Tutorials
インタラクティブなチュートリアルで Weights & Biases の使用を開始しましょう。
基本
以下のチュートリアルでは、機械学習の 実験管理 、モデル評価、ハイパーパラメータチューニング、モデルとデータセットの バージョン管理 など、W&B の基本を説明します。
人気のある ML フレームワーク のチュートリアル
W&B で人気のある ML フレームワーク とライブラリを使用する方法に関するステップバイステップの情報については、以下のチュートリアルを参照してください。
その他のリソース
W&B AI Academy にアクセスして、 アプリケーション で LLM をトレーニング、 ファインチューン し、使用する方法を学びます。MLOps および LLMOps ソリューションを実装します。W&B コース で実際の ML の課題に取り組みます。
- 大規模言語モデル (LLM)
- 効果的な MLOps
- W&B Models
1 - Track experiments
W&B を使用して、機械学習 の実験管理、モデル のチェックポイント、チーム とのコラボレーションなどを行います。
この ノートブック では、単純な PyTorch モデル を使用して、機械学習 の 実験 を作成および追跡します。ノートブック の終わりまでに、チーム の他の メンバー と共有およびカスタマイズできるインタラクティブな プロジェクト ダッシュボード が作成されます。ダッシュボード の例はこちら
前提条件
W&B Python SDK をインストールして ログイン します。
# W&B アカウントにログインします
import wandb
import random
import math
# wandb-core を使用します。wandb の新しい バックエンド 用に一時的に使用されます
wandb.require("core")
W&B で 機械学習 の 実験 をシミュレートおよび追跡する
機械学習 の 実験 を作成、追跡、および視覚化します。これを行うには:
- W&B run を初期化し、追跡する ハイパーパラメータ を渡します。
- トレーニング ループ 内で、精度 や 損失 などの メトリクス を ログ に記録します。
import random
import math
# シミュレートされた 5 つの 実験 を起動します
total_runs = 5
for run in range(total_runs):
# 1️. この スクリプト を追跡するために新しい run を開始します
wandb.init(
# この run が ログ に記録される プロジェクト を設定します
project="basic-intro",
# run 名を渡します (そうでない場合は、sunshine-lollypop-10 のようにランダムに割り当てられます)
name=f"experiment_{run}",
# ハイパーパラメータ と run メタデータ を追跡します
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
})
# この簡単な ブロック は、メトリクス を ログ に記録する トレーニング ループ をシミュレートします
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# 2️. スクリプト から W&B に メトリクス を ログ に記録します
wandb.log({"acc": acc, "loss": loss})
# run に完了のマークを付けます
wandb.finish()
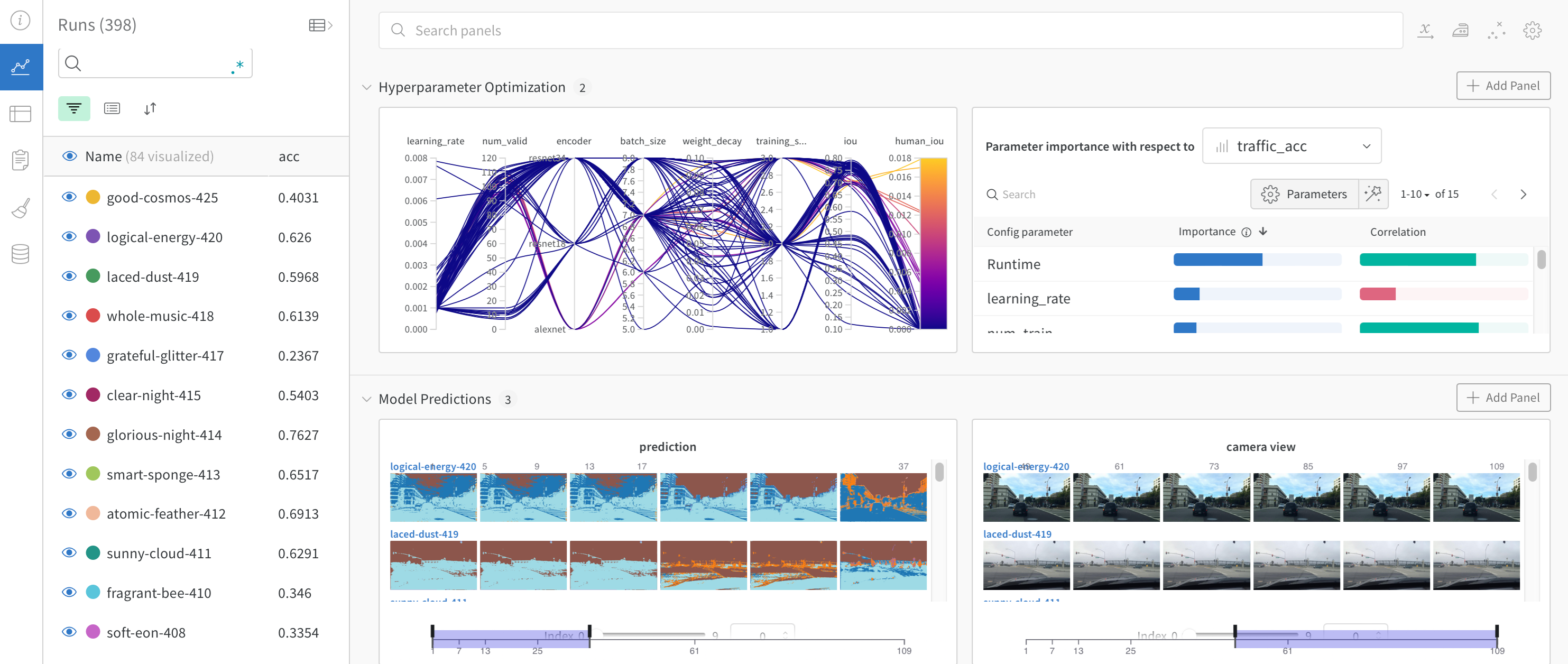
W&B プロジェクト で 機械学習 がどのように実行されたかを確認します。前の セル から出力された URL リンク をコピーして貼り付けます。URL は、グラフ を表示する ダッシュボード を含む W&B プロジェクト にリダイレクトされます。
次の画像は、ダッシュボード がどのように見えるかを示しています。
W&B を 疑似 機械学習 トレーニング ループ に統合する方法がわかったので、基本的な PyTorch ニューラルネットワーク を使用して 機械学習 の 実験 を追跡しましょう。次の コード は、組織 内の 他の チーム と共有できる モデル の チェックポイント を W&B にアップロードします。
Pytorch を使用して 機械学習 の 実験 を追跡する
