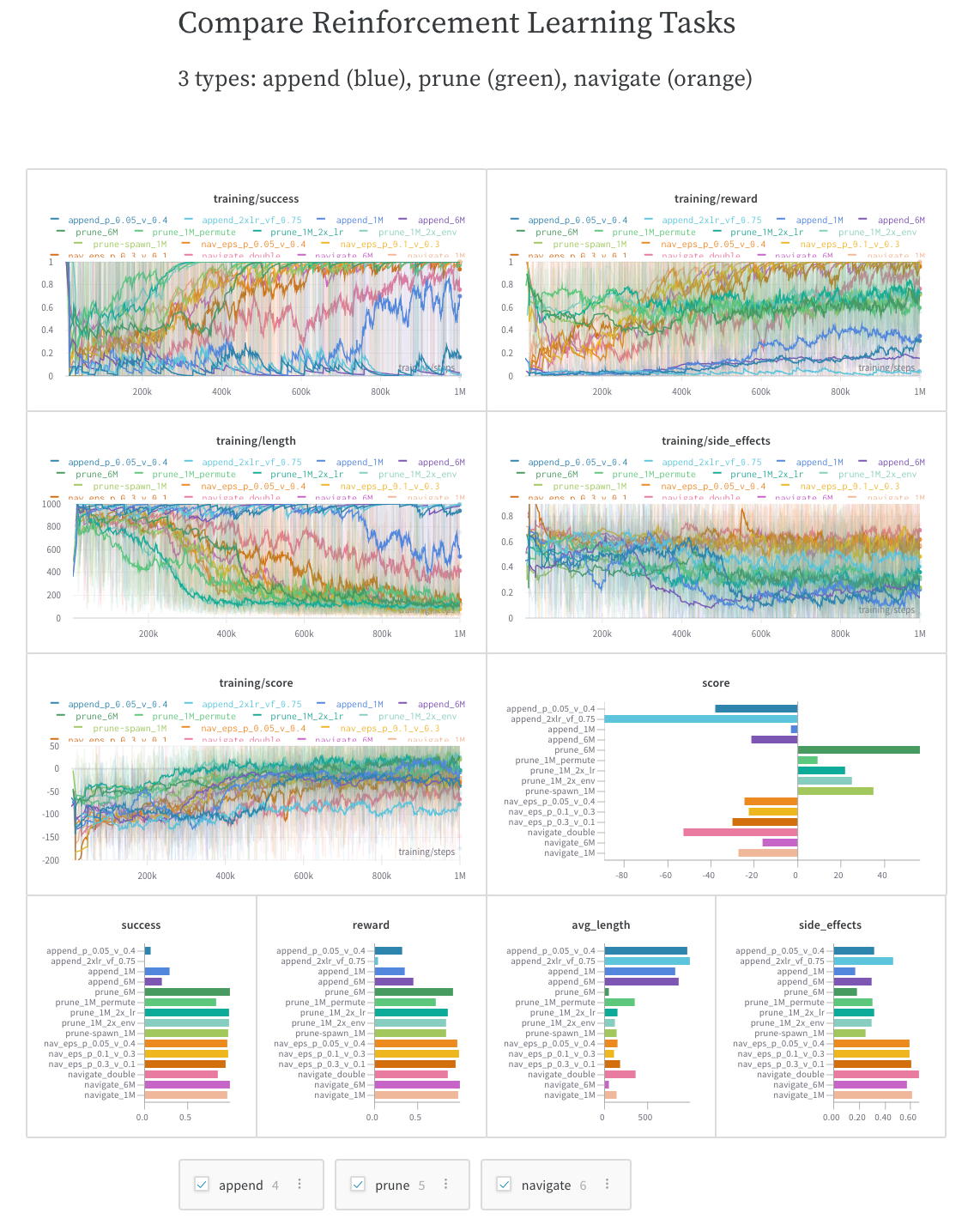
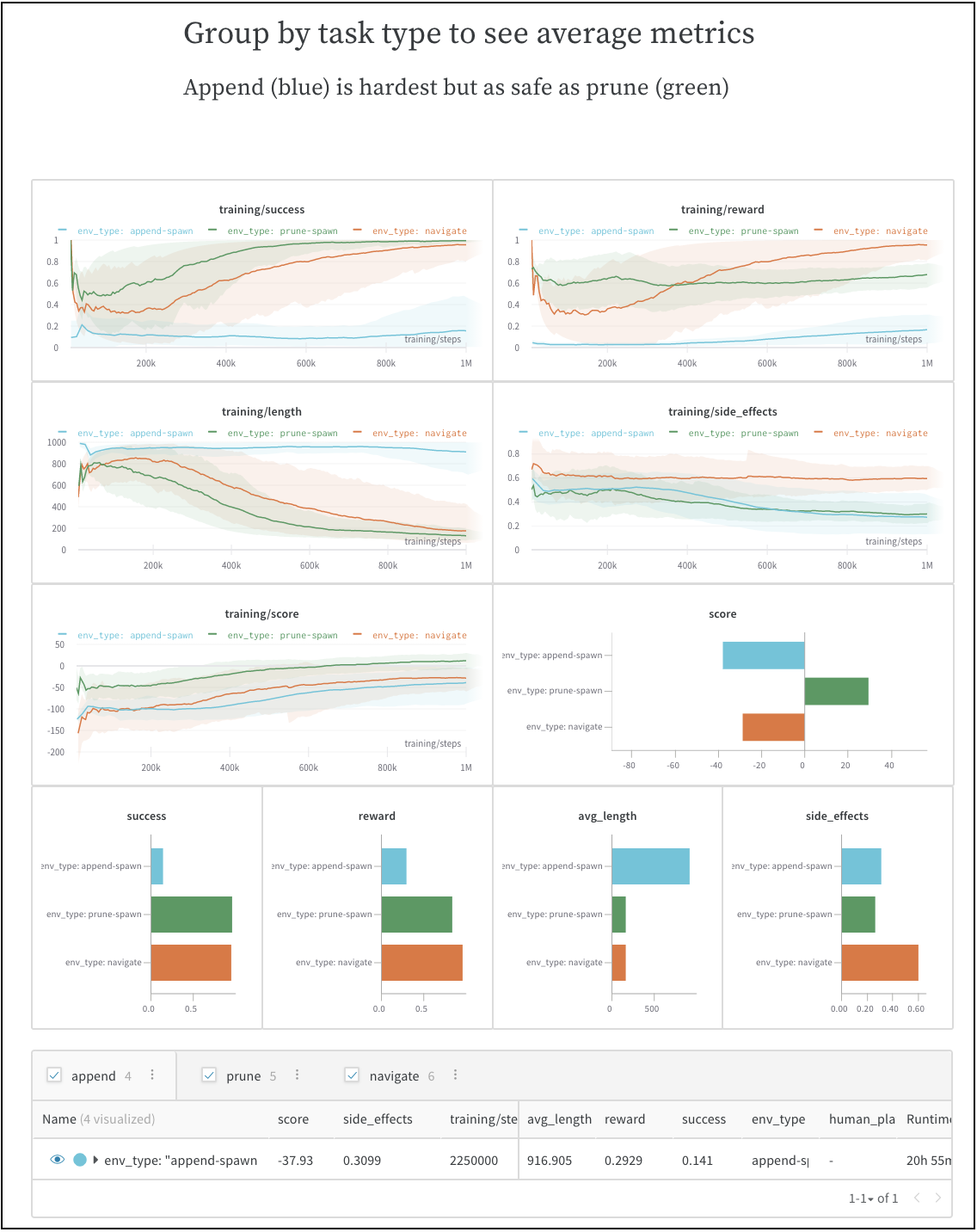
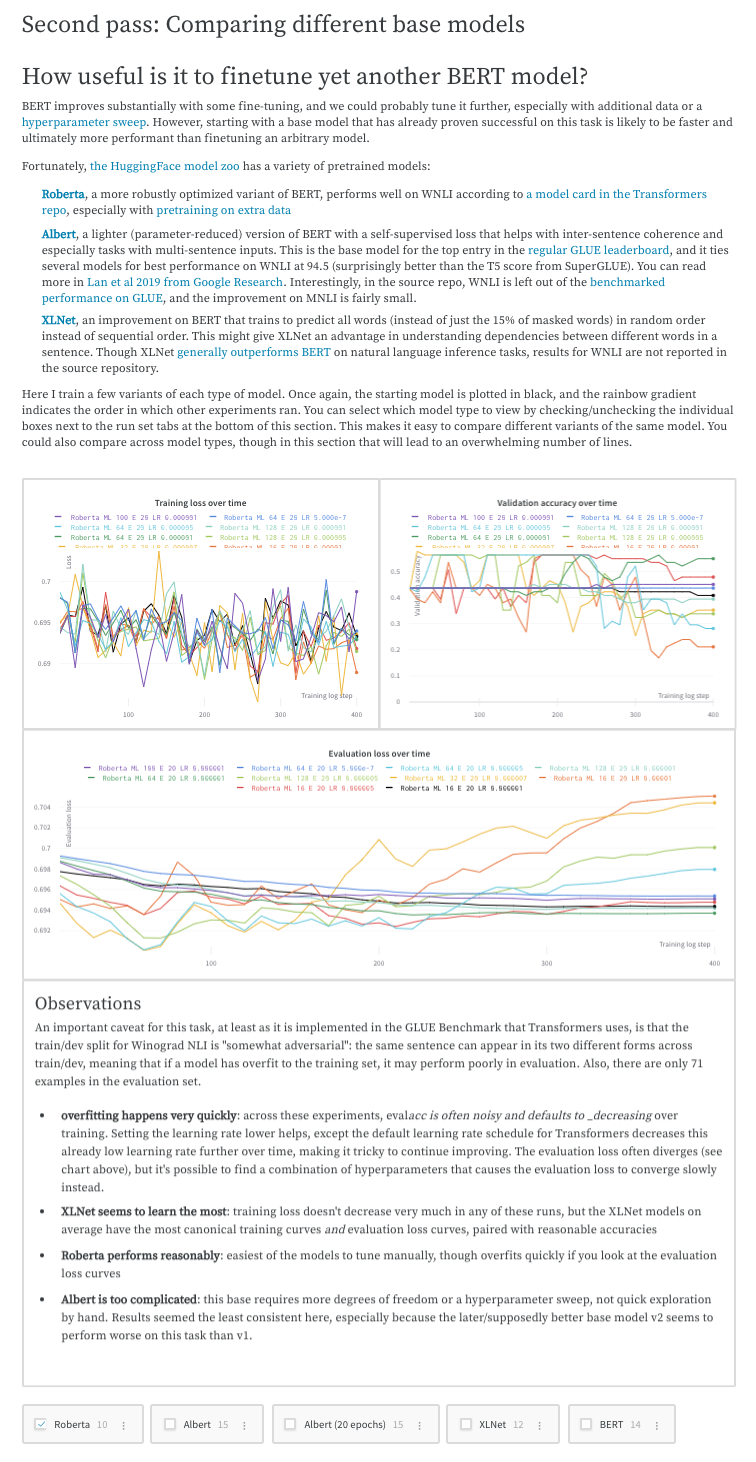
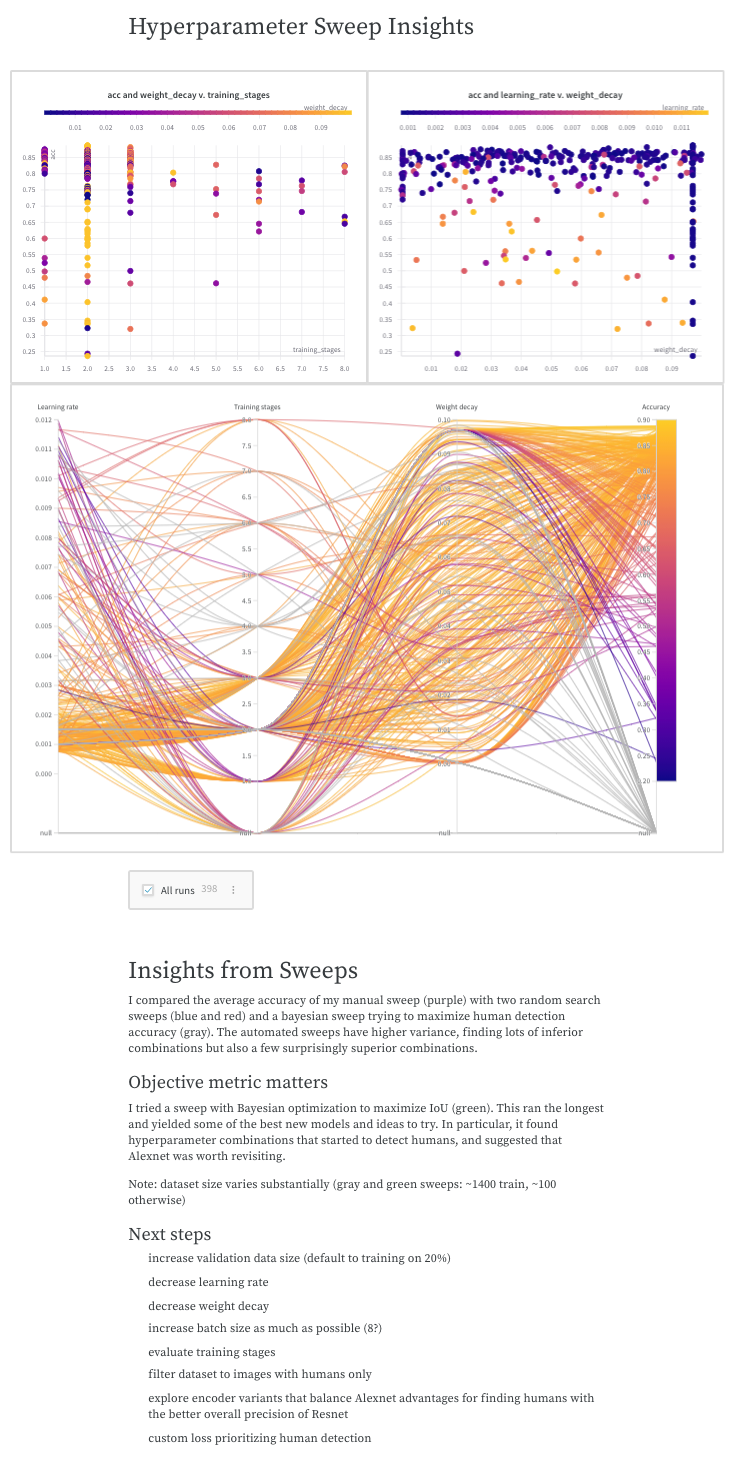
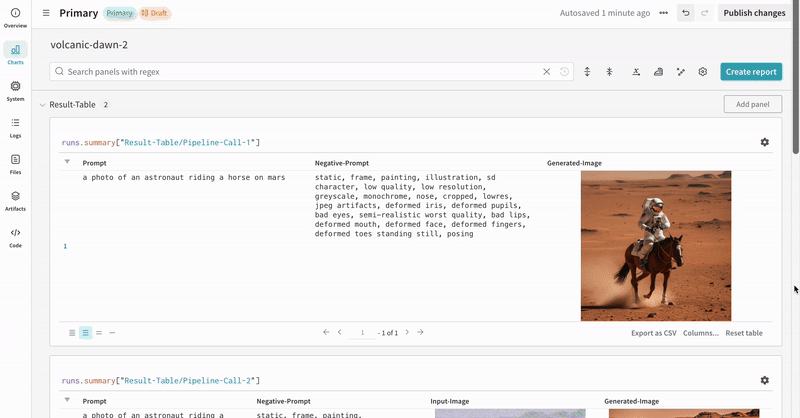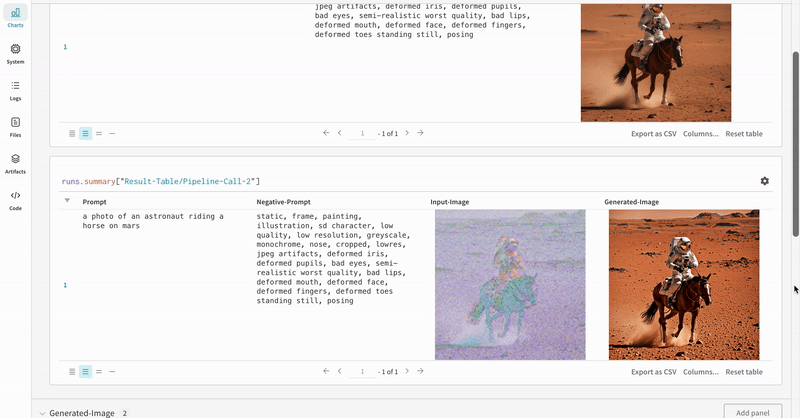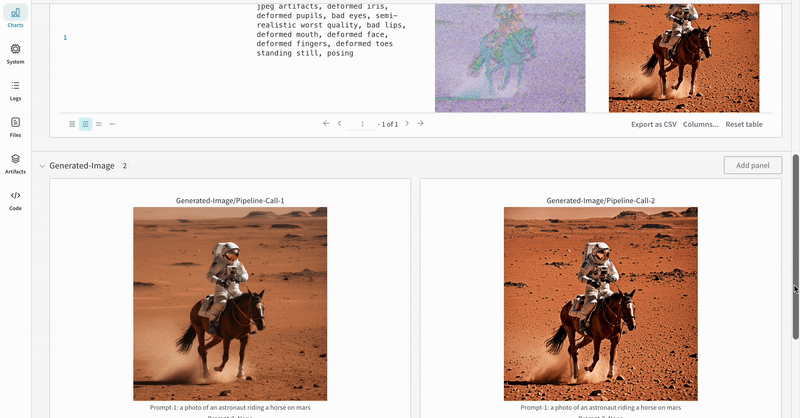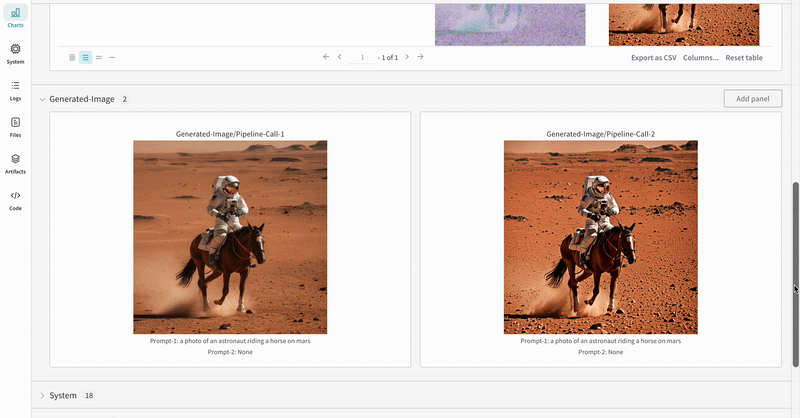
Guides
W&B の概要と、初めての ユーザー 向けの開始方法に関するリンクを紹介します。
W&Bとは?
Weights & Biases (W&B) は、AI 開発者向けプラットフォームであり、モデルのトレーニング、モデルの微調整、基盤モデルの活用を支援するツールを提供します。
W&B は、Models , Weave , そして Core の3つの主要なコンポーネントで構成されています。
W&B Models
W&B Weave
W&B Core
W&B の仕組み
W&B を初めて使用するユーザーで、機械学習モデルと実験のトレーニング、追跡、可視化に関心がある場合は、次のセクションをこの順序でお読みください。
W&B の基本的な計算単位である runs について学びます。
Experiments を使用して、機械学習の実験を作成および追跡します。Artifacts を使用して、データセット と モデル の バージョン管理を行うための、W&B の柔軟で軽量な構成要素を見つけます。Sweeps を使用して、ハイパーパラメーター 探索を自動化し、可能なモデルの空間を探索します。Registry を使用して、トレーニング から プロダクション までの モデル ライフサイクルを管理します。Data Visualization ガイドで、モデル バージョン全体の予測を可視化します。Reports を使用して、runs の整理、可視化の埋め込みと自動化、発見事項の記述、および コラボレーター との更新の共有を行います。
VIDEO
W&B を初めて使用しますか?
quickstart を試して、W&B のインストール方法と、W&B を コード に追加する方法を学んでください。
1 - W&B Quickstart
W&B クイックスタート
あらゆる規模の機械学習実験を追跡、可視化、管理するために W&B をインストールします。
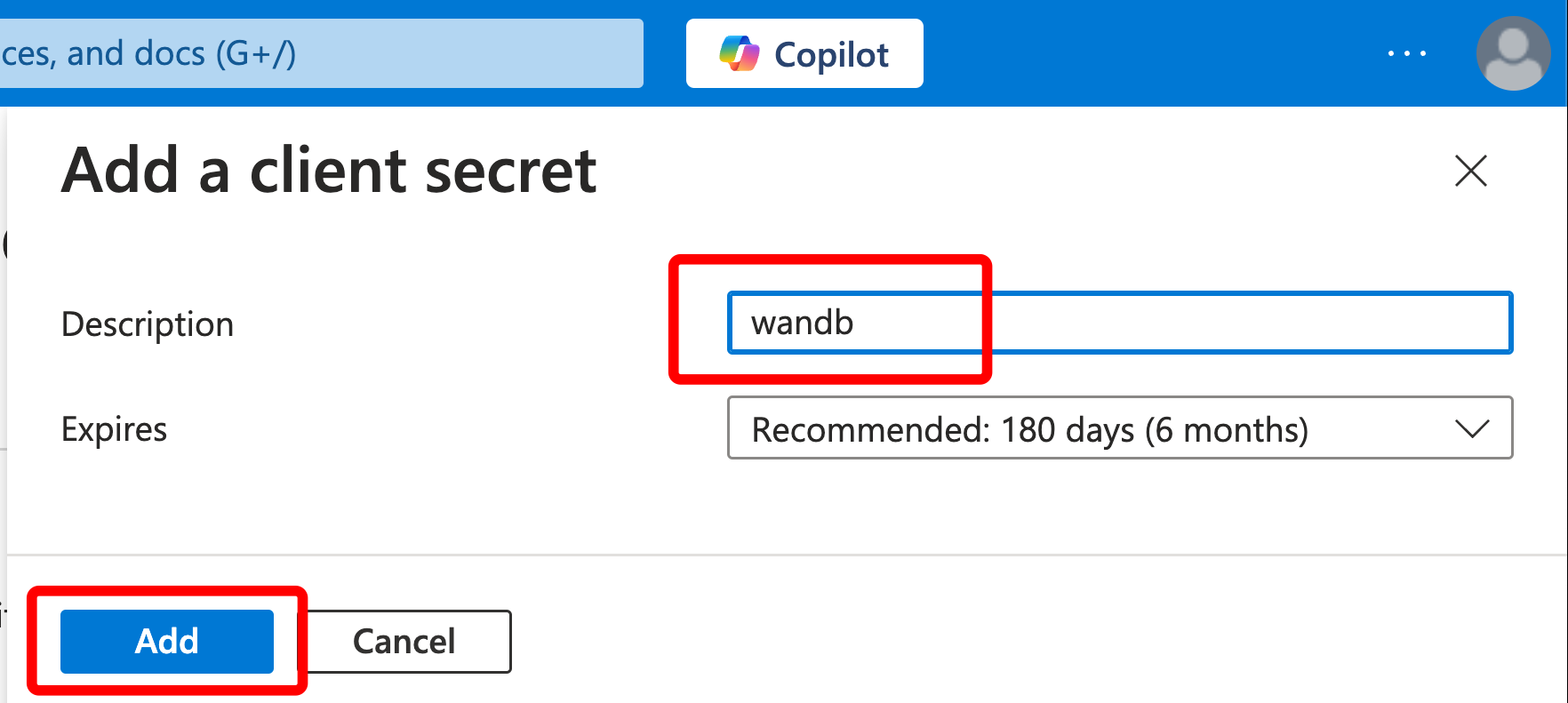
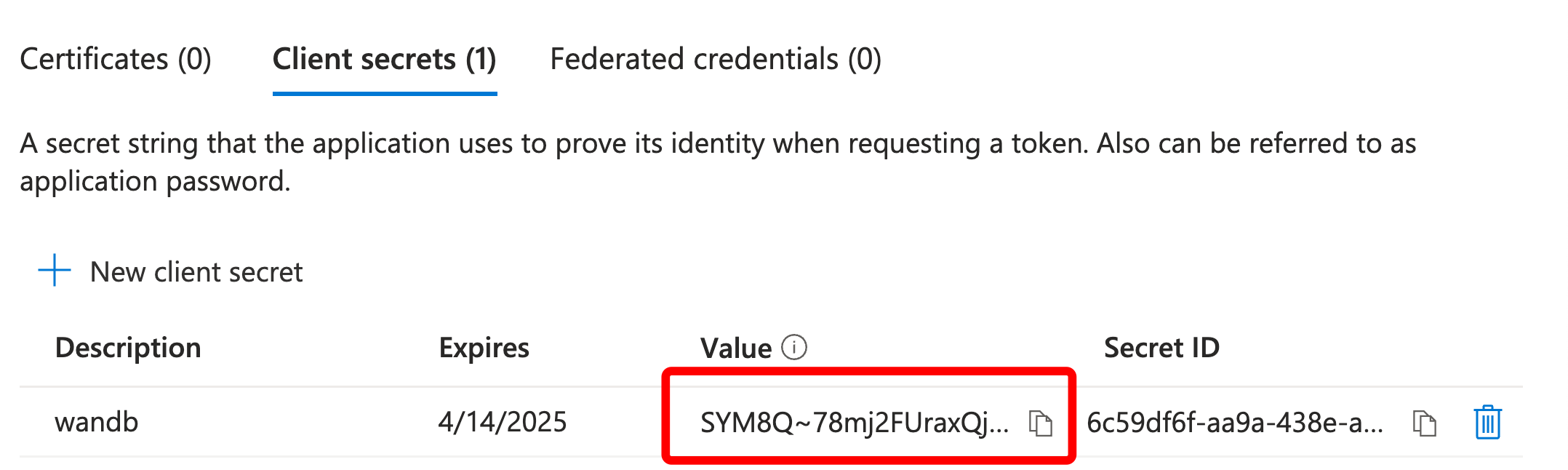
サインアップして APIキーを作成する
W&B で機械を認証するには、ユーザープロフィールまたは wandb.ai/authorize から APIキーを生成します。APIキーをコピーして安全に保管してください。
wandb ライブラリをインストールしてログインする
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
run を開始してハイパーパラメータを追跡する
Python スクリプトまたは notebook で、wandb.init()config パラメータに辞書を使用して、ハイパーパラメータの名前と値を指定します。
run = wandb. init(
project= "my-awesome-project" , # プロジェクトを指定
config= { # ハイパーパラメータとメタデータを追跡
"learning_rate" : 0.01 ,
"epochs" : 10 ,
},
)
run は、W&B のコア要素として機能し、メトリクスを追跡 、ログを作成 などに使用されます。
コンポーネントを組み立てる
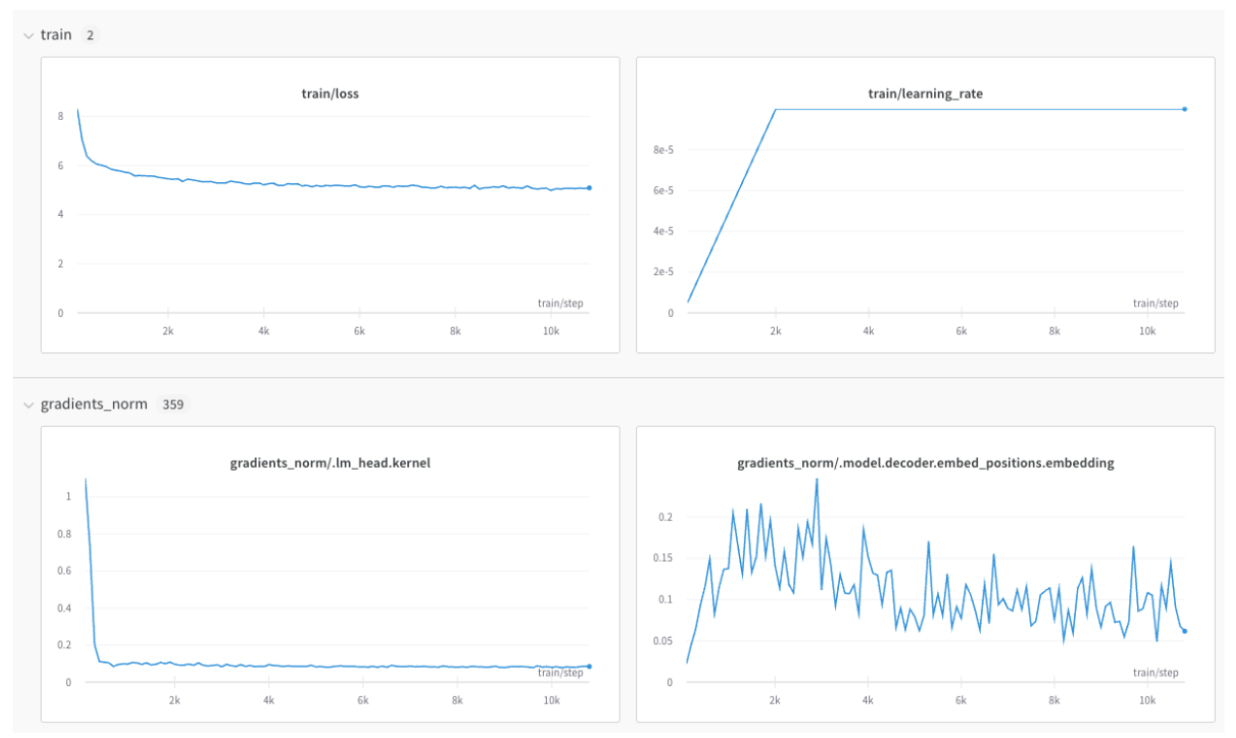
このモックトレーニングスクリプトは、シミュレートされた精度と損失のメトリクスを W&B に記録します。
# train.py
import wandb
import random
wandb. login()
epochs = 10
lr = 0.01
run = wandb. init(
project= "my-awesome-project" , # プロジェクトを指定
config= { # ハイパーパラメータとメタデータを追跡
"learning_rate" : lr,
"epochs" : epochs,
},
)
offset = random. random() / 5
print(f "lr: { lr} " )
# トレーニング run をシミュレートする
for epoch in range(2 , epochs):
acc = 1 - 2 **- epoch - random. random() / epoch - offset
loss = 2 **- epoch + random. random() / epoch + offset
print(f "epoch= { epoch} , accuracy= { acc} , loss= { loss} " )
wandb. log({"accuracy" : acc, "loss" : loss})
# run.log_code()
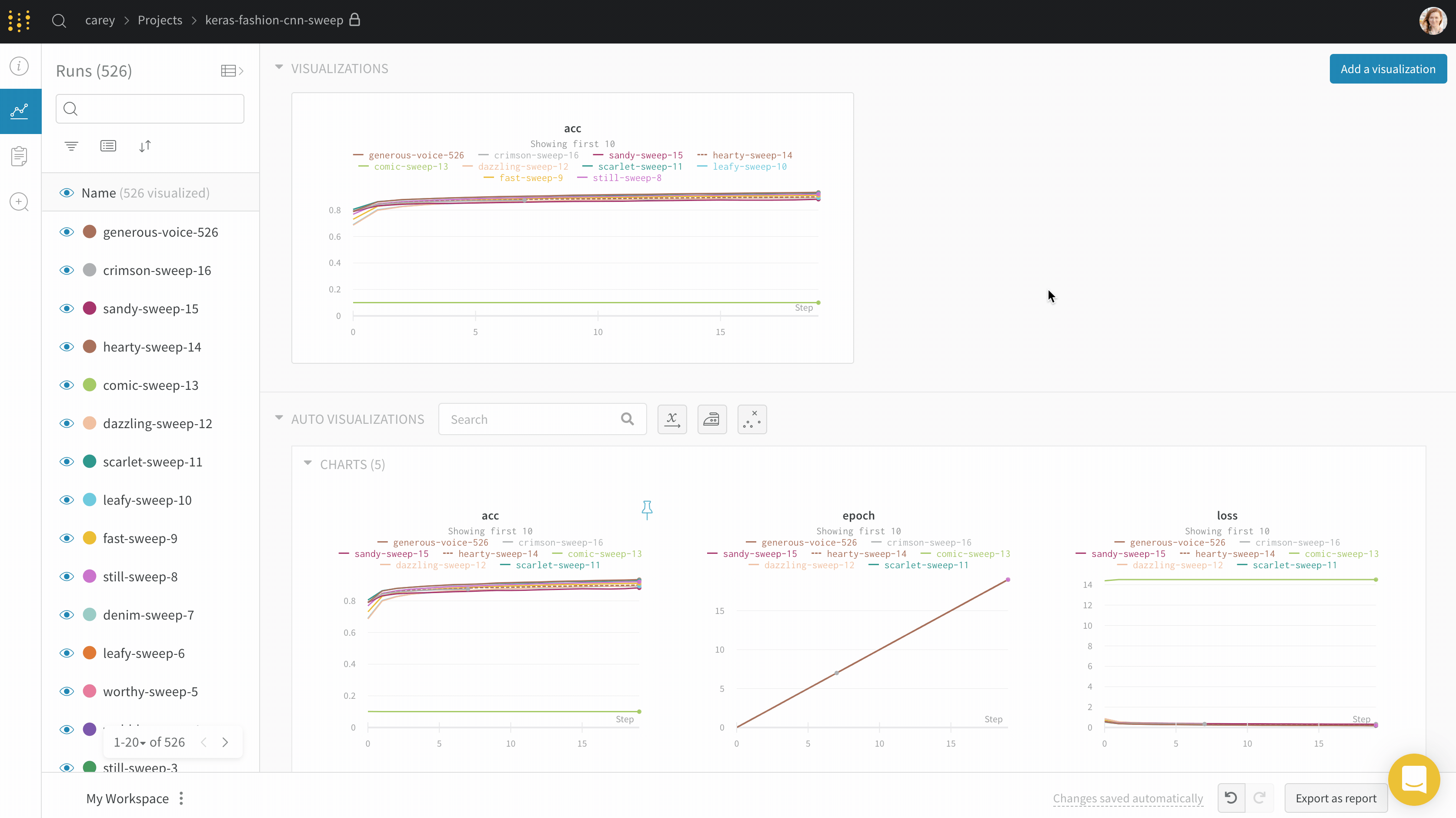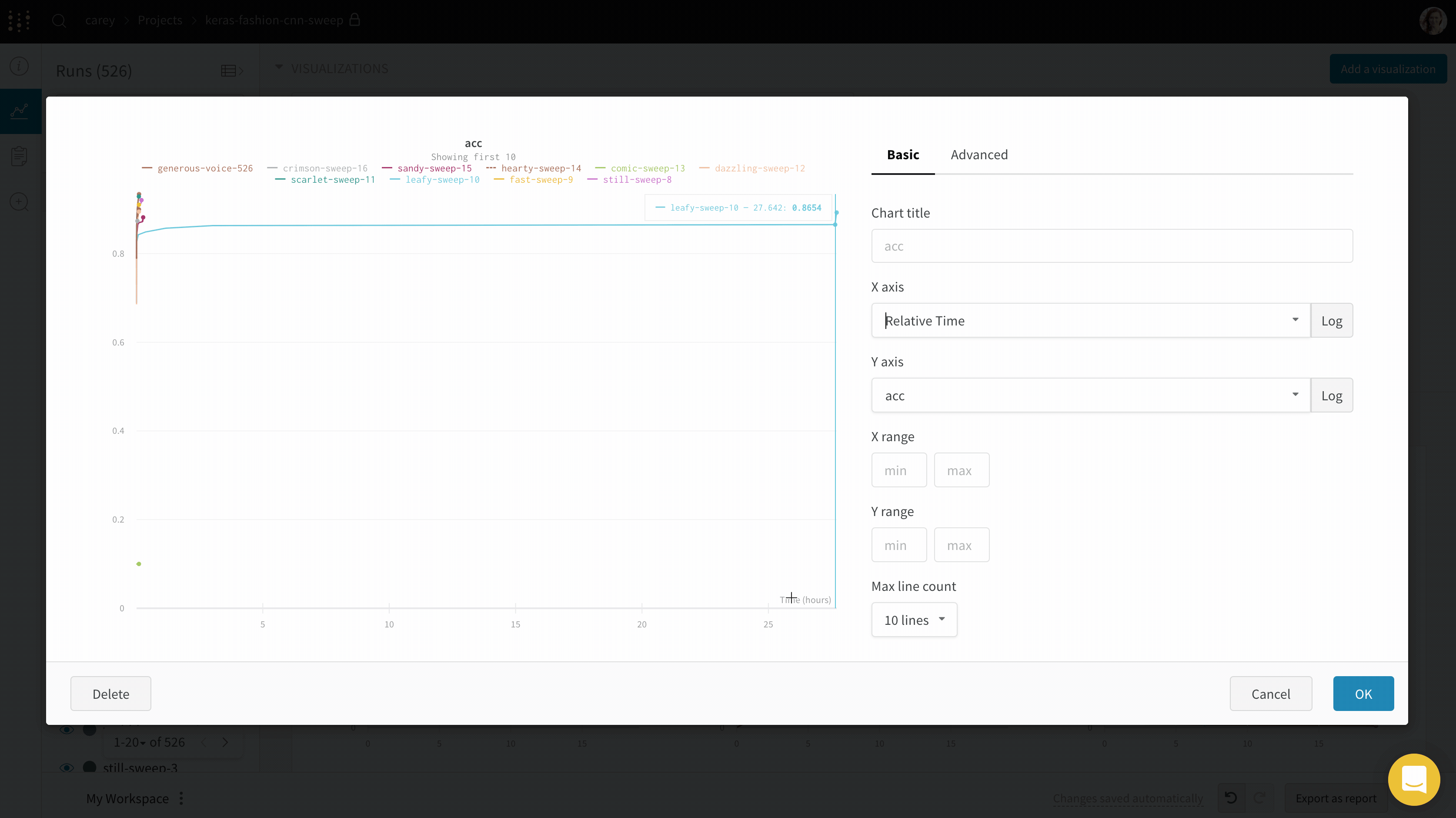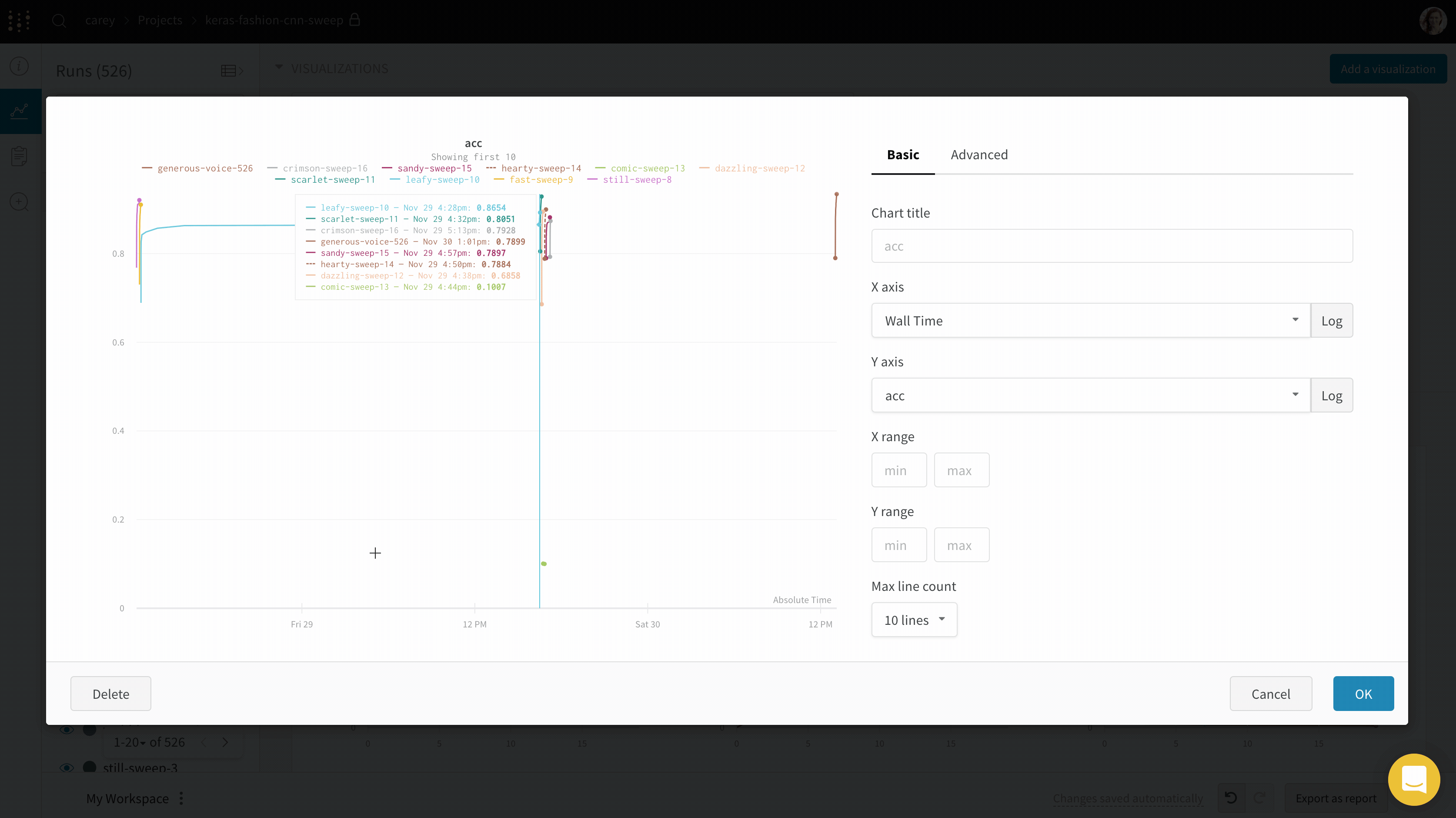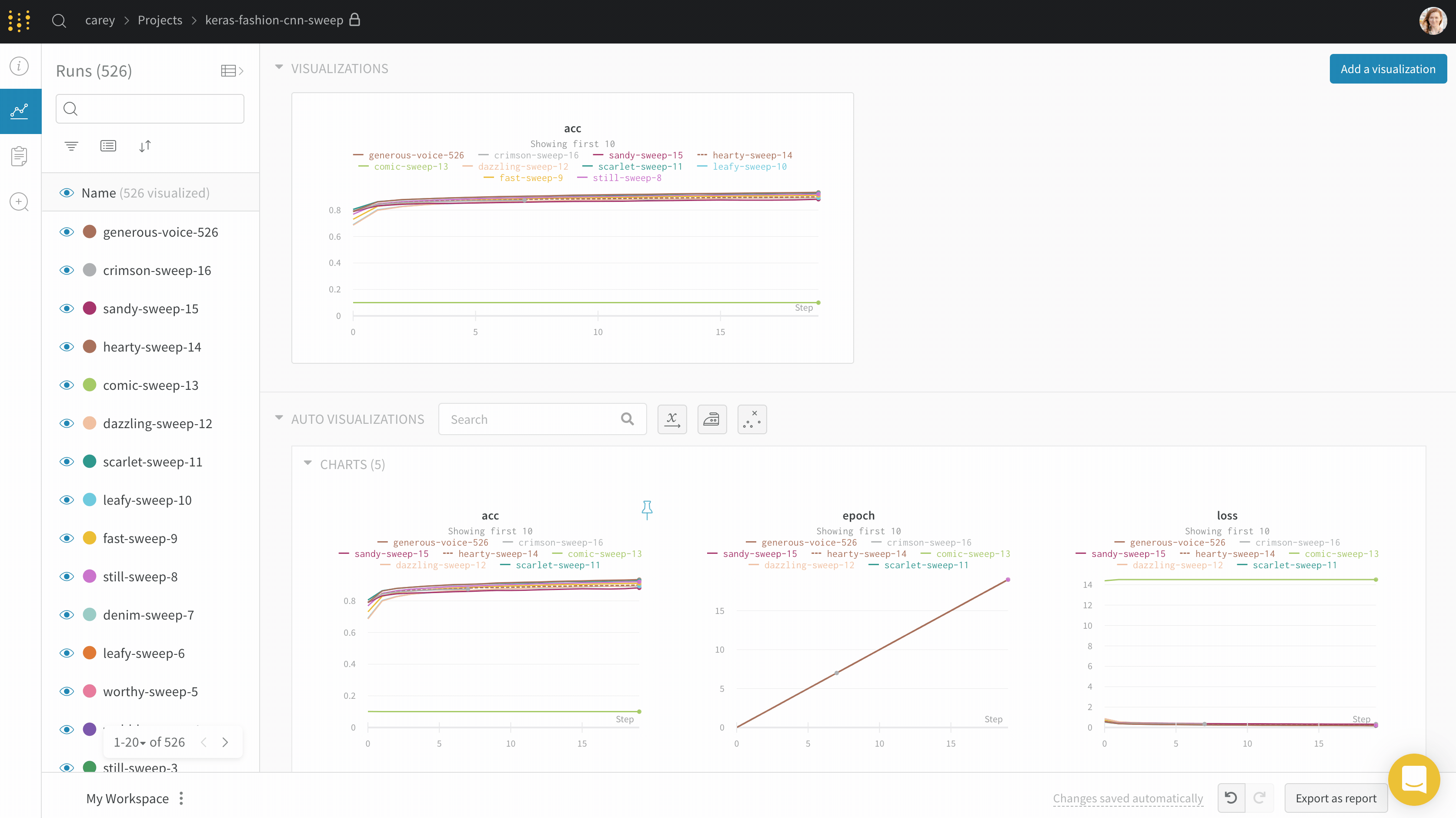
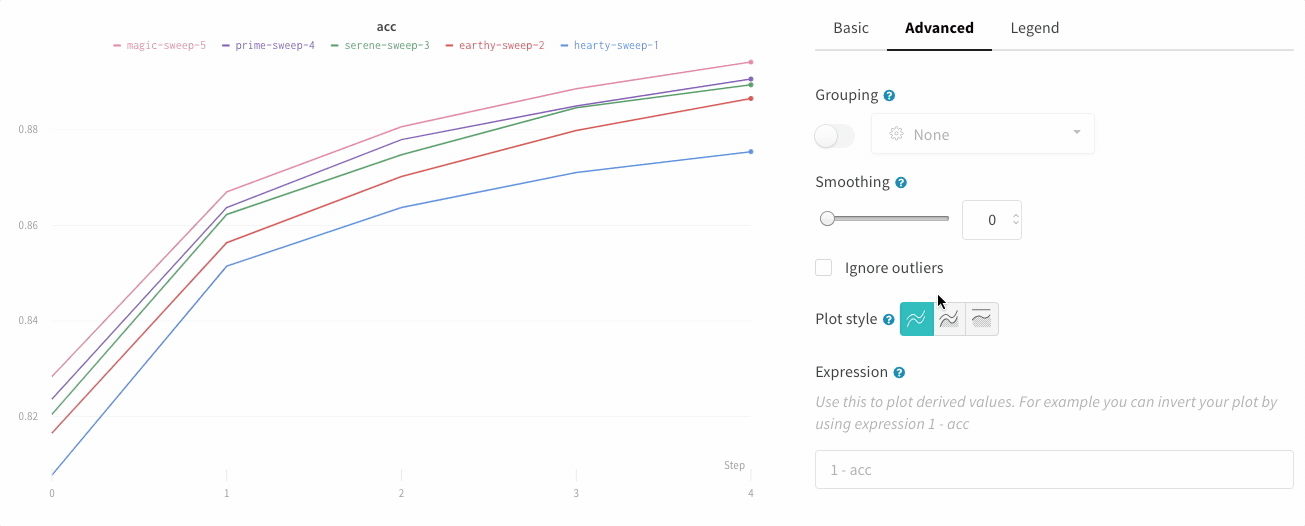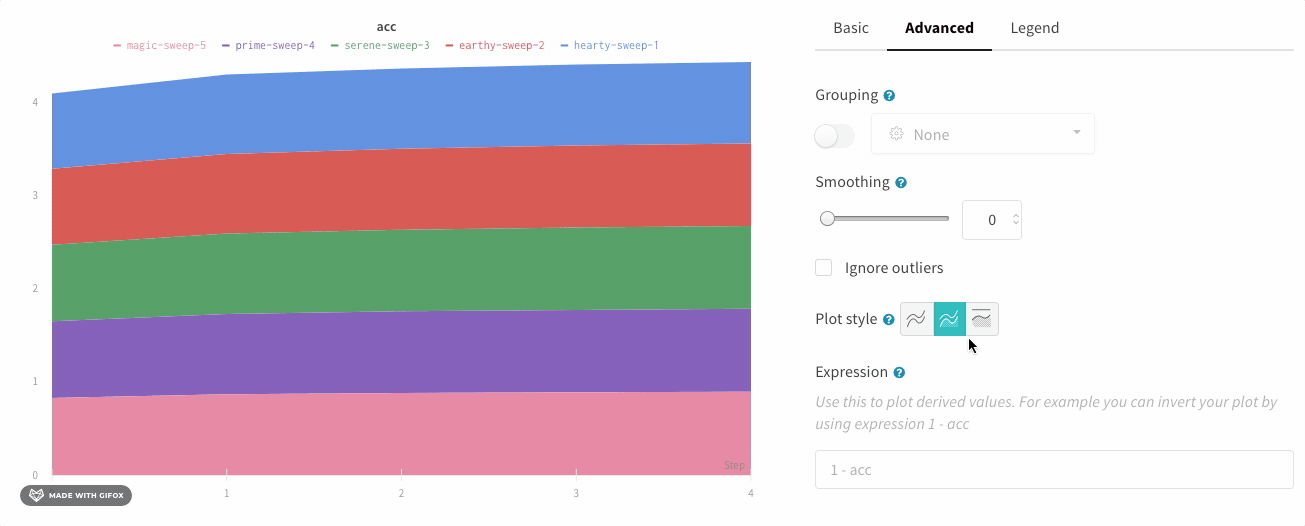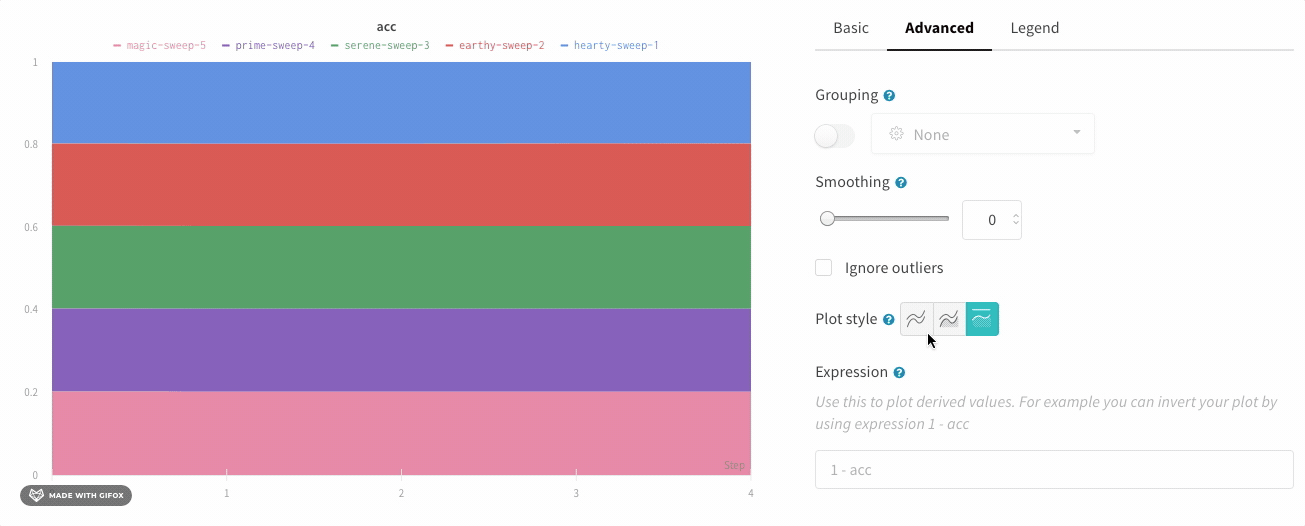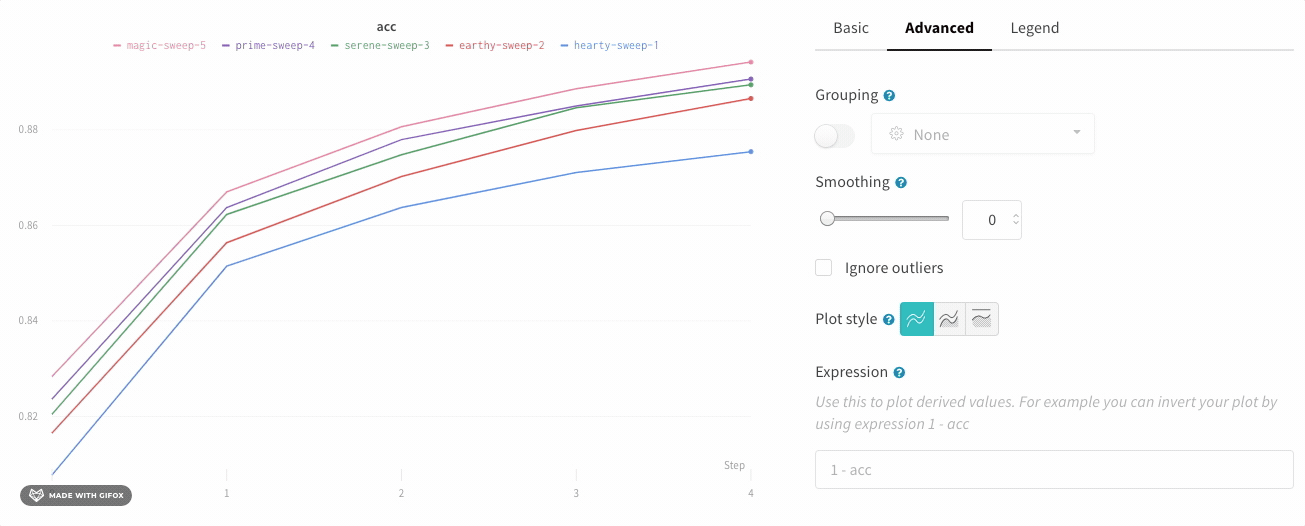
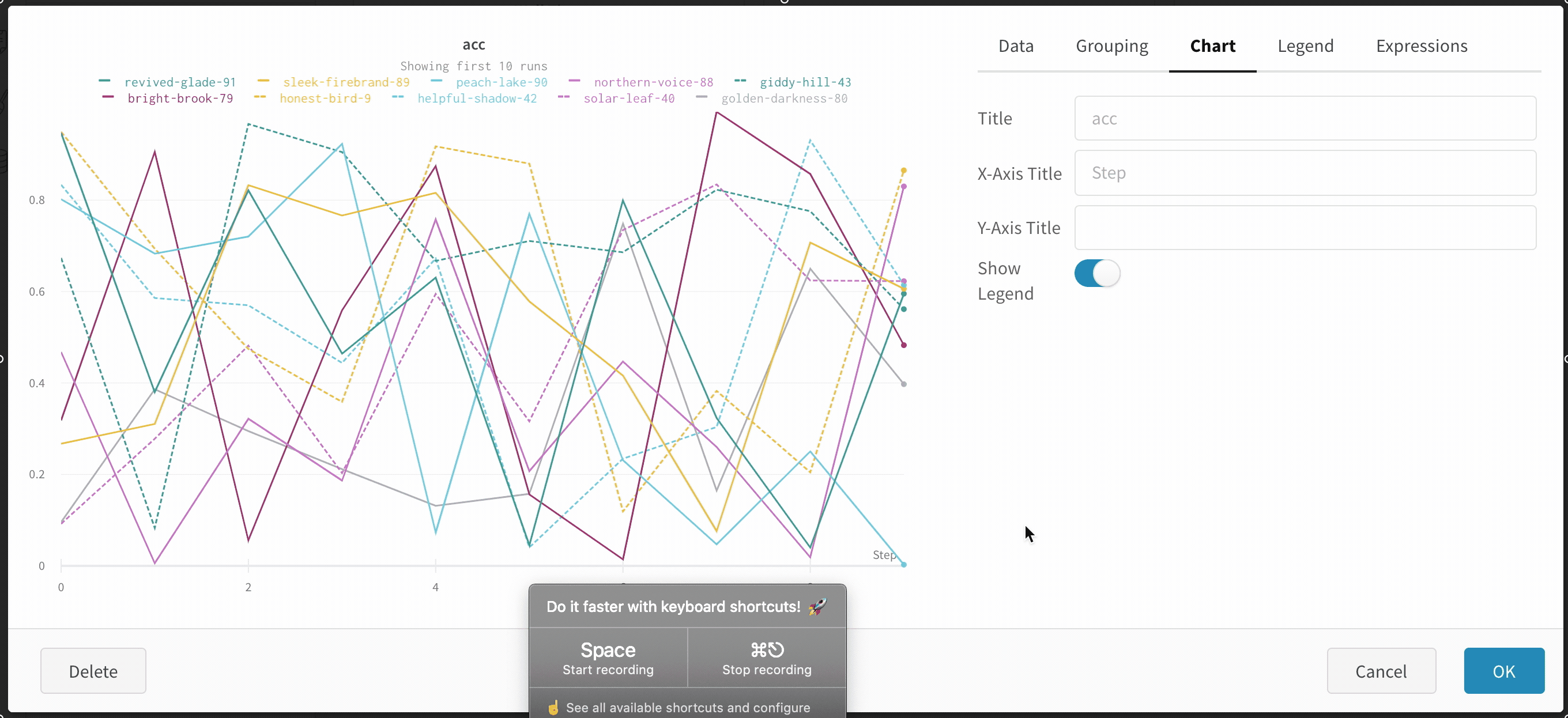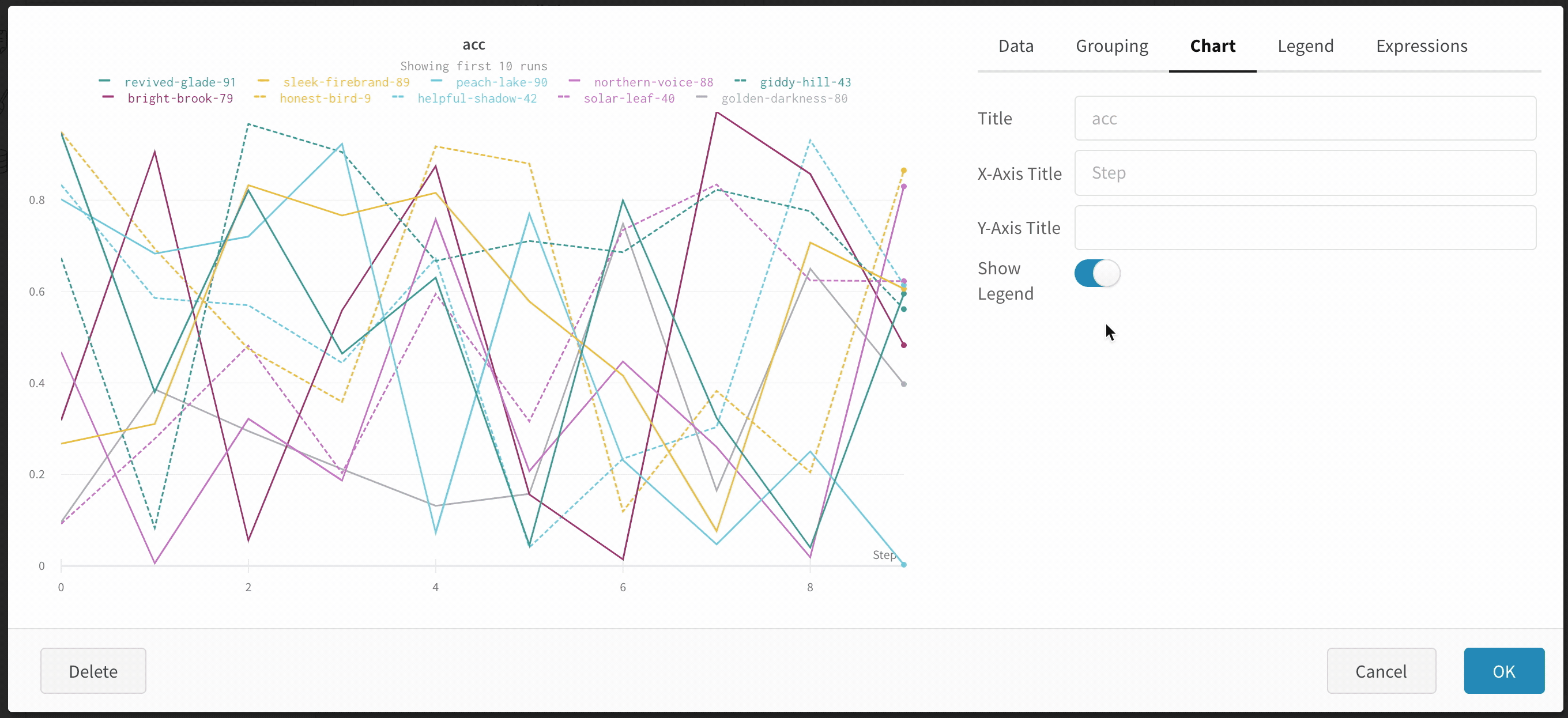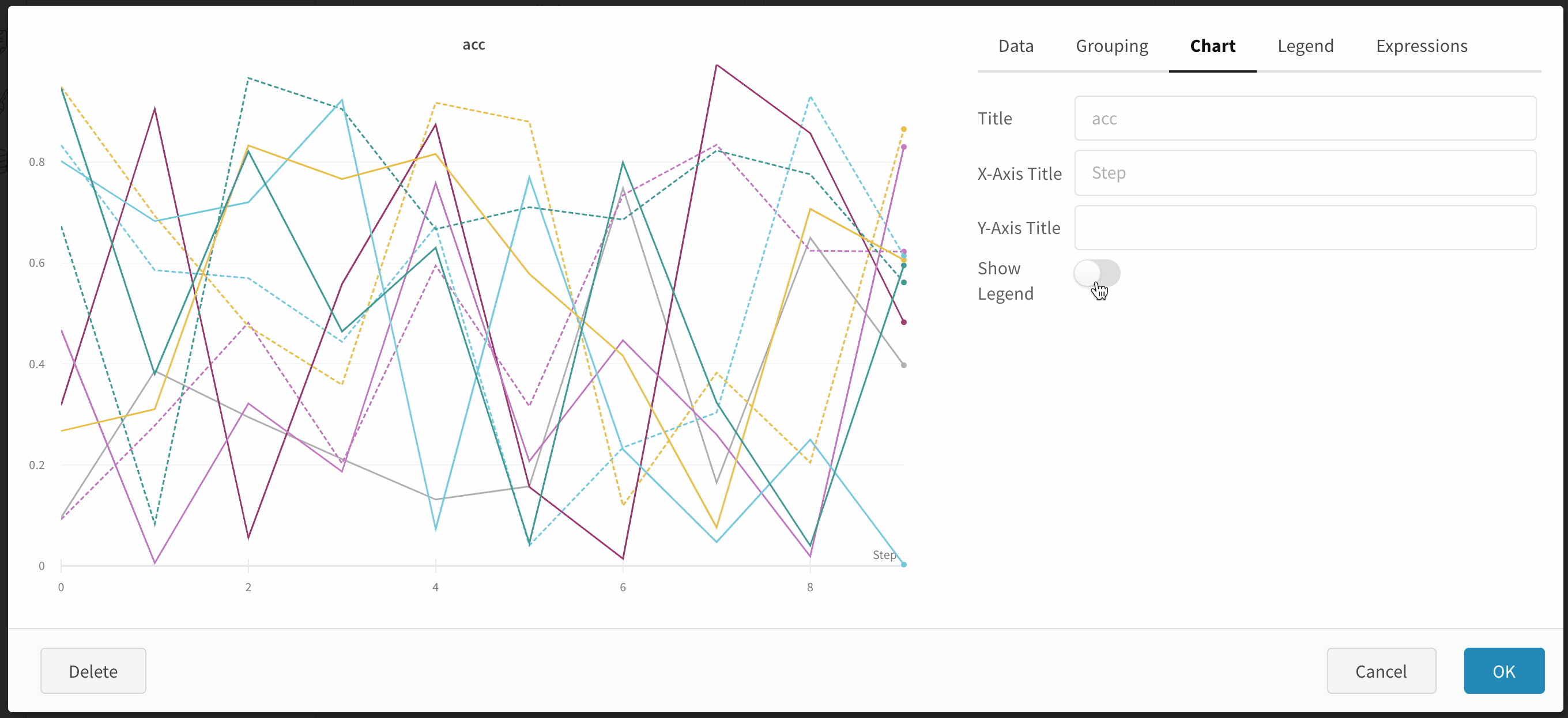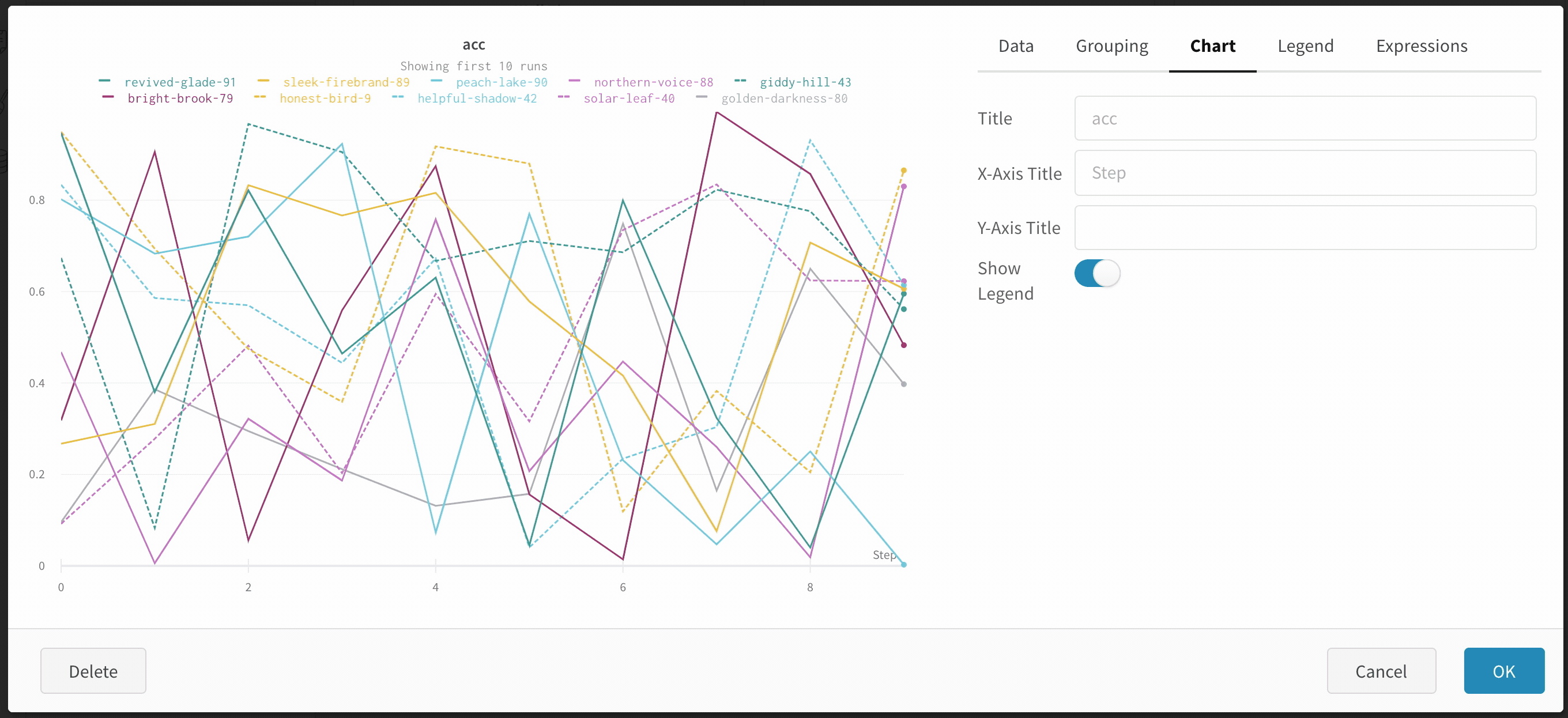
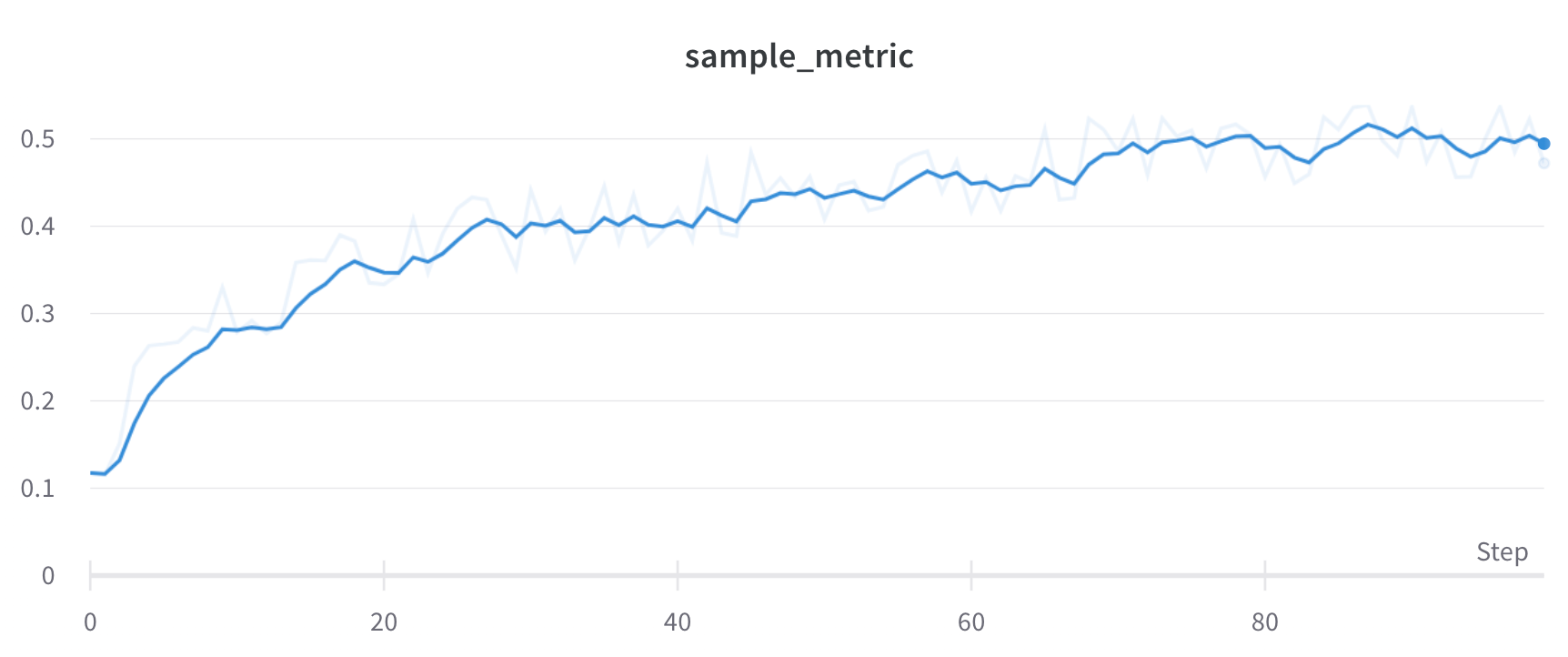
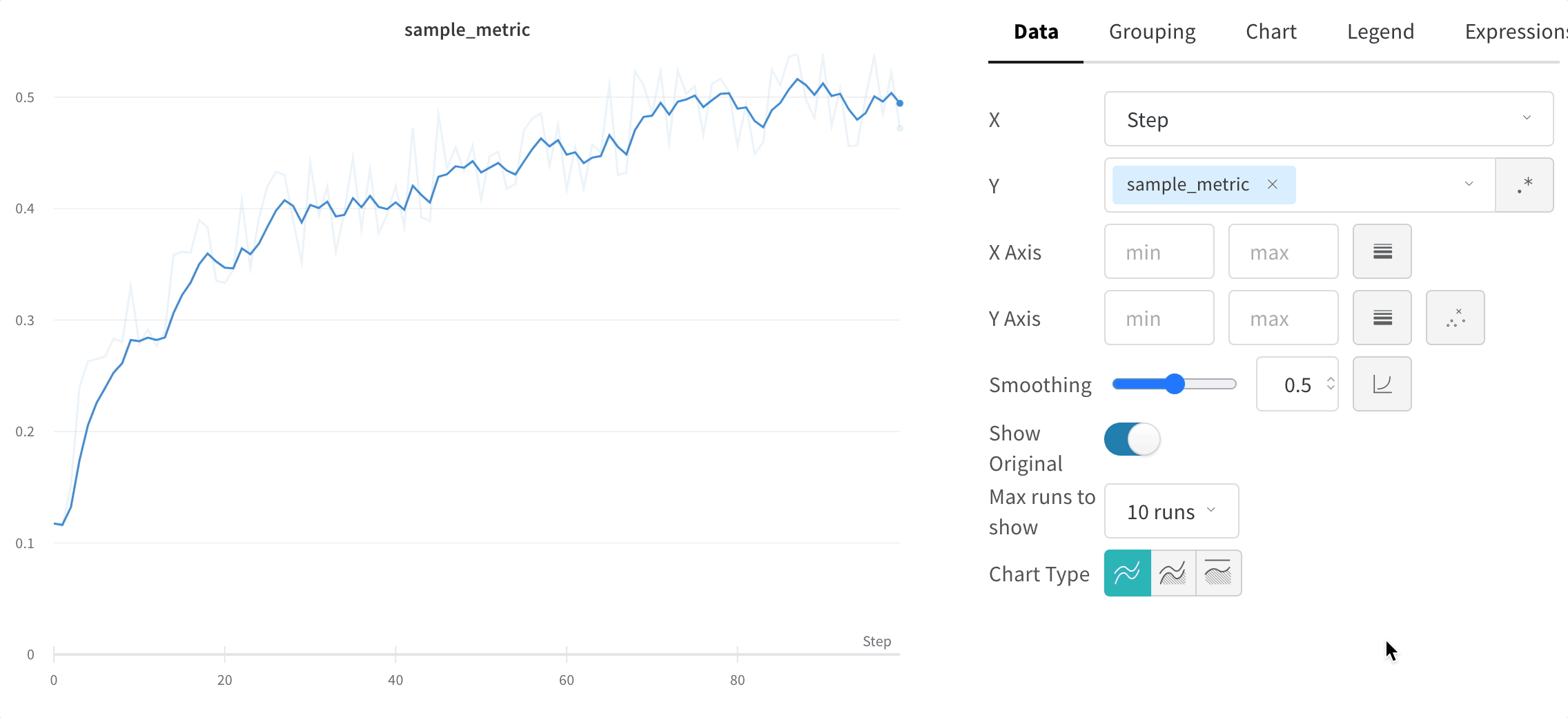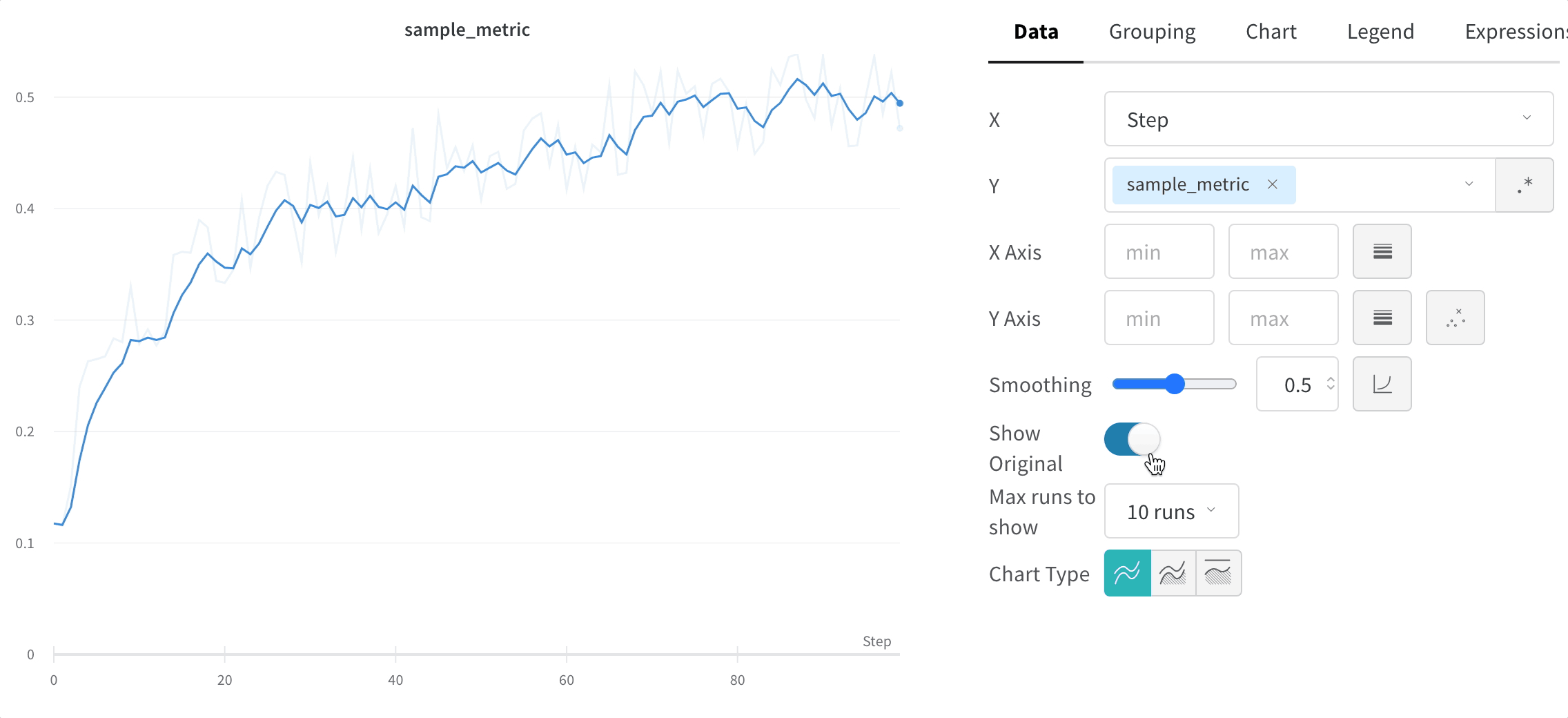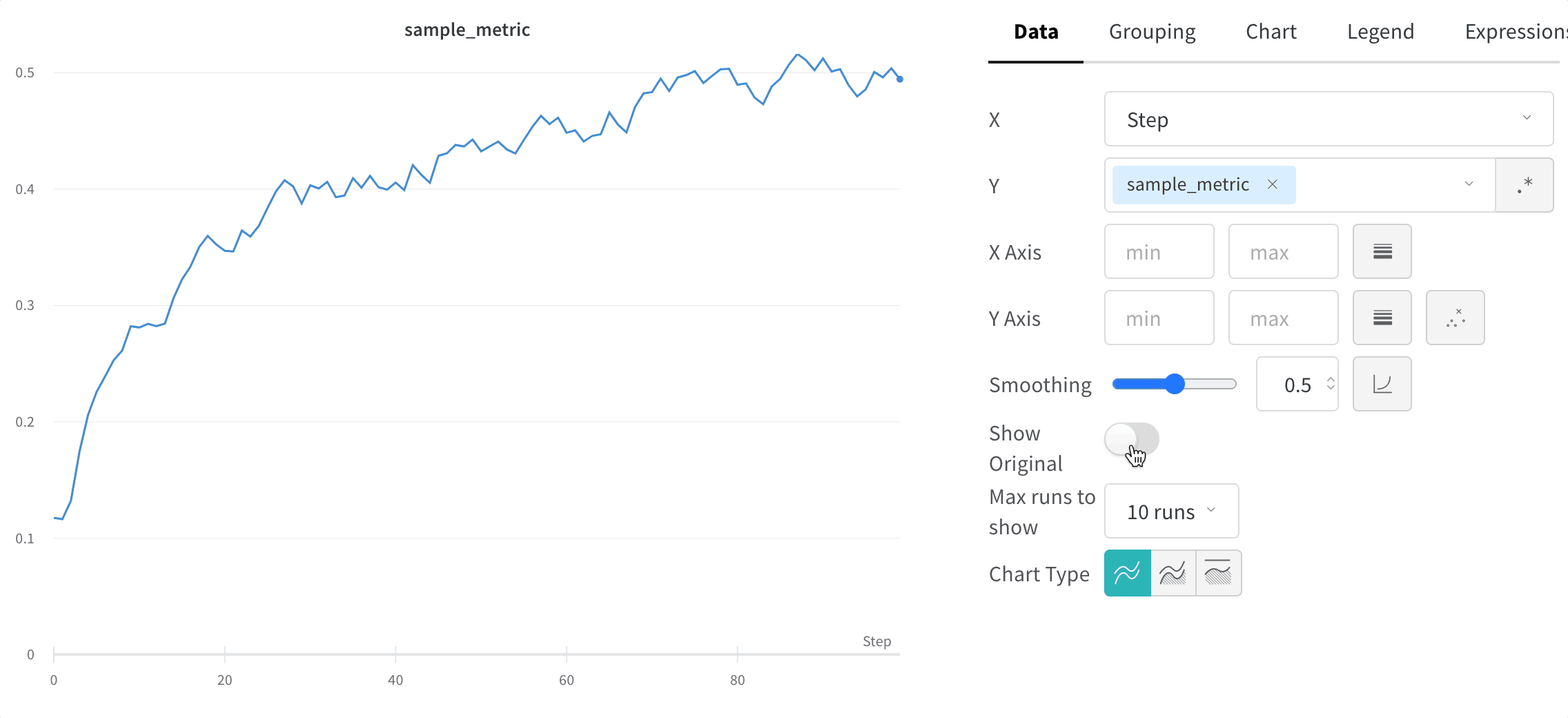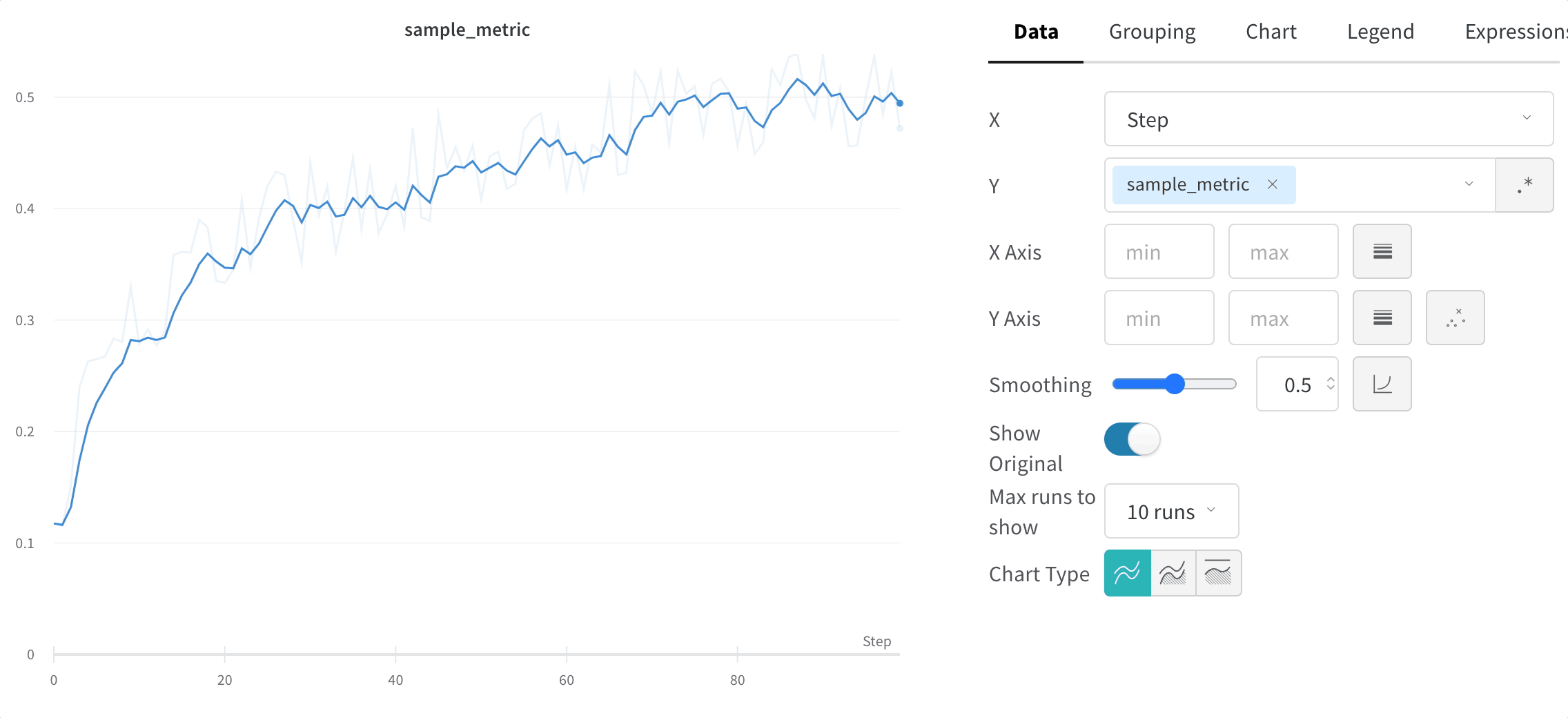
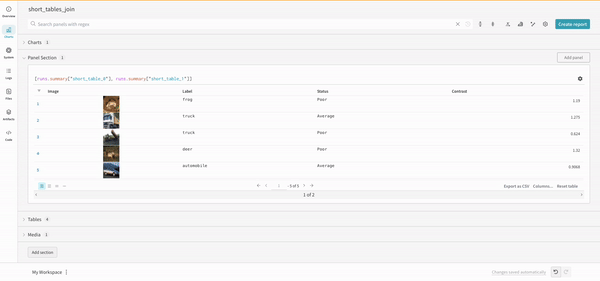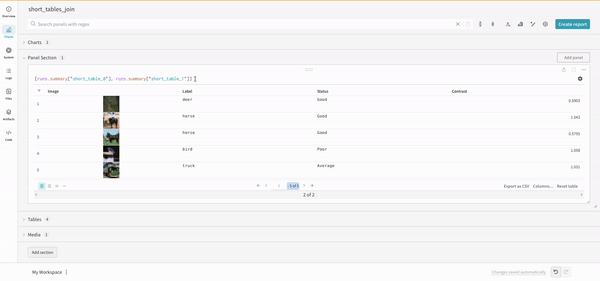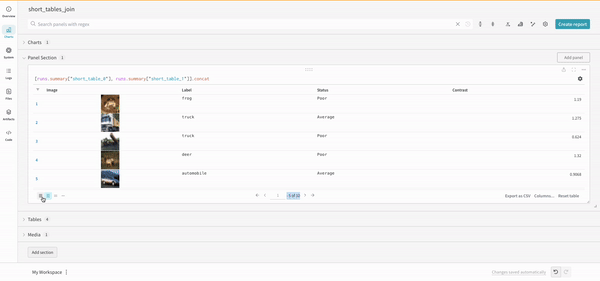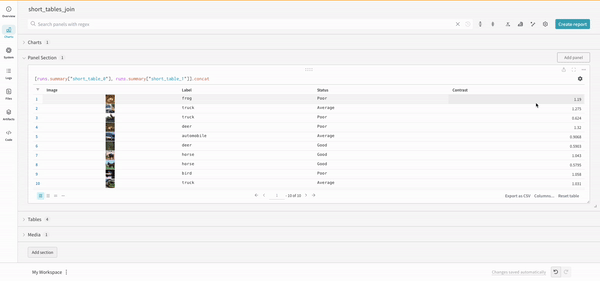
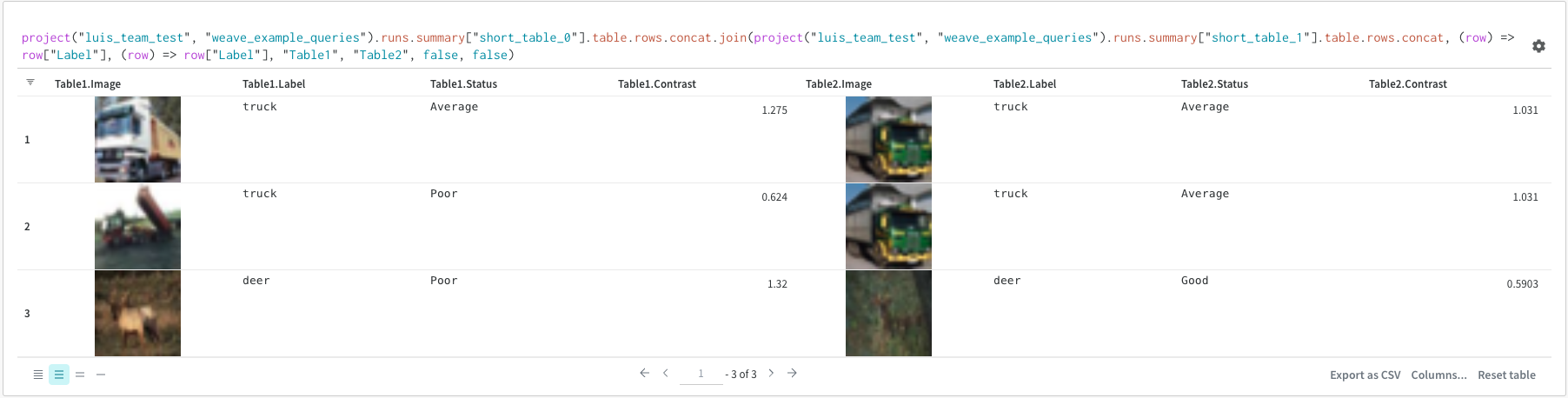
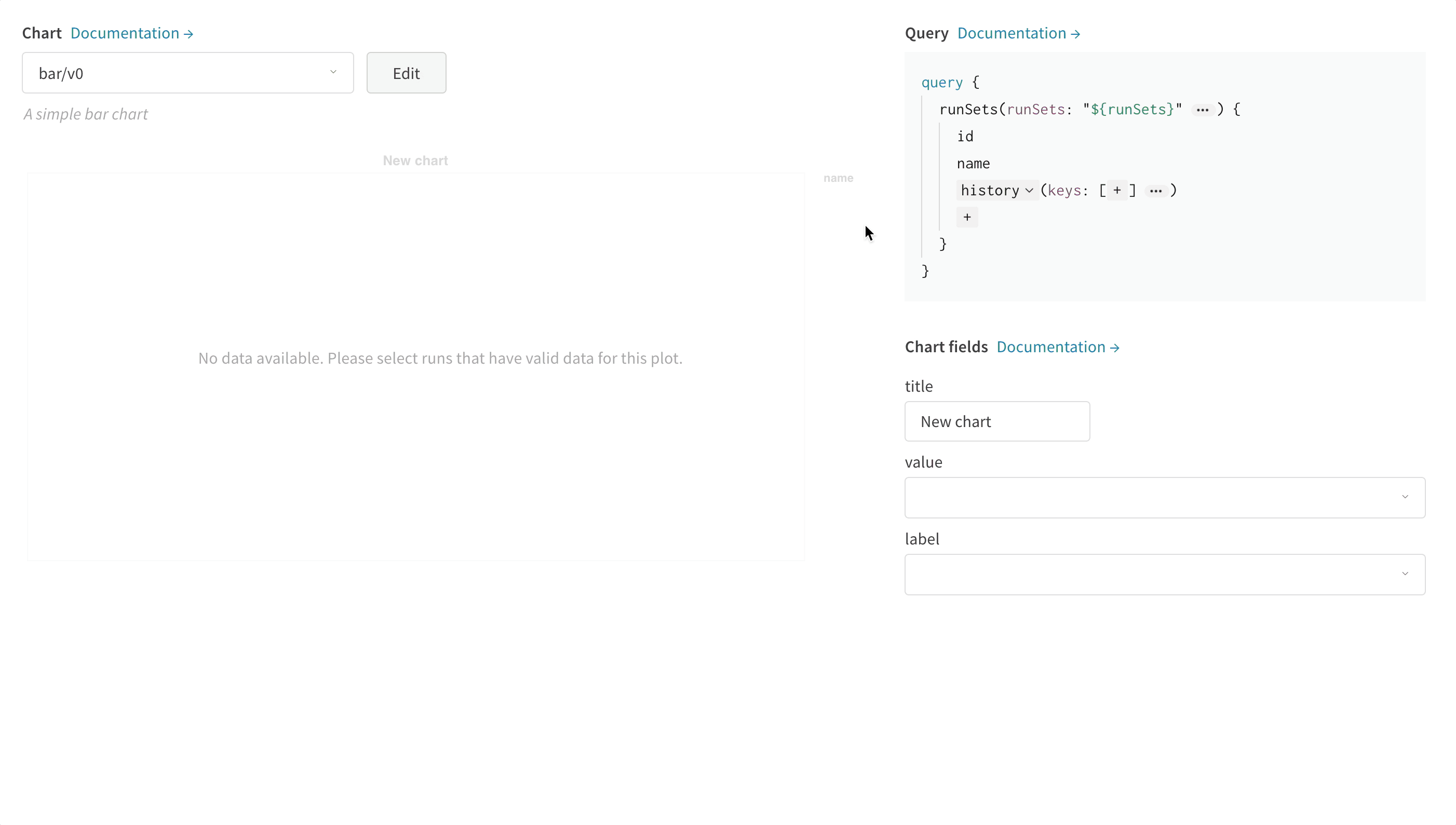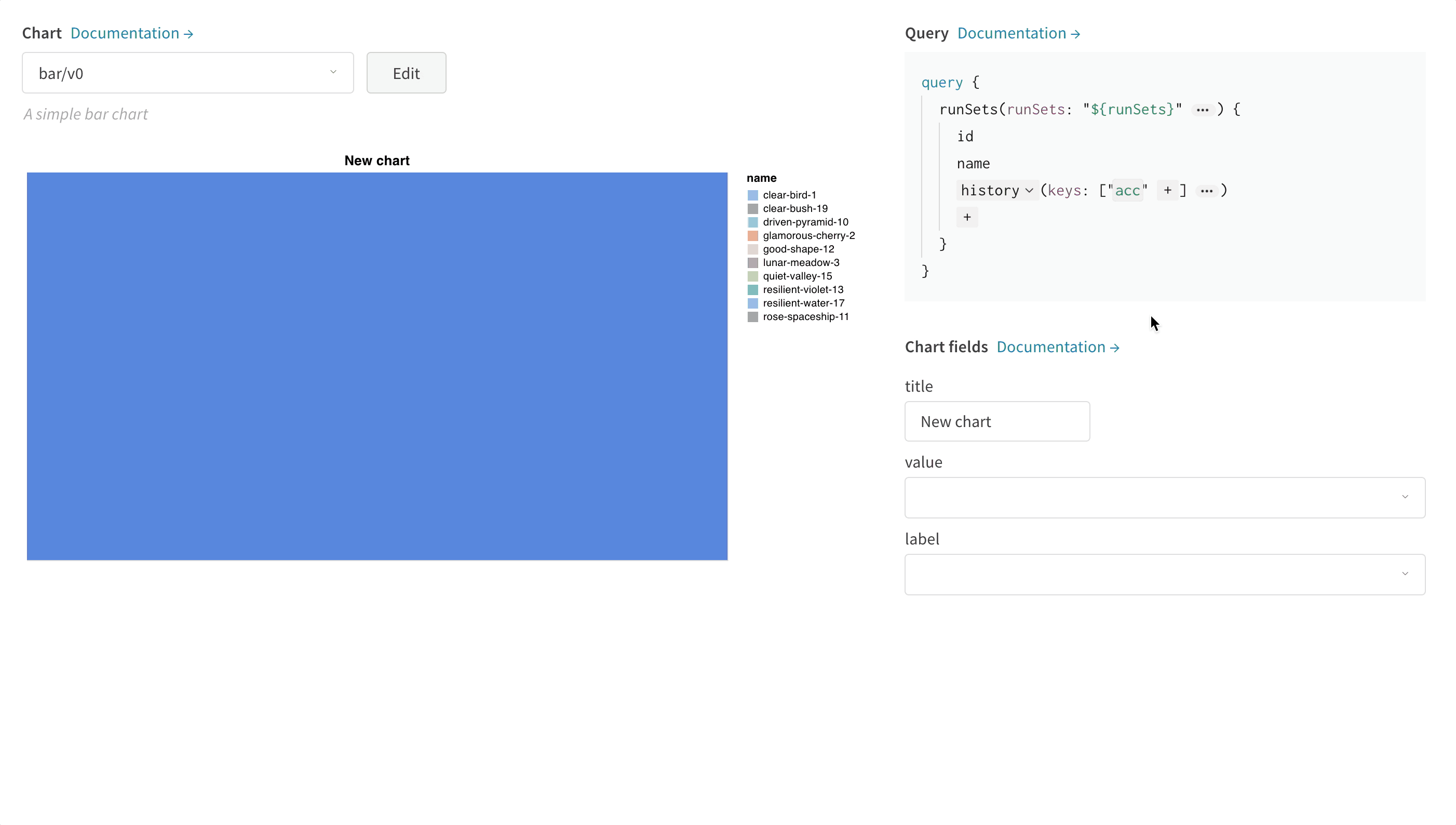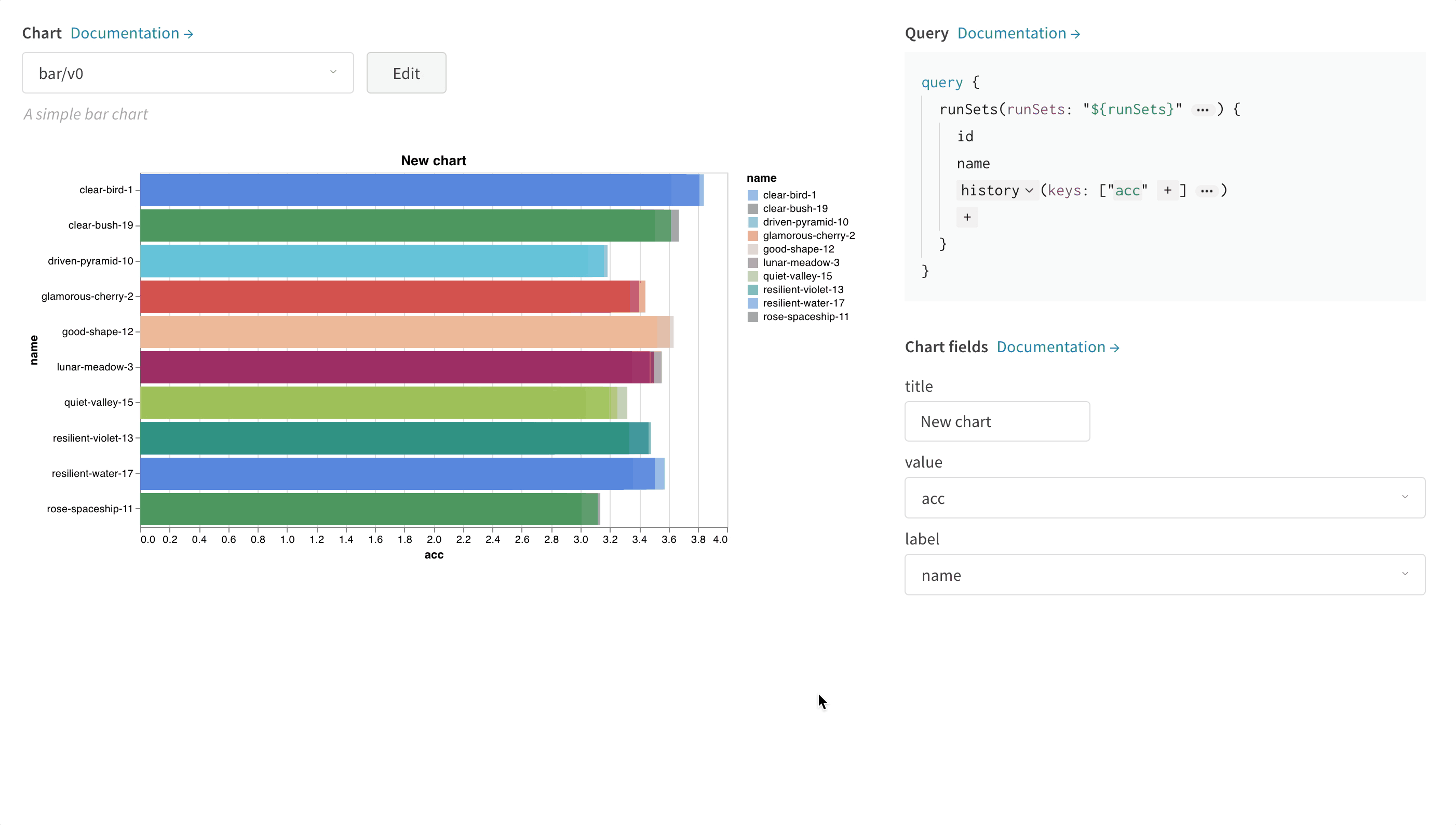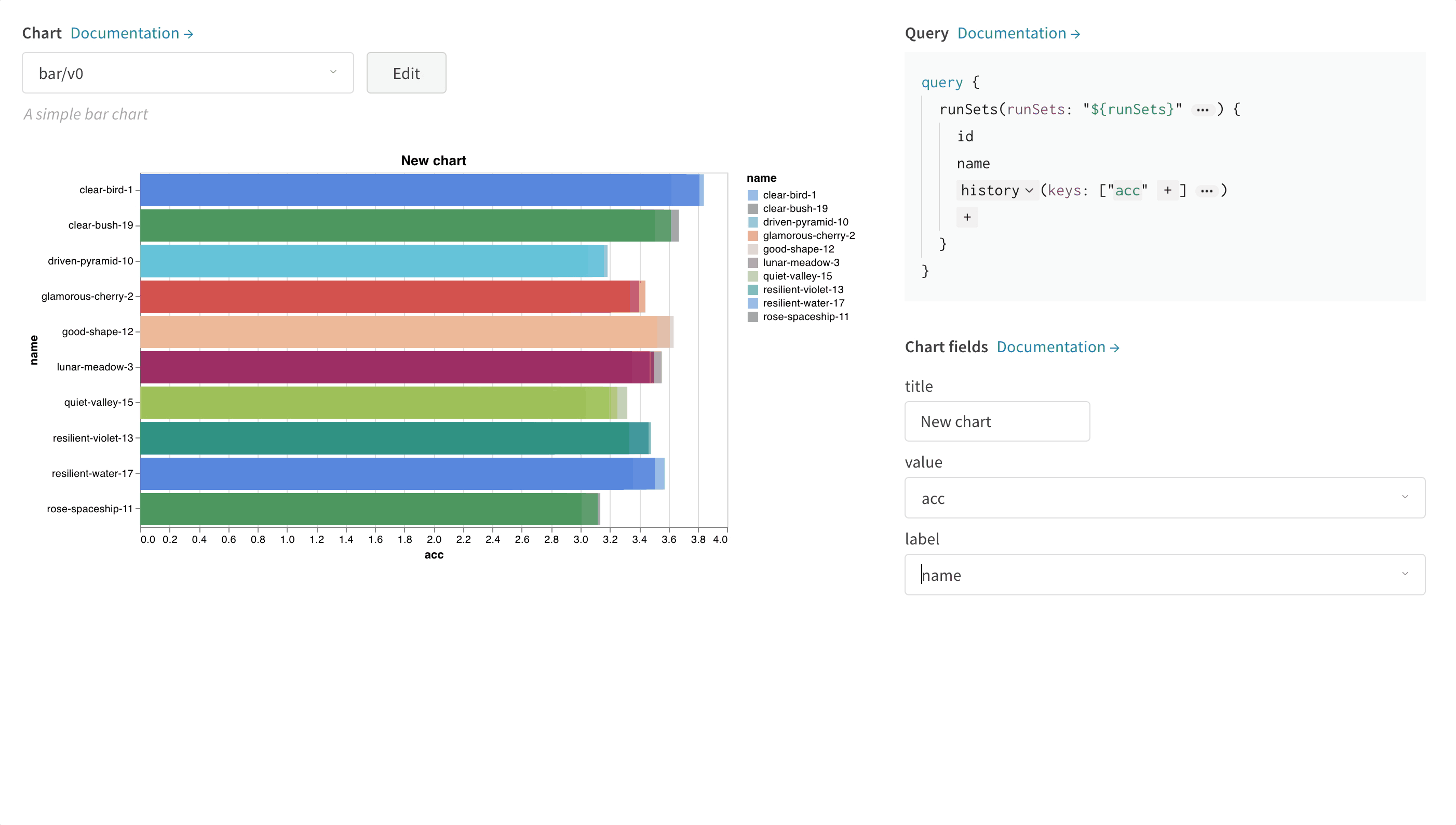
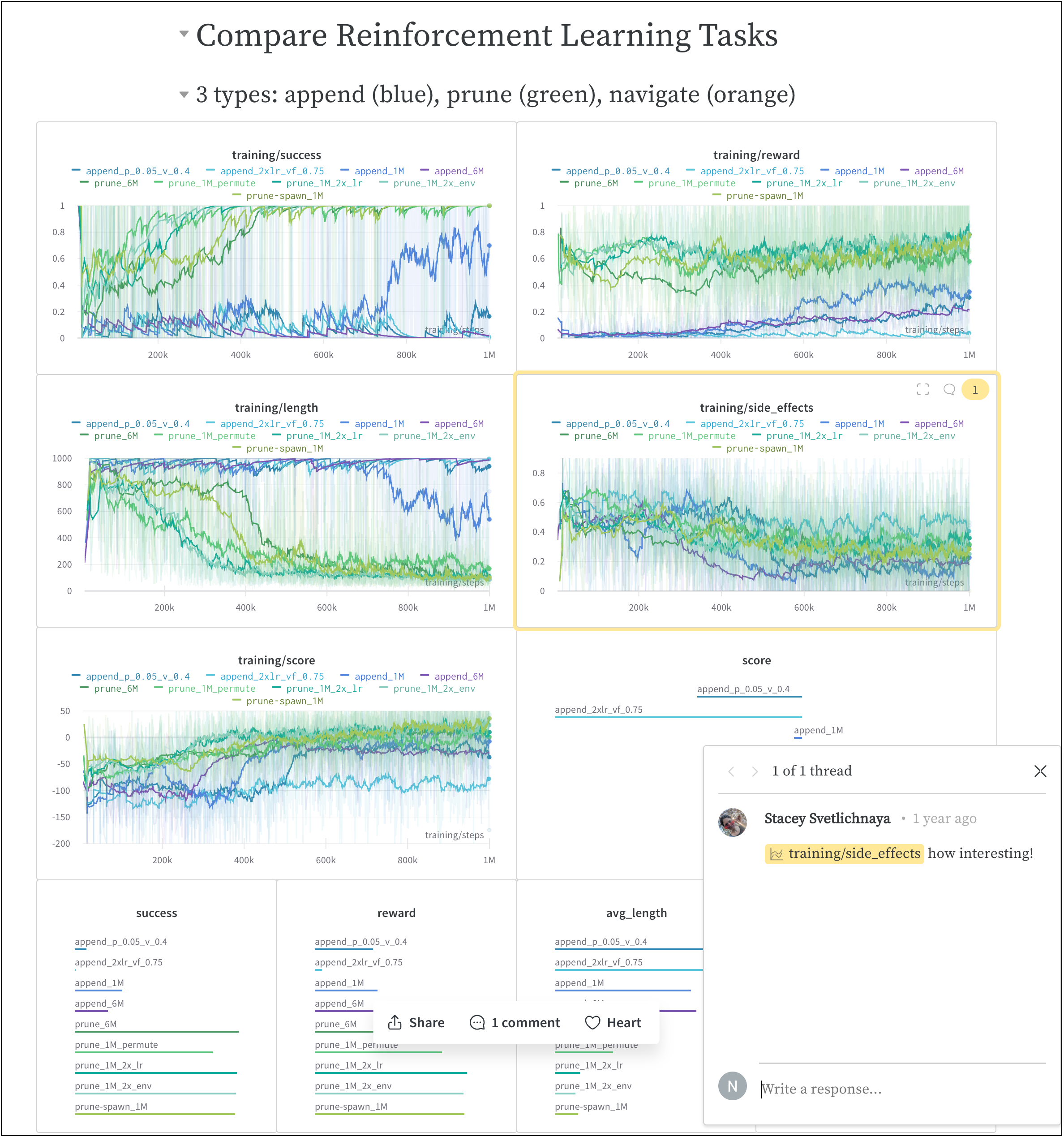
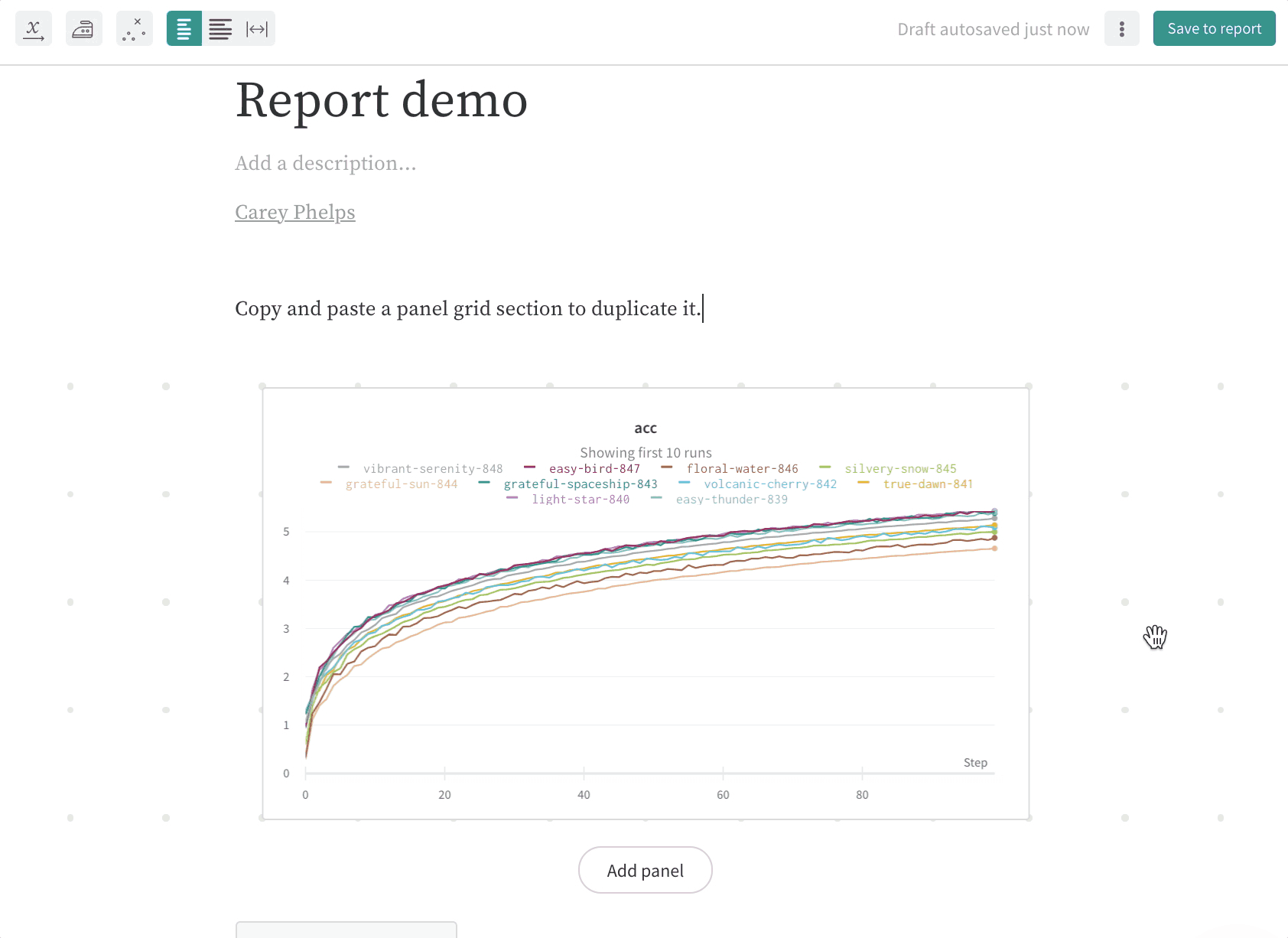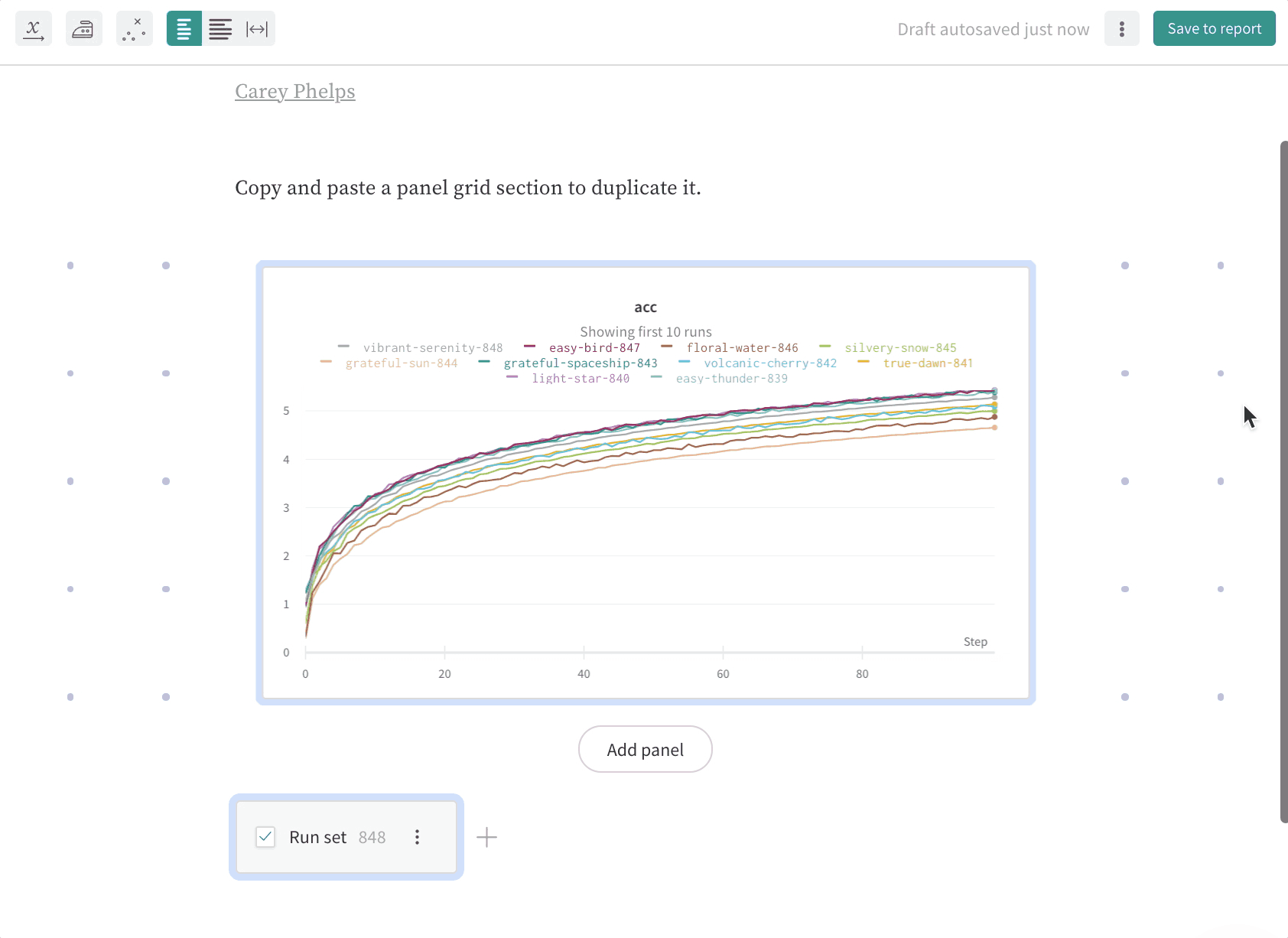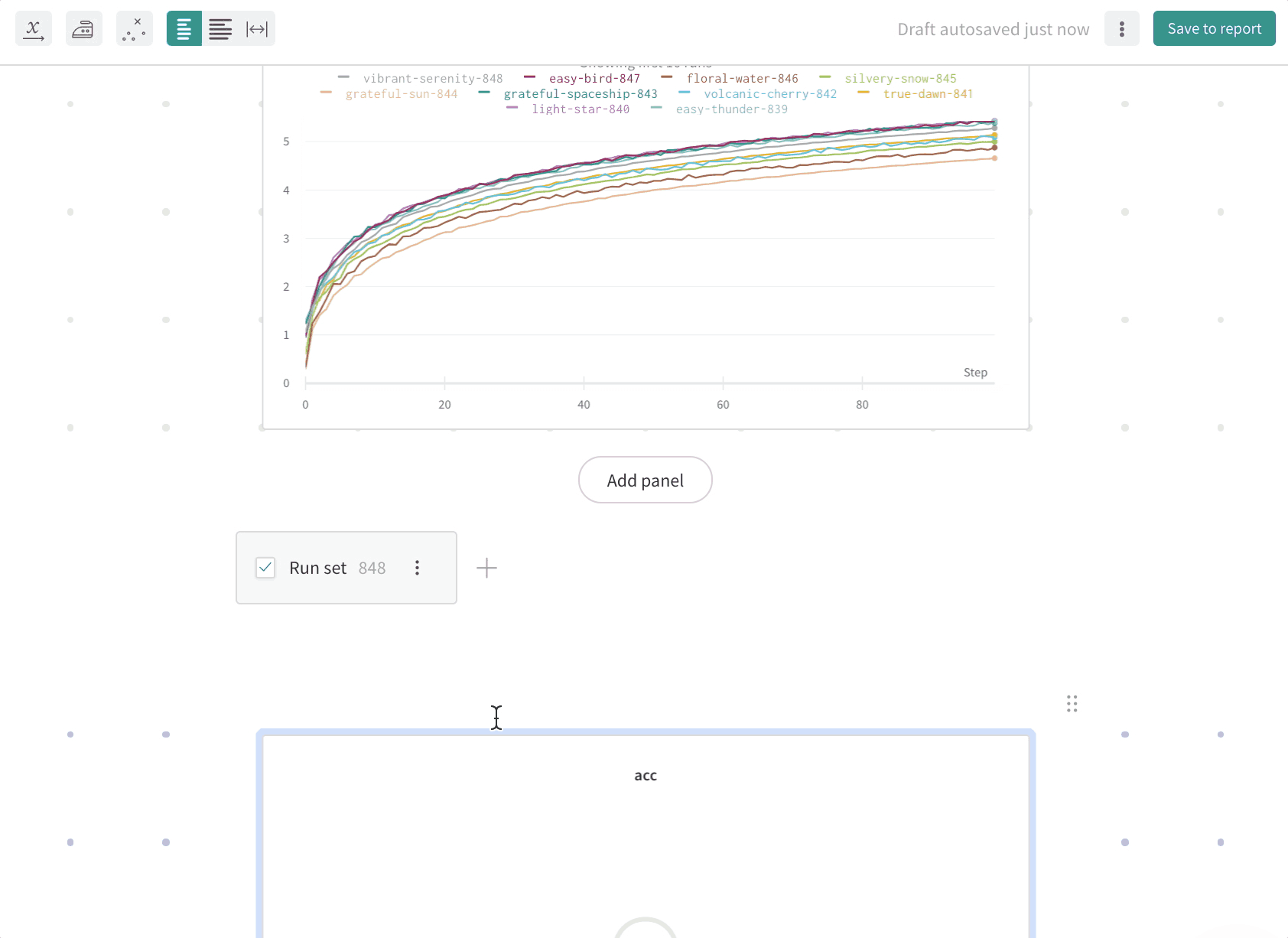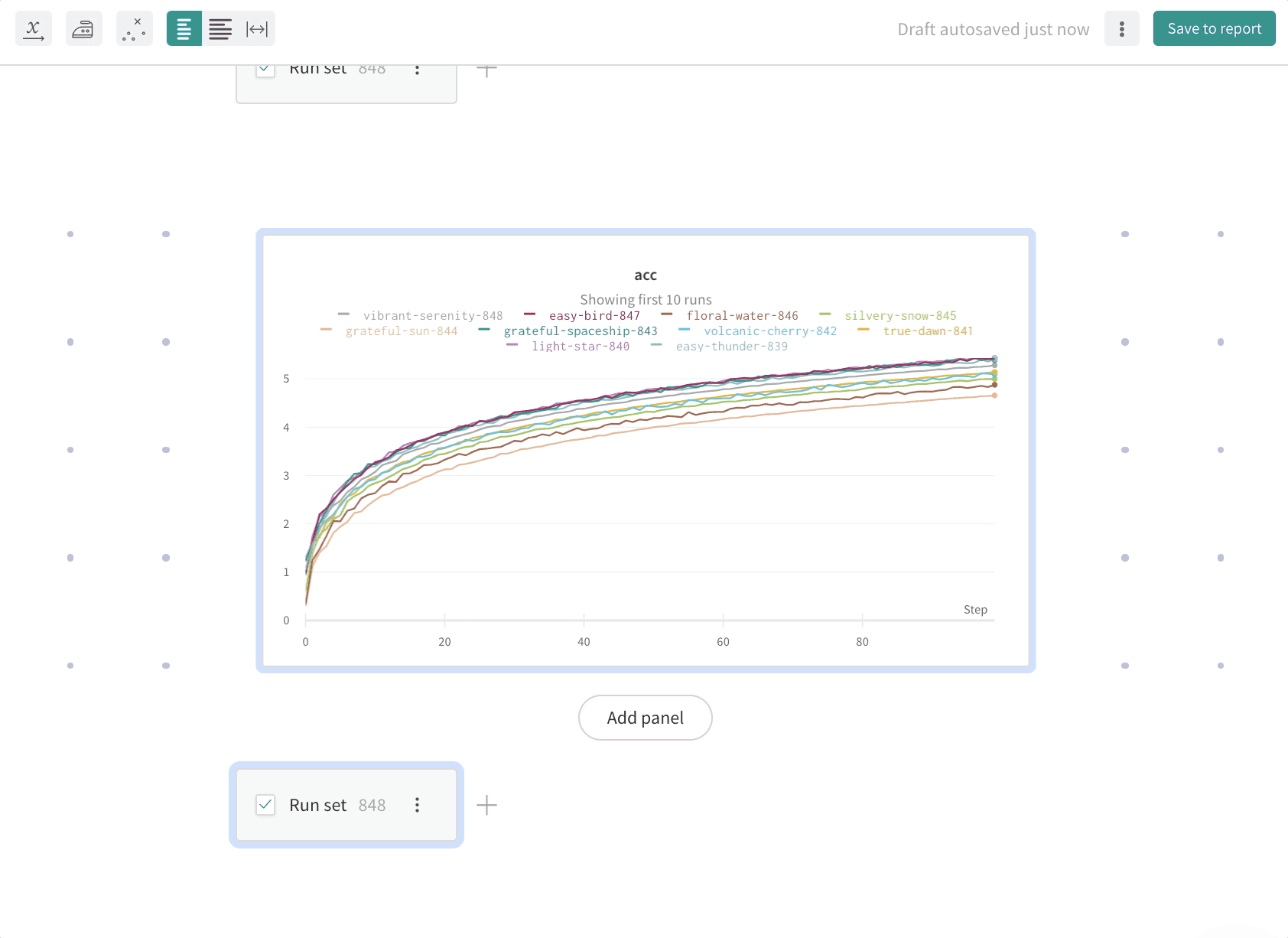
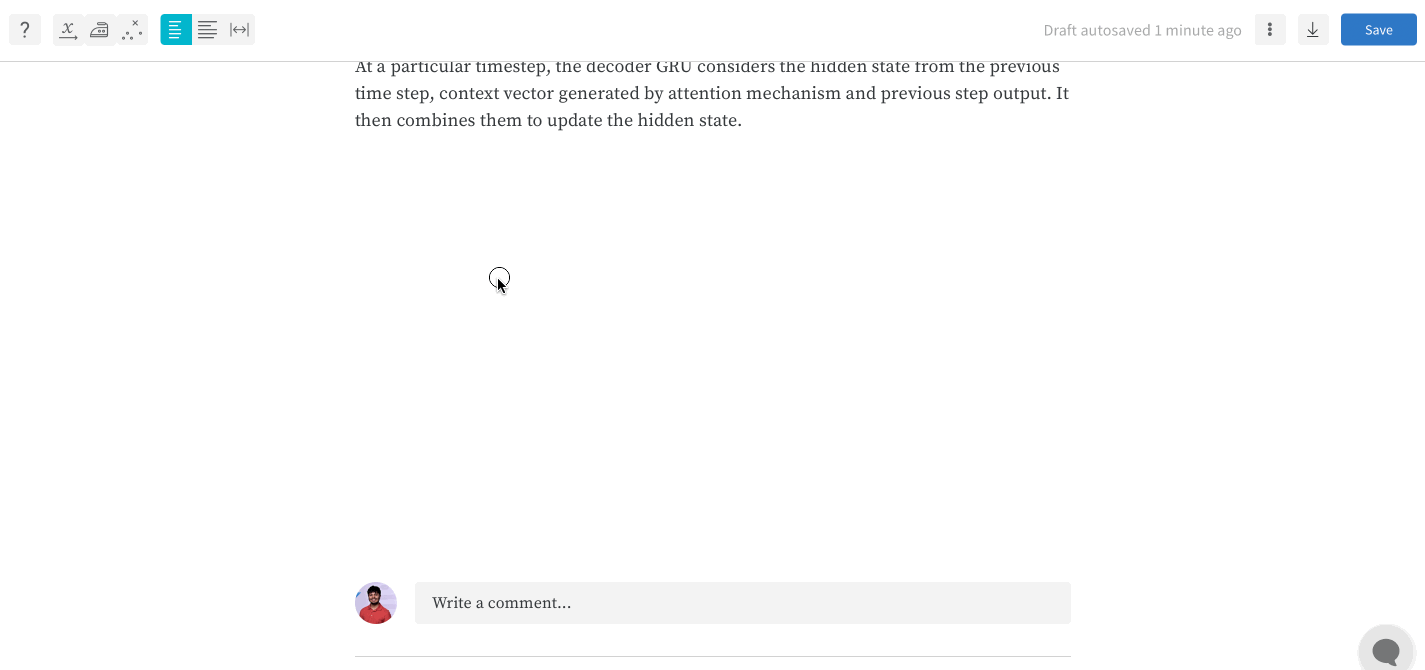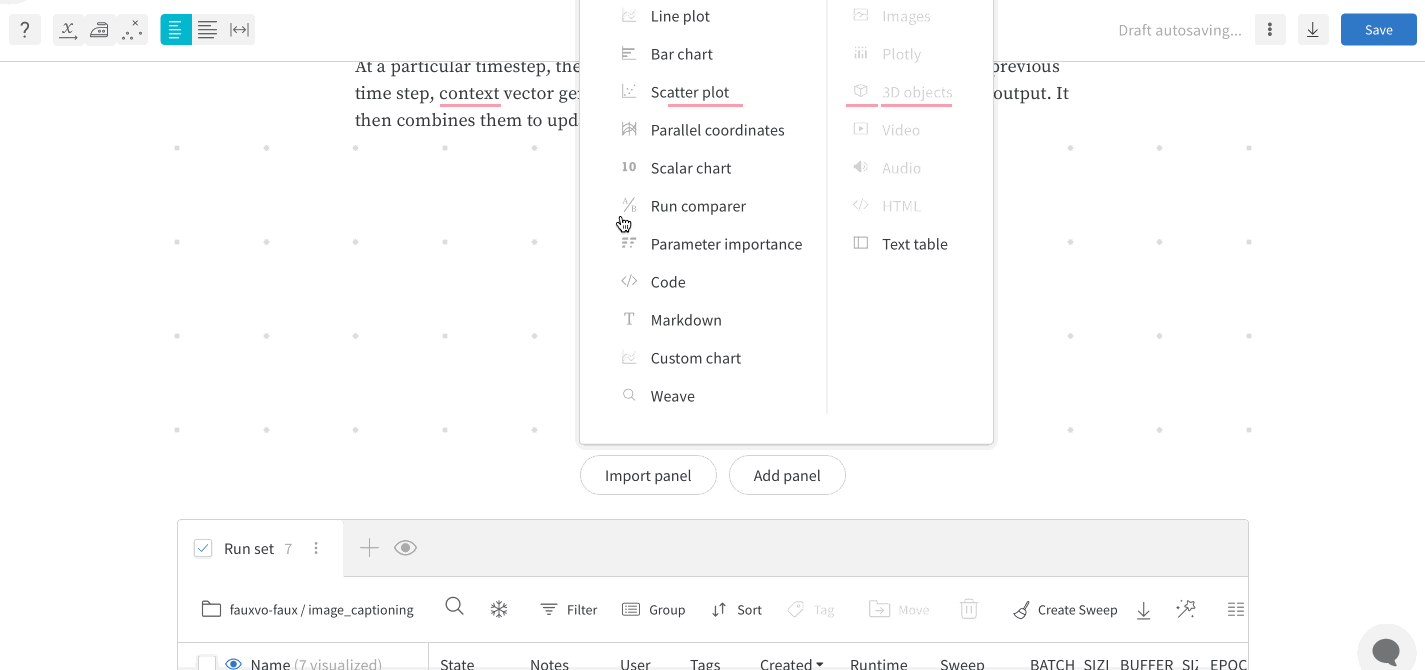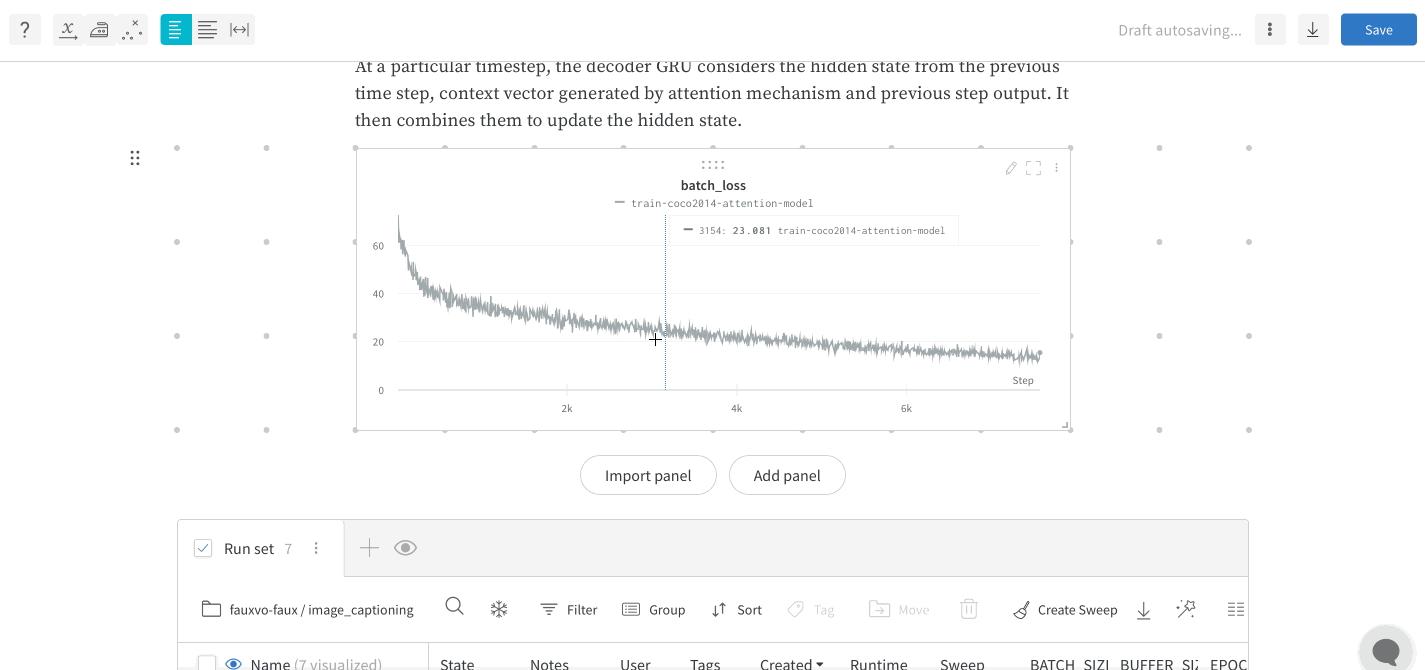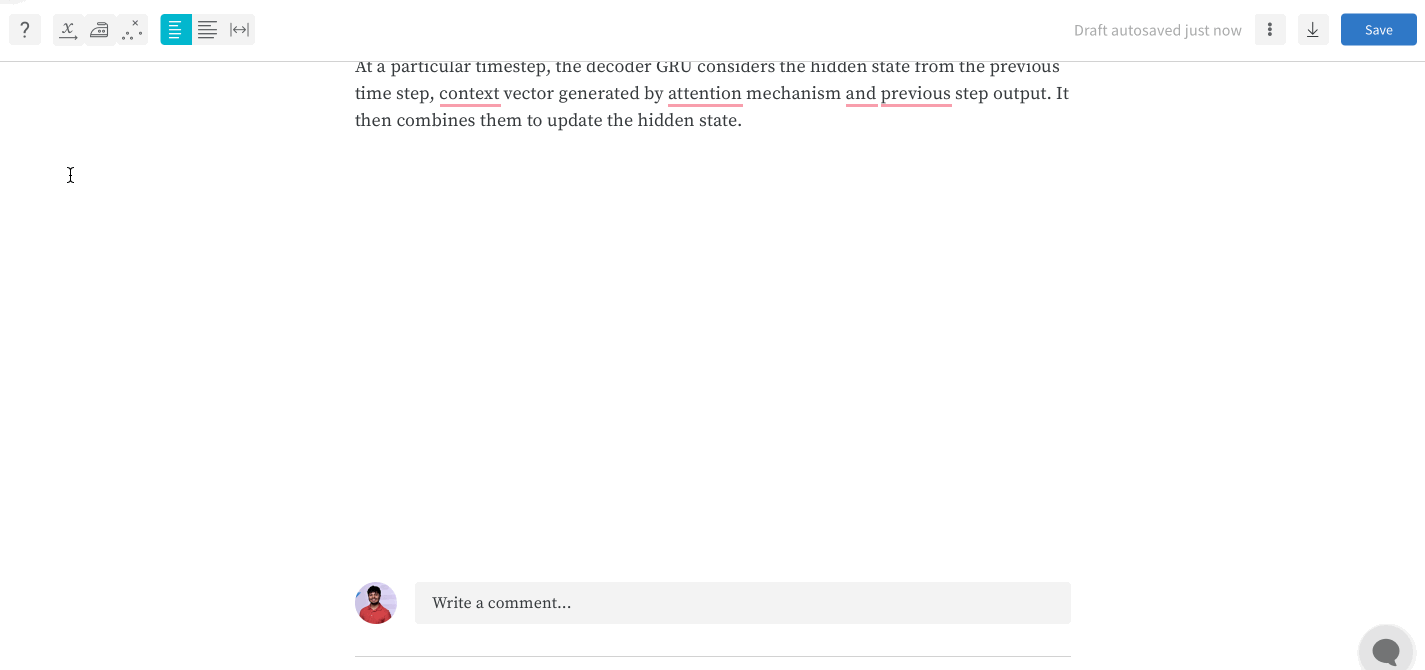
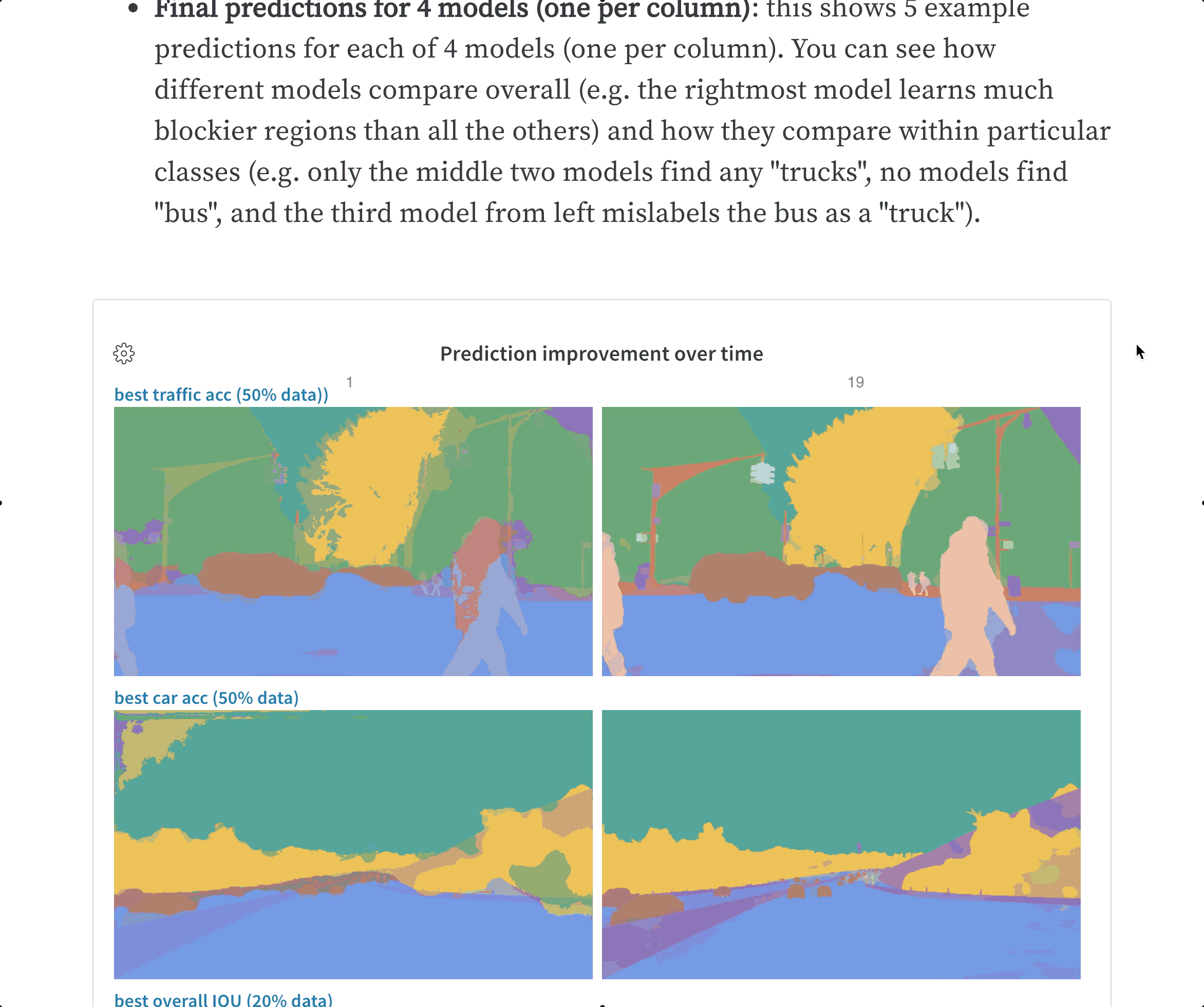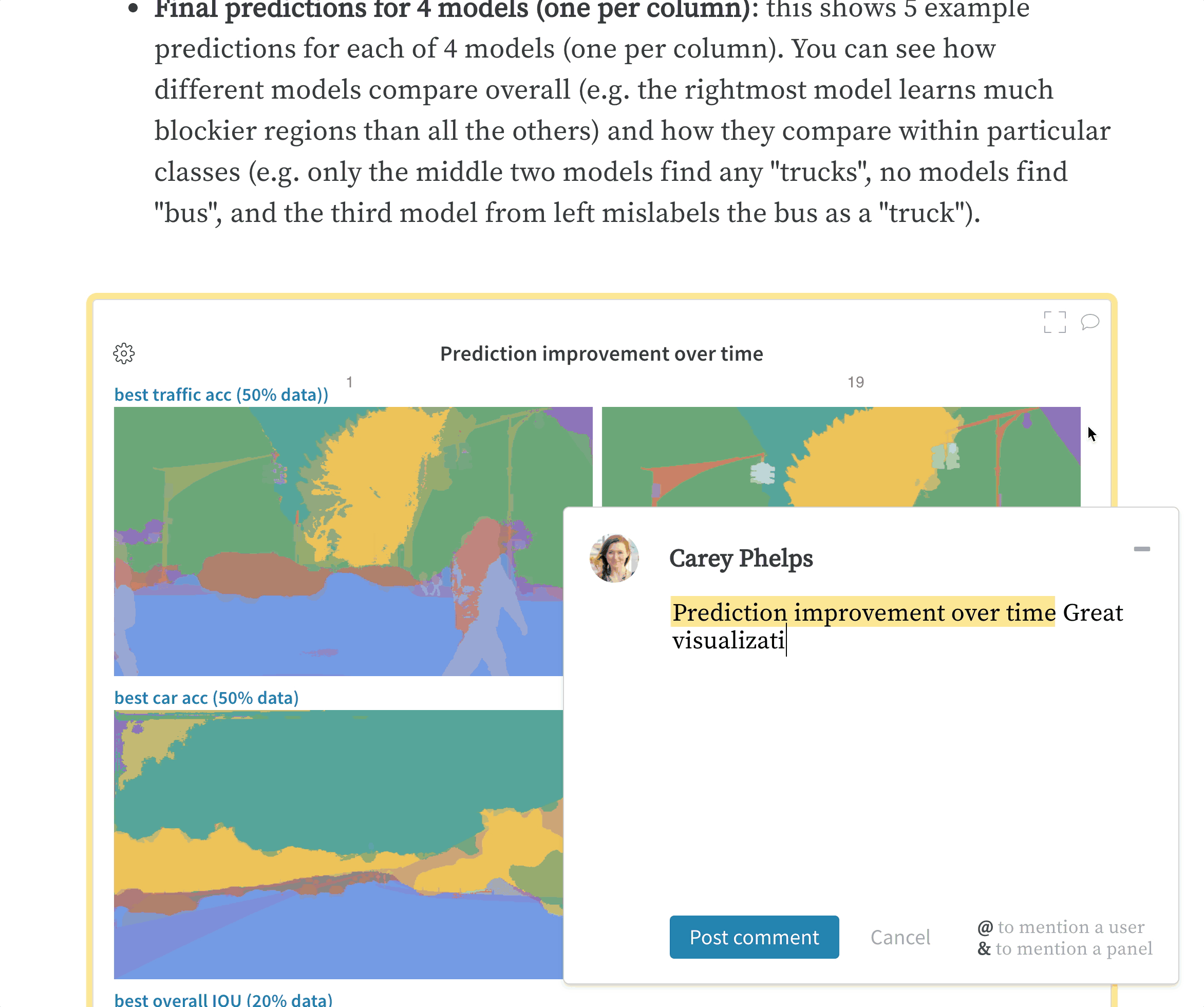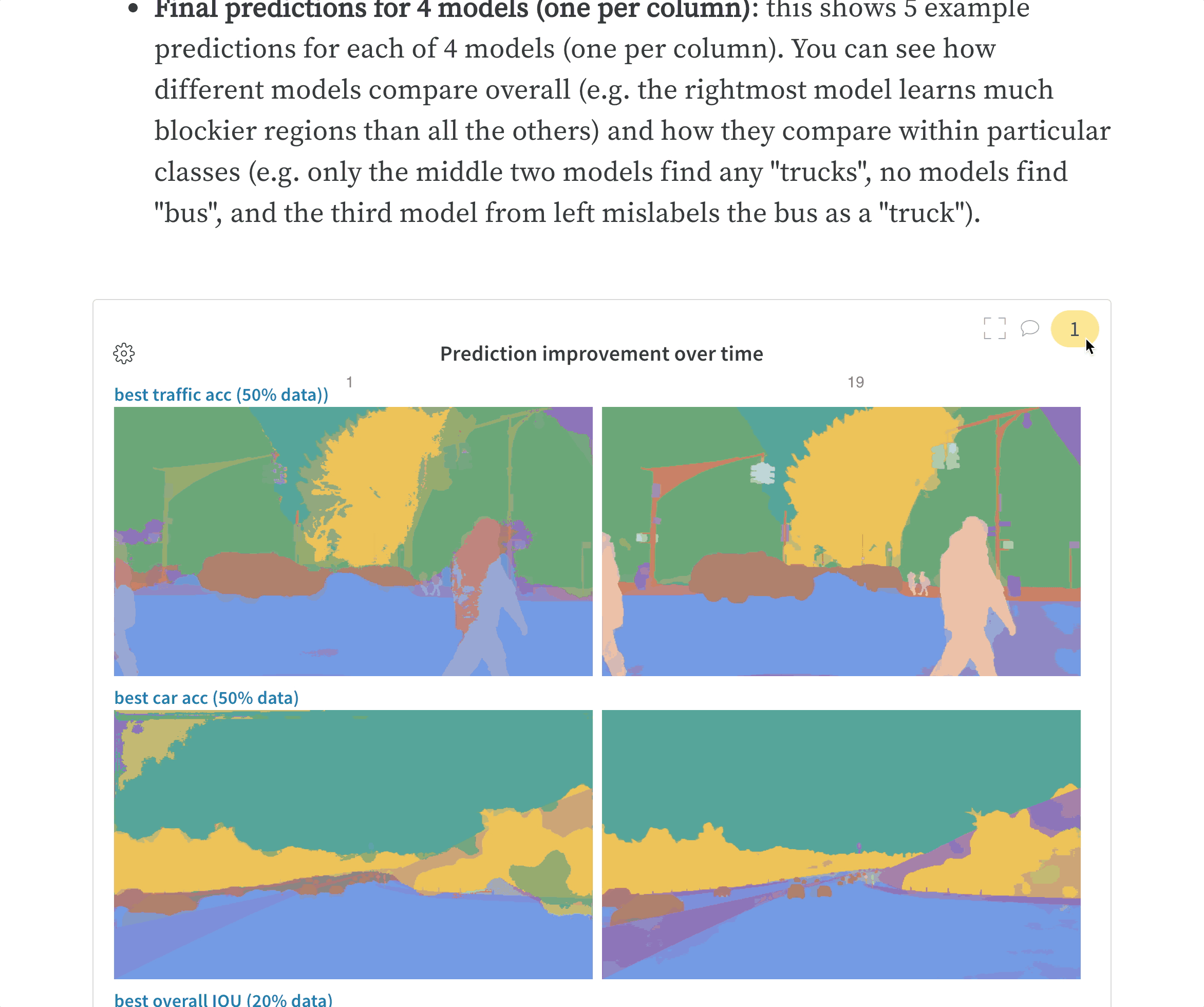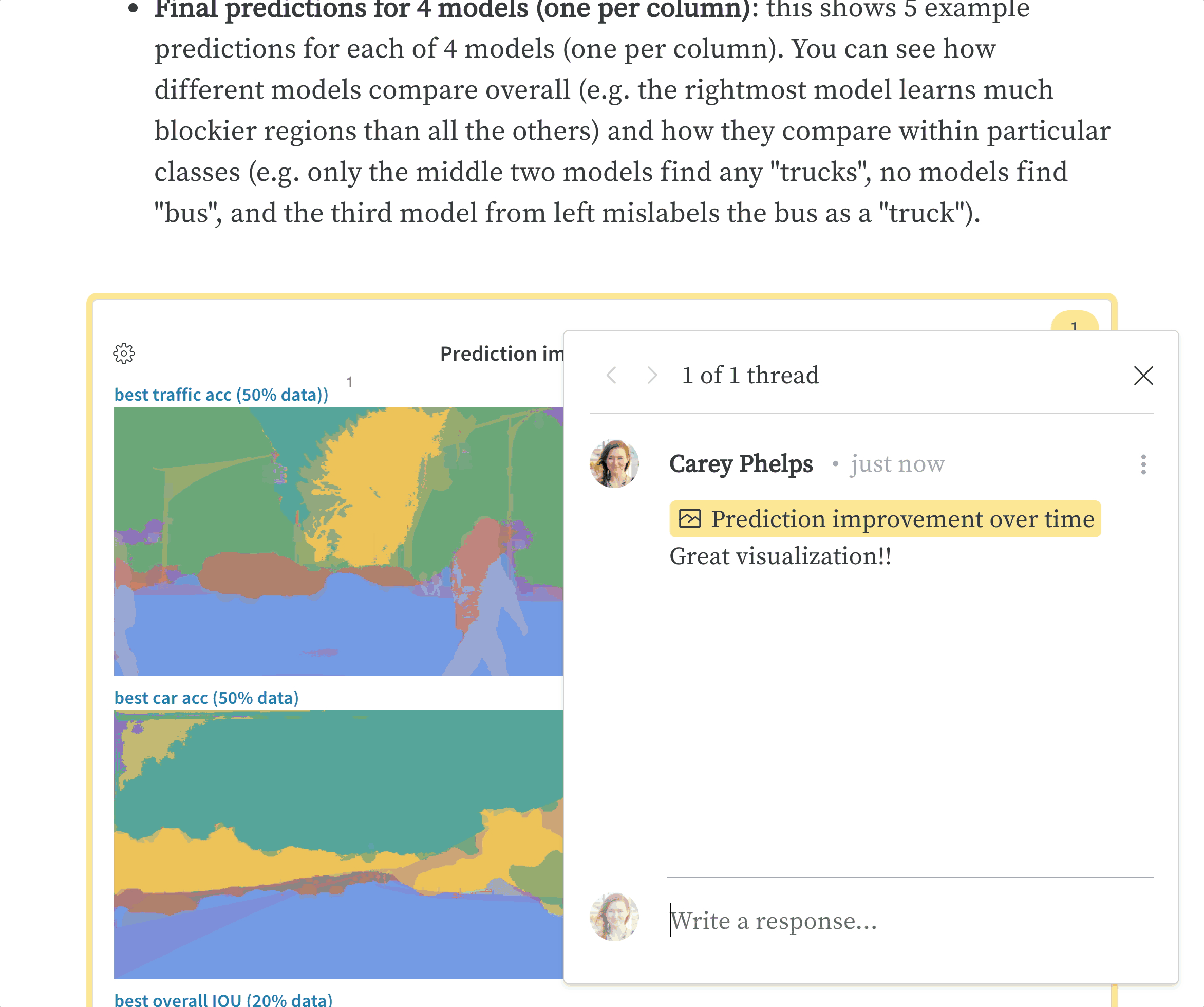
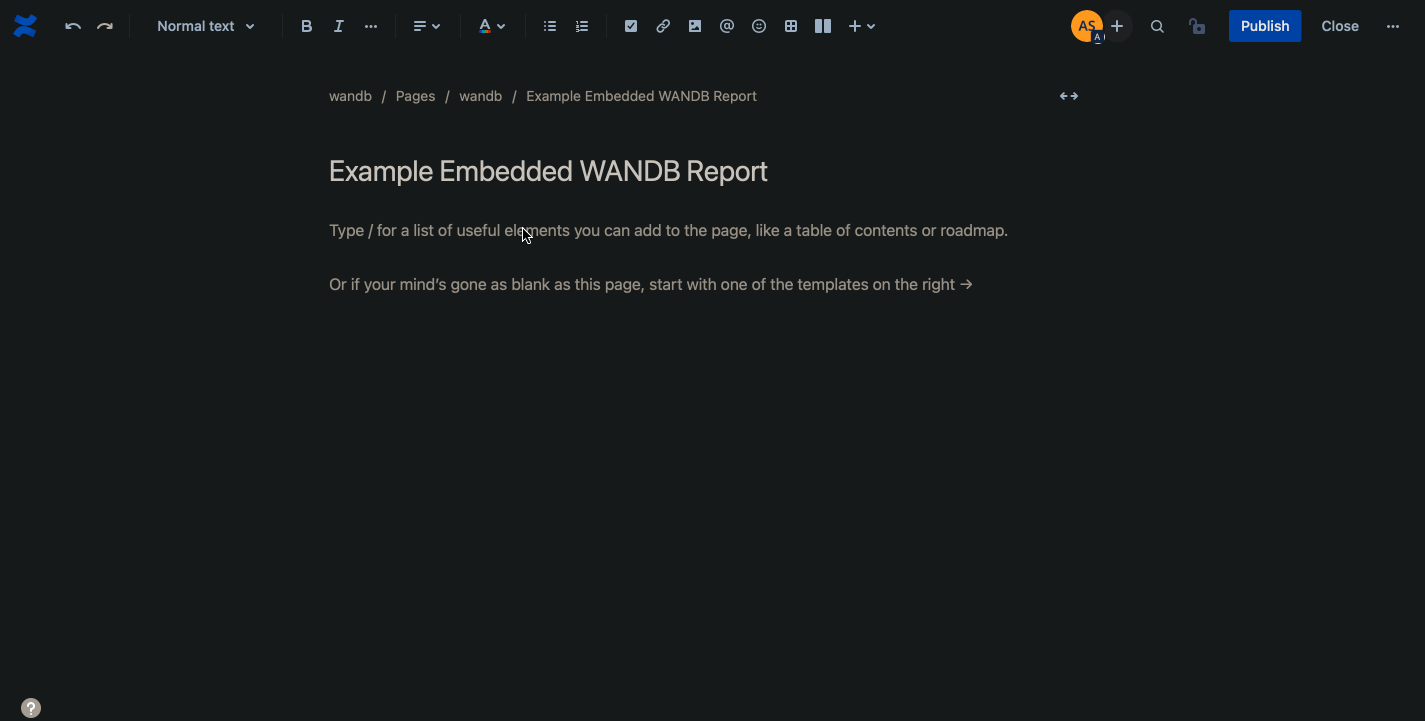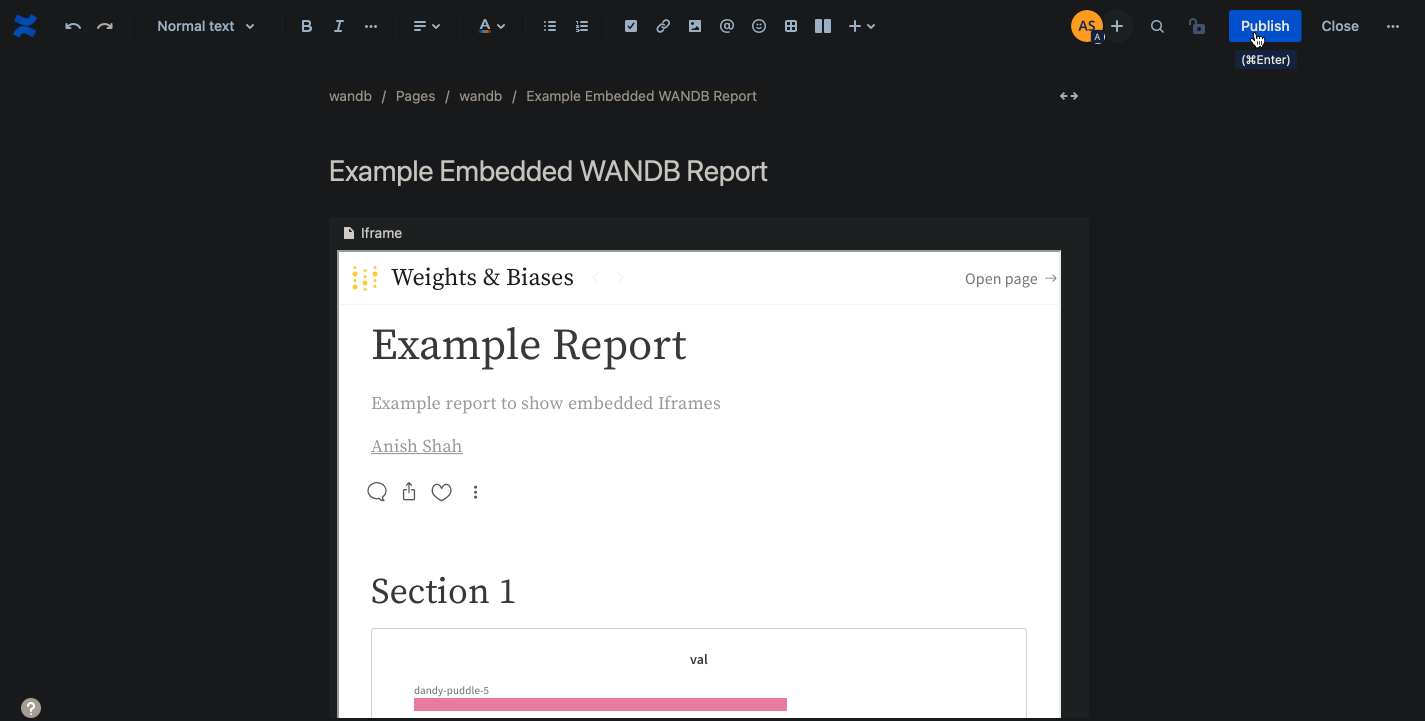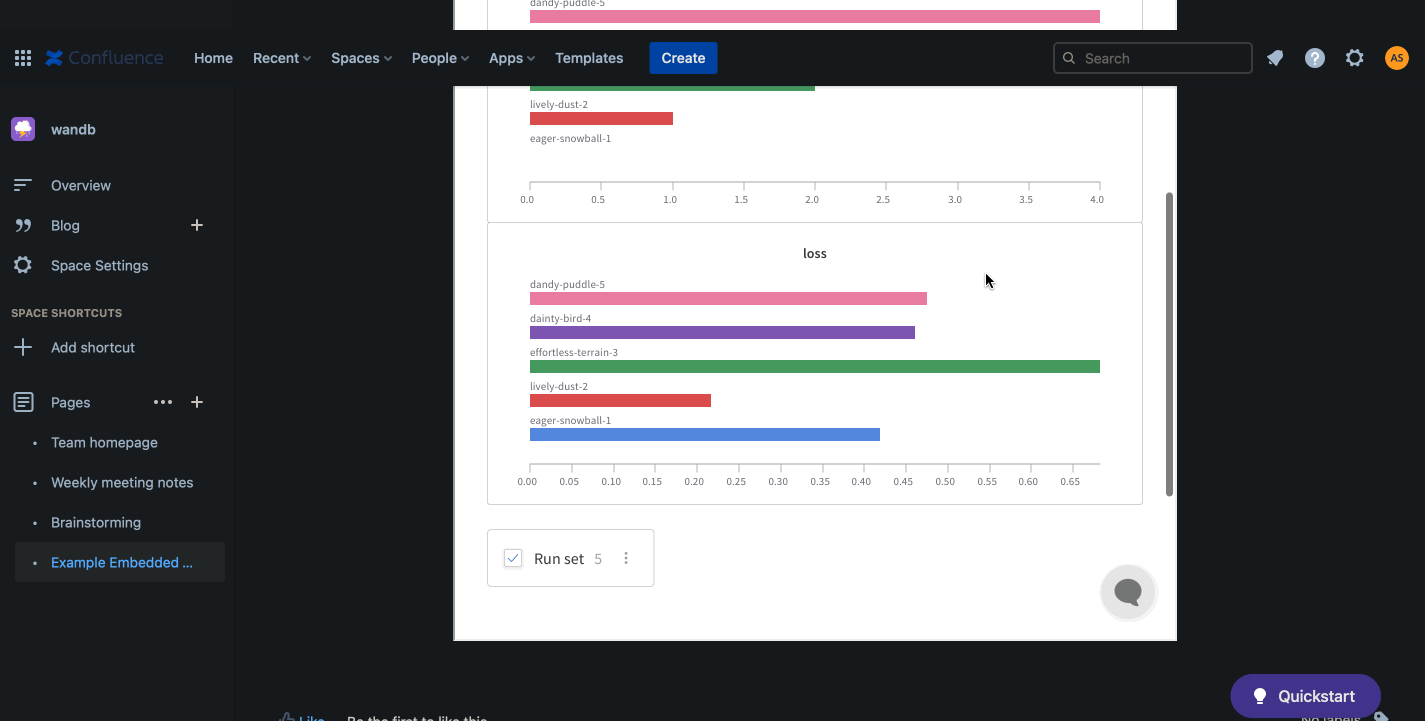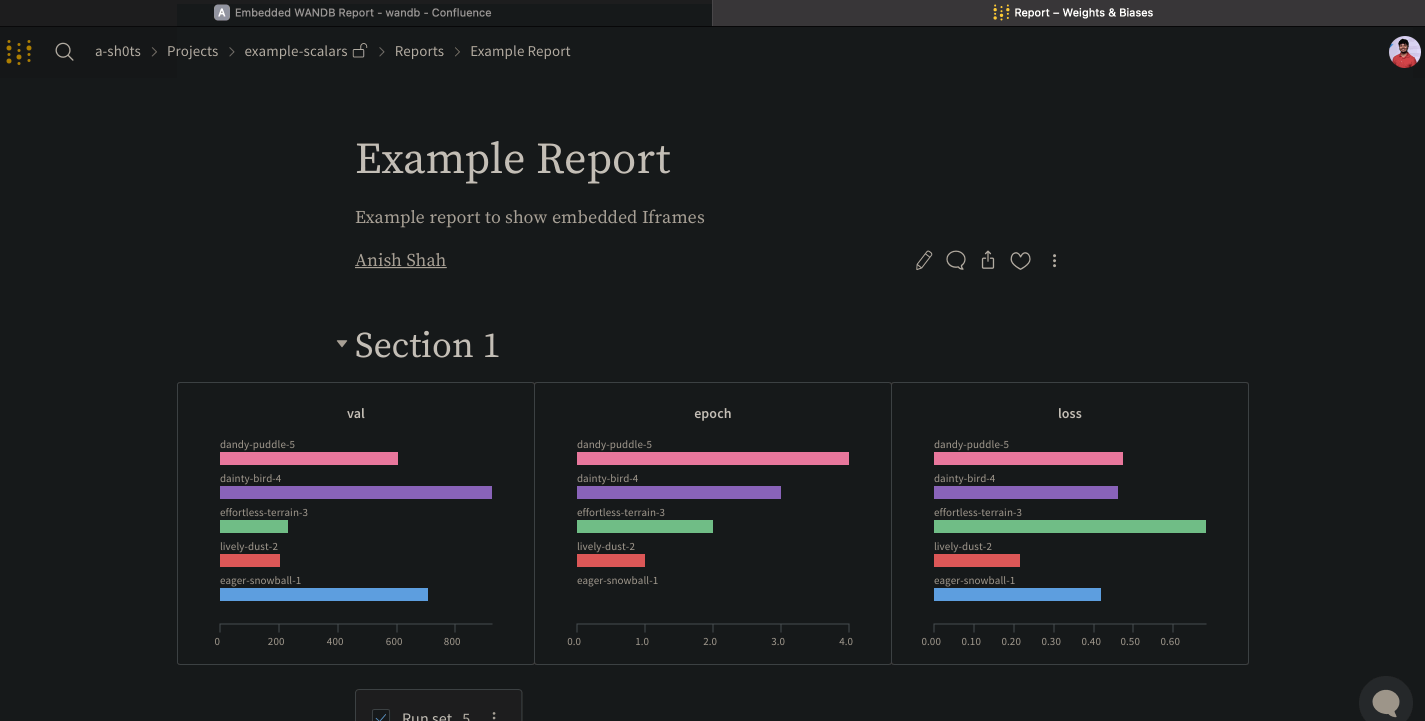
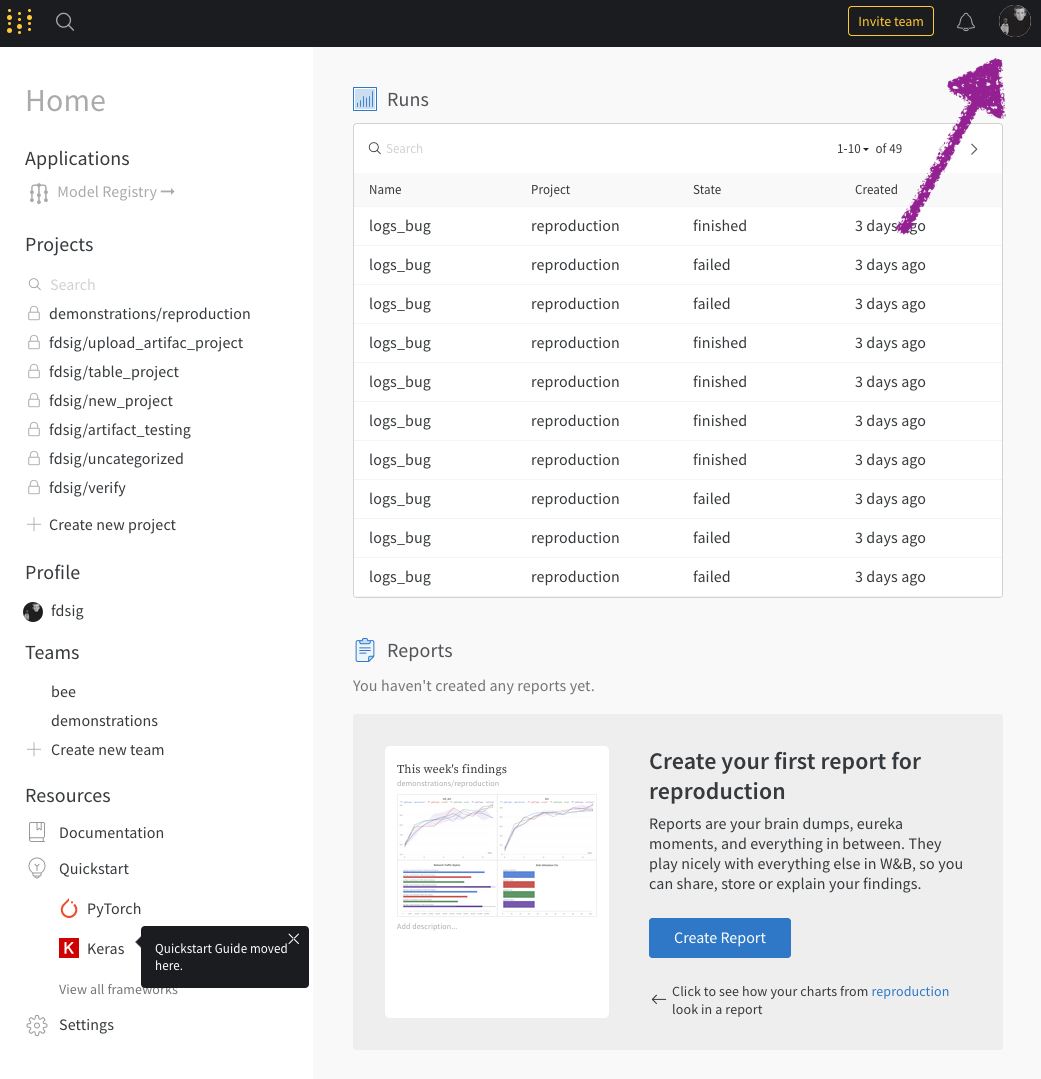
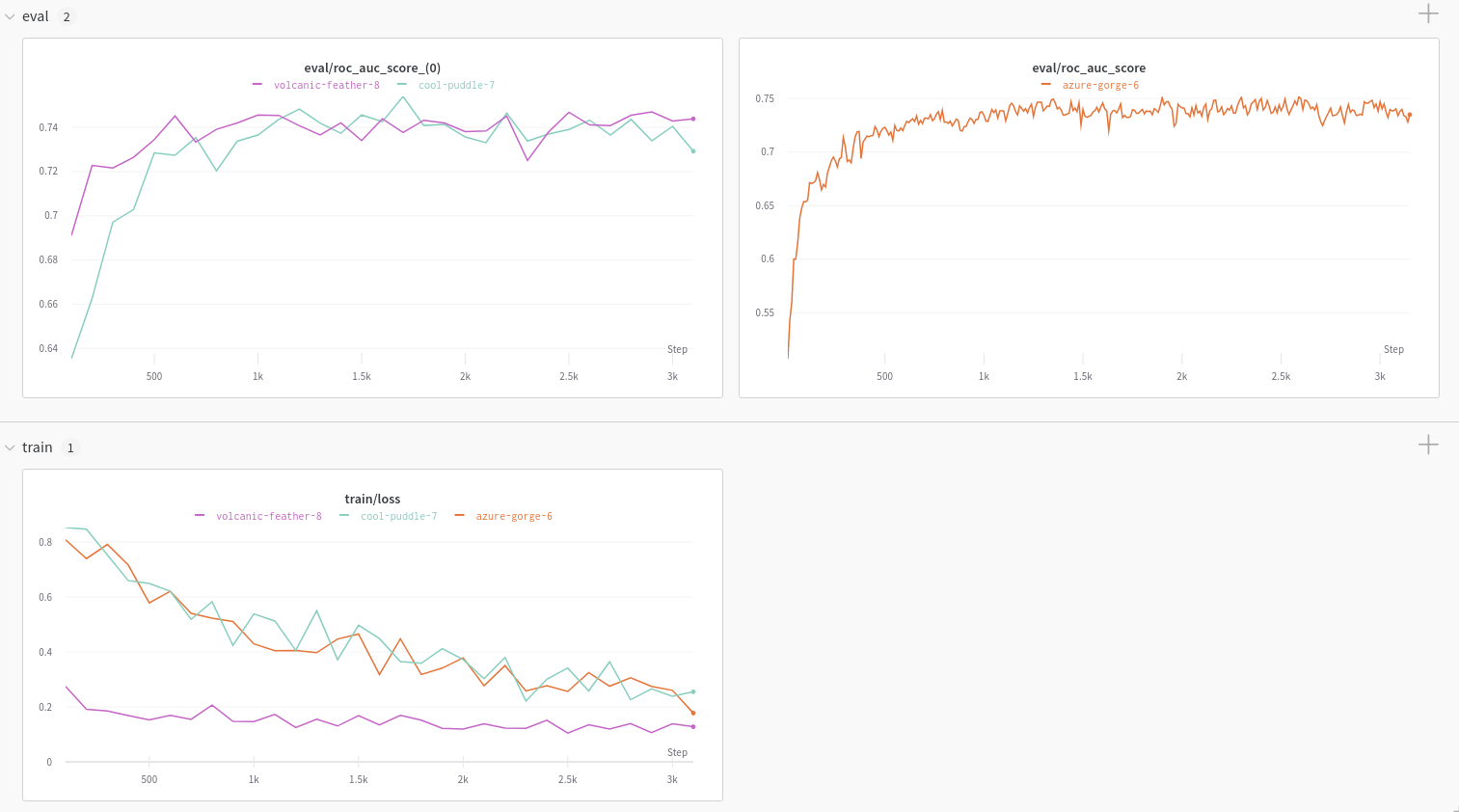
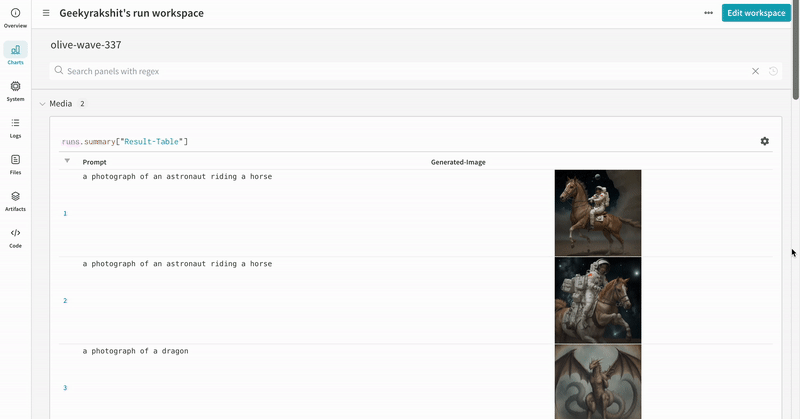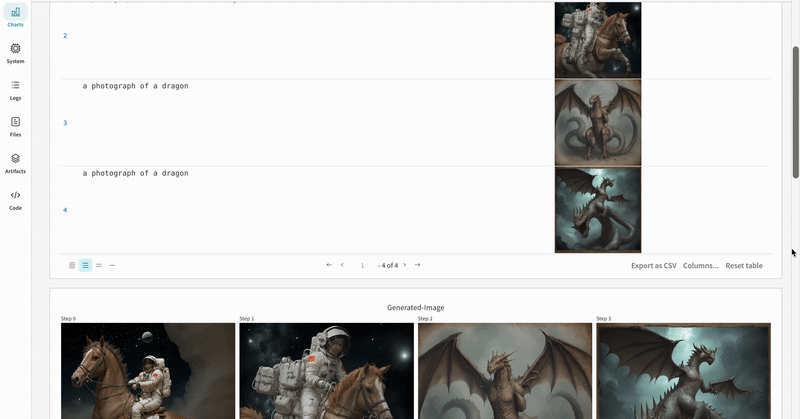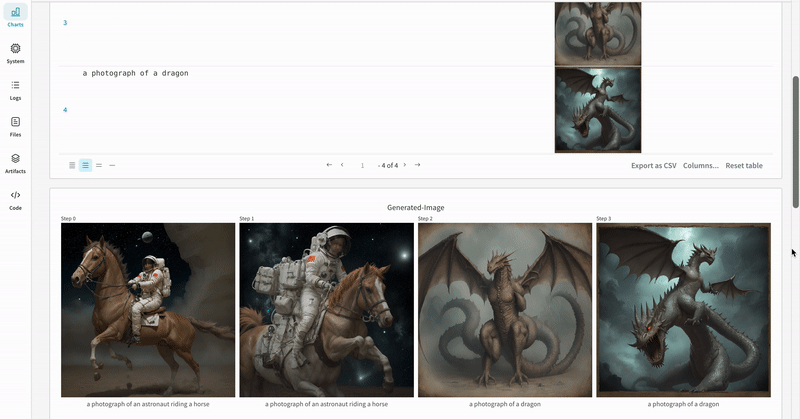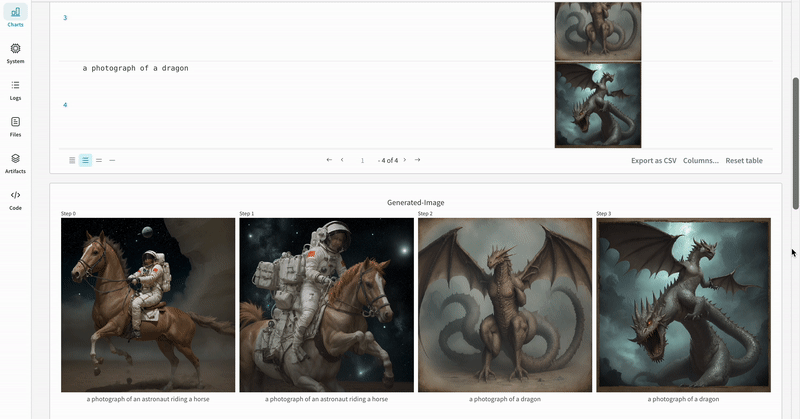
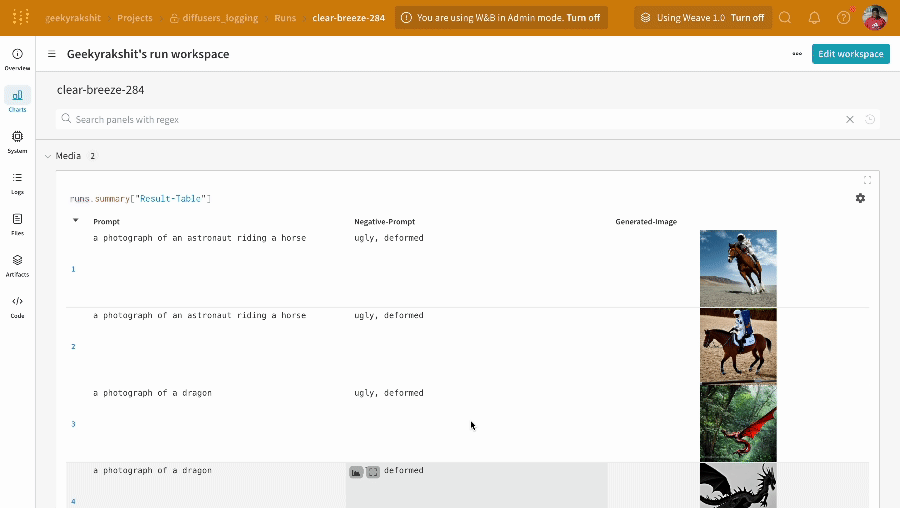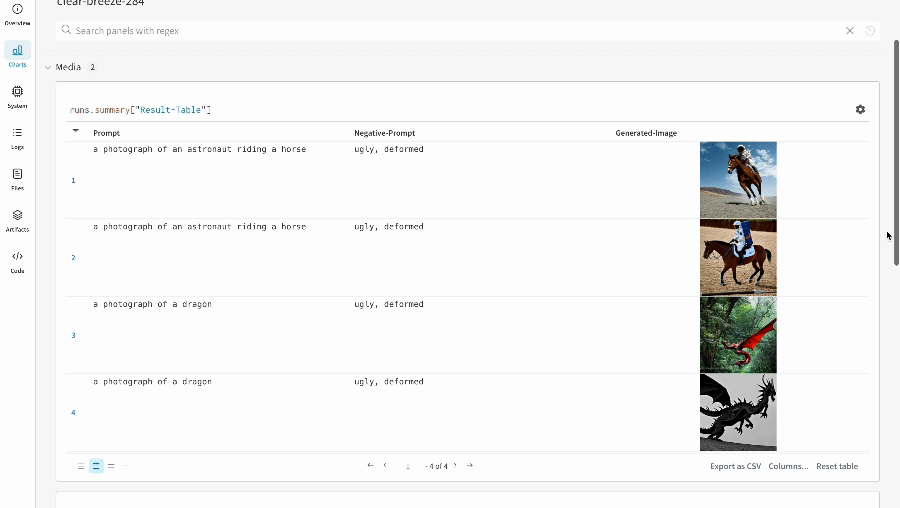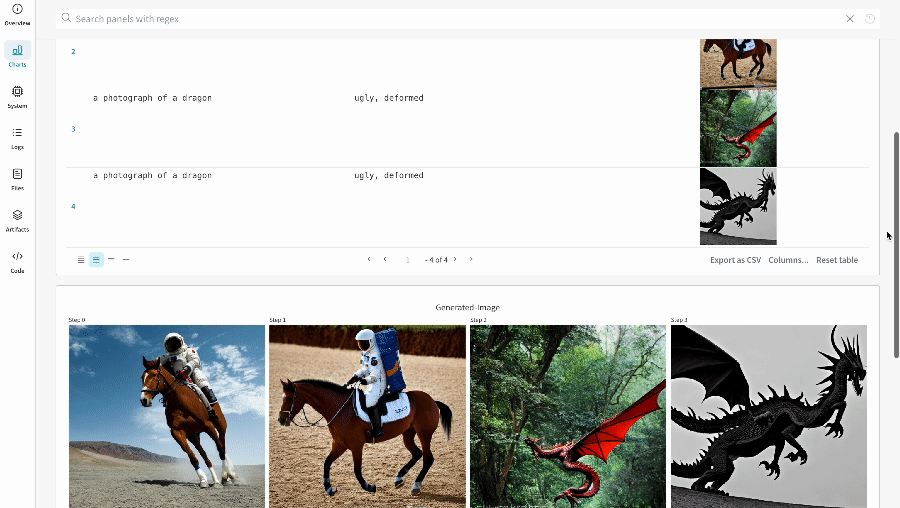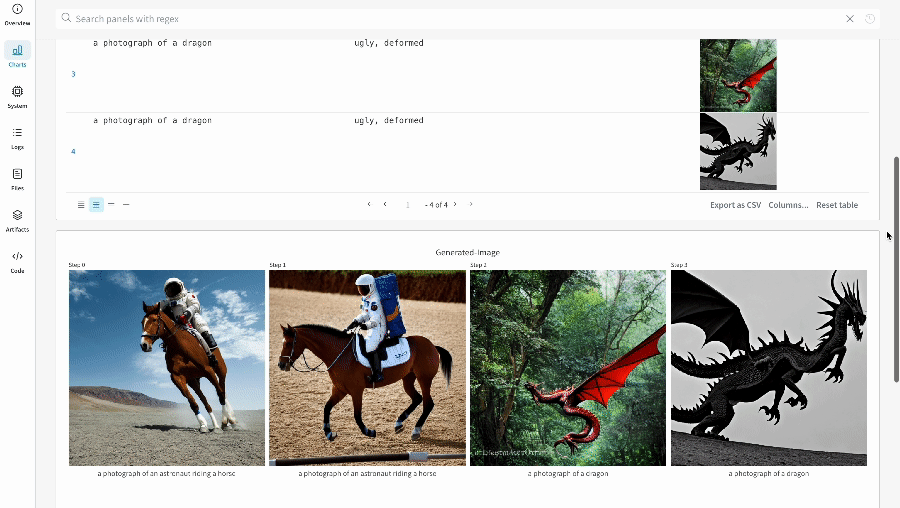
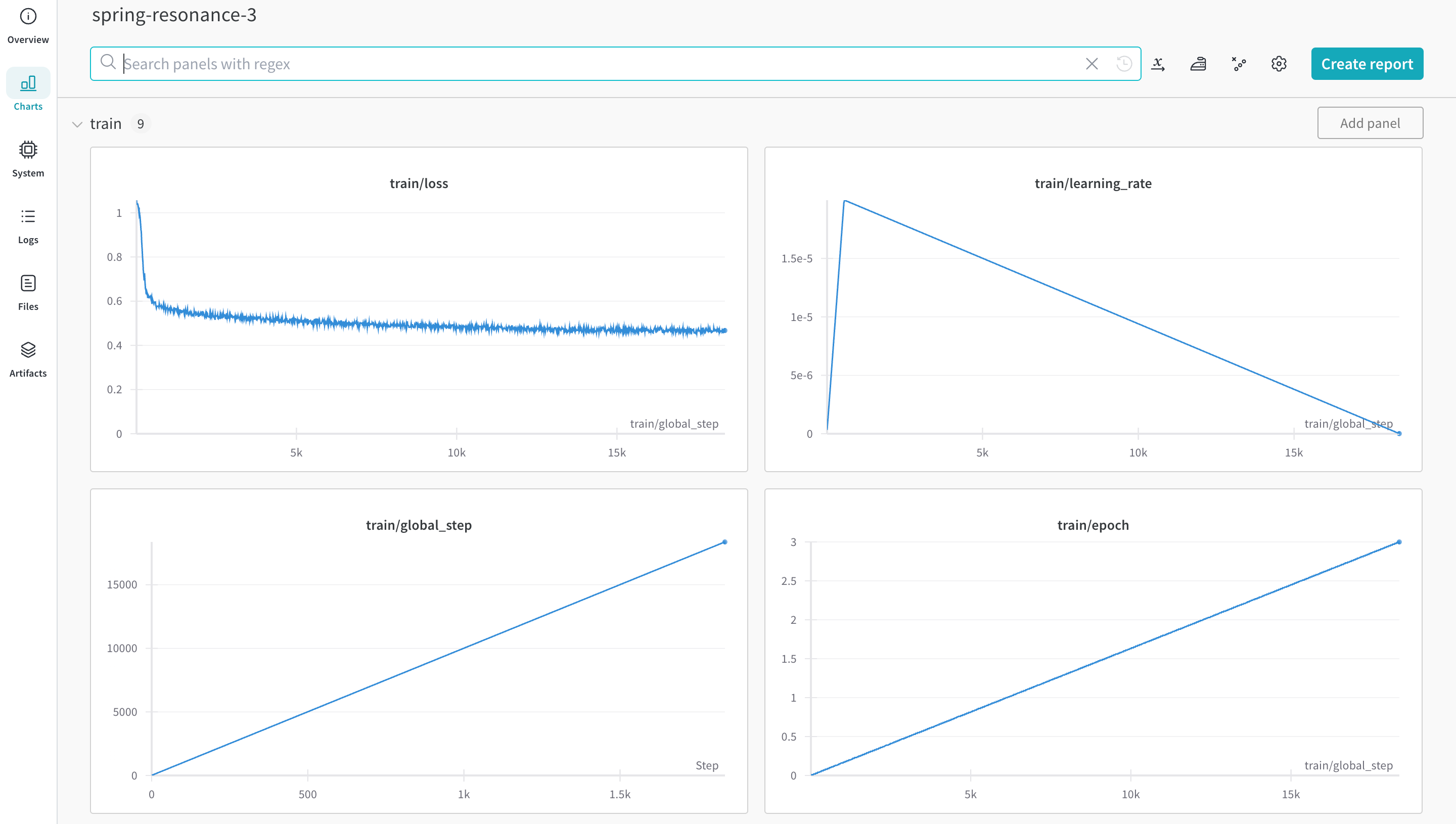
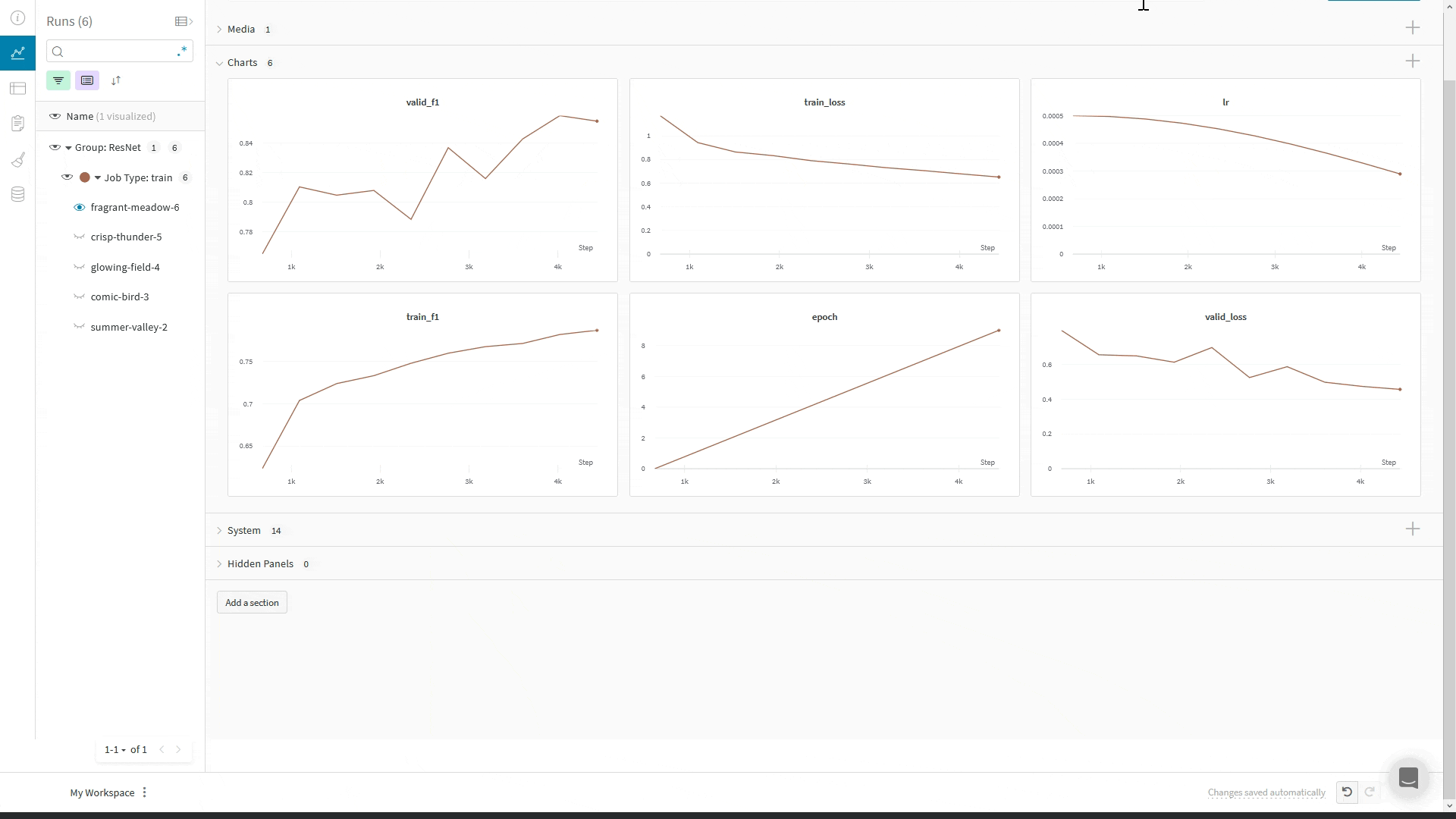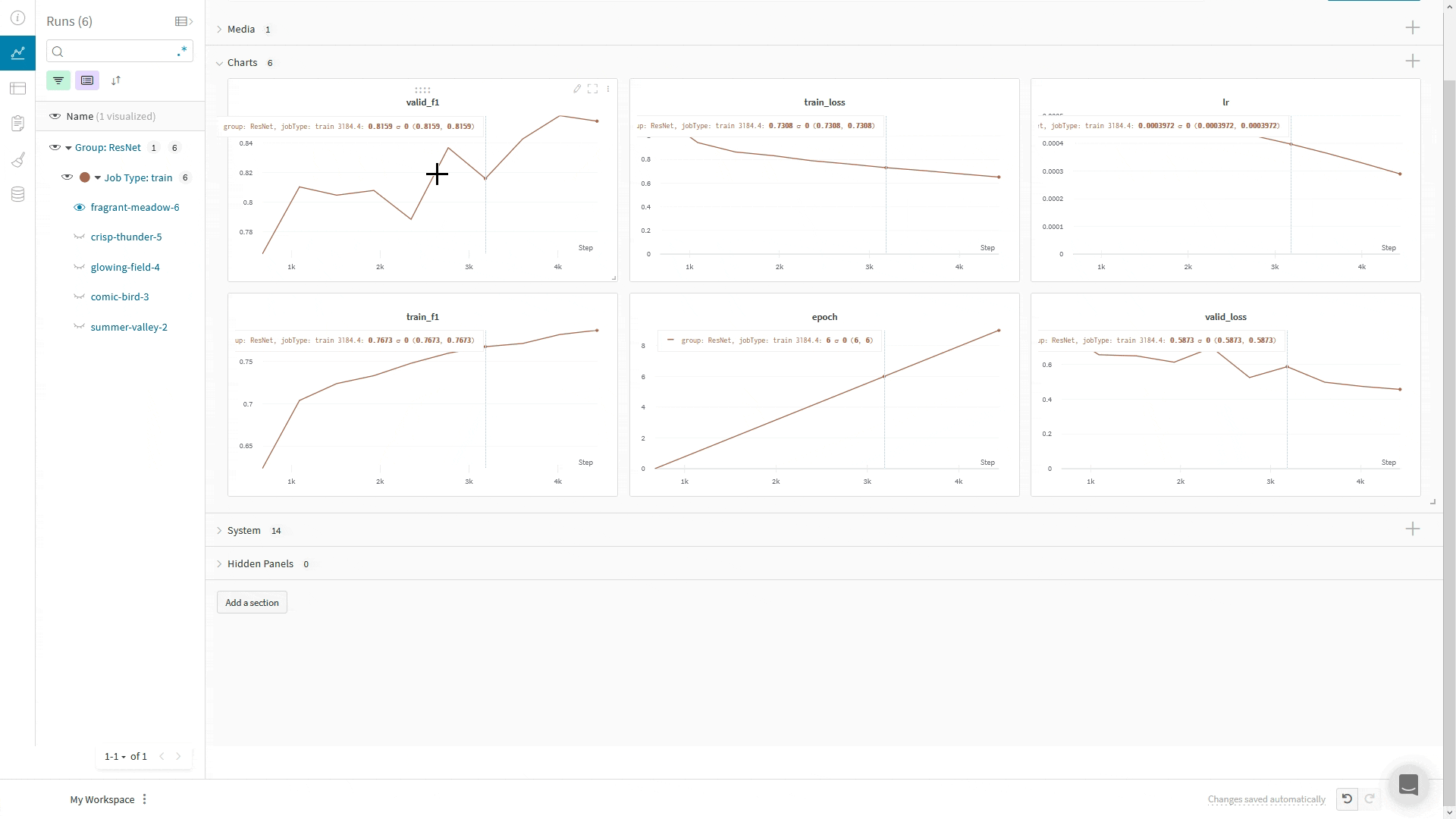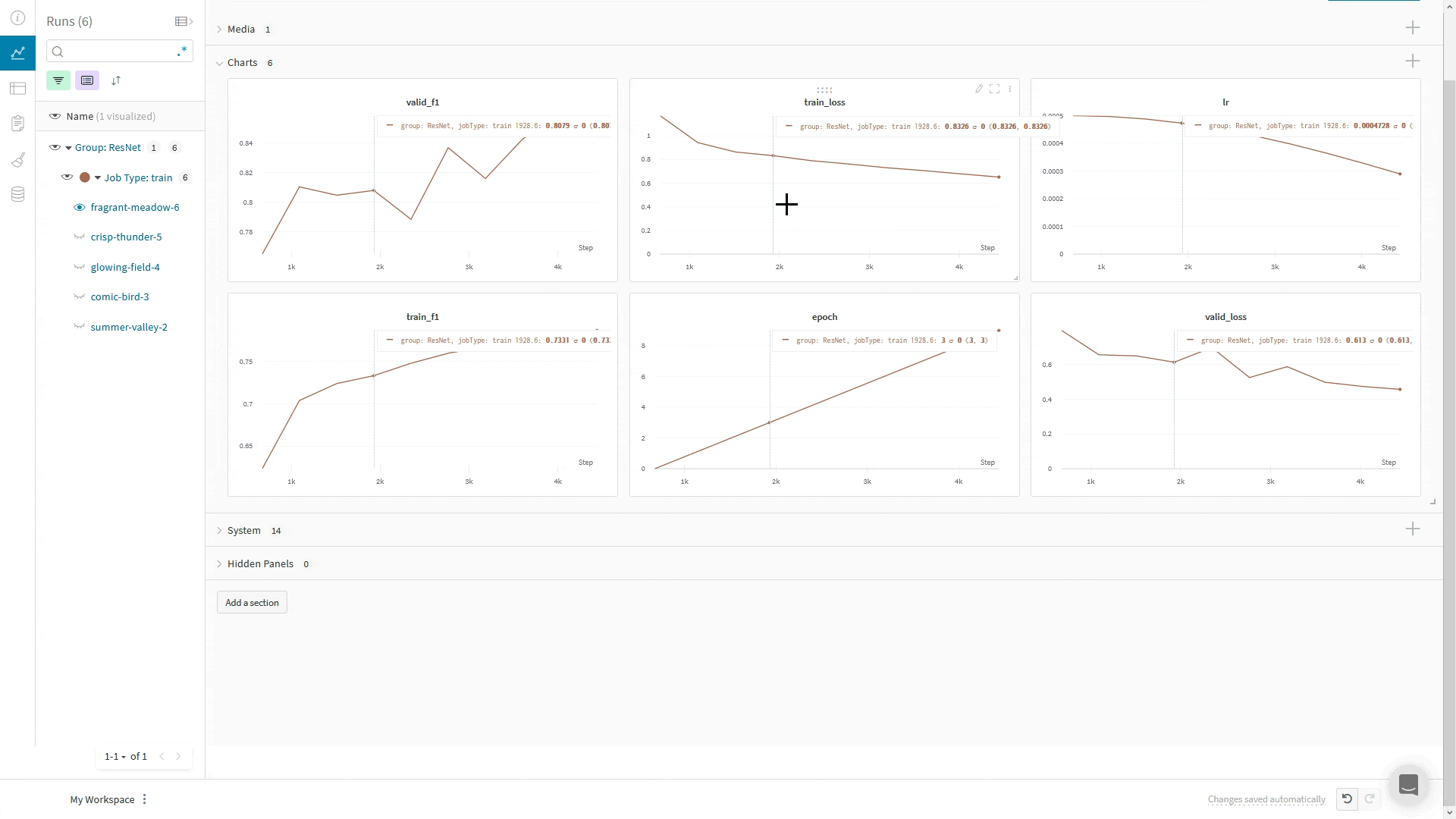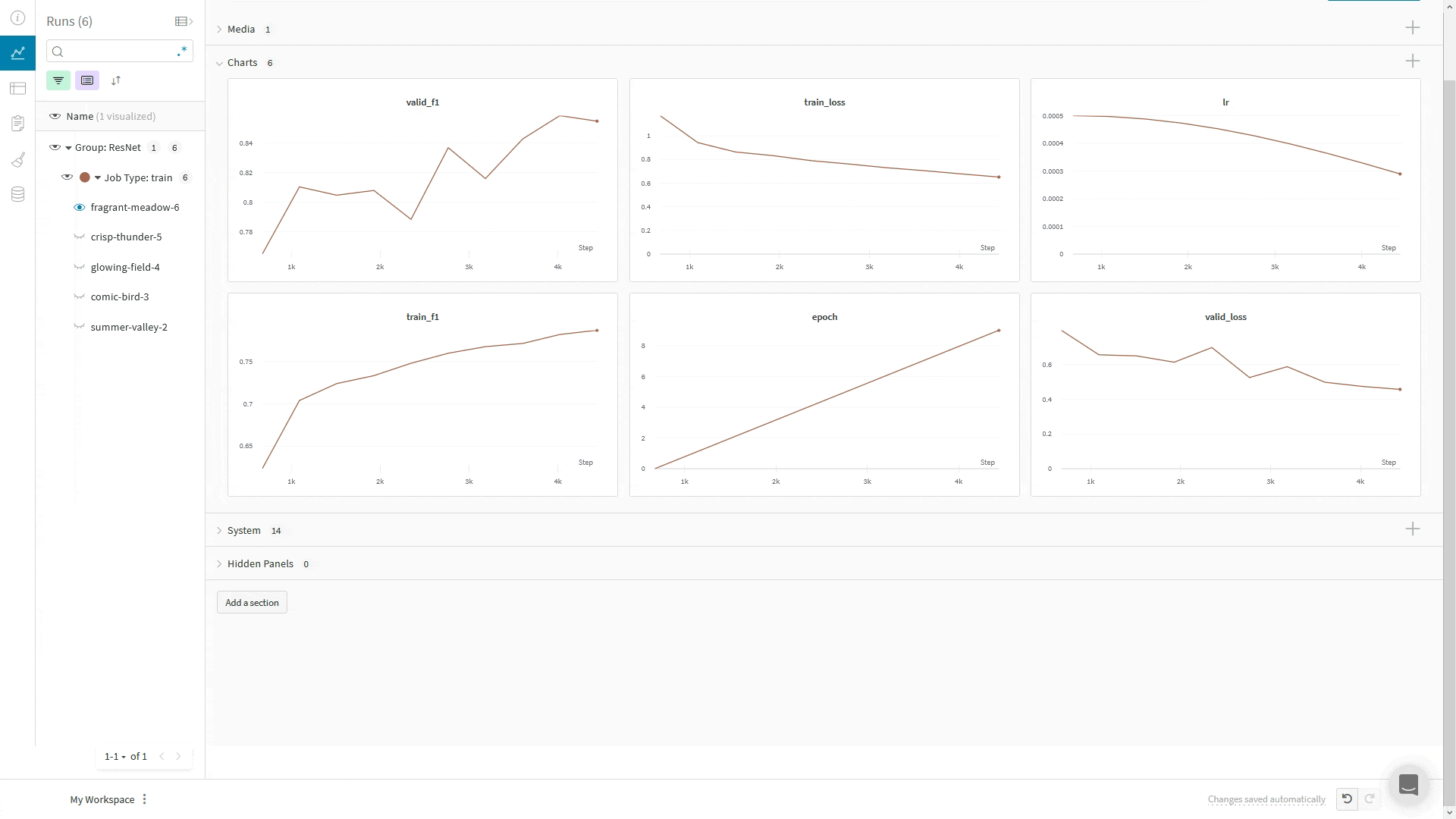
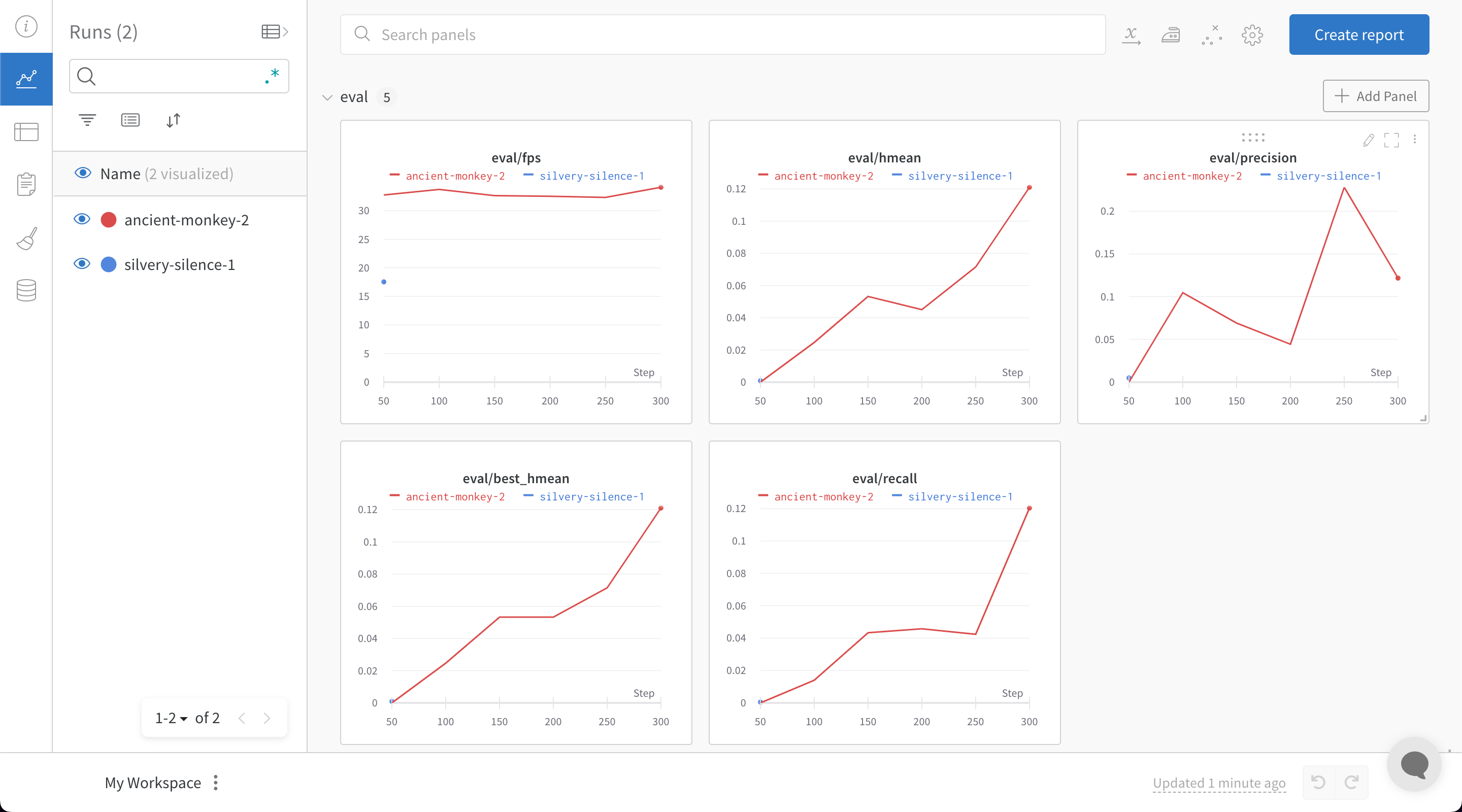
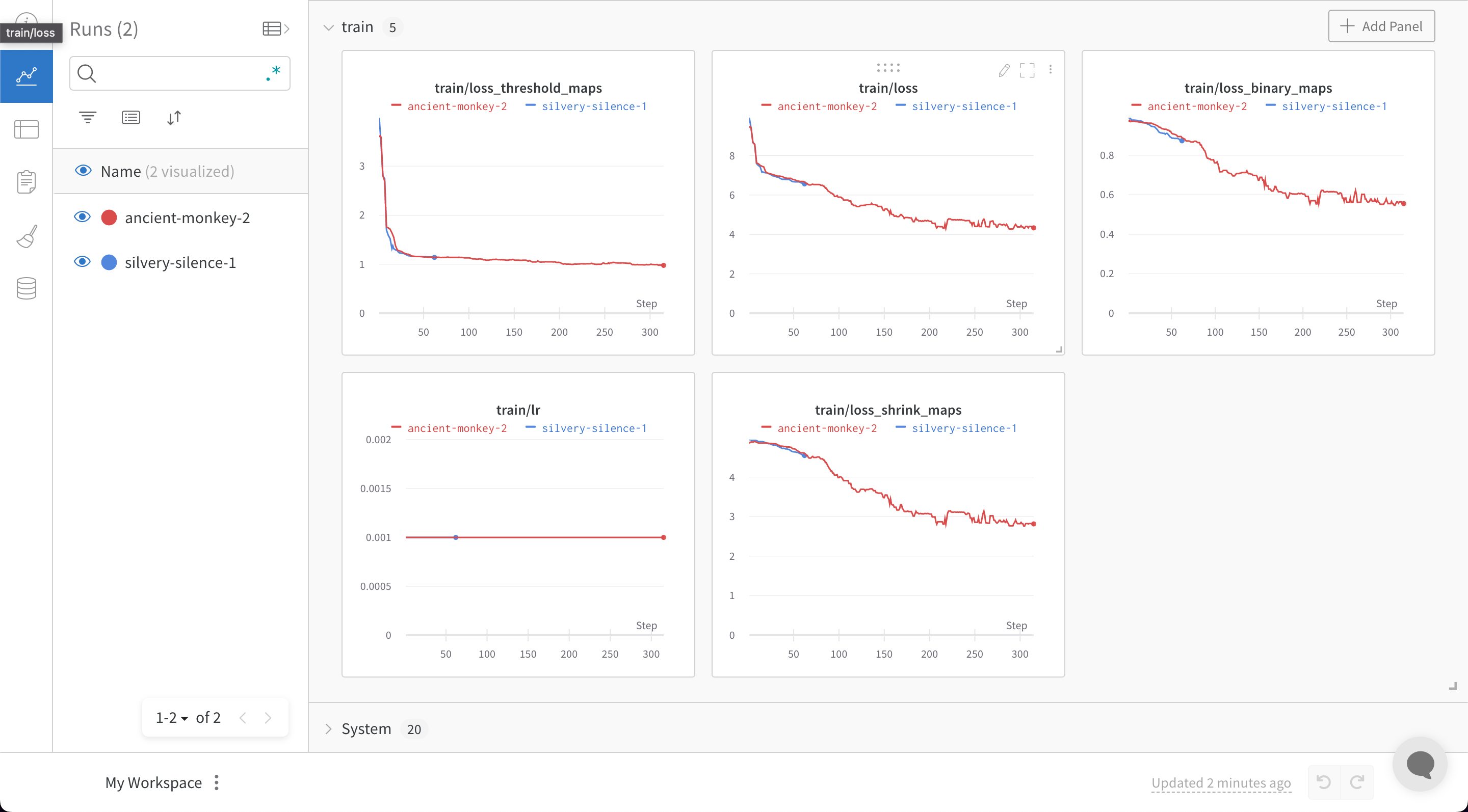
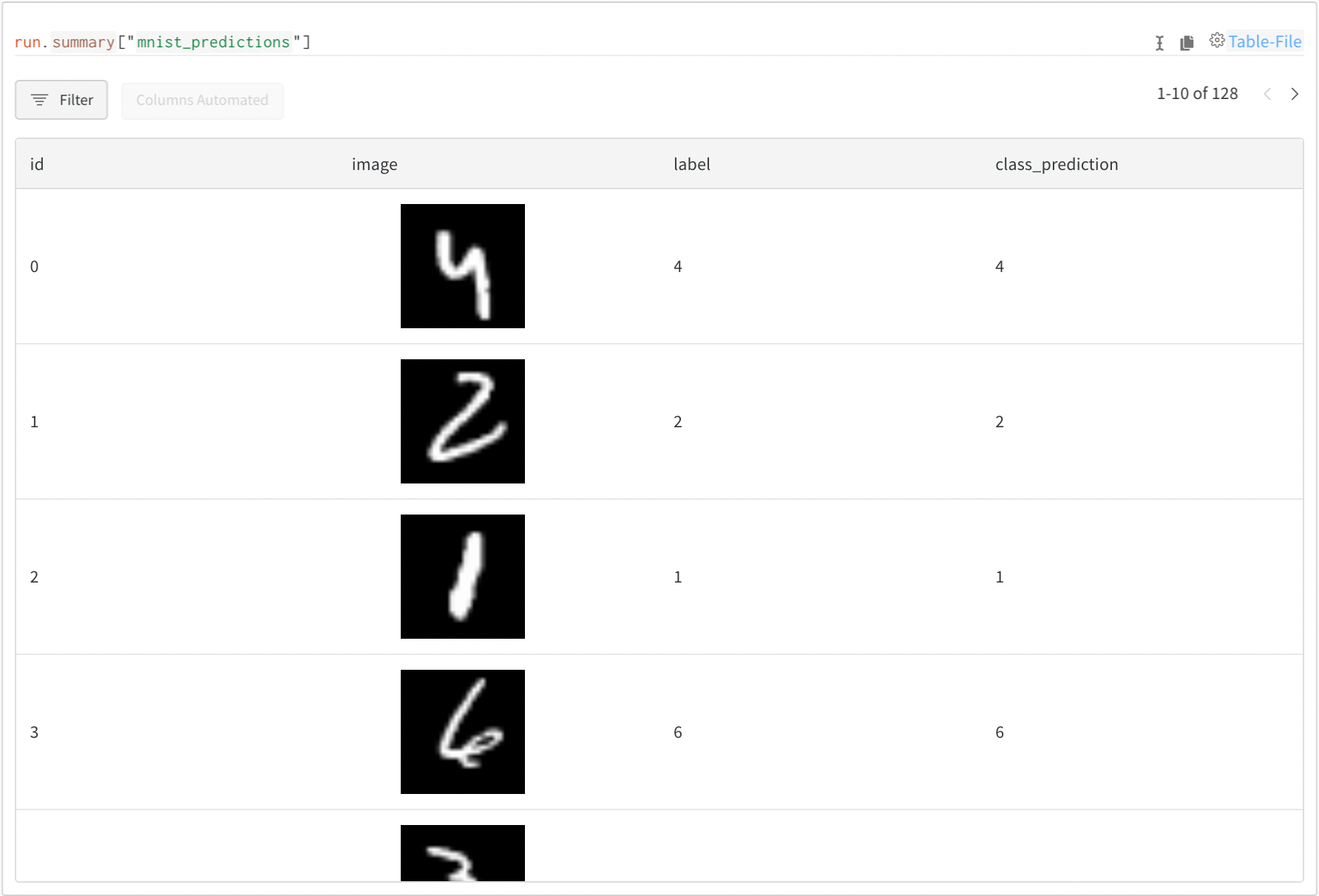
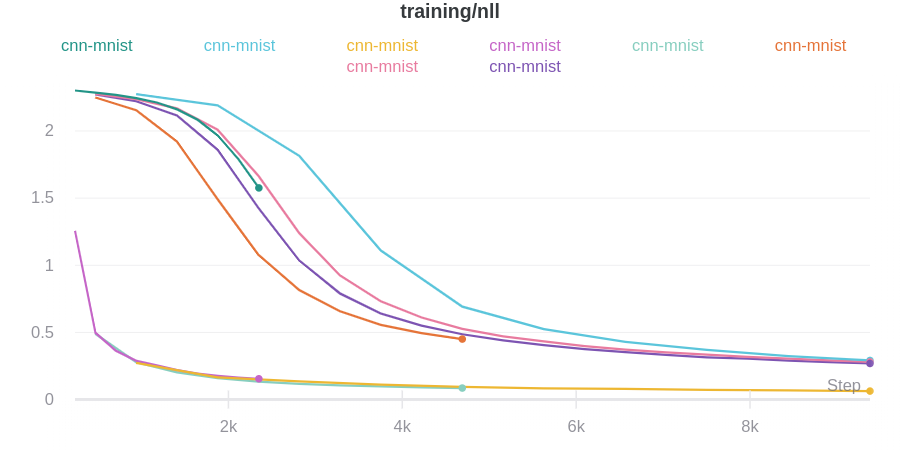
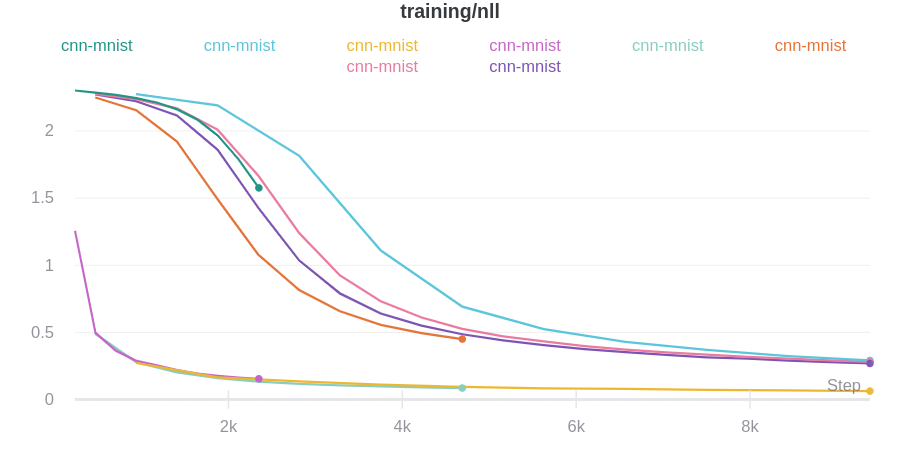
wandb.ai/home にアクセスして、精度や損失などの記録されたメトリクスと、各トレーニングステップ中にそれらがどのように変化したかを確認します。次の図は、各 run から追跡された損失と精度を示しています。各 run オブジェクトは、生成された名前とともに [Runs ] 欄に表示されます。
次のステップ
W&B エコシステムのその他の機能を探索します。
W&B と PyTorch のようなフレームワーク、Hugging Face のようなライブラリ、SageMaker のようなサービスを組み合わせた W&B Integration チュートリアル を読みます。
W&B Reports を使用して、run を整理し、可視化を自動化し、学びを要約し、コラボレーターと更新を共有します。W&B Artifacts を作成して、機械学習パイプライン全体のデータセット、モデル、依存関係、および結果を追跡します。W&B Sweeps でハイパーパラメータの検索を自動化し、モデルを最適化します。中央ダッシュボード で run を分析し、モデルの予測を可視化し、インサイトを共有します。W&B AI Academy にアクセスして、実践的なコースを通じて LLM、MLOps、および W&B Models について学びます。
2 - W&B Models
W&B Models は、モデルを整理し、生産性とコラボレーションを向上させ、大規模なプロダクション ML を提供したい ML エンジニアのための SoR (system of record) です。
W&B Models を使用すると、次のことが可能です。
機械学習エンジニアは、W&B Models を ML の SoR (system of record) として信頼して、実験の追跡と可視化、モデルのバージョンとリネージの管理、およびハイパーパラメーターの最適化を行っています。
2.1 - Experiments
W&B で 機械学習 の 実験 を トラックします。
数行のコードで 機械学習 の 実験 を追跡します。次に、インタラクティブ ダッシュボード で 結果 を確認するか、Public API を使用して、プログラムで アクセス できるように データ を Python にエクスポートできます。
PyTorch , Keras , or Scikit のような一般的な フレームワーク を使用する場合は、W&B インテグレーション を活用してください。インテグレーション の完全なリストと、W&B を コード に追加する方法については、インテグレーション ガイド を参照してください。
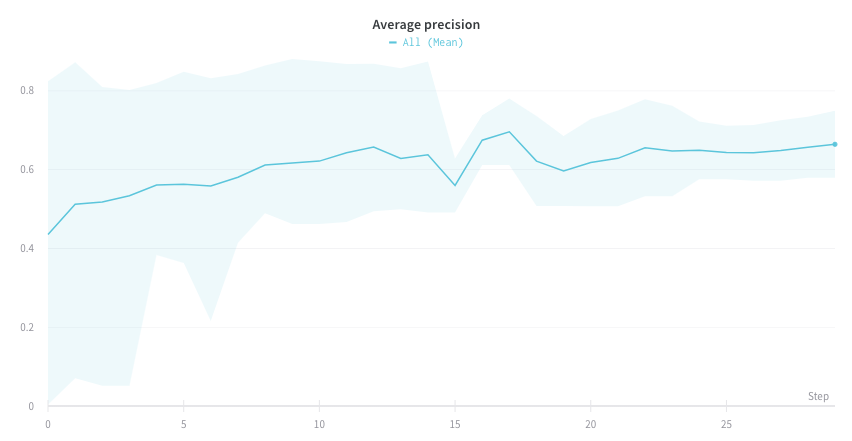
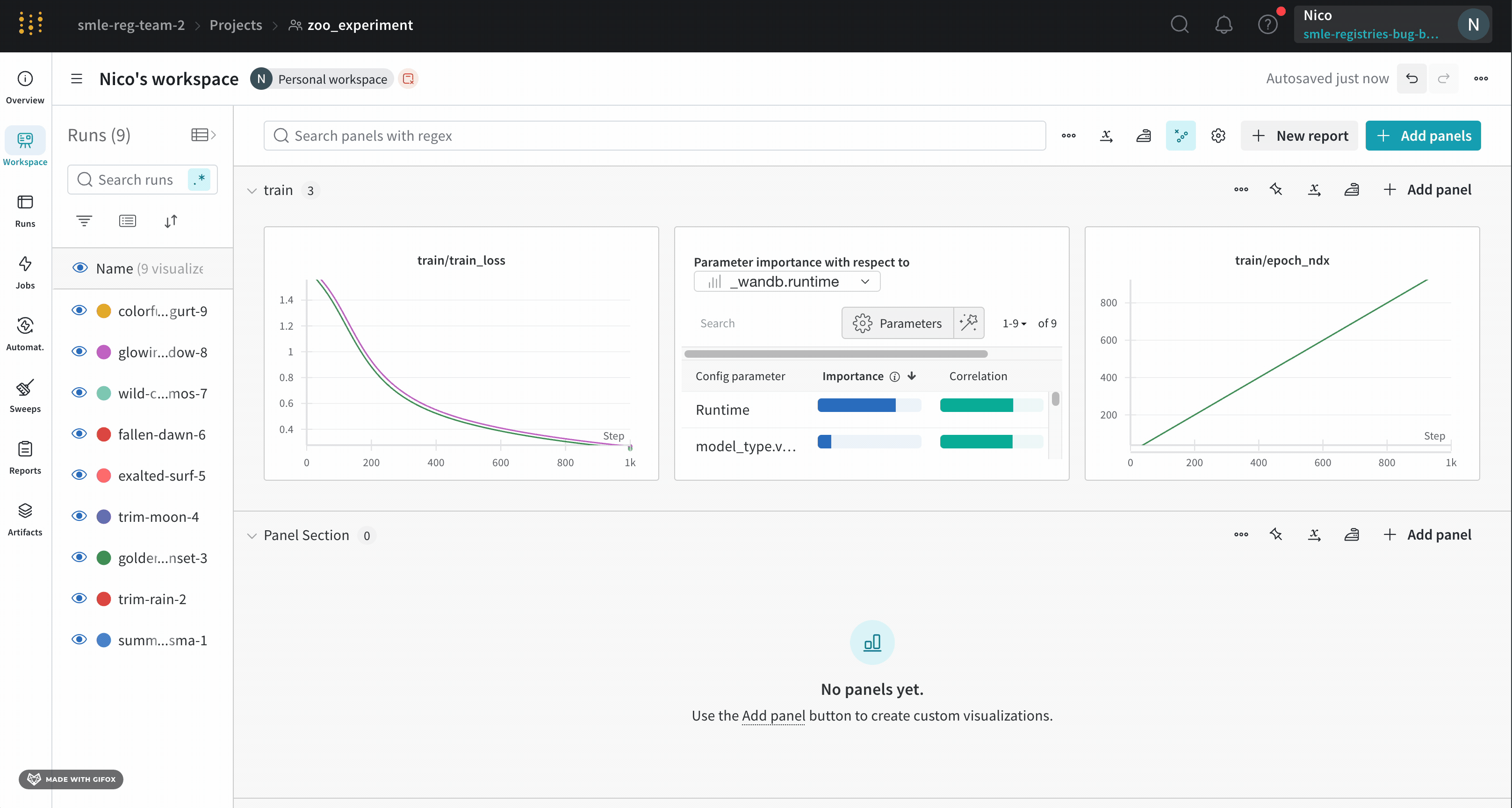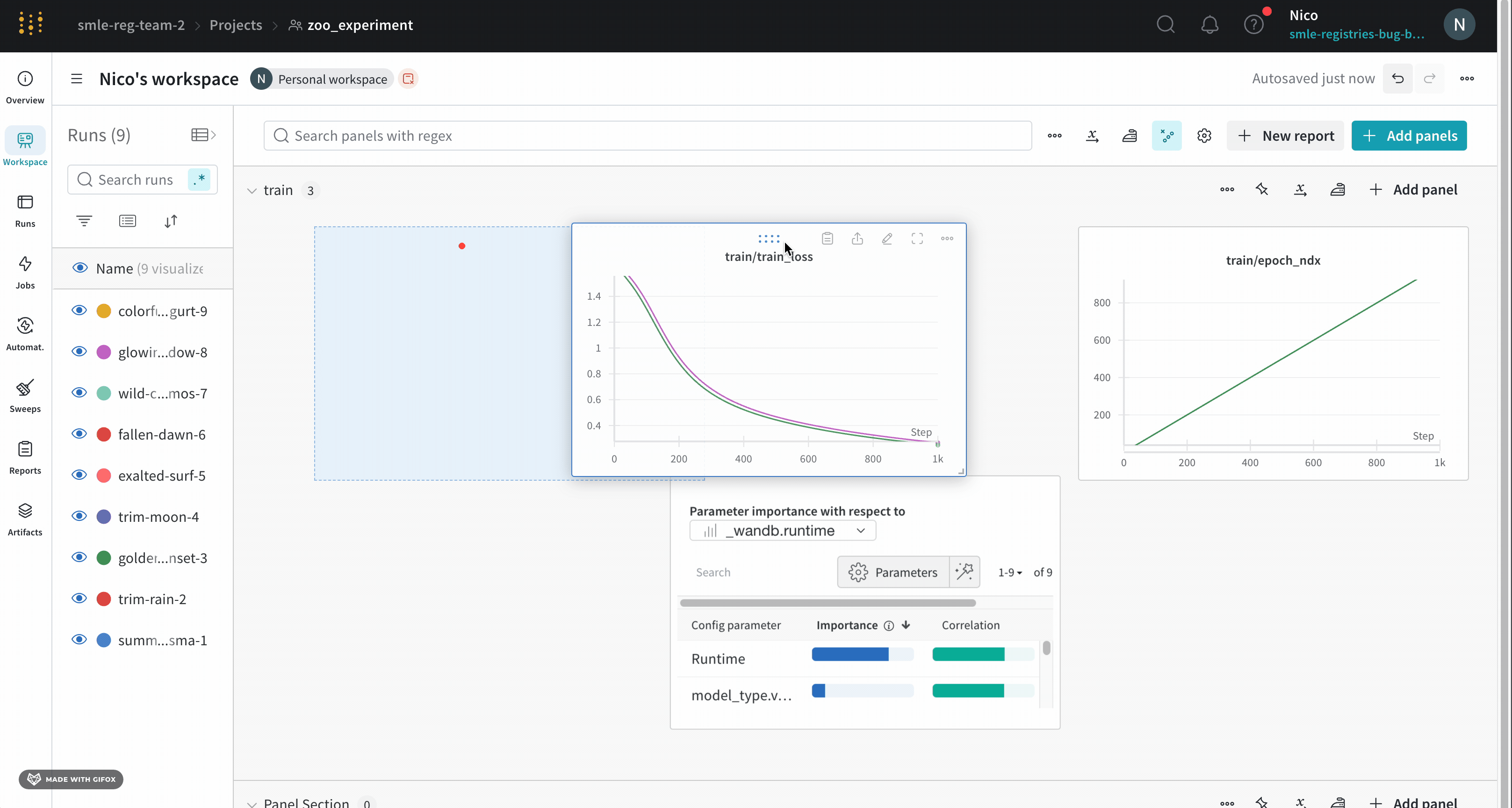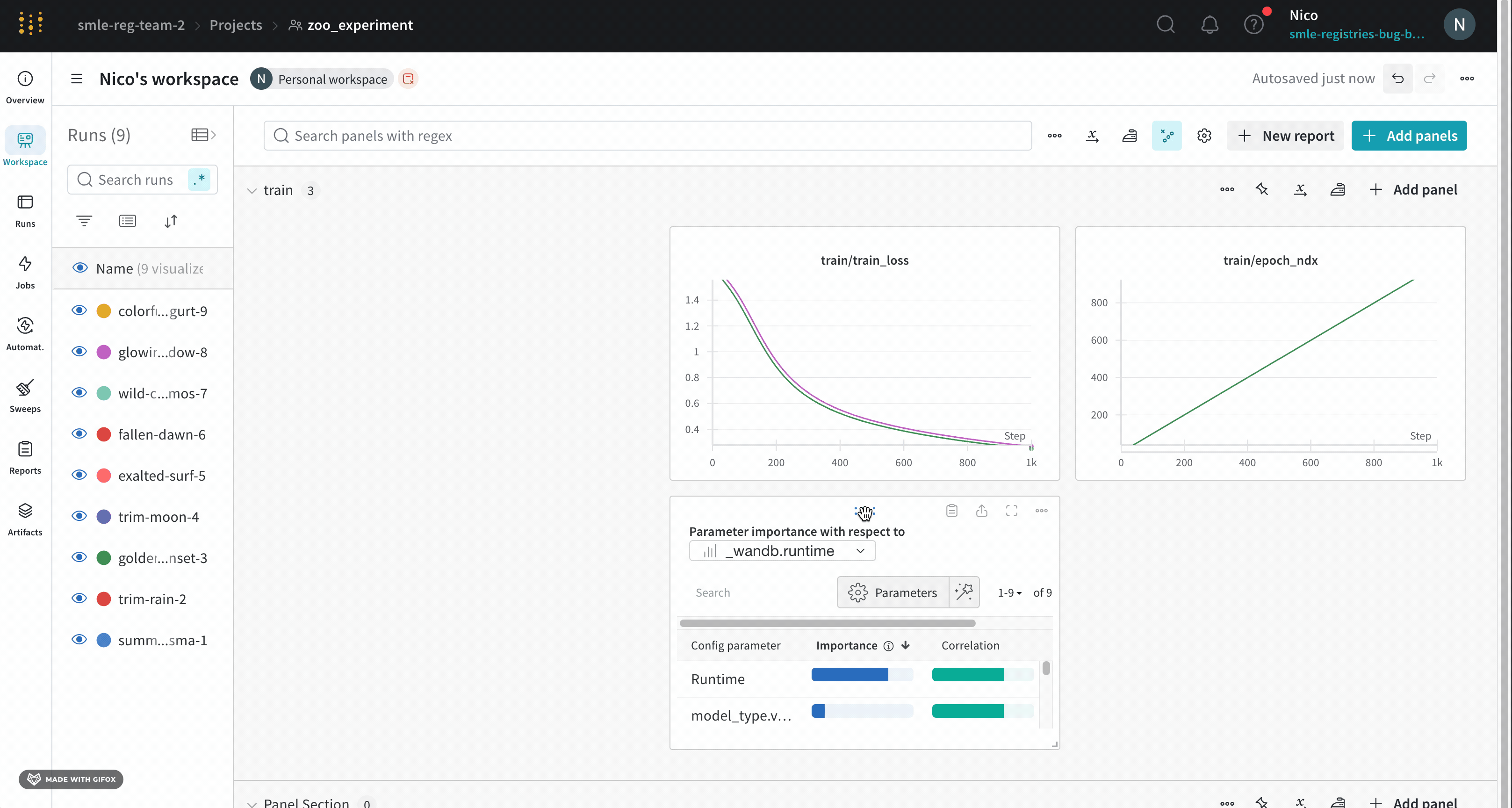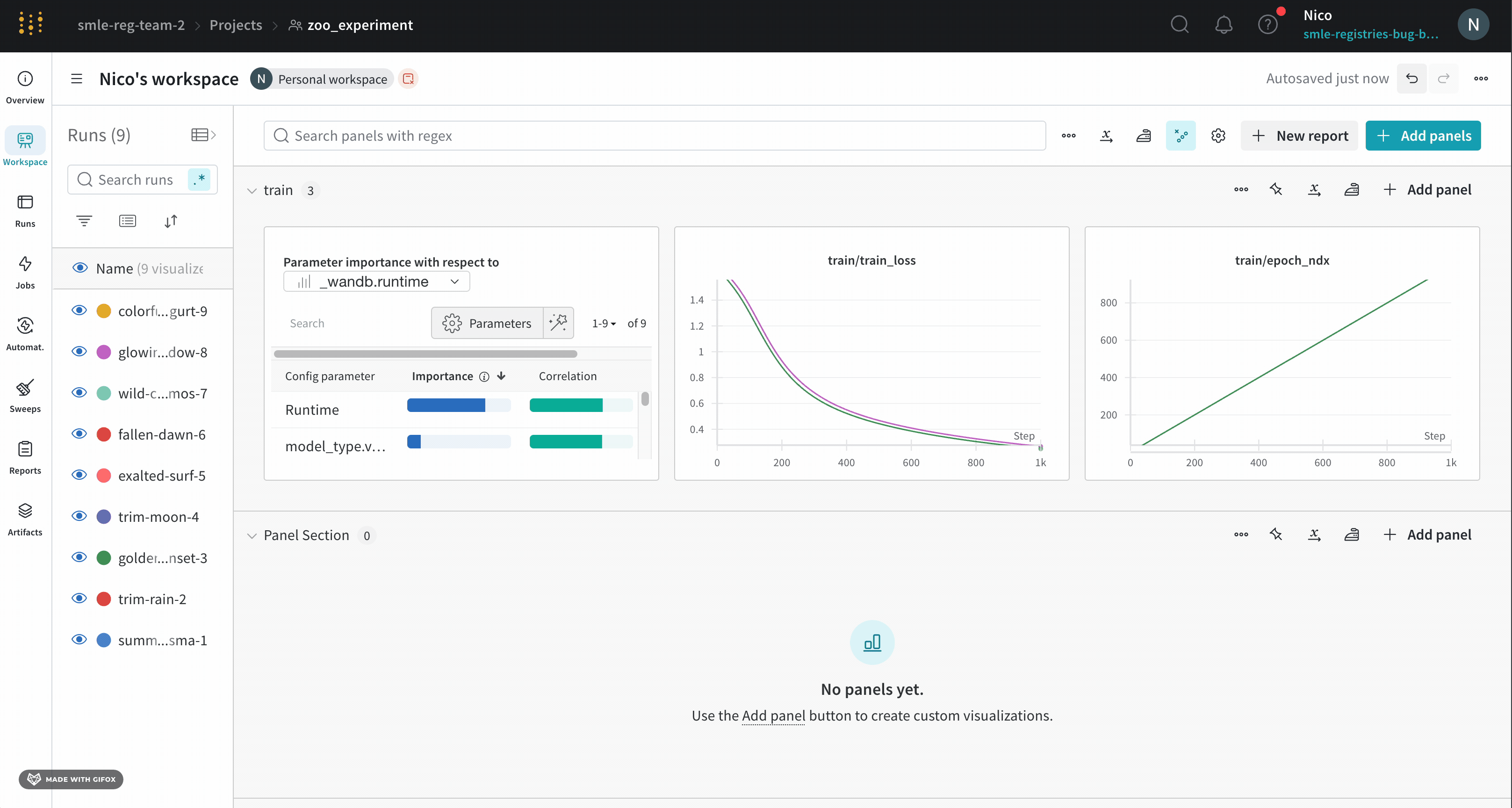
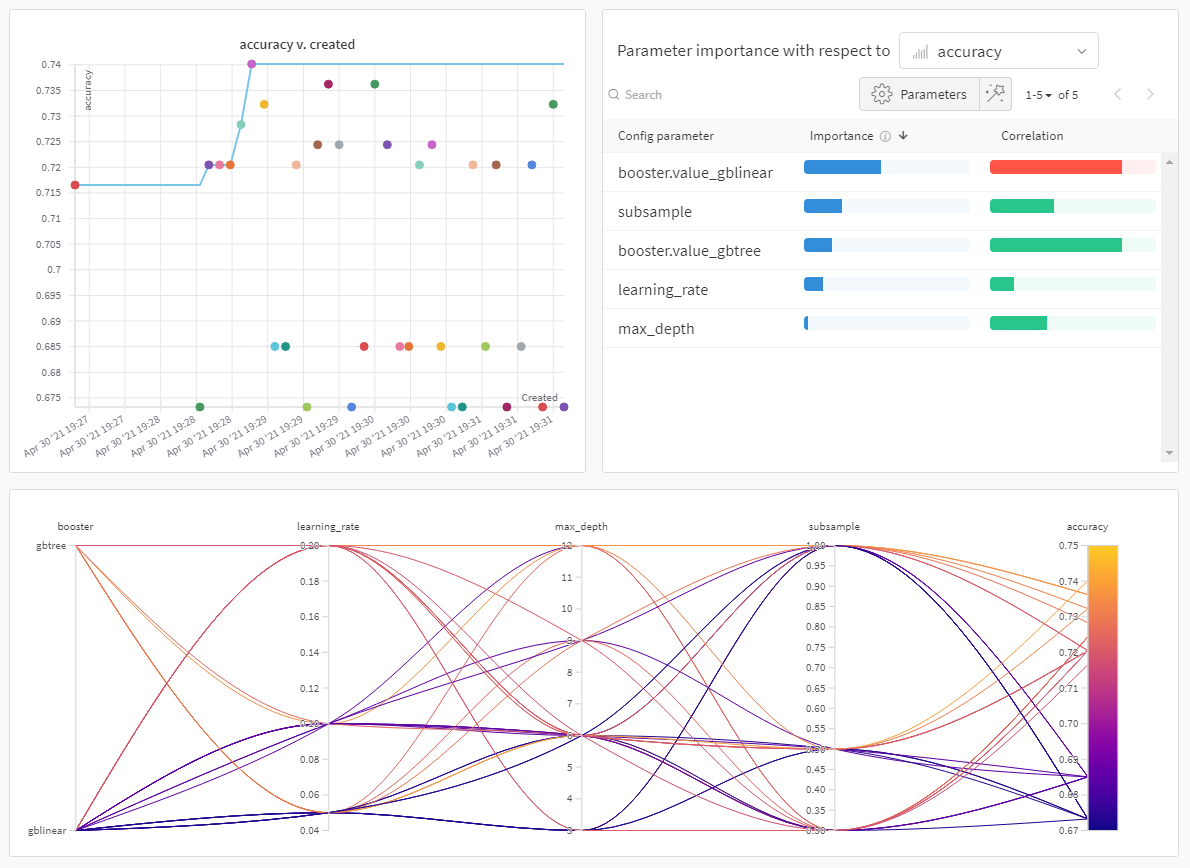
上の図は、複数の runs にわたって メトリクス を表示および比較できる ダッシュボード の例を示しています。
仕組み
数行の コード で 機械学習 の 実験 を追跡します。
W&B run を作成します。学習率や モデル タイプなどの ハイパーパラメーター の 辞書 を 設定 (run.config
トレーニング ループで、精度や 損失 などの メトリクス (run.log()
モデル の 重みや 予測 の テーブル など、run の 出力 を保存します。
次の コード は、一般的な W&B の 実験 管理 ワークフロー を示しています。
# Start a run.
#
# When this block exits, it waits for logged data to finish uploading.
# If an exception is raised, the run is marked failed.
with wandb. init(entity= "" , project= "my-project-name" ) as run:
# Save mode inputs and hyperparameters.
run. config. learning_rate = 0.01
# Run your experiment code.
for epoch in range(num_epochs):
# Do some training...
# Log metrics over time to visualize model performance.
run. log({"loss" : loss})
# Upload model outputs as artifacts.
run. log_artifact(model)
はじめに
ユースケース に応じて、次の リソース を調べて W&B Experiments を開始してください。
ベストプラクティス と ヒント
実験 と ログ の ベストプラクティス と ヒント については、Best Practices: Experiments and Logging を参照してください。
2.1.1 - Create an experiment
W&B の 実験 を作成します。
W&B Python SDK を使用して、 機械学習 の 実験 を追跡します。次に、インタラクティブな ダッシュボード で 結果 を確認するか、W&B Public API でプログラムから アクセス できるように データ を Python にエクスポートできます。
この ガイド では、W&B の構成要素を使用して W&B の 実験 を作成する方法について説明します。
W&B の 実験 を作成する方法
W&B の 実験 は、次の 4 つの ステップ で作成します。
W&B Run の初期化 ハイパーパラメーター の 辞書 をキャプチャ トレーニング ループ 内で メトリクス を ログ 記録 W&B に アーティファクト を ログ 記録
W&B run の初期化
wandb.init()
次の コードスニペット は、この run を識別するために、説明が “My first experiment” である “cat-classification” という名前の W&B の プロジェクト で run を作成します。タグ “baseline” および “paper1” は、この run が将来の論文出版を目的とした ベースライン 実験 であることを思い出させるために含まれています。
import wandb
with wandb. init(
project= "cat-classification" ,
notes= "My first experiment" ,
tags= ["baseline" , "paper1" ],
) as run:
...
wandb.init() は、Run オブジェクト を返します。
注意:run は、wandb.init() を呼び出すときに プロジェクト が既に存在する場合、既存の プロジェクト に追加されます。たとえば、“cat-classification” という プロジェクト が既にある場合、その プロジェクト は引き続き存在し、削除されません。代わりに、新しい run がその プロジェクト に追加されます。
ハイパーパラメーター の 辞書 をキャプチャ
学習率や モデル タイプなどの ハイパーパラメーター の 辞書 を保存します。config でキャプチャする モデル の 設定 は、 後で 結果 を整理してクエリするのに役立ちます。
with wandb. init(
... ,
config= {"epochs" : 100 , "learning_rate" : 0.001 , "batch_size" : 128 },
) as run:
...
実験 の構成方法の詳細については、実験 の構成 を参照してください。
トレーニング ループ 内で メトリクス を ログ 記録
run.log()
model, dataloader = get_model(), get_data()
for epoch in range(run. config. epochs):
for batch in dataloader:
loss, accuracy = model. training_step()
run. log({"accuracy" : accuracy, "loss" : loss})
W&B で ログ 記録できるさまざまな データ タイプ の詳細については、実験 中の データ の ログ 記録 を参照してください。
W&B に アーティファクト を ログ 記録
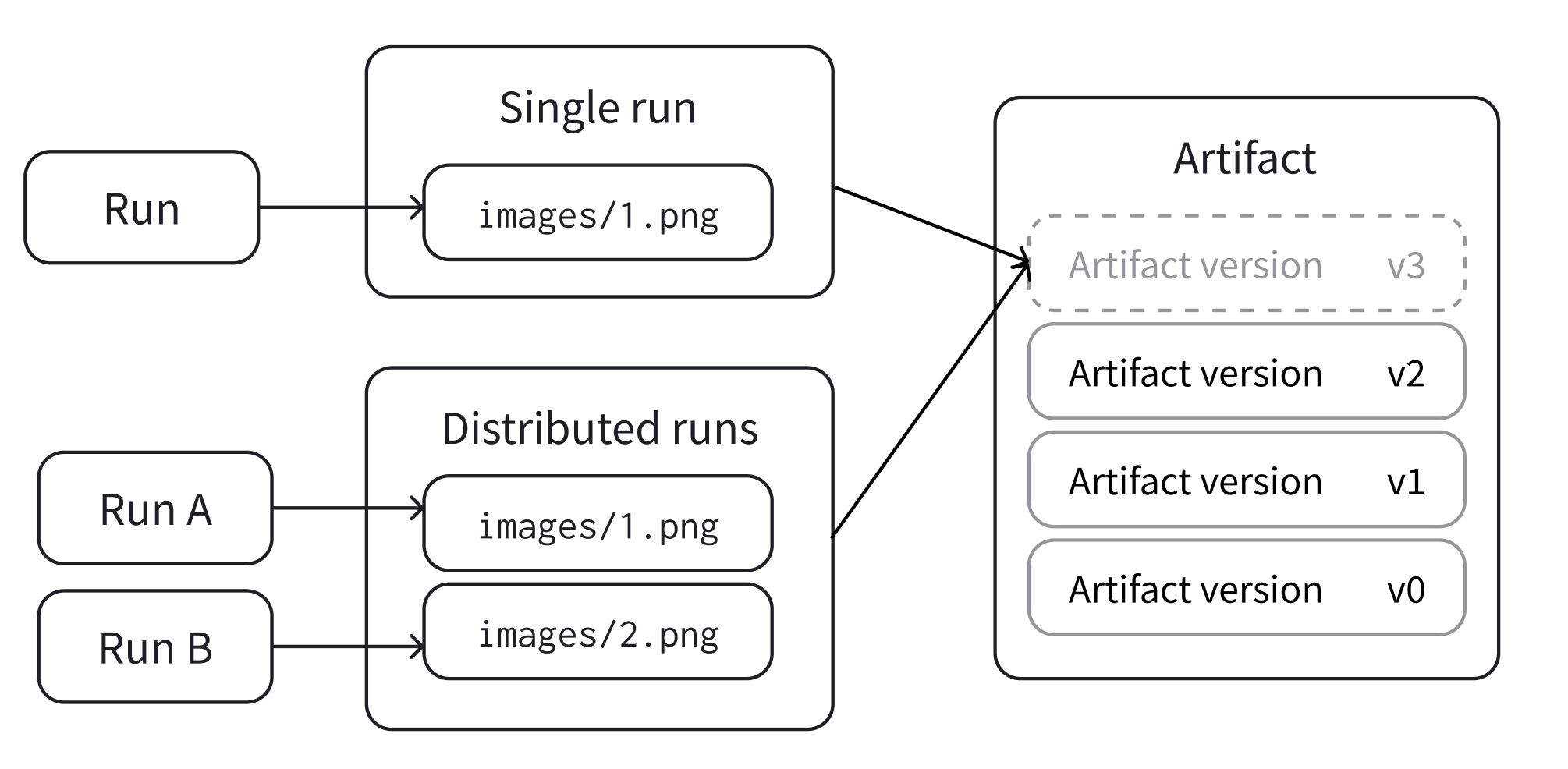
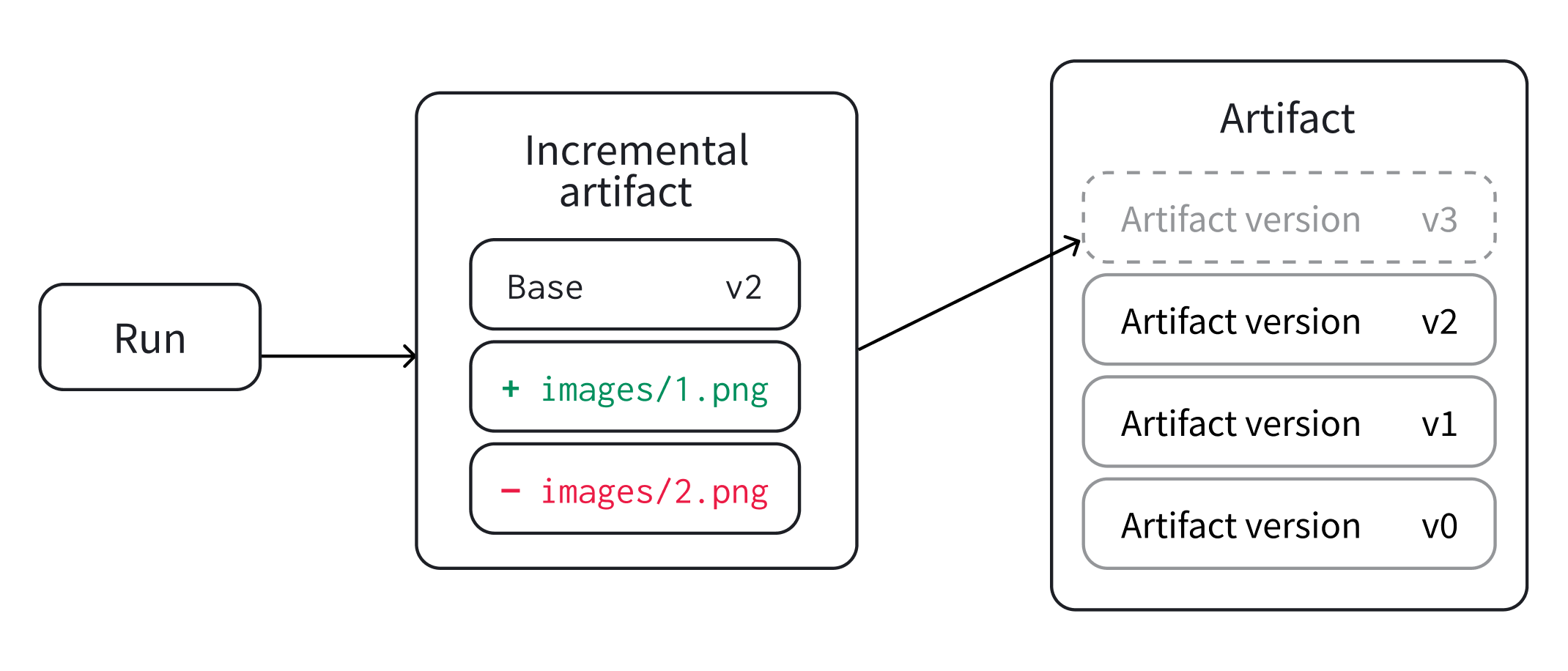
オプションで、W&B Artifact を ログ 記録します。Artifacts を使用すると、 データセット と モデル を簡単に バージョン管理 できます。
# You can save any file or even a directory. In this example, we pretend
# the model has a save() method that outputs an ONNX file.
model. save("path_to_model.onnx" )
run. log_artifact("path_to_model.onnx" , name= "trained-model" , type= "model" )
Artifacts または Registry での モデル の バージョン管理 について詳しく学びましょう。
まとめ
上記の コードスニペット を使用した完全な スクリプト は、以下にあります。
import wandb
with wandb. init(
project= "cat-classification" ,
notes= "" ,
tags= ["baseline" , "paper1" ],
# Record the run's hyperparameters.
config= {"epochs" : 100 , "learning_rate" : 0.001 , "batch_size" : 128 },
) as run:
# Set up model and data.
model, dataloader = get_model(), get_data()
# Run your training while logging metrics to visualize model performance.
for epoch in range(run. config["epochs" ]):
for batch in dataloader:
loss, accuracy = model. training_step()
run. log({"accuracy" : accuracy, "loss" : loss})
# Upload the trained model as an artifact.
model. save("path_to_model.onnx" )
run. log_artifact("path_to_model.onnx" , name= "trained-model" , type= "model" )
次の ステップ : 実験 を視覚化する
W&B ダッシュボード を、 機械学習 モデル からの 結果 を整理して視覚化するための一元的な場所として使用します。数回クリックするだけで、パラレル座標図 、パラメータ の重要性分析 などの豊富な インタラクティブ な グラフ を構築できます。その他 もあります。
実験 と特定の run の表示方法の詳細については、実験 からの 結果 の視覚化 を参照してください。
ベストプラクティス
以下は、 実験 を作成する際に考慮すべき推奨 ガイドライン です。
run を完了させる : wandb.init() を with ステートメント で使用して、 コード が完了するか 例外 が発生したときに、run が自動的に完了としてマークされるようにします。
Config : ハイパーパラメーター 、 architecture 、 データセット 、 モデル を再現するために使用したいその他のものを追跡します。これらは列に表示されます。 config 列を使用して、アプリ で run を動的にグループ化、並べ替え、フィルター処理します。Project : プロジェクト は、一緒に比較できる 実験 の セット です。各 プロジェクト には専用の ダッシュボード ページがあり、さまざまな モデル バージョン を比較するために、さまざまな run のグループを簡単にオン/オフにできます。Notes : スクリプト から直接クイック コミット メッセージ を設定します。W&B App の run の 概要 セクション で ノート を編集して アクセス します。Tags : ベースライン run とお気に入りの run を識別します。タグ を使用して run をフィルター処理できます。W&B App の プロジェクト の ダッシュボード の 概要 セクション で、 後で タグ を編集できます。複数の run セット を作成して 実験 を比較する : 実験 を比較するときは、 メトリクス を簡単に比較できるように複数の run セット を作成します。同じ グラフ または グラフ のグループで run セット のオン/オフを切り替えることができます。
次の コードスニペット は、上記の ベストプラクティス を使用して W&B の 実験 を定義する方法を示しています。
import wandb
config = {
"learning_rate" : 0.01 ,
"momentum" : 0.2 ,
"architecture" : "CNN" ,
"dataset_id" : "cats-0192" ,
}
with wandb. init(
project= "detect-cats" ,
notes= "tweak baseline" ,
tags= ["baseline" , "paper1" ],
config= config,
) as run:
...
W&B の 実験 を定義する際に使用できる パラメータ の詳細については、API Reference Guide の wandb.init
2.1.2 - Configure experiments
実験 の 設定 を保存するには、 辞書 のような オブジェクト を使用します
config プロパティを使用すると、トレーニングの設定を保存できます。
ハイパーパラメータ
データセット名やモデルタイプなどの入力設定
実験のその他の独立変数
run.config プロパティを使用すると、実験の分析や将来の作業の再現が容易になります。W&B App で設定値ごとにグループ化したり、異なる W&B の run の設定を比較したり、各トレーニング設定がアウトプットに与える影響を評価したりできます。config プロパティは、複数の辞書のようなオブジェクトから構成できる辞書のようなオブジェクトです。
損失や精度などの出力メトリクスや従属変数を保存するには、run.config の代わりに run.log を使用してください。
実験設定の構成
通常、設定はトレーニングスクリプトの最初に定義されます。ただし、機械学習のワークフローは異なる場合があるため、トレーニングスクリプトの最初に設定を定義する必要はありません。
config 変数名では、ピリオド(.)の代わりにダッシュ(-)またはアンダースコア(_)を使用してください。
スクリプトがルートより下の run.config キーにアクセスする場合は、属性アクセス構文 config.key.value の代わりに辞書アクセス構文 ["key"]["value"] を使用してください。
以下のセクションでは、実験設定を定義するさまざまな一般的なシナリオについて概説します。
初期化時に設定を構成する
W&B Run としてデータを同期およびログ記録するためのバックグラウンド プロセスを生成するために、wandb.init() API を呼び出すときに、スクリプトの先頭で辞書を渡します。
次のコードスニペットは、設定値を持つ Python 辞書を定義する方法と、W&B Run を初期化するときにその辞書を引数として渡す方法を示しています。
import wandb
# config 辞書オブジェクトを定義します
config = {
"hidden_layer_sizes" : [32 , 64 ],
"kernel_sizes" : [3 ],
"activation" : "ReLU" ,
"pool_sizes" : [2 ],
"dropout" : 0.5 ,
"num_classes" : 10 ,
}
# W&B を初期化するときに config 辞書を渡します
with wandb. init(project= "config_example" , config= config) as run:
...
config としてネストされた辞書を渡すと、W&B はドットを使用して名前をフラット化します。
Python の他の辞書にアクセスするのと同じように、辞書から値にアクセスします。
# インデックス値としてキーを使用して値にアクセスします
hidden_layer_sizes = run. config["hidden_layer_sizes" ]
kernel_sizes = run. config["kernel_sizes" ]
activation = run. config["activation" ]
# Python 辞書 get() メソッド
hidden_layer_sizes = run. config. get("hidden_layer_sizes" )
kernel_sizes = run. config. get("kernel_sizes" )
activation = run. config. get("activation" )
開発者ガイドと例全体を通して、設定値を個別の変数にコピーしています。このステップはオプションです。これは、読みやすさのために行われています。
argparse で設定を構成する
argparse オブジェクトで設定を構成できます。argparse (引数パーサーの略)は、Python 3.2 以降の標準ライブラリモジュールであり、コマンドライン引数のすべての柔軟性と機能を活用するスクリプトを簡単に作成できます。
これは、コマンドラインから起動されたスクリプトの結果を追跡するのに役立ちます。
次の Python スクリプトは、パーサーオブジェクトを定義して実験設定を定義および設定する方法を示しています。関数 train_one_epoch および evaluate_one_epoch は、このデモンストレーションの目的でトレーニングループをシミュレートするために提供されています。
# config_experiment.py
import argparse
import random
import numpy as np
import wandb
# トレーニングと評価のデモコード
def train_one_epoch (epoch, lr, bs):
acc = 0.25 + ((epoch / 30 ) + (random. random() / 10 ))
loss = 0.2 + (1 - ((epoch - 1 ) / 10 + random. random() / 5 ))
return acc, loss
def evaluate_one_epoch (epoch):
acc = 0.1 + ((epoch / 20 ) + (random. random() / 10 ))
loss = 0.25 + (1 - ((epoch - 1 ) / 10 + random. random() / 6 ))
return acc, loss
def main (args):
# W&B Run を開始します
with wandb. init(project= "config_example" , config= args) as run:
# config 辞書から値にアクセスし、読みやすくするために変数に格納します
lr = run. config["learning_rate" ]
bs = run. config["batch_size" ]
epochs = run. config["epochs" ]
# トレーニングをシミュレートし、値を W&B に記録します
for epoch in np. arange(1 , epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
run. log(
{
"epoch" : epoch,
"train_acc" : train_acc,
"train_loss" : train_loss,
"val_acc" : val_acc,
"val_loss" : val_loss,
}
)
if __name__ == "__main__" :
parser = argparse. ArgumentParser(
formatter_class= argparse. ArgumentDefaultsHelpFormatter
)
parser. add_argument("-b" , "--batch_size" , type= int, default= 32 , help= "バッチサイズ" )
parser. add_argument(
"-e" , "--epochs" , type= int, default= 50 , help= "トレーニングエポック数"
)
parser. add_argument(
"-lr" , "--learning_rate" , type= int, default= 0.001 , help= "学習率"
)
args = parser. parse_args()
main(args)
スクリプト全体で設定を構成する
スクリプト全体で config オブジェクトにパラメーターを追加できます。次のコードスニペットは、新しいキーと値のペアを config オブジェクトに追加する方法を示しています。
import wandb
# config 辞書オブジェクトを定義します
config = {
"hidden_layer_sizes" : [32 , 64 ],
"kernel_sizes" : [3 ],
"activation" : "ReLU" ,
"pool_sizes" : [2 ],
"dropout" : 0.5 ,
"num_classes" : 10 ,
}
# W&B を初期化するときに config 辞書を渡します
with wandb. init(project= "config_example" , config= config) as run:
# W&B を初期化した後に config を更新します
run. config["dropout" ] = 0.2
run. config. epochs = 4
run. config["batch_size" ] = 32
一度に複数の値を更新できます。
run. config. update({"lr" : 0.1 , "channels" : 16 })
Run の完了後に設定を構成する
W&B Public API を使用して、完了した Run の config を更新します。
API には、エンティティ、プロジェクト名、および Run の ID を指定する必要があります。これらの詳細は、Run オブジェクトまたは W&B App UI で確認できます。
with wandb. init() as run:
...
# 現在のスクリプトまたはノートブックから開始された場合は、Run オブジェクトから次の値を見つけるか、W&B App UI からコピーできます。
username = run. entity
project = run. project
run_id = run. id
# api.run() は wandb.init() とは異なる型のオブジェクトを返すことに注意してください。
api = wandb. Api()
api_run = api. run(f " { username} / { project} / { run_id} " )
api_run. config["bar" ] = 32
api_run. update()
absl.FLAGSabsl フラグ
flags. DEFINE_string("model" , None , "実行するモデル" ) # name, default, help
run. config. update(flags. FLAGS) # absl フラグを config に追加します
ファイルベースの Configs
config-defaults.yaml という名前のファイルを Run スクリプトと同じディレクトリーに配置すると、Run はファイルで定義されたキーと値のペアを自動的に取得し、run.config に渡します。
次のコードスニペットは、サンプルの config-defaults.yaml YAML ファイルを示しています。
batch_size :
desc : 各ミニバッチのサイズ
value : 32
config-defaults.yaml から自動的にロードされたデフォルト値をオーバーライドするには、wandb.init の config 引数で更新された値を設定します。次に例を示します。
import wandb
# カスタム値を渡して config-defaults.yaml をオーバーライドします
with wandb. init(config= {"epochs" : 200 , "batch_size" : 64 }) as run:
...
config-defaults.yaml 以外の構成ファイルをロードするには、--configs コマンドライン 引数を使用し、ファイルへのパスを指定します。
python train.py --configs other-config.yaml
ファイルベースの Configs のユースケース例
Run のメタデータを含む YAML ファイルと、Python スクリプトにハイパーパラメーターの辞書があるとします。ネストされた config オブジェクトに両方を保存できます。
hyperparameter_defaults = dict(
dropout= 0.5 ,
batch_size= 100 ,
learning_rate= 0.001 ,
)
config_dictionary = dict(
yaml= my_yaml_file,
params= hyperparameter_defaults,
)
with wandb. init(config= config_dictionary) as run:
...
