Embed objects
2 minute read
埋め込み は、オブジェクト(人、画像、投稿、単語など)を数値のリスト、つまり ベクトル で表現するために使用されます。 機械学習とデータサイエンスのユースケースでは、埋め込みは、さまざまなアプリケーションでさまざまなアプローチを使用して生成できます。このページでは、読者が埋め込みについてよく理解しており、W&B 内で視覚的に分析することに関心があることを前提としています。
埋め込みの例
Hello World
W&B を使用すると、wandb.Table クラスを使用して埋め込みをログに記録できます。それぞれが 5 次元で構成される 3 つの埋め込みの次の例を考えてみましょう。
import wandb
wandb.init(project="embedding_tutorial")
embeddings = [
# D1 D2 D3 D4 D5
[0.2, 0.4, 0.1, 0.7, 0.5], # 埋め込み 1
[0.3, 0.1, 0.9, 0.2, 0.7], # 埋め込み 2
[0.4, 0.5, 0.2, 0.2, 0.1], # 埋め込み 3
]
wandb.log(
{"embeddings": wandb.Table(columns=["D1", "D2", "D3", "D4", "D5"], data=embeddings)}
)
wandb.finish()
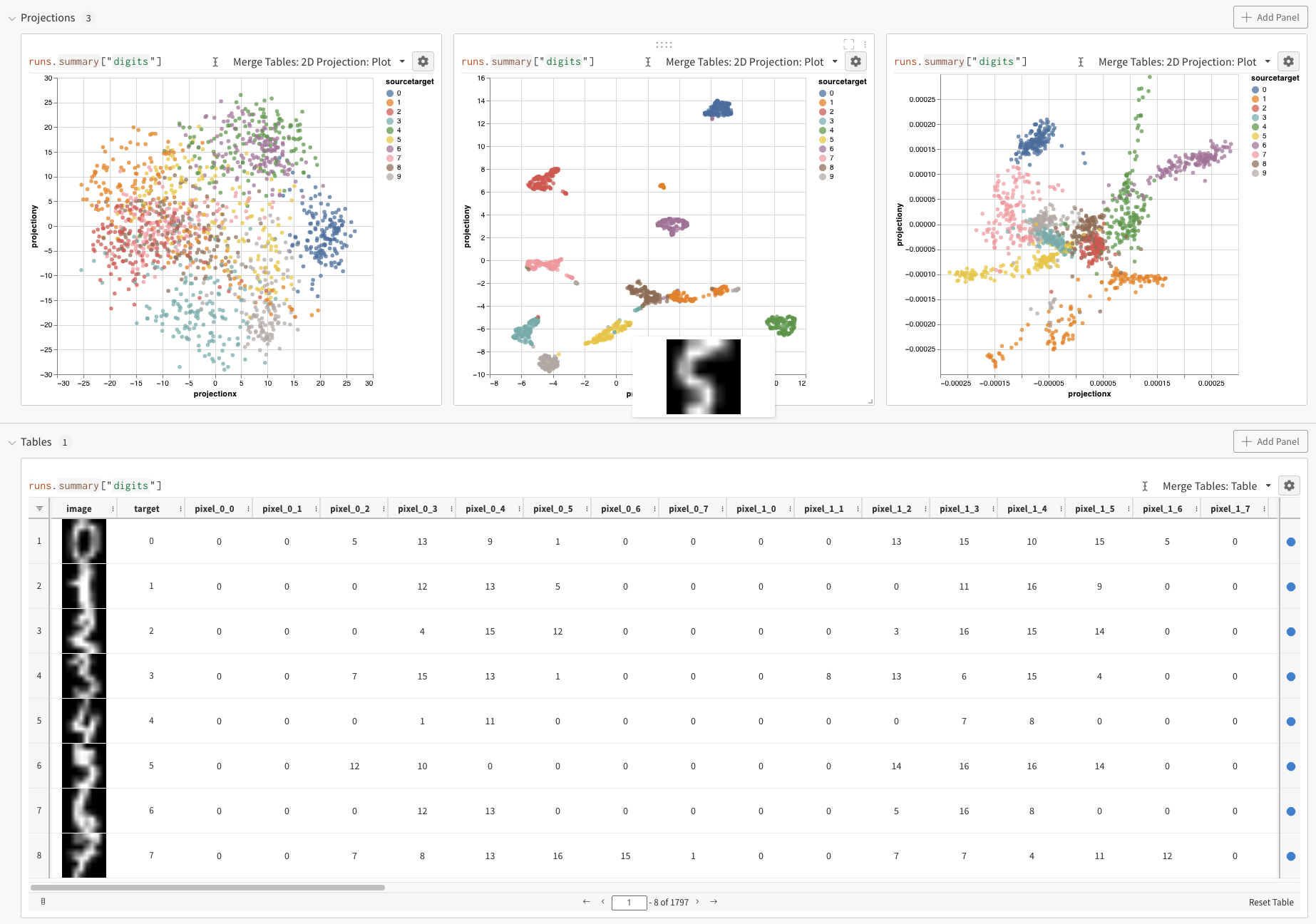
上記のコードを実行すると、W&B ダッシュボードにデータを含む新しい Table が表示されます。 右上のパネルセレクターから [2D Projection] を選択して、埋め込みを 2 次元でプロットできます。 スマートデフォルトが自動的に選択されます。これは、歯車アイコンをクリックしてアクセスできる設定メニューで簡単にオーバーライドできます。 この例では、利用可能な 5 つの数値次元すべてを自動的に使用します。
Digits MNIST