次の コード セル は、単純な MNIST 分類器 を定義してトレーニングします。トレーニング 中に、W&B が URL を出力します。プロジェクト ページ リンク をクリックして、結果 が W&B プロジェクト に ライブ で ストリーミング されるのを確認します。
W&B run は、メトリクス、システム 情報、ハイパーパラメータ、ターミナル 出力 を自動的に ログ に記録し、モデル の 入力 と 出力 を含む インタラクティブな テーブル が表示されます。
PyTorch Dataloader を設定する
次の セル は、機械学習 モデル をトレーニングするために必要な便利な 関数 をいくつか定義しています。関数 自体は W&B 固有ではないため、ここでは詳細には説明しません。forward pass および backward pass トレーニング ループ の定義方法、PyTorch DataLoaders を使用して トレーニング 用の データ を ロードする方法、および torch.nn.Sequential クラス を使用して PyTorch モデル を定義する方法については、PyTorch ドキュメント を参照してください。
# @title
import torch, torchvision
import torch.nn as nn
from torchvision.datasets import MNIST
import torchvision.transforms as T
MNIST.mirrors = [
mirror for mirror in MNIST.mirrors if "http://yann.lecun.com/" not in mirror
]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
def get_dataloader(is_train, batch_size, slice=5):
"トレーニング データローダー を取得します"
full_dataset = MNIST(
root=".", train=is_train, transform=T.ToTensor(), download=True
)
sub_dataset = torch.utils.data.Subset(
full_dataset, indices=range(0, len(full_dataset), slice)
)
loader = torch.utils.data.DataLoader(
dataset=sub_dataset,
batch_size=batch_size,
shuffle=True if is_train else False,
pin_memory=True,
num_workers=2,
)
return loader
def get_model(dropout):
"単純な モデル"
model = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(256, 10),
).to(device)
return model
def validate_model(model, valid_dl, loss_func, log_images=False, batch_idx=0):
"検証 データセット での モデル の パフォーマンス を計算し、wandb.Table を ログ に記録します"
model.eval()
val_loss = 0.0
with torch.inference_mode():
correct = 0
for i, (images, labels) in enumerate(valid_dl):
images, labels = images.to(device), labels.to(device)
# Forward pass ➡
outputs = model(images)
val_loss += loss_func(outputs, labels) * labels.size(0)
# 精度 を計算して 累積します
_, predicted = torch.max(outputs.data, 1)
correct += (predicted == labels).sum().item()
# 画像 の 1 つの バッチ を ダッシュボード に ログ に記録します (常に同じ batch_idx)。
if i == batch_idx and log_images:
log_image_table(images, predicted, labels, outputs.softmax(dim=1))
return val_loss / len(valid_dl.dataset), correct / len(valid_dl.dataset)
予測値 と 真の 値 を比較する teble を作成する
次の セル は W&B 固有なので、見ていきましょう。
セル では、log_image_table という 関数 を定義します。厳密に言うと、オプション ですが、この 関数 は W&B テーブル オブジェクト を作成します。テーブル オブジェクト を使用して、モデル が 各画像 に対して 予測した内容を示す テーブル を作成します。
より具体的には、各 行 は、モデル に与えられた画像 と、予測値 および 実際の値 (ラベル) で構成されます。
def log_image_table(images, predicted, labels, probs):
"画像、ラベル、および 予測 を含む wandb.Table を ログ に記録します"
# 画像、ラベル、および 予測 を ログ に記録するための wandb テーブル を作成します
table = wandb.Table(
columns=["image", "pred", "target"] + [f"score_{i}" for i in range(10)]
)
for img, pred, targ, prob in zip(
images.to("cpu"), predicted.to("cpu"), labels.to("cpu"), probs.to("cpu")
):
table.add_data(wandb.Image(img[0].numpy() * 255), pred, targ, *prob.numpy())
wandb.log({"predictions_table": table}, commit=False)
モデル をトレーニングし、チェックポイント をアップロードします
次の コード は、モデル の チェックポイント をトレーニングして プロジェクト に保存します。通常どおり モデル の チェックポイント を使用して、トレーニング 中の モデル の パフォーマンス を評価します。
W&B を使用すると、保存された モデル と モデル の チェックポイント を チーム または 組織 の 他の メンバー と簡単に共有することもできます。モデル と モデル の チェックポイント を チーム 外の メンバー と共有する方法については、W&B Registry を参照してください。
# ドロップアウト率 を変えて 3 つの 実験 を起動します
for _ in range(3):
# wandb run を初期化します
wandb.init(
project="pytorch-intro",
config={
"epochs": 5,
"batch_size": 128,
"lr": 1e-3,
"dropout": random.uniform(0.01, 0.80),
},
)
# config をコピーします
config = wandb.config
# データ を取得します
train_dl = get_dataloader(is_train=True, batch_size=config.batch_size)
valid_dl = get_dataloader(is_train=False, batch_size=2 * config.batch_size)
n_steps_per_epoch = math.ceil(len(train_dl.dataset) / config.batch_size)
# 単純な MLP モデル
model = get_model(config.dropout)
# 損失 と オプティマイザー を作成します
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=config.lr)
# トレーニング
example_ct = 0
step_ct = 0
for epoch in range(config.epochs):
model.train()
for step, (images, labels) in enumerate(train_dl):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