TensorFlow v1 フラグ
TensorFlow フラグを wandb.config オブジェクトに直接渡すことができます。
with wandb. init() as run:
run. config. epochs = 4
flags = tf. app. flags
flags. DEFINE_string("data_dir" , "/tmp/data" )
flags. DEFINE_integer("batch_size" , 128 , "バッチサイズ" )
run. config. update(flags. FLAGS) # tensorflow フラグを config として追加します
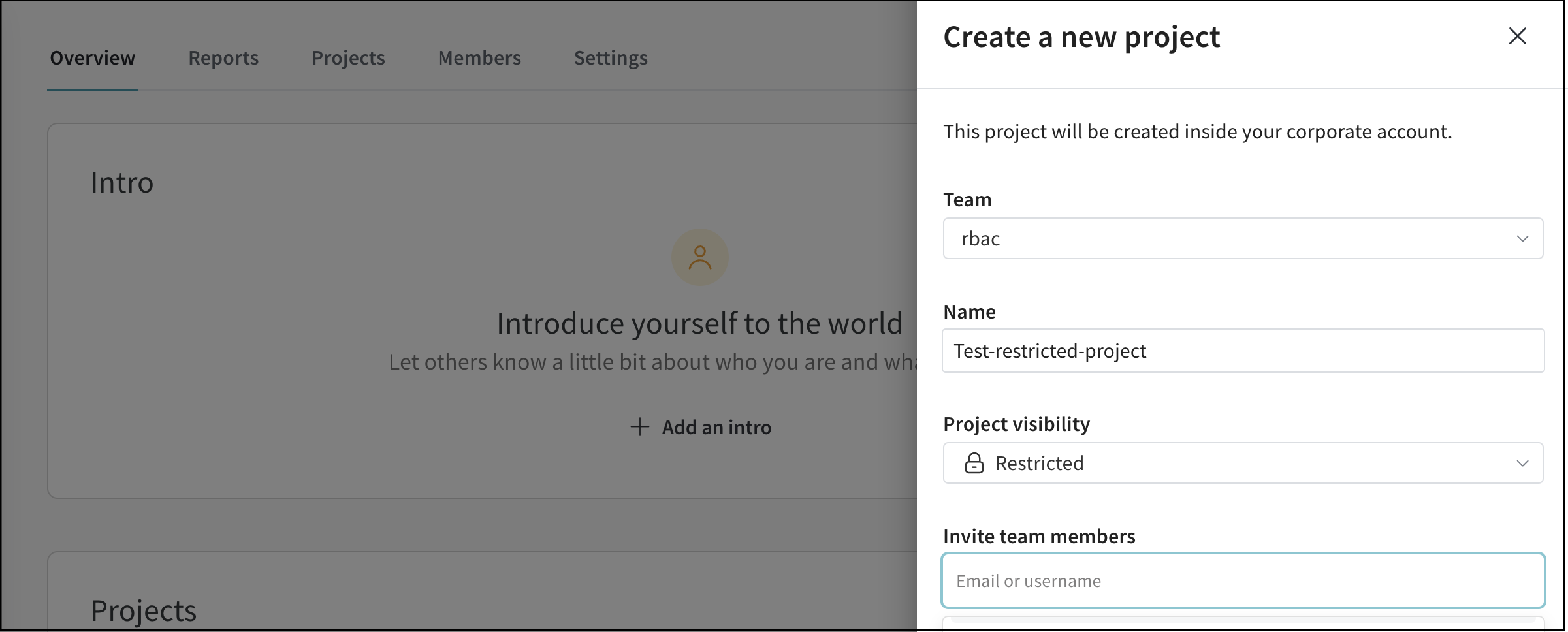
2.1.3 - Projects
モデルのバージョンを比較し、スクラッチ ワークスペース で結果を調査し、 学び をレポートにエクスポートして、メモと 可視化 を保存します。
project は、結果の可視化、実験の比較、Artifactsの表示とダウンロード、オートメーションの作成などを行う中心的な場所です。
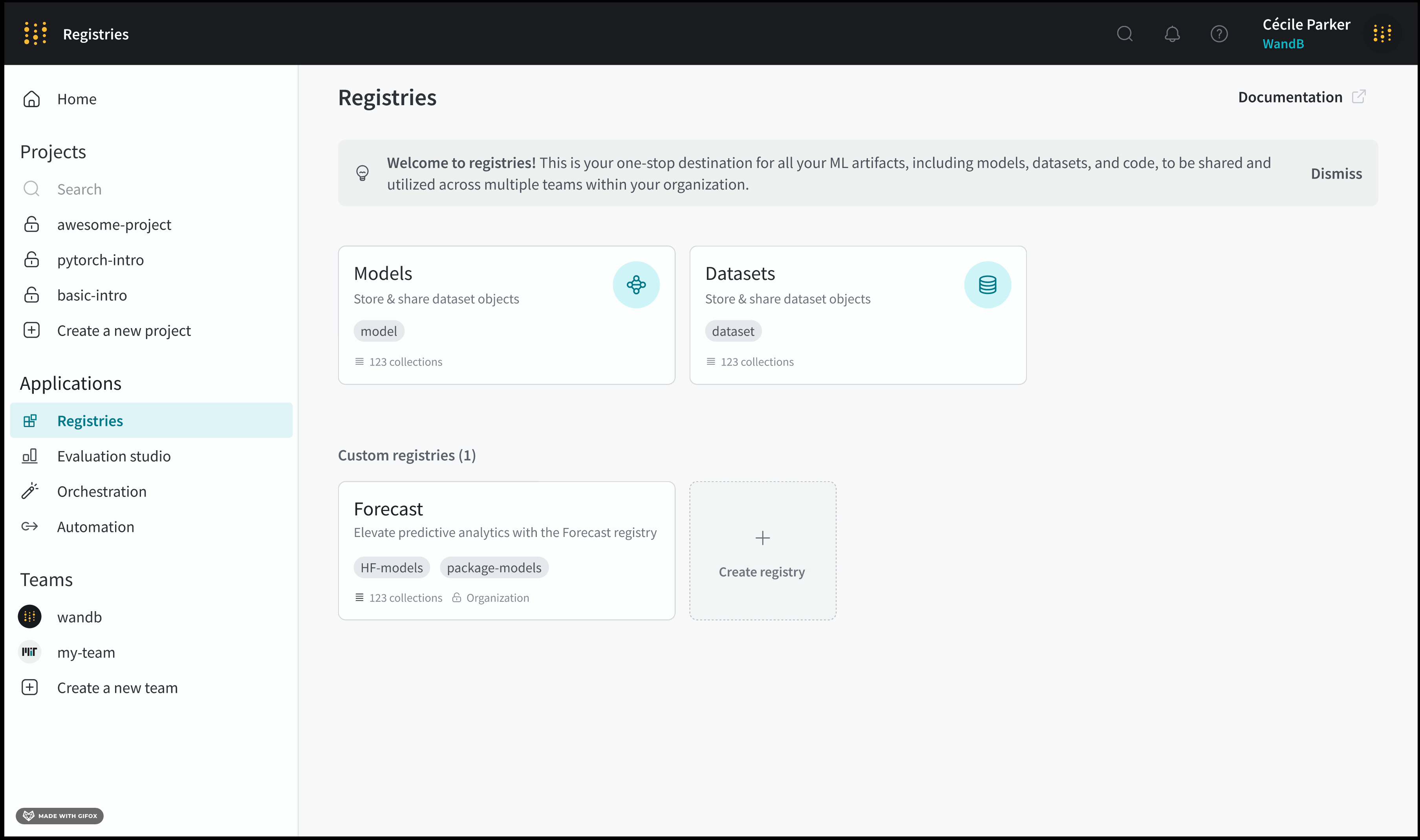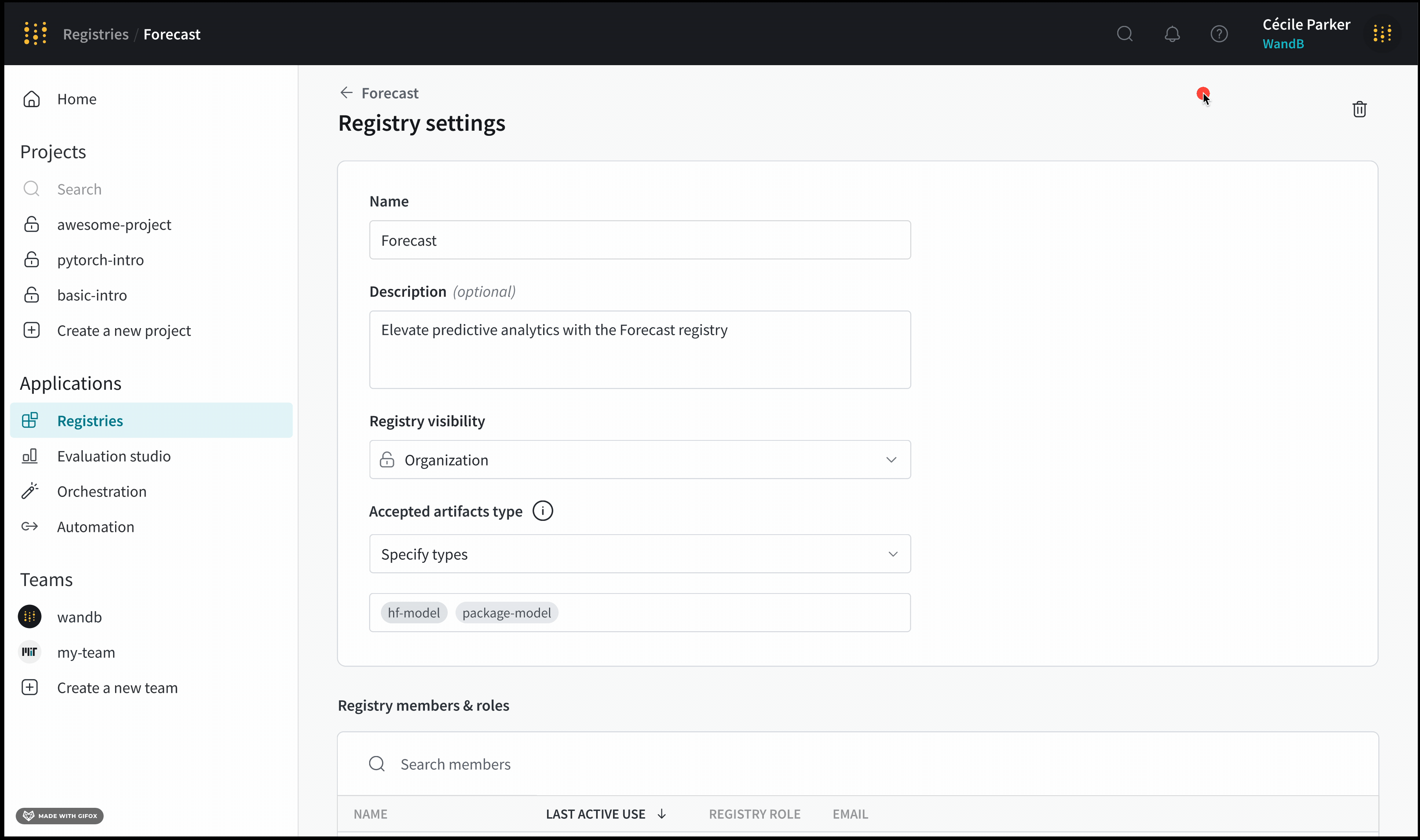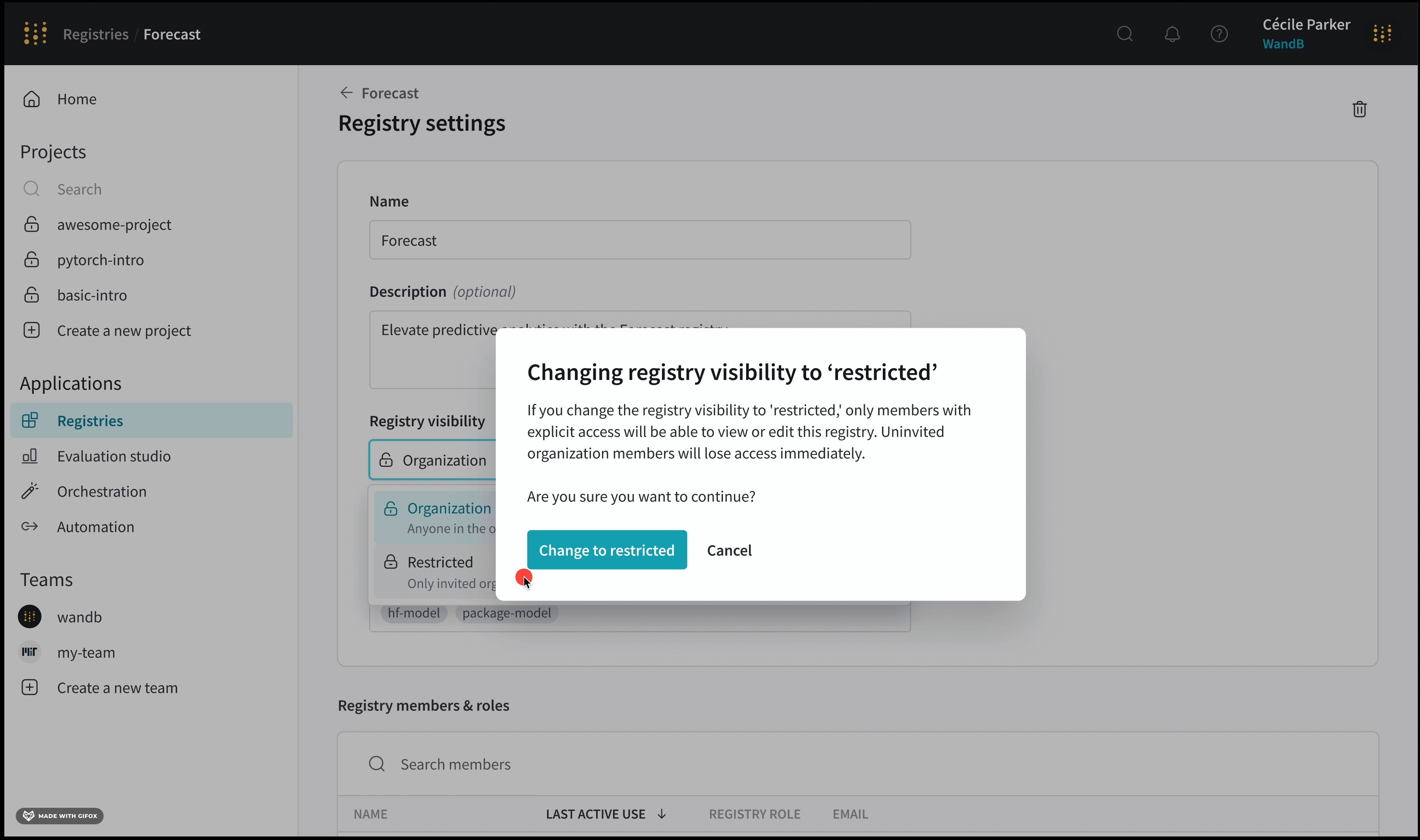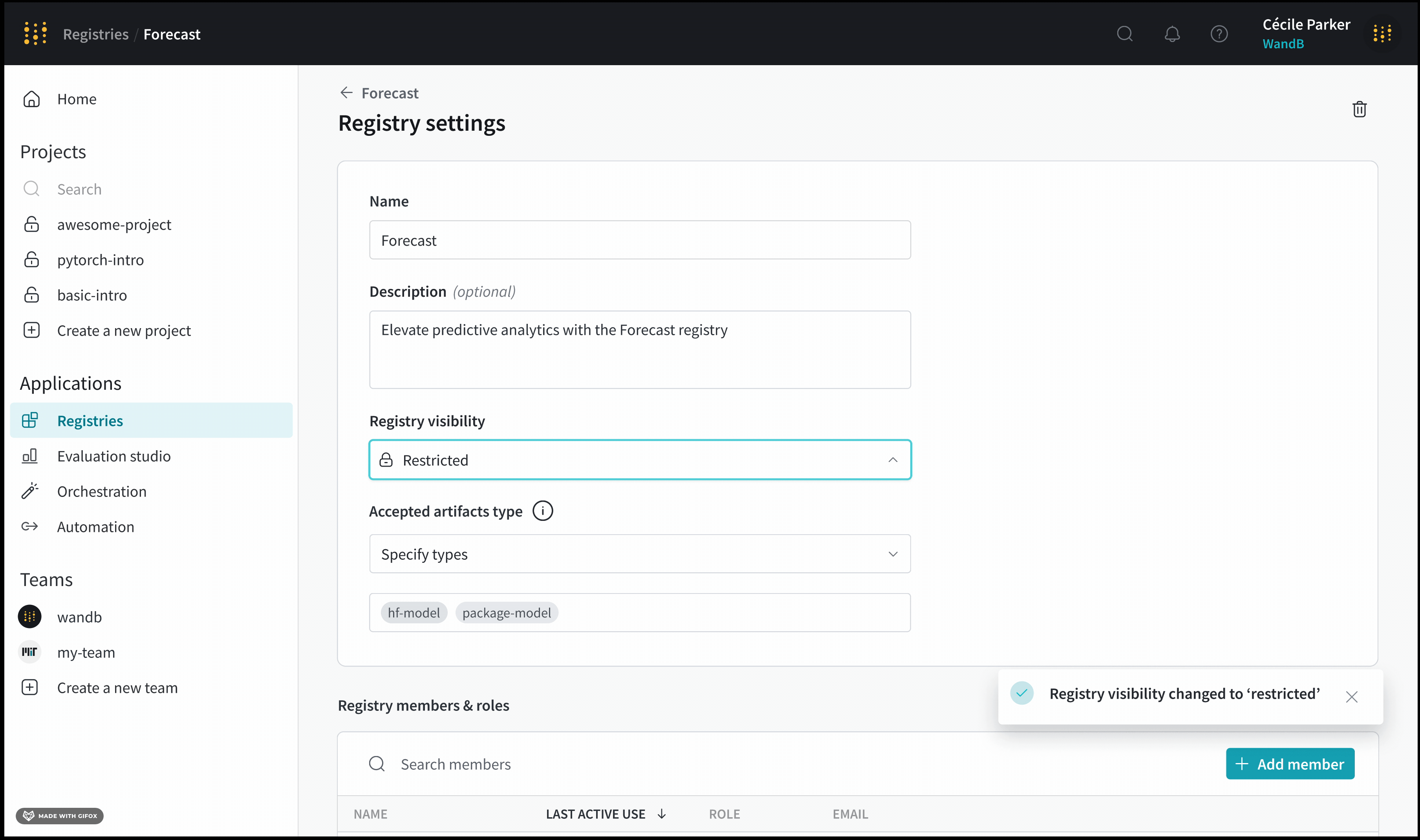
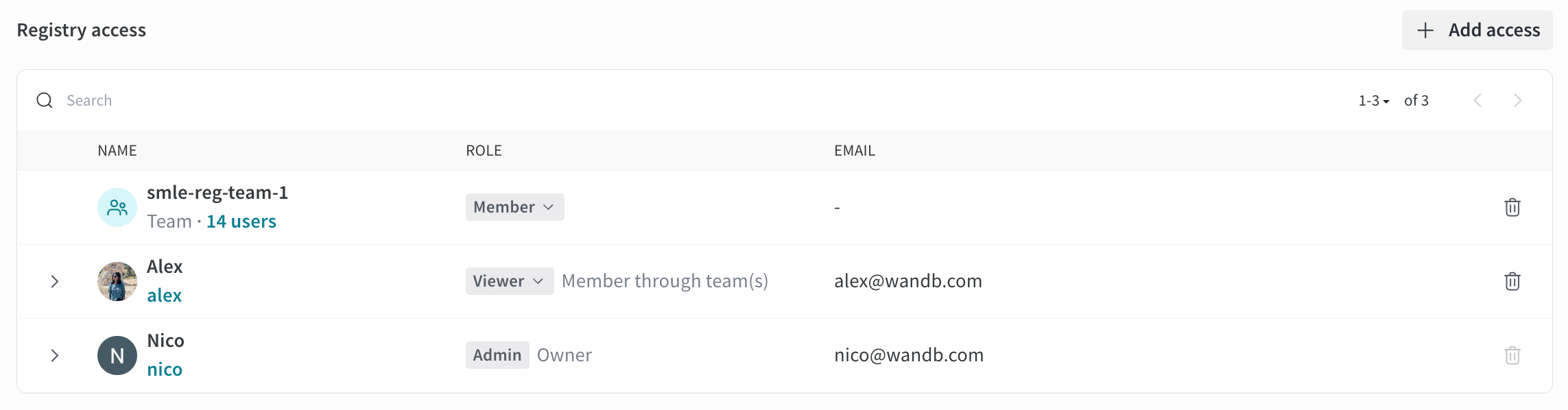
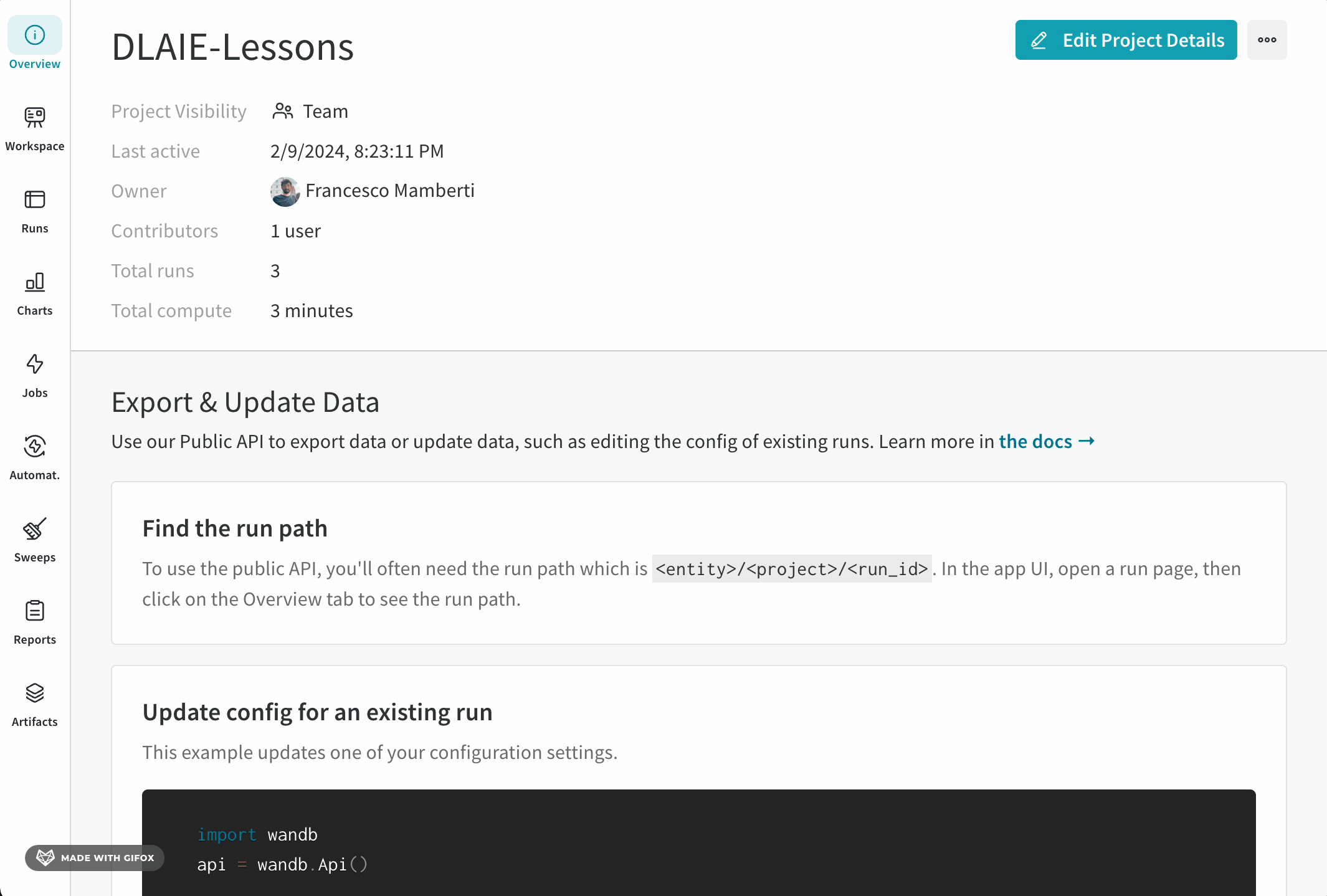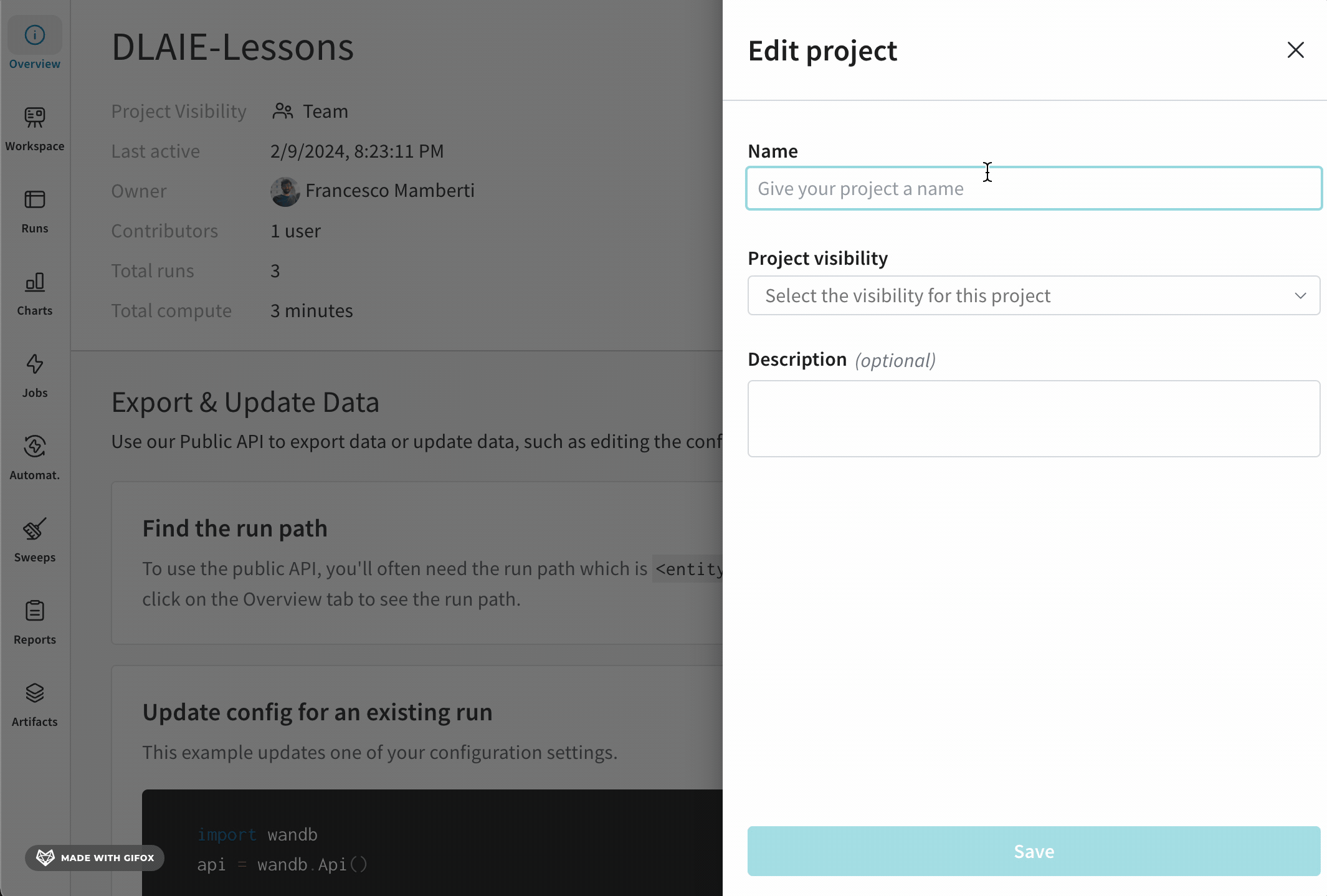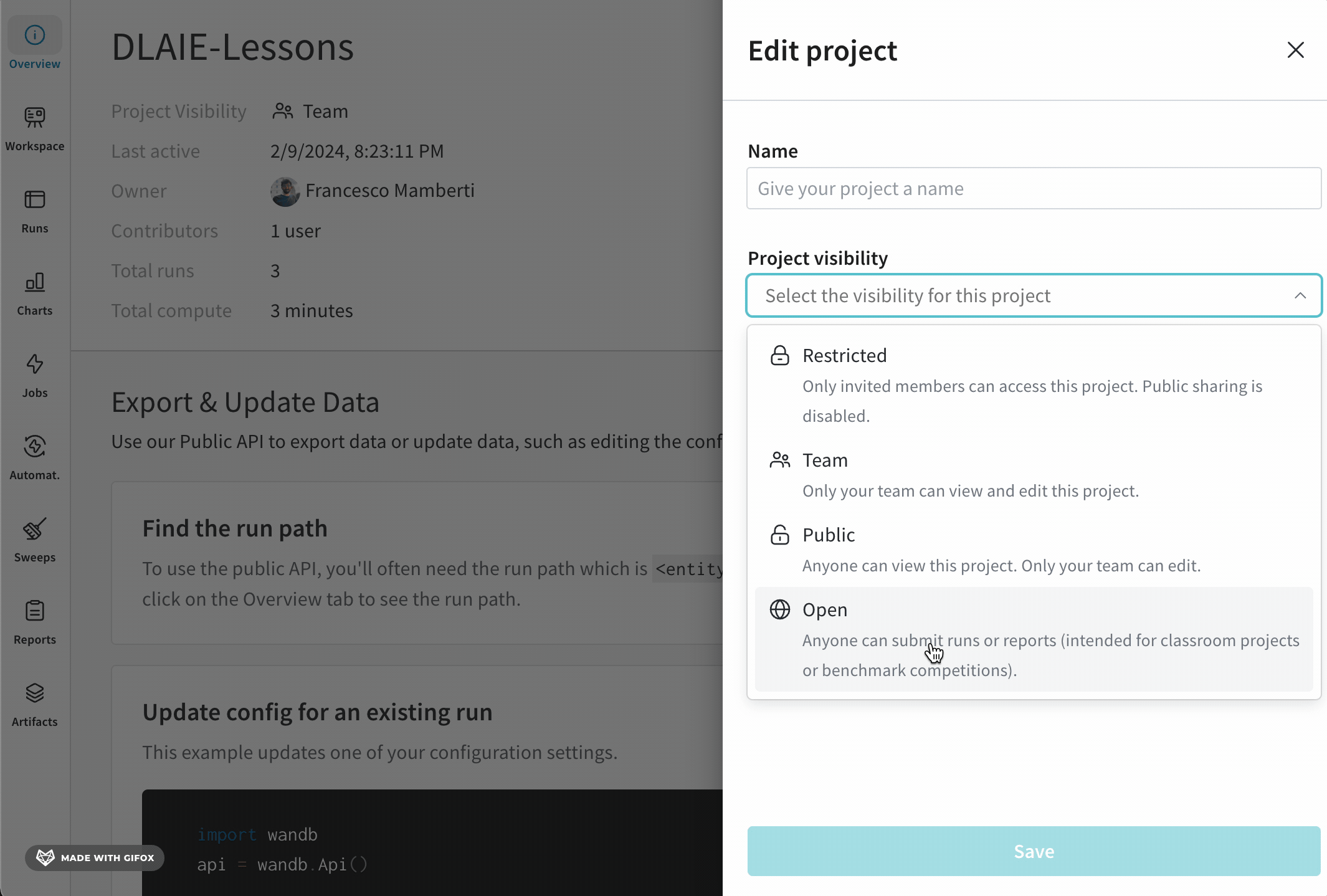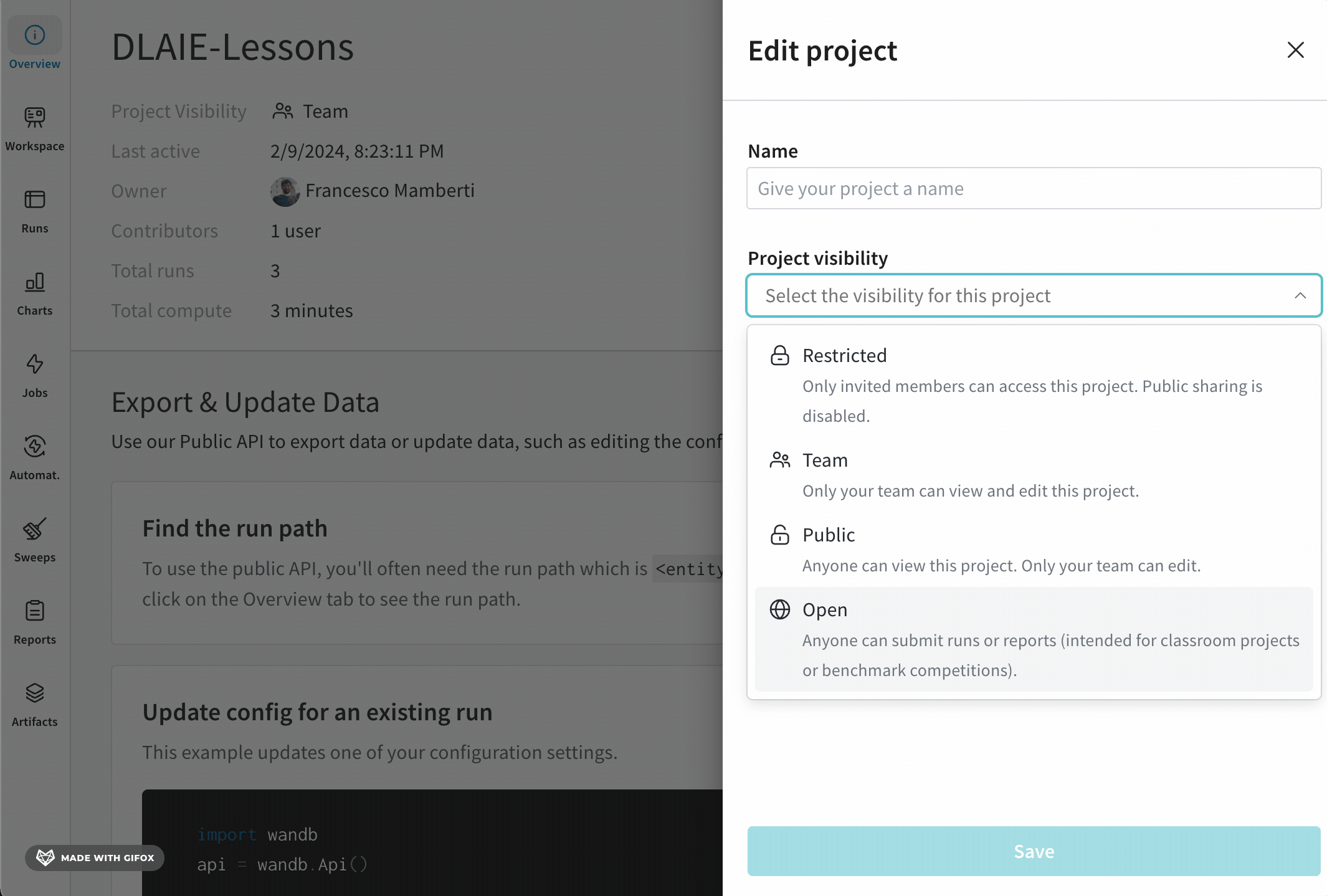
各projectには、誰がそれにアクセスできるかを決定する可視性の設定があります。誰が project にアクセスできるかの詳細については、
Project visibility を参照してください。
各 project には、サイドバーからアクセスできる次のものが含まれています。
Overview Workspace Runs Automations : project で構成されたオートメーションSweeps Reports Artifacts
Overview タブ
Project name : project の名前。W&B は、project フィールドに指定した名前で run を初期化すると、project を作成します。project の名前は、右上隅にある Edit ボタンを選択すると、いつでも変更できます。Description : project の説明。Project visibility : project の可視性。誰がアクセスできるかを決定する可視性設定。詳細については、Project visibility を参照してください。Last active : この project に最後にデータが記録されたときのタイムスタンプOwner : この project のエンティティContributors : この project に貢献する ユーザー の数Total runs : この project 内の run の総数Total compute : この合計を取得するために、project 内のすべての run 時間を合計します。Undelete runs : ドロップダウン メニューをクリックし、[Undelete all runs] をクリックして、project 内で削除された run を復元します。Delete project : 右隅にあるドット メニューをクリックして、project を削除します。
ライブの例を見る
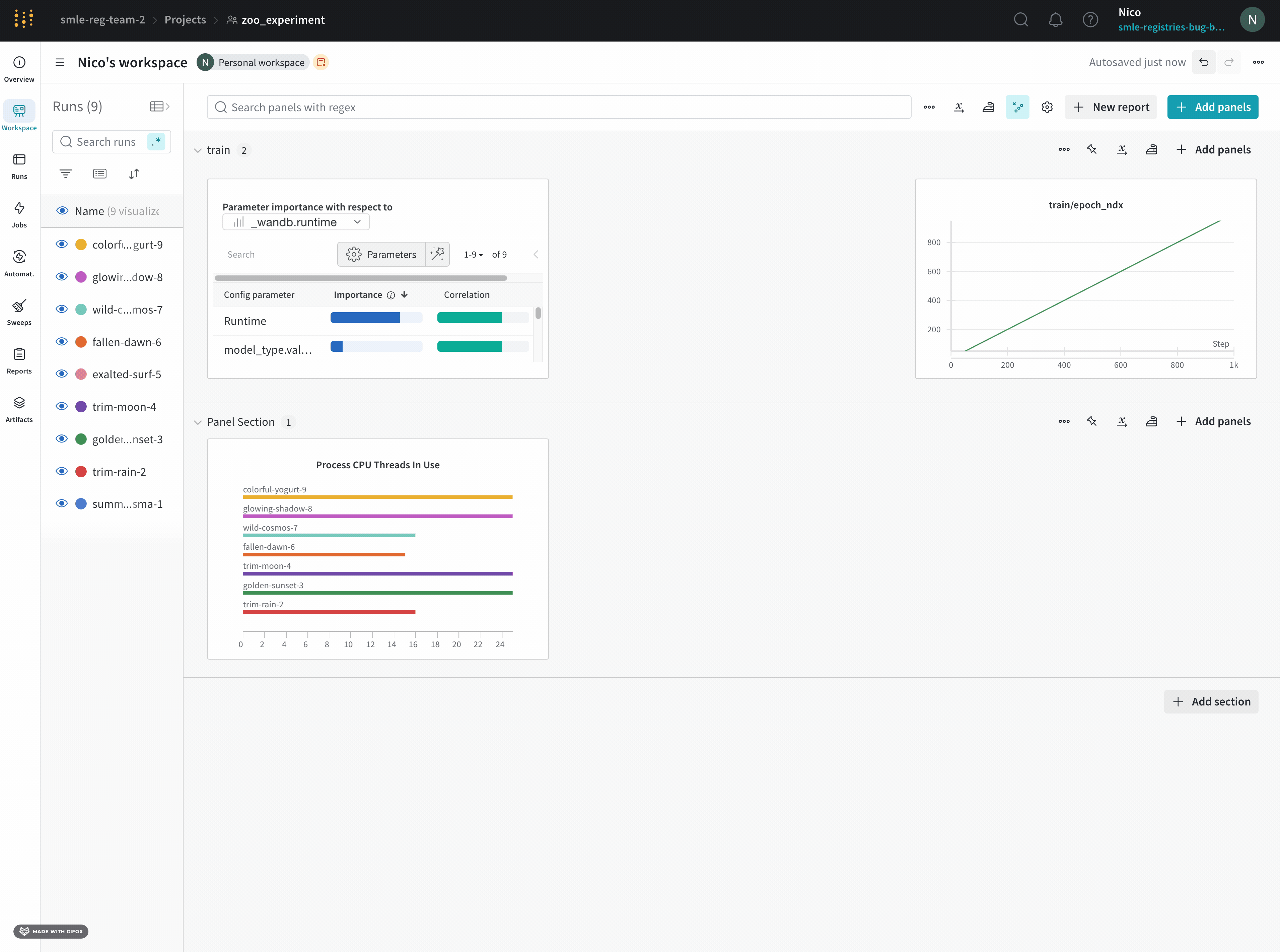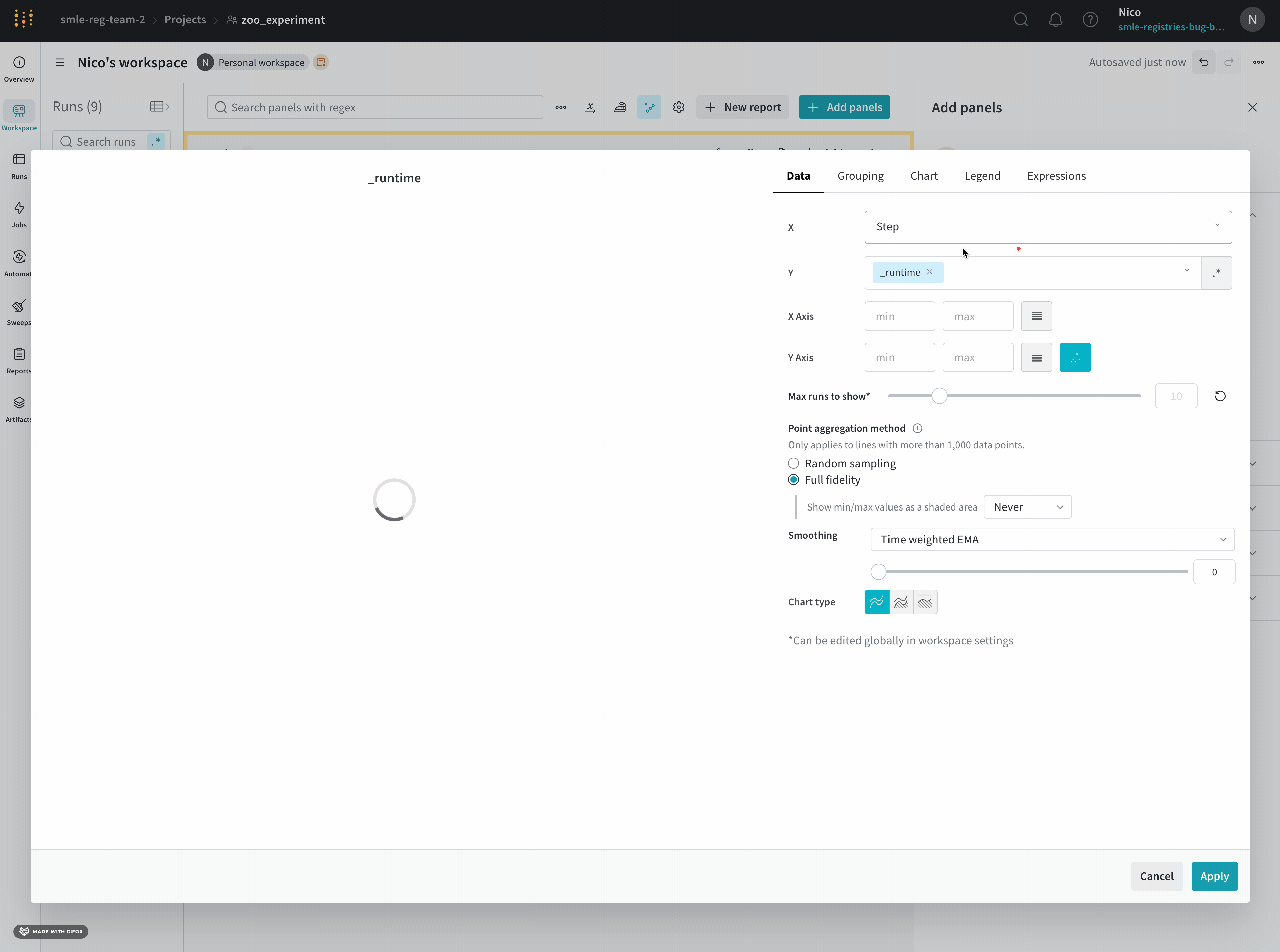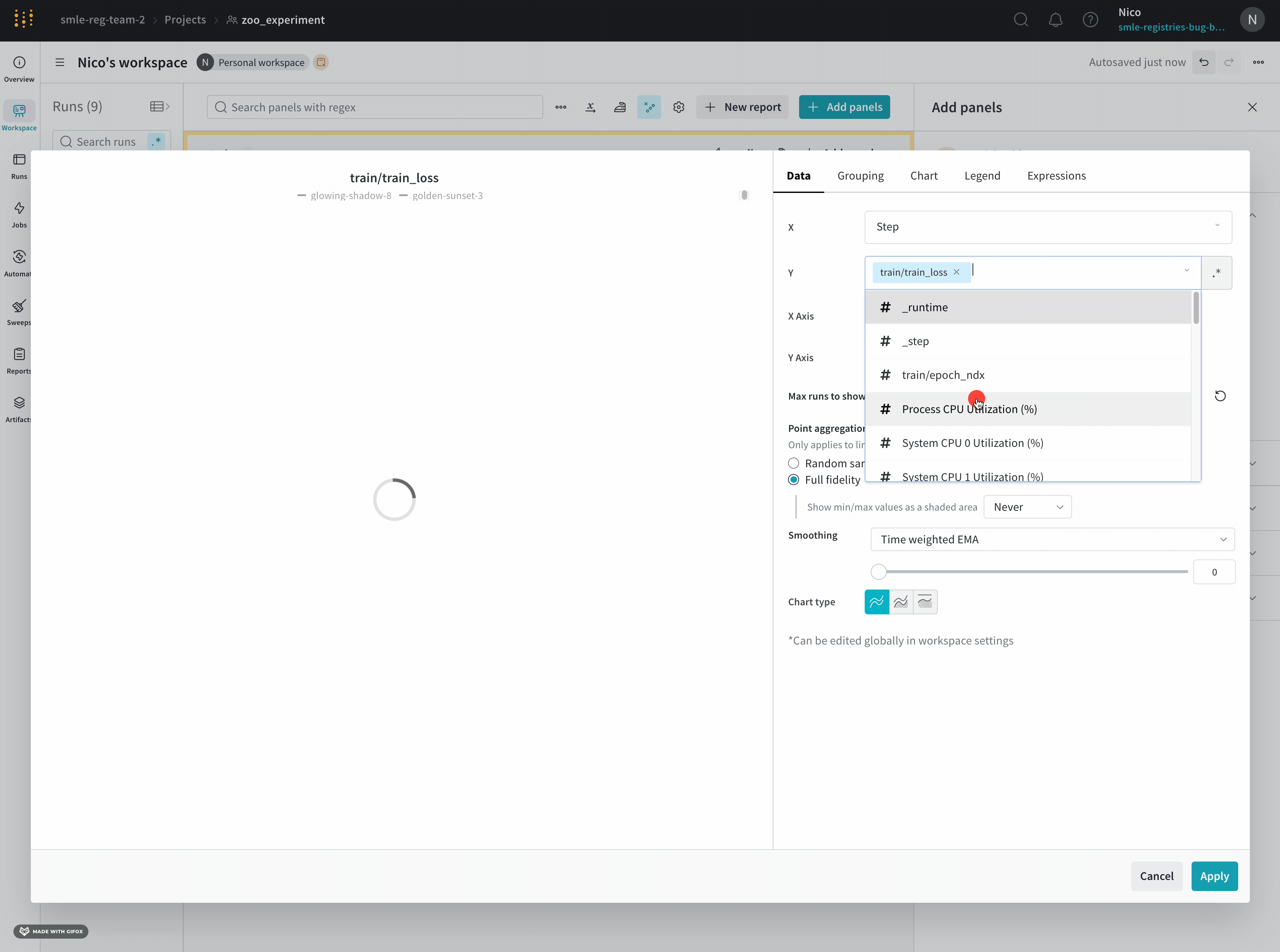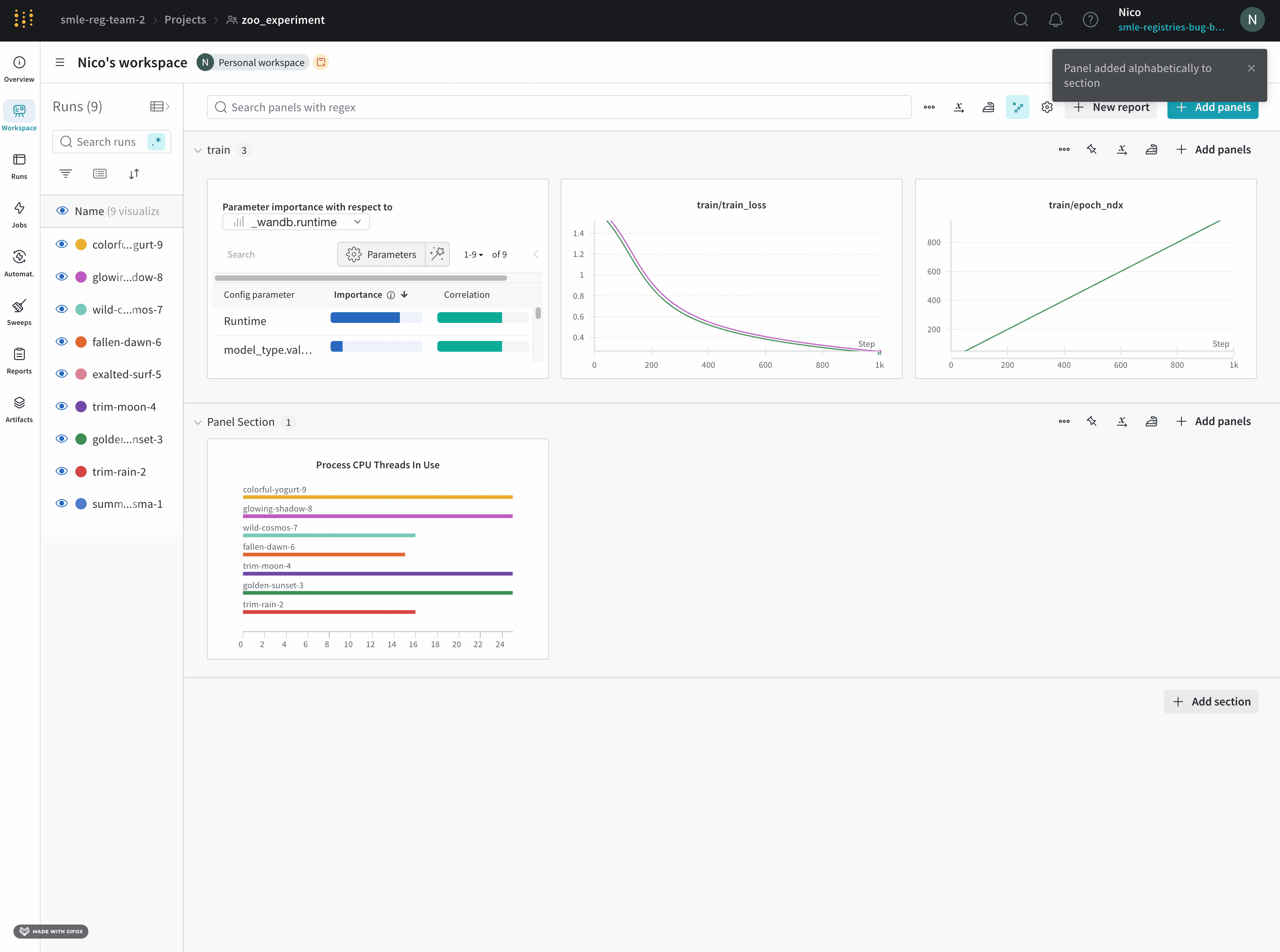
Workspace タブ
project の workspace は、実験を比較するための個人的なサンドボックスを提供します。異なるアーキテクチャ、ハイパーパラメーター、データセット、プロセッシングなどで同じ問題に取り組んでいる、比較できる Models を整理するために project を使用します。
Runs Sidebar : project 内のすべての run のリスト。
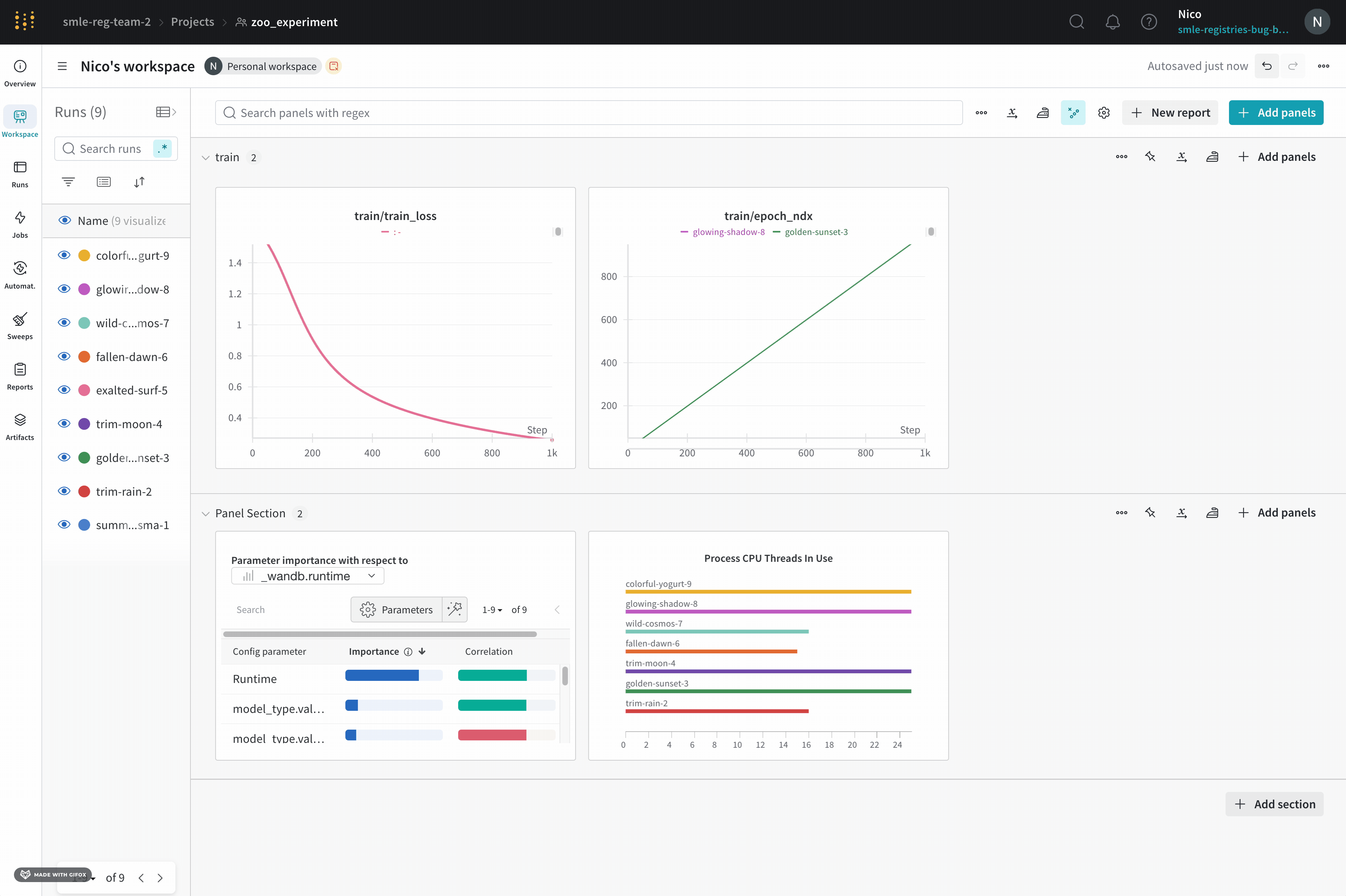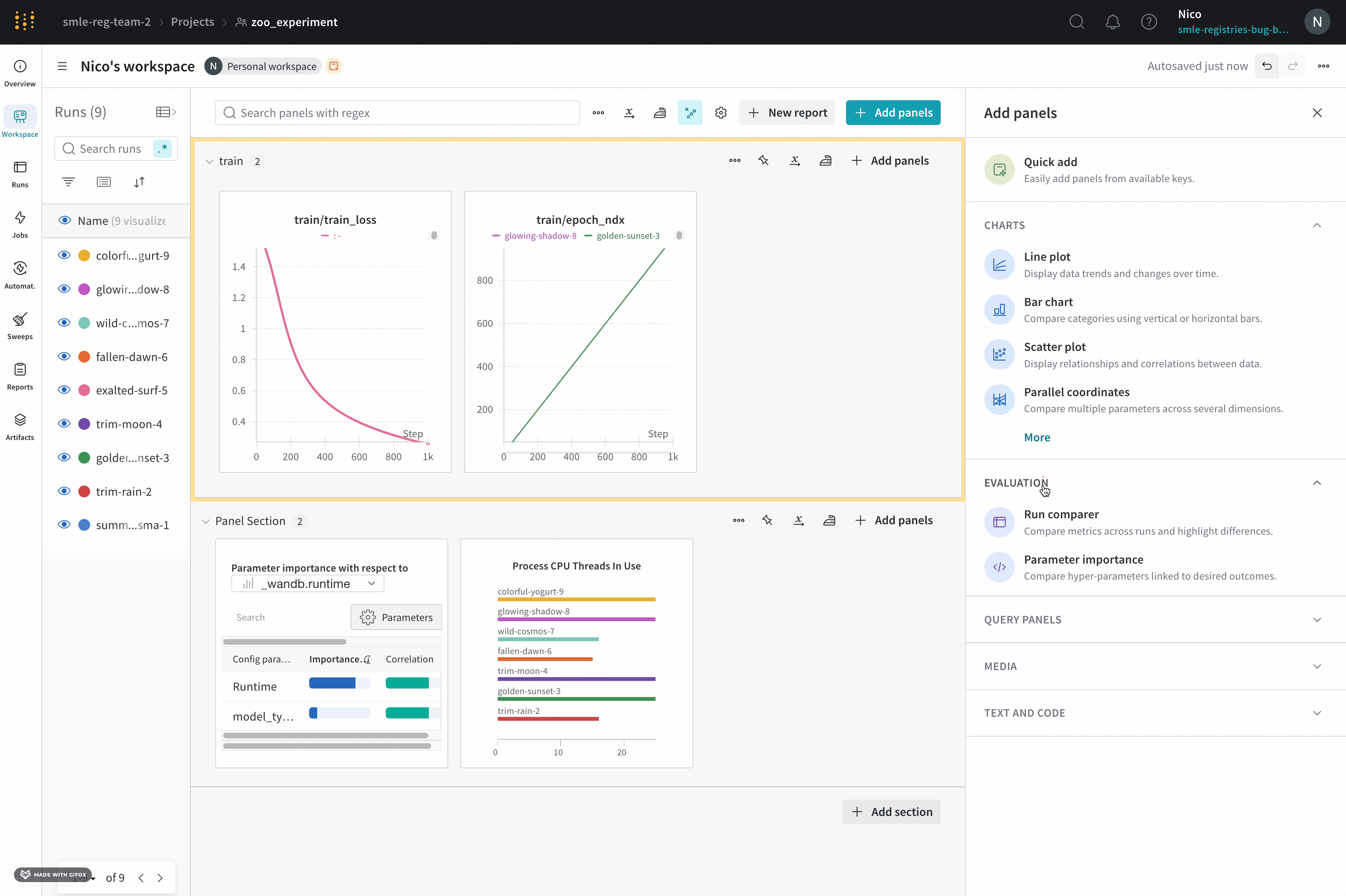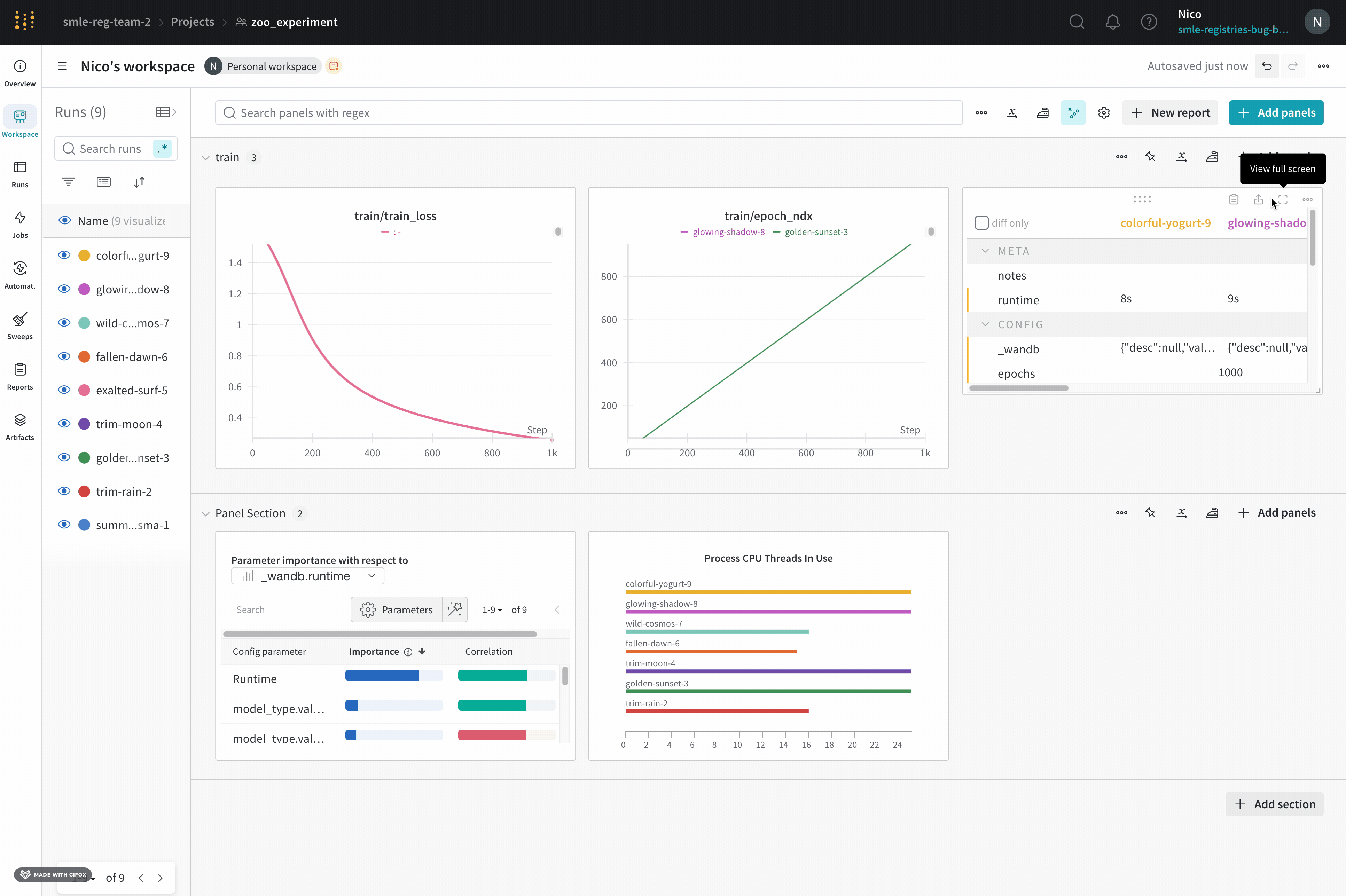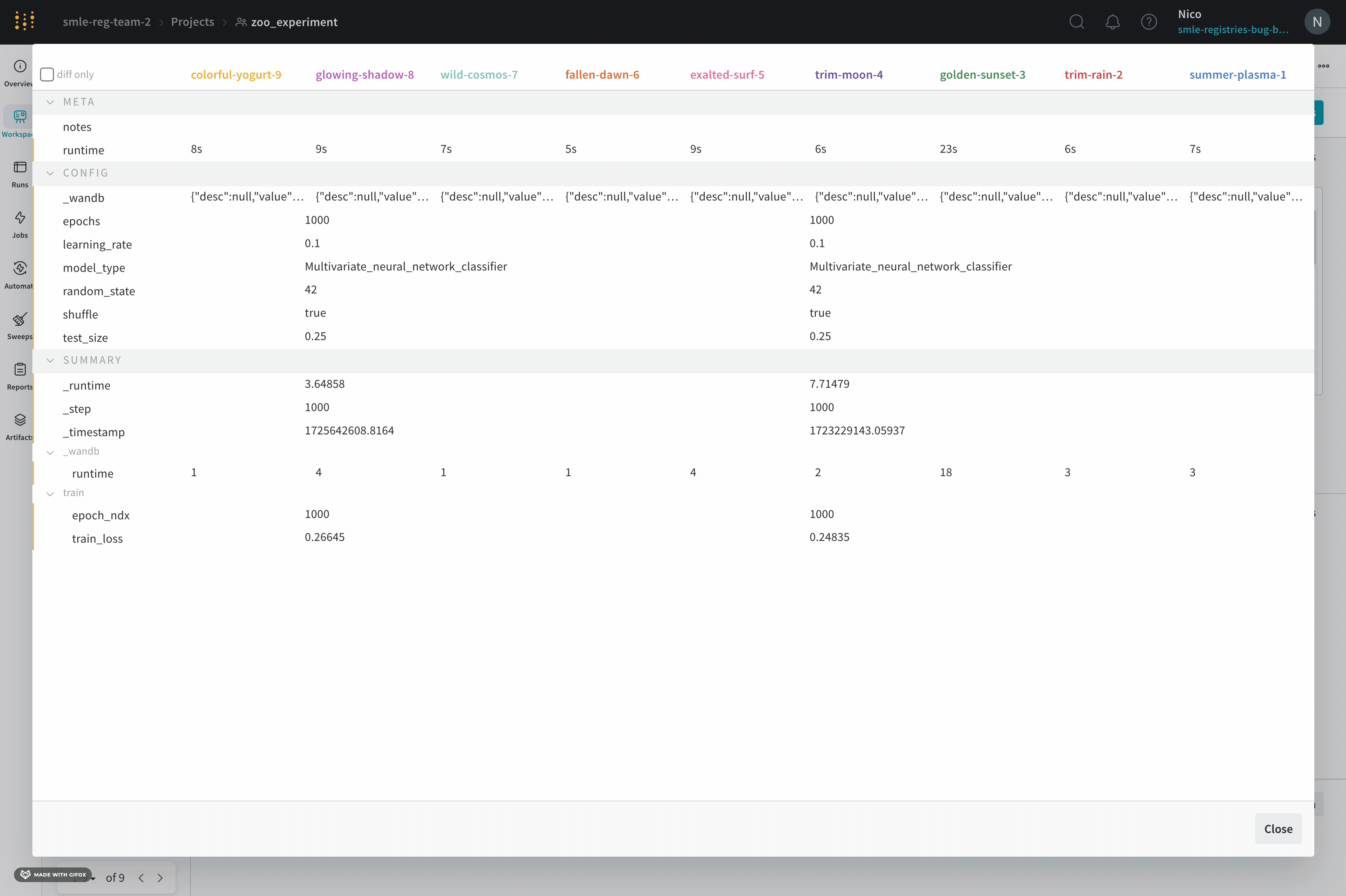
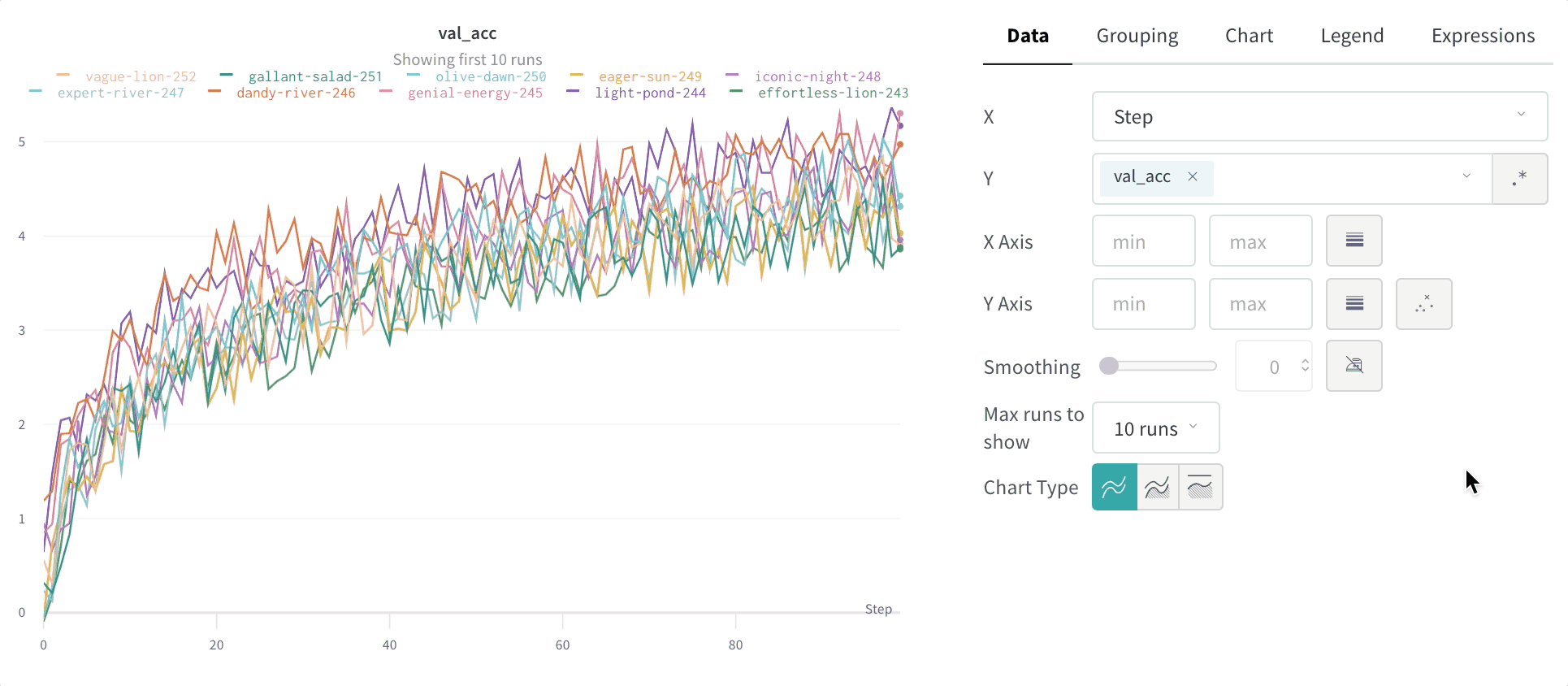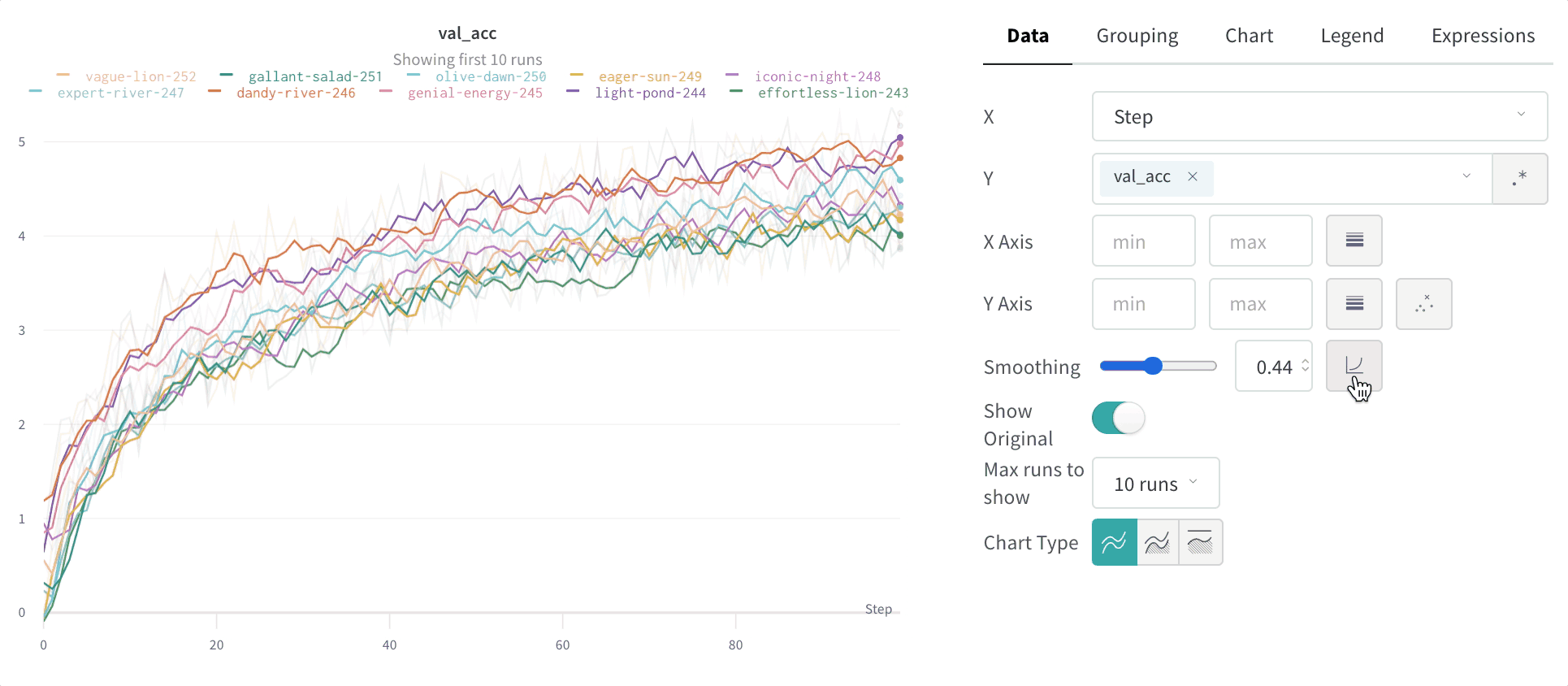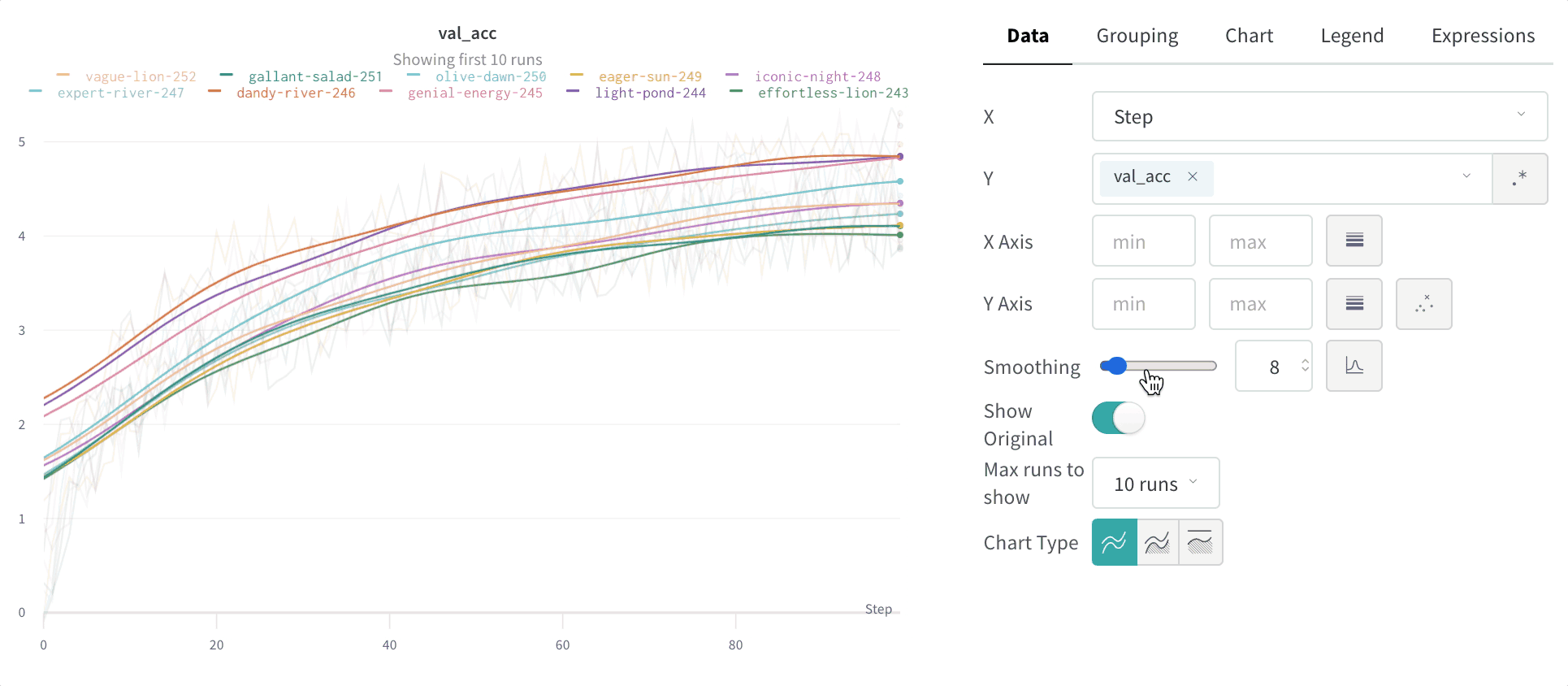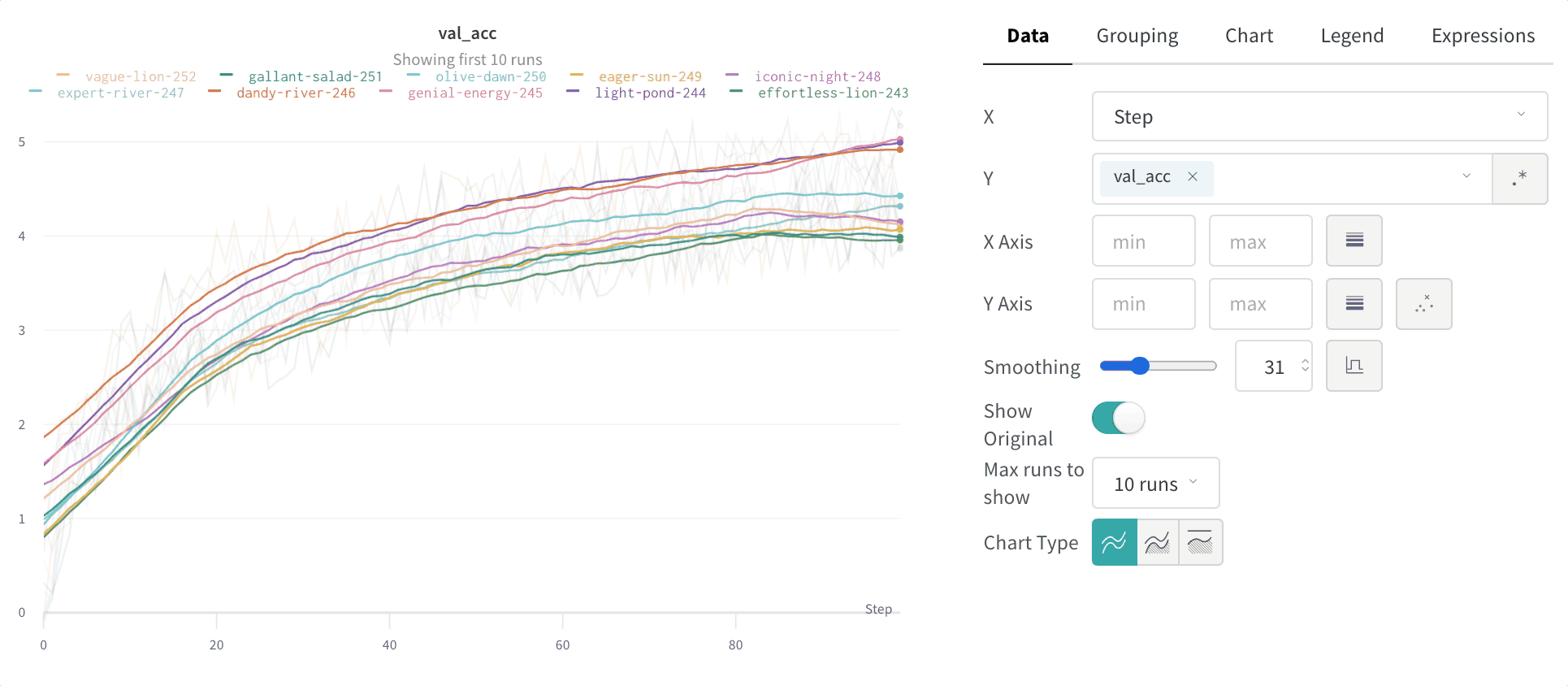
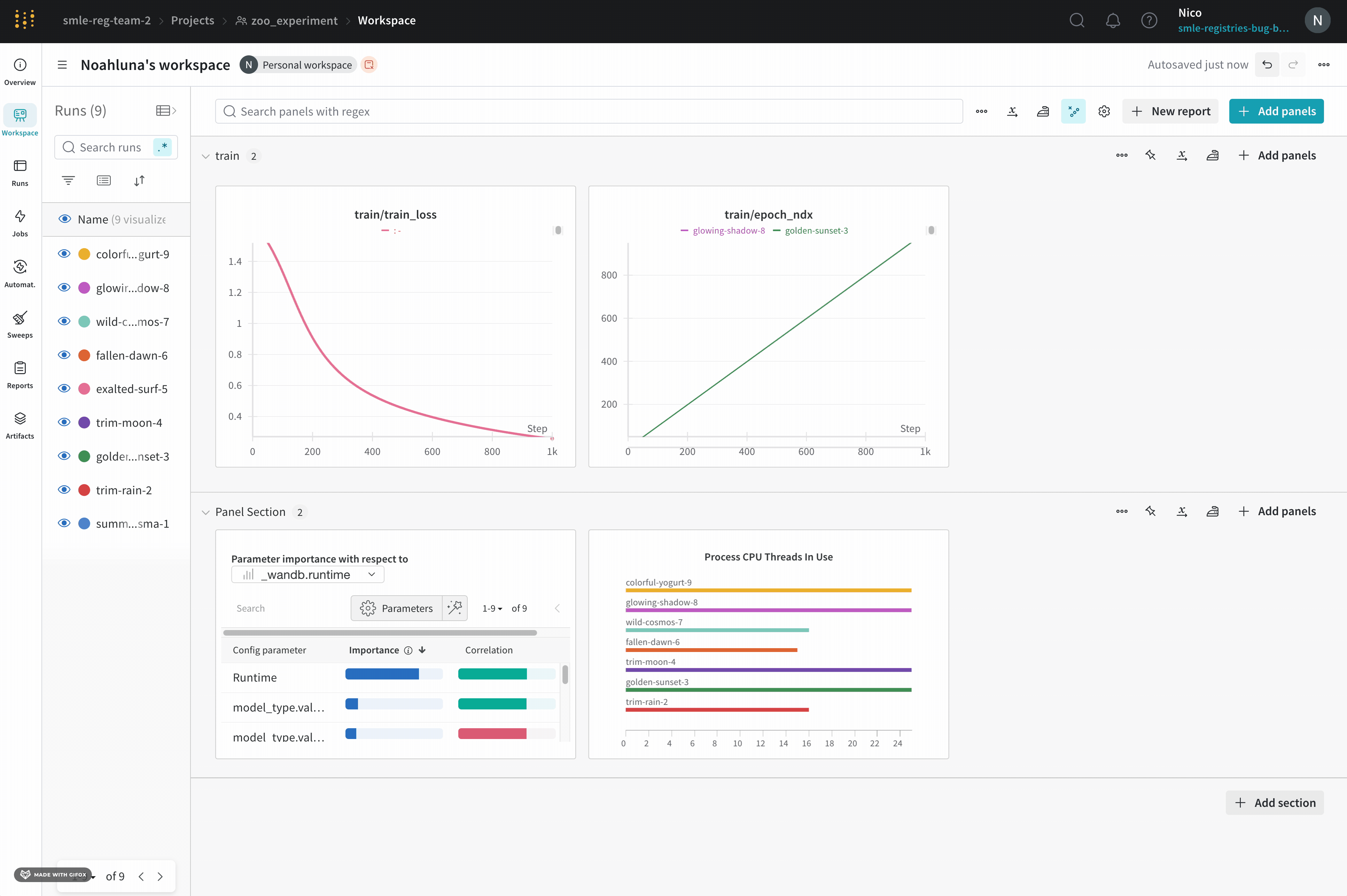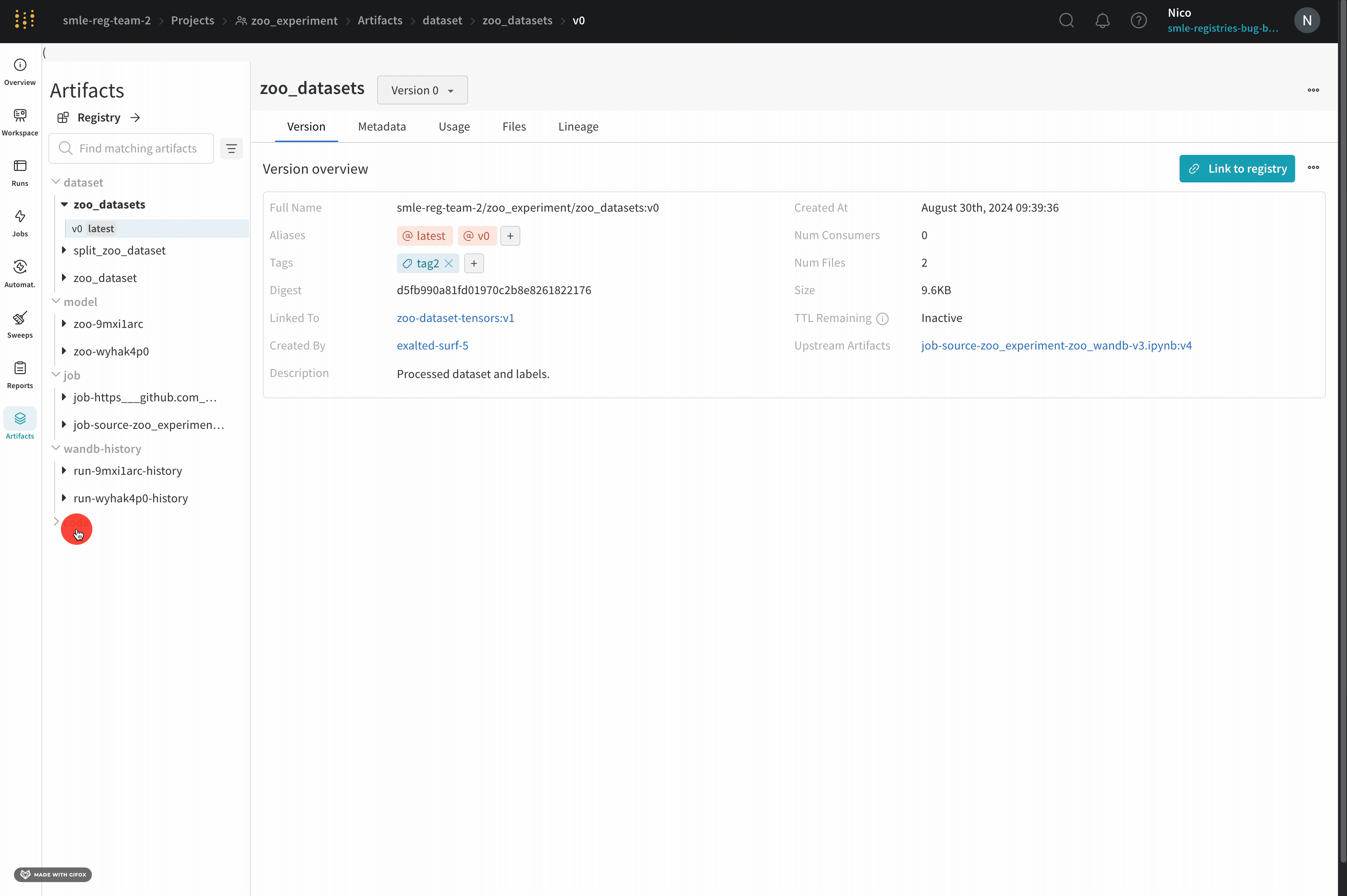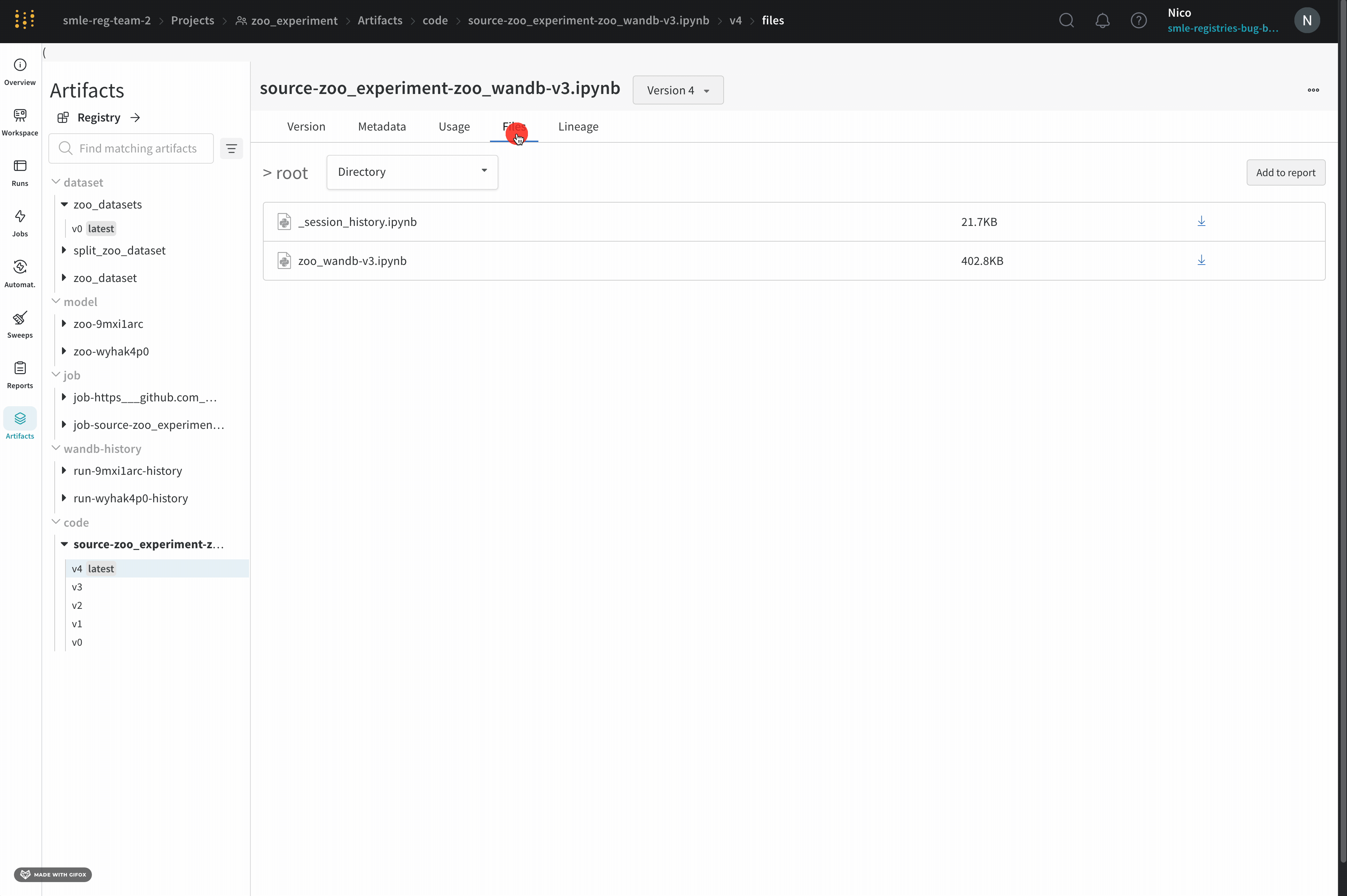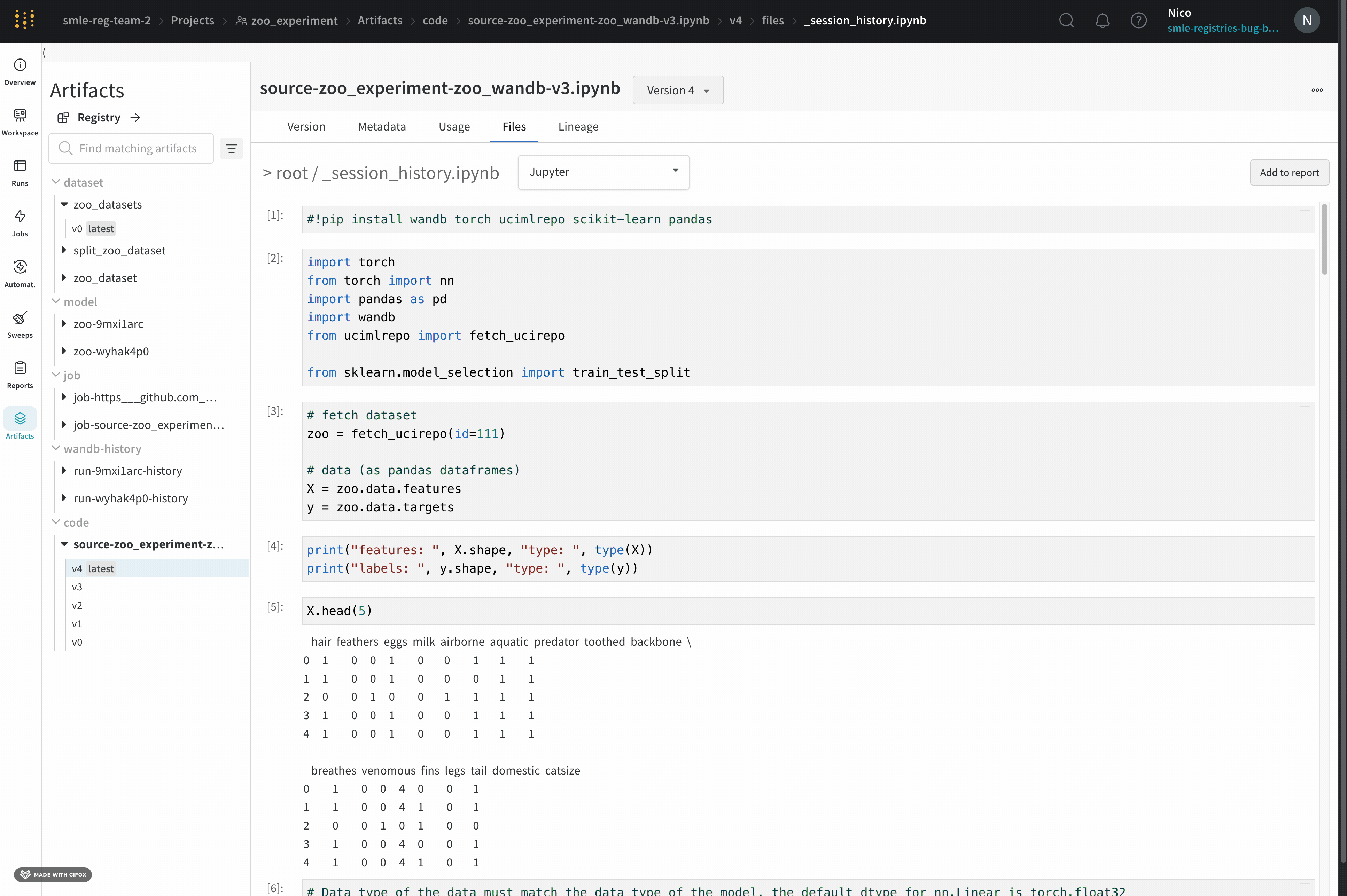
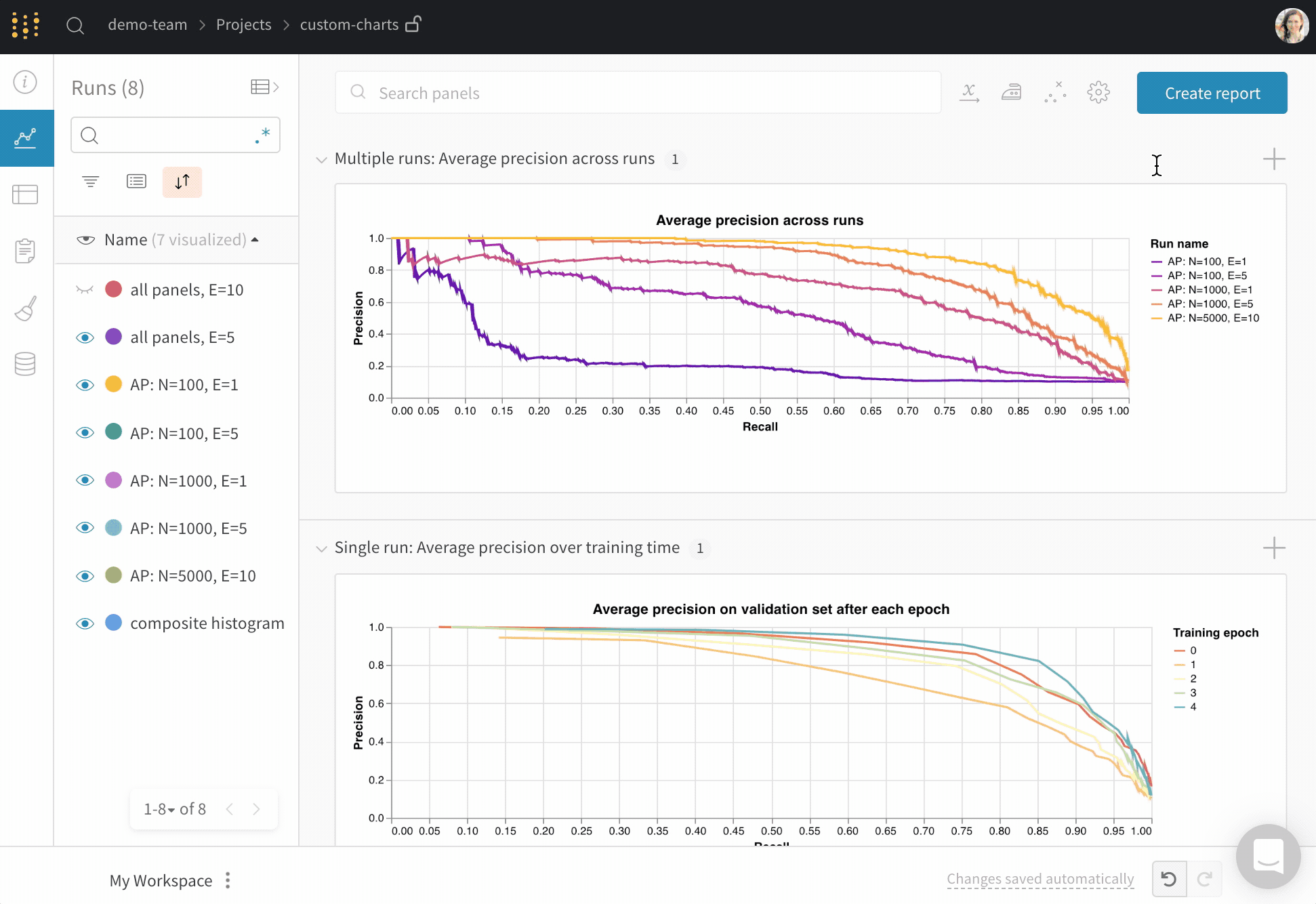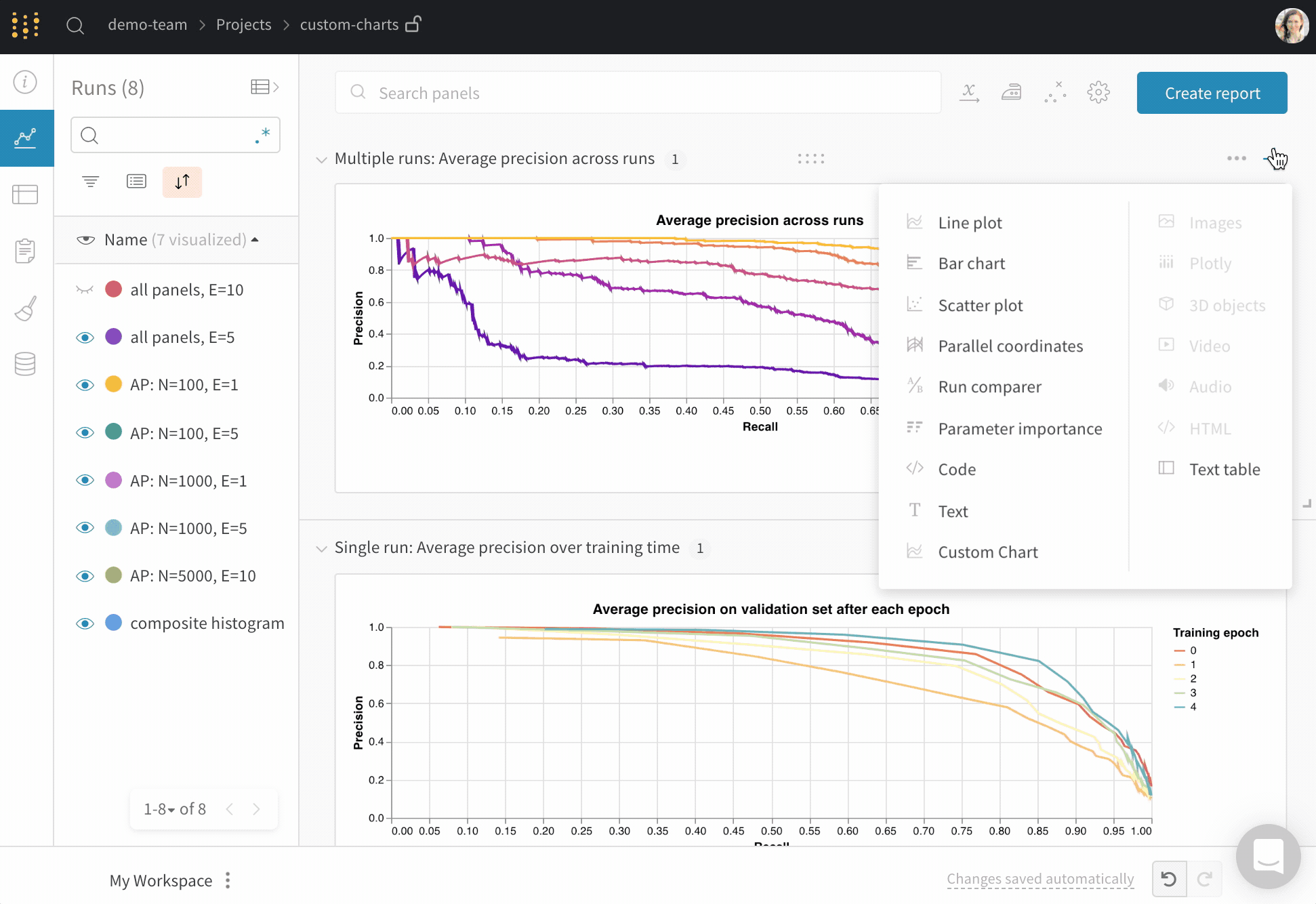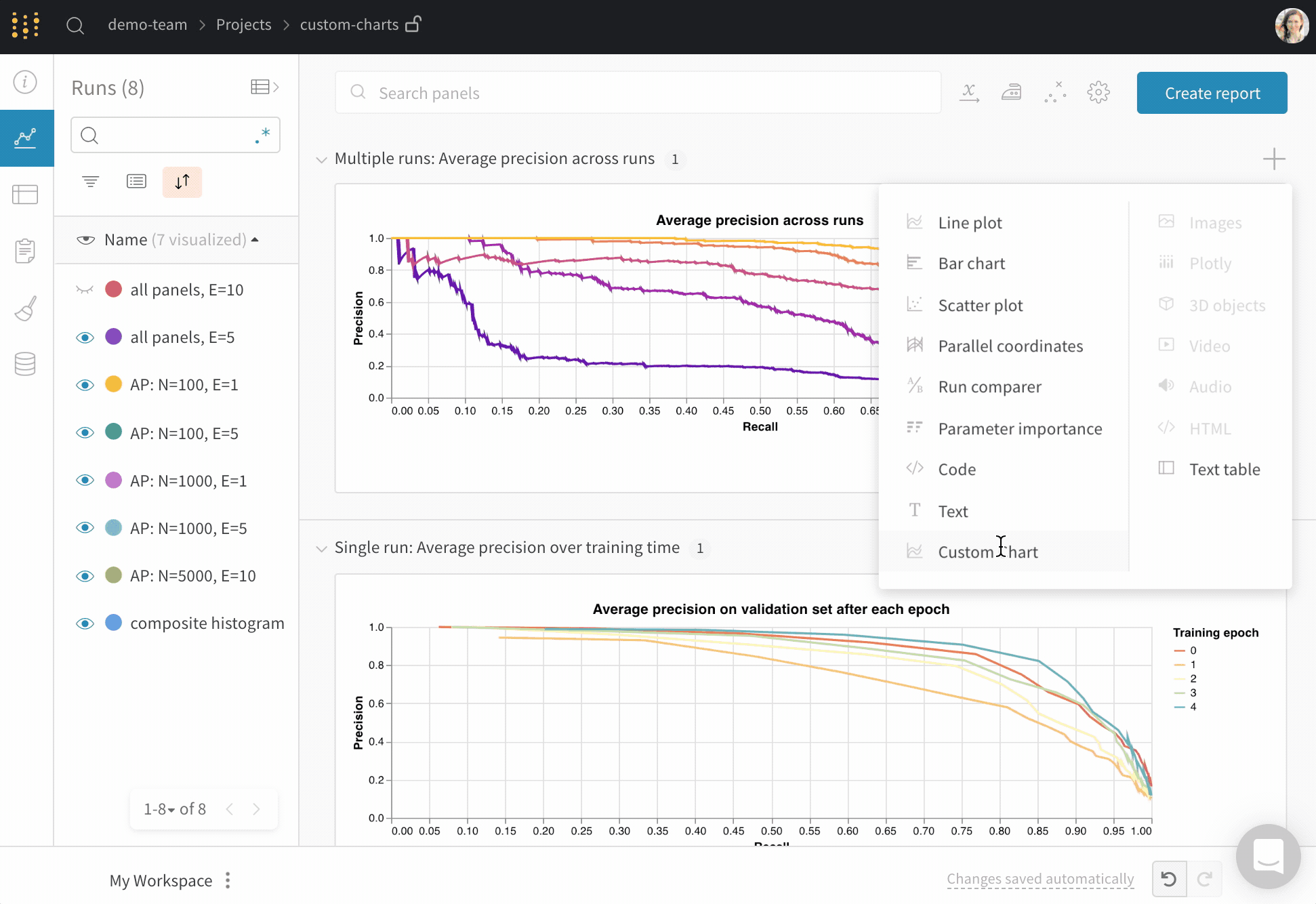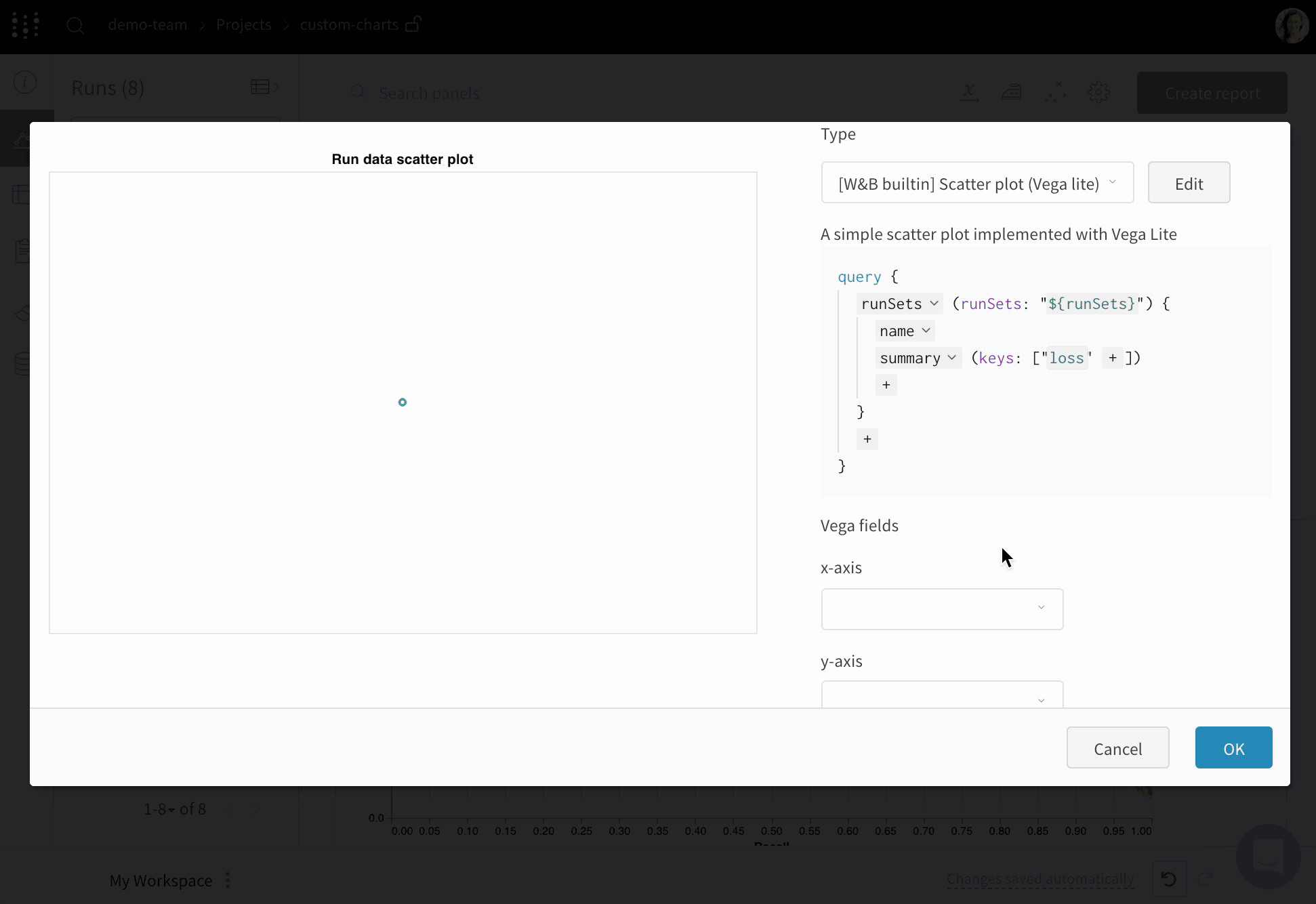
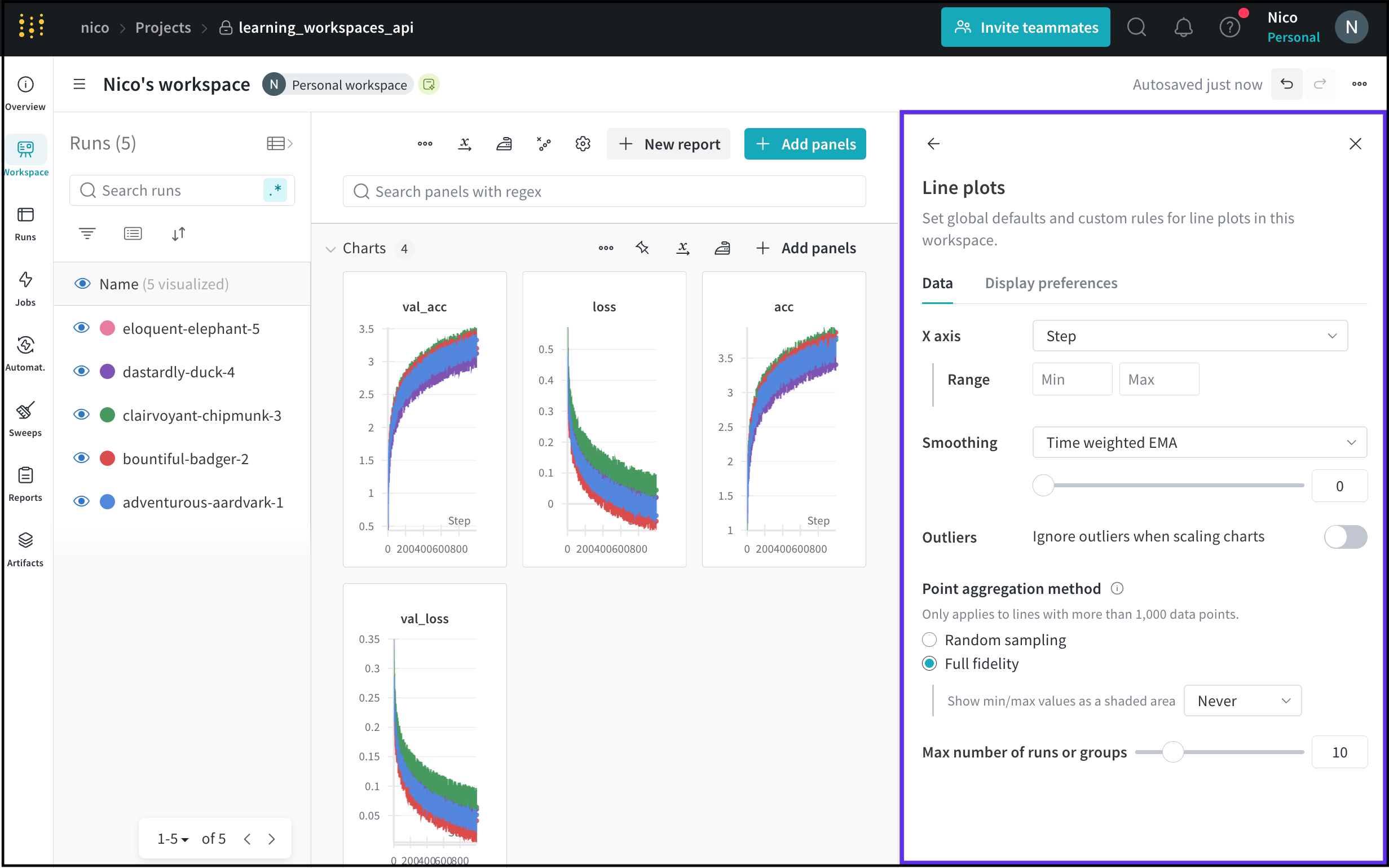
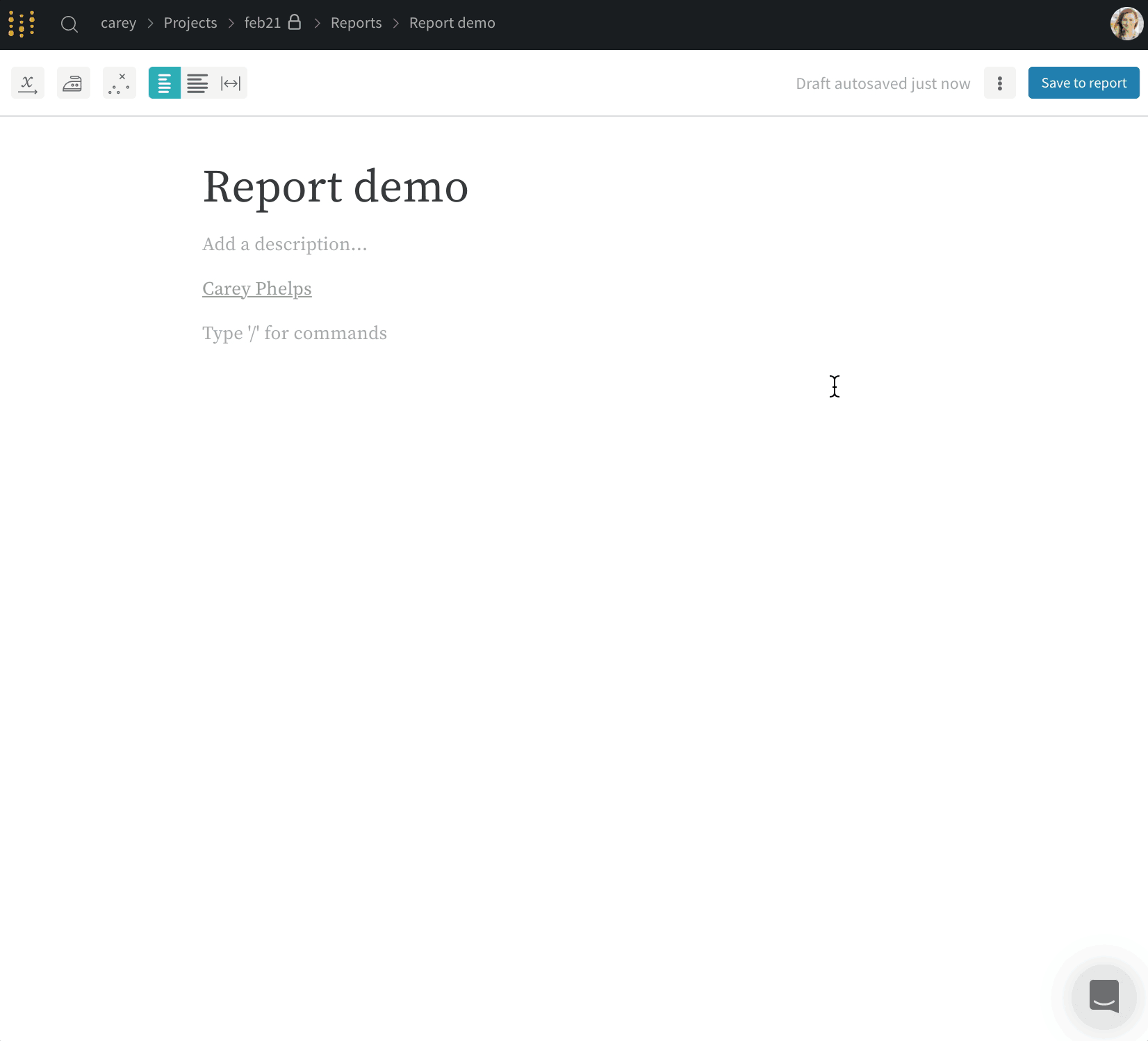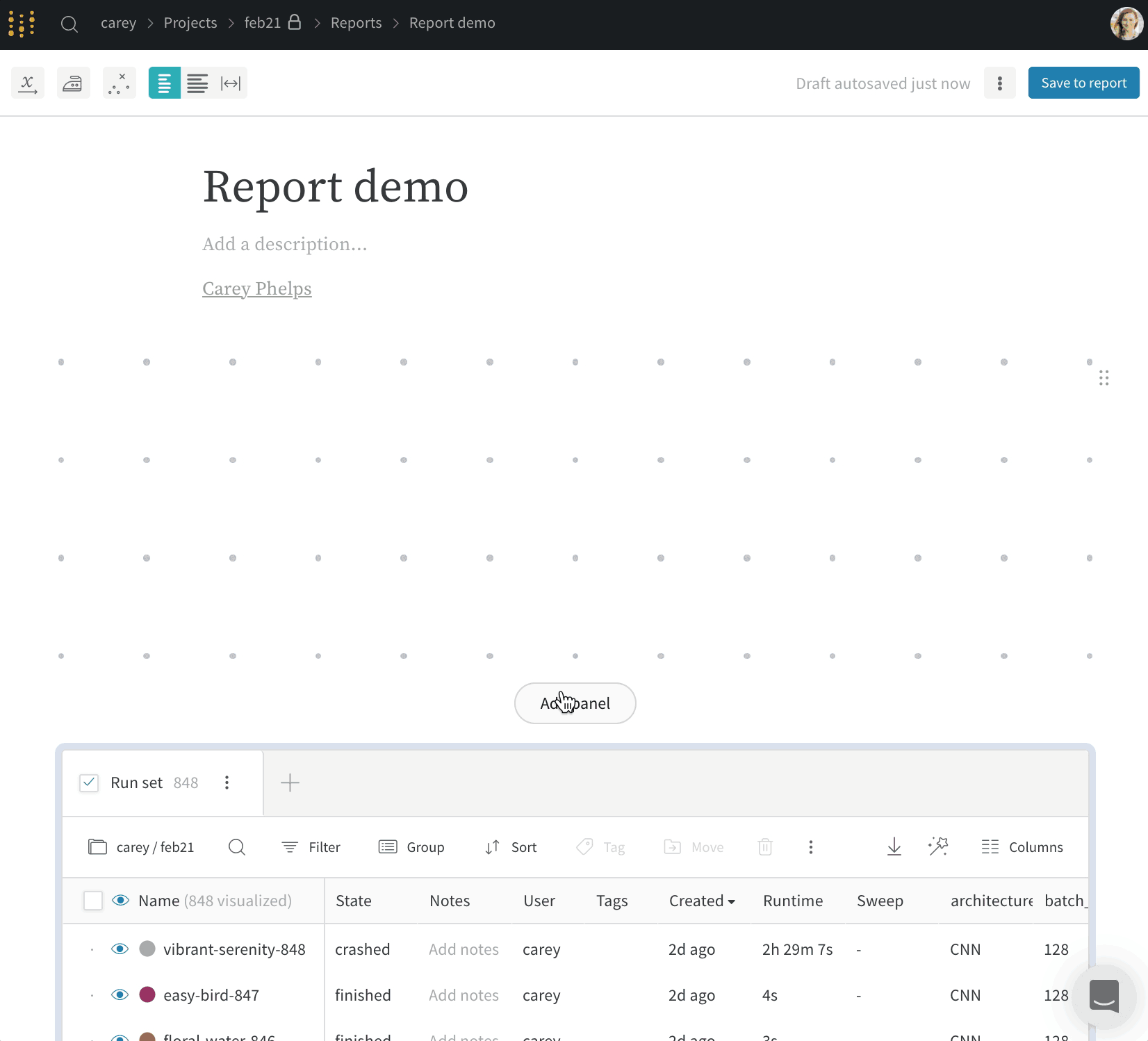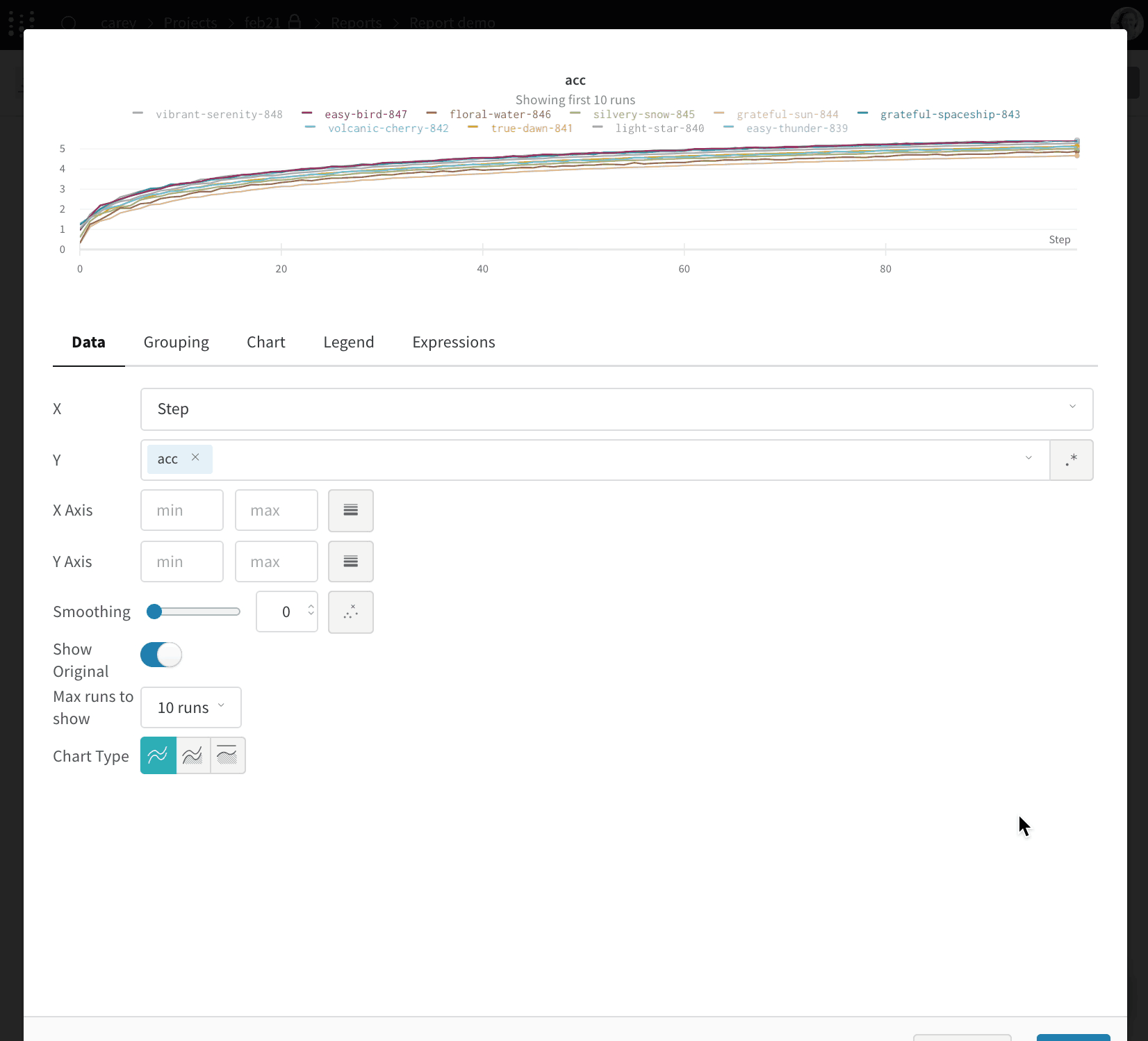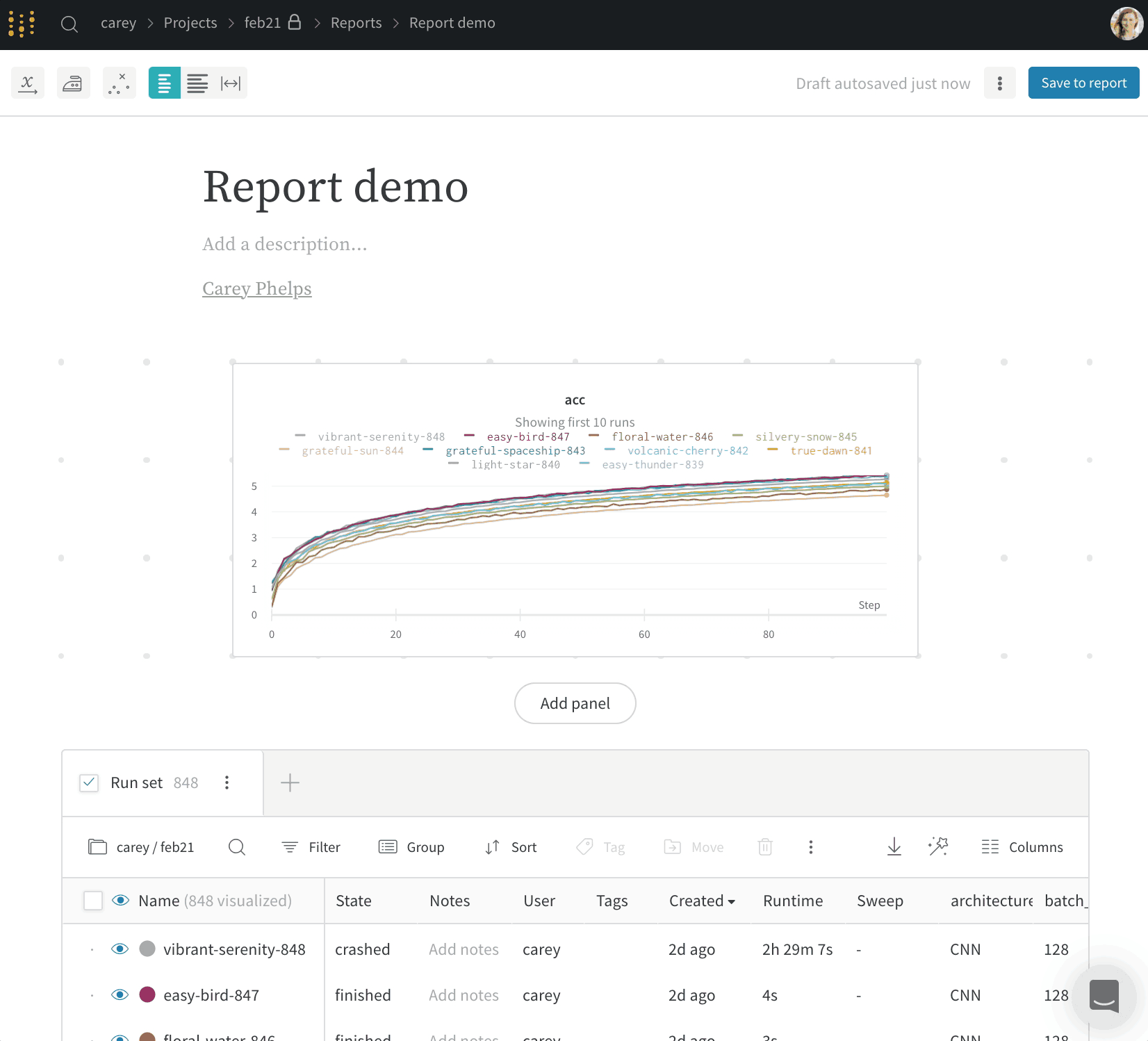
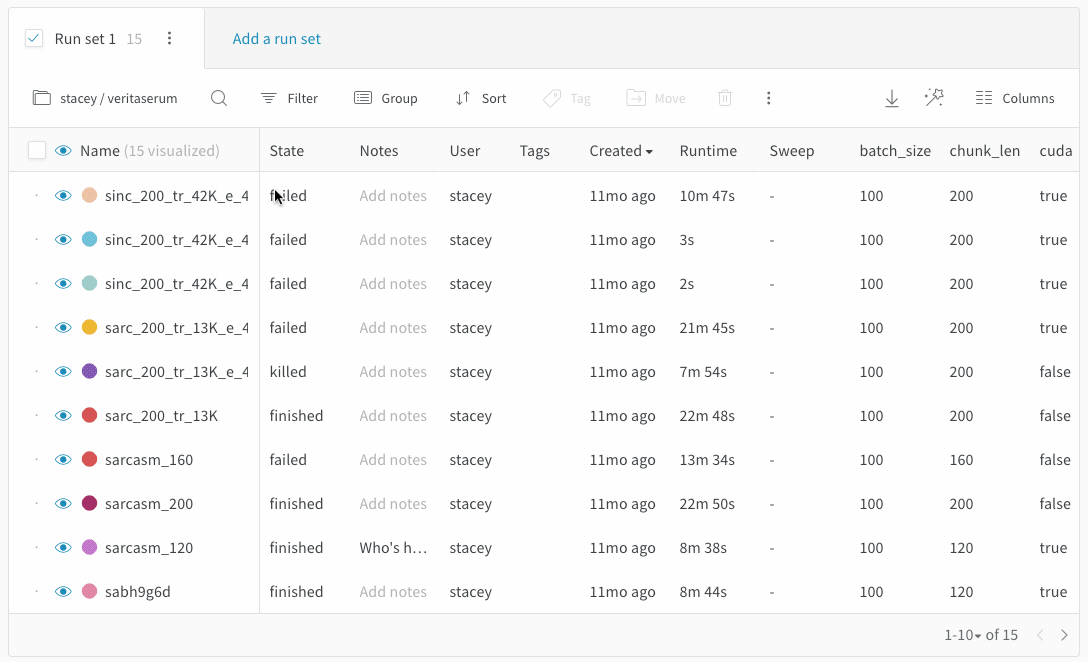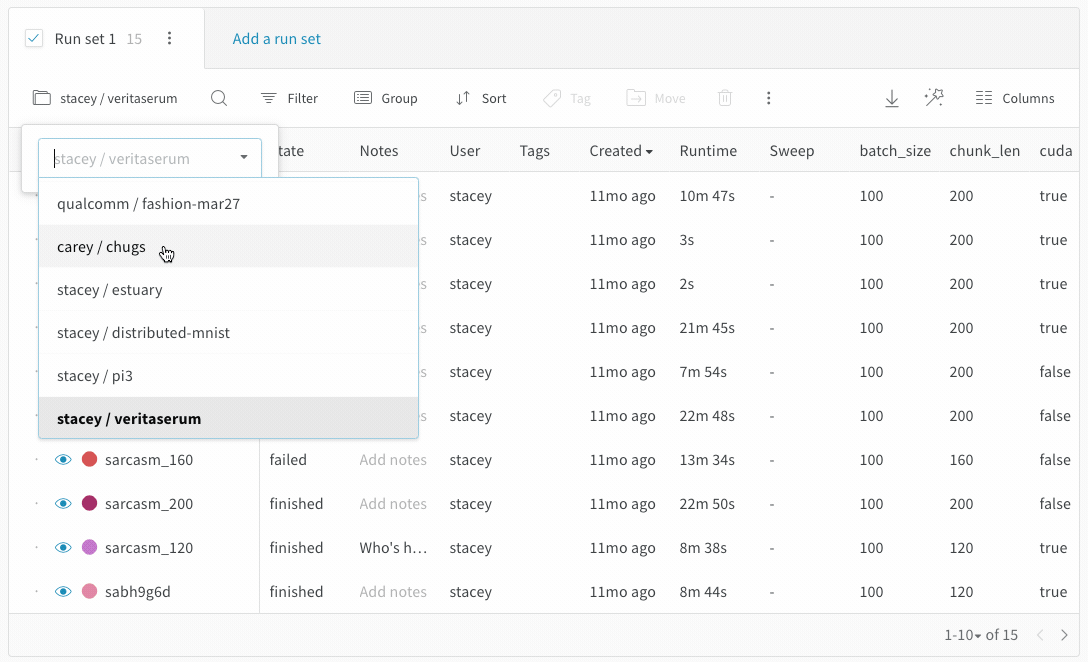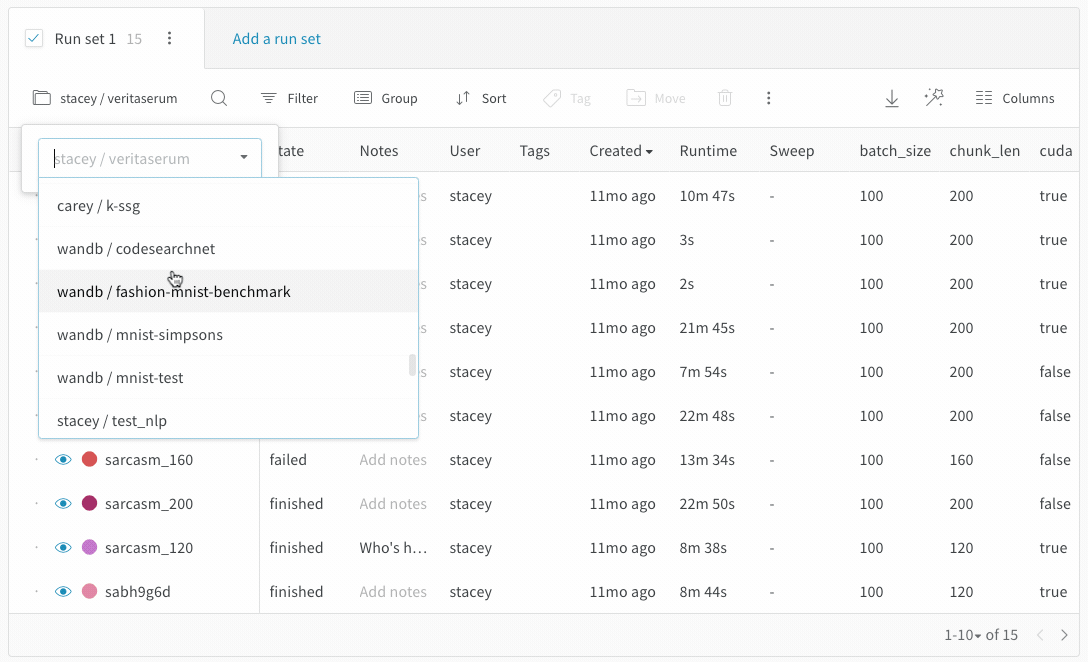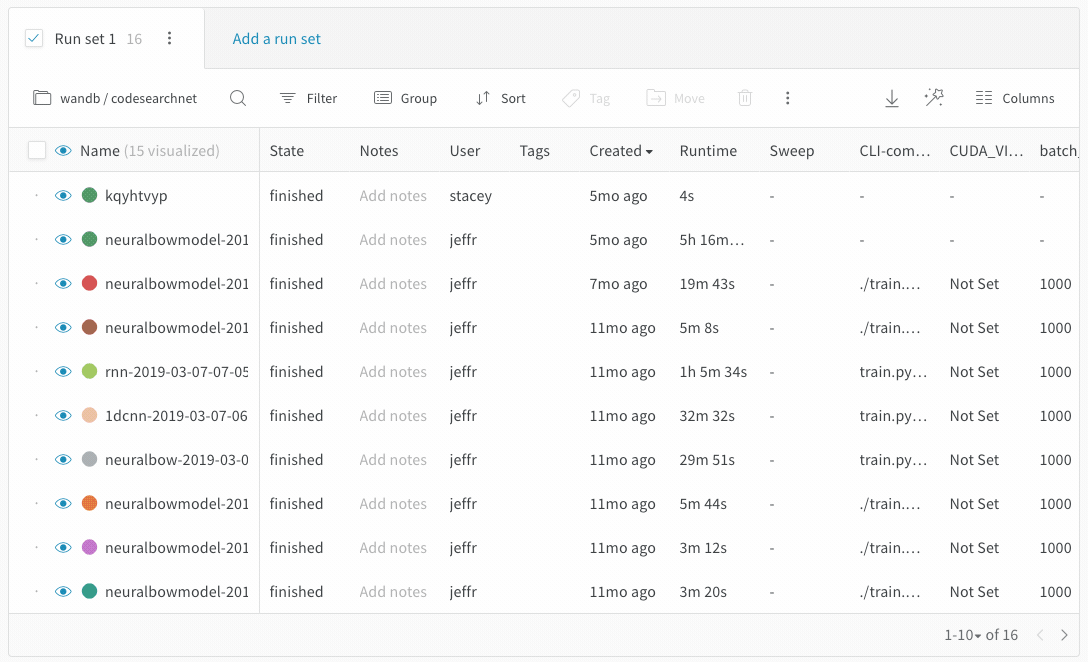
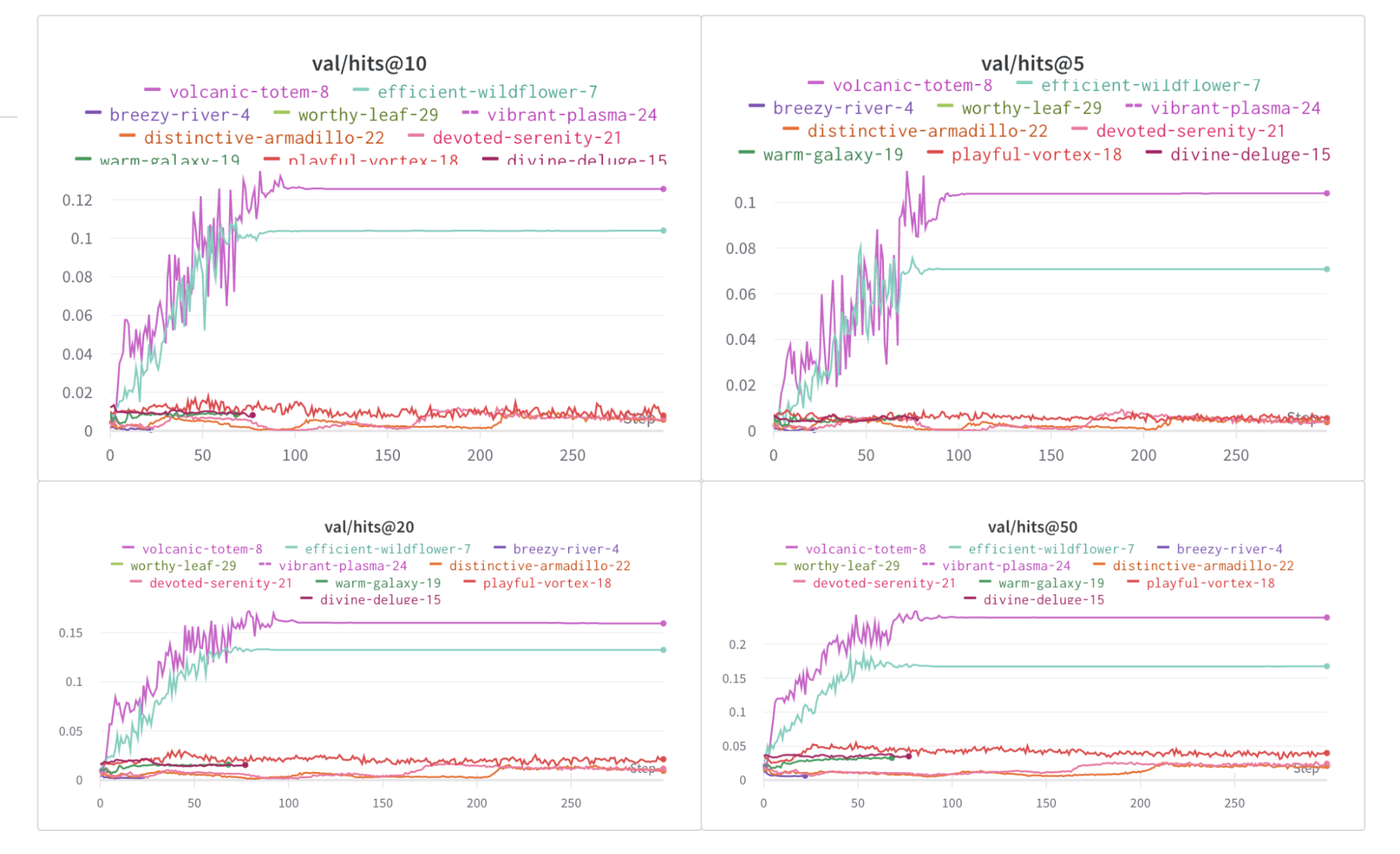
Dot menu : サイドバーの行にカーソルを合わせると、左側にメニューが表示されます。このメニューを使用して、run の名前を変更したり、run を削除したり、アクティブな run を停止したりできます。Visibility icon : グラフ上の run のオンとオフを切り替えるには、目のアイコンをクリックします。Color : run の色をプリセットのいずれか、またはカスタムの色に変更します。Search : 名前で run を検索します。これにより、プロットで表示される run もフィルター処理されます。Filter : サイドバー フィルターを使用して、表示される run のセットを絞り込みます。Group : 設定列を選択して、たとえばアーキテクチャごとに run を動的にグループ化します。グループ化すると、プロットには平均値に沿った線と、グラフ上のポイントの分散の影付き領域が表示されます。Sort : 損失が最小または精度が最大の run など、run の並べ替えに使用する値を選択します。並べ替えは、グラフに表示される run に影響します。Expand button : サイドバーをテーブル全体に展開します。Run count : 上部のかっこ内の数値は、project 内の run の総数です。数値 (N visualized) は、目のアイコンがオンになっており、各プロットで可視化できる run の数です。以下の例では、グラフには 183 の run のうち最初の 10 個のみが表示されています。グラフを編集して、表示される run の最大数を増やします。
Runs tab で列をピン留め、非表示、または順序を変更すると、Runs サイドバーにこれらのカスタマイズが反映されます。
Panels layout : このスクラッチ スペースを使用して、結果を調べたり、チャートを追加および削除したり、さまざまなメトリクスに基づいて Models のバージョンを比較したりできます。
ライブの例を見る
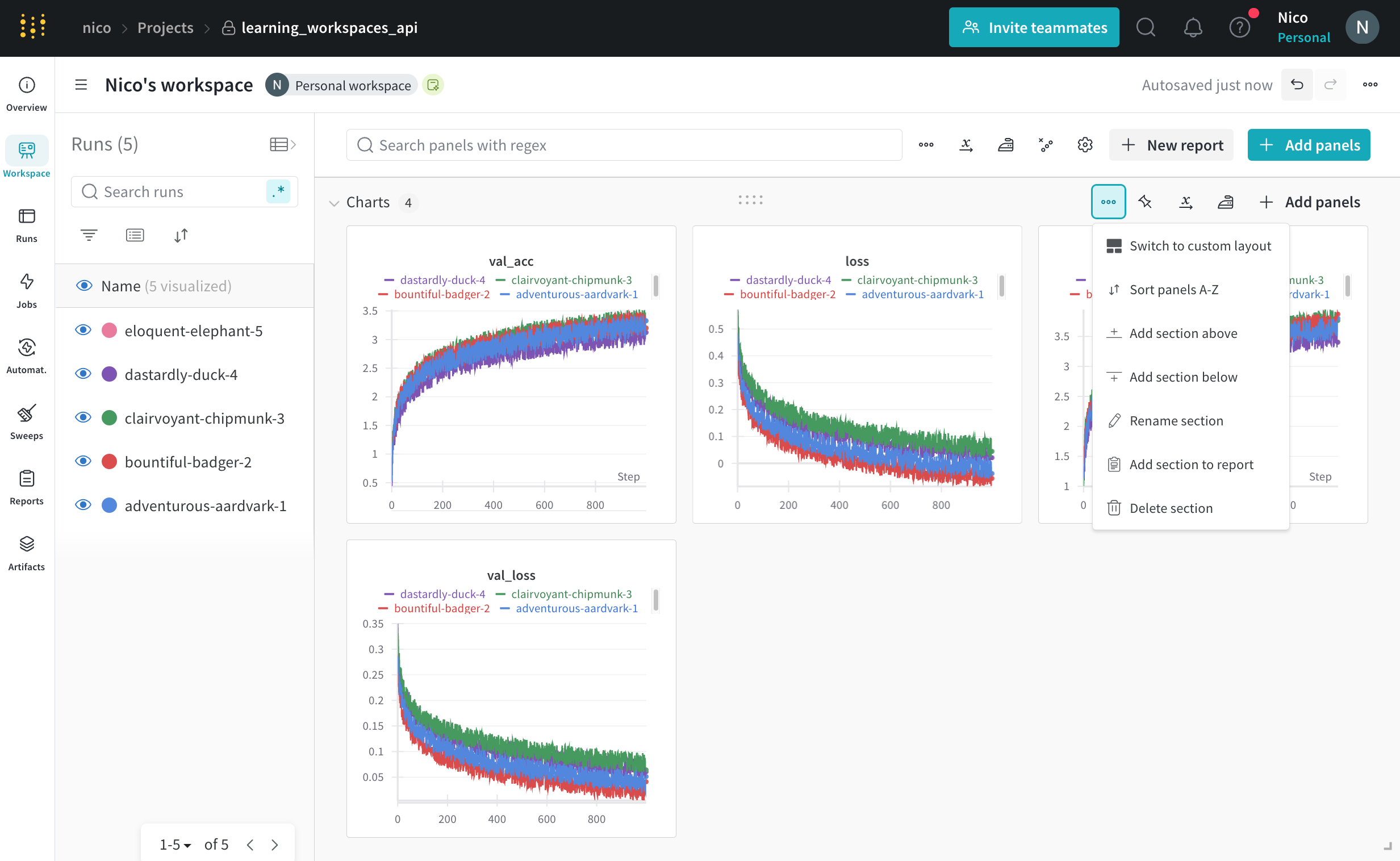
パネルのセクションを追加する
セクション ドロップダウン メニューをクリックし、[Add section] をクリックして、パネルの新しいセクションを作成します。セクションの名前を変更したり、ドラッグして再編成したり、セクションを展開および折りたたんだりできます。
各セクションの右上隅にはオプションがあります。
Switch to custom layout : カスタム レイアウトでは、パネルのサイズを個別に変更できます。Switch to standard layout : 標準レイアウトでは、セクション内のすべてのパネルのサイズを一度に変更でき、ページネーションが提供されます。Add section : ドロップダウン メニューから上下にセクションを追加するか、ページの下部にあるボタンをクリックして新しいセクションを追加します。Rename section : セクションのタイトルを変更します。Export section to report : このパネルのセクションを新しい Report に保存します。Delete section : セクション全体とすべてのチャートを削除します。これは、ワークスペース バーのページの下部にある元に戻すボタンで元に戻すことができます。Add panel : プラス ボタンをクリックして、セクションにパネルを追加します。
セクション間でパネルを移動する
パネルをドラッグ アンド ドロップして、セクションに再配置および整理します。パネルの右上隅にある [Move] ボタンをクリックして、パネルの移動先のセクションを選択することもできます。
パネルのサイズを変更する
Standard layout : すべてのパネルのサイズは同じに維持され、パネルのページがあります。右下隅をクリックしてドラッグすると、パネルのサイズを変更できます。セクションの右下隅をクリックしてドラッグすると、セクションのサイズを変更できます。Custom layout : すべてのパネルのサイズは個別に設定され、ページはありません。
メトリクスを検索する
ワークスペースの検索ボックスを使用して、パネルを絞り込みます。この検索は、パネルのタイトル (デフォルトでは可視化されたメトリクスの名前) と一致します。
Runs タブ
Runs タブを使用して、run をフィルター処理、グループ化、および並べ替えます。
次のタブは、Runs タブで実行できる一般的なアクションを示しています。
Customize columns
Sort
Filter
Group
Runs タブには、project 内の run に関する詳細が表示されます。デフォルトでは、多数の列が表示されます。
表示されているすべての列を表示するには、ページを水平方向にスクロールします。
列の順序を変更するには、列を左右にドラッグします。
列を固定するには、列名にカーソルを合わせ、表示されるアクション メニュー ... をクリックして、Pin column をクリックします。固定された列は、Name 列の後のページの左側に表示されます。固定された列を固定解除するには、Unpin column を選択します。
列を非表示にするには、列名にカーソルを合わせ、表示されるアクション メニュー ... をクリックして、Hide column をクリックします。現在非表示になっているすべての列を表示するには、Columns をクリックします。
複数の列を一度に表示、非表示、固定、および固定解除するには、Columns をクリックします。
非表示の列の名前をクリックして、非表示を解除します。
表示されている列の名前をクリックして、非表示にします。
表示されている列の横にあるピン アイコンをクリックして、固定します。
Runs タブをカスタマイズすると、カスタマイズは Workspace タブ の Runs セレクターにも反映されます。
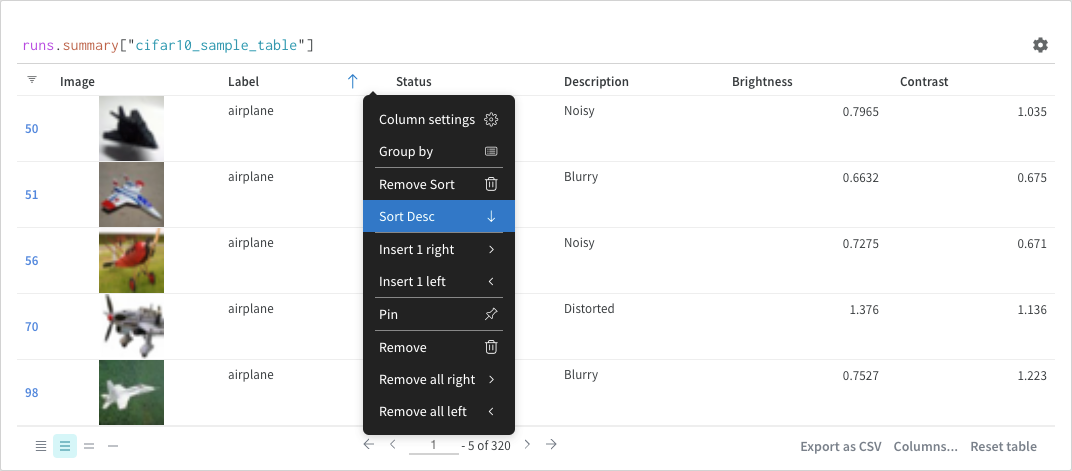
テーブル内のすべての行を、指定された列の値で並べ替えます。
マウスを列タイトルに合わせます。ケバブ メニュー (3 つの縦のドキュメント) が表示されます。
ケバブ メニュー (3 つの縦のドット) で選択します。
Sort Asc または Sort Desc を選択して、行をそれぞれ昇順または降順に並べ替えます。
上記の画像は、val_acc という名前のテーブル列の並べ替えオプションを表示する方法を示しています。
ダッシュボードの左上にある Filter ボタンを使用して、式で行全体をフィルター処理します。
Add filter を選択して、行に 1 つ以上のフィルターを追加します。3 つのドロップダウン メニューが表示されます。左から右へ、フィルター タイプは、列名、演算子、および値に基づいています。
列名
二項関係
値
受け入れられる値
文字列
=, ≠, ≤, ≥, IN, NOT IN,
整数、浮動小数点数、文字列、タイムスタンプ、null
式エディターには、列名と論理述語構造のオートコンプリートを使用して、各項のオプションのリストが表示されます。「and」または「or」(および場合によっては括弧) を使用して、複数の論理述語を 1 つの式に接続できます。
上記の画像は、`val_loss` 列に基づいたフィルターを示しています。フィルターは、検証損失が 1 以下の run を表示します。
列ヘッダーの Group by ボタンを使用して、特定の列の値で行全体をグループ化します。
デフォルトでは、これにより、他の数値列が、グループ全体のその列の値の分布を示すヒストグラムに変わります。グループ化は、データ内のより高レベルのパターンを理解するのに役立ちます。
Reports タブ
1 か所で結果のすべてのスナップショットを確認し、チームと学びを共有します。
Sweeps タブ
project から新しい sweep を開始します。
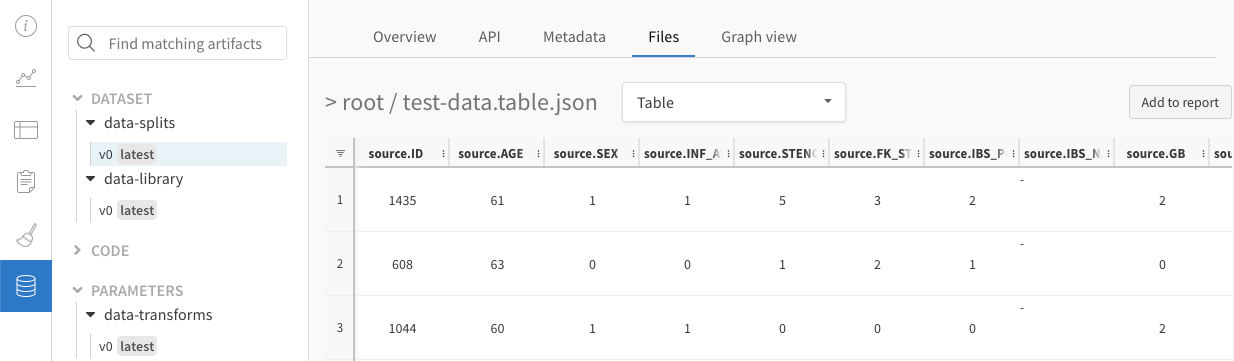
Artifacts タブ
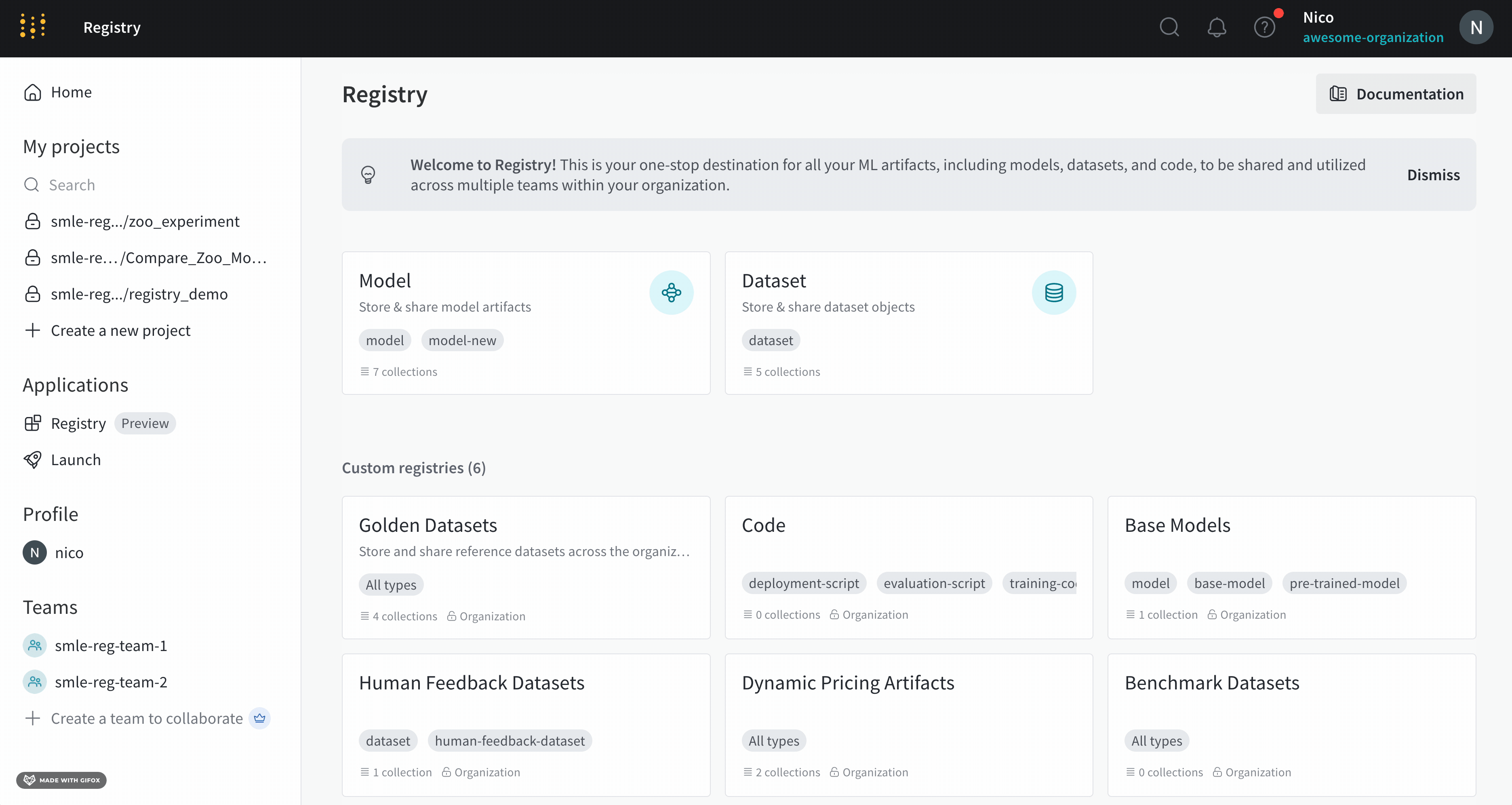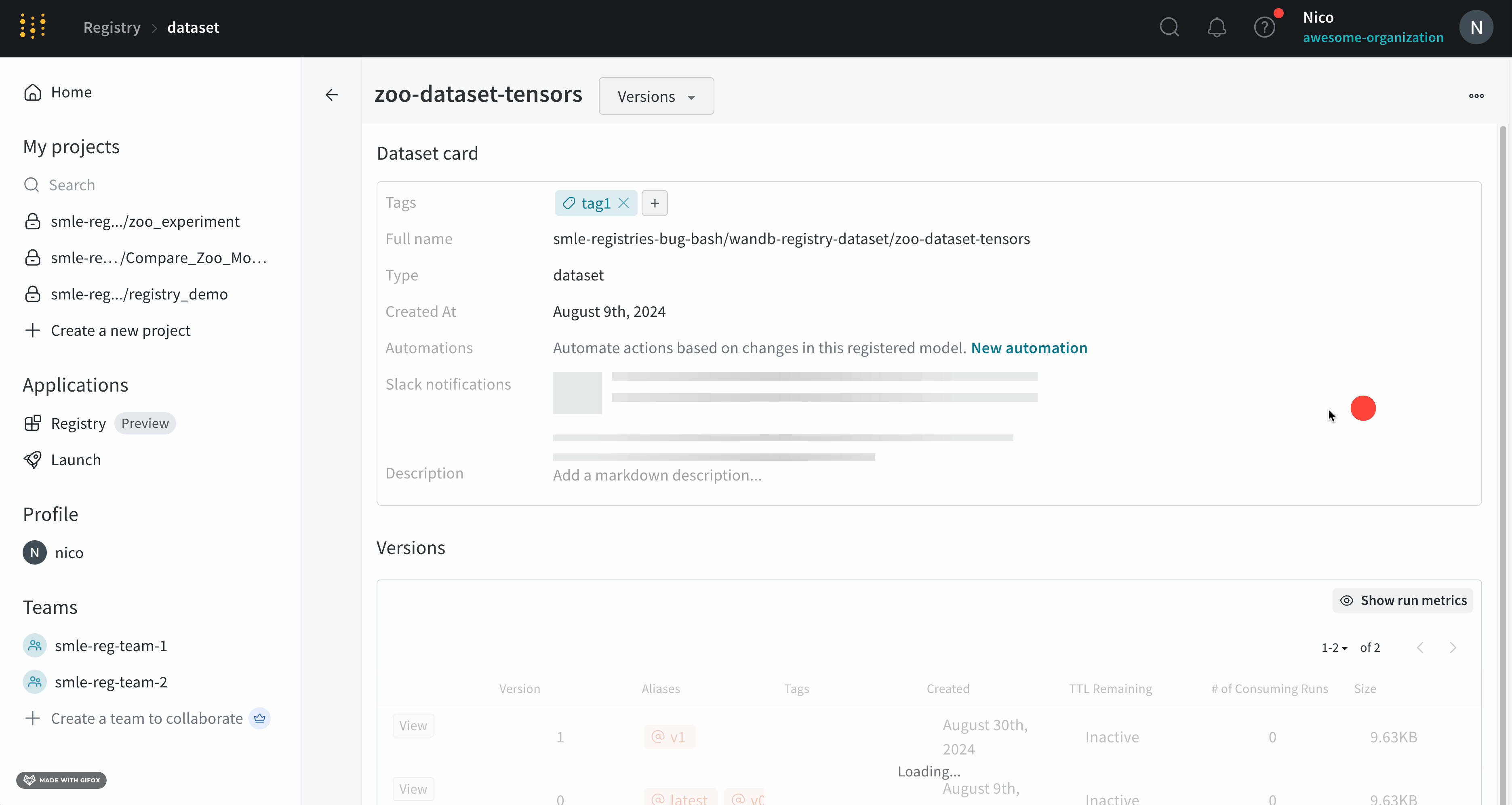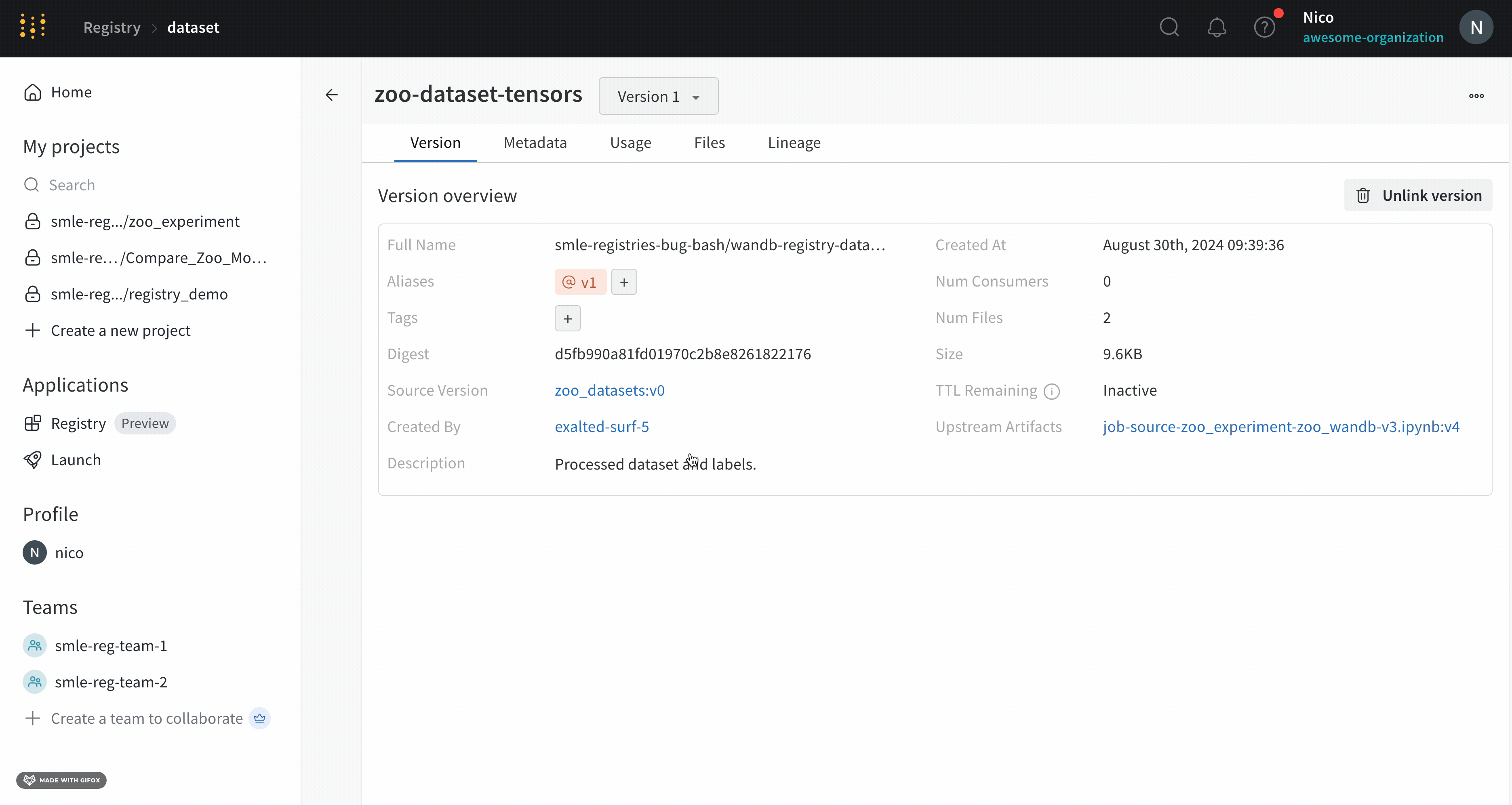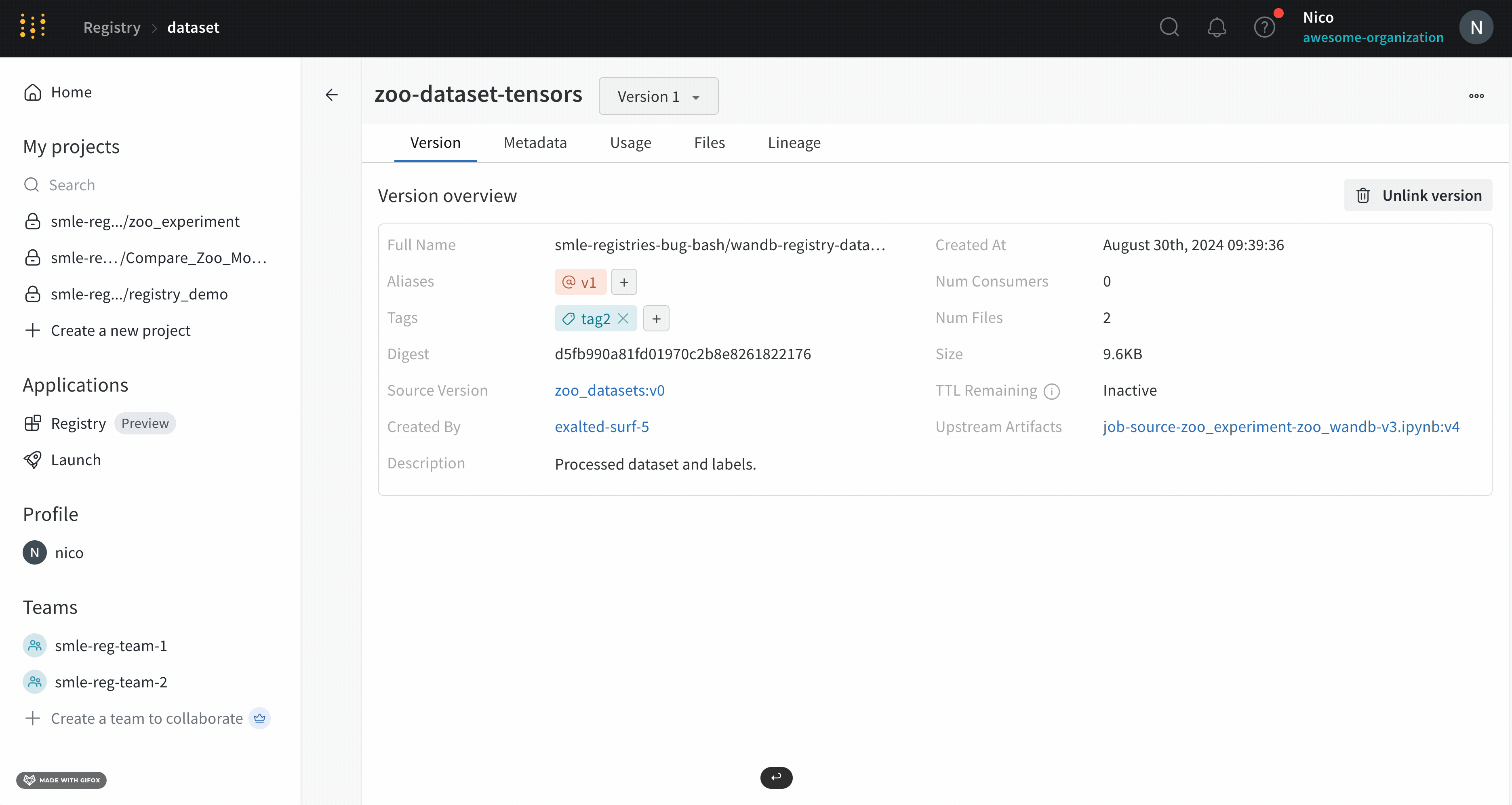
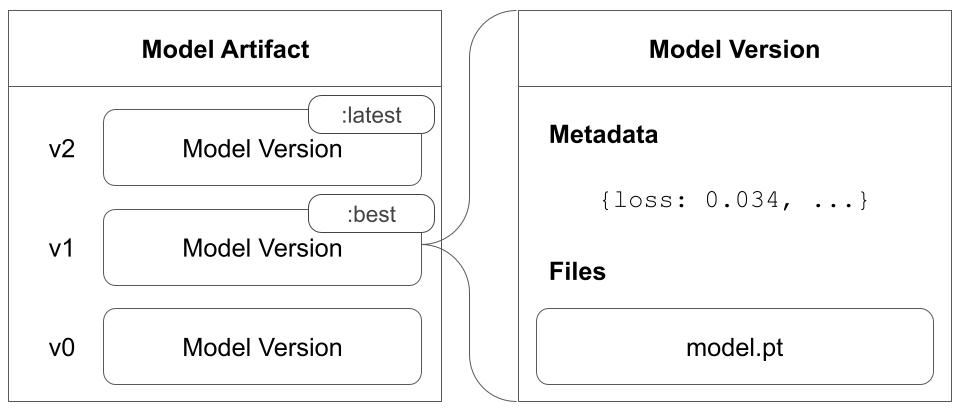
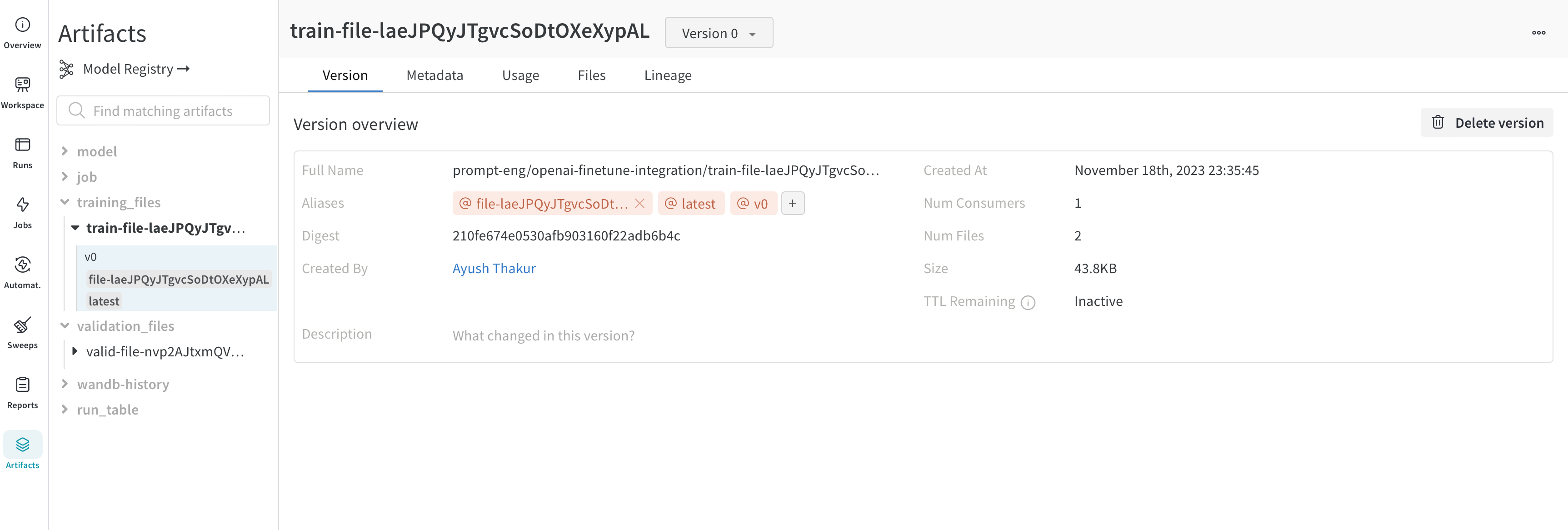
トレーニングデータセットや fine-tuned models から、メトリクスとメディアのテーブル まで、project に関連付けられているすべての Artifacts を表示します。
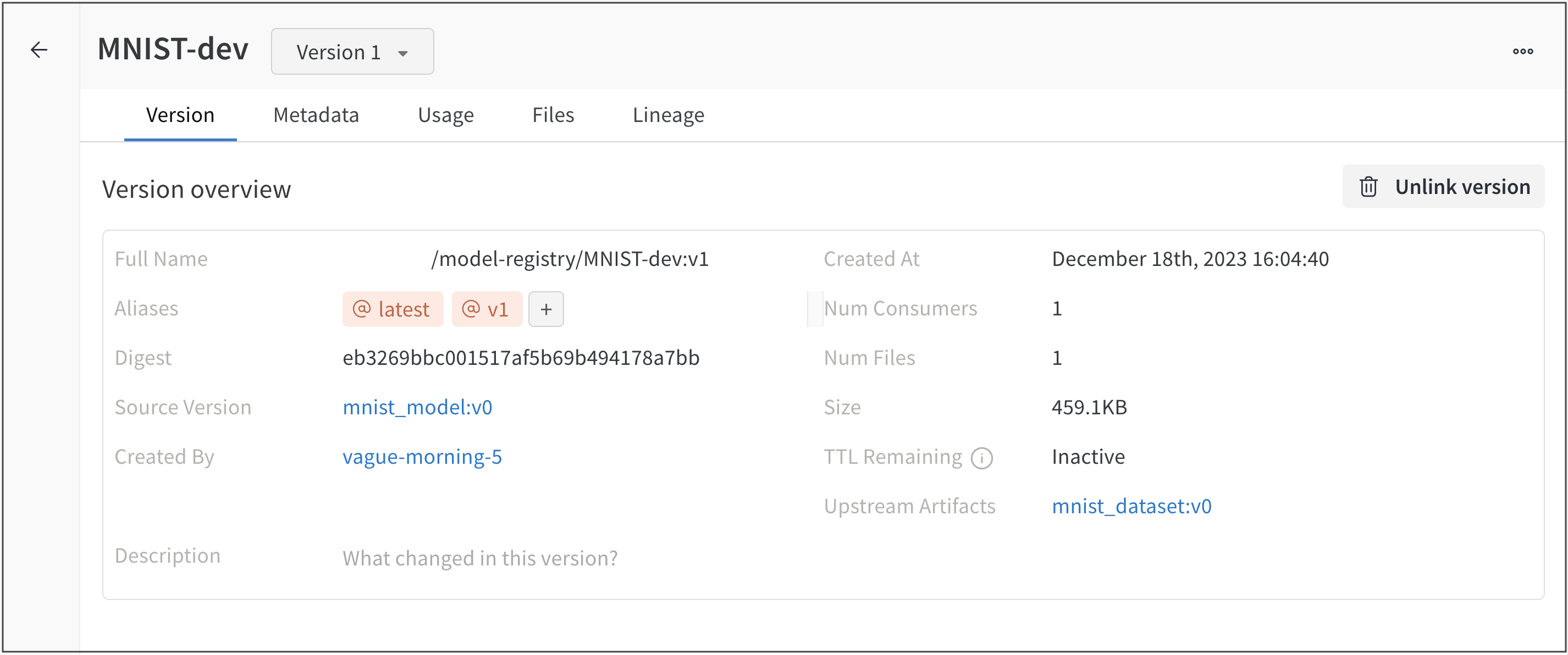
Overview パネル
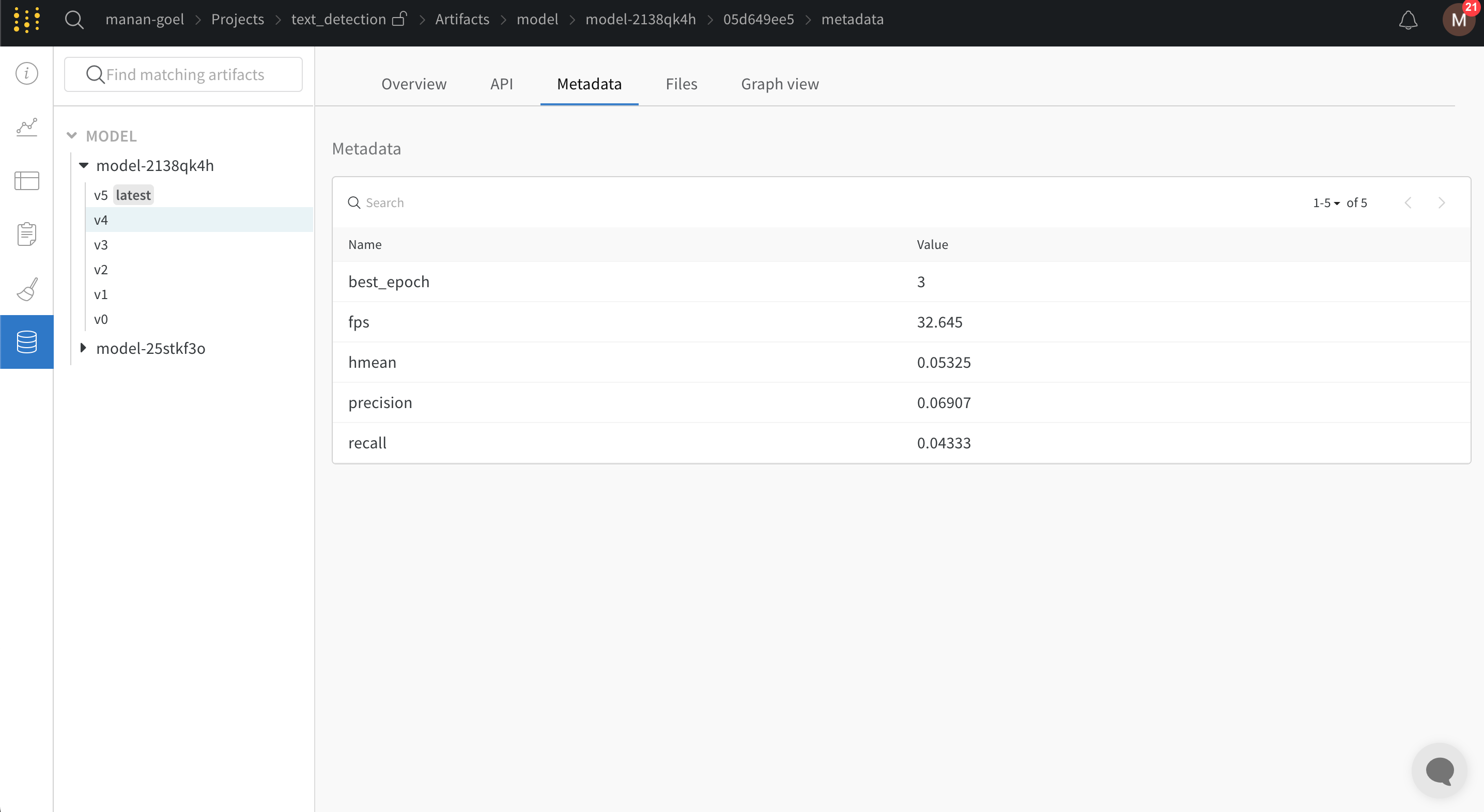
Overview パネルには、Artifacts の名前とバージョン、変更を検出して重複を防ぐために使用されるハッシュ ダイジェスト、作成日、エイリアスなど、Artifacts に関するさまざまな高度な情報が表示されます。ここでエイリアスを追加または削除したり、バージョンと Artifacts 全体の両方に関するメモを取ることができます。
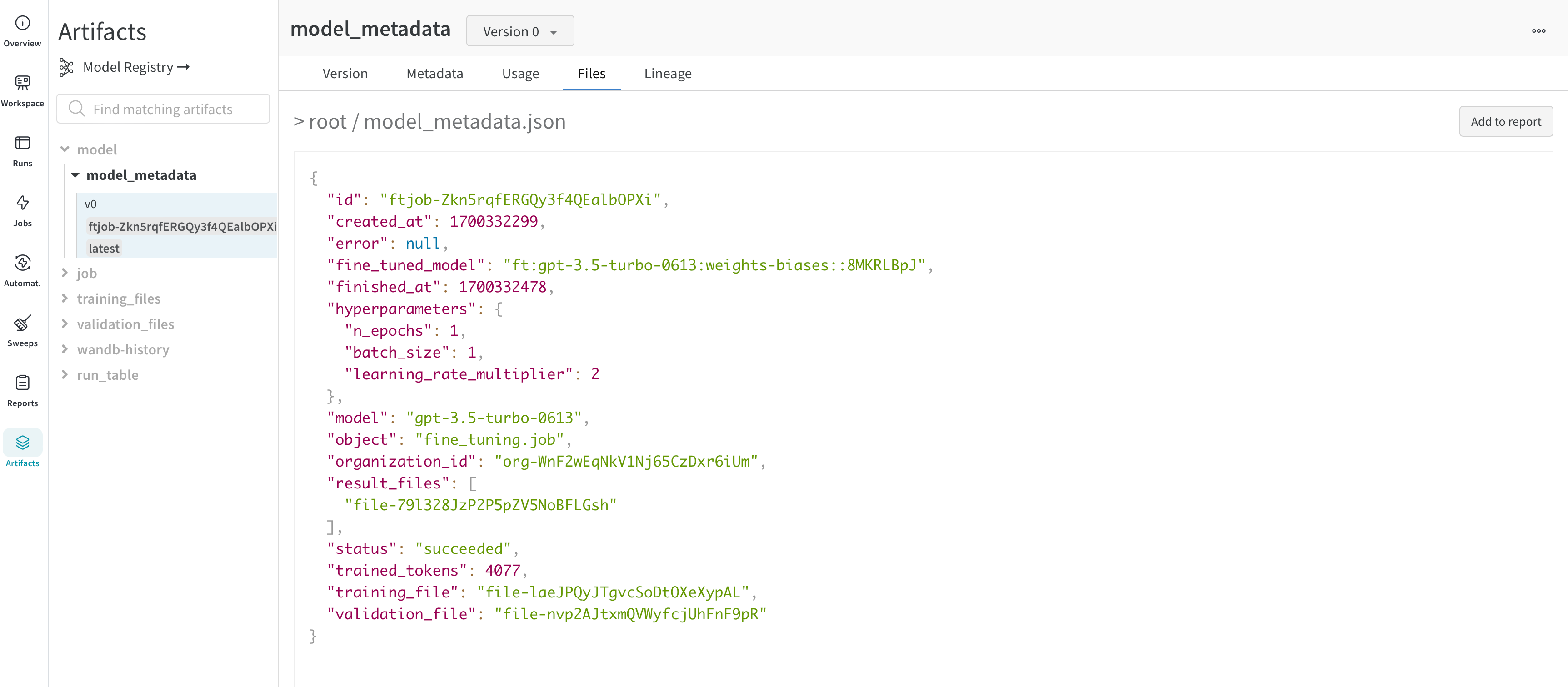
Metadata パネルは、Artifacts のメタデータへのアクセスを提供します。このメタデータは、Artifacts の構築時に提供されます。このメタデータには、Artifacts を再構築するために必要な構成 引数 、詳細情報が見つかる URL、または Artifacts を記録した run 中に生成されたメトリクスが含まれる場合があります。さらに、Artifacts を生成した run の構成と、Artifacts のロギング時の履歴メトリクスを確認できます。
Usage パネル
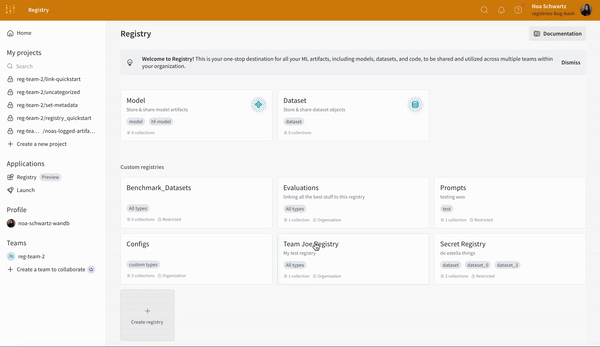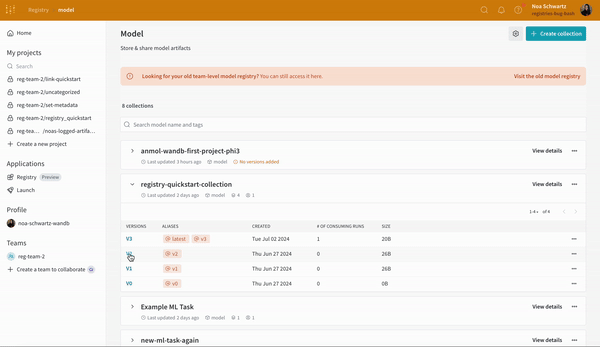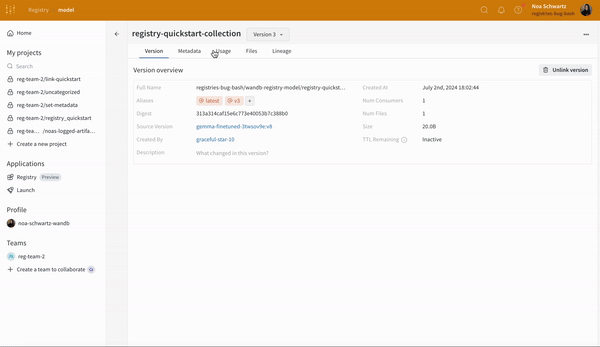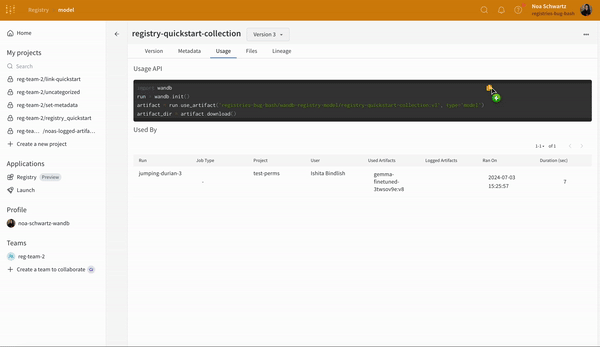
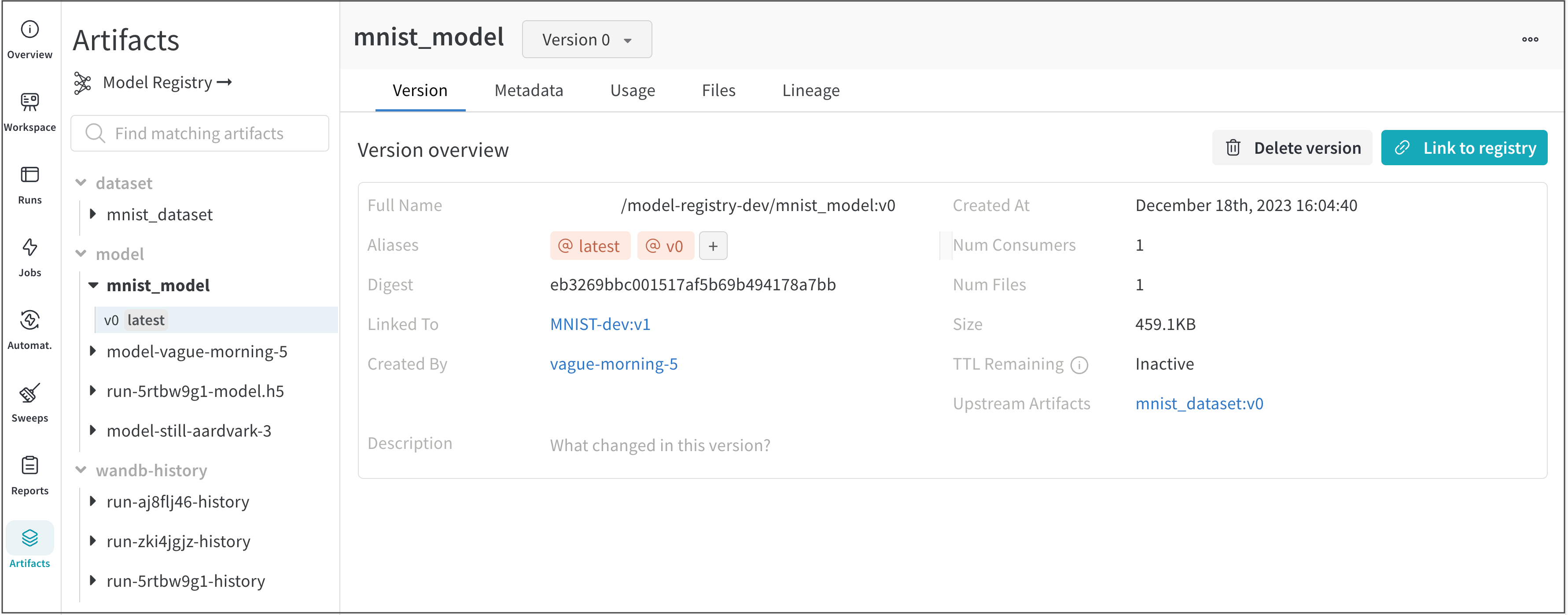
Usage パネルは、ウェブ アプリの外 (たとえば、ローカル マシン上) で使用するために Artifacts をダウンロードするためのコード スニペットを提供します。このセクションでは、Artifacts を出力した run と、Artifacts を入力として使用する run も示し、リンクします。
Files パネル
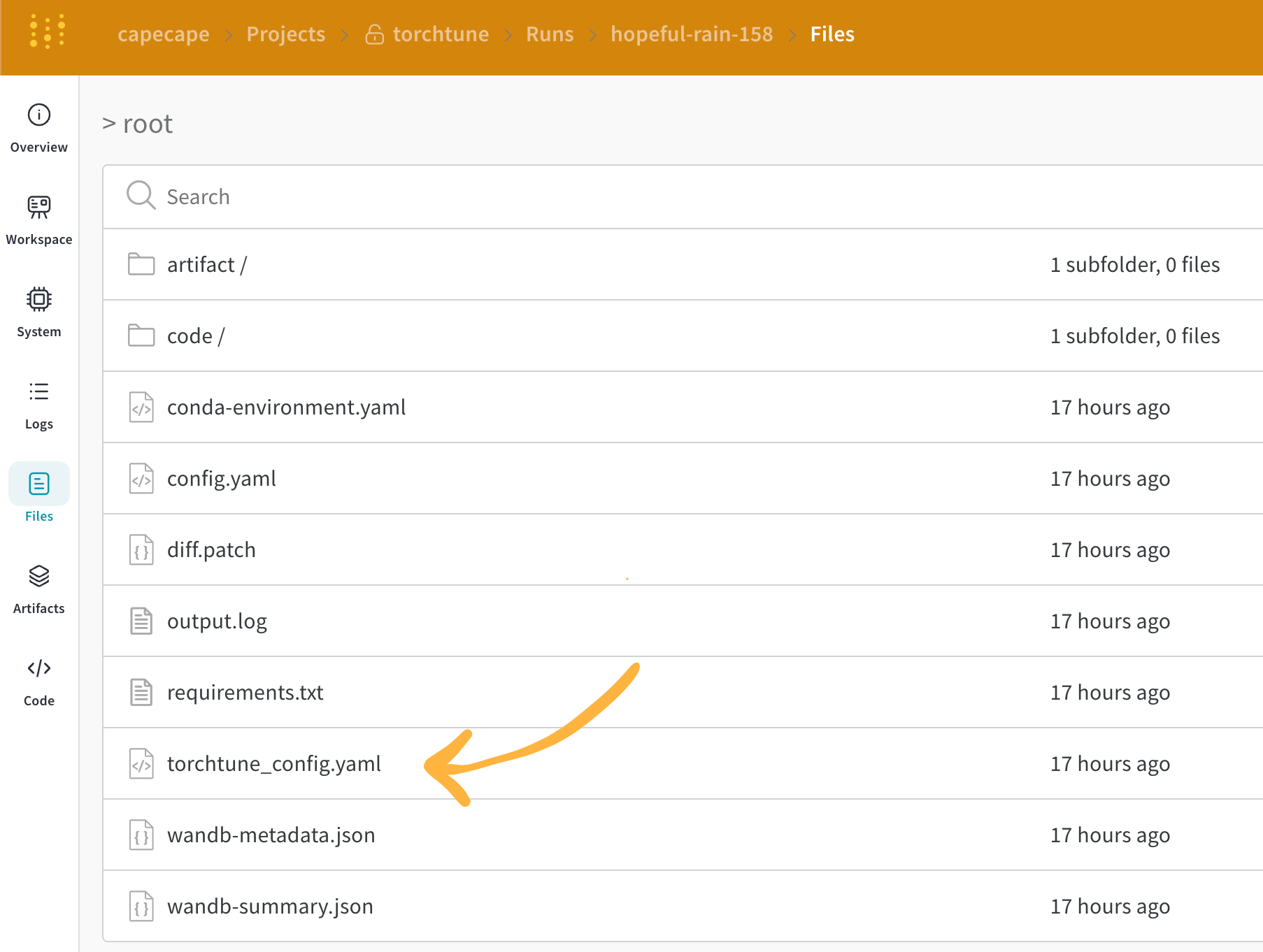
Files パネルには、Artifacts に関連付けられているファイルとフォルダーがリストされます。W&B は、run の特定のファイルを自動的にアップロードします。たとえば、requirements.txt は run が使用した各ライブラリのバージョンを示し、wandb-metadata.json および wandb-summary.json には run に関する情報が含まれています。run の構成に応じて、Artifacts やメディアなど、他のファイルがアップロードされる場合があります。このファイル ツリーをナビゲートして、W&B ウェブ アプリでコンテンツを直接表示できます。
Artifacts に関連付けられた Tables は、このコンテキストで特に豊富でインタラクティブです。Artifacts で Tables を使用する方法について詳しくは、こちら をご覧ください。
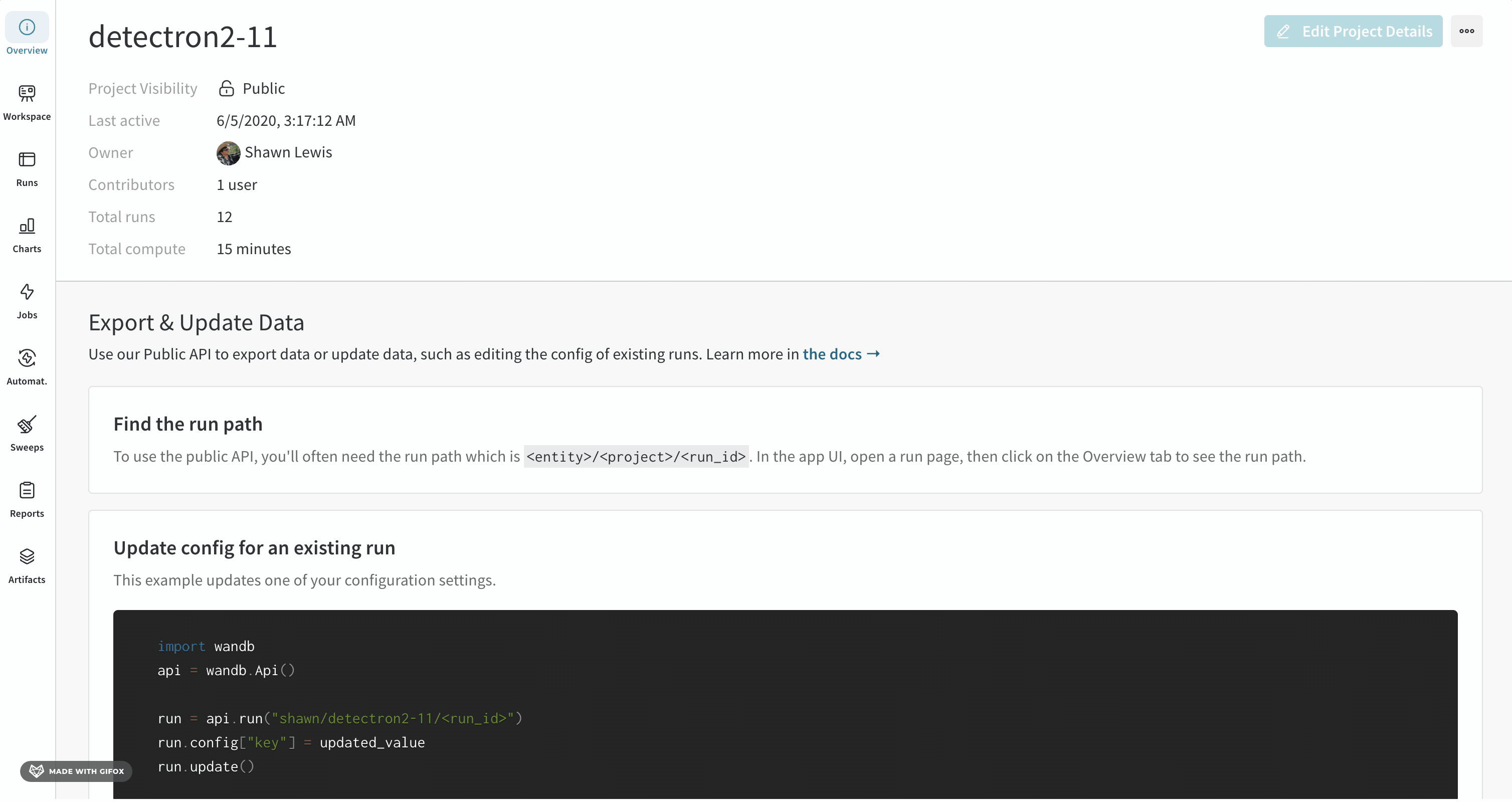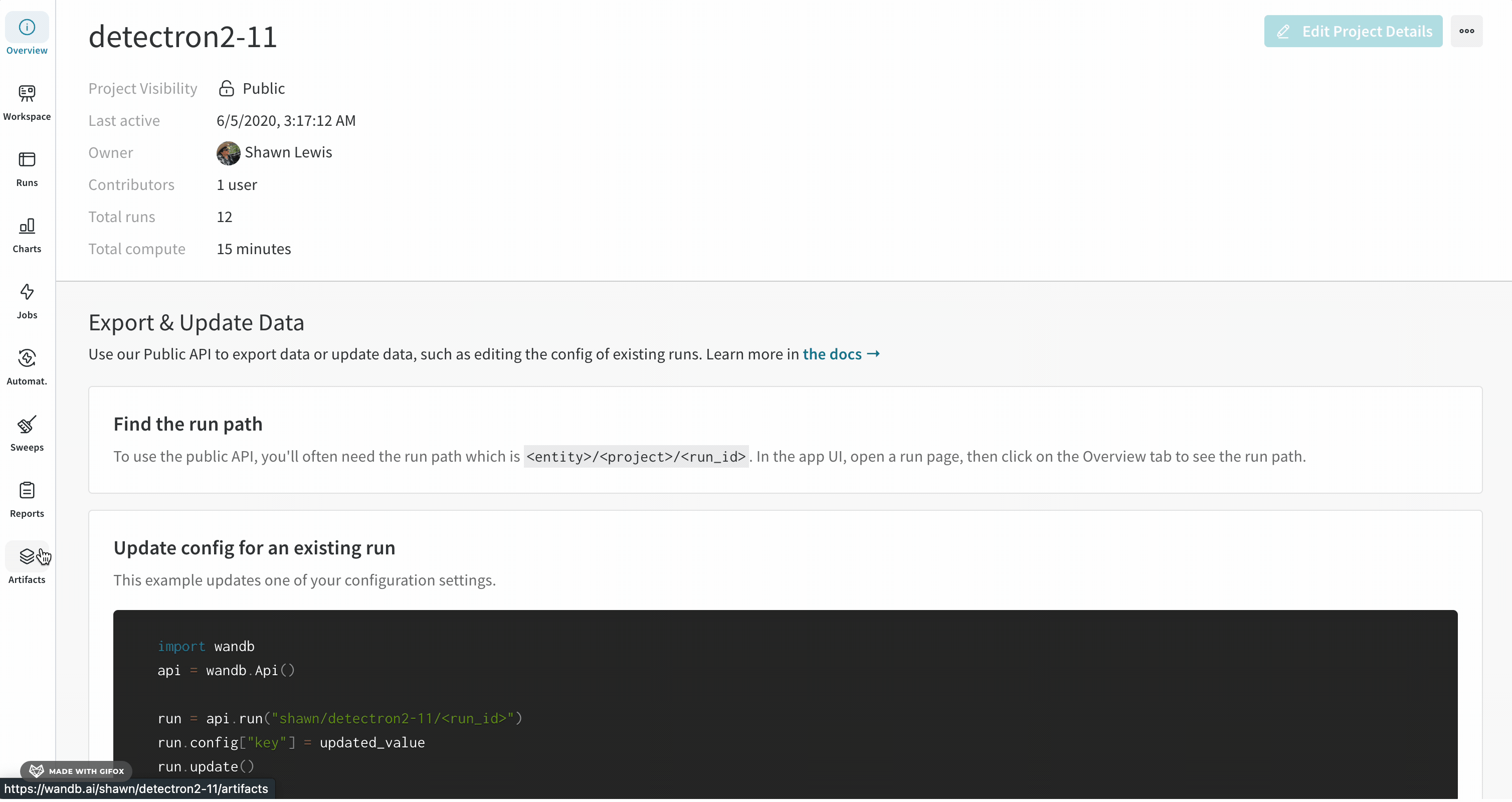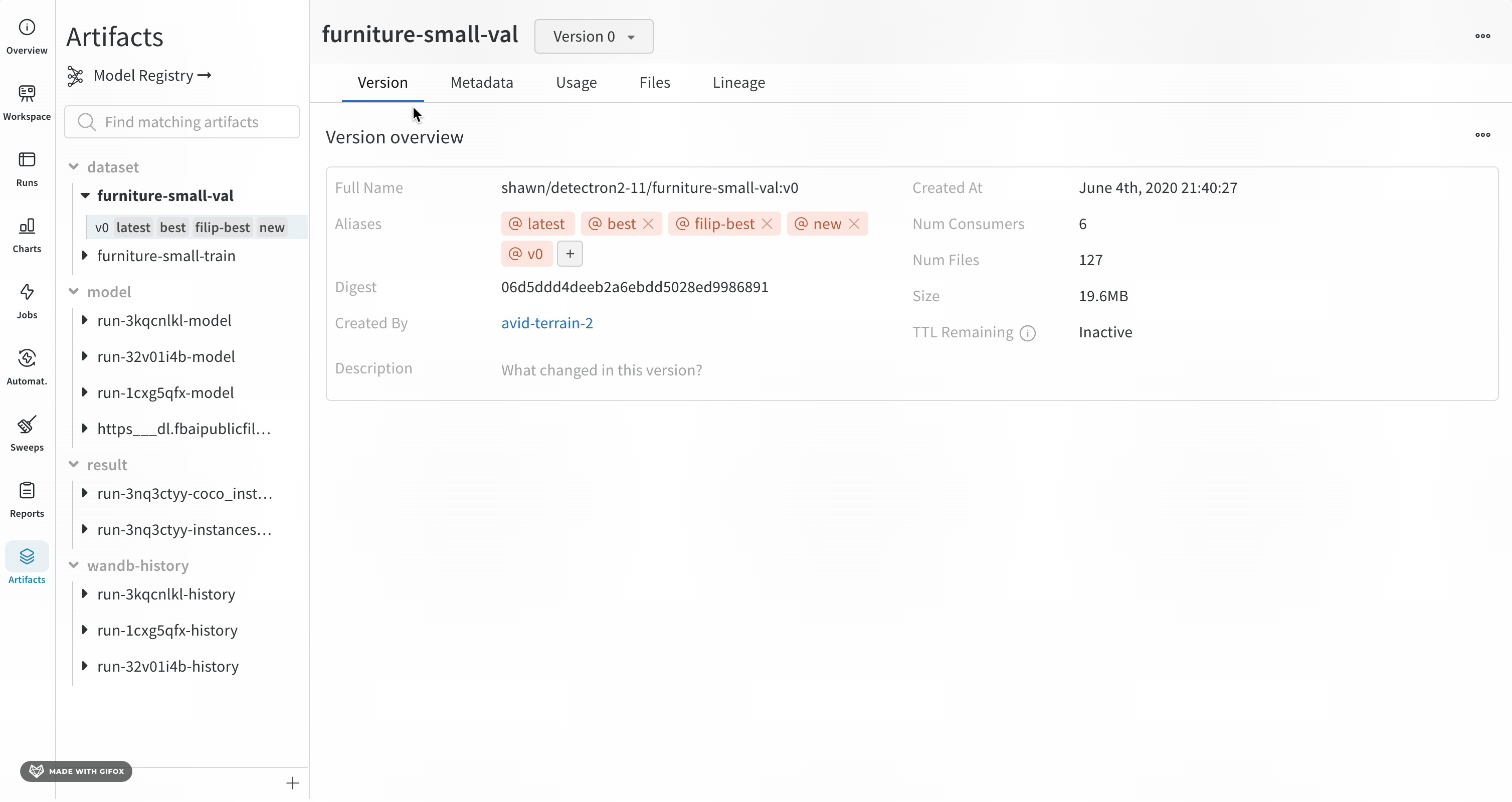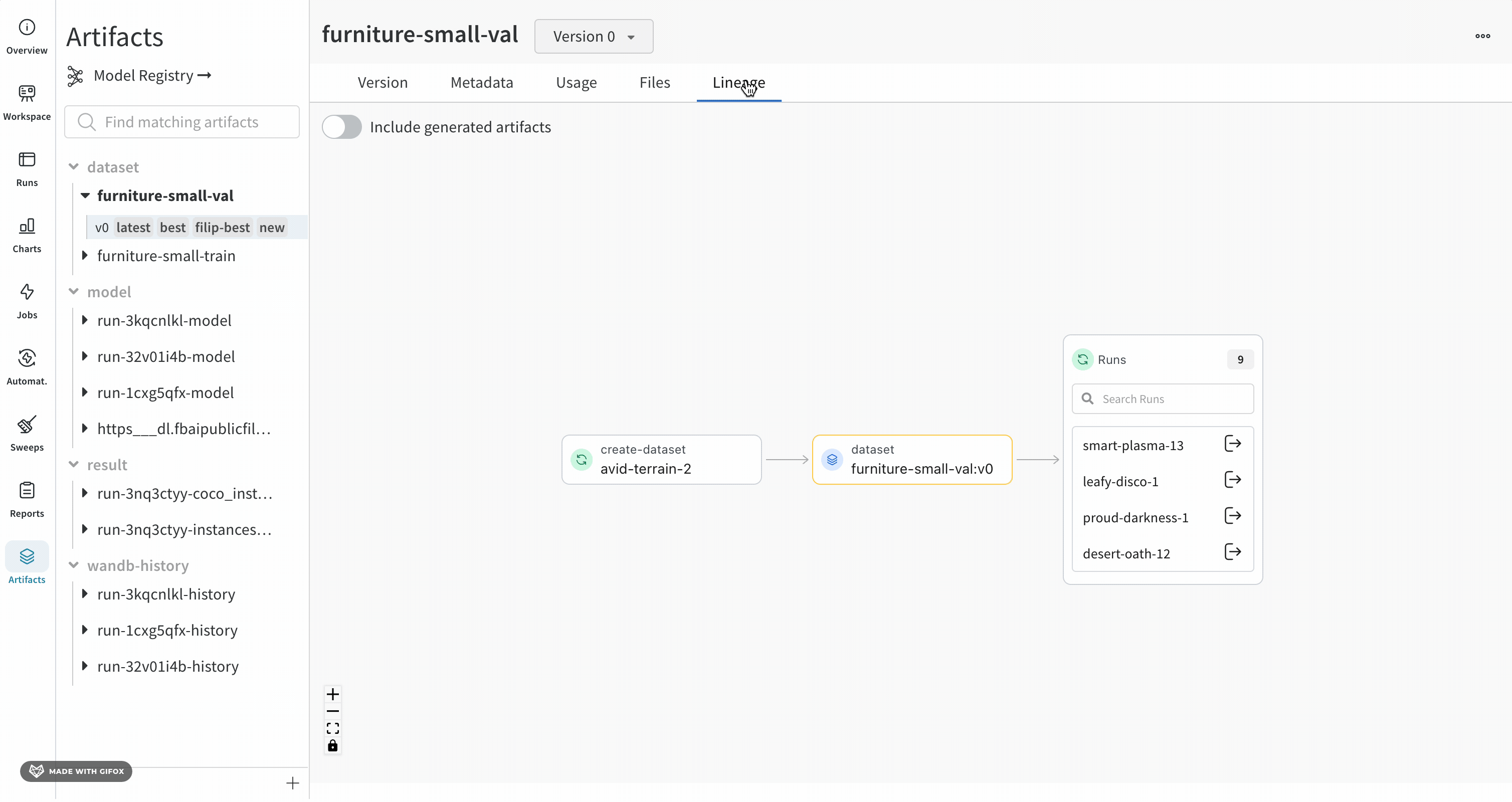
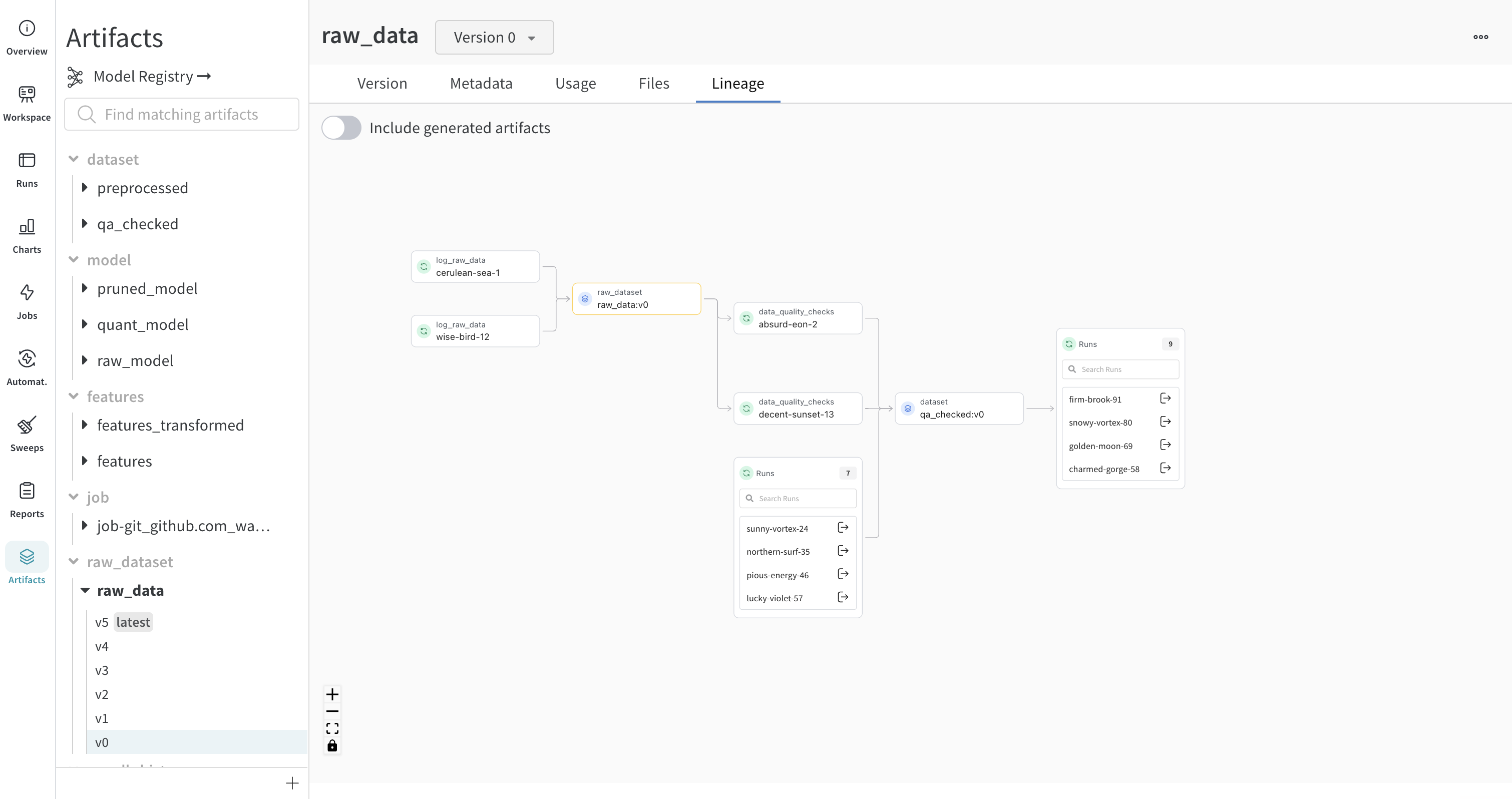
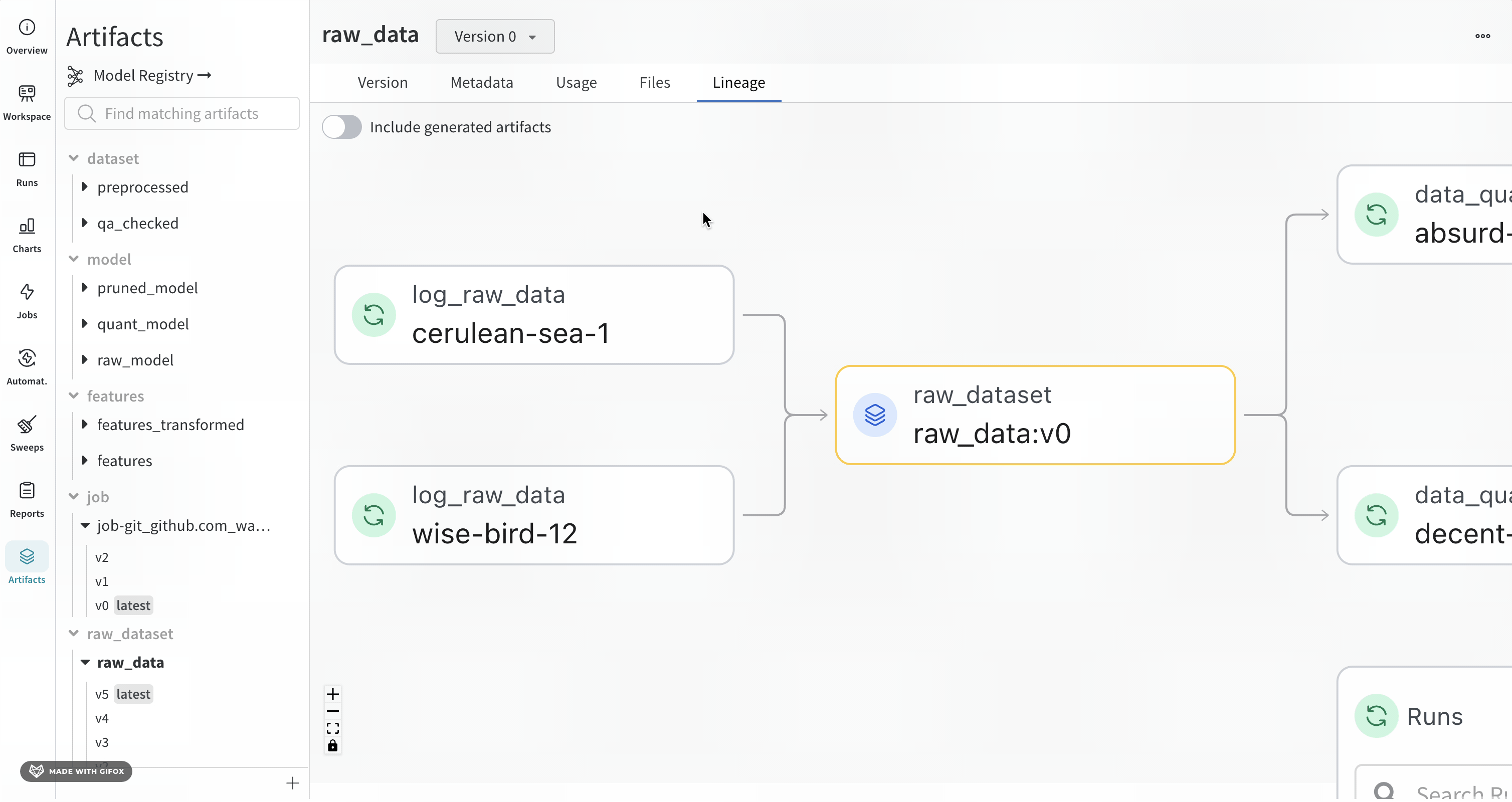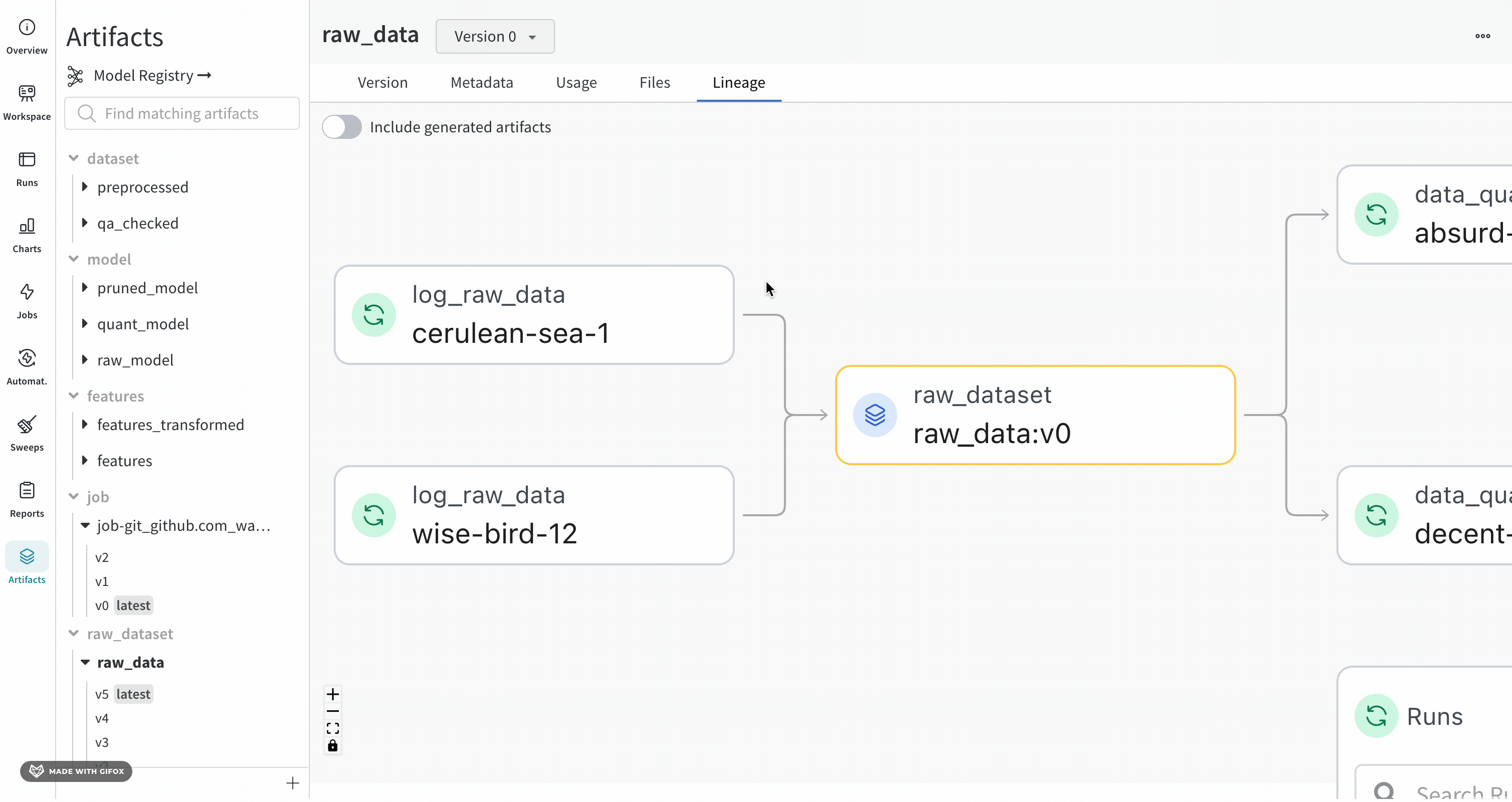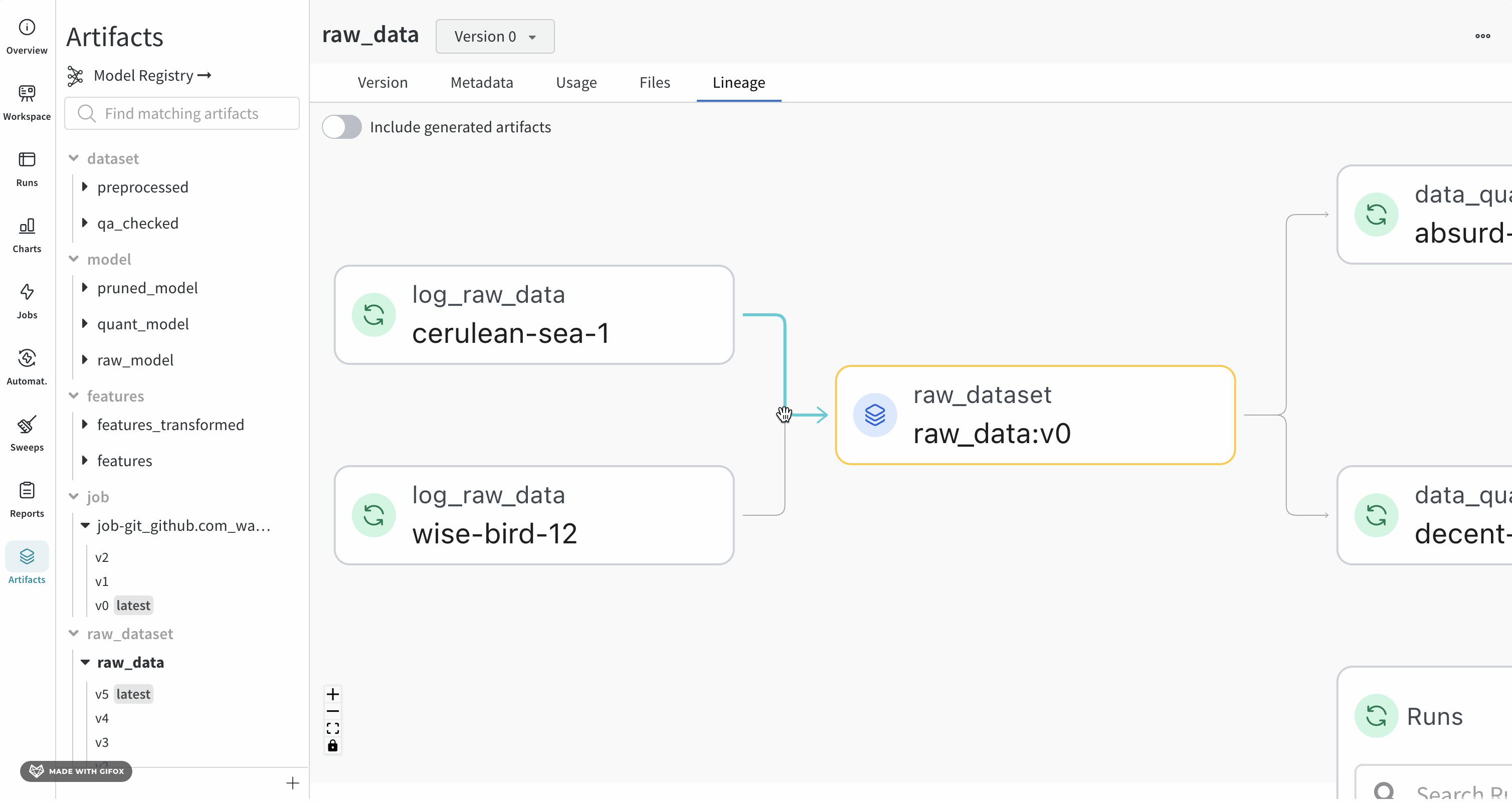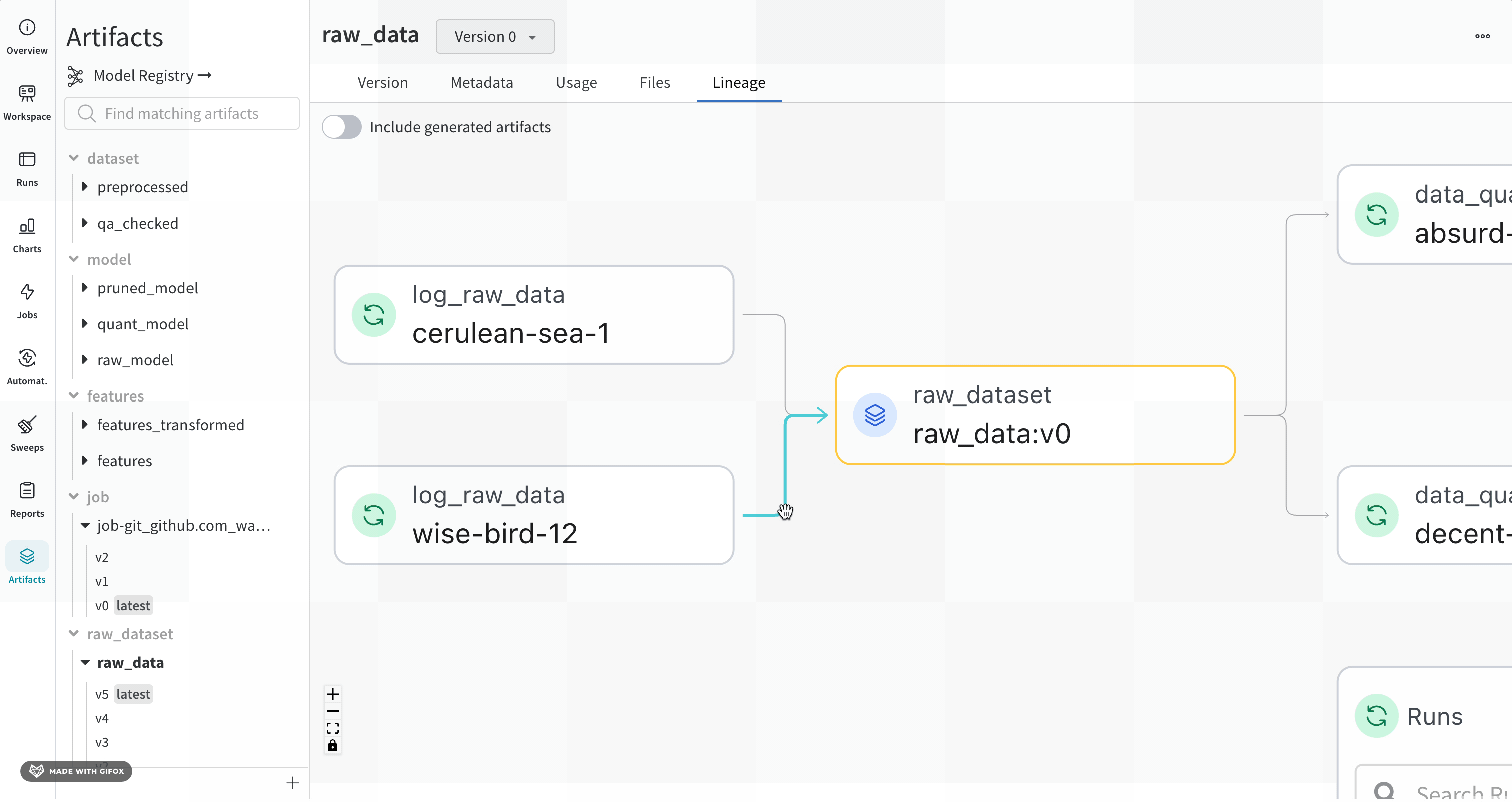
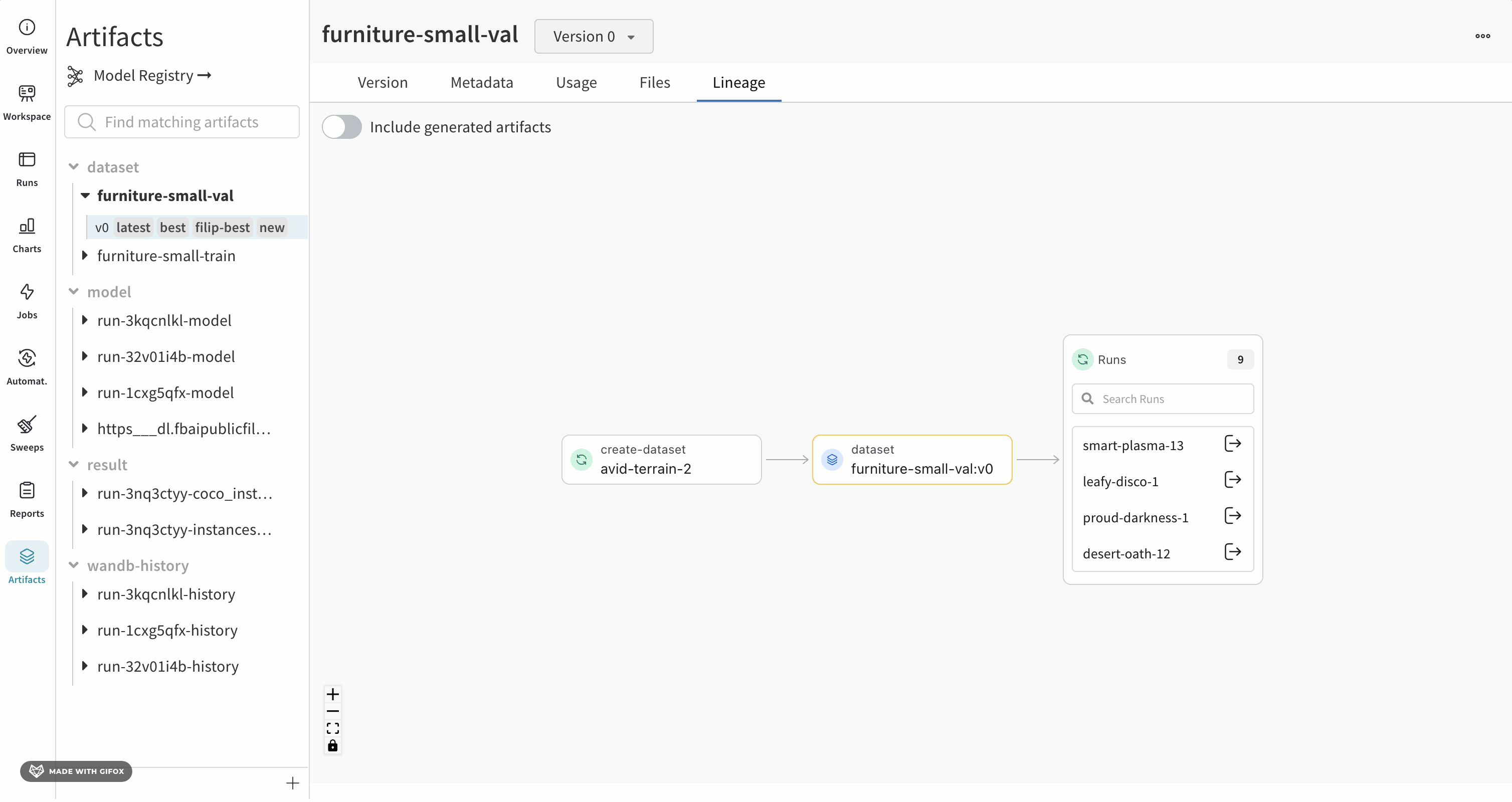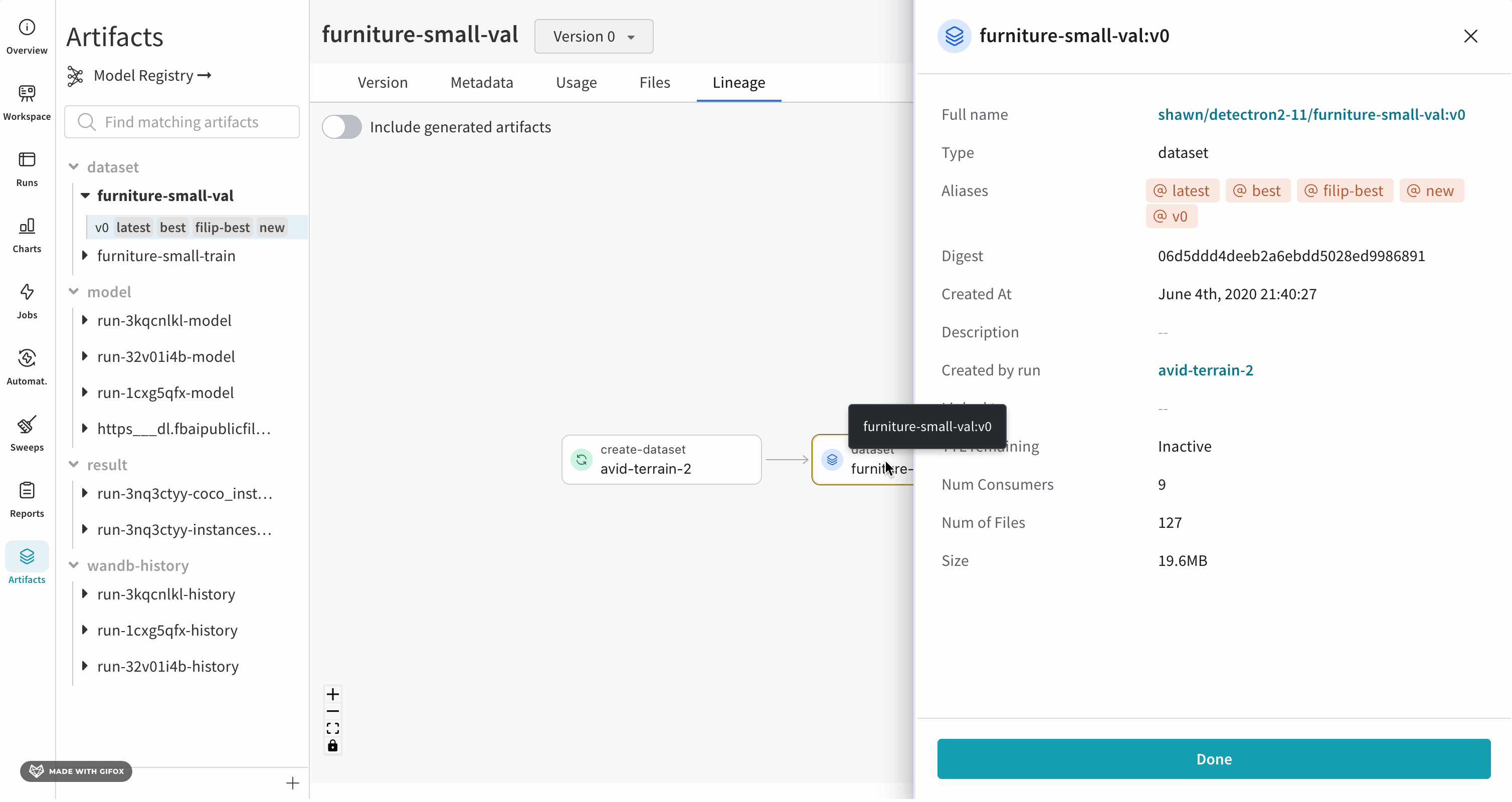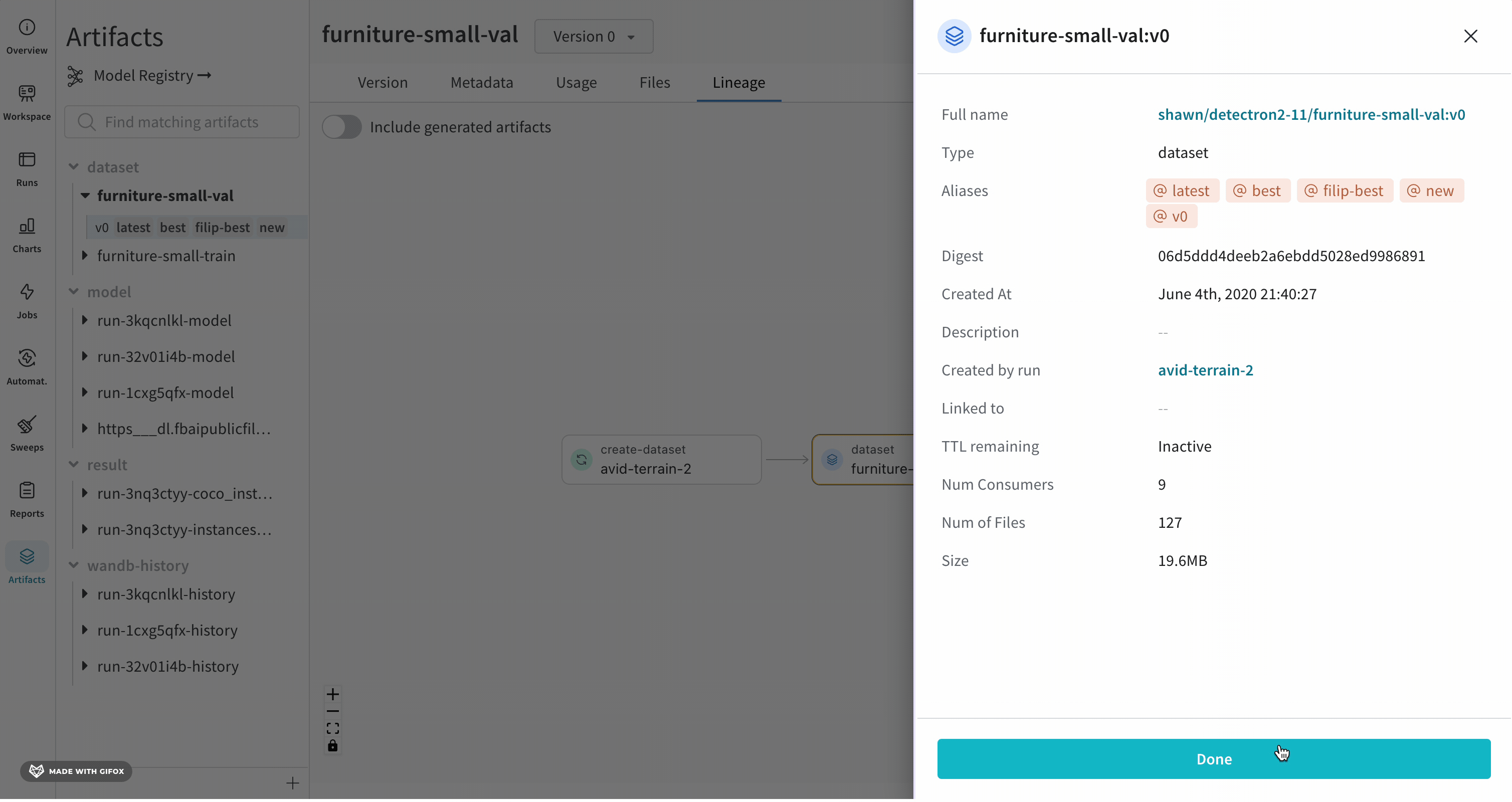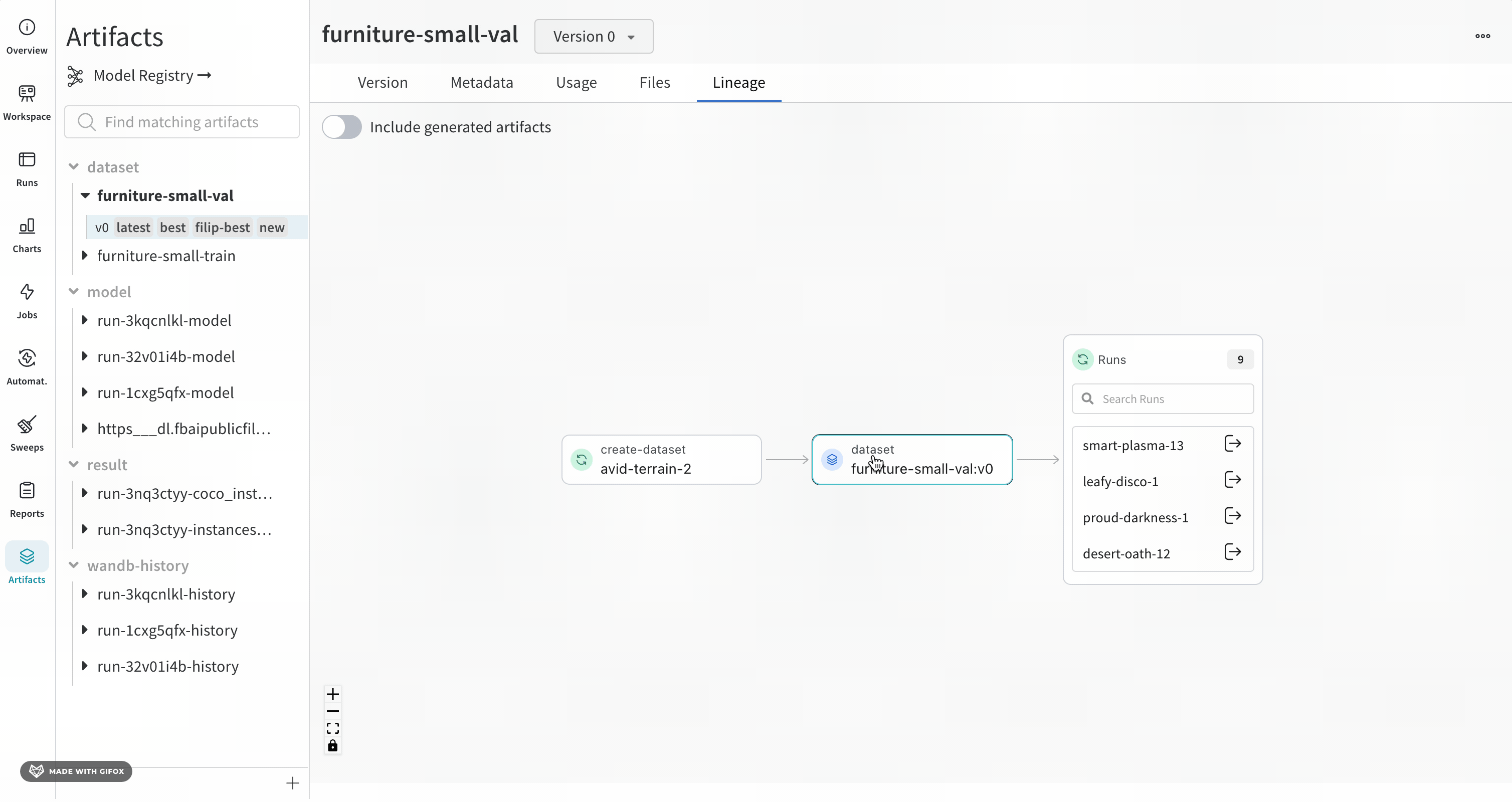
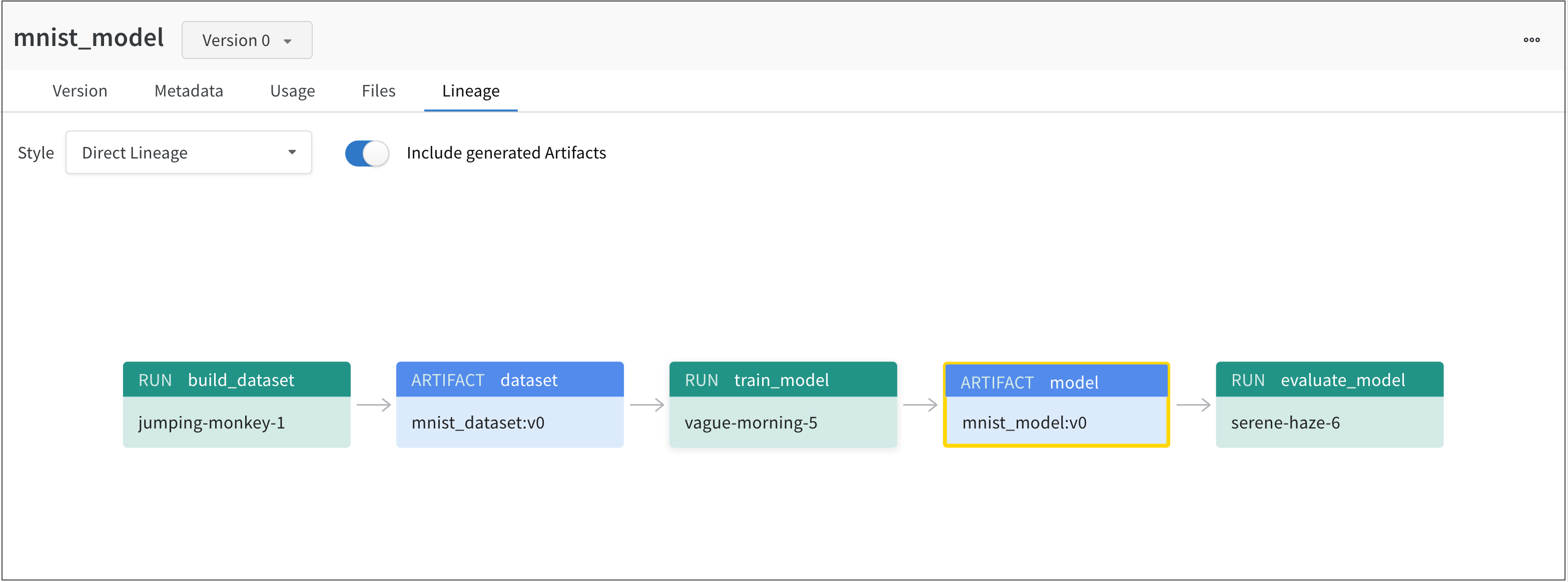
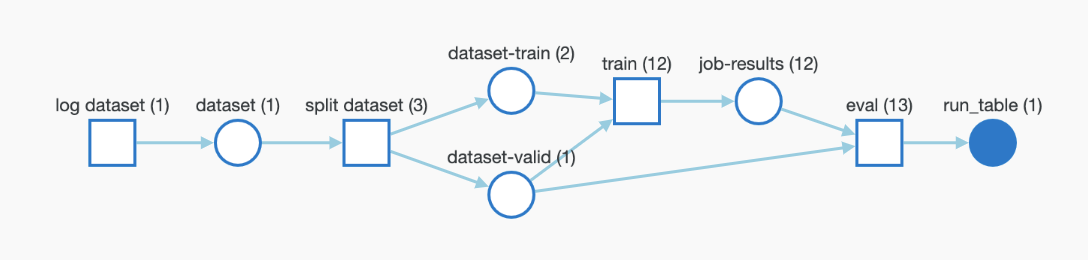
Lineage パネル
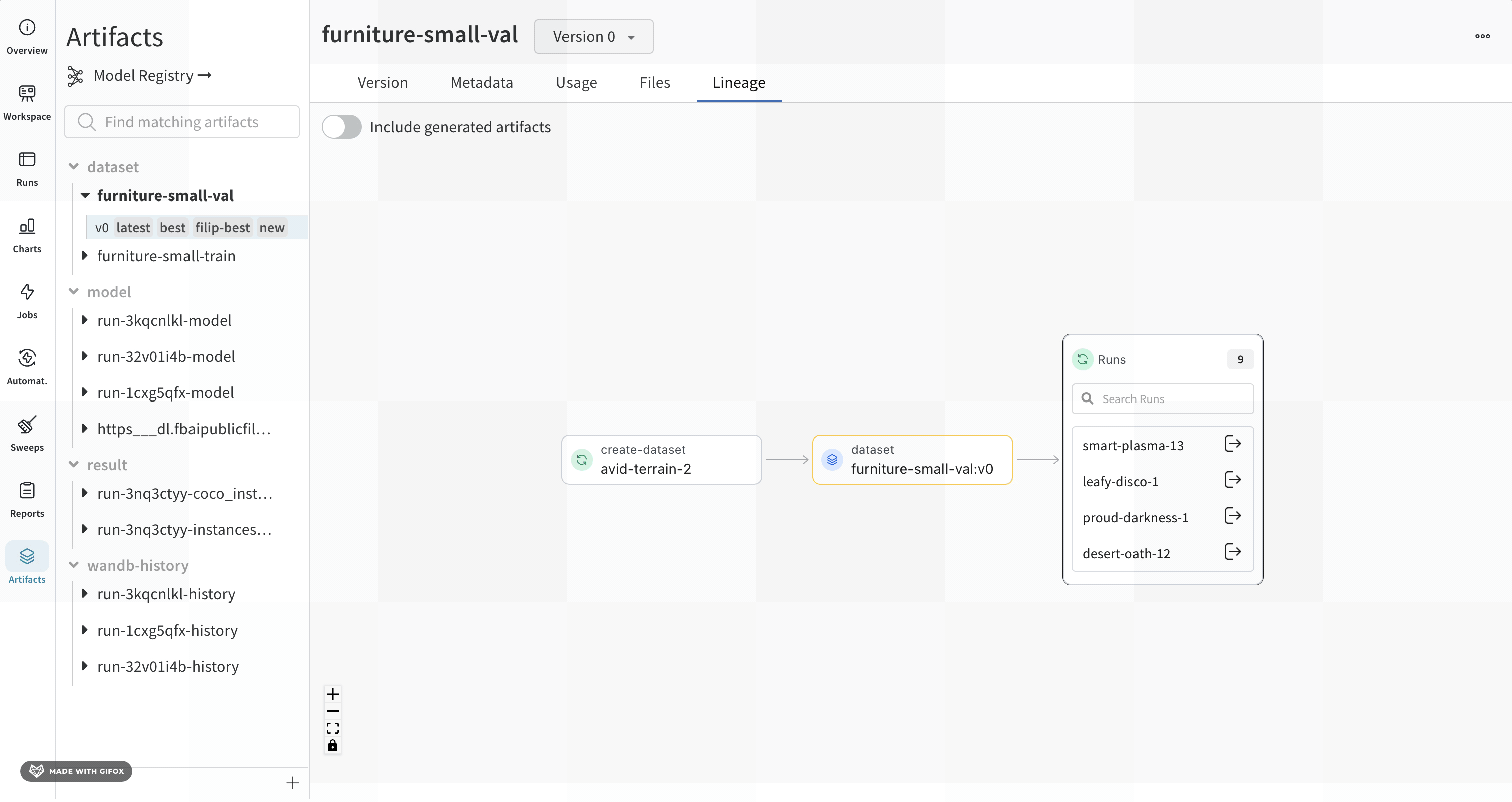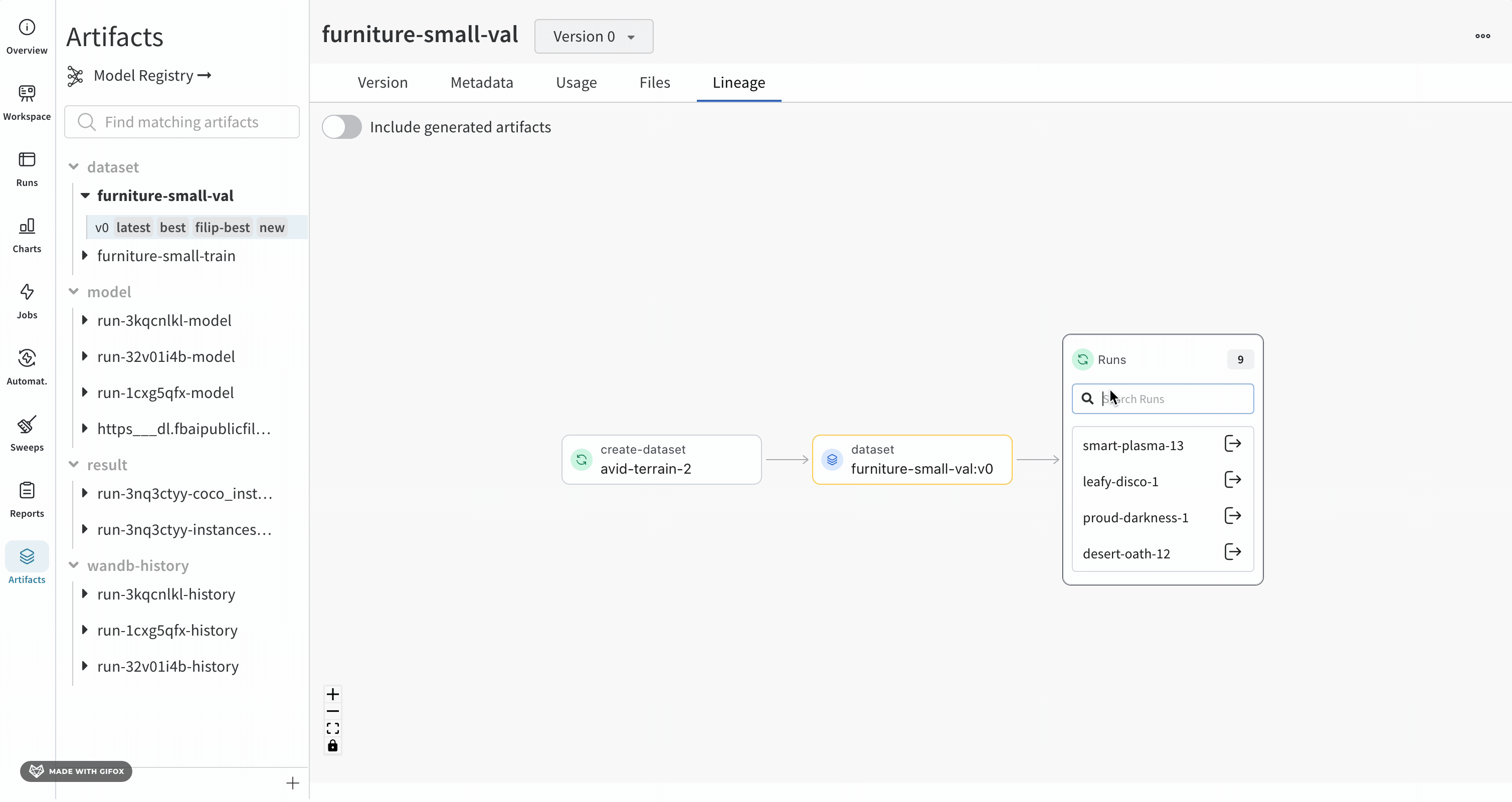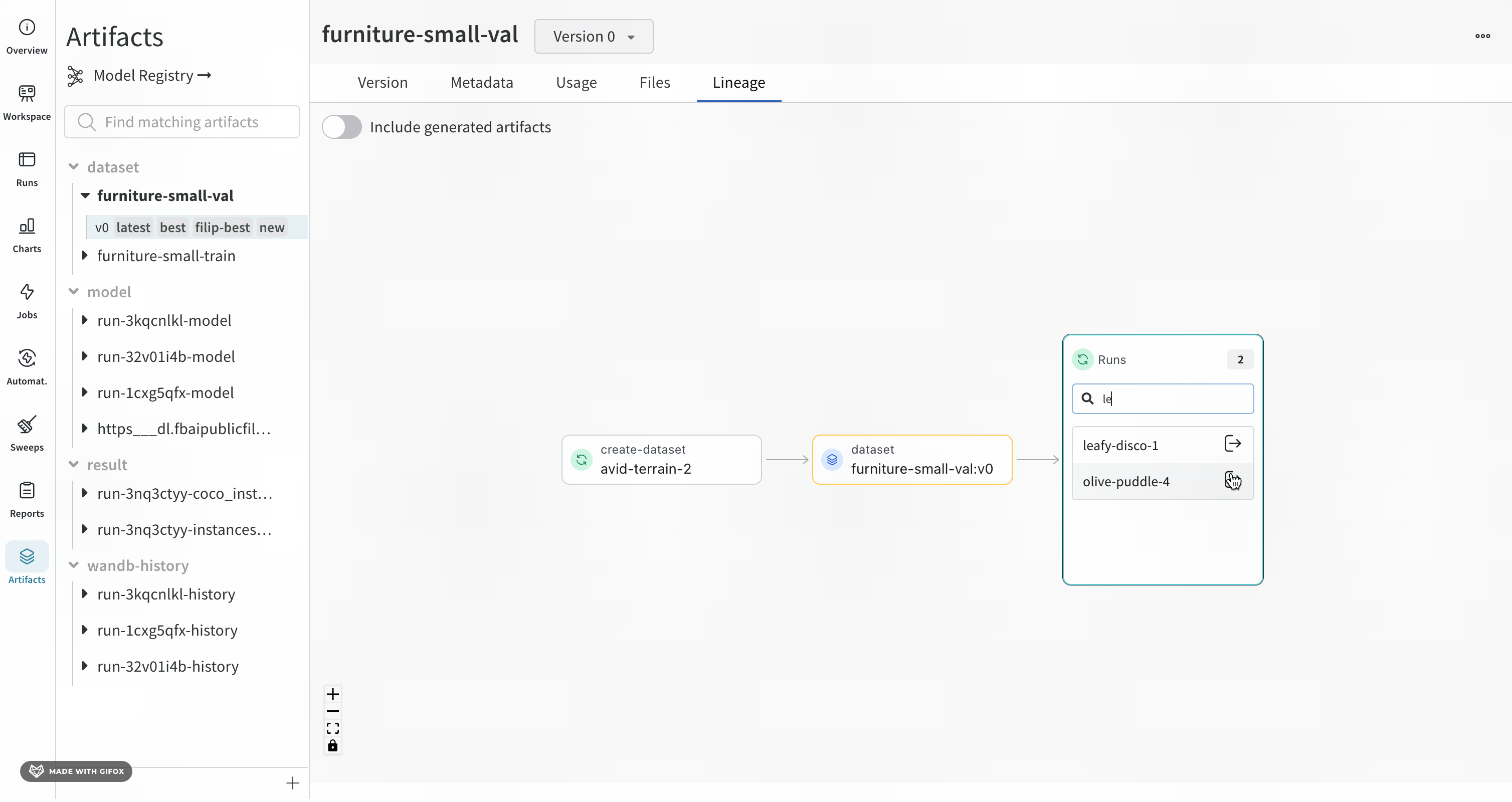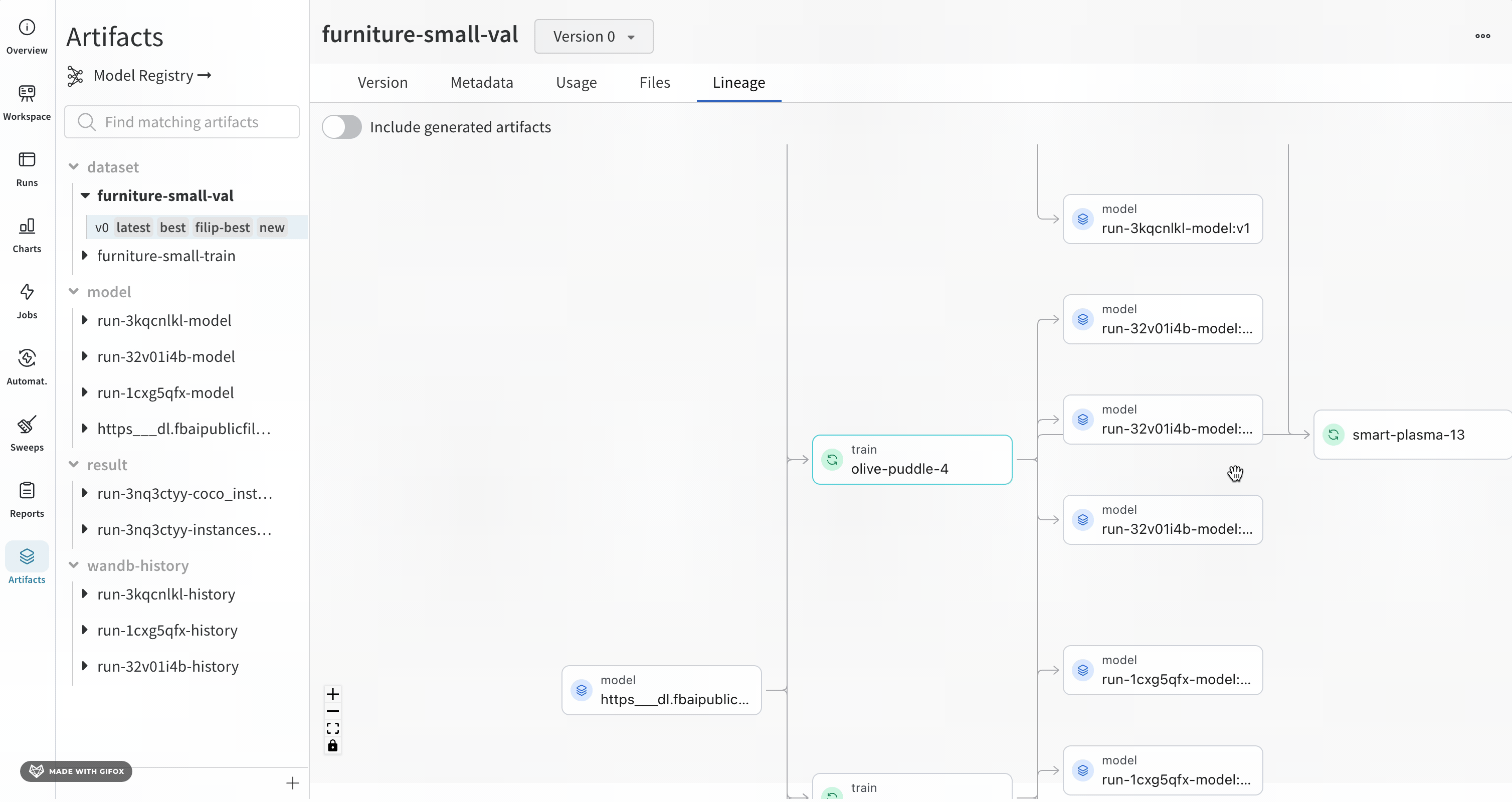
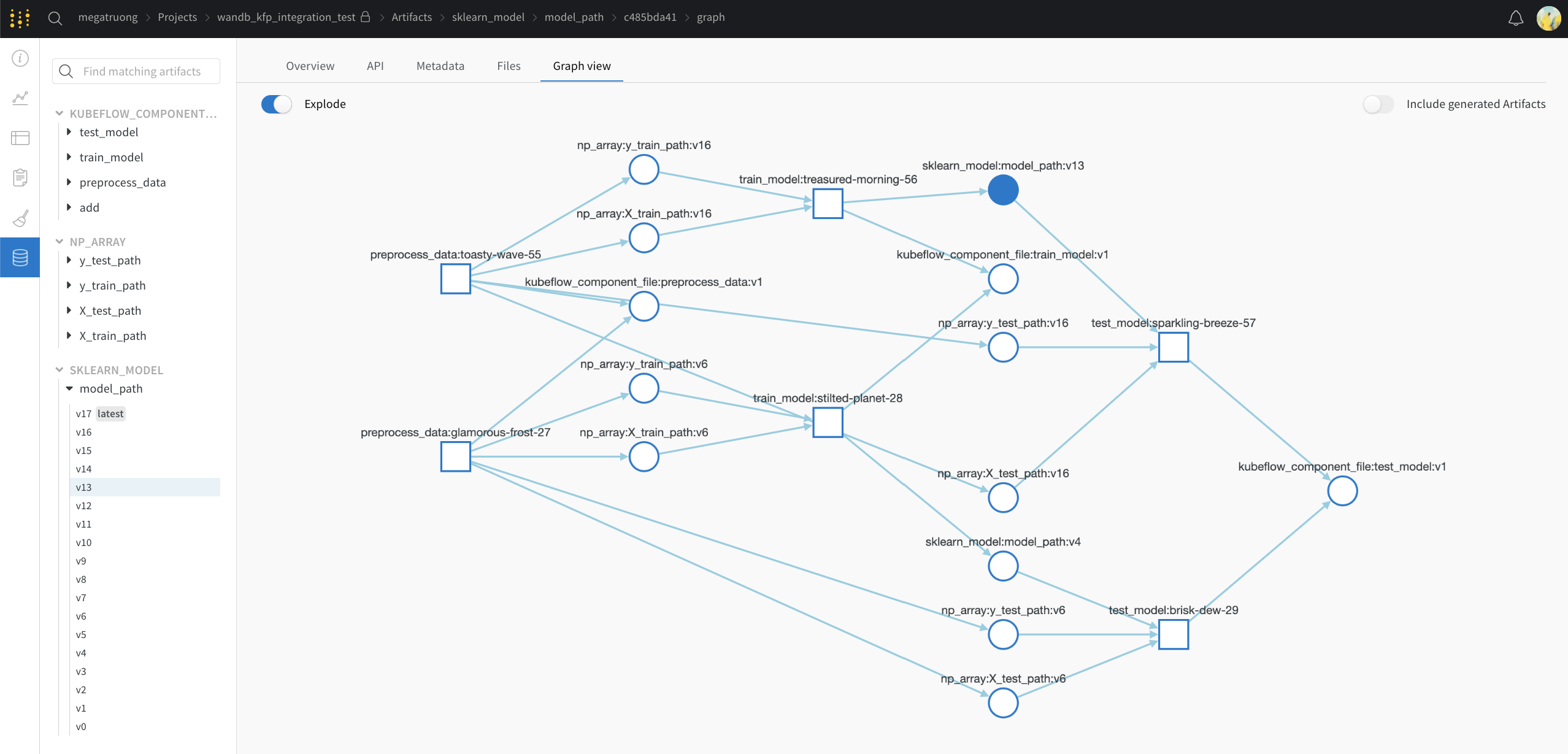
Lineage パネルは、project に関連付けられているすべての Artifacts と、それらを相互に接続する run のビューを提供します。これは、run タイプをブロックとして、Artifacts を円として表示し、特定のタイプの run が特定のタイプの Artifacts を消費または生成するときを示す矢印を表示します。左側の列で選択された特定の Artifacts のタイプが強調表示されます。
[Explode] トグルをクリックすると、個々の Artifacts バージョンと、それらを接続する特定の run がすべて表示されます。
Action History Audit タブ
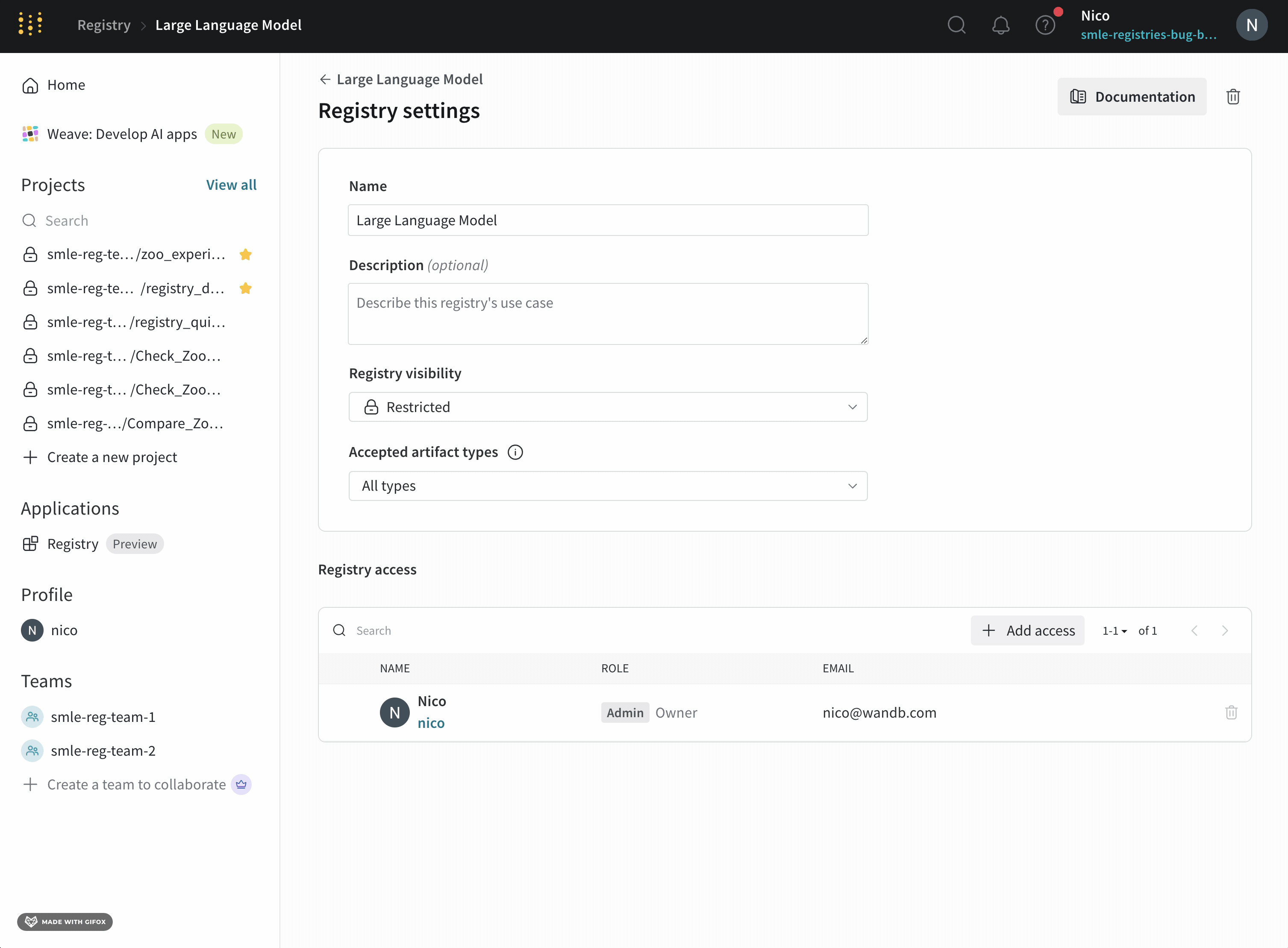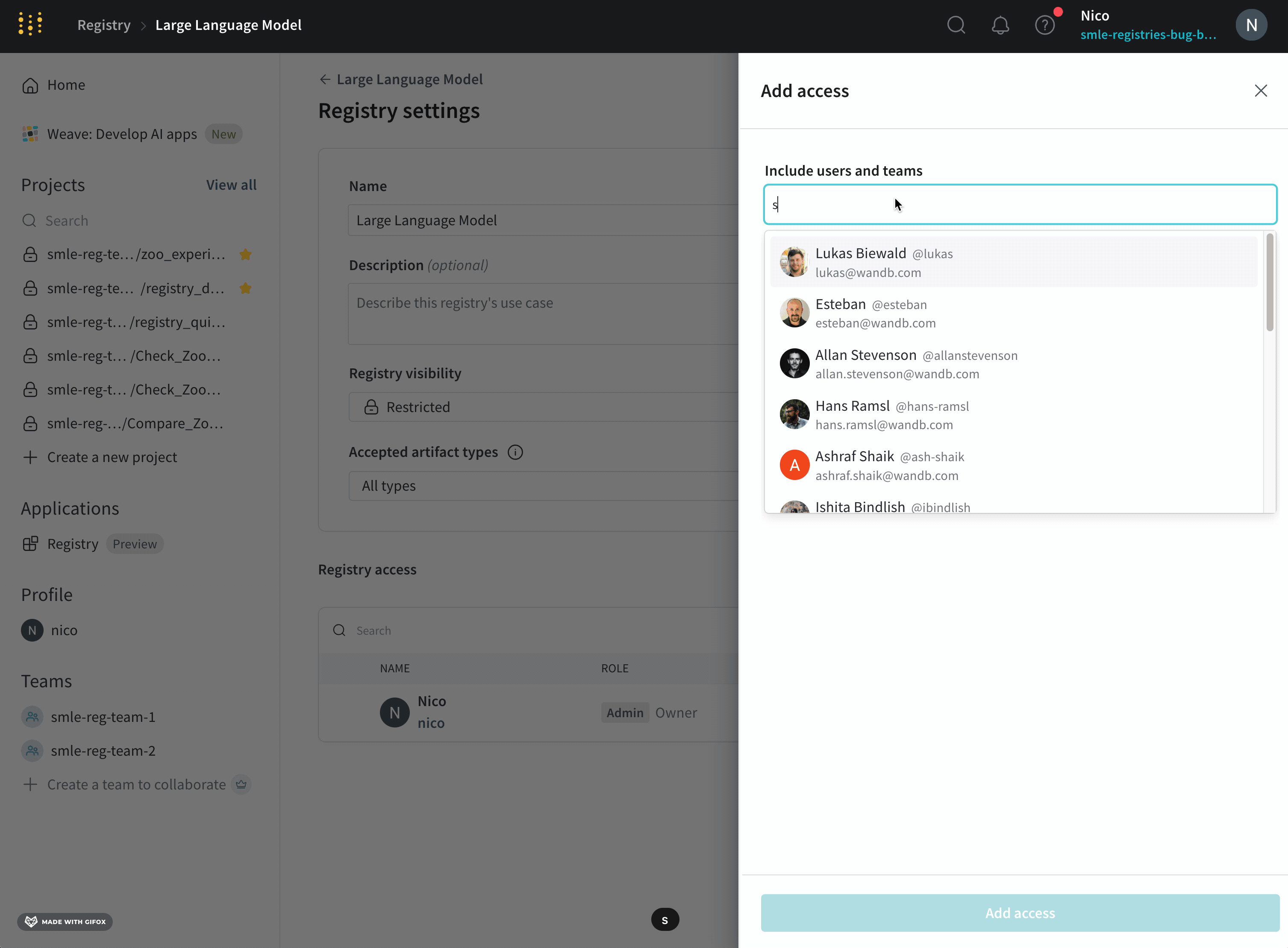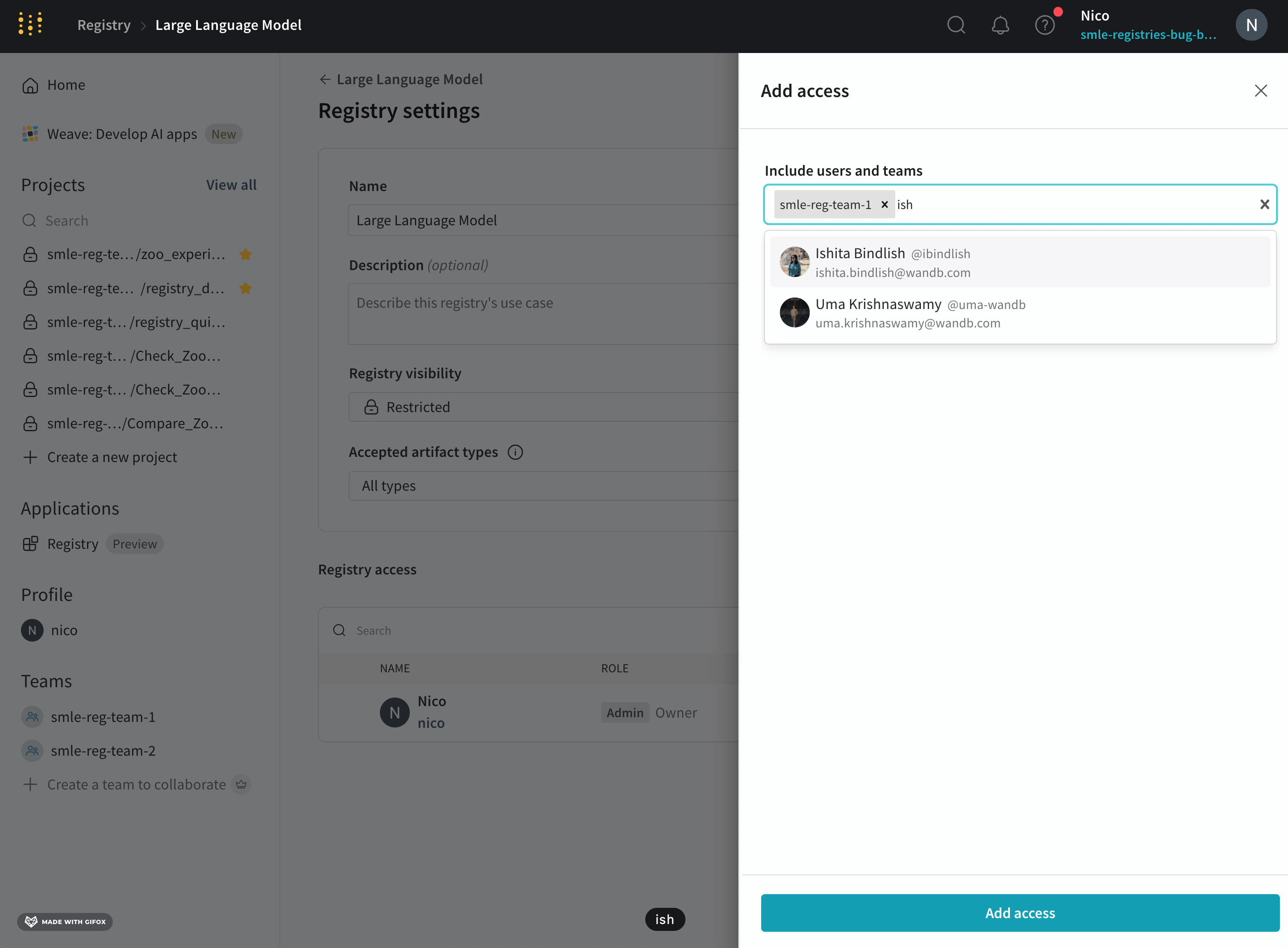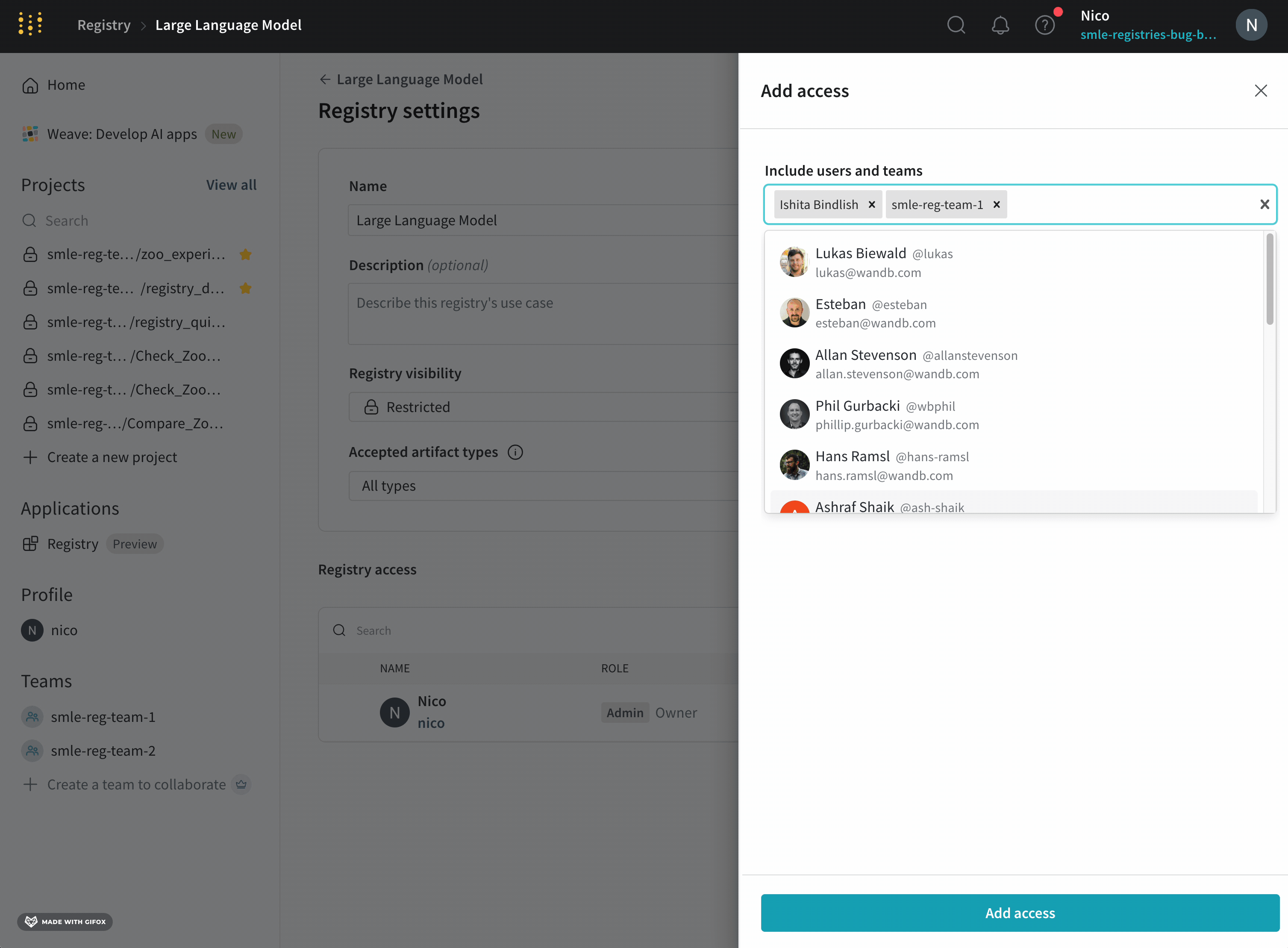
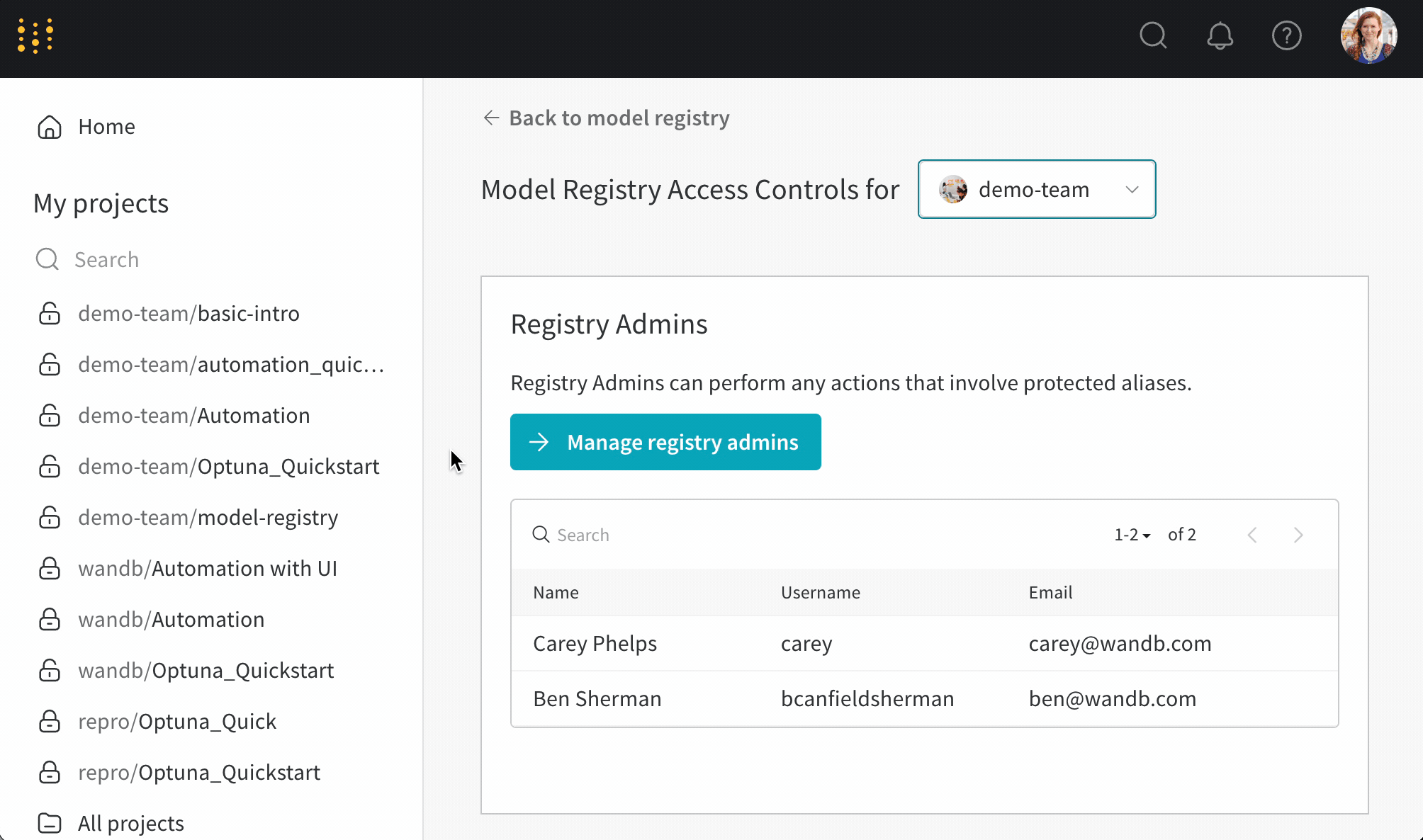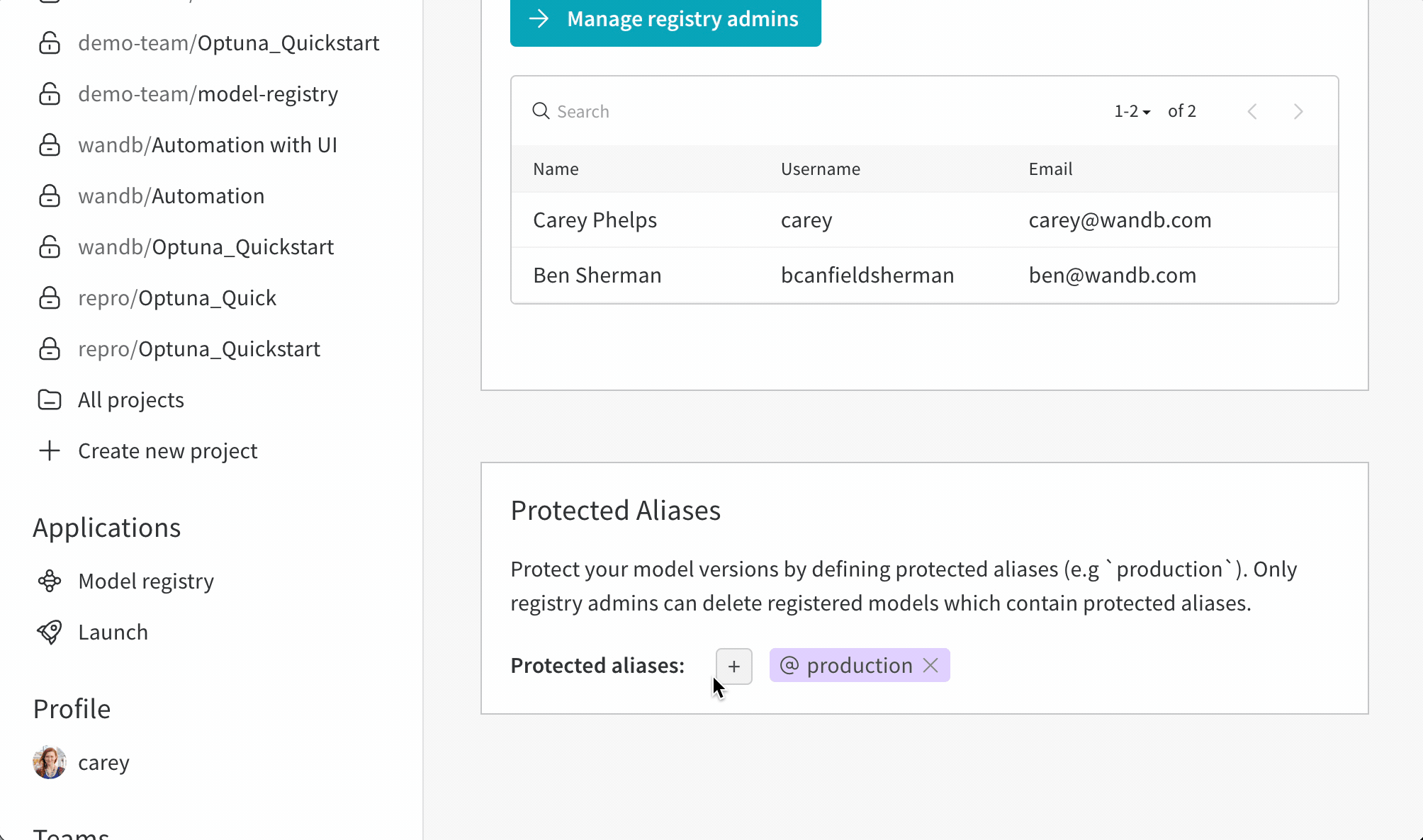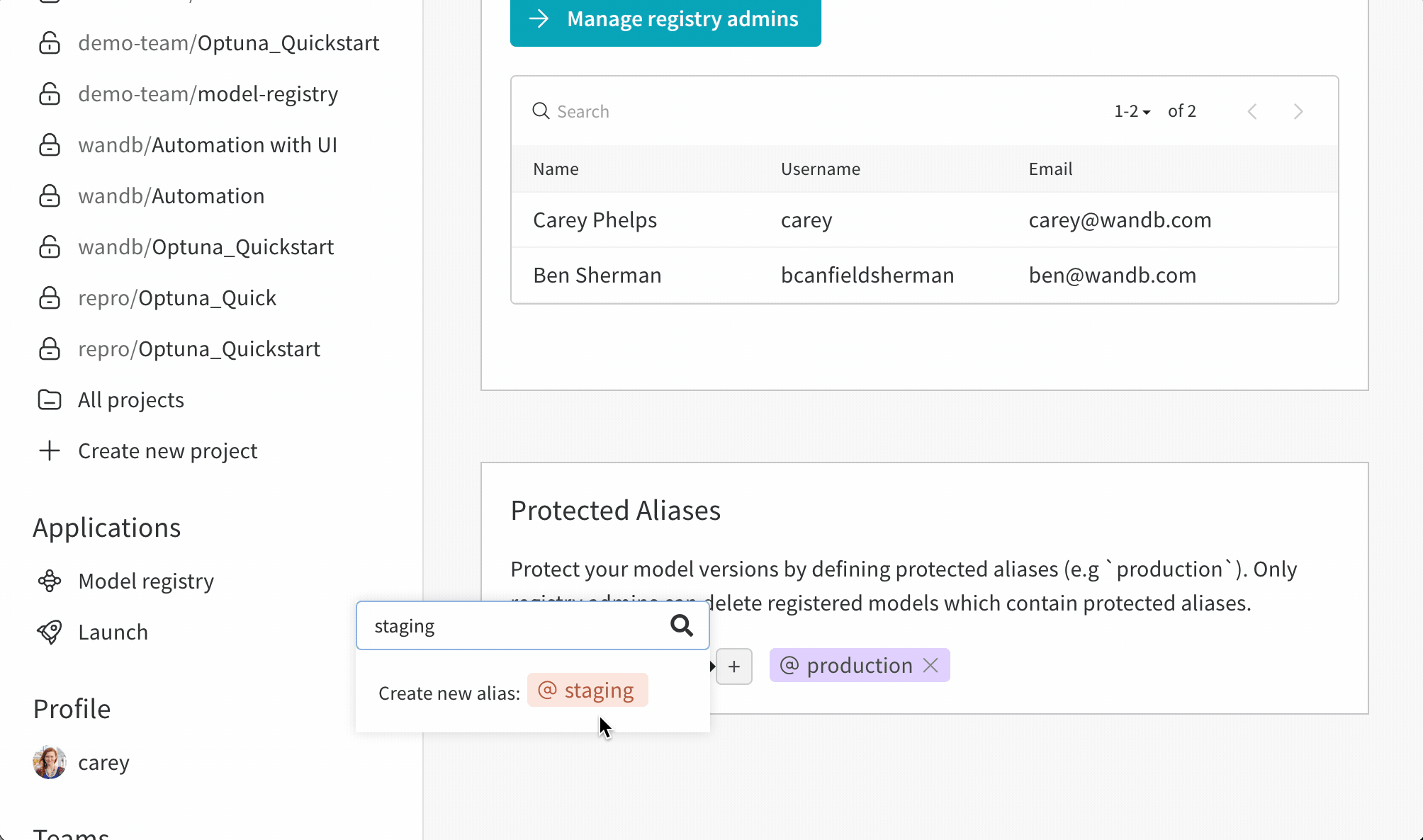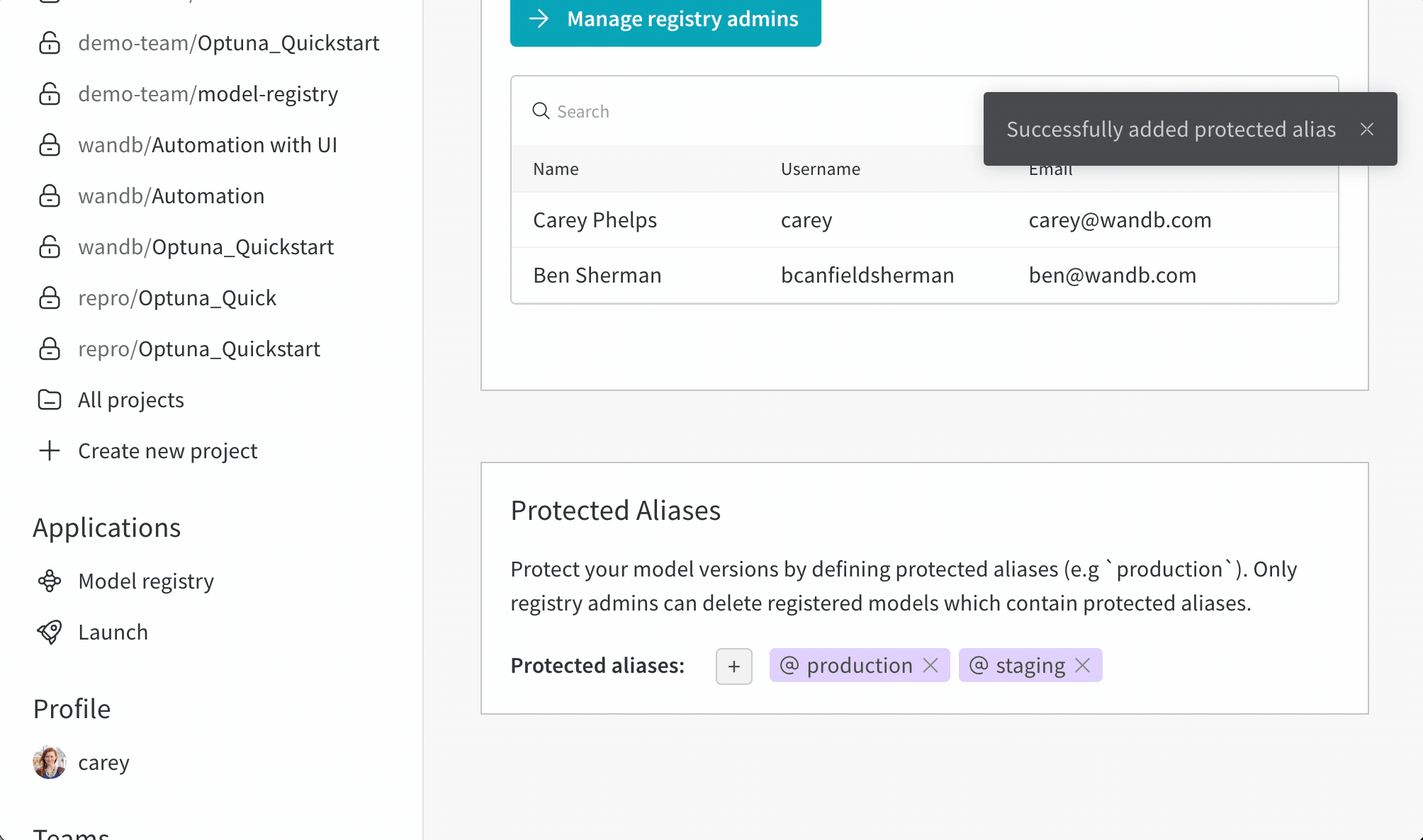
アクション履歴監査タブには、リソースの進化全体を監査できるように、Collection のすべてのエイリアス アクションとメンバーシップの変更が表示されます。
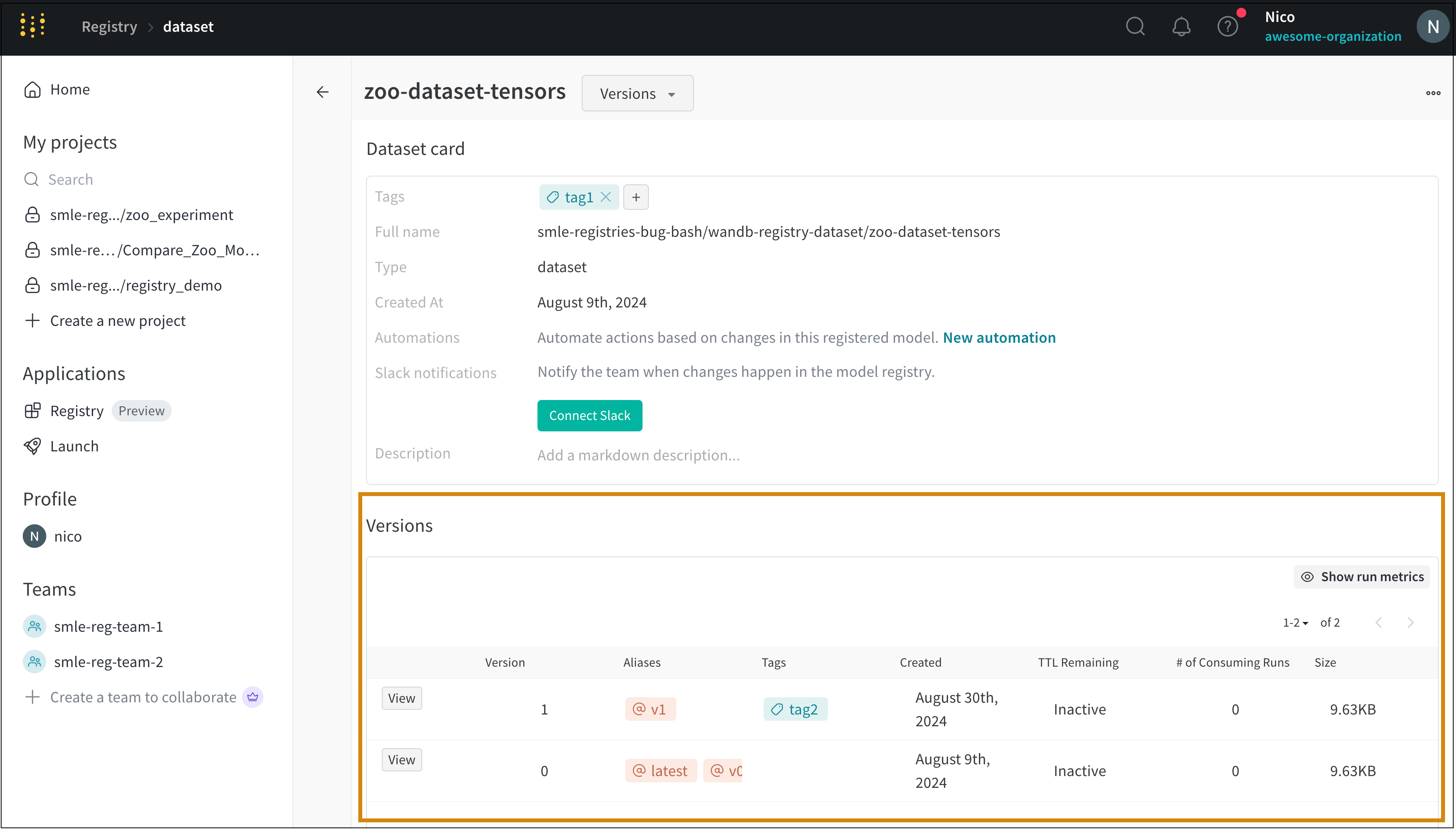
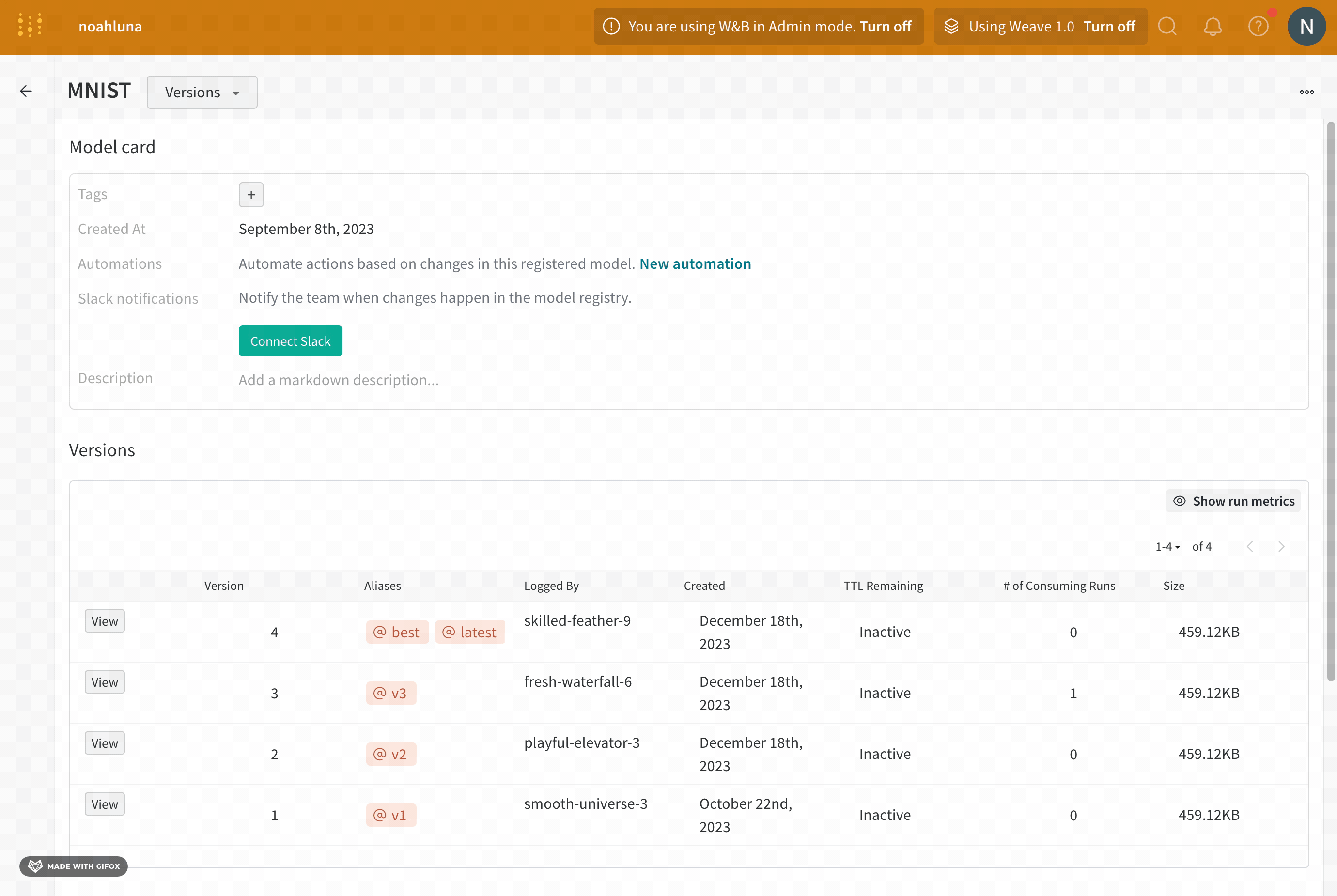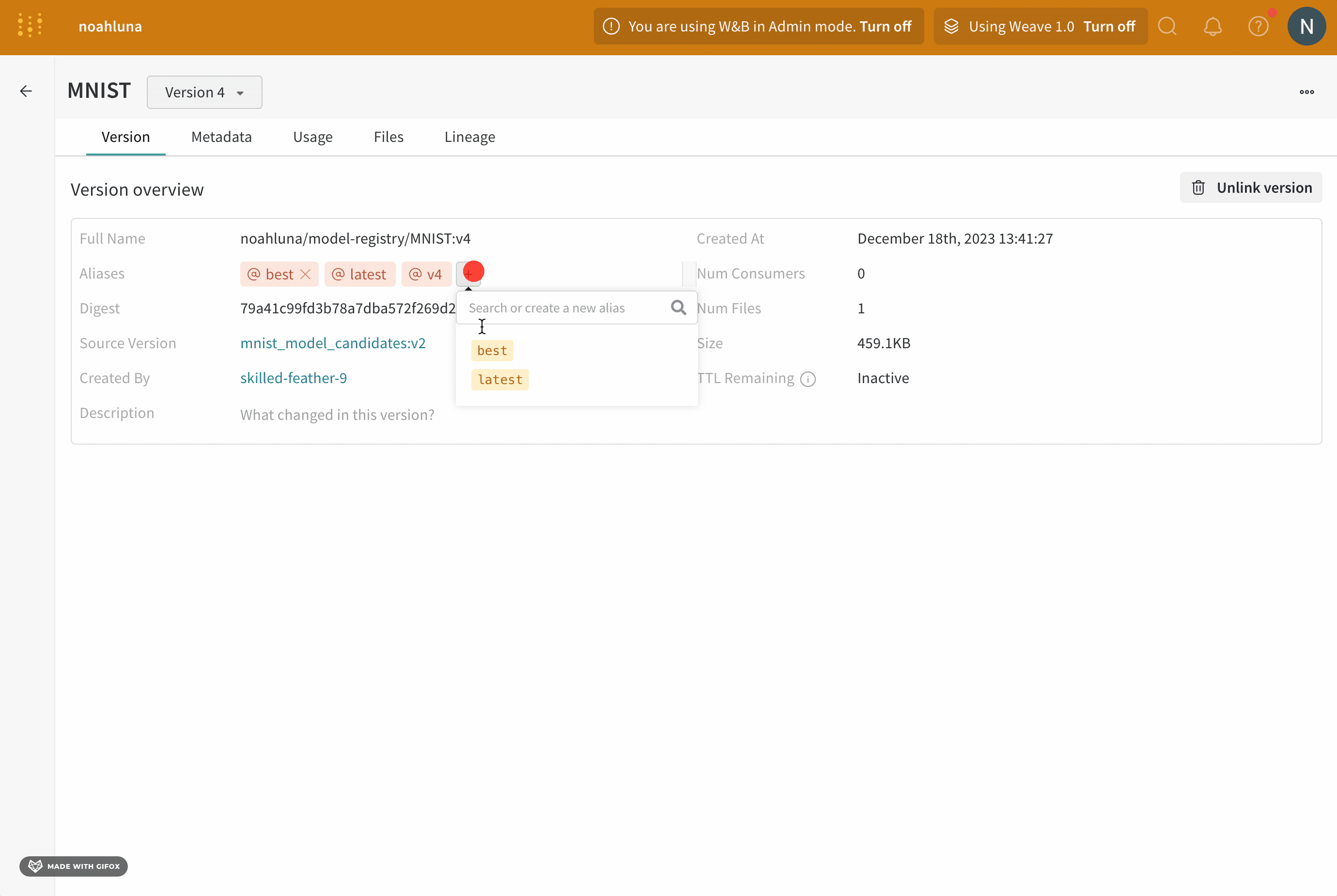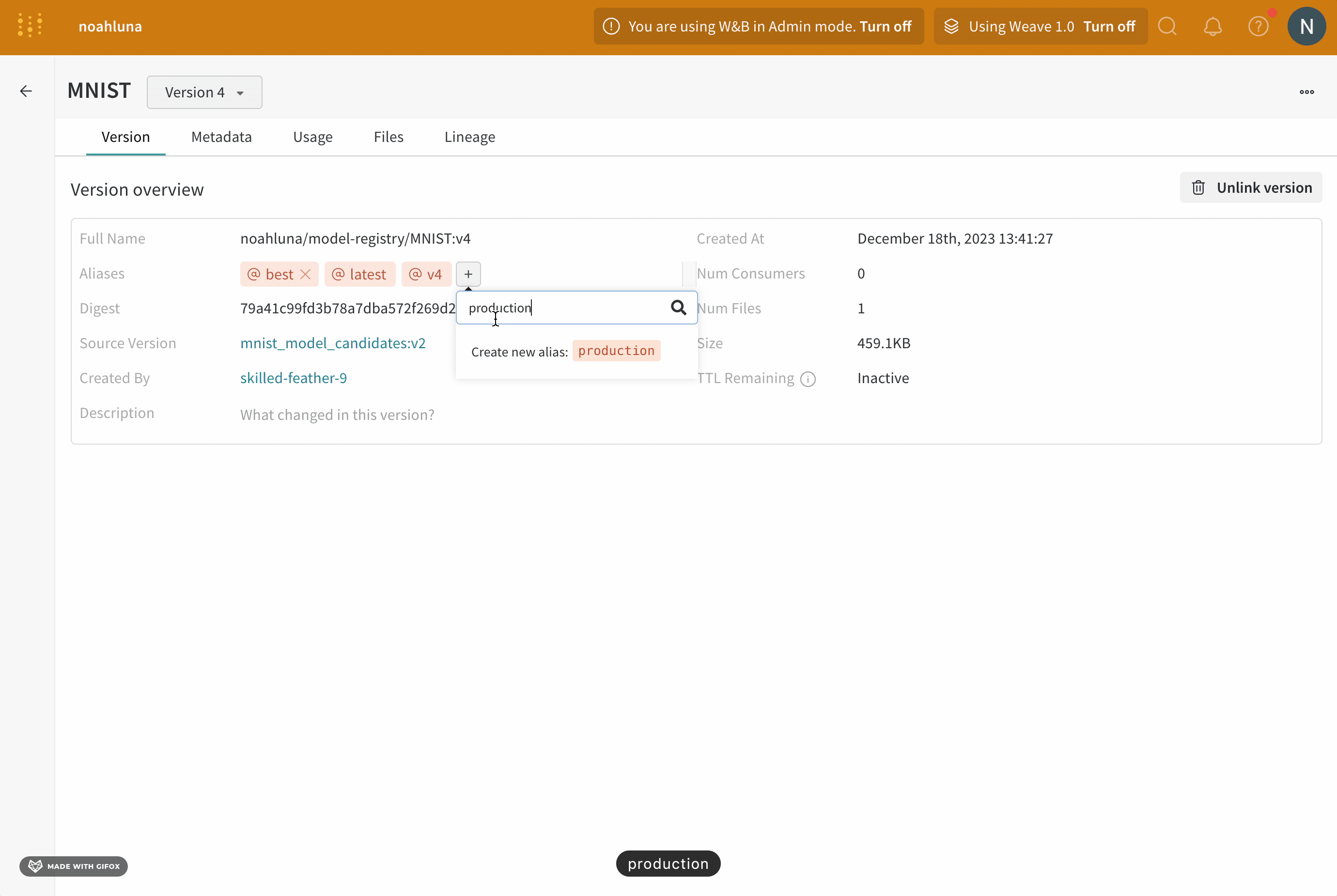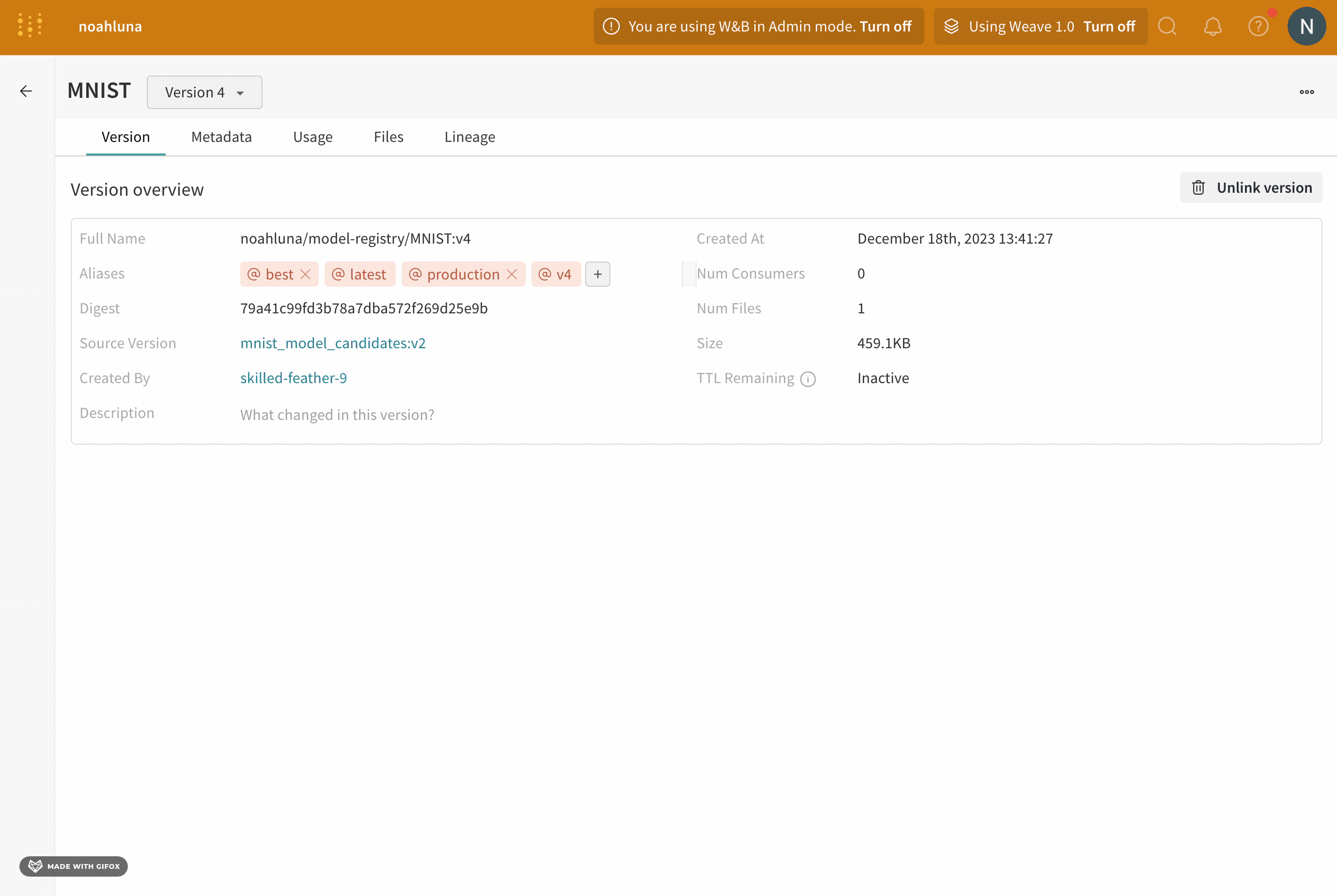
Versions タブ
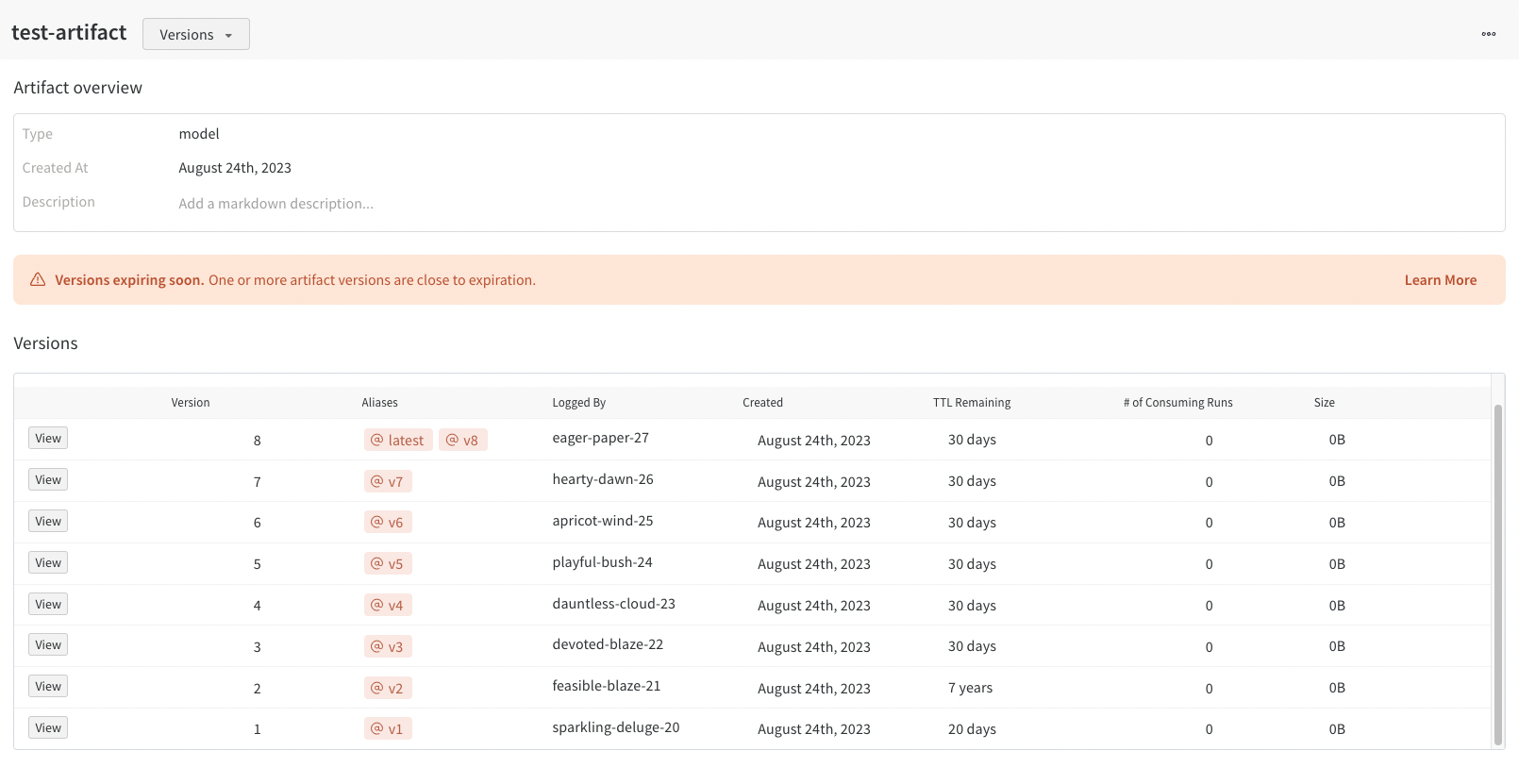
Versions タブには、Artifacts のすべてのバージョンと、バージョンのロギング時の Run History の各数値の値の列が表示されます。これにより、パフォーマンスを比較し、関心のあるバージョンをすばやく特定できます。
project にスターを付ける
project にスターを追加して、その project を重要としてマークします。あなたとあなたのチームがスターで重要としてマークした project は、組織のホームページの上部に表示されます。
たとえば、次の画像は、重要としてマークされている 2 つの project、zoo_experiment と registry_demo を示しています。両方の project は、組織のホームページの Starred projects セクションの上部に表示されます。
project を重要としてマークするには、project の Overview タブ内またはチームのプロファイル ページの 2 つの方法があります。
Project overview
Team profile
W&B アプリ ( https://wandb.ai/<team>/<project-name> ) で W&B project に移動します。
project サイドバーから Overview タブを選択します。
右上隅にある Edit ボタンの横にあるスター アイコンを選択します。
チームのプロファイル ページ ( https://wandb.ai/<team>/projects ) に移動します。
Projects タブを選択します。スターを付ける project の横にマウスを合わせます。表示されるスター アイコンをクリックします。
たとえば、次の画像は、“Compare_Zoo_Models” project の横にあるスター アイコンを示しています。
アプリの左上隅にある組織名をクリックして、project が組織のランディング ページに表示されることを確認します。
project を削除する
Overview タブの右側にある 3 つのドットをクリックして、project を削除できます。
project が空の場合、右上にあるドロップダウン メニューをクリックし、Delete project を選択して削除できます。
project にメモを追加する
説明の概要として、またはワークスペース内のマークダウン パネルとして、project にメモを追加します。
説明の概要を project に追加する
ページに追加する説明は、プロファイルの Overview タブに表示されます。
W&B project に移動します。
project サイドバーから Overview タブを選択します。
右上隅にある [Edit] を選択します。
Description フィールドにメモを追加します。Save ボタンを選択します。
Create reports to create descriptive notes comparing runs W&B Report を作成して、プロットとマークダウンを並べて追加することもできます。異なるセクションを使用して異なる run を表示し、作業内容に関するストーリーを伝えます。
run ワークスペースにメモを追加する
W&B project に移動します。
project サイドバーから Workspace タブを選択します。
右上隅にある Add panels ボタンを選択します。
表示されるモーダルから TEXT AND CODE ドロップダウンを選択します。
Markdown を選択します。ワークスペースに表示されるマークダウン パネルにメモを追加します。
2.1.4 - View experiments results
インタラクティブな 可視化 で run のデータを探索できるプレイグラウンド
W&B workspace は、チャートをカスタマイズし、モデルの 結果 を探索するための個人的なサンドボックスです。W&B workspace は、 Tables と Panel sections で構成されています。
Tables : あなたの project に ログ されたすべての run は、その project のテーブルにリストされます。run のオン/オフ、色の変更、テーブルの 展開 などを行い、各 run のノート、config、サマリー metrics を確認できます。Panel sections : 1つまたは複数の panels を含むセクション。新しい パネル を作成し、それらを整理し、workspace の スナップショット を保存するために Reports にエクスポートします。
Workspace の種類
workspace には、主に Personal workspaces と Saved views の2つのカテゴリがあります。
Personal workspaces: model と data visualization を詳細に 分析 するための、カスタマイズ可能な workspace です。workspace のオーナーのみが 編集 して変更を保存できます。チームメイトは personal workspace を表示できますが、他の ユーザー の personal workspace を変更することはできません。Saved views: Saved views は、workspace のコラボレーティブな スナップショット です。あなたの team の誰でも、保存された workspace view を表示、 編集 、および変更を保存できます。実験管理 、runs などをレビューおよび議論するために、保存された workspace view を使用します。
次の図は、Cécile-parker のチームメイトによって作成された複数の personal workspace を示しています。この project には、保存された view はありません。
保存された workspace view
カスタマイズされた workspace view で team のコラボレーションを改善します。保存された View を作成して、チャートと data の好みの 設定 を整理します。
新しい保存済み workspace view を作成する
personal workspace または保存された view に移動します。
workspace を 編集 します。
workspace の右上隅にあるミートボールメニュー(3つの水平ドット)をクリックします。Save as a new view をクリックします。
新しい保存された view は、workspace ナビゲーションメニューに表示されます。
保存された workspace view を 更新 する
保存された変更は、保存された view の以前の状態を 上書き します。保存されていない変更は保持されません。W&B で保存された workspace view を 更新 するには:
保存された view に移動します。
workspace 内で、チャートと data に必要な変更を加えます。
Save ボタンをクリックして、変更を確定します。
workspace view への 更新 を保存すると、確認ダイアログが表示されます。今後このプロンプトを表示しない場合は、保存を確定する前に Do not show this modal next time オプションを選択してください。
保存された workspace view を 削除 する
不要になった保存された view を削除します。
削除する保存された view に移動します。
view の右上にある3つの水平線(… )を選択します。
Delete view を選択します。削除を確定して、workspace メニューから view を削除します。
workspace view を共有する
workspace の URL を直接共有して、カスタマイズされた workspace を team と共有します。workspace project への アクセス 権を持つすべての ユーザー は、その workspace の保存された View を見ることができます。
プログラムで workspace を作成する
wandb-workspacesW&B workspace と Reports をプログラムで 操作 するための Python library です。
wandb-workspaceswandb-workspacesW&B workspace と Reports をプログラムで 操作 するための Python library です。
workspace の プロパティ は、次のように定義できます。
panel の レイアウト、色、およびセクションの 順序 を 設定 します。
デフォルトのx軸、セクションの 順序 、および コラプス 状態など、workspace の 設定 を構成します。
セクション内に パネル を追加およびカスタマイズして、workspace view を整理します。
URL を使用して、既存の workspace を ロード および 変更 します。
既存の workspace への変更を保存するか、新しい view として保存します。
簡単な 式 を使用して、runs をプログラムで フィルタリング、グループ化、およびソートします。
色や 可視性 などの 設定 で、run の外観をカスタマイズします。
統合 と再利用のために、ある workspace から別の workspace に view をコピーします。
Workspace API をインストールする
wandb に加えて、wandb-workspaces をインストールしてください。
pip install wandb wandb-workspaces
プログラムで workspace view を定義して保存する
import wandb_workspaces.reports.v2 as wr
workspace = ws. Workspace(entity= "your-entity" , project= "your-project" , views= [... ])
workspace. save()
既存の view を 編集 する
existing_workspace = ws. Workspace. from_url("workspace-url" )
existing_workspace. views[0 ] = ws. View(name= "my-new-view" , sections= [... ])
existing_workspace. save()
workspace の saved view を別の workspace にコピーする
old_workspace = ws. Workspace. from_url("old-workspace-url" )
old_workspace_view = old_workspace. views[0 ]
new_workspace = ws. Workspace(entity= "new-entity" , project= "new-project" , views= [old_workspace_view])
new_workspace. save()
workspace API の包括的な例については、wandb-workspace examplesProgrammatic Workspaces チュートリアルを参照してください。
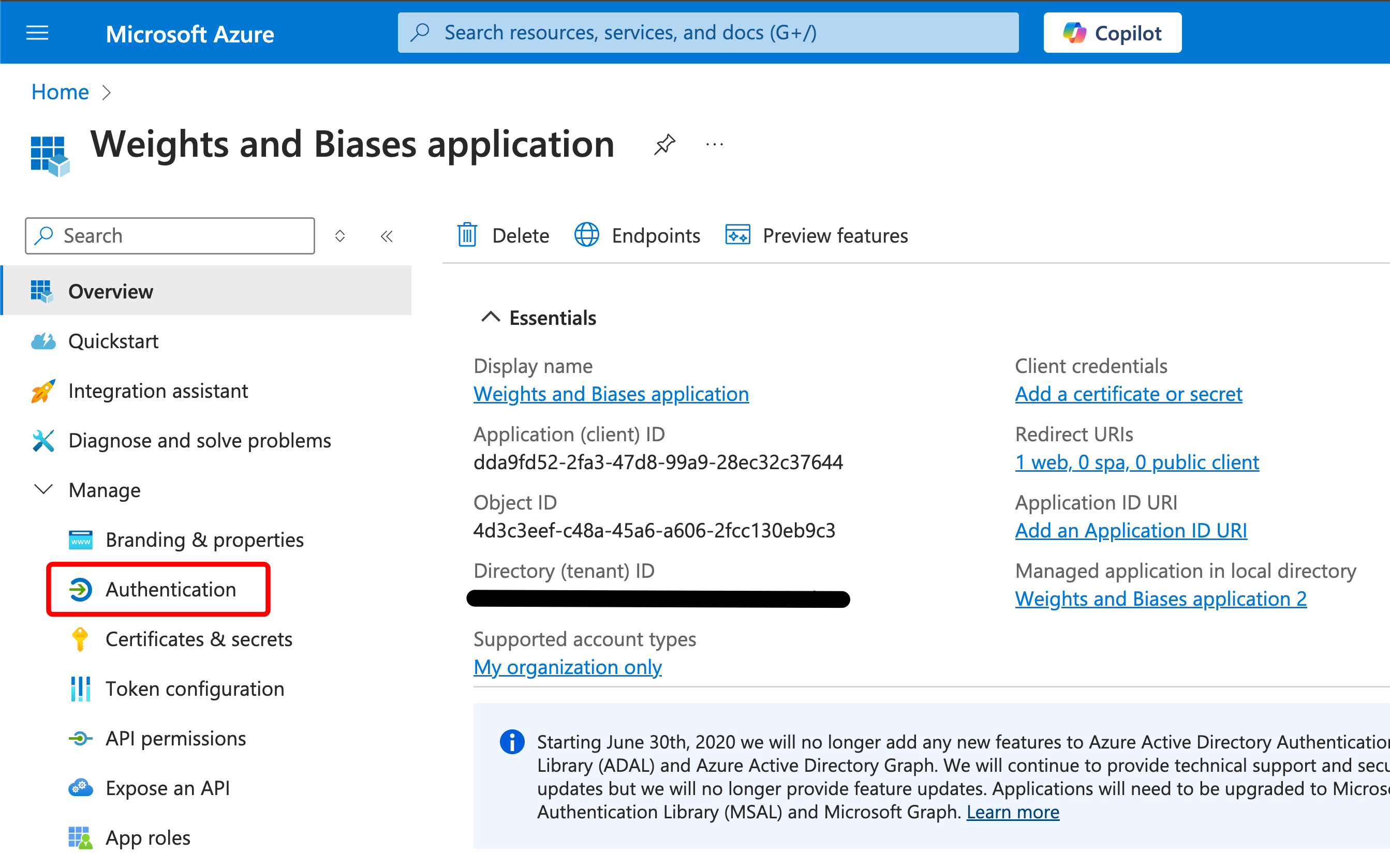
2.1.5 - What are runs?
