これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
Create and deploy jobs
- 1: Add job to queue
- 2: Create a launch job
- 3: Manage job inputs
- 4: Monitor launch queue
- 5: View launch jobs
1 - Add job to queue
次のページでは、Launch キューに Launch ジョブを追加する方法について説明します。
キューにジョブを追加する
W&B App を使用してインタラクティブに、または W&B CLI を使用してプログラムで、ジョブをキューに追加します。
W&B App を使用して、プログラムでジョブをキューに追加します。
- W&B の Project ページに移動します。
- 左側のパネルで、Jobs アイコンを選択します。
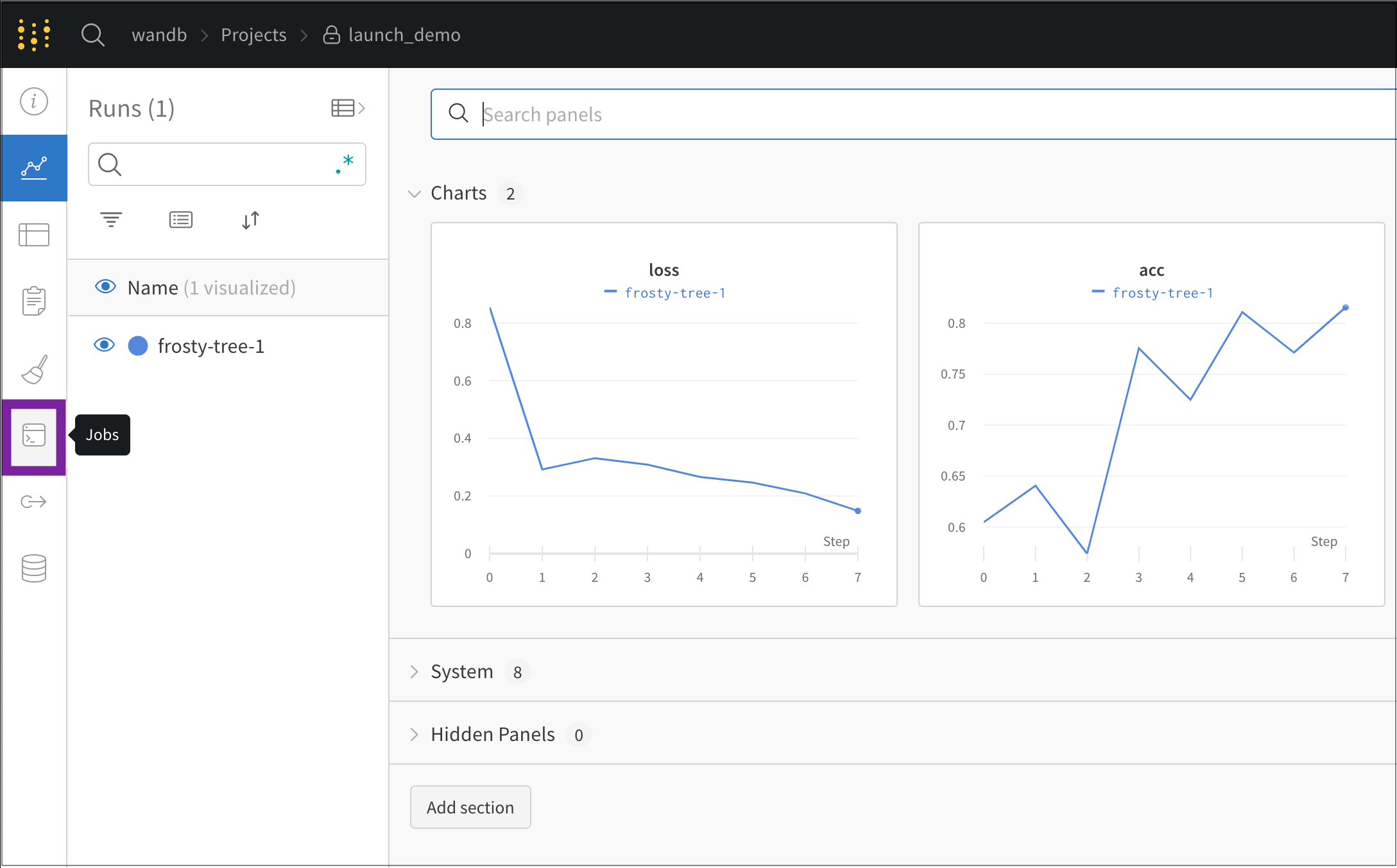
- Jobs ページには、以前に実行された W&B の run から作成された W&B の Launch ジョブのリストが表示されます。
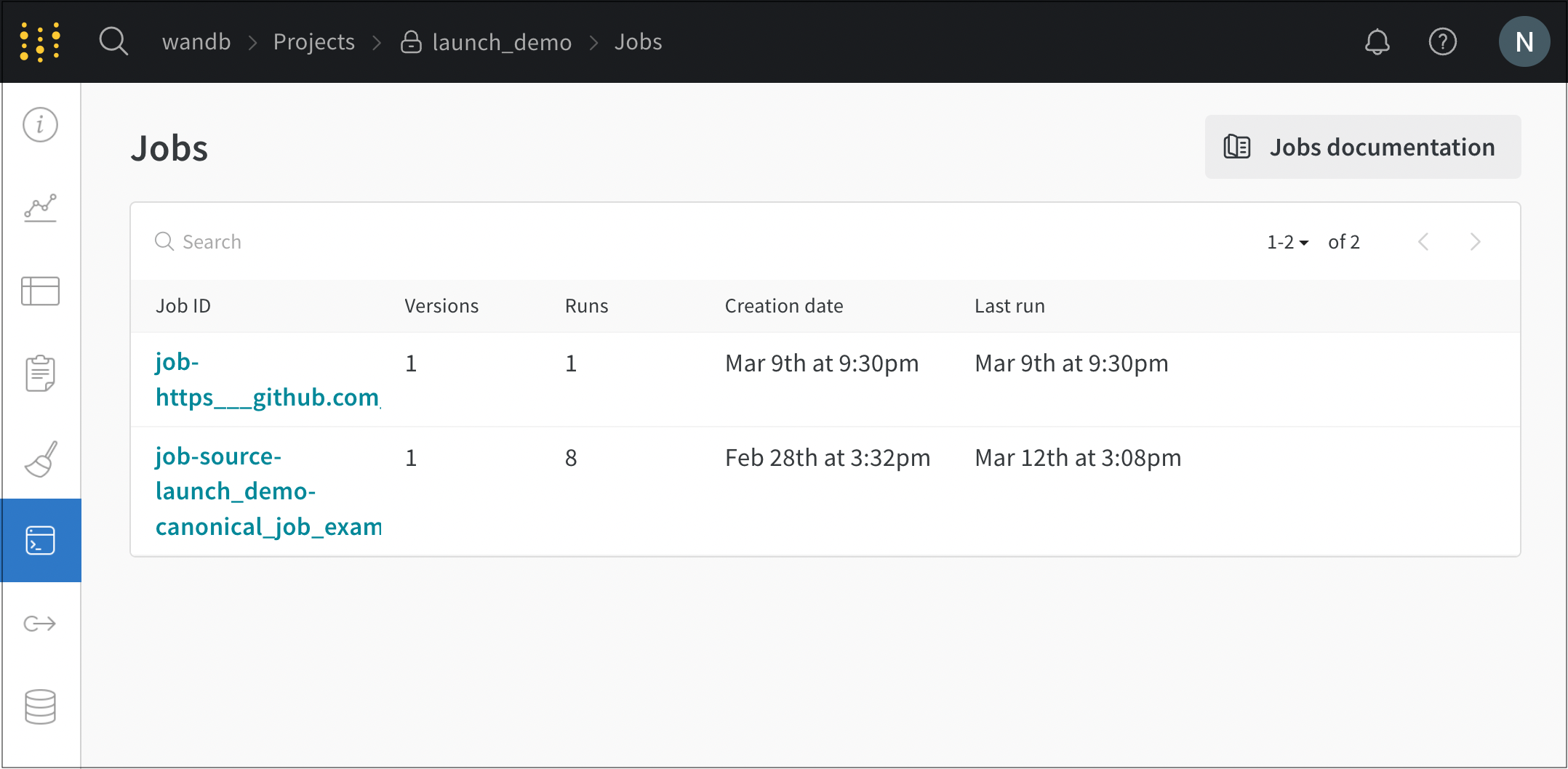
- ジョブ名の横にある Launch ボタンを選択します。モーダルがページの右側に表示されます。
- Job version ドロップダウンから、使用する Launch ジョブのバージョンを選択します。Launch ジョブは、他の W&B Artifact と同様にバージョン管理されています。ジョブの実行に使用されるソフトウェアの依存関係またはソースコードを変更すると、同じ Launch ジョブの異なるバージョンが作成されます。
- Overrides セクション内で、Launch ジョブに設定されているすべての入力に新しい値を指定します。一般的なオーバーライドには、新しいエントリポイントコマンド、引数、または新しい W&B の run の
wandb.configの値が含まれます。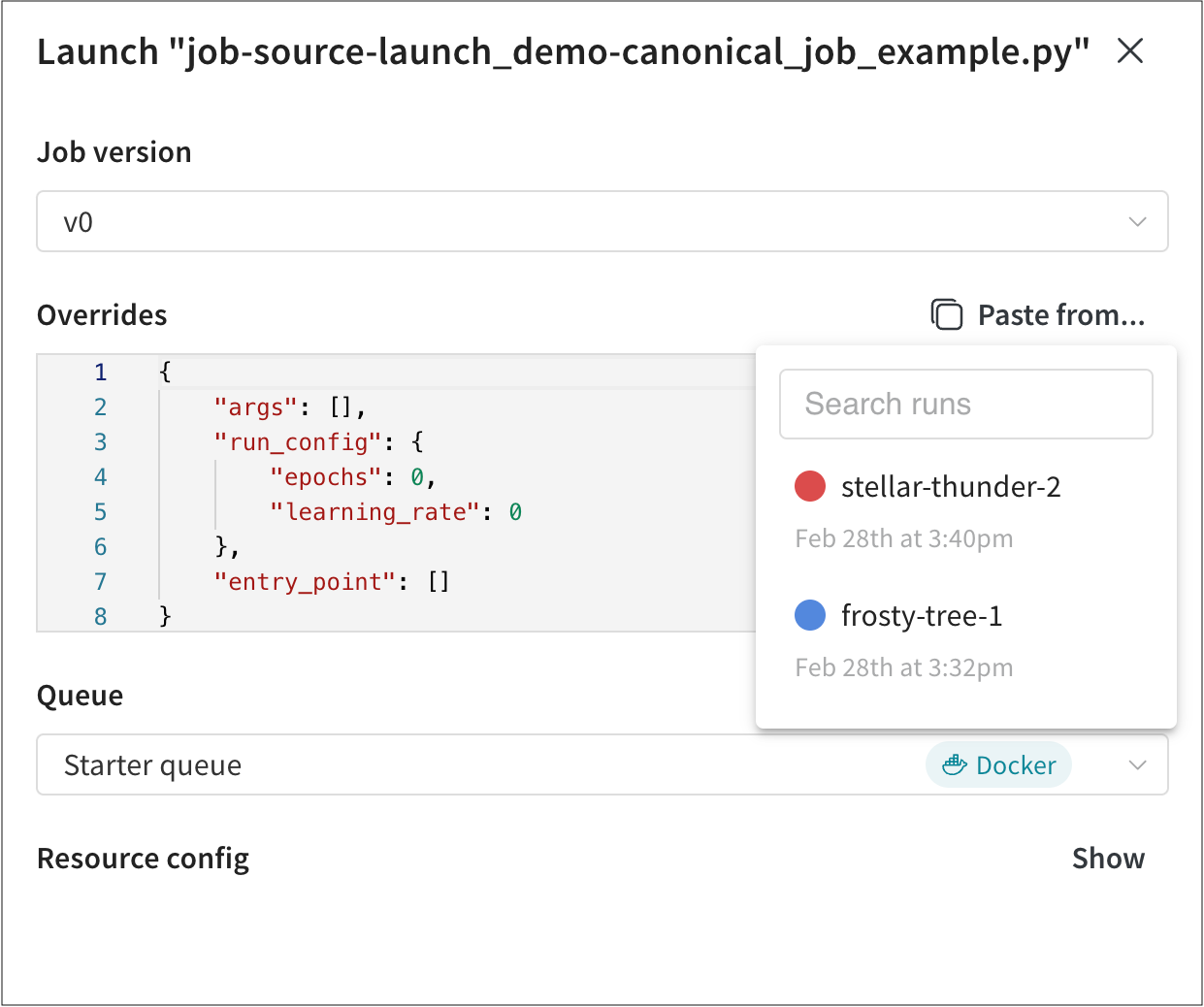 Paste from… ボタンをクリックして、Launch ジョブを使用した他の W&B の run から値をコピーして貼り付けることができます。
Paste from… ボタンをクリックして、Launch ジョブを使用した他の W&B の run から値をコピーして貼り付けることができます。 - Queue ドロップダウンから、Launch ジョブを追加する Launch キューの名前を選択します。
- Job Priority ドロップダウンを使用して、Launch ジョブの優先度を指定します。Launch キューが優先順位付けをサポートしていない場合、Launch ジョブの優先度は「Medium」に設定されます。
- (オプション)チーム管理者がキュー構成テンプレートを作成した場合にのみ、この手順に従ってください
Queue Configurations フィールド内で、チームの管理者によって作成された構成オプションの値を指定します。
たとえば、次の例では、チーム管理者はチームが使用できる AWS インスタンスタイプを構成しました。この場合、チームメンバーは
ml.m4.xlargeまたはml.p3.xlargeコンピュートインスタンスタイプのいずれかを選択して、モデルをトレーニングできます。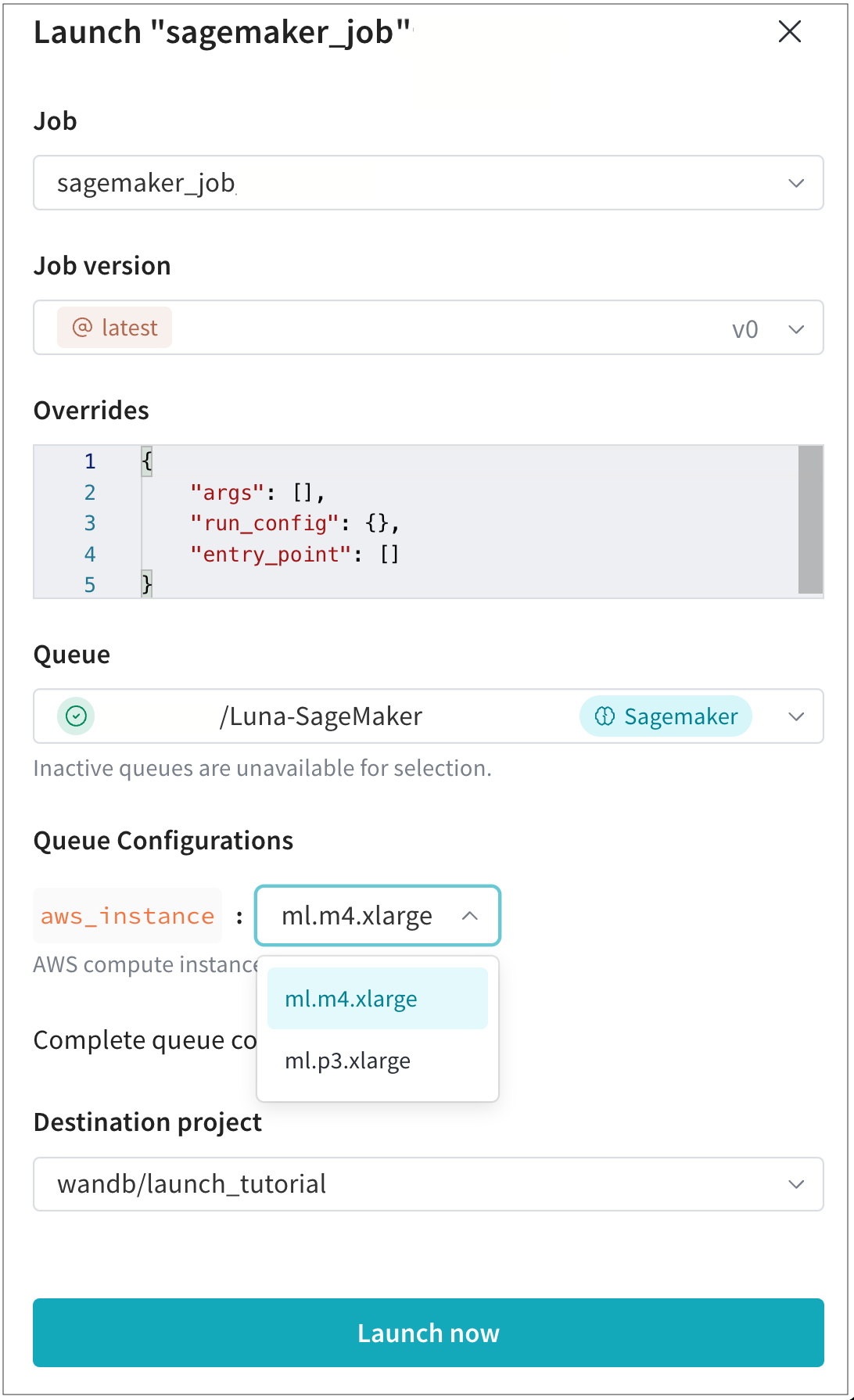
- 結果の run が表示される Destination project を選択します。この Project は、キューと同じエンティティに属している必要があります。
- Launch now ボタンを選択します。
wandb launch コマンドを使用して、ジョブをキューに追加します。ハイパー パラメーターのオーバーライドを含む JSON 構成を作成します。たとえば、クイックスタート ガイドのスクリプトを使用して、次のオーバーライドを含む JSON ファイルを作成します。
{
"overrides": {
"args": [],
"run_config": {
"learning_rate": 0,
"epochs": 0
},
"entry_point": []
}
}
キュー構成をオーバーライドする場合、または Launch キューに構成リソースが定義されていない場合は、config.json ファイルで resource_args キーを指定できます。たとえば、上記の例に続いて、config.json ファイルは次のようになります。
{
"overrides": {
