Tutorial: Use custom charts
less than a minute
カスタムチャートを使用すると、パネルにロードするデータとその可視化を制御できます。
1. データを W&B にログ記録する
まず、スクリプトにデータをログ記録します。トレーニングの開始時に設定された単一のポイント(ハイパーパラメータなど)には、wandb.config を使用します。時間の経過に伴う複数のポイントには、wandb.log() を使用し、wandb.Table() を使用してカスタム 2D 配列をログ記録します。ログに記録されるキーごとに最大 10,000 個のデータポイントをログに記録することをお勧めします。
# データのカスタムテーブルをログ記録する
my_custom_data = [[x1, y1, z1], [x2, y2, z2]]
wandb.log(
{"custom_data_table": wandb.Table(data=my_custom_data, columns=["x", "y", "z"])}
)
クイックなサンプルノートブックを試してデータテーブルをログに記録してください。次のステップでは、カスタムチャートを設定します。結果として得られるチャートがライブ Reportでどのように見えるかを確認してください。
2. クエリを作成する
可視化するデータをログに記録したら、プロジェクトページに移動し、**+**ボタンをクリックして新しいパネルを追加し、カスタムチャートを選択します。この Workspaceで一緒に操作できます。

クエリを追加する
- 「summary」をクリックし、「historyTable」を選択して、run の履歴からデータを取得する新しいクエリを設定します。
wandb.Table()をログに記録したキーを入力します。上記のコードスニペットでは、my_custom_tableでした。サンプルノートブックでは、キーはpr_curveとroc_curveです。
Vega フィールドを設定する
クエリがこれらの列をロードするようになったので、Vega フィールドのドロップダウンメニューで選択するオプションとして使用できます。
