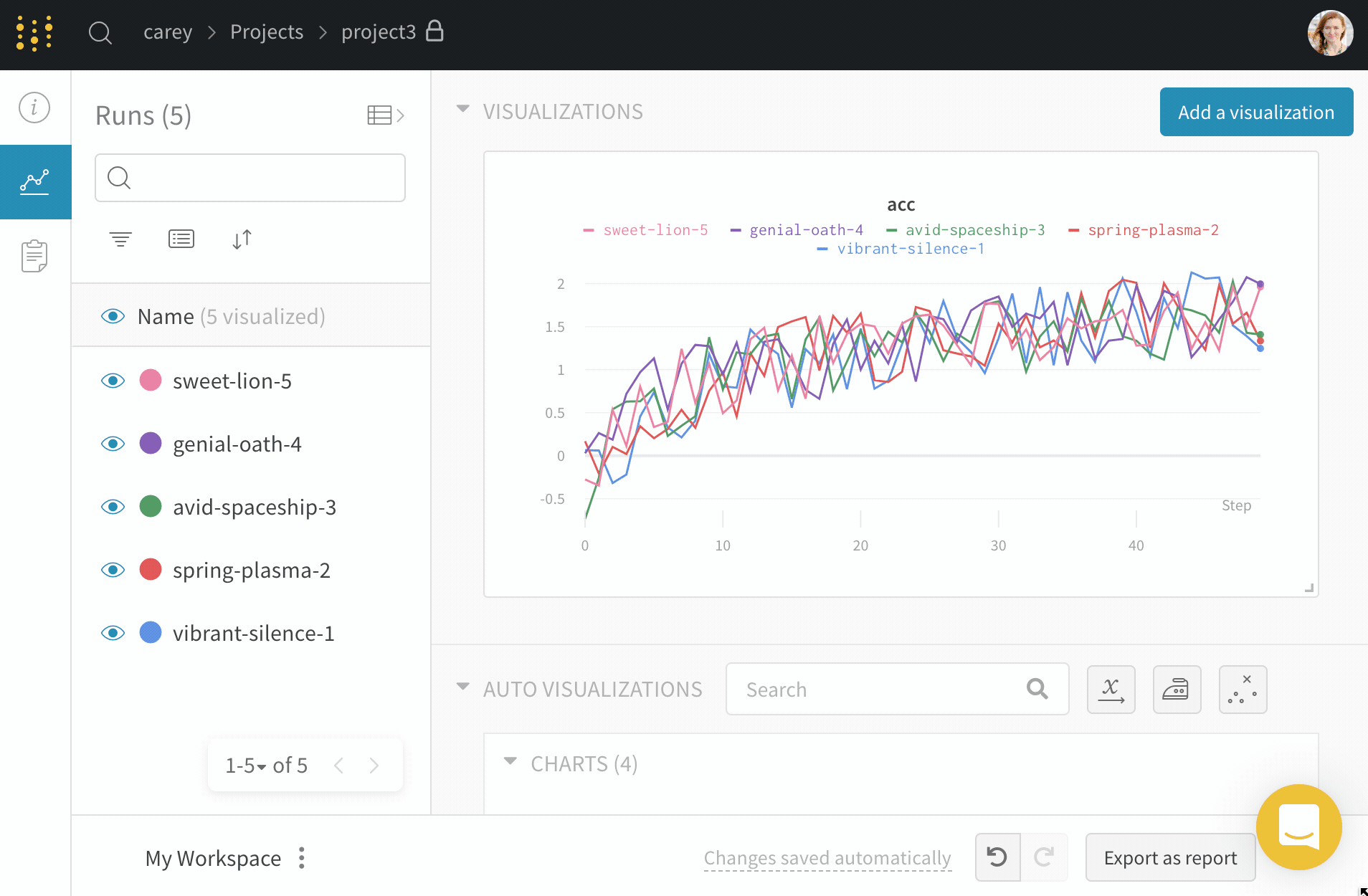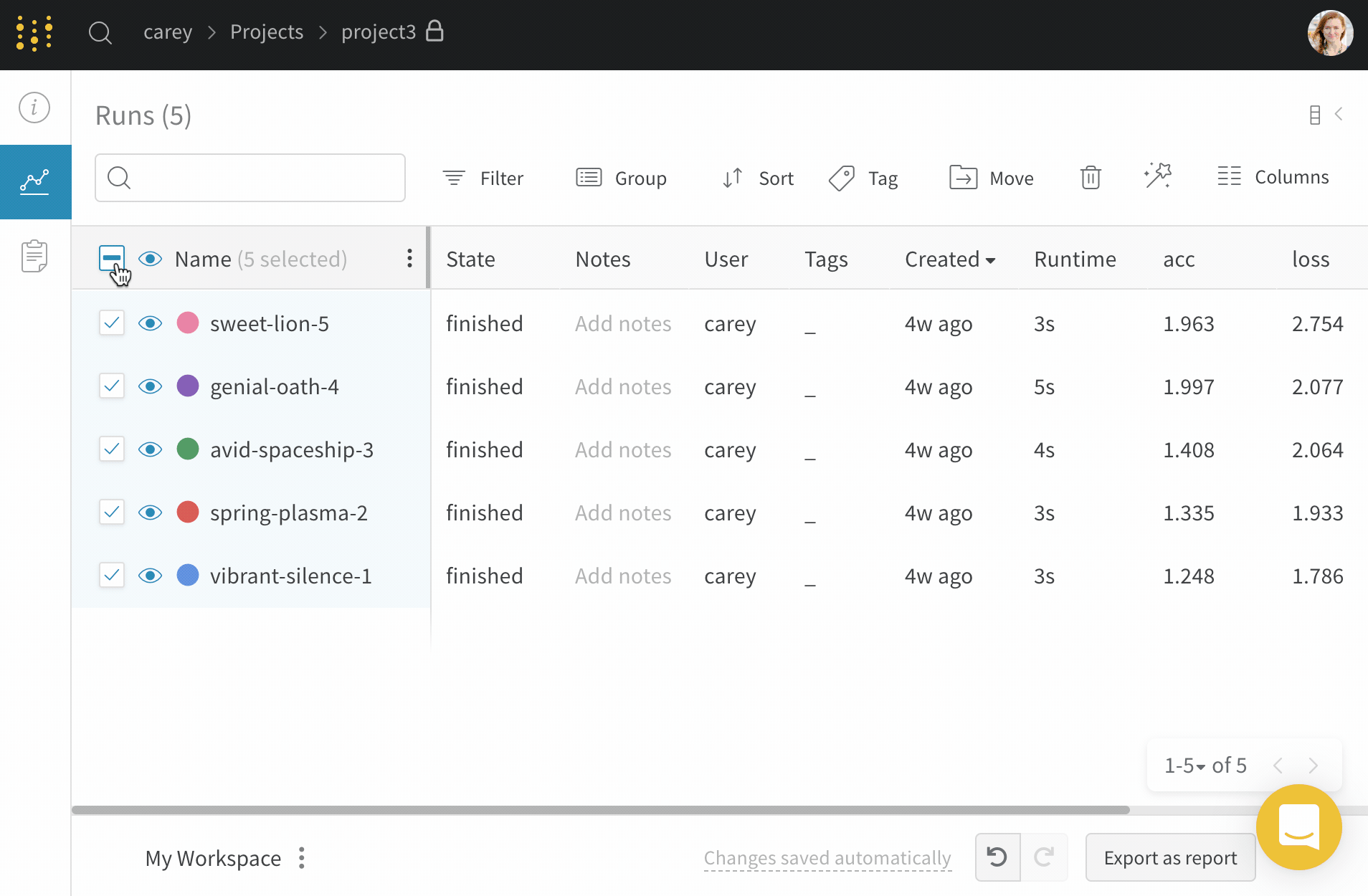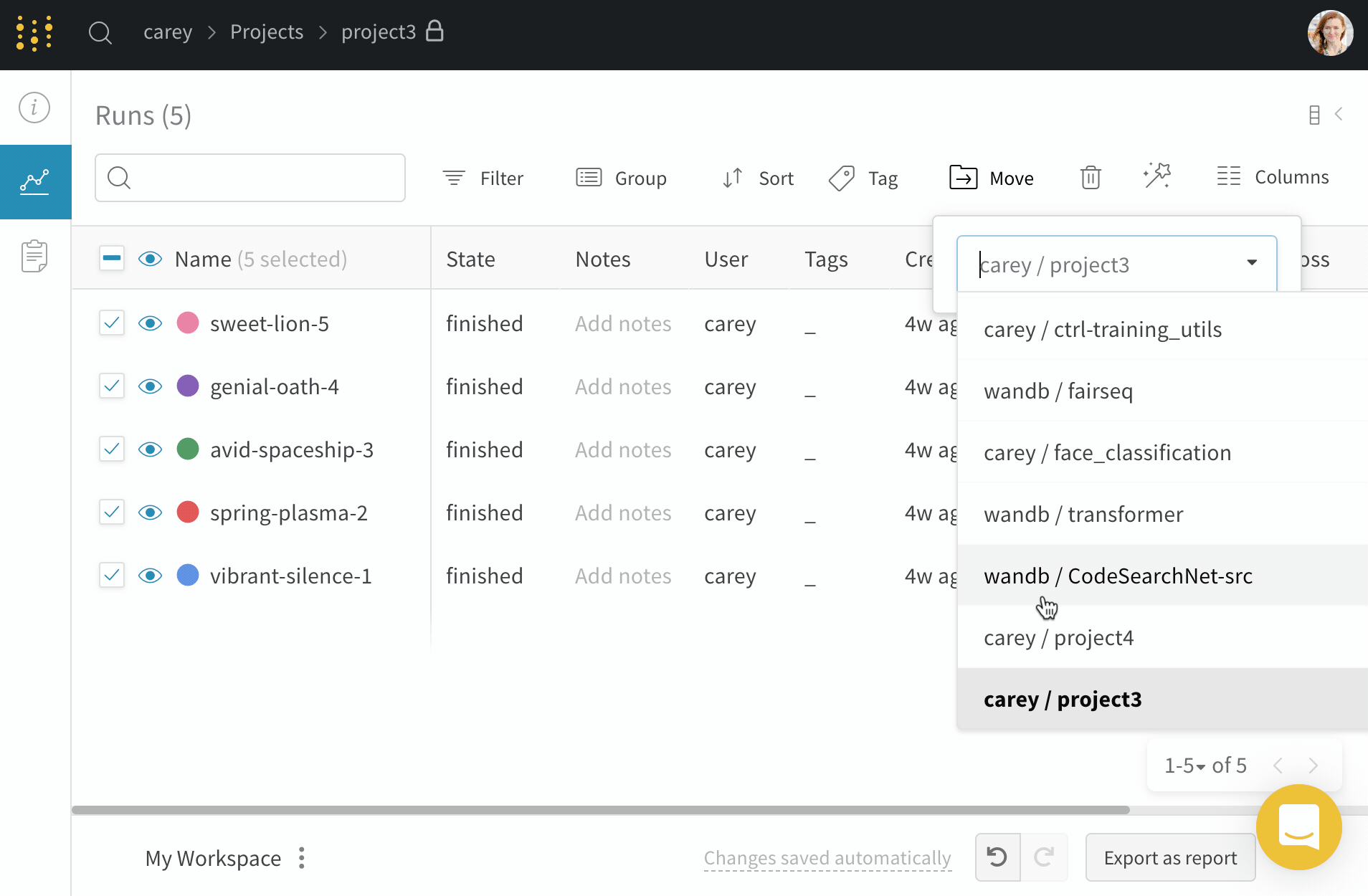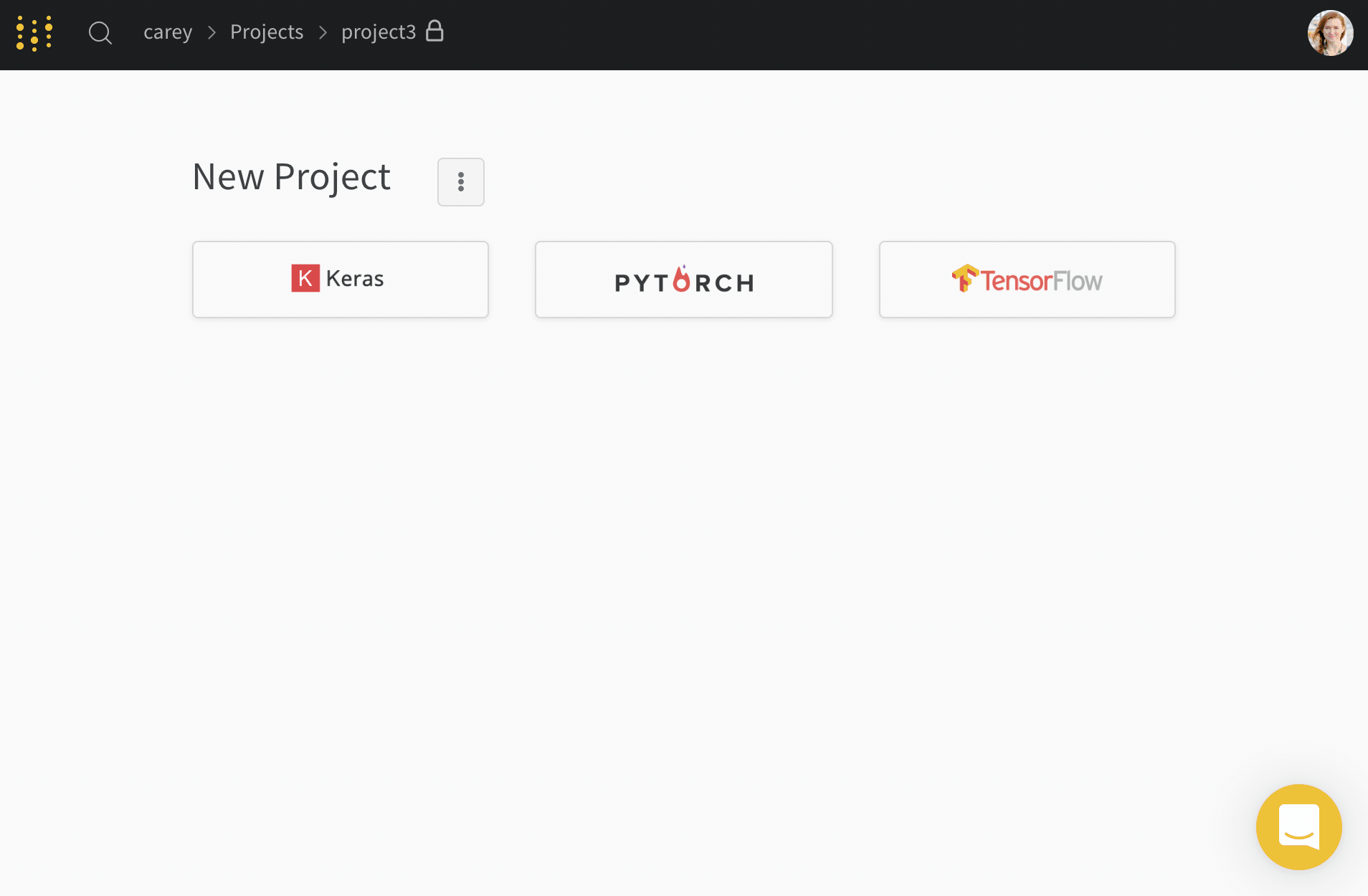
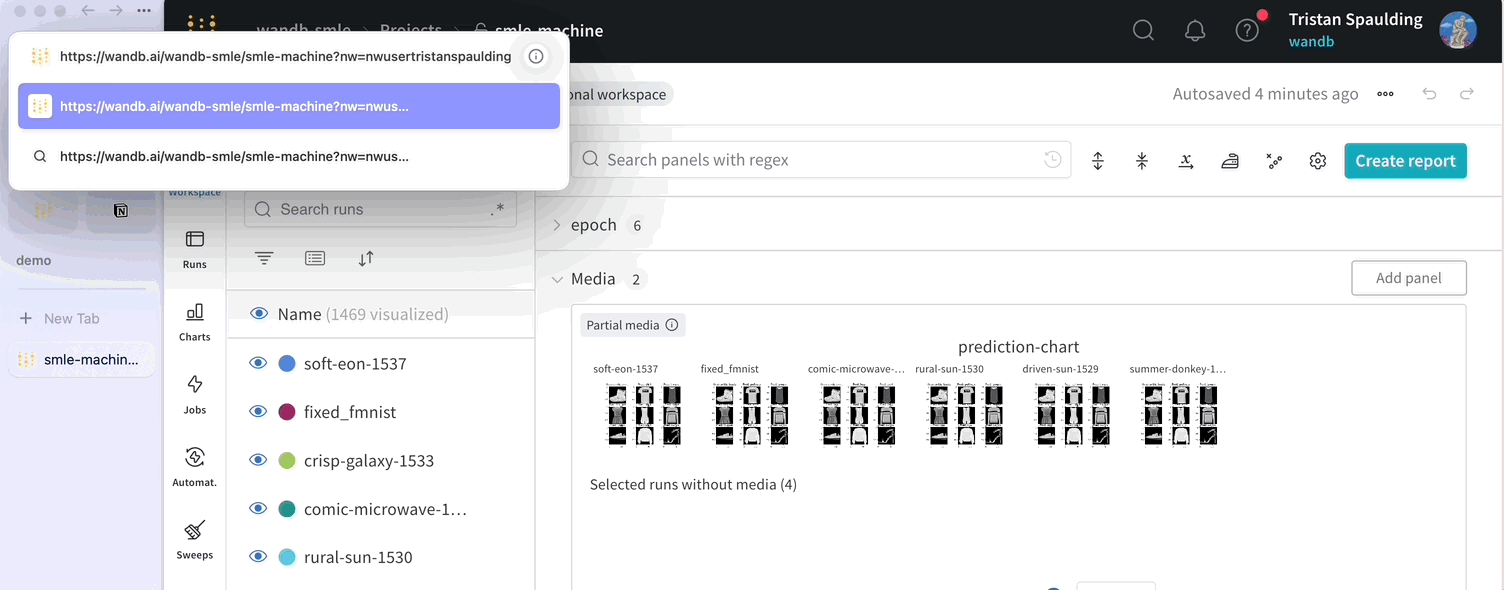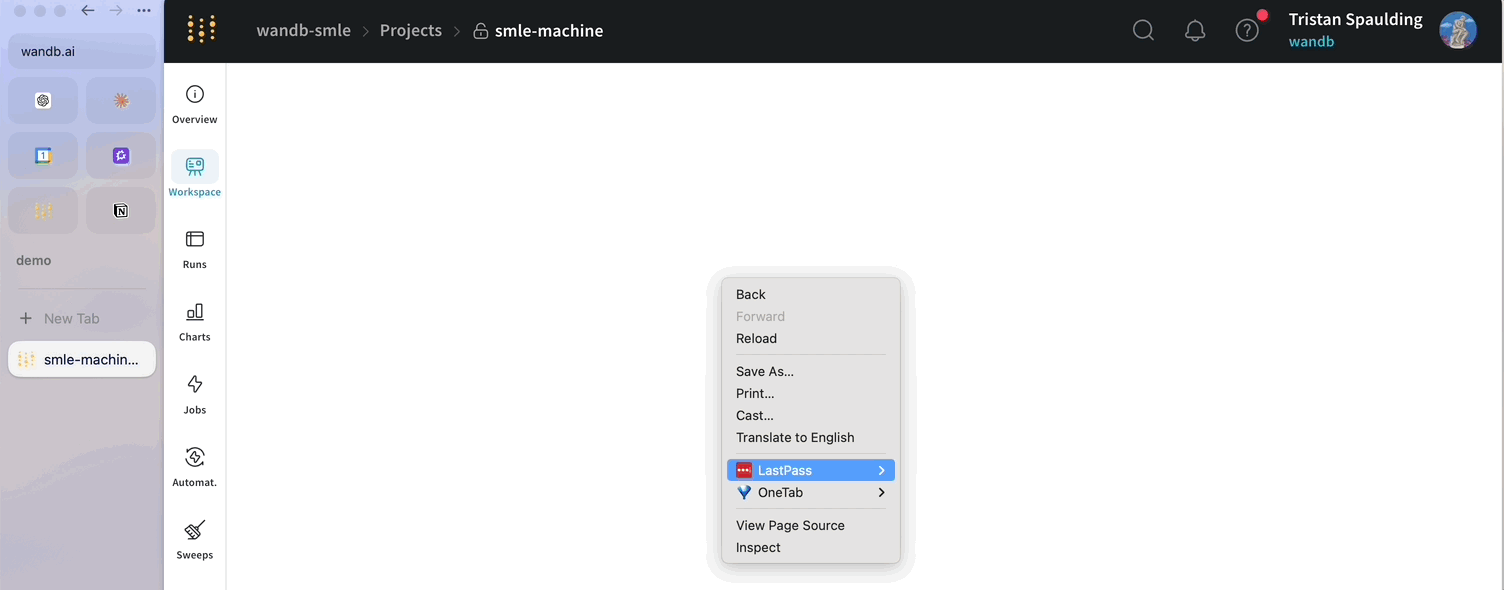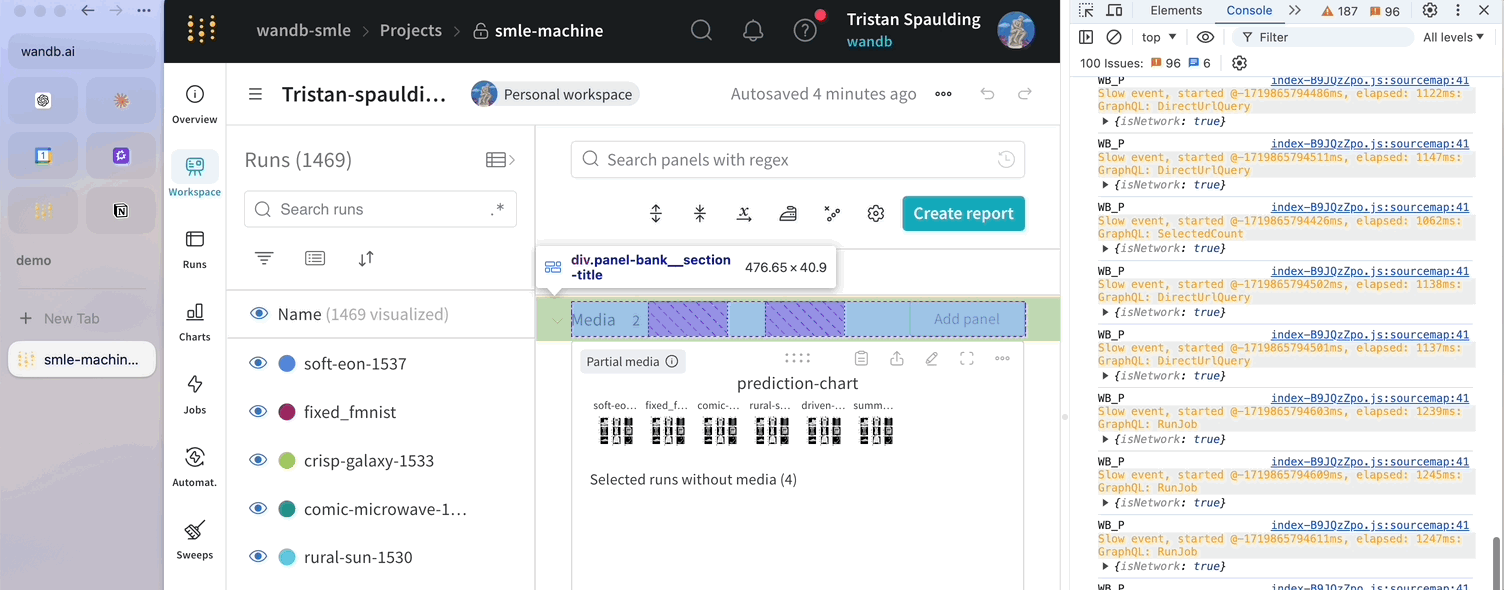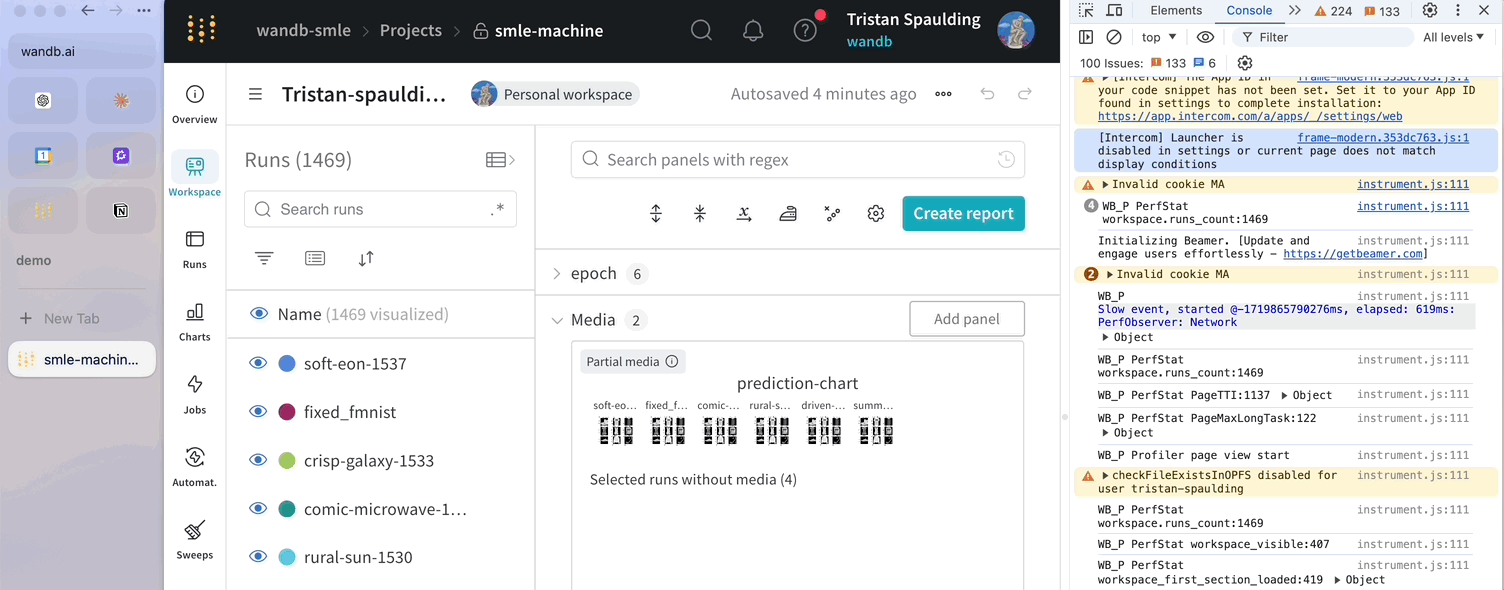
Dot menu : サイドバーの行にカーソルを合わせると、左側にメニューが表示されます。このメニューを使用して、run の名前を変更したり、run を削除したり、アクティブな run を停止したりできます。Visibility icon : グラフ上の run のオンとオフを切り替えるには、目のアイコンをクリックします。Color : run の色をプリセットのいずれか、またはカスタムの色に変更します。Search : 名前で run を検索します。これにより、プロットで表示される run もフィルター処理されます。Filter : サイドバー フィルターを使用して、表示される run のセットを絞り込みます。Group : 設定列を選択して、たとえばアーキテクチャごとに run を動的にグループ化します。グループ化すると、プロットには平均値に沿った線と、グラフ上のポイントの分散の影付き領域が表示されます。Sort : 損失が最小または精度が最大の run など、run の並べ替えに使用する値を選択します。並べ替えは、グラフに表示される run に影響します。Expand button : サイドバーをテーブル全体に展開します。Run count : 上部のかっこ内の数値は、project 内の run の総数です。数値 (N visualized) は、目のアイコンがオンになっており、各プロットで可視化できる run の数です。以下の例では、グラフには 183 の run のうち最初の 10 個のみが表示されています。グラフを編集して、表示される run の最大数を増やします。
Runs tab で列をピン留め、非表示、または順序を変更すると、Runs サイドバーにこれらのカスタマイズが反映されます。
Panels layout : このスクラッチ スペースを使用して、結果を調べたり、チャートを追加および削除したり、さまざまなメトリクスに基づいて Models のバージョンを比較したりできます。
ライブの例を見る
パネルのセクションを追加する
セクション ドロップダウン メニューをクリックし、[Add section] をクリックして、パネルの新しいセクションを作成します。セクションの名前を変更したり、ドラッグして再編成したり、セクションを展開および折りたたんだりできます。
各セクションの右上隅にはオプションがあります。
Switch to custom layout : カスタム レイアウトでは、パネルのサイズを個別に変更できます。Switch to standard layout : 標準レイアウトでは、セクション内のすべてのパネルのサイズを一度に変更でき、ページネーションが提供されます。Add section : ドロップダウン メニューから上下にセクションを追加するか、ページの下部にあるボタンをクリックして新しいセクションを追加します。Rename section : セクションのタイトルを変更します。Export section to report : このパネルのセクションを新しい Report に保存します。Delete section : セクション全体とすべてのチャートを削除します。これは、ワークスペース バーのページの下部にある元に戻すボタンで元に戻すことができます。Add panel : プラス ボタンをクリックして、セクションにパネルを追加します。
セクション間でパネルを移動する
パネルをドラッグ アンド ドロップして、セクションに再配置および整理します。パネルの右上隅にある [Move] ボタンをクリックして、パネルの移動先のセクションを選択することもできます。
パネルのサイズを変更する
Standard layout : すべてのパネルのサイズは同じに維持され、パネルのページがあります。右下隅をクリックしてドラッグすると、パネルのサイズを変更できます。セクションの右下隅をクリックしてドラッグすると、セクションのサイズを変更できます。Custom layout : すべてのパネルのサイズは個別に設定され、ページはありません。
メトリクスを検索する
ワークスペースの検索ボックスを使用して、パネルを絞り込みます。この検索は、パネルのタイトル (デフォルトでは可視化されたメトリクスの名前) と一致します。
Runs タブ
Runs タブを使用して、run をフィルター処理、グループ化、および並べ替えます。
次のタブは、Runs タブで実行できる一般的なアクションを示しています。
Customize columns
Sort
Filter
Group
Runs タブには、project 内の run に関する詳細が表示されます。デフォルトでは、多数の列が表示されます。
表示されているすべての列を表示するには、ページを水平方向にスクロールします。
列の順序を変更するには、列を左右にドラッグします。
列を固定するには、列名にカーソルを合わせ、表示されるアクション メニュー ... をクリックして、Pin column をクリックします。固定された列は、Name 列の後のページの左側に表示されます。固定された列を固定解除するには、Unpin column を選択します。
列を非表示にするには、列名にカーソルを合わせ、表示されるアクション メニュー ... をクリックして、Hide column をクリックします。現在非表示になっているすべての列を表示するには、Columns をクリックします。
複数の列を一度に表示、非表示、固定、および固定解除するには、Columns をクリックします。
非表示の列の名前をクリックして、非表示を解除します。
表示されている列の名前をクリックして、非表示にします。
表示されている列の横にあるピン アイコンをクリックして、固定します。
Runs タブをカスタマイズすると、カスタマイズは Workspace タブ の Runs セレクターにも反映されます。
テーブル内のすべての行を、指定された列の値で並べ替えます。
マウスを列タイトルに合わせます。ケバブ メニュー (3 つの縦のドキュメント) が表示されます。
ケバブ メニュー (3 つの縦のドット) で選択します。
Sort Asc または Sort Desc を選択して、行をそれぞれ昇順または降順に並べ替えます。
上記の画像は、val_acc という名前のテーブル列の並べ替えオプションを表示する方法を示しています。
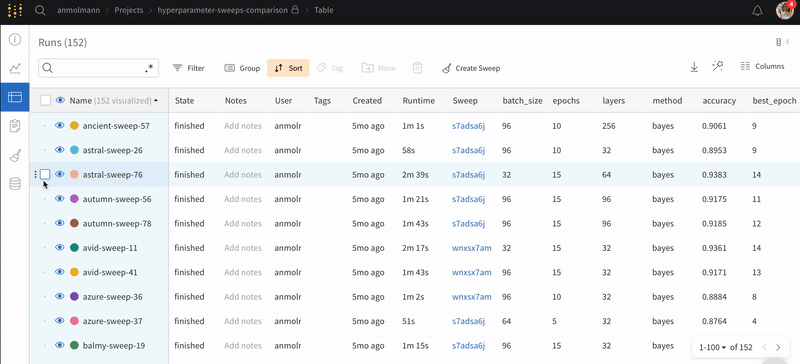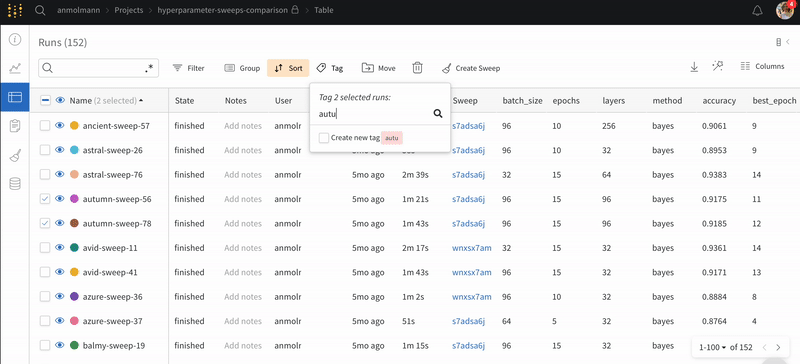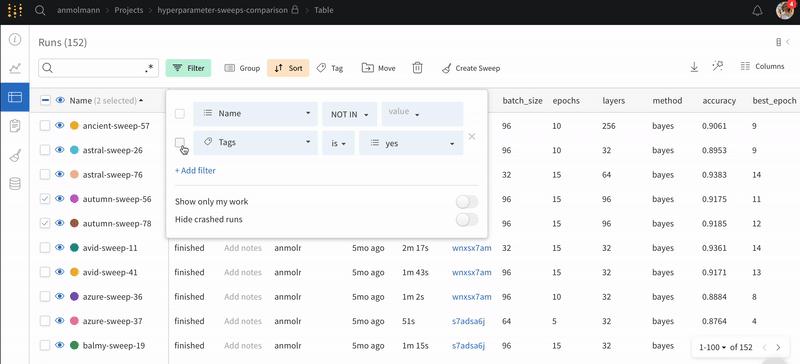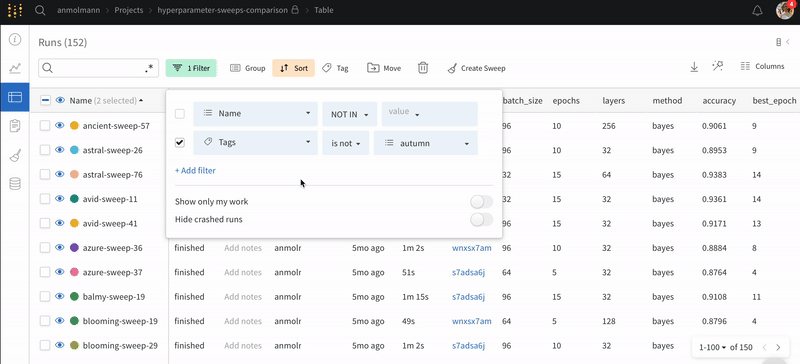
ダッシュボードの左上にある Filter ボタンを使用して、式で行全体をフィルター処理します。
Add filter を選択して、行に 1 つ以上のフィルターを追加します。3 つのドロップダウン メニューが表示されます。左から右へ、フィルター タイプは、列名、演算子、および値に基づいています。
列名
二項関係
値
受け入れられる値
文字列
=, ≠, ≤, ≥, IN, NOT IN,
整数、浮動小数点数、文字列、タイムスタンプ、null
式エディターには、列名と論理述語構造のオートコンプリートを使用して、各項のオプションのリストが表示されます。「and」または「or」(および場合によっては括弧) を使用して、複数の論理述語を 1 つの式に接続できます。
上記の画像は、`val_loss` 列に基づいたフィルターを示しています。フィルターは、検証損失が 1 以下の run を表示します。
列ヘッダーの Group by ボタンを使用して、特定の列の値で行全体をグループ化します。
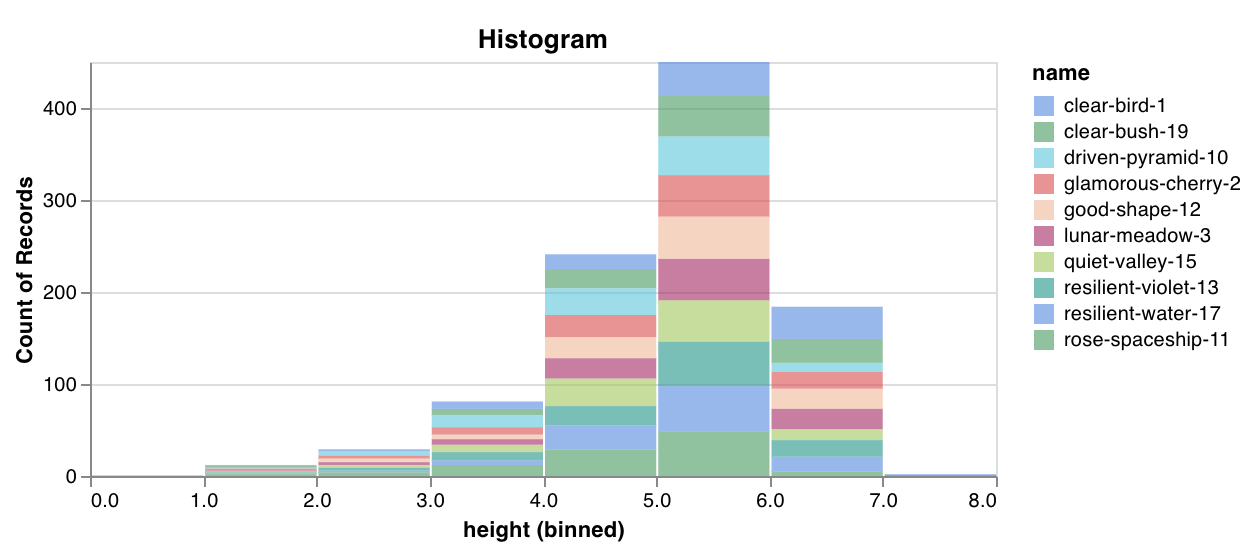
デフォルトでは、これにより、他の数値列が、グループ全体のその列の値の分布を示すヒストグラムに変わります。グループ化は、データ内のより高レベルのパターンを理解するのに役立ちます。
Reports タブ
1 か所で結果のすべてのスナップショットを確認し、チームと学びを共有します。
Sweeps タブ
project から新しい sweep を開始します。
Artifacts タブ
トレーニングデータセットや fine-tuned models から、メトリクスとメディアのテーブル まで、project に関連付けられているすべての Artifacts を表示します。
Overview パネル
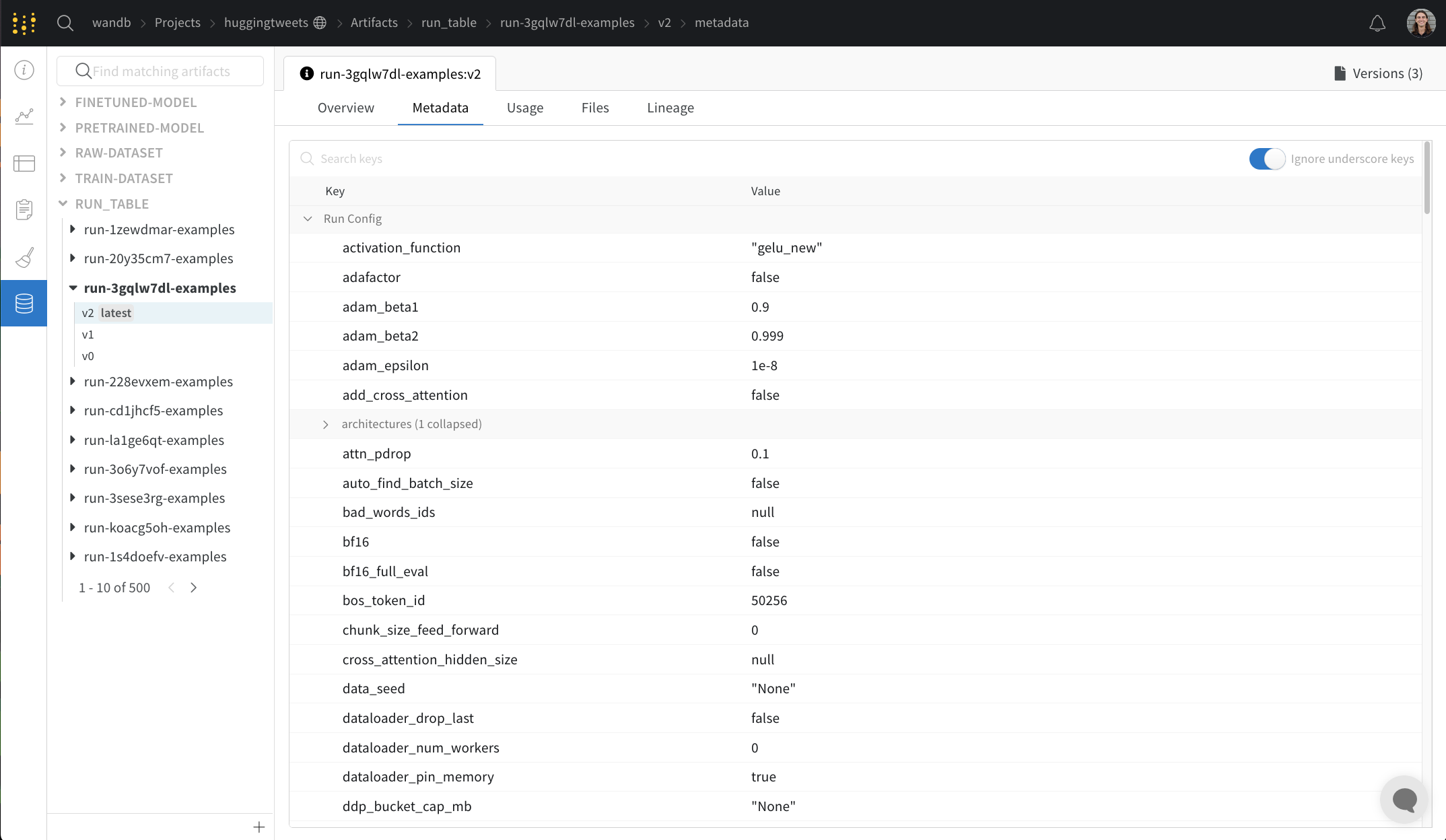
Overview パネルには、Artifacts の名前とバージョン、変更を検出して重複を防ぐために使用されるハッシュ ダイジェスト、作成日、エイリアスなど、Artifacts に関するさまざまな高度な情報が表示されます。ここでエイリアスを追加または削除したり、バージョンと Artifacts 全体の両方に関するメモを取ることができます。
Metadata パネルは、Artifacts のメタデータへのアクセスを提供します。このメタデータは、Artifacts の構築時に提供されます。このメタデータには、Artifacts を再構築するために必要な構成 引数 、詳細情報が見つかる URL、または Artifacts を記録した run 中に生成されたメトリクスが含まれる場合があります。さらに、Artifacts を生成した run の構成と、Artifacts のロギング時の履歴メトリクスを確認できます。
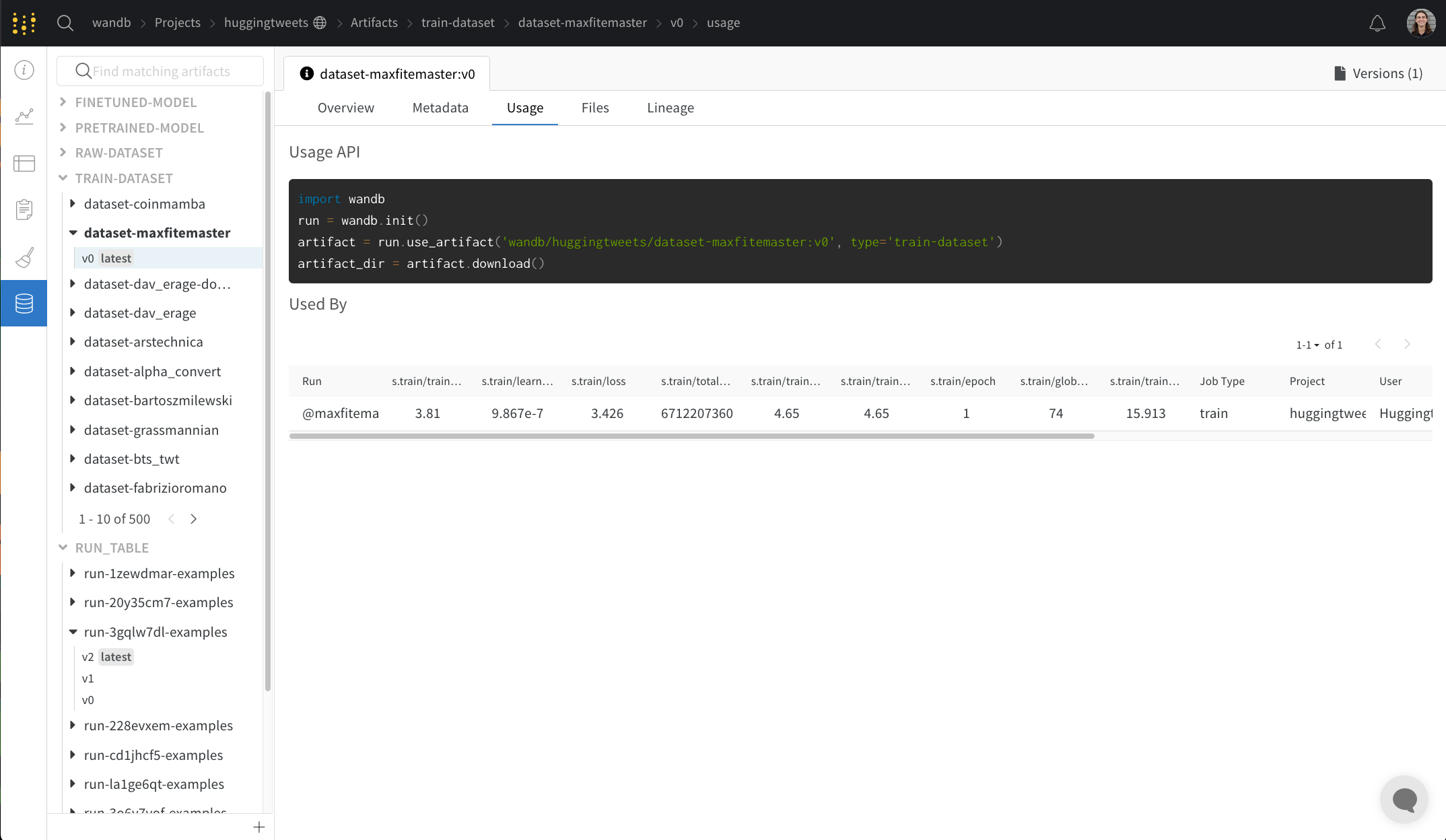
Usage パネル
Usage パネルは、ウェブ アプリの外 (たとえば、ローカル マシン上) で使用するために Artifacts をダウンロードするためのコード スニペットを提供します。このセクションでは、Artifacts を出力した run と、Artifacts を入力として使用する run も示し、リンクします。
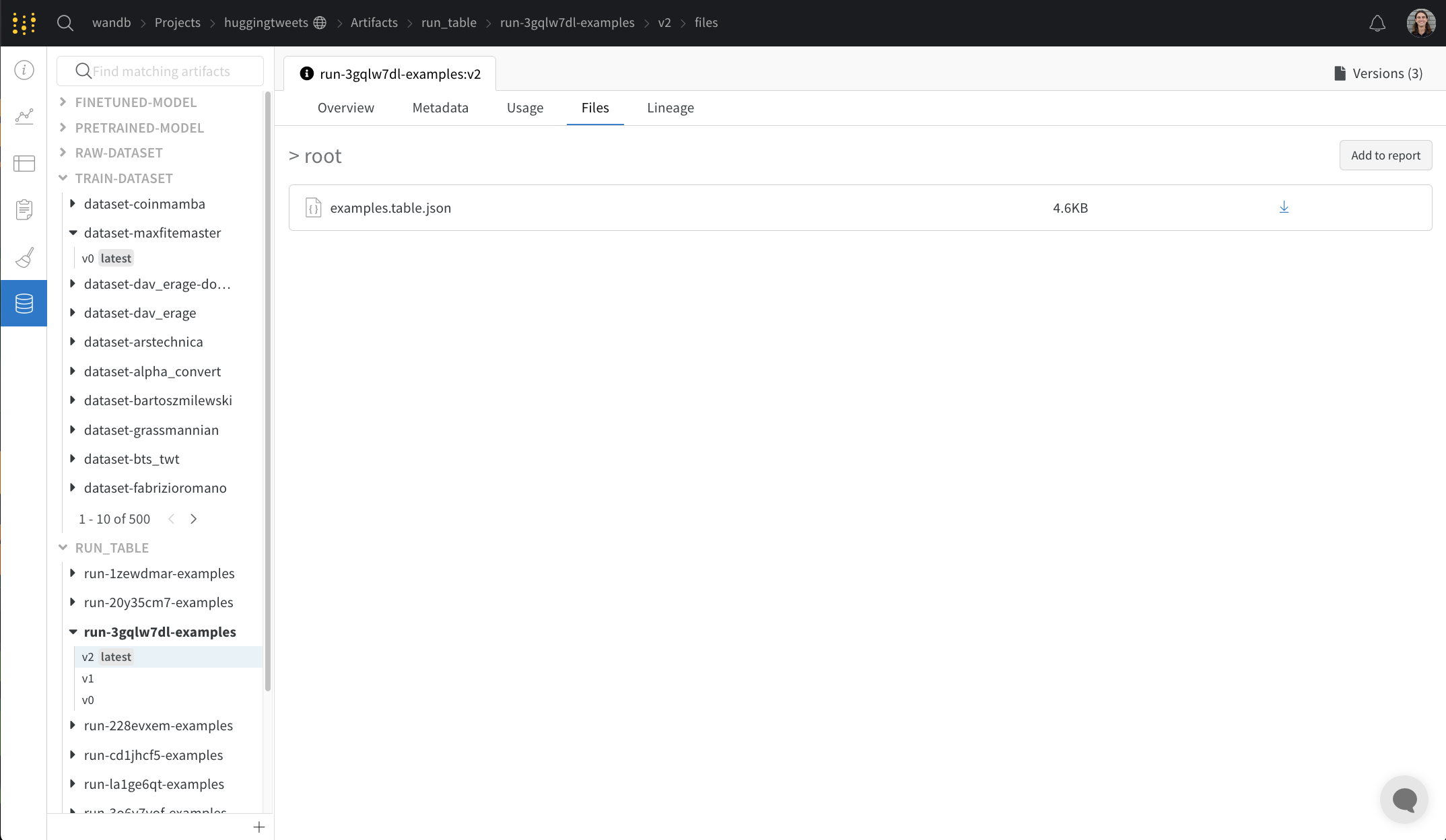
Files パネル
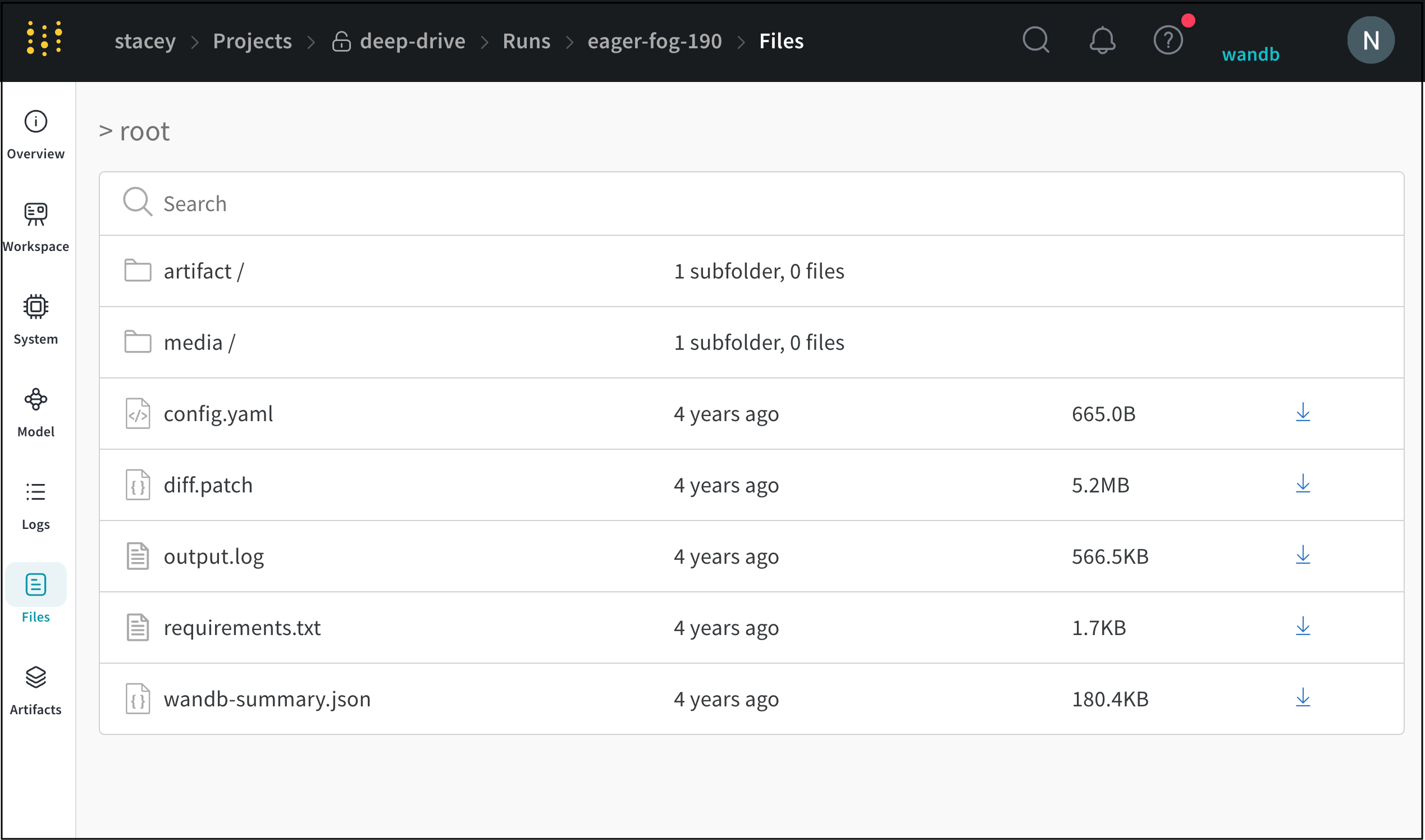
Files パネルには、Artifacts に関連付けられているファイルとフォルダーがリストされます。W&B は、run の特定のファイルを自動的にアップロードします。たとえば、requirements.txt は run が使用した各ライブラリのバージョンを示し、wandb-metadata.json および wandb-summary.json には run に関する情報が含まれています。run の構成に応じて、Artifacts やメディアなど、他のファイルがアップロードされる場合があります。このファイル ツリーをナビゲートして、W&B ウェブ アプリでコンテンツを直接表示できます。
Artifacts に関連付けられた Tables は、このコンテキストで特に豊富でインタラクティブです。Artifacts で Tables を使用する方法について詳しくは、こちら をご覧ください。
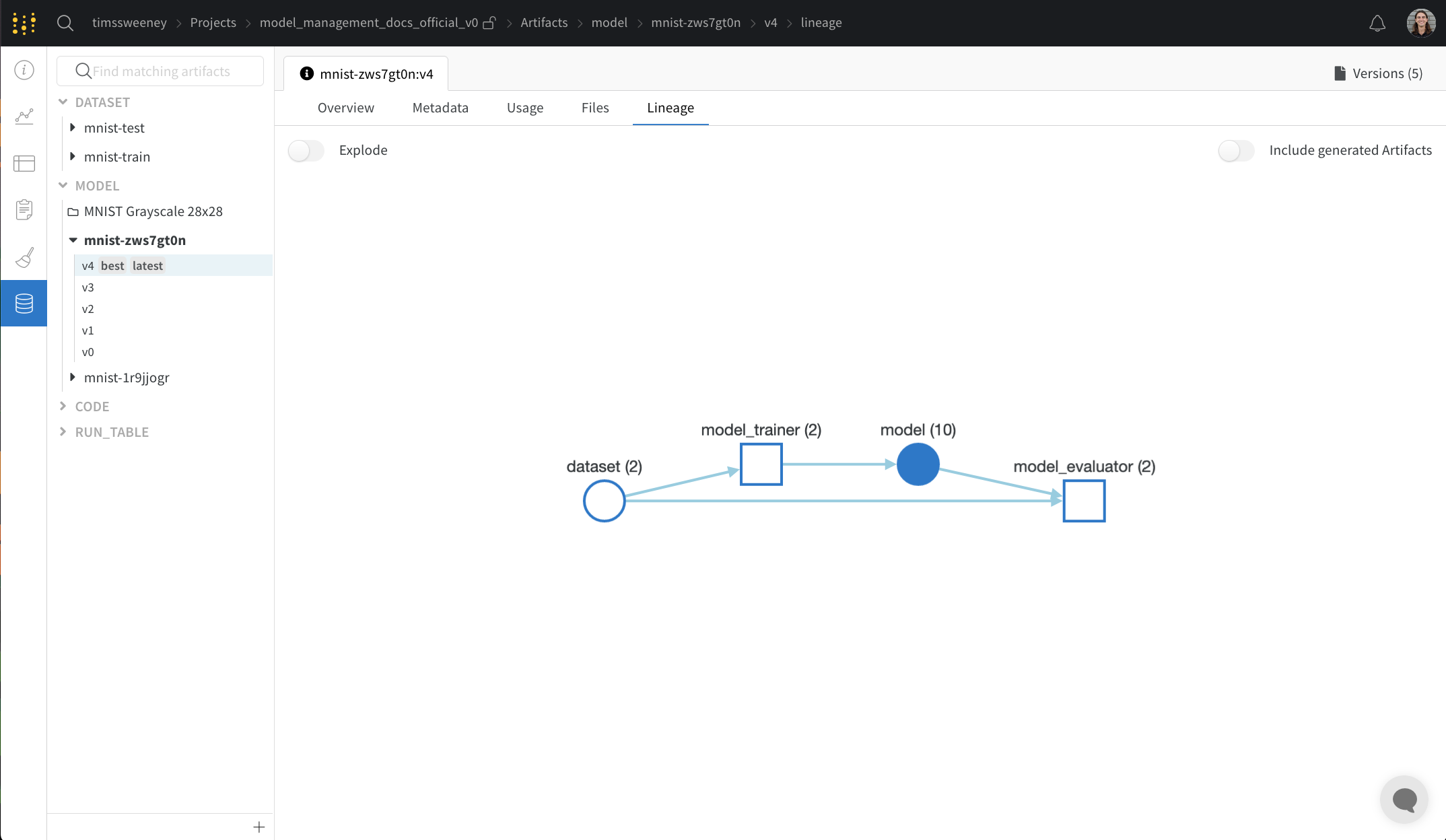
Lineage パネル
Lineage パネルは、project に関連付けられているすべての Artifacts と、それらを相互に接続する run のビューを提供します。これは、run タイプをブロックとして、Artifacts を円として表示し、特定のタイプの run が特定のタイプの Artifacts を消費または生成するときを示す矢印を表示します。左側の列で選択された特定の Artifacts のタイプが強調表示されます。
[Explode] トグルをクリックすると、個々の Artifacts バージョンと、それらを接続する特定の run がすべて表示されます。
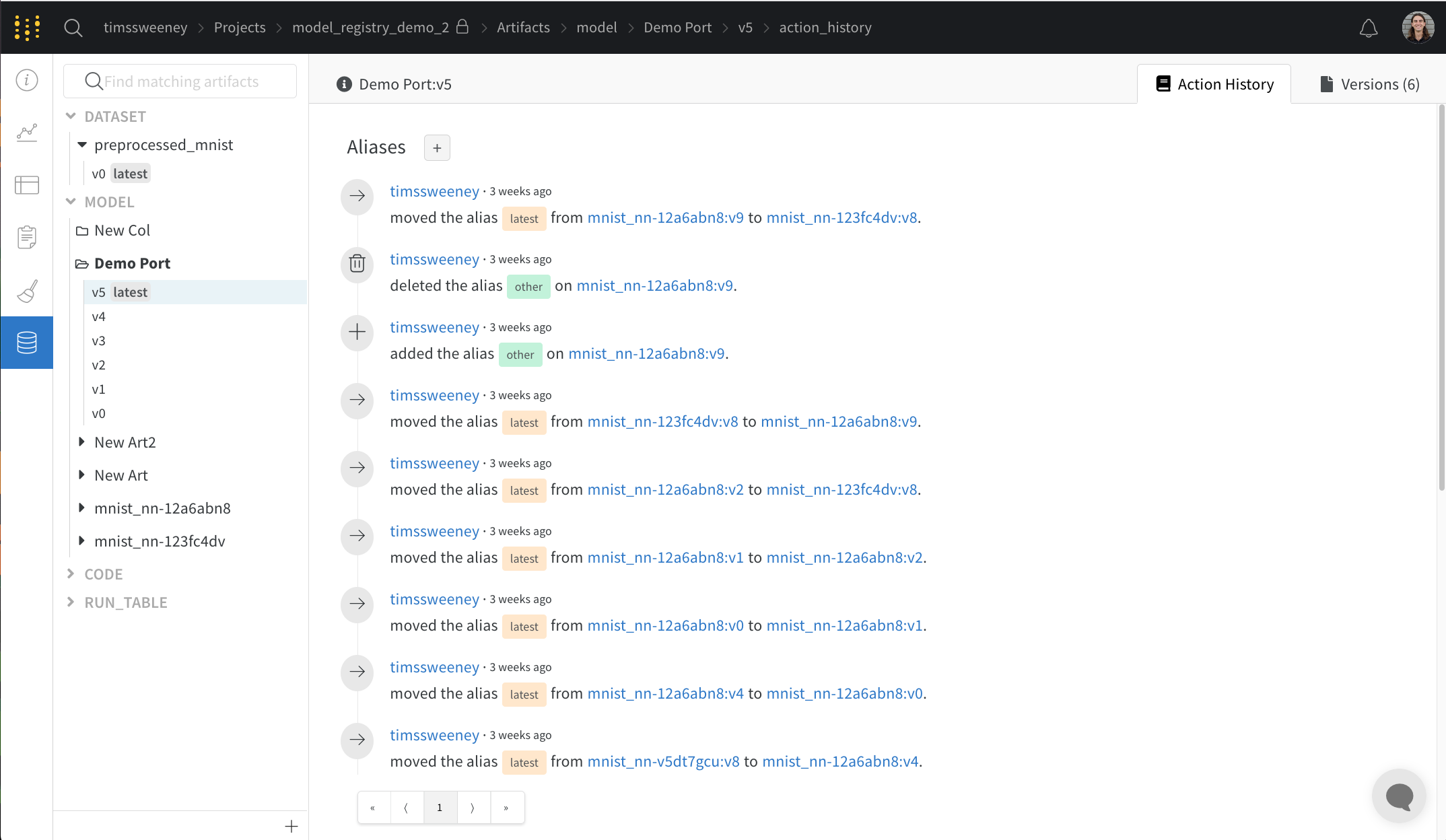
Action History Audit タブ
アクション履歴監査タブには、リソースの進化全体を監査できるように、Collection のすべてのエイリアス アクションとメンバーシップの変更が表示されます。