W&B の基本的な構成要素である Runs について学びましょう。
run は、W&B によってログされる計算の単一の単位です。W&B の run は、プロジェクト全体の原子要素と考えることができます。つまり、各 run は、モデルのトレーニングと結果のログ、ハイパーパラメーターの スイープ など、特定の計算の記録です。
run を開始する一般的なパターンには、以下が含まれますが、これらに限定されません。
W&B は、作成した run を プロジェクト wandb.Api.Run
run.log でログするものはすべて、その run に記録されます。次のコードスニペットを検討してください。
import wandb
run = wandb. init(entity= "nico" , project= "awesome-project" )
run. log({"accuracy" : 0.9 , "loss" : 0.1 })
最初の行は、W&B Python SDK をインポートします。2 行目は、エンティティ nico の下の プロジェクト awesome-project で run を初期化します。3 行目は、モデルの 精度 と 損失 をその run にログします。
ターミナル 内で、W&B は以下を返します。
wandb: Syncing run earnest-sunset-1
wandb: ⭐️ View project at https://wandb.ai/nico/awesome-project
wandb: 🚀 View run at https://wandb.ai/nico/awesome-project/runs/1jx1ud12
wandb:
wandb:
wandb: Run history:
wandb: accuracy
wandb: loss
wandb:
wandb: Run summary:
wandb: accuracy 0.9
wandb: loss 0.5
wandb:
wandb: 🚀 View run earnest-sunset-1 at: https://wandb.ai/nico/awesome-project/runs/1jx1ud12
wandb: ⭐️ View project at: https://wandb.ai/nico/awesome-project
wandb: Synced 6 W&B file( s) , 0 media file( s) , 0 artifact file( s) and 0 other file( s)
wandb: Find logs at: ./wandb/run-20241105_111006-1jx1ud12/logs
ターミナル で W&B が返す URL は、W&B App UI の run の ワークスペース にリダイレクトします。ワークスペース で生成される パネル は、単一のポイントに対応していることに注意してください。
単一の時点での メトリクス のログは、それほど役に立たない場合があります。判別モデルのトレーニングの場合のより現実的な例は、一定の間隔で メトリクス をログすることです。たとえば、次のコードスニペットを検討してください。
epochs = 10
lr = 0.01
run = wandb. init(
entity= "nico" ,
project= "awesome-project" ,
config= {
"learning_rate" : lr,
"epochs" : epochs,
},
)
offset = random. random() / 5
# simulating a training run
for epoch in range(epochs):
acc = 1 - 2 **- epoch - random. random() / (epoch + 1 ) - offset
loss = 2 **- epoch + random. random() / (epoch + 1 ) + offset
print(f "epoch= { epoch} , accuracy= { acc} , loss= { loss} " )
run. log({"accuracy" : acc, "loss" : loss})
これにより、次の出力が返されます。
wandb: Syncing run jolly-haze-4
wandb: ⭐️ View project at https://wandb.ai/nico/awesome-project
wandb: 🚀 View run at https://wandb.ai/nico/awesome-project/runs/pdo5110r
lr: 0.01
epoch= 0, accuracy= -0.10070974957523078, loss= 1.985328507123956
epoch= 1, accuracy= 0.2884687745057535, loss= 0.7374362314407752
epoch= 2, accuracy= 0.7347387967382066, loss= 0.4402409835486663
epoch= 3, accuracy= 0.7667969248039795, loss= 0.26176963846423457
epoch= 4, accuracy= 0.7446848791003173, loss= 0.24808611724405083
epoch= 5, accuracy= 0.8035095836268268, loss= 0.16169791827329466
epoch= 6, accuracy= 0.861349032371624, loss= 0.03432578493587426
epoch= 7, accuracy= 0.8794926436276016, loss= 0.10331872172219471
epoch= 8, accuracy= 0.9424839917077272, loss= 0.07767793473500445
epoch= 9, accuracy= 0.9584880427028566, loss= 0.10531971149250456
wandb: 🚀 View run jolly-haze-4 at: https://wandb.ai/nico/awesome-project/runs/pdo5110r
wandb: Find logs at: wandb/run-20241105_111816-pdo5110r/logs
トレーニング スクリプト は run.log を 10 回呼び出します。スクリプト が run.log を呼び出すたびに、W&B はその エポック の 精度 と 損失 をログします。W&B が前の出力から出力する URL を選択すると、W&B App UI の run の ワークスペース に移動します。
スクリプト が wandb.init メソッド を 1 回だけ呼び出すため、W&B はシミュレートされたトレーニング ループ を jolly-haze-4 という単一の run 内でキャプチャすることに注意してください。
別の例として、sweep 中に、W&B は指定した ハイパーパラメーター 探索 空間を探索します。W&B は、sweep が作成する新しい ハイパーパラメーター の組み合わせを、一意の run として実装します。
run を初期化する
wandb.init()
山かっこ (< >) で囲まれた値を、自分の値に置き換えてください。
import wandb
run = wandb. init(entity= "<entity>" , project= "<project>" )
run を初期化すると、W&B は プロジェクト フィールド に指定した プロジェクト (wandb.init(project="<project>" に run をログします。W&B は、 プロジェクト がまだ存在しない場合は、新しい プロジェクト を作成します。プロジェクト がすでに存在する場合は、W&B はその プロジェクト に run を保存します。
プロジェクト 名を指定しない場合、W&B は run を Uncategorized という プロジェクト に保存します。
W&B の各 run には、run ID と呼ばれる一意の識別子があります一意の ID を指定する か、W&B に ID をランダムに生成させる ことができます。
各 run には、人間が読める run 名 としても知られる一意でない識別子もあります
たとえば、次のコードスニペットを考えてみましょう。
import wandb
run = wandb. init(entity= "wandbee" , project= "awesome-project" )
コードスニペット は、次の出力を生成します。
🚀 View run exalted-darkness-6 at:
https://wandb.ai/nico/awesome-project/runs/pgbn9y21
Find logs at: wandb/run-20241106_090747-pgbn9y21/logs
上記の コード が id パラメータ の 引数 を指定しなかったため、W&B は一意の run ID を作成します。nico は run をログした エンティティ 、awesome-project は run がログされる プロジェクト の名前、exalted-darkness-6 は run の名前、pgbn9y21 は run ID です。
Notebook users run の最後に run.finish() を指定して、run が完了したことを示します。これにより、run が プロジェクト に適切にログされ、バックグラウンド で継続されないようになります。
import wandb
run = wandb. init(entity= "<entity>" , project= "<project>" )
# Training code, logging, and so forth
run. finish()
各 run には、run の現在のステータス を記述する 状態 があります。可能な run の 状態 の完全なリストについては、Run の 状態 を参照してください。
Run の 状態
次のテーブルは、run がとりうる 状態 を記述しています。
状態
説明
Finished
run が終了し、 完全に データ が同期されたか、wandb.finish() が呼び出されました
Failed
run が 0 以外の終了ステータス で終了しました
Crashed
run が 内部 プロセス で ハートビート の送信を停止しました。これは、 マシン が クラッシュ した場合に発生する可能性があります
Running
run はまだ実行中で、最近 ハートビート を送信しました
一意の run 識別子
Run ID は、run の一意の識別子です。デフォルトでは、新しい run を初期化すると、W&B が ランダム で一意の run ID を生成します 。run を初期化するときに、独自の 一意の run ID を指定する こともできます。
自動生成された run ID
run を初期化するときに run ID を指定しない場合、W&B は ランダム な run ID を生成します。run の一意の ID は、W&B App UI で確認できます。
https://wandb.ai/home の W&B App UI に移動します。run の初期化時に指定した W&B プロジェクト に移動します。
プロジェクト の ワークスペース 内で、[Runs ] タブ を選択します。
[Overview ] タブ を選択します。
W&B は、[Run パス ] フィールド に一意の run ID を表示します。run パス は、 チーム の名前、 プロジェクト の名前、run ID で構成されます。一意の ID は、run パス の最後の部分です。
たとえば、次の図では、一意の run ID は 9mxi1arc です。
カスタム run ID
wandb.initid パラメータ を渡すことで、独自の run ID を指定できます。
import wandb
run = wandb. init(entity= "<project>" , project= "<project>" , id= "<run-id>" )
run の一意の ID を使用して、W&B App UI で run の Overview ページ に直接移動できます。次のセルは、特定の run の URL パス を示しています。
https://wandb.ai/<entity>/<project>/<run-id>
山かっこ (< >) で囲まれた値は、エンティティ 、 プロジェクト 、run ID の実際の値の プレースホルダー です。
run に名前を付ける
run の名前は、人間が読める一意でない識別子です。
デフォルトでは、W&B は新しい run を初期化するときに ランダム な run 名を生成します。run の名前は、 プロジェクト の ワークスペース 内と、run の Overview ページ の上部に表示されます。
run 名は、 プロジェクト ワークスペース で run をすばやく識別する方法として使用します。
wandb.initname パラメータ を渡すことで、run の名前を指定できます。
import wandb
run = wandb. init(entity= "<project>" , project= "<project>" , name= "<run-name>" )
run にメモを追加する
特定の run に追加するメモは、[Overview ] タブ の run ページ と、 プロジェクト ページ の run のテーブルに表示されます。
W&B プロジェクト に移動します
プロジェクト サイドバー から [Workspace ] タブ を選択します
run セレクター からメモを追加する run を選択します
[Overview ] タブ を選択します
[Description ] フィールド の横にある 鉛筆 アイコン を選択し、メモを追加します
run を停止する
W&B App または プログラム で run を停止します。
run を初期化した ターミナル または コード エディタ に移動します。
Ctrl+D を押して run を停止します。
たとえば、上記の手順に従うと、 ターミナル は次のようになります。
KeyboardInterrupt
wandb: 🚀 View run legendary-meadow-2 at: https://wandb.ai/nico/history-blaster-4/runs/o8sdbztv
wandb: Synced 5 W&B file( s) , 0 media file( s) , 0 artifact file( s) and 1 other file( s)
wandb: Find logs at: ./wandb/run-20241106_095857-o8sdbztv/logs
W&B App UI に移動して、run が アクティブ でなくなったことを確認します。
run がログされている プロジェクト に移動します。
run の名前を選択します。
停止する run の名前は、 ターミナル または コード エディタ の出力から確認できます。たとえば、上記の例では、run の名前は legendary-meadow-2 です。
3. プロジェクト サイドバー から [**Overview**] タブ を選択します。
[State ] フィールド の横で、run の 状態 が running から Killed に変わります。
run がログされている プロジェクト に移動します。
run セレクター 内で停止する run を選択します。
プロジェクト サイドバー から [Overview ] タブ を選択します。
[State ] フィールド の横にある上部の ボタン を選択します。
[State ] フィールド の横で、run の 状態 が running から Killed に変わります。
可能な run の 状態 の完全なリストについては、State フィールド を参照してください。
ログに記録された run を表示する
run の 状態、run にログされた Artifacts、run 中に記録された ログ ファイル など、特定の run に関する情報を表示します。
特定の run を表示するには:
https://wandb.ai/home の W&B App UI に移動します。
run の初期化時に指定した W&B プロジェクト に移動します。
プロジェクト サイドバー 内で、[Workspace ] タブ を選択します。
run セレクター 内で、表示する run をクリックするか、run 名の一部を入力して、一致する run を フィルター します。
デフォルトでは、長い run 名は読みやすくするために中央で切り捨てられます。代わりに、run 名を先頭または末尾で切り捨てるには、run のリストの上部にある アクション ... メニュー をクリックし、[Run 名のトリミング ] を設定して、末尾、中央、または先頭をトリミングします。
特定の run の URL パス には、次の形式があることに注意してください。
https://wandb.ai/<team-name>/<project-name>/runs/<run-id>
山かっこ (< >) で囲まれた値は、 チーム 名、 プロジェクト 名、run ID の実際の値の プレースホルダー です。
Overviewタブ
[Overview ] タブ を使用して、 プロジェクト 内の特定の run 情報について学習します。次に例を示します。
Author : run を作成する W&B エンティティ 。Command : run を初期化する コマンド 。Description : 提供した run の説明。run の作成時に説明を指定しない場合、このフィールド は空です。W&B App UI を使用するか、Python SDK で プログラム で説明を run に追加できます。Duration : run が アクティブ に計算または データ をログしている時間。一時停止または待機は除きます。Git リポジトリ : run に関連付けられている git リポジトリ。git を有効にする して、このフィールド を表示する必要があります。Host name : W&B が run を計算する場所。 マシン で ローカル に run を初期化する場合は、 マシン の名前が表示されます。Name : run の名前。OS : run を初期化する オペレーティング システム 。Python 実行可能ファイル : run を開始する コマンド 。Python バージョン : run を作成する Python バージョン を指定します。Run パス : entity/project/run-ID の形式で一意の run 識別子を識別します。Runtime : run の開始から終了までの合計時間を測定します。これは、run の ウォール クロック 時間です。Runtime には、run が一時停止している時間または リソース を待機している時間が含まれますが、Duration は含まれません。Start time : run を初期化する タイムスタンプ 。State : run の 状態 。System hardware : W&B が run の計算に使用する ハードウェア 。Tags : 文字列のリスト。タグ は、関連する run をまとめて編成したり、baseline や production などの一時的なラベル を適用したりするのに役立ちます。W&B CLI バージョン : run コマンド を ホスト した マシン にインストールされている W&B CLI バージョン 。
W&B は、概要セクション の下に次の情報を保存します。
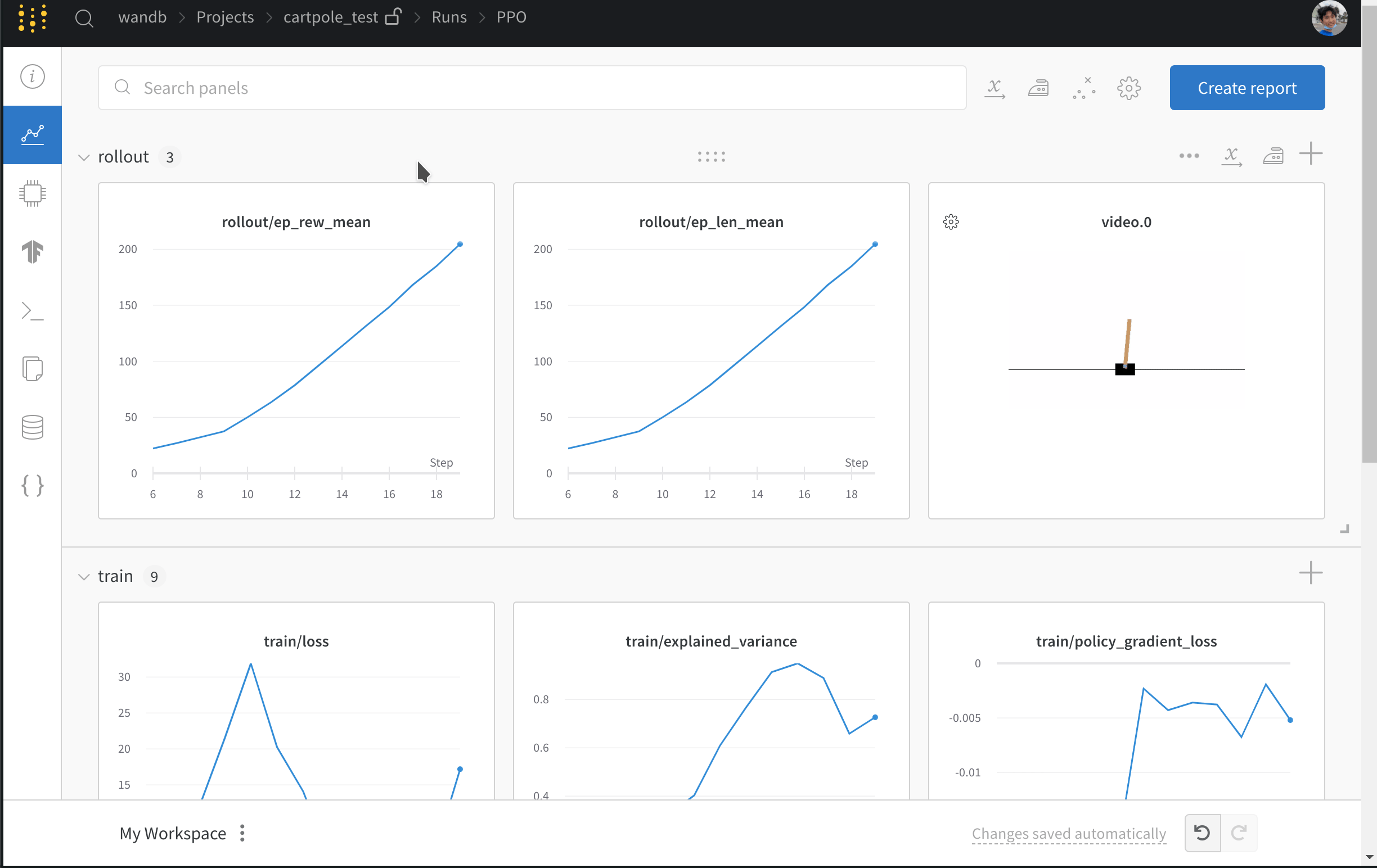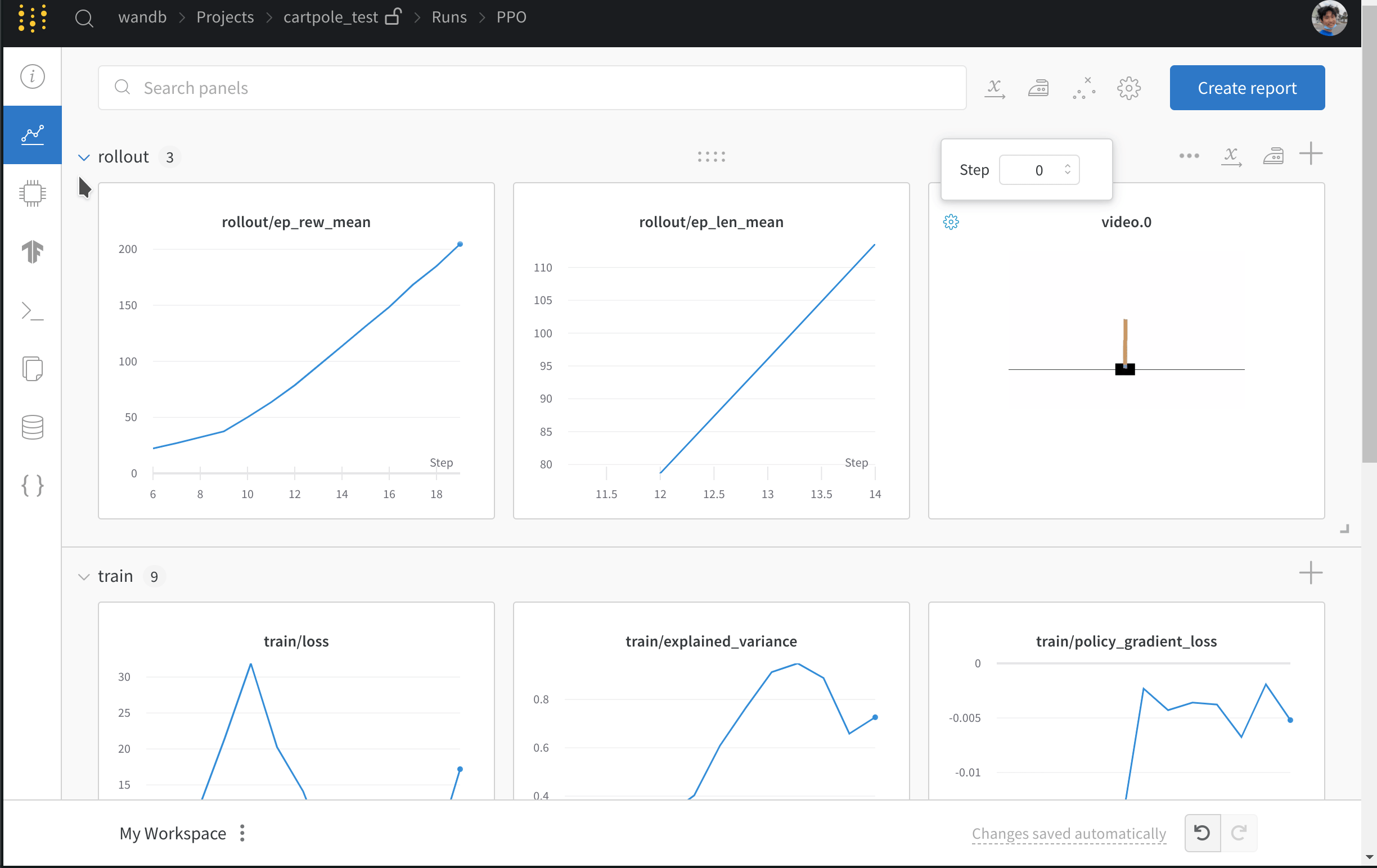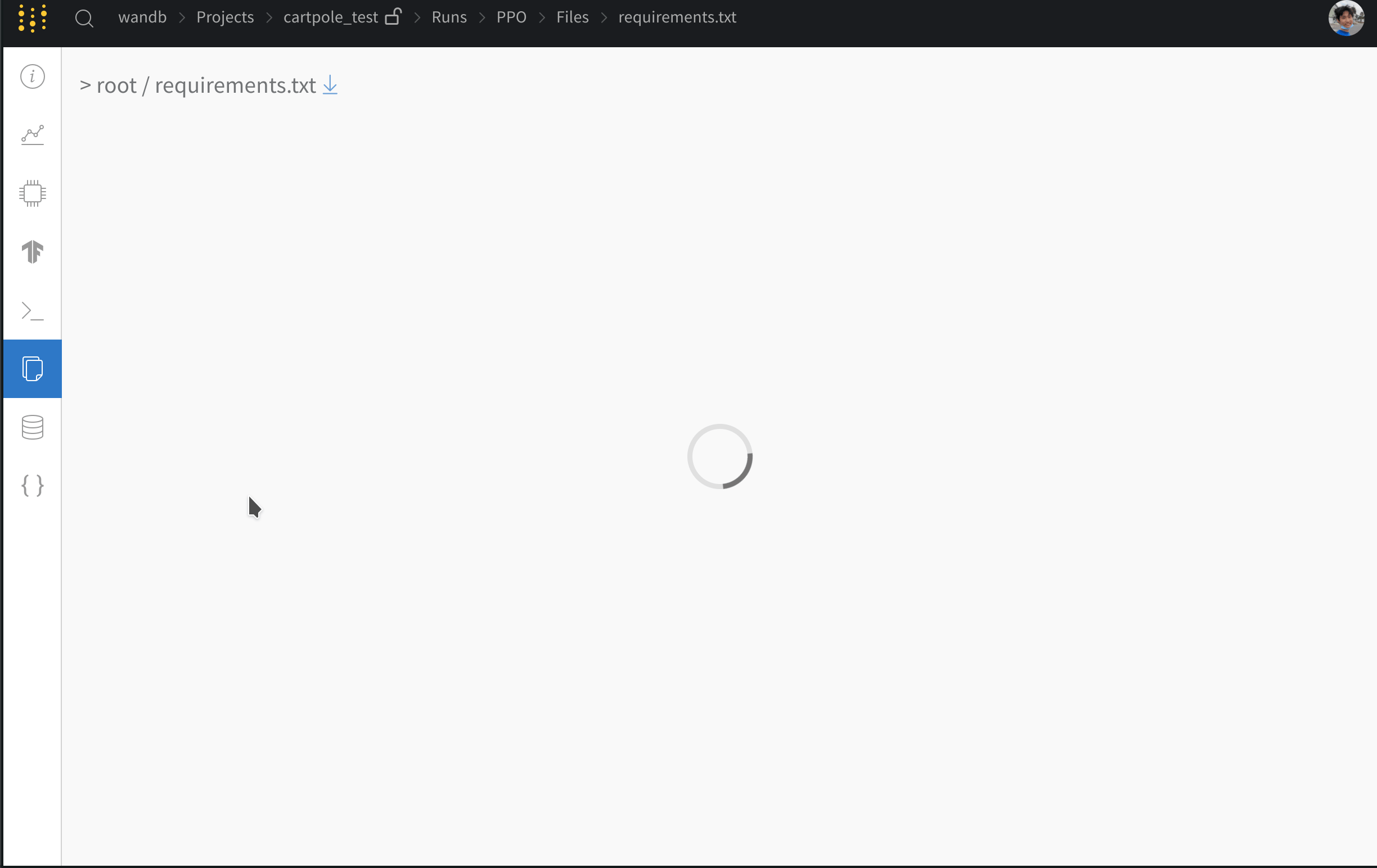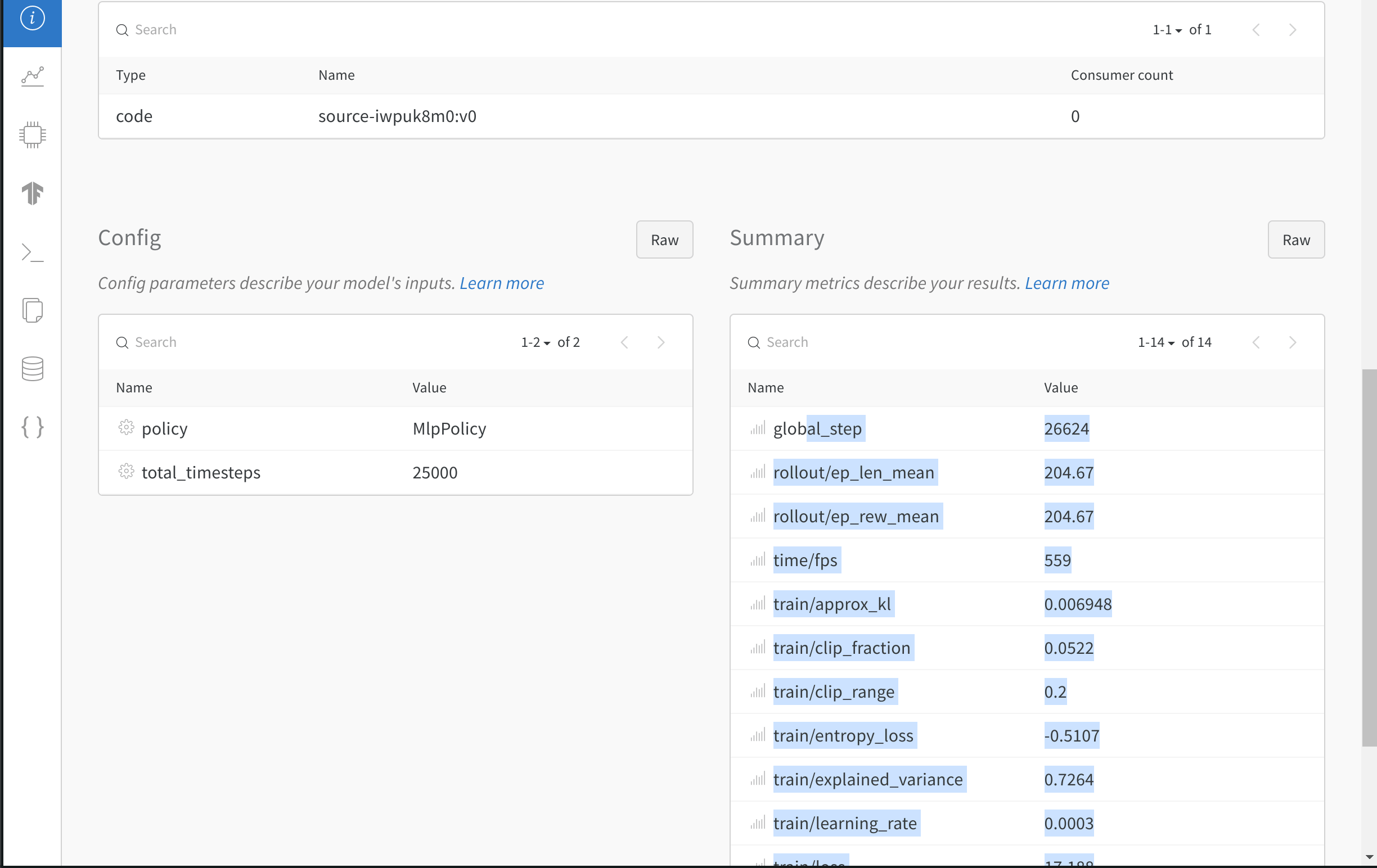
Artifact Outputs : run によって生成された Artifacts 出力。Config : wandb.configSummary : wandb.log()
プロジェクト の概要の例はこちら をご覧ください。
Workspaceタブ
[Workspace] タブ を使用して、自動生成された カスタム プロット 、 システム メトリクス など、 可視化 を表示、検索、 グループ化 、および配置します。
プロジェクト ワークスペース の例はこちら をご覧ください
Runsタブ
[Runs] タブ を使用して、run を フィルター 、 グループ化 、および並べ替えます。
次のタブ は、[Runs] タブ で実行できる一般的な アクション の一部を示しています。
Customize columns
Sort
Filter
Group
[Runs] タブ には、 プロジェクト 内の run に関する詳細が表示されます。デフォルトでは、多数の 列 が表示されます。
表示されているすべての 列 を表示するには、 ページ を水平方向に スクロール します。
列 の順序を変更するには、 列 を左または右に ドラッグ します。
列 を ピン留め するには、 列 名の上に カーソル を置き、表示される アクション メニュー ... をクリックし、[Pin column ] をクリックします。ピン留め された 列 は、[Name ] 列 の後、 ページ の左側の近くに表示されます。ピン留め された 列 の ピン留め を解除するには、[Unpin column ] を選択します
列 を非表示にするには、 列 名の上に カーソル を置き、表示される アクション メニュー ... をクリックし、[Hide column ] をクリックします。現在非表示になっているすべての 列 を表示するには、[Columns ] をクリックします。
複数の 列 を一度に表示、非表示、 ピン留め 、および ピン留め 解除するには、[Columns ] をクリックします。
非表示の 列 の名前をクリックして、非表示を解除します。
表示されている 列 の名前をクリックして、非表示にします。
表示されている 列 の横にある ピン アイコン をクリックして ピン留め します。
[Runs] タブ を カスタマイズ すると、 カスタマイズ はWorkspace タブ の [Runs ] セレクター にも反映されます。
指定された 列 の値で テーブル 内のすべての行を並べ替えます。
マウス を 列 タイトル の上に移動します。ケバブ メニュー (3 つの垂直 ドット) が表示されます。
ケバブ メニュー (3 つの垂直 ドット) を選択します。
[Sort Asc ] または [Sort Desc ] を選択して、行をそれぞれ 昇順 または 降順 に並べ替えます。
上の図は、val_acc という名前の テーブル 列 の並べ替え オプション を表示する方法を示しています。
ダッシュボード の上にある [Filter ] ボタン を使用して、 式 で すべての行を フィルター します。
[Add filter ] を選択して、1 つまたは複数の フィルター を行に追加します。3 つの ドロップダウン メニュー が表示されます。左から右への フィルター タイプ は、 列 名、 オペレーター 、および値に基づいています
列 名
二項関係
値
受け入れられる値
文字列
=, ≠, ≤, ≥, IN, NOT IN,
整数, float, 文字列, タイムスタンプ , null
式 エディター には、 列 名のオートコンプリート と論理述語構造を使用して、各 項 の オプション のリストが表示されます。「and」または「or」(および場合によっては 括弧 ) を使用して、複数の論理述語を 1 つの 式 に接続できます。
上の図は、`val_loss` 列 に基づく フィルター を示しています。この フィルター は、 検証 損失 が 1 以下 の run を表示します。
ダッシュボード の上にある [Group by ] ボタン を使用して、特定の 列 の値で行を グループ化 します。
デフォルトでは、これにより、他の数値 列 が、その グループ 全体の 列 の値の分布を示す ヒストグラム に変わります。グループ化 は、 データ のより高レベルの パターン を理解するのに役立ちます。
Systemタブ
[System タブ ] には、CPU 使用率、 システム メモリ 、 ディスク I/O、 ネットワーク トラフィック、GPU 使用率など、特定の run に対して追跡される システム メトリクス が表示されます。
W&B が追跡する システム メトリクス の完全なリストについては、System メトリクス を参照してください。
システム タブ の例はこちら をご覧ください。
Logsタブ
[Log タブ ] には、 コマンドライン に出力された出力 (標準出力 (stdout) や 標準 エラー (stderr) など) が表示されます。
右上隅にある [Download ] ボタン を選択して、 ログ ファイル をダウンロードします。
ログ タブ の例はこちら をご覧ください。
Filesタブ
[Files タブ ] を使用して、モデル チェックポイント 、 検証 セット の例など、特定の run に関連付けられた ファイル を表示します
ファイル タブ の例はこちら をご覧ください。
Artifactsタブ
[Artifacts ] タブ には、指定された run の 入力 および 出力 アーティファクト が一覧表示されます。
アーティファクト タブ の例はこちら をご覧ください。
run を削除する
W&B App を使用して、 プロジェクト から 1 つまたは複数の run を削除します。
削除する run が含まれている プロジェクト に移動します。
プロジェクト サイドバー から [Runs ] タブ を選択します。
削除する run の横にある チェックボックス をオンにします。
テーブル の上にある [Delete ] ボタン ( ゴミ箱 アイコン ) を選択します。
表示される モーダル から、[Delete ] を選択します。
特定の ID を持つ run が削除されると、その ID を再度使用できなくなる場合があります。以前に削除された ID で run を開始しようとすると、 エラー が表示され、開始が防止されます。
多数の run を含む プロジェクト の場合、検索バー を使用して 正規表現 を使用して削除する run を フィルター するか、 フィルター ボタン を使用して、ステータス 、 タグ 、またはその他のプロパティ に基づいて run を フィルター できます。
run を整理する
このセクション では、 グループ と ジョブタイプ を使用して run を整理する方法について説明します。run を グループ (たとえば、 実験 名) に割り当て、 ジョブタイプ (たとえば、 前処理 、 トレーニング 、 評価 、 デバッグ ) を指定することで、 ワークフロー を効率化し、モデル の比較を改善できます。
run に グループ または ジョブタイプ を割り当てる
W&B の各 run は、[グループ ] と [ジョブタイプ ] で 分類 できます。
グループ : 実験 の広範な カテゴリ で、run の整理と フィルター に使用されます。ジョブタイプ : preprocessing、training、evaluation など、run の 機能 。
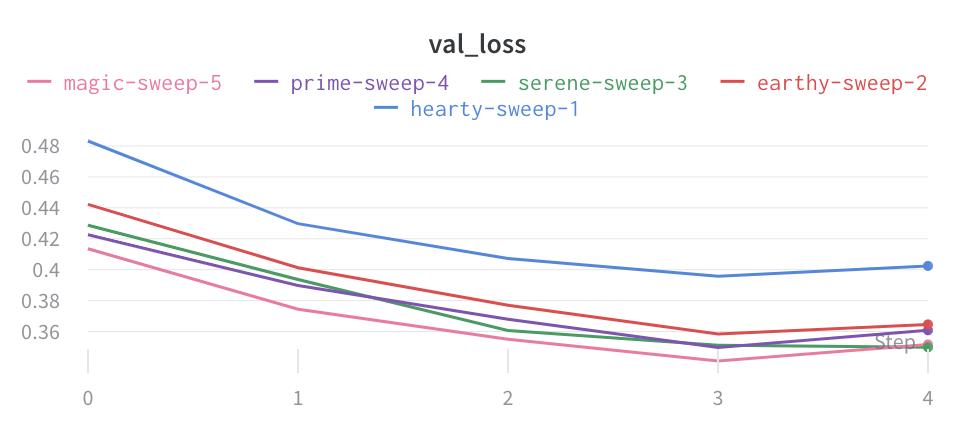
次のワークスペース の例 では、Fashion-MNIST データセット から 増え続ける量の データ を使用して ベースライン モデル を トレーニング します。ワークスペース では、使用される データ 量を色で表します。
黄色から濃い緑 は、 ベースライン モデル の データ 量が増加していることを示します。水色からバイオレット、マゼンタ は、追加の パラメータ を持つ、より複雑な「double」モデルの データ 量を示します。
W&B の フィルター オプション と検索バーを使用して、特定の条件に基づいて run を比較します。次に例を示します。
同じ データセット での トレーニング 。
同じ テストセット での 評価 。
フィルター を適用すると、[Table ] ビュー が自動的に更新されます。これにより、モデル 間の パフォーマンス の違いを特定できます。たとえば、一方のモデル で他方のモデル よりも大幅に困難な クラス を特定できます。
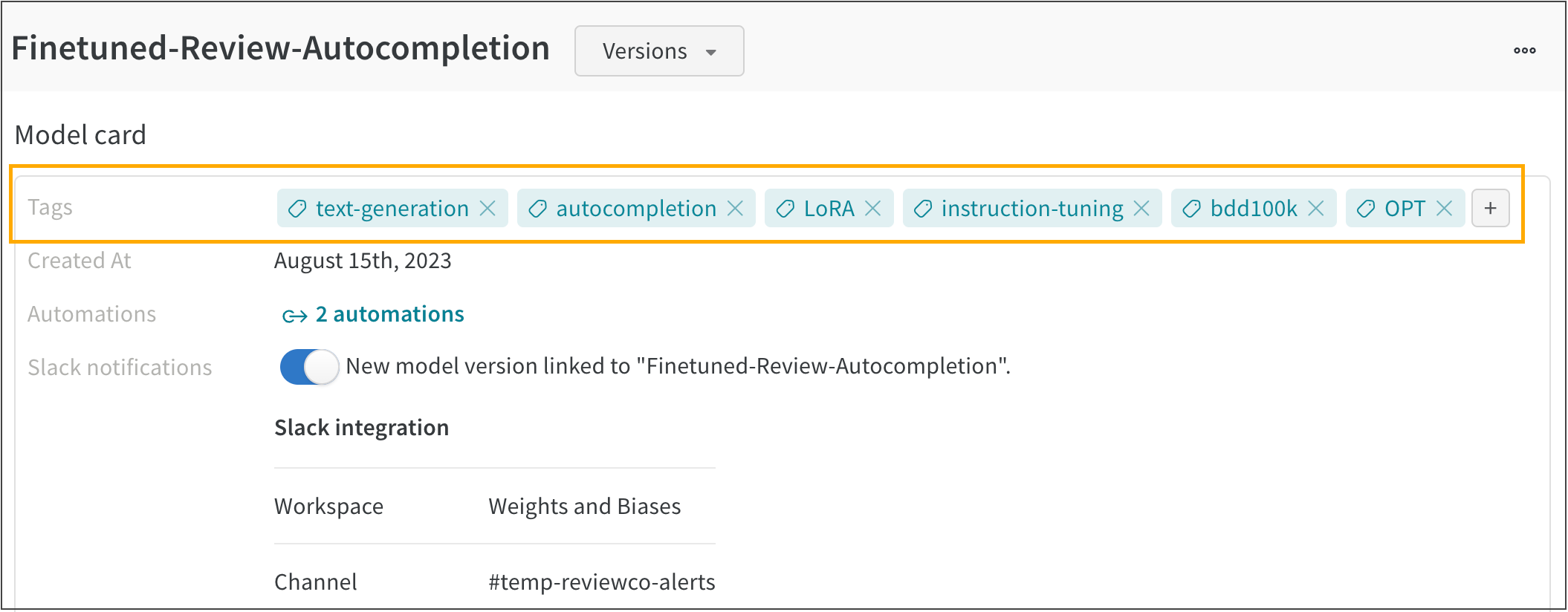
2.1.5.1 - Add labels to runs with tags
ログに記録されたメトリクスや Artifact データからは明らかでない、特定の機能を持つ run にラベルを付けるために、タグを追加します。
例えば、run の model が in_production であること、run が preemptible であること、この run が baseline を表していることなどを表すタグを、run に追加できます。
1つまたは複数の run にタグを追加する
プログラムで、またはインタラクティブに、run にタグを追加します。
ユースケースに応じて、ニーズに最も適した以下のタブを選択してください。
W&B Python SDK
Public API
Project page
Run page
run の作成時にタグを追加できます。
import wandb
run = wandb. init(
entity= "entity" ,
project= "<project-name>" ,
tags= ["tag1" , "tag2" ]
)
run を初期化した後にタグを更新することもできます。例えば、以下のコードスニペットは、特定のメトリクスが事前定義された閾値を超えた場合にタグを更新する方法を示しています。
import wandb
run = wandb. init(
entity= "entity" ,
project= "capsules" ,
tags= ["debug" ]
)
# python logic to train model
if current_loss < threshold:
run. tags = run. tags + ("release_candidate" ,)
run の作成後、Public API を使用してタグを更新できます。例:
run = wandb. Api(). run(" {entity} / {project} /{run-id}" )
run. tags. append("tag1" ) # you can choose tags based on run data here
run. update()
この方法は、多数の run に同じタグを付けるのに最適です。
プロジェクトの Workspace に移動します。
プロジェクトのサイドバーから Runs を選択します。
テーブルから1つまたは複数の run を選択します。
1つまたは複数の run を選択したら、テーブルの上の Tag ボタンを選択します。
追加するタグを入力し、Create new tag チェックボックスを選択してタグを追加します。
この方法は、1つの run に手動でタグを適用するのに最適です。
プロジェクトの Workspace に移動します。
プロジェクトの Workspace 内の run のリストから run を選択します。
プロジェクトのサイドバーから Overview を選択します。
Tags の横にある灰色のプラスアイコン(+ )ボタンを選択します。追加するタグを入力し、テキストボックスの下にある Add を選択して新しいタグを追加します。
1つまたは複数の run からタグを削除する
タグは、W&B App UI を使用して run から削除することもできます。
この方法は、多数の run からタグを削除するのに最適です。
プロジェクトの Run サイドバーで、右上にあるテーブルアイコンを選択します。これにより、サイドバーが展開されて Runs テーブル全体が表示されます。
テーブル内の run にカーソルを合わせると、左側にチェックボックスが表示されます。または、ヘッダー行にすべての run を選択するためのチェックボックスがあります。
チェックボックスを選択して、一括操作を有効にします。
タグを削除する run を選択します。
run の行の上にある Tag ボタンを選択します。
タグの横にあるチェックボックスを選択して、run からタグを削除します。
Run ページの左側のサイドバーで、一番上の Overview タブを選択します。run のタグがここに表示されます。
タグにカーソルを合わせ、“x” を選択して run から削除します。
2.1.5.2 - Filter and search runs
プロジェクトページでサイドバーとテーブルを使用する方法
WandB にログされた run からの洞察を得るには、プロジェクトページを使用してください。Workspace ページと Runs ページの両方から、run をフィルタリングおよび検索できます。
run をフィルタリングする
フィルターボタンを使用して、ステータス、タグ、またはその他のプロパティに基づいて run をフィルタリングします。
タグで run をフィルタリングする
フィルターボタンを使用して、タグに基づいて run をフィルタリングします。
正規表現で run をフィルタリングする
正規表現で目的の検索結果が得られない場合は、タグ を使用して、Runs Table で run をフィルタリングできます。タグは、run の作成時または完了後に追加できます。タグが run に追加されると、以下の gif に示すようにタグフィルターを追加できます。
run を検索する
正規表現 を使用して、指定した正規表現に一致する run を検索します。検索ボックスにクエリを入力すると、Workspace 上のグラフに表示される run が絞り込まれるとともに、テーブルの行もフィルタリングされます。
run をグループ化する
1 つまたは複数の列 (非表示の列を含む) で run をグループ化するには:
検索ボックスの下にある、罫線が引かれた用紙のような Group ボタンをクリックします。
結果をグループ化する 1 つまたは複数の列を選択します。
グループ化された run の各セットは、デフォルトで折りたたまれています。展開するには、グループ名の横にある矢印をクリックします。
最小値と最大値で run を並べ替える
ログに記録されたメトリクスの最小値または最大値で、run テーブルを並べ替えます。これは、記録された最高 (または最低) の値を表示する場合に特に役立ちます。
次のステップでは、記録された最小値または最大値に基づいて、特定のメトリクスで run テーブルを並べ替える方法について説明します。
並べ替えに使用するメトリクスを含む列にマウスを合わせます。
ケバブメニュー (縦の 3 本線) を選択します。
ドロップダウンから、Show min または Show max を選択します。
同じドロップダウンから、Sort by asc または Sort by desc を選択して、それぞれ昇順または降順で並べ替えます。
run の検索終了時間
クライアント プロセスからの最後のハートビートをログに記録する End Time という名前の列を提供します。このフィールドはデフォルトで非表示になっています。
Runs Table を CSV にエクスポート
ダウンロードボタンを使用して、すべての run、ハイパーパラメーター 、およびサマリー メトリクスのテーブルを CSV にエクスポートします。
2.1.5.3 - Fork a run
W&B の run をフォークする
run をフォークする機能はプライベートプレビュー版です。この機能へのアクセスをご希望の場合は、W&B Support (
support@wandb.com ) までご連絡ください。
既存の W&B の run から「フォーク」するには、wandb.init()fork_from を使用します。run からフォークすると、W&B はソース run の run ID と step を使用して新しい run を作成します。
run をフォークすると、元の run に影響を与えることなく、実験の特定の時点から異なるパラメータまたは model を調べることができます。
run をフォークするには、wandb
run をフォークするには、単調増加する step が必要です。define_metric()
フォークされた run を開始する
run をフォークするには、wandb.init()fork_from 引数を使用し、フォーク元のソース run ID とソース run からの step を指定します。
import wandb
# 後でフォークされる run を初期化する
original_run = wandb. init(project= "your_project_name" , entity= "your_entity_name" )
# ... トレーニングまたはログの記録を実行 ...
original_run. finish()
# 特定の step から run をフォークする
forked_run = wandb. init(
project= "your_project_name" ,
entity= "your_entity_name" ,
fork_from= f " { original_run. id} ?_step=200" ,
)
イミュータブルな run ID を使用する
イミュータブルな run ID を使用して、特定の run への一貫性があり、変更されない参照を確保します。ユーザーインターフェースからイミュータブルな run ID を取得するには、次の手順に従います。
Overviewタブにアクセスする: ソース run のページの Overviewタブ
イミュータブルな Run ID をコピーする: Overview タブの右上隅にある ... メニュー (3 つのドット) をクリックします。ドロップダウンメニューから [イミュータブルな Run ID をコピー] オプションを選択します。
これらの手順に従うことで、run への安定した変更されない参照が得られ、run のフォークに使用できます。
フォークされた run から続行する
フォークされた run を初期化したら、新しい run へのログ記録を続行できます。継続性のために同じメトリクスをログに記録し、新しいメトリクスを導入できます。
たとえば、次のコード例は、最初に run をフォークし、次に 200 のトレーニング step から始まるフォークされた run にメトリクスをログに記録する方法を示しています。
import wandb
import math
# 最初の run を初期化し、いくつかのメトリクスをログに記録する
run1 = wandb. init("your_project_name" , entity= "your_entity_name" )
for i in range(300 ):
run1. log({"metric" : i})
run1. finish()
# 特定の step で最初の run からフォークし、step 200 から始まるメトリクスをログに記録する
run2 = wandb. init(
"your_project_name" , entity= "your_entity_name" , fork_from= f " { run1. id} ?_step=200"
)
# 新しい run でログ記録を続行する
# 最初のいくつかの step では、run1 からメトリクスをそのままログに記録する
# Step 250 以降は、スパイキーパターンをログに記録し始める
for i in range(200 , 300 ):
if i < 250 :
run2. log({"metric" : i}) # スパイクなしで run1 からログ記録を続行する
else :
# Step 250 からスパイキーな振る舞いを導入する
subtle_spike = i + (2 * math. sin(i / 3.0 )) # 微妙なスパイキーパターンを適用する
run2. log({"metric" : subtle_spike})
# さらに、すべての step で新しいメトリクスをログに記録する
run2. log({"additional_metric" : i * 1.1 })
run2. finish()
巻き戻しとフォークの互換性 フォークは、run の管理と実験においてより柔軟性を提供することで、rewind
run からフォークすると、W&B は特定のポイントで run から新しいブランチを作成し、異なるパラメータまたは model を試すことができます。
run を巻き戻すと、W&B は run の履歴自体を修正または変更できます。
2.1.5.4 - Group runs into experiments
トレーニング と評価の run を、より大規模な Experiments にグループ化します。
個々のジョブをグループ化して実験をまとめるには、一意の group 名を wandb.init() に渡します。
ユースケース
分散トレーニング: 実験が、より大きな全体の一部として捉えられるべき個別のトレーニング スクリプトや評価スクリプトに分割されている場合は、グループ化を使用します。複数のプロセス : 複数のより小さなプロセスをグループ化して、1つの実験としてまとめます。K-分割交差検証 : 異なる乱数シードを持つrunをグループ化して、より大規模な実験を把握します。Sweepsとグループ化を用いたk-分割交差検証の例 をご覧ください。
グループ化を設定するには、次の3つの方法があります。
1. スクリプトでグループを設定する
オプションの group と job_type を wandb.init() に渡します。これにより、個々のrunを含む実験ごとに専用のグループページが作成されます。例:wandb.init(group="experiment_1", job_type="eval")
2. グループ環境変数を設定する
WANDB_RUN_GROUP を使用して、runのグループを環境変数として指定します。詳細については、環境変数 Group は、Project 内で一意であり、グループ内のすべてのrunで共有される必要があります。wandb.util.generate_id() を使用して、すべてのプロセスで使用する一意の8文字の文字列を生成できます。たとえば、os.environ["WANDB_RUN_GROUP"] = "experiment-" + wandb.util.generate_id() のようにします。
3. UIでグループ化を切り替える
任意の設定列で動的にグループ化できます。たとえば、wandb.config を使用してバッチサイズまたは学習率をログに記録する場合、Webアプリケーションでこれらのハイパーパラメーターを動的にグループ化できます。
グループ化による分散トレーニング
wandb.init() でグループ化を設定すると、UIでrunがデフォルトでグループ化されます。これは、テーブルの上部にある Group ボタンをクリックしてオン/オフを切り替えることができます。グループ化を設定した サンプルコード から生成された プロジェクトの例 を示します。サイドバーの各「Group」行をクリックすると、その実験専用のグループページに移動できます。
上記のプロジェクトページから、左側のサイドバーにある Group をクリックして、このページ のような専用ページに移動できます。
UI での動的なグループ化
任意の列(例えば、ハイパーパラメーター)でrunをグループ化できます。その様子を以下に示します。
サイドバー : Runはエポック数でグループ化されています。グラフ : 各線はグループの平均値を表し、網掛けは分散を示します。この振る舞いはグラフ設定で変更できます。
グループ化をオフにする
グループ化ボタンをクリックして、グループフィールドをいつでもクリアできます。これにより、テーブルとグラフはグループ化されていない状態に戻ります。
グラフ設定のグループ化
グラフの右上隅にある編集ボタンをクリックし、Advanced タブを選択して、線と網掛けを変更します。各グループの線の平均値、最小値、または最大値を選択できます。網掛けの場合、網掛けをオフにしたり、最小値と最大値、標準偏差、および標準誤差を表示したりできます。
2.1.5.5 - Move runs
このページでは、ある run を別の project へ、team の内外へ、またはある team から別の team へ移動する方法について説明します。現在の場所と新しい場所で run にアクセスできる必要があります。
Runs タブをカスタマイズするには、Project page を参照してください。
project 間で run を移動する
ある project から別の project へ run を移動するには:
移動する run が含まれている project に移動します。
project のサイドバーから Runs タブを選択します。
移動する run の横にあるチェックボックスをオンにします。
テーブルの上にある Move ボタンを選択します。
ドロップダウンから移動先の project を選択します。
team へ run を移動する
自分がメンバーである team へ run を移動するには:
移動する run が含まれている project に移動します。
project のサイドバーから Runs タブを選択します。
移動する run の横にあるチェックボックスをオンにします。
テーブルの上にある Move ボタンを選択します。
ドロップダウンから移動先の team と project を選択します。
2.1.5.6 - Resume a run
一時停止または終了した W&B Run を再開する
run が停止またはクラッシュした場合に、run がどのように振る舞うかを指定します。run を再開するか、run が自動的に再開できるようにするには、id パラメータに対して、その run に関連付けられた一意の run ID を指定する必要があります。
run = wandb. init(entity= "<entity>" , \
project= "<project>" , id= "<run ID>" , resume= "<resume>" )
W&B は、run を保存する W&B の Project 名を提供することを推奨します。
W&B がどのように応答するかを決定するために、次の引数のいずれかを resume パラメータに渡します。いずれの場合も、W&B は最初に run ID がすでに存在するかどうかを確認します。
引数
説明
Run ID が存在する場合
Run ID が存在しない場合
ユースケース
"must"W&B は、run ID で指定された run を再開する必要があります。
W&B は同じ run ID で run を再開します。
W&B はエラーを発生させます。
同じ run ID を使用する必要がある run を再開します。
"allow"W&B は、run ID が存在する場合に run を再開することを許可します。
W&B は同じ run ID で run を再開します。
W&B は、指定された run ID で新しい run を初期化します。
既存の run を上書きせずに run を再開します。
"never"W&B は、run ID で指定された run を再開することを許可しません。
W&B はエラーを発生させます。
W&B は、指定された run ID で新しい run を初期化します。
resume="auto" を指定して、W&B が自動的に run の再起動を試みるようにすることもできます。ただし、同じディレクトリーから run を再起動する必要があります。run を自動的に再開できるようにする セクションを参照してください。
以下のすべての例で、<> で囲まれた値を独自の値に置き換えてください。
同じ run ID を使用する必要がある run を再開する
run が停止、クラッシュ、または失敗した場合、同じ run ID を使用して再開できます。これを行うには、run を初期化し、以下を指定します。
resume パラメータを "must" (resume="must") に設定します。停止またはクラッシュした run の run ID を指定します。
次のコードスニペットは、W&B Python SDK でこれを実現する方法を示しています。
run = wandb. init(entity= "<entity>" , \
project= "<project>" , id= "<run ID>" , resume= "must" )
既存の run を上書きせずに run を再開する
既存の run を上書きせずに、停止またはクラッシュした run を再開します。これは、プロセスが正常に終了しない場合に特に役立ちます。次回 W&B を起動すると、W&B は最後のステップからログの記録を開始します。
W&B で run を初期化するときに、resume パラメータを "allow" (resume="allow") に設定します。停止またはクラッシュした run の run ID を指定します。次のコードスニペットは、W&B Python SDK でこれを実現する方法を示しています。
import wandb
run = wandb. init(entity= "<entity>" , \
project= "<project>" , id= "<run ID>" , resume= "allow" )
run を自動的に再開できるようにする
次のコードスニペットは、Python SDK または環境変数を使用して、run を自動的に再開できるようにする方法を示しています。
W&B Python SDK
Shell script
次のコードスニペットは、Python SDK で W&B の run ID を指定する方法を示しています。
<> で囲まれた値を独自の値に置き換えてください。
run = wandb. init(entity= "<entity>" , \
project= "<project>" , id= "<run ID>" , resume= "<resume>" )
次の例は、bash スクリプトで W&B の WANDB_RUN_ID 変数を指定する方法を示しています。
RUN_ID= " $1"
WANDB_RESUME= allow WANDB_RUN_ID= " $RUN_ID" python eval.py
ターミナル内で、W&B の run ID と共にシェルスクリプトを実行できます。次のコードスニペットは、run ID akj172 を渡します。
sh run_experiment.sh akj172
自動再開は、プロセスが失敗したプロセスと同じファイルシステム上で再起動された場合にのみ機能します。
たとえば、Users/AwesomeEmployee/Desktop/ImageClassify/training/ というディレクトリーで train.py という Python スクリプトを実行するとします。train.py 内で、スクリプトは自動再開を有効にする run を作成します。次に、トレーニングスクリプトが停止したとします。この run を再開するには、Users/AwesomeEmployee/Desktop/ImageClassify/training/ 内で train.py スクリプトを再起動する必要があります。
ファイルシステムを共有できない場合は、
WANDB_RUN_ID 環境変数を指定するか、W&B Python SDK で run ID を渡します。run ID の詳細については、「run とは何ですか?」ページの
カスタム run ID セクションを参照してください。
プリエンプティブ Sweeps run の再開
中断された sweep run を自動的に再キューします。これは、プリエンプティブキューの SLURM ジョブ、EC2 スポットインスタンス、または Google Cloud プリエンプティブ VM など、プリエンプションの影響を受けるコンピューティング環境で sweep agent を実行する場合に特に役立ちます。
mark_preempting
run = wandb. init() # run を初期化します
run. mark_preempting()
次の表は、sweep run の終了ステータスに基づいて W&B が run をどのように処理するかを示しています。
ステータス
振る舞い
ステータスコード 0
Run は正常に終了したと見なされ、再キューされません。
ゼロ以外のステータス
W&B は、run を sweep に関連付けられた run キューに自動的に追加します。
ステータスなし
Run は sweep run キューに追加されます。Sweep agent は、キューが空になるまで run キューから run を消費します。キューが空になると、sweep キューは sweep 検索アルゴリズムに基づいて新しい run の生成を再開します。
2.1.5.7 - Rewind a run
巻き戻し
run の巻き戻し
run を巻き戻すオプションは、プライベートプレビュー版です。この機能へのアクセスをご希望の場合は、W&B Support(support@wandb.com)までご連絡ください。
W&B は現在、以下をサポートしていません。
ログの巻き戻し : ログは新しい run セグメントでリセットされます。システムメトリクスの巻き戻し : W&B は、巻き戻しポイントより後の新しいシステムメトリクスのみを記録します。Artifact の関連付け : W&B は、Artifact をそれを生成するソース run に関連付けます。
run を巻き戻すには、W&B Python SDK バージョン >= 0.17.1 が必要です。
単調増加するステップを使用する必要があります。define_metric()
run を巻き戻して、元のデータを失うことなく、run の履歴を修正または変更します。さらに、run を巻き戻すと、その時点から新しいデータを記録できます。W&B は、新たに記録された履歴に基づいて、巻き戻した run のサマリーメトリクスを再計算します。これは、次の振る舞いを意味します。
履歴の切り捨て : W&B は履歴を巻き戻しポイントまで切り捨て、新しいデータロギングを可能にします。サマリーメトリクス : 新たに記録された履歴に基づいて再計算されます。設定の保持 : W&B は元の設定を保持し、新しい設定をマージできます。
run を巻き戻すと、W&B は run の状態を指定されたステップにリセットし、元のデータを保持し、一貫した run ID を維持します。これは次のことを意味します。
run のアーカイブ : W&B は元の run をアーカイブします。アーカイブされた run は、Run Overview Artifact の関連付け : Artifact をそれを生成する run に関連付けます。不変の run ID : 正確な状態からのフォークの一貫性のために導入されました。不変の run ID のコピー : run 管理を改善するために、不変の run ID をコピーするボタン。
巻き戻しとフォークの互換性 フォークは巻き戻しを補完します。
run からフォークすると、W&B は特定の時点で run から新しいブランチを作成し、さまざまなパラメータや Models を試すことができます。
run を巻き戻すと、W&B を使用して run の履歴自体を修正または変更できます。
run の巻き戻し
resume_from を使用して wandb.init()
import wandb
import math
# Initialize the first run and log some metrics
# Replace with your_project_name and your_entity_name!
run1 = wandb. init(project= "your_project_name" , entity= "your_entity_name" )
for i in range(300 ):
run1. log({"metric" : i})
run1. finish()
# Rewind from the first run at a specific step and log the metric starting from step 200
run2 = wandb. init(project= "your_project_name" , entity= "your_entity_name" , resume_from= f " { run1. id} ?_step=200" )
# Continue logging in the new run
# For the first few steps, log the metric as is from run1
# After step 250, start logging the spikey pattern
for i in range(200 , 300 ):
if i < 250 :
run2. log({"metric" : i, "step" : i}) # Continue logging from run1 without spikes
else :
# Introduce the spikey behavior starting from step 250
subtle_spike = i + (2 * math. sin(i / 3.0 )) # Apply a subtle spikey pattern
run2. log({"metric" : subtle_spike, "step" : i})
# Additionally log the new metric at all steps
run2. log({"additional_metric" : i * 1.1 , "step" : i})
run2. finish()
アーカイブされた run の表示
run を巻き戻した後、W&B App UI でアーカイブされた run を調べることができます。アーカイブされた run を表示するには、次の手順に従います。
Overview タブにアクセスする : run のページの Overview タブ Forked From フィールドを見つける : Overview タブ内で、Forked From フィールドを見つけます。このフィールドは、再開の履歴をキャプチャします。Forked From フィールドには、ソース run へのリンクが含まれており、元の run にトレースバックして、巻き戻し履歴全体を理解できます。
Forked From フィールドを使用すると、アーカイブされた再開の ツリー を簡単にナビゲートし、各巻き戻しのシーケンスとオリジンに関する洞察を得ることができます。
巻き戻した run からフォークする
巻き戻した run からフォークするには、wandb.init() の fork_from
import wandb
# Fork the run from a specific step
forked_run = wandb. init(
project= "your_project_name" ,
entity= "your_entity_name" ,
fork_from= f " { rewind_run. id} ?_step=500" ,
)
# Continue logging in the new run
for i in range(500 , 1000 ):
forked_run. log({"metric" : i* 3 })
forked_run. finish()
2.1.5.8 - Send an alert
Python コードからトリガーされたアラートを Slack またはメールに送信します。
run がクラッシュした場合、またはカスタムトリガーで Slack またはメールでアラートを作成します。たとえば、トレーニングループの勾配が爆発し始めた場合 (NaN を報告)、または ML パイプライン のステップが完了した場合にアラートを作成できます。アラートは、個人 プロジェクト と Team プロジェクト の両方を含む、run を初期化するすべての プロジェクト に適用されます。
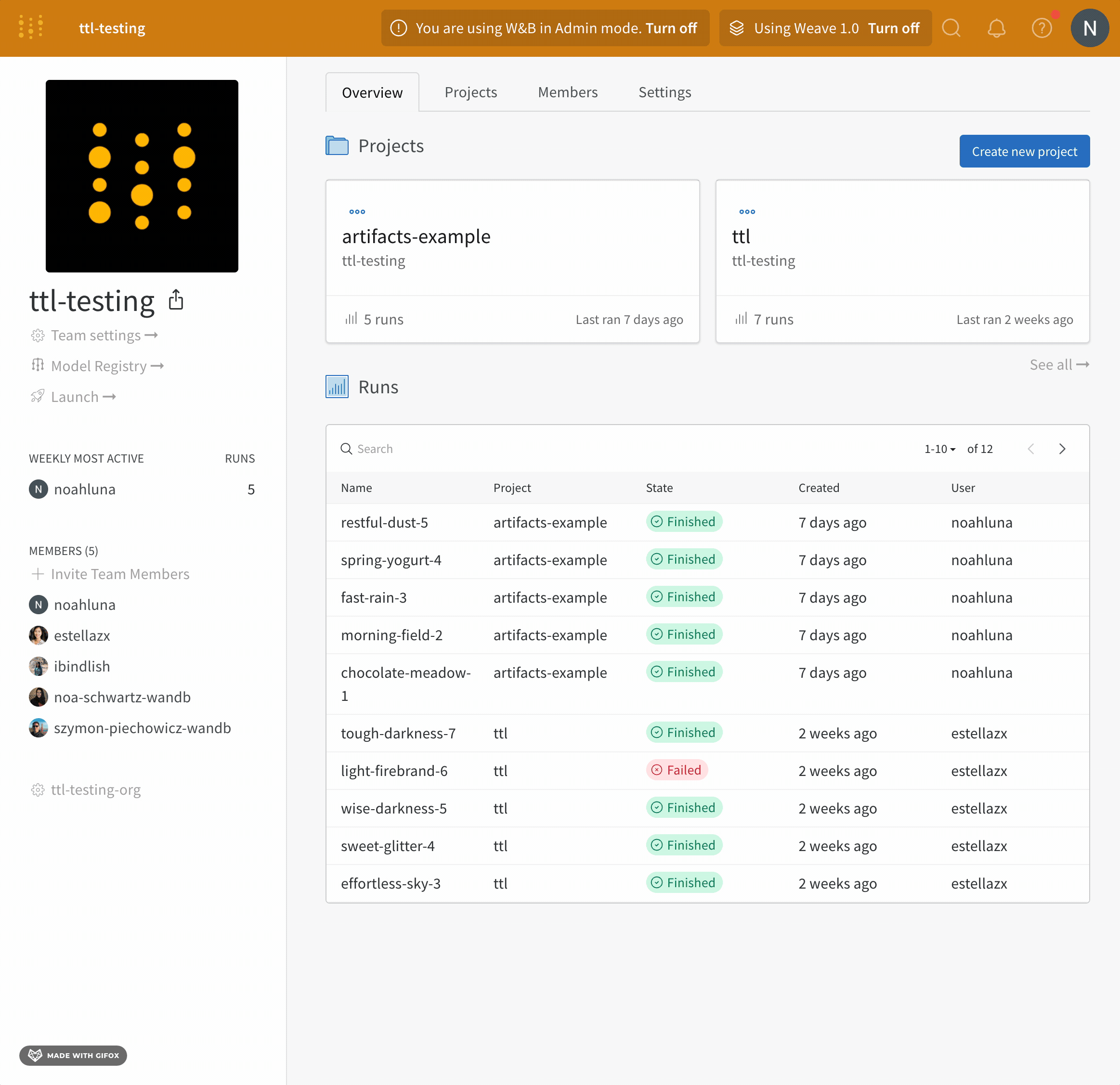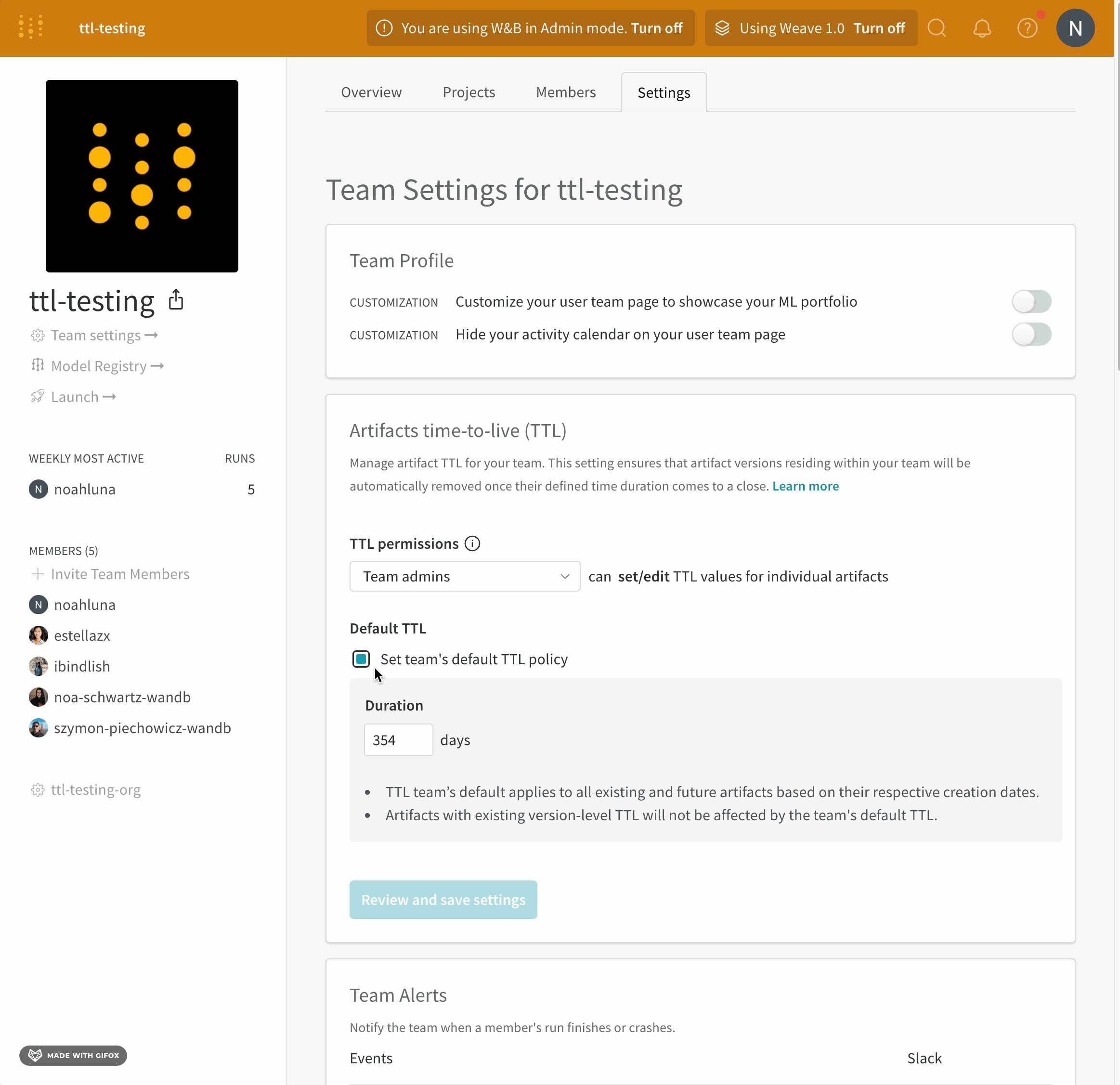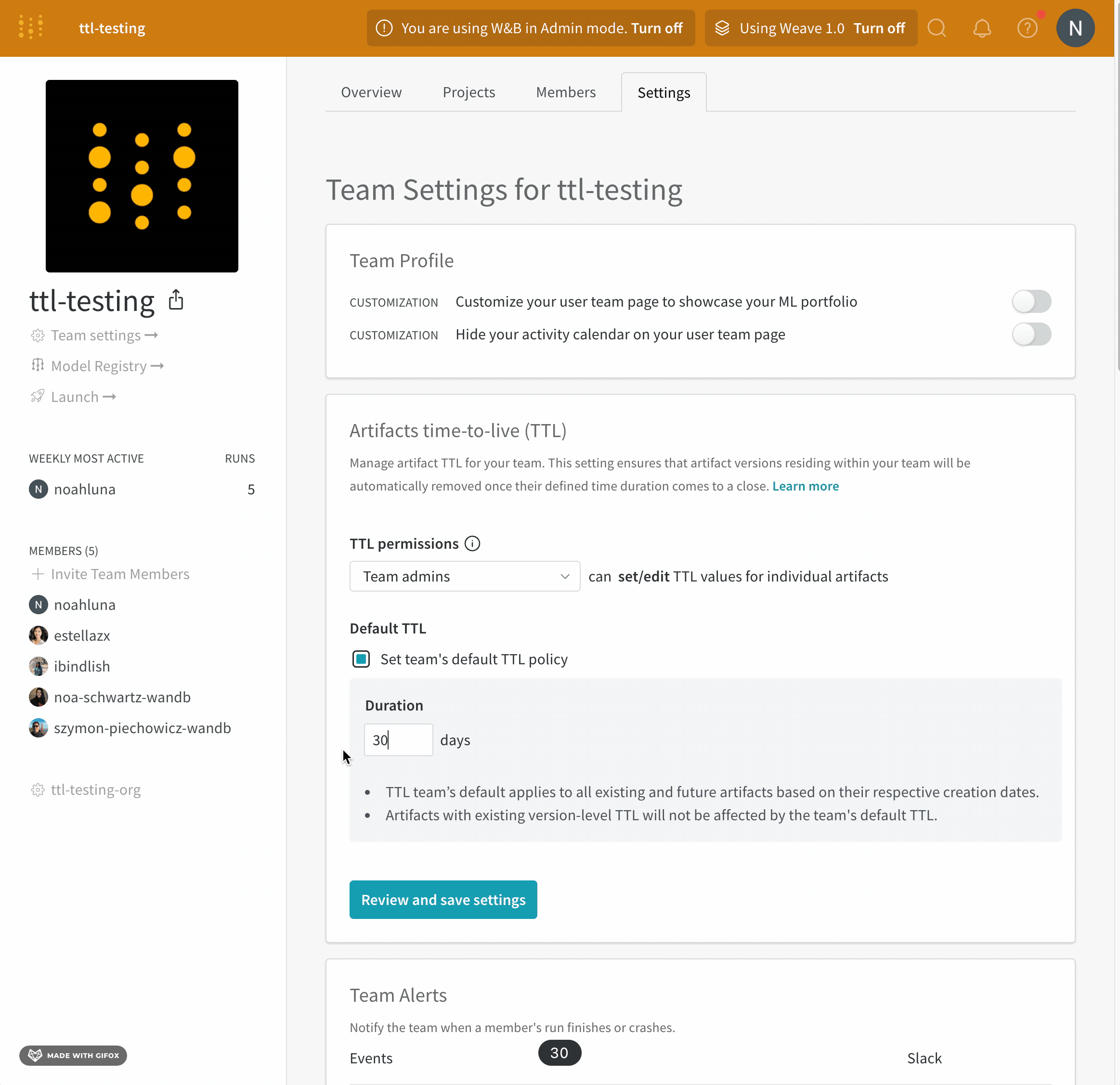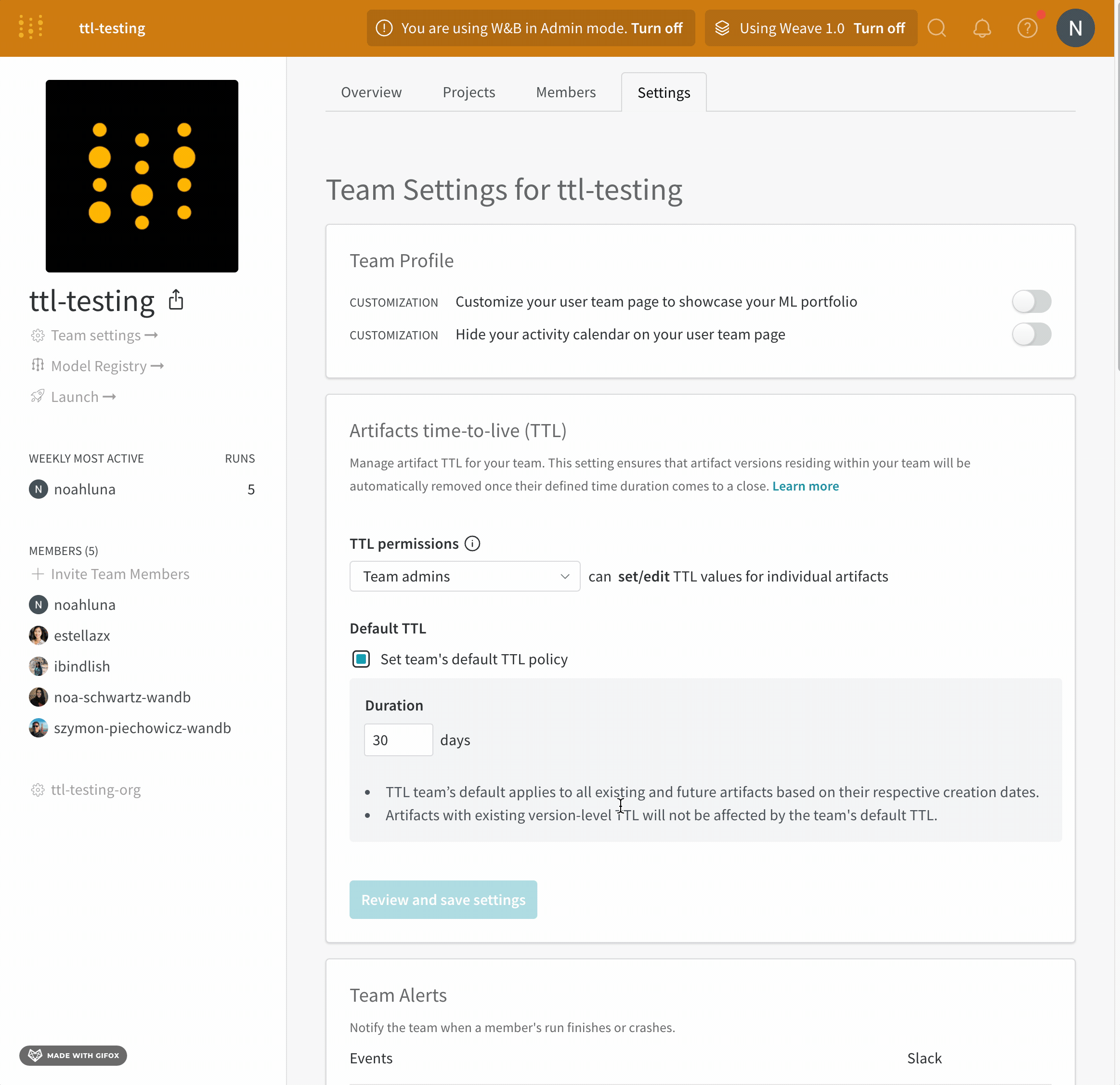
次に、Slack (またはメール) で W&B Alerts メッセージを確認します。
アラートの作成方法
次の ガイド は、マルチテナント cloud のアラートにのみ適用されます。
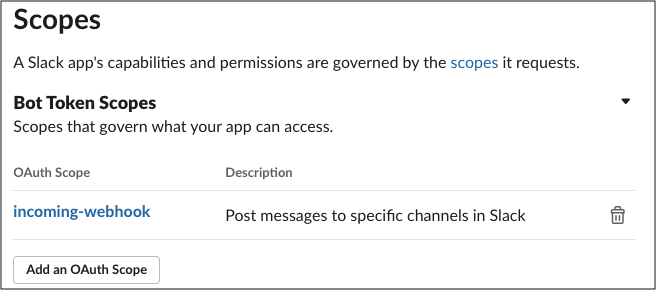
W&B Server を Private Cloud または W&B Dedicated Cloud で使用している場合は、このドキュメント を参照して、Slack アラートを設定してください。
アラートを設定するには、主に次の 2 つのステップがあります。
W&B の ユーザー 設定 でアラートをオンにします
run.alert() を code に追加しますアラートが適切に設定されていることを確認します
1. W&B ユーザー 設定でアラートをオンにする
ユーザー 設定 で:
アラート セクションまでスクロールしますスクリプト可能な run アラート をオンにして、run.alert() からアラートを受信しますSlack に接続 を使用して、アラートを投稿する Slack channel を選択します。アラートを非公開にするため、Slackbot channel をお勧めします。メール は、W&B にサインアップしたときに使用したメール アドレスに送信されます。これらのアラートがすべてフォルダーに移動し、受信トレイがいっぱいにならないように、メールでフィルターを設定することをお勧めします。
W&B Alerts を初めて設定する場合、またはアラートの受信方法を変更する場合は、これを行う必要があります。
2. run.alert() を code に追加する
アラートをトリガーする場所に、run.alert() を code ( notebook または Python スクリプト のいずれか) に追加します
import wandb
run = wandb. init()
run. alert(title= "High Loss" , text= "Loss is increasing rapidly" )
3. Slack またはメールを確認する
Slack またはメールでアラート メッセージを確認します。何も受信しなかった場合は、ユーザー 設定 で スクリプト可能なアラート のメールまたは Slack がオンになっていることを確認してください。
例
このシンプルなアラートは、精度がしきい値を下回ると警告を送信します。この例では、少なくとも 5 分間隔でアラートを送信します。
import wandb
from wandb import AlertLevel
run = wandb. init()
if acc < threshold:
run. alert(
title= "Low accuracy" ,
text= f "Accuracy { acc} is below the acceptable threshold { threshold} " ,
level= AlertLevel. WARN,
wait_duration= 300 ,
)
ユーザーをタグ付けまたはメンションする方法
アラートのタイトルまたはテキストのいずれかで、@ 記号の後に Slack ユーザー ID を続けて入力して、自分自身または同僚をタグ付けします。Slack ユーザー ID は、Slack プロフィール ページから確認できます。
run. alert(title= "Loss is NaN" , text= f "Hey <@U1234ABCD> loss has gone to NaN" )
Team アラート
Team 管理者は、Team 設定ページ wandb.ai/teams/your-team で Team のアラートを設定できます。
Team アラートは、Team の全員に適用されます。W&B は、アラートを非公開にするため、Slackbot channel を使用することをお勧めします。
アラートの送信先 Slack channel の変更
アラートの送信先 channel を変更するには、Slack の接続を解除 をクリックしてから、再接続します。再接続後、別の Slack channel を選択します。
2.1.6 - Log objects and media
メトリクス 、動画、カスタムプロットなどを追跡
W&B Python SDK を使用して、メトリクス、メディア、またはカスタム オブジェクトの辞書をステップと共にログに記録します。W&B は、各ステップ中にキーと値のペアを収集し、wandb.log() でデータをログに記録するたびに、それらを 1 つの統合された辞書に保存します。スクリプトからログに記録されたデータは、ローカル マシンの wandb というディレクトリーに保存され、W&B クラウドまたは プライベート サーバー に同期されます。
キーと値のペアは、各ステップで同じ値を渡す場合にのみ、1 つの統合された辞書に保存されます。step に対して異なる値をログに記録すると、W&B は収集されたすべてのキーと値をメモリーに書き込みます。
wandb.log の各呼び出しは、デフォルトで新しい step となります。W&B は、チャートとパネルを作成する際に、ステップをデフォルトの x 軸として使用します。オプションで、カスタム x 軸を作成して使用したり、カスタムの集計メトリクスをキャプチャしたりできます。詳細については、ログ軸のカスタマイズ を参照してください。
wandb.log() を使用して、各 step に対して連続した値 (0、1、2 など) をログに記録します。特定の履歴ステップに書き込むことはできません。W&B は、「現在」および「次」のステップにのみ書き込みます。
自動的にログに記録されるデータ
W&B は、W&B の Experiments 中に次の情報を自動的にログに記録します。
システム メトリクス : CPU と GPU の使用率、ネットワークなど。これらは、run ページ の [System] タブに表示されます。GPU の場合、これらは nvidia-smiコマンドライン : stdout と stderr が取得され、run ページ の [Logs] タブに表示されます。
アカウントの Settings page で Code Saving をオンにして、以下をログに記録します。
Git commit : 最新の git commit を取得し、run ページの Overview タブに表示します。また、コミットされていない変更がある場合は、diff.patch ファイルも表示します。依存関係 : requirements.txt ファイルがアップロードされ、run の files タブに表示されます。また、run の wandb ディレクトリーに保存したファイルも表示されます。
特定の W&B API 呼び出しでログに記録されるデータ
W&B を使用すると、ログに記録する内容を正確に決定できます。以下に、一般的にログに記録されるオブジェクトをいくつか示します。
Datasets : 画像またはその他の dataset サンプルを W&B にストリーミングするには、それらを具体的にログに記録する必要があります。プロット : wandb.plot を wandb.log と共に使用して、チャートを追跡します。詳細については、プロットのログ を参照してください。Tables : wandb.Table を使用してデータをログに記録し、W&B で視覚化およびクエリを実行します。詳細については、Tables のログ を参照してください。PyTorch 勾配 : wandb.watch(model) を追加して、UI で重みの勾配をヒストグラムとして表示します。設定情報 : ハイパーパラメータ、dataset へのリンク、または使用しているアーキテクチャーの名前を config パラメータとしてログに記録します。wandb.init(config=your_config_dictionary) のように渡されます。詳細については、PyTorch Integrations ページを参照してください。メトリクス : wandb.log を使用して、model からのメトリクスを表示します。トレーニング ループ内から精度や損失などのメトリクスをログに記録すると、UI でライブ更新グラフが表示されます。
一般的なワークフロー
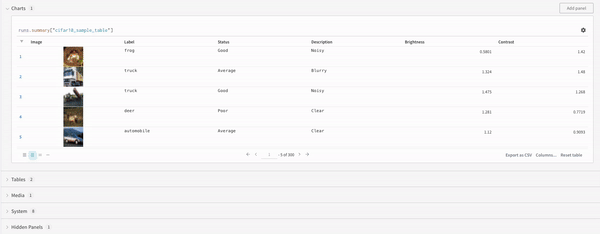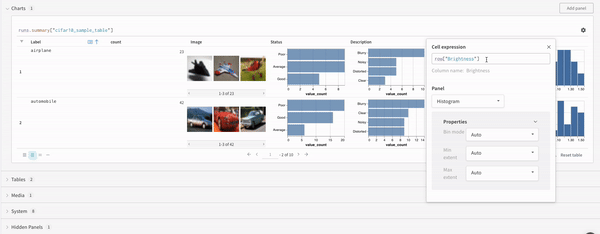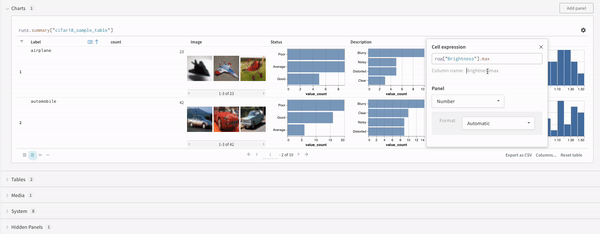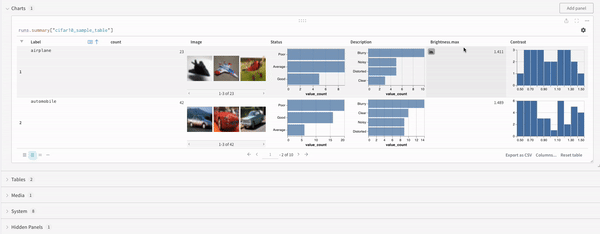
最高精度を比較する : run 全体でメトリクスの最高値を比較するには、そのメトリクスの集計値を設定します。デフォルトでは、集計は各キーに対してログに記録した最後の値に設定されます。これは、UI のテーブルで役立ちます。UI では、集計メトリクスに基づいて run をソートおよびフィルター処理し、最終的な精度ではなく 最高 精度に基づいてテーブルまたは棒グラフで run を比較できます。例: wandb.run.summary["best_accuracy"] = best_accuracy1 つのチャートで複数のメトリクスを表示する : wandb.log({"acc'": 0.9, "loss": 0.1}) のように、wandb.log への同じ呼び出しで複数のメトリクスをログに記録すると、それらは両方とも UI でプロットに使用できるようになります。x 軸をカスタマイズする : 同じログ呼び出しにカスタム x 軸を追加して、W&B dashboard で別の軸に対してメトリクスを視覚化します。例: wandb.log({'acc': 0.9, 'epoch': 3, 'batch': 117})。特定のメトリクスのデフォルトの x 軸を設定するには、Run.define_metric() を使用します。リッチ メディアとチャートをログに記録する : wandb.log は、画像や動画などのメディア から Tables および Charts まで、さまざまなデータ型のログ記録をサポートしています。
ベストプラクティスとヒント
Experiments とログ記録のベストプラクティスとヒントについては、ベストプラクティス: Experiments とログ記録 を参照してください。
2.1.6.1 - Create and track plots from experiments
機械学習 の 実験 からプロットを作成および追跡します。
wandb.plot のメソッドを使用すると、トレーニング中に時間とともに変化するグラフを含め、wandb.log でグラフを追跡できます。カスタムグラフ作成フレームワークの詳細については、このガイド を確認してください。
基本的なグラフ
これらのシンプルなグラフを使用すると、メトリクスと結果の基本的な可視化を簡単に構築できます。
Line
Scatter
Bar
Histogram
Multi-line
wandb.plot.line()
カスタム折れ線グラフ (任意の軸上の接続された順序付きポイントのリスト) を記録します。
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb. Table(data= data, columns= ["x" , "y" ])
wandb. log(
{
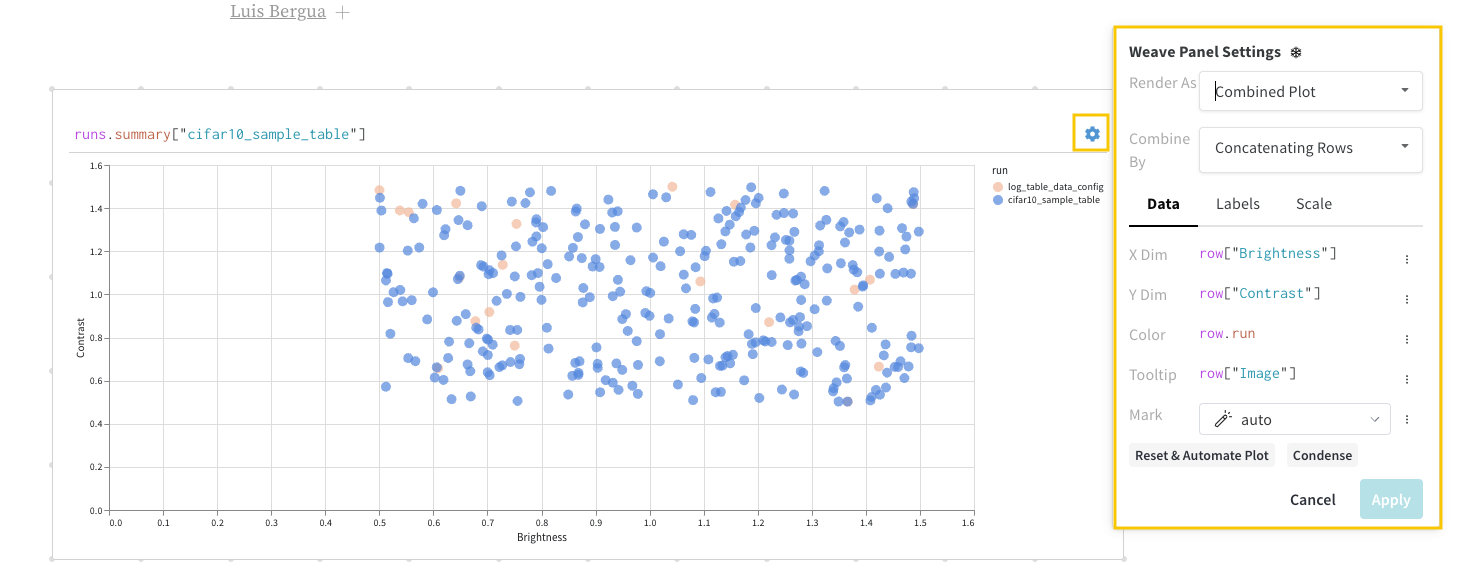
"my_custom_plot_id" : wandb. plot. line(
table, "x" , "y" , title= "Custom Y vs X Line Plot"
)
}
)
これを使用して、任意の2つの次元で曲線を記録できます。2つの値のリストを互いにプロットする場合、リスト内の値の数は正確に一致する必要があります。たとえば、各ポイントにはxとyが必要です。
アプリで表示
コードを実行
wandb.plot.scatter()
カスタム散布図 (任意の軸xとyのペア上のポイント (x、y) のリスト) を記録します。
data = [[x, y] for (x, y) in zip(class_x_scores, class_y_scores)]
table = wandb. Table(data= data, columns= ["class_x" , "class_y" ])
wandb. log({"my_custom_id" : wandb. plot. scatter(table, "class_x" , "class_y" )})
これを使用して、任意の2つの次元で散布ポイントを記録できます。2つの値のリストを互いにプロットする場合、リスト内の値の数は正確に一致する必要があります。たとえば、各ポイントにはxとyが必要です。
アプリで表示
コードを実行
wandb.plot.bar()
カスタム棒グラフ (ラベル付きの値のリストを棒として表示) を数行でネイティブに記録します。
data = [[label, val] for (label, val) in zip(labels, values)]
table = wandb. Table(data= data, columns= ["label" , "value" ])
wandb. log(
{
"my_bar_chart_id" : wandb. plot. bar(
table, "label" , "value" , title= "Custom Bar Chart"
)
}
)
これを使用して、任意の棒グラフを記録できます。リスト内のラベルと値の数は正確に一致する必要があります。各データポイントには、ラベルと値の両方が必要です。
アプリで表示
コードを実行
wandb.plot.histogram()
カスタムヒストグラム (値のリストを、出現のカウント/頻度でビンにソート) を数行でネイティブに記録します。予測信頼度スコアのリスト (scores) があり、その分布を可視化するとします。
data = [[s] for s in scores]
table = wandb. Table(data= data, columns= ["scores" ])
wandb. log({"my_histogram" : wandb. plot. histogram(table, "scores" , title= "Histogram" )})
これを使用して、任意のヒストグラムを記録できます。data は、行と列の2D配列をサポートすることを目的としたリストのリストであることに注意してください。
アプリで表示
コードを実行
wandb.plot.line_series()
複数の線、または複数の異なるx-y座標ペアのリストを、1つの共有x-y軸セットにプロットします。
wandb. log(
{
"my_custom_id" : wandb. plot. line_series(
xs= [0 , 1 , 2 , 3 , 4 ],
ys= [[10 , 20 , 30 , 40 , 50 ], [0.5 , 11 , 72 , 3 , 41 ]],
keys= ["metric Y" , "metric Z" ],
title= "Two Random Metrics" ,
xname= "x units" ,
)
}
)
xポイントとyポイントの数が正確に一致する必要があることに注意してください。複数のy値のリストに一致するx値のリストを1つ、またはy値のリストごとに個別のx値のリストを提供できます。
アプリで表示
モデル評価グラフ
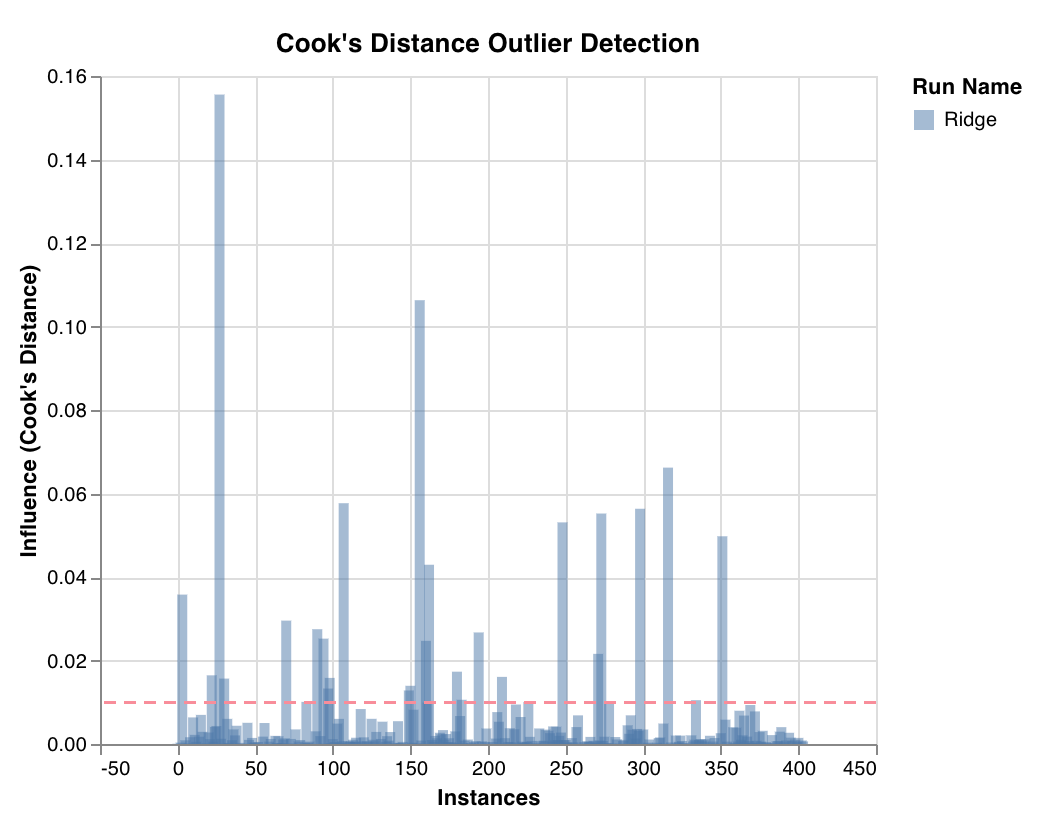
これらのプリセットグラフには、wandb.plot メソッドが組み込まれており、スクリプトから直接グラフをすばやく簡単に記録し、UIで探している正確な情報を確認できます。
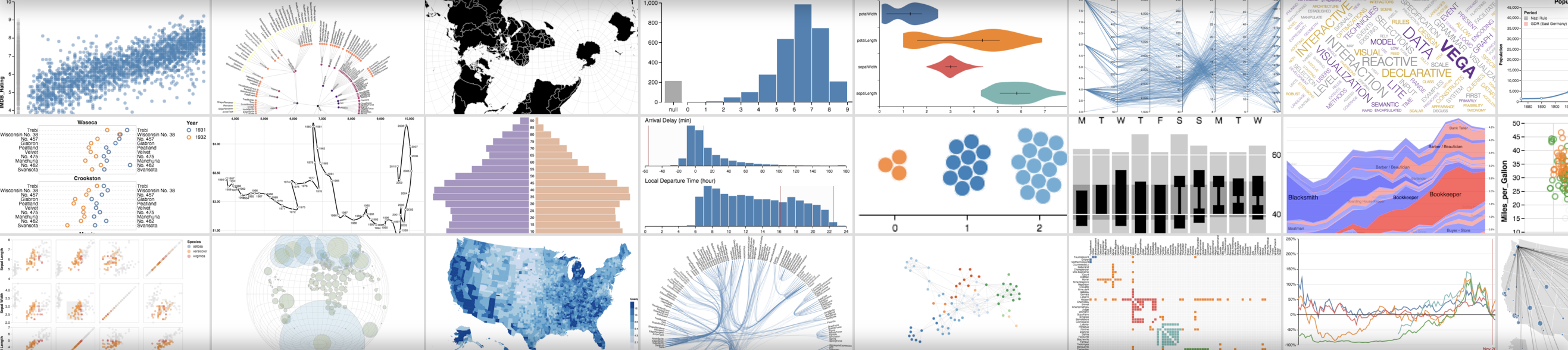
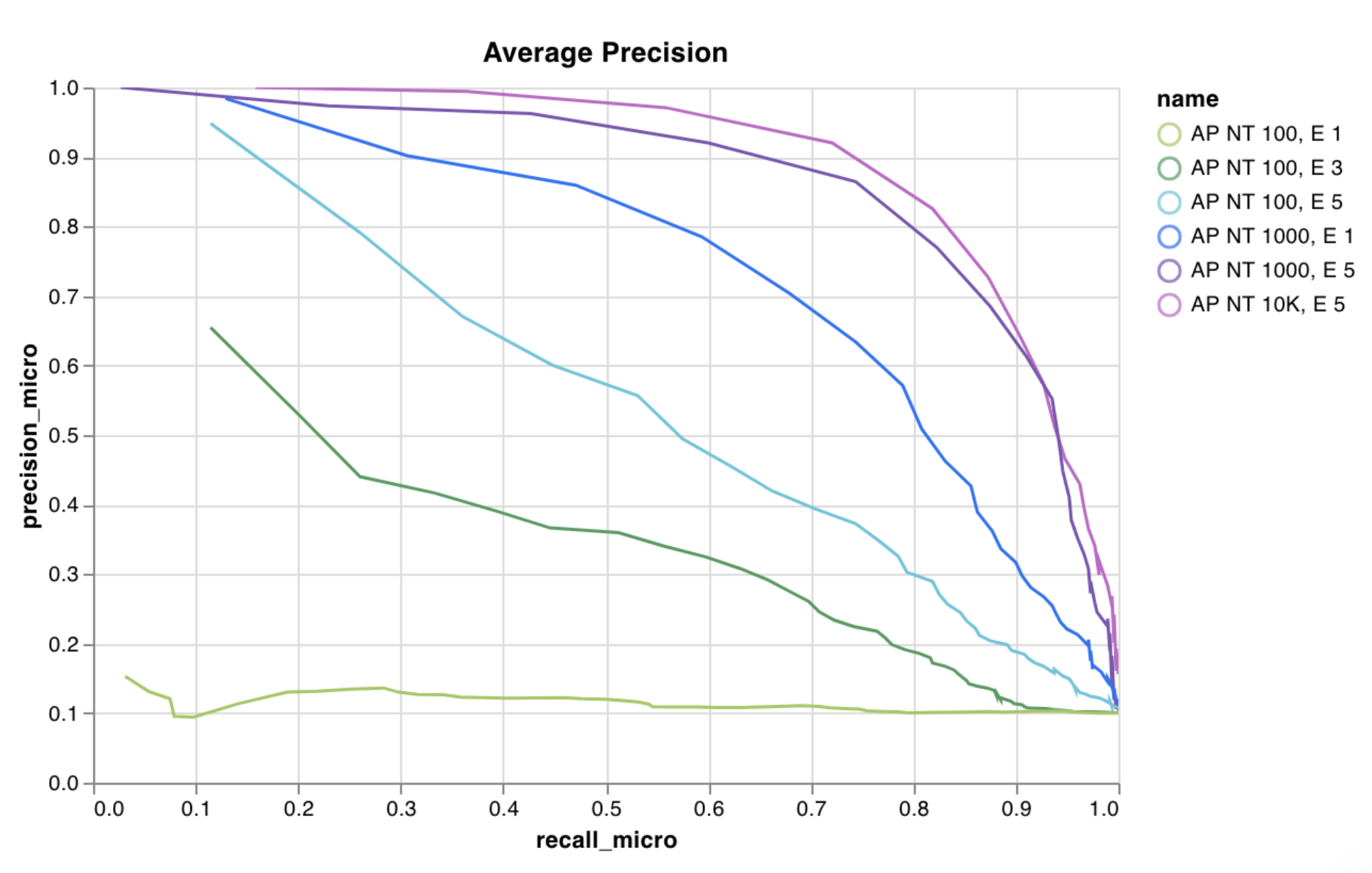
Precision-recall curves
ROC curves
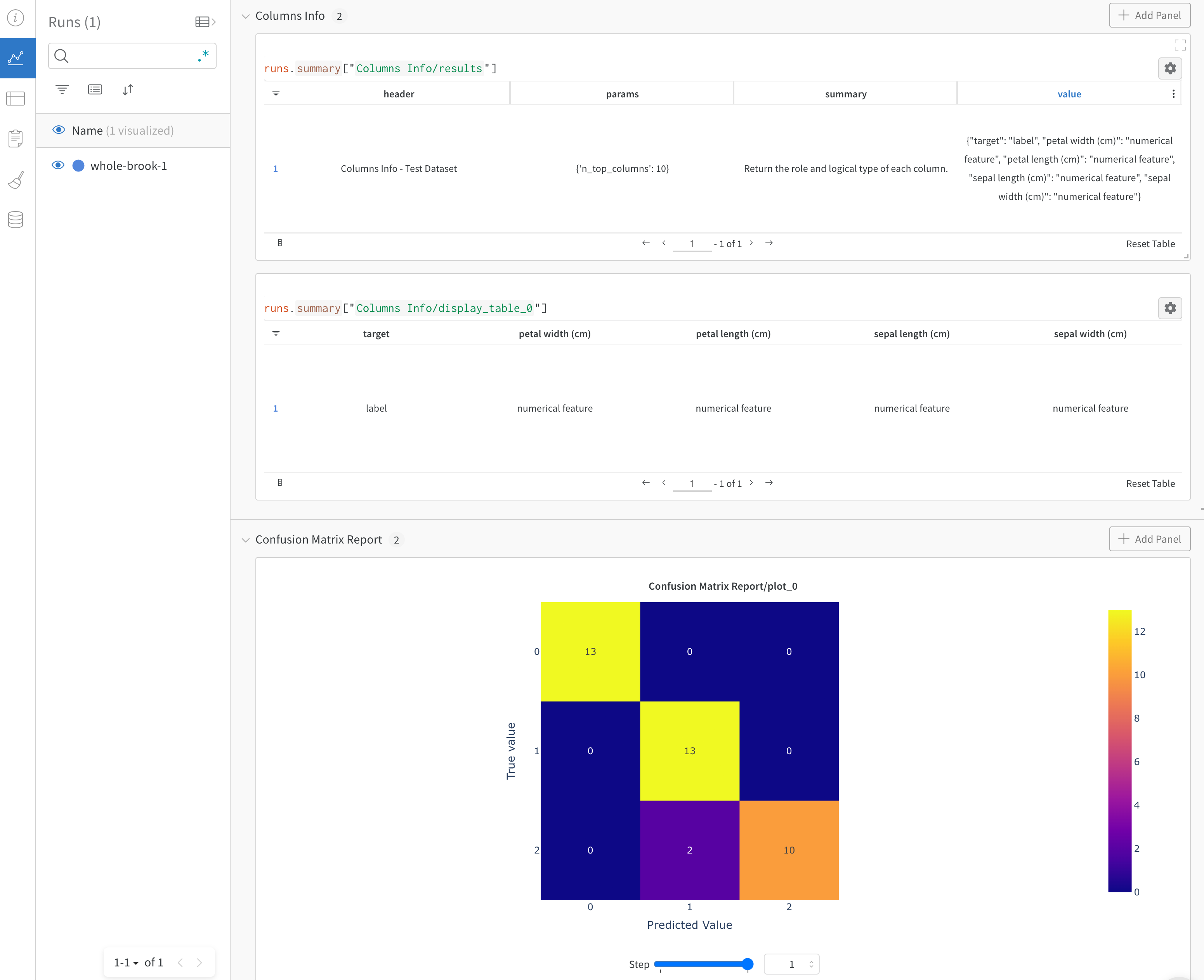
Confusion matrix
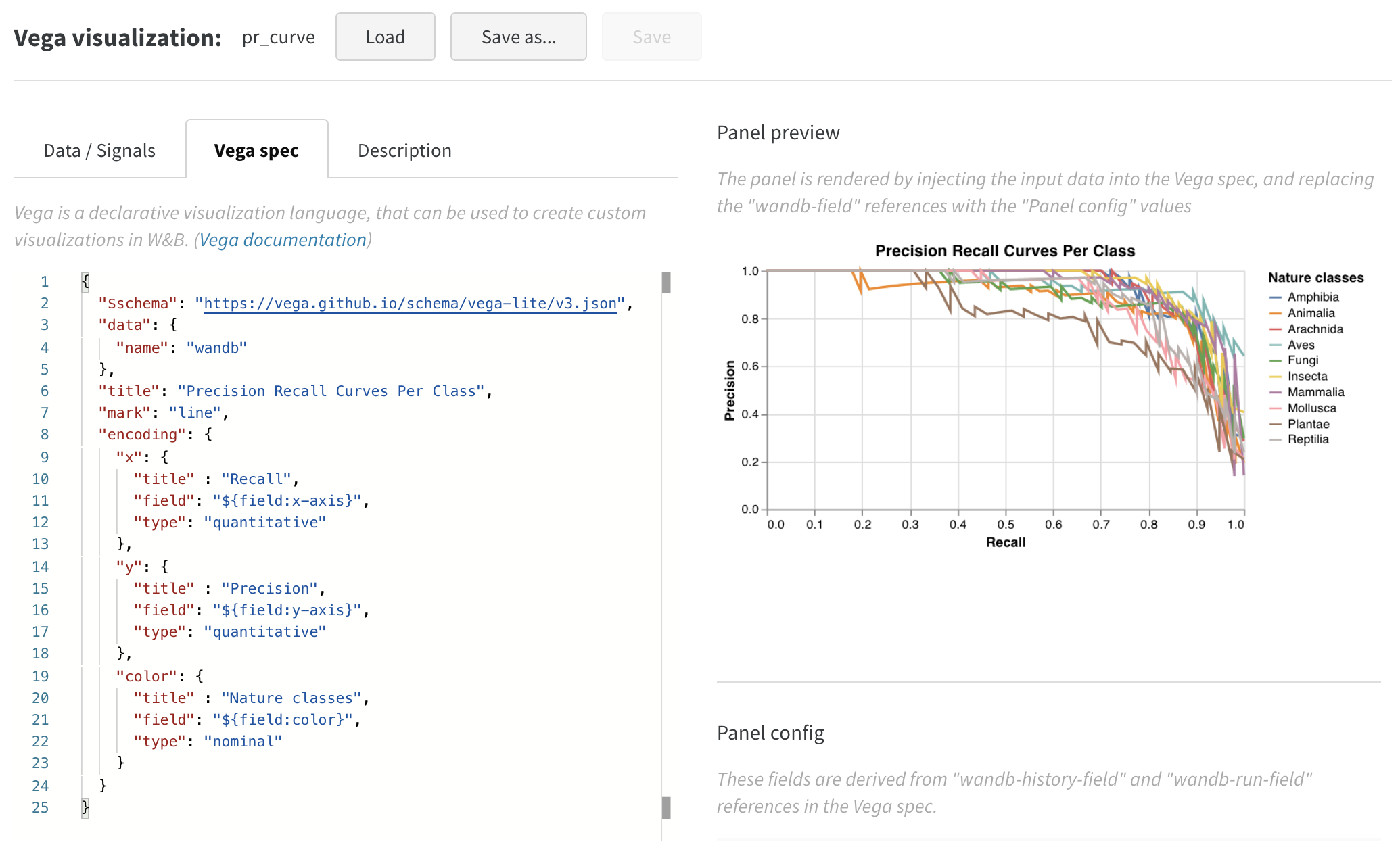
wandb.plot.pr_curve()
1行で PR曲線 を作成します。
wandb. log({"pr" : wandb. plot. pr_curve(ground_truth, predictions)})
コードが以下にアクセスできる場合は、いつでもこれを記録できます。
例のセットに対するモデルの予測スコア (predictions)
それらの例に対応する正解ラベル (ground_truth)
(オプション) ラベル/クラス名のリスト (labels=["cat", "dog", "bird"...] ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合)
(オプション) プロットで可視化するラベルのサブセット (引き続きリスト形式)
アプリで表示
コードを実行
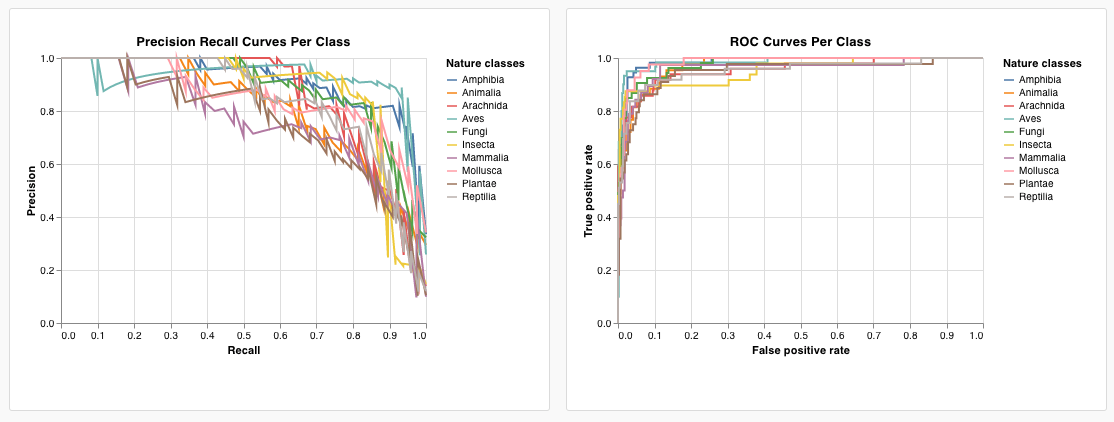
wandb.plot.roc_curve()
1行で ROC曲線 を作成します。
wandb. log({"roc" : wandb. plot. roc_curve(ground_truth, predictions)})
コードが以下にアクセスできる場合は、いつでもこれを記録できます。
例のセットに対するモデルの予測スコア (predictions)
それらの例に対応する正解ラベル (ground_truth)
(オプション) ラベル/クラス名のリスト (labels=["cat", "dog", "bird"...] ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合)
(オプション) プロットで可視化するこれらのラベルのサブセット (引き続きリスト形式)
アプリで表示
コードを実行
wandb.plot.confusion_matrix()
1行で多クラス 混同行列 を作成します。
cm = wandb. plot. confusion_matrix(
y_true= ground_truth, preds= predictions, class_names= class_names
)
wandb. log({"conf_mat" : cm})
コードが以下にアクセスできる場合は、いつでもこれを記録できます。
例のセットに対するモデルの予測ラベル (preds) または正規化された確率スコア (probs)。確率は、(例の数、クラスの数) の形状である必要があります。確率または予測のいずれかを提供できますが、両方はできません。
それらの例に対応する正解ラベル (y_true)
class_names の文字列としてのラベル/クラス名の完全なリスト。例: インデックス0が cat、1が dog、2が bird の場合、class_names=["cat", "dog", "bird"]。
アプリで表示
コードを実行
インタラクティブなカスタムグラフ
完全にカスタマイズするには、組み込みの カスタムグラフプリセット を調整するか、新しいプリセットを作成し、グラフを保存します。グラフIDを使用して、スクリプトからそのカスタムプリセットに直接データを記録します。
# プロットする列を含むテーブルを作成します
table = wandb. Table(data= data, columns= ["step" , "height" ])
# テーブルの列からグラフのフィールドへのマッピング
fields = {"x" : "step" , "value" : "height" }
# テーブルを使用して、新しいカスタムグラフプリセットを設定します
# 独自の保存されたグラフプリセットを使用するには、vega_spec_nameを変更します
# タイトルを編集するには、string_fieldsを変更します
my_custom_chart = wandb. plot_table(
vega_spec_name= "carey/new_chart" ,
data_table= table,
fields= fields,
string_fields= {"title" : "Height Histogram" },
)
コードを実行
Matplotlib および Plotly プロット
wandb.plot を使用した W&B カスタムグラフ を使用する代わりに、matplotlib および Plotly で生成されたグラフを記録できます。
import matplotlib.pyplot as plt
plt. plot([1 , 2 , 3 , 4 ])
plt. ylabel("some interesting numbers" )
wandb. log({"chart" : plt})
matplotlib プロットまたは figure オブジェクトを wandb.log() に渡すだけです。デフォルトでは、プロットを Plotly プロットに変換します。プロットを画像として記録する場合は、プロットを wandb.Image に渡すことができます。Plotly グラフも直接受け入れます。
「空のプロットを記録しようとしました」というエラーが表示される場合は、fig = plt.figure() を使用してプロットとは別に figure を保存し、wandb.log の呼び出しで fig を記録できます。
カスタム HTML を W&B Tables に記録する
W&B は、Plotly および Bokeh からのインタラクティブなグラフを HTML として記録し、それらを Tables に追加することをサポートしています。
インタラクティブな Plotly グラフを HTML に変換して、wandb Tables に記録できます。
import wandb
import plotly.express as px
# 新しい run を初期化します
run = wandb. init(project= "log-plotly-fig-tables" , name= "plotly_html" )
# テーブルを作成します
table = wandb. Table(columns= ["plotly_figure" ])
# Plotly figure のパスを作成します
path_to_plotly_html = "./plotly_figure.html"
# Plotly figure の例
fig = px. scatter(x= [0 , 1 , 2 , 3 , 4 ], y= [0 , 1 , 4 , 9 , 16 ])
# Plotly figure を HTML に書き込みます
# auto_play を False に設定すると、アニメーション化された Plotly グラフが
# テーブル内で自動的に再生されるのを防ぎます
fig. write_html(path_to_plotly_html, auto_play= False )
# Plotly figure を HTML ファイルとして Table に追加します
table. add_data(wandb. Html(path_to_plotly_html))
# Table を記録します
run. log({"test_table" : table})
wandb. finish()
インタラクティブな Bokeh グラフを HTML に変換して、wandb Tables に記録できます。
from scipy.signal import spectrogram
import holoviews as hv
import panel as pn
from scipy.io import wavfile
import numpy as np
from bokeh.resources import INLINE
hv. extension("bokeh" , logo= False )
import wandb
def save_audio_with_bokeh_plot_to_html (audio_path, html_file_name):
sr, wav_data = wavfile. read(audio_path)
duration = len(wav_data) / sr
f, t, sxx = spectrogram(wav_data, sr)
spec_gram = hv. Image((t, f, np. log10(sxx)), ["Time (s)" , "Frequency (hz)" ]). opts(
width= 500 , height= 150 , labelled= []
)
audio = pn. pane. Audio(wav_data, sample_rate= sr, name= "Audio" , throttle= 500 )
slider = pn. widgets. FloatSlider(end= duration, visible= False )
line = hv. VLine(0 ). opts(color= "white" )
slider. jslink(audio, value= "time" , bidirectional= True )
slider. jslink(line, value= "glyph.location" )
combined = pn. Row(audio, spec_gram * line, slider). save(html_file_name)
html_file_name = "audio_with_plot.html"
audio_path = "hello.wav"
save_audio_with_bokeh_plot_to_html(audio_path, html_file_name)
wandb_html = wandb. Html(html_file_name)
run = wandb. init(project= "audio_test" )
my_table = wandb. Table(columns= ["audio_with_plot" ], data= [[wandb_html], [wandb_html]])
run. log({"audio_table" : my_table})
run. finish()
2.1.6.2 - Customize log axes
define_metric を使用して、カスタムのX軸 を設定します。カスタムのX軸は、トレーニング中に過去の異なるタイムステップに非同期で ログ を記録する必要がある場合に役立ちます。たとえば、エピソードごとの報酬とステップごとの報酬を追跡する強化学習で役立ちます。
Google Colab で define_metric を実際に試してみる →
軸のカスタマイズ
デフォルトでは、すべての メトリクス は同じX軸(W&Bの内部 step)に対して ログ が記録されます。場合によっては、前のステップに ログ を記録したり、別のX軸を使用したりすることがあります。
カスタムのX軸 メトリクス を設定する例を次に示します(デフォルトのステップの代わりに)。
import wandb
wandb. init()
# カスタムのX軸メトリクスを定義
wandb. define_metric("custom_step" )
# どのメトリクスをそれに対してプロットするかを定義
wandb. define_metric("validation_loss" , step_metric= "custom_step" )
for i in range(10 ):
log_dict = {
"train_loss" : 1 / (i + 1 ),
"custom_step" : i** 2 ,
"validation_loss" : 1 / (i + 1 ),
}
wandb. log(log_dict)
X軸は、グロブを使用して設定することもできます。現在、文字列のプレフィックスを持つグロブのみが使用可能です。次の例では、プレフィックス "train/" を持つ ログ に記録されたすべての メトリクス をX軸 "train/step" にプロットします。
import wandb
wandb. init()
# カスタムのX軸メトリクスを定義
wandb. define_metric("train/step" )
# 他のすべての train/ メトリクス がこのステップを使用するように設定
wandb. define_metric("train/*" , step_metric= "train/step" )
for i in range(10 ):
log_dict = {
"train/step" : 2 ** i, # 内部W&Bステップによる指数関数的な増加
"train/loss" : 1 / (i + 1 ), # X軸は train/step
"train/accuracy" : 1 - (1 / (1 + i)), # X軸は train/step
"val/loss" : 1 / (1 + i), # X軸は内部 wandb step
}
wandb. log(log_dict)
2.1.6.3 - Log distributed training experiments
W&B を使用して、複数の GPU を使用した分散型トレーニング の 実験管理 を ログ 記録します。
分散トレーニングでは、モデルは複数の GPU を並行して使用してトレーニングされます。W&B は、分散トレーニング の 実験管理 を追跡するための 2 つのパターンをサポートしています。
単一 プロセス : W&B (wandb.initwandb.logPyTorch Distributed Data Parallel (DDP) クラスを使用した分散トレーニング の 実験 を ログ 記録するための一般的なソリューションです。場合によっては、マルチプロセッシング キュー (または別の通信プリミティブ) を使用して、他の プロセス からメインの ログ 記録 プロセス にデータを送り込む ユーザー もいます。多数の プロセス : W&B (wandb.initwandb.loggroup パラメータ (wandb.init(group='group-name')) を使用して、共有 実験 を定義し、 ログ 記録された 値 を W&B App UI にまとめて グループ化します。
以下の例では、単一 マシン 上の 2 つの GPU で PyTorch DDP を使用して、W&B で メトリクス を追跡する方法を示します。PyTorch DDP (torch.nn の DistributedDataParallel) は、分散トレーニング 用の一般的な ライブラリ です。基本的な原則は、あらゆる分散トレーニング 設定に適用されますが、実装の詳細は異なる場合があります。
これらの例の背後にある コード を W&B GitHub の examples リポジトリ (
こちら ) で確認してください。特に、単一 プロセス および 多数 プロセス の メソッド を実装する方法については、
log-dpp.py Python スクリプトを参照してください。
方法 1: 単一 プロセス
この方法では、ランク 0 の プロセス のみを追跡します。この方法を実装するには、W&B (wandb.init) を初期化し、W&B Run を開始して、ランク 0 の プロセス 内で メトリクス (wandb.log) を ログ 記録します。この方法はシンプルで堅牢ですが、他の プロセス から モデル の メトリクス (たとえば、バッチからの 損失 値 または 入力) を ログ 記録しません。使用量 や メモリ などの システム メトリクス は、その情報がすべての プロセス で利用できるため、すべての GPU に対して ログ 記録されます。
この方法を使用して、単一の プロセス から利用可能な メトリクス のみを追跡します 。一般的な例としては、GPU/CPU の使用率、共有 検証セット での 振る舞い 、 勾配 と パラメータ 、および代表的な データ 例での 損失 値 などがあります。
サンプル Python スクリプト (log-ddp.py) 内で、ランクが 0 かどうかを確認します。これを行うには、まず torch.distributed.launch で複数の プロセス を 起動します。次に、--local_rank コマンドライン 引数 でランクを確認します。ランクが 0 に設定されている場合、train()wandb ログ 記録を条件付きで設定します。Python スクリプト内で、次のチェックを使用します。
if __name__ == "__main__" :
# Get args
args = parse_args()
if args. local_rank == 0 : # only on main process
# Initialize wandb run
run = wandb. init(
entity= args. entity,
project= args. project,
)
# Train model with DDP
train(args, run)
else :
train(args)
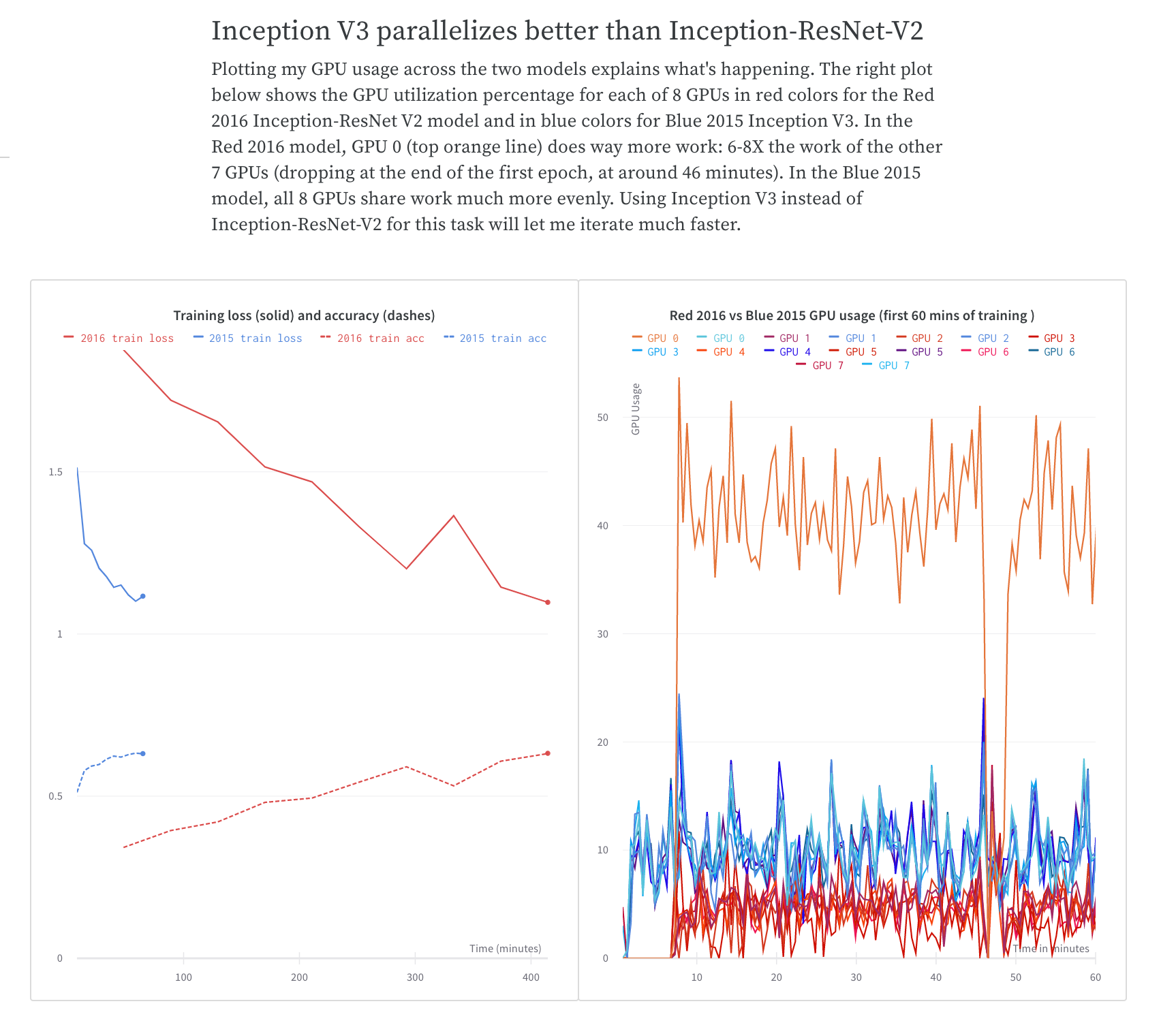
W&B App UI を調べて、単一の プロセス から追跡された メトリクス の ダッシュボード 例 を表示します。ダッシュボード には、両方の GPU で追跡された 温度 や 使用率 などの システム メトリクス が表示されます。
ただし、 エポック と バッチサイズ の関数としての 損失 値 は、単一の GPU からのみ ログ 記録されました。
方法 2: 多数の プロセス
この方法では、ジョブ内の各 プロセス を追跡し、各 プロセス から wandb.init() と wandb.log() を個別に呼び出します。すべての プロセス が適切に終了するように、トレーニング の最後に wandb.finish() を呼び出すことをお勧めします。これにより、run が完了したことを示します。
この方法により、より多くの情報が ログ 記録にアクセスできるようになります。ただし、複数の W&B Runs が W&B App UI に 報告 されることに注意してください。複数の 実験 にわたって W&B Runs を追跡することが難しい場合があります。これを軽減するには、W&B を初期化する際に group パラメータ に 値 を指定して、どの W&B Run が特定の 実験 に属しているかを追跡します。トレーニング と 評価 の W&B Runs を 実験 で追跡する方法の詳細については、Run のグループ化 を参照してください。
個々の プロセス から メトリクス を追跡する場合は、この方法を使用してください 。一般的な例としては、各 ノード 上の データ と 予測 (データ 分布 の デバッグ 用) や、メイン ノード 外の個々の バッチ 上の メトリクス などがあります。この方法は、すべての ノード から システム メトリクス を取得したり、メイン ノード で利用可能な概要 統計 を取得したりするために必要ではありません。
次の Python コード スニペット は、W&B を初期化するときに group パラメータ を設定する方法を示しています。
if __name__ == "__main__" :
# Get args
args = parse_args()
# Initialize run
run = wandb. init(
entity= args. entity,
project= args. project,
group= "DDP" , # all runs for the experiment in one group
)
# Train model with DDP
train(args, run)
W&B App UI を調べて、複数の プロセス から追跡された メトリクス の ダッシュボード 例 を表示します。左側のサイドバーに 2 つの W&B Runs が グループ化 されていることに注意してください。グループ をクリックして、 実験 専用のグループ ページ を表示します。専用のグループ ページ には、各 プロセス からの メトリクス が個別に表示されます。
上記の画像は、W&B App UI ダッシュボード を示しています。サイドバーには、2 つの 実験 が表示されます。1 つは「null」というラベルが付いており、2 つ目 (黄色のボックスで囲まれています) は「DPP」と呼ばれています。グループ を展開すると (グループ ドロップダウン を選択)、その 実験 に関連付けられている W&B Runs が表示されます。
W&B Service を使用して、一般的な分散トレーニング の問題を回避する
W&B と分散トレーニング を使用する際に発生する可能性のある一般的な問題が 2 つあります。
トレーニング の開始時にハングする - wandb マルチプロセッシング が分散トレーニング からの マルチプロセッシング に干渉すると、wandb プロセス がハングする可能性があります。トレーニング の最後にハングする - wandb プロセス がいつ終了する必要があるかを認識していない場合、トレーニング ジョブ がハングする可能性があります。Python スクリプト の最後に wandb.finish() API を呼び出して、Run が完了したことを W&B に伝えます。wandb.finish() API は、データの アップロード を終了し、W&B を終了させます。
分散ジョブ の信頼性を向上させるために、wandb service を使用することをお勧めします。上記のトレーニング の問題はどちらも、wandb service が利用できない W&B SDK の バージョン でよく見られます。
W&B Service を有効にする
W&B SDK の バージョン によっては、W&B Service がデフォルトで有効になっている場合があります。
W&B SDK 0.13.0 以降
W&B Service は、W&B SDK 0.13.0 以降の バージョン ではデフォルトで有効になっています。
W&B SDK 0.12.5 以降
Python スクリプト を変更して、W&B SDK バージョン 0.12.5 以降で W&B Service を有効にします。wandb.require メソッド を使用し、メイン関数内で 文字列 "service" を渡します。
if __name__ == "__main__" :
main()
def main ():
wandb. require("service" )
# rest-of-your-script-goes-here
最適なエクスペリエンスを得るには、最新 バージョン に アップグレード することをお勧めします。
W&B SDK 0.12.4 以前
W&B SDK バージョン 0.12.4 以前を使用している場合は、マルチスレッド を代わりに使用するために、WANDB_START_METHOD 環境 変数 を "thread" に設定します。
マルチプロセッシング の ユースケース 例
次の コード スニペット は、高度な分散 ユースケース の一般的な方法を示しています。
プロセス の スポーン
スポーンされた プロセス で W&B Run を開始する場合は、メイン関数で wandb.setup() メソッド を使用します。
import multiprocessing as mp
def do_work (n):
run = wandb. init(config= dict(n= n))
run. log(dict(this= n * n))
def main ():
wandb. setup()
pool = mp. Pool(processes= 4 )
pool. map(do_work, range(4 ))
if __name__ == "__main__" :
main()
W&B Run を共有する
W&B Run オブジェクト を 引数 として渡して、 プロセス 間で W&B Runs を共有します。
def do_work (run):
run. log(dict(this= 1 ))
def main ():
run = wandb. init()
p = mp. Process(target= do_work, kwargs= dict(run= run))
p. start()
p. join()
if __name__ == "__main__" :
main()
ログ 記録の順序は保証されないことに注意してください。同期は スクリプト の作成者が行う必要があります。
2.1.6.4 - Log media and objects
3D ポイントクラウド や分子から、HTML やヒストグラムまで、リッチメディアを ログ に記録します。
画像、動画、音声など、様々な形式のメディアに対応しています。リッチメディアを ログ に記録して、結果を調査し、 run 、 model 、 dataset を視覚的に比較できます。例やハウツー ガイド については、以下をお読みください。
メディアタイプのリファレンス ドキュメントをお探しですか?
こちらのページ をご覧ください。
事前準備
W&B SDK でメディア オブジェクト を ログ に記録するには、追加の依存関係をインストールする必要がある場合があります。
これらの依存関係をインストールするには、次の コマンド を実行します。
画像
画像 を ログ に記録して、入力、出力、フィルターの重み、アクティベーションなどを追跡します。
画像 は、NumPy 配列から、PIL 画像 として、またはファイルシステムから直接 ログ に記録できます。
ステップから画像 を ログ に記録するたびに、UI に表示するために保存されます。画像 パネル を展開し、ステップ スライダーを使用して、異なるステップの画像 を確認します。これにより、 model の出力が トレーニング 中にどのように変化するかを簡単に比較できます。
トレーニング 中に ログ 記録がボトルネックになるのを防ぐため、また結果を表示する際に画像 の読み込みがボトルネックになるのを防ぐため、ステップごとに 50 枚未満の画像 を ログ に記録することをお勧めします。
配列を画像として ログ 記録
PIL 画像 の ログ 記録
ファイルから画像 の ログ 記録
torchvisionmake_grid
配列は Pillow を使用して png に変換されます。
images = wandb. Image(image_array, caption= "Top: Output, Bottom: Input" )
wandb. log({"examples" : images})
最後の次元が 1 の場合はグレースケール画像、3 の場合は RGB、4 の場合は RGBA であると想定されます。配列に float が含まれている場合は、0 から 255 までの整数に変換します。画像 の正規化方法を変更する場合は、modePIL.Image
配列から画像 への変換を完全に制御するには、PIL.Image
images = [PIL. Image. fromarray(image) for image in image_array]
wandb. log({"examples" : [wandb. Image(image) for image in images]})
さらに細かく制御するには、好きな方法で画像 を作成し、ディスクに保存して、ファイルパスを指定します。
im = PIL. fromarray(... )
rgb_im = im. convert("RGB" )
rgb_im. save("myimage.jpg" )
wandb. log({"example" : wandb. Image("myimage.jpg" )})
画像 オーバーレイ
セグメンテーション マスク
バウンディングボックス
セマンティックセグメンテーション マスク を ログ に記録し、W&B UI で (不透明度を変更したり、経時的な変化を表示したりするなど) 操作します。
オーバーレイを ログ に記録するには、次の キー と 値 を持つ 辞書 を wandb.Image の masks キーワード 引数 に指定する必要があります。
画像 マスク を表す 2 つの キー のいずれか 1 つ。
"mask_data": 各ピクセル の整数クラス ラベル を含む 2D NumPy 配列"path": (string) 保存された画像 マスク ファイル へのパス
"class_labels": (オプション) 画像 マスク 内の整数クラス ラベル を読み取り可能なクラス名に マッピング する 辞書
複数の マスク を ログ に記録するには、次の コード スニペット のように、複数の キー を持つ マスク 辞書 を ログ に記録します。
ライブ例を見る
サンプル コード
mask_data = np. array([[1 , 2 , 2 , ... , 2 , 2 , 1 ], ... ])
class_labels = {1 : "tree" , 2 : "car" , 3 : "road" }
mask_img = wandb. Image(
image,
masks= {
"predictions" : {"mask_data" : mask_data, "class_labels" : class_labels},
"ground_truth" : {
# ...
},
# ...
},
)
画像 と共に バウンディングボックス を ログ に記録し、フィルターとトグルを使用して、UI でさまざまなボックス セット を動的に 可視化 します。
ライブ例を見る
バウンディングボックス を ログ に記録するには、次の キー と 値 を持つ 辞書 を wandb.Image の boxes キーワード 引数 に指定する必要があります。
box_data: 各ボックス に対して 1 つの 辞書 の リスト。ボックス 辞書 の形式については、以下で説明します。
position: 以下で説明するように、2 つの形式のいずれかでボックス の位置とサイズを表す 辞書。ボックス はすべて同じ形式を使用する必要はありません。
オプション 1: {"minX", "maxX", "minY", "maxY"}。各ボックス の次元の上限と下限を定義する座標セットを指定します。オプション 2: {"middle", "width", "height"}。[x,y] として middle 座標を指定する座標セットと、スカラーとして width と height を指定します。
class_id: ボックス のクラス ID を表す整数。以下の class_labels キー を参照してください。scores: スコア の文字列ラベルと数値の 値 の 辞書。UI でボックス をフィルタリングするために使用できます。domain: ボックス 座標の単位/形式を指定します。ボックス 座標が画像 の次元の範囲内の整数など、ピクセル空間で表される場合は、これを「pixel」に設定します 。デフォルトでは、 domain は画像 の分数/パーセンテージであると見なされ、0 から 1 の間の浮動小数点数として表されます。box_caption: (オプション) このボックス のラベル テキストとして表示される文字列
class_labels: (オプション) class_id を文字列に マッピング する 辞書。デフォルトでは、クラス ラベル class_0、class_1 などを生成します。
この例をご覧ください。
class_id_to_label = {
1 : "car" ,
2 : "road" ,
3 : "building" ,
# ...
}
img = wandb. Image(
image,
boxes= {
"predictions" : {
"box_data" : [
{
# one box expressed in the default relative/fractional domain
"position" : {"minX" : 0.1 , "maxX" : 0.2 , "minY" : 0.3 , "maxY" : 0.4 },
"class_id" : 2 ,
"box_caption" : class_id_to_label[2 ],
"scores" : {"acc" : 0.1 , "loss" : 1.2 },
# another box expressed in the pixel domain
# (for illustration purposes only, all boxes are likely
# to be in the same domain/format)
"position" : {"middle" : [150 , 20 ], "width" : 68 , "height" : 112 },
"domain" : "pixel" ,
"class_id" : 3 ,
"box_caption" : "a building" ,
"scores" : {"acc" : 0.5 , "loss" : 0.7 },
# ...
# Log as many boxes an as needed
}
],
"class_labels" : class_id_to_label,
},
# Log each meaningful group of boxes with a unique key name
"ground_truth" : {
# ...
},
},
)
wandb. log({"driving_scene" : img})
テーブル の画像 オーバーレイ
セグメンテーション マスク
バウンディングボックス
テーブル に セグメンテーション マスク を ログ 記録するには、テーブル の各行に wandb.Image オブジェクト を指定する必要があります。
コード スニペット に例を示します。
table = wandb. Table(columns= ["ID" , "Image" ])
for id, img, label in zip(ids, images, labels):
mask_img = wandb. Image(
img,
masks= {
"prediction" : {"mask_data" : label, "class_labels" : class_labels}
# ...
},
)
table. add_data(id, img)
wandb. log({"Table" : table})
テーブル に バウンディングボックス を持つ 画像 を ログ 記録するには、テーブル の各行に wandb.Image オブジェクト を指定する必要があります。
コード スニペット に例を示します。
table = wandb. Table(columns= ["ID" , "Image" ])
for id, img, boxes in zip(ids, images, boxes_set):
box_img = wandb. Image(
img,
boxes= {
"prediction" : {
"box_data" : [
{
"position" : {
"minX" : box["minX" ],
"minY" : box["minY" ],
"maxX" : box["maxX" ],
"maxY" : box["maxY" ],
},
"class_id" : box["class_id" ],
"box_caption" : box["caption" ],
"domain" : "pixel" ,
}
for box in boxes
],
"class_labels" : class_labels,
}
},
)
ヒストグラム
基本的な ヒストグラム の ログ 記録
柔軟な ヒストグラム の ログ 記録
概要の ヒストグラム
リスト、配列、 テンソル などの数値のシーケンスが最初の 引数 として指定された場合、np.histogram を呼び出すことで ヒストグラム を自動的に構築します。すべての配列/ テンソル はフラット化されます。オプションの num_bins キーワード 引数 を使用して、デフォルトの 64 ビン をオーバーライドできます。サポートされているビンの最大数は 512 です。
UI では、 ヒストグラム は x 軸に トレーニング ステップ、y 軸に メトリック 値、色で表されるカウントでプロットされ、 トレーニング 全体で ログ 記録された ヒストグラム の比較が容易になります。1 回限りの ヒストグラム の ログ 記録の詳細については、この パネル の「概要の ヒストグラム 」 タブ を参照してください。
wandb. log({"gradients" : wandb. Histogram(grads)})
さらに詳細に制御する場合は、np.histogram を呼び出し、返された タプル を np_histogram キーワード 引数 に渡します。
np_hist_grads = np. histogram(grads, density= True , range= (0.0 , 1.0 ))
wandb. log({"gradients" : wandb. Histogram(np_hist_grads)})
wandb. run. summary. update( # if only in summary, only visible on overview tab
{"final_logits" : wandb. Histogram(logits)}
)
'obj'、'gltf'、'glb'、'babylon'、'stl'、'pts.json' 形式のファイルを ログ 記録すると、 run 終了時に UI でレンダリングされます。
wandb. log(
{
"generated_samples" : [
wandb. Object3D(open("sample.obj" )),
wandb. Object3D(open("sample.gltf" )),
wandb. Object3D(open("sample.glb" )),
]
}
)
ライブ例を見る
ヒストグラム が概要にある場合、Run Page の Overviewタブ に表示されます。履歴にある場合、Chartsタブ に時間の経過に伴うビンのヒートマップをプロットします。
3D 可視化
バウンディングボックス を持つ 3D ポイントクラウド と Lidar シーンを ログ 記録します。レンダリングするポイントの座標と色を含む NumPy 配列を渡します。
point_cloud = np. array([[0 , 0 , 0 , COLOR]])
wandb. log({"point_cloud" : wandb. Object3D(point_cloud)})
:::info
W&B UI はデータを 300,000 ポイント で切り捨てます。
:::
NumPy 配列形式
柔軟な配色に対応するため、3 つの異なる形式の NumPy 配列がサポートされています。
[[x, y, z], ...] nx3[[x, y, z, c], ...] nx4 | c は[1, 14]` の範囲のカテゴリです (セグメンテーション に役立ちます)。[[x, y, z, r, g, b], ...] nx6 | r,g,b は赤、緑、青のカラー チャンネル の [0,255] の範囲の値です。
Python オブジェクト
このスキーマを使用すると、Python オブジェクト を定義し、以下に示すように from_point_cloud メソッド に渡すことができます。
points は、上記の単純な ポイントクラウド レンダラーと同じ形式 を使用してレンダリングするポイントの座標と色を含む NumPy 配列です。boxes は、3 つの属性を持つ Python 辞書 の NumPy 配列です。
corners- 8 つの角の リストlabel- ボックス にレンダリングされるラベルを表す文字列 (オプション)color- ボックス の色を表す RGB 値score - バウンディングボックス に表示される数値。表示される バウンディングボックス をフィルタリングするために使用できます (たとえば、score > 0.75 の バウンディングボックス のみを表示する場合)。(オプション)
type は、レンダリングするシーン タイプを表す文字列です。現在、サポートされている値は lidar/beta のみです。
point_list = [
[
2566.571924017235 , # x
746.7817289698219 , # y
- 15.269245470863748 ,# z
76.5 , # red
127.5 , # green
89.46617199365393 # blue
],
[ 2566.592983606823 , 746.6791987335685 , - 15.275803826279521 , 76.5 , 127.5 , 89.45471117247024 ],
[ 2566.616361739416 , 746.4903185513501 , - 15.28628929674075 , 76.5 , 127.5 , 89.41336375503832 ],
[ 2561.706014951675 , 744.5349468458361 , - 14.877496818222781 , 76.5 , 127.5 , 82.21868245418283 ],
[ 2561.5281847916694 , 744.2546118233013 , - 14.867862032341005 , 76.5 , 127.5 , 81.87824684536432 ],
[ 2561.3693562897465 , 744.1804761656741 , - 14.854129178142523 , 76.5 , 127.5 , 81.64137897587152 ],
[ 2561.6093071504515 , 744.0287526628543 , - 14.882135189841177 , 76.5 , 127.5 , 81.89871499537098 ],
# ... and so on
]
run. log({"my_first_point_cloud" : wandb. Object3D. from_point_cloud(
points = point_list,
boxes = [{
"corners" : [
[ 2601.2765123137915 , 767.5669506323393 , - 17.816764802288663 ],
[ 2599.7259021588347 , 769.0082337923552 , - 17.816764802288663 ],
[ 2599.7259021588347 , 769.0082337923552 , - 19.66876480228866 ],
[ 2601.2765123137915 , 767.5669506323393 , - 19.66876480228866 ],
[ 2604.8684867834395 , 771.4313904894723 , - 17.816764802288663 ],
[ 2603.3178766284827 , 772.8726736494882 , - 17.816764802288663 ],
[ 2603.3178766284827 , 772.8726736494882 , - 19.66876480228866 ],
[ 2604.8684867834395 , 771.4313904894723 , - 19.66876480228866 ]
],
"color" : [0 , 0 , 255 ], # color in RGB of the bounding box
"label" : "car" , # string displayed on the bounding box
"score" : 0.6 # numeric displayed on the bounding box
}],
vectors = [
{"start" : [0 , 0 , 0 ], "end" : [0.1 , 0.2 , 0.5 ], "color" : [255 , 0 , 0 ]}, # color is optional
],
point_cloud_type = "lidar/beta" ,
)})
ポイントクラウド を表示するときは、control キー を押しながらマウスを使用すると、スペース内を移動できます。
ポイントクラウド ファイル
the from_file メソッド を使用して、 ポイントクラウド データがいっぱいの JSON ファイルをロードできます。
run. log({"my_cloud_from_file" : wandb. Object3D. from_file(
"./my_point_cloud.pts.json"
)})
ポイントクラウド データの形式設定方法の例を以下に示します。
{
"boxes" : [
{
"color" : [
0 ,
255 ,
0
],
"score" : 0.35 ,
"label" : "My label" ,
"corners" : [
[
2589.695869075582 ,
760.7400443552185 ,
-18.044831294622487
],
[
2590.719039645323 ,
762.3871153874499 ,
-18.044831294622487
],
[
2590.719039645323 ,
762.3871153874499 ,
-19.54083129462249
],
[
2589.695869075582 ,
760.7400443552185 ,
-19.54083129462249
],
[
2594.9666662674313 ,
757.4657929961453 ,
-18.044831294622487
],
[
2595.9898368371723 ,
759.1128640283766 ,
-18.044831294622487
],
[
2595.9898368371723 ,
759.1128640283766 ,
-19.54083129462249
],
[
2594.9666662674313 ,
757.4657929961453 ,
-19.54083129462249
]
]
}
],
"points" : [
[
2566.571924017235 ,
746.7817289698219 ,
-15.269245470863748 ,
76.5 ,
127.5 ,
89.46617199365393
],
[
2566.592983606823 ,
746.6791987335685 ,
-15.275803826279521 ,
76.5 ,
127.5 ,
89.45471117247024
],
[
2566.616361739416 ,
746.4903185513501 ,
-15.28628929674075 ,
76.5 ,
127.5 ,
89.41336375503832
]
],
"type" : "lidar/beta"
}
NumPy 配列
上記で定義されている同じ配列形式 を使用して、 from_numpy メソッド で numpy 配列を直接使用して、 ポイントクラウド を定義できます。
run. log({"my_cloud_from_numpy_xyz" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 ], # x, y, z
[1 , 1 , 1 ],
[1.2 , 1 , 1.2 ]
]
)
)})
run. log({"my_cloud_from_numpy_cat" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 , 1 ], # x, y, z, category
[1 , 1 , 1 , 1 ],
[1.2 , 1 , 1.2 , 12 ],
[1.2 , 1 , 1.3 , 12 ],
[1.2 , 1 , 1.4 , 12 ],
[1.2 , 1 , 1.5 , 12 ],
[1.2 , 1 , 1.6 , 11 ],
[1.2 , 1 , 1.7 , 11 ],
]
)
)})
run. log({"my_cloud_from_numpy_rgb" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 , 255 , 0 , 0 ], # x, y, z, r, g, b
[1 , 1 , 1 , 0 , 255 , 0 ],
[1.2 , 1 , 1.3 , 0 , 255 , 255 ],
[1.2 , 1 , 1.4 , 0 , 255 , 255 ],
[1.2 , 1 , 1.5 , 0 , 0 , 255 ],
[1.2 , 1 , 1.1 , 0 , 0 , 255 ],
[1.2 , 1 , 0.9 , 0 , 0 , 255 ],
]
)
)})
wandb. log({"protein" : wandb. Molecule("6lu7.pdb" )})
10 個のファイルタイプ ( pdb、pqr、mmcif、mcif、cif、sdf、sd、gro、mol2、または mmtf) のいずれかで分子データを ログ 記録します。
W&B は、SMILES 文字列、rdkitmol ファイル、および rdkit.Chem.rdchem.Mol オブジェクト からの分子データの ログ 記録もサポートしています。
resveratrol = rdkit. Chem. MolFromSmiles("Oc1ccc(cc1)C=Cc1cc(O)cc(c1)O" )
wandb. log(
{
"resveratrol" : wandb. Molecule. from_rdkit(resveratrol),
"green fluorescent protein" : wandb. Molecule. from_rdkit("2b3p.mol" ),
"acetaminophen" : wandb. Molecule. from_smiles("CC(=O)Nc1ccc(O)cc1" ),
}
)
run が終了すると、UI で分子の 3D 可視化を操作できるようになります。
AlphaFold を使用したライブ例を見る
PNG 画像
wandb.Imagenumpy 配列または PILImage の インスタンス を PNG に変換します。
wandb. log({"example" : wandb. Image(... )})
# Or multiple images
wandb. log({"example" : [wandb. Image(... ) for img in images]})
動画
動画は、wandb.Video
wandb. log({"example" : wandb. Video("myvideo.mp4" )})
これで、メディア ブラウザー で動画を表示できます。プロジェクト ワークスペース 、 run ワークスペース 、または レポート に移動し、[可視化 を追加 ] をクリックして、リッチメディア パネル を追加します。
分子の 2D 表示
wandb.Imagerdkit
molecule = rdkit. Chem. MolFromSmiles("CC(=O)O" )
rdkit. Chem. AllChem. Compute2DCoords(molecule)
rdkit. Chem. AllChem. GenerateDepictionMatching2DStructure(molecule, molecule)
pil_image = rdkit. Chem. Draw. MolToImage(molecule, size= (300 , 300 ))
wandb. log({"acetic_acid" : wandb. Image(pil_image)})
その他のメディア
W&B は、さまざまなその他のメディアタイプの ログ 記録もサポートしています。
音声
wandb. log({"whale songs" : wandb. Audio(np_array, caption= "OooOoo" , sample_rate= 32 )})
ステップごとに最大 100 個のオーディオ クリップ を ログ 記録できます。詳細な使用方法については、audio-file
動画
wandb. log({"video" : wandb. Video(numpy_array_or_path_to_video, fps= 4 , format= "gif" )})
numpy 配列が指定されている場合、次元は時間、 チャンネル 、幅、高さの順であると想定されます。デフォルトでは、4 fps の gif 画像 を作成します (ffmpegmoviepy"gif"、"mp4"、"webm"、および "ogg" です。文字列を wandb.Video に渡すと、ファイルが存在し、サポートされている形式であることをアサートしてから、wandb にアップロードします。BytesIO オブジェクト を渡すと、指定された形式を拡張子として持つ一時ファイルが作成されます。
W&B Run ページと Project ページでは、[メディア] セクションに動画が表示されます。
詳細な使用方法については、video-file
テキスト
wandb.Table を使用して、UI に表示される テーブル にテキストを ログ 記録します。デフォルトでは、列 ヘッダー は ["Input", "Output", "Expected"] です。最適な UI パフォーマンスを確保するために、デフォルトの最大行数は 10,000 に設定されています。ただし、 ユーザー は wandb.Table.MAX_ROWS = {DESIRED_MAX} を使用して、最大値を明示的にオーバーライドできます。
columns = ["Text" , "Predicted Sentiment" , "True Sentiment" ]
# Method 1
data = [["I love my phone" , "1" , "1" ], ["My phone sucks" , "0" , "-1" ]]
table = wandb. Table(data= data, columns= columns)
wandb. log({"examples" : table})
# Method 2
table = wandb. Table(columns= columns)
table. add_data("I love my phone" , "1" , "1" )
table. add_data("My phone sucks" , "0" , "-1" )
wandb. log({"examples" : table})
pandas DataFrame オブジェクト を渡すこともできます。
table = wandb. Table(dataframe= my_dataframe)
詳細な使用方法については、string
HTML
wandb. log({"custom_file" : wandb. Html(open("some.html" ))})
wandb. log({"custom_string" : wandb. Html('<a href="https://mysite">Link</a>' )})
カスタム HTML は任意の キー で ログ 記録でき、これにより、 run ページに HTML パネル が表示されます。デフォルトでは、デフォルトのスタイルが挿入されます。inject=False を渡すことで、デフォルトのスタイルをオフにすることができます。
wandb. log({"custom_file" : wandb. Html(open("some.html" ), inject= False )})
詳細な使用方法については、html-file
2.1.6.5 - Log models
モデルのログ
以下のガイドでは、モデルを W&B の run に記録し、それらを操作する方法について説明します。
以下の API は、実験管理のワークフローの一部としてモデルを追跡するのに役立ちます。このページに記載されている API を使用して、モデルを run に記録し、メトリクス、テーブル、メディア、その他のオブジェクトにアクセスします。
以下のことを行いたい場合は、W&B Artifacts を使用することをお勧めします。
モデル以外に、データセット、プロンプトなど、シリアル化されたデータのさまざまなバージョンを作成および追跡する。
W&B で追跡されるモデルまたはその他のオブジェクトのリネージグラフ を調べる。
これらのメソッドで作成されたモデル artifacts を操作する(プロパティの更新 (メタデータ、エイリアス、および説明) など)。
W&B Artifacts および高度なバージョン管理のユースケースの詳細については、Artifacts のドキュメントを参照してください。
モデルを run に記録する
指定したディレクトリー内のコンテンツを含むモデル artifact を記録するには、log_modellog_model
モデルを W&B run の入力または出力としてマークすると、モデルの依存関係とモデルの関連付けを追跡できます。W&B App UI 内でモデルのリネージを表示します。詳細については、Artifacts チャプターの アーティファクトグラフの探索とトラバース ページを参照してください。
モデルファイルが保存されているパスを path パラメーターに指定します。パスは、ローカルファイル、ディレクトリー、または s3://bucket/path などの外部バケットへの参照 URI にすることができます。
<> で囲まれた値は、独自の値に置き換えてください。
import wandb
# W&B の run を初期化します
run = wandb. init(project= "<your-project>" , entity= "<your-entity>" )
# モデルをログに記録します
run. log_model(path= "<path-to-model>" , name= "<name>" )
オプションで、name パラメーターにモデル artifact の名前を指定します。name が指定されていない場合、W&B は入力パスのベース名を run ID を先頭に付加したものを名前として使用します。
ユーザーまたは W&B がモデルに割り当てる
name を記録しておいてください。
use_model メソッドでモデルパスを取得するには、モデルの名前が必要です。
可能なパラメーターの詳細については、API Reference ガイドの log_model
例: モデルを run にログ記録する
import os
import wandb
from tensorflow import keras
from tensorflow.keras import layers
config = {"optimizer" : "adam" , "loss" : "categorical_crossentropy" }
# W&B の run を初期化します
run = wandb. init(entity= "charlie" , project= "mnist-experiments" , config= config)
# ハイパーパラメーター
loss = run. config["loss" ]
optimizer = run. config["optimizer" ]
metrics = ["accuracy" ]
num_classes = 10
input_shape = (28 , 28 , 1 )
# トレーニングアルゴリズム
model = keras. Sequential(
[
layers. Input(shape= input_shape),
layers. Conv2D(32 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Conv2D(64 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Flatten(),
layers. Dropout(0.5 ),
layers. Dense(num_classes, activation= "softmax" ),
]
)
# トレーニング用にモデルを構成する
model. compile(loss= loss, optimizer= optimizer, metrics= metrics)
# モデルを保存
model_filename = "model.h5"
local_filepath = "./"
full_path = os. path. join(local_filepath, model_filename)
model. save(filepath= full_path)
# モデルを W&B run にログ記録する
run. log_model(path= full_path, name= "MNIST" )
run. finish()
ユーザーが log_model を呼び出すと、MNIST という名前のモデル artifact が作成され、ファイル model.h5 がモデル artifact に追加されました。ターミナルまたはノートブックには、モデルがログに記録された run に関する情報を見つける場所の情報が表示されます。
View run different- surf- 5 at: https:// wandb. ai/ charlie/ mnist- experiments/ runs/ wlby6fuw
Synced 5 W& B file(s), 0 media file(s), 1 artifact file(s) and 0 other file(s)
Find logs at: ./ wandb/ run- 20231206_103511 - wlby6fuw/ logs
ログに記録されたモデルをダウンロードして使用する
以前に W&B run に記録されたモデルファイルにアクセスしてダウンロードするには、use_model
取得するモデルファイルが保存されているモデル artifact の名前を指定します。指定する名前は、既存のログに記録されたモデル artifact の名前と一致する必要があります。
log_model でファイルを最初にログに記録したときに name を定義しなかった場合、割り当てられるデフォルトの名前は、入力パスのベース名に run ID が付加されたものです。
<> で囲まれた他の値は必ず置き換えてください。
import wandb
# run を初期化します
run = wandb. init(project= "<your-project>" , entity= "<your-entity>" )
# モデルにアクセスしてダウンロードします。ダウンロードされた artifact へのパスを返します
downloaded_model_path = run. use_model(name= "<your-model-name>" )
use_model 関数は、ダウンロードされたモデルファイルのパスを返します。このモデルを後でリンクする場合は、このパスを記録しておいてください。上記のコードスニペットでは、返されたパスは downloaded_model_path という名前の変数に格納されています。
例: ログに記録されたモデルをダウンロードして使用する
たとえば、上記のコードスニペットでは、ユーザーが use_model API を呼び出しました。取得するモデル artifact の名前と、バージョン/エイリアスを指定しました。次に、API から返されたパスを downloaded_model_path 変数に格納しました。
import wandb
entity = "luka"
project = "NLP_Experiments"
alias = "latest" # モデルバージョンのセマンティックニックネームまたは識別子
model_artifact_name = "fine-tuned-model"
# run を初期化します
run = wandb. init(project= project, entity= entity)
# モデルにアクセスしてダウンロードします。ダウンロードされた artifact へのパスを返します
downloaded_model_path = run. use_model(name = f " { model_artifact_name} : { alias} " )
可能なパラメーターと戻り値の型の詳細については、API Reference ガイドの use_model
モデルをログに記録して W&B Model Registry にリンクする
link_model メソッドは、現在、間もなく非推奨になる従来の W&B Model Registry とのみ互換性があります。新しいエディションのモデルレジストリにモデル artifact をリンクする方法については、Registry の
ドキュメント を参照してください。
link_modelW&B Model Registry にリンクします。登録済みモデルが存在しない場合、W&B は registered_model_name パラメーターに指定した名前で新しいモデルを作成します。
モデルをリンクすることは、チームの他のメンバーが表示および利用できるモデルの一元化されたチームリポジトリにモデルを「ブックマーク」または「公開」することに似ています。
モデルをリンクすると、そのモデルは Registry で複製されたり、project から移動してレジストリに移動したりすることはありません。リンクされたモデルは、project 内の元のモデルへのポインターです。
Registry を使用して、タスクごとに最適なモデルを整理し、モデルライフサイクルを管理し、ML ライフサイクル全体で簡単な追跡と監査を促進し、webhook またはジョブでダウンストリームアクションを自動化 します。
Registered Model は、Model Registry 内のリンクされたモデルバージョンのコレクションまたはフォルダーです。登録済みモデルは通常、単一のモデリングユースケースまたはタスクの候補モデルを表します。
上記のコードスニペットは、link_model<> で囲まれた他の値は必ず置き換えてください。
import wandb
run = wandb. init(entity= "<your-entity>" , project= "<your-project>" )
run. link_model(path= "<path-to-model>" , registered_model_name= "<registered-model-name>" )
run. finish()
オプションのパラメーターの詳細については、API Reference ガイドの link_model
registered-model-name が Model Registry 内に既に存在する登録済みモデルの名前と一致する場合、モデルはその登録済みモデルにリンクされます。そのような登録済みモデルが存在しない場合は、新しいモデルが作成され、モデルが最初にリンクされます。
たとえば、Model Registry に "Fine-Tuned-Review-Autocompletion" という名前の既存の登録済みモデルがあるとします (例はこちら を参照)。また、いくつかのモデルバージョンが既にリンクされているとします: v0、v1、v2。link_model を registered-model-name="Fine-Tuned-Review-Autocompletion" で呼び出すと、新しいモデルはこの既存の登録済みモデルに v3 としてリンクされます。この名前の登録済みモデルが存在しない場合は、新しいモデルが作成され、新しいモデルは v0 としてリンクされます。
例: モデルをログに記録して W&B Model Registry にリンクする
たとえば、上記のコードスニペットはモデルファイルをログに記録し、モデルを登録済みモデル名 "Fine-Tuned-Review-Autocompletion" にリンクします。
これを行うには、ユーザーは link_model API を呼び出します。API を呼び出すときに、モデルのコンテンツを指すローカルファイルパス (path) と、リンク先の登録済みモデルの名前 (registered_model_name) を指定します。
import wandb
path = "/local/dir/model.pt"
registered_model_name = "Fine-Tuned-Review-Autocompletion"
run = wandb. init(project= "llm-evaluation" , entity= "noa" )
run. link_model(path= path, registered_model_name= registered_model_name)
run. finish()
リマインダー: 登録済みモデルには、ブックマークされたモデルバージョンのコレクションが格納されています。
2.1.6.6 - Log summary metrics
トレーニング中に時間とともに変化する値に加えて、モデルや前処理ステップを要約する単一の値を追跡することも重要です。この情報を W&B の Run の summary 辞書に記録します。Run の summary 辞書は、numpy 配列、PyTorch テンソル、または TensorFlow テンソルを処理できます。値がこれらの型のいずれかである場合、バイナリファイルにテンソル全体を保持し、min、平均、分散、パーセンタイルなどの高度な メトリクス を summary オブジェクトに格納します。
wandb.log で最後に記録された値は、W&B Run の summary 辞書として自動的に設定されます。summary メトリクス 辞書が変更されると、前の値は失われます。
次の コードスニペット は、カスタム summary メトリクス を W&B に提供する方法を示しています。
wandb. init(config= args)
best_accuracy = 0
for epoch in range(1 , args. epochs + 1 ):
test_loss, test_accuracy = test()
if test_accuracy > best_accuracy:
wandb. summary["best_accuracy" ] = test_accuracy
best_accuracy = test_accuracy
トレーニングが完了した後、既存の W&B Run の summary 属性を更新できます。W&B Public API を使用して、summary 属性を更新します。
api = wandb. Api()
run = api. run("username/project/run_id" )
run. summary["tensor" ] = np. random. random(1000 )
run. summary. update()
summary メトリクス のカスタマイズ
カスタム summary メトリクス は、wandb.summary でトレーニングの最適なステップでモデルのパフォーマンスをキャプチャするのに役立ちます。たとえば、最終値の代わりに、最大精度または最小損失値をキャプチャしたい場合があります。
デフォルトでは、summary は履歴からの最終値を使用します。summary メトリクス をカスタマイズするには、define_metric で summary 引数に渡します。これは、次の値を受け入れます。
"min""max""mean""best""last""none"
"best" は、オプションの objective 引数を "minimize" または "maximize" に設定した場合にのみ使用できます。
次の例では、損失と精度の最小値と最大値を summary に追加します。
import wandb
import random
random. seed(1 )
wandb. init()
# 損失の最小値と最大値のsummary値
wandb. define_metric("loss" , summary= "min" )
wandb. define_metric("loss" , summary= "max" )
# 精度に対する最小値と最大値のsummary値
wandb. define_metric("acc" , summary= "min" )
wandb. define_metric("acc" , summary= "max" )
for i in range(10 ):
log_dict = {
"loss" : random. uniform(0 , 1 / (i + 1 )),
"acc" : random. uniform(1 / (i + 1 ), 1 ),
}
wandb. log(log_dict)
summary メトリクス の表示
run の Overview ページまたは project の runs テーブルで summary 値を表示します。
Run Overview
Run Table
W&B Public API
W&B App に移動します。
Workspace タブを選択します。runs のリストから、summary 値を記録した run の名前をクリックします。
Overview タブを選択します。Summary セクションで summary 値を表示します。
W&B App に移動します。
Runs タブを選択します。runs テーブル内で、summary 値の名前に基づいて、列内の summary 値を表示できます。
W&B Public API を使用して、run の summary 値を取得できます。
次の コード例 は、W&B Public API と pandas を使用して、特定の run に記録された summary 値を取得する方法の 1 つを示しています。
import wandb
import pandas
entity = "<your-entity>"
project = "<your-project>"
run_name = "<your-run-name>" # summary 値を持つ run の名前
all_runs = []
for run in api. runs(f " { entity} / { project_name} " ):
print("Fetching details for run: " , run. id, run. name)
run_data = {
"id" : run. id,
"name" : run. name,
"url" : run. url,
"state" : run. state,
"tags" : run. tags,
"config" : run. config,
"created_at" : run. created_at,
"system_metrics" : run. system_metrics,
"summary" : run. summary,
"project" : run. project,
"entity" : run. entity,
"user" : run. user,
"path" : run. path,
"notes" : run. notes,
"read_only" : run. read_only,
"history_keys" : run. history_keys,
"metadata" : run. metadata,
}
all_runs. append(run_data)
# DataFrameに変換
df = pd. DataFrame(all_runs)
# カラム名 (run) に基づいて行を取得し、dictionary に変換します。
df[df['name' ]== run_name]. summary. reset_index(drop= True ). to_dict()
2.1.6.7 - Log tables
W&B でテーブルをログします。
wandb.Table を使用してデータをログに記録し、Weights & Biases(W&B)で視覚化およびクエリを実行します。このガイドでは、次の方法について説明します。
テーブルの作成 データの追加 データの取得 テーブルの保存
テーブルの作成
Tableを定義するには、データの各行に表示する列を指定します。各行は、トレーニングデータセット内の単一のアイテム、トレーニング中の特定のステップまたはエポック、テストアイテムに対するモデルによる予測、モデルによって生成されたオブジェクトなどです。各列には、数値、テキスト、ブール値、画像、動画、音声などの固定タイプがあります。タイプを事前に指定する必要はありません。各列に名前を付け、その型のデータのみをその列インデックスに渡してください。詳細な例については、こちらのレポート をご覧ください。
wandb.Table コンストラクターは、次の2つの方法で使用します。
行のリスト: 名前付きの列とデータの行をログに記録します。たとえば、次のコードスニペットは、2行3列のテーブルを生成します。
wandb. Table(columns= ["a" , "b" , "c" ], data= [["1a" , "1b" , "1c" ], ["2a" , "2b" , "2c" ]])
Pandas DataFrame: wandb.Table(dataframe=my_df) を使用して DataFrame をログに記録します。列名は DataFrame から抽出されます。
既存の配列またはデータフレームから
# モデルが4つの画像に対する予測を返したと仮定します
# 次のフィールドが利用可能です:
# - 画像ID
# - wandb.Image() にラップされた画像ピクセル
# - モデルの予測ラベル
# - 正解ラベル
my_data = [
[0 , wandb. Image("img_0.jpg" ), 0 , 0 ],
[1 , wandb. Image("img_1.jpg" ), 8 , 0 ],
[2 , wandb. Image("img_2.jpg" ), 7 , 1 ],
[3 , wandb. Image("img_3.jpg" ), 1 , 1 ],
]
# 対応する列を持つ wandb.Table() を作成します
columns = ["id" , "image" , "prediction" , "truth" ]
test_table = wandb. Table(data= my_data, columns= columns)
データの追加
テーブルは変更可能です。スクリプトの実行中に、最大200,000行までテーブルにデータを追加できます。テーブルにデータを追加する方法は2つあります。
行の追加 : table.add_data("3a", "3b", "3c")。新しい行はリストとして表されないことに注意してください。行がリスト形式の場合は、スター表記 * を使用して、リストを位置引数に展開します: table.add_data(*my_row_list)。行には、テーブルの列数と同じ数のエントリが含まれている必要があります。列の追加 : table.add_column(name="col_name", data=col_data)。col_data の長さは、テーブルの現在の行数と等しくなければならないことに注意してください。ここで、col_data はリストデータまたは NumPy NDArray にすることができます。
データの増分追加
このコードサンプルは、W&Bテーブルを段階的に作成および入力する方法を示しています。可能なすべてのラベルの信頼性スコアを含む、事前定義された列を持つテーブルを定義し、推論中にデータを1行ずつ追加します。runの再開時にテーブルにデータを段階的に追加する こともできます。
# 各ラベルの信頼性スコアを含む、テーブルの列を定義します
columns = ["id" , "image" , "guess" , "truth" ]
for digit in range(10 ): # 各桁 (0-9) の信頼性スコア列を追加します
columns. append(f "score_ { digit} " )
# 定義された列でテーブルを初期化します
test_table = wandb. Table(columns= columns)
# テストデータセットを反復処理し、データをテーブルに行ごとに追加します
# 各行には、画像ID、画像、予測ラベル、正解ラベル、および信頼性スコアが含まれます
for img_id, img in enumerate(mnist_test_data):
true_label = mnist_test_data_labels[img_id] # 正解ラベル
guess_label = my_model. predict(img) # 予測ラベル
test_table. add_data(
img_id, wandb. Image(img), guess_label, true_label
) # 行データをテーブルに追加します
runの再開時にデータを追加する
Artifactから既存のテーブルをロードし、データの最後の行を取得して、更新されたメトリクスを追加することにより、再開されたrunでW&Bテーブルを段階的に更新できます。次に、互換性のためにテーブルを再初期化し、更新されたバージョンをW&Bに記録します。
# アーティファクトから既存のテーブルをロードします
best_checkpt_table = wandb. use_artifact(table_tag). get(table_name)
# 再開のためにテーブルからデータの最後の行を取得します
best_iter, best_metric_max, best_metric_min = best_checkpt_table. data[- 1 ]
# 必要に応じて最適なメトリクスを更新します
# 更新されたデータをテーブルに追加します
best_checkpt_table. add_data(best_iter, best_metric_max, best_metric_min)
# 互換性を確保するために、更新されたデータでテーブルを再初期化します
best_checkpt_table = wandb. Table(
columns= ["col1" , "col2" , "col3" ], data= best_checkpt_table. data
)
# 更新されたテーブルを Weights & Biases に記録します
wandb. log({table_name: best_checkpt_table})
データの取得
データがTableにある場合、列または行でアクセスします。
行イテレーター : ユーザーは、for ndx, row in table.iterrows(): ... などのTableの行イテレーターを使用して、データの行を効率的に反復処理できます。列の取得 : ユーザーは、table.get_column("col_name") を使用してデータの列を取得できます。便宜上、ユーザーは convert_to="numpy" を渡して、列をプリミティブの NumPy NDArray に変換できます。これは、列に wandb.Image などのメディアタイプが含まれている場合に、基になるデータに直接アクセスできるようにする場合に役立ちます。
テーブルの保存
スクリプトでデータのテーブル(たとえば、モデル予測のテーブル)を生成したら、結果をライブで視覚化するために、W&Bに保存します。
テーブルをrunに記録する
wandb.log() を使用して、次のようにテーブルをrunに保存します。
run = wandb. init()
my_table = wandb. Table(columns= ["a" , "b" ], data= [["1a" , "1b" ], ["2a" , "2b" ]])
run. log({"table_key" : my_table})
テーブルが同じキーに記録されるたびに、テーブルの新しいバージョンが作成され、バックエンドに保存されます。これは、モデルの予測が時間の経過とともにどのように改善されるかを確認したり、同じキーに記録されている限り、異なるrun間でテーブルを比較したりするために、複数のトレーニングステップで同じテーブルを記録できることを意味します。最大200,000行をログに記録できます。
200,000行を超える行をログに記録するには、次の制限をオーバーライドできます。
wandb.Table.MAX_ARTIFACT_ROWS = X
ただし、これにより、UIでのクエリの遅延など、パフォーマンスの問題が発生する可能性があります。
プログラムでテーブルにアクセスする
バックエンドでは、Tables は Artifacts として保持されます。特定のバージョンにアクセスする場合は、Artifact API を使用してアクセスできます。
with wandb. init() as run:
my_table = run. use_artifact("run-<run-id>-<table-name>:<tag>" ). get("<table-name>" )
Artifactsの詳細については、開発者ガイドのArtifactsチャプター を参照してください。
テーブルの視覚化
このように記録されたテーブルは、runページとプロジェクトページの両方の Workspace に表示されます。詳細については、テーブルの視覚化と分析 を参照してください。
Artifact テーブル
artifact.add() を使用して、ワークスペースではなく、runの Artifacts セクションにテーブルをログに記録します。これは、一度ログに記録して、将来のrunで参照するデータセットがある場合に役立ちます。
run = wandb. init(project= "my_project" )
# 意味のあるステップごとに wandb Artifact を作成します
test_predictions = wandb. Artifact("mnist_test_preds" , type= "predictions" )
# [上記のように予測データを構築します]
test_table = wandb. Table(data= data, columns= columns)
test_predictions. add(test_table, "my_test_key" )
run. log_artifact(test_predictions)
画像データを使用した artifact.add() の詳細な例 と、Artifacts と Tables を使用して 表形式データのバージョン管理と重複排除を行う方法 の例については、このレポートを参照してください。
Artifact テーブルの結合
ローカルで構築したテーブル、または他の Artifacts から取得したテーブルを wandb.JoinedTable(table_1, table_2, join_key) を使用して結合できます。
引数
説明
table_1
(str, wandb.Table, ArtifactEntry) Artifact 内の wandb.Table へのパス、テーブルオブジェクト、または ArtifactEntry
table_2
(str, wandb.Table, ArtifactEntry) Artifact 内の wandb.Table へのパス、テーブルオブジェクト、または ArtifactEntry
join_key
(str, [str, str]) 結合を実行するキー
Artifact コンテキストで以前に記録した2つの Tables を結合するには、Artifact からそれらを取得し、結果を新しい Table に結合します。
たとえば、'original_songs' という元の曲の Table と、同じ曲の合成バージョンの別の Table 'synth_songs' を読み取る方法を示します。次のコード例では、2つのテーブルを "song_id" で結合し、結果のテーブルを新しい W&B Table としてアップロードします。
import wandb
run = wandb. init(project= "my_project" )
# 元の曲のテーブルを取得します
orig_songs = run. use_artifact("original_songs:latest" )
orig_table = orig_songs. get("original_samples" )
# 合成された曲のテーブルを取得します
synth_songs = run. use_artifact("synth_songs:latest" )
synth_table = synth_songs. get("synth_samples" )
# テーブルを "song_id" で結合します
join_table = wandb. JoinedTable(orig_table, synth_table, "song_id" )
join_at = wandb. Artifact("synth_summary" , "analysis" )
# テーブルを Artifact に追加し、W&B に記録します
join_at. add(join_table, "synth_explore" )
run. log_artifact(join_at)
異なる Artifact オブジェクトに保存されている2つの以前に保存されたテーブルを結合する方法の例については、このチュートリアル を参照してください。
2.1.6.8 - Track CSV files with experiments
W&B へのデータのインポートとログ記録
W&B Python Library を使用して CSV ファイルをログに記録し、W&B Dashboard で可視化します。 W&B Dashboard は、機械学習モデルの結果を整理して可視化するための中央の場所です。これは、W&B にログ記録されていない以前の機械学習実験の情報を含む CSV ファイル がある場合、またはデータセットを含む CSV ファイル がある場合に特に役立ちます。
データセットのCSVファイルをインポートしてログに記録する
CSV ファイルの内容を再利用しやすくするために、W&B Artifacts を利用することをお勧めします。
まず、CSV ファイルをインポートします。次のコードスニペットで、iris.csv ファイル名を CSV ファイルの名前に置き換えます。
import wandb
import pandas as pd
# Read our CSV into a new DataFrame
new_iris_dataframe = pd. read_csv("iris.csv" )
CSV ファイルを W&B テーブルに変換して、W&B Dashboards を利用します。
# Convert the DataFrame into a W&B Table
iris_table = wandb. Table(dataframe= new_iris_dataframe)
次に、W&B Artifact を作成し、テーブルを Artifact に追加します。
# Add the table to an Artifact to increase the row
# limit to 200000 and make it easier to reuse
iris_table_artifact = wandb. Artifact("iris_artifact" , type= "dataset" )
iris_table_artifact. add(iris_table, "iris_table" )
# Log the raw csv file within an artifact to preserve our data
iris_table_artifact. add_file("iris.csv" )
W&B Artifacts の詳細については、Artifacts のチャプター を参照してください。
最後に、wandb.init で W&B Run を開始し、W&B に追跡およびログを記録します。
# Start a W&B run to log data
run = wandb. init(project= "tables-walkthrough" )
# Log the table to visualize with a run...
run. log({"iris" : iris_table})
# and Log as an Artifact to increase the available row limit!
run. log_artifact(iris_table_artifact)
wandb.init() API は、Run にデータをログ記録するための新しいバックグラウンド プロセスを生成し、(デフォルトで) データを wandb.ai に同期します。 W&B Workspace Dashboard でライブ可視化を表示します。次の画像は、コードスニペットのデモの出力を示しています。
上記のコードスニペットを含む完全なスクリプトは、以下にあります。
import wandb
import pandas as pd
# Read our CSV into a new DataFrame
new_iris_dataframe = pd. read_csv("iris.csv" )
# Convert the DataFrame into a W&B Table
iris_table = wandb. Table(dataframe= new_iris_dataframe)
# Add the table to an Artifact to increase the row
# limit to 200000 and make it easier to reuse
iris_table_artifact = wandb. Artifact("iris_artifact" , type= "dataset" )
iris_table_artifact. add(iris_table, "iris_table" )
# log the raw csv file within an artifact to preserve our data
iris_table_artifact. add_file("iris.csv" )
# Start a W&B run to log data
run = wandb. init(project= "tables-walkthrough" )
# Log the table to visualize with a run...
run. log({"iris" : iris_table})
# and Log as an Artifact to increase the available row limit!
run. log_artifact(iris_table_artifact)
# Finish the run (useful in notebooks)
run. finish()
Experiments の CSV ファイルをインポートしてログに記録する
場合によっては、CSV ファイルに experiment の詳細が含まれている場合があります。このような CSV ファイルにある一般的な詳細は次のとおりです。
Experiment
Model Name
Notes
Tags
Num Layers
Final Train Acc
Final Val Acc
Training Losses
Experiment 1
mnist-300-layers
Overfit way too much on training data
[latest]
300
0.99
0.90
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
Experiment 2
mnist-250-layers
Current best model
[prod, best]
250
0.95
0.96
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
Experiment 3
mnist-200-layers
Did worse than the baseline model. Need to debug
[debug]
200
0.76
0.70
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
…
…
…
…
…
…
…
Experiment N
mnist-X-layers
NOTES
…
…
…
…
[…, …]
W&B は、experiments の CSV ファイルを取得し、W&B Experiment Run に変換できます。次のコードスニペットとコードスクリプトは、experiments の CSV ファイルをインポートしてログに記録する方法を示しています。
まず、CSV ファイルを読み込み、Pandas DataFrame に変換します。 experiments.csv を CSV ファイルの名前に置き換えます。
import wandb
import pandas as pd
FILENAME = "experiments.csv"
loaded_experiment_df = pd. read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers" ]
SUMMARY_COLS = ["Final Train Acc" , "Final Val Acc" ]
METRIC_COLS = ["Training Losses" ]
# Format Pandas DataFrame to make it easier to work with
for i, row in loaded_experiment_df. iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
次に、wandb.init()
run = wandb. init(
project= PROJECT_NAME, name= run_name, tags= tags, notes= notes, config= config
)
experiment の実行中に、W&B で表示、クエリ、および分析できるように、メトリクスのすべてのインスタンスをログに記録することができます。これを行うには、run.log()
オプションで、run の結果を定義するために、最終的なサマリーメトリクスをログに記録できます。これを行うには、W&B define_metricrun.summary.update() を使用して、サマリーメトリクスを run に追加します。
run. summary. update(summaries)
サマリーメトリクスの詳細については、サマリーメトリクスのログ記録 を参照してください。
以下は、上記のサンプルテーブルを W&B Dashboard に変換する完全なスクリプトの例です。
FILENAME = "experiments.csv"
loaded_experiment_df = pd. read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers" ]
SUMMARY_COLS = ["Final Train Acc" , "Final Val Acc" ]
METRIC_COLS = ["Training Losses" ]
for i, row in loaded_experiment_df. iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
run = wandb. init(
project= PROJECT_NAME, name= run_name, tags= tags, notes= notes, config= config
)
for key, val in metrics. items():
if isinstance(val, list):
for _val in val:
run. log({key: _val})
else :
run. log({key: val})
run. summary. update(summaries)
run. finish()
2.1.7 - Track Jupyter notebooks
Jupyter で W&B を使用して、 ノートブック から離れることなくインタラクティブな 可視化 を取得できます。
Jupyter で W&B を使用すると、ノートブックから離れることなくインタラクティブな可視化を得ることができます。カスタムの 分析 、 実験 、プロトタイプを組み合わせて、すべて完全に ログ に記録します。
Jupyter ノートブック で W&B を使用する ユースケース
**反復的な 実験 **: パラメータを調整しながら 実験 を実行および再実行すると、手動でメモを取らなくても、実行したすべての run が W&B に自動的に保存されます。
コード の保存 : モデル を再現する際、ノートブック のどのセルがどの順序で実行されたかを知ることは困難です。 設定 ページ で コード の保存をオンにすると、各 実験 のセル実行の記録が保存されます。**カスタム 分析 **: run が W&B に ログ されると、API からデータフレームを取得してカスタム 分析 を実行し、それらの 結果 を W&B に ログ して レポート で保存および共有することが簡単になります。
ノートブック での始め方
次の コード でノートブックを開始して W&B をインストールし、アカウントをリンクします。
!pip install wandb -qqq
import wandb
wandb.login()
次に、 実験 を設定し、 ハイパーパラメータ を保存します。
wandb. init(
project= "jupyter-projo" ,
config= {
"batch_size" : 128 ,
"learning_rate" : 0.01 ,
"dataset" : "CIFAR-100" ,
},
)
wandb.init() を実行した後、%%wandb を使用して新しいセルを開始すると、ノートブック にライブグラフが表示されます。このセルを複数回実行すると、データが run に追加されます。
%%wandb
# Your training loop here
# ここにトレーニングループを記述します
このサンプルノートブック でお試しください。
ノートブック でライブ W&B インターフェースを直接レンダリングする
%wandb マジックを使用して、既存の ダッシュボード 、 Sweeps 、または Reports をノートブック で直接表示することもできます。
# Display a project workspace
# プロジェクトワークスペースを表示する
%wandb USERNAME/PROJECT
# Display a single run
# 単一のrunを表示する
%wandb USERNAME/PROJECT/runs/RUN_ID
# Display a sweep
# sweepを表示する
%wandb USERNAME/PROJECT/sweeps/SWEEP_ID
# Display a report
# reportを表示する
%wandb USERNAME/PROJECT/reports/REPORT_ID
# Specify the height of embedded iframe
# 埋め込みiframeの高さを指定する
%wandb USERNAME/PROJECT -h 2048
%%wandb または %wandb マジックの代わりに、wandb.init() を実行した後、wandb.run で任意のセルを終了してインライングラフを表示するか、API から返された report 、 sweep 、または run オブジェクトで ipython.display(...) を呼び出すことができます。
# Initialize wandb.run first
# 最初にwandb.runを初期化します
wandb. init()
# If cell outputs wandb.run, you'll see live graphs
# セルがwandb.runを出力する場合、ライブグラフが表示されます
wandb. run
W&B の追加の Jupyter 機能
Colab での簡単な認証 : Colab で wandb.init を初めて呼び出すと、ブラウザで W&B に現在 ログイン している場合、 ランタイム が自動的に認証されます。run ページの Overviewタブ に、Colab へのリンクが表示されます。Jupyter Magic: ダッシュボード 、 Sweeps 、および Reports をノートブック で直接表示します。%wandb マジックは、 プロジェクト 、 Sweeps 、または Reports へのパスを受け入れ、W&B インターフェースをノートブック で直接レンダリングします。docker コンテナ 化された Jupyter の Launch : wandb docker --jupyter を呼び出して dockerコンテナ を起動し、 コード をマウントし、Jupyter がインストールされていることを確認して、ポート 8888 で起動します。恐れることなく任意の順序でセルを実行する : デフォルトでは、run を finished としてマークするために、次に wandb.init が呼び出されるまで待機します。これにより、複数のセル(たとえば、データをセットアップするセル、 トレーニング するセル、テストするセル)を好きな順序で実行し、すべて同じ run に ログ できます。 設定 で コード の保存をオンにすると、実行されたセルも、実行された順序と実行された状態で ログ に記録され、最も非線形の パイプライン でも再現できます。Jupyter ノートブック で run を手動で完了としてマークするには、run.finish を呼び出します。
import wandb
run = wandb. init()
# training script and logging goes here
# ここにトレーニングスクリプトとロギングを記述します
run. finish()
2.1.8 - Experiments limits and performance
推奨される範囲内で ログ を記録することで、W&B のページをより速く、より応答性の高い状態に保つことができます。
以下の推奨範囲内でログを記録することで、W&B 内のページをより高速かつ応答性の高い状態に保つことができます。
ログ記録に関する考慮事項
wandb.log を使用して実験 メトリクス を追跡します。記録された メトリクス は、グラフを生成し、 テーブル に表示されます。ログに記録するデータが多すぎると、アプリケーションの動作が遅くなる可能性があります。
個別のメトリクス数
パフォーマンスを向上させるには、 プロジェクト 内の個別の メトリクス の合計数を 10,000 未満に抑えてください。
import wandb
wandb. log(
{
"a" : 1 , # "a" は個別のメトリクス
"b" : {
"c" : "hello" , # "b.c" は個別のメトリクス
"d" : [1 , 2 , 3 ], # "b.d" は個別のメトリクス
},
}
)
W&B は、ネストされた 値 を自動的にフラット化します。つまり、 辞書 を渡すと、W&B はそれをドットで区切られた 名前に変換します。 config 値 の場合、W&B は 名前に 3 つのドットをサポートします。 summary 値 の場合、W&B は 4 つのドットをサポートします。
ワークスペース の動作が突然遅くなった場合は、最近の runs が意図せずに数千もの新しい メトリクス を記録していないか確認してください。(これは、数千ものプロットがあるセクションで、表示されている run が 1 つまたは 2 つしかないことで簡単に見つけることができます。)記録されている場合は、それらの runs を削除し、目的の メトリクス で再作成することを検討してください。
値 の幅
ログに記録する単一の 値 のサイズを 1 MB 未満に、単一の wandb.log 呼び出しの合計サイズを 25 MB 未満に制限します。この制限は、wandb.Image、wandb.Audio などの wandb.Media タイプには適用されません。
# ❌ 推奨されません
wandb. log({"wide_key" : range(10000000 )})
# ❌ 推奨されません
with f as open("large_file.json" , "r" ):
large_data = json. load(f)
wandb. log(large_data)
幅の広い 値 は、幅の広い 値 を持つ メトリクス だけでなく、run 内のすべての メトリクス のプロットの読み込み時間に影響を与える可能性があります。
推奨量よりも幅の広い 値 をログに記録した場合でも、データは保存および追跡されます。ただし、プロットの読み込みが遅くなる可能性があります。
メトリクス の頻度
ログに記録する メトリクス に適切なログ記録頻度を選択してください。一般的な経験則として、 メトリクス の幅が広いほど、ログに記録する頻度を低くする必要があります。W&B は以下を推奨します。
スカラー: メトリクス ごとに <100,000 ログポイント
メディア: メトリクス ごとに <50,000 ログポイント
ヒストグラム: メトリクス ごとに <10,000 ログポイント
# 合計 100 万ステップのトレーニングループ
for step in range(1000000 ):
# ❌ 推奨されません
wandb. log(
{
"scalar" : step, # 100,000 スカラー
"media" : wandb. Image(... ), # 100,000 画像
"histogram" : wandb. Histogram(... ), # 100,000 ヒストグラム
}
)
# ✅ 推奨
if step % 1000 == 0 :
wandb. log(
{
"histogram" : wandb. Histogram(... ), # 10,000 ヒストグラム
},
commit= False ,
)
if step % 200 == 0 :
wandb. log(
{
"media" : wandb. Image(... ), # 50,000 画像
},
commit= False ,
)
if step % 100 == 0 :
wandb. log(
{
"scalar" : step, # 100,000 スカラー
},
commit= True ,
) # バッチ処理されたステップごとのメトリクスをまとめてコミット
ガイドラインを超えても、W&B はログに記録されたデータを受け入れ続けますが、ページ の読み込みが遅くなる場合があります。
Config サイズ
run config の合計サイズを 10 MB 未満に制限します。大きい 値 をログに記録すると、 プロジェクト ワークスペース と runs テーブル の操作が遅くなる可能性があります。
# ✅ 推奨
wandb. init(
config= {
"lr" : 0.1 ,
"batch_size" : 32 ,
"epochs" : 4 ,
}
)
# ❌ 推奨されません
wandb. init(
config= {
"steps" : range(10000000 ),
}
)
# ❌ 推奨されません
with f as open("large_config.json" , "r" ):
large_config = json. load(f)
wandb. init(config= large_config)
ワークスペース に関する考慮事項
Run count
読み込み時間を短縮するには、単一の プロジェクト 内の runs の合計数を以下に抑えてください。
SaaS Cloud で 100,000
専用クラウド または 自己管理 で 10,000
これらのしきい値を超える run カウントは、 プロジェクト ワークスペース または runs テーブル を含む操作、特に runs の グルーピング 時、または runs 中に多数の個別の メトリクス を収集する場合に、速度が低下する可能性があります。メトリクス 数 セクションも参照してください。
チームが頻繁に同じ runs のセット(最近の runs のセットなど)に アクセス する場合は、あまり頻繁に使用されない runs をまとめて移動する ことを検討して、新しい「アーカイブ」 プロジェクト に移動し、作業 プロジェクト にはより少ない runs のセットを残します。
ワークスペース のパフォーマンス
このセクションでは、 ワークスペース のパフォーマンスを最適化するためのヒントを紹介します。
パネル 数
デフォルトでは、 ワークスペース は 自動 であり、ログに記録された キー ごとに標準 パネル を生成します。大規模な プロジェクト の ワークスペース に、ログに記録された多くの キー の パネル が含まれている場合、 ワークスペース の読み込みと使用に時間がかかる場合があります。パフォーマンスを向上させるには、次のことができます。
ワークスペース を手動モードにリセットします。これには、デフォルトで パネル が含まれていません。
クイック追加 を使用して、視覚化する必要があるログに記録された キー の パネル を選択的に追加します。
未使用の パネル を 1 つずつ削除しても、パフォーマンスへの影響はほとんどありません。代わりに、 ワークスペース をリセットし、必要な パネル のみを選択的に追加し直します。
ワークスペース の構成の詳細については、パネル を参照してください。
セクション 数
ワークスペース 内に数百ものセクションがあると、パフォーマンスが低下する可能性があります。 メトリクス の高レベルの グルーピング に基づいてセクションを作成し、 メトリクス ごとに 1 つのセクションというアンチパターンを避けることを検討してください。
セクションが多すぎてパフォーマンスが低下している場合は、サフィックスではなくプレフィックスでセクションを作成するように ワークスペース 設定を検討してください。これにより、セクションの数が減り、パフォーマンスが向上する可能性があります。
メトリクス 数
run あたり 5000 ~ 100,000 個の メトリクス をログに記録する場合は、W&B は手動 ワークスペース を使用することをお勧めします。手動モードでは、さまざまな メトリクス のセットを探索するために、必要に応じて パネル を簡単に追加および削除できます。より集中的なプロットのセットを使用すると、 ワークスペース の読み込みが速くなります。プロットされていない メトリクス は、通常どおり収集および保存されます。
ワークスペース を手動モードにリセットするには、 ワークスペース のアクション ... メニューをクリックし、ワークスペース のリセット をクリックします。ワークスペース をリセットしても、runs の保存された メトリクス には影響しません。ワークスペース の管理の詳細 をご覧ください。
ファイル 数
単一の run でアップロードされるファイルの総数を 1,000 未満に抑えてください。多数の ファイル をログに記録する必要がある場合は、W&B Artifacts を使用できます。単一の run で 1,000 個を超える ファイル があると、run ページ の速度が低下する可能性があります。
Reports と ワークスペース
レポート は、 パネル 、テキスト、 メディア の任意の配置を自由に構成できるため、同僚と洞察を簡単に共有できます。
対照的に、 ワークスペース では、数百から数十万もの runs にわたって、数十から数千もの メトリクス を高密度かつ高性能に 分析 できます。ワークスペース には、 Reports と比較して、最適化された キャッシュ 、クエリ、および読み込み機能があります。ワークスペース は、主に プレゼンテーション ではなく 分析 に使用される プロジェクト 、または 20 個以上のプロットをまとめて表示する必要がある場合にお勧めです。
Python スクリプト のパフォーマンス
Python スクリプト のパフォーマンスが低下する原因はいくつかあります。
データ のサイズが大きすぎる。データ サイズが大きいと、トレーニングループに 1 ミリ秒を超えるオーバーヘッドが発生する可能性があります。
ネットワーク の速度と、W&B バックエンド の構成方法
wandb.log を 1 秒間に数回以上呼び出す。これは、wandb.log が呼び出されるたびに、トレーニングループにわずかな遅延が追加されるためです。
頻繁なログ記録により、トレーニング runs が遅くなっていませんか?ログ記録戦略を変更してパフォーマンスを向上させる方法については、
この Colab を参照してください。
W&B は、レート制限を超える制限は一切主張しません。W&B Python SDK は、制限を超える要求に対して、指数関数的な「バックオフ」および「再試行」要求を自動的に完了します。W&B Python SDK は、 コマンドライン で「ネットワーク 障害 」で応答します。無償アカウントの場合、W&B は、使用量が合理的なしきい値を超える極端な場合に連絡する場合があります。
レート制限
W&B SaaS Cloud API は、システムの整合性を維持し、可用性を確保するために、レート制限を実装しています。この対策により、単一の ユーザー が共有 インフラストラクチャー で利用可能なリソースを独占することを防ぎ、すべての ユーザー がサービスに アクセス できる状態を維持します。さまざまな理由で、より低いレート制限が発生する可能性があります。
レート制限は変更される可能性があります。
レート制限 HTTP ヘッダー
上記の テーブル は、レート制限 HTTP ヘッダー を示しています。
ヘッダー 名
説明
RateLimit-Limit
1 つの時間枠で使用可能な クォータ 量。0 ~ 1000 の範囲でスケーリングされます。
RateLimit-Remaining
現在のレート制限ウィンドウの クォータ 量。0 ~ 1000 の範囲でスケーリングされます。
RateLimit-Reset
現在の クォータ がリセットされるまでの秒数
メトリクス ログ記録 API のレート制限
スクリプト 内の wandb.log 呼び出しは、 メトリクス ログ記録 API を利用して、トレーニングデータ を W&B にログ記録します。この API は、オンラインまたはオフライン同期 のいずれかを通じて実行されます。いずれの場合も、ローリングタイムウィンドウでレート制限 クォータ 制限が課されます。これには、合計リクエストサイズとリクエストレートの制限が含まれます。後者は、ある時間の長さにおけるリクエスト数を示します。
W&B は、W&B プロジェクト ごとにレート制限を適用します。したがって、チームに 3 つの プロジェクト がある場合、各 プロジェクト には独自のレート制限 クォータ があります。チーム および エンタープライズ プラン の ユーザー は、無料 プラン の ユーザー よりも高いレート制限があります。
メトリクス ログ記録 API の使用中にレート制限に達すると、標準出力に エラー を示す関連 メッセージ が表示されます。
メトリクス ログ記録 API レート制限を下回るための推奨事項
レート制限を超えると、レート制限がリセットされるまで run.finish() が遅延する可能性があります。これを回避するには、次の戦略を検討してください。
W&B Python SDK バージョン を更新する: 最新バージョンの W&B Python SDK を使用していることを確認します。W&B Python SDK は定期的に更新され、要求を正常に再試行し、 クォータ の使用を最適化するための拡張 メカニズム が含まれています。
メトリクス ログ記録頻度を下げる:
クォータ を節約するために、 メトリクス のログ記録頻度を最小限に抑えます。たとえば、epoch ごとに メトリクス をログ記録するのではなく、5 epoch ごとにログ記録するように コード を変更できます。
if epoch % 5 == 0 : # 5 epoch ごとにメトリクスをログ記録する
wandb. log({"acc" : accuracy, "loss" : loss})
手動データ 同期: レート制限されている場合、W&B は run データ をローカル に保存します。 コマンド wandb sync <run-file-path> を使用して、データを手動で同期できます。詳細については、wandb sync
GraphQL API のレート制限
W&B Models UI および SDK のパブリック API は、GraphQL リクエスト を サーバー に送信して、データのクエリと変更を行います。SaaS Cloud 内のすべての GraphQL リクエスト について、W&B は、承認されていないリクエスト の場合は IP アドレス ごとに、承認されているリクエスト の場合は ユーザー ごとにレート制限を適用します。制限は、固定された時間枠内のリクエストレート(1 秒あたりのリクエスト数)に基づいており、料金 プラン によってデフォルトの制限が決定されます。 プロジェクト パス (たとえば、 Reports 、 runs 、 Artifacts )を指定する関連 SDK リクエスト の場合、W&B は プロジェクト ごとにレート制限を適用します。これは、データベース のクエリ時間によって測定されます。
チーム および エンタープライズ プラン の ユーザー は、無料 プラン の ユーザー よりも高いレート制限を受け取ります。
W&B Models SDK のパブリック API の使用中にレート制限に達すると、標準出力に エラー を示す関連 メッセージ が表示されます。
GraphQL API レート制限を下回るための推奨事項
W&B Models SDK のパブリック API を使用して大量のデータを フェッチ する場合は、リクエスト の間に少なくとも 1 秒待機することを検討してください。429 ステータス コード を受信した場合、または応答ヘッダー に RateLimit-Remaining=0 が表示された場合は、再試行する前に RateLimit-Reset で指定された秒数待機します。
ブラウザ に関する考慮事項
W&B アプリ は メモリ を大量に消費する可能性があり、Chrome で最高のパフォーマンスを発揮します。コンピューター の メモリ に応じて、W&B を 3 つ以上の タブ で同時にアクティブにすると、パフォーマンスが低下する可能性があります。予期しないパフォーマンスの低下が発生した場合は、他の タブ または アプリケーション を閉じることを検討してください。
W&B へのパフォーマンス問題の報告
W&B はパフォーマンスを重視しており、遅延のすべての レポート を調査します。調査を迅速化するために、読み込み時間が遅いことを報告する場合は、主要な メトリクス とパフォーマンス イベント をキャプチャする W&B の組み込みパフォーマンスロガーの呼び出しを検討してください。読み込みが遅い ページ に URL パラメータ &PERF_LOGGING を追加し、コンソール の出力をアカウントチームまたは サポート と共有します。
2.1.9 - Reproduce experiments
チームメンバーが作成した実験を再現して、その結果を検証します。
実験を再現する前に、以下をメモする必要があります。
run が記録された project の名前
再現したい run の名前
実験を再現するには:
run が記録されている project に移動します。
左側のサイドバーで [Workspace ] タブを選択します。
run のリストから、再現する run を選択します。
[概要 ] をクリックします。
次に、特定のハッシュで実験の コード をダウンロードするか、実験の リポジトリ 全体をクローンします。
Python スクリプトまたは notebook のダウンロード
GitHub
実験の Python スクリプトまたは notebook をダウンロードします。
[Command ] フィールドで、実験を作成したスクリプトの名前をメモします。
左側の ナビゲーションバー で [Code ] タブを選択します。
スクリプトまたは notebook に対応するファイルの横にある [ダウンロード ] をクリックします。
チームメイトが実験の作成に使用した GitHub リポジトリをクローンします。これを行うには:
必要に応じて、チームメイトが実験の作成に使用した GitHub リポジトリへの アクセス権 を取得します。
[Git リポジトリ ] フィールドをコピーします。ここには GitHub リポジトリの URL が含まれています。
リポジトリをクローンします。
git clone https://github.com/your-repo.git && cd your-repo
[Git state ] フィールドをコピーして ターミナル に貼り付けます。Git state は、チームメイトが実験の作成に使用した正確なコミットをチェックアウトする一連の Git コマンドです。上記の コードスニペット で指定された 値 を独自の値に置き換えます。
git checkout -b "<run-name>" 0123456789012345678901234567890123456789
左側の ナビゲーションバー で [ファイル ] を選択します。
requirements.txt ファイルをダウンロードして、作業 ディレクトリー に保存します。この ディレクトリー には、クローンされた GitHub リポジトリ、またはダウンロードされた Python スクリプトまたは notebook のいずれかが含まれている必要があります。
(推奨)Python 仮想 環境 を作成します。
requirements.txt ファイルで指定された 要件 をインストールします。
pip install -r requirements.txt
コード と依存関係が揃ったので、スクリプトまたは notebook を実行して実験を再現できます。リポジトリをクローンした場合は、スクリプトまたは notebook がある ディレクトリー に移動する必要がある場合があります。それ以外の場合は、作業 ディレクトリー からスクリプトまたは notebook を実行できます。
Python notebook
Python スクリプト
Python notebook をダウンロードした場合は、notebook をダウンロードした ディレクトリー に移動し、ターミナル で次の コマンド を実行します。
Python スクリプトをダウンロードした場合は、スクリプトをダウンロードした ディレクトリー に移動し、ターミナル で次の コマンド を実行します。<> で囲まれた 値 は独自の値に置き換えてください。
python <your-script-name>.py
2.1.10 - Import and export data
MLFlow から<について>データ をインポートしたり、W&B に保存した<について>データ をエクスポートまたは更新したりします。
W&B Public API を使用して、データのエクスポートまたはデータのインポートを行います。
この機能には python>=3.8 が必要です。
MLFlow からのデータのインポート
W&B は、実験、run、Artifacts、メトリクス、その他のメタデータなど、MLFlow からのデータのインポートをサポートしています。
依存関係をインストールします。
# 注:これには py38+ が必要です
pip install wandb[ importers]
W&B にログインします。以前にログインしていない場合は、プロンプトに従ってください。
既存の MLFlow サーバーからすべての run をインポートします。
from wandb.apis.importers.mlflow import MlflowImporter
importer = MlflowImporter(mlflow_tracking_uri= "..." )
runs = importer. collect_runs()
importer. import_runs(runs)
デフォルトでは、importer.collect_runs() は MLFlow サーバーからすべての run を収集します。特定のサブセットをアップロードする場合は、独自の run イテラブルを作成してインポーターに渡すことができます。
import mlflow
from wandb.apis.importers.mlflow import MlflowRun
client = mlflow. tracking. MlflowClient(mlflow_tracking_uri)
runs: Iterable[MlflowRun] = []
for run in mlflow_client. search_runs(... ):
runs. append(MlflowRun(run, client))
importer. import_runs(runs)
Databricks MLFlow からインポートする場合は、最初にDatabricks CLI を構成する 必要がある場合があります。
前のステップで mlflow-tracking-uri="databricks" を設定します。
Artifacts のインポートをスキップするには、artifacts=False を渡します。
importer. import_runs(runs, artifacts= False )
特定の W&B entity と project にインポートするには、Namespace を渡します。
from wandb.apis.importers import Namespace
importer. import_runs(runs, namespace= Namespace(entity, project))
データのエクスポート
Public API を使用して、W&B に保存したデータをエクスポートまたは更新します。この API を使用する前に、スクリプトからデータをログに記録します。詳細については、クイックスタート を確認してください。
Public API のユースケース
データのエクスポート : Jupyter Notebook でカスタム分析を行うためのデータフレームをプルダウンします。データを調べたら、新しい分析 run を作成して結果をログに記録することで、調査結果を同期できます。例:wandb.init(job_type="analysis")既存の Runs の更新 : W&B run に関連してログに記録されたデータを更新できます。たとえば、アーキテクチャや最初にログに記録されなかったハイパーパラメーターなど、追加情報を含めるように一連の run の config を更新したい場合があります。
利用可能な機能の詳細については、生成されたリファレンスドキュメント を参照してください。
APIキーの作成
APIキーは、W&B に対するマシンの認証を行います。APIキーは、ユーザープロファイルから生成できます。
右上隅にあるユーザープロファイルアイコンをクリックします。
ユーザー設定 を選択し、APIキー セクションまでスクロールします。表示 をクリックします。表示された APIキーをコピーします。APIキーを非表示にするには、ページをリロードします。
run パスの検索
Public API を使用するには、run パス <entity>/<project>/<run_id> が必要になることがよくあります。アプリ UI で、run ページを開き、Overviewタブ をクリックして、run パスを取得します。
Run データのエクスポート
完了した run またはアクティブな run からデータをダウンロードします。一般的な使用法としては、Jupyter ノートブックでカスタム分析を行うためのデータフレームのダウンロードや、自動化された環境でのカスタムロジックの使用などがあります。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run オブジェクトの最も一般的に使用される属性は次のとおりです。
属性
意味
run.configトレーニング run のハイパーパラメーターや、データセット Artifact を作成する run の前処理メソッドなど、run の設定情報の辞書。これらを実行の入力と考えてください。
run.history()損失など、モデルのトレーニング中に変化する値を格納するための辞書のリスト。コマンド wandb.log() はこのオブジェクトに追加されます。
run.summaryrun の結果をまとめた情報の辞書。これには、精度や損失などのスカラーや、大きなファイルを含めることができます。デフォルトでは、wandb.log() は summary をログに記録された時系列の最終値に設定します。summary の内容は直接設定することもできます。summary を run の出力と考えてください。
過去の run のデータを変更または更新することもできます。デフォルトでは、api オブジェクトの単一インスタンスがすべてのネットワークリクエストをキャッシュします。ユースケースで実行中のスクリプトでリアルタイムの情報が必要な場合は、api.flush() を呼び出して更新された値を取得します。
さまざまな属性について
以下の run について
n_epochs = 5
config = {"n_epochs" : n_epochs}
run = wandb. init(project= project, config= config)
for n in range(run. config. get("n_epochs" )):
run. log(
{"val" : random. randint(0 , 1000 ), "loss" : (random. randint(0 , 1000 ) / 1000.00 )}
)
run. finish()
これらは、上記の run オブジェクト属性のさまざまな出力です。
run.configrun.history() _step val loss _runtime _timestamp
0 0 500 0.244 4 1644345412
1 1 45 0.521 4 1644345412
2 2 240 0.785 4 1644345412
3 3 31 0.305 4 1644345412
4 4 525 0.041 4 1644345412
run.summary{
"_runtime" : 4 ,
"_step" : 4 ,
"_timestamp" : 1644345412 ,
"_wandb" : {"runtime" : 3 },
"loss" : 0.041 ,
"val" : 525 ,
}
サンプリング
デフォルトの履歴メソッドは、メトリクスを固定数のサンプルにサンプリングします(デフォルトは 500 です。これは samples __ 引数で変更できます)。大規模な run ですべてのデータをエクスポートする場合は、run.scan_history() メソッドを使用できます。詳細については、APIリファレンス を参照してください。
複数の Run のクエリ
DataFrame と CSV
MongoDB スタイル
このサンプルスクリプトは project を検索し、名前、config、summary 統計を含む Runs の CSV を出力します。<entity> と <project> を、それぞれ W&B entity と project の名前に置き換えます。
import pandas as pd
import wandb
api = wandb. Api()
entity, project = "<entity>" , "<project>"
runs = api. runs(entity + "/" + project)
summary_list, config_list, name_list = [], [], []
for run in runs:
# .summary には、精度などの
# メトリクスの出力キー/値が含まれています。
# 大きなファイルを省略するために ._json_dict を呼び出します
summary_list. append(run. summary. _json_dict)
# .config にはハイパーパラメーターが含まれています。
# _ で始まる特殊な値を削除します。
config_list. append({k: v for k, v in run. config. items() if not k. startswith("_" )})
# .name は run の人間が読める名前です。
name_list. append(run. name)
runs_df = pd. DataFrame(
{"summary" : summary_list, "config" : config_list, "name" : name_list}
)
runs_df. to_csv("project.csv" )
W&B API は、api.runs() を使用して project 内の Runs をクエリする方法も提供します。最も一般的なユースケースは、カスタム分析のために Runs データをエクスポートすることです。クエリインターフェイスは、MongoDB が使用するもの と同じです。
runs = api. runs(
"username/project" ,
{"$or" : [{"config.experiment_name" : "foo" }, {"config.experiment_name" : "bar" }]},
)
print(f "Found { len(runs)} runs" )
api.runs を呼び出すと、反復可能でリストのように動作する Runs オブジェクトが返されます。デフォルトでは、オブジェクトは必要に応じて一度に 50 個の Runs を順番にロードしますが、per_page キーワード引数を使用して、ページごとにロードされる数を変更できます。
api.runs は order キーワード引数も受け入れます。デフォルトの順序は -created_at です。結果を昇順で並べ替えるには、+created_at を指定します。config または summary の値でソートすることもできます。たとえば、summary.val_acc や config.experiment_name などです。
エラー処理
W&B サーバーとの通信中にエラーが発生すると、wandb.CommError が発生します。元の例外は、exc 属性を介して調べることができます。
API 経由で最新の git コミットを取得する
UI で、run をクリックし、run ページの Overview タブをクリックして、最新の git コミットを確認します。これはファイル wandb-metadata.json にもあります。Public API を使用して、run.commit で git ハッシュを取得できます。
run の実行中に run の名前と ID を取得する
wandb.init() を呼び出した後、スクリプトからランダムな run ID または人間が読める run 名に次のようにアクセスできます。
一意の run ID (8 文字のハッシュ): wandb.run.id
ランダムな run 名 (人間が読める): wandb.run.name
Runs に役立つ識別子を設定する方法について検討している場合は、次のことをお勧めします。
Run ID : 生成されたハッシュのままにします。これは、project 内の Runs 間で一意である必要があります。Run 名 : これは、チャート上の異なる行を区別できるように、短く、読みやすく、できれば一意である必要があります。Run ノート : これは、run で何をしているかを簡単に説明するのに最適な場所です。これは、wandb.init(notes="ここにノート") で設定できます。Run タグ : Run タグで動的に追跡し、UI のフィルターを使用して、関心のある Runs のみにテーブルを絞り込みます。スクリプトからタグを設定し、UI の Runs テーブルと run ページの Overview タブの両方で編集できます。詳細な手順については、こちら を参照してください。
Public API の例
matplotlib または seaborn で視覚化するためにデータをエクスポートする
一般的なエクスポートパターンのいくつかの例については、API 例 を確認してください。カスタムプロットまたは展開された Runs テーブルのダウンロードボタンをクリックして、ブラウザーから CSV をダウンロードすることもできます。
run からメトリクスを読み取る
この例では、"<entity>/<project>/<run_id>" に保存された run の wandb.log({"accuracy": acc}) で保存されたタイムスタンプと精度を出力します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
if run. state == "finished" :
for i, row in run. history(). iterrows():
print(row["_timestamp" ], row["accuracy" ])
Runs のフィルター
MongoDB Query Language を使用してフィルターできます。
日付
runs = api. runs(
"<entity>/<project>" ,
{"$and" : [{"created_at" : {"$lt" : "YYYY-MM-DDT##" , "$gt" : "YYYY-MM-DDT##" }}]},
)
run から特定のメトリクスを読み取る
run から特定のメトリクスをプルするには、keys 引数を使用します。run.history() を使用する場合のデフォルトのサンプル数は 500 です。特定のメトリクスを含まないログに記録されたステップは、出力データフレームに NaN として表示されます。keys 引数を指定すると、API はリストされたメトリクスキーを含むステップをより頻繁にサンプリングします。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
if run. state == "finished" :
for i, row in run. history(keys= ["accuracy" ]). iterrows():
print(row["_timestamp" ], row["accuracy" ])
2 つの Run の比較
これにより、run1 と run2 で異なる config パラメーターが出力されます。
import pandas as pd
import wandb
api = wandb. Api()
# <entity>、<project>、<run_id> に置き換えます
run1 = api. run("<entity>/<project>/<run_id>" )
run2 = api. run("<entity>/<project>/<run_id>" )
df = pd. DataFrame([run1. config, run2. config]). transpose()
df. columns = [run1. name, run2. name]
print(df[df[run1. name] != df[run2. name]])
出力:
c_10_sgd_0.025_0.01_long_switch base_adam_4_conv_2fc
batch_size 32 16
n_conv_layers 5 4
Optimizer rmsprop adam
run のメトリクスを、run の完了後に更新する
この例では、以前の run の精度を 0.9 に設定します。また、以前の run の精度ヒストグラムを numpy_array のヒストグラムになるように変更します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run. summary["accuracy" ] = 0.9
run. summary["accuracy_histogram" ] = wandb. Histogram(numpy_array)
run. summary. update()
完了した run でメトリクスの名前を変更する
この例では、テーブルの summary 列の名前を変更します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run. summary["new_name" ] = run. summary["old_name" ]
del run. summary["old_name" ]
run. summary. update()
列の名前の変更は、テーブルにのみ適用されます。チャートは引き続き元の名前でメトリクスを参照します。
既存の Run の config を更新する
この例では、config 設定の 1 つを更新します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run. config["key" ] = updated_value
run. update()
システムリソースの消費量を CSV ファイルにエクスポートする
以下のスニペットは、システムリソースの消費量を検索し、CSV に保存します。
import wandb
run = wandb. Api(). run("<entity>/<project>/<run_id>" )
system_metrics = run. history(stream= "events" )
system_metrics. to_csv("sys_metrics.csv" )
サンプリングされていないメトリクスデータを取得する
履歴からデータをプルすると、デフォルトで 500 ポイントにサンプリングされます。run.scan_history() を使用して、ログに記録されたすべてのデータポイントを取得します。次に、履歴に記録されたすべての loss データポイントをダウンロードする例を示します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
history = run. scan_history()
losses = [row["loss" ] for row in history]
履歴からページネーションされたデータを取得する
メトリクスがバックエンドでゆっくりとフェッチされている場合、または API リクエストがタイムアウトしている場合は、個々のリクエストがタイムアウトしないように、scan_history のページサイズを小さくしてみてください。デフォルトのページサイズは 500 なので、さまざまなサイズを試して最適なものを確認できます。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run. scan_history(keys= sorted(cols), page_size= 100 )
project 内のすべての Runs からメトリクスを CSV ファイルにエクスポートする
このスクリプトは、project 内の Runs をプルダウンし、名前、config、summary 統計を含む Runs のデータフレームと CSV を生成します。<entity> と <project> を、それぞれ W&B entity と project の名前に置き換えます。
import pandas as pd
import wandb
api = wandb. Api()
entity, project = "<entity>" , "<project>"
runs = api. runs(entity + "/" + project)
summary_list, config_list, name_list = [], [], []
for run in runs:
# .summary には、精度などの
# メトリクスの出力キー/値が含まれています。
# 大きなファイルを省略するために ._json_dict を呼び出します
summary_list. append(run. summary. _json_dict)
# .config にはハイパーパラメーターが含まれています。
# _ で始まる特殊な値を削除します。
config_list. append({k: v for k, v in run. config. items() if not k. startswith("_" )})
# .name は run の人間が読める名前です。
name_list. append(run. name)
runs_df = pd. DataFrame(
{"summary" : summary_list, "config" : config_list, "name" : name_list}
)
runs_df. to_csv("project.csv" )
Run の開始時刻を取得する
このコードスニペットは、run が作成された時刻を取得します。
import wandb
api = wandb. Api()
run = api. run("entity/project/run_id" )
start_time = run. created_at
完了した run にファイルをアップロードする
以下のコードスニペットは、選択したファイルを完了した run にアップロードします。
import wandb
api = wandb. Api()
run = api. run("entity/project/run_id" )
run. upload_file("file_name.extension" )
Run からファイルをダウンロードする
これは、cifar project の run ID uxte44z7 に関連付けられたファイル “model-best.h5” を検索し、ローカルに保存します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
run. file("model-best.h5" ). download()
Run からすべてのファイルをダウンロードする
これは、run に関連付けられたすべてのファイルを検索し、ローカルに保存します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
for file in run. files():
file. download()
特定の sweep から Runs を取得する
このスニペットは、特定の sweep に関連付けられたすべての Runs をダウンロードします。
import wandb
api = wandb. Api()
sweep = api. sweep("<entity>/<project>/<sweep_id>" )
sweep_runs = sweep. runs
Sweep から最適な Run を取得する
次のスニペットは、指定された sweep から最適な Run を取得します。
import wandb
api = wandb. Api()
sweep = api. sweep("<entity>/<project>/<sweep_id>" )
best_run = sweep. best_run()
best_run は、sweep config の metric パラメータによって定義された最適なメトリクスを持つ Run です。
Sweep から最適なモデルファイルをダウンロードする
このスニペットは、モデルファイルを model.h5 に保存した Runs を使用して、検証精度が最も高いモデルファイルを sweep からダウンロードします。
import wandb
api = wandb. Api()
sweep = api. sweep("<entity>/<project>/<sweep_id>" )
runs = sorted(sweep. runs, key= lambda run: run. summary. get("val_acc" , 0 ), reverse= True )
val_acc = runs[0 ]. summary. get("val_acc" , 0 )
print(f "Best run { runs[0 ]. name} with { val_acc} % val accuracy" )
runs[0 ]. file("model.h5" ). download(replace= True )
print("Best model saved to model-best.h5" )
指定された拡張子を持つすべてのファイルを Run から削除する
このスニペットは、指定された拡張子を持つファイルを Run から削除します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
extension = ".png"
files = run. files()
for file in files:
if file. name. endswith(extension):
file. delete()
システムメトリクスデータをダウンロードする
このスニペットは、run のすべてのシステムリソース消費量メトリクスを含むデータフレームを生成し、CSV に保存します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
system_metrics = run. history(stream= "events" )
system_metrics. to_csv("sys_metrics.csv" )
Summary メトリクスの更新
辞書を渡して summary メトリクスを更新できます。
summary. update({"key" : val})
Run を実行したコマンドを取得する
各 Run は、Run の概要ページで Run を起動したコマンドをキャプチャします。このコマンドを API からプルダウンするには、次を実行します。
import wandb
api = wandb. Api()
run = api. run("<entity>/<project>/<run_id>" )
meta = json. load(run. file("wandb-metadata.json" ). download())
program = ["python" ] + [meta["program" ]] + meta["args" ]
2.1.11 - Environment variables
W&B の 環境 変数 を設定します。
自動化された環境でスクリプトを実行する場合、スクリプトの実行前またはスクリプト内で設定された環境変数で wandb を制御できます。
# これは秘密であり、バージョン管理にチェックインすべきではありません
WANDB_API_KEY= $YOUR_API_KEY
# 名前とメモはオプション
WANDB_NAME= "My first run"
WANDB_NOTES= "Smaller learning rate, more regularization."