"args": [],
"run_config": {
"learning_rate": 0,
"epochs": 0
},
"entry_point": []
},
"resource_args": {
"<resource-type>" : {
"<key>": "<value>"
}
}
}
<> 内の値を独自の値に置き換えます。
queue(-q) フラグのキューの名前、job(-j) フラグのジョブの名前、および config(-c) フラグの構成ファイルへのパスを指定します。
wandb launch -j <job> -q <queue-name> \
-e <entity-name> -c path/to/config.json
W&B の Teams で作業する場合は、キューが使用するエンティティを示すために entity フラグ (-e) を指定することをお勧めします。
2 - Create a launch job
Launch jobsは、W&B runを再現するための設計図です。Jobsは、ワークロードを実行するために必要なソース コード、依存関係、および入力をキャプチャするW&B Artifactsです。
wandb launch コマンドでjobsを作成および実行します。
wandb job create コマンドを使用します。詳細については、コマンドリファレンスドキュメントを参照してください。Git jobs
W&B Launchを使用して、コードやその他の追跡対象アセットがリモートgitリポジトリの特定のコミット、ブランチ、またはタグからクローンされるGitベースのjobを作成できます。コードを含むURIを指定するには、--uriまたは-uフラグを使用し、必要に応じてサブディレクトリーを指定するには、--build-contextフラグを使用します。
次のコマンドを使用して、gitリポジトリから「hello world」jobを実行します。
wandb launch --uri "https://github.com/wandb/launch-jobs.git" --build-context jobs/hello_world --dockerfile Dockerfile.wandb --project "hello-world" --job-name "hello-world" --entry-point "python job.py"
このコマンドは次のことを行います。
- W&B Launch jobs repositoryを一時ディレクトリーにクローンします。
- hello プロジェクトにhello-world-gitという名前のjobを作成します。このjobは、リポジトリのデフォルトブランチの先頭にあるコミットに関連付けられています。
jobs/hello_worldディレクトリーとDockerfile.wandbからコンテナーイメージを構築します。- コンテナーを起動し、
python job.pyを実行します。
特定のブランチまたはコミットハッシュからjobを構築するには、-g、--git-hash引数を追加します。引数の完全なリストについては、wandb launch --helpを実行してください。
リモートURLの形式
Launch jobに関連付けられたgitリモートは、HTTPSまたはSSH URLのいずれかになります。URLタイプは、jobソース コードの取得に使用されるプロトコルを決定します。
| リモートURLタイプ | URL形式 | アクセスと認証の要件 |
|---|---|---|
| https | https://github.com/organization/repository.git |
gitリモートで認証するためのユーザー名とパスワード |
| ssh | git@github.com:organization/repository.git |
gitリモートで認証するためのsshキー |
正確なURL形式は、ホスティングプロバイダーによって異なることに注意してください。wandb launch --uriで作成されたjobsは、指定された--uriで指定された転送プロトコルを使用します。
Code artifact jobs
Jobsは、W&B Artifactに保存されている任意のソース コードから作成できます。--uriまたは-u引数を持つローカルディレクトリーを使用して、新しいcode artifactとjobを作成します。
まず、空のディレクトリーを作成し、次のコンテンツを含むmain.pyという名前のPythonスクリプトを追加します。
import wandb
with wandb.init() as run:
run.log({"metric": 0.5})
次のコンテンツを含むrequirements.txtファイルを追加します。
wandb>=0.17.1
ディレクトリーをcode artifactとして記録し、次のコマンドでjobを起動します。
wandb launch --uri . --job-name hello-world-code --project launch-quickstart --entry-point "python main.py"
上記のコマンドは次のことを行います。
- 現在のディレクトリーを
hello-world-codeという名前のcode artifactとして記録します。 launch-quickstartプロジェクトにhello-world-codeという名前のjobを作成します。- 現在のディレクトリーとLaunchのデフォルトのDockerfileからコンテナーイメージを構築します。デフォルトのDockerfileは、
requirements.txtファイルをインストールし、エントリポイントをpython main.pyに設定します。
Image jobs
または、既製のDockerイメージからjobsを構築することもできます。これは、MLコード用の確立された構築システムがすでに存在する場合、またはjobのコードまたは要件を調整する予定はないが、ハイパーパラメーターまたはさまざまなインフラストラクチャースケールを試したい場合に役立ちます。
イメージはDockerレジストリからプルされ、指定されたエントリポイント、またはエントリポイントが指定されていない場合はデフォルトのエントリポイントで実行されます。--docker-imageオプションに完全なイメージタグを渡して、Dockerイメージからjobを作成および実行します。
既製のイメージから単純なjobを実行するには、次のコマンドを使用します。
wandb launch --docker-image "wandb/job_hello_world:main" --project "hello-world"
Automatic job creation
W&Bは、追跡されたソース コードを含むrunに対してjobを自動的に作成および追跡します。これは、Launchでrunが作成されなかった場合でも同様です。Runは、次の3つの条件のいずれかが満たされた場合に、追跡されたソース コードを持っていると見なされます。
- Runに関連付けられたgitリモートとコミットハッシュがある
- Runがcode artifactを記録した(詳細については、
Run.log_codeを参照してください) - Runが、イメージタグに設定された
WANDB_DOCKER環境変数を持つDockerコンテナーで実行された
Launch jobがW&B runによって自動的に作成された場合、GitリモートURLはローカルgitリポジトリから推測されます。
Launch job names
デフォルトでは、W&Bはjob名を自動的に生成します。名前は、jobの作成方法(GitHub、code artifact、またはDockerイメージ)に応じて生成されます。または、環境変数またはW&B Python SDKを使用してLaunch jobの名前を定義することもできます。
次の表は、jobソースに基づいてデフォルトで使用されるjob命名規則を示しています。
| ソース | 命名規則 |
|---|---|
| GitHub | job-<git-remote-url>-<path-to-script> |
| Code artifact | job-<code-artifact-name> |
| Docker image | job-<image-name> |
W&B環境変数またはW&B Python SDKを使用してjobに名前を付けます。
WANDB_JOB_NAME環境変数を優先job名に設定します。次に例を示します。
WANDB_JOB_NAME=awesome-job-name
wandb.Settingsを使用してjobの名前を定義します。次に、wandb.initでW&Bを初期化するときに、このオブジェクトを渡します。次に例を示します。
settings = wandb.Settings(job_name="my-job-name")
wandb.init(settings=settings)
Containerization
Jobsはコンテナー内で実行されます。Image jobsは既製のDockerイメージを使用しますが、Gitおよびcode artifact jobsはコンテナー構築手順を必要とします。
Jobのコンテナー化は、wandb launchへの引数とjobソース コード内のファイルを使用してカスタマイズできます。
