これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
Launch integration guides
- 1: Dagster
- 2: Launch multinode jobs with Volcano
- 3: NVIDIA NeMo Inference Microservice Deploy Job
- 4: Spin up a single node GPU cluster with Minikube
1 - Dagster
Dagster と W&B (Weights & Biases) を使用して、MLOps パイプラインを編成し、ML アセットを維持します。W&B との統合により、Dagster 内で次のことが容易になります。
- W&B Artifacts の使用と作成。
- W&B Registry で Registered Models の使用と作成。
- W&B Launch を使用した、専用コンピューティングでのトレーニングジョブの実行。
- ops およびアセットでの wandb クライアントの使用。
W&B Dagster インテグレーションは、W&B 固有の Dagster リソースと IO Manager を提供します。
wandb_resource: W&B API に対して認証および通信するために使用される Dagster リソース。wandb_artifacts_io_manager: W&B Artifacts の消費に使用される Dagster IO Manager。
次のガイドでは、Dagster で W&B を使用するための前提条件を満たす方法、ops およびアセットで W&B Artifacts を作成および使用する方法、W&B Launch の使用方法、推奨されるベストプラクティスについて説明します。
始める前に
Weights & Biases 内で Dagster を使用するには、次のリソースが必要です。
- W&B APIキー。
- W&B entity (ユーザーまたは Team): エンティティとは、W&B Runs と Artifacts を送信するユーザー名または Team 名です。run を記録する前に、W&B App UI でアカウントまたは Team エンティティを作成してください。エンティティを指定しない場合、run はデフォルトのエンティティ (通常はユーザー名) に送信されます。Project Defaults の設定でデフォルトのエンティティを変更します。
- W&B project: W&B Runs が保存される Project の名前。
W&B App でユーザーまたは Team のプロフィールページを確認して、W&B エンティティを見つけてください。既存の W&B Project を使用することも、新しい Project を作成することもできます。新しい Project は、W&B App のホームページまたはユーザー/Team のプロフィールページで作成できます。Project が存在しない場合、最初に使用するときに自動的に作成されます。以下の手順では、APIキーを取得する方法について説明します。
APIキーを取得する方法
- W&B にログイン します。注: W&B Server を使用している場合は、インスタンスのホスト名について管理者に問い合わせてください。
- 認証ページ またはユーザー/Team の設定に移動して、APIキーを収集します。本番環境では、サービスアカウント を使用してそのキーを所有することをお勧めします。
- その APIキーの環境変数を設定します。
export WANDB_API_KEY=YOUR_KEY.
以下の例では、Dagster コードで APIキーを指定する場所を示しています。wandb_config ネストされた辞書内でエンティティと Project 名を必ず指定してください。異なる W&B Project を使用する場合は、異なる wandb_config 値を異なる ops/アセットに渡すことができます。渡すことができるキーの詳細については、以下の構成セクションを参照してください。
例: @job の構成
# add this to your config.yaml
# alternatively you can set the config in Dagit's Launchpad or JobDefinition.execute_in_process
# Reference: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # replace this with your W&B entity
project: my_project # replace this with your W&B project
@job(
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
"io_manager": wandb_artifacts_io_manager,
}
)
def simple_job_example():
my_op()
例: アセットを使用した @repository の構成
from dagster_wandb import wandb_artifacts_io_manager, wandb_resource
from dagster import (
load_assets_from_package_module,
make_values_resource,
repository,
with_resources,
)
from . import assets
@repository
def my_repository():
return [
*with_resources(
load_assets_from_package_module(assets),
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
"wandb_artifacts_manager": wandb_artifacts_io_manager.configured(
{"cache_duration_in_minutes": 60} # only cache files for one hour
),
},
resource_config_by_key={
"wandb_config": {
"config": {
"entity": "my_entity", # replace this with your W&B entity
"project": "my_project", # replace this with your W&B project
}
}
},
),
]
@job の例とは対照的に、この例では IO Manager のキャッシュ期間を構成していることに注意してください。
構成
以下の構成オプションは、インテグレーションによって提供される W&B 固有の Dagster リソースおよび IO Manager の設定として使用されます。
wandb_resource: W&B API との通信に使用される Dagster リソース。提供された APIキーを使用して自動的に認証します。プロパティ:api_key: (str, 必須): W&B API との通信に必要な W&B APIキー。host: (str, オプション): 使用する API ホストサーバー。W&B Server を使用している場合にのみ必要です。デフォルトはパブリッククラウドホストhttps://api.wandb.aiです。
wandb_artifacts_io_manager: W&B Artifacts を消費するための Dagster IO Manager。プロパティ:base_dir: (int, オプション) ローカルストレージとキャッシュに使用されるベースディレクトリー。W&B Artifacts と W&B Run のログは、そのディレクトリーから書き込まれ、読み取られます。デフォルトでは、DAGSTER_HOMEディレクトリーを使用しています。cache_duration_in_minutes: (int, オプション) W&B Artifacts と W&B Run ログをローカルストレージに保持する時間を定義します。その時間の間、開かれなかったファイルとディレクトリーのみがキャッシュから削除されます。キャッシュのパージは、IO Manager の実行の最後に発生します。キャッシュを完全にオフにする場合は、0 に設定できます。キャッシュを使用すると、同じマシンで実行されているジョブ間で Artifact が再利用される場合に速度が向上します。デフォルトは 30 日です。run_id: (str, オプション): 再開に使用されるこの Run の一意の ID。Project 内で一意である必要があり、Run を削除した場合は ID を再利用できません。UI での識別に役立つ短い説明名には name フィールドを使用し、Run 全体でハイパーパラメーターを比較するために保存するには config を使用します。ID には、次の特殊文字を含めることはできません:/\#?%:..IO Manager が Run を再開できるようにするには、Dagster 内で実験管理を行うときに Run ID を設定する必要があります。デフォルトでは、Dagster Run ID (例:7e4df022-1bf2-44b5-a383-bb852df4077e) に設定されています。run_name: (str, オプション) UI でこの Run を識別するのに役立つ、この Run の短い表示名。デフォルトでは、dagster-run-[Dagster Run ID の最初の 8 文字]という形式の文字列です。たとえば、dagster-run-7e4df022です。run_tags: (list[str], オプション): UI でこの Run のタグのリストを設定する文字列のリスト。タグは、Run をまとめて編成したり、baselineやproductionなどの一時的なラベルを適用したりするのに役立ちます。UI でタグを簡単に追加および削除したり、特定のタグを持つ Run のみに絞り込んだりできます。インテグレーションで使用される W&B Run には、dagster_wandbタグが付けられます。
W&B Artifacts を使用する
W&B Artifact との統合は、Dagster IO Manager に依存しています。
