これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
Integration tutorials
- 1: PyTorch
- 2: PyTorch Lightning
- 3: Hugging Face
- 4: TensorFlow
- 5: TensorFlow Sweeps
- 6: 3D brain tumor segmentation with MONAI
- 7: Keras
- 8: Keras models
- 9: Keras tables
- 10: XGBoost Sweeps
1 - PyTorch
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、および プロジェクト の コラボレーションを行います。

この ノートブック の内容
この ノートブック では、 Weights & Biases を PyTorch コード に 統合して、 実験管理 を パイプライン に 追加する方法を紹介します。
# ライブラリをインポート
import wandb
# 新しい 実験 を開始
wandb.init(project="new-sota-model")
# config で ハイパーパラメーター の 辞書 をキャプチャ
wandb.config = {"learning_rate": 0.001, "epochs": 100, "batch_size": 128}
# モデル と データ をセットアップ
model, dataloader = get_model(), get_data()
# オプション: 勾配 を追跡
wandb.watch(model)
for batch in dataloader:
metrics = model.training_step()
# トレーニング ループ 内で メトリクス を ログ に記録して、 モデル の パフォーマンス を視覚化します。
wandb.log(metrics)
# オプション: 最後に モデル を保存
model.to_onnx()
wandb.save("model.onnx")
ビデオ チュートリアルをご覧ください。
注: Step で始まるセクションは、既存の パイプライン に W&B を 統合 するために必要なすべてです。残りの部分は、 データ を ロード し、 モデル を定義するだけです。
インストール、インポート、および ログイン
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from tqdm.auto import tqdm
# 決定論的な 振る舞い を確認
torch.backends.cudnn.deterministic = True
random.seed(hash("setting random seeds") % 2**32 - 1)
np.random.seed(hash("improves reproducibility") % 2**32 - 1)
torch.manual_seed(hash("by removing stochasticity") % 2**32 - 1)
torch.cuda.manual_seed_all(hash("so runs are repeatable") % 2**32 - 1)
# デバイス の 設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# MNIST ミラー の リスト から 低速 ミラー を削除
torchvision.datasets.MNIST.mirrors = [mirror for mirror in torchvision.datasets.MNIST.mirrors
if not mirror.startswith("http://yann.lecun.com")]
Step 0: W&B の インストール
まず、 ライブラリ を取得する必要があります。
wandb は pip を使用して簡単に インストール できます。
!pip install wandb onnx -Uq
Step 1: W&B の インポート と ログイン
データ を Web サービス に ログ に記録するには、 ログイン する必要があります。
W&B を初めて使用する場合は、表示される リンク で 無料 アカウント にサインアップする必要があります。
import wandb
wandb.login()
実験 と パイプライン を定義
wandb.init を使用して メタデータ と ハイパーパラメーター を追跡
プログラムで、最初に行うことは 実験 を定義することです。 ハイパーパラメーター は何ですか? どのような メタデータ がこの run に 関連付けられていますか?
この 情報 を config 辞書 (または同様の オブジェクト ) に保存し、必要に応じて アクセス するのは非常に一般的な ワークフロー です。
この 例 では、いくつかの ハイパーパラメーター のみを変えることができ、残りは手動で コーディング しています。
ただし、 モデル の 任意の部分を config の一部にすることができます。
また、いくつかの メタデータ も含めます。MNIST データセット と 畳み込み アーキテクチャー を使用しています。たとえば、後で同じ プロジェクト で CIFAR 上の完全に接続された アーキテクチャー を使用する場合、これは run を分離するのに役立ちます。
config = dict(
epochs=5,
classes=10,
kernels=[16, 32],
batch_size=128,
learning_rate=0.005,
dataset="MNIST",
architecture="CNN")
次に、 モデル トレーニング に非常に一般的な 全体的な パイプライン を定義しましょう。
- まず、 モデル 、 関連 データ 、および オプティマイザー を
makeし、次に - モデル をそれに応じて
trainし、最後に testして、 トレーニング の 結果 を確認します。
これらの 関数 を以下に実装します。
def model_pipeline(hyperparameters):
# wandb に 開始 するように指示
with wandb.init(project="pytorch-demo", config=hyperparameters):
# wandb.config を介してすべての HPs に アクセス して、 ログ が 実行 と一致するようにします。
config = wandb.config
# モデル 、 データ 、および 最適化 の 問題 を作成
model, train_loader, test_loader, criterion, optimizer = make(config)
print(model)
# それらを使用して モデル を トレーニング
train(model, train_loader, criterion, optimizer, config)
# 最終的な パフォーマンス を テスト
test(model, test_loader)
return model
標準的な パイプライン との唯一の違いは、それがすべて wandb.init の コンテキスト 内で発生することです。
この 関数 を 呼び出すと、 コード と サーバー 間の 通信回線 が 設定 されます。
config 辞書 を wandb.init に 渡すと、その 情報 がすべてすぐに ログ に記録されるため、 実験 で使用するように 設定 した ハイパーパラメーター の 値 を常に把握できます。
選択および ログ に記録した 値 が モデル で常に使用されるようにするために、 オブジェクト の wandb.config コピー を使用することをお勧めします。
いくつかの 例 を 参照 するには、以下の make の 定義 を確認してください。
サイド ノート: コード を 個別の プロセス で 実行 するように注意してください。これにより、こちら側の 問題 (巨大な海の モンスター が データセンター を攻撃するなど) によって コード が クラッシュ しないようにします。 クラーケン が 深海 に戻るなど、 問題 が解決されたら、
wandb syncで データ を ログ に記録できます。
def make(config):
# データ を作成
train, test = get_data(train=True), get_data(train=False)
train_loader = make_loader(train, batch_size=config.batch_size)
test_loader = make_loader(test, batch_size=config.batch_size)
# モデル を作成
model = ConvNet(config.kernels, config.classes).to(device)
# 損失 と オプティマイザー を作成
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
model.parameters(), lr=config.learning_rate)
return model, train_loader, test_loader, criterion, optimizer
データ の ロード と モデル を定義
次に、 データ の ロード 方法と モデル の 外観を指定する必要があります。
この部分は非常に重要ですが、wandb がなくても同じであるため、詳しく説明しません。
def get_data(slice=5, train=True):
full_dataset = torchvision.datasets.MNIST(root=".",
train=train,
transform=transforms.ToTensor(),
download=True)
# [::slice] で スライス するのと同等
sub_dataset = torch.utils.data.Subset(
full_dataset, indices=range(0, len(full_dataset), slice))
return sub_dataset
def make_loader(dataset, batch_size):
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True, num_workers=2)
return loader
モデル を定義するのは通常楽しい部分です。
しかし、wandb では何も変わらないため、 標準的な ConvNet アーキテクチャー を使用します。
これをいじって 実験 を試すことを恐れないでください。すべての 結果 は wandb.ai に ログ 記録されます。
# 従来の畳み込み ニューラルネットワーク
class ConvNet(nn.Module):
def __init__(self, kernels, classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, kernels[0], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, kernels[1], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * kernels[-1], classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
トレーニング ロジック を定義
model_pipeline で 進めて、train 方法を指定します。
ここでは、2 つの wandb 関数 が 役立ちます。watch と log です。
wandb.watch で 勾配 を追跡し、wandb.log で その他 すべてを追跡
wandb.watch は、 トレーニング のすべての log_freq ステップ で、 モデル の 勾配 と パラメータ を ログ に記録します。
必要なのは、 トレーニング を開始する前にそれを 呼び出すことだけです。
残りの トレーニング コード は同じままです。 エポック と バッチ を 反復処理し、 forward pass と backward pass を 実行 し、オプティマイザー を 適用 します。
def train(model, loader, criterion, optimizer, config):
# モデル が 実行 する 内容 ( 勾配 、 重み など) を wandb に 監視 させる。
wandb.watch(model, criterion, log="all", log_freq=10)
# トレーニング を 実行 し、wandb で 追跡
total_batches = len(loader) * config.epochs
example_ct = 0 # 確認された 例 の 数
batch_ct = 0
for epoch in tqdm(range(config.epochs)):
for _, (images, labels) in enumerate(loader):
loss = train_batch(images, labels, model, optimizer, criterion)
example_ct += len(images)
batch_ct += 1
# 25 回目の バッチ ごとに メトリクス を レポート
if ((batch_ct + 1) % 25) == 0:
train_log(loss, example_ct, epoch)
def train_batch(images, labels, model, optimizer, criterion):
images, labels = images.to(device), labels.to(device)
# Forward pass ➡
outputs = model(images)
loss = criterion(outputs, labels)
# Backward pass ⬅
optimizer.zero_grad()
loss.backward()
# オプティマイザー で ステップ
optimizer.step()
return loss
唯一の違いは ログ コード にあります。以前は ターミナル に 出力 して メトリクス を レポート していた可能性がありますが、 同じ 情報 を wandb.log に 渡すようになりました。
wandb.log は、 キー として 文字列 を持つ 辞書 を想定しています。これらの 文字列 は、 ログ に記録される オブジェクト を識別します。これらが 値 を 構成します。オプションで、 トレーニング のどの step にいるかを ログ に記録することもできます。
サイド ノート: バッチサイズ 全体で 比較 しやすくするために、 モデル が 確認 した 例 の 数を 使用するのが好きですが、 生の ステップ または バッチ カウント を使用できます。より 長い トレーニング run の 場合、
エポックごとに ログ に記録することも 理にかなっています。
def train_log(loss, example_ct, epoch):
# 魔法が起こる場所
wandb.log({"epoch": epoch, "loss": loss}, step=example_ct)
print(f"Loss after {str(example_ct).zfill(5)} examples: {loss:.3f}")
テスト ロジック を定義
モデル の トレーニング が完了したら、それを テスト します。たとえば、 プロダクション からの 新鮮な データ に対して 実行 したり、手作業で キュレーション された 例 に 適用 したりします。
(オプション) wandb.save を 呼び出す
これは、 モデル の アーキテクチャー と 最終的な パラメータ を ディスク に保存する絶好の機会でもあります。最大限の 互換性を得るために、Open Neural Network eXchange (ONNX) 形式で モデル を エクスポート します。
その ファイル名 を wandb.save に 渡すと、 モデル の パラメータ が W&B の サーバー に 保存されます。どの .h5 または .pb がどの トレーニング run に 対応 するかを 追跡 できなくなることはありません。
モデル を保存、 バージョン管理 、および 配布 するための、より 高度な wandb 機能 については、Artifacts ツールを ご覧ください。
def test(model, test_loader):
model.eval()
# いくつかの テスト 例 で モデル を 実行
with torch.no_grad():
correct, total = 0, 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy of the model on the {total} " +
f"test images: {correct / total:%}")
wandb.log({"test_accuracy": correct / total})
# 交換可能な ONNX 形式 で モデル を保存
torch.onnx.export(model, images, "model.onnx")
wandb.save("model.onnx")
トレーニング を 実行 し、wandb.ai で メトリクス を ライブ で 監視
パイプライン 全体を定義し、いくつかの W&B コード を 挿入 したので、完全に 追跡 された 実験 を 実行 する 準備ができました。
ドキュメント、 プロジェクト ページ ( プロジェクト 内のすべての run を 整理します)、および この run の 結果 が 保存される Run ページへの リンク がいくつか レポート されます。
Run ページに 移動 し、これらの タブ を 確認 してください。
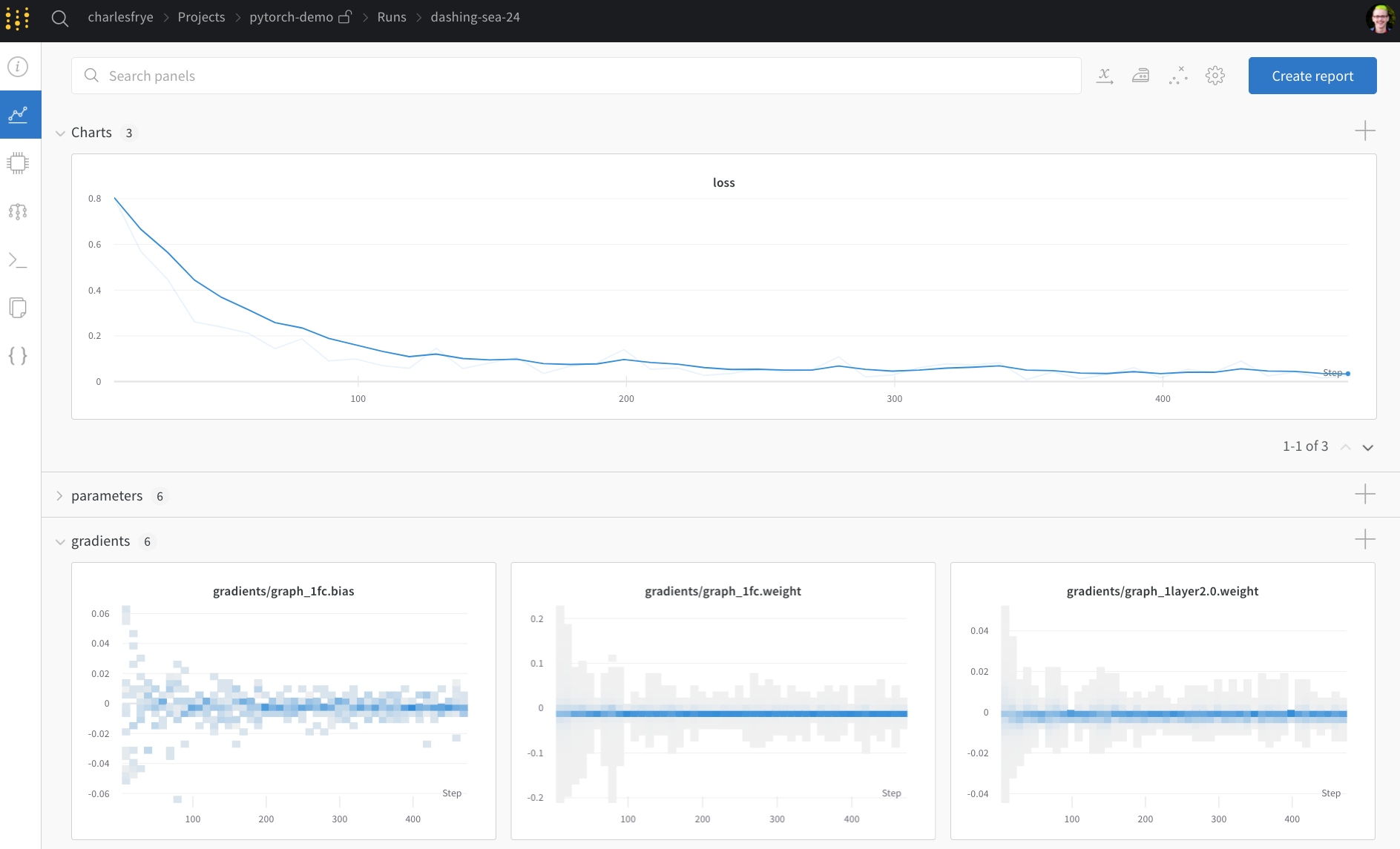
- Charts: トレーニング 全体で モデル の 勾配 、 パラメータ 値、および 損失 が ログ に記録されます。
- System: ディスク I/O 使用率、 CPU および GPU メトリクス (温度が急上昇するのを 監視 します) などの さまざまな システム メトリクス が含まれています。