# wandb/settings ファイルをチェックインしない場合にのみ必要
WANDB_ENTITY= $username
WANDB_PROJECT= $project
# スクリプトをクラウドに同期させたくない場合
os. environ["WANDB_MODE" ] = "offline"
# sweep ID トラッキングを Run オブジェクトと関連クラスに追加
os. environ["WANDB_SWEEP_ID" ] = "b05fq58z"
オプションの環境変数
これらのオプションの環境変数を使用して、リモートマシンでの認証の設定などを行います。
変数名
使用法
WANDB_ANONYMOUS これを allow、never、または must に設定して、ユーザーが秘密の URL で匿名の run を作成できるようにします。
WANDB_API_KEY アカウントに関連付けられた認証 key を設定します。設定ページ で key を確認できます。リモートマシンで wandb login が実行されていない場合は、これを設定する必要があります。
WANDB_BASE_URL wandb/local を使用している場合は、この環境変数を http://YOUR_IP:YOUR_PORT に設定する必要があります
WANDB_CACHE_DIR これはデフォルトで ~/.cache/wandb になっています。この場所をこの環境変数で上書きできます
WANDB_CONFIG_DIR これはデフォルトで ~/.config/wandb になっています。この場所をこの環境変数で上書きできます
WANDB_CONFIG_PATHS wandb.config にロードする yaml ファイルのコンマ区切りリスト。config を参照してください。
WANDB_CONSOLE stdout / stderr ログを無効にするには、これを “off” に設定します。これは、サポートする環境ではデフォルトで “on” になっています。
WANDB_DATA_DIR ステージング Artifacts がアップロードされる場所。デフォルトの場所はプラットフォームによって異なります。これは、platformdirs Python パッケージの user_data_dir の値を使用するためです。
WANDB_DIR トレーニングスクリプトからの wandb ディレクトリーの相対位置ではなく、生成されたすべてのファイルをここに保存するには、これを絶対パスに設定します。このディレクトリーが存在し、プロセスを実行するユーザーが書き込むことができることを確認してください 。これは、ダウンロードされた Artifacts の場所には影響しないことに注意してください。代わりに WANDB_ARTIFACT_DIR を使用して設定できます
WANDB_ARTIFACT_DIR トレーニングスクリプトからの artifacts ディレクトリーの相対位置ではなく、ダウンロードされたすべての Artifacts をここに保存するには、これを絶対パスに設定します。このディレクトリーが存在し、プロセスを実行するユーザーが書き込むことができることを確認してください。これは、生成されたメタデータファイルの場所には影響しないことに注意してください。代わりに WANDB_DIR を使用して設定できます
WANDB_DISABLE_GIT wandb が git リポジトリをプローブして最新のコミット/差分をキャプチャするのを防ぎます。
WANDB_DISABLE_CODE wandb が ノートブック または git の差分を保存しないようにするには、これを true に設定します。git リポジトリにいる場合は、現在のコミットを保存します。
WANDB_DOCKER run の復元を有効にするには、これを docker イメージのダイジェストに設定します。これは、wandb docker コマンドで自動的に設定されます。wandb docker my/image/name:tag --digest を実行して、イメージのダイジェストを取得できます
WANDB_ENTITY run に関連付けられたエンティティ。トレーニングスクリプトのディレクトリーで wandb init を実行した場合、wandb という名前のディレクトリーが作成され、ソース管理にチェックインできるデフォルトのエンティティが保存されます。そのファイルを作成したくない場合、またはファイルを上書きしたい場合は、環境変数を使用できます。
WANDB_ERROR_REPORTING wandb が致命的なエラーをそのエラー追跡システムにログ記録しないようにするには、これを false に設定します。
WANDB_HOST システムが提供するホスト名を使用したくない場合に、wandb インターフェイスに表示するホスト名を設定します
WANDB_IGNORE_GLOBS 無視するファイル glob のコンマ区切りリストにこれを設定します。これらのファイルはクラウドに同期されません。
WANDB_JOB_NAME wandb によって作成されたジョブの名前を指定します。
WANDB_JOB_TYPE run のさまざまなタイプを示すために、“トレーニング” や “評価” などのジョブタイプを指定します。詳細については、グループ化 を参照してください。
WANDB_MODE これを “offline” に設定すると、wandb は run のメタデータをローカルに保存し、サーバーに同期しません。これを disabled に設定すると、wandb は完全にオフになります。
WANDB_NAME run の人間が読める名前。設定されていない場合は、ランダムに生成されます
WANDB_NOTEBOOK_NAME jupyter で実行している場合は、この変数で ノートブック の名前を設定できます。これを自動的に検出しようとします。
WANDB_NOTES run に関するより長いメモ。マークダウンは許可されており、UI で後で編集できます。
WANDB_PROJECT run に関連付けられた プロジェクト。これは wandb init で設定することもできますが、環境変数が値を上書きします。
WANDB_RESUME デフォルトでは、これは never に設定されています。auto に設定すると、wandb は失敗した run を自動的に再開します。must に設定すると、起動時に run が強制的に存在します。常に独自のユニークな ID を生成する場合は、これを allow に設定し、常に WANDB_RUN_ID を設定します。
WANDB_RUN_GROUP run を自動的にグループ化するための実験名を指定します。詳細については、グループ化 を参照してください。
WANDB_RUN_ID スクリプトの単一の run に対応するグローバルに一意の文字列(プロジェクトごと)にこれを設定します。64 文字以下である必要があります。単語以外の文字はすべてダッシュに変換されます。これは、障害が発生した場合に既存の run を再開するために使用できます。
WANDB_SILENT wandb ログステートメントを非表示にするには、これを true に設定します。これが設定されている場合、すべてのログは WANDB_DIR /debug.log に書き込まれます
WANDB_SHOW_RUN オペレーティングシステムがサポートしている場合、run URL でブラウザーを自動的に開くには、これを true に設定します。
WANDB_SWEEP_ID sweep ID トラッキングを Run オブジェクトと関連クラスに追加し、UI に表示します。
WANDB_TAGS run に適用されるタグのコンマ区切りリスト。
WANDB_USERNAME run に関連付けられた チーム のメンバーの ユーザー 名。これは、サービスアカウント API key とともに使用して、自動 run の チーム のメンバーへの属性を有効にすることができます。
WANDB_USER_EMAIL run に関連付けられた チーム のメンバーのメール。これは、サービスアカウント API key とともに使用して、自動 run の チーム のメンバーへの属性を有効にすることができます。
Singularity 環境
Singularity でコンテナーを実行している場合は、上記の変数の前に SINGULARITYENV_ を付けることで環境変数を渡すことができます。Singularity 環境変数の詳細については、こちら を参照してください。
AWS での実行
AWS でバッチジョブを実行している場合は、W&B 認証情報でマシンを簡単に認証できます。設定ページ から API key を取得し、AWS バッチジョブ仕様 で WANDB_API_KEY 環境変数を設定します。
2.2 - Sweeps
W&B Sweeps を使用したハイパーパラメータ探索と モデル の最適化
W&B Sweeps を使用して、ハイパーパラメータの検索を自動化し、豊富なインタラクティブな 実験管理 を視覚化します。ベイズ、グリッド検索、ランダムなどの一般的な検索メソッドから選択して、ハイパーパラメータ空間を検索します。1つまたは複数のマシンに スイープ をスケールおよび並列化します。
仕組み
2つの W&B CLI コマンドで スイープ を作成します。
スイープ を初期化する
wandb sweep --project <propject-name> <path-to-config file>
sweep agent を起動する
上記の コードスニペット と、このページにリンクされている Colab は、W&B CLI で スイープ を初期化および作成する方法を示しています。 スイープ設定を定義し、 スイープ を初期化し、 スイープ を開始するために使用する W&B Python SDK コマンドのステップごとの概要については、Sweeps の
Walkthrough を参照してください。
開始方法
ユースケース に応じて、次のリソースを参照して W&B Sweeps を開始してください。
スイープ設定を定義し、 スイープ を初期化し、 スイープ を開始するために使用する W&B Python SDK コマンドのステップごとの概要については、sweeps walkthrough を参照してください。
この chapter では、次の方法について説明します。
W&B Sweeps でハイパーパラメータ最適化を調査する 厳選された Sweep experiments のリスト を見てみましょう。 result は W&B Reports に保存されます。
ステップごとのビデオについては、Tune Hyperparameters Easily with W&B Sweeps を参照してください。
2.2.1 - Tutorial: Define, initialize, and run a sweep
Sweeps クイックスタート では、sweep の定義、初期化、および実行方法について説明します。主な手順は4つあります。
このページでは、sweep の定義、初期化、および実行方法について説明します。主な手順は4つあります。
トレーニング コードのセットアップ sweep configuration での探索空間の定義 sweep の初期化 sweep agent の起動
次のコードをコピーして Jupyter Notebook または Python スクリプトに貼り付けます。
# W&B Python ライブラリをインポートして W&B にログインします
import wandb
wandb. login()
# 1: 目的関数/トレーニング関数を定義します
def objective (config):
score = config. x** 3 + config. y
return score
def main ():
wandb. init(project= "my-first-sweep" )
score = objective(wandb. config)
wandb. log({"score" : score})
# 2: 探索空間を定義します
sweep_configuration = {
"method" : "random" ,
"metric" : {"goal" : "minimize" , "name" : "score" },
"parameters" : {
"x" : {"max" : 0.1 , "min" : 0.01 },
"y" : {"values" : [1 , 3 , 7 ]},
},
}
# 3: sweep を開始します
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "my-first-sweep" )
wandb. agent(sweep_id, function= main, count= 10 )
以下のセクションでは、コード サンプルの各ステップを分解して説明します。
トレーニング コードのセットアップ
wandb.config から ハイパーパラメーター の値を受け取り、それらを使用して model をトレーニングし、メトリクスを返すトレーニング関数を定義します。
必要に応じて、W&B Run の出力を保存する project の名前を指定します (wandb.init
sweep と run は両方とも同じ project に存在する必要があります。したがって、W&B を初期化するときに指定する名前は、sweep を初期化するときに指定する project の名前と一致する必要があります。
# 1: 目的関数/トレーニング関数を定義します
def objective (config):
score = config. x** 3 + config. y
return score
def main ():
wandb. init(project= "my-first-sweep" )
score = objective(wandb. config)
wandb. log({"score" : score})
sweep configuration での探索空間の定義
辞書で sweep する ハイパーパラメーター を指定します。configuration オプションについては、sweep configuration の定義 を参照してください。
上記の例は、ランダム検索 ('method':'random') を使用する sweep configuration を示しています。sweep は、バッチサイズ、エポック、および学習率について、configuration にリストされている値のランダムなセットをランダムに選択します。
W&B は、"goal": "minimize" が関連付けられている場合、metric キーで指定された メトリクス を最小化します。この場合、W&B は メトリクス score ("name": "score") の最小化のために最適化します。
# 2: 探索空間を定義します
sweep_configuration = {
"method" : "random" ,
"metric" : {"goal" : "minimize" , "name" : "score" },
"parameters" : {
"x" : {"max" : 0.1 , "min" : 0.01 },
"y" : {"values" : [1 , 3 , 7 ]},
},
}
Sweep の初期化
W&B は Sweep Controller を使用して、クラウド (標準)、ローカル (ローカル) で1つまたは複数のマシンにわたる Sweeps を管理します。Sweep Controller の詳細については、ローカルでの検索と停止アルゴリズム を参照してください。
sweep 識別番号は、sweep を初期化するときに返されます。
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "my-first-sweep" )
sweep の初期化の詳細については、sweep の初期化 を参照してください。
Sweep の開始
wandb.agent
wandb. agent(sweep_id, function= main, count= 10 )
結果の可視化 (オプション)
project を開いて、W&B App ダッシュボードでライブ結果を確認します。数回クリックするだけで、パラレル座標図 、パラメーター の重要性分析 などの豊富なインタラクティブなグラフを構築できます。詳細
結果の可視化方法の詳細については、sweep 結果の可視化 を参照してください。ダッシュボードの例については、このサンプルSweeps Project を参照してください。
エージェント の停止 (オプション)
ターミナル で、Ctrl+C を押して現在の run を停止します。もう一度押すと、agent が終了します。
2.2.2 - Add W&B (wandb) to your code
W&B を Python コード スクリプトまたは Jupyter Notebook に追加します。
W&B Python SDK をスクリプトまたは Jupyter Notebook に追加する方法は多数あります。以下に、W&B Python SDK を独自のコードに統合する方法の「ベストプラクティス」の例を示します。
元のトレーニングスクリプト
Python スクリプトに次のコードがあるとします。ここでは、典型的なトレーニングループを模倣する main という関数を定義します。エポックごとに、トレーニングデータセットと検証データセットで精度と損失が計算されます。これらの値は、この例の目的のためにランダムに生成されます。
ここでは、ハイパーパラメータの値を格納する config という 辞書 を定義しました。セルの最後に、main 関数を呼び出して、モックトレーニングコードを実行します。
import random
import numpy as np
def train_one_epoch (epoch, lr, bs):
acc = 0.25 + ((epoch / 30 ) + (random. random() / 10 ))
loss = 0.2 + (1 - ((epoch - 1 ) / 10 + random. random() / 5 ))
return acc, loss
def evaluate_one_epoch (epoch):
acc = 0.1 + ((epoch / 20 ) + (random. random() / 10 ))
loss = 0.25 + (1 - ((epoch - 1 ) / 10 + random. random() / 6 ))
return acc, loss
# config variable with hyperparameter values
config = {"lr" : 0.0001 , "bs" : 16 , "epochs" : 5 }
def main ():
# Note that we define values from `wandb.config`
# instead of defining hard values
# ハードコードされた値を定義する代わりに、`wandb.config` から値を定義することに注意してください
lr = config["lr" ]
bs = config["bs" ]
epochs = config["epochs" ]
for epoch in np. arange(1 , epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
print("epoch: " , epoch)
print("training accuracy:" , train_acc, "training loss:" , train_loss)
print("validation accuracy:" , val_acc, "training loss:" , val_loss)
W&B Python SDK を使用したトレーニングスクリプト
次のコード例は、W&B Python SDK をコードに追加する方法を示しています。CLI で W&B Sweep ジョブを開始する場合は、[CLI] タブを確認してください。Jupyter Notebook または Python スクリプト内で W&B Sweep ジョブを開始する場合は、[Python SDK] タブを確認してください。
W&B Sweep を作成するために、次のコード例を追加しました。
Weights & Biases Python SDK をインポートします。
キーと値のペアで sweep configuration を定義する 辞書 オブジェクトを作成します。以下の例では、バッチサイズ (batch_size)、エポック数 (epochs)、および学習率 (lr) の ハイパーパラメータ は、各 sweep 中に変化します。sweep configuration の作成方法の詳細については、sweep configuration の定義 を参照してください。
sweep configuration 辞書 を wandb.sweepsweep_id) が返されます。sweep の初期化方法の詳細については、sweep の初期化 を参照してください。
wandb.init()W&B Run としてデータを同期およびログ記録するバックグラウンド プロセス を生成します。(オプション) ハードコードされた値を定義する代わりに、wandb.config から値を定義します。
最適化する メトリクス を wandb.logsweep_configuration) 内で、val_acc 値を最大化するように sweep を定義しました。
wandb.agentfunction=main) を指定し、試行する run の最大数を 4 (count=4) に設定します。W&B Sweep の開始方法の詳細については、sweep agent の開始 を参照してください。
import wandb
import numpy as np
import random
# Define sweep config
# sweep configuration を定義する
sweep_configuration = {
"method" : "random" ,
"name" : "sweep" ,
"metric" : {"goal" : "maximize" , "name" : "val_acc" },
"parameters" : {
"batch_size" : {"values" : [16 , 32 , 64 ]},
"epochs" : {"values" : [5 , 10 , 15 ]},
"lr" : {"max" : 0.1 , "min" : 0.0001 },
},
}
# Initialize sweep by passing in config.
# (Optional) Provide a name of the project.
# configuration を渡して sweep を初期化します。
# (オプション) Project の名前を指定します。
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "my-first-sweep" )
# Define training function that takes in hyperparameter
# values from `wandb.config` and uses them to train a
# model and return metric
# `wandb.config` から ハイパーパラメータ 値を取得し、それらを使用して
# モデルをトレーニングし、メトリクス を返すトレーニング関数を定義する
def train_one_epoch (epoch, lr, bs):
acc = 0.25 + ((epoch / 30 ) + (random. random() / 10 ))
loss = 0.2 + (1 - ((epoch - 1 ) / 10 + random. random() / 5 ))
return acc, loss
def evaluate_one_epoch (epoch):
acc = 0.1 + ((epoch / 20 ) + (random. random() / 10 ))
loss = 0.25 + (1 - ((epoch - 1 ) / 10 + random. random() / 6 ))
return acc, loss
def main ():
run = wandb. init()
# note that we define values from `wandb.config`
# instead of defining hard values
# ハードコードされた値を定義する代わりに、`wandb.config` から値を定義することに注意してください
lr = wandb. config. lr
bs = wandb. config. batch_size
epochs = wandb. config. epochs
for epoch in np. arange(1 , epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb. log(
{
"epoch" : epoch,
"train_acc" : train_acc,
"train_loss" : train_loss,
"val_acc" : val_acc,
"val_loss" : val_loss,
}
)
# Start sweep job.
# sweep ジョブを開始します。
wandb. agent(sweep_id, function= main, count= 4 )
W&B Sweep を作成するには、まず YAML configuration ファイルを作成します。configuration ファイルには、sweep で探索する ハイパーパラメータ が含まれています。以下の例では、バッチサイズ (batch_size)、エポック数 (epochs)、および学習率 (lr) の ハイパーパラメータ は、各 sweep 中に変化します。
# config.yaml
program : train.py
method : random
name : sweep
metric :
goal : maximize
name : val_acc
parameters :
batch_size :
values : [16 ,32 ,64 ]
lr :
min : 0.0001
max : 0.1
epochs :
values : [5 , 10 , 15 ]
W&B Sweep configuration の作成方法の詳細については、sweep configuration の定義 を参照してください。
YAML ファイルの program キーに Python スクリプトの名前を指定する必要があることに注意してください。
次に、次のコード例を追加します。
Wieghts & Biases Python SDK (wandb) と PyYAML (yaml) をインポートします。PyYAML は、YAML configuration ファイルを読み込むために使用されます。
configuration ファイルを読み込みます。
wandb.init()W&B Run としてデータを同期およびログ記録するバックグラウンド プロセス を生成します。config オブジェクトを config パラメータに渡します。ハードコードされた値を使用する代わりに、wandb.config から ハイパーパラメータ 値を定義します。
最適化する メトリクス を wandb.logsweep_configuration) 内で、val_acc 値を最大化するように sweep を定義しました。
import wandb
import yaml
import random
import numpy as np
def train_one_epoch (epoch, lr, bs):
acc = 0.25 + ((epoch / 30 ) + (random. random() / 10 ))
loss = 0.2 + (1 - ((epoch - 1 ) / 10 + random. random() / 5 ))
return acc, loss
def evaluate_one_epoch (epoch):
acc = 0.1 + ((epoch / 20 ) + (random. random() / 10 ))
loss = 0.25 + (1 - ((epoch - 1 ) / 10 + random. random() / 6 ))
return acc, loss
def main ():
# Set up your default hyperparameters
# デフォルトのハイパーパラメータを設定する
with open("./config.yaml" ) as file:
config = yaml. load(file, Loader= yaml. FullLoader)
run = wandb. init(config= config)
# Note that we define values from `wandb.config`
# instead of defining hard values
# ハードコードされた値を定義する代わりに、`wandb.config` から値を定義することに注意してください
lr = wandb. config. lr
bs = wandb. config. batch_size
epochs = wandb. config. epochs
for epoch in np. arange(1 , epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb. log(
{
"epoch" : epoch,
"train_acc" : train_acc,
"train_loss" : train_loss,
"val_acc" : val_acc,
"val_loss" : val_loss,
}
)
# Call the main function.
# main 関数を呼び出します。
main()
CLI に移動します。CLI 内で、sweep agent が試行する run の最大数を設定します。この手順はオプションです。次の例では、最大数を 5 に設定します。
次に、wandb sweep--project) の Project の名前を指定します。
wandb sweep --project sweep-demo-cli config.yaml
これにより、sweep ID が返されます。sweep の初期化方法の詳細については、sweep の初期化 を参照してください。
sweep ID をコピーし、次の コードスニペット の sweepID を置き換えて、wandb agent
wandb agent --count $NUM your-entity/sweep-demo-cli/sweepID
sweep ジョブの開始方法の詳細については、sweep ジョブの開始 を参照してください。
メトリクス をログに記録する際の考慮事項
sweep configuration で指定した メトリクス を明示的に W&B にログに記録してください。サブディレクトリー内で sweep の メトリクス をログに記録しないでください。
たとえば、次の疑似コードを考えてみましょう。ユーザーは 検証 損失 ("val_loss": loss) をログに記録したいと考えています。最初に、値を 辞書 に渡します。ただし、wandb.log に渡される 辞書 は、辞書 内のキーと値のペアに明示的にアクセスしません。
# Import the W&B Python Library and log into W&B
# W&B Python ライブラリをインポートし、W&B にログインします
import wandb
import random
def train ():
offset = random. random() / 5
acc = 1 - 2 **- epoch - random. random() / epoch - offset
loss = 2 **- epoch + random. random() / epoch + offset
val_metrics = {"val_loss" : loss, "val_acc" : acc}
return val_metrics
def main ():
wandb. init(entity= "<entity>" , project= "my-first-sweep" )
val_metrics = train()
# Incorrect. You must explicitly access the
# key-value pair in the dictionary
# 間違いです。 辞書 のキーと値のペアに明示的にアクセスする必要があります
# 正しいメトリクス の記録方法については、次のコードブロックを参照してください
wandb. log({"val_loss" : val_metrics})
sweep_configuration = {
"method" : "random" ,
"metric" : {"goal" : "minimize" , "name" : "val_loss" },
"parameters" : {
"x" : {"max" : 0.1 , "min" : 0.01 },
"y" : {"values" : [1 , 3 , 7 ]},
},
}
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "my-first-sweep" )
wandb. agent(sweep_id, function= main, count= 10 )
代わりに、Python 辞書 内のキーと値のペアに明示的にアクセスします。たとえば、次のコードは、辞書 を wandb.log メソッドに渡すときに、キーと値のペアを指定します。
# Import the W&B Python Library and log into W&B
# W&B Python ライブラリをインポートし、W&B にログインします
import wandb
import random
def train ():
offset = random. random() / 5
acc = 1 - 2 **- epoch - random. random() / epoch - offset
loss = 2 **- epoch + random. random() / epoch + offset
val_metrics = {"val_loss" : loss, "val_acc" : acc}
return val_metrics
def main ():
wandb. init(entity= "<entity>" , project= "my-first-sweep" )
val_metrics = train()
wandb. log({"val_loss" , val_metrics["val_loss" ]})
sweep_configuration = {
"method" : "random" ,
"metric" : {"goal" : "minimize" , "name" : "val_loss" },
"parameters" : {
"x" : {"max" : 0.1 , "min" : 0.01 },
"y" : {"values" : [1 , 3 , 7 ]},
},
}
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "my-first-sweep" )
wandb. agent(sweep_id, function= main, count= 10 )
2.2.3 - Define a sweep configuration
sweep の 設定ファイルを作成する方法について説明します。
W&B Sweep は、ハイパーパラメーターの値を探索する戦略と、それらを評価するコードを組み合わせたものです。この戦略は、すべてのオプションを試すという単純なものから、ベイズ最適化やHyperband (BOHB ) のように複雑なものまであります。
Python 辞書 または YAML ファイルで sweep configuration を定義します。sweep configuration の定義方法は、sweep の管理方法によって異なります。
sweep を初期化し、コマンドラインから sweep agent を開始する場合は、YAML ファイルで sweep configuration を定義します。Python スクリプトまたは Jupyter notebook 内で sweep を初期化して完全に開始する場合は、Python 辞書で sweep を定義します。
以下のガイドでは、sweep configuration のフォーマット方法について説明します。トップレベルの sweep configuration キーの包括的なリストについては、Sweep configuration options を参照してください。
基本構造
両方の sweep configuration フォーマットオプション (YAML と Python 辞書) は、キーと 値 のペアとネストされた構造を利用します。
sweep configuration 内のトップレベルキーを使用して、sweep の名前 (nameparametersmethod
たとえば、次のコードスニペットは、YAML ファイル内と Python 辞書内で定義された同じ sweep configuration を示しています。sweep configuration 内には、program、name、method、metric、および parameters という 5 つのトップレベルキーが指定されています。
CLI
Python script or Jupyter notebook
コマンドライン (CLI) からインタラクティブに Sweeps を管理する場合は、YAML ファイルで sweep configuration を定義します。
program : train.py
name : sweepdemo
method : bayes
metric :
goal : minimize
name : validation_loss
parameters :
learning_rate :
min : 0.0001
max : 0.1
batch_size :
values : [16 , 32 , 64 ]
epochs :
values : [5 , 10 , 15 ]
optimizer :
values : ["adam" , "sgd" ]
Python スクリプトまたは Jupyter notebook でトレーニングアルゴリズムを定義する場合は、Python 辞書データ構造で sweep を定義します。
次のコードスニペットは、sweep_configuration という変数に sweep configuration を格納します。
sweep_configuration = {
"name" : "sweepdemo" ,
"method" : "bayes" ,
"metric" : {"goal" : "minimize" , "name" : "validation_loss" },
"parameters" : {
"learning_rate" : {"min" : 0.0001 , "max" : 0.1 },
"batch_size" : {"values" : [16 , 32 , 64 ]},
"epochs" : {"values" : [5 , 10 , 15 ]},
"optimizer" : {"values" : ["adam" , "sgd" ]},
},
}
トップレベルの parameters キー内には、learning_rate、batch_size、epoch、および optimizer というキーがネストされています。指定するネストされたキーごとに、1 つまたは複数の 値 、分布、確率などを指定できます。詳細については、Sweep configuration options の parameters セクションを参照してください。
二重にネストされたパラメータ
sweep configuration は、ネストされたパラメータをサポートしています。ネストされたパラメータを区切るには、トップレベルのパラメータ名の下に追加の parameters キーを使用します。sweep config は、複数レベルのネスティングをサポートしています。
ベイズまたはランダムなハイパーパラメータ検索を使用する場合は、確率分布をランダム変数に指定します。各ハイパーパラメータについて:
sweep config にトップレベルの parameters キーを作成します。
parameters キー内に、以下をネストします。
最適化するハイパーパラメータの名前を指定します。
distribution キーに使用する分布を指定します。ハイパーパラメータ名の下に distribution キーと 値 のペアをネストします。探索する 1 つまたは複数の 値 を指定します。値 (または 値 ) は、分布キーとインラインである必要があります。
(オプション) トップレベルのパラメータ名の下に追加の parameters キーを使用して、ネストされたパラメータを区切ります。
sweep configuration で定義されたネストされたパラメータは、W&B run configuration で指定されたキーを上書きします。
たとえば、train.py Python スクリプトで次の設定で W&B run を初期化するとします (1 ~ 2 行を参照)。次に、sweep_configuration という辞書で sweep configuration を定義します (4 ~ 13 行を参照)。次に、sweep config 辞書を wandb.sweep に渡して、sweep config を初期化します (16 行を参照)。
def main ():
run = wandb. init(config= {"nested_param" : {"manual_key" : 1 }})
sweep_configuration = {
"top_level_param" : 0 ,
"nested_param" : {
"learning_rate" : 0.01 ,
"double_nested_param" : {"x" : 0.9 , "y" : 0.8 },
},
}
# Sweep を config に渡して初期化します。
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "<project>" )
# Sweep ジョブを開始します。
wandb. agent(sweep_id, function= main, count= 4 )
W&B run の初期化時に渡される nested_param.manual_key にはアクセスできません。run.config は、sweep configuration 辞書で定義されているキーと 値 のペアのみを保持します。
Sweep configuration テンプレート
次のテンプレートは、パラメータを構成し、検索制約を指定する方法を示しています。<> で囲まれた hyperparameter_name をハイパーパラメータの名前に置き換え、 値 を置き換えます。
program : <insert>
method : <insert>
parameter :
hyperparameter_name0 :
value : 0
hyperparameter_name1 :
values : [0 , 0 , 0 ]
hyperparameter_name :
distribution : <insert>
value : <insert>
hyperparameter_name2 :
distribution : <insert>
min : <insert>
max : <insert>
q : <insert>
hyperparameter_name3 :
distribution : <insert>
values :
- <list_of_values>
- <list_of_values>
- <list_of_values>
early_terminate :
type : hyperband
s : 0
eta : 0
max_iter : 0
command :
- ${Command macro}
- ${Command macro}
- ${Command macro}
- ${Command macro}
Sweep configuration の例
CLI
Python script or Jupyter notebook
program : train.py
method : random
metric :
goal : minimize
name : loss
parameters :
batch_size :
distribution : q_log_uniform_values
max : 256
min : 32
q : 8
dropout :
values : [0.3 , 0.4 , 0.5 ]
epochs :
value : 1
fc_layer_size :
values : [128 , 256 , 512 ]
learning_rate :
distribution : uniform
max : 0.1
min : 0
optimizer :
values : ["adam" , "sgd" ]
sweep_config = {
"method" : "random" ,
"metric" : {"goal" : "minimize" , "name" : "loss" },
"parameters" : {
"batch_size" : {
"distribution" : "q_log_uniform_values" ,
"max" : 256 ,
"min" : 32 ,
"q" : 8 ,
},
"dropout" : {"values" : [0.3 , 0.4 , 0.5 ]},
"epochs" : {"value" : 1 },
"fc_layer_size" : {"values" : [128 , 256 , 512 ]},
"learning_rate" : {"distribution" : "uniform" , "max" : 0.1 , "min" : 0 },
"optimizer" : {"values" : ["adam" , "sgd" ]},
},
}
Bayes hyperband の例
program : train.py
method : bayes
metric :
goal : minimize
name : val_loss
parameters :
dropout :
values : [0.15 , 0.2 , 0.25 , 0.3 , 0.4 ]
hidden_layer_size :
values : [96 , 128 , 148 ]
layer_1_size :
values : [10 , 12 , 14 , 16 , 18 , 20 ]
layer_2_size :
values : [24 , 28 , 32 , 36 , 40 , 44 ]
learn_rate :
values : [0.001 , 0.01 , 0.003 ]
decay :
values : [1e-5 , 1e-6 , 1e-7 ]
momentum :
values : [0.8 , 0.9 , 0.95 ]
epochs :
value : 27
early_terminate :
type : hyperband
s : 2
eta : 3
max_iter : 27
次のタブは、early_terminate の最小または最大イテレーション数を指定する方法を示しています。
Maximum number of iterations
Minimum number of iterations
この例のブラケットは [3, 3*eta, 3*eta*eta, 3*eta*eta*eta] で、これは [3, 9, 27, 81] と同じです。
early_terminate :
type : hyperband
min_iter : 3
この例のブラケットは [27/eta, 27/eta/eta] で、これは [9, 3] と同じです。
early_terminate :
type : hyperband
max_iter : 27
s : 2
コマンドの例
program : main.py
metric :
name : val_loss
goal : minimize
method : bayes
parameters :
optimizer.config.learning_rate :
min : !!float 1e-5
max : 0.1
experiment :
values : [expt001, expt002]
optimizer :
values : [sgd, adagrad, adam]
command :
- ${env}
- ${interpreter}
- ${program}
- ${args_no_hyphens}
/usr/bin/env python train.py --param1= value1 --param2= value2
python train.py --param1= value1 --param2= value2
次のタブは、一般的なコマンドマクロを指定する方法を示しています。
Set Python interpreter
Add extra parameters
Omit arguments
Hydra
{$interpreter} マクロを削除し、python インタープリターをハードコードするために 値 を明示的に指定します。たとえば、次のコードスニペットは、これを行う方法を示しています。
command :
- ${env}
- python3
- ${program}
- ${args}
以下は、sweep configuration パラメータで指定されていない追加のコマンドライン引数を追加する方法を示しています。
command :
- ${env}
- ${interpreter}
- ${program}
- "--config"
- "your-training-config.json"
- ${args}
プログラムが引数解析を使用していない場合は、引数をすべて渡すことを避け、wandb.init が sweep パラメータを wandb.config に自動的に取り込むことを利用できます。
command :
- ${env}
- ${interpreter}
- ${program}
Hydra などの ツール が期待する方法で引数を渡すようにコマンドを変更できます。詳細については、Hydra with W&B を参照してください。
command :
- ${env}
- ${interpreter}
- ${program}
- ${args_no_hyphens}
2.2.3.1 - Sweep configuration options
sweep configurationは、ネストされたキーと値のペアで構成されています。sweep configuration内のトップレベルキーを使用して、検索するパラメータ(parametermethod
以下の表は、トップレベルのsweep configurationキーと簡単な説明を示しています。各キーの詳細については、それぞれのセクションを参照してください。
トップレベルキー
説明
program(必須)実行するトレーニングスクリプト
entityこのsweepのエンティティ
projectこのsweepのプロジェクト
descriptionsweepのテキストによる説明
namesweepの名前。W&B UIに表示されます。
method(必須)検索戦略
metric最適化するメトリック(特定の検索戦略と停止基準でのみ使用されます)
parameters(必須)検索するパラメータ範囲
early_terminate早期停止基準
commandトレーニングスクリプトを呼び出し、引数を渡すためのコマンド構造
run_capこのsweepのrunの最大数
sweep configurationの構造化方法の詳細については、Sweep configuration の構造を参照してください。
metricmetric トップレベルのsweep configurationキーを使用して、最適化する名前、目標、およびターゲットメトリックを指定します。
キー
説明
name最適化するメトリックの名前。
goalminimize または maximize(デフォルトは minimize)。
target最適化しているメトリックの目標値。指定した目標値にrunが到達した場合、sweepは新しいrunを作成しません。(runがターゲットに到達すると)runを実行しているアクティブなエージェントは、エージェントが新しいrunの作成を停止するまでrunの完了を待ちます。
parametersYAMLファイルまたはPythonスクリプトで、parametersをトップレベルキーとして指定します。parametersキーの中で、最適化するハイパーパラメータの名前を指定します。一般的なハイパーパラメータには、学習率、バッチサイズ、エポック、オプティマイザーなどがあります。sweep configurationで定義するハイパーパラメータごとに、1つまたは複数の検索制約を指定します。
次の表は、サポートされているハイパーパラメータ検索制約を示しています。ハイパーパラメータとユースケースに基づいて、以下の検索制約のいずれかを使用して、sweep agentに検索場所(分布の場合)または検索または使用するもの(value、valuesなど)を指示します。
検索制約
説明
valuesこのハイパーパラメータの有効な値をすべて指定します。gridと互換性があります。
valueこのハイパーパラメータの単一の有効な値を指定します。gridと互換性があります。
distribution確率分布 を指定します。デフォルト値については、この表の後の注記を参照してください。
probabilitiesrandomを使用する場合に、valuesの各要素を選択する確率を指定します。
min、max(intまたは float)最大値と最小値。intの場合、int_uniform分散ハイパーパラメータ用。floatの場合、uniform分散ハイパーパラメータ用。
mu(float)normal - または lognormal - 分散ハイパーパラメータの平均パラメータ。
sigma(float)normal - または lognormal - 分散ハイパーパラメータの標準偏差パラメータ。
q(float)量子化されたハイパーパラメータの量子化ステップサイズ。
parametersルートレベルのパラメータ内に他のパラメータをネストします。
分布 が指定されていない場合、W&Bは次の条件に基づいて次の分布を設定します。
valuesを指定した場合はcategoricalmaxとminを整数として指定した場合はint_uniformmaxとminをfloatとして指定した場合はuniformvalueにセットを提供した場合はconstant methodmethodキーでハイパーパラメータ検索戦略を指定します。選択できるハイパーパラメータ検索戦略は、グリッド、ランダム、ベイズ探索の3つです。
グリッド検索
ハイパーパラメータ値のすべての組み合わせを反復処理します。グリッド検索は、各反復で使用するハイパーパラメータ値のセットについて、情報に基づかない決定を行います。グリッド検索は、計算コストが高くなる可能性があります。
グリッド検索は、連続検索空間内で検索している場合、永久に実行されます。
ランダム検索
分布に基づいて、各反復でランダムで情報に基づかないハイパーパラメータ値のセットを選択します。コマンドライン、Pythonスクリプト内、またはW&B App UI からプロセスを停止しない限り、ランダム検索は永久に実行されます。
ランダム(method: random)検索を選択した場合は、メトリックキーで分布空間を指定します。
ベイズ探索
ランダム およびグリッド 検索とは対照的に、ベイズモデルは情報に基づいた決定を行います。ベイズ最適化は、確率モデルを使用して、目的関数を評価する前に代用関数で値をテストする反復プロセスを通じて、使用する値を決定します。ベイズ探索は、連続パラメータの数が少ない場合にはうまく機能しますが、スケールは劣ります。ベイズ探索の詳細については、ベイズ最適化入門論文 を参照してください。
ベイズ探索は、コマンドライン、Pythonスクリプト内、またはW&B App UI からプロセスを停止しない限り、永久に実行されます。
ランダムおよびベイズ探索の分布オプション
parameterキー内で、ハイパーパラメータの名前をネストします。次に、distributionキーを指定し、値の分布を指定します。
次の表は、W&Bがサポートする分布を示しています。
distributionキーの値説明
constant定数分布。使用する定数(value)を指定する必要があります。
categoricalカテゴリ分布。このハイパーパラメータの有効な値(values)をすべて指定する必要があります。
int_uniform整数に対する離散一様分布。maxとminを整数として指定する必要があります。
uniform連続一様分布。maxとminをfloatとして指定する必要があります。
q_uniform量子化された一様分布。round(X / q) * qを返します。ここで、Xは一様です。qのデフォルトは1です。
log_uniform対数一様分布。exp(min)とexp(max)の間の値Xを返します。自然対数はminとmaxの間で均等に分布します。
log_uniform_values対数一様分布。minとmaxの間の値Xを返します。log(X)はlog(min)とlog(max)の間で均等に分布します。
q_log_uniform量子化された対数一様分布。round(X / q) * qを返します。ここで、Xはlog_uniformです。qのデフォルトは1です。
q_log_uniform_values量子化された対数一様分布。round(X / q) * qを返します。ここで、Xはlog_uniform_valuesです。qのデフォルトは1です。
inv_log_uniform逆対数一様分布。Xを返します。ここで、log(1/X)はminとmaxの間で均等に分布します。
inv_log_uniform_values逆対数一様分布。Xを返します。ここで、log(1/X)はlog(1/max)とlog(1/min)の間で均等に分布します。
normal正規分布。平均mu(デフォルト0)および標準偏差sigma(デフォルト1)で正規分布した値を返します。
q_normal量子化された正規分布。round(X / q) * qを返します。ここで、Xはnormalです。Qのデフォルトは1です。
log_normal対数正規分布。自然対数log(X)が平均mu(デフォルト0)および標準偏差sigma(デフォルト1)で正規分布するように、値Xを返します。
q_log_normal量子化された対数正規分布。round(X / q) * qを返します。ここで、Xはlog_normalです。qのデフォルトは1です。
early_terminateパフォーマンスの低いrunを停止するには、早期終了(early_terminate)を使用します。早期終了が発生した場合、W&Bは新しいハイパーパラメータ値のセットで新しいrunを作成する前に、現在のrunを停止します。
early_terminateを使用する場合は、停止アルゴリズムを指定する必要があります。sweep configuration内のearly_terminate内にtypeキーをネストします。
停止アルゴリズム
Hyperband ハイパーパラメータ最適化は、プログラムを停止するか、事前設定された1つ以上の反復回数(ブラケット と呼ばれる)で続行するかを評価します。
W&Bのrunがブラケットに到達すると、sweepはそのrunのメトリックを以前に報告されたすべてのメトリック値と比較します。runのメトリック値が高すぎる場合(目標が最小化の場合)、またはrunのメトリックが低すぎる場合(目標が最大化の場合)、sweepはrunを終了します。
ブラケットは、ログに記録された反復回数に基づいています。ブラケットの数は、最適化するメトリックをログに記録する回数に対応します。反復は、ステップ、エポック、またはその間の何かに対応できます。ステップカウンターの数値は、ブラケットの計算には使用されません。
ブラケットスケジュールを作成するには、min_iterまたはmax_iterのいずれかを指定します。
キー
説明
min_iter最初のブラケットの反復を指定します
max_iter最大反復回数を指定します。
sブラケットの総数を指定します(max_iterに必要)。
etaブラケット乗数スケジュールを指定します(デフォルト:3)。
strict元のHyperband論文に厳密に従って、runをより積極的にプルーニングする「strict」モードを有効にします。デフォルトはfalseです。
Hyperbandは、数分ごとに終了する
W&B run を確認します。runまたは反復が短い場合、終了runのタイムスタンプは、指定されたブラケットと異なる場合があります。
commandcommandキー内のネストされた値を使用して、形式と内容を変更します。ファイル名などの固定コンポーネントを直接含めることができます。
Unixシステムでは、/usr/bin/envは、OSが環境に基づいて正しいPythonインタープリターを選択するようにします。
W&Bは、コマンドの可変コンポーネントに対して次のマクロをサポートしています。
コマンドマクロ
説明
${env}Unixシステムでは/usr/bin/env、Windowsでは省略。
${interpreter}pythonに展開されます。
${program}sweep configurationのprogramキーで指定されたトレーニングスクリプトのファイル名。
${args}--param1=value1 --param2=value2の形式のハイパーパラメータとその値。
${args_no_boolean_flags}--param1=value1の形式のハイパーパラメータとその値。ただし、ブールパラメータはTrueの場合は--boolean_flag_paramの形式になり、Falseの場合は省略されます。
${args_no_hyphens}param1=value1 param2=value2の形式のハイパーパラメータとその値。
${args_json}JSONとしてエンコードされたハイパーパラメータとその値。
${args_json_file}JSONとしてエンコードされたハイパーパラメータとその値を含むファイルへのパス。
${envvar}環境変数を渡す方法。${envvar:MYENVVAR} はMYENVVAR環境変数の値に展開されます。
2.2.4 - Initialize a sweep
W&B Sweep の初期化
W&B は、クラウド(標準)、ローカル(ローカル)の 1 台以上のマシンで Sweeps を管理するために、 Sweep Controller を使用します。run が完了すると、sweep controller は、実行する新しい run を記述した新しい一連の指示を発行します。これらの指示は、実際に run を実行する エージェント によって取得されます。典型的な W&B Sweep では、コントローラは W&B サーバー上に存在します。エージェントは あなたの マシン上に存在します。
以下のコードスニペットは、CLI および Jupyter Notebook または Python スクリプト内で Sweeps を初期化する方法を示しています。
sweep を初期化する前に、sweep configuration が YAML ファイルまたはスクリプト内のネストされた Python 辞書 object で定義されていることを確認してください。詳細については、sweep configuration の定義 を参照してください。
W&B Sweep と W&B Run は、同じ project 内にある必要があります。したがって、W&B を初期化するときに指定する名前 (wandb.initwandb.sweep
Python script or notebook
CLI
W&B SDK を使用して sweep を初期化します。sweep configuration 辞書を sweep パラメータに渡します。オプションで、W&B Run の出力を保存する project パラメータ(project)の project 名を指定します。project が指定されていない場合、run は「未分類」の project に配置されます。
import wandb
# sweep configuration の例
sweep_configuration = {
"method" : "random" ,
"name" : "sweep" ,
"metric" : {"goal" : "maximize" , "name" : "val_acc" },
"parameters" : {
"batch_size" : {"values" : [16 , 32 , 64 ]},
"epochs" : {"values" : [5 , 10 , 15 ]},
"lr" : {"max" : 0.1 , "min" : 0.0001 },
},
}
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "project-name" )
wandb.sweep
W&B CLI を使用して sweep を初期化します。configuration ファイルの名前を指定します。オプションで、project フラグの project 名を指定します。project が指定されていない場合、W&B Run は「未分類」の project に配置されます。
wandb sweepsweeps_demo project の sweep を初期化し、configuration に config.yaml ファイルを使用します。
wandb sweep --project sweeps_demo config.yaml
このコマンドは、sweep ID を出力します。sweep ID には、Entity 名と project 名が含まれます。sweep ID をメモしておいてください。
2.2.5 - Start or stop a sweep agent
複数のマシン上で W&B Sweep エージェントを開始または停止します。
複数のマシン上の 1 つまたは複数のエージェントで W&B Sweep を開始します。W&B Sweep エージェントは、ハイパーパラメータのために W&B Sweep ( wandb sweep) を初期化したときに起動した W&B サーバーにクエリを実行し、それらを使用してモデルトレーニングを実行します。
W&B Sweep エージェントを開始するには、W&B Sweep を初期化したときに返された W&B Sweep ID を指定します。W&B Sweep ID の形式は次のとおりです。
以下に詳細を示します。
entity: W&B のユーザー名または Team 名。
project: W&B Run の出力を保存する Project の名前。Project が指定されていない場合、run は「未分類」Project に配置されます。
sweep_ID: W&B によって生成された、疑似ランダムな一意の ID。
Jupyter Notebook または Python スクリプト内で W&B Sweep エージェントを開始する場合、W&B Sweep が実行する関数の名前を指定します。
以下のコードスニペットは、W&B でエージェントを開始する方法を示しています。設定ファイルが既にあって、W&B Sweep を初期化済みであることを前提としています。設定ファイルを定義する方法の詳細については、Sweep 設定の定義 を参照してください。
CLI
Python script or notebook
wandb agent コマンドを使用して sweep を開始します。sweep を初期化したときに返された sweep ID を指定します。以下のコードスニペットをコピーして貼り付け、sweep_id を sweep ID に置き換えます。
W&B Python SDK ライブラリを使用して sweep を開始します。sweep を初期化したときに返された sweep ID を指定します。さらに、sweep が実行する関数の名前を指定します。
wandb. agent(sweep_id= sweep_id, function= function_name)
W&B エージェントの停止
ランダム探索とベイズ探索は永久に実行されます。コマンドライン、python スクリプト内、または
Sweeps UI からプロセスを停止する必要があります。
オプションで、W&B Run の数を Sweep エージェントが試行する回数を指定します。次のコードスニペットは、CLI および Jupyter Notebook、Python スクリプト内で W&B Runs の最大数を設定する方法を示しています。
Python script or notebook
CLI
まず、sweep を初期化します。詳細については、Sweeps の初期化 を参照してください。
sweep_id = wandb.sweep(sweep_config)
次に、sweep ジョブを開始します。sweep の開始から生成された sweep ID を指定します。試行する run の最大数を設定するには、count パラメータに整数値を渡します。
sweep_id, count = "dtzl1o7u" , 10
wandb. agent(sweep_id, count= count)
sweep agent の完了後、同じスクリプトまたは Notebook 内で新しい run を開始する場合は、新しい run を開始する前に wandb.teardown() を呼び出す必要があります。
まず、wandb sweepSweeps の初期化 を参照してください。
wandb sweep config.yaml
試行する run の最大数を設定するには、count フラグに整数値を渡します。
NUM= 10
SWEEPID= "dtzl1o7u"
wandb agent -- count $ NUM $ SWEEPID
2.2.6 - Parallelize agents
マルチコアまたはマルチ GPU マシンで W&B Sweep エージェント を並列化します。
マルチコアまたはマルチ GPU マシンで W&B Sweep エージェントを並列化します。開始する前に、W&B Sweep を初期化していることを確認してください。W&B Sweep の初期化方法の詳細については、Sweeps の初期化 を参照してください。
マルチ CPU マシンでの並列化
ユースケースに応じて、次のタブで CLI を使用するか、Jupyter Notebook 内で W&B Sweep エージェントを並列化する方法を検討してください。
wandb agentsweep を初期化 したときに返された sweep ID を指定します。
ローカルマシンで複数のターミナルウィンドウを開きます。
次の コードスニペット をコピーして貼り付け、sweep_id を sweep ID に置き換えます。
W&B Python SDK ライブラリを使用して、Jupyter Notebook 内で複数の CPU に W&B Sweep エージェントを並列化します。sweep を初期化 したときに返された sweep ID があることを確認してください。さらに、sweep が function パラメータに対して実行する関数の名前を指定します。
複数の Jupyter Notebook を開きます。
複数の Jupyter Notebook に W&B Sweep ID をコピーして貼り付け、W&B Sweep を並列化します。たとえば、sweep ID が sweep_id という変数に格納され、関数の名前が function_name の場合、次の コードスニペット を複数の Jupyter Notebook に貼り付けて、sweep を並列化できます。
wandb. agent(sweep_id= sweep_id, function= function_name)
マルチ GPU マシンでの並列化
次の手順に従って、CUDA Toolkit を使用してターミナルで複数の GPU に W&B Sweep エージェントを並列化します。
ローカルマシンで複数のターミナルウィンドウを開きます。
W&B Sweep ジョブ (wandb agentCUDA_VISIBLE_DEVICES で使用する GPU インスタンスを指定します。CUDA_VISIBLE_DEVICES に、使用する GPU インスタンスに対応する整数値を割り当てます。
たとえば、ローカルマシンに 2 つの NVIDIA GPU があるとします。ターミナルウィンドウを開き、CUDA_VISIBLE_DEVICES を 0 (CUDA_VISIBLE_DEVICES=0) に設定します。次の例の sweep_ID を、W&B Sweep を初期化したときに返される W&B Sweep ID に置き換えます。
ターミナル 1
CUDA_VISIBLE_DEVICES= 0 wandb agent sweep_ID
2 番目のターミナルウィンドウを開きます。CUDA_VISIBLE_DEVICES を 1 (CUDA_VISIBLE_DEVICES=1) に設定します。上記の コードスニペット で説明されている sweep_ID に同じ W&B Sweep ID を貼り付けます。
ターミナル 2
CUDA_VISIBLE_DEVICES= 1 wandb agent sweep_ID
2.2.7 - Visualize sweep results
W&B App UIでW&B Sweepsの結果を可視化します。
W&B App UI で W&B Sweeps の結果を可視化します。https://wandb.ai/home にある W&B App UI に移動します。W&B Sweep を初期化する際に指定した project を選択します。project の workspace にリダイレクトされます。左側のパネルにある Sweep icon (ほうきのアイコン) を選択します。Sweep UI で、リストから Sweep の名前を選択します。
デフォルトでは、W&B は W&B Sweep ジョブを開始すると、自動的にパラレル座標図、パラメータのインポータンスプロット、および散布図を作成します。
パラレル座標図は、多数のハイパーパラメータとモデルのメトリクスの関係を一目でまとめたものです。パラレル座標図の詳細については、パラレル座標 を参照してください。
散布図 (左) は、Sweep 中に生成された W&B Runs を比較します。散布図の詳細については、散布図 を参照してください。
パラメータのインポータンスプロット (右) は、メトリクスの望ましい値の最良の予測因子であり、メトリクスの望ましい値と高度に相関するハイパーパラメータをリストします。パラメータのインポータンスプロットの詳細については、パラメータの重要性 を参照してください。
自動的に使用される従属値と独立値 (x 軸と y 軸) を変更できます。各 panel 内には、Edit panel という鉛筆アイコンがあります。Edit panel を選択します。モデルが表示されます。モーダル内で、グラフの振る舞いを変更できます。
すべてのデフォルトの W&B 可視化オプションの詳細については、Panels を参照してください。W&B Sweep の一部ではない W&B Runs からプロットを作成する方法については、Data Visualization のドキュメント を参照してください。
2.2.8 - Manage sweeps with the CLI
CLI を使用して、W&B Sweep を一時停止、再開、およびキャンセルします。
CLI で W&B Sweep を一時停止、再開、キャンセルします。W&B Sweep を一時停止すると、Sweep が再開されるまで新しい W&B Run を実行しないように W&B エージェント に指示します。Sweep を再開すると、新しい W&B Run の実行を続行するようにエージェントに指示します。W&B Sweep を停止すると、新しい W&B Run の作成または実行を停止するように W&B Sweep エージェントに指示します。W&B Sweep をキャンセルすると、現在実行中の W&B Run を強制終了し、新しい Run の実行を停止するように Sweep エージェントに指示します。
いずれの場合も、W&B Sweep を初期化したときに生成された W&B Sweep ID を指定してください。必要に応じて、新しい ターミナル ウィンドウを開いて、次のコマンドを実行します。W&B Sweep が現在の ターミナル ウィンドウに出力ステートメントを出力している場合は、新しい ターミナル ウィンドウを開くとコマンドを実行しやすくなります。
次のガイダンスに従って、sweep を一時停止、再開、およびキャンセルします。
Sweep の一時停止
新しい W&B Run の実行を一時的に停止するように W&B Sweep を一時停止します。W&B Sweep を一時停止するには、wandb sweep --pause コマンドを使用します。一時停止する W&B Sweep ID を指定します。
wandb sweep --pause entity/project/sweep_ID
Sweep の再開
wandb sweep --resume コマンドを使用して、一時停止した W&B Sweep を再開します。再開する W&B Sweep ID を指定します。
wandb sweep --resume entity/project/sweep_ID
Sweep の停止
新しい W&B Run の実行を停止し、現在実行中の Run を終了させるには、W&B sweep を完了させます。
wandb sweep --stop entity/project/sweep_ID
Sweep のキャンセル
実行中のすべての run を強制終了し、新しい run の実行を停止するには、sweep をキャンセルします。W&B Sweep をキャンセルするには、wandb sweep --cancel コマンドを使用します。キャンセルする W&B Sweep ID を指定します。
wandb sweep --cancel entity/project/sweep_ID
CLI コマンドオプションの完全なリストについては、wandb sweep CLI リファレンス ガイドを参照してください。
複数のエージェントにまたがる sweep の一時停止、再開、停止、およびキャンセル
単一の ターミナル から複数のエージェントにまたがって W&B Sweep を一時停止、再開、停止、またはキャンセルします。たとえば、マルチコアマシンがあるとします。W&B Sweep を初期化した後、新しい ターミナル ウィンドウを開き、各新しい ターミナル に Sweep ID をコピーします。
任意の ターミナル 内から、wandb sweep CLI コマンドを使用して、W&B Sweep を一時停止、再開、停止、またはキャンセルします。たとえば、次の コードスニペット は、CLI を使用して複数の エージェント にまたがる W&B Sweep を一時停止する方法を示しています。
wandb sweep --pause entity/project/sweep_ID
エージェント 全体で Sweep を再開するには、Sweep ID と共に --resume フラグを指定します。
wandb sweep --resume entity/project/sweep_ID
W&B エージェント を並列化する方法の詳細については、エージェント の並列化 を参照してください。
2.2.9 - Learn more about sweeps
Sweeps に役立つ情報源を集めました。
学術論文
Li, Lisha, 他. “Hyperband: A novel bandit-based approach to hyperparameter optimization. ” The Journal of Machine Learning Research 18.1 (2017): 6765-6816.
Sweep Experiments
以下の W&B Reports は、W&B Sweeps を使用したハイパーパラメーター最適化を調査する Projects の例を示しています。
selfm-anaged
次のハウツー ガイドでは、W&B を使用して実際の問題を解決する方法を示します。
Sweep GitHub リポジトリ
W&B はオープンソースを提唱し、コミュニティからの貢献を歓迎します。GitHub リポジトリは https://github.com/wandb/sweeps にあります。W&B オープンソースリポジトリへの貢献方法については、W&B GitHub のContribution guidelines を参照してください。
2.2.10 - Manage algorithms locally
W&B クラウド でホストされているサービスを使用する代わりに、ローカルでアルゴリズムを検索して停止します。
ハイパーパラメータコントローラは、デフォルトで Weights & Biased によってクラウドサービスとしてホストされています。W&B エージェントはコントローラと通信して、トレーニングに使用するパラメータの次のセットを決定します。コントローラは、どの run を停止できるかを判断するために、早期停止アルゴリズムを実行する役割も担っています。
ローカルコントローラの機能を使用すると、ユーザーはローカルで検索および停止アルゴリズムを開始できます。ローカルコントローラを使用すると、ユーザーはコードを検査および調査して、問題をデバッグしたり、クラウドサービスに組み込むことができる新機能を開発したりできます。
この機能は、 Sweeps ツール用の新しいアルゴリズムのより迅速な開発とデバッグをサポートするために提供されています。実際のハイパーパラメータ最適化のワークロードを目的としたものではありません。
始める前に、W&B SDK(wandb)をインストールする必要があります。コマンドラインに次のコードスニペットを入力します。
pip install wandb sweeps
以下の例では、設定ファイルとトレーニングループが Python スクリプトまたは Jupyter Notebook で定義されていることを前提としています。設定ファイルを定義する方法の詳細については、sweep configuration の定義 を参照してください。
コマンドラインからローカルコントローラを実行する
通常、Weights & Biased がクラウドサービスとしてホストするハイパーパラメータコントローラを使用する場合と同様に、sweep を初期化します。コントローラフラグ(controller)を指定して、W&B sweep ジョブにローカルコントローラを使用することを示します。
wandb sweep --controller config.yaml
または、sweep の初期化とローカルコントローラを使用することの指定を2つのステップに分けることもできます。
ステップを分けるには、まず、次のキーと値を sweep の YAML 設定ファイルに追加します。
次に、sweep を初期化します。
sweep を初期化したら、wandb controller
# wandb sweep コマンドは sweep_id を出力します
wandb controller { user} /{ entity} /{ sweep_id}
ローカルコントローラを使用するように指定したら、1つ以上の Sweep agent を起動して sweep を実行します。通常と同じように W&B Sweep を開始します。詳細については、Sweep agent の開始 を参照してください。
W&B Python SDK でローカルコントローラを実行する
次のコードスニペットは、W&B Python SDK でローカルコントローラを指定および使用する方法を示しています。
Python SDK でコントローラを使用する最も簡単な方法は、sweep ID をwandb.controllerrun メソッドを使用して、sweep ジョブを開始します。
sweep = wandb. controller(sweep_id)
sweep. run()
コントローラーループをより細かく制御したい場合:
import wandb
sweep = wandb. controller(sweep_id)
while not sweep. done():
sweep. print_status()
sweep. step()
time. sleep(5 )
または、提供されるパラメータをさらに制御することもできます。
import wandb
sweep = wandb. controller(sweep_id)
while not sweep. done():
params = sweep. search()
sweep. schedule(params)
sweep. print_status()
コードで sweep を完全に指定する場合は、次のようにします。
import wandb
sweep = wandb. controller()
sweep. configure_search("grid" )
sweep. configure_program("train-dummy.py" )
sweep. configure_controller(type= "local" )
sweep. configure_parameter("param1" , value= 3 )
sweep. create()
sweep. run()
2.2.11 - Sweeps troubleshooting
W&B Sweep でよくある問題をトラブルシューティングします。
提案されたガイダンスに従って、一般的なエラーメッセージのトラブルシューティングを行います。
CommError, Run does not exist および ERROR Error uploadingこれらの 2 つのエラーメッセージが両方とも返された場合、W&B の Run ID が定義されている可能性があります。例として、Jupyter Notebook または Python スクリプトのどこかに、次のようなコードスニペットが定義されている可能性があります。
wandb. init(id= "some-string" )
W&B は W&B Sweeps によって作成された Runs に対して、ランダムでユニークな ID を自動的に生成するため、W&B Sweeps の Run ID を設定することはできません。
W&B の Run ID は、1 つの project 内でユニークである必要があります。
W&B を初期化する際に、テーブルやグラフに表示されるカスタム名を付けたい場合は、name パラメータに名前を渡すことをお勧めします。例:
wandb. init(name= "a helpful readable run name" )
Cuda out of memoryこのエラーメッセージが表示された場合は、コードをリファクタリングして、プロセスベースの実行を使用するようにします。より具体的には、コードを Python スクリプトに書き換えます。さらに、W&B Python SDK ではなく、CLI から W&B Sweep Agent を呼び出します。
例として、コードを train.py という Python スクリプトに書き換えたとします。トレーニングスクリプトの名前 (train.py) を YAML Sweep configuration ファイル (config.yaml(この例)) に追加します。
program : train.py
method : bayes
metric :
name : validation_loss
goal : maximize
parameters :
learning_rate :
min : 0.0001
max : 0.1
optimizer :
values : ["adam" , "sgd" ]
次に、次のコードを train.py Python スクリプトに追加します。
if _name_ == "_main_" :
train()
CLI に移動し、wandb sweep で W&B Sweep を初期化します。
返された W&B Sweep ID をメモします。次に、Python SDK (wandb.agentwandb agentsweep_ID を、前の手順で返された Sweep ID に置き換えます。
anaconda 400 error次のエラーは通常、最適化しているメトリックをログに記録しない場合に発生します。
wandb: ERROR Error while calling W&B API: anaconda 400 error:
{ "code" : 400, "message" : "TypeError: bad operand type for unary -: 'NoneType'" }
YAML ファイルまたはネストされた辞書の中で、最適化する「metric」という名前のキーを指定します。このメトリックを必ずログに記録 (wandb.log) してください。さらに、Python スクリプトまたは Jupyter Notebook 内で Sweep を最適化するために定義した 正確な メトリック名を使用してください。設定ファイルの詳細については、Sweep configuration の定義 を参照してください。
2.2.12 - Sweeps UI
Sweeps UI のさまざまなコンポーネントについて説明します。
State (ステート) 、作成時間(Created )、sweep を開始した Entity (Creator )、完了した run の数(Run count )、sweep の計算にかかった時間(Compute time )は、Sweeps UI に表示されます。sweep が作成すると予想される run の数(Est. Runs )は、離散的な検索空間でグリッド検索を行う場合に提供されます。また、sweep をクリックして、インターフェースから sweep を一時停止、再開、停止、または強制終了することもできます。
2.2.13 - Tutorial: Create sweep job from project
既存の W&B プロジェクトから sweep ジョブを作成する方法のチュートリアル。
このチュートリアルでは、既存の W&B の プロジェクト から sweep job を作成する方法について説明します。ここでは、Fashion MNIST データセット を使用して、PyTorch の畳み込み ニューラルネットワーク に画像の分類方法を学習させます。必要な コード と データセット は、W&B のリポジトリにあります。https://github.com/wandb/examples/tree/master/examples/pytorch/pytorch-cnn-fashion
この W&B ダッシュボード で 結果 を確認してください。
1. プロジェクト を作成する
まず、 ベースライン を作成します。W&B examples GitHub リポジトリ から PyTorch MNIST データセット のサンプル モデル をダウンロードします。次に、 モデル を トレーニング します。トレーニング スクリプト は、examples/pytorch/pytorch-cnn-fashion ディレクトリー 内にあります。
このリポジトリをクローンします git clone https://github.com/wandb/examples.git
このサンプルを開きます cd examples/pytorch/pytorch-cnn-fashion
run を手動で実行します python train.py
オプションで、W&B App UI ダッシュボード に表示される例を確認してください。
プロジェクト ページの例を見る →
2. sweep を作成する
プロジェクト ページから、サイドバーの Sweep tab を開き、Create Sweep を選択します。
自動生成された 設定 は、完了した run に基づいて sweep する 値 を推測します。試したい ハイパーパラメーター の範囲を指定するには、 設定 を編集します。sweep を 起動 すると、ホストされている W&B sweep server で新しい プロセス が開始されます。この集中型 サービス は、 トレーニング job を実行している マシン である エージェント を調整します。
3. エージェント を 起動 する
次に、 ローカル で エージェント を 起動 します。作業を分散して sweep job をより迅速に完了したい場合は、最大 20 個の エージェント を異なる マシン で 並行 して 起動 できます。エージェント は、次に試す パラメータ のセットを出力します。
これで sweep が実行されました。次の図は、サンプル sweep job の実行中に ダッシュボード がどのように表示されるかを示しています。プロジェクト ページの例を見る →
既存の run で新しい sweep をシードする
以前に ログ に記録した既存の run を使用して、新しい sweep を 起動 します。
プロジェクト テーブル を開きます。
テーブル の左側にある チェックボックス で、使用する run を選択します。
ドロップダウン をクリックして、新しい sweep を作成します。
これで、sweep が サーバー 上にセットアップされます。run の実行を開始するには、1 つ以上の エージェント を 起動 するだけです。
新しい sweep を ベイジアン sweep として開始すると、選択した run によって ガウス 過程 もシードされます。
2.3 - Tables
データセットを反復処理し、モデル の予測を理解する
W&B Tables を使用して、テーブル形式のデータを可視化およびクエリします。例:
同じテストセットで異なるモデルがどのように機能するかを比較する
データ内のパターンを特定する
サンプルモデルの予測を視覚的に確認する
一般的に誤分類された例を見つけるためにクエリする
W&B ML コースのサンプル project でご覧ください。
仕組み
Table は、各カラムが単一のデータ型を持つデータの二次元グリッドです。Tables は、プリミティブ型と数値型、およびネストされたリスト、辞書、リッチメディア型をサポートしています。
Table をログする
数行のコードで Table をログします。
import wandb
run = wandb. init(project= "table-test" )
my_table = wandb. Table(columns= ["a" , "b" ], data= [["a1" , "b1" ], ["a2" , "b2" ]])
run. log({"Table Name" : my_table})
開始方法
2.3.1 - Tutorial: Log tables, visualize and query data
W&B Tables の使い方を5分間の クイックスタート で見てみましょう。
次の クイックスタート では、データテーブル のログ記録、データの可視化、およびデータのクエリ方法について説明します。
下のボタンを選択して、MNIST データに関する PyTorch の クイックスタート のサンプル プロジェクト を試してください。
1. テーブル のログを記録する
W&B で テーブル のログを記録します。新しい テーブル を構築するか、Pandas Dataframe を渡すことができます。
テーブル を構築する
Pandas Dataframe
新しい テーブル を構築してログに記録するには、以下を使用します。
例を次に示します。
import wandb
run = wandb. init(project= "table-test" )
# Create and log a new table.
my_table = wandb. Table(columns= ["a" , "b" ], data= [["a1" , "b1" ], ["a2" , "b2" ]])
run. log({"Table Name" : my_table})
Pandas Dataframe を wandb.Table() に渡して、新しい テーブル を作成します。
import wandb
import pandas as pd
df = pd. read_csv("my_data.csv" )
run = wandb. init(project= "df-table" )
my_table = wandb. Table(dataframe= df)
wandb. log({"Table Name" : my_table})
サポートされている データ 型の詳細については、W&B API リファレンス ガイド の wandb.Table
2. プロジェクト ワークスペース で テーブル を可視化する
ワークスペース で結果の テーブル を表示します。
W&B アプリ で プロジェクト に移動します。
プロジェクト ワークスペース で run の名前を選択します。一意の テーブル の キー ごとに新しい パネル が追加されます。
この例では、my_table は キー Table Name でログに記録されます。
3. モデル の バージョン 間で比較する
複数の W&B の Runs からサンプル テーブル をログに記録し、プロジェクト ワークスペース で結果を比較します。この サンプル ワークスペース では、同じ テーブル 内の複数の異なる バージョン から行を結合する方法を示します。
テーブル フィルター、ソート、およびグループ化機能を使用して、モデル の結果を探索および評価します。
2.3.2 - Visualize and analyze tables
W&B Tables を可視化、分析します。
W&B Tables をカスタマイズして、 機械学習 モデルの性能に関する質問に答えたり、 データを分析したりできます。
インタラクティブにデータを探索して、以下を実現します。
モデル、 エポック、 個々のサンプル間で、 変更を正確に比較する
データにおけるより高レベルのパターンを理解する
可視化 サンプルでインサイトを捉え、 伝達する
W&B Tables は、 次の 振る舞い をします。
Artifacts コンテキストではステートレス : Artifacts バージョンとともに記録されたテーブルは、 ブラウザ ウィンドウを閉じるとデフォルト状態にリセットされます。Workspace または Report コンテキストではステートフル : 単一 run の Workspace 、 複数 run の Project Workspace 、 または Report でテーブルに加えた変更は保持されます。
現在の W&B Table ビューを保存する方法については、 ビューを保存 を参照してください。
2つのテーブルを表示する方法
マージされたビュー または 並べて表示するビュー で2つのテーブルを比較します。 例えば、 下の図はMNIST データのテーブル比較を示しています。
次の手順に従って、 2つのテーブルを比較します。
W&B App で Project に移動します。
左側の パネル で Artifacts アイコンを選択します。
Artifacts バージョンを選択します。
次の図では、 5 エポック (インタラクティブな例はこちら ) の後、 MNIST 検証データに対するモデルの 予測 を示します。
サイドバー で比較する2番目の Artifacts バージョンにマウスを合わせ、 表示されたら [比較] をクリックします。 例えば、 下の図では、 トレーニング の5 エポック後に同じモデルによって行われたMNIST の 予測 と比較するために、 「v4」 というラベルの バージョン を選択します。
マージされたビュー
最初は、 両方のテーブルがマージされて表示されます。 最初に選択されたテーブルのインデックスは0で青色で強調表示され、 2番目のテーブルのインデックスは1で黄色で強調表示されます。マージされたテーブルのライブ例はこちら をご覧ください。
マージされたビューからは、 以下が可能です。
結合キーを選択する : 左上のドロップダウンを使用して、 2つのテーブルの結合キーとして使用する列を設定します。 通常、 これは データセット 内の特定の例のファイル名や、 生成されたサンプル のインクリメント インデックスなど、 各行の一意の識別子です。 現在、 任意の 列を選択できますが、 判読できないテーブルやクエリの速度低下が発生する可能性があることに注意してください。結合する代わりに連結する : このドロップダウンで [すべてのテーブルを連結する] を選択すると、 列全体を結合する代わりに、 両方のテーブルから すべての行を結合 して、 より大きなテーブルにすることができます。各テーブルを明示的に参照する : フィルター式で0、 1、 * を使用して、 1つまたは両方のテーブル インスタンス の列を明示的に指定します。詳細な数値の差をヒストグラムとして可視化する : 任意のセルの値を一目で比較できます。
並べて表示するビュー
2つのテーブルを並べて表示するには、 最初のドロップダウンを [テーブルをマージ: テーブル] から [リスト: テーブル] に変更し、 それぞれ [ページ サイズ] を更新します。 ここで、 最初に選択したテーブルは左側にあり、 2番目のテーブルは右側にあります。 また、 [垂直] チェックボックスをクリックして、 これらのテーブルを垂直方向に比較することもできます。
テーブルを一目で比較する : 任意の操作 (ソート、 フィルタリング、 グループ化) を両方のテーブルにまとめて適用し、 変更や違いをすばやく見つけます。 例えば、 推測でグループ化された不正な 予測 、 全体で最も難しいネガティブ、 真のラベル ごとの信頼度スコア分布などを表示します。2つのテーブルを個別に探索する : スクロールして、 目的の側面/行に焦点を当てます。
Artifacts を比較する
時間の経過とともにテーブルを比較 したり、 モデル バリアント を比較 したりすることもできます。
時間の経過とともにテーブルを比較する
トレーニング の意味のあるステップごとに Artifacts にテーブルを記録して、 トレーニング 時間中のモデルの性能を分析します。 例えば、 すべての検証ステップの終了時、 トレーニング の50 エポックごと、 または パイプライン に適した頻度でテーブルを記録できます。 並べて表示するビューを使用して、 モデル 予測 の変化を可視化します。
トレーニング 時間中の 予測 の可視化に関するより詳細なウォークスルーについては、 この Report およびこのインタラクティブな ノートブック の例 を参照してください。
モデル バリアント 全体でテーブルを比較する
2つの異なるモデルに対して同じステップで記録された2つの Artifacts バージョンを比較して、 異なる 設定 (ハイパーパラメーター 、 ベース アーキテクチャー など) 全体でモデルの性能を分析します。
例えば、 baseline と新しいモデル バリアント である 2x_layers_2x_lr の間で 予測 を比較します。この場合、 最初の畳み込みレイヤーは32から64に、 2番目のレイヤーは128から256に、 学習率は0.001から0.002に倍増します。このライブ例 から、 並べて表示するビューを使用して、 1 (左側のタブ) 対 5 トレーニング エポック (右側のタブ) 後の不正な 予測 に絞り込みます。
1 トレーニング エポック
5 トレーニング エポック
ビューを保存
run Workspace 、 Project Workspace 、 または Report で操作するテーブルは、 ビューの状態を自動的に保存します。 テーブル操作を適用して ブラウザ を閉じると、 次にテーブルに移動したときに、 テーブルには最後に表示された 設定 が保持されます。
Artifacts コンテキストで操作するテーブルはステートレスのままです。
特定の状態で Workspace からテーブルを保存するには、 W&B Report にエクスポートします。 テーブルを Report にエクスポートするには、 次の手順を実行します。
Workspace 可視化 パネル の右上隅にあるケバブ アイコン (3つの垂直ドット) を選択します。
[パネルを共有] または [レポートに追加] を選択します。
例
これらの Reports は、 W&B Tables のさまざまな ユースケース を示しています。
2.3.3 - Example tables
W&B テーブル の例
次のセクションでは、テーブルを使用できる方法のいくつかを紹介します。
データの表示
モデルトレーニングまたは評価中に、メトリクスとリッチメディアをログに記録し、クラウドまたは ホスティングインスタンス に同期された永続的なデータベースで結果を可視化します。
たとえば、写真データセットのバランスの取れた分割を示すこのテーブル を確認してください。
データをインタラクティブに探索する
テーブルの表示、並べ替え、フィルタリング、グループ化、結合、およびクエリを実行して、データとモデルのパフォーマンスを理解します。静的なファイルを参照したり、分析スクリプトを再実行したりする必要はありません。
たとえば、スタイルが転送されたオーディオに関するこのレポート を参照してください。
モデルのバージョンを比較する
さまざまなトレーニングエポック、データセット、ハイパーパラメーターの選択、モデルアーキテクチャーなどで、結果をすばやく比較します。
たとえば、同じテスト画像で 2 つのモデルを比較するこのテーブル を参照してください。
すべての詳細を追跡し、全体像を把握する
特定のステップで特定の予測を可視化するためにズームインします。集計統計を表示し、エラーのパターンを特定し、改善の機会を理解するためにズームアウトします。このツールは、単一のモデルトレーニングのステップを比較したり、異なるモデルバージョン間で結果を比較したりするために使用できます。
たとえば、MNIST データセットで 1 回、次に 5 回のエポック後の結果を分析するこのサンプルテーブル を参照してください。
W&B Tables を使用したプロジェクト例
以下は、W&B Tables を使用する実際の W&B のProjectsのハイライトです。
画像分類
このレポート を読むか、この colab に従うか、artifacts コンテキスト を調べて、CNN が iNaturalist の写真から 10 種類の生物(植物、鳥、昆虫など)を識別する方法を確認してください。
オーディオ
音色転送に関するこのレポート でオーディオテーブルを操作します。録音されたクジラの歌と、バイオリンやトランペットなどの楽器で同じメロディーをシンセサイズした演奏を比較できます。この colab を使用して、独自の曲を録音し、W&B でシンセサイズされたバージョンを探索することもできます。
テキスト
トレーニングデータまたは生成された出力からテキストサンプルを参照し、関連フィールドで動的にグループ化し、モデルのバリアントまたは実験設定全体で評価を調整します。テキストを Markdown としてレンダリングするか、ビジュアル差分モードを使用してテキストを比較します。このレポート で、シェイクスピアを生成するための単純な文字ベースの RNN を探索してください。
ビデオ
トレーニング中にログに記録されたビデオを参照および集計して、モデルを理解します。副作用を最小限に抑える ことを目指す RL エージェント向けの SafeLife ベンチマーク を使用した初期の例を次に示します。
表形式データ
バージョン管理と重複排除を使用して 表形式データを分割および事前処理する方法に関するレポート を表示します。
モデルバリアントの比較(セマンティックセグメンテーション)
セマンティックセグメンテーション用の Tables のログを記録し、異なるモデルを比較する インタラクティブノートブック と ライブ例 。この Table で独自のクエリを試してください。
トレーニング時間に対する改善の分析
時間経過に伴う予測の可視化 と、それに付随する インタラクティブノートブック に関する詳細なレポート。
2.3.4 - Export table data
テーブルからデータをエクスポートする方法。
すべての W&B Artifacts と同様に、Tables は pandas のデータフレームに変換して、簡単にデータのエクスポートができます。
table を artifact に変換するまず、テーブルを artifact に変換する必要があります。これを行うには、artifact.get(table, "table_name") を使用するのが最も簡単です。
# 新しいテーブルを作成してログに記録します。
with wandb. init() as r:
artifact = wandb. Artifact("my_dataset" , type= "dataset" )
table = wandb. Table(
columns= ["a" , "b" , "c" ], data= [(i, i * 2 , 2 ** i) for i in range(10 )]
)
artifact. add(table, "my_table" )
wandb. log_artifact(artifact)
# 作成した artifact を使用して、作成したテーブルを取得します。
with wandb. init() as r:
artifact = r. use_artifact("my_dataset:latest" )
table = artifact. get("my_table" )
artifact を Dataframe に変換する次に、テーブルをデータフレームに変換します。
# 前のコード例から続けて:
df = table. get_dataframe()
データのエクスポート
これで、データフレームがサポートする任意の方法を使用してエクスポートできます。
# テーブルデータを .csv に変換する
df. to_csv("example.csv" , encoding= "utf-8" )
次のステップ
2.4 - W&B App UI Reference
2.4.1 - Panels
ワークスペース パネルの 可視化 を使用して、ログに記録された データ を キー ごとに探索し、 ハイパーパラメータ と出力 メトリクス の関係を 可視化 することができます。
ワークスペース のモード
W&B の プロジェクト は、2つの異なる ワークスペース モードをサポートしています。 ワークスペース 名の横にあるアイコンは、そのモードを示しています。
アイコン
ワークスペース モード
自動 ワークスペース は、 プロジェクト で ログ されたすべての キー に対して パネル を自動的に生成します。 自動 ワークスペース を選択する:プロジェクト の利用可能なすべての データを 可視化 して、すぐに開始したい場合。 ログ に記録する キー の数が少ない小規模な プロジェクト の場合。 より広範な 分析 を行う場合。 クイック 追加 を使用して再作成できます。
手動 ワークスペース は、空白の状態から始まり、 ユーザー が意図的に追加した パネル のみを表示します。 手動 ワークスペース を選択する:プロジェクト で ログ された キー の一部のみを重視する場合。 より集中的な 分析 を行う場合。 ワークスペース のパフォーマンスを向上させ、あまり役に立たない パネル の読み込みを回避する場合。 クイック 追加 を使用して、手動 ワークスペース とそのセクションに役立つ 可視化 をすばやく簡単に追加できます。
ワークスペース での パネル の生成方法を変更するには、ワークスペース をリセット します。
ワークスペース への変更を元に戻す ワークスペース への変更を元に戻すには、[元に戻す] ボタン (左を指す矢印) をクリックするか、CMD + Z (macOS) または CTRL + Z (Windows / Linux) を入力します。
ワークスペース のリセット
ワークスペース をリセットするには:
ワークスペース の上部にあるアクション メニュー ... をクリックします。
ワークスペース をリセット をクリックします。
ワークスペース のレイアウトを 設定 するには、 ワークスペース の上部にある Settings をクリックし、次に Workspace layout をクリックします。
検索中に空のセクションを非表示にする (デフォルトでオン)パネル をアルファベット順に並べ替える (デフォルトでオフ)セクション構成 (デフォルトでは最初の プレフィックス でグループ化)。 この 設定 を変更するには:
南京錠アイコンをクリックします。
セクション内の パネル をグループ化する方法を選択します。
ワークスペース の折れ線 プロット のデフォルトを 設定 するには、折れ線 プロット を参照してください。
セクションのレイアウトを 設定 するには、歯車アイコンをクリックし、次に Display preferences をクリックします。
ツールチップ で色付きの run 名をオンまたはオフにする (デフォルトでオン)コンパニオン チャート のツールチップにハイライトされた run のみを表示する (デフォルトでオフ)ツールチップ に表示される run の数 (単一の run 、すべての run 、または Default )プライマリ チャート のツールチップ に完全な run 名を表示する (デフォルトでオフ)
パネル をフルスクリーン モード で表示する
フルスクリーン モード では、 run セレクター が表示され、 パネル は、通常 1000 バケットではなく、10,000 バケットの高精度サンプリング モード プロット を使用します。
パネル をフルスクリーン モード で表示するには:
パネル の上にマウスを置きます。
パネル のアクション メニュー ... をクリックし、次にファインダーまたは正方形の4つの角を示すアウトラインのようなフルスクリーン ボタンをクリックします。
フルスクリーン モード で表示中に パネル を共有 すると、表示されるリンクは自動的にフルスクリーン モード で開きます。
フルスクリーン モード から パネル の ワークスペース に戻るには、 ページ の上部にある左向きの矢印をクリックします。
パネル の追加
このセクションでは、 ワークスペース に パネル を追加するさまざまな方法を示します。
パネル を手動で追加する
グローバル またはセクション レベルで、 ワークスペース に パネル を1つずつ追加します。
パネル をグローバルに追加するには、 パネル 検索フィールドの近くにあるコントロール バーの Add panels をクリックします。
代わりに パネル をセクションに直接追加するには、セクションのアクション ... メニューをクリックし、次に + Add panels をクリックします。
チャート など、追加する パネル のタイプを選択します。 パネル の 設定 詳細が表示され、デフォルトが選択されています。
必要に応じて、 パネル とその表示 設定 をカスタマイズします。 設定 オプションは、選択する パネル のタイプによって異なります。 各タイプの パネル のオプションの詳細については、以下の関連セクション (たとえば、折れ線 プロット または棒グラフ ) を参照してください。
Apply をクリックします。
パネル をクイック追加する
Quick add を使用して、選択した キー ごとに パネル をグローバル またはセクション レベルで自動的に追加します。
削除された パネル がない自動 ワークスペース の場合、 ワークスペース にはすでに ログ されたすべての キー の パネル が含まれているため、Quick add オプションは表示されません。 Quick add を使用して、削除した パネル を再度追加できます。
Quick add を使用して パネル をグローバルに追加するには、 パネル 検索フィールドの近くにあるコントロール バーの Add panels をクリックし、次に Quick add をクリックします。Quick add を使用して パネル をセクションに直接追加するには、セクションのアクション ... メニューをクリックし、Add panels をクリックして、次に Quick add をクリックします。パネル のリストが表示されます。 チェックマークが付いている各 パネル は、すでに ワークスペース に含まれています。
利用可能なすべての パネル を追加するには、リストの上部にある Add panels ボタンをクリックします。 Quick Add リストが閉じ、新しい パネル が ワークスペース に表示されます。
リストから個々の パネル を追加するには、 パネル の行の上にマウスを置き、次に Add をクリックします。 追加する パネル ごとにこの手順を繰り返し、右上にある X をクリックして Quick Add リストを閉じます。 新しい パネル が ワークスペース に表示されます。
必要に応じて、 パネル の 設定 をカスタマイズします。
パネル の共有
このセクションでは、リンクを使用して パネル を共有する方法を示します。
リンクを使用して パネル を共有するには、次のいずれかを実行します。
パネル をフルスクリーン モード で表示しているときに、ブラウザから URL をコピーします。
アクション メニュー ... をクリックし、Copy panel URL を選択します。
リンクを ユーザー または チーム と共有します。 ユーザー がリンクに アクセス すると、 パネル がフルスクリーン モード で開きます。
フルスクリーン モード から パネル の ワークスペース に戻るには、 ページ の上部にある左向きの矢印をクリックします。
プログラムで パネル のフルスクリーン リンクを作成する
オートメーション の作成 など、特定の状況では、 パネル のフルスクリーン URL を含めると便利な場合があります。 このセクションでは、 パネル のフルスクリーン URL の形式を示します。 以下の例では、エンティティ 、 プロジェクト 、 パネル 、およびセクション名を角かっこで囲んで置き換えます。
https://wandb.ai/<ENTITY_NAME>/<PROJECT_NAME>?panelDisplayName=<PANEL_NAME>&panelSectionName=<SECTON_NAME>
同じセクション内の複数の パネル が同じ名前を持つ場合、この URL はその名前の最初の パネル を開きます。
ソーシャル メディア で パネル を埋め込むか共有する
Webサイトに パネル を埋め込んだり、ソーシャル メディア で共有したりするには、リンクを知っている人なら誰でも パネル を表示できる必要があります。 プロジェクト がプライベートの場合、 プロジェクト の メンバー のみ パネル を表示できます。 プロジェクト がパブリックの場合、リンクを知っている人なら誰でも パネル を表示できます。
ソーシャル メディア で パネル を埋め込んだり共有したりするための コード を取得するには:
ワークスペース から、 パネル の上にマウスを置き、次にアクション メニュー ... をクリックします。
Share タブをクリックします。Only those who are invited have access を Anyone with the link can view に変更します。 そうしないと、次の手順の選択肢は使用できません。Share on Twitter 、 Share on Reddit 、 Share on LinkedIn 、または Copy embed link を選択します。
パネル レポート をメールで送信する
スタンドアロン レポート として単一の パネル をメールで送信するには:
パネル の上にマウスを置き、次に パネル のアクション メニュー ... をクリックします。
Share panel in report をクリックします。Invite タブを選択します。メール アドレス または ユーザー 名を入力します。
必要に応じて、can view を can edit に変更します。
Invite をクリックします。 W&B は、共有している パネル のみを含む レポート へのクリック可能なリンクを記載したメールを ユーザー に送信します。
パネル を共有 する場合とは異なり、受信者はこの レポート から ワークスペース にアクセスできません。
パネル の管理
パネル の編集
パネル を編集するには:
鉛筆アイコンをクリックします。
パネル の 設定 を変更します。
パネル を別のタイプに変更するには、タイプを選択してから 設定 を 設定 します。
Apply をクリックします。
パネル の移動
パネル を別のセクションに移動するには、 パネル のドラッグ ハンドルを使用できます。 代わりに、リストから新しいセクションを選択するには:
必要に応じて、最後のセクションの後に Add section をクリックして、新しいセクションを作成します。
パネル のアクション ... メニューをクリックします。
Move をクリックし、次に新しいセクションを選択します。
ドラッグ ハンドルを使用して、セクション内の パネル を再配置することもできます。
パネル の複製
パネル を複製するには:
パネル の上部にあるアクション ... メニューをクリックします。
Duplicate をクリックします。
必要に応じて、複製された パネル をカスタマイズ または移動 できます。
パネル の削除
パネル を削除するには:
パネル の上にマウスを置きます。
アクション ... メニューを選択します。
Delete をクリックします。
手動 ワークスペース からすべての パネル を削除するには、アクション ... メニューをクリックし、次に Clear all panels をクリックします。
自動または手動 ワークスペース からすべての パネル を削除するには、ワークスペース をリセット できます。 デフォルトの パネル セットで開始するには Automatic を選択し、 パネル のない空の ワークスペース で開始するには Manual を選択します。
セクションの管理
デフォルトでは、 ワークスペース のセクションには、 キー の ログ 階層が反映されます。 ただし、手動 ワークスペース では、セクションは パネル の追加を開始した後にのみ表示されます。
セクションの追加
セクションを追加するには、最後のセクションの後に Add section をクリックします。
既存のセクションの前または後に新しいセクションを追加するには、代わりにセクションのアクション ... メニューをクリックし、次に New section below または New section above をクリックします。
セクションの パネル の管理
多数の パネル を含むセクションは、Standard grid レイアウトを使用している場合、デフォルトで ページ 分割されます。 ページ 上の パネル のデフォルトの数は、 パネル の 設定 とセクション内の パネル のサイズによって異なります。
セクションで使用されているレイアウトを確認するには、セクションのアクション ... メニューをクリックします。 セクションのレイアウトを変更するには、Layout grid セクションで Standard grid または Custom grid を選択します。
パネル のサイズを変更するには、 パネル の上にマウスを置き、ドラッグ ハンドルをクリックしてドラッグし、 パネル のサイズを調整します。
セクションで Standard grid が使用されている場合、1つの パネル のサイズを変更すると、セクション内のすべての パネル のサイズが変更されます。
セクションで Custom grid が使用されている場合、各 パネル のサイズを個別にカスタマイズできます。
セクションが ページ 分割されている場合は、 ページ に表示する パネル の数をカスタマイズできます。
セクションの上部にある 1 to of をクリックします。ここで、<X> は表示されている パネル の数、<Y> は パネル の合計数です。
ページ ごとに表示する パネル の数 (最大100) を選択します。
多数の パネル がある場合にすべての パネル を表示するには、Custom grid レイアウトを使用するように パネル を 設定 します。 セクションのアクション ... メニューをクリックし、次に Layout grid セクションで Custom grid を選択します
セクションから パネル を削除するには:
パネル の上にマウスを置き、次にアクション ... メニューをクリックします。
Delete をクリックします。
ワークスペース を自動 ワークスペース にリセットすると、削除されたすべての パネル が再び表示されます。
セクションの名前を変更する
セクションの名前を変更するには、アクション ... メニューをクリックし、次に Rename section をクリックします。
セクションの削除
セクションを削除するには、... メニューをクリックし、次に Delete section をクリックします。 これにより、セクションとその パネル が削除されます。
2.4.1.1 - Line plots
メトリクスを可視化し、軸をカスタマイズして、プロット上の複数の線を比較します。
折れ線グラフは、wandb.log() で時間の経過とともにメトリクスをプロットすると、デフォルトで表示されます。チャートの設定をカスタマイズして、同じプロット上に複数の線を比較したり、カスタム軸を計算したり、ラベルの名前を変更したりできます。
折れ線グラフの設定を編集する
このセクションでは、個々の折れ線グラフ パネル、セクション内のすべての折れ線グラフ パネル、またはワークスペース内のすべての折れ線グラフ パネルの設定を編集する方法について説明します。
カスタムの X 軸を使用する場合は、Y 軸のログに使用するのと同じ wandb.log() の呼び出しでログに記録されていることを確認してください。
個々の折れ線グラフ
折れ線グラフの個々の設定は、セクションまたはワークスペースの折れ線グラフの設定よりも優先されます。折れ線グラフをカスタマイズするには:
マウスをパネルの上に置き、歯車アイコンをクリックします。
表示されるモーダル内で、タブを選択して 設定 を編集します。
適用 をクリックします。
折れ線グラフの設定
折れ線グラフでは、次の設定を構成できます。
日付 : プロットのデータの表示に関する詳細を構成します。
X : X 軸に使用する値を選択します (デフォルトは ステップ )。X 軸を 相対時間 に変更するか、W&B でログに記録した値に基づいてカスタム軸を選択できます。
相対時間 (Wall) は、プロセスが開始してからのクロック時間です。したがって、run を開始して 1 日後に再開し、何かをログに記録した場合、24 時間後にプロットされます。相対時間 (プロセス) は、実行中のプロセス内の時間です。したがって、run を開始して 10 秒間実行し、1 日後に再開した場合、そのポイントは 10 秒でプロットされます。Wall Time は、グラフ上の最初の run の開始からの経過時間 (分) です。ステップ は、デフォルトで wandb.log() が呼び出されるたびに増分され、モデルからログに記録したトレーニング ステップの数を反映することになっています。
Y : メトリクスや時間の経過とともに変化するハイパーパラメーターなど、ログに記録された値から 1 つ以上の Y 軸を選択します。X 軸 および Y 軸 の最小値と最大値 (オプション)。ポイント集計メソッド 。ランダム サンプリング (デフォルト) または フル フィデリティ 。 サンプリング を参照してください。スムージング : 折れ線グラフのスムージングを変更します。デフォルトは 時間加重 EMA です。その他の値には、スムージングなし 、移動平均 、および ガウス があります。外れ値 : デフォルトのプロットの最小スケールと最大スケールから外れ値を排除するようにリスケールします。run またはグループの最大数 : この数を増やすことで、折れ線グラフに一度に表示される線を増やします。デフォルトは 10 runs です。利用可能な run が 10 よりも多いが、グラフが表示数を制限している場合、チャートの上部に「最初の 10 runs を表示」というメッセージが表示されます。チャートの種類 : 折れ線グラフ、面グラフ、およびパーセンテージ面グラフを切り替えます。
グループ化 : プロットで run をグループ化および集計するかどうか、またその方法を構成します。
グループ化 : 列を選択すると、その列に同じ値を持つすべての run がグループ化されます。集計 : 集計—グラフ上の線の値。オプションは、グループの平均、中央値、最小値、および最大値です。
チャート : パネル、X 軸、Y 軸、および -軸のタイトルを指定し、凡例の表示/非表示を切り替え、その位置を構成します。
凡例 : パネルの凡例の外観をカスタマイズします (有効になっている場合)。
凡例 : プロットの凡例の各線の凡例のフィールド。凡例テンプレート : 凡例の完全にカスタマイズ可能なテンプレートを定義します。線のプロットの上部にあるテンプレートに表示するテキストと変数、およびマウスをプロットの上に置いたときに表示される凡例を正確に指定します。
式 : カスタム計算式をパネルに追加します。
Y 軸式 : 計算されたメトリクスをグラフに追加します。ログに記録されたメトリクスのいずれか、およびハイパーパラメーターなどの設定値を使用して、カスタム線を計算できます。X 軸式 : カスタム式を使用して計算された値を使用するように X 軸をリスケールします。役立つ変数には、デフォルトの X 軸の **_step** が含まれ、要約値を参照するための構文は ${summary:value} です。
セクション内のすべての折れ線グラフ
セクション内のすべての折れ線グラフのデフォルト設定をカスタマイズするには、折れ線グラフのワークスペース設定をオーバーライドします。
セクションの歯車アイコンをクリックして、その設定を開きます。
表示されるモーダル内で、データ または 表示設定 タブを選択して、セクションのデフォルト設定を構成します。各 データ 設定の詳細については、前のセクション 個々の折れ線グラフ を参照してください。各表示設定の詳細については、セクション レイアウトの構成 を参照してください。
ワークスペース内のすべての折れ線グラフ
ワークスペース内のすべての折れ線グラフのデフォルト設定をカスタマイズするには:
ワークスペースの設定をクリックします。これには、設定 というラベルの付いた歯車が付いています。
折れ線グラフ をクリックします。表示されるモーダル内で、データ または 表示設定 タブを選択して、ワークスペースのデフォルト設定を構成します。
プロット上の平均値を可視化する
いくつかの異なる Experiments があり、プロット上の値の平均を表示する場合は、テーブルのグループ化機能を使用できます。run テーブルの上にある [グループ] をクリックし、[すべて] を選択して、グラフに平均値を表示します。
平均化する前のグラフは次のようになります。
次の画像は、グループ化された線を使用して runs 全体の平均値を表すグラフを示しています。
プロット上の NaN 値を可視化する
wandb.log を使用して、PyTorch テンソルを含む NaN 値を折れ線グラフにプロットすることもできます。例:
wandb. log({"test" : [... , float("nan" ), ... ]})
1 つのチャートで 2 つのメトリクスを比較する
ページの右上隅にある パネルを追加 ボタンを選択します。
表示される左側のパネルから、[評価] ドロップダウンを展開します。
Run comparer を選択します。
折れ線グラフの色を変更する
runs のデフォルトの色が比較に役立たない場合があります。これを克服するために、wandb には、手動で色を変更できる 2 つのインスタンスが用意されています。
各 run には、初期化時にデフォルトでランダムな色が割り当てられます。
いずれかの色をクリックすると、カラー パレットが表示され、そこから必要な色を手動で選択できます。
設定を編集するパネルの上にマウスを置きます。
表示される鉛筆アイコンを選択します。
[凡例 ] タブを選択します。
異なる X 軸で可視化する
実験にかかった絶対時間を確認したり、実験が実行された曜日を確認したりする場合は、X 軸を切り替えることができます。ステップから相対時間、そして Wall Time に切り替える例を次に示します。
面グラフ
折れ線グラフの設定の [詳細設定] タブで、異なるプロット スタイルをクリックして、面グラフまたはパーセンテージ面グラフを取得します。
ズーム
長方形をクリックしてドラッグし、垂直方向と水平方向に同時にズームします。これにより、X 軸と Y 軸のズームが変更されます。
チャートの凡例を非表示にする
この単純なトグルを使用して、折れ線グラフの凡例をオフにします。
2.4.1.1.1 - Line plot reference
X軸
折れ線グラフのX軸には、W&B.log でログに記録した値を設定できます。ただし、常に数値としてログに記録されている必要があります。
Y軸の変数
Y軸の変数には、wandb.log でログに記録した値を設定できます。ただし、数値、数値の配列、または数値のヒストグラムをログに記録している必要があります。変数のポイント数が1500を超える場合、W&B は1500ポイントまでサンプルダウンします。
runs テーブルで run の色を変更すると、Y軸の線の色を変更できます。
X範囲とY範囲
プロットのXとYの最大値と最小値を変更できます。
X範囲のデフォルトは、X軸の最小値から最大値までです。
Y範囲のデフォルトは、メトリクスの最小値とゼロからメトリクスの最大値までです。
最大 run /グループ数
デフォルトでは、10個の run または run のグループのみがプロットされます。run は run テーブルまたは run セットの上部から取得されるため、run テーブルまたは run セットをソートすると、表示される run を変更できます。
凡例
チャートの凡例を制御して、ログに記録した任意の run の任意の設定値と、作成時間や run を作成した ユーザー など、run からのメタデータを表示できます。
例:
${run:displayName} - ${config:dropout} は、各 run の凡例名を royal-sweep - 0.5 のようにします。ここで、royal-sweep は run 名で、0.5 は dropout という名前の設定 パラメータ です。
[[ ]] 内に値を設定すると、チャートにカーソルを合わせたときに、ポイント固有の値をクロスヘアに表示できます。たとえば、\[\[ $x: $y ($original) ]] は “2: 3 (2.9)” のように表示されます。
[[ ]] 内でサポートされている値は次のとおりです。
値
意味
${x}X値
${y}Y値(平滑化調整を含む)
${original}Y値(平滑化調整を含まない)
${mean}グループ化された run の平均
${stddev}グループ化された run の標準偏差
${min}グループ化された run の最小
${max}グループ化された run の最大
${percent}合計のパーセント(積み上げ面グラフの場合)
グルーピング
グルーピングをオンにしてすべての run を集計したり、個々の変数でグループ化したりできます。テーブル内でグループ化してグルーピングをオンにすることもできます。グループは自動的にグラフに表示されます。
平滑化
平滑化係数 を0から1の間に設定できます。0は平滑化なし、1は最大平滑化です。
外れ値を無視する
デフォルトのプロットの最小スケールと最大スケールから外れ値を排除するようにプロットをリスケールします。プロットに対する設定の影響は、プロットのサンプリングモードによって異なります。
ランダムサンプリングモード を使用するプロットの場合、[外れ値を無視する ]を有効にすると、5%から95%のポイントのみが表示されます。外れ値が表示されても、他のポイントとは異なる形式にはなりません。フルフィデリティモード を使用するプロットの場合、すべてのポイントが常に表示され、各バケットの最後の値に凝縮されます。[外れ値を無視する ]が有効になっている場合、各バケットの最小境界と最大境界が網掛け表示されます。それ以外の場合、領域は網掛け表示されません。
式
式を使用すると、1-精度などの メトリクス から派生した値をプロットできます。現在、単一の メトリクス をプロットしている場合にのみ機能します。単純な算術式(+、-、*、/、%)、および累乗の場合は ** を実行できます。
プロットスタイル
折れ線グラフのスタイルを選択します。
折れ線グラフ:
面グラフ:
パーセンテージ面グラフ:
2.4.1.1.2 - Point aggregation
Data Visualization の精度とパフォーマンスを向上させるために、折れ線グラフ内でポイント集約メソッドを使用します。ポイント集約モードには、full fidelity(完全精度) と random sampling(ランダムサンプリング) の2種類があります。W&B はデフォルトで完全精度モードを使用します。
Full fidelity
完全精度モードを使用すると、W&B はデータポイントの数に基づいて、x軸を動的なバケットに分割します。次に、各バケット内の最小値、最大値、平均値を計算し、折れ線グラフのポイント集約をレンダリングします。
ポイント集約に完全精度モードを使用する主な利点は3つあります。
極端な値とスパイクを保持する: データ内の極端な値とスパイクを保持します。
最小点と最大点のレンダリング方法を設定する: W&B App を使用して、極端な(最小/最大)値を影付きの領域として表示するかどうかをインタラクティブに決定します。
データ忠実度を損なわずにデータを探索する: W&B は、特定のデータポイントにズームインすると、x軸のバケットサイズを再計算します。これにより、精度を損なわずにデータを探索できます。キャッシュを使用して、以前に計算された集約を保存し、ロード時間を短縮します。これは、大規模なデータセットをナビゲートする場合に特に役立ちます。
最小点と最大点のレンダリング方法を設定する
折れ線グラフの周りの影付き領域で最小値と最大値を表示または非表示にします。
次の画像は、青い折れ線グラフを示しています。水色の影付き領域は、各バケットの最小値と最大値を表しています。
折れ線グラフで最小値と最大値をレンダリングするには、次の3つの方法があります。
Never : 最小/最大値は影付きの領域として表示されません。x軸バケット全体の集約された線のみを表示します。On hover : 最小/最大値の影付き領域は、チャートにカーソルを合わせると動的に表示されます。このオプションを使用すると、ビューがすっきりした状態に保たれ、範囲をインタラクティブに検査できます。Always : 最小/最大影付き領域は、チャート内のすべてのバケットに対して常に表示され、常に値の全範囲を視覚化できます。チャートで多くの Runs が可視化されている場合、これは視覚的なノイズになる可能性があります。
デフォルトでは、最小値と最大値は影付き領域として表示されません。影付き領域オプションのいずれかを表示するには、次の手順に従います。
ワークスペース内のすべてのチャート
ワークスペース内の個々のチャート
W&B の Projects に移動します。
左側のタブで Workspace アイコンを選択します。
画面の右上隅にある歯車アイコンを、Add panels ボタンの左側の横にあるアイコンを選択します。
表示される UI スライダーから、Line plots を選択します。
Point aggregation セクション内で、Show min/max values as a shaded area ドロップダウンメニューから On over または Always を選択します。
W&B の Projects に移動します。
左側のタブで Workspace アイコンを選択します。
完全精度モードを有効にする折れ線グラフ パネルを選択します。
表示されるモーダル内で、Show min/max values as a shaded area ドロップダウンメニューから On hover または Always を選択します。
データ忠実度を損なわずにデータを探索する
極端な値やスパイクなどの重要なポイントを見逃すことなく、データセットの特定領域を分析します。折れ線グラフをズームインすると、W&B は各バケット内の最小値、最大値、平均値を計算するために使用されるバケットサイズを調整します。
W&B は x軸をデフォルトで1000個のバケットに動的に分割します。各バケットについて、W&B は次の値を計算します。
Minimum : そのバケット内の最小値。Maximum : そのバケット内の最大値。Average : そのバケット内のすべてのポイントの平均値。
W&B は、完全なデータ表現を保持し、すべてのプロットに極端な値を含める方法でバケット内の値をプロットします。1,000ポイント以下にズームインすると、完全精度モードは追加の集約なしですべてのデータポイントをレンダリングします。
折れ線グラフをズームインするには、次の手順に従います。
W&B の Projects に移動します。
左側のタブで Workspace アイコンを選択します。
オプションで、折れ線グラフ パネルを ワークスペース に追加するか、既存の折れ線グラフ パネルに移動します。
クリックしてドラッグし、ズームインする特定の領域を選択します。
折れ線グラフのグループ化と式 折れ線グラフのグループ化を使用すると、W&B は選択したモードに基づいて以下を適用します。
非ウィンドウ サンプリング (グループ化) : x軸上の Runs 全体でポイントを整列させます。複数のポイントが同じ x 値を共有する場合、平均が計算されます。それ以外の場合は、個別のポイントとして表示されます。ウィンドウ サンプリング (グループ化と式) : x軸を 250 個のバケットまたは最長線のポイント数 (いずれか小さい方) に分割します。W&B は各バケット内のポイントの平均を取ります。Full fidelity (グループ化と式) : 非ウィンドウ サンプリングと同様ですが、パフォーマンスと詳細のバランスを取るために、Run ごとに最大 500 ポイントを取得します。 Random sampling
ランダムサンプリングは、1500個のランダムにサンプリングされたポイントを使用して折れ線グラフをレンダリングします。ランダムサンプリングは、多数のデータポイントがある場合にパフォーマンス上の理由で役立ちます。
ランダムサンプリングは、非決定論的にサンプリングします。これは、ランダムサンプリングがデータ内の重要な外れ値やスパイクを除外することがあり、データ精度が低下することを意味します。
ランダムサンプリングを有効にする
デフォルトでは、W&B は完全精度モードを使用します。ランダムサンプリングを有効にするには、次の手順に従います。
ワークスペース内のすべてのチャート
ワークスペース内の個々のチャート
W&B の Projects に移動します。
左側のタブで Workspace アイコンを選択します。
画面の右上隅にある歯車アイコンを、Add panels ボタンの左側の横にあるアイコンを選択します。
表示される UI スライダーから、Line plots を選択します。
Point aggregation セクションから Random sampling を選択します。
W&B の Projects に移動します。
左側のタブで Workspace アイコンを選択します。
ランダムサンプリングを有効にする折れ線グラフ パネルを選択します。
表示されるモーダル内で、Point aggregation method セクションから Random sampling を選択します。
サンプリングされていないデータへのアクセス
W&B Run API を使用して、Run 中にログに記録された メトリクス の完全な履歴にアクセスできます。次の例は、特定の Run から損失値を取得して処理する方法を示しています。
# W&B API を初期化します
run = api. run("l2k2/examples-numpy-boston/i0wt6xua" )
# 'Loss' メトリクスの履歴を取得します
history = run. scan_history(keys= ["Loss" ])
# 履歴から損失値を抽出します
losses = [row["Loss" ] for row in history]
2.4.1.1.3 - Smooth line plots
折れ線グラフでは、スムージングを使ってノイズの多いデータ のトレンドを確認します。
W&B は3種類の平滑化をサポートしています。
これらの機能を インタラクティブな W&B レポート でライブで確認できます。
指数移動平均 (デフォルト)
指数平滑化は、過去の点の重みを指数関数的に減衰させることで、 時系列 データを平滑化する手法です。範囲は0から1です。背景については、指数平滑化 を参照してください。時系列の初期の値がゼロに偏らないように、バイアス除去項が追加されています。
EMAアルゴリズムは、線上の点の密度 (x軸の範囲の単位あたりの y 値の数) を考慮します。これにより、異なる特性を持つ複数の線を同時に表示する際に、一貫した平滑化が可能になります。
以下は、この仕組みの内部動作を示すサンプル コードです。
const smoothingWeight = Math.min (Math.sqrt (smoothingParam || 0 ), 0.999 );
let lastY = yValues .length > 0 ? 0 : NaN ;
let debiasWeight = 0 ;
return yValues .map ((yPoint , index ) => {
const prevX = index > 0 ? index - 1 : 0 ;
// VIEWPORT_SCALEは、結果をチャートのx軸範囲にスケールします
const changeInX =
((xValues [index ] - xValues [prevX ]) / rangeOfX ) * VIEWPORT_SCALE ;
const smoothingWeightAdj = Math.pow (smoothingWeight , changeInX );
lastY = lastY * smoothingWeightAdj + yPoint ;
debiasWeight = debiasWeight * smoothingWeightAdj + 1 ;
return lastY / debiasWeight ;
});
これは アプリ内 では次のようになります。
ガウシアン平滑化
ガウシアン平滑化 (またはガウシアン カーネル平滑化) は、点の加重平均を計算します。ここで、重みは平滑化 パラメータ として指定された標準偏差を持つガウス分布に対応します。を参照してください。平滑化された 値 は、すべての入力x 値 に対して計算されます。
TensorBoard の 振る舞い と一致させることを気にしない場合は、ガウシアン平滑化は平滑化に適した標準的な選択肢です。指数移動平均とは異なり、値の前後に発生する点に基づいて点が平滑化されます。
これは アプリ内 では次のようになります。
移動平均
移動平均は、指定されたx 値 の前後のウィンドウ内の点の平均で点を置き換える平滑化アルゴリズムです。https://en.wikipedia.org/wiki/Moving_average の「Boxcar Filter」を参照してください。移動平均に選択された パラメータ は、Weights and Biases に移動平均で考慮する点の数を伝えます。
点 がx軸上で不均等に配置されている場合は、ガウシアン平滑化の使用を検討してください。
次の画像は、実行中のアプリが アプリ内 でどのように見えるかを示しています。
指数移動平均 (非推奨)
TensorBoard EMAアルゴリズムは、一貫した点密度 (x軸の単位あたりにプロットされる点の数) を持たない同じチャート上の複数の線を正確に平滑化できないため、非推奨になりました。
指数移動平均は、TensorBoard の平滑化アルゴリズムと一致するように実装されています。範囲は0から1です。背景については、指数平滑化 を参照してください。時系列の初期の値がゼロに偏らないように、バイアス除去項が追加されています。
以下は、この仕組みの内部動作を示すサンプル コードです。
data .forEach (d => {
const nextVal = d ;
last = last * smoothingWeight + (1 - smoothingWeight ) * nextVal ;
numAccum ++ ;
debiasWeight = 1.0 - Math.pow (smoothingWeight , numAccum );
smoothedData .push (last / debiasWeight );
これは アプリ内 では次のようになります。
実装の詳細
すべての平滑化アルゴリズムはサンプリングされた データ で実行されます。つまり、1500を超える点を ログ に記録すると、平滑化アルゴリズムは サーバー から点がダウンロードされた 後 に実行されます。平滑化アルゴリズムの目的は、 データ 内のパターンをすばやく見つけるのに役立つことです。多数の ログ に記録された点 を持つ メトリクス で正確な平滑化された 値 が必要な場合は、API を介して メトリクス をダウンロードし、独自の平滑化 メソッド を実行する方が良い場合があります。
元のデータを非表示にする
デフォルトでは、元の平滑化されていない データ が背景に薄い線として表示されます。これをオフにするには、[元のデータを表示] トグルをクリックします。
2.4.1.2 - Bar plots
メトリクスを可視化し、軸をカスタマイズして、カテゴリカルデータを棒グラフとして比較します。
棒グラフは、カテゴリカルデータを長方形の棒で表示し、垂直または水平にプロットできます。棒グラフは、すべてのログに記録された値の長さが1の場合、デフォルトで wandb.log() で表示されます。
チャートの設定で、表示する最大 run 数を制限したり、configで run をグループ化したり、ラベルの名前を変更したりできます。
棒グラフのカスタマイズ
また、Box プロットまたは Violin プロットを作成して、多くの要約統計量を1つのチャートタイプにまとめることもできます。
run テーブルで run をグループ化します。
ワークスペース で「パネルを追加」をクリックします。
標準の「棒グラフ」を追加し、プロットするメトリックを選択します。
「グループ化」タブで、「箱ひげ図」または「バイオリン」などを選択して、これらのスタイルをプロットします。
2.4.1.3 - Parallel coordinates
機械学習 の 実験 における 結果 を比較する
並列座標チャートは、多数のハイパーパラメータとモデル の メトリクス の関係を一目で把握できるようにまとめたものです。
軸 : wandb.configwandb.log線 : 各線は単一の run を表します。線にマウスオーバーすると、run に関する詳細がツールチップに表示されます。現在のフィルタに一致するすべての線が表示されますが、目のアイコンをオフにすると、線はグレー表示になります。
並列座標パネルの作成
ワークスペース のランディングページに移動します
パネルを追加 をクリックします並列座標 を選択します
パネル の 設定
パネル を構成するには、パネル の右上隅にある編集ボタンをクリックします。
ツールチップ : マウスオーバーすると、各 run の情報を示す凡例が表示されますタイトル : 軸のタイトルを編集して、より読みやすくします勾配 : 好みの色範囲に合わせて 勾配 をカスタマイズします対数スケール : 各軸は、対数スケールで個別に表示するように設定できます軸の反転 : 軸の方向を切り替えます。これは、精度と損失の両方を列として持つ場合に便利です
ライブ並列座標パネルを操作する
2.4.1.4 - Scatter plots
このページでは、W&B で散布図を使用する方法について説明します。
ユースケース
散布図を使用して、複数の run を比較し、実験のパフォーマンスを可視化します。
最小値、最大値、および平均値の線を描画します。
メタデータツールチップをカスタマイズします。
点の色を制御します。
軸の範囲を調整します。
軸にログスケールを使用します。
例
次の例は、数週間の実験におけるさまざまな model の検証精度を表示する散布図を示しています。ツールチップには、バッチサイズ、ドロップアウト、および軸の値が含まれています。線は、検証精度の移動平均も示しています。
ライブの例を見る →
散布図の作成
W&B UI で散布図を作成するには:
[Workspaces ] タブに移動します。
[Charts ] パネルで、アクションメニュー ... をクリックします。
ポップアップメニューから、[Add panels ] を選択します。
[Add panels ] メニューで、[Scatter plot ] を選択します。
表示するデータのプロットするために、x 軸と y 軸を設定します。オプションで、軸の最大範囲と最小範囲を設定するか、z 軸を追加します。
[Apply ] をクリックして、散布図を作成します。
[Charts] パネルで新しい散布図を表示します。
2.4.1.5 - Save and diff code
デフォルトでは、W&B は最新の git コミットハッシュのみを保存します。より多くのコード機能を有効にすると、UI で Experiments 間のコードを動的に比較できます。
wandb バージョン 0.8.28 以降、W&B は wandb.init() を呼び出すメインのトレーニングファイルからコードを保存できます。
ライブラリコードを保存する
コードの保存を有効にすると、W&B は wandb.init() を呼び出したファイルからコードを保存します。追加のライブラリコードを保存するには、次の 3 つのオプションがあります。
wandb.init() を呼び出した後、wandb.run.log_code(".") を呼び出すimport wandb
wandb. init()
wandb. run. log_code("." )
code_dir を設定して、設定オブジェクトを wandb.init に渡すimport wandb
wandb. init(settings= wandb. Settings(code_dir= "." ))
これにより、現在のディレクトリーとそのすべてのサブディレクトリーにあるすべての Python ソースコードファイルが Artifacts としてキャプチャされます。保存されるソースコードファイルの種類と場所をより詳細に制御するには、リファレンスドキュメント を参照してください。
UI でコードの保存を設定する
プログラムでコードの保存を設定するだけでなく、W&B アカウントの Settings でこの機能を切り替えることもできます。これにより、アカウントに関連付けられているすべての Teams に対してコードの保存が有効になることに注意してください。
デフォルトでは、W&B はすべての Teams に対してコードの保存を無効にします。
W&B アカウントにログインします。
Settings > Privacy に移動します。Project and content security で、Disable default code saving をオンにします。
コード比較ツール
異なる W&B の Runs で使用されるコードを比較します。
ページの右上隅にある Add panels ボタンを選択します。
TEXT AND CODE ドロップダウンを展開し、Code を選択します。
Jupyter セッション履歴
W&B は、Jupyter ノートブックセッションで実行されたコードの履歴を保存します。Jupyter 内で wandb.init() を呼び出すと、W&B は現在のセッションで実行されたコードの履歴を含む Jupyter ノートブックを自動的に保存する hook を追加します。
コードを含む project のワークスペースに移動します。
左側のナビゲーションバーで Artifacts タブを選択します。
code artifact を展開します。Files タブを選択します。
これにより、セッションで実行されたセルと、iPython の display メソッドを呼び出すことによって作成された出力が表示されます。これにより、特定の run で Jupyter 内で実行されたコードを正確に確認できます。可能な場合、W&B はコードディレクトリーにある最新バージョンのノートブックも保存します。
2.4.1.6 - Parameter importance
モデルのハイパーパラメーターと出力メトリクスの関係を可視化します。
どのハイパーパラメータが最も優れた予測因子であり、メトリクスの望ましい値と高度に相関しているかを調べます。
相関 は、ハイパーパラメータと選択したメトリクス(この場合は val_loss)の間の線形相関です。したがって、高い相関は、ハイパーパラメータが高い値を持つ場合、メトリクスも高い値を持つことを意味し、その逆もまた同様です。相関は見るべき優れたメトリクスですが、入力間の二次的な相互作用を捉えることができず、大きく異なる範囲の入力を比較するのが面倒になる可能性があります。
したがって、W&B は 重要度 メトリクスも計算します。W&B は、ハイパーパラメータを入力として、メトリクスをターゲット出力としてランダムフォレストをトレーニングし、ランダムフォレストのフィーチャーの重要度の値をレポートします。
この手法のアイデアは、Jeremy Howard との会話に触発されました。彼は、Fast.ai でハイパーパラメータ空間を調査するために、ランダムフォレストのフィーチャーの重要度の使用を開拓しました。W&B は、この 講義 (およびこれらの ノート )をチェックして、この分析の背後にある動機について詳しく学ぶことを強くお勧めします。
ハイパーパラメータの重要度パネルは、高度に相関するハイパーパラメータ間の複雑な相互作用を解きほぐします。そうすることで、モデルのパフォーマンスを予測するという点で、どのハイパーパラメータが最も重要であるかを示すことにより、ハイパーパラメータの検索を微調整するのに役立ちます。
ハイパーパラメータの重要度パネルの作成
W&B の Projects に移動します。
Add panels ボタンを選択します。CHARTS ドロップダウンを展開し、ドロップダウンから Parallel coordinates を選択します。
空の panel が表示される場合は、runs がグループ化されていないことを確認してください
パラメータマネージャーを使用すると、表示および非表示のパラメータを手動で設定できます。
ハイパーパラメータの重要度パネルの解釈
この panel には、トレーニングスクリプトの wandb.config オブジェクトに渡されたすべてのパラメータが表示されます。次に、これらの config パラメータのフィーチャーの重要度と相関関係が、選択したモデルメトリクス(この場合は val_loss)に関して表示されます。
重要度
重要度の列には、選択したメトリクスの予測に各ハイパーパラメータがどの程度役立ったかが表示されます。多数のハイパーパラメータのチューニングを開始し、このプロットを使用して、さらに調査する価値のあるハイパーパラメータを絞り込むシナリオを想像してください。後続の Sweeps は、最も重要なハイパーパラメータに限定できるため、より優れたモデルをより迅速かつ安価に見つけることができます。
W&B は、ツリーベースのモデルを使用して重要度を計算します。これは、線形モデルよりも、カテゴリデータと正規化されていないデータの両方に対して寛容であるためです。
前の画像では、epochs, learning_rate, batch_size および weight_decay が非常に重要であることがわかります。
相関
相関は、個々のハイパーパラメータとメトリクスの値の間の線形関係を捉えます。SGD オプティマイザーなどのハイパーパラメータの使用と val_loss の間に有意な関係があるかどうかという質問に答えます(この場合の答えはイエスです)。相関値の範囲は -1 から 1 で、正の値は正の線形相関を表し、負の値は負の線形相関を表し、0 の値は相関がないことを表します。一般に、どちらかの方向に 0.7 より大きい値は強い相関を表します。
このグラフを使用して、メトリクスとの相関が高い値をさらに調べたり(この場合は、確率的勾配降下法または adam を rmsprop または nadam よりも選択したり)、より多くのエポックでトレーニングしたりできます。
相関は、必ずしも因果関係ではなく、関連性の証拠を示しています。
相関は外れ値に敏感です。特に試行されたハイパーパラメータのサンプルサイズが小さい場合、強い関係を中程度の関係に変える可能性があります。
そして最後に、相関はハイパーパラメータとメトリクスの間の線形関係のみを捉えます。強い多項式関係がある場合、相関によって捉えられません。
重要度と相関の間の格差は、重要度がハイパーパラメータ間の相互作用を考慮するのに対し、相関は個々のハイパーパラメータがメトリクスの値に与える影響のみを測定するという事実に起因します。次に、相関は線形関係のみを捉え、重要度はより複雑な関係を捉えることができます。
ご覧のとおり、重要度と相関はどちらも、ハイパーパラメータがモデルのパフォーマンスにどのように影響するかを理解するための強力な Tool です。
2.4.1.7 - Compare run metrics
複数の run 間でメトリクスを比較する
Run Comparer を使用して、run間で異なるメトリクスを確認できます。
ページの右上隅にある [Add panels ] ボタンを選択します。
表示される左側のパネルで、[Evaluation] ドロップダウンを展開します。
[Run comparer ] を選択します。
diff only オプションを切り替えて、run間で値が同じ行を非表示にします。
2.4.1.8 - Query panels
このページのいくつかの機能はベータ版で、機能フラグの背後に隠されています。関連するすべての機能をアンロックするには、プロフィールページの自己紹介に weave-plot を追加してください。
W&B Weave をお探しですか? 生成 AI アプリケーション構築のための W&B のツールスイートですか? Weave のドキュメントはこちらにあります:
wandb.me/weave 。
クエリー パネルを使用して、データをクエリーし、インタラクティブに視覚化します。
クエリー パネルの作成
ワークスペースまたは レポート 内にクエリーを追加します。
プロジェクト ワークスペース
W&B Report
プロジェクト の ワークスペース に移動します。
右上隅にある「Add panel( パネル を追加)」をクリックします。
ドロップダウンから「Query panel(クエリー パネル )」を選択します。
「/Query panel(/クエリー パネル )」と入力して選択します。
または、クエリーを 一連の Runs に関連付けることもできます。
レポート 内で、「/Panel grid(/ パネル グリッド)」と入力して選択します。
「Add panel( パネル を追加)」ボタンをクリックします。
ドロップダウンから「Query panel(クエリー パネル )」を選択します。
クエリーのコンポーネント
式
クエリー式を使用して、Runs、Artifacts、Models、Tables など、W&B に保存されているデータをクエリーします。
例: テーブル のクエリー
W&B Table をクエリーするとします。 トレーニング コード で、"cifar10_sample_table"というテーブルを ログ に記録します。
import wandb
wandb. log({"cifar10_sample_table" :< MY_TABLE> })
クエリー パネル 内では、次のコードでテーブルをクエリーできます。
runs. summary["cifar10_sample_table" ]
これを分解すると次のようになります。
runs は、クエリー パネル が ワークスペース にある場合、クエリー パネル 式に自動的に挿入される変数です。 その「値」は、特定の ワークスペース で表示できる Runs のリストです。 run で使用できるさまざまな属性については、こちらをお読みください 。summary は、Run の Summary オブジェクトを返す op です。 Op は mapped です。つまり、この op はリスト内の各 Run に適用され、Summary オブジェクトのリストが生成されます。["cifar10_sample_table"] は、predictions という パラメータ を持つ Pick op(角かっこで示されます)です。 Summary オブジェクトは ディクショナリー または マップ のように動作するため、この操作は各 Summary オブジェクトから predictions フィールドを選択します。
独自のクエリーをインタラクティブに作成する方法については、この レポート を参照してください。
設定
パネル の左上隅にある歯車アイコンを選択して、クエリー 設定 を展開します。 これにより、 ユーザー は パネル のタイプと、結果 パネル の パラメータ を 設定 できます。
結果 パネル
最後に、クエリー結果 パネル は、選択したクエリー パネル を使用して、クエリー式の結果をレンダリングし、データ をインタラクティブな形式で表示するように 設定 によって 設定 されます。 次の画像は、同じデータの Table とプロットを示しています。
基本操作
クエリー パネル 内で実行できる一般的な操作を次に示します。
並べ替え
列オプションから並べ替えを行います。
フィルター
クエリーで直接 フィルター するか、左上隅にある フィルター ボタンを使用できます(2 番目の画像)。
マップ
マップ 操作はリストを反復処理し、データ 内の各要素に関数を適用します。 これは、 パネル クエリー で直接行うか、列オプションから新しい列を挿入して行うことができます。
グループ化
クエリーまたは列オプションを使用してグループ化できます。
連結
連結操作を使用すると、2 つのテーブルを連結し、 パネル 設定 から連結または結合できます。
結合
クエリーでテーブルを直接結合することも可能です。 次のクエリー式を検討してください。
project("luis_team_test" , "weave_example_queries" ). runs. summary["short_table_0" ]. table. rows. concat. join(\
project("luis_team_test" , "weave_example_queries" ). runs. summary["short_table_1" ]. table. rows. concat,\
(row) => row["Label" ],(row) => row["Label" ], "Table1" , "Table2" ,\
"false" , "false" )
左側のテーブルは、次のように生成されます。
project("luis_team_test" , "weave_example_queries" ). \
runs. summary["short_table_0" ]. table. rows. concat. join
右側のテーブルは、次のように生成されます。
project("luis_team_test" , "weave_example_queries" ). \
runs. summary["short_table_1" ]. table. rows. concat
説明:
(row) => row["Label"] は各テーブルのセレクターであり、結合する列を決定します"Table1" と "Table2" は、結合時の各テーブルの名前ですtrue と false は、左側の内部/外部結合 設定 用です
Runs オブジェクト
クエリー パネル を使用して runs オブジェクトにアクセスします。 Run オブジェクトは、 Experiments のレコードを保存します。 詳細については、 レポート のこのセクション を参照してください。簡単にまとめると、runs オブジェクトには次のものが含まれます。
summary: Run の結果をまとめた情報の ディクショナリー 。 これは、精度や損失などのスカラー、または大きなファイルにすることができます。 デフォルトでは、wandb.log() は Summary を ログ に記録された 時系列 の最終値に 設定 します。 Summary の内容を直接 設定 できます。 Summary を Run の出力として考えてください。history: 損失など、モデル の トレーニング 中に変化する値を保存するための ディクショナリー のリスト。 コマンド wandb.log() はこの オブジェクト に追加されます。config: トレーニング Run の ハイパー パラメータ ーや、データセット Artifact を作成する Run の 前処理 メソッド など、Run の 設定 情報の ディクショナリー 。 これらを Run の「入力」と考えてください。
Artifacts へのアクセス
Artifacts は W&B の 中核となる概念です。 これらは、 バージョン 管理された名前付きのファイルと ディレクトリー のコレクションです。 Artifacts を使用して、モデル の重み、データセット 、およびその他のファイルまたは ディレクトリー を追跡します。 Artifacts は W&B に保存され、ダウンロードしたり、他の Runs で使用したりできます。 詳細と例については、 レポート のこのセクション を参照してください。 Artifacts には通常、project オブジェクト からアクセスします。
project.artifactVersion(): プロジェクト 内の指定された名前と バージョン の特定の Artifact バージョン を返します。project.artifact(""): プロジェクト 内の指定された名前の Artifact を返します。 次に、.versions を使用して、この Artifact のすべての バージョン のリストを取得できます。project.artifactType(): プロジェクト 内の指定された名前の artifactType を返します。 次に、.artifacts を使用して、このタイプのすべての Artifacts のリストを取得できます。project.artifactTypes: プロジェクト 下にあるすべての Artifact タイプ のリストを返します。
2.4.1.8.1 - Embed objects
W&B の Embedding Projector を使用すると、PCA、UMAP、t-SNE などの一般的な次元削減アルゴリズムを使用して、多次元埋め込みを 2D 平面にプロットできます。
埋め込み は、オブジェクト(人、画像、投稿、単語など)を数値のリスト、つまり ベクトル で表現するために使用されます。 機械学習とデータサイエンスのユースケースでは、埋め込みは、さまざまなアプリケーションでさまざまなアプローチを使用して生成できます。このページでは、読者が埋め込みについてよく理解しており、W&B 内で視覚的に分析することに関心があることを前提としています。
埋め込みの例
Hello World
W&B を使用すると、wandb.Table クラスを使用して埋め込みをログに記録できます。それぞれが 5 次元で構成される 3 つの埋め込みの次の例を考えてみましょう。
import wandb
wandb. init(project= "embedding_tutorial" )
embeddings = [
# D1 D2 D3 D4 D5
[0.2 , 0.4 , 0.1 , 0.7 , 0.5 ], # 埋め込み 1
[0.3 , 0.1 , 0.9 , 0.2 , 0.7 ], # 埋め込み 2
[0.4 , 0.5 , 0.2 , 0.2 , 0.1 ], # 埋め込み 3
]
wandb. log(
{"embeddings" : wandb. Table(columns= ["D1" , "D2" , "D3" , "D4" , "D5" ], data= embeddings)}
)
wandb. finish()
上記のコードを実行すると、W&B ダッシュボードにデータを含む新しい Table が表示されます。 右上のパネルセレクターから [2D Projection] を選択して、埋め込みを 2 次元でプロットできます。 スマートデフォルトが自動的に選択されます。これは、歯車アイコンをクリックしてアクセスできる設定メニューで簡単にオーバーライドできます。 この例では、利用可能な 5 つの数値次元すべてを自動的に使用します。
Digits MNIST
上記の例は、埋め込みをログに記録する基本的なメカニズムを示していますが、通常はより多くの次元とサンプルを扱っています。 MNIST Digits データセット(UCI ML 手書き数字データセット s ) について考えてみましょう。SciKit-Learn 経由で利用できます。 このデータセットには 1797 件のレコードがあり、それぞれに 64 の次元があります。 この問題は、10 クラス分類のユースケースです。 入力データを画像に変換して、可視化することもできます。
import wandb
from sklearn.datasets import load_digits
wandb. init(project= "embedding_tutorial" )
# データセットをロードする
ds = load_digits(as_frame= True )
df = ds. data
# 「target」列を作成する
df["target" ] = ds. target. astype(str)
cols = df. columns. tolist()
df = df[cols[- 1 :] + cols[:- 1 ]]
# 「image」列を作成する
df["image" ] = df. apply(
lambda row: wandb. Image(row[1 :]. values. reshape(8 , 8 ) / 16.0 ), axis= 1
)
cols = df. columns. tolist()
df = df[cols[- 1 :] + cols[:- 1 ]]
wandb. log({"digits" : df})
wandb. finish()
上記のコードを実行すると、再び UI に Table が表示されます。 [2D Projection] を選択すると、埋め込みの定義、色付け、アルゴリズム (PCA、UMAP、t-SNE)、アルゴリズムのパラメータ、さらにはオーバーレイ (この場合は、ポイントにカーソルを合わせると画像が表示されます) を設定できます。 この特定のケースでは、これらはすべて「スマートデフォルト」であり、[2D Projection] を 1 回クリックすると、非常によく似たものが表示されます。 (ここをクリックして操作 この例を参照してください)。
ログ記録のオプション
埋め込みは、さまざまな形式でログに記録できます。
単一の埋め込み列: 多くの場合、データはすでに「マトリックス」のような形式になっています。 この場合、単一の埋め込み列を作成できます。ここで、セル値のデータ型は list[int]、list[float]、または np.ndarray になります。複数の数値列: 上記の 2 つの例では、このアプローチを使用し、次元ごとに列を作成します。 現在、セルには python int または float を使用できます。
さらに、すべてのテーブルと同様に、テーブルの構築方法に関して多くのオプションがあります。
wandb.Table(dataframe=df) を使用して dataframe から直接wandb.Table(data=[...], columns=[...]) を使用して データのリスト から直接テーブルを 行ごとに (コードにループがある場合に最適) 段階的に構築 します。 table.add_data(...) を使用してテーブルに行を追加します
テーブルに 埋め込み列 を追加します (埋め込み形式の予測のリストがある場合に最適)。 table.add_col("col_name", ...)
計算された列 を追加します (テーブルにマップする関数または model がある場合に最適)。 table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
プロットオプション
[2D Projection] を選択した後、歯車アイコンをクリックしてレンダリング設定を編集できます。 目的の列を選択することに加えて (上記を参照)、目的のアルゴリズム (および目的のパラメータ) を選択できます。 以下に、それぞれ UMAP と t-SNE のパラメータを示します。
注: 現在、3 つのアルゴリズムすべてで、ランダムなサブセットの 1000 行と 50 次元にダウンサンプリングしています。
2.4.2 - Custom charts
W&B のプロジェクトでカスタムグラフを作成できます。任意のデータのテーブルを記録し、必要な方法で正確に可視化します。Vega の機能を使用して、フォント、色、ツールチップの詳細を制御します。
仕組み
データ の ログ : スクリプトから、config とサマリーデータを記録します。グラフのカスタマイズ : GraphQL クエリでログに記録されたデータを取得します。強力な可視化文法である Vega を使用して、クエリの結果を可視化します。グラフのログ : wandb.plot_table() を使用して、スクリプトから独自のプリセットを呼び出します。
期待されるデータが表示されない場合は、探している列が選択された runs に記録されていない可能性があります。グラフを保存し、runs テーブルに戻り、目 のアイコンを使用して選択した runs を確認します。
スクリプトからグラフをログ
組み込みプリセット
W&B には、スクリプトから直接ログに記録できる多数の組み込みグラフプリセットがあります。これには、折れ線グラフ、散布図、棒グラフ、ヒストグラム、PR曲線、ROC曲線が含まれます。
折れ線グラフ
散布図
棒グラフ
ヒストグラム
PR曲線
ROC曲線
wandb.plot.line()
任意の軸 x と y 上の接続された順序付けられた点 (x,y) のリストであるカスタム折れ線グラフをログに記録します。
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb. Table(data= data, columns= ["x" , "y" ])
wandb. log(
{
"my_custom_plot_id" : wandb. plot. line(
table, "x" , "y" , title= "Custom Y vs X Line Plot"
)
}
)
折れ線グラフは、任意の2つの次元で曲線をログに記録します。2つの値のリストを互いにプロットする場合、リスト内の値の数は完全に一致する必要があります (たとえば、各ポイントには x と y が必要です)。
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.scatter()
カスタム散布図 (任意の軸 x と y のペア上の点のリスト (x, y)) をログに記録します。
data = [[x, y] for (x, y) in zip(class_x_prediction_scores, class_y_prediction_scores)]
table = wandb. Table(data= data, columns= ["class_x" , "class_y" ])
wandb. log({"my_custom_id" : wandb. plot. scatter(table, "class_x" , "class_y" )})
これを使用して、任意の2つの次元で散布点をログに記録できます。2つの値のリストを互いにプロットする場合、リスト内の値の数は完全に一致する必要があることに注意してください (たとえば、各ポイントには x と y が必要です)。
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.bar()
カスタム棒グラフ (ラベル付きの値のリストを棒として) を数行でネイティブにログに記録します。
data = [[label, val] for (label, val) in zip(labels, values)]
table = wandb. Table(data= data, columns= ["label" , "value" ])
wandb. log(
{
"my_bar_chart_id" : wandb. plot. bar(
table, "label" , "value" , title= "Custom Bar Chart"
)
}
)
これを使用して、任意の棒グラフをログに記録できます。リスト内のラベルと値の数は完全に一致する必要があることに注意してください (たとえば、各データポイントには両方が必要です)。
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.histogram()
カスタムヒストグラム (値のソートされたリストを、発生のカウント/頻度でビンに分類) を数行でネイティブにログに記録します。予測信頼度スコア (scores) のリストがあり、その分布を可視化するとします。
data = [[s] for s in scores]
table = wandb. Table(data= data, columns= ["scores" ])
wandb. log({"my_histogram" : wandb. plot. histogram(table, "scores" , title= None )})
これを使用して、任意のヒストグラムをログに記録できます。data はリストのリストであり、行と列の2D配列をサポートすることを目的としています。
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.pr_curve()
適合率-再現率曲線 を1行で作成します。
plot = wandb. plot. pr_curve(ground_truth, predictions, labels= None , classes_to_plot= None )
wandb. log({"pr" : plot})
コードが以下にアクセスできる場合は、いつでもこれをログに記録できます。
例のセットに対するモデルの予測スコア (predictions)
これらの例に対応する正解ラベル (ground_truth)
(オプション) ラベル/クラス名のリスト (labels=["cat", "dog", "bird"...] (ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合))
(オプション) プロットで可視化するラベルのサブセット (リスト形式のまま)
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
wandb.plot.roc_curve()
ROC曲線 を1行で作成します。
plot = wandb. plot. roc_curve(
ground_truth, predictions, labels= None , classes_to_plot= None
)
wandb. log({"roc" : plot})
コードが以下にアクセスできる場合は、いつでもこれをログに記録できます。
例のセットに対するモデルの予測スコア (predictions)
これらの例に対応する正解ラベル (ground_truth)
(オプション) ラベル/クラス名のリスト (labels=["cat", "dog", "bird"...] (ラベルインデックス0がcat、1 = dog、2 = birdなどを意味する場合))
(オプション) プロットで可視化するこれらのラベルのサブセット (リスト形式のまま)
レポートの例 を参照するか、Google Colabノートブックの例 をお試しください。
カスタムプリセット
組み込みプリセットを調整するか、新しいプリセットを作成して、グラフを保存します。グラフIDを使用して、スクリプトからそのカスタムプリセットに直接データをログに記録します。Google Colabノートブックの例 をお試しください。
# プロットする列を含むテーブルを作成します
table = wandb. Table(data= data, columns= ["step" , "height" ])
# テーブルの列からグラフのフィールドへのマッピング
fields = {"x" : "step" , "value" : "height" }
# テーブルを使用して、新しいカスタムグラフプリセットを作成します
# 独自の保存されたグラフプリセットを使用するには、vega_spec_name を変更します
my_custom_chart = wandb. plot_table(
vega_spec_name= "carey/new_chart" ,
data_table= table,
fields= fields,
)
データの ログ
スクリプトから次のデータ型をログに記録し、カスタムグラフで使用できます。
Config : experiment の初期設定 (独立変数)。これには、トレーニングの開始時に wandb.config のキーとしてログに記録した名前付きフィールドが含まれます。例: wandb.config.learning_rate = 0.0001サマリー : トレーニング中にログに記録された単一の値 (結果または従属変数)。例: wandb.log({"val_acc" : 0.8})。wandb.log() を介してトレーニング中にこのキーに複数回書き込むと、サマリーはそのキーの最終値に設定されます。履歴 : ログに記録されたスカラーの完全な時系列は、history フィールドを介してクエリで使用できますsummaryTable : 複数の値のリストをログに記録する必要がある場合は、wandb.Table() を使用してそのデータを保存し、カスタム パネルでクエリを実行します。historyTable : 履歴データを確認する必要がある場合は、カスタムグラフ パネルで historyTable をクエリします。wandb.Table() を呼び出すか、カスタムグラフをログに記録するたびに、そのステップの履歴に新しいテーブルが作成されます。
カスタムテーブルをログする方法
wandb.Table() を使用して、データを2D配列としてログに記録します。通常、このテーブルの各行は1つのデータポイントを表し、各列はプロットする各データポイントの関連フィールド/次元を示します。カスタム パネルを構成すると、テーブル全体が wandb.log() (custom_data_table below) に渡される名前付きキーを介してアクセスできるようになり、個々のフィールドは列名 (x、y、および z) を介してアクセスできるようになります。 experiment 全体で複数のタイムステップでテーブルをログに記録できます。各テーブルの最大サイズは10,000行です。Google Colab の例 をお試しください。
# データのカスタムテーブルをログ
my_custom_data = [[x1, y1, z1], [x2, y2, z2]]
wandb. log(
{"custom_data_table" : wandb. Table(data= my_custom_data, columns= ["x" , "y" , "z" ])}
)
グラフのカスタマイズ
新しいカスタムグラフを追加して開始し、クエリを編集して表示されている runs からデータを選択します。クエリは GraphQL を使用して、runs の config、サマリー、および履歴フィールドからデータをフェッチします。
カスタム可視化
右上隅の グラフ を選択して、デフォルトのプリセットから開始します。次に、グラフフィールド を選択して、クエリから取得しているデータをグラフの対応するフィールドにマッピングします。
次の画像は、メトリクスを選択し、それを下の棒グラフフィールドにマッピングする方法の例を示しています。
Vega を編集する方法
パネルの上部にある 編集 をクリックして、Vega 編集モードに移動します。ここでは、UI でインタラクティブなグラフを作成する Vega 仕様 を定義できます。グラフのあらゆる側面を変更できます。たとえば、タイトルを変更したり、別の配色を選択したり、曲線を接続された線としてではなく一連の点として表示したりできます。また、Vega 変換を使用して値の配列をヒストグラムにビン化するなど、データ自体に変更を加えることもできます。パネルプレビューはインタラクティブに更新されるため、Vega 仕様またはクエリを編集するときの変更の効果を確認できます。Vega のドキュメントとチュートリアル を参照してください。
フィールド参照
W&B からグラフにデータをプルするには、Vega 仕様の任意の場所に "${field:<field-name>}" 形式のテンプレート文字列を追加します。これにより、右側の グラフフィールド 領域にドロップダウンが作成され、ユーザーはクエリ結果の列を選択して Vega にマッピングできます。
フィールドのデフォルト値を設定するには、次の構文を使用します: "${field:<field-name>:<placeholder text>}"
グラフプリセットの保存
モーダルの下部にあるボタンを使用して、特定の可視化パネルに変更を適用します。または、Vega 仕様を保存して、プロジェクトの他の場所で使用することもできます。再利用可能なグラフ定義を保存するには、Vega エディターの上部にある 名前を付けて保存 をクリックし、プリセットに名前を付けます。
記事とガイド
W&B 機械学習 可視化 IDE カスタムグラフを使用した NLP 注意ベース モデルの可視化 カスタムグラフを使用した勾配フローに対する注意の影響の可視化 任意の曲線をログ
一般的なユースケース
エラーバー付きのカスタム棒グラフ
カスタム x-y 座標を必要とするモデル検証メトリクスを表示する (適合率-再現率曲線など)
2つの異なるモデル/ experiment からのデータ分布をヒストグラムとしてオーバーレイする
トレーニング中の複数のポイントでのスナップショットを介してメトリクスの変化を表示する
W&B でまだ利用できない独自の可視化を作成する (そして、うまくいけばそれを世界と共有する)
2.4.2.1 - Tutorial: Use custom charts
W&B UI でカスタムチャート機能を使用する方法のチュートリアル
カスタムチャートを使用すると、パネルにロードするデータとその可視化を制御できます。
1. データを W&B にログ記録する
まず、スクリプトにデータをログ記録します。トレーニングの開始時に設定された単一のポイント(ハイパーパラメータなど)には、wandb.config を使用します。時間の経過に伴う複数のポイントには、wandb.log() を使用し、wandb.Table() を使用してカスタム 2D 配列をログ記録します。ログに記録されるキーごとに最大 10,000 個のデータポイントをログに記録することをお勧めします。
# データのカスタムテーブルをログ記録する
my_custom_data = [[x1, y1, z1], [x2, y2, z2]]
wandb. log(
{"custom_data_table" : wandb. Table(data= my_custom_data, columns= ["x" , "y" , "z" ])}
)
クイックなサンプルノートブック を試してデータテーブルをログに記録してください。次のステップでは、カスタムチャートを設定します。結果として得られるチャートがライブ Report でどのように見えるかを確認してください。
2. クエリを作成する
可視化するデータをログに記録したら、プロジェクトページに移動し、**+**ボタンをクリックして新しいパネルを追加し、カスタムチャート を選択します。この Workspace で一緒に操作できます。
クエリを追加する
「summary」をクリックし、「historyTable」を選択して、run の履歴からデータを取得する新しいクエリを設定します。
wandb.Table() をログに記録したキーを入力します。上記のコードスニペットでは、my_custom_table でした。サンプルノートブック では、キーは pr_curve と roc_curve です。
Vega フィールドを設定する
クエリがこれらの列をロードするようになったので、Vega フィールドのドロップダウンメニューで選択するオプションとして使用できます。
x 軸: runSets_historyTable_r (再現率)y 軸: runSets_historyTable_p (精度)色: runSets_historyTable_c (クラスラベル)
3. チャートをカスタマイズする
見た目はかなり良いですが、散布図から折れ線グラフに切り替えたいと思います。「編集 」をクリックして、この組み込みチャートの Vega 仕様を変更します。この Workspace で一緒に操作できます。
Vega 仕様を更新して、可視化をカスタマイズしました。
プロット、凡例、x 軸、および y 軸のタイトルを追加します(各フィールドの「title」を設定します)。
「mark」の値を「point」から「line」に変更します。
使用されていない「size」フィールドを削除します。
これをプリセットとして保存して、このプロジェクトの他の場所で使用できるようにするには、ページの上部にある「名前を付けて保存 」をクリックします。結果は次のようになり、ROC 曲線が表示されます。
ボーナス: 複合ヒストグラム
ヒストグラムは、数値分布を可視化して、より大きなデータセットを理解するのに役立ちます。複合ヒストグラムは、同じビンに複数の分布を表示し、異なるモデル間、またはモデル内の異なるクラス間で、2 つ以上のメトリクスを比較できます。運転シーンでオブジェクトを検出するセマンティックセグメンテーションモデルの場合、精度と intersection over union (IOU) の最適化の効果を比較したり、異なるモデルが車(データ内の大きく一般的な領域)と交通標識(はるかに小さく、一般的でない領域)をどの程度検出できるかを知りたい場合があります。デモ Colab では、10 種類の生物のクラスのうち 2 つの信頼度スコアを比較できます。
カスタム複合ヒストグラムパネルの独自のバージョンを作成するには:
Workspace または Report で新しいカスタムチャートパネルを作成します(「カスタムチャート」可視化を追加することによって)。右上にある「編集」ボタンをクリックして、組み込みのパネルタイプから Vega 仕様を変更します。
その組み込みの Vega 仕様を、Vega の複合ヒストグラムの MVP コード に置き換えます。メインタイトル、軸タイトル、入力ドメイン、およびその他の詳細を、この Vega 仕様で直接Vega 構文を使用して 変更できます(色を変更したり、3 番目のヒストグラムを追加したりすることもできます:)
右側のクエリを変更して、wandb ログから正しいデータをロードします。フィールド summaryTable を追加し、対応する tableKey を class_scores に設定して、run によってログに記録された wandb.Table をフェッチします。これにより、class_scores としてログに記録された wandb.Table の列を使用して、ドロップダウンメニューから 2 つのヒストグラムビンセット(red_bins と blue_bins)を設定できます。私の例では、赤いビンの動物クラスの予測スコアと、青いビンの植物の予測スコアを選択しました。
プレビューレンダリングに表示されるプロットに満足するまで、Vega 仕様とクエリの変更を続けることができます。完了したら、上部の「名前を付けて保存 」をクリックし、カスタムプロットに名前を付けて再利用できるようにします。次に、「パネルライブラリから適用 」をクリックして、プロットを完了します。
これは、非常に簡単な実験からの結果がどのように見えるかです。1 エポックでわずか 1000 個のサンプルでトレーニングすると、ほとんどの画像が植物ではないと非常に確信しており、どの画像が動物である可能性があるかについては非常に不確かなモデルが生成されます。
2.4.3 - Manage workspace, section, and panel settings
特定の ワークスペース ページ内には、ワークスペース、セクション、パネルという3つの異なる設定レベルがあります。ワークスペース の 設定 は、ワークスペース 全体に適用されます。セクション の 設定 は、セクション内のすべてのパネルに適用されます。パネル の 設定 は、個々のパネルに適用されます。
ワークスペース の 設定
ワークスペース の 設定は、すべてのセクションと、それらのセクション内のすべてのパネルに適用されます。編集できるワークスペース の 設定には、ワークスペース の レイアウト 折れ線グラフ ワークスペース の レイアウト は ワークスペース の構造を決定し、折れ線グラフ の 設定は ワークスペース 内の折れ線グラフのデフォルト設定を制御します。
この ワークスペース の全体的な構造に適用される設定を編集するには:
プロジェクト の ワークスペース に移動します。
New report ボタンの横にある歯車アイコンをクリックして、ワークスペース の 設定を表示します。ワークスペース のレイアウトを変更するには Workspace layout を選択し、ワークスペース 内の折れ線グラフのデフォルト設定を構成するには Line plots を選択します。
ワークスペース の レイアウト オプション
ワークスペース のレイアウトを構成して、ワークスペース の全体的な構造を定義します。これには、セクション分割ロジックとパネルの構成が含まれます。
ワークスペース のレイアウト オプション ページには、ワークスペース がパネルを自動的に生成するか、手動で生成するかが表示されます。ワークスペース のパネル生成モードを調整するには、Panels を参照してください。
次の表は、各ワークスペース のレイアウト オプションについて説明したものです。
ワークスペース の 設定
説明
検索時に空のセクションを非表示にする パネルを検索するときに、パネルを含まないセクションを非表示にします。
パネルをアルファベット順に並べ替える ワークスペース 内のパネルをアルファベット順に並べ替えます。
セクション の 構成 既存のすべてのセクションとパネルを削除し、新しいセクション名で再作成します。新しく作成されたセクションを、最初のプレフィックスまたは最後のプレフィックスでグループ化します。
W&B は、最後のプレフィックスでグループ化するのではなく、最初のプレフィックスでセクションを構成することを推奨します。最初のプレフィックスでグループ化すると、セクションの数が減り、パフォーマンスが向上する可能性があります。
折れ線グラフ の オプション
Line plots ワークスペース の 設定を変更して、ワークスペース 内の折れ線グラフのグローバルなデフォルトとカスタムルールを設定します。
Line plots の 設定では、Data と Display preferences という2つのメイン設定を編集できます。Data タブには、次の設定が含まれています。
折れ線グラフ の 設定
説明
X軸 折れ線グラフのX軸のスケール。X軸はデフォルトで Step に設定されています。X軸のオプションのリストについては、次の表を参照してください。
範囲 X軸に表示する最小値と最大値の設定。
Smoothing 折れ線グラフの Smoothing を変更します。Smoothing の詳細については、Smooth line plots を参照してください。
Outliers デフォルトのプロットの最小スケールと最大スケールから外れ値を排除するためにリスケールします。
Point aggregation method Data Visualization の精度とパフォーマンスを向上させます。詳細については、Point aggregation を参照してください。
Max number of runs or groups 折れ線グラフに表示される Runs またはグループの数を制限します。
Step に加えて、X軸には次のオプションがあります。
X軸 オプション
説明
相対時間 (Wall) プロセス の開始からのタイムスタンプ。たとえば、run を開始し、翌日にその run を再開するとします。その後、何かを log に記録すると、記録されたポイントは24時間になります。
相対時間 (Process) 実行中のプロセス内のタイムスタンプ。たとえば、run を開始して10秒間続行するとします。翌日にその run を再開します。ポイントは10秒として記録されます。
Wall Time グラフ上の最初の run の開始からの経過時間 (分)。
Step wandb.log() を呼び出すたびに増分します。
Display preferences タブでは、次の設定を切り替えることができます。
表示設定
説明
Remove legends from all panels パネルの凡例を削除します
Display colored run names in tooltips ツールチップ内に Runs を色付きのテキストとして表示します
Only show highlighted run in companion chart tooltip チャートのツールチップに強調表示された Runs のみを表示します
Number of runs shown in tooltips ツールチップに Runs の数を表示します
Display full run names on the primary chart tooltip チャートのツールチップに run のフルネームを表示します
セクション の 設定
セクション の 設定は、そのセクション内のすべてのパネルに適用されます。ワークスペース の セクション 内では、パネルの並べ替え、パネルの再配置、セクション名の変更を行うことができます。
セクション の 設定を変更するには、セクション の右上隅にある3つの水平ドット (… ) を選択します。
ドロップダウンから、セクション全体に適用される次の設定を編集できます。
セクション の 設定
説明
Rename a section セクションの名前を変更します
Sort panels A-Z セクション内のパネルをアルファベット順に並べ替えます
Rearrange panels セクション内のパネルを選択してドラッグし、パネルを手動で並べ替えます
次のアニメーションは、セクション内のパネルを再配置する方法を示しています。
上記の表で説明されている設定に加えて、Add section below 、Add section above 、Delete section 、Add section to report など、ワークスペース でのセクションの表示方法を編集することもできます。
パネル の 設定
個々のパネルの 設定をカスタマイズして、同じプロット上に複数の線を比較したり、カスタム軸を計算したり、ラベルの名前を変更したりできます。パネルの 設定を編集するには:
編集するパネルにマウスを合わせます。
表示される鉛筆アイコンを選択します。
表示されるモーダル内で、パネルの データ、表示設定などに関連する設定を編集できます。
パネルに適用できる設定の完全なリストについては、Edit line panel settings を参照してください。
2.4.4 - Settings
Weights & Biases の 設定ページ を使用して、個々の ユーザー プロフィールまたは Team の 設定 をカスタマイズします。
個々の ユーザー アカウント内では、プロフィール画像、表示名、地理的な場所、自己紹介情報、アカウントに関連付けられたメールアドレスを編集したり、runs のアラートを管理したりできます。設定 ページを使用して、GitHub リポジトリをリンクしたり、アカウントを削除したりすることもできます。詳細については、ユーザー settings を参照してください。
Team settings ページを使用して、新しいメンバーを Team に招待または削除したり、Team runs のアラートを管理したり、プライバシー 設定を変更したり、ストレージの使用状況を表示および管理したりできます。Team settings の詳細については、Team settings を参照してください。
2.4.4.1 - Manage user settings
プロフィール情報、アカウントのデフォルト、アラート、ベータ版製品への参加、GitHub インテグレーション、ストレージ使用量、アカウントの有効化を管理し、 ユーザー 設定で Teams を作成します。
ユーザープロファイルページに移動し、右上隅にあるユーザーアイコンを選択します。ドロップダウンから、設定 を選択します。
プロフィール
プロフィール セクションでは、アカウント名と所属機関を管理および変更できます。オプションで、略歴、場所、個人または所属機関のウェブサイトへのリンクを追加したり、プロフィール画像をアップロードしたりできます。
イントロダクションを編集する
イントロダクションを編集するには、プロフィールの最上部にある 編集 をクリックします。開く WYSIWYG エディターは Markdown をサポートしています。
行を編集するには、それをクリックします。時間を節約するために、/ と入力し、リストから Markdown を選択できます。
項目のドラッグハンドルを使用して、移動します。
ブロックを削除するには、ドラッグハンドルをクリックし、削除 をクリックします。
変更を保存するには、保存 をクリックします。
ソーシャルバッジを追加する
X で @weights_biases アカウントのフォローバッジを追加するには、バッジ画像を指す HTML <img> タグを含む Markdown スタイルのリンクを追加できます。
[<img src="https://img.shields.io/twitter/follow/weights_biases?style=social" alt="X: @weights_biases" > ](https://x.com/intent/follow?screen_name=weights_biases )
<img> タグでは、width、height、またはその両方を指定できます。いずれか一方のみを指定した場合、画像のプロポーションは維持されます。
Teams
Team セクションで新しい team を作成します。新しい team を作成するには、新しい team ボタンを選択し、以下を入力します。
Team 名 - team の名前。team 名は一意である必要があります。Team 名は変更できません。Team タイプ - 仕事 または 学術 ボタンを選択します。会社/組織 - team の会社または組織の名前を入力します。ドロップダウンメニューを選択して、会社または組織を選択します。オプションで、新しい組織を入力できます。
管理アカウントのみが team を作成できます。
ベータ機能
ベータ機能 セクションでは、オプションで楽しいアドオンや開発中の新製品の先行プレビューを有効にできます。有効にするベータ機能の横にあるトグルスイッチを選択します。
アラート
wandb.alert() で、run がクラッシュまたは終了した場合、またはカスタムアラートを設定した場合に通知を受け取ります。メールまたは Slack で通知を受信します。アラートを受信するイベントタイプの横にあるスイッチを切り替えます。
Runs finished : Weights and Biases の run が正常に終了したかどうか。Run crashed : run が完了しなかった場合に通知します。
アラートの設定と管理方法の詳細については、wandb.alert でアラートを送信 を参照してください。
個人の GitHub integration
個人の Github アカウントを接続します。Github アカウントを接続するには:
Github に接続 ボタンを選択します。これにより、オープン認証 (OAuth) ページにリダイレクトされます。組織アクセス セクションで、アクセスを許可する組織を選択します。wandb を認証 します。
アカウントを削除する
アカウントを削除 ボタンを選択して、アカウントを削除します。
アカウントの削除は元に戻せません。
ストレージ
ストレージ セクションでは、アカウントが Weights and Biases サーバーで使用した総メモリ使用量を説明します。デフォルトのストレージプランは 100GB です。ストレージと価格の詳細については、価格 ページを参照してください。
2.4.4.2 - Manage billing settings
組織の課金 設定 を管理
ユーザープロフィールページに移動し、右上隅にあるユーザーアイコンを選択します。ドロップダウンから、Billing を選択するか、Settings を選択し、Billing タブを選択します。
プラン詳細
Plan details セクションでは、組織の現在のプラン、料金、制限、使用状況の概要が示されます。
ユーザーの詳細とリストを表示するには、Manage users をクリックします。
使用状況の詳細を表示するには、View usage をクリックします。
組織が使用するストレージの量(無料と有料の両方)。ここから、追加のストレージを購入したり、現在使用中のストレージを管理したりできます。ストレージの設定 の詳細をご覧ください。
ここから、プランを比較したり、営業担当者と話をしたりできます。
プランの使用状況
このセクションでは、現在の使用状況を視覚的にまとめ、今後の使用料金を表示します。月ごとの使用状況の詳細な分析情報を得るには、個々のタイルで View usage をクリックします。カレンダー月、Team、または Project ごとに使用状況をエクスポートするには、Export CSV をクリックします。
使用状況アラート
有料プランをご利用の組織の場合、管理者は、特定のしきい値に達すると、1 回の請求期間につき 1 回 、メールでアラートを受信します。また、請求管理者 の場合は、組織の制限を増やす方法、それ以外の場合は、請求管理者に連絡する方法の詳細も記載されています。Pro plan では、請求管理者のみが使用状況アラートを受信します。
これらのアラートは構成できず、次の場合に送信されます。
組織が、プランに応じた使用量のカテゴリの月間制限に近づいている場合(使用時間の 85%)および制限の 100% に達した場合。
組織の請求期間の累積平均料金が、200 ドル、450 ドル、700 ドル、および 1000 ドルのしきい値を超えた場合。これらの超過料金は、組織が追跡時間、ストレージ、または Weave data ingestion に対して、プランに含まれる量よりも多くの使用量を累積した場合に発生します。
使用状況または請求に関するご質問は、アカウントTeamまたはサポートにお問い合わせください。
支払い方法
このセクションには、組織に登録されている支払い方法が表示されます。支払い方法を追加していない場合は、プランをアップグレードするか、有料ストレージを追加するときに、追加するように求められます。
請求管理者
このセクションには、現在の請求管理者が表示されます。請求管理者は組織の管理者であり、請求関連のすべてのメールを受信し、支払い方法を表示および管理できます。
W&B Dedicated Cloud では、複数のユーザーが請求管理者になることができます。W&B Multi-tenant Cloud では、一度に 1 人のユーザーのみが請求管理者になることができます。
請求管理者を変更するか、ロールを追加のユーザーに割り当てるには、次の手順に従います。
Manage roles をクリックします。ユーザーを検索します。
そのユーザーの行にある Billing admin フィールドをクリックします。
概要を読んでから、Change billing user をクリックします。
請求書
クレジットカードで支払う場合、このセクションでは毎月の請求書を表示できます。
銀行振込で支払う Enterprise アカウントの場合、このセクションは空白です。ご不明な点がございましたら、アカウントTeamにお問い合わせください。
組織が料金を発生させない場合、請求書は生成されません。
2.4.4.3 - Manage team settings
Team Settings ページで、 Team のメンバー、アバター、アラート、およびプライバシー設定を管理します。
チーム設定
チームのメンバー、アバター、アラート、プライバシー、利用状況などの設定を変更します。Organization の管理者と チーム の管理者は、チーム の設定を表示および編集できます。
管理アカウントタイプのみが、チーム設定を変更したり、チームからメンバーを削除したりできます。
メンバー
「メンバー」セクションには、保留中の招待と、チームへの参加招待を承認したメンバーのリストが表示されます。リストに表示される各メンバーには、メンバーの名前、ユーザー名、メールアドレス、チームの役割、および Models と Weave へのアクセス権限が表示されます。これらは Organization から継承されます。標準のチームの役割 Admin 、 Member 、および View-only から選択できます。Organization がカスタムロール を作成している場合は、代わりにカスタムロールを割り当てることができます。
チームの作成方法、チームの管理方法、チームのメンバーシップと役割の管理方法については、チームの追加と管理 を参照してください。誰が新しいメンバーを招待できるかを設定し、チームのその他のプライバシー設定を構成するには、プライバシー を参照してください。
アバター
アバター セクションに移動し、画像をアップロードしてアバターを設定します。
アバターを更新 を選択して、ファイルダイアログを表示します。ファイルダイアログから、使用する画像を選択します。
アラート
run がクラッシュ、完了、またはカスタムアラートを設定したときに、チームに通知します。チームは、メールまたは Slack でアラートを受信できます。
アラートを受信するイベントタイプの横にあるスイッチを切り替えます。Weights and Biases は、デフォルトで次のイベントタイプのオプションを提供します。
Runs finished : Weights and Biases の run が正常に完了したかどうか。Run crashed : run が完了しなかった場合。
アラートの設定と管理方法の詳細については、wandb.alert でアラートを送信 を参照してください。
Slack 通知
チームの Automations が、新しい Artifact が作成されたときや、run メトリクスが定義されたしきい値を満たしたときなど、Registry または プロジェクト でイベントが発生したときに通知を送信できる Slack の送信先を設定します。Slack オートメーションの作成 を参照してください。
This feature is available for all Enterprise licenses.
Webhook
チームの Automations が、新しい Artifact が作成されたときや、run メトリクスが定義されたしきい値を満たしたときなど、Registry または プロジェクト でイベントが発生したときに実行できる Webhook を設定します。Webhook オートメーションの作成 を参照してください。
This feature is available for all Enterprise licenses.
プライバシー
プライバシー セクションに移動して、プライバシー設定を変更します。プライバシー設定を変更できるのは、Organization の管理者のみです。
将来の プロジェクト を公開したり、 Reports を公開共有したりする機能をオフにします。
チーム管理者だけでなく、チームメンバーが他のメンバーを招待できるようにします。
コードの保存をデフォルトでオンにするかどうかを管理します。
利用状況
利用状況 セクションでは、チームが Weights and Biases サーバーで使用した総メモリ使用量について説明します。デフォルトのストレージプランは 100GB です。ストレージと価格の詳細については、価格 ページを参照してください。
ストレージ
ストレージ セクションでは、チームの データ に使用されている クラウド ストレージ バケットの設定について説明します。詳細については、セキュアストレージコネクタ を参照するか、セルフホスティングの場合は W&B Server のドキュメントを確認してください。
2.4.4.4 - Manage email settings
[ 設定 ] ページからメールを管理します。
W&B プロフィールの 設定 ページで、メールの種類やプライマリ メール アドレスの追加、削除、管理ができます。W&B ダッシュボード の右上にあるプロフィール アイコンを選択します。ドロップダウンから、設定 を選択します。設定 ページ内で、Emails ダッシュボード までスクロールします。
プライマリ メール の管理
プライマリ メール は 😎 の絵文字でマークされています。プライマリ メール は、W&B アカウント を作成した際に提供したメール アドレスで自動的に定義されます。
ケバブ ドロップダウンを選択して、Weights And Biases アカウント に関連付けられたプライマリ メール を変更します。
検証済みのメールのみをプライマリとして設定できます。
メール の追加
+ Add Email を選択して、メール を追加します。これにより、Auth0 ページに移動します。新しいメール の認証情報を入力するか、シングル サインオン (SSO) を使用して接続できます。
メール の削除
ケバブ ドロップダウンを選択し、Delete Emails を選択して、W&B アカウント に登録されているメール を削除します。
プライマリ メール は削除できません。削除する前に、別のメール をプライマリ メール として設定する必要があります。
ログイン 方法
[ログイン 方法] 列には、アカウント に関連付けられているログイン 方法が表示されます。
W&B アカウント を作成すると、確認メール がメール アカウント に送信されます。メール アカウント は、メール アドレス を確認するまで検証されていないと見なされます。未検証のメール は赤で表示されます。
メール アドレス で再度ログインして、メール アカウント に送信された最初の確認メール が既になくても、2 通目の確認メール を取得してみてください。
アカウント ログイン の問題については、support@wandb.com までお問い合わせください。
2.4.4.5 - Manage teams
同僚と共同作業し、結果を共有して、チーム全体のすべての 実験 を追跡します。
W&B Teams を、より優れたモデルをより迅速に構築するための ML チーム用の一元的なワークスペースとして使用します。
チームが試したすべての実験を追跡し 、作業の重複をなくします。
以前にトレーニングしたモデルを保存して再現します。
上司や共同研究者と進捗状況や結果を共有します。
回帰を検出し、パフォーマンスが低下した場合に直ちに警告を受けます。
モデルのパフォーマンスを評価し、モデルのバージョンを比較します。
コラボレーションチームを作成する
無料の W&B アカウントにサインアップまたはログインします。
ナビゲーションバーの [Invite Team(チームを招待) ] をクリックします。
チームを作成し、共同研究者を招待します。
チームの設定については、チームの設定を管理 を参照してください。
注 :新しいチームを作成できるのは、組織の管理者のみです。
チームプロファイルを作成する
チームのプロファイルページをカスタマイズして、イントロダクションを表示したり、一般公開またはチームメンバーに公開されている Reports と Projects を紹介したりできます。 Reports 、 Projects 、および外部リンクを提示します。
最高の公開 Reports を紹介して、最高の research を訪問者にアピールします
最もアクティブな Projects を紹介して、チームメイトが見つけやすくします
会社や research ラボのウェブサイト、および公開した論文への外部リンクを追加して、共同研究者を見つけます
チームメンバーを削除する
チーム管理者は、チームの設定ページを開き、退職するメンバーの名前の横にある削除ボタンをクリックできます。 run は、ユーザーが退席した後もチームに記録されたままになります。
チームの役割と権限を管理する
同僚をチームに招待するときに、チームの役割を選択します。次のチームの役割オプションがあります。
管理者 :チーム管理者は、他の管理者またはチームメンバーを追加および削除できます。すべての Projects を変更する権限と、完全な削除権限を持っています。これには、 Runs 、 Projects 、 Artifacts 、および Sweeps の削除が含まれますが、これらに限定されません。メンバー :チームの通常のメンバー。デフォルトでは、管理者のみがチームメンバーを招待できます。この振る舞いを変更するには、チームの設定を管理 を参照してください。
チームメンバーは、自分が作成した run のみ削除できます。メンバー A と B がいるとします。メンバー B は、 run をチーム B の Project からメンバー A が所有する別の Project に移動します。メンバー A は、メンバー B がメンバー A の Project に移動した run を削除できません。管理者は、チームメンバーが作成した Runs と Sweep Runs を管理できます。
表示のみ(エンタープライズ限定機能) :表示のみのメンバーは、 Runs 、 Reports 、 Workspace など、チーム内のアセットを表示できます。 Reports をフォローしてコメントできますが、 Project の概要、 Reports 、 Runs を作成、編集、または削除することはできません。カスタムロール(エンタープライズ限定機能) :カスタムロールを使用すると、組織管理者は、表示のみ またはメンバー ロールのいずれかに基づいて、追加の権限を付与して、きめ細かいアクセス制御を実現する新しいロールを作成できます。次に、チーム管理者は、これらのカスタムロールをそれぞれのチームのユーザーに割り当てることができます。詳細については、W&B Teams のカスタムロールの紹介 を参照してください。サービスアカウント(エンタープライズ限定機能) :サービスアカウントを使用してワークフローを自動化する を参照してください。
W&B は、チームに複数の管理者を持つことを推奨しています。これは、プライマリアドミンが利用できない場合でも、管理操作を継続できるようにするためのベストプラクティスです。
チームの設定
チーム設定を使用すると、チームとそのメンバーの設定を管理できます。これらの権限を使用すると、W&B 内でチームを効果的に監督および整理できます。
権限
表示のみ
チームメンバー
チーム管理者
チームメンバーを追加する
X
チームメンバーを削除する
X
チーム設定を管理する
X
レジストリ
次の表に、特定のチームのすべての Projects に適用される権限を示します。
権限
表示のみ
チームメンバー
レジストリ管理者
チーム管理者
エイリアスを追加する
X
X
X
モデルをレジストリに追加する
X
X
X
レジストリでモデルを表示する
X
X
X
X
モデルをダウンロードする
X
X
X
X
レジストリ管理者を追加または削除する
X
X
保護されたエイリアスを追加または削除する
X
保護されたエイリアスの詳細については、レジストリアクセス制御 を参照してください。
Reports
Report 権限は、 Reports を作成、表示、および編集するためのアクセスを許可します。次の表に、特定のチームのすべての Reports に適用される権限を示します。
権限
表示のみ
チームメンバー
チーム管理者
Reports を表示する
X
X
X
Reports を作成する
X
X
Reports を編集する
X (チームメンバーは自分の Reports のみ編集できます)
X
Reports を削除する
X (チームメンバーは自分の Reports のみ編集できます)
X
実験管理
次の表に、特定のチームのすべての実験管理に適用される権限を示します。
権限
表示のみ
チームメンバー
チーム管理者
実験管理メタデータ(履歴メトリクス、システムメトリクス、ファイル、ログを含む)を表示する
X
X
X
実験管理パネルとワークスペースを編集する
X
X
実験管理をログに記録する
X
X
実験管理を削除する
X (チームメンバーは自分が作成した実験管理のみ削除できます)
X
実験管理を停止する
X (チームメンバーは自分が作成した実験管理のみ停止できます)
X
Artifacts
次の表に、特定のチームのすべての Artifacts に適用される権限を示します。
権限
表示のみ
チームメンバー
チーム管理者
Artifacts を表示する
X
X
X
Artifacts を作成する
X
X
Artifacts を削除する
X
X
メタデータを編集する
X
X
エイリアスを編集する
X
X
エイリアスを削除する
X
X
Artifacts をダウンロードする
X
X
システム設定(W&B Server のみ)
システム権限を使用して、チームとそのメンバーを作成および管理し、システム設定を調整します。これらの権限により、W&B インスタンスを効果的に管理および保守できます。
権限
表示のみ
チームメンバー
チーム管理者
システム管理者
システム設定を構成する
X
チームを作成/削除する
X
チームサービスアカウントの振る舞い
トレーニング環境でチームを構成する場合、そのチームのサービスアカウントを使用して、そのチーム内のプライベートまたはパブリック Projects で Runs を記録できます。さらに、環境に WANDB_USERNAME または WANDB_USER_EMAIL 変数が存在し、参照されているユーザーがそのチームに属している場合、それらの Runs をユーザーに帰属させることができます。
トレーニング環境でチームを構成しない 場合にサービスアカウントを使用すると、 Runs はそのサービスアカウントの親チーム内の名前付き Project に記録されます。この場合も同様に、環境に WANDB_USERNAME または WANDB_USER_EMAIL 変数が存在し、参照されているユーザーがサービスアカウントの親チームに属している場合、 Runs をユーザーに帰属させることができます。
サービスアカウントは、親チームとは異なるチームのプライベート Project に Runs を記録できません。サービスアカウントは、 Project が Open Project の可視性に設定されている場合にのみ、 Runs を Project に記録できます。
チームトライアル
W&B のプランの詳細については、価格ページ を参照してください。ダッシュボード UI またはエクスポート API を使用して、いつでもすべてのデータをダウンロードできます。
プライバシー設定
チーム設定ページで、すべてのチーム Project のプライバシー設定を確認できます。
app.wandb.ai/teams/your-team-name
高度な設定
セキュアストレージコネクタ
チームレベルのセキュアストレージコネクタを使用すると、チームは W&B で独自のクラウドストレージバケットを使用できます。これにより、機密性の高いデータや厳格なコンプライアンス要件を持つチームに対して、より優れたデータアクセス制御とデータ分離が提供されます。詳細については、セキュアストレージコネクタ を参照してください。
2.4.4.6 - Manage storage
W&B の データストレージを管理する方法。
ストレージ制限に近づいている、または超過している場合、データを管理するための複数の方法があります。最適な方法は、アカウントの種類と現在のプロジェクトの設定によって異なります。
ストレージ消費量の管理
W&B は、ストレージ消費量を最適化するためのさまざまなメソッドを提供しています。
データを削除する
ストレージ制限内に収まるように、データを削除することもできます。これを行うには、いくつかの方法があります。
アプリ UI を使用してインタラクティブにデータを削除します。
Artifacts に TTL ポリシーを設定 して、自動的に削除されるようにします。
2.4.4.7 - System metrics
W&B によって自動的に ログ される メトリクス。
このページでは、W&B SDK によって追跡されるシステム メトリクスの詳細な情報を提供します。
wandb は、システム メトリクスを15秒ごとに自動的にログに記録します。
CPU
プロセスの CPU 使用率 (%) (CPU)
利用可能な CPU 数で正規化された、プロセスによる CPU 使用率の割合。
W&B は、このメトリクスに cpu タグを割り当てます。
プロセスの CPU スレッド数
プロセスで使用されるスレッドの数。
W&B は、このメトリクスに proc.cpu.threads タグを割り当てます。
Disk
デフォルトでは、使用状況メトリクスは / パスに対して収集されます。監視するパスを構成するには、次の設定を使用します。
run = wandb. init(
settings= wandb. Settings(
x_stats_disk_paths= ("/System/Volumes/Data" , "/home" , "/mnt/data" ),
),
)
ディスク使用率 (%)
指定されたパスの合計システムディスク使用量をパーセンテージで表します。
W&B は、このメトリクスに disk.{path}.usagePercent タグを割り当てます。
ディスク使用量
指定されたパスの合計システムディスク使用量をギガバイト (GB) で表します。
アクセス可能なパスがサンプリングされ、各パスのディスク使用量 (GB 単位) がサンプルに追加されます。
W&B は、このメトリクスに disk.{path}.usageGB タグを割り当てます。
Disk In
合計システムディスクの読み取り量をメガバイト (MB) で示します。
最初のサンプルが取得されると、最初のディスク読み取りバイト数が記録されます。後続のサンプルでは、現在の読み取りバイト数と初期値の差が計算されます。
W&B は、このメトリクスに disk.in タグを割り当てます。
Disk Out
合計システムディスクの書き込み量をメガバイト (MB) で表します。
Disk In と同様に、最初のサンプルが取得されると、最初のディスク書き込みバイト数が記録されます。後続のサンプルでは、現在の書き込みバイト数と初期値の差が計算されます。
W&B は、このメトリクスに disk.out タグを割り当てます。
Memory
プロセスのメモリ常駐セットサイズ (RSS) をメガバイト (MB) で表します。RSS は、メインメモリ (RAM) に保持されているプロセスによって占有されているメモリの部分です。
W&B は、このメトリクスに proc.memory.rssMB タグを割り当てます。
プロセスのメモリ使用率 (%)
利用可能な合計メモリに対するプロセスのメモリ使用量をパーセンテージで示します。
W&B は、このメトリクスに proc.memory.percent タグを割り当てます。
メモリ使用率 (%)
利用可能な合計メモリに対する合計システムメモリ使用量をパーセンテージで表します。
W&B は、このメトリクスに memory_percent タグを割り当てます。
利用可能なメモリ
利用可能な合計システムメモリをメガバイト (MB) で示します。
W&B は、このメトリクスに proc.memory.availableMB タグを割り当てます。
Network
ネットワーク送信
ネットワーク経由で送信された合計バイト数を表します。
最初のバイト送信は、メトリクスが最初に初期化されたときに記録されます。後続のサンプルでは、現在のバイト送信数と初期値の差が計算されます。
W&B は、このメトリクスに network.sent タグを割り当てます。
ネットワーク受信
ネットワーク経由で受信した合計バイト数を示します。
ネットワーク送信 と同様に、最初のバイト受信は、メトリクスが最初に初期化されたときに記録されます。後続のサンプルでは、現在のバイト受信数と初期値の差が計算されます。
W&B は、このメトリクスに network.recv タグを割り当てます。
NVIDIA GPU
以下に説明するメトリクスに加えて、プロセスまたはその子孫が特定の GPU を使用する場合、W&B は対応するメトリクスを gpu.process.{gpu_index}.{metric_name} としてキャプチャします。
GPU メモリ使用率
各 GPU の GPU メモリ使用率をパーセントで表します。
W&B は、このメトリクスに gpu.{gpu_index}.memory タグを割り当てます。
GPU 割り当て済みメモリ
各 GPU の利用可能な合計メモリに対する GPU 割り当て済みメモリをパーセンテージで示します。
W&B は、このメトリクスに gpu.{gpu_index}.memoryAllocated タグを割り当てます。
GPU 割り当て済みメモリ (バイト単位)
各 GPU の GPU 割り当て済みメモリをバイト単位で指定します。
W&B は、このメトリクスに gpu.{gpu_index}.memoryAllocatedBytes タグを割り当てます。
GPU 使用率
各 GPU の GPU 使用率をパーセントで反映します。
W&B は、このメトリクスに gpu.{gpu_index}.gpu タグを割り当てます。
GPU 温度
各 GPU の GPU 温度を摂氏で示します。
W&B は、このメトリクスに gpu.{gpu_index}.temp タグを割り当てます。
GPU 消費電力 (ワット単位)
各 GPU の GPU 消費電力をワット単位で示します。
W&B は、このメトリクスに gpu.{gpu_index}.powerWatts タグを割り当てます。
GPU 消費電力 (%)
各 GPU の電力容量に対する GPU 消費電力をパーセンテージで反映します。
W&B は、このメトリクスに gpu.{gpu_index}.powerPercent タグを割り当てます。
GPU SM クロック速度
GPU 上のストリーミングマルチプロセッサ (SM) のクロック速度を MHz で表します。このメトリクスは、計算タスクを担当する GPU コア内の処理速度を示します。
W&B は、このメトリクスに gpu.{gpu_index}.smClock タグを割り当てます。
GPU メモリクロック速度
GPU メモリのクロック速度を MHz で表します。これは、GPU メモリとプロセッシングコア間のデータ転送速度に影響します。
W&B は、このメトリクスに gpu.{gpu_index}.memoryClock タグを割り当てます。
GPU グラフィックスクロック速度
GPU 上のグラフィックスレンダリング操作のベースクロック速度を MHz で表します。このメトリクスは、可視化またはレンダリングタスク中のパフォーマンスを反映することがよくあります。
W&B は、このメトリクスに gpu.{gpu_index}.graphicsClock タグを割り当てます。
GPU 修正済みメモリ エラー
W&B がエラーチェックプロトコルによって自動的に修正する GPU 上のメモリ エラーの数を追跡します。これは、回復可能なハードウェアの問題を示します。
W&B は、このメトリクスに gpu.{gpu_index}.correctedMemoryErrors タグを割り当てます。
GPU 未修正メモリ エラー
W&B が修正しなかった GPU 上のメモリ エラーの数を追跡します。これは、処理の信頼性に影響を与える可能性のある回復不能なエラーを示します。
W&B は、このメトリクスに gpu.{gpu_index}.unCorrectedMemoryErrors タグを割り当てます。
GPU エンコーダー使用率
GPU のビデオエンコーダーの使用率をパーセンテージで表します。これは、エンコードタスク (ビデオレンダリングなど) の実行時にエンコーダーの負荷を示します。
W&B は、このメトリクスに gpu.{gpu_index}.encoderUtilization タグを割り当てます。
AMD GPU
W&B は、AMD が提供する rocm-smi ツール (rocm-smi -a --json) の出力からメトリクスを抽出します。
ROCm 6.x (最新) および 5.x 形式がサポートされています。ROCm 形式の詳細については、AMD ROCm ドキュメント を参照してください。新しい形式には、より詳細な情報が含まれています。
AMD GPU 使用率
各 AMD GPU デバイスの GPU 使用率をパーセントで表します。
W&B は、このメトリクスに gpu.{gpu_index}.gpu タグを割り当てます。
AMD GPU 割り当て済みメモリ
各 AMD GPU デバイスの利用可能な合計メモリに対する GPU 割り当て済みメモリをパーセンテージで示します。
W&B は、このメトリクスに gpu.{gpu_index}.memoryAllocated タグを割り当てます。
AMD GPU 温度
各 AMD GPU デバイスの GPU 温度を摂氏で示します。
W&B は、このメトリクスに gpu.{gpu_index}.temp タグを割り当てます。
AMD GPU 消費電力 (ワット単位)
各 AMD GPU デバイスの GPU 消費電力をワット単位で示します。
W&B は、このメトリクスに gpu.{gpu_index}.powerWatts タグを割り当てます。
AMD GPU 消費電力 (%)
各 AMD GPU デバイスの電力容量に対する GPU 消費電力をパーセンテージで反映します。
W&B は、このメトリクスに gpu.{gpu_index}.powerPercent タグを割り当てます。
Apple ARM Mac GPU
Apple GPU 使用率
特に ARM Mac 上の Apple GPU デバイスの GPU 使用率をパーセントで示します。
W&B は、このメトリクスに gpu.0.gpu タグを割り当てます。
Apple GPU 割り当て済みメモリ
ARM Mac 上の Apple GPU デバイスの利用可能な合計メモリに対する GPU 割り当て済みメモリをパーセンテージで示します。
W&B は、このメトリクスに gpu.0.memoryAllocated タグを割り当てます。
Apple GPU 温度
ARM Mac 上の Apple GPU デバイスの GPU 温度を摂氏で示します。
W&B は、このメトリクスに gpu.0.temp タグを割り当てます。
Apple GPU 消費電力 (ワット単位)
ARM Mac 上の Apple GPU デバイスの GPU 消費電力をワット単位で示します。
W&B は、このメトリクスに gpu.0.powerWatts タグを割り当てます。
Apple GPU 消費電力 (%)
ARM Mac 上の Apple GPU デバイスの電力容量に対する GPU 消費電力をパーセンテージで示します。
W&B は、このメトリクスに gpu.0.powerPercent タグを割り当てます。
Graphcore IPU
Graphcore IPU (Intelligence Processing Units) は、機械学習タスク専用に設計された独自のハードウェアアクセラレータです。
IPU デバイスメトリクス
これらのメトリクスは、特定の IPU デバイスのさまざまな統計を表します。各メトリクスには、デバイス ID (device_id) と、それを識別するためのメトリックキー (metric_key) があります。W&B は、このメトリクスに ipu.{device_id}.{metric_key} タグを割り当てます。
メトリクスは、Graphcore の gcipuinfo バイナリと対話する独自の gcipuinfo ライブラリを使用して抽出されます。sample メソッドは、プロセス ID (pid) に関連付けられた各 IPU デバイスのこれらのメトリクスを取得します。時間の経過とともに変化するメトリクス、またはデバイスのメトリクスが初めて取得された場合にのみ、冗長なデータのログ記録を回避するためにログに記録されます。
各メトリクスについて、メソッド parse_metric が使用されて、メトリクスの値をその生の文字列表現から抽出します。次に、メトリクスは aggregate メソッドを使用して複数のサンプルに集約されます。
以下に、利用可能なメトリクスとその単位を示します。
ボードの平均温度 (average board temp (C)): IPU ボードの温度 (摂氏)。ダイの平均温度 (average die temp (C)): IPU ダイの温度 (摂氏)。クロック速度 (clock (MHz)): IPU のクロック速度 (MHz)。IPU 電力 (ipu power (W)): IPU の消費電力 (ワット)。IPU 使用率 (ipu utilisation (%)): IPU 使用率 (パーセント)。IPU セッション使用率 (ipu utilisation (session) (%)): 現在のセッションに固有の IPU 使用率 (パーセント)。データリンク速度 (speed (GT/s)): データ伝送速度 (ギガ転送/秒)。
Google Cloud TPU
Tensor Processing Units (TPU) は、機械学習ワークロードを高速化するために使用される Google 独自のカスタム開発 ASIC (特定用途向け集積回路) です。
TPU メモリ使用量
TPU コアあたりの現在の高帯域幅メモリ使用量 (バイト単位)。
W&B は、このメトリクスに tpu.{tpu_index}.memoryUsageBytes タグを割り当てます。
TPU メモリ使用量 (%)
TPU コアあたりの現在の高帯域幅メモリ使用量 (パーセント)。
W&B は、このメトリクスに tpu.{tpu_index}.memoryUsageBytes タグを割り当てます。
TPU デューティサイクル
TPU デバイスあたりの TensorCore デューティサイクル (%)。アクセラレータ TensorCore がアクティブに処理していたサンプル期間中の時間の割合を追跡します。値が大きいほど、TensorCore の使用率が高いことを意味します。
W&B は、このメトリクスに tpu.{tpu_index}.dutyCycle タグを割り当てます。
AWS Trainium
AWS Trainium は、AWS が提供する特殊なハードウェアプラットフォームで、機械学習ワークロードの高速化に重点を置いています。AWS の neuron-monitor ツールは、AWS Trainium メトリクスをキャプチャするために使用されます。
Trainium Neuron Core 使用率
NeuronCore ごとの使用率 (%) (コアごとに報告)。
W&B は、このメトリクスに trn.{core_index}.neuroncore_utilization タグを割り当てます。
Trainium ホストメモリ使用量、合計
ホスト上の合計メモリ消費量 (バイト単位)。
W&B は、このメトリクスに trn.host_total_memory_usage タグを割り当てます。
Trainium Neuron デバイスの合計メモリ使用量
Neuron デバイス上の合計メモリ使用量 (バイト単位)。
W&B は、このメトリクスに trn.neuron_device_total_memory_usage) タグを割り当てます。
Trainium ホストメモリ使用量の内訳:
以下は、ホスト上のメモリ使用量の内訳です。
アプリケーションメモリ (trn.host_total_memory_usage.application_memory): アプリケーションで使用されるメモリ。定数 (trn.host_total_memory_usage.constants): 定数に使用されるメモリ。DMA バッファ (trn.host_total_memory_usage.dma_buffers): ダイレクトメモリアクセスバッファに使用されるメモリ。テンソル (trn.host_total_memory_usage.tensors): テンソルに使用されるメモリ。
Trainium Neuron Core メモリ使用量の内訳
NeuronCore ごとの詳細なメモリ使用量情報:
定数 (trn.{core_index}.neuroncore_memory_usage.constants)モデルコード (trn.{core_index}.neuroncore_memory_usage.model_code)モデル共有スクラッチパッド (trn.{core_index}.neuroncore_memory_usage.model_shared_scratchpad)ランタイムメモリ (trn.{core_index}.neuroncore_memory_usage.runtime_memory)テンソル (trn.{core_index}.neuroncore_memory_usage.tensors)
OpenMetrics
OpenMetrics / Prometheus 互換のデータを公開する外部エンドポイントからメトリクスをキャプチャしてログに記録します。消費されるエンドポイントに適用されるカスタム正規表現ベースのメトリクスフィルタをサポートします。
このレポート を参照して、NVIDIA DCGM-Exporter を使用して GPU クラスターのパフォーマンスを監視する特定のケースで、この機能を使用する方法の詳細な例を確認してください。
2.4.4.8 - Anonymous mode
W&B アカウントなしでデータを ログ および可視化する
誰でも簡単に実行できるようにしたいコードを公開していますか? 匿名モードを使用すると、W&B のアカウントを最初に作成しなくても、誰でもあなたのコードを実行し、W&B のダッシュボードを確認し、結果を可視化できます。
匿名モードで結果を記録できるようにするには、以下のようにします。
import wandb
wandb. init(anonymous= "allow" )
たとえば、次のコードスニペットは、W&B で Artifacts を作成およびログに記録する方法を示しています。
import wandb
run = wandb. init(anonymous= "allow" )
artifact = wandb. Artifact(name= "art1" , type= "foo" )
artifact. add_file(local_path= "path/to/file" )
run. log_artifact(artifact)
run. finish()
ノートブックの例 を試して、匿名モードの動作を確認してください。
3 - W&B Weave
Weave は、LLM アプリケーション を追跡および評価するための軽量な ツールキット です。 W&B Weave を使用して、LLM の実行フローを視覚化および検査し、LLM の入出力を分析し、中間 結果を表示し、プロンプトと LLM チェーンの 設定を安全に保存および管理します。
W&B Weave を使用すると、次のことができます。
言語 model の入力、出力、および トレース を ログ に記録してデバッグする
言語 model の ユースケース に対して厳密な、同等の 評価 を構築する
実験 から 評価 、 プロダクション まで、LLM ワークフロー 全体で生成されたすべての情報を整理する
開始方法
ユースケース に応じて、次のリソースを参照して W&B Weave を開始してください。
4 - W&B Core
W&B Core は、W&B Models と W&B Weave をサポートする基盤となる フレームワーク であり、それ自体が W&B Platform によってサポートされています。
W&B Core は、ML ライフサイクル全体にわたる機能を提供します。W&B Core を使用すると、次のことができます。
4.1 - Artifacts
W&B Artifacts の概要、その仕組み、およびそれらの使用を開始する方法について説明します。
W&B Artifacts を使用して、W&B Runs の入力および出力としてデータを追跡およびバージョン管理します。たとえば、モデルトレーニング run は、データセットを入力として受け取り、トレーニング済みのモデルを出力として生成する場合があります。ハイパー パラメーター、メタデータ、およびメトリクスを run に記録できます。また、artifact を使用して、モデルのトレーニングに使用されるデータセットを入力として、結果のモデル チェックポイントを別の artifact として、ログ記録、追跡、およびバージョン管理できます。
ユースケース
Artifact は、runs の入力および出力として、ML ワークフロー全体で使用できます。データセット、モデル、またはその他の artifact を、処理の入力として使用できます。
ユースケース
入力
出力
モデルトレーニング
データセット (トレーニングおよび検証データ)
トレーニング済みモデル
データセットの前処理
データセット (未加工データ)
データセット (前処理済みデータ)
モデルの評価
モデル + データセット (テストデータ)
W&B Table
モデルの最適化
モデル
最適化されたモデル
以降のコード スニペットは、順番に実行することを目的としています。
artifact を作成する
4 行のコードで artifact を作成します。
W&B run を作成します。wandb.Artifactモデル ファイルやデータセットなど、1 つ以上のファイルを artifact オブジェクトに追加します。
artifact を W&B に記録します。
たとえば、次のコード スニペットは、dataset.h5 というファイルを example_artifact という artifact に記録する方法を示しています。
import wandb
run = wandb. init(project= "artifacts-example" , job_type= "add-dataset" )
artifact = wandb. Artifact(name= "example_artifact" , type= "dataset" )
artifact. add_file(local_path= "./dataset.h5" , name= "training_dataset" )
artifact. save()
# artifact バージョン "my_data" を dataset.h5 のデータを持つデータセットとして記録します
Amazon S3 バケットなどの外部オブジェクト ストレージに保存されているファイルまたはディレクトリーへの参照を追加する方法については、
外部ファイルの追跡 ページを参照してください。
artifact をダウンロードする
use_artifact
上記のコード スニペットに従って、次のコード ブロックは training_dataset artifact の使用方法を示しています。
artifact = run. use_artifact(
"training_dataset:latest"
) # "my_data" artifact を使用して run オブジェクトを返します
これにより、artifact オブジェクトが返されます。
次に、返されたオブジェクトを使用して、artifact のすべてのコンテンツをダウンロードします。
datadir = (
artifact. download()
) # `my_data` artifact 全体をデフォルトのディレクトリーにダウンロードします。
次のステップ
artifact をバージョン管理 および更新 する方法を学びます。
オートメーション を使用して、artifact の変更に応じてダウンストリーム ワークフローをトリガーしたり、Slack channel に通知したりする方法を学びます。トレーニング済みモデルを格納するスペースであるレジストリ について学びます。
Python SDK および CLI リファレンス ガイドをご覧ください。
4.1.1 - Create an artifact
W&B の Artifact を作成、構築します。1 つまたは複数のファイル、または URI 参照を Artifact に追加する方法を学びます。
W&B Python SDK を使用して、W&B Runs から Artifacts を構築します。ファイル、ディレクトリー、URI、および並列 run からのファイルを Artifacts に追加 できます。ファイルを Artifacts に追加したら、Artifacts を W&B サーバーまたは独自のプライベートサーバー に保存します。
Amazon S3 に保存されているファイルなど、外部ファイルを追跡する方法については、外部ファイルを追跡 のページを参照してください。
Artifacts を構築する方法
W&B Artifact は、次の3つのステップで構築します。
1. wandb.Artifact() で Artifacts Python オブジェクトを作成する
wandb.Artifact()
Name : Artifacts の名前を指定します。名前は、一意で記述的で、覚えやすいものにする必要があります。Artifacts 名を使用して、W&B App UI で Artifacts を識別したり、その Artifacts を使用する場合に使用したりします。Type : タイプを指定します。タイプは、シンプルで記述的で、機械学習 パイプライン の単一のステップに対応している必要があります。一般的な Artifacts タイプには、'dataset' または 'model' があります。
指定する「name」と「type」は、有向非巡回グラフの作成に使用されます。つまり、W&B App で Artifacts の リネージ を表示できます。
詳細については、Artifacts グラフを探索およびトラバース を参照してください。
タイプ パラメータ に別のタイプを指定した場合でも、Artifacts は同じ名前にすることはできません。つまり、タイプ dataset の cats という名前の Artifacts と、タイプ model の同じ名前の別の Artifacts を作成することはできません。
Artifacts オブジェクトを初期化するときに、オプションで説明と メタデータ を指定できます。利用可能な属性と パラメータ の詳細については、Python SDK リファレンス ガイドの wandb.Artifact
次の例は、データセット Artifacts を作成する方法を示しています。
import wandb
artifact = wandb. Artifact(name= "<replace>" , type= "<replace>" )
上記の コードスニペット の文字列 引数 を、自分の名前とタイプに置き換えます。
2. 1つ以上のファイルを Artifacts に追加する
Artifacts メソッド を使用して、ファイル、ディレクトリー、外部 URI 参照 (Amazon S3 など) などを追加します。たとえば、単一のテキスト ファイルを追加するには、add_file
artifact. add_file(local_path= "hello_world.txt" , name= "optional-name" )
add_dirArtifacts を更新 を参照してください。
3. Artifacts を W&B サーバー に保存する
最後に、Artifacts を W&B サーバー に保存します。Artifacts は run に関連付けられています。したがって、run オブジェクト の log_artifact()
# W&B Run を作成します。'job-type' を置き換えます。
run = wandb. init(project= "artifacts-example" , job_type= "job-type" )
run. log_artifact(artifact)
オプションで、W&B run の外部で Artifacts を構築できます。詳細については、外部ファイルを追跡 を参照してください。
log_artifact の呼び出しは、パフォーマンスの高いアップロードのために非同期的に実行されます。これにより、ループで Artifacts を ログ 記録するときに、予期しない 振る舞い が発生する可能性があります。次に例を示します。
for i in range(10 ):
a = wandb. Artifact(
"race" ,
type= "dataset" ,
metadata= {
"index" : i,
},
)
# ... Artifacts a にファイルを追加 ...
run. log_artifact(a)
Artifacts バージョン v0 は、Artifacts が任意の順序で ログ 記録される可能性があるため、 メタデータ に 0 のインデックスを持つことは保証されません。
Artifacts にファイルを追加する
次のセクションでは、さまざまなファイル タイプ と並列 run から Artifacts を構築する方法について説明します。
次の例では、複数のファイルとディレクトリー構造を持つ プロジェクト ディレクトリー があると仮定します。
project-directory
|-- images
| |-- cat.png
| +-- dog.png
|-- checkpoints
| +-- model.h5
+-- model.h5
単一のファイルを追加する
上記の コードスニペット は、単一のローカル ファイルを Artifacts に追加する方法を示しています。
# 単一のファイルを追加
artifact. add_file(local_path= "path/file.format" )
たとえば、作業ローカル ディレクトリー に 'file.txt' という名前のファイルがあるとします。
artifact. add_file("path/file.txt" ) # `file.txt' として追加されました
Artifacts には、次のコンテンツが含まれるようになりました。
file.txt
オプションで、name パラメータ に Artifacts 内の目的の パス を渡します。
artifact. add_file(local_path= "path/file.format" , name= "new/path/file.format" )
Artifacts は次のように保存されます。
new/path/file.txt
API 呼び出し
結果の Artifacts
artifact.add_file('model.h5')model.h5
artifact.add_file('checkpoints/model.h5')model.h5
artifact.add_file('model.h5', name='models/mymodel.h5')models/mymodel.h5
複数のファイルを追加する
上記の コードスニペット は、ローカル ディレクトリー 全体を Artifacts に追加する方法を示しています。
# ディレクトリー を再帰的に追加
artifact. add_dir(local_path= "path/file.format" , name= "optional-prefix" )
上記の API 呼び出しは、上記の Artifacts コンテンツを生成します。
API 呼び出し
結果の Artifacts
artifact.add_dir('images')cat.png
dog.png
artifact.add_dir('images', name='images')images/cat.png
images/dog.png
artifact.new_file('hello.txt')hello.txt
URI 参照を追加する
Artifacts は、W&B ライブラリ が処理する方法を知っている スキーム を URI が持つ場合、再現性のために チェックサム やその他の情報を追跡します。
add_reference'uri' 文字列を自分の URI に置き換えます。オプションで、name パラメータ に Artifacts 内の目的の パス を渡します。
# URI 参照を追加
artifact. add_reference(uri= "uri" , name= "optional-name" )
Artifacts は現在、次の URI スキーム をサポートしています。
http(s)://: HTTP 経由でアクセス可能なファイルへの パス 。Artifacts は、HTTP サーバー が ETag および Content-Length レスポンス ヘッダー をサポートしている場合、etag および サイズ メタデータ の形式で チェックサム を追跡します。s3://: S3 内の オブジェクト または オブジェクト プレフィックス への パス 。Artifacts は、参照されている オブジェクト の チェックサム および バージョン 管理情報 ( バケット で オブジェクト の バージョン 管理が有効になっている場合) を追跡します。オブジェクト プレフィックス は、プレフィックス の下の オブジェクト を含むように拡張され、最大 10,000 個の オブジェクト が含まれます。gs://: GCS 内の オブジェクト または オブジェクト プレフィックス への パス 。Artifacts は、参照されている オブジェクト の チェックサム および バージョン 管理情報 ( バケット で オブジェクト の バージョン 管理が有効になっている場合) を追跡します。オブジェクト プレフィックス は、プレフィックス の下の オブジェクト を含むように拡張され、最大 10,000 個の オブジェクト が含まれます。
上記の API 呼び出しは、上記の Artifacts を生成します。
API 呼び出し
結果の Artifacts コンテンツ
artifact.add_reference('s3://my-bucket/model.h5')model.h5
artifact.add_reference('s3://my-bucket/checkpoints/model.h5')model.h5
artifact.add_reference('s3://my-bucket/model.h5', name='models/mymodel.h5')models/mymodel.h5
artifact.add_reference('s3://my-bucket/images')cat.png
dog.png
artifact.add_reference('s3://my-bucket/images', name='images')images/cat.png
images/dog.png
並列 run から Artifacts にファイルを追加する
大規模な データセット または分散 トレーニング の場合、複数の並列 run が単一の Artifacts に貢献する必要がある場合があります。
import wandb
import time
# デモ の目的で、ray を使用して並列で run を 起動 します。
# ただし、並列 run は、どのように編成してもかまいません。
import ray
ray. init()
artifact_type = "dataset"
artifact_name = "parallel-artifact"
table_name = "distributed_table"
parts_path = "parts"
num_parallel = 5
# 並列 ライター の各 バッチ には、独自の
# 一意の グループ 名が必要です。
group_name = "writer-group- {} " . format(round(time. time()))
@ray.remote
def train (i):
"""
ライター ジョブ 。各 ライター は、1つの画像を Artifacts に追加します。
"""
with wandb. init(group= group_name) as run:
artifact = wandb. Artifact(name= artifact_name, type= artifact_type)
# データを wandb テーブル に追加します。この場合、サンプル データ を使用します
table = wandb. Table(columns= ["a" , "b" , "c" ], data= [[i, i * 2 , 2 ** i]])
# テーブル を Artifacts 内の フォルダ に追加します
artifact. add(table, " {} /table_ {} " . format(parts_path, i))
# Artifacts を アップサート すると、Artifacts のデータ が作成または追加されます
run. upsert_artifact(artifact)
# 並列で run を 起動 します
result_ids = [train. remote(i) for i in range(num_parallel)]
# すべての ライター に 参加 して、ファイル が
# Artifacts を終了する前に追加されていることを確認します。
ray. get(result_ids)
# すべての ライター が終了したら、Artifacts を終了して、
# 準備完了にします。
with wandb. init(group= group_name) as run:
artifact = wandb. Artifact(artifact_name, type= artifact_type)
# テーブル の フォルダ を指す "PartitionTable" を作成します
# Artifacts に追加します。
artifact. add(wandb. data_types. PartitionedTable(parts_path), table_name)
# Finish artifact は Artifacts を確定し、この バージョン への将来の "upsert" を許可しません
run. finish_artifact(artifact)
4.1.2 - Download and use artifacts
複数のプロジェクトから Artifacts をダウンロードして使用します。
W&B サーバーにすでに保存されている Artifacts をダウンロードして使用するか、必要に応じて重複排除のために Artifacts オブジェクトを構築して渡します。
表示専用のシートを持つチームメンバーは、Artifacts をダウンロードできません。
W&B に保存されている Artifacts のダウンロードと使用
W&B Run の内部または外部で、W&B に保存されている Artifacts をダウンロードして使用します。Public API (wandb.ApiPublic API Reference guide を参照してください。
まず、W&B Python SDK をインポートします。次に、W&B Run を作成します。
import wandb
run = wandb. init(project= "<example>" , job_type= "<job-type>" )
use_artifact'latest' を持つ 'bike-dataset' という Artifacts を指定します。
artifact = run. use_artifact("bike-dataset:latest" )
返されたオブジェクトを使用して、Artifacts のすべてのコンテンツをダウンロードします。
datadir = artifact. download()
オプションで、ルートパラメータにパスを渡して、Artifacts のコンテンツを特定のディレクトリーにダウンロードできます。詳細については、Python SDK Reference Guide を参照してください。
get_path
path = artifact. get_path(name)
これは、パス name にあるファイルのみをフェッチします。これは、次のメソッドを持つ Entry オブジェクトを返します。
Entry.download: パス name にある Artifacts からファイルをダウンロードしますEntry.ref: add_reference がエントリをリファレンスとして保存した場合、URI を返します
W&B が処理する方法を知っているスキームを持つリファレンスは、Artifacts ファイルとまったく同じようにダウンロードされます。詳細については、Track external files を参照してください。
まず、W&B SDK をインポートします。次に、Public API クラスから Artifacts を作成します。その Artifacts に関連付けられたエンティティ、プロジェクト、Artifacts、エイリアスを指定します。
import wandb
api = wandb. Api()
artifact = api. artifact("entity/project/artifact:alias" )
返されたオブジェクトを使用して、Artifacts のコンテンツをダウンロードします。
オプションで、root パラメータにパスを渡して、Artifacts のコンテンツを特定のディレクトリーにダウンロードできます。詳細については、API Reference Guide を参照してください。
wandb artifact get コマンドを使用して、W&B サーバーから Artifacts をダウンロードします。
$ wandb artifact get project/artifact:alias --root mnist/
Artifacts の部分的なダウンロード
オプションで、プレフィックスに基づいて Artifacts の一部をダウンロードできます。path_prefix パラメータを使用すると、単一のファイルまたはサブフォルダーのコンテンツをダウンロードできます。
artifact = run. use_artifact("bike-dataset:latest" )
artifact. download(path_prefix= "bike.png" ) # bike.png のみをダウンロードします
または、特定のディレクトリーからファイルをダウンロードすることもできます。
artifact. download(path_prefix= "images/bikes/" ) # images/bikes ディレクトリー内のファイルをダウンロードします
別のプロジェクトの Artifacts の使用
Artifacts の名前をプロジェクト名とともに指定して、Artifacts を参照します。エンティティ名とともに Artifacts の名前を指定することで、エンティティ間で Artifacts を参照することもできます。
次のコード例は、別のプロジェクトから Artifacts をクエリして、現在の W&B run への入力として使用する方法を示しています。
import wandb
run = wandb. init(project= "<example>" , job_type= "<job-type>" )
# 別のプロジェクトから Artifacts の W&B をクエリして、それをマークします
# この run への入力として。
artifact = run. use_artifact("my-project/artifact:alias" )
# 別のエンティティからの Artifacts を使用して、入力としてマークします
# この run に。
artifact = run. use_artifact("my-entity/my-project/artifact:alias" )
Artifacts の同時構築と使用
Artifacts を同時に構築して使用します。Artifacts オブジェクトを作成し、それを use_artifact に渡します。これにより、Artifacts がまだ存在しない場合は W&B に作成されます。use_artifact
import wandb
artifact = wandb. Artifact("reference model" )
artifact. add_file("model.h5" )
run. use_artifact(artifact)
Artifacts の構築の詳細については、Construct an artifact を参照してください。
4.1.3 - Update an artifact
W&B Run の内外で既存の Artifact を更新します。
Artifact の description、metadata、および alias を更新するために希望する value を渡します。W&B サーバー上の Artifact を更新するには、save() メソッドを呼び出します。W&B の Run 中または Run の外部で Artifact を更新できます。
Run の外部で Artifact を更新するには、W&B Public API(wandb.Apiwandb.Artifact
モデルレジストリ内のモデルにリンクされている Artifact の エイリアス を更新することはできません。
次のコード例は、wandb.Artifact
import wandb
run = wandb. init(project= "<example>" )
artifact = run. use_artifact("<artifact-name>:<alias>" )
artifact. description = "<description>"
artifact. save()
次のコード例は、wandb.Api API を使用して、Artifact の description を更新する方法を示しています。
import wandb
api = wandb. Api()
artifact = api. artifact("entity/project/artifact:alias" )
# description を更新
artifact. description = "My new description"
# 選択的に metadata の キー を更新
artifact. metadata["oldKey" ] = "new value"
# metadata を完全に置き換え
artifact. metadata = {"newKey" : "new value" }
# エイリアス を追加
artifact. aliases. append("best" )
# エイリアス を削除
artifact. aliases. remove("latest" )
# エイリアス を完全に置き換え
artifact. aliases = ["replaced" ]
# すべての Artifact の変更を永続化
artifact. save()
詳細については、Weights and Biases Artifact API を参照してください。
単一の Artifact と同じ方法で、Artifact のコレクションを更新することもできます。
import wandb
run = wandb. init(project= "<example>" )
api = wandb. Api()
artifact = api. artifact_collection(type= "<type-name>" , collection= "<collection-name>" )
artifact. name = "<new-collection-name>"
artifact. description = "<This is where you'd describe the purpose of your collection.>"
artifact. save()
詳細については、Artifacts Collection のリファレンスを参照してください。
4.1.4 - Create an artifact alias
W&B Artifacts のカスタムエイリアスを作成します。
エイリアス を使用して、特定の バージョン へのポインタとして使用します。デフォルトでは、Run.log_artifact はログに記録された バージョン に latest エイリアス を追加します。
アーティファクト の バージョン v0 は、初めて アーティファクト を ログ に記録する際に作成され、 アーティファクト にアタッチされます。W&B は、同じ アーティファクト に再度 ログ を記録する際に、コンテンツの チェックサム を計算します。アーティファクト が変更された場合、W&B は新しい バージョン v1 を保存します。
たとえば、 トレーニング スクリプト で データセット の最新 バージョン を取得したい場合は、その アーティファクト を使用する際に latest を指定します。次の コード 例は、latest という エイリアス を持つ bike-dataset という名前の最新の データセット アーティファクト をダウンロードする方法を示しています。
import wandb
run = wandb. init(project= "<example-project>" )
artifact = run. use_artifact("bike-dataset:latest" )
artifact. download()
カスタム エイリアス を アーティファクト バージョン に適用することもできます。たとえば、 モデル の チェックポイント が メトリック AP-50 で最高であることを示したい場合は、 モデル アーティファクト を ログ に記録する際に、'best-ap50' という 文字列を エイリアス として追加できます。
artifact = wandb. Artifact("run-3nq3ctyy-bike-model" , type= "model" )
artifact. add_file("model.h5" )
run. log_artifact(artifact, aliases= ["latest" , "best-ap50" ])
4.1.5 - Create an artifact version
単一の run 、または分散された プロセス から新しい アーティファクト の バージョン を作成します。
単一の run で、または分散されたrunと共同で、新しいアーティファクトのバージョンを作成します。オプションで、インクリメンタルアーティファクト として知られる、以前のバージョンから新しいアーティファクトのバージョンを作成できます。
元のアーティファクトのサイズが著しく大きい場合に、アーティファクト内のファイルのサブセットに変更を適用する必要がある場合は、インクリメンタルアーティファクトを作成することをお勧めします。
新しいアーティファクトのバージョンをゼロから作成する
新しいアーティファクトのバージョンを作成する方法は2つあります。単一のrunから作成する方法と、分散されたrunから作成する方法です。それらは次のように定義されます。
単一のrun : 単一のrunは、新しいバージョンのすべてのデータを提供します。これは最も一般的なケースであり、runが必要なデータを完全に再作成する場合に最適です。例:分析のために保存されたモデルまたはモデルの予測をテーブルに出力するなど。分散されたrun : runのセットが集合的に新しいバージョンのすべてのデータを提供します。これは、多くの場合並行してデータを生成する複数のrunを持つ分散ジョブに最適です。例:分散方式でモデルを評価し、予測を出力するなど。
W&B は、プロジェクトに存在しない名前を wandb.Artifact API に渡すと、新しいアーティファクトを作成し、v0 エイリアスを割り当てます。同じアーティファクトに再度ログを記録すると、W&B はコンテンツのチェックサムを計算します。アーティファクトが変更された場合、W&B は新しいバージョン v1 を保存します。
wandb.Artifact API に名前とアーティファクトのタイプを渡し、それがプロジェクト内の既存のアーティファクトと一致する場合、W&B は既存のアーティファクトを取得します。取得されたアーティファクトのバージョンは1より大きくなります。
単一のrun
アーティファクト内のすべてのファイルを生成する単一のrunで、Artifactの新しいバージョンをログに記録します。このケースは、単一のrunがアーティファクト内のすべてのファイルを生成する場合に発生します。
ユースケースに基づいて、以下のタブのいずれかを選択して、runの内側または外側に新しいアーティファクトのバージョンを作成します。
W&B run内でアーティファクトのバージョンを作成します。
wandb.init でrunを作成します。wandb.Artifact で新しいアーティファクトを作成するか、既存のアーティファクトを取得します。.add_file でアーティファクトにファイルを追加します。.log_artifact でアーティファクトをrunにログ記録します。
with wandb. init() as run:
artifact = wandb. Artifact("artifact_name" , "artifact_type" )
# `.add`、`.add_file`、`.add_dir`、および `.add_reference` を使用して、
# ファイルとアセットをアーティファクトに追加します
artifact. add_file("image1.png" )
run. log_artifact(artifact)
W&B runの外側でアーティファクトのバージョンを作成します。
wanb.Artifact で新しいアーティファクトを作成するか、既存のアーティファクトを取得します。.add_file でアーティファクトにファイルを追加します。.save でアーティファクトを保存します。
artifact = wandb. Artifact("artifact_name" , "artifact_type" )
# `.add`、`.add_file`、`.add_dir`、および `.add_reference` を使用して、
# ファイルとアセットをアーティファクトに追加します
artifact. add_file("image1.png" )
artifact. save()
分散されたrun
コミットする前に、runのコレクションがバージョンで共同作業できるようにします。これは、1つのrunが新しいバージョンのすべてのデータを提供する上記の単一runモードとは対照的です。
コレクション内の各runは、同じバージョンで共同作業するために、同じ一意のID(distributed_id と呼ばれます)を認識している必要があります。デフォルトでは、存在する場合、W&B は wandb.init(group=GROUP) によって設定されたrunの group を distributed_id として使用します。
バージョンの状態を永続的にロックする、バージョンを「コミット」する最終的なrunが必要です。
共同アーティファクトに追加するには upsert_artifact を使用し、コミットを完了するには finish_artifact を使用します。
次の例を検討してください。異なるrun(以下では Run 1 、Run 2 、および Run 3 としてラベル付け)は、upsert_artifact で同じアーティファクトに異なる画像ファイルを追加します。
Run 1:
with wandb. init() as run:
artifact = wandb. Artifact("artifact_name" , "artifact_type" )
# `.add`、`.add_file`、`.add_dir`、および `.add_reference` を使用して、
# ファイルとアセットをアーティファクトに追加します
artifact. add_file("image1.png" )
run. upsert_artifact(artifact, distributed_id= "my_dist_artifact" )
Run 2:
with wandb. init() as run:
artifact = wandb. Artifact("artifact_name" , "artifact_type" )
# `.add`、`.add_file`、`.add_dir`、および `.add_reference` を使用して、
# ファイルとアセットをアーティファクトに追加します
artifact. add_file("image2.png" )
run. upsert_artifact(artifact, distributed_id= "my_dist_artifact" )
Run 3
Run 1とRun 2が完了した後に実行する必要があります。finish_artifact を呼び出すRunはアーティファクトにファイルを含めることができますが、必須ではありません。
with wandb. init() as run:
artifact = wandb. Artifact("artifact_name" , "artifact_type" )
# ファイルとアセットをアーティファクトに追加します
# `.add`、`.add_file`、`.add_dir`、および `.add_reference`
artifact. add_file("image3.png" )
run. finish_artifact(artifact, distributed_id= "my_dist_artifact" )
既存のバージョンから新しいアーティファクトのバージョンを作成する
変更されていないファイルを再インデックスする必要なく、以前のアーティファクトのバージョンからファイルのサブセットを追加、変更、または削除します。以前のアーティファクトのバージョンからファイルのサブセットを追加、変更、または削除すると、インクリメンタルアーティファクト として知られる新しいアーティファクトのバージョンが作成されます。
発生する可能性のあるインクリメンタルな変更のタイプごとのシナリオを次に示します。
add: 新しいバッチを収集した後、データセットに新しいファイルのサブセットを定期的に追加します。
remove: 複数の重複ファイルを発見し、アーティファクトから削除したいとします。
update: ファイルのサブセットのアノテーションを修正し、古いファイルを正しいファイルに置き換えたいとします。
インクリメンタルアーティファクトと同じ機能を実行するために、アーティファクトをゼロから作成できます。ただし、アーティファクトをゼロから作成する場合、アーティファクトのすべてのコンテンツをローカルディスクに用意する必要があります。インクリメンタルな変更を行う場合、以前のアーティファクトのバージョンからファイルを変更せずに、単一のファイルを追加、削除、または変更できます。
インクリメンタルアーティファクトは、単一のrun内またはrunのセット(分散モード)で作成できます。
以下の手順に従って、アーティファクトをインクリメンタルに変更します。
インクリメンタルな変更を実行するアーティファクトのバージョンを取得します。
saved_artifact = run. use_artifact("my_artifact:latest" )
client = wandb. Api()
saved_artifact = client. artifact("my_artifact:latest" )
次を使用してドラフトを作成します。
draft_artifact = saved_artifact. new_draft()
次のバージョンで表示したいインクリメンタルな変更を実行します。既存のエントリを追加、削除、または変更できます。
これらの変更を実行する方法の例については、以下のタブのいずれかを選択してください。
add_file メソッドを使用して、既存のアーティファクトのバージョンにファイルを追加します。
draft_artifact. add_file("file_to_add.txt" )
add_dir メソッドを使用してディレクトリーを追加することで、複数のファイルを追加することもできます。
remove メソッドを使用して、既存のアーティファクトのバージョンからファイルを削除します。
draft_artifact. remove("file_to_remove.txt" )
ディレクトリーパスを渡すことで、remove メソッドを使用して複数のファイルを削除することもできます。
ドラフトから古いコンテンツを削除し、新しいコンテンツを再度追加して、コンテンツを変更または置き換えます。
draft_artifact. remove("modified_file.txt" )
draft_artifact. add_file("modified_file.txt" )
最後に、変更をログに記録または保存します。以下のタブは、W&B runの内側と外側で変更を保存する方法を示しています。ユースケースに合ったタブを選択してください。
run. log_artifact(draft_artifact)
まとめると、上記のコード例は次のようになります。
with wandb. init(job_type= "データセットの変更" ) as run:
saved_artifact = run. use_artifact(
"my_artifact:latest"
) # アーティファクトをフェッチしてrunに入力します
draft_artifact = saved_artifact. new_draft() # ドラフトバージョンを作成します
# ドラフトバージョン内のファイルのサブセットを変更します
draft_artifact. add_file("file_to_add.txt" )
draft_artifact. remove("dir_to_remove/" )
run. log_artifact(
artifact
) # 変更をログに記録して新しいバージョンを作成し、runへの出力としてマークします
client = wandb. Api()
saved_artifact = client. artifact("my_artifact:latest" ) # アーティファクトをロードします
draft_artifact = saved_artifact. new_draft() # ドラフトバージョンを作成します
# ドラフトバージョン内のファイルのサブセットを変更します
draft_artifact. remove("deleted_file.txt" )
draft_artifact. add_file("modified_file.txt" )
draft_artifact. save() # ドラフトへの変更をコミットします
4.1.6 - Track external files
W&B の外部に保存されたファイル (Amazon S3 バケット 、GCS バケット 、HTTP ファイル サーバー 、NFS 共有など) を追跡します。
参照 Artifacts を使用して、W&Bシステム外に保存されたファイル(例えば、Amazon S3 バケット、GCS バケット、Azure Blob、HTTP ファイルサーバー、あるいは NFS 共有など)を追跡します。W&B CLI を使用し、W&B Run の外で Artifacts をログ記録します。
run の外で Artifacts をログ記録する
run の外で Artifact をログ記録すると、W&B は run を作成します。各 Artifact は run に属し、その run は プロジェクト に属します。Artifact(バージョン)はコレクションにも属し、タイプを持ちます。
wandb artifact putproject/artifact_name)を指定します。オプションで、タイプ(TYPE)を指定します。以下のコードスニペットの PATH を、アップロードする Artifact のファイルパスに置き換えます。
$ wandb artifact put --name project/artifact_name --type TYPE PATH
指定した プロジェクト が存在しない場合、W&B は新しい プロジェクト を作成します。Artifact のダウンロード方法については、Artifacts のダウンロードと使用 を参照してください。
W&B の外で Artifacts を追跡する
W&B Artifacts を使用して、データセット の バージョン管理 と モデルリネージ を行い、参照 Artifacts を使用して W&B サーバーの外に保存されたファイルを追跡します。このモードでは、Artifact は URL、サイズ、チェックサムなどのファイルに関する メタデータ のみを保存します。基になる データ がシステムから離れることはありません。ファイルを W&B サーバーに保存する方法については、クイックスタート を参照してください。
以下では、参照 Artifacts を構築する方法と、ワークフロー に組み込む最適な方法について説明します。
Amazon S3 / GCS / Azure Blob Storage 参照
W&B Artifacts を使用して、データセット と モデル の バージョン管理 を行い、クラウド ストレージ バケット内の参照を追跡します。Artifact の参照を使用すると、既存のストレージ レイアウトを変更することなく、シームレスに追跡を バケット の上に重ねることができます。
Artifacts は、基盤となるクラウド ストレージ ベンダー(AWS、GCP、Azure など)を抽象化します。以下のセクションで説明する情報は、Amazon S3、Google Cloud Storage、Azure Blob Storage に均一に適用されます。
W&B Artifacts は、MinIO を含む、Amazon S3 互換のインターフェースをサポートします。AWS_S3_ENDPOINT_URL 環境変数 を MinIO サーバーを指すように設定すると、以下の スクリプト はそのまま動作します。
次の構造の バケット があると仮定します。
s3://my-bucket
+-- datasets/
| +-- mnist/
+-- models/
+-- cnn/
mnist/ の下には、画像のコレクションである データセット があります。これを Artifact で追跡してみましょう。
import wandb
run = wandb. init()
artifact = wandb. Artifact("mnist" , type= "dataset" )
artifact. add_reference("s3://my-bucket/datasets/mnist" )
run. log_artifact(artifact)
デフォルトでは、W&B はオブジェクト プレフィックス を追加する際に 10,000 オブジェクト の制限を課します。この制限は、add_reference の呼び出しで max_objects= を指定することで調整できます。
新しい参照 Artifact mnist:latest は、通常の Artifact と同様に見え、動作します。唯一の違いは、Artifact が S3/GCS/Azure オブジェクト に関する メタデータ (ETag、サイズ、オブジェクト の バージョン管理 が バケット で有効になっている場合は バージョン ID など)のみで構成されていることです。
W&B は、使用している クラウド プロバイダー に基づいて、認証情報 を検索するためのデフォルトのメカニズムを使用します。使用する認証情報 の詳細については、 クラウド プロバイダー の ドキュメント を参照してください。
AWS の場合、 バケット が設定された ユーザー のデフォルト リージョン にない場合は、AWS_REGION 環境変数 を バケット リージョン と一致するように設定する必要があります。
この Artifact は、通常の Artifact と同様に操作します。App UI では、ファイル ブラウザー を使用して参照 Artifact のコンテンツ を調べたり、完全な依存関係グラフ を調べたり、Artifact の バージョン管理 された履歴をスキャンしたりできます。
画像、オーディオ、ビデオ、ポイント クラウド などのリッチ メディア は、 バケット の CORS 設定によっては、App UI で レンダリング されない場合があります。 バケット の CORS 設定で app.wandb.ai のリストを許可すると、App UI でそのようなリッチ メディア を適切に レンダリング できます。
会社の VPN がある場合、プライベート バケット の パネル が App UI で レンダリング されない場合があります。VPN 内の IP を ホワイトリスト に登録するように バケット の アクセス ポリシー を更新できます。
参照 Artifact をダウンロードする
import wandb
run = wandb. init()
artifact = run. use_artifact("mnist:latest" , type= "dataset" )
artifact_dir = artifact. download()
W&B は、参照 Artifact をダウンロードする際に、Artifact がログ記録されたときに記録された メタデータ を使用して、基盤となる バケット からファイル を取得します。 バケット で オブジェクト の バージョン管理 が有効になっている場合、W&B は Artifact がログ記録された時点でのファイルの 状態 に対応する オブジェクト バージョン を取得します。これは、 バケット のコンテンツ を進化させても、特定の モデル がトレーニング された データの 正確な イテレーション を指すことができることを意味します。Artifact は トレーニング 時の バケット の スナップショット として機能するためです。
ワークフロー の一部としてファイルを上書きする場合は、ストレージ バケット で「オブジェクト の バージョン管理 」を有効にすることをお勧めします。 バケット で バージョン管理 が有効になっている場合、上書きされたファイルへの参照を持つ Artifacts は、古い オブジェクト バージョン が保持されるため、そのまま残ります。
ユースケース に基づいて、オブジェクト の バージョン管理 を有効にする 手順 を読んでください:AWS , GCP , Azure .