Build context
構築コンテキストという用語は、コンテナーイメージを構築するためにDockerデーモンに送信されるファイルとディレクトリーのツリーを指します。デフォルトでは、Launchはjobソース コードのルートを構築コンテキストとして使用します。サブディレクトリーを構築コンテキストとして指定するには、jobの作成および起動時にwandb launchの--build-context引数を使用します。
--build-context引数は、複数のプロジェクトを含むモノレポを指すGit jobsを操作する場合に特に役立ちます。サブディレクトリーを構築コンテキストとして指定することで、モノレポ内の特定のプロジェクトのコンテナーイメージを構築できます。
--build-context引数を公式のW&B Launch jobsリポジトリで使用する方法のデモについては、上記の例を参照してください。
Dockerfile
Dockerfileは、Dockerイメージを構築するための命令を含むテキストファイルです。デフォルトでは、Launchはrequirements.txtファイルをインストールするデフォルトのDockerfileを使用します。カスタムDockerfileを使用するには、wandb launchの--dockerfile引数を使用してファイルへのパスを指定します。
Dockerfileパスは、構築コンテキストを基準にして指定されます。たとえば、構築コンテキストがjobs/hello_worldで、Dockerfileがjobs/hello_worldディレクトリーにある場合、--dockerfile引数はDockerfile.wandbに設定する必要があります。--dockerfile引数を公式のW&B Launch jobsリポジトリで使用する方法のデモについては、上記の例を参照してください。
Requirements file
カスタムDockerfileが提供されていない場合、LaunchはインストールするPython依存関係の構築コンテキストを検索します。requirements.txtファイルが構築コンテキストのルートに見つかった場合、Launchはそのファイルにリストされている依存関係をインストールします。それ以外の場合、pyproject.tomlファイルが見つかった場合、Launchはproject.dependenciesセクションから依存関係をインストールします。
3 - Manage job inputs
Launch のコアな体験は、ハイパーパラメーターやデータセットのような様々なジョブ入力を容易に実験し、これらのジョブを適切なハードウェアにルーティングすることです。ジョブが作成されると、最初の作成者以外の ユーザー は、W&B GUIまたはCLIを介してこれらの入力を調整できます。CLIまたはUIから起動する際にジョブ入力を設定する方法については、ジョブをエンキューする ガイド を参照してください。
このセクションでは、ジョブで調整できる入力をプログラムで制御する方法について説明します。
デフォルトでは、W&B ジョブ は Run.config 全体をジョブへの入力としてキャプチャしますが、 Launch SDK は、run config 内の選択した キー を制御したり、JSONまたはYAMLファイルを 入力 として指定したりする機能を提供します。
wandb-core が必要です。詳細については、wandb-core README を参照してください。Run オブジェクト の再構成
ジョブ内の wandb.init によって返される Run オブジェクト は、デフォルトで再構成できます。 Launch SDK は、ジョブの起動時に Run.config オブジェクト のどの部分を再構成できるかをカスタマイズする方法を提供します。
import wandb
from wandb.sdk import launch
# Required for launch sdk use.
wandb.require("core")
config = {
"trainer": {
"learning_rate": 0.01,
"batch_size": 32,
"model": "resnet",
"dataset": "cifar10",
"private": {
"key": "value",
},
},
"seed": 42,
}
with wandb.init(config=config):
launch.manage_wandb_config(
include=["trainer"],
exclude=["trainer.private"],
)