Versions タブ
Versions タブには、Artifacts のすべてのバージョンと、バージョンのロギング時の Run History の各数値の値の列が表示されます。これにより、パフォーマンスを比較し、関心のあるバージョンをすばやく特定できます。
project にスターを付ける
project にスターを追加して、その project を重要としてマークします。あなたとあなたのチームがスターで重要としてマークした project は、組織のホームページの上部に表示されます。
たとえば、次の画像は、重要としてマークされている 2 つの project、zoo_experiment と registry_demo を示しています。両方の project は、組織のホームページの Starred projects セクションの上部に表示されます。
project を重要としてマークするには、project の Overview タブ内またはチームのプロファイル ページの 2 つの方法があります。
Project overview
Team profile
W&B アプリ ( https://wandb.ai/<team>/<project-name> ) で W&B project に移動します。
project サイドバーから Overview タブを選択します。
右上隅にある Edit ボタンの横にあるスター アイコンを選択します。
チームのプロファイル ページ ( https://wandb.ai/<team>/projects ) に移動します。
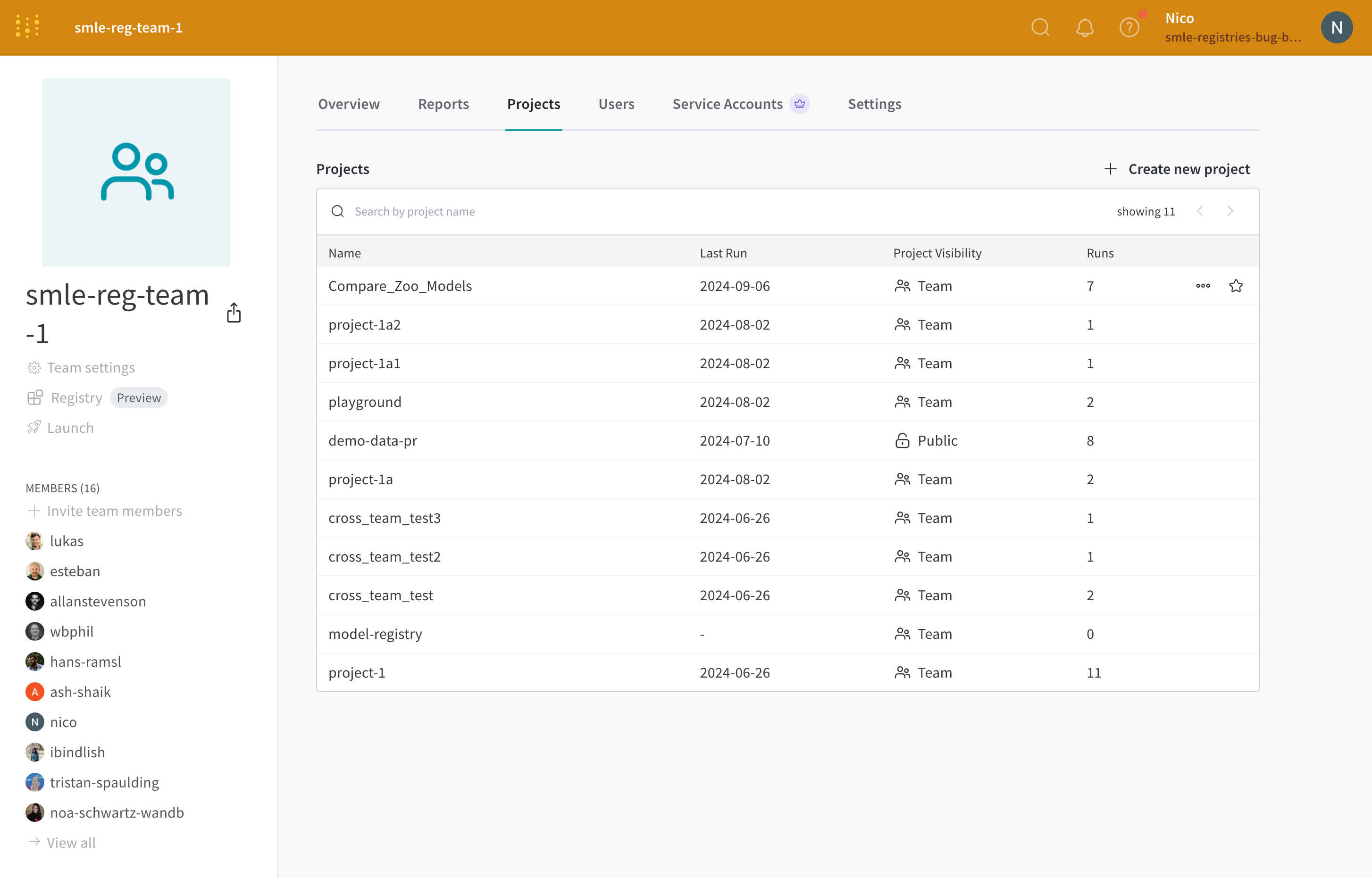
Projects タブを選択します。スターを付ける project の横にマウスを合わせます。表示されるスター アイコンをクリックします。
たとえば、次の画像は、“Compare_Zoo_Models” project の横にあるスター アイコンを示しています。
アプリの左上隅にある組織名をクリックして、project が組織のランディング ページに表示されることを確認します。
project を削除する
Overview タブの右側にある 3 つのドットをクリックして、project を削除できます。
project が空の場合、右上にあるドロップダウン メニューをクリックし、Delete project を選択して削除できます。
project にメモを追加する
説明の概要として、またはワークスペース内のマークダウン パネルとして、project にメモを追加します。
説明の概要を project に追加する
ページに追加する説明は、プロファイルの Overview タブに表示されます。
W&B project に移動します。
project サイドバーから Overview タブを選択します。
右上隅にある [Edit] を選択します。
Description フィールドにメモを追加します。Save ボタンを選択します。
Create reports to create descriptive notes comparing runs W&B Report を作成して、プロットとマークダウンを並べて追加することもできます。異なるセクションを使用して異なる run を表示し、作業内容に関するストーリーを伝えます。
run ワークスペースにメモを追加する
W&B project に移動します。
project サイドバーから Workspace タブを選択します。
右上隅にある Add panels ボタンを選択します。
表示されるモーダルから TEXT AND CODE ドロップダウンを選択します。
Markdown を選択します。ワークスペースに表示されるマークダウン パネルにメモを追加します。
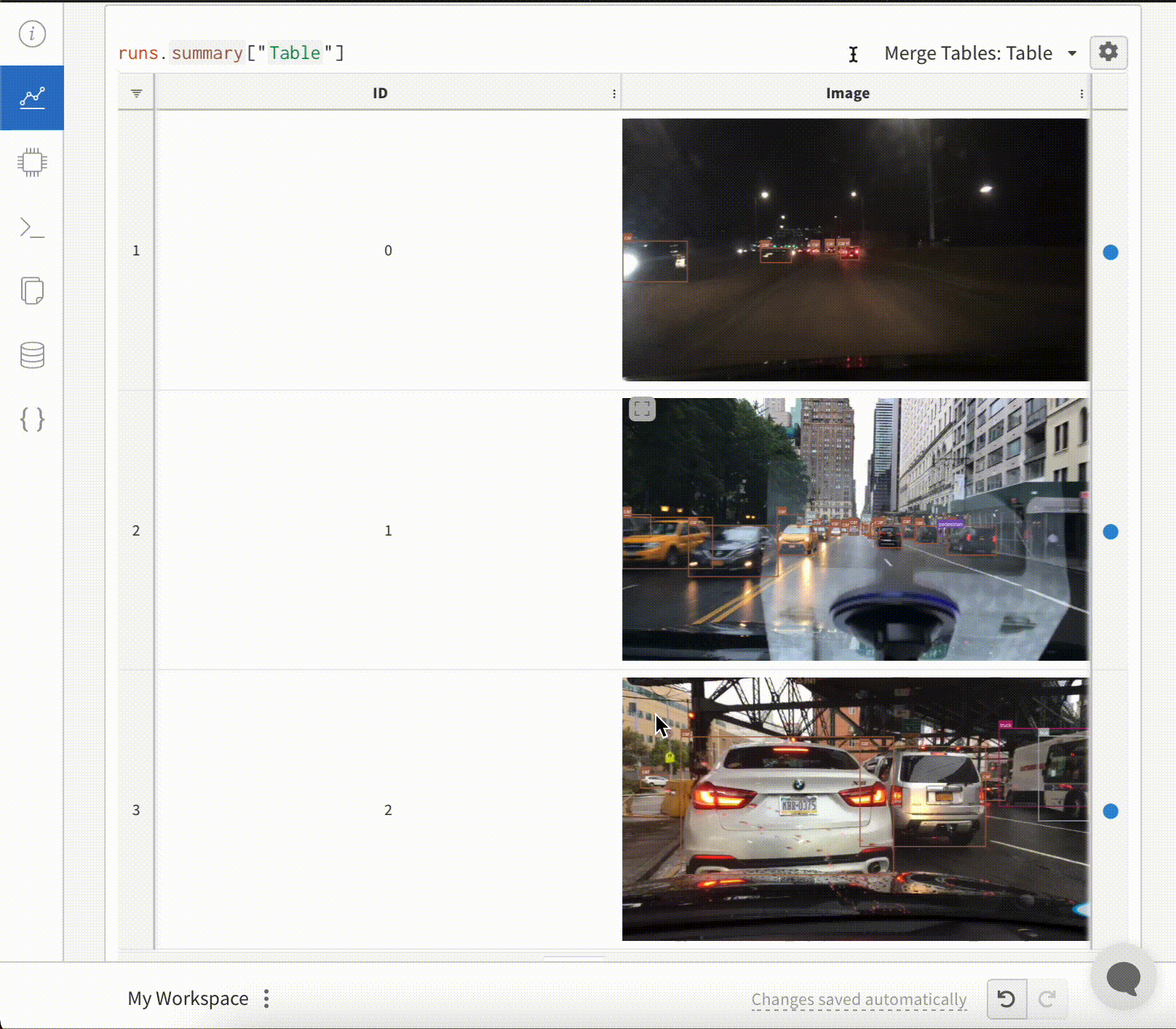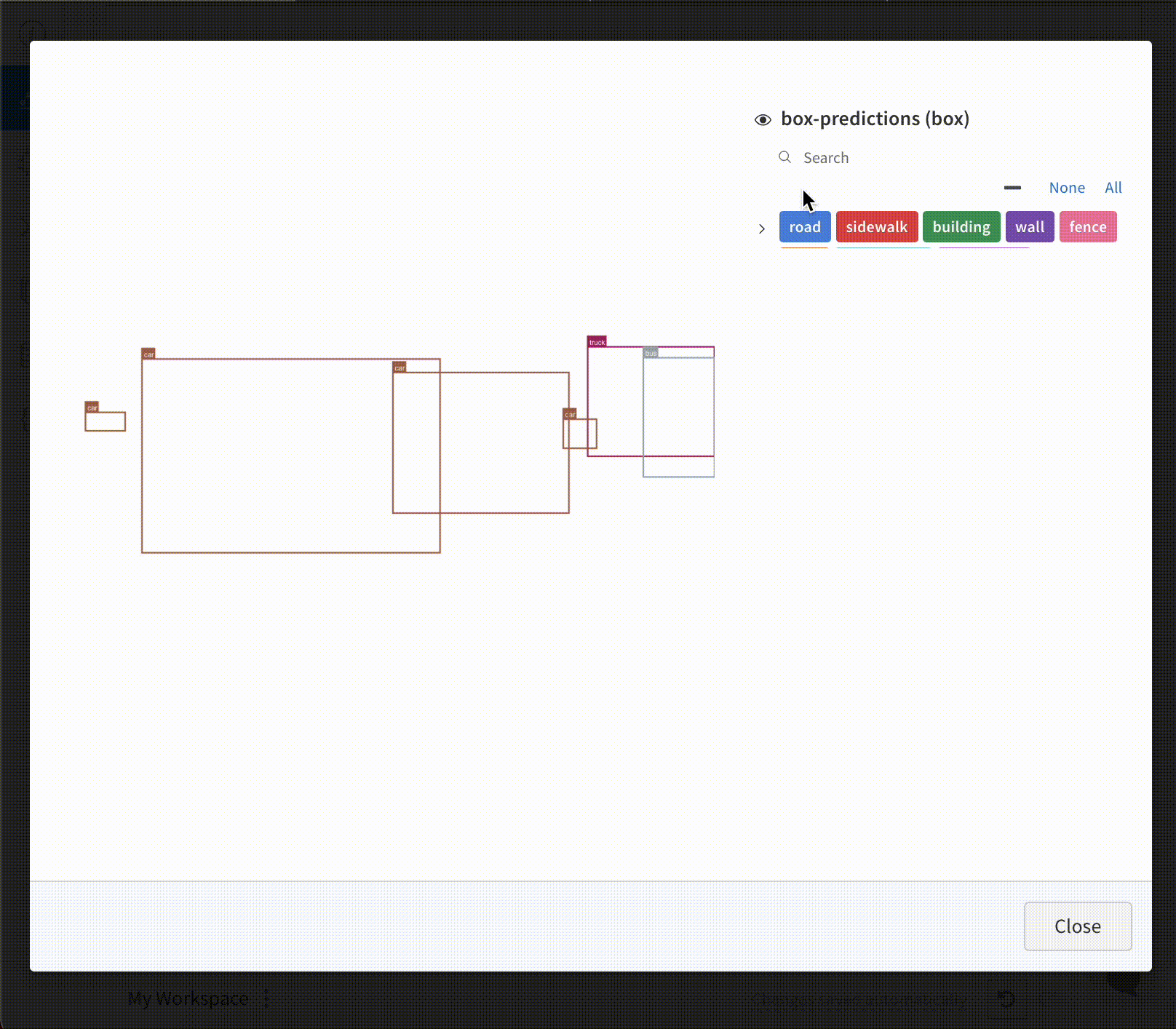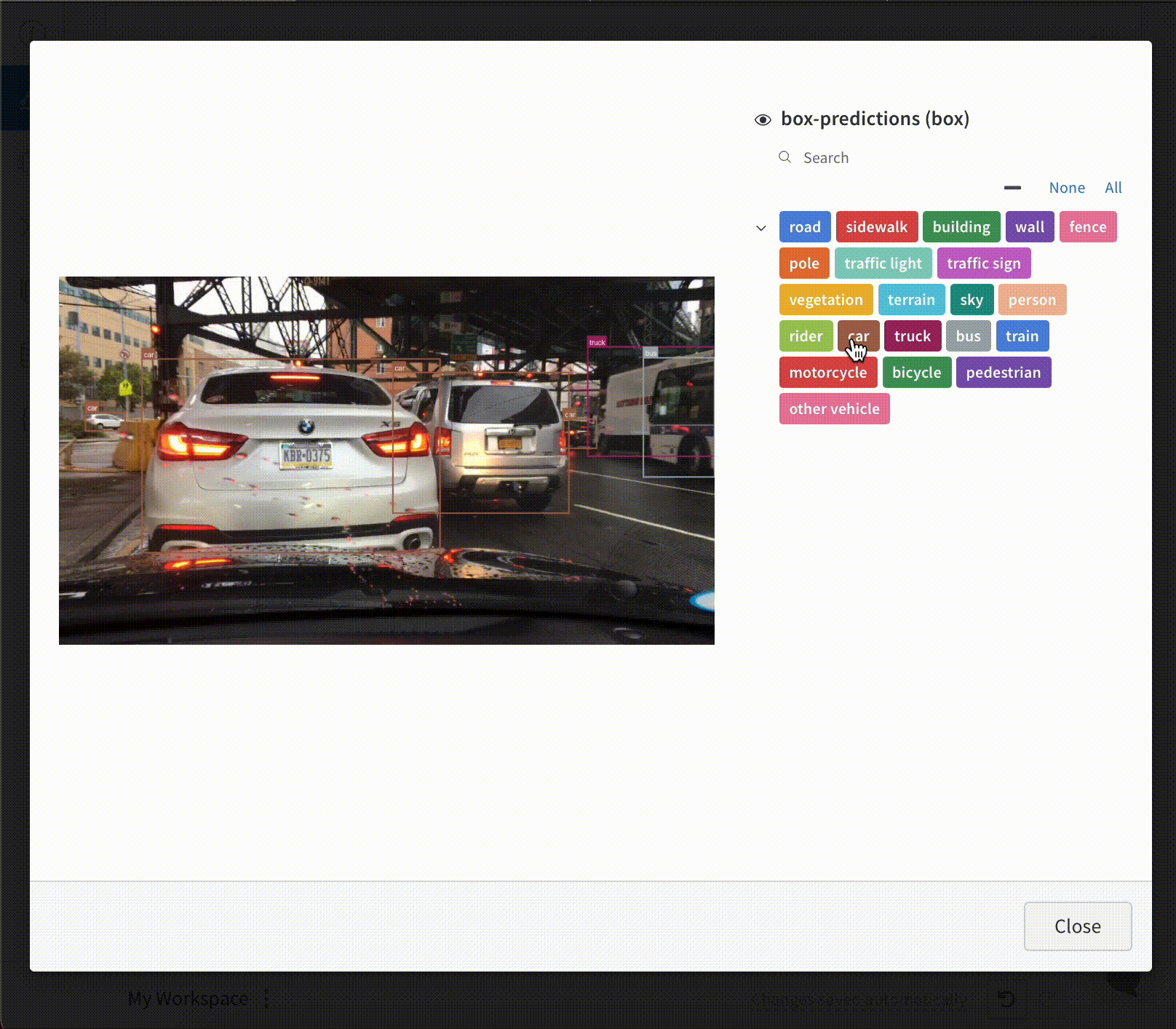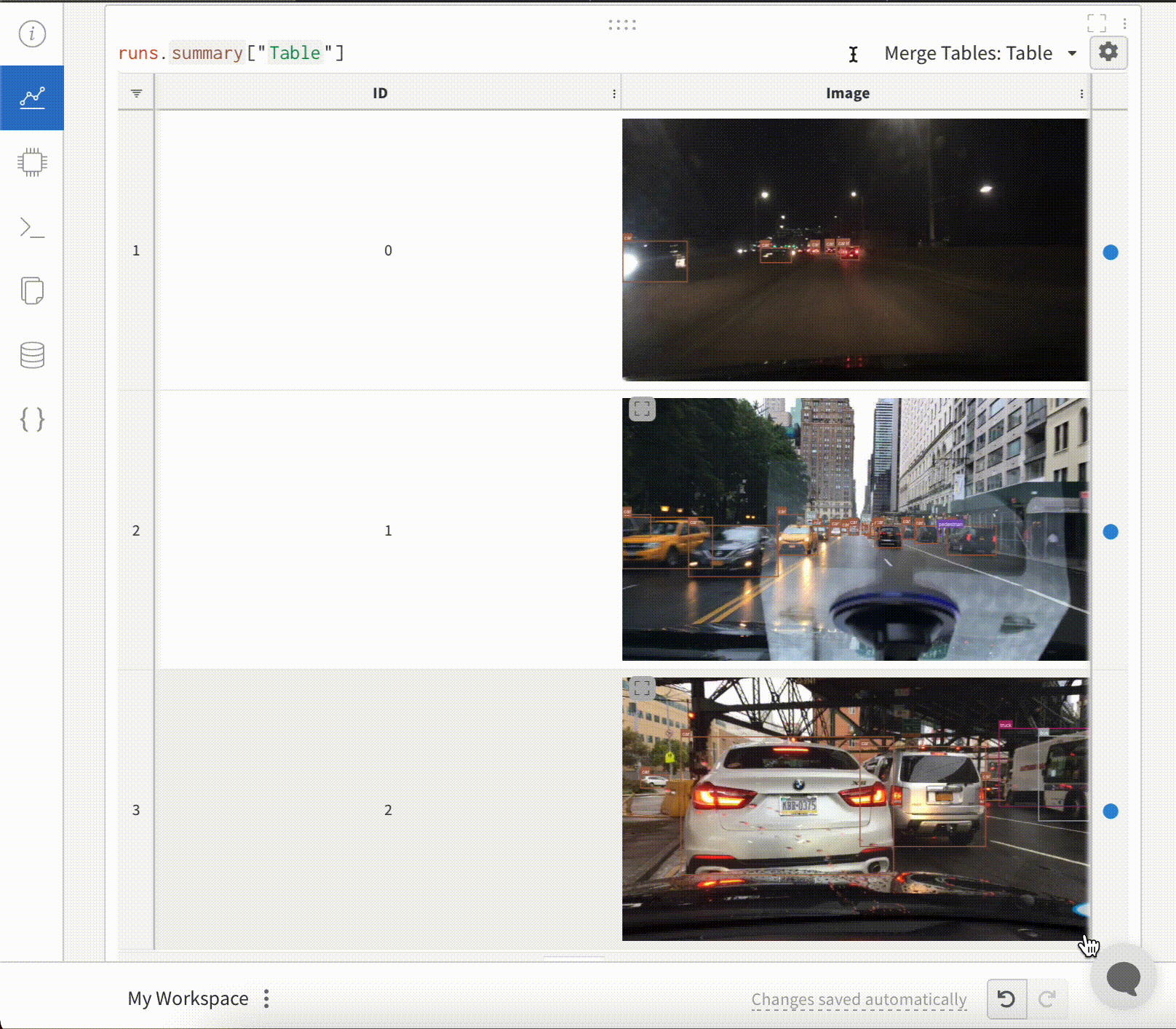
4 - View experiments results
インタラクティブな 可視化 で run のデータを探索できるプレイグラウンド
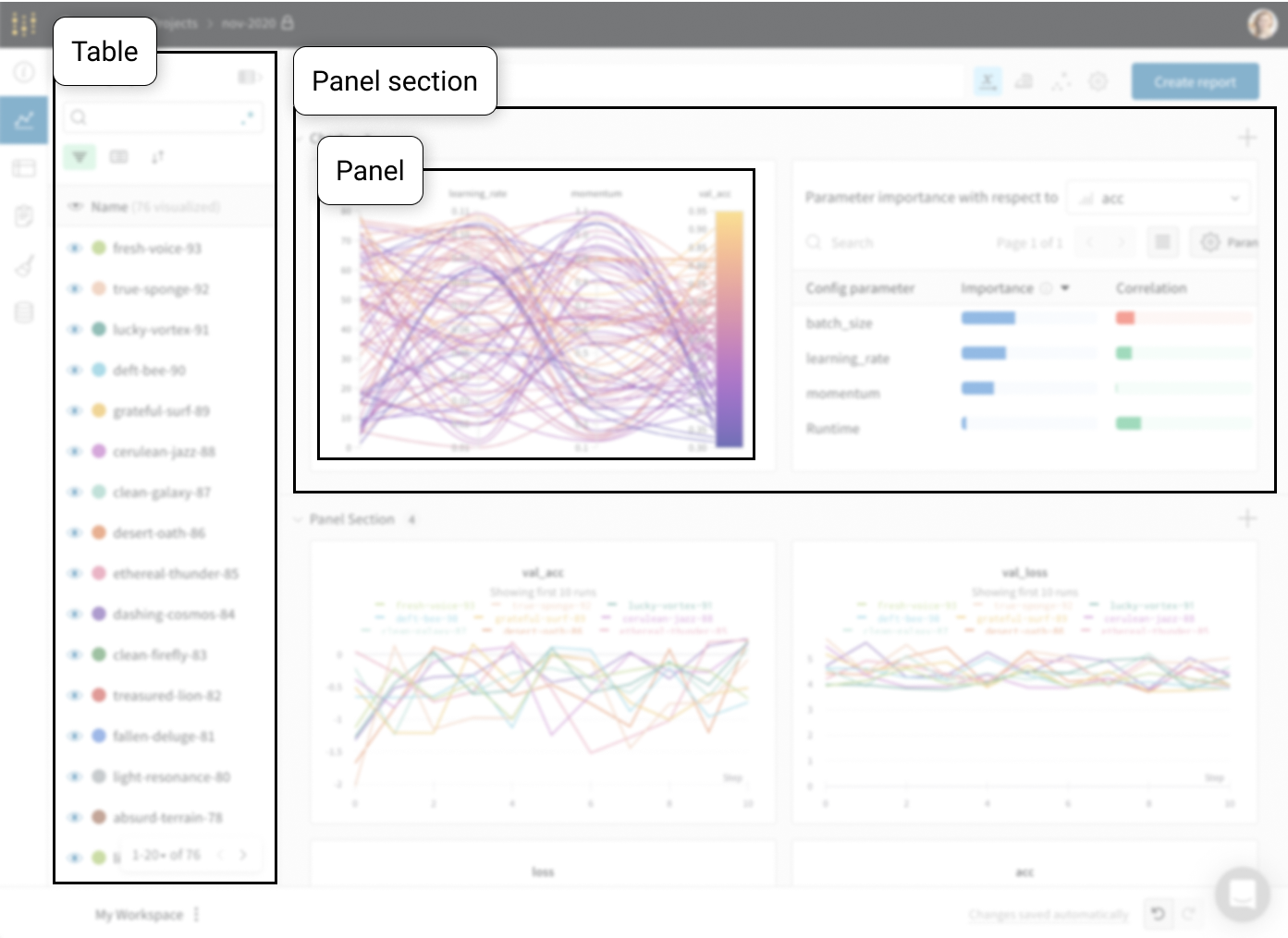
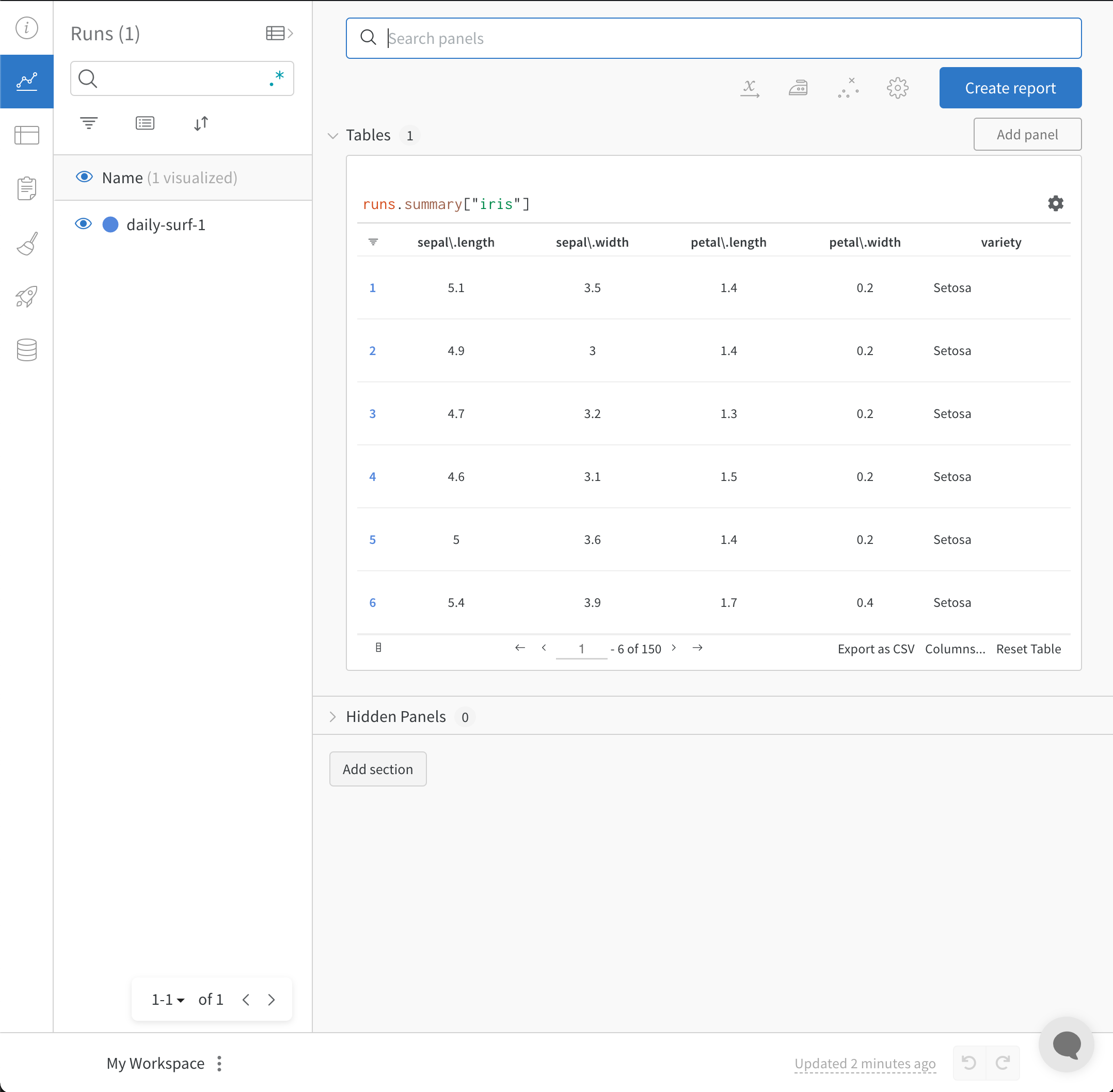
W&B workspace は、チャートをカスタマイズし、モデルの 結果 を探索するための個人的なサンドボックスです。W&B workspace は、 Tables と Panel sections で構成されています。
Tables : あなたの project に ログ されたすべての run は、その project のテーブルにリストされます。run のオン/オフ、色の変更、テーブルの 展開 などを行い、各 run のノート、config、サマリー metrics を確認できます。Panel sections : 1つまたは複数の panels を含むセクション。新しい パネル を作成し、それらを整理し、workspace の スナップショット を保存するために Reports にエクスポートします。
Workspace の種類
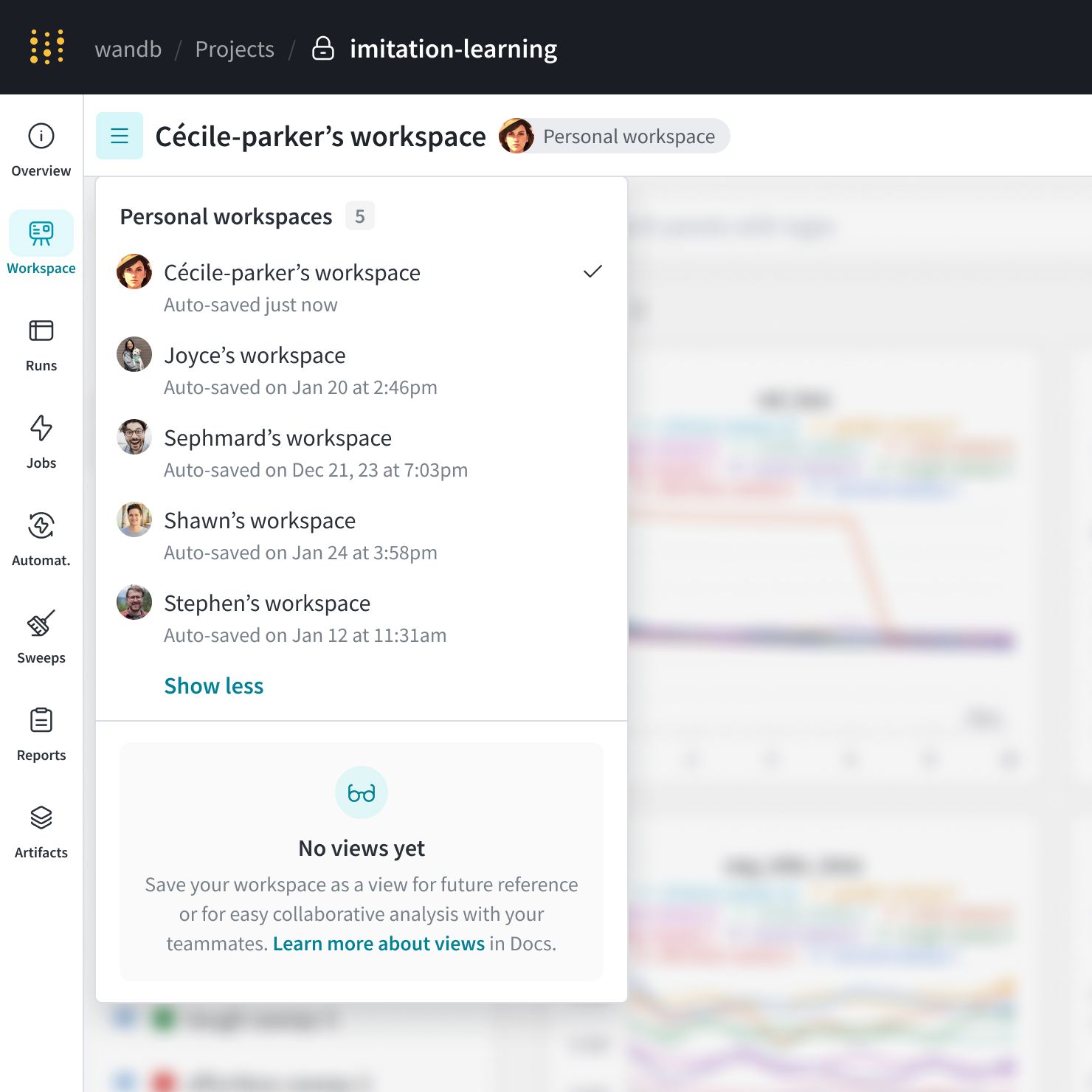
workspace には、主に Personal workspaces と Saved views の2つのカテゴリがあります。
Personal workspaces: model と data visualization を詳細に 分析 するための、カスタマイズ可能な workspace です。workspace のオーナーのみが 編集 して変更を保存できます。チームメイトは personal workspace を表示できますが、他の ユーザー の personal workspace を変更することはできません。Saved views: Saved views は、workspace のコラボレーティブな スナップショット です。あなたの team の誰でも、保存された workspace view を表示、 編集 、および変更を保存できます。実験管理 、runs などをレビューおよび議論するために、保存された workspace view を使用します。
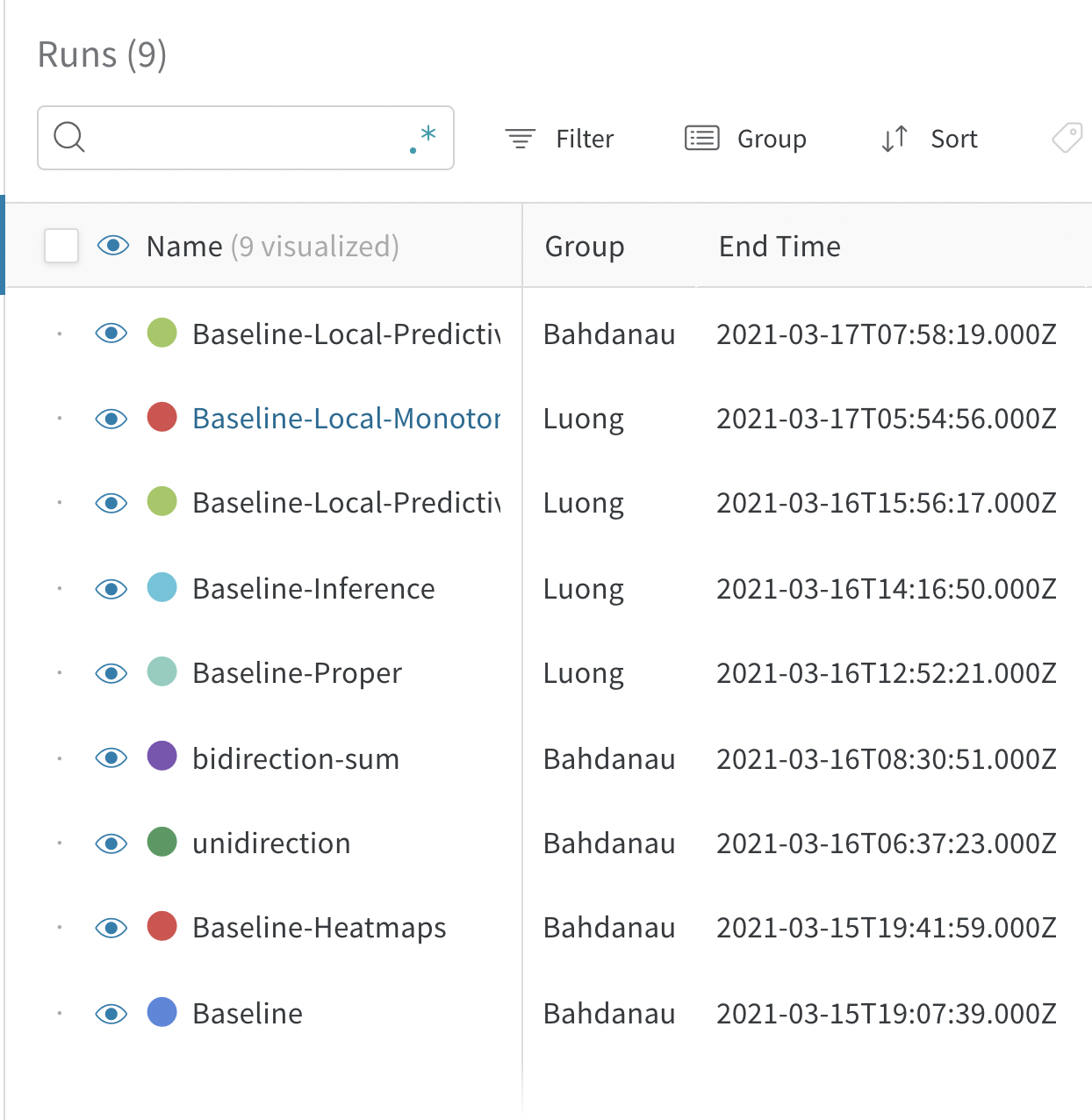
次の図は、Cécile-parker のチームメイトによって作成された複数の personal workspace を示しています。この project には、保存された view はありません。
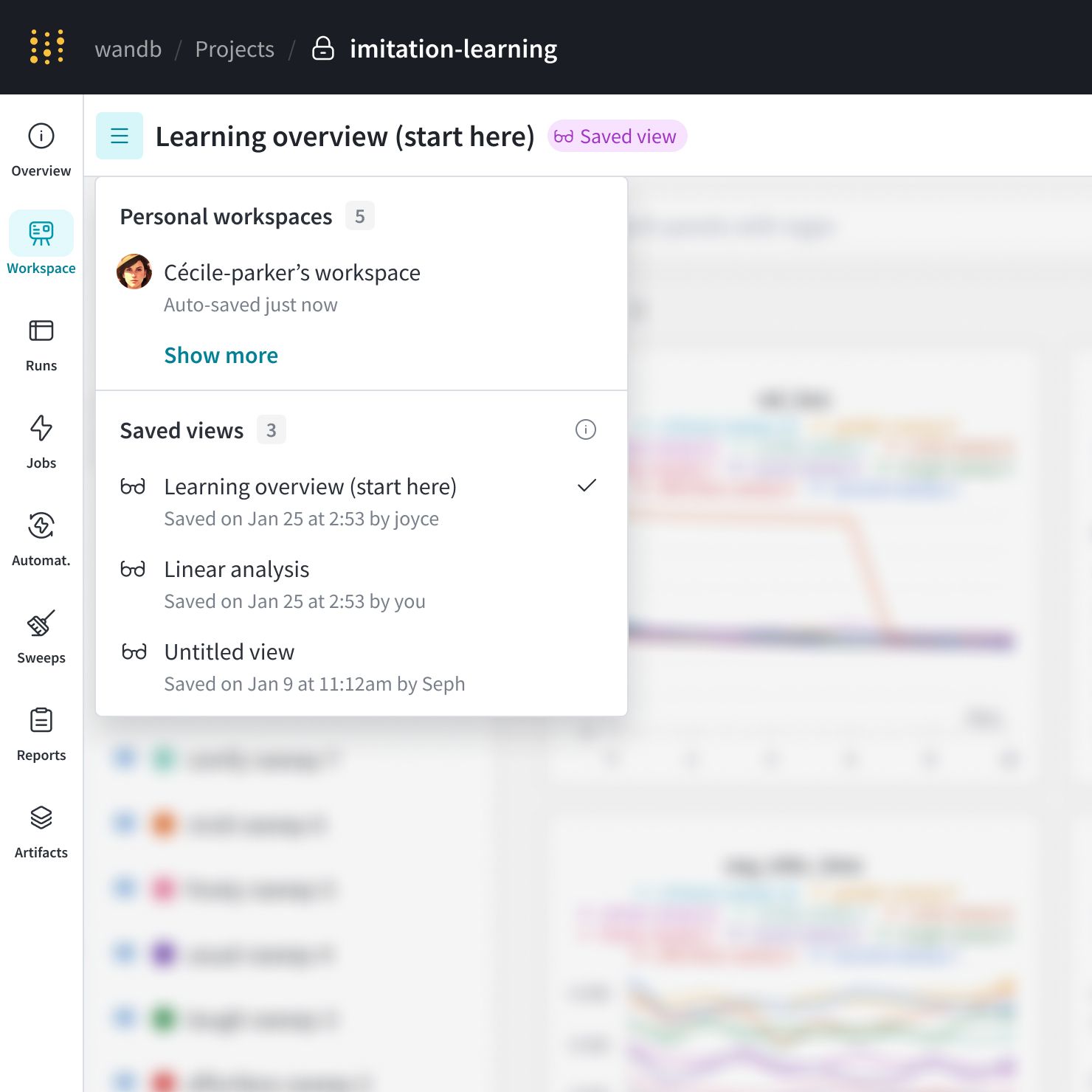
保存された workspace view
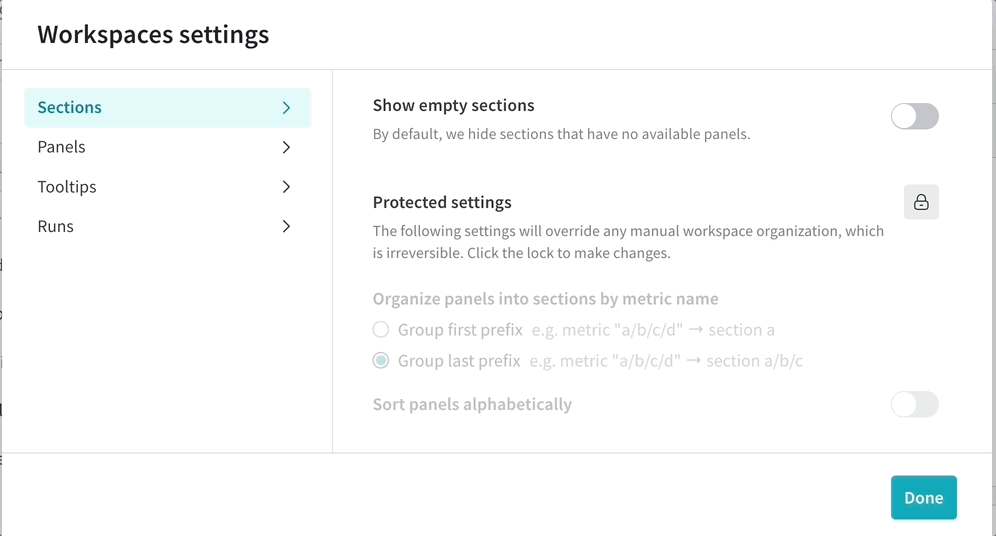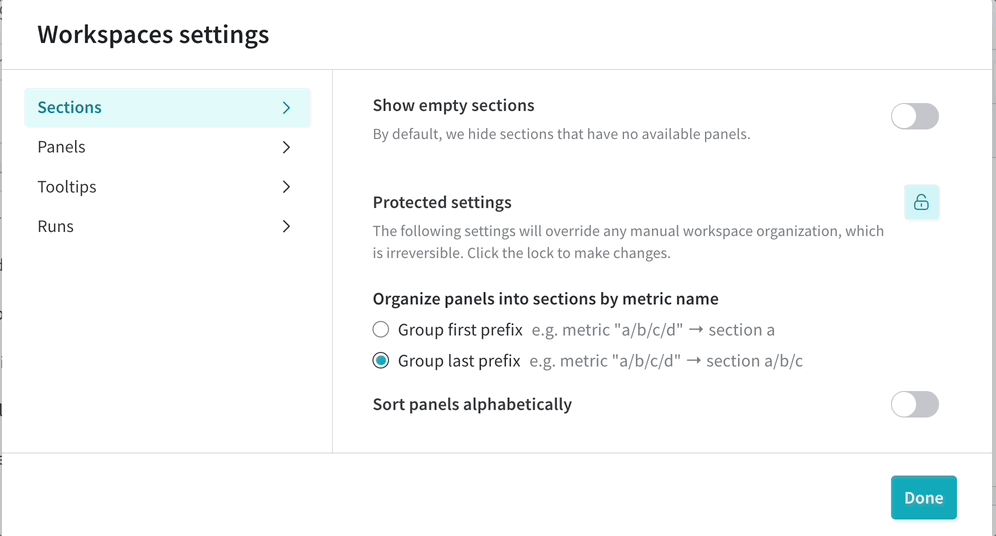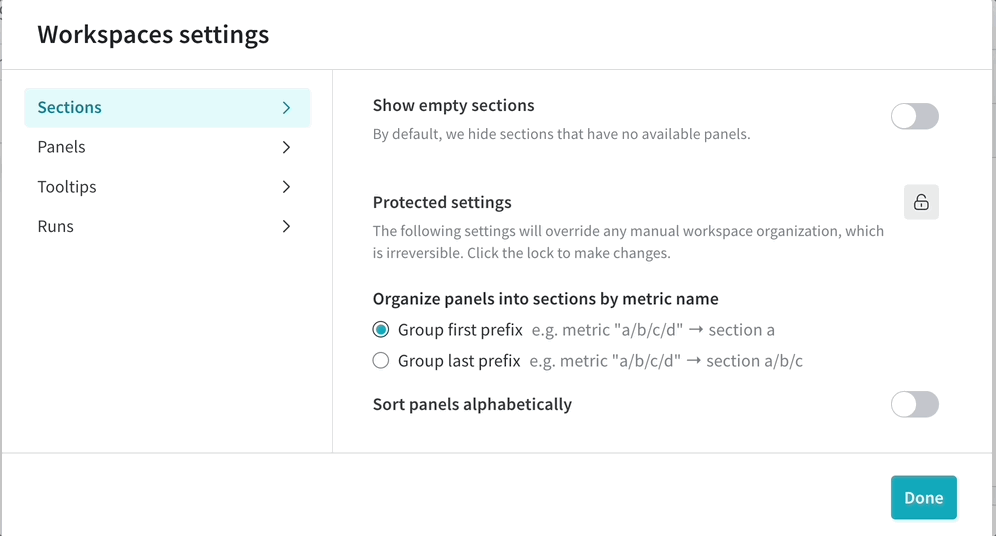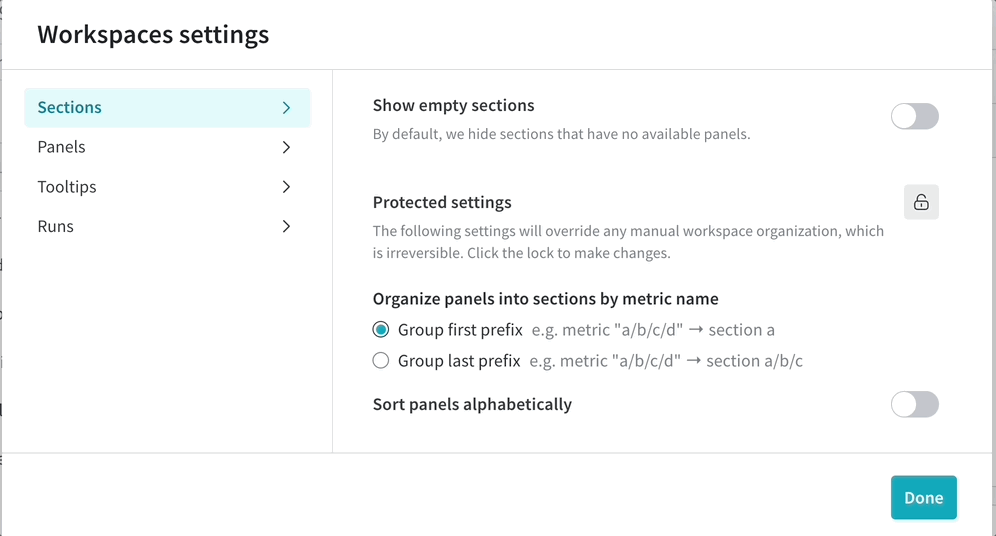
カスタマイズされた workspace view で team のコラボレーションを改善します。保存された View を作成して、チャートと data の好みの 設定 を整理します。
新しい保存済み workspace view を作成する
personal workspace または保存された view に移動します。
workspace を 編集 します。
workspace の右上隅にあるミートボールメニュー(3つの水平ドット)をクリックします。Save as a new view をクリックします。
新しい保存された view は、workspace ナビゲーションメニューに表示されます。
保存された workspace view を 更新 する
保存された変更は、保存された view の以前の状態を 上書き します。保存されていない変更は保持されません。W&B で保存された workspace view を 更新 するには:
保存された view に移動します。
workspace 内で、チャートと data に必要な変更を加えます。
Save ボタンをクリックして、変更を確定します。
workspace view への 更新 を保存すると、確認ダイアログが表示されます。今後このプロンプトを表示しない場合は、保存を確定する前に Do not show this modal next time オプションを選択してください。
保存された workspace view を 削除 する
不要になった保存された view を削除します。
削除する保存された view に移動します。
view の右上にある3つの水平線(… )を選択します。
Delete view を選択します。削除を確定して、workspace メニューから view を削除します。
workspace view を共有する
workspace の URL を直接共有して、カスタマイズされた workspace を team と共有します。workspace project への アクセス 権を持つすべての ユーザー は、その workspace の保存された View を見ることができます。
プログラムで workspace を作成する
wandb-workspacesW&B workspace と Reports をプログラムで 操作 するための Python library です。
wandb-workspaceswandb-workspacesW&B workspace と Reports をプログラムで 操作 するための Python library です。
workspace の プロパティ は、次のように定義できます。
panel の レイアウト、色、およびセクションの 順序 を 設定 します。
デフォルトのx軸、セクションの 順序 、および コラプス 状態など、workspace の 設定 を構成します。
セクション内に パネル を追加およびカスタマイズして、workspace view を整理します。
URL を使用して、既存の workspace を ロード および 変更 します。
既存の workspace への変更を保存するか、新しい view として保存します。
簡単な 式 を使用して、runs をプログラムで フィルタリング、グループ化、およびソートします。
色や 可視性 などの 設定 で、run の外観をカスタマイズします。
統合 と再利用のために、ある workspace から別の workspace に view をコピーします。
Workspace API をインストールする
wandb に加えて、wandb-workspaces をインストールしてください。
pip install wandb wandb-workspaces
プログラムで workspace view を定義して保存する
import wandb_workspaces.reports.v2 as wr
workspace = ws. Workspace(entity= "your-entity" , project= "your-project" , views= [... ])
workspace. save()
既存の view を 編集 する
existing_workspace = ws. Workspace. from_url("workspace-url" )
existing_workspace. views[0 ] = ws. View(name= "my-new-view" , sections= [... ])
existing_workspace. save()
workspace の saved view を別の workspace にコピーする
old_workspace = ws. Workspace. from_url("old-workspace-url" )
old_workspace_view = old_workspace. views[0 ]
new_workspace = ws. Workspace(entity= "new-entity" , project= "new-project" , views= [old_workspace_view])
new_workspace. save()
workspace API の包括的な例については、wandb-workspace examplesProgrammatic Workspaces チュートリアルを参照してください。
5 - What are runs?
