Hugging Face Diffusers
4 minute read
Hugging Face Diffusers は、画像、音声、さらには分子の3D構造を生成するための、最先端の学習済み拡散モデルのための頼りになるライブラリです。Weights & Biases のインテグレーションは、その使いやすさを損なうことなく、インタラクティブな集中 ダッシュボードに、豊富で柔軟な 実験管理、メディアの 可視化、パイプライン アーキテクチャ、および 設定管理を追加します。
たった2行で次世代のログ記録
わずか2行のコードを含めるだけで、プロンプト、ネガティブプロンプト、生成されたメディア、および 実験 に関連付けられた config をすべて記録します。以下は、ログ記録を開始するための2行のコードです。
# import the autolog function
from wandb.integration.diffusers import autolog
# call the autolog before calling the pipeline
autolog(init=dict(project="diffusers_logging"))
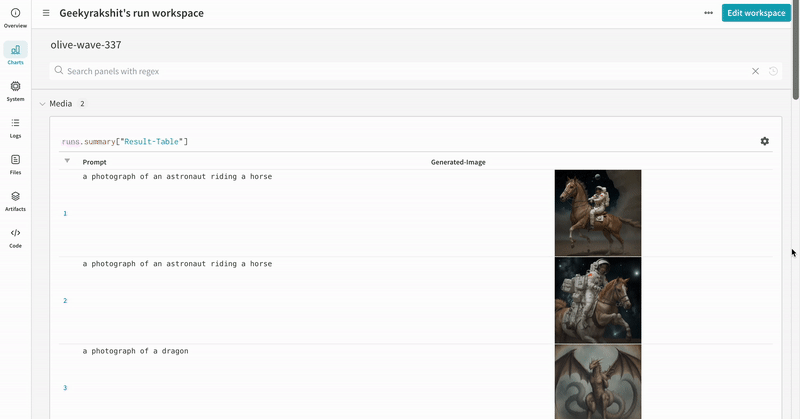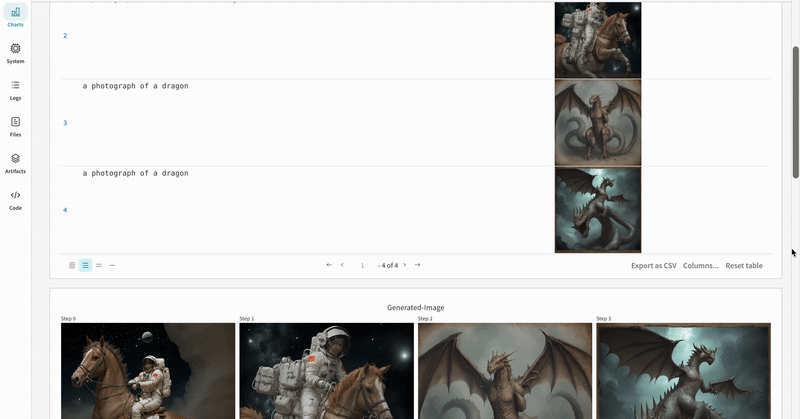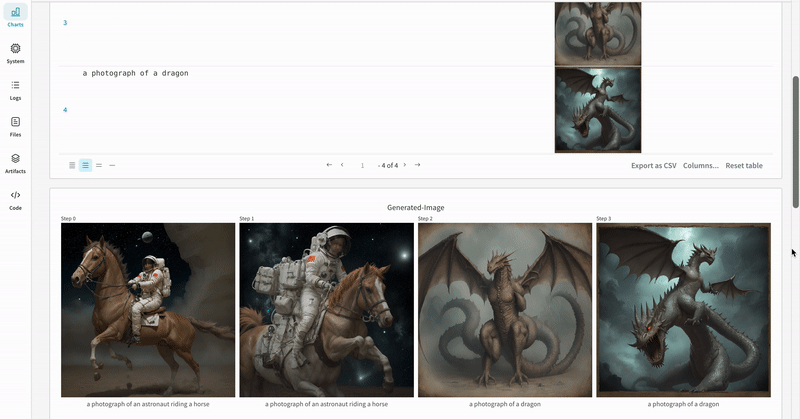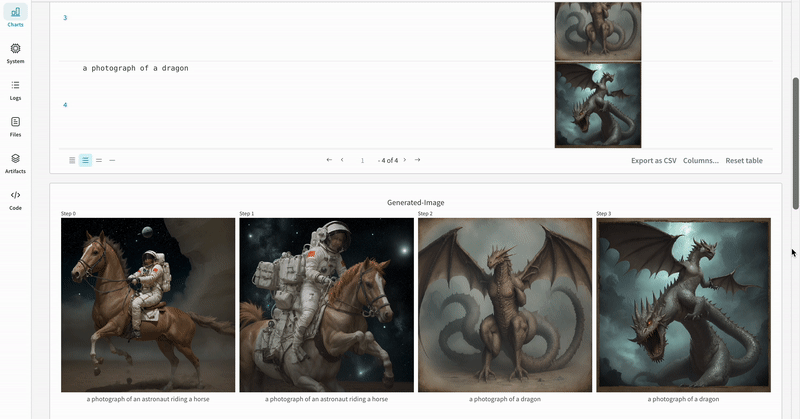 |
|---|
| 実験 の 結果 がどのように記録されるかの例。 |
はじめに
-
diffusers、transformers、accelerate、およびwandbをインストールします。-
コマンドライン:
pip install --upgrade diffusers transformers accelerate wandb -
ノートブック:
!pip install --upgrade diffusers transformers accelerate wandb
-
-
