Log distributed training experiments
4 minute read
分散トレーニングでは、モデルは複数の GPU を並行して使用してトレーニングされます。W&B は、分散トレーニング の 実験管理 を追跡するための 2 つのパターンをサポートしています。
- 単一 プロセス: W&B (
wandb.init) を初期化し、単一の プロセス から 実験 (wandb.log) を ログ 記録します。これは、PyTorch Distributed Data Parallel (DDP) クラスを使用した分散トレーニング の 実験 を ログ 記録するための一般的なソリューションです。場合によっては、マルチプロセッシング キュー (または別の通信プリミティブ) を使用して、他の プロセス からメインの ログ 記録 プロセス にデータを送り込む ユーザー もいます。 - 多数の プロセス: W&B (
wandb.init) を初期化し、すべての プロセス で 実験 (wandb.log) を ログ 記録します。各 プロセス は、事実上別の 実験 です。W&B を初期化する際にgroupパラメータ (wandb.init(group='group-name')) を使用して、共有 実験 を定義し、 ログ 記録された 値 を W&B App UI にまとめて グループ化します。
以下の例では、単一 マシン 上の 2 つの GPU で PyTorch DDP を使用して、W&B で メトリクス を追跡する方法を示します。PyTorch DDP (torch.nn の DistributedDataParallel) は、分散トレーニング 用の一般的な ライブラリ です。基本的な原則は、あらゆる分散トレーニング 設定に適用されますが、実装の詳細は異なる場合があります。
log-dpp.py Python スクリプトを参照してください。方法 1: 単一 プロセス
この方法では、ランク 0 の プロセス のみを追跡します。この方法を実装するには、W&B (wandb.init) を初期化し、W&B Run を開始して、ランク 0 の プロセス 内で メトリクス (wandb.log) を ログ 記録します。この方法はシンプルで堅牢ですが、他の プロセス から モデル の メトリクス (たとえば、バッチからの 損失 値 または 入力) を ログ 記録しません。使用量 や メモリ などの システム メトリクス は、その情報がすべての プロセス で利用できるため、すべての GPU に対して ログ 記録されます。