- Logs: トレーニング 中に 標準出力 に プッシュ されたすべてのものの コピー があります。
- Files: トレーニング が完了すると、
model.onnxを クリック して、Netron モデル ビューアーで ネットワーク を 表示 できます。
run が 終了 すると、with wandb.init ブロック が 終了 するときに、 セル の 出力 に 結果 の 概要 も 出力 されます。
# パイプライン を使用して モデル を 構築、 トレーニング 、および 分析
model = model_pipeline(config)
Sweeps で ハイパーパラメーター を テスト
この 例 では、単一の ハイパーパラメーター セット のみを調べました。 しかし、ほとんどの ML ワークフロー の 重要な部分は、多くの ハイパーパラメーター を 反復処理することです。
Weights & Biases Sweeps を使用すると、 ハイパーパラメーター の テスト を 自動化し、 可能な モデル と 最適化 戦略 の スペース を 探索 できます。
W&B Sweeps を使用した PyTorch での ハイパーパラメーター の 最適化 を確認
Weights & Biases で ハイパーパラメーター sweep を 実行 するのは非常に簡単です。簡単な 3 つの ステップ があります。
-
sweep を定義: 検索 する パラメータ 、 検索 戦略、 最適化 メトリクス などを 指定する 辞書 または YAML ファイル を 作成 して、これを行います。
-
sweep を 初期化:
sweep_id = wandb.sweep(sweep_config) -
sweep agent を 実行:
wandb.agent(sweep_id, function=train)
これで、 ハイパーパラメーター sweep の 実行 はすべて完了です。
例 ギャラリー
ギャラリー →で W&B で 追跡 および 視覚化 された プロジェクト の 例 を ご覧ください
高度な 設定
- 環境変数: 管理対象 クラスター で トレーニング を 実行 できるように、 環境変数 で APIキー を 設定 します。
- オフライン モード:
dryrunモード を 使用 して オフライン で トレーニング し、後で 結果 を 同期 します。 - オンプレミス: プライベートクラウド または お客様の インフラストラクチャー 内の エアギャップ サーバー に W&B を インストール します。 学術関係者から エンタープライズ チーム まで、あらゆる ユーザー 向けの ローカル インストール があります。
- Sweeps: チューニング 用の 軽量 ツール を 使用 して、 ハイパーパラメーター 検索 を 迅速に 設定 します。
2 - PyTorch Lightning
PyTorch Lightning を使用して画像分類のパイプラインを構築します。コードの可読性と再現性を高めるために、こちらの スタイル ガイド に従います。これに関するわかりやすい説明は、こちらにあります。PyTorch Lightning と W&B のセットアップ
このチュートリアルでは、PyTorch Lightning と Weights & Biases が必要です。
pip install lightning -q
pip install wandb -qU
import lightning.pytorch as pl
# お気に入りの 機械学習 トラッキング ツール
from lightning.pytorch.loggers import WandbLogger
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import random_split, DataLoader
from torchmetrics import Accuracy
from torchvision import transforms
from torchvision.datasets import CIFAR10
import wandb
次に、wandb アカウントにログインする必要があります。
wandb.login()
DataModule - 価値のあるデータ パイプライン
DataModule は、データ関連のフックを LightningModule から分離して、データセットに依存しないモデルを開発できるようにする方法です。
データパイプラインを 1 つの共有可能で再利用可能なクラスにまとめます。 datamodule は、PyTorch でのデータ処理に関わる次の 5 つのステップをカプセル化します。
- ダウンロード/トークン化/プロセッシング。
- クリーンアップして、(場合によっては)ディスクに保存します。
- データセット内にロードします。
- 変換(回転、トークン化など)を適用します。
- DataLoader 内にラップします。
datamodule の詳細については、こちらをご覧ください。 Cifar-10 データセット用の datamodule を構築してみましょう。
class CIFAR10DataModule(pl.LightningDataModule):
def __init__(self, batch_size, data_dir: str = './'):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
self.num_classes = 10
def prepare_data(self):
CIFAR10(self.data_dir, train=True, download=True)
CIFAR10(self.data_dir, train=False, download=True)
def setup(self, stage=None):
# dataloader で使用するトレーニング/検証データセットを割り当てます
if stage == 'fit' or stage is None:
cifar_full = CIFAR10(self.data_dir, train=True, transform=self.transform)
self.cifar_train, self.cifar_val = random_split(cifar_full, [45000, 5000])
# dataloader で使用するテストデータセットを割り当てます
if stage == 'test' or stage is None:
self.cifar_test = CIFAR10(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.cifar_train, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.cifar_val, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.cifar_test, batch_size=self.batch_size)
コールバック
callback は、プロジェクト間で再利用できる自己完結型のプログラムです。 PyTorch Lightning には、定期的に使用されるいくつかの 組み込み callbacksが付属しています。 PyTorch Lightning の callbacks の詳細については、こちらをご覧ください。
組み込み Callbacks
このチュートリアルでは、組み込みの Early Stopping と Model Checkpoint の callbacks を使用します。 これらは Trainer に渡すことができます。
カスタム Callbacks
カスタム Keras callback に慣れている場合は、PyTorch パイプラインで同じことができる機能は、まさに嬉しいおまけです。
画像分類を実行しているので、モデルの予測をいくつかの画像のサンプルで視覚化できると役立ちます。 これを callback の形式にすることで、初期段階でモデルをデバッグできます。
class ImagePredictionLogger(pl.callbacks.Callback):
def __init__(self, val_samples, num_samples=32):
super().__init__()
self.num_samples = num_samples
self.val_imgs, self.val_labels = val_samples
def on_validation_epoch_end(self, trainer, pl_module):
# テンソルを CPU に取り込みます
val_imgs = self.val_imgs.to(device=pl_module.device)
val_labels = self.val_labels.to(device=pl_module.device)
# モデルの予測を取得します
logits = pl_module(val_imgs)
preds = torch.argmax(logits, -1)
# 画像を wandb Image として記録します
trainer.logger.experiment.log({
"examples":[wandb.Image(x, caption=f"Pred:{pred}, Label:{y}")
for x, pred, y in zip(val_imgs[:self.num_samples],
preds[:self.num_samples],
val_labels[:self.num_samples])]
})
LightningModule - システムの定義
LightningModule は、モデルではなくシステムを定義します。 ここでは、システムはすべての研究コードを 1 つのクラスにグループ化して、自己完結型にします。 LightningModule は、PyTorch コードを次の 5 つのセクションに整理します。
- 計算 (
__init__)。 - トレーニング ループ (
training_step) - 検証ループ (
validation_step) - テスト ループ (
test_step) - オプティマイザー (
configure_optimizers)
したがって、簡単に共有できるデータセットに依存しないモデルを構築できます。 Cifar-10 分類用のシステムを構築してみましょう。
class LitModel(pl.LightningModule):
def __init__(self, input_shape, num_classes, learning_rate=2e-4):
super().__init__()
# ハイパーパラメータを記録します
self.save_hyperparameters()
self.learning_rate = learning_rate
self.conv1 = nn.Conv2d(3, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 32, 3, 1)
self.conv3 = nn.Conv2d(32, 64, 3, 1)
self.conv4 = nn.Conv2d(64, 64, 3, 1)
self.pool1 = torch.nn.MaxPool2d(2)
self.pool2 = torch.nn.MaxPool2d(2)
n_sizes = self._get_conv_output(input_shape)
self.fc1 = nn.Linear(n_sizes, 512)
self.fc2 = nn.Linear(512, 128)
self.fc3 = nn.Linear(128, num_classes)
self.accuracy = Accuracy(task='multiclass', num_classes=num_classes)
# conv ブロックから Linear レイヤーに入る出力テンソルのサイズを返します。
def _get_conv_output(self, shape):
batch_size = 1
input = torch.autograd.Variable(torch.rand(batch_size, *shape))
output_feat = self._forward_features(input)
n_size = output_feat.data.view(batch_size, -1).size(1)
return n_size
# conv ブロックから特徴テンソルを返します
def _forward_features(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = self.pool2(F.relu(self.conv4(x)))
return x
# 推論中に使用されます
def forward(self, x):
x = self._forward_features(x)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.log_softmax(self.fc3(x), dim=1)
return x
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
# トレーニング メトリクス
preds = torch.argmax(logits, dim=1)
acc = self.accuracy(preds, y)
self.log('train_loss', loss, on_step=True, on_epoch=True, logger=True)
self.log('train_acc', acc, on_step=True, on_epoch=True, logger=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
# 検証メトリクス
preds = torch.argmax(logits, dim=1)
acc = self.accuracy(preds, y)
self.log('val_loss', loss, prog_bar=True)
self.log('val_acc', acc, prog_bar=True)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
# 検証メトリクス
preds = torch.argmax(logits, dim=1)
acc = self.accuracy(preds, y)
self.log('test_loss', loss, prog_bar=True)
self.log('test_acc', acc, prog_bar=True)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
return optimizer
トレーニングと評価
DataModule を使用してデータパイプラインを整理し、LightningModule を使用してモデル アーキテクチャ + トレーニング ループを整理したので、PyTorch Lightning Trainer がそれ以外のすべてを自動化します。
Trainer は以下を自動化します。
- エポックとバッチの反復
optimizer.step()、backward、zero_grad()の呼び出し.eval()の呼び出し、grads の有効化/無効化- 重みの保存とロード
- Weights & Biases ロギング
- 複数 GPU トレーニングのサポート
- TPU サポート
- 16 ビット トレーニングのサポート
dm = CIFAR10DataModule(batch_size=32)
# x_dataloader にアクセスするには、prepare_data と setup を呼び出す必要があります。
dm.prepare_data()
dm.setup()
# 画像予測を記録するためにカスタム ImagePredictionLogger callback で必要なサンプル。
val_samples = next(iter(dm.val_dataloader()))
val_imgs, val_labels = val_samples[0], val_samples[1]
val_imgs.shape, val_labels.shape
model = LitModel((3, 32, 32), dm.num_classes)
# wandb logger を初期化します
wandb_logger = WandbLogger(project='wandb-lightning', job_type='train')
# Callbacks を初期化します
early_stop_callback = pl.callbacks.EarlyStopping(monitor="val_loss")
checkpoint_callback = pl.callbacks.ModelCheckpoint()
# trainer を初期化します
trainer = pl.Trainer(max_epochs=2,
logger=wandb_logger,
callbacks=[early_stop_callback,
ImagePredictionLogger(val_samples),
checkpoint_callback],
)
# モデルをトレーニングします
trainer.fit(model, dm)
# ⚡⚡ 保持されたテスト セットでモデルを評価します
trainer.test(dataloaders=dm.test_dataloader())
# wandb run を閉じます
wandb.finish()
最終的な考え
私は TensorFlow/Keras エコシステム出身で、PyTorch はエレガントなフレームワークですが、少し圧倒されると感じています。 これはあくまで私の個人的な経験です。 PyTorch Lightning を調べているうちに、PyTorch から遠ざかっていた理由のほとんどが解消されていることに気づきました。 私が興奮している点の簡単なまとめを以下に示します。
- 以前: 従来の PyTorch モデルの定義は、あちこちに散らばっていました。 モデルは
model.pyスクリプトに、トレーニング ループはtrain.pyファイルに記述されていました。 パイプラインを理解するには、何度も見返す必要がありました。 - 現在:
LightningModuleは、モデルがtraining_step、validation_stepなどと共に定義されているシステムとして機能します。 これで、モジュール式になり、共有できるようになりました。 - 以前: TensorFlow/Keras の最も優れている点は、入力データ パイプラインです。 データセット カタログは豊富で、成長を続けています。 PyTorch のデータ パイプラインは、これまでで最大の難点でした。 通常の PyTorch コードでは、データのダウンロード/クリーンアップ/準備は通常、多くのファイルに分散しています。
- 現在: DataModule は、データ パイプラインを 1 つの共有可能で再利用可能なクラスにまとめます。 これは単に、
train_dataloader、val_dataloader(s)、test_dataloader(s) のコレクションであり、必要な変換とデータ プロセッシング/ダウンロードの手順が付属しています。 - 以前: Keras を使用すると、
model.fitを呼び出してモデルをトレーニングし、model.predictを呼び出して推論を実行できます。model.evaluateは、テストデータに対する古き良き単純な評価を提供しました。 これは PyTorch には当てはまりません。 通常、個別のtrain.pyファイルとtest.pyファイルが見つかります。 - 現在:
LightningModuleが導入されたことで、Trainerがすべてを自動化します。 モデルをトレーニングおよび評価するには、trainer.fitとtrainer.testを呼び出すだけで済みます。 - 以前: TensorFlow は TPU が大好きですが、PyTorch は…
- 現在: PyTorch Lightning を使用すると、複数の GPU や TPU 上でも同じモデルを簡単にトレーニングできます。
- 以前: 私は Callbacks の大ファンで、カスタム callbacks を記述することを好みます。 Early Stopping のように些細なことでも、従来の PyTorch では議論の対象となっていました。
- 現在: PyTorch Lightning を使用すると、Early Stopping と Model Checkpointing を簡単に使用できます。 カスタム callbacks を記述することもできます。
🎨 まとめとリソース
このレポートがお役に立てば幸いです。 コードを試して、選択したデータセットを使用して画像分類器をトレーニングすることをお勧めします。
PyTorch Lightning の詳細については、次のリソースをご覧ください。
- ステップごとのウォークスルー - これは公式チュートリアルの 1 つです。 ドキュメントは非常によく書かれており、優れた学習リソースとして強くお勧めします。
- Weights & Biases で Pytorch Lightning を使用する - これは、W&B を PyTorch Lightning で使用する方法の詳細を学ぶために実行できる簡単な colab です。
3 - Hugging Face
 Hugging Face モデルのパフォーマンスを、シームレスな W&B インテグレーションで素早く可視化しましょう。
Hugging Face モデルのパフォーマンスを、シームレスな W&B インテグレーションで素早く可視化しましょう。
モデル間で、ハイパーパラメーター、出力メトリクス、 GPU 使用率などのシステム統計を比較します。
W&B を使うべき理由
- 統合ダッシュボード : すべてのモデルメトリクスと予測の一元的なリポジトリ
- 軽量 : Hugging Face と統合するために必要なコード変更はありません
- アクセス可能 : 個人およびアカデミックチームは無料
- セキュア : デフォルトでは、すべての Projects がプライベートです
- 信頼性 : OpenAI、トヨタ、Lyft などの機械学習チームで使用されています
W&B は、機械学習モデルの GitHub のようなものだと考えてください。機械学習の Experiments をプライベートなホストされたダッシュボードに保存します。スクリプトをどこで実行していても、すべてのバージョンのモデルが保存されるので、安心して迅速に Experiments を行うことができます。
W&B の軽量インテグレーションは、あらゆる Python スクリプトで動作し、モデルのトラッキングと可視化を開始するには、無料の W&B アカウントにサインアップするだけです。
Hugging Face Transformers リポジトリでは、 Trainer に、トレーニングおよび評価メトリクスを各ロギングステップで W&B に自動的にログ記録するように設定しました。
インテグレーションの仕組みの詳細はこちら: Hugging Face + W&B Report。
インストール、インポート、ログイン
Hugging Face と Weights & Biases のライブラリ、およびこのチュートリアルの GLUE データセットとトレーニングスクリプトをインストールします。
- Hugging Face Transformers: 自然言語モデルとデータセット
- Weights & Biases: 実験管理と可視化
- GLUE dataset: 言語理解ベンチマークデータセット
- GLUE script: シーケンス分類用のモデルトレーニングスクリプト
!pip install datasets wandb evaluate accelerate -qU
!wget https://raw.githubusercontent.com/huggingface/transformers/refs/heads/main/examples/pytorch/text-classification/run_glue.py
# run_glue.py スクリプトには transformers dev が必要です
!pip install -q git+https://github.com/huggingface/transformers
続行する前に、無料アカウントにサインアップ してください。
APIキーを入力
サインアップしたら、次のセルを実行し、リンクをクリックして APIキーを取得し、この notebook を認証します。
import wandb
wandb.login()
オプションで、環境変数を設定して W&B のロギングをカスタマイズできます。詳細については、ドキュメント を参照してください。
# オプション: 勾配とパラメータの両方をログに記録する
%env WANDB_WATCH=all
モデルのトレーニング
次に、ダウンロードしたトレーニングスクリプト run_glue.py を呼び出して、トレーニングが自動的に Weights & Biases ダッシュボードに追跡されることを確認します。このスクリプトは、 Microsoft Research Paraphrase Corpus (意味的に同等かどうかを示す人間の注釈が付いた文のペア) で BERT をファインチューンします。
%env WANDB_PROJECT=huggingface-demo
%env TASK_NAME=MRPC
!python run_glue.py \
--model_name_or_path bert-base-uncased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 256 \
--per_device_train_batch_size 32 \
--learning_rate 2e-4 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir \
--logging_steps 50
ダッシュボードで結果を可視化
上記に出力されたリンクをクリックするか、wandb.ai にアクセスして、結果がライブでストリーミングされるのを確認します。ブラウザで run を表示するためのリンクは、すべての依存関係がロードされた後に表示されます。次の出力を探してください: “wandb: 🚀 View run at [URL to your unique run]”
モデルのパフォーマンスを可視化 多数の Experiments を見渡し、興味深い学びをズームインし、高次元のデータを可視化するのは簡単です。
アーキテクチャーの比較 BERT vs DistilBERT を比較した例を次に示します。自動ラインプロットの可視化により、トレーニングを通じて評価精度に異なるアーキテクチャーがどのように影響するかを簡単に確認できます。
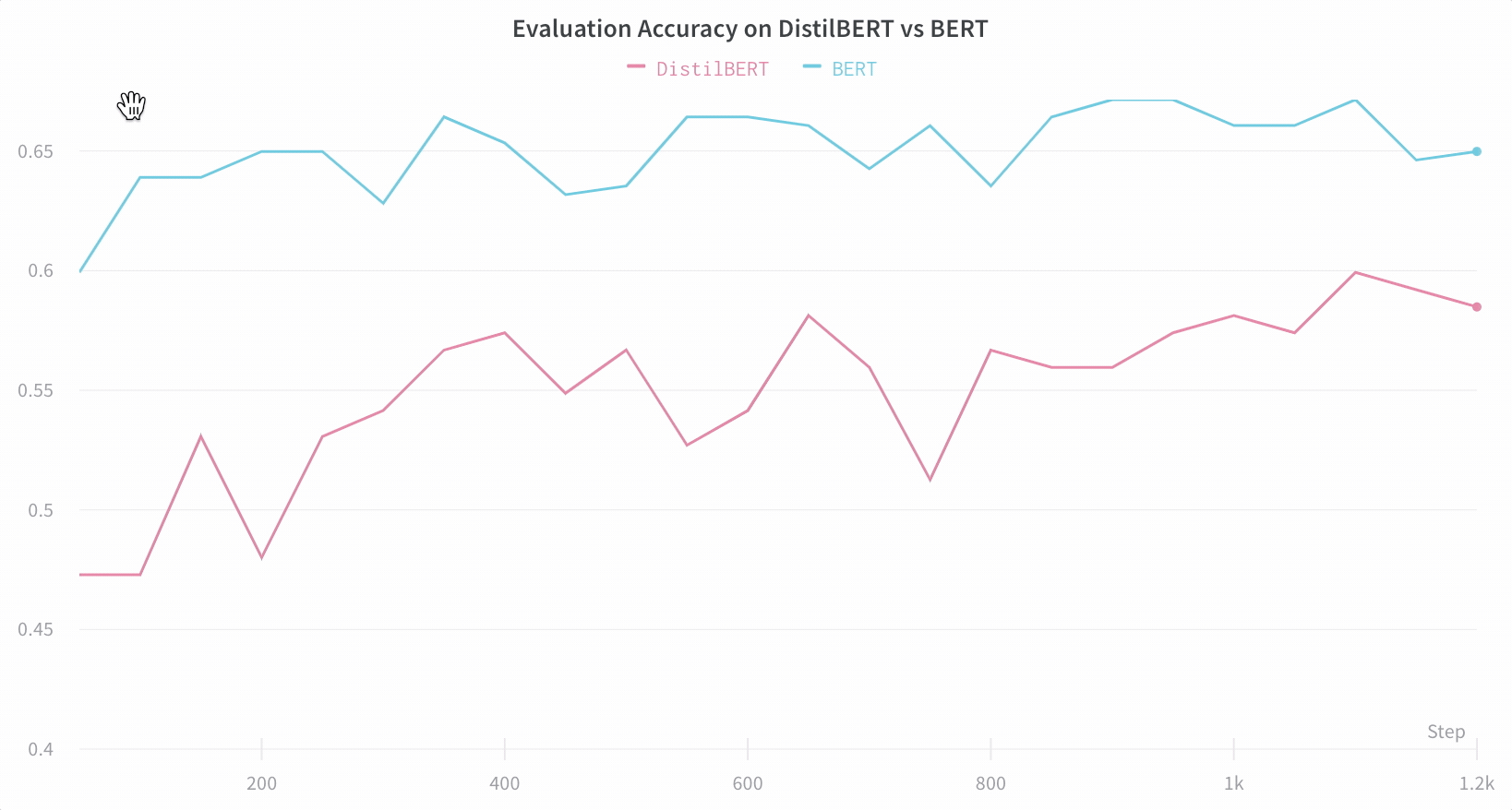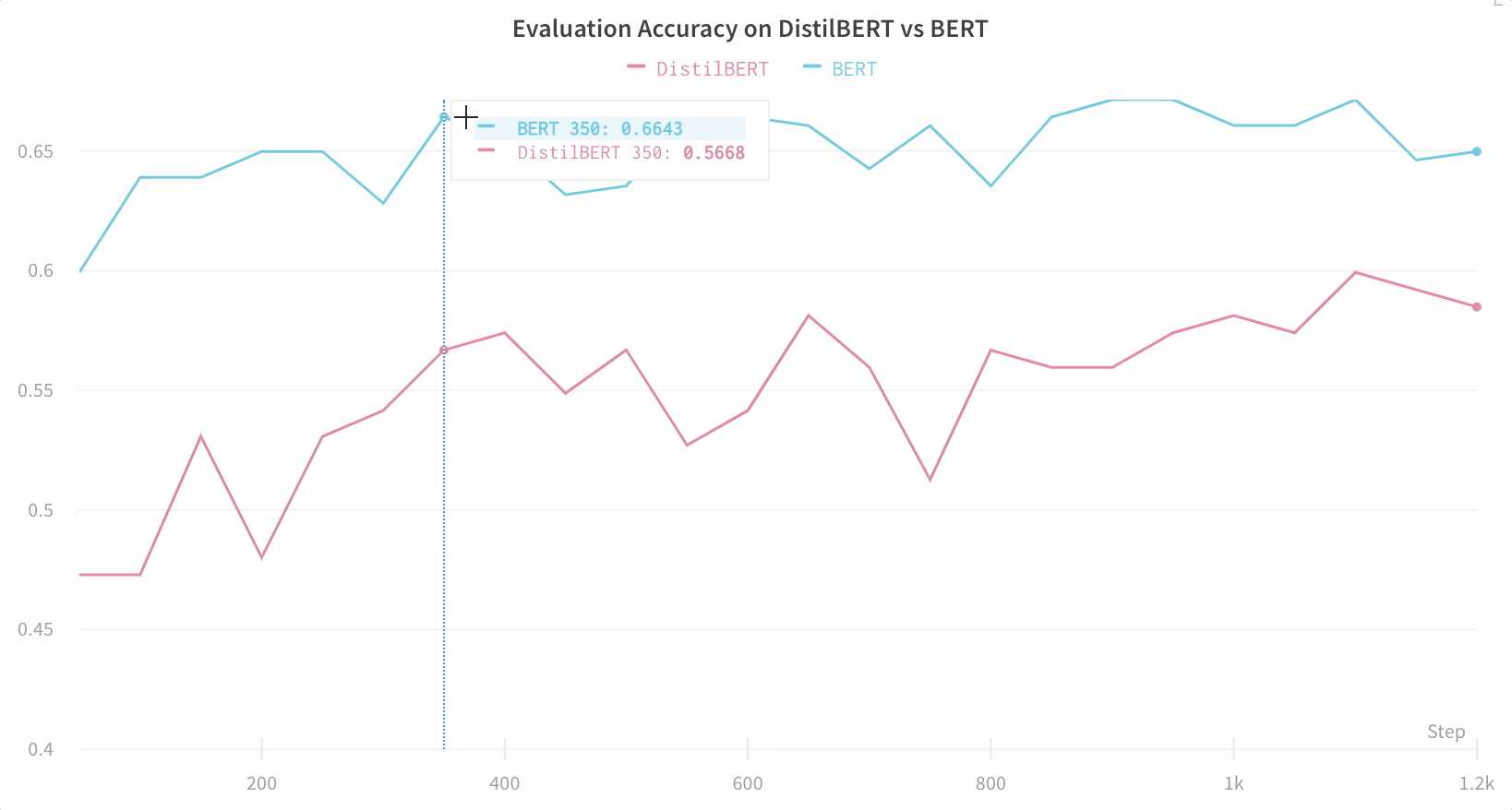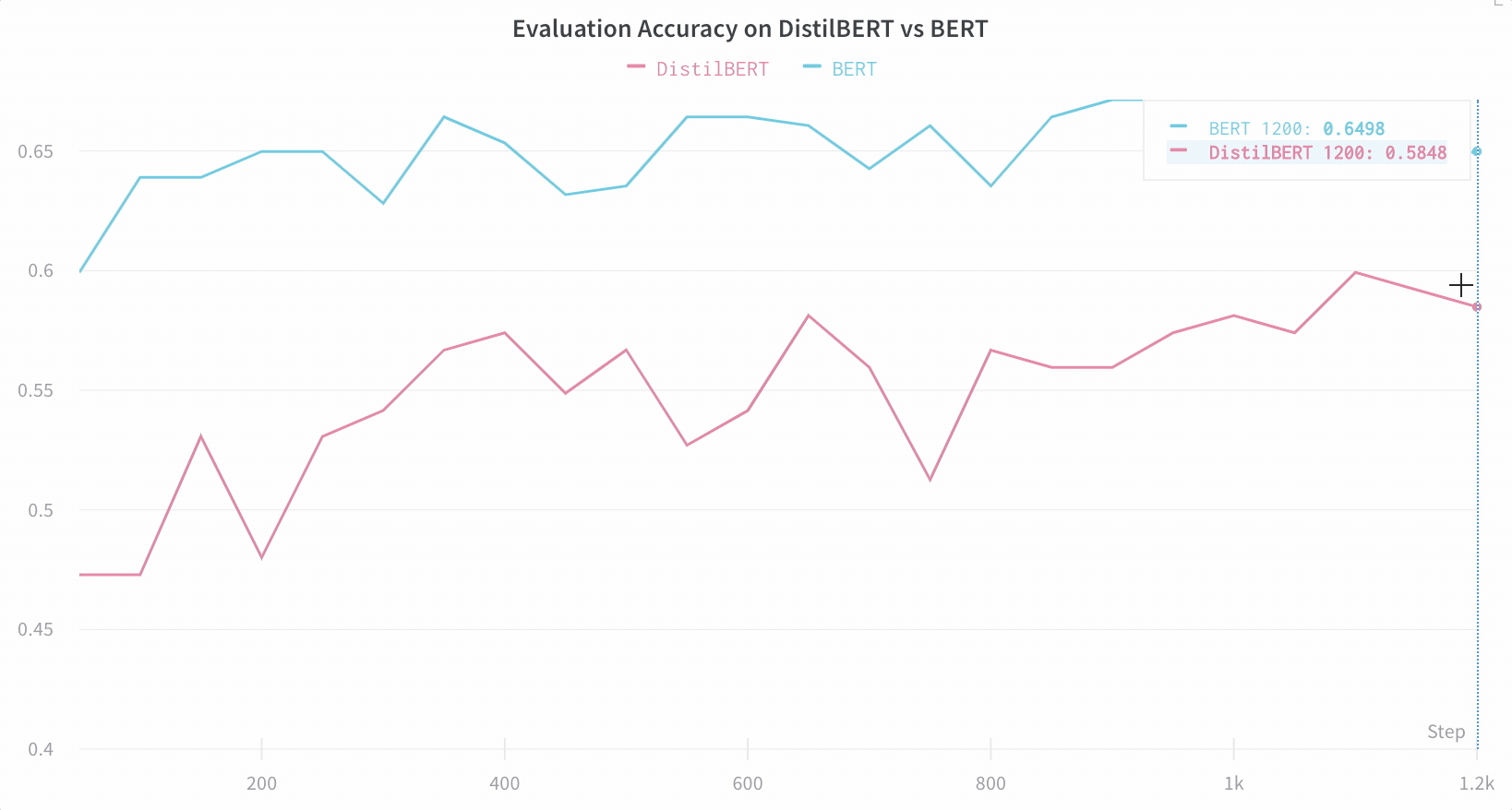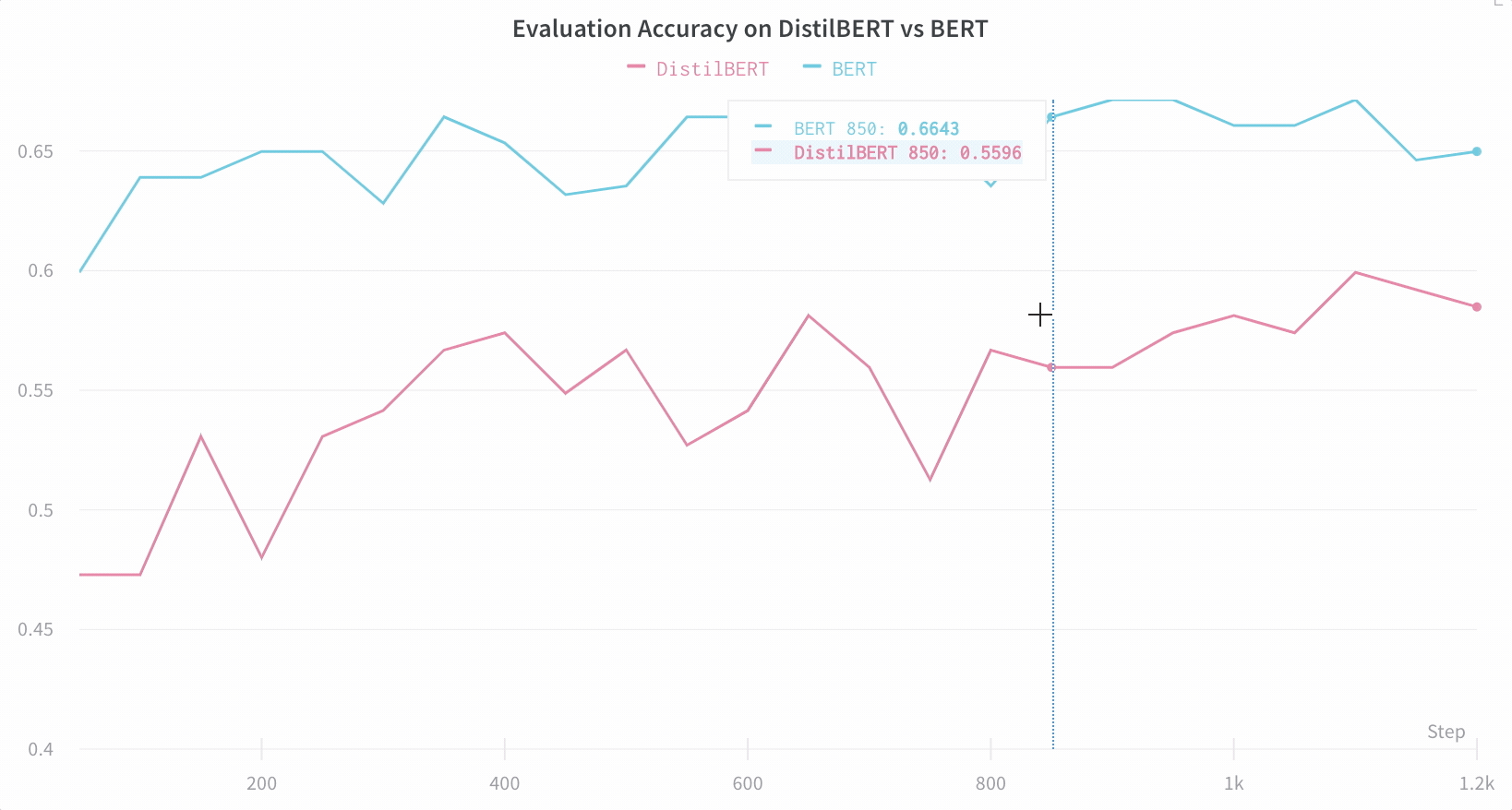
デフォルトで重要な情報を簡単に追跡
Weights & Biases は、 Experiment ごとに新しい run を保存します。デフォルトで保存される情報は次のとおりです。
- ハイパーパラメーター: モデルの Settings は Config に保存されます
- モデルメトリクス: ストリーミングされるメトリクスの時系列データは Log に保存されます
- ターミナルログ: コマンドライン出力が保存され、タブで利用できます
- システムメトリクス: GPU および CPU 使用率、メモリ、温度など
より詳しく知る
- ドキュメント: Weights & Biases と Hugging Face のインテグレーションに関するドキュメント
- ビデオ: チュートリアル、実践者とのインタビュー、および YouTube チャンネルのその他の情報
- お問い合わせ先: ご質問は contact@wandb.com までメッセージをお送りください
4 - TensorFlow
このノートブックの内容
- Weights & Biases と TensorFlow パイプラインを簡単に統合して、 実験管理 を行います。
keras.metricsでメトリクスを計算しますwandb.logを使用して、カスタムトレーニングループでこれらのメトリクスを記録します。
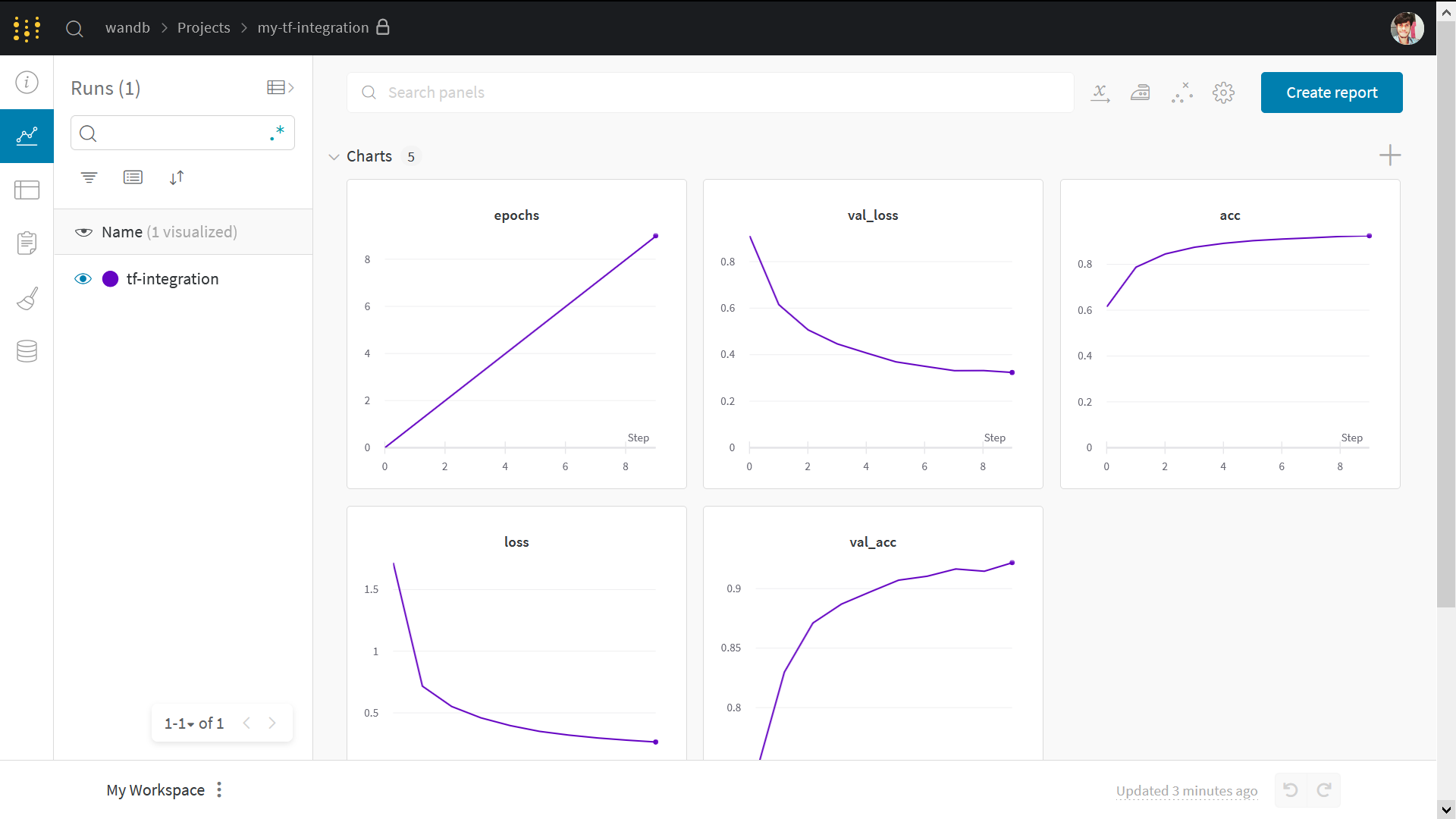
注意: Step で始まるセクションは、既存のコードに W&B を統合するために必要なものです。残りは標準的な MNIST の例です。
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import cifar10
インストール、インポート、ログイン
W&B のインストール
%%capture
!pip install wandb
W&B のインポートとログイン
import wandb
from wandb.integration.keras import WandbMetricsLogger
wandb.login()
補足: W&B を初めて使用する場合、またはログインしていない場合は、
wandb.login()の実行後に表示されるリンクからサインアップ/ログインページに移動します。サインアップはワンクリックで簡単に行えます。
データセットの準備
# トレーニングデータセットの準備
BATCH_SIZE = 64
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = np.reshape(x_train, (-1, 784))
x_test = np.reshape(x_test, (-1, 784))
# tf.data を使用して入力パイプラインを構築
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(BATCH_SIZE)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(BATCH_SIZE)
モデルとトレーニングループの定義
def make_model():
inputs = keras.Input(shape=(784,), name="digits")
x1 = keras.layers.Dense(64, activation="relu")(inputs)
x2 = keras.layers.Dense(64, activation="relu")(x1)
outputs = keras.layers.Dense(10, name="predictions")(x2)
return keras.Model(inputs=inputs, outputs=outputs)
def train_step(x, y, model, optimizer, loss_fn, train_acc_metric):
with tf.GradientTape() as tape:
logits = model(x, training=True)
loss_value = loss_fn(y, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return loss_value
def test_step(x, y, model, loss_fn, val_acc_metric):
val_logits = model(x, training=False)
loss_value = loss_fn(y, val_logits)
val_acc_metric.update_state(y, val_logits)
return loss_value
トレーニングループに wandb.log を追加
def train(
train_dataset,
val_dataset,
model,
optimizer,
train_acc_metric,
val_acc_metric,
epochs=10,
log_step=200,
val_log_step=50,
):
for epoch in range(epochs):
print("\nStart of epoch %d" % (epoch,))
train_loss = []
val_loss = []
# データセットのバッチを反復処理します
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
loss_value = train_step(
x_batch_train,
y_batch_train,
model,
optimizer,
loss_fn,
train_acc_metric,
)
train_loss.append(float(loss_value))
# 各エポックの最後に検証ループを実行します
for step, (x_batch_val, y_batch_val) in enumerate(val_dataset):
val_loss_value = test_step(
x_batch_val, y_batch_val, model, loss_fn, val_acc_metric
)
val_loss.append(float(val_loss_value))
# 各エポックの最後にメトリクスを表示します
train_acc = train_acc_metric.result()
print("Training acc over epoch: %.4f" % (float(train_acc),))
val_acc = val_acc_metric.result()
print("Validation acc: %.4f" % (float(val_acc),))
# 各エポックの最後にメトリクスをリセットします
train_acc_metric.reset_states()
val_acc_metric.reset_states()
# ⭐: wandb.log を使用してメトリクスを記録
wandb.log(
{
"epochs": epoch,
"loss": np.mean(train_loss),
"acc": float(train_acc),
"val_loss": np.mean(val_loss),
"val_acc": float(val_acc),
}
)
トレーニングの実行
wandb.init を呼び出して run を開始する
これにより、実験を開始したことが通知され、 固有の ID と ダッシュボード が提供されます。
# プロジェクト名とオプションで構成を使用して wandb を初期化します。
# 構成値をいろいろ試して、wandb ダッシュボードで結果を確認してください。
config = {
"learning_rate": 0.001,
"epochs": 10,
"batch_size": 64,
"log_step": 200,
"val_log_step": 50,
"architecture": "CNN",
"dataset": "CIFAR-10",
}
run = wandb.init(project='my-tf-integration', config=config)
config = run.config
# モデルを初期化します。
model = make_model()
# モデルをトレーニングするためのオプティマイザーをインスタンス化します。
optimizer = keras.optimizers.SGD(learning_rate=config.learning_rate)
# 損失関数をインスタンス化します。
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# メトリクスを準備します。
train_acc_metric = keras.metrics.SparseCategoricalAccuracy()
val_acc_metric = keras.metrics.SparseCategoricalAccuracy()
train(
train_dataset,
val_dataset,
model,
optimizer,
train_acc_metric,
val_acc_metric,
epochs=config.epochs,
log_step=config.log_step,
val_log_step=config.val_log_step,
)
run.finish() # Jupyter/Colab で、終了したことを知らせます!
