Hugging Face Transformers
6 minute read
Hugging Face Transformers ライブラリを使用すると、BERTのような最先端の NLP モデルや、混合精度や勾配チェックポイントなどのトレーニング手法を簡単に使用できます。W&B integration は、使いやすさを損なうことなく、インタラクティブな集中ダッシュボードに、豊富で柔軟な実験管理とモデルの バージョン管理を追加します。
わずか数行で次世代のロギング
os.environ["WANDB_PROJECT"] = "<my-amazing-project>" # W&B プロジェクトに名前を付ける
os.environ["WANDB_LOG_MODEL"] = "checkpoint" # すべてのモデルチェックポイントをログに記録
from transformers import TrainingArguments, Trainer
args = TrainingArguments(..., report_to="wandb") # W&B ロギングをオンにする
trainer = Trainer(..., args=args)
はじめに: 実験の トラッキング
サインアップして API キーを作成する
API キーは、お使いのマシンを W&B に対して認証します。API キーは、ユーザープロフィールから生成できます。
- 右上隅にあるユーザープロフィールアイコンをクリックします。
- [User Settings]を選択し、[API Keys]セクションまでスクロールします。
- [Reveal]をクリックします。表示された API キーをコピーします。API キーを非表示にするには、ページをリロードします。
wandb ライブラリをインストールしてログインする
wandb ライブラリをローカルにインストールしてログインするには:
-
WANDB_API_KEY環境変数 を API キーに設定します。export WANDB_API_KEY=<your_api_key> -
wandbライブラリをインストールしてログインします。pip install wandb wandb login
pip install wandb
import wandb
wandb.login()
!pip install wandb
import wandb
wandb.login()
W&B を初めて使用する場合は、クイックスタート を確認してください。
プロジェクトに名前を付ける
W&B の Project とは、関連する run からログに記録されたすべてのチャート、データ、およびモデルが保存される場所です。プロジェクトに名前を付けると、作業を整理し、単一のプロジェクトに関するすべての情報を 1 か所にまとめて管理できます。
run をプロジェクトに追加するには、WANDB_PROJECT 環境変数をプロジェクト名に設定するだけです。WandbCallback は、このプロジェクト名の環境変数を取得し、run の設定時に使用します。
WANDB_PROJECT=amazon_sentiment_analysis
import os
os.environ["WANDB_PROJECT"]="amazon_sentiment_analysis"
%env WANDB_PROJECT=amazon_sentiment_analysis
Trainer を初期化する 前に 、必ずプロジェクト名を設定してください。プロジェクト名が指定されていない場合、プロジェクト名はデフォルトで huggingface になります。
トレーニングの run を W&B に記録する
コード内またはコマンドラインで Trainer のトレーニング引数を定義する際に 最も重要なステップ は、W&B でのロギングを有効にするために、report_to を "wandb" に設定することです。
TrainingArguments の logging_steps 引数は、トレーニング中にトレーニングメトリクスが W&B にプッシュされる頻度を制御します。run_name 引数を使用して、W&B のトレーニング run に名前を付けることもできます。
これで完了です。モデルは、トレーニング中に損失、評価メトリクス、モデルトポロジー、および勾配を W&B に記録します。
python run_glue.py \ # Python スクリプトを実行する
--report_to wandb \ # W&B へのロギングを有効にする
--run_name bert-base-high-lr \ # W&B run の名前 (オプション)