上記の例は、埋め込みをログに記録する基本的なメカニズムを示していますが、通常はより多くの次元とサンプルを扱っています。 MNIST Digits データセット(UCI ML 手書き数字データセットs) について考えてみましょう。SciKit-Learn 経由で利用できます。 このデータセットには 1797 件のレコードがあり、それぞれに 64 の次元があります。 この問題は、10 クラス分類のユースケースです。 入力データを画像に変換して、可視化することもできます。
import wandb
from sklearn.datasets import load_digits
wandb.init(project="embedding_tutorial")
# データセットをロードする
ds = load_digits(as_frame=True)
df = ds.data
# 「target」列を作成する
df["target"] = ds.target.astype(str)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
# 「image」列を作成する
df["image"] = df.apply(
lambda row: wandb.Image(row[1:].values.reshape(8, 8) / 16.0), axis=1
)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
wandb.log({"digits": df})
wandb.finish()
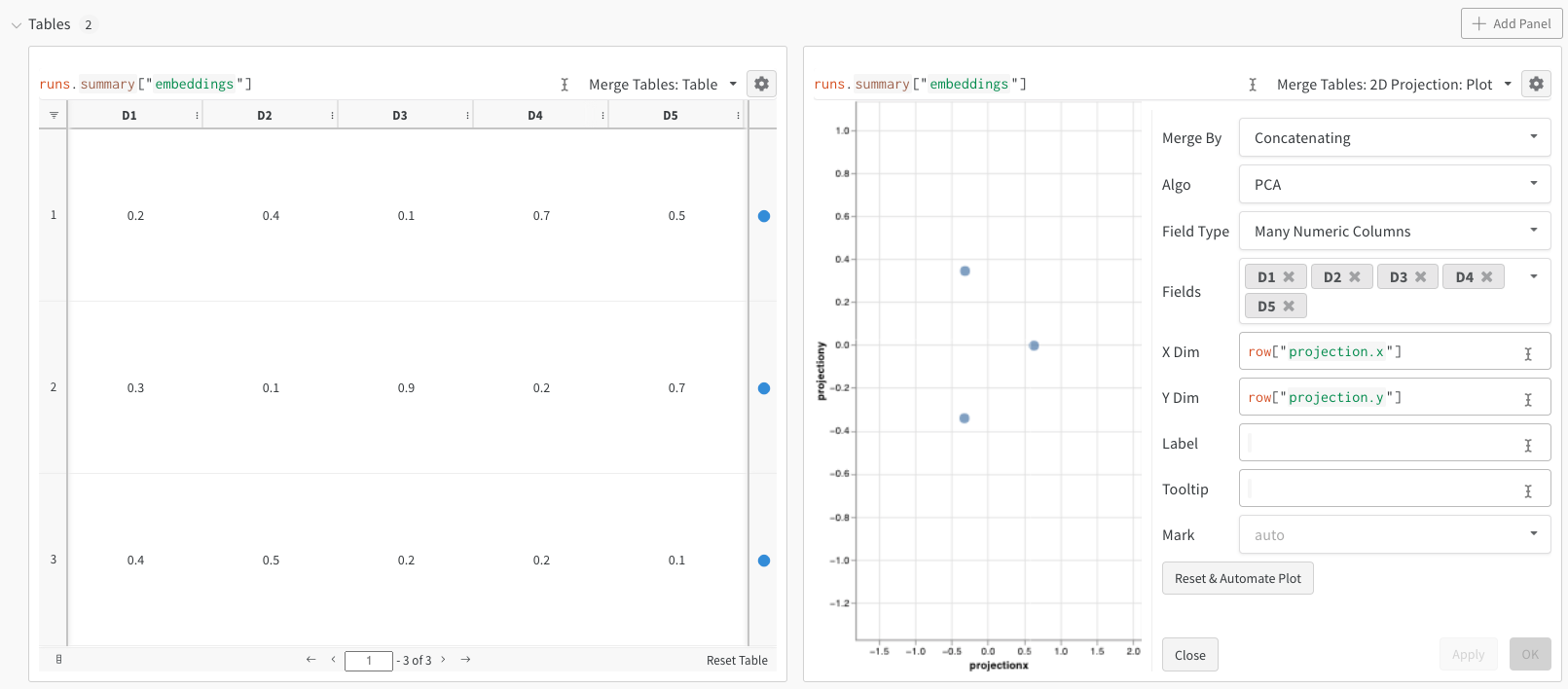
上記のコードを実行すると、再び UI に Table が表示されます。 [2D Projection] を選択すると、埋め込みの定義、色付け、アルゴリズム (PCA、UMAP、t-SNE)、アルゴリズムのパラメータ、さらにはオーバーレイ (この場合は、ポイントにカーソルを合わせると画像が表示されます) を設定できます。 この特定のケースでは、これらはすべて「スマートデフォルト」であり、[2D Projection] を 1 回クリックすると、非常によく似たものが表示されます。 (ここをクリックして操作この例を参照してください)。
ログ記録のオプション
埋め込みは、さまざまな形式でログに記録できます。