autologを使用して Weights & Biases の run を初期化し、サポートされているすべての パイプライン 呼び出しからの入力と出力を自動的に追跡します。wandb.init()に必要な パラメータ の 辞書 を受け入れるinitパラメータ を使用して、autolog()関数を呼び出すことができます。autolog()を呼び出すと、Weights & Biases の run が初期化され、サポートされているすべての パイプライン 呼び出しからの入力と出力が自動的に追跡されます。- 各 パイプライン 呼び出しは、ワークスペース 内の独自の テーブルに追跡され、パイプライン 呼び出しに関連付けられた config は、その run の config 内の ワークフロー のリストに追加されます。
- プロンプト、ネガティブプロンプト、および生成されたメディアは、
wandb.Tableに記録されます。 - シードや パイプライン アーキテクチャ を含む、実験 に関連付けられたその他すべての config は、run の config セクションに保存されます。
- 各 パイプライン 呼び出しで生成されたメディアは、run の メディア パネルにも記録されます。
サポートされている パイプライン 呼び出しのリストは、[こちら](https://github.com/wandb/wandb/blob/main/wandb/integration/diffusers/autologger.py#L12-L72)にあります。このインテグレーションの新しい機能をリクエストしたり、それに関連するバグを報告したりする場合は、[https://github.com/wandb/wandb/issues](https://github.com/wandb/wandb/issues) で issue をオープンしてください。例
Autologging
以下は、動作中の autolog の簡単な エンドツーエンド の例です。