IO Manager は、アセットまたは op の出力を保存し、ダウンストリームのアセットまたは op の入力としてロードする役割を担う、ユーザーが提供するオブジェクトです。たとえば、IO Manager はファイルシステムのファイルからオブジェクトを保存およびロードできます。
この統合は、W&B Artifacts の IO Manager を提供します。これにより、Dagster の @op または @asset は、W&B Artifacts をネイティブに作成および消費できます。以下は、Python リストを含むデータセット型の W&B Artifact を生成する @asset の簡単な例です。
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3] # this will be stored in an Artifact
Artifact を書き込むには、@op、@asset、および @multi_asset にメタデータ構成をアノテーションできます。同様に、Dagster の外部で作成された場合でも、W&B Artifacts を消費することもできます。
W&B Artifacts を書き込む
続行する前に、W&B Artifacts の使用方法を十分に理解しておくことをお勧めします。Artifacts に関するガイド を参照してください。
W&B Artifact を書き込むには、Python 関数からオブジェクトを返します。W&B では、次のオブジェクトがサポートされています。
- Python オブジェクト (int、dict、list…)
- W&B オブジェクト (Table, Image, Graph…)
- W&B Artifact オブジェクト
以下の例では、Dagster アセット (@asset) で W&B Artifacts を書き込む方法を示しています。
pickle モジュールでシリアル化できるものはすべて、インテグレーションによって作成された Artifact に pickle 化されて追加されます。コンテンツは、Dagster 内でその Artifact を読み取るときに unpickle 化されます (アーティファクトの読み取り を参照して詳細を確認してください)。
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3]
W&B は、複数の Pickle ベースのシリアル化モジュール (pickle、dill、cloudpickle、joblib) をサポートしています。ONNX や PMML などのより高度なシリアル化を使用することもできます。詳細については、シリアル化 セクションを参照してください。
ネイティブの W&B オブジェクト (例: Table、Image、または Graph) は、インテグレーションによって作成された Artifact に追加されます。以下は、Table を使用した例です。
import wandb
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset_in_table():
return wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
複雑なユースケースでは、独自の Artifact オブジェクトを構築する必要がある場合があります。インテグレーションは、インテグレーションの両側でメタデータを拡張するなど、役立つ追加機能も提供します。
import wandb
MY_ASSET = "my_asset"
@asset(
name=MY_ASSET,
io_manager_key="wandb_artifacts_manager",
)
def create_artifact():
artifact = wandb.Artifact(MY_ASSET, "dataset")
table = wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
artifact.add(table, "my_table")
return artifact
構成
wandb_artifact_configuration と呼ばれる構成ディクショナリは、@op、@asset、および @multi_asset で設定できます。このディクショナリは、メタデータとしてデコレーター引数で渡す必要があります。この構成は、W&B Artifacts の IO Manager の読み取りと書き込みを制御するために必要です。
@op の場合、Out メタデータ引数を介して出力メタデータに配置されます。
@asset の場合、アセットのメタデータ引数に配置されます。
@multi_asset の場合、AssetOut メタデータ引数を介して各出力メタデータに配置されます。
以下のコード例では、@op、@asset、および @multi_asset 計算でディクショナリを構成する方法を示しています。
@op の例:
@op(
out=Out(
metadata={
"wandb_artifact_configuration": {
"name": "my_artifact",
"type": "dataset",
}
}
)
)
def create_dataset():
return [1, 2, 3]
@asset の例:
@asset(
name="my_artifact",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3]
@asset にはすでに名前があるため、構成を介して名前を渡す必要はありません。インテグレーションは、Artifact 名をアセット名として設定します。
@multi_asset の例:
@multi_asset(
name="create_datasets",
outs={
"first_table": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "training_dataset",
}
},
io_manager_key="wandb_artifacts_manager",
),
"second_table": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "validation_dataset",
}
},
io_manager_key="wandb_artifacts_manager",
),
},
group_name="my_multi_asset_group",
)
def create_datasets():
first_table = wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
second_table = wandb.Table(columns=["d", "e"], data=[[4, 5]])
return first_table, second_table
サポートされているプロパティ:
name: (str) この Artifact の人間が判読できる名前。これは、UI でこの Artifact を識別したり、use_artifact 呼び出しで参照したりする方法です。名前には、文字、数字、アンダースコア、ハイフン、およびドットを含めることができます。名前は、Project 全体で一意である必要があります。@opに必須。type: (str) Artifact のタイプ。Artifact を編成および区別するために使用されます。一般的なタイプにはデータセットまたはモデルがありますが、文字、数字、アンダースコア、ハイフン、およびドットを含む任意の文字列を使用できます。出力が Artifact でない場合は必須。description: (str) Artifact の説明を提供する自由形式のテキスト。説明は UI で Markdown レンダリングされるため、テーブルやリンクなどを配置するのに適しています。aliases: (list[str]) Artifact に適用する 1 つ以上のエイリアスを含む配列。インテグレーションは、設定されているかどうかに関係なく、「latest」タグもそのリストに追加します。これは、モデルとデータセットのバージョン管理を管理するための効果的な方法です。add_dirs: (list[dict[str, Any]]): Artifact に含めるローカルディレクトリーごとの構成を含む配列。SDK の同名メソッドと同じ引数をサポートしています。add_files: (list[dict[str, Any]]): Artifact に含めるローカルファイルごとの構成を含む配列。SDK の同名メソッドと同じ引数をサポートしています。add_references: (list[dict[str, Any]]): Artifact に含める外部参照ごとの構成を含む配列。SDK の同名メソッドと同じ引数をサポートしています。serialization_module: (dict) 使用するシリアル化モジュールの構成。詳細については、シリアル化セクションを参照してください。name: (str) シリアル化モジュールの名前。受け入れられる値:pickle、dill、cloudpickle、joblib。モジュールはローカルで利用可能である必要があります。parameters: (dict[str, Any]) シリアル化関数に渡されるオプションの引数。そのモジュールのダンプメソッドと同じパラメーターを受け入れます。たとえば、{"compress": 3, "protocol": 4}です。
高度な例:
@asset(
name="my_advanced_artifact",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
"description": "My *Markdown* description",
"aliases": ["my_first_alias", "my_second_alias"],
"add_dirs": [
{
"name": "My directory",
"local_path": "path/to/directory",
}
],
"add_files": [
{
"name": "validation_dataset",
"local_path": "path/to/data.json",
},
{
"is_tmp": True,
"local_path": "path/to/temp",
},
],
"add_references": [