W&B の基本的な構成要素である Runs について学びましょう。
run は、W&B によってログされる計算の単一の単位です。W&B の run は、プロジェクト全体の原子要素と考えることができます。つまり、各 run は、モデルのトレーニングと結果のログ、ハイパーパラメーターの スイープ など、特定の計算の記録です。
run を開始する一般的なパターンには、以下が含まれますが、これらに限定されません。
W&B は、作成した run を プロジェクト wandb.Api.Run
run.log でログするものはすべて、その run に記録されます。次のコードスニペットを検討してください。
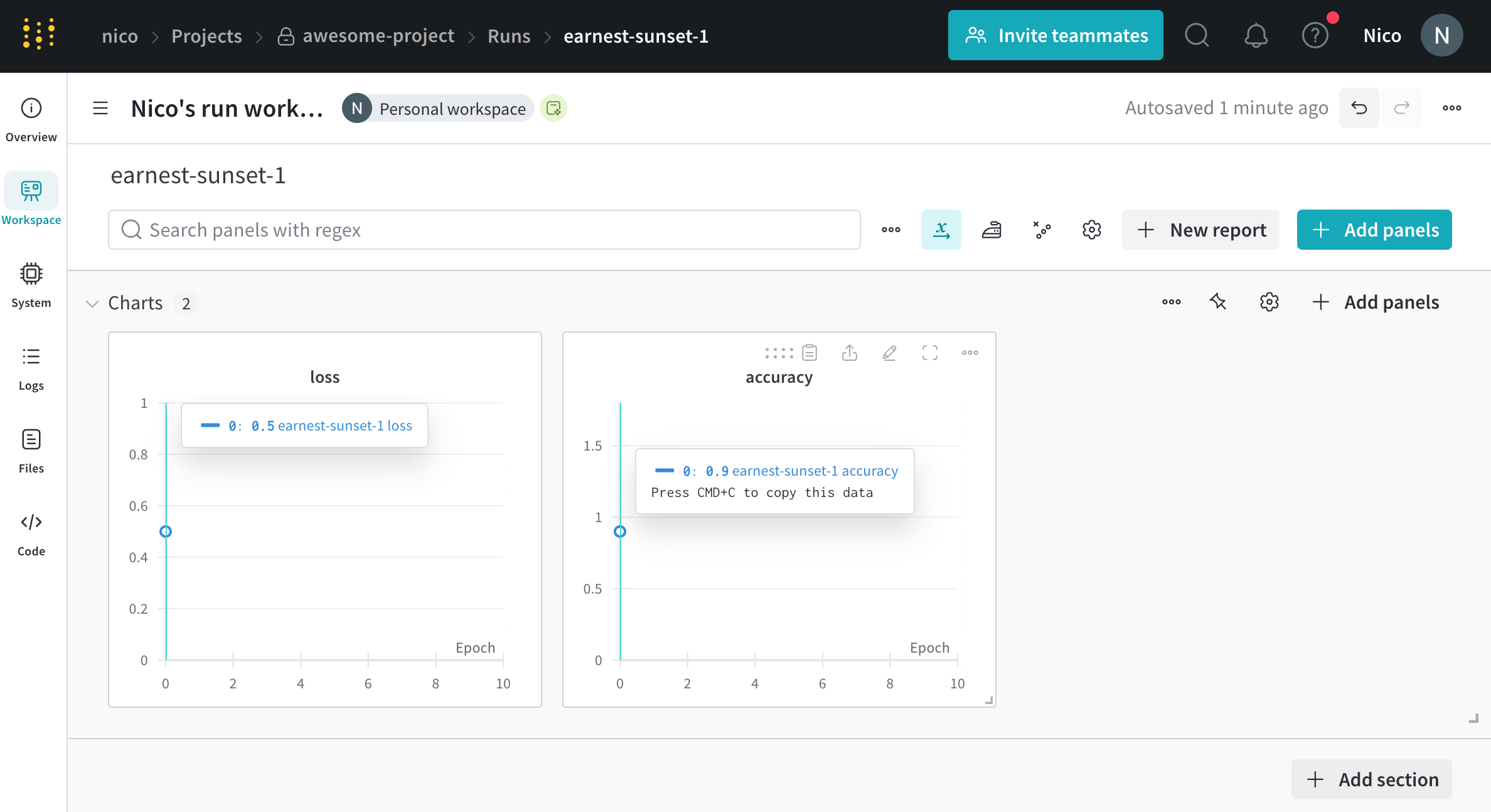
import wandb
run = wandb. init(entity= "nico" , project= "awesome-project" )
run. log({"accuracy" : 0.9 , "loss" : 0.1 })
最初の行は、W&B Python SDK をインポートします。2 行目は、エンティティ nico の下の プロジェクト awesome-project で run を初期化します。3 行目は、モデルの 精度 と 損失 をその run にログします。
ターミナル 内で、W&B は以下を返します。
wandb: Syncing run earnest-sunset-1
wandb: ⭐️ View project at https://wandb.ai/nico/awesome-project
wandb: 🚀 View run at https://wandb.ai/nico/awesome-project/runs/1jx1ud12
wandb:
wandb:
wandb: Run history:
wandb: accuracy
wandb: loss
wandb:
wandb: Run summary:
wandb: accuracy 0.9
wandb: loss 0.5
wandb:
wandb: 🚀 View run earnest-sunset-1 at: https://wandb.ai/nico/awesome-project/runs/1jx1ud12
wandb: ⭐️ View project at: https://wandb.ai/nico/awesome-project
wandb: Synced 6 W&B file( s) , 0 media file( s) , 0 artifact file( s) and 0 other file( s)
wandb: Find logs at: ./wandb/run-20241105_111006-1jx1ud12/logs
ターミナル で W&B が返す URL は、W&B App UI の run の ワークスペース にリダイレクトします。ワークスペース で生成される パネル は、単一のポイントに対応していることに注意してください。
単一の時点での メトリクス のログは、それほど役に立たない場合があります。判別モデルのトレーニングの場合のより現実的な例は、一定の間隔で メトリクス をログすることです。たとえば、次のコードスニペットを検討してください。
epochs = 10
lr = 0.01
run = wandb. init(
entity= "nico" ,
project= "awesome-project" ,
config= {
"learning_rate" : lr,
"epochs" : epochs,
},
)
offset = random. random() / 5
# simulating a training run
for epoch in range(epochs):
acc = 1 - 2 **- epoch - random. random() / (epoch + 1 ) - offset
loss = 2 **- epoch + random. random() / (epoch + 1 ) + offset
print(f "epoch= { epoch} , accuracy= { acc} , loss= { loss} " )
run. log({"accuracy" : acc, "loss" : loss})
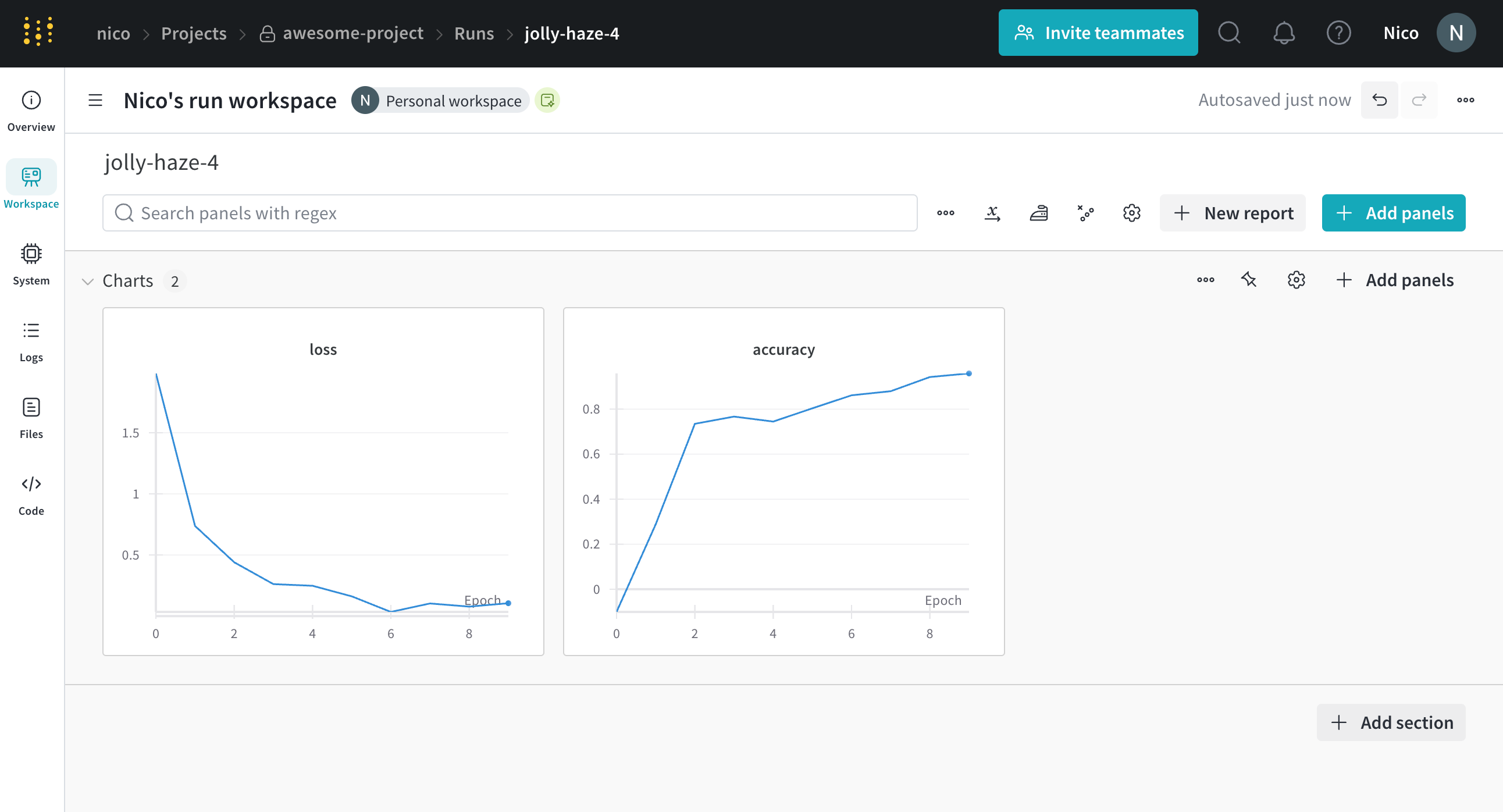
これにより、次の出力が返されます。
wandb: Syncing run jolly-haze-4
wandb: ⭐️ View project at https://wandb.ai/nico/awesome-project
wandb: 🚀 View run at https://wandb.ai/nico/awesome-project/runs/pdo5110r
lr: 0.01
epoch= 0, accuracy= -0.10070974957523078, loss= 1.985328507123956
epoch= 1, accuracy= 0.2884687745057535, loss= 0.7374362314407752
epoch= 2, accuracy= 0.7347387967382066, loss= 0.4402409835486663
epoch= 3, accuracy= 0.7667969248039795, loss= 0.26176963846423457
epoch= 4, accuracy= 0.7446848791003173, loss= 0.24808611724405083
epoch= 5, accuracy= 0.8035095836268268, loss= 0.16169791827329466
epoch= 6, accuracy= 0.861349032371624, loss= 0.03432578493587426
epoch= 7, accuracy= 0.8794926436276016, loss= 0.10331872172219471
epoch= 8, accuracy= 0.9424839917077272, loss= 0.07767793473500445
epoch= 9, accuracy= 0.9584880427028566, loss= 0.10531971149250456
wandb: 🚀 View run jolly-haze-4 at: https://wandb.ai/nico/awesome-project/runs/pdo5110r
wandb: Find logs at: wandb/run-20241105_111816-pdo5110r/logs
トレーニング スクリプト は run.log を 10 回呼び出します。スクリプト が run.log を呼び出すたびに、W&B はその エポック の 精度 と 損失 をログします。W&B が前の出力から出力する URL を選択すると、W&B App UI の run の ワークスペース に移動します。
スクリプト が wandb.init メソッド を 1 回だけ呼び出すため、W&B はシミュレートされたトレーニング ループ を jolly-haze-4 という単一の run 内でキャプチャすることに注意してください。
別の例として、sweep 中に、W&B は指定した ハイパーパラメーター 探索 空間を探索します。W&B は、sweep が作成する新しい ハイパーパラメーター の組み合わせを、一意の run として実装します。
run を初期化する
wandb.init()
山かっこ (< >) で囲まれた値を、自分の値に置き換えてください。
import wandb
run = wandb. init(entity= "<entity>" , project= "<project>" )
run を初期化すると、W&B は プロジェクト フィールド に指定した プロジェクト (wandb.init(project="<project>" に run をログします。W&B は、 プロジェクト がまだ存在しない場合は、新しい プロジェクト を作成します。プロジェクト がすでに存在する場合は、W&B はその プロジェクト に run を保存します。
プロジェクト 名を指定しない場合、W&B は run を Uncategorized という プロジェクト に保存します。
W&B の各 run には、run ID と呼ばれる一意の識別子があります一意の ID を指定する か、W&B に ID をランダムに生成させる ことができます。
各 run には、人間が読める run 名 としても知られる一意でない識別子もあります
たとえば、次のコードスニペットを考えてみましょう。
import wandb
run = wandb. init(entity= "wandbee" , project= "awesome-project" )
コードスニペット は、次の出力を生成します。
🚀 View run exalted-darkness-6 at:
https://wandb.ai/nico/awesome-project/runs/pgbn9y21
Find logs at: wandb/run-20241106_090747-pgbn9y21/logs
上記の コード が id パラメータ の 引数 を指定しなかったため、W&B は一意の run ID を作成します。nico は run をログした エンティティ 、awesome-project は run がログされる プロジェクト の名前、exalted-darkness-6 は run の名前、pgbn9y21 は run ID です。
Notebook users run の最後に run.finish() を指定して、run が完了したことを示します。これにより、run が プロジェクト に適切にログされ、バックグラウンド で継続されないようになります。
import wandb
run = wandb. init(entity= "<entity>" , project= "<project>" )
# Training code, logging, and so forth
run. finish()
各 run には、run の現在のステータス を記述する 状態 があります。可能な run の 状態 の完全なリストについては、Run の 状態 を参照してください。
Run の 状態
次のテーブルは、run がとりうる 状態 を記述しています。
状態
説明
Finished
run が終了し、 完全に データ が同期されたか、wandb.finish() が呼び出されました
Failed
run が 0 以外の終了ステータス で終了しました
Crashed
run が 内部 プロセス で ハートビート の送信を停止しました。これは、 マシン が クラッシュ した場合に発生する可能性があります
Running
run はまだ実行中で、最近 ハートビート を送信しました
一意の run 識別子
Run ID は、run の一意の識別子です。デフォルトでは、新しい run を初期化すると、W&B が ランダム で一意の run ID を生成します 。run を初期化するときに、独自の 一意の run ID を指定する こともできます。
自動生成された run ID
run を初期化するときに run ID を指定しない場合、W&B は ランダム な run ID を生成します。run の一意の ID は、W&B App UI で確認できます。
https://wandb.ai/home の W&B App UI に移動します。run の初期化時に指定した W&B プロジェクト に移動します。
プロジェクト の ワークスペース 内で、[Runs ] タブ を選択します。
[Overview ] タブ を選択します。
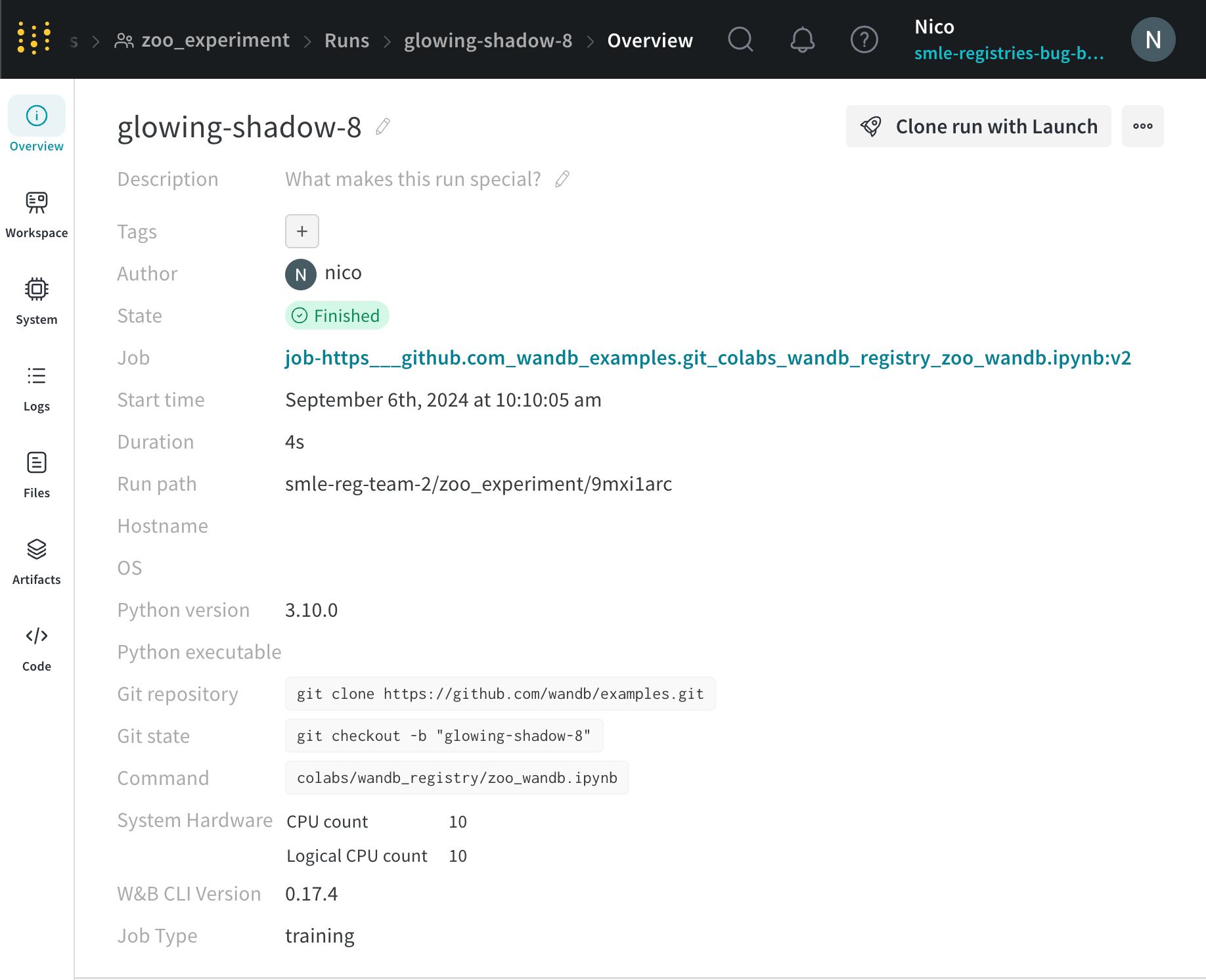
W&B は、[Run パス ] フィールド に一意の run ID を表示します。run パス は、 チーム の名前、 プロジェクト の名前、run ID で構成されます。一意の ID は、run パス の最後の部分です。
たとえば、次の図では、一意の run ID は 9mxi1arc です。
カスタム run ID
wandb.initid パラメータ を渡すことで、独自の run ID を指定できます。
import wandb
run = wandb. init(entity= "<project>" , project= "<project>" , id= "<run-id>" )
run の一意の ID を使用して、W&B App UI で run の Overview ページ に直接移動できます。次のセルは、特定の run の URL パス を示しています。
https://wandb.ai/<entity>/<project>/<run-id>
山かっこ (< >) で囲まれた値は、エンティティ 、 プロジェクト 、run ID の実際の値の プレースホルダー です。
run に名前を付ける
run の名前は、人間が読める一意でない識別子です。
デフォルトでは、W&B は新しい run を初期化するときに ランダム な run 名を生成します。run の名前は、 プロジェクト の ワークスペース 内と、run の Overview ページ の上部に表示されます。
run 名は、 プロジェクト ワークスペース で run をすばやく識別する方法として使用します。
wandb.initname パラメータ を渡すことで、run の名前を指定できます。
import wandb
run = wandb. init(entity= "<project>" , project= "<project>" , name= "<run-name>" )
run にメモを追加する
特定の run に追加するメモは、[Overview ] タブ の run ページ と、 プロジェクト ページ の run のテーブルに表示されます。
W&B プロジェクト に移動します
プロジェクト サイドバー から [Workspace ] タブ を選択します
run セレクター からメモを追加する run を選択します
[Overview ] タブ を選択します
[Description ] フィールド の横にある 鉛筆 アイコン を選択し、メモを追加します
run を停止する
W&B App または プログラム で run を停止します。
run を初期化した ターミナル または コード エディタ に移動します。
Ctrl+D を押して run を停止します。
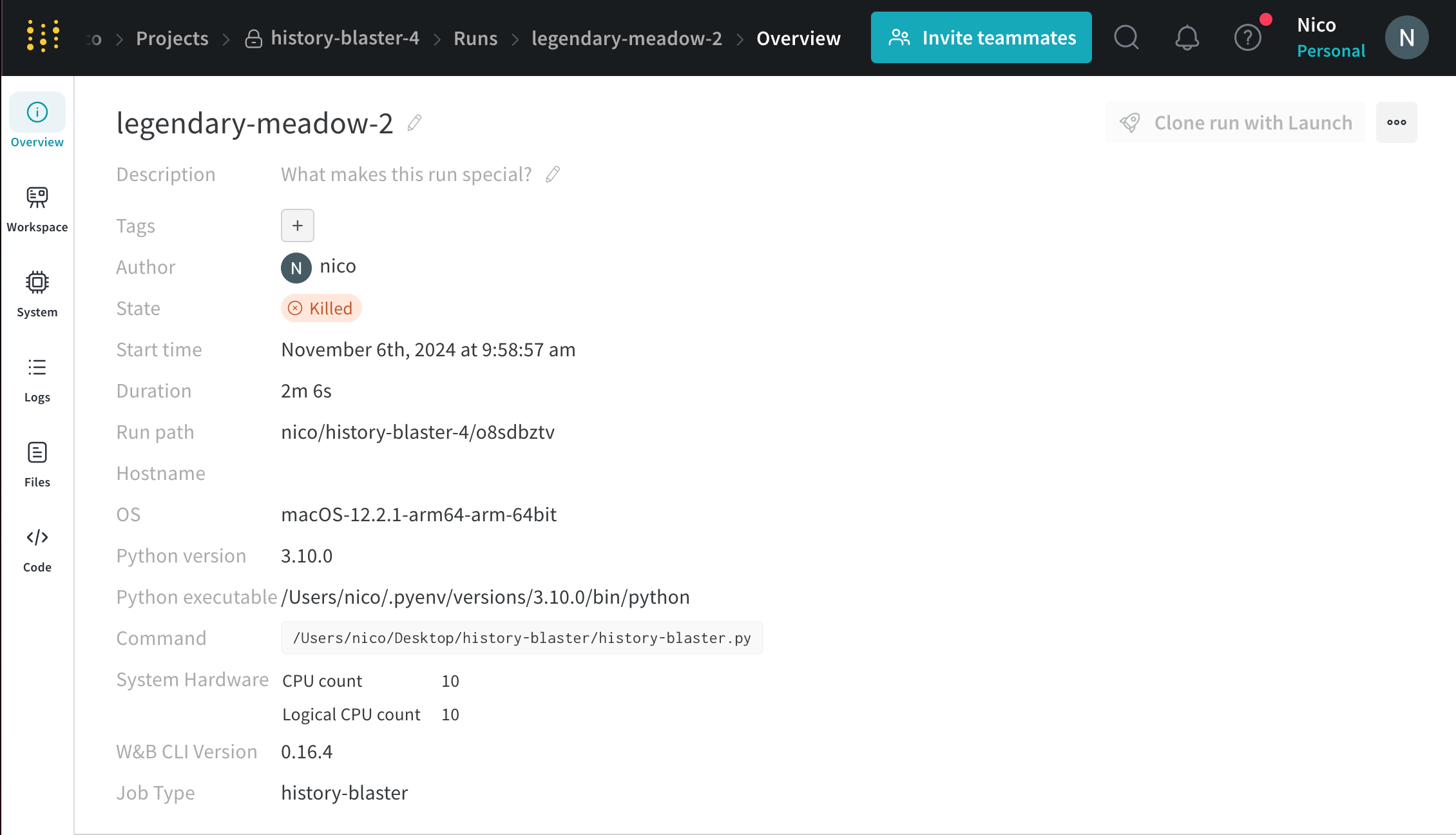
たとえば、上記の手順に従うと、 ターミナル は次のようになります。
KeyboardInterrupt
wandb: 🚀 View run legendary-meadow-2 at: https://wandb.ai/nico/history-blaster-4/runs/o8sdbztv
wandb: Synced 5 W&B file( s) , 0 media file( s) , 0 artifact file( s) and 1 other file( s)
wandb: Find logs at: ./wandb/run-20241106_095857-o8sdbztv/logs
W&B App UI に移動して、run が アクティブ でなくなったことを確認します。
run がログされている プロジェクト に移動します。
run の名前を選択します。
停止する run の名前は、 ターミナル または コード エディタ の出力から確認できます。たとえば、上記の例では、run の名前は legendary-meadow-2 です。
3. プロジェクト サイドバー から [**Overview**] タブ を選択します。
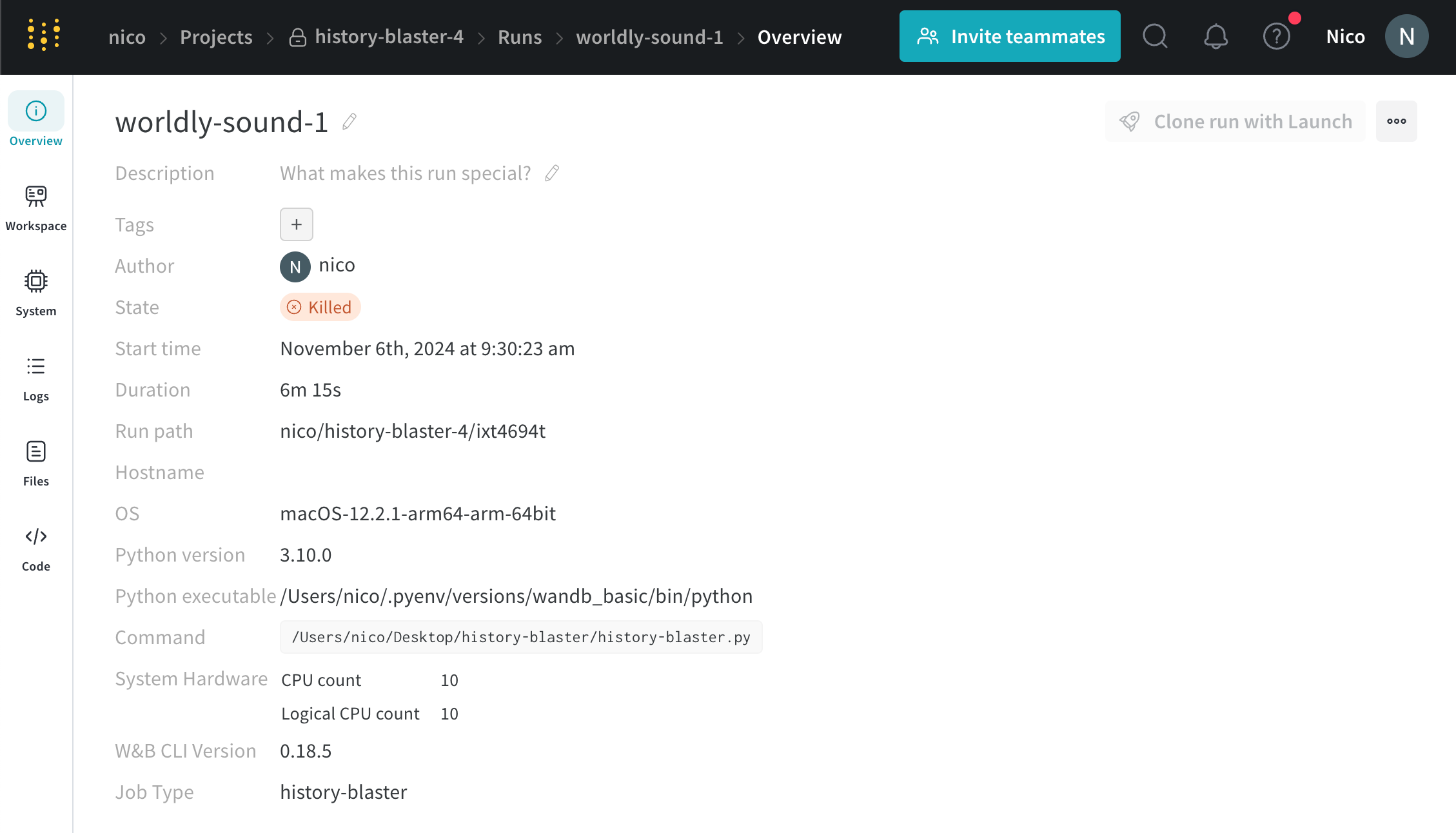
[State ] フィールド の横で、run の 状態 が running から Killed に変わります。
run がログされている プロジェクト に移動します。
run セレクター 内で停止する run を選択します。
プロジェクト サイドバー から [Overview ] タブ を選択します。
[State ] フィールド の横にある上部の ボタン を選択します。
[State ] フィールド の横で、run の 状態 が running から Killed に変わります。
可能な run の 状態 の完全なリストについては、State フィールド を参照してください。
ログに記録された run を表示する
run の 状態、run にログされた Artifacts、run 中に記録された ログ ファイル など、特定の run に関する情報を表示します。
特定の run を表示するには:
https://wandb.ai/home の W&B App UI に移動します。
run の初期化時に指定した W&B プロジェクト に移動します。
プロジェクト サイドバー 内で、[Workspace ] タブ を選択します。
run セレクター 内で、表示する run をクリックするか、run 名の一部を入力して、一致する run を フィルター します。
デフォルトでは、長い run 名は読みやすくするために中央で切り捨てられます。代わりに、run 名を先頭または末尾で切り捨てるには、run のリストの上部にある アクション ... メニュー をクリックし、[Run 名のトリミング ] を設定して、末尾、中央、または先頭をトリミングします。
特定の run の URL パス には、次の形式があることに注意してください。
https://wandb.ai/<team-name>/<project-name>/runs/<run-id>
山かっこ (< >) で囲まれた値は、 チーム 名、 プロジェクト 名、run ID の実際の値の プレースホルダー です。
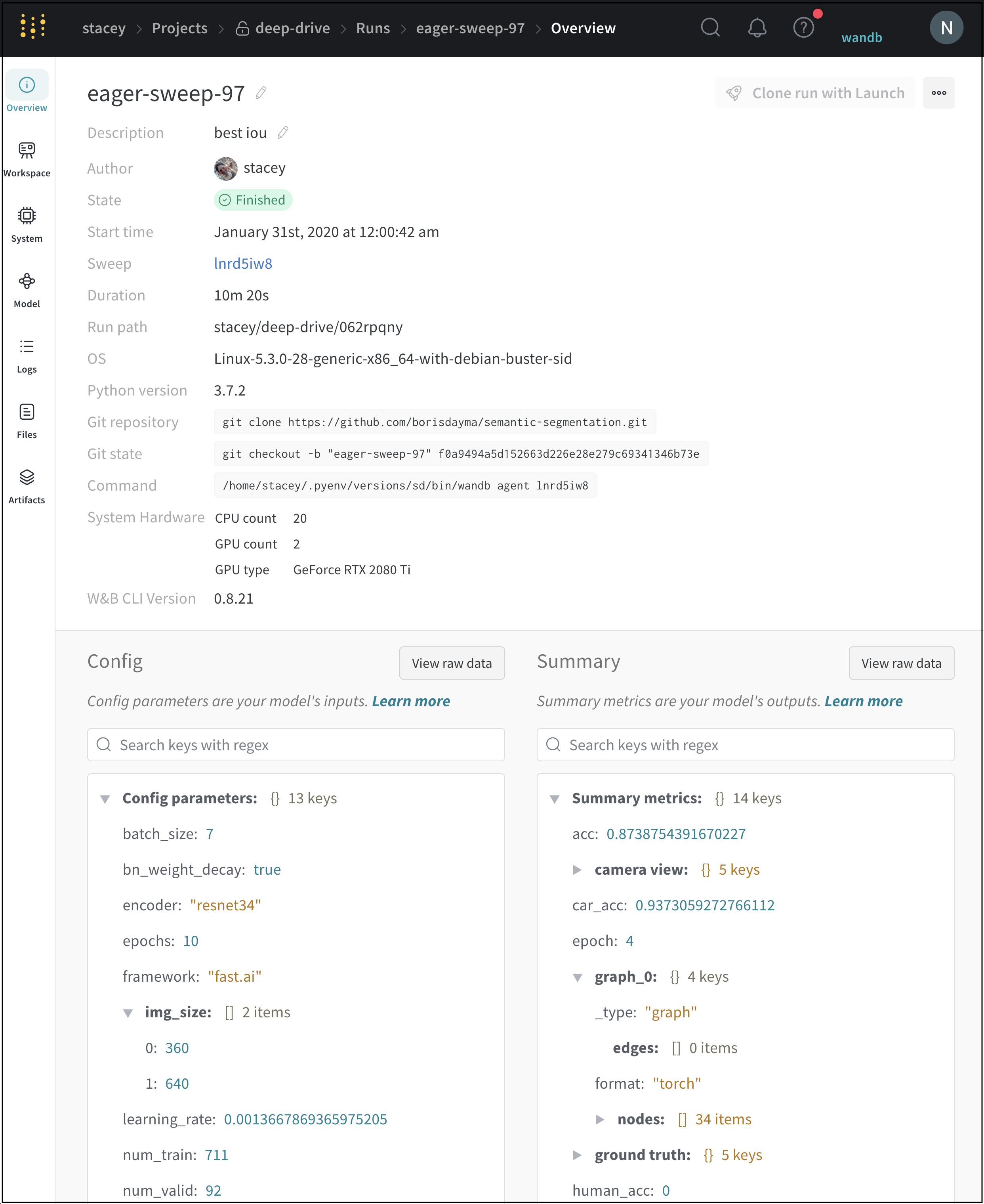
Overviewタブ
[Overview ] タブ を使用して、 プロジェクト 内の特定の run 情報について学習します。次に例を示します。
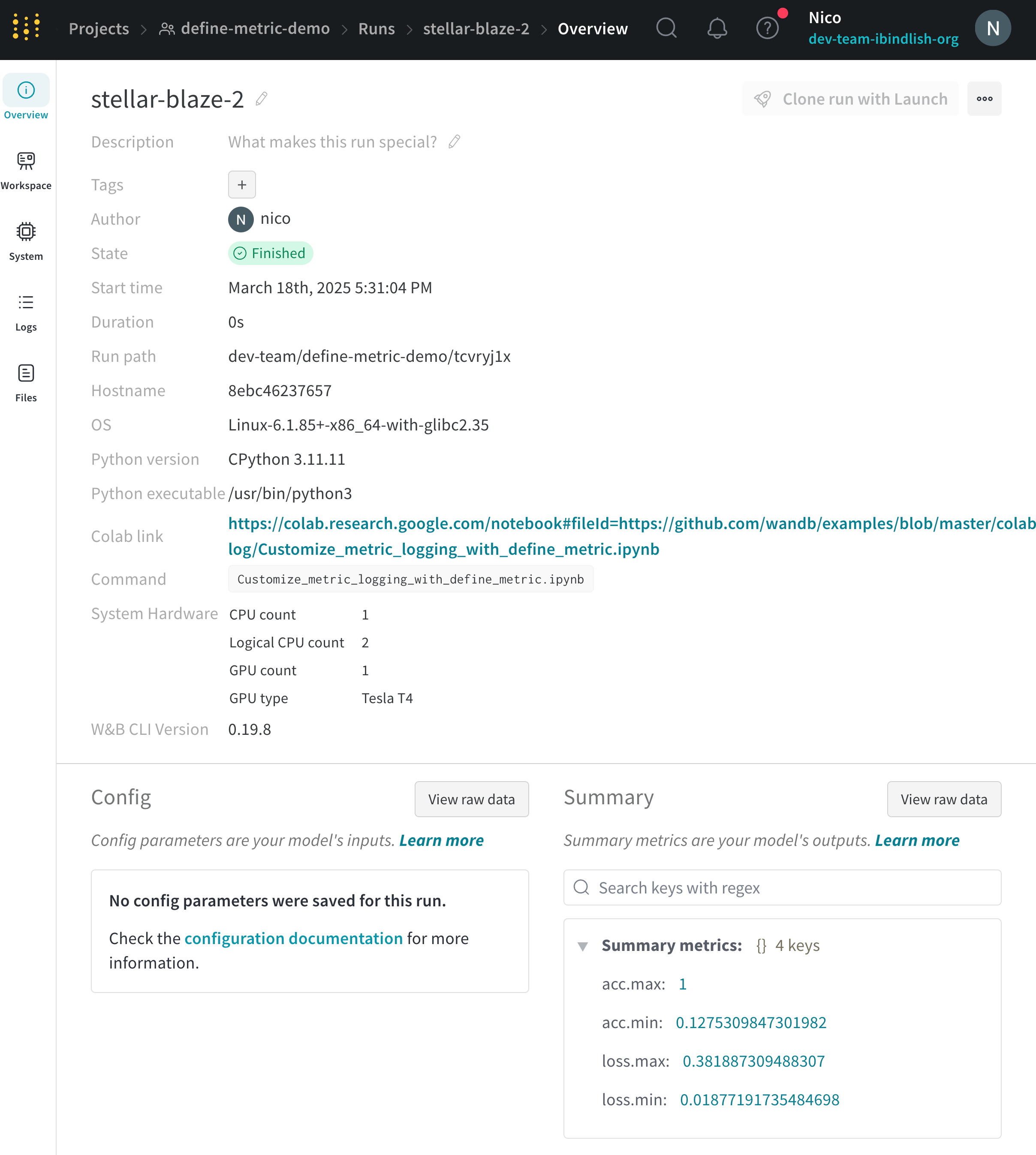
Author : run を作成する W&B エンティティ 。Command : run を初期化する コマンド 。Description : 提供した run の説明。run の作成時に説明を指定しない場合、このフィールド は空です。W&B App UI を使用するか、Python SDK で プログラム で説明を run に追加できます。Duration : run が アクティブ に計算または データ をログしている時間。一時停止または待機は除きます。Git リポジトリ : run に関連付けられている git リポジトリ。git を有効にする して、このフィールド を表示する必要があります。Host name : W&B が run を計算する場所。 マシン で ローカル に run を初期化する場合は、 マシン の名前が表示されます。Name : run の名前。OS : run を初期化する オペレーティング システム 。Python 実行可能ファイル : run を開始する コマンド 。Python バージョン : run を作成する Python バージョン を指定します。Run パス : entity/project/run-ID の形式で一意の run 識別子を識別します。Runtime : run の開始から終了までの合計時間を測定します。これは、run の ウォール クロック 時間です。Runtime には、run が一時停止している時間または リソース を待機している時間が含まれますが、Duration は含まれません。Start time : run を初期化する タイムスタンプ 。State : run の 状態 。System hardware : W&B が run の計算に使用する ハードウェア 。Tags : 文字列のリスト。タグ は、関連する run をまとめて編成したり、baseline や production などの一時的なラベル を適用したりするのに役立ちます。W&B CLI バージョン : run コマンド を ホスト した マシン にインストールされている W&B CLI バージョン 。
W&B は、概要セクション の下に次の情報を保存します。
Artifact Outputs : run によって生成された Artifacts 出力。Config : wandb.configSummary : wandb.log()
プロジェクト の概要の例はこちら をご覧ください。
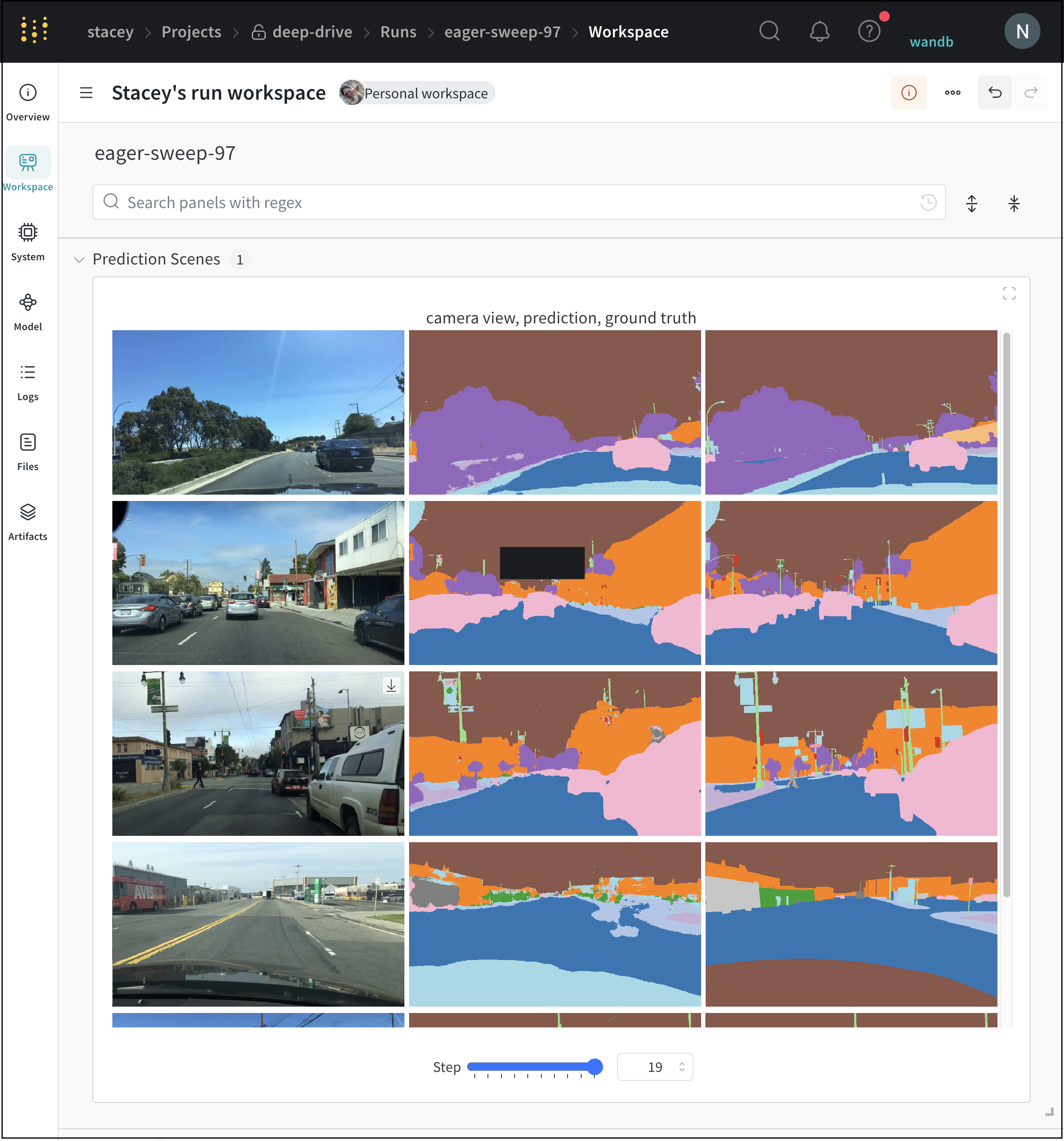
Workspaceタブ
[Workspace] タブ を使用して、自動生成された カスタム プロット 、 システム メトリクス など、 可視化 を表示、検索、 グループ化 、および配置します。
プロジェクト ワークスペース の例はこちら をご覧ください
Runsタブ
[Runs] タブ を使用して、run を フィルター 、 グループ化 、および並べ替えます。
次のタブ は、[Runs] タブ で実行できる一般的な アクション の一部を示しています。
Customize columns
Sort
Filter
Group
[Runs] タブ には、 プロジェクト 内の run に関する詳細が表示されます。デフォルトでは、多数の 列 が表示されます。
表示されているすべての 列 を表示するには、 ページ を水平方向に スクロール します。
列 の順序を変更するには、 列 を左または右に ドラッグ します。
列 を ピン留め するには、 列 名の上に カーソル を置き、表示される アクション メニュー ... をクリックし、[Pin column ] をクリックします。ピン留め された 列 は、[Name ] 列 の後、 ページ の左側の近くに表示されます。ピン留め された 列 の ピン留め を解除するには、[Unpin column ] を選択します
列 を非表示にするには、 列 名の上に カーソル を置き、表示される アクション メニュー ... をクリックし、[Hide column ] をクリックします。現在非表示になっているすべての 列 を表示するには、[Columns ] をクリックします。
複数の 列 を一度に表示、非表示、 ピン留め 、および ピン留め 解除するには、[Columns ] をクリックします。
非表示の 列 の名前をクリックして、非表示を解除します。
表示されている 列 の名前をクリックして、非表示にします。
表示されている 列 の横にある ピン アイコン をクリックして ピン留め します。
[Runs] タブ を カスタマイズ すると、 カスタマイズ はWorkspace タブ の [Runs ] セレクター にも反映されます。
指定された 列 の値で テーブル 内のすべての行を並べ替えます。
マウス を 列 タイトル の上に移動します。ケバブ メニュー (3 つの垂直 ドット) が表示されます。
ケバブ メニュー (3 つの垂直 ドット) を選択します。
[Sort Asc ] または [Sort Desc ] を選択して、行をそれぞれ 昇順 または 降順 に並べ替えます。
上の図は、val_acc という名前の テーブル 列 の並べ替え オプション を表示する方法を示しています。
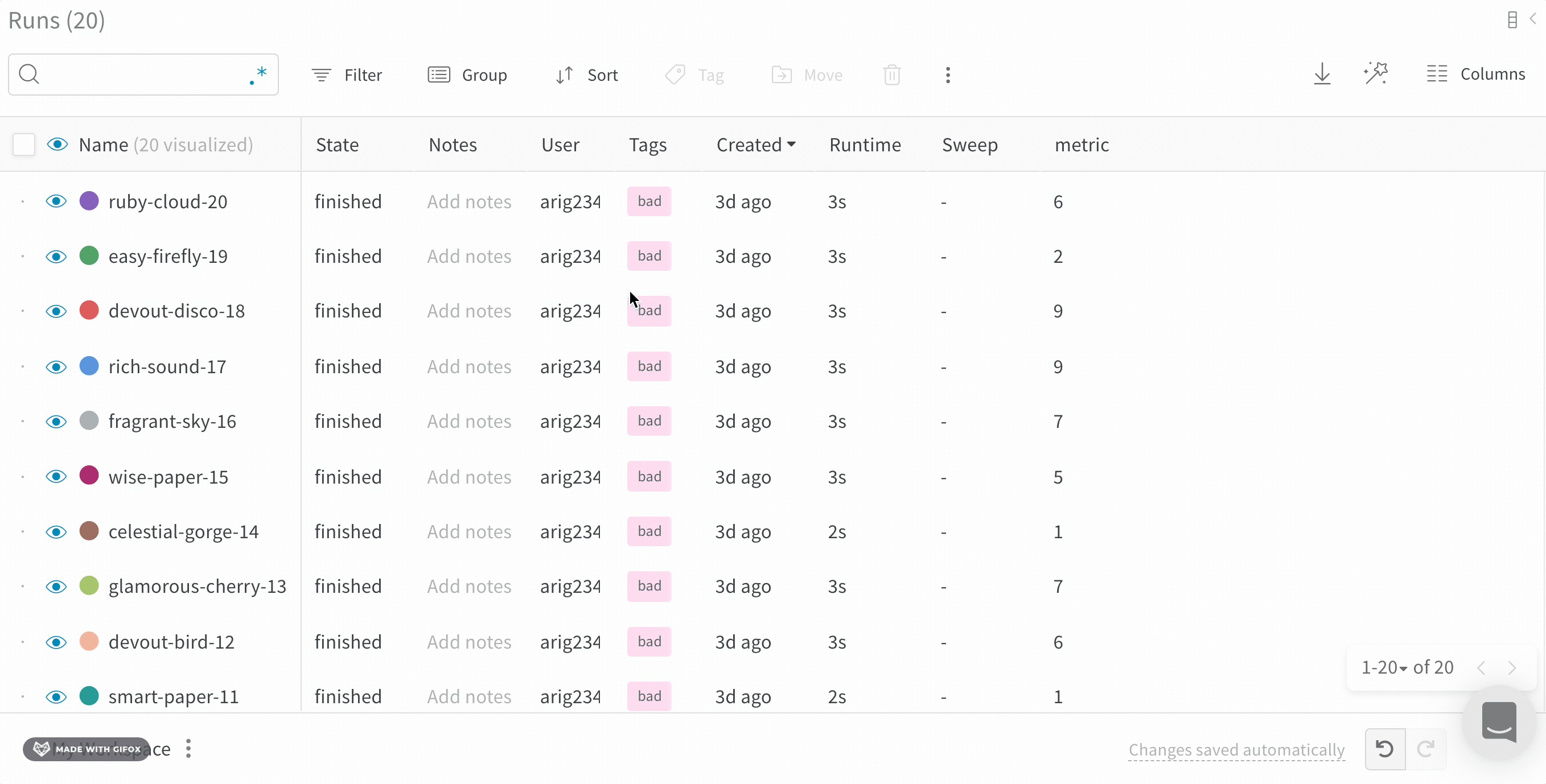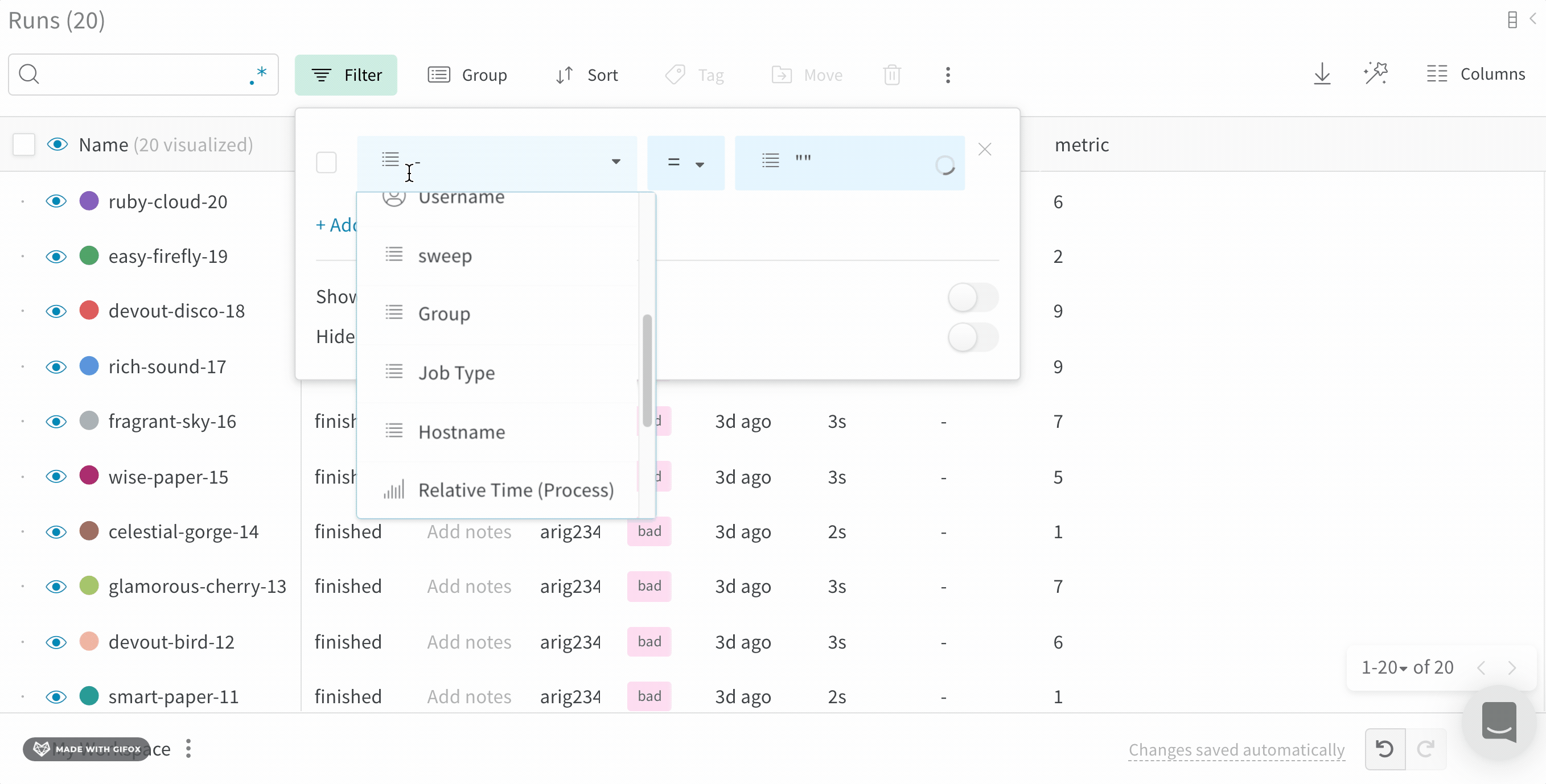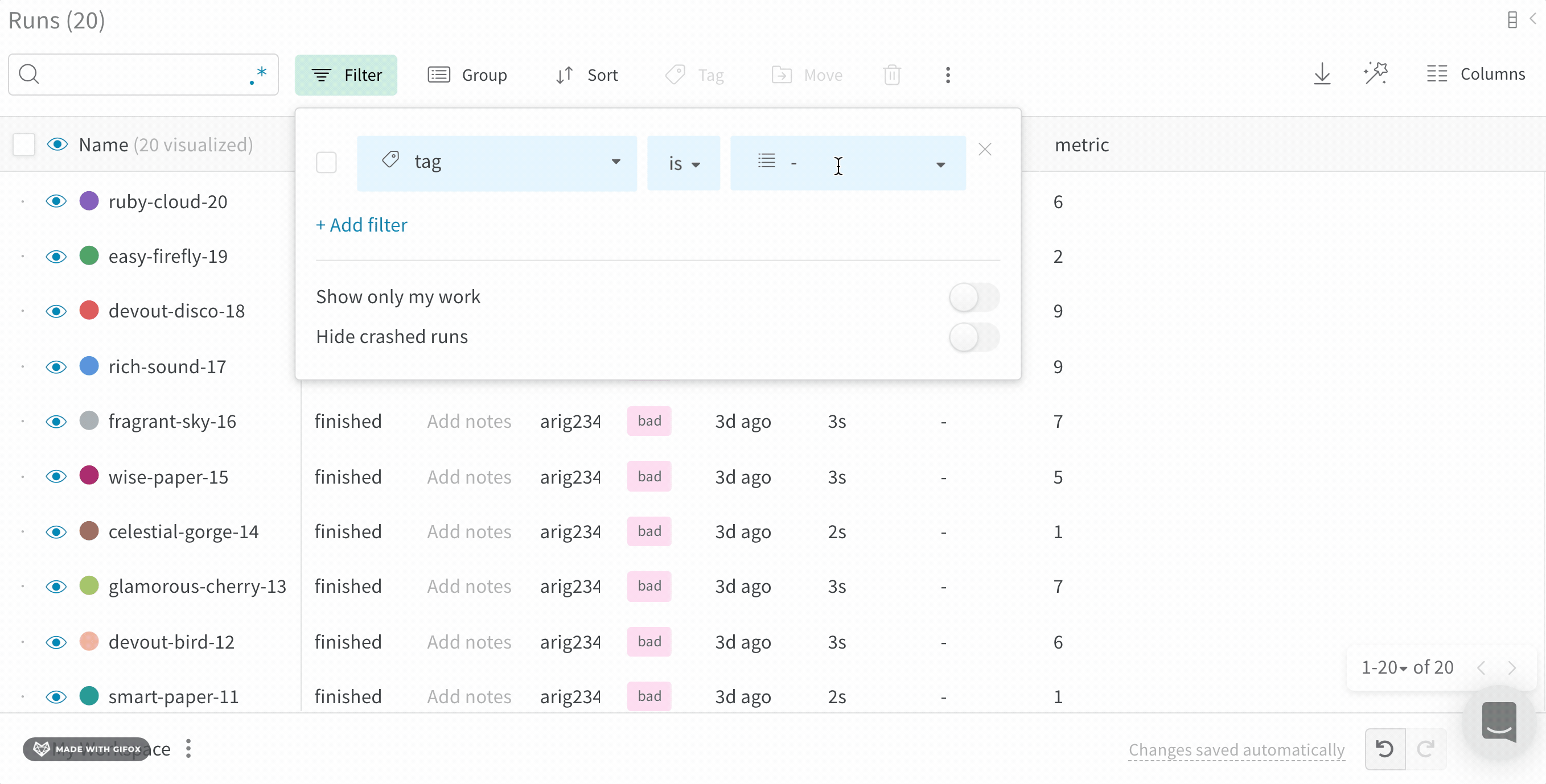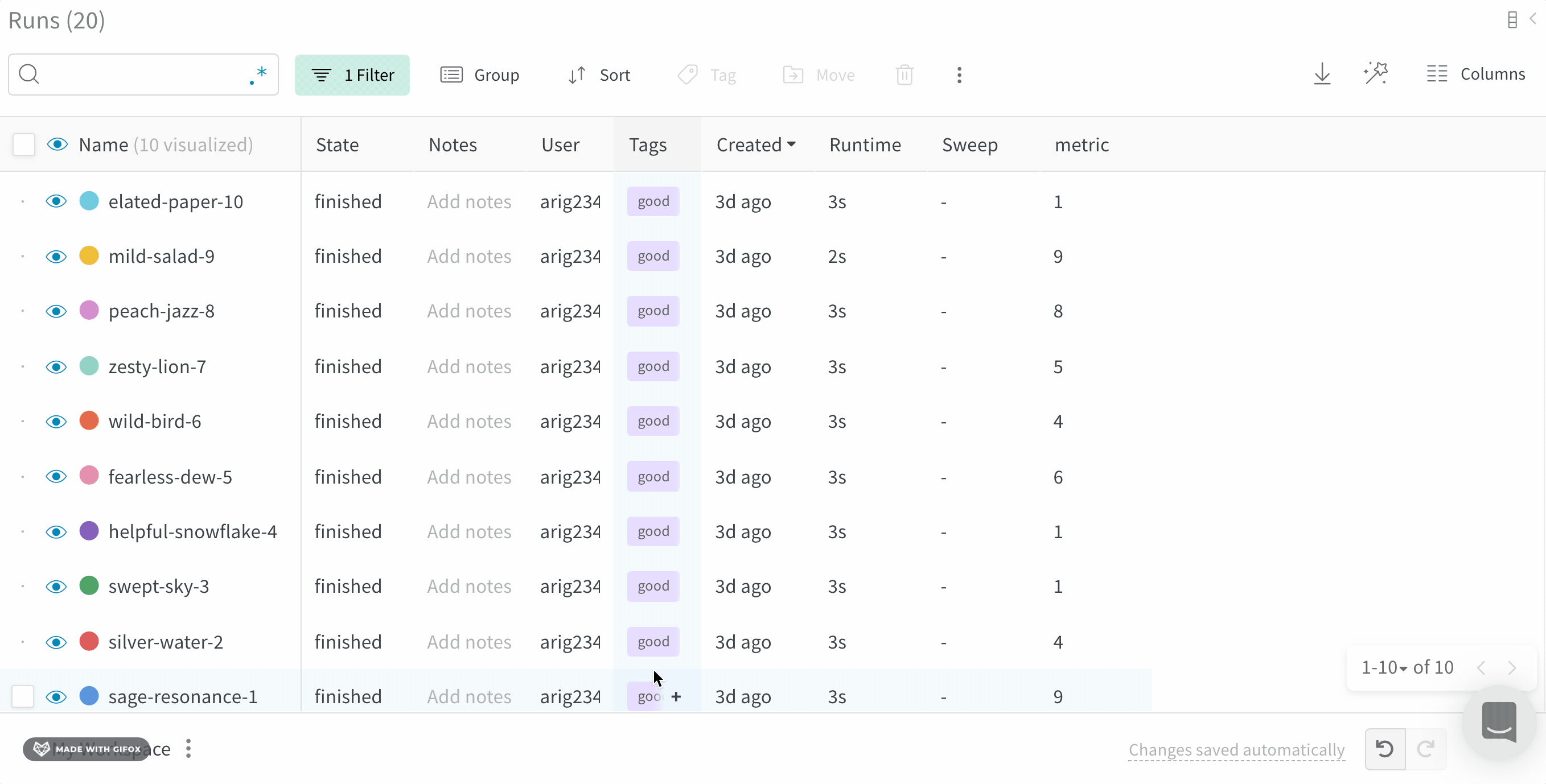
ダッシュボード の上にある [Filter ] ボタン を使用して、 式 で すべての行を フィルター します。
[Add filter ] を選択して、1 つまたは複数の フィルター を行に追加します。3 つの ドロップダウン メニュー が表示されます。左から右への フィルター タイプ は、 列 名、 オペレーター 、および値に基づいています
列 名
二項関係
値
受け入れられる値
文字列
=, ≠, ≤, ≥, IN, NOT IN,
整数, float, 文字列, タイムスタンプ , null
式 エディター には、 列 名のオートコンプリート と論理述語構造を使用して、各 項 の オプション のリストが表示されます。「and」または「or」(および場合によっては 括弧 ) を使用して、複数の論理述語を 1 つの 式 に接続できます。
上の図は、`val_loss` 列 に基づく フィルター を示しています。この フィルター は、 検証 損失 が 1 以下 の run を表示します。
ダッシュボード の上にある [Group by ] ボタン を使用して、特定の 列 の値で行を グループ化 します。
デフォルトでは、これにより、他の数値 列 が、その グループ 全体の 列 の値の分布を示す ヒストグラム に変わります。グループ化 は、 データ のより高レベルの パターン を理解するのに役立ちます。
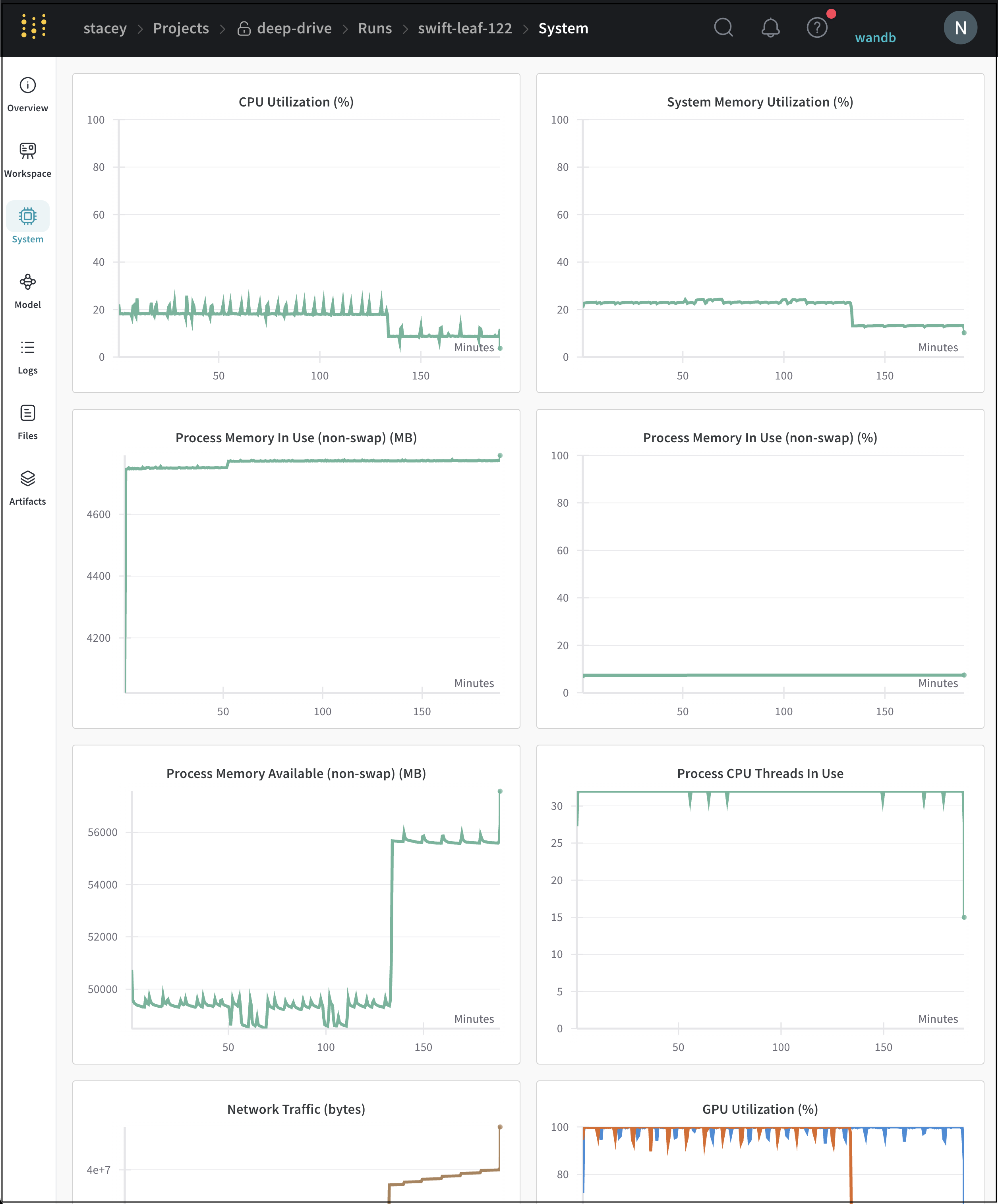
Systemタブ
[System タブ ] には、CPU 使用率、 システム メモリ 、 ディスク I/O、 ネットワーク トラフィック、GPU 使用率など、特定の run に対して追跡される システム メトリクス が表示されます。
W&B が追跡する システム メトリクス の完全なリストについては、System メトリクス を参照してください。
システム タブ の例はこちら をご覧ください。
Logsタブ
[Log タブ ] には、 コマンドライン に出力された出力 (標準出力 (stdout) や 標準 エラー (stderr) など) が表示されます。
右上隅にある [Download ] ボタン を選択して、 ログ ファイル をダウンロードします。
ログ タブ の例はこちら をご覧ください。
Filesタブ
[Files タブ ] を使用して、モデル チェックポイント 、 検証 セット の例など、特定の run に関連付けられた ファイル を表示します
ファイル タブ の例はこちら をご覧ください。
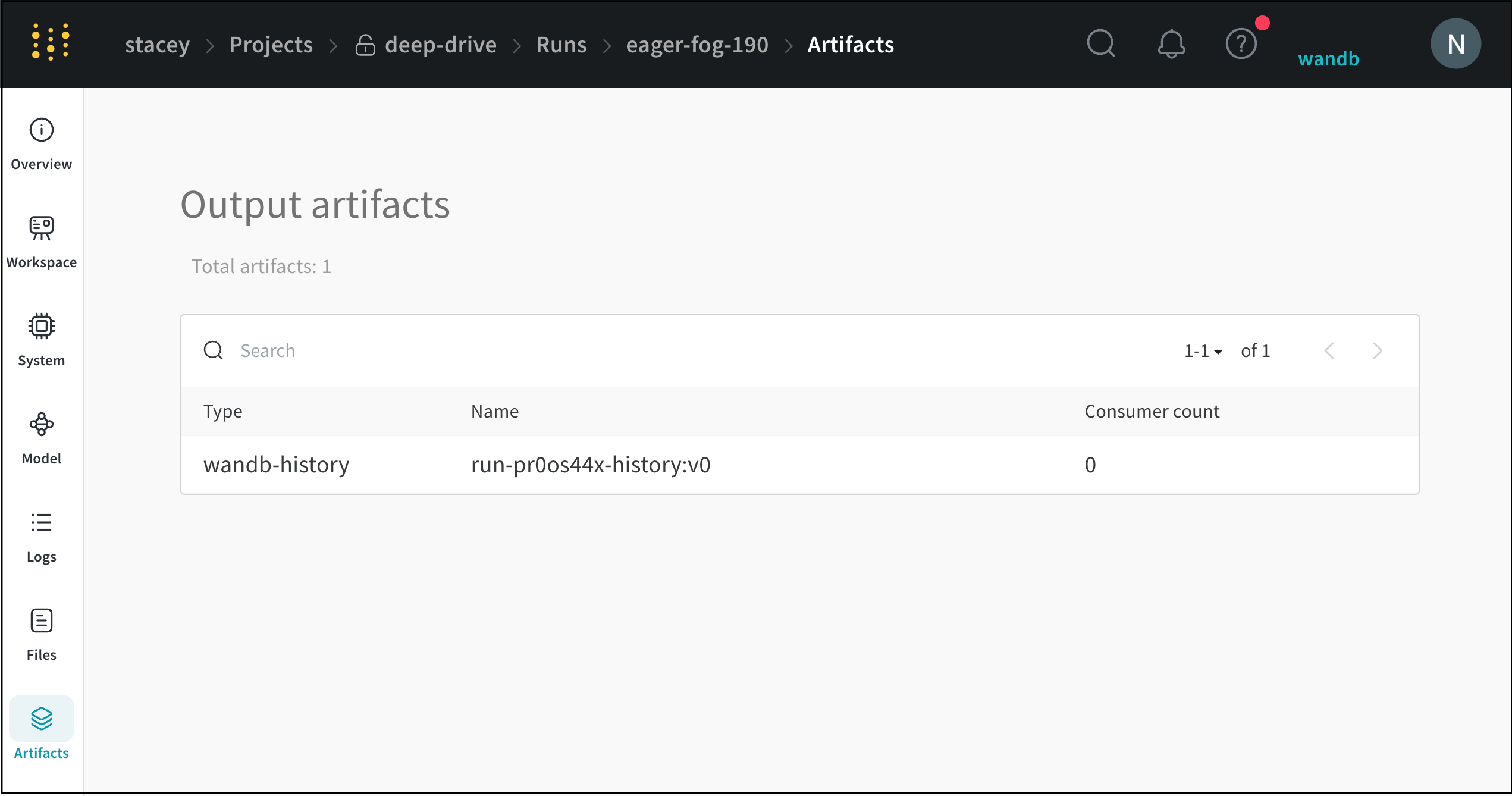
Artifactsタブ
[Artifacts ] タブ には、指定された run の 入力 および 出力 アーティファクト が一覧表示されます。
アーティファクト タブ の例はこちら をご覧ください。
run を削除する
W&B App を使用して、 プロジェクト から 1 つまたは複数の run を削除します。
削除する run が含まれている プロジェクト に移動します。
プロジェクト サイドバー から [Runs ] タブ を選択します。
削除する run の横にある チェックボックス をオンにします。
テーブル の上にある [Delete ] ボタン ( ゴミ箱 アイコン ) を選択します。
表示される モーダル から、[Delete ] を選択します。
特定の ID を持つ run が削除されると、その ID を再度使用できなくなる場合があります。以前に削除された ID で run を開始しようとすると、 エラー が表示され、開始が防止されます。
多数の run を含む プロジェクト の場合、検索バー を使用して 正規表現 を使用して削除する run を フィルター するか、 フィルター ボタン を使用して、ステータス 、 タグ 、またはその他のプロパティ に基づいて run を フィルター できます。
run を整理する
このセクション では、 グループ と ジョブタイプ を使用して run を整理する方法について説明します。run を グループ (たとえば、 実験 名) に割り当て、 ジョブタイプ (たとえば、 前処理 、 トレーニング 、 評価 、 デバッグ ) を指定することで、 ワークフロー を効率化し、モデル の比較を改善できます。
run に グループ または ジョブタイプ を割り当てる
W&B の各 run は、[グループ ] と [ジョブタイプ ] で 分類 できます。
グループ : 実験 の広範な カテゴリ で、run の整理と フィルター に使用されます。ジョブタイプ : preprocessing、training、evaluation など、run の 機能 。