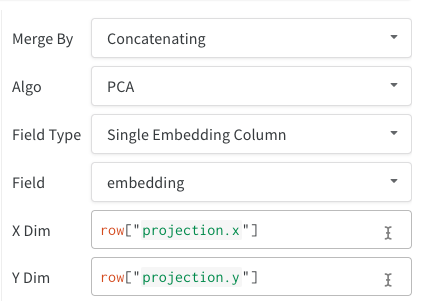
- 単一の埋め込み列: 多くの場合、データはすでに「マトリックス」のような形式になっています。 この場合、単一の埋め込み列を作成できます。ここで、セル値のデータ型は
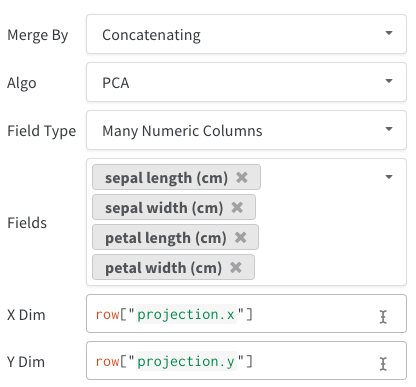
list[int]、list[float]、またはnp.ndarrayになります。 - 複数の数値列: 上記の 2 つの例では、このアプローチを使用し、次元ごとに列を作成します。 現在、セルには python
intまたはfloatを使用できます。
さらに、すべてのテーブルと同様に、テーブルの構築方法に関して多くのオプションがあります。
wandb.Table(dataframe=df)を使用して dataframe から直接wandb.Table(data=[...], columns=[...])を使用して データのリスト から直接- テーブルを 行ごとに (コードにループがある場合に最適) 段階的に構築 します。
table.add_data(...)を使用してテーブルに行を追加します - テーブルに 埋め込み列 を追加します (埋め込み形式の予測のリストがある場合に最適)。
table.add_col("col_name", ...) - 計算された列 を追加します (テーブルにマップする関数または model がある場合に最適)。
table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
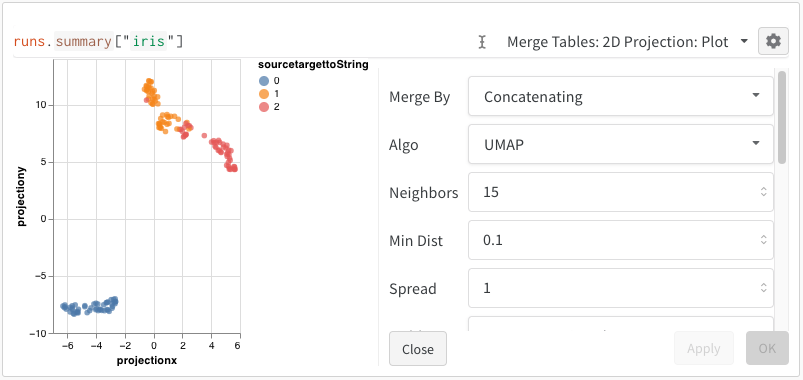
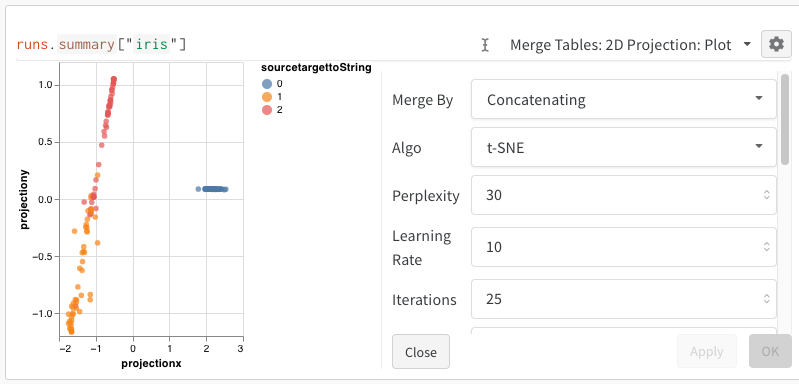
プロットオプション
[2D Projection] を選択した後、歯車アイコンをクリックしてレンダリング設定を編集できます。 目的の列を選択することに加えて (上記を参照)、目的のアルゴリズム (および目的のパラメータ) を選択できます。 以下に、それぞれ UMAP と t-SNE のパラメータを示します。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.