import torch from diffusers import DiffusionPipeline # import the autolog function from wandb.integration.diffusers import autolog # call the autolog before calling the pipeline autolog(init=dict(project="diffusers_logging")) # Initialize the diffusion pipeline pipeline = DiffusionPipeline.from_pretrained( "stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16 ).to("cuda") # Define the prompts, negative prompts, and seed. prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"] negative_prompt = ["ugly, deformed", "ugly, deformed"] generator = torch.Generator(device="cpu").manual_seed(10) # call the pipeline to generate the images images = pipeline( prompt, negative_prompt=negative_prompt, num_images_per_prompt=2, generator=generator, )import torch from diffusers import DiffusionPipeline import wandb # import the autolog function from wandb.integration.diffusers import autolog # call the autolog before calling the pipeline autolog(init=dict(project="diffusers_logging")) # Initialize the diffusion pipeline pipeline = DiffusionPipeline.from_pretrained( "stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16 ).to("cuda") # Define the prompts, negative prompts, and seed. prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"] negative_prompt = ["ugly, deformed", "ugly, deformed"] generator = torch.Generator(device="cpu").manual_seed(10) # call the pipeline to generate the images images = pipeline( prompt, negative_prompt=negative_prompt, num_images_per_prompt=2, generator=generator, ) # Finish the experiment wandb.finish()-
単一の 実験 の結果:
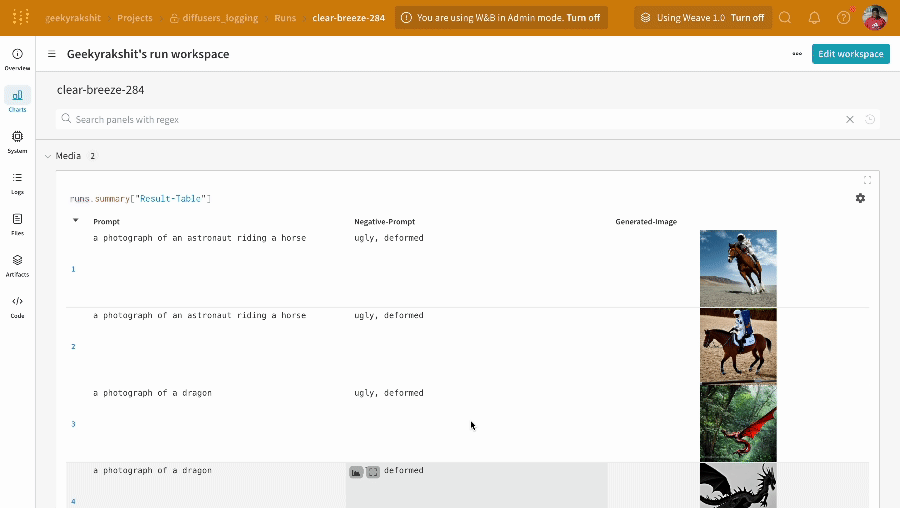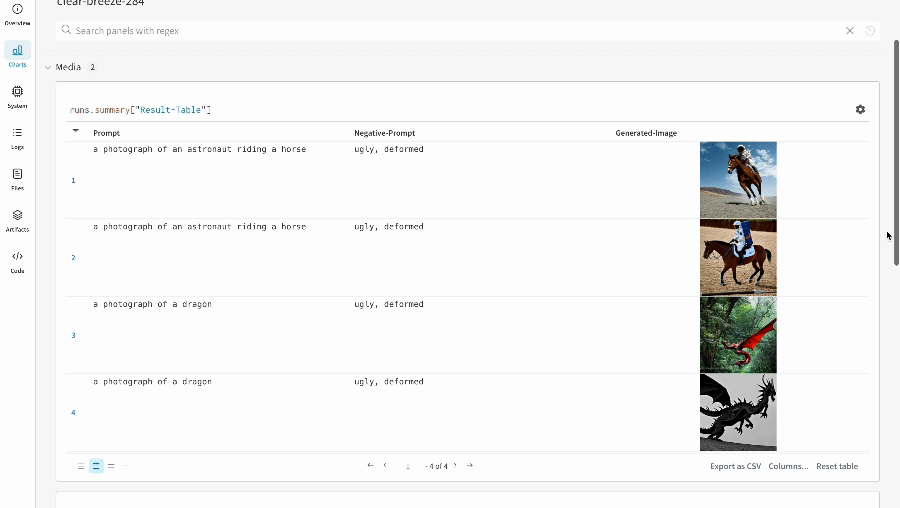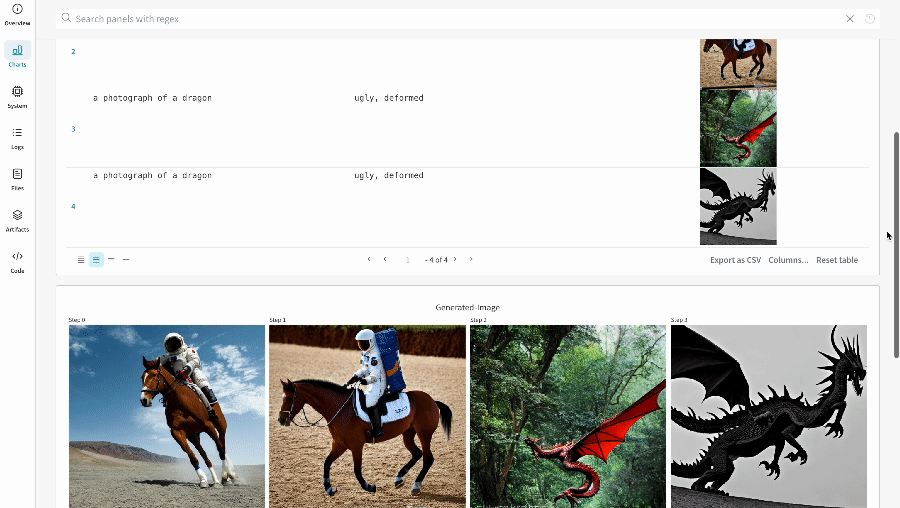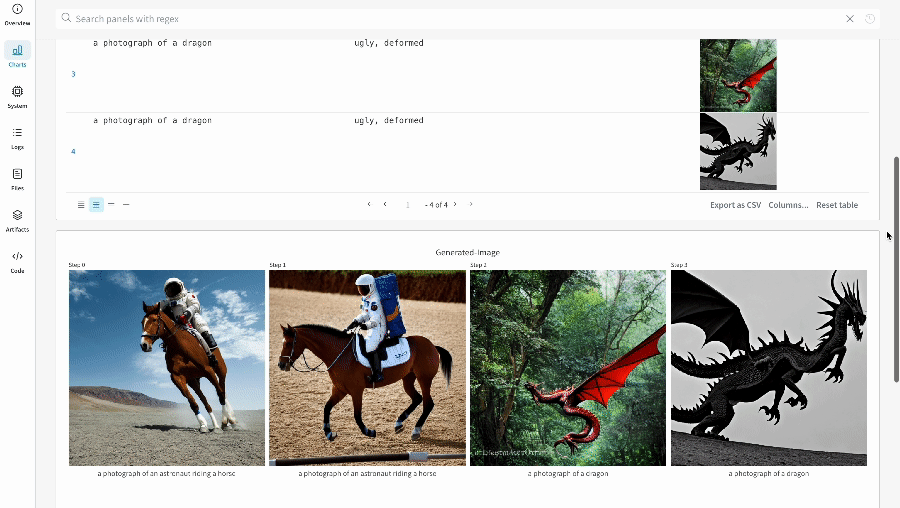
-
複数の 実験 の結果:
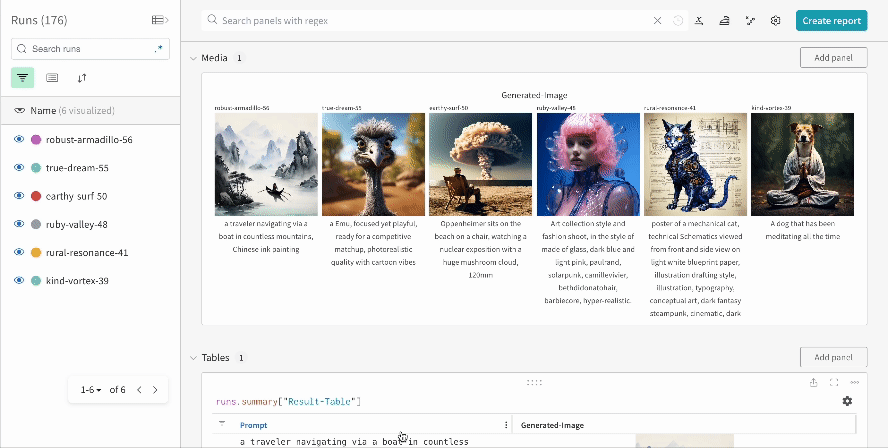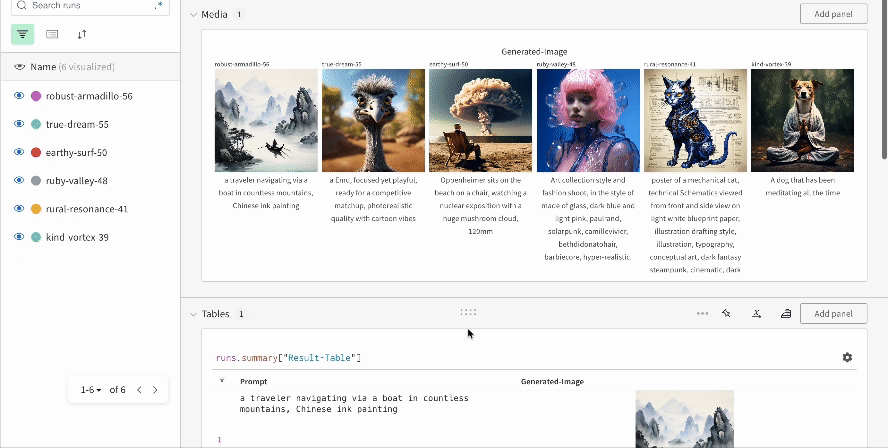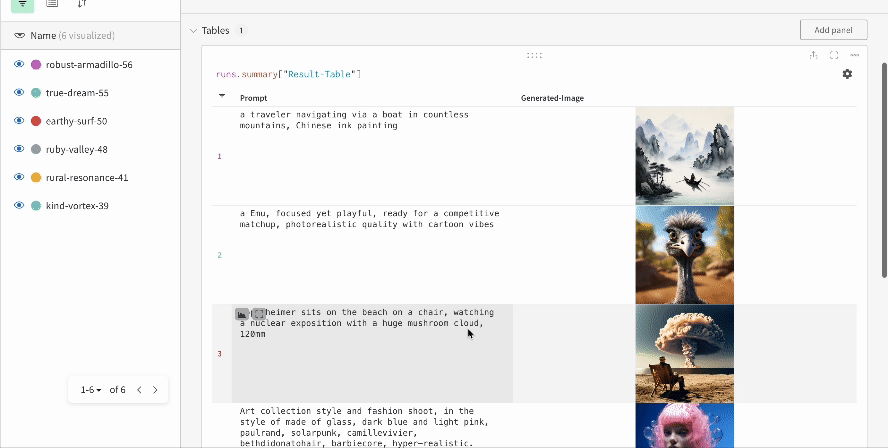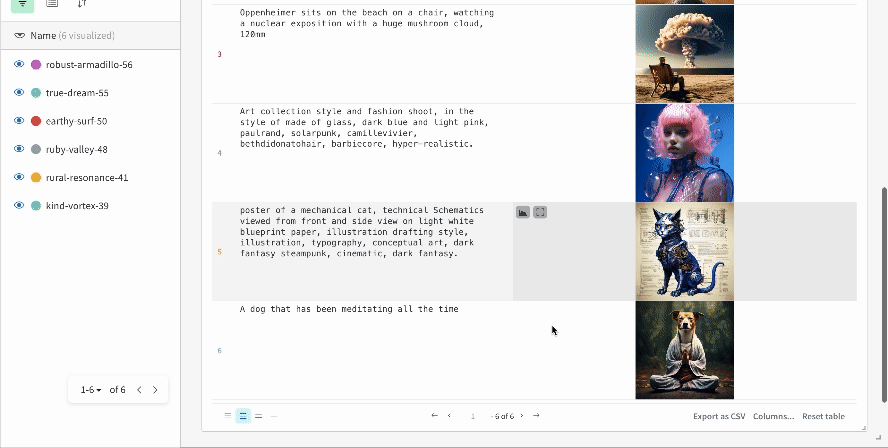
-
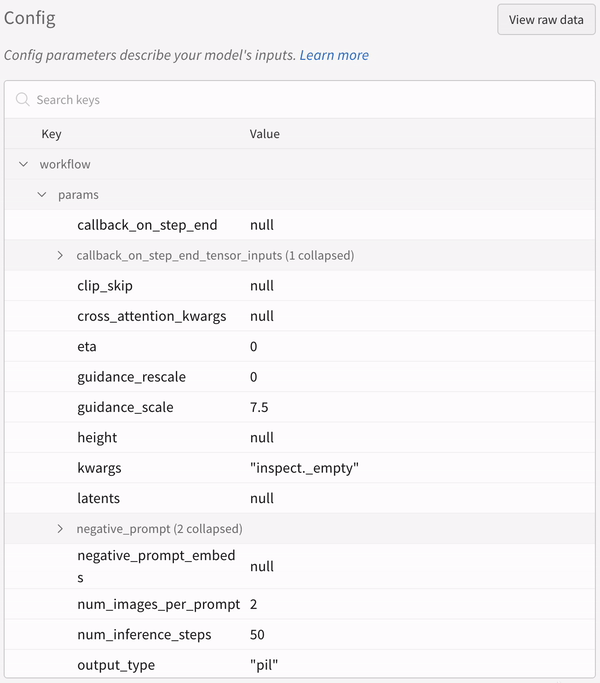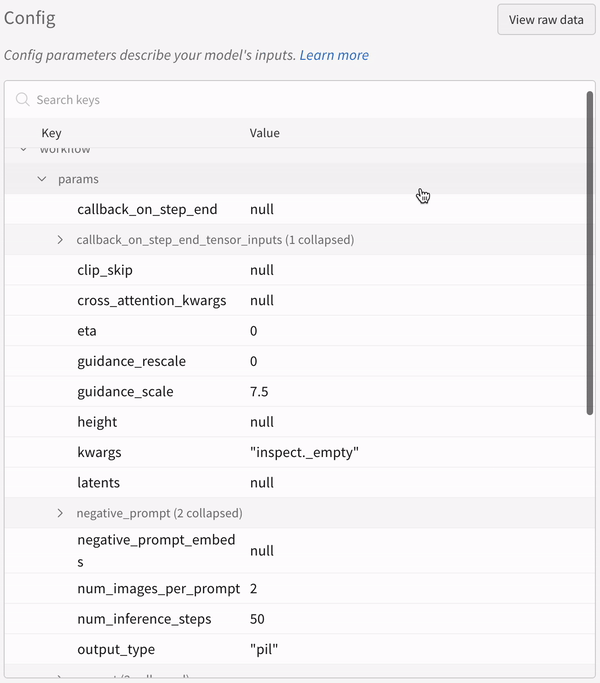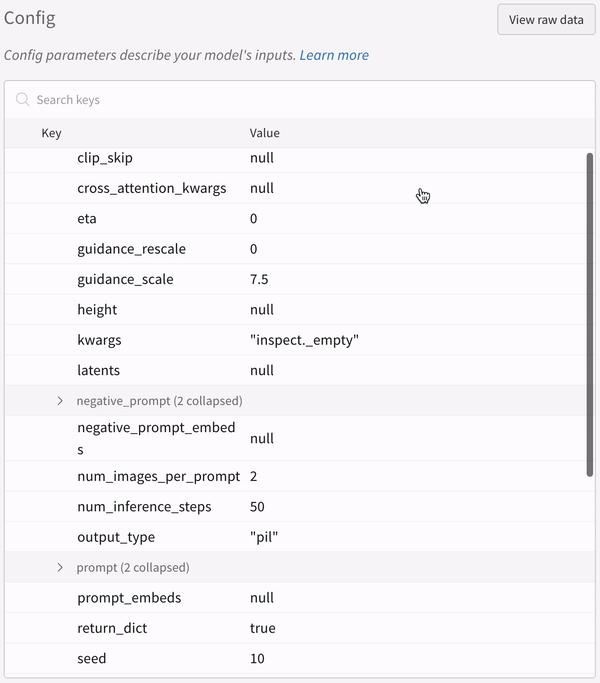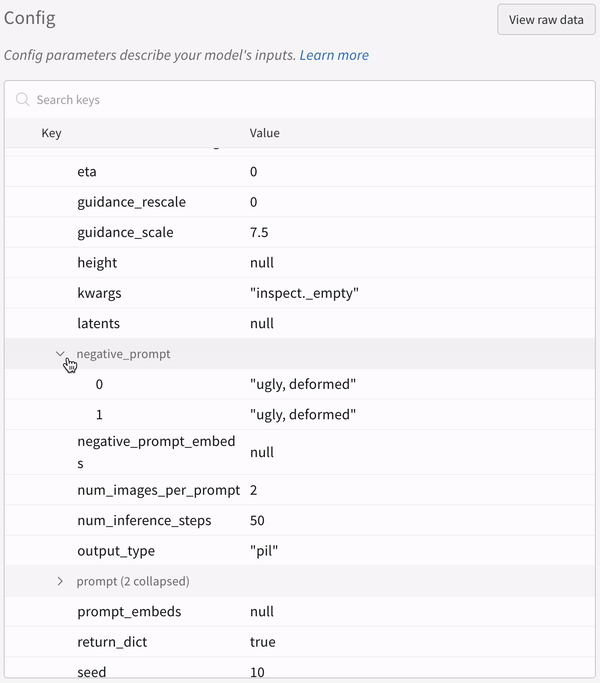
実験 の config:
パイプライン を呼び出した後、IPython ノートブック 環境でコードを実行する場合は、wandb.finish()を明示的に呼び出す必要があります。これは、Python スクリプトを実行する場合は必要ありません。複数 パイプライン ワークフロー の追跡
このセクションでは、
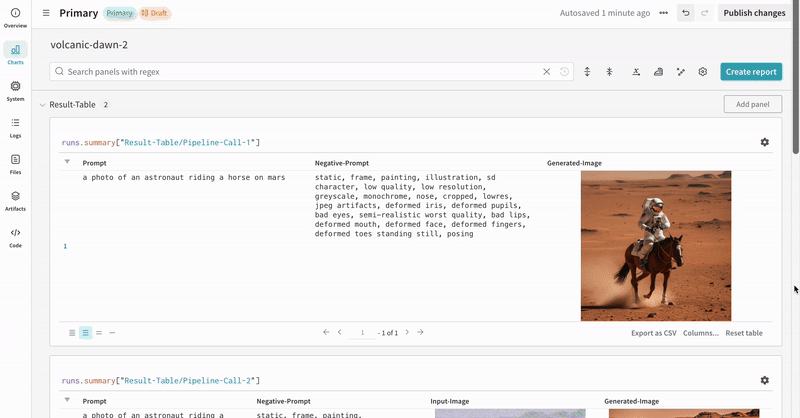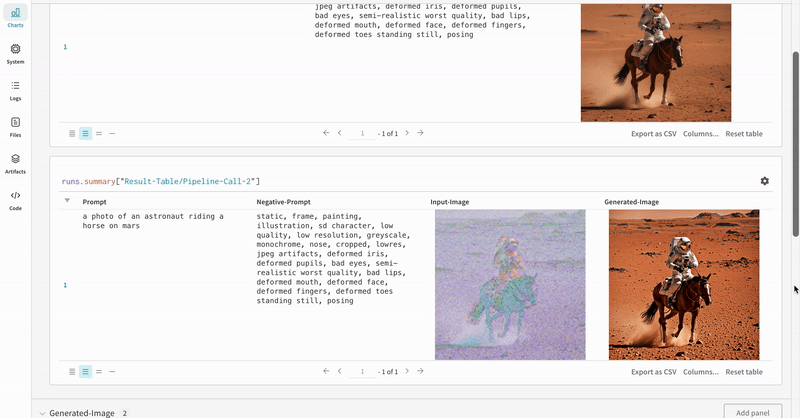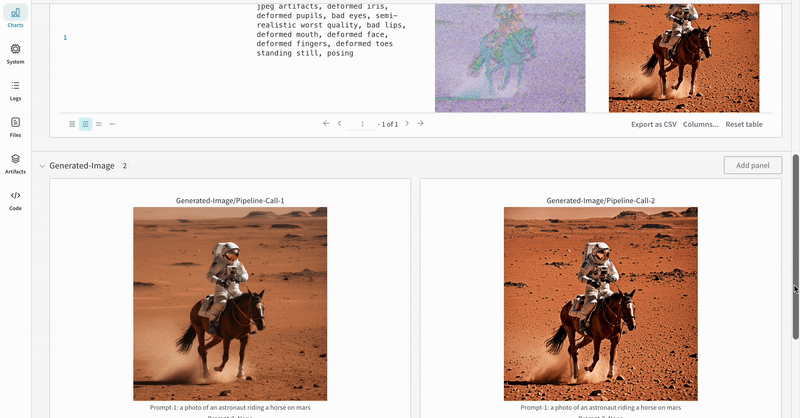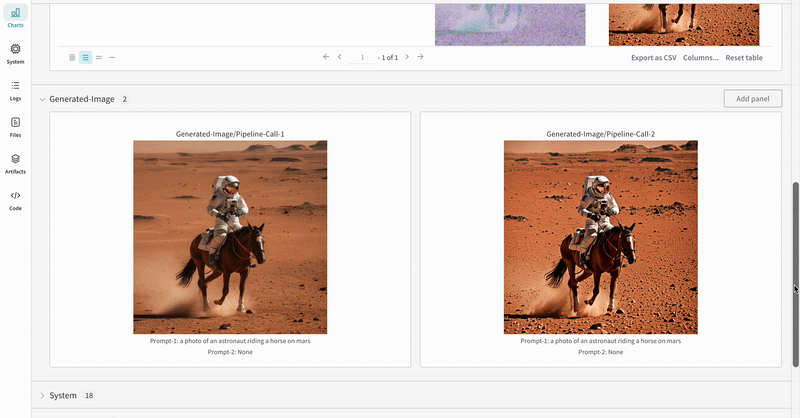
StableDiffusionXLPipelineによって生成された潜在空間が対応するリファイナーによって改良される、典型的な Stable Diffusion XL + Refiner ワークフロー での autolog を示します。import torch from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline from wandb.integration.diffusers import autolog # initialize the SDXL base pipeline base_pipeline = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True, ) base_pipeline.enable_model_cpu_offload() # initialize the SDXL refiner pipeline refiner_pipeline = StableDiffusionXLImg2ImgPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-refiner-1.0", text_encoder_2=base_pipeline.text_encoder_2, vae=base_pipeline.vae, torch_dtype=torch.float16, use_safetensors=True, variant="fp16", ) refiner_pipeline.enable_model_cpu_offload() prompt = "a photo of an astronaut riding a horse on mars" negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing" # Make the experiment reproducible by controlling randomness. # The seed would be automatically logged to WandB. seed = 42 generator_base = torch.Generator(device="cuda").manual_seed(seed) generator_refiner = torch.Generator(device="cuda").manual_seed(seed) # Call WandB Autolog for Diffusers. This would automatically log # the prompts, generated images, pipeline architecture and all # associated experiment configs to Weights & Biases, thus making your # image generation experiments easy to reproduce, share and analyze. autolog(init=dict(project="sdxl")) # Call the base pipeline to generate the latents image = base_pipeline( prompt=prompt, negative_prompt=negative_prompt, output_type="latent", generator=generator_base, ).images[0] # Call the refiner pipeline to generate the refined image image = refiner_pipeline( prompt=prompt, negative_prompt=negative_prompt, image=image[None, :], generator=generator_refiner, ).images[0]import torch from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline import wandb from wandb.integration.diffusers import autolog # initialize the SDXL base pipeline base_pipeline = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True, ) base_pipeline.enable_model_cpu_offload() # initialize the SDXL refiner pipeline refiner_pipeline = StableDiffusionXLImg2ImgPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-refiner-1.0", text_encoder_2=base_pipeline.text_encoder_2, vae=base_pipeline.vae, torch_dtype=torch.float16, use_safetensors=True, variant="fp16", ) refiner_pipeline.enable_model_cpu_offload() prompt = "a photo of an astronaut riding a horse on mars" negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing" # Make the experiment reproducible by controlling randomness. # The seed would be automatically logged to WandB. seed = 42 generator_base = torch.Generator(device="cuda").manual_seed(seed) generator_refiner = torch.Generator(device="cuda").manual_seed(seed) # Call WandB Autolog for Diffusers. This would automatically log # the prompts, generated images, pipeline architecture and all # associated experiment configs to Weights & Biases, thus making your # image generation experiments easy to reproduce, share and analyze. autolog(init=dict(project="sdxl")) # Call the base pipeline to generate the latents image = base_pipeline( prompt=prompt, negative_prompt=negative_prompt, output_type="latent", generator=generator_base, ).images[0] # Call the refiner pipeline to generate the refined image image = refiner_pipeline( prompt=prompt, negative_prompt=negative_prompt, image=image[None, :], generator=generator_refiner, ).images[0] # Finish the experiment wandb.finish()- Stable Diffisuion XL + Refiner の 実験 の例:
その他のリソース
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.