サンプル Python スクリプト (log-ddp.py) 内で、ランクが 0 かどうかを確認します。これを行うには、まず torch.distributed.launch で複数の プロセス を 起動します。次に、--local_rank コマンドライン 引数 でランクを確認します。ランクが 0 に設定されている場合、train() 関数で wandb ログ 記録を条件付きで設定します。Python スクリプト内で、次のチェックを使用します。
if __name__ == "__main__":
# Get args
args = parse_args()
if args.local_rank == 0: # only on main process
# Initialize wandb run
run = wandb.init(
entity=args.entity,
project=args.project,
)
# Train model with DDP
train(args, run)
else:
train(args)
W&B App UI を調べて、単一の プロセス から追跡された メトリクス の ダッシュボード 例 を表示します。ダッシュボード には、両方の GPU で追跡された 温度 や 使用率 などの システム メトリクス が表示されます。
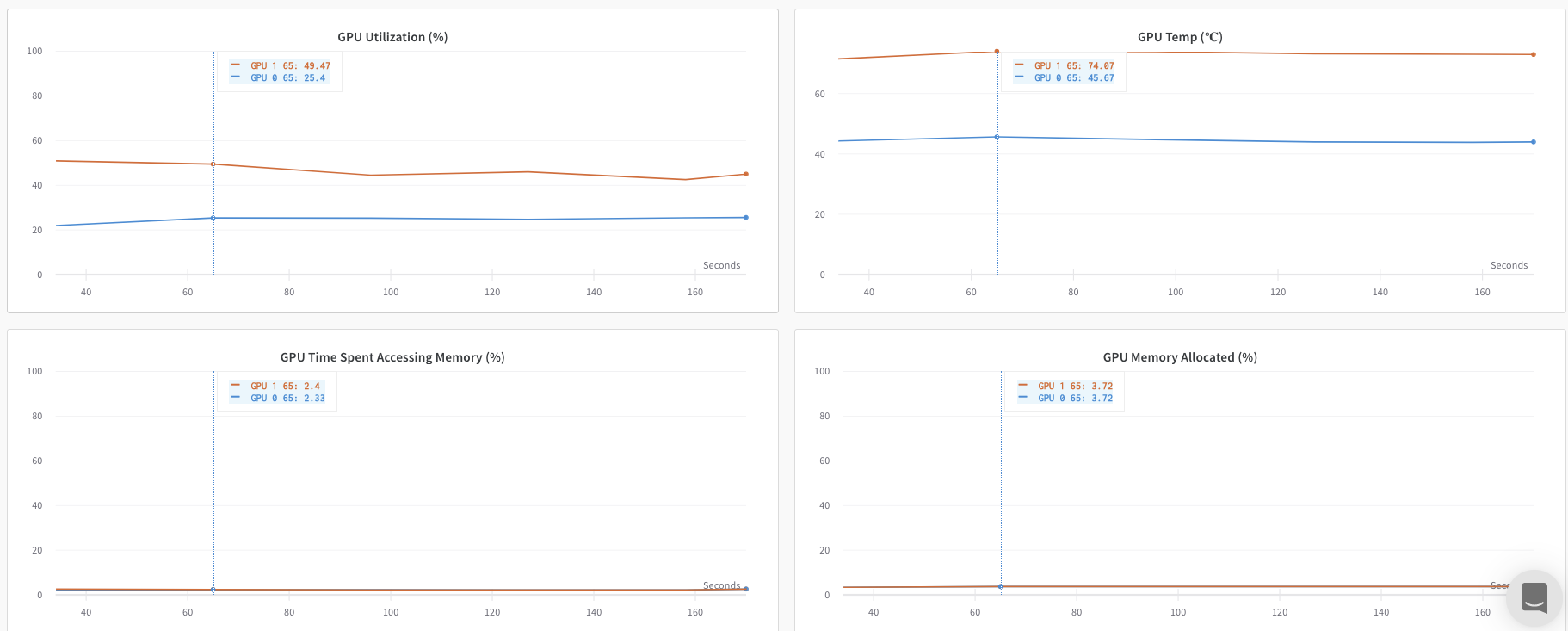
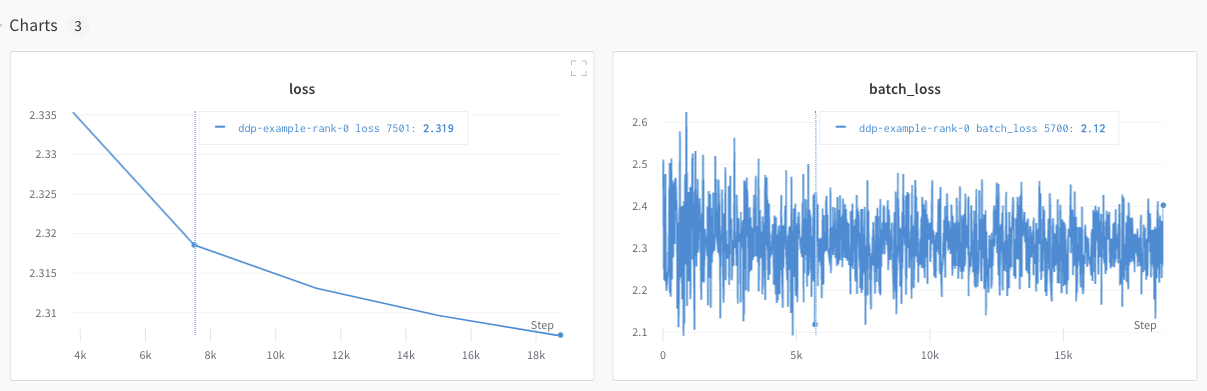
ただし、 エポック と バッチサイズ の関数としての 損失 値 は、単一の GPU からのみ ログ 記録されました。
方法 2: 多数の プロセス
この方法では、ジョブ内の各 プロセス を追跡し、各 プロセス から wandb.init() と wandb.log() を個別に呼び出します。すべての プロセス が適切に終了するように、トレーニング の最後に wandb.finish() を呼び出すことをお勧めします。これにより、run が完了したことを示します。
この方法により、より多くの情報が ログ 記録にアクセスできるようになります。ただし、複数の W&B Runs が W&B App UI に 報告 されることに注意してください。複数の 実験 にわたって W&B Runs を追跡することが難しい場合があります。これを軽減するには、W&B を初期化する際に group パラメータ に 値 を指定して、どの W&B Run が特定の 実験 に属しているかを追跡します。トレーニング と 評価 の W&B Runs を 実験 で追跡する方法の詳細については、Run のグループ化 を参照してください。
次の Python コード スニペット は、W&B を初期化するときに group パラメータ を設定する方法を示しています。