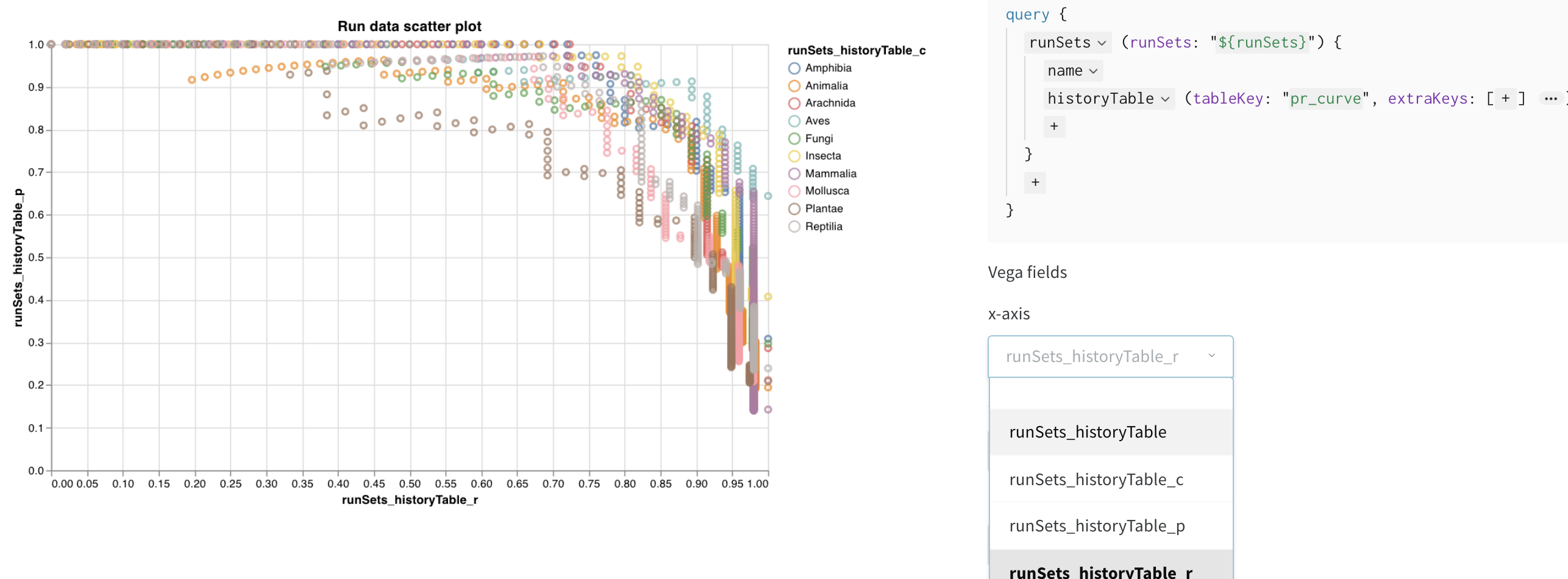
- x 軸: runSets_historyTable_r (再現率)
- y 軸: runSets_historyTable_p (精度)
- 色: runSets_historyTable_c (クラスラベル)
3. チャートをカスタマイズする
見た目はかなり良いですが、散布図から折れ線グラフに切り替えたいと思います。「編集」をクリックして、この組み込みチャートの Vega 仕様を変更します。この Workspaceで一緒に操作できます。

Vega 仕様を更新して、可視化をカスタマイズしました。
- プロット、凡例、x 軸、および y 軸のタイトルを追加します(各フィールドの「title」を設定します)。
- 「mark」の値を「point」から「line」に変更します。
- 使用されていない「size」フィールドを削除します。
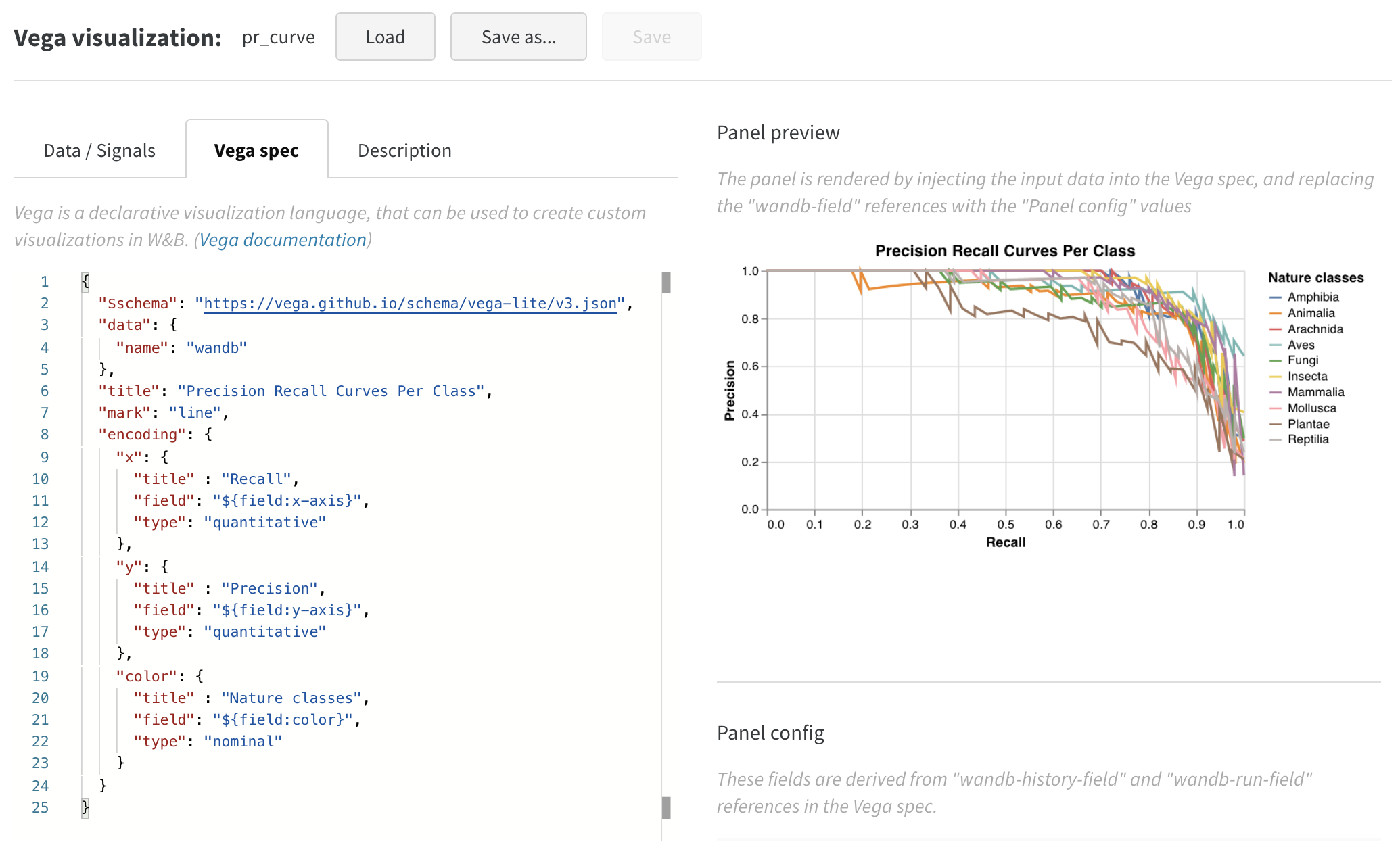
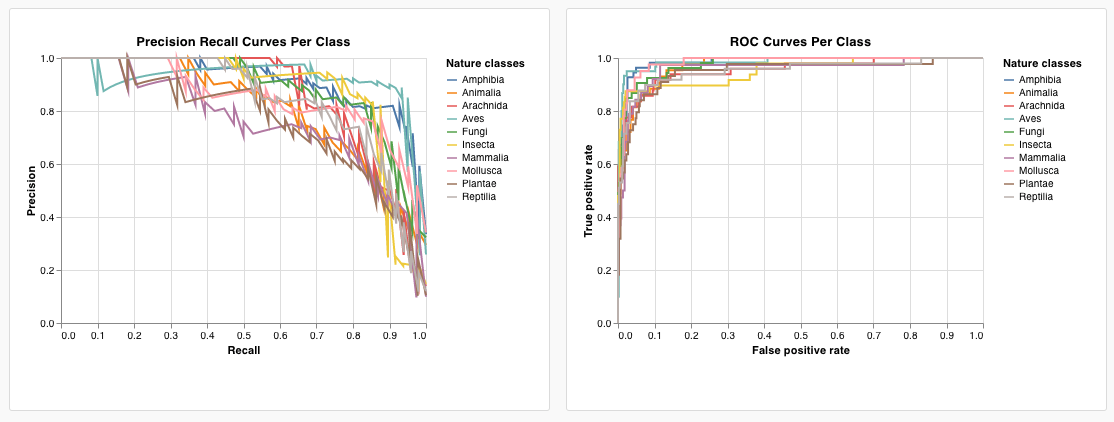