結果の可視化
上記の run page リンクをクリックして、ライブ結果を確認してください。
Sweep 101
Weights & Biases Sweeps を使用して、ハイパーパラメーターの最適化を自動化し、可能なモデルの空間を探索します。
W&B Sweeps を使用した TensorFlow でのハイパーパラメーター最適化を確認する
W&B Sweeps を使用する利点
- 簡単なセットアップ: 数行のコードだけで W&B sweeps を実行できます。
- 透明性: 使用しているすべてのアルゴリズムを引用し、コードはオープンソースです。
- 強力: sweeps は完全にカスタマイズおよび構成可能です。数十台のマシンで sweep を起動できます。ラップトップで sweep を開始するのと同じくらい簡単です。
サンプルギャラリー
W&B で追跡および可視化された プロジェクト の例を、サンプルギャラリーでご覧ください。完全接続 →
ベストプラクティス
- Projects: 複数の runs を プロジェクト に記録して比較します。
wandb.init(project="project-name") - Groups: 複数の プロセス または 交差検証 folds の場合、各 プロセス を runs として記録し、それらをグループ化します。
wandb.init(group="experiment-1") - Tags: 現在の ベースライン または プロダクション モデル を追跡するために タグ を追加します。
- Notes: テーブルに ノート を入力して、runs 間の変更を追跡します。
- Reports: 同僚と共有するために進捗状況に関する簡単なメモを取り、ML プロジェクト の ダッシュボード と スナップショット を作成します。
高度な設定
5 - TensorFlow Sweeps
機械学習 の 実験管理 、 データセット の バージョン管理 、 プロジェクト の コラボレーション に W&B を 使用します。
W&B Sweeps を 使用して ハイパーパラメーター の 最適化 を 自動化し、インタラクティブな ダッシュボード で モデル の 可能性 を 探ります。
Sweeps を 使用する 理由
- クイックセットアップ: 数行の コード で W&B sweeps を 実行します。
- 透明性: プロジェクト では 使用されている すべての アルゴリズム が 引用されており、 コード は オープンソース です。
- 強力: Sweeps は カスタマイズ オプション を 提供し、複数 の マシン または ラップトップ で 簡単に 実行できます。
詳細については、 Sweep の ドキュメント を 参照してください。
この ノートブック で 説明する 内容
- TensorFlow で W&B Sweep と カスタム トレーニング ループ を 開始する 手順。
- 画像分類タスク に 最適な ハイパーパラメーター を 見つける。
注: Step で 始まる セクション は、 ハイパーパラメーター sweep を 実行するために 必要 な コード を 示しています。残りの 部分 は 簡単 な 例 を 設定します。
インストール、インポート、ログイン
W&B の インストール
pip install wandb
W&B の インポート と ログイン
import tqdm
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import cifar10
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import wandb
from wandb.integration.keras import WandbMetricsLogger
wandb.login()
wandb.login() を 実行した 後 の リンク は サインアップ / ログイン ページ に 移動します。データセット の 準備
# トレーニングデータセット の 準備
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
x_train = np.reshape(x_train, (-1, 784))
x_test = np.reshape(x_test, (-1, 784))
分類器 MLP の 構築
def Model():
inputs = keras.Input(shape=(784,), name="digits")
x1 = keras.layers.Dense(64, activation="relu")(inputs)
x2 = keras.layers.Dense(64, activation="relu")(x1)
outputs = keras.layers.Dense(10, name="predictions")(x2)
return keras.Model(inputs=inputs, outputs=outputs)
def train_step(x, y, model, optimizer, loss_fn, train_acc_metric):
with tf.GradientTape() as tape:
logits = model(x, training=True)
loss_value = loss_fn(y, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return loss_value
def test_step(x, y, model, loss_fn, val_acc_metric):
val_logits = model(x, training=False)
loss_value = loss_fn(y, val_logits)
val_acc_metric.update_state(y, val_logits)
return loss_value
トレーニング ループ の 作成
def train(
train_dataset,
val_dataset,
model,
optimizer,
loss_fn,
train_acc_metric,
val_acc_metric,
epochs=10,
log_step=200,
val_log_step=50,
):
for epoch in range(epochs):
print("\nStart of epoch %d" % (epoch,))
train_loss = []
val_loss = []
# データセット の バッチ を 反復処理します
for step, (x_batch_train, y_batch_train) in tqdm.tqdm(
enumerate(train_dataset), total=len(train_dataset)
):
loss_value = train_step(
x_batch_train,
y_batch_train,
model,
optimizer,
loss_fn,
train_acc_metric,
)
train_loss.append(float(loss_value))
# 各 エポック の 最後に 検証 ループ を 実行します
for step, (x_batch_val, y_batch_val) in enumerate(val_dataset):
val_loss_value = test_step(
x_batch_val, y_batch_val, model, loss_fn, val_acc_metric
)
val_loss.append(float(val_loss_value))
# 各 エポック の 最後に メトリクス を 表示します
train_acc = train_acc_metric.result()
print("Training acc over epoch: %.4f" % (float(train_acc),))
val_acc = val_acc_metric.result()
print("Validation acc: %.4f" % (float(val_acc),))
# 各 エポック の 最後に メトリクス を リセットします
train_acc_metric.reset_states()
val_acc_metric.reset_states()
# 3️⃣ wandb.log を 使用して メトリクス を ログ に 記録します
wandb.log(
{
"epochs": epoch,
"loss": np.mean(train_loss),
"acc": float(train_acc),
"val_loss": np.mean(val_loss),
"val_acc": float(val_acc),
}
)
sweep の 設定
sweep を 設定する 手順:
- 最適化する ハイパーパラメーター を 定義します
- 最適化 method を 選択します:
random、grid、またはbayes bayesの 目標 と メトリクス を 設定します (例:val_lossの 最小化)- 実行 を 早期 に 終了させるには、
hyperbandを 使用します
詳細については、 W&B Sweeps の ドキュメント を 参照してください。
sweep_config = {
"method": "random",
"metric": {"name": "val_loss", "goal": "minimize"},
"early_terminate": {"type": "hyperband", "min_iter": 5},
"parameters": {
"batch_size": {"values": [32, 64, 128, 256]},
"learning_rate": {"values": [0.01, 0.005, 0.001, 0.0005, 0.0001]},
},
}
トレーニング ループ の ラップ
train を 呼び出す 前 に wandb.config を 使用して ハイパーパラメーター を 設定する sweep_train の よう な 関数 を 作成します。
def sweep_train(config_defaults=None):
# デフォルト値 の 設定
config_defaults = {"batch_size": 64, "learning_rate": 0.01}
# サンプル プロジェクト名 で wandb を 初期化します
wandb.init(config=config_defaults) # これは Sweep で 上書きされます
# 他の ハイパーパラメーター を 設定 (存在する場合)
wandb.config.epochs = 2
wandb.config.log_step = 20
wandb.config.val_log_step = 50
wandb.config.architecture_name = "MLP"
wandb.config.dataset_name = "MNIST"
# tf.data を 使用して 入力 パイプライン を 構築します
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = (
train_dataset.shuffle(buffer_size=1024)
.batch(wandb.config.batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(wandb.config.batch_size).prefetch(
buffer_size=tf.data.AUTOTUNE
)
# モデル の 初期化
model = Model()
# モデル を トレーニング する ため に オプティマイザー を インスタンス化します。
optimizer = keras.optimizers.SGD(learning_rate=wandb.config.learning_rate)
# 損失関数 を インスタンス化します。
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# メトリクス を 準備します。
train_acc_metric = keras.metrics.SparseCategoricalAccuracy()
val_acc_metric = keras.metrics.SparseCategoricalAccuracy()
train(
train_dataset,
val_dataset,
model,
optimizer,
loss_fn,
train_acc_metric,
val_acc_metric,
epochs=wandb.config.epochs,
log_step=wandb.config.log_step,
val_log_step=wandb.config.val_log_step,
)
sweep の 初期化 と パーソナル デジタル アシスタント の 実行
sweep_id = wandb.sweep(sweep_config, project="sweeps-tensorflow")
count パラメータ で 実行 の 数 を 制限します。クイック 実行 の 場合 は 10 に 設定します。必要 に 応じて 増やします。
wandb.agent(sweep_id, function=sweep_train, count=10)
結果 の 可視化
ライブ結果 を 表示する に は、 前 の Sweep URL リンク を クリックします。
例 の ギャラリー
ギャラリー で W&B で トラッキング および 可視化 され た プロジェクト を 探索します。
ベストプラクティス
- Projects: 複数 の run を プロジェクト に 記録して 比較します。
wandb.init(project="project-name") - Groups: 複数 の プロセス または 交差検証 フォールド の run として 各 プロセス を ログ に 記録し、それら を グループ化します。
wandb.init(group='experiment-1') - Tags: タグ を 使用して、 ベースライン または プロダクション モデル を 追跡します。
- Notes: テーブル に ノート を 入力して、run 間 の 変更 を 追跡します。
- Reports: Reports を 使用して、進捗状況 の メモ、同僚 と の 共有、ML プロジェクト の ダッシュボード と スナップショット の 作成 を 行います。
高度 な 設定
6 - 3D brain tumor segmentation with MONAI
このチュートリアルでは、MONAI を使用してマルチラベル 3D 脳腫瘍セグメンテーションタスクのトレーニング ワークフローを構築し、Weights & Biases の 実験管理 および データ可視化 機能を使用する方法を説明します。このチュートリアルには、次の機能が含まれています。
- Weights & Biases の run を初期化し、再現性のために run に関連付けられたすべての構成を同期します。
- MONAI transform API:
- 辞書形式のデータに対する MONAI Transforms。
- MONAI
transformsAPI に従って新しい transform を定義する方法。 - データ拡張のために強度をランダムに調整する方法。
- データのロードと可視化:
- メタデータ付きの
Nifti画像をロードし、画像のリストをロードしてスタックします。 - トレーニングと検証を高速化するために IO と transform をキャッシュします。
wandb.Tableと Weights & Biases 上のインタラクティブなセグメンテーション オーバーレイを使用してデータを可視化します。
- メタデータ付きの
- 3D
SegResNetモデルのトレーニング- MONAI の
networks、losses、およびmetricsAPI を使用します。 - PyTorch トレーニング ループを使用して 3D
SegResNetモデルをトレーニングします。 - Weights & Biases を使用してトレーニングの experiment を追跡します。
- モデルの チェックポイント を Weights & Biases 上の モデル Artifacts としてログに記録し、バージョン管理します。
- MONAI の
wandb.Tableと Weights & Biases 上のインタラクティブなセグメンテーション オーバーレイを使用して、検証データセットの 予測 を可視化して比較します。
セットアップとインストール
まず、MONAI と Weights & Biases の両方の最新バージョンをインストールします。
!python -c "import monai" || pip install -q -U "monai[nibabel, tqdm]"
!python -c "import wandb" || pip install -q -U wandb
import os
import numpy as np
from tqdm.auto import tqdm
import wandb
from monai.apps import DecathlonDataset
from monai.data import DataLoader, decollate_batch
from monai.losses import DiceLoss
from monai.inferers import sliding_window_inference
from monai.metrics import DiceMetric
from monai.networks.nets import SegResNet
from monai.transforms import (
Activations,
AsDiscrete,
Compose,
LoadImaged,
MapTransform,
NormalizeIntensityd,
Orientationd,
RandFlipd,
RandScaleIntensityd,
RandShiftIntensityd,
RandSpatialCropd,
Spacingd,
EnsureTyped,
EnsureChannelFirstd,
)
from monai.utils import set_determinism
import torch
次に、W&B を使用するために Colab インスタンスを認証します。
wandb.login()
W&B Run の初期化
新しい W&B run を開始して experiment の追跡を開始します。
wandb.init(project="monai-brain-tumor-segmentation")
適切な構成システムの使用は、再現性のある 機械学習 の推奨されるベスト プラクティスです。W&B を使用して、すべての experiment の ハイパーパラメーター を追跡できます。
config = wandb.config
config.seed = 0
config.roi_size = [224, 224, 144]
config.batch_size = 1
config.num_workers = 4
config.max_train_images_visualized = 20
config.max_val_images_visualized = 20
config.dice_loss_smoothen_numerator = 0
config.dice_loss_smoothen_denominator = 1e-5
config.dice_loss_squared_prediction = True
config.dice_loss_target_onehot = False
config.dice_loss_apply_sigmoid = True
config.initial_learning_rate = 1e-4
config.weight_decay = 1e-5
config.max_train_epochs = 50
config.validation_intervals = 1
config.dataset_dir = "./dataset/"
config.checkpoint_dir = "./checkpoints"
config.inference_roi_size = (128, 128, 64)
config.max_prediction_images_visualized = 20
また、モジュールのランダム シードを設定して、確定的トレーニングを有効または無効にする必要もあります。
set_determinism(seed=config.seed)
# ディレクトリを作成する
os.makedirs(config.dataset_dir, exist_ok=True)
os.makedirs(config.checkpoint_dir, exist_ok=True)
データのロードと変換
ここでは、monai.transforms API を使用して、マルチクラス ラベルを one-hot 形式のマルチラベル セグメンテーション タスクに変換するカスタム transform を作成します。
class ConvertToMultiChannelBasedOnBratsClassesd(MapTransform):
"""
brats クラスに基づいてラベルをマルチ チャンネルに変換します:
label 1 は周囲浮腫です
label 2 は GD 増強腫瘍です
label 3 は壊死性および非増強性腫瘍コアです
可能なクラスは TC (腫瘍コア)、WT (全腫瘍) および ET (増強腫瘍) です。
参考: https://github.com/Project-MONAI/tutorials/blob/main/3d_segmentation/brats_segmentation_3d.ipynb
"""
def __call__(self, data):
d = dict(data)
for key in self.keys:
result = []
# label 2 と label 3 をマージして TC を構築する
result.append(torch.logical_or(d[key] == 2, d[key] == 3))
# labels 1、2、3 をマージして WT を構築する
result.append(
torch.logical_or(
torch.logical_or(d[key] == 2, d[key] == 3), d[key] == 1
)
)
# label 2 は ET です
result.append(d[key] == 2)
d[key] = torch.stack(result, axis=0).float()
return d
次に、トレーニング データセットと検証データセットの transform をそれぞれ設定します。
train_transform = Compose(
[
# 4 つの Nifti 画像をロードして一緒にスタックする
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys="image"),
EnsureTyped(keys=["image", "label"]),
ConvertToMultiChannelBasedOnBratsClassesd(keys="label"),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(
keys=["image", "label"],
pixdim=(1.0, 1.0, 1.0),
mode=("bilinear", "nearest"),
),
RandSpatialCropd(
keys=["image", "label"], roi_size=config.roi_size, random_size=False
),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=0),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=1),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=2),
NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True),
RandScaleIntensityd(keys="image", factors=0.1, prob=1.0),
RandShiftIntensityd(keys="image", offsets=0.1, prob=1.0),
]
)
val_transform = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys="image"),
EnsureTyped(keys=["image", "label"]),
ConvertToMultiChannelBasedOnBratsClassesd(keys="label"),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(
keys=["image", "label"],
pixdim=(1.0, 1.0, 1.0),
mode=("bilinear", "nearest"),
),
NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True),
]
)
データセット
この experiment に使用される データセット は、http://medicaldecathlon.com/ から提供されています。マルチモーダル マルチサイト MRI データ (FLAIR、T1w、T1gd、T2w) を使用して、グリオーマ、壊死/活性腫瘍、および浮腫をセグメント化します。データセット は、750 個の 4D ボリューム (484 トレーニング + 266 テスト) で構成されています。
DecathlonDataset を使用して、 データセット を自動的にダウンロードして抽出します。これは、MONAI CacheDataset を継承しており、cache_num=N を設定してトレーニング用に N 個のアイテムをキャッシュし、メモリ サイズに応じて、デフォルトの 引数 を使用して検証用にすべてのアイテムをキャッシュできます。
train_dataset = DecathlonDataset(
root_dir=config.dataset_dir,
task="Task01_BrainTumour",
transform=val_transform,
section="training",
download=True,
cache_rate=0.0,
num_workers=4,
)
val_dataset = DecathlonDataset(
root_dir=config.dataset_dir,
task="Task01_BrainTumour",
transform=val_transform,
section="validation",
download=False,
cache_rate=0.0,
num_workers=4,
)
train_transform を train_dataset に適用する代わりに、val_transform をトレーニング データセット と 検証 データセット の両方に適用します。これは、トレーニングの前に、 データセット の両方の分割から サンプル を 可視化 するためです。データセット の可視化
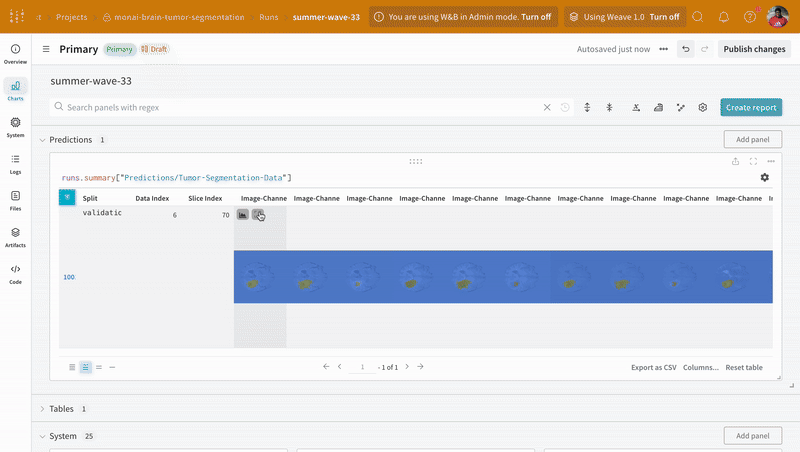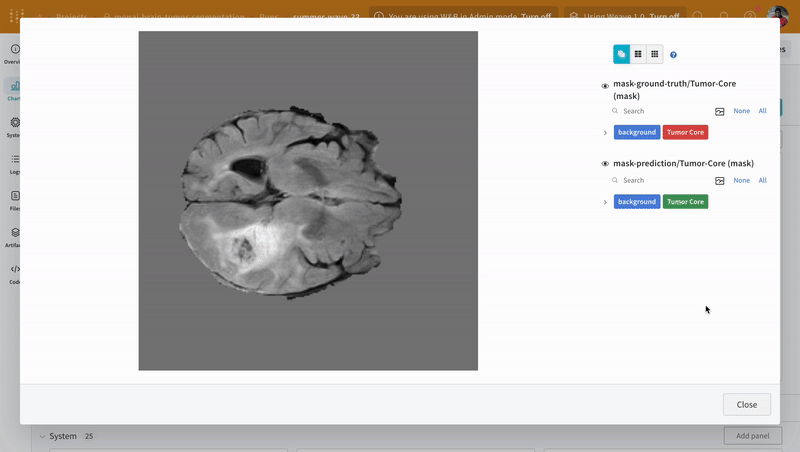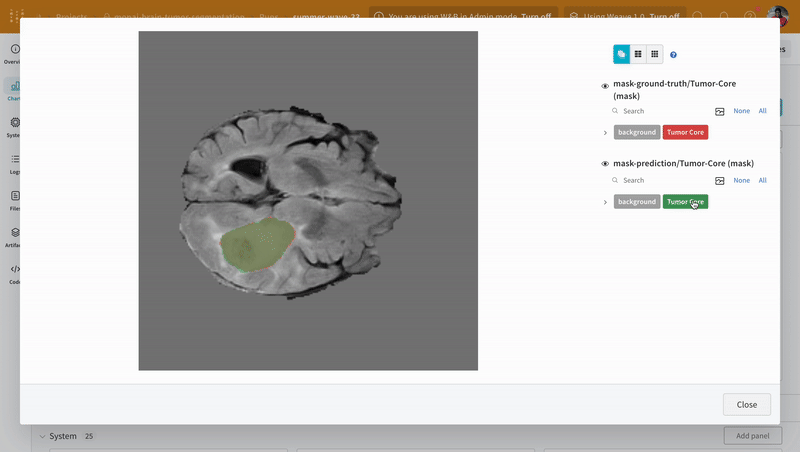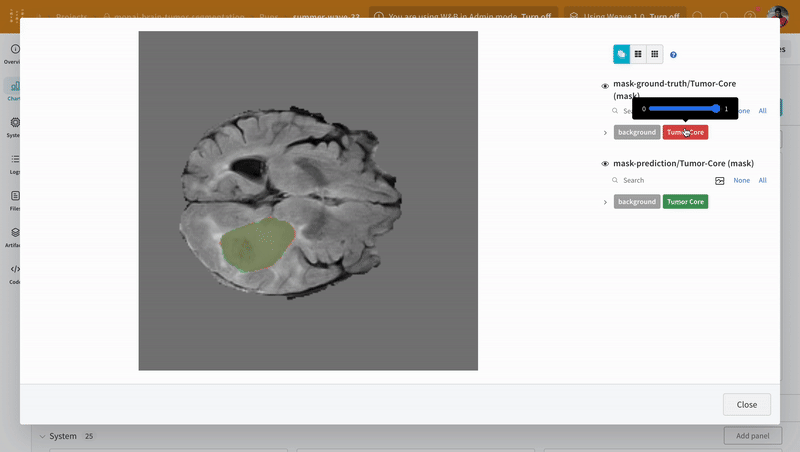
Weights & Biases は、画像、ビデオ、オーディオなどをサポートしています。リッチ メディアをログに記録して 結果 を調査し、run、モデル、および データセット を視覚的に比較できます。セグメンテーション マスク オーバーレイ システム を使用して、データ ボリュームを可視化します。Tables でセグメンテーション マスクをログに記録するには、テーブル の各行に wandb.Image オブジェクトを指定する必要があります。
次に、疑似コードの例を示します。
table = wandb.Table(columns=["ID", "Image"])
for id, img, label in zip(ids, images, labels):