if __name__ == "__main__":
# Get args
args = parse_args()
# Initialize run
run = wandb.init(
entity=args.entity,
project=args.project,
group="DDP", # all runs for the experiment in one group
)
# Train model with DDP
train(args, run)
W&B App UI を調べて、複数の プロセス から追跡された メトリクス の ダッシュボード 例 を表示します。左側のサイドバーに 2 つの W&B Runs が グループ化 されていることに注意してください。グループ をクリックして、 実験 専用のグループ ページ を表示します。専用のグループ ページ には、各 プロセス からの メトリクス が個別に表示されます。
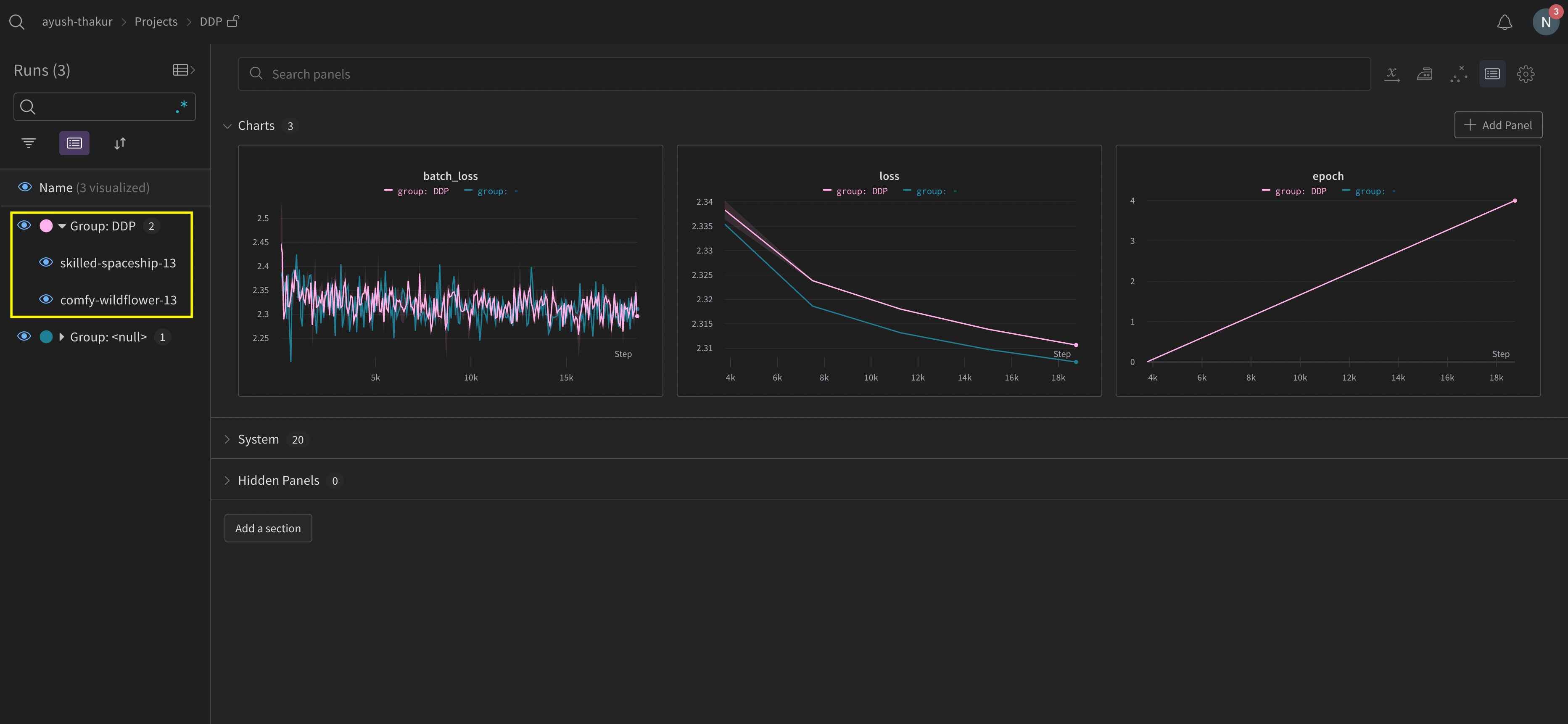
上記の画像は、W&B App UI ダッシュボード を示しています。サイドバーには、2 つの 実験 が表示されます。1 つは「null」というラベルが付いており、2 つ目 (黄色のボックスで囲まれています) は「DPP」と呼ばれています。グループ を展開すると (グループ ドロップダウン を選択)、その 実験 に関連付けられている W&B Runs が表示されます。
W&B Service を使用して、一般的な分散トレーニング の問題を回避する
W&B と分散トレーニング を使用する際に発生する可能性のある一般的な問題が 2 つあります。
- トレーニング の開始時にハングする -
wandbマルチプロセッシング が分散トレーニング からの マルチプロセッシング に干渉すると、wandbプロセス がハングする可能性があります。 - トレーニング の最後にハングする -
wandbプロセス がいつ終了する必要があるかを認識していない場合、トレーニング ジョブ がハングする可能性があります。Python スクリプト の最後にwandb.finish()API を呼び出して、Run が完了したことを W&B に伝えます。wandb.finish() API は、データの アップロード を終了し、W&B を終了させます。
分散ジョブ の信頼性を向上させるために、wandb service を使用することをお勧めします。上記のトレーニング の問題はどちらも、wandb service が利用できない W&B SDK の バージョン でよく見られます。
W&B Service を有効にする