これをプリセットとして保存して、このプロジェクトの他の場所で使用できるようにするには、ページの上部にある「名前を付けて保存」をクリックします。結果は次のようになり、ROC 曲線が表示されます。
ボーナス: 複合ヒストグラム
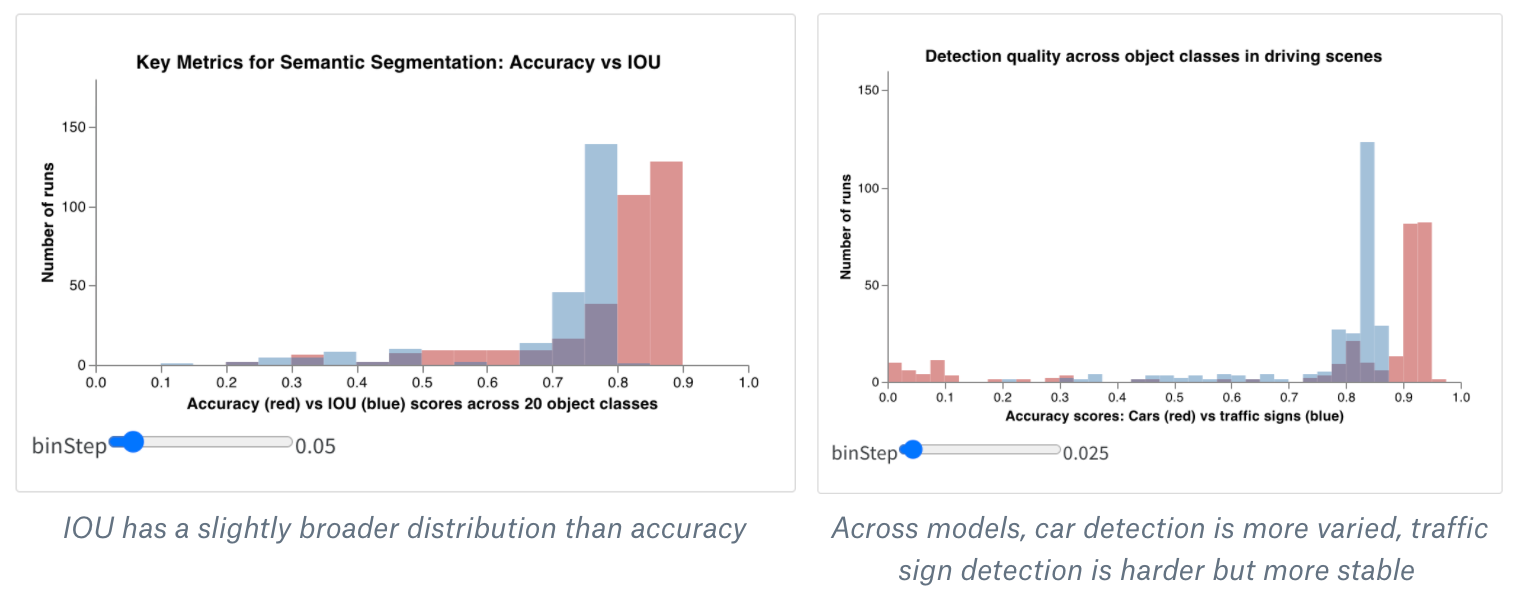
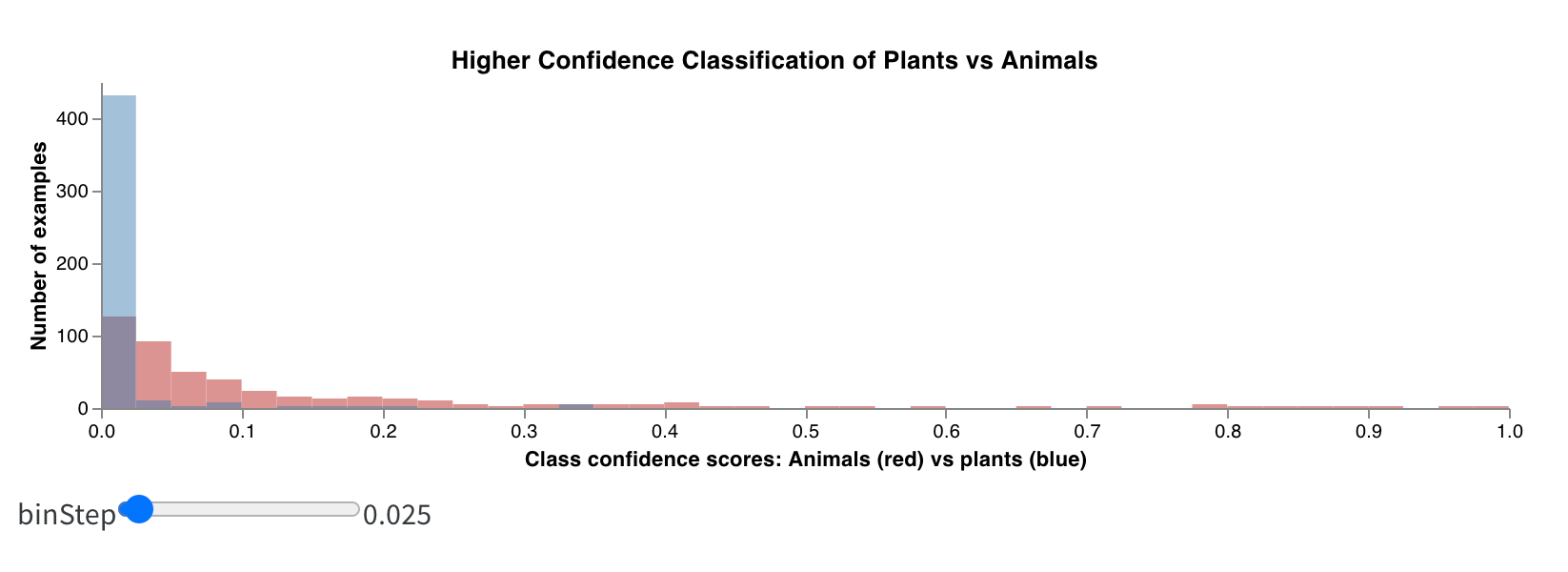
ヒストグラムは、数値分布を可視化して、より大きなデータセットを理解するのに役立ちます。複合ヒストグラムは、同じビンに複数の分布を表示し、異なるモデル間、またはモデル内の異なるクラス間で、2 つ以上のメトリクスを比較できます。運転シーンでオブジェクトを検出するセマンティックセグメンテーションモデルの場合、精度と intersection over union (IOU) の最適化の効果を比較したり、異なるモデルが車(データ内の大きく一般的な領域)と交通標識(はるかに小さく、一般的でない領域)をどの程度検出できるかを知りたい場合があります。デモ Colabでは、10 種類の生物のクラスのうち 2 つの信頼度スコアを比較できます。