# Etc.
関数 launch.manage_wandb_config は、Run.config オブジェクト の入力値を 受け入れる ようにジョブを構成します。オプションの include および exclude オプションは、ネストされた config オブジェクト 内のパスのプレフィックスを受け取ります。これは、たとえば、ジョブがエンド ユーザー に公開したくないオプションを持つ ライブラリ を使用する場合に役立ちます。
include プレフィックス が指定されている場合、include プレフィックス に一致する config 内のパスのみが入力値を 受け入れます。exclude プレフィックス が指定されている場合、exclude リスト に一致するパスは入力値から除外されません。パスが include と exclude の両方のプレフィックス に一致する場合、exclude プレフィックス が優先されます。
上記の例では、パス ["trainer.private"] は private キー を trainer オブジェクト から除外し、パス ["trainer"] は trainer オブジェクト にないすべての キー を除外します。
\ でエスケープされた . を使用して、名前に . が付いた キー を除外します。
たとえば、r"trainer\.private" は、trainer オブジェクト の下の private キー ではなく、trainer.private キー を除外します。
上記の r プレフィックス は、raw 文字列 を表すことに注意してください。
上記の コード がパッケージ化され、ジョブとして実行される場合、ジョブの入力 タイプ は次のようになります。
{
"trainer": {
"learning_rate": "float",
"batch_size": "int",
"model": "str",
"dataset": "str",
},
}
W&B CLI または UI からジョブを起動すると、 ユーザー は4つの trainer パラメータ のみをオーバーライドできます。
run config 入力 へのアクセス
run config 入力 で起動されたジョブは、Run.config を介して入力値に アクセス できます。ジョブ コード の wandb.init によって返される Run には、入力値が自動的に設定されます。ジョブ コード の任意の場所で run config 入力 値をロードするには、
from wandb.sdk import launch
run_config_overrides = launch.load_wandb_config()
を使用します。
ファイル の再構成
Launch SDK は、ジョブ コード の config ファイル に保存されている入力値を管理する方法も提供します。これは、この torchtune の例やこの Axolotl config のように、多くの ディープラーニング および大規模言語 モデル の ユースケース で一般的なパターンです。
Run.config オブジェクト を介して制御する必要があります。launch.manage_config_file 関数 を使用すると、config ファイル を Launch ジョブ への入力として追加できるため、ジョブの起動時に config ファイル 内の値を編集できます。
デフォルトでは、launch.manage_config_file が使用されている場合、run config 入力 はキャプチャされません。launch.manage_wandb_config を呼び出すと、この 振る舞い がオーバーライドされます。
次の例を考えてみましょう。
import yaml
import wandb
from wandb.sdk import launch
# Required for launch sdk use.
wandb.require("core")
launch.manage_config_file("config.yaml")
with open("config.yaml", "r") as f:
config = yaml.safe_load(f)
with wandb.init(config=config):
# Etc.
pass
コード が隣接するファイル config.yaml で実行されると想像してください。
learning_rate: 0.01
batch_size: 32
model: resnet
dataset: cifar10
launch.manage_config_file の呼び出しは、config.yaml ファイル をジョブへの入力として追加し、W&B CLI または UI から起動するときに再構成できるようにします。
include および exclude キーワード arg は、launch.manage_wandb_config と同じ方法で、config ファイル の許容される入力 キー をフィルタリングするために使用できます。
config ファイル 入力 へのアクセス