統合する
次のコード例は、Amazon S3、GCS、または Azure で データセット を追跡するために使用できる簡単な ワークフロー を示しています。
import wandb
run = wandb. init()
artifact = wandb. Artifact("mnist" , type= "dataset" )
artifact. add_reference("s3://my-bucket/datasets/mnist" )
# Artifact を追跡し、この run への入力としてマークします。
# バケット 内のファイル が変更された場合にのみ、新しい Artifact バージョン がログ記録されます。
run. use_artifact(artifact)
artifact_dir = artifact. download()
# ここで トレーニング を実行します...
モデル を追跡するために、 トレーニング スクリプト が モデル ファイル を バケット にアップロードした後、 モデル Artifact をログ記録できます。
import boto3
import wandb
run = wandb. init()
# トレーニング はこちら...
s3_client = boto3. client("s3" )
s3_client. upload_file("my_model.h5" , "my-bucket" , "models/cnn/my_model.h5" )
model_artifact = wandb. Artifact("cnn" , type= "model" )
model_artifact. add_reference("s3://my-bucket/models/cnn/" )
run. log_artifact(model_artifact)
GCP または Azure の参照によって Artifacts を追跡する方法のエンドツーエンド の チュートリアル については、次の レポート を参照してください。
ファイルシステム 参照
データセット に 高速 に アクセス するためのもう 1 つの一般的なパターンは、すべての トレーニング ジョブ を実行しているマシンでリモート ファイルシステム に NFS マウント ポイント を公開することです。トレーニング スクリプト の観点から見ると、ファイル がローカル ファイルシステム にあるように見えるため、これは クラウド ストレージ バケット よりもさらに簡単なソリューションになる可能性があります。幸いなことに、その使いやすさは、ファイルシステム への参照を追跡するために Artifacts を使用することにも拡張されます(マウントされているかどうかに関係なく)。
次の構造のファイルシステム が /mount にマウントされていると仮定します。
mount
+-- datasets/
| +-- mnist/
+-- models/
+-- cnn/
mnist/ の下には、画像のコレクションである データセット があります。これを Artifact で追跡してみましょう。
import wandb
run = wandb. init()
artifact = wandb. Artifact("mnist" , type= "dataset" )
artifact. add_reference("file:///mount/datasets/mnist/" )
run. log_artifact(artifact)
デフォルトでは、W&B は ディレクトリー への参照を追加する際に 10,000 ファイル の制限を課します。この制限は、add_reference の呼び出しで max_objects= を指定することで調整できます。
URL には 3 つのスラッシュ があることに注意してください。最初のコンポーネント は、ファイルシステム 参照の使用を示す file:// プレフィックス です。2 番目のコンポーネント は、 データセット へのパス /mount/datasets/mnist/ です。
結果として得られる Artifact mnist:latest は、通常の Artifact と同じように見え、動作します。唯一の違いは、Artifact がファイル に関する メタデータ (サイズ や MD5 チェックサム など)のみで構成されていることです。ファイル 自体がシステムから離れることはありません。
この Artifact は、通常の Artifact と同じように操作できます。UI では、ファイル ブラウザー を使用して参照 Artifact のコンテンツ を参照したり、完全な依存関係グラフ を調べたり、Artifact の バージョン管理 された履歴をスキャンしたりできます。ただし、 データ 自体が Artifact に含まれていないため、UI は画像 やオーディオ などのリッチ メディア を レンダリング できません。
参照 Artifact のダウンロードは簡単です。
import wandb
run = wandb. init()
artifact = run. use_artifact("entity/project/mnist:latest" , type= "dataset" )
artifact_dir = artifact. download()
ファイルシステム 参照の場合、download() 操作は参照されたパスからファイルをコピーして Artifact ディレクトリー を構築します。上記の例では、/mount/datasets/mnist のコンテンツ が ディレクトリー artifacts/mnist:v0/ にコピーされます。Artifact に上書きされたファイル への参照が含まれている場合、Artifact を再構築できなくなるため、download() は エラー をスローします。
すべてをまとめると、マウントされたファイルシステム の下にある データセット を追跡するために使用できる簡単な ワークフロー を次に示します。
import wandb
run = wandb. init()
artifact = wandb. Artifact("mnist" , type= "dataset" )
artifact. add_reference("file:///mount/datasets/mnist/" )
# Artifact を追跡し、この run への入力としてマークします。
# ディレクトリー の下のファイル が変更された場合にのみ、新しい Artifact バージョン がログ記録されます。
run. use_artifact(artifact)
artifact_dir = artifact. download()
# ここで トレーニング を実行します...
モデル を追跡するために、 トレーニング スクリプト が モデル ファイル をマウント ポイント に書き込んだ後、 モデル Artifact をログ記録できます。
import wandb
run = wandb. init()
# トレーニング はこちら...
# モデル を ディスク に書き込みます
model_artifact = wandb. Artifact("cnn" , type= "model" )
model_artifact. add_reference("file:///mount/cnn/my_model.h5" )
run. log_artifact(model_artifact)
4.1.7 - Manage data
4.1.7.1 - Delete an artifact
App UI を使用してインタラクティブに、または W&B SDK を使用してプログラム的に Artifacts を削除します。
App UIまたは W&B SDK を使用して、アーティファクトをインタラクティブに、またはプログラムで削除できます。アーティファクトを削除すると、W&B はそのアーティファクトを 論理削除 としてマークします。つまり、アーティファクトは削除対象としてマークされますが、ファイルはストレージからすぐに削除されるわけではありません。
アーティファクトの内容は、論理削除、つまり削除保留状態のままとなり、定期的に実行されるガベージコレクション プロセスが、削除対象としてマークされたすべてのアーティファクトを確認します。ガベージコレクション プロセスは、アーティファクトとその関連ファイルが、以前または以降のアーティファクト バージョンで使用されていない場合、ストレージから関連ファイルを削除します。
このページのセクションでは、特定のアーティファクト バージョンを削除する方法、アーティファクト コレクションを削除する方法、エイリアスを使用または使用せずにアーティファクトを削除する方法などについて説明します。アーティファクトが W&B から削除されるタイミングは、TTL ポリシーでスケジュールできます。詳細については、アーティファクト TTL ポリシーによるデータ保持の管理 を参照してください。
TTL ポリシーで削除がスケジュールされているアーティファクト、W&B SDK で削除されたアーティファクト、または W&B App UI で削除されたアーティファクトは、最初に論理削除されます。論理削除されたアーティファクトは、完全に削除される前にガベージコレクションの対象となります。
アーティファクト バージョンを削除する
アーティファクト バージョンを削除するには:
アーティファクトの名前を選択します。これにより、アーティファクト ビューが展開され、そのアーティファクトに関連付けられているすべてのアーティファクト バージョンが一覧表示されます。
アーティファクトのリストから、削除するアーティファクト バージョンを選択します。
ワークスペースの右側にあるケバブ ドロップダウンを選択します。
削除を選択します。
アーティファクト バージョンは、delete() メソッドを使用してプログラムで削除することもできます。以下の例を参照してください。
エイリアスを持つ複数のアーティファクト バージョンを削除する
次のコード例は、エイリアスが関連付けられているアーティファクトを削除する方法を示しています。アーティファクトを作成したエンティティ、プロジェクト名、run ID を指定します。
import wandb
run = api. run("entity/project/run_id" )
for artifact in run. logged_artifacts():
artifact. delete()
アーティファクトに1つ以上のエイリアスがある場合にエイリアスを削除するには、delete_aliases パラメータをブール値 True に設定します。
import wandb
run = api. run("entity/project/run_id" )
for artifact in run. logged_artifacts():
# 1つ以上エイリアスを持つ
# アーティファクトを削除するには
# delete_aliases=True を設定します
artifact. delete(delete_aliases= True )
特定のエイリアスを持つ複数のアーティファクト バージョンを削除する
次のコードは、特定のエイリアスを持つ複数のアーティファクト バージョンを削除する方法を示しています。アーティファクトを作成したエンティティ、プロジェクト名、run ID を指定します。削除ロジックを独自のものに置き換えます。
import wandb
runs = api. run("entity/project_name/run_id" )
# エイリアス 'v3' と 'v4' を持つアーティファクトを削除します
for artifact_version in runs. logged_artifacts():
# 独自の削除ロジックに置き換えます。
if artifact_version. name[- 2 :] == "v3" or artifact_version. name[- 2 :] == "v4" :
artifact. delete(delete_aliases= True )
エイリアスを持たないアーティファクトのすべてのバージョンを削除する
次のコードスニペットは、エイリアスを持たないアーティファクトのすべてのバージョンを削除する方法を示しています。wandb.Api の project および entity キーに、プロジェクトとエンティティの名前をそれぞれ指定します。<> をアーティファクトの名前に置き換えます。
import wandb
# wandb.Api メソッドを使用する場合は、
# エンティティとプロジェクト名を指定してください。
api = wandb. Api(overrides= {"project" : "project" , "entity" : "entity" })
artifact_type, artifact_name = "<>" # タイプと名前を指定
for v in api. artifact_versions(artifact_type, artifact_name):
# 'latest' などのエイリアスを持たないバージョンをクリーンアップします。
# 注: ここには、必要な削除ロジックを入れることができます。
if len(v. aliases) == 0 :
v. delete()
アーティファクト コレクションを削除する
アーティファクト コレクションを削除するには:
削除するアーティファクト コレクションに移動し、その上にカーソルを置きます。
アーティファクト コレクション名の横にあるケバブ ドロップダウンを選択します。
削除を選択します。
delete() メソッドを使用して、プログラムでアーティファクト コレクションを削除することもできます。wandb.Api の project および entity キーに、プロジェクトとエンティティの名前をそれぞれ指定します。
import wandb
# wandb.Api メソッドを使用する場合は、
# エンティティとプロジェクト名を指定してください。
api = wandb. Api(overrides= {"project" : "project" , "entity" : "entity" })
collection = api. artifact_collection(
"<artifact_type>" , "entity/project/artifact_collection_name"
)
collection. delete()
W&B のホスト方法に基づいてガベージコレクションを有効にする方法
W&B の共有クラウドを使用している場合、ガベージコレクションはデフォルトで有効になっています。W&B のホスト方法によっては、ガベージコレクションを有効にするために追加の手順が必要になる場合があります。これには以下が含まれます。
次の表は、デプロイメントの種類に基づいてガベージコレクションを有効にするための要件を満たす方法を示しています。
X は、要件を満たす必要があることを示します。
note
セキュア ストレージ コネクタは、現在 Google Cloud Platform および Amazon Web Services でのみ利用可能です。
4.1.7.2 - Manage artifact data retention
Time to live ポリシー (TTL)
W&B Artifact time-to-live(TTL)ポリシーを使用して、Artifacts が W&B から削除されるタイミングをスケジュールします。アーティファクトを削除すると、W&B はそのアーティファクトを ソフト削除 としてマークします。つまり、アーティファクトは削除対象としてマークされますが、ファイルはストレージからすぐに削除されるわけではありません。W&B が Artifacts を削除する方法の詳細については、Artifacts の削除 ページを参照してください。
W&B アプリで Artifacts TTL を使用してデータ保持を管理する方法については、こちらの ビデオチュートリアルをご覧ください。
W&B は、モデルレジストリにリンクされたモデル Artifacts の TTL ポリシーを設定するオプションを無効にします。これは、リンクされたモデルがプロダクションワークフローで使用されている場合に誤って期限切れにならないようにするためです。
チーム管理者のみが チームの設定 を表示し、(1)TTL ポリシーを設定または編集できるユーザーを許可するか、(2)チームのデフォルト TTL を設定するなど、チームレベルの TTL 設定にアクセスできます。
W&B アプリ UI のアーティファクトの詳細で TTL ポリシーを設定または編集するオプションが表示されない場合、またはプログラムで TTL を設定してもアーティファクトの TTL プロパティが正常に変更されない場合は、チーム管理者がそのための権限を付与していません。
自動生成された Artifacts
ユーザーが生成した Artifacts のみ、TTL ポリシーを使用できます。W&B によって自動生成された Artifacts は、TTL ポリシーを設定できません。
次の Artifact の種類は、自動生成された Artifact を示します。
run_tablecodejobwandb-* で始まる任意の Artifact の種類
W&B プラットフォーム で、またはプログラムで Artifact の種類を確認できます。
import wandb
run = wandb. init(project= "<my-project-name>" )
artifact = run. use_artifact(artifact_or_name= "<my-artifact-name>" )
print(artifact. type)
<> で囲まれた値を独自の値に置き換えます。
TTL ポリシーを編集および設定できるユーザーを定義する
チーム内で TTL ポリシーを設定および編集できるユーザーを定義します。TTL 権限をチーム管理者のみに付与するか、チーム管理者とチームメンバーの両方に TTL 権限を付与できます。
チーム管理者のみが、TTL ポリシーを設定または編集できるユーザーを定義できます。
チームのプロファイルページに移動します。
[設定 ] タブを選択します。
[Artifacts time-to-live (TTL) section ] に移動します。
[TTL permissions dropdown ] で、TTL ポリシーを設定および編集できるユーザーを選択します。
[Review and save settings ] をクリックします。
変更を確認し、[Save settings ] を選択します。
TTL ポリシーを作成する
アーティファクトを作成するとき、またはアーティファクトの作成後に遡及的に、アーティファクトの TTL ポリシーを設定します。
以下のすべてのコードスニペットについて、<> で囲まれたコンテンツを自分の情報に置き換えて、コードスニペットを使用します。
アーティファクトを作成するときに TTL ポリシーを設定する
W&B Python SDK を使用して、アーティファクトを作成するときに TTL ポリシーを定義します。TTL ポリシーは通常、日数で定義されます。
アーティファクトを作成するときに TTL ポリシーを定義することは、通常
アーティファクトを作成 する方法と似ています。ただし、アーティファクトの
ttl 属性に時間デルタを渡す点が異なります。
手順は次のとおりです。
アーティファクトを作成 します。ファイル、ディレクトリー、参照など、アーティファクトにコンテンツを追加 します。
Python の標準ライブラリの一部である datetime.timedelta
アーティファクトをログに記録 します。
次のコードスニペットは、アーティファクトを作成し、TTL ポリシーを設定する方法を示しています。
import wandb
from datetime import timedelta
run = wandb. init(project= "<my-project-name>" , entity= "<my-entity>" )
artifact = wandb. Artifact(name= "<artifact-name>" , type= "<type>" )
artifact. add_file("<my_file>" )
artifact. ttl = timedelta(days= 30 ) # TTL ポリシーを設定
run. log_artifact(artifact)
上記のコードスニペットは、アーティファクトの TTL ポリシーを 30 日に設定します。つまり、W&B は 30 日後にアーティファクトを削除します。
アーティファクトを作成した後で TTL ポリシーを設定または編集する
W&B アプリ UI または W&B Python SDK を使用して、既に存在するアーティファクトの TTL ポリシーを定義します。
アーティファクトの TTL を変更すると、アーティファクトが期限切れになるまでの時間は、アーティファクトの createdAt タイムスタンプを使用して計算されます。
アーティファクトを取得 します。時間デルタをアーティファクトの ttl 属性に渡します。
save
次のコードスニペットは、アーティファクトの TTL ポリシーを設定する方法を示しています。
import wandb
from datetime import timedelta
artifact = run. use_artifact("<my-entity/my-project/my-artifact:alias>" )
artifact. ttl = timedelta(days= 365 * 2 ) # 2 年後に削除
artifact. save()
上記のコード例では、TTL ポリシーを 2 年に設定しています。
W&B アプリ UI で W&B プロジェクトに移動します。
左側のパネルでアーティファクトアイコンを選択します。
アーティファクトのリストから、TTL ポリシーを編集するアーティファクトの種類を展開します。
TTL ポリシーを編集するアーティファクトバージョンを選択します。
[バージョン ] タブをクリックします。
ドロップダウンから [TTL ポリシーの編集 ] を選択します。
表示されるモーダル内で、TTL ポリシードロップダウンから [カスタム ] を選択します。
[TTL 期間 ] フィールドに、TTL ポリシーを日数単位で設定します。
[TTL の更新 ] ボタンを選択して、変更を保存します。
チームのデフォルト TTL ポリシーを設定する
チーム管理者のみが、チームのデフォルト TTL ポリシーを設定できます。
チームのデフォルト TTL ポリシーを設定します。デフォルト TTL ポリシーは、それぞれの作成日に基づいて、既存および将来のすべてのアーティファクトに適用されます。既存のバージョンレベルの TTL ポリシーを持つアーティファクトは、チームのデフォルト TTL の影響を受けません。
チームのプロファイルページに移動します。
[設定 ] タブを選択します。
[Artifacts time-to-live (TTL) section ] に移動します。
[チームのデフォルト TTL ポリシーを設定 ] をクリックします。
[期間 ] フィールドに、TTL ポリシーを日数単位で設定します。
[Review and save settings ] をクリックします。
変更を確認し、[Save settings ] を選択します。
run の外部で TTL ポリシーを設定する
パブリック API を使用して、run を取得せずにアーティファクトを取得し、TTL ポリシーを設定します。TTL ポリシーは通常、日数で定義されます。
次のコードサンプルは、パブリック API を使用してアーティファクトを取得し、TTL ポリシーを設定する方法を示しています。
api = wandb. Api()
artifact = api. artifact("entity/project/artifact:alias" )
artifact. ttl = timedelta(days= 365 ) # 1 年後に削除
artifact. save()
TTL ポリシーを無効化する
W&B Python SDK または W&B アプリ UI を使用して、特定のアーティファクトバージョンの TTL ポリシーを無効化します。
アーティファクトを取得 します。アーティファクトの ttl 属性を None に設定します。
save
次のコードスニペットは、アーティファクトの TTL ポリシーをオフにする方法を示しています。
artifact = run. use_artifact("<my-entity/my-project/my-artifact:alias>" )
artifact. ttl = None
artifact. save()
W&B アプリ UI で W&B プロジェクトに移動します。
左側のパネルでアーティファクトアイコンを選択します。
アーティファクトのリストから、TTL ポリシーを編集するアーティファクトの種類を展開します。
TTL ポリシーを編集するアーティファクトバージョンを選択します。
[バージョン] タブをクリックします。
[レジストリへのリンク ] ボタンの横にあるミートボール UI アイコンをクリックします。
ドロップダウンから [TTL ポリシーの編集 ] を選択します。
表示されるモーダル内で、TTL ポリシードロップダウンから [非アクティブ化 ] を選択します。
[TTL の更新 ] ボタンを選択して、変更を保存します。
TTL ポリシーを表示する
Python SDK または W&B アプリ UI でアーティファクトの TTL ポリシーを表示します。
print ステートメントを使用して、アーティファクトの TTL ポリシーを表示します。次の例は、アーティファクトを取得し、その TTL ポリシーを表示する方法を示しています。
artifact = run. use_artifact("<my-entity/my-project/my-artifact:alias>" )
print(artifact. ttl)
W&B アプリ UI でアーティファクトの TTL ポリシーを表示します。
https://wandb.ai で W&B アプリに移動します。W&B プロジェクトに移動します。
プロジェクト内で、左側のサイドバーにある [Artifacts] タブを選択します。
コレクションをクリックします。
コレクションビュー内では、選択したコレクション内のすべてのアーティファクトを表示できます。[Time to Live] 列には、そのアーティファクトに割り当てられた TTL ポリシーが表示されます。
4.1.7.3 - Manage artifact storage and memory allocation
W&B Artifacts のストレージ、メモリアロケーションを管理します。
W&B は artifact ファイルを、デフォルトで米国にあるプライベートな Google Cloud Storage バケットに保存します。すべてのファイルは、保存時および転送時に暗号化されます。
機密性の高いファイルについては、Private Hosting をセットアップするか、reference artifacts を使用することをお勧めします。
トレーニング中、W&B はログ、アーティファクト、および設定ファイルを次のローカルディレクトリーにローカルに保存します。
ファイル
デフォルトの場所
デフォルトの場所を変更するには、以下を設定します:
ログ
./wandbwandb.init の dir 、または WANDB_DIR 環境変数を設定
artifacts
~/.cache/wandbWANDB_CACHE_DIR 環境変数
configs
~/.config/wandbWANDB_CONFIG_DIR 環境変数
アップロード用に artifacts をステージング
~/.cache/wandb-data/WANDB_DATA_DIR 環境変数
ダウンロードされた artifacts
./artifactsWANDB_ARTIFACT_DIR 環境変数
環境変数を使用して W&B を構成するための完全なガイドについては、環境変数のリファレンス を参照してください。
wandb が初期化されるマシンによっては、これらのデフォルトフォルダーがファイルシステムの書き込み可能な場所に配置されていない場合があります。これにより、エラーが発生する可能性があります。
ローカル artifact キャッシュのクリーンアップ
W&B は artifact ファイルをキャッシュして、ファイルを共有する バージョン 間でのダウンロードを高速化します。時間の経過とともに、このキャッシュディレクトリーが大きくなる可能性があります。wandb artifact cache cleanup
次のコードスニペットは、キャッシュのサイズを 1GB に制限する方法を示しています。コードスニペットをコピーして ターミナル に貼り付けます。
$ wandb artifact cache cleanup 1GB
4.1.8 - Explore artifact graphs
自動的に作成された有向非巡回 W&B Artifact グラフをトラバースします。
W&B は、特定の run が ログに記録した Artifacts と、特定の run が使用する Artifacts を自動的に追跡します。これらの Artifacts には、データセット、モデル、評価結果などが含まれます。Artifacts のリネージを調べることで、機械学習のライフサイクル全体で生成されるさまざまな Artifacts を追跡および管理できます。
リネージ
Artifacts のリネージを追跡することには、いくつかの重要な利点があります。
再現性: すべての Artifacts のリネージを追跡することで、チームは Experiments、モデル、および結果を再現できます。これは、デバッグ、実験、および機械学習モデルの検証に不可欠です。
バージョン管理: Artifacts のリネージには、Artifacts のバージョン管理と、時間の経過に伴う変更の追跡が含まれます。これにより、チームは必要に応じてデータまたはモデルの以前のバージョンにロールバックできます。
監査: Artifacts とその変換の詳細な履歴を持つことで、組織は規制およびガバナンスの要件を遵守できます。
コラボレーションと知識の共有: Artifacts のリネージは、試行錯誤の明確な記録を提供することにより、チームメンバー間のより良いコラボレーションを促進します。これは、努力の重複を回避し、開発プロセスを加速するのに役立ちます。
Artifacts のリネージの検索
[Artifacts ] タブで Artifacts を選択すると、Artifacts のリネージを確認できます。このグラフビューには、パイプラインの概要が表示されます。
Artifacts グラフを表示するには:
W&B App UI で プロジェクト に移動します。
左側の パネル で Artifacts アイコンを選択します。
[Lineage ] を選択します。
リネージグラフのナビゲート
指定した Artifacts またはジョブタイプが名前の前に表示され、Artifacts は青いアイコンで、runs は緑のアイコンで表示されます。矢印は、グラフ上の run または Artifacts の入出力を詳細に示します。
Artifacts のタイプと名前は、左側のサイドバーと [Lineage ] タブの両方で確認できます。
より詳細なビューを表示するには、個々の Artifacts または run をクリックして、特定のオブジェクトに関する詳細情報を取得します。
Artifacts クラスター
グラフのレベルに 5 つ以上の runs または Artifacts がある場合、クラスターが作成されます。クラスターには、runs または Artifacts の特定の バージョン を検索するための検索バーがあり、クラスターから個々のノードをプルして、クラスター内のノードのリネージの調査を続行します。
ノードをクリックすると、ノードの概要を示すプレビューが開きます。矢印をクリックすると、個々の run または Artifacts が抽出され、抽出されたノードのリネージを調べることができます。
API を使用してリネージを追跡する
W&B API を使用してグラフをナビゲートすることもできます。
Artifacts を作成します。まず、wandb.init で run を作成します。次に、wandb.Artifact で新しい Artifacts を作成するか、既存の Artifacts を取得します。次に、.add_file で Artifacts にファイルを追加します。最後に、.log_artifact で Artifacts を run に ログ します。完成した コード は次のようになります。
with wandb. init() as run:
artifact = wandb. Artifact("artifact_name" , "artifact_type" )
# Add Files and Assets to the artifact using
# `.add`, `.add_file`, `.add_dir`, and `.add_reference`
artifact. add_file("image1.png" )
run. log_artifact(artifact)
Artifacts オブジェクトの logged_byused_by
# Walk up and down the graph from an artifact:
producer_run = artifact. logged_by()
consumer_runs = artifact. used_by()
次のステップ
4.1.9 - Artifact data privacy and compliance
W&B のファイルがデフォルトでどこに保存されるかについて学びましょう。機密情報の保存、保存方法について説明します。
ファイルを Artifacts としてログに記録すると、ファイルは W&B が管理する Google Cloud バケットにアップロードされます。バケットの内容は、保存時も転送時も暗号化されます。Artifact ファイルは、対応する プロジェクト への アクセス権 を持つ ユーザー のみに表示されます。
Artifact の バージョン を削除すると、 データベース 内でソフト削除としてマークされ、ストレージコストから削除されます。Artifact 全体を削除すると、 完全に削除されるようにキューに入れられ、そのすべてのコンテンツが W&B バケット から削除されます。ファイルの削除に関して特別なニーズがある場合は、カスタマーサポート までご連絡ください。
マルチテナント 環境 に存在できない機密性の高い データセット の場合、 クラウド バケット に接続された プライベート W&B サーバー 、または reference artifacts を使用できます。Reference artifacts は、ファイルの内容を W&B に送信せずに、 プライベート バケット への参照を追跡します。Reference artifacts は、 バケット または サーバー 上のファイルへのリンクを保持します。つまり、W&B はファイル自体ではなく、ファイルに関連付けられた メタデータ のみを追跡します。
Reference artifact は、非 Reference artifact を作成するのと同じように作成します。
import wandb
run = wandb. init()
artifact = wandb. Artifact("animals" , type= "dataset" )
artifact. add_reference("s3://my-bucket/animals" )
代替案については、contact@wandb.com までお問い合わせいただき、 プライベートクラウド および オンプレミス のインストールについてご相談ください。
4.1.10 - Tutorial: Create, track, and use a dataset artifact
Artifacts クイックスタート では、W&B で データセット artifact を作成、追跡、使用する方法を紹介します。
このチュートリアルでは、W&B Runs からデータセット Artifactsを作成、追跡、および使用する方法を示します。
1. W&Bにログイン
W&Bライブラリをインポートし、W&Bにログインします。まだお持ちでない場合は、無料のW&Bアカウントにサインアップする必要があります。
import wandb
wandb. login()
2. runを初期化
wandb.init()
# W&B Runを作成します。この例では、データセット Artifactsの作成方法を示すため、ジョブタイプとして「dataset」を指定します。
run = wandb. init(project= "artifacts-example" , job_type= "upload-dataset" )
3. artifact オブジェクトを作成
wandb.Artifact()name パラメータと type パラメータに指定します。
たとえば、次のコードスニペットは、‘bicycle-dataset’ という名前で ‘dataset’ というラベルの artifact を作成する方法を示しています。
artifact = wandb. Artifact(name= "bicycle-dataset" , type= "dataset" )
artifact の構成方法の詳細については、Artifactsの構築 を参照してください。
データセットを artifact に追加
artifact にファイルを追加します。一般的なファイルタイプには、Models や Datasets などがあります。次の例では、マシンにローカルに保存されている dataset.h5 という名前のデータセットを artifact に追加します。
# ファイルをartifactのコンテンツに追加します。
artifact. add_file(local_path= "dataset.h5" )
上記のコードスニペットのファイル名 dataset.h5 を、artifact に追加するファイルへのパスに置き換えます。
4. データセットをログに記録
W&B run オブジェクトの log_artifact() メソッドを使用して、artifact のバージョンを保存し、artifact を run の出力として宣言します。
# artifact のバージョンを W&B に保存し、この run の出力としてマークします。
run. log_artifact(artifact)
artifact をログに記録すると、デフォルトで 'latest' エイリアスが作成されます。 artifact のエイリアスとバージョンの詳細については、カスタムエイリアスを作成する と新しい artifact バージョンを作成する をそれぞれ参照してください。
5. artifact をダウンロードして使用する
次のコード例は、W&B サーバーにログして保存した artifact を使用するために実行できる手順を示しています。
まず、wandb.init()
次に、run オブジェクトの use_artifact()
3 番目に、artifact の download()
# W&B Runを作成します。ここでは、この run をトレーニングの追跡に使用するため、'type' に 'training' を指定します。
run = wandb. init(project= "artifacts-example" , job_type= "training" )
# W&B に artifact を照会し、この run への入力としてマークします。
artifact = run. use_artifact("bicycle-dataset:latest" )
# artifact のコンテンツをダウンロードします
artifact_dir = artifact. download()
または、パブリック API(wandb.Api)を使用して、Run の外部にある W&B にすでに保存されているデータをエクスポート(または更新)できます。 詳細については、外部ファイルを追跡する を参照してください。
4.2 - Secrets
W&B secrets の概要、その仕組み、およびその使用を開始する方法について説明します。
W&B Secret Manager を使用すると、アクセス トークン、ベアラートークン、API キー、パスワードなどの機密性の高い文字列である secrets(シークレット) を安全かつ一元的に保存、管理、および挿入できます。W&B Secret Manager を使用すると、機密性の高い文字列をコードに直接追加したり、Webhook のヘッダーまたは ペイロード を構成したりする必要がなくなります。
シークレットは、各 Teams の Secret Manager の、Team Settings(チーム設定) の Team secrets(チームシークレット) セクションに保存および管理されます。
W&B の管理者のみが、シークレットの作成、編集、または削除を実行できます。
シークレットは、Azure、GCP、または AWS でホストする W&B Server deployments を含め、W&B のコア部分として含まれています。別の種類のデプロイメントを使用している場合は、W&B アカウントチームに連絡して、W&B でシークレットを使用する方法について話し合ってください。
W&B Server では、セキュリティ ニーズを満たすセキュリティ対策を構成する必要があります。
W&B は、高度なセキュリティ機能で構成された、AWS、GCP、または Azure が提供するクラウド プロバイダーのシークレット マネージャーの W&B インスタンスにシークレットを保存することを強くお勧めします。
クラウド シークレット マネージャー (AWS、GCP、または Azure) の W&B インスタンスを使用できない場合、およびクラスターを使用した場合に発生する可能性のあるセキュリティ脆弱性を防ぐ方法を理解している場合を除き、Kubernetes クラスターをシークレット ストアのバックエンドとして使用しないことをお勧めします。
Add a secret(シークレットの追加)
シークレットを追加するには:
受信サービスで受信 Webhook の認証が必要な場合は、必要なトークンまたは API キーを生成します。必要に応じて、パスワード マネージャーなどを使用して、機密性の高い文字列を安全に保存します。
W&B にログインし、チームの Settings(設定) ページに移動します。
Team Secrets(チームシークレット) セクションで、New secret(新しいシークレット) をクリックします。文字、数字、およびアンダースコア (_) を使用して、シークレットの名前を指定します。
機密性の高い文字列を Secret(シークレット) フィールドに貼り付けます。
Add secret(シークレットの追加) をクリックします。
Webhook を構成するときに、Webhook オートメーションに使用するシークレットを指定します。詳細については、Webhook の構成 セクションを参照してください。
Rotate a secret(シークレットのローテーション)
シークレットをローテーションしてその値を更新するには:
シークレットの行にある鉛筆アイコンをクリックして、シークレットの詳細を開きます。
Secret(シークレット) を新しい値に設定します。必要に応じて、Reveal secret(シークレットを表示) をクリックして新しい値を確認します。Add secret(シークレットの追加) をクリックします。シークレットの値が更新され、以前の値に解決されなくなります。
シークレットを作成または更新した後は、その現在の値を表示できなくなります。代わりに、シークレットを新しい値にローテーションします。
Delete a secret(シークレットの削除)
シークレットを削除するには:
シークレットの行にあるゴミ箱アイコンをクリックします。
確認ダイアログを読み、Delete(削除) をクリックします。シークレットはすぐに完全に削除されます。
Manage access to secrets(シークレットへのアクセス管理)
チームのオートメーションは、チームのシークレットを使用できます。シークレットを削除する前に、それを使用するオートメーションが動作を停止しないように、更新または削除してください。
4.3 - Registry
W&B Registry は現在パブリックプレビュー中です。
こちらの セクションで、デプロイメントタイプに対して有効にする方法を学んでください。
W&B Registry は、組織内の artifact バージョンの厳選された中央リポジトリです。組織内で許可 を持っている ユーザー は、所属する Teams に関係なく、すべての artifact のライフサイクルをダウンロード 、共有、および共同で管理できます。
Registry を使用して、artifact の バージョン を追跡 し、artifact の使用状況と変更の履歴を監査し、artifact のガバナンスとコンプライアンスを確保し、モデル CI/CD などのダウンストリーム プロセス を自動化 できます。
要約すると、W&B Registry を使用して以下を行います。
上の図は、“Model” および “Dataset” コア registry とカスタム registry を含む Registry App を示しています。
基本を学ぶ
各組織には、モデル および データセット artifact を整理するために使用できる Models および Datasets という 2 つの registry が最初から含まれています。組織のニーズに基づいて他の artifact タイプ を整理するために、追加の registry を作成 できます。
各registry は、1 つ以上のコレクション で構成されています。各コレクションは、明確なタスクまたは ユースケース を表します。
artifact を registry に追加するには、まず特定の artifact バージョン を W&B に ログ します 。artifact を ログ するたびに、W&B はその artifact に バージョン を自動的に割り当てます。artifact バージョン は 0 からインデックスを開始するため、最初の バージョン は v0、2 番目の バージョン は v1 のようになります。
artifact を W&B に ログ したら、その特定の artifact バージョン を registry 内のコレクションにリンクできます。
「リンク」という用語は、W&B が artifact を保存する場所と、registry 内で artifact に アクセス できる場所とを接続するポインタを指します。artifact をコレクションにリンクしても、W&B は artifact を複製しません。
例として、次の コード 例は、“my_model.txt” という名前のモデル artifact をコア registry の “first-collection” という名前のコレクションに ログ してリンクする方法を示しています。
W&B run を初期化します。
artifact を W&B に ログ します。
artifact バージョン をリンクするコレクションと registry の名前を指定します。
artifact をコレクションにリンクします。
この Python コード を スクリプト に保存して実行します。W&B Python SDK バージョン 0.18.6 以降が必要です。
import wandb
import random
# Artifact を追跡するために W&B run を初期化します。
run = wandb. init(project= "registry_quickstart" )
# ログ できるようにシミュレートされたモデルファイルを作成します
with open("my_model.txt" , "w" ) as f:
f. write("Model: " + str(random. random()))
# Artifact を W&B に ログ します
logged_artifact = run. log_artifact(
artifact_or_path= "./my_model.txt" ,
name= "gemma-finetuned" ,
type= "model" # artifact タイプを指定します
)
# artifact を公開するコレクションと registry の名前を指定します
COLLECTION_NAME = "first-collection"
REGISTRY_NAME = "model"
# artifact を registry にリンクします
run. link_artifact(
artifact= logged_artifact,
target_path= f "wandb-registry- { REGISTRY_NAME} / { COLLECTION_NAME} "
)
返された run オブジェクトの link_artifact(target_path = "") メソッドで指定したコレクションが、指定した registry 内に存在しない場合、W&B は自動的にコレクションを作成します。
ターミナル に表示される URL は、W&B が artifact を保存する プロジェクト に移動します。
Registry App に移動して、 ユーザー と組織の他のメンバーが公開する artifact バージョン を表示します。これを行うには、まず W&B に移動します。[アプリケーション] の下の左側のサイドバーで Registry を選択します。“Model” registry を選択します。registry 内に、リンクされた artifact バージョン を持つ “first-collection” コレクションが表示されます。
artifact バージョン を registry 内のコレクションにリンクすると、組織のメンバーは、適切な権限を持っている場合、artifact バージョン の表示、ダウンロード、管理、ダウンストリーム オートメーション の作成などを行うことができます。
artifact バージョン が (たとえば、
run.log_artifact() を使用して) メトリクス を ログ する場合、詳細ページからその バージョン の メトリクス を表示したり、コレクションのページから artifact バージョン 全体で メトリクス を比較したりできます。
registry でリンクされた artifact を表示 を参照してください。
W&B Registry を有効にする
デプロイメントタイプに基づいて、次の条件を満たして W&B Registry を有効にします。
デプロイメントタイプ
有効にする方法
Multi-tenant Cloud
アクションは不要です。W&B Registry は W&B App で利用できます。
専用クラウド
アカウントチームにお問い合わせください。ソリューションアーキテクト (SA) チームが、インスタンスのオペレーターコンソール内で W&B Registry を有効にします。インスタンスがサーバーリリースバージョン 0.59.2 以降であることを確認してください。
Self-Managed
ENABLE_REGISTRY_UI という名前の 環境変数 を有効にします。サーバー で 環境変数 を有効にする方法の詳細については、これらのドキュメント を参照してください。セルフマネージドインスタンスでは、インフラストラクチャ 管理者 がこの 環境変数 を有効にして true に設定する必要があります。インスタンスがサーバーリリースバージョン 0.59.2 以降であることを確認してください。
開始するためのリソース
ユースケース に応じて、W&B Registry を開始するための次のリソースをご覧ください。
チュートリアルビデオをご覧ください。
W&B の Model CI/CD コースを受講して、次の方法を学びましょう。
W&B Registry を使用して、artifact の管理と バージョン 管理、リネージ の追跡、さまざまなライフサイクルステージでのモデル のプロモーションを行います。
Webhook を使用して、モデル 管理 ワークフロー を自動化します。
registry を外部 ML システム および ツール と統合して、モデル の 評価 、監視、および デプロイメント を行います。
レガシー Model Registry から W&B Registry への移行
レガシー Model Registry は、正確な日付はまだ決定されていませんが、廃止が予定されています。レガシー Model Registry を廃止する前に、W&B はレガシー Model Registry のコンテンツを W&B Registry に移行します。
レガシー Model Registry から W&B Registry への移行 プロセス の詳細については、レガシー Model Registry からの移行 を参照してください。
移行が行われるまで、W&B はレガシー Model Registry と新しい Registry の両方をサポートします。
レガシー Model Registry を表示するには、W&B App の Model Registry に移動します。ページの上部に、レガシー Model Registry App UI の使用を有効にするバナーが表示されます。
ご質問がある場合、または移行に関する懸念について W&B Product Team と話したい場合は、support@wandb.com までご連絡ください。
4.3.1 - Registry types
W&B は、コアレジストリ と カスタムレジストリ の2種類のレジストリをサポートしています。
コアレジストリ
コアレジストリは、特定の ユースケース ( Models と Datasets ) のためのテンプレートです。
デフォルトでは、Models レジストリは "model" artifact タイプを受け入れるように設定され、Dataset レジストリは "dataset" artifact タイプを受け入れるように設定されています。管理者は、追加の受け入れ可能な artifact タイプを追加できます。
上の図は、W&B Registry App UI の Models と Dataset コアレジストリと、Fine_Tuned_Models というカスタムレジストリを示しています。
コアレジストリは、組織の可視性 を持っています。レジストリ管理者は、コアレジストリの可視性を変更できません。
カスタムレジストリ
カスタムレジストリは、"model" artifact タイプまたは "dataset" artifact タイプに制限されません。
初期の データ 収集から最終的な モデル の デプロイメント まで、機械学習 パイプライン の各ステップに対してカスタムレジストリを作成できます。
たとえば、トレーニング された モデル のパフォーマンスを評価するために、キュレーションされた データセット を整理するために「Benchmark_Datasets」というレジストリを作成できます。このレジストリ内には、「User_Query_Insurance_Answer_Test_Data」というコレクションがあり、トレーニング 中に モデル が見たことのない ユーザー の質問と、対応する専門家によって検証された回答のセットが含まれている場合があります。
カスタムレジストリは、組織または制限付きの可視性 を持つことができます。レジストリ管理者は、カスタムレジストリの可視性を組織から制限付きに変更できます。ただし、レジストリ管理者は、カスタムレジストリの可視性を制限付きから組織の可視性には変更できません。
カスタムレジストリの作成方法については、カスタムレジストリの作成 を参照してください。
まとめ
次の表は、コアレジストリとカスタムレジストリの違いをまとめたものです。
Core
Custom
可視性
組織の可視性のみ。可視性は変更できません。
組織または制限付き。可視性は組織から制限付きの可視性へ変更できます。
メタデータ
事前設定されており、 ユーザー は編集できません。
ユーザー が編集できます。
Artifact タイプ
事前設定されており、受け入れられた artifact タイプは削除できません。 ユーザー は追加の受け入れられた artifact タイプを追加できます。
管理者は、受け入れられたタイプを定義できます。
カスタマイズ
既存のリストにタイプを追加できます。
レジストリ名、説明、可視性、および受け入れられた artifact タイプを編集します。
4.3.2 - Create a custom registry
カスタムレジストリは、使用できるアーティファクトのタイプに対する柔軟性と制御を提供し、レジストリの可視性を制限できます。
コアレジストリとカスタムレジストリの完全な比較については、レジストリの種類 の概要表を参照してください。
カスタムレジストリの作成
カスタムレジストリを作成するには:
https://wandb.ai/registry/ にある Registry App に移動します。Custom registry 内で、Create registry ボタンをクリックします。Name フィールドにレジストリの名前を入力します。必要に応じて、レジストリに関する説明を入力します。
Registry visibility ドロップダウンから、レジストリを表示できるユーザーを選択します。レジストリの可視性オプションの詳細については、レジストリの可視性の種類 を参照してください。Accepted artifacts type ドロップダウンから、All types または Specify types を選択します。(Specify types を選択した場合) レジストリが受け入れる1つ以上のアーティファクトタイプを追加します。
Create registry ボタンをクリックします。
アーティファクトタイプは、レジストリの設定に保存されると、レジストリから削除できません。
たとえば、次の図は、ユーザーが作成しようとしている Fine_Tuned_Models という名前のカスタムレジストリを示しています。レジストリは、レジストリに手動で追加されたメンバーのみに Restricted されています。
可視性の種類
レジストリの可視性 は、誰がそのレジストリにアクセスできるかを決定します。カスタムレジストリの可視性を制限すると、指定されたメンバーのみがレジストリにアクセスできるようになります。
カスタムレジストリには、次の2つのタイプのレジストリ可視性オプションがあります。
可視性
説明
Restricted
招待された組織メンバーのみがレジストリにアクセスできます。
Organization
組織内のすべてのユーザーがレジストリにアクセスできます。
チーム管理者またはレジストリ管理者は、カスタムレジストリの可視性を設定できます。
Restricted の可視性でカスタムレジストリを作成したユーザーは、レジストリ管理者として自動的にレジストリに追加されます。
カスタムレジストリの可視性の構成
チーム管理者またはレジストリ管理者は、カスタムレジストリの作成中または作成後に、カスタムレジストリの可視性を割り当てることができます。
既存のカスタムレジストリの可視性を制限するには:
https://wandb.ai/registry/ にある Registry App に移動します。レジストリを選択します。
右上隅にある歯車アイコンをクリックします。
Registry visibility ドロップダウンから、目的のレジストリ可視性を選択します。Restricted visibility を選択した場合:
このレジストリへのアクセスを許可する組織のメンバーを追加します。Registry members and roles セクションまでスクロールし、Add member ボタンをクリックします。
Member フィールドに、追加するメンバーのメールアドレスまたはユーザー名を追加します。Add new member をクリックします。
チーム管理者がカスタムレジストリを作成するときに、カスタムレジストリの可視性を割り当てる方法の詳細については、カスタムレジストリの作成 を参照してください。
4.3.3 - Configure registry access
Registry の管理者は、Registry の設定を構成することで、Registry のロールを設定 、ユーザーを追加 、または ユーザーを削除 できます。
ユーザーの管理
ユーザーまたは Teams の追加
Registry の管理者は、個々の ユーザー または Teams 全体を Registry に追加できます。 ユーザー または Teams を Registry に追加するには:
Registry (https://wandb.ai/registry/ ) に移動します。
ユーザー または Teams を追加する Registry を選択します。
右上隅にある歯車アイコンをクリックして、Registry の 設定 にアクセスします。
Registry access セクションで、Add access をクリックします。Include users and teams フィールドに、1 つ以上の ユーザー 名、メールアドレス、または Teams 名を指定します。Add access をクリックします。
Registry での ユーザー ロールの設定 、または Registry ロールの権限 について詳細をご覧ください。
ユーザー または Teams の削除
Registry の管理者は、個々の ユーザー または Teams 全体を Registry から削除できます。 ユーザー または Teams を Registry から削除するには:
Registry (https://wandb.ai/registry/ ) に移動します。
ユーザー を削除する Registry を選択します。
右上隅にある歯車アイコンをクリックして、Registry の 設定 にアクセスします。
Registry access セクションに移動し、削除する ユーザー 名、メールアドレス、または Teams を入力します。Delete ボタンをクリックします。
Teams から ユーザー を削除すると、その ユーザー の Registry へのアクセス権も削除されます。
Registry ロール
Registry 内の各 ユーザー は、その Registry で何ができるかを決定する Registry ロール を持っています。
W&B は、ユーザー または Teams が Registry に追加されると、デフォルトの Registry ロールを自動的に割り当てます。
エンティティ
デフォルトの Registry ロール
Teams
Viewer
ユーザー (管理者以外)
Viewer
組織の管理者
Admin
Registry の管理者は、Registry 内の ユーザー および Teams のロールを割り当てまたは変更できます。
詳細については、Registry での ユーザー ロールの設定 を参照してください。
W&B ロールの種類 W&B には、2 種類のロールがあります。Teams ロール と Registry ロール です。
Teams でのロールは、Registry でのロールに影響を与えたり、関係したりすることはありません。
次の表に、ユーザー が持つことができるさまざまなロールと、その権限を示します。
権限
権限グループ
Viewer
Member
Admin
コレクションの詳細を表示する
Read
X
X
X
リンクされた Artifact の詳細を表示する
Read
X
X
X
使用法: use_artifact を使用して Registry 内の Artifact を消費する
Read
X
X
X
リンクされた Artifact をダウンロードする
Read
X
X
X
Artifact のファイルビューアーからファイルをダウンロードする
Read
X
X
X
Registry を検索する
Read
X
X
X
Registry の 設定 と ユーザー リストを表示する
Read
X
X
X
コレクションの新しい自動化を作成する
Create
X
X
新しい バージョン が追加されたときに Slack 通知をオンにする
Create
X
X
新しいコレクションを作成する
Create
X
X
新しいカスタム Registry を作成する
Create
X
X
コレクションカード (説明) を編集する
Update
X
X
リンクされた Artifact の説明を編集する
Update
X
X
コレクションのタグを追加または削除する
Update
X
X
リンクされた Artifact から エイリアス を追加または削除する
Update
X
X
新しい Artifact をリンクする
Update
X
X
Registry で許可されている種類のリストを編集する
Update
X
X
カスタム Registry 名を編集する
Update
X
X
コレクションを削除する
Delete
X
X
自動化を削除する
Delete
X
X
Registry から Artifact のリンクを解除する
Delete
X
X
Registry で許可されている Artifact の種類を編集する
Admin
X
Registry の表示設定 (Organization または Restricted) を変更する
Admin
X
Registry に ユーザー を追加する
Admin
X
Registry で ユーザー のロールを割り当てるか変更する
Admin
X
継承された権限
Registry での ユーザー の権限は、個人または Teams メンバーシップによって割り当てられた、その ユーザー に割り当てられた最高の特権レベルによって異なります。
たとえば、Registry の管理者が Nico という ユーザー を Registry A に追加し、Viewer Registry ロールを割り当てるとします。次に、Registry の管理者が Foundation Model Team という Teams を Registry A に追加し、Foundation Model Team に Member Registry ロールを割り当てます。
Nico は Foundation Model Team のメンバーであり、Member は Registry のメンバーです。Member は Viewer よりも多くの権限を持っているため、W&B は Nico に Member ロールを付与します。
次の表は、ユーザー の個々の Registry ロールと、メンバーである Teams の Registry ロールとの間で競合が発生した場合の、最高の権限レベルを示しています。
Teams Registry ロール
個々の Registry ロール
継承された Registry ロール
Viewer
Viewer
Viewer
Member
Viewer
Member
Admin
Viewer
Admin
競合がある場合、W&B は ユーザー の名前の横に最高の権限レベルを表示します。
たとえば、次の画像では、Alex は smle-reg-team-1 Teams のメンバーであるため、Member ロールの特権を継承しています。
Registry ロールの構成
Registry (https://wandb.ai/registry/ ) に移動します。
構成する Registry を選択します。
右上隅にある歯車アイコンをクリックします。
Registry members and roles セクションまでスクロールします。Member フィールド内で、権限を編集する ユーザー または Teams を検索します。Registry role 列で、ユーザー のロールをクリックします。ドロップダウンから、ユーザー に割り当てるロールを選択します。
4.3.4 - Create a collection
コレクション とは、レジストリ内のリンクされた artifact バージョンのセットです。各コレクションは、明確なタスクまたはユースケースを表します。
たとえば、コア Dataset レジストリ内には複数のコレクションが存在する場合があります。各コレクションには、MNIST、CIFAR-10、ImageNet など、異なるデータセットが含まれています。
別の例として、「chatbot」というレジストリがあり、モデル artifact のコレクション、データセット artifact の別のコレクション、ファインチューンされたモデル artifact の別のコレクションが含まれている場合があります。
レジストリとそのコレクションをどのように編成するかは、あなた次第です。
W&B Model Registry に精通している場合は、登録済みモデルをご存知かもしれません。Model Registry の登録済みモデルは、W&B Registry ではコレクションと呼ばれるようになりました。
コレクションタイプ
各コレクションは、1 つ、かつ 1 つのみの artifact の タイプ を受け入れます。指定するタイプは、あなたと組織の他のメンバーがそのコレクションにリンクできる artifact の種類を制限します。
artifact のタイプは、Python などのプログラミング言語のデータ型に似ていると考えることができます。このアナロジーでは、コレクションは文字列、整数、または浮動小数点数を格納できますが、これらのデータ型の組み合わせは格納できません。
たとえば、「データセット」 artifact タイプを受け入れるコレクションを作成するとします。これは、タイプ「データセット」を持つ将来の artifact バージョンのみをこのコレクションにリンクできることを意味します。同様に、モデル artifact タイプのみを受け入れるコレクションには、タイプ「model」の artifact のみをリンクできます。
artifact オブジェクトを作成するときに、artifact のタイプを指定します。wandb.Artifact() の type フィールドに注意してください。
import wandb
# Initialize a run
run = wandb. init(
entity = "<team_entity>" ,
project = "<project>"
)
# Create an artifact object
artifact = wandb. Artifact(
name= "<artifact_name>" ,
type= "<artifact_type>"
)
コレクションを作成するときは、定義済みの artifact タイプのリストから選択できます。利用可能な artifact タイプは、コレクションが属するレジストリによって異なります。
artifact をコレクションにリンクする、または新しいコレクションを作成する前に、コレクションが受け入れる artifact のタイプを調べてください 。
コレクションが受け入れる artifact のタイプを確認する
コレクションにリンクする前に、コレクションが受け入れる artifact タイプを調べてください。コレクションが受け入れる artifact タイプは、W&B Python SDK を使用してプログラムで、または W&B App を使用してインタラクティブに調べることができます。
その artifact タイプを受け入れないコレクションに artifact をリンクしようとすると、エラーメッセージが表示されます。
W&B App
Python SDK (Beta)
受け入れられる artifact タイプは、ホームページのレジストリカード、またはレジストリの設定ページにあります。
どちらの方法でも、まず W&B Registry App に移動します。
Registry App のホームページ内で、そのレジストリのレジストリカードまでスクロールすると、受け入れられる artifact タイプを表示できます。レジストリカード内の灰色の水平方向の楕円は、そのレジストリが受け入れる artifact タイプを示しています。
たとえば、上記の画像は、Registry App ホームページの複数のレジストリカードを示しています。Model レジストリカード内には、model と model-new の 2 つの artifact タイプが表示されています。
レジストリの設定ページ内で受け入れられる artifact タイプを表示するには:
設定を表示するレジストリカードをクリックします。
右上隅にある歯車アイコンをクリックします。
受け入れられる artifact タイプ フィールドまでスクロールします。
W&B Python SDK を使用して、レジストリが受け入れる artifact タイプをプログラムで表示します。
import wandb
registry_name = "<registry_name>"
artifact_types = wandb. Api(). project(name= f "wandb-registry- { registry_name} " ). artifact_types()
print(artifact_type. name for artifact_type in artifact_types)
上記のコードスニペットでは run を初期化しないことに注意してください。これは、W&B API をクエリするだけで、experiment、artifact などを追跡しない場合は、run を作成する必要がないためです。
コレクションが受け入れる artifact のタイプがわかったら、コレクションを作成 できます。
コレクションを作成する
レジストリ内にインタラクティブまたはプログラムでコレクションを作成します。コレクションの作成後に、コレクションが受け入れる artifact のタイプを変更することはできません。
プログラムでコレクションを作成する
wandb.init.link_artifact() メソッドを使用して、artifact をコレクションにリンクします。target_path フィールドに、コレクションとレジストリの両方を次の形式のパスとして指定します。
f "wandb-registry- { registry_name} / { collection_name} "
ここで、registry_name はレジストリの名前、collection_name はコレクションの名前です。プレフィックス wandb-registry- をレジストリ名に必ず追加してください。
存在しないコレクションに artifact をリンクしようとすると、W&B は自動的にコレクションを作成します。存在するコレクションを指定すると、W&B は artifact を既存のコレクションにリンクします。
上記のコードスニペットは、プログラムでコレクションを作成する方法を示しています。<> で囲まれた他の値を必ず独自の値に置き換えてください。
import wandb
# Initialize a run
run = wandb. init(entity = "<team_entity>" , project = "<project>" )
# Create an artifact object
artifact = wandb. Artifact(
name = "<artifact_name>" ,
type = "<artifact_type>"
)
registry_name = "<registry_name>"
collection_name = "<collection_name>"
target_path = f "wandb-registry- { registry_name} / { collection_name} "
# Link the artifact to a collection
run. link_artifact(artifact = artifact, target_path = target_path)
run. finish()
インタラクティブにコレクションを作成する
次の手順では、W&B Registry App UI を使用してレジストリ内にコレクションを作成する方法について説明します。
W&B App UI の Registry App に移動します。
レジストリを選択します。
右上隅にある コレクションを作成 ボタンをクリックします。
名前 フィールドにコレクションの名前を入力します。タイプ ドロップダウンからタイプを選択します。または、レジストリがカスタム artifact タイプを有効にする場合は、このコレクションが受け入れる 1 つまたは複数の artifact タイプを入力します。必要に応じて、説明 フィールドにコレクションの説明を入力します。
必要に応じて、タグ フィールドに 1 つまたは複数のタグを追加します。
バージョンのリンク をクリックします。プロジェクト ドロップダウンから、artifact が保存されているプロジェクトを選択します。Artifact コレクションドロップダウンから、artifact を選択します。バージョン ドロップダウンから、コレクションにリンクする artifact バージョンを選択します。コレクションを作成 ボタンをクリックします。
4.3.5 - Link an artifact version to a registry
Artifact の バージョンをコレクションにリンクして、組織内の他のメンバーが利用できるようにします。
Artifact をレジストリにリンクすると、その Artifact がそのレジストリに「公開」されます。そのレジストリへのアクセス権を持つ ユーザー は、コレクション内のリンクされた Artifact の バージョン にアクセスできます。
言い換えれば、Artifact をレジストリ コレクションにリンクすると、その Artifact の バージョン がプライベートなプロジェクトレベルのスコープから、共有の組織レベルのスコープに移行します。
Artifact をコレクションにリンクする
Artifact の バージョン を、インタラクティブまたはプログラムでコレクションにリンクします。
Artifact をレジストリにリンクする前に、そのコレクションが許可する Artifact の type を確認してください。コレクションの type について詳しくは、
コレクションを作成する の「コレクション の type」をご覧ください。
ユースケース に基づいて、以下のタブに記載されている手順に従って、Artifact の バージョン をリンクしてください。
Artifact の バージョン がメトリクスを ログ に記録している場合 (たとえば、
run.log_artifact() を使用するなど)、その バージョン の詳細ページからその バージョン のメトリクスを表示したり、Artifact のページから Artifact の バージョン 全体のメトリクスを比較したりできます。
レジストリ内のリンクされた Artifact を表示する を参照してください。
Python SDK
Registry App
Artifact browser
wandb.init.Run.link_artifact()
Artifact をコレクションにリンクする前に、コレクションが属するレジストリがすでに存在することを確認してください。レジストリが存在することを確認するには、W&B App UI の Registry アプリ に移動し、レジストリの名前を検索します。
target_path パラメータ を使用して、Artifact の バージョン のリンク先となるコレクションとレジストリを指定します。ターゲット パス は、プレフィックス「wandb-registry」、レジストリの名前、およびフォワード スラッシュで区切られたコレクションの名前で構成されます。
wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}
以下の コードスニペット をコピーして貼り付け、既存のレジストリ内のコレクションに Artifact の バージョン をリンクします。「<>」で囲まれた 値 を自分の 値 に置き換えます。
import wandb
# Run を初期化する
run = wandb. init(
entity = "<team_entity>" ,
project = "<project_name>"
)
# Artifact オブジェクトを作成する
# type パラメータ は、Artifact オブジェクト の type と
# コレクション の type の両方を指定します
artifact = wandb. Artifact(name = "<name>" , type = "<type>" )
# Artifact オブジェクト にファイルを追加します。
# ローカルマシン 上のファイルへの パス を指定します。
artifact. add_file(local_path = "<local_path_to_artifact>" )
# Artifact のリンク先のコレクションとレジストリを指定します
REGISTRY_NAME = "<registry_name>"
COLLECTION_NAME = "<collection_name>"
target_path= f "wandb-registry- { REGISTRY_NAME} / { COLLECTION_NAME} "
# Artifact をコレクションにリンクする
run. link_artifact(artifact = artifact, target_path = target_path)
Artifact の バージョン を Model Registry または Dataset registry にリンクする場合は、Artifact の type をそれぞれ "model" または "dataset" に設定します。
Registry App に移動します。
Artifact の バージョン をリンクするコレクションの名前の横に マウス を合わせます。
詳細を表示 の横にある ミートボール メニュー アイコン (3 つの水平ドット) を選択します。ドロップダウンから、新しい バージョン をリンク を選択します。
表示されるサイドバーから、Team ドロップダウンから チーム の名前を選択します。
Project ドロップダウンから、Artifact を含むプロジェクトの名前を選択します。Artifact ドロップダウンから、Artifact の名前を選択します。バージョン ドロップダウンから、コレクションにリンクする Artifact の バージョン を選択します。
W&B App のプロジェクト の Artifact ブラウザ (https://wandb.ai/<entity>/<project>/artifacts) に移動します。
左側のサイドバーにある Artifact アイコンを選択します。
レジストリにリンクする Artifact の バージョン をクリックします。
バージョン の概要 セクション内で、レジストリにリンク ボタンをクリックします。画面の右側に表示されるモーダルから、レジストリ モデル を選択 メニュー ドロップダウンから Artifact を選択します。
次のステップ をクリックします。(オプション) エイリアス ドロップダウンから エイリアス を選択します。
レジストリにリンク をクリックします。
Registry アプリ で、リンクされた Artifact の メタデータ、バージョン データ、使用状況、リネージ 情報を表示します。
レジストリ内のリンクされた Artifact を表示する
Registry アプリ で、メタデータ、リネージ、使用状況情報など、リンクされた Artifact に関する情報を表示します。
Registry アプリ に移動します。
Artifact をリンクしたレジストリの名前を選択します。
コレクションの名前を選択します。
コレクションの Artifact がメトリクスを ログ に記録する場合は、メトリクスの表示 をクリックして バージョン 全体のメトリクスを比較します。
Artifact の バージョン のリストから、アクセスする バージョン を選択します。バージョン 番号は、v0 から始まるリンクされた各 Artifact の バージョン にインクリメントに割り当てられます。
Artifact の バージョン に関する詳細を表示するには、バージョン をクリックします。このページのタブから、その バージョン のメタデータ (ログ に記録されたメトリクスを含む)、リネージ、および使用状況情報を表示できます。
バージョン タブ内の フルネーム フィールドに注意してください。リンクされた Artifact のフルネームは、レジストリ、コレクション名、および Artifact の バージョン の エイリアス または インデックス で構成されます。
wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}:v{INTEGER}
プログラムで Artifact の バージョン にアクセスするには、リンクされた Artifact のフルネームが必要です。
トラブルシューティング
Artifact をリンクできない場合は、以下に示す一般的な確認事項を再確認してください。
個人の アカウント から Artifact を ログ に記録する
個人の Entity で W&B に ログ に記録された Artifact は、レジストリにリンクできません。組織内の チーム Entity を使用して Artifact を ログ に記録していることを確認してください。組織の チーム 内で ログ に記録された Artifact のみ、組織のレジストリにリンクできます。
Artifact をレジストリにリンクする場合は、チーム Entity で Artifact を ログ に記録していることを確認してください。
チーム Entity を検索する
W&B は、チーム の名前を チーム の Entity として使用します。たとえば、チーム の名前が team-awesome の場合、チーム Entity は team-awesome です。
次の方法で チーム の名前を確認できます。
チーム の W&B プロファイル ページに移動します。
サイト の URL をコピーします。これは https://wandb.ai/<team> の形式です。<team> は チーム の名前と チーム の Entity の両方です。
チーム Entity から ログ に記録する
wandb.init()entity を指定しない場合、run はデフォルト の Entity を使用します。これは チーム Entity である場合とそうでない場合があります。
import wandb
run = wandb. init(
entity= '<team_entity>' ,
project= '<project_name>'
)
run.log_artifact を使用して、または Artifact オブジェクト を作成し、次にファイルを Artifact オブジェクト に追加して、Artifact を run に ログ に記録します。
artifact = wandb. Artifact(name= "<artifact_name>" , type= "<type>" )
Artifact の ログ 方法について詳しくは、Artifact を構築する をご覧ください。
Artifact が個人の Entity に ログ に記録されている場合は、組織内の Entity に再度 ログ に記録する必要があります。
W&B App UI でレジストリの パス を確認する
UI を使用してレジストリの パス を確認するには、空のコレクションを作成してコレクションの詳細を表示するか、コレクションの ホーム ページで自動生成された コード をコピーして貼り付けます。
自動生成された コード をコピーして貼り付けます
https://wandb.ai/registry/ で Registry アプリ に移動します。Artifact をリンクするレジストリをクリックします。
ページの上部に、自動生成された コード ブロックが表示されます。
これを コード にコピーして貼り付け、パス の最後の部分をコレクションの名前に置き換えてください。
空のコレクションを作成する
https://wandb.ai/registry/ で Registry アプリ に移動します。Artifact をリンクするレジストリをクリックします。
空のコレクションをクリックします。空のコレクションが存在しない場合は、新しいコレクションを作成します。
表示される コードスニペット 内で、.link_artifact() 内の target_path フィールドを特定します。
(オプション) コレクションを削除します。
たとえば、概説されている手順を完了した後、target_path パラメータ を使用して コード ブロックを見つけます。
target_path =
"smle-registries-bug-bash/wandb-registry-Golden Datasets/raw_images"
これをコンポーネント に分解すると、プログラムで Artifact をリンクするための パス を作成するために使用する必要があるものを確認できます。
ORG_ENTITY_NAME = "smle-registries-bug-bash"
REGISTRY_NAME = "Golden Datasets"
COLLECTION_NAME = "raw_images"
一時コレクションのコレクションの名前を、Artifact のリンク先のコレクションの名前に置き換えてください。
```
4.3.6 - Download an artifact from a registry
W&B Python SDK を使用して、レジストリにリンクされた artifact をダウンロードします。artifact をダウンロードして使用するには、レジストリの名前、コレクションの名前、およびダウンロードする artifact バージョンのエイリアスまたはインデックスを知っておく必要があります。
artifact のプロパティがわかったら、リンクされた artifact へのパスを構築 して artifact をダウンロードできます。または、W&B App UI から事前生成されたコードスニペットをコピーして貼り付け て、レジストリにリンクされた artifact をダウンロードすることもできます。
リンクされた artifact へのパスを構築
レジストリにリンクされた artifact をダウンロードするには、そのリンクされた artifact のパスを知っておく必要があります。パスは、レジストリ名、コレクション名、およびアクセスする artifact バージョンのエイリアスまたはインデックスで構成されます。
レジストリ、コレクション、および artifact バージョンのエイリアスまたはインデックスを取得したら、次の文字列テンプレートを使用して、リンクされた artifact へのパスを構築できます。
# バージョンインデックスが指定された Artifact 名
f "wandb-registry- { REGISTRY} / { COLLECTION} :v { INDEX} "
# エイリアスが指定された Artifact 名
f "wandb-registry- { REGISTRY} / { COLLECTION} : { ALIAS} "
中かっこ{}内の値を、アクセスするレジストリ、コレクション、および artifact バージョンのエイリアスまたはインデックスの名前に置き換えます。
artifact バージョンをコア Model Registry またはコア Dataset Registry にそれぞれリンクするには、modelまたはdatasetを指定します。
リンクされた artifact のパスを取得したら、wandb.init.use_artifact メソッドを使用して artifact にアクセスし、そのコンテンツをダウンロードします。次のコードスニペットは、W&B Registry にリンクされた artifact を使用およびダウンロードする方法を示しています。<>内の値を自分の値に置き換えてください。
import wandb
REGISTRY = '<registry_name>'
COLLECTION = '<collection_name>'
ALIAS = '<artifact_alias>'
run = wandb. init(
entity = '<team_name>' ,
project = '<project_name>'
)
artifact_name = f "wandb-registry- { REGISTRY} / { COLLECTION} : { ALIAS} "
# artifact_name = '<artifact_name>' # Registry App で指定されたフルネームをコピーして貼り付けます
fetched_artifact = run. use_artifact(artifact_or_name = artifact_name)
download_path = fetched_artifact. download()
.use_artifact() メソッドは、run を作成し、ダウンロードした artifact をその run への入力としてマークします。artifact を run への入力としてマークすると、W&B はその artifact のリネージを追跡できます。
run を作成したくない場合は、wandb.Api() オブジェクトを使用して artifact にアクセスできます。
import wandb
REGISTRY = "<registry_name>"
COLLECTION = "<collection_name>"
VERSION = "<version>"
api = wandb. Api()
artifact_name = f "wandb-registry- { REGISTRY} / { COLLECTION} : { VERSION} "
artifact = api. artifact(name = artifact_name)
例:W&B Registry にリンクされた Artifact を使用およびダウンロードする
次のコード例は、ユーザーが Fine-tuned Models レジストリの phi3-finetuned というコレクションにリンクされた artifact をダウンロードする方法を示しています。artifact バージョンのエイリアスは production に設定されています。
import wandb
TEAM_ENTITY = "product-team-applications"
PROJECT_NAME = "user-stories"
REGISTRY = "Fine-tuned Models"
COLLECTION = "phi3-finetuned"
ALIAS = 'production'
# 指定された Team と Project 内で Run を初期化します
run = wandb. init(entity= TEAM_ENTITY, project = PROJECT_NAME)
artifact_name = f "wandb-registry- { REGISTRY} / { COLLECTION} : { ALIAS} "
# Artifact にアクセスし、リネージ追跡のために Run への入力としてマークします
fetched_artifact = run. use_artifact(artifact_or_name = name)
# Artifact をダウンロードします。ダウンロードしたコンテンツへのパスを返します
downloaded_path = fetched_artifact. download()
可能なパラメータと戻り値の型の詳細については、API Reference ガイドの use_artifactArtifact.download()
複数の組織に属する個人 Entity を持つ Users 複数の組織に属する個人 Entity を持つ Users は、レジストリにリンクされた artifact にアクセスする際に、組織の名前を指定するか、Team Entity を使用する必要があります。
import wandb
REGISTRY = "<registry_name>"
COLLECTION = "<collection_name>"
VERSION = "<version>"
# API をインスタンス化するために、Team Entity を使用していることを確認してください
api = wandb. Api(overrides= {"entity" : "<team-entity>" })
artifact_name = f "wandb-registry- { REGISTRY} / { COLLECTION} : { VERSION} "
artifact = api. artifact(name = artifact_name)
# パスで組織の表示名または組織 Entity を使用します
api = wandb. Api()
artifact_name = f " { ORG_NAME} /wandb-registry- { REGISTRY} / { COLLECTION} : { VERSION} "
artifact = api. artifact(name = artifact_name)
ORG_NAME は、組織の表示名です。マルチテナント SaaS ユーザーは、組織の設定ページ(https://wandb.ai/account-settings/)で組織の名前を見つけることができます。Dedicated Cloud および Self-Managed ユーザーは、アカウント管理者に連絡して、組織の表示名を確認してください。
事前生成されたコードスニペットをコピーして貼り付け
W&B は、Python スクリプト、notebook、またはターミナルにコピーして貼り付けて、レジストリにリンクされた artifact をダウンロードできるコードスニペットを作成します。
Registry App に移動します。
artifact が含まれているレジストリの名前を選択します。
コレクションの名前を選択します。
artifact バージョンのリストから、アクセスするバージョンを選択します。
Usage タブを選択します。Usage API セクションに表示されているコードスニペットをコピーします。コードスニペットを Python スクリプト、notebook、またはターミナルに貼り付けます。
4.3.7 - Find registry items
W&B Registry App のグローバル検索バー を使用して、レジストリ、コレクション、アーティファクト バージョン タグ、コレクション タグ、または エイリアス を検索します。MongoDB スタイルのクエリを使用して、W&B Python SDK を使用して特定の条件に基づいてレジストリ、コレクション、およびアーティファクト バージョンをフィルタリング できます。
表示する権限を持つアイテムのみが検索結果に表示されます。
レジストリ アイテムの検索
レジストリ アイテムを検索するには:
W&B Registry App に移動します。
ページ上部の検索バーに検索語句を指定します。Enter キーを押して検索します。
指定した用語が既存のレジストリ、コレクション名、アーティファクト バージョン タグ、コレクション タグ、または エイリアス と一致する場合、検索結果は検索バーの下に表示されます。
MongoDB スタイルのクエリでレジストリ アイテムをクエリする
wandb.Api().registries()クエリ述語 を使用して、1 つ以上の MongoDB スタイルのクエリ に基づいて、レジストリ、コレクション、およびアーティファクト バージョンをフィルタリングします。
次の表に、フィルタリングするアイテムのタイプに基づいて使用できるクエリ名を示します。
クエリ名
registries
name, description, created_at, updated_at
collections
name, tag, description, created_at, updated_at
versions
tag, alias, created_at, updated_at, metadata
次の コードスニペット は、一般的な検索シナリオを示しています。
wandb.Api().registries() メソッドを使用するには、まず W&B Python SDK (wandb
import wandb
# (オプション) 可読性を高めるために wandb.Api() クラスのインスタンスを作成します
api = wandb. Api()
文字列 model を含むすべての registries をフィルタリングします。
# 文字列 `model` を含むすべての registries をフィルタリングします
registry_filters = {
"name" : {"$regex" : "model" }
}
# フィルタに一致するすべての registries のイテラブルを返します
registries = api. registries(filter= registry_filters)
コレクション名に文字列 yolo を含む、registry に関係なく、すべての collections をフィルタリングします。
# コレクション名に文字列 `yolo` を含む、registry に関係なく、
# すべての collections をフィルタリングします
collection_filters = {
"name" : {"$regex" : "yolo" }
}
# フィルタに一致するすべての collections のイテラブルを返します
collections = api. registries(). collections(filter= collection_filters)
コレクション名に文字列 yolo を含み、cnn をタグとして持つ、registry に関係なく、すべての collections をフィルタリングします。
# コレクション名に文字列 `yolo` を含み、
# `cnn` をタグとして持つ、registry に関係なく、すべての collections をフィルタリングします
collection_filters = {
"name" : {"$regex" : "yolo" },
"tag" : "cnn"
}
# フィルタに一致するすべての collections のイテラブルを返します
collections = api. registries(). collections(filter= collection_filters)
文字列 model を含み、タグ image-classification または latest エイリアス のいずれかを持つすべてのアーティファクト バージョンを検索します。
# 文字列 `model` を含み、
# タグ `image-classification` または `latest` エイリアス のいずれかを持つすべてのアーティファクト バージョンを検索します
registry_filters = {
"name" : {"$regex" : "model" }
}
# 論理 $or 演算子を使用してアーティファクト バージョンをフィルタリングします
version_filters = {
"$or" : [
{"tag" : "image-classification" },
{"alias" : "production" }
]
}
# フィルタに一致するすべてのアーティファクト バージョンのイテラブルを返します
artifacts = api. registries(filter= registry_filters). collections(). versions(filter= version_filters)
論理クエリオペレーター の詳細については、MongoDB のドキュメントを参照してください。
前の コードスニペット の artifacts イテラブルの各アイテムは、Artifact クラスのインスタンスです。つまり、各アーティファクトの属性 ( name 、 collection 、 aliases 、 tags 、 created_at など) にアクセスできます。
for art in artifacts:
print(f "artifact name: { art. name} " )
print(f "collection artifact belongs to: { art. collection. name} " )
print(f "artifact aliases: { art. aliases} " )
print(f "tags attached to artifact: { art. tags} " )
print(f "artifact created at: { art. created_at} \n " )
アーティファクト オブジェクトの属性の完全なリストについては、API Reference ドキュメントの Artifacts Class を参照してください。
2024-01-08 から 2025-03-04 の 13:10 UTC の間に作成された、registry または collection に関係なく、すべてのアーティファクト バージョンをフィルタリングします。
# 2024-01-08 から 2025-03-04 の 13:10 UTC の間に作成されたすべてのアーティファクト バージョンを検索します。
artifact_filters = {
"alias" : "latest" ,
"created_at" : {"$gte" : "2024-01-08" , "$lte" : "2025-03-04 13:10:00" },
}
# フィルタに一致するすべてのアーティファクト バージョンのイテラブルを返します
artifacts = api. registries(). collections(). versions(filter= artifact_filters)
日付と時刻を YYYY-MM-DD HH:MM:SS 形式で指定します。日付のみでフィルタリングする場合は、時間、分、秒を省略できます。
クエリ比較 の詳細については、MongoDB のドキュメントを参照してください。
4.3.8 - Organize versions with tags
タグを使用して、コレクションまたはコレクション内のアーティファクト のバージョンを整理します。タグの追加、削除、編集は、Python SDK または W&B App UI で行えます。
レジストリ内のコレクションまたは Artifacts バージョンを整理するために、タグを作成して追加します。W&B App UIまたは W&B Python SDK を使用して、コレクションまたは Artifacts バージョンにタグを追加、変更、表示、または削除します。
タグとエイリアスの使い分け 特定の Artifacts バージョンを一意に参照する必要がある場合は、エイリアスを使用します。たとえば、artifact_name:alias が常に単一の特定のバージョンを指すようにするために、‘production’ や ’latest’ などのエイリアスを使用します。
グループ化や検索の柔軟性を高めたい場合は、タグを使用します。タグは、複数のバージョンまたはコレクションが同じラベルを共有でき、特定の識別子に1つのバージョンのみが関連付けられているという保証が不要な場合に最適です。
コレクションにタグを追加する
W&B App UIまたは Python SDK を使用して、コレクションにタグを追加します。
W&B App UIを使用して、コレクションにタグを追加します。
W&B Registry(https://wandb.ai/registry)に移動します。
レジストリカードをクリックします。
コレクションの名前の横にある [詳細を表示 ] をクリックします。
コレクションカード内で、[タグ ] フィールドの横にあるプラスアイコン(+ )をクリックし、タグの名前を入力します。
キーボードの Enter キーを押します。
import wandb
COLLECTION_TYPE = "<collection_type>"
ORG_NAME = "<org_name>"
REGISTRY_NAME = "<registry_name>"
COLLECTION_NAME = "<collection_name>"
full_name = f " { ORG_NAME} /wandb-registry- { REGISTRY_NAME} / { COLLECTION_NAME} "
collection = wandb. Api(). artifact_collection(
type_name = COLLECTION_TYPE,
name = full_name
)
collection. tags = ["your-tag" ]
collection. save()
コレクションに属するタグを更新する
tags 属性を再割り当てするか、変更することで、プログラムでタグを更新します。W&B は、インプレースミューテーションではなく、tags 属性を再割り当てすることを推奨しており、これは良い Python のプラクティスです。
たとえば、次のコードスニペットは、再割り当てでリストを更新する一般的な方法を示しています。簡潔にするために、コレクションにタグを追加するセクション のコード例を続けます。
collection. tags = [* collection. tags, "new-tag" , "other-tag" ]
collection. tags = collection. tags + ["new-tag" , "other-tag" ]
collection. tags = set(collection. tags) - set(tags_to_delete)
collection. tags = [] # deletes all tags
次のコードスニペットは、インプレースミューテーションを使用して、Artifacts バージョンに属するタグを更新する方法を示しています。
collection. tags += ["new-tag" , "other-tag" ]
collection. tags. append("new-tag" )
collection. tags. extend(["new-tag" , "other-tag" ])
collection. tags[:] = ["new-tag" , "other-tag" ]
collection. tags. remove("existing-tag" )
collection. tags. pop()
collection. tags. clear()
コレクションに属するタグを表示する
W&B App UIを使用して、コレクションに追加されたタグを表示します。
W&B Registry(https://wandb.ai/registry)に移動します。
レジストリカードをクリックします。
コレクションの名前の横にある [詳細を表示 ] をクリックします。
コレクションに1つ以上のタグがある場合、[タグ ] フィールドの横にあるコレクションカード内でそれらのタグを表示できます。
コレクションに追加されたタグは、そのコレクションの名前の横にも表示されます。
たとえば、上記の画像では、「tag1」というタグが「zoo-dataset-tensors」コレクションに追加されました。
コレクションからタグを削除する
W&B App UIを使用して、コレクションからタグを削除します。
W&B Registry(https://wandb.ai/registry)に移動します。
レジストリカードをクリックします。
コレクションの名前の横にある [詳細を表示 ] をクリックします。
コレクションカード内で、削除するタグの名前にマウスを合わせます。
キャンセルボタン(X アイコン)をクリックします。
Artifacts バージョンにタグを追加する
W&B App UIまたは Python SDK を使用して、コレクションにリンクされた Artifacts バージョンにタグを追加します。
W&B Registry(https://wandb.ai/registry)に移動します。
レジストリカードをクリックします。
タグを追加するコレクションの名前の横にある [詳細を表示 ] をクリックします。
[バージョン ] までスクロールダウンします。
Artifacts バージョンの横にある [表示 ] をクリックします。
[バージョン ] タブ内で、[タグ ] フィールドの横にあるプラスアイコン(+ )をクリックし、タグの名前を入力します。
キーボードの Enter キーを押します。
タグを追加または更新する Artifacts バージョンをフェッチします。Artifacts バージョンを取得したら、Artifacts オブジェクトの tag 属性にアクセスして、その Artifacts にタグを追加または変更できます。Artifacts の tag 属性に1つまたは複数のタグをリストとして渡します。
他の Artifacts と同様に、run を作成せずに W&B から Artifacts をフェッチするか、run を作成してその run 内で Artifacts をフェッチできます。いずれの場合も、Artifacts オブジェクトの save メソッドを呼び出して、W&B サーバー上の Artifacts を更新してください。
以下の適切なコードセルをコピーして貼り付け、Artifacts バージョンのタグを追加または変更します。<> の値を自分の値に置き換えます。
次のコードスニペットは、新しい run を作成せずに Artifacts をフェッチしてタグを追加する方法を示しています。
import wandb
ARTIFACT_TYPE = "<TYPE>"
ORG_NAME = "<org_name>"
REGISTRY_NAME = "<registry_name>"
COLLECTION_NAME = "<collection_name>"
VERSION = "<artifact_version>"
artifact_name = f " { ORG_NAME} /wandb-registry- { REGISTRY_NAME} / { COLLECTION_NAME} :v { VERSION} "
artifact = wandb. Api(). artifact(name = artifact_name, type = ARTIFACT_TYPE)
artifact. tags = ["tag2" ] # リストで1つ以上のタグを提供します
artifact. save()
次のコードスニペットは、新しい run を作成して Artifacts をフェッチし、タグを追加する方法を示しています。
import wandb
ORG_NAME = "<org_name>"
REGISTRY_NAME = "<registry_name>"
COLLECTION_NAME = "<collection_name>"
VERSION = "<artifact_version>"
run = wandb. init(entity = "<entity>" , project= "<project>" )
artifact_name = f " { ORG_NAME} /wandb-registry- { REGISTRY_NAME} / { COLLECTION_NAME} :v { VERSION} "
artifact = run. use_artifact(artifact_or_name = artifact_name)
artifact. tags = ["tag2" ] # リストで1つ以上のタグを提供します
artifact. save()
Artifacts バージョンに属するタグを更新する
tags 属性を再割り当てするか、変更することで、プログラムでタグを更新します。W&B は、インプレースミューテーションではなく、tags 属性を再割り当てすることを推奨しており、これは良い Python のプラクティスです。
たとえば、次のコードスニペットは、再割り当てでリストを更新する一般的な方法を示しています。簡潔にするために、Artifacts バージョンにタグを追加するセクション のコード例を続けます。
artifact. tags = [* artifact. tags, "new-tag" , "other-tag" ]
artifact. tags = artifact. tags + ["new-tag" , "other-tag" ]
artifact. tags = set(artifact. tags) - set(tags_to_delete)
artifact. tags = [] # deletes all tags
次のコードスニペットは、インプレースミューテーションを使用して、Artifacts バージョンに属するタグを更新する方法を示しています。
artifact. tags += ["new-tag" , "other-tag" ]
artifact. tags. append("new-tag" )
artifact. tags. extend(["new-tag" , "other-tag" ])
artifact. tags[:] = ["new-tag" , "other-tag" ]
artifact. tags. remove("existing-tag" )
artifact. tags. pop()
artifact. tags. clear()
Artifacts バージョンに属するタグを表示する
W&B App UIまたは Python SDK を使用して、レジストリにリンクされている Artifacts バージョンに属するタグを表示します。
W&B Registry(https://wandb.ai/registry)に移動します。
レジストリカードをクリックします。
タグを追加するコレクションの名前の横にある [詳細を表示 ] をクリックします。
[バージョン ] セクションまでスクロールダウンします。
Artifacts バージョンに1つ以上のタグがある場合、[タグ ] 列内でそれらのタグを表示できます。
タグを表示する Artifacts バージョンをフェッチします。Artifacts バージョンを取得したら、Artifacts オブジェクトの tag 属性を表示して、その Artifacts に属するタグを表示できます。
他の Artifacts と同様に、run を作成せずに W&B から Artifacts をフェッチするか、run を作成してその run 内で Artifacts をフェッチできます。
以下の適切なコードセルをコピーして貼り付け、Artifacts バージョンのタグを追加または変更します。<> の値を自分の値に置き換えます。
次のコードスニペットは、新しい run を作成せずに Artifacts バージョンのタグをフェッチして表示する方法を示しています。
import wandb
ARTIFACT_TYPE = "<TYPE>"
ORG_NAME = "<org_name>"
REGISTRY_NAME = "<registry_name>"
COLLECTION_NAME = "<collection_name>"
VERSION = "<artifact_version>"
artifact_name = f " { ORG_NAME} /wandb-registry- { REGISTRY_NAME} / { COLLECTION_NAME} :v { VERSION} "
artifact = wandb. Api(). artifact(name = artifact_name, type = artifact_type)
print(artifact. tags)
次のコードスニペットは、新しい run を作成して Artifacts バージョンのタグをフェッチして表示する方法を示しています。
import wandb
ORG_NAME = "<org_name>"
REGISTRY_NAME = "<registry_name>"
COLLECTION_NAME = "<collection_name>"
VERSION = "<artifact_version>"
run = wandb. init(entity = "<entity>" , project= "<project>" )
artifact_name = f " { ORG_NAME} /wandb-registry- { REGISTRY_NAME} / { COLLECTION_NAME} :v { VERSION} "
artifact = run. use_artifact(artifact_or_name = artifact_name)
print(artifact. tags)
Artifacts バージョンからタグを削除する
W&B Registry(https://wandb.ai/registry)に移動します。
レジストリカードをクリックします。
タグを追加するコレクションの名前の横にある [詳細を表示 ] をクリックします。
[バージョン ] までスクロールダウンします。
Artifacts バージョンの横にある [表示 ] をクリックします。
[バージョン ] タブ内で、タグの名前にマウスを合わせます。
キャンセルボタン(X アイコン)をクリックします。
既存のタグを検索する
W&B App UIを使用して、コレクションおよび Artifacts バージョンで既存のタグを検索します。
W&B Registry(https://wandb.ai/registry)に移動します。
レジストリカードをクリックします。
検索バーにタグの名前を入力します。
特定のタグを持つ Artifacts バージョンを検索する
W&B Python SDK を使用して、タグのセットを持つ Artifacts バージョンを検索します。
import wandb
api = wandb. Api()
tagged_artifact_versions = api. artifacts(
type_name = "<artifact_type>" ,
name = "<artifact_name>" ,
tags = ["<tag_1>" , "<tag_2>" ]
)
for artifact_version in tagged_artifact_versions:
print(artifact_version. tags)
4.3.9 - Annotate collections
コレクションに人に優しいテキストを追加して、ユーザーがコレクションの目的とそれに含まれる Artifacts を理解できるようにします。
コレクションによっては、トレーニングデータ、モデルアーキテクチャー、タスク、ライセンス、参考文献、およびデプロイメントに関する情報を含めることをお勧めします。以下に、コレクションでドキュメント化する価値のあるトピックをいくつか示します。
W&B は、少なくとも以下の詳細を含めることを推奨します。
Summary : コレクションの目的。機械学習実験に使用される機械学習 フレームワーク。License : 機械学習 モデルの使用に関連する法的条件と許可。これにより、モデルの ユーザー は、モデルを利用できる法的枠組みを理解できます。一般的なライセンスには、Apache 2.0、MIT、GPL などがあります。References : 関連する 研究 論文、データセット、または外部リソースへの引用または参照。
コレクションにトレーニングデータが含まれている場合は、次の詳細を含めることを検討してください。
Training data : 使用されるトレーニングデータを記述します。Processing : トレーニングデータセットに対して行われた処理。Data storage : そのデータはどこに保存され、どのようにアクセスするか。
コレクションに機械学習 モデルが含まれている場合は、次の詳細を含めることを検討してください。
Architecture : モデルアーキテクチャー、レイヤー、および特定の設計の選択に関する情報。Task : コレクション モデル が実行するように設計されているタスクまたは問題の特定のタイプ。これは、モデルの意図された機能を分類したものです。Deserialize the model : チームの誰かがモデルをメモリーにロードする方法に関する情報を提供します。Task : 機械学習 モデル が実行するように設計されているタスクまたは問題の特定のタイプ。これは、モデルの意図された機能を分類したものです。Deployment : モデルがどのように、どこにデプロイされるかの詳細、およびワークフロー オーケストレーション プラットフォームなどの他のエンタープライズ システムにモデルを統合する方法に関するガイダンス。
コレクションに説明を追加する
W&B Registry UI または Python SDK を使用して、コレクションにインタラクティブまたはプログラムで説明を追加します。
W&B Registry UI
Python SDK
https://wandb.ai/registry/ で W&B Registry に移動します。コレクションをクリックします。
コレクション名の横にある [詳細を表示 ] を選択します。
[Description ] フィールドに、コレクションに関する情報を入力します。Markdown markup language でテキストの書式を設定します。
wandb.Api().artifact_collection()description プロパティを使用して、コレクションに説明を追加または更新します。
type_name パラメータにコレクションのタイプを指定し、name パラメータにコレクションのフルネームを指定します。コレクションの名前は、プレフィックス “wandb-registry”、レジストリの名前、およびフォワード スラッシュで区切られたコレクションの名前で構成されます。
wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}
次のコード スニペットを Python スクリプトまたは ノートブック にコピーして貼り付けます。山かっこ (<>) で囲まれた値を独自の値に置き換えます。
import wandb
api = wandb. Api()
collection = api. artifact_collection(
type_name = "<collection_type>" ,
name = "<collection_name>"
)
collection. description = "This is a description."
collection. save()
たとえば、次の画像は、モデルのアーキテクチャー、意図された使用法、パフォーマンス情報などを文書化したコレクションを示しています。
4.3.10 - Create and view lineage maps
W&B Registry で リネージ マップを作成します。
W&B Registry内のコレクションでは、ML 実験で使用される Artifacts の履歴を表示できます。この履歴は リネージグラフ と呼ばれます。
コレクションの一部ではない、W&B に記録した Artifacts のリネージグラフも表示できます。
リネージグラフは、Artifacts を記録する特定の run を示すことができます。さらに、リネージグラフは、どの run が Artifacts を入力として使用したかを示すこともできます。言い換えれば、リネージグラフは run の入力と出力を示すことができます。
たとえば、以下の画像は、ML 実験全体で作成および使用された Artifacts を示しています。
左から右へ、画像は以下を示しています。
複数の runs が split_zoo_dataset:v4 アーティファクトを記録します。
“rural-feather-20” run は、トレーニングに split_zoo_dataset:v4 アーティファクトを使用します。
“rural-feather-20” run の出力は、zoo-ylbchv20:v0 というモデルアーティファクトです。
“northern-lake-21” という run は、モデルアーティファクト zoo-ylbchv20:v0 を使用してモデルを評価します。
run の入力を追跡する
wandb.init.use_artifact API を使用して、Artifacts を run の入力または依存関係としてマークします。
以下のコードスニペットは、use_artifact の使用方法を示しています。山括弧 (< >) で囲まれた値を自分の値に置き換えてください。
import wandb
# Initialize a run
run = wandb. init(project= "<project>" , entity= "<entity>" )
# Get artifact, mark it as a dependency
artifact = run. use_artifact(artifact_or_name= "<name>" , aliases= "<alias>" )
run の出力を追跡する
Artifacts を run の出力として宣言するには、(wandb.init.log_artifact
以下のコードスニペットは、wandb.init.log_artifact API の使用方法を示しています。山括弧 (< >) で囲まれた値を必ず自分の値に置き換えてください。
import wandb
# Initialize a run
run = wandb. init(entity "<entity>" , project = "<project>" ,)
artifact = wandb. Artifact(name = "<artifact_name>" , type = "<artifact_type>" )
artifact. add_file(local_path = "<local_filepath>" , name= "<optional-name>" )
# Log the artifact as an output of the run
run. log_artifact(artifact_or_path = artifact)
Artifacts の作成に関する詳細については、Artifacts の作成 を参照してください。
コレクションでリネージグラフを表示する
W&B Registry でコレクションにリンクされた Artifacts のリネージを表示します。
W&B Registry に移動します。
Artifacts を含むコレクションを選択します。
ドロップダウンから、リネージグラフを表示する Artifacts のバージョンをクリックします。
「リネージ」タブを選択します。
Artifacts のリネージグラフページにアクセスすると、そのリネージグラフ内の任意のノードに関する追加情報を表示できます。
run の ID、run の名前、run の状態など、その run の詳細を表示するには、run ノードを選択します。例として、以下の画像は rural-feather-20 run に関する情報を示しています。
Artifacts のフルネーム、タイプ、作成時間、および関連するエイリアスなど、その Artifacts の詳細を表示するには、Artifacts ノードを選択します。
4.3.11 - Migrate from legacy Model Registry
W&B は、レガシーな W&B Model Registry から新しい W&B Registry へとアセットを移行します。この移行は完全に W&B によって管理およびトリガーされ、 ユーザー からの介入は必要ありません。この プロセス は、既存の ワークフロー を最小限に中断するように、可能な限りシームレスになるように設計されています。
移行は、新しい W&B Registry が Model Registry で現在利用可能なすべての機能を含むと実行されます。W&B は、現在の ワークフロー 、 コード ベース、および参照を保持しようとします。
この ガイド は生きたドキュメントであり、より多くの情報が利用可能になるにつれて定期的に更新されます。ご質問やサポートについては、support@wandb.com までお問い合わせください。
W&B Registry は、従来の Model Registry とどのように異なりますか
W&B Registry は、 モデル 、 データセット 、およびその他の アーティファクト を管理するための、より堅牢で柔軟な 環境 を提供するように設計された、さまざまな新機能と拡張機能を紹介します。
レガシー Model Registry を表示するには、W&B アプリ の Model Registry に移動します。ページの上部にバナーが表示され、レガシー Model Registry アプリ UI を使用できます。
組織の可視性
レガシー Model Registry にリンクされた Artifacts は、 チーム レベルの可視性を持ちます。これは、 チーム の メンバー のみがレガシー W&B Model Registry で Artifacts を表示できることを意味します。W&B Registry は、組織レベルの可視性を持ちます。これは、適切な 権限 を持つ組織全体の メンバー が、 レジストリ にリンクされた Artifacts を表示できることを意味します。
レジストリ への可視性を制限する
カスタム レジストリ を表示および アクセス できる ユーザー を制限します。カスタム レジストリ を作成するとき、またはカスタム レジストリ を作成した後に、 レジストリ への可視性を制限できます。制限された レジストリ では、選択された メンバー のみ コンテンツ に アクセス でき、 プライバシー と制御を維持します。レジストリ の可視性の詳細については、レジストリ の可視性タイプ を参照してください。
カスタム レジストリ を作成する
従来の Model Registry とは異なり、W&B Registry は モデル または データセット レジストリ に限定されません。特定の ワークフロー または プロジェクト のニーズに合わせて調整されたカスタム レジストリ を作成でき、任意の オブジェクト タイプを保持できます。この柔軟性により、 チーム は独自の要件に従って Artifacts を整理および管理できます。カスタム レジストリ の作成方法の詳細については、カスタム レジストリ を作成する を参照してください。
カスタム アクセス 制御
各 レジストリ は詳細な アクセス 制御をサポートしており、 メンバー には管理者、 メンバー 、または閲覧者などの特定の ロール を割り当てることができます。管理者は、 メンバー の追加または削除、 ロール の設定、可視性の構成など、 レジストリ の 設定 を管理できます。これにより、 チーム は レジストリ 内の Artifacts を表示、管理、および操作できる ユーザー を確実に制御できます。
用語の更新
登録済み モデル は、コレクション と呼ばれるようになりました。
変更の概要
レガシー W&B Model Registry
W&B Registry
Artifact の可視性
チーム の メンバー のみ Artifacts を表示または アクセス できます
組織内の メンバー は、適切な 権限 を持っていれば、 レジストリ にリンクされた Artifacts を表示または アクセス できます
カスタム アクセス 制御
利用不可
利用可能
カスタム レジストリ
利用不可
利用可能
用語の更新
モデル バージョン への ポインター (リンク)の セット は、*登録済み モデル *と呼ばれます。
アーティファクト バージョン への ポインター (リンク)の セット は、コレクション と呼ばれます。
wandb.init.link_modelModel Registry 固有の API
現在、レガシー Model Registry とのみ互換性があります
移行の準備
W&B は、登録済みの モデル (現在はコレクションと呼ばれています)と、関連する Artifacts バージョン を、レガシー Model Registry から W&B Registry に移行します。この プロセス は自動的に実行され、 ユーザー からの アクション は必要ありません。
チーム の可視性から組織の可視性へ
移行後、 モデル レジストリ は組織レベルの可視性を持つようになります。 ロール を割り当てる ことで、 レジストリ への アクセス 権を持つ ユーザー を制限できます。これにより、特定の メンバー のみが特定の レジストリ に アクセス できるようになります。
移行により、レガシー W&B Model Registry 内の現在の チーム レベルの登録済み モデル (まもなくコレクションと呼ばれるようになります)の既存の 権限 境界が保持されます。レガシー Model Registry で現在定義されている 権限 は、新しい Registry で保持されます。これは、現在特定の チーム メンバー に制限されているコレクションが、移行中および移行後も保護された状態を維持することを意味します。
Artifacts パスの継続性
現在、 アクション は必要ありません。
移行中
W&B は移行 プロセス を開始します。移行は、W&B サービス の中断を最小限に抑える時間帯に実行されます。レガシー Model Registry は、移行が開始されると読み取り専用状態に移行し、参照用に アクセス 可能な状態を維持します。
移行後
移行後、コレクション、 Artifacts バージョン 、および関連する 属性 は、新しい W&B Registry 内で完全に アクセス 可能になります。焦点は、現在の ワークフロー が確実にそのまま残るようにすることであり、変更をナビゲートするのに役立つ継続的なサポートが利用可能です。
新しい レジストリ を使用する
ユーザー は、W&B Registry で利用可能な新機能と性能を調査することをお勧めします。Registry は、現在依存している機能をサポートするだけでなく、カスタム レジストリ 、可視性の向上、柔軟な アクセス 制御などの拡張機能も導入します。
早期に W&B Registry を試してみたい場合、または新しい ユーザー がレガシー W&B Model Registry ではなく Registry から開始したい場合は、サポートをご利用いただけます。この機能を有効にするには、support@wandb.com またはセールス MLE までご連絡ください。早期移行は BETA バージョン に移行することに注意してください。BETA バージョン の W&B Registry は、レガシー Model Registry のすべての機能または特徴を備えていない可能性があります。
詳細および W&B Registry のすべての機能の詳細については、W&B Registry ガイド を参照してください。
よくある質問
W&B が Model Registry から W&B Registry に アセット を移行するのはなぜですか?
W&B は、新しい Registry でより高度な機能と性能を提供するために、 プラットフォーム を進化させています。この移行は、 モデル 、 データセット 、およびその他の Artifacts を管理するための、より統合された強力な ツール セット を提供するためのステップです。
移行前に何をする必要がありますか?
移行前に ユーザー が行う必要のある アクション はありません。W&B が移行を処理し、 ワークフロー と参照が確実に保持されるようにします。
モデル Artifacts への アクセス は失われますか?
いいえ、 モデル Artifacts への アクセス は移行後も保持されます。レガシー Model Registry は読み取り専用状態のままになり、関連するすべての データ が新しい Registry に移行されます。
Artifacts に関連する メタデータ は保持されますか?
はい、 Artifacts の作成、 リネージ 、およびその他の 属性 に関連する重要な メタデータ は、移行中に保持されます。ユーザー は、移行後も関連するすべての メタデータ に引き続き アクセス でき、 Artifacts の 整合性 とトレーサビリティが確実に維持されるようにします。
ヘルプが必要な場合は誰に連絡すればよいですか?
ご質問やご不明な点がございましたら、サポートをご利用いただけます。サポートが必要な場合は、support@wandb.com までご連絡ください。
4.3.12 - Model registry
モデルレジストリを使用して、トレーニングからプロダクションまでのモデルのライフサイクルを管理します。
W&B は最終的に W&B Model Registry のサポートを停止します。 ユーザー は、代わりにモデルアーティファクトの バージョン をリンクおよび共有するために、W&B Registry を使用することをお勧めします。 W&B Registry は、従来の W&B Model Registry の機能を拡張します。 W&B Registry の詳細については、Registry のドキュメント を参照してください。
W&B は、従来の Model Registry にリンクされている既存のモデルアーティファクトを、近い将来、新しい W&B Registry に移行します。 移行 プロセス の詳細については、従来の Model Registry からの移行 を参照してください。
W&B Model Registry には、 ML 実践者がプロダクション 用の候補を公開し、ダウンストリーム の チーム や関係者が利用できる、 チーム がトレーニング したモデルが格納されています。 これは、ステージング されたモデル/候補モデルを格納し、ステージング に関連する ワークフロー を管理するために使用されます。
W&B Model Registry では、次のことが可能です。
仕組み
いくつかの簡単なステップで、ステージング されたモデルを追跡および管理します。
モデル バージョン を ログ に記録する : トレーニング スクリプト で、数行の コード を追加して、モデルファイルを Artifacts として W&B に保存します。パフォーマンス を比較する : ライブ チャート をチェックして、モデル トレーニング と検証からの メトリクス とサンプル 予測 を比較します。 どのモデル バージョン が最も優れた パフォーマンス を発揮したかを特定します。Registry にリンクする : Python でプログラムで、または W&B UI でインタラクティブに、登録されたモデルにリンクして、最適なモデル バージョン をブックマークします。
次の コード スニペット は、モデルを ログ に記録して Model Registry にリンクする方法を示しています。
import wandb
import random
# Start a new W&B run
run = wandb. init(project= "models_quickstart" )
# Simulate logging model metrics
run. log({"acc" : random. random()})
# Create a simulated model file
with open("my_model.h5" , "w" ) as f:
f. write("Model: " + str(random. random()))
# Log and link the model to the Model Registry
run. link_model(path= "./my_model.h5" , registered_model_name= "MNIST" )
run. finish()
モデルの移行を CI/CD ワークフロー に接続する : 候補モデルを ワークフロー ステージを介して移行し、Webhooks で ダウンストリーム アクション を自動化 します。
開始方法
ユースケース に応じて、次の リソース を調べて W&B Models の使用を開始してください。
2 部構成のビデオ シリーズをご覧ください。
モデルの ログ 記録と登録 Model Registry での モデルの消費とダウンストリーム プロセス の自動化 。
W&B Python SDK コマンド のステップごとの概要については、モデルのウォークスルー を読んで、データセット Artifacts の作成、追跡、および使用に使用できます。
以下について学びます。
Model Registry が ML ワークフロー にどのように適合し、モデル管理にそれを使用する利点については、こちら の レポート を確認してください。
W&B Enterprise Model Management コース を受講して、以下を学びます。
W&B Model Registry を使用して、モデルの管理と バージョン 管理、 リネージ の追跡、およびさまざまなライフサイクル ステージでのモデルのプロモーションを行います。
Webhooks を使用して、モデル管理 ワークフロー を自動化します。
Model Registry が、モデルの 評価、モニタリング 、および デプロイメント のためのモデル開発ライフサイクルにおいて、外部 ML システム および ツール とどのように統合されるかを確認します。
4.3.12.1 - Tutorial: Use W&B for model management
W&B を使用して Model Management を行う方法について説明します。
以下のチュートリアルでは、モデルを W&B に記録する方法を紹介します。このチュートリアルを終えるまでに、以下のことができるようになります。
MNIST データセットと Keras フレームワークを使用してモデルを作成し、トレーニングする。
トレーニングしたモデルを W&B の project に記録する
使用したデータセットを作成したモデルへの依存関係としてマークする
モデルを W&B モデルレジストリにリンクする。
レジストリにリンクするモデルのパフォーマンスを評価する
モデルの version を production 用としてマークする。
このガイドに記載されている順序で コード スニペットをコピーしてください。
モデルレジストリに固有ではないコードは、折りたたみ可能なセルに隠されています。
セットアップ
始める前に、このチュートリアルに必要な Python の依存関係をインポートします。
import wandb
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from wandb.integration.keras import WandbMetricsLogger
from sklearn.model_selection import train_test_split
W&B の entity を entity 変数に指定します。
データセット Artifact を作成する
まず、データセットを作成します。次の コード スニペットは、MNIST データセットをダウンロードする関数を作成します。
def generate_raw_data (train_size= 6000 ):
eval_size = int(train_size / 6 )
(x_train, y_train), (x_eval, y_eval) = keras. datasets. mnist. load_data()
x_train = x_train. astype("float32" ) / 255
x_eval = x_eval. astype("float32" ) / 255
x_train = np. expand_dims(x_train, - 1 )
x_eval = np. expand_dims(x_eval, - 1 )
print("Generated {} rows of training data." . format(train_size))
print("Generated {} rows of eval data." . format(eval_size))
return (x_train[:train_size], y_train[:train_size]), (
x_eval[:eval_size],
y_eval[:eval_size],
)
# データセットを作成します
(x_train, y_train), (x_eval, y_eval) = generate_raw_data()
次に、データセットを W&B にアップロードします。これを行うには、アーティファクト オブジェクトを作成し、そのアーティファクトにデータセットを追加します。
project = "model-registry-dev"
model_use_case_id = "mnist"
job_type = "build_dataset"
# W&B の run を初期化します
run = wandb. init(entity= entity, project= project, job_type= job_type)
# トレーニングデータ用の W&B テーブルを作成します
train_table = wandb. Table(data= [], columns= [])
train_table. add_column("x_train" , x_train)
train_table. add_column("y_train" , y_train)
train_table. add_computed_columns(lambda ndx, row: {"img" : wandb. Image(row["x_train" ])})
# 評価データ用の W&B テーブルを作成します
eval_table = wandb. Table(data= [], columns= [])
eval_table. add_column("x_eval" , x_eval)
eval_table. add_column("y_eval" , y_eval)
eval_table. add_computed_columns(lambda ndx, row: {"img" : wandb. Image(row["x_eval" ])})
# Artifact オブジェクトを作成します
artifact_name = " {} _dataset" . format(model_use_case_id)
artifact = wandb. Artifact(name= artifact_name, type= "dataset" )
# wandb.WBValue オブジェクトを Artifact に追加します。
artifact. add(train_table, "train_table" )
artifact. add(eval_table, "eval_table" )
# Artifact に加えられた変更を永続化します。
artifact. save()
# W&B にこの run が完了したことを伝えます。
run. finish()
データセットなどのファイルを Artifact に保存すると、モデルの依存関係を追跡できるため、モデルのログを記録する際に役立ちます。
モデルをトレーニングする
前のステップで作成した Artifact データセットを使用してモデルをトレーニングします。
データセット Artifact を run への入力として宣言する
前のステップで作成したデータセット Artifact を W&B の run への入力として宣言します。Artifact を run への入力として宣言すると、特定のモデルのトレーニングに使用されたデータセット (およびデータセットの version) を追跡できるため、モデルのログを記録する際に特に役立ちます。W&B は、収集された情報を使用して、リネージマップ を作成します。
use_artifact API を使用して、データセット Artifact を run の入力として宣言し、Artifact 自体を取得します。
job_type = "train_model"
config = {
"optimizer" : "adam" ,
"batch_size" : 128 ,
"epochs" : 5 ,
"validation_split" : 0.1 ,
}
# W&B の run を初期化します
run = wandb. init(project= project, job_type= job_type, config= config)
# データセット Artifact を取得します
version = "latest"
name = " {} : {} " . format(" {} _dataset" . format(model_use_case_id), version)
artifact = run. use_artifact(artifact_or_name= name)
# データフレームから特定の内容を取得します
train_table = artifact. get("train_table" )
x_train = train_table. get_column("x_train" , convert_to= "numpy" )
y_train = train_table. get_column("y_train" , convert_to= "numpy" )
モデルの入力と出力を追跡する方法の詳細については、モデルリネージ マップの作成を参照してください。
モデルを定義してトレーニングする
このチュートリアルでは、Keras を使用して MNIST データセットから画像を分類する 2D Convolutional Neural Network (CNN) を定義します。
MNIST データで CNN をトレーニングする
# 設定ディクショナリの値を簡単にアクセスできるように変数に格納します
num_classes = 10
input_shape = (28 , 28 , 1 )
loss = "categorical_crossentropy"
optimizer = run. config["optimizer" ]
metrics = ["accuracy" ]
batch_size = run. config["batch_size" ]
epochs = run. config["epochs" ]
validation_split = run. config["validation_split" ]
# モデルアーキテクチャを作成します
model = keras. Sequential(
[
layers. Input(shape= input_shape),
layers. Conv2D(32 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Conv2D(64 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Flatten(),
layers. Dropout(0.5 ),
layers. Dense(num_classes, activation= "softmax" ),
]
)
model. compile(loss= loss, optimizer= optimizer, metrics= metrics)
# トレーニングデータのラベルを生成します
y_train = keras. utils. to_categorical(y_train, num_classes)
# トレーニングセットとテストセットを作成します
x_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size= 0.33 )
次に、モデルをトレーニングします。
# モデルをトレーニングします
model. fit(
x= x_t,
y= y_t,
batch_size= batch_size,
epochs= epochs,
validation_data= (x_v, y_v),
callbacks= [WandbCallback(log_weights= True , log_evaluation= True )],
)
最後に、モデルをローカルマシンに保存します。
# モデルをローカルに保存します
path = "model.h5"
model. save(path)
モデルをログに記録してモデルレジストリにリンクする
link_modelW&B モデルレジストリ にリンクします。
path = "./model.h5"
registered_model_name = "MNIST-dev"
run. link_model(path= path, registered_model_name= registered_model_name)
run. finish()
registered-model-name に指定した名前がまだ存在しない場合、W&B は登録済みモデルを作成します。
オプションのパラメータの詳細については、API リファレンスガイドのlink_model
モデルのパフォーマンスを評価する
1 つ以上のモデルのパフォーマンスを評価するのは一般的な方法です。
まず、前のステップで W&B に保存された評価データセット Artifact を取得します。
job_type = "evaluate_model"
# run を初期化します
run = wandb. init(project= project, entity= entity, job_type= job_type)
model_use_case_id = "mnist"
version = "latest"
# データセット Artifact を取得し、依存関係としてマークします
artifact = run. use_artifact(
" {} : {} " . format(" {} _dataset" . format(model_use_case_id), version)
)
# 目的のデータフレームを取得します
eval_table = artifact. get("eval_table" )
x_eval = eval_table. get_column("x_eval" , convert_to= "numpy" )
y_eval = eval_table. get_column("y_eval" , convert_to= "numpy" )
評価する W&B から モデル version をダウンロードします。use_model API を使用して、モデルにアクセスしてダウンロードします。
alias = "latest" # エイリアス
name = "mnist_model" # モデル Artifact の名前
# モデルにアクセスしてダウンロードします。ダウンロードした Artifact へのパスを返します
downloaded_model_path = run. use_model(name= f " { name} : { alias} " )
Keras モデルをロードし、損失を計算します。
model = keras. models. load_model(downloaded_model_path)
y_eval = keras. utils. to_categorical(y_eval, 10 )
(loss, _) = model. evaluate(x_eval, y_eval)
score = (loss, _)
最後に、損失メトリクスを W&B の run に記録します。
# # メトリクス、画像、テーブル、または評価に役立つデータを記録します。
run. log(data= {"loss" : (loss, _)})
モデル version を昇格させる
モデル エイリアス
たとえば、モデルのパフォーマンスを評価した後、そのモデルが production の準備ができていると確信したとします。そのモデル version を昇格させるには、production エイリアスをその特定のモデル version に追加します。
production エイリアスは、モデルを production 準備完了としてマークするために使用される最も一般的なエイリアスの 1 つです。
W&B アプリ UI を使用してインタラクティブに、または Python SDK を使用してプログラムで、モデル version にエイリアスを追加できます。次の手順では、W&B モデルレジストリアプリでエイリアスを追加する方法を示します。
https://wandb.ai/registry/model でモデルレジストリアプリに移動します。登録済みモデルの名前の横にある [詳細を表示 ] をクリックします。
[バージョン ] セクション内で、昇格させるモデル version の名前の横にある [表示 ] ボタンをクリックします。
[エイリアス ] フィールドの横にあるプラス アイコン ([+ ]) をクリックします。
表示されるフィールドに production と入力します。
キーボードの Enter キーを押します。
4.3.12.2 - Model Registry Terms and Concepts
モデルレジストリ の用語と概念
W&B の モデルレジストリ の主要コンポーネントは、以下の用語で説明されます。モデル バージョン モデル artifact registered model
モデル バージョン
モデル バージョンは、単一のモデル チェックポイント を表します。モデル バージョンは、実験 内におけるモデルとそのファイルの特定時点での スナップショット です。
モデル バージョンは、トレーニング されたモデルを記述するデータと メタデータ の不変の ディレクトリー です。W&B は、モデルの アーキテクチャー と学習済み パラメータ を後で保存(および復元)できるように、モデル バージョンにファイルを追加することをお勧めします。
モデル バージョンは、1つの モデル artifact にのみ属します。モデル バージョンは、ゼロまたは複数の registered model に属することができます。モデル バージョンは、モデル artifact に ログ された順にモデル artifact に保存されます。W&B は、(同じモデル artifact に) ログ するモデルの内容が以前のモデル バージョンと異なる場合、新しいモデル バージョンを自動的に作成します。
モデリング ライブラリ (たとえば、PyTorch や Keras ) によって提供されるシリアル化 プロセス から生成されたファイルをモデル バージョン内に保存します。
モデル エイリアス
モデル エイリアス は、 registered model 内のモデル バージョンを、セマンティックに関連する識別子で一意に識別または参照できる、変更可能な文字列です。エイリアス は、 registered model の 1 つの バージョン にのみ割り当てることができます。これは、 エイリアス がプログラムで使用される場合に一意の バージョン を参照する必要があるためです。また、 エイリアス を使用してモデルの状態 (チャンピオン、候補、本番) をキャプチャすることもできます。
"best"、"latest"、"production"、"staging" などの エイリアス を使用して、特別な目的を持つモデル バージョン をマークするのが一般的な方法です。
たとえば、モデルを作成し、それに "best" エイリアス を割り当てるとします。run.use_model でその特定のモデルを参照できます。
import wandb
run = wandb. init()
name = f " { entity/ project/ model_artifact_name} : { alias} "
run. use_model(name= name)
モデル タグ
モデル タグ は、1 つまたは複数の registered model に属する キーワード または ラベル です。
モデル タグ を使用して、 registered model を カテゴリ に整理し、 モデルレジストリ の検索バーでそれらの カテゴリ を検索します。モデル タグ は、 Registered Model Card の上部に表示されます。これらを使用して、 registered model を ML タスク 、所有 チーム 、または 優先度 でグループ化することもできます。同じモデル タグ を複数の registered model に追加して、グループ化できます。
モデル タグ は、グループ化と発見可能性のために registered model に適用される ラベル であり、
モデル エイリアス とは異なります。モデル エイリアス は、プログラムでモデル バージョン を取得するために使用する一意の識別子または ニックネーム です。タグ を使用して モデルレジストリ 内の タスク を整理する方法の詳細については、
モデル の整理 を参照してください。
モデル artifact
モデル artifact は、 ログ された モデル バージョン のコレクションです。モデル バージョンは、モデル artifact に ログ された順にモデル artifact に保存されます。
モデル artifact には、1 つ以上のモデル バージョン を含めることができます。モデル バージョン が ログ されていない場合、モデル artifact は空になる可能性があります。
たとえば、モデル artifact を作成するとします。モデル トレーニング 中に、 チェックポイント 中にモデルを定期的に保存します。各 チェックポイント は、独自の モデル バージョン に対応します。モデル トレーニング 中に作成され、 チェックポイント の保存されたすべてのモデル バージョン は、 トレーニング スクリプト の開始時に作成した同じモデル artifact に保存されます。
次の図は、v0、v1、v2 の 3 つのモデル バージョン を含むモデル artifact を示しています。
モデル artifact の例はこちら でご覧ください。
Registered model
Registered model は、モデル バージョン への ポインタ (リンク) のコレクションです。registered model は、同じ ML タスク の候補モデルの「 ブックマーク 」の フォルダー と考えることができます。registered model の各「 ブックマーク 」は、モデル artifact に属する モデル バージョン への ポインタ です。モデル タグ を使用して、 registered model をグループ化できます。
Registered model は、多くの場合、単一のモデリング ユースケース または タスク の候補モデルを表します。たとえば、使用するモデルに基づいて、さまざまな 画像分類 タスク の registered model を作成する場合があります:ImageClassifier-ResNet50、ImageClassifier-VGG16、DogBreedClassifier-MobileNetV2 など。モデル バージョン には、 registered model にリンクされた順に バージョン 番号が割り当てられます。
Registered Model の例はこちら でご覧ください。
4.3.12.3 - Track a model
W&B Python SDK で、 モデル 、 モデル の依存関係、およびその モデル に関連するその他の情報を追跡します。
W&B Python SDKで、モデル、モデルの依存関係、およびそのモデルに関連するその他の情報を追跡します。
W&Bは内部で、モデル Artifact のリネージを作成します。これは、W&B App UIで表示したり、W&B Python SDKでプログラム的に表示したりできます。詳細については、モデルリネージマップの作成 を参照してください。
モデルをログに記録する方法
モデルをログに記録するには、run.log_model APIを使用します。モデルファイルが保存されているパスを path パラメータに指定します。パスは、ローカルファイル、ディレクトリー、または s3://bucket/path などの外部バケットへの参照URI にすることができます。
オプションで、name パラメータにモデル Artifactの名前を指定します。name が指定されていない場合、W&Bはrun IDを先頭に付加した入力パスのベース名を使用します。
以下のコードスニペットをコピーして貼り付けます。<> で囲まれた値は、ご自身の値に置き換えてください。
import wandb
# W&B runを初期化する
run = wandb. init(project= "<project>" , entity= "<entity>" )
# モデルをログに記録する
run. log_model(path= "<path-to-model>" , name= "<name>" )
例: Keras モデルをW&Bにログする
以下のコード例は、畳み込みニューラルネットワーク (CNN) モデルをW&Bにログする方法を示しています。
import os
import wandb
from tensorflow import keras
from tensorflow.keras import layers
config = {"optimizer" : "adam" , "loss" : "categorical_crossentropy" }
# W&B runを初期化する
run = wandb. init(entity= "charlie" , project= "mnist-project" , config= config)
# トレーニングアルゴリズム
loss = run. config["loss" ]
optimizer = run. config["optimizer" ]
metrics = ["accuracy" ]
num_classes = 10
input_shape = (28 , 28 , 1 )
model = keras. Sequential(
[
layers. Input(shape= input_shape),
layers. Conv2D(32 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Conv2D(64 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Flatten(),
layers. Dropout(0.5 ),
layers. Dense(num_classes, activation= "softmax" ),
]
)
model. compile(loss= loss, optimizer= optimizer, metrics= metrics)
# モデルを保存
model_filename = "model.h5"
local_filepath = "./"
full_path = os. path. join(local_filepath, model_filename)
model. save(filepath= full_path)
# モデルをログに記録する
run. log_model(path= full_path, name= "MNIST" )
# W&B に run を終了することを明示的に伝える。
run. finish()
4.3.12.4 - Create a registered model
モデリングタスクのすべての候補モデルを保持するために、登録済み モデル を作成します。
モデリングタスクのすべての候補モデルを保持するために、registered model を作成します。 registered model は、Model Registry 内でインタラクティブに、または Python SDK でプログラム的に作成できます。
プログラムで registered model を作成する
W&B Python SDK でモデルをプログラム的に登録します。 registered model が存在しない場合、W&B は自動的に registered model を作成します。
必ず、<> で囲まれた値を独自の値に置き換えてください。
import wandb
run = wandb. init(entity= "<entity>" , project= "<project>" )
run. link_model(path= "<path-to-model>" , registered_model_name= "<registered-model-name>" )
run. finish()
registered_model_name に指定した名前は、Model Registry App に表示される名前です。
インタラクティブに registered model を作成する
Model Registry App 内でインタラクティブに registered model を作成します。
https://wandb.ai/registry/model で Model Registry App に移動します。
Model Registry ページの右上にある New registered model ボタンをクリックします。
表示される パネル で、registered model が属する Entities を Owning Entity ドロップダウンから選択します。
Name フィールドにモデルの名前を入力します。Type ドロップダウンから、registered model にリンクする Artifacts のタイプを選択します。(オプション)Description フィールドにモデルに関する説明を追加します。
(オプション)Tags フィールドに、1 つ以上のタグを追加します。
Register model をクリックします。
モデルを Model Registry に手動でリンクすることは、1 回限りのモデルに役立ちます。ただし、多くの場合、プログラムでモデルバージョンを Model Registry にリンクする ことが役立ちます。
たとえば、毎晩のジョブがあるとします。毎晩作成されるモデルを手動でリンクするのは面倒です。代わりに、モデルを評価するスクリプトを作成し、モデルのパフォーマンスが向上した場合、W&B Python SDK を使用してそのモデルを Model Registry にリンクすることができます。
4.3.12.5 - Link a model version
W&B App を使用するか、Python SDK でプログラム的に モデル の バージョン を Registered Model にリンクします。
W&B App または Python SDK で、モデルのバージョンを登録済みモデルにリンクします。
プログラムでモデルをリンクする
link_modelW&B モデルレジストリ にリンクします。
必ず <> で囲まれた値を独自の値に置き換えてください。
import wandb
run = wandb. init(entity= "<entity>" , project= "<project>" )
run. link_model(path= "<path-to-model>" , registered_model_name= "<登録済みモデル名>" )
run. finish()
registered-model-name パラメータに指定した名前がまだ存在しない場合、W&B によって登録済みモデルが作成されます。
たとえば、モデルレジストリに「Fine-Tuned-Review-Autocompletion 」(registered-model-name="Fine-Tuned-Review-Autocompletion") という名前の既存の登録済みモデルがあるとします。また、いくつかのモデルバージョンがそれ(v0、v1、v2)にリンクされているとします。新しいモデルをプログラムでリンクし、同じ登録済みモデル名 (registered-model-name="Fine-Tuned-Review-Autocompletion") を使用すると、W&B はこのモデルを既存の登録済みモデルにリンクし、モデルバージョン v3 を割り当てます。この名前の登録済みモデルが存在しない場合は、新しい登録済みモデルが作成され、モデルバージョン v0 が割り当てられます。
“Fine-Tuned-Review-Autocompletion” 登録済みモデルの例はこちら をご覧ください。
インタラクティブにモデルをリンクする
モデルレジストリ または Artifact ブラウザを使用して、インタラクティブにモデルをリンクします。
https://wandb.ai/registry/model のモデルレジストリ App に移動します。新しいモデルをリンクする登録済みモデルの名前の横にマウスを置きます。
詳細を表示 の横にあるミートボールメニューアイコン (3 つの水平ドット) を選択します。ドロップダウンから、新しいバージョンをリンク を選択します。
Project ドロップダウンから、モデルを含む project の名前を選択します。モデル Artifact ドロップダウンから、モデル artifact の名前を選択します。バージョン ドロップダウンから、登録済みモデルにリンクするモデル バージョンを選択します。
W&B App の project の Artifact ブラウザに移動します: https://wandb.ai/<entity>/<project>/artifacts
左側のサイドバーにある Artifacts アイコンを選択します。
レジストリにリンクするモデル バージョンをクリックします。
バージョンの概要 セクション内で、レジストリにリンク ボタンをクリックします。画面の右側に表示されるモーダルから、登録済みモデルを選択 メニューのドロップダウンから登録済みモデルを選択します。
次のステップ をクリックします。(オプション) エイリアス ドロップダウンからエイリアスを選択します。
レジストリにリンク をクリックします。
リンクされたモデルのソースを表示する
リンクされたモデルのソースを表示する方法は 2 つあります。モデルが ログ されている project 内の Artifact ブラウザと W&B モデルレジストリです。
ポインタは、モデルレジストリ内の特定のモデルバージョンをソース モデル artifact (モデルが ログ されている project 内にある) に接続します。ソース モデル artifact には、モデルレジストリへのポインタもあります。
https://wandb.ai/registry/model でモデルレジストリに移動します。
登録済みモデルの名前の横にある 詳細を表示 を選択します。
バージョン セクション内で、調査するモデルバージョンの横にある 表示 を選択します。右側の パネル 内の バージョン タブをクリックします。
バージョンの概要 セクション内に、ソースバージョン フィールドを含む行があります。ソースバージョン フィールドには、モデルの名前とモデルのバージョンの両方が表示されます。
たとえば、次の図は、MNIST-dev という名前の登録済みモデルにリンクされた mnist_model という名前の v0 モデル バージョンを示しています (ソースバージョン フィールド mnist_model:v0 を参照)。
W&B App の project の Artifact ブラウザに移動します: https://wandb.ai/<entity>/<project>/artifacts
左側のサイドバーにある Artifacts アイコンを選択します。
Artifacts パネルから モデル ドロップダウン メニューを展開します。
モデルレジストリにリンクされているモデルの名前とバージョンを選択します。
右側の パネル 内の バージョン タブをクリックします。
バージョンの概要 セクション内に、リンク先 フィールドを含む行があります。リンク先 フィールドには、登録済みモデルの名前と、それが持つバージョン (registered-model-name:version) の両方が表示されます。
たとえば、次の図では、MNIST-dev という名前の登録済みモデルがあります (リンク先 フィールドを参照)。バージョン v0 (mnist_model:v0) を持つ mnist_model という名前のモデル バージョンは、MNIST-dev 登録済みモデルを指しています。
4.3.12.6 - Organize models
モデルタグを使用すると、登録されたモデルをカテゴリに分類し、それらのカテゴリを検索できます。
https://wandb.ai/registry/model の W&B Model Registry アプリケーションに移動します。
モデルタグを追加する登録済みモデルの名前の横にある View details(詳細を見る) を選択します。
Model card(モデルカード) セクションまでスクロールします。
Tags(タグ) フィールドの横にあるプラスボタン(+ )をクリックします。
タグの名前を入力するか、既存のモデルタグを検索します。
たとえば、次の図は、FineTuned-Review-Autocompletion という登録済みモデルに追加された複数のモデルタグを示しています。
4.3.12.7 - Create model lineage map
このページでは、従来の W&B Model Registry でリネージグラフを作成する方法について説明します。W&B Registry のリネージグラフについては、リネージマップの作成と表示 を参照してください。
モデル アーティファクト を W&B に ログ 記録する便利な機能は、リネージグラフです。リネージグラフは、 run によって ログ 記録された アーティファクト と、特定の run で使用された アーティファクト を示します。
つまり、モデル アーティファクト を ログ 記録すると、少なくともモデル アーティファクト を使用または生成した W&B の run を表示できます。依存関係を追跡する 場合、モデル アーティファクト で使用される入力も表示されます。
たとえば、次の図は、ML 実験 全体で作成および使用された アーティファクト を示しています。
左から右へ、画像は以下を示しています。
jumping-monkey-1 W&B run は、mnist_dataset:v0 データセット アーティファクト を作成しました。vague-morning-5 W&B run は、mnist_dataset:v0 データセット アーティファクト を使用してモデルをトレーニングしました。この W&B run の出力は、mnist_model:v0 というモデル アーティファクト でした。serene-haze-6 という run は、モデル アーティファクト ( mnist_model:v0) を使用してモデルを評価しました。
アーティファクト の依存関係を追跡する
use_artifact API を使用して、データセット アーティファクト を W&B run への入力として宣言し、依存関係を追跡します。
次の コード スニペット は、use_artifact API の使用方法を示しています。
# run を初期化する
run = wandb. init(project= project, entity= entity)
# アーティファクト を取得し、依存関係としてマークします
artifact = run. use_artifact(artifact_or_name= "name" , aliases= "<alias>" )
アーティファクト を取得したら、その アーティファクト を使用して (たとえば) モデルのパフォーマンスを評価できます。
例: モデルをトレーニングし、データセット をモデルの入力として追跡します
job_type = "train_model"
config = {
"optimizer" : "adam" ,
"batch_size" : 128 ,
"epochs" : 5 ,
"validation_split" : 0.1 ,
}
run = wandb. init(project= project, job_type= job_type, config= config)
version = "latest"
name = " {} : {} " . format(" {} _dataset" . format(model_use_case_id), version)
artifact = run. use_artifact(name)
train_table = artifact. get("train_table" )
x_train = train_table. get_column("x_train" , convert_to= "numpy" )
y_train = train_table. get_column("y_train" , convert_to= "numpy" )
# config 辞書 からの値を簡単にアクセスできるように変数に格納します
num_classes = 10
input_shape = (28 , 28 , 1 )
loss = "categorical_crossentropy"
optimizer = run. config["optimizer" ]
metrics = ["accuracy" ]
batch_size = run. config["batch_size" ]
epochs = run. config["epochs" ]
validation_split = run. config["validation_split" ]
# モデル アーキテクチャ を作成する
model = keras. Sequential(
[
layers. Input(shape= input_shape),
layers. Conv2D(32 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Conv2D(64 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Flatten(),
layers. Dropout(0.5 ),
layers. Dense(num_classes, activation= "softmax" ),
]
)
model. compile(loss= loss, optimizer= optimizer, metrics= metrics)
# トレーニング データ のラベルを生成する
y_train = keras. utils. to_categorical(y_train, num_classes)
# トレーニング セット と テスト セット を作成する
x_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size= 0.33 )
# モデルをトレーニングする
model. fit(
x= x_t,
y= y_t,
batch_size= batch_size,
epochs= epochs,
validation_data= (x_v, y_v),
callbacks= [WandbCallback(log_weights= True , log_evaluation= True )],
)
# モデルをローカルに保存する
path = "model.h5"
model. save(path)
path = "./model.h5"
registered_model_name = "MNIST-dev"
name = "mnist_model"
run. link_model(path= path, registered_model_name= registered_model_name, name= name)
run. finish()
4.3.12.8 - Document machine learning model
モデルカード に説明を追加して、 モデル を文書化します。
登録済みモデルのモデルカードに説明を追加して、 機械学習 モデルの側面を文書化します。文書化する価値のあるトピックには、次のものがあります。
概要 : モデルの概要。モデルの目的。モデルが使用する 機械学習 フレームワークなど。トレーニングデータ : 使用したトレーニングデータ、トレーニングデータセットで実行された処理、そのデータの保存場所などを記述します。アーキテクチャー : モデルアーキテクチャー、レイヤー、および特定の設計の選択に関する情報。モデルのデシリアライズ : チームの誰かがモデルをメモリーにロードする方法に関する情報を提供します。タスク : 機械学習 モデルが実行するように設計されている特定のタイプのタスクまたは問題。モデルの意図された機能の分類です。ライセンス : 機械学習 モデルの使用に関連する法的条件と許可。モデル ユーザーがモデルを利用できる法的枠組みを理解するのに役立ちます。参考文献 : 関連する 研究 論文、データセット、または外部リソースへの引用または参考文献。デプロイメント : モデルのデプロイ方法と場所の詳細、および ワークフロー オーケストレーション プラットフォーム などの他のエンタープライズ システムへのモデルの統合方法に関するガイダンス。
モデルカードに説明を追加する
https://wandb.ai/registry/model にある W&B Model Registry アプリケーションに移動します。モデルカードを作成する登録済みモデルの名前の横にある [詳細を表示 ] を選択します。
[モデルカード ] セクションに移動します。
[説明 ] フィールドに、 機械学習 モデルに関する情報を提供します。Markdown マークアップ言語 を使用して、モデルカード内のテキストの書式を設定します。
たとえば、次の図は、Credit-card Default Prediction 登録済みモデルのモデルカードを示しています。
4.3.12.9 - Download a model version
W&B Python SDK でモデルをダウンロードする方法
W&B Python SDK を使用して、Model Registry にリンクしたモデル artifact をダウンロードします。
モデルを再構築し、デシリアライズして、操作できる形式にするための追加の Python 関数、API 呼び出しはお客様の責任で提供する必要があります。
W&B では、モデルをメモリにロードする方法に関する情報をモデルカードに記載することをお勧めします。詳細については、機械学習モデルのドキュメント ページを参照してください。
<> 内の values はお客様ご自身のものに置き換えてください。
import wandb
# run を初期化する
run = wandb. init(project= "<project>" , entity= "<entity>" )
# モデルにアクセスしてダウンロードします。ダウンロードした artifact への path を返します
downloaded_model_path = run. use_model(name= "<your-model-name>" )
以下のいずれかの形式でモデル version を参照してください。
latest - 最新の latest エイリアスを使用して、最も新しくリンクされたモデル version を指定します。v# - v0、v1、v2 などを使用して、Registered Model 内の特定の version を取得しますalias - ユーザー と Teams がモデル version に割り当てたカスタム alias を指定します
可能なパラメータと戻り値の型について詳しくは、API Reference ガイドのuse_model
例: ログに記録されたモデルをダウンロードして使用する
たとえば、次のコード snippet では、ユーザー が use_model API を呼び出しました。フェッチするモデル artifact の名前を指定し、version/alias も指定しました。次に、API から返された path を downloaded_model_path 変数に格納しました。
import wandb
entity = "luka"
project = "NLP_Experiments"
alias = "latest" # モデル version のセマンティックなニックネームまたは識別子
model_artifact_name = "fine-tuned-model"
# run を初期化する
run = wandb. init()
# モデルにアクセスしてダウンロードします。ダウンロードした artifact への path を返します
downloaded_model_path = run. use_model(name= f " { entity/ project/ model_artifact_name} : { alias} " )
2024 年に予定されている W&B Model Registry の廃止 次のタブは、まもなく廃止される Model Registry を使用してモデル artifact を消費する方法を示しています。
W&B Registry を使用して、モデル artifact を追跡、整理、消費します。詳細については、Registry docs を参照してください。
<> 内の values はお客様ご自身のものに置き換えてください。
import wandb
# run を初期化する
run = wandb. init(project= "<project>" , entity= "<entity>" )
# モデルにアクセスしてダウンロードします。ダウンロードした artifact への path を返します
downloaded_model_path = run. use_model(name= "<your-model-name>" )
以下のいずれかの形式でモデル version を参照してください。
latest - 最新の latest エイリアスを使用して、最も新しくリンクされたモデル version を指定します。v# - v0、v1、v2 などを使用して、Registered Model 内の特定の version を取得しますalias - ユーザー と Teams がモデル version に割り当てたカスタム alias を指定します
可能なパラメータと戻り値の型について詳しくは、API Reference ガイドのuse_model
https://wandb.ai/registry/model にある Model Registry App に移動します。ダウンロードするモデルが含まれている登録済みモデルの名前の横にある詳細を表示 を選択します。
[Versions] セクションで、ダウンロードするモデル version の横にある [View] ボタンを選択します。
ファイル タブを選択します。ダウンロードするモデルファイルの横にあるダウンロードボタンをクリックします。
4.3.12.10 - Create alerts and notifications
新しい モデル バージョン が モデルレジストリ にリンクされたときに Slack 通知を受け取ります。
新しいモデル バージョンがモデルレジストリにリンクされたときに、Slack通知を受信します。
W&B モデルレジストリのアプリ(https://wandb.ai/registry/model )に移動します。
通知を受信したい Registered Model を選択します。
[Connect Slack ] ボタンをクリックします。
OAuth ページに表示される手順に従って、Slack workspace で W&B を有効にします。
チームの Slack 通知を設定すると、通知を受信する Registered Model を選択できます。
チームの Slack 通知が設定されている場合、[Connect Slack ] ボタンの代わりに、[New model version linked to… ] と表示されるトグルが表示されます。
以下のスクリーンショットは、Slack 通知が設定されている FMNIST 分類器の Registered Model を示しています。
新しいモデル バージョンが FMNIST 分類器の Registered Model にリンクされるたびに、メッセージが接続された Slack チャンネルに自動的に投稿されます。
4.3.12.11 - Manage data governance and access control
モデルレジストリのロールベース アクセス制御(RBAC)を使用して、保護されたエイリアスを更新できるユーザーを制御します。
モデル開発 パイプライン の主要な段階を表すために、 保護されたエイリアス を使用します。 モデルレジストリ管理者 のみが、保護されたエイリアスを追加、変更、または削除できます。モデルレジストリ管理者は、保護されたエイリアスを定義して使用できます。W&B は、管理者以外の ユーザー がモデル バージョン から保護されたエイリアスを追加または削除することをブロックします。
Team 管理者または現在のレジストリ管理者のみが、レジストリ管理者のリストを管理できます。
たとえば、 staging と production を保護されたエイリアスとして設定するとします。Team のメンバーは誰でも新しいモデル バージョンを追加できます。ただし、管理者のみが staging または production エイリアスを追加できます。
アクセス制御の設定
次の手順では、Team の モデルレジストリ の アクセス 制御を設定する方法について説明します。
W&B モデルレジストリ アプリ ( https://wandb.ai/registry/model ) に移動します。
ページの右上にある歯車ボタンを選択します。
[レジストリ管理者の管理 ] ボタンを選択します。
[メンバー ] タブで、モデル バージョン から保護されたエイリアスを追加および削除する アクセス 権を付与する ユーザー を選択します。
保護されたエイリアスの追加
W&B モデルレジストリ アプリ ( https://wandb.ai/registry/model ) に移動します。
ページの右上にある歯車ボタンを選択します。
[保護されたエイリアス ] セクションまで下にスクロールします。
プラス アイコン ( + ) アイコンをクリックして、新しいエイリアスを追加します。
4.4 - Reports
機械学習 プロジェクト のための プロジェクト 管理とコラボレーション ツール
W&B Reports の用途:
Runs の整理。
可視化の埋め込みと自動化。
学び の記述。
コラボレーターとの更新情報の共有(LaTeX zip ファイルまたは PDF として)。
次の画像は、トレーニングの過程で W&B に ログ された メトリクス から作成された レポート のセクションを示しています。
上記の画像が取得された レポート は こちら からご覧ください。
仕組み
数回クリックするだけで、コラボレーティブな レポート を作成できます。
W&B App で W&B project workspace に移動します。
workspace の右上隅にある [Create report ] (レポート の作成) ボタンをクリックします。
[Create Report ] (レポート の作成) という タイトル のモーダルが表示されます。 レポート に追加するグラフと パネル を選択します (グラフと パネル は後で追加または削除できます)。
[Create report ] (レポート の作成) をクリックします。
レポート を希望の状態に編集します。
[Publish to project ] (project に公開) をクリックします。
[Share ] (共有) ボタンをクリックして、コラボレーターと レポート を共有します。
W&B Python SDK を使用して インタラクティブ およびプログラムで レポート を作成する方法の詳細については、レポート の作成 ページを参照してください。
開始方法
ユースケース に応じて、次のリソースを調べて W&B Reports を開始してください。
推奨される ベストプラクティス とヒント
Experiments と ログ の ベストプラクティス とヒントについては、Best Practices: Reports を参照してください。
4.4.1 - Create a report
W&B の App UI を使用するか、Weights & Biases SDK を使用してプログラムで W&B Report を作成します。
W&B App UI または W&B Python SDK を使用して、プログラムでインタラクティブに report を作成します。
App UI
Report tab
W&B Python SDK
W&B App で project の workspace に移動します。
workspace の右上隅にある [Create report ] をクリックします。
モーダルが表示されます。最初に表示するグラフを選択します。グラフは report インターフェイスから後で追加または削除できます。
[Filter run sets ] オプションを選択して、新しい run が report に追加されないようにします。このオプションはオン/オフを切り替えることができます。[Create report ] をクリックすると、下書き report が report タブで使用できるようになり、作業を続けることができます。
W&B App で project の workspace に移動します。
project の [Reports ] タブ (クリップボードの画像) を選択します。
report ページで [Create Report ] ボタンを選択します。
wandb ライブラリを使用して、プログラムで report を作成します。
W&B SDK と Workspaces API をインストールします。
pip install wandb wandb-workspaces
次に、ワークスペースをインポートします。
import wandb
import wandb_workspaces.reports.v2 as wr
wandb_workspaces.reports.v2.Report を使用して report を作成します。Report Class Public API (wandb.apis.reports
report = wr. Report(project= "report_standard" )
report を保存します。Reports は、.save() メソッドを呼び出すまで W&B サーバーにアップロードされません。
App UI またはプログラムで report をインタラクティブに編集する方法については、Edit a report を参照してください。
4.4.2 - Edit a report
App UI を使用してインタラクティブに、または W&B SDK を使用してプログラム的に レポート を編集します。
App UIまたは W&B SDKでプログラム的に、インタラクティブにレポートを編集できます。
Reports は ブロック で構成されています。ブロックはレポートの本文を構成します。これらのブロック内には、テキスト、画像、埋め込み 可視化、実験からのプロットと run、および パネル グリッドを追加できます。
パネル グリッド は、パネルと run sets を保持する特定のタイプのブロックです。Run sets は、W&B のプロジェクトに記録された runs の集合です。パネルは run set データの 可視化です。
レポートをプログラムで編集する場合は、W&B Python SDKに加えて wandb-workspaces がインストールされていることを確認してください。
pip install wandb wandb-workspaces
プロットを追加する
各パネル グリッドには、run sets のセットとパネルのセットがあります。セクションの下部にある run sets は、グリッド内のパネルに表示されるデータを制御します。異なる runs のセットからデータを取得するグラフを追加する場合は、新しいパネル グリッドを作成します。
レポートにスラッシュ (/) を入力して、ドロップダウン メニューを表示します。[パネルを追加 ] を選択して、パネルを追加します。折れ線グラフ、散布図、平行座標グラフなど、W&B でサポートされている任意のパネルを追加できます。
SDKを使用して、プログラムでプロットをレポートに追加します。1つ以上のプロットまたはグラフ オブジェクトのリストを PanelGrid Public API Classの panels パラメータに渡します。関連するPythonクラスを使用してプロットまたはグラフ オブジェクトを作成します。
次の例は、折れ線グラフと散布図を作成する方法を示しています。
import wandb
import wandb_workspaces.reports.v2 as wr
report = wr. Report(
project= "report-editing" ,
title= "An amazing title" ,
description= "A descriptive description." ,
)
blocks = [
wr. PanelGrid(
panels= [
wr. LinePlot(x= "time" , y= "velocity" ),
wr. ScatterPlot(x= "time" , y= "acceleration" ),
]
)
]
report. blocks = blocks
report. save()
プログラムでレポートに追加できる利用可能なプロットとグラフの詳細については、wr.panels を参照してください。
Run sets を追加する
App UIまたは W&B SDKを使用して、プロジェクトからrun setsをインタラクティブに追加します。
レポートにスラッシュ (/) を入力して、ドロップダウン メニューを表示します。ドロップダウンから、[パネル グリッド] を選択します。これにより、レポートが作成されたプロジェクトから run set が自動的にインポートされます。
wr.Runset() および wr.PanelGrid クラスを使用して、プロジェクトから run sets を追加します。次の手順では、run set を追加する方法について説明します。
wr.Runset() オブジェクト インスタンスを作成します。プロジェクトの run sets が含まれるプロジェクトの名前を project パラメータに、プロジェクトを所有するエンティティを entity パラメータに指定します。wr.PanelGrid() オブジェクト インスタンスを作成します。1つ以上の run set オブジェクトのリストを runsets パラメータに渡します。1つ以上の wr.PanelGrid() オブジェクト インスタンスをリストに格納します。
パネル グリッド インスタンスのリストで report インスタンス ブロック属性を更新します。
import wandb
import wandb_workspaces.reports.v2 as wr
report = wr. Report(
project= "report-editing" ,
title= "An amazing title" ,
description= "A descriptive description." ,
)
panel_grids = wr. PanelGrid(
runsets= [wr. RunSet(project= "<project-name>" , entity= "<entity-name>" )]
)
report. blocks = [panel_grids]
report. save()
オプションで、SDKへの1回の呼び出しで run sets とパネルを追加できます。
import wandb
report = wr. Report(
project= "report-editing" ,
title= "An amazing title" ,
description= "A descriptive description." ,
)
panel_grids = wr. PanelGrid(
panels= [
wr. LinePlot(
title= "line title" ,
x= "x" ,
y= ["y" ],
range_x= [0 , 100 ],
range_y= [0 , 100 ],
log_x= True ,
log_y= True ,
title_x= "x axis title" ,
title_y= "y axis title" ,
ignore_outliers= True ,
groupby= "hyperparam1" ,
groupby_aggfunc= "mean" ,
groupby_rangefunc= "minmax" ,
smoothing_factor= 0.5 ,
smoothing_type= "gaussian" ,
smoothing_show_original= True ,
max_runs_to_show= 10 ,
plot_type= "stacked-area" ,
font_size= "large" ,
legend_position= "west" ,
),
wr. ScatterPlot(
title= "scatter title" ,
x= "y" ,
y= "y" ,
# z='x',
range_x= [0 , 0.0005 ],
range_y= [0 , 0.0005 ],
# range_z=[0,1],
log_x= False ,
log_y= False ,
# log_z=True,
running_ymin= True ,
running_ymean= True ,
running_ymax= True ,
font_size= "small" ,
regression= True ,
),
],
runsets= [wr. RunSet(project= "<project-name>" , entity= "<entity-name>" )],
)
report. blocks = [panel_grids]
report. save()
Run set を固定する
レポートは、プロジェクトからの最新のデータを表示するために、run sets を自動的に更新します。Run set を固定 することで、レポート内の run set を保持できます。Run set を固定すると、ある時点でのレポート内の run set の状態が保持されます。
レポートの表示中に run set を固定するには、[フィルタ] ボタンの近くにあるパネル グリッド内の雪のアイコンをクリックします。
コード ブロックを追加する
App UIまたは W&B SDKを使用して、インタラクティブにコード ブロックをレポートに追加します。
レポートにスラッシュ (/) を入力して、ドロップダウン メニューを表示します。ドロップダウンから [コード ] を選択します。
コード ブロックの右側にあるプログラミング言語の名前を選択します。これにより、ドロップダウンが展開されます。ドロップダウンから、プログラミング言語の構文を選択します。Javascript、Python、CSS、JSON、HTML、Markdown、および YAML から選択できます。
wr.CodeBlock クラスを使用して、プログラムでコード ブロックを作成します。それぞれ言語パラメータとコード パラメータに表示する言語の名前とコードを指定します。
たとえば、次の例は YAML ファイルのリストを示しています。
import wandb
import wandb_workspaces.reports.v2 as wr
report = wr. Report(project= "report-editing" )
report. blocks = [
wr. CodeBlock(
code= ["this:" , "- is" , "- a" , "cool:" , "- yaml" , "- file" ], language= "yaml"
)
]
report. save()
これにより、次のようなコード ブロックがレンダリングされます。
this :
- is
- a
cool :
- yaml
- file
次の例は、Pythonコード ブロックを示しています。
report = wr. Report(project= "report-editing" )
report. blocks = [wr. CodeBlock(code= ["Hello, World!" ], language= "python" )]
report. save()
これにより、次のようなコード ブロックがレンダリングされます。
Markdown を追加する
App UIまたは W&B SDKを使用して、インタラクティブに Markdown をレポートに追加します。
レポートにスラッシュ (/) を入力して、ドロップダウン メニューを表示します。ドロップダウンから [Markdown ] を選択します。
wandb.apis.reports.MarkdownBlock クラスを使用して、プログラムで Markdown ブロックを作成します。文字列を text パラメータに渡します。
import wandb
import wandb_workspaces.reports.v2 as wr
report = wr. Report(project= "report-editing" )
report. blocks = [
wr. MarkdownBlock(text= "Markdown cell with *italics* and **bold** and $e=mc^2$" )
]
これにより、次のような Markdown ブロックがレンダリングされます。
HTML 要素を追加する
App UIまたは W&B SDKを使用して、インタラクティブに HTML 要素をレポートに追加します。
レポートにスラッシュ (/) を入力して、ドロップダウン メニューを表示します。ドロップダウンからテキスト ブロックのタイプを選択します。たとえば、H2 見出しブロックを作成するには、[見出し 2] オプションを選択します。
1つ以上のHTML要素のリストを wandb.apis.reports.blocks 属性に渡します。次の例は、H1、H2、および順序なしリストを作成する方法を示しています。
import wandb
import wandb_workspaces.reports.v2 as wr
report = wr. Report(project= "report-editing" )
report. blocks = [
wr. H1(text= "How Programmatic Reports work" ),
wr. H2(text= "Heading 2" ),
wr. UnorderedList(items= ["Bullet 1" , "Bullet 2" ]),
]
report. save()
これにより、HTML要素が次のようにレンダリングされます。
リッチ メディア リンクを埋め込む
App UIまたは W&B SDKを使用して、レポート内にリッチ メディアを埋め込みます。
URLをコピーしてレポートに貼り付け、レポート内にリッチ メディアを埋め込みます。次のアニメーションは、Twitter、YouTube、および SoundCloud から URL をコピーして貼り付ける方法を示しています。
ツイート リンクの URL をコピーしてレポートに貼り付け、レポート内でツイートを表示します。
Youtube
YouTube ビデオの URL リンクをコピーして貼り付け、ビデオをレポートに埋め込みます。
SoundCloud
SoundCloud リンクをコピーして貼り付け、オーディオ ファイルをレポートに埋め込みます。
1つ以上の埋め込みメディア オブジェクトのリストを wandb.apis.reports.blocks 属性に渡します。次の例は、ビデオと Twitter メディアをレポートに埋め込む方法を示しています。
import wandb
import wandb_workspaces.reports.v2 as wr
report = wr. Report(project= "report-editing" )
report. blocks = [
wr. Video(url= "https://www.youtube.com/embed/6riDJMI-Y8U" ),
wr. Twitter(
embed_html= '<blockquote class="twitter-tweet"><p lang="en" dir="ltr">The voice of an angel, truly. <a href="https://twitter.com/hashtag/MassEffect?src=hash&ref_src=twsrc %5E tfw">#MassEffect</a> <a href="https://t.co/nMev97Uw7F">pic.twitter.com/nMev97Uw7F</a></p>— Mass Effect (@masseffect) <a href="https://twitter.com/masseffect/status/1428748886655569924?ref_src=twsrc %5E tfw">August 20, 2021</a></blockquote> \n '
),
]
report. save()
パネル グリッドを複製および削除する
再利用したいレイアウトがある場合は、パネル グリッドを選択してコピーして貼り付け、同じレポートに複製したり、別のレポートに貼り付けたりすることもできます。
右上隅にあるドラッグ ハンドルを選択して、パネル グリッド セクション全体を強調表示します。クリックしてドラッグして、パネル グリッド、テキスト、見出しなどのレポート内の領域を強調表示して選択します。
パネル グリッドを選択し、キーボードの delete を押してパネル グリッドを削除します。
ヘッダーを折りたたんで Reports を整理する
Report のヘッダーを折りたたんで、テキスト ブロック内のコンテンツを非表示にします。レポートが読み込まれると、展開されているヘッダーのみがコンテンツを表示します。レポートでヘッダーを折りたたむと、コンテンツを整理し、過剰なデータ読み込みを防ぐことができます。次の gif は、そのプロセスを示しています。
複数の次元にわたる関係を可視化する
複数の次元にわたる関係を効果的に 可視化 するには、カラー グラデーションを使用して変数の1つを表します。これにより、明瞭さが向上し、パターンが解釈しやすくなります。
カラー グラデーションで表す変数を選択します (例: ペナルティ スコア、学習率など)。これにより、トレーニング時間 (x軸) にわたって、ペナルティ (色) が報酬/副作用 (y軸) とどのように相互作用するかをより明確に理解できます。
主要な傾向を強調表示します。特定の runs のグループにカーソルを合わせると、 可視化 でそれらが強調表示されます。
4.4.3 - Collaborate on reports
W&B Reports を同僚、共同作業者、およびチームと共有してコラボレーションできます。
レポートを保存したら、Share ボタンを選択して共同作業ができます。Edit ボタンを選択すると、レポートのドラフトコピーが作成されます。ドラフトレポートは自動保存されます。変更を共有レポートに公開するには、Save to report を選択します。
編集の競合が発生した場合、警告通知が表示されます。これは、あなたと別の共同作業者が同じレポートを同時に編集した場合に発生する可能性があります。警告通知は、潜在的な編集の競合を解決するのに役立ちます。
レポートにコメントする
レポートの パネル にコメントボタンをクリックすると、その パネル に直接コメントを追加できます。
4.4.4 - Clone and export reports
W&B の レポート を PDF または LaTeX としてエクスポートします。
レポート のエクスポート
レポート をPDFまたは LaTeXとしてエクスポートします。 レポート 内で、ケバブアイコンを選択してドロップダウンメニューを展開します。[Download ] を選択し、PDFまたは LaTeX出力形式を選択します。
レポート の複製
レポート 内で、ケバブアイコンを選択してドロップダウンメニューを展開します。[Clone this report ] ボタンを選択します。モーダルで、複製された レポート の宛先を選択します。[Clone report ] を選択します。
レポート を複製して、 プロジェクト のテンプレートと形式を再利用します。チームのアカウント内で プロジェクト を複製すると、複製された プロジェクト はチームに表示されます。個人のアカウント内で複製された プロジェクト は、その ユーザー にのみ表示されます。
URLから Report をロードして、テンプレートとして使用します。
report = wr. Report(
project= PROJECT, title= "Quickstart Report" , description= "That was easy!"
) # 作成
report. save() # 保存
new_report = wr. Report. from_url(report. url) # ロード
new_report.blocks内のコンテンツを編集します。
pg = wr. PanelGrid(
runsets= [
wr. Runset(ENTITY, PROJECT, "First Run Set" ),
wr. Runset(ENTITY, PROJECT, "Elephants Only!" , query= "elephant" ),
],
panels= [
wr. LinePlot(x= "Step" , y= ["val_acc" ], smoothing_factor= 0.8 ),
wr. BarPlot(metrics= ["acc" ]),
wr. MediaBrowser(media_keys= "img" , num_columns= 1 ),
wr. RunComparer(diff_only= "split" , layout= {"w" : 24 , "h" : 9 }),
],
)
new_report. blocks = (
report. blocks[:1 ] + [wr. H1("Panel Grid Example" ), pg] + report. blocks[1 :]
)
new_report. save()
4.4.5 - Embed a report
W&B Reports を Notion に直接埋め込んだり、HTML IFrame 要素で埋め込んだりできます。
HTML iframe 要素
レポート の右上隅にある [共有 ] ボタンを選択します。モーダルウィンドウが表示されます。モーダルウィンドウ内で、[埋め込みコードをコピー ] を選択します。コピーされたコードは、インラインフレーム (IFrame) HTML 要素内にレンダリングされます。コピーしたコードを、選択した iframe HTML 要素に貼り付けます。
公開 レポートのみが埋め込み時に表示可能です。
Confluence
次のアニメーションは、Confluence の IFrame セル内にレポートへの直接リンクを挿入する方法を示しています。
Notion
次のアニメーションは、Notion の Embed ブロックとレポートの埋め込みコードを使用して、レポートを Notion ドキュメントに挿入する方法を示しています。
Gradio
gr.HTML 要素を使用すると、Gradio Apps 内に W&B Reports を埋め込み、Hugging Face Spaces 内で使用できます。
import gradio as gr
def wandb_report (url):
iframe = f '<iframe src= { url} style="border:none;height:1024px;width:100%">'
return gr. HTML(iframe)
with gr. Blocks() as demo:
report = wandb_report(
"https://wandb.ai/_scott/pytorch-sweeps-demo/reports/loss-22-10-07-16-00-17---VmlldzoyNzU2NzAx"
)
demo. launch()
4.4.6 - Compare runs across projects
異なるプロジェクトのrunを、プロジェクトを跨いだReportsで比較します。
クロスプロジェクト レポートを使用して、2 つの異なるプロジェクトの run を比較します。run セット テーブルのプロジェクト セレクターを使用して、プロジェクトを選択します。
セクション内の 可視化 は、最初のアクティブな runset から列をプルします。ラインプロットで探している メトリクス が見つからない場合は、セクションで最初にチェックされた run セットにその列があることを確認してください。
この機能は、 時系列 ラインの履歴データをサポートしていますが、異なるプロジェクトから異なるサマリー メトリクス をプルすることはサポートしていません。つまり、別のプロジェクトでのみ ログ に記録される列から散布図を作成することはできません。
2 つのプロジェクトの run を比較する必要があり、列が機能しない場合は、一方のプロジェクトの run にタグを追加し、それらの run をもう一方のプロジェクトに移動します。各プロジェクトの run のみをフィルタリングできますが、 レポート には両方の run セットのすべての列が含まれます。
表示専用の レポート リンク
プライベート プロジェクト または Team プロジェクトにある レポート への表示専用リンクを共有します。
表示専用の レポート リンクは、URL に秘密の アクセス トークンを追加するため、リンクを開いた人は誰でもページを表示できます。誰でもマジック リンクを使用して、最初に ログ インしなくても レポート を表示できます。W&B Local プライベート クラウド インストールをご利用のお客様の場合、これらのリンクはファイアウォールの内側に保持されるため、プライベート インスタンスへの アクセス 権と表示専用リンクへの アクセス 権を持つチームのメンバーのみが レポート を表示できます。
表示専用モード では、 ログ インしていない人は、チャートを表示したり、マウスオーバーして 値 のツールチップを表示したり、チャートを拡大/縮小したり、テーブル内の列をスクロールしたりできます。表示モードの場合、新しいチャートや新しいテーブル クエリを作成して データを探索することはできません。表示専用の レポート リンクの訪問者は、run をクリックして run ページに移動することはできません。また、表示専用の訪問者には共有モーダルは表示されませんが、代わりにホバーすると、次のようなツールチップが表示されます: 表示専用アクセスでは共有は利用できません。
マジック リンクは、「プライベート」および「Team」プロジェクトでのみ使用できます。「パブリック」(誰でも表示可能)または「オープン」(誰でもrunを表示および投稿可能)プロジェクトの場合、このプロジェクトはパブリックであり、すでにリンクを持っている人なら誰でも利用できるため、リンクをオン/オフにすることはできません。
グラフを レポート に送信する
ワークスペース からグラフを レポート に送信して、進捗状況を追跡します。 レポート にコピーするチャートまたは パネル のドロップダウン メニューをクリックし、Add to report をクリックして宛先の レポート を選択します。
4.4.7 - Example reports
Reports ギャラリー
Notes: 素早い要約で 可視化を追加
プロジェクトの開発で重要な観察、将来の作業のためのアイデア、または達成されたマイルストーンを記録します。 Report 内のすべての実験 run は、パラメータ、メトリクス、ログ、およびコードにリンクされるため、作業の完全なコンテキストを保存できます。
テキストを書き留め、関連するグラフを取り込んで、洞察を説明します。
トレーニング時間の比較を共有する方法の例については、Inception-ResNet-V2 が遅すぎる場合の対処法 W&B Report を参照してください。
参照と将来のインタラクションのために、複雑なコードベースから最良の例を保存します。 Lyft dataset からの LIDAR ポイントクラウドを可視化し、3D バウンディングボックスで注釈を付ける方法の例については、LIDAR ポイントクラウド W&B Report を参照してください。
Collaboration: 同僚と 学びを共有
プロジェクトの開始方法を説明し、これまでに観察した内容を共有し、最新の 学び をまとめます。同僚は、 Report の任意の panel または最後にコメントを使用して、提案をしたり、詳細を議論したりできます。
同僚が自分で探索し、追加の洞察を得て、次のステップをより適切に計画できるように、動的な settings を含めます。この例では、3 種類の experiments を個別に可視化、比較、または平均化できます。
ベンチマークの最初の run と観察を共有する方法の例については、SafeLife ベンチマーク experiments W&B Report を参照してください。
スライダーと構成可能なメディア panel を使用して、 model の結果または training の進捗状況を紹介します。スライダー付きの W&B Report の例については、かわいい動物とポストモダンのスタイル転送: マルチドメイン画像合成のための StarGAN v2 report をご覧ください。
Work log: 試したことを追跡し、次のステップを計画
プロジェクトを進める際に、 experiments、学び、注意点、および次のステップに関する考えを書き留め、すべてを 1 か所に整理します。これにより、スクリプト以外の重要な部分をすべて「文書化」できます。 学び を report する方法の例については、Who Is Them? Text Disambiguation With Transformers W&B Report を参照してください。
model がどのように、そしてなぜ開発されたのかを理解するために、あなたと他の人が後で参照できるプロジェクトのストーリーを語ります。 学び を report する方法については、運転席からの眺め W&B Report を参照してください。
OpenAI Robotics チームが W&B Reports を使用して大規模な machine learning プロジェクトをどのように実行したかを調査するために W&B Reports がどのように使用されたかの例については、W&B Reports を使用したエンドツーエンドの Learning Dexterity を参照してください。
4.5 - Automations
This feature requires a Pro or Enterprise plan .
このページでは、W&B の automations について説明します。W&B のイベント(artifact Artifacts のバージョンが作成されたときなど)に基づいて、自動モデルテストやデプロイメントなどのワークフローステップをトリガーする オートメーションの作成 を行います。
たとえば、新しいバージョンが作成されたときに Slack チャンネルに投稿したり、production エイリアスが Artifacts に追加されたときに webhook を実行して自動テストをトリガーしたりできます。
Overview
Automation は、特定の event が Registry または Project で発生したときに実行できます。
Registry 内の Artifacts の場合、Automation の実行を次のように設定できます。
新しい Artifacts バージョンがコレクションにリンクされたとき。たとえば、新しい候補 Models のテストと検証のワークフローをトリガーします。
エイリアスが Artifacts バージョンに追加されたとき。たとえば、エイリアスが Model バージョンに追加されたときに、デプロイメント ワークフローをトリガーします。
Project 内の Artifacts の場合、Automation の実行を次のように設定できます。
新しいバージョンが Artifacts に追加されたとき。たとえば、Dataset Artifacts の新しいバージョンが特定のコレクションに追加されたときに、Training ジョブを開始します。
エイリアスが Artifacts バージョンに追加されたとき。たとえば、エイリアス「redaction」が Dataset Artifacts に追加されたときに、PII 編集ワークフローをトリガーします。
詳細については、オートメーションイベントとスコープ を参照してください。
オートメーションを作成 するには、次の手順を実行します。
必要に応じて、アクセストークン、パスワード、または機密性の高い設定の詳細など、Automation で必要な機密文字列の secrets を設定します。Secrets は、Team Settings で定義されます。Secrets は、webhook Automation で最も一般的に使用され、認証情報またはトークンをプレーンテキストで公開したり、webhook のペイロードにハードコーディングしたりすることなく、webhook の外部サービスに安全に渡すために使用されます。
W&B が Slack に投稿したり、ユーザーに代わって webhook を実行したりすることを承認するように、webhook または Slack 通知を設定します。単一の Automation アクション(webhook または Slack 通知)を複数の Automation で使用できます。これらのアクションは、Team Settings で定義されます。
Project または Registry で、Automation を作成します。
監視する event (新しい Artifacts バージョンが追加されたときなど)を定義します。
イベントが発生したときに実行するアクション(Slack チャンネルへの投稿または webhook の実行)を定義します。Webhook の場合は、アクセストークンに使用する secret、および必要に応じてペイロードとともに送信する secret を指定します。
次のステップ
4.5.1 - Create an automation
This feature requires a Pro or Enterprise plan .
このページでは、W&B のオートメーション の作成と管理の概要について説明します。詳細な手順については、Slack オートメーションの作成 またはWebhook オートメーションの作成 を参照してください。
オートメーションに関するチュートリアルをお探しですか?
要件
Team admin は、チームの Projects のオートメーション、および Webhook、シークレット、Slack 接続などのオートメーションのコンポーネントを作成および管理できます。Team settings を参照してください。
Registry automation を作成するには、Registry へのアクセス権が必要です。Registry アクセスの設定 を参照してください。
Slack オートメーションを作成するには、選択した Slack インスタンスと channel に投稿する権限が必要です。
オートメーションの作成
Project または Registry の [Automations ] タブからオートメーションを作成します。大まかに言って、オートメーションを作成するには、次の手順に従います。
必要に応じて、アクセス・トークン、パスワード、SSH キーなど、オートメーションに必要な機密文字列ごとにW&B シークレットを作成 します。シークレットは [Team Settings ] で定義します。シークレットは、Webhook オートメーションで最も一般的に使用されます。
W&B が Slack に投稿したり、代わりに Webhook を実行したりできるように、Webhook または Slack 通知を設定して W&B を承認します。1 つのオートメーションアクション(Webhook または Slack 通知)を複数のオートメーションで使用できます。これらのアクションは [Team Settings ] で定義します。
Project または Registry で、監視するイベントと実行するアクション(Slack への投稿や Webhook の実行など)を指定するオートメーションを作成します。Webhook オートメーションを作成する場合は、送信するペイロードを設定します。
詳細については、以下を参照してください。
オートメーションの表示と管理
Project または Registry の [Automations ] タブからオートメーションを表示および管理します。
オートメーションの詳細を表示するには、その名前をクリックします。
オートメーションを編集するには、そのアクション ... メニューをクリックし、[Edit automation ] をクリックします。
オートメーションを削除するには、そのアクション ... メニューをクリックし、[Delete automation ] をクリックします。
次のステップ
4.5.1.1 - Create a Slack automation
This feature requires a Pro or Enterprise plan .
このページでは、Slack オートメーション の作成方法について説明します。Webhook オートメーションを作成するには、代わりに Webhook オートメーションの作成 を参照してください。
大まかに言うと、Slack オートメーションを作成するには、次の手順を実行します。
Slack インテグレーションの追加 。これにより、Weights & Biases が Slack インスタンスと channel に投稿することを承認します。Slack オートメーションの作成 。これにより、監視する event と投稿先の channel が定義されます。
Slack に接続する
Team の管理者は、Team に Slack の送信先を追加できます。
Weights & Biases にログインして、Team Settings ページに移動します。
[Slack channel integrations ] セクションで、[Connect Slack ] をクリックして新しい Slack インスタンスを追加します。既存の Slack インスタンスに channel を追加するには、[New integration ] をクリックします。
必要に応じて、ブラウザで Slack にサインインします。プロンプトが表示されたら、選択した Slack channel に投稿する権限を Weights & Biases に付与します。ページを読んでから、[Search for a channel ] をクリックして、channel 名を入力します。リストから channel を選択し、[Allow ] をクリックします。
Slack で、選択した channel に移動します。[Your Slack handle] added an integration to this channel: Weights & Biases のような投稿が表示された場合、インテグレーションは正しく構成されています。
これで、構成した Slack channel に通知する オートメーションの作成 ができます。
Slack 接続の表示と管理
Team の管理者は、Team の Slack インスタンスと channel を表示および管理できます。
Weights & Biases にログインして、[Team Settings ] に移動します。
[Slack channel integrations ] セクションで、各 Slack の送信先を表示します。
送信先を削除するには、ゴミ箱アイコンをクリックします。
オートメーションの作成
Weights & Biases Team を Slack に接続 したら、[Registry ] または [Project ] を選択し、次の手順に従って Slack channel に通知するオートメーションを作成します。
Registry の管理者は、その Registry でオートメーションを作成できます。
Weights & Biases にログインします。
Registry の名前をクリックして、詳細を表示します。
Registry を対象範囲とするオートメーションを作成するには、[Automations ] タブをクリックし、[Create automation ] をクリックします。Registry を対象範囲とするオートメーションは、そのすべてのコレクション (将来作成されるコレクションを含む) に自動的に適用されます。
Registry 内の特定のコレクションのみを対象範囲とするオートメーションを作成するには、コレクションのアクション ... メニューをクリックし、[Create automation ] をクリックします。または、コレクションを表示しているときに、コレクションの詳細ページの [Automations ] セクションにある [Create automation ] ボタンを使用して、コレクションのオートメーションを作成します。
監視する Event
表示される追加フィールドに入力します。これは、イベントによって異なります。たとえば、[An artifact alias is added ] を選択した場合は、[Alias regex ] を指定する必要があります。
[Next step ] をクリックします。
Slack インテグレーション を所有する Team を選択します。
[Action type ] を [Slack notification ] に設定します。Slack channel を選択し、[Next step ] をクリックします。
オートメーションの名前を入力します。必要に応じて、説明を入力します。
[Create automation ] をクリックします。
Weights & Biases の管理者は、Project でオートメーションを作成できます。
Weights & Biases にログインします。
Project ページに移動し、[Automations ] タブをクリックします。
[Create automation ] をクリックします。
監視する Event
表示される追加フィールドに入力します。これは、イベントによって異なります。たとえば、[An artifact alias is added ] を選択した場合は、[Alias regex ] を指定する必要があります。
[Next step ] をクリックします。
Slack インテグレーション を所有する Team を選択します。
[Action type ] を [Slack notification ] に設定します。Slack channel を選択し、[Next step ] をクリックします。
オートメーションの名前を入力します。必要に応じて、説明を入力します。
[Create automation ] をクリックします。
オートメーションの表示と管理
Registry のオートメーションは、Registry の [Automations ] タブから管理します。
コレクションのオートメーションは、コレクションの詳細ページの [Automations ] セクションから管理します。
これらのページのいずれかから、Registry の管理者は既存のオートメーションを管理できます。
オートメーションの詳細を表示するには、その名前をクリックします。
オートメーションを編集するには、アクション ... メニューをクリックし、[Edit automation ] をクリックします。
オートメーションを削除するには、アクション ... メニューをクリックし、[Delete automation ] をクリックします。確認が必要です。
Weights & Biases の管理者は、Project の [Automations ] タブから Project のオートメーションを表示および管理できます。
オートメーションの詳細を表示するには、その名前をクリックします。
オートメーションを編集するには、アクション ... メニューをクリックし、[Edit automation ] をクリックします。
オートメーションを削除するには、アクション ... メニューをクリックし、[Delete automation ] をクリックします。確認が必要です。
4.5.1.2 - Create a webhook automation
This feature requires a Pro or Enterprise plan .
このページでは、webhook オートメーション の作成方法について説明します。Slack オートメーションを作成するには、代わりに Slack オートメーションの作成 を参照してください。
大まかに言うと、webhook オートメーションを作成するには、次の手順を実行します。
必要に応じて、アクセストークン、パスワード、SSH キーなど、オートメーションに必要な機密文字列ごとに W&B シークレットを作成 します。シークレットは、 Team の設定で定義されます。
webhook を作成 して、エンドポイントと認証の詳細を定義し、インテグレーションに必要なシークレットへのアクセスを許可します。オートメーションを作成 して、監視する イベント と、Weights & Biases が送信するペイロードを定義します。ペイロードに必要なシークレットへのオートメーションアクセスを許可します。
webhook を作成する
Team の管理者は、 Team に webhook を追加できます。
webhook に Bearer トークンが必要な場合、またはそのペイロードに機密文字列が必要な場合は、webhook を作成する前に
それを含むシークレットを作成 してください。webhook に対して設定できるアクセストークンとその他のシークレットは、それぞれ最大 1 つです。webhook の認証および認可の要件は、webhook のサービスによって決まります。
Weights & Biases にログインし、Team の Settings ページに移動します。
Webhooks セクションで、New webhook をクリックします。
webhook の名前を入力します。
webhook のエンドポイント URL を入力します。
webhook に Bearer トークンが必要な場合は、Access token をそれを含む シークレット に設定します。webhook オートメーションを使用すると、Weights & Biases は Authorization: Bearer HTTP ヘッダーをアクセストークンに設定し、${ACCESS_TOKEN} ペイロード変数 でトークンにアクセスできます。
webhook のペイロードにパスワードまたはその他の機密文字列が必要な場合は、Secret をそれを含むシークレットに設定します。webhook を使用するオートメーションを設定すると、名前の先頭に $ を付けることで、ペイロード変数 としてシークレットにアクセスできます。
webhook のアクセストークンがシークレットに保存されている場合は、次の手順も完了して、シークレットをアクセストークンとして指定する 必要 があります。
Weights & Biases がエンドポイントに接続して認証できることを確認するには:
必要に応じて、テストするペイロードを指定します。ペイロードで webhook がアクセスできるシークレットを参照するには、名前の先頭に $ を付けます。このペイロードはテスト専用であり、保存されません。オートメーションのペイロードは、オートメーションを作成 するときに設定します。シークレットとアクセストークンが POST リクエストのどこに指定されているかを確認するには、webhook のトラブルシューティング を参照してください。
Test をクリックします。Weights & Biases は、設定した資格情報を使用して webhook のエンドポイントへの接続を試みます。ペイロードを指定した場合は、Weights & Biases がそれを送信します。
テストが成功しない場合は、webhook の設定を確認して、もう一度お試しください。必要に応じて、webhook のトラブルシューティング を参照してください。
これで、webhook を使用する オートメーションを作成 できます。
オートメーションを作成する
webhook を設定 したら、Registry または Project を選択し、次の手順に従って webhook をトリガーするオートメーションを作成します。
Registry 管理者は、その Registry でオートメーションを作成できます。Registry オートメーションは、今後追加されるものを含め、Registry 内のすべてのコレクションに適用されます。
Weights & Biases にログインします。
Registry の名前をクリックして詳細を表示します。
Registry の範囲に設定されたオートメーションを作成するには、Automations タブをクリックし、Create automation をクリックします。Registry の範囲に設定されたオートメーションは、そのすべてのコレクション(今後作成されるものを含む)に自動的に適用されます。
Registry 内の特定のコレクションのみを範囲とするオートメーションを作成するには、コレクションのアクション ... メニューをクリックし、Create automation をクリックします。または、コレクションを表示しながら、コレクションの詳細ページの Automations セクションにある Create automation ボタンを使用して、コレクションのオートメーションを作成します。
監視する Event An artifact alias is added を選択した場合は、Alias regex を指定する必要があります。Next step をクリックします。
webhook を所有する Team を選択します。
Action type を Webhooks に設定し、使用する webhook を選択します。
webhook のアクセストークンを設定した場合は、${ACCESS_TOKEN} ペイロード変数 でトークンにアクセスできます。webhook のシークレットを設定した場合は、名前の先頭に $ を付けることで、ペイロードでアクセスできます。webhook の要件は、webhook のサービスによって決まります。
Next step をクリックします。
オートメーションの名前を入力します。必要に応じて、説明を入力します。Create automation をクリックします。
Weights & Biases 管理者は、Project でオートメーションを作成できます。
Weights & Biases にログインし、Project ページに移動します。
サイドバーで、Automations をクリックします。
Create automation をクリックします。
監視する Event
イベントに応じて表示される追加フィールドに入力します。たとえば、An artifact alias is added を選択した場合は、Alias regex を指定する必要があります。
必要に応じて、コレクションフィルターを指定します。それ以外の場合、オートメーションは、今後追加されるものを含め、Project 内のすべてのコレクションに適用されます。
Next step をクリックします。
webhook を所有する Team を選択します。
Action type を Webhooks に設定し、使用する webhook を選択します。
webhook にペイロードが必要な場合は、ペイロードを作成して Payload フィールドに貼り付けます。webhook のアクセストークンを設定した場合は、${ACCESS_TOKEN} ペイロード変数 でトークンにアクセスできます。webhook のシークレットを設定した場合は、名前の先頭に $ を付けることで、ペイロードでアクセスできます。webhook の要件は、webhook のサービスによって決まります。
Next step をクリックします。
オートメーションの名前を入力します。必要に応じて、説明を入力します。Create automation をクリックします。
オートメーションの表示と管理
Registry のオートメーションは、Registry の Automations タブから管理します。
コレクションのオートメーションは、コレクションの詳細ページの Automations セクションから管理します。
これらのページのいずれかから、Registry 管理者は既存のオートメーションを管理できます。
オートメーションの詳細を表示するには、その名前をクリックします。
オートメーションを編集するには、アクション ... メニューをクリックし、Edit automation をクリックします。
オートメーションを削除するには、アクション ... メニューをクリックし、Delete automation をクリックします。確認が必要です。
Weights & Biases 管理者は、Project の Automations タブから Project のオートメーションを表示および管理できます。
オートメーションの詳細を表示するには、その名前をクリックします。
オートメーションを編集するには、アクション ... メニューをクリックし、Edit automation をクリックします。
オートメーションを削除するには、アクション ... メニューをクリックし、Delete automation をクリックします。確認が必要です。
ペイロードリファレンス
これらのセクションを使用して、webhook のペイロードを作成します。webhook とそのペイロードのテストの詳細については、webhook のトラブルシューティング を参照してください。
ペイロード変数
このセクションでは、webhook のペイロードの作成に使用できる変数について説明します。
変数
詳細
${project_name}アクションをトリガーした変更を所有する Project の名前。
${entity_name}アクションをトリガーした変更を所有する Entity または Team の名前。
${event_type}アクションをトリガーしたイベントのタイプ。
${event_author}アクションをトリガーしたユーザー。
${artifact_collection_name}Artifact バージョンがリンクされている Artifact コレクションの名前。
${artifact_metadata.<KEY>}アクションをトリガーした Artifact バージョンからの任意のトップレベル メタデータ キーの値。<KEY> をトップレベル メタデータ キーの名前に置き換えます。トップレベル メタデータ キーのみが、webhook のペイロードで使用できます。
${artifact_version}アクションをトリガーした Artifact バージョンの Wandb.Artifact
${artifact_version_string}アクションをトリガーした Artifact バージョンの string 表現。
${ACCESS_TOKEN}アクセストークンが設定されている場合は、webhook で設定されたアクセストークンの値。アクセストークンは、Authorization: Bearer HTTP ヘッダーで自動的に渡されます。
${SECRET_NAME}設定されている場合は、webhook で設定されたシークレットの値。SECRET_NAME をシークレットの名前に置き換えます。
ペイロードの例
このセクションには、一般的なユースケースの webhook ペイロードの例が含まれています。この例では、ペイロード変数 の使用方法を示します。
GitHub リポジトリディスパッチ
Microsoft Teams 通知
Slack 通知
Weights & Biases からリポジトリディスパッチを送信して、GitHub アクションをトリガーします。たとえば、on キーのトリガーとしてリポジトリディスパッチを受け入れる GitHub ワークフローファイルがあるとします。
on :
repository_dispatch :
types : BUILD_AND_DEPLOY
リポジトリのペイロードは、次のようになります。
{
"event_type" : "BUILD_AND_DEPLOY" ,
"client_payload" :
{
"event_author" : "${event_author}" ,
"artifact_version" : "${artifact_version}" ,
"artifact_version_string" : "${artifact_version_string}" ,
"artifact_collection_name" : "${artifact_collection_name}" ,
"project_name" : "${project_name}" ,
"entity_name" : "${entity_name}"
}
}
webhook ペイロードの event_type キーは、GitHub ワークフロー YAML ファイルの types フィールドと一致する必要があります。
レンダリングされたテンプレート文字列の内容と配置は、オートメーションが設定されているイベントまたはモデルバージョンによって異なります。${event_type} は、LINK_ARTIFACT または ADD_ARTIFACT_ALIAS のいずれかとしてレンダリングされます。以下に、マッピングの例を示します。
${event_type} --> "LINK_ARTIFACT" or "ADD_ARTIFACT_ALIAS"
${event_author} --> "<wandb-user>"
${artifact_version} --> "wandb-artifact://_id/QXJ0aWZhY3Q6NTE3ODg5ODg3""
${artifact_version_string} --> "<entity>/model-registry/<registered_model_name>:<alias>"
${artifact_collection_name} --> "<registered_model_name>"
${project_name} --> "model-registry"
${entity_name} --> "<entity>"
テンプレート文字列を使用して、Weights & Biases から GitHub Actions およびその他のツールにコンテキストを動的に渡します。これらのツールが Python スクリプトを呼び出すことができる場合は、Weights & Biases API を使用して、登録されたモデル Artifacts を利用できます。
このペイロードの例は、webhook を使用して Teams チャンネルに通知する方法を示しています。
{
"@type" : "MessageCard" ,
"@context" : "http://schema.org/extensions" ,
"summary" : "New Notification" ,
"sections" : [
{
"activityTitle" : "Notification from WANDB" ,
"text" : "This is an example message sent via Teams webhook." ,
"facts" : [
{
"name" : "Author" ,
"value" : "${event_author}"
},
{
"name" : "Event Type" ,
"value" : "${event_type}"
}
],
"markdown" : true
}
]
}
テンプレート文字列を使用して、実行時に Weights & Biases データをペイロードに挿入できます(上記の Teams の例に示すように)。
このセクションは、履歴を目的として提供されています。現在 webhook を使用して Slack と統合している場合は、[新しい Slack インテグレーション]({{ relref “#create-a-slack-automation”}}) を使用するように構成を更新することをお勧めします。
Slack API ドキュメント で強調表示されている手順に従って、Slack アプリを設定し、受信 webhook インテグレーションを追加します。Bot User OAuth Token で指定されたシークレットが、Weights & Biases webhook のアクセストークンであることを確認してください。
以下は、ペイロードの例です。
{
"text" : "New alert from WANDB!" ,
"blocks" : [
{
"type" : "section" ,
"text" : {
"type" : "mrkdwn" ,
"text" : "Registry event: ${event_type}"
}
},
{
"type" :"section" ,
"text" : {
"type" : "mrkdwn" ,
"text" : "New version: ${artifact_version_string}"
}
},
{
"type" : "divider"
},
{
"type" : "section" ,
"text" : {
"type" : "mrkdwn" ,
"text" : "Author: ${event_author}"
}
}
]
}
webhook のトラブルシューティング
Weights & Biases App UI を使用してインタラクティブに、または Bash スクリプトを使用してプログラムで webhook のトラブルシューティングを行います。新しい webhook を作成するとき、または既存の webhook を編集するときに、webhook のトラブルシューティングを行うことができます。
Weights & Biases App UI
Bash スクリプト
Team 管理者は、Weights & Biases App UI を使用して webhook をインタラクティブにテストできます。
Weights & Biases Team の Settings ページに移動します。
Webhooks セクションまでスクロールします。webhook の名前の横にある水平方向の 3 つのドキュメント(ミートボールアイコン)をクリックします。
Test を選択します。表示される UI パネルから、表示されるフィールドに POST リクエストを貼り付けます。
Test webhook をクリックします。Weights & Biases App UI 内で、Weights & Biases はエンドポイントからの応答を投稿します。
デモンストレーションについては、ビデオ Weights & Biases での Webhook のテスト をご覧ください。
このシェルスクリプトは、トリガーされたときに Weights & Biases が webhook オートメーションに送信するリクエストと同様の POST リクエストを生成する 1 つの方法を示しています。
以下のコードをコピーしてシェルスクリプトに貼り付け、webhook のトラブルシューティングを行います。次の独自の値(バリュー)を指定します。
ACCESS_TOKENSECRETPAYLOADAPI_ENDPOINT
webhook_test.sh
4.5.2 - Automation events and scopes
This feature requires a Pro or Enterprise plan .
オートメーション は、特定のイベントが project または registry のスコープ内で発生したときに開始できます。 project の スコープ は、[スコープの技術的な定義を挿入] を指します。このページでは、各スコープ内で オートメーション をトリガーできるイベントについて説明します。
オートメーション の詳細については、オートメーション の概要 または オートメーション の作成 を参照してください。
Registry
このセクションでは、Registry 内の オートメーション のスコープとイベントについて説明します。
https://wandb.ai/registry/ で Registry App に移動します。registry の名前をクリックし、Automations タブで オートメーション を表示および作成します。
オートメーション の作成 の詳細について説明します。
スコープ
次のスコープで Registry オートメーション を作成できます。
Registry レベル: オートメーション は、特定の registry 内のコレクション (今後追加されるコレクションを含む) で発生するイベントを監視します。コレクション レベル: 特定の registry 内の単一のコレクション。
イベント
Registry オートメーション は、次のイベントを監視できます。
新しい Artifact をコレクションにリンクする : registry に追加された新しい Models または Datasets をテストおよび検証します。新しい エイリアス を Artifact の バージョン に追加する : 新しい Artifact バージョン に特定の エイリアス が適用されたときに、 ワークフロー の特定のステップをトリガーします。たとえば、production エイリアス が適用されたときに model をデプロイします。
Project
このセクションでは、project 内の オートメーション のスコープとイベントについて説明します。
W&B App ( https://wandb.ai/<team>/<project-name> ) で W&B project に移動します。
Automations タブで オートメーション を表示および作成します。
オートメーション の作成 の詳細について説明します。
スコープ
次のスコープで project オートメーション を作成できます。
Project レベル: オートメーション は、 project 内のコレクションで発生するイベントを監視します。
コレクション レベル: 指定したフィルターに一致する project 内のすべてのコレクション。
イベント
project オートメーション は、次のイベントを監視できます。
Artifact の新しい バージョン がコレクションに作成される : Artifact の各 バージョン に定期的なアクションを適用します。コレクション の指定はオプションです。たとえば、新しい dataset Artifact バージョン が作成されたときに training ジョブを開始します。Artifact エイリアス が追加される : project またはコレクション内の新しい Artifact バージョン に特定の エイリアス が適用されたときに、 ワークフロー の特定のステップをトリガーします。たとえば、Artifact に test-set-quality-check エイリアス が適用されたときに、一連のダウンストリーム プロセッシング ステップを実行します。
次のステップ
5 - W&B Platform
W&B Platform は、Core 、Models 、Weave などの W&B 製品をサポートする、基盤となるインフラストラクチャー、 ツール 、およびガバナンスの足場です。
W&B Platform は、次の3つの異なる デプロイメント オプションで利用できます。
次の責任分担表は、主な違いの概要を示しています。
Multi-tenant Cloud
Dedicated Cloud
Customer-managed
MySQL / DB 管理
W&B が完全にホストおよび管理
W&B が クラウド 上またはお客様が選択したリージョンで完全にホストおよび管理
お客様が完全にホストおよび管理
オブジェクトストレージ (S3/GCS/Blob storage)
オプション1 : W&B が完全にホストオプション2 : お客様は、Secure Storage Connector を使用して、 チーム ごとに独自の バケット を構成できますオプション1 : W&B が完全にホストオプション2 : お客様は、Secure Storage Connector を使用して、インスタンスまたは チーム ごとに独自の バケット を構成できますお客様が完全にホストおよび管理
SSO サポート
Auth0 経由で W&B が管理
オプション1 : お客様が管理オプション2 : Auth0 経由で W&B が管理お客様が完全に管理
W&B サービス (App)
W&B が完全に管理
W&B が完全に管理
お客様が完全に管理
App セキュリティー
W&B が完全に管理
W&B とお客様の共同責任
お客様が完全に管理
メンテナンス (アップグレード、 バックアップ など)
W&B が管理
W&B が管理
お客様が管理
サポート
サポート SLA
サポート SLA
サポート SLA
サポートされている クラウド インフラストラクチャー
GCP
AWS、GCP、Azure
AWS、GCP、Azure、 オンプレミス ベアメタル
デプロイメント オプション
次のセクションでは、各 デプロイメント タイプの概要について説明します。
W&B Multi-tenant Cloud
W&B Multi-tenant Cloud は、W&B の クラウド インフラストラクチャー に デプロイ されたフルマネージド サービスです。ここでは、希望する規模で W&B 製品にシームレスに アクセス でき、費用対効果の高い価格オプション、最新の機能と機能の継続的なアップデートを利用できます。プライベート デプロイメント のセキュリティーが不要で、セルフサービスでのオンボーディングが重要であり、コスト効率が重要な場合は、製品 トライアル に Multi-tenant Cloud を使用するか、 プロダクション AI ワークフロー を管理することをお勧めします。
詳細については、W&B Multi-tenant Cloud を参照してください。
W&B Dedicated Cloud
W&B Dedicated Cloud は、W&B の クラウド インフラストラクチャー に デプロイ された シングルテナント のフルマネージド サービスです。 データ 常駐を含む厳格なガバナンス コントロールへの準拠が組織で必要であり、高度なセキュリティー機能を必要とし、セキュリティー、スケール、およびパフォーマンスの特性を備えた必要な インフラストラクチャー を構築および管理する必要がないことによって AI の運用コストを最適化しようとしている場合は、W&B をオンボーディングするのに最適な場所です。
詳細については、W&B Dedicated Cloud を参照してください。
W&B Customer-Managed
このオプションを使用すると、独自の管理対象 インフラストラクチャー に W&B Server を デプロイ して管理できます。W&B Server は、W&B Platform と、サポートされている W&B 製品を 実行 するための自己完結型のパッケージ化されたメカニズムです。既存の インフラストラクチャー がすべて オンプレミス にあり、W&B Dedicated Cloud では満たされない厳格な規制ニーズが組織にある場合は、このオプションをお勧めします。このオプションを使用すると、W&B Server をサポートするために必要な インフラストラクチャー のプロビジョニング、および継続的な メンテナンス とアップグレードを管理する責任を完全に負います。
詳細については、W&B Self Managed を参照してください。
次のステップ
W&B 製品のいずれかを試してみたい場合は、Multi-tenant Cloud を使用することをお勧めします。エンタープライズ向けのセットアップをお探しの場合は、 トライアル に適した デプロイメント タイプをこちら から選択してください。
5.1 - Deployment options
5.1.1 - Use W&B Multi-tenant SaaS
W&B Multi-tenant Cloud は、W&B の Google Cloud Platform (GCP) アカウント内の GPC の北米リージョン にデプロイされた、フルマネージドのプラットフォームです。 W&B Multi-tenant Cloud は、GCP の自動スケーリングを利用して、トラフィックの増減に基づいてプラットフォームが適切にスケーリングされるようにします。
データセキュリティ
エンタープライズプラン以外のユーザーの場合、すべての data は共有クラウドストレージにのみ保存され、共有クラウドコンピューティングサービスで処理されます。料金プランによっては、ストレージ制限が適用される場合があります。
エンタープライズプランのユーザーは、セキュアストレージコネクタを使用して、独自の bucket (BYOB) を持ち込む ことができます。team level で、model、datasets などのファイルを保存できます。複数の Teams に対して 1 つの bucket を設定することも、異なる W&B Teams に対して個別の buckets を使用することもできます。team に対してセキュアストレージコネクタを設定しない場合、その data は共有クラウドストレージに保存されます。
Identity and access management (IAM)
エンタープライズプランをご利用の場合、W&B Organization でセキュアな認証と効果的な承認のために、identity and access managements 機能を使用できます。 Multi-tenant Cloud の IAM では、次の機能が利用可能です。
OIDC または SAML による SSO 認証。 Organization の SSO を設定する場合は、W&B team またはサポートにお問い合わせください。
Organization のスコープ内および team 内で、適切な user ロールを設定 します。
W&B project のスコープを定義して、制限付き projects で、誰が W&B runs を表示、編集、送信できるかを制限します。
モニター
Organization 管理者は、アカウントビューの [Billing] タブから、アカウントの使用状況と請求を管理できます。 Multi-tenant Cloud 上の共有クラウドストレージを使用している場合、管理者は organization 内の異なる Teams 間でストレージ使用量を最適化できます。
メンテナンス
W&B Multi-tenant Cloud は、マルチテナントのフルマネージドプラットフォームです。 W&B Multi-tenant Cloud は W&B によって管理されているため、W&B プラットフォームのプロビジョニングとメンテナンスのオーバーヘッドとコストは発生しません。
コンプライアンス
Multi-tenant Cloud のセキュリティコントロールは、定期的 内部および外部で監査されます。 SOC2 レポートおよびその他のセキュリティとコンプライアンスに関するドキュメントをリクエストするには、W&B Security Portal を参照してください。
次のステップ
エンタープライズ機能以外をお探しの場合は、Multi-tenant Cloud に直接アクセス してください。エンタープライズプランを開始するには、このフォーム を送信してください。
5.1.2 - Dedicated Cloud
専用クラウド (シングルテナントSaaS)
W&B 専用クラウド は、W&B の AWS、GCP、または Azure クラウドアカウントにデプロイされた、シングルテナントで完全に管理されたプラットフォームです。各 専用クラウド インスタンスは、他の W&B 専用クラウド インスタンスから独立したネットワーク、コンピューティング、ストレージを持っています。お客様の W&B 固有の メタデータ と データ は、独立したクラウドストレージに保存され、独立したクラウドコンピューティングサービスを使用して処理されます。
W&B 専用クラウド は、各クラウドプロバイダーの複数のグローバルリージョン で利用可能です。
データセキュリティ
セキュアストレージコネクタ を使用して、インスタンスおよび Team レベル で、お客様自身の バケット (BYOB) を持ち込み、モデル、データセット などのファイル を保存できます。
W&B マルチテナント Cloud と同様に、複数の Team に対して単一の バケット を構成するか、異なる Team に対して別々の バケット を使用できます。Team に対してセキュアストレージコネクタを構成しない場合、その データ はインスタンスレベルの バケット に保存されます。
セキュアストレージコネクタによる BYOB に加えて、IP 許可リスト を利用して、信頼できるネットワークロケーションからのみ 専用クラウド インスタンスへの アクセス を制限できます。
また、クラウドプロバイダーのセキュアな接続ソリューション を使用して、専用クラウド インスタンスにプライベートに接続することもできます。
ID と アクセス 管理 (IAM)
W&B Organization でセキュアな認証と効果的な認可のために、ID と アクセス 管理機能を使用します。専用クラウド インスタンスの IAM では、次の機能が利用可能です。
モニター
監査 ログ を使用して、Team 内の ユーザー アクティビティを追跡し、エンタープライズガバナンス要件に準拠します。また、W&B Organization Dashboard で 専用クラウド インスタンスの Organization の使用状況を表示できます。
メンテナンス
W&B マルチテナント Cloud と同様に、専用クラウド では W&B プラットフォーム のプロビジョニングとメンテナンスのオーバーヘッドとコストは発生しません。
W&B が 専用クラウド での更新をどのように管理するかを理解するには、サーバー リリース プロセス を参照してください。
コンプライアンス
W&B 専用クラウド のセキュリティコントロールは、定期的 に内部および外部で監査されます。製品評価の演習のためにセキュリティおよびコンプライアンスドキュメントをリクエストするには、W&B Security Portal を参照してください。
移行オプション
自己管理インスタンス またはマルチテナント Cloud からの 専用クラウド への移行がサポートされています。
次のステップ
専用クラウド の使用にご興味がある場合は、このフォーム を送信してください。
5.1.2.1 - Supported Dedicated Cloud regions
AWS、GCP、および Azure は、世界中の複数の場所でクラウドコンピューティングサービスをサポートしています。グローバルリージョンは、データ所在地とコンプライアンス、レイテンシー、コスト効率などに関連する要件を満たすのに役立ちます。W&B は、専用クラウドで利用可能な多くのグローバルリージョンをサポートしています。
ご希望の AWS、GCP、または Azure リージョンがリストにない場合は、W&B Support にお問い合わせください。W&B は、関連するリージョンに専用クラウドに必要なすべてのサービスがあるかどうかを検証し、評価の結果に応じてサポートを優先順位付けできます。
サポートされている AWS リージョン
次の表は、W&B が現在専用クラウドインスタンスでサポートしている AWS リージョン を示しています。
リージョンの場所
リージョン名
米国東部 (オハイオ)
us-east-2
米国東部 (バージニア北部)
us-east-1
米国西部 (北カリフォルニア)
us-west-1
米国西部 (オレゴン)
us-west-2
カナダ (中部)
ca-central-1
ヨーロッパ (フランクフルト)
eu-central-1
ヨーロッパ (アイルランド)
eu-west-1
ヨーロッパ (ロンドン)
eu-west-2
ヨーロッパ (ミラノ)
eu-south-1
ヨーロッパ (ストックホルム)
eu-north-1
アジアパシフィック (ムンバイ)
ap-south-1
アジアパシフィック (シンガポール)
ap-southeast-1
アジアパシフィック (シドニー)
ap-southeast-2
アジアパシフィック (東京)
ap-northeast-1
アジアパシフィック (ソウル)
ap-northeast-2
AWS リージョンの詳細については、AWS ドキュメントの リージョン、アベイラビリティーゾーン、およびローカルゾーン を参照してください。
AWS リージョンを選択する際に考慮すべき要素の概要については、ワークロードのリージョンを選択する際に考慮すべきこと を参照してください。
サポートされている GCP リージョン
次の表は、W&B が現在専用クラウドインスタンスでサポートしている GCP リージョン を示しています。
リージョンの場所
リージョン名
サウスカロライナ
us-east1
バージニア北部
us-east4
アイオワ
us-central1
オレゴン
us-west1
ロサンゼルス
us-west2
ラスベガス
us-west4
トロント
northamerica-northeast2
ベルギー
europe-west1
ロンドン
europe-west2
フランクフルト
europe-west3
オランダ
europe-west4
シドニー
australia-southeast1
東京
asia-northeast1
ソウル
asia-northeast3
GCP リージョンの詳細については、GCP ドキュメントの リージョンとゾーン を参照してください。
サポートされている Azure リージョン
次の表は、W&B が現在専用クラウドインスタンスでサポートしている Azure リージョン を示しています。
リージョンの場所
リージョン名
バージニア
eastus
アイオワ
centralus
ワシントン
westus2
カリフォルニア
westus
カナダ中部
canadacentral
フランス中部
francecentral
オランダ
westeurope
東京、埼玉
japaneast
ソウル
koreacentral
Azure リージョンの詳細については、Azure ドキュメントの Azure geography を参照してください。
5.1.2.2 - Export data from Dedicated cloud
専用クラウド からのデータのエクスポート
もし、 専用クラウド インスタンスで管理されている全てのデータをエクスポートしたい場合は、W&B SDK API を使用して、runs、metrics、Artifacts などを抽出できます。詳しくは、インポートとエクスポート API を参照してください。以下の表は、主要なエクスポートの ユースケース をまとめたものです。
Secure Storage Connector で 専用クラウド に保存されている Artifacts を管理している場合、W&B SDK API を使用して Artifacts をエクスポートする必要はないかもしれません。
W&B SDK API を使用してすべてのデータをエクスポートすると、多数の runs や Artifacts がある場合に処理が遅くなる可能性があります。W&B では、 専用クラウド インスタンスに負荷がかかりすぎないように、適切なサイズのバッチでエクスポート プロセス を実行することをお勧めします。
5.1.3 - Self-managed
W&B をプロダクション環境にデプロイする
セルフマネージドクラウドまたはオンプレミスインフラストラクチャーの使用
AWS、GCP、または Azure クラウドアカウント または オンプレミスインフラストラクチャー に W&B Server をデプロイします。
お客様の IT/DevOps/MLOps チームは、お客様のデプロイメントのプロビジョニング、アップグレードの管理、およびセルフマネージドな W&B Server インスタンスの継続的なメンテナンスを担当します。
セルフマネージドクラウドアカウント内への W&B Server のデプロイ
W&B は、W&B Server を AWS、GCP、または Azure クラウドアカウントにデプロイするために、公式の W&B Terraform スクリプトを使用することを推奨します。
AWS , GCP または Azure での W&B Server のセットアップ方法の詳細については、特定のクラウドプロバイダーのドキュメントを参照してください。
オンプレミスインフラストラクチャーへの W&B Server のデプロイ
オンプレミスインフラストラクチャーに W&B Server をセットアップするには、いくつかのインフラストラクチャーコンポーネントを設定する必要があります。これらのコンポーネントには、以下が含まれますが、これらに限定されません。
(強く推奨) Kubernetes cluster
MySQL 8 database cluster
Amazon S3 互換 object storage
Redis cache cluster
オンプレミスインフラストラクチャーへの W&B Server のインストール方法の詳細については、オンプレミスインフラストラクチャーへのインストール を参照してください。W&B は、さまざまなコンポーネントに関する推奨事項を提供し、インストールプロセスを通じてガイダンスを提供できます。
カスタムクラウドプラットフォームへの W&B Server のデプロイ
AWS、GCP、または Azure ではないクラウドプラットフォームに W&B Server をデプロイできます。そのための要件は、オンプレミスインフラストラクチャー にデプロイする場合と同様です。
W&B Server のライセンスの取得
W&B サーバーの設定を完了するには、W&B trial ライセンスが必要です。Deploy Manager を開いて、無料の trial ライセンスを生成してください。
まだ W&B アカウントをお持ちでない場合は、アカウントを作成して無料ライセンスを生成してください。
重要なセキュリティやその他のエンタープライズフレンドリーな機能のサポートを含む W&B Server のエンタープライズライセンスが必要な場合は、このフォームを送信 するか、W&B チームにお問い合わせください。
URL をクリックすると、Get a License for W&B Local フォームにリダイレクトされます。次の情報を提供してください。
Choose Platform ステップで、デプロイメントタイプを選択します。Basic Information ステップで、ライセンスの所有者を選択するか、新しい組織を追加します。Get a License ステップの Name of Instance フィールドにインスタンスの名前を入力し、必要に応じて Description フィールドに説明を入力します。Generate License Key ボタンを選択します。
ページに、デプロイメントの概要と、インスタンスに関連付けられたライセンスが表示されます。
5.1.3.1 - Reference Architecture
W&B リファレンス アーキテクチャー
このページでは、Weights & Biases のデプロイメントのリファレンスアーキテクチャについて説明し、プラットフォームのプロダクションデプロイメントをサポートするために推奨されるインフラストラクチャとリソースの概要を示します。
Weights & Biases (W&B) に選択したデプロイメント環境に応じて、さまざまなサービスがデプロイメントの回復性を高めるのに役立ちます。
たとえば、主要なクラウドプロバイダーは、データベースの構成、メンテナンス、高可用性、および回復性の複雑さを軽減するのに役立つ、堅牢なマネージドデータベースサービスを提供しています。
このリファレンスアーキテクチャは、一般的なデプロイメントシナリオに対応し、最適なパフォーマンスと信頼性を実現するために、W&B のデプロイメントをクラウドベンダーサービスと統合する方法を示しています。
開始する前に
プロダクション環境でアプリケーションを実行するには、独自の課題があり、W&B も例外ではありません。プロセスの合理化を目指していますが、固有のアーキテクチャと設計上の決定によっては、特定の複雑さが発生する可能性があります。通常、プロダクションデプロイメントの管理には、ハードウェア、オペレーティングシステム、ネットワーク、ストレージ、セキュリティ、W&B プラットフォーム自体、およびその他の依存関係を含む、さまざまなコンポーネントの監視が含まれます。この責任は、環境の初期設定とその継続的なメンテナンスの両方に及びます。
W&B を使用した自己管理アプローチが、チームと特定の要件に適しているかどうかを慎重に検討してください。
プロダクショングレードのアプリケーションを実行および保守する方法をしっかりと理解しておくことは、自己管理の W&B をデプロイする前に重要な前提条件となります。チームが支援を必要とする場合は、当社の Professional Services チームとパートナーが、実装と最適化のサポートを提供します。
W&B を自分で管理する代わりに、W&B を実行するためのマネージドソリューションの詳細については、W&B Multi-tenant Cloud および W&B Dedicated Cloud を参照してください。
インフラストラクチャ
アプリケーション層
アプリケーション層は、ノード障害に対する回復性を持つ、マルチノード Kubernetes クラスターで構成されています。Kubernetes クラスターは、W&B の pod を実行および保守します。
ストレージ層
ストレージ層は、MySQL データベースとオブジェクトストレージで構成されています。MySQL データベースはメタデータを格納し、オブジェクトストレージはモデルやデータセットなどの Artifacts を格納します。
インフラストラクチャ要件
Kubernetes
W&B Server アプリケーションは、複数の pod をデプロイする Kubernetes Operator としてデプロイされます。このため、W&B には次のものを持つ Kubernetes クラスターが必要です。
完全に構成され、機能する Ingress コントローラー。
Persistent Volumes をプロビジョニングする機能。
MySQL
W&B は、メタデータを MySQL データベースに格納します。データベースのパフォーマンスとストレージ要件は、モデルパラメータと関連するメタデータの形状によって異なります。たとえば、トレーニング run を追跡するほどデータベースのサイズが大きくなり、run テーブル、ユーザー Workspace 、および Reports のクエリに基づいてデータベースの負荷が増加します。
自己管理の MySQL データベースをデプロイする場合は、以下を検討してください。
バックアップ 。データベースを別の施設に定期的にバックアップする必要があります。W&B は、少なくとも 1 週間の保持期間で毎日バックアップすることをお勧めします。パフォーマンス 。サーバーが実行されているディスクは高速である必要があります。W&B は、SSD または高速化された NAS でデータベースを実行することをお勧めします。監視 。データベースの負荷を監視する必要があります。CPU 使用率がシステムの 40% を超えて 5 分以上維持されている場合は、サーバーのリソースが不足している可能性が高いことを示しています。可用性 。可用性と耐久性の要件に応じて、プライマリサーバーからリアルタイムですべての更新をストリーミングし、プライマリサーバーがクラッシュまたは破損した場合にフェイルオーバーに使用できる、別のマシン上のホットスタンバイを構成することができます。
オブジェクトストレージ
W&B には、次のいずれかにデプロイされた、事前署名付き URL と CORS をサポートするオブジェクトストレージが必要です。
Amazon S3
Azure Cloud Storage
Google Cloud Storage
Amazon S3 と互換性のあるストレージサービス
バージョン
ソフトウェア
最小バージョン
Kubernetes
v1.29
MySQL
v8.0.0, “General Availability” リリースのみ
ネットワーク
ネットワーク化されたデプロイメントでは、インストール時と実行時の_両方_で、これらのエンドポイントへの出力が必要です。
エアギャップデプロイメントの詳細については、エアギャップインスタンス用の Kubernetes operator を参照してください。
トレーニングインフラストラクチャと、 Experiments のニーズを追跡する各システムには、W&B とオブジェクトストレージへのアクセスが必要です。
DNS
W&B デプロイメントの完全修飾ドメイン名 (FQDN) は、A レコードを使用して、イングレス/ロードバランサーの IP アドレスに解決される必要があります。
SSL/TLS
W&B では、クライアントとサーバー間の安全な通信のために、有効な署名付き SSL/TLS 証明書が必要です。SSL/TLS 終端は、イングレス/ロードバランサーで発生する必要があります。W&B Server アプリケーションは、SSL または TLS 接続を終端しません。
注意: W&B は、自己署名証明書とカスタム CA の使用を推奨していません。
サポートされている CPU アーキテクチャ
W&B は、Intel (x86) CPU アーキテクチャで実行されます。ARM はサポートされていません。
インフラストラクチャのプロビジョニング
Terraform は、プロダクション用に W&B をデプロイする推奨される方法です。Terraform を使用して、必要なリソース、他のリソースへの参照、および依存関係を定義します。W&B は、主要なクラウドプロバイダー向けの Terraform モジュールを提供しています。詳細については、自己管理のクラウドアカウント内で W&B Server をデプロイする を参照してください。
サイジング
デプロイメントを計画する際の開始点として、次の一般的なガイドラインを使用してください。W&B は、新しいデプロイメントのすべてのコンポーネントを注意深く監視し、観察された使用パターンに基づいて調整することをお勧めします。時間の経過とともにプロダクションデプロイメントを監視し続け、最適なパフォーマンスを維持するために必要に応じて調整します。
Models のみ
Kubernetes
環境
CPU
メモリ
ディスク
テスト/開発
2 コア
16 GB
100 GB
プロダクション
8 コア
64 GB
100 GB
数値は Kubernetes ワーカーノードごとの値です。
MySQL
環境
CPU
メモリ
ディスク
テスト/開発
2 コア
16 GB
100 GB
プロダクション
8 コア
64 GB
500 GB
数値は MySQL ノードごとの値です。
Weave のみ
Kubernetes
環境
CPU
メモリ
ディスク
テスト/開発
4 コア
32 GB
100 GB
プロダクション
12 コア
96 GB
100 GB
数値は Kubernetes ワーカーノードごとの値です。
MySQL
環境
CPU
メモリ
ディスク
テスト/開発
2 コア
16 GB
100 GB
プロダクション
8 コア
64 GB
500 GB
数値は MySQL ノードごとの値です。
Models と Weave
Kubernetes
環境
CPU
メモリ
ディスク
テスト/開発
4 コア
32 GB
100 GB
プロダクション
16 コア
128 GB
100 GB
数値は Kubernetes ワーカーノードごとの値です。
MySQL
環境
CPU
メモリ
ディスク
テスト/開発
2 コア
16 GB
100 GB
プロダクション
8 コア
64 GB
500 GB
数値は MySQL ノードごとの値です。
クラウドプロバイダーのインスタンス推奨事項
サービス
クラウド
Kubernetes
MySQL
オブジェクトストレージ
AWS
EKS
RDS Aurora
S3
GCP
GKE
Google Cloud SQL - Mysql
Google Cloud Storage (GCS)
Azure
AKS
Azure Database for Mysql
Azure Blob Storage
マシンタイプ
これらの推奨事項は、クラウドインフラストラクチャでの W&B の自己管理デプロイメントの各ノードに適用されます。
AWS
環境
K8s (Models のみ)
K8s (Weave のみ)
K8s (Models&Weave)
MySQL
テスト/開発
r6i.large
r6i.xlarge
r6i.xlarge
db.r6g.large
プロダクション
r6i.2xlarge
r6i.4xlarge
r6i.4xlarge
db.r6g.2xlarge
GCP
環境
K8s (Models のみ)
K8s (Weave のみ)
K8s (Models&Weave)
MySQL
テスト/開発
n2-highmem-2
n2-highmem-4
n2-highmem-4
db-n1-highmem-2
プロダクション
n2-highmem-8
n2-highmem-16
n2-highmem-16
db-n1-highmem-8
Azure
環境
K8s (Models のみ)
K8s (Weave のみ)
K8s (Models&Weave)
MySQL
テスト/開発
Standard_E2_v5
Standard_E4_v5
Standard_E4_v5
MO_Standard_E2ds_v4
プロダクション
Standard_E8_v5
Standard_E16_v5
Standard_E16_v5
MO_Standard_E8ds_v4
5.1.3.2 - Run W&B Server on Kubernetes
Kubernetes Operator を使用して W&B Platform をデプロイする
W&B Kubernetes Operator
W&B Kubernetes Operatorを使用すると、Kubernetes上でのW&B Serverのデプロイ、管理、トラブルシューティング、およびスケーリングを簡素化できます。このOperatorは、W&Bインスタンスのスマートアシスタントとして考えることができます。
W&B Serverのアーキテクチャと設計は、AI開発者向け ツール の機能を拡張し、高パフォーマンス、優れたスケーラビリティ、および容易な管理のための適切なプリミティブを提供するために、継続的に進化しています。この進化は、コンピューティングサービス、関連するストレージ、およびそれらの間の接続に適用されます。デプロイメントタイプ全体での継続的な更新と改善を促進するために、W&B は Kubernetes operator を使用します。
W&B は、この operator を使用して、AWS、GCP、および Azure パブリック クラウド上に Dedicated cloud インスタンスをデプロイおよび管理します。
Kubernetes operator の詳細については、KubernetesドキュメントのOperator pattern を参照してください。
アーキテクチャ移行の理由
従来、W&B アプリケーションは、Kubernetes クラスター内の単一のデプロイメントおよび pod として、または単一の Docker コンテナとしてデプロイされていました。W&B は、データベースと Object Store を外部化することを推奨しており、今後も推奨していきます。データベースと Object Store を外部化すると、アプリケーションの状態が分離されます。
アプリケーションの成長に伴い、モノリシックなコンテナから分散システム(マイクロサービス)に進化する必要性が明らかになりました。この変更により、バックエンドロジックの処理が容易になり、Kubernetes インフラストラクチャの機能がシームレスに組み込まれます。分散システムは、W&B が依存する追加機能に不可欠な新しいサービスのデプロイもサポートします。
2024年以前は、Kubernetes関連の変更を行うには、terraform-kubernetes-wandb Terraformモジュールを手動で更新する必要がありました。Terraformモジュールを更新することで、クラウドプロバイダー間での互換性が確保され、必要なTerraform変数が構成され、バックエンドまたはKubernetesレベルの変更ごとにTerraformが適用されます。
このプロセスは、W&Bサポートが各顧客のTerraformモジュールのアップグレードを支援する必要があったため、スケーラブルではありませんでした。
解決策は、中央のdeploy.wandb.ai サーバーに接続して、特定のリリースチャネルの最新の仕様変更をリクエストし、適用する operator を実装することでした。ライセンスが有効である限り、更新が受信されます。Helm は、W&B operator のデプロイメントメカニズムと、W&B Kubernetesスタックのすべての構成テンプレートを operator が処理する手段の両方として使用されます(Helm-ception)。
仕組み
Operator は、helm またはソースからインストールできます。詳細な手順については、charts/operator を参照してください。
インストールプロセスでは、controller-managerというデプロイメントが作成され、weightsandbiases.apps.wandb.comというカスタムリソース 定義(shortName:wandb)が使用されます。これは単一のspecを取得し、それをクラスターに適用します。
apiVersion : apiextensions.k8s.io/v1
kind : CustomResourceDefinition
metadata :
name : weightsandbiases.apps.wandb.com
controller-managerは、カスタムリソースの仕様、リリースチャネル、およびユーザー定義の構成に基づいて、charts/operator-wandb をインストールします。構成仕様の階層により、ユーザー側で最大限の構成の柔軟性が実現し、W&B は新しいイメージ、構成、機能、および Helm の更新を自動的にリリースできます。
構成オプションについては、構成仕様の階層 および構成リファレンス を参照してください。
構成仕様の階層
構成仕様は、高レベルの仕様が低レベルの仕様をオーバーライドする階層モデルに従います。その仕組みは次のとおりです。
リリースチャネルの値 : この基本レベルの構成では、W&B によってデプロイメント用に設定されたリリースチャネルに基づいて、デフォルト値と構成が設定されます。ユーザー入力値 : ユーザーは、システムコンソールを介して、リリースチャネルの仕様によって提供されるデフォルト設定をオーバーライドできます。カスタムリソースの値 : ユーザーからの仕様の最上位レベル。ここで指定された値は、ユーザー入力とリリースチャネルの両方の仕様をオーバーライドします。構成オプションの詳細については、構成リファレンス を参照してください。
この階層モデルにより、構成は柔軟で、さまざまなニーズに合わせてカスタマイズでき、アップグレードと変更に対する管理可能で体系的なアプローチを維持できます。
W&B Kubernetes Operatorを使用するための要件
W&B Kubernetes operator で W&B をデプロイするには、次の要件を満たす必要があります。
リファレンスアーキテクチャ を参照してください。さらに、有効な W&B Server ライセンスを取得 してください。
自己管理型インストールを設定および構成する方法の詳細な説明については、こちら のガイドを参照してください。
インストール方法によっては、次の要件を満たす必要がある場合があります。
Kubectl がインストールされ、正しい Kubernetes クラスターコンテキストで構成されている。
Helm がインストールされている。
エアギャップ環境へのインストール
エアギャップ環境に W&B Kubernetes Operator をインストールする方法については、Kubernetes を使用したエアギャップ環境での W&B のデプロイ のチュートリアルを参照してください。
W&B Server アプリケーションのデプロイ
このセクションでは、W&B Kubernetes operator をデプロイするさまざまな方法について説明します。
W&B Operator は、W&B Server のデフォルトであり、推奨されるインストール方法です。
次のいずれかを選択してください。
必要な外部サービスをすべてプロビジョニングし、Helm CLI を使用して W&B を Kubernetes にデプロイする場合は、こちら に進んでください。
インフラストラクチャと W&B Server を Terraform で管理する場合は、こちら に進んでください。
W&B Cloud Terraform Modules を利用する場合は、こちら に進んでください。
Helm CLI を使用した W&B のデプロイ
W&B は、W&B Kubernetes operator を Kubernetes クラスターにデプロイするための Helm Chart を提供します。このアプローチを使用すると、Helm CLI または ArgoCD などの継続的デリバリー ツールで W&B Server をデプロイできます。上記の要件が満たされていることを確認してください。
Helm CLI を使用して W&B Kubernetes Operator をインストールするには、次の手順に従います。
W&B Helm リポジトリを追加します。W&B Helm チャートは、W&B Helm リポジトリで入手できます。次のコマンドを使用してリポジトリを追加します。
helm repo add wandb https://charts.wandb.ai
helm repo update
Kubernetes クラスターに Operator をインストールします。以下をコピーして貼り付けます。
helm upgrade --install operator wandb/operator -n wandb-cr --create-namespace
W&B Server のインストールをトリガーするように W&B operator カスタムリソースを構成します。この構成例を operator.yaml というファイルにコピーして、W&B デプロイメントをカスタマイズできるようにします。構成リファレンス を参照してください。
apiVersion : apps.wandb.com/v1
kind : WeightsAndBiases
metadata :
labels :
app.kubernetes.io/instance : wandb
app.kubernetes.io/name : weightsandbiases
name : wandb
namespace : default
spec :
chart :
url : http://charts.yourdomain.com
name : operator-wandb
version : 0.18.0
values :
global :
host : https://wandb.yourdomain.com
license : xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
bucket :
accessKey : xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
secretKey : xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
name: s3.yourdomain.com:port #Ex. : s3.yourdomain.com:9000
path : bucket_name
provider : s3
region : us-east-1
mysql :
database : wandb
host : mysql.home.lab
password : password
port : 3306
user : wandb
extraEnv :
ENABLE_REGISTRY_UI : 'true'
# Ensure it's set to use your own MySQL
mysql :
install : false
app :
image :
repository : registry.yourdomain.com/local
tag : 0.59.2
console :
image :
repository : registry.yourdomain.com/console
tag : 2.12.2
ingress :
annotations :
nginx.ingress.kubernetes.io/proxy-body-size : 64m
class : nginx
W&B Server アプリケーションをインストールおよび構成できるように、カスタム構成で Operator を起動します。
kubectl apply -f operator.yaml
デプロイメントが完了するまで待ちます。これには数分かかります。
Web UI を使用してインストールを検証するには、最初 の 管理 ユーザー アカウントを作成し、インストールの検証 に概説されている検証手順に従います。
この方法では、Terraform の Infrastructure-as-Code アプローチを活用して、一貫性と再現性を実現し、特定の要件に合わせてカスタマイズされたデプロイメントが可能です。公式の W&B Helm ベースの Terraform モジュールは、こちら にあります。
次のコードは、開始点として使用でき、本番環境グレードのデプロイメントに必要なすべての構成オプションが含まれています。
module "wandb" {
source = "wandb/wandb/helm"
spec = {
values = {
global = {
host = "https://<HOST_URI>"
license = "eyJhbGnUzaH...j9ZieKQ2x5GGfw"
bucket = {
< details depend on the provider >
}
mysql = {
< redacted >
}
}
ingress = {
annotations = {
"a" = "b"
"x" = "y"
}
}
}
}
}
構成オプションは構成リファレンス で説明されているものと同じですが、構文は HashiCorp Configuration Language(HCL)に従う必要があることに注意してください。Terraform モジュールは、W&B カスタムリソース定義(CRD)を作成します。
W&B&Biases 自体が Helm Terraform モジュールを使用して顧客向けの「Dedicated cloud」インストールをデプロイする方法については、次のリンクを参照してください。
W&B は、AWS、GCP、および Azure 用の一連の Terraform モジュールを提供します。これらのモジュールは、Kubernetes クラスター、ロードバランサー、MySQL データベースなど、インフラストラクチャ全体と W&B Server アプリケーションをデプロイします。W&B Kubernetes Operator は、次のバージョンの公式 W&B クラウド固有の Terraform モジュールですでに事前構築されています。
この統合により、最小限のセットアップでインスタンスに W&B Kubernetes Operator を使用する準備が整い、クラウド環境での W&B Server のデプロイと管理への合理化されたパスが提供されます。
これらのモジュールの使用方法の詳細については、ドキュメントの自己管理型インストールセクションのこのセクション を参照してください。
インストールの検証
インストールを検証するために、W&B はW&B CLI を使用することをお勧めします。verify コマンドは、すべてのコンポーネントと構成を検証するいくつかのテストを実行します。
この手順では、最初の 管理 ユーザー アカウントがブラウザーで作成されていることを前提としています。
インストールを検証するには、次の手順に従います。
W&B CLI をインストールします。
W&B にログインします。
wandb login --host= https://YOUR_DNS_DOMAIN
例:
wandb login --host= https://wandb.company-name.com
インストールを検証します。
インストールが成功し、完全に動作する W&B デプロイメントでは、次の出力が表示されます。
Default host selected: https://wandb.company-name.com
Find detailed logs for this test at: /var/folders/pn/b3g3gnc11_sbsykqkm3tx5rh0000gp/T/tmpdtdjbxua/wandb
Checking if logged in...................................................✅
Checking signed URL upload..............................................✅
Checking ability to send large payloads through proxy...................✅
Checking requests to base url...........................................✅
Checking requests made over signed URLs.................................✅
Checking CORs configuration of the bucket...............................✅
Checking wandb package version is up to date............................✅
Checking logged metrics, saving and downloading a file..................✅
Checking artifact save and download workflows...........................✅
W&B 管理コンソールへのアクセス
W&B Kubernetes operator には、管理コンソールが付属しています。これは${HOST_URI}/consoleにあります。たとえば、https://wandb.company-name.com/ console などです。
管理コンソールにログインするには、次の2つの方法があります。
ブラウザで W&B アプリケーションを開き、ログインします。${HOST_URI}/で W&B アプリケーションにログインします。たとえば、https://wandb.company-name.com/
コンソールにアクセスします。右上隅のアイコンをクリックし、次にシステムコンソール をクリックします。管理者権限を持つユーザーのみがシステムコンソール エントリを表示できます。
オプション 1 が機能しない場合にのみ、次の手順を使用してコンソールにアクセスすることをお勧めします。
ブラウザでコンソールアプリケーションを開きます。上記の URL を開き、ログイン画面にリダイレクトします。
インストールによって生成される Kubernetes シークレットからパスワードを取得します。
kubectl get secret wandb-password -o jsonpath= '{.data.password}' | base64 -d
コンソールにログインします。コピーしたパスワードを貼り付け、次にログイン をクリックします。
W&B Kubernetes operator の更新
このセクションでは、W&B Kubernetes operator を更新する方法について説明します。
W&B Kubernetes operator を更新しても、W&B サーバーアプリケーションは更新されません。
W&B operator を更新する手順に進む前に、W&B Kubernetes operator を使用しない Helm チャートを使用している場合は、こちら の手順を参照してください。
以下のコードスニペットをコピーしてターミナルに貼り付けます。
まず、helm repo update
次に、helm upgrade
helm upgrade operator wandb/operator -n wandb-cr --reuse-values
W&B Server アプリケーションの更新
W&B Kubernetes operator を使用する場合は、W&B Server アプリケーションを更新する必要はなくなりました。
operator は、W&B のソフトウェアの新しいバージョンがリリースされると、W&B Server アプリケーションを自動的に更新します。
自己管理型インスタンスの W&B Operator への移行
次のセクションでは、独自の W&B Server インストールを自己管理することから、W&B Operator を使用してこれを行うように移行する方法について説明します。移行プロセスは、W&B Server のインストール方法によって異なります。
W&B Operator は、W&B Server のデフォルトであり、推奨されるインストール方法です。ご不明な点がございましたら、
カスタマーサポート または W&B チームにお問い合わせください。
移行プロセスの詳細については、こちら に進んでください。
ご不明な点がある場合や、サポートが必要な場合は、カスタマーサポート または W&B チームにお問い合わせください。
ご不明な点がある場合や、サポートが必要な場合は、カスタマーサポート または W&B チームにお問い合わせください。
Operator ベースの Helm チャートへの移行
Operator ベースの Helm チャートに移行するには、次の手順に従います。
現在の W&B 構成を取得します。W&B が非 operator ベースのバージョンの Helm チャートでデプロイされた場合は、次のように値をエクスポートします。
W&B が Kubernetes マニフェストでデプロイされた場合は、次のように値をエクスポートします。
kubectl get deployment wandb -o yaml
これで、次のステップに必要なすべての構成値が揃いました。
operator.yaml というファイルを作成します。構成リファレンス で説明されている形式に従ってください。ステップ 1 の値を使用します。
現在のデプロイメントを 0 pod にスケールします。このステップでは、現在のデプロイメントを停止します。
kubectl scale --replicas= 0 deployment wandb
Helm チャートリポジトリを更新します。
新しい Helm チャートをインストールします。
helm upgrade --install operator wandb/operator -n wandb-cr --create-namespace
新しい Helm チャートを構成し、W&B アプリケーションのデプロイメントをトリガーします。新しい構成を適用します。
kubectl apply -f operator.yaml
デプロイメントが完了するまでに数分かかります。
インストールを検証します。インストールの検証 の手順に従って、すべてが正常に動作することを確認します。
古いインストールを削除します。古い Helm チャートをアンインストールするか、マニフェストで作成されたリソースを削除します。
Operator ベースの Helm チャートに移行するには、次の手順に従います。
Terraform 構成を準備します。Terraform 構成で古いデプロイメントの Terraform コードをこちら で説明されているコードに置き換えます。以前と同じ変数を設定します。tfvars ファイルがある場合は変更しないでください。
Terraform run を実行します。terraform init、plan、および apply を実行します。
インストールを検証します。インストールの検証 の手順に従って、すべてが正常に動作することを確認します。
古いインストールを削除します。古い Helm チャートをアンインストールするか、マニフェストで作成されたリソースを削除します。
W&B Server の構成リファレンス
このセクションでは、W&B Server アプリケーションの構成オプションについて説明します。アプリケーションは、WeightsAndBiases というカスタムリソース定義として構成を受け取ります。一部の構成オプションは以下の構成で公開され、一部は環境変数として設定する必要があります。
ドキュメントには、基本 および詳細 の2つの環境変数リストがあります。Helm Chart を使用して必要な構成オプションが公開されていない場合にのみ、環境変数を使用してください。
本番環境デプロイメント用の W&B Server アプリケーション構成ファイルには、次の内容が必要です。この YAML ファイルは、バージョン、環境変数、データベースなどの外部リソース、およびその他の必要な設定を含む、W&B デプロイメントの目的の状態を定義します。
apiVersion : apps.wandb.com/v1
kind : WeightsAndBiases
metadata :
labels :
app.kubernetes.io/name : weightsandbiases
app.kubernetes.io/instance : wandb
name : wandb
namespace : default
spec :
values :
global :
host : https://<HOST_URI>
license : eyJhbGnUzaH...j9ZieKQ2x5GGfw
bucket :
<details depend on the provider>
mysql :
<redacted>
ingress :
annotations :
<redacted>
W&B Helm リポジトリ で値の完全なセットを見つけ、オーバーライドする必要がある値のみを変更します。
完全な例
これは、GCP Ingress と GCS(GCP Object storage)を備えた GCP Kubernetes を使用する構成例です。
apiVersion : apps.wandb.com/v1
kind : WeightsAndBiases
metadata :
labels :
app.kubernetes.io/name : weightsandbiases
app.kubernetes.io/instance : wandb
name : wandb
namespace : default
spec :
values :
global :
host : https://abc-wandb.sandbox-gcp.wandb.ml
bucket :
name : abc-wandb-moving-pipefish
provider : gcs
mysql :
database : wandb_local
host : 10.218.0.2
name : wandb_local
password : 8wtX6cJHizAZvYScjDzZcUarK4zZGjpV
port : 3306
user : wandb
license : eyJhbGnUzaHgyQjQyQWhEU3...ZieKQ2x5GGfw
ingress :
annotations :
ingress.gcp.kubernetes.io/pre-shared-cert : abc-wandb-cert-creative-puma
kubernetes.io/ingress.class : gce
kubernetes.io/ingress.global-static-ip-name : abc-wandb-operator-address
ホスト
# プロトコルを含む FQDN を指定します
global :
# ホスト名の例、独自のものに置き換えます
host : https://wandb.example.com
オブジェクトストレージ (バケット)
AWS
global :
bucket :
provider : "s3"
name : ""
kmsKey : ""
region : ""
GCP
global :
bucket :
provider : "gcs"
name : ""
Azure
global :
bucket :
provider : "az"
name : ""
secretKey : ""
その他のプロバイダー (Minio、Ceph など)
その他の S3 互換プロバイダーの場合は、次のようにバケット構成を設定します。
global :
bucket :
# 値の例、独自のものに置き換えます
provider : s3
name : storage.example.com
kmsKey : null
path : wandb
region : default
accessKey : 5WOA500...P5DK7I
secretKey : HDKYe4Q...JAp1YyjysnX
AWS の外部でホストされている S3 互換ストレージの場合、kmsKey は null である必要があります。
シークレットから accessKey と secretKey を参照するには:
global :
bucket :
# 値の例、独自のものに置き換えます
provider : s3
name : storage.example.com
kmsKey : null
path : wandb
region : default
secret :
secretName : bucket-secret
accessKeyName : ACCESS_KEY
secretKeyName : SECRET_KEY
MySQL
global :
mysql :
# 値の例、独自のものに置き換えます
host : db.example.com
port : 3306
database : wandb_local
user : wandb
password : 8wtX6cJH...ZcUarK4zZGjpV
シークレットから password を参照するには:
global :
mysql :
# 値の例、独自のものに置き換えます
host : db.example.com
port : 3306
database : wandb_local
user : wandb
passwordSecret :
name : database-secret
passwordKey : MYSQL_WANDB_PASSWORD
ライセンス
global :
# ライセンスの例、独自のものに置き換えます
license : eyJhbGnUzaHgyQjQy...VFnPS_KETXg1hi
シークレットから license を参照するには:
global :
licenseSecret :
name : license-secret
key : CUSTOMER_WANDB_LICENSE
Ingress
Ingress クラスを特定するには、この FAQエントリ を参照してください。
TLS なし
global :
# 重要: Ingress は YAML で ‘global’ と同じレベルにあります (子ではありません)
ingress :
class : ""
TLS あり
証明書を含むシークレットを作成します
kubectl create secret tls wandb-ingress-tls --key wandb-ingress-tls.key --cert wandb-ingress-tls.crt
Ingress 構成でシークレットを参照します
global :
# 重要: Ingress は YAML で ‘global’ と同じレベルにあります (子ではありません)
ingress :
class : ""
annotations :
{}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
tls :
- secretName : wandb-ingress-tls
hosts :
- <HOST_URI>
Nginx の場合は、次の注釈を追加する必要がある場合があります。
ingress:
annotations:
nginx.ingress.kubernetes.io/proxy-body-size: 64m
カスタム Kubernetes ServiceAccount
カスタム Kubernetes サービスアカウントを指定して、W&B pod を実行します。
次のスニペットは、指定された名前でデプロイメントの一部としてサービスアカウントを作成します。
app :
serviceAccount :
name : custom-service-account
create : true
parquet :
serviceAccount :
name : custom-service-account
create : true
global :
...
サブシステム “app” と “parquet” は、指定されたサービスアカウントで実行されます。他のサブシステムは、デフォルトのサービスアカウントで実行されます。
サービスアカウントがクラスターにすでに存在する場合は、create: false を設定します。
app :
serviceAccount :
name : custom-service-account
create : false
parquet :
serviceAccount :
name : custom-service-account
create : false
global :
...
app、parquet、console など、さまざまなサブシステムでサービスアカウントを指定できます。
app :
serviceAccount :
name : custom-service-account
create : true
console :
serviceAccount :
name : custom-service-account
create : true
global :
...
サービスアカウントは、サブシステム間で異なる場合があります。
app :
serviceAccount :
name : custom-service-account
create : false
console :
serviceAccount :
name : another-custom-service-account
create : true
global :
...
外部 Redis
redis :
install : false
global :
redis :
host : ""
port : 6379
password : ""
parameters : {}
caCert : ""
シークレットから password を参照するには:
kubectl create secret generic redis-secret --from-literal=redis-password=supersecret
以下の構成で参照します。
redis :
install : false
global :
redis :
host : redis.example
port : 9001
auth :
enabled : true
secret : redis-secret
key : redis-password
LDAP
TLS なし
global :
ldap :
enabled : true
# "ldap://" または "ldaps://" を含む LDAP サーバーアドレス
host :
# ユーザーの検索に使用する LDAP 検索ベース
baseDN :
# バインドする LDAP ユーザー (匿名バインドを使用しない場合)
bindDN :
# バインドする LDAP パスワードを含むシークレット名とキー (匿名バインドを使用しない場合)
bindPW :
# 電子メールとグループ ID 属性の LDAP 属性名をコンマ区切りの文字列値として指定します。
attributes :
# LDAP グループ許可リスト
groupAllowList :
# LDAP TLS を有効にする
tls : false
TLS あり
LDAP TLS 証明書構成には、証明書コンテンツで事前に作成された構成マップが必要です。
構成マップを作成するには、次のコマンドを使用します。
kubectl create configmap ldap-tls-cert --from-file=certificate.crt
次の例のように、YAML で構成マップを使用します。
global :
ldap :
enabled : true
# "ldap://" または "ldaps://" を含む LDAP サーバーアドレス
host :
# ユーザーの検索に使用する LDAP 検索ベース
baseDN :
# バインドする LDAP ユーザー (匿名バインドを使用しない場合)
bindDN :
# バインドする LDAP パスワードを含むシークレット名とキー (匿名バインドを使用しない場合)
bindPW :
# 電子メールとグループ ID 属性の LDAP 属性名をコンマ区切りの文字列値として指定します。
attributes :
# LDAP グループ許可リスト
groupAllowList :
# LDAP TLS を有効にする
tls : true
# LDAP サーバーの CA 証明書を含む ConfigMap 名とキー
tlsCert :
configMap :
name : "ldap-tls-cert"
key : "certificate.crt"
OIDC SSO
global :
auth :
sessionLengthHours : 720
oidc :
clientId : ""
secret : ""
# IdP が必要な場合にのみ含めます。
authMethod : ""
issuer : ""
authMethod はオプションです。
SMTP
global :
email :
smtp :
host : ""
port : 587
user : ""
password : ""
環境変数
global :
extraEnv :
GLOBAL_ENV : "example"
カスタム認証局
customCACerts はリストであり、多くの証明書を使用できます。customCACerts で指定された認証局は、W&B Server アプリケーションにのみ適用されます。
global :
customCACerts :
- |
-----BEGIN CERTIFICATE-----
MIIBnDCCAUKgAwIBAg.....................fucMwCgYIKoZIzj0EAwIwLDEQ
MA4GA1UEChMHSG9tZU.....................tZUxhYiBSb290IENBMB4XDTI0
MDQwMTA4MjgzMFoXDT.....................oNWYggsMo8O+0mWLYMAoGCCqG
SM49BAMCA0gAMEUCIQ.....................hwuJgyQRaqMI149div72V2QIg
P5GD+5I+02yEp58Cwxd5Bj2CvyQwTjTO4hiVl1Xd0M0=
-----END CERTIFICATE-----
- |
-----BEGIN CERTIFICATE-----
MIIBxTCCAWugAwIB.......................qaJcwCgYIKoZIzj0EAwIwLDEQ
MA4GA1UEChMHSG9t.......................tZUxhYiBSb290IENBMB4XDTI0
MDQwMTA4MjgzMVoX.......................UK+moK4nZYvpNpqfvz/7m5wKU
SAAwRQIhAIzXZMW4.......................E8UFqsCcILdXjAiA7iTluM0IU
aIgJYVqKxXt25blH/VyBRzvNhViesfkNUQ==
-----END CERTIFICATE-----
CA 証明書は、ConfigMap にも保存できます。
global :
caCertsConfigMap : custom-ca-certs
ConfigMap は次のようになります。
apiVersion : v1
kind : ConfigMap
metadata :
name : custom-ca-certs
data :
ca-cert1.crt : |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
ca-cert2.crt : |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
ConfigMap を使用する場合、ConfigMap の各キーは .crt で終わる必要があります (例: my-cert.crt または ca-cert1.crt)。この命名規則は、update-ca-certificates が各証明書を解析してシステムの CA ストアに追加するために必要です。
カスタムセキュリティコンテキスト
各 W&B コンポーネントは、次の形式のカスタムセキュリティコンテキスト構成をサポートしています。
pod :
securityContext :
runAsNonRoot : true
runAsUser : 1001
runAsGroup : 0
fsGroup : 1001
fsGroupChangePolicy : Always
seccompProfile :
type : RuntimeDefault
container :
securityContext :
capabilities :
drop :
- ALL
readOnlyRootFilesystem : false
allowPrivilegeEscalation : false
runAsGroup: の有効な値は 0 のみです。他の値はエラーです。
たとえば、アプリケーション pod を構成するには、構成にセクション app を追加します。
global :
...
app :
pod :
securityContext :
runAsNonRoot : true
runAsUser : 1001
runAsGroup : 0
fsGroup : 1001
fsGroupChangePolicy : Always
seccompProfile :
type : RuntimeDefault
container :
securityContext :
capabilities :
drop :
- ALL
readOnlyRootFilesystem : false
allowPrivilegeEscalation : false
同じ概念が、console、weave、weave-trace、および parquet にも適用されます。
W&B Operator の構成リファレンス
このセクションでは、W&B Kubernetes operator(wandb-controller-manager)の構成オプションについて説明します。operator は、構成を YAML ファイルの形式で受け取ります。
デフォルトでは、W&B Kubernetes operator に構成ファイルは必要ありません。必要な場合は、構成ファイルを作成します。たとえば、カスタム認証局を指定したり、エアギャップ環境にデプロイしたりするために、構成ファイルが必要になる場合があります。
仕様のカスタマイズの完全なリストについては、Helm リポジトリ を参照してください。
カスタム CA
カスタム認証局(customCACerts)はリストであり、多くの証明書を使用できます。これらの認証局を追加すると、W&B Kubernetes operator(wandb-controller-manager)にのみ適用されます。
customCACerts :
- |
-----BEGIN CERTIFICATE-----
MIIBnDCCAUKgAwIBAg.....................fucMwCgYIKoZIzj0EAwIwLDEQ
MA4GA1UEChMHSG9tZU.....................tZUxhYiBSb290IENBMB4XDTI0
MDQwMTA4MjgzMFoXDT.....................oNWYggsMo8O+0mWLYMAoGCCqG
SM49BAMCA0gAMEUCIQ.....................hwuJgyQRaqMI149div72V2QIg
P5GD+5I+02yEp58Cwxd5Bj2CvyQwTjTO4hiVl1Xd0M0=
-----END CERTIFICATE-----
- |
-----BEGIN CERTIFICATE-----
MIIBxTCCAWugAwIB.......................qaJcwCgYIKoZIzj0EAwIwLDEQ
MA4GA1UEChMHSG9t.......................tZUxhYiBSb290IENBMB4XDTI0
MDQwMTA4MjgzMVoX.......................UK+moK4nZYvpNpqfvz/7m5wKU
SAAwRQIhAIzXZMW4.......................E8UFqsCcILdXjAiA7iTluM0IU
aIgJYVqKxXt25blH/VyBRzvNhViesfkNUQ==
-----END CERTIFICATE-----
CA 証明書は、ConfigMap にも保存できます。
caCertsConfigMap : custom-ca-certs
ConfigMap は次のようになります。
apiVersion : v1
kind : ConfigMap
metadata :
name : custom-ca-certs
data :
ca-cert1.crt : |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
ca-cert2.crt : |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
ConfigMap の各キーは .crt で終わる必要があります (例: my-cert.crt または ca-cert1.crt)。この命名規則は、update-ca-certificates が各証明書を解析してシステムの CA ストアに追加するために必要です。
FAQ
個々の pod の目的/役割は何ですか?
wandb-appwandb-console/console 経由でアクセスします。wandb-otelwandb-prometheuswandb-parquetwandb-app pod とは別のバックエンドマイクロサービス。データベースデータを Parquet 形式でオブジェクトストレージにエクスポートします。wandb-weavewandb-weave-tracewandb-app pod 経由でアクセスします。
W&B Operator Console のパスワードを取得する方法
W&B Kubernetes Operator 管理コンソールへのアクセス を参照してください。
Ingress が機能しない場合に W&B Operator Console にアクセスする方法
Kubernetes クラスターに到達できるホストで、次のコマンドを実行します。
kubectl port-forward svc/wandb-console 8082
ブラウザで https://localhost:8082/ console を使用してコンソールにアクセスします。
パスワードの取得方法については、W&B Kubernetes Operator 管理コンソールへのアクセス (オプション 2)を参照してください。
W&B Server のログを表示する方法
アプリケーション pod の名前は wandb-app-xxx です。
kubectl get pods
kubectl logs wandb-XXXXX-XXXXX
Kubernetes Ingress クラスを識別する方法
次のコマンドを実行して、クラスターにインストールされている Ingress クラスを取得できます。
5.1.3.2.1 - Kubernetes operator for air-gapped instances
Kubernetes Operator で W&B プラットフォーム をデプロイする (エアギャップ)
イントロダクション
このガイドでは、エアギャップされた顧客管理環境に W&B Platform をデプロイするためのステップごとの手順を説明します。
内部リポジトリまたはレジストリを使用して、Helm chartとコンテナイメージをホストします。 Kubernetes クラスターへの適切なアクセス権を持つシェルコンソールですべてのコマンドを実行します。
Kubernetes アプリケーションのデプロイに使用する継続的デリバリー ツールで、同様のコマンドを利用できます。
ステップ 1: 前提条件
開始する前に、ご使用の環境が次の要件を満たしていることを確認してください。
Kubernetes バージョン >= 1.28
Helm バージョン >= 3
必要な W&B イメージを持つ内部コンテナレジストリへのアクセス
W&B Helm chart 用の内部 Helm リポジトリへのアクセス
ステップ 2: 内部コンテナレジストリの準備
デプロイメントに進む前に、次のコンテナイメージが内部コンテナレジストリで利用可能であることを確認する必要があります。
これらのイメージは、W&B コンポーネントを正常にデプロイするために重要です。 W&B は、WSM を使用してコンテナレジストリを準備することを推奨します。
組織がすでに内部コンテナレジストリを使用している場合は、イメージをそこに追加できます。 それ以外の場合は、次のセクションに従って、WSM と呼ばれるものを使用してコンテナリポジトリを準備します。
Operator の要件の追跡、およびイメージのアップグレードの確認とダウンロードは、WSM を使用 するか、組織独自のプロセスを使用することによって、ユーザーが行う必要があります。
WSM のインストール
次のいずれかの方法を使用して WSM をインストールします。
WSM には、機能する Docker インストールが必要です。
Bash
GitHub から Bash スクリプトを直接実行します。
curl -sSL https://raw.githubusercontent.com/wandb/wsm/main/install.sh | bash
スクリプトは、スクリプトを実行したフォルダーにバイナリをダウンロードします。 別のフォルダーに移動するには、次を実行します。
sudo mv wsm /usr/local/bin
GitHub
W&B が管理する GitHub リポジトリ wandb/wsm(https://github.com/wandb/wsm)から WSM をダウンロードまたはクローンします。 最新リリースについては、wandb/wsm の リリースノート を参照してください。
イメージとそのバージョンのリスト
wsm list を使用して、イメージバージョンの最新リストを取得します。
出力は次のようになります。
:package: Starting the process to list all images required for deployment...
Operator Images:
wandb/controller:1.16.1
W&B Images:
wandb/local:0.62.2
docker.io/bitnami/redis:7.2.4-debian-12-r9
quay.io/prometheus-operator/prometheus-config-reloader:v0.67.0
quay.io/prometheus/prometheus:v2.47.0
otel/opentelemetry-collector-contrib:0.97.0
wandb/console:2.13.1
Here are the images required to deploy W&B. Ensure these images are available in your internal container registry and update the values.yaml accordingly.
イメージのダウンロード
wsm download を使用して、最新バージョンのすべてのイメージをダウンロードします。
出力は次のようになります。
Downloading operator helm chart
Downloading wandb helm chart
✓ wandb/controller:1.16.1
✓ docker.io/bitnami/redis:7.2.4-debian-12-r9
✓ otel/opentelemetry-collector-contrib:0.97.0
✓ quay.io/prometheus-operator/prometheus-config-reloader:v0.67.0
✓ wandb/console:2.13.1
✓ quay.io/prometheus/prometheus:v2.47.0
Done! Installed 7 packages.
WSM は、各イメージの .tgz アーカイブを bundle ディレクトリーにダウンロードします。
ステップ 3: 内部 Helm chart リポジトリの準備
コンテナイメージに加えて、次の Helm chartが内部 Helm Chart リポジトリで利用可能であることも確認する必要があります。 前のステップで紹介した WSM ツールは、Helm chartもダウンロードできます。 または、ここでダウンロードしてください。
operator chartは、Controller Manager とも呼ばれる W&B Operator をデプロイするために使用されます。 platform chartは、カスタムリソース定義 (CRD) で構成された値を使用して W&B Platform をデプロイするために使用されます。
ステップ 4: Helm リポジトリの設定
次に、内部リポジトリから W&B Helm chartをプルするように Helm リポジトリを設定します。 次のコマンドを実行して、Helm リポジトリを追加および更新します。
helm repo add local-repo https://charts.yourdomain.com
helm repo update
ステップ 5: Kubernetes operator のインストール
コントローラマネージャとも呼ばれる W&B Kubernetes operator は、W&B platform コンポーネントの管理を担当します。 エアギャップ環境にインストールするには、内部コンテナレジストリを使用するように構成する必要があります。
これを行うには、内部コンテナレジストリを使用するようにデフォルトのイメージ設定をオーバーライドし、キー airgapped: true を設定して、予想されるデプロイメントタイプを示す必要があります。 次に示すように、values.yaml ファイルを更新します。
image :
repository : registry.yourdomain.com/library/controller
tag : 1.13.3
airgapped : true
タグを、内部レジストリで使用可能なバージョンに置き換えます。
operator と CRD をインストールします。
helm upgrade --install operator wandb/operator -n wandb --create-namespace -f values.yaml
サポートされている値の詳細については、Kubernetes operator GitHub リポジトリ を参照してください。
ステップ 6: W&B カスタムリソースの設定
W&B Kubernetes operator をインストールしたら、内部 Helm リポジトリとコンテナレジストリを指すようにカスタムリソース (CR) を構成する必要があります。
この設定により、Kubernetes operator は、W&B platform の必要なコンポーネントをデプロイするときに、内部レジストリとリポジトリを使用することが保証されます。
この CR の例を wandb.yaml という新しいファイルにコピーします。
apiVersion : apps.wandb.com/v1
kind : WeightsAndBiases
metadata :
labels :
app.kubernetes.io/instance : wandb
app.kubernetes.io/name : weightsandbiases
name : wandb
namespace : default
spec :
chart :
url : http://charts.yourdomain.com
name : operator-wandb
version : 0.18.0
values :
global :
host : https://wandb.yourdomain.com
license : xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
bucket :
accessKey : xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
secretKey : xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
name: s3.yourdomain.com:port #Ex. : s3.yourdomain.com:9000
path : bucket_name
provider : s3
region : us-east-1
mysql :
database : wandb
host : mysql.home.lab
password : password
port : 3306
user : wandb
extraEnv :
ENABLE_REGISTRY_UI : 'true'
# If install: true, Helm installs a MySQL database for the deployment to use. Set to `false` to use your own external MySQL deployment.
mysql :
install : false
app :
image :
repository : registry.yourdomain.com/local
tag : 0.59.2
console :
image :
repository : registry.yourdomain.com/console
tag : 2.12.2
ingress :
annotations :
nginx.ingress.kubernetes.io/proxy-body-size : 64m
class : nginx
W&B platform をデプロイするために、Kubernetes Operator は CR の値を使用して、内部リポジトリから operator-wandb Helm chart を構成します。
すべてのタグ/バージョンを、内部レジストリで使用可能なバージョンに置き換えます。
上記の構成ファイルの作成の詳細については、こちら をご覧ください。
Kubernetes operator と CR が構成されたので、wandb.yaml 構成を適用して W&B platform をデプロイします。
kubectl apply -f wandb.yaml
FAQ
デプロイメントプロセス中に、以下のよくある質問 (FAQ) とトラブルシューティングのヒントを参照してください。
別の ingress クラスがあります。 そのクラスを使用できますか?
はい、values.yaml で ingress 設定を変更することで、ingress クラスを構成できます。
証明書バンドルに複数の証明書があります。 それは機能しますか?
証明書を values.yaml の customCACerts セクションの複数のエントリに分割する必要があります。
Kubernetes operator が無人アップデートを適用するのを防ぐにはどうすればよいですか。 それは可能ですか?
W&B console から自動アップデートをオフにすることができます。 サポートされているバージョンに関する質問については、W&B チームにお問い合わせください。 また、W&B は過去 6 か月以内にリリースされた platform バージョンをサポートしていることに注意してください。 W&B は定期的なアップグレードを実行することをお勧めします。
環境がパブリックリポジトリに接続されていない場合、デプロイメントは機能しますか?
構成で airgapped を true に設定すると、Kubernetes operator は内部リソースのみを使用し、パブリックリポジトリへの接続を試みません。
5.1.3.3 - Install on public cloud
5.1.3.3.1 - Deploy W&B Platform on AWS
AWS 上で W&B サーバー をホストする。
W&B は、W&B Server AWS Terraform Module を使用して、AWS にプラットフォームをデプロイすることをお勧めします。
開始する前に、W&B は、Terraform で利用可能な リモートバックエンド のいずれかを選択して、State File を保存することをお勧めします。
State File は、すべてのコンポーネントを再作成せずに、アップグレードを展開したり、デプロイメントに変更を加えたりするために必要なリソースです。
Terraform Module は、次の 必須 コンポーネントをデプロイします。
ロードバランサー
AWS Identity & Access Management (IAM)
AWS Key Management System (KMS)
Amazon Aurora MySQL
Amazon VPC
Amazon S3
Amazon Route53
Amazon Certificate Manager (ACM)
Amazon Elastic Load Balancing (ALB)
Amazon Secrets Manager
その他のデプロイメントオプションには、次のオプションコンポーネントを含めることもできます。
Redis 用 Elastic Cache
SQS
前提条件のアクセス許可
Terraform を実行するアカウントは、イントロダクションで説明されているすべてのコンポーネントを作成でき、IAM Policies と IAM Roles を作成し、リソースにロールを割り当てるアクセス許可が必要です。
一般的な手順
このトピックの手順は、このドキュメントで説明されているすべてのデプロイメントオプションに共通です。
開発環境を準備します。
Terraform をインストールします。W&B は、バージョン管理のために Git リポジトリーを作成することをお勧めします。
terraform.tfvars ファイルを作成します。
tvfars ファイルの内容は、インストールタイプに応じてカスタマイズできますが、最小限の推奨設定は以下の例のようになります。
namespace = "wandb"
license = "xxxxxxxxxxyyyyyyyyyyyzzzzzzz"
subdomain = "wandb-aws"
domain_name = "wandb.ml"
zone_id = "xxxxxxxxxxxxxxxx"
allowed_inbound_cidr = [ "0.0.0.0/0" ]
allowed_inbound_ipv6_cidr = [ "::/0" ]
eks_cluster_version = "1.29"
namespace 変数は、Terraform によって作成されたすべてのリソースのプレフィックスとなる文字列であるため、デプロイする前に tvfars ファイルで変数を定義してください。
subdomain と domain の組み合わせで、W&B が設定される FQDN が形成されます。上記の例では、W&B FQDN は wandb-aws.wandb.ml になり、FQDN レコードが作成される DNS zone_id になります。
allowed_inbound_cidr と allowed_inbound_ipv6_cidr の両方も設定が必要です。モジュールでは、これは必須入力です。上記の例では、すべてのソースからの W&B インストールへのアクセスを許可しています。
ファイル versions.tf を作成します。
このファイルには、AWS に W&B をデプロイするために必要な Terraform および Terraform プロバイダーのバージョンが含まれます。
provider "aws" {
region = "eu-central-1"
default_tags {
tags = {
GithubRepo = "terraform-aws-wandb"
GithubOrg = "wandb"
Enviroment = "Example"
Example = "PublicDnsExternal"
}
}
}
AWS プロバイダーの設定については、Terraform Official Documentation を参照してください。
オプションですが、強く推奨されるのは、このドキュメントの冒頭で説明した リモートバックエンド構成 を追加することです。
ファイル variables.tf を作成します。
terraform.tfvars で設定されたすべてのオプションについて、Terraform は対応する変数宣言を必要とします。
variable "namespace" {
type = string
description = "リソースに使用される名前のプレフィックス"
}
variable "domain_name" {
type = string
description = "インスタンスへのアクセスに使用されるドメイン名。"
}
variable "subdomain" {
type = string
default = null
description = "Weights & Biases UI にアクセスするためのサブドメイン。"
}
variable "license" {
type = string
}
variable "zone_id" {
type = string
description = "Weights & Biases サブドメインを作成するドメイン。"
}
variable "allowed_inbound_cidr" {
description = "wandb-server へのアクセスが許可されている CIDR。"
nullable = false
type = list(string)
}
variable "allowed_inbound_ipv6_cidr" {
description = "wandb-server へのアクセスが許可されている CIDR。"
nullable = false
type = list(string)
}
variable "eks_cluster_version" {
description = "EKS クラスター kubernetes バージョン"
nullable = false
type = string
}
推奨されるデプロイメントオプション
これは、すべての 必須 コンポーネントを作成し、Kubernetes Cluster に最新バージョンの W&B をインストールする、最も簡単なデプロイメントオプション構成です。
main.tf を作成します。
「一般的な手順」でファイルを作成したのと同じディレクトリーに、次の内容で main.tf ファイルを作成します。
module "wandb_infra" {
source = "wandb/wandb/aws"
version = "~>7.0"
namespace = var.namespace
domain_name = var.domain_name
subdomain = var.subdomain
zone_id = var.zone_id
allowed_inbound_cidr = var.allowed_inbound_cidr
allowed_inbound_ipv6_cidr = var.allowed_inbound_ipv6_cidr
public_access = true
external_dns = true
kubernetes_public_access = true
kubernetes_public_access_cidrs = ["0.0.0.0/0"]
eks_cluster_version = var.eks_cluster_version
}
data "aws_eks_cluster" "eks_cluster_id" {
name = module.wandb_infra.cluster_name
}
data "aws_eks_cluster_auth" "eks_cluster_auth" {
name = module.wandb_infra.cluster_name
}
provider "kubernetes" {
host = data.aws_eks_cluster.eks_cluster_id.endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.eks_cluster_id.certificate_authority.0.data)
token = data.aws_eks_cluster_auth.eks_cluster_auth.token
}
provider "helm" {
kubernetes {
host = data.aws_eks_cluster.eks_cluster_id.endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.eks_cluster_id.certificate_authority.0.data)
token = data.aws_eks_cluster_auth.eks_cluster_auth.token
}
}
output "url" {
value = module.wandb_infra.url
}
output "bucket" {
value = module.wandb_infra.bucket_name
}
W&B をデプロイします。
W&B をデプロイするには、次のコマンドを実行します。
terraform init
terraform apply -var-file=terraform.tfvars
REDIS を有効にする
別のデプロイメントオプションでは、Redis を使用して SQL クエリをキャッシュし、実験のメトリクスをロードする際のアプリケーションの応答を高速化します。
キャッシュを有効にするには、推奨されるデプロイメント セクションで説明されているのと同じ main.tf ファイルにオプション create_elasticache_subnet = true を追加する必要があります。
module "wandb_infra" {
source = "wandb/wandb/aws"
version = "~>7.0"
namespace = var.namespace
domain_name = var.domain_name
subdomain = var.subdomain
zone_id = var.zone_id
**create_elasticache_subnet = true**
}
[...]
メッセージブローカー(キュー)を有効にする
デプロイメントオプション 3 は、外部 message broker を有効にすることで構成されています。これは、W&B にブローカーが埋め込まれているため、オプションです。このオプションは、パフォーマンスの向上をもたらしません。
メッセージブローカーを提供する AWS リソースは SQS であり、これを有効にするには、推奨されるデプロイメント セクションで説明されているのと同じ main.tf にオプション use_internal_queue = false を追加する必要があります。
module "wandb_infra" {
source = "wandb/wandb/aws"
version = "~>7.0"
namespace = var.namespace
domain_name = var.domain_name
subdomain = var.subdomain
zone_id = var.zone_id
**use_internal_queue = false**
[...]
}
その他のデプロイメントオプション
3 つのデプロイメントオプションすべてを組み合わせて、すべての構成を同じファイルに追加できます。
Terraform Module は、標準オプションと Deployment - Recommended にある最小構成とともに組み合わせることができるいくつかのオプションを提供します。
手動構成
Amazon S3 バケットを W&B のファイルストレージバックエンドとして使用するには、次の操作を行う必要があります。
バケットと、そのバケットからオブジェクト作成通知を受信する SQS キューを構成する必要があります。インスタンスには、このキューから読み取るためのアクセス許可が必要です。
S3 バケットとバケット通知の作成
Amazon S3 バケットを作成し、バケット通知を有効にするには、以下の手順に従います。
AWS コンソールで Amazon S3 に移動します。
[バケットの作成 ] を選択します。
[詳細設定 ] で、[イベント ] セクションの [通知の追加 ] を選択します。
以前に構成した SQS キューに送信されるように、すべてのオブジェクト作成イベントを構成します。
CORS アクセスを有効にします。CORS 構成は次のようになります。
<?xml version="1.0" encoding="UTF-8"?>
<CORSConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<CORSRule>
<AllowedOrigin>http://YOUR-W&B-SERVER-IP</AllowedOrigin>
<AllowedMethod>GET</AllowedMethod>
<AllowedMethod>PUT</AllowedMethod>
<AllowedHeader>*</AllowedHeader>
</CORSRule>
</CORSConfiguration>
SQS キューの作成
SQS キューを作成するには、以下の手順に従います。
AWS コンソールで Amazon SQS に移動します。
[キューの作成 ] を選択します。
[詳細 ] セクションで、[標準 ] キュータイプを選択します。
[アクセス ポリシー] セクションで、次のプリンシパルへのアクセス許可を追加します。
SendMessageReceiveMessageChangeMessageVisibilityDeleteMessageGetQueueUrl
オプションで、[アクセス ポリシー ] セクションに高度なアクセス ポリシーを追加します。たとえば、ステートメントを含む Amazon SQS にアクセスするためのポリシーは次のとおりです。
{
"Version" : "2012-10-17" ,
"Statement" : [
{
"Effect" : "Allow" ,
"Principal" : "*" ,
"Action" : ["sqs:SendMessage" ],
"Resource" : "<sqs-queue-arn>" ,
"Condition" : {
"ArnEquals" : { "aws:SourceArn" : "<s3-bucket-arn>" }
}
}
]
}
W&B を実行するノードへのアクセス許可の付与
W&B サーバーが実行されているノードは、Amazon S3 および Amazon SQS へのアクセスを許可するように構成する必要があります。選択したサーバーデプロイメントのタイプに応じて、次のポリシー ステートメントをノードロールに追加する必要がある場合があります。
{
"Statement" :[
{
"Sid" :"" ,
"Effect" :"Allow" ,
"Action" :"s3:*" ,
"Resource" :"arn:aws:s3:::<WANDB_BUCKET>"
},
{
"Sid" :"" ,
"Effect" :"Allow" ,
"Action" :[
"sqs:*"
],
"Resource" :"arn:aws:sqs:<REGION>:<ACCOUNT>:<WANDB_QUEUE>"
}
]
}
W&B サーバーの設定
最後に、W&B サーバーを設定します。
http(s)://YOUR-W&B-SERVER-HOST/system-admin で W&B 設定ページに移動します。[**外部ファイルストレージバックエンドを使用する ] オプションを有効にします。
次の形式で、Amazon S3 バケット、リージョン、および Amazon SQS キューに関する情報を提供します。
ファイルストレージバケット : s3://<bucket-name>ファイルストレージリージョン (AWS のみ) : <region>通知サブスクリプション : sqs://<queue-name>
[設定の更新 ] を選択して、新しい設定を適用します。
W&B バージョンをアップグレードする
W&B を更新するには、ここに概説されている手順に従います。
wandb_app モジュールの構成に wandb_version を追加します。アップグレードする W&B のバージョンを指定します。たとえば、次の行は W&B バージョン 0.48.1 を指定します。
module "wandb_app" {
source = "wandb/wandb/kubernetes"
version = "~>1.0"
license = var.license
wandb_version = "0.48.1"
または、wandb_version を terraform.tfvars に追加し、同じ名前の変数を作成して、リテラル値を使用する代わりに var.wandb_version を使用することもできます。
構成を更新した後、推奨されるデプロイメントセクション で説明されている手順を完了します。
このセクションでは、terraform-aws-wandb モジュールを使用して、プレオペレーター 環境から ポストオペレーター 環境にアップグレードするために必要な手順について詳しく説明します。
W&B アーキテクチャでは、Kubernetes
operator パターンへの移行が必要です。アーキテクチャの移行に関する詳細な説明については、
このセクション を参照してください。
移行前後のアーキテクチャ
以前の W&B アーキテクチャでは、次のものが使用されていました。
module "wandb_infra" {
source = "wandb/wandb/aws"
version = "1.16.10"
...
}
インフラストラクチャを制御します。
また、このモジュールを使用して W&B サーバーをデプロイします。
module "wandb_app" {
source = "wandb/wandb/kubernetes"
version = "1.12.0"
}
移行後のアーキテクチャでは、次のものが使用されます。
module "wandb_infra" {
source = "wandb/wandb/aws"
version = "4.7.2"
...
}
インフラストラクチャのインストールと Kubernetes クラスターへの W&B サーバーのデプロイの両方を管理するため、post-operator.tf では module "wandb_app" は不要になります。
このアーキテクチャの移行により、SRE/インフラストラクチャチームによる手動の Terraform 操作を必要とせずに、追加機能 (OpenTelemetry、Prometheus、HPA、Kafka、およびイメージ更新など) を有効にできます。
W&B Pre-Operator の基本インストールを開始するには、post-operator.tf に .disabled ファイル拡張子があり、pre-operator.tf がアクティブであることを確認します (.disabled` 拡張子がない)。これらのファイルは、ここ にあります。
前提条件
移行プロセスを開始する前に、次の前提条件が満たされていることを確認してください。
エグレス : デプロイメントはエアギャップにできません。Release Channel deploy.wandb.ai へのアクセスが必要です。AWS 認証情報 : AWS リソースと対話するように構成された適切な AWS 認証情報。Terraform のインストール : 最新バージョンの Terraform がシステムにインストールされている必要があります。Route53 ホストゾーン : アプリケーションが提供されるドメインに対応する既存の Route53 ホストゾーン。Pre-Operator Terraform ファイル : pre-operator.tf および関連する変数ファイル (例: pre-operator.tfvars) が正しく設定されていることを確認します。
Pre-Operator の設定
次の Terraform コマンドを実行して、Pre-Operator セットアップの構成を初期化して適用します。
terraform init -upgrade
terraform apply -var-file= ./pre-operator.tfvars
pre-operator.tf は次のようになります。
namespace = "operator-upgrade"
domain_name = "sandbox-aws.wandb.ml"
zone_id = "Z032246913CW32RVRY0WU"
subdomain = "operator-upgrade"
wandb_license = "ey..."
wandb_version = "0.51.2"
pre-operator.tf 構成は、次の 2 つのモジュールを呼び出します。
module "wandb_infra" {
source = "wandb/wandb/aws"
version = "1.16.10"
...
}
このモジュールはインフラストラクチャを起動します。
module "wandb_app" {
source = "wandb/wandb/kubernetes"
version = "1.12.0"
}
このモジュールはアプリケーションをデプロイします。
Post-Operator の設定
pre-operator.tf に .disabled 拡張子があり、post-operator.tf がアクティブであることを確認します。
post-operator.tfvars には、追加の変数が含まれています。
...
# wandb_version = "0.51.2" は、リリースチャネルを介して管理されるか、ユーザースペックで設定されるようになりました。
# アップグレードに必要なオペレーター変数:
size = "small"
enable_dummy_dns = true
enable_operator_alb = true
custom_domain_filter = "sandbox-aws.wandb.ml"
次のコマンドを実行して、Post-Operator 構成を初期化して適用します。
terraform init -upgrade
terraform apply -var-file= ./post-operator.tfvars
プランと適用手順では、次のリソースが更新されます。
actions :
create :
- aws_efs_backup_policy.storage_class
- aws_efs_file_system.storage_class
- aws_efs_mount_target.storage_class["0"]
- aws_efs_mount_target.storage_class["1"]
- aws_eks_addon.efs
- aws_iam_openid_connect_provider.eks
- aws_iam_policy.secrets_manager
- aws_iam_role_policy_attachment.ebs_csi
- aws_iam_role_policy_attachment.eks_efs
- aws_iam_role_policy_attachment.node_secrets_manager
- aws_security_group.storage_class_nfs
- aws_security_group_rule.nfs_ingress
- random_pet.efs
- aws_s3_bucket_acl.file_storage
- aws_s3_bucket_cors_configuration.file_storage
- aws_s3_bucket_ownership_controls.file_storage
- aws_s3_bucket_server_side_encryption_configuration.file_storage
- helm_release.operator
- helm_release.wandb
- aws_cloudwatch_log_group.this[0]
- aws_iam_policy.default
- aws_iam_role.default
- aws_iam_role_policy_attachment.default
- helm_release.external_dns
- aws_default_network_acl.this[0]
- aws_default_route_table.default[0]
- aws_iam_policy.default
- aws_iam_role.default
- aws_iam_role_policy_attachment.default
- helm_release.aws_load_balancer_controller
update_in_place :
- aws_iam_policy.node_IMDSv2
- aws_iam_policy.node_cloudwatch
- aws_iam_policy.node_kms
- aws_iam_policy.node_s3
- aws_iam_policy.node_sqs
- aws_eks_cluster.this[0]
- aws_elasticache_replication_group.default
- aws_rds_cluster.this[0]
- aws_rds_cluster_instance.this["1"]
- aws_default_security_group.this[0]
- aws_subnet.private[0]
- aws_subnet.private[1]
- aws_subnet.public[0]
- aws_subnet.public[1]
- aws_launch_template.workers["primary"]
destroy :
- kubernetes_config_map.config_map
- kubernetes_deployment.wandb
- kubernetes_priority_class.priority
- kubernetes_secret.secret
- kubernetes_service.prometheus
- kubernetes_service.service
- random_id.snapshot_identifier[0]
replace :
- aws_autoscaling_attachment.autoscaling_attachment["primary"]
- aws_route53_record.alb
- aws_eks_node_group.workers["primary"]
次のようなものが表示されます。
post-operator.tf には、次のように 1 つがあります。
module "wandb_infra" {
source = "wandb/wandb/aws"
version = "4.7.2"
...
}
ポストオペレーター構成の変更点:
必要なプロバイダーの更新 : プロバイダーの互換性を保つために、required_providers.aws.version を 3.6 から 4.0 に変更します。DNS とロード バランサーの構成 : Ingress を介して DNS レコードと AWS ロード バランサーの設定を管理するために、enable_dummy_dns と enable_operator_alb を統合します。ライセンスとサイズの構成 : 新しい運用要件に合わせて、license パラメーターと size パラメーターを wandb_infra モジュールに直接転送します。カスタムドメインの処理 : 必要に応じて、kube-system 名前空間内の外部 DNS ポッドログを確認して DNS の問題をトラブルシューティングするために、custom_domain_filter を使用します。Helm プロバイダーの構成 : Helm プロバイダーを有効にして構成し、Kubernetes リソースを効果的に管理します。
provider "helm" {
kubernetes {
host = data .aws_eks_cluster .app_cluster .endpoint
cluster_ca_certificate = base64decode (data .aws_eks_cluster .app_cluster .certificate_authority [0 ].data )
token = data .aws_eks_cluster_auth .app_cluster .token
exec {
api_version = "client.authentication.k8s.io/v1beta1"
args = ["eks", "get-token", "--cluster-name" , data .aws_eks_cluster .app_cluster .name ]
command = "aws"
}
}
}
この包括的な設定により、オペレーターモデルによって有効になる新しい効率と機能を活用して、Pre-Operator 構成から Post-Operator 構成へのスムーズな移行が保証されます。
5.1.3.3.2 - Deploy W&B Platform on GCP
GCP 上での W&B サーバー のホスティング。
W&B Server の自己管理を行う場合、GCP 上にプラットフォームをデプロイするために、W&B Server GCP Terraform Module を使用することを推奨します。
モジュールのドキュメントは広範囲にわたり、利用可能なすべてのオプションが記載されています。
開始する前に、Terraform の リモートバックエンド のいずれかを選択して、State File を保存することを推奨します。
State File は、すべてのコンポーネントを再作成せずに、アップグレードを展開したり、デプロイメントに変更を加えたりするために必要なリソースです。
Terraform Module は、以下の必須コンポーネントをデプロイします。
VPC
Cloud SQL for MySQL
Cloud Storage Bucket
Google Kubernetes Engine
KMS Crypto Key
Load Balancer
その他のデプロイメントオプションには、以下のオプションコンポーネントを含めることもできます。
Redis 用のメモリーストア
Pub/Sub メッセージシステム
事前requisite 権限
Terraform を実行するアカウントには、使用する GCP プロジェクトで roles/owner のロールが必要です。
一般的な手順
このトピックの手順は、このドキュメントで説明するすべてのデプロイメントオプションに共通です。
開発環境を準備します。
Terraform をインストールします。使用するコードで Git リポジトリを作成することをお勧めしますが、ファイルをローカルに保存することもできます。
Google Cloud Console でプロジェクトを作成します。GCP で認証します (gcloud をインストールしてください)。
gcloud auth application-default login
terraform.tfvars ファイルを作成します。
tvfars ファイルの内容は、インストールタイプに応じてカスタマイズできますが、最小限の推奨設定は以下の例のようになります。
project_id = "wandb-project"
region = "europe-west2"
zone = "europe-west2-a"
namespace = "wandb"
license = "xxxxxxxxxxyyyyyyyyyyyzzzzzzz"
subdomain = "wandb-gcp"
domain_name = "wandb.ml"
ここで定義する変数は、デプロイメントの前に決定する必要があります。namespace 変数は、Terraform によって作成されるすべてのリソースに接頭辞を付ける文字列になります。
subdomain と domain の組み合わせで、Weights & Biases が設定される FQDN が形成されます。上記の例では、Weights & Biases の FQDN は wandb-gcp.wandb.ml になります。
ファイル variables.tf を作成します。
terraform.tfvars で設定されたすべてのオプションについて、Terraform は対応する変数宣言を必要とします。
variable "project_id" {
type = string
description = "Project ID"
}
variable "region" {
type = string
description = "Google region"
}
variable "zone" {
type = string
description = "Google zone"
}
variable "namespace" {
type = string
description = "Namespace prefix used for resources"
}
variable "domain_name" {
type = string
description = "Weights & Biases UI にアクセスするためのドメイン名"
}
variable "subdomain" {
type = string
description = "Weights & Biases UI にアクセスするためのサブドメイン"
}
variable "license" {
type = string
description = "W&B License"
}
デプロイメント - 推奨 (~20 分)
これは最も簡単なデプロイメントオプションの設定で、すべての Mandatory コンポーネントを作成し、Kubernetes Cluster に最新バージョンの W&B をインストールします。
main.tf を作成します。
一般的な手順 でファイルを作成したのと同じディレクトリーに、次の内容で main.tf ファイルを作成します。
provider "google" {
project = var.project_id
region = var.region
zone = var.zone
}
provider "google-beta" {
project = var.project_id
region = var.region
zone = var.zone
}
data "google_client_config" "current" {}
provider "kubernetes" {
host = "https://${module.wandb.cluster_endpoint}"
cluster_ca_certificate = base64decode(module.wandb.cluster_ca_certificate)
token = data.google_client_config.current.access_token
}
# Spin up all required services
module "wandb" {
source = "wandb/wandb/google"
version = "~> 5.0"
namespace = var.namespace
license = var.license
domain_name = var.domain_name
subdomain = var.subdomain
}
# You'll want to update your DNS with the provisioned IP address
output "url" {
value = module.wandb.url
}
output "address" {
value = module.wandb.address
}
output "bucket_name" {
value = module.wandb.bucket_name
}
W&B をデプロイします。
W&B をデプロイするには、次のコマンドを実行します。
terraform init
terraform apply -var-file=terraform.tfvars
REDIS キャッシュを使用したデプロイメント
別のデプロイメントオプションでは、Redis を使用して SQL クエリをキャッシュし、実験のメトリクスをロードする際のアプリケーションの応答を高速化します。
キャッシュを有効にするには、推奨される デプロイメントオプションのセクション で指定されている同じ main.tf ファイルにオプション create_redis = true を追加する必要があります。
[...]
module "wandb" {
source = "wandb/wandb/google"
version = "~> 1.0"
namespace = var.namespace
license = var.license
domain_name = var.domain_name
subdomain = var.subdomain
allowed_inbound_cidrs = ["*"]
#Enable Redis
create_redis = true
}
[...]