次のワークスペース の例 では、Fashion-MNIST データセット から 増え続ける量の データ を使用して ベースライン モデル を トレーニング します。ワークスペース では、使用される データ 量を色で表します。
黄色から濃い緑 は、 ベースライン モデル の データ 量が増加していることを示します。水色からバイオレット、マゼンタ は、追加の パラメータ を持つ、より複雑な「double」モデルの データ 量を示します。
W&B の フィルター オプション と検索バーを使用して、特定の条件に基づいて run を比較します。次に例を示します。
同じ データセット での トレーニング 。
同じ テストセット での 評価 。
フィルター を適用すると、[Table ] ビュー が自動的に更新されます。これにより、モデル 間の パフォーマンス の違いを特定できます。たとえば、一方のモデル で他方のモデル よりも大幅に困難な クラス を特定できます。
5.1 - Add labels to runs with tags
ログに記録されたメトリクスや Artifact データからは明らかでない、特定の機能を持つ run にラベルを付けるために、タグを追加します。
例えば、run の model が in_production であること、run が preemptible であること、この run が baseline を表していることなどを表すタグを、run に追加できます。
1つまたは複数の run にタグを追加する
プログラムで、またはインタラクティブに、run にタグを追加します。
ユースケースに応じて、ニーズに最も適した以下のタブを選択してください。
W&B Python SDK
Public API
Project page
Run page
run の作成時にタグを追加できます。
import wandb
run = wandb. init(
entity= "entity" ,
project= "<project-name>" ,
tags= ["tag1" , "tag2" ]
)
run を初期化した後にタグを更新することもできます。例えば、以下のコードスニペットは、特定のメトリクスが事前定義された閾値を超えた場合にタグを更新する方法を示しています。
import wandb
run = wandb. init(
entity= "entity" ,
project= "capsules" ,
tags= ["debug" ]
)
# python logic to train model
if current_loss < threshold:
run. tags = run. tags + ("release_candidate" ,)
run の作成後、Public API を使用してタグを更新できます。例:
run = wandb. Api(). run(" {entity} / {project} /{run-id}" )
run. tags. append("tag1" ) # you can choose tags based on run data here
run. update()
この方法は、多数の run に同じタグを付けるのに最適です。
プロジェクトの Workspace に移動します。
プロジェクトのサイドバーから Runs を選択します。
テーブルから1つまたは複数の run を選択します。
1つまたは複数の run を選択したら、テーブルの上の Tag ボタンを選択します。
追加するタグを入力し、Create new tag チェックボックスを選択してタグを追加します。
この方法は、1つの run に手動でタグを適用するのに最適です。
プロジェクトの Workspace に移動します。
プロジェクトの Workspace 内の run のリストから run を選択します。
プロジェクトのサイドバーから Overview を選択します。
Tags の横にある灰色のプラスアイコン(+ )ボタンを選択します。追加するタグを入力し、テキストボックスの下にある Add を選択して新しいタグを追加します。
1つまたは複数の run からタグを削除する
タグは、W&B App UI を使用して run から削除することもできます。
この方法は、多数の run からタグを削除するのに最適です。
プロジェクトの Run サイドバーで、右上にあるテーブルアイコンを選択します。これにより、サイドバーが展開されて Runs テーブル全体が表示されます。
テーブル内の run にカーソルを合わせると、左側にチェックボックスが表示されます。または、ヘッダー行にすべての run を選択するためのチェックボックスがあります。
チェックボックスを選択して、一括操作を有効にします。
タグを削除する run を選択します。
run の行の上にある Tag ボタンを選択します。
タグの横にあるチェックボックスを選択して、run からタグを削除します。
Run ページの左側のサイドバーで、一番上の Overview タブを選択します。run のタグがここに表示されます。
タグにカーソルを合わせ、“x” を選択して run から削除します。
5.2 - Filter and search runs
プロジェクトページでサイドバーとテーブルを使用する方法
WandB にログされた run からの洞察を得るには、プロジェクトページを使用してください。Workspace ページと Runs ページの両方から、run をフィルタリングおよび検索できます。
run をフィルタリングする
フィルターボタンを使用して、ステータス、タグ、またはその他のプロパティに基づいて run をフィルタリングします。
タグで run をフィルタリングする
フィルターボタンを使用して、タグに基づいて run をフィルタリングします。
正規表現で run をフィルタリングする
正規表現で目的の検索結果が得られない場合は、タグ を使用して、Runs Table で run をフィルタリングできます。タグは、run の作成時または完了後に追加できます。タグが run に追加されると、以下の gif に示すようにタグフィルターを追加できます。
run を検索する
正規表現 を使用して、指定した正規表現に一致する run を検索します。検索ボックスにクエリを入力すると、Workspace 上のグラフに表示される run が絞り込まれるとともに、テーブルの行もフィルタリングされます。
run をグループ化する
1 つまたは複数の列 (非表示の列を含む) で run をグループ化するには:
検索ボックスの下にある、罫線が引かれた用紙のような Group ボタンをクリックします。
結果をグループ化する 1 つまたは複数の列を選択します。
グループ化された run の各セットは、デフォルトで折りたたまれています。展開するには、グループ名の横にある矢印をクリックします。
最小値と最大値で run を並べ替える
ログに記録されたメトリクスの最小値または最大値で、run テーブルを並べ替えます。これは、記録された最高 (または最低) の値を表示する場合に特に役立ちます。
次のステップでは、記録された最小値または最大値に基づいて、特定のメトリクスで run テーブルを並べ替える方法について説明します。
並べ替えに使用するメトリクスを含む列にマウスを合わせます。
ケバブメニュー (縦の 3 本線) を選択します。
ドロップダウンから、Show min または Show max を選択します。
同じドロップダウンから、Sort by asc または Sort by desc を選択して、それぞれ昇順または降順で並べ替えます。
run の検索終了時間
クライアント プロセスからの最後のハートビートをログに記録する End Time という名前の列を提供します。このフィールドはデフォルトで非表示になっています。
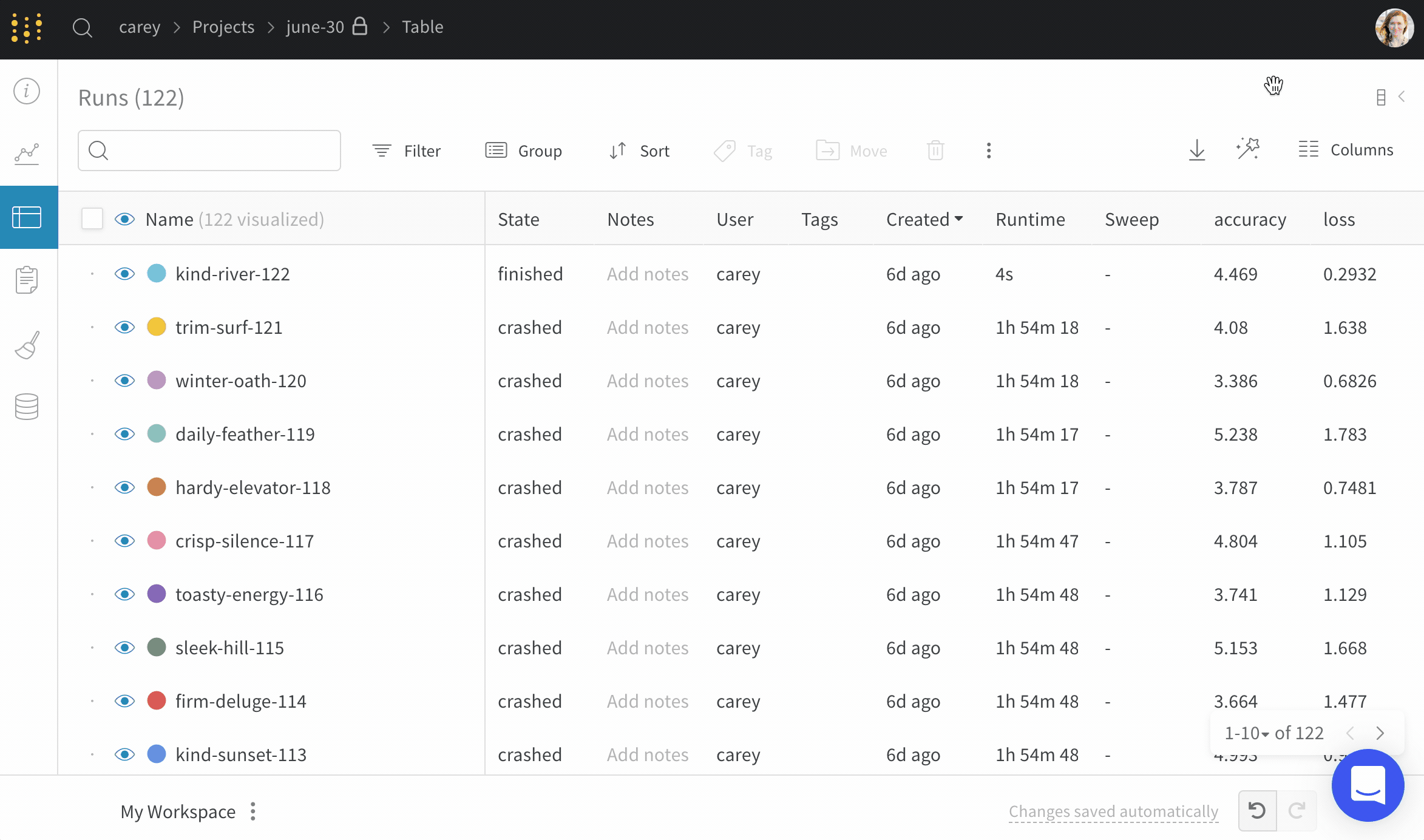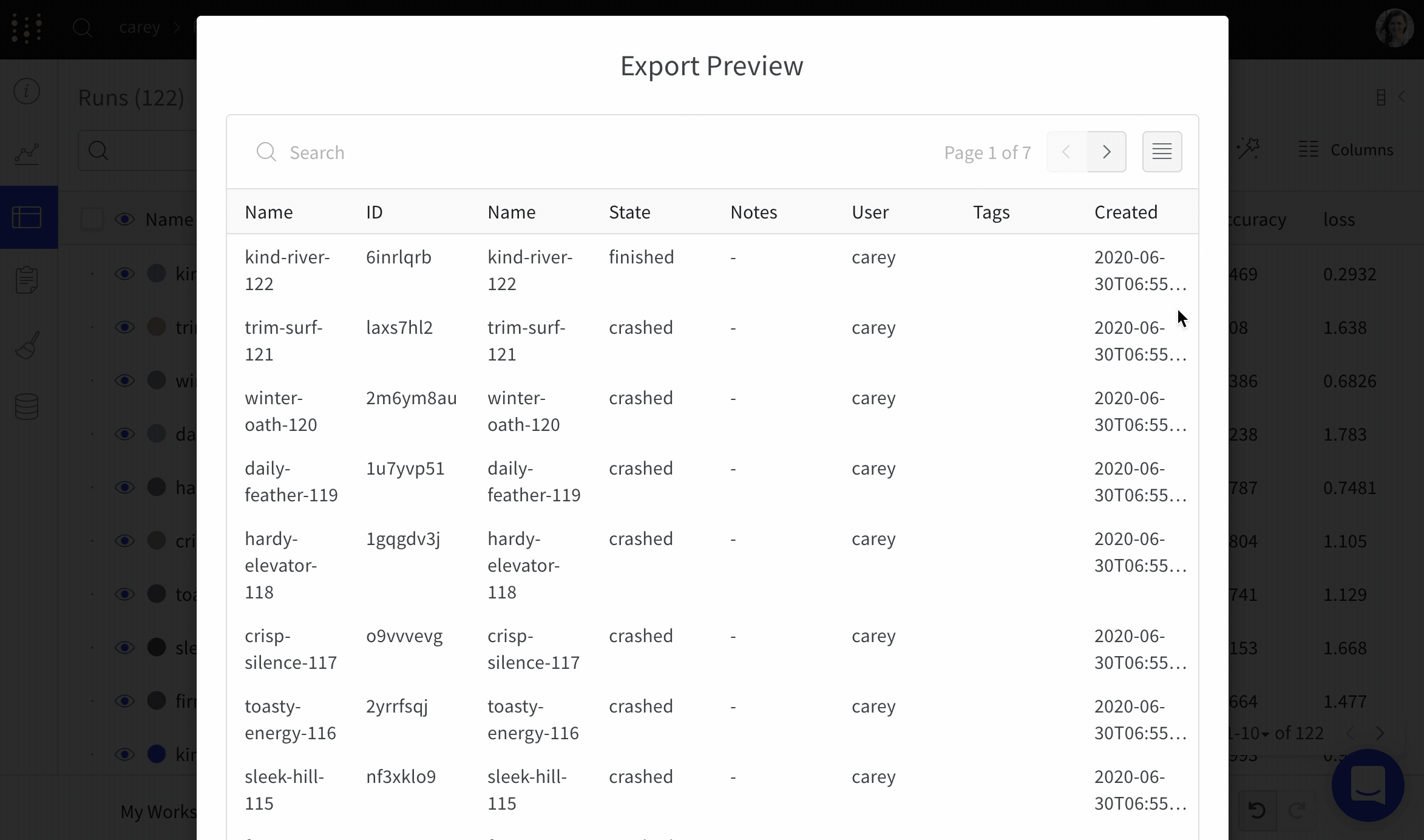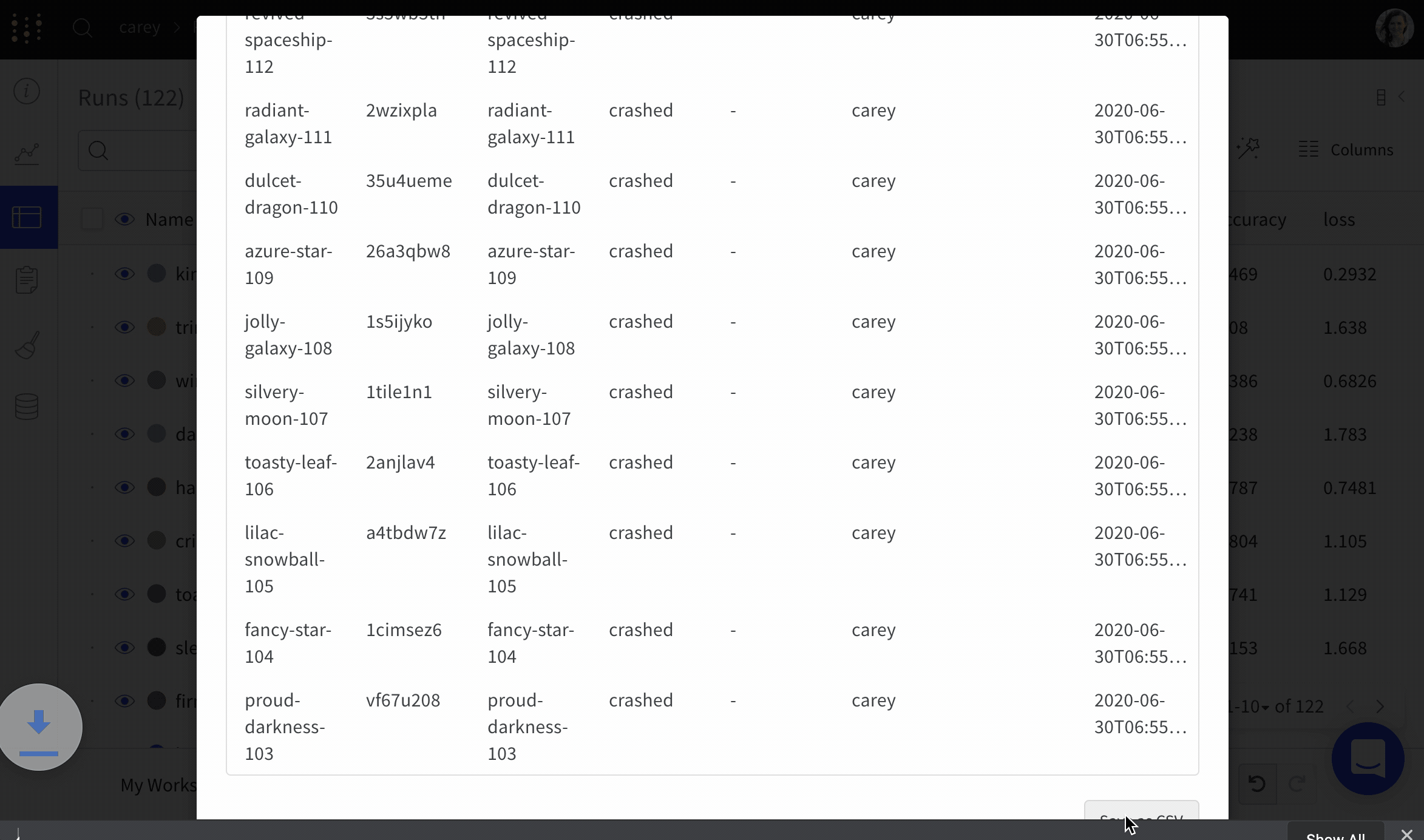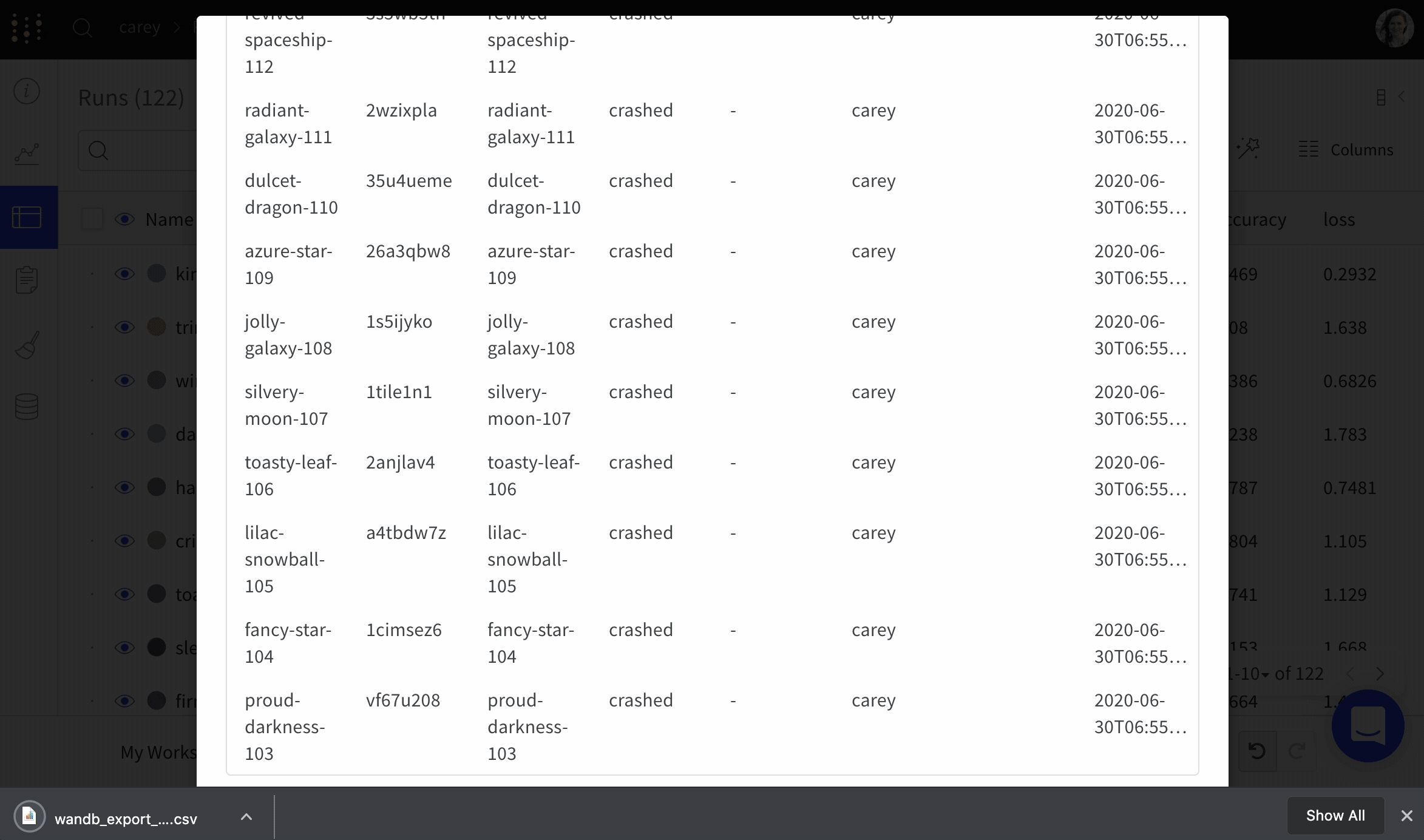
Runs Table を CSV にエクスポート
ダウンロードボタンを使用して、すべての run、ハイパーパラメーター 、およびサマリー メトリクスのテーブルを CSV にエクスポートします。
5.3 - Fork a run
W&B の run をフォークする
run をフォークする機能はプライベートプレビュー版です。この機能へのアクセスをご希望の場合は、W&B Support (
support@wandb.com ) までご連絡ください。
既存の W&B の run から「フォーク」するには、wandb.init()fork_from を使用します。run からフォークすると、W&B はソース run の run ID と step を使用して新しい run を作成します。
run をフォークすると、元の run に影響を与えることなく、実験の特定の時点から異なるパラメータまたは model を調べることができます。
run をフォークするには、wandb
run をフォークするには、単調増加する step が必要です。define_metric()
フォークされた run を開始する
run をフォークするには、wandb.init()fork_from 引数を使用し、フォーク元のソース run ID とソース run からの step を指定します。
import wandb
# 後でフォークされる run を初期化する
original_run = wandb. init(project= "your_project_name" , entity= "your_entity_name" )
# ... トレーニングまたはログの記録を実行 ...
original_run. finish()
# 特定の step から run をフォークする
forked_run = wandb. init(
project= "your_project_name" ,
entity= "your_entity_name" ,
fork_from= f " { original_run. id} ?_step=200" ,
)
イミュータブルな run ID を使用する
イミュータブルな run ID を使用して、特定の run への一貫性があり、変更されない参照を確保します。ユーザーインターフェースからイミュータブルな run ID を取得するには、次の手順に従います。
Overviewタブにアクセスする: ソース run のページの Overviewタブ
イミュータブルな Run ID をコピーする: Overview タブの右上隅にある ... メニュー (3 つのドット) をクリックします。ドロップダウンメニューから [イミュータブルな Run ID をコピー] オプションを選択します。
これらの手順に従うことで、run への安定した変更されない参照が得られ、run のフォークに使用できます。
フォークされた run から続行する
フォークされた run を初期化したら、新しい run へのログ記録を続行できます。継続性のために同じメトリクスをログに記録し、新しいメトリクスを導入できます。
たとえば、次のコード例は、最初に run をフォークし、次に 200 のトレーニング step から始まるフォークされた run にメトリクスをログに記録する方法を示しています。
import wandb
import math
# 最初の run を初期化し、いくつかのメトリクスをログに記録する
run1 = wandb. init("your_project_name" , entity= "your_entity_name" )
for i in range(300 ):
run1. log({"metric" : i})
run1. finish()
# 特定の step で最初の run からフォークし、step 200 から始まるメトリクスをログに記録する
run2 = wandb. init(
"your_project_name" , entity= "your_entity_name" , fork_from= f " { run1. id} ?_step=200"
)
# 新しい run でログ記録を続行する
# 最初のいくつかの step では、run1 からメトリクスをそのままログに記録する
# Step 250 以降は、スパイキーパターンをログに記録し始める
for i in range(200 , 300 ):
if i < 250 :
run2. log({"metric" : i}) # スパイクなしで run1 からログ記録を続行する
else :
# Step 250 からスパイキーな振る舞いを導入する
subtle_spike = i + (2 * math. sin(i / 3.0 )) # 微妙なスパイキーパターンを適用する
run2. log({"metric" : subtle_spike})
# さらに、すべての step で新しいメトリクスをログに記録する
run2. log({"additional_metric" : i * 1.1 })
run2. finish()
巻き戻しとフォークの互換性 フォークは、run の管理と実験においてより柔軟性を提供することで、rewind
run からフォークすると、W&B は特定のポイントで run から新しいブランチを作成し、異なるパラメータまたは model を試すことができます。
run を巻き戻すと、W&B は run の履歴自体を修正または変更できます。
5.4 - Group runs into experiments
トレーニング と評価の run を、より大規模な Experiments にグループ化します。
個々のジョブをグループ化して実験をまとめるには、一意の group 名を wandb.init() に渡します。
ユースケース
分散トレーニング: 実験が、より大きな全体の一部として捉えられるべき個別のトレーニング スクリプトや評価スクリプトに分割されている場合は、グループ化を使用します。複数のプロセス : 複数のより小さなプロセスをグループ化して、1つの実験としてまとめます。K-分割交差検証 : 異なる乱数シードを持つrunをグループ化して、より大規模な実験を把握します。Sweepsとグループ化を用いたk-分割交差検証の例 をご覧ください。
グループ化を設定するには、次の3つの方法があります。
1. スクリプトでグループを設定する
オプションの group と job_type を wandb.init() に渡します。これにより、個々のrunを含む実験ごとに専用のグループページが作成されます。例:wandb.init(group="experiment_1", job_type="eval")
2. グループ環境変数を設定する
WANDB_RUN_GROUP を使用して、runのグループを環境変数として指定します。詳細については、環境変数 Group は、Project 内で一意であり、グループ内のすべてのrunで共有される必要があります。wandb.util.generate_id() を使用して、すべてのプロセスで使用する一意の8文字の文字列を生成できます。たとえば、os.environ["WANDB_RUN_GROUP"] = "experiment-" + wandb.util.generate_id() のようにします。
3. UIでグループ化を切り替える
任意の設定列で動的にグループ化できます。たとえば、wandb.config を使用してバッチサイズまたは学習率をログに記録する場合、Webアプリケーションでこれらのハイパーパラメーターを動的にグループ化できます。
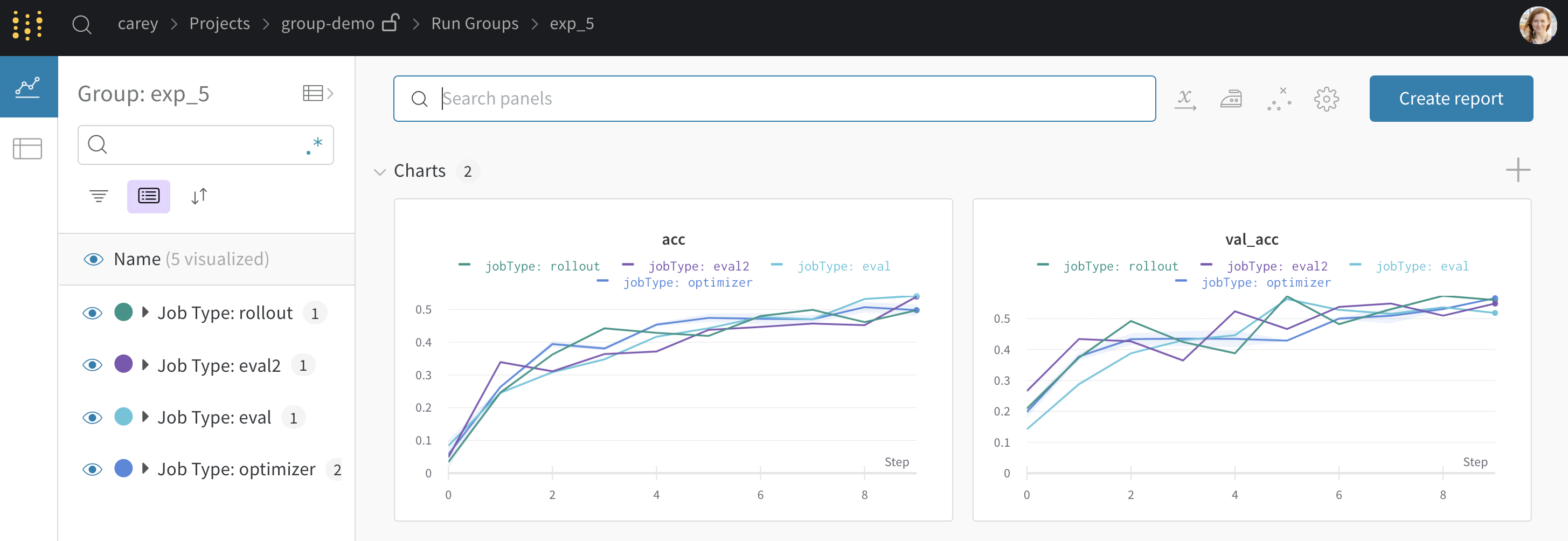
グループ化による分散トレーニング
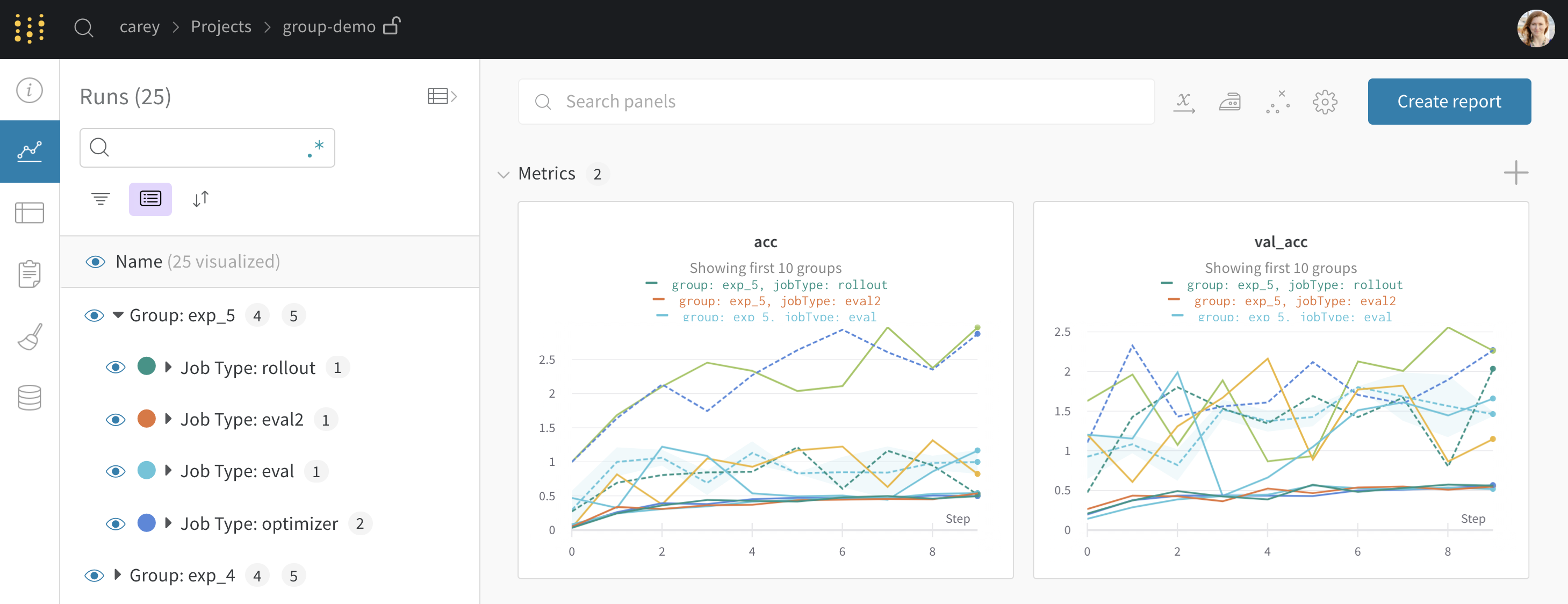
wandb.init() でグループ化を設定すると、UIでrunがデフォルトでグループ化されます。これは、テーブルの上部にある Group ボタンをクリックしてオン/オフを切り替えることができます。グループ化を設定した サンプルコード から生成された プロジェクトの例 を示します。サイドバーの各「Group」行をクリックすると、その実験専用のグループページに移動できます。
上記のプロジェクトページから、左側のサイドバーにある Group をクリックして、このページ のような専用ページに移動できます。
UI での動的なグループ化
任意の列(例えば、ハイパーパラメーター)でrunをグループ化できます。その様子を以下に示します。
サイドバー : Runはエポック数でグループ化されています。グラフ : 各線はグループの平均値を表し、網掛けは分散を示します。この振る舞いはグラフ設定で変更できます。
グループ化をオフにする
グループ化ボタンをクリックして、グループフィールドをいつでもクリアできます。これにより、テーブルとグラフはグループ化されていない状態に戻ります。
グラフ設定のグループ化
グラフの右上隅にある編集ボタンをクリックし、Advanced タブを選択して、線と網掛けを変更します。各グループの線の平均値、最小値、または最大値を選択できます。網掛けの場合、網掛けをオフにしたり、最小値と最大値、標準偏差、および標準誤差を表示したりできます。
5.5 - Move runs
このページでは、ある run を別の project へ、team の内外へ、またはある team から別の team へ移動する方法について説明します。現在の場所と新しい場所で run にアクセスできる必要があります。
Runs タブをカスタマイズするには、Project page を参照してください。
project 間で run を移動する
ある project から別の project へ run を移動するには:
移動する run が含まれている project に移動します。
project のサイドバーから Runs タブを選択します。
移動する run の横にあるチェックボックスをオンにします。
テーブルの上にある Move ボタンを選択します。
ドロップダウンから移動先の project を選択します。
team へ run を移動する
自分がメンバーである team へ run を移動するには:
移動する run が含まれている project に移動します。
project のサイドバーから Runs タブを選択します。
移動する run の横にあるチェックボックスをオンにします。
テーブルの上にある Move ボタンを選択します。
ドロップダウンから移動先の team と project を選択します。
5.6 - Resume a run
一時停止または終了した W&B Run を再開する
run が停止またはクラッシュした場合に、run がどのように振る舞うかを指定します。run を再開するか、run が自動的に再開できるようにするには、id パラメータに対して、その run に関連付けられた一意の run ID を指定する必要があります。
run = wandb. init(entity= "<entity>" , \
project= "<project>" , id= "<run ID>" , resume= "<resume>" )
W&B は、run を保存する W&B の Project 名を提供することを推奨します。
W&B がどのように応答するかを決定するために、次の引数のいずれかを resume パラメータに渡します。いずれの場合も、W&B は最初に run ID がすでに存在するかどうかを確認します。
引数
説明
Run ID が存在する場合
Run ID が存在しない場合
ユースケース
"must"W&B は、run ID で指定された run を再開する必要があります。
W&B は同じ run ID で run を再開します。
W&B はエラーを発生させます。
同じ run ID を使用する必要がある run を再開します。
"allow"W&B は、run ID が存在する場合に run を再開することを許可します。
W&B は同じ run ID で run を再開します。
W&B は、指定された run ID で新しい run を初期化します。
既存の run を上書きせずに run を再開します。
"never"W&B は、run ID で指定された run を再開することを許可しません。
W&B はエラーを発生させます。
W&B は、指定された run ID で新しい run を初期化します。
resume="auto" を指定して、W&B が自動的に run の再起動を試みるようにすることもできます。ただし、同じディレクトリーから run を再起動する必要があります。run を自動的に再開できるようにする セクションを参照してください。
以下のすべての例で、<> で囲まれた値を独自の値に置き換えてください。
同じ run ID を使用する必要がある run を再開する
run が停止、クラッシュ、または失敗した場合、同じ run ID を使用して再開できます。これを行うには、run を初期化し、以下を指定します。
resume パラメータを "must" (resume="must") に設定します。停止またはクラッシュした run の run ID を指定します。
次のコードスニペットは、W&B Python SDK でこれを実現する方法を示しています。
run = wandb. init(entity= "<entity>" , \
project= "<project>" , id= "<run ID>" , resume= "must" )
既存の run を上書きせずに run を再開する
既存の run を上書きせずに、停止またはクラッシュした run を再開します。これは、プロセスが正常に終了しない場合に特に役立ちます。次回 W&B を起動すると、W&B は最後のステップからログの記録を開始します。
W&B で run を初期化するときに、resume パラメータを "allow" (resume="allow") に設定します。停止またはクラッシュした run の run ID を指定します。次のコードスニペットは、W&B Python SDK でこれを実現する方法を示しています。
import wandb
run = wandb. init(entity= "<entity>" , \
project= "<project>" , id= "<run ID>" , resume= "allow" )
run を自動的に再開できるようにする
次のコードスニペットは、Python SDK または環境変数を使用して、run を自動的に再開できるようにする方法を示しています。
W&B Python SDK
Shell script
次のコードスニペットは、Python SDK で W&B の run ID を指定する方法を示しています。
<> で囲まれた値を独自の値に置き換えてください。
run = wandb. init(entity= "<entity>" , \
project= "<project>" , id= "<run ID>" , resume= "<resume>" )
次の例は、bash スクリプトで W&B の WANDB_RUN_ID 変数を指定する方法を示しています。
RUN_ID= " $1"
WANDB_RESUME= allow WANDB_RUN_ID= " $RUN_ID" python eval.py
ターミナル内で、W&B の run ID と共にシェルスクリプトを実行できます。次のコードスニペットは、run ID akj172 を渡します。
sh run_experiment.sh akj172
自動再開は、プロセスが失敗したプロセスと同じファイルシステム上で再起動された場合にのみ機能します。
たとえば、Users/AwesomeEmployee/Desktop/ImageClassify/training/ というディレクトリーで train.py という Python スクリプトを実行するとします。train.py 内で、スクリプトは自動再開を有効にする run を作成します。次に、トレーニングスクリプトが停止したとします。この run を再開するには、Users/AwesomeEmployee/Desktop/ImageClassify/training/ 内で train.py スクリプトを再起動する必要があります。
ファイルシステムを共有できない場合は、
WANDB_RUN_ID 環境変数を指定するか、W&B Python SDK で run ID を渡します。run ID の詳細については、「run とは何ですか?」ページの
カスタム run ID セクションを参照してください。
プリエンプティブ Sweeps run の再開
中断された sweep run を自動的に再キューします。これは、プリエンプティブキューの SLURM ジョブ、EC2 スポットインスタンス、または Google Cloud プリエンプティブ VM など、プリエンプションの影響を受けるコンピューティング環境で sweep agent を実行する場合に特に役立ちます。
mark_preempting
run = wandb. init() # run を初期化します
run. mark_preempting()
次の表は、sweep run の終了ステータスに基づいて W&B が run をどのように処理するかを示しています。
ステータス
振る舞い
ステータスコード 0
Run は正常に終了したと見なされ、再キューされません。
ゼロ以外のステータス
W&B は、run を sweep に関連付けられた run キューに自動的に追加します。
ステータスなし
Run は sweep run キューに追加されます。Sweep agent は、キューが空になるまで run キューから run を消費します。キューが空になると、sweep キューは sweep 検索アルゴリズムに基づいて新しい run の生成を再開します。
5.7 - Rewind a run
巻き戻し
run の巻き戻し
run を巻き戻すオプションは、プライベートプレビュー版です。この機能へのアクセスをご希望の場合は、W&B Support(support@wandb.com)までご連絡ください。
W&B は現在、以下をサポートしていません。
ログの巻き戻し : ログは新しい run セグメントでリセットされます。システムメトリクスの巻き戻し : W&B は、巻き戻しポイントより後の新しいシステムメトリクスのみを記録します。Artifact の関連付け : W&B は、Artifact をそれを生成するソース run に関連付けます。
run を巻き戻すには、W&B Python SDK バージョン >= 0.17.1 が必要です。
単調増加するステップを使用する必要があります。define_metric()
run を巻き戻して、元のデータを失うことなく、run の履歴を修正または変更します。さらに、run を巻き戻すと、その時点から新しいデータを記録できます。W&B は、新たに記録された履歴に基づいて、巻き戻した run のサマリーメトリクスを再計算します。これは、次の振る舞いを意味します。
履歴の切り捨て : W&B は履歴を巻き戻しポイントまで切り捨て、新しいデータロギングを可能にします。サマリーメトリクス : 新たに記録された履歴に基づいて再計算されます。設定の保持 : W&B は元の設定を保持し、新しい設定をマージできます。
run を巻き戻すと、W&B は run の状態を指定されたステップにリセットし、元のデータを保持し、一貫した run ID を維持します。これは次のことを意味します。
run のアーカイブ : W&B は元の run をアーカイブします。アーカイブされた run は、Run Overview Artifact の関連付け : Artifact をそれを生成する run に関連付けます。不変の run ID : 正確な状態からのフォークの一貫性のために導入されました。不変の run ID のコピー : run 管理を改善するために、不変の run ID をコピーするボタン。
巻き戻しとフォークの互換性 フォークは巻き戻しを補完します。
run からフォークすると、W&B は特定の時点で run から新しいブランチを作成し、さまざまなパラメータや Models を試すことができます。
run を巻き戻すと、W&B を使用して run の履歴自体を修正または変更できます。
run の巻き戻し
resume_from を使用して wandb.init()