# その他のコマンドライン引数
from transformers import TrainingArguments, Trainer
args = TrainingArguments(
# その他の args と kwargs
report_to="wandb", # W&B へのロギングを有効にする
run_name="bert-base-high-lr", # W&B run の名前 (オプション)
logging_steps=1, # W&B へのロギング頻度
)
trainer = Trainer(
# その他の args と kwargs
args=args, # トレーニングの引数
)
trainer.train() # トレーニングを開始して W&B にログを記録する
Trainer を TensorFlow TFTrainer に交換するだけです。モデルチェックポイントをオンにする
Artifacts を使用すると、最大 100GB のモデルとデータセットを無料で保存し、Weights & Biases Registry を使用できます。Registry を使用すると、モデルを登録して探索および評価したり、ステージングの準備をしたり、本番環境にデプロイしたりできます。
Hugging Face モデルチェックポイントを Artifacts に記録するには、WANDB_LOG_MODEL 環境変数を次の いずれか に設定します。
checkpoint:TrainingArgumentsからargs.save_stepsごとにチェックポイントをアップロードします。end:load_best_model_at_endも設定されている場合は、トレーニングの最後にモデルをアップロードします。false: モデルをアップロードしません。
WANDB_LOG_MODEL="checkpoint"
import os
os.environ["WANDB_LOG_MODEL"] = "checkpoint"
%env WANDB_LOG_MODEL="checkpoint"
これから初期化する Transformers Trainer はすべて、モデルを W&B プロジェクトにアップロードします。ログに記録したモデルチェックポイントは、Artifacts UI で表示でき、完全なモデルリネージが含まれています (UI のモデルチェックポイントの例は こちら を参照してください)。
WANDB_LOG_MODEL が end に設定されている場合は model-{run_id} として、WANDB_LOG_MODEL が checkpoint に設定されている場合は checkpoint-{run_id} として、モデルは W&B Artifacts に保存されます。
ただし、TrainingArguments で run_name を渡すと、モデルは model-{run_name} または checkpoint-{run_name} として保存されます。W&B Registry
チェックポイントを Artifacts に記録したら、最高のモデルチェックポイントを登録し、Registry を使用してチーム全体で一元化できます。Registry を使用すると、タスクごとに最適なモデルを整理したり、モデルのライフサイクルを管理したり、ML ライフサイクル全体を追跡および監査したり、ダウンストリームアクションを 自動化 したりできます。
モデル Artifact をリンクするには、Registry を参照してください。
トレーニング中に評価出力を可視化する
トレーニング中または評価中にモデル出力を可視化することは、モデルのトレーニング方法を実際に理解するために不可欠なことがよくあります。
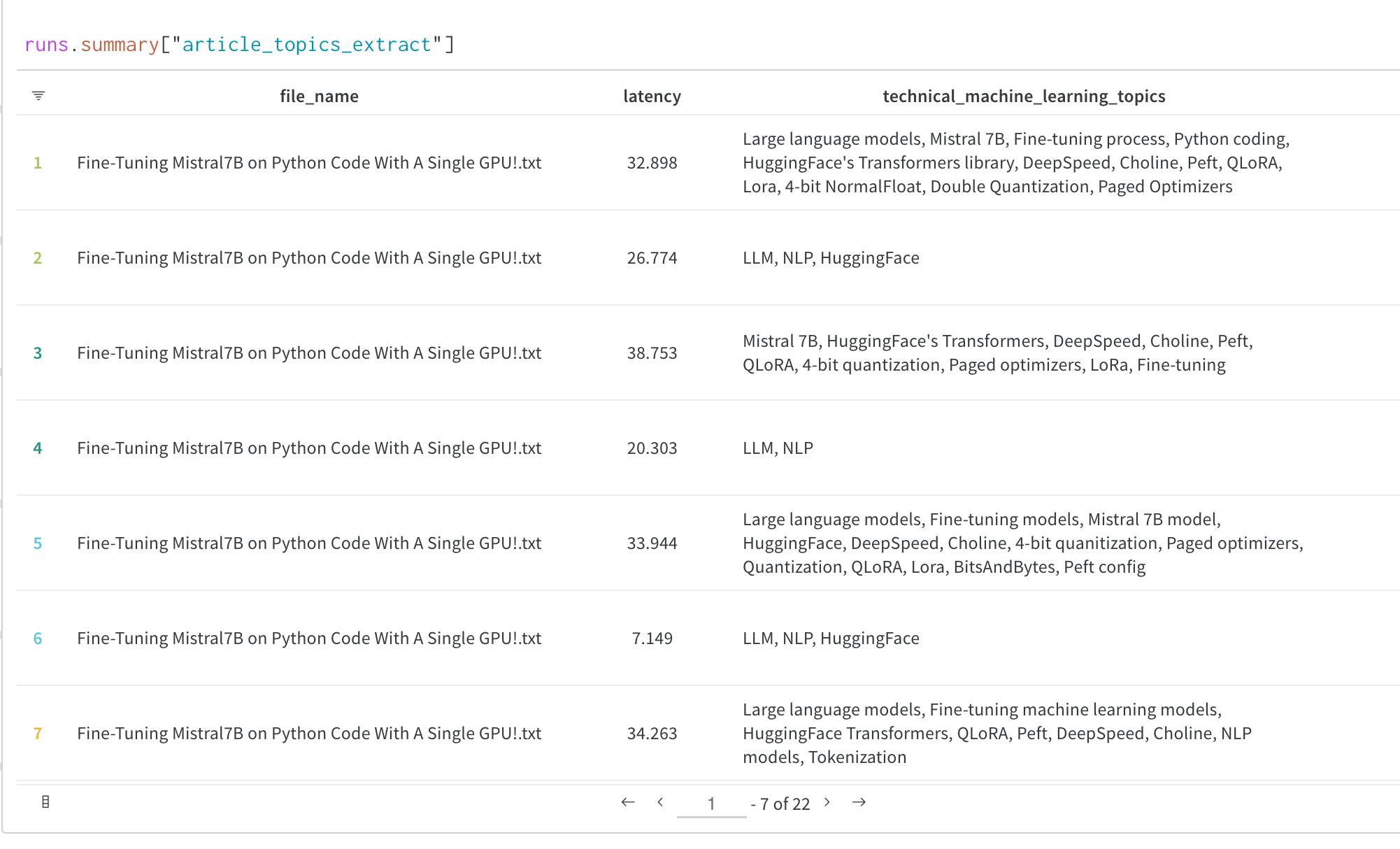
Transformers Trainer のコールバックシステムを使用すると、モデルのテキスト生成出力やその他の予測などの追加の役立つデータを W&B Tables に W&B に記録できます。
トレーニング中に評価出力を記録して、次のような W&B Table に記録する方法の詳細については、以下の カスタムロギングセクション を参照してください。
W&B Run を終了する (ノートブックのみ)
トレーニングが Python スクリプトにカプセル化されている場合、スクリプトが終了すると W&B run は終了します。
Jupyter または Google Colab ノートブックを使用している場合は、wandb.finish() を呼び出して、トレーニングが完了したことを伝える必要があります。
trainer.train() # トレーニングを開始して W&B にログを記録する
# トレーニング後の分析、テスト、その他のログに記録されたコード
wandb.finish()