外部キューを使用したデプロイメント
デプロイメントオプション 3 は、外部 message broker を有効にすることです。W&B にはブローカーが組み込まれているため、これはオプションです。このオプションは、パフォーマンスの向上をもたらしません。
メッセージブローカーを提供する GCP リソースは Pub/Sub であり、これを有効にするには、推奨される デプロイメントオプションのセクション で指定されている同じ main.tf にオプション use_internal_queue = false を追加する必要があります。
[...]
module "wandb" {
source = "wandb/wandb/google"
version = "~> 1.0"
namespace = var.namespace
license = var.license
domain_name = var.domain_name
subdomain = var.subdomain
allowed_inbound_cidrs = ["*"]
#Create and use Pub/Sub
use_internal_queue = false
}
[...]
その他のデプロイメントオプション
3 つのデプロイメントオプションすべてを組み合わせて、すべての構成を同じファイルに追加できます。
Terraform Module は、標準オプションと Deployment - Recommended にある最小限の構成とともに組み合わせることができるいくつかのオプションを提供します。
手動構成
GCP Storage バケットを W&B のファイルストレージバックエンドとして使用するには、以下を作成する必要があります。
PubSub トピックとサブスクリプションを作成する
PubSub トピックとサブスクリプションを作成するには、以下の手順に従ってください。
GCP Console 内の Pub/Sub サービスに移動します。
[トピックを作成 ] を選択し、トピックの名前を指定します。
ページの下部で、[サブスクリプションを作成 ] を選択します。[配信タイプ ] が [プル ] に設定されていることを確認します。
[作成 ] をクリックします。
インスタンスを実行しているサービスアカウントまたはアカウントに、このサブスクリプションに対する pubsub.admin ロールがあることを確認してください。詳細については、https://cloud.google.com/pubsub/docs/access-control#console を参照してください。
ストレージバケットを作成する
[Cloud Storage バケット ] ページに移動します。
[バケットを作成 ] を選択し、バケットの名前を指定します。[標準 ] ストレージクラス を選択してください。
インスタンスを実行しているサービスアカウントまたはアカウントに、以下の両方があることを確認してください。
前の手順で作成したバケットへのアクセス
このバケットに対する storage.objectAdmin ロール。詳細については、https://cloud.google.com/storage/docs/access-control/using-iam-permissions#bucket-add を参照してください。
インスタンスが署名付きファイル URL を作成するには、GCP で iam.serviceAccounts.signBlob 権限も必要です。インスタンスを実行しているサービスアカウントまたは IAM メンバーに Service Account Token Creator ロールを追加して、権限を有効にします。
CORS アクセスを有効にします。これはコマンドラインでのみ実行できます。まず、次の CORS 構成で JSON ファイルを作成します。
cors:
- maxAgeSeconds: 3600
method:
- GET
- PUT
origin:
- '<YOUR_W&B_SERVER_HOST>'
responseHeader:
- Content-Type
オリジンのスキーム、ホスト、ポートの値が正確に一致する必要があることに注意してください。
gcloud がインストールされ、正しい GCP プロジェクトにログインしていることを確認します。次に、以下を実行します。
gcloud storage buckets update gs://<BUCKET_NAME> --cors-file= <CORS_CONFIG_FILE>
PubSub 通知を作成する
ストレージバケットから Pub/Sub トピックへの通知ストリームを作成するには、コマンドラインで以下の手順に従ってください。
通知ストリームを作成するには、CLI を使用する必要があります。gcloud がインストールされていることを確認してください。
GCP プロジェクトにログインします。
ターミナルで以下を実行します。
gcloud pubsub topics list # list names of topics for reference
gcloud storage ls # list names of buckets for reference
# create bucket notification
gcloud storage buckets notifications create gs://<BUCKET_NAME> --topic= <TOPIC_NAME>
詳細については、Cloud Storage の Web サイトをご覧ください。
W&B サーバーを設定する
最後に、http(s)://YOUR-W&B-SERVER-HOST/console/settings/system で W&B の [システム接続] ページに移動します。
プロバイダー Google Cloud Storage (gcs) を選択します。
GCS バケットの名前を指定します。
[設定を更新 ] を押して、新しい設定を適用します。
W&B サーバーをアップグレードする
W&B を更新するには、ここで概説する手順に従ってください。
wandb_app モジュールの構成に wandb_version を追加します。アップグレードする W&B のバージョンを指定します。たとえば、次の行は W&B バージョン 0.48.1 を指定します。
module "wandb_app" {
source = "wandb/wandb/kubernetes"
version = "~>5.0"
license = var.license
wandb_version = "0.58.1"
または、wandb_version を terraform.tfvars に追加し、同じ名前の変数を作成して、リテラル値を使用する代わりに var.wandb_version を使用することもできます。
構成を更新したら、デプロイメントオプションのセクション で説明されている手順を完了します。
5.1.3.3.3 - Deploy W&B Platform on Azure
Azure 上での W&B サーバー のホスティング
W&B Server の自己管理を選択した場合、Azure にプラットフォームをデプロイするには、W&B Server Azure Terraform Module を使用することをお勧めします。
このモジュールのドキュメントは広範囲にわたり、利用可能なすべてのオプションが記載されています。このドキュメントでは、いくつかのデプロイメントオプションについて説明します。
開始する前に、Terraform で利用可能な remote backends のいずれかを選択して、State File を保存することをお勧めします。
State File は、すべてのコンポーネントを再作成せずに、アップグレードを展開したり、デプロイメントに変更を加えたりするために必要なリソースです。
Terraform Module は、次の mandatory コンポーネントをデプロイします。
Azure Resource Group
Azure Virtual Network (VPC)
Azure MySQL Fliexible Server
Azure Storage Account & Blob Storage
Azure Kubernetes Service
Azure Application Gateway
その他のデプロイメントオプションには、次のオプションコンポーネントも含まれます。
Azure Cache for Redis
Azure Event Grid
前提条件となる権限 AzureRM プロバイダーを設定する最も簡単な方法は、Azure CLI を使用することですが、Azure Service Principal を使用した自動化も役立ちます。
使用する認証方法に関係なく、Terraform を実行するアカウントは、イントロダクションで説明されているすべてのコンポーネントを作成できる必要があります。
一般的な手順
このトピックの手順は、このドキュメントで説明されているすべてのデプロイメントオプションに共通です。
開発 環境 を準備します。
Terraform をインストールします。使用する コード で Git リポジトリを作成することをお勧めしますが、ファイルをローカルに保持することもできます。
terraform.tfvars ファイルを作成します。tvfars ファイルの内容は、インストールタイプに応じてカスタマイズできますが、推奨される最小限の内容は以下の例のようになります。
namespace = "wandb"
wandb_license = "xxxxxxxxxxyyyyyyyyyyyzzzzzzz"
subdomain = "wandb-aws"
domain_name = "wandb.ml"
location = "westeurope"
ここで定義されている変数は、デプロイメントの前に決定する必要があります。namespace 変数は、Terraform によって作成されたすべてのリソースにプレフィックスを付ける 文字列 になります。
subdomain と domain の組み合わせで、Weights & Biases が設定される FQDN が形成されます。上記の例では、Weights & Biases の FQDN は wandb-aws.wandb.ml になり、FQDN レコードが作成される DNS zone_id になります。
ファイル versions.tf を作成します。 このファイルには、Weights & Biases を AWS にデプロイするために必要な Terraform および Terraform プロバイダーの バージョン が含まれます。
terraform {
required_version = "~> 1.3"
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "~> 3.17"
}
}
}
AWS プロバイダーを設定するには、Terraform Official Documentation を参照してください。
オプションで、強く推奨されますが 、このドキュメントの冒頭で説明した remote backend configuration を追加できます。
ファイル variables.tf を作成します。terraform.tfvars で設定されたすべてのオプションについて、Terraform は対応する変数宣言を必要とします。
variable "namespace" {
type = string
description = "String used for prefix resources."
}
variable "location" {
type = string
description = "Azure Resource Group location"
}
variable "domain_name" {
type = string
description = "Domain for accessing the Weights & Biases UI."
}
variable "subdomain" {
type = string
default = null
description = "Subdomain for accessing the Weights & Biases UI. Default creates record at Route53 Route."
}
variable "license" {
type = string
description = "Your wandb/local license"
}
推奨されるデプロイメント
これは最も簡単なデプロイメントオプションの設定で、すべての Mandatory コンポーネントを作成し、最新 バージョン の W&B を Kubernetes Cluster にインストールします。
main.tf を作成します。General Steps でファイルを作成したのと同じ ディレクトリー に、次の内容で main.tf ファイルを作成します。
provider "azurerm" {
features {}
}
provider "kubernetes" {
host = module.wandb.cluster_host
cluster_ca_certificate = base64decode( module.wandb.cluster_ca_certificate)
client_key = base64decode( module.wandb.cluster_client_key)
client_certificate = base64decode( module.wandb.cluster_client_certificate)
}
provider "helm" {
kubernetes {
host = module.wandb.cluster_host
cluster_ca_certificate = base64decode( module.wandb.cluster_ca_certificate)
client_key = base64decode( module.wandb.cluster_client_key)
client_certificate = base64decode( module.wandb.cluster_client_certificate)
}
}
# Spin up all required services
module "wandb" {
source = "wandb/wandb/azurerm"
version = "~> 1.2"
namespace = var.namespace
location = var.location
license = var.license
domain_name = var.domain_name
subdomain = var.subdomain
deletion_protection = false
tags = {
"Example" : "PublicDns"
}
}
output "address" {
value = module.wandb.address
}
output "url" {
value = module.wandb.url
}
W&B にデプロイします。 W&B をデプロイするには、次の コマンド を実行します。
terraform init
terraform apply -var-file=terraform.tfvars
REDIS Cache を使用したデプロイメント
別のデプロイメントオプションでは、SQL クエリをキャッシュし、Experiments の Metrics をロードする際のアプリケーション応答を高速化するために Redis を使用します。
キャッシュを有効にするには、推奨されるデプロイメント で使用したのと同じ main.tf ファイルにオプション create_redis = true を追加する必要があります。
# Spin up all required services
module "wandb" {
source = "wandb/wandb/azurerm"
version = "~> 1.2"
namespace = var.namespace
location = var.location
license = var.license
domain_name = var.domain_name
subdomain = var.subdomain
create_redis = true # Create Redis
[ ...]
外部キューを使用したデプロイメント
デプロイメントオプション 3 は、外部 message broker を有効にすることで構成されます。W&B にはブローカーが組み込まれているため、これはオプションです。このオプションは、パフォーマンスの向上をもたらしません。
message broker を提供する Azure リソースは Azure Event Grid であり、これを有効にするには、推奨されるデプロイメント で使用したのと同じ main.tf にオプション use_internal_queue = false を追加する必要があります。
# Spin up all required services
module "wandb" {
source = "wandb/wandb/azurerm"
version = "~> 1.2"
namespace = var.namespace
location = var.location
license = var.license
domain_name = var.domain_name
subdomain = var.subdomain
use_internal_queue = false # Enable Azure Event Grid
[ ...]
}
その他のデプロイメントオプション
3 つのデプロイメントオプションすべてを組み合わせて、すべての構成を同じファイルに追加できます。
Terraform Module には、標準オプションと 推奨されるデプロイメント にある最小限の構成とともに組み合わせることができる、いくつかのオプションが用意されています。
5.1.3.4 - Deploy W&B Platform On-premises
W&B サーバー をオンプレミス の インフラストラクチャー 上でホストする
関連する質問については、W&B のセールスチーム (contact@wandb.com ) にお問い合わせください。
インフラストラクチャーのガイドライン
W&B のデプロイメントを開始する前に、リファレンスアーキテクチャー 、特にインフラストラクチャーの要件を参照してください。
MySQL データベース
W&B では、MySQL 5.7 の使用は推奨されません。MySQL 5.7 を使用している場合は、最新バージョンの W&B Server との最適な互換性を得るために、MySQL 8 に移行してください。現在、W&B Server は MySQL 8 のバージョン 8.0.28 以降のみをサポートしています。
スケーラブルな MySQL データベースの運用を簡単にするエンタープライズサービスが多数あります。W&B では、以下のソリューションのいずれかを検討することをお勧めします。
https://www.percona.com/software/mysql-database/percona-server
https://github.com/mysql/mysql-operator
W&B Server MySQL 8.0 を実行する場合、または MySQL 5.7 から 8.0 にアップグレードする場合は、以下の条件を満たしてください。
binlog_format = 'ROW'
innodb_online_alter_log_max_size = 268435456
sync_binlog = 1
innodb_flush_log_at_trx_commit = 1
binlog_row_image = 'MINIMAL'
MySQL 8.0 での sort_buffer_size の処理方法の変更により、sort_buffer_size パラメータをデフォルト値の 262144 から更新する必要がある場合があります。W&B と MySQL が効率的に連携するように、値を 67108864 (64MiB) に設定することをお勧めします。MySQL は v8.0.28 以降でこの設定をサポートしています。
データベースに関する考慮事項
次の SQL クエリで、データベースと ユーザーを作成します。SOME_PASSWORD は任意のパスワードに置き換えてください。
CREATE USER 'wandb_local' @ '%' IDENTIFIED BY 'SOME_PASSWORD' ;
CREATE DATABASE wandb_local CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
GRANT ALL ON wandb_local.* TO 'wandb_local' @ '%' WITH GRANT OPTION ;
これは、SSL 証明書が信頼されている場合にのみ機能します。W&B は自己署名証明書をサポートしていません。
パラメータグループの設定
データベースのパフォーマンスを調整するために、次のパラメータグループが設定されていることを確認してください。
binlog_format = 'ROW'
innodb_online_alter_log_max_size = 268435456
sync_binlog = 1
innodb_flush_log_at_trx_commit = 1
binlog_row_image = 'MINIMAL'
sort_buffer_size = 67108864
オブジェクトストレージ
オブジェクトストレージは、Minio cluster で外部ホストすることも、署名付き URL をサポートする Amazon S3 互換のオブジェクトストレージでホストすることもできます。オブジェクトストレージが署名付き URL をサポートしているかどうかを確認するには、次のスクリプト を実行してください。
また、オブジェクトストレージには、次の CORS ポリシーを適用する必要があります。
<?xml version="1.0" encoding="UTF-8"?>
<CORSConfiguration xmlns= "http://s3.amazonaws.com/doc/2006-03-01/" >
<CORSRule>
<AllowedOrigin> http://YOUR-W& B-SERVER-IP</AllowedOrigin>
<AllowedMethod> GET</AllowedMethod>
<AllowedMethod> PUT</AllowedMethod>
<AllowedMethod> HEAD</AllowedMethod>
<AllowedHeader> *</AllowedHeader>
</CORSRule>
</CORSConfiguration>
Amazon S3 互換のオブジェクトストレージに接続するときに、接続文字列で認証情報を指定できます。たとえば、次のように指定できます。
s3://$ACCESS_KEY:$SECRET_KEY@$HOST/$BUCKET_NAME
オブジェクトストレージに信頼できる SSL 証明書を設定している場合は、W&B が TLS 経由でのみ接続するように指示することもできます。これを行うには、URL に tls クエリパラメータを追加します。たとえば、次の URL の例は、Amazon S3 URI に TLS クエリパラメータを追加する方法を示しています。
s3://$ACCESS_KEY:$SECRET_KEY@$HOST/$BUCKET_NAME?tls=true
これは、SSL 証明書が信頼されている場合にのみ機能します。W&B は自己署名証明書をサポートしていません。
サードパーティのオブジェクトストレージを使用する場合は、BUCKET_QUEUE を internal:// に設定します。これにより、W&B サーバーは、外部の SQS キューまたは同等のものに依存する代わりに、すべてのオブジェクト通知を内部で管理するように指示されます。
独自のオブジェクトストレージを実行する際に考慮すべき最も重要な点は次のとおりです。
ストレージ容量とパフォーマンス 。磁気ディスクを使用しても問題ありませんが、これらのディスクの容量を監視する必要があります。W&B の平均的な使用量では、10 ギガバイトから 100 ギガバイトになります。ヘビーな使用では、ペタバイト単位のストレージを消費する可能性があります。フォールトトレランス 。少なくとも、オブジェクトを保存する物理ディスクは RAID アレイ上にある必要があります。minio を使用する場合は、分散モード で実行することを検討してください。可用性 。ストレージが利用可能であることを確認するために、監視を設定する必要があります。
独自のオブジェクトストレージサービスを実行する代わりに、次のようなエンタープライズの代替手段が多数あります。
https://aws.amazon.com/s3/outposts/ https://www.netapp.com/data-storage/storagegrid/
MinIO のセットアップ
minio を使用する場合は、次のコマンドを実行して バケット を作成できます。
mc config host add local http://$MINIO_HOST:$MINIO_PORT " $MINIO_ACCESS_KEY" " $MINIO_SECRET_KEY" --api s3v4
mc mb --region= us-east1 local/local-files
W&B Server アプリケーションを Kubernetes にデプロイする
推奨されるインストール方法は、公式の W&B Helm チャートを使用する方法です。W&B Server アプリケーションをデプロイするには、このセクション に従ってください。
OpenShift
W&B は、OpenShift Kubernetes cluster 内からの運用をサポートしています。
W&B では、公式の W&B Helm チャートを使用してインストールすることをお勧めします。
特権のない ユーザー として コンテナ を実行する
デフォルトでは、コンテナ は $UID 999 を使用します。オーケストレーターが非 root ユーザー で コンテナ を実行する必要がある場合は、$UID >= 100000 および $GID 0 を指定します。
W&B は、ファイルシステムの権限が適切に機能するように、root グループ ($GID=0) として起動する必要があります。
Kubernetes のセキュリティコンテキストの例を次に示します。
spec:
securityContext:
runAsUser: 100000
runAsGroup: 0
ネットワーク
ロードバランサー
適切なネットワーク境界でネットワークリクエストを停止する ロードバランサー を実行します。
一般的な ロードバランサー には次のものがあります。
Nginx Ingress Istio Caddy Cloudflare Apache HAProxy
機械学習 ペイロード を実行するために使用されるすべてのマシンと、Web ブラウザー を介してサービスにアクセスするために使用されるデバイスが、この エンドポイント と通信できることを確認してください。
SSL / TLS
W&B Server は SSL を停止しません。セキュリティポリシーで信頼できるネットワーク内での SSL 通信が必要な場合は、Istio や side car containers などの ツール の使用を検討してください。ロードバランサー 自体が有効な証明書で SSL を終端する必要があります。自己署名証明書の使用はサポートされておらず、ユーザー に多くの問題を引き起こします。可能であれば、Let’s Encrypt のようなサービスを使用すると、ロードバランサー に信頼できる証明書を提供できます。Caddy や Cloudflare などのサービスは、SSL を管理します。
Nginx の設定例
以下は、Nginx をリバースプロキシとして使用した設定例です。
events {}
http {
# If we receive X-Forwarded-Proto, pass it through; otherwise, pass along the
# scheme used to connect to this server
# X-Forwarded-Proto を受信した場合は、そのまま渡します。それ以外の場合は、このサーバーへの接続に使用されたスキームを渡します。
map $http_x_forwarded_proto $proxy_x_forwarded_proto {
default $http_x_forwarded_proto;
'' $scheme;
}
# Also, in the above case, force HTTPS
# また、上記の場合、HTTPS を強制します
map $http_x_forwarded_proto $sts {
default '' ;
"https" "max-age=31536000 ; includeSubDomains" ;
}
# If we receive X-Forwarded-Host, pass it though; otherwise, pass along $http_host
# X-Forwarded-Host を受信した場合は、そのまま渡します。それ以外の場合は、$http_host を渡します。
map $http_x_forwarded_host $proxy_x_forwarded_host {
default $http_x_forwarded_host;
'' $http_host;
}
# If we receive X-Forwarded-Port, pass it through; otherwise, pass along the
# server port the client connected to
# X-Forwarded-Port を受信した場合は、そのまま渡します。それ以外の場合は、クライアントが接続したサーバーポートを渡します。
map $http_x_forwarded_port $proxy_x_forwarded_port {
default $http_x_forwarded_port;
'' $server_port;
}
# If we receive Upgrade, set Connection to "upgrade"; otherwise, delete any
# Connection header that may have been passed to this server
# Upgrade を受信した場合は、Connection を "upgrade" に設定します。それ以外の場合は、このサーバーに渡された可能性のある Connection ヘッダーを削除します。
map $http_upgrade $proxy_connection {
default upgrade ;
'' close ;
}
server {
listen 443 ssl ;
server_name www.example.com ;
ssl_certificate www.example.com.crt ;
ssl_certificate_key www.example.com.key ;
proxy_http_version 1 .1 ;
proxy_buffering off ;
proxy_set_header Host $http_host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $proxy_connection;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $proxy_x_forwarded_proto;
proxy_set_header X-Forwarded-Host $proxy_x_forwarded_host;
location / {
proxy_pass http:// $YOUR_UPSTREAM_SERVER_IP:8080/;
}
keepalive_timeout 10 ;
}
}
インストール の検証
W&B Server が正しく設定されていることを確認します。ターミナル で次の コマンド を実行します。
pip install wandb
wandb login --host= https://YOUR_DNS_DOMAIN
wandb verify
ログ ファイル を調べて、W&B Server の起動時に発生した エラー を確認します。次の コマンド を実行します。
kubectl get pods
kubectl logs wandb-XXXXX-XXXXX
エラー が発生した場合は、W&B Support にお問い合わせください。
5.1.3.5 - Update W&B license and version
さまざまなインストール メソッドにおける W&B (Weights & Biases) の バージョン およびライセンスを更新するための ガイド。
W&B サーバー のバージョンとライセンスの更新は、W&B サーバー のインストール時と同じ方法で行います。以下の表は、さまざまなデプロイメント方法に基づいてライセンスとバージョンを更新する方法をまとめたものです。
Terraform でライセンスとバージョンを更新します。次の表に、W&B が管理する Terraform モジュールをクラウド プラットフォーム ごとに示します。
まず、適切なクラウド プロバイダー 用に W&B が管理している Terraform モジュールに移動します。クラウド プロバイダー に基づいて適切な Terraform モジュールを見つけるには、上記の表を参照してください。
Terraform の 設定 内で、Terraform wandb_app モジュール 設定 の wandb_version と license を更新します。
module "wandb_app" {
source = "wandb/wandb/<cloud-specific-module>"
version = "new_version"
license = "new_license_key" # 新しいライセンスキー
= "new_wandb_version" # 希望する W&B の バージョン
}
terraform plan と terraform apply で Terraform 設定 を適用します。
terraform init
terraform apply
(オプション) terraform.tfvars または他の .tfvars ファイルを使用する場合。
新しい W&B の バージョン とライセンス キー で terraform.tfvars ファイルを更新または作成します。
terraform plan -var-file= "terraform.tfvars"
設定 を適用します。Terraform ワークスペース ディレクトリー で以下を実行します。
terraform apply -var-file= "terraform.tfvars"
Helm で更新
spec で W&B を更新
Helm chart *.yaml 設定 ファイルで、image.tag や license の 値 を変更して、新しい バージョン を指定します。
license : 'new_license'
image :
repository : wandb/local
tag : 'new_version'
次の コマンド で Helm アップグレード を実行します。
helm repo update
helm upgrade --namespace= wandb --create-namespace \
${ chart_version} \
${ wandb_install_spec.yaml}
ライセンスとバージョンを直接更新
新しいライセンス キー とイメージ タグ を 環境 変数 として設定します。
export LICENSE= 'new_license'
export TAG= 'new_version'
以下の コマンド で Helm リリース をアップグレードし、新しい 値 を既存の 設定 とマージします。
helm repo update
helm upgrade --namespace= wandb --create-namespace \
${ chart_version} \
= $LICENSE --set image.tag= $TAG
詳細については、パブリック リポジトリー の アップグレード ガイド を参照してください。
admin UI で更新
このメソッド は、通常セルフホスト Docker インストールで、W&B サーバー コンテナー の 環境 変数 で設定されていないライセンスを更新する場合にのみ機能します。
W&B Deployment Page から新しいライセンスを取得し、アップグレードする デプロイメント の正しい organization と デプロイメント ID に一致することを確認します。<host-url>/system-settings で W&B Admin UI にアクセスします。ライセンス管理セクションに移動します。
新しいライセンス キー を入力して変更を保存します。
5.2 - Identity and access management (IAM)
W&B Platform には、W&B 内に3つの IAM スコープがあります。Organizations 、Teams 、および Projects です。
Organization
Organization は、W&B アカウントまたはインスタンスのルートスコープです。アカウントまたはインスタンス内のすべてのアクションは、そのルートスコープのコンテキスト内で実行されます。これには、ユーザーの管理、Teams の管理、Teams 内の Projects の管理、使用状況の追跡などが含まれます。
Multi-tenant Cloud を使用している場合、複数の Organization を持つことができ、それぞれが事業部門、個人のユーザー、他の企業との共同パートナーシップなどに対応する場合があります。
Dedicated Cloud または Self-managed instance を使用している場合は、1つの Organization に対応します。貴社は、事業部門や部署に対応するために、複数の Dedicated Cloud または Self-managed instance を持つことができますが、これは厳密には、貴社のビジネスまたは部署全体で AI 実務者を管理するためのオプションの方法です。
詳細については、Organization の管理 を参照してください。
Team
Team は、Organization 内のサブスコープであり、事業部門/機能、部署、または社内の project team に対応する場合があります。デプロイメントの種類と料金プランに応じて、Organization 内に複数の Team を持つことができます。
AI projects は、Team のコンテキスト内で編成されます。Team 内のアクセス制御は、親 Organization レベルの管理者である場合とそうでない場合がある Team 管理者によって管理されます。
詳細については、Team の追加と管理 を参照してください。
Project
Project は、Team 内のサブスコープであり、特定の意図された結果を持つ実際の AI project に対応します。Team 内に複数の project を持つことができます。各 project には、誰がアクセスできるかを決定する可視性モードがあります。
すべての project は、Workspaces と Reports で構成され、関連する Artifacts 、Sweeps 、および Automations にリンクされています。
5.2.1 - Authentication
5.2.1.1 - Configure SSO with LDAP
W&B サーバー LDAP サーバーで認証情報を認証します。次のガイドでは、W&B サーバーの 設定を構成する方法について説明します。必須およびオプションの設定、システム設定 UI から LDAP 接続を構成する手順について説明します。また、アドレス、ベース識別名、属性など、LDAP 設定のさまざまな入力に関する情報も提供します。これらの属性は、W&B App UI または 環境変数を使用して指定できます。匿名バインド、または管理者 DN とパスワードを使用したバインドのいずれかをセットアップできます。
W&B 管理者ロールのみが LDAP 認証を有効化および構成できます。
LDAP 接続を構成する
W&B App
Environment variable
W&B App に移動します。
右上からプロフィール アイコンを選択します。ドロップダウンから、[システム 設定 ] を選択します。
[LDAP クライアントを構成 ] を切り替えます。
フォームに詳細を追加します。各入力の詳細については、[パラメータの構成 ] セクションを参照してください。
[設定の更新 ] をクリックして、設定をテストします。これにより、W&B サーバーとのテスト クライアント/接続が確立されます。
接続が確認されたら、[LDAP 認証を有効にする ] を切り替え、[設定の更新 ] ボタンを選択します。
次の 環境変数を使用して LDAP 接続を設定します。
環境変数
必須
例
LOCAL_LDAP_ADDRESSはい
ldaps://ldap.example.com:636
LOCAL_LDAP_BASE_DNはい
email=mail,group=gidNumber
LOCAL_LDAP_BIND_DNいいえ
cn=admin, dc=example,dc=org
LOCAL_LDAP_BIND_PWいいえ
LOCAL_LDAP_ATTRIBUTESはい
email=mail, group=gidNumber
LOCAL_LDAP_TLS_ENABLEいいえ
LOCAL_LDAP_GROUP_ALLOW_LISTいいえ
LOCAL_LDAP_LOGINいいえ
各 環境変数の定義については、設定 パラメータ セクションを参照してください。わかりやすくするために、環境変数プレフィックス LOCAL_LDAP が定義名から省略されていることに注意してください。
設定 パラメータ
次の表に、必須およびオプションの LDAP 構成を示し、説明します。
環境変数
定義
必須
ADDRESSこれは、W&B サーバーをホストする VPC 内の LDAP サーバーの アドレスです。
はい
BASE_DNルート パスは検索の開始元であり、この ディレクトリーにクエリを実行するために必要です。
はい
BIND_DNLDAP サーバーに登録されている管理 ユーザーのパス。LDAP サーバーが認証されていないバインドをサポートしていない場合に必要です。指定した場合、W&B サーバーはこの ユーザーとして LDAP サーバーに接続します。それ以外の場合、W&B サーバーは匿名バインドを使用して接続します。
いいえ
BIND_PW管理 ユーザーのパスワード。これはバインドの認証に使用されます。空白のままにすると、W&B サーバーは匿名バインドを使用して接続します。
いいえ
ATTRIBUTESメールとグループ ID の属性名をコンマ区切りの文字列値として指定します。
はい
TLS_ENABLETLS を有効にします。
いいえ
GROUP_ALLOW_LISTグループ許可リスト。
いいえ
LOGINこれは、W&B サーバーに LDAP を使用して認証するように指示します。True または False に設定します。オプションで、LDAP 構成をテストするために false に設定します。LDAP 認証を開始するには、これを true に設定します。
いいえ
5.2.1.2 - Configure SSO with OIDC
W&B Server の OpenID Connect (OIDC) 互換アイデンティティプロバイダーのサポートにより、Okta、Keycloak、Auth0、Google、Entra などの外部アイデンティティプロバイダーを介したユーザーアイデンティティとグループメンバーシップの管理が可能になります。
OpenID Connect (OIDC)
W&B Server は、外部 Identity Provider (IdP) との統合のために、以下の OIDC 認証フローをサポートしています。
フォームポストによる暗黙的フロー
Proof Key for Code Exchange (PKCE) を使用した認証コードフロー
これらのフローはユーザーを認証し、アクセス制御を管理するために必要なアイデンティティ情報 (ID トークンの形式) を W&B Server に提供します。
ID トークンは、ユーザーの名前、ユーザー名、メール、グループメンバーシップなどのユーザーのアイデンティティ情報を含む JWT です。W&B Server はこのトークンを使用してユーザーを認証し、システム内の適切なロールまたはグループにマップします。
W&B Server のコンテキストでは、アクセス トークンはユーザーに代わって API へのリクエストを承認しますが、W&B Server の主な関心事はユーザー認証とアイデンティティであるため、ID トークンのみが必要です。
環境変数を使用して、IAM オプションを設定 して、専用クラウド または Self-managed インスタンスを構成できます。
専用クラウド または Self-managed W&B Server インストール用に Identity Provider を構成するには、次のガイドラインに従って、さまざまな IdP に従ってください。W&B の SaaS バージョンを使用している場合は、support@wandb.com に連絡して、組織の Auth0 テナントの構成を支援してください。
認証に AWS Cognito を設定するには、以下の手順に従ってください。
まず、AWS アカウントにサインインし、AWS Cognito アプリケーションに移動します。
IdP でアプリケーションを構成するために、許可されたコールバック URL を指定します。
コールバック URL として http(s)://YOUR-W&B-HOST/oidc/callback を追加します。YOUR-W&B-HOST を W&B ホストパスに置き換えます。
IdP がユニバーサルログアウトをサポートしている場合は、ログアウト URL を http(s)://YOUR-W&B-HOST に設定します。YOUR-W&B-HOST を W&B ホストパスに置き換えます。
たとえば、アプリケーションが https://wandb.mycompany.com で実行されている場合、YOUR-W&B-HOST を wandb.mycompany.com に置き換えます。
以下の図は、AWS Cognito で許可されたコールバックとサインアウト URL を指定する方法を示しています。
wandb/local は、デフォルトで form_post 応答タイプによる implicit 付与
PKCE Code Exchange フローを使用する authorization_code 付与を実行するように wandb/local を構成することもできます。
AWS Cognito がトークンをアプリに配信する方法を構成するために、1 つ以上の OAuth 付与タイプを選択します。
W&B には特定の OpenID Connect (OIDC) スコープが必要です。AWS Cognito アプリから以下を選択します。
“openid”
“profile”
“email”
たとえば、AWS Cognito アプリの UI は次の図のようになります。
設定ページで Auth Method を選択するか、OIDC_AUTH_METHOD 環境変数を設定して、wandb/local にどの付与を行うかを指示します。
Auth Method を pkce に設定する必要があります。
クライアント ID と OIDC 発行者の URL が必要です。OpenID ディスカバリドキュメントは $OIDC_ISSUER/.well-known/openid-configuration で利用可能である必要があります。
たとえば、ユーザープール セクション内の アプリの統合 タブから Cognito IdP URL にユーザープール ID を追加して、発行者 URL を生成できます。
IDP URL に “Cognito ドメイン” を使用しないでください。Cognito は、https://cognito-idp.$REGION.amazonaws.com/$USER_POOL_ID でディスカバリドキュメントを提供します。
Okta を認証用に設定するには、以下の手順に従ってください。
https://login.okta.com/ で Okta ポータルにログインします。
左側で、Applications を選択し、次に Applications をもう一度選択します。
「Create App integration」をクリックします。
「Create a new app integration」という画面で、OIDC - OpenID Connect と Single-Page Application を選択します。次に、「Next」をクリックします。
「New Single-Page App Integration」という画面で、以下の値を入力して Save をクリックします。
アプリケーション統合名(例: “Weights & Biases”)
付与タイプ: Authorization Code と Implicit (hybrid) の両方を選択します
Sign-in redirect URIs: https://YOUR_W_AND_B_URL/oidc/callback
Sign-out redirect URIs: https://YOUR_W_AND_B_URL/logout
Assignments: Skip group assignment for now を選択します
作成した Okta アプリケーションの概要画面で、General タブの Client Credentials の下の Client ID をメモします。
Okta OIDC Issuer URL を識別するには、左側の Settings を選択し、次に Account を選択します。
Okta UI には、Organization Contact の下に会社名が表示されます。
OIDC 発行者 URL の形式は https://COMPANY.okta.com です。COMPANY を対応する値に置き換えます。メモしておいてください。
Azure ポータル (https://portal.azure.com/ ) にログインします。
「Microsoft Entra ID」サービスを選択します。
左側で、「App registrations」を選択します。
上部で、「New registration」をクリックします。
「Register an application」という画面で、以下の値を入力します。
名前を指定します(例: “Weights and Biases application”)
デフォルトでは、選択されているアカウントの種類は「Accounts in this organizational directory only (Default Directory only - Single tenant)」です。必要に応じて変更します。
リダイレクト URI をタイプ Web で値 https://YOUR_W_AND_B_URL/oidc/callback で構成します
「Register」をクリックします。
「Application (client) ID」と「Directory (tenant) ID」をメモします。
左側で、Authentication をクリックします。
左側で、「Certificates & secrets」をクリックします。
「Client secrets」をクリックし、次に「New client secret」をクリックします。
「Add a client secret」という画面で、以下の値を入力します。
説明を入力します(例: “wandb”)
「Expires」はそのままにするか、必要に応じて変更します。
「Add」をクリックします。
シークレットの「Value」をメモします。「Secret ID」は必要ありません。
これで、次の 3 つの値をメモしておく必要があります。
OIDC クライアント ID
OIDC クライアントシークレット
テナント ID は OIDC Issuer URL に必要です
OIDC 発行者 URL の形式は https://login.microsoftonline.com/${TenantID}/v2.0 です
W&B Server で SSO をセットアップする
SSO を設定するには、管理者権限と以下の情報が必要です。
OIDC クライアント ID
OIDC 認証方式 (implicit または pkce)
OIDC Issuer URL
OIDC クライアントシークレット (オプション、IdP の設定方法によって異なります)
IdP が OIDC クライアントシークレットを必要とする場合は、環境変数 OIDC_CLIENT_SECRET で指定します。
W&B Server UI を使用するか、環境変数 を wandb/local pod に渡すことによって、SSO を設定できます。環境変数は UI より優先されます。
SSO の設定後にインスタンスにログインできない場合は、LOCAL_RESTORE=true 環境変数を設定してインスタンスを再起動できます。これにより、コンテナログに一時パスワードが出力され、SSO が無効になります。SSO の問題を解決したら、その環境変数を削除して SSO を再度有効にする必要があります。
システムコンソールは、システム設定ページの後継です。W&B Kubernetes Operator ベースのデプロイで使用できます。
W&B 管理コンソールへのアクセス を参照してください。
Settings に移動し、次に Authentication に移動します。Type ドロップダウンで OIDC を選択します。
値を入力します。
Save をクリックします。
ログアウトし、再度ログインします。今回は IdP ログイン画面を使用します。
Weights&Biases インスタンスにサインインします。
W&B アプリケーションに移動します。
ドロップダウンから、System Settings を選択します。
発行者、クライアント ID、および認証方式を入力します。
Update settings を選択します。
SSO の設定後にインスタンスにログインできない場合は、LOCAL_RESTORE=true 環境変数を設定してインスタンスを再起動できます。これにより、コンテナログに一時パスワードが出力され、SSO がオフになります。SSO の問題を解決したら、その環境変数を削除して SSO を再度有効にする必要があります。
Security Assertion Markup Language (SAML)
W&B Server は SAML をサポートしていません。
5.2.1.3 - Use federated identities with SDK
Identity federation を使用して、W&B SDK 経由で組織の認証情報を使用してサインインします。W&B organization の管理者が organization 向けに SSO を設定している場合、すでに組織の認証情報を使用して W&B アプリの UI にサインインしているはずです。その意味で、identity federation は W&B SDK の SSO のようなものですが、JSON Web Tokens (JWT) を直接使用します。identity federation は、APIキー の代替として使用できます。
RFC 7523 は、SDK との identity federation の基礎を形成します。
Identity federation は、すべてのプラットフォームタイプ(SaaS Cloud、Dedicated Cloud、および Self-managed インスタンス)の Enterprise プランで Preview として利用できます。ご不明な点がございましたら、W&B チームにお問い合わせください。
このドキュメントでは、identity provider と JWT issuer という用語は同じ意味で使用されます。どちらも、この機能のコンテキストでは同じものを指します。
JWT issuer の設定
最初の手順として、organization の管理者は、W&B organization と公開されている JWT issuer の間の federation を設定する必要があります。
organization の ダッシュボード で Settings タブに移動します
Authentication オプションで、Set up JWT Issuer を押しますテキストボックスに JWT issuer の URL を追加し、Create を押します
W&B は、${ISSUER_URL}/.well-known/oidc-configuration のパスで OIDC discovery document を自動的に検索し、discovery document 内の関連する URL で JSON Web Key Set (JWKS) を見つけようとします。JWKS は、JWT が関連する identity provider によって発行されたことを確認するために、JWT のリアルタイム検証に使用されます。
JWT を使用して W&B にアクセスする
JWT issuer が W&B organization 用に設定されると、ユーザーはその identity provider によって発行された JWT を使用して、関連する W&B プロジェクト へのアクセスを開始できます。JWT を使用するメカニズムは次のとおりです。
organization で利用可能なメカニズムのいずれかを使用して、identity provider にサインインする必要があります。一部のプロバイダーには、API または SDK を使用して自動化された方法でアクセスできますが、関連する UI を使用してのみアクセスできるプロバイダーもあります。詳細については、W&B organization の管理者または JWT issuer の所有者にお問い合わせください。
identity provider へのサインイン後に JWT を取得したら、安全な場所にファイルに保存し、環境変数 WANDB_IDENTITY_TOKEN_FILE に絶対ファイルパスを設定します。
W&B SDK または CLI を使用して W&B project にアクセスします。SDK または CLI は、JWT を自動的に検出し、JWT が正常に検証された後、W&B access token と交換する必要があります。W&B access token は、AI ワークフローを有効にするための関連する API にアクセスするために使用されます。つまり、run、メトリクス、Artifacts などを ログ に記録します。access token は、デフォルトで ~/.config/wandb/credentials.json のパスに保存されます。環境変数 WANDB_CREDENTIALS_FILE を指定することで、そのパスを変更できます。
JWT は、APIキー、パスワードなどの有効期間の長い認証情報の欠点に対処するための有効期間の短い認証情報です。identity provider で設定された JWT の有効期限に応じて、JWT を継続的に更新し、環境変数 WANDB_IDENTITY_TOKEN_FILE で参照されるファイルに保存されていることを確認する必要があります。
W&B access token にもデフォルトの有効期限があり、その後、SDK または CLI は JWT を使用して自動的に更新を試みます。その時点でユーザー JWT も期限切れになり、更新されない場合、認証エラーが発生する可能性があります。可能であれば、JWT の取得と有効期限後の更新メカニズムは、W&B SDK または CLI を使用する AI ワークロードの一部として実装する必要があります。
JWT の検証
JWT を W&B access token と交換し、project にアクセスする ワークフロー の一部として、JWT は次の検証を受けます。
JWT 署名は、W&B organization レベルで JWKS を使用して検証されます。これは最初の防御線であり、これが失敗した場合、JWKS または JWT の署名方法に問題があることを意味します。
JWT の iss クレームは、organization レベルで設定された issuer URL と同じである必要があります。
JWT の sub クレームは、W&B organization で設定されているユーザーのメールアドレスと同じである必要があります。
JWT の aud クレームは、AI ワークフローの一部としてアクセスしている project を収容する W&B organization の名前と同じである必要があります。Dedicated Cloud または Self-managed インスタンスの場合、インスタンスレベルの環境変数 SKIP_AUDIENCE_VALIDATION を true に設定して、オーディエンスクレームの検証をスキップするか、オーディエンスとして wandb を使用できます。
JWT の exp クレームは、トークンが有効かどうか、または期限切れで更新が必要かどうかを確認するためにチェックされます。
外部サービスアカウント
W&B は、有効期間の長い APIキー を持つ組み込みのサービスアカウントを長年サポートしてきました。SDK および CLI 向けの identity federation 機能を使用すると、organization レベルで設定されているのと同じ issuer によって発行されている限り、JWT を認証に使用できる外部サービスアカウントも導入できます。team 管理者は、組み込みのサービスアカウントと同様に、team のスコープ内で外部サービスアカウントを設定できます。
外部サービスアカウントを設定するには:
team の Service Accounts タブに移動します
New service account を押しますサービスアカウントの名前を入力し、Authentication Method として Federated Identity を選択し、Subject を入力して、Create を押します
外部サービスアカウントの JWT の sub クレームは、team 管理者が team レベルの Service Accounts タブでサブジェクトとして設定したものと同じである必要があります。そのクレームは、JWT の検証 の一部として検証されます。aud クレームの要件は、ヒューマンユーザー JWT の要件と同様です。
外部サービスアカウントの JWT を使用して W&B にアクセスする 場合、通常は、初期 JWT を生成し、継続的に更新する ワークフロー を自動化する方が簡単です。外部サービスアカウントを使用して ログ に記録された run をヒューマンユーザーに帰属させたい場合は、組み込みのサービスアカウントの場合と同様に、AI ワークフローの環境変数 WANDB_USERNAME または WANDB_USER_EMAIL を設定できます。
W&B は、柔軟性と簡素さのバランスを取るために、データ感度のレベルが異なる AI ワークロード全体で、組み込みおよび外部サービスアカウントを組み合わせて使用することをお勧めします。
5.2.1.4 - Use service accounts to automate workflows
組織とチームのスコープを持つサービスアカウントを使用して、自動化された、または非インタラクティブな ワークフロー を管理します。
サービスアカウントは、チーム内またはチーム間で、プロジェクトを横断して共通タスクを自動的に実行できる、人間ではないまたは機械の ユーザー を表します。
組織の 管理者 は、組織の スコープ で サービスアカウント を作成できます。
チーム の 管理者 は、その チーム の スコープ で サービスアカウント を作成できます。
サービスアカウント の APIキー を使用すると、呼び出し元は サービスアカウント の スコープ 内の プロジェクト から読み取りまたは書き込みができます。
サービスアカウント を使用すると、複数の ユーザー または チーム による ワークフロー の集中管理、W&B Models の 実験管理 の自動化、または W&B Weave の トレース の ログ記録 が可能になります。 環境変数 WANDB_USERNAME または WANDB_USER_EMAIL のいずれかを使用することにより、人間の ユーザー の ID を サービスアカウント によって管理される ワークフロー に関連付けるオプションがあります。
組織スコープ の サービスアカウント
組織に スコープ された サービスアカウント は、 制限付き プロジェクト を除き、 チーム に関係なく、組織内のすべての プロジェクト で読み取りおよび書き込みの権限を持ちます。組織スコープ の サービスアカウント が 制限付き プロジェクト に アクセス するには、その プロジェクト の 管理者 が サービスアカウント を プロジェクト に明示的に追加する必要があります。
組織の 管理者 は、組織またはアカウント ダッシュボード の [ Service Accounts ] タブから、組織スコープ の サービスアカウント の APIキー を取得できます。
新しい組織スコープ の サービスアカウント を作成するには:
組織 ダッシュボード の [ Service Accounts ] タブにある [ New service account ] ボタンをクリックします。
[ Name ] を入力します。
サービスアカウント のデフォルト チーム を選択します。
[ Create ] をクリックします。
新しく作成された サービスアカウント の横にある [ Copy API key ] をクリックします。
コピーした APIキー を、シークレットマネージャーまたはその他の安全で アクセス 可能な場所に保存します。
組織スコープ の サービスアカウント には、組織内のすべての チーム が所有する制限のない プロジェクト に アクセス できる場合でも、デフォルト チーム が必要です。これにより、モデルトレーニング または 生成AI アプリ の 環境 で WANDB_ENTITY 変数 が 設定 されていない場合に、 ワークロード が失敗するのを防ぐことができます。別の チーム の プロジェクト で組織スコープ の サービスアカウント を使用するには、WANDB_ENTITY 環境変数 をその チーム に設定する必要があります。
チームスコープ の サービスアカウント
チームスコープ の サービスアカウント は、その チーム 内のすべての プロジェクト で読み取りおよび書き込みができます。ただし、その チーム 内の 制限付き プロジェクト は除きます。チームスコープ の サービスアカウント が 制限付き プロジェクト に アクセス するには、その プロジェクト の 管理者 が サービスアカウント を プロジェクト に明示的に追加する必要があります。
チーム の 管理者 として、チームスコープ の サービスアカウント の APIキー を <WANDB_HOST_URL>/<your-team-name>/service-accounts で取得できます。または、チーム の [ Team settings ] に移動し、[ Service Accounts ] タブを参照することもできます。
チーム の新しい チーム スコープ の サービスアカウント を作成するには:
チーム の [ Service Accounts ] タブにある [ New service account ] ボタンをクリックします。
[ Name ] を入力します。
認証 方法として [ Generate API key (Built-in) ] を選択します。
[ Create ] をクリックします。
新しく作成された サービスアカウント の横にある [ Copy API key ] をクリックします。
コピーした APIキー を、シークレットマネージャーまたはその他の安全で アクセス 可能な場所に保存します。
チームスコープ の サービスアカウント を使用する モデルトレーニング または 生成AI アプリ 環境 で チーム を構成しない場合、モデル の run または Weave トレース は、 サービスアカウント の親 チーム 内の名前付き プロジェクト に ログ 記録 されます。このようなシナリオでは、WANDB_USERNAME または WANDB_USER_EMAIL 変数 を使用した ユーザー 属性は、参照される ユーザー が サービスアカウント の親 チーム の一部である場合を除き、機能しません 。
外部 サービスアカウント
Built-in サービスアカウント に加えて、W&B は、JSON Web Tokens (JWT) を発行できる ID プロバイダー (IdP) との Identity federation を使用して、W&B SDK および CLI を使用した チーム スコープ の External service accounts もサポートしています。
5.2.2 - Access management
組織内の ユーザー と Teams を管理する
一意の組織ドメインで W&B に最初にサインアップした ユーザー は、その組織の インスタンス管理者ロール として割り当てられます。組織管理者は、特定の ユーザー に チーム 管理者ロールを割り当てます。
W&B では、組織内に複数のインスタンス管理者を持つことを推奨します。これは、プライマリアドミンが利用できない場合でも、管理業務を継続できるようにするためのベストプラクティスです。
チーム管理者 は、 チーム 内で管理権限を持つ組織内の ユーザー です。
組織管理者は、https://wandb.ai/account-settings/ で組織のアカウント 設定 にアクセスして使用し、 ユーザー の招待、 ユーザー のロールの割り当てまたは更新、 Teams の作成、組織からの ユーザー の削除、請求管理者の割り当てなどを行うことができます。詳細については、ユーザー の追加と管理 を参照してください。
組織管理者が チーム を作成すると、インスタンス管理者または チーム 管理者は次のことができます。
デフォルトでは、管理者のみがその チーム に ユーザー を招待したり、 チーム から ユーザー を削除したりできます。この 振る舞い を変更するには、チーム の 設定 を参照してください。
チームメンバー のロールを割り当てるか、更新します。
新しい ユーザー が組織に参加したときに、自動的に ユーザー を チーム に追加します。
組織管理者と チーム 管理者の両方が、https://wandb.ai/<your-team-name> の チーム ダッシュボード を使用して Teams を管理します。詳細、および チーム のデフォルトのプライバシー 設定 の構成については、Teams の追加と管理 を参照してください。
特定の Projects への可視性を制限する
W&B の Project のスコープを定義して、誰が W&B の Runs を表示、編集、および送信できるかを制限します。 チーム が機密 データ を扱う場合、 Project を表示できる ユーザー を制限すると特に役立ちます。
組織管理者、 チーム 管理者、または Project のオーナーは、 Project の可視性を 設定 および編集できます。
詳細については、Project の可視性 を参照してください。
5.2.2.1 - Manage your organization
組織の管理者として、組織内の 個々のユーザーを管理 したり、Teams を管理 したりできます。
Team の管理者として、Teams を管理 できます。
以下のワークフローは、インスタンス管理者のロールを持つユーザーに適用されます。インスタンス管理者権限が必要と思われる場合は、組織の管理者に連絡してください。
組織内のユーザー管理を簡素化したい場合は、ユーザーと Team の管理の自動化 を参照してください。
組織名の変更
以下のワークフローは、W&B Multi-tenant SaaS Cloud にのみ適用されます。
https://wandb.ai/home に移動します。ページの右上隅にある ユーザーメニュー ドロップダウンを選択します。ドロップダウンの アカウント セクションで、設定 を選択します。
設定 タブ内で、一般 を選択します。名前の変更 ボタンを選択します。表示されるモーダル内で、組織の新しい名前を入力し、名前を保存 ボタンを選択します。
ユーザーの追加と管理
管理者として、組織のダッシュボードを使用して以下を行います。
ユーザーの招待または削除。
ユーザーの組織ロールの割り当てまたは更新、およびカスタムロールの作成。
課金管理者の割り当て。
組織管理者が組織にユーザーを追加する方法はいくつかあります。
招待によるメンバー追加
SSO による自動プロビジョニング
ドメインキャプチャ
シートと料金
以下の表は、Models と Weave のシートの仕組みをまとめたものです。
製品
シート
料金の基準
Models
セットごとに支払い
Models の有料シートの数と、発生した使用量によって、全体のサブスクリプション料金が決まります。各ユーザーには、フル、ビューアー、アクセスなしの 3 種類のシートタイプのうち 1 つを割り当てることができます
Weave
無料
使用量ベース
ユーザーの招待
管理者は、ユーザーを組織、および組織内の特定の Team に招待できます。
Multi-tenant SaaS Cloud
Dedicated or Self-managed
https://wandb.ai/home に移動します。ページの右上隅にある ユーザーメニュー ドロップダウンを選択します。ドロップダウンの アカウント セクションで、ユーザー を選択します。
新しいユーザーを招待 を選択します。表示されるモーダルで、メールアドレスまたはユーザー名 フィールドにユーザーのメールアドレスまたはユーザー名を入力します。
(推奨) Team を選択 ドロップダウンメニューから、ユーザーを Team に追加します。
ロールを選択 ドロップダウンから、ユーザーに割り当てるロールを選択します。ユーザーのロールは後で変更できます。可能なロールの詳細については、ロールの割り当て に記載されている表を参照してください。招待を送信 ボタンを選択します。
W&B は、招待を送信 ボタンを選択した後、サードパーティのメールサーバーを使用して、ユーザーのメールアドレスに招待リンクを送信します。ユーザーは招待を承諾すると、組織にアクセスできます。
https://<org-name>.io/console/settings/ に移動します。<org-name> を組織名に置き換えます。ユーザーを追加 ボタンを選択します。表示されるモーダルで、メールアドレス フィールドに新しいユーザーのメールアドレスを入力します。
ロール ドロップダウンから、ユーザーに割り当てるロールを選択します。ユーザーのロールは後で変更できます。可能なロールの詳細については、ロールの割り当て に記載されている表を参照してください。W&B がサードパーティのメールサーバーを使用して、ユーザーのメールアドレスに招待リンクを送信する場合は、ユーザーに招待メールを送信 ボックスをオンにします。
新しいユーザーを追加 ボタンを選択します。
ユーザーの自動プロビジョニング
SSO を構成し、SSO プロバイダーが許可している場合、一致するメールアドレスドメインを持つ W&B ユーザーは、シングルサインオン (SSO) で W&B Organization にサインインできます。SSO は、すべてのエンタープライズライセンスで利用できます。
認証に SSO を有効にする W&B は、シングルサインオン (SSO) を使用して認証することを強く推奨および推奨します。組織の SSO を有効にするには、W&B Team にお問い合わせください。
Dedicated cloud または Self-managed インスタンスで SSO を設定する方法の詳細については、OIDC での SSO または LDAP での SSO を参照してください。
W&B は、自動プロビジョニングユーザーにデフォルトで「メンバー」ロールを割り当てます。自動プロビジョニングされたユーザーのロールはいつでも変更できます。
SSO を使用したユーザーの自動プロビジョニングは、Dedicated cloud インスタンスと Self-managed デプロイメントではデフォルトでオンになっています。自動プロビジョニングはオフにすることができます。自動プロビジョニングをオフにすると、特定のユーザーを選択的に W&B 組織に追加できます。
以下のタブでは、デプロイメントタイプに基づいて SSO をオフにする方法について説明します。
Dedicated cloud
Self-managed
Dedicated cloud インスタンスを使用している場合に、SSO での自動プロビジョニングをオフにする場合は、W&B Team にお問い合わせください。
W&B Console を使用して、SSO での自動プロビジョニングをオフにします。
https://<org-name>.io/console/settings/ に移動します。<org-name> を組織名に置き換えます。セキュリティ を選択しますSSO プロビジョニングを無効にする を選択して、SSO での自動プロビジョニングをオフにします。
SSO での自動プロビジョニングは、組織管理者が個々のユーザー招待状を生成する必要がないため、大規模にユーザーを組織に追加する場合に役立ちます。
カスタムロールの作成
Dedicated cloud または Self-managed デプロイメントでカスタムロールを作成または割り当てるには、エンタープライズライセンスが必要です。
組織管理者は、表示のみまたはメンバーロールに基づいて新しいロールを作成し、追加の権限を追加して、きめ細かいアクセス制御を実現できます。Team 管理者は、Team メンバーにカスタムロールを割り当てることができます。カスタムロールは組織レベルで作成されますが、Team レベルで割り当てられます。
カスタムロールを作成するには:
Multi-tenant SaaS Cloud
Dedicated or Self-managed
https://wandb.ai/home に移動します。ページの右上隅にある ユーザーメニュー ドロップダウンを選択します。ドロップダウンの アカウント セクションで、設定 を選択します。
ロール をクリックします。カスタムロール セクションで、ロールを作成 をクリックします。ロールの名前を入力します。オプションで説明を入力します。
カスタムロールのベースにするロールを選択します (ビューアー または メンバー )。
権限を追加するには、権限を検索 フィールドをクリックし、追加する 1 つ以上の権限を選択します。
カスタムロールの権限 セクションを確認します。ここには、ロールが持つ権限がまとめられています。ロールを作成 をクリックします。
W&B Console を使用して、SSO での自動プロビジョニングをオフにします。
https://<org-name>.io/console/settings/ に移動します。<org-name> を組織名に置き換えます。カスタムロール セクションで、ロールを作成 をクリックします。ロールの名前を入力します。オプションで説明を入力します。
カスタムロールのベースにするロールを選択します (ビューアー または メンバー )。
権限を追加するには、権限を検索 フィールドをクリックし、追加する 1 つ以上の権限を選択します。
カスタムロールの権限 セクションを確認します。ここには、ロールが持つ権限がまとめられています。ロールを作成 をクリックします。
これで、Team 管理者は Team の設定 から Team のメンバーにカスタムロールを割り当てることができます。
ドメインキャプチャ
ドメインキャプチャは、従業員が会社組織に参加するのに役立ち、新しいユーザーが会社の管轄外で資産を作成しないようにします。
ドメインは一意である必要があります ドメインは一意の識別子です。つまり、別の組織ですでに使用されているドメインは使用できません。
Multi-tenant SaaS Cloud
Dedicated or Self-managed
ドメインキャプチャを使用すると、@example.com などの会社のメールアドレスを持つユーザーを W&B SaaS cloud organization に自動的に追加できます。これにより、すべての従業員が適切な組織に参加し、新しいユーザーが会社の管轄外で資産を作成しないようにします。
以下の表は、ドメインキャプチャが有効な場合と無効な場合における、新規および既存のユーザーの振る舞いをまとめたものです。
ドメインキャプチャあり
ドメインキャプチャなし
新規ユーザー
検証済みのドメインから W&B にサインアップしたユーザーは、自動的に組織のデフォルト Team のメンバーとして追加されます。Team への参加を有効にすると、サインアップ時に参加する追加の Team を選択できます。招待状があれば、他の組織や Team にも参加できます。
ユーザーは、利用可能な集中管理された組織があることを知らずに、W&B アカウントを作成できます。
招待されたユーザー
招待されたユーザーは、招待を承諾すると自動的に組織に参加します。招待されたユーザーは、自動的に組織のデフォルト Team のメンバーとして追加されるわけではありません。招待状があれば、他の組織や Team にも参加できます。
招待されたユーザーは、招待を承諾すると自動的に組織に参加します。招待状があれば、他の組織や Team にも参加できます。
既存のユーザー
ドメインからの検証済みのメールアドレスを持つ既存のユーザーは、W&B App 内で組織の Team に参加できます。既存のユーザーが組織に参加する前に作成したすべてのデータは保持されます。W&B は既存のユーザーのデータを移行しません。
既存の W&B ユーザーは、複数の組織や Team に分散している可能性があります。
招待されていない新規ユーザーが組織に参加するときに、デフォルトの Team に自動的に割り当てるには:
https://wandb.ai/home に移動します。ページの右上隅にある ユーザーメニュー ドロップダウンを選択します。ドロップダウンから、設定 を選択します。
設定 タブ内で、一般 を選択します。ドメインキャプチャ 内の ドメインの要求 ボタンを選択します。新しいユーザーが自動的に参加する Team を デフォルト Team ドロップダウンから選択します。利用可能な Team がない場合は、Team の設定を更新する必要があります。Team の追加と管理 の手順を参照してください。
メールアドレスドメインの要求 ボタンをクリックします。
招待されていない新しいユーザーを Team に自動的に割り当てるには、Team の設定内でドメイン一致を有効にする必要があります。
https://wandb.ai/<team-name> で Team のダッシュボードに移動します。<team-name> は、ドメイン一致を有効にする Team の名前です。Team のダッシュボードの左側にあるグローバルナビゲーションで Team の設定 を選択します。
プライバシー セクション内で、“サインアップ時に、一致するメールアドレスドメインを持つ新しいユーザーにこの Team への参加を推奨する” オプションを切り替えます。
ドメインキャプチャを構成するには、Dedicated または Self-managed デプロイメントタイプを使用している場合は、W&B アカウント Team にお問い合わせください。構成が完了すると、W&B SaaS インスタンスは、会社のメールアドレスで W&B アカウントを作成するユーザーに、Dedicated または Self-managed インスタンスへのアクセスを要求するために管理者に連絡するように自動的に促します。
ドメインキャプチャあり
ドメインキャプチャなし
新規ユーザー
検証済みのドメインから SaaS cloud で W&B にサインアップしたユーザーは、カスタマイズしたメールアドレスで管理者に連絡するように自動的に促されます。SaaS cloud で組織を作成して、製品をトライアルできます。
ユーザーは、会社に集中管理された Dedicated インスタンスがあることを知らずに、W&B SaaS cloud アカウントを作成できます。
既存のユーザー
既存の W&B ユーザーは、複数の組織や Team に分散している可能性があります。
既存の W&B ユーザーは、複数の組織や Team に分散している可能性があります。
ユーザーのロールの割り当てまたは更新
Organization のすべてのメンバーは、W&B Models と Weave の両方に対して組織ロールとシートを持っています。シートのタイプによって、課金ステータスと各製品ラインで実行できるアクションが決まります。
最初にユーザーを組織に招待するときに、ユーザーに組織ロールを割り当てます。ユーザーのロールは後で変更できます。
組織内のユーザーは、次のいずれかのロールを持つことができます。
ロール
説明
admin
他のユーザーを組織に追加または削除したり、ユーザーロールを変更したり、カスタムロールを管理したり、Team を追加したりできるインスタンス管理者。W&B は、管理者が不在の場合に備えて、複数の管理者がいることを推奨します。
Member
インスタンス管理者によって招待された、組織の通常のユーザー。組織メンバーは、他のユーザーを招待したり、組織内の既存のユーザーを管理したりすることはできません。
Viewer (エンタープライズ限定機能)
インスタンス管理者によって招待された、組織の表示専用ユーザー。ビューアーは、組織とメンバーである基盤となる Team への読み取りアクセスのみを持っています。
カスタムロール (エンタープライズ限定機能)
カスタムロールを使用すると、組織管理者は、上記の表示専用またはメンバーロールから継承し、追加の権限を追加して、きめ細かいアクセス制御を実現することで、新しいロールを作成できます。Team 管理者は、これらのカスタムロールをそれぞれの Team のユーザーに割り当てることができます。
ユーザーのロールを変更するには:
https://wandb.ai/home に移動します。ページの右上隅にある ユーザーメニュー ドロップダウンを選択します。ドロップダウンから、ユーザー を選択します。
検索バーにユーザーの名前またはメールアドレスを入力します。
ユーザーの名前の横にある TEAM ROLE ドロップダウンからロールを選択します。
ユーザーのアクセスの割り当てまたは更新
組織内のユーザーは、フル、ビューアー、またはアクセスなしのいずれかのモデルシートまたは Weave アクセスタイプを持っています。
シートタイプ
説明
Full
このロールタイプのユーザーは、Models または Weave のデータを書き込み、読み取り、エクスポートするための完全な権限を持っています。
Viewer
組織の表示専用ユーザー。ビューアーは、組織と所属する基盤となる Team への読み取りアクセスのみを持ち、Models または Weave への表示のみのアクセスを持っています。
No access
このロールのユーザーは、Models または Weave 製品にアクセスできません。
モデルシートタイプと Weave アクセスタイプは組織レベルで定義され、Team に継承されます。ユーザーのシートタイプを変更する場合は、組織の設定に移動し、次の手順に従ってください。
SaaS ユーザーの場合は、https://wandb.ai/account-settings/<organization>/settings で組織の設定に移動します。山かっこ (<>) で囲まれた値を組織名に置き換えてください。他の Dedicated および Self-managed デプロイメントの場合は、https://<your-instance>.wandb.io/org/dashboard に移動します。
ユーザー タブを選択します。ロール ドロップダウンから、ユーザーに割り当てるシートタイプを選択します。
組織のロールとサブスクリプションタイプによって、組織内で利用できるシートタイプが決まります。
ユーザーの削除
https://wandb.ai/home に移動します。ページの右上隅にある ユーザーメニュー ドロップダウンを選択します。ドロップダウンから、ユーザー を選択します。
検索バーにユーザーの名前またはメールアドレスを入力します。
表示されたら、省略記号または 3 つのドットのアイコン (… ) を選択します。
ドロップダウンから、メンバーを削除 を選択します。
課金管理者の割り当て
https://wandb.ai/home に移動します。ページの右上隅にある ユーザーメニュー ドロップダウンを選択します。ドロップダウンから、ユーザー を選択します。
検索バーにユーザーの名前またはメールアドレスを入力します。
課金管理者 列で、課金管理者として割り当てるユーザーを選択します。
Team の追加と管理
組織のダッシュボードを使用して、組織内に Team を作成および管理します。組織管理者または Team 管理者は次のことができます。
ユーザーを Team に招待したり、Team からユーザーを削除したりします。
Team メンバーのロールを管理します。
組織に参加するときに、ユーザーを Team に自動的に追加します。
https://wandb.ai/<team-name> の Team のダッシュボードで Team のストレージを管理します。
Team の作成
組織のダッシュボードを使用して Team を作成します。
https://wandb.ai/home に移動します。左側のナビゲーションパネルの Team の下にある コラボレーションする Team を作成 を選択します。
表示されるモーダルの Team 名 フィールドに Team の名前を入力します。
ストレージタイプを選択します。
Team を作成 ボタンを選択します。
Team を作成 ボタンを選択すると、W&B は https://wandb.ai/<team-name> の新しい Team ページにリダイレクトします。<team-name> は、Team の作成時に入力した名前で構成されます。
Team を作成したら、その Team にユーザーを追加できます。
Team へのユーザーの招待
組織内の Team にユーザーを招待します。Team のダッシュボードを使用して、メールアドレスまたは W&B のユーザー名を使用してユーザーを招待します (すでに W&B アカウントを持っている場合)。
https://wandb.ai/<team-name> に移動します。ダッシュボードの左側にあるグローバルナビゲーションで Team の設定 を選択します。
ユーザー タブを選択します。新しいユーザーを招待 を選択します。表示されるモーダルで、メールアドレスまたはユーザー名 フィールドにユーザーのメールアドレスを入力し、Team ロールを選択 ドロップダウンからユーザーに割り当てるロールを選択します。ユーザーが Team で持つことができるロールの詳細については、Team ロール を参照してください。
招待を送信 ボタンを選択します。
デフォルトでは、Team またはインスタンス管理者のみが Team にメンバーを招待できます。この振る舞いを変更するには、Team の設定 を参照してください。
メールでの招待を使用して手動でユーザーを招待するだけでなく、新しいユーザーの メールが組織のドメインと一致する 場合、新しいユーザーを Team に自動的に追加できます。
サインアップ時にメンバーを Team 組織に一致させる
組織内の新しいユーザーがサインアップ時に組織内の Teams を見つけられるようにします。新しいユーザーは、組織の検証済みメールアドレスドメインと一致する検証済みのメールアドレスドメインを持っている必要があります。検証済みの新しいユーザーは、W&B アカウントにサインアップするときに、組織に属する検証済みの Team のリストを表示できます。
組織管理者は、ドメインの要求を有効にする必要があります。ドメインキャプチャを有効にするには、ドメインキャプチャ に記載されている手順を参照してください。
Team メンバーのロールの割り当てまたは更新
Team メンバーの名前の横にあるアカウントタイプのアイコンを選択します。
ドロップダウンから、Team メンバーに持たせるアカウントタイプを選択します。
次の表に、Team のメンバーに割り当てることができるロールを示します。
ロール
定義
admin
Team 内で他のユーザーを追加および削除したり、ユーザーロールを変更したり、Team の設定を構成したりできるユーザー。
Member
Team の通常のユーザー。Team 管理者によってメールまたは組織レベルのユーザー名で招待されます。メンバーユーザーは、他のユーザーを Team に招待することはできません。
View-Only (エンタープライズ限定機能)
Team の表示専用ユーザー。Team 管理者によってメールまたは組織レベルのユーザー名で招待されます。表示専用ユーザーは、Team とそのコンテンツへの読み取りアクセスのみを持っています。
Service (エンタープライズ限定機能)
サービスワーカーまたはサービスアカウントは、run 自動化ツールで W&B を利用するのに役立つ APIキーです。Team のサービスアカウントから APIキーを使用する場合は、環境変数 WANDB_USERNAME を設定して、run を適切なユーザーに正しく帰属させるようにしてください。
カスタムロール (エンタープライズ限定機能)
カスタムロールを使用すると、組織管理者は、上記の表示専用またはメンバーロールから継承し、追加の権限を追加して、きめ細かいアクセス制御を実現することで、新しいロールを作成できます。Team 管理者は、これらのカスタムロールをそれぞれの Team のユーザーに割り当てることができます。詳細については、この記事 を参照してください。
Dedicated cloud または Self-managed デプロイメントのエンタープライズライセンスのみが、Team のメンバーにカスタムロールを割り当てることができます。
Team からのユーザーの削除
Team のダッシュボードを使用して Team からユーザーを削除します。run を作成したメンバーがその Team にいなくなった場合でも、W&B は Team で作成された run を保持します。
https://wandb.ai/<team-name> に移動します。左側のナビゲーションバーで Team の設定 を選択します。
ユーザー タブを選択します。削除するユーザーの名前の横にマウスを移動します。表示されたら、省略記号または 3 つのドットのアイコン (… ) を選択します。
ドロップダウンから、ユーザーを削除 を選択します。
5.2.2.2 - Manage access control for projects
可視性スコープと プロジェクト レベルのロールを使用して、 プロジェクト の アクセス を管理します。
W&B のプロジェクトのスコープを定義して、誰が W&B の run を表示、編集、送信できるかを制限します。
いくつかのコントロールを組み合わせて、W&B の Teams 内のプロジェクトに対するアクセスレベルを設定できます。可視性スコープ は、より高レベルなメカニズムです。これを使用して、どのユーザーグループがプロジェクト内の run を表示または送信できるかを制御します。Team または Restricted の可視性スコープを持つプロジェクトの場合、プロジェクトレベルのロール を使用して、各 ユーザー がプロジェクト内で持つアクセスレベルを制御できます。
プロジェクトのオーナー、 Team 管理者、または組織管理者は、プロジェクトの可視性を設定または編集できます。
可視性スコープ
選択できるプロジェクトの可視性スコープは 4 つあります。最も公開されているものから最もプライベートなものの順に示します。
スコープ
説明
Open
プロジェクトについて知っている人なら誰でも、それを表示し、 run または Report を送信できます。
Public
プロジェクトについて知っている人なら誰でも、それを表示できます。あなたの Team のみが、 run または Report を送信できます。
Team
親 Team のメンバーのみが、プロジェクトを表示し、 run または Report を送信できます。 Team 外部の人は、プロジェクトにアクセスできません。
Restricted
親 Team から招待されたメンバーのみが、プロジェクトを表示し、 run または Report を送信できます。
機密 データ に関連する ワークフロー で共同作業する場合は、プロジェクトのスコープを Restricted に設定します。 Team 内に制限付きプロジェクトを作成する場合、関連する 実験 、 Artifacts 、 Reports などで共同作業するために、 Team から特定のメンバーを招待または追加できます。
他のプロジェクトスコープとは異なり、 Team のすべてのメンバーが制限付きプロジェクトへの暗黙的なアクセス権を取得するわけではありません。同時に、 Team 管理者は必要に応じて制限付きプロジェクトに参加できます。
新規または既存のプロジェクトに可視性スコープを設定する
プロジェクトの可視性スコープは、プロジェクトの作成時、または後で編集するときに設定します。
プロジェクトのオーナーまたは Team 管理者のみが、その可視性スコープを設定または編集できます。
Team 管理者が Team のプライバシー設定内で 将来のすべての Team プロジェクトを非公開にする (公開共有は許可されません) を有効にすると、その Team の Open および Public プロジェクトの可視性スコープが無効になります。この場合、 Team は Team および Restricted スコープのみを使用できます。
新しいプロジェクトを作成するときに可視性スコープを設定する
SaaS Cloud、 専用クラウド 、またはセルフマネージドインスタンスで、W&B 組織に移動します。
左側のサイドバーの My projects セクションにある Create a new project ボタンをクリックします。または、 Team の Projects タブに移動し、右上隅にある Create new project ボタンをクリックします。
親 Team を選択し、プロジェクトの名前を入力したら、Project Visibility ドロップダウンから目的のスコープを選択します。
Restricted の可視性スコープを選択した場合は、次の手順を完了してください。
Invite team members フィールドに、1 人または複数の W&B の チームメンバー の名前を入力します。プロジェクトで共同作業するために不可欠なメンバーのみを追加してください。
制限付きプロジェクトのメンバーは、後で Users タブから追加または削除できます。
既存のプロジェクトの可視性スコープを編集する
W&B の プロジェクト に移動します。
左側の列で Overview タブを選択します。
右上隅にある Edit Project Details ボタンをクリックします。
Project Visibility ドロップダウンから、目的のスコープを選択します。
Restricted の可視性スコープを選択した場合は、次の手順を完了してください。
プロジェクトの Users タブに移動し、Add user ボタンをクリックして、特定の ユーザー を制限付きプロジェクトに招待します。
Team のメンバーをプロジェクトに必要な チームメンバー として招待しない限り、 Team のすべてのメンバーは、可視性スコープを Team から Restricted に変更すると、プロジェクトへのアクセスを失います。
可視性スコープを Restricted から Team に変更すると、 Team のすべてのメンバーがプロジェクトへのアクセス権を取得します。
制限付きプロジェクトの ユーザー リストから チームメンバー を削除すると、その チームメンバー はそのプロジェクトへのアクセスを失います。
制限付きスコープに関するその他の重要な注意事項
制限付きプロジェクトで Team レベルの サービス アカウント を使用する場合は、その サービス アカウント をプロジェクトに明示的に招待または追加する必要があります。そうしないと、 Team レベルの サービス アカウント はデフォルトで制限付きプロジェクトにアクセスできません。
制限付きプロジェクトから run を移動することはできませんが、制限されていないプロジェクトから制限付きプロジェクトに run を移動することはできます。
Team のプライバシー設定 将来のすべての Team プロジェクトを非公開にする (公開共有は許可されません) に関係なく、制限付きプロジェクトの可視性を Team スコープのみに変換できます。
制限付きプロジェクトのオーナーが親 Team の一部でなくなった場合、 Team 管理者はプロジェクトのシームレスな運用を確保するためにオーナーを変更する必要があります。
プロジェクトレベルのロール
Team 内の Team または Restricted スコープのプロジェクトの場合、 ユーザー に特定のロールを割り当てることができます。これは、その ユーザー の Team レベルのロールとは異なる場合があります。たとえば、 ユーザー が Team レベルで Member ロールを持っている場合、その Team 内の Team または Restricted スコープのプロジェクト内で、その ユーザー に View-Only 、Admin 、または使用可能なカスタムロールを割り当てることができます。
プロジェクトレベルのロールは、SaaS Cloud、 専用クラウド 、およびセルフマネージドインスタンスでプレビュー中です。
ユーザー にプロジェクトレベルのロールを割り当てる
W&B の プロジェクト に移動します。
左側の列で Overview タブを選択します。
プロジェクトの Users タブに移動します。
Project Role フィールドで、関係する ユーザー に現在割り当てられているロールをクリックします。これにより、他の使用可能なロールを一覧表示するドロップダウンが開きます。ドロップダウンから別のロールを選択します。すぐに保存されます。
ユーザー のプロジェクトレベルのロールを Team レベルのロールとは異なるように変更すると、プロジェクトレベルのロールに * が含まれて、違いを示します。
プロジェクトレベルのロールに関するその他の重要な注意事項
デフォルトでは、Team または Restricted スコープのプロジェクト内のすべての ユーザー のプロジェクトレベルのロールは、それぞれの Team レベルのロールを 継承 します。
Team レベルで View-only ロールを持っている ユーザー のプロジェクトレベルのロールを 変更することはできません 。
特定のプロジェクト内の ユーザー のプロジェクトレベルのロールが Team レベルのロール と同じである 場合、 Team 管理者が Team レベルのロールを変更すると、関連するプロジェクトロールは Team レベルのロールを追跡するように自動的に変更されます。
特定のプロジェクト内の ユーザー のプロジェクトレベルのロールを、Team レベルのロール とは異なる ように変更した場合、 Team 管理者が Team レベルのロールを変更しても、関連するプロジェクトレベルのロールはそのままになります。
プロジェクトレベルのロールが Team レベルのロールと異なる場合に、 ユーザー を restricted プロジェクトから削除し、しばらくしてからその ユーザー をプロジェクトに再度追加すると、デフォルトの動作により Team レベルのロールを継承します。必要に応じて、プロジェクトレベルのロールを再度変更して、 Team レベルのロールと異なるようにする必要があります。
5.2.3 - Automate user and team management
SCIM API
SCIM API を使用して、ユーザーと、ユーザーが所属する Teams を効率的かつ反復可能な方法で管理します。SCIM API を使用して、カスタムロールを管理したり、W&B organization 内の Users にロールを割り当てることもできます。ロールエンドポイントは、公式の SCIM スキーマの一部ではありません。W&B は、カスタムロールの自動管理をサポートするために、ロールエンドポイントを追加します。
SCIM API は、特に次のような場合に役立ちます。
大規模なユーザーのプロビジョニングとプロビジョニング解除を管理する
SCIM をサポートする Identity Provider で Users を管理する
SCIM API には、大きく分けて User 、Group 、Roles の 3 つのカテゴリがあります。
User SCIM API
User SCIM API を使用すると、User の作成、非アクティブ化、詳細の取得、または W&B organization 内のすべての Users の一覧表示が可能です。この API は、定義済みまたはカスタムロールを organization 内の Users に割り当てることもサポートしています。
DELETE User エンドポイントを使用して、W&B organization 内の User を非アクティブ化します。非アクティブ化された Users は、サインインできなくなります。ただし、非アクティブ化された Users は、organization の User リストに引き続き表示されます。
非アクティブ化された User を User リストから完全に削除するには、organization から User を削除する 必要があります。
必要に応じて、非アクティブ化された User を再度有効にすることができます。
Group SCIM API
Group SCIM API を使用すると、organization 内の Teams の作成や削除など、W&B Teams を管理できます。PATCH Group を使用して、既存の Team に Users を追加または削除します。
W&B には、同じロールを持つ Users のグループ という概念はありません。W&B の Team はグループによく似ており、異なるロールを持つ多様なペルソナが、関連する Projects のセットで共同作業を行うことができます。Teams は、異なるグループの Users で構成できます。Team の各 User に、Team 管理者、メンバー、閲覧者、またはカスタムロールを割り当てます。
W&B は、グループと W&B Teams の類似性から、Group SCIM API エンドポイントを W&B Teams にマッピングします。
Custom role API
Custom role SCIM API を使用すると、organization 内のカスタムロールの作成、一覧表示、または更新など、カスタムロールを管理できます。
カスタムロールを削除する場合は注意してください。
DELETE Role エンドポイントを使用して、W&B organization 内のカスタムロールを削除します。カスタムロールが継承する定義済みのロールは、操作前にカスタムロールが割り当てられているすべての Users に割り当てられます。
PUT Role エンドポイントを使用して、カスタムロールの継承されたロールを更新します。この操作は、カスタムロール内の既存の、つまり継承されていないカスタム権限には影響しません。
W&B Python SDK API
SCIM API で User と Team の管理を自動化できるのと同じように、W&B Python SDK API で利用できる メソッド の一部もその目的に使用できます。次の メソッド に注意してください。
Method name
Purpose
create_user(email, admin=False)organization に User を追加し、オプションで organization 管理者にします。
user(userNameOrEmail)organization 内の既存の User を返します。
user.teams()User の Teams を返します。user(userNameOrEmail) メソッド を使用して User オブジェクトを取得できます。
create_team(teamName, adminUserName)新しい Team を作成し、オプションで organization レベルの User を Team 管理者にします。
team(teamName)organization 内の既存の Team を返します。
Team.invite(userNameOrEmail, admin=False)Team に User を追加します。team(teamName) メソッド を使用して Team オブジェクトを取得できます。
Team.create_service_account(description)Team にサービスアカウントを追加します。team(teamName) メソッド を使用して Team オブジェクトを取得できます。
Member.delete()Team からメンバー User を削除します。team オブジェクトの members 属性を使用して、Team 内のメンバー オブジェクトのリストを取得できます。また、team(teamName) メソッド を使用して Team オブジェクトを取得できます。
5.2.4 - Manage users, groups, and roles with SCIM
System for Cross-domain Identity Management(SCIM)API を使用すると、インスタンスまたは organization の管理者は、W&B organization 内の user、グループ、およびカスタムロールを管理できます。SCIM グループは W&B の Teams にマッピングされます。
SCIM API は <host-url>/scim/ でアクセスでき、RC7643 プロトコル にあるフィールドのサブセットを使用して、/Users および /Groups エンドポイントをサポートします。さらに、公式の SCIM スキーマにはない /Roles エンドポイントが含まれています。W&B は、W&B organization でのカスタムロールの自動管理をサポートするために、/Roles エンドポイントを追加します。
複数のエンタープライズ SaaS Cloud organization の管理者である場合は、SCIM API リクエストの送信先となる organization を構成する必要があります。プロフィール画像をクリックし、User Settings をクリックします。設定の名前は Default API organization です。これは、Dedicated Cloud , Self-managed instances , および SaaS Cloud を含む、すべてのホスティングオプションで必要です。SaaS Cloud では、organization 管理者は、SCIM API リクエストが正しい organization に送信されるように、user 設定でデフォルトの organization を構成する必要があります。
選択したホスティングオプションによって、このページの例で使用される <host-url> プレースホルダーの value が決定されます。
さらに、例では user ID(abc や def など)を使用します。実際のリクエストとレスポンスでは、user ID にハッシュ value が設定されます。
認証
organization またはインスタンスの管理者は、 APIキー を使用して基本認証で SCIM API にアクセスできます。HTTP リクエストの Authorization ヘッダーを文字列 Basic に設定し、その後にスペース、次に username:API-KEY の形式で base-64 エンコードされた文字列を設定します。つまり、username と APIキー を : 文字で区切られた value に置き換え、その結果を base-64 エンコードします。たとえば、demo:p@55w0rd として認証するには、ヘッダーを Authorization: Basic ZGVtbzpwQDU1dzByZA== にする必要があります。
User リソース
SCIM の user リソースは W&B の Users にマッピングされます。
User を取得
{
"active" : true ,
"displayName" : "Dev User 1" ,
"emails" : {
"Value" : "dev-user1@test.com" ,
"Display" : "" ,
"Type" : "" ,
"Primary" : true
},
"id" : "abc" ,
"meta" : {
"resourceType" : "User" ,
"created" : "2023-10-01T00:00:00Z" ,
"lastModified" : "2023-10-01T00:00:00Z" ,
"location" : "Users/abc"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:User"
],
"userName" : "dev-user1"
}
Users をリスト表示
{
"Resources" : [
{
"active" : true ,
"displayName" : "Dev User 1" ,
"emails" : {
"Value" : "dev-user1@test.com" ,
"Display" : "" ,
"Type" : "" ,
"Primary" : true
},
"id" : "abc" ,
"meta" : {
"resourceType" : "User" ,
"created" : "2023-10-01T00:00:00Z" ,
"lastModified" : "2023-10-01T00:00:00Z" ,
"location" : "Users/abc"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:User"
],
"userName" : "dev-user1"
}
],
"itemsPerPage" : 9999 ,
"schemas" : [
"urn:ietf:params:scim:api:messages:2.0:ListResponse"
],
"startIndex" : 1 ,
"totalResults" : 1
}
User を作成
エンドポイント : <host-url>/scim/Usersメソッド : POST説明 : 新しい user リソースを作成します。サポートされているフィールド :
フィールド
タイプ
必須
emails
複数値の配列
はい(primary メールが設定されていることを確認してください)
userName
文字列
はい
{
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:User"
],
"emails" : [
{
"primary" : true ,
"value" : "admin-user2@test.com"
}
],
"userName" : "dev-user2"
}
{
"active" : true ,
"displayName" : "Dev User 2" ,
"emails" : {
"Value" : "dev-user2@test.com" ,
"Display" : "" ,
"Type" : "" ,
"Primary" : true
},
"id" : "def" ,
"meta" : {
"resourceType" : "User" ,
"created" : "2023-10-01T00:00:00Z" ,
"location" : "Users/def"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:User"
],
"userName" : "dev-user2"
}
User を削除
エンドポイント : <host-url>/scim/Users/{id}メソッド : DELETE説明 : user の一意の ID を指定して、SaaS Cloud organization または Dedicated Cloud あるいは Self-managed インスタンスから user を完全に削除します。必要に応じて、User を作成 API を使用して、user を organization またはインスタンスに再度追加します。リクエストの例 :
User を一時的に非アクティブ化するには、
PATCH エンドポイントを使用する
User を非アクティブ化 API を参照してください。
User を非アクティブ化
フィールド
タイプ
必須
op
文字列
操作のタイプ。許可される value は replace のみです。
value
オブジェクト
User を非アクティブ化することを示すオブジェクト {"active": false}。
User の非アクティブ化および再アクティブ化の操作は、
SaaS Cloud ではサポートされていません。
{
"schemas" : ["urn:ietf:params:scim:api:messages:2.0:PatchOp" ],
"Operations" : [
{
"op" : "replace" ,
"value" : {"active" : false }
}
]
}
レスポンスの例 :
これにより、User オブジェクトが返されます。
{
"active" : true ,
"displayName" : "Dev User 1" ,
"emails" : {
"Value" : "dev-user1@test.com" ,
"Display" : "" ,
"Type" : "" ,
"Primary" : true
},
"id" : "abc" ,
"meta" : {
"resourceType" : "User" ,
"created" : "2023-10-01T00:00:00Z" ,
"lastModified" : "2023-10-01T00:00:00Z" ,
"location" : "Users/abc"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:User"
],
"userName" : "dev-user1"
}
User を再アクティブ化
エンドポイント : <host-url>/scim/Users/{id}メソッド : PATCH説明 : user の一意の ID を指定して、Dedicated Cloud または Self-managed インスタンス内の非アクティブ化された user を再アクティブ化します。サポートされているフィールド :
フィールド
タイプ
必須
op
文字列
操作のタイプ。許可される value は replace のみです。
value
オブジェクト
User を再アクティブ化することを示すオブジェクト {"active": true}。
User の非アクティブ化および再アクティブ化の操作は、
SaaS Cloud ではサポートされていません。
{
"schemas" : ["urn:ietf:params:scim:api:messages:2.0:PatchOp" ],
"Operations" : [
{
"op" : "replace" ,
"value" : {"active" : true }
}
]
}
レスポンスの例 :
これにより、User オブジェクトが返されます。
{
"active" : true ,
"displayName" : "Dev User 1" ,
"emails" : {
"Value" : "dev-user1@test.com" ,
"Display" : "" ,
"Type" : "" ,
"Primary" : true
},
"id" : "abc" ,
"meta" : {
"resourceType" : "User" ,
"created" : "2023-10-01T00:00:00Z" ,
"lastModified" : "2023-10-01T00:00:00Z" ,
"location" : "Users/abc"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:User"
],
"userName" : "dev-user1"
}
User に organization レベルのロールを割り当てる
エンドポイント : <host-url>/scim/Users/{id}メソッド : PATCH説明 : user に organization レベルのロールを割り当てます。ロールは、こちら で説明されているように、admin、viewer、または member のいずれかになります。SaaS Cloud の場合は、user 設定で SCIM API 用に正しい organization を構成していることを確認してください。サポートされているフィールド :
フィールド
タイプ
必須
op
文字列
操作のタイプ。許可される value は replace のみです。
path
文字列
ロールの割り当て操作が有効になるスコープ。許可される value は organizationRole のみです。
value
文字列
user に割り当てる定義済みの organization レベルのロール。admin、viewer、または member のいずれかになります。このフィールドでは、定義済みのロールの大文字と小文字は区別されません。
{
"schemas" : ["urn:ietf:params:scim:api:messages:2.0:PatchOp" ],
"Operations" : [
{
"op" : "replace" ,
"path" : "organizationRole" ,
"value" : "admin" // user の organization スコープのロールを admin に設定します
]
}
レスポンスの例 :
これにより、User オブジェクトが返されます。
{
"active" : true ,
"displayName" : "Dev User 1" ,
"emails" : {
"Value" : "dev-user1@test.com" ,
"Display" : "" ,
"Type" : "" ,
"Primary" : true
},
"id" : "abc" ,
"meta" : {
"resourceType" : "User" ,
"created" : "2023-10-01T00:00:00Z" ,
"lastModified" : "2023-10-01T00:00:00Z" ,
"location" : "Users/abc"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:User"
],
"userName" : "dev-user1" ,
"teamRoles" : [ // user が所属するすべての Teams における user のロールを返します
"teamName" : "team1" ,
"roleName" : "admin"
}
],
"organizationRole" : "admin" // organization スコープにおける user のロールを返します
User に Team レベルのロールを割り当てる
エンドポイント : <host-url>/scim/Users/{id}メソッド : PATCH説明 : user に Team レベルのロールを割り当てます。ロールは、こちら で説明されているように、admin、viewer、member、またはカスタムロールのいずれかになります。SaaS Cloud の場合は、user 設定で SCIM API 用に正しい organization を構成していることを確認してください。サポートされているフィールド :
フィールド
タイプ
必須
op
文字列
操作のタイプ。許可される value は replace のみです。
path
文字列
ロールの割り当て操作が有効になるスコープ。許可される value は teamRoles のみです。
value
オブジェクト配列
オブジェクトが teamName および roleName 属性で構成される 1 オブジェクト配列。teamName は user がロールを保持する Team の名前で、roleName は admin、viewer、member、またはカスタムロールのいずれかになります。このフィールドでは、定義済みのロールの大文字と小文字は区別されず、カスタムロールの大文字と小文字は区別されます。
{
"schemas" : ["urn:ietf:params:scim:api:messages:2.0:PatchOp" ],
"Operations" : [
{
"op" : "replace" ,
"path" : "teamRoles" ,
"value" : [
{
"roleName" : "admin" , // 定義済みのロールの場合、ロール名の大文字と小文字は区別されず、カスタムロールの場合は大文字と小文字が区別されます
"teamName" : "team1" // Team team1 における user のロールを admin に設定します
]
}
]
}
レスポンスの例 :
これにより、User オブジェクトが返されます。
{
"active" : true ,
"displayName" : "Dev User 1" ,
"emails" : {
"Value" : "dev-user1@test.com" ,
"Display" : "" ,
"Type" : "" ,
"Primary" : true
},
"id" : "abc" ,
"meta" : {
"resourceType" : "User" ,
"created" : "2023-10-01T00:00:00Z" ,
"lastModified" : "2023-10-01T00:00:00Z" ,
"location" : "Users/abc"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:User"
],
"userName" : "dev-user1" ,
"teamRoles" : [ // user が所属するすべての Teams における user のロールを返します
"teamName" : "team1" ,
"roleName" : "admin"
}
],
"organizationRole" : "admin" // organization スコープにおける user のロールを返します
Group リソース
SCIM のグループリソースは W&B の Teams にマッピングされます。つまり、W&B デプロイメントで SCIM グループを作成すると、W&B の Team が作成されます。他のグループエンドポイントにも同じことが当てはまります。
Team を取得
エンドポイント : <host-url>/scim/Groups/{id}メソッド : GET説明 : Team の一意の ID を指定して、Team 情報を取得します。リクエストの例 :
{
"displayName" : "wandb-devs" ,
"id" : "ghi" ,
"members" : [
{
"Value" : "abc" ,
"Ref" : "" ,
"Type" : "" ,
"Display" : "dev-user1"
}
],
"meta" : {
"resourceType" : "Group" ,
"created" : "2023-10-01T00:00:00Z" ,
"lastModified" : "2023-10-01T00:00:00Z" ,
"location" : "Groups/ghi"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:Group"
]
}
Teams をリスト表示
エンドポイント : <host-url>/scim/Groupsメソッド : GET説明 : Teams のリストを取得します。リクエストの例 :
{
"Resources" : [
{
"displayName" : "wandb-devs" ,
"id" : "ghi" ,
"members" : [
{
"Value" : "abc" ,
"Ref" : "" ,
"Type" : "" ,
"Display" : "dev-user1"
}
],
"meta" : {
"resourceType" : "Group" ,
"created" : "2023-10-01T00:00:00Z" ,
"lastModified" : "2023-10-01T00:00:00Z" ,
"location" : "Groups/ghi"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:Group"
]
}
],
"itemsPerPage" : 9999 ,
"schemas" : [
"urn:ietf:params:scim:api:messages:2.0:ListResponse"
],
"startIndex" : 1 ,
"totalResults" : 1
}
Team を作成
エンドポイント : <host-url>/scim/Groupsメソッド : POST説明 : 新しい Team リソースを作成します。サポートされているフィールド :
フィールド
タイプ
必須
displayName
文字列
はい
members
複数値の配列
はい(value サブフィールドは必須で、user ID にマッピングされます)
dev-user2 をメンバーとして、wandb-support という Team を作成します。
{
"schemas" : ["urn:ietf:params:scim:schemas:core:2.0:Group" ],
"displayName" : "wandb-support" ,
"members" : [
{
"value" : "def"
}
]
}
{
"displayName" : "wandb-support" ,
"id" : "jkl" ,
"members" : [
{
"Value" : "def" ,
"Ref" : "" ,
"Type" : "" ,
"Display" : "dev-user2"
}
],
"meta" : {
"resourceType" : "Group" ,
"created" : "2023-10-01T00:00:00Z" ,
"lastModified" : "2023-10-01T00:00:00Z" ,
"location" : "Groups/jkl"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:Group"
]
}
Team を更新
エンドポイント : <host-url>/scim/Groups/{id}メソッド : PATCH説明 : 既存の Team のメンバーシップリストを更新します。サポートされている操作 : メンバーの add、メンバーの removeリクエストの例 :
dev-user2 を wandb-devs に追加します
{
"schemas" : ["urn:ietf:params:scim:api:messages:2.0:PatchOp" ],
"Operations" : [
{
"op" : "add" ,
"path" : "members" ,
"value" : [
{
"value" : "def" ,
}
]
}
]
}
{
"displayName" : "wandb-devs" ,
"id" : "ghi" ,
"members" : [
{
"Value" : "abc" ,
"Ref" : "" ,
"Type" : "" ,
"Display" : "dev-user1"
},
{
"Value" : "def" ,
"Ref" : "" ,
"Type" : "" ,
"Display" : "dev-user2"
}
],
"meta" : {
"resourceType" : "Group" ,
"created" : "2023-10-01T00:00:00Z" ,
"lastModified" : "2023-10-01T00:01:00Z" ,
"location" : "Groups/ghi"
},
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:Group"
]
}
Team を削除
Team の削除は、Teams にリンクされている追加データがあるため、現在 SCIM API ではサポートされていません。すべてを削除することを確認するには、アプリから Teams を削除します。
Role リソース
SCIM のロールリソースは W&B のカスタムロールにマッピングされます。前述のように、/Roles エンドポイントは公式の SCIM スキーマの一部ではありません。W&B は、W&B organization でのカスタムロールの自動管理をサポートするために、/Roles エンドポイントを追加します。
カスタムロールを取得
エンドポイント: <host-url>/scim/Roles/{id}メソッド : GET説明 : ロールの一意の ID を指定して、カスタムロールの情報を取得します。リクエストの例 :
{
"description" : "A sample custom role for example" ,
"id" : "Um9sZTo3" ,
"inheritedFrom" : "member" , // indicates the predefined role
"meta" : {
"resourceType" : "Role" ,
"created" : "2023-11-20T23:10:14Z" ,
"lastModified" : "2023-11-20T23:31:23Z" ,
"location" : "Roles/Um9sZTo3"
},
"name" : "Sample custom role" ,
"organizationID" : "T3JnYW5pemF0aW9uOjE0ODQ1OA==" ,
"permissions" : [
{
"name" : "artifact:read" ,
"isInherited" : true // inherited from member predefined role
...
...
{
"name" : "project:update" ,
"isInherited" : false // custom permission added by admin
],
"schemas" : [
""
]
}
カスタムロールをリスト表示
エンドポイント: <host-url>/scim/Rolesメソッド : GET説明 : W&B organization 内のすべてのカスタムロールの情報を取得しますリクエストの例 :
{
"Resources" : [
{
"description" : "A sample custom role for example" ,
"id" : "Um9sZTo3" ,
"inheritedFrom" : "member" , // indicates the predefined role that the custom role inherits from
"meta" : {
"resourceType" : "Role" ,
"created" : "2023-11-20T23:10:14Z" ,
"lastModified" : "2023-11-20T23:31:23Z" ,
"location" : "Roles/Um9sZTo3"
},
"name" : "Sample custom role" ,
"organizationID" : "T3JnYW5pemF0aW9uOjE0ODQ1OA==" ,
"permissions" : [
{
"name" : "artifact:read" ,
"isInherited" : true // inherited from member predefined role
...
...
{
"name" : "project:update" ,
"isInherited" : false // custom permission added by admin
],
"schemas" : [
""
]
},
{
"description" : "Another sample custom role for example" ,
"id" : "Um9sZToxMg==" ,
"inheritedFrom" : "viewer" , // indicates the predefined role that the custom role inherits from
"meta" : {
"resourceType" : "Role" ,
"created" : "2023-11-21T01:07:50Z" ,
"location" : "Roles/Um9sZToxMg=="
},
"name" : "Sample custom role 2" ,
"organizationID" : "T3JnYW5pemF0aW9uOjE0ODQ1OA==" ,
"permissions" : [
{
"name" : "launchagent:read" ,
"isInherited" : true // inherited from viewer predefined role
...
...
{
"name" : "run:stop" ,
"isInherited" : false // custom permission added by admin
],
"schemas" : [
""
]
}
],
"itemsPerPage" : 9999 ,
"schemas" : [
"urn:ietf:params:scim:api:messages:2.0:ListResponse"
],
"startIndex" : 1 ,
"totalResults" : 2
}
カスタムロールを作成
エンドポイント : <host-url>/scim/Rolesメソッド : POST説明 : W&B organization に新しいカスタムロールを作成します。サポートされているフィールド :
フィールド
タイプ
必須
name
文字列
カスタムロールの名前
description
文字列
カスタムロールの説明
permissions
オブジェクト配列
各オブジェクトに w&bobject:operation の形式の value を持つ name 文字列フィールドが含まれる、権限オブジェクトの配列。たとえば、W&B の Runs に対する削除操作の権限オブジェクトには、name として run:delete が設定されます。
inheritedFrom
文字列
カスタムロールが継承する定義済みのロール。member または viewer のいずれかになります。
{
"schemas" : ["urn:ietf:params:scim:schemas:core:2.0:Role" ],
"name" : "Sample custom role" ,
"description" : "A sample custom role for example" ,
"permissions" : [
{
"name" : "project:update"
}
],
"inheritedFrom" : "member"
}
{
"description" : "A sample custom role for example" ,
"id" : "Um9sZTo3" ,
"inheritedFrom" : "member" , // indicates the predefined role
"meta" : {
"resourceType" : "Role" ,
"created" : "2023-11-20T23:10:14Z" ,
"lastModified" : "2023-11-20T23:31:23Z" ,
"location" : "Roles/Um9sZTo3"
},
"name" : "Sample custom role" ,
"organizationID" : "T3JnYW5pemF0aW9uOjE0ODQ1OA==" ,
"permissions" : [
{
"name" : "artifact:read" ,
"isInherited" : true // inherited from member predefined role
...
...
{
"name" : "project:update" ,
"isInherited" : false // custom permission added by admin
],
"schemas" : [
""
]
}
カスタムロールを削除
エンドポイント : <host-url>/scim/Roles/{id}メソッド : DELETE説明 : W&B organization 内のカスタムロールを削除します。使用には注意してください 。カスタムロールが継承した定義済みのロールが、操作前にカスタムロールを割り当てられていたすべての Users に割り当てられるようになりました。リクエストの例 :
カスタムロールの権限を更新
エンドポイント : <host-url>/scim/Roles/{id}メソッド : PATCH説明 : W&B organization のカスタムロールで、カスタム権限を追加または削除します。サポートされているフィールド :
フィールド
タイプ
必須
operations
オブジェクト配列
操作オブジェクトの配列
op
文字列
操作オブジェクト内の操作のタイプ。add または remove のいずれかになります。
path
文字列
操作オブジェクト内の静的フィールド。許可される value は permissions のみです。
value
オブジェクト配列
各オブジェクトに w&bobject:operation の形式の value を持つ name 文字列フィールドが含まれる、権限オブジェクトの配列。たとえば、W&B の Runs に対する削除操作の権限オブジェクトには、name として run:delete が設定されます。
{
"schemas" : ["urn:ietf:params:scim:api:messages:2.0:PatchOp" ],
"Operations" : [
{
"op" : "add" , // indicates the type of operation, other possible value being `remove`
"path" : "permissions" ,
"value" : [
{
"name" : "project:delete"
}
]
}
]
}
{
"description" : "A sample custom role for example" ,
"id" : "Um9sZTo3" ,
"inheritedFrom" : "member" , // indicates the predefined role
"meta" : {
"resourceType" : "Role" ,
"created" : "2023-11-20T23:10:14Z" ,
"lastModified" : "2023-11-20T23:31:23Z" ,
"location" : "Roles/Um9sZTo3"
},
"name" : "Sample custom role" ,
"organizationID" : "T3JnYW5pemF0aW9uOjE0ODQ1OA==" ,
"permissions" : [
{
"name" : "artifact:read" ,
"isInherited" : true // inherited from member predefined role
...
...
{
"name" : "project:update" ,
"isInherited" : false // existing custom permission added by admin before the update
{
"name" : "project:delete" ,
"isInherited" : false // new custom permission added by admin as part of the update
],
"schemas" : [
""
]
}
カスタムロールのメタデータを更新
エンドポイント : <host-url>/scim/Roles/{id}メソッド : PUT説明 : W&B organization のカスタムロールの名前、説明、または継承されたロールを更新します。この操作は、カスタムロールの既存の(つまり、継承されていない)カスタム権限には影響しません。サポートされているフィールド :
フィールド
タイプ
必須
name
文字列
カスタムロールの名前
description
文字列
カスタムロールの説明
inheritedFrom
文字列
カスタムロールが継承する定義済みのロール。member または viewer のいずれかになります。
{
"schemas" : ["urn:ietf:params:scim:schemas:core:2.0:Role" ],
"name" : "Sample custom role" ,
"description" : "A sample custom role for example but now based on viewer" ,
"inheritedFrom" : "viewer"
}
{
"description" : "A sample custom role for example but now based on viewer" , // changed the descripton per the request
"id" : "Um9sZTo3" ,
"inheritedFrom" : "viewer" , // indicates the predefined role which is changed per the request
"meta" : {
"resourceType" : "Role" ,
"created" : "2023-11-20T23:10:14Z" ,
"lastModified" : "2023-11-20T23:31:23Z" ,
"location" : "Roles/Um9sZTo3"
},
"name" : "Sample custom role" ,
"organizationID" : "T3JnYW5pemF0aW9uOjE0ODQ1OA==" ,
"permissions" : [
{
"name" : "artifact:read" ,
"isInherited" : true // inherited from viewer predefined role
... // Any permissions that are in member predefined role but not in viewer will not be inherited post the update
"name" : "project:update" ,
"isInherited" : false // custom permission added by admin
{
"name" : "project:delete" ,
"isInherited" : false // custom permission added by admin
],
"schemas" : [
""
]
}
5.2.5 - Advanced IAM configuration
基本的な環境変数 に加えて、環境変数を使用して、専用クラウド またはセルフマネージド インスタンスのIAMオプションを構成できます。
IAMのニーズに応じて、インスタンスに対して次のいずれかの環境変数を選択してください。
環境変数
説明
DISABLE_SSO_PROVISIONING
これを true に設定すると、W&Bインスタンスでの ユーザー の自動プロビジョニングがオフになります。
SESSION_LENGTH
デフォルトの ユーザー セッションの有効期限を変更する場合は、この変数を目的の時間数に設定します。たとえば、SESSION_LENGTHを 24 に設定すると、セッションの有効期限が24時間に構成されます。デフォルト値は720時間です。
GORILLA_ENABLE_SSO_GROUP_CLAIMS
OIDCベースのSSOを使用している場合は、この変数を true に設定すると、OIDCグループに基づいてインスタンス内のW&B team メンバーシップが自動化されます。 ユーザー OIDCトークンに groups クレームを追加します。各エントリが ユーザー が所属するW&B teamの名前である文字列配列である必要があります。配列には、 ユーザー が所属するすべての team が含まれている必要があります。
GORILLA_LDAP_GROUP_SYNC
LDAPベースのSSOを使用している場合は、true に設定すると、LDAPグループに基づいてインスタンス内のW&B team メンバーシップが自動化されます。
GORILLA_OIDC_CUSTOM_SCOPES
OIDCベースのSSOを使用している場合は、W&BインスタンスがIDプロバイダーに要求する必要がある追加のスコープ を指定できます。W&Bは、これらのカスタムスコープによってSSO機能を変更することはありません。
GORILLA_USE_IDENTIFIER_CLAIMS
OIDCベースのSSOを使用している場合は、この変数を true に設定して、IDプロバイダーからの特定のOIDCクレームを使用して ユーザー の ユーザー 名とフルネームを強制します。設定する場合は、preferred_username および name OIDCクレームで、強制される ユーザー 名とフルネームを構成していることを確認してください。 ユーザー 名には、英数字と、特殊文字としてアンダースコアとハイフンのみを含めることができます。
GORILLA_DISABLE_PERSONAL_ENTITY
これを true に設定すると、W&Bインスタンス内の個人の ユーザー project がオフになります。設定すると、 ユーザー は個人の entity に新しい個人 project を作成できなくなり、既存の個人 project への書き込みもオフになります。
GORILLA_DISABLE_ADMIN_TEAM_ACCESS
これを true に設定すると、組織またはインスタンス管理者がW&B teamに自己参加または自己追加することを制限し、Data & AIペルソナのみが team 内の project にアクセスできるようにします。
W&Bは、GORILLA_DISABLE_ADMIN_TEAM_ACCESS など、これらの 設定 の一部を有効にする前に、注意を払い、すべての影響を理解することをお勧めします。ご不明な点がございましたら、W&B teamにお問い合わせください。
5.3 - Data security
5.3.1 - Bring your own bucket (BYOB)
Bring your own bucket (BYOB) を使用すると、W&B の Artifacts やその他の関連する機密データを、お客様の クラウド または オンプレミス の インフラストラクチャー に保存できます。専用クラウド または SaaS Cloud の場合、お客様の バケット に保存する データ は、W&B が管理する インフラストラクチャー にコピーされません。
W&B SDK / CLI / UI とお客様の バケット 間の通信は、事前署名付き URL を使用して行われます。
W&B は、W&B Artifacts を削除するためにガベージコレクション プロセス を使用します。詳細については、Artifacts の削除 を参照してください。
バケット を構成する際にサブパスを指定して、W&B が バケット のルートにあるフォルダーにファイルを保存しないようにすることができます。これは、組織の バケット ガバナンス ポリシーへの準拠を向上させるのに役立ちます。
中央データベースに保存されるデータと バケット に保存されるデータ
BYOB 機能を使用する場合、特定の種類の データ は W&B 中央データベースに保存され、他の種類の データ はお客様の バケット に保存されます。
データベース
ユーザー 、 Teams、Artifacts、Experiments、および Projects の メタデータ
Reports
Experiment ログ
システム メトリクス
バケット
Experiment ファイルと メトリクス
Artifact ファイル
メディア ファイル
Run ファイル
設定オプション
ストレージ バケット を構成できる スコープ は、インスタンス レベル または Team レベル の 2 つです。
インスタンス レベル: 組織内で関連する 権限 を持つ ユーザー は、インスタンス レベルのストレージ バケット に保存されているファイルに アクセス できます。
Team レベル: W&B Team の メンバー は、Team レベルで構成された バケット に保存されているファイルに アクセス できます。Team レベルのストレージ バケット を使用すると、機密性の高い データ や厳格なコンプライアンス要件を持つ Teams に対して、より優れた データ アクセス制御と データ 分離が可能になります。
インスタンス レベルで バケット を構成することも、組織内の 1 つまたは複数の Teams に対して個別に構成することもできます。
たとえば、組織に Kappa という Team があるとします。組織 (および Team Kappa) は、デフォルトでインスタンス レベルのストレージ バケット を使用します。次に、Omega という Team を作成します。Team Omega を作成するときに、その Team の Team レベルのストレージ バケット を構成します。Team Omega によって生成されたファイルは、Team Kappa からは アクセス できません。ただし、Team Kappa によって作成されたファイルは、Team Omega から アクセス できます。Team Kappa の データを分離する場合は、Team レベルのストレージ バケット を構成する必要があります。
Team レベルのストレージ バケット は、特に異なる事業部門や部署が 1 つの インスタンス を共有して インフラストラクチャー と管理リソースを効率的に利用する場合、
自己管理 インスタンス にも同じメリットをもたらします。これは、個別の顧客エンゲージメントのために AI ワークフロー を管理する個別の プロジェクト Teams を持つ企業にも当てはまります。
可用性マトリックス
次の表は、さまざまな W&B サーバー デプロイメント タイプ における BYOB の可用性を示しています。X は、その機能が特定の デプロイメント タイプ で利用できることを意味します。
W&B サーバー デプロイメント タイプ
インスタンス レベル
Team レベル
追加情報
専用クラウド
X
X
インスタンス および Team レベルの BYOB は、Amazon Web Services、Google Cloud Platform、および Microsoft Azure で利用できます。Team レベルの BYOB の場合、同じ クラウド または別の クラウド 内の クラウド ネイティブ ストレージ バケット、または クラウド または オンプレミス の インフラストラクチャー でホストされている MinIO などの S3 互換のセキュア ストレージに接続できます。
SaaS Cloud
適用外
X
Team レベルの BYOB は、Amazon Web Services と Google Cloud Platform でのみ利用できます。W&B は、Microsoft Azure のデフォルトのストレージ バケット と唯一のストレージ バケット を完全に管理します。
自己管理
X
X
インスタンス レベルの BYOB は、インスタンス がお客様によって完全に管理されているため、デフォルトです。自己管理 インスタンス が クラウド にある場合、Team レベルの BYOB 用に、同じ クラウド または別の クラウド 内の クラウド ネイティブ ストレージ バケット に接続できます。インスタンス または Team レベルの BYOB のいずれかに対して、MinIO などの S3 互換のセキュア ストレージを使用することもできます。
専用クラウド または 自己管理 インスタンス の インスタンス または Team レベルのストレージ バケット 、または SaaS Cloud アカウントの Team レベルのストレージ バケット を構成すると、これらの スコープ のストレージ バケット を変更または再構成することはできません。これには、別の バケット に データを移行したり、メイン プロダクト ストレージ内の関連する参照を再マップしたりすることも含まれます。W&B では、インスタンス または Team レベルの スコープ のいずれかを構成する前に、ストレージ バケット のレイアウトを慎重に計画することを推奨します。ご不明な点がございましたら、W&B Team までお問い合わせください。
Team レベルの BYOB 向けのクロス クラウド または S3 互換ストレージ
専用クラウド または 自己管理 インスタンス の Team レベルの BYOB 用に、別の クラウド 内の クラウド ネイティブ ストレージ バケット 、または MinIO などの S3 互換ストレージ バケット に接続できます。
クロス クラウド または S3 互換ストレージの使用を有効にするには、W&B インスタンス の GORILLA_SUPPORTED_FILE_STORES 環境 変数を使用して、次のいずれかの形式で、関連する アクセス キー を含むストレージ バケット を指定します。
専用クラウド または 自己管理 インスタンス で Team レベルの BYOB 用に S3 互換ストレージを構成する
次の形式でパスを指定します。
s3://<accessKey>:<secretAccessKey>@<url_endpoint>/<bucketName>?region=<region>?tls=true
region パラメータ は必須です。ただし、W&B インスタンス が AWS にあり、W&B インスタンス ノード で構成された AWS_REGION が S3 互換ストレージ用に構成された リージョン と一致する場合は除きます。
専用クラウド または 自己管理 インスタンス で Team レベルの BYOB 用にクロス クラウド ネイティブ ストレージを構成する
W&B インスタンス とストレージ バケット の場所固有の形式でパスを指定します。
GCP または Azure の W&B インスタンス から AWS の バケット へ:
s3://<accessKey>:<secretAccessKey>@<s3_regional_url_endpoint>/<bucketName>
GCP または AWS の W&B インスタンス から Azure の バケット へ:
az://:<urlEncodedAccessKey>@<storageAccountName>/<containerName>
AWS または Azure の W&B インスタンス から GCP の バケット へ:
gs://<serviceAccountEmail>:<urlEncodedPrivateKey>@<bucketName>
Team レベルの BYOB 用の S3 互換ストレージへの接続は、
SaaS Cloud では利用できません。また、Team レベルの BYOB 用の AWS バケット への接続は、その インスタンス が GCP にあるため、
SaaS Cloud ではクロス クラウド です。そのクロス クラウド 接続は、
専用クラウド および
自己管理 インスタンス で以前に概説した アクセス キー と環境 変数 ベースのメカニズムを使用しません。
詳細については、W&B サポート (support@wandb.com ) までお問い合わせください。
W&B プラットフォーム と同じ クラウド 内の クラウド ストレージ
ユースケース に基づいて、Team または インスタンス レベルでストレージ バケット を構成します。ストレージ バケット のプロビジョニングまたは構成方法は、Azure の アクセス メカニズムを除き、構成されているレベルに関係なく同じです。
W&B では、必要な アクセス メカニズムと関連する IAM 権限 とともにストレージ バケット をプロビジョニングするために、W&B が管理する Terraform モジュール を使用することを推奨します。
KMS キー をプロビジョニングします。
W&B では、S3 バケット 上の データを 暗号化および復号化するために、KMS キー をプロビジョニングする必要があります。キー の使用タイプは ENCRYPT_DECRYPT である必要があります。次の ポリシー を キー に割り当てます。
{
"Version" : "2012-10-17" ,
"Statement" : [
{
"Sid" : "Internal" ,
"Effect" : "Allow" ,
"Principal" : { "AWS" : "<Your_Account_Id>" },
"Action" : "kms:*" ,
"Resource" : "<aws_kms_key.key.arn>"
},
{
"Sid" : "External" ,
"Effect" : "Allow" ,
"Principal" : { "AWS" : "<aws_principal_and_role_arn>" },
"Action" : [
"kms:Decrypt" ,
"kms:Describe*" ,
"kms:Encrypt" ,
"kms:ReEncrypt*" ,
"kms:GenerateDataKey*"
],
"Resource" : "<aws_kms_key.key.arn>"
}
]
}
<Your_Account_Id> と <aws_kms_key.key.arn> を適宜置き換えます。
SaaS Cloud または 専用クラウド を使用している場合は、<aws_principal_and_role_arn> を対応する 値 に置き換えます。
SaaS Cloud : arn:aws:iam::725579432336:role/WandbIntegration専用クラウド : arn:aws:iam::830241207209:root
この ポリシー は、AWS アカウント に キー へのフル アクセス を許可し、W&B プラットフォーム をホストする AWS アカウント に必要な 権限 も割り当てます。KMS キー ARN の記録を保持します。
S3 バケット をプロビジョニングします。
次の手順に従って、AWS アカウント で S3 バケット をプロビジョニングします。
任意の名前で S3 バケット を作成します。オプションで、すべての W&B ファイルを保存するためのサブパスとして構成できるフォルダーを作成します。
バケット の バージョン管理 を有効にします。
前のステップの KMS キー を使用して、サーバー 側の 暗号化 を有効にします。
次の ポリシー で CORS を構成します。
[
{
"AllowedHeaders" : [
"*"
],
"AllowedMethods" : [
"GET" ,
"HEAD" ,
"PUT"
],
"AllowedOrigins" : [
"*"
],
"ExposeHeaders" : [
"ETag"
],
"MaxAgeSeconds" : 3600
}
]
W&B プラットフォーム をホストする AWS アカウント に必要な S3 権限 を付与します。これには、お客様の クラウド インフラストラクチャー または ユーザー の ブラウザー 内の AI ワークロード が バケット への アクセス に使用する 事前署名付き URL を生成するための 権限 が必要です。
{
"Version" : "2012-10-17" ,
"Id" : "WandBAccess" ,
"Statement" : [
{
"Sid" : "WAndBAccountAccess" ,
"Effect" : "Allow" ,
"Principal" : { "AWS" : "<aws_principal_and_role_arn>" },
"Action" : [
"s3:GetObject*" ,
"s3:GetEncryptionConfiguration" ,
"s3:ListBucket" ,
"s3:ListBucketMultipartUploads" ,
"s3:ListBucketVersions" ,
"s3:AbortMultipartUpload" ,
"s3:DeleteObject" ,
"s3:PutObject" ,
"s3:GetBucketCORS" ,
"s3:GetBucketLocation" ,
"s3:GetBucketVersioning"
],
"Resource" : [
"arn:aws:s3:::<wandb_bucket>" ,
"arn:aws:s3:::<wandb_bucket>/*"
]
}
]
}
<wandb_bucket> を適宜置き換え、 バケット 名の記録を保持します。専用クラウド を使用している場合は、インスタンス レベルの BYOB の場合に備えて、 バケット 名を W&B Team と共有します。任意の デプロイメント タイプ の Team レベルの BYOB の場合は、Team の作成中に バケット を構成します 。
SaaS Cloud または 専用クラウド を使用している場合は、<aws_principal_and_role_arn> を対応する 値 に置き換えます。
SaaS Cloud : arn:aws:iam::725579432336:role/WandbIntegration専用クラウド : arn:aws:iam::830241207209:root
詳細については、AWS 自己管理 ホスティング ガイド を参照してください。
GCS バケット をプロビジョニングします。
次の手順に従って、GCP プロジェクト で GCS バケット をプロビジョニングします。
任意の名前で GCS バケット を作成します。オプションで、すべての W&B ファイルを保存するためのサブパスとして構成できるフォルダーを作成します。
ソフト削除を有効にします。
オブジェクト の バージョン管理 を有効にします。
暗号化 タイプ を Google-managed に設定します。
gsutil で CORS ポリシー を設定します。これは UI では実行できません。
cors-policy.json というファイルをローカルに作成します。
次の CORS ポリシー をファイルにコピーして保存します。
[
{
"origin" : ["*" ],
"responseHeader" : ["Content-Type" ],
"exposeHeaders" : ["ETag" ],
"method" : ["GET" , "HEAD" , "PUT" ],
"maxAgeSeconds" : 3600
}
]
<bucket_name> を正しい バケット 名に置き換え、gsutil を実行します。
gsutil cors set cors-policy.json gs://<bucket_name>
バケット の ポリシー を確認します。<bucket_name> を正しい バケット 名に置き換えます。
gsutil cors get gs://<bucket_name>
SaaS Cloud または 専用クラウド を使用している場合は、W&B プラットフォーム にリンクされている GCP サービス アカウント に Storage Admin ロール を付与します。
SaaS Cloud の場合、アカウント は wandb-integration@wandb-production.iam.gserviceaccount.com です。専用クラウド の場合、アカウント は deploy@wandb-production.iam.gserviceaccount.com です。
バケット 名の記録を保持します。専用クラウド を使用している場合は、インスタンス レベルの BYOB の場合に備えて、 バケット 名を W&B Team と共有します。任意の デプロイメント タイプ の Team レベルの BYOB の場合は、Team の作成中に バケット を構成します 。
Azure Blob Storage をプロビジョニングします。
インスタンス レベルの BYOB の場合、この Terraform モジュール を使用していない場合は、次の手順に従って Azure サブスクリプション で Azure Blob Storage バケット をプロビジョニングします。
任意の名前で バケット を作成します。オプションで、すべての W&B ファイルを保存するためのサブパスとして構成できるフォルダーを作成します。
BLOB とコンテナー のソフト削除を有効にします。
バージョン管理 を有効にします。
バケット で CORS ポリシー を構成します。
UI から CORS ポリシー を設定するには、BLOB ストレージに移動し、[設定] -> [リソース共有 (CORS)] までスクロールして、次のように設定します。
パラメータ
値
許可される オリジン
*
許可される メソッド
GET、HEAD、PUT
許可される ヘッダー
*
公開される ヘッダー
*
最大年齢
3600
ストレージ アカウント の アクセス キー を生成し、ストレージ アカウント 名とともに記録を保持します。専用クラウド を使用している場合は、安全な共有メカニズムを使用して、ストレージ アカウント 名と アクセス キー を W&B Team と共有します。
Team レベルの BYOB の場合、W&B では、必要な アクセス メカニズムと 権限 とともに Azure Blob Storage バケット をプロビジョニングするために、Terraform を使用することを推奨します。専用クラウド を使用する場合は、インスタンス の OIDC 発行者 URL を指定します。Team の作成中に バケット を構成する ために必要な詳細をメモしておきます。
ストレージ アカウント 名
ストレージ コンテナー 名
マネージド ID クライアント ID
Azure テナント ID
W&B で BYOB を構成する
W&B Team を作成するときに Team レベルでストレージ バケット を構成するには:
[Team 名] フィールドに Team の名前を入力します。
[ストレージ タイプ] オプションで [外部ストレージ] を選択します。
ドロップダウンから [新しい バケット ] を選択するか、既存の バケット を選択します。
複数の W&B Teams が同じ クラウド ストレージ バケット を使用できます。これを有効にするには、ドロップダウンから既存の クラウド ストレージ バケット を選択します。
[クラウド プロバイダー] ドロップダウンから、 クラウド プロバイダーを選択します。
[名前] フィールドにストレージ バケット の名前を入力します。専用クラウド または Azure 上の 自己管理 インスタンス がある場合は、[アカウント 名] フィールドと [コンテナー 名] フィールドに値を入力します。
(オプション) オプションの [パス] フィールドに バケット サブパスを入力します。W&B が バケット のルートにあるフォルダーにファイルを保存しないようにする場合は、これを行います。
(AWS バケット を使用している場合はオプション) [KMS キー ARN] フィールドに KMS 暗号化 キー の ARN を入力します。
(Azure バケット を使用している場合はオプション) [テナント ID] フィールドと [マネージド ID クライアント ID] フィールドに値を入力します。
(SaaS Cloud ではオプション) Team の作成時に Team メンバー を招待します。
[Team を作成] ボタンを押します。
バケット への アクセス に問題がある場合、または バケット の 設定 が無効な場合、ページの下部に エラー または 警告 が表示されます。
専用クラウド または 自己管理 インスタンス の インスタンス レベルの BYOB を構成するには、W&B サポート (support@wandb.com ) までお問い合わせください。
5.3.2 - Access BYOB using pre-signed URLs
W&B は、AI ワークロードまたは ユーザー のブラウザーからの blob ストレージへの アクセス を簡素化するために、事前署名付き URL を使用します。事前署名付き URL の基本情報については、AWS S3 の事前署名付き URL 、Google Cloud Storage の署名付き URL 、Azure Blob Storage の Shared Access Signature を参照してください。
必要な場合、ネットワーク内の AI ワークロードまたは ユーザー ブラウザー クライアントは、W&B Platform から事前署名付き URL を要求します。W&B Platform は、関連する blob ストレージに アクセス し、必要な権限を持つ事前署名付き URL を生成し、クライアントに返します。次に、クライアントは事前署名付き URL を使用して blob ストレージに アクセス し、 オブジェクト のアップロードまたは取得操作を行います。 オブジェクト のダウンロードの URL 有効期限は 1 時間、 オブジェクト のアップロードは 24 時間です。これは、一部の大きな オブジェクト をチャンク単位でアップロードするのに時間がかかる場合があるためです。
Team レベルの アクセス 制御
各事前署名付き URL は、W&B platform の team level access control に基づいて、特定の バケット に制限されています。 ユーザー が secure storage connector を使用して blob ストレージ バケット にマッピングされている team の一部であり、その ユーザー がその team の一部である場合、リクエスト に対して生成された事前署名付き URL には、他の team にマッピングされた blob ストレージ バケット に アクセス する権限はありません。
W&B は、 ユーザー が所属するはずの team のみに追加することをお勧めします。
ネットワーク制限
W&B は、 バケット で IAM ポリシー ベースの制限を使用することにより、事前署名付き URL を使用して blob ストレージに アクセス できるネットワークを制限することをお勧めします。
AWS の場合、VPC または IP アドレス ベースのネットワーク制限 を使用できます。これにより、W&B 固有の バケット には、AI ワークロードが実行されているネットワークからのみ、または ユーザー が W&B UI を使用して アーティファクト に アクセス する場合、 ユーザー マシンにマッピングされるゲートウェイ IP アドレスからのみ アクセス されるようになります。
監査 ログ
W&B は、blob ストレージ 固有の 監査 ログ に加えて、W&B audit logs を使用することもお勧めします。後者については、AWS S3 access logs 、Google Cloud Storage audit logs および Monitor Azure blob storage を参照してください。管理者およびセキュリティ team は、 監査 ログ を使用して、W&B 製品でどの ユーザー が何をしているかを追跡し、特定の ユーザー に対して一部の操作を制限する必要があると判断した場合に必要なアクションを実行できます。
事前署名付き URL は、W&B でサポートされている唯一の blob ストレージ アクセス メカニズムです。W&B は、リスク許容度に応じて、上記のセキュリティ制御のリストの一部または全部を構成することをお勧めします。
5.3.3 - Configure IP allowlisting for Dedicated Cloud
専用クラウド インスタンスへの アクセス を、許可された IP アドレス のリストのみに制限できます。これは、AI ワークロードから W&B API への アクセス と、 ユーザー のブラウザーから W&B アプリ UI への アクセス の両方に適用されます。 専用クラウド インスタンスに対して IP アドレス許可リストが設定されると、W&B は許可されていない場所からのリクエストをすべて拒否します。 専用クラウド インスタンスの IP アドレス許可リストを構成するには、W&B チームにお問い合わせください。
IP アドレス許可リストは、AWS、GCP、Azure の 専用クラウド インスタンスで利用できます。
IP アドレス許可リストは、セキュアプライベート接続 で使用できます。セキュアプライベート接続で IP アドレス許可リストを使用する場合、W&B は、AI ワークロードからのすべてのトラフィックと、可能な場合は ユーザー ブラウザーからのトラフィックの大部分にセキュアプライベート接続を使用し、特権のある場所からのインスタンス管理には IP アドレス許可リストを使用することをお勧めします。
W&B では、個々の「/32」IP アドレスではなく、企業またはビジネスの出力ゲートウェイに割り当てられた
CIDR ブロック を使用することを強くお勧めします。個々の IP アドレスの使用はスケーラブルではなく、クラウドごとに厳密な制限があります。
5.3.4 - Configure private connectivity to Dedicated Cloud
専用クラウド インスタンスには、クラウドプロバイダーのセキュアなプライベートネットワーク経由で接続できます。これは、AI ワークロードから W&B API へのアクセス、およびオプションで ユーザー のブラウザーから W&B アプリ UI へのアクセスに適用されます。プライベート接続を使用する場合、関連するリクエストとレスポンスは、パブリックネットワークまたはインターネットを経由しません。
セキュアなプライベート接続は、Dedicated Cloud の高度なセキュリティオプションとして近日提供予定です。
セキュアなプライベート接続は、AWS、GCP、Azure の Dedicated Cloud インスタンスで利用できます。
有効にすると、W&B はインスタンス用のプライベートエンドポイントサービスを作成し、接続するための関連する DNS URI を提供します。これにより、クラウドアカウントにプライベートエンドポイントを作成し、関連するトラフィックをプライベートエンドポイントサービスにルーティングできます。プライベートエンドポイントは、クラウド VPC または VNet 内で実行されている AI トレーニング ワークロードのセットアップが容易です。ユーザー のブラウザーから W&B アプリ UI へのトラフィックに同じメカニズムを使用するには、企業ネットワークからクラウドアカウントのプライベートエンドポイントへの適切な DNS ベースのルーティングを構成する必要があります。
この機能を使用したい場合は、W&B チームにお問い合わせください。
セキュアなプライベート接続は、IP 許可リスト で使用できます。IP 許可リストにセキュアなプライベート接続を使用する場合、W&B は、AI ワークロードからのすべてのトラフィック、および可能な場合は ユーザー のブラウザーからのトラフィックの大部分に対してセキュアなプライベート接続を保護し、特権のある場所からのインスタンス管理には IP 許可リストを使用することをお勧めします。
5.3.5 - Data encryption in Dedicated cloud
W&B は、各 専用クラウド で、W&B が管理するクラウドネイティブな キー を使用して、W&B が管理するデータベースと オブジェクト ストレージを暗号化します。これは、各 クラウド における顧客管理の暗号化キー (CMEK) 機能を使用することで実現しています。この場合、W&B は クラウド プロバイダーの「顧客」として機能し、W&B プラットフォーム をサービスとして提供します。W&B 管理の キー を使用するということは、W&B が各 クラウド で データを暗号化するために使用する キー を管理できることを意味し、すべてのお客様に高度に安全な プラットフォーム を提供するという約束を強化することになります。
W&B は、各顧客インスタンス内の データを暗号化するために「一意の キー 」を使用し、専用クラウド テナント間の分離をさらに強化します。この機能は、AWS、Azure、GCP で利用できます。
2024 年 8 月より前に W&B がプロビジョニングした GCP および Azure 上の 専用クラウド インスタンスは、W&B が管理するデータベースと オブジェクト ストレージの暗号化に、デフォルトの クラウド プロバイダー管理の キー を使用します。2024 年 8 月以降に W&B が作成した新しいインスタンスのみが、関連する暗号化に W&B 管理のクラウドネイティブな キー を使用します。
AWS 上の 専用クラウド インスタンスは、2024 年 8 月以前から、暗号化に W&B 管理のクラウドネイティブな キー を使用しています。
W&B は通常、お客様が独自のクラウドネイティブな キー を持ち込んで、専用クラウド インスタンス内の W&B が管理するデータベースと オブジェクト ストレージを暗号化することを許可していません。これは、組織内の複数の Teams と担当者が、さまざまな理由で クラウド インフラストラクチャー にアクセスできる可能性があるためです。これらの Teams または担当者の中には、組織のテクノロジー スタックにおける重要なコンポーネントとしての W&B に関する知識がない場合があり、クラウドネイティブな キー を完全に削除したり、W&B の アクセス を取り消したりする可能性があります。このような行為は、組織の W&B インスタンス内のすべての データを破損させ、回復不能な状態にする可能性があります。
組織が独自のクラウドネイティブな キー を使用して、W&B が管理するデータベースと オブジェクト ストレージを暗号化し、AI ワークフロー での 専用クラウド の使用を承認する必要がある場合、W&B は例外ベースでそれをレビューできます。承認された場合、暗号化にクラウドネイティブな キー を使用することは、W&B 専用クラウド の「責任共有モデル」に準拠します。組織内の ユーザー が、専用クラウド インスタンスが稼働しているときに、キー を削除したり、W&B の アクセス を取り消したりした場合、W&B は結果として生じる データ の損失または破損について責任を負わず、そのような データの回復についても責任を負いません。
5.4 - Configure privacy settings
組織と Team の管理者は、それぞれ組織と Team のスコープで一連のプライバシー設定を構成できます。組織スコープで構成した場合、組織管理者はその設定を組織内のすべての Team に対して適用します。
W&B は、組織管理者が組織内のすべての Team 管理者と User に事前に伝えてから、プライバシー設定を適用することを推奨します。これは、ワークフローにおける予期しない変更を避けるためです。
Team のプライバシー設定を構成する
Team 管理者は、Team の Settings タブの Privacy セクション内で、それぞれの Team のプライバシー設定を構成できます。各設定は、組織スコープで適用されていない限り構成可能です。
この Team をすべての非メンバーから隠す
今後のすべての Team の Projects をプライベートにする (パブリック共有は許可されません)
すべての Team メンバーが他のメンバーを招待できるようにする (管理者だけでなく)
プライベート Project の Reports について、Team の外部へのパブリック共有をオフにします。これにより、既存の Magic Link がオフになります。
組織の Email ドメインが一致する User がこの Team に参加できるようにする。
デフォルトで Code の保存を有効にする。
すべての Team にプライバシー設定を適用する
組織管理者は、アカウントまたは組織の ダッシュボード の Settings タブの Privacy セクション内で、組織内のすべての Team にプライバシー設定を適用できます。組織管理者が設定を適用すると、Team 管理者はそれぞれの Team 内でそれを構成できなくなります。
Team の可視性制限を適用する
このオプションを有効にすると、すべての Team が非メンバーから隠されます
今後の Projects にプライバシーを適用する
このオプションを有効にすると、すべての Team の今後のすべての Projects がプライベートまたは 制限付き になるように適用されます
招待コントロールを適用する
このオプションを有効にすると、管理者以外のメンバーが Team にメンバーを招待できなくなります
Report の共有コントロールを適用する
このオプションを有効にすると、プライベート Project 内の Reports のパブリック共有が無効になり、既存の Magic Link が無効になります
Team のセルフ参加制限を適用する
デフォルトの Code 保存制限を適用する
このオプションを有効にすると、すべての Team でデフォルトで Code の保存が無効になります
5.5 - Monitoring and usage
5.5.1 - Track user activity with audit logs
W&B の監査ログを使用すると、組織内のユーザーアクティビティを追跡し、企業のガバナンス要件に準拠できます。監査ログは JSON 形式で利用できます。監査ログスキーマ を参照してください。
監査ログへのアクセス方法は、W&B プラットフォームのデプロイメントタイプによって異なります。
監査ログを取得した後、Pandas 、Amazon Redshift 、Google BigQuery 、または Microsoft Fabric などのツールを使用して分析できます。一部の監査ログ分析ツールは JSON をサポートしていません。分析ツールに関するドキュメントを参照して、分析の前に JSON 形式の監査ログを変換するためのガイドラインと要件を確認してください。
監査ログスキーマ
この表は、監査ログエントリに表示される可能性のあるすべてのキーをアルファベット順に示しています。アクションと状況に応じて、特定ログエントリには、可能なフィールドのサブセットのみが含まれる場合があります。
キー
定義
actionイベントの アクション 。
actor_emailアクションを開始したユーザーのメールアドレス (該当する場合)。
actor_ipアクションを開始したユーザーの IP アドレス。
actor_user_idアクションを実行したログインユーザーの ID (該当する場合)。
artifact_assetアクションに関連付けられた Artifact ID (該当する場合)。
artifact_digestアクションに関連付けられた Artifact ダイジェスト (該当する場合)。
artifact_qualified_nameアクションに関連付けられた Artifact の完全名 (該当する場合)。
artifact_sequence_assetアクションに関連付けられた Artifact シーケンス ID (該当する場合)。
cli_versionアクションを開始した Python SDK のバージョン (該当する場合)。
entity_assetアクションに関連付けられた Entity または Team ID (該当する場合)。
entity_nameEntity または Team 名 (該当する場合)。
project_assetアクションに関連付けられた Project (該当する場合)。
project_nameアクションに関連付けられた Project の名前 (該当する場合)。
report_assetアクションに関連付けられた Report ID (該当する場合)。
report_nameアクションに関連付けられた Report の名前 (該当する場合)。
response_codeアクションの HTTP レスポンスコード (該当する場合)。
timestampRFC3339 形式 でのイベントの時刻。たとえば、2023-01-23T12:34:56Z は、2023 年 1 月 23 日の 12:34:56 UTC を表します。
user_assetアクションが影響を与える User アセット (アクションを実行するユーザーではなく) (該当する場合)。
user_emailアクションが影響を与える User のメールアドレス (アクションを実行するユーザーのメールアドレスではなく) (該当する場合)。
個人情報 (PII)
メールアドレスや Projects、Teams、Reports の名前などの個人情報 (PII) は、API エンドポイントオプションでのみ利用できます。
監査ログの取得
組織またはインスタンス管理者は、エンドポイント audit_logs/ で Audit Logging API を使用して、W&B インスタンスの監査ログを取得できます。
管理者以外のユーザーが監査ログを取得しようとすると、HTTP 403 エラーが発生し、アクセスが拒否されたことを示します。
複数の Enterprise SaaS Cloud 組織の管理者である場合は、監査ログ API リクエストの送信先となる組織を構成する必要があります。プロファイル画像をクリックし、[User Settings] をクリックします。設定の名前は [Default API organization] です。
インスタンスの正しい API エンドポイントを決定します。
以下の手順では、<API-endpoint> を API エンドポイントに置き換えます。
ベースエンドポイントから完全な API エンドポイントを作成し、オプションで URL パラメータを含めます。
anonymize: true に設定すると、PII が削除されます。デフォルトは false です。監査ログの取得時に PII を除外 を参照してください。SaaS Cloud ではサポートされていません。
numDays: ログは today - numdays から最新のものまで取得されます。デフォルトは 0 で、today のログのみが返されます。SaaS Cloud の場合、過去最大 7 日間の監査ログを取得できます。
startDate: オプションの日付で、形式は YYYY-MM-DD です。SaaS Cloud でのみサポートされています。
startDate と numDays は相互に作用します。
startDate と numDays の両方を設定した場合、ログは startDate から startDate + numDays まで返されます。startDate を省略して numDays を含めた場合、ログは today から numDays まで返されます。startDate も numDays も設定しない場合、ログは today に対してのみ返されます。
Web ブラウザーまたは Postman 、HTTPie 、cURL などのツールを使用して、構築された完全修飾 API エンドポイントに対して HTTP GET リクエストを実行します。
API レスポンスには、改行で区切られた JSON オブジェクトが含まれています。オブジェクトには、監査ログがインスタンスレベルのバケットに同期される場合と同様に、スキーマ で説明されているフィールドが含まれます。これらの場合、監査ログはバケットの /wandb-audit-logs ディレクトリーにあります。
基本認証の使用
API キーで基本認証を使用して監査ログ API にアクセスするには、HTTP リクエストの Authorization ヘッダーを文字列 Basic の後にスペース、次に username:API-KEY 形式の base-64 エンコードされた文字列に設定します。つまり、ユーザー名と API キーを : 文字で区切られた値に置き換え、その結果を base-64 エンコードします。たとえば、demo:p@55w0rd として認証する場合、ヘッダーは Authorization: Basic ZGVtbzpwQDU1dzByZA== にする必要があります。
監査ログの取得時に PII を除外
Self-managed および Dedicated Cloud の場合、W&B 組織またはインスタンス管理者は、監査ログの取得時に PII を除外できます。SaaS Cloud の場合、API エンドポイントは常に、PII を含む監査ログの関連フィールドを返します。これは構成できません。
PII を除外するには、anonymize=true URL パラメータを渡します。たとえば、W&B インスタンスの URL が https://mycompany.wandb.io で、過去 1 週間のユーザーアクティビティの監査ログを取得し、PII を除外する場合は、次のような API エンドポイントを使用します。
https://mycompany.wandb.io/admin/audit_logs?numDays=7&anonymize=true.
アクション
次の表は、W&B によって記録できるアクションをアルファベット順に説明しています。
アクション
定義
artifact:createArtifact が作成されました。
artifact:delete Artifact が削除されました。
artifact:readArtifact が読み取られました。
project:deleteProject が削除されました。
project:readProject が読み取られました。
report:readReport が読み取られました。1
run:delete_manyRun のバッチが削除されました。
run:deleteRun が削除されました。
run:stopRun が停止されました。
run:undelete_manyRun のバッチがゴミ箱から復元されました。
run:update_manyRun のバッチが更新されました。
run:updateRun が更新されました。
sweep:create_agentsweep agent が作成されました。
team:create_service_accountサービスアカウントが Team に対して作成されました。
team:createTeam が作成されました。
team:deleteTeam が削除されました。
team:invite_userUser が Team に招待されました。
team:uninviteUser またはサービスアカウントが Team から招待解除されました。
user:create_api_keyUser の APIキー が作成されました。1
user:createUser が作成されました。1
user:deactivateUser が非アクティブ化されました。1
user:delete_api_keyUser の APIキー が削除されました。1
user:initiate_loginUser がログインを開始しました。1
user:loginUser がログインしました。1
user:logoutUser がログアウトしました。1
user:permanently_deleteUser が完全に削除されました。1
user:reactivateUser が再アクティブ化されました。1
user:readUser プロファイルが読み取られました。1
user:updateUser が更新されました。1
1 : SaaS Cloud では、次の監査ログは収集されません。
オープンまたはパブリック Projects。
report:read アクション。特定の組織に関連付けられていない User アクション。
5.5.2 - Use Prometheus monitoring
W&B サーバー で Prometheus を使用します。Prometheus のインストールは、kubernetes ClusterIP サービス として公開されます。
Prometheus の メトリクス エンドポイント (/metrics) にアクセスするには、以下の手順に従ってください。
Kubernetes CLI ツールキット kubectl で クラスター に接続します。詳細については、Kubernetes の クラスターへのアクセス のドキュメントを参照してください。
次の コマンド で、 クラスター の内部 アドレス を見つけます。
kubectl describe svc prometheus
Kubernetes クラスター で実行されているコンテナ内で、kubectl exec<internal address>/metrics でエンドポイントにアクセスします。
以下の コマンド をコピーして ターミナル で実行し、<internal address> を内部 アドレス に置き換えます。
kubectl exec <internal address>/metrics
テスト pod が起動します。これは、ネットワーク内のものにアクセスするためだけに exec できます。
kubectl run -it testpod --image= alpine bin/ash --restart= Never --rm
そこから、ネットワークへの内部 アクセス を維持するか、kubernetes nodeport サービスを使用して自分で公開するかを選択できます。
5.5.3 - Configure Slack alerts
W&B Server を Slack と連携させます。
Slack アプリケーションの作成
以下の手順に従って Slack アプリケーションを作成します。
https://api.slack.com/apps にアクセスし、Create an App を選択します。
App Name フィールドにアプリの名前を入力します。
アプリの開発に使用する Slack ワークスペースを選択します。使用する Slack ワークスペースが、アラートに使用するワークスペースと同じであることを確認してください。
Slack アプリケーションの設定
左側のサイドバーで、OAth & Permissions を選択します。
Scopes セクションで、ボットに incoming_webhook スコープを付与します。スコープは、開発ワークスペースでアクションを実行するための権限をアプリに付与します。
ボットの OAuth スコープの詳細については、Slack API ドキュメントのボットの OAuth スコープの理解に関するチュートリアルを参照してください。
リダイレクト URL が W&B インストールを指すように設定します。ホスト URL がローカル システム 設定で設定されている URL と同じ URL を使用します。インスタンスへの DNS マッピングが異なる場合は、複数の URL を指定できます。
Save URLs を選択します。
オプションで、Restrict API Token Usage で IP 範囲を指定し、W&B インスタンスの IP または IP 範囲を許可リストに登録できます。許可される IP アドレスを制限すると、Slack アプリケーションのセキュリティをさらに強化できます。
W&B への Slack アプリケーションの登録
デプロイメントに応じて、W&B インスタンスの System Settings または System Console ページに移動します。
表示されている System ページに応じて、以下のいずれかのオプションに従ってください。
Slack client ID と Slack secret を入力し、Save をクリックします。Settings の Basic Information に移動して、アプリケーションの client ID と secret を確認します。
W&B アプリで Slack インテグレーションを設定して、すべてが機能していることを確認します。
5.5.4 - View organization dashboard
W&B の組織利用状況の表示
Organization dashboard を使用して、組織の W&B の利用状況を全体的に把握できます。ダッシュボードはタブで構成されています。
Users : 各 ユーザー の詳細(名前、メールアドレス、Teams、役割、最終アクティビティなど)をリスト表示します。Service accounts : サービスアカウントの詳細をリスト表示し、サービスアカウントを作成できます。Activity : 各 ユーザー のアクティビティの詳細をリスト表示します。Teams : 各 Team の詳細(ユーザー数、追跡時間など)をリスト表示し、管理者が Team に参加できるようにします。Billing : 組織の料金を要約し、請求 Reports の実行とエクスポートを可能にし、ライセンスの詳細(有効期限など)を表示します。Settings : プライバシーと認証に関連するカスタムロールと設定を構成できます。
ユーザー のステータスの表示
Users タブには、すべての ユーザー と、各 ユーザー に関する データ がリスト表示されます。「最終アクティブ」列には、 ユーザー が招待を承諾したかどうかと、 ユーザー の現在のステータスが表示されます。
Invite pending : 管理者が招待を送信しましたが、 ユーザー が招待を承諾していません。Active : ユーザー が招待を承諾し、アカウントを作成しました。- : ユーザー は以前はアクティブでしたが、過去 6 か月間アクティブではありません。Deactivated : 管理者が ユーザー のアクセスを取り消しました。
アクティビティで ユーザー のリストを並べ替えるには、[最終アクティブ] 列の見出しをクリックします。
組織が W&B をどのように使用しているかの表示と共有
Users タブから、組織が W&B をどのように使用しているかの詳細を CSV 形式で表示します。
[新しい ユーザー を招待] ボタンの横にあるアクション ... メニューをクリックします。
[CSV としてエクスポート] をクリックします。ダウンロードされる CSV ファイルには、組織の各 ユーザー の詳細( ユーザー 名、メール アドレス、最終アクティブ時間、役割など)がリスト表示されます。
ユーザー アクティビティの表示
Users タブの 最終アクティブ 列を使用して、個々の ユーザー の アクティビティの概要 を取得します。
最終アクティブ で ユーザー のリストを並べ替えるには、列名をクリックします。ユーザー の最終アクティビティの詳細を表示するには、 ユーザー の 最終アクティブ フィールドにマウスを合わせます。ユーザー が追加された時期と、 ユーザー がアクティブであった合計日数を示すツールチップが表示されます。
ユーザー は、次のいずれかに該当する場合に アクティブ になります。
W&B にログインする。
W&B App で任意のページを表示する。
Runs を ログ する。
SDK を使用して experiment を追跡する。
何らかの方法で W&B Server とやり取りする。
経時的なアクティブ ユーザー の表示
Activity タブのプロットを使用して、経時的にアクティブな ユーザー 数を集計して表示します。
Activity タブをクリックします。アクティブ ユーザー の合計 プロットは、一定期間にアクティブであった ユーザー 数を示します(デフォルトは 3 か月)。経時的なアクティブ ユーザー プロットは、一定期間のアクティブ ユーザー の変動を示します(デフォルトは 6 か月)。ポイントにマウスを合わせると、その日付の ユーザー 数が表示されます。
プロットの期間を変更するには、ドロップダウンを使用します。選択できるオプションは次のとおりです。
過去 30 日間
過去 3 か月
過去 6 か月
過去 12 か月
全期間
5.6 - Configure SMTP
W&B サーバー では、インスタンスまたは Team に ユーザー を追加すると、メールによる招待が送信されます。これらのメールによる招待を送信するために、W&B はサードパーティのメールサーバーを使用します。組織によっては、企業ネットワークから送信されるトラフィックに関する厳格なポリシーがあり、その結果、これらのメールによる招待がエンド ユーザー に送信されない場合があります。W&B サーバー には、社内の SMTP サーバー 経由でこれらの招待メールを送信するように構成するオプションがあります。
構成するには、以下の手順に従ってください。
dockerコンテナ または kubernetes の デプロイメント で GORILLA_EMAIL_SINK 環境 変数 を smtp://<user:password>@smtp.host.com:<port> に設定します。
username と password はオプションです。認証を必要としないように設計された SMTP サーバー を使用している場合は、環境 変数 の 値 を GORILLA_EMAIL_SINK=smtp://smtp.host.com:<port> のように設定するだけです。
SMTP で一般的に使用される ポート 番号 は、 ポート 587、465、および 25 です。これは、使用しているメール サーバー の種類によって異なる場合があることに注意してください。
SMTP のデフォルトの送信者メール アドレス (最初は noreply@wandb.com に設定されています)を構成するには、サーバー 上の GORILLA_EMAIL_FROM_ADDRESS 環境 変数 を目的の送信者メール アドレス に更新します。
5.7 - Configure environment variables
W&B サーバー のインストールを設定する方法
System Settings 管理 UI を使用してインスタンスレベルの 設定 を行うことに加えて、W&B は 環境変数 を使用してコードでこれらの 値 を 設定 する 方法 も提供します。また、IAM の 高度な 設定 も参照してください。
環境変数 のリファレンス
環境変数
説明
LICENSE
wandb/ローカルライセンス
MYSQL
MySQL 接続文字列
BUCKET
データ を 保存 する S3 / GCS バケット
BUCKET_QUEUE
オブジェクト 作成 イベント 用の SQS / Google PubSub キュー
NOTIFICATIONS_QUEUE
run イベント を パブリッシュする SQS キュー
AWS_REGION
バケット が存在する AWS リージョン
HOST
インスタンス の FQD。例えば、https://my.domain.net です。
OIDC_ISSUER
Open ID Connect ID プロバイダーの URL。例えば、https://cognito-idp.us-east-1.amazonaws.com/us-east-1_uiIFNdacd です。
OIDC_CLIENT_ID
ID プロバイダー内の アプリケーション の クライアント ID
OIDC_AUTH_METHOD
implicit (デフォルト) または pkce。詳細については、以下を参照してください。
SLACK_CLIENT_ID
アラートに使用する Slack アプリケーション の クライアント ID
SLACK_SECRET
アラートに使用する Slack アプリケーション の シークレット
LOCAL_RESTORE
インスタンス に アクセス できない場合は、一時的に true に 設定 できます。一時的な 認証情報 については、コンテナ からの ログ を確認してください。
REDIS
W&B で 外部 REDIS インスタンス を セットアップするために使用できます。
LOGGING_ENABLED
true に 設定 すると、 アクセス ログ が stdout に ストリーム されます。この 変数 を 設定 しなくても、サイドカー コンテナ をマウントして /var/log/gorilla.log を監視できます。
GORILLA_ALLOW_USER_TEAM_CREATION
true に 設定 すると、管理者以外の ユーザー が 新しい Teams を 作成 できるようになります。デフォルトでは false です。
GORILLA_DATA_RETENTION_PERIOD
削除された run の データ を保持する期間 (時間単位)。削除された run データ は 復元できません。入力 値 に h を追加します。たとえば、"24h"。
ENABLE_REGISTRY_UI
true に 設定 すると、新しい W&B Registry UI が有効になります。
GORILLA_DATA_RETENTION_PERIOD 環境変数 は 慎重に使用してください。環境変数 が 設定 されると、データ は 直ちに削除されます。また、このフラグを有効にする前に、データベース と ストレージ バケット の両方を バックアップ することをお勧めします。
高度な 信頼性 設定
Redis
外部 Redis サーバー の 設定 はオプションですが、 production システム では推奨されます。Redis は、サービスの信頼性を向上させ、特に 大規模な Projects での ロード時間 を短縮するために キャッシュ を有効にするのに役立ちます。高可用性 (HA) を備えた ElastiCache などの マネージド Redis サービス と、次の 仕様 を使用してください。
最小 4GB の メモリ、推奨 8GB
Redis バージョン 6.x
転送中の 暗号化
認証 が有効
W&B で Redis インスタンス を 設定 するには、http(s)://YOUR-W&B-SERVER-HOST/system-admin の W&B 設定 ページ に移動します。[外部 Redis インスタンス を 使用 する] オプション を有効にし、次の 形式 で Redis 接続文字列 を入力します。
コンテナ または Kubernetes デプロイメント で 環境変数 REDIS を使用して Redis を 設定 することもできます。または、REDIS を Kubernetes シークレット として 設定 することもできます。
この ページ では、Redis インスタンス が デフォルト ポート 6379 で 実行されていることを前提としています。別の ポート を 設定 し、 認証 を 設定 し、redis インスタンス で TLS を有効にする 場合 、接続文字列 の 形式 は redis://$USER:$PASSWORD@$HOST:$PORT?tls=true のようになります。
5.8 - Release process for W&B Server
W&B サーバー のリリース プロセス
頻度とデプロイメントの種類
W&B Server のリリースは、Dedicated Cloud と Self-managed のデプロイメントに適用されます。サーバーのリリースには、次の3種類があります。
リリースの種類
説明
月次
月次リリースには、新機能、機能拡張、および中程度と低程度の重大度のバグ修正が含まれます。
パッチ
パッチリリースには、重大および高重大度のバグ修正が含まれます。パッチは、必要に応じてまれにリリースされます。
機能
機能リリースは、新製品の特定のリリース日を対象としています。これは、標準の月次リリースよりも前に発生することがあります。
すべてのリリースは、受け入れテスト段階が完了すると、すべての Dedicated Cloud インスタンスに直ちにデプロイされます。これにより、管理対象インスタンスは完全に更新され、関連する顧客は最新の機能と修正を利用できます。Self-managed インスタンスを使用している顧客は、自身のスケジュールで 更新プロセス を行う必要があります。その際、最新の Docker イメージ を使用できます。リリースサポートとサポート終了 を参照してください。
一部の高度な機能は、エンタープライズライセンスでのみ利用できます。したがって、最新の Docker イメージを入手しても、エンタープライズライセンスがない場合は、関連する高度な機能を利用できません。
一部の新機能はプライベートプレビューで開始されます。これは、デザインパートナーまたはアーリーアダプターのみが利用できることを意味します。インスタンスでプライベートプレビュー機能を使用するには、W&B チームがその機能を有効にする必要があります。
リリースノート
すべてのリリースのリリースノートは、GitHub の W&B Server Releases で入手できます。Slack を使用している顧客は、W&B Slack チャンネルで自動リリース通知を受信できます。これらの更新を有効にするには、W&B チームにお問い合わせください。
リリース更新とダウンタイム
サーバーのリリースでは、通常、Dedicated Cloud インスタンス、および適切なローリングアップデートプロセスを実装している Self-managed デプロイメントを使用している顧客に対して、インスタンスのダウンタイムは必要ありません。
ダウンタイムは、次のシナリオで発生する可能性があります。
新しい機能または機能拡張には、コンピューティング、ストレージ、ネットワークなどの基盤となるインフラストラクチャーの変更が必要です。W&B は、関連する事前通知を Dedicated Cloud の顧客に送信するように努めています。
セキュリティパッチによるインフラストラクチャーの変更、または特定のバージョンの サポート終了 を回避するための変更。緊急の変更の場合、Dedicated Cloud の顧客は事前通知を受け取らない場合があります。ここでの優先事項は、フリートを安全に保ち、完全にサポートすることです。
どちらの場合も、アップデートは例外なくすべての Dedicated Cloud インスタンスにロールアウトされます。Self-managed インスタンスを使用している顧客は、自身のスケジュールでこのような更新を管理する必要があります。リリースサポートとサポート終了 を参照してください。
リリースサポートとサポート終了ポリシー
W&B は、リリース日から6か月間、すべてのサーバーリリースをサポートします。Dedicated Cloud インスタンスは自動的に更新されます。Self-managed インスタンスを使用している顧客は、サポートポリシーに準拠するために、デプロイメントをタイムリーに更新する必要があります。W&B からのサポートが大幅に制限されるため、6か月以上前のバージョンを使用することは避けてください。
W&B は、Self-managed インスタンスを使用している顧客に対し、少なくとも四半期ごとに最新リリースでデプロイメントを更新することを強く推奨します。これにより、最新かつ最高の機能を使用しながら、リリースのサポート終了を十分に回避できます。
6 - Integrations
W&B の インテグレーション により、既存の プロジェクト 内で 実験管理 と データ バージョン管理 を迅速かつ簡単にセットアップできます。PyTorch などの ML フレームワーク、Hugging Face などの ML ライブラリ、または Amazon SageMaker などの クラウド サービス向けの インテグレーション をご確認ください。
VIDEO
関連リソース
6.1 - Add wandb to any library
任意のライブラリに wandb を追加する
このガイドでは、強力な 実験管理 、GPU とシステム監視、モデルチェックポイントなど、独自のライブラリのための機能を W&B と統合するためのベストプラクティスを提供します。
W&B の使用方法をまだ学習中の場合は、先に進む前に、
実験管理 など、これらのドキュメントにある他の W&B ガイドを確認することをお勧めします。
以下では、作業中のコードベースが単一の Python トレーニングスクリプトまたは Jupyter ノートブックよりも複雑な場合の、ベストなヒントとベストプラクティスについて説明します。取り上げるトピックは次のとおりです。
セットアップ要件
ユーザーログイン
wandb の Run の開始
Run の設定の定義
W&B へのログ記録
分散トレーニング
モデルチェックポイントなど
ハイパーパラメータの チューニング
高度な インテグレーション
セットアップ要件
開始する前に、ライブラリの依存関係に W&B を必須にするかどうかを決定します。
インストール時に W&B を必須とする
W&B Python ライブラリ(wandb)を依存関係ファイルに追加します。たとえば、requirements.txt ファイルに追加します。
torch== 1.8.0
...
wandb== 0.13 .*
インストール時に W&B をオプションにする
W&B SDK(wandb)をオプションにするには、2つの方法があります。
A. ユーザーが手動でインストールせずに wandb 機能を使用しようとしたときにエラーを発生させ、適切なエラーメッセージを表示します。
try :
import wandb
except ImportError :
raise ImportError (
"You are trying to use wandb which is not currently installed."
"Please install it using pip install wandb"
)
B. Python パッケージを構築している場合は、wandb をオプションの依存関係として pyproject.toml ファイルに追加します。
[project ]
name = "my_awesome_lib"
version = "0.1.0"
dependencies = [
"torch" ,
"sklearn"
]
[project .optional-dependencies ]
dev = [
"wandb"
]
ユーザーログイン
APIキー を作成する
APIキー は、クライアントまたはマシンを W&B に対して認証します。 APIキー は、ユーザープロフィールから生成できます。
右上隅にあるユーザープロフィールアイコンをクリックします。
[User Settings(ユーザー設定) ]を選択し、[API Keys(APIキー) ]セクションまでスクロールします。
[Reveal(表示) ]をクリックします。表示された APIキー をコピーします。 APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
Command Line
Python
Python notebook
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
ユーザーが上記の手順に従わずに初めて wandb を使用する場合、スクリプトが wandb.init を呼び出すと、自動的にログインを求められます。
Run を開始する
W&B Run は、W&B によって記録される計算の単位です。通常、トレーニング実験ごとに単一の W&B Run を関連付けます。
W&B を初期化し、コード内で Run を開始するには:
オプションで、プロジェクトの名前を指定したり、エンティティパラメーターのユーザー名やチーム名(wandb_entity)とともに、コード内の wandb_project などのパラメーターを使用して、ユーザー自身に設定させたりできます。
run = wandb. init(project= wandb_project, entity= wandb_entity)
Run を終了するには、run.finish() を呼び出す必要があります。これがインテグレーションの設計で機能する場合は、Run をコンテキストマネージャーとして使用します。
# When this block exits, it calls run.finish() automatically.
# If it exits due to an exception, it uses run.finish(exit_code=1) which
# marks the run as failed.
with wandb. init() as run:
...
wandb.init をいつ呼び出すか?ライブラリは、W&B Run をできるだけ早く作成する必要があります。これは、エラーメッセージを含むコンソール内のすべての出力が W&B Run の一部として記録されるためです。これにより、デバッグが容易になります。
wandb をオプションの依存関係として使用するユーザーがライブラリを使用する際に wandb をオプションにしたい場合は、次のいずれかの方法があります。
trainer = my_trainer(... , use_wandb= True )
python train.py ... --use-wandb
または、wandb.init で wandb を disabled に設定します。
wandb. init(mode= "disabled" )
export WANDB_MODE= disabled
または
または、wandb をオフラインに設定します。これは、wandb を実行しますが、インターネット経由で W&B に通信しようとはしません。
Environment Variable
Bash
export WANDB_MODE= offline
または
os. environ['WANDB_MODE' ] = 'offline'
Run の設定を定義する
wandb の Run の設定を使用すると、W&B Run の作成時にモデル、データセットなどに関するメタデータを提供できます。この情報を使用して、さまざまな実験を比較し、主な違いをすばやく理解できます。
ログに記録できる一般的な設定パラメーターは次のとおりです。
モデル名、バージョン、アーキテクチャー パラメーターなど。
データセット名、バージョン、トレーニング/検証の例の数など。
学習率、 バッチサイズ 、 オプティマイザー などのトレーニングパラメーター。
次のコードスニペットは、設定をログに記録する方法を示しています。
config = {"batch_size" : 32 , ... }
wandb. init(... , config= config)
Run の設定を更新する
設定を更新するには、run.config.update を使用します。パラメーターが辞書の定義後に取得される場合に、設定辞書を更新すると便利です。たとえば、モデルのインスタンス化後にモデルのパラメーターを追加する場合があります。
run. config. update({"model_parameters" : 3500 })
設定ファイルの定義方法の詳細については、実験の設定 を参照してください。
W&B にログを記録する
メトリクス を記録する
キーの値が メトリクス の名前である辞書を作成します。この辞書オブジェクトをrun.log
for epoch in range(NUM_EPOCHS):
for input, ground_truth in data:
prediction = model(input)
loss = loss_fn(prediction, ground_truth)
metrics = { "loss" : loss }
run. log(metrics)
メトリクス がたくさんある場合は、train/... や val/... などの メトリクス 名にプレフィックスを使用することで、UI で自動的にグループ化できます。これにより、トレーニングと検証の メトリクス 、または分離したいその他の メトリクス タイプ用に、W&B Workspace に個別のセクションが作成されます。
metrics = {
"train/loss" : 0.4 ,
"train/learning_rate" : 0.4 ,
"val/loss" : 0.5 ,
"val/accuracy" : 0.7
}
run. log(metrics)
run.log の詳細を見る
X軸のずれを防ぐ
同じトレーニングステップに対して run.log を複数回呼び出すと、wandb SDK は run.log を呼び出すたびに内部ステップカウンターをインクリメントします。このカウンターは、トレーニングループのトレーニングステップと一致しない場合があります。
この状況を回避するには、run.define_metric で X軸ステップを明示的に定義します。wandb.init を呼び出した直後に1回定義します。
with wandb. init(... ) as run:
run. define_metric("*" , step_metric= "global_step" )
グロブパターン * は、すべての メトリクス がチャートで global_step を X軸として使用することを意味します。特定の メトリクス のみを global_step に対してログに記録する場合は、代わりにそれらを指定できます。
run. define_metric("train/loss" , step_metric= "global_step" )
次に、run.log を呼び出すたびに、 メトリクス 、step メトリクス 、および global_step をログに記録します。
for step, (input, ground_truth) in enumerate(data):
...
run. log({"global_step" : step, "train/loss" : 0.1 })
run. log({"global_step" : step, "eval/loss" : 0.2 })
たとえば、検証ループ中に「global_step」が利用できないなど、独立したステップ変数にアクセスできない場合、「global_step」の以前にログに記録された値が wandb によって自動的に使用されます。この場合、メトリクス に必要なときに定義されるように、 メトリクス の初期値をログに記録してください。
画像、テーブル、音声などをログに記録する
メトリクス に加えて、プロット、ヒストグラム、テーブル、テキスト、および画像、ビデオ、オーディオ、3D などのメディアをログに記録できます。
データをログに記録する際の考慮事項は次のとおりです。
メトリクス をログに記録する頻度はどのくらいですか? オプションにする必要がありますか?
視覚化に役立つデータの種類は何ですか?
画像の場合は、サンプル予測、セグメンテーションマスクなどをログに記録して、時間の経過に伴う変化を確認できます。
テキストの場合は、サンプル予測のテーブルをログに記録して、後で調べることができます。
メディア、オブジェクト、プロットなどのログ記録の詳細 をご覧ください。
分散トレーニング
分散環境をサポートするフレームワークの場合は、次のいずれかの ワークフロー を採用できます。
どの プロセス が「メイン」 プロセス であるかを検出し、そこで wandb のみを使用します。他の プロセス からの必要なデータは、最初にメイン プロセス にルーティングする必要があります(この ワークフロー を推奨します)。
すべての プロセス で wandb を呼び出し、すべてに同じ一意の group 名を付けて自動的にグループ化します。
詳細については、分散トレーニング実験のログを記録する を参照してください。
モデルチェックポイントなどを記録する
フレームワークがモデルまたはデータセットを使用または生成する場合は、それらをログに記録して完全なトレーサビリティを実現し、W&B Artifacts を介して パイプライン 全体を wandb で自動的に監視できます。
Artifacts を使用する場合、ユーザーに次のことを定義させることは役立つかもしれませんが、必須ではありません。
モデルチェックポイントまたはデータセットをログに記録する機能(オプションにする場合)。
入力として使用される Artifact のパス/参照(ある場合)。たとえば、user/project/artifact です。
Artifacts をログに記録する頻度。
モデルチェックポイント を記録する
モデルチェックポイント を W&B にログを記録できます。一意の wandb Run ID を利用して出力 モデルチェックポイント に名前を付け、Run 間で区別すると便利です。また、有用な メタデータ を追加することもできます。さらに、以下に示すように、各モデルに エイリアス を追加することもできます。
metadata = {"eval/accuracy" : 0.8 , "train/steps" : 800 }
artifact = wandb. Artifact(
name= f "model- { run. id} " ,
metadata= metadata,
type= "model"
)
artifact. add_dir("output_model" ) # local directory where the model weights are stored
aliases = ["best" , "epoch_10" ]
run. log_artifact(artifact, aliases= aliases)
カスタム エイリアス の作成方法については、カスタム エイリアス を作成する を参照してください。
出力 Artifacts は、任意の頻度(たとえば、エポックごと、500ステップごとなど)でログに記録でき、自動的に バージョン 管理されます。
学習済み モデル または データセット をログに記録および追跡する
学習済み モデル や データセット など、トレーニングへの入力として使用される Artifacts をログに記録できます。次のスニペットは、Artifact をログに記録し、上記のグラフに示すように、実行中の Run に入力として追加する方法を示しています。
artifact_input_data = wandb. Artifact(name= "flowers" , type= "dataset" )
artifact_input_data. add_file("flowers.npy" )
run. use_artifact(artifact_input_data)
Artifact をダウンロードする
Artifact(データセット、モデルなど)を再利用すると、wandb はローカルにコピーをダウンロード(およびキャッシュ)します。
artifact = run. use_artifact("user/project/artifact:latest" )
local_path = artifact. download("./tmp" )
Artifacts は W&B の Artifacts セクションにあり、自動的に生成される エイリアス (latest、v2、v3)またはログ記録時に手動で生成される エイリアス (best_accuracy など)で参照できます。
(wandb.init を介して)wandb Run を作成せずに Artifact をダウンロードするには(たとえば、分散環境または単純な推論の場合)、代わりにwandb API で Artifact を参照できます。
artifact = wandb. Api(). artifact("user/project/artifact:latest" )
local_path = artifact. download()
詳細については、Artifacts のダウンロードと使用 を参照してください。
ハイパーパラメーター を チューニング する
ライブラリで W&B ハイパーパラメーター チューニング 、W&B Sweeps を活用したい場合は、ライブラリに追加することもできます。
高度な インテグレーション
高度な W&B インテグレーション がどのようなものかについては、次の インテグレーション を参照してください。ほとんどの インテグレーション はこれほど複雑ではありません。
6.2 - Azure OpenAI Fine-Tuning
W&B を使用して Azure OpenAI モデルを ファインチューン する方法。
イントロダクション
Microsoft Azure 上で GPT-3.5 または GPT-4 モデルをファインチューニングする際、W&B を使用することで、メトリクスの自動的なキャプチャや W&B の 実験管理 および評価 ツールによる体系的な評価が促進され、モデルのパフォーマンスを追跡、分析、改善できます。
前提条件
ワークフローの概要
1. ファインチューニングのセットアップ
Azure OpenAI の要件に従ってトレーニングデータを準備します。
Azure OpenAI でファインチューニングジョブを設定します。
W&B は、ファインチューニングプロセスを自動的に追跡し、メトリクスとハイパーパラメータをログに記録します。
2. 実験管理
ファインチューニング中、W&B は以下をキャプチャします。
トレーニング および 検証メトリクス
モデル ハイパーパラメータ
リソース使用率
トレーニング Artifacts
3. モデルの評価
ファインチューニング後、W&B Weave を使用して以下を行います。
参照データセットに対するモデル出力を評価します
異なるファインチューニング Runs 全体のパフォーマンスを比較します
特定のテストケースにおけるモデルの 振る舞い を分析します
データに基づいたモデル選択の意思決定を行います
実際の例
追加リソース
6.3 - Catalyst
Pytorch のフレームワークである Catalyst に W&B を統合する方法。
Catalyst は、再現性 、迅速な実験 、およびコードベースの再利用に重点を置いたディープラーニング のR&D用 PyTorch フレームワーク で、新しいものを創造できます。
Catalyst には、 パラメータ 、 メトリクス 、画像、およびその他の Artifacts を ログ 記録するための W&B インテグレーション が含まれています。
Python と Hydra を使用した例を含む、インテグレーション のドキュメント を確認してください。
インタラクティブな例
Catalyst と W&B の インテグレーション の動作を確認するには、example colab を実行してください。
6.4 - Cohere fine-tuning
W&B を使用して Cohere モデル を ファインチューン する方法。
Weights & Biases を使用すると、Cohere モデルのファイン チューニング メトリクスと設定をログに記録して、モデルのパフォーマンスを分析および理解し、同僚と結果を共有できます。
この Cohere のガイド には、ファイン チューニング run を開始する方法の完全な例が記載されています。また、Cohere API ドキュメントはこちら にあります。
Cohere のファイン チューニング result をログに記録する
Cohere のファイン チューニング ログを W&B Workspace に追加するには:
W&B API キー、W&B entity、および project 名を使用して WandbConfig を作成します。W&B API キーは、https://wandb.ai/authorize で確認できます。
この設定を、モデル名、データセット、ハイパー パラメーターとともに FinetunedModel オブジェクトに渡して、ファイン チューニング run を開始します。
from cohere.finetuning import WandbConfig, FinetunedModel
# W&B の詳細を含む config を作成する
wandb_ft_config = WandbConfig(
api_key= "<wandb_api_key>" ,
entity= "my-entity" , # 提供された API キーに関連付けられている有効な entity である必要があります
project= "cohere-ft" ,
)
... # データセットとハイパー パラメーターを設定する
# cohere でファイン チューニング run を開始する
cmd_r_finetune = co. finetuning. create_finetuned_model(
request= FinetunedModel(
name= "command-r-ft" ,
settings= Settings(
base_model=...
dataset_id=...
hyperparameters=...
wandb= wandb_ft_config # ここに W&B config を渡す
),
),
)
作成した W&B project で、モデルのファイン チューニング トレーニング、検証メトリクス、およびハイパー パラメーターを表示します。
Runs を整理する
W&B の Runs は自動的に整理され、ジョブタイプ、ベース model、学習率、その他のハイパー パラメーターなどの任意の設定 parameter に基づいてフィルタリング/ソートできます。
さらに、Runs の名前を変更したり、メモを追加したり、タグを作成してグループ化したりできます。
リソース
6.5 - Databricks
W&B と Databricks を統合する方法。
W&B は、Databricks 環境で W&B Jupyter notebook のエクスペリエンスをカスタマイズすることにより、Databricks と統合されます。
Databricks の設定
クラスターに wandb をインストールする
クラスターの設定に移動し、クラスターを選択して、ライブラリ をクリックします。新規インストール をクリックし、PyPI を選択して、パッケージ wandb を追加します。
認証の設定
W&B アカウントを認証するには、notebook がクエリできる Databricks シークレットを追加します。
# databricks cli をインストールする
pip install databricks-cli
# databricks UI からトークンを生成する
databricks configure --token
# 次の 2 つのコマンドのいずれかを使用してスコープを作成します (Databricks でセキュリティ機能が有効になっているかどうかによって異なります)。
# セキュリティ アドオンを使用する場合
databricks secrets create-scope --scope wandb
# セキュリティ アドオンを使用しない場合
databricks secrets create-scope --scope wandb --initial-manage-principal users
# https://app.wandb.ai/authorize から api_key を追加します
databricks secrets put --scope wandb --key api_key
例
簡単な例
import os
import wandb
api_key = dbutils. secrets. get("wandb" , "api_key" )
wandb. login(key= api_key)
wandb. init()
wandb. log({"foo" : 1 })
Sweeps
wandb.sweep() または wandb.agent() を使用しようとする notebook に必要なセットアップ (一時的):
import os
# これらは将来的には不要になります
os. environ["WANDB_ENTITY" ] = "my-entity"
os. environ["WANDB_PROJECT" ] = "my-project-that-exists"
6.6 - DeepChecks
DeepChecks と W&B の統合方法。
DeepChecks は、機械学習 モデル と データの検証を支援します。たとえば、データの整合性の検証、分布の検査、データ分割の検証、モデル の評価、異なる モデル 間の比較などを、最小限の労力で行うことができます。
DeepChecks と wandb の インテグレーション についてもっと読む ->
はじめに
DeepChecks を Weights & Biases とともに使用するには、まず Weights & Biases アカウント にサインアップする 必要があります こちら 。DeepChecks の Weights & Biases の インテグレーション を使用すると、次のよう にすぐに開始できます。
import wandb
wandb. login()
# deepchecks から チェック をインポートします
from deepchecks.checks import ModelErrorAnalysis
# チェック を実行します
result = ModelErrorAnalysis()
# その 結果 を wandb にプッシュします
result. to_wandb()
DeepChecks テストスイート 全体 を Weights & Biases に ログ することもできます
import wandb
wandb. login()
# deepchecks から full_suite テスト をインポートします
from deepchecks.suites import full_suite
# DeepChecks テストスイート を作成して実行します
suite_result = full_suite(). run(... )
# thes の 結果 を wandb にプッシュします
# ここでは、必要な wandb.init の config と 引数 を渡すことができます
suite_result. to_wandb(project= "my-suite-project" , config= {"suite-name" : "full-suite" })
例
``この レポート
この Weights & Biases の インテグレーション に関する質問や問題がありますか? DeepChecks github repository で issue をオープンしてください。私たちがキャッチして回答します :)
6.7 - DeepChem
DeepChem ライブラリと W&B を統合する方法。
DeepChem library は、創薬、材料科学、化学、生物学における深層学習の利用を民主化するオープンソースのツールを提供します。この W&B の インテグレーション により、DeepChem を使用してモデルを トレーニング する際に、シンプルで使いやすい 実験管理 とモデルの チェックポイント が追加されます。
3 行のコードで DeepChem のログを記録
logger = WandbLogger(… )
model = TorchModel(… , wandb_logger= logger)
model. fit(… )
Report と Google Colab
W&B with DeepChem: Molecular Graph Convolutional Networks の記事で、W&B DeepChem インテグレーション を使用して生成されたチャートの例をご覧ください。
すぐにコードを試したい場合は、こちらの Google Colab
Experiments の追跡
KerasModel または TorchModel タイプの DeepChem モデル用に W&B をセットアップします。
サインアップして API キー を作成する
API キー は、W&B へのマシンの認証を行います。API キー は、 ユーザー プロフィールから生成できます。
右上隅にある ユーザー プロフィール アイコンをクリックします。
[User Settings ] を選択し、[API Keys ] セクションまでスクロールします。
[Reveal ] をクリックします。表示された API キー をコピーします。API キー を非表示にするには、ページをリロードします。
wandb ライブラリ をインストールしてログインするwandb ライブラリ をローカルにインストールしてログインするには:
Command Line
Python
Python notebook
WANDB_API_KEY 環境変数 を API キー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリ をインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
トレーニング および 評価 データ を W&B に ログ 記録する
トレーニング 損失と 評価 メトリクス は、自動的に W&B に ログ 記録できます。オプションの 評価 は、DeepChem ValidationCallback を使用して有効にできます。WandbLogger は ValidationCallback コールバックを検出し、生成された メトリクス を ログ 記録します。
from deepchem.models import TorchModel, ValidationCallback
vc = ValidationCallback(… ) # optional
model = TorchModel(… , wandb_logger= logger)
model. fit(… , callbacks= [vc])
logger. finish()
from deepchem.models import KerasModel, ValidationCallback
vc = ValidationCallback(… ) # optional
model = KerasModel(… , wandb_logger= logger)
model. fit(… , callbacks= [vc])
logger. finish()
6.8 - Docker
W&B と Docker を統合する方法。
Docker インテグレーション
W&B は、 コード が実行された Docker イメージ へのポインターを保存できます。これにより、以前の 実験 を実行された環境に正確に復元できます。 wandb ライブラリ は、この状態を永続化するために WANDB_DOCKER 環境変数 を探します。この状態を自動的に設定するいくつかのヘルパーを提供します。
ローカル開発
wandb docker は、 dockerコンテナ を起動し、 wandb 環境変数 を渡し、 コード をマウントし、 wandb がインストールされていることを確認する コマンド です。デフォルトでは、この コマンド は TensorFlow、PyTorch、Keras、Jupyter がインストールされた Docker イメージ を使用します。同じ コマンド を使用して、独自の Docker イメージ を起動できます: wandb docker my/image:latest。この コマンド は、現在の ディレクトリー を コンテナ の “/app” ディレクトリー にマウントします。これは “–dir” フラグで変更できます。
本番環境
wandb docker-run コマンド は、 本番環境 の ワークロード 用に提供されています。これは nvidia-docker のドロップイン代替となることを意図しています。これは docker run コマンド へのシンプルなラッパーで、 認証情報 と WANDB_DOCKER 環境変数 を呼び出しに追加します。 “–runtime” フラグを渡さず、 nvidia-docker がマシンで利用可能な場合、これにより ランタイム が nvidia に設定されます。
Kubernetes
Kubernetes で トレーニング の ワークロード を実行し、 k8s API が pod に公開されている場合(デフォルトの場合)。 wandb は、 Docker イメージ のダイジェストについて API にクエリを実行し、 WANDB_DOCKER 環境変数 を自動的に設定します。
復元
run が WANDB_DOCKER 環境変数 で計測されている場合、 wandb restore username/project:run_id を呼び出すと、 コード を復元する新しいブランチをチェックアウトし、 トレーニング に使用された正確な Docker イメージ を元の コマンド で事前に設定して 起動 します。
6.9 - Farama Gymnasium
Farama Gymnasium と W&B を統合する方法。
Farama Gymnasium を使用している場合、gymnasium.wrappers.Monitor で生成された環境の動画が自動的にログに記録されます。monitor_gym キーワード 引数 を wandb.initTrue に設定するだけです。
当社の Gymnasium インテグレーション は非常に軽量です。 gymnasium からログに記録されている 動画ファイルの名前を確認 し、その名前を付けます。一致するものが見つからない場合は、"videos" にフォールバックします。より詳細な制御が必要な場合は、いつでも手動で 動画をログに記録 できます。
CleanRL ライブラリ で Gymnasium を使用する方法の詳細については、こちらの Reports をご覧ください。
6.10 - fastai
fastai を使用してモデルをトレーニングする場合、W&B には WandbCallback を使用した簡単なインテグレーションがあります。インタラクティブなドキュメントと例はこちら →
サインアップして API キーを作成する
API キーは、W&B に対してお客様のマシンを認証します。API キーは、ユーザー プロフィールから生成できます。
右上隅にあるユーザー プロフィール アイコンをクリックします。
ユーザー設定 を選択し、API キー セクションまでスクロールします。表示 をクリックします。表示された API キーをコピーします。API キーを非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を API キーに設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
learner または fit メソッドに WandbCallback を追加するimport wandb
from fastai.callback.wandb import *
# start logging a wandb run
wandb. init(project= "my_project" )
# To log only during one training phase
learn. fit(... , cbs= WandbCallback())
# To log continuously for all training phases
learn = learner(... , cbs= WandbCallback())
WandbCallback 引数
WandbCallback は、次の引数を受け入れます。
Args
Description
log
モデルのログを記録するかどうか: gradients 、parameters、all または None (デフォルト)。損失とメトリクスは常にログに記録されます。
log_preds
予測サンプルをログに記録するかどうか (デフォルトは True)。
log_preds_every_epoch
エポックごとに予測をログに記録するか、最後にログに記録するか (デフォルトは False)
log_model
モデルをログに記録するかどうか (デフォルトは False)。これには SaveModelCallback も必要です
model_name
保存する file の名前。SaveModelCallback をオーバーライドします
log_dataset
False (デフォルト)True は、learn.dls.path で参照されるフォルダーをログに記録します。パスを明示的に定義して、ログに記録するフォルダーを参照できます。 注: サブフォルダー “models” は常に無視されます。
dataset_name
ログに記録されたデータセットの名前 (デフォルトは folder name)。
valid_dl
予測サンプルに使用されるアイテムを含む DataLoaders (デフォルトは learn.dls.valid からのランダムなアイテム。
n_preds
ログに記録された予測の数 (デフォルトは 36)。
seed
ランダム サンプルを定義するために使用されます。
カスタム ワークフローでは、データセットとモデルを手動でログに記録できます。
log_dataset(path, name=None, metadata={})log_model(path, name=None, metadata={})
注: サブフォルダー “models” はすべて無視されます。
分散トレーニング
fastai は、コンテキスト マネージャー distrib_ctx を使用して分散トレーニングをサポートします。W&B はこれを自動的にサポートし、すぐに使える Multi-GPU の Experiments を追跡できるようにします。
この最小限の例を確認してください。
import wandb
from fastai.vision.all import *
from fastai.distributed import *
from fastai.callback.wandb import WandbCallback
wandb. require(experiment= "service" )
path = rank0_first(lambda : untar_data(URLs. PETS) / "images" )
def train ():
dls = ImageDataLoaders. from_name_func(
path,
get_image_files(path),
valid_pct= 0.2 ,
label_func= lambda x: x[0 ]. isupper(),
item_tfms= Resize(224 ),
)
wandb. init("fastai_ddp" , entity= "capecape" )
cb = WandbCallback()
learn = vision_learner(dls, resnet34, metrics= error_rate, cbs= cb). to_fp16()
with learn. distrib_ctx(sync_bn= False ):
learn. fit(1 )
if __name__ == "__main__" :
train()
次に、ターミナルで次を実行します。
$ torchrun --nproc_per_node 2 train.py
この場合、マシンには 2 つの GPU があります。
ノートブック内で分散トレーニングを直接実行できるようになりました。
import wandb
from fastai.vision.all import *
from accelerate import notebook_launcher
from fastai.distributed import *
from fastai.callback.wandb import WandbCallback
wandb. require(experiment= "service" )
path = untar_data(URLs. PETS) / "images"
def train ():
dls = ImageDataLoaders. from_name_func(
path,
get_image_files(path),
valid_pct= 0.2 ,
label_func= lambda x: x[0 ]. isupper(),
item_tfms= Resize(224 ),
)
wandb. init("fastai_ddp" , entity= "capecape" )
cb = WandbCallback()
learn = vision_learner(dls, resnet34, metrics= error_rate, cbs= cb). to_fp16()
with learn. distrib_ctx(in_notebook= True , sync_bn= False ):
learn. fit(1 )
notebook_launcher(train, num_processes= 2 )
メイン プロセスでのみログを記録する
上記の例では、wandb はプロセスごとに 1 つの run を起動します。トレーニングの最後に、2 つの run が作成されます。これは混乱を招く可能性があるため、メイン プロセスでのみログに記録したい場合があります。そのためには、どのプロセスに手動でいるかを検出し、他のすべてのプロセスで run を作成 ( wandb.init を呼び出す) しないようにする必要があります。
import wandb
from fastai.vision.all import *
from fastai.distributed import *
from fastai.callback.wandb import WandbCallback
wandb. require(experiment= "service" )
path = rank0_first(lambda : untar_data(URLs. PETS) / "images" )
def train ():
cb = []
dls = ImageDataLoaders. from_name_func(
path,
get_image_files(path),
valid_pct= 0.2 ,
label_func= lambda x: x[0 ]. isupper(),
item_tfms= Resize(224 ),
)
if rank_distrib() == 0 :
run = wandb. init("fastai_ddp" , entity= "capecape" )
cb = WandbCallback()
learn = vision_learner(dls, resnet34, metrics= error_rate, cbs= cb). to_fp16()
with learn. distrib_ctx(sync_bn= False ):
learn. fit(1 )
if __name__ == "__main__" :
train()
ターミナルで次を呼び出します。
$ torchrun --nproc_per_node 2 train.py
import wandb
from fastai.vision.all import *
from accelerate import notebook_launcher
from fastai.distributed import *
from fastai.callback.wandb import WandbCallback
wandb. require(experiment= "service" )
path = untar_data(URLs. PETS) / "images"
def train ():
cb = []
dls = ImageDataLoaders. from_name_func(
path,
get_image_files(path),
valid_pct= 0.2 ,
label_func= lambda x: x[0 ]. isupper(),
item_tfms= Resize(224 ),
)
if rank_distrib() == 0 :
run = wandb. init("fastai_ddp" , entity= "capecape" )
cb = WandbCallback()
learn = vision_learner(dls, resnet34, metrics= error_rate, cbs= cb). to_fp16()
with learn. distrib_ctx(in_notebook= True , sync_bn= False ):
learn. fit(1 )
notebook_launcher(train, num_processes= 2 )
例
6.10.1 - fastai v1
このドキュメントは fastai v1 用です。
現在のバージョンの fastai を使用している場合は、
fastai のページ を参照してください。
fastai v1 を使用するスクリプトの場合、モデルのトポロジー、損失、メトリクス、重み、勾配、サンプル予測、および最高のトレーニング済みモデルを自動的にログに記録できる コールバック があります。
import wandb
from wandb.fastai import WandbCallback
wandb. init()
learn = cnn_learner(data, model, callback_fns= WandbCallback)
learn. fit(epochs)
リクエストされたログデータは、 コールバック コンストラクターを通じて設定可能です。
from functools import partial
learn = cnn_learner(
data, model, callback_fns= partial(WandbCallback, input_type= "images" )
)
トレーニング の開始時にのみ WandbCallback を使用することも可能です。この場合、インスタンス化する必要があります。
learn. fit(epochs, callbacks= WandbCallback(learn))
カスタム パラメータ は、その段階で指定することもできます。
learn. fit(epochs, callbacks= WandbCallback(learn, input_type= "images" ))
コード 例
この インテグレーション の動作を確認するためのいくつかの例を作成しました。
Fastai v1
オプション
WandbCallback() クラス は、多数のオプションをサポートしています。
キーワード 引数
デフォルト
説明
learn
N/A
フック する fast.ai の学習器。
save_model
True
各ステップで改善された場合、モデルを保存します。トレーニング の最後に最高のモデルもロードします。
mode
auto
min、max、または auto: monitor で指定された トレーニング メトリクス をステップ間で比較する方法。
monitor
None
最高のモデルを保存するためにパフォーマンスを測定するために使用される トレーニング メトリクス。None は、検証損失をデフォルトにします。
log
gradients
gradients、parameters、all、または None。損失と メトリクス は常にログに記録されます。
input_type
None
images または None。サンプル予測を表示するために使用されます。
validation_data
None
input_type が設定されている場合、サンプル予測に使用されるデータ。
predictions
36
input_type が設定され、validation_data が None の場合に行う予測の数。
seed
12345
input_type が設定され、validation_data が None の場合、サンプル予測のために乱数ジェネレーターを初期化します。
6.11 - Hugging Face Transformers
Hugging Face Transformers ライブラリを使用すると、BERTのような最先端の NLP モデルや、混合精度や勾配チェックポイントなどのトレーニング手法を簡単に使用できます。W&B integration は、使いやすさを損なうことなく、インタラクティブな集中ダッシュボードに、豊富で柔軟な実験管理とモデルの バージョン管理を追加します。
わずか数行で次世代のロギング
os. environ["WANDB_PROJECT" ] = "<my-amazing-project>" # W&B プロジェクトに名前を付ける
os. environ["WANDB_LOG_MODEL" ] = "checkpoint" # すべてのモデルチェックポイントをログに記録
from transformers import TrainingArguments, Trainer
args = TrainingArguments(... , report_to= "wandb" ) # W&B ロギングをオンにする
trainer = Trainer(... , args= args)
はじめに: 実験の トラッキング
サインアップして API キーを作成する
API キーは、お使いのマシンを W&B に対して認証します。API キーは、ユーザープロフィールから生成できます。
右上隅にあるユーザープロフィールアイコンをクリックします。
[User Settings ]を選択し、[API Keys ]セクションまでスクロールします。
[Reveal ]をクリックします。表示された API キーをコピーします。API キーを非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
Command Line
Python
Python notebook
WANDB_API_KEY 環境変数 を API キーに設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
W&B を初めて使用する場合は、クイックスタート
プロジェクトに名前を付ける
W&B の Project とは、関連する run からログに記録されたすべてのチャート、データ、およびモデルが保存される場所です。プロジェクトに名前を付けると、作業を整理し、単一のプロジェクトに関するすべての情報を 1 か所にまとめて管理できます。
run をプロジェクトに追加するには、WANDB_PROJECT 環境変数をプロジェクト名に設定するだけです。WandbCallback は、このプロジェクト名の環境変数を取得し、run の設定時に使用します。
Command Line
Python
Python notebook
WANDB_PROJECT= amazon_sentiment_analysis
import os
os. environ["WANDB_PROJECT" ]= "amazon_sentiment_analysis"
%env WANDB_PROJECT=amazon_sentiment_analysis
Trainer を初期化する 前に 、必ずプロジェクト名を設定してください。
プロジェクト名が指定されていない場合、プロジェクト名はデフォルトで huggingface になります。
トレーニングの run を W&B に記録する
コード内またはコマンドラインで Trainer のトレーニング引数を定義する際に 最も重要なステップ は、W&B でのロギングを有効にするために、report_to を "wandb" に設定することです。
TrainingArguments の logging_steps 引数は、トレーニング中にトレーニングメトリクスが W&B にプッシュされる頻度を制御します。run_name 引数を使用して、W&B のトレーニング run に名前を付けることもできます。
これで完了です。モデルは、トレーニング中に損失、評価メトリクス、モデルトポロジー、および勾配を W&B に記録します。
python run_glue.py \ # Python スクリプトを実行する
--report_to wandb \ # W&B へのロギングを有効にする
--run_name bert-base-high-lr \ # W&B run の名前 (オプション)
# その他のコマンドライン引数
from transformers import TrainingArguments, Trainer
args = TrainingArguments(
# その他の args と kwargs
report_to= "wandb" , # W&B へのロギングを有効にする
run_name= "bert-base-high-lr" , # W&B run の名前 (オプション)
logging_steps= 1 , # W&B へのロギング頻度
)
trainer = Trainer(
# その他の args と kwargs
args= args, # トレーニングの引数
)
trainer. train() # トレーニングを開始して W&B にログを記録する
TensorFlow を使用していますか?PyTorch Trainer を TensorFlow TFTrainer に交換するだけです。
モデルチェックポイントをオンにする
Artifacts を使用すると、最大 100GB のモデルとデータセットを無料で保存し、Weights & Biases Registry を使用できます。Registry を使用すると、モデルを登録して探索および評価したり、ステージングの準備をしたり、本番環境にデプロイしたりできます。
Hugging Face モデルチェックポイントを Artifacts に記録するには、WANDB_LOG_MODEL 環境変数を次の いずれか に設定します。
checkpointTrainingArgumentsargs.save_steps ごとにチェックポイントをアップロードします。endload_best_model_at_end も設定されている場合は、トレーニングの最後にモデルをアップロードします。false
Command Line
Python
Python notebook
WANDB_LOG_MODEL= "checkpoint"
import os
os. environ["WANDB_LOG_MODEL" ] = "checkpoint"
%env WANDB_LOG_MODEL="checkpoint"
これから初期化する Transformers Trainer はすべて、モデルを W&B プロジェクトにアップロードします。ログに記録したモデルチェックポイントは、Artifacts UI で表示でき、完全なモデルリネージが含まれています (UI のモデルチェックポイントの例は こちら を参照してください)。
デフォルトでは、
WANDB_LOG_MODEL が
end に設定されている場合は
model-{run_id} として、
WANDB_LOG_MODEL が
checkpoint に設定されている場合は
checkpoint-{run_id} として、モデルは W&B Artifacts に保存されます。
ただし、
TrainingArguments で
run_name を渡すと、モデルは
model-{run_name} または
checkpoint-{run_name} として保存されます。
W&B Registry
チェックポイントを Artifacts に記録したら、最高のモデルチェックポイントを登録し、Registry 自動化 したりできます。
モデル Artifact をリンクするには、Registry を参照してください。
トレーニング中に評価出力を可視化する
トレーニング中または評価中にモデル出力を可視化することは、モデルのトレーニング方法を実際に理解するために不可欠なことがよくあります。
Transformers Trainer のコールバックシステムを使用すると、モデルのテキスト生成出力やその他の予測などの追加の役立つデータを W&B Tables に W&B に記録できます。
トレーニング中に評価出力を記録して、次のような W&B Table に記録する方法の詳細については、以下の カスタムロギングセクション
W&B Run を終了する (ノートブックのみ)
トレーニングが Python スクリプトにカプセル化されている場合、スクリプトが終了すると W&B run は終了します。
Jupyter または Google Colab ノートブックを使用している場合は、wandb.finish() を呼び出して、トレーニングが完了したことを伝える必要があります。
trainer. train() # トレーニングを開始して W&B にログを記録する
# トレーニング後の分析、テスト、その他のログに記録されたコード
wandb. finish()
結果を可視化する
トレーニング結果をログに記録したら、W&B Dashboard で結果を動的に調べることができます。柔軟でインタラクティブな可視化により、多数の run を一度に比較したり、興味深い発見を拡大したり、複雑なデータから洞察を引き出したりするのが簡単です。
高度な機能と FAQ
最適なモデルを保存するにはどうすればよいですか?
load_best_model_at_end=True で TrainingArguments を Trainer に渡すと、W&B は最適なパフォーマンスのモデルチェックポイントを Artifacts に保存します。
モデルチェックポイントを Artifacts として保存する場合は、Registry に昇格させることができます。Registry では、次のことができます。
ML タスクごとに最適なモデルバージョンを整理します。
モデルを一元化してチームと共有します。
本番環境用にモデルをステージングするか、詳細な評価のためにブックマークします。
ダウンストリーム CI/CD プロセスをトリガーします。
保存されたモデルをロードするにはどうすればよいですか?
WANDB_LOG_MODEL を使用してモデルを W&B Artifacts に保存した場合は、追加のトレーニングまたは推論を実行するためにモデルの重みをダウンロードできます。以前に使用したのと同じ Hugging Face アーキテクチャにロードするだけです。
# 新しい run を作成する
with wandb. init(project= "amazon_sentiment_analysis" ) as run:
# Artifact の名前とバージョンを渡す
my_model_name = "model-bert-base-high-lr:latest"
my_model_artifact = run. use_artifact(my_model_name)
# モデルの重みをフォルダーにダウンロードしてパスを返す
model_dir = my_model_artifact. download()
# 同じモデルクラスを使用して、そのフォルダーから Hugging Face モデルをロードする
model = AutoModelForSequenceClassification. from_pretrained(
model_dir, num_labels= num_labels
)
# 追加のトレーニングを実行するか、推論を実行する
チェックポイントからトレーニングを再開するにはどうすればよいですか?
WANDB_LOG_MODEL='checkpoint' を設定した場合は、model_dir を TrainingArguments の model_name_or_path 引数として使用し、resume_from_checkpoint=True を Trainer に渡すことで、トレーニングを再開することもできます。
last_run_id = "xxxxxxxx" # wandb ワークスペースから run_id を取得する
# run_id から wandb run を再開する
with wandb. init(
project= os. environ["WANDB_PROJECT" ],
id= last_run_id,
resume= "must" ,
) as run:
# Artifact を run に接続する
my_checkpoint_name = f "checkpoint- { last_run_id} :latest"
my_checkpoint_artifact = run. use_artifact(my_model_name)
# チェックポイントをフォルダーにダウンロードしてパスを返す
checkpoint_dir = my_checkpoint_artifact. download()
# モデルとトレーナーを再初期化する
model = AutoModelForSequenceClassification. from_pretrained(
"<model_name>" , num_labels= num_labels
)
# ここに素晴らしいトレーニング引数を記述する。
training_args = TrainingArguments()
trainer = Trainer(model= model, args= training_args)
# チェックポイントディレクトリを使用して、チェックポイントからトレーニングを再開する
trainer. train(resume_from_checkpoint= checkpoint_dir)
トレーニング中に評価サンプルを記録して表示するにはどうすればよいですか?
Transformers Trainer を介した W&B へのロギングは、Transformers ライブラリの WandbCallbackWandbCallback をサブクラス化し、Trainer クラスの追加メソッドを活用する追加機能を追加して、このコールバックを変更できます。
以下は、この新しいコールバックを HF Trainer に追加する一般的なパターンであり、さらに下には、評価出力を W&B Table に記録するコード完全な例があります。
# Trainer を通常どおりインスタンス化する
trainer = Trainer()
# 新しいロギングコールバックをインスタンス化し、Trainer オブジェクトを渡す
evals_callback = WandbEvalsCallback(trainer, tokenizer, ... )
# コールバックを Trainer に追加する
trainer. add_callback(evals_callback)
# 通常どおり Trainer トレーニングを開始する
trainer. train()
トレーニング中に評価サンプルを表示する
次のセクションでは、WandbCallback をカスタマイズして、モデルの予測を実行し、トレーニング中に評価サンプルを W&B Table に記録する方法について説明します。Trainer コールバックの on_evaluate メソッドを使用して、すべての eval_steps を実行します。
ここでは、tokenizer を使用してモデル出力から予測とラベルをデコードする decode_predictions 関数を作成しました。
次に、予測とラベルから pandas DataFrame を作成し、DataFrame に epoch 列を追加します。
最後に、DataFrame から wandb.Table を作成し、wandb に記録します。
さらに、予測を freq エポックごとに記録することで、ロギングの頻度を制御できます。
注 : 通常の WandbCallback とは異なり、このカスタムコールバックは、Trainer の初期化中ではなく、Trainer がインスタンス化された後 にトレーナーに追加する必要があります。
これは、Trainer インスタンスが初期化中にコールバックに渡されるためです。
from transformers.integrations import WandbCallback
import pandas as pd
def decode_predictions (tokenizer, predictions):
labels = tokenizer. batch_decode(predictions. label_ids)
logits = predictions. predictions. argmax(axis=- 1 )
prediction_text = tokenizer. batch_decode(logits)
return {"labels" : labels, "predictions" : prediction_text}
class WandbPredictionProgressCallback (WandbCallback):
"""Custom WandbCallback to log model predictions during training.
This callback logs model predictions and labels to a wandb.Table at each
logging step during training. It allows to visualize the
model predictions as the training progresses.
Attributes:
trainer (Trainer): The Hugging Face Trainer instance.
tokenizer (AutoTokenizer): The tokenizer associated with the model.
sample_dataset (Dataset): A subset of the validation dataset
for generating predictions.
num_samples (int, optional): Number of samples to select from
the validation dataset for generating predictions. Defaults to 100.
freq (int, optional): Frequency of logging. Defaults to 2.
"""
def __init__(self, trainer, tokenizer, val_dataset, num_samples= 100 , freq= 2 ):
"""Initializes the WandbPredictionProgressCallback instance.
Args:
trainer (Trainer): The Hugging Face Trainer instance.
tokenizer (AutoTokenizer): The tokenizer associated
with the model.
val_dataset (Dataset): The validation dataset.
num_samples (int, optional): Number of samples to select from
the validation dataset for generating predictions.
Defaults to 100.
freq (int, optional): Frequency of logging. Defaults to 2.
"""
super(). __init__()
self. trainer = trainer
self. tokenizer = tokenizer
self. sample_dataset = val_dataset. select(range(num_samples))
self. freq = freq
def on_evaluate (self, args, state, control, ** kwargs):
super(). on_evaluate(args, state, control, ** kwargs)
# control the frequency of logging by logging the predictions
# every `freq` epochs
if state. epoch % self. freq == 0 :
# generate predictions
predictions = self. trainer. predict(self. sample_dataset)
# decode predictions and labels
predictions = decode_predictions(self. tokenizer, predictions)
# add predictions to a wandb.Table
predictions_df = pd. DataFrame(predictions)
predictions_df["epoch" ] = state. epoch
records_table = self. _wandb. Table(dataframe= predictions_df)
# log the table to wandb
self. _wandb. log({"sample_predictions" : records_table})
# まず、Trainer をインスタンス化する
trainer = Trainer(
model= model,
args= training_args,
train_dataset= lm_datasets["train" ],
eval_dataset= lm_datasets["validation" ],
)
# WandbPredictionProgressCallback をインスタンス化する
progress_callback = WandbPredictionProgressCallback(
trainer= trainer,
tokenizer= tokenizer,
val_dataset= lm_dataset["validation" ],
num_samples= 10 ,
freq= 2 ,
)
# コールバックをトレーナーに追加する
trainer. add_callback(progress_callback)
詳細な例については、こちらの colab を参照してください。
その他の W&B 設定はありますか?
環境変数を設定することで、Trainer でログに記録される内容をさらに構成できます。W&B 環境変数の完全なリストは、こちら にあります。
環境変数
使用法
WANDB_PROJECTプロジェクトに名前を付けます (デフォルトでは huggingface)
WANDB_LOG_MODELモデルチェックポイントを W&B Artifact として記録します (デフォルトでは false)
false (デフォルト): モデルチェックポイントなしcheckpoint: チェックポイントは args.save_steps ごとにアップロードされます (Trainer の TrainingArguments で設定)。end: 最終的なモデルチェックポイントはトレーニングの最後にアップロードされます。
WANDB_WATCHモデルの勾配、パラメーター、またはそのどちらもログに記録するかどうかを設定します
false (デフォルト): 勾配またはパラメーターのロギングなしgradients: 勾配のヒストグラムをログに記録しますall: 勾配とパラメーターのヒストグラムをログに記録します
WANDB_DISABLEDロギングを完全にオフにするには true に設定します (デフォルトでは false)
WANDB_SILENTwandb によって出力される出力を抑制するには true に設定します (デフォルトでは false)
WANDB_WATCH= all
WANDB_SILENT= true
%env WANDB_WATCH=all
%env WANDB_SILENT=true
wandb.init をカスタマイズするにはどうすればよいですか?Trainer が使用する WandbCallback は、Trainer が初期化されるときに内部で wandb.init を呼び出します。Trainer が初期化される前に wandb.init を呼び出すことで、run を手動で設定することもできます。これにより、W&B run の構成を完全に制御できます。
init に渡したい可能性のあるものの例を以下に示します。wandb.init の使用方法の詳細については、リファレンスドキュメントをご確認ください 。
wandb. init(
project= "amazon_sentiment_analysis" ,
name= "bert-base-high-lr" ,
tags= ["baseline" , "high-lr" ],
group= "bert" ,
)
その他のリソース
以下は、Transformer と W&B に関連する 6 つの記事です。
Hugging Face Transformers のハイパーパラメーター最適化
Hugging Face Transformers のハイパーパラメーター最適化のための 3 つの戦略 (グリッド検索、ベイズ最適化、Population Based Training) が比較されます。
Hugging Face transformers から標準的な uncased BERT モデルを使用し、SuperGLUE ベンチマークから RTE データセットでファインチューニングしたいと考えています。
結果は、Population Based Training が Hugging Face transformer モデルのハイパーパラメーター最適化に最も効果的なアプローチであることを示しています。
完全なレポートは こちら をお読みください。
Hugging Tweets: ツイートを生成するモデルをトレーニングする
この記事では、著者は、誰かのツイートで学習済みの GPT2 HuggingFace Transformer モデルを 5 分でファインチューニングする方法を示しています。
このモデルは、ツイートのダウンロード、データセットの最適化、初期実験、ユーザー間の損失の比較、モデルのファインチューニングというパイプラインを使用しています。
完全なレポートは こちら をお読みください。
Hugging Face BERT および WB を使用した文分類
この記事では、自然言語処理における最近の画期的な進歩の力を活用して、文分類子を作成します。ここでは、NLP への転移学習の応用例に焦点を当てます。
単一文分類には、言語的許容度 (CoLA) データセットを使用します。これは、2018 年 5 月に初めて公開された、文法的に正しいか正しくないかというラベルが付けられた文のセットです。
Google の BERT を使用して、さまざまな NLP タスクで最小限の労力で高性能モデルを作成します。
完全なレポートは こちら をお読みください。
Hugging Face モデルのパフォーマンスを追跡するためのステップバイステップガイド
W&B と Hugging Face transformers を使用して、GLUE ベンチマークで DistilBERT (BERT より 40% 小さいが、BERT の精度の 97% を保持する Transformer) をトレーニングします。
GLUE ベンチマークは、NLP モデルをトレーニングするための 9 つのデータセットとタスクのコレクションです。
完全なレポートは こちら をお読みください。
HuggingFace での早期停止の例
早期停止の正規化を使用して Hugging Face Transformer をファインチューニングは、PyTorch または TensorFlow でネイティブに行うことができます。
TensorFlow での EarlyStopping コールバックの使用は、tf.keras.callbacks.EarlyStopping コールバックを使用すると簡単です。
PyTorch では、既製の早期停止メソッドはありませんが、GitHub Gist で利用できる作業中の早期停止フックがあります。
完全なレポートは こちら をお読みください。
カスタムデータセットで Hugging Face Transformers をファインチューンする方法
カスタム IMDB データセットでセンチメント分析 (バイナリ分類) 用に DistilBERT transformer をファインチューンします。
完全なレポートは こちら をお読みください。
ヘルプの入手または機能のリクエスト
Hugging Face W&B integration に関する問題、質問、または機能のリクエストについては、Hugging Face フォーラムのこのスレッド に投稿するか、Hugging Face Transformers GitHub repo で issue をオープンしてください。
6.12 - Hugging Face Diffusers
Hugging Face Diffusers は、画像、音声、さらには分子の3D構造を生成するための、最先端の学習済み拡散モデルのための頼りになるライブラリです。Weights & Biases のインテグレーションは、その使いやすさを損なうことなく、インタラクティブな集中 ダッシュボードに、豊富で柔軟な 実験管理、メディアの 可視化、パイプライン アーキテクチャ、および 設定管理を追加します。
たった2行で次世代のログ記録
わずか2行のコードを含めるだけで、プロンプト、ネガティブプロンプト、生成されたメディア、および 実験 に関連付けられた config をすべて記録します。以下は、ログ記録を開始するための2行のコードです。
# import the autolog function
from wandb.integration.diffusers import autolog
# call the autolog before calling the pipeline
autolog(init= dict(project= "diffusers_logging" ))
実験 の 結果 がどのように記録されるかの例。
はじめに
diffusers、transformers、accelerate、および wandb をインストールします。
コマンドライン:
pip install --upgrade diffusers transformers accelerate wandb
ノートブック:
!pip install --upgrade diffusers transformers accelerate wandb
autolog を使用して Weights & Biases の run を初期化し、サポートされているすべての パイプライン 呼び出し からの入力と出力を自動的に追跡します。
wandb.init()init パラメータ を使用して、autolog() 関数を呼び出すことができます。
autolog() を呼び出すと、Weights & Biases の run が初期化され、サポートされているすべての パイプライン 呼び出し からの入力と出力が自動的に追跡されます。
各 パイプライン 呼び出しは、ワークスペース 内の独自の テーブル に追跡され、パイプライン 呼び出しに関連付けられた config は、その run の config 内の ワークフロー のリストに追加されます。
プロンプト、ネガティブプロンプト、および生成されたメディアは、wandb.Table
シードや パイプライン アーキテクチャ を含む、実験 に関連付けられたその他すべての config は、run の config セクションに保存されます。
各 パイプライン 呼び出しで生成されたメディアは、run の メディア パネル にも記録されます。
サポートされている パイプライン 呼び出しのリストは、[こちら](https://github.com/wandb/wandb/blob/main/wandb/integration/diffusers/autologger.py#L12-L72)にあります。このインテグレーションの新しい機能をリクエストしたり、それに関連するバグを報告したりする場合は、[https://github.com/wandb/wandb/issues](https://github.com/wandb/wandb/issues) で issue をオープンしてください。
例
Autologging
以下は、動作中の autolog の簡単な エンドツーエンド の例です。
import torch
from diffusers import DiffusionPipeline
# import the autolog function
from wandb.integration.diffusers import autolog
# call the autolog before calling the pipeline
autolog(init= dict(project= "diffusers_logging" ))
# Initialize the diffusion pipeline
pipeline = DiffusionPipeline. from_pretrained(
"stabilityai/stable-diffusion-2-1" , torch_dtype= torch. float16
). to("cuda" )
# Define the prompts, negative prompts, and seed.
prompt = ["a photograph of an astronaut riding a horse" , "a photograph of a dragon" ]
negative_prompt = ["ugly, deformed" , "ugly, deformed" ]
generator = torch. Generator(device= "cpu" ). manual_seed(10 )
# call the pipeline to generate the images
images = pipeline(
prompt,
negative_prompt= negative_prompt,
num_images_per_prompt= 2 ,
generator= generator,
)
import torch
from diffusers import DiffusionPipeline
import wandb
# import the autolog function
from wandb.integration.diffusers import autolog
# call the autolog before calling the pipeline
autolog(init= dict(project= "diffusers_logging" ))
# Initialize the diffusion pipeline
pipeline = DiffusionPipeline. from_pretrained(
"stabilityai/stable-diffusion-2-1" , torch_dtype= torch. float16
). to("cuda" )
# Define the prompts, negative prompts, and seed.
prompt = ["a photograph of an astronaut riding a horse" , "a photograph of a dragon" ]
negative_prompt = ["ugly, deformed" , "ugly, deformed" ]
generator = torch. Generator(device= "cpu" ). manual_seed(10 )
# call the pipeline to generate the images
images = pipeline(
prompt,
negative_prompt= negative_prompt,
num_images_per_prompt= 2 ,
generator= generator,
)
# Finish the experiment
wandb. finish()
単一の 実験 の結果:
複数の 実験 の結果:
実験 の config:
パイプライン を呼び出した後、IPython ノートブック 環境でコードを実行する場合は、
wandb.finish()を明示的に呼び出す必要があります。これは、Python スクリプトを実行する場合は必要ありません。
複数 パイプライン ワークフロー の追跡
このセクションでは、StableDiffusionXLPipelineStable Diffusion XL + Refiner ワークフロー での autolog を示します。
import torch
from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline
from wandb.integration.diffusers import autolog
# initialize the SDXL base pipeline
base_pipeline = StableDiffusionXLPipeline. from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0" ,
torch_dtype= torch. float16,
variant= "fp16" ,
use_safetensors= True ,
)
base_pipeline. enable_model_cpu_offload()
# initialize the SDXL refiner pipeline
refiner_pipeline = StableDiffusionXLImg2ImgPipeline. from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0" ,
text_encoder_2= base_pipeline. text_encoder_2,
vae= base_pipeline. vae,
torch_dtype= torch. float16,
use_safetensors= True ,
variant= "fp16" ,
)
refiner_pipeline. enable_model_cpu_offload()
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing"
# Make the experiment reproducible by controlling randomness.
# The seed would be automatically logged to WandB.
seed = 42
generator_base = torch. Generator(device= "cuda" ). manual_seed(seed)
generator_refiner = torch. Generator(device= "cuda" ). manual_seed(seed)
# Call WandB Autolog for Diffusers. This would automatically log
# the prompts, generated images, pipeline architecture and all
# associated experiment configs to Weights & Biases, thus making your
# image generation experiments easy to reproduce, share and analyze.
autolog(init= dict(project= "sdxl" ))
# Call the base pipeline to generate the latents
image = base_pipeline(
prompt= prompt,
negative_prompt= negative_prompt,
output_type= "latent" ,
generator= generator_base,
). images[0 ]
# Call the refiner pipeline to generate the refined image
image = refiner_pipeline(
prompt= prompt,
negative_prompt= negative_prompt,
image= image[None , :],
generator= generator_refiner,
). images[0 ]
import torch
from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline
import wandb
from wandb.integration.diffusers import autolog
# initialize the SDXL base pipeline
base_pipeline = StableDiffusionXLPipeline. from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0" ,
torch_dtype= torch. float16,
variant= "fp16" ,
use_safetensors= True ,
)
base_pipeline. enable_model_cpu_offload()
# initialize the SDXL refiner pipeline
refiner_pipeline = StableDiffusionXLImg2ImgPipeline. from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0" ,
text_encoder_2= base_pipeline. text_encoder_2,
vae= base_pipeline. vae,
torch_dtype= torch. float16,
use_safetensors= True ,
variant= "fp16" ,
)
refiner_pipeline. enable_model_cpu_offload()
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing"
# Make the experiment reproducible by controlling randomness.
# The seed would be automatically logged to WandB.
seed = 42
generator_base = torch. Generator(device= "cuda" ). manual_seed(seed)
generator_refiner = torch. Generator(device= "cuda" ). manual_seed(seed)
# Call WandB Autolog for Diffusers. This would automatically log
# the prompts, generated images, pipeline architecture and all
# associated experiment configs to Weights & Biases, thus making your
# image generation experiments easy to reproduce, share and analyze.
autolog(init= dict(project= "sdxl" ))
# Call the base pipeline to generate the latents
image = base_pipeline(
prompt= prompt,
negative_prompt= negative_prompt,
output_type= "latent" ,
generator= generator_base,
). images[0 ]
# Call the refiner pipeline to generate the refined image
image = refiner_pipeline(
prompt= prompt,
negative_prompt= negative_prompt,
image= image[None , :],
generator= generator_refiner,
). images[0 ]
# Finish the experiment
wandb. finish()
Stable Diffisuion XL + Refiner の 実験 の例:
その他のリソース
6.13 - Hugging Face AutoTrain
Hugging Face AutoTrain は、自然言語処理(NLP)タスク、コンピュータビジョン(CV)タスク、音声タスク、さらには表形式タスクのために、最先端のモデルをトレーニングするためのノーコード ツールです。
Weights & Biases は Hugging Face AutoTrain に直接統合されており、実験管理と構成管理を提供します。これは、実験の CLI コマンドで単一の パラメータ を使用するのと同じくらい簡単です。
前提条件のインストール
autotrain-advanced と wandb をインストールします。
pip install --upgrade autotrain-advanced wandb
!pip install --upgrade autotrain-advanced wandb
これらの変更を示すために、このページでは、GSM8k Benchmarks で pass@1 の SoTA 結果を達成するために、数学 データセット で LLM を微調整します。
データセット を準備する
Hugging Face AutoTrain は、適切に機能するために、CSV カスタム データセット が特定の形式になっていることを想定しています。
トレーニング ファイルには、トレーニングで使用する text 列が含まれている必要があります。最良の結果を得るには、text 列のデータが ### Human: Question?### Assistant: Answer. 形式に準拠している必要があります。timdettmers/openassistant-guanaco
ただし、MetaMathQA dataset には、query、response、および type 列が含まれています。最初に、この データセット を前処理します。type 列を削除し、query 列と response 列の内容を ### Human: Query?### Assistant: Response. 形式の新しい text 列に結合します。トレーニングでは、結果の データセット rishiraj/guanaco-style-metamath
autotrain を使用してトレーニングするコマンドラインまたは ノートブック から autotrain advanced を使用してトレーニングを開始できます。--log 引数を使用するか、--log wandb を使用して、W&B run に 結果 を ログ します。
autotrain llm \
\
\
\
\
\
\
\
4 \
3 \
1024 \
\
16 \
32 \
\
\
4 \
10 \
\
\
\
\
\
\
# ハイパーパラメータ を設定する
learning_rate = 2e-5
num_epochs = 3
batch_size = 4
block_size = 1024
trainer = "sft"
warmup_ratio = 0.03
weight_decay = 0.
gradient_accumulation = 4
lora_r = 16
lora_alpha = 32
lora_dropout = 0.05
logging_steps = 10
# トレーニングを実行する
!autotrain llm \
--train \
--model "HuggingFaceH4/zephyr-7b-alpha" \
--project-name "zephyr-math" \
--log "wandb" \
--data-path data/ \
--text-column text \
--lr str(learning_rate) \
--batch-size str(batch_size) \
--epochs str(num_epochs) \
--block-size str(block_size) \
--warmup-ratio str(warmup_ratio) \
--lora-r str(lora_r) \
--lora-alpha str(lora_alpha) \
--lora-dropout str(lora_dropout) \
--weight-decay str(weight_decay) \
--gradient-accumulation str(gradient_accumulation) \
--logging-steps str(logging_steps) \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token str(hf_token) \
--repo-id "rishiraj/zephyr-math"
その他のリソース
6.14 - Hugging Face Accelerate
大規模なトレーニングと推論を、シンプル、効率的、かつ適応的に
Hugging Face Accelerate は、あらゆる分散設定で同じ PyTorch コードを実行できるようにし、大規模なモデルトレーニングと推論を簡素化するライブラリです。
Accelerate には、以下に示す Weights & Biases Tracker が含まれています。Accelerate Trackers の詳細については、[こちら (https://huggingface.co/docs/accelerate/main/en/usage_guides/tracking) のドキュメント] を参照してください。
Accelerate でログ記録を開始する
Accelerate と Weights & Biases を使い始めるには、以下の疑似コードに従ってください。
from accelerate import Accelerator
# Tell the Accelerator object to log with wandb
accelerator = Accelerator(log_with= "wandb" )
# Initialise your wandb run, passing wandb parameters and any config information
accelerator. init_trackers(
project_name= "my_project" ,
config= {"dropout" : 0.1 , "learning_rate" : 1e-2 }
init_kwargs= {"wandb" : {"entity" : "my-wandb-team" }}
)
...
# Log to wandb by calling `accelerator.log`, `step` is optional
accelerator. log({"train_loss" : 1.12 , "valid_loss" : 0.8 }, step= global_step)
# Make sure that the wandb tracker finishes correctly
accelerator. end_training()
さらに詳しく説明すると、次のことが必要です。
Accelerator クラスを初期化するときに log_with="wandb" を渡します。
init_trackers
project_name を介したプロジェクト名ネストされた dict を介して wandb.initinit_kwargs
config を介して、wandb の run に記録するその他の実験設定情報
.log メソッドを使用して Weigths & Biases にログを記録します。step 引数はオプションです。トレーニングが終了したら、.end_training を呼び出します。
W&B tracker へのアクセス
W&B tracker にアクセスするには、Accelerator.get_tracker() メソッドを使用します。tracker の .name 属性に対応する文字列を渡すと、main プロセスの tracker が返されます。
wandb_tracker = accelerator. get_tracker("wandb" )
そこから、通常どおり wandb の run オブジェクトを操作できます。
wandb_tracker. log_artifact(some_artifact_to_log)
Accelerate に組み込まれた Trackers は、正しいプロセスで自動的に実行されるため、Tracker がメインプロセスでのみ実行されるように設計されている場合、自動的に実行されます。
Accelerate のラッピングを完全に削除したい場合は、次の方法で同じ結果を得ることができます。
wandb_tracker = accelerator. get_tracker("wandb" , unwrap= True )
with accelerator. on_main_process:
wandb_tracker. log_artifact(some_artifact_to_log)
Accelerate の記事
以下は、楽しめるかもしれない Accelerate の記事です。
Weights & Biases でスーパーチャージされた HuggingFace Accelerate
この記事では、HuggingFace Accelerate が提供するものと、結果を Weights & Biases に記録しながら、分散トレーニングと評価をどれだけ簡単に行えるかを見ていきます。
完全なレポートは こちら をお読みください。
6.15 - Hydra
W&B と Hydra を統合する方法。
Hydra は、 研究 および他の複雑な アプリケーション の開発を簡素化するオープンソースの Python フレームワーク です。主な機能は、構成ファイルと コマンドライン を介して、構成を構成してオーバーライドすることにより、階層的な構成を動的に作成できることです。
W&B のパワーを利用しながら、構成管理に Hydra を引き続き使用できます。
メトリクス の 追跡
wandb.init と wandb.log を使用して、通常どおりに メトリクス を 追跡 します。ここでは、 wandb.entity と wandb.project は hydra 構成ファイル内で定義されています。
import wandb
@hydra.main (config_path= "configs/" , config_name= "defaults" )
def run_experiment (cfg):
run = wandb. init(entity= cfg. wandb. entity, project= cfg. wandb. project)
wandb. log({"loss" : loss})
ハイパーパラメーター の 追跡
Hydra は、構成 辞書 とのインターフェースをとるためのデフォルトの方法として omegaconf を使用します。 OmegaConf の 辞書 は、プリミティブ 辞書 のサブクラスではないため、Hydra の Config を wandb.config に直接渡すと、 ダッシュボード で予期しない結果が生じます。 omegaconf.DictConfig をプリミティブな dict 型に変換してから wandb.config に渡す必要があります。
@hydra.main (config_path= "configs/" , config_name= "defaults" )
def run_experiment (cfg):
wandb. config = omegaconf. OmegaConf. to_container(
cfg, resolve= True , throw_on_missing= True
)
wandb. init(entity= cfg. wandb. entity, project= cfg. wandb. project)
wandb. log({"loss" : loss})
model = Model(** wandb. config. model. configs)
マルチプロセッシング の トラブルシューティング
開始時に プロセス がハングする場合は、この既知の問題 が原因である可能性があります。これを解決するには、次のいずれかとして、wandb.init に追加の settings パラメータ を追加して、wandb の マルチプロセッシング プロトコル を変更してみてください。
wandb. init(settings= wandb. Settings(start_method= "thread" ))
または、シェルから グローバル 環境変数 を設定します。
$ export WANDB_START_METHOD= thread
ハイパーパラメーター の 最適化
W&B Sweeps は、高度にスケーラブルな ハイパーパラメーター 検索 プラットフォーム であり、最小限の要件コードで W&B の 実験 に関する興味深い洞察と 可視化 を提供します。 Sweeps は、コーディング要件なしで Hydra プロジェクト とシームレスに統合されます。必要なのは、通常どおりにスイープするさまざまな パラメータ を記述した構成ファイルだけです。
簡単な sweep.yaml ファイルの例を次に示します。
program : main.py
method : bayes
metric :
goal : maximize
name : test/accuracy
parameters :
dataset :
values : [mnist, cifar10]
command :
- ${env}
- python
- ${program}
- ${args_no_hyphens}
sweep を呼び出します。
wandb sweep sweep.yaml` \
W&B は プロジェクト 内に sweep を自動的に作成し、sweep を実行する各マシンで実行する wandb agent コマンド を返します。
Hydra の デフォルト に存在しない パラメータ を渡す
Hydra は、 コマンド の前に + を使用して、デフォルト の構成ファイルに存在しない追加の パラメータ を コマンドライン から渡すことをサポートしています。たとえば、次のように呼び出すだけで、いくつかの 値 を持つ追加の パラメータ を渡すことができます。
$ python program.py +experiment= some_experiment
Hydra Experiments を構成するときと同様に、このような + 構成を スイープ することはできません。これを回避するには、デフォルト の空のファイルで experiment パラメータ を初期化し、W&B Sweep を使用して、呼び出しごとにこれらの空の構成をオーバーライドします。詳細については、この W&B Report
6.16 - Keras
Keras コールバック
W&B には Keras 用の 3 つのコールバックがあり、wandb v0.13.4 から利用できます。従来の WandbCallback については、下にスクロールしてください。
WandbMetricsLogger実験管理 には、このコールバックを使用します。トレーニングと検証のメトリクスをシステムメトリクスとともに Weights & Biases に記録します。
WandbModelCheckpointArtifacts に記録するには、このコールバックを使用します。
WandbEvalCallbackTables に記録して、インタラクティブな可視化を実現します。
これらの新しいコールバック:
Keras の設計理念に準拠しています。
すべてに単一のコールバック(WandbCallback)を使用することによる認知負荷を軽減します。
Keras ユーザーがコールバックをサブクラス化してニッチなユースケースをサポートすることで、コールバックを簡単に変更できるようにします。
WandbMetricsLogger で実験を追跡するWandbMetricsLogger は、on_epoch_end、on_batch_end などのコールバックメソッドが引数として受け取る Keras の logs 辞書を自動的に記録します。
これにより、以下が追跡されます。
model.compile で定義されたトレーニングおよび検証のメトリクス。システム (CPU/GPU/TPU) メトリクス。
学習率 (固定値と学習率スケジューラの両方)。
import wandb
from wandb.integration.keras import WandbMetricsLogger
# 新しい W&B の run を初期化します。
wandb. init(config= {"bs" : 12 })
# WandbMetricsLogger を model.fit に渡します。
model. fit(
X_train, y_train, validation_data= (X_test, y_test), callbacks= [WandbMetricsLogger()]
)
WandbMetricsLogger リファレンス
パラメータ
説明
log_freq(epoch、batch、または int): epoch の場合、各エポックの最後にメトリクスを記録します。batch の場合、各バッチの最後にメトリクスを記録します。int の場合、その数のバッチの最後にメトリクスを記録します。デフォルトは epoch です。
initial_global_step(int): 学習率スケジューラを使用している場合に、いくつかの initial_epoch からトレーニングを再開するときに学習率を正しく記録するには、この引数を使用します。これは step_size * initial_step として計算できます。デフォルトは 0 です。
WandbModelCheckpoint を使用してモデルをチェックポイントするWandbModelCheckpoint コールバックを使用して、Keras モデル (SavedModel 形式) またはモデルの重みを定期的に保存し、モデルの バージョン管理 用の wandb.Artifact として W&B にアップロードします。
このコールバックは tf.keras.callbacks.ModelCheckpoint
このコールバックは以下を保存します。
モニターに基づいて最高のパフォーマンスを達成したモデル。
パフォーマンスに関係なく、すべてのエポックの終わりにモデル。
エポックの終わり、または固定数のトレーニングバッチの後。
モデルの重みのみ、またはモデル全体。
SavedModel 形式または .h5 形式のいずれかでモデル。
このコールバックを WandbMetricsLogger と組み合わせて使用します。
import wandb
from wandb.integration.keras import WandbMetricsLogger, WandbModelCheckpoint
# 新しい W&B の run を初期化します。
wandb. init(config= {"bs" : 12 })
# WandbModelCheckpoint を model.fit に渡します。
model. fit(
X_train,
y_train,
validation_data= (X_test, y_test),
callbacks= [
WandbMetricsLogger(),
WandbModelCheckpoint("models" ),
],
)
WandbModelCheckpoint リファレンス
パラメータ
説明
filepath(str): モードファイルを保存するパス。
monitor(str): 監視するメトリック名。
verbose(int): 詳細モード、0 または 1。モード 0 はサイレントで、モード 1 はコールバックがアクションを実行するときにメッセージを表示します。
save_best_only(Boolean): save_best_only=True の場合、最新のモデル、または monitor および mode 属性で定義されている、最良と見なされるモデルのみを保存します。
save_weights_only(Boolean): True の場合、モデルの重みのみを保存します。
mode(auto、min、または max): val_acc の場合は max に、val_loss の場合は min に設定します。
save_freq(“epoch” または int): 「epoch」を使用する場合、コールバックは各エポックの後にモデルを保存します。整数を使用する場合、コールバックはこの数のバッチの終わりにモデルを保存します。val_acc や val_loss などの検証メトリクスを監視する場合、これらのメトリクスはエポックの最後にのみ使用できるため、save_freq を “epoch” に設定する必要があることに注意してください。
options(str): save_weights_only が true の場合はオプションの tf.train.CheckpointOptions オブジェクト、save_weights_only が false の場合はオプションの tf.saved_model.SaveOptions オブジェクト。
initial_value_threshold(float): 監視するメトリックの浮動小数点初期「最良」値。
N エポック後にチェックポイントを記録する
デフォルト (save_freq="epoch") では、コールバックは各エポックの後にチェックポイントを作成し、アーティファクトとしてアップロードします。特定の数のバッチの後にチェックポイントを作成するには、save_freq を整数に設定します。N エポック後にチェックポイントを作成するには、train データローダーのカーディナリティを計算し、それを save_freq に渡します。
WandbModelCheckpoint(
filepath= "models/" ,
save_freq= int((trainloader. cardinality()* N). numpy())
)
TPU アーキテクチャでチェックポイントを効率的に記録する
TPU でチェックポイントを作成しているときに、UnimplementedError: File system scheme '[local]' not implemented エラーメッセージが表示される場合があります。これは、モデルディレクトリー (filepath) がクラウドストレージバケットパス (gs://bucket-name/...) を使用する必要があり、このバケットが TPU サーバーからアクセスできる必要があるために発生します。ただし、チェックポイント作成にはローカルパスを使用できます。これは Artifacts としてアップロードされます。
checkpoint_options = tf. saved_model. SaveOptions(experimental_io_device= "/job:localhost" )
WandbModelCheckpoint(
filepath= "models/,
options= checkpoint_options,
)
WandbEvalCallback を使用してモデルの予測を可視化するWandbEvalCallback は、主にモデルの予測、次にデータセットの可視化のための Keras コールバックを構築するための抽象ベースクラスです。
この抽象コールバックは、データセットとタスクに関して不可知論的です。これを使用するには、このベースの WandbEvalCallback コールバッククラスから継承し、add_ground_truth メソッドと add_model_prediction メソッドを実装します。
WandbEvalCallback は、次のメソッドを提供するユーティリティクラスです。
データと予測の wandb.Table インスタンスを作成します。
データと予測の Tables を wandb.Artifact として記録します。
データテーブル on_train_begin を記録します。
予測テーブル on_epoch_end を記録します。
次の例では、画像分類タスクに WandbClfEvalCallback を使用しています。この例のコールバックは、検証データ (data_table) を W&B に記録し、推論を実行し、すべてのエポックの終わりに予測 (pred_table) を W&B に記録します。
import wandb
from wandb.integration.keras import WandbMetricsLogger, WandbEvalCallback
# モデル予測の可視化コールバックを実装します。
class WandbClfEvalCallback (WandbEvalCallback):
def __init__(
self, validation_data, data_table_columns, pred_table_columns, num_samples= 100
):
super(). __init__(data_table_columns, pred_table_columns)
self. x = validation_data[0 ]
self. y = validation_data[1 ]
def add_ground_truth (self, logs= None ):
for idx, (image, label) in enumerate(zip(self. x, self. y)):
self. data_table. add_data(idx, wandb. Image(image), label)
def add_model_predictions (self, epoch, logs= None ):
preds = self. model. predict(self. x, verbose= 0 )
preds = tf. argmax(preds, axis=- 1 )
table_idxs = self. data_table_ref. get_index()
for idx in table_idxs:
pred = preds[idx]
self. pred_table. add_data(
epoch,
self. data_table_ref. data[idx][0 ],
self. data_table_ref. data[idx][1 ],
self. data_table_ref. data[idx][2 ],
pred,
)
# ...
# 新しい W&B の run を初期化します。
wandb. init(config= {"hyper" : "parameter" })
# コールバックを Model.fit に追加します。
model. fit(
X_train,
y_train,
validation_data= (X_test, y_test),
callbacks= [
WandbMetricsLogger(),
WandbClfEvalCallback(
validation_data= (X_test, y_test),
data_table_columns= ["idx" , "image" , "label" ],
pred_table_columns= ["epoch" , "idx" , "image" , "label" , "pred" ],
),
],
)
WandbEvalCallback リファレンス
パラメータ
説明
data_table_columns(list) data_table の列名のリスト
pred_table_columns(list) pred_table の列名のリスト
メモリフットプリントの詳細
on_train_begin メソッドが呼び出されると、data_table を W&B に記録します。W&B Artifact としてアップロードされると、data_table_ref クラス変数を使用してアクセスできるこのテーブルへの参照を取得します。data_table_ref は、self.data_table_ref[idx][n] のようにインデックスを付けることができる 2D リストです。ここで、idx は行番号で、n は列番号です。以下の例で使用法を見てみましょう。
コールバックをカスタマイズする
on_train_begin メソッドまたは on_epoch_end メソッドをオーバーライドして、よりきめ細かい制御を行うことができます。N バッチ後にサンプルを記録する場合は、on_train_batch_end メソッドを実装できます。
💡
WandbEvalCallback を継承してモデル予測の可視化のためのコールバックを実装していて、明確にする必要がある場合や修正する必要がある場合は、
issue を開いてお知らせください。
WandbCallback [レガシー]W&B ライブラリの WandbCallbackmodel.fit で追跡されるすべてのメトリクスと損失値を自動的に保存します。
import wandb
from wandb.integration.keras import WandbCallback
wandb. init(config= {"hyper" : "parameter" })
... # Keras でモデルをセットアップするコード
# コールバックを model.fit に渡します。
model. fit(
X_train, y_train, validation_data= (X_test, y_test), callbacks= [WandbCallback()]
)
短いビデオ 1 分以内に Keras と Weights & Biases を使い始める をご覧ください。
より詳細なビデオについては、Weights & Biases と Keras を統合する をご覧ください。Colab Jupyter Notebook を確認できます。
WandbCallback クラスは、監視するメトリックの指定、重みと勾配の追跡、training_data と validation_data での予測の記録など、さまざまなログ構成オプションをサポートしています。
詳細については、keras.WandbCallback のリファレンスドキュメント
WandbCallback
Keras によって収集されたメトリクスから履歴データを自動的に記録します: 損失と keras_model.compile() に渡されたもの。
monitor および mode 属性で定義されているように、「最良」のトレーニングステップに関連付けられた run の概要メトリクスを設定します。これはデフォルトで、最小の val_loss を持つエポックになります。WandbCallback はデフォルトで、最良の epoch に関連付けられたモデルを保存します。オプションで勾配とパラメーターのヒストグラムを記録します。
オプションで、wandb が可視化するためにトレーニングデータと検証データを保存します。
WandbCallback リファレンス
引数
monitor(str) 監視するメトリックの名前。デフォルトは val_loss。
mode(str) {auto、min、max} のいずれか。min - モニターが最小化されたときにモデルを保存します max - モニターが最大化されたときにモデルを保存します auto - モデルを保存するタイミングを推測しようとします (デフォルト)。
save_modelTrue - モニターが以前のエポックをすべて上回ったときにモデルを保存します False - モデルを保存しません
save_graph(boolean) True の場合、モデルグラフを wandb に保存します (デフォルトは True)。
save_weights_only(boolean) True の場合、モデルの重みのみを保存します (model.save_weights(filepath))。それ以外の場合は、完全なモデルを保存します)。
log_weights(boolean) True の場合、モデルのレイヤーの重みのヒストグラムを保存します。
log_gradients(boolean) True の場合、トレーニング勾配のヒストグラムを記録します
training_data(tuple) model.fit に渡されるのと同じ形式 (X,y)。これは勾配を計算するために必要です。log_gradients が True の場合は必須です。
validation_data(tuple) model.fit に渡されるのと同じ形式 (X,y)。wandb が可視化するためのデータのセット。このフィールドを設定すると、すべてのエポックで、wandb は少数の予測を行い、後で可視化するために結果を保存します。
generator(generator) wandb が可視化するための検証データを返すジェネレーター。このジェネレーターはタプル (X,y) を返す必要があります。wandb が特定のデータ例を可視化するには、validate_data またはジェネレーターのいずれかを設定する必要があります。
validation_steps(validation_data がジェネレーターの場合、完全な検証セットに対してジェネレーターを実行するステップ数 (int)。
labels(list) wandb でデータを可視化している場合、このラベルのリストは、複数のクラスを持つ分類子を構築している場合に、数値出力を理解可能な文字列に変換します。バイナリ分類子の場合、2 つのラベルのリスト [false のラベル、true のラベル] を渡すことができます。validate_data と generator の両方が false の場合、これは何も行いません。
predictions(int) 可視化のために各エポックで行う予測の数。最大は 100 です。
input_type(string) 可視化を支援するモデル入力のタイプ。(image、images、segmentation_mask) のいずれかになります。
output_type(string) モデル出力のタイプを可視化するのに役立ちます。(image、images、segmentation_mask) のいずれかになります。
log_evaluation(boolean) True の場合、各エポックで検証データとモデルの予測を含む Table を保存します。詳細については、validation_indexes、validation_row_processor、および output_row_processor を参照してください。
class_colors([float, float, float]) 入力または出力がセグメンテーションマスクの場合、各クラスの rgb タプル (範囲 0 ~ 1) を含む配列。
log_batch_frequency(integer) None の場合、コールバックはすべてのエポックを記録します。整数に設定すると、コールバックは log_batch_frequency バッチごとにトレーニングメトリクスを記録します。
log_best_prefix(string) None の場合、追加の概要メトリクスは保存されません。文字列に設定すると、監視対象のメトリックとエポックにプレフィックスを付加し、結果を概要メトリクスとして保存します。
validation_indexes([wandb.data_types._TableLinkMixin]) 各検証例に関連付けるインデックスキーの順序付きリスト。log_evaluation が True で、validation_indexes を提供する場合、検証データの Table は作成されません。代わりに、各予測を TableLinkMixin で表される行に関連付けます。行キーのリストを取得するには、Table.get_index() を使用します。
validation_row_processor(Callable) 検証データに適用する関数。通常はデータを可視化するために使用されます。この関数は、ndx (int) と row (dict) を受け取ります。モデルに単一の入力がある場合、row["input"] には行の入力データが含まれます。それ以外の場合は、入力スロットの名前が含まれます。適合関数が単一のターゲットを受け取る場合、row["target"] には行のターゲットデータが含まれます。それ以外の場合は、出力スロットの名前が含まれます。たとえば、入力データが単一の配列である場合、データを画像として可視化するには、プロセッサとして lambda ndx, row: {"img": wandb.Image(row["input"])} を指定します。log_evaluation が False であるか、validation_indexes が存在する場合は無視されます。
output_row_processor(Callable) validation_row_processor と同じですが、モデルの出力に適用されます。row["output"] には、モデル出力の結果が含まれます。
infer_missing_processors(Boolean) validation_row_processor と output_row_processor が欠落している場合に、推論するかどうかを決定します。デフォルトは True です。labels を指定すると、W&B は必要に応じて分類タイプのプロセッサを推論しようとします。
log_evaluation_frequency(int) 評価結果を記録する頻度を決定します。デフォルトは 0 で、トレーニングの最後にのみ記録します。すべてのエポックで記録するには 1 に、他のすべてのエポックで記録するには 2 に設定します。log_evaluation が False の場合は効果がありません。
よくある質問
Keras マルチプロセッシングを wandb で使用するにはどうすればよいですか?use_multiprocessing=True を設定すると、次のエラーが発生する可能性があります。
Error("You must call wandb.init() before wandb.config.batch_size" )
これを回避するには:
Sequence クラスの構築で、wandb.init(group='...') を追加します。main で、if __name__ == "__main__": を使用していることを確認し、残りのスクリプト ロジックをその中に入れます。
6.17 - Kubeflow Pipelines (kfp)
W&B と Kubeflow Pipelines を統合する方法。
Kubeflow Pipelines (kfp) は、Docker コンテナに基づいて、移植可能でスケーラブルな 機械学習 (ML) ワークフローを構築およびデプロイするためのプラットフォームです。
このインテグレーションにより、ユーザーはデコレーターを kfp python 関数コンポーネントに適用して、 パラメータと Artifacts を W&B に自動的に記録できます。
この機能は wandb==0.12.11 で有効になり、kfp<2.0.0 が必要です。
サインアップして API キーを作成する
API キーは、お使いのマシンを W&B に対して認証します。API キーは、ユーザープロファイルから生成できます。
右上隅にあるユーザープロファイルアイコンをクリックします。
[User Settings ] を選択し、[API Keys ] セクションまでスクロールします。
[Reveal ] をクリックします。表示された API キーをコピーします。API キーを非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
コマンドライン
Python
Python notebook
API キーに WANDB_API_KEY 環境変数 を設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
コンポーネントをデコレートする
@wandb_log デコレーターを追加し、通常どおりにコンポーネントを作成します。これにより、パイプラインを実行するたびに、入力/出力 パラメータ と Artifacts が自動的に W&B に記録されます。
from kfp import components
from wandb.integration.kfp import wandb_log
@wandb_log
def add (a: float, b: float) -> float:
return a + b
add = components. create_component_from_func(add)
環境変数をコンテナに渡す
環境変数 をコンテナに明示的に渡す必要がある場合があります。双方向のリンクを行うには、環境変数 WANDB_KUBEFLOW_URL を Kubeflow Pipelines インスタンスのベース URL に設定する必要があります。たとえば、https://kubeflow.mysite.com です。
import os
from kubernetes.client.models import V1EnvVar
def add_wandb_env_variables (op):
env = {
"WANDB_API_KEY" : os. getenv("WANDB_API_KEY" ),
"WANDB_BASE_URL" : os. getenv("WANDB_BASE_URL" ),
}
for name, value in env. items():
op = op. add_env_variable(V1EnvVar(name, value))
return op
@dsl.pipeline (name= "example-pipeline" )
def example_pipeline (param1: str, param2: int):
conf = dsl. get_pipeline_conf()
conf. add_op_transformer(add_wandb_env_variables)
プログラムでデータにアクセスする
Kubeflow Pipelines UI 経由
W&B でログに記録された Kubeflow Pipelines UI の Run をクリックします。
[ Input/Output ] タブと [ ML Metadata ] タブで、入力と出力に関する詳細を確認します。
[ Visualizations ] タブから W&B Web アプリを表示します。
Web アプリ UI 経由
Web アプリ UI には、Kubeflow Pipelines の [ Visualizations ] タブと同じコンテンツがありますが、より広いスペースがあります。Web アプリ UI の詳細はこちら をご覧ください。
パブリック API 経由 (プログラムによるアクセス)
Kubeflow Pipelines から W&B へのコンセプトマッピング
Kubeflow Pipelines のコンセプトから W&B へのマッピングを次に示します。
きめ細かいロギング
ロギングをより細かく制御したい場合は、コンポーネントに wandb.log および wandb.log_artifact 呼び出しを追加できます。
明示的な wandb.log_artifacts 呼び出しを使用
以下の例では、モデルをトレーニングしています。@wandb_log デコレーターは、関連する入力と出力を自動的に追跡します。トレーニングプロセスをログに記録する場合は、次のように明示的にロギングを追加できます。
@wandb_log
def train_model (
train_dataloader_path: components. InputPath("dataloader" ),
test_dataloader_path: components. InputPath("dataloader" ),
model_path: components. OutputPath("pytorch_model" ),
):
...
for epoch in epochs:
for batch_idx, (data, target) in enumerate(train_dataloader):
...
if batch_idx % log_interval == 0 :
wandb. log(
{"epoch" : epoch, "step" : batch_idx * len(data), "loss" : loss. item()}
)
...
wandb. log_artifact(model_artifact)
暗黙的な wandb インテグレーションを使用
サポートするフレームワーク インテグレーション を使用している場合は、コールバックを直接渡すこともできます。
@wandb_log
def train_model (
train_dataloader_path: components. InputPath("dataloader" ),
test_dataloader_path: components. InputPath("dataloader" ),
model_path: components. OutputPath("pytorch_model" ),
):
from pytorch_lightning.loggers import WandbLogger
from pytorch_lightning import Trainer
trainer = Trainer(logger= WandbLogger())
... # do training
6.18 - LightGBM
W&B で ツリー を追跡しましょう。
wandb ライブラリには、 LightGBM 用の特別な コールバック が含まれています。また、 Weights & Biases の汎用的な ログ 機能を使用すると、 ハイパーパラメーター 探索 のような大規模な 実験 を簡単に追跡できます。
from wandb.integration.lightgbm import wandb_callback, log_summary
import lightgbm as lgb
# メトリクス を W&B に ログ 記録
gbm = lgb. train(... , callbacks= [wandb_callback()])
# 特徴量の インポータンスプロット を ログ 記録し、 モデル の チェックポイント を W&B にアップロード
log_summary(gbm, save_model_checkpoint= True )
Sweeps を使用した ハイパーパラメーター の調整
モデル のパフォーマンスを最大限に引き出すには、 ツリー の深さや学習率などの ハイパーパラメーター を調整する必要があります。Weights & Biases には、大規模な ハイパーパラメーター のテスト 実験 を構成、編成、分析するための強力な ツールキットである Sweeps が含まれています。
これらの ツール の詳細と、XGBoost で Sweeps を使用する方法の例については、このインタラクティブな Colab ノートブック をご覧ください。
6.19 - Metaflow
Metaflow と W&B を統合する方法。
概要
Metaflow は、ML ワークフローを作成および実行するために Netflix によって作成されたフレームワークです。
このインテグレーションを使用すると、Metaflow の ステップとフロー にデコレータを適用して、パラメータと Artifacts を自動的に W&B にログ記録できます。
ステップをデコレートすると、そのステップ内の特定の種類に対するログ記録をオフまたはオンにします。
フローをデコレートすると、フロー内のすべてのステップに対するログ記録をオフまたはオンにします。
クイックスタート
サインアップして APIキー を作成する
APIキー は、お使いのマシンを W&B に対して認証します。APIキー は、ユーザープロファイルから生成できます。
右上隅にあるユーザープロファイルアイコンをクリックします。
[User Settings ] を選択し、[API Keys ] セクションまでスクロールします。
[Reveal ] をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install -Uqqq metaflow fastcore wandb
wandb login
pip install -Uqqq metaflow fastcore wandb
import wandb
wandb. login()
!pip install -Uqqq metaflow fastcore wandb
import wandb
wandb.login()
フローとステップをデコレートする
ステップをデコレートすると、そのステップ内の特定の種類に対するログ記録をオフまたはオンにします。
この例では、start 内のすべての Datasets と Models がログ記録されます。
from wandb.integration.metaflow import wandb_log
class WandbExampleFlow (FlowSpec):
@wandb_log (datasets= True , models= True , settings= wandb. Settings(... ))
@step
def start (self):
self. raw_df = pd. read_csv(... ). # pd.DataFrame -> upload as dataset
self. model_file = torch. load(... ) # nn.Module -> upload as model
self. next(self. transform)
フローをデコレートすることは、すべての構成ステップをデフォルトでデコレートすることと同じです。
この場合、WandbExampleFlow のすべてのステップは、Datasets と Models をデフォルトでログ記録します。これは、各ステップを @wandb_log(datasets=True, models=True) でデコレートするのと同じです。
from wandb.integration.metaflow import wandb_log
@wandb_log (datasets= True , models= True ) # decorate all @step
class WandbExampleFlow (FlowSpec):
@step
def start (self):
self. raw_df = pd. read_csv(... ). # pd.DataFrame -> upload as dataset
self. model_file = torch. load(... ) # nn.Module -> upload as model
self. next(self. transform)
フローをデコレートすることは、すべてのステップをデフォルトでデコレートすることと同じです。つまり、後で別の @wandb_log でステップをデコレートすると、フローレベルのデコレーションがオーバーライドされます。
この例では:
start と mid は Datasets と Models の両方をログ記録します。end は Datasets も Models もログ記録しません。
from wandb.integration.metaflow import wandb_log
@wandb_log (datasets= True , models= True ) # same as decorating start and mid
class WandbExampleFlow (FlowSpec):
# this step will log datasets and models
@step
def start (self):
self. raw_df = pd. read_csv(... ). # pd.DataFrame -> upload as dataset
self. model_file = torch. load(... ) # nn.Module -> upload as model
self. next(self. mid)
# this step will also log datasets and models
@step
def mid (self):
self. raw_df = pd. read_csv(... ). # pd.DataFrame -> upload as dataset
self. model_file = torch. load(... ) # nn.Module -> upload as model
self. next(self. end)
# this step is overwritten and will NOT log datasets OR models
@wandb_log (datasets= False , models= False )
@step
def end (self):
self. raw_df = pd. read_csv(... ).
self. model_file = torch. load(... )
プログラムでデータにアクセスする
キャプチャした情報には、次の 3 つの方法でアクセスできます。wandb クライアントライブラリweb アプリ UI を使用、または Public API を使用してプログラムでアクセスできます。Parameter は W&B の configOverview タブ にあります。datasets、models、および others は W&B Artifacts に保存され、Artifacts タブ にあります。Base python タイプは W&B の summaryPublic API のガイド を参照してください。
クイックリファレンス
データ
クライアントライブラリ
UI
Parameter(...)wandb.configOverview タブ, Config
datasets、models、otherswandb.use_artifact("{var_name}:latest")Artifacts タブ
Base Python タイプ (dict、list、str など)
wandb.summaryOverview タブ, Summary
wandb_log kwargs
kwarg
オプション
datasetsTrue: データセットであるインスタンス変数をログに記録しますFalse
modelsTrue: モデルであるインスタンス変数をログに記録しますFalse
othersTrue: シリアル化可能なものをピクルとしてログに記録しますFalse
settingswandb.Settings(…): このステップまたはフローに独自の wandb 設定を指定しますNone: wandb.Settings() を渡すのと同じですデフォルトでは、以下の場合:
settings.run_group が None の場合、{flow_name}/{run_id} に設定されますsettings.run_job_type が None の場合、{run_job_type}/{step_name} に設定されます
よくある質問
実際に何をログに記録しますか?すべてのインスタンス変数とローカル変数をログに記録しますか?
wandb_log はインスタンス変数のみをログに記録します。ローカル変数は決してログに記録されません。これは、不要なデータのログ記録を回避するのに役立ちます。
どのデータ型がログに記録されますか?
現在、これらのタイプをサポートしています。
ログ設定
タイプ
デフォルト (常にオン)
dict, list, set, str, int, float, bool
datasets
modelsnn.Modulesklearn.base.BaseEstimator
others
ログ記録の振る舞いを構成するにはどうすればよいですか?
変数の種類
振る舞い
例
データ型
インスタンス
自動ログ記録
self.accuracyfloat
インスタンス
datasets=True の場合にログ記録self.dfpd.DataFrame
インスタンス
datasets=False の場合はログ記録されませんself.dfpd.DataFrame
ローカル
決してログ記録されない
accuracyfloat
ローカル
決してログ記録されない
dfpd.DataFrame
Artifacts のリネージは追跡されますか?
はい。Artifact がステップ A の出力であり、ステップ B の入力である場合、リネージ DAG が自動的に構築されます。
この振る舞いの例については、この notebook と対応する W&B Artifacts ページ を参照してください。
6.20 - MMEngine
MMEngine は OpenMMLab によって開発された、PyTorch をベースとした ディープラーニング モデルのトレーニングを行うための基盤 ライブラリです。MMEngine は OpenMMLab アルゴリズム ライブラリの次世代トレーニング アーキテクチャーを実装し、OpenMMLab 内の 30 以上のアルゴリズム ライブラリに統一された実行基盤を提供します。そのコア コンポーネントには、トレーニング エンジン、評価エンジン、およびモジュール管理が含まれます。
Weights and Biases は、専用の WandbVisBackend
トレーニング および 評価 メトリクスを ログに記録する。
実験 の config を ログに記録および管理する。
グラフ、画像、スカラーなどの追加レコードを ログに記録する。
はじめに
openmim と wandb をインストールします。
pip install -q -U openmim wandb
!pip install -q -U openmim wandb
次に、mim を使用して mmengine と mmcv をインストールします。
mim install -q mmengine mmcv
!mim install -q mmengine mmcv
WandbVisBackend を MMEngine Runner で使用するこのセクションでは、mmengine.runner.RunnerWandbVisBackend を使用する典型的な ワークフロー を示します。
可視化 config から visualizer を定義します。
from mmengine.visualization import Visualizer
# 可視化 config を定義します
visualization_cfg = dict(
name= "wandb_visualizer" ,
vis_backends= [
dict(
type= 'WandbVisBackend' ,
init_kwargs= dict(project= "mmengine" ),
)
],
save_dir= "runs/wandb"
)
# 可視化 config から visualizer を取得します
visualizer = Visualizer. get_instance(** visualization_cfg)
[W&B run 初期化](/ja/ref/python/init/) の入力 パラメータ に、 引数 の 辞書 を `init_kwargs` に渡します。
visualizer で runner を初期化し、runner.train() を呼び出します。
from mmengine.runner import Runner
# PyTorch のトレーニング ヘルパーである mmengine Runner を構築します
runner = Runner(
model,
work_dir= 'runs/gan/' ,
train_dataloader= train_dataloader,
train_cfg= train_cfg,
optim_wrapper= opt_wrapper_dict,
visualizer= visualizer, # visualizer を渡します
)
# トレーニングを開始します
runner. train()
OpenMMLab コンピュータビジョン ライブラリで WandbVisBackend を使用する
WandbVisBackend は、MMDetection などの OpenMMLab コンピュータビジョン ライブラリ で 実験 を追跡するためにも簡単に使用できます。
# デフォルトの ランタイム config からベース config を継承します
_base_ = ["../_base_/default_runtime.py" ]
# `WandbVisBackend` config 辞書を、
# ベース config からの `visualizer` の `vis_backends` に割り当てます
_base_. visualizer. vis_backends = [
dict(
type= 'WandbVisBackend' ,
init_kwargs= {
'project' : 'mmdet' ,
'entity' : 'geekyrakshit'
},
),
]
6.21 - MMF
Meta AI の MMF と W&B を統合する方法。
Meta AI の MMF ライブラリの WandbLogger クラスを使用すると、Weights & Biases でトレーニング/検証 メトリクス、システム (GPU および CPU) メトリクス、モデル チェックポイント、および設定 パラメータをログに記録できます。
現在の機能
MMF の WandbLogger では、現在、次の機能がサポートされています。
トレーニングと検証の メトリクス
経時的な学習率
W&B Artifacts へのモデル チェックポイントの保存
GPU および CPU システム メトリクス
トレーニング設定 パラメータ
設定 パラメータ
wandb ロギングを有効化およびカスタマイズするために、MMF 設定で次のオプションを使用できます。
training:
wandb:
enabled: true
# エンティティは、run の送信先となる ユーザー名または Teams 名です。
# デフォルトでは、run は ユーザー アカウントにログ記録されます。
entity: null
# wandb で 実験 をログ記録する際に使用する Project 名
project: mmf
# wandb で プロジェクト の下に 実験 をログ記録する際に使用する 実験/run 名。
# デフォルトの 実験 名は次のとおりです: ${training.experiment_name}
name: ${training.experiment_name}
# モデル の チェックポイント を有効にして、チェックポイント を W&B Artifacts に保存します
log_model_checkpoint: true
# wandb.init() に渡す追加の 引数 値。
# 使用可能な 引数 (例:
# job_type: 'train'
# tags: ['tag1', 'tag2']
# については、/ref/python/init のドキュメントを参照してください。
env:
# wandb の メタデータ が保存される ディレクトリー への パス を変更するには
# (デフォルト: env.log_dir):
wandb_logdir: ${env:MMF_WANDB_LOGDIR,}
6.22 - MosaicML Composer
最先端のアルゴリズムでニューラルネットワークをトレーニング
Composer は、ニューラルネットワークのトレーニングをより良く、より速く、より安価にするためのライブラリです。ニューラルネットワークのトレーニングを加速させ、汎化性能を向上させるための多くの最先端の メソッド が含まれています。また、オプションの Trainer APIを使用すると、さまざまな拡張機能を簡単に 構成 できます。
Weights & Biases は、ML 実験 の ログ を記録するための軽量なラッパーを提供します。ただし、2つを自分で組み合わせる必要はありません。Weights & Biases は、WandBLogger を介して Composer ライブラリに直接組み込まれています。
Weights & Biases への ログ の記録を開始する
from composer import Trainer
from composer.loggers import WandBLogger
trainer = Trainer(... , logger= WandBLogger())
Composer の WandBLogger の使用
Composer ライブラリは、Trainer の WandBLogger クラスを使用して、 メトリクス を Weights & Biases に ログ します。ロガーをインスタンス化して Trainer に渡すのと同じくらい簡単です。
wandb_logger = WandBLogger(project= "gpt-5" , log_artifacts= True )
trainer = Trainer(logger= wandb_logger)
ロガーの 引数
WandbLogger の パラメータ については、完全なリストと説明について Composer のドキュメント を参照してください。
パラメータ
説明
projectWeights & Biases の プロジェクト 名 (str, optional)
groupWeights & Biases の グループ 名 (str, optional)
nameWeights & Biases の run 名。指定されていない場合、State.run_name が使用されます (str, optional)
entityWeights & Biases の エンティティ 名 ( ユーザー 名または Weights & Biases の Teams 名など) (str, optional)
tagsWeights & Biases の タグ (List[str], optional)
log_artifactsチェックポイント を wandb に ログ するかどうか、デフォルト: false (bool, optional)
rank_zero_onlyランク 0 の プロセス でのみ ログ を記録するかどうか。Artifacts を ログ に記録する場合は、すべてのランクで ログ に記録することを強くお勧めします。ランク ≥1 からの Artifacts は保存されず、関連情報が破棄される可能性があります。たとえば、Deepspeed ZeRO を使用する場合、すべてのランクからの Artifacts がないと チェックポイント から復元することは不可能です。デフォルト: True (bool, optional)
init_kwargswandb config などの wandb.init に渡す パラメータ 完全なリストについては、こちら wandb.init が受け入れます
一般的な使用法は次のとおりです。
init_kwargs = {"notes":"この 実験 でより高い学習率をテストする",
"config":{"arch":"Llama",
"use_mixed_precision":True
}
}
wandb_logger = WandBLogger(log_artifacts=True, init_kwargs=init_kwargs)
予測 サンプル の ログ
Composer の Callbacks システムを使用して、WandBLogger 経由で Weights & Biases に ログ を記録するタイミングを制御できます。この例では、検証画像と 予測 の サンプル が ログ に記録されます。
import wandb
from composer import Callback, State, Logger
class LogPredictions (Callback):
def __init__(self, num_samples= 100 , seed= 1234 ):
super(). __init__()
self. num_samples = num_samples
self. data = []
def eval_batch_end (self, state: State, logger: Logger):
"""バッチ ごとに 予測 を計算し、self.data に保存します"""
if state. timer. epoch == state. max_duration: #最後の val エポック で
if len(self. data) < self. num_samples:
n = self. num_samples
x, y = state. batch_pair
outputs = state. outputs. argmax(- 1 )
data = [[wandb. Image(x_i), y_i, y_pred] for x_i, y_i, y_pred in list(zip(x[:n], y[:n], outputs[:n]))]
self. data += data
def eval_end (self, state: State, logger: Logger):
"wandb.Table を作成して ログ に記録します"
columns = ['image' , 'ground truth' , 'prediction' ]
table = wandb. Table(columns= columns, data= self. data[:self. num_samples])
wandb. log({'sample_table' :table}, step= int(state. timer. batch))
...
trainer = Trainer(
...
loggers= [WandBLogger()],
callbacks= [LogPredictions()]
)
6.23 - OpenAI API
OpenAI API で W&B を使用する方法。
W&B OpenAI API インテグレーションを使用すると、ファインチューンされたモデルを含むすべての OpenAI モデルのリクエスト、レスポンス、トークン数、モデルの メタデータ を ログ に記録できます。
API の入力と出力を ログ に記録すると、さまざまなプロンプトのパフォーマンスを迅速に評価し、さまざまなモデル 設定 (温度など) を比較し、トークンの使用量などの他の使用状況 メトリクス を追跡できます。
OpenAI Python API ライブラリ をインストール
W&B autolog インテグレーションは、OpenAI バージョン 0.28.1 以前で動作します。
OpenAI Python API バージョン 0.28.1 をインストールするには、以下を実行します。
pip install openai== 0.28.1
OpenAI Python API の使用
1. autolog をインポートして初期化する
まず、wandb.integration.openai から autolog をインポートして初期化します。
import os
import openai
from wandb.integration.openai import autolog
autolog({"project" : "gpt5" })
オプションで、wandb.init() が受け入れる 引数 を持つ 辞書 を autolog に渡すことができます。これには、 プロジェクト 名、 チーム 名、 エンティティ などが含まれます。wandb.init
2. OpenAI API を呼び出す
OpenAI API への各呼び出しは、W&B に自動的に ログ 記録されるようになりました。
os. environ["OPENAI_API_KEY" ] = "XXX"
chat_request_kwargs = dict(
model= "gpt-3.5-turbo" ,
messages= [
{"role" : "system" , "content" : "You are a helpful assistant." },
{"role" : "user" , "content" : "Who won the world series in 2020?" },
{"role" : "assistant" , "content" : "The Los Angeles Dodgers" },
{"role" : "user" , "content" : "Where was it played?" },
],
)
response = openai. ChatCompletion. create(** chat_request_kwargs)
3. OpenAI API の入力とレスポンスを表示する
ステップ 1 で autolog によって生成された W&B run リンクをクリックします。これにより、W&B アプリ の プロジェクト ワークスペース にリダイレクトされます。
作成した run を選択して、トレース テーブル、トレース タイムライン、および使用された OpenAI LLM のモデル アーキテクチャ を表示します。
autolog をオフにする
OpenAI API の使用が終了したら、すべての W&B プロセス を閉じるために disable() を呼び出すことをお勧めします。
これで、入力と補完が W&B に ログ 記録され、 分析 の準備が整い、同僚と共有できます。
6.24 - OpenAI Fine-Tuning
W&B を使用して OpenAI モデルを ファインチューン する方法。
OpenAI GPT-3.5 または GPT-4 モデルのファインチューニングのメトリクスと設定を W&B に記録します。W&B の エコシステム を利用して、ファインチューニング の 実験 、 モデル 、 データセット を追跡し、同僚と 結果 を共有します。
W&B と OpenAI を ファインチューニング 用に 統合 する方法に関する補足情報については、OpenAI のドキュメントのWeights and Biases Integration セクションを参照してください。
OpenAI Python API のインストールまたはアップデート
W&B OpenAI ファインチューニング インテグレーション は、OpenAI バージョン 1.0 以降で動作します。OpenAI Python API ライブラリの最新バージョンについては、PyPI のドキュメントを参照してください。
OpenAI Python API をインストールするには、以下を実行します。
OpenAI Python API がすでにインストールされている場合は、以下を実行してアップデートできます。
OpenAI ファインチューニング の 結果 を 同期 する
W&B を OpenAI の ファインチューニング API と 統合 して、ファインチューニング の メトリクス と 設定 を W&B に 記録 します。これを行うには、wandb.integration.openai.fine_tuning モジュールの WandbLogger クラスを使用します。
from wandb.integration.openai.fine_tuning import WandbLogger
# Finetuning logic
WandbLogger. sync(fine_tune_job_id= FINETUNE_JOB_ID)
ファインチューン を 同期 する
スクリプト から 結果 を 同期 します。
from wandb.integration.openai.fine_tuning import WandbLogger
# one line command
WandbLogger. sync()
# passing optional parameters
WandbLogger. sync(
fine_tune_job_id= None ,
num_fine_tunes= None ,
project= "OpenAI-Fine-Tune" ,
entity= None ,
overwrite= False ,
model_artifact_name= "model-metadata" ,
model_artifact_type= "model" ,
** kwargs_wandb_init
)
リファレンス
引数
説明
fine_tune_job_id
これは、client.fine_tuning.jobs.create を使用して ファインチューン ジョブ を 作成 するときに取得する OpenAI Fine-Tune ID です。この 引数 が None (デフォルト) の場合、まだ W&B に 同期 されていないすべての OpenAI ファインチューン ジョブ が W&B に 同期 されます。
openai_client
初期化された OpenAI クライアント を sync に渡します。クライアント が 提供 されない場合、ロガー自体によって初期化されます。デフォルトでは None です。
num_fine_tunes
ID が 提供 されない場合、同期 されていないすべての ファインチューン が W&B に 記録 されます。この 引数 を使用すると、 同期 する 最新 の ファインチューン の 数 を 選択 できます。num_fine_tunes が 5 の場合、最新 の 5 つの ファインチューン が 選択 されます。
project
ファインチューン の メトリクス 、 モデル 、 データ などが 記録 される Weights and Biases プロジェクト 名。デフォルトでは、 プロジェクト 名は “OpenAI-Fine-Tune” です。
entity
run の送信先の W&B ユーザー 名または チーム 名。デフォルトでは、デフォルト の エンティティ が使用されます。通常は ユーザー 名です。
overwrite
同じ ファインチューン ジョブ の 既存 の wandb run を 強制的に ログ に 記録 して 上書き します。デフォルトでは False です。
wait_for_job_success
OpenAI の ファインチューニング ジョブ が 開始 されると、通常、少し時間がかかります。メトリクス が ファインチューン ジョブ の 完了後すぐに W&B に 記録 されるようにするために、この 設定 では、60 秒ごとに ファインチューン ジョブ の ステータス が succeeded に 変わるかどうかを チェック します。ファインチューン ジョブ が 成功 したと 検出 されると、メトリクス は 自動的に W&B に 同期 されます。デフォルトでは True に 設定 されています。
model_artifact_name
ログ に 記録 される モデル Artifacts の 名前。デフォルトは "model-metadata" です。
model_artifact_type
ログ に 記録 される モデル Artifacts の タイプ。デフォルトは "model" です。
**kwargs_wandb_init
wandb.init()
データセット の バージョン管理 と 可視化
バージョン管理
ファインチューニング 用に OpenAI に アップロード する トレーニング データ と 検証 データ は、より簡単な バージョン 管理のために W&B Artifacts として 自動的に ログ に 記録 されます。以下は、Artifacts の トレーニング ファイル の ビュー です。ここでは、この ファイル を ログ に 記録 した W&B run、ログ に 記録 された日時、これが データセット のどの バージョン であるか、メタデータ 、および トレーニングデータ から トレーニング された モデル への DAG リネージ を確認できます。
可視化
データセット は W&B テーブル として 可視化 され、データセット の 探索 、 検索 、および 操作 を行うことができます。以下の W&B テーブル を使用して 可視化 された トレーニング サンプル を チェック してください。
ファインチューニング された モデル と モデル の バージョン管理
OpenAI は、ファインチューニング された モデル の ID を 提供 します。モデル の 重み に アクセス できないため、WandbLogger は、 モデル の すべての 詳細 ( ハイパーパラメーター 、 データ ファイル ID など) と fine_tuned_model ID を含む model_metadata.json ファイル を 作成 し、W&B Artifacts として ログ に 記録 します。
この モデル ( メタデータ ) Artifacts は、W&B Registry の モデル にさらに リンク できます。
よくある質問
チーム で ファインチューン の 結果 を W&B で共有するにはどうすればよいですか?