{
"uri": "https://picsum.photos/200/300",
"name": "External HTTP reference to an image",
},
{
"uri": "s3://my-bucket/datasets/mnist",
"name": "External S3 reference",
},
],
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_advanced_artifact():
return [1, 2, 3]
アセットは、インテグレーションの両側で役立つメタデータを使用して具体化されます。
- W&B 側: ソースインテグレーションの名前とバージョン、使用された Python バージョン、pickle プロトコルバージョンなど。
- Dagster 側:
- Dagster Run ID
- W&B Run: ID、名前、パス、URL
- W&B Artifact: ID、名前、タイプ、バージョン、サイズ、URL
- W&B Entity
- W&B Project
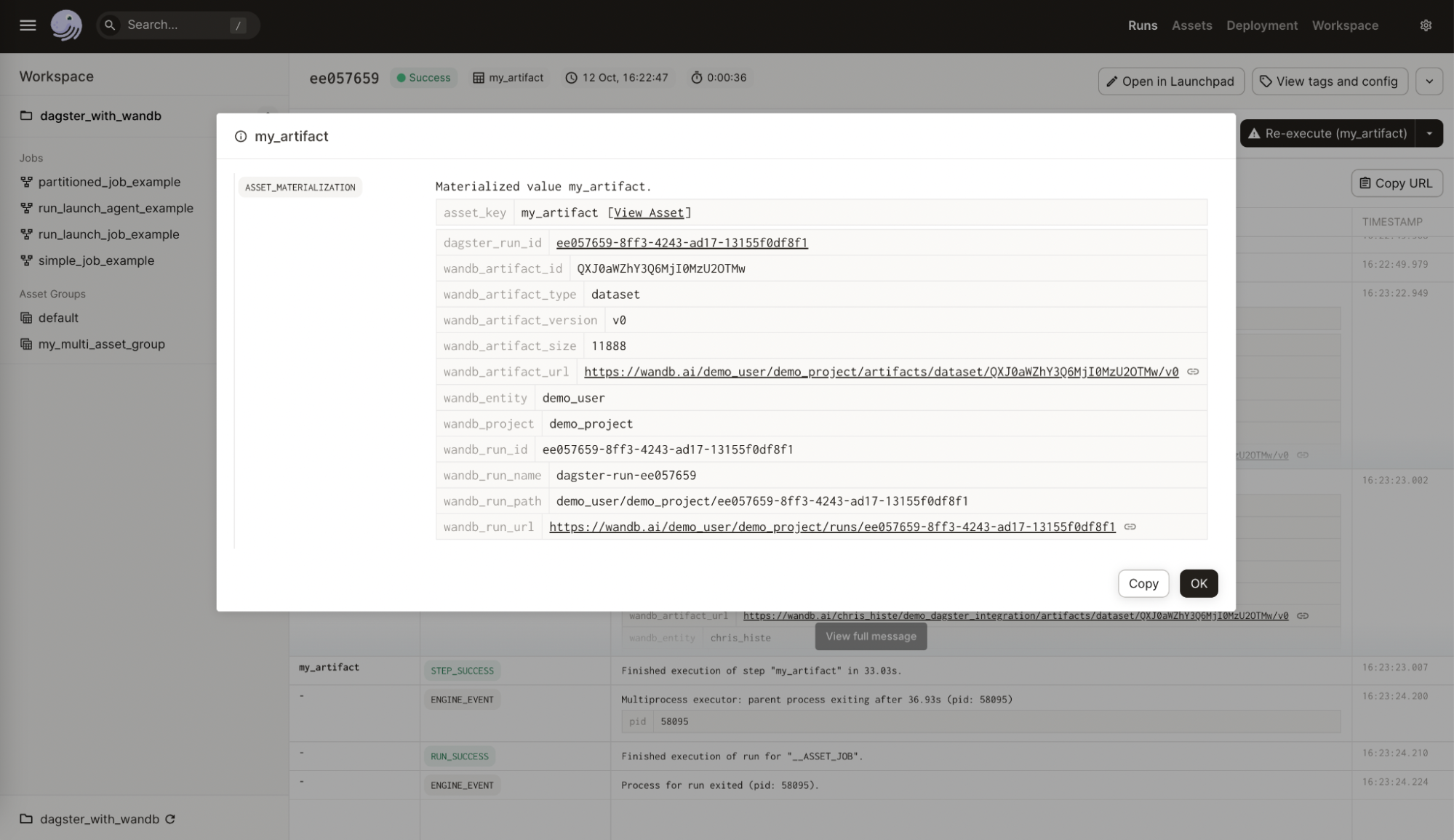
以下の画像は、Dagster アセットに追加された W&B からのメタデータを示しています。この情報は、インテグレーションなしでは利用できません。
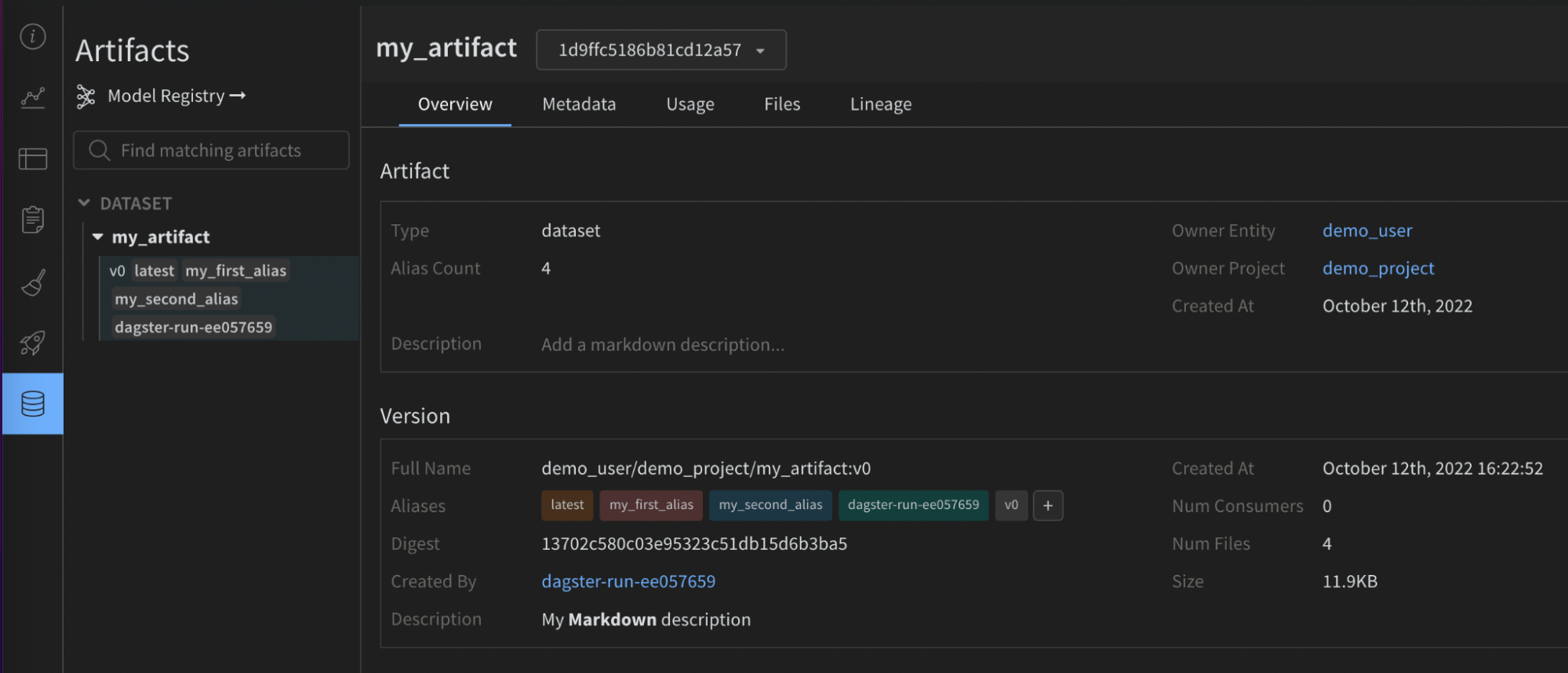
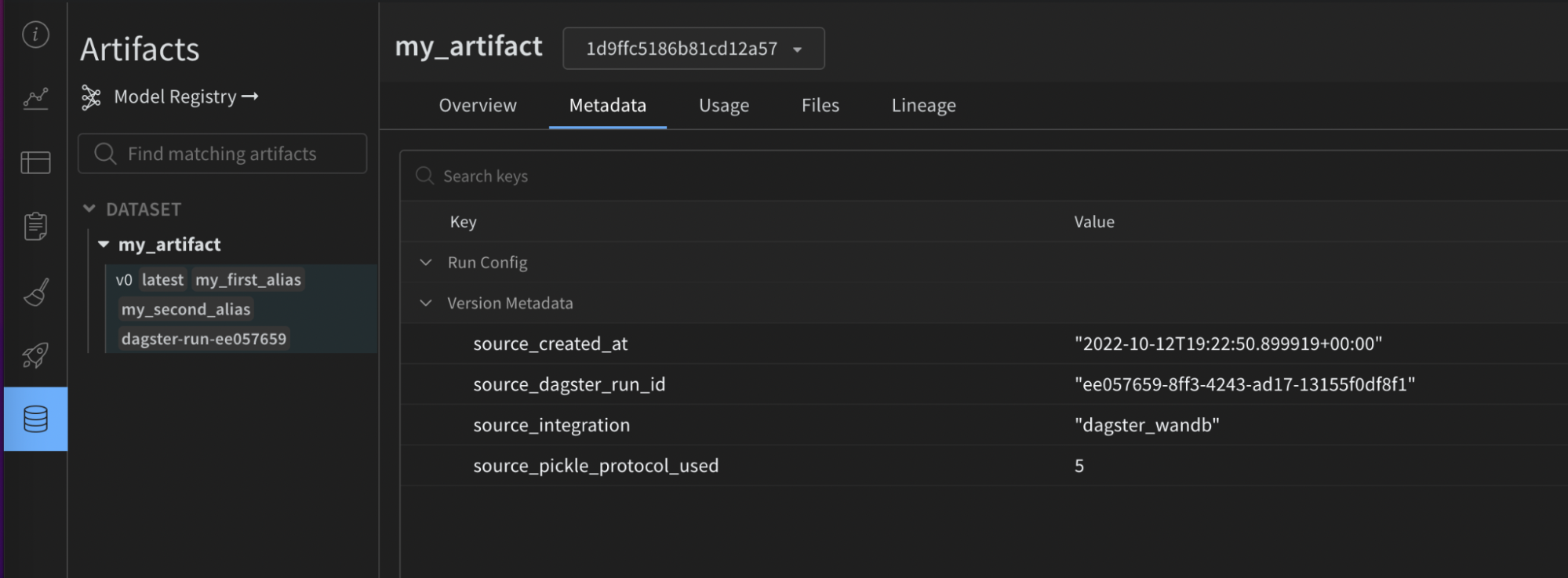
次の画像は、提供された構成が W&B Artifact 上の役立つメタデータでどのようにエンリッチされたかを示しています。この情報は、再現性とメンテナンスに役立ちます。この情報は、インテグレーションなしでは利用できません。
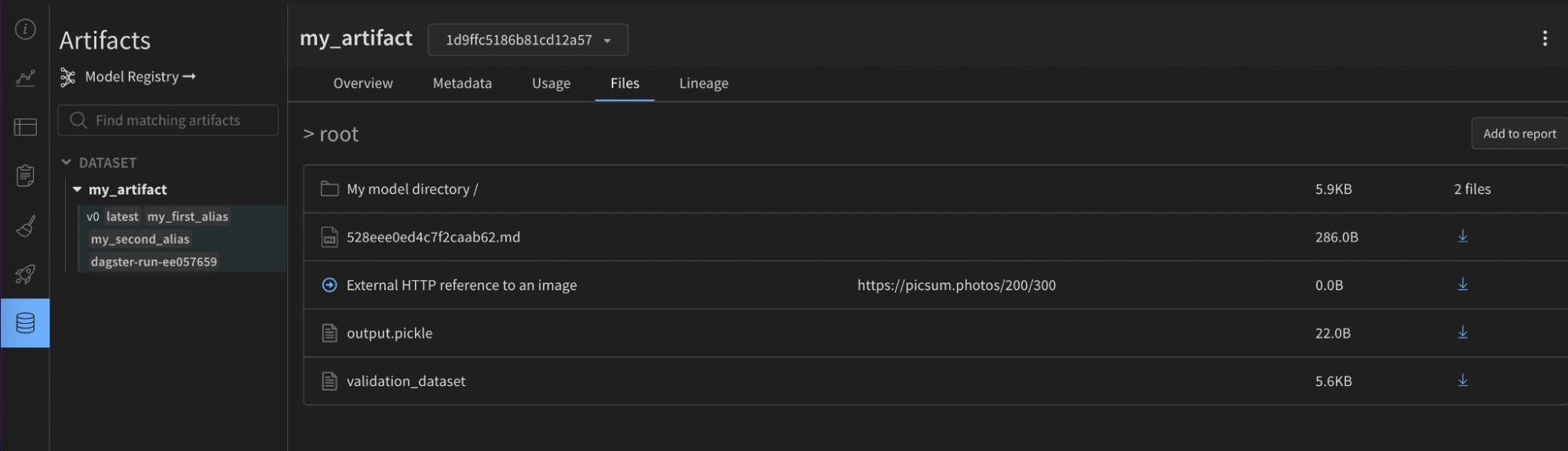
mypy のような静的型チェッカーを使用する場合は、次のものを使用して構成型定義オブジェクトをインポートします。
from dagster_wandb import WandbArtifactConfiguration
パーティションの使用
このインテグレーションは、Dagster パーティション をネイティブにサポートしています。
以下は、DailyPartitionsDefinition を使用してパーティション化された例です。
@asset(
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01", end_date="2023-02-01"),
name="my_daily_partitioned_asset",
compute_kind="wandb",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
}
},
)
def create_my_daily_partitioned_asset(context):
partition_key = context.asset_partition_key_for_output()
context.log.info(f"Creating partitioned asset for {partition_key}")
return random.randint(0, 100)
このコードは、パーティションごとに 1 つの W&B Artifact を生成します。パーティションキーが追加されたアセット名の下の Artifact パネル (UI) で Artifact を表示します。たとえば、my_daily_partitioned_asset.2023-01-01、my_daily_partitioned_asset.2023-01-02、または my_daily_partitioned_asset.2023-01-03 です。複数のディメンションにわたってパーティション化されたアセットは、ドット区切りの形式で各ディメンションを示します。たとえば、my_asset.car.blue です。
このインテグレーションでは、1 つの Run 内で複数のパーティションを具体化することはできません。アセットを具体化するには、複数の Run を実行する必要があります。これは、アセットを具体化するときに Dagit で実行できます。
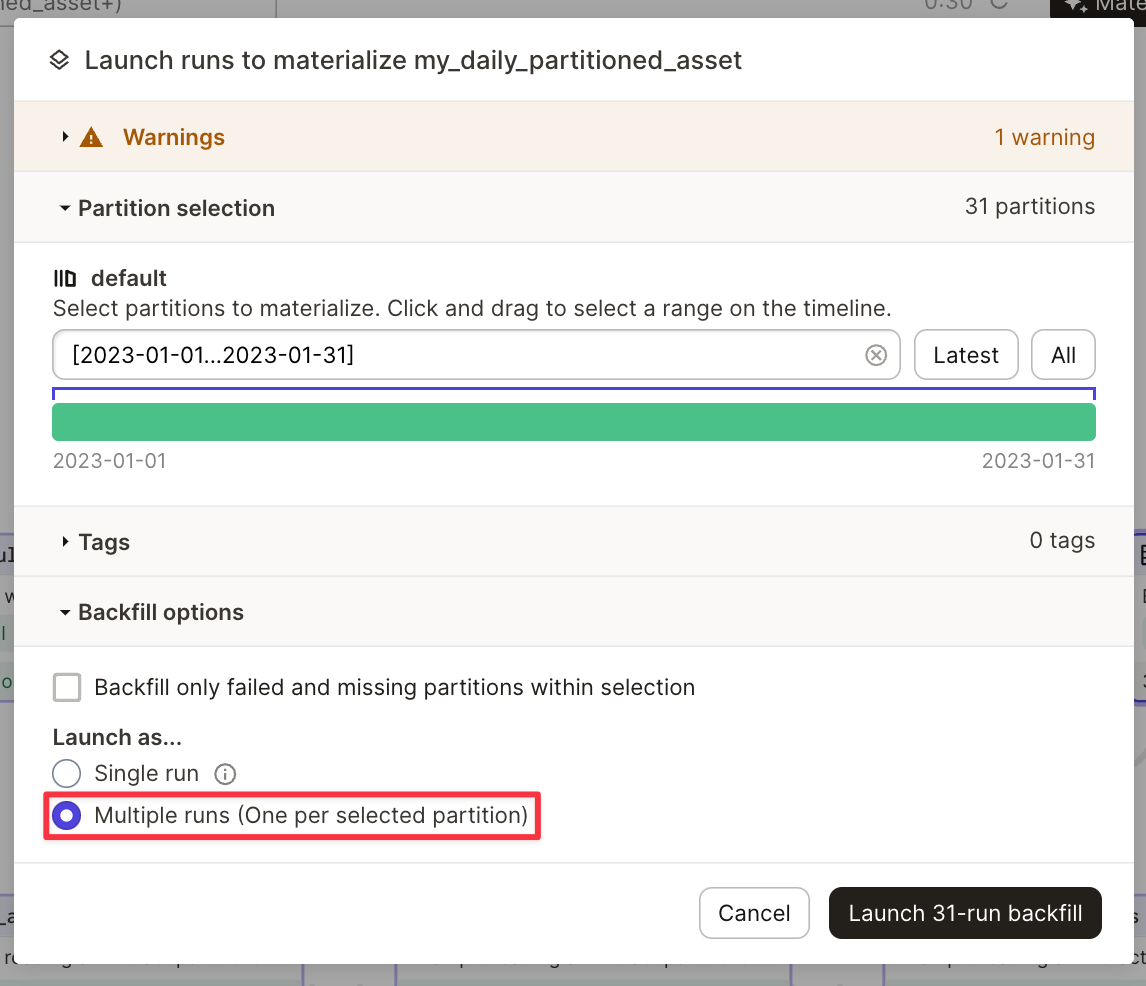
高度な使用法
W&B Artifacts を読み取る
W&B Artifacts の読み取りは、書き込みに似ています。wandb_artifact_configuration と呼ばれる構成ディクショナリは、@op または @asset で設定できます。唯一の違いは、出力ではなく入力で構成を設定する必要があることです。
@op の場合、In メタデータ引数を介して入力メタデータに配置されます。Artifact の名前を明示的に渡す必要があります。
@asset の場合、Asset In メタデータ引数を介して入力メタデータに配置されます。親アセットの名前と一致する必要があるため、Artifact 名を渡さないでください。
インテグレーションの外部で作成された Artifact に依存関係を持たせたい場合は、SourceAsset を使用する必要があります。常にそのアセットの最新バージョンを読み取ります。
次の例では、さまざまな ops から Artifact を読み取る方法を示しています。
@op からの Artifact の読み取り
@op(
ins={
"artifact": In(
metadata={
"wandb_artifact_configuration": {
"name": "my_artifact",
}
}
)
},
io_manager_key="wandb_artifacts_manager"
)
def read_artifact(context, artifact):
context.log.info(artifact)
別の @asset によって作成された Artifact の読み取り
@asset(
name="my_asset",
ins={
"artifact": AssetIn(
# if you don't want to rename the input argument you can remove 'key'
key="parent_dagster_asset_name",
input_manager_key="wandb_artifacts_manager",
)
},
)
def read_artifact(context, artifact):
context.log.info(artifact)
Dagster の外部で作成された Artifact の読み取り:
my_artifact = SourceAsset(
key=AssetKey("my_artifact"), # the name of the W&B Artifact
description="Artifact created outside Dagster",
io_manager_key="wandb_artifacts_manager",
)
@asset
def read_artifact(context, my_artifact):
context.log.info(my_artifact)
構成
以下の構成は、IO Manager が収集し、装飾された関数への入力として提供する内容を示すために使用されます。次の読み取りパターンがサポートされています。
- Artifact 内に含まれる名前付きオブジェクトを取得するには、get を使用します。
@asset(
ins={
"table": AssetIn(
key="my_artifact_with_table",
metadata={
"wandb_artifact_configuration": {
"get": "my_table",
}
},
input_manager_key="wandb_artifacts_manager",
)
}
)
def get_table(context, table):
context.log.info(table.get_column("a"))
- Artifact 内に含まれるダウンロードされたファイルのローカルパスを取得するには、get_path を使用します。
@asset(
ins={
"path": AssetIn(
key="my_artifact_with_file",
metadata={
"wandb_artifact_configuration": {
"get_path": "name_of_file",
}
},
input_manager_key="wandb_artifacts_manager",
)
}
)
def get_path(context, path):
context.log.info(path)
- Artifact オブジェクト全体を取得するには (コンテンツをローカルにダウンロードした場合):
@asset(
ins={
"artifact": AssetIn(
key="my_artifact",
input_manager_key="wandb_artifacts_manager",
)
},
)
def get_artifact(context, artifact):
context.log.info(artifact.name)
サポートされているプロパティ
get: (str) Artifact の相対名にある W&B オブジェクトを取得します。get_path: (str) Artifact の相対名にあるファイルのパスを取得します。
シリアル化構成
デフォルトでは、インテグレーションは標準の pickle モジュールを使用しますが、一部のオブジェクトはそれと互換性がありません。たとえば、yield を使用する関数は、pickle 化しようとするとエラーが発生します。
より多くの Pickle ベースのシリアル化モジュール (dill、cloudpickle、joblib) をサポートしています。ONNX や PMML などのより高度なシリアル化を使用することもできます。シリアル化された文字列を返すか、Artifact を直接作成することで、それらを使用できます。適切な選択はユースケースによって異なります。この件に関する利用可能な文献を参照してください。
Pickle ベースのシリアル化モジュール