結果を可視化する
トレーニング結果をログに記録したら、W&B Dashboard で結果を動的に調べることができます。柔軟でインタラクティブな可視化により、多数の run を一度に比較したり、興味深い発見を拡大したり、複雑なデータから洞察を引き出したりするのが簡単です。
高度な機能と FAQ
最適なモデルを保存するにはどうすればよいですか?
load_best_model_at_end=True で TrainingArguments を Trainer に渡すと、W&B は最適なパフォーマンスのモデルチェックポイントを Artifacts に保存します。
モデルチェックポイントを Artifacts として保存する場合は、Registry に昇格させることができます。Registry では、次のことができます。
- ML タスクごとに最適なモデルバージョンを整理します。
- モデルを一元化してチームと共有します。
- 本番環境用にモデルをステージングするか、詳細な評価のためにブックマークします。
- ダウンストリーム CI/CD プロセスをトリガーします。
保存されたモデルをロードするにはどうすればよいですか?
WANDB_LOG_MODEL を使用してモデルを W&B Artifacts に保存した場合は、追加のトレーニングまたは推論を実行するためにモデルの重みをダウンロードできます。以前に使用したのと同じ Hugging Face アーキテクチャにロードするだけです。
# 新しい run を作成する
with wandb.init(project="amazon_sentiment_analysis") as run:
# Artifact の名前とバージョンを渡す
my_model_name = "model-bert-base-high-lr:latest"
my_model_artifact = run.use_artifact(my_model_name)
# モデルの重みをフォルダーにダウンロードしてパスを返す
model_dir = my_model_artifact.download()
# 同じモデルクラスを使用して、そのフォルダーから Hugging Face モデルをロードする
model = AutoModelForSequenceClassification.from_pretrained(
model_dir, num_labels=num_labels
)
# 追加のトレーニングを実行するか、推論を実行する
チェックポイントからトレーニングを再開するにはどうすればよいですか?
WANDB_LOG_MODEL='checkpoint' を設定した場合は、model_dir を TrainingArguments の model_name_or_path 引数として使用し、resume_from_checkpoint=True を Trainer に渡すことで、トレーニングを再開することもできます。
last_run_id = "xxxxxxxx" # wandb ワークスペースから run_id を取得する
# run_id から wandb run を再開する
with wandb.init(
project=os.environ["WANDB_PROJECT"],
id=last_run_id,
resume="must",
) as run:
# Artifact を run に接続する
my_checkpoint_name = f"checkpoint-{last_run_id}:latest"
my_checkpoint_artifact = run.use_artifact(my_model_name)
# チェックポイントをフォルダーにダウンロードしてパスを返す
checkpoint_dir = my_checkpoint_artifact.download()
# モデルとトレーナーを再初期化する
model = AutoModelForSequenceClassification.from_pretrained(
"<model_name>", num_labels=num_labels
)
# ここに素晴らしいトレーニング引数を記述する。
training_args = TrainingArguments()
trainer = Trainer(model=model, args=training_args)
# チェックポイントディレクトリを使用して、チェックポイントからトレーニングを再開する
trainer.train(resume_from_checkpoint=checkpoint_dir)
トレーニング中に評価サンプルを記録して表示するにはどうすればよいですか?