以下を使用して、ファインチューン ジョブ を チーム アカウント に ログ に 記録 します。
WandbLogger. sync(entity= "YOUR_TEAM_NAME" )
run を 整理 するにはどうすればよいですか?
W&B run は 自動的に 整理 され、 ジョブタイプ 、 ベース モデル 、 学習率 、 トレーニング ファイル名 、その他の ハイパーパラメーター など、任意の設定 パラメータ に 基づいて フィルタリング/ソート できます。
さらに、run の 名前 を 変更 したり、メモ を 追加 したり、 タグ を 作成 して グループ化 したりできます。
満足したら、 ワークスペース を 保存 し、それを使用して レポート を 作成 し、run と 保存 された Artifacts ( トレーニング / 検証 ファイル ) から データ を インポート できます。
ファインチューニング された モデル に アクセス するにはどうすればよいですか?
ファインチューニング された モデル ID は、Artifacts (model_metadata.json) および 設定 として W&B に ログ に 記録 されます。
import wandb
ft_artifact = wandb. run. use_artifact("ENTITY/PROJECT/model_metadata:VERSION" )
artifact_dir = artifact. download()
ここで、VERSION は次のいずれかです。
v2 などの バージョン 番号ft-xxxxxxxxx などの ファインチューン IDlatest や 手動 で 追加 された エイリアス など、自動的に 追加 された エイリアス
次に、ダウンロード した model_metadata.json ファイル を 読み取ることで、fine_tuned_model ID に アクセス できます。
ファインチューン が 正常 に 同期 されなかった場合はどうなりますか?
ファインチューン が W&B に 正常 に ログ に 記録 されなかった場合は、overwrite=True を使用して、ファインチューン ジョブ ID を 渡すことができます。
WandbLogger. sync(
fine_tune_job_id= "FINE_TUNE_JOB_ID" ,
overwrite= True ,
)
W&B で データセット と モデル を 追跡 できますか?
トレーニング および 検証 データ は、Artifacts として W&B に 自動的に ログ に 記録 されます。ファインチューニング された モデル の ID を含む メタデータ も、Artifacts として ログ に 記録 されます。
wandb.Artifact、wandb.log などの 低レベル の wandb API を使用して パイプライン を 常に 制御 できます。これにより、 データ と モデル の 完全 な トレーサビリティ が 可能 になります。
リソース
6.25 - OpenAI Gym
W&B を OpenAI Gym と統合する方法。
2021年以降 Gym をメンテナンスしてきたチームは、今後の開発をすべて Gymnasium に移行しました。Gymnasium は Gym のドロップイン代替品 (import gymnasium as gym) であり、Gym は今後アップデートを受け取ることはありません。(出典 )
Gym はもはや活発にメンテナンスされているプロジェクトではないため、Gymnasium との インテグレーション をお試しください。
OpenAI Gym を使用している場合、Weights & Biases は gym.wrappers.Monitor によって生成された 環境 の動画を自動的に ログ します。wandb.initmonitor_gym キーワード 引数 を True に設定するか、wandb.gym.monitor() を呼び出すだけです。
当社の gym インテグレーション は非常に軽量です。gym から ログ されている動画ファイルの名前を 確認 し、それにちなんで名前を付けるか、一致するものが見つからない場合は "videos" にフォールバックします。より詳細な制御が必要な場合は、いつでも手動で 動画を ログ できます。
CleanRL による OpenRL Benchmark では、OpenAI Gym の例でこの インテグレーション を使用しています。gym での使用方法を示すソース コード (特定の Runs に使用される特定のコード を含む) を見つけることができます。
6.26 - PaddleDetection
PaddleDetection と W&B の統合方法。
PaddleDetection は、PaddlePaddle に基づくエンドツーエンドの オブジェクト検出開発キットです。ネットワークコンポーネント、データ拡張、損失などの構成可能なモジュールを使用して、さまざまな主流のオブジェクトを検出し、インスタンスをセグメント化し、キーポイントを追跡および検出します。
PaddleDetection には、すべての トレーニング および 検証 メトリクスに加えて、モデル チェックポイント とそれに対応する メタデータ をログに記録する、組み込みの W&B インテグレーションが含まれています。
PaddleDetection WandbLogger は、トレーニング 中にトレーニング および 評価 メトリクス を Weights & Biases に ログ 記録するだけでなく、モデル チェックポイント も ログ 記録します。
W&B の ブログ 記事を読む COCO2017 データセット の サブセット で、YOLOX モデル を PaddleDetection と 統合 する方法について説明します。
サインアップ して APIキー を作成する
APIキー は、W&B に対して マシン を 認証 します。APIキー は、 ユーザー プロフィールから生成できます。
右上隅にある ユーザー プロフィール アイコンをクリックします。
ユーザー 設定 を選択し、APIキー セクションまでスクロールします。表示 をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードしてください。
wandb ライブラリ を インストール して ログイン するwandb ライブラリ をローカルに インストール して ログイン するには:
コマンドライン
Python
Python ノートブック
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリ を インストール して ログイン します。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
トレーニング スクリプト で WandbLogger をアクティブにする
PaddleDetection の train.py への 引数 を介して wandb を使用するには:
--use_wandb フラグを追加します最初の wandb 引数 は -o を前に付ける必要があります (これは一度だけ渡す必要があります)
個々の wandb 引数 には、プレフィックス wandb- が含まれている必要があります。たとえば、wandb.initwandb- プレフィックス が付きます。
python tools/train.py
-c config.yml \
--use_wandb \
\
wandb-project= MyDetector \
= MyTeam \
= ./logs
wandb キー の下の config.yml ファイル に wandb 引数 を追加します。
wandb:
project: MyProject
entity: MyTeam
save_dir: ./logs
train.py ファイル を実行すると、W&B ダッシュボード への リンク が生成されます。
フィードバック または 問題点
Weights & Biases インテグレーション に関する フィードバック や 問題 がある場合は、PaddleDetection GitHub で 問題 を提起するか、support@wandb.com にメールを送信してください。
6.27 - PaddleOCR
PaddleOCR と W&B を統合する方法。
PaddleOCR は、多言語に対応した、素晴らしい、最先端の、そして実用的なOCRツールを開発し、PaddlePaddle で実装されたモデルのトレーニングをより良く行い、実際に活用できるようにすることを目的としています。PaddleOCR は、OCRに関連する様々な最先端のアルゴリズムをサポートし、産業ソリューションを開発しました。PaddleOCR には、トレーニング と評価メトリクスを、対応するメタデータ と共にモデル のチェックポイント をログ記録するための Weights & Biases のインテグレーションが付属しています。
ブログ と Colab の例
ICDAR2015 データセット で PaddleOCR を使用してモデル をトレーニングする方法については、こちら Google Colab こちら W&B对您的OCR模型进行训练和调试
サインアップ して APIキー を作成する
APIキー は、W&B に対してお客様のマシン を認証します。APIキー は、ユーザー プロファイル から生成できます。
右上隅にあるユーザー プロファイル アイコン をクリックします。
[User Settings ] を選択し、[API Keys ] セクション までスクロールします。
[Reveal ] をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページ をリロードします。
wandb ライブラリ をインストール してログイン するwandb ライブラリ をローカル にインストール してログイン するには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリ をインストール してログイン します。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
config.yml ファイル に wandb を追加するPaddleOCR では、yaml ファイル を使用して構成変数 を指定する必要があります。構成 yaml ファイル の末尾に次のスニペット を追加すると、すべてのトレーニング と検証メトリクス が、モデル チェックポイント と共に W&B ダッシュボード に自動的に記録されます。
wandb.initwandb ヘッダー の下に追加することもできます。
wandb:
project: CoolOCR # (オプション) これは wandb プロジェクト名 です
entity: my_team # (オプション) wandb team を使用している場合は、ここに team 名を渡すことができます
name: MyOCRModel # (オプション) これは wandb run の名前です
config.yml ファイル を train.py に渡すyaml ファイル は、PaddleOCR リポジトリ で利用可能な トレーニング スクリプト への 引数 として提供されます。
python tools/train.py -c config.yml
Weights & Biases をオンにして train.py ファイル を実行すると、W&B ダッシュボード に移動するためのリンク が生成されます。
フィードバック または問題点
Weights & Biases のインテグレーションに関するフィードバック や問題がある場合は、PaddleOCR GitHub で issue をオープン するか、support@wandb.com にメール でご連絡ください。
6.28 - Prodigy
W&B と Prodigy を統合する方法。
Prodigy は、機械学習モデルのトレーニング および 評価 データ、エラー分析、データ の検査 および クリーニングを作成するためのアノテーション ツールです。W&B テーブル を使用すると、W&B 内でデータセット (など) をログ記録、可視化、分析、および共有できます。
Prodigy との W&B インテグレーション は、Prodigy でアノテーションを付けたデータセットを W&B に直接アップロードして テーブル で使用するための、シンプルで使いやすい機能を追加します。
次のようなコードを数行実行します。
import wandb
from wandb.integration.prodigy import upload_dataset
with wandb. init(project= "prodigy" ):
upload_dataset("news_headlines_ner" )
次のような、視覚的でインタラクティブな共有可能な テーブル を取得します。
クイックスタート
wandb.integration.prodigy.upload_dataset を使用して、アノテーションが付けられた Prodigy データセットをローカルの Prodigy データベースから W&B の テーブル 形式で直接アップロードします。インストール および セットアップを含む Prodigy の詳細については、Prodigy ドキュメント を参照してください。
W&B は、画像 および 固有表現フィールドを wandb.Imagewandb.Html
詳細な例を読む
W&B Prodigy インテグレーションで生成された可視化の例については、W&B テーブル を使用した Prodigy データセットの可視化 を参照してください。
spaCy も使用しますか?
W&B には spaCy との インテグレーション もあります。ドキュメントはこちら をご覧ください。
6.29 - PyTorch
PyTorch は、Python の ディープラーニング において最も人気のある フレームワーク の 1 つで、特に 研究 者の間で人気があります。W&B は、 勾配 の ログ 記録から CPU および GPU での コード のプロファイリングまで、PyTorch を第一級でサポートします。
ぜひ、 Colabノートブック で インテグレーション をお試しください。
サンプルリポジトリ で スクリプト を確認することもできます。これには、Fashion MNIST で Hyperband を使用した ハイパーパラメーター 最適化に関するものや、それが生成する W&B Dashboard などがあります。
wandb.watch で 勾配 を ログ 記録する勾配 を自動的に ログ 記録するには、wandb.watch
import wandb
wandb. init(config= args)
model = ... # モデル をセットアップ
# Magic
wandb. watch(model, log_freq= 100 )
model. train()
for batch_idx, (data, target) in enumerate(train_loader):
output = model(data)
loss = F. nll_loss(output, target)
loss. backward()
optimizer. step()
if batch_idx % args. log_interval == 0 :
wandb. log({"loss" : loss})
同じ スクリプト で複数の モデル を追跡する必要がある場合は、各 モデル で wandb.watch を個別に呼び出すことができます。この関数の リファレンス ドキュメントは こちら にあります。
順方向と逆方向のパスの後に wandb.log が呼び出されるまで、 勾配 、 メトリクス 、および グラフ は ログ 記録されません。
画像とメディアを ログ 記録する
画像 データ を含む PyTorch の Tensors を wandb.Imagetorchvision
images_t = ... # PyTorch の Tensor として画像を生成またはロード
wandb. log({"examples" : [wandb. Image(im) for im in images_t]})
PyTorch およびその他の フレームワーク で リッチメディア を W&B に ログ 記録する方法の詳細については、メディア ログ 記録 ガイド を確認してください。
モデル の 予測 や派生した メトリクス など、メディアと一緒に 情報 を含める場合は、wandb.Table を使用します。
my_table = wandb. Table()
my_table. add_column("image" , images_t)
my_table. add_column("label" , labels)
my_table. add_column("class_prediction" , predictions_t)
# W&B に テーブル を ログ 記録
wandb. log({"mnist_predictions" : my_table})
データセット と モデル の ログ 記録と視覚化の詳細については、W&B Tables の ガイド を確認してください。
PyTorch コード のプロファイル
W&B は、PyTorch Kineto の Tensorboard plugin と直接 統合 されており、PyTorch コード のプロファイル、CPU と GPU の通信の詳細の検査、および ボトルネック と 最適化 の特定のための ツール を提供します。
profile_dir = "path/to/run/tbprofile/"
profiler = torch. profiler. profile(
schedule= schedule, # スケジューリング の詳細については、プロファイラー のドキュメントを参照してください
on_trace_ready= torch. profiler. tensorboard_trace_handler(profile_dir),
with_stack= True ,
)
with profiler:
... # ここでプロファイルするコードを実行
# 詳細な使用方法については、プロファイラー のドキュメントを参照してください
# wandb Artifact を作成
profile_art = wandb. Artifact("trace" , type= "profile" )
# pt.trace.json ファイルを Artifact に追加
profile_art. add_file(glob. glob(profile_dir + ".pt.trace.json" ))
# artifact をログに記録
profile_art. save()
動作する サンプル コード を この Colab で確認して実行してください。
インタラクティブな トレース 表示 ツール は Chrome Trace Viewer に基づいており、Chrome ブラウザー で最適に動作します。
6.30 - PyTorch Geometric
PyTorch Geometric 、または PyG は、幾何学的ディープラーニングで最も人気のあるライブラリの 1 つであり、W&B はグラフの可視化と Experiments の追跡において非常にうまく機能します。
Pytorch Geometric をインストールしたら、以下の手順に従って開始してください。
サインアップして API キーを作成する
API キー は、お使いのマシンを W&B に対して認証します。API キーは、 ユーザー プロフィールから生成できます。
右上隅にある ユーザー プロフィール アイコンをクリックします。
ユーザー 設定 を選択し、API キー セクションまでスクロールします。表示 をクリックします。表示された API キーをコピーします。API キーを非表示にするには、ページをリロードしてください。
wandb ライブラリをインストールしてログインするローカルに wandb ライブラリをインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境 変数 を API キー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
グラフを可視化する
エッジ数、ノード数など、入力グラフに関する詳細を保存できます。W&B は Plotly チャートと HTML パネル の ログ をサポートしているため、グラフ用に作成した 可視化 は W&B にも ログ できます。
PyVis を使用する
次のスニペットは、PyVis と HTML でそれを行う方法を示しています。
from pyvis.network import Network
Import wandb
wandb. init(project= ’ graph_vis’ )
net = Network(height= "750px" , width= "100%" , bgcolor= "#222222" , font_color= "white" )
# Add the edges from the PyG graph to the PyVis network
for e in tqdm(g. edge_index. T):
src = e[0 ]. item()
dst = e[1 ]. item()
net. add_node(dst)
net. add_node(src)
net. add_edge(src, dst, value= 0.1 )
# Save the PyVis visualisation to a HTML file
net. show("graph.html" )
wandb. log({"eda/graph" : wandb. Html("graph.html" )})
wandb. finish()
Plotly を使用する
Plotly を使用してグラフの 可視化 を作成するには、まず PyG グラフを networkx オブジェクトに変換する必要があります。次に、ノードとエッジの両方に対して Plotly 散布図を作成する必要があります。次のスニペットをこのタスクに使用できます。
def create_vis (graph):
G = to_networkx(graph)
pos = nx. spring_layout(G)
edge_x = []
edge_y = []
for edge in G. edges():
x0, y0 = pos[edge[0 ]]
x1, y1 = pos[edge[1 ]]
edge_x. append(x0)
edge_x. append(x1)
edge_x. append(None )
edge_y. append(y0)
edge_y. append(y1)
edge_y. append(None )
edge_trace = go. Scatter(
x= edge_x, y= edge_y,
line= dict(width= 0.5 , color= '#888' ),
hoverinfo= 'none' ,
mode= 'lines'
)
node_x = []
node_y = []
for node in G. nodes():
x, y = pos[node]
node_x. append(x)
node_y. append(y)
node_trace = go. Scatter(
x= node_x, y= node_y,
mode= 'markers' ,
hoverinfo= 'text' ,
line_width= 2
)
fig = go. Figure(data= [edge_trace, node_trace], layout= go. Layout())
return fig
wandb. init(project= ’ visualize_graph’ )
wandb. log({‘ graph’ : wandb. Plotly(create_vis(graph))})
wandb. finish()
メトリクス を ログ する
W&B を使用して、Experiments や、損失関数、精度などの関連 メトリクス を追跡できます。次の行を トレーニング ループに追加します。
wandb. log({
‘ train/ loss’ : training_loss,
‘ train/ acc’ : training_acc,
‘ val/ loss’ : validation_loss,
‘ val/ acc’ : validation_acc
})
その他のリソース
6.31 - Pytorch torchtune
torchtune は、大規模言語モデル(LLM)の作成、微調整、および実験 プロセスを効率化するために設計された PyTorch ベースのライブラリです。さらに、torchtune には W&B でのログ記録 のサポートが組み込まれており、トレーニング プロセスの追跡と 可視化が強化されています。
torchtune を使用した Mistral 7B の微調整 に関する W&B ブログ投稿を確認してください。
すぐに使える W&B ロギング
起動時に コマンドライン 引数をオーバーライドします。
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
= torchtune.utils.metric_logging.WandBLogger \
= "llama3_lora" \
= 5
レシピの構成で W&B ロギングを有効にします。
# inside llama3/8B_lora_single_device.yaml
metric_logger :
_component_ : torchtune.utils.metric_logging.WandBLogger
project : llama3_lora
log_every_n_steps : 5
W&B メトリクス ロガーを使用する
metric_logger セクションを変更して、レシピの構成ファイルで W&B ロギングを有効にします。_component_ を torchtune.utils.metric_logging.WandBLogger クラスに変更します。project 名と log_every_n_steps を渡して、ロギングの 振る舞いをカスタマイズすることもできます。
wandb.init メソッドと同様に、他の kwargs を渡すこともできます。たとえば、チームで作業している場合は、entity 引数を WandBLogger クラスに渡して、チーム名を指定できます。
# inside llama3/8B_lora_single_device.yaml
metric_logger :
_component_ : torchtune.utils.metric_logging.WandBLogger
project : llama3_lora
entity : my_project
job_type : lora_finetune_single_device
group : my_awesome_experiments
log_every_n_steps : 5
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
= torchtune.utils.metric_logging.WandBLogger \
= "llama3_lora" \
= "my_project" \
= "lora_finetune_single_device" \
= "my_awesome_experiments" \
= 5
ログに記録される内容
W&B ダッシュボードを調べて、ログに記録されたメトリクスを確認できます。デフォルトでは、W&B は構成ファイルと起動オーバーライドからすべての ハイパーパラメーター を記録します。
W&B は、概要 タブで解決された構成をキャプチャします。W&B は、ファイル タブ に YAML 形式で構成も保存します。
記録されたメトリクス
各レシピには、独自のトレーニング ループがあります。各レシピを確認して、ログに記録されたメトリクスを確認してください。これらはデフォルトで含まれています。
メトリクス
説明
lossモデルの損失
lr学習率
tokens_per_secondモデルの 1 秒あたりの トークン 数
grad_normモデルの勾配ノルム
global_stepトレーニング ループの現在のステップに対応します。勾配の累積を考慮します。基本的に、オプティマイザー のステップが実行されるたびに、モデルが更新され、勾配が累積され、モデルが gradient_accumulation_steps ごとに 1 回更新されます
global_step は、トレーニング ステップの数と同じではありません。トレーニング ループの現在のステップに対応します。勾配の累積を考慮します。基本的に、オプティマイザー のステップが実行されるたびに、global_step は 1 ずつ増加します。たとえば、データローダーに 10 個のバッチがあり、勾配累積ステップが 2 で、3 エポック実行する場合、オプティマイザー は 15 回ステップを実行します。この場合、global_step は 1 から 15 の範囲になります。
torchtune の合理化された設計により、カスタム メトリクスを簡単に追加したり、既存のメトリクスを変更したりできます。たとえば、current_epoch をエポックの総数のパーセンテージとしてログに記録するなど、対応する レシピ ファイル を変更するだけで済みます。
# inside `train.py` function in the recipe file
self. _metric_logger. log_dict(
{"current_epoch" : self. epochs * self. global_step / self. _steps_per_epoch},
step= self. global_step,
)
これは急速に進化しているライブラリであり、現在のメトリクスは変更される可能性があります。カスタム メトリクスを追加する場合は、レシピを変更して、対応する self._metric_logger.* 関数を呼び出す必要があります。
チェックポイント の保存とロード
torchtune ライブラリは、さまざまな チェックポイント 形式 をサポートしています。使用しているモデルの 出所に応じて、適切な チェックポイント クラス に切り替える必要があります。
モデルの チェックポイント を W&B Artifacts に保存する場合は、対応するレシピ内で save_checkpoint 関数をオーバーライドするのが最も簡単な解決策です。
モデルの チェックポイント を W&B Artifacts に保存するために save_checkpoint 関数をオーバーライドする方法の例を次に示します。
def save_checkpoint (self, epoch: int) -> None :
...
## Let's save the checkpoint to W&B
## depending on the Checkpointer Class the file will be named differently
## Here is an example for the full_finetune case
checkpoint_file = Path. joinpath(
self. _checkpointer. _output_dir, f "torchtune_model_ { epoch} "
). with_suffix(".pt" )
wandb_artifact = wandb. Artifact(
name= f "torchtune_model_ { epoch} " ,
type= "model" ,
# description of the model checkpoint
description= "Model checkpoint" ,
# you can add whatever metadata you want as a dict
metadata= {
utils. SEED_KEY: self. seed,
utils. EPOCHS_KEY: self. epochs_run,
utils. TOTAL_EPOCHS_KEY: self. total_epochs,
utils. MAX_STEPS_KEY: self. max_steps_per_epoch,
},
)
wandb_artifact. add_file(checkpoint_file)
wandb. log_artifact(wandb_artifact)
6.32 - PyTorch Ignite
PyTorch Ignite と W&B を統合する方法
Igniteは、トレーニングおよび検証中に、メトリクス、モデル/ オプティマイザー の パラメータ 、 勾配 を ログ に記録するための Weights & Biases ハンドラーをサポートしています。また、モデル の チェックポイント を Weights & Biases クラウド に ログ 記録するためにも使用できます。このクラスは、wandb モジュール のラッパーでもあります。つまり、このラッパーを使用して任意の wandb 関数を呼び出すことができます。モデル の パラメータ と 勾配 を保存する方法の例を参照してください。
基本的な設定
from argparse import ArgumentParser
import wandb
import torch
from torch import nn
from torch.optim import SGD
from torch.utils.data import DataLoader
import torch.nn.functional as F
from torchvision.transforms import Compose, ToTensor, Normalize
from torchvision.datasets import MNIST
from ignite.engine import Events, create_supervised_trainer, create_supervised_evaluator
from ignite.metrics import Accuracy, Loss
from tqdm import tqdm
class Net (nn. Module):
def __init__(self):
super(Net, self). __init__()
self. conv1 = nn. Conv2d(1 , 10 , kernel_size= 5 )
self. conv2 = nn. Conv2d(10 , 20 , kernel_size= 5 )
self. conv2_drop = nn. Dropout2d()
self. fc1 = nn. Linear(320 , 50 )
self. fc2 = nn. Linear(50 , 10 )
def forward (self, x):
x = F. relu(F. max_pool2d(self. conv1(x), 2 ))
x = F. relu(F. max_pool2d(self. conv2_drop(self. conv2(x)), 2 ))
x = x. view(- 1 , 320 )
x = F. relu(self. fc1(x))
x = F. dropout(x, training= self. training)
x = self. fc2(x)
return F. log_softmax(x, dim=- 1 )
def get_data_loaders (train_batch_size, val_batch_size):
data_transform = Compose([ToTensor(), Normalize((0.1307 ,), (0.3081 ,))])
train_loader = DataLoader(MNIST(download= True , root= "." , transform= data_transform, train= True ),
batch_size= train_batch_size, shuffle= True )
val_loader = DataLoader(MNIST(download= False , root= "." , transform= data_transform, train= False ),
batch_size= val_batch_size, shuffle= False )
return train_loader, val_loader
ignite で WandBLogger を使用することは、モジュール式の プロセス です。まず、WandBLogger オブジェクト を作成します。次に、メトリクス を自動的に ログ 記録するために、それを trainer または evaluator にアタッチします。この例:
トレーナー オブジェクト にアタッチされたトレーニング損失を ログ 記録します。
evaluator にアタッチされた検証損失を ログ 記録します。
学習率などのオプションの パラメータ を ログ 記録します。
モデル を監視します。
from ignite.contrib.handlers.wandb_logger import *
def run (train_batch_size, val_batch_size, epochs, lr, momentum, log_interval):
train_loader, val_loader = get_data_loaders(train_batch_size, val_batch_size)
model = Net()
device = 'cpu'
if torch. cuda. is_available():
device = 'cuda'
optimizer = SGD(model. parameters(), lr= lr, momentum= momentum)
trainer = create_supervised_trainer(model, optimizer, F. nll_loss, device= device)
evaluator = create_supervised_evaluator(model,
metrics= {'accuracy' : Accuracy(),
'nll' : Loss(F. nll_loss)},
device= device)
desc = "ITERATION - loss: {:.2f} "
pbar = tqdm(
initial= 0 , leave= False , total= len(train_loader),
desc= desc. format(0 )
)
#WandBlogger Object Creation
wandb_logger = WandBLogger(
project= "pytorch-ignite-integration" ,
name= "cnn-mnist" ,
config= {"max_epochs" : epochs,"batch_size" :train_batch_size},
tags= ["pytorch-ignite" , "mninst" ]
)
wandb_logger. attach_output_handler(
trainer,
event_name= Events. ITERATION_COMPLETED,
tag= "training" ,
output_transform= lambda loss: {"loss" : loss}
)
wandb_logger. attach_output_handler(
evaluator,
event_name= Events. EPOCH_COMPLETED,
tag= "training" ,
metric_names= ["nll" , "accuracy" ],
global_step_transform= lambda * _: trainer. state. iteration,
)
wandb_logger. attach_opt_params_handler(
trainer,
event_name= Events. ITERATION_STARTED,
optimizer= optimizer,
param_name= 'lr' # optional
)
wandb_logger. watch(model)
オプションで、ignite EVENTS を利用して、メトリクス を ターミナル に直接 ログ 記録できます。
@trainer.on (Events. ITERATION_COMPLETED(every= log_interval))
def log_training_loss (engine):
pbar. desc = desc. format(engine. state. output)
pbar. update(log_interval)
@trainer.on (Events. EPOCH_COMPLETED)
def log_training_results (engine):
pbar. refresh()
evaluator. run(train_loader)
metrics = evaluator. state. metrics
avg_accuracy = metrics['accuracy' ]
avg_nll = metrics['nll' ]
tqdm. write(
"Training Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f} "
. format(engine. state. epoch, avg_accuracy, avg_nll)
)
@trainer.on (Events. EPOCH_COMPLETED)
def log_validation_results (engine):
evaluator. run(val_loader)
metrics = evaluator. state. metrics
avg_accuracy = metrics['accuracy' ]
avg_nll = metrics['nll' ]
tqdm. write(
"Validation Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f} "
. format(engine. state. epoch, avg_accuracy, avg_nll))
pbar. n = pbar. last_print_n = 0
trainer. run(train_loader, max_epochs= epochs)
pbar. close()
if __name__ == "__main__" :
parser = ArgumentParser()
parser. add_argument('--batch_size' , type= int, default= 64 ,
help= 'input batch size for training (default: 64)' )
parser. add_argument('--val_batch_size' , type= int, default= 1000 ,
help= 'input batch size for validation (default: 1000)' )
parser. add_argument('--epochs' , type= int, default= 10 ,
help= 'number of epochs to train (default: 10)' )
parser. add_argument('--lr' , type= float, default= 0.01 ,
help= 'learning rate (default: 0.01)' )
parser. add_argument('--momentum' , type= float, default= 0.5 ,
help= 'SGD momentum (default: 0.5)' )
parser. add_argument('--log_interval' , type= int, default= 10 ,
help= 'how many batches to wait before logging training status' )
args = parser. parse_args()
run(args. batch_size, args. val_batch_size, args. epochs, args. lr, args. momentum, args. log_interval)
このコードは、これらの 可視化 を生成します。
詳細については、Ignite Docs を参照してください。
6.33 - PyTorch Lightning
PyTorch Lightning は、PyTorch のコードを整理し、分散トレーニングや 16 ビット精度などの高度な機能を簡単に追加できる軽量ラッパーを提供します。W&B は、ML 実験をログ記録するための軽量ラッパーを提供します。Weights & Biases は、WandbLogger
Lightning との統合
PyTorch Logger
Fabric Logger
from lightning.pytorch.loggers import WandbLogger
from lightning.pytorch import Trainer
wandb_logger = WandbLogger(log_model= "all" )
trainer = Trainer(logger= wandb_logger)
wandb.log() の使用: WandbLogger は、Trainer の global_step を使用して W&B にログを記録します。コード内で wandb.log を直接追加で呼び出す場合は、wandb.log() で step 引数を使用しないでください 。
代わりに、他のメトリクスと同様に、Trainer の global_step をログに記録します。
wandb. log({"accuracy" :0.99 , "trainer/global_step" : step})
import lightning as L
from wandb.integration.lightning.fabric import WandbLogger
wandb_logger = WandbLogger(log_model= "all" )
fabric = L. Fabric(loggers= [wandb_logger])
fabric. launch()
fabric. log_dict({"important_metric" : important_metric})
サインアップして APIキー を作成
APIキー は、W&B に対してマシンを認証します。APIキー は、ユーザープロフィールから生成できます。
右上隅にあるユーザープロフィールアイコンをクリックします。
ユーザー設定 を選択し、APIキー セクションまでスクロールします。表示 をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするローカルに wandb ライブラリをインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
PyTorch Lightning の WandbLogger を使用する
PyTorch Lightning には、メトリクスやモデルの重み、メディアなどをログに記録するための複数の WandbLogger クラスがあります。
Lightning と統合するには、WandbLogger をインスタンス化し、Lightning の Trainer または Fabric に渡します。
PyTorch Logger
Fabric Logger
trainer = Trainer(logger= wandb_logger)
fabric = L. Fabric(loggers= [wandb_logger])
fabric. launch()
fabric. log_dict({
"important_metric" : important_metric
})
一般的なロガーの引数
以下は、WandbLogger で最もよく使用されるパラメーターの一部です。すべてのロガー引数の詳細については、PyTorch Lightning のドキュメントを確認してください。
パラメータ
説明
projectログを記録する wandb Project を定義します。
namewandb run に名前を付けます。
log_modellog_model="all" の場合はすべてのモデルをログに記録し、log_model=True の場合はトレーニングの最後にログに記録します。
save_dirデータが保存されるパス
ハイパーパラメーター をログに記録する
PyTorch Logger
Fabric Logger
class LitModule (LightningModule):
def __init__(self, * args, ** kwarg):
self. save_hyperparameters()
wandb_logger. log_hyperparams(
{
"hyperparameter_1" : hyperparameter_1,
"hyperparameter_2" : hyperparameter_2,
}
)
追加の構成パラメーター をログに記録する
# パラメータ を 1 つ追加
wandb_logger. experiment. config["key" ] = value
# 複数の パラメータ を追加
wandb_logger. experiment. config. update({key1: val1, key2: val2})
# wandb モジュールを直接使用
wandb. config["key" ] = value
wandb. config. update()
勾配、 パラメータ のヒストグラム、およびモデルのトポロジをログに記録する
モデルオブジェクトを wandblogger.watch() に渡して、トレーニング中にモデルの勾配と パラメータ を監視できます。PyTorch Lightning WandbLogger ドキュメントを参照してください。
メトリクス をログに記録する
PyTorch Logger
Fabric Logger
WandbLogger を使用すると、LightningModule 内 (例: training_step メソッドまたは validation_step メソッド) で self.log('my_metric_name', metric_vale) を呼び出すことで、メトリクス を W&B にログ記録できます。
以下のコードスニペットは、メトリクス と LightningModule の ハイパーパラメーター をログ記録するように LightningModule を定義する方法を示しています。この例では、torchmetrics
import torch
from torch.nn import Linear, CrossEntropyLoss, functional as F
from torch.optim import Adam
from torchmetrics.functional import accuracy
from lightning.pytorch import LightningModule
class My_LitModule (LightningModule):
def __init__(self, n_classes= 10 , n_layer_1= 128 , n_layer_2= 256 , lr= 1e-3 ):
"""モデル パラメータ を定義するために使用されるメソッド"""
super(). __init__()
# mnist images are (1, 28, 28) (channels, width, height)
self. layer_1 = Linear(28 * 28 , n_layer_1)
self. layer_2 = Linear(n_layer_1, n_layer_2)
self. layer_3 = Linear(n_layer_2, n_classes)
self. loss = CrossEntropyLoss()
self. lr = lr
# ハイパー パラメータ を self.hparams に保存 (W&B によって自動的にログ記録)
self. save_hyperparameters()
def forward (self, x):
"""推論 input -> output に使用されるメソッド"""
# (b, 1, 28, 28) -> (b, 1*28*28)
batch_size, channels, width, height = x. size()
x = x. view(batch_size, - 1 )
# 3 x (linear + relu) を実行しましょう
x = F. relu(self. layer_1(x))
x = F. relu(self. layer_2(x))
x = self. layer_3(x)
return x
def training_step (self, batch, batch_idx):
"""単一のバッチから損失を返す必要があります"""
_, loss, acc = self. _get_preds_loss_accuracy(batch)
# 損失とメトリックをログに記録
self. log("train_loss" , loss)
self. log("train_accuracy" , acc)
return loss
def validation_step (self, batch, batch_idx):
"""メトリクス のログ記録に使用"""
preds, loss, acc = self. _get_preds_loss_accuracy(batch)
# 損失とメトリックをログに記録
self. log("val_loss" , loss)
self. log("val_accuracy" , acc)
return preds
def configure_optimizers (self):
"""モデル オプティマイザー を定義します"""
return Adam(self. parameters(), lr= self. lr)
def _get_preds_loss_accuracy (self, batch):
"""train/valid/test ステップが類似しているため、便利な関数"""
x, y = batch
logits = self(x)
preds = torch. argmax(logits, dim= 1 )
loss = self. loss(logits, y)
acc = accuracy(preds, y)
return preds, loss, acc
import lightning as L
import torch
import torchvision as tv
from wandb.integration.lightning.fabric import WandbLogger
import wandb
fabric = L. Fabric(loggers= [wandb_logger])
fabric. launch()
model = tv. models. resnet18()
optimizer = torch. optim. SGD(model. parameters(), lr= lr)
model, optimizer = fabric. setup(model, optimizer)
train_dataloader = fabric. setup_dataloaders(
torch. utils. data. DataLoader(train_dataset, batch_size= batch_size)
)
model. train()
for epoch in range(num_epochs):
for batch in train_dataloader:
optimizer. zero_grad()
loss = model(batch)
loss. backward()
optimizer. step()
fabric. log_dict({"loss" : loss})
メトリクス の最小値/最大値をログに記録する
wandb の define_metricdefine_metric _ が使用されていない場合、最後にログに記録された値がサマリーメトリックに表示されます。define_metric のリファレンスドキュメントはこちら 、ガイドはこちら をご覧ください。
W&B に W&B サマリーメトリックの最大検証精度を追跡するように指示するには、トレーニングの開始時に 1 回だけ wandb.define_metric を呼び出します。
PyTorch Logger
Fabric Logger
class My_LitModule (LightningModule):
...
def validation_step (self, batch, batch_idx):
if trainer. global_step == 0 :
wandb. define_metric("val_accuracy" , summary= "max" )
preds, loss, acc = self. _get_preds_loss_accuracy(batch)
# 損失とメトリックをログに記録
self. log("val_loss" , loss)
self. log("val_accuracy" , acc)
return preds
wandb. define_metric("val_accuracy" , summary= "max" )
fabric = L. Fabric(loggers= [wandb_logger])
fabric. launch()
fabric. log_dict({"val_accuracy" : val_accuracy})
モデル をチェックポイントする
モデル のチェックポイントを W&B Artifacts として保存するには、Lightning の ModelCheckpointWandbLogger で log_model 引数を設定します。
PyTorch Logger
Fabric Logger
trainer = Trainer(logger= wandb_logger, callbacks= [checkpoint_callback])
fabric = L. Fabric(loggers= [wandb_logger], callbacks= [checkpoint_callback])
latest および best エイリアスは、W&B Artifact からモデル のチェックポイントを簡単に取得できるように自動的に設定されます。
# 参照は Artifacts パネルで取得できます
# "VERSION" は、バージョン ("v2" など) またはエイリアス ("latest" または "best") にすることができます
checkpoint_reference = "USER/PROJECT/MODEL-RUN_ID:VERSION"
# チェックポイントをローカルにダウンロードします (まだキャッシュされていない場合)
wandb_logger. download_artifact(checkpoint_reference, artifact_type= "model" )
# チェックポイントをローカルにダウンロードします (まだキャッシュされていない場合)
run = wandb. init(project= "MNIST" )
artifact = run. use_artifact(checkpoint_reference, type= "model" )
artifact_dir = artifact. download()
PyTorch Logger
Fabric Logger
# チェックポイントを読み込む
model = LitModule. load_from_checkpoint(Path(artifact_dir) / "model.ckpt" )
# 未加工のチェックポイントを要求する
full_checkpoint = fabric. load(Path(artifact_dir) / "model.ckpt" )
model. load_state_dict(full_checkpoint["model" ])
optimizer. load_state_dict(full_checkpoint["optimizer" ])
ログに記録するモデル のチェックポイントは、W&B Artifacts UI で表示でき、完全なモデル リネージが含まれています (UI のサンプル モデル のチェックポイントをこちら で参照してください)。
最適なモデル のチェックポイントをブックマークし、チーム全体で一元化するには、W&B モデルレジストリ にリンクできます。
ここでは、タスクごとに最適なモデル を整理したり、モデル のライフサイクルを管理したり、ML ライフサイクル全体で簡単な追跡と監査を容易にしたり、Webhook またはジョブでダウンストリームアクションを自動化 したりできます。
画像、テキストなどをログに記録する
WandbLogger には、メディアをログ記録するための log_image、log_text、および log_table メソッドがあります。
また、wandb.log または trainer.logger.experiment.log を直接呼び出して、オーディオ、分子、点群、3D オブジェクトなどの他のメディアタイプをログに記録することもできます。
画像のログ記録
テキストのログ記録
テーブル のログ記録
# テンソル、numpy 配列、または PIL 画像を使用
wandb_logger. log_image(key= "samples" , images= [img1, img2])
# キャプションを追加
wandb_logger. log_image(key= "samples" , images= [img1, img2], caption= ["tree" , "person" ])
# ファイルパスを使用
wandb_logger. log_image(key= "samples" , images= ["img_1.jpg" , "img_2.jpg" ])
# trainer で .log を使用
trainer. logger. experiment. log(
{"samples" : [wandb. Image(img, caption= caption) for (img, caption) in my_images]},
step= current_trainer_global_step,
)
# データはリストのリストである必要があります
columns = ["input" , "label" , "prediction" ]
my_data = [["cheese" , "english" , "english" ], ["fromage" , "french" , "spanish" ]]
# 列とデータを使用
wandb_logger. log_text(key= "my_samples" , columns= columns, data= my_data)
# pandas DataFrame を使用
wandb_logger. log_text(key= "my_samples" , dataframe= my_dataframe)
# テキスト キャプション、画像、オーディオを含む W&B テーブル をログに記録
columns = ["caption" , "image" , "sound" ]
# データはリストのリストである必要があります
my_data = [
["cheese" , wandb. Image(img_1), wandb. Audio(snd_1)],
["wine" , wandb. Image(img_2), wandb. Audio(snd_2)],
]
# テーブル をログに記録
wandb_logger. log_table(key= "my_samples" , columns= columns, data= data)
Lightning のコールバックシステムを使用すると、この例では検証画像と予測のサンプルをログに記録します。WandbLogger 経由で Weights & Biases にログを記録するタイミングを制御できます。
import torch
import wandb
import lightning.pytorch as pl
from lightning.pytorch.loggers import WandbLogger
# or
# from wandb.integration.lightning.fabric import WandbLogger
class LogPredictionSamplesCallback (Callback):
def on_validation_batch_end (
self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx
):
"""検証バッチが終了したときに呼び出されます。"""
# `outputs` は `LightningModule.validation_step` から取得されます
# これは、この場合のモデル予測に対応します
# 最初のバッチから 20 個のサンプル画像予測をログに記録しましょう
if batch_idx == 0 :
n = 20
x, y = batch
images = [img for img in x[:n]]
captions = [
f "Ground Truth: { y_i} - Prediction: { y_pred} "
for y_i, y_pred in zip(y[:n], outputs[:n])
]
# オプション 1: `WandbLogger.log_image` で画像をログに記録する
wandb_logger. log_image(key= "sample_images" , images= images, caption= captions)
# オプション 2: 画像と予測を W&B テーブル としてログに記録する
columns = ["image" , "ground truth" , "prediction" ]
data = [
[wandb. Image(x_i), y_i, y_pred] or x_i,
y_i,
y_pred in list(zip(x[:n], y[:n], outputs[:n])),
]
wandb_logger. log_table(key= "sample_table" , columns= columns, data= data)
trainer = pl. Trainer(callbacks= [LogPredictionSamplesCallback()])
Lightning と W&B で複数の GPU を使用する
PyTorch Lightning には、DDP インターフェイスによるマルチ GPU サポートがあります。ただし、PyTorch Lightning の設計では、GPU のインスタンス化方法に注意する必要があります。
Lightning は、トレーニングループの各 GPU (またはランク) が、まったく同じ方法 (同じ初期条件) でインスタンス化される必要があると想定しています。ただし、ランク 0 プロセスのみが wandb.run オブジェクトにアクセスでき、ゼロ以外のランク プロセスの場合: wandb.run = None。これにより、ゼロ以外のプロセスが失敗する可能性があります。このような状況は、ランク 0 プロセスがゼロ以外のランク プロセスが参加するのを待機するため、デッドロック 状態になる可能性があります。
このため、トレーニングコードのセットアップ方法には注意してください。トレーニングコードを wandb.run オブジェクトから独立させることをお勧めします。
class MNISTClassifier (pl. LightningModule):
def __init__(self):
super(MNISTClassifier, self). __init__()
self. model = nn. Sequential(
nn. Flatten(),
nn. Linear(28 * 28 , 128 ),
nn. ReLU(),
nn. Linear(128 , 10 ),
)
self. loss = nn. CrossEntropyLoss()
def forward (self, x):
return self. model(x)
def training_step (self, batch, batch_idx):
x, y = batch
y_hat = self. forward(x)
loss = self. loss(y_hat, y)
self. log("train/loss" , loss)
return {"train_loss" : loss}
def validation_step (self, batch, batch_idx):
x, y = batch
y_hat = self. forward(x)
loss = self. loss(y_hat, y)
self. log("val/loss" , loss)
return {"val_loss" : loss}
def configure_optimizers (self):
return torch. optim. Adam(self. parameters(), lr= 0.001 )
def main ():
# すべての乱数シードを同じ値に設定します。
# これは、分散トレーニング環境では重要です。
# 各ランクは、独自の初期重みセットを取得します。
# 一致しない場合、勾配も一致しません。
# 収束しない可能性のあるトレーニングにつながります。
pl. seed_everything(1 )
train_loader = DataLoader(train_dataset, batch_size= 64 , shuffle= True , num_workers= 4 )
val_loader = DataLoader(val_dataset, batch_size= 64 , shuffle= False , num_workers= 4 )
model = MNISTClassifier()
wandb_logger = WandbLogger(project= "<project_name>" )
callbacks = [
ModelCheckpoint(
dirpath= "checkpoints" ,
every_n_train_steps= 100 ,
),
]
trainer = pl. Trainer(
max_epochs= 3 , gpus= 2 , logger= wandb_logger, strategy= "ddp" , callbacks= callbacks
)
trainer. fit(model, train_loader, val_loader)
例
Colab のビデオチュートリアルをこちら でフォローできます。
よくある質問
W&B は Lightning とどのように統合されますか?
コア統合は、Lightning loggers API に基づいており、フレームワークに依存しない方法で多くのログ記録コードを記述できます。Logger は、Lightning Trainer に渡され、その API の豊富なフックアンドコールバックシステム に基づいてトリガーされます。これにより、研究コードがエンジニアリングコードおよびログ記録コードから適切に分離されます。
追加のコードなしで統合は何をログに記録しますか?
モデル のチェックポイントを W&B に保存します。そこで表示したり、ダウンロードして将来の run で使用したりできます。システムメトリクス (GPU 使用率やネットワーク I/O など)、ハードウェアや OS 情報などの環境情報、コード の状態 (git コミットと差分パッチ、ノートブック の内容、セッション履歴を含む)、および標準出力に出力されるものをキャプチャします。
トレーニングのセットアップで wandb.run を使用する必要がある場合はどうすればよいですか?
アクセスする必要がある変数のスコープを自分で拡張する必要があります。つまり、初期条件がすべてのプロセスで同じであることを確認してください。
if os. environ. get("LOCAL_RANK" , None ) is None :
os. environ["WANDB_DIR" ] = wandb. run. dir
そうである場合は、os.environ["WANDB_DIR"] を使用してモデル のチェックポイントディレクトリーを設定できます。これにより、ゼロ以外のランクプロセスは wandb.run.dir にアクセスできます。
6.34 - Ray Tune
W&B と Ray Tune を統合する方法。
W&B は、2 つの軽量な インテグレーション を提供することで、Ray と統合します。
WandbLoggerCallback 関数は、 Tune に報告された メトリクス を Wandb API に自動的に ログ します。関数 API で使用できる setup_wandb() 関数は、 Tune の トレーニング 情報で Wandb API を自動的に初期化します。通常どおり Wandb API を使用できます。たとえば、wandb.log() を使用して、 トレーニング プロセスを ログ します。
インテグレーション の 設定
from ray.air.integrations.wandb import WandbLoggerCallback
Wandb の 設定 は、tune.run() の config パラメータに wandb の キー を渡すことによって行われます (以下の例を参照)。
wandb config エントリ の内容は、 キーワード 引数として wandb.init() に渡されます。例外として、次の 設定 は WandbLoggerCallback 自体を 設定 するために使用されます。
パラメータ
project (str): Wandb の プロジェクト 名。必須。
api_key_file (str): Wandb APIキー を含むファイルへのパス。
api_key (str): Wandb APIキー 。api_key_file を 設定 する代替手段。
excludes (list): ログ から除外する メトリクス のリスト。
log_config (bool): results ディクショナリ の config パラメータ を ログ するかどうか。デフォルトは False。
upload_checkpoints (bool): True の場合、 モデル の チェックポイント は Artifacts としてアップロードされます。デフォルトは False。
例
from ray import tune, train
from ray.air.integrations.wandb import WandbLoggerCallback
def train_fc (config):
for i in range(10 ):
train. report({"mean_accuracy" : (i + config["alpha" ]) / 10 })
tuner = tune. Tuner(
train_fc,
param_space= {
"alpha" : tune. grid_search([0.1 , 0.2 , 0.3 ]),
"beta" : tune. uniform(0.5 , 1.0 ),
},
run_config= train. RunConfig(
callbacks= [
WandbLoggerCallback(
project= "<your-project>" , api_key= "<your-api-key>" , log_config= True
)
]
),
)
results = tuner. fit()
setup_wandb
from ray.air.integrations.wandb import setup_wandb
このユーティリティ関数は、Ray Tune で使用するために Wandb を初期化するのに役立ちます。基本的な使用法では、 トレーニング 関数で setup_wandb() を呼び出します。
from ray.air.integrations.wandb import setup_wandb
def train_fn (config):
# Initialize wandb
wandb = setup_wandb(config)
for i in range(10 ):
loss = config["a" ] + config["b" ]
wandb. log({"loss" : loss})
tune. report(loss= loss)
tuner = tune. Tuner(
train_fn,
param_space= {
# define search space here
"a" : tune. choice([1 , 2 , 3 ]),
"b" : tune. choice([4 , 5 , 6 ]),
# wandb configuration
"wandb" : {"project" : "Optimization_Project" , "api_key_file" : "/path/to/file" },
},
)
results = tuner. fit()
コード例
インテグレーション の動作を確認するための例をいくつか作成しました。
6.35 - SageMaker
W&B と Amazon SageMaker の統合方法について。
W&B は Amazon SageMaker と連携し、ハイパーパラメータの自動読み取り、分散 run のグループ化、チェックポイントからの run の再開を自動で行います。
認証
W&B は、トレーニングスクリプトを基準とした secrets.env という名前のファイルを探し、wandb.init() が呼び出されると、それらを環境にロードします。secrets.env ファイルは、実験の launch に使用するスクリプトで wandb.sagemaker_auth(path="source_dir") を呼び出すことによって生成できます。このファイルを必ず .gitignore に追加してください!
既存のエスティメーター
SageMaker の事前構成済みエスティメーターのいずれかを使用している場合は、wandb を含む requirements.txt をソースディレクトリーに追加する必要があります。
Python 2 を実行しているエスティメーターを使用している場合は、wandb をインストールする前に、この wheel から直接 psutil をインストールする必要があります。
https://wheels.galaxyproject.org/packages/psutil-5.4.8-cp27-cp27mu-manylinux1_x86_64.whl