カスタム複合ヒストグラムパネルの独自のバージョンを作成するには:
- Workspace または Report で新しいカスタムチャートパネルを作成します(「カスタムチャート」可視化を追加することによって)。右上にある「編集」ボタンをクリックして、組み込みのパネルタイプから Vega 仕様を変更します。
- その組み込みの Vega 仕様を、Vega の複合ヒストグラムの MVP コードに置き換えます。メインタイトル、軸タイトル、入力ドメイン、およびその他の詳細を、この Vega 仕様で直接Vega 構文を使用して変更できます(色を変更したり、3 番目のヒストグラムを追加したりすることもできます:)
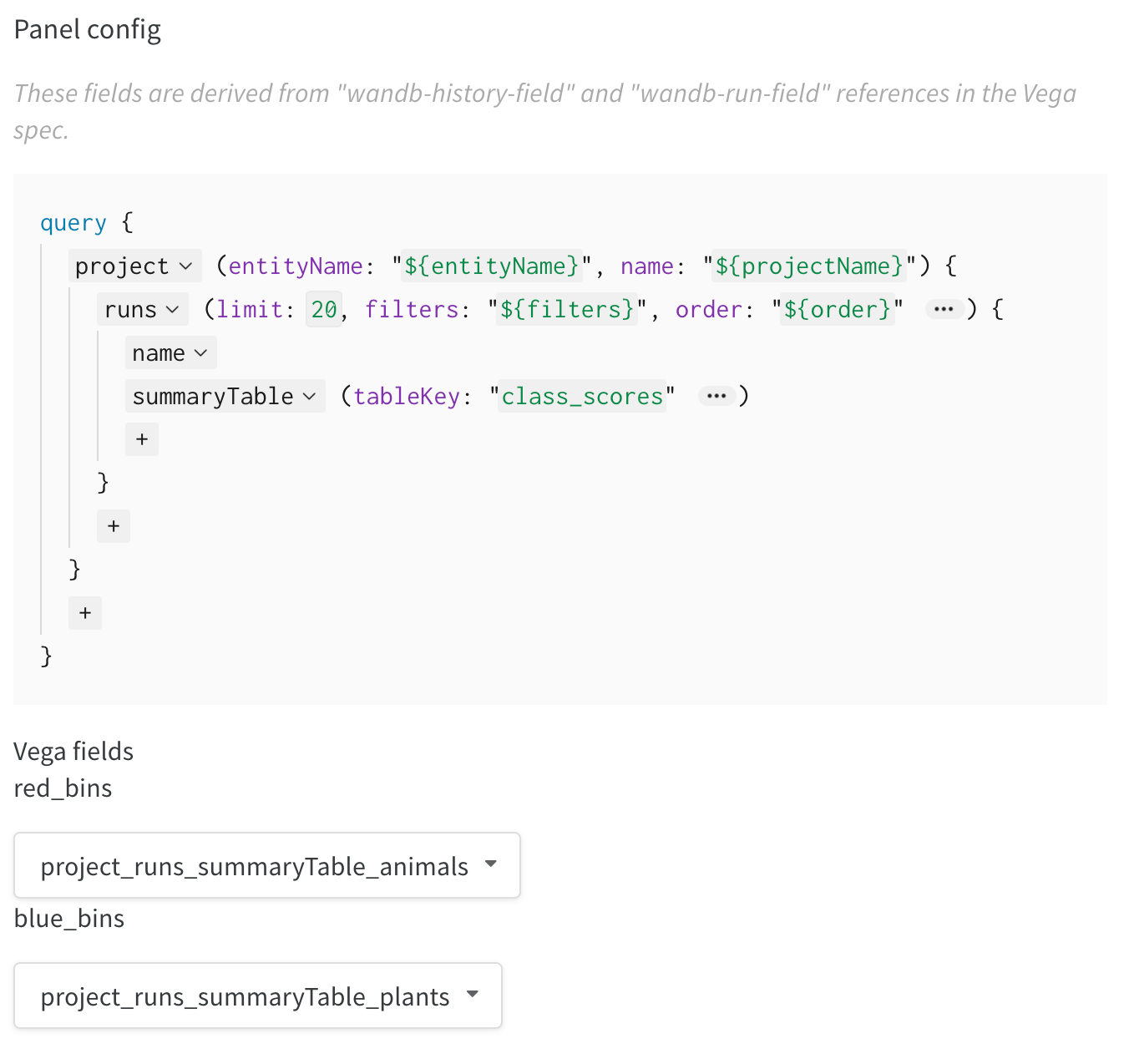
- 右側のクエリを変更して、wandb ログから正しいデータをロードします。フィールド
summaryTableを追加し、対応するtableKeyをclass_scoresに設定して、run によってログに記録されたwandb.Tableをフェッチします。これにより、class_scoresとしてログに記録されたwandb.Tableの列を使用して、ドロップダウンメニューから 2 つのヒストグラムビンセット(red_binsとblue_bins)を設定できます。私の例では、赤いビンの動物クラスの予測スコアと、青いビンの植物の予測スコアを選択しました。 - プレビューレンダリングに表示されるプロットに満足するまで、Vega 仕様とクエリの変更を続けることができます。完了したら、上部の「名前を付けて保存」をクリックし、カスタムプロットに名前を付けて再利用できるようにします。次に、「パネルライブラリから適用」をクリックして、プロットを完了します。
これは、非常に簡単な実験からの結果がどのように見えるかです。1 エポックでわずか 1000 個のサンプルでトレーニングすると、ほとんどの画像が植物ではないと非常に確信しており、どの画像が動物である可能性があるかについては非常に不確かなモデルが生成されます。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.