Transformers Trainer を介した W&B へのロギングは、Transformers ライブラリの WandbCallback によって処理されます。Hugging Face ロギングをカスタマイズする必要がある場合は、WandbCallback をサブクラス化し、Trainer クラスの追加メソッドを活用する追加機能を追加して、このコールバックを変更できます。
以下は、この新しいコールバックを HF Trainer に追加する一般的なパターンであり、さらに下には、評価出力を W&B Table に記録するコード完全な例があります。
# Trainer を通常どおりインスタンス化する
trainer = Trainer()
# 新しいロギングコールバックをインスタンス化し、Trainer オブジェクトを渡す
evals_callback = WandbEvalsCallback(trainer, tokenizer, ...)
# コールバックを Trainer に追加する
trainer.add_callback(evals_callback)
# 通常どおり Trainer トレーニングを開始する
trainer.train()
トレーニング中に評価サンプルを表示する
次のセクションでは、WandbCallback をカスタマイズして、モデルの予測を実行し、トレーニング中に評価サンプルを W&B Table に記録する方法について説明します。Trainer コールバックの on_evaluate メソッドを使用して、すべての eval_steps を実行します。
ここでは、tokenizer を使用してモデル出力から予測とラベルをデコードする decode_predictions 関数を作成しました。
次に、予測とラベルから pandas DataFrame を作成し、DataFrame に epoch 列を追加します。
最後に、DataFrame から wandb.Table を作成し、wandb に記録します。
さらに、予測を freq エポックごとに記録することで、ロギングの頻度を制御できます。
注: 通常の WandbCallback とは異なり、このカスタムコールバックは、Trainer の初期化中ではなく、Trainer がインスタンス化された後にトレーナーに追加する必要があります。
これは、Trainer インスタンスが初期化中にコールバックに渡されるためです。
from transformers.integrations import WandbCallback
import pandas as pd
def decode_predictions(tokenizer, predictions):
labels = tokenizer.batch_decode(predictions.label_ids)
logits = predictions.predictions.argmax(axis=-1)
prediction_text = tokenizer.batch_decode(logits)
return {"labels": labels, "predictions": prediction_text}
class WandbPredictionProgressCallback(WandbCallback):
"""Custom WandbCallback to log model predictions during training.
This callback logs model predictions and labels to a wandb.Table at each
logging step during training. It allows to visualize the
model predictions as the training progresses.
Attributes:
trainer (Trainer): The Hugging Face Trainer instance.
tokenizer (AutoTokenizer): The tokenizer associated with the model.
sample_dataset (Dataset): A subset of the validation dataset
for generating predictions.
num_samples (int, optional): Number of samples to select from
the validation dataset for generating predictions. Defaults to 100.
freq (int, optional): Frequency of logging. Defaults to 2.
"""
def __init__(self, trainer, tokenizer, val_dataset, num_samples=100, freq=2):
"""Initializes the WandbPredictionProgressCallback instance.
Args:
trainer (Trainer): The Hugging Face Trainer instance.
tokenizer (AutoTokenizer): The tokenizer associated
with the model.
val_dataset (Dataset): The validation dataset.
num_samples (int, optional): Number of samples to select from
the validation dataset for generating predictions.
Defaults to 100.
freq (int, optional): Frequency of logging. Defaults to 2.
"""
super().__init__()
self.trainer = trainer
self.tokenizer = tokenizer
self.sample_dataset = val_dataset.select(range(num_samples))
self.freq = freq
def on_evaluate(self, args, state, control, **kwargs):
super().on_evaluate(args, state, control, **kwargs)
# control the frequency of logging by logging the predictions
# every `freq` epochs
if state.epoch % self.freq == 0:
# generate predictions
predictions = self.trainer.predict(self.sample_dataset)
# decode predictions and labels
predictions = decode_predictions(self.tokenizer, predictions)
# add predictions to a wandb.Table
predictions_df = pd.DataFrame(predictions)
predictions_df["epoch"] = state.epoch
records_table = self._wandb.Table(dataframe=predictions_df)
# log the table to wandb
self._wandb.log({"sample_predictions": records_table})
# まず、Trainer をインスタンス化する
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"],
eval_dataset=lm_datasets["validation"],
)
# WandbPredictionProgressCallback をインスタンス化する
progress_callback = WandbPredictionProgressCallback(
trainer=trainer,
tokenizer=tokenizer,
val_dataset=lm_dataset["validation"],
num_samples=10,
freq=2,
)
# コールバックをトレーナーに追加する
trainer.add_callback(progress_callback)
詳細な例については、こちらの colab を参照してください。
その他の W&B 設定はありますか?