train_loss = loss_func(outputs, labels)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
example_ct += len(images)
metrics = {
"train/train_loss": train_loss,
"train/epoch": (step + 1 + (n_steps_per_epoch * epoch))
/ n_steps_per_epoch,
"train/example_ct": example_ct,
}
if step + 1 < n_steps_per_epoch:
# train メトリクス を wandb に ログ に記録します
wandb.log(metrics)
step_ct += 1
val_loss, accuracy = validate_model(
model, valid_dl, loss_func, log_images=(epoch == (config.epochs - 1))
)
# train および 検証 メトリクス を wandb に ログ に記録します
val_metrics = {"val/val_loss": val_loss, "val/val_accuracy": accuracy}
wandb.log({**metrics, **val_metrics})
# モデル の チェックポイント を wandb に保存します
torch.save(model, "my_model.pt")
wandb.log_model(
"./my_model.pt",
"my_mnist_model",
aliases=[f"epoch-{epoch+1}_dropout-{round(wandb.config.dropout, 4)}"],
)
print(
f"Epoch: {epoch+1}, Train Loss: {train_loss:.3f}, Valid Loss: {val_loss:3f}, Accuracy: {accuracy:.2f}"
)
# テスト セット がある場合、これは 概要 メトリクス として ログ に記録する方法です
wandb.summary["test_accuracy"] = 0.8
# wandb run を閉じます
wandb.finish()
これで、W&B を使用して 最初の モデル をトレーニングしました。上記の リンク のいずれかをクリックして、メトリクス を確認し、W&B アプリ UI の Artifacts タブ で保存された モデル の チェックポイント を確認してください
(オプション) W&B Alert を設定する
W&B Alerts を作成して、Python コード から Slack または メール に アラート を送信します。
コード からトリガーされた Slack または メール アラート を初めて送信する場合は、次の 2 つの 手順に従います。
- W&B の ユーザー 設定 で Alerts をオンにします
wandb.alert() を コード に追加します。例:
wandb.alert(title="Low accuracy", text=f"Accuracy is below the acceptable threshold")
次の セル は、wandb.alert の使用方法を示す最小限の例を示しています
# wandb run を開始します
wandb.init(project="pytorch-intro")
# モデル トレーニング ループ をシミュレートします
acc_threshold = 0.3
for training_step in range(1000):
# 精度 の 乱数 を生成します
accuracy = round(random.random() + random.random(), 3)
print(f"Accuracy is: {accuracy}, {acc_threshold}")
# 精度 を wandb に ログ に記録します
wandb.log({"Accuracy": accuracy})
# 精度 が しきい値 を下回る場合は、W&B Alert を起動して run を停止します
if accuracy <= acc_threshold:
# wandb Alert を送信します
wandb.alert(
title="Low Accuracy",