Launch によって作成された run で launch.manage_config_file が呼び出されると、launch は config ファイル の内容を入力値でパッチします。パッチされた config ファイル は、ジョブ 環境 で使用できます。
launch.manage_config_file を呼び出してください。ジョブ の Launch ドロワー UI のカスタマイズ
ジョブ の入力 の スキーマ を定義すると、ジョブ を起動するためのカスタム UI を作成できます。ジョブ の スキーマ を定義するには、launch.manage_wandb_config または launch.manage_config_file の呼び出しに含めます。スキーマ は、JSON Schema の形式の python 辞書 、または Pydantic モデル クラス のいずれかになります。
次の例は、次の プロパティ を持つ スキーマ を示しています。
seed、整数trainer、いくつかの キー が指定された 辞書 :trainer.learning_rate、ゼロより大きい floattrainer.batch_size、16、64、または256のいずれかである必要がある整数trainer.dataset、cifar10またはcifar100のいずれかである必要がある 文字列
schema = {
"type": "object",
"properties": {
"seed": {
"type": "integer"
}
"trainer": {
"type": "object",
"properties": {
"learning_rate": {
"type": "number",
"description": "Learning rate of the model",
"exclusiveMinimum": 0,
},
"batch_size": {
"type": "integer",
"description": "Number of samples per batch",
"enum": [16, 64, 256]
},
"dataset": {
"type": "string",
"description": "Name of the dataset to use",
"enum": ["cifar10", "cifar100"]
}
}
}
}
}
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=schema,
)
一般に、次の JSON Schema 属性 がサポートされています。
| 属性 | 必須 | 注記 |
|---|---|---|
type |
はい | number 、 integer 、 string 、または object のいずれかである必要があります。 |
title |
いいえ | プロパティ の表示名をオーバーライドします |
description |
いいえ | プロパティ ヘルパー テキスト を指定します |
enum |
いいえ | フリーフォーム テキスト 入力 の代わりに ドロップダウン 選択 を作成します |
minimum |
いいえ | type が number または integer の場合にのみ許可されます |
maximum |
いいえ | type が number または integer の場合にのみ許可されます |
exclusiveMinimum |
いいえ | type が number または integer の場合にのみ許可されます |
exclusiveMaximum |
いいえ | type が number または integer の場合にのみ許可されます |
properties |
いいえ | type が object の場合、ネストされた 構成 を定義するために使用されます |
次の例は、次の プロパティ を持つ スキーマ を示しています。
seed、整数trainer、いくつかのサブ 属性 が指定された スキーマ :trainer.learning_rate、ゼロより大きい floattrainer.batch_size、1〜256(両端を含む)の範囲の整数trainer.dataset、cifar10またはcifar100のいずれかである必要がある 文字列
class DatasetEnum(str, Enum):
cifar10 = "cifar10"
cifar100 = "cifar100"
class Trainer(BaseModel):
learning_rate: float = Field(gt=0, description="Learning rate of the model")
batch_size: int = Field(ge=1, le=256, description="Number of samples per batch")
dataset: DatasetEnum = Field(title="Dataset", description="Name of the dataset to use")
class Schema(BaseModel):
seed: int
