NVIDIA NeMo Inference Microservice Deploy Job
less than a minute
W&B から NVIDIA NeMo Inference Microservice にモデル Artifact をデプロイするには、W&B Launch を使用します。W&B Launch は、モデル Artifact を NVIDIA NeMo Model に変換し、実行中の NIM/Triton サーバーにデプロイします。
W&B Launch は現在、以下の互換性のあるモデルタイプを受け入れています。
デプロイ時間は、モデルとマシンの種類によって異なります。ベースとなる Llama2-7b の構成には、GCP の
a2-ultragpu-1g で約 1 分かかります。クイックスタート
-
まだ Launch キューを作成 していない場合は作成します。以下のキュー構成の例を参照してください。
net: host gpus: all # 特定の GPU のセット、またはすべてを使用する場合は `all` runtime: nvidia # nvidia container runtime も必要 volume: - model-store:/model-store/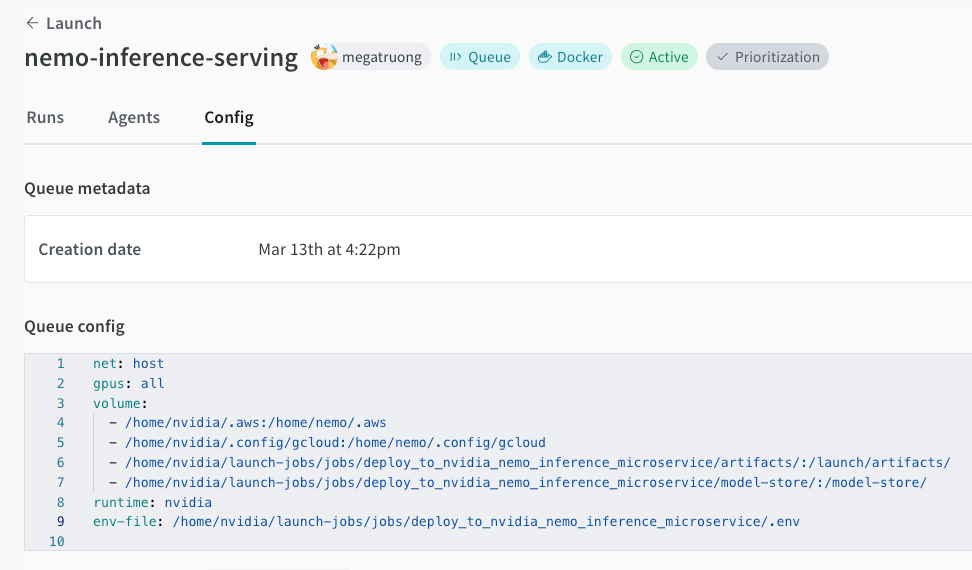
-
プロジェクト でこのジョブを作成します。
wandb job create -n "deploy-to-nvidia-nemo-inference-microservice" \ -e $ENTITY \ -p $PROJECT \ -E jobs/deploy_to_nvidia_nemo_inference_microservice/job.py \ -g andrew/nim-updates \ git https://github.com/wandb/launch-jobs -