wandb_artifact_configuration の serialization_module ディクショナリを使用して、使用するシリアル化を構成できます。モジュールが Dagster を実行しているマシンで使用できることを確認してください。
インテグレーションは、その Artifact を読み取るときに使用するシリアル化モジュールを自動的に認識します。
現在サポートされているモジュールは、pickle、dill、cloudpickle、および joblib です。
以下は、joblib でシリアル化された「モデル」を作成し、それを推論に使用する簡単な例です。
@asset(
name="my_joblib_serialized_model",
compute_kind="Python",
metadata={
"wandb_artifact_configuration": {
"type": "model",
"serialization_module": {
"name": "joblib"
},
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_model_serialized_with_joblib():
# This is not a real ML model but this would not be possible with the pickle module
return lambda x, y: x + y
@asset(
name="inference_result_from_joblib_serialized_model",
compute_kind="Python",
ins={
"my_joblib_serialized_model": AssetIn(
input_manager_key="wandb_artifacts_manager",
)
},
metadata={
"wandb_artifact_configuration": {
"type": "results",
}
},
io_manager_key="wandb_artifacts_manager",
)
def use_model_serialized_with_joblib(
context: OpExecutionContext, my_joblib_serialized_model
):
inference_result = my_joblib_serialized_model(1, 2)
context.log.info(inference_result) # Prints: 3
return inference_result
高度なシリアル化形式 (ONNX、PMML)
ONNX や PMML のような交換ファイル形式を使用するのが一般的です。インテグレーションはこれらの形式をサポートしていますが、Pickle ベースのシリアル化よりも少し手間がかかります。
これらの形式を使用するには、2 つの異なる方法があります。
- モデルを選択した形式に変換し、その形式の文字列表現を通常の Python オブジェクトであるかのように返します。インテグレーションはその文字列を pickle 化します。次に、その文字列を使用してモデルを再構築できます。
- シリアル化されたモデルを使用して新しいローカルファイルを作成し、add_file 構成を使用してそのファイルでカスタム Artifact を構築します。
以下は、ONNX を使用してシリアル化される Scikit-learn モデルの例です。
import numpy
import onnxruntime as rt
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from dagster import AssetIn, AssetOut, asset, multi_asset
@multi_asset(
compute_kind="Python",
outs={
"my_onnx_model": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "model",
}
},
io_manager_key="wandb_artifacts_manager",
),
"my_test_set": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "test_set",
}
},
io_manager_key="wandb_artifacts_manager",
),
},
group_name="onnx_example",
)
def create_onnx_model():
# Inspired from https://onnx.ai/sklearn-onnx/
# Train a model.
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
clr = RandomForestClassifier()
clr.fit(X_train, y_train)
# Convert into ONNX format
initial_type = [("float_input", FloatTensorType([None, 4]))]
onx = convert_sklearn(clr, initial_types=initial_type)
# Write artifacts (model + test_set)
return onx.SerializeToString(), {"X_test": X_test, "y_test": y_test}
@asset(
name="experiment_results",
compute_kind="Python",
ins={
"my_onnx_model": AssetIn(
input_manager_key="wandb_artifacts_manager",
),
"my_test_set": AssetIn(
input_manager_key="wandb_artifacts_manager",
),
},
group_name="onnx_example",
)
def use_onnx_model(context, my_onnx_model, my_test_set):
# Inspired from https://onnx.ai/sklearn-onnx/
# Compute the prediction with ONNX Runtime
sess = rt.InferenceSession(my_onnx_model)
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onx = sess.run(
[label_name], {input_name: my_test_set["X_test"].astype(numpy.float32)}
)[0]
context.log.info(pred_onx)
return pred_onx
パーティションの使用
このインテグレーションは、Dagster パーティション をネイティブにサポートしています。
アセットの 1 つ、複数、またはすべてのパーティションを選択的に読み取ることができます。
すべてのパーティションは辞書で提供され、キーと値はそれぞれパーティションキーと Artifact コンテンツを表します。
アップストリーム @asset のすべてのパーティションを読み取ります。これらは辞書として提供されます。この辞書では、キーと値はそれぞれパーティションキーと Artifact コンテンツに対応しています。
@asset(
compute_kind="wandb",
ins={"my_daily_partitioned_asset": AssetIn()},
output_required=False,
)
def read_all_partitions(context, my_daily_partitioned_asset):
for partition, content in my_daily_partitioned_asset.items():
context.log.info(f"partition={partition}, content={content}")
AssetIn の partition_mapping 構成を使用すると、特定のパーティションを選択できます。この場合、TimeWindowPartitionMapping を採用しています。
@asset(
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01", end_date="2023-02-01"),
compute_kind="wandb",
ins={
"my_daily_partitioned_asset": AssetIn(
partition_mapping=TimeWindowPartitionMapping(start_offset=-1)
)
},
output_required=False,
)
def read_specific_partitions(context, my_daily_partitioned_asset):
for partition, content in my_daily_partitioned_asset.items():
context.log.info(f"partition={partition}, content={content}")
構成オブジェクト metadata は、Weights & Biases (wandb) が Project 内のさまざまな Artifact パーティションとどのように対話するかを構成するために使用されます。
オブジェクト metadata には、wandb_artifact_configuration という名前のキーが含まれており、さらにネストされたオブジェクト partitions が含まれています。
partitions オブジェクトは、各パーティションの名前をその構成にマップします。各パーティションの構成では、そこからデータを取得する方法を指定できます。これらの構成には、各パーティションの要件に応じて、get、version、および alias という異なるキーを含めることができます。
構成キー
get:getキーは、データをフェッチする W&B オブジェクト (Table, Image…) の名前を指定します。version:versionキーは、Artifact の特定のバージョンをフェッチする場合に使用されます。alias:aliasキーを使用すると、エイリアスで Artifact を取得できます。