W&B SDK の バージョン によっては、W&B Service がデフォルトで有効になっている場合があります。
W&B SDK 0.13.0 以降
W&B Service は、W&B SDK 0.13.0 以降の バージョン ではデフォルトで有効になっています。
W&B SDK 0.12.5 以降
Python スクリプト を変更して、W&B SDK バージョン 0.12.5 以降で W&B Service を有効にします。wandb.require メソッド を使用し、メイン関数内で 文字列 "service" を渡します。
if __name__ == "__main__":
main()
def main():
wandb.require("service")
# rest-of-your-script-goes-here
最適なエクスペリエンスを得るには、最新 バージョン に アップグレード することをお勧めします。
W&B SDK 0.12.4 以前
W&B SDK バージョン 0.12.4 以前を使用している場合は、マルチスレッド を代わりに使用するために、WANDB_START_METHOD 環境 変数 を "thread" に設定します。
マルチプロセッシング の ユースケース 例
次の コード スニペット は、高度な分散 ユースケース の一般的な方法を示しています。
プロセス の スポーン
スポーンされた プロセス で W&B Run を開始する場合は、メイン関数で wandb.setup() メソッド を使用します。
import multiprocessing as mp
def do_work(n):
run = wandb.init(config=dict(n=n))
run.log(dict(this=n * n))
def main():
wandb.setup()
pool = mp.Pool(processes=4)
pool.map(do_work, range(4))
if __name__ == "__main__":
main()
W&B Run を共有する
W&B Run オブジェクト を 引数 として渡して、 プロセス 間で W&B Runs を共有します。
def do_work(run):
run.log(dict(this=1))
def main():
run = wandb.init()
p = mp.Process(target=do_work, kwargs=dict(run=run))
p.start()
p.join()
if __name__ == "__main__":
main()
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.