Create model lineage map
2 minute read
このページでは、従来の W&B Model Registry でリネージグラフを作成する方法について説明します。W&B Registry のリネージグラフについては、リネージマップの作成と表示を参照してください。
W&B は、従来の W&B Model Registry から新しい W&B Registry にアセットを移行します。この移行は完全に管理され、W&B によってトリガーされるため、 ユーザー による介入は必要ありません。このプロセスは、既存の ワークフロー を可能な限り中断することなく、シームレスに行われるように設計されています。従来の Model Registry からの移行を参照してください。
モデル アーティファクト を W&B に ログ 記録する便利な機能は、リネージグラフです。リネージグラフは、 run によって ログ 記録された アーティファクト と、特定の run で使用された アーティファクト を示します。
つまり、モデル アーティファクト を ログ 記録すると、少なくともモデル アーティファクト を使用または生成した W&B の run を表示できます。依存関係を追跡する場合、モデル アーティファクト で使用される入力も表示されます。
たとえば、次の図は、ML 実験 全体で作成および使用された アーティファクト を示しています。
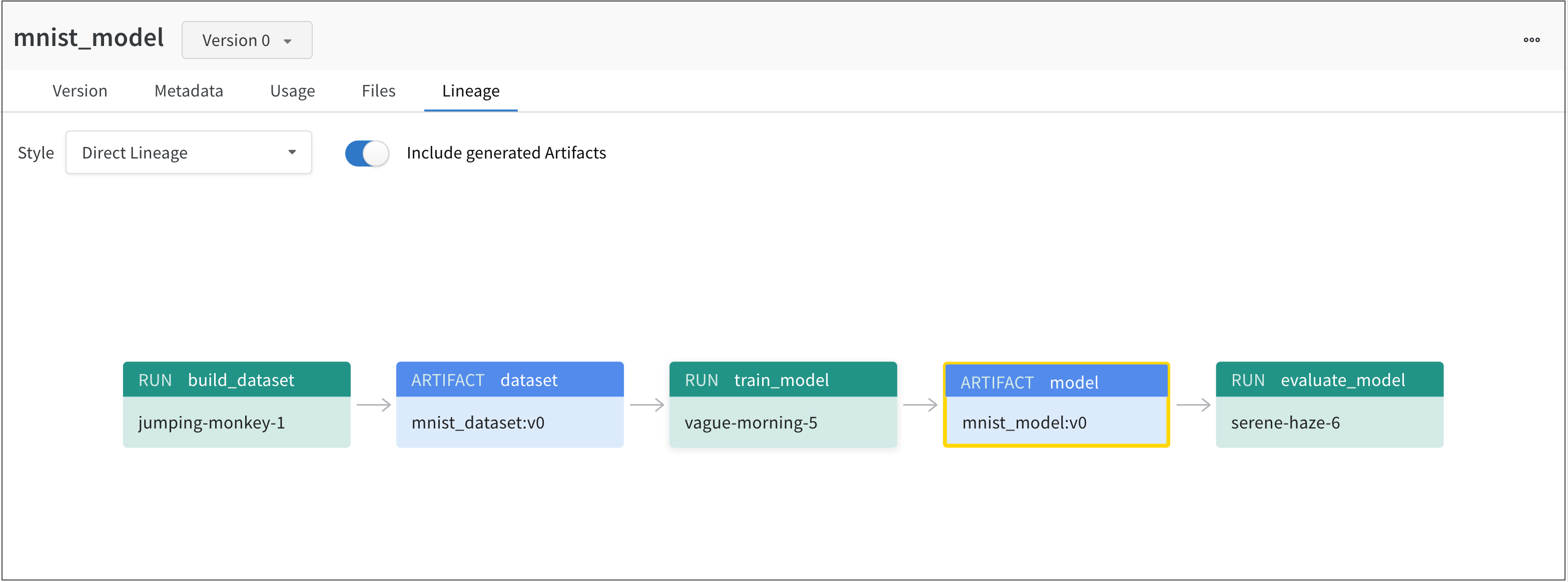
左から右へ、画像は以下を示しています。
jumping-monkey-1W&B run は、mnist_dataset:v0データセット アーティファクト を作成しました。vague-morning-5W&B run は、mnist_dataset:v0データセット アーティファクト を使用してモデルをトレーニングしました。この W&B run の出力は、mnist_model:v0というモデル アーティファクト でした。serene-haze-6という run は、モデル アーティファクト (mnist_model:v0) を使用してモデルを評価しました。
アーティファクト の依存関係を追跡する
use_artifact API を使用して、データセット アーティファクト を W&B run への入力として宣言し、依存関係を追跡します。
次の コード スニペット は、use_artifact API の使用方法を示しています。
# run を初期化する
run = wandb.init(project=project, entity=entity)
# アーティファクト を取得し、依存関係としてマークします
artifact = run.use_artifact(artifact_or_name="name", aliases="<alias>")
アーティファクト を取得したら、その アーティファクト を使用して (たとえば) モデルのパフォーマンスを評価できます。
例: モデルをトレーニングし、データセット をモデルの入力として追跡します
job_type = "train_model"
config = {
"optimizer": "adam",
"batch_size": 128,
"epochs": 5,
"validation_split": 0.1,
}
run = wandb.init(project=project, job_type=job_type, config=config)
version = "latest"
name = "{}:{}".format("{}_dataset".format(model_use_case_id), version)
artifact = run.use_artifact(name)
train_table = artifact.get("train_table")
x_train = train_table.get_column("x_train", convert_to="numpy")
y_train = train_table.get_column("y_train", convert_to="numpy")
# config 辞書 からの値を簡単にアクセスできるように変数に格納します
num_classes = 10
input_shape = (28, 28, 1)
loss = "categorical_crossentropy"
optimizer = run.config["optimizer"]
metrics = ["accuracy"]
batch_size = run.config["batch_size"]
epochs = run.config["epochs"]
validation_split = run.config["validation_split"]
# モデル アーキテクチャ を作成する
model = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# トレーニング データ のラベルを生成する
y_train = keras.utils.to_categorical(y_train, num_classes)
# トレーニング セット と テスト セット を作成する
x_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size=0.33)
# モデルをトレーニングする
model.fit(
x=x_t,
y=y_t,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_v, y_v),
callbacks=[WandbCallback(log_weights=True, log_evaluation=True)],
)
# モデルをローカルに保存する
path = "model.h5"
model.save(path)
path = "./model.h5"
registered_model_name = "MNIST-dev"
name = "mnist_model"
run.link_model(path=path, registered_model_name=registered_model_name, name=name)
run.finish()
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.