ワイルドカード構成
ワイルドカード "*" は、構成されていないすべてのパーティションを表します。これにより、partitions オブジェクトで明示的に言及されていないパーティションにデフォルト構成が提供されます。
たとえば、
"*": {
"get": "default_table_name",
},
この構成は、明示的に構成されていないすべてのパーティションについて、データが default_table_name という名前のテーブルからフェッチされることを意味します。
特定のパーティション構成
キーを使用して特定の構成を提供することで、特定のパーティションのワイルドカード構成をオーバーライドできます。
たとえば、
"yellow": {
"get": "custom_table_name",
},
この構成は、yellow という名前のパーティションの場合、データが custom_table_name という名前のテーブルからフェッチされ、ワイルドカード構成がオーバーライドされることを意味します。
バージョン管理とエイリアス
バージョン管理とエイリアスの目的で、構成に特定の version および alias キーを指定できます。
バージョンについては、
"orange": {
"version": "v0",
},
この構成は、orange Artifact パーティションのバージョン v0 からデータをフェッチします。
エイリアスについては、
"blue": {
"alias": "special_alias",
},
この構成は、エイリアス special_alias (構成では blue と呼ばれる) を持つ Artifact パーティションのテーブル default_table_name からデータをフェッチします。
高度な使用法
インテグレーションの高度な使用法を表示するには、次の完全なコード例を参照してください。
W&B Launch の使用
続行する前に、W&B Launch の使用方法を十分に理解しておくことをお勧めします。Launch に関するガイド: /guides/launch を参照してください。
Dagster インテグレーションは、以下に役立ちます。
- Dagster インスタンスで 1 つまたは複数の Launch エージェントを実行します。
- Dagster インスタンス内でローカル Launch ジョブを実行します。
- オンプレミスまたはクラウドでリモート Launch ジョブを実行します。
Launch エージェント
このインテグレーションは、run_launch_agent と呼ばれるインポート可能な @op を提供します。これは、Launch エージェントを起動し、手動で停止するまで長時間実行されるプロセスとして実行します。
エージェントは、Launch キューをポーリングし、ジョブを実行 (または外部サービスにディスパッチして実行) するプロセスです。
構成については、リファレンスドキュメント を参照してください。
また、Launchpad ですべてのプロパティの役立つ説明を表示することもできます。
簡単な例
# add this to your config.yaml
# alternatively you can set the config in Dagit's Launchpad or JobDefinition.execute_in_process
# Reference: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # replace this with your W&B entity
project: my_project # replace this with your W&B project
ops:
run_launch_agent:
config:
max_jobs: -1
queues:
- my_dagster_queue
from dagster_wandb.launch.ops import run_launch_agent
from dagster_wandb.resources import wandb_resource
from dagster import job, make_values_resource
@job(
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
},
)
def run_launch_agent_example():
run_launch_agent()
Launch ジョブ
このインテグレーションは、run_launch_job と呼ばれるインポート可能な @op を提供します。Launch ジョブを実行します。
Launch ジョブは、実行されるためにキューに割り当てられます。キューを作成するか、デフォルトのキューを使用できます。そのキューをリッスンするアクティブなエージェントがあることを確認してください。Dagster インスタンス内でエージェントを実行できますが、Kubernetes でデプロイ可能なエージェントを使用することも検討できます。
構成については、リファレンスドキュメント を参照してください。
また、Launchpad ですべてのプロパティの役立つ説明を表示することもできます。
簡単な例
# add this to your config.yaml
# alternatively you can set the config in Dagit's Launchpad or JobDefinition.execute_in_process
# Reference: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # replace this with your W&B entity
project: my_project # replace this with your W&B project
ops:
my_launched_job:
config:
entry_point:
- python
- train.py
queue: my_dagster_queue
uri: https://github.com/wandb/example-dagster-integration-with-launch
from dagster_wandb.launch.ops import run_launch_job
from dagster_wandb.resources import wandb_resource
from dagster import job, make_values_resource
@job(resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
},
)
def run_launch_job_example():
run_launch_job.alias("my_launched_job")() # we rename the job with an alias
ベストプラクティス
-
IO Manager を使用して Artifacts を読み書きします。
Artifact.download()またはRun.log_artifact()を直接使用する必要はありません。これらのメソッドは、インテグレーションによって処理されます。Artifact に保存するデータを返すだけで、残りはインテグレーションに任せます。これにより、W&B での Artifact のリネージが向上します。 -
複雑なユースケースでのみ Artifact オブジェクトを自分で構築します。 Python オブジェクトと W&B オブジェクトは、ops/アセットから返される必要があります。インテグレーションは、Artifact のバンドルを処理します。 複雑なユースケースでは、Dagster ジョブで Artifact を直接構築できます。ソースインテグレーションの名前とバージョン、使用された Python バージョン、pickle プロトコルバージョンなどのメタデータエンリッチメントのために、Artifact オブジェクトをインテグレーションに渡すことをお勧めします。
-
メタデータを介してファイル、ディレクトリー、および外部参照を Artifacts に追加します。 インテグレーション
wandb_artifact_configurationオブジェクトを使用して、ファイル、ディレクトリー、または外部参照 (Amazon S3、GCS、HTTP…) を追加します。詳細については、Artifact 構成セクション の高度な例を参照してください。 -
Artifact が生成される場合は、@op の代わりに @asset を使用します。 Artifacts はアセットです。Dagster がそのアセットを維持する場合は、アセットを使用することをお勧めします。これにより、Dagit Asset Catalog での可観測性が向上します。
-
SourceAsset を使用して、Dagster の外部で作成された Artifact を消費します。 これにより、インテグレーションを利用して外部で作成された Artifact を読み取ることができます。それ以外の場合は、インテグレーションによって作成された Artifact のみを使用できます。
-
W&B Launch を使用して、大規模モデルの専用コンピューティングでのトレーニングを編成します。 Dagster クラスター内で小さなモデルをトレーニングでき、GPU ノードを備えた Kubernetes クラスターで Dagster を実行できます。大規模なモデルトレーニングには、W&B Launch を使用することをお勧めします。これにより、インスタンスの過負荷を防ぎ、より適切なコンピューティングへのアクセスを提供できます。
-
Dagster 内で実験管理を行う場合は、W&B Run ID を Dagster Run ID の値に設定します。 Run を再開可能 にし、W&B Run ID を Dagster Run ID または選択した文字列に設定することをお勧めします。この推奨事項に従うと、Dagster 内でモデルをトレーニングするときに、W&B メトリクスと W&B Artifacts が同じ W&B Run に保存されるようになります。
W&B Run ID を Dagster Run ID に設定します。
wandb.init(
id=context.run_id,
resume="allow",
...
)
または、独自の W&B Run ID を選択して、IO Manager 構成に渡します。