text=f"Accuracy {accuracy} at step {training_step} is below the acceptable theshold, {acc_threshold}",
)
print("Alert triggered")
break
# run に完了のマークを付けます (Jupyter ノートブック で役立ちます)
wandb.finish()
W&B Alerts の 完全な ドキュメント はこちら にあります。
次のステップ
次の チュートリアル では、W&B Sweeps を使用して ハイパーパラメータ の 最適化 を行う方法を学習します。
PyTorch を使用した ハイパーパラメータ sweep
2 - Visualize predictions with tables
ここでは、MNIST データで PyTorch を使用して、トレーニングの過程におけるモデルの予測を追跡、視覚化、および比較する方法について説明します。
学習内容:
- モデルのトレーニングまたは評価中に、メトリクス、画像、テキストなどを
wandb.Table() に ログ 記録する方法
- これらのテーブルの表示、並べ替え、フィルタリング、グループ化、結合、インタラクティブなクエリ、および探索
- 特定の画像、ハイパーパラメータ / モデル バージョン、またはタイム ステップ間でモデルの予測または 結果 を動的に比較します。
Examples
特定の画像の予測スコアを比較する
ライブ 例:トレーニングの 1 エポック後と 5 エポック後の予測を比較する →
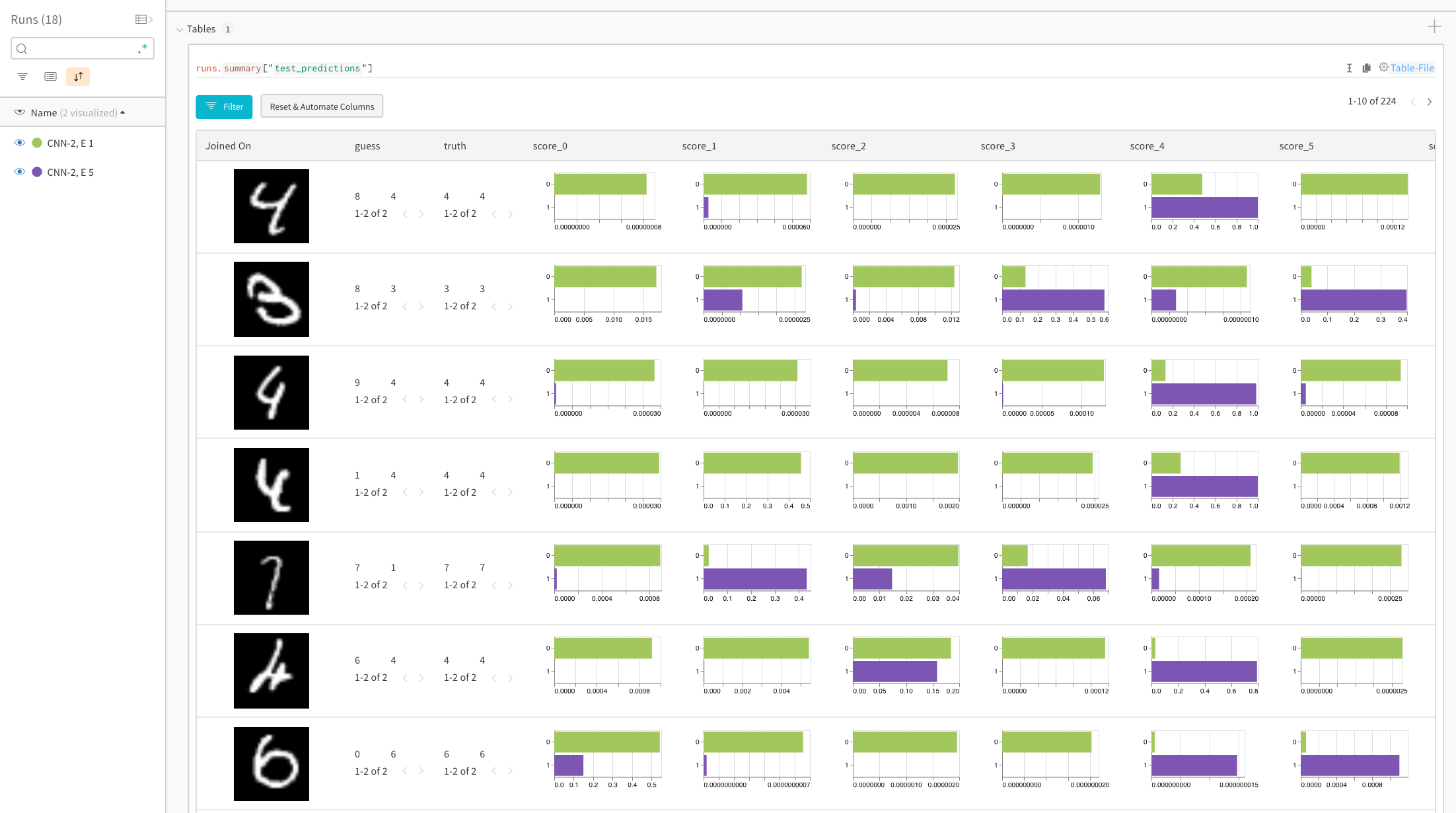
ヒストグラムは、2 つのモデル間のクラスごとのスコアを比較します。各ヒストグラムの上部の緑色のバーは、1 エポックのみトレーニングされたモデル「CNN-2, 1 epoch」(ID 0)を表します。下部の紫色のバーは、5 エポックトレーニングされたモデル「CNN-2, 5 epochs」(ID 1)を表します。画像は、モデルが一致しない場合にフィルタリングされます。たとえば、最初の行では、「4」は 1 エポック後、考えられるすべての数字で高いスコアを取得しますが、5 エポック後には、正しいラベルで最も高いスコアを獲得し、残りの部分では非常に低いスコアを獲得します。
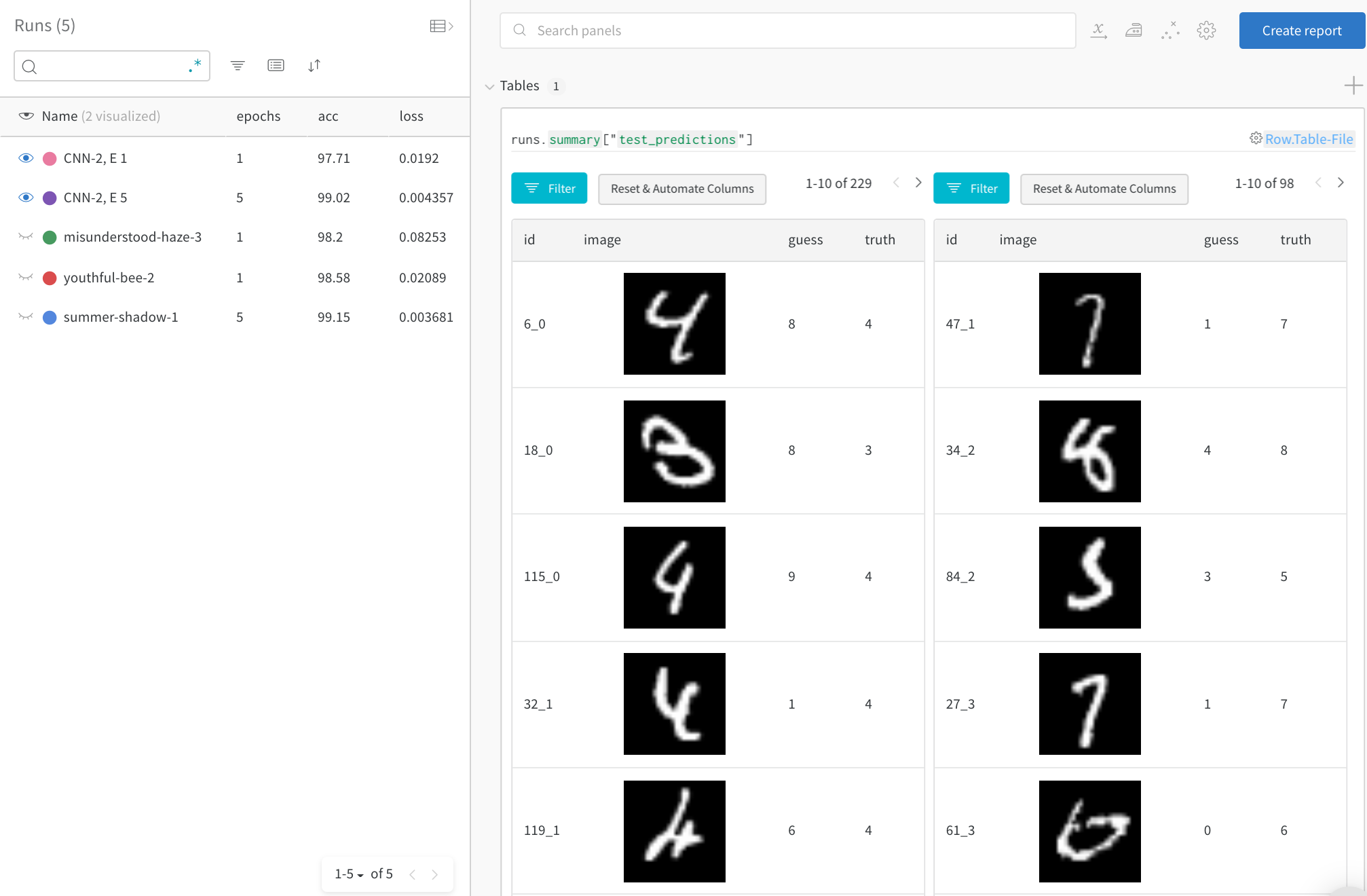
時間の経過に伴う上位のエラーに焦点を当てる
ライブ 例 →
完全なテスト データで、誤った予測(「推測」!=「真実」の行にフィルタリング)を確認します。1 回のトレーニング エポック後には 229 個の間違った推測がありますが、5 エポック後には 98 個しかないことに注意してください。
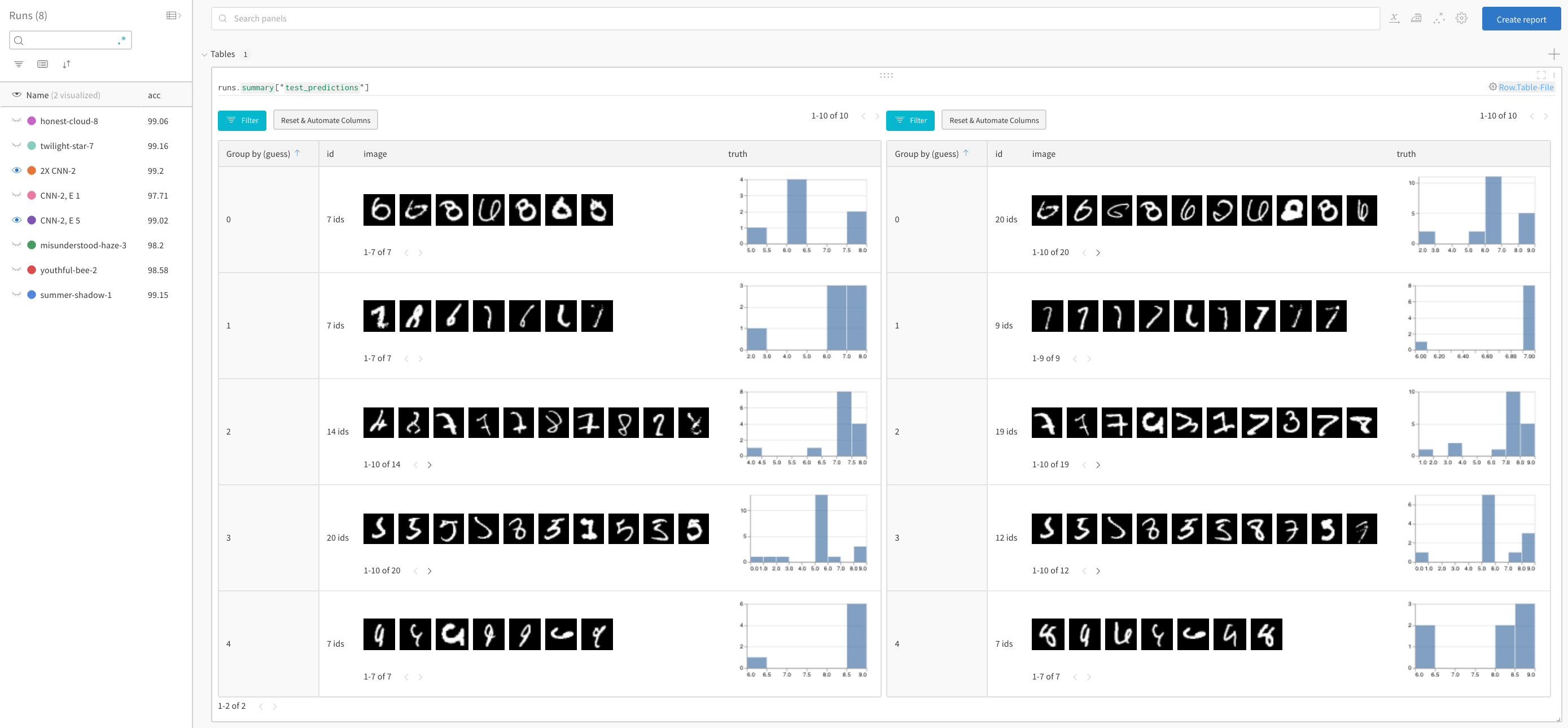
モデル のパフォーマンスを比較し、パターンを見つける
ライブ 例で詳細をご覧ください →
正解を除外し、推測ごとにグループ化して、誤って分類された画像の 例 と、真のラベルの基礎となる分布を、2 つのモデルを並べて表示します。レイヤー サイズと学習率が 2 倍のモデル バリアントが左側にあり、ベースラインが右側にあります。ベースラインでは、推測されたクラスごとにわずかに多くの間違いが発生することに注意してください。
サインアップまたはログイン
サインアップまたはログイン して W&B にアクセスし、ブラウザで 実験 を表示して操作します。
この例では、便利なホスト 環境として Google Colab を使用していますが、どこからでも独自のトレーニング スクリプト を実行し、W&B の 実験管理 ツール で メトリクス を視覚化できます。
アカウントに ログ インします。
import wandb
wandb.login()
WANDB_PROJECT = "mnist-viz"
0. セットアップ
依存関係をインストールし、MNIST をダウンロードし、PyTorch を使用してトレーニング データセット と テストデータセット を作成します。
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as T
import torch.nn.functional as F
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# トレーニングデータローダーを作成します
def get_dataloader(is_train, batch_size, slice=5):