mask_img = wandb.Image(
img,
masks={
"prediction": {"mask_data": label, "class_labels": class_labels}
# ...
},
)
table.add_data(id, img)
wandb.log({"Table": table})
次に、サンプル画像、ラベル、wandb.Table オブジェクト、および関連するメタデータを受け取り、Weights & Biases ダッシュボードにログに記録されるテーブル の行に入力する簡単なユーティリティ関数を作成します。
def log_data_samples_into_tables(
sample_image: np.array,
sample_label: np.array,
split: str = None,
data_idx: int = None,
table: wandb.Table = None,
):
num_channels, _, _, num_slices = sample_image.shape
with tqdm(total=num_slices, leave=False) as progress_bar:
for slice_idx in range(num_slices):
ground_truth_wandb_images = []
for channel_idx in range(num_channels):
ground_truth_wandb_images.append(
masks = {
"ground-truth/Tumor-Core": {
"mask_data": sample_label[0, :, :, slice_idx],
"class_labels": {0: "background", 1: "Tumor Core"},
},
"ground-truth/Whole-Tumor": {
"mask_data": sample_label[1, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Whole Tumor"},
},
"ground-truth/Enhancing-Tumor": {
"mask_data": sample_label[2, :, :, slice_idx] * 3,
"class_labels": {0: "background", 3: "Enhancing Tumor"},
},
}
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks=masks,
)
)
table.add_data(split, data_idx, slice_idx, *ground_truth_wandb_images)
progress_bar.update(1)
return table
次に、wandb.Table オブジェクトと、データ可視化で入力できるようにするために構成される 列 を定義します。
table = wandb.Table(
columns=[
"Split",
"Data Index",
"Slice Index",
"Image-Channel-0",
"Image-Channel-1",
"Image-Channel-2",
"Image-Channel-3",
]
)
次に、train_dataset と val_dataset をそれぞれループして、データ サンプル の 可視化 を生成し、ダッシュボード にログに記録するテーブル の行に入力します。
# train_dataset の 可視化 を生成する
max_samples = (
min(config.max_train_images_visualized, len(train_dataset))
if config.max_train_images_visualized > 0
else len(train_dataset)
)
progress_bar = tqdm(
enumerate(train_dataset[:max_samples]),
total=max_samples,
desc="トレーニング データセット の 可視化 を生成しています:",
)
for data_idx, sample in progress_bar:
sample_image = sample["image"].detach().cpu().numpy()
sample_label = sample["label"].detach().cpu().numpy()
table = log_data_samples_into_tables(
sample_image,
sample_label,
split="train",
data_idx=data_idx,
table=table,
)
# val_dataset の 可視化 を生成する
max_samples = (
min(config.max_val_images_visualized, len(val_dataset))
if config.max_val_images_visualized > 0
else len(val_dataset)
)
progress_bar = tqdm(
enumerate(val_dataset[:max_samples]),
total=max_samples,
desc="検証 データセット の 可視化 を生成しています:",
)
for data_idx, sample in progress_bar:
sample_image = sample["image"].detach().cpu().numpy()
sample_label = sample["label"].detach().cpu().numpy()
table = log_data_samples_into_tables(
sample_image,
sample_label,
split="val",
data_idx=data_idx,
table=table,
)
# テーブル をダッシュボードにログに記録する
wandb.log({"Tumor-Segmentation-Data": table})
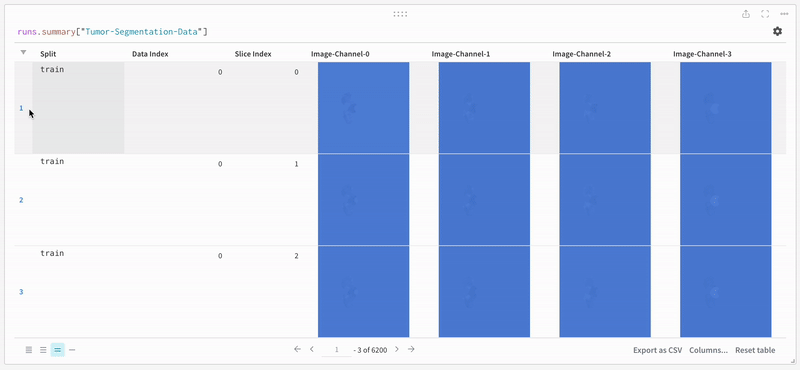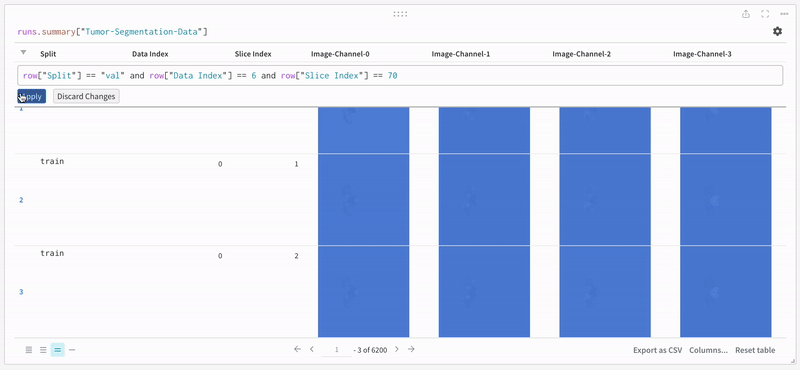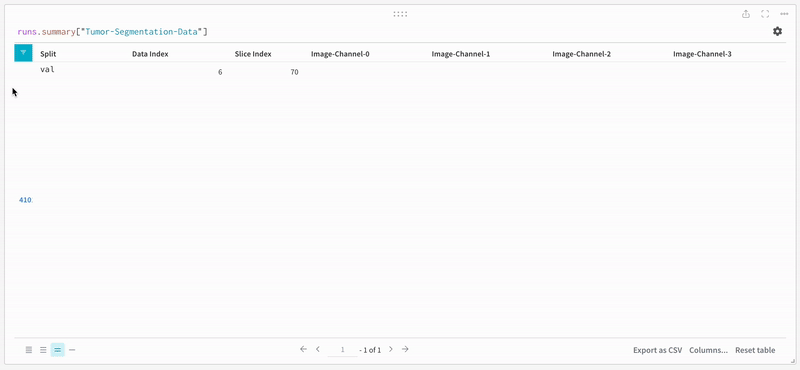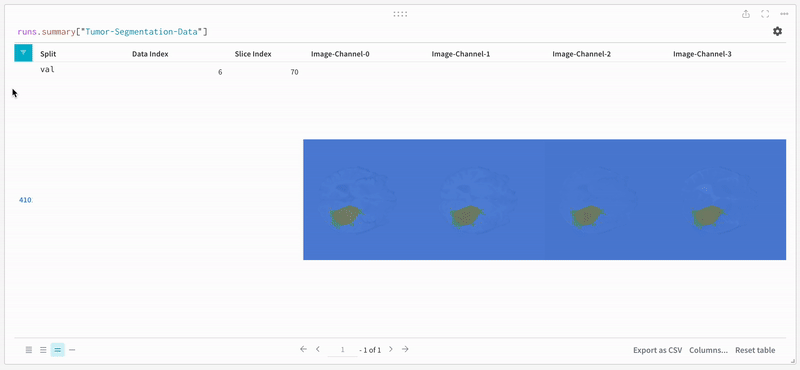
データ は、インタラクティブなテーブル形式で W&B ダッシュボード に表示されます。各行にそれぞれのセグメンテーション マスク がオーバーレイされたデータ ボリュームの特定の スライス の各 チャンネル を確認できます。Weave クエリ を記述して、テーブル のデータをフィルタリングし、特定の 1 つの行に焦点を当てることができます。
 |
|---|
| ログに記録されたテーブル データの例。 |
画像を開き、インタラクティブなオーバーレイを使用して各セグメンテーション マスク を操作する方法を確認します。
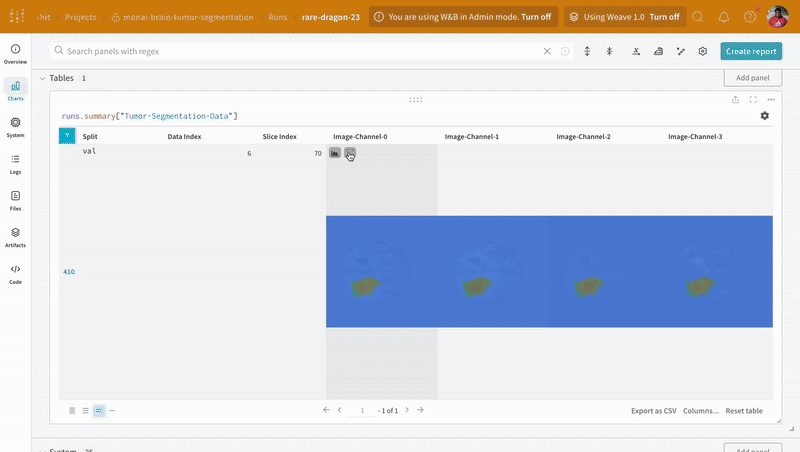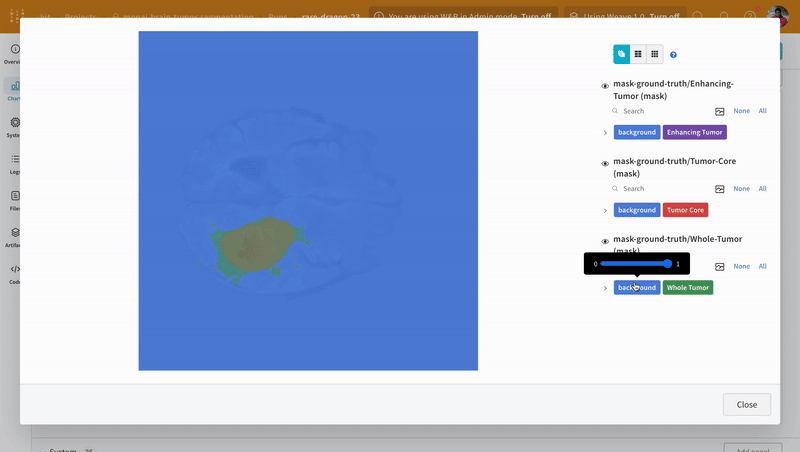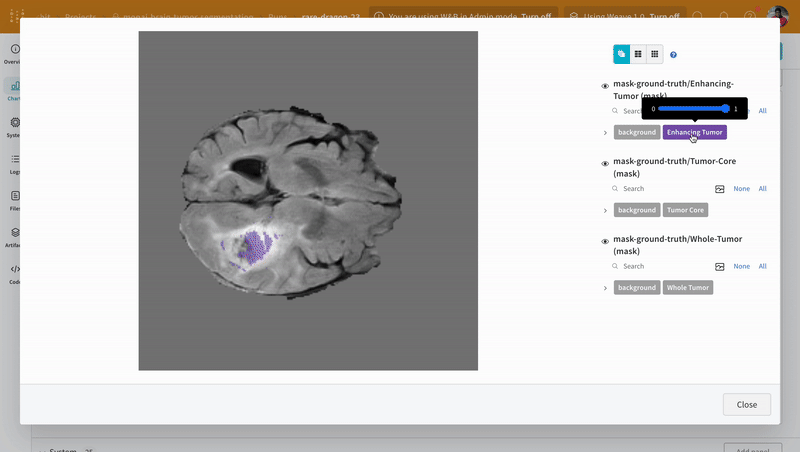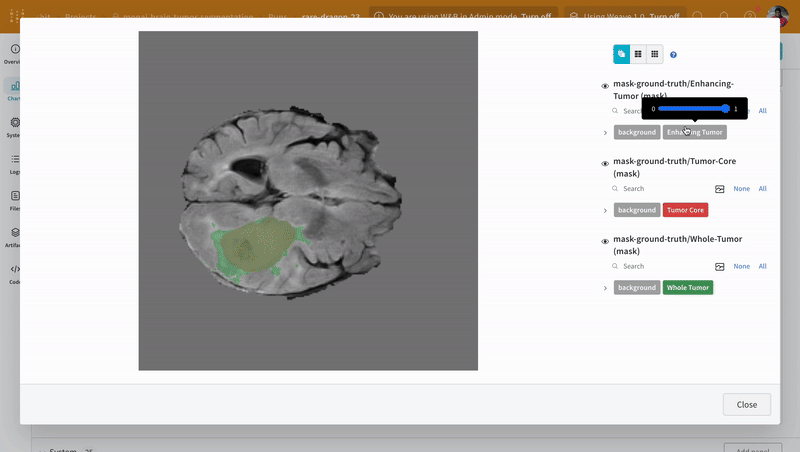 |
|---|
| 可視化されたセグメンテーション マップ の例。 |
データのロード
データセット からデータをロードするために、PyTorch DataLoaders を作成します。DataLoaders を作成する前に、トレーニング用にデータを事前処理および変換するために、train_dataset の transform を train_transform に設定します。
# train_transforms をトレーニング データセット に適用する
train_dataset.transform = train_transform
# train_loader を作成する
train_loader = DataLoader(
train_dataset,
batch_size=config.batch_size,
shuffle=True,
num_workers=config.num_workers,
)
# val_loader を作成する
val_loader = DataLoader(
val_dataset,
batch_size=config.batch_size,
shuffle=False,
num_workers=config.num_workers,
)
モデル、損失、および オプティマイザー の作成
このチュートリアルでは、論文 自動エンコーダー正則化を使用した 3D MRI 脳腫瘍セグメンテーション に基づいて SegResNet モデルを作成します。SegResNet モデルは、monai.networks API の一部として PyTorch モジュールとして実装され、 オプティマイザー と 学習率 スケジューラ も実装されています。
device = torch.device("cuda:0")
# モデルを作成する
model = SegResNet(
blocks_down=[1, 2, 2, 4],
blocks_up=[1, 1, 1],
init_filters=16,
in_channels=4,
out_channels=3,
dropout_prob=0.2,
).to(device)
# オプティマイザー を作成する
optimizer = torch.optim.Adam(
model.parameters(),
config.initial_learning_rate,
weight_decay=config.weight_decay,
)
# 学習率 スケジューラ を作成する
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=config.max_train_epochs
)
monai.losses API を使用して損失をマルチラベル DiceLoss として定義し、monai.metrics API を使用して対応する dice メトリクスを定義します。
loss_function = DiceLoss(
smooth_nr=config.dice_loss_smoothen_numerator,
smooth_dr=config.dice_loss_smoothen_denominator,
squared_pred=config.dice_loss_squared_prediction,
to_onehot_y=config.dice_loss_target_onehot,
sigmoid=config.dice_loss_apply_sigmoid,
)
dice_metric = DiceMetric(include_background=True, reduction="mean")
dice_metric_batch = DiceMetric(include_background=True, reduction="mean_batch")
post_trans = Compose([Activations(sigmoid=True), AsDiscrete(threshold=0.5)])
# 自動混合精度を使用してトレーニングを高速化する
scaler = torch.cuda.amp.GradScaler()
torch.backends.cudnn.benchmark = True
混合精度推論用の小さなユーティリティを定義します。これは、トレーニング プロセスの検証ステップ中、およびトレーニング後にモデルを実行する場合に役立ちます。
def inference(model, input):
def _compute(input):
return sliding_window_inference(
inputs=input,
roi_size=(240, 240, 160),
sw_batch_size=1,
predictor=model,
overlap=0.5,
)
with torch.cuda.amp.autocast():
return _compute(input)
トレーニングと検証
トレーニングの前に、トレーニング および 検証 experiment を追跡するために、後で wandb.log() でログに記録される メトリクス プロパティを定義します。
wandb.define_metric("epoch/epoch_step")
wandb.define_metric("epoch/*", step_metric="epoch/epoch_step")
wandb.define_metric("batch/batch_step")
wandb.define_metric("batch/*", step_metric="batch/batch_step")
wandb.define_metric("validation/validation_step")
wandb.define_metric("validation/*", step_metric="validation/validation_step")
batch_step = 0
validation_step = 0
metric_values = []
metric_values_tumor_core = []
metric_values_whole_tumor = []
metric_values_enhanced_tumor = []
標準的な PyTorch トレーニング ループを実行する
# W&B Artifact オブジェクトを定義する
artifact = wandb.Artifact(
name=f"{wandb.run.id}-checkpoint", type="model"
)
epoch_progress_bar = tqdm(range(config.max_train_epochs), desc="トレーニング:")
for epoch in epoch_progress_bar:
model.train()
epoch_loss = 0
total_batch_steps = len(train_dataset) // train_loader.batch_size
batch_progress_bar = tqdm(train_loader, total=total_batch_steps, leave=False)
# トレーニング ステップ
for batch_data in batch_progress_bar:
inputs, labels = (
batch_data["image"].to(device),
batch_data["label"].to(device),
)
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = loss_function(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
epoch_loss += loss.item()
batch_progress_bar.set_description(f"train_loss: {loss.item():.4f}:")
## バッチごとのトレーニング損失を W&B にログに記録する
wandb.log({"batch/batch_step": batch_step, "batch/train_loss": loss.item()})
batch_step += 1
lr_scheduler.step()
epoch_loss /= total_batch_steps
## バッチごとのトレーニング損失と 学習率 を W&B にログに記録する
wandb.log(
{
"epoch/epoch_step": epoch,
"epoch/mean_train_loss": epoch_loss,
"epoch/learning_rate": lr_scheduler.get_last_lr()[0],
}
)
epoch_progress_bar.set_description(f"トレーニング: train_loss: {epoch_loss:.4f}:")
# 検証と モデル チェックポイント ステップ
if (epoch + 1) % config.validation_intervals == 0:
model.eval()
with torch.no_grad():
for val_data in val_loader:
val_inputs, val_labels = (
val_data["image"].to(device),
val_data["label"].to(device),
)
val_outputs = inference(model, val_inputs)
val_outputs = [post_trans(i) for i in decollate_batch(val_outputs)]
dice_metric(y_pred=val_outputs, y=val_labels)
dice_metric_batch(y_pred=val_outputs, y=val_labels)
metric_values.append(dice_metric.aggregate().item())
metric_batch = dice_metric_batch.aggregate()
metric_values_tumor_core.append(metric_batch[0].item())
metric_values_whole_tumor.append(metric_batch[1].item())
metric_values_enhanced_tumor.append(metric_batch[2].item())
dice_metric.reset()
dice_metric_batch.reset()
checkpoint_path = os.path.join(config.checkpoint_dir, "model.pth")
torch.save(model.state_dict(), checkpoint_path)
# W&B Artifacts を使用して モデル チェックポイント をログに記録し、バージョン管理する。
artifact.add_file(local_path=checkpoint_path)
wandb.log_artifact(artifact, aliases=[f"epoch_{epoch}"])
# 検証 メトリクス を W&B ダッシュボード にログに記録する。
wandb.log(
{
"validation/validation_step": validation_step,
"validation/mean_dice": metric_values[-1],
"validation/mean_dice_tumor_core": metric_values_tumor_core[-1],
"validation/mean_dice_whole_tumor": metric_values_whole_tumor[-1],
"validation/mean_dice_enhanced_tumor": metric_values_enhanced_tumor[-1],
}
)
validation_step += 1
# この Artifact がログ記録を完了するまで待機する
artifact.wait()
wandb.log でコードをインストルメント化すると、トレーニング および 検証 プロセスに関連付けられたすべての メトリクス だけでなく、W&B ダッシュボード 上のすべてのシステム メトリクス (この場合は CPU と GPU) も追跡できます。
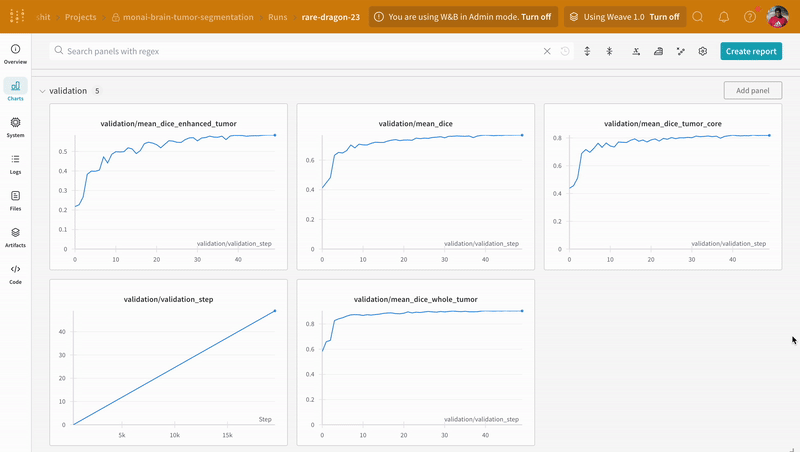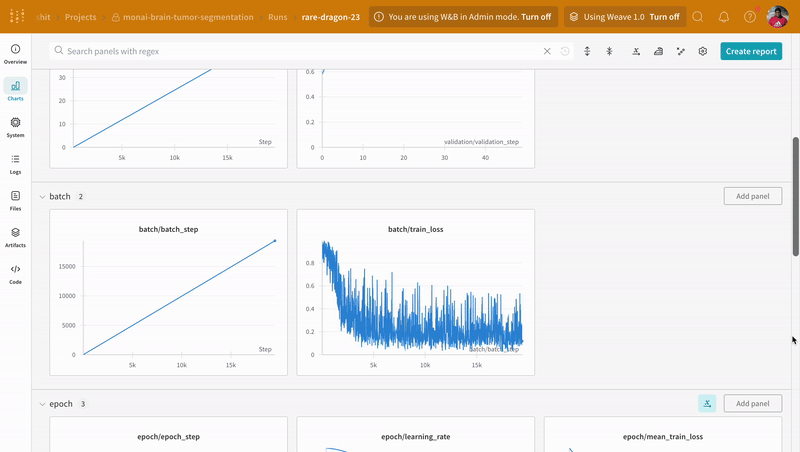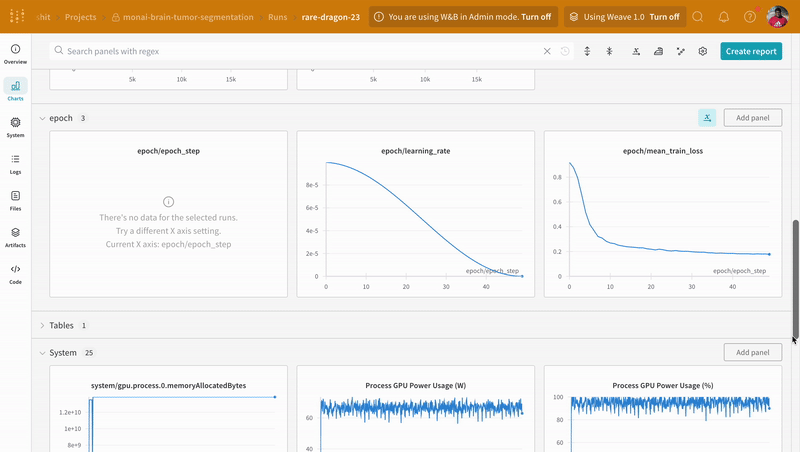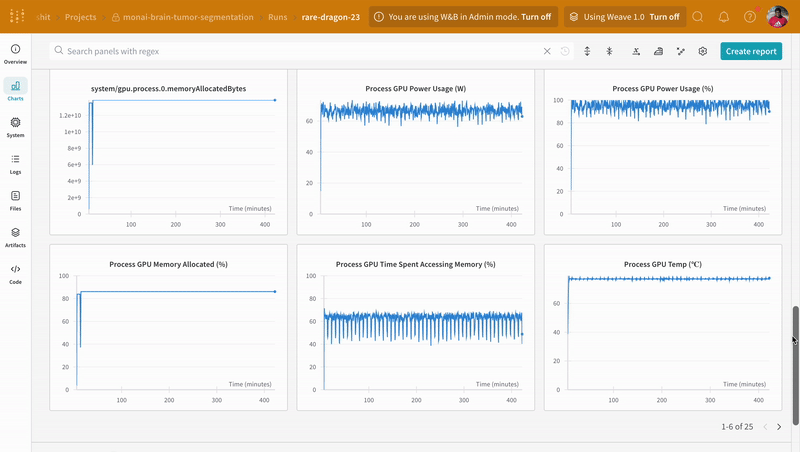 |
|---|
| W&B でのトレーニング および 検証 プロセスの追跡の例。 |
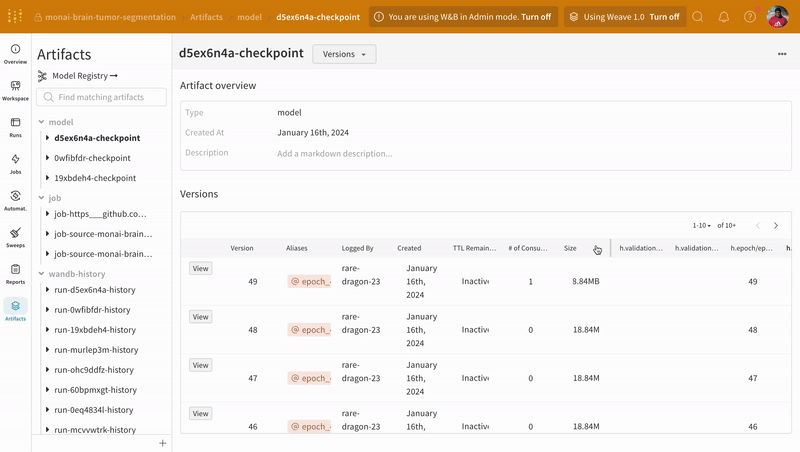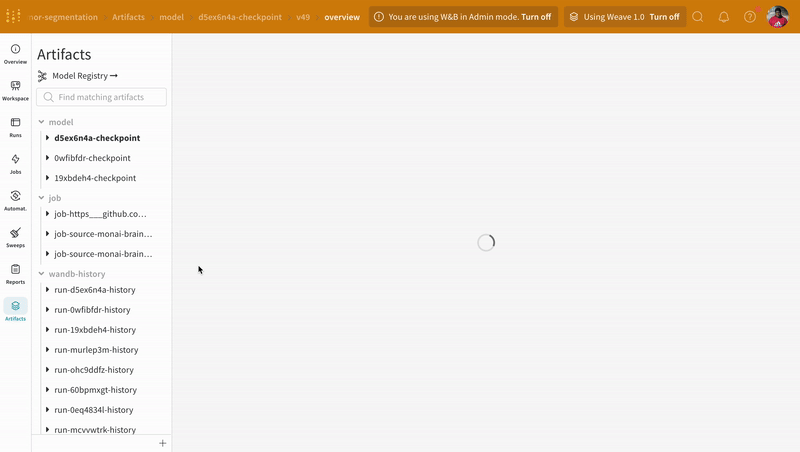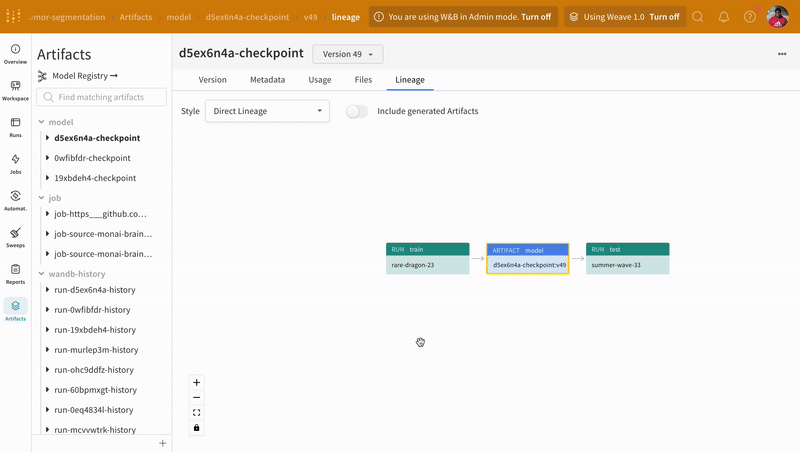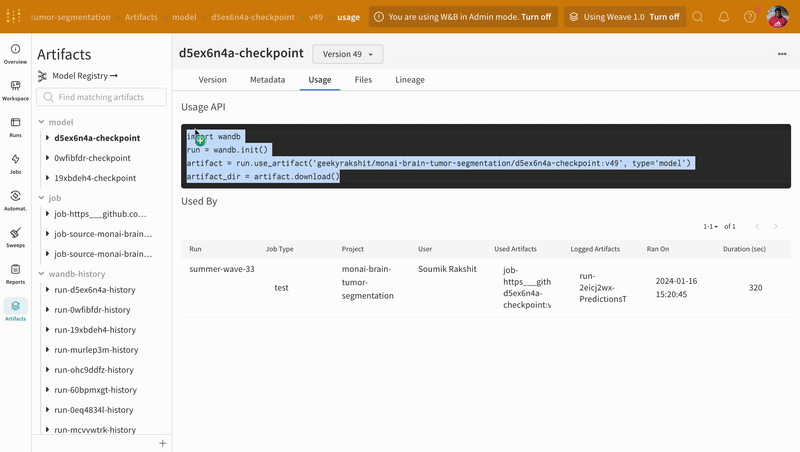
W&B run ダッシュボード の Artifacts タブに移動して、トレーニング 中にログに記録された モデル チェックポイント Artifacts のさまざまな バージョン にアクセスします。
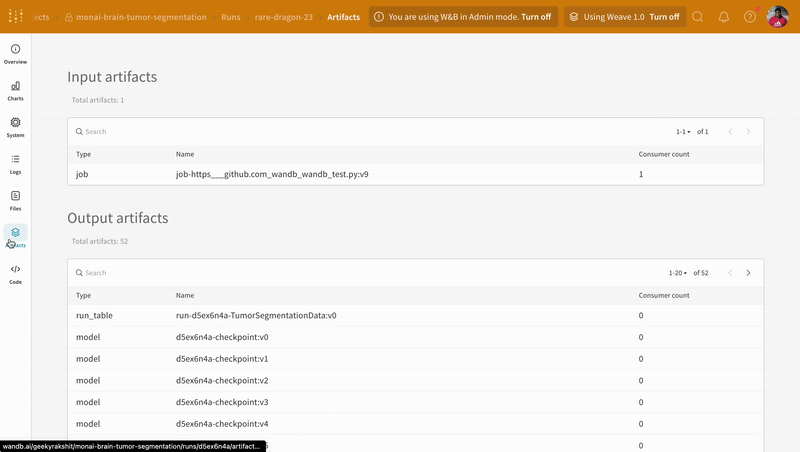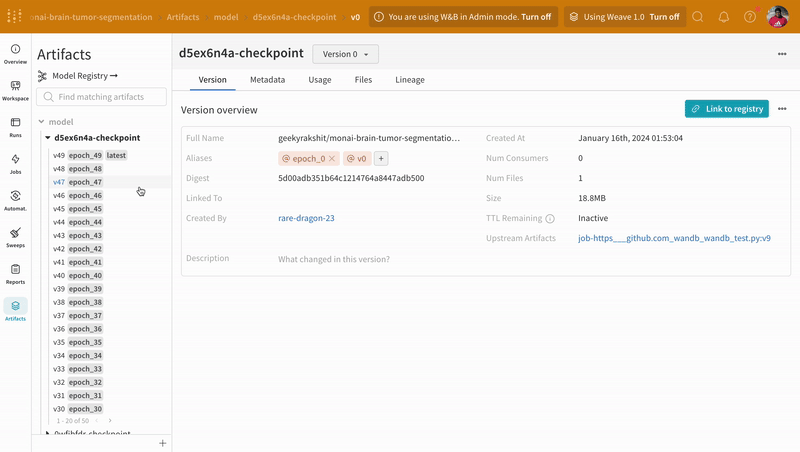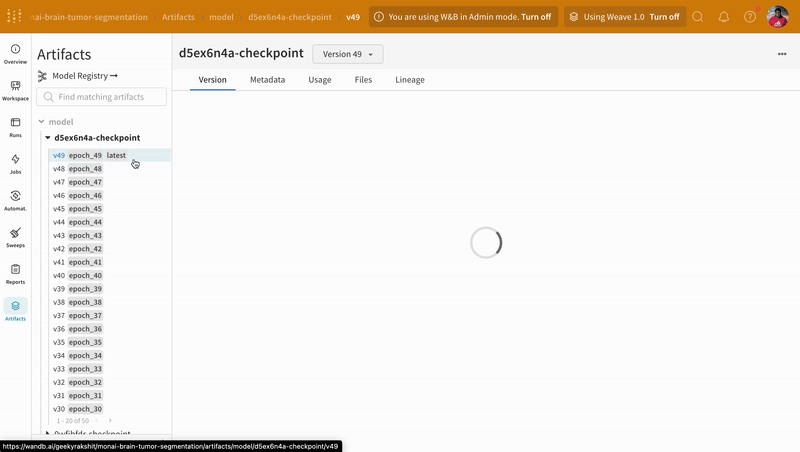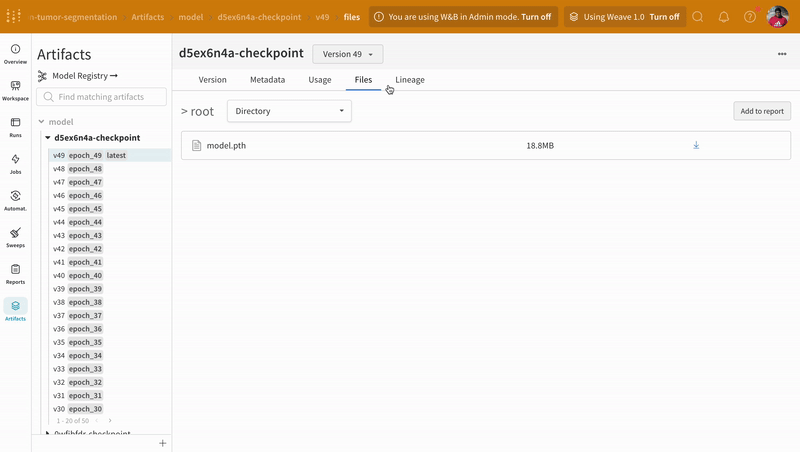 |
|---|
| W&B での モデル チェックポイント のログ記録と バージョン管理 の例。 |
推論
Artifacts インターフェイスを使用すると、最適な モデル チェックポイント である Artifact の バージョン を選択できます。この場合、エポックごとの平均トレーニング損失です。Artifact のリネージ全体を調べて、必要な バージョン を使用することもできます。
 |
|---|
| W&B での モデル Artifact の追跡の例。 |
エポックごとの平均トレーニング損失が最適なモデル Artifact の バージョン をフェッチし、チェックポイント 状態 辞書 をモデルにロードします。
model_artifact = wandb.use_artifact(
"geekyrakshit/monai-brain-tumor-segmentation/d5ex6n4a-checkpoint:v49",
type="model",
)
model_artifact_dir = model_artifact.download()
model.load_state_dict(torch.load(os.path.join(model_artifact_dir, "model.pth")))
model.eval()
予測 の可視化と 正解 ラベルとの比較
インタラクティブなセグメンテーション マスク オーバーレイを使用して、学習済み モデル の 予測 を 可視化 し、対応する 正解 セグメンテーション マスク と比較するための別のユーティリティ関数を作成します。
def log_predictions_into_tables(
sample_image: np.array,
sample_label: np.array,
predicted_label: np.array,
split: str = None,
data_idx: int = None,
table: wandb.Table = None,
):
num_channels, _, _, num_slices = sample_image.shape
with tqdm(total=num_slices, leave=False) as progress_bar:
for slice_idx in range(num_slices):
wandb_images = []
for channel_idx in range(num_channels):
wandb_images += [
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks={
"ground-truth/Tumor-Core": {
"mask_data": sample_label[0, :, :, slice_idx],
"class_labels": {0: "background", 1: "Tumor Core"},
},
"prediction/Tumor-Core": {
"mask_data": predicted_label[0, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Tumor Core"},
},
},
),
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks={
"ground-truth/Whole-Tumor": {
"mask_data": sample_label[1, :, :, slice_idx],
"class_labels": {0: "background", 1: "Whole Tumor"},
},
"prediction/Whole-Tumor": {
"mask_data": predicted_label[1, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Whole Tumor"},
},
},
),
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks={
"ground-truth/Enhancing-Tumor": {
"mask_data": sample_label[2, :, :, slice_idx],
"class_labels": {0: "background", 1: "Enhancing Tumor"},
},
"prediction/Enhancing-Tumor": {
"mask_data": predicted_label[2, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Enhancing Tumor"},
},
},
),
]
table.add_data(split, data_idx, slice_idx, *wandb_images)
progress_bar.update(1)
return table
予測 結果を 予測 テーブル にログに記録します。
# 予測 テーブル を作成する
prediction_table = wandb.Table(
columns=[
"Split",
"Data Index",
"Slice Index",
"Image-Channel-0/Tumor-Core",
"Image-Channel-1/Tumor-Core",
"Image-Channel-2/Tumor-Core",
"Image-Channel-3/Tumor-Core",
"Image-Channel-0/Whole-Tumor",
"Image-Channel-1/Whole-Tumor",
"Image-Channel-2/Whole-Tumor",
"Image-Channel-3/Whole-Tumor",
"Image-Channel-0/Enhancing-Tumor",
"Image-Channel-1/Enhancing-Tumor",
"Image-Channel-2/Enhancing-Tumor",
"Image-Channel-3/Enhancing-Tumor",
]
)
# 推論 と 可視化 を実行する
with torch.no_grad():
config.max_prediction_images_visualized
max_samples = (
min(config.max_prediction_images_visualized, len(val_dataset))
if config.max_prediction_images_visualized > 0
else len(val_dataset)
)
progress_bar = tqdm(
enumerate(val_dataset[:max_samples]),
total=max_samples,
desc="予測 を生成しています:",
)
for data_idx, sample in progress_bar:
val_input = sample["image"].unsqueeze(0).to(device)
val_output = inference(model, val_input)
val_output = post_trans(val_output[0])
prediction_table = log_predictions_into_tables(
sample_image=sample["image"].cpu().numpy(),
sample_label=sample["label"].cpu().numpy(),
predicted_label=val_output.cpu().numpy(),
data_idx=data_idx,
split="validation",
table=prediction_table,
)
wandb.log({"Predictions/Tumor-Segmentation-Data": prediction_table})
# experiment を終了する
wandb.finish()
インタラクティブなセグメンテーション マスク オーバーレイを使用して、各クラスの 予測 されたセグメンテーション マスク と 正解 ラベルを分析および比較します。
 |
|---|
| W&B での 予測 と 正解 の 可視化 の例。 |
謝辞とその他のリソース
7 - Keras
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、および プロジェクト コラボレーションを行います。
この Colab ノートブック では、WandbMetricsLogger コールバック を紹介します。この コールバック を実験管理に使用します。これは、トレーニング および バリデーション の メトリクス を、システム メトリクス とともに Weights and Biases に ログ します。
セットアップとインストール
まず、Weights and Biases の最新 バージョン をインストールしましょう。次に、この Colab インスタンスを認証して W&B を使用します。
pip install -qq -U wandb
import os
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow_datasets as tfds
# Weights and Biases 関連のインポート
import wandb
from wandb.integration.keras import WandbMetricsLogger
W&B を初めて使用する場合、または ログイン していない場合は、wandb.login() の実行後に表示されるリンクからサインアップ/ログイン ページに移動できます。無料アカウントへのサインアップは、数回クリックするだけで簡単に行えます。
wandb.login()
ハイパーパラメータ
適切な config システムを使用することは、再現性のある 機械学習 において推奨されるベスト プラクティスです。W&B を使用して、すべての 実験 の ハイパーパラメータ を追跡できます。この Colab では、シンプルな Python dict を config システムとして使用します。
configs = dict(
num_classes=10,
shuffle_buffer=1024,
batch_size=64,
image_size=28,
image_channels=1,
earlystopping_patience=3,
learning_rate=1e-3,
epochs=10,
)
データセット
この Colab では、TensorFlow Dataset カタログの CIFAR100 データセット を使用します。TensorFlow/Keras を使用して、シンプルな 画像分類 パイプライン を構築することを目指します。
train_ds, valid_ds = tfds.load("fashion_mnist", split=["train", "test"])
AUTOTUNE = tf.data.AUTOTUNE
def parse_data(example):
# 画像を取得
image = example["image"]
# image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# ラベルを取得
label = example["label"]
label = tf.one_hot(label, depth=configs["num_classes"])
return image, label
def get_dataloader(ds, configs, dataloader_type="train"):
dataloader = ds.map(parse_data, num_parallel_calls=AUTOTUNE)
if dataloader_type == "train":
dataloader = dataloader.shuffle(configs["shuffle_buffer"])