wandb
完全な例は GitHub で確認し、詳細については blog を参照してください。
SageMaker と W&B を使用したセンチメント分析アナライザーのデプロイに関する チュートリアル もお読みいただけます。
W&B の sweep agent は、SageMaker インテグレーションが無効になっている場合にのみ、SageMaker ジョブで期待どおりに動作します。wandb.init の呼び出しを変更して、SageMaker インテグレーションをオフにします。
wandb. init(... , settings= wandb. Settings(sagemaker_disable= True ))
6.36 - Scikit-Learn
数行のコードで、scikit-learn モデルのパフォーマンスを可視化して比較するために wandb を使用できます。サンプルを試す →
はじめに
サインアップして APIキー を作成する
APIキー は、W&B に対してお客様のマシンを認証します。APIキー は、ユーザー プロファイルから生成できます。
右上隅にあるユーザー プロファイル アイコンをクリックします。
User Settings を選択し、API Keys セクションまでスクロールします。Reveal をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするローカルに wandb ライブラリをインストールしてログインするには:
コマンドライン
Python
Python notebook
APIキー に WANDB_API_KEY 環境変数 を設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
メトリクス をログする
import wandb
wandb. init(project= "visualize-sklearn" )
y_pred = clf. predict(X_test)
accuracy = sklearn. metrics. accuracy_score(y_true, y_pred)
# If logging metrics over time, then use wandb.log
# 時間経過とともにメトリクスをログする場合は、wandb.log を使用します
wandb. log({"accuracy" : accuracy})
# OR to log a final metric at the end of training you can also use wandb.summary
# または、トレーニングの最後に最終メトリクスをログするには、wandb.summary を使用することもできます
wandb. summary["accuracy" ] = accuracy
プロットを作成する
ステップ 1: wandb をインポートし、新しい run を初期化します
import wandb
wandb. init(project= "visualize-sklearn" )
ステップ 2: プロットを可視化します
個々のプロット
モデル をトレーニングして 予測 を行った後、wandb でプロットを生成して 予測 を分析できます。サポートされているチャートの完全なリストについては、以下の サポートされているプロット セクションを参照してください。
# Visualize single plot
# 単一のプロットを可視化します
wandb. sklearn. plot_confusion_matrix(y_true, y_pred, labels)
すべてのプロット
W&B には、いくつかの関連するプロットをプロットする plot_classifier などの関数があります。
# Visualize all classifier plots
# すべての分類器プロットを可視化します
wandb. sklearn. plot_classifier(
clf,
X_train,
X_test,
y_train,
y_test,
y_pred,
y_probas,
labels,
model_name= "SVC" ,
feature_names= None ,
)
# All regression plots
# すべての回帰プロット
wandb. sklearn. plot_regressor(reg, X_train, X_test, y_train, y_test, model_name= "Ridge" )
# All clustering plots
# すべてのクラスタリングプロット
wandb. sklearn. plot_clusterer(
kmeans, X_train, cluster_labels, labels= None , model_name= "KMeans"
)
既存の Matplotlib プロット
Matplotlib で作成されたプロットも W&B ダッシュボードにログできます。そのためには、最初に plotly をインストールする必要があります。
最後に、プロットは次のように W&B のダッシュボードにログできます。
import matplotlib.pyplot as plt
import wandb
wandb. init(project= "visualize-sklearn" )
# do all the plt.plot(), plt.scatter(), etc. here.
# ここに plt.plot(), plt.scatter() などをすべて記述します。
# ...
# instead of doing plt.show() do:
# plt.show() を実行する代わりに、次を実行します。
wandb. log({"plot" : plt})
サポートされているプロット
学習曲線
さまざまな長さの データセット でモデル をトレーニングし、トレーニング セットと テストセット の両方について、クロス検証されたスコアと データセット サイズのプロットを生成します。
wandb.sklearn.plot_learning_curve(model, X, y)
model (clf または reg): 適合された回帰子または分類器を受け入れます。
X (arr): データセット の特徴。
y (arr): データセット のラベル。
ROC
ROC 曲線は、真陽性率 (y 軸) 対 偽陽性率 (x 軸) をプロットします。理想的なスコアは TPR = 1 および FPR = 0 であり、これは左上の点です。通常、ROC 曲線下面積 (AUC-ROC) を計算し、AUC-ROC が大きいほど優れています。
wandb.sklearn.plot_roc(y_true, y_probas, labels)
y_true (arr): テストセット のラベル。
y_probas (arr): テストセット の 予測 確率。
labels (list): ターゲット変数 (y) の名前付きラベル。
クラスの割合
トレーニング セットと テストセット のターゲット クラスの分布をプロットします。不均衡なクラスを検出し、1 つのクラスが モデル に不均衡な影響を与えないようにするのに役立ちます。
wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])
y_train (arr): トレーニング セットのラベル。
y_test (arr): テストセット のラベル。
labels (list): ターゲット変数 (y) の名前付きラベル。
適合率 - 再現率曲線
さまざまなしきい値に対する 適合率 と 再現率 の間のトレードオフを計算します。曲線下面積が大きいほど、高い 再現率 と高い 適合率 の両方を表し、高い 適合率 は低い 偽陽性率 に関連し、高い 再現率 は低い 偽陰性率 に関連します。
両方の高いスコアは、分類器が正確な 結果 を返している (高い 適合率 ) だけでなく、すべての陽性の 結果 の大部分を返している (高い 再現率 ) ことを示しています。PR 曲線は、クラスが非常に不均衡な場合に役立ちます。
wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)
y_true (arr): テストセット のラベル。
y_probas (arr): テストセット の 予測 確率。
labels (list): ターゲット変数 (y) の名前付きラベル。
特徴の重要度
分類タスクにおける各特徴の重要度を評価およびプロットします。feature_importances_ 属性を持つ分類器 ( ツリー など) でのみ機能します。
wandb.sklearn.plot_feature_importances(model, ['width', 'height, 'length'])
model (clf): 適合された分類器を受け入れます。
feature_names (list): 特徴の名前。特徴インデックスを対応する名前に置き換えることで、プロットを読みやすくします。
較正曲線
分類器の 予測 確率がどの程度較正されているか、および較正されていない分類器を較正する方法をプロットします。ベースラインのロジスティック回帰 モデル 、 引数 として渡された モデル 、およびその等方性較正とシグモイド較正の両方によって推定された 予測 確率を比較します。
較正曲線が対角線に近いほど優れています。転置されたシグモイドのような曲線は 過学習された 分類器を表し、シグモイドのような曲線は 学習不足 の分類器を表します。モデル の等方性較正とシグモイド較正をトレーニングし、それらの曲線を比較することで、モデル が 過学習 または 学習不足 であるかどうか、またそうである場合、どの較正 (シグモイドまたは等方性) がこれを修正するのに役立つかを把握できます。
詳細については、sklearn のドキュメント を参照してください。
wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')
model (clf): 適合された分類器を受け入れます。
X (arr): トレーニング セットの特徴。
y (arr): トレーニング セットのラベル。
model_name (str): モデル 名。デフォルトは ‘Classifier’
混同行列
混同行列を計算して、分類の精度を評価します。モデル の 予測 の品質を評価し、モデル が間違える 予測 のパターンを見つけるのに役立ちます。対角線は、実際のラベルが 予測 されたラベルと等しい場合など、モデル が正しく取得した 予測 を表します。
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
y_true (arr): テストセット のラベル。
y_pred (arr): テストセット の 予測 されたラベル。
labels (list): ターゲット変数 (y) の名前付きラベル。
サマリーメトリクス
mse、mae、r2 スコアなど、分類のサマリー メトリクス を計算します。f1、精度、 適合率 、 再現率 など、回帰のサマリー メトリクス を計算します。
wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)
model (clf または reg): 適合された回帰子または分類器を受け入れます。
X (arr): トレーニング セットの特徴。
y (arr): トレーニング セットのラベル。
X_test (arr): テストセット の特徴。
y_test (arr): テストセット のラベル。
エルボープロット
トレーニング時間とともに、クラスター の数に応じて説明される分散の割合を測定およびプロットします。最適な クラスター の数を選択するのに役立ちます。
wandb.sklearn.plot_elbow_curve(model, X_train)
model (clusterer): 適合されたクラスタラーを受け入れます。
X (arr): トレーニング セットの特徴。
シルエットプロット
1 つの クラスター 内の各点が隣接する クラスター 内の点にどれだけ近いかを測定してプロットします。クラスター の太さは、 クラスター サイズに対応します。垂直線は、すべての点の平均シルエットスコアを表します。
+1 に近いシルエット係数は、サンプルが隣接する クラスター から遠く離れていることを示します。0 の値は、サンプルが 2 つの隣接する クラスター 間の決定境界上または非常に近いことを示し、負の値は、それらのサンプルが間違った クラスター に割り当てられた可能性があることを示します。
一般に、すべてのシルエット クラスター スコアが平均以上 (赤い線を超えている) であり、できるだけ 1 に近いことが望ましいです。また、 データ 内の基礎となるパターンを反映する クラスター サイズも推奨されます。
wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])
model (clusterer): 適合されたクラスタラーを受け入れます。
X (arr): トレーニング セットの特徴。
cluster_labels (list): クラスター ラベルの名前。クラスター インデックスを対応する名前に置き換えることで、プロットを読みやすくします。
外れ値候補プロット
Cook の距離を介して回帰 モデル に対する データポイント の影響を測定します。大きく歪んだ影響を持つインスタンスは、潜在的に外れ値である可能性があります。外れ値の検出に役立ちます。
wandb.sklearn.plot_outlier_candidates(model, X, y)
model (regressor): 適合された分類器を受け入れます。
X (arr): トレーニング セットの特徴。
y (arr): トレーニング セットのラベル。
残差プロット
予測 されたターゲット値 (y 軸) と実際のターゲット値と 予測 されたターゲット値の差 (x 軸) を測定してプロットし、残差誤差の分布を測定してプロットします。
一般に、適切に適合された モデル の残差はランダムに分布している必要があります。これは、優れた モデル はランダム誤差を除く データセット 内のほとんどの現象を考慮するためです。
wandb.sklearn.plot_residuals(model, X, y)
例
6.37 - Simple Transformers
Hugging Face の Transformers ライブラリ と W&B を統合する方法。
このライブラリは、Hugging Face の Transformers ライブラリをベースにしています。Simple Transformers を使用すると、Transformer モデルを迅速にトレーニングおよび評価できます。モデルの初期化、モデルのトレーニング、モデルの評価に必要なコードはわずか 3 行です。Sequence Classification(シーケンス分類)、Token Classification(トークン分類、固有表現認識)、Question Answering(質問応答)、Language Model Fine-Tuning(言語モデルのファインチューニング)、Language Model Training(言語モデルのトレーニング)、Language Generation(言語生成)、T5 モデル、Seq2Seq Tasks(Seq2Seq タスク)、Multi-Modal Classification(マルチモーダル分類)、Conversational AI(会話型 AI)をサポートしています。
モデルトレーニングを可視化するために Weights and Biases を使用するには、args 辞書の wandb_project 属性に W&B のプロジェクト名を設定します。これにより、すべてのハイパーパラメーター 値、トレーニング損失、評価メトリクスが指定されたプロジェクトに記録されます。
model = ClassificationModel('roberta' , 'roberta-base' , args= {'wandb_project' : 'project-name' })
wandb.init に渡される追加の 引数 は、wandb_kwargs として渡すことができます。
構造
このライブラリは、すべての NLP タスクに個別のクラスを持つように設計されています。同様の機能を提供するクラスはグループ化されています。
simpletransformers.classification - すべての Classification(分類)モデルが含まれます。
ClassificationModelMultiLabelClassificationModel
simpletransformers.ner - すべての Named Entity Recognition(固有表現認識)モデルが含まれます。
simpletransformers.question_answering - すべての Question Answering(質問応答)モデルが含まれます。
以下に最小限の例をいくつか示します。
MultiLabel Classification(マルチラベル分類)
model = MultiLabelClassificationModel("distilbert","distilbert-base-uncased",num_labels=6,
args={"reprocess_input_data": True, "overwrite_output_dir": True, "num_train_epochs":epochs,'learning_rate':learning_rate,
'wandb_project': "simpletransformers"},
)
# モデルをトレーニング
model.train_model(train_df)
# モデルを評価
result, model_outputs, wrong_predictions = model.eval_model(eval_df)
Question Answering(質問応答)
train_args = {
'learning_rate': wandb.config.learning_rate,
'num_train_epochs': 2,
'max_seq_length': 128,
'doc_stride': 64,
'overwrite_output_dir': True,
'reprocess_input_data': False,
'train_batch_size': 2,
'fp16': False,
'wandb_project': "simpletransformers"
}
model = QuestionAnsweringModel('distilbert', 'distilbert-base-cased', args=train_args)
model.train_model(train_data)
SimpleTransformers は、一般的な自然言語タスクのためのクラスとトレーニング スクリプトを提供します。以下は、このライブラリでサポートされているグローバル 引数 の完全なリストと、そのデフォルトの 引数 です。
global_args = {
"adam_epsilon": 1e-8,
"best_model_dir": "outputs/best_model",
"cache_dir": "cache_dir/",
"config": {},
"do_lower_case": False,
"early_stopping_consider_epochs": False,
"early_stopping_delta": 0,
"early_stopping_metric": "eval_loss",
"early_stopping_metric_minimize": True,
"early_stopping_patience": 3,
"encoding": None,
"eval_batch_size": 8,
"evaluate_during_training": False,
"evaluate_during_training_silent": True,
"evaluate_during_training_steps": 2000,
"evaluate_during_training_verbose": False,
"fp16": True,
"fp16_opt_level": "O1",
"gradient_accumulation_steps": 1,
"learning_rate": 4e-5,
"local_rank": -1,
"logging_steps": 50,
"manual_seed": None,
"max_grad_norm": 1.0,
"max_seq_length": 128,
"multiprocessing_chunksize": 500,
"n_gpu": 1,
"no_cache": False,
"no_save": False,
"num_train_epochs": 1,
"output_dir": "outputs/",
"overwrite_output_dir": False,
"process_count": cpu_count() - 2 if cpu_count() > 2 else 1,
"reprocess_input_data": True,
"save_best_model": True,
"save_eval_checkpoints": True,
"save_model_every_epoch": True,
"save_steps": 2000,
"save_optimizer_and_scheduler": True,
"silent": False,
"tensorboard_dir": None,
"train_batch_size": 8,
"use_cached_eval_features": False,
"use_early_stopping": False,
"use_multiprocessing": True,
"wandb_kwargs": {},
"wandb_project": None,
"warmup_ratio": 0.06,
"warmup_steps": 0,
"weight_decay": 0,
}
詳細なドキュメントについては、github の simpletransformers を参照してください。
最も人気のある GLUE ベンチマーク データセットで transformers のトレーニングをカバーするこちらの Weights and Biases report を確認してください。colab で自分で試してみてください 。
6.38 - Skorch
Skorch と W&B を統合する方法。
Skorch で Weights & Biases を使用すると、各エポック後に、すべてのモデルパフォーマンスメトリクス、モデルトポロジ、およびコンピューティングリソースとともに、最高のパフォーマンスを持つモデルを自動的にログ記録できます。 wandb_run.dir に保存されたすべてのファイルは、W&B サーバーに自動的にログ記録されます。
run の例 を参照してください。
パラメータ
パラメータ
タイプ
説明
wandb_runwandb.wandb_run. Runデータのログ記録に使用される wandb run。
save_modelbool (default=True)
最適なモデルのチェックポイントを保存し、W&B サーバー上の Run にアップロードするかどうか。
keys_ignoredstr または str のリスト (default=None)
tensorboard にログ記録しないキーまたはキーのリスト。 ユーザーが提供するキーに加えて、event_ で始まるキーや _best で終わるキーはデフォルトで無視されることに注意してください。
コード例
このインテグレーションの動作を確認するための例をいくつか作成しました。
# wandb をインストール
... pip install wandb
import wandb
from skorch.callbacks import WandbLogger
# wandb Run を作成
wandb_run = wandb. init()
# 代替案: W&B アカウントなしで wandb Run を作成
wandb_run = wandb. init(anonymous= "allow" )
# ハイパーパラメータをログ記録 (オプション)
wandb_run. config. update({"learning rate" : 1e-3 , "batch size" : 32 })
net = NeuralNet(... , callbacks= [WandbLogger(wandb_run)])
net. fit(X, y)
メソッドリファレンス
メソッド
説明
initialize()コールバックの初期状態を(再)設定します。
on_batch_begin(net[, X, y, training])各バッチの開始時に呼び出されます。
on_batch_end(net[, X, y, training])各バッチの終了時に呼び出されます。
on_epoch_begin(net[, dataset_train, …])各エポックの開始時に呼び出されます。
on_epoch_end(net, **kwargs)最後の履歴ステップから値をログ記録し、最適なモデルを保存します。
on_grad_computed(net, named_parameters[, X, …])勾配が計算された後、更新ステップが実行される前に、バッチごとに 1 回呼び出されます。
on_train_begin(net, **kwargs)モデルトポロジをログ記録し、勾配の hook を追加します。
on_train_end(net[, X, y])トレーニングの終了時に呼び出されます。
6.39 - spaCy
spaCy は、人気のある「産業用強度」の NLP ライブラリであり、高速かつ正確なモデルを最小限の手間で実現します。spaCy v3 以降、Weights & Biases を spacy train
サインアップして APIキー を作成する
APIキー は、お使いのマシンを W&B に対して認証します。APIキー は、ユーザープロフィール から生成できます。
右上隅にあるユーザープロフィールアイコンをクリックします。
ユーザー設定 を選択し、APIキー セクションまでスクロールします。公開 をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードしてください。
wandb ライブラリをインストールしてログインするローカルに wandb ライブラリをインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 を APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
WandbLogger を spaCy 設定ファイルに追加するspaCy の設定ファイルは、ロギングだけでなく、トレーニングのあらゆる側面(GPU 割り当て、オプティマイザー の選択、データセット のパスなど)を指定するために使用されます。最小限の構成として、[training.logger] の下に、キー @loggers に値 "spacy.WandbLogger.v3" と project_name を指定する必要があります。
spaCy のトレーニング設定ファイルの仕組みと、トレーニングをカスタマイズするために渡すことができるその他のオプションの詳細については、
spaCy のドキュメント を参照してください。
[training. logger]
@loggers = "spacy.WandbLogger.v3"
project_name = "my_spacy_project"
remove_config_values = ["paths.train" , "paths.dev" , "corpora.train.path" , "corpora.dev.path" ]
log_dataset_dir = "./corpus"
model_log_interval = 1000
Name
Description
project_namestr 。W&B の Project の名前。まだ存在しない場合、Project は自動的に作成されます。
remove_config_valuesList[str] 。W&B にアップロードする前に、設定から除外する値のリスト。デフォルトは [] です。
model_log_intervalOptional int。デフォルトは None。設定すると、モデルのバージョン管理 が Artifacts で有効になります。モデルのチェックポイントのロギング間隔までのステップ数を渡します。デフォルトは None です。
log_dataset_dirOptional str。パスを渡すと、トレーニングの開始時にデータセット が Artifacts としてアップロードされます。デフォルトは None です。
entityOptional str 。渡された場合、run は指定された entity に作成されます
run_nameOptional str 。指定された場合、run は指定された名前で作成されます。
トレーニングを開始する
WandbLogger を spaCy トレーニング設定に追加したら、通常どおり spacy train を実行できます。
コマンドライン
Python
Python notebook
python - m spacy train \
config. cfg \
-- output ./ output \
-- paths. train ./ train \
-- paths. dev ./ dev
python - m spacy train \
config. cfg \
-- output ./ output \
-- paths. train ./ train \
-- paths. dev ./ dev
!python -m spacy train \
config.cfg \
--output ./output \
--paths.train ./train \
--paths.dev ./dev
トレーニングが開始されると、トレーニング run の W&B ページ へのリンクが出力されます。このリンクをクリックすると、Weights & Biases Web UI で、この run の 実験管理 ダッシュボード に移動します。
6.40 - Stable Baselines 3
Stable Baseline 3 と W&B を統合する方法。
Stable Baselines 3 (SB3) は、PyTorch で記述された強化学習アルゴリズムの信頼性の高い実装のセットです。W&B の SB3 インテグレーション:
損失やエピソードリターンなどのメトリクスを記録します。
エージェントがゲームをプレイする動画をアップロードします。
トレーニング済みのモデルを保存します。
モデルのハイパーパラメーターをログに記録します。
モデルの勾配ヒストグラムをログに記録します。
W&B を使用した SB3 のトレーニング run の 例 を確認してください。
SB3 の 実験管理
from wandb.integration.sb3 import WandbCallback
model. learn(... , callback= WandbCallback())
WandbCallback の引数
引数
使い方
verbosesb3 出力の詳細度
model_save_pathモデルが保存されるフォルダーへのパス。デフォルト値は `None` なので、モデルはログに記録されません。
model_save_freqモデルを保存する頻度
gradient_save_freq勾配をログに記録する頻度。デフォルト値は 0 なので、勾配はログに記録されません。
基本的な例
W&B SB3 インテグレーションは、TensorBoard からのログ出力を使用してメトリクスを記録します。
import gym
from stable_baselines3 import PPO
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.vec_env import DummyVecEnv, VecVideoRecorder
import wandb
from wandb.integration.sb3 import WandbCallback
config = {
"policy_type" : "MlpPolicy" ,
"total_timesteps" : 25000 ,
"env_name" : "CartPole-v1" ,
}
run = wandb. init(
project= "sb3" ,
config= config,
sync_tensorboard= True , # sb3 の tensorboard メトリクスを自動アップロード
monitor_gym= True , # エージェントがゲームをプレイする動画を自動アップロード
save_code= True , # オプション
)
def make_env ():
env = gym. make(config["env_name" ])
env = Monitor(env) # リターンなどの統計を記録
return env
env = DummyVecEnv([make_env])
env = VecVideoRecorder(
env,
f "videos/ { run. id} " ,
record_video_trigger= lambda x: x % 2000 == 0 ,
video_length= 200 ,
)
model = PPO(config["policy_type" ], env, verbose= 1 , tensorboard_log= f "runs/ { run. id} " )
model. learn(
total_timesteps= config["total_timesteps" ],
callback= WandbCallback(
gradient_save_freq= 100 ,
model_save_path= f "models/ { run. id} " ,
verbose= 2 ,
),
)
run. finish()
6.41 - TensorBoard
W&B は、W&B マルチテナント SaaS 用の埋め込み TensorBoard をサポートしています。
TensorBoard の ログ を クラウド にアップロードし、同僚やクラスメートとすばやく 結果 を共有して、 分析 を一元的な場所に保管できます。
はじめに
import wandb
# `sync_tensorboard=True` で wandb の run を開始します。
wandb. init(project= "my-project" , sync_tensorboard= True )
# TensorBoard を使用したトレーニングコード
...
# [オプション] W&B に TensorBoard の ログ をアップロードするために、wandb の run を終了します ( Colabノートブック で実行している場合)。
wandb. finish()
例 を確認してください。
run が完了すると、W&B で TensorBoard イベントファイルに アクセス し、ネイティブの W&B チャートで メトリクス を視覚化できます。さらに、システムの CPU や GPU の使用率、git の状態、run が使用した ターミナル コマンドなど、役立つ追加情報も表示できます。
W&B は、すべての TensorFlow バージョンで TensorBoard をサポートしています。W&B は、PyTorch および TensorBoardX を使用した TensorBoard 1.14 以降もサポートしています。
よくある質問
TensorBoard に ログ 記録されない メトリクス を W&B に ログ 記録するにはどうすればよいですか?
TensorBoard に ログ 記録されていない追加のカスタム メトリクス を ログ 記録する必要がある場合は、コードで wandb.log を呼び出すことができます。wandb.log({"custom": 0.8})
Tensorboard を同期すると、wandb.log の step 引数 の設定はオフになります。別の step カウントを設定する場合は、step メトリクス とともに メトリクス を ログ 記録できます。
wandb.log({"custom": 0.8, "global_step": global_step})
wandb で TensorBoard を使用している場合、TensorBoard をどのように構成しますか?TensorBoard の パッチ 適用方法をより詳細に制御する場合は、wandb.init に sync_tensorboard=True を渡す代わりに、wandb.tensorboard.patch を呼び出すことができます。
import wandb
wandb. tensorboard. patch(root_logdir= "<logging_directory>" )
wandb. init()
# W&B に TensorBoard の ログ をアップロードするために、wandb の run を終了します ( Colabノートブック で実行している場合)。
wandb. finish()
TensorBoard > 1.14 を PyTorch で使用している場合は、バニラ TensorBoard に パッチ が適用されていることを確認するために tensorboard_x=False をこの メソッド に渡し、 パッチ が適用されていることを確認するために pytorch=True を渡すことができます。これらのオプションには両方とも、これらのライブラリのどの バージョン がインポートされたかに応じて、スマートなデフォルトがあります。
デフォルトでは、tfevents ファイルと .pbtxt ファイルも同期します。これにより、お客様に代わって TensorBoard インスタンスを ローンンチ することができます。run ページに TensorBoard タブ が表示されます。この 振る舞い は、save=False を wandb.tensorboard.patch に渡すことでオフにできます。
import wandb
wandb. init()
wandb. tensorboard. patch(save= False , tensorboard_x= True )
# Colabノートブック で実行している場合は、wandb の run を終了して、TensorBoard の ログ を W&B にアップロードします。
wandb. finish()
tf.summary.create_file_writer を呼び出すか、torch.utils.tensorboard を介して SummaryWriter を構築する 前に 、wandb.init または wandb.tensorboard.patch のいずれかを呼び出す必要があります。
履歴 TensorBoard の run を同期するにはどうすればよいですか?
既存の tfevents ファイルがローカルに保存されていて、それらを W&B にインポートする場合は、wandb sync log_dir を実行します。ここで、log_dir は tfevents ファイルを含むローカル ディレクトリー です。
Google Colab または Jupyter を TensorBoard で使用するにはどうすればよいですか?
Jupyter または Colabノートブック でコードを実行している場合は、トレーニングの最後に wandb.finish() を呼び出すようにしてください。これにより、wandb の run が終了し、TensorBoard の ログ が W&B にアップロードされて視覚化できるようになります。wandb は スクリプト の完了時に自動的に完了するため、.py スクリプト を実行する場合はこれは必要ありません。
ノートブック 環境で シェル コマンド を実行するには、!wandb sync directoryname のように ! を先頭に付ける必要があります。
PyTorch を TensorBoard で使用するにはどうすればよいですか?
PyTorch の TensorBoard インテグレーション を使用する場合は、PyTorch Profiler JSON ファイルを手動でアップロードする必要がある場合があります。
wandb. save(glob. glob(f "runs/*.pt.trace.json" )[0 ], base_path= f "runs" )
6.42 - TensorFlow
はじめに
TensorBoard をすでに使用している場合、wandb との連携は簡単です。
import tensorflow as tf
import wandb
wandb. init(config= tf. flags. FLAGS, sync_tensorboard= True )
カスタム メトリクスのログ
TensorBoard に記録されていない追加のカスタム メトリクスを記録する必要がある場合は、コード内で wandb.log を呼び出すことができます。wandb.log({"custom": 0.8})
Tensorboard を同期すると、wandb.log の step 引数の設定はオフになります。別のステップ数を設定する場合は、次のようにステップ メトリクスを使用してメトリクスを記録できます。
wandb. log({"custom" : 0.8 , "global_step" :global_step}, step= global_step)
TensorFlow estimators hook
ログに記録する内容をより詳細に制御したい場合は、wandb は TensorFlow estimators 用の hook も提供します。グラフ内のすべての tf.summary の値を記録します。
import tensorflow as tf
import wandb
wandb. init(config= tf. FLAGS)
estimator. train(hooks= [wandb. tensorflow. WandbHook(steps_per_log= 1000 )])
手動でのログ
TensorFlow でメトリクスをログに記録する最も簡単な方法は、TensorFlow ロガーで tf.summary をログに記録することです。
import wandb
with tf. Session() as sess:
# ...
wandb. tensorflow. log(tf. summary. merge_all())
TensorFlow 2 では、カスタム ループでモデルをトレーニングするための推奨される方法は、tf.GradientTape を使用することです。詳細については、こちら をご覧ください。wandb を組み込んでカスタム TensorFlow トレーニング ループでメトリクスをログに記録する場合は、次のスニペットに従ってください。
with tf. GradientTape() as tape:
# Get the probabilities
predictions = model(features)
# Calculate the loss
loss = loss_func(labels, predictions)
# Log your metrics
wandb. log("loss" : loss. numpy())
# Get the gradients
gradients = tape. gradient(loss, model. trainable_variables)
# Update the weights
optimizer. apply_gradients(zip(gradients, model. trainable_variables))
完全な例はこちら にあります。
W&B と TensorBoard の違いは何ですか?
共同創設者が W&B の開発を開始したとき、OpenAI の不満を抱えた TensorBoard ユーザーのためにツールを構築することに触発されました。改善に重点を置いている点をいくつかご紹介します。
モデルの再現 : Weights & Biases は、実験 、探索、および後でモデルを再現するのに適しています。メトリクスだけでなく、ハイパーパラメーターとコードのバージョンもキャプチャし、プロジェクトを再現できるように、バージョン管理ステータスとモデルのチェックポイントを保存できます。自動編成 : コラボレーターからプロジェクトを引き継ぐ場合でも、休暇から戻ってきた場合でも、古いプロジェクトを整理する場合でも、W&B を使用すると、試行されたすべてのモデルを簡単に確認できるため、誰も時間、 GPU サイクル、またはカーボンを無駄に実験を再実行することはありません。高速で柔軟なインテグレーション : W&B を 5 分でプロジェクトに追加します。無料のオープンソース Python パッケージをインストールし、コードに数行追加するだけで、モデルを実行するたびに、適切なログに記録されたメトリクスとレコードが得られます。永続的で集中化されたダッシュボード : ローカル マシン、共有ラボ クラスター、クラウドのスポット インスタンスなど、モデルをどこでトレーニングする場合でも、結果は同じ集中化されたダッシュボードに共有されます。さまざまなマシンから TensorBoard ファイルをコピーして整理する時間を費やす必要はありません。強力な テーブル : さまざまなモデルの結果を検索、フィルタリング、ソート、およびグループ化します。数千のモデル バージョンを確認し、さまざまなタスクに最適なモデルを簡単に見つけることができます。TensorBoard は、大規模なプロジェクトでうまく機能するように構築されていません。コラボレーション ツール : W&B を使用して、複雑な 機械学習 プロジェクトを整理します。W&B へのリンクを簡単に共有でき、プライベート Teams を使用して、全員が結果を共有プロジェクトに送信できます。Reports を介したコラボレーションもサポートしています。インタラクティブな 可視化を追加し、markdown で作業内容を記述します。これは、作業ログを保持し、上司と学びを共有したり、ラボや Teams に学びを提示したりするのに最適な方法です。
無料アカウント を始めましょう
例
インテグレーションの仕組みを示すために、いくつかの例を作成しました。
6.43 - W&B for Julia
W&B を Julia と統合する方法。
Julia プログラミング言語で機械学習 の 実験 を実行している方のために、コミュニティの貢献者の方が、wandb.jl と呼ばれる Julia バインディングの非公式セットを作成しました。
wandb.jl リポジトリのドキュメント に例があります。以下は「はじめに」の例です。
using Wandb, Dates, Logging
# Start a new run, tracking hyperparameters in config
lg = WandbLogger(project = "Wandb.jl" ,
name = "wandbjl-demo- $ (now())" ,
config = Dict ("learning_rate" => 0.01 ,
"dropout" => 0.2 ,
"architecture" => "CNN" , # アーキテクチャー
"dataset" => "CIFAR-100" )) # データセット
# Use LoggingExtras.jl to log to multiple loggers together
global_logger(lg)
# Simulating the training or evaluation loop
for x ∈ 1 : 50
acc = log(1 + x + rand() * get_config(lg, "learning_rate" ) + rand() + get_config(lg, "dropout" ))
loss = 10 - log(1 + x + rand() + x * get_config(lg, "learning_rate" ) + rand() + get_config(lg, "dropout" ))
# Log metrics from your script to W&B
@info "metrics" accuracy= acc loss= loss
end
# Finish the run
close(lg)
6.44 - XGBoost
W&B で ツリー を追跡します。
wandb ライブラリには、XGBoost でのトレーニングからメトリクス、config、および保存されたブースターを記録するための WandbCallback コールバックがあります。ここでは、XGBoost WandbCallback からの出力を含む、ライブの Weights & Biases ダッシュボード
始め方
XGBoost のメトリクス、config、およびブースターモデルを Weights & Biases に記録するには、WandbCallback を XGBoost に渡すだけです。
from wandb.integration.xgboost import WandbCallback
import xgboost as XGBClassifier
...
# Start a wandb run
run = wandb. init()
# Pass WandbCallback to the model
bst = XGBClassifier()
bst. fit(X_train, y_train, callbacks= [WandbCallback(log_model= True )])
# Close your wandb run
run. finish()
XGBoost と Weights & Biases でのロギングの詳細については、この notebook
WandbCallback リファレンス機能
WandbCallback を XGBoost モデルに渡すと、次のようになります。
ブースターモデルの構成を Weights & Biases に記録します。
XGBoost によって収集された評価 メトリクス (rmse、accuracy など) を Weights & Biases に記録します。
XGBoost によって収集されたトレーニング メトリクス (eval_set にデータを提供する場合) を記録します。
最高のスコアと最高のイテレーションを記録します。
トレーニング済みのモデルを保存して Weights & Biases Artifacts にアップロードします (log_model = True の場合)。
log_feature_importance=True (デフォルト) の場合、特徴量のインポータンスプロットを記録します。define_metric=True (デフォルト) の場合、wandb.summary で最適な評価 メトリクスをキャプチャします。
引数
log_model: (boolean) True の場合、モデルを保存して Weights & Biases Artifacts にアップロードします。
log_feature_importance: (boolean) True の場合、特徴量のインポータンス棒グラフを記録します。
importance_type: (str) ツリー モデルの場合は {weight, gain, cover, total_gain, total_cover} のいずれか。線形モデルの場合は weight。
define_metric: (boolean) True (デフォルト) の場合、wandb.summary でトレーニングの最後のステップではなく、最適なステップでのモデルのパフォーマンスをキャプチャします。
WandbCallback のソース コード を確認できます。
その他の例については、GitHub の examples リポジトリ を確認してください。
Sweeps でハイパーパラメータを チューニングする
モデルのパフォーマンスを最大限に引き出すには、ツリーの深さや学習率などのハイパーパラメータを チューニングする必要があります。Weights & Biases には、大規模なハイパーパラメータ テスト実験を構成、調整、および分析するための強力な ツールキットである Sweeps が含まれています。
この XGBoost & Sweeps Python スクリプト を試すこともできます。
6.45 - YOLOv5
Ultralytics’ YOLOv5 (「You Only Look Once」) モデルファミリーは、苦痛を伴うことなく、畳み込みニューラルネットワークによるリアルタイムの オブジェクト検出を可能にします。
Weights & Biases は YOLOv5 に直接統合されており、実験の メトリクス 追跡、モデルと データセット の バージョン管理 、豊富なモデル 予測 の 可視化 などを提供します。YOLO の 実験 を実行する前に、pip install を 1 回実行するだけで簡単に利用できます。
W&B のすべての ログ 機能は、
PyTorch DDP などの データ並列マルチ GPU トレーニングと互換性があります。
コアな 実験 を追跡する
wandb をインストールするだけで、組み込みの W&B ログ 機能 が有効になります。システム メトリクス 、モデル メトリクス 、および インタラクティブな ダッシュボード に ログ されるメディアです。
pip install wandb
git clone https:// github. com/ ultralytics/ yolov5. git
python yolov5/ train. py # 小さなデータセットで小さなネットワークをトレーニングします。
wandb によって標準出力に出力されたリンクをたどってください。
インテグレーション をカスタマイズする
いくつかの簡単な コマンドライン 引数 を YOLO に渡すことで、さらに多くの W&B 機能を活用できます。
--save_period に数値を渡すと、W&B は save_period エポック の終了ごとに モデル バージョン を保存します。モデル バージョン には、モデルの 重み が含まれており、 検証セット で最高のパフォーマンスを発揮するモデルにタグを付けます。--upload_dataset フラグをオンにすると、 データ バージョン管理 のために データセット もアップロードされます。--bbox_interval に数値を渡すと、データ可視化 が有効になります。bbox_interval エポック の終了ごとに、 検証セット 上のモデルの出力が W&B にアップロードされます。
モデルの バージョン管理 のみ
モデルの バージョン管理 と データ可視化
python yolov5/ train. py -- epochs 20 -- save_period 1
python yolov5/ train. py -- epochs 20 -- save_period 1 \
-- upload_dataset -- bbox_interval 1
すべての W&B アカウントには、 データセット と モデル 用に 100 GB の無料ストレージが付属しています。
このようになります。
データ と モデル の バージョン管理 により、セットアップなしで、一時停止またはクラッシュした 実験 を任意のデバイスから再開できます。詳細については、
Colab をご覧ください。
6.46 - Ultralytics
Ultralytics は、画像分類、オブジェクト検出、画像セグメンテーション、姿勢推定などのタスクのための、最先端のコンピュータビジョン モデルの本拠地です。リアルタイムオブジェクト検出モデルの YOLO シリーズの最新版である YOLOv8 をホストするだけでなく、SAM (Segment Anything Model) 、RT-DETR 、YOLO-NAS などの他の強力なコンピュータビジョン モデルもホストしています。これらのモデルの実装を提供するだけでなく、Ultralytics は、使いやすい API を使用してこれらのモデルをトレーニング、ファインチューン、および適用するための、すぐに使える ワークフローも提供します。
始めましょう
ultralytics と wandb をインストールします。
```shell
pip install --upgrade ultralytics==8.0.238 wandb
# or
# conda install ultralytics
```
```bash
!pip install --upgrade ultralytics==8.0.238 wandb
```
開発チームは、ultralyticsv8.0.238 以下のバージョンとの インテグレーションをテストしました。インテグレーションに関する問題点を報告するには、yolov8 タグを付けて GitHub issue を作成してください。
実験管理の追跡と検証結果の可視化
このセクションでは、トレーニング、ファインチューン、および検証に Ultralytics モデルを使用し、W&B を使用して実験管理の追跡、モデルのチェックポイント、およびモデルのパフォーマンスの可視化を実行する典型的なワークフローを示します。
この レポートで インテグレーションについて確認することもできます。W&B で Ultralytics を強化する
Ultralytics で W&B インテグレーションを使用するには、wandb.integration.ultralytics.add_wandb_callback 関数をインポートします。
import wandb
from wandb.integration.ultralytics import add_wandb_callback
from ultralytics import YOLO
選択した YOLO モデルを初期化し、モデルで推論を実行する前に、そのモデルで add_wandb_callback 関数を呼び出します。これにより、トレーニング、ファインチューン、検証、または推論を実行すると、実験 ログと画像が自動的に保存され、W&B 上の コンピュータビジョン タスクのインタラクティブなオーバーレイ を使用して、グラウンドトゥルースとそれぞれの予測結果が重ねられ、追加の洞察が wandb.Table
# Initialize YOLO Model
model = YOLO("yolov8n.pt" )
# Add W&B callback for Ultralytics
add_wandb_callback(model, enable_model_checkpointing= True )
# Train/fine-tune your model
# At the end of each epoch, predictions on validation batches are logged
# to a W&B table with insightful and interactive overlays for
# computer vision tasks
model. train(project= "ultralytics" , data= "coco128.yaml" , epochs= 5 , imgsz= 640 )
# Finish the W&B run
wandb. finish()
Ultralytics のトレーニングまたはファインチューン ワークフローのために W&B を使用して追跡された実験は、次のようになります。
YOLO Fine-tuning Experiments W&B Table を使用して、エポックごとの検証結果を可視化する方法を次に示します。
WandB Validation Visualization Table 予測結果の可視化
このセクションでは、推論に Ultralytics モデルを使用し、W&B を使用して結果を可視化する典型的なワークフローを示します。
Google Colab でコードを試すことができます:Open in Colab 。
この レポートで インテグレーションについて確認することもできます。W&B で Ultralytics を強化する
Ultralytics で W&B インテグレーションを使用するには、wandb.integration.ultralytics.add_wandb_callback 関数をインポートする必要があります。
import wandb
from wandb.integration.ultralytics import add_wandb_callback
from ultralytics.engine.model import YOLO
インテグレーションをテストするために、いくつかの画像をダウンロードします。静止画像、ビデオ、またはカメラ ソースを使用できます。推論ソースの詳細については、Ultralytics のドキュメント を確認してください。
!wget https://raw.githubusercontent.com/wandb/examples/ultralytics/colabs/ultralytics/assets/img1.png
!wget https://raw.githubusercontent.com/wandb/examples/ultralytics/colabs/ultralytics/assets/img2.png
!wget https://raw.githubusercontent.com/wandb/examples/ultralytics/colabs/ultralytics/assets/img4.png
!wget https://raw.githubusercontent.com/wandb/examples/ultralytics/colabs/ultralytics/assets/img5.png
次に、wandb.init を使用して W&B run を初期化します。
# Initialize W&B run
wandb. init(project= "ultralytics" , job_type= "inference" )
次に、目的の YOLO モデルを初期化し、モデルで推論を実行する前に、そのモデルで add_wandb_callback 関数を呼び出します。これにより、推論を実行すると、コンピュータビジョン タスクのインタラクティブなオーバーレイ でオーバーレイされた画像が自動的にログに記録され、追加の洞察が wandb.Table
# Initialize YOLO Model
model = YOLO("yolov8n.pt" )
# Add W&B callback for Ultralytics
add_wandb_callback(model, enable_model_checkpointing= True )
# Perform prediction which automatically logs to a W&B Table
# with interactive overlays for bounding boxes, segmentation masks
model(
[
"./assets/img1.jpeg" ,
"./assets/img3.png" ,
"./assets/img4.jpeg" ,
"./assets/img5.jpeg" ,
]
)
# Finish the W&B run
wandb. finish()
トレーニングまたはファインチューン ワークフローの場合、wandb.init() を使用して run を明示的に初期化する必要はありません。ただし、コードに予測のみが含まれる場合は、run を明示的に作成する必要があります。
インタラクティブな bbox オーバーレイは次のようになります。
WandB Image Overlay W&B 画像オーバーレイの詳細については、こちら を参照してください。
その他のリソース
6.47 - YOLOX
W&B と YOLOX を統合する方法。
YOLOX は、 オブジェクト検出において強力なパフォーマンスを発揮する、アンカーフリー版の YOLO です。 YOLOX W&B インテグレーションを使用すると、トレーニング、検証、およびシステムに関連する メトリクス の ログ 記録をオンにすることができ、単一の コマンドライン 引数で 予測 をインタラクティブに検証できます。
サインアップして APIキー を作成する
APIキー は、W&B へのあなたの マシン を認証します。APIキー は、 ユーザー プロフィールから生成できます。
右上隅にある ユーザー プロフィール アイコンをクリックします。
[User Settings ](ユーザー 設定 )を選択し、[API Keys ](APIキー )セクションまでスクロールします。
[Reveal ](表示)をクリックします。表示された APIキー をコピーします。APIキー を非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインするwandb ライブラリをローカルにインストールしてログインするには:
コマンドライン
Python
Python notebook
WANDB_API_KEY 環境変数 をあなたの APIキー に設定します。
export WANDB_API_KEY= <your_api_key>
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
import wandb
wandb. login()
!pip install wandb
import wandb
wandb.login()
メトリクス を ログ 記録する
--logger wandb コマンドライン 引数を使用して、wandb での ログ 記録をオンにします。オプションで、wandb.initwandb- を付けます。
num_eval_imges は、 モデル の評価のために W&B の テーブル に ログ 記録される 検証セット の画像と 予測 の数を制御します。
# wandb にログイン
wandb login
# `wandb` ロガー 引数 を使用して yolox トレーニング スクリプトを呼び出す
python tools/train.py .... --logger wandb \
\
wandb-name <run-name> \
\
\
\
例
YOLOX のトレーニング および 検証 メトリクス を使用した ダッシュボード の例 ->
この W&B インテグレーション に関する質問や問題がありますか?YOLOX repository で issue をオープンしてください。
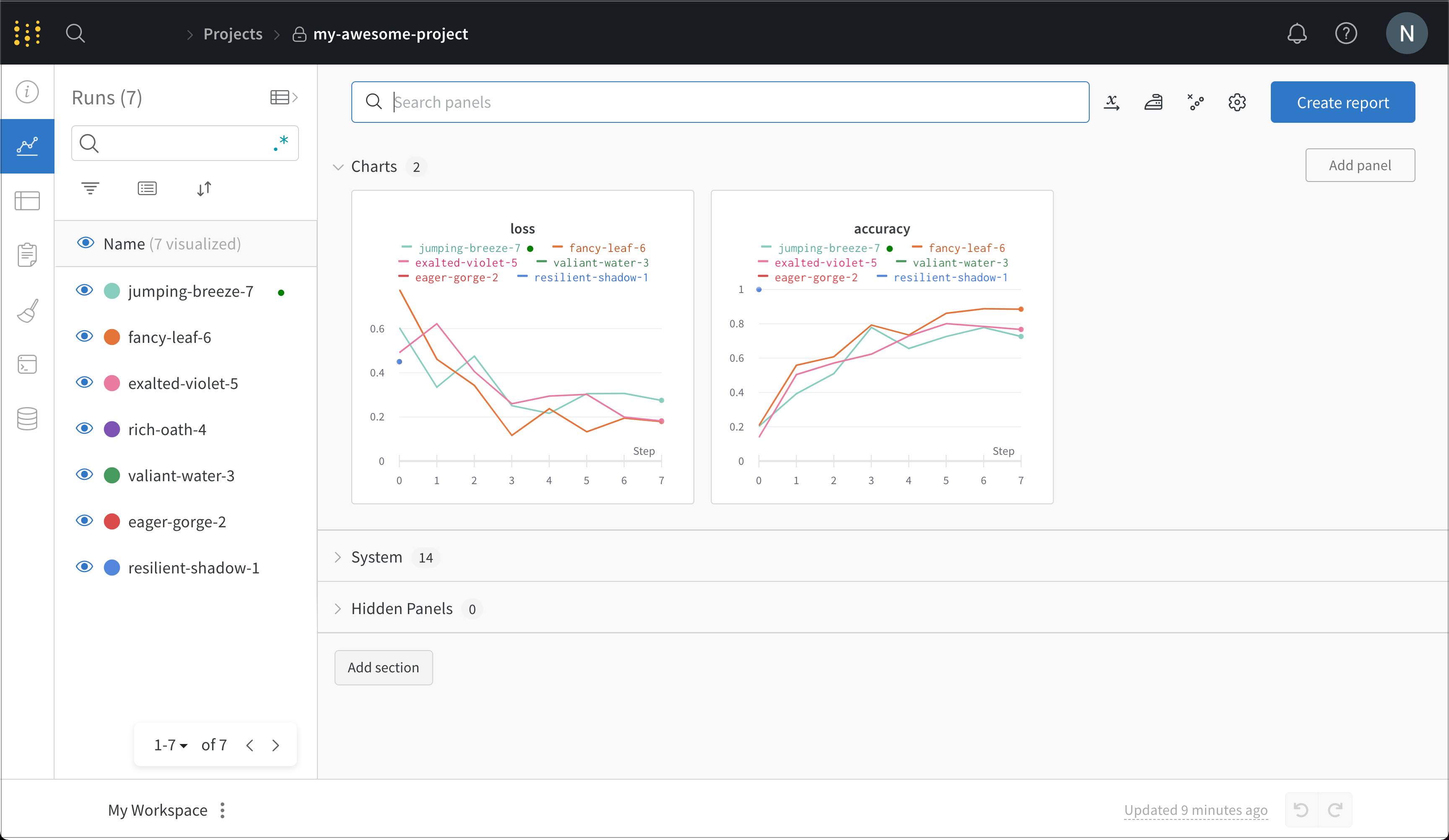
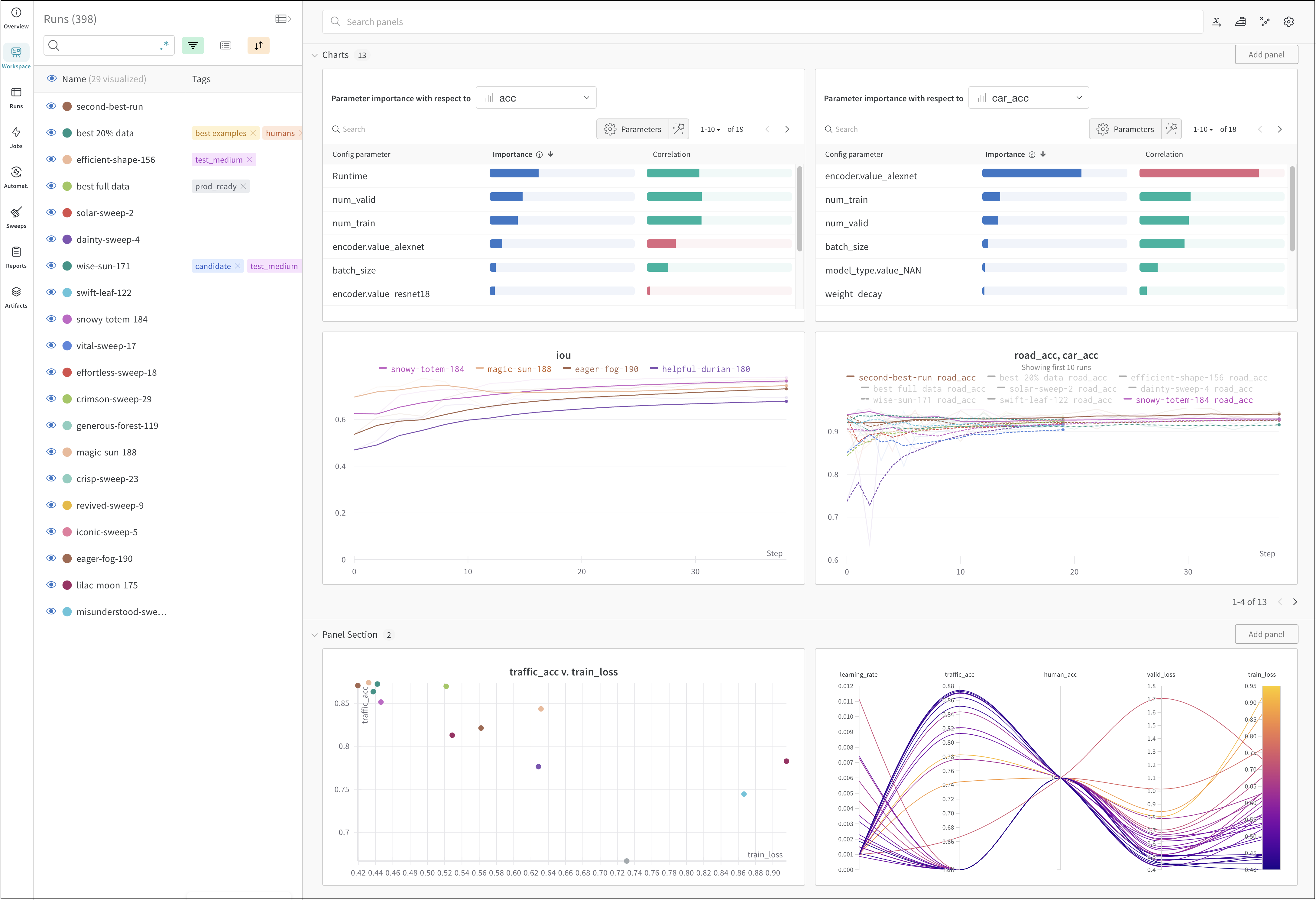
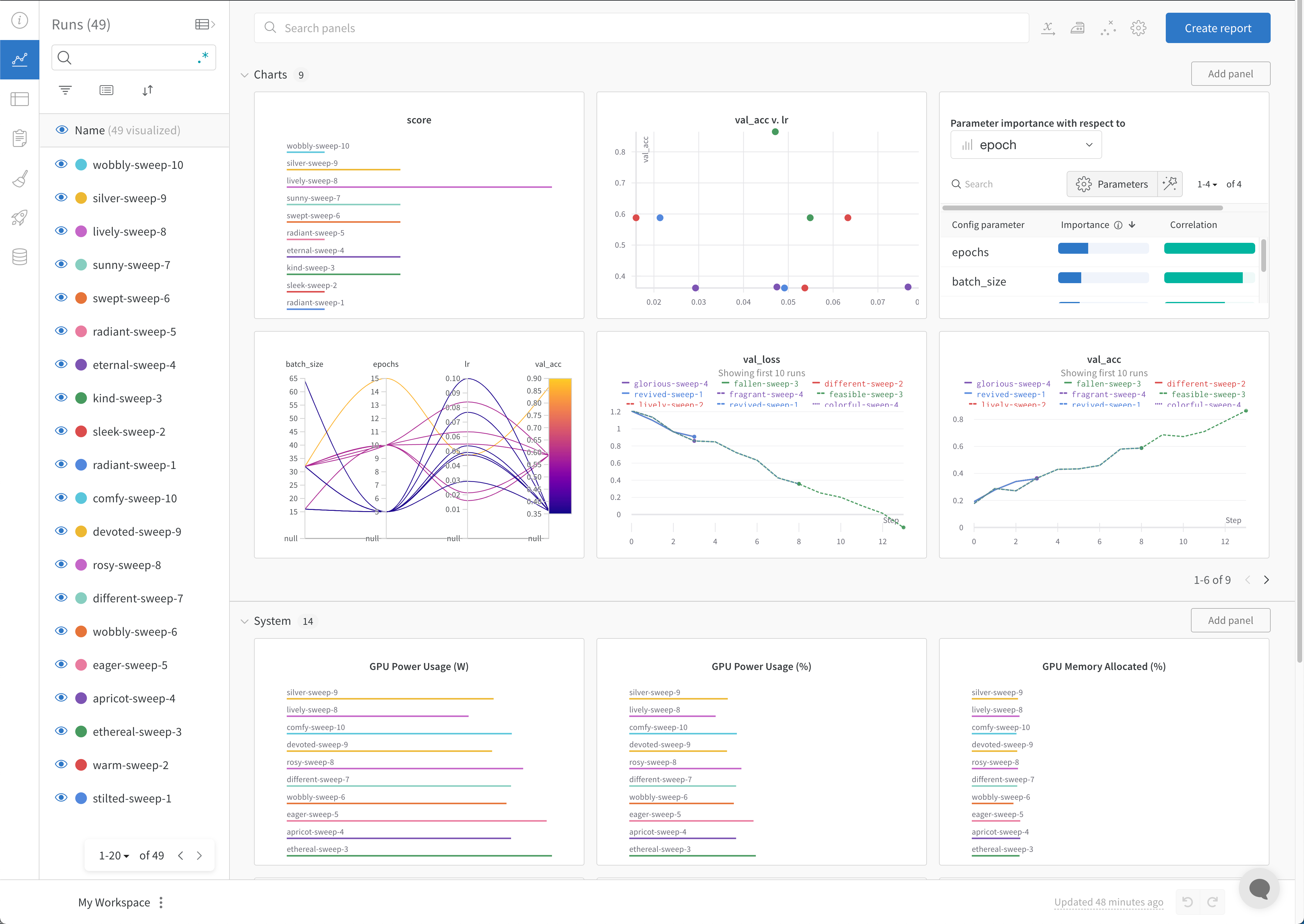
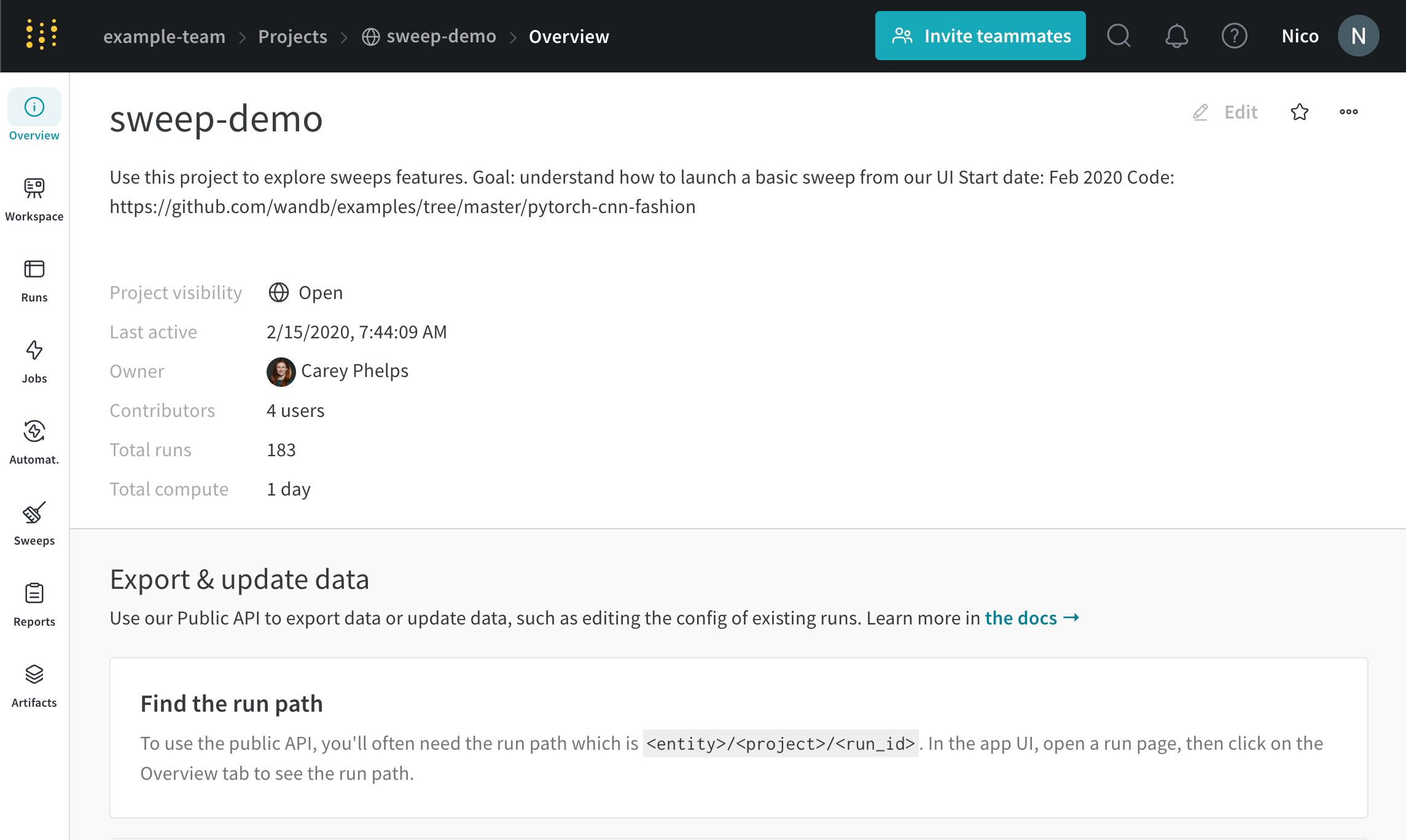
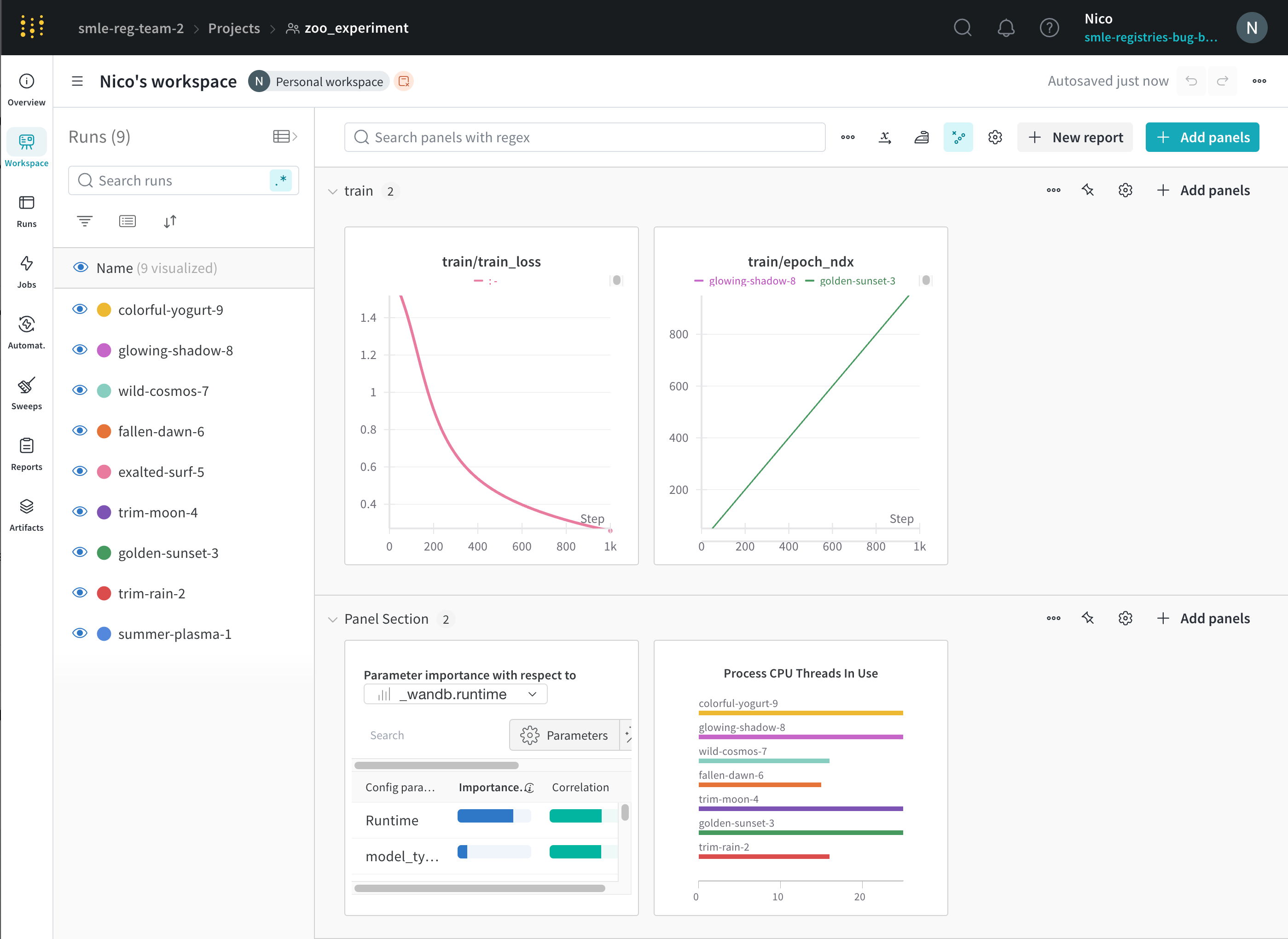
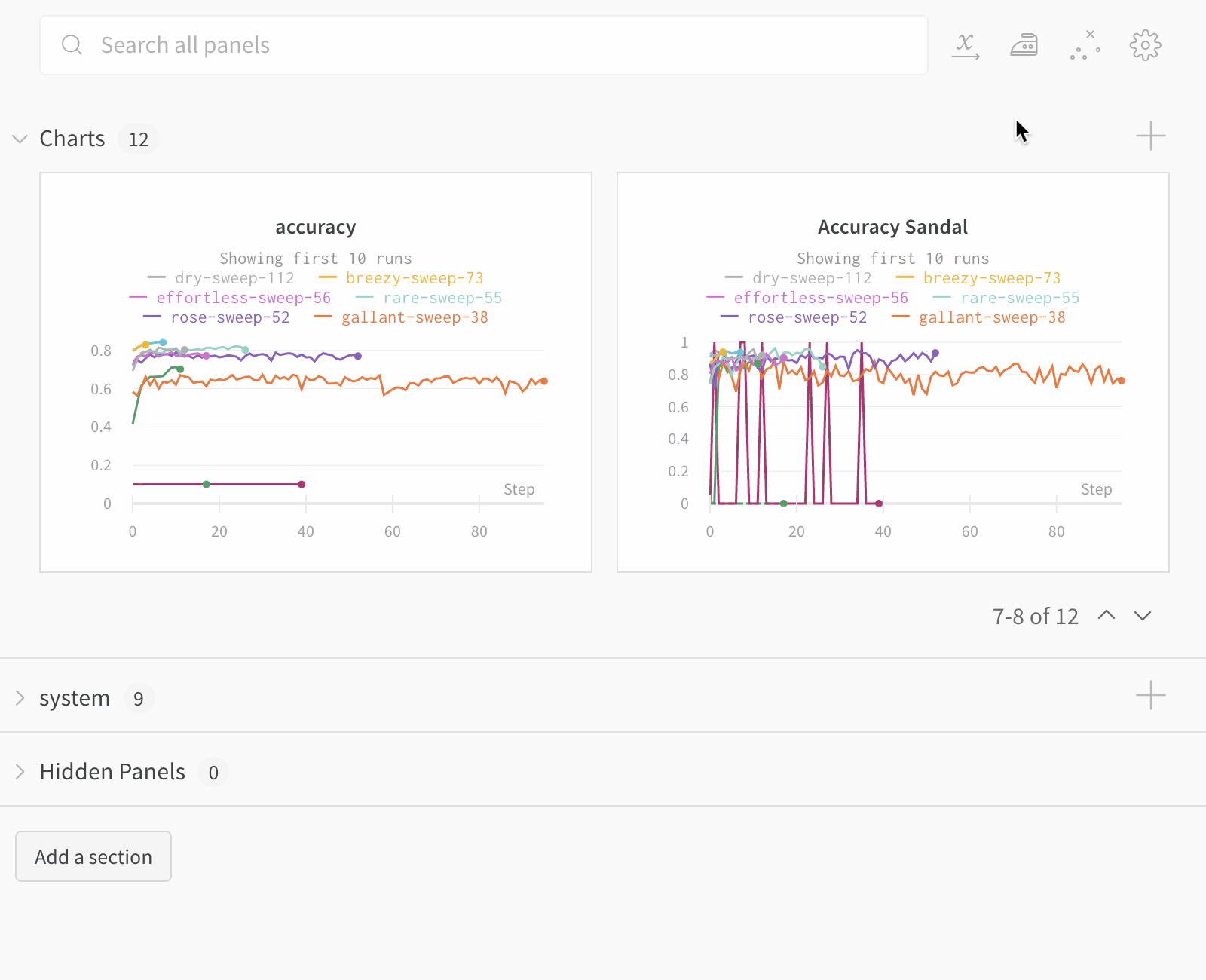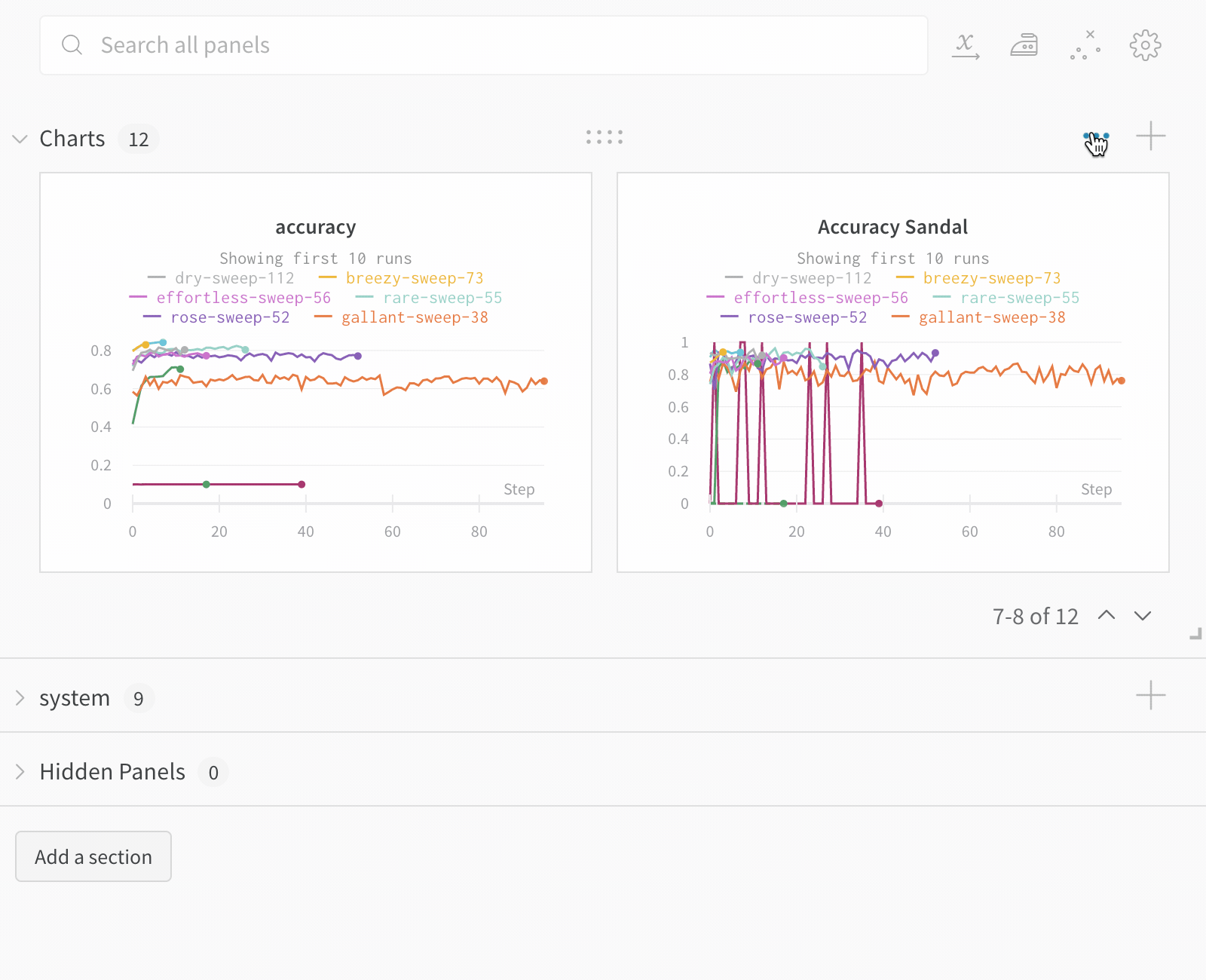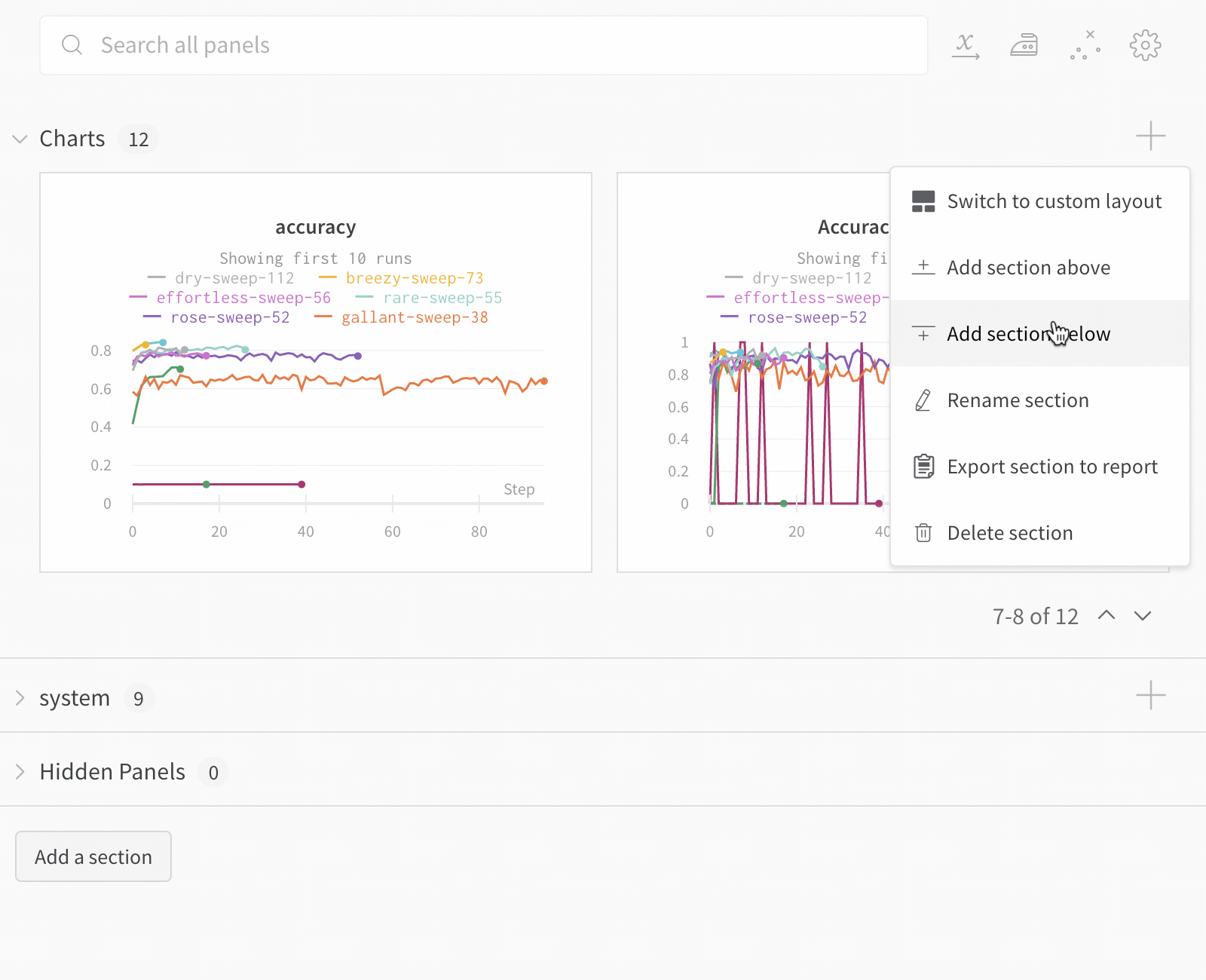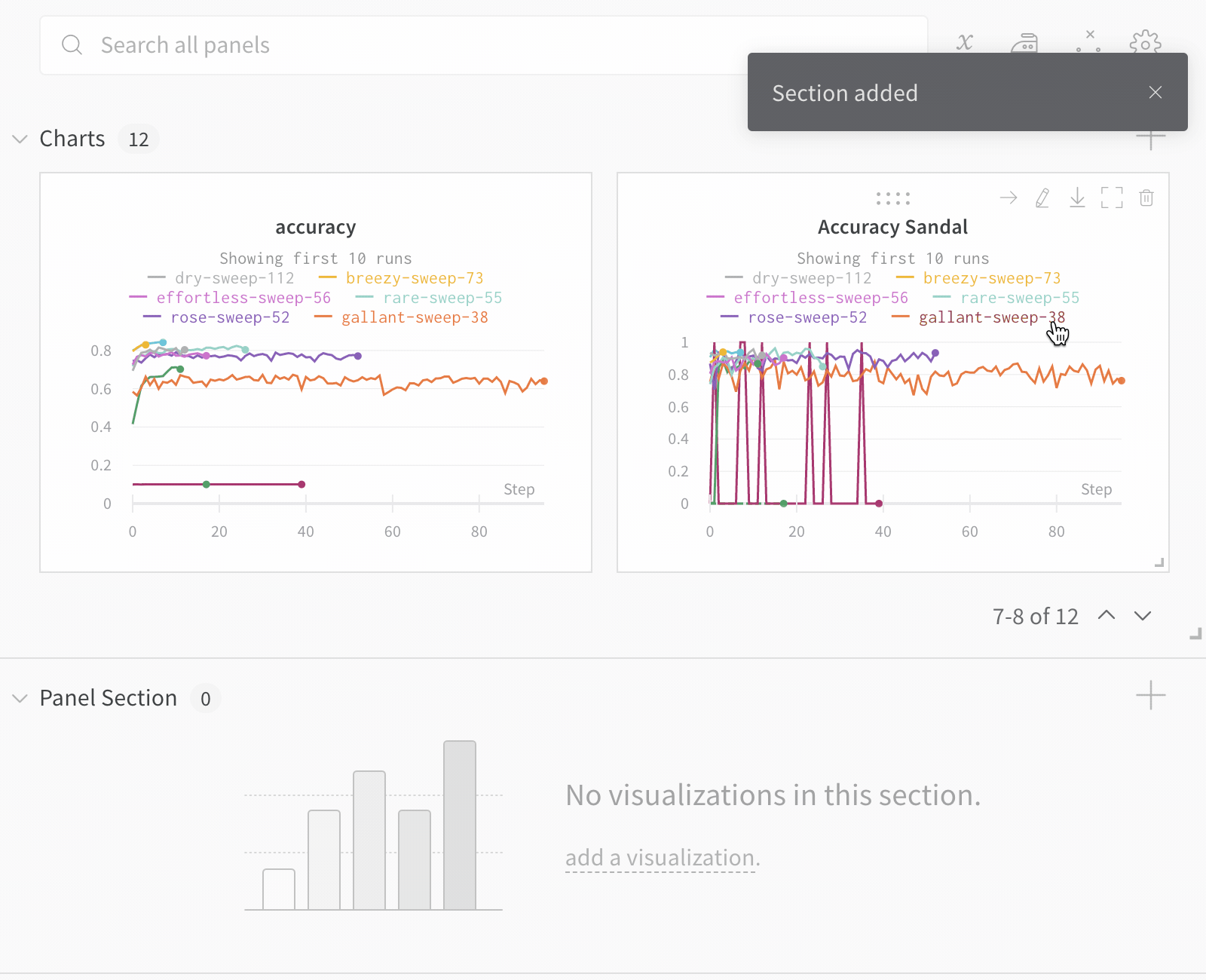
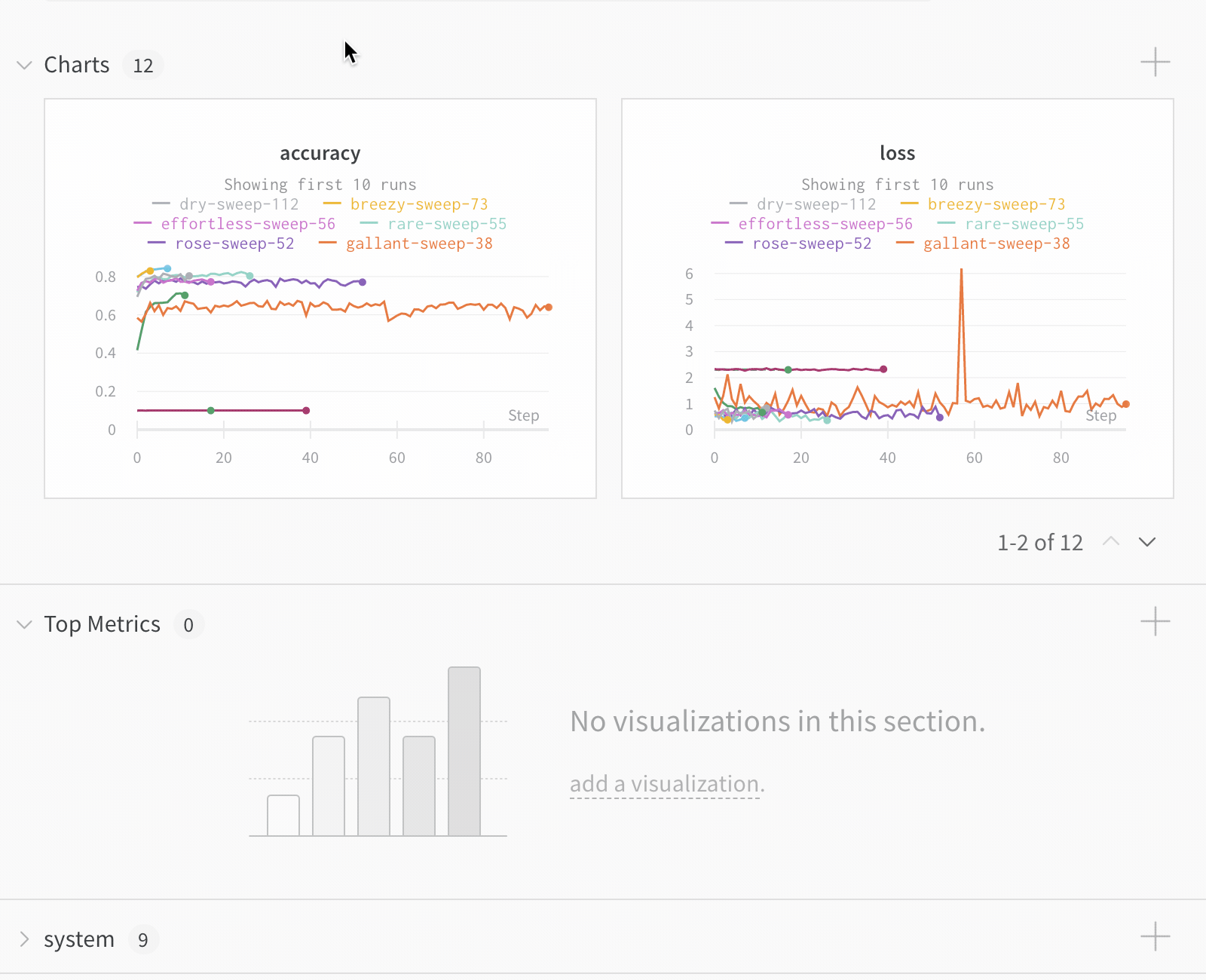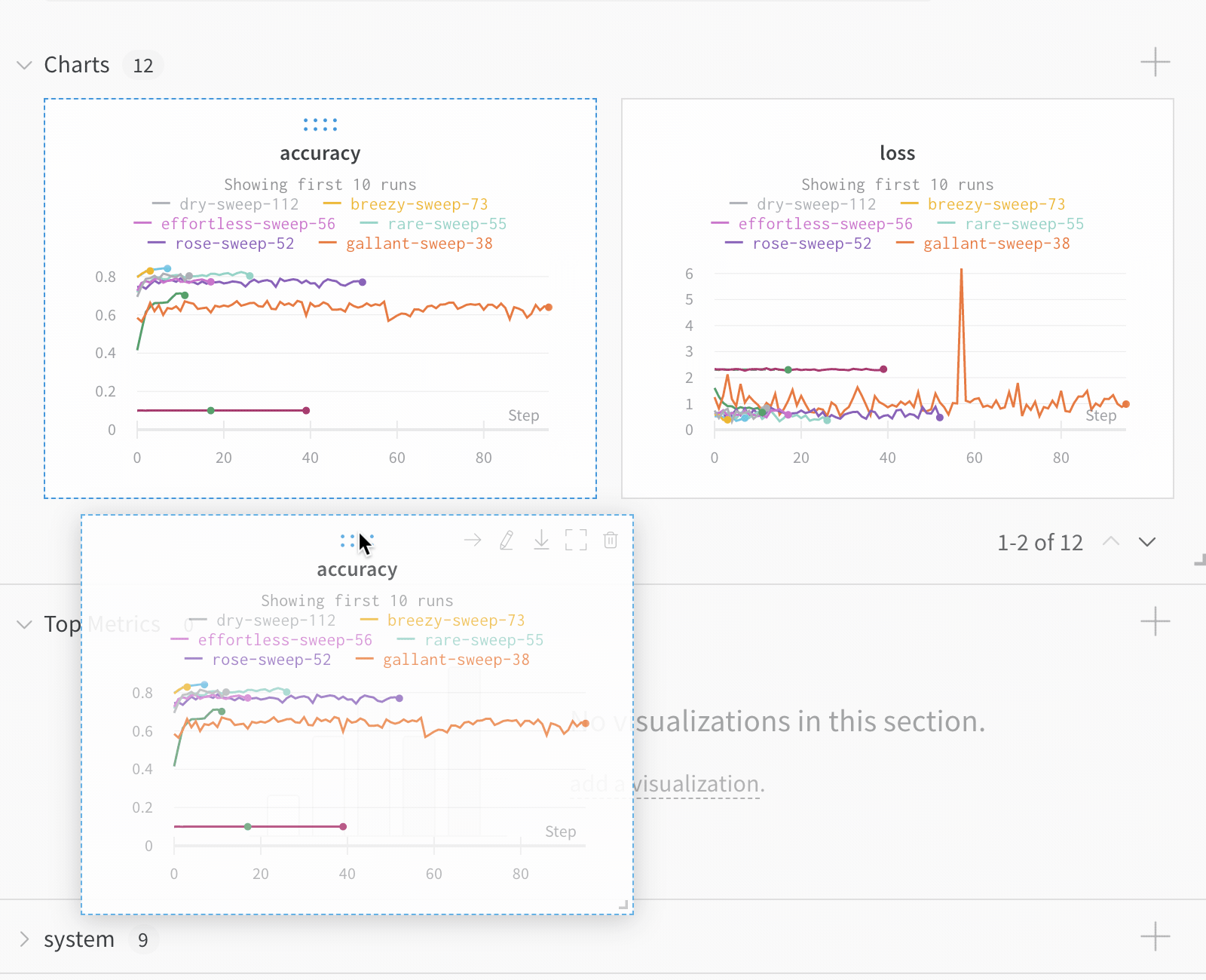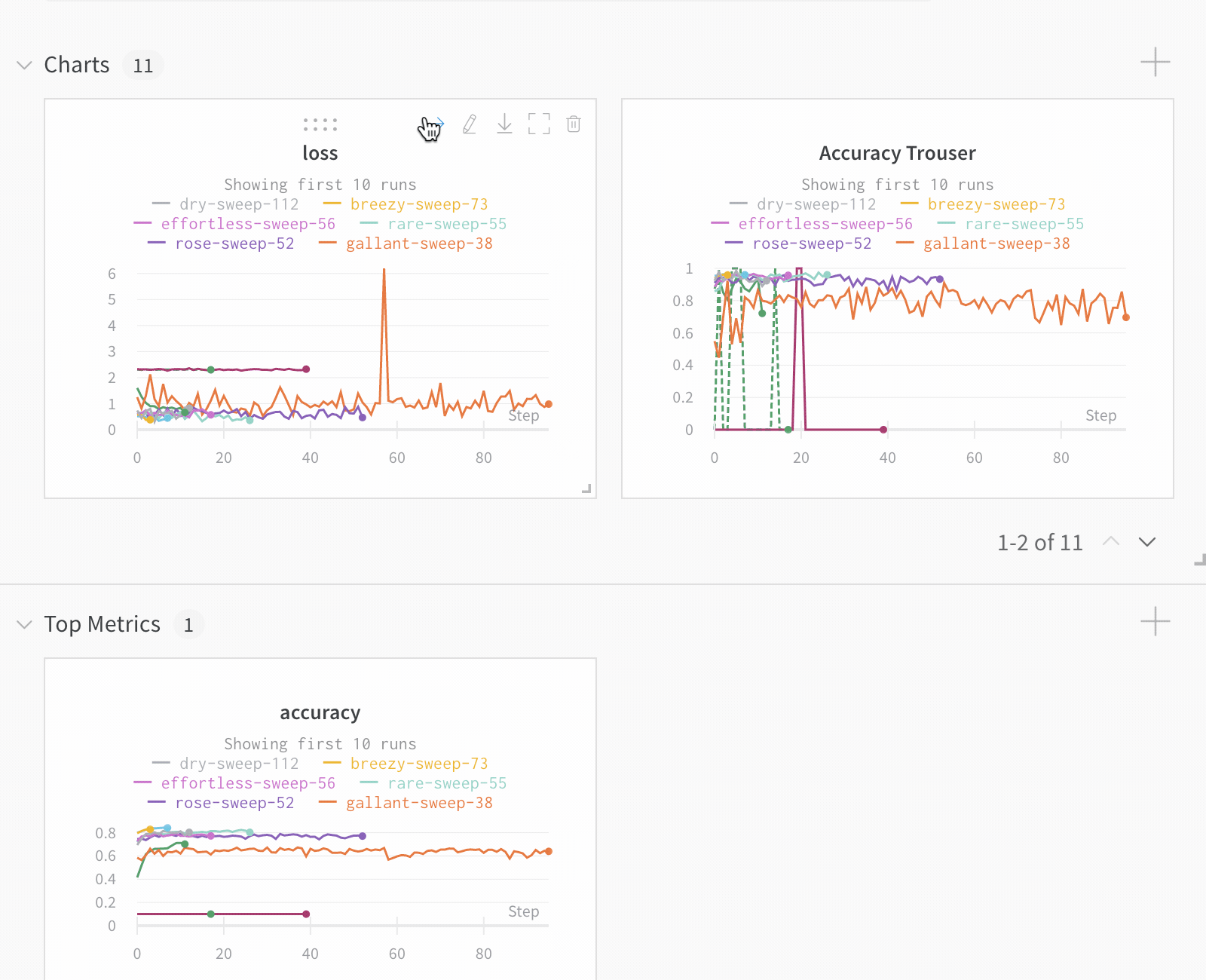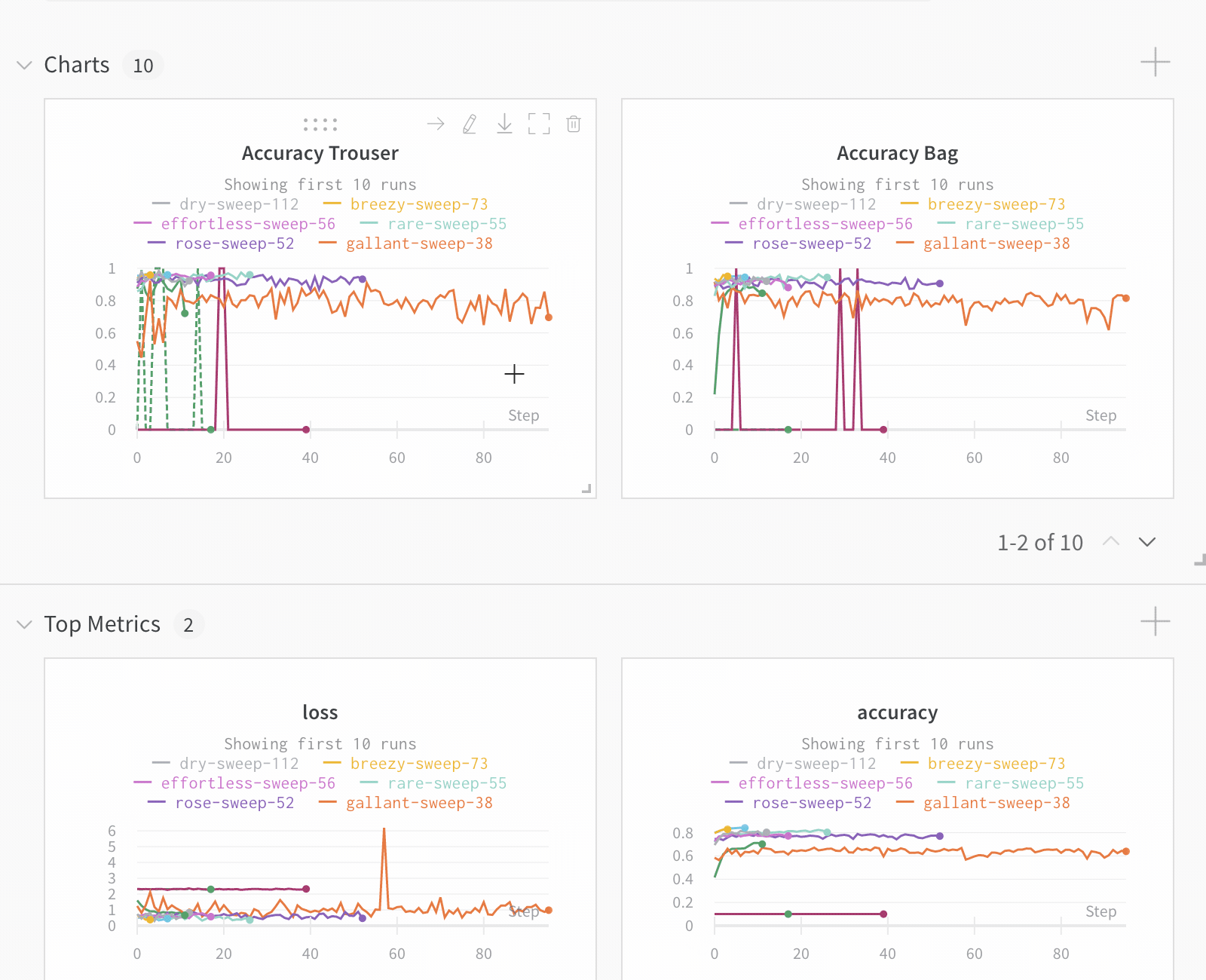
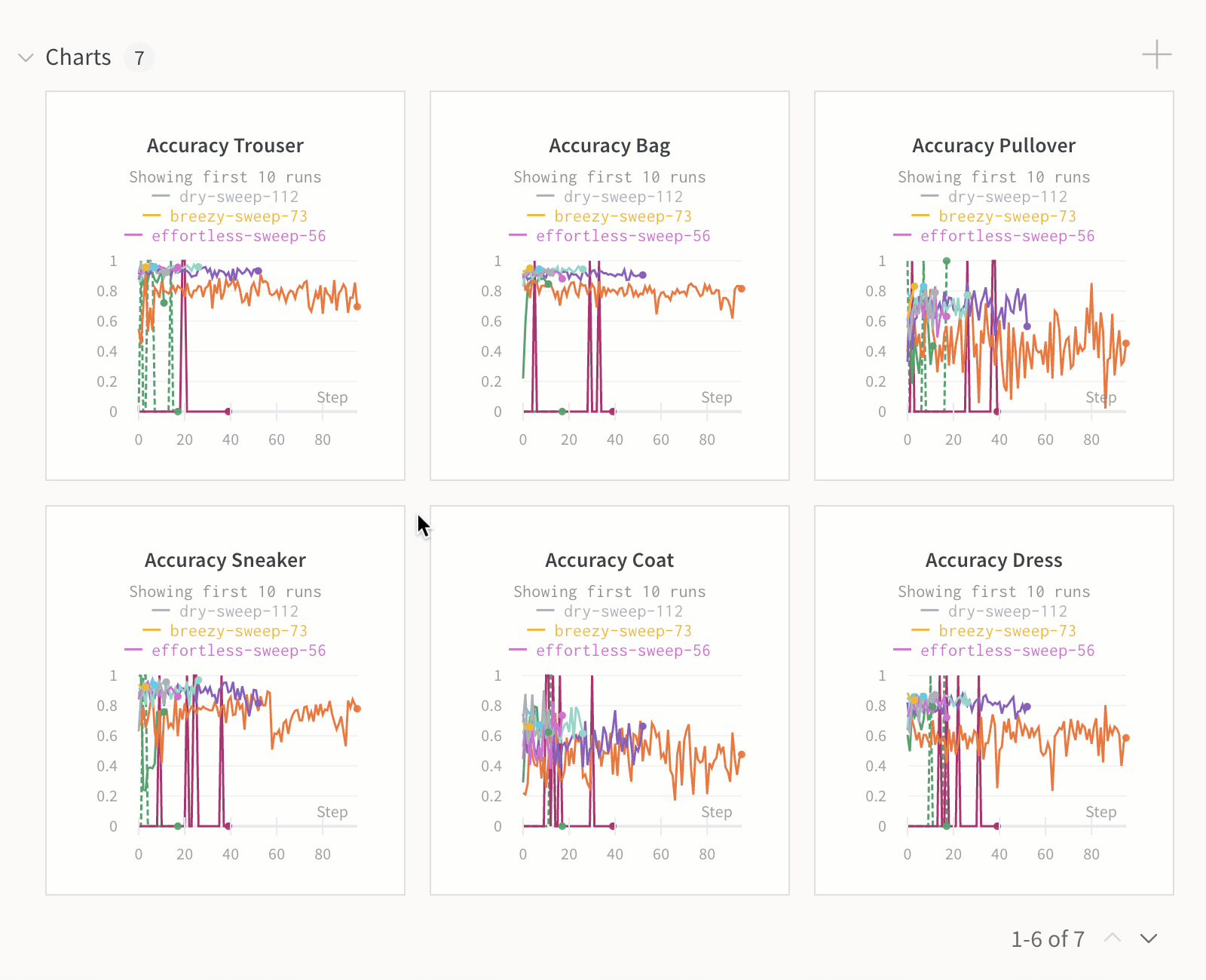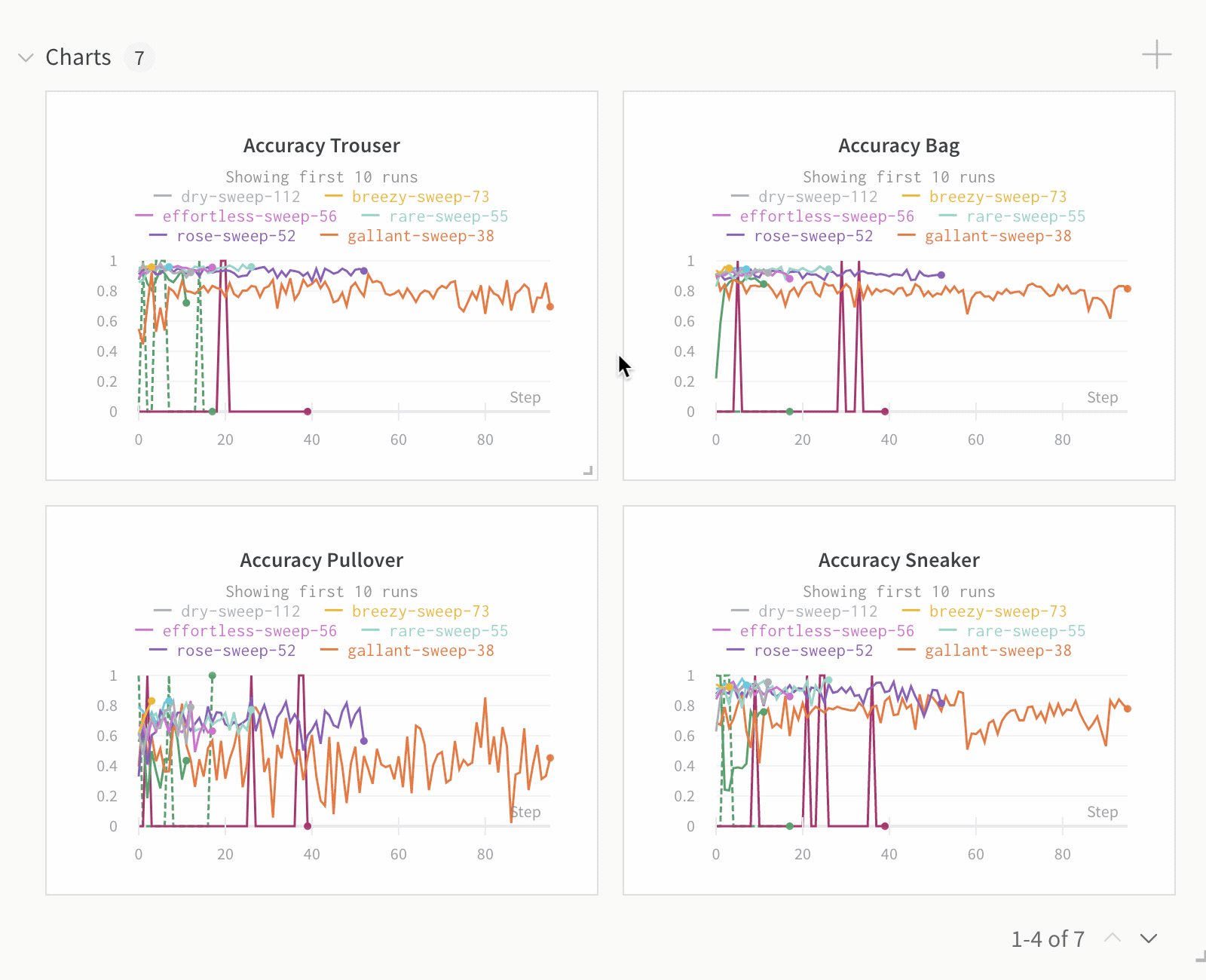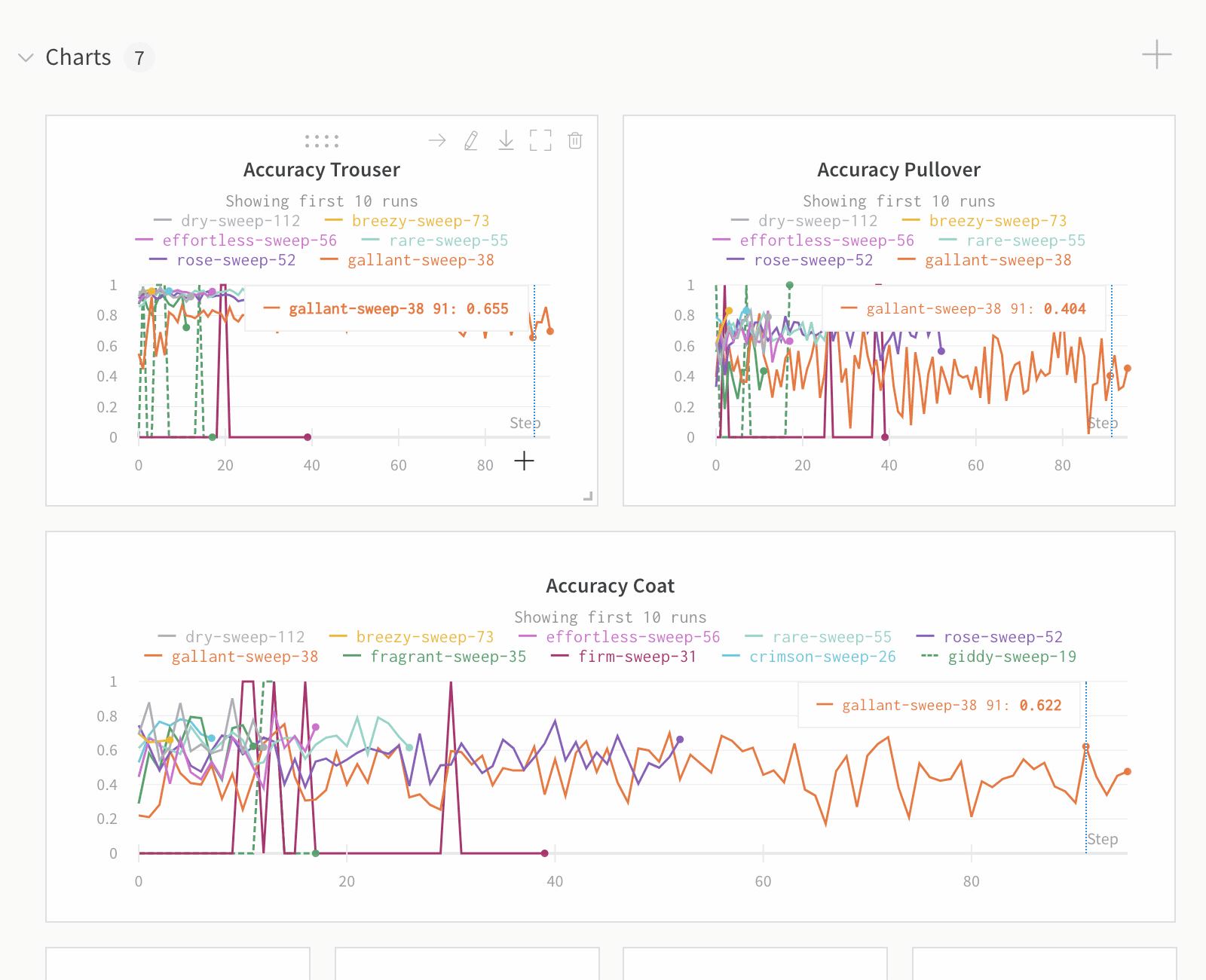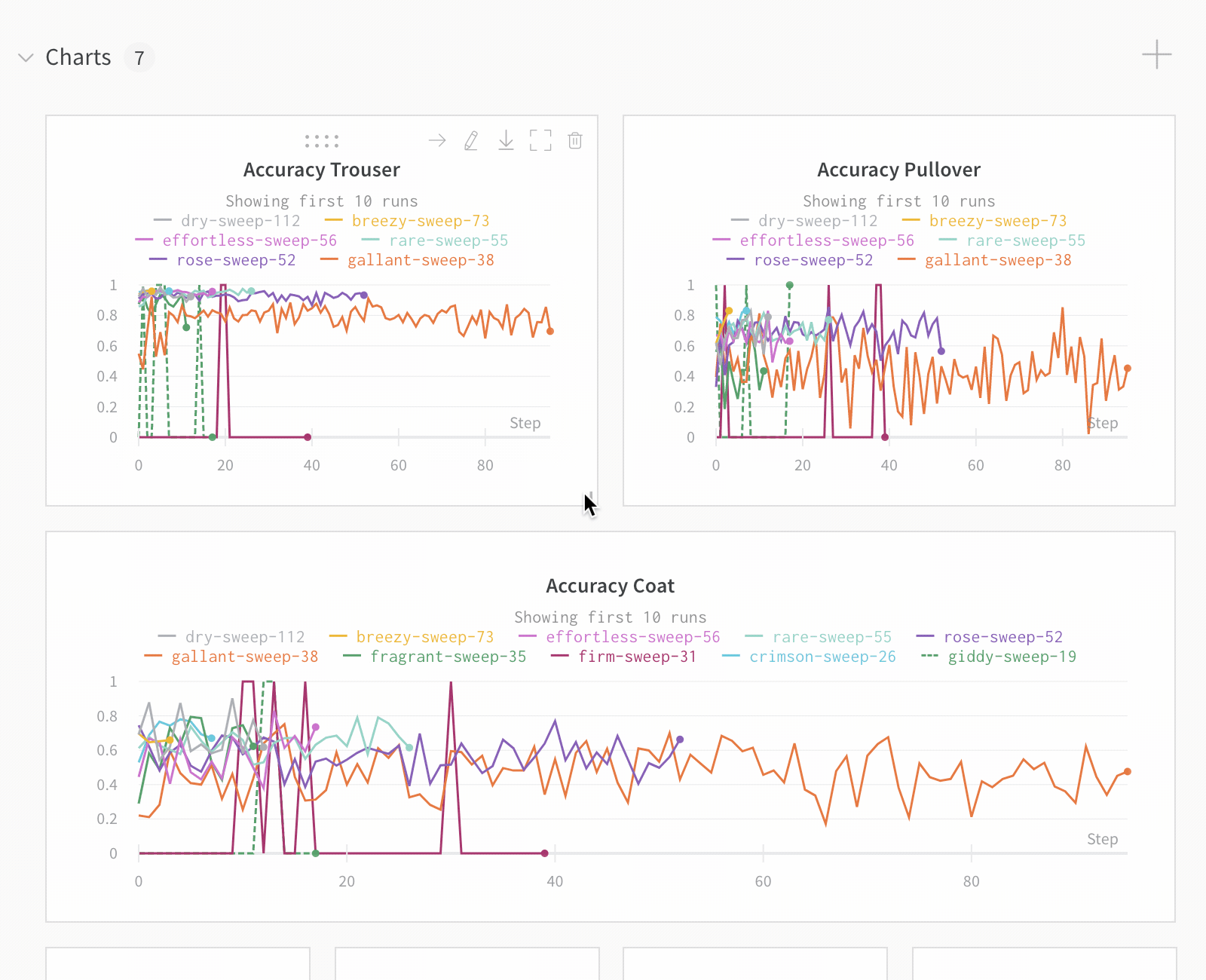
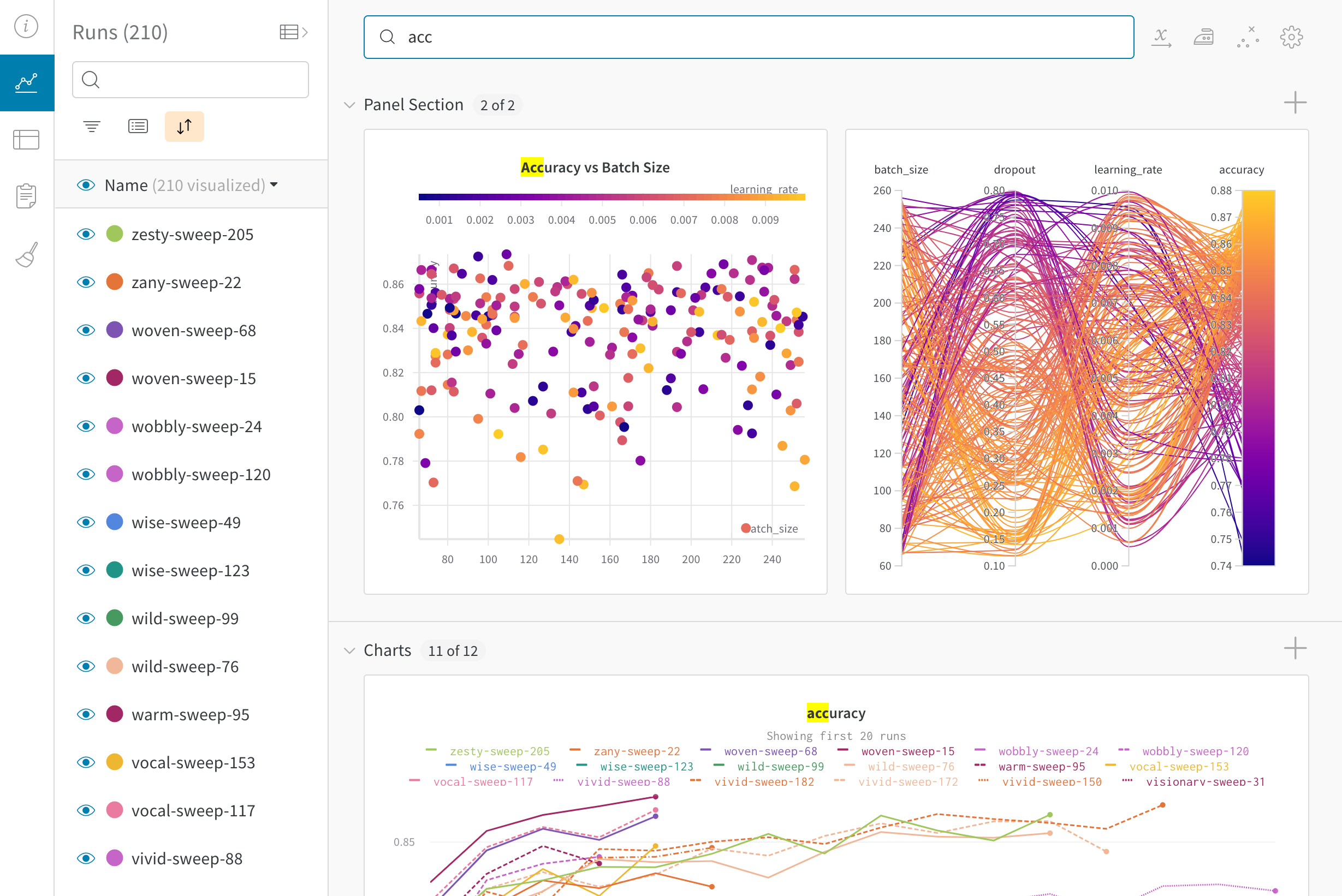
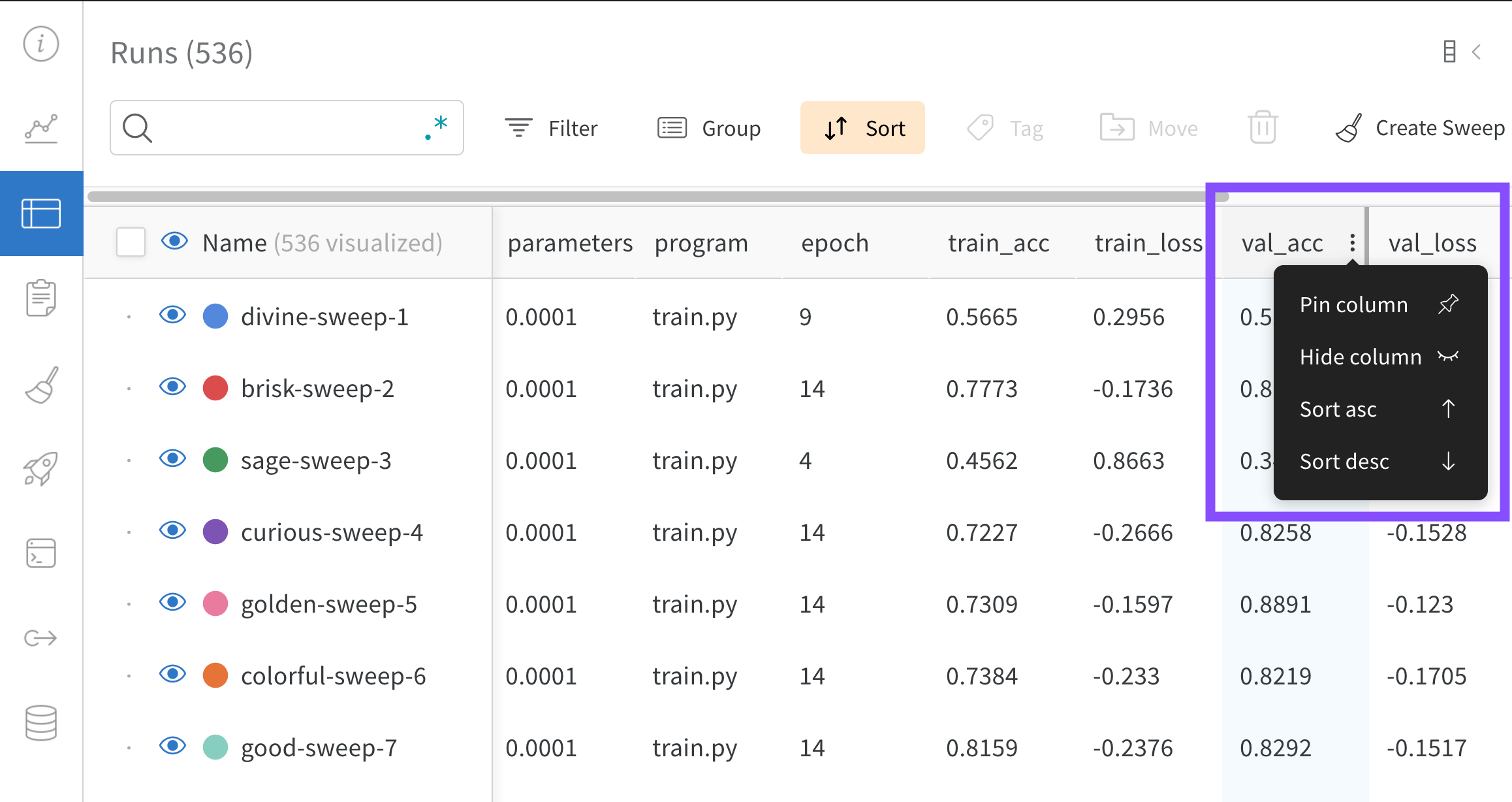
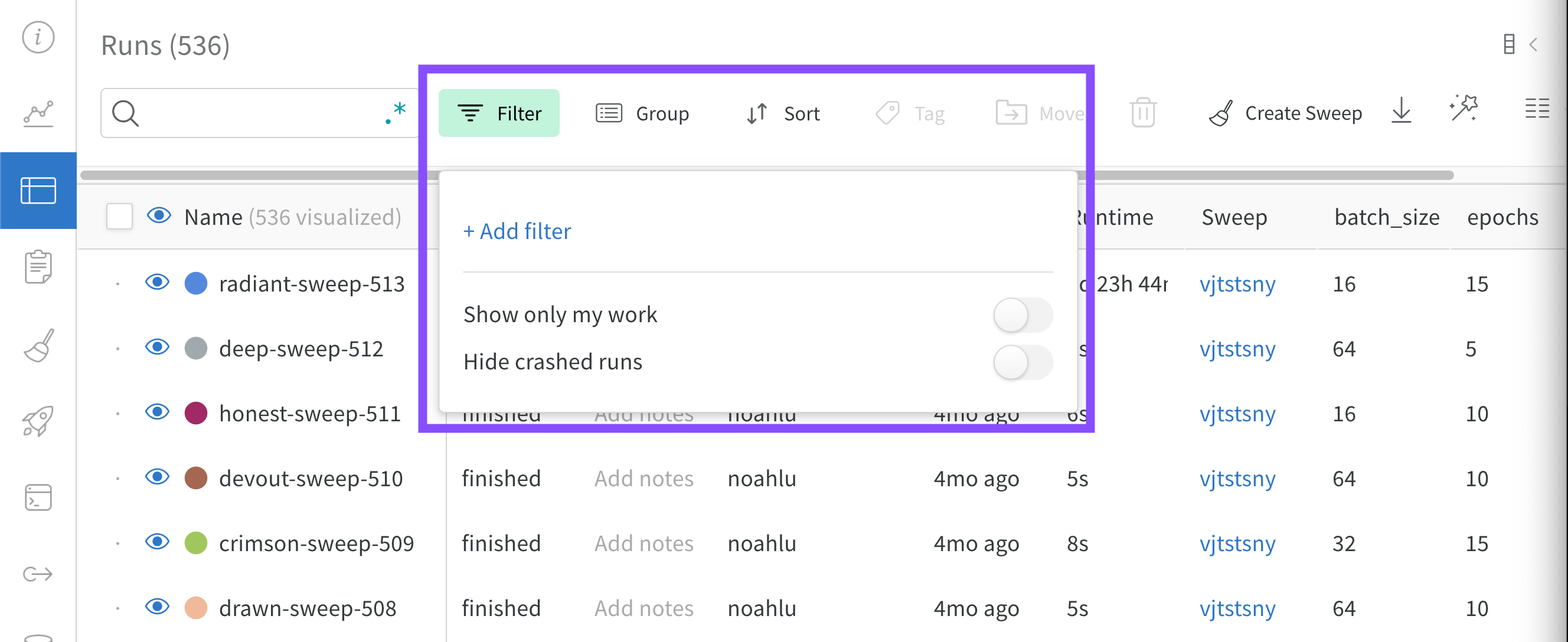
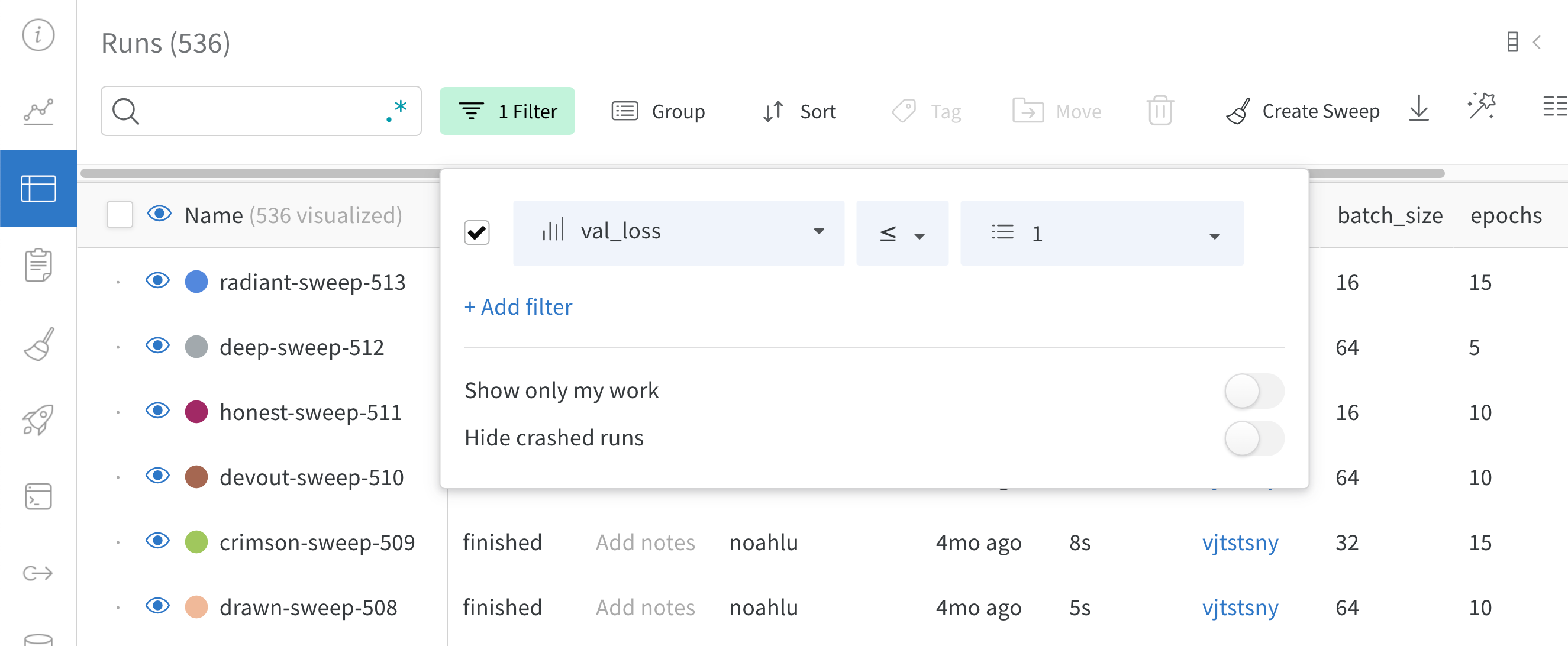 上記の画像は、`val_loss` 列に基づいたフィルターを示しています。フィルターは、検証損失が 1 以下の run を表示します。
上記の画像は、`val_loss` 列に基づいたフィルターを示しています。フィルターは、検証損失が 1 以下の run を表示します。
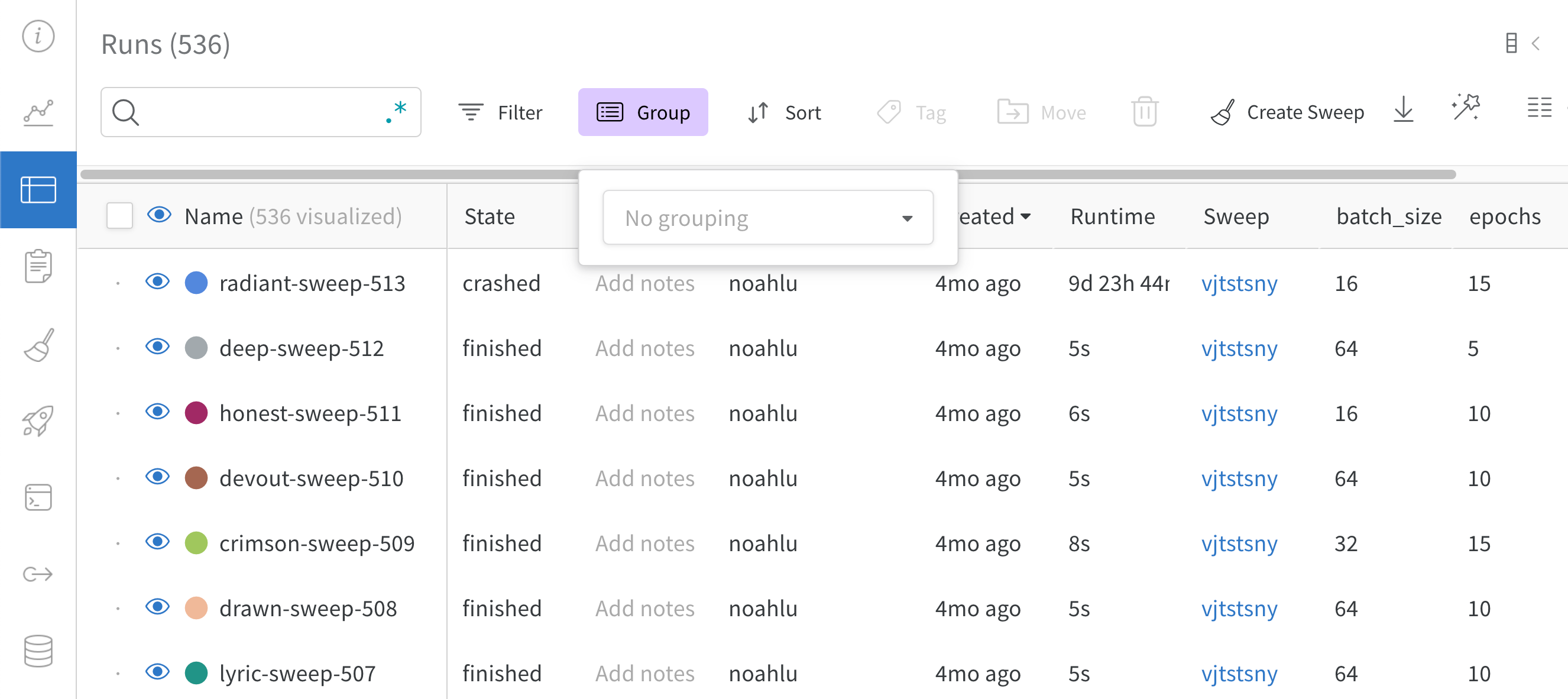
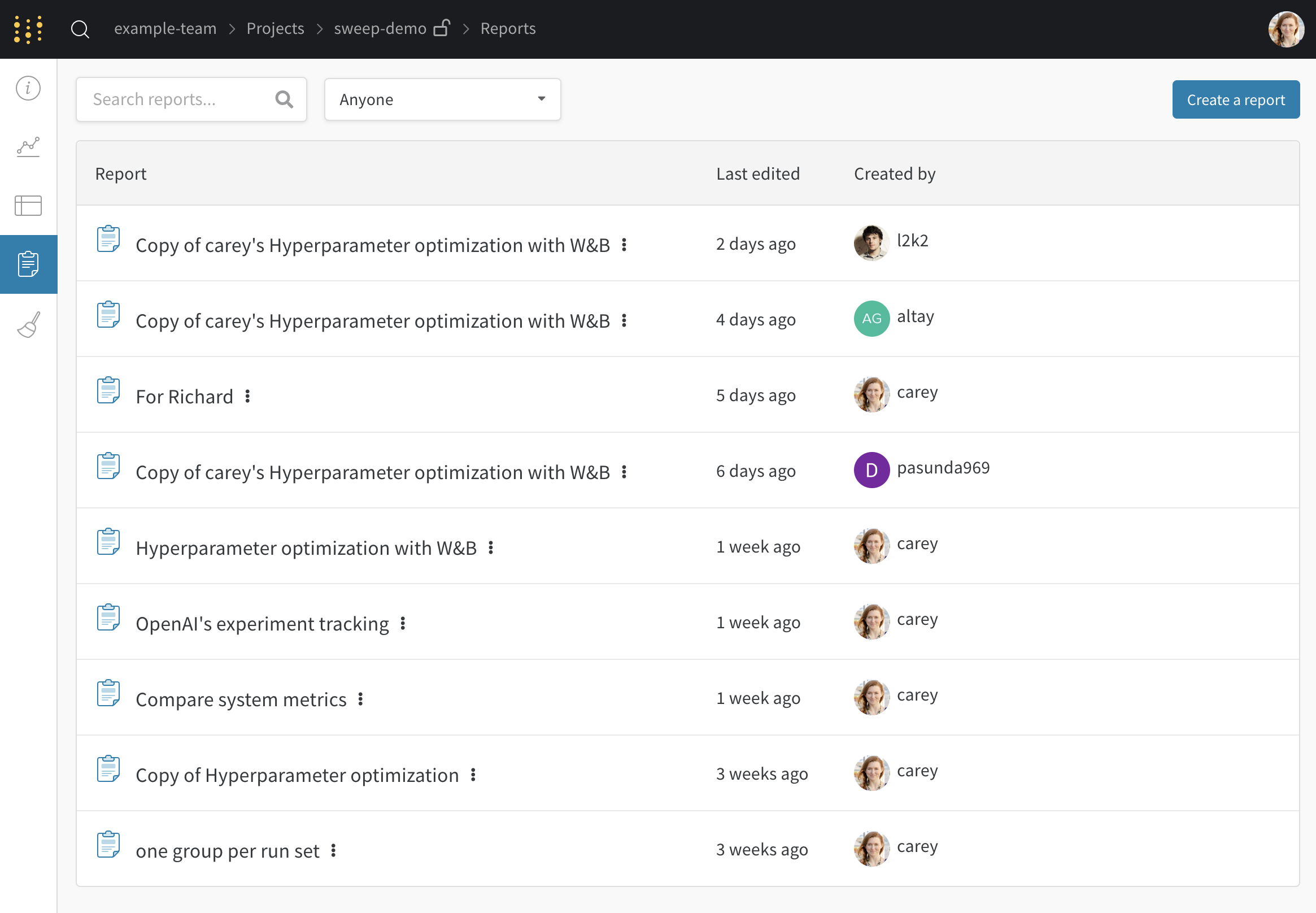
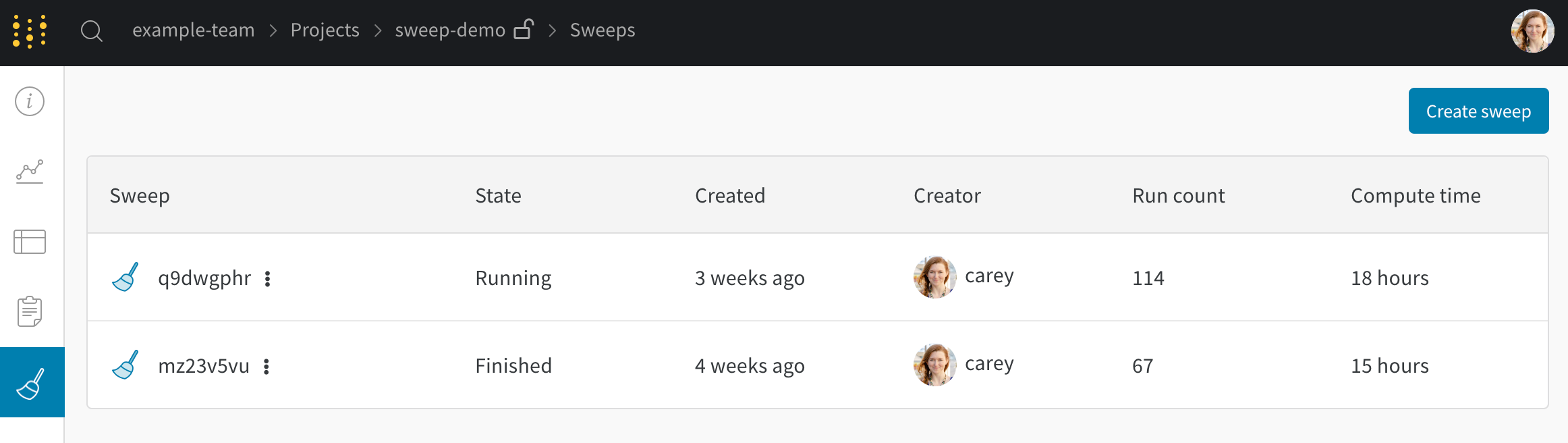
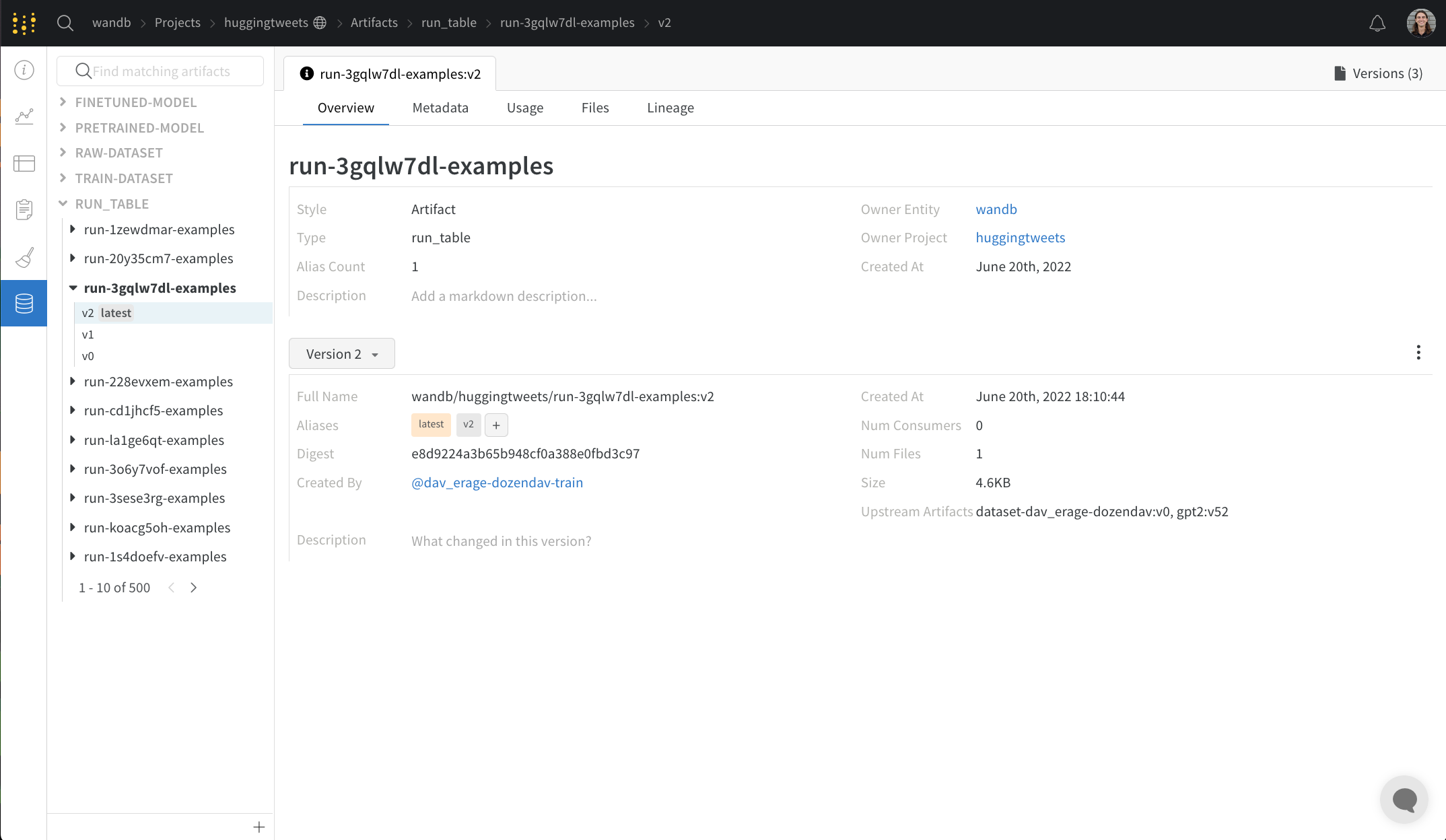
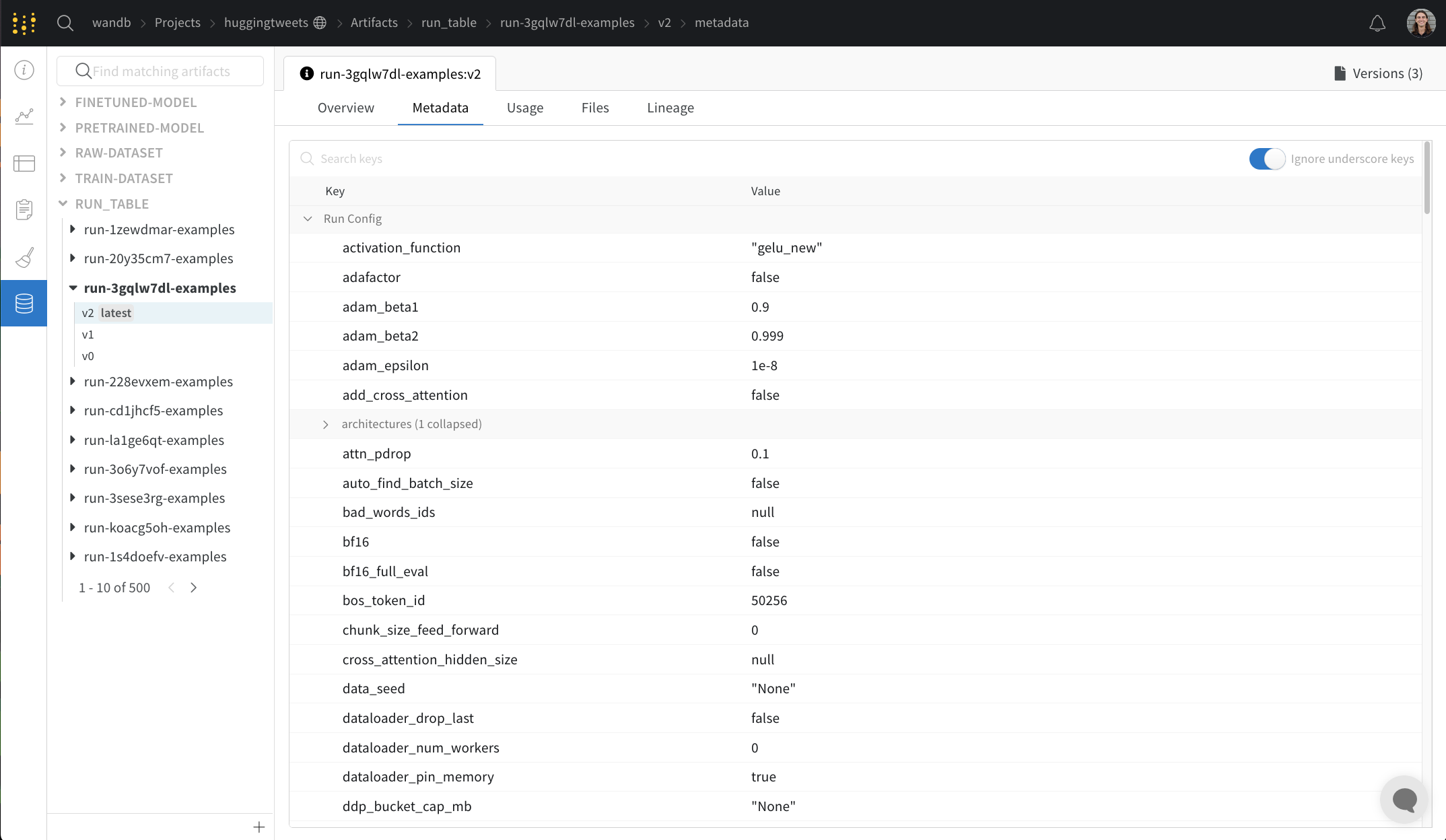
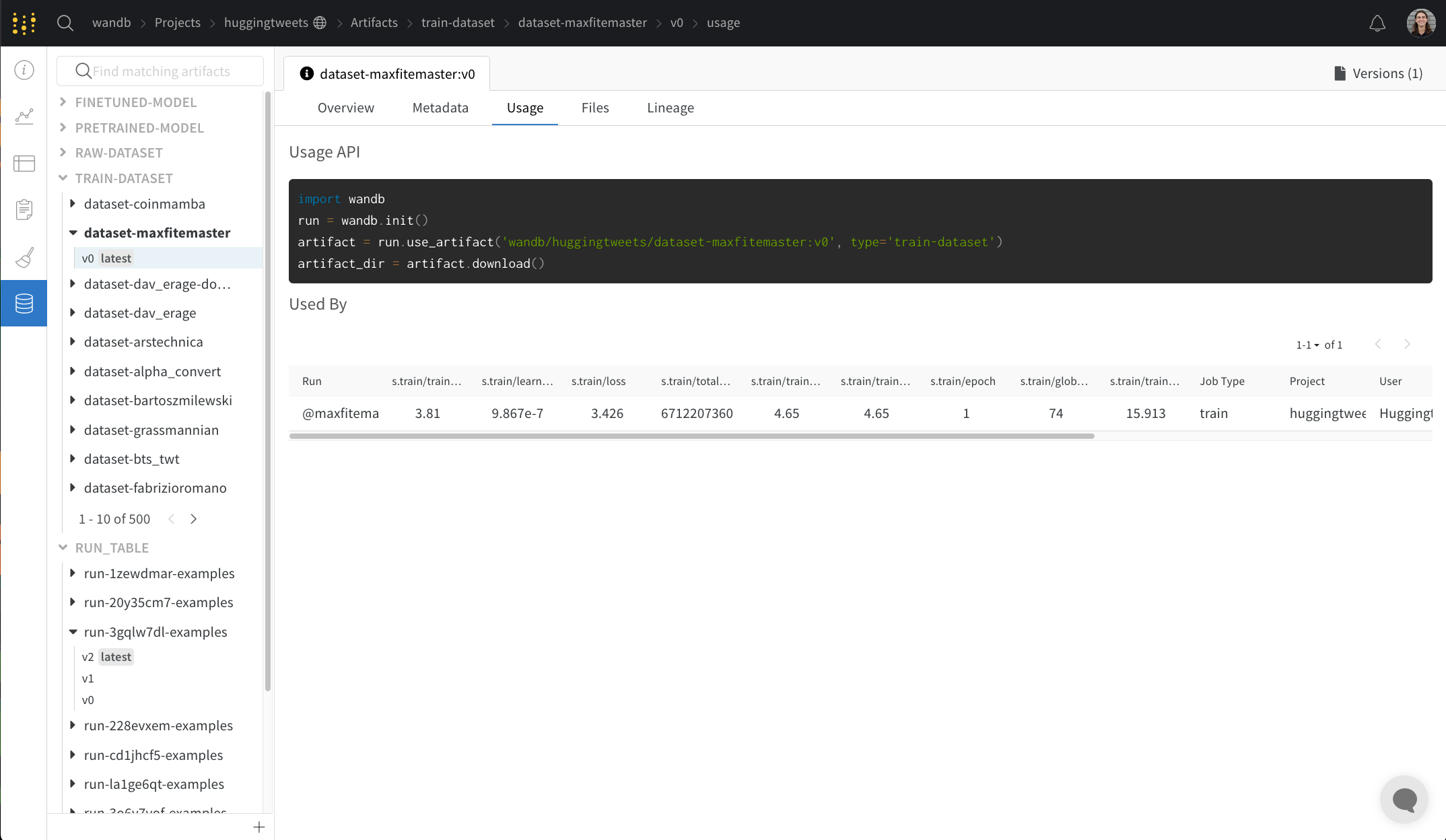
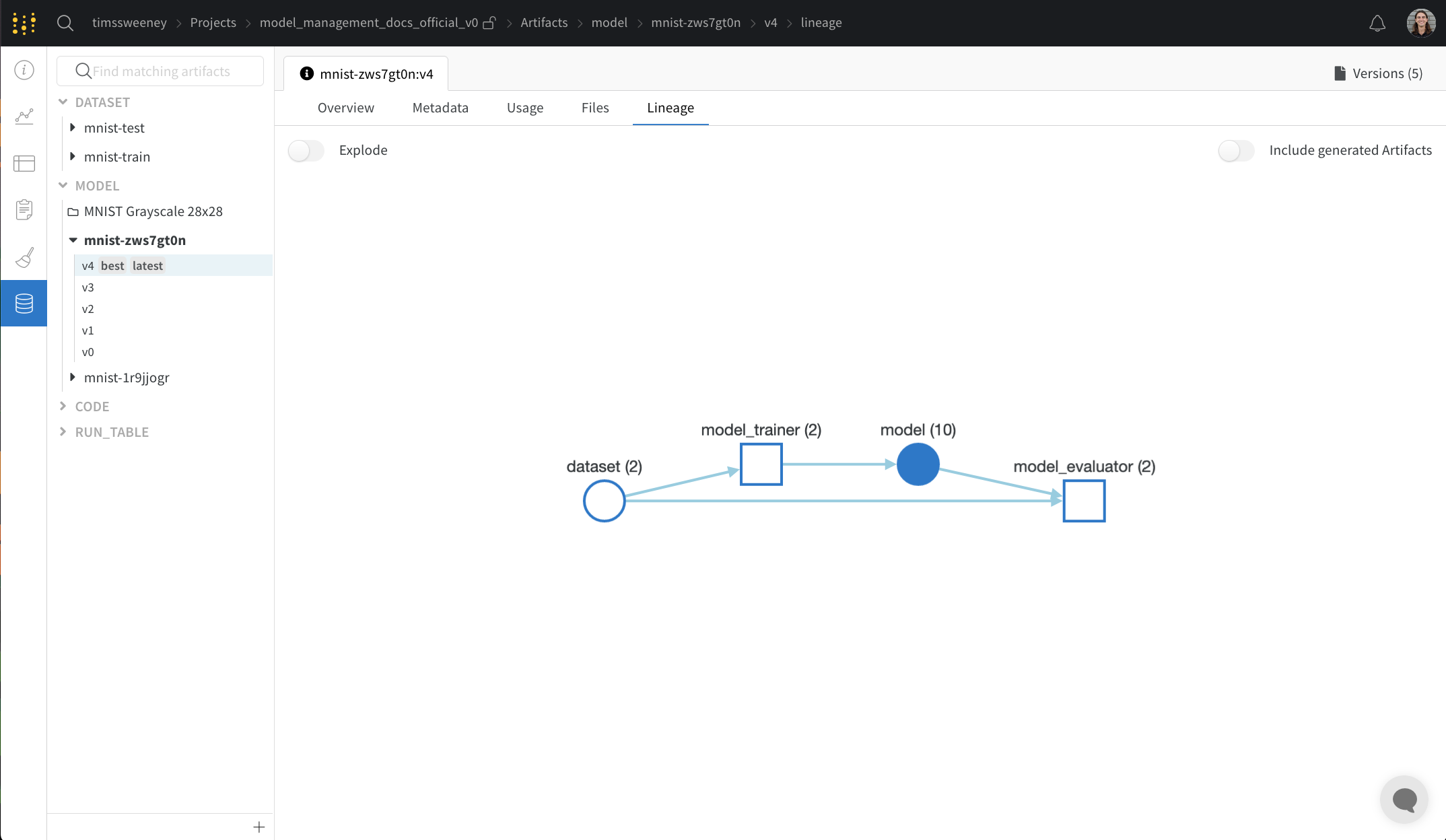
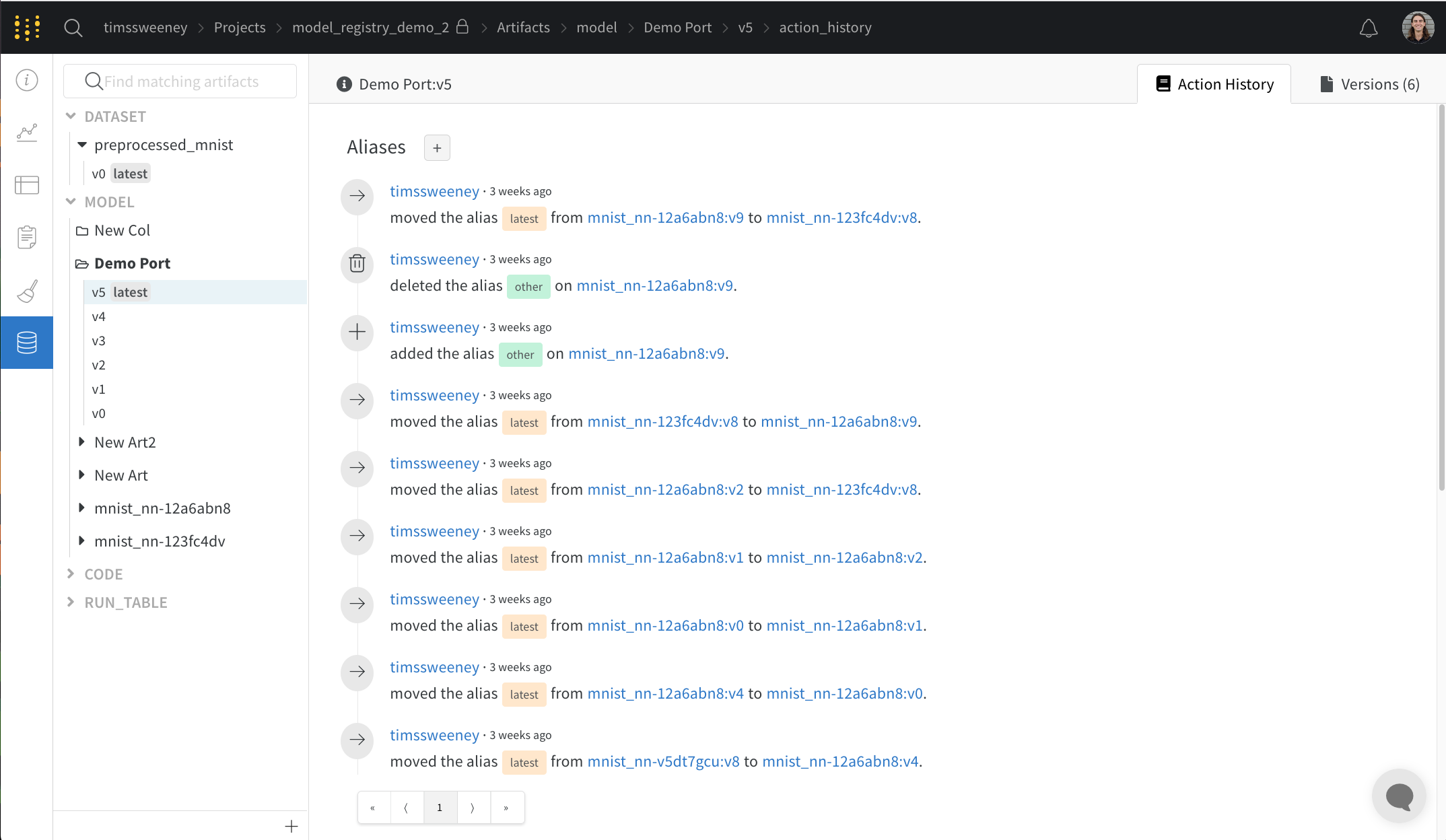
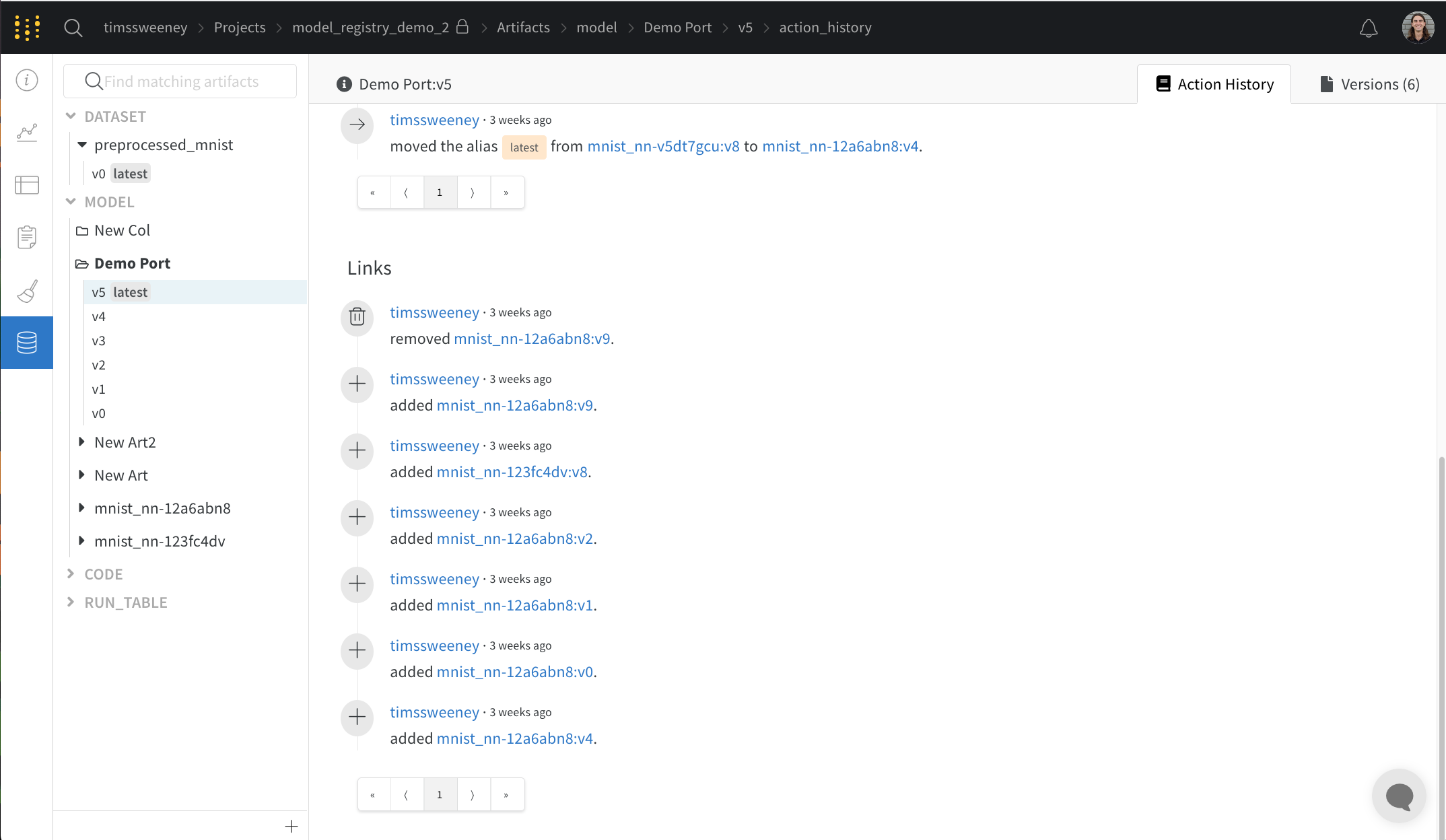
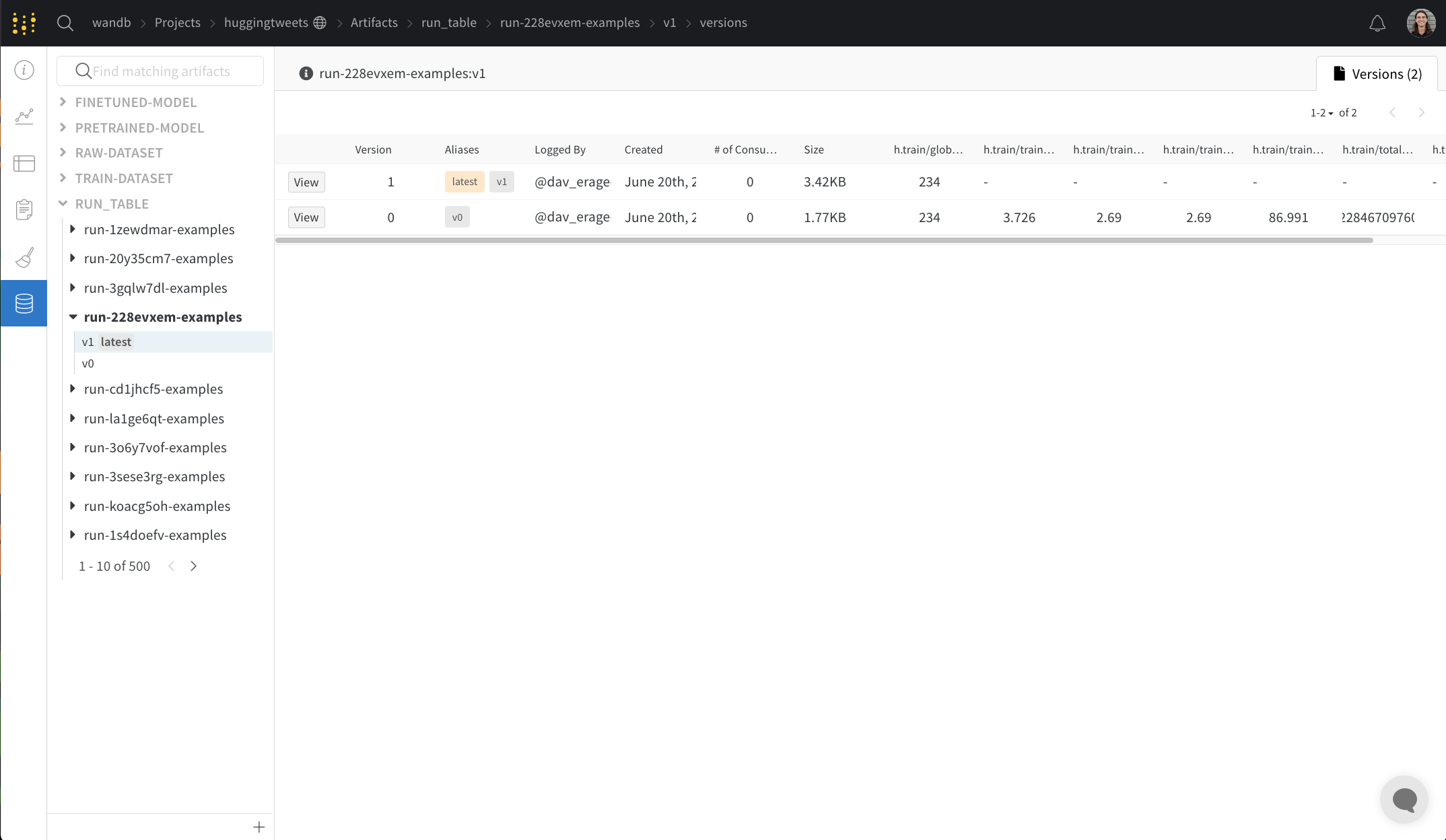

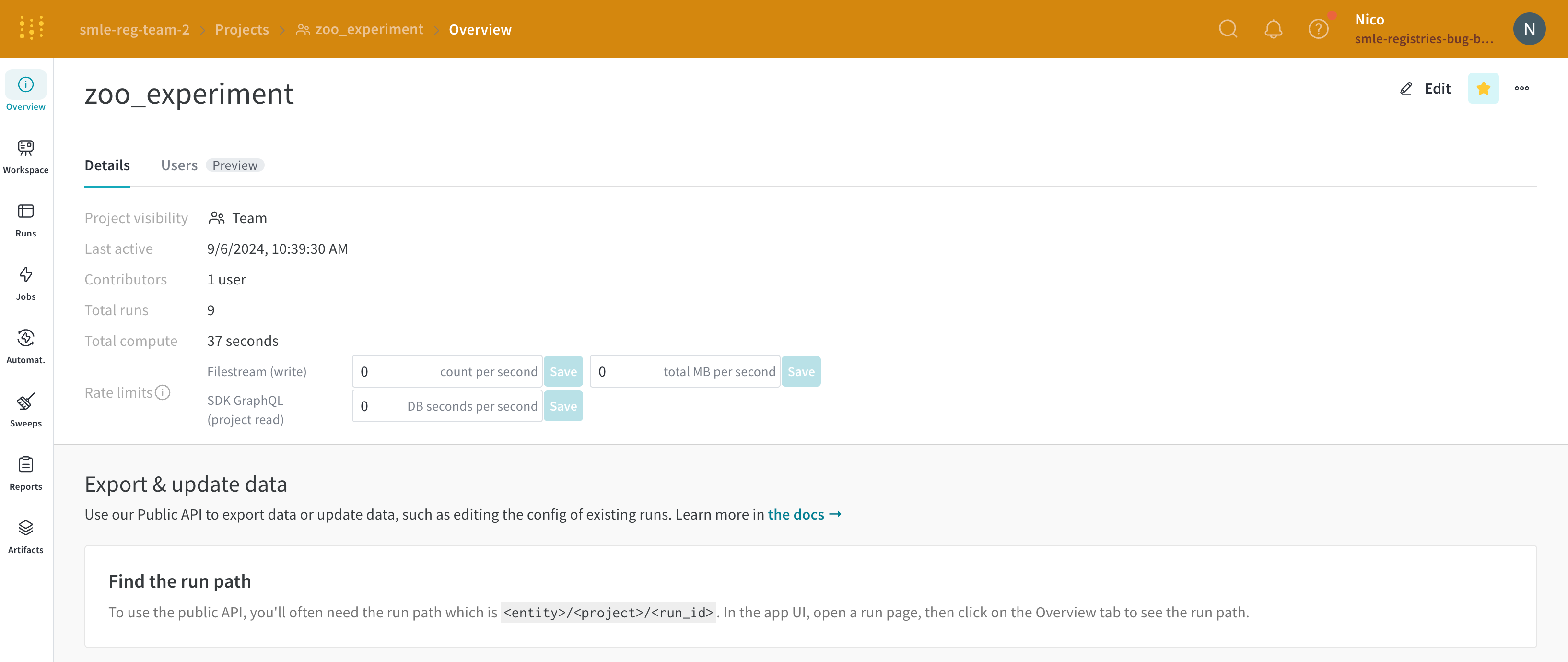
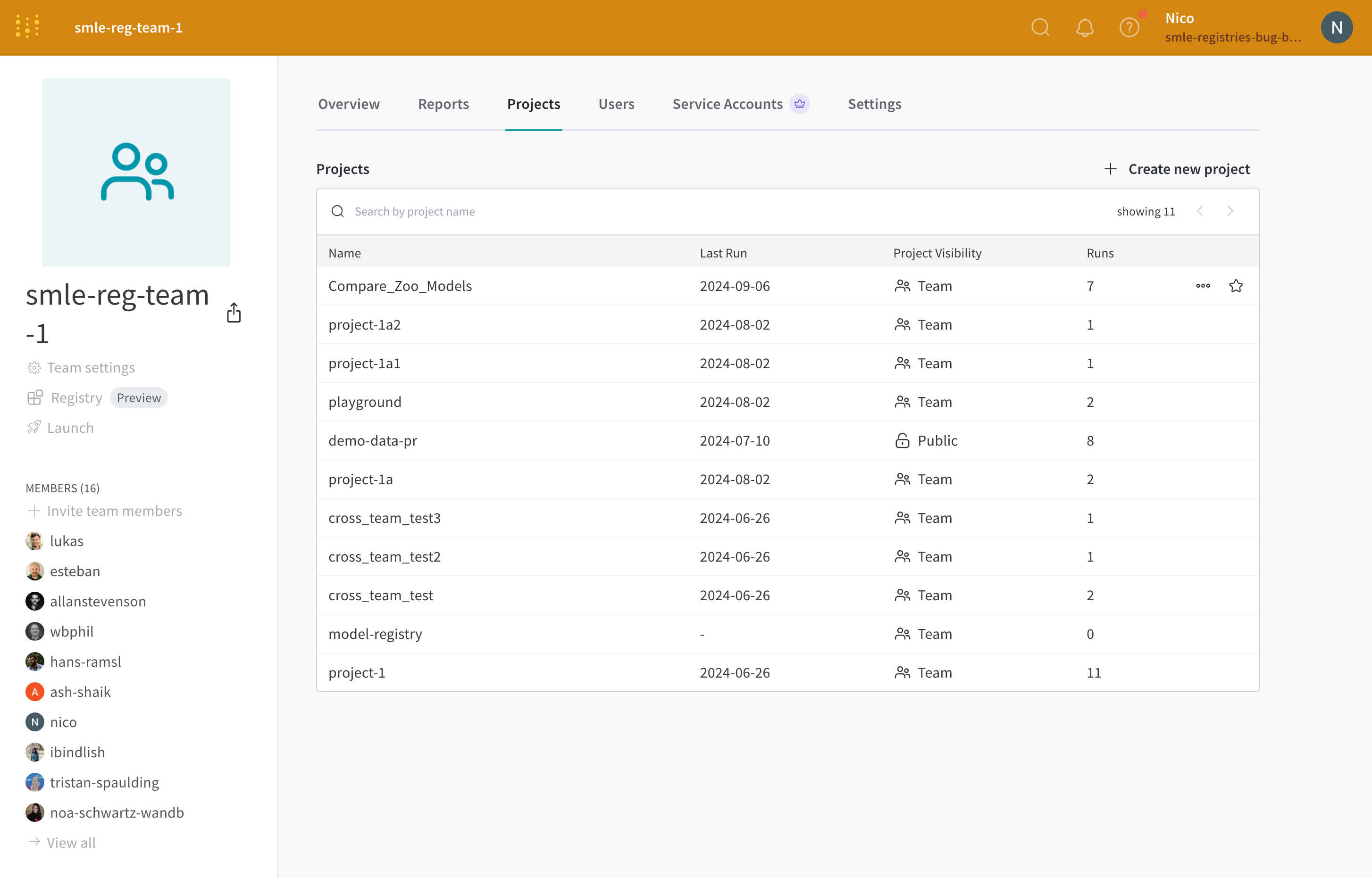
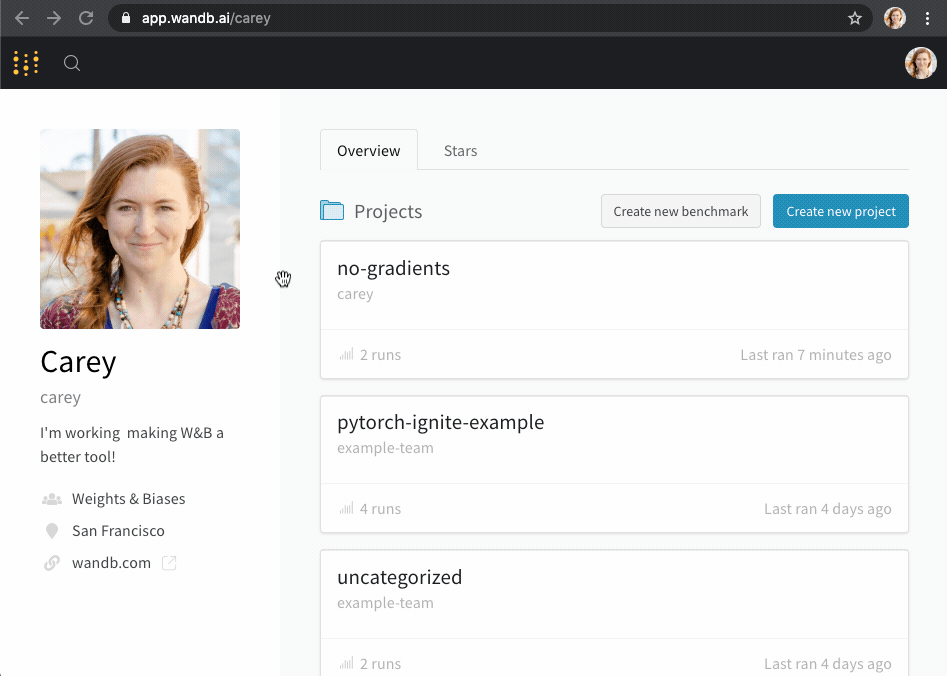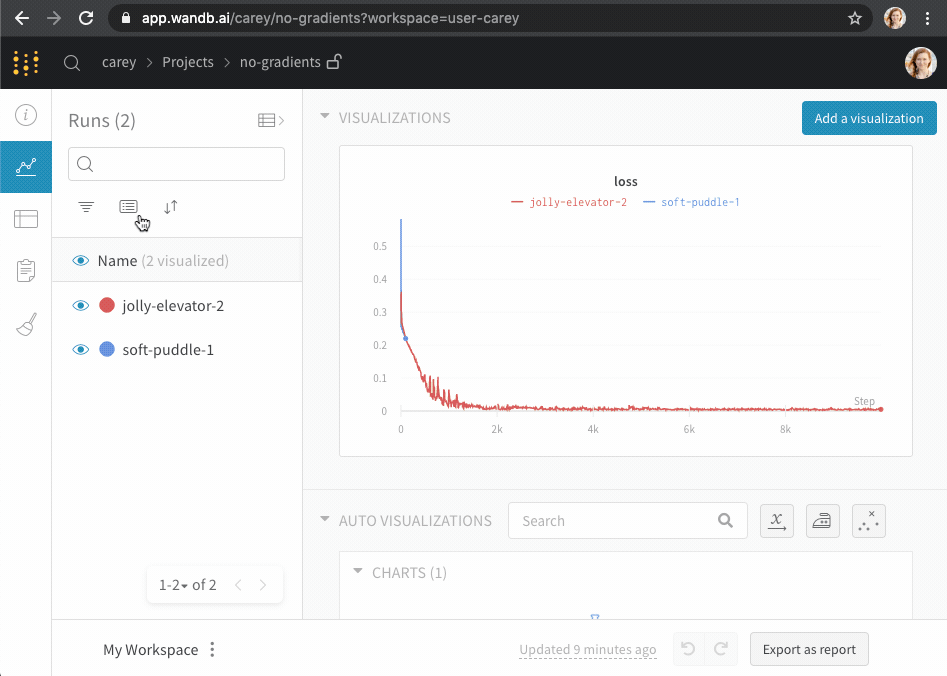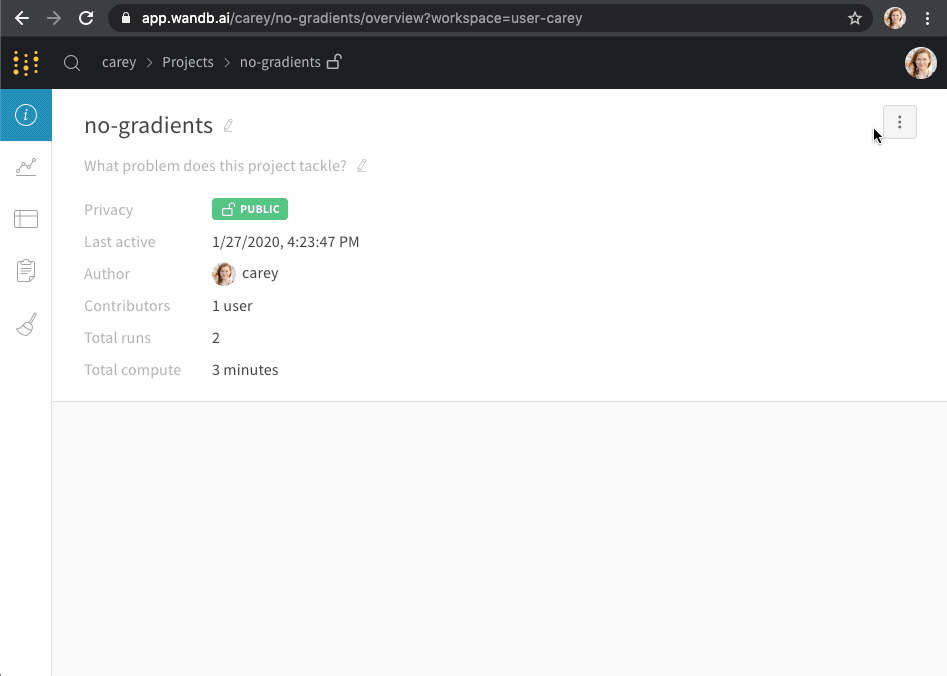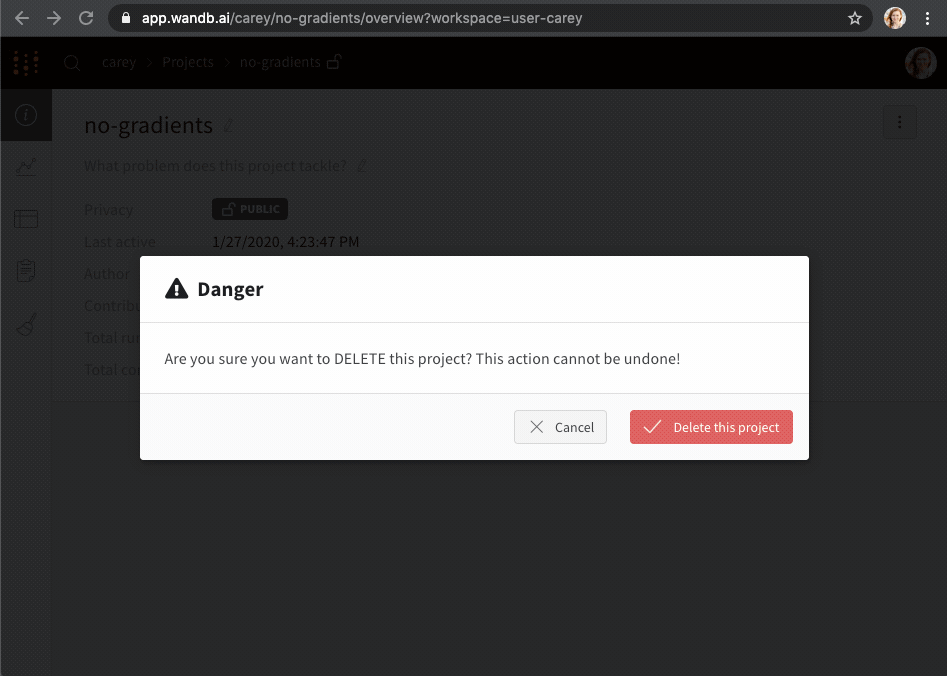
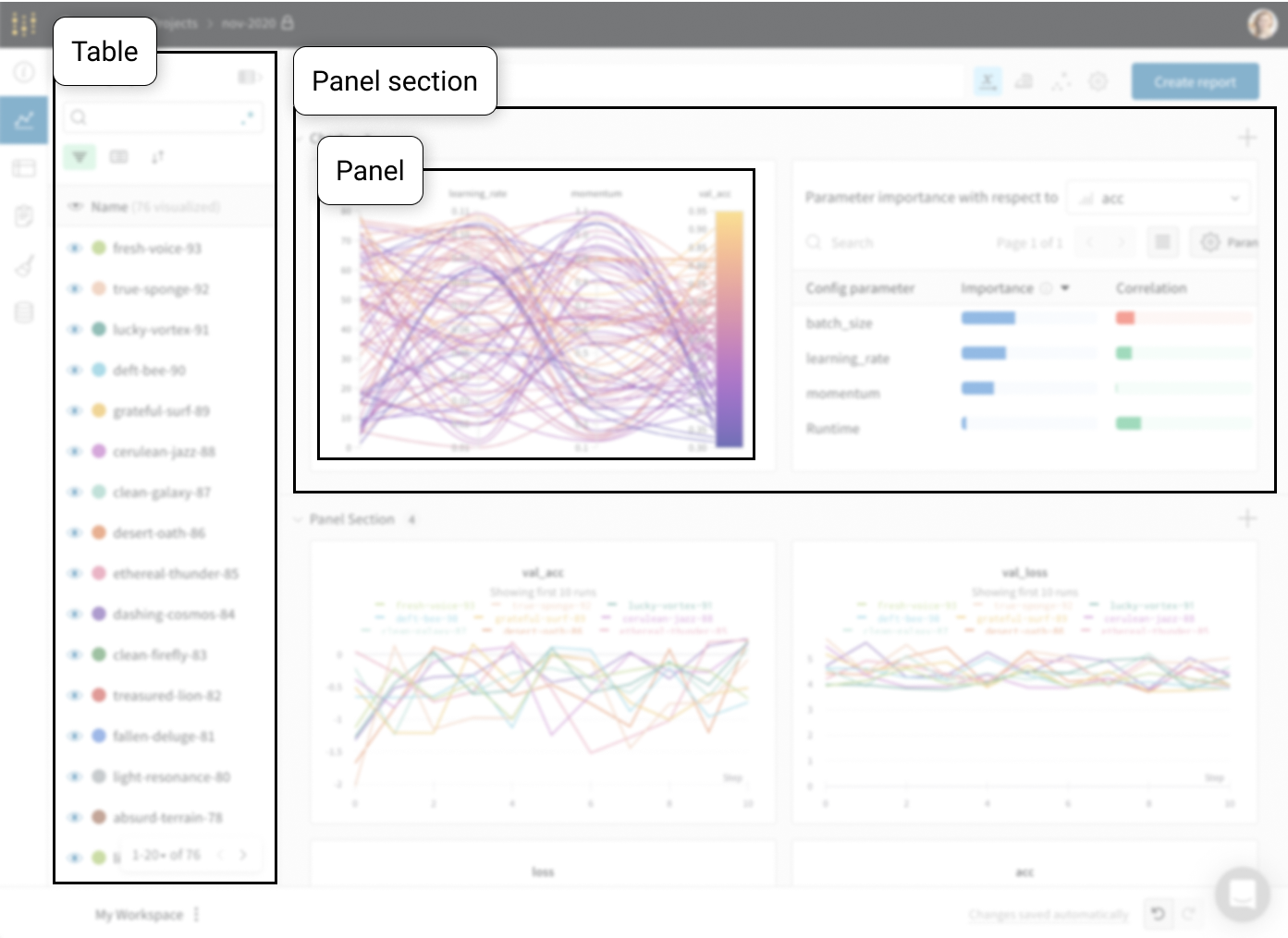
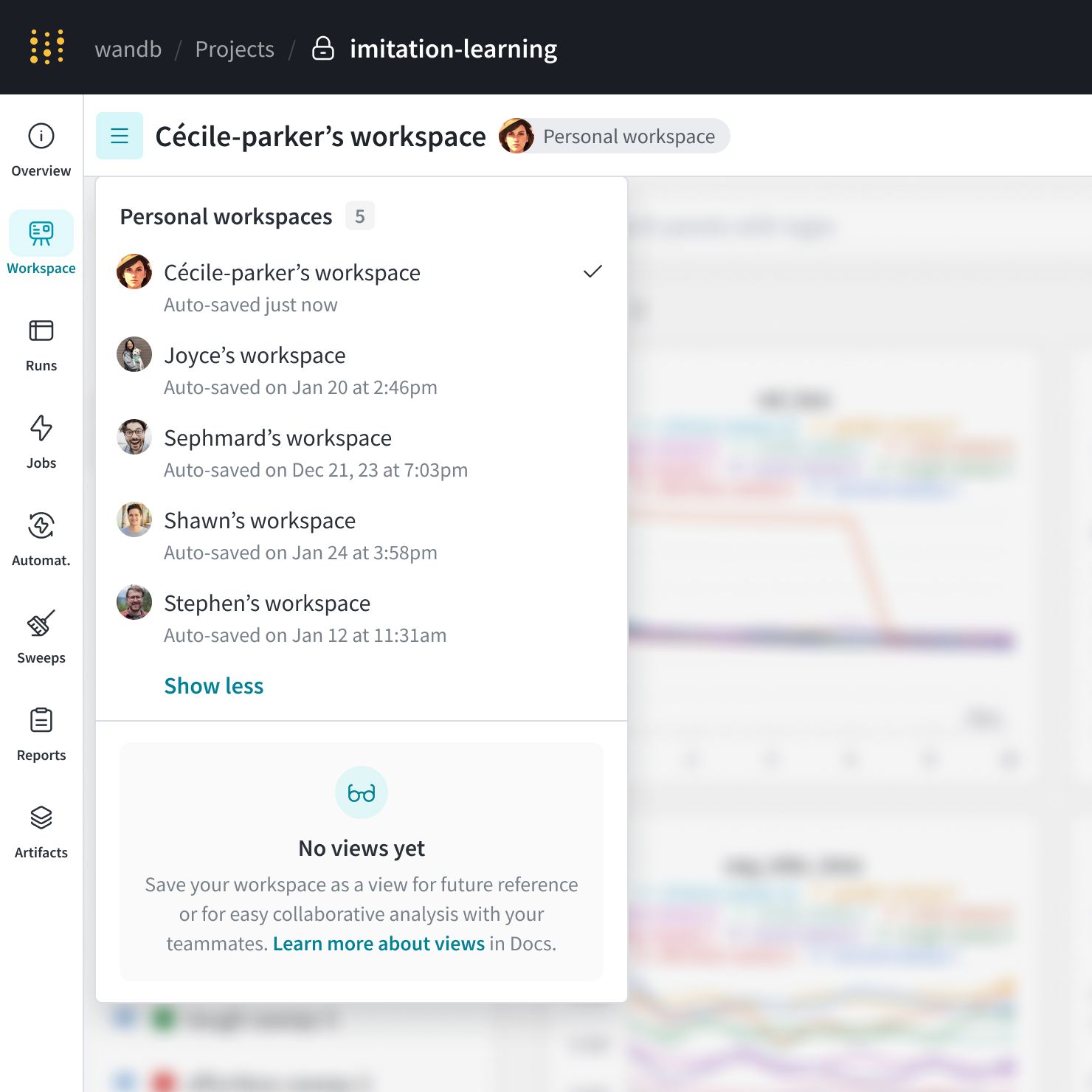
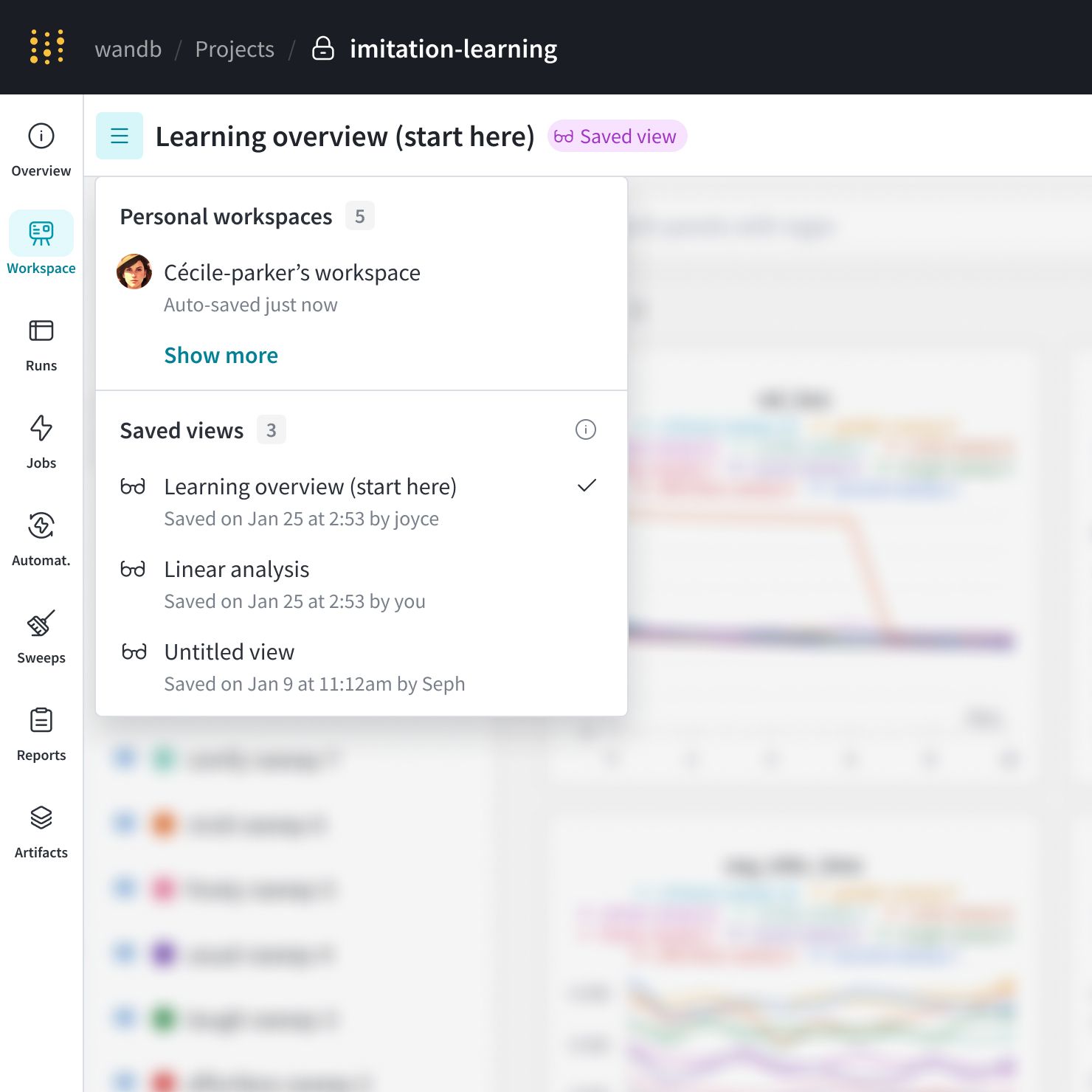
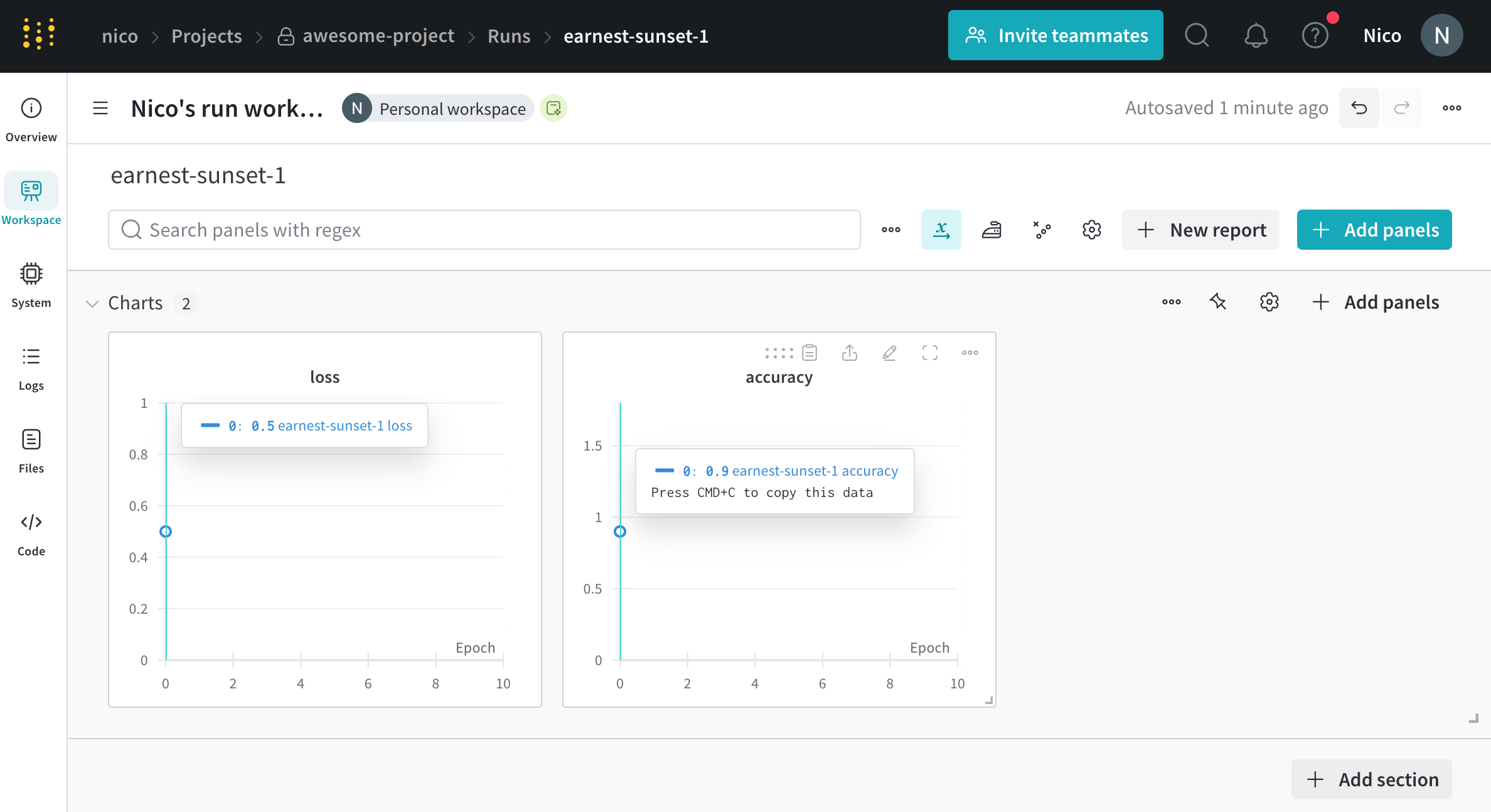
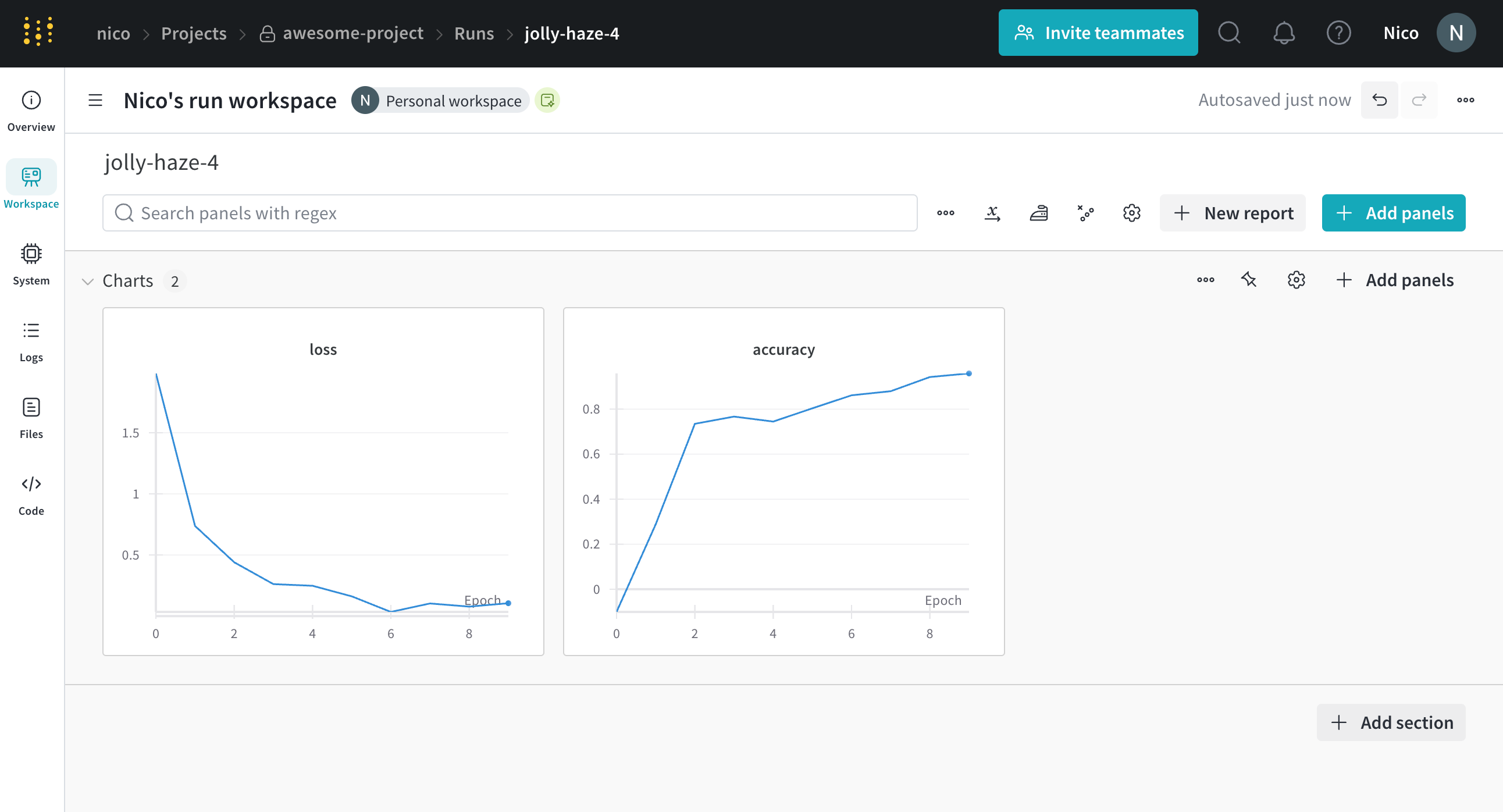
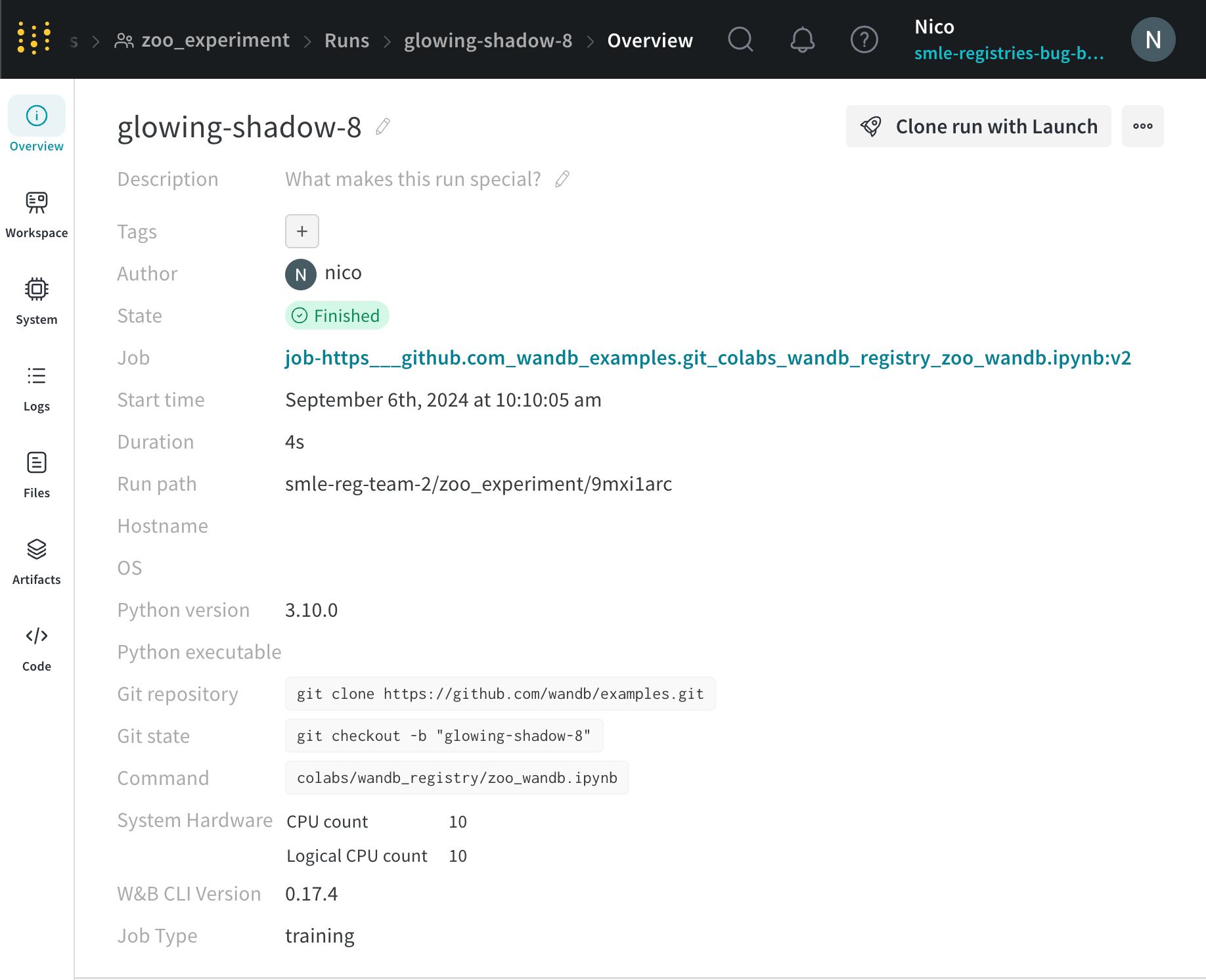
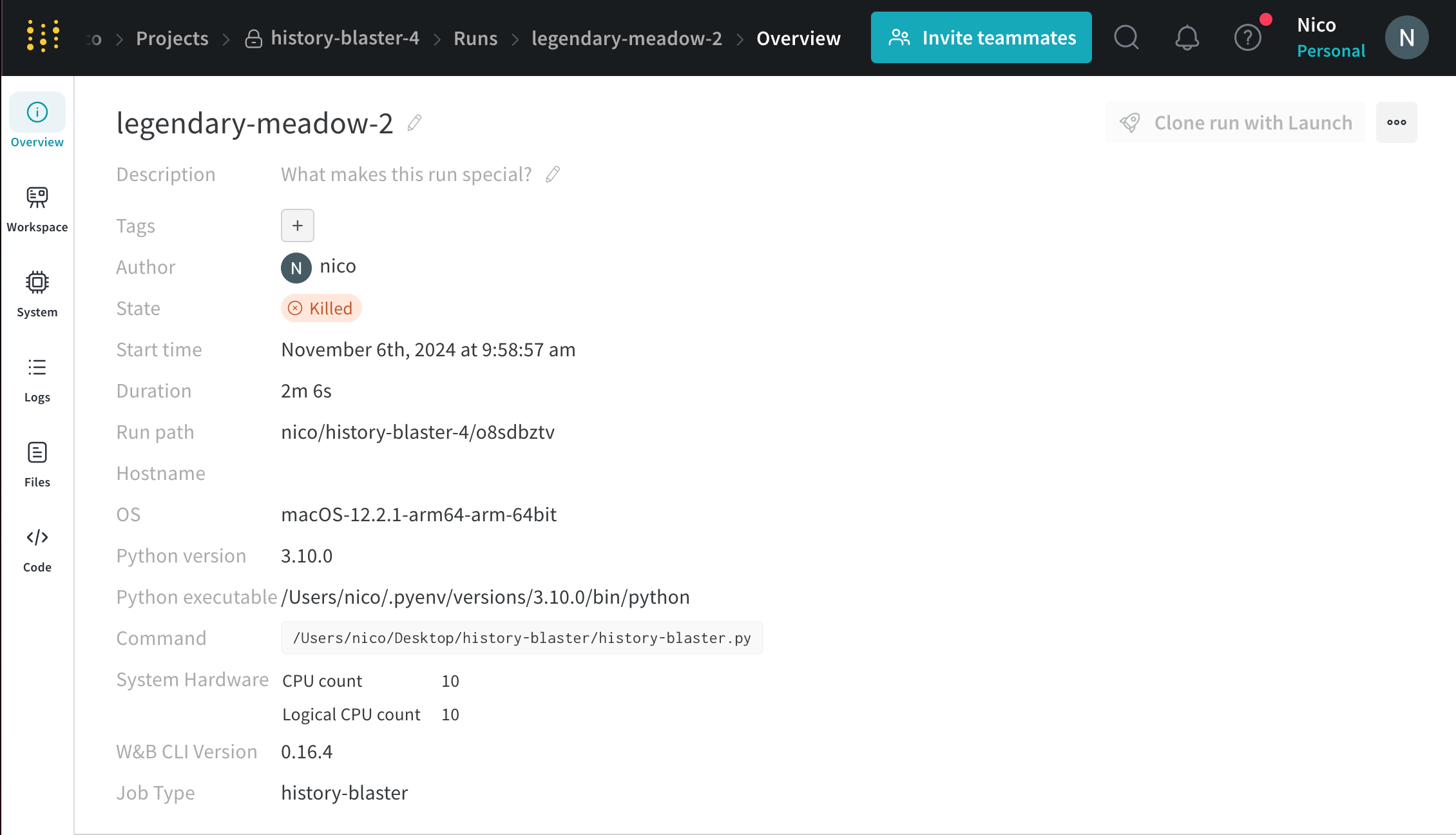
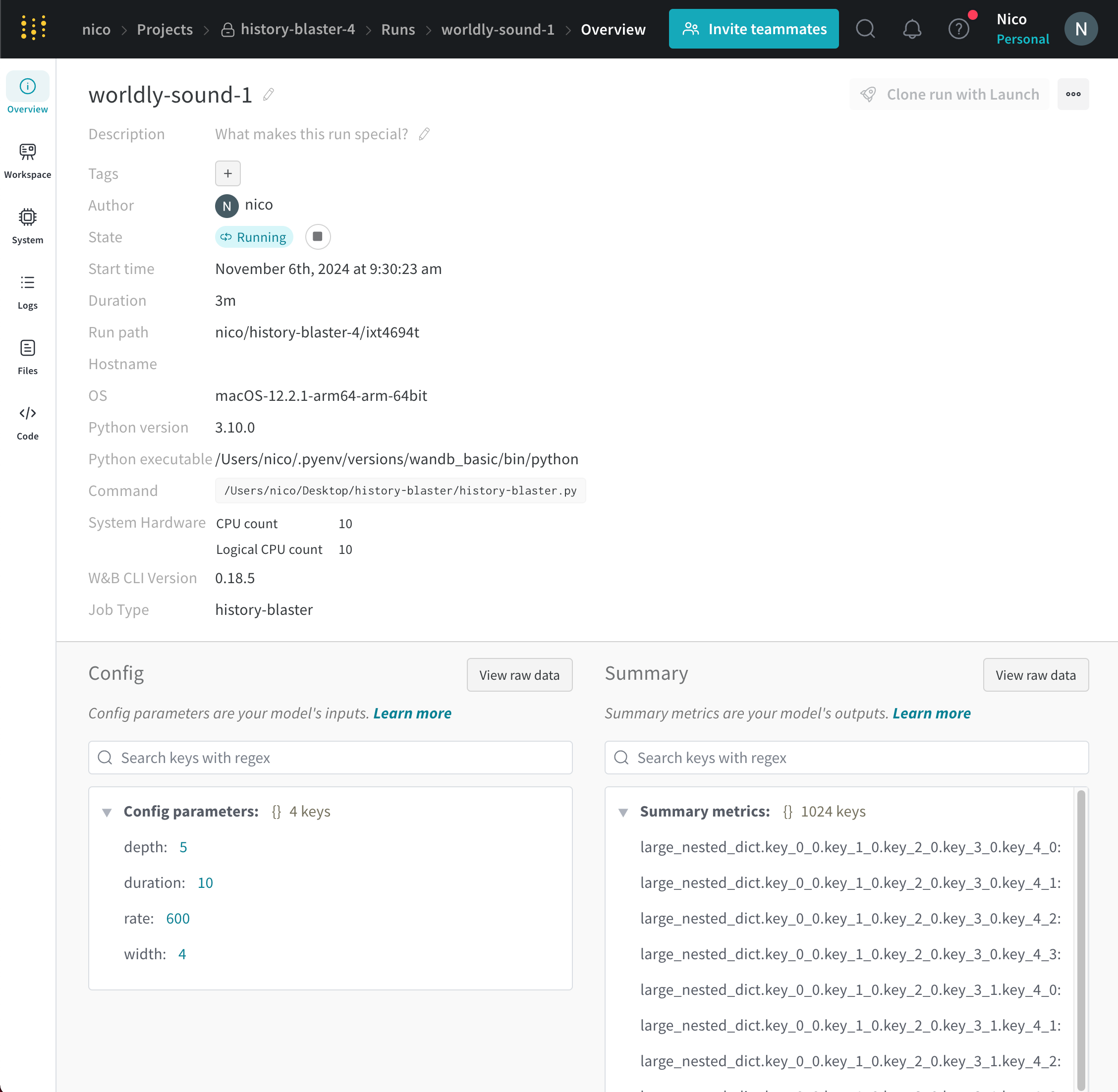
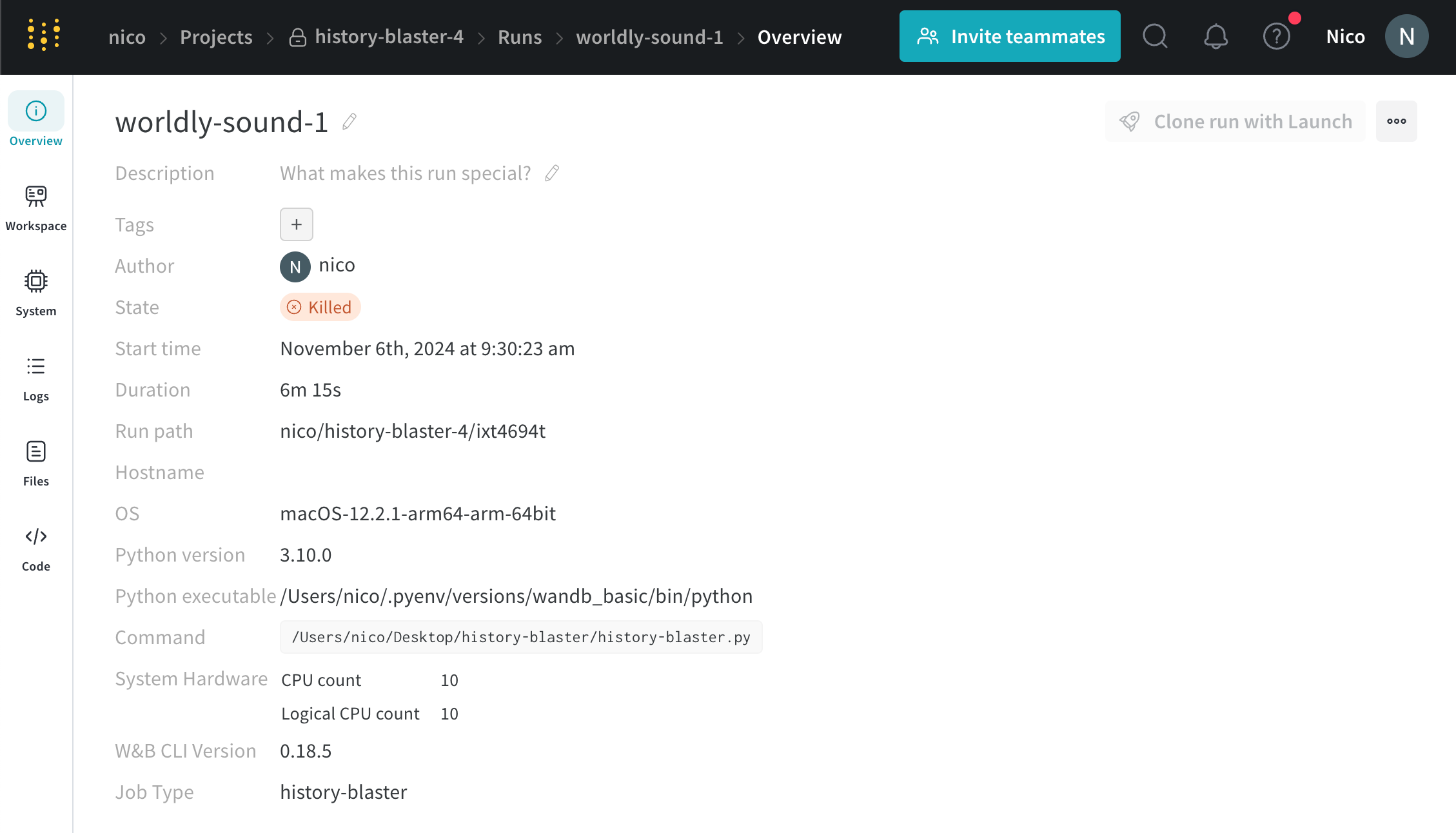
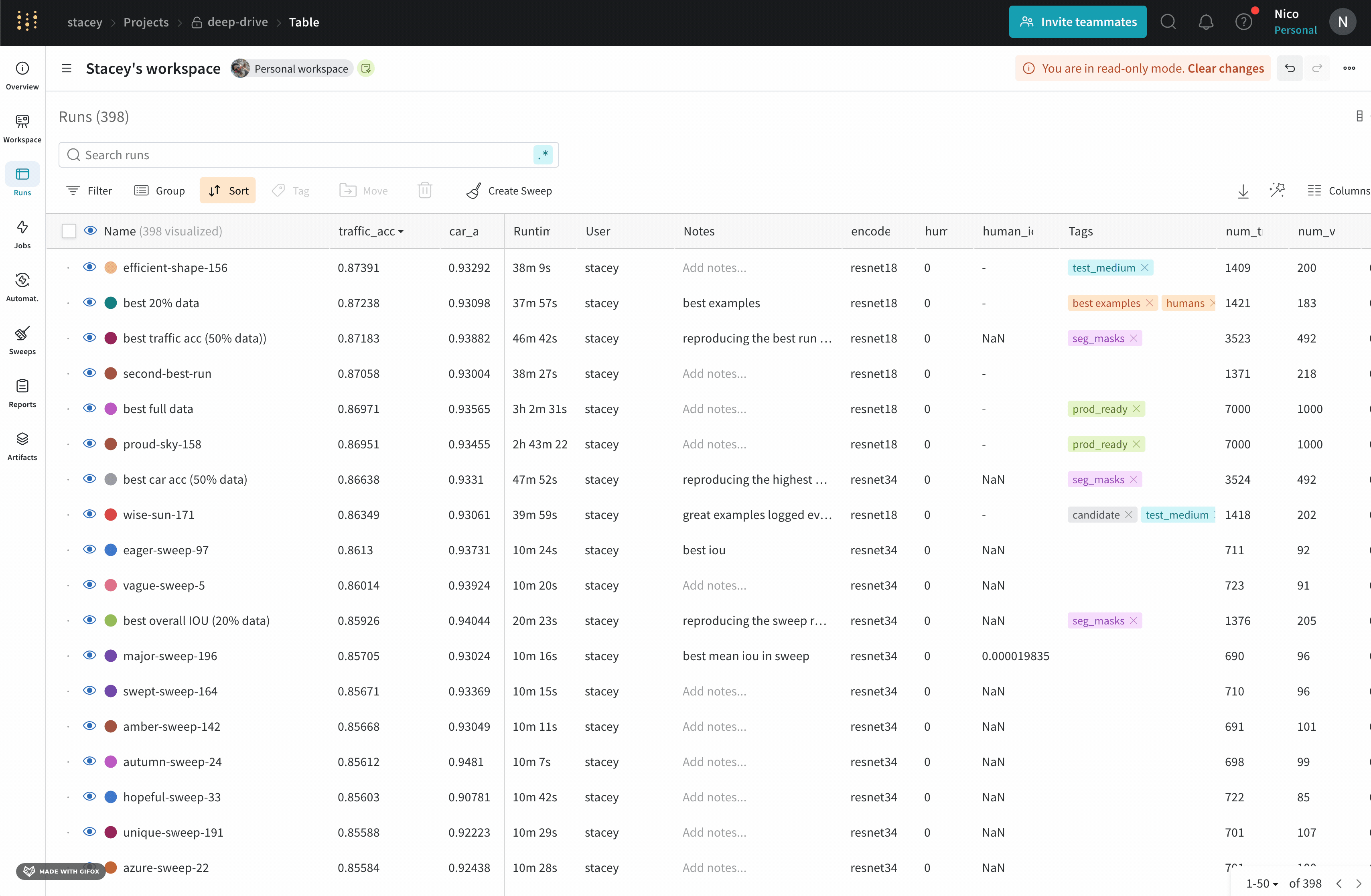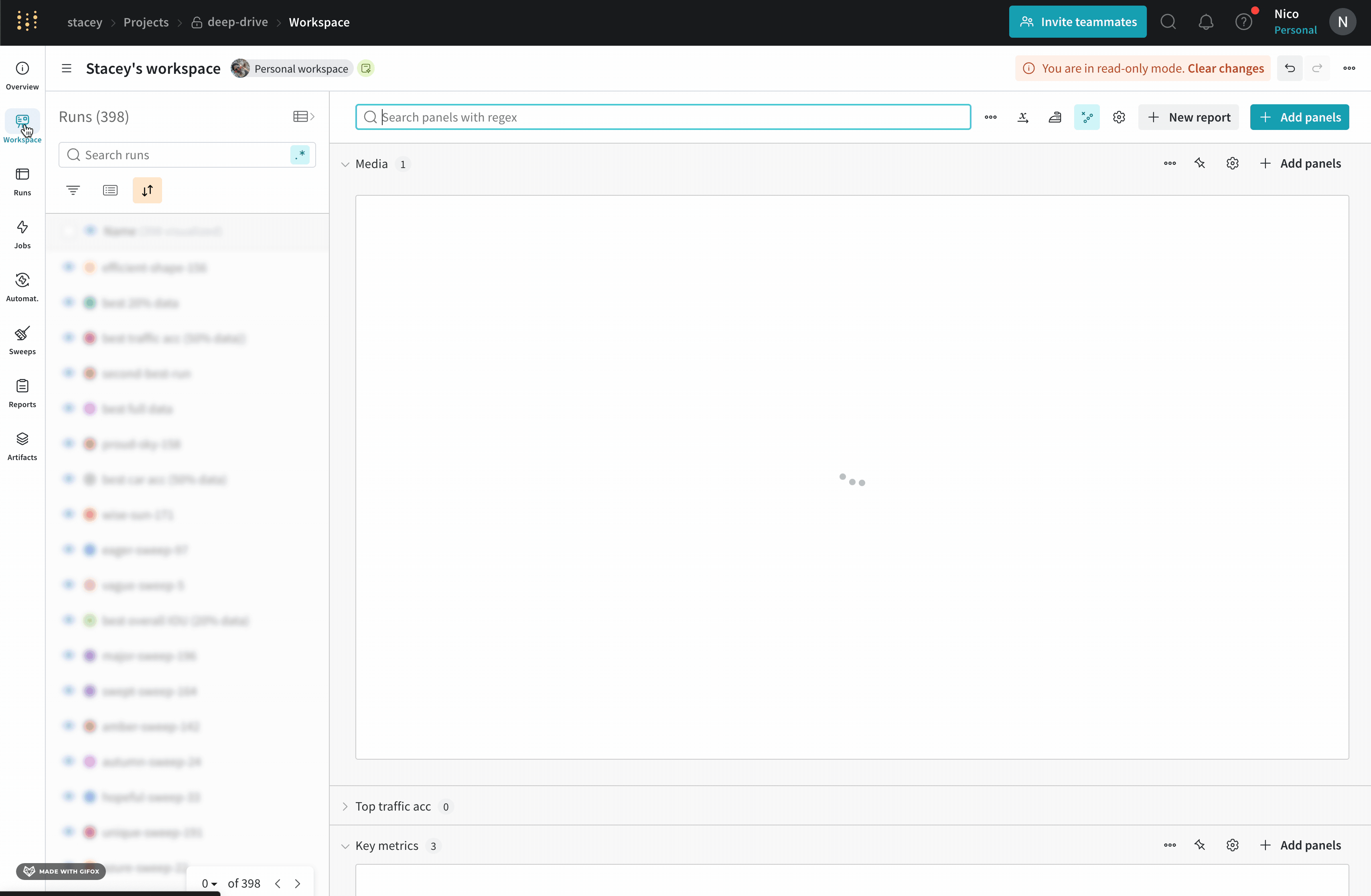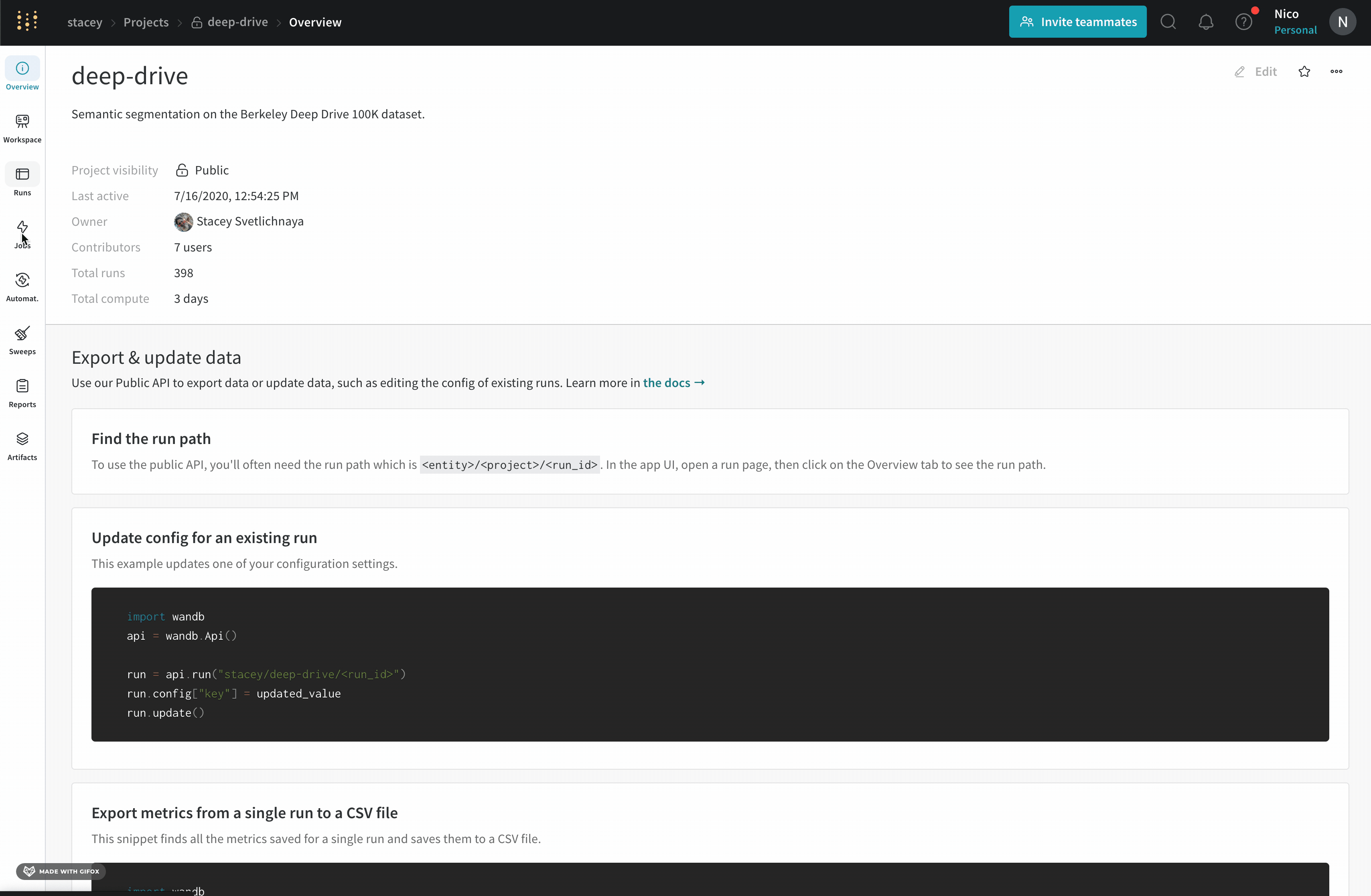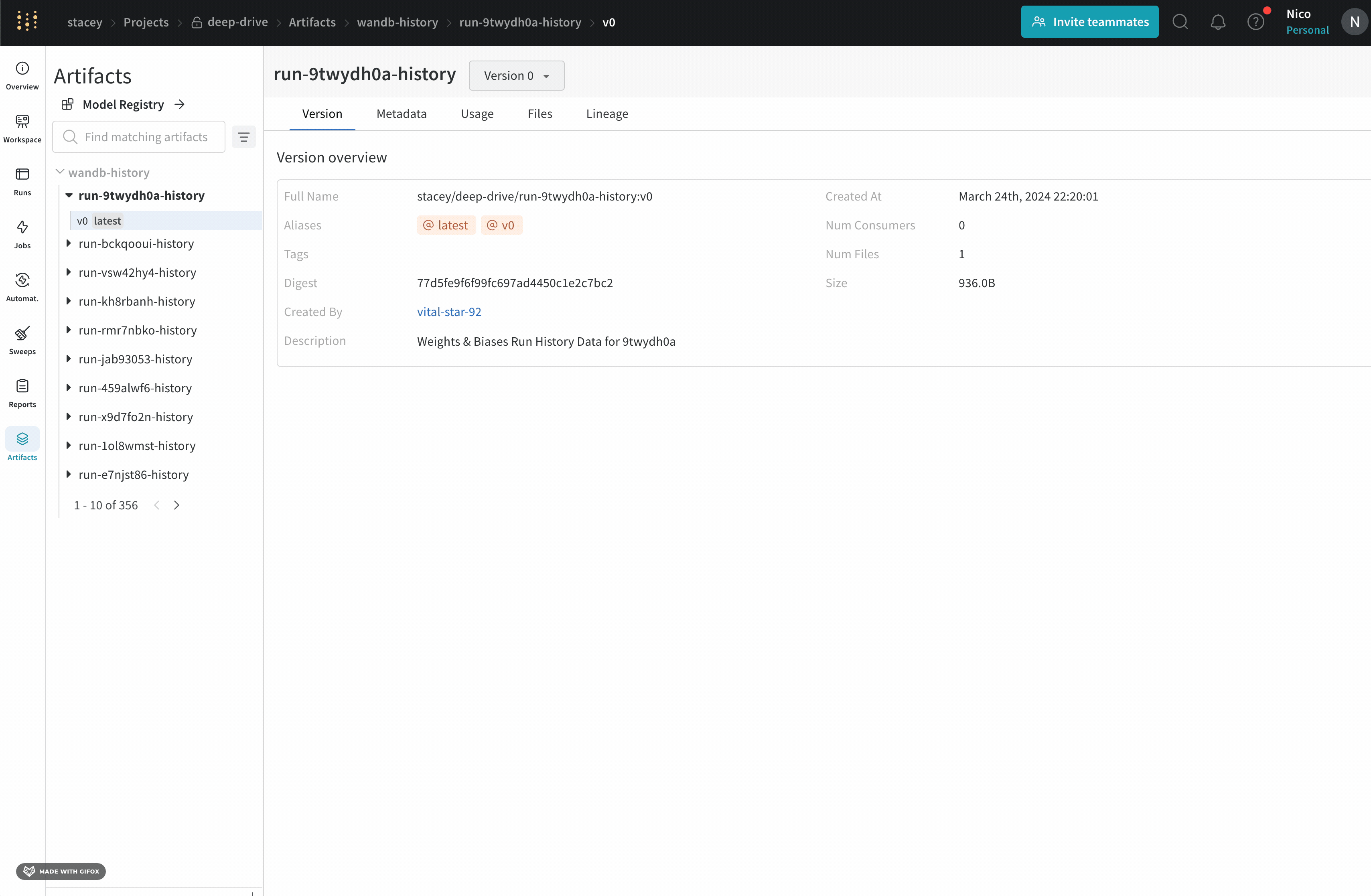
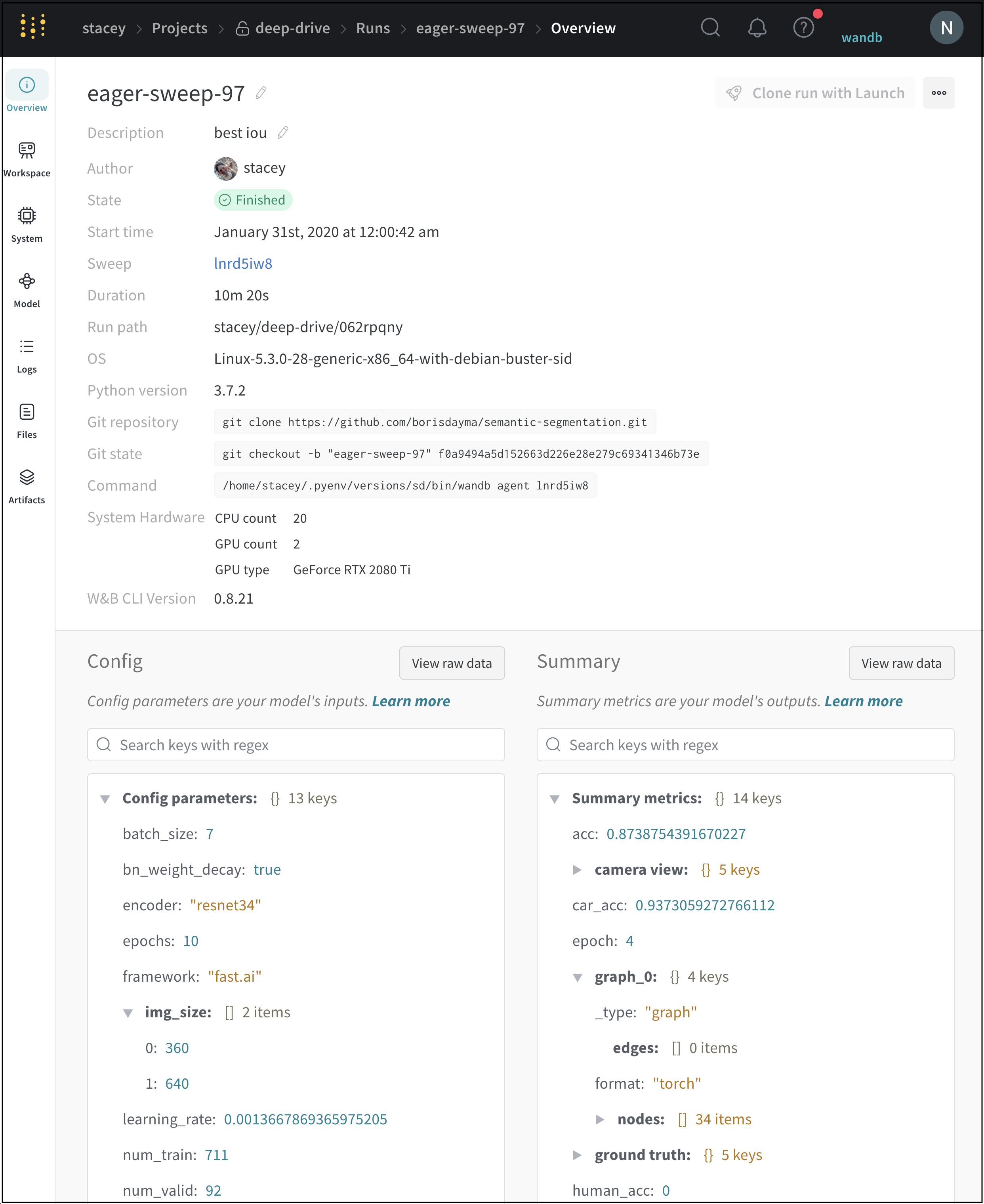
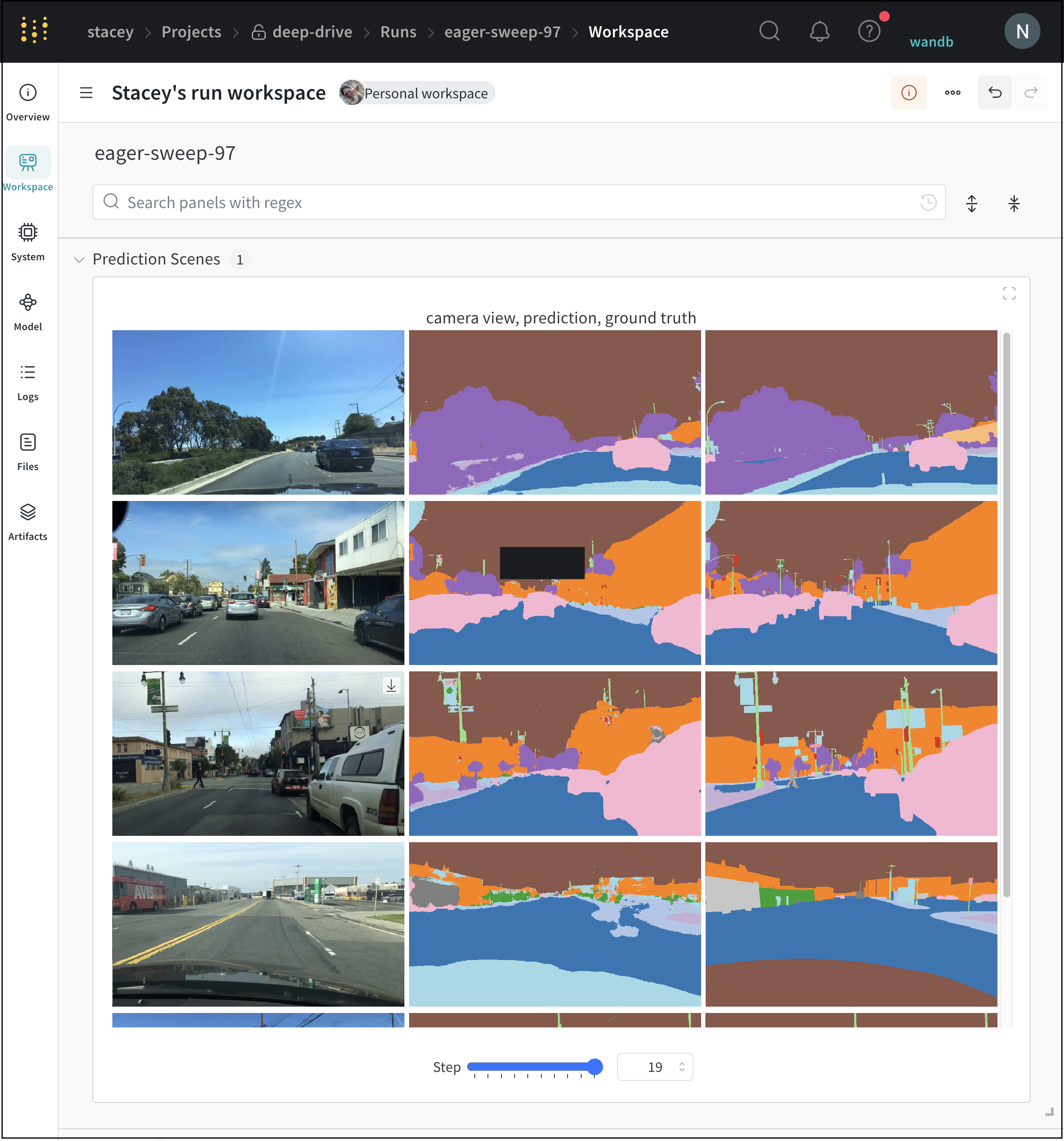
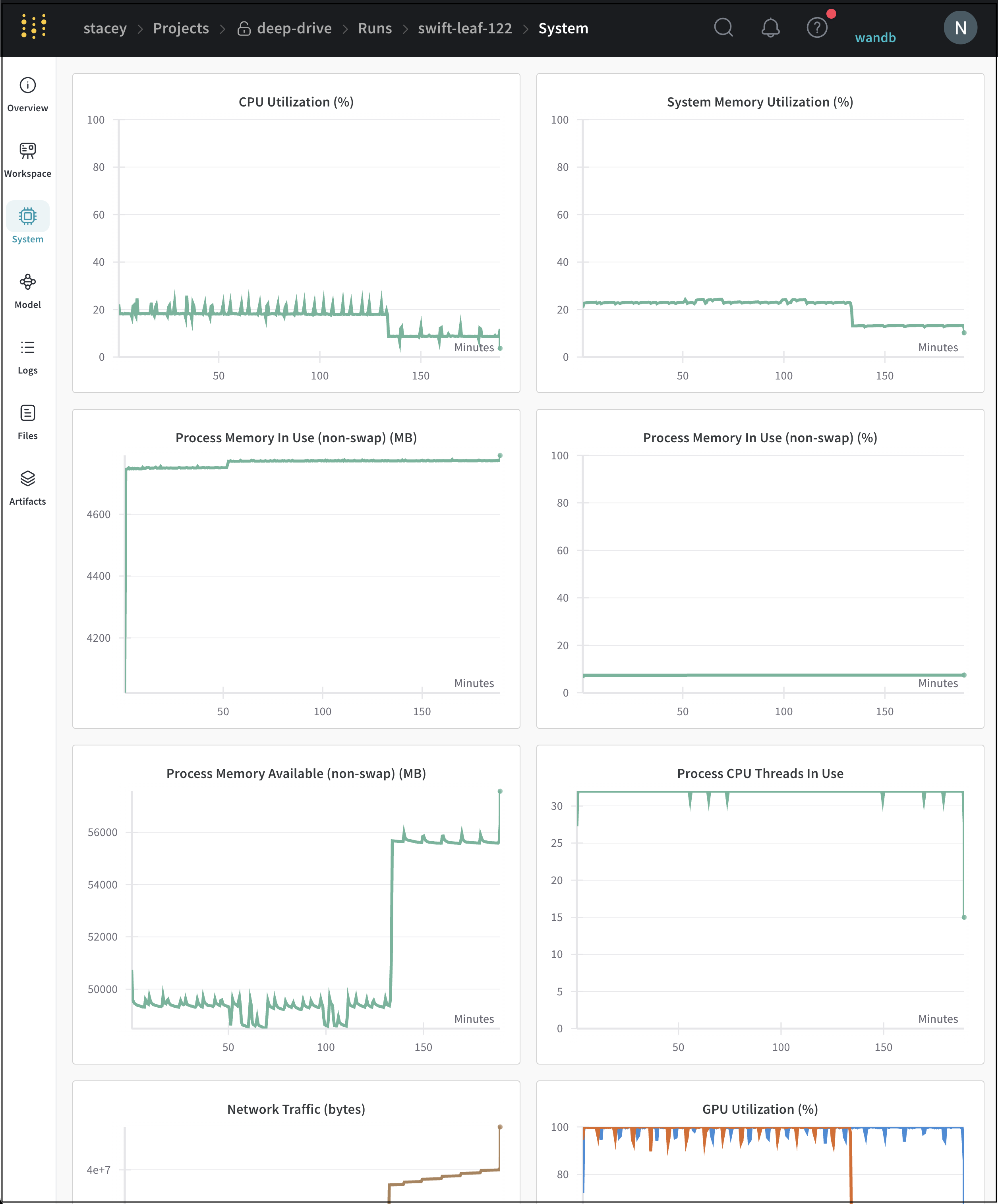
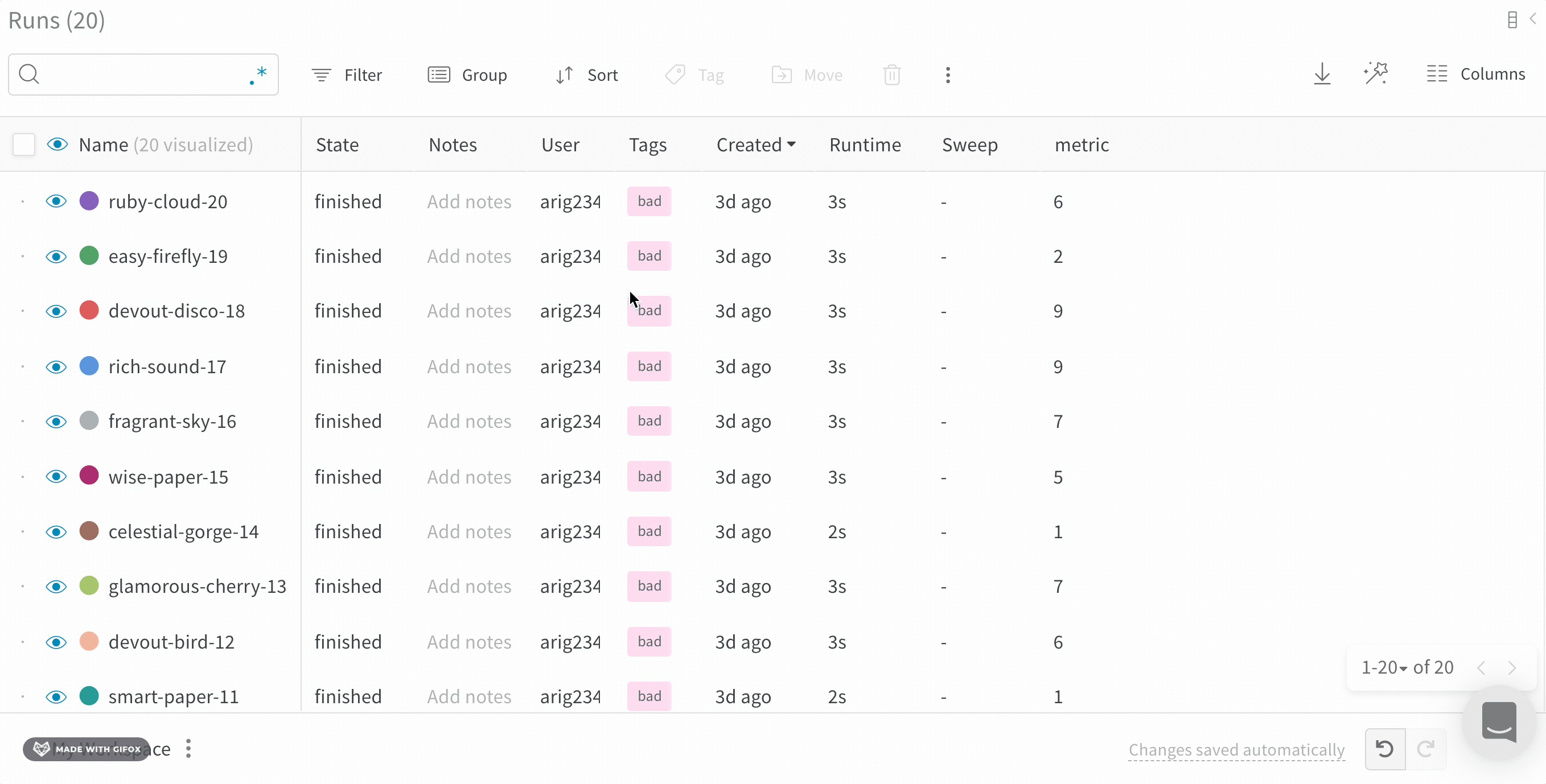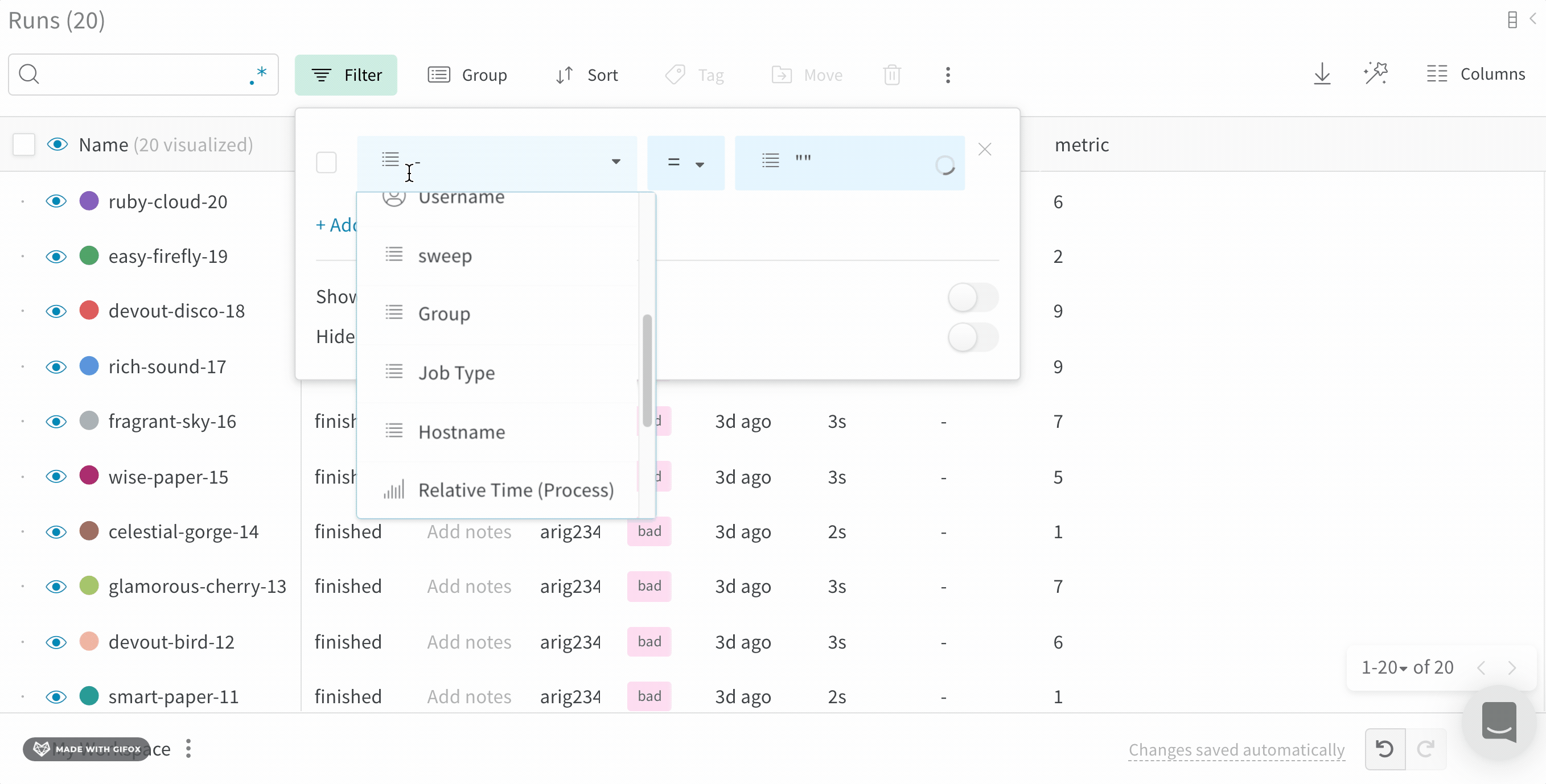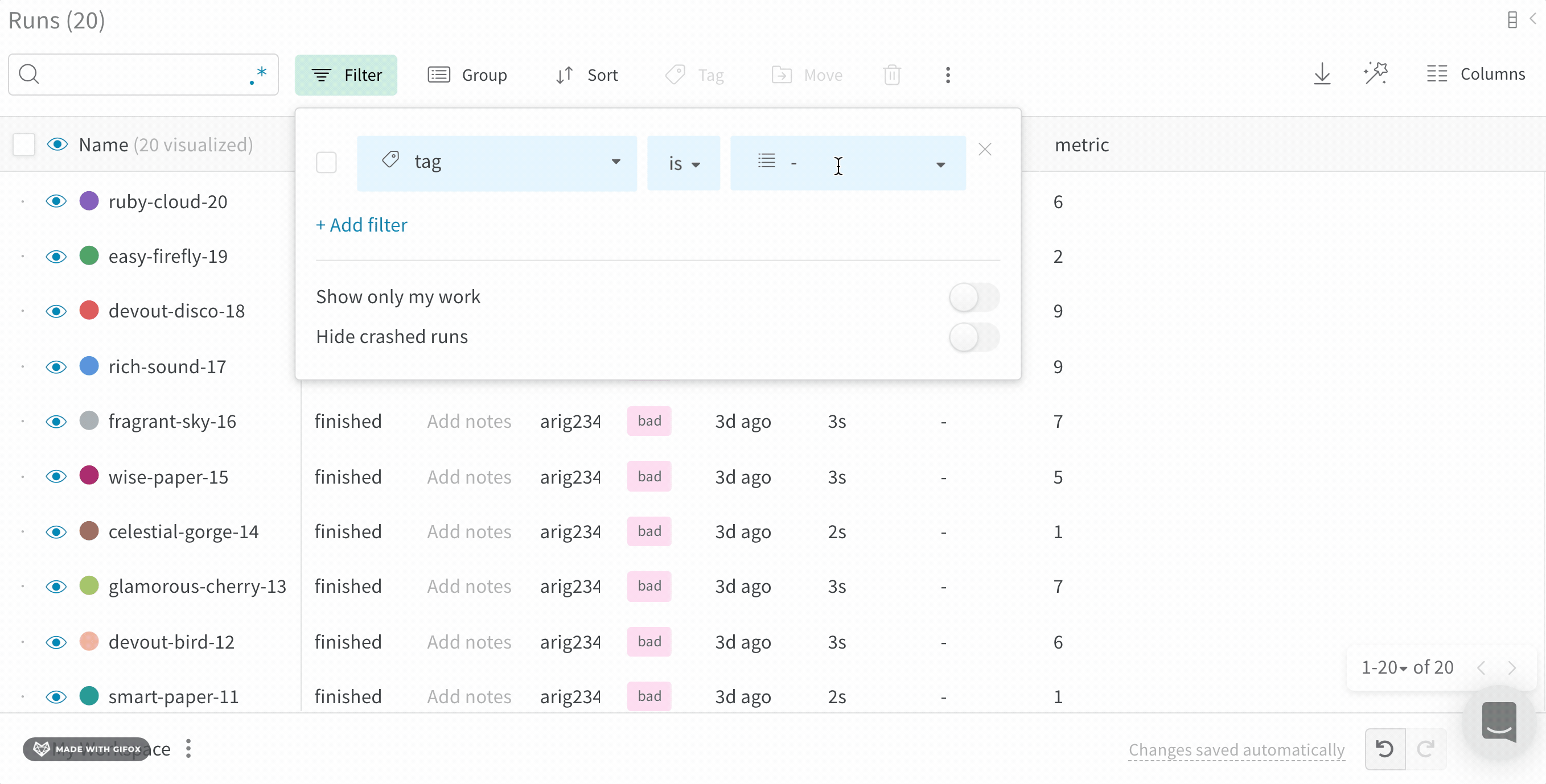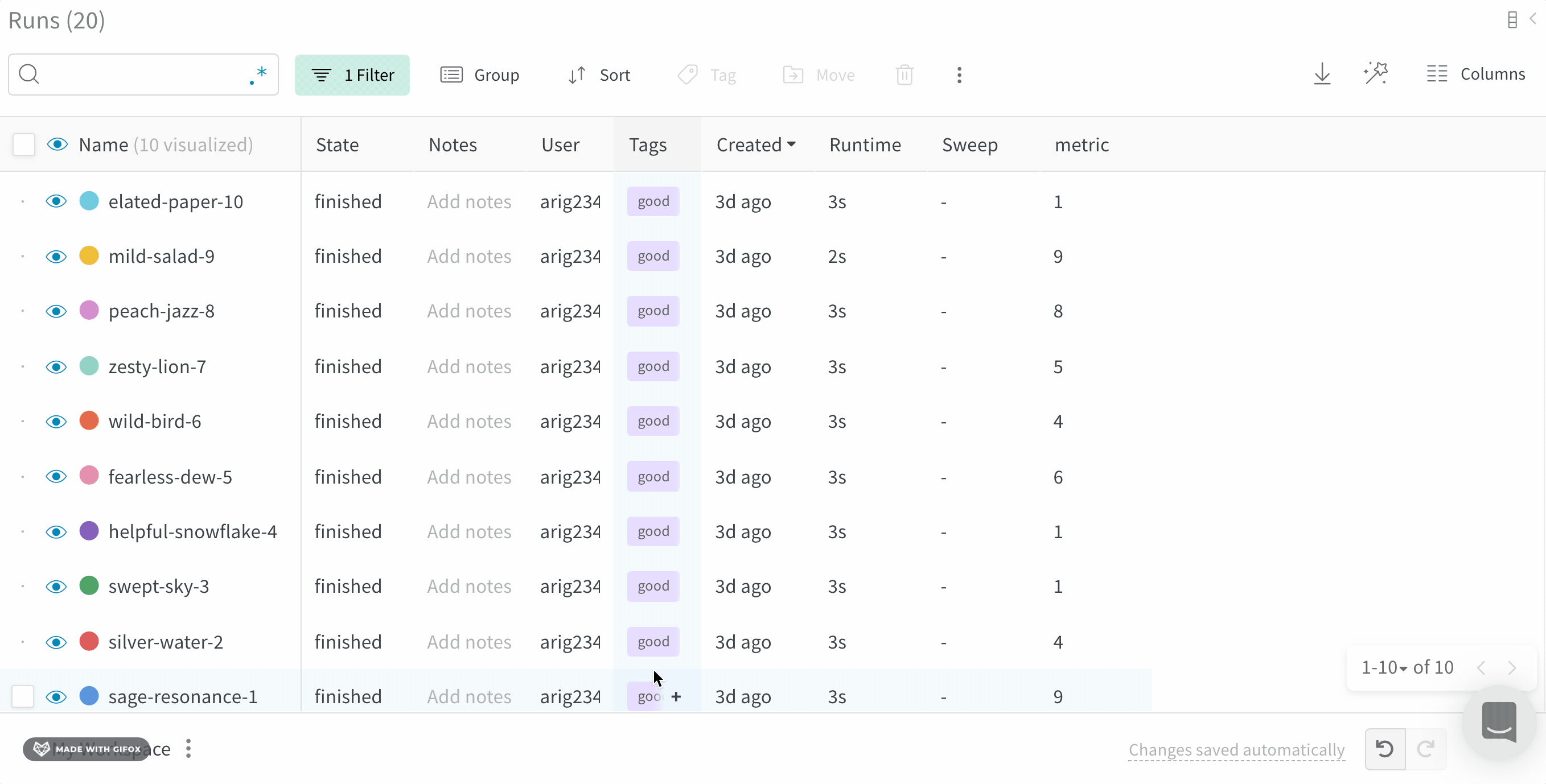
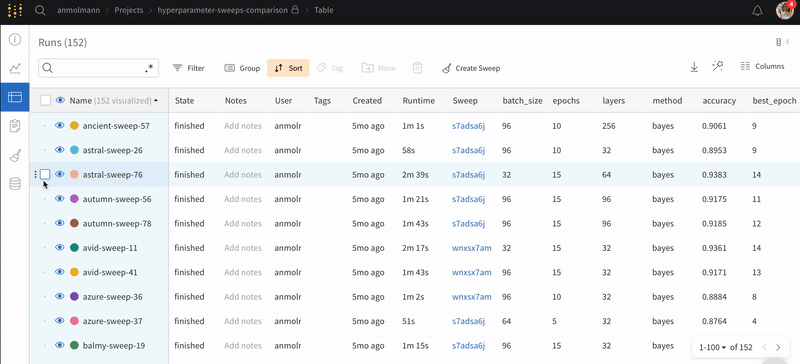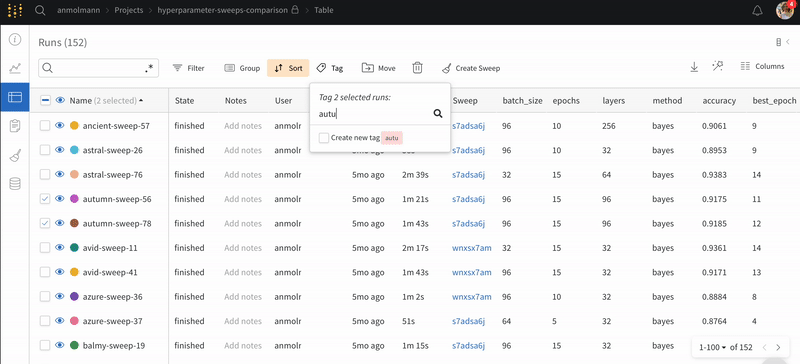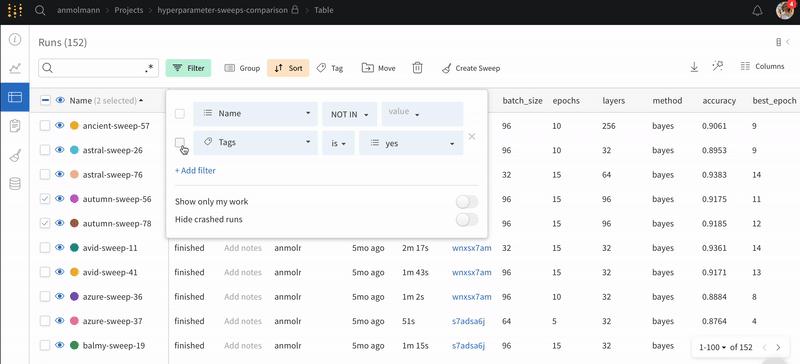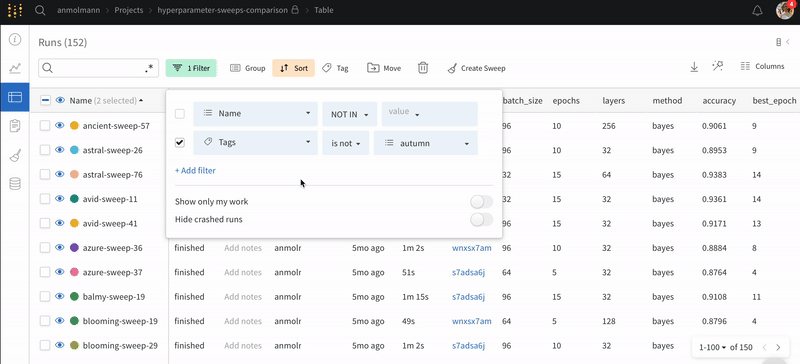
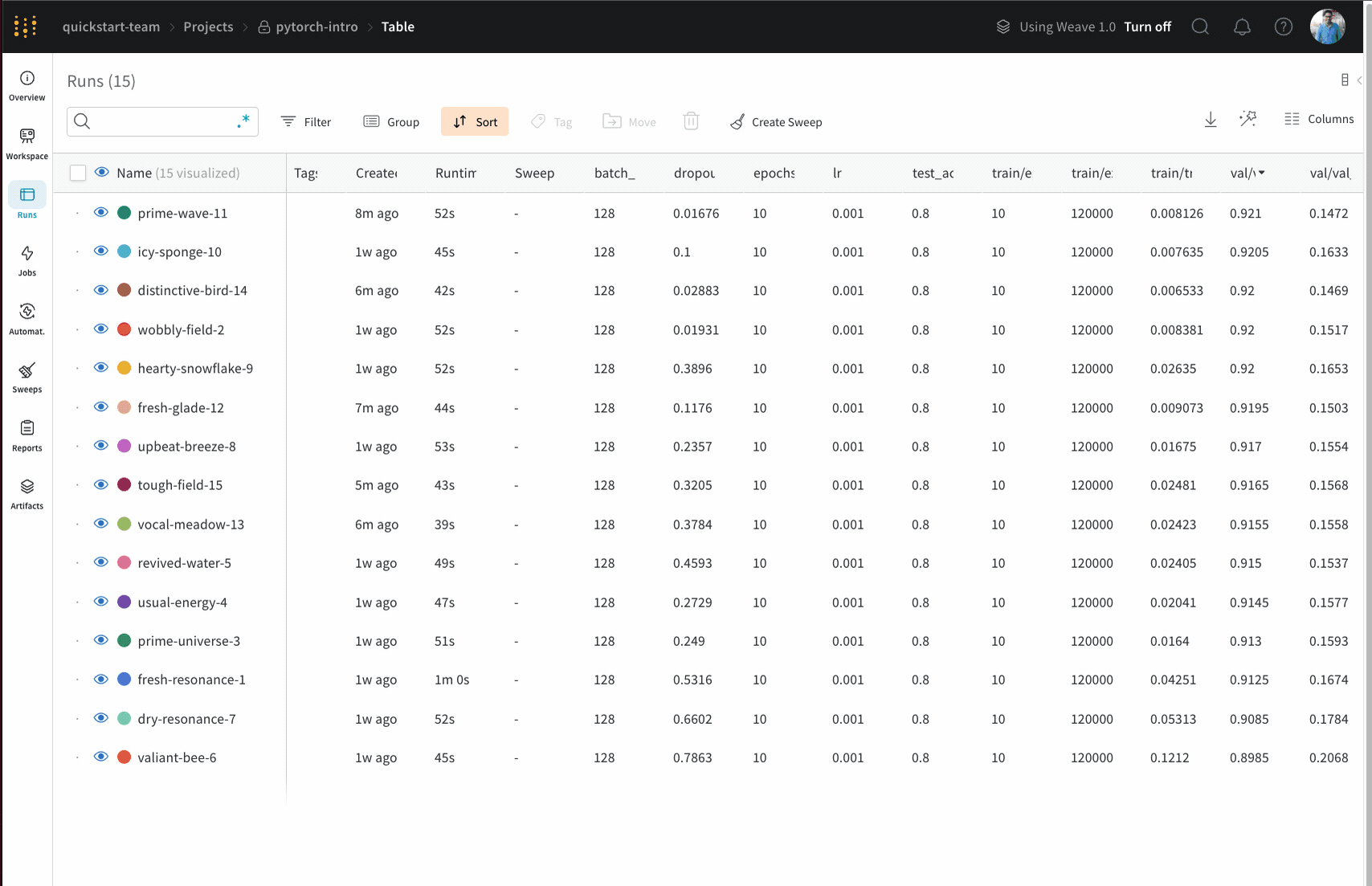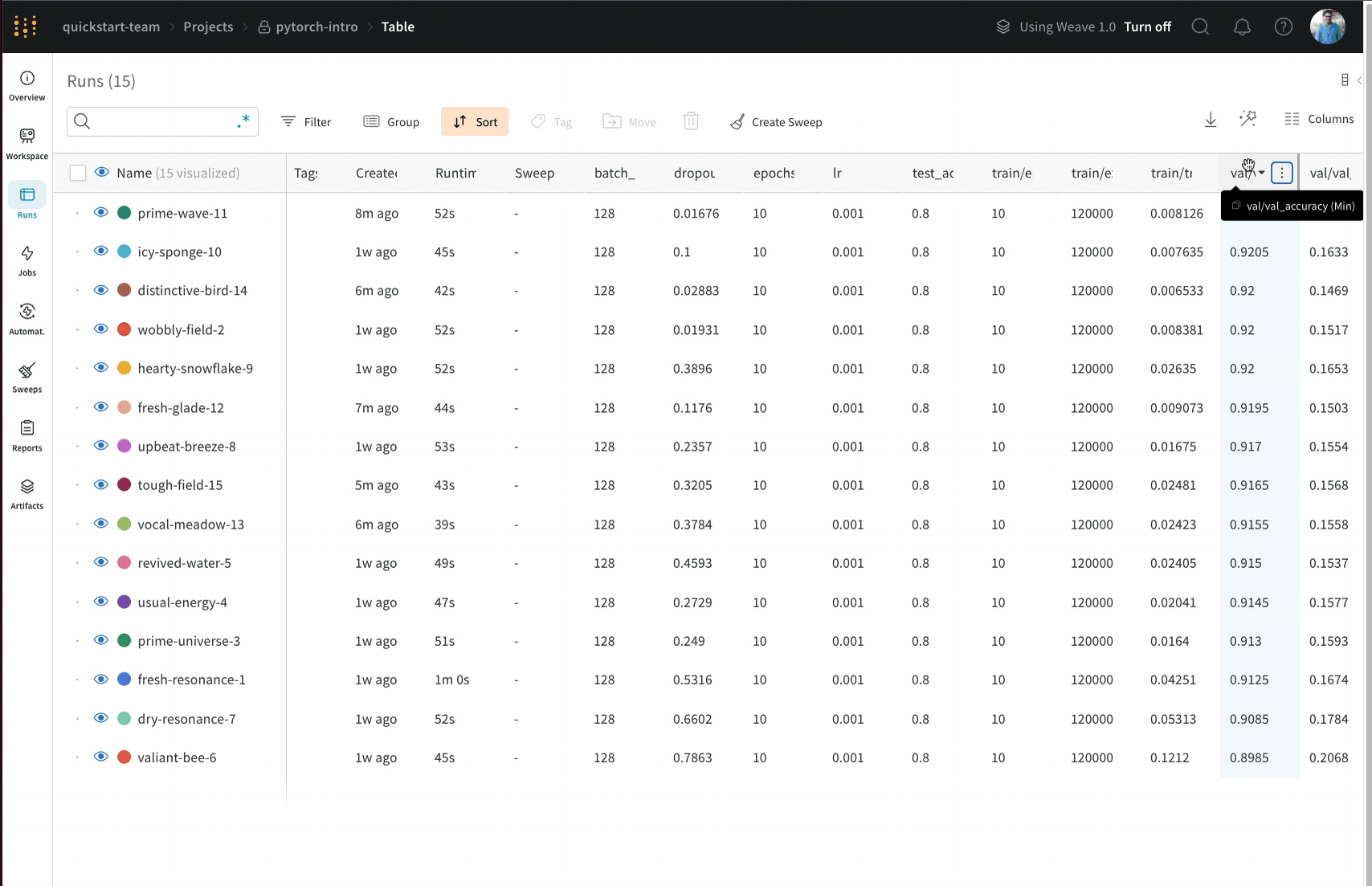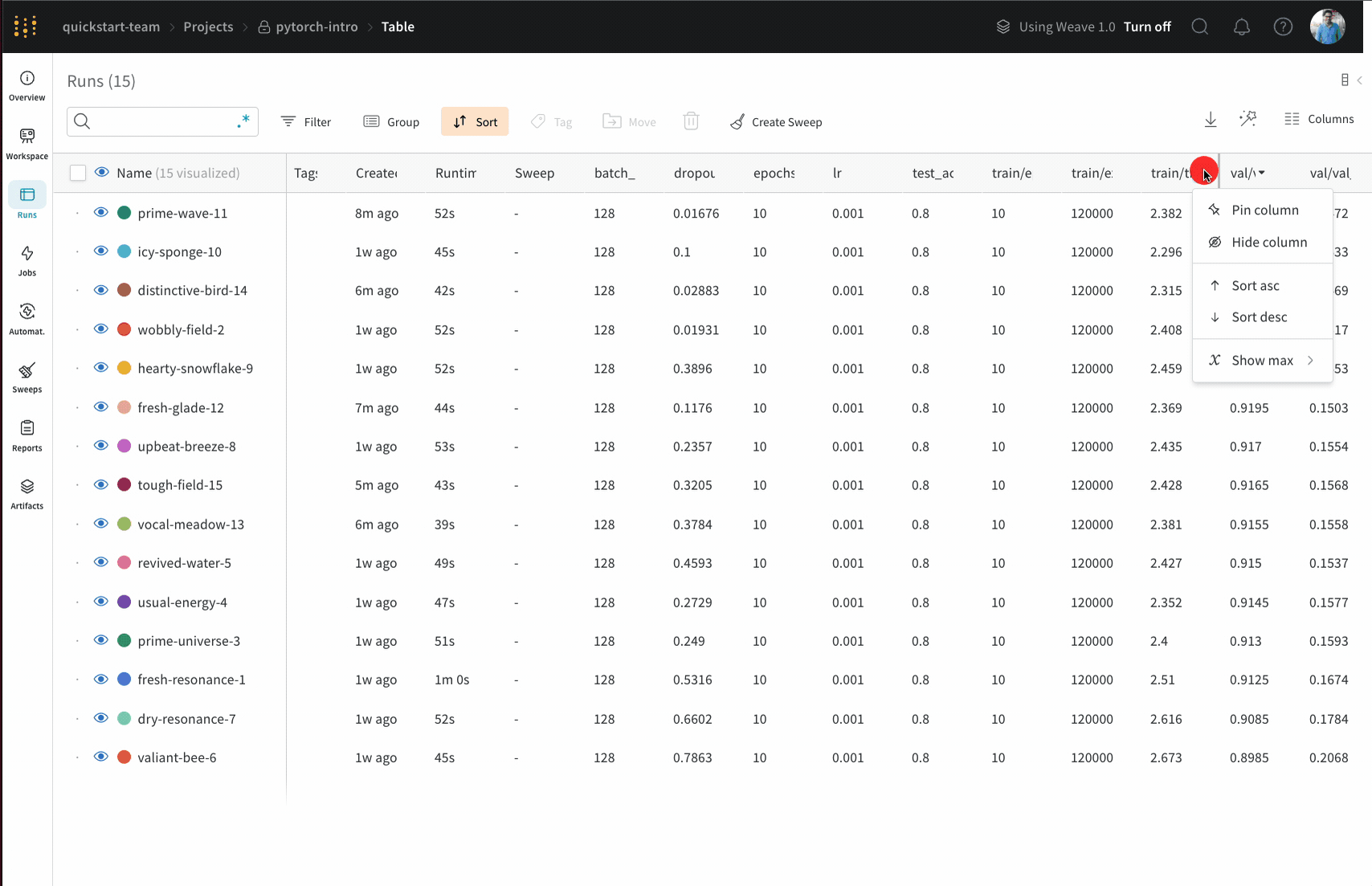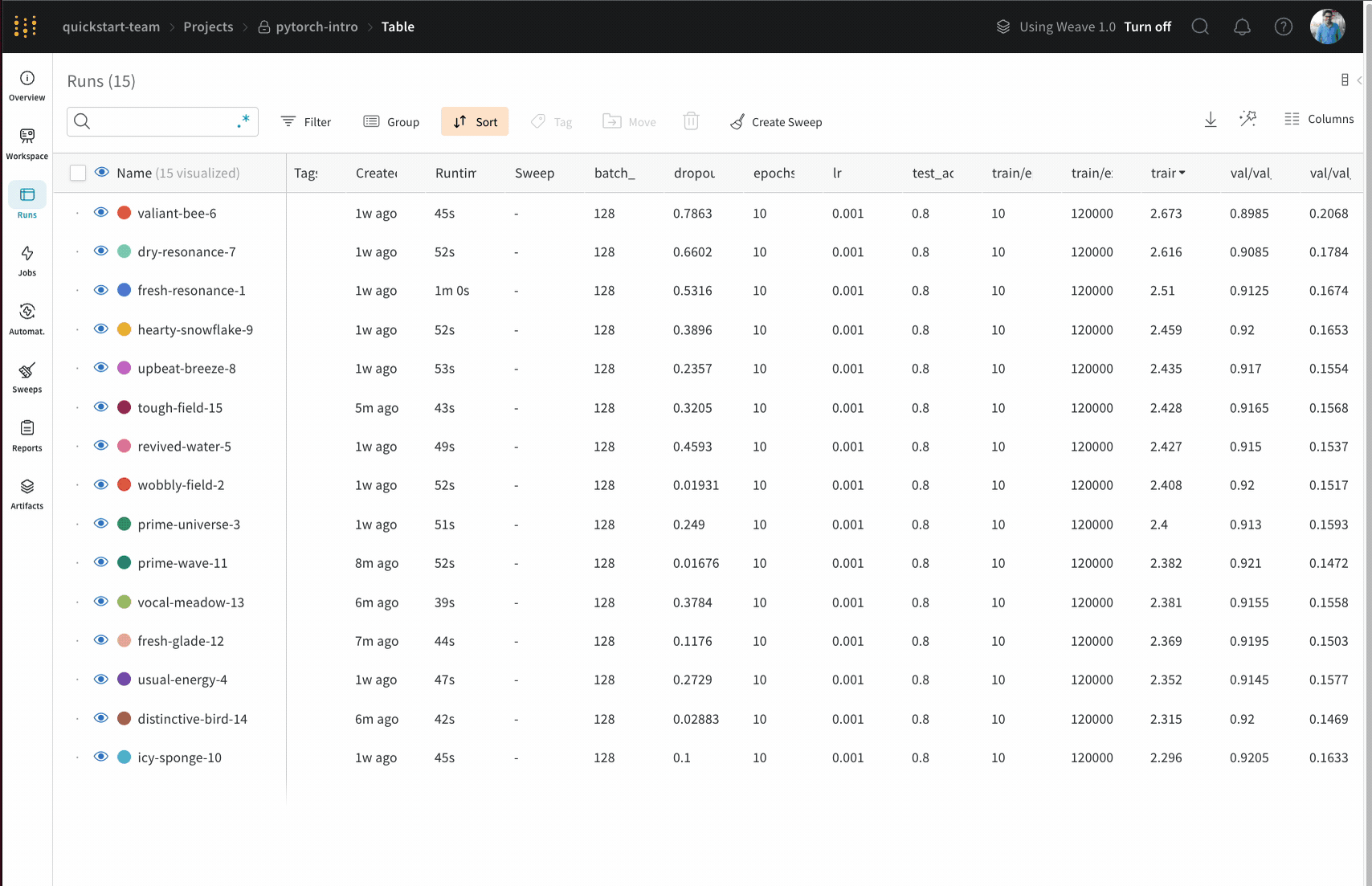
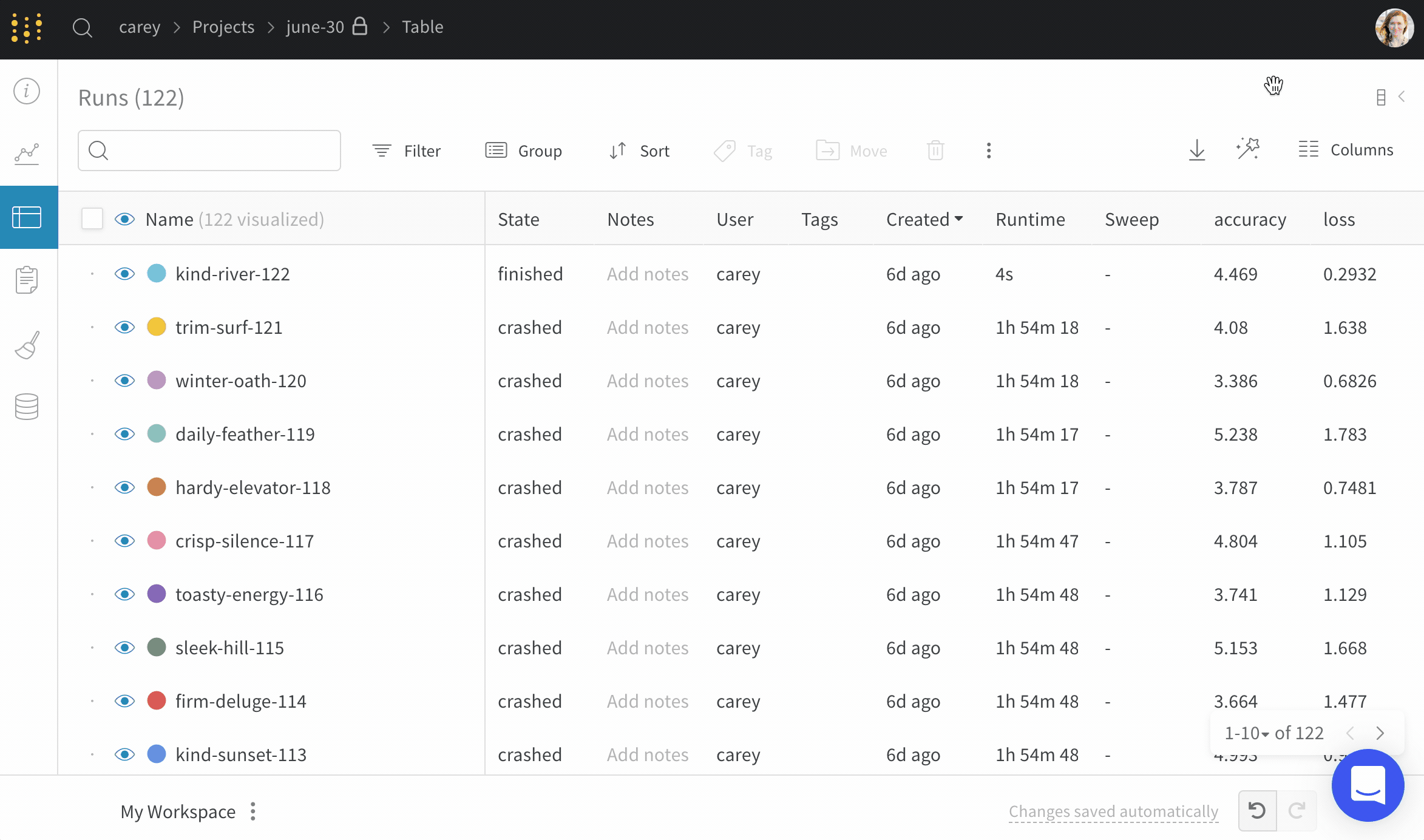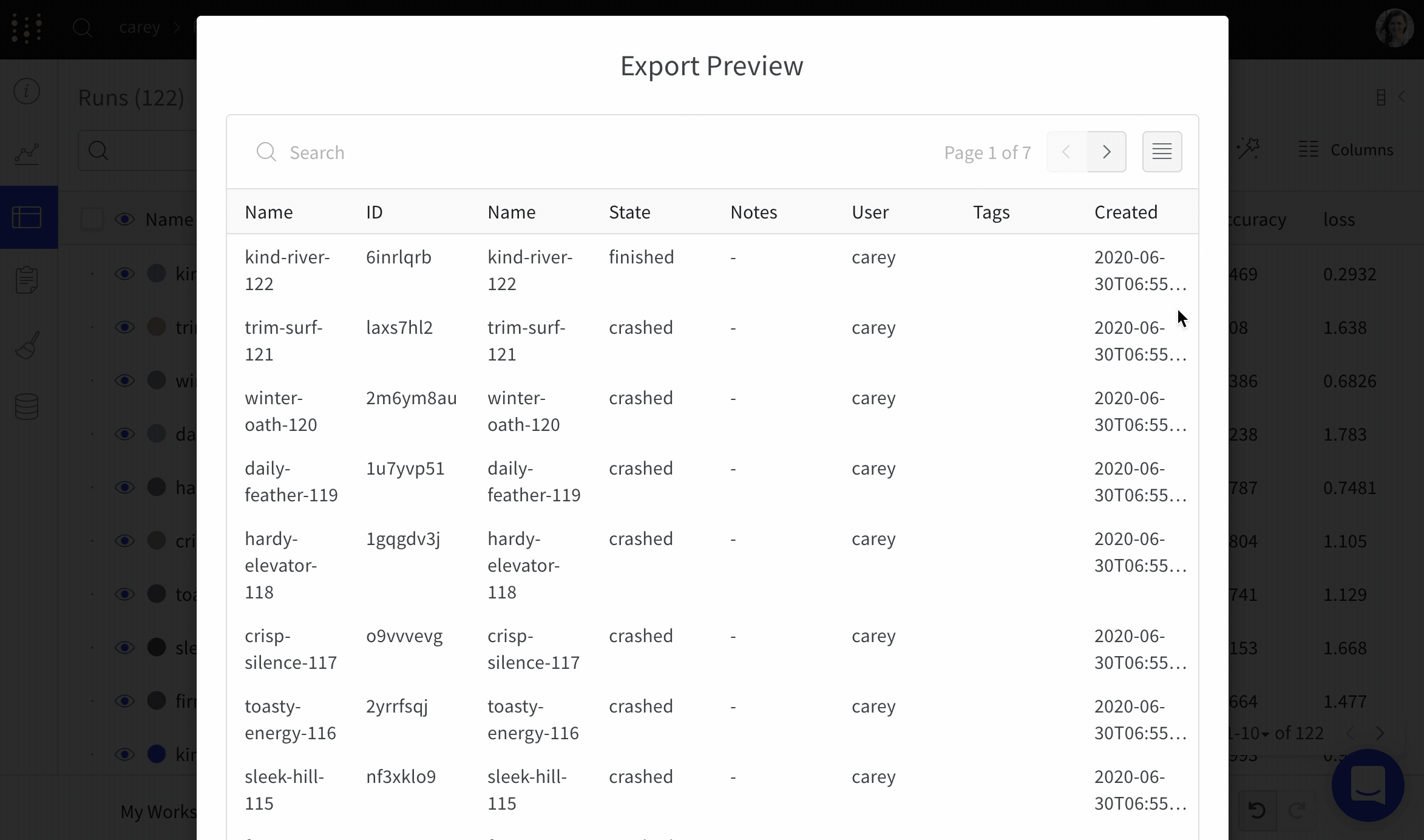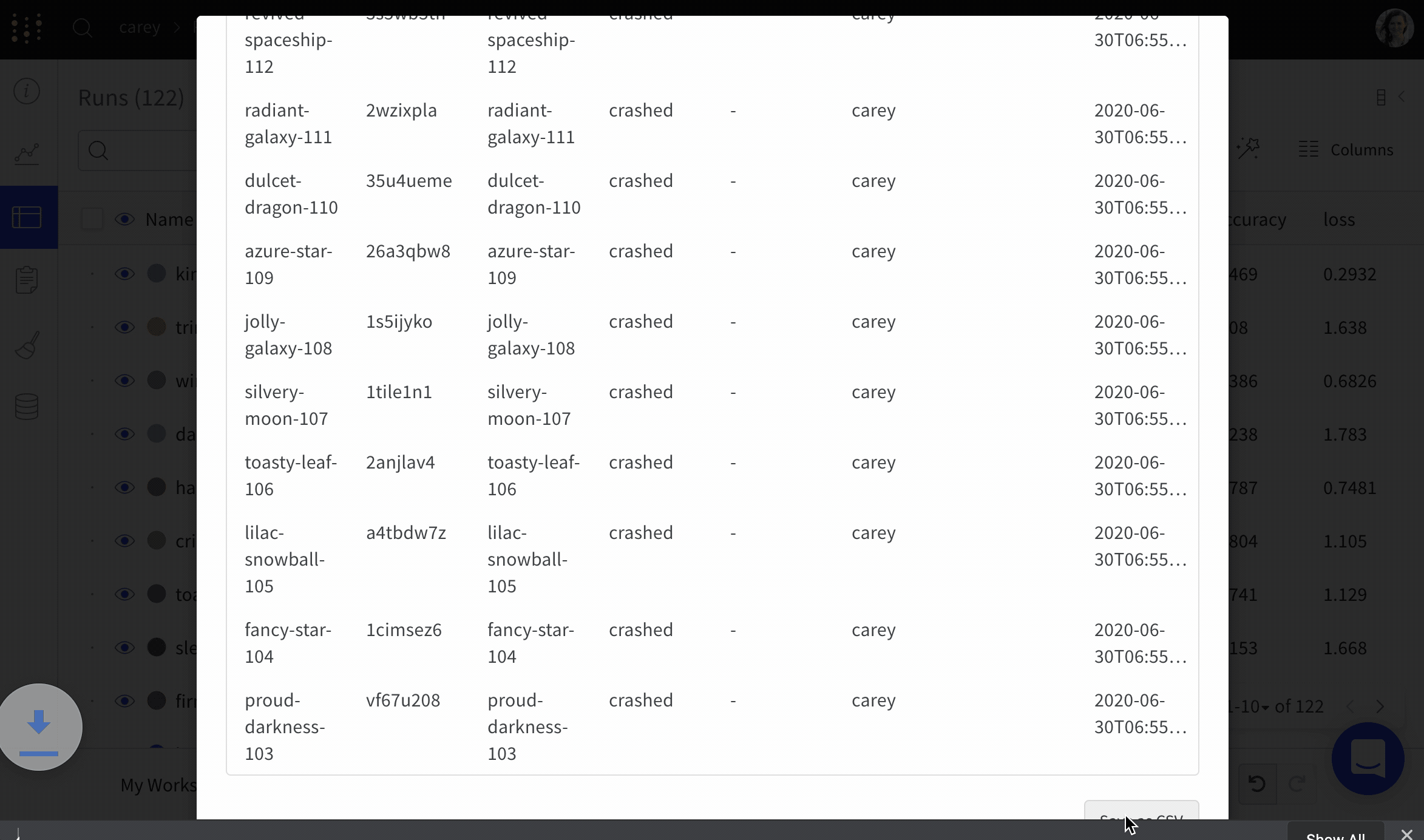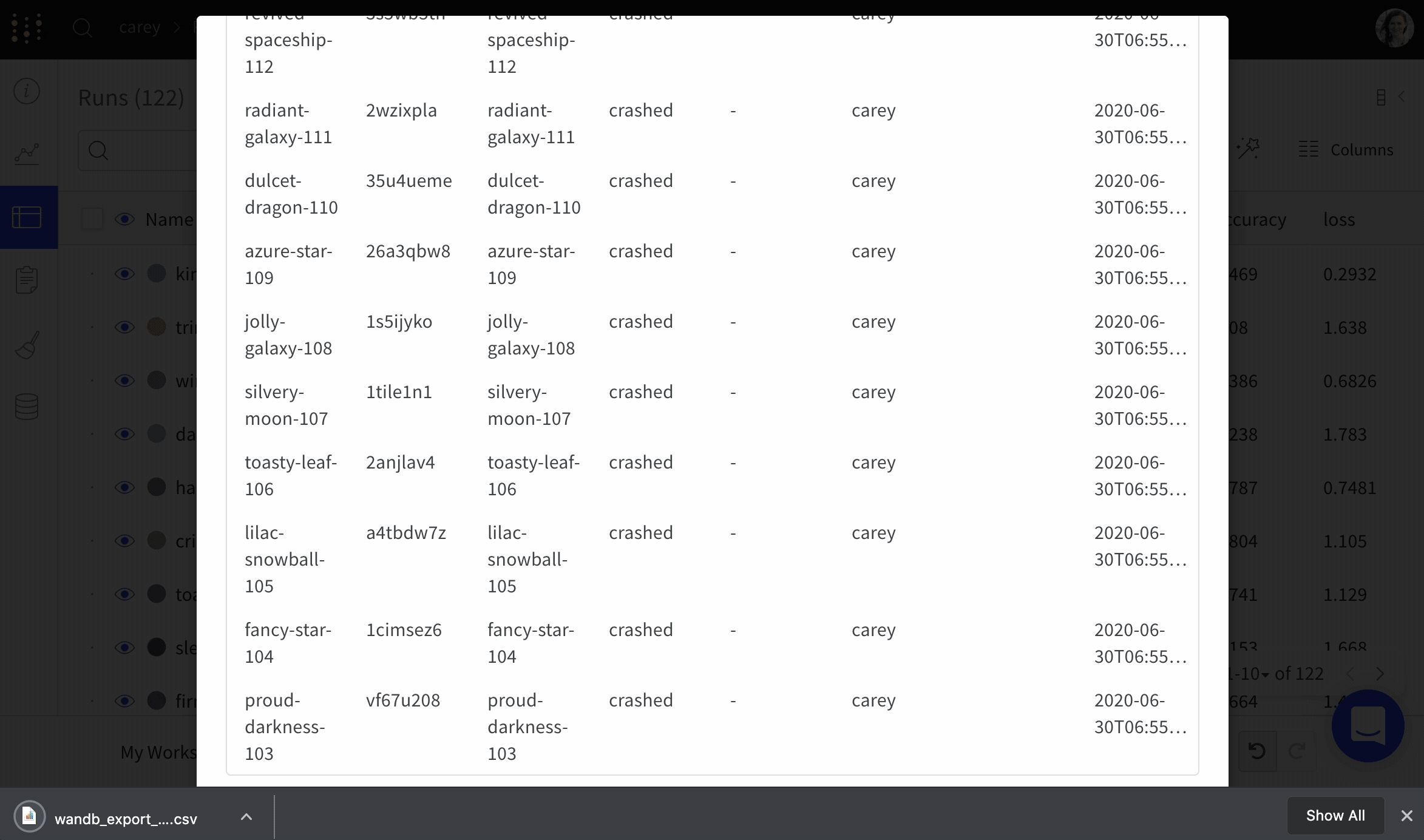
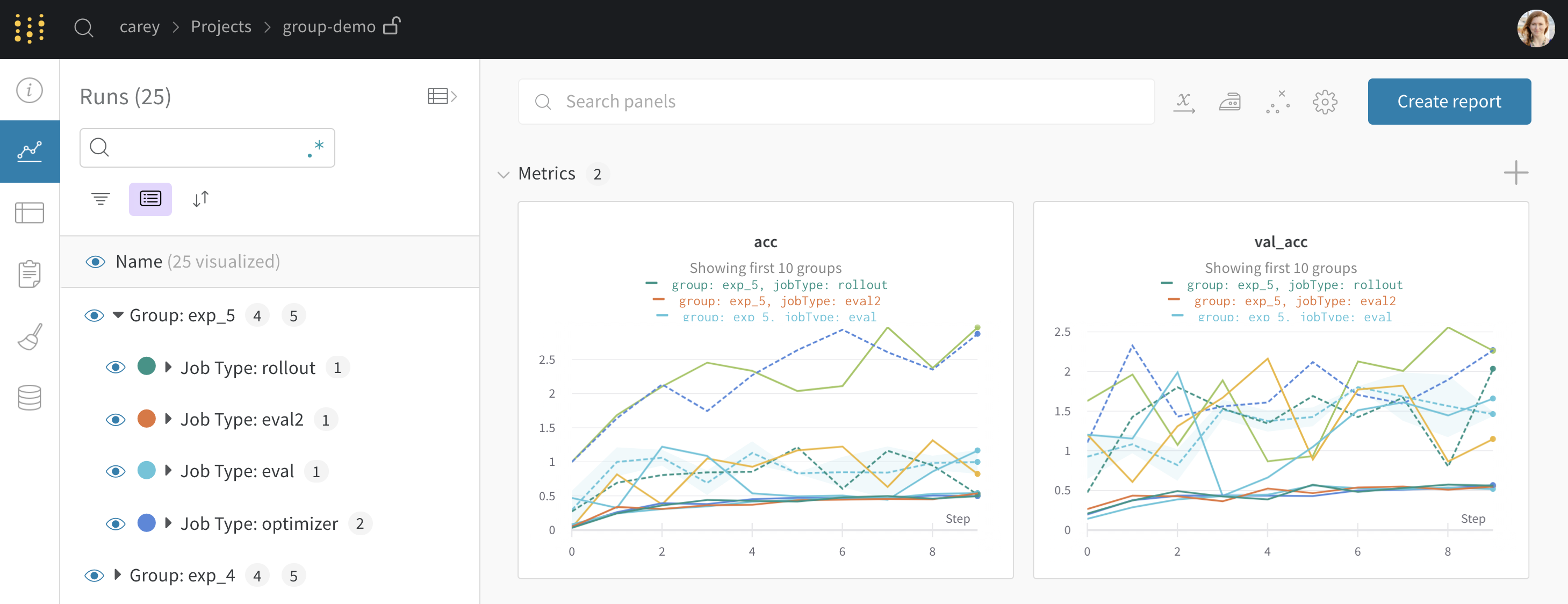
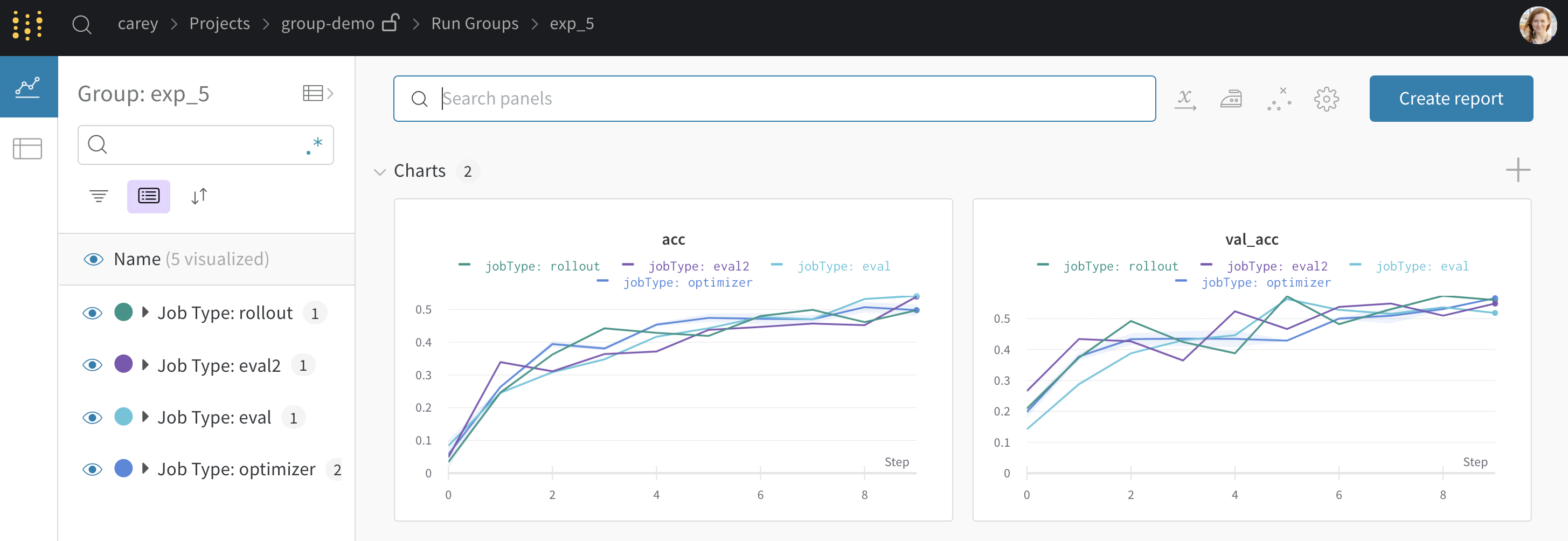
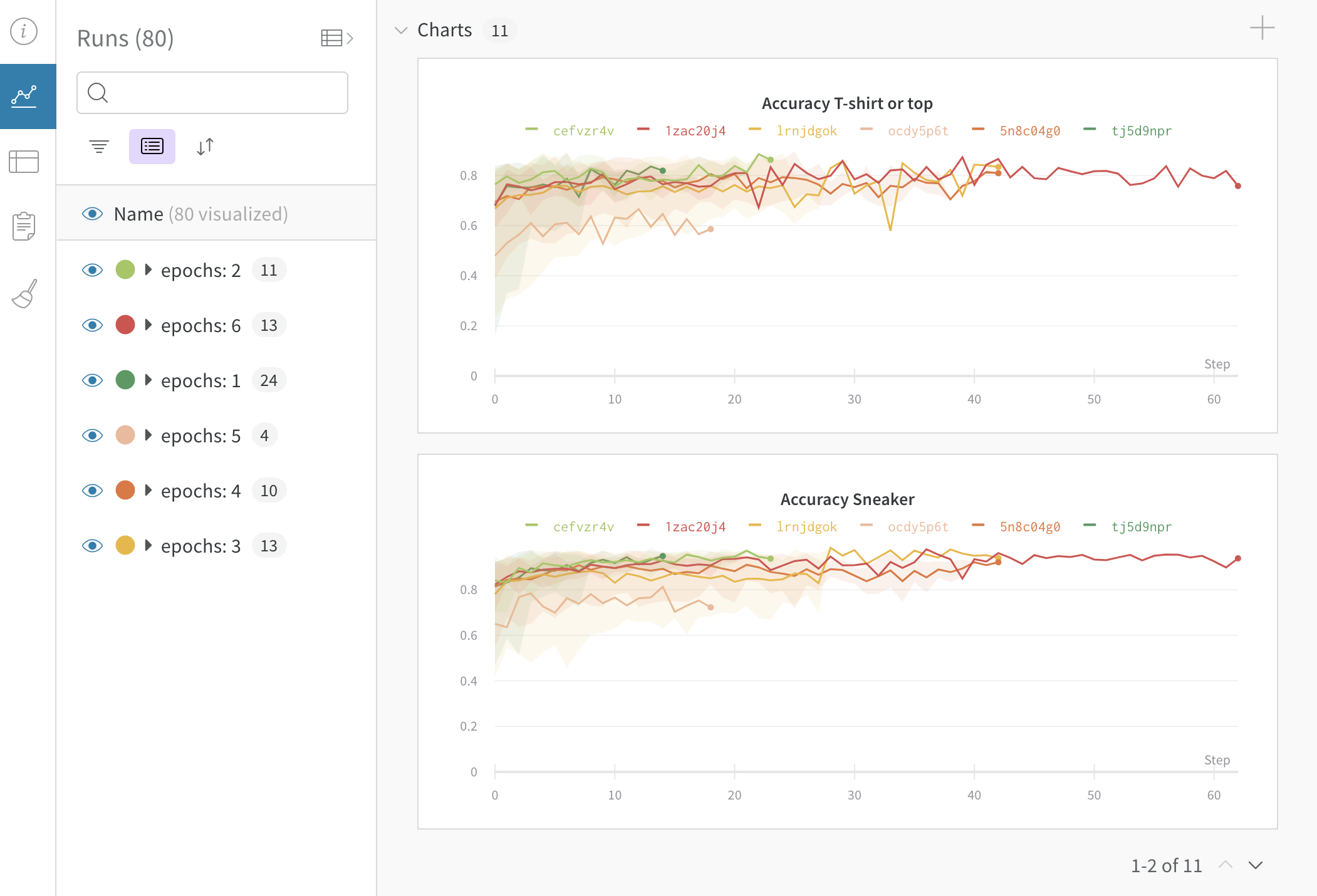
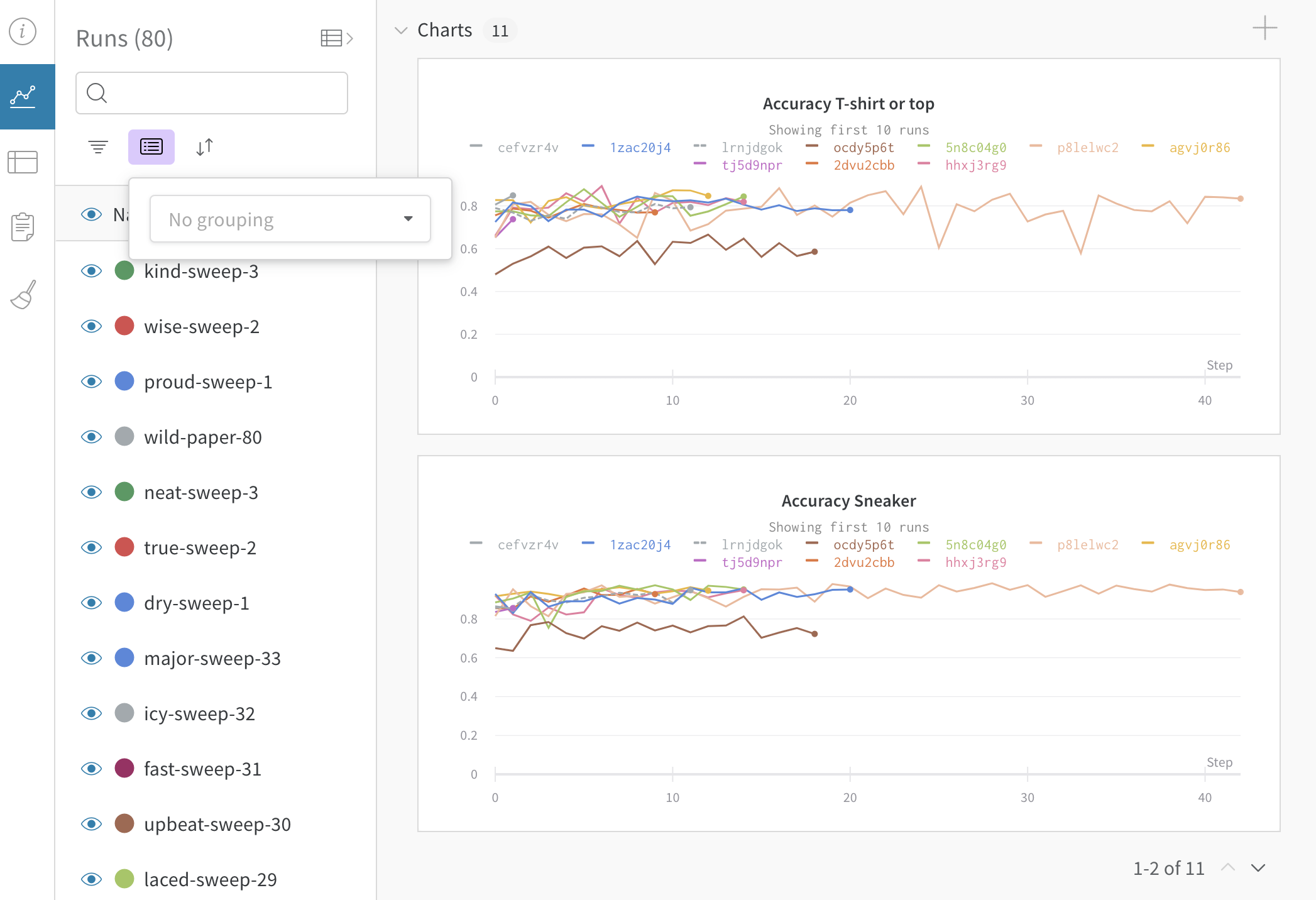
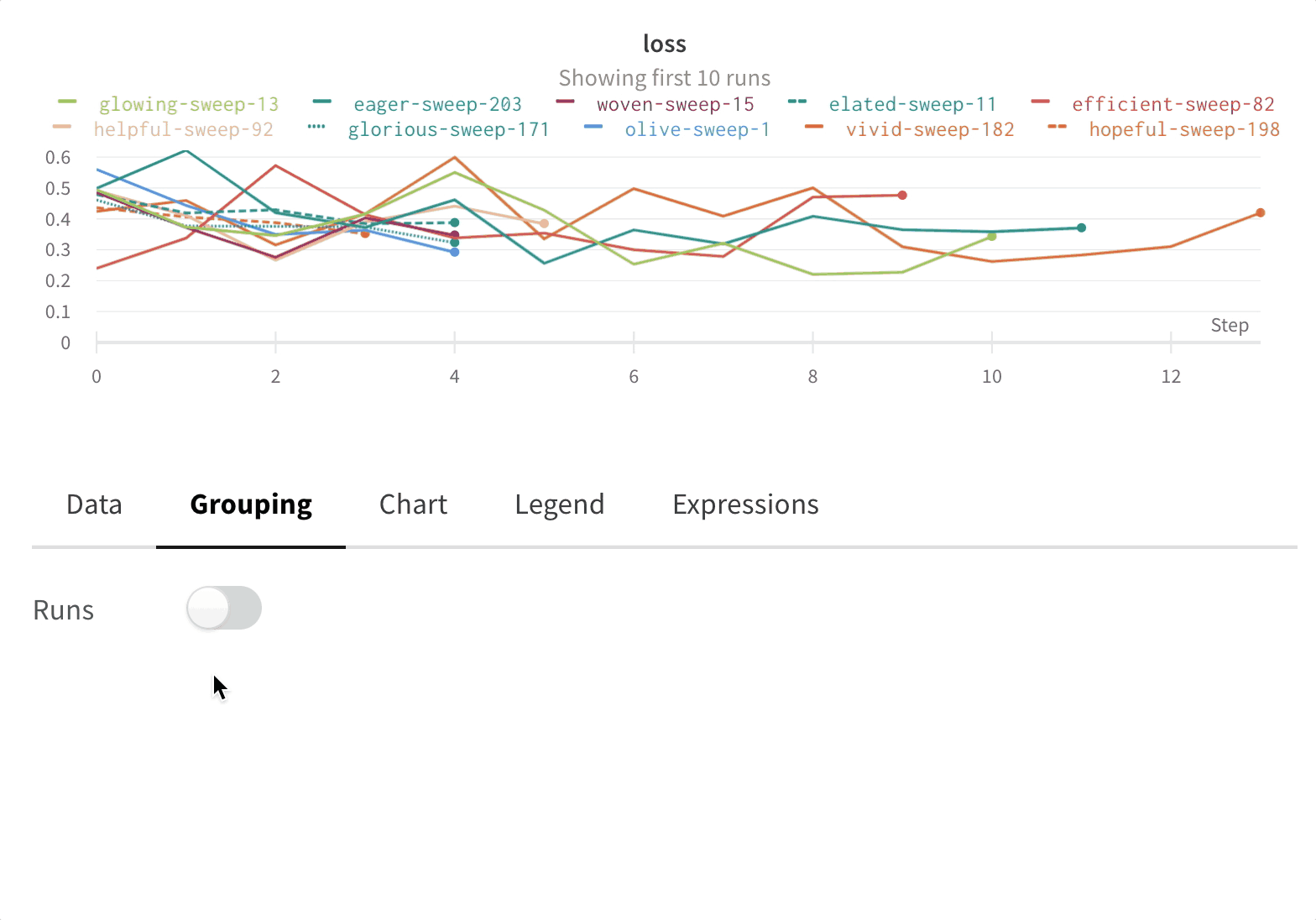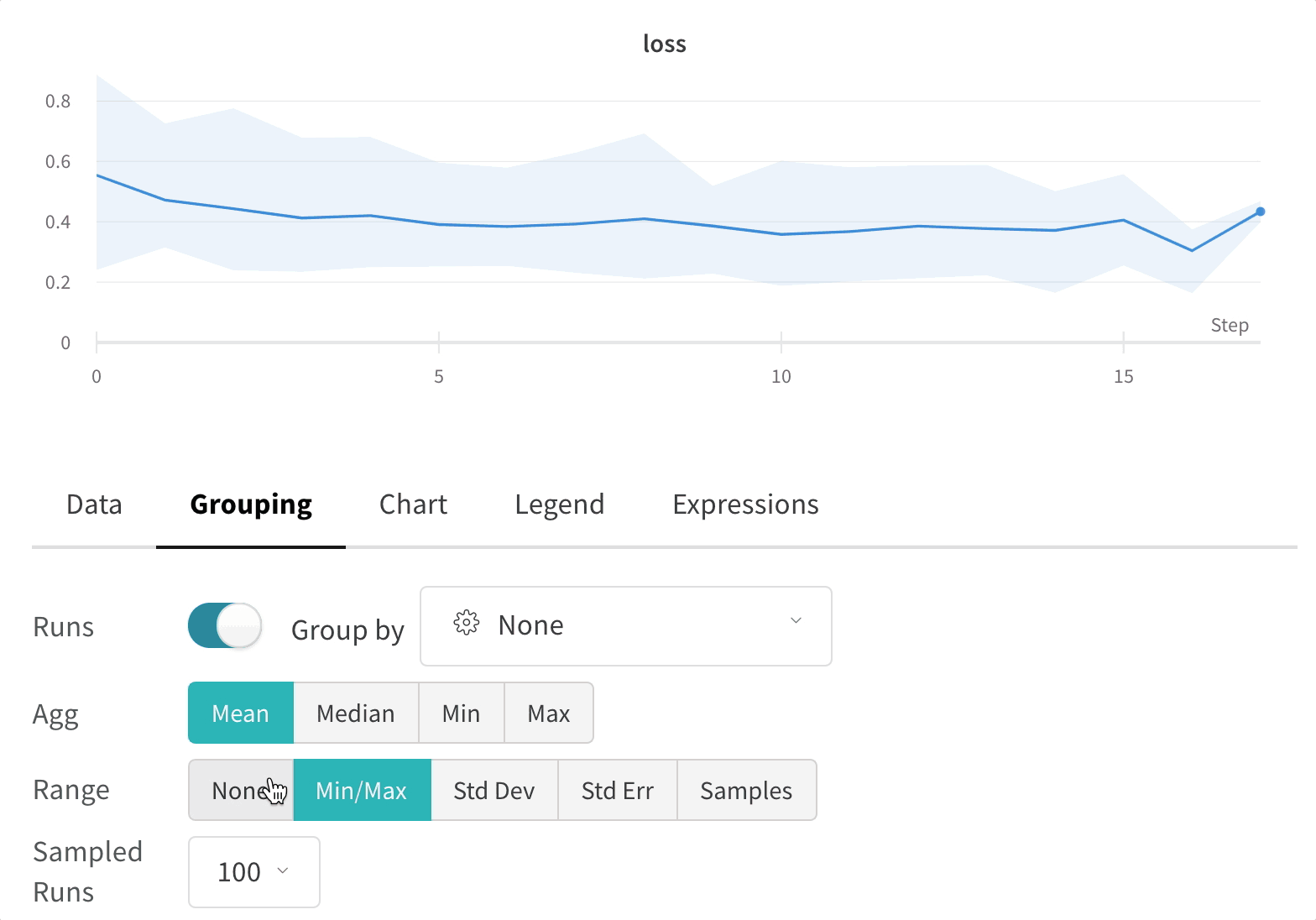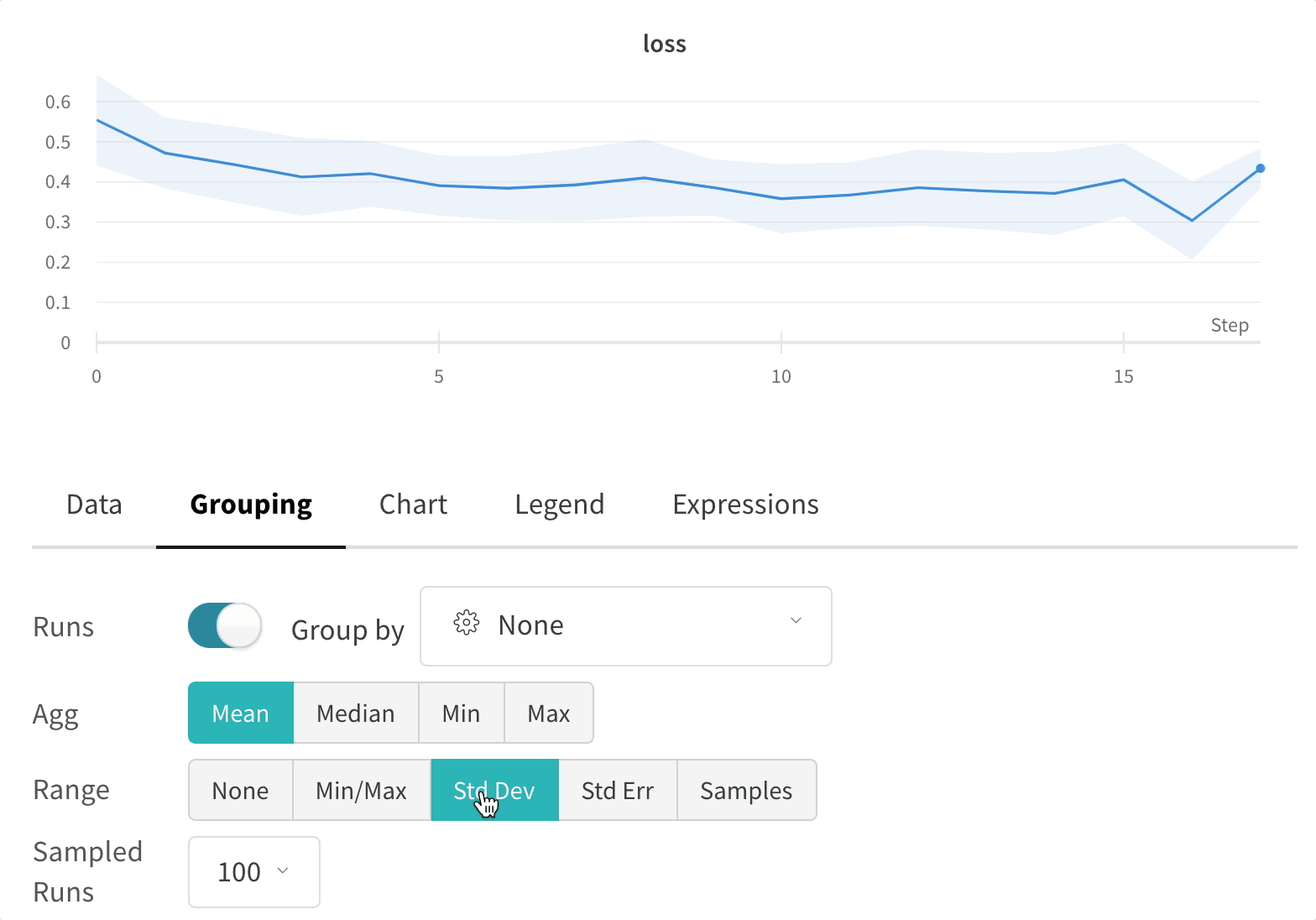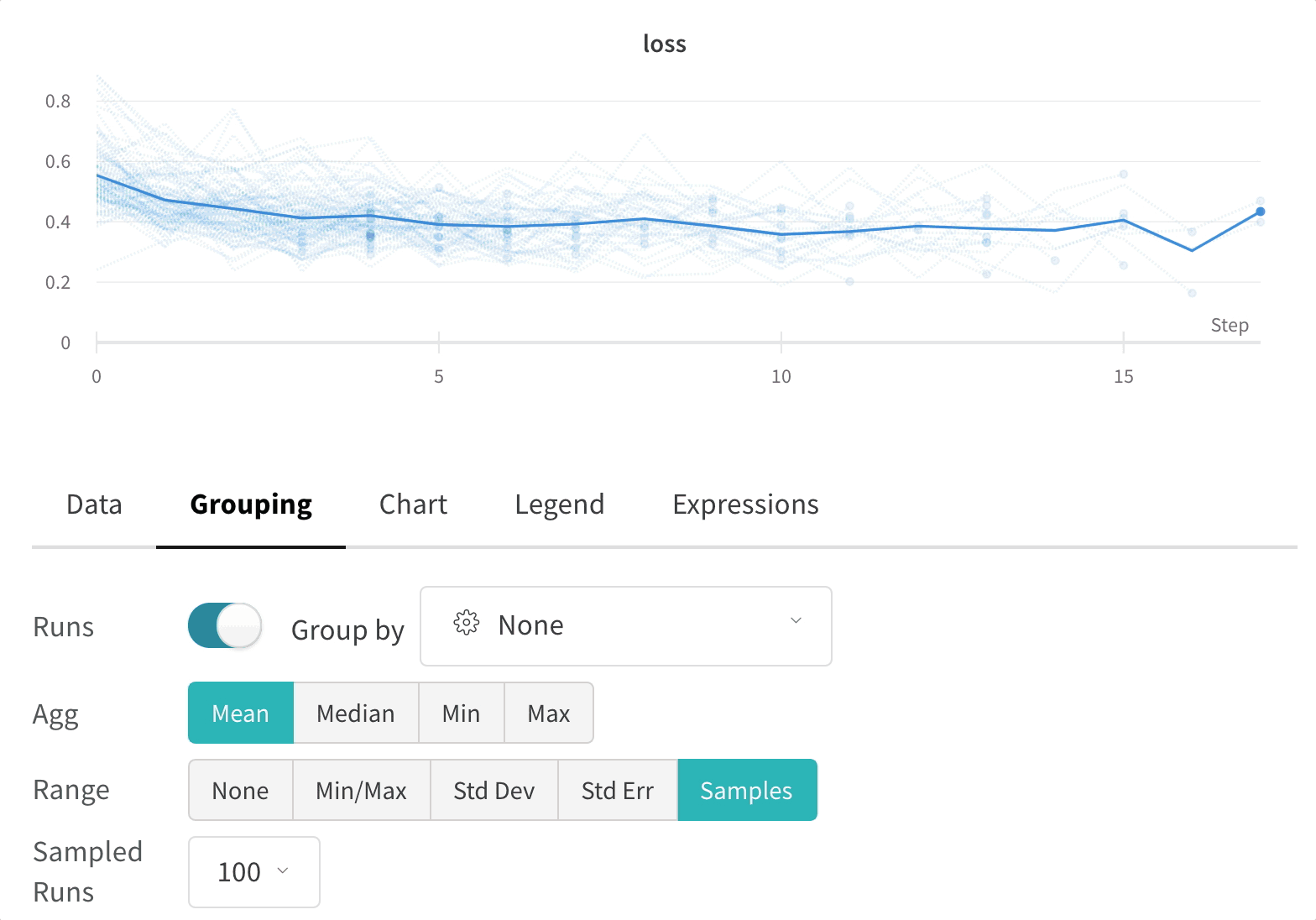
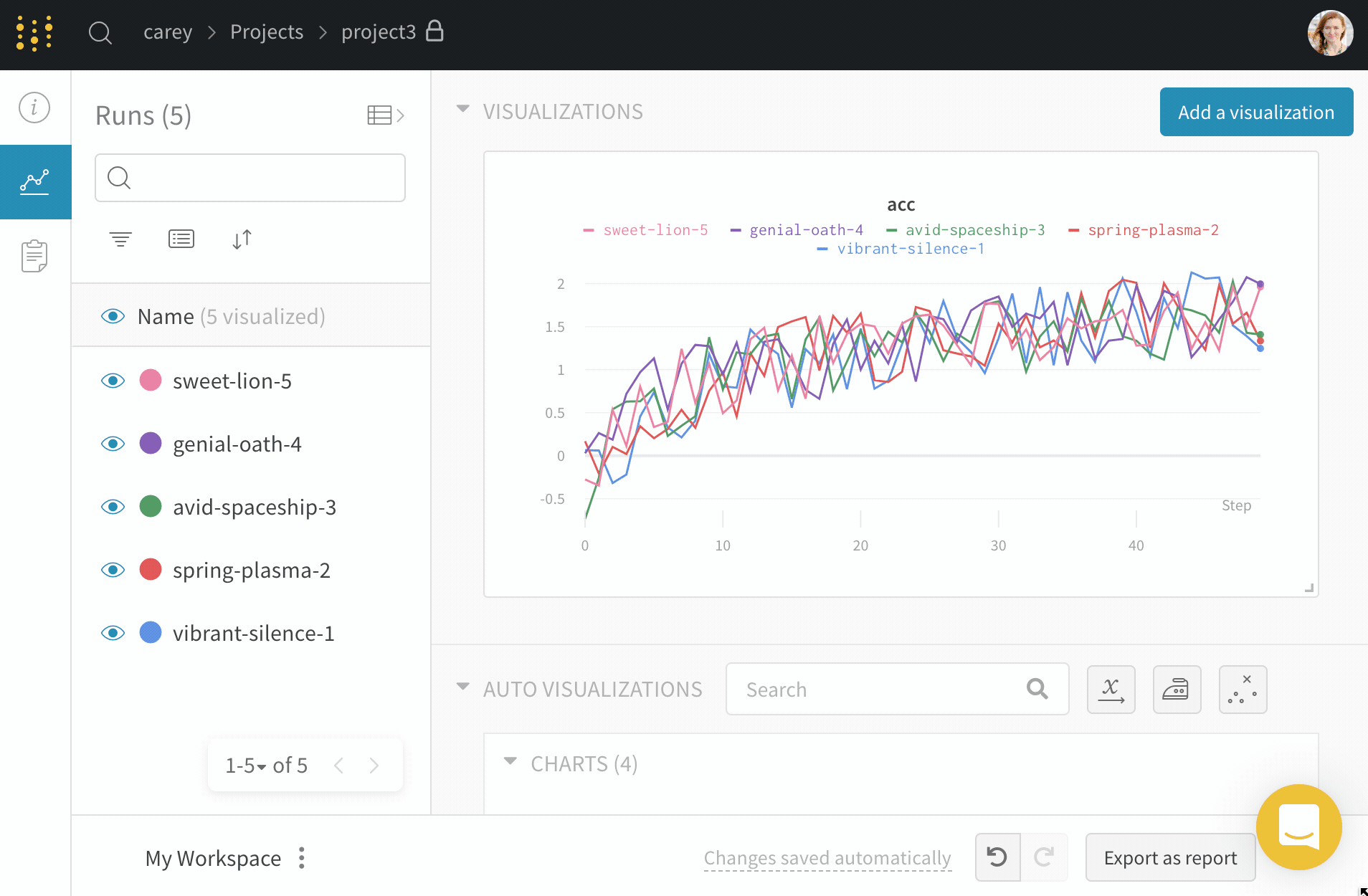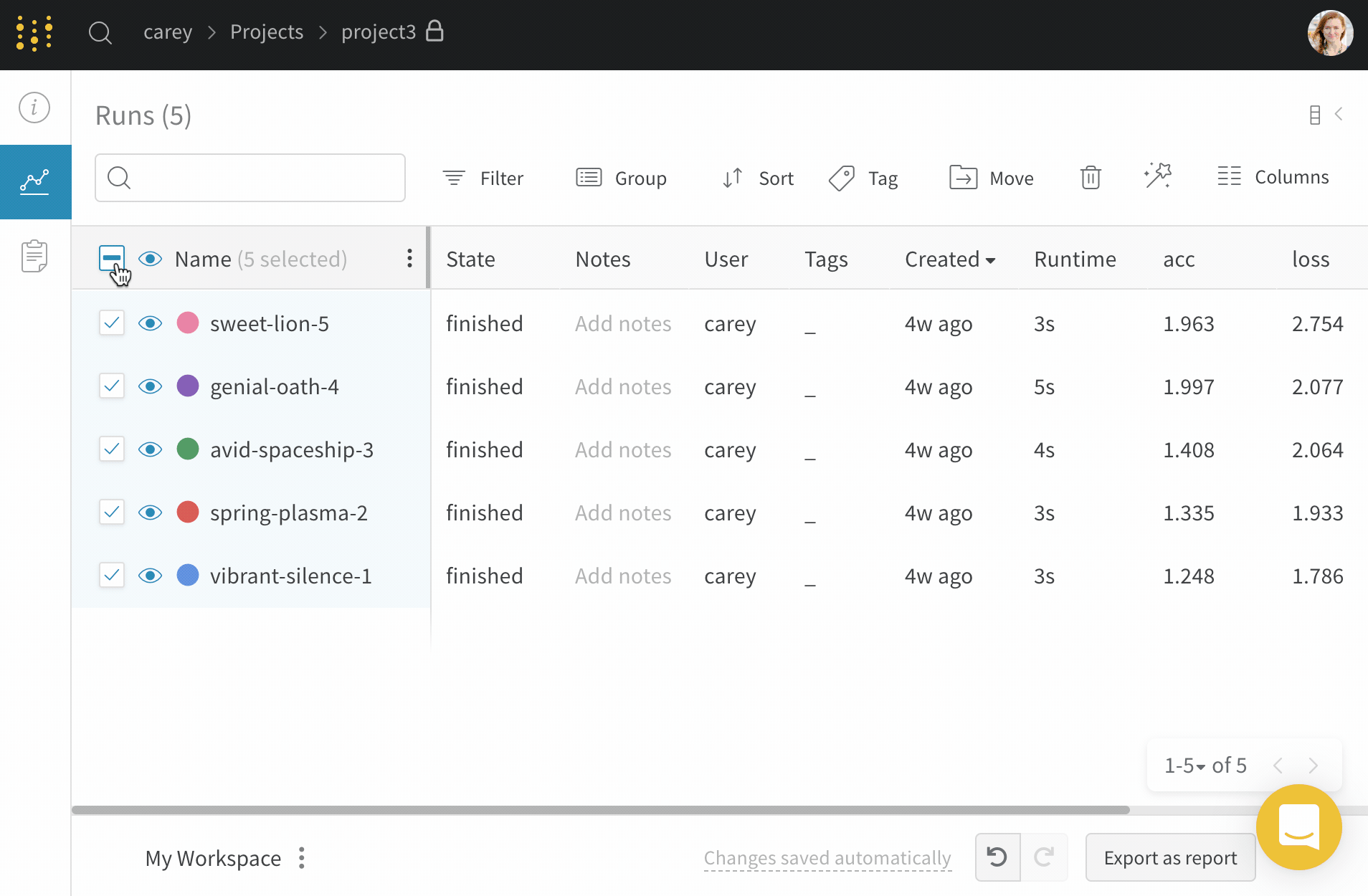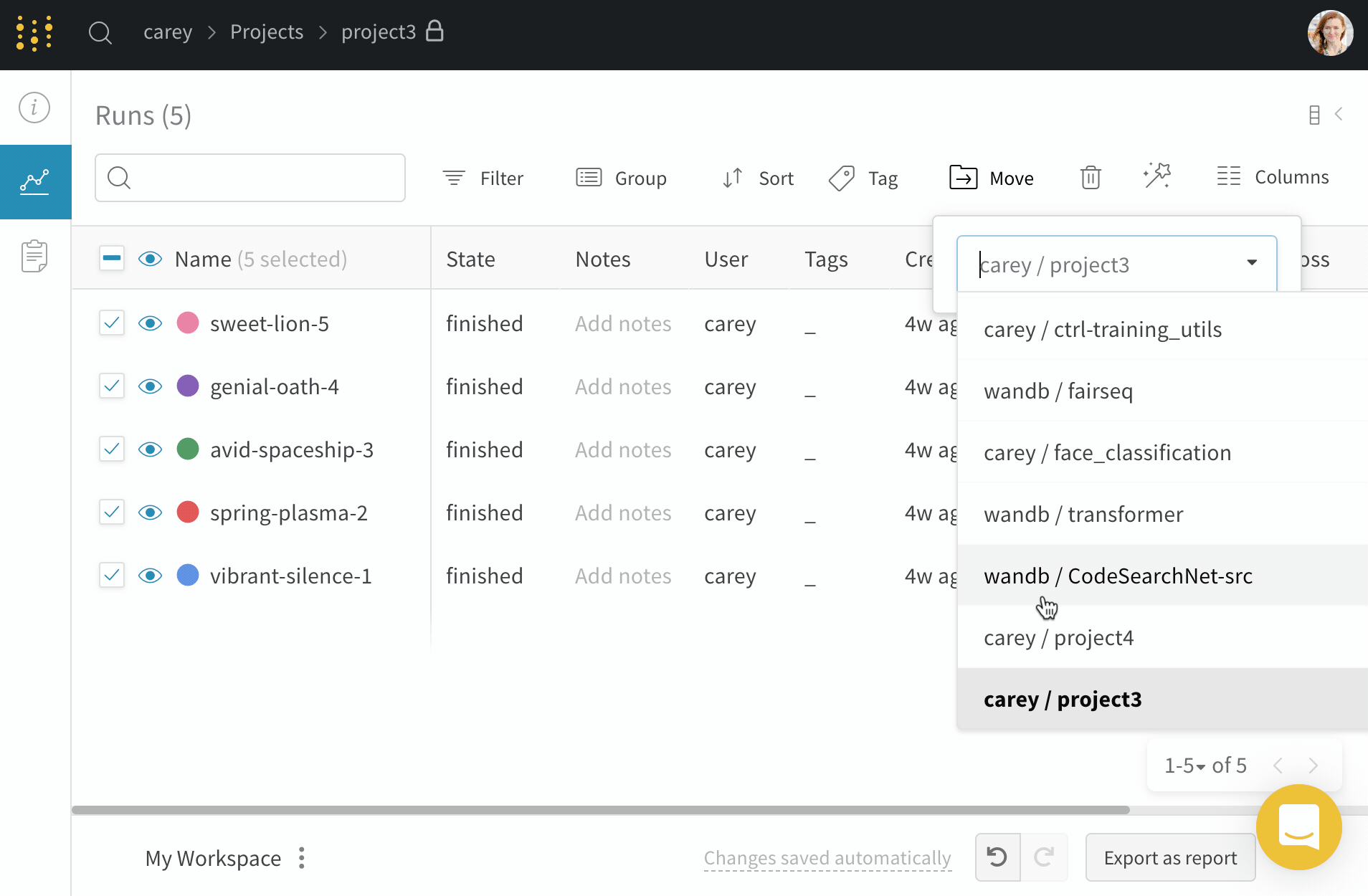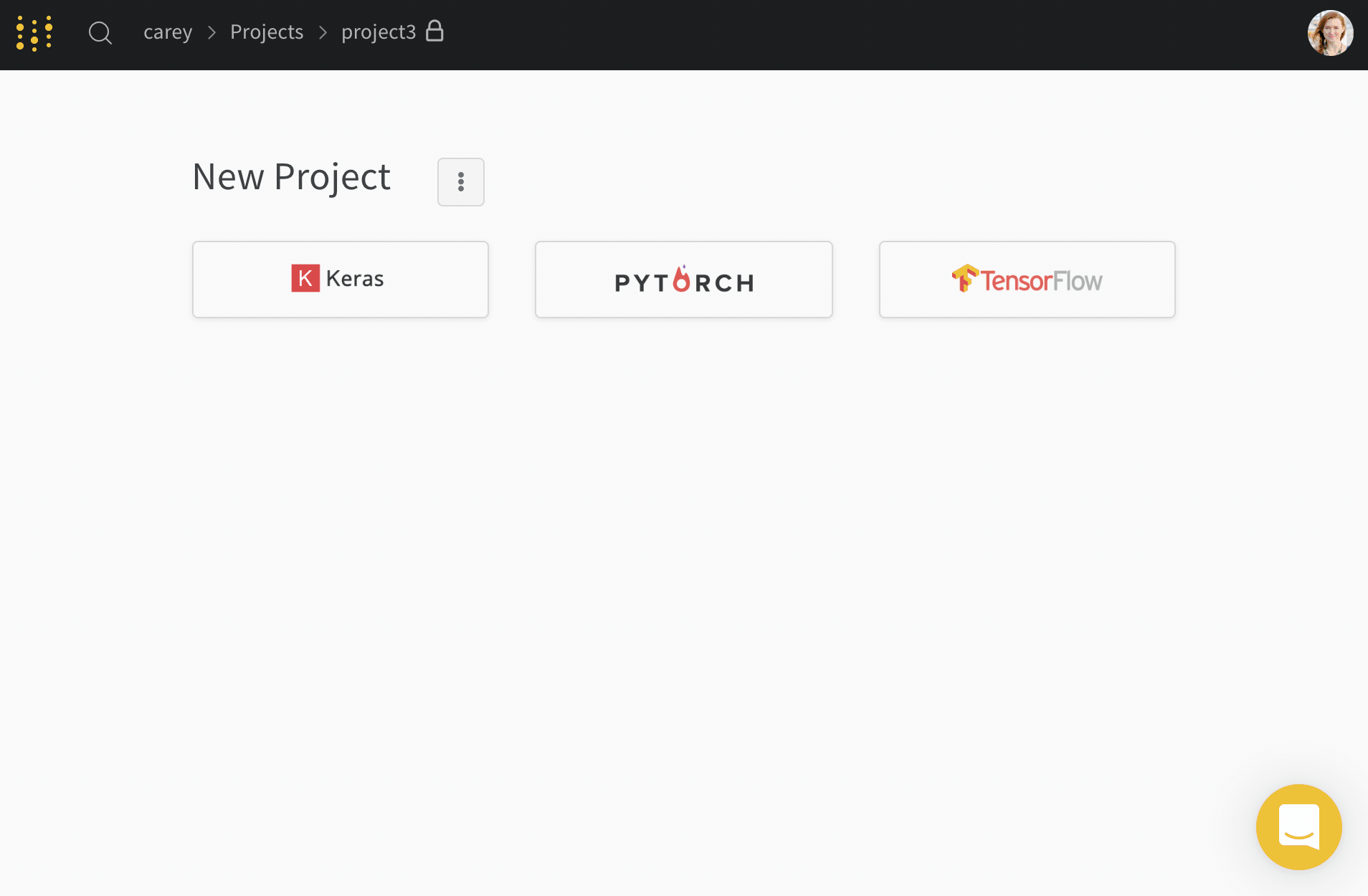
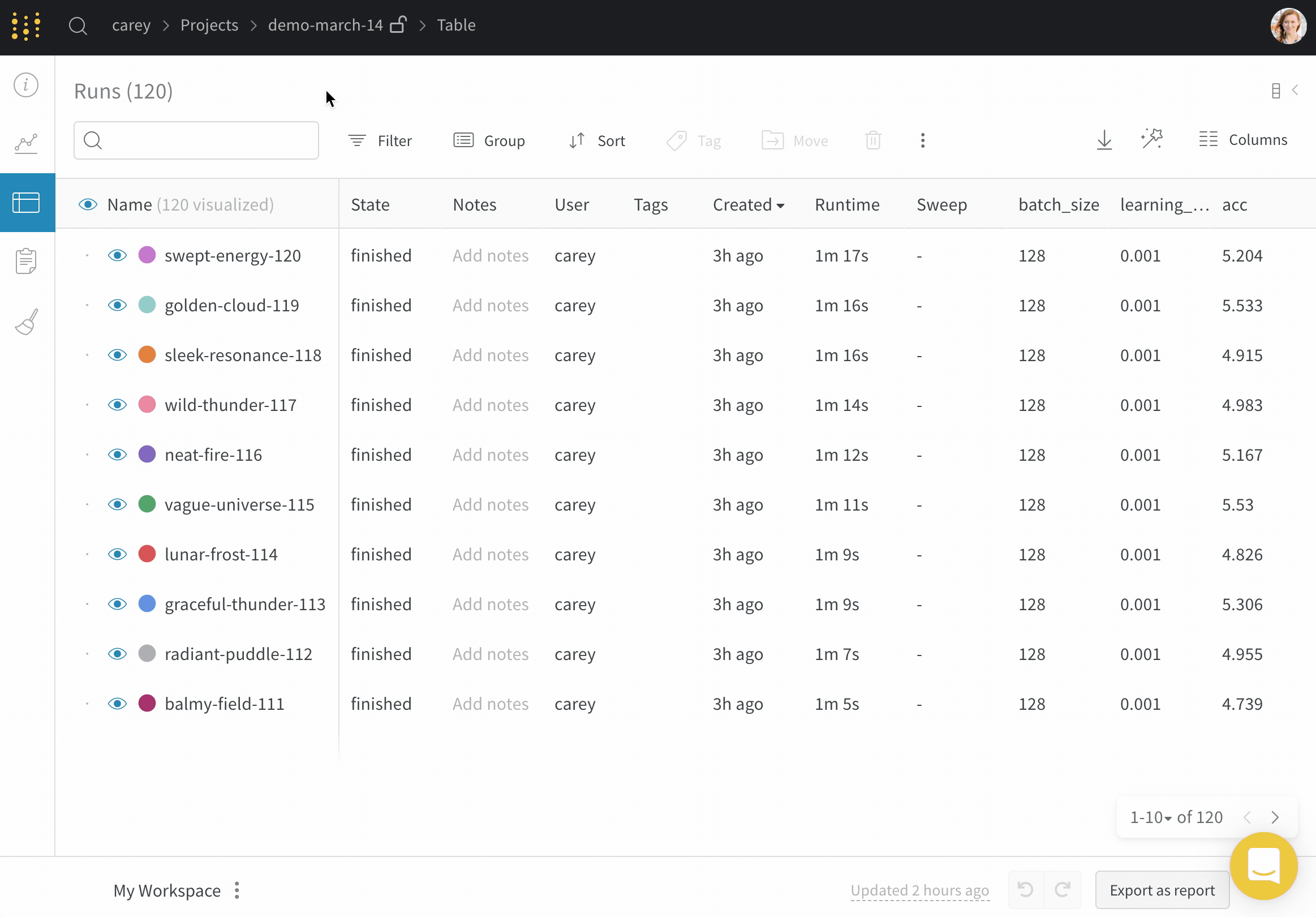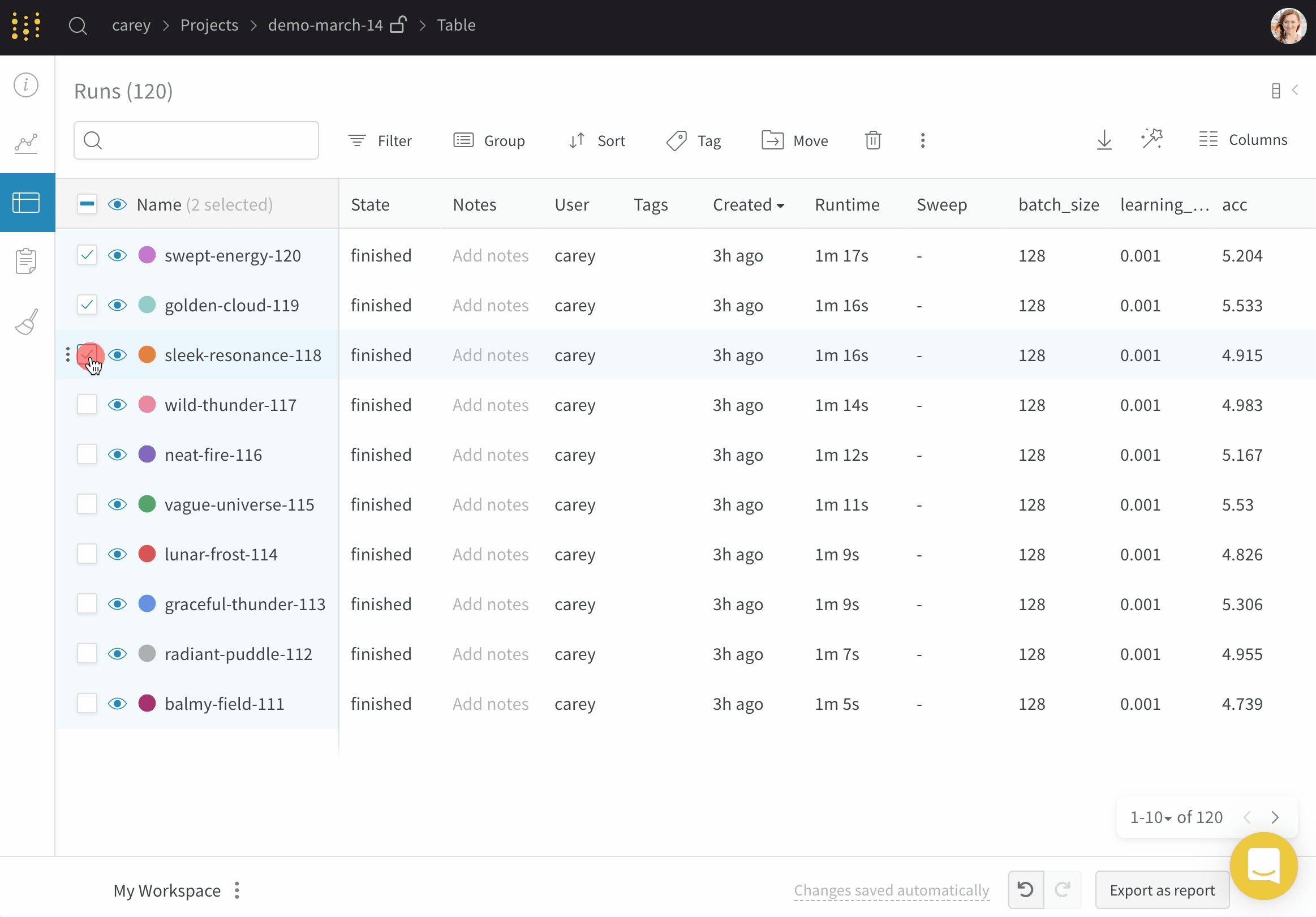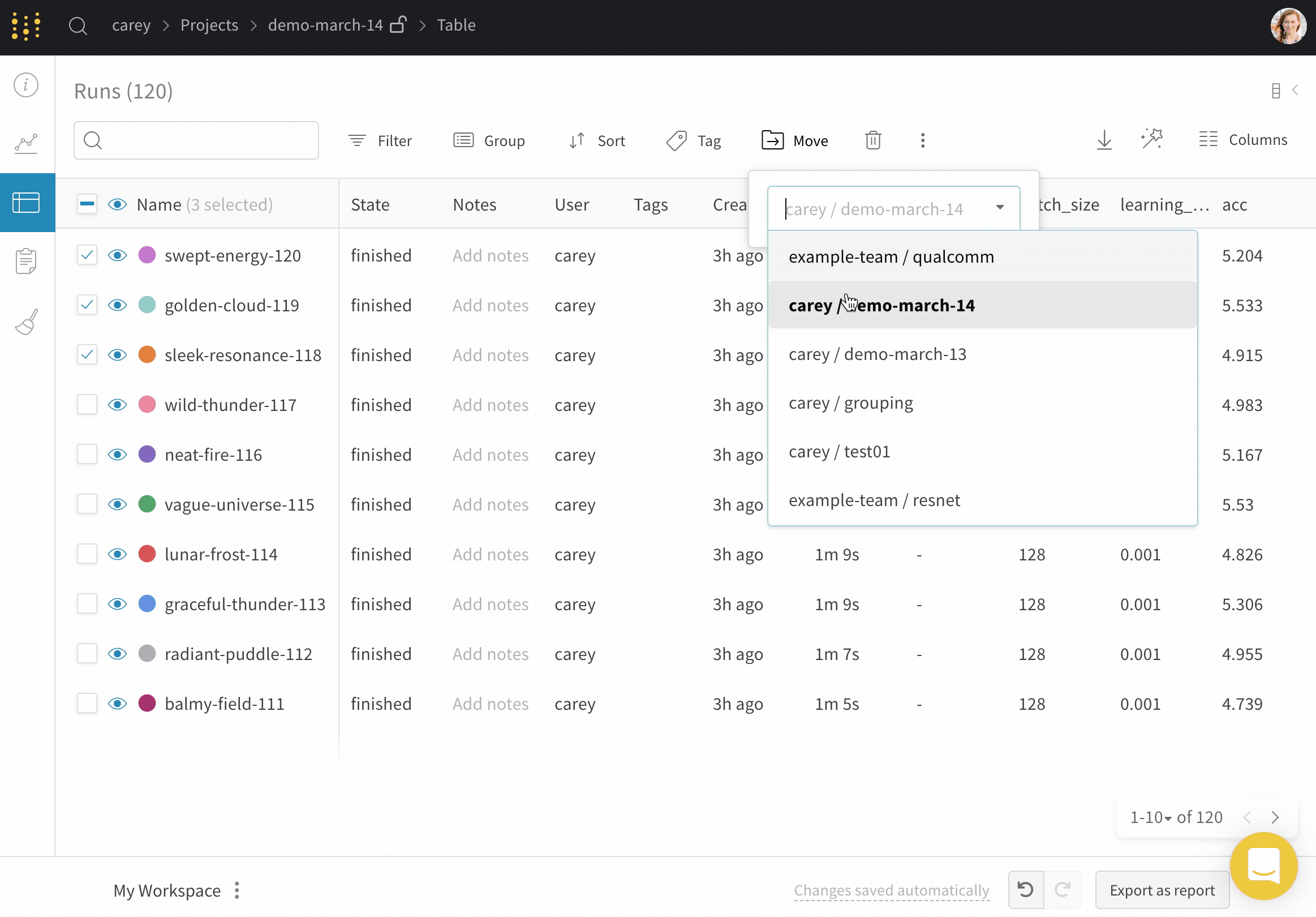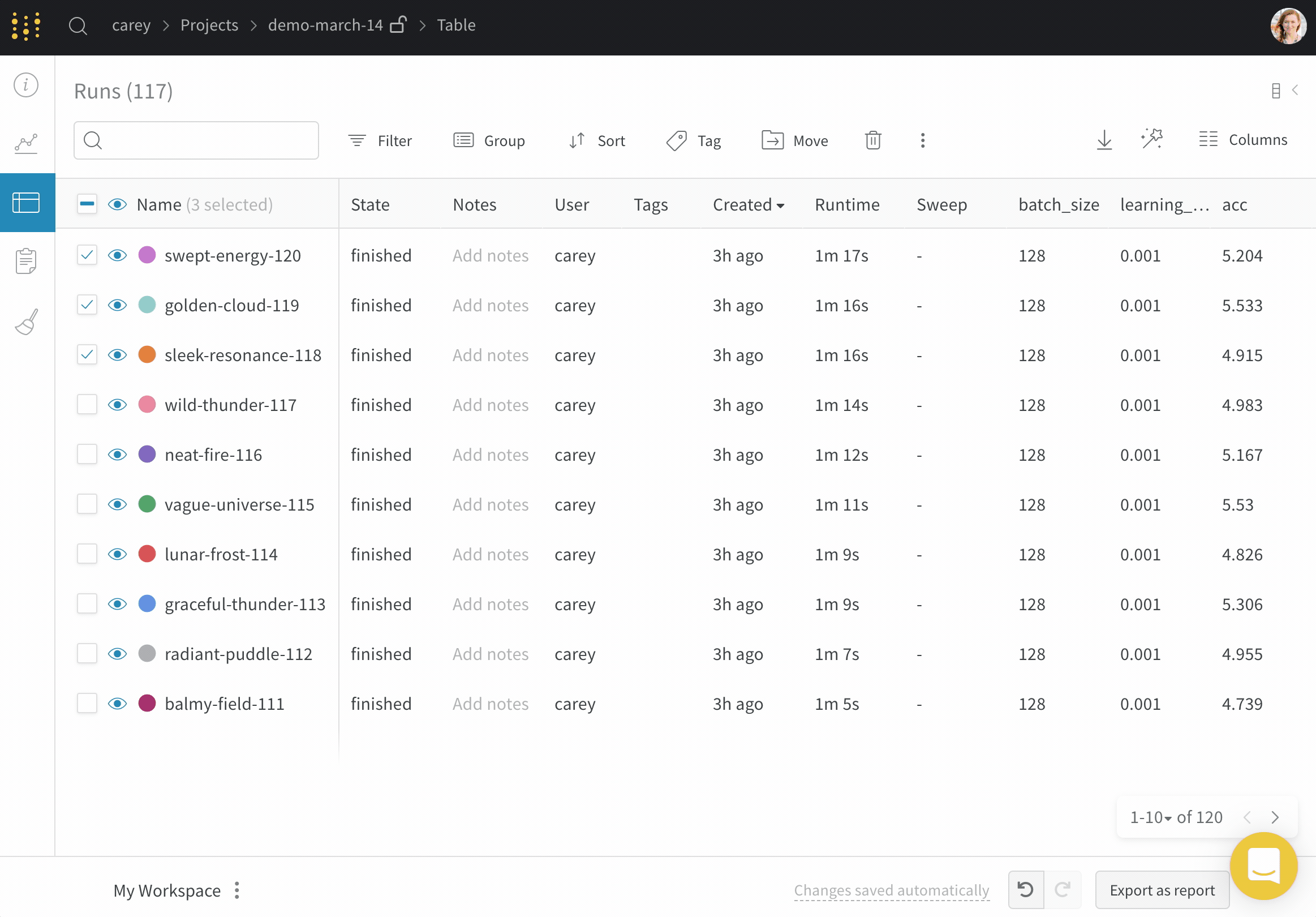
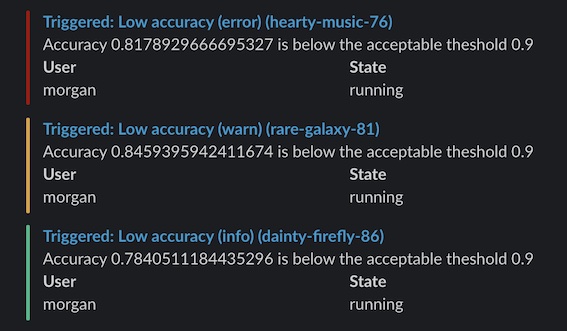
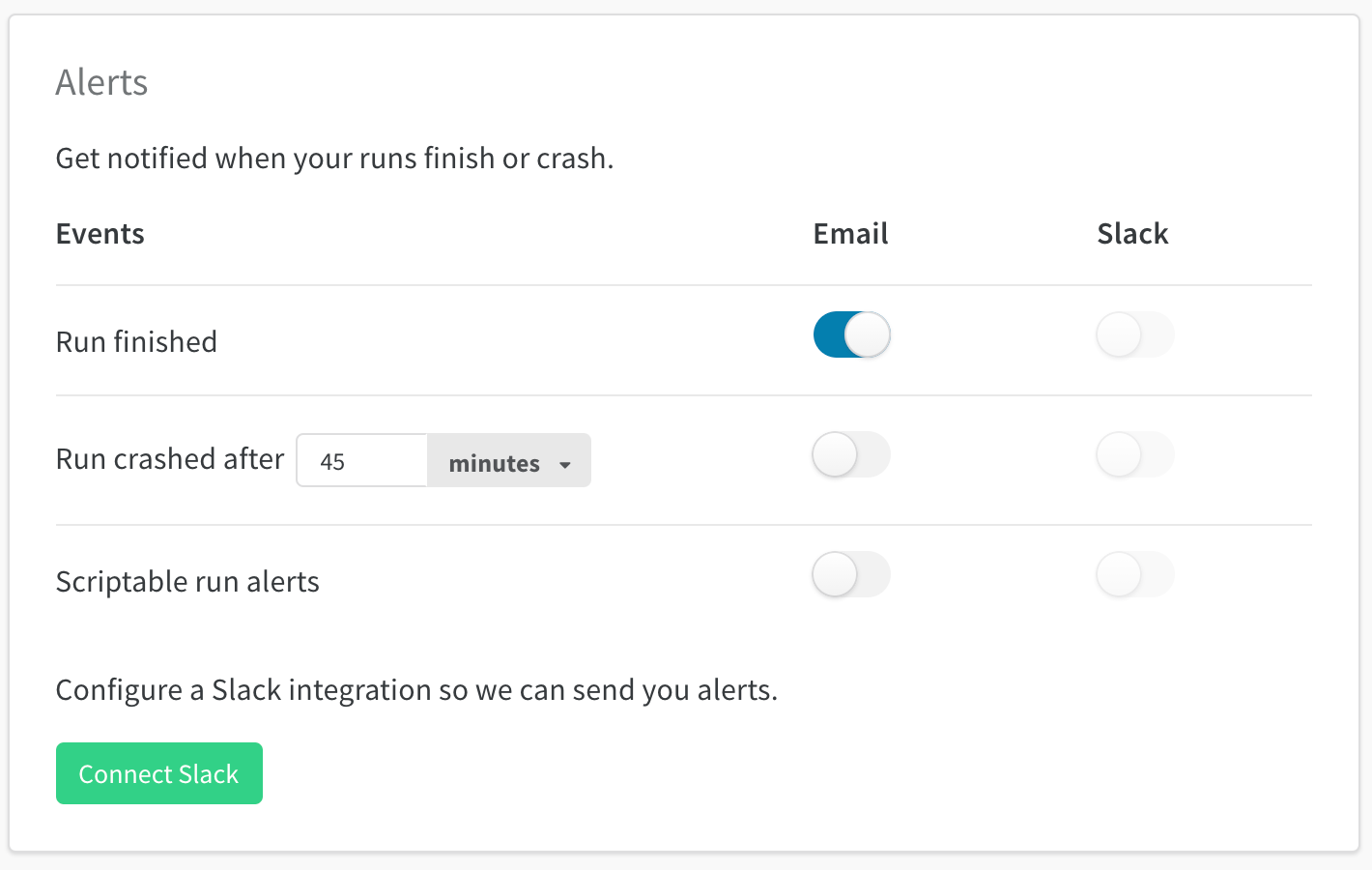
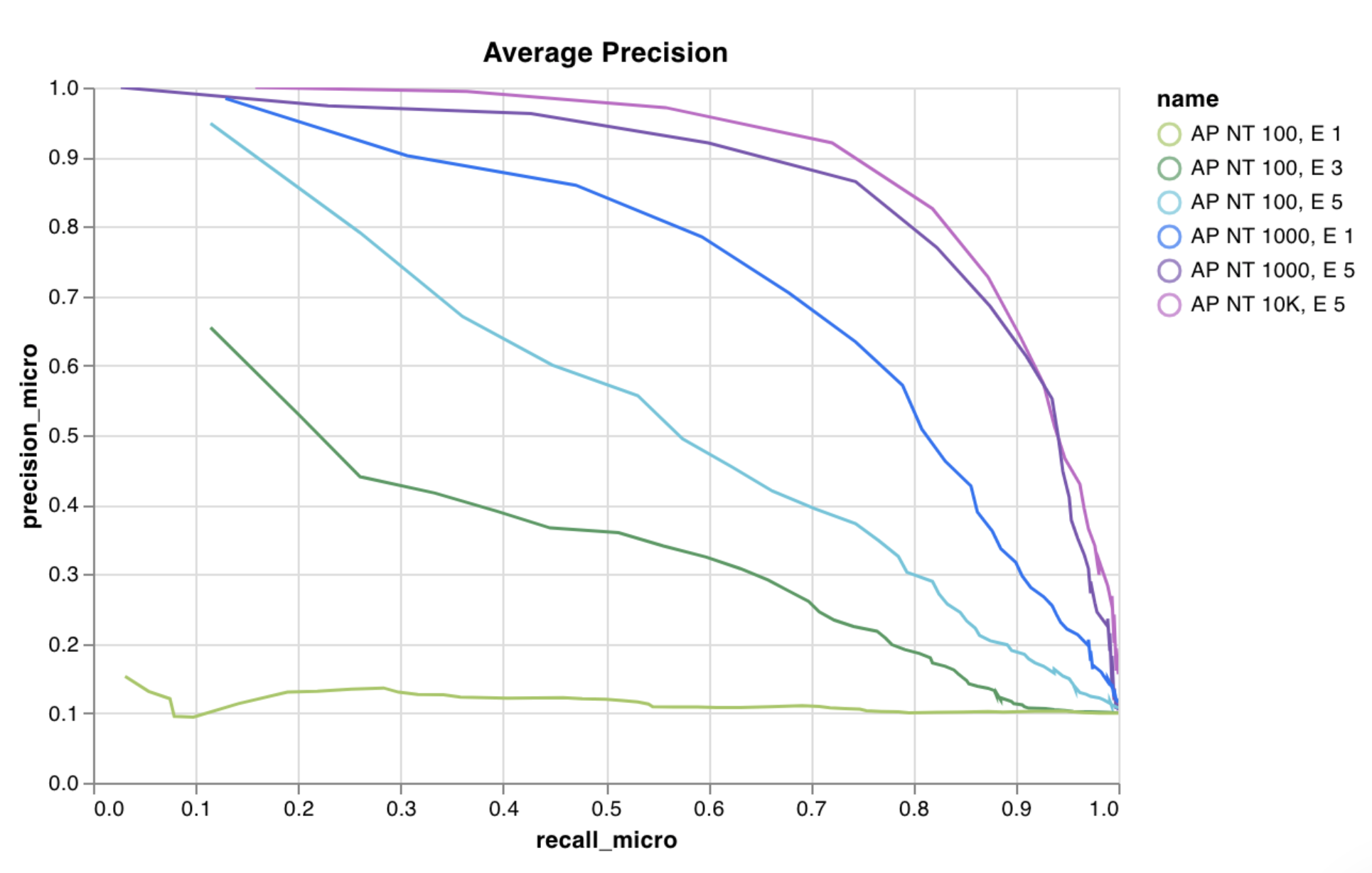
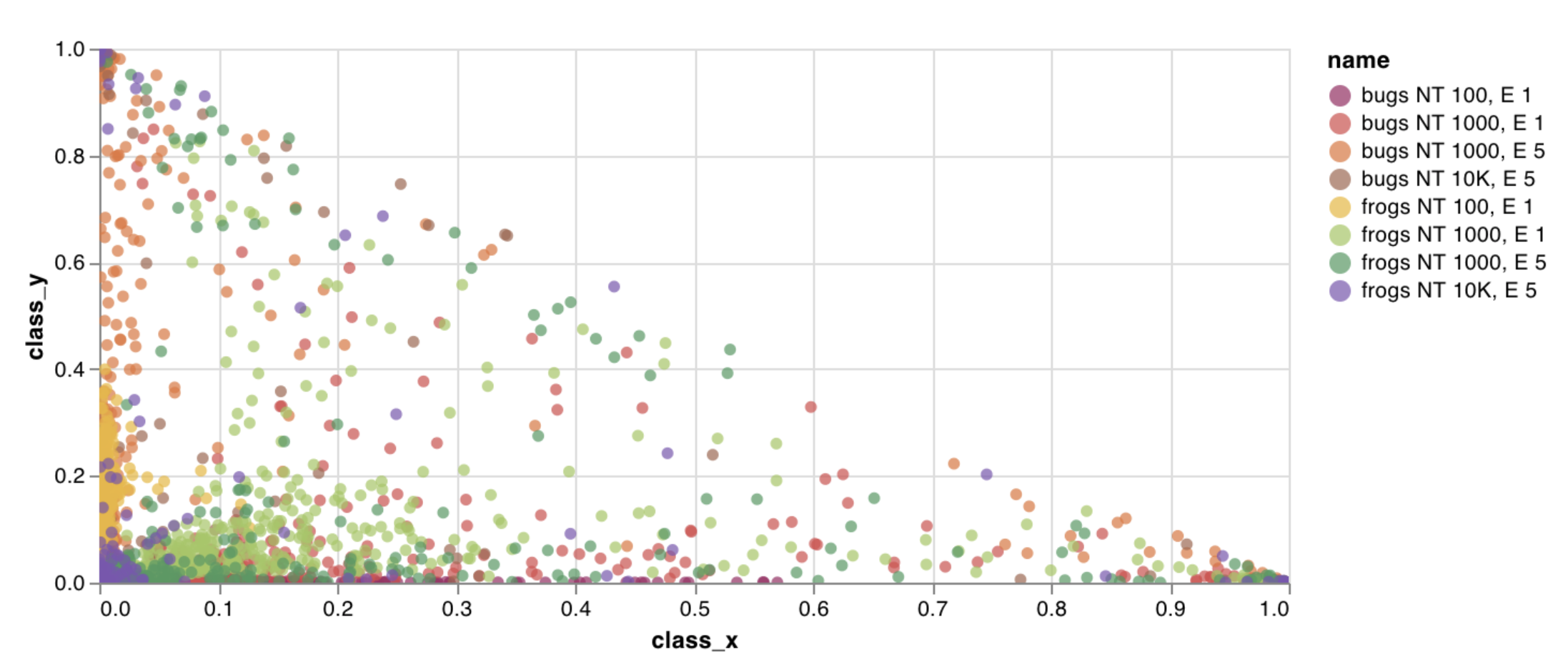
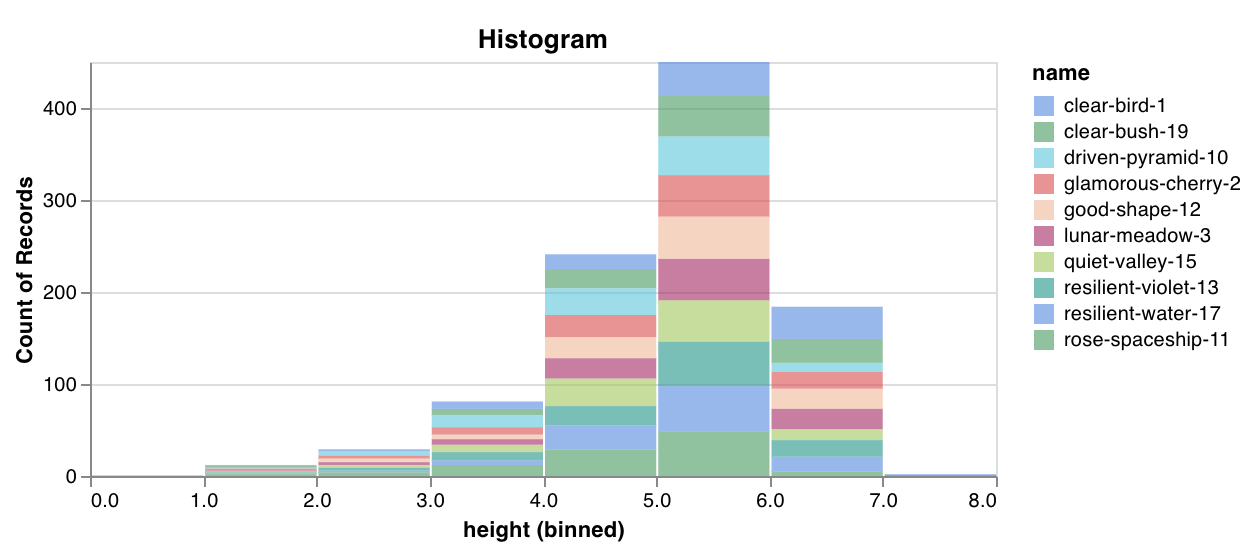
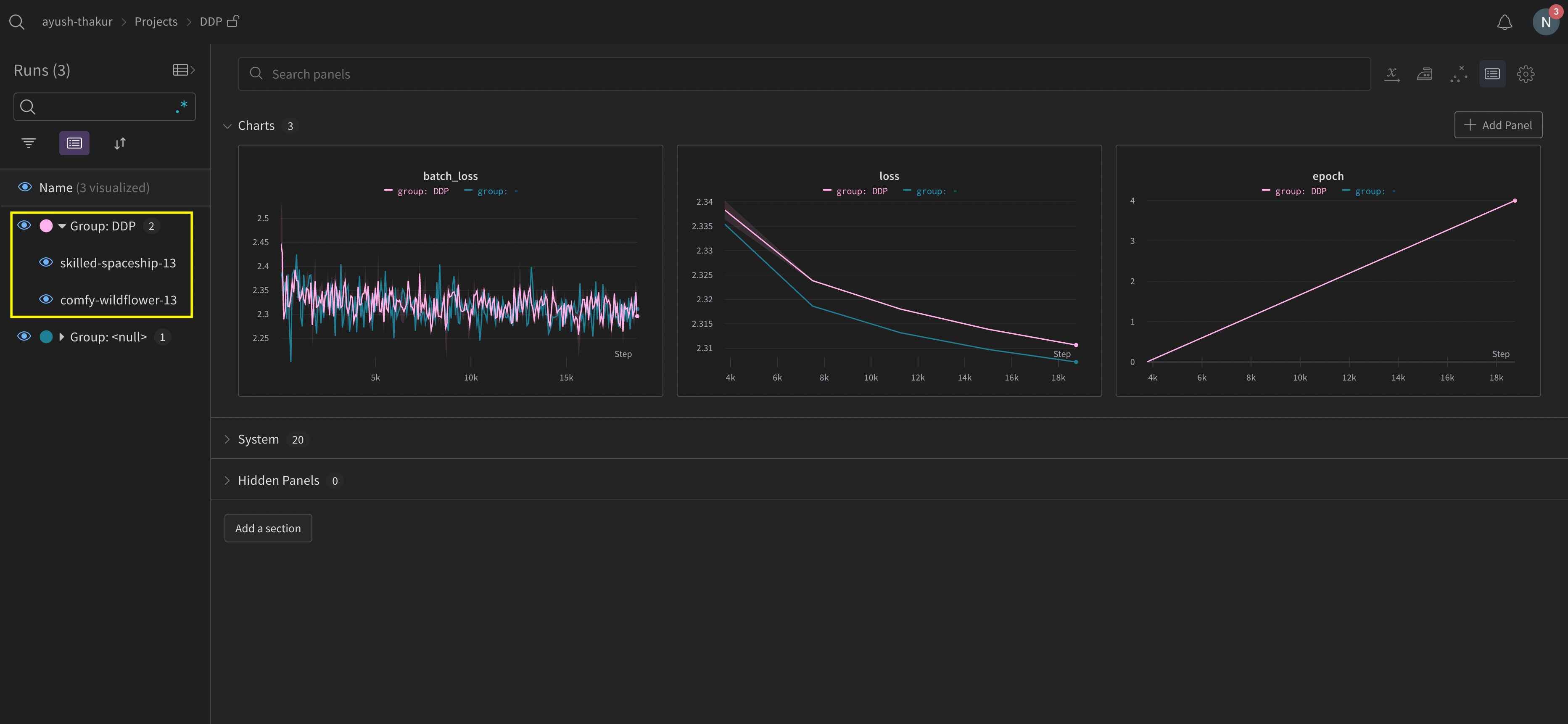


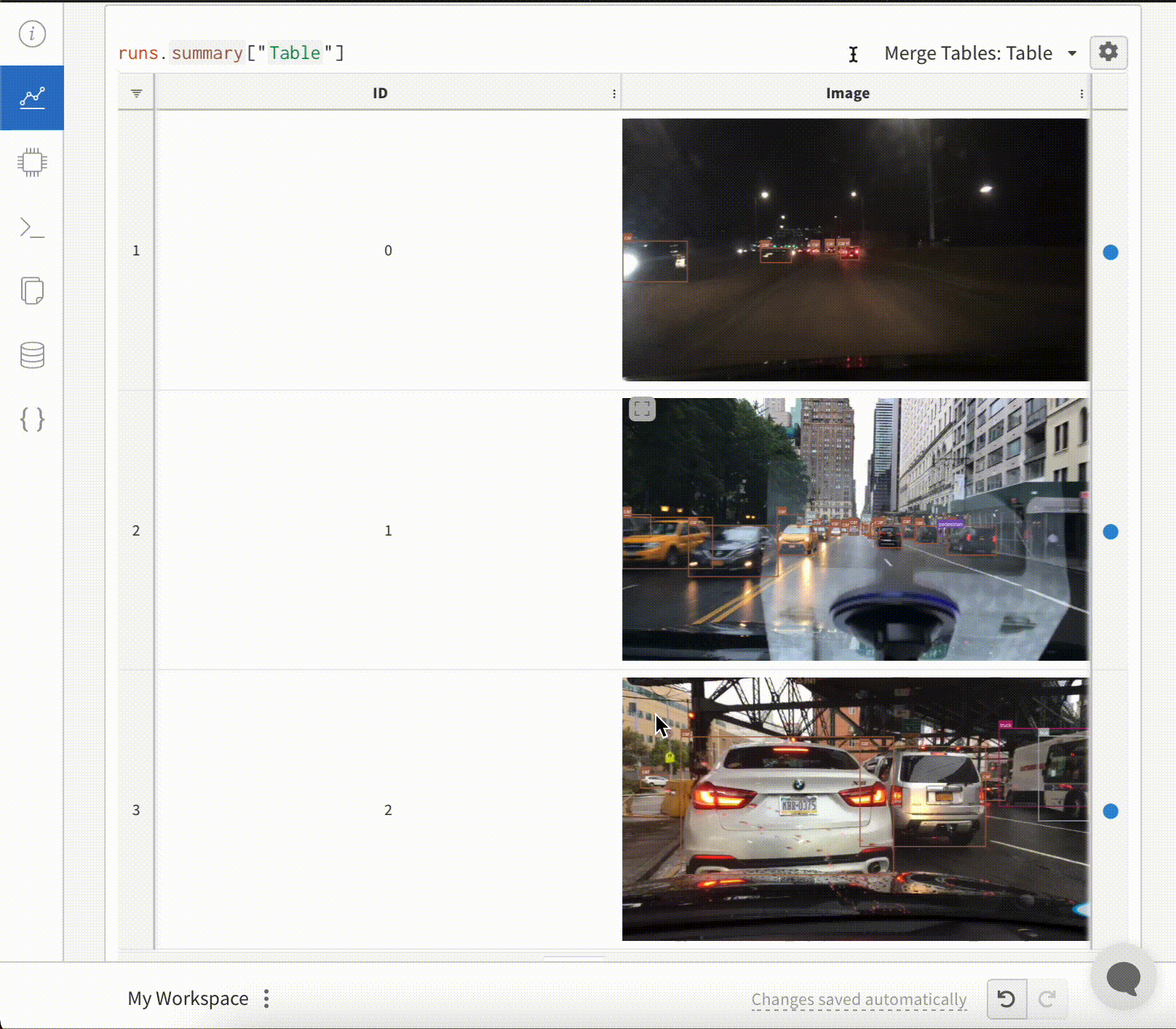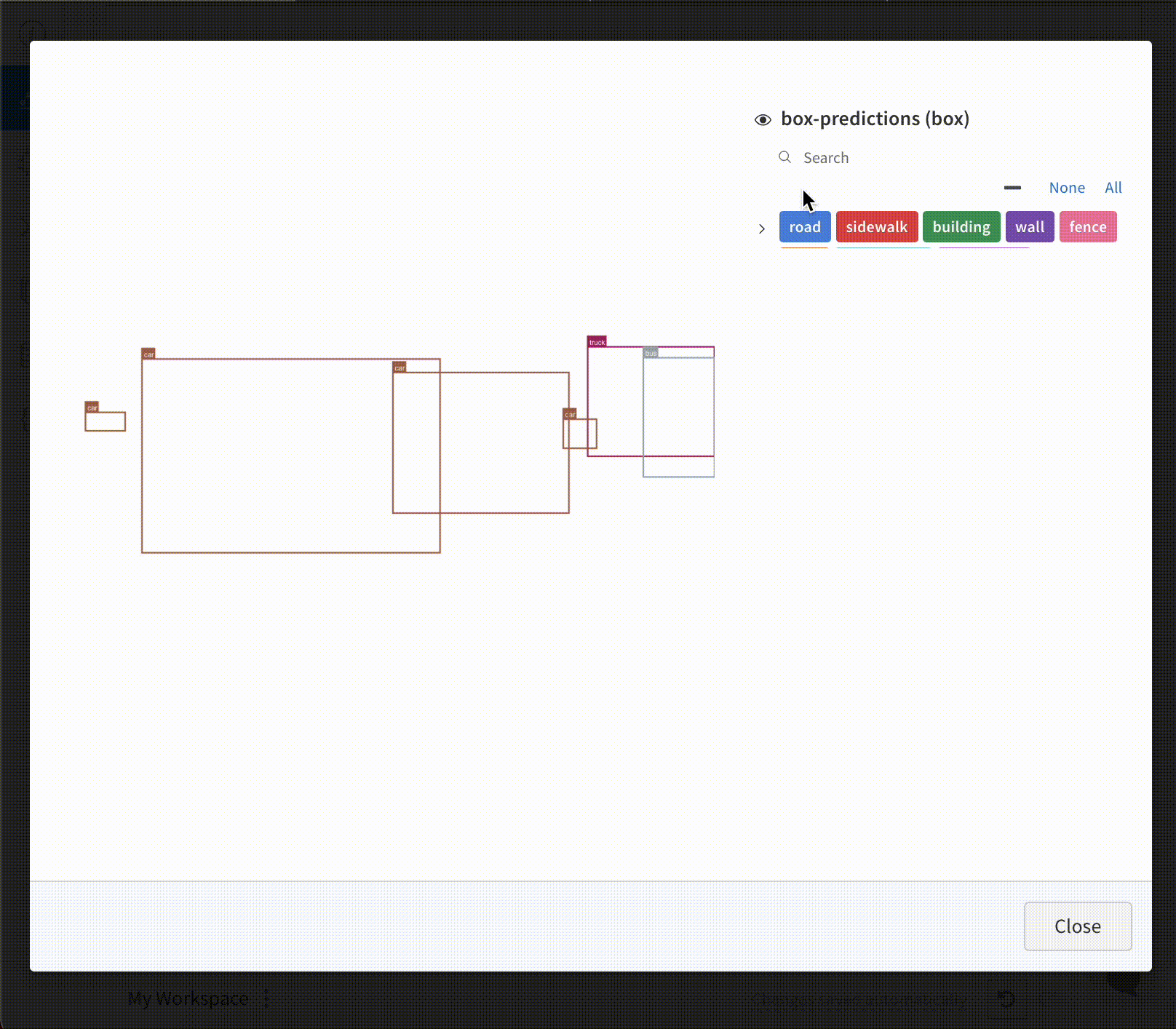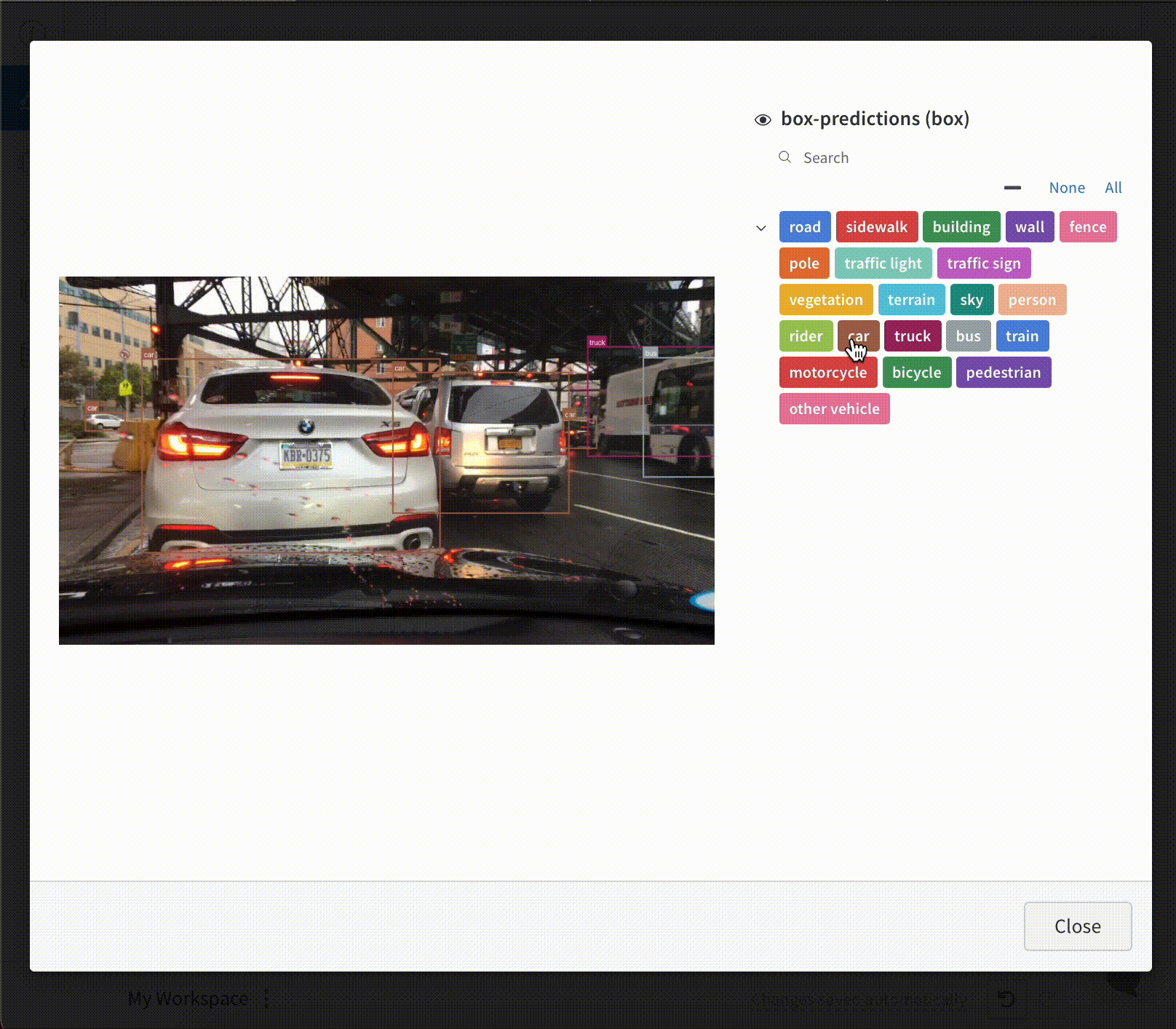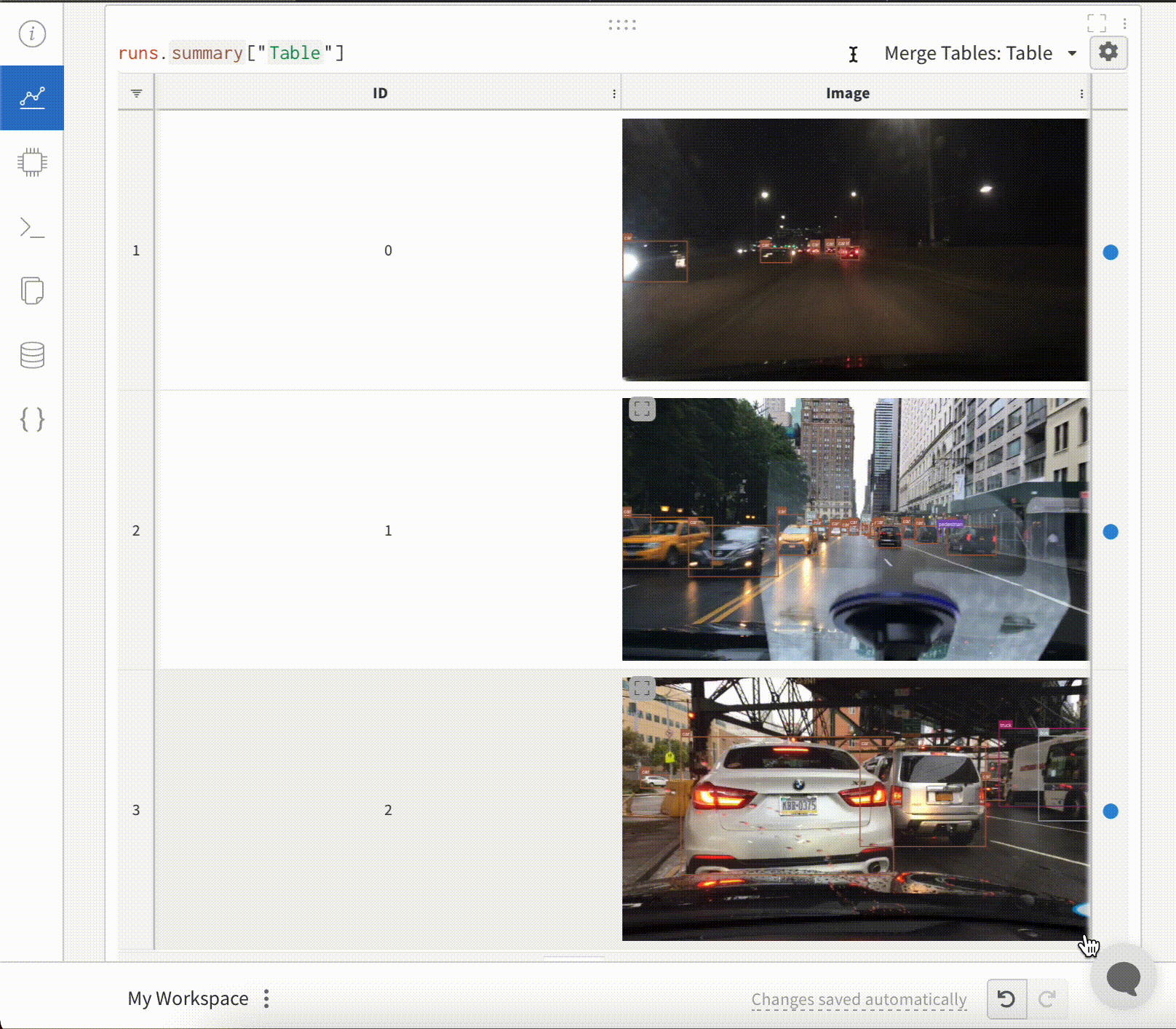
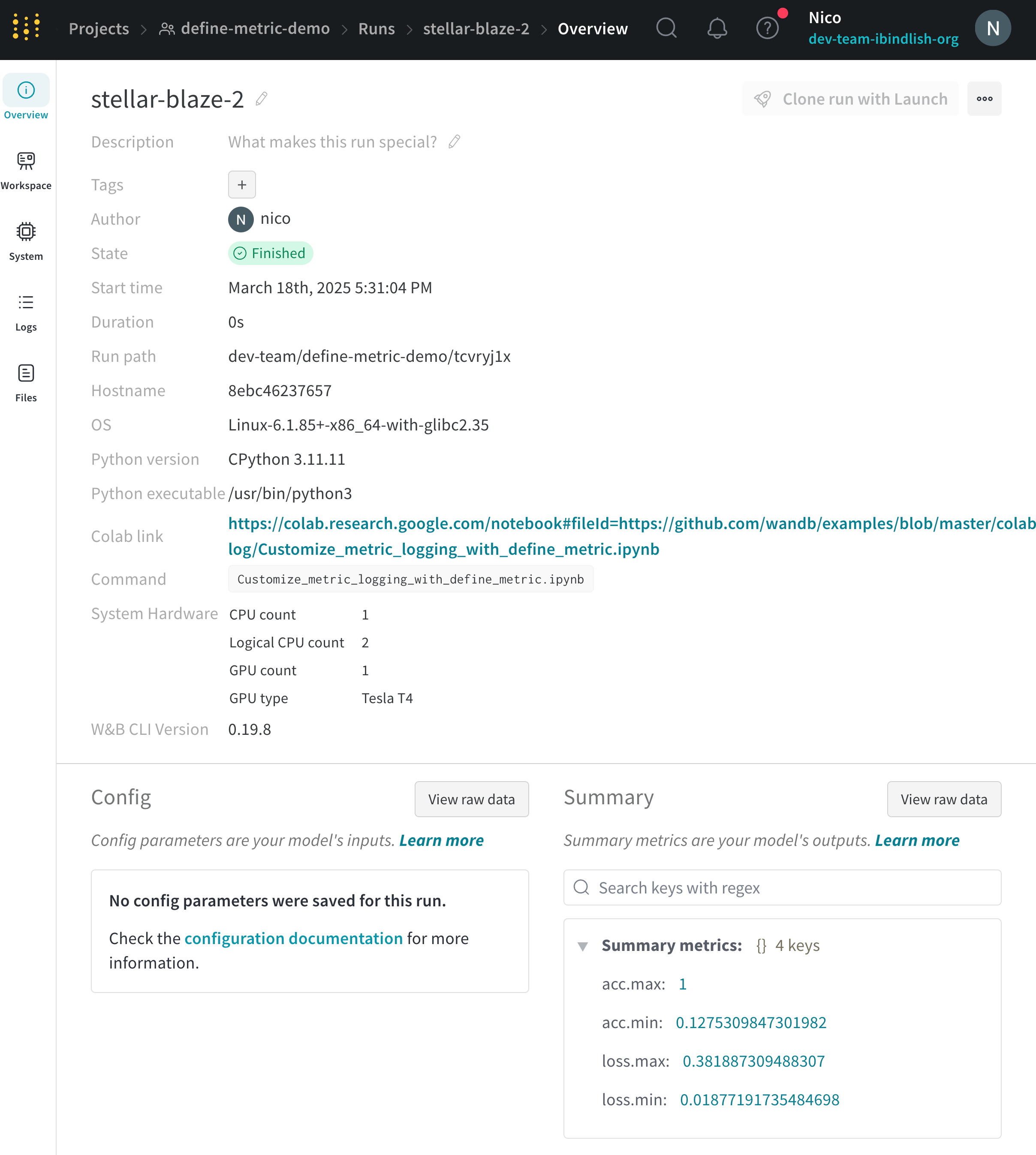
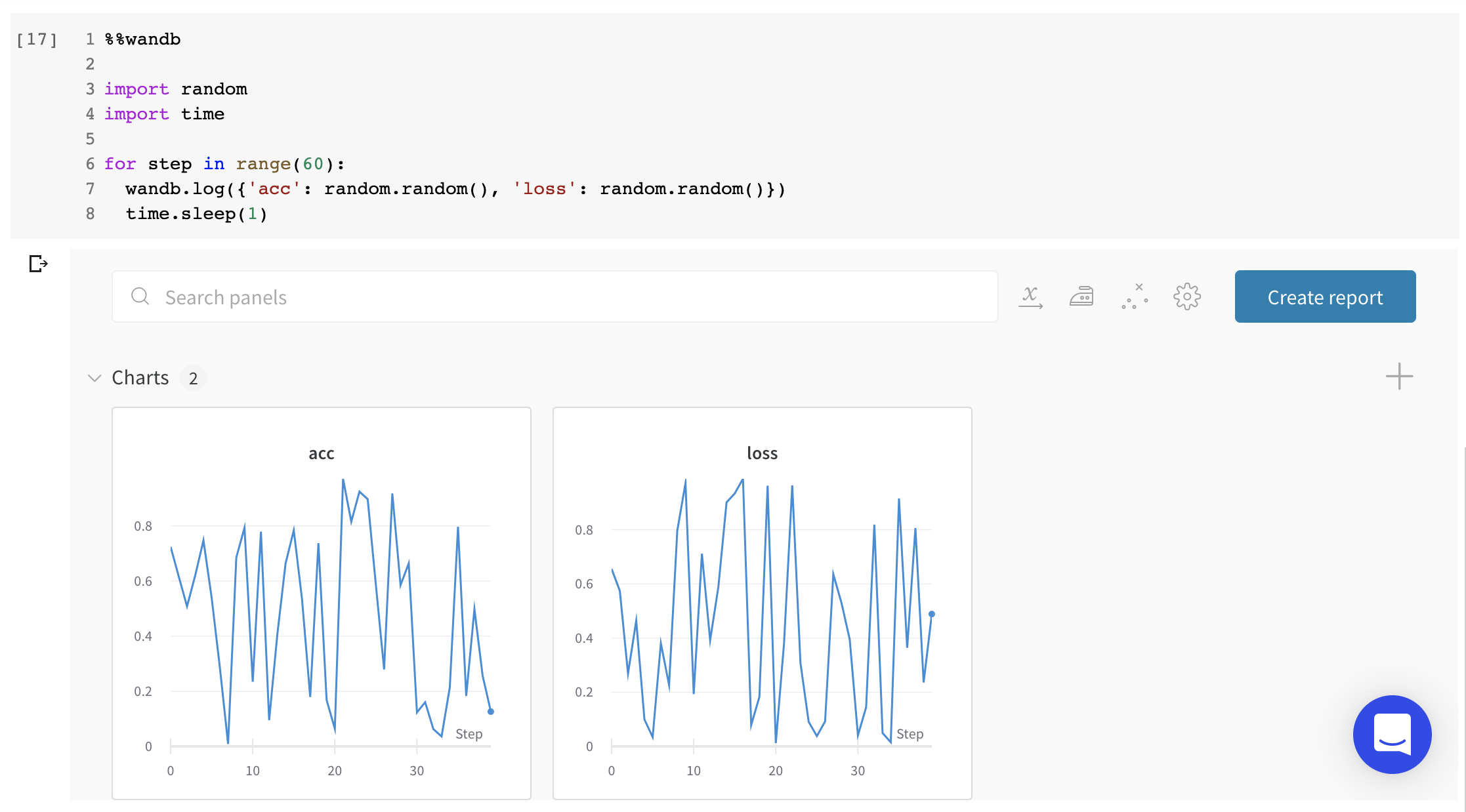
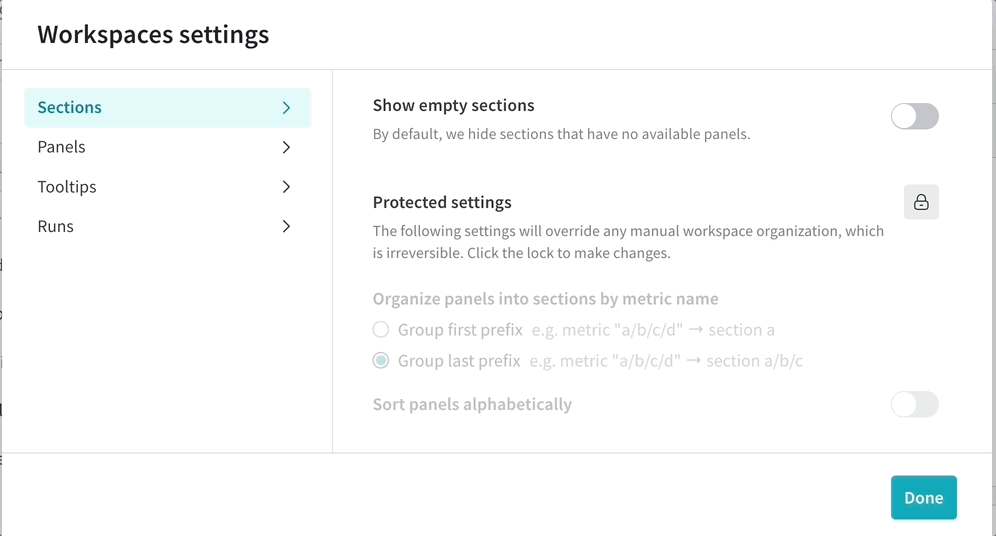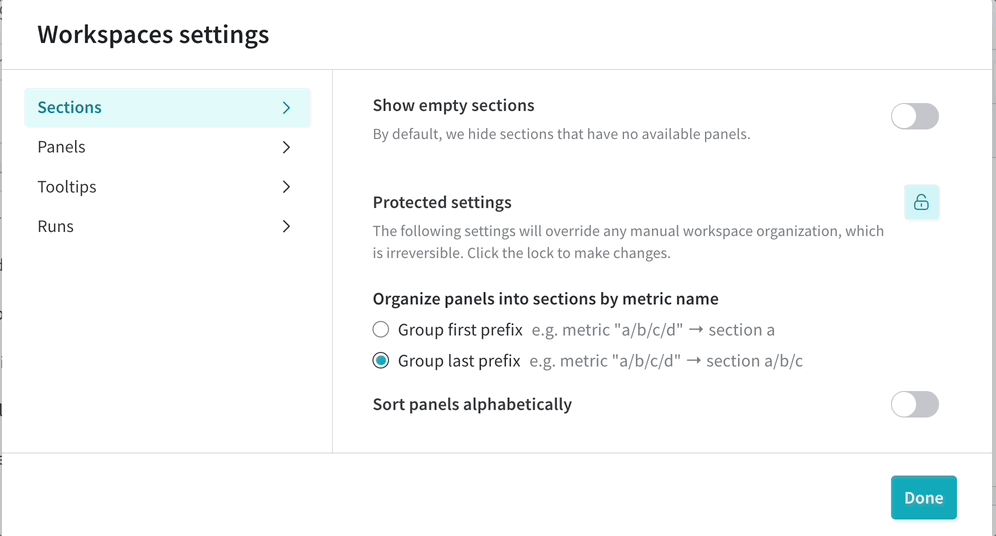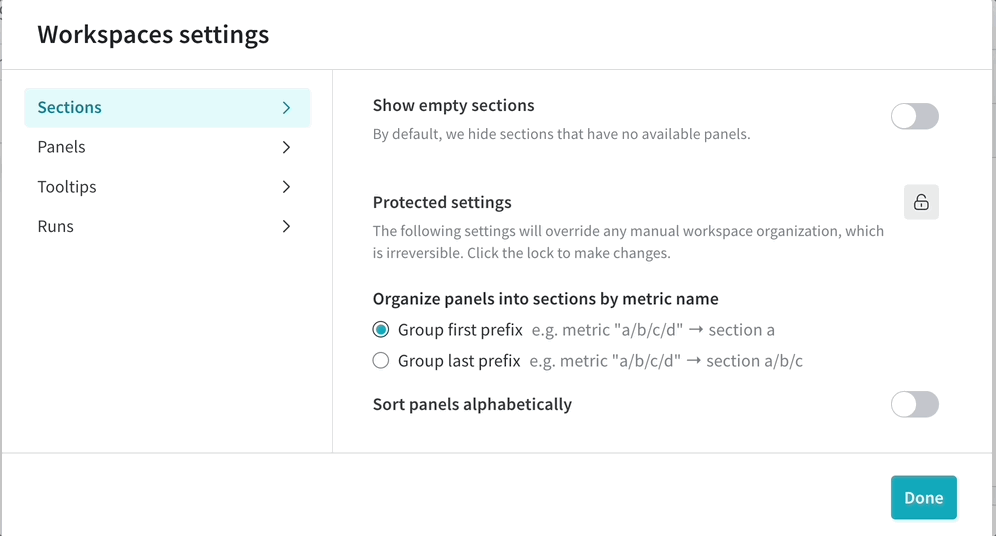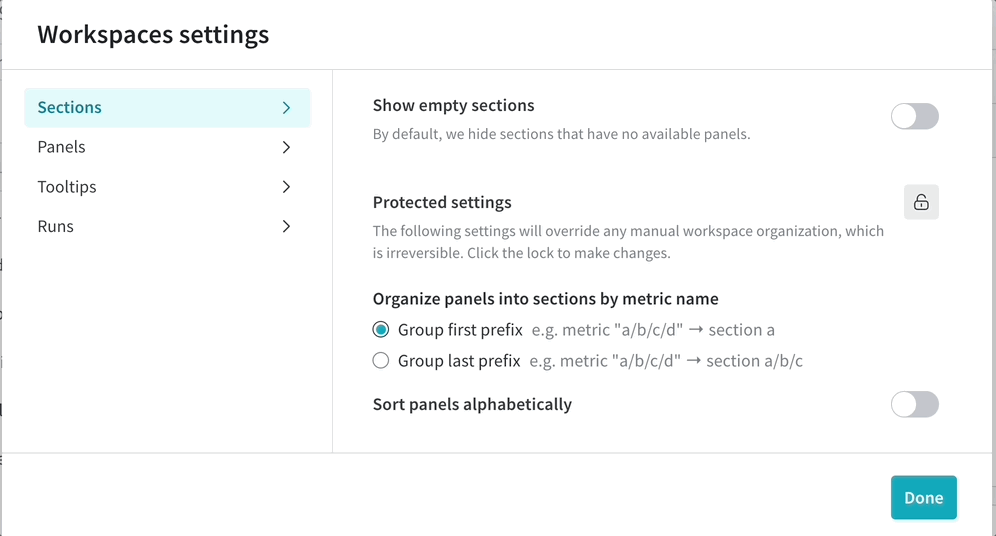
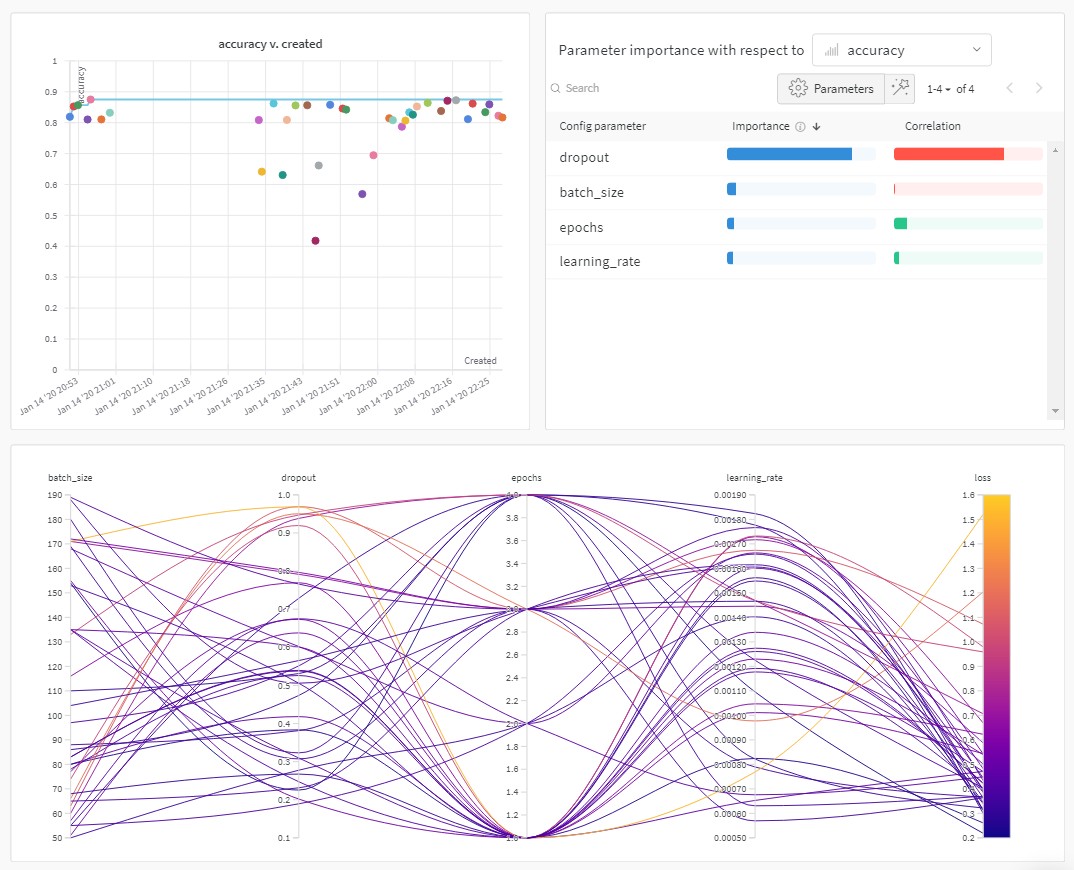
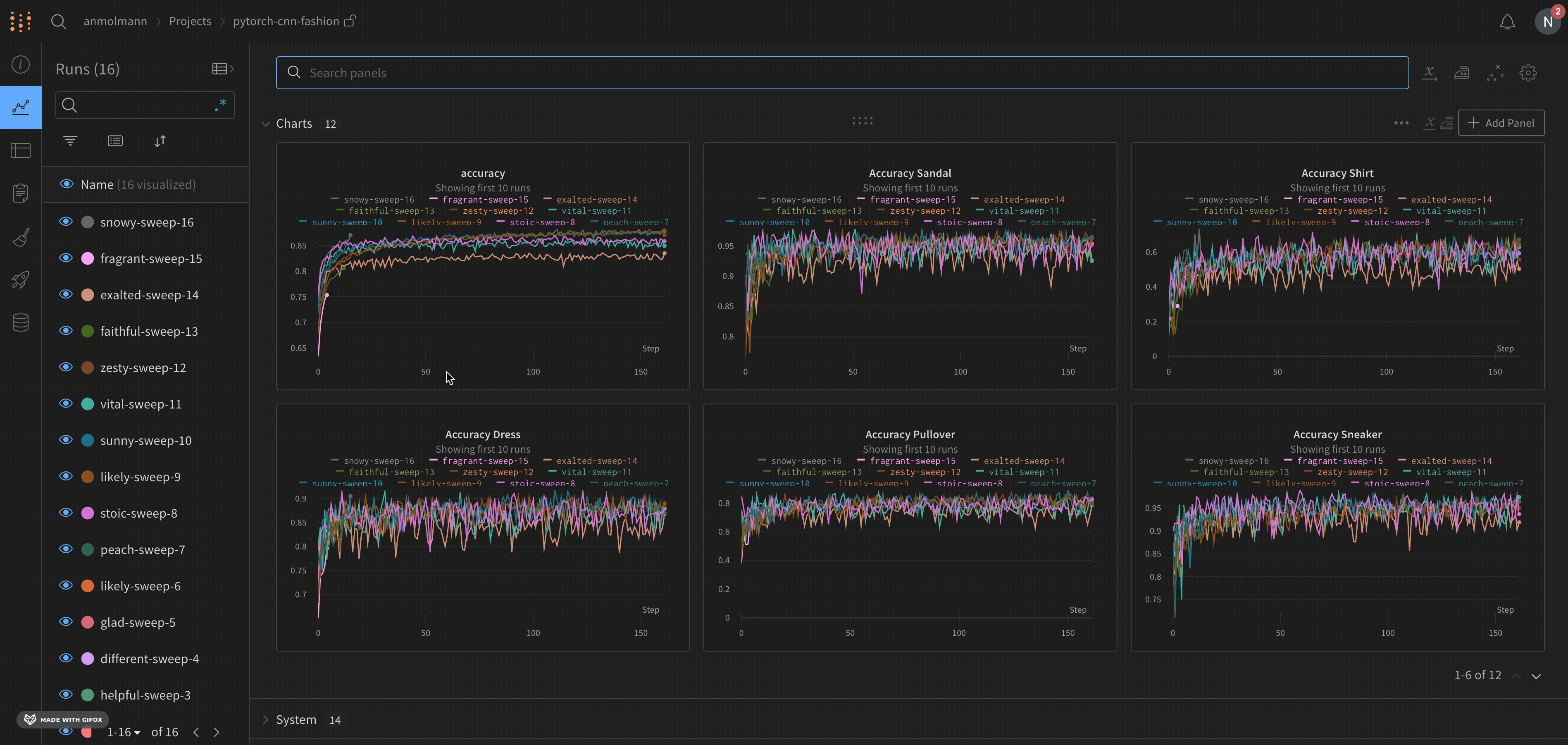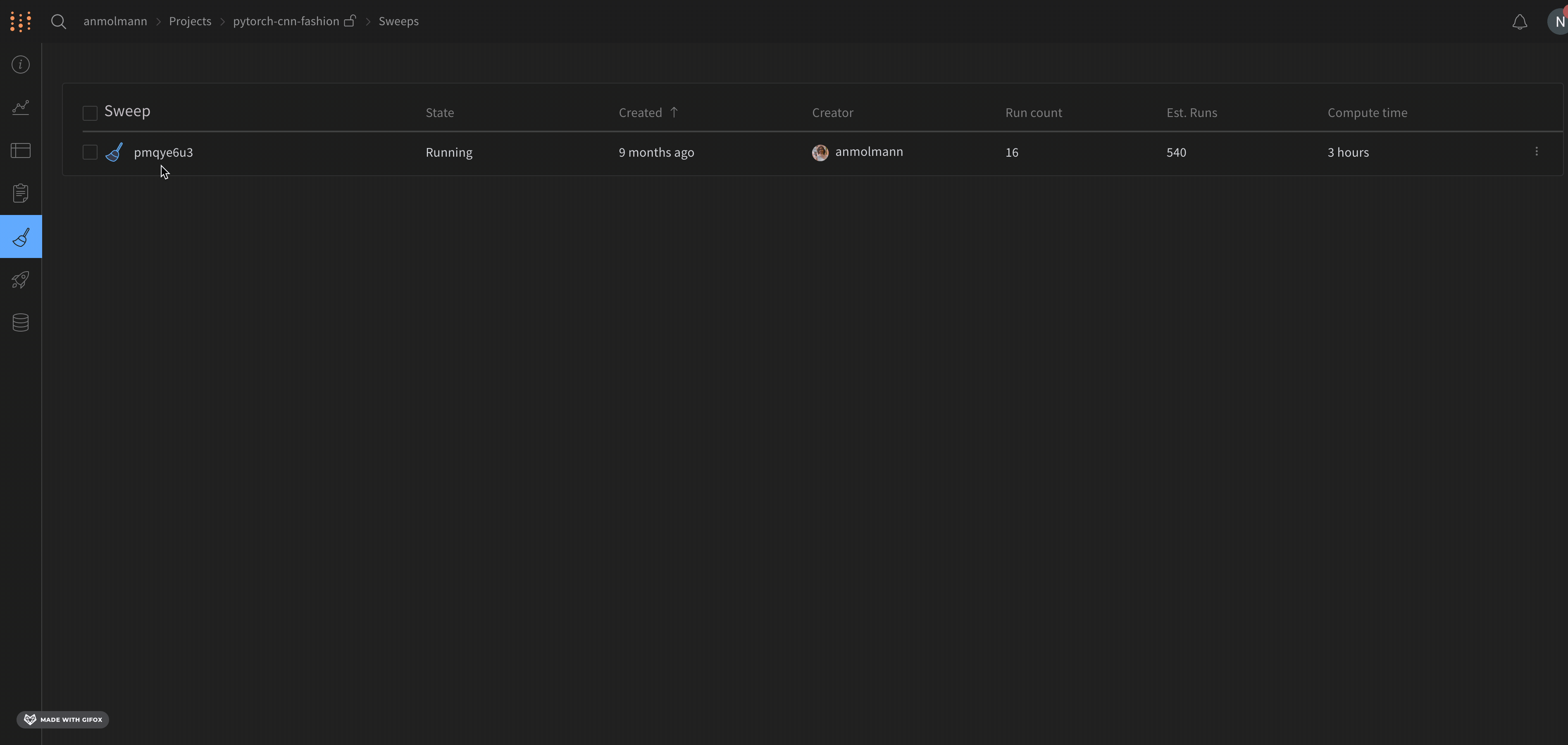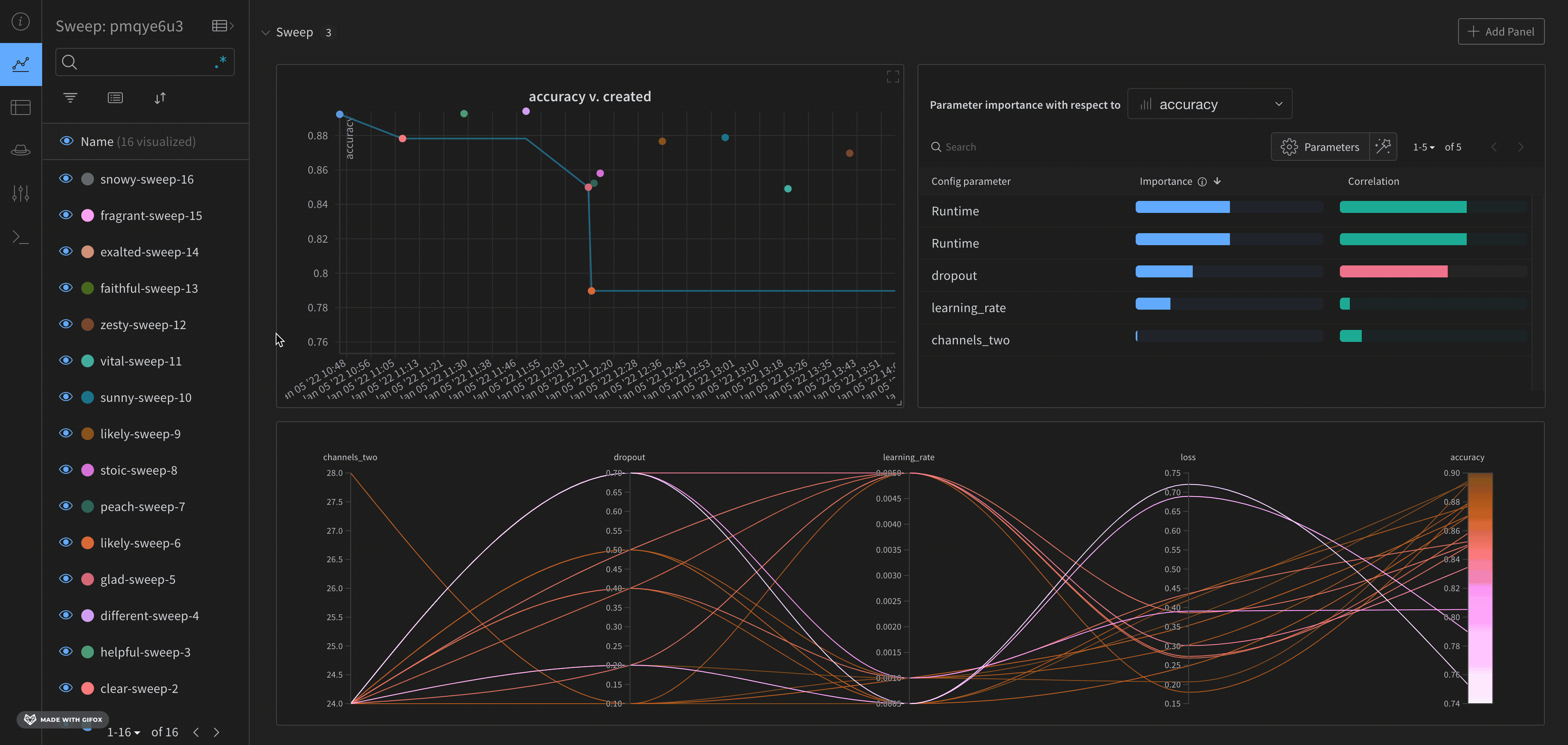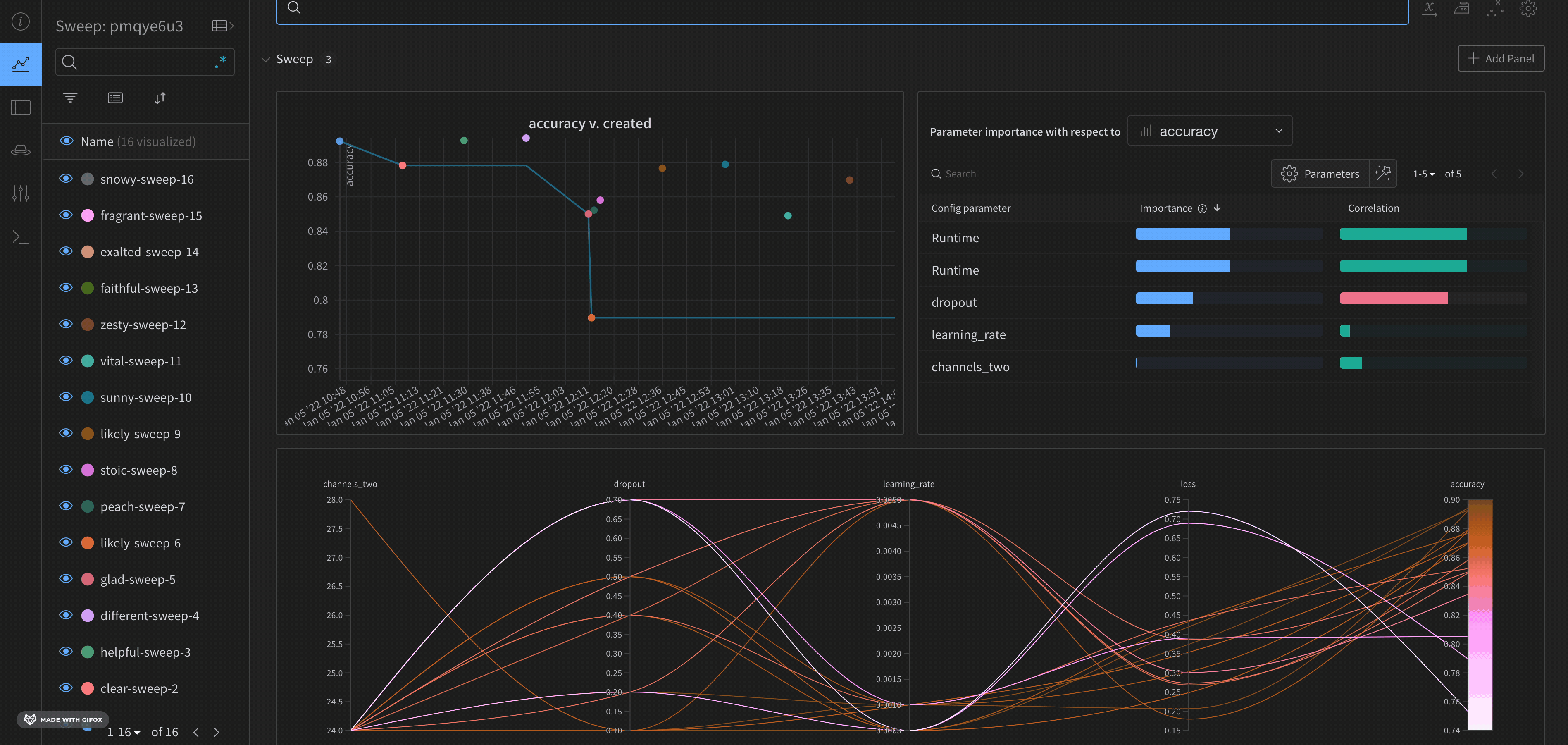
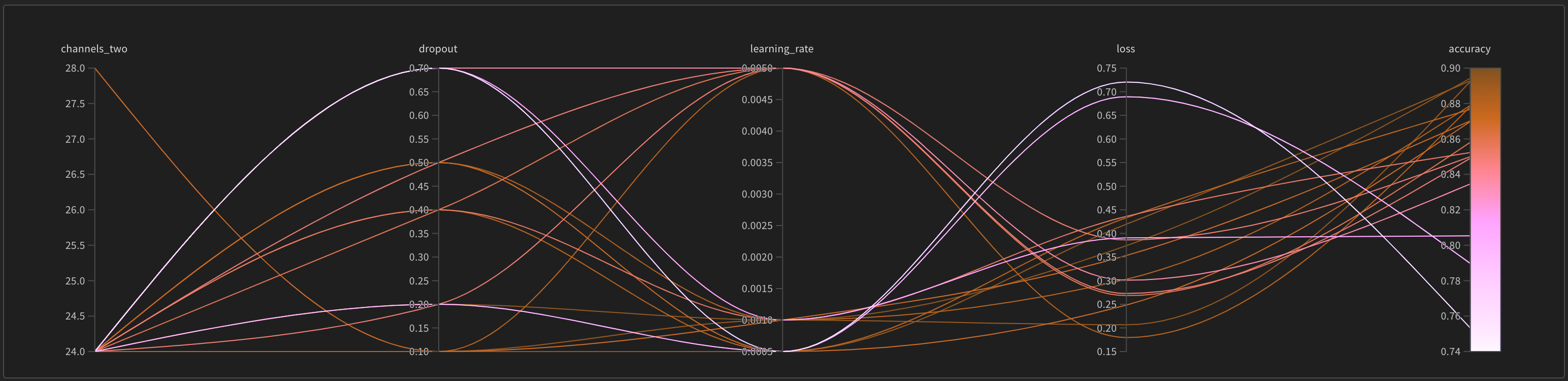
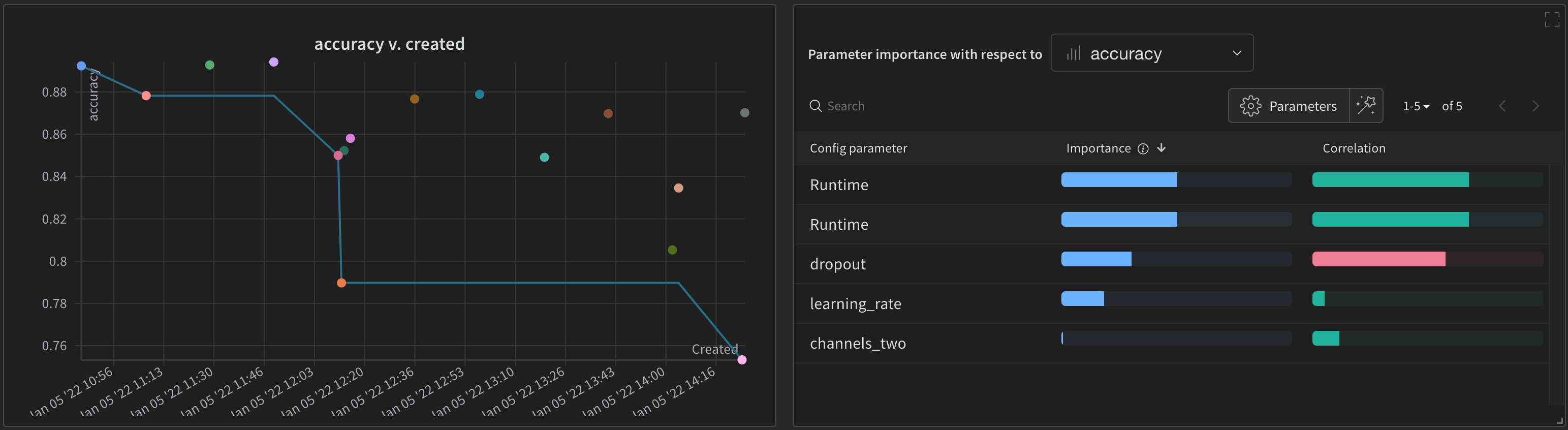
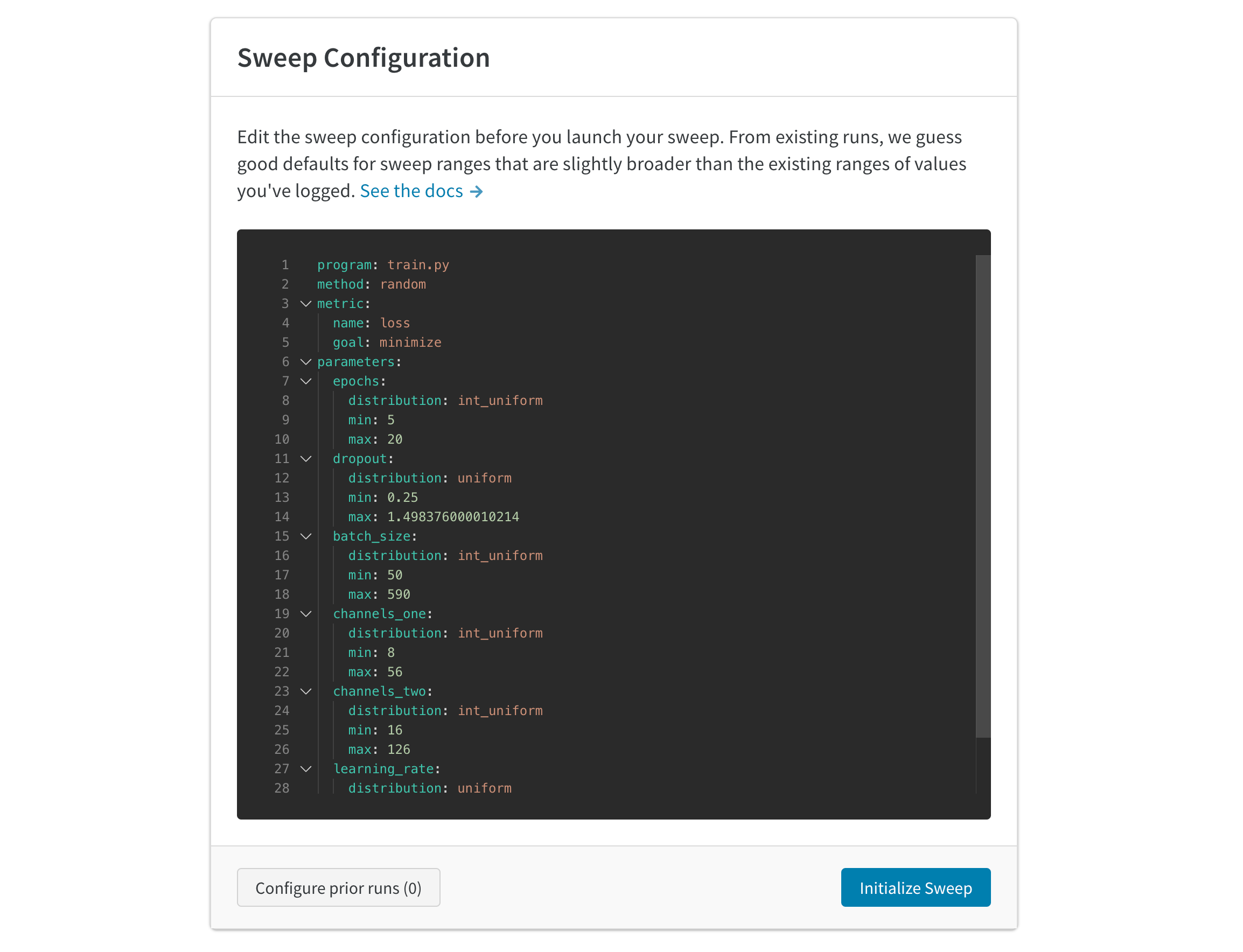
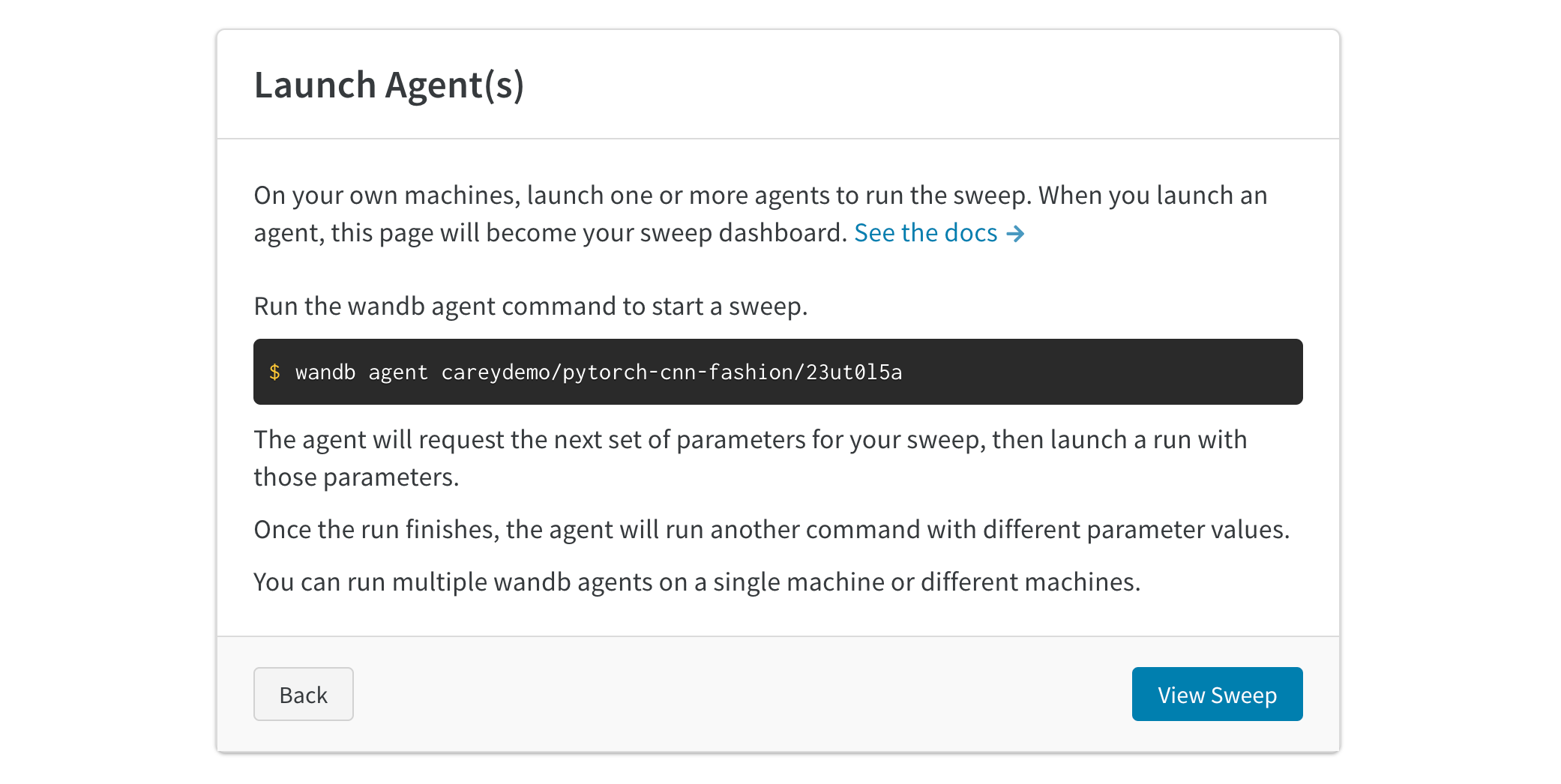
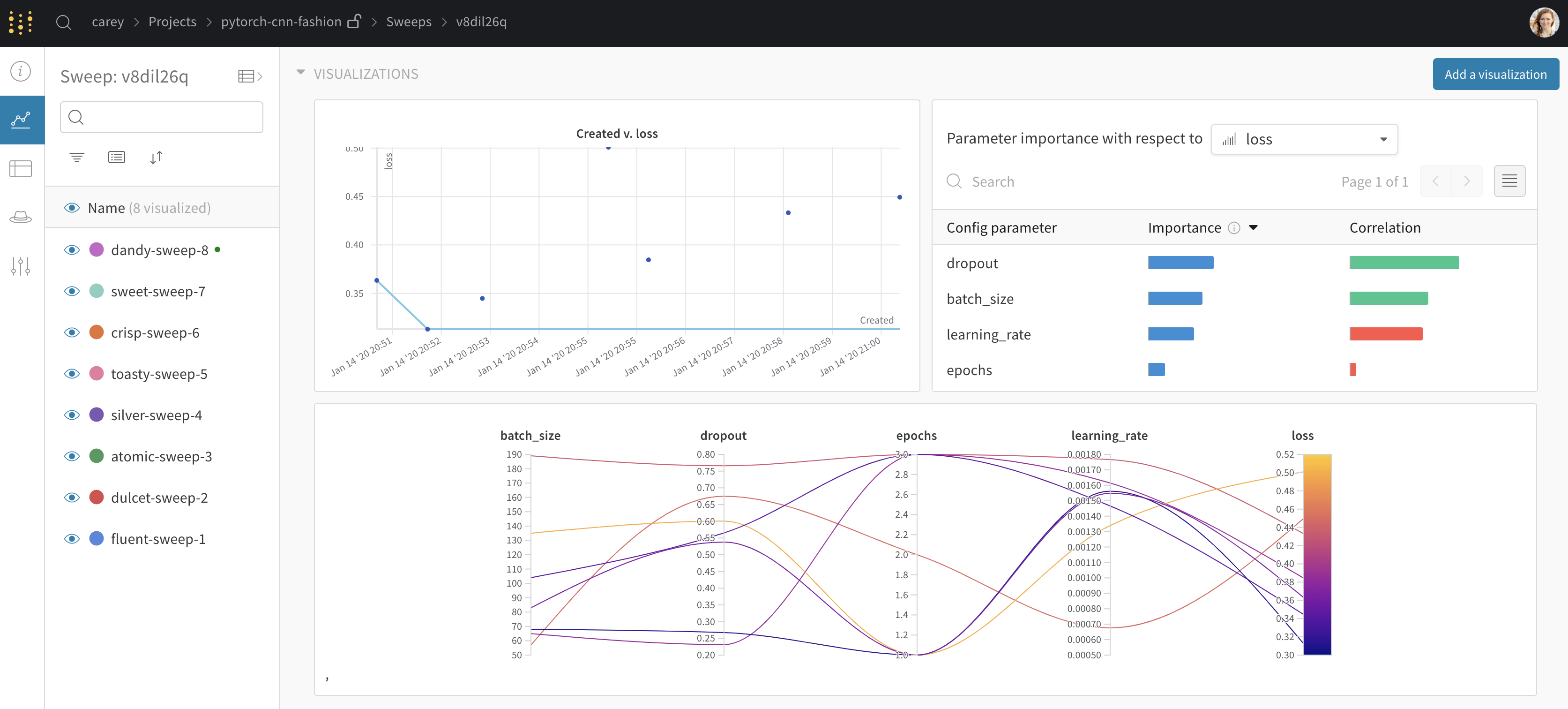
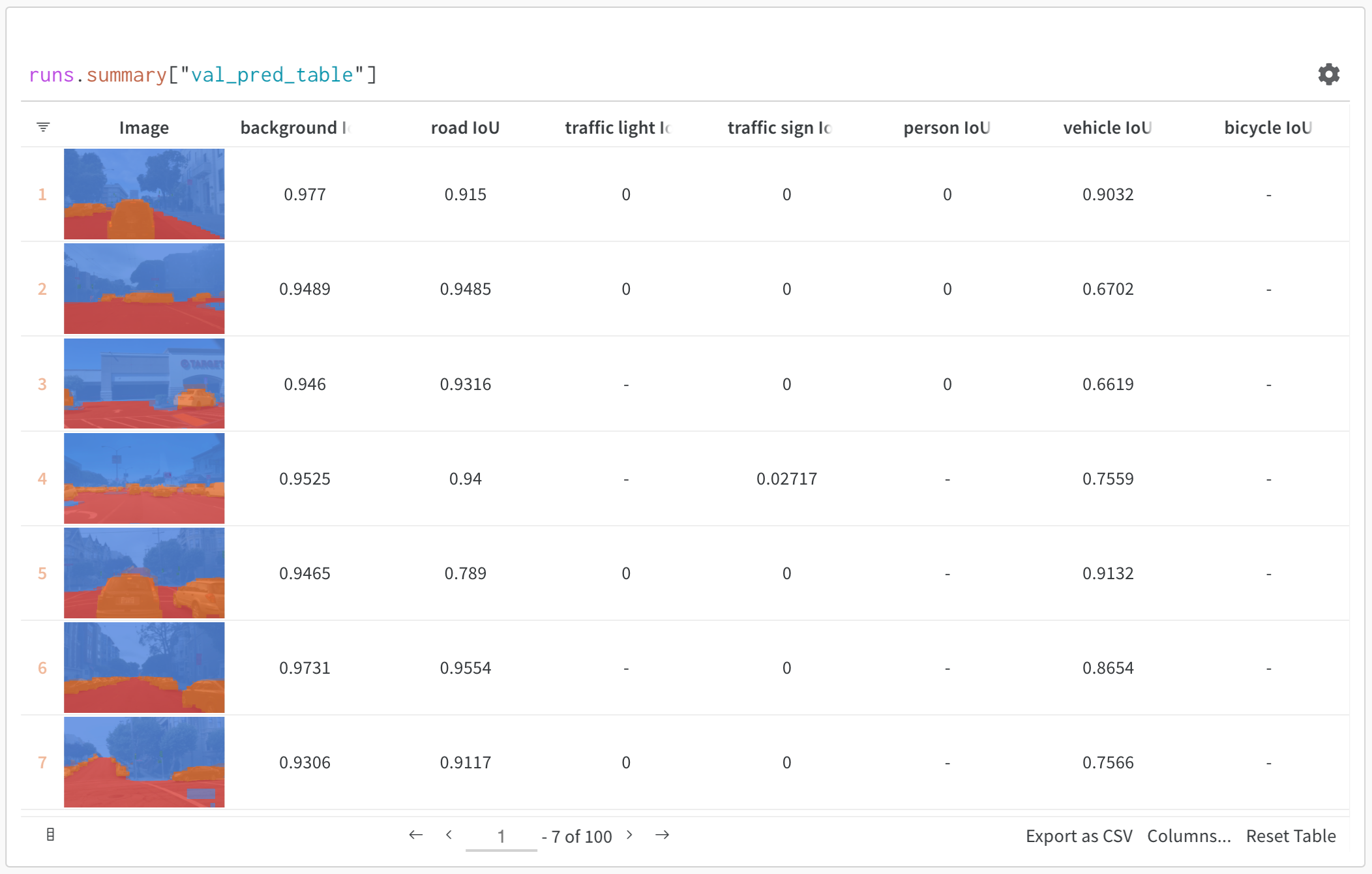 上の画像は、セマンティックセグメンテーションとカスタムメトリクスを含むテーブルを示しています。このテーブルは、
上の画像は、セマンティックセグメンテーションとカスタムメトリクスを含むテーブルを示しています。このテーブルは、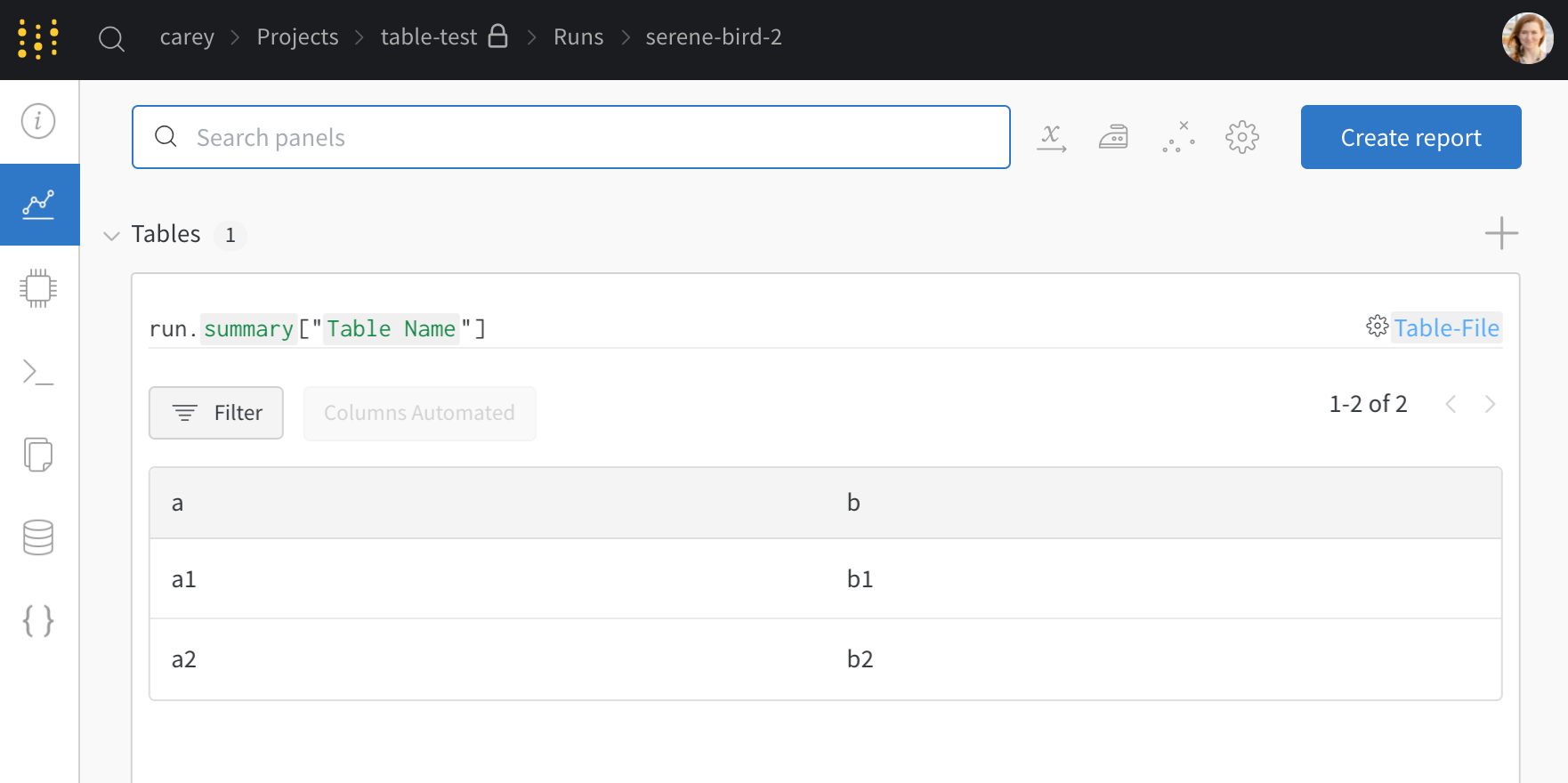
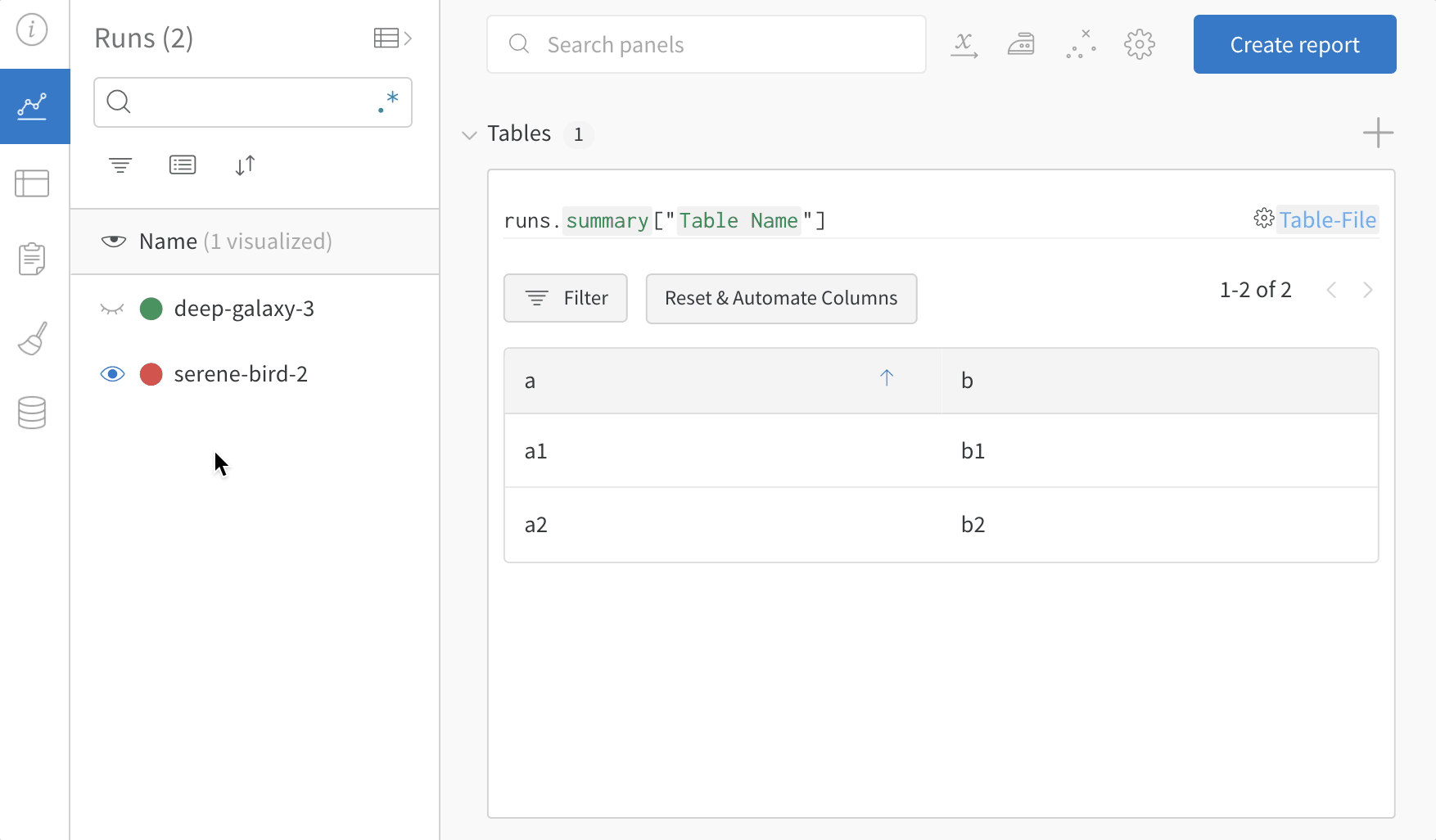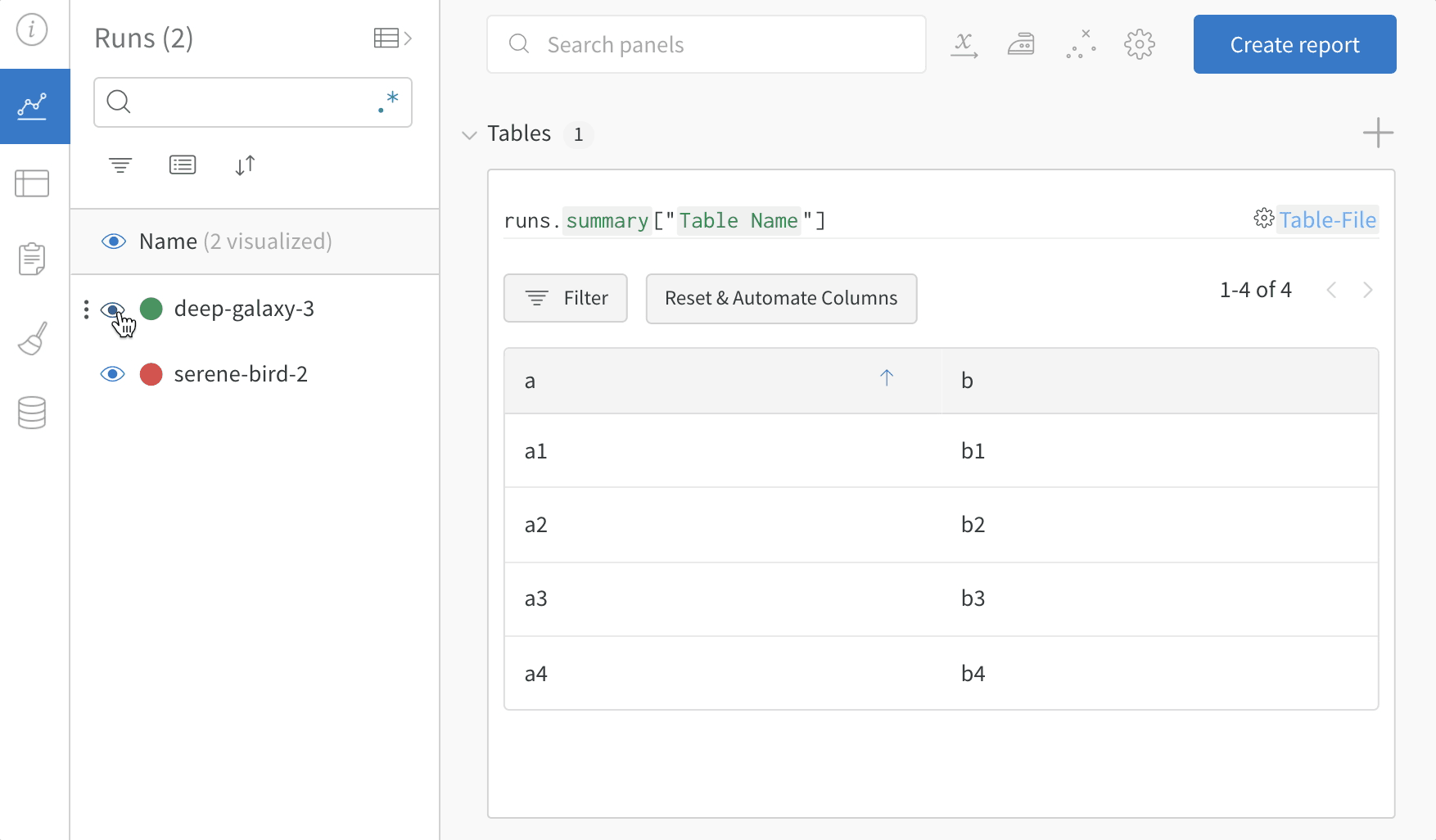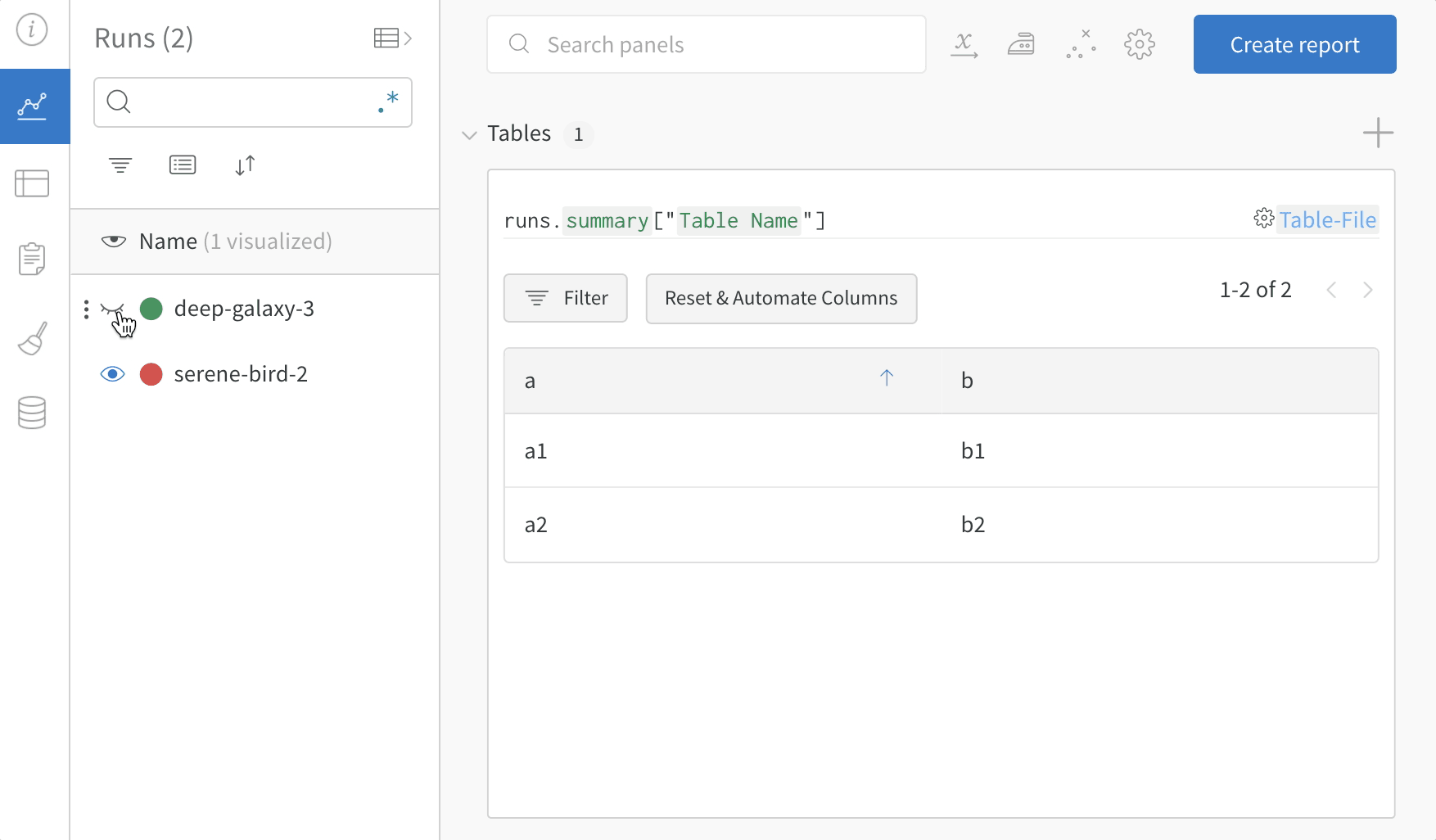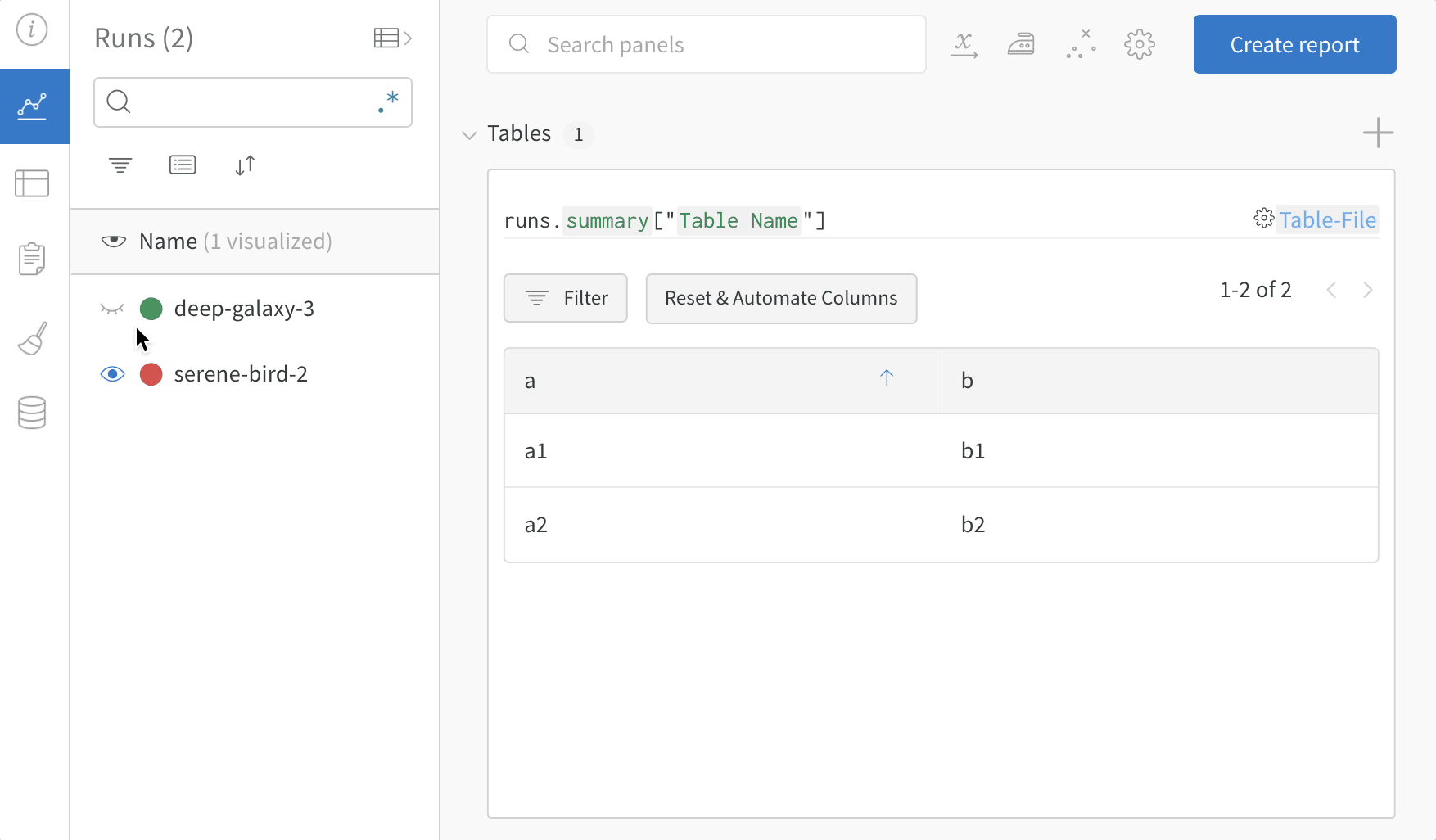
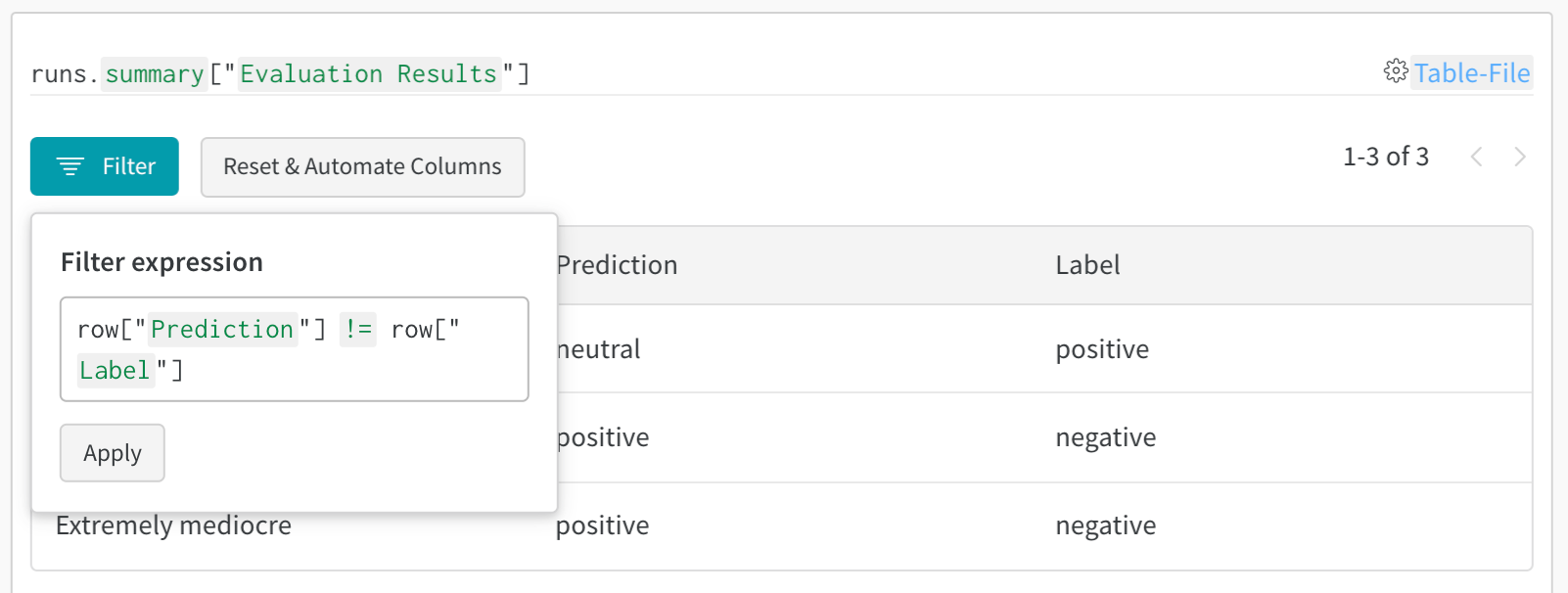
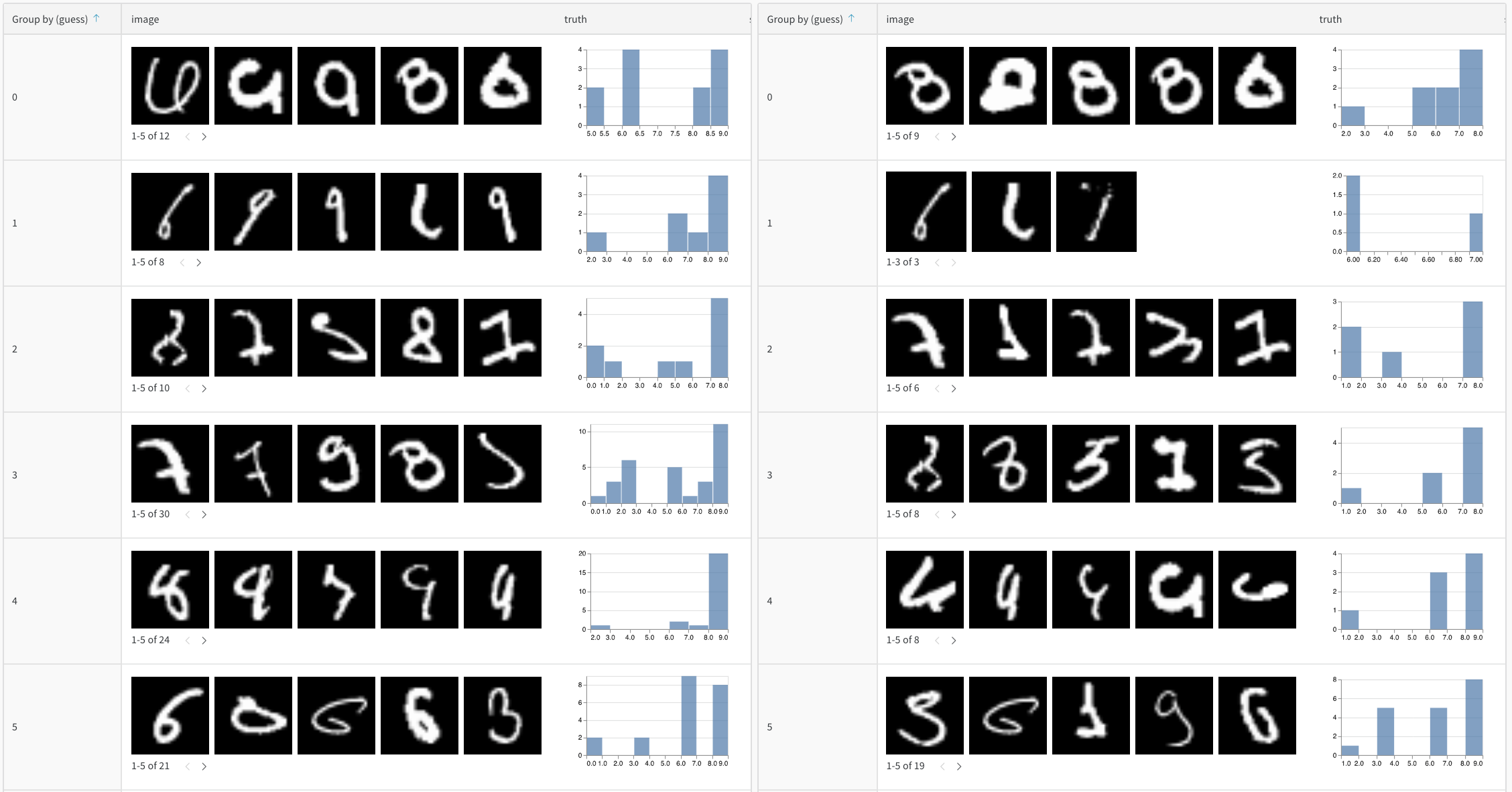
![[予測] をクリックしてテーブルを表示します](https://docs.wandb.ai/images/data_vis/preds_mnist.png)
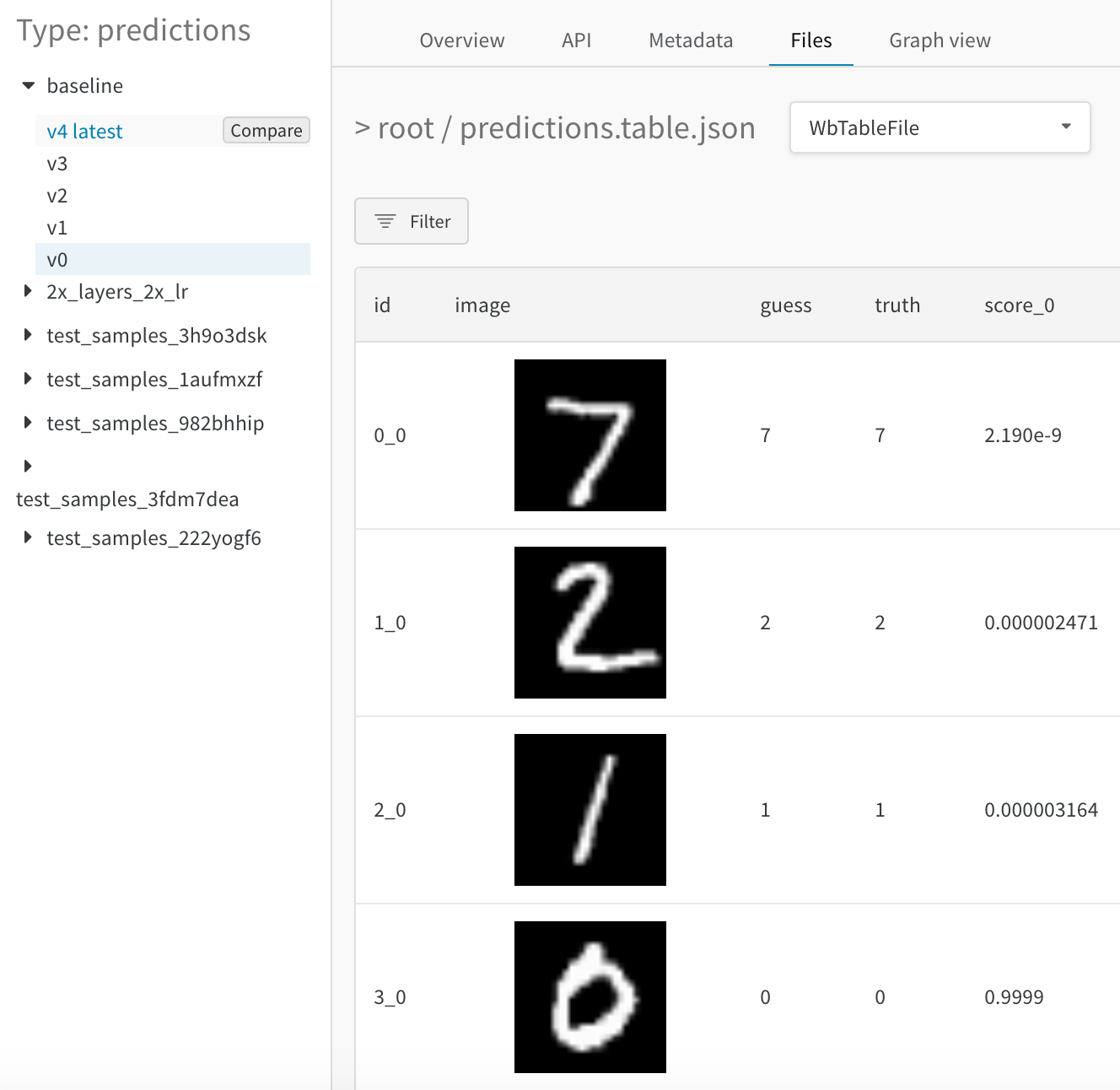
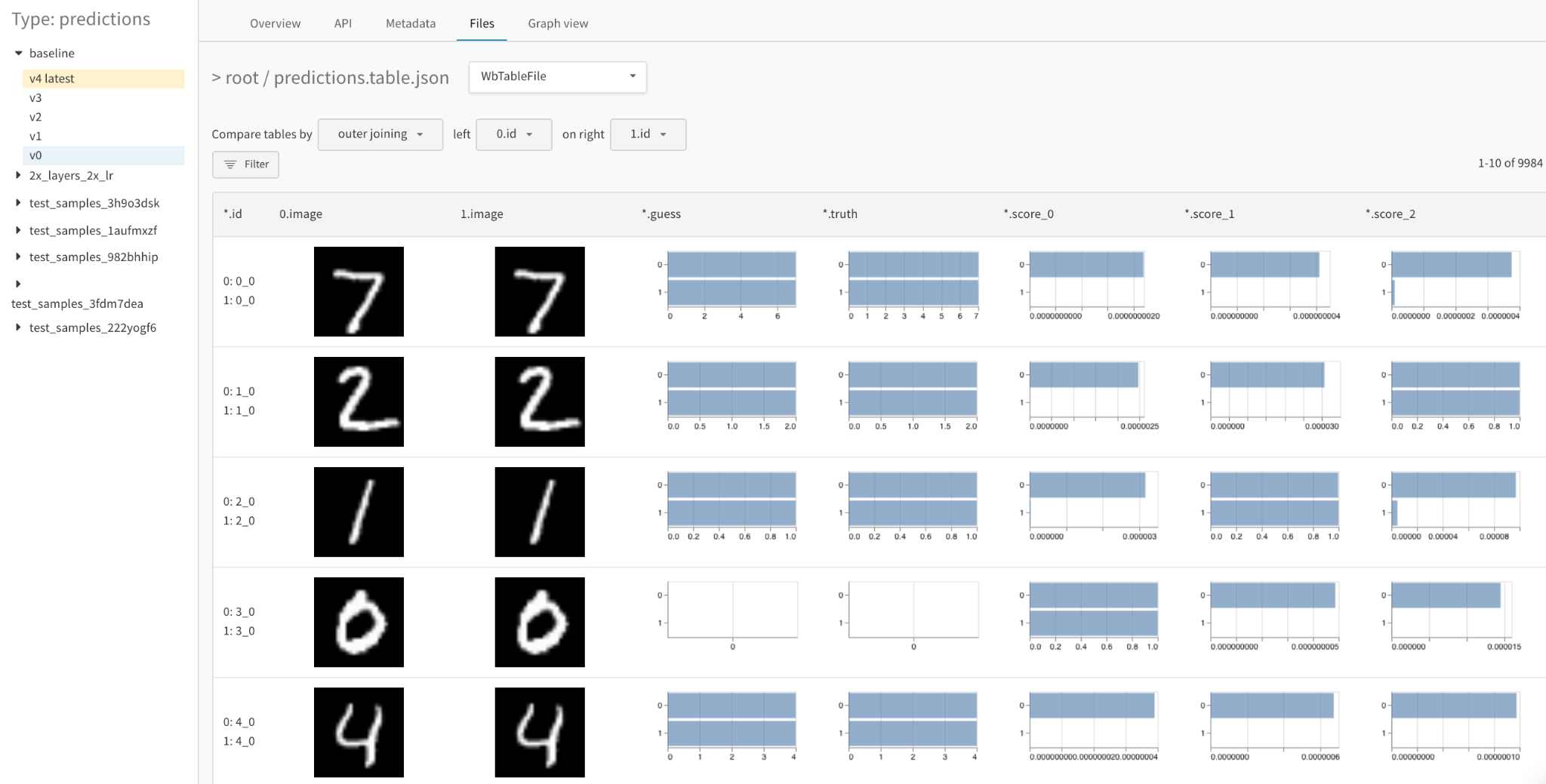
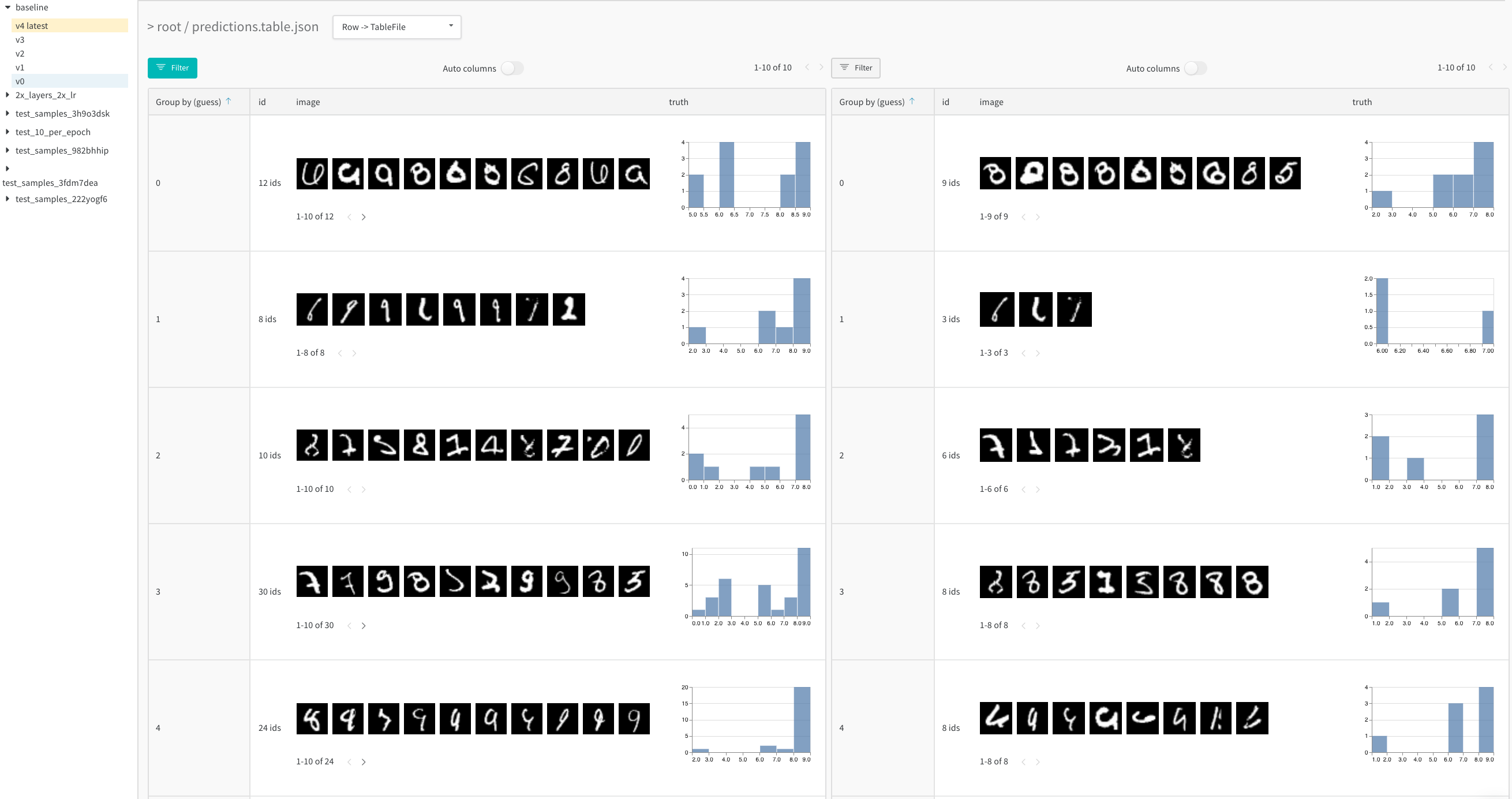
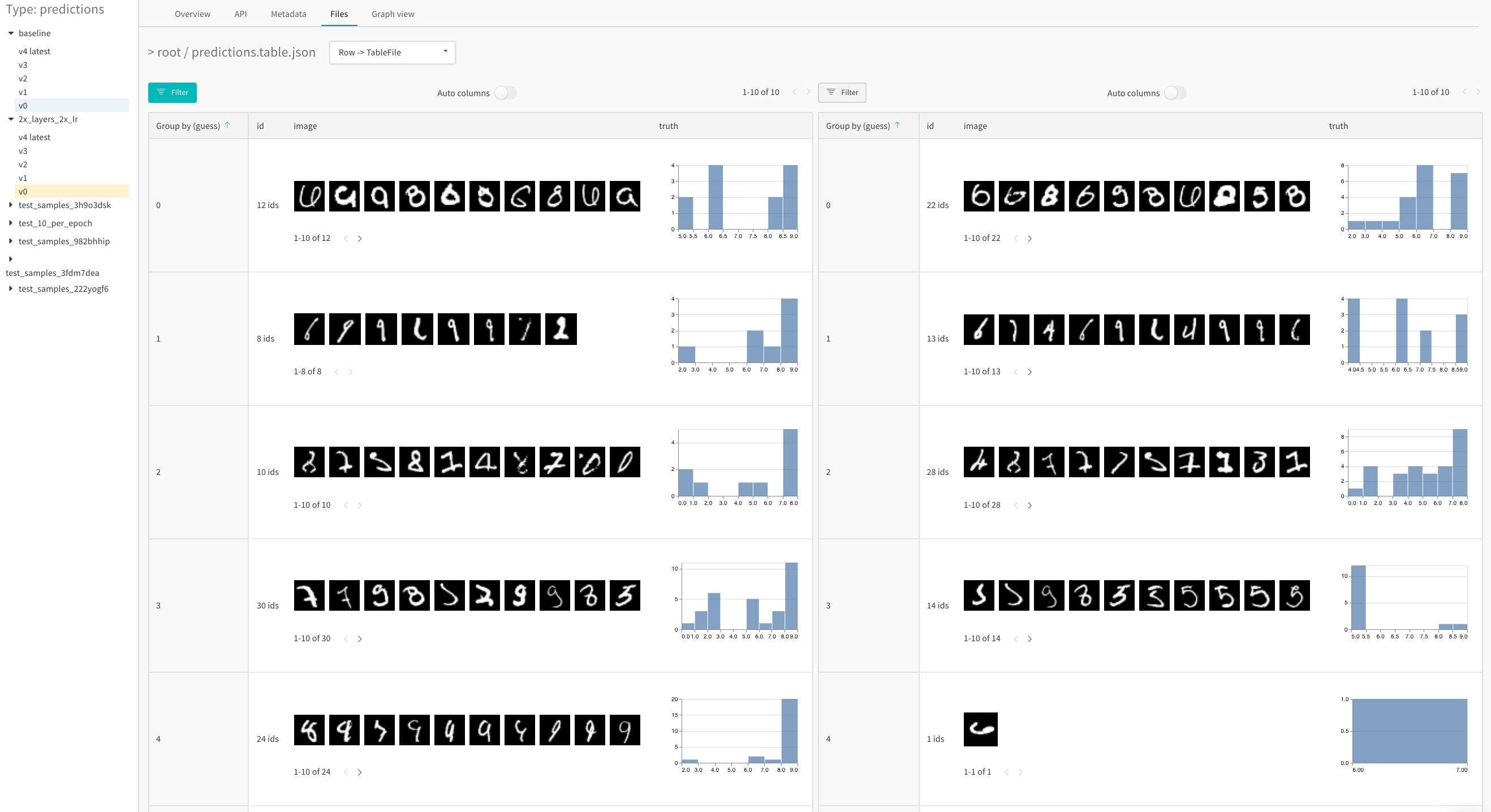
![5 エポック後、 [ダブル] バリアント は ベースライン に追いついています。](https://docs.wandb.ai/images/data_vis/compare_across_variants_after_5_epochs.png)
![[パネルを共有] を選択すると新しい Report が作成され、 [レポートに追加] を選択すると既存の Report に追加できます。](https://docs.wandb.ai/images/data_vis/share_your_view.png)