trainer: Trainer
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=Schema,
)
クラス の インスタンス を使用することもできます。
t = Trainer(learning_rate=0.01, batch_size=32, dataset=DatasetEnum.cifar10)
s = Schema(seed=42, trainer=t)
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
input_schema=s,
)
ジョブ 入力 スキーマ を追加すると、 Launch ドロワー に構造化されたフォームが作成され、ジョブ の起動が容易になります。
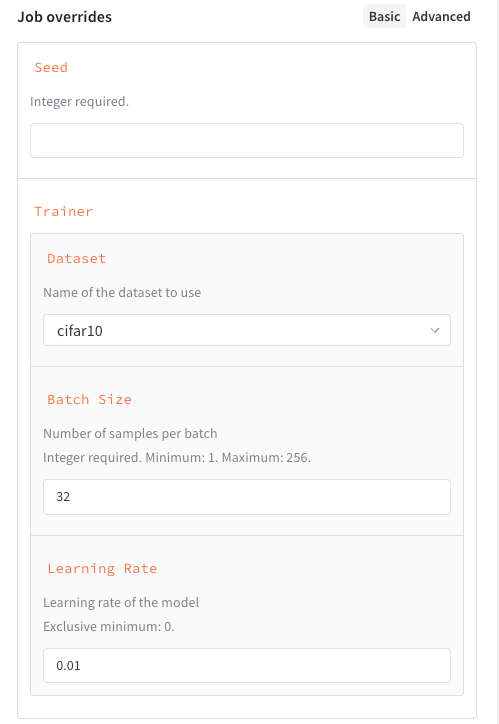
4 - Monitor launch queue
インタラクティブな Queue monitoring dashboard を使用して、 Launch キューの使用率が高いかアイドル状態かを確認したり、実行中のワークロードを視覚化したり、非効率なジョブを見つけたりできます。 Launch キューダッシュボードは、コンピューティングハードウェアまたはクラウド リソースを効果的に使用しているかどうかを判断する場合に特に役立ちます。
より詳細な 分析を行うために、このページから W&B の 実験管理 ワークスペースや、Datadog、NVIDIA Base Command、クラウドコンソールなどの外部 インフラストラクチャー 監視プロバイダーにリンクできます。
ダッシュボードとプロット
Monitor タブを使用すると、過去7日間に発生したキューのアクティビティを表示できます。左側の パネル を使用して、時間範囲、グループ化、フィルターを制御します。
ダッシュボードには、パフォーマンスと効率に関する よくある質問 に答える多くのプロットが含まれています。以下のセクションでは、キューダッシュボードのUI要素について説明します。
ジョブステータス
Job status プロットは、各時間間隔で実行中、保留中、キューイング中、または完了したジョブの数を示します。 Job status プロットを使用して、キュー内のアイドル期間を特定します。
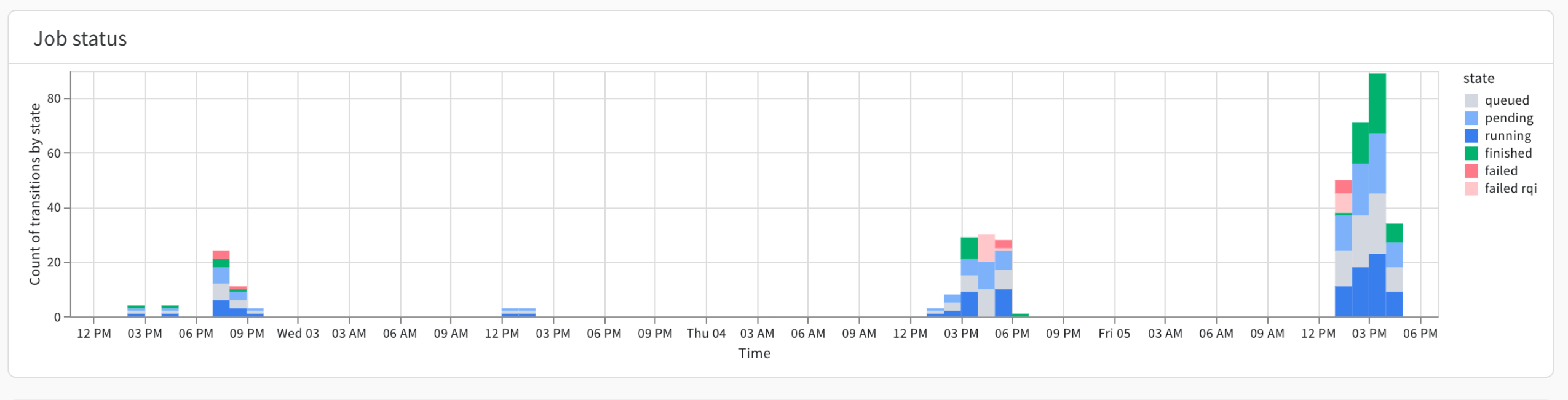
たとえば、固定リソース(DGX BasePodなど)があるとします。固定リソースでアイドルキューが観察された場合、これは スイープ などの優先度の低いプリエンプティブ Launch ジョブを実行する機会があることを示唆している可能性があります。
一方、クラウド リソースを使用していて、アクティビティが定期的に発生しているとします。アクティビティが定期的に発生する場合は、特定の時間帯にリソースを予約することでコストを節約できる可能性があります。
プロットの右側には、 Launch ジョブの [ステータス] (/ja/guides/launch/launch-view-jobs/#check-the-status-of-a-job)を示すキーがあります。
Queued アイテムは、ワークロードを他のキューにシフトする機会を示している可能性があります。失敗の急増は、 Launch ジョブのセットアップでサポートが必要な ユーザー を特定するのに役立ちます。キューイング時間
Queued time プロットは、 Launch ジョブが特定の日付または時間範囲のキューにあった時間(秒単位)を示します。
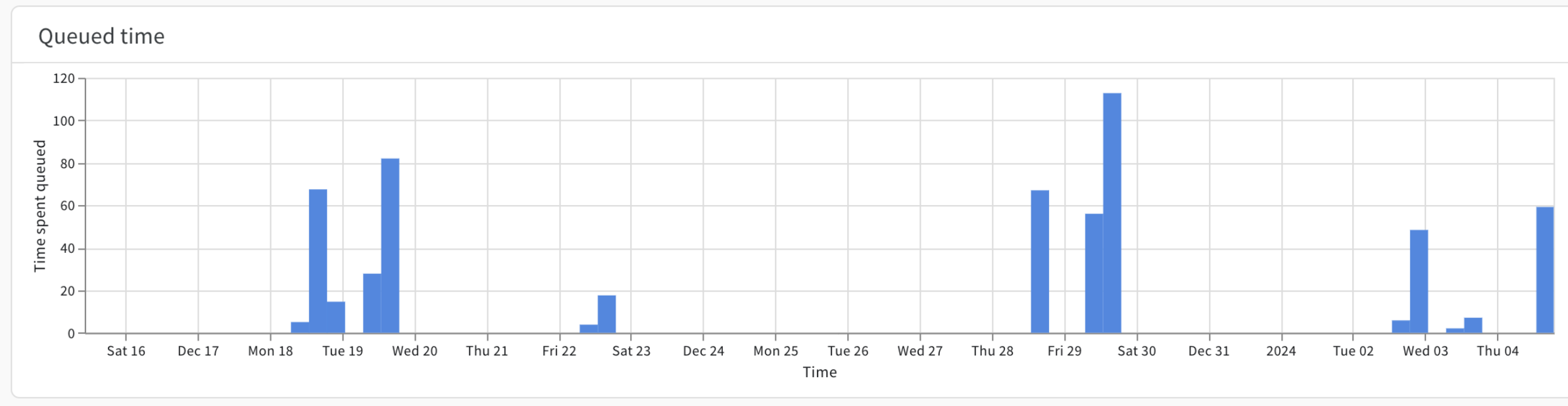
x軸は指定した時間枠を示し、y軸は Launch ジョブが Launch キューにあった時間(秒単位)を示します。たとえば、特定の日にある Launch ジョブが10個キューイングされているとします。これらの10個の Launch ジョブが平均60秒ずつ待機する場合、 Queue time プロットは600秒を示します。
左側のバーにある Grouping コントロールを使用して、各ジョブの色をカスタマイズします。
これにより、どの ユーザー とジョブがキュー容量の不足による影響を受けているかを特定するのに特に役立ちます。
ジョブのrun
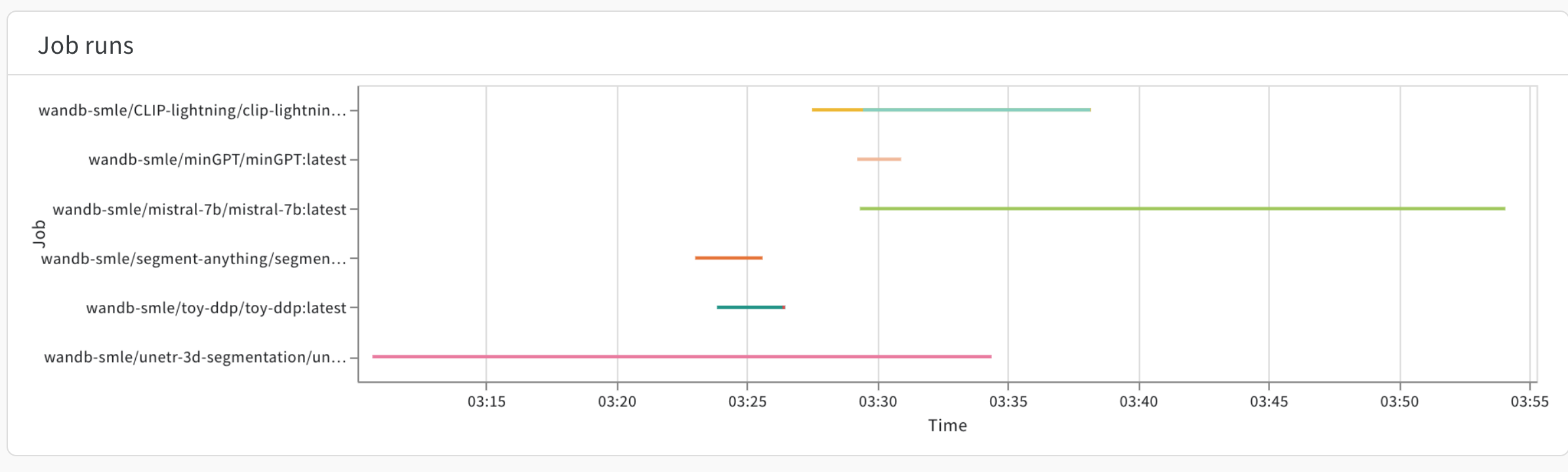
このプロットは、特定の期間に実行されたすべてのジョブの開始と終了を示し、runごとに異なる色で表示されます。これにより、特定の時点でキューが処理していたワークロードを一目で簡単に確認できます。
パネル の右下にある選択 ツール を使用してジョブをブラッシングし、下のテーブルに詳細を入力します。
CPU と GPU の使用率
GPU use by a job 、 CPU use by a job 、 GPU memory by job 、 System memory by job を使用して、 Launch ジョブの効率を表示します。
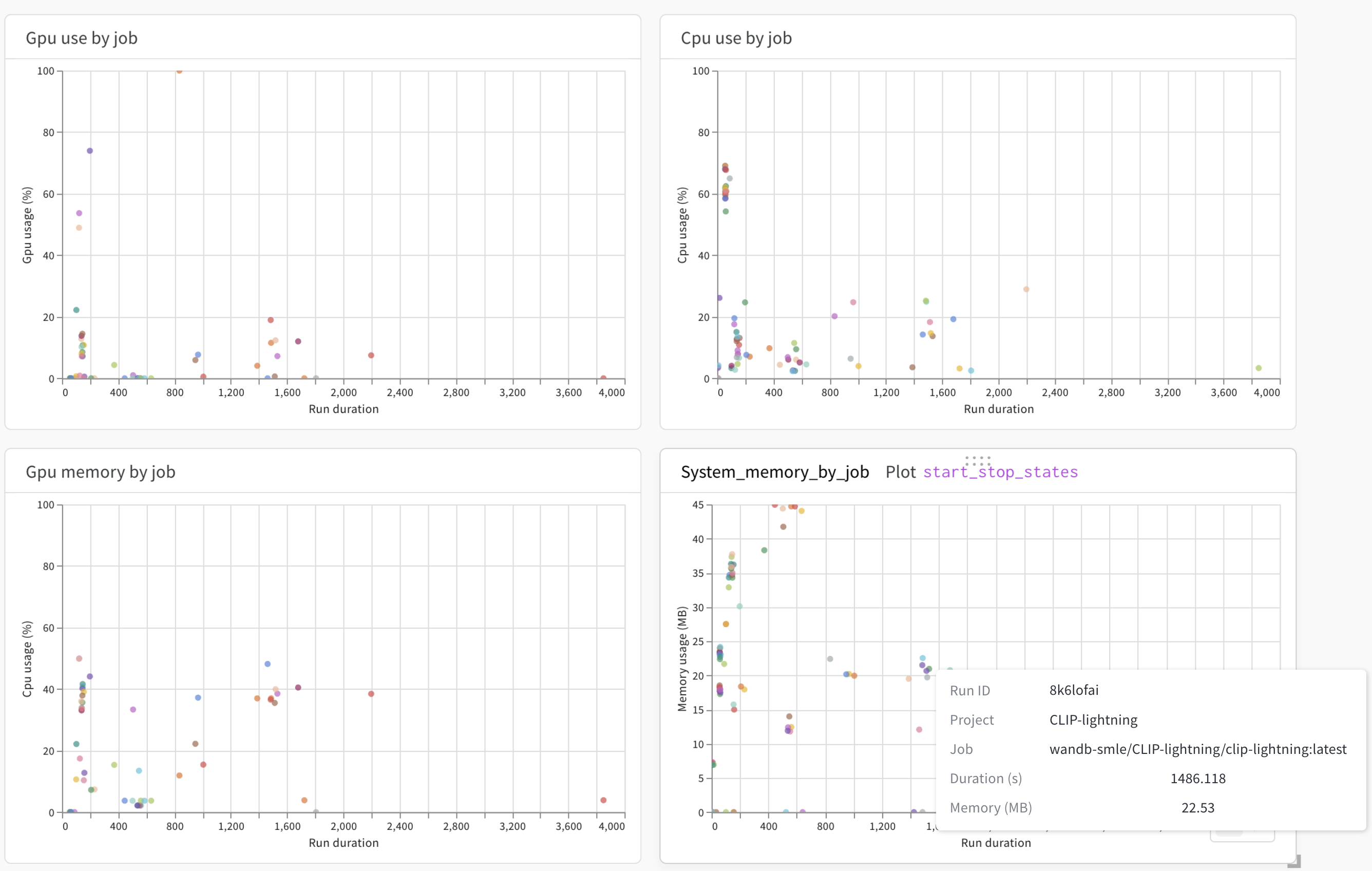