GPU マシンで エージェント を起動します。
wandb launch-agent -e $ENTITY -p $PROJECT -q $QUEUE -
Launch UI から、必要な構成でデプロイメント Launch ジョブを送信します。
- CLI から送信することもできます。
wandb launch -d gcr.io/playground-111/deploy-to-nemo:latest \ -e $ENTITY \ -p $PROJECT \ -q $QUEUE \ -c $CONFIG_JSON_FNAME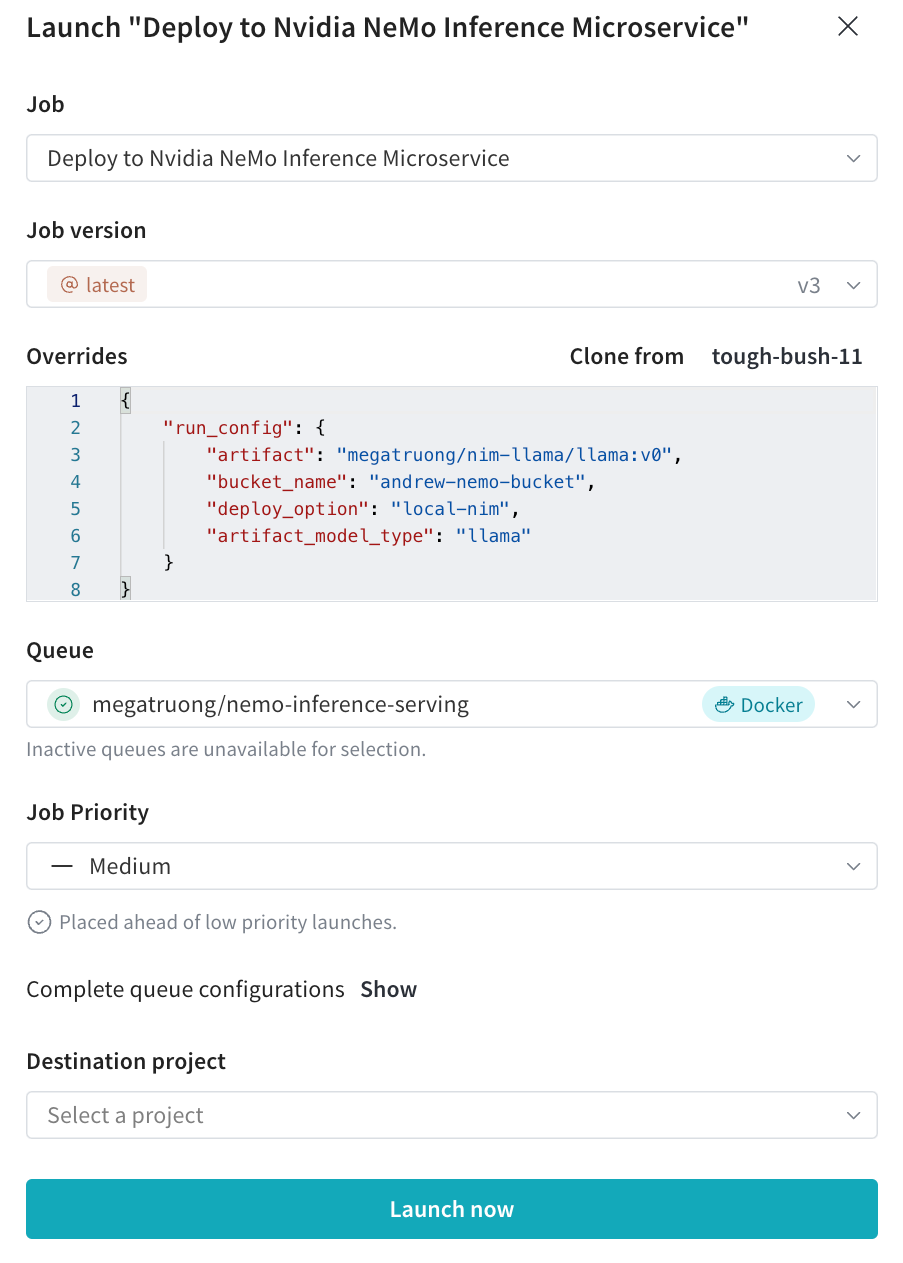
- CLI から送信することもできます。
-
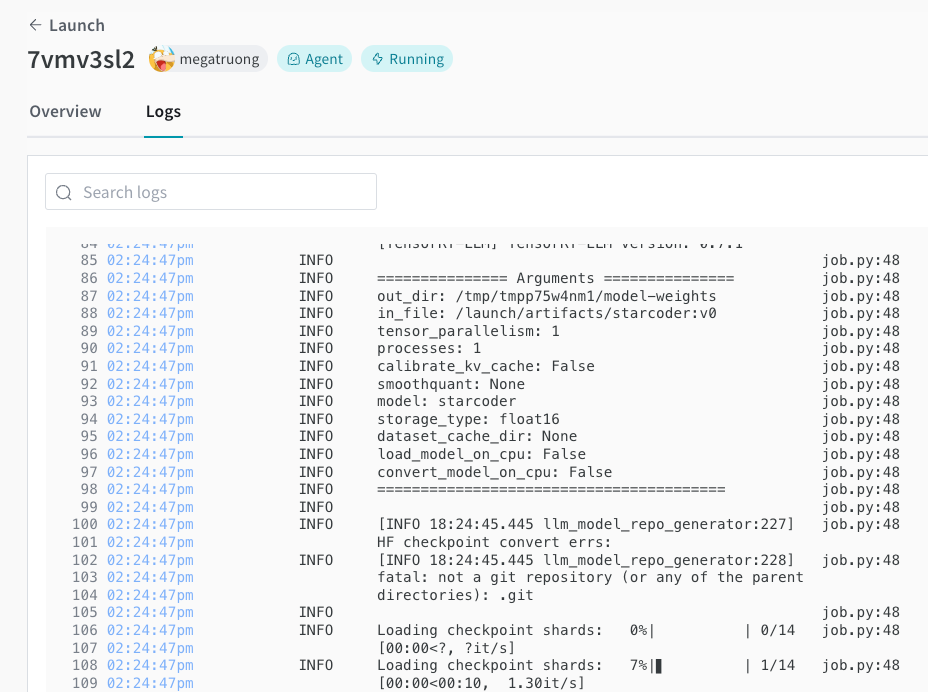
デプロイメント プロセス を Launch UI で追跡できます。
-
完了したら、すぐにエンドポイントを curl してモデルをテストできます。モデル名は常に
ensembleです。#!/bin/bash curl -X POST "http://0.0.0.0:9999/v1/completions" \ -H "accept: application/json" \ -H "Content-Type: application/json" \ -d '{ "model": "ensemble", "prompt": "Tell me a joke", "max_tokens": 256, "temperature": 0.5, "n": 1, "stream": false, "stop": "string", "frequency_penalty": 0.0 }'
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.