"トレーニングデータローダーを取得します"
ds = torchvision.datasets.MNIST(root=".", train=is_train, transform=T.ToTensor(), download=True)
loader = torch.utils.data.DataLoader(dataset=ds,
batch_size=batch_size,
shuffle=True if is_train else False,
pin_memory=True, num_workers=2)
return loader
1. モデル と トレーニング スケジュールを定義する
- 実行する エポック 数を設定します。各 エポック は トレーニング ステップと検証 (テスト) ステップで構成されます。オプションで、テスト ステップごとに ログ に記録するデータ量を構成します。ここでは、デモを簡素化するために、視覚化するバッチ数とバッチあたりの画像数が少なく設定されています。
- ( pytorch-tutorial コードに従って) シンプルな畳み込み ニューラルネットワーク を定義します。
- PyTorch を使用してトレーニング セット と テスト セット にロードします。
# 実行するエポック数
# 各エポックにはトレーニングステップとテストステップが含まれるため、これにより、
# ログに記録するテスト予測のテーブル数が設定されます
EPOCHS = 1
# 各テストステップのテストデータからログに記録するバッチ数
# (デモを簡素化するためにデフォルトでは低く設定されています)
NUM_BATCHES_TO_LOG = 10 #79
# テストバッチごとにログに記録する画像数
# (デモを簡素化するためにデフォルトでは低く設定されています)
NUM_IMAGES_PER_BATCH = 32 #128
# トレーニング構成とハイパーパラメータ
NUM_CLASSES = 10
BATCH_SIZE = 32
LEARNING_RATE = 0.001
L1_SIZE = 32
L2_SIZE = 64
# これを変更すると、隣接するレイヤーの形状を変更する必要がある場合があります
CONV_KERNEL_SIZE = 5
# 2層の畳み込みニューラルネットワークを定義します
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, L1_SIZE, CONV_KERNEL_SIZE, stride=1, padding=2),
nn.BatchNorm2d(L1_SIZE),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(L1_SIZE, L2_SIZE, CONV_KERNEL_SIZE, stride=1, padding=2),
nn.BatchNorm2d(L2_SIZE),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*L2_SIZE, NUM_CLASSES)
self.softmax = nn.Softmax(NUM_CLASSES)
def forward(self, x):
# 特定のレイヤーの形状を確認するには、以下をコメント解除してください。
#print("x: ", x.size())
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
train_loader = get_dataloader(is_train=True, batch_size=BATCH_SIZE)
test_loader = get_dataloader(is_train=False, batch_size=2*BATCH_SIZE)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
2. トレーニング を実行し、テスト予測を ログ に記録する
エポック ごとに、トレーニング ステップとテスト ステップを実行します。各テスト ステップで、テスト予測を格納する wandb.Table() を作成します。これらは、ブラウザで視覚化したり、動的にクエリしたり、並べて比較したりできます。
# W&B: このモデルのトレーニングを追跡するために、新しい run を初期化します
wandb.init(project="table-quickstart")