import wandb
import math
# Initialize the first run and log some metrics
# Replace with your_project_name and your_entity_name!
run1 = wandb. init(project= "your_project_name" , entity= "your_entity_name" )
for i in range(300 ):
run1. log({"metric" : i})
run1. finish()
# Rewind from the first run at a specific step and log the metric starting from step 200
run2 = wandb. init(project= "your_project_name" , entity= "your_entity_name" , resume_from= f " { run1. id} ?_step=200" )
# Continue logging in the new run
# For the first few steps, log the metric as is from run1
# After step 250, start logging the spikey pattern
for i in range(200 , 300 ):
if i < 250 :
run2. log({"metric" : i, "step" : i}) # Continue logging from run1 without spikes
else :
# Introduce the spikey behavior starting from step 250
subtle_spike = i + (2 * math. sin(i / 3.0 )) # Apply a subtle spikey pattern
run2. log({"metric" : subtle_spike, "step" : i})
# Additionally log the new metric at all steps
run2. log({"additional_metric" : i * 1.1 , "step" : i})
run2. finish()
アーカイブされた run の表示
run を巻き戻した後、W&B App UI でアーカイブされた run を調べることができます。アーカイブされた run を表示するには、次の手順に従います。
Overview タブにアクセスする : run のページの Overview タブ Forked From フィールドを見つける : Overview タブ内で、Forked From フィールドを見つけます。このフィールドは、再開の履歴をキャプチャします。Forked From フィールドには、ソース run へのリンクが含まれており、元の run にトレースバックして、巻き戻し履歴全体を理解できます。
Forked From フィールドを使用すると、アーカイブされた再開の ツリー を簡単にナビゲートし、各巻き戻しのシーケンスとオリジンに関する洞察を得ることができます。
巻き戻した run からフォークする
巻き戻した run からフォークするには、wandb.init() の fork_from
import wandb
# Fork the run from a specific step
forked_run = wandb. init(
project= "your_project_name" ,
entity= "your_entity_name" ,
fork_from= f " { rewind_run. id} ?_step=500" ,
)
# Continue logging in the new run
for i in range(500 , 1000 ):
forked_run. log({"metric" : i* 3 })
forked_run. finish()
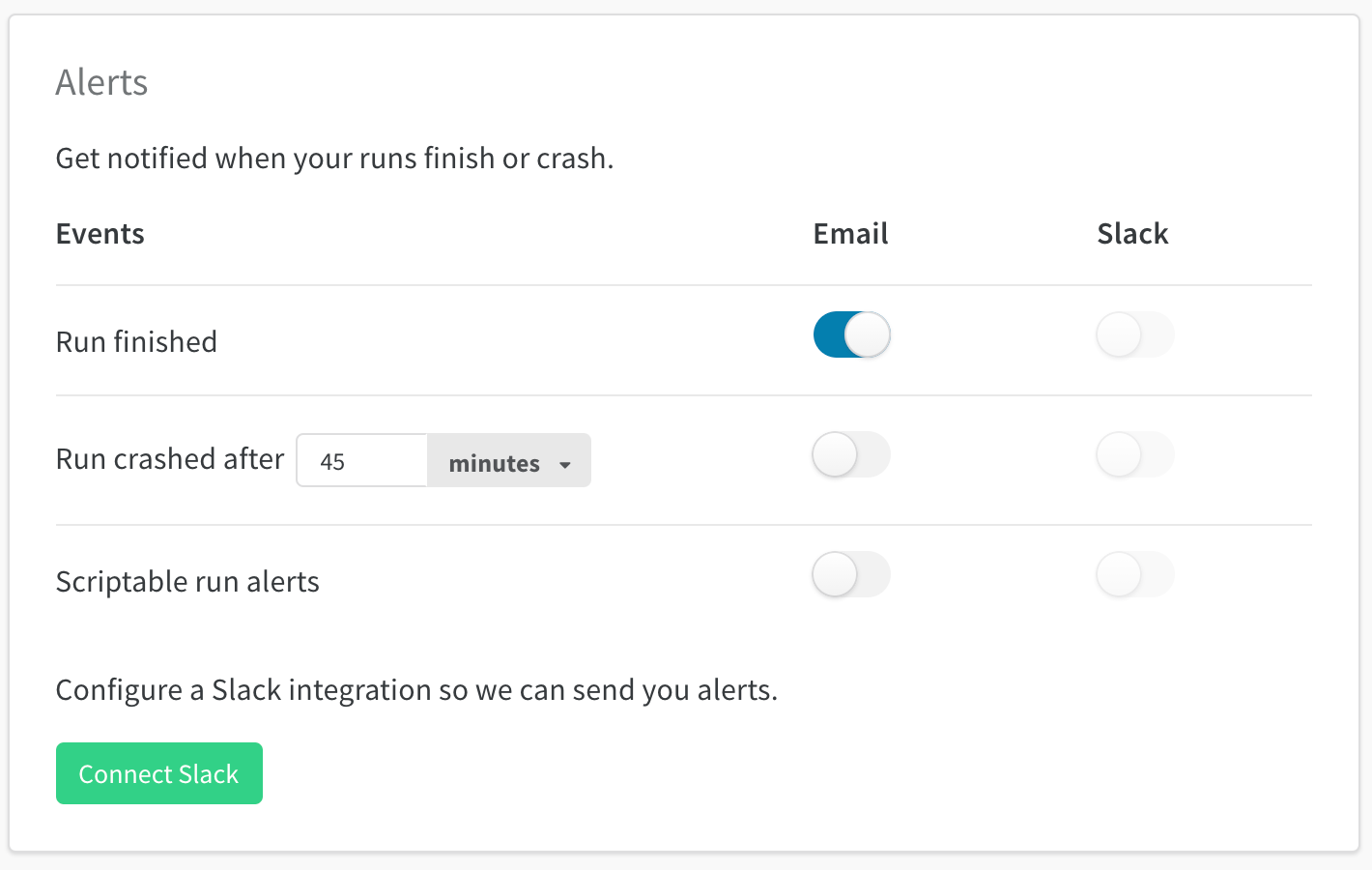
5.8 - Send an alert
Python コードからトリガーされたアラートを Slack またはメールに送信します。
run がクラッシュした場合、またはカスタムトリガーで Slack またはメールでアラートを作成します。たとえば、トレーニングループの勾配が爆発し始めた場合 (NaN を報告)、または ML パイプライン のステップが完了した場合にアラートを作成できます。アラートは、個人 プロジェクト と Team プロジェクト の両方を含む、run を初期化するすべての プロジェクト に適用されます。
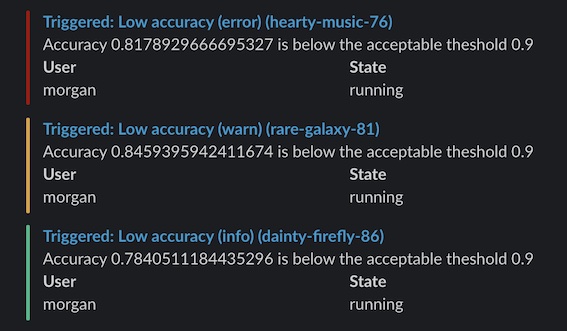
次に、Slack (またはメール) で W&B Alerts メッセージを確認します。
アラートの作成方法
次の ガイド は、マルチテナント cloud のアラートにのみ適用されます。
W&B Server を Private Cloud または W&B Dedicated Cloud で使用している場合は、このドキュメント を参照して、Slack アラートを設定してください。
アラートを設定するには、主に次の 2 つのステップがあります。
W&B の ユーザー 設定 でアラートをオンにします
run.alert() を code に追加しますアラートが適切に設定されていることを確認します
1. W&B ユーザー 設定でアラートをオンにする
ユーザー 設定 で:
アラート セクションまでスクロールしますスクリプト可能な run アラート をオンにして、run.alert() からアラートを受信しますSlack に接続 を使用して、アラートを投稿する Slack channel を選択します。アラートを非公開にするため、Slackbot channel をお勧めします。メール は、W&B にサインアップしたときに使用したメール アドレスに送信されます。これらのアラートがすべてフォルダーに移動し、受信トレイがいっぱいにならないように、メールでフィルターを設定することをお勧めします。
W&B Alerts を初めて設定する場合、またはアラートの受信方法を変更する場合は、これを行う必要があります。
2. run.alert() を code に追加する
アラートをトリガーする場所に、run.alert() を code ( notebook または Python スクリプト のいずれか) に追加します
import wandb
run = wandb. init()
run. alert(title= "High Loss" , text= "Loss is increasing rapidly" )
3. Slack またはメールを確認する
Slack またはメールでアラート メッセージを確認します。何も受信しなかった場合は、ユーザー 設定 で スクリプト可能なアラート のメールまたは Slack がオンになっていることを確認してください。
例
このシンプルなアラートは、精度がしきい値を下回ると警告を送信します。この例では、少なくとも 5 分間隔でアラートを送信します。
import wandb
from wandb import AlertLevel
run = wandb. init()
if acc < threshold:
run. alert(
title= "Low accuracy" ,
text= f "Accuracy { acc} is below the acceptable threshold { threshold} " ,
level= AlertLevel. WARN,
wait_duration= 300 ,
)
ユーザーをタグ付けまたはメンションする方法
アラートのタイトルまたはテキストのいずれかで、@ 記号の後に Slack ユーザー ID を続けて入力して、自分自身または同僚をタグ付けします。Slack ユーザー ID は、Slack プロフィール ページから確認できます。
run. alert(title= "Loss is NaN" , text= f "Hey <@U1234ABCD> loss has gone to NaN" )
Team アラート
Team 管理者は、Team 設定ページ wandb.ai/teams/your-team で Team のアラートを設定できます。
Team アラートは、Team の全員に適用されます。W&B は、アラートを非公開にするため、Slackbot channel を使用することをお勧めします。
アラートの送信先 Slack channel の変更
アラートの送信先 channel を変更するには、Slack の接続を解除 をクリックしてから、再接続します。再接続後、別の Slack channel を選択します。
6 - Log objects and media
メトリクス 、動画、カスタムプロットなどを追跡
W&B Python SDK を使用して、メトリクス、メディア、またはカスタム オブジェクトの辞書をステップと共にログに記録します。W&B は、各ステップ中にキーと値のペアを収集し、wandb.log() でデータをログに記録するたびに、それらを 1 つの統合された辞書に保存します。スクリプトからログに記録されたデータは、ローカル マシンの wandb というディレクトリーに保存され、W&B クラウドまたは プライベート サーバー に同期されます。
キーと値のペアは、各ステップで同じ値を渡す場合にのみ、1 つの統合された辞書に保存されます。step に対して異なる値をログに記録すると、W&B は収集されたすべてのキーと値をメモリーに書き込みます。
wandb.log の各呼び出しは、デフォルトで新しい step となります。W&B は、チャートとパネルを作成する際に、ステップをデフォルトの x 軸として使用します。オプションで、カスタム x 軸を作成して使用したり、カスタムの集計メトリクスをキャプチャしたりできます。詳細については、ログ軸のカスタマイズ を参照してください。
wandb.log() を使用して、各 step に対して連続した値 (0、1、2 など) をログに記録します。特定の履歴ステップに書き込むことはできません。W&B は、「現在」および「次」のステップにのみ書き込みます。
自動的にログに記録されるデータ
W&B は、W&B の Experiments 中に次の情報を自動的にログに記録します。
システム メトリクス : CPU と GPU の使用率、ネットワークなど。これらは、run ページ の [System] タブに表示されます。GPU の場合、これらは nvidia-smiコマンドライン : stdout と stderr が取得され、run ページ の [Logs] タブに表示されます。
アカウントの Settings page で Code Saving をオンにして、以下をログに記録します。
Git commit : 最新の git commit を取得し、run ページの Overview タブに表示します。また、コミットされていない変更がある場合は、diff.patch ファイルも表示します。依存関係 : requirements.txt ファイルがアップロードされ、run の files タブに表示されます。また、run の wandb ディレクトリーに保存したファイルも表示されます。
特定の W&B API 呼び出しでログに記録されるデータ
W&B を使用すると、ログに記録する内容を正確に決定できます。以下に、一般的にログに記録されるオブジェクトをいくつか示します。
Datasets : 画像またはその他の dataset サンプルを W&B にストリーミングするには、それらを具体的にログに記録する必要があります。プロット : wandb.plot を wandb.log と共に使用して、チャートを追跡します。詳細については、プロットのログ を参照してください。Tables : wandb.Table を使用してデータをログに記録し、W&B で視覚化およびクエリを実行します。詳細については、Tables のログ を参照してください。PyTorch 勾配 : wandb.watch(model) を追加して、UI で重みの勾配をヒストグラムとして表示します。設定情報 : ハイパーパラメータ、dataset へのリンク、または使用しているアーキテクチャーの名前を config パラメータとしてログに記録します。wandb.init(config=your_config_dictionary) のように渡されます。詳細については、PyTorch Integrations ページを参照してください。メトリクス : wandb.log を使用して、model からのメトリクスを表示します。トレーニング ループ内から精度や損失などのメトリクスをログに記録すると、UI でライブ更新グラフが表示されます。
一般的なワークフロー
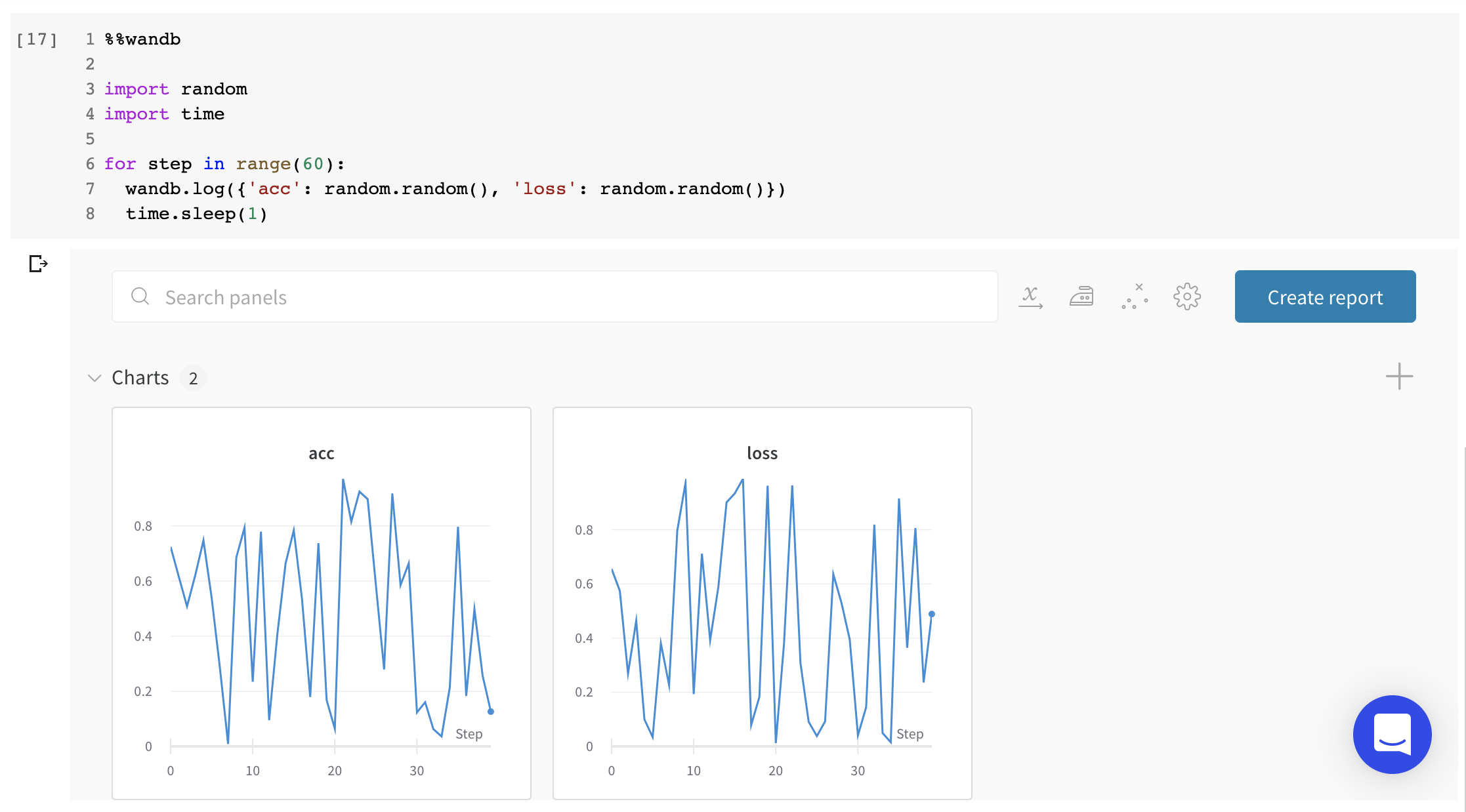
最高精度を比較する : run 全体でメトリクスの最高値を比較するには、そのメトリクスの集計値を設定します。デフォルトでは、集計は各キーに対してログに記録した最後の値に設定されます。これは、UI のテーブルで役立ちます。UI では、集計メトリクスに基づいて run をソートおよびフィルター処理し、最終的な精度ではなく 最高 精度に基づいてテーブルまたは棒グラフで run を比較できます。例: wandb.run.summary["best_accuracy"] = best_accuracy1 つのチャートで複数のメトリクスを表示する : wandb.log({"acc'": 0.9, "loss": 0.1}) のように、wandb.log への同じ呼び出しで複数のメトリクスをログに記録すると、それらは両方とも UI でプロットに使用できるようになります。x 軸をカスタマイズする : 同じログ呼び出しにカスタム x 軸を追加して、W&B dashboard で別の軸に対してメトリクスを視覚化します。例: wandb.log({'acc': 0.9, 'epoch': 3, 'batch': 117})。特定のメトリクスのデフォルトの x 軸を設定するには、Run.define_metric() を使用します。リッチ メディアとチャートをログに記録する : wandb.log は、画像や動画などのメディア から Tables および Charts まで、さまざまなデータ型のログ記録をサポートしています。
ベストプラクティスとヒント
Experiments とログ記録のベストプラクティスとヒントについては、ベストプラクティス: Experiments とログ記録 を参照してください。
6.1 - Create and track plots from experiments
機械学習 の 実験 からプロットを作成および追跡します。
wandb.plot のメソッドを使用すると、トレーニング中に時間とともに変化するグラフを含め、wandb.log でグラフを追跡できます。カスタムグラフ作成フレームワークの詳細については、このガイド を確認してください。
基本的なグラフ
これらのシンプルなグラフを使用すると、メトリクスと結果の基本的な可視化を簡単に構築できます。
Line
Scatter
Bar
Histogram
Multi-line
wandb.plot.line()
カスタム折れ線グラフ (任意の軸上の接続された順序付きポイントのリスト) を記録します。
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb. Table(data= data, columns= ["x" , "y" ])
wandb. log(
{
"my_custom_plot_id" : wandb. plot. line(
table, "x" , "y" , title= "Custom Y vs X Line Plot"
)
}
)
これを使用して、任意の2つの次元で曲線を記録できます。2つの値のリストを互いにプロットする場合、リスト内の値の数は正確に一致する必要があります。たとえば、各ポイントにはxとyが必要です。
アプリで表示
コードを実行
wandb.plot.scatter()
カスタム散布図 (任意の軸xとyのペア上のポイント (x、y) のリスト) を記録します。
data = [[x, y] for (x, y) in zip(class_x_scores, class_y_scores)]
table = wandb. Table(data= data, columns= ["class_x" , "class_y" ])
wandb. log({"my_custom_id" : wandb. plot. scatter(table, "class_x" , "class_y" )})
これを使用して、任意の2つの次元で散布ポイントを記録できます。2つの値のリストを互いにプロットする場合、リスト内の値の数は正確に一致する必要があります。たとえば、各ポイントにはxとyが必要です。
アプリで表示
コードを実行
wandb.plot.bar()
カスタム棒グラフ (ラベル付きの値のリストを棒として表示) を数行でネイティブに記録します。
data = [[label, val] for (label, val) in zip(labels, values)]
table = wandb. Table(data= data, columns= ["label" , "value" ])
wandb. log(
{
"my_bar_chart_id" : wandb. plot. bar(
table, "label" , "value" , title= "Custom Bar Chart"
)
}
)
これを使用して、任意の棒グラフを記録できます。リスト内のラベルと値の数は正確に一致する必要があります。各データポイントには、ラベルと値の両方が必要です。
アプリで表示
コードを実行
wandb.plot.histogram()
カスタムヒストグラム (値のリストを、出現のカウント/頻度でビンにソート) を数行でネイティブに記録します。予測信頼度スコアのリスト (scores) があり、その分布を可視化するとします。
data = [[s] for s in scores]
table = wandb. Table(data= data, columns= ["scores" ])
wandb. log({"my_histogram" : wandb. plot. histogram(table, "scores" , title= "Histogram" )})
これを使用して、任意のヒストグラムを記録できます。data は、行と列の2D配列をサポートすることを目的としたリストのリストであることに注意してください。
アプリで表示
コードを実行
wandb.plot.line_series()
複数の線、または複数の異なるx-y座標ペアのリストを、1つの共有x-y軸セットにプロットします。
wandb. log(
{
"my_custom_id" : wandb. plot. line_series(
xs= [0 , 1 , 2 , 3 , 4 ],
ys= [[10 , 20 , 30 , 40 , 50 ], [0.5 , 11 , 72 , 3 , 41 ]],
keys= ["metric Y" , "metric Z" ],
title= "Two Random Metrics" ,
xname= "x units" ,
)
}
)
xポイントとyポイントの数が正確に一致する必要があることに注意してください。複数のy値のリストに一致するx値のリストを1つ、またはy値のリストごとに個別のx値のリストを提供できます。
アプリで表示
モデル評価グラフ
これらのプリセットグラフには、wandb.plot メソッドが組み込まれており、スクリプトから直接グラフをすばやく簡単に記録し、UIで探している正確な情報を確認できます。
Precision-recall curves
ROC curves
Confusion matrix
wandb.plot.pr_curve()
1行で PR曲線 を作成します。
wandb. log({"pr" : wandb. plot. pr_curve(ground_truth, predictions)})
コードが以下にアクセスできる場合は、いつでもこれを記録できます。
例のセットに対するモデルの予測スコア (predictions)
それらの例に対応する正解ラベル (ground_truth)
(オプション) ラベル/クラス名のリスト (labels=["cat", "dog", "bird"...] ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合)
(オプション) プロットで可視化するラベルのサブセット (引き続きリスト形式)
アプリで表示
コードを実行
wandb.plot.roc_curve()
1行で ROC曲線 を作成します。
wandb. log({"roc" : wandb. plot. roc_curve(ground_truth, predictions)})
コードが以下にアクセスできる場合は、いつでもこれを記録できます。
例のセットに対するモデルの予測スコア (predictions)
それらの例に対応する正解ラベル (ground_truth)
(オプション) ラベル/クラス名のリスト (labels=["cat", "dog", "bird"...] ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合)
(オプション) プロットで可視化するこれらのラベルのサブセット (引き続きリスト形式)
アプリで表示
コードを実行
wandb.plot.confusion_matrix()
1行で多クラス 混同行列 を作成します。
cm = wandb. plot. confusion_matrix(
y_true= ground_truth, preds= predictions, class_names= class_names
)
wandb. log({"conf_mat" : cm})
コードが以下にアクセスできる場合は、いつでもこれを記録できます。
例のセットに対するモデルの予測ラベル (preds) または正規化された確率スコア (probs)。確率は、(例の数、クラスの数) の形状である必要があります。確率または予測のいずれかを提供できますが、両方はできません。
それらの例に対応する正解ラベル (y_true)
class_names の文字列としてのラベル/クラス名の完全なリスト。例: インデックス0が cat、1が dog、2が bird の場合、class_names=["cat", "dog", "bird"]。
アプリで表示
コードを実行
インタラクティブなカスタムグラフ
完全にカスタマイズするには、組み込みの カスタムグラフプリセット を調整するか、新しいプリセットを作成し、グラフを保存します。グラフIDを使用して、スクリプトからそのカスタムプリセットに直接データを記録します。
# プロットする列を含むテーブルを作成します
table = wandb. Table(data= data, columns= ["step" , "height" ])
# テーブルの列からグラフのフィールドへのマッピング
fields = {"x" : "step" , "value" : "height" }
# テーブルを使用して、新しいカスタムグラフプリセットを設定します
# 独自の保存されたグラフプリセットを使用するには、vega_spec_nameを変更します
# タイトルを編集するには、string_fieldsを変更します
my_custom_chart = wandb. plot_table(
vega_spec_name= "carey/new_chart" ,
data_table= table,
fields= fields,
string_fields= {"title" : "Height Histogram" },
)
コードを実行
Matplotlib および Plotly プロット
wandb.plot を使用した W&B カスタムグラフ を使用する代わりに、matplotlib および Plotly で生成されたグラフを記録できます。
import matplotlib.pyplot as plt
plt. plot([1 , 2 , 3 , 4 ])
plt. ylabel("some interesting numbers" )
wandb. log({"chart" : plt})
matplotlib プロットまたは figure オブジェクトを wandb.log() に渡すだけです。デフォルトでは、プロットを Plotly プロットに変換します。プロットを画像として記録する場合は、プロットを wandb.Image に渡すことができます。Plotly グラフも直接受け入れます。
「空のプロットを記録しようとしました」というエラーが表示される場合は、fig = plt.figure() を使用してプロットとは別に figure を保存し、wandb.log の呼び出しで fig を記録できます。
カスタム HTML を W&B Tables に記録する
W&B は、Plotly および Bokeh からのインタラクティブなグラフを HTML として記録し、それらを Tables に追加することをサポートしています。
インタラクティブな Plotly グラフを HTML に変換して、wandb Tables に記録できます。
import wandb
import plotly.express as px
# 新しい run を初期化します
run = wandb. init(project= "log-plotly-fig-tables" , name= "plotly_html" )
# テーブルを作成します
table = wandb. Table(columns= ["plotly_figure" ])
# Plotly figure のパスを作成します
path_to_plotly_html = "./plotly_figure.html"
# Plotly figure の例
fig = px. scatter(x= [0 , 1 , 2 , 3 , 4 ], y= [0 , 1 , 4 , 9 , 16 ])
# Plotly figure を HTML に書き込みます
# auto_play を False に設定すると、アニメーション化された Plotly グラフが
# テーブル内で自動的に再生されるのを防ぎます
fig. write_html(path_to_plotly_html, auto_play= False )
# Plotly figure を HTML ファイルとして Table に追加します
table. add_data(wandb. Html(path_to_plotly_html))
# Table を記録します
run. log({"test_table" : table})
wandb. finish()
インタラクティブな Bokeh グラフを HTML に変換して、wandb Tables に記録できます。
from scipy.signal import spectrogram
import holoviews as hv
import panel as pn
from scipy.io import wavfile
import numpy as np
from bokeh.resources import INLINE
hv. extension("bokeh" , logo= False )
import wandb
def save_audio_with_bokeh_plot_to_html (audio_path, html_file_name):
sr, wav_data = wavfile. read(audio_path)
duration = len(wav_data) / sr
f, t, sxx = spectrogram(wav_data, sr)
spec_gram = hv. Image((t, f, np. log10(sxx)), ["Time (s)" , "Frequency (hz)" ]). opts(
width= 500 , height= 150 , labelled= []
)
audio = pn. pane. Audio(wav_data, sample_rate= sr, name= "Audio" , throttle= 500 )
slider = pn. widgets. FloatSlider(end= duration, visible= False )
line = hv. VLine(0 ). opts(color= "white" )
slider. jslink(audio, value= "time" , bidirectional= True )
slider. jslink(line, value= "glyph.location" )
combined = pn. Row(audio, spec_gram * line, slider). save(html_file_name)
html_file_name = "audio_with_plot.html"
audio_path = "hello.wav"
save_audio_with_bokeh_plot_to_html(audio_path, html_file_name)
wandb_html = wandb. Html(html_file_name)
run = wandb. init(project= "audio_test" )
my_table = wandb. Table(columns= ["audio_with_plot" ], data= [[wandb_html], [wandb_html]])
run. log({"audio_table" : my_table})
run. finish()
6.2 - Customize log axes
define_metric を使用して、カスタムのX軸 を設定します。カスタムのX軸は、トレーニング中に過去の異なるタイムステップに非同期で ログ を記録する必要がある場合に役立ちます。たとえば、エピソードごとの報酬とステップごとの報酬を追跡する強化学習で役立ちます。
Google Colab で define_metric を実際に試してみる →
軸のカスタマイズ
デフォルトでは、すべての メトリクス は同じX軸(W&Bの内部 step)に対して ログ が記録されます。場合によっては、前のステップに ログ を記録したり、別のX軸を使用したりすることがあります。
カスタムのX軸 メトリクス を設定する例を次に示します(デフォルトのステップの代わりに)。
import wandb
wandb. init()
# カスタムのX軸メトリクスを定義
wandb. define_metric("custom_step" )
# どのメトリクスをそれに対してプロットするかを定義
wandb. define_metric("validation_loss" , step_metric= "custom_step" )
for i in range(10 ):
log_dict = {
"train_loss" : 1 / (i + 1 ),
"custom_step" : i** 2 ,
"validation_loss" : 1 / (i + 1 ),
}
wandb. log(log_dict)
X軸は、グロブを使用して設定することもできます。現在、文字列のプレフィックスを持つグロブのみが使用可能です。次の例では、プレフィックス "train/" を持つ ログ に記録されたすべての メトリクス をX軸 "train/step" にプロットします。
import wandb
wandb. init()
# カスタムのX軸メトリクスを定義
wandb. define_metric("train/step" )
# 他のすべての train/ メトリクス がこのステップを使用するように設定
wandb. define_metric("train/*" , step_metric= "train/step" )
for i in range(10 ):
log_dict = {
"train/step" : 2 ** i, # 内部W&Bステップによる指数関数的な増加
"train/loss" : 1 / (i + 1 ), # X軸は train/step
"train/accuracy" : 1 - (1 / (1 + i)), # X軸は train/step
"val/loss" : 1 / (1 + i), # X軸は内部 wandb step
}
wandb. log(log_dict)
6.3 - Log distributed training experiments
W&B を使用して、複数の GPU を使用した分散型トレーニング の 実験管理 を ログ 記録します。
分散トレーニングでは、モデルは複数の GPU を並行して使用してトレーニングされます。W&B は、分散トレーニング の 実験管理 を追跡するための 2 つのパターンをサポートしています。
単一 プロセス : W&B (wandb.initwandb.logPyTorch Distributed Data Parallel (DDP) クラスを使用した分散トレーニング の 実験 を ログ 記録するための一般的なソリューションです。場合によっては、マルチプロセッシング キュー (または別の通信プリミティブ) を使用して、他の プロセス からメインの ログ 記録 プロセス にデータを送り込む ユーザー もいます。多数の プロセス : W&B (wandb.initwandb.loggroup パラメータ (wandb.init(group='group-name')) を使用して、共有 実験 を定義し、 ログ 記録された 値 を W&B App UI にまとめて グループ化します。
以下の例では、単一 マシン 上の 2 つの GPU で PyTorch DDP を使用して、W&B で メトリクス を追跡する方法を示します。PyTorch DDP (torch.nn の DistributedDataParallel) は、分散トレーニング 用の一般的な ライブラリ です。基本的な原則は、あらゆる分散トレーニング 設定に適用されますが、実装の詳細は異なる場合があります。
これらの例の背後にある コード を W&B GitHub の examples リポジトリ (
こちら ) で確認してください。特に、単一 プロセス および 多数 プロセス の メソッド を実装する方法については、
log-dpp.py Python スクリプトを参照してください。
方法 1: 単一 プロセス
この方法では、ランク 0 の プロセス のみを追跡します。この方法を実装するには、W&B (wandb.init) を初期化し、W&B Run を開始して、ランク 0 の プロセス 内で メトリクス (wandb.log) を ログ 記録します。この方法はシンプルで堅牢ですが、他の プロセス から モデル の メトリクス (たとえば、バッチからの 損失 値 または 入力) を ログ 記録しません。使用量 や メモリ などの システム メトリクス は、その情報がすべての プロセス で利用できるため、すべての GPU に対して ログ 記録されます。
この方法を使用して、単一の プロセス から利用可能な メトリクス のみを追跡します 。一般的な例としては、GPU/CPU の使用率、共有 検証セット での 振る舞い 、 勾配 と パラメータ 、および代表的な データ 例での 損失 値 などがあります。
サンプル Python スクリプト (log-ddp.py) 内で、ランクが 0 かどうかを確認します。これを行うには、まず torch.distributed.launch で複数の プロセス を 起動します。次に、--local_rank コマンドライン 引数 でランクを確認します。ランクが 0 に設定されている場合、train()wandb ログ 記録を条件付きで設定します。Python スクリプト内で、次のチェックを使用します。
if __name__ == "__main__" :
# Get args
args = parse_args()
if args. local_rank == 0 : # only on main process
# Initialize wandb run
run = wandb. init(
entity= args. entity,
project= args. project,
)
# Train model with DDP
train(args, run)
else :
train(args)
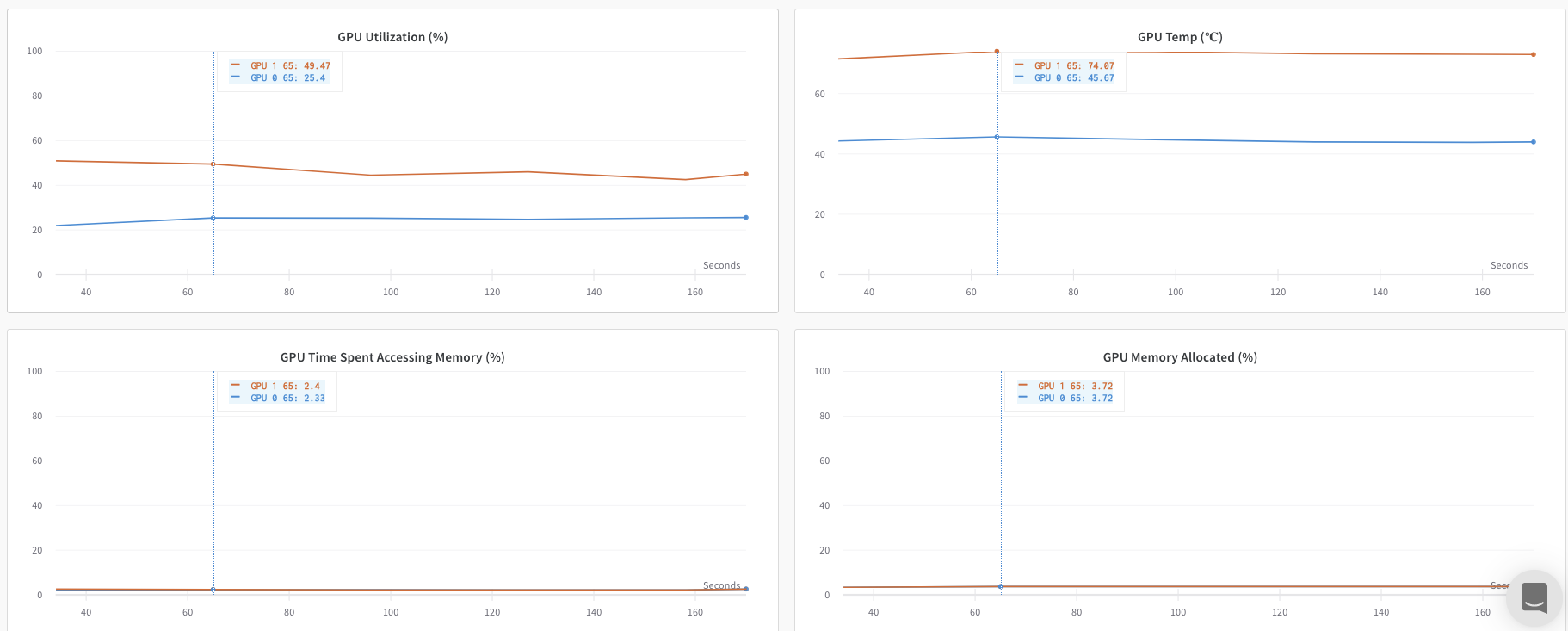
W&B App UI を調べて、単一の プロセス から追跡された メトリクス の ダッシュボード 例 を表示します。ダッシュボード には、両方の GPU で追跡された 温度 や 使用率 などの システム メトリクス が表示されます。
ただし、 エポック と バッチサイズ の関数としての 損失 値 は、単一の GPU からのみ ログ 記録されました。
方法 2: 多数の プロセス
この方法では、ジョブ内の各 プロセス を追跡し、各 プロセス から wandb.init() と wandb.log() を個別に呼び出します。すべての プロセス が適切に終了するように、トレーニング の最後に wandb.finish() を呼び出すことをお勧めします。これにより、run が完了したことを示します。
この方法により、より多くの情報が ログ 記録にアクセスできるようになります。ただし、複数の W&B Runs が W&B App UI に 報告 されることに注意してください。複数の 実験 にわたって W&B Runs を追跡することが難しい場合があります。これを軽減するには、W&B を初期化する際に group パラメータ に 値 を指定して、どの W&B Run が特定の 実験 に属しているかを追跡します。トレーニング と 評価 の W&B Runs を 実験 で追跡する方法の詳細については、Run のグループ化 を参照してください。
個々の プロセス から メトリクス を追跡する場合は、この方法を使用してください 。一般的な例としては、各 ノード 上の データ と 予測 (データ 分布 の デバッグ 用) や、メイン ノード 外の個々の バッチ 上の メトリクス などがあります。この方法は、すべての ノード から システム メトリクス を取得したり、メイン ノード で利用可能な概要 統計 を取得したりするために必要ではありません。
次の Python コード スニペット は、W&B を初期化するときに group パラメータ を設定する方法を示しています。
if __name__ == "__main__" :
# Get args
args = parse_args()
# Initialize run
run = wandb. init(
entity= args. entity,
project= args. project,
group= "DDP" , # all runs for the experiment in one group
)
# Train model with DDP
train(args, run)
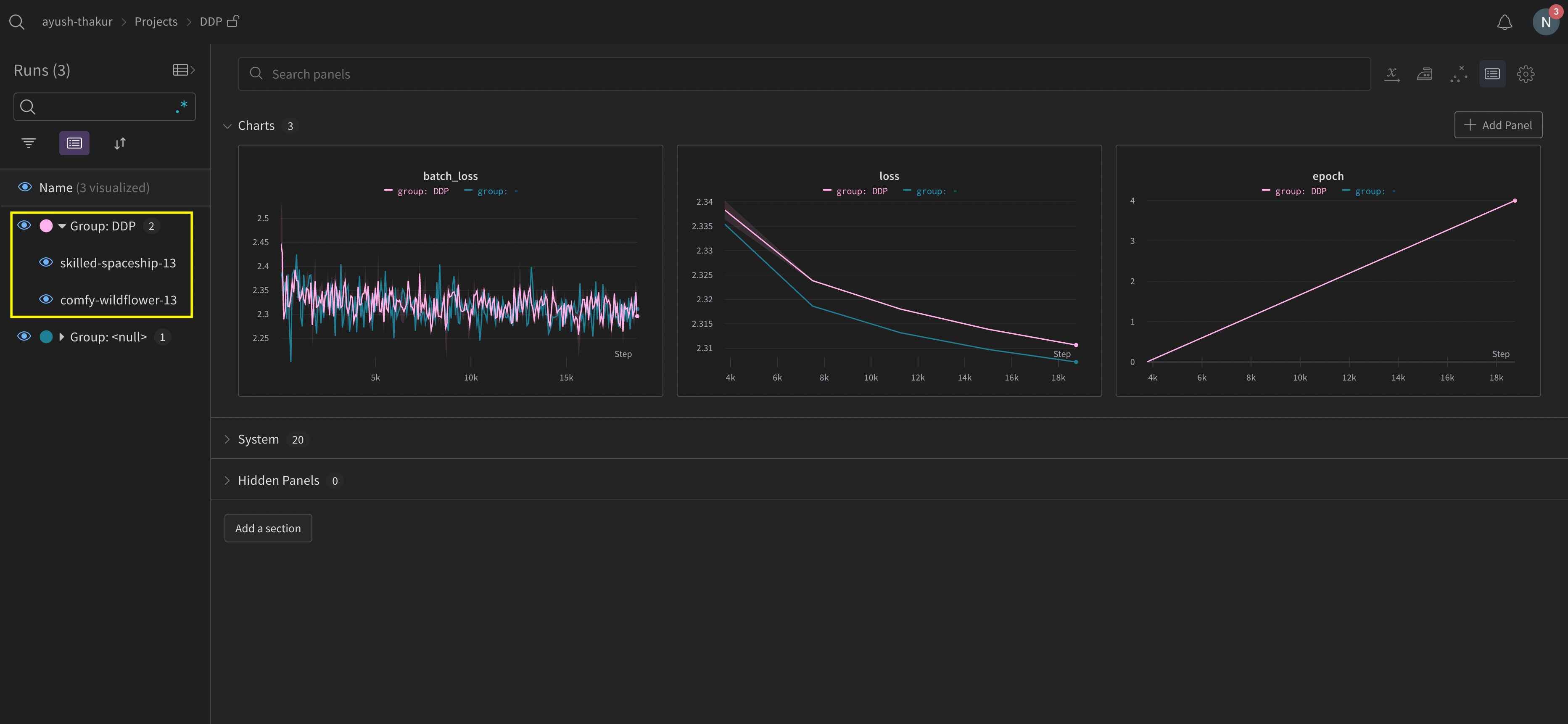
W&B App UI を調べて、複数の プロセス から追跡された メトリクス の ダッシュボード 例 を表示します。左側のサイドバーに 2 つの W&B Runs が グループ化 されていることに注意してください。グループ をクリックして、 実験 専用のグループ ページ を表示します。専用のグループ ページ には、各 プロセス からの メトリクス が個別に表示されます。
上記の画像は、W&B App UI ダッシュボード を示しています。サイドバーには、2 つの 実験 が表示されます。1 つは「null」というラベルが付いており、2 つ目 (黄色のボックスで囲まれています) は「DPP」と呼ばれています。グループ を展開すると (グループ ドロップダウン を選択)、その 実験 に関連付けられている W&B Runs が表示されます。
W&B Service を使用して、一般的な分散トレーニング の問題を回避する
W&B と分散トレーニング を使用する際に発生する可能性のある一般的な問題が 2 つあります。
トレーニング の開始時にハングする - wandb マルチプロセッシング が分散トレーニング からの マルチプロセッシング に干渉すると、wandb プロセス がハングする可能性があります。トレーニング の最後にハングする - wandb プロセス がいつ終了する必要があるかを認識していない場合、トレーニング ジョブ がハングする可能性があります。Python スクリプト の最後に wandb.finish() API を呼び出して、Run が完了したことを W&B に伝えます。wandb.finish() API は、データの アップロード を終了し、W&B を終了させます。
分散ジョブ の信頼性を向上させるために、wandb service を使用することをお勧めします。上記のトレーニング の問題はどちらも、wandb service が利用できない W&B SDK の バージョン でよく見られます。
W&B Service を有効にする
W&B SDK の バージョン によっては、W&B Service がデフォルトで有効になっている場合があります。
W&B SDK 0.13.0 以降
W&B Service は、W&B SDK 0.13.0 以降の バージョン ではデフォルトで有効になっています。
W&B SDK 0.12.5 以降
Python スクリプト を変更して、W&B SDK バージョン 0.12.5 以降で W&B Service を有効にします。wandb.require メソッド を使用し、メイン関数内で 文字列 "service" を渡します。
if __name__ == "__main__" :
main()
def main ():
wandb. require("service" )
# rest-of-your-script-goes-here
最適なエクスペリエンスを得るには、最新 バージョン に アップグレード することをお勧めします。
W&B SDK 0.12.4 以前
W&B SDK バージョン 0.12.4 以前を使用している場合は、マルチスレッド を代わりに使用するために、WANDB_START_METHOD 環境 変数 を "thread" に設定します。
マルチプロセッシング の ユースケース 例
次の コード スニペット は、高度な分散 ユースケース の一般的な方法を示しています。
プロセス の スポーン
スポーンされた プロセス で W&B Run を開始する場合は、メイン関数で wandb.setup() メソッド を使用します。
import multiprocessing as mp
def do_work (n):
run = wandb. init(config= dict(n= n))
run. log(dict(this= n * n))
def main ():
wandb. setup()
pool = mp. Pool(processes= 4 )
pool. map(do_work, range(4 ))
if __name__ == "__main__" :
main()
W&B Run を共有する
W&B Run オブジェクト を 引数 として渡して、 プロセス 間で W&B Runs を共有します。
def do_work (run):
run. log(dict(this= 1 ))
def main ():
run = wandb. init()
p = mp. Process(target= do_work, kwargs= dict(run= run))
p. start()
p. join()
if __name__ == "__main__" :
main()
ログ 記録の順序は保証されないことに注意してください。同期は スクリプト の作成者が行う必要があります。
6.4 - Log media and objects
3D ポイントクラウド や分子から、HTML やヒストグラムまで、リッチメディアを ログ に記録します。
画像、動画、音声など、様々な形式のメディアに対応しています。リッチメディアを ログ に記録して、結果を調査し、 run 、 model 、 dataset を視覚的に比較できます。例やハウツー ガイド については、以下をお読みください。
メディアタイプのリファレンス ドキュメントをお探しですか?