dataloader = dataloader.batch(configs["batch_size"]).prefetch(AUTOTUNE)
return dataloader
trainloader = get_dataloader(train_ds, configs)
validloader = get_dataloader(valid_ds, configs, dataloader_type="valid")
モデル
def get_model(configs):
backbone = tf.keras.applications.mobilenet_v2.MobileNetV2(
weights="imagenet", include_top=False
)
backbone.trainable = False
inputs = layers.Input(
shape=(configs["image_size"], configs["image_size"], configs["image_channels"])
)
resize = layers.Resizing(32, 32)(inputs)
neck = layers.Conv2D(3, (3, 3), padding="same")(resize)
preprocess_input = tf.keras.applications.mobilenet.preprocess_input(neck)
x = backbone(preprocess_input)
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(configs["num_classes"], activation="softmax")(x)
return models.Model(inputs=inputs, outputs=outputs)
tf.keras.backend.clear_session()
model = get_model(configs)
model.summary()
モデル の コンパイル
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=[
"accuracy",
tf.keras.metrics.TopKCategoricalAccuracy(k=5, name="top@5_accuracy"),
],
)
トレーニング
# W&B run を初期化
run = wandb.init(project="intro-keras", config=configs)
# モデル をトレーニング
model.fit(
trainloader,
epochs=configs["epochs"],
validation_data=validloader,
callbacks=[
WandbMetricsLogger(log_freq=10)
], # ここで WandbMetricsLogger を使用していることに注意してください
)
# W&B run を閉じる
run.finish()
8 - Keras models
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、および プロジェクト の コラボレーションを行います。
この Colab ノートブック では、WandbModelCheckpoint コールバック について紹介します。この コールバック を使用して、モデル の チェックポイント を Weights & Biases Artifacts に ログ 記録します。
セットアップとインストール
まず、Weights & Biases の最新バージョンをインストールしましょう。次に、この Colab インスタンスを認証して W&B を使用します。
!pip install -qq -U wandb
import os
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow_datasets as tfds
# Weights and Biases 関連のインポート
import wandb
from wandb.integration.keras import WandbMetricsLogger
from wandb.integration.keras import WandbModelCheckpoint
W&B を初めて使用する場合、または ログイン していない場合は、wandb.login() の実行後に表示されるリンクからサインアップ/ログイン ページに移動します。無料アカウント へのサインアップは、数回クリックするだけで簡単に行えます。
wandb.login()
ハイパーパラメーター
再現性のある 機械学習 のためには、適切な config システムを使用することが推奨されるベストプラクティスです。W&B を使用して、すべての 実験 の ハイパーパラメーター を追跡できます。この Colab では、単純な Python dict を config システムとして使用します。
configs = dict(
num_classes = 10,
shuffle_buffer = 1024,
batch_size = 64,
image_size = 28,
image_channels = 1,
earlystopping_patience = 3,
learning_rate = 1e-3,
epochs = 10
)
データセット
この Colab では、TensorFlow Dataset カタログの CIFAR100 データセット を使用します。TensorFlow/Keras を使用して、単純な 画像分類 パイプライン を構築することを目指します。
train_ds, valid_ds = tfds.load('fashion_mnist', split=['train', 'test'])
AUTOTUNE = tf.data.AUTOTUNE
def parse_data(example):
# 画像を取得
image = example["image"]
# image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# ラベルを取得
label = example["label"]
label = tf.one_hot(label, depth=configs["num_classes"])
return image, label
def get_dataloader(ds, configs, dataloader_type="train"):
dataloader = ds.map(parse_data, num_parallel_calls=AUTOTUNE)
if dataloader_type=="train":
dataloader = dataloader.shuffle(configs["shuffle_buffer"])
dataloader = (
dataloader
.batch(configs["batch_size"])
.prefetch(AUTOTUNE)
)
return dataloader
trainloader = get_dataloader(train_ds, configs)
validloader = get_dataloader(valid_ds, configs, dataloader_type="valid")
モデル
def get_model(configs):
backbone = tf.keras.applications.mobilenet_v2.MobileNetV2(weights='imagenet', include_top=False)
backbone.trainable = False
inputs = layers.Input(shape=(configs["image_size"], configs["image_size"], configs["image_channels"]))
resize = layers.Resizing(32, 32)(inputs)
neck = layers.Conv2D(3, (3,3), padding="same")(resize)
preprocess_input = tf.keras.applications.mobilenet.preprocess_input(neck)
x = backbone(preprocess_input)
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(configs["num_classes"], activation="softmax")(x)
return models.Model(inputs=inputs, outputs=outputs)
tf.keras.backend.clear_session()
model = get_model(configs)
model.summary()
モデルのコンパイル
model.compile(
optimizer = "adam",
loss = "categorical_crossentropy",
metrics = ["accuracy", tf.keras.metrics.TopKCategoricalAccuracy(k=5, name='top@5_accuracy')]
)
学習
# W&B run を初期化
run = wandb.init(
project = "intro-keras",
config = configs
)
# モデルを学習
model.fit(
trainloader,
epochs = configs["epochs"],
validation_data = validloader,
callbacks = [
WandbMetricsLogger(log_freq=10),
WandbModelCheckpoint(filepath="models/") # ここで WandbModelCheckpoint を使用していることに注意してください
]
)
# W&B run を閉じる
run.finish()
9 - Keras tables
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、および プロジェクト コラボレーションを行います。
この Colab ノートブック では、モデルの 予測 の 可視化 および データセット の 可視化に役立つ コールバック を構築するために継承できる抽象 コールバック である WandbEvalCallback を紹介します。
セットアップとインストール
まず、Weights & Biases の最新 バージョン をインストールしましょう。次に、この colab インスタンスを 認証 して W&B を使用します。
pip install -qq -U wandb
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow_datasets as tfds
# Weights and Biases related imports
import wandb
from wandb.integration.keras import WandbMetricsLogger
from wandb.integration.keras import WandbModelCheckpoint
from wandb.integration.keras import WandbEvalCallback
W&B を初めて使用する場合、または ログイン していない場合は、wandb.login() の実行後に表示されるリンクからサインアップ/ログイン ページに移動します。無料アカウント へのサインアップは、数回クリックするだけで簡単に行えます。
wandb.login()
ハイパーパラメーター
再現性のある 機械学習 には、適切な config システムを使用することをお勧めします。W&B を使用して、すべての 実験 の ハイパーパラメーター を追跡できます。この colab では、単純な Python の dict を config システムとして使用します。
configs = dict(
num_classes=10,
shuffle_buffer=1024,
batch_size=64,
image_size=28,
image_channels=1,
earlystopping_patience=3,
learning_rate=1e-3,
epochs=10,
)
データセット
この colab では、TensorFlow Dataset カタログの CIFAR100 データセット を使用します。TensorFlow/Keras を使用して、単純な 画像分類 パイプライン を構築することを目指します。
train_ds, valid_ds = tfds.load("fashion_mnist", split=["train", "test"])
AUTOTUNE = tf.data.AUTOTUNE
def parse_data(example):
# Get image
image = example["image"]
# image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# Get label
label = example["label"]
label = tf.one_hot(label, depth=configs["num_classes"])
return image, label
def get_dataloader(ds, configs, dataloader_type="train"):
dataloader = ds.map(parse_data, num_parallel_calls=AUTOTUNE)
if dataloader_type=="train":
dataloader = dataloader.shuffle(configs["shuffle_buffer"])
dataloader = (
dataloader
.batch(configs["batch_size"])
.prefetch(AUTOTUNE)
)
return dataloader
trainloader = get_dataloader(train_ds, configs)
validloader = get_dataloader(valid_ds, configs, dataloader_type="valid")
モデル
def get_model(configs):
backbone = tf.keras.applications.mobilenet_v2.MobileNetV2(
weights="imagenet", include_top=False
)
backbone.trainable = False
inputs = layers.Input(
shape=(configs["image_size"], configs["image_size"], configs["image_channels"])
)
resize = layers.Resizing(32, 32)(inputs)
neck = layers.Conv2D(3, (3, 3), padding="same")(resize)
preprocess_input = tf.keras.applications.mobilenet.preprocess_input(neck)
x = backbone(preprocess_input)
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(configs["num_classes"], activation="softmax")(x)
return models.Model(inputs=inputs, outputs=outputs)
tf.keras.backend.clear_session()
model = get_model(configs)
model.summary()
モデルのコンパイル
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=[
"accuracy",
tf.keras.metrics.TopKCategoricalAccuracy(k=5, name="top@5_accuracy"),
],
)
WandbEvalCallback
WandbEvalCallback は、主にモデルの 予測 の 可視化、次に データセット の 可視化のための Keras コールバック を構築するための抽象基本クラスです。