# W&B: config を使用してハイパーパラメータをログに記録します
cfg = wandb.config
cfg.update({"epochs" : EPOCHS, "batch_size": BATCH_SIZE, "lr" : LEARNING_RATE,
"l1_size" : L1_SIZE, "l2_size": L2_SIZE,
"conv_kernel" : CONV_KERNEL_SIZE,
"img_count" : min(10000, NUM_IMAGES_PER_BATCH*NUM_BATCHES_TO_LOG)})
# モデル、損失、およびオプティマイザーを定義します
model = ConvNet(NUM_CLASSES).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
# テスト画像のバッチの予測をログに記録するための便利な関数
def log_test_predictions(images, labels, outputs, predicted, test_table, log_counter):
# すべてのクラスの信頼性スコアを取得します
scores = F.softmax(outputs.data, dim=1)
log_scores = scores.cpu().numpy()
log_images = images.cpu().numpy()
log_labels = labels.cpu().numpy()
log_preds = predicted.cpu().numpy()
# 画像の順序に基づいて ID を追加します
_id = 0
for i, l, p, s in zip(log_images, log_labels, log_preds, log_scores):
# 必要な情報をデータテーブルに追加します。
# ID、画像ピクセル、モデルの推測、真のラベル、すべてのクラスのスコア
img_id = str(_id) + "_" + str(log_counter)
test_table.add_data(img_id, wandb.Image(i), p, l, *s)
_id += 1
if _id == NUM_IMAGES_PER_BATCH:
break
# モデルをトレーニングします
total_step = len(train_loader)
for epoch in range(EPOCHS):
# トレーニングステップ
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# backward と最適化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# W&B: トレーニングステップ全体の損失をログに記録します。UI にライブで視覚化されます
wandb.log({"loss" : loss})
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, EPOCHS, i+1, total_step, loss.item()))
# W&B: 各テストステップの予測を保存するための Table を作成します
columns=["id", "image", "guess", "truth"]
for digit in range(10):
columns.append("score_" + str(digit))
test_table = wandb.Table(columns=columns)
# モデルをテストします
model.eval()
log_counter = 0
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
if log_counter < NUM_BATCHES_TO_LOG:
log_test_predictions(images, labels, outputs, predicted, test_table, log_counter)
log_counter += 1
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = 100 * correct / total
# W&B: UI で視覚化するために、トレーニングエポック全体の精度をログに記録します
wandb.log({"epoch" : epoch, "acc" : acc})