wandb.init(
id="my_resumable_run_id",
resume="allow",
...
)
@job(
resource_defs={
"io_manager": wandb_artifacts_io_manager.configured(
{"wandb_run_id": "my_resumable_run_id"}
),
}
)
-
大規模な W&B Artifacts の場合は、get または get_path で必要なデータのみを収集します。 デフォルトでは、インテグレーションは Artifact 全体をダウンロードします。非常に大きな Artifact を使用している場合は、必要な特定のファイルまたはオブジェクトのみを収集する必要があります。これにより、速度とリソースの使用率が向上します。
-
Python オブジェクトの場合は、ユースケースに合わせて pickle モジュールを調整します。 デフォルトでは、W&B インテグレーションは標準の pickle モジュールを使用します。ただし、一部のオブジェクトはそれと互換性がありません。たとえば、yield を使用する関数は、pickle 化しようとするとエラーが発生します。W&B は、他の Pickle ベースのシリアル化モジュール (dill、cloudpickle、joblib) をサポートしています。
シリアル化された文字列を返すか、Artifact を直接作成することで、ONNX や PMML などのより高度なシリアル化を使用することもできます。適切な選択はユースケースによって異なります。この件に関する利用可能な文献を参照してください。
2 - Launch multinode jobs with Volcano
このチュートリアルでは、Kubernetes 上で W&B と Volcano を使用して、マルチノードのトレーニングジョブを起動するプロセスを説明します。
概要
このチュートリアルでは、W&B Launch を使用して Kubernetes 上でマルチノードジョブを実行する方法を学びます。手順は次のとおりです。
- Weights & Biases のアカウントと Kubernetes クラスターがあることを確認します。
- volcano ジョブの Launch キューを作成します。
- Launch エージェントを Kubernetes クラスターにデプロイします。
- 分散トレーニングジョブを作成します。
- 分散トレーニングを Launch します。
前提条件
始める前に、以下が必要です。
- Weights & Biases アカウント
- Kubernetes クラスター
Launch キューを作成する
最初のステップは、Launch キューを作成することです。wandb.ai/launch にアクセスし、画面の右上隅にある青い キューを作成 ボタンをクリックします。キューの作成ドロワーが画面の右側からスライドして表示されます。エンティティを選択し、名前を入力して、キューのタイプとして Kubernetes を選択します。
設定セクションでは、volcano job テンプレートを入力します。このキューから Launch された Run は、このジョブ仕様を使用して作成されるため、必要に応じてこの設定を変更してジョブをカスタマイズできます。
この設定ブロックは、Kubernetes ジョブ仕様、volcano ジョブ仕様、または Launch したいその他のカスタムリソース定義(CRD)を受け入れることができます。設定ブロックでマクロを使用 して、この仕様の内容を動的に設定できます。
このチュートリアルでは、Volcano の pytorch プラグイン を使用するマルチノード pytorch トレーニングの設定を使用します。次の設定を YAML または JSON としてコピーして貼り付けることができます。
kind: Job
spec:
tasks:
- name: master
policies:
- event: TaskCompleted
action: CompleteJob
replicas: 1
template:
spec:
containers:
- name: master
image: ${image_uri}
imagePullPolicy: IfNotPresent
restartPolicy: OnFailure
- name: worker
replicas: 1
template:
spec:
containers:
- name: worker
image: ${image_uri}
workingDir: /home
imagePullPolicy: IfNotPresent
restartPolicy: OnFailure
plugins:
pytorch:
- --master=master
- --worker=worker
- --port=23456
minAvailable: 1
schedulerName: volcano
metadata:
name: wandb-job-${run_id}
labels:
wandb_entity: ${entity_name}
wandb_project: ${project_name}
namespace: wandb
apiVersion: batch.volcano.sh/v1alpha1
{
"kind": "Job",
"spec": {
"tasks": [
{
"name": "master",
"policies": [
{
"event": "TaskCompleted",
"action": "CompleteJob"
}
],
"replicas": 1,
"template": {
"spec": {
"containers": [
{
"name": "master",
"image": "${image_uri}",
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "OnFailure"
}
}
},
{
"name": "worker",
"replicas": 1,
"template": {
"spec": {
"containers": [
{
"name": "worker",
"image": "${image_uri}",
"workingDir": "/home",
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "OnFailure"
}
}
}
],
"plugins": {
"pytorch": [
"--master=master",
"--worker=worker",
"--port=23456"
]
},
"minAvailable": 1,
"schedulerName": "volcano"
},
"metadata": {
"name": "wandb-job-${run_id}",
"labels": {
"wandb_entity": "${entity_name}",
"wandb_project": "${project_name}"
},
"namespace": "wandb"
},
"apiVersion": "batch.volcano.sh/v1alpha1"
}
ドロワーの下部にある キューを作成 ボタンをクリックして、キューの作成を完了します。
Volcano をインストールする
Kubernetes クラスターに Volcano をインストールするには、公式インストールガイド に従ってください。
Launch エージェントをデプロイする
キューを作成したので、キューからジョブをプルして実行するために Launch エージェントをデプロイする必要があります。これを行う最も簡単な方法は、W&B の公式 helm-charts リポジトリの launch-agent チャート を使用することです。README の指示に従ってチャートを Kubernetes クラスターにインストールし、必ず前に作成したキューをポーリングするようにエージェントを設定してください。
トレーニングジョブを作成する
Volcano の pytorch プラグインは、pytorch コードが DDP を正しく使用している限り、MASTER_ADDR、RANK、WORLD_SIZE など、pytorch DPP が機能するために必要な環境変数を自動的に構成します。カスタム python コードで DDP を使用する方法の詳細については、pytorch のドキュメント を参照してください。
Trainer を介したマルチノードトレーニング とも互換性があります。Launch 🚀
キューとクラスターがセットアップされたので、分散トレーニングを Launch する時間です。まず、Volcano の pytorch プラグインを使用して、ランダムデータで単純な多層パーセプトロンをトレーニングする ジョブ を使用します。ジョブのソースコードはこちらにあります。
このジョブを Launch するには、ジョブのページ にアクセスし、画面の右上隅にある Launch ボタンをクリックします。ジョブを Launch するキューを選択するように求められます。
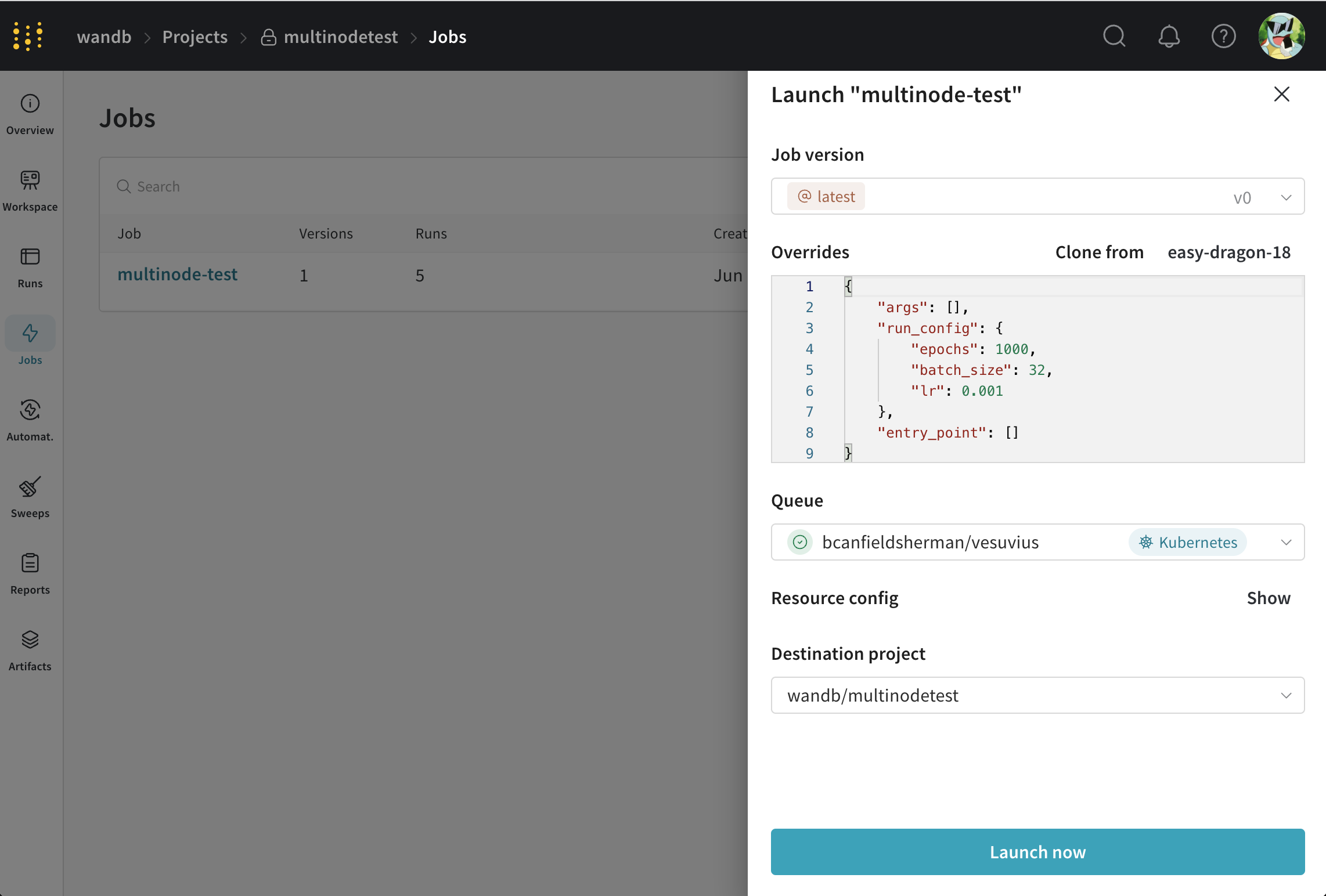
- ジョブのパラメータを任意に設定します。
- 先ほど作成したキューを選択します。
- リソース設定 セクションで volcano ジョブを変更して、ジョブのパラメータを変更します。たとえば、
workerタスクのreplicasフィールドを変更することで、worker の数を変更できます。 - Launch 🚀 をクリックします
W&B UI からジョブの進行状況を監視し、必要に応じてジョブを停止できます。
3 - NVIDIA NeMo Inference Microservice Deploy Job
W&B から NVIDIA NeMo Inference Microservice にモデル Artifact をデプロイするには、W&B Launch を使用します。W&B Launch は、モデル Artifact を NVIDIA NeMo Model に変換し、実行中の NIM/Triton サーバーにデプロイします。
W&B Launch は現在、以下の互換性のあるモデルタイプを受け入れています。
a2-ultragpu-1g で約 1 分かかります。クイックスタート
-
まだ Launch キューを作成 していない場合は作成します。以下のキュー構成の例を参照してください。