こちらのページ をご覧ください。
事前準備
W&B SDK でメディア オブジェクト を ログ に記録するには、追加の依存関係をインストールする必要がある場合があります。
これらの依存関係をインストールするには、次の コマンド を実行します。
画像
画像 を ログ に記録して、入力、出力、フィルターの重み、アクティベーションなどを追跡します。
画像 は、NumPy 配列から、PIL 画像 として、またはファイルシステムから直接 ログ に記録できます。
ステップから画像 を ログ に記録するたびに、UI に表示するために保存されます。画像 パネル を展開し、ステップ スライダーを使用して、異なるステップの画像 を確認します。これにより、 model の出力が トレーニング 中にどのように変化するかを簡単に比較できます。
トレーニング 中に ログ 記録がボトルネックになるのを防ぐため、また結果を表示する際に画像 の読み込みがボトルネックになるのを防ぐため、ステップごとに 50 枚未満の画像 を ログ に記録することをお勧めします。
配列を画像として ログ 記録
PIL 画像 の ログ 記録
ファイルから画像 の ログ 記録
torchvisionmake_grid
配列は Pillow を使用して png に変換されます。
images = wandb. Image(image_array, caption= "Top: Output, Bottom: Input" )
wandb. log({"examples" : images})
最後の次元が 1 の場合はグレースケール画像、3 の場合は RGB、4 の場合は RGBA であると想定されます。配列に float が含まれている場合は、0 から 255 までの整数に変換します。画像 の正規化方法を変更する場合は、modePIL.Image
配列から画像 への変換を完全に制御するには、PIL.Image
images = [PIL. Image. fromarray(image) for image in image_array]
wandb. log({"examples" : [wandb. Image(image) for image in images]})
さらに細かく制御するには、好きな方法で画像 を作成し、ディスクに保存して、ファイルパスを指定します。
im = PIL. fromarray(... )
rgb_im = im. convert("RGB" )
rgb_im. save("myimage.jpg" )
wandb. log({"example" : wandb. Image("myimage.jpg" )})
画像 オーバーレイ
セグメンテーション マスク
バウンディングボックス
セマンティックセグメンテーション マスク を ログ に記録し、W&B UI で (不透明度を変更したり、経時的な変化を表示したりするなど) 操作します。
オーバーレイを ログ に記録するには、次の キー と 値 を持つ 辞書 を wandb.Image の masks キーワード 引数 に指定する必要があります。
画像 マスク を表す 2 つの キー のいずれか 1 つ。
"mask_data": 各ピクセル の整数クラス ラベル を含む 2D NumPy 配列"path": (string) 保存された画像 マスク ファイル へのパス
"class_labels": (オプション) 画像 マスク 内の整数クラス ラベル を読み取り可能なクラス名に マッピング する 辞書
複数の マスク を ログ に記録するには、次の コード スニペット のように、複数の キー を持つ マスク 辞書 を ログ に記録します。
ライブ例を見る
サンプル コード
mask_data = np. array([[1 , 2 , 2 , ... , 2 , 2 , 1 ], ... ])
class_labels = {1 : "tree" , 2 : "car" , 3 : "road" }
mask_img = wandb. Image(
image,
masks= {
"predictions" : {"mask_data" : mask_data, "class_labels" : class_labels},
"ground_truth" : {
# ...
},
# ...
},
)
画像 と共に バウンディングボックス を ログ に記録し、フィルターとトグルを使用して、UI でさまざまなボックス セット を動的に 可視化 します。
ライブ例を見る
バウンディングボックス を ログ に記録するには、次の キー と 値 を持つ 辞書 を wandb.Image の boxes キーワード 引数 に指定する必要があります。
box_data: 各ボックス に対して 1 つの 辞書 の リスト。ボックス 辞書 の形式については、以下で説明します。
position: 以下で説明するように、2 つの形式のいずれかでボックス の位置とサイズを表す 辞書。ボックス はすべて同じ形式を使用する必要はありません。
オプション 1: {"minX", "maxX", "minY", "maxY"}。各ボックス の次元の上限と下限を定義する座標セットを指定します。オプション 2: {"middle", "width", "height"}。[x,y] として middle 座標を指定する座標セットと、スカラーとして width と height を指定します。
class_id: ボックス のクラス ID を表す整数。以下の class_labels キー を参照してください。scores: スコア の文字列ラベルと数値の 値 の 辞書。UI でボックス をフィルタリングするために使用できます。domain: ボックス 座標の単位/形式を指定します。ボックス 座標が画像 の次元の範囲内の整数など、ピクセル空間で表される場合は、これを「pixel」に設定します 。デフォルトでは、 domain は画像 の分数/パーセンテージであると見なされ、0 から 1 の間の浮動小数点数として表されます。box_caption: (オプション) このボックス のラベル テキストとして表示される文字列
class_labels: (オプション) class_id を文字列に マッピング する 辞書。デフォルトでは、クラス ラベル class_0、class_1 などを生成します。
この例をご覧ください。
class_id_to_label = {
1 : "car" ,
2 : "road" ,
3 : "building" ,
# ...
}
img = wandb. Image(
image,
boxes= {
"predictions" : {
"box_data" : [
{
# one box expressed in the default relative/fractional domain
"position" : {"minX" : 0.1 , "maxX" : 0.2 , "minY" : 0.3 , "maxY" : 0.4 },
"class_id" : 2 ,
"box_caption" : class_id_to_label[2 ],
"scores" : {"acc" : 0.1 , "loss" : 1.2 },
# another box expressed in the pixel domain
# (for illustration purposes only, all boxes are likely
# to be in the same domain/format)
"position" : {"middle" : [150 , 20 ], "width" : 68 , "height" : 112 },
"domain" : "pixel" ,
"class_id" : 3 ,
"box_caption" : "a building" ,
"scores" : {"acc" : 0.5 , "loss" : 0.7 },
# ...
# Log as many boxes an as needed
}
],
"class_labels" : class_id_to_label,
},
# Log each meaningful group of boxes with a unique key name
"ground_truth" : {
# ...
},
},
)
wandb. log({"driving_scene" : img})
テーブル の画像 オーバーレイ
セグメンテーション マスク
バウンディングボックス
テーブル に セグメンテーション マスク を ログ 記録するには、テーブル の各行に wandb.Image オブジェクト を指定する必要があります。
コード スニペット に例を示します。
table = wandb. Table(columns= ["ID" , "Image" ])
for id, img, label in zip(ids, images, labels):
mask_img = wandb. Image(
img,
masks= {
"prediction" : {"mask_data" : label, "class_labels" : class_labels}
# ...
},
)
table. add_data(id, img)
wandb. log({"Table" : table})
テーブル に バウンディングボックス を持つ 画像 を ログ 記録するには、テーブル の各行に wandb.Image オブジェクト を指定する必要があります。
コード スニペット に例を示します。
table = wandb. Table(columns= ["ID" , "Image" ])
for id, img, boxes in zip(ids, images, boxes_set):
box_img = wandb. Image(
img,
boxes= {
"prediction" : {
"box_data" : [
{
"position" : {
"minX" : box["minX" ],
"minY" : box["minY" ],
"maxX" : box["maxX" ],
"maxY" : box["maxY" ],
},
"class_id" : box["class_id" ],
"box_caption" : box["caption" ],
"domain" : "pixel" ,
}
for box in boxes
],
"class_labels" : class_labels,
}
},
)
ヒストグラム
基本的な ヒストグラム の ログ 記録
柔軟な ヒストグラム の ログ 記録
概要の ヒストグラム
リスト、配列、 テンソル などの数値のシーケンスが最初の 引数 として指定された場合、np.histogram を呼び出すことで ヒストグラム を自動的に構築します。すべての配列/ テンソル はフラット化されます。オプションの num_bins キーワード 引数 を使用して、デフォルトの 64 ビン をオーバーライドできます。サポートされているビンの最大数は 512 です。
UI では、 ヒストグラム は x 軸に トレーニング ステップ、y 軸に メトリック 値、色で表されるカウントでプロットされ、 トレーニング 全体で ログ 記録された ヒストグラム の比較が容易になります。1 回限りの ヒストグラム の ログ 記録の詳細については、この パネル の「概要の ヒストグラム 」 タブ を参照してください。
wandb. log({"gradients" : wandb. Histogram(grads)})
さらに詳細に制御する場合は、np.histogram を呼び出し、返された タプル を np_histogram キーワード 引数 に渡します。
np_hist_grads = np. histogram(grads, density= True , range= (0.0 , 1.0 ))
wandb. log({"gradients" : wandb. Histogram(np_hist_grads)})
wandb. run. summary. update( # if only in summary, only visible on overview tab
{"final_logits" : wandb. Histogram(logits)}
)
'obj'、'gltf'、'glb'、'babylon'、'stl'、'pts.json' 形式のファイルを ログ 記録すると、 run 終了時に UI でレンダリングされます。
wandb. log(
{
"generated_samples" : [
wandb. Object3D(open("sample.obj" )),
wandb. Object3D(open("sample.gltf" )),
wandb. Object3D(open("sample.glb" )),
]
}
)
ライブ例を見る
ヒストグラム が概要にある場合、Run Page の Overviewタブ に表示されます。履歴にある場合、Chartsタブ に時間の経過に伴うビンのヒートマップをプロットします。
3D 可視化
バウンディングボックス を持つ 3D ポイントクラウド と Lidar シーンを ログ 記録します。レンダリングするポイントの座標と色を含む NumPy 配列を渡します。
point_cloud = np. array([[0 , 0 , 0 , COLOR]])
wandb. log({"point_cloud" : wandb. Object3D(point_cloud)})
:::info
W&B UI はデータを 300,000 ポイント で切り捨てます。
:::
NumPy 配列形式
柔軟な配色に対応するため、3 つの異なる形式の NumPy 配列がサポートされています。
[[x, y, z], ...] nx3[[x, y, z, c], ...] nx4 | c は[1, 14]` の範囲のカテゴリです (セグメンテーション に役立ちます)。[[x, y, z, r, g, b], ...] nx6 | r,g,b は赤、緑、青のカラー チャンネル の [0,255] の範囲の値です。
Python オブジェクト
このスキーマを使用すると、Python オブジェクト を定義し、以下に示すように from_point_cloud メソッド に渡すことができます。
points は、上記の単純な ポイントクラウド レンダラーと同じ形式 を使用してレンダリングするポイントの座標と色を含む NumPy 配列です。boxes は、3 つの属性を持つ Python 辞書 の NumPy 配列です。
corners- 8 つの角の リストlabel- ボックス にレンダリングされるラベルを表す文字列 (オプション)color- ボックス の色を表す RGB 値score - バウンディングボックス に表示される数値。表示される バウンディングボックス をフィルタリングするために使用できます (たとえば、score > 0.75 の バウンディングボックス のみを表示する場合)。(オプション)
type は、レンダリングするシーン タイプを表す文字列です。現在、サポートされている値は lidar/beta のみです。
point_list = [
[
2566.571924017235 , # x
746.7817289698219 , # y
- 15.269245470863748 ,# z
76.5 , # red
127.5 , # green
89.46617199365393 # blue
],
[ 2566.592983606823 , 746.6791987335685 , - 15.275803826279521 , 76.5 , 127.5 , 89.45471117247024 ],
[ 2566.616361739416 , 746.4903185513501 , - 15.28628929674075 , 76.5 , 127.5 , 89.41336375503832 ],
[ 2561.706014951675 , 744.5349468458361 , - 14.877496818222781 , 76.5 , 127.5 , 82.21868245418283 ],
[ 2561.5281847916694 , 744.2546118233013 , - 14.867862032341005 , 76.5 , 127.5 , 81.87824684536432 ],
[ 2561.3693562897465 , 744.1804761656741 , - 14.854129178142523 , 76.5 , 127.5 , 81.64137897587152 ],
[ 2561.6093071504515 , 744.0287526628543 , - 14.882135189841177 , 76.5 , 127.5 , 81.89871499537098 ],
# ... and so on
]
run. log({"my_first_point_cloud" : wandb. Object3D. from_point_cloud(
points = point_list,
boxes = [{
"corners" : [
[ 2601.2765123137915 , 767.5669506323393 , - 17.816764802288663 ],
[ 2599.7259021588347 , 769.0082337923552 , - 17.816764802288663 ],
[ 2599.7259021588347 , 769.0082337923552 , - 19.66876480228866 ],
[ 2601.2765123137915 , 767.5669506323393 , - 19.66876480228866 ],
[ 2604.8684867834395 , 771.4313904894723 , - 17.816764802288663 ],
[ 2603.3178766284827 , 772.8726736494882 , - 17.816764802288663 ],
[ 2603.3178766284827 , 772.8726736494882 , - 19.66876480228866 ],
[ 2604.8684867834395 , 771.4313904894723 , - 19.66876480228866 ]
],
"color" : [0 , 0 , 255 ], # color in RGB of the bounding box
"label" : "car" , # string displayed on the bounding box
"score" : 0.6 # numeric displayed on the bounding box
}],
vectors = [
{"start" : [0 , 0 , 0 ], "end" : [0.1 , 0.2 , 0.5 ], "color" : [255 , 0 , 0 ]}, # color is optional
],
point_cloud_type = "lidar/beta" ,
)})
ポイントクラウド を表示するときは、control キー を押しながらマウスを使用すると、スペース内を移動できます。
ポイントクラウド ファイル
the from_file メソッド を使用して、 ポイントクラウド データがいっぱいの JSON ファイルをロードできます。
run. log({"my_cloud_from_file" : wandb. Object3D. from_file(
"./my_point_cloud.pts.json"
)})
ポイントクラウド データの形式設定方法の例を以下に示します。
{
"boxes" : [
{
"color" : [
0 ,
255 ,
0
],
"score" : 0.35 ,
"label" : "My label" ,
"corners" : [
[
2589.695869075582 ,
760.7400443552185 ,
-18.044831294622487
],
[
2590.719039645323 ,
762.3871153874499 ,
-18.044831294622487
],
[
2590.719039645323 ,
762.3871153874499 ,
-19.54083129462249
],
[
2589.695869075582 ,
760.7400443552185 ,
-19.54083129462249
],
[
2594.9666662674313 ,
757.4657929961453 ,
-18.044831294622487
],
[
2595.9898368371723 ,
759.1128640283766 ,
-18.044831294622487
],
[
2595.9898368371723 ,
759.1128640283766 ,
-19.54083129462249
],
[
2594.9666662674313 ,
757.4657929961453 ,
-19.54083129462249
]
]
}
],
"points" : [
[
2566.571924017235 ,
746.7817289698219 ,
-15.269245470863748 ,
76.5 ,
127.5 ,
89.46617199365393
],
[
2566.592983606823 ,
746.6791987335685 ,
-15.275803826279521 ,
76.5 ,
127.5 ,
89.45471117247024
],
[
2566.616361739416 ,
746.4903185513501 ,
-15.28628929674075 ,
76.5 ,
127.5 ,
89.41336375503832
]
],
"type" : "lidar/beta"
}
NumPy 配列
上記で定義されている同じ配列形式 を使用して、 from_numpy メソッド で numpy 配列を直接使用して、 ポイントクラウド を定義できます。
run. log({"my_cloud_from_numpy_xyz" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 ], # x, y, z
[1 , 1 , 1 ],
[1.2 , 1 , 1.2 ]
]
)
)})
run. log({"my_cloud_from_numpy_cat" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 , 1 ], # x, y, z, category
[1 , 1 , 1 , 1 ],
[1.2 , 1 , 1.2 , 12 ],
[1.2 , 1 , 1.3 , 12 ],
[1.2 , 1 , 1.4 , 12 ],
[1.2 , 1 , 1.5 , 12 ],
[1.2 , 1 , 1.6 , 11 ],
[1.2 , 1 , 1.7 , 11 ],
]
)
)})
run. log({"my_cloud_from_numpy_rgb" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 , 255 , 0 , 0 ], # x, y, z, r, g, b
[1 , 1 , 1 , 0 , 255 , 0 ],
[1.2 , 1 , 1.3 , 0 , 255 , 255 ],
[1.2 , 1 , 1.4 , 0 , 255 , 255 ],
[1.2 , 1 , 1.5 , 0 , 0 , 255 ],
[1.2 , 1 , 1.1 , 0 , 0 , 255 ],
[1.2 , 1 , 0.9 , 0 , 0 , 255 ],
]
)
)})
wandb. log({"protein" : wandb. Molecule("6lu7.pdb" )})
10 個のファイルタイプ ( pdb、pqr、mmcif、mcif、cif、sdf、sd、gro、mol2、または mmtf) のいずれかで分子データを ログ 記録します。
W&B は、SMILES 文字列、rdkitmol ファイル、および rdkit.Chem.rdchem.Mol オブジェクト からの分子データの ログ 記録もサポートしています。
resveratrol = rdkit. Chem. MolFromSmiles("Oc1ccc(cc1)C=Cc1cc(O)cc(c1)O" )
wandb. log(
{
"resveratrol" : wandb. Molecule. from_rdkit(resveratrol),
"green fluorescent protein" : wandb. Molecule. from_rdkit("2b3p.mol" ),
"acetaminophen" : wandb. Molecule. from_smiles("CC(=O)Nc1ccc(O)cc1" ),
}
)
run が終了すると、UI で分子の 3D 可視化を操作できるようになります。
AlphaFold を使用したライブ例を見る
PNG 画像
wandb.Imagenumpy 配列または PILImage の インスタンス を PNG に変換します。
wandb. log({"example" : wandb. Image(... )})
# Or multiple images
wandb. log({"example" : [wandb. Image(... ) for img in images]})
動画
動画は、wandb.Video
wandb. log({"example" : wandb. Video("myvideo.mp4" )})
これで、メディア ブラウザー で動画を表示できます。プロジェクト ワークスペース 、 run ワークスペース 、または レポート に移動し、[可視化 を追加 ] をクリックして、リッチメディア パネル を追加します。
分子の 2D 表示
wandb.Imagerdkit
molecule = rdkit. Chem. MolFromSmiles("CC(=O)O" )
rdkit. Chem. AllChem. Compute2DCoords(molecule)
rdkit. Chem. AllChem. GenerateDepictionMatching2DStructure(molecule, molecule)
pil_image = rdkit. Chem. Draw. MolToImage(molecule, size= (300 , 300 ))
wandb. log({"acetic_acid" : wandb. Image(pil_image)})
その他のメディア
W&B は、さまざまなその他のメディアタイプの ログ 記録もサポートしています。
音声
wandb. log({"whale songs" : wandb. Audio(np_array, caption= "OooOoo" , sample_rate= 32 )})
ステップごとに最大 100 個のオーディオ クリップ を ログ 記録できます。詳細な使用方法については、audio-file
動画
wandb. log({"video" : wandb. Video(numpy_array_or_path_to_video, fps= 4 , format= "gif" )})
numpy 配列が指定されている場合、次元は時間、 チャンネル 、幅、高さの順であると想定されます。デフォルトでは、4 fps の gif 画像 を作成します (ffmpegmoviepy"gif"、"mp4"、"webm"、および "ogg" です。文字列を wandb.Video に渡すと、ファイルが存在し、サポートされている形式であることをアサートしてから、wandb にアップロードします。BytesIO オブジェクト を渡すと、指定された形式を拡張子として持つ一時ファイルが作成されます。
W&B Run ページと Project ページでは、[メディア] セクションに動画が表示されます。
詳細な使用方法については、video-file
テキスト
wandb.Table を使用して、UI に表示される テーブル にテキストを ログ 記録します。デフォルトでは、列 ヘッダー は ["Input", "Output", "Expected"] です。最適な UI パフォーマンスを確保するために、デフォルトの最大行数は 10,000 に設定されています。ただし、 ユーザー は wandb.Table.MAX_ROWS = {DESIRED_MAX} を使用して、最大値を明示的にオーバーライドできます。
columns = ["Text" , "Predicted Sentiment" , "True Sentiment" ]
# Method 1
data = [["I love my phone" , "1" , "1" ], ["My phone sucks" , "0" , "-1" ]]
table = wandb. Table(data= data, columns= columns)
wandb. log({"examples" : table})
# Method 2
table = wandb. Table(columns= columns)
table. add_data("I love my phone" , "1" , "1" )
table. add_data("My phone sucks" , "0" , "-1" )
wandb. log({"examples" : table})
pandas DataFrame オブジェクト を渡すこともできます。
table = wandb. Table(dataframe= my_dataframe)
詳細な使用方法については、string
HTML
wandb. log({"custom_file" : wandb. Html(open("some.html" ))})
wandb. log({"custom_string" : wandb. Html('<a href="https://mysite">Link</a>' )})
カスタム HTML は任意の キー で ログ 記録でき、これにより、 run ページに HTML パネル が表示されます。デフォルトでは、デフォルトのスタイルが挿入されます。inject=False を渡すことで、デフォルトのスタイルをオフにすることができます。
wandb. log({"custom_file" : wandb. Html(open("some.html" ), inject= False )})
詳細な使用方法については、html-file
6.5 - Log models
モデルのログ
以下のガイドでは、モデルを W&B の run に記録し、それらを操作する方法について説明します。
以下の API は、実験管理のワークフローの一部としてモデルを追跡するのに役立ちます。このページに記載されている API を使用して、モデルを run に記録し、メトリクス、テーブル、メディア、その他のオブジェクトにアクセスします。
以下のことを行いたい場合は、W&B Artifacts を使用することをお勧めします。
モデル以外に、データセット、プロンプトなど、シリアル化されたデータのさまざまなバージョンを作成および追跡する。
W&B で追跡されるモデルまたはその他のオブジェクトのリネージグラフ を調べる。
これらのメソッドで作成されたモデル artifacts を操作する(プロパティの更新 (メタデータ、エイリアス、および説明) など)。
W&B Artifacts および高度なバージョン管理のユースケースの詳細については、Artifacts のドキュメントを参照してください。
モデルを run に記録する
指定したディレクトリー内のコンテンツを含むモデル artifact を記録するには、log_modellog_model
モデルを W&B run の入力または出力としてマークすると、モデルの依存関係とモデルの関連付けを追跡できます。W&B App UI 内でモデルのリネージを表示します。詳細については、Artifacts チャプターの アーティファクトグラフの探索とトラバース ページを参照してください。
モデルファイルが保存されているパスを path パラメーターに指定します。パスは、ローカルファイル、ディレクトリー、または s3://bucket/path などの外部バケットへの参照 URI にすることができます。
<> で囲まれた値は、独自の値に置き換えてください。
import wandb
# W&B の run を初期化します
run = wandb. init(project= "<your-project>" , entity= "<your-entity>" )
# モデルをログに記録します
run. log_model(path= "<path-to-model>" , name= "<name>" )
オプションで、name パラメーターにモデル artifact の名前を指定します。name が指定されていない場合、W&B は入力パスのベース名を run ID を先頭に付加したものを名前として使用します。
ユーザーまたは W&B がモデルに割り当てる
name を記録しておいてください。
use_model メソッドでモデルパスを取得するには、モデルの名前が必要です。
可能なパラメーターの詳細については、API Reference ガイドの log_model
例: モデルを run にログ記録する
import os
import wandb
from tensorflow import keras
from tensorflow.keras import layers
config = {"optimizer" : "adam" , "loss" : "categorical_crossentropy" }
# W&B の run を初期化します
run = wandb. init(entity= "charlie" , project= "mnist-experiments" , config= config)
# ハイパーパラメーター
loss = run. config["loss" ]
optimizer = run. config["optimizer" ]
metrics = ["accuracy" ]
num_classes = 10
input_shape = (28 , 28 , 1 )
# トレーニングアルゴリズム
model = keras. Sequential(
[
layers. Input(shape= input_shape),
layers. Conv2D(32 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Conv2D(64 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Flatten(),
layers. Dropout(0.5 ),
layers. Dense(num_classes, activation= "softmax" ),
]
)
# トレーニング用にモデルを構成する
model. compile(loss= loss, optimizer= optimizer, metrics= metrics)
# モデルを保存
model_filename = "model.h5"
local_filepath = "./"
full_path = os. path. join(local_filepath, model_filename)
model. save(filepath= full_path)
# モデルを W&B run にログ記録する
run. log_model(path= full_path, name= "MNIST" )
run. finish()
ユーザーが log_model を呼び出すと、MNIST という名前のモデル artifact が作成され、ファイル model.h5 がモデル artifact に追加されました。ターミナルまたはノートブックには、モデルがログに記録された run に関する情報を見つける場所の情報が表示されます。
View run different- surf- 5 at: https:// wandb. ai/ charlie/ mnist- experiments/ runs/ wlby6fuw
Synced 5 W& B file(s), 0 media file(s), 1 artifact file(s) and 0 other file(s)
Find logs at: ./ wandb/ run- 20231206_103511 - wlby6fuw/ logs
ログに記録されたモデルをダウンロードして使用する
以前に W&B run に記録されたモデルファイルにアクセスしてダウンロードするには、use_model
取得するモデルファイルが保存されているモデル artifact の名前を指定します。指定する名前は、既存のログに記録されたモデル artifact の名前と一致する必要があります。
log_model でファイルを最初にログに記録したときに name を定義しなかった場合、割り当てられるデフォルトの名前は、入力パスのベース名に run ID が付加されたものです。
<> で囲まれた他の値は必ず置き換えてください。
import wandb
# run を初期化します
run = wandb. init(project= "<your-project>" , entity= "<your-entity>" )
# モデルにアクセスしてダウンロードします。ダウンロードされた artifact へのパスを返します
downloaded_model_path = run. use_model(name= "<your-model-name>" )
use_model 関数は、ダウンロードされたモデルファイルのパスを返します。このモデルを後でリンクする場合は、このパスを記録しておいてください。上記のコードスニペットでは、返されたパスは downloaded_model_path という名前の変数に格納されています。
例: ログに記録されたモデルをダウンロードして使用する
たとえば、上記のコードスニペットでは、ユーザーが use_model API を呼び出しました。取得するモデル artifact の名前と、バージョン/エイリアスを指定しました。次に、API から返されたパスを downloaded_model_path 変数に格納しました。
import wandb
entity = "luka"
project = "NLP_Experiments"
alias = "latest" # モデルバージョンのセマンティックニックネームまたは識別子
model_artifact_name = "fine-tuned-model"
# run を初期化します
run = wandb. init(project= project, entity= entity)
# モデルにアクセスしてダウンロードします。ダウンロードされた artifact へのパスを返します
downloaded_model_path = run. use_model(name = f " { model_artifact_name} : { alias} " )
可能なパラメーターと戻り値の型の詳細については、API Reference ガイドの use_model
モデルをログに記録して W&B Model Registry にリンクする
link_model メソッドは、現在、間もなく非推奨になる従来の W&B Model Registry とのみ互換性があります。新しいエディションのモデルレジストリにモデル artifact をリンクする方法については、Registry の
ドキュメント を参照してください。
link_modelW&B Model Registry にリンクします。登録済みモデルが存在しない場合、W&B は registered_model_name パラメーターに指定した名前で新しいモデルを作成します。
モデルをリンクすることは、チームの他のメンバーが表示および利用できるモデルの一元化されたチームリポジトリにモデルを「ブックマーク」または「公開」することに似ています。
モデルをリンクすると、そのモデルは Registry で複製されたり、project から移動してレジストリに移動したりすることはありません。リンクされたモデルは、project 内の元のモデルへのポインターです。
Registry を使用して、タスクごとに最適なモデルを整理し、モデルライフサイクルを管理し、ML ライフサイクル全体で簡単な追跡と監査を促進し、webhook またはジョブでダウンストリームアクションを自動化 します。
Registered Model は、Model Registry 内のリンクされたモデルバージョンのコレクションまたはフォルダーです。登録済みモデルは通常、単一のモデリングユースケースまたはタスクの候補モデルを表します。
上記のコードスニペットは、link_model<> で囲まれた他の値は必ず置き換えてください。
import wandb
run = wandb. init(entity= "<your-entity>" , project= "<your-project>" )
run. link_model(path= "<path-to-model>" , registered_model_name= "<registered-model-name>" )
run. finish()
オプションのパラメーターの詳細については、API Reference ガイドの link_model
registered-model-name が Model Registry 内に既に存在する登録済みモデルの名前と一致する場合、モデルはその登録済みモデルにリンクされます。そのような登録済みモデルが存在しない場合は、新しいモデルが作成され、モデルが最初にリンクされます。
たとえば、Model Registry に "Fine-Tuned-Review-Autocompletion" という名前の既存の登録済みモデルがあるとします (例はこちら を参照)。また、いくつかのモデルバージョンが既にリンクされているとします: v0、v1、v2。link_model を registered-model-name="Fine-Tuned-Review-Autocompletion" で呼び出すと、新しいモデルはこの既存の登録済みモデルに v3 としてリンクされます。この名前の登録済みモデルが存在しない場合は、新しいモデルが作成され、新しいモデルは v0 としてリンクされます。
例: モデルをログに記録して W&B Model Registry にリンクする
たとえば、上記のコードスニペットはモデルファイルをログに記録し、モデルを登録済みモデル名 "Fine-Tuned-Review-Autocompletion" にリンクします。
これを行うには、ユーザーは link_model API を呼び出します。API を呼び出すときに、モデルのコンテンツを指すローカルファイルパス (path) と、リンク先の登録済みモデルの名前 (registered_model_name) を指定します。
import wandb
path = "/local/dir/model.pt"
registered_model_name = "Fine-Tuned-Review-Autocompletion"
run = wandb. init(project= "llm-evaluation" , entity= "noa" )
run. link_model(path= path, registered_model_name= registered_model_name)
run. finish()
リマインダー: 登録済みモデルには、ブックマークされたモデルバージョンのコレクションが格納されています。
6.6 - Log summary metrics
トレーニング中に時間とともに変化する値に加えて、モデルや前処理ステップを要約する単一の値を追跡することも重要です。この情報を W&B の Run の summary 辞書に記録します。Run の summary 辞書は、numpy 配列、PyTorch テンソル、または TensorFlow テンソルを処理できます。値がこれらの型のいずれかである場合、バイナリファイルにテンソル全体を保持し、min、平均、分散、パーセンタイルなどの高度な メトリクス を summary オブジェクトに格納します。
wandb.log で最後に記録された値は、W&B Run の summary 辞書として自動的に設定されます。summary メトリクス 辞書が変更されると、前の値は失われます。
次の コードスニペット は、カスタム summary メトリクス を W&B に提供する方法を示しています。
wandb. init(config= args)
best_accuracy = 0
for epoch in range(1 , args. epochs + 1 ):
test_loss, test_accuracy = test()
if test_accuracy > best_accuracy:
wandb. summary["best_accuracy" ] = test_accuracy
best_accuracy = test_accuracy
トレーニングが完了した後、既存の W&B Run の summary 属性を更新できます。W&B Public API を使用して、summary 属性を更新します。
api = wandb. Api()
run = api. run("username/project/run_id" )
run. summary["tensor" ] = np. random. random(1000 )
run. summary. update()
summary メトリクス のカスタマイズ
カスタム summary メトリクス は、wandb.summary でトレーニングの最適なステップでモデルのパフォーマンスをキャプチャするのに役立ちます。たとえば、最終値の代わりに、最大精度または最小損失値をキャプチャしたい場合があります。
デフォルトでは、summary は履歴からの最終値を使用します。summary メトリクス をカスタマイズするには、define_metric で summary 引数に渡します。これは、次の値を受け入れます。
"min""max""mean""best""last""none"
"best" は、オプションの objective 引数を "minimize" または "maximize" に設定した場合にのみ使用できます。
次の例では、損失と精度の最小値と最大値を summary に追加します。
import wandb
import random
random. seed(1 )
wandb. init()
# 損失の最小値と最大値のsummary値
wandb. define_metric("loss" , summary= "min" )
wandb. define_metric("loss" , summary= "max" )
# 精度に対する最小値と最大値のsummary値
wandb. define_metric("acc" , summary= "min" )
wandb. define_metric("acc" , summary= "max" )
for i in range(10 ):
log_dict = {
"loss" : random. uniform(0 , 1 / (i + 1 )),
"acc" : random. uniform(1 / (i + 1 ), 1 ),
}
wandb. log(log_dict)
summary メトリクス の表示
run の Overview ページまたは project の runs テーブルで summary 値を表示します。
Run Overview
Run Table
W&B Public API
W&B App に移動します。
Workspace タブを選択します。runs のリストから、summary 値を記録した run の名前をクリックします。
Overview タブを選択します。Summary セクションで summary 値を表示します。
W&B App に移動します。
Runs タブを選択します。runs テーブル内で、summary 値の名前に基づいて、列内の summary 値を表示できます。
W&B Public API を使用して、run の summary 値を取得できます。
次の コード例 は、W&B Public API と pandas を使用して、特定の run に記録された summary 値を取得する方法の 1 つを示しています。
import wandb
import pandas
entity = "<your-entity>"
project = "<your-project>"
run_name = "<your-run-name>" # summary 値を持つ run の名前
all_runs = []
for run in api. runs(f " { entity} / { project_name} " ):
print("Fetching details for run: " , run. id, run. name)
run_data = {
"id" : run. id,
"name" : run. name,
"url" : run. url,
"state" : run. state,
"tags" : run. tags,
"config" : run. config,
"created_at" : run. created_at,
"system_metrics" : run. system_metrics,
"summary" : run. summary,
"project" : run. project,
"entity" : run. entity,
"user" : run. user,
"path" : run. path,
"notes" : run. notes,
"read_only" : run. read_only,
"history_keys" : run. history_keys,
"metadata" : run. metadata,
}
all_runs. append(run_data)
# DataFrameに変換
df = pd. DataFrame(all_runs)
# カラム名 (run) に基づいて行を取得し、dictionary に変換します。
df[df['name' ]== run_name]. summary. reset_index(drop= True ). to_dict()
6.7 - Log tables
W&B でテーブルをログします。
wandb.Table を使用してデータをログに記録し、Weights & Biases(W&B)で視覚化およびクエリを実行します。このガイドでは、次の方法について説明します。
テーブルの作成 データの追加 データの取得 テーブルの保存
テーブルの作成
Tableを定義するには、データの各行に表示する列を指定します。各行は、トレーニングデータセット内の単一のアイテム、トレーニング中の特定のステップまたはエポック、テストアイテムに対するモデルによる予測、モデルによって生成されたオブジェクトなどです。各列には、数値、テキスト、ブール値、画像、動画、音声などの固定タイプがあります。タイプを事前に指定する必要はありません。各列に名前を付け、その型のデータのみをその列インデックスに渡してください。詳細な例については、こちらのレポート をご覧ください。
wandb.Table コンストラクターは、次の2つの方法で使用します。
行のリスト: 名前付きの列とデータの行をログに記録します。たとえば、次のコードスニペットは、2行3列のテーブルを生成します。
wandb. Table(columns= ["a" , "b" , "c" ], data= [["1a" , "1b" , "1c" ], ["2a" , "2b" , "2c" ]])
Pandas DataFrame: wandb.Table(dataframe=my_df) を使用して DataFrame をログに記録します。列名は DataFrame から抽出されます。
既存の配列またはデータフレームから
# モデルが4つの画像に対する予測を返したと仮定します
# 次のフィールドが利用可能です:
# - 画像ID
# - wandb.Image() にラップされた画像ピクセル
# - モデルの予測ラベル
# - 正解ラベル
my_data = [
[0 , wandb. Image("img_0.jpg" ), 0 , 0 ],
[1 , wandb. Image("img_1.jpg" ), 8 , 0 ],
[2 , wandb. Image("img_2.jpg" ), 7 , 1 ],
[3 , wandb. Image("img_3.jpg" ), 1 , 1 ],
]
# 対応する列を持つ wandb.Table() を作成します
columns = ["id" , "image" , "prediction" , "truth" ]
test_table = wandb. Table(data= my_data, columns= columns)
データの追加
テーブルは変更可能です。スクリプトの実行中に、最大200,000行までテーブルにデータを追加できます。テーブルにデータを追加する方法は2つあります。
行の追加 : table.add_data("3a", "3b", "3c")。新しい行はリストとして表されないことに注意してください。行がリスト形式の場合は、スター表記 * を使用して、リストを位置引数に展開します: table.add_data(*my_row_list)。行には、テーブルの列数と同じ数のエントリが含まれている必要があります。列の追加 : table.add_column(name="col_name", data=col_data)。col_data の長さは、テーブルの現在の行数と等しくなければならないことに注意してください。ここで、col_data はリストデータまたは NumPy NDArray にすることができます。
データの増分追加
このコードサンプルは、W&Bテーブルを段階的に作成および入力する方法を示しています。可能なすべてのラベルの信頼性スコアを含む、事前定義された列を持つテーブルを定義し、推論中にデータを1行ずつ追加します。runの再開時にテーブルにデータを段階的に追加する こともできます。
# 各ラベルの信頼性スコアを含む、テーブルの列を定義します
columns = ["id" , "image" , "guess" , "truth" ]
for digit in range(10 ): # 各桁 (0-9) の信頼性スコア列を追加します
columns. append(f "score_ { digit} " )
# 定義された列でテーブルを初期化します
test_table = wandb. Table(columns= columns)
# テストデータセットを反復処理し、データをテーブルに行ごとに追加します
# 各行には、画像ID、画像、予測ラベル、正解ラベル、および信頼性スコアが含まれます
for img_id, img in enumerate(mnist_test_data):
true_label = mnist_test_data_labels[img_id] # 正解ラベル
guess_label = my_model. predict(img) # 予測ラベル
test_table. add_data(
img_id, wandb. Image(img), guess_label, true_label
) # 行データをテーブルに追加します
runの再開時にデータを追加する
Artifactから既存のテーブルをロードし、データの最後の行を取得して、更新されたメトリクスを追加することにより、再開されたrunでW&Bテーブルを段階的に更新できます。次に、互換性のためにテーブルを再初期化し、更新されたバージョンをW&Bに記録します。
# アーティファクトから既存のテーブルをロードします
best_checkpt_table = wandb. use_artifact(table_tag). get(table_name)
# 再開のためにテーブルからデータの最後の行を取得します
best_iter, best_metric_max, best_metric_min = best_checkpt_table. data[- 1 ]
# 必要に応じて最適なメトリクスを更新します
# 更新されたデータをテーブルに追加します
best_checkpt_table. add_data(best_iter, best_metric_max, best_metric_min)
# 互換性を確保するために、更新されたデータでテーブルを再初期化します
best_checkpt_table = wandb. Table(
columns= ["col1" , "col2" , "col3" ], data= best_checkpt_table. data
)
# 更新されたテーブルを Weights & Biases に記録します
wandb. log({table_name: best_checkpt_table})
データの取得
データがTableにある場合、列または行でアクセスします。
行イテレーター : ユーザーは、for ndx, row in table.iterrows(): ... などのTableの行イテレーターを使用して、データの行を効率的に反復処理できます。列の取得 : ユーザーは、table.get_column("col_name") を使用してデータの列を取得できます。便宜上、ユーザーは convert_to="numpy" を渡して、列をプリミティブの NumPy NDArray に変換できます。これは、列に wandb.Image などのメディアタイプが含まれている場合に、基になるデータに直接アクセスできるようにする場合に役立ちます。
テーブルの保存
スクリプトでデータのテーブル(たとえば、モデル予測のテーブル)を生成したら、結果をライブで視覚化するために、W&Bに保存します。
テーブルをrunに記録する
wandb.log() を使用して、次のようにテーブルをrunに保存します。
run = wandb. init()
my_table = wandb. Table(columns= ["a" , "b" ], data= [["1a" , "1b" ], ["2a" , "2b" ]])
run. log({"table_key" : my_table})
テーブルが同じキーに記録されるたびに、テーブルの新しいバージョンが作成され、バックエンドに保存されます。これは、モデルの予測が時間の経過とともにどのように改善されるかを確認したり、同じキーに記録されている限り、異なるrun間でテーブルを比較したりするために、複数のトレーニングステップで同じテーブルを記録できることを意味します。最大200,000行をログに記録できます。
200,000行を超える行をログに記録するには、次の制限をオーバーライドできます。
wandb.Table.MAX_ARTIFACT_ROWS = X
ただし、これにより、UIでのクエリの遅延など、パフォーマンスの問題が発生する可能性があります。
プログラムでテーブルにアクセスする
バックエンドでは、Tables は Artifacts として保持されます。特定のバージョンにアクセスする場合は、Artifact API を使用してアクセスできます。
with wandb. init() as run:
my_table = run. use_artifact("run-<run-id>-<table-name>:<tag>" ). get("<table-name>" )
Artifactsの詳細については、開発者ガイドのArtifactsチャプター を参照してください。
テーブルの視覚化
このように記録されたテーブルは、runページとプロジェクトページの両方の Workspace に表示されます。詳細については、テーブルの視覚化と分析 を参照してください。
Artifact テーブル
artifact.add() を使用して、ワークスペースではなく、runの Artifacts セクションにテーブルをログに記録します。これは、一度ログに記録して、将来のrunで参照するデータセットがある場合に役立ちます。
run = wandb. init(project= "my_project" )
# 意味のあるステップごとに wandb Artifact を作成します
test_predictions = wandb. Artifact("mnist_test_preds" , type= "predictions" )
# [上記のように予測データを構築します]
test_table = wandb. Table(data= data, columns= columns)
test_predictions. add(test_table, "my_test_key" )
run. log_artifact(test_predictions)
画像データを使用した artifact.add() の詳細な例 と、Artifacts と Tables を使用して 表形式データのバージョン管理と重複排除を行う方法 の例については、このレポートを参照してください。
Artifact テーブルの結合
ローカルで構築したテーブル、または他の Artifacts から取得したテーブルを wandb.JoinedTable(table_1, table_2, join_key) を使用して結合できます。
引数
説明
table_1
(str, wandb.Table, ArtifactEntry) Artifact 内の wandb.Table へのパス、テーブルオブジェクト、または ArtifactEntry
table_2
(str, wandb.Table, ArtifactEntry) Artifact 内の wandb.Table へのパス、テーブルオブジェクト、または ArtifactEntry
join_key
(str, [str, str]) 結合を実行するキー
Artifact コンテキストで以前に記録した2つの Tables を結合するには、Artifact からそれらを取得し、結果を新しい Table に結合します。
たとえば、'original_songs' という元の曲の Table と、同じ曲の合成バージョンの別の Table 'synth_songs' を読み取る方法を示します。次のコード例では、2つのテーブルを "song_id" で結合し、結果のテーブルを新しい W&B Table としてアップロードします。
import wandb
run = wandb. init(project= "my_project" )
# 元の曲のテーブルを取得します
orig_songs = run. use_artifact("original_songs:latest" )
orig_table = orig_songs. get("original_samples" )
# 合成された曲のテーブルを取得します
synth_songs = run. use_artifact("synth_songs:latest" )
synth_table = synth_songs. get("synth_samples" )
# テーブルを "song_id" で結合します
join_table = wandb. JoinedTable(orig_table, synth_table, "song_id" )
join_at = wandb. Artifact("synth_summary" , "analysis" )
# テーブルを Artifact に追加し、W&B に記録します
join_at. add(join_table, "synth_explore" )
run. log_artifact(join_at)
異なる Artifact オブジェクトに保存されている2つの以前に保存されたテーブルを結合する方法の例については、このチュートリアル を参照してください。
6.8 - Track CSV files with experiments
W&B へのデータのインポートとログ記録
W&B Python Library を使用して CSV ファイルをログに記録し、W&B Dashboard で可視化します。 W&B Dashboard は、機械学習モデルの結果を整理して可視化するための中央の場所です。これは、W&B にログ記録されていない以前の機械学習実験の情報を含む CSV ファイル がある場合、またはデータセットを含む CSV ファイル がある場合に特に役立ちます。
データセットのCSVファイルをインポートしてログに記録する
CSV ファイルの内容を再利用しやすくするために、W&B Artifacts を利用することをお勧めします。
まず、CSV ファイルをインポートします。次のコードスニペットで、iris.csv ファイル名を CSV ファイルの名前に置き換えます。
import wandb
import pandas as pd
# Read our CSV into a new DataFrame
new_iris_dataframe = pd. read_csv("iris.csv" )
CSV ファイルを W&B テーブルに変換して、W&B Dashboards を利用します。
# Convert the DataFrame into a W&B Table
iris_table = wandb. Table(dataframe= new_iris_dataframe)
次に、W&B Artifact を作成し、テーブルを Artifact に追加します。
# Add the table to an Artifact to increase the row
# limit to 200000 and make it easier to reuse
iris_table_artifact = wandb. Artifact("iris_artifact" , type= "dataset" )
iris_table_artifact. add(iris_table, "iris_table" )
# Log the raw csv file within an artifact to preserve our data
iris_table_artifact. add_file("iris.csv" )
W&B Artifacts の詳細については、Artifacts のチャプター を参照してください。
最後に、wandb.init で W&B Run を開始し、W&B に追跡およびログを記録します。
# Start a W&B run to log data
run = wandb. init(project= "tables-walkthrough" )
# Log the table to visualize with a run...
run. log({"iris" : iris_table})
# and Log as an Artifact to increase the available row limit!
run. log_artifact(iris_table_artifact)
wandb.init() API は、Run にデータをログ記録するための新しいバックグラウンド プロセスを生成し、(デフォルトで) データを wandb.ai に同期します。 W&B Workspace Dashboard でライブ可視化を表示します。次の画像は、コードスニペットのデモの出力を示しています。
上記のコードスニペットを含む完全なスクリプトは、以下にあります。
import wandb
import pandas as pd
# Read our CSV into a new DataFrame
new_iris_dataframe = pd. read_csv("iris.csv" )
# Convert the DataFrame into a W&B Table
iris_table = wandb. Table(dataframe= new_iris_dataframe)
# Add the table to an Artifact to increase the row
# limit to 200000 and make it easier to reuse
iris_table_artifact = wandb. Artifact("iris_artifact" , type= "dataset" )
iris_table_artifact. add(iris_table, "iris_table" )
# log the raw csv file within an artifact to preserve our data
iris_table_artifact. add_file("iris.csv" )
# Start a W&B run to log data
run = wandb. init(project= "tables-walkthrough" )
# Log the table to visualize with a run...
run. log({"iris" : iris_table})