環境変数を設定することで、Trainer でログに記録される内容をさらに構成できます。W&B 環境変数の完全なリストは、こちら にあります。
| 環境変数 | 使用法 |
|---|---|
WANDB_PROJECT |
プロジェクトに名前を付けます (デフォルトでは huggingface) |
WANDB_LOG_MODEL |
モデルチェックポイントを W&B Artifact として記録します (デフォルトでは
|
WANDB_WATCH |
モデルの勾配、パラメーター、またはそのどちらもログに記録するかどうかを設定します
|
WANDB_DISABLED |
ロギングを完全にオフにするには true に設定します (デフォルトでは false) |
WANDB_SILENT |
wandb によって出力される出力を抑制するには true に設定します (デフォルトでは false) |
WANDB_WATCH=all
WANDB_SILENT=true
%env WANDB_WATCH=all
%env WANDB_SILENT=true
wandb.init をカスタマイズするにはどうすればよいですか?
Trainer が使用する WandbCallback は、Trainer が初期化されるときに内部で wandb.init を呼び出します。Trainer が初期化される前に wandb.init を呼び出すことで、run を手動で設定することもできます。これにより、W&B run の構成を完全に制御できます。
init に渡したい可能性のあるものの例を以下に示します。wandb.init の使用方法の詳細については、リファレンスドキュメントをご確認ください。
wandb.init(
project="amazon_sentiment_analysis",
name="bert-base-high-lr",
tags=["baseline", "high-lr"],
group="bert",
)
その他のリソース
以下は、Transformer と W&B に関連する 6 つの記事です。
Hugging Face Transformers のハイパーパラメーター最適化
- Hugging Face Transformers のハイパーパラメーター最適化のための 3 つの戦略 (グリッド検索、ベイズ最適化、Population Based Training) が比較されます。
- Hugging Face transformers から標準的な uncased BERT モデルを使用し、SuperGLUE ベンチマークから RTE データセットでファインチューニングしたいと考えています。
- 結果は、Population Based Training が Hugging Face transformer モデルのハイパーパラメーター最適化に最も効果的なアプローチであることを示しています。
完全なレポートは こちら をお読みください。
Hugging Tweets: ツイートを生成するモデルをトレーニングする
- この記事では、著者は、誰かのツイートで学習済みの GPT2 HuggingFace Transformer モデルを 5 分でファインチューニングする方法を示しています。
- このモデルは、ツイートのダウンロード、データセットの最適化、初期実験、ユーザー間の損失の比較、モデルのファインチューニングというパイプラインを使用しています。
完全なレポートは こちら をお読みください。
Hugging Face BERT および WB を使用した文分類
- この記事では、自然言語処理における最近の画期的な進歩の力を活用して、文分類子を作成します。ここでは、NLP への転移学習の応用例に焦点を当てます。
- 単一文分類には、言語的許容度 (CoLA) データセットを使用します。これは、2018 年 5 月に初めて公開された、文法的に正しいか正しくないかというラベルが付けられた文のセットです。
- Google の BERT を使用して、さまざまな NLP タスクで最小限の労力で高性能モデルを作成します。
完全なレポートは こちら をお読みください。
Hugging Face モデルのパフォーマンスを追跡するためのステップバイステップガイド
- W&B と Hugging Face transformers を使用して、GLUE ベンチマークで DistilBERT (BERT より 40% 小さいが、BERT の精度の 97% を保持する Transformer) をトレーニングします。
- GLUE ベンチマークは、NLP モデルをトレーニングするための 9 つのデータセットとタスクのコレクションです。
完全なレポートは こちら をお読みください。
HuggingFace での早期停止の例
- 早期停止の正規化を使用して Hugging Face Transformer をファインチューニングは、PyTorch または TensorFlow でネイティブに行うことができます。
- TensorFlow での EarlyStopping コールバックの使用は、
tf.keras.callbacks.EarlyStoppingコールバックを使用すると簡単です。 - PyTorch では、既製の早期停止メソッドはありませんが、GitHub Gist で利用できる作業中の早期停止フックがあります。
完全なレポートは こちら をお読みください。
カスタムデータセットで Hugging Face Transformers をファインチューンする方法
カスタム IMDB データセットでセンチメント分析 (バイナリ分類) 用に DistilBERT transformer をファインチューンします。
完全なレポートは こちら をお読みください。
ヘルプの入手または機能のリクエスト
Hugging Face W&B integration に関する問題、質問、または機能のリクエストについては、Hugging Face フォーラムのこのスレッド に投稿するか、Hugging Face Transformers GitHub repo で issue をオープンしてください。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.