これは、 データセット とタスクに依存しない抽象 コールバック です。これを使用するには、この基本 コールバック クラスから継承し、add_ground_truth および add_model_prediction メソッド を実装します。
WandbEvalCallback は、次のことに役立つ メソッド を提供する ユーティリティ クラスです。
- データ と 予測 の
wandb.Tableインスタンスを作成する - データ と 予測 の テーブル を
wandb.Artifactとして ログ に記録する on_train_beginで データテーブル を ログ に記録するon_epoch_endで 予測 テーブル を ログ に記録する
例として、以下に 画像分類 タスク の WandbClfEvalCallback を実装しました。この コールバック の例:
- 検証 データ (
data_table) を W&B に ログ 記録します。 - 推論 を実行し、すべての エポック の最後に 予測 (
pred_table) を W&B に ログ 記録します。
メモリフットプリントを削減する方法
on_train_begin メソッド が呼び出されると、data_table を W&B に ログ 記録します。W&B Artifact としてアップロードされると、data_table_ref クラス変数を使用して アクセス できるこの テーブル への参照を取得します。data_table_ref は、self.data_table_ref[idx][n] のように インデックス を付けることができる 2D リストです。ここで、idx は行番号、n は列番号です。以下の例で使用方法を見てみましょう。
class WandbClfEvalCallback(WandbEvalCallback):
def __init__(
self, validloader, data_table_columns, pred_table_columns, num_samples=100
):
super().__init__(data_table_columns, pred_table_columns)
self.val_data = validloader.unbatch().take(num_samples)
def add_ground_truth(self, logs=None):
for idx, (image, label) in enumerate(self.val_data):
self.data_table.add_data(idx, wandb.Image(image), np.argmax(label, axis=-1))
def add_model_predictions(self, epoch, logs=None):
# Get predictions
preds = self._inference()
table_idxs = self.data_table_ref.get_index()
for idx in table_idxs:
pred = preds[idx]
self.pred_table.add_data(
epoch,
self.data_table_ref.data[idx][0],
self.data_table_ref.data[idx][1],
self.data_table_ref.data[idx][2],
pred,
)
def _inference(self):
preds = []
for image, label in self.val_data:
pred = self.model(tf.expand_dims(image, axis=0))
argmax_pred = tf.argmax(pred, axis=-1).numpy()[0]
preds.append(argmax_pred)
return preds
訓練
# Initialize a W&B run
run = wandb.init(project="intro-keras", config=configs)
# Train your model
model.fit(
trainloader,
epochs=configs["epochs"],
validation_data=validloader,
callbacks=[
WandbMetricsLogger(log_freq=10),
WandbClfEvalCallback(
validloader,
data_table_columns=["idx", "image", "ground_truth"],
pred_table_columns=["epoch", "idx", "image", "ground_truth", "prediction"],
), # Notice the use of WandbEvalCallback here
],
)
# Close the W&B run
run.finish()
10 - XGBoost Sweeps
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、 プロジェクト の コラボレーションを行いましょう。
ツリーベースの モデル から最高のパフォーマンスを引き出すには、適切な ハイパーパラメーター を選択する必要があります。
early_stopping_rounds はいくつにするべきでしょうか? ツリーの max_depth はどのくらいにすべきでしょうか?
高次元の ハイパーパラメーター 空間を検索して、最もパフォーマンスの高い モデル を見つけるのは、非常に扱いにくくなる可能性があります。 ハイパーパラメーター Sweeps は、 モデル の バトルロイヤル を実施し、勝者を決定するための、組織的かつ効率的な方法を提供します。 これは、最適な値を見つけるために、 ハイパーパラメーター 値の組み合わせを自動的に検索することによって実現されます。
この チュートリアル では、Weights & Biases を使用して、XGBoost モデル で高度な ハイパーパラメーター Sweeps を 3 つの簡単なステップで実行する方法を説明します。
まず、以下の プロット を確認してください。
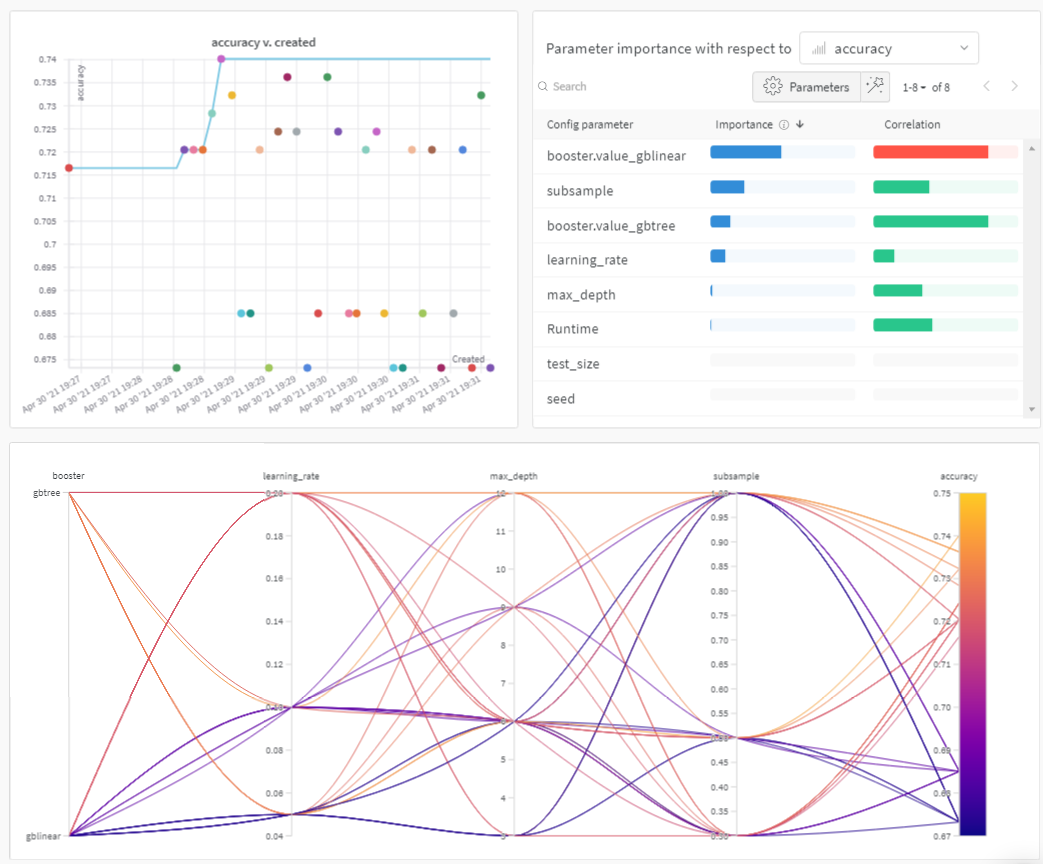
Sweeps: 概要
Weights & Biases で ハイパーパラメーター sweep を実行するのは非常に簡単です。簡単な 3 つのステップがあります。
-
sweep の定義: sweep を指定する 辞書 のような オブジェクト を作成してこれを行います。検索する パラメータ ー、使用する検索戦略、最適化する メトリクス を指定します。
-
sweep の初期化: 1 行の コード で sweep を初期化し、sweep 設定 の 辞書 を渡します。
sweep_id = wandb.sweep(sweep_config) -
sweep agent の実行: これも 1 行の コード で実行できます。
wandb.agent()を呼び出し、sweep_idと モデル の アーキテクチャー を定義して トレーニング する 関数 を渡します。wandb.agent(sweep_id, function=train)
以上が ハイパーパラメーター sweep の実行に必要なすべてです。
以下の ノートブック では、これら 3 つのステップについてさらに詳しく説明します。
この ノートブック をフォークして、 パラメータ ーを調整したり、独自の データセット で モデル を試したりすることを強くお勧めします。
リソース
!pip install wandb -qU
import wandb
wandb.login()
1. Sweep を定義する
Weights & Biases の Sweeps は、わずか数行の コード で、必要な方法で Sweeps を正確に 設定 するための強力な レバー を提供します。sweep の 設定 は、 辞書 または YAML ファイルとして定義できます。
一緒にいくつか見ていきましょう。
- メトリクス: これは、Sweeps が最適化しようとしている メトリクス です。メトリクス は、
name(この メトリクス は トレーニング スクリプト によって ログ に記録される必要があります)とgoal(maximizeまたはminimize)を受け取ることができます。 - 検索戦略:
"method"キーを使用して指定します。Sweeps では、いくつかの異なる検索戦略をサポートしています。 - グリッド検索: ハイパーパラメーター 値のすべての組み合わせを反復処理します。
- ランダム検索: ハイパーパラメーター 値のランダムに選択された組み合わせを反復処理します。
- ベイズ探索: ハイパーパラメーター を メトリクス スコア の確率にマッピングする確率 モデル を作成し、 メトリクス を改善する可能性が高い パラメータ ーを選択します。 ベイズ最適化 の目的は、 ハイパーパラメーター 値の選択により多くの時間を費やすことですが、そうすることで、試す ハイパーパラメーター 値を少なくすることです。
- パラメータ ー: ハイパーパラメーター 名、 離散値 、範囲、または各反復でその値を抽出する 分布 を含む 辞書 。
詳細については、すべての sweep 設定 オプション のリストを参照してください。
sweep_config = {
"method": "random", # try grid or random
"metric": {
"name": "accuracy",
"goal": "maximize"
},
"parameters": {
"booster": {
"values": ["gbtree","gblinear"]
},
"max_depth": {
"values": [3, 6, 9, 12]
},
"learning_rate": {
"values": [0.1, 0.05, 0.2]
},
"subsample": {
"values": [1, 0.5, 0.3]
}
}
}
2. Sweep の初期化
wandb.sweep を呼び出すと、Sweep Controller が起動します。これは、クエリを実行するすべての ユーザー に parameters の 設定 を提供し、wandb ログ を介して metrics のパフォーマンスが返されることを期待する集中化された プロセス です。
sweep_id = wandb.sweep(sweep_config, project="XGBoost-sweeps")
トレーニング プロセス を定義する
sweep を実行する前に、 モデル を作成して トレーニング する 関数 を定義する必要があります。これは、 ハイパーパラメーター 値を受け取り、 メトリクス を出力する 関数 です。
また、wandb を スクリプト に統合する必要があります。
主な コンポーネント は 3 つあります。
wandb.init(): 新しい W&B run を初期化します。各 run は、 トレーニング スクリプト の単一の実行です。wandb.config: すべての ハイパーパラメーター を 設定 オブジェクト に保存します。これにより、アプリを使用して、 ハイパーパラメーター 値で run をソートして比較できます。wandb.log(): メトリクス と、画像、ビデオ、オーディオ ファイル 、HTML、 プロット 、 ポイント クラウド などの カスタム オブジェクト を ログ に記録します。
また、 データ をダウンロードする必要があります。
!wget https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv
# XGBoost model for Pima Indians dataset
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
def train():
config_defaults = {
"booster": "gbtree",
"max_depth": 3,
"learning_rate": 0.1,
"subsample": 1,
"seed": 117,
"test_size": 0.33,
}
wandb.init(config=config_defaults) # defaults are over-ridden during the sweep
config = wandb.config
# load data and split into predictors and targets
dataset = loadtxt("pima-indians-diabetes.data.csv", delimiter=",")
X, Y = dataset[:, :8], dataset[:, 8]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size=config.test_size,
random_state=config.seed)
# fit model on train
model = XGBClassifier(booster=config.booster, max_depth=config.max_depth,
learning_rate=config.learning_rate, subsample=config.subsample)
model.fit(X_train, y_train)
# make predictions on test
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy:.0%}")
wandb.log({"accuracy": accuracy})
3. agent で Sweep を実行する
次に、wandb.agent を呼び出して sweep を起動します。
W&B に ログイン しているすべての マシン で wandb.agent を呼び出すことができます。
sweep_id、- データセット と
train関数
があり、その マシン が sweep に参加します。
注:
randomsweep は、デフォルトで永久に実行され、 牛が家に帰るまで、またはアプリ UI から sweep をオフにするまで、新しい パラメータ ーの組み合わせを試します。agentが完了する run の合計countを指定することで、これを防ぐことができます。
wandb.agent(sweep_id, train, count=25)
結果を 可視化 する
sweep が完了したので、結果を見てみましょう。
Weights & Biases は、多くの役立つ プロット を自動的に生成します。
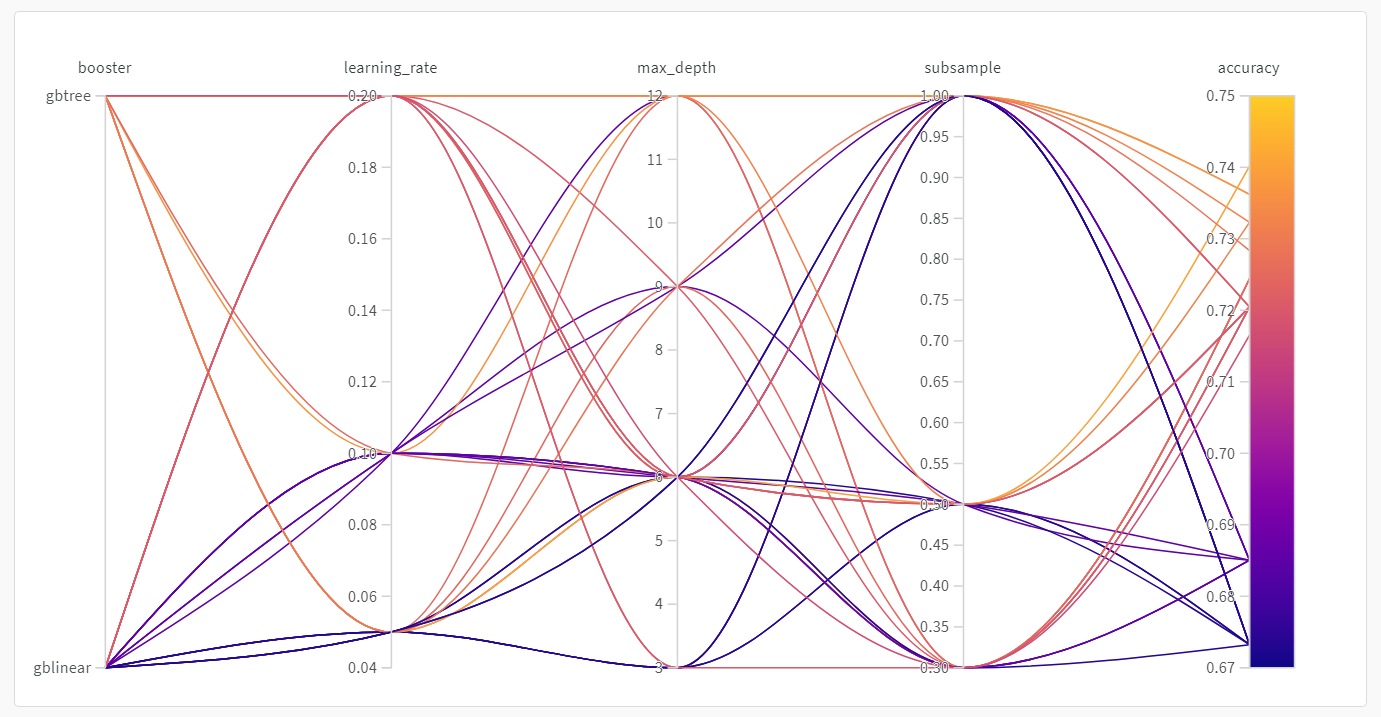
並列座標 プロット
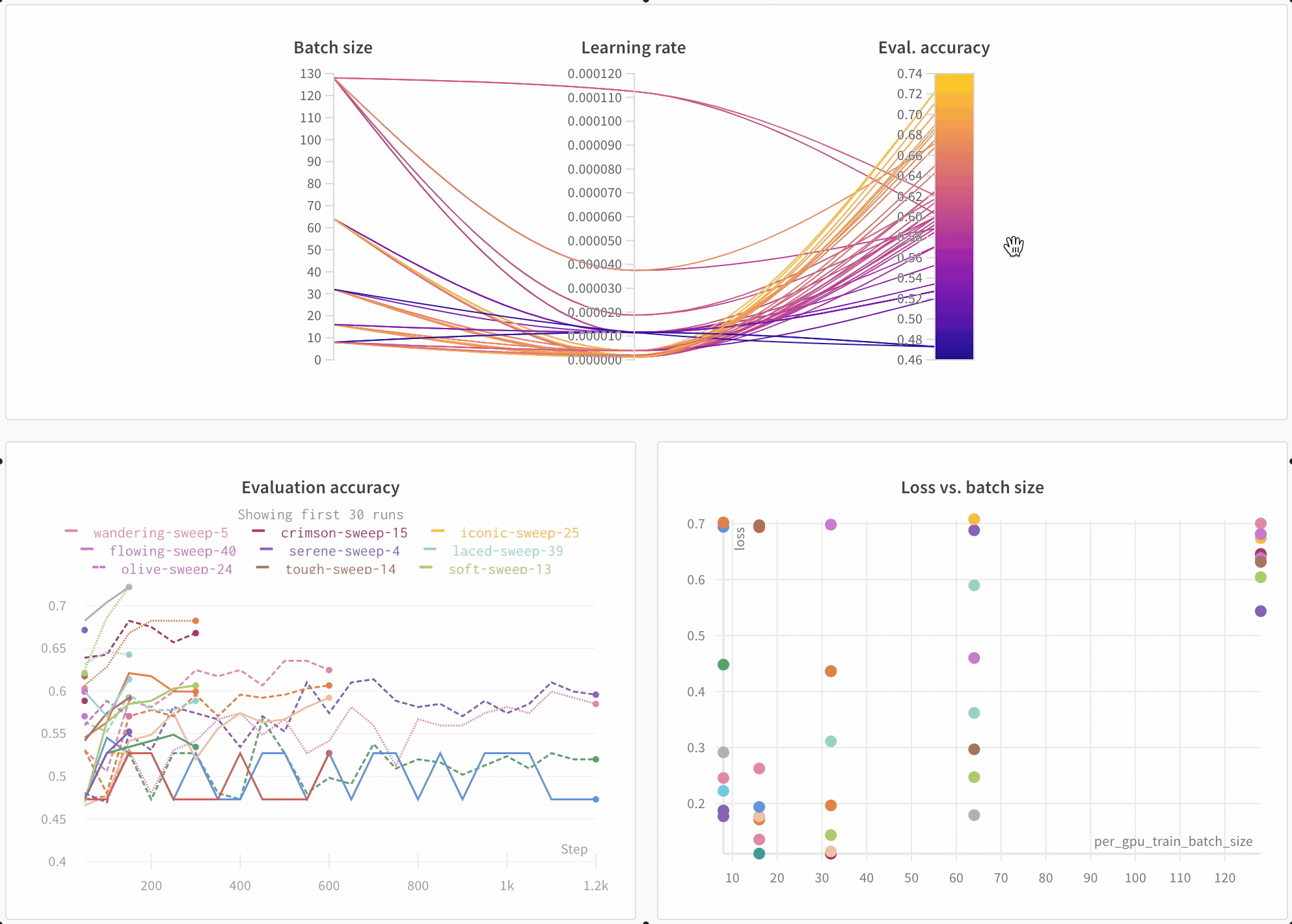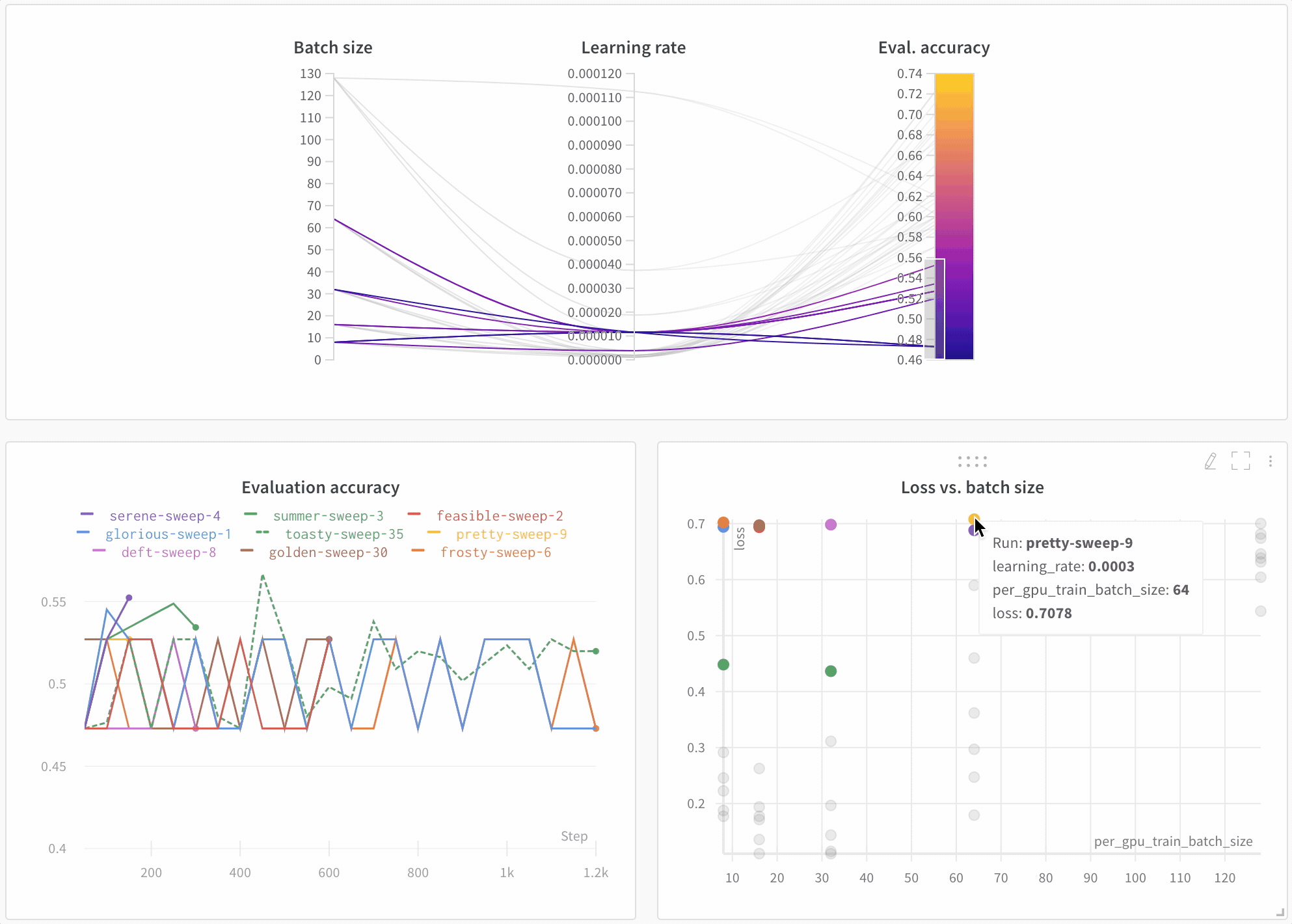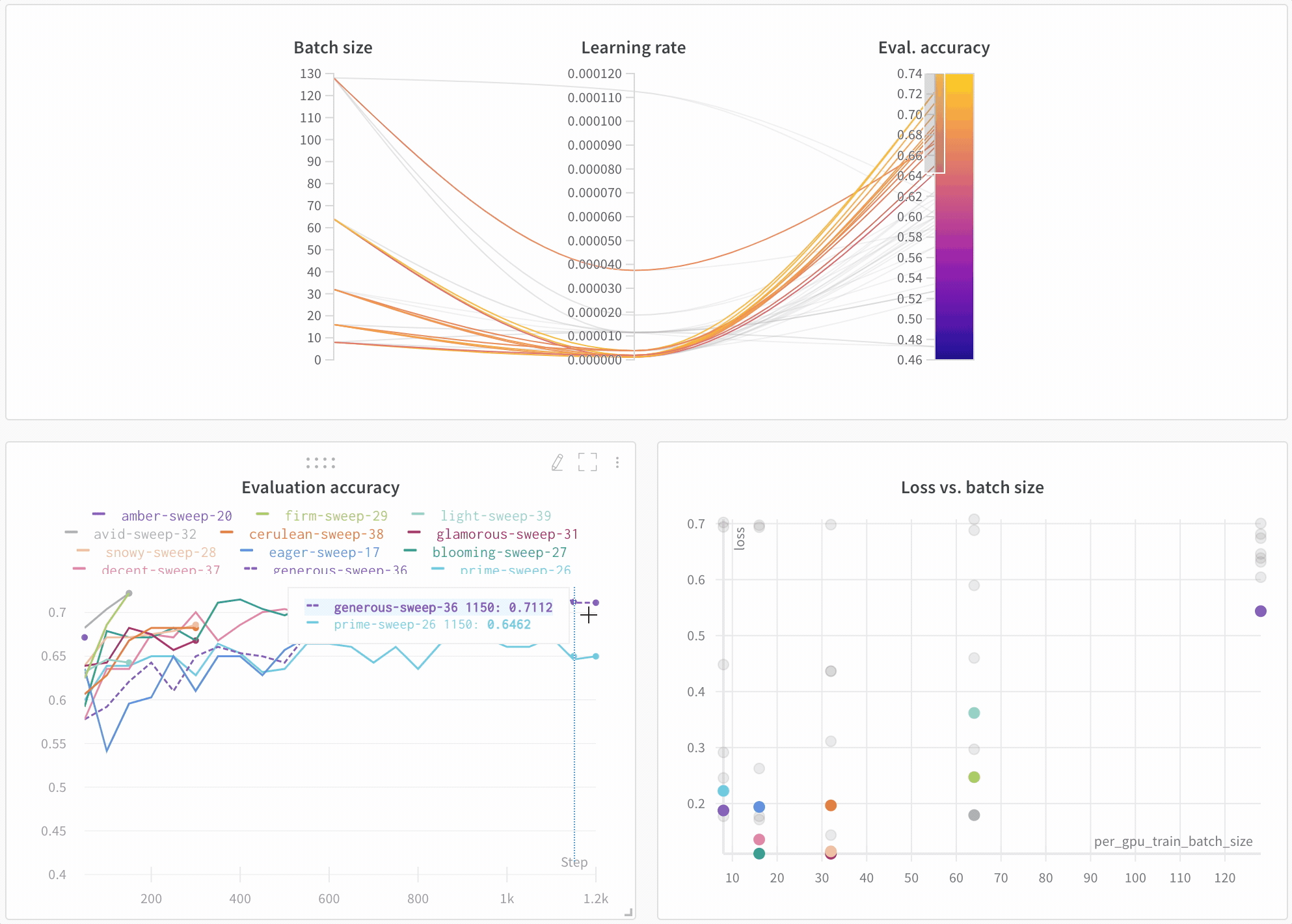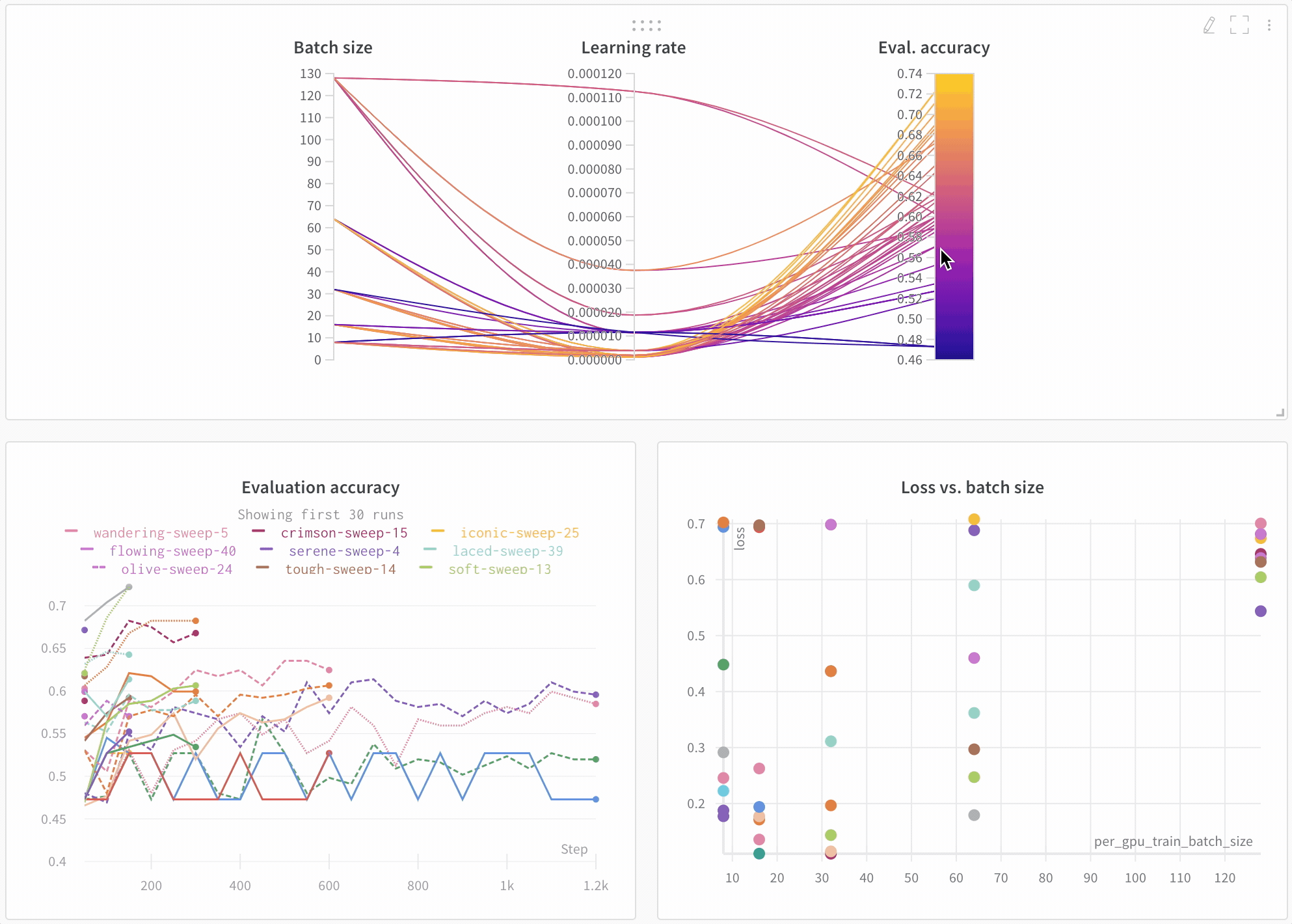
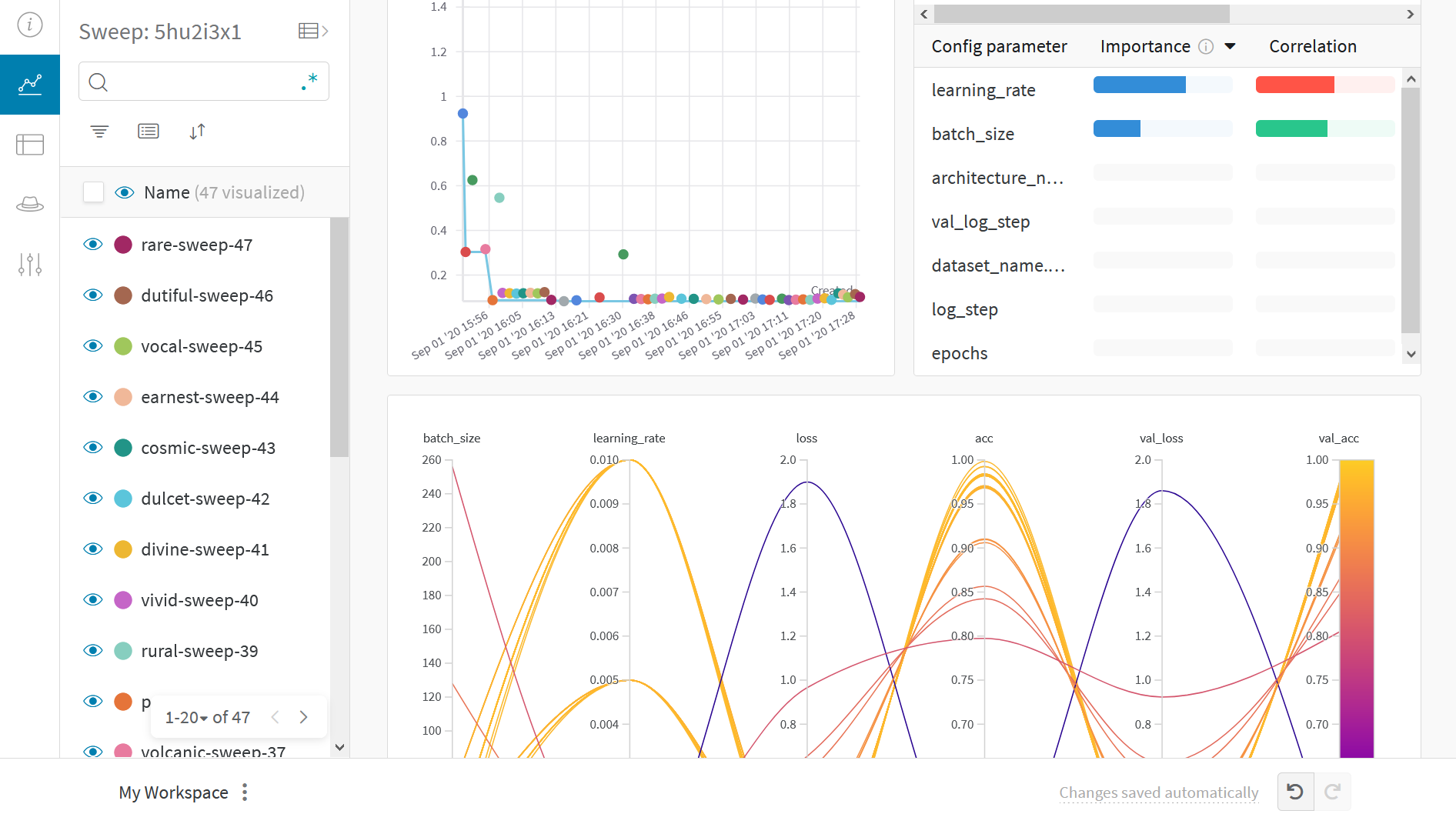
この プロット は、 ハイパーパラメーター 値を モデル メトリクス にマッピングします。これは、最高の モデル パフォーマンスにつながった ハイパーパラメーター の組み合わせを絞り込むのに役立ちます。
この プロット は、学習者としてツリーを使用すると、単純な線形 モデル を学習者として使用するよりもわずかに、 しかし驚くほどではありませんが、 パフォーマンスが向上することを示しているようです。
ハイパーパラメーター の インポータンスプロット
ハイパーパラメーター の インポータンスプロット は、どの ハイパーパラメーター 値が メトリクス に最も大きな影響を与えたかを示します。
線形予測子として扱い、相関関係と特徴量の重要度(結果に対して ランダムフォレスト を トレーニング した後)の両方を報告し、どの パラメータ ーが最大の影響を与えたか、 そしてその影響がプラスかマイナスかを確認できるようにします。
この チャート を読むと、上記の並列座標 チャート で気付いた傾向が定量的に確認できます。 検証精度 への最大の影響は、学習者の選択によるものであり、gblinear 学習者は一般的に gbtree 学習者よりも劣っていました。
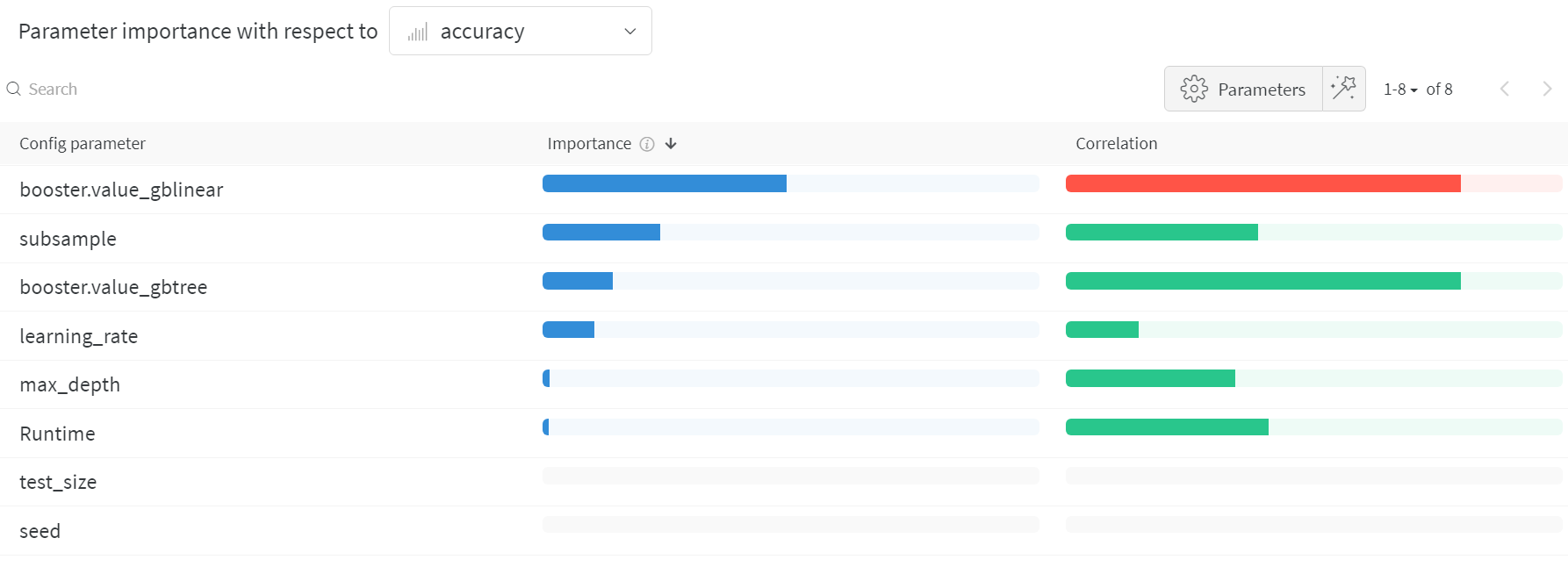
これらの 可視化 は、最も重要な パラメータ ー(および値の範囲)に焦点を当てることで、時間とリソースを節約し、高価な ハイパーパラメーター 最適化 を実行するのに役立ち、それによってさらに調査する価値があります。