# and Log as an Artifact to increase the available row limit!
run. log_artifact(iris_table_artifact)
# Finish the run (useful in notebooks)
run. finish()
Experiments の CSV ファイルをインポートしてログに記録する
場合によっては、CSV ファイルに experiment の詳細が含まれている場合があります。このような CSV ファイルにある一般的な詳細は次のとおりです。
Experiment
Model Name
Notes
Tags
Num Layers
Final Train Acc
Final Val Acc
Training Losses
Experiment 1
mnist-300-layers
Overfit way too much on training data
[latest]
300
0.99
0.90
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
Experiment 2
mnist-250-layers
Current best model
[prod, best]
250
0.95
0.96
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
Experiment 3
mnist-200-layers
Did worse than the baseline model. Need to debug
[debug]
200
0.76
0.70
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
…
…
…
…
…
…
…
Experiment N
mnist-X-layers
NOTES
…
…
…
…
[…, …]
W&B は、experiments の CSV ファイルを取得し、W&B Experiment Run に変換できます。次のコードスニペットとコードスクリプトは、experiments の CSV ファイルをインポートしてログに記録する方法を示しています。
まず、CSV ファイルを読み込み、Pandas DataFrame に変換します。 experiments.csv を CSV ファイルの名前に置き換えます。
import wandb
import pandas as pd
FILENAME = "experiments.csv"
loaded_experiment_df = pd. read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers" ]
SUMMARY_COLS = ["Final Train Acc" , "Final Val Acc" ]
METRIC_COLS = ["Training Losses" ]
# Format Pandas DataFrame to make it easier to work with
for i, row in loaded_experiment_df. iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
次に、wandb.init()
run = wandb. init(
project= PROJECT_NAME, name= run_name, tags= tags, notes= notes, config= config
)
experiment の実行中に、W&B で表示、クエリ、および分析できるように、メトリクスのすべてのインスタンスをログに記録することができます。これを行うには、run.log()
オプションで、run の結果を定義するために、最終的なサマリーメトリクスをログに記録できます。これを行うには、W&B define_metricrun.summary.update() を使用して、サマリーメトリクスを run に追加します。
run. summary. update(summaries)
サマリーメトリクスの詳細については、サマリーメトリクスのログ記録 を参照してください。
以下は、上記のサンプルテーブルを W&B Dashboard に変換する完全なスクリプトの例です。
FILENAME = "experiments.csv"
loaded_experiment_df = pd. read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers" ]
SUMMARY_COLS = ["Final Train Acc" , "Final Val Acc" ]
METRIC_COLS = ["Training Losses" ]
for i, row in loaded_experiment_df. iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
run = wandb. init(
project= PROJECT_NAME, name= run_name, tags= tags, notes= notes, config= config
)
for key, val in metrics. items():
if isinstance(val, list):
for _val in val:
run. log({key: _val})
else :
run. log({key: val})
run. summary. update(summaries)
run. finish()
7 - Track Jupyter notebooks
Jupyter で W&B を使用して、 ノートブック から離れることなくインタラクティブな 可視化 を取得できます。
Jupyter で W&B を使用すると、ノートブックから離れることなくインタラクティブな可視化を得ることができます。カスタムの 分析 、 実験 、プロトタイプを組み合わせて、すべて完全に ログ に記録します。
Jupyter ノートブック で W&B を使用する ユースケース
**反復的な 実験 **: パラメータを調整しながら 実験 を実行および再実行すると、手動でメモを取らなくても、実行したすべての run が W&B に自動的に保存されます。
コード の保存 : モデル を再現する際、ノートブック のどのセルがどの順序で実行されたかを知ることは困難です。 設定 ページ で コード の保存をオンにすると、各 実験 のセル実行の記録が保存されます。**カスタム 分析 **: run が W&B に ログ されると、API からデータフレームを取得してカスタム 分析 を実行し、それらの 結果 を W&B に ログ して レポート で保存および共有することが簡単になります。
ノートブック での始め方
次の コード でノートブックを開始して W&B をインストールし、アカウントをリンクします。
!pip install wandb -qqq
import wandb
wandb.login()
次に、 実験 を設定し、 ハイパーパラメータ を保存します。
wandb. init(
project= "jupyter-projo" ,
config= {
"batch_size" : 128 ,
"learning_rate" : 0.01 ,
"dataset" : "CIFAR-100" ,
},
)
wandb.init() を実行した後、%%wandb を使用して新しいセルを開始すると、ノートブック にライブグラフが表示されます。このセルを複数回実行すると、データが run に追加されます。
%%wandb
# Your training loop here
# ここにトレーニングループを記述します
このサンプルノートブック でお試しください。
ノートブック でライブ W&B インターフェースを直接レンダリングする
%wandb マジックを使用して、既存の ダッシュボード 、 Sweeps 、または Reports をノートブック で直接表示することもできます。
# Display a project workspace
# プロジェクトワークスペースを表示する
%wandb USERNAME/PROJECT
# Display a single run
# 単一のrunを表示する
%wandb USERNAME/PROJECT/runs/RUN_ID
# Display a sweep
# sweepを表示する
%wandb USERNAME/PROJECT/sweeps/SWEEP_ID
# Display a report
# reportを表示する
%wandb USERNAME/PROJECT/reports/REPORT_ID
# Specify the height of embedded iframe
# 埋め込みiframeの高さを指定する
%wandb USERNAME/PROJECT -h 2048
%%wandb または %wandb マジックの代わりに、wandb.init() を実行した後、wandb.run で任意のセルを終了してインライングラフを表示するか、API から返された report 、 sweep 、または run オブジェクトで ipython.display(...) を呼び出すことができます。
# Initialize wandb.run first
# 最初にwandb.runを初期化します
wandb. init()
# If cell outputs wandb.run, you'll see live graphs
# セルがwandb.runを出力する場合、ライブグラフが表示されます
wandb. run
W&B の追加の Jupyter 機能
Colab での簡単な認証 : Colab で wandb.init を初めて呼び出すと、ブラウザで W&B に現在 ログイン している場合、 ランタイム が自動的に認証されます。run ページの Overviewタブ に、Colab へのリンクが表示されます。Jupyter Magic: ダッシュボード 、 Sweeps 、および Reports をノートブック で直接表示します。%wandb マジックは、 プロジェクト 、 Sweeps 、または Reports へのパスを受け入れ、W&B インターフェースをノートブック で直接レンダリングします。docker コンテナ 化された Jupyter の Launch : wandb docker --jupyter を呼び出して dockerコンテナ を起動し、 コード をマウントし、Jupyter がインストールされていることを確認して、ポート 8888 で起動します。恐れることなく任意の順序でセルを実行する : デフォルトでは、run を finished としてマークするために、次に wandb.init が呼び出されるまで待機します。これにより、複数のセル(たとえば、データをセットアップするセル、 トレーニング するセル、テストするセル)を好きな順序で実行し、すべて同じ run に ログ できます。 設定 で コード の保存をオンにすると、実行されたセルも、実行された順序と実行された状態で ログ に記録され、最も非線形の パイプライン でも再現できます。Jupyter ノートブック で run を手動で完了としてマークするには、run.finish を呼び出します。
import wandb
run = wandb. init()
# training script and logging goes here
# ここにトレーニングスクリプトとロギングを記述します
run. finish()
8 - Experiments limits and performance
推奨される範囲内で ログ を記録することで、W&B のページをより速く、より応答性の高い状態に保つことができます。
以下の推奨範囲内でログを記録することで、W&B 内のページをより高速かつ応答性の高い状態に保つことができます。
ログ記録に関する考慮事項
wandb.log を使用して実験 メトリクス を追跡します。記録された メトリクス は、グラフを生成し、 テーブル に表示されます。ログに記録するデータが多すぎると、アプリケーションの動作が遅くなる可能性があります。
個別のメトリクス数
パフォーマンスを向上させるには、 プロジェクト 内の個別の メトリクス の合計数を 10,000 未満に抑えてください。
import wandb
wandb. log(
{
"a" : 1 , # "a" は個別のメトリクス
"b" : {
"c" : "hello" , # "b.c" は個別のメトリクス
"d" : [1 , 2 , 3 ], # "b.d" は個別のメトリクス
},
}
)
W&B は、ネストされた 値 を自動的にフラット化します。つまり、 辞書 を渡すと、W&B はそれをドットで区切られた 名前に変換します。 config 値 の場合、W&B は 名前に 3 つのドットをサポートします。 summary 値 の場合、W&B は 4 つのドットをサポートします。
ワークスペース の動作が突然遅くなった場合は、最近の runs が意図せずに数千もの新しい メトリクス を記録していないか確認してください。(これは、数千ものプロットがあるセクションで、表示されている run が 1 つまたは 2 つしかないことで簡単に見つけることができます。)記録されている場合は、それらの runs を削除し、目的の メトリクス で再作成することを検討してください。
値 の幅
ログに記録する単一の 値 のサイズを 1 MB 未満に、単一の wandb.log 呼び出しの合計サイズを 25 MB 未満に制限します。この制限は、wandb.Image、wandb.Audio などの wandb.Media タイプには適用されません。
# ❌ 推奨されません
wandb. log({"wide_key" : range(10000000 )})
# ❌ 推奨されません
with f as open("large_file.json" , "r" ):
large_data = json. load(f)
wandb. log(large_data)
幅の広い 値 は、幅の広い 値 を持つ メトリクス だけでなく、run 内のすべての メトリクス のプロットの読み込み時間に影響を与える可能性があります。
推奨量よりも幅の広い 値 をログに記録した場合でも、データは保存および追跡されます。ただし、プロットの読み込みが遅くなる可能性があります。
メトリクス の頻度
ログに記録する メトリクス に適切なログ記録頻度を選択してください。一般的な経験則として、 メトリクス の幅が広いほど、ログに記録する頻度を低くする必要があります。W&B は以下を推奨します。
スカラー: メトリクス ごとに <100,000 ログポイント
メディア: メトリクス ごとに <50,000 ログポイント
ヒストグラム: メトリクス ごとに <10,000 ログポイント
# 合計 100 万ステップのトレーニングループ
for step in range(1000000 ):
# ❌ 推奨されません
wandb. log(
{
"scalar" : step, # 100,000 スカラー
"media" : wandb. Image(... ), # 100,000 画像
"histogram" : wandb. Histogram(... ), # 100,000 ヒストグラム
}
)
# ✅ 推奨
if step % 1000 == 0 :
wandb. log(
{
"histogram" : wandb. Histogram(... ), # 10,000 ヒストグラム
},
commit= False ,
)
if step % 200 == 0 :
wandb. log(
{
"media" : wandb. Image(... ), # 50,000 画像
},
commit= False ,
)
if step % 100 == 0 :
wandb. log(
{
"scalar" : step, # 100,000 スカラー
},
commit= True ,
) # バッチ処理されたステップごとのメトリクスをまとめてコミット
ガイドラインを超えても、W&B はログに記録されたデータを受け入れ続けますが、ページ の読み込みが遅くなる場合があります。
Config サイズ
run config の合計サイズを 10 MB 未満に制限します。大きい 値 をログに記録すると、 プロジェクト ワークスペース と runs テーブル の操作が遅くなる可能性があります。
# ✅ 推奨
wandb. init(
config= {
"lr" : 0.1 ,
"batch_size" : 32 ,
"epochs" : 4 ,
}
)
# ❌ 推奨されません
wandb. init(
config= {
"steps" : range(10000000 ),
}
)
# ❌ 推奨されません
with f as open("large_config.json" , "r" ):
large_config = json. load(f)
wandb. init(config= large_config)
ワークスペース に関する考慮事項
Run count
読み込み時間を短縮するには、単一の プロジェクト 内の runs の合計数を以下に抑えてください。
SaaS Cloud で 100,000
専用クラウド または 自己管理 で 10,000
これらのしきい値を超える run カウントは、 プロジェクト ワークスペース または runs テーブル を含む操作、特に runs の グルーピング 時、または runs 中に多数の個別の メトリクス を収集する場合に、速度が低下する可能性があります。メトリクス 数 セクションも参照してください。
チームが頻繁に同じ runs のセット(最近の runs のセットなど)に アクセス する場合は、あまり頻繁に使用されない runs をまとめて移動する ことを検討して、新しい「アーカイブ」 プロジェクト に移動し、作業 プロジェクト にはより少ない runs のセットを残します。
ワークスペース のパフォーマンス
このセクションでは、 ワークスペース のパフォーマンスを最適化するためのヒントを紹介します。
パネル 数
デフォルトでは、 ワークスペース は 自動 であり、ログに記録された キー ごとに標準 パネル を生成します。大規模な プロジェクト の ワークスペース に、ログに記録された多くの キー の パネル が含まれている場合、 ワークスペース の読み込みと使用に時間がかかる場合があります。パフォーマンスを向上させるには、次のことができます。
ワークスペース を手動モードにリセットします。これには、デフォルトで パネル が含まれていません。
クイック追加 を使用して、視覚化する必要があるログに記録された キー の パネル を選択的に追加します。
未使用の パネル を 1 つずつ削除しても、パフォーマンスへの影響はほとんどありません。代わりに、 ワークスペース をリセットし、必要な パネル のみを選択的に追加し直します。
ワークスペース の構成の詳細については、パネル を参照してください。
セクション 数
ワークスペース 内に数百ものセクションがあると、パフォーマンスが低下する可能性があります。 メトリクス の高レベルの グルーピング に基づいてセクションを作成し、 メトリクス ごとに 1 つのセクションというアンチパターンを避けることを検討してください。
セクションが多すぎてパフォーマンスが低下している場合は、サフィックスではなくプレフィックスでセクションを作成するように ワークスペース 設定を検討してください。これにより、セクションの数が減り、パフォーマンスが向上する可能性があります。
メトリクス 数
run あたり 5000 ~ 100,000 個の メトリクス をログに記録する場合は、W&B は手動 ワークスペース を使用することをお勧めします。手動モードでは、さまざまな メトリクス のセットを探索するために、必要に応じて パネル を簡単に追加および削除できます。より集中的なプロットのセットを使用すると、 ワークスペース の読み込みが速くなります。プロットされていない メトリクス は、通常どおり収集および保存されます。
ワークスペース を手動モードにリセットするには、 ワークスペース のアクション ... メニューをクリックし、ワークスペース のリセット をクリックします。ワークスペース をリセットしても、runs の保存された メトリクス には影響しません。ワークスペース の管理の詳細 をご覧ください。
ファイル 数
単一の run でアップロードされるファイルの総数を 1,000 未満に抑えてください。多数の ファイル をログに記録する必要がある場合は、W&B Artifacts を使用できます。単一の run で 1,000 個を超える ファイル があると、run ページ の速度が低下する可能性があります。
Reports と ワークスペース
レポート は、 パネル 、テキスト、 メディア の任意の配置を自由に構成できるため、同僚と洞察を簡単に共有できます。
対照的に、 ワークスペース では、数百から数十万もの runs にわたって、数十から数千もの メトリクス を高密度かつ高性能に 分析 できます。ワークスペース には、 Reports と比較して、最適化された キャッシュ 、クエリ、および読み込み機能があります。ワークスペース は、主に プレゼンテーション ではなく 分析 に使用される プロジェクト 、または 20 個以上のプロットをまとめて表示する必要がある場合にお勧めです。
Python スクリプト のパフォーマンス
Python スクリプト のパフォーマンスが低下する原因はいくつかあります。
データ のサイズが大きすぎる。データ サイズが大きいと、トレーニングループに 1 ミリ秒を超えるオーバーヘッドが発生する可能性があります。
ネットワーク の速度と、W&B バックエンド の構成方法
wandb.log を 1 秒間に数回以上呼び出す。これは、wandb.log が呼び出されるたびに、トレーニングループにわずかな遅延が追加されるためです。
頻繁なログ記録により、トレーニング runs が遅くなっていませんか?ログ記録戦略を変更してパフォーマンスを向上させる方法については、
この Colab を参照してください。
W&B は、レート制限を超える制限は一切主張しません。W&B Python SDK は、制限を超える要求に対して、指数関数的な「バックオフ」および「再試行」要求を自動的に完了します。W&B Python SDK は、 コマンドライン で「ネットワーク 障害 」で応答します。無償アカウントの場合、W&B は、使用量が合理的なしきい値を超える極端な場合に連絡する場合があります。
レート制限
W&B SaaS Cloud API は、システムの整合性を維持し、可用性を確保するために、レート制限を実装しています。この対策により、単一の ユーザー が共有 インフラストラクチャー で利用可能なリソースを独占することを防ぎ、すべての ユーザー がサービスに アクセス できる状態を維持します。さまざまな理由で、より低いレート制限が発生する可能性があります。
レート制限は変更される可能性があります。
レート制限 HTTP ヘッダー
上記の テーブル は、レート制限 HTTP ヘッダー を示しています。
ヘッダー 名
説明
RateLimit-Limit
1 つの時間枠で使用可能な クォータ 量。0 ~ 1000 の範囲でスケーリングされます。
RateLimit-Remaining
現在のレート制限ウィンドウの クォータ 量。0 ~ 1000 の範囲でスケーリングされます。
RateLimit-Reset
現在の クォータ がリセットされるまでの秒数
メトリクス ログ記録 API のレート制限
スクリプト 内の wandb.log 呼び出しは、 メトリクス ログ記録 API を利用して、トレーニングデータ を W&B にログ記録します。この API は、オンラインまたはオフライン同期 のいずれかを通じて実行されます。いずれの場合も、ローリングタイムウィンドウでレート制限 クォータ 制限が課されます。これには、合計リクエストサイズとリクエストレートの制限が含まれます。後者は、ある時間の長さにおけるリクエスト数を示します。
W&B は、W&B プロジェクト ごとにレート制限を適用します。したがって、チームに 3 つの プロジェクト がある場合、各 プロジェクト には独自のレート制限 クォータ があります。チーム および エンタープライズ プラン の ユーザー は、無料 プラン の ユーザー よりも高いレート制限があります。
メトリクス ログ記録 API の使用中にレート制限に達すると、標準出力に エラー を示す関連 メッセージ が表示されます。
メトリクス ログ記録 API レート制限を下回るための推奨事項
レート制限を超えると、レート制限がリセットされるまで run.finish() が遅延する可能性があります。これを回避するには、次の戦略を検討してください。
W&B Python SDK バージョン を更新する: 最新バージョンの W&B Python SDK を使用していることを確認します。W&B Python SDK は定期的に更新され、要求を正常に再試行し、 クォータ の使用を最適化するための拡張 メカニズム が含まれています。
メトリクス ログ記録頻度を下げる:
クォータ を節約するために、 メトリクス のログ記録頻度を最小限に抑えます。たとえば、epoch ごとに メトリクス をログ記録するのではなく、5 epoch ごとにログ記録するように コード を変更できます。
if epoch % 5 == 0 : # 5 epoch ごとにメトリクスをログ記録する
wandb. log({"acc" : accuracy, "loss" : loss})
手動データ 同期: レート制限されている場合、W&B は run データ をローカル に保存します。 コマンド wandb sync <run-file-path> を使用して、データを手動で同期できます。詳細については、wandb sync
GraphQL API のレート制限
W&B Models UI および SDK のパブリック API は、GraphQL リクエスト を サーバー に送信して、データのクエリと変更を行います。SaaS Cloud 内のすべての GraphQL リクエスト について、W&B は、承認されていないリクエスト の場合は IP アドレス ごとに、承認されているリクエスト の場合は ユーザー ごとにレート制限を適用します。制限は、固定された時間枠内のリクエストレート(1 秒あたりのリクエスト数)に基づいており、料金 プラン によってデフォルトの制限が決定されます。 プロジェクト パス (たとえば、 Reports 、 runs 、 Artifacts )を指定する関連 SDK リクエスト の場合、W&B は プロジェクト ごとにレート制限を適用します。これは、データベース のクエリ時間によって測定されます。
チーム および エンタープライズ プラン の ユーザー は、無料 プラン の ユーザー よりも高いレート制限を受け取ります。
W&B Models SDK のパブリック API の使用中にレート制限に達すると、標準出力に エラー を示す関連 メッセージ が表示されます。
GraphQL API レート制限を下回るための推奨事項
W&B Models SDK のパブリック API を使用して大量のデータを フェッチ する場合は、リクエスト の間に少なくとも 1 秒待機することを検討してください。429 ステータス コード を受信した場合、または応答ヘッダー に RateLimit-Remaining=0 が表示された場合は、再試行する前に RateLimit-Reset で指定された秒数待機します。
ブラウザ に関する考慮事項
W&B アプリ は メモリ を大量に消費する可能性があり、Chrome で最高のパフォーマンスを発揮します。コンピューター の メモリ に応じて、W&B を 3 つ以上の タブ で同時にアクティブにすると、パフォーマンスが低下する可能性があります。予期しないパフォーマンスの低下が発生した場合は、他の タブ または アプリケーション を閉じることを検討してください。
W&B へのパフォーマンス問題の報告
W&B はパフォーマンスを重視しており、遅延のすべての レポート を調査します。調査を迅速化するために、読み込み時間が遅いことを報告する場合は、主要な メトリクス とパフォーマンス イベント をキャプチャする W&B の組み込みパフォーマンスロガーの呼び出しを検討してください。読み込みが遅い ページ に URL パラメータ &PERF_LOGGING を追加し、コンソール の出力をアカウントチームまたは サポート と共有します。
9 - Reproduce experiments
チームメンバーが作成した実験を再現して、その結果を検証します。
実験を再現する前に、以下をメモする必要があります。
run が記録された project の名前
再現したい run の名前
実験を再現するには:
run が記録されている project に移動します。
左側のサイドバーで [Workspace ] タブを選択します。
run のリストから、再現する run を選択します。
[概要 ] をクリックします。
次に、特定のハッシュで実験の コード をダウンロードするか、実験の リポジトリ 全体をクローンします。
Python スクリプトまたは notebook のダウンロード
GitHub
実験の Python スクリプトまたは notebook をダウンロードします。
[Command ] フィールドで、実験を作成したスクリプトの名前をメモします。
左側の ナビゲーションバー で [Code ] タブを選択します。
スクリプトまたは notebook に対応するファイルの横にある [ダウンロード ] をクリックします。
チームメイトが実験の作成に使用した GitHub リポジトリをクローンします。これを行うには:
必要に応じて、チームメイトが実験の作成に使用した GitHub リポジトリへの アクセス権 を取得します。
[Git リポジトリ ] フィールドをコピーします。ここには GitHub リポジトリの URL が含まれています。
リポジトリをクローンします。
git clone https://github.com/your-repo.git && cd your-repo
[Git state ] フィールドをコピーして ターミナル に貼り付けます。Git state は、チームメイトが実験の作成に使用した正確なコミットをチェックアウトする一連の Git コマンドです。上記の コードスニペット で指定された 値 を独自の値に置き換えます。
git checkout -b "<run-name>" 0123456789012345678901234567890123456789
左側の ナビゲーションバー で [ファイル ] を選択します。
requirements.txt ファイルをダウンロードして、作業 ディレクトリー に保存します。この ディレクトリー には、クローンされた GitHub リポジトリ、またはダウンロードされた Python スクリプトまたは notebook のいずれかが含まれている必要があります。
(推奨)Python 仮想 環境 を作成します。
requirements.txt ファイルで指定された 要件 をインストールします。
pip install -r requirements.txt
コード と依存関係が揃ったので、スクリプトまたは notebook を実行して実験を再現できます。リポジトリをクローンした場合は、スクリプトまたは notebook がある ディレクトリー に移動する必要がある場合があります。それ以外の場合は、作業 ディレクトリー からスクリプトまたは notebook を実行できます。
Python notebook
Python スクリプト
Python notebook をダウンロードした場合は、notebook をダウンロードした ディレクトリー に移動し、ターミナル で次の コマンド を実行します。
Python スクリプトをダウンロードした場合は、スクリプトをダウンロードした ディレクトリー に移動し、ターミナル で次の コマンド を実行します。<> で囲まれた 値 は独自の値に置き換えてください。
python <your-script-name>.py
10 - Import and export data
MLFlow から<について>データ をインポートしたり、W&B に保存した<について>データ をエクスポートまたは更新したりします。
W&B Public API を使用して、データのエクスポートまたはデータのインポートを行います。
この機能には python>=3.8 が必要です。
MLFlow からのデータのインポート
W&B は、実験、run、Artifacts、メトリクス、その他のメタデータなど、MLFlow からのデータのインポートをサポートしています。
依存関係をインストールします。
# 注:これには py38+ が必要です
pip install wandb[ importers]
W&B にログインします。以前にログインしていない場合は、プロンプトに従ってください。
既存の MLFlow サーバーからすべての run をインポートします。
from wandb.apis.importers.mlflow import MlflowImporter
importer = MlflowImporter(mlflow_tracking_uri= "..." )
runs = importer. collect_runs()
importer. import_runs(runs)
デフォルトでは、importer.collect_runs() は MLFlow サーバーからすべての run を収集します。特定のサブセットをアップロードする場合は、独自の run イテラブルを作成してインポーターに渡すことができます。
import mlflow
from wandb.apis.importers.mlflow import MlflowRun
client = mlflow. tracking. MlflowClient(mlflow_tracking_uri)
runs: Iterable[MlflowRun] = []
for run in mlflow_client. search_runs(... ):
runs. append(MlflowRun(run, client))
importer. import_runs(runs)
Databricks MLFlow からインポートする場合は、最初にDatabricks CLI を構成する 必要がある場合があります。
前のステップで mlflow-tracking-uri="databricks" を設定します。
Artifacts のインポートをスキップするには、artifacts=False を渡します。
importer. import_runs(runs, artifacts= False )
特定の W&B entity と project にインポートするには、Namespace を渡します。
from wandb.apis.importers import Namespace
importer. import_runs(runs, namespace= Namespace(entity, project))
データのエクスポート
Public API を使用して、W&B に保存したデータをエクスポートまたは更新します。この API を使用する前に、スクリプトからデータをログに記録します。詳細については、クイックスタート を確認してください。
Public API のユースケース