net: host gpus: all # 特定の GPU のセット、またはすべてを使用する場合は `all` runtime: nvidia # nvidia container runtime も必要 volume: - model-store:/model-store/
-
プロジェクト でこのジョブを作成します。
wandb job create -n "deploy-to-nvidia-nemo-inference-microservice" \ -e $ENTITY \ -p $PROJECT \ -E jobs/deploy_to_nvidia_nemo_inference_microservice/job.py \ -g andrew/nim-updates \ git https://github.com/wandb/launch-jobs -
GPU マシンで エージェント を起動します。
wandb launch-agent -e $ENTITY -p $PROJECT -q $QUEUE -
Launch UI から、必要な構成でデプロイメント Launch ジョブを送信します。
- CLI から送信することもできます。
wandb launch -d gcr.io/playground-111/deploy-to-nemo:latest \ -e $ENTITY \ -p $PROJECT \ -q $QUEUE \ -c $CONFIG_JSON_FNAME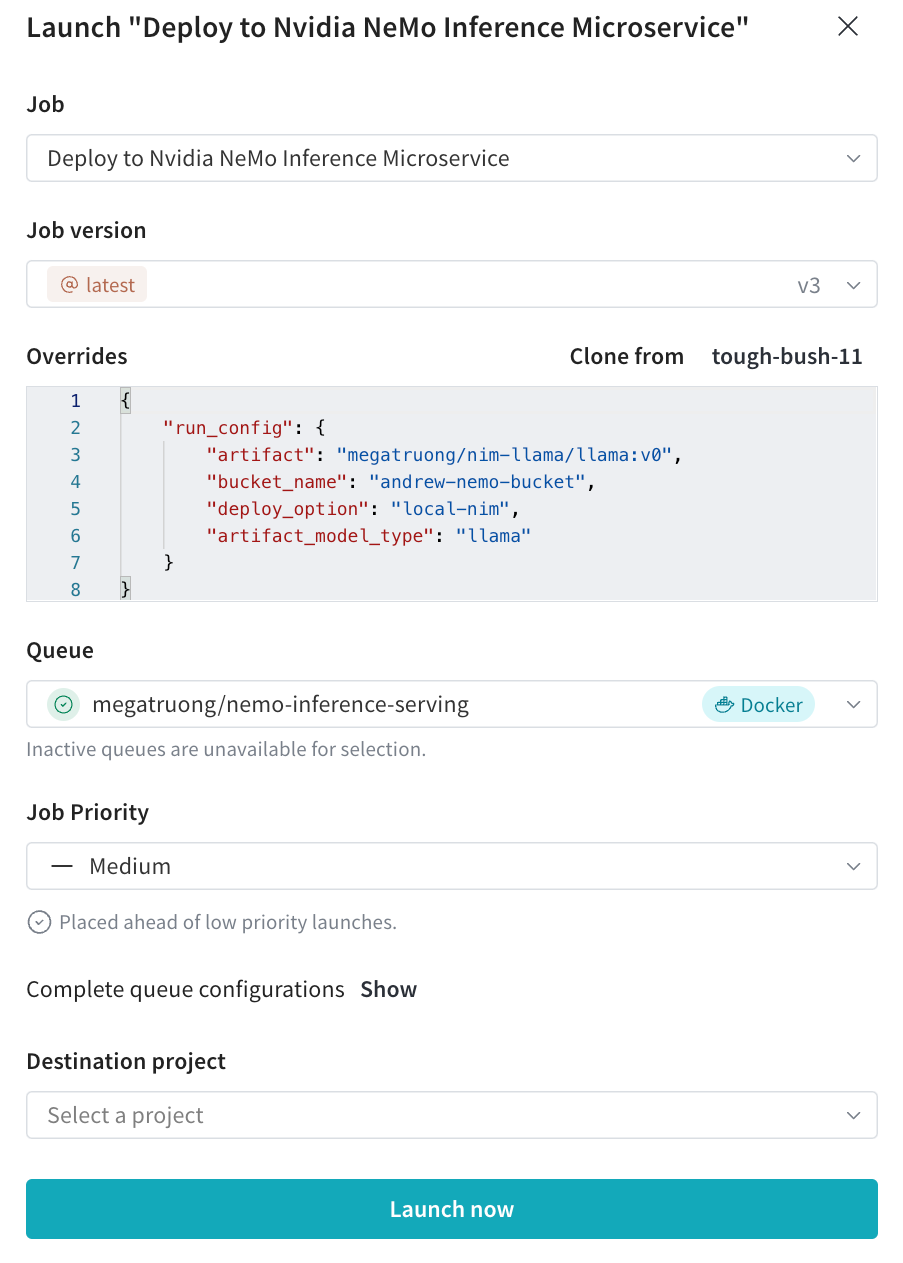
- CLI から送信することもできます。
-
デプロイメント プロセス を Launch UI で追跡できます。
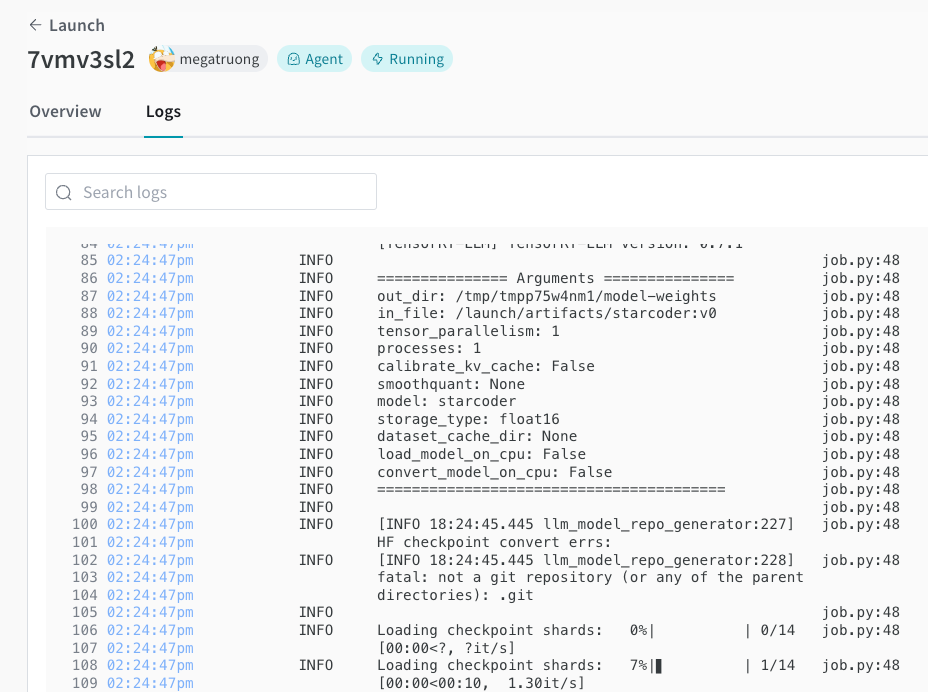
-
完了したら、すぐにエンドポイントを curl してモデルをテストできます。モデル名は常に
ensembleです。#!/bin/bash curl -X POST "http://0.0.0.0:9999/v1/completions" \ -H "accept: application/json" \ -H "Content-Type: application/json" \ -d '{ "model": "ensemble", "prompt": "Tell me a joke", "max_tokens": 256, "temperature": 0.5, "n": 1, "stream": false, "stop": "string", "frequency_penalty": 0.0 }'
4 - Spin up a single node GPU cluster with Minikube
GPU ワークロードをスケジュールおよび実行できる Minikube クラスターで W&B Launch をセットアップします。
このチュートリアルは、複数の GPU を搭載したマシンに直接アクセスできるユーザーを対象としています。クラウドマシンをレンタルしているユーザーは対象としていません。
クラウドマシンに minikube クラスターをセットアップする場合は、クラウドプロバイダーが提供する GPU をサポートする Kubernetes クラスターを作成することをお勧めします。たとえば、AWS、GCP、Azure、Coreweave などのクラウドプロバイダーには、GPU をサポートする Kubernetes クラスターを作成するツールがあります。
単一の GPU を搭載したマシンで GPU のスケジューリングを行うために minikube クラスターをセットアップする場合は、Launch Docker queue を使用することをお勧めします。チュートリアルは、楽しみのために実行することもできますが、GPU のスケジューリングはあまり役に立ちません。
背景
Nvidia container toolkit により、Docker で GPU 対応の ワークフローを簡単に実行できるようになりました。1 つの制限は、ボリュームによる GPU のスケジューリングに対するネイティブサポートがないことです。docker run コマンドで GPU を使用する場合は、ID または存在するすべての GPU で特定の GPU を要求する必要があります。これにより、多くの分散 GPU 対応ワークロードが非現実的になります。Kubernetes はボリュームリクエストによるスケジューリングをサポートしていますが、GPU スケジューリングを備えたローカル Kubernetes クラスターのセットアップには、最近までかなりの時間と労力がかかりました。シングルノード Kubernetes クラスターを実行するための最も一般的なツールの 1 つである Minikube は、最近 GPU スケジューリングのサポート をリリースしました 🎉 このチュートリアルでは、マルチ GPU マシンに Minikube クラスターを作成し、W&B Launch 🚀 を使用して同時 Stable Diffusion 推論ジョブをクラスターに Launch します。
前提条件
開始する前に、以下が必要です。
- W&B アカウント。
- 以下がインストールされ、実行されている Linux マシン:
- Docker ランタイム
- 使用する GPU のドライバー
- Nvidia container toolkit
n1-standard-16 Google Cloud Compute Engine インスタンスを使用しました。Launch ジョブのキューを作成する
まず、Launch ジョブの Launch キューを作成します。
- wandb.ai/launch(または、プライベート W&B サーバーを使用している場合は
<your-wandb-url>/launch)に移動します。 - 画面の右上隅にある青色の Create a queue ボタンをクリックします。キュー作成ドロワーが画面の右側からスライドして表示されます。
- エンティティを選択し、名前を入力して、キューのタイプとして Kubernetes を選択します。
- ドロワーの Config セクションでは、Launch キューの Kubernetes ジョブ仕様 を入力します。このキューから Launch された Run は、このジョブ仕様を使用して作成されるため、必要に応じてこの設定を変更してジョブをカスタマイズできます。このチュートリアルでは、以下のサンプル設定を YAML または JSON としてキュー設定にコピーして貼り付けることができます。
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: '{{gpus}}'
restartPolicy: Never
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
}
}
}
],
"restartPolicy": "Never"
}
},
"backoffLimit": 0
}
}
キュー構成の詳細については、Set up Launch on Kubernetes および Advanced queue setup guide を参照してください。
${image_uri} および {{gpus}} 文字列は、キュー構成で使用できる 2 種類の変数テンプレートの例です。${image_uri} テンプレートは、エージェントによって Launch しているジョブのイメージ URI に置き換えられます。{{gpus}} テンプレートは、ジョブの送信時に Launch UI、CLI、または SDK からオーバーライドできるテンプレート変数を作成するために使用されます。これらの値はジョブ仕様に配置され、ジョブで使用されるイメージと GPU リソースを制御するために正しいフィールドを変更します。
- Parse configuration ボタンをクリックして、
gpusテンプレート変数のカスタマイズを開始します。 - Type を
Integerに設定し、Default、Min、および Max を選択した値に設定します。 テンプレート変数の制約に違反するこのキューに Run を送信しようとすると、拒否されます。
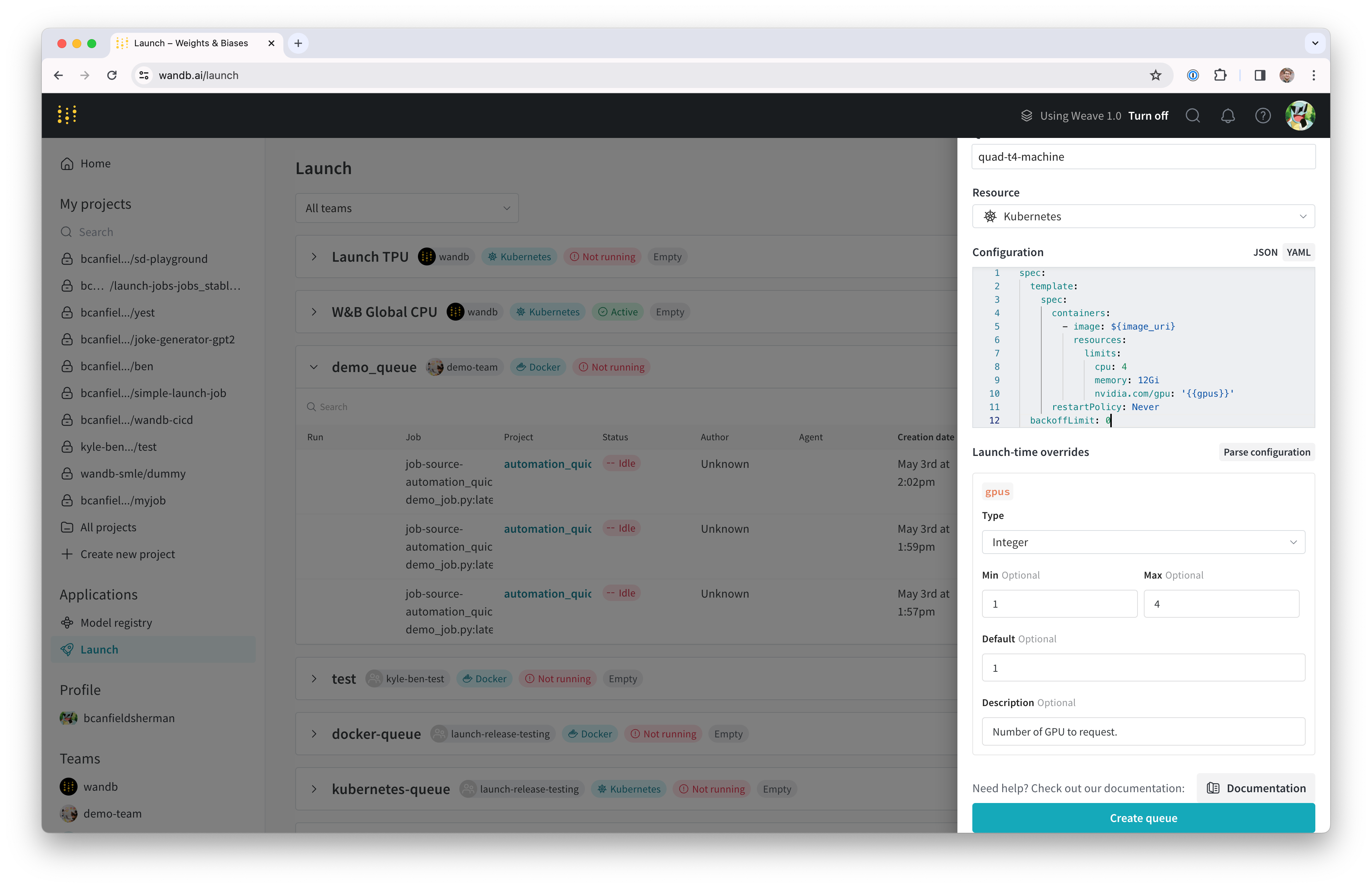
- Create queue をクリックしてキューを作成します。新しいキューのキューページにリダイレクトされます。
次のセクションでは、作成したキューからジョブをプルして実行できるエージェントをセットアップします。
Docker + NVIDIA CTK のセットアップ
Docker と Nvidia container toolkit がマシンに既にセットアップされている場合は、このセクションをスキップできます。
システムでの Docker container エンジンのセットアップ手順については、Docker のドキュメント を参照してください。
Docker をインストールしたら、Nvidia のドキュメントの手順に従って Nvidia container toolkit をインストールします。
コンテナランタイムが GPU にアクセスできることを検証するには、以下を実行します。
docker run --gpus all ubuntu nvidia-smi
マシンに接続されている GPU を記述する nvidia-smi 出力が表示されます。たとえば、セットアップでの出力は次のようになります。
Wed Nov 8 23:25:53 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 Tesla T4 Off | 00000000:00:06.0 Off | 0 |
| N/A 40C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 Tesla T4 Off | 00000000:00:07.0 Off | 0 |
| N/A 39C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Minikube のセットアップ
Minikube の GPU サポートには、バージョン v1.32.0 以降が必要です。最新のインストールヘルプについては、Minikube のインストールドキュメント を参照してください。このチュートリアルでは、次のコマンドを使用して最新の Minikube リリースをインストールしました。
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