たとえば、 GPU memory by job を使用して、W&B の run が完了するまでに長い時間がかかったかどうか、CPUコアの使用率が低いかどうかを確認できます。
各プロットのx軸は、 Launch ジョブによって作成されたW&B の run の継続時間(秒単位)を示します。データポイントにマウスを合わせると、run ID、runが属する プロジェクト 、W&B の run を作成した Launch ジョブなど、W&B の run に関する情報が表示されます。
エラー
Errors パネルには、特定の Launch キューで発生したエラーが表示されます。具体的には、Errors パネルには、エラーが発生したときのタイムスタンプ、エラーが発生した Launch ジョブの名前、および作成されたエラーメッセージが表示されます。デフォルトでは、エラーは最新のものから古いものの順に並べられています。
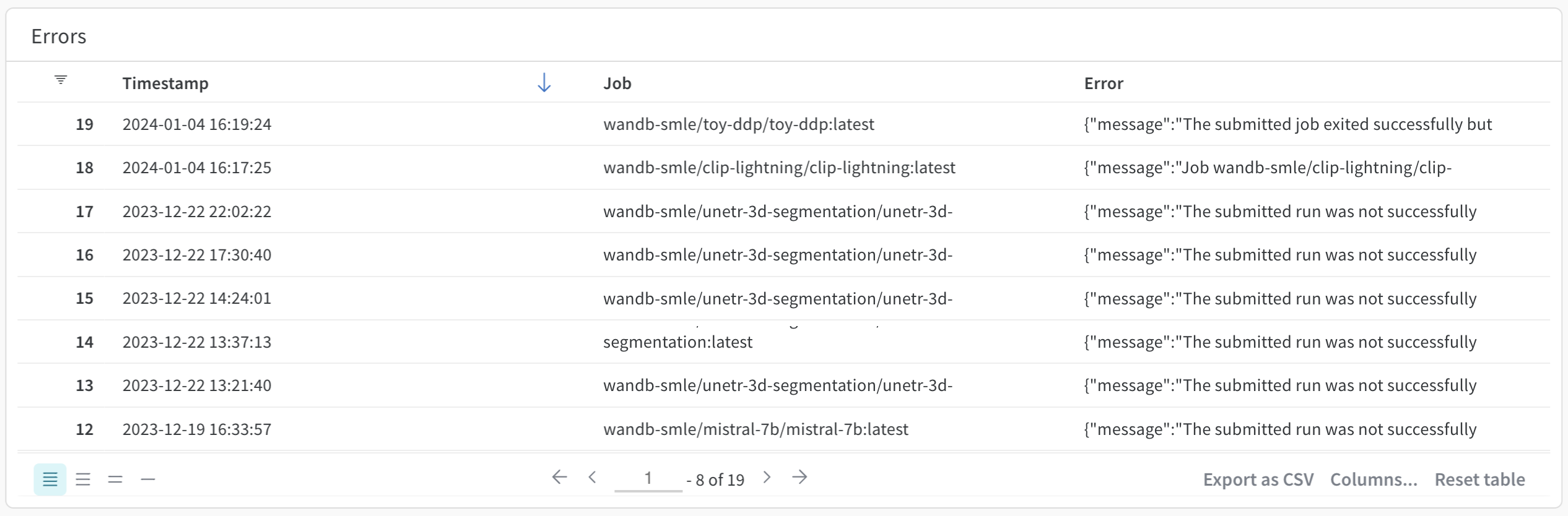
Errors パネルを使用して、 ユーザー を特定してブロックを解除します。
外部リンク
キューの可観測性ダッシュボードのビューは、すべてのキュータイプで一貫性がありますが、多くの場合、 環境 固有のモニターに直接ジャンプすると役立ちます。これを実現するには、キューの可観測性ダッシュボードからコンソールへのリンクを直接追加します。
ページ の下部にある Manage Links をクリックして パネル を開きます。必要な ページ の完全なURLを追加します。次に、ラベルを追加します。追加したリンクは、 External Links セクションに表示されます。
5 - View launch jobs
以下のページでは、キューに追加された Launch ジョブに関する情報を表示する方法について説明します。
ジョブの表示
W&B アプリでキューに追加されたジョブを表示します。
- W&B アプリ (https://wandb.ai/home) に移動します。
- 左側のサイドバーの [Applications] セクションで [Launch] を選択します。
- [All entities] ドロップダウンを選択し、Launch ジョブが属するエンティティを選択します。
- Launch アプリケーションページから折りたたみ可能なUIを展開して、その特定のキューに追加されたジョブのリストを表示します。
たとえば、次の図は、job-source-launch_demo-canonical というジョブから作成された2つの run を示しています。このジョブは Start queue というキューに追加されました。キューにリストされている最初の run は resilient-snowball と呼ばれ、2番目の run は earthy-energy-165 と呼ばれます。
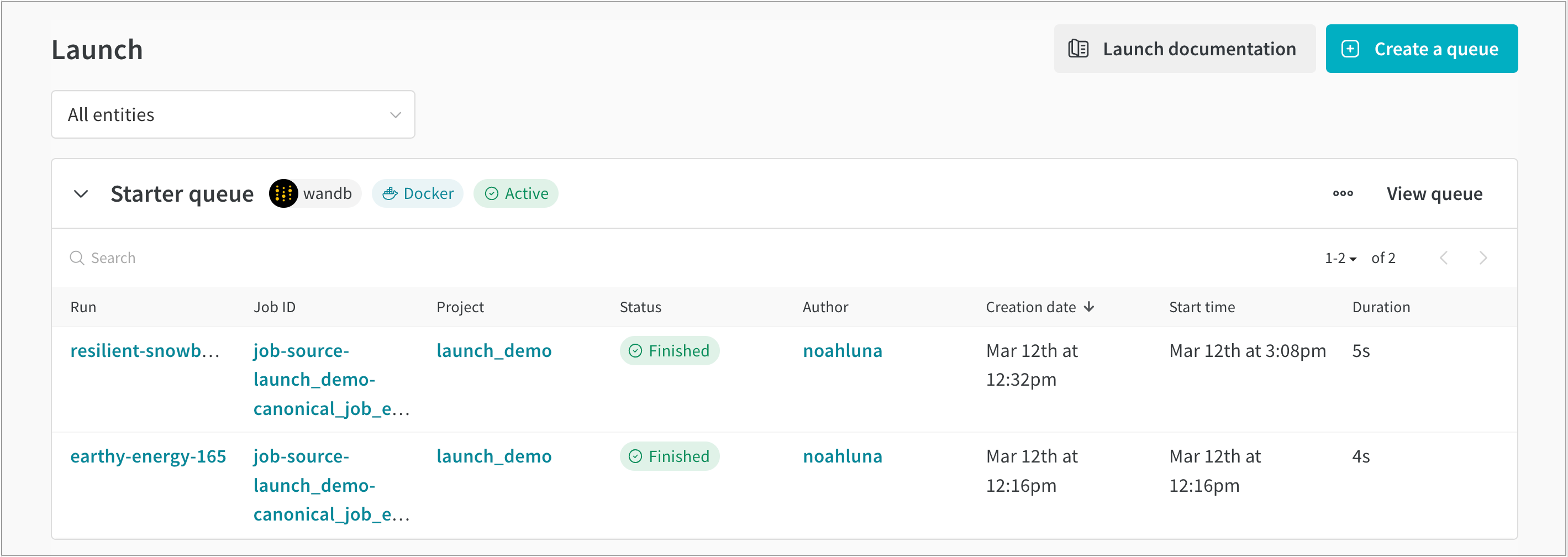
W&B アプリのUI内では、Launch ジョブから作成された run に関する追加情報を見つけることができます。
- Run: そのジョブに割り当てられた W&B の run の名前。
- Job ID: ジョブの名前。
- Project: run が属する project の名前。
- Status: キューに入れられた run のステータス。
- Author: run を作成した W&B エンティティ。
- Creation date: キューが作成されたときのタイムスタンプ。
- Start time: ジョブが開始されたときのタイムスタンプ。
- Duration: ジョブの run が完了するまでにかかった時間(秒単位)。
ジョブのリスト表示
W&B CLI を使用して、project 内に存在するジョブのリストを表示します。W&B job list コマンドを使用し、Launch ジョブが属する project とエンティティの名前をそれぞれ --project および --entity フラグで指定します。
wandb job list --entity your-entity --project project-name
ジョブのステータスを確認する
次の表は、キューに入れられた run が持つことができるステータスを定義しています。
| Status | Description |
|---|---|
| Idle | run はアクティブなエージェントのないキューにあります。 |
| Queued | run はエージェントが処理するのを待機しているキューにあります。 |
| Pending | run はエージェントによって取得されましたが、まだ開始されていません。これは、 cluster でリソースが利用できないことが原因である可能性があります。 |
| Running | run は現在実行中です。 |
| Killed | ジョブは user によって強制終了されました。 |
| Crashed | run はデータの送信を停止したか、正常に開始されませんでした。 |
| Failed | run がゼロ以外の終了コードで終了したか、run の開始に失敗しました。 |
| Finished | ジョブは正常に完了しました。 |