データのエクスポート : Jupyter Notebook でカスタム分析を行うためのデータフレームをプルダウンします。データを調べたら、新しい分析 run を作成して結果をログに記録することで、調査結果を同期できます。例:wandb.init(job_type="analysis")既存の Runs の更新 : W&B run に関連してログに記録されたデータを更新できます。たとえば、アーキテクチャや最初にログに記録されなかったハイパーパラメーターなど、追加情報を含めるように一連の run の config を更新したい場合があります。
利用可能な機能の詳細については、生成されたリファレンスドキュメント を参照してください。
APIキーの作成
APIキーは、W&B に対するマシンの認証を行います。APIキーは、ユーザープロファイルから生成できます。
右上隅にあるユーザープロファイルアイコンをクリックします。
ユーザー設定 を選択し、APIキー セクションまでスクロールします。表示 をクリックします。表示された APIキーをコピーします。APIキーを非表示にするには、ページをリロードします。
run パスの検索
Public API を使用するには、run パス <entity>/<project>/<run_id> が必要になることがよくあります。アプリ UI で、run ページを開き、Overviewタブ をクリックして、run パスを取得します。
Run データのエクスポート
完了した run またはアクティブな run からデータをダウンロードします。一般的な使用法としては、Jupyter ノートブックでカスタム分析を行うためのデータフレームのダウンロードや、自動化された環境でのカスタムロジックの使用などがあります。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run オブジェクトの最も一般的に使用される属性は次のとおりです。
属性
意味
run.configトレーニング run のハイパーパラメーターや、データセット Artifact を作成する run の前処理メソッドなど、run の設定情報の辞書。これらを実行の入力と考えてください。
run.history()損失など、モデルのトレーニング中に変化する値を格納するための辞書のリスト。コマンド wandb.log() はこのオブジェクトに追加されます。
run.summaryrun の結果をまとめた情報の辞書。これには、精度や損失などのスカラーや、大きなファイルを含めることができます。デフォルトでは、wandb.log() は summary をログに記録された時系列の最終値に設定します。summary の内容は直接設定することもできます。summary を run の出力と考えてください。
過去の run のデータを変更または更新することもできます。デフォルトでは、api オブジェクトの単一インスタンスがすべてのネットワークリクエストをキャッシュします。ユースケースで実行中のスクリプトでリアルタイムの情報が必要な場合は、api.flush() を呼び出して更新された値を取得します。
さまざまな属性について
以下の run について
n_epochs = 5
config = {"n_epochs" : n_epochs}
run = wandb. init(project= project, config= config)
for n in range(run. config. get("n_epochs" )):
run. log(
{"val" : random. randint(0 , 1000 ), "loss" : (random. randint(0 , 1000 ) / 1000.00 )}
)
run. finish()
これらは、上記の run オブジェクト属性のさまざまな出力です。
run.configrun.history() _step val loss _runtime _timestamp
0 0 500 0.244 4 1644345412
1 1 45 0.521 4 1644345412
2 2 240 0.785 4 1644345412
3 3 31 0.305 4 1644345412
4 4 525 0.041 4 1644345412
run.summary{
"_runtime" : 4 ,
"_step" : 4 ,
"_timestamp" : 1644345412 ,
"_wandb" : {"runtime" : 3 },
"loss" : 0.041 ,
"val" : 525 ,
}
サンプリング
デフォルトの履歴メソッドは、メトリクスを固定数のサンプルにサンプリングします(デフォルトは 500 です。これは samples __ 引数で変更できます)。大規模な run ですべてのデータをエクスポートする場合は、run.scan_history() メソッドを使用できます。詳細については、APIリファレンス を参照してください。
複数の Run のクエリ
DataFrame と CSV
MongoDB スタイル
このサンプルスクリプトは project を検索し、名前、config、summary 統計を含む Runs の CSV を出力します。<entity> と <project> を、それぞれ W&B entity と project の名前に置き換えます。
import pandas as pd
import wandb
api = wandb. Api()
entity, project = "<entity>" , "<project>"
runs = api. runs(entity + "/" + project)
summary_list, config_list, name_list = [], [], []
for run in runs:
# .summary には、精度などの
# メトリクスの出力キー/値が含まれています。
# 大きなファイルを省略するために ._json_dict を呼び出します
summary_list. append(run. summary. _json_dict)
# .config にはハイパーパラメーターが含まれています。
# _ で始まる特殊な値を削除します。
config_list. append({k: v for k, v in run. config. items() if not k. startswith("_" )})
# .name は run の人間が読める名前です。
name_list. append(run. name)
runs_df = pd. DataFrame(
{"summary" : summary_list, "config" : config_list, "name" : name_list}
)
runs_df. to_csv("project.csv" )
W&B API は、api.runs() を使用して project 内の Runs をクエリする方法も提供します。最も一般的なユースケースは、カスタム分析のために Runs データをエクスポートすることです。クエリインターフェイスは、MongoDB が使用するもの と同じです。
runs = api. runs(
"username/project" ,
{"$or" : [{"config.experiment_name" : "foo" }, {"config.experiment_name" : "bar" }]},
)
print(f "Found { len(runs)} runs" )
api.runs を呼び出すと、反復可能でリストのように動作する Runs オブジェクトが返されます。デフォルトでは、オブジェクトは必要に応じて一度に 50 個の Runs を順番にロードしますが、per_page キーワード引数を使用して、ページごとにロードされる数を変更できます。
api.runs は order キーワード引数も受け入れます。デフォルトの順序は -created_at です。結果を昇順で並べ替えるには、+created_at を指定します。config または summary の値でソートすることもできます。たとえば、summary.val_acc や config.experiment_name などです。
エラー処理
W&B サーバーとの通信中にエラーが発生すると、wandb.CommError が発生します。元の例外は、exc 属性を介して調べることができます。
API 経由で最新の git コミットを取得する
UI で、run をクリックし、run ページの Overview タブをクリックして、最新の git コミットを確認します。これはファイル wandb-metadata.json にもあります。Public API を使用して、run.commit で git ハッシュを取得できます。
run の実行中に run の名前と ID を取得する
wandb.init() を呼び出した後、スクリプトからランダムな run ID または人間が読める run 名に次のようにアクセスできます。
一意の run ID (8 文字のハッシュ): wandb.run.id
ランダムな run 名 (人間が読める): wandb.run.name
Runs に役立つ識別子を設定する方法について検討している場合は、次のことをお勧めします。
Run ID : 生成されたハッシュのままにします。これは、project 内の Runs 間で一意である必要があります。Run 名 : これは、チャート上の異なる行を区別できるように、短く、読みやすく、できれば一意である必要があります。Run ノート : これは、run で何をしているかを簡単に説明するのに最適な場所です。これは、wandb.init(notes="ここにノート") で設定できます。Run タグ : Run タグで動的に追跡し、UI のフィルターを使用して、関心のある Runs のみにテーブルを絞り込みます。スクリプトからタグを設定し、UI の Runs テーブルと run ページの Overview タブの両方で編集できます。詳細な手順については、こちら を参照してください。
Public API の例
matplotlib または seaborn で視覚化するためにデータをエクスポートする
一般的なエクスポートパターンのいくつかの例については、API 例 を確認してください。カスタムプロットまたは展開された Runs テーブルのダウンロードボタンをクリックして、ブラウザーから CSV をダウンロードすることもできます。
run からメトリクスを読み取る
この例では、"<entity>/<project>/<run_id>" に保存された run の wandb.log({"accuracy": acc}) で保存されたタイムスタンプと精度を出力します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
if run. state == "finished" :
for i, row in run. history(). iterrows():
print(row["_timestamp" ], row["accuracy" ])
Runs のフィルター
MongoDB Query Language を使用してフィルターできます。
日付
runs = api. runs(
"<entity>/<project>" ,
{"$and" : [{"created_at" : {"$lt" : "YYYY-MM-DDT##" , "$gt" : "YYYY-MM-DDT##" }}]},
)
run から特定のメトリクスを読み取る
run から特定のメトリクスをプルするには、keys 引数を使用します。run.history() を使用する場合のデフォルトのサンプル数は 500 です。特定のメトリクスを含まないログに記録されたステップは、出力データフレームに NaN として表示されます。keys 引数を指定すると、API はリストされたメトリクスキーを含むステップをより頻繁にサンプリングします。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
if run. state == "finished" :
for i, row in run. history(keys= ["accuracy" ]). iterrows():
print(row["_timestamp" ], row["accuracy" ])
2 つの Run の比較
これにより、run1 と run2 で異なる config パラメーターが出力されます。
import pandas as pd
import wandb
api = wandb. Api()
# <entity>、<project>、<run_id> に置き換えます
run1 = api. run("<entity>/<project>/<run_id>" )
run2 = api. run("<entity>/<project>/<run_id>" )
df = pd. DataFrame([run1. config, run2. config]). transpose()
df. columns = [run1. name, run2. name]
print(df[df[run1. name] != df[run2. name]])
出力:
c_10_sgd_0.025_0.01_long_switch base_adam_4_conv_2fc
batch_size 32 16
n_conv_layers 5 4
Optimizer rmsprop adam
run のメトリクスを、run の完了後に更新する
この例では、以前の run の精度を 0.9 に設定します。また、以前の run の精度ヒストグラムを numpy_array のヒストグラムになるように変更します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run. summary["accuracy" ] = 0.9
run. summary["accuracy_histogram" ] = wandb. Histogram(numpy_array)
run. summary. update()
完了した run でメトリクスの名前を変更する
この例では、テーブルの summary 列の名前を変更します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run. summary["new_name" ] = run. summary["old_name" ]
del run. summary["old_name" ]
run. summary. update()
列の名前の変更は、テーブルにのみ適用されます。チャートは引き続き元の名前でメトリクスを参照します。
既存の Run の config を更新する
この例では、config 設定の 1 つを更新します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run. config["key" ] = updated_value
run. update()
システムリソースの消費量を CSV ファイルにエクスポートする
以下のスニペットは、システムリソースの消費量を検索し、CSV に保存します。
import wandb
run = wandb. Api(). run("<entity>/<project>/<run_id>" )
system_metrics = run. history(stream= "events" )
system_metrics. to_csv("sys_metrics.csv" )
サンプリングされていないメトリクスデータを取得する
履歴からデータをプルすると、デフォルトで 500 ポイントにサンプリングされます。run.scan_history() を使用して、ログに記録されたすべてのデータポイントを取得します。次に、履歴に記録されたすべての loss データポイントをダウンロードする例を示します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
history = run. scan_history()
losses = [row["loss" ] for row in history]
履歴からページネーションされたデータを取得する
メトリクスがバックエンドでゆっくりとフェッチされている場合、または API リクエストがタイムアウトしている場合は、個々のリクエストがタイムアウトしないように、scan_history のページサイズを小さくしてみてください。デフォルトのページサイズは 500 なので、さまざまなサイズを試して最適なものを確認できます。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run. scan_history(keys= sorted(cols), page_size= 100 )
project 内のすべての Runs からメトリクスを CSV ファイルにエクスポートする
このスクリプトは、project 内の Runs をプルダウンし、名前、config、summary 統計を含む Runs のデータフレームと CSV を生成します。<entity> と <project> を、それぞれ W&B entity と project の名前に置き換えます。
import pandas as pd
import wandb
api = wandb. Api()
entity, project = "<entity>" , "<project>"
runs = api. runs(entity + "/" + project)
summary_list, config_list, name_list = [], [], []
for run in runs:
# .summary には、精度などの
# メトリクスの出力キー/値が含まれています。
# 大きなファイルを省略するために ._json_dict を呼び出します
summary_list. append(run. summary. _json_dict)
# .config にはハイパーパラメーターが含まれています。
# _ で始まる特殊な値を削除します。
config_list. append({k: v for k, v in run. config. items() if not k. startswith("_" )})
# .name は run の人間が読める名前です。
name_list. append(run. name)
runs_df = pd. DataFrame(
{"summary" : summary_list, "config" : config_list, "name" : name_list}
)
runs_df. to_csv("project.csv" )
Run の開始時刻を取得する
このコードスニペットは、run が作成された時刻を取得します。
import wandb
api = wandb. Api()
run = api. run("entity/project/run_id" )
start_time = run. created_at
完了した run にファイルをアップロードする
以下のコードスニペットは、選択したファイルを完了した run にアップロードします。
import wandb
api = wandb. Api()
run = api. run("entity/project/run_id" )
run. upload_file("file_name.extension" )
Run からファイルをダウンロードする
これは、cifar project の run ID uxte44z7 に関連付けられたファイル “model-best.h5” を検索し、ローカルに保存します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run. file("model-best.h5" ). download()
Run からすべてのファイルをダウンロードする
これは、run に関連付けられたすべてのファイルを検索し、ローカルに保存します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
for file in run. files():
file. download()
特定の sweep から Runs を取得する
このスニペットは、特定の sweep に関連付けられたすべての Runs をダウンロードします。
import wandb
api = wandb. Api()
sweep = api. sweep("<entity>/<project>/<sweep_id>" )
sweep_runs = sweep. runs
Sweep から最適な Run を取得する
次のスニペットは、指定された sweep から最適な Run を取得します。
import wandb
api = wandb. Api()
sweep = api. sweep("<entity>/<project>/<sweep_id>" )
best_run = sweep. best_run()
best_run は、sweep config の metric パラメータによって定義された最適なメトリクスを持つ Run です。
Sweep から最適なモデルファイルをダウンロードする
このスニペットは、モデルファイルを model.h5 に保存した Runs を使用して、検証精度が最も高いモデルファイルを sweep からダウンロードします。
import wandb
api = wandb. Api()
sweep = api. sweep("<entity>/<project>/<sweep_id>" )
runs = sorted(sweep. runs, key= lambda run: run. summary. get("val_acc" , 0 ), reverse= True )
val_acc = runs[0 ]. summary. get("val_acc" , 0 )
print(f "Best run { runs[0 ]. name} with { val_acc} % val accuracy" )
runs[0 ]. file("model.h5" ). download(replace= True )
print("Best model saved to model-best.h5" )
指定された拡張子を持つすべてのファイルを Run から削除する
このスニペットは、指定された拡張子を持つファイルを Run から削除します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
extension = ".png"
files = run. files()
for file in files:
if file. name. endswith(extension):
file. delete()
システムメトリクスデータをダウンロードする
このスニペットは、run のすべてのシステムリソース消費量メトリクスを含むデータフレームを生成し、CSV に保存します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
system_metrics = run. history(stream= "events" )
system_metrics. to_csv("sys_metrics.csv" )
Summary メトリクスの更新
辞書を渡して summary メトリクスを更新できます。
summary. update({"key" : val})
Run を実行したコマンドを取得する
各 Run は、Run の概要ページで Run を起動したコマンドをキャプチャします。このコマンドを API からプルダウンするには、次を実行します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
meta = json. load(run. file("wandb-metadata.json" ). download())
program = ["python" ] + [meta["program" ]] + meta["args" ]
11 - Environment variables
W&B の 環境 変数 を設定します。
自動化された環境でスクリプトを実行する場合、スクリプトの実行前またはスクリプト内で設定された環境変数で wandb を制御できます。
# これは秘密であり、バージョン管理にチェックインすべきではありません
WANDB_API_KEY= $YOUR_API_KEY
# 名前とメモはオプション
WANDB_NAME= "My first run"
WANDB_NOTES= "Smaller learning rate, more regularization."
# wandb/settings ファイルをチェックインしない場合にのみ必要
WANDB_ENTITY= $username
WANDB_PROJECT= $project
# スクリプトをクラウドに同期させたくない場合
os. environ["WANDB_MODE" ] = "offline"
# sweep ID トラッキングを Run オブジェクトと関連クラスに追加
os. environ["WANDB_SWEEP_ID" ] = "b05fq58z"
オプションの環境変数
これらのオプションの環境変数を使用して、リモートマシンでの認証の設定などを行います。
変数名
使用法
WANDB_ANONYMOUS これを allow、never、または must に設定して、ユーザーが秘密の URL で匿名の run を作成できるようにします。
WANDB_API_KEY アカウントに関連付けられた認証 key を設定します。設定ページ で key を確認できます。リモートマシンで wandb login が実行されていない場合は、これを設定する必要があります。
WANDB_BASE_URL wandb/local を使用している場合は、この環境変数を http://YOUR_IP:YOUR_PORT に設定する必要があります
WANDB_CACHE_DIR これはデフォルトで ~/.cache/wandb になっています。この場所をこの環境変数で上書きできます
WANDB_CONFIG_DIR これはデフォルトで ~/.config/wandb になっています。この場所をこの環境変数で上書きできます
WANDB_CONFIG_PATHS wandb.config にロードする yaml ファイルのコンマ区切りリスト。config を参照してください。
WANDB_CONSOLE stdout / stderr ログを無効にするには、これを “off” に設定します。これは、サポートする環境ではデフォルトで “on” になっています。
WANDB_DATA_DIR ステージング Artifacts がアップロードされる場所。デフォルトの場所はプラットフォームによって異なります。これは、platformdirs Python パッケージの user_data_dir の値を使用するためです。
WANDB_DIR トレーニングスクリプトからの wandb ディレクトリーの相対位置ではなく、生成されたすべてのファイルをここに保存するには、これを絶対パスに設定します。このディレクトリーが存在し、プロセスを実行するユーザーが書き込むことができることを確認してください 。これは、ダウンロードされた Artifacts の場所には影響しないことに注意してください。代わりに WANDB_ARTIFACT_DIR を使用して設定できます
WANDB_ARTIFACT_DIR トレーニングスクリプトからの artifacts ディレクトリーの相対位置ではなく、ダウンロードされたすべての Artifacts をここに保存するには、これを絶対パスに設定します。このディレクトリーが存在し、プロセスを実行するユーザーが書き込むことができることを確認してください。これは、生成されたメタデータファイルの場所には影響しないことに注意してください。代わりに WANDB_DIR を使用して設定できます
WANDB_DISABLE_GIT wandb が git リポジトリをプローブして最新のコミット/差分をキャプチャするのを防ぎます。
WANDB_DISABLE_CODE wandb が ノートブック または git の差分を保存しないようにするには、これを true に設定します。git リポジトリにいる場合は、現在のコミットを保存します。
WANDB_DOCKER run の復元を有効にするには、これを docker イメージのダイジェストに設定します。これは、wandb docker コマンドで自動的に設定されます。wandb docker my/image/name:tag --digest を実行して、イメージのダイジェストを取得できます
WANDB_ENTITY run に関連付けられたエンティティ。トレーニングスクリプトのディレクトリーで wandb init を実行した場合、wandb という名前のディレクトリーが作成され、ソース管理にチェックインできるデフォルトのエンティティが保存されます。そのファイルを作成したくない場合、またはファイルを上書きしたい場合は、環境変数を使用できます。
WANDB_ERROR_REPORTING wandb が致命的なエラーをそのエラー追跡システムにログ記録しないようにするには、これを false に設定します。
WANDB_HOST システムが提供するホスト名を使用したくない場合に、wandb インターフェイスに表示するホスト名を設定します
WANDB_IGNORE_GLOBS 無視するファイル glob のコンマ区切りリストにこれを設定します。これらのファイルはクラウドに同期されません。
WANDB_JOB_NAME wandb によって作成されたジョブの名前を指定します。
WANDB_JOB_TYPE run のさまざまなタイプを示すために、“トレーニング” や “評価” などのジョブタイプを指定します。詳細については、グループ化 を参照してください。
WANDB_MODE これを “offline” に設定すると、wandb は run のメタデータをローカルに保存し、サーバーに同期しません。これを disabled に設定すると、wandb は完全にオフになります。
WANDB_NAME run の人間が読める名前。設定されていない場合は、ランダムに生成されます
WANDB_NOTEBOOK_NAME jupyter で実行している場合は、この変数で ノートブック の名前を設定できます。これを自動的に検出しようとします。
WANDB_NOTES run に関するより長いメモ。マークダウンは許可されており、UI で後で編集できます。
WANDB_PROJECT run に関連付けられた プロジェクト。これは wandb init で設定することもできますが、環境変数が値を上書きします。
WANDB_RESUME デフォルトでは、これは never に設定されています。auto に設定すると、wandb は失敗した run を自動的に再開します。must に設定すると、起動時に run が強制的に存在します。常に独自のユニークな ID を生成する場合は、これを allow に設定し、常に WANDB_RUN_ID を設定します。
WANDB_RUN_GROUP run を自動的にグループ化するための実験名を指定します。詳細については、グループ化 を参照してください。
WANDB_RUN_ID スクリプトの単一の run に対応するグローバルに一意の文字列(プロジェクトごと)にこれを設定します。64 文字以下である必要があります。単語以外の文字はすべてダッシュに変換されます。これは、障害が発生した場合に既存の run を再開するために使用できます。
WANDB_SILENT wandb ログステートメントを非表示にするには、これを true に設定します。これが設定されている場合、すべてのログは WANDB_DIR /debug.log に書き込まれます
WANDB_SHOW_RUN オペレーティングシステムがサポートしている場合、run URL でブラウザーを自動的に開くには、これを true に設定します。
WANDB_SWEEP_ID sweep ID トラッキングを Run オブジェクトと関連クラスに追加し、UI に表示します。
WANDB_TAGS run に適用されるタグのコンマ区切りリスト。
WANDB_USERNAME run に関連付けられた チーム のメンバーの ユーザー 名。これは、サービスアカウント API key とともに使用して、自動 run の チーム のメンバーへの属性を有効にすることができます。
WANDB_USER_EMAIL run に関連付けられた チーム のメンバーのメール。これは、サービスアカウント API key とともに使用して、自動 run の チーム のメンバーへの属性を有効にすることができます。
Singularity 環境
Singularity でコンテナーを実行している場合は、上記の変数の前に SINGULARITYENV_ を付けることで環境変数を渡すことができます。Singularity 環境変数の詳細については、こちら を参照してください。
AWS での実行
AWS でバッチジョブを実行している場合は、W&B 認証情報でマシンを簡単に認証できます。設定ページ から API key を取得し、AWS バッチジョブ仕様 で WANDB_API_KEY 環境変数を設定します。
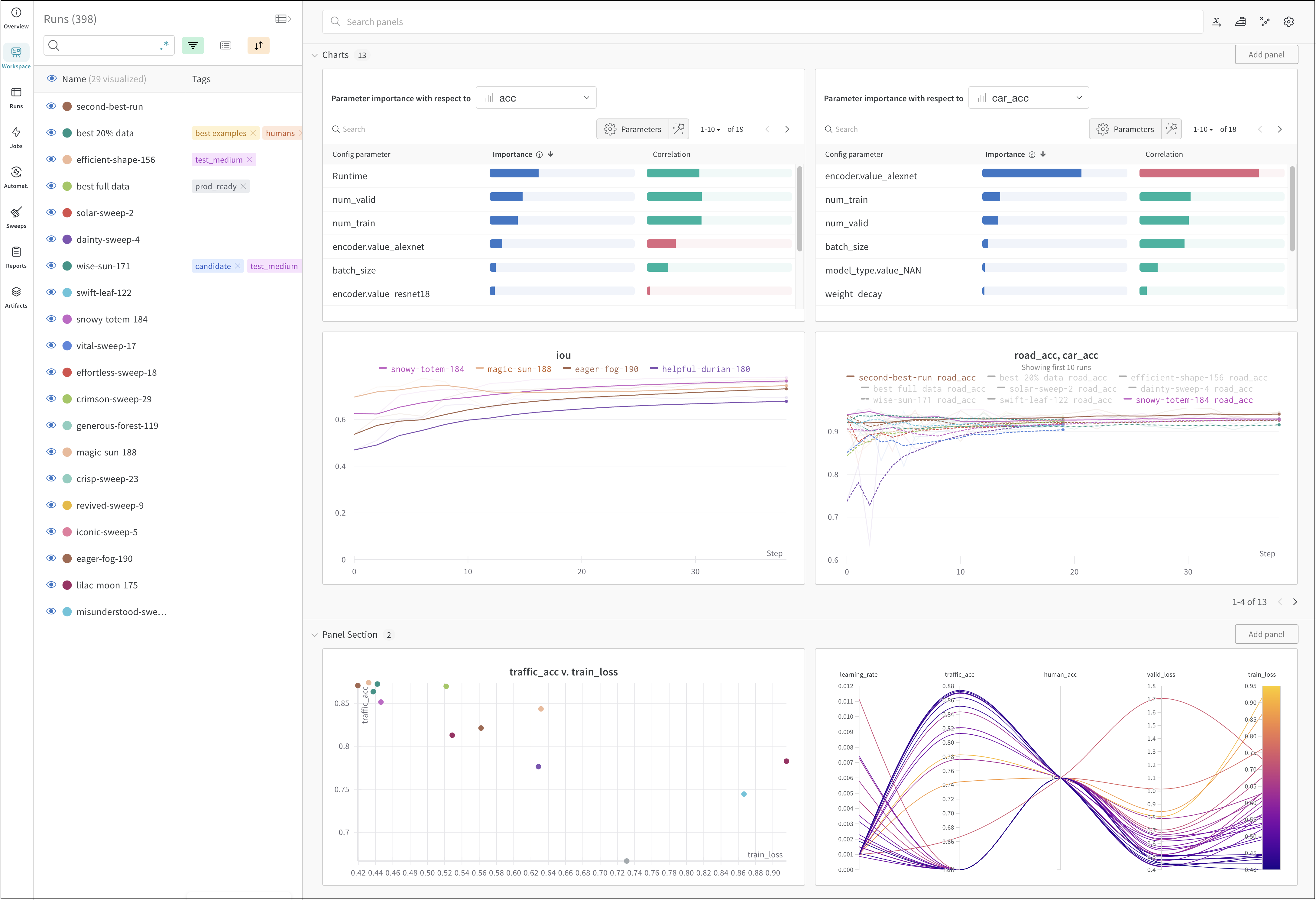
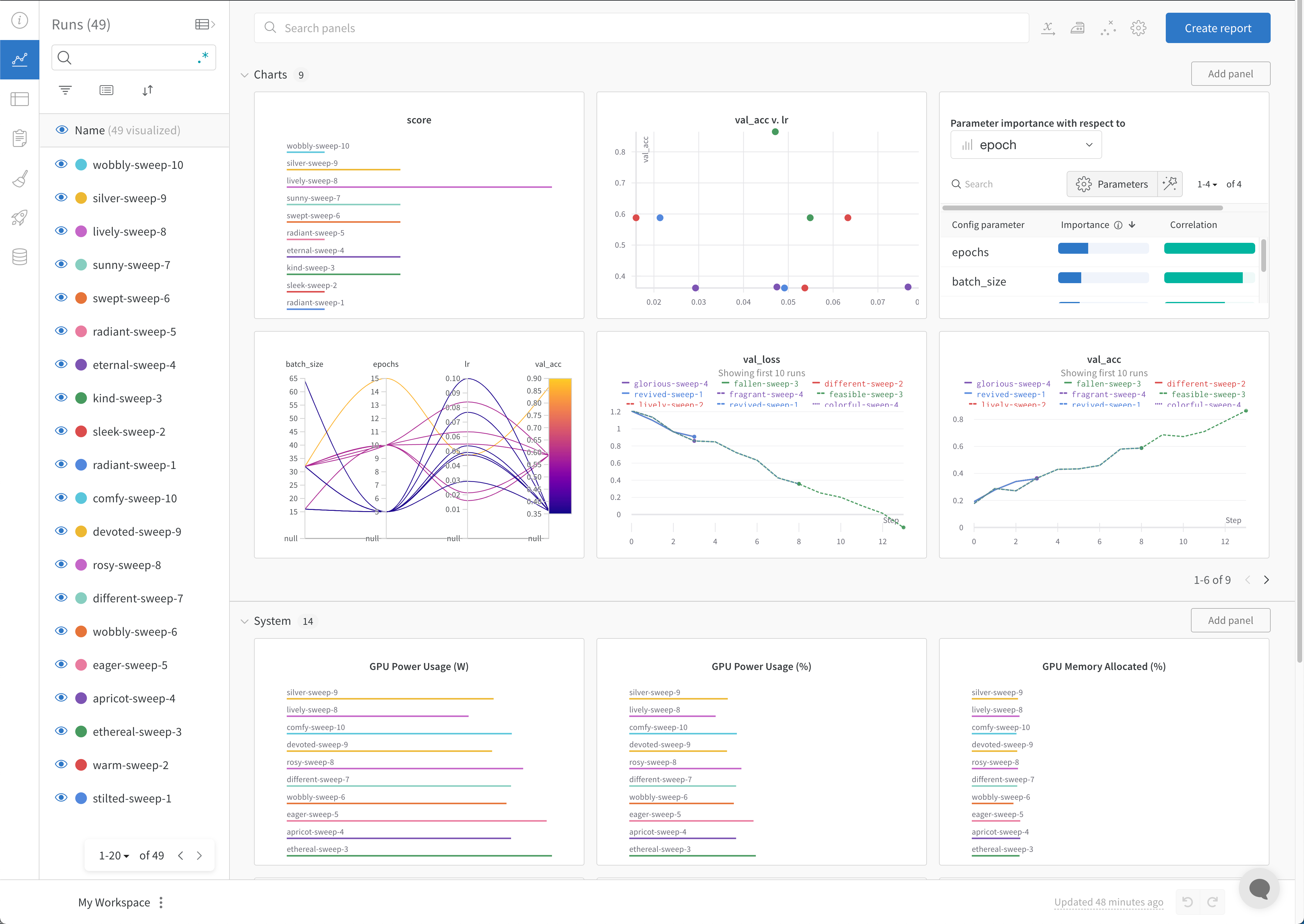
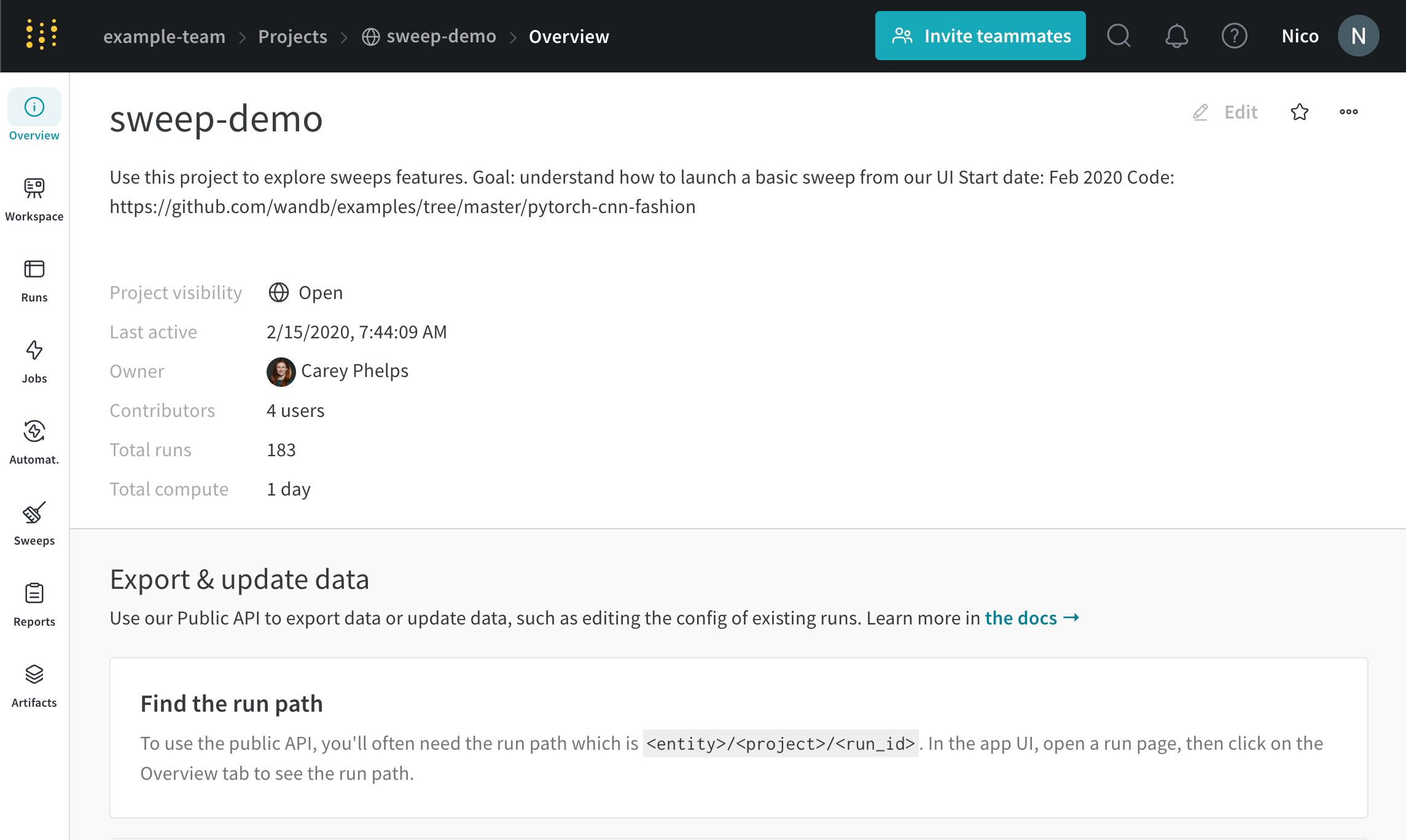
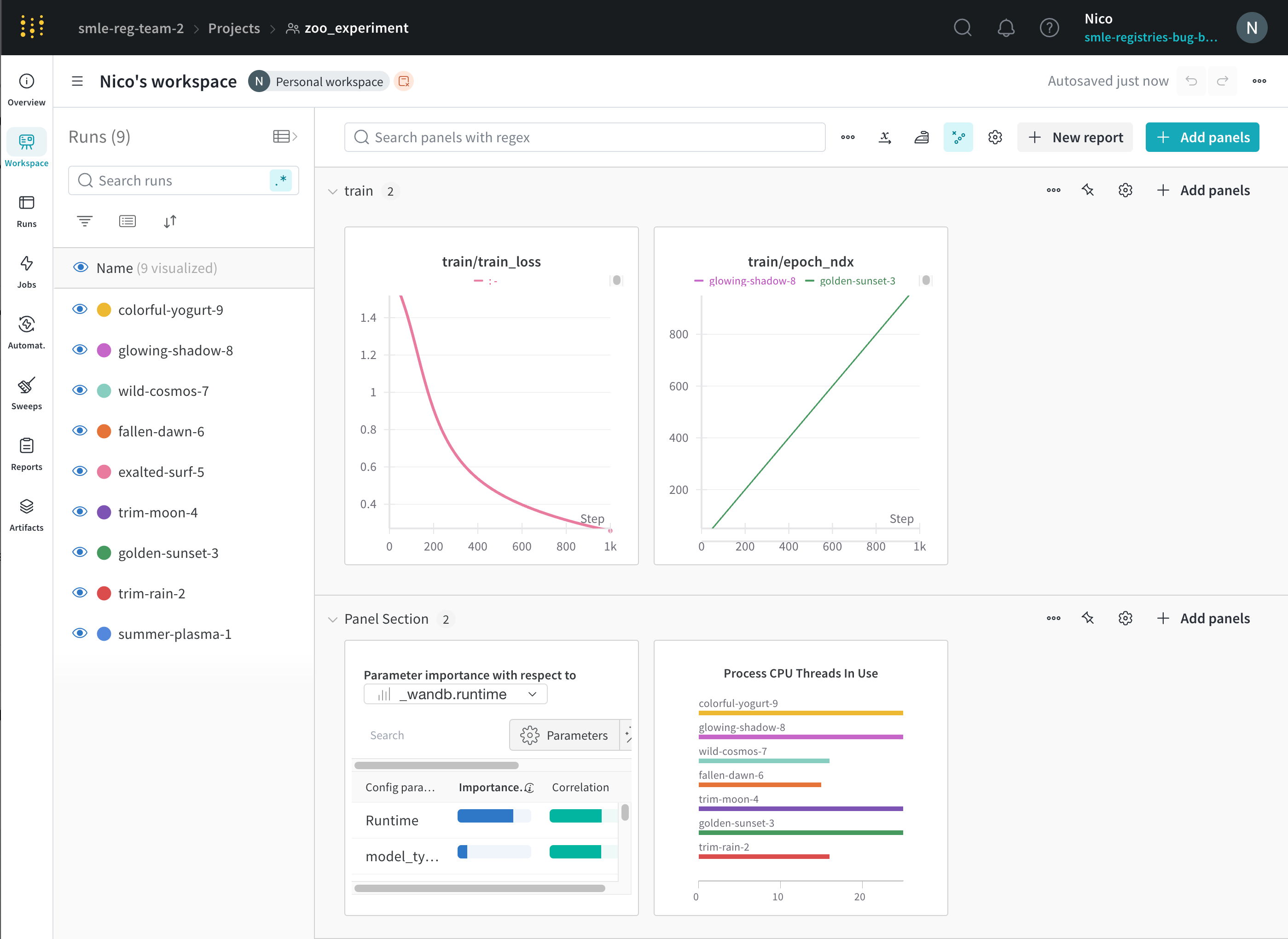
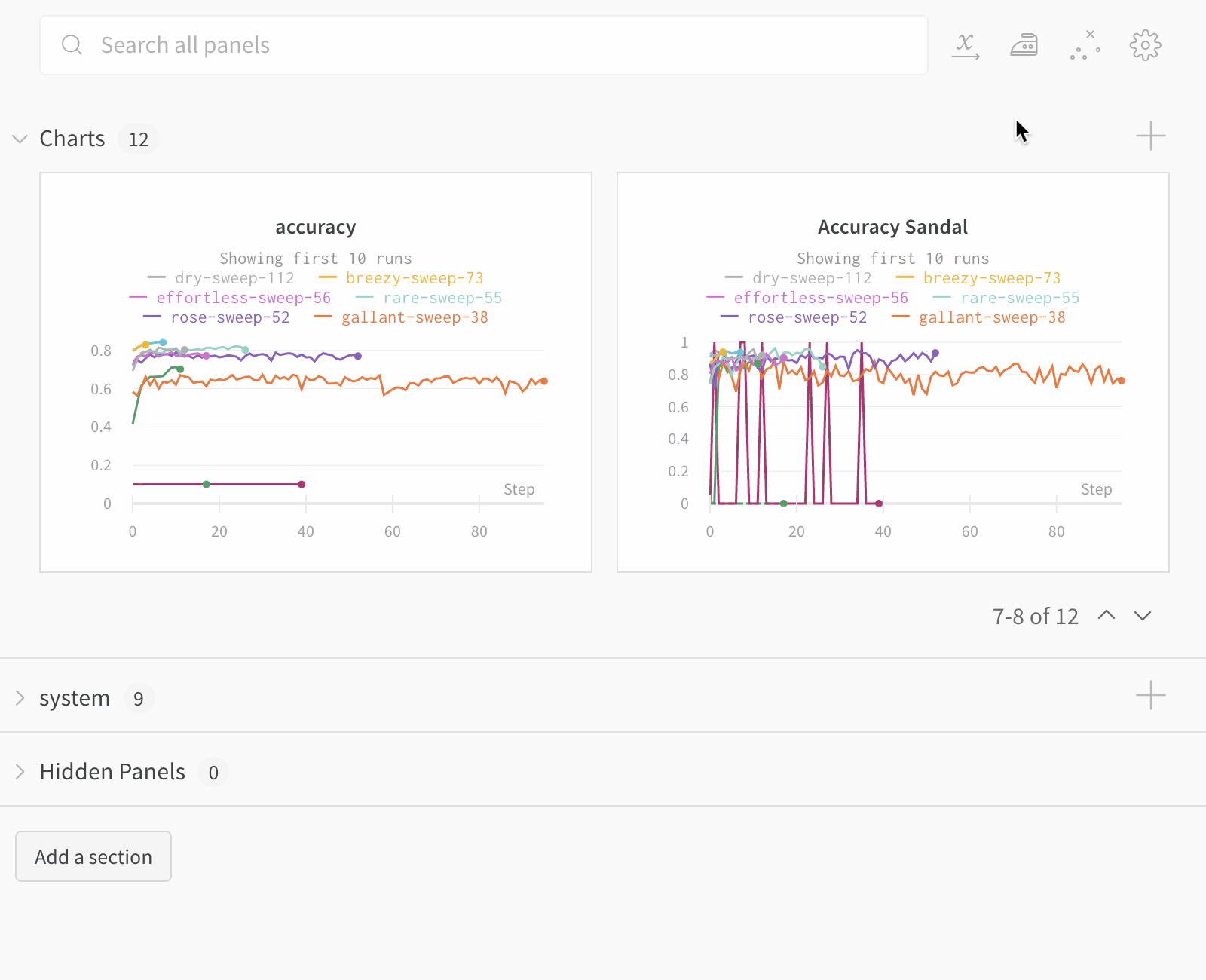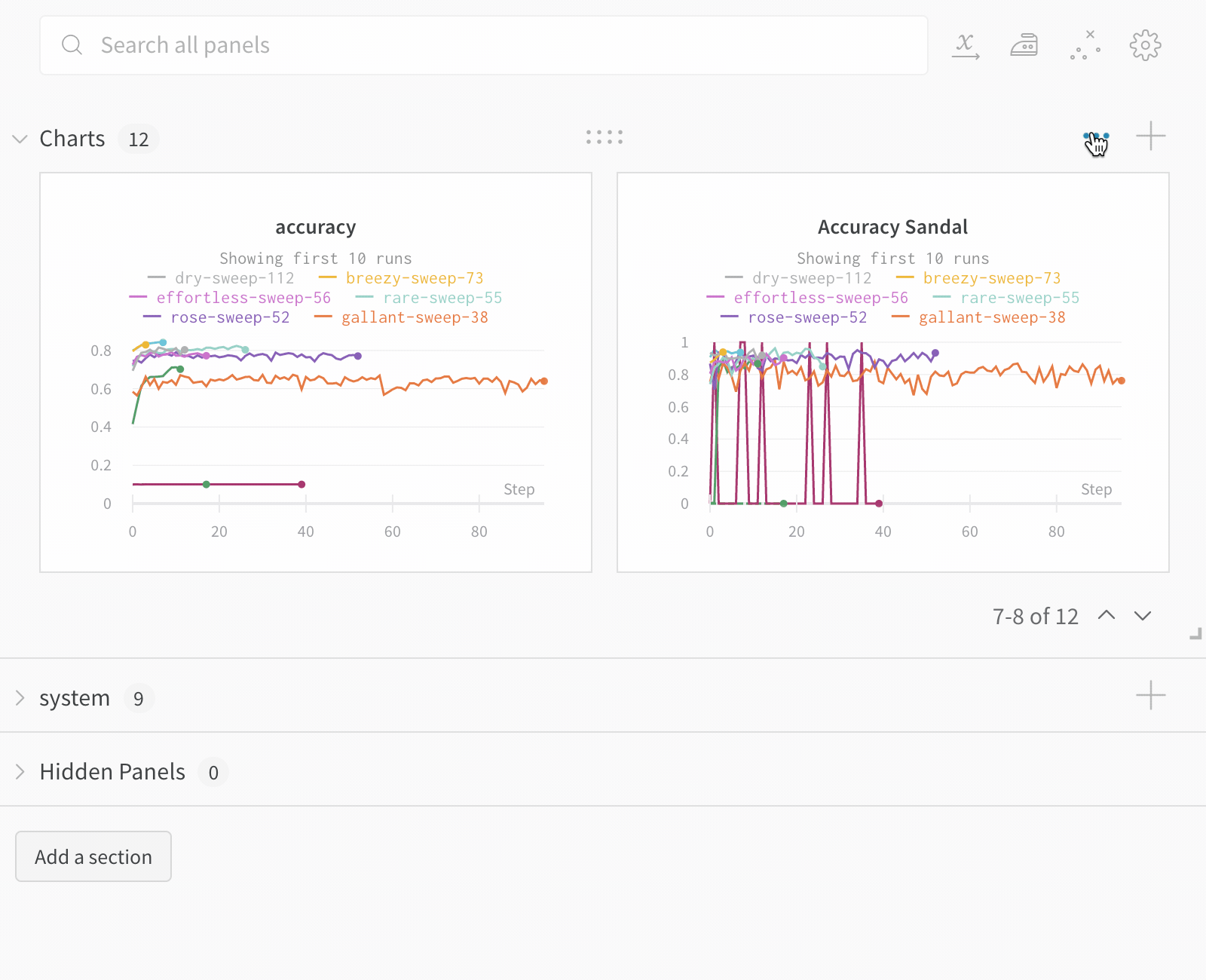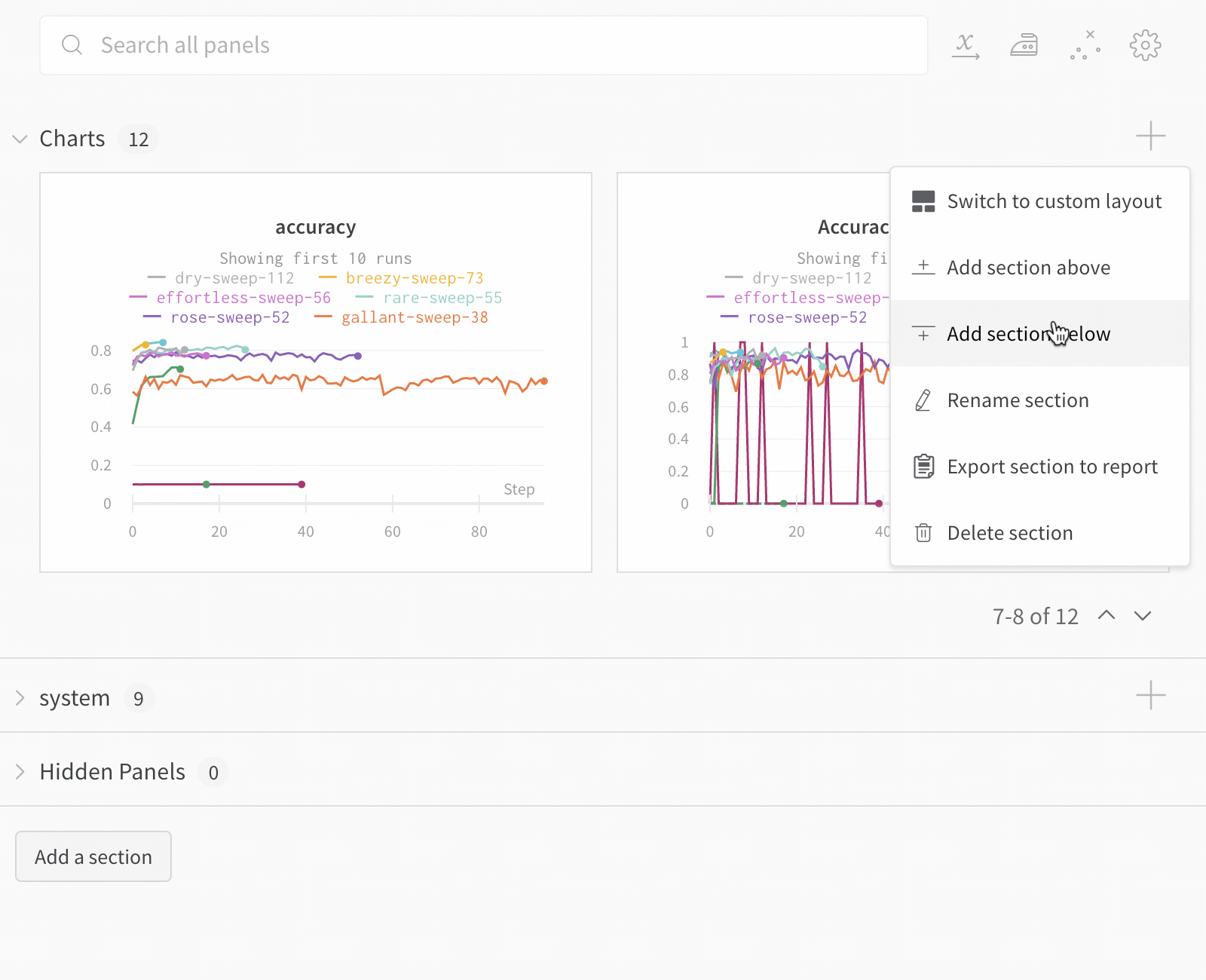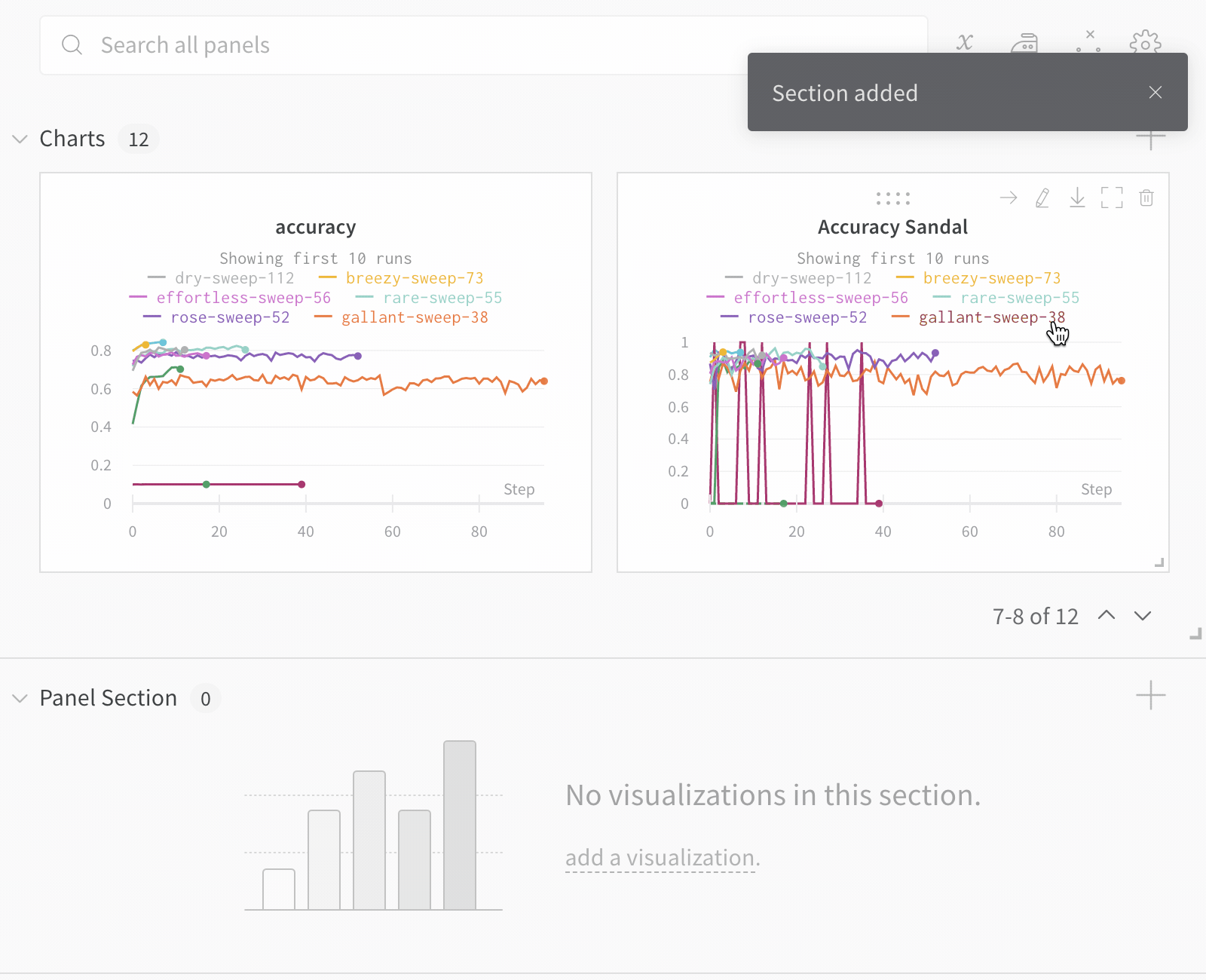
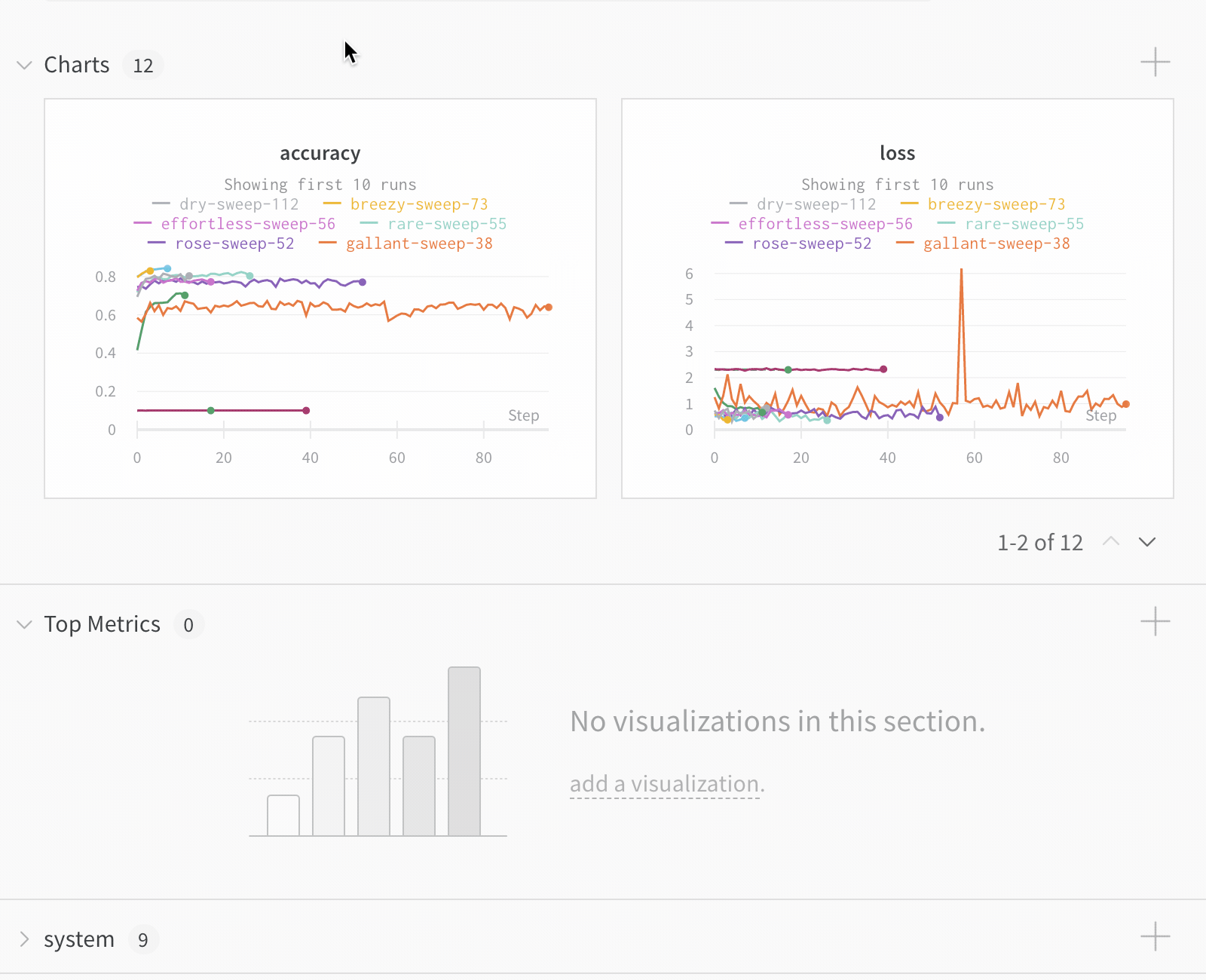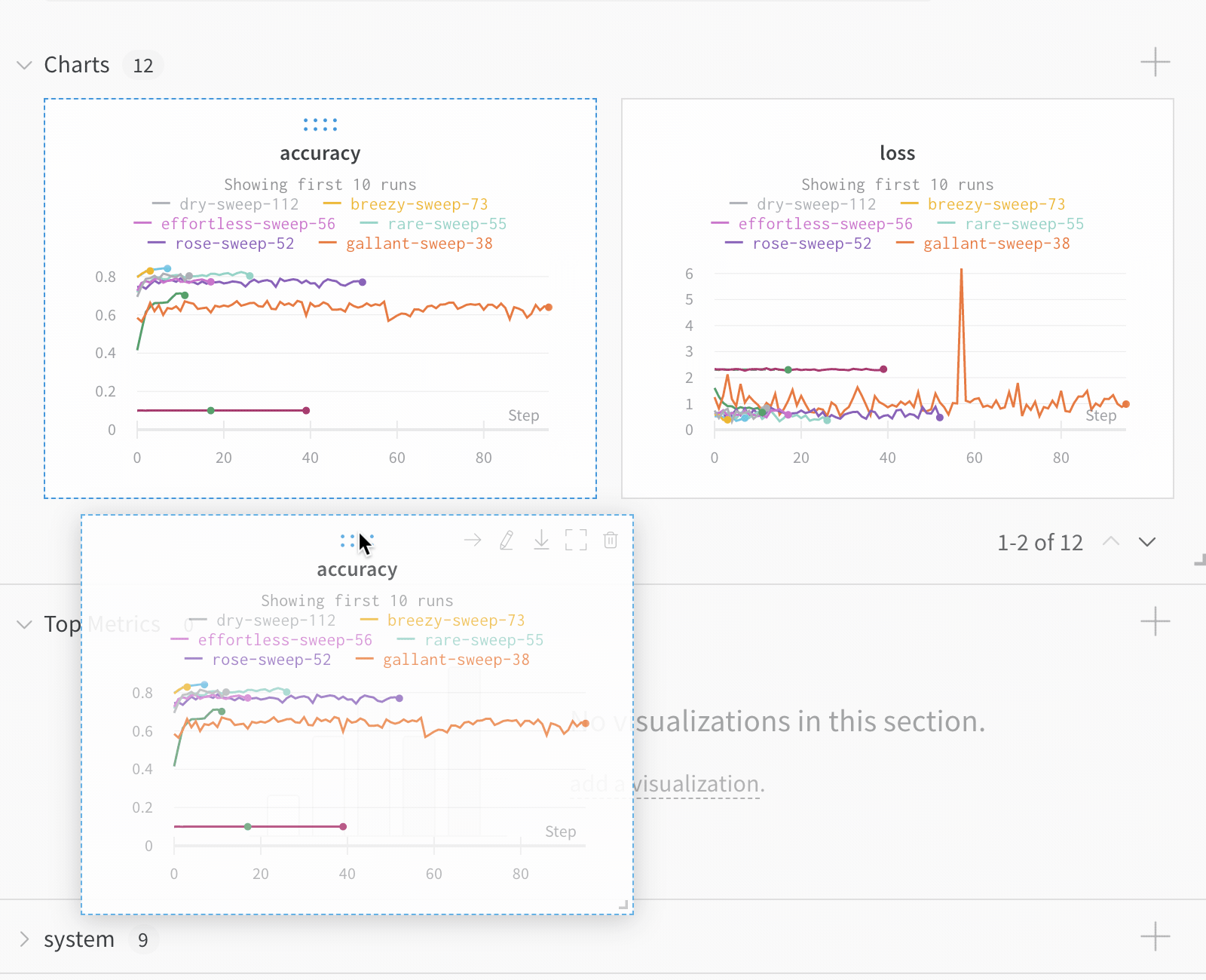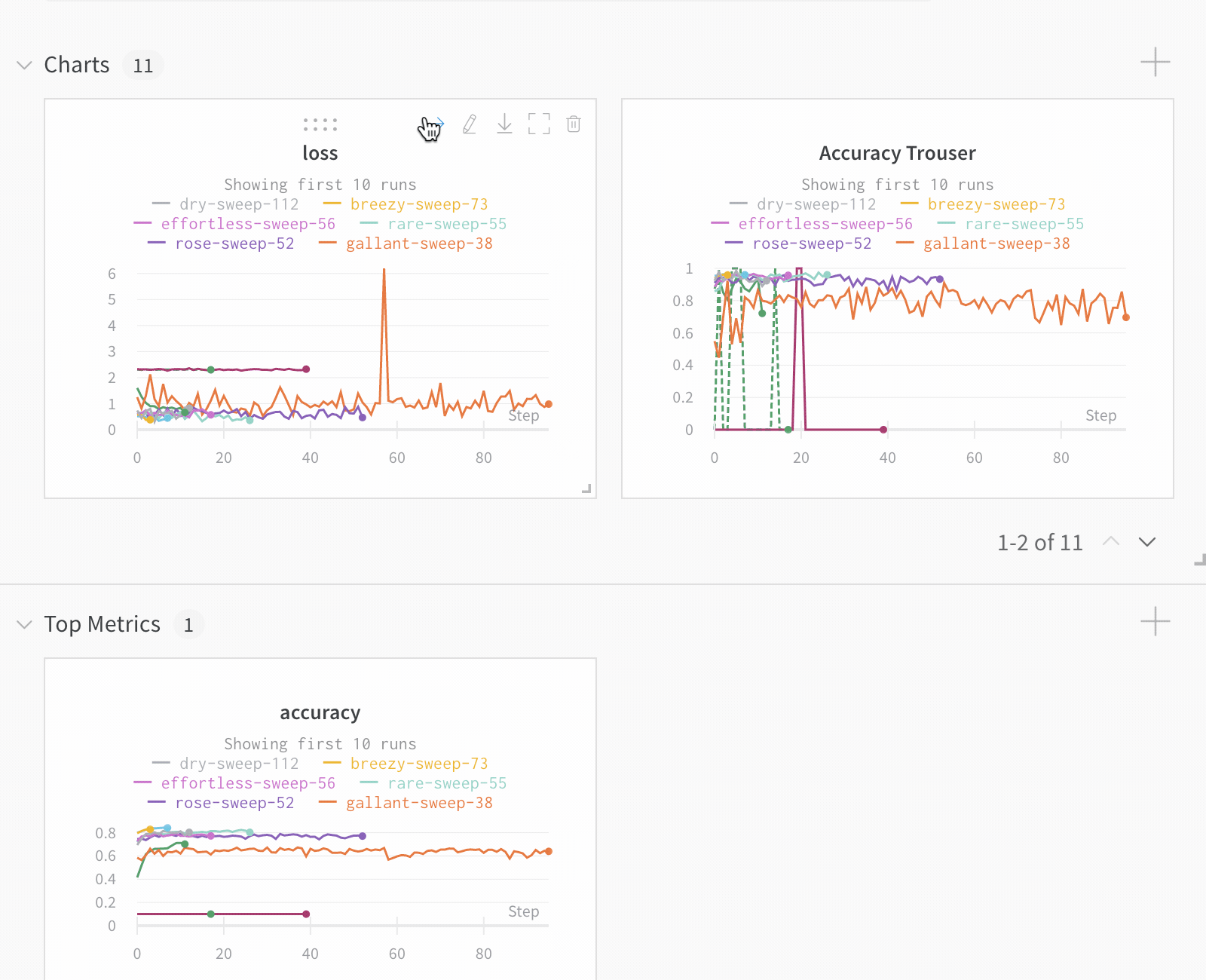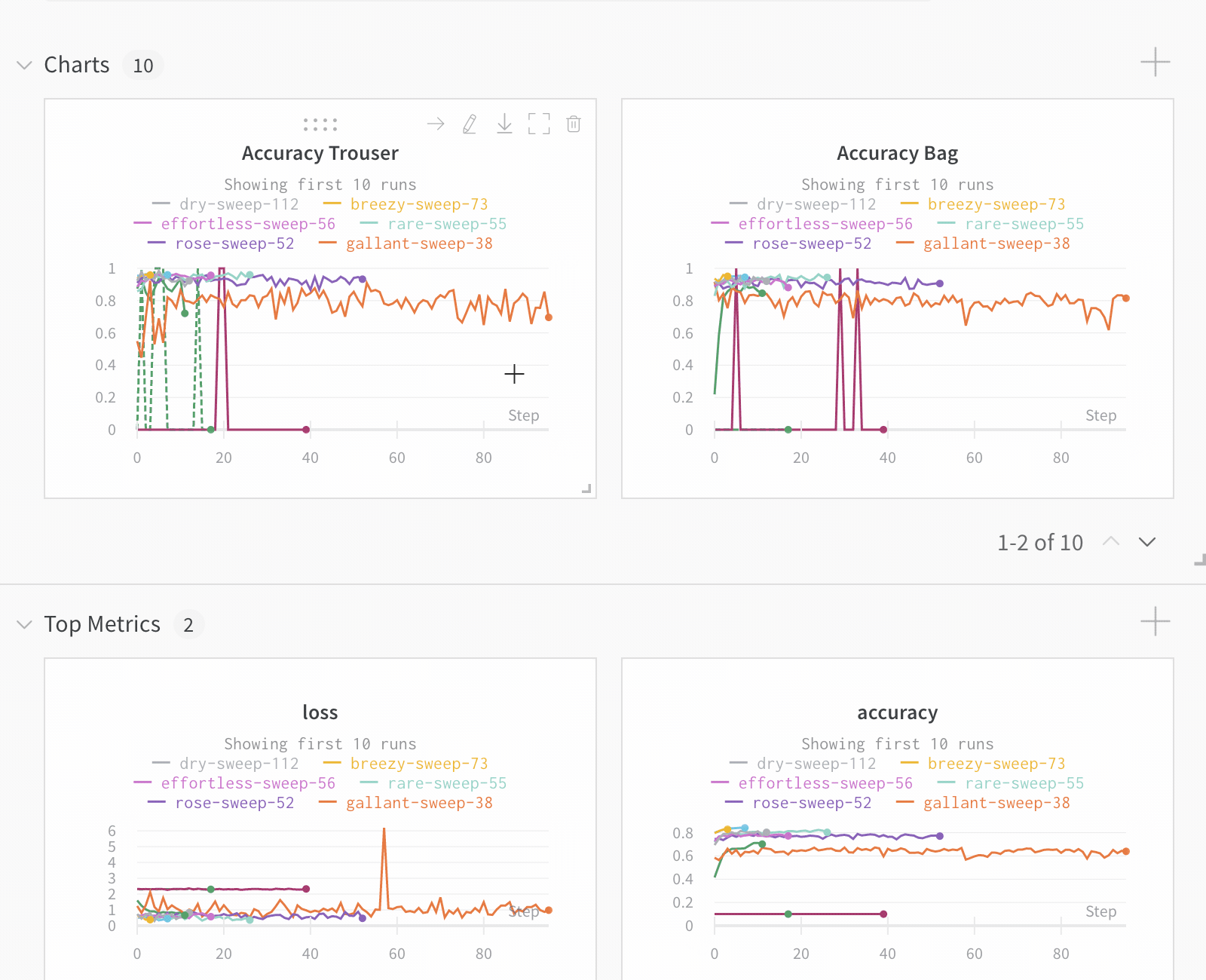
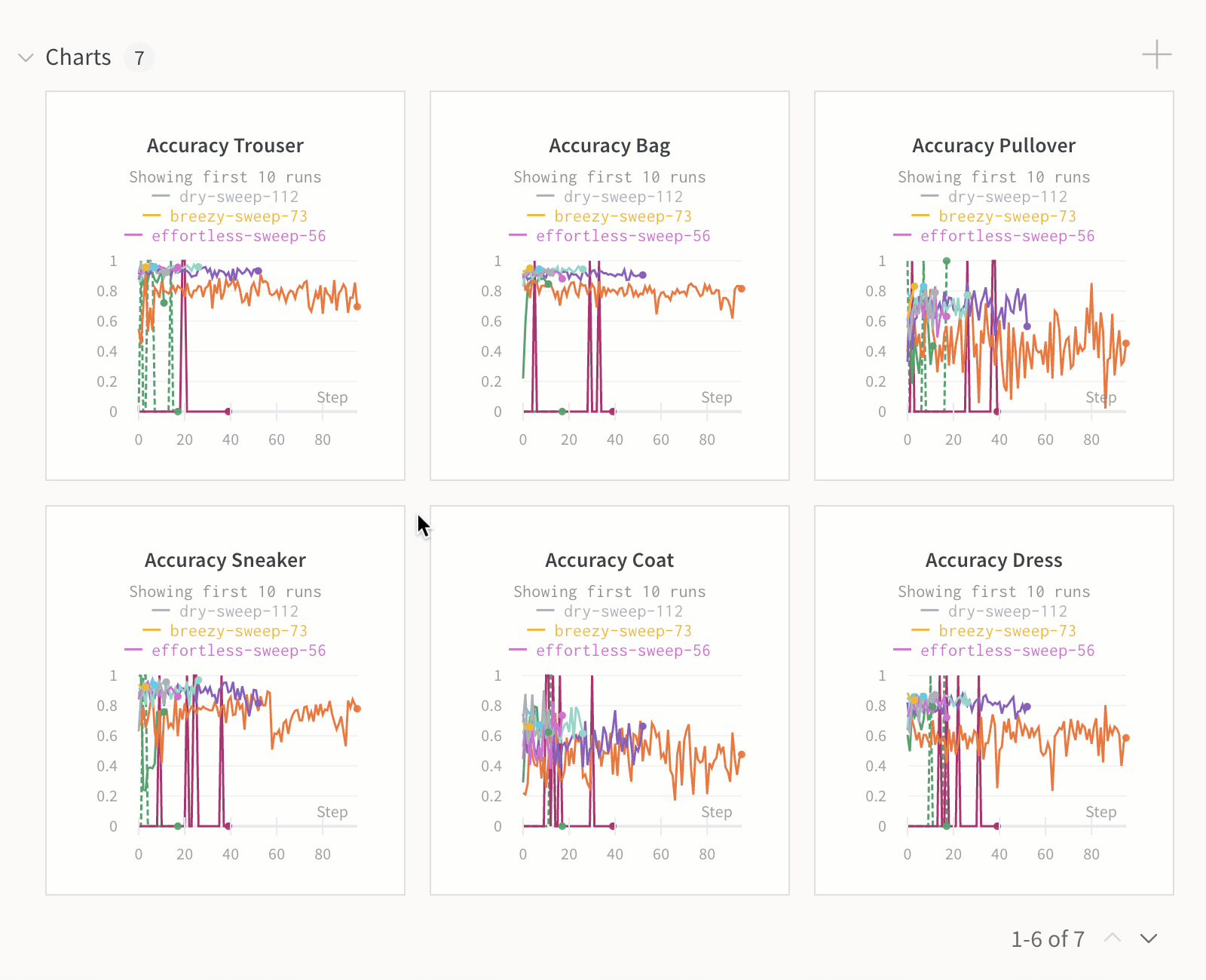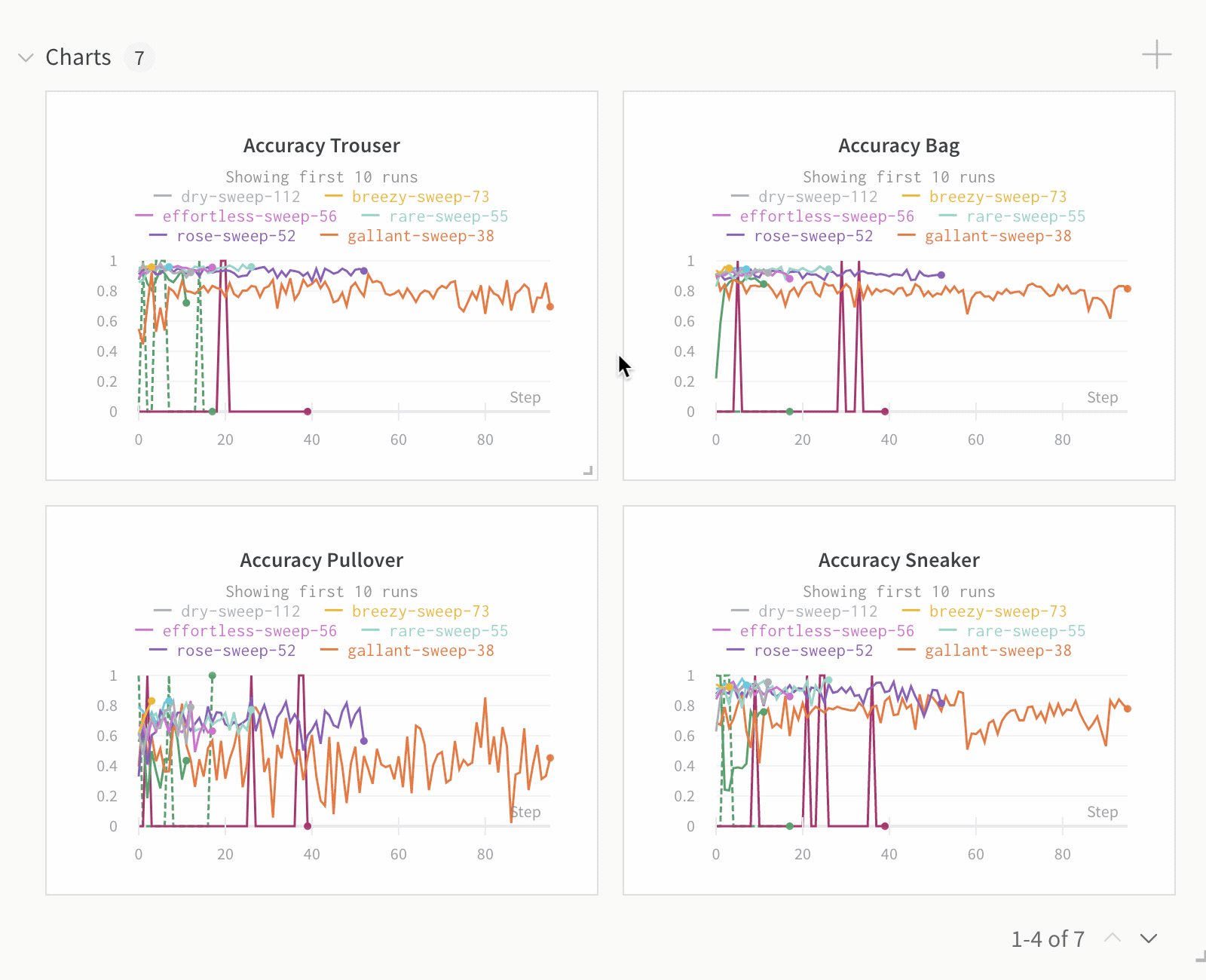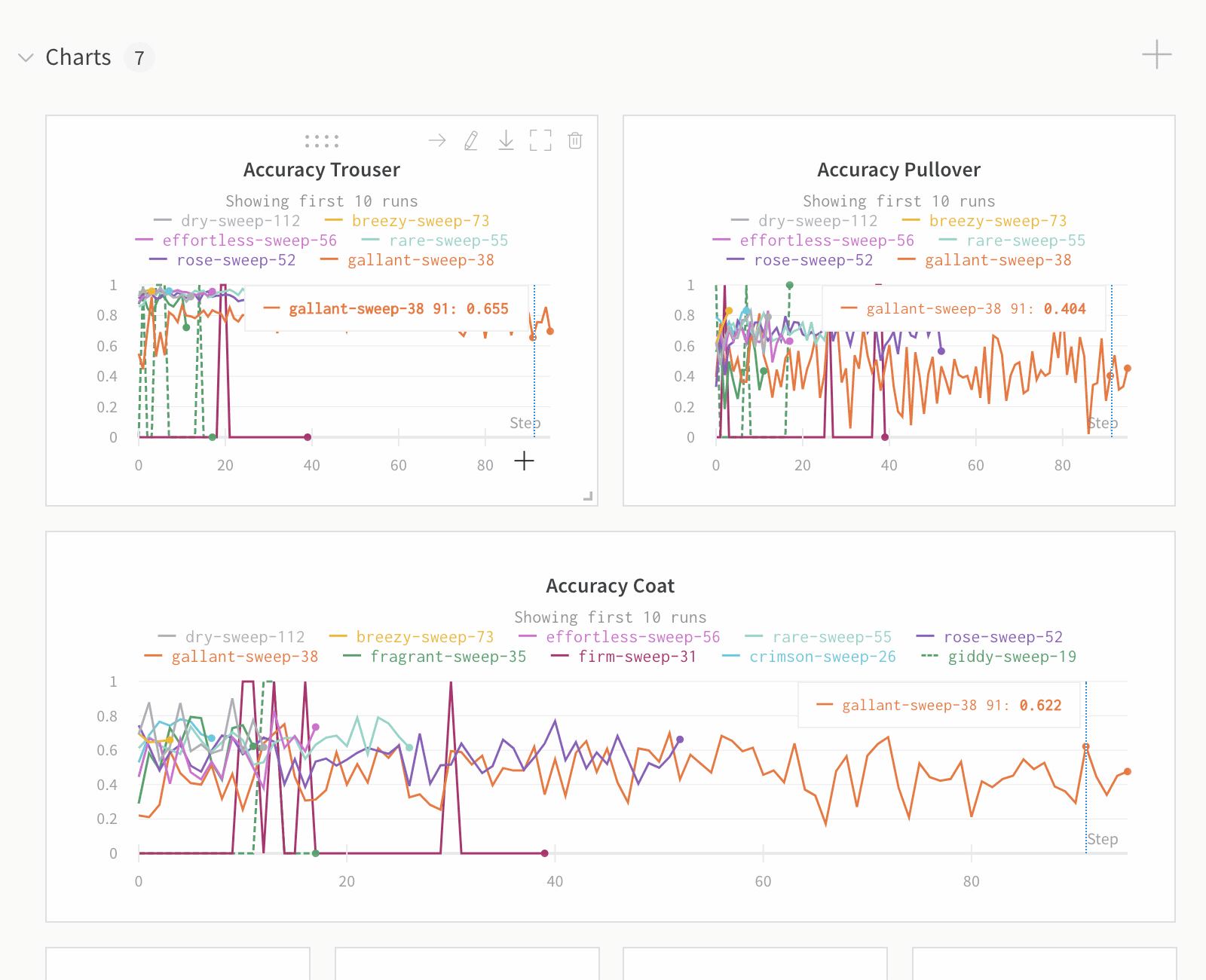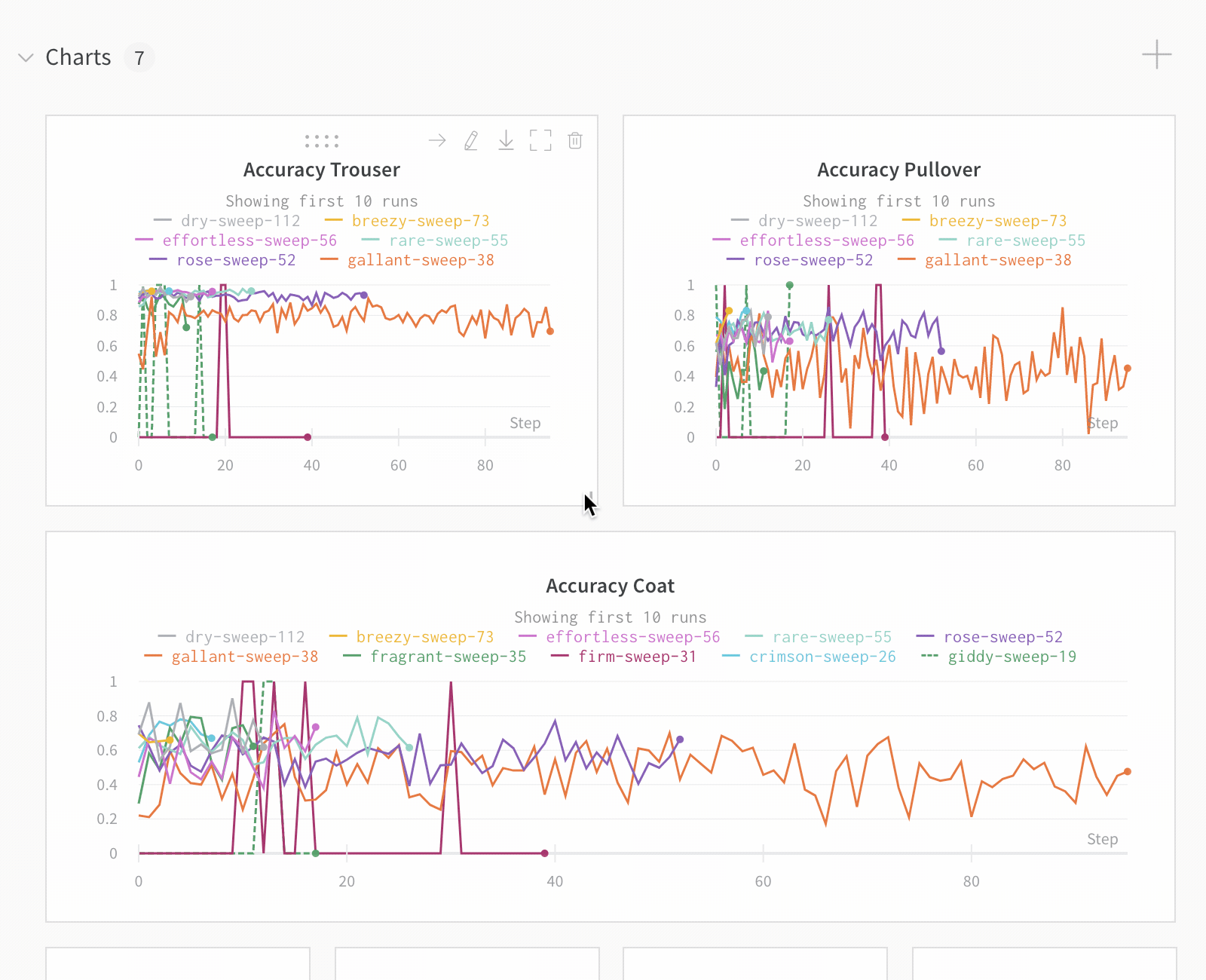
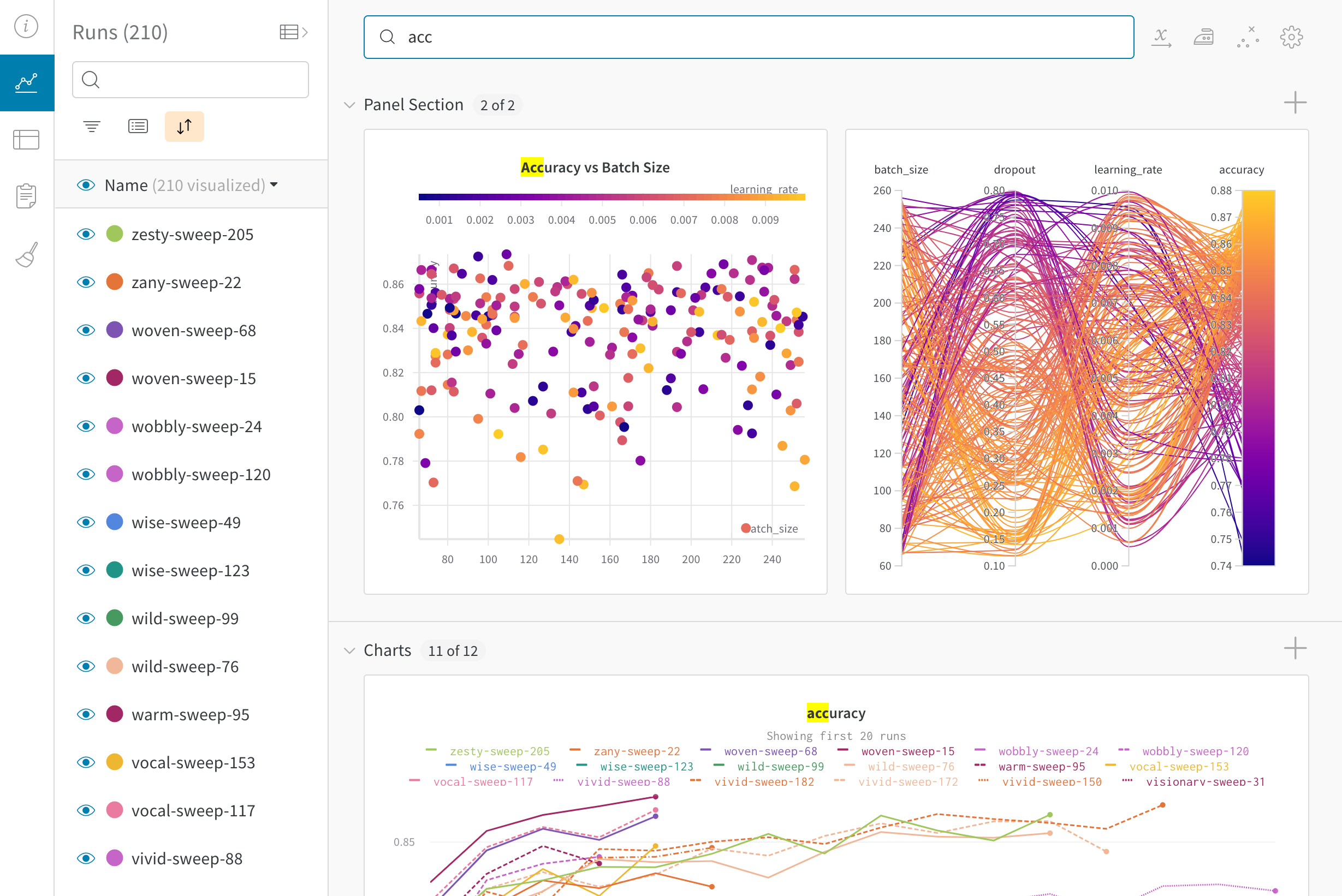
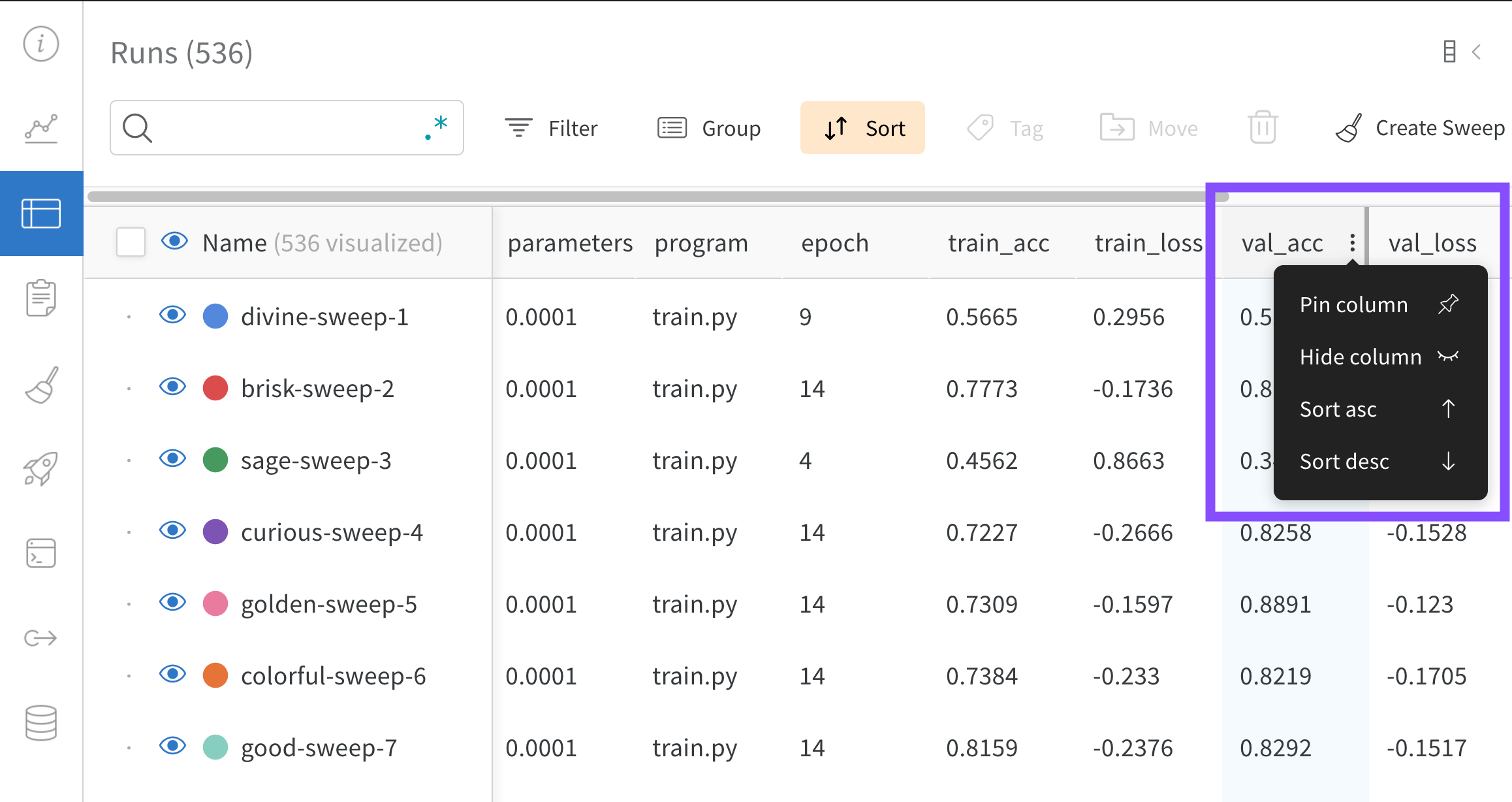
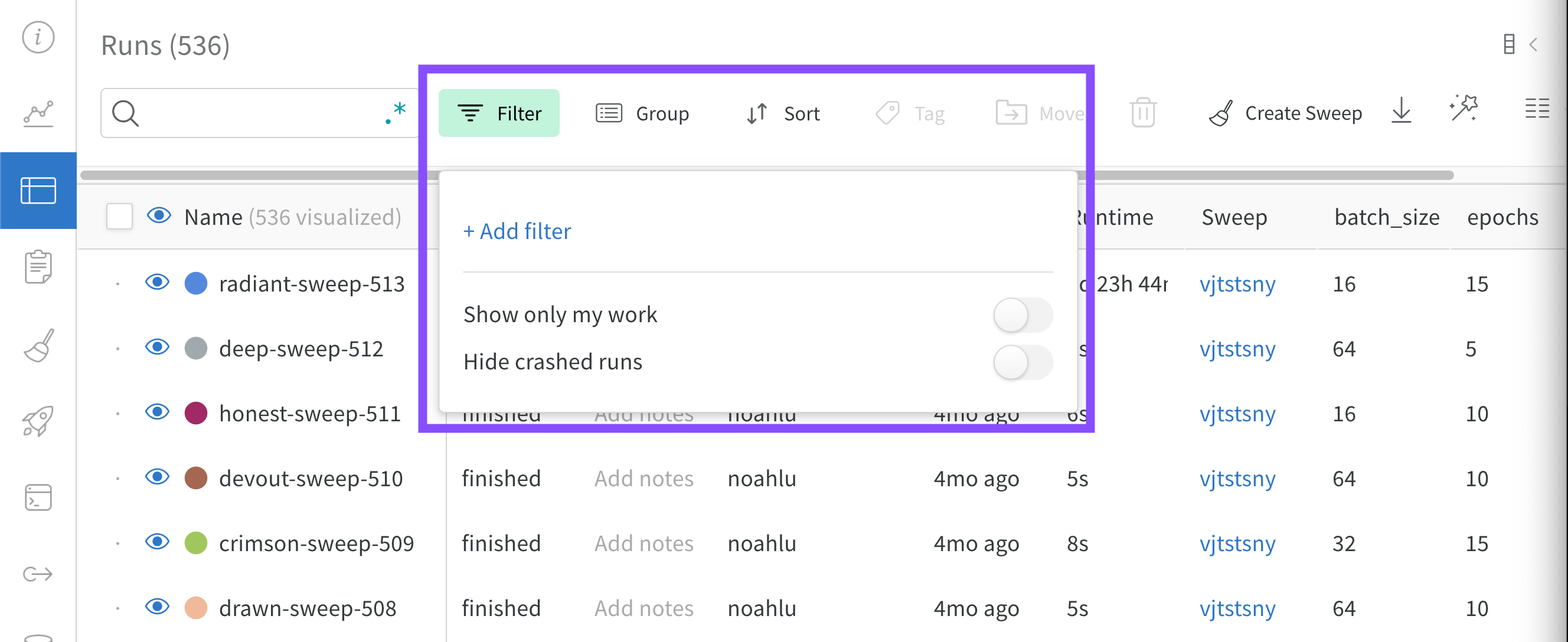
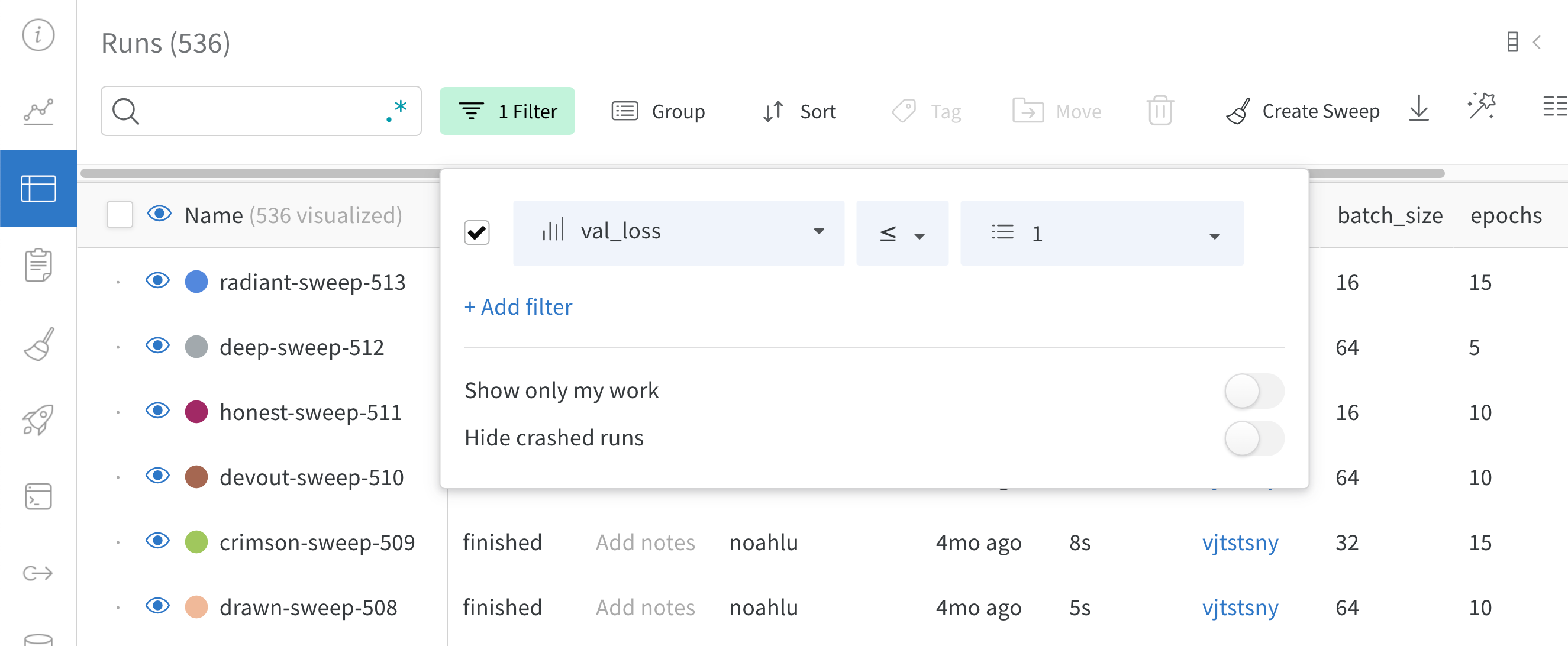 上記の画像は、`val_loss` 列に基づいたフィルターを示しています。フィルターは、検証損失が 1 以下の run を表示します。
上記の画像は、`val_loss` 列に基づいたフィルターを示しています。フィルターは、検証損失が 1 以下の run を表示します。