次のステップでは、GPU を使用して minikube クラスターを起動します。マシンで、以下を実行します。
minikube start --gpus all
上記のコマンドの出力は、クラスターが正常に作成されたかどうかを示します。
Launch エージェントの起動
新しいクラスターの Launch エージェントは、wandb launch-agent を直接呼び出すか、W&B が管理する helm チャート を使用して Launch エージェントをデプロイすることで起動できます。
このチュートリアルでは、エージェントをホストマシン上で直接実行します。
エージェントをローカルで実行するには、デフォルトの Kubernetes API コンテキストが Minikube クラスターを参照していることを確認してください。次に、以下を実行します。
pip install "wandb[launch]"
エージェントの依存関係をインストールします。エージェントの認証をセットアップするには、wandb login を実行するか、WANDB_API_KEY 環境変数を設定します。
エージェントを起動するには、次のコマンドを実行します。
wandb launch-agent -j <max-number-concurrent-jobs> -q <queue-name> -e <queue-entity>
ターミナル内で、Launch エージェントがポーリングメッセージの出力を開始するのを確認できます。
おめでとうございます。Launch キューをポーリングする Launch エージェントができました。ジョブがキューに追加されると、エージェントがそれを取得し、Minikube クラスターで実行するようにスケジュールします。
ジョブの Launch
エージェントにジョブを送信しましょう。W&B アカウントにログインしているターミナルから、次のコマンドで簡単な「hello world」を Launch できます。
wandb launch -d wandb/job_hello_world:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
任意のジョブまたはイメージでテストできますが、クラスターがイメージをプルできることを確認してください。詳細については、Minikube のドキュメント を参照してください。パブリックジョブのいずれかを使用してテスト することもできます。
(オプション) NFS を使用したモデルとデータのキャッシュ
ML ワークロードの場合、多くの場合、複数のジョブが同じデータにアクセスできるようにする必要があります。たとえば、データセットやモデルの重みなどの大きなアセットを繰り返しダウンロードするのを避けるために、共有キャッシュを用意することができます。Kubernetes は、Persistent Volumes と Persistent Volume Claims を通じてこれをサポートします。Persistent Volumes を使用して、Kubernetes ワークロードに volumeMounts を作成し、共有キャッシュへの直接ファイルシステムアクセスを提供できます。
このステップでは、モデルの重みの共有キャッシュとして使用できるネットワークファイルシステム (NFS) サーバーをセットアップします。最初のステップは、NFS をインストールして構成することです。このプロセスはオペレーティングシステムによって異なります。VM は Ubuntu を実行しているため、nfs-kernel-server をインストールし、/srv/nfs/kubedata にエクスポートを構成しました。
sudo apt-get install nfs-kernel-server
sudo mkdir -p /srv/nfs/kubedata
sudo chown nobody:nogroup /srv/nfs/kubedata
sudo sh -c 'echo "/srv/nfs/kubedata *(rw,sync,no_subtree_check,no_root_squash,no_all_squash,insecure)" >> /etc/exports'
sudo exportfs -ra
sudo systemctl restart nfs-kernel-server
ホストファイルシステム内のサーバーのエクスポート場所と、NFS サーバーのローカル IP アドレスをメモしておきます。次のステップでこの情報が必要になります。
次に、この NFS の Persistent Volume と Persistent Volume Claim を作成する必要があります。Persistent Volumes は高度にカスタマイズ可能ですが、ここでは簡単にするために簡単な構成を使用します。
以下の yaml を nfs-persistent-volume.yaml というファイルにコピーし、必要なボリューム容量とクレームリクエストを必ず入力してください。PersistentVolume.spec.capcity.storage フィールドは、基になるボリュームの最大サイズを制御します。PersistentVolumeClaim.spec.resources.requests.stroage を使用して、特定のクレームに割り当てられたボリューム容量を制限できます。ユースケースでは、それぞれに同じ値を使用するのが理にかなっています。
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 100Gi # Set this to your desired capacity.
accessModes:
- ReadWriteMany
nfs:
server: <your-nfs-server-ip> # TODO: Fill this in.
path: '/srv/nfs/kubedata' # Or your custom path
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi # Set this to your desired capacity.
storageClassName: ''
volumeName: nfs-pv
次のコマンドを使用して、クラスター内にリソースを作成します。
kubectl apply -f nfs-persistent-volume.yaml
Run がこのキャッシュを利用できるようにするには、Launch キュー構成に volumes と volumeMounts を追加する必要があります。Launch 構成を編集するには、wandb.ai/launch(または wandb サーバーのユーザーの場合は <your-wandb-url>/launch)に戻り、キューを見つけてキューページをクリックし、Edit config タブをクリックします。元の構成は次のように変更できます。
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: "{{gpus}}"
volumeMounts:
- name: nfs-storage
mountPath: /root/.cache
restartPolicy: Never
volumes:
- name: nfs-storage
persistentVolumeClaim:
claimName: nfs-pvc
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
},
"volumeMounts": [
{
"name": "nfs-storage",
"mountPath": "/root/.cache"
}
]
}
}
],
"restartPolicy": "Never",
"volumes": [
{
"name": "nfs-storage",
"persistentVolumeClaim": {
"claimName": "nfs-pvc"
}
}
]
}
},
"backoffLimit": 0
}
}
これで、NFS はジョブを実行しているコンテナ内の /root/.cache にマウントされます。コンテナが root 以外のユーザーとして実行されている場合、マウントパスを調整する必要があります。Huggingface のライブラリと W&B Artifacts はどちらもデフォルトで $HOME/.cache/ を使用するため、ダウンロードは 1 回だけ行う必要があります。
Stable Diffusion を使用する
新しいシステムをテストするために、Stable Diffusion の推論パラメーターを試してみます。 デフォルトのプロンプトと適切なパラメーターを使用して、単純な Stable Diffusion 推論ジョブを実行するには、以下を実行します。
wandb launch -d wandb/job_stable_diffusion_inference:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
上記のコマンドは、コンテナイメージ wandb/job_stable_diffusion_inference:main をキューに送信します。
エージェントがジョブを取得してクラスターで実行するようにスケジュールすると、
接続によっては、イメージのプルに時間がかかる場合があります。
wandb.ai/launch(または wandb サーバーのユーザーの場合は <your-wandb-url>/launch)のキューページでジョブのステータスを確認できます。
Run が完了すると、指定したプロジェクトにジョブ Artifact が作成されます。
プロジェクトのジョブページ(<project-url>/jobs)を確認して、ジョブ Artifact を見つけることができます。そのデフォルト名は job-wandb_job_stable_diffusion_inference である必要がありますが、ジョブの名前の横にある鉛筆アイコンをクリックして、ジョブのページで好きな名前に変更できます。
これで、このジョブを使用して、クラスターでより多くの Stable Diffusion 推論を実行できます。 ジョブページから、右上隅にある Launch ボタンをクリックして、 新しい推論ジョブを構成し、キューに送信できます。ジョブ構成ページには、元の Run のパラメーターがあらかじめ入力されていますが、Launch ドロワーの Overrides セクションで値を変更することで、好きなように変更できます。