print('Test Accuracy of the model on the 10000 test images: {} %'.format(acc))
# W&B: 予測テーブルを wandb にログに記録します
wandb.log({"test_predictions" : test_table})
# W&B: run を完了としてマークします (マルチセル ノートブック に役立ちます)
wandb.finish()
次は何ですか?
次のチュートリアルでは、W&B Sweeps を使用してハイパーパラメータを最適化する方法 を学習します。
3 - Tune hyperparameters with sweeps
望ましいメトリクス(モデルの精度など)を満たす機械学習モデルを見つけることは、通常、複数の反復を必要とする冗長な作業です。さらに悪いことに、特定のトレーニング run にどの ハイパーパラメーター の組み合わせを使用するか不明確な場合があります。
W&B Sweeps を使用すると、学習率、 バッチサイズ 、隠れ層の数、 オプティマイザー の種類など、 ハイパーパラメーター の値の組み合わせを自動的に検索するための、組織化され効率的な方法を作成し、目的のメトリクスに基づいてモデルを最適化する値を見つけることができます。
このチュートリアルでは、W&B PyTorch インテグレーションを使用して ハイパーパラメーター 探索を作成します。ビデオチュートリアルをご覧ください。
Sweeps:概要
Weights & Biases で ハイパーパラメーター sweep を実行するのは非常に簡単です。簡単な3つのステップがあります。
-
sweep を定義する: 検索する パラメータ 、検索戦略、最適化 メトリクス などを指定する 辞書 または YAML ファイル を作成することにより、これを行います。
-
sweep を初期化する: 1行の コード で sweep を初期化し、sweep 設定の 辞書 を渡します。
sweep_id = wandb.sweep(sweep_config)
-
sweep agent を実行する: 1行の コード でも実行でき、wandb.agent() を呼び出し、実行する sweep_id と、モデル アーキテクチャー を定義してトレーニング する関数を渡します。
wandb.agent(sweep_id, function=train)
始める前に
W&B をインストールし、W&B Python SDK を ノートブック にインポートします。
!pip install でインストール:
!pip install wandb -Uq
- W&B をインポート:
import wandb
- W&B にログインし、プロンプトが表示されたら APIキー を入力します。
wandb.login()
ステップ1️:sweep を定義する
W&B Sweep は、多数の ハイパーパラメーター 値を試すための戦略と、それらを評価する コード を組み合わせたものです。
sweep を開始する前に、 sweep 設定 で sweep 戦略を定義する必要があります。
Jupyter Notebook で sweep を開始する場合、sweep 用に作成する sweep 設定は、ネストされた 辞書 にする必要があります。
コマンドライン 内で sweep を実行する場合は、YAML ファイル で sweep 設定を指定する必要があります。
検索方法を選択
まず、設定 辞書 内で ハイパーパラメーター 検索方法を指定します。グリッド、 ランダム 検索、 ベイズ探索 の3つの ハイパーパラメーター 検索戦略から選択できます。
このチュートリアルでは、 ランダム 検索を使用します。 ノートブック 内で、 辞書 を作成し、method キーに random を指定します。
sweep_config = {
'method': 'random'
}
最適化する メトリクス を指定します。 ランダム 検索方法を使用する sweep の メトリクス と目標を指定する必要はありません。ただし、後で参照できるように、sweep の目標を追跡することをお勧めします。
metric = {
'name': 'loss',
'goal': 'minimize'
}
sweep_config['metric'] = metric
検索する ハイパーパラメーター を指定する
これで、sweep 設定で検索方法が指定されたので、検索する ハイパーパラメーター を指定します。
これを行うには、1つ以上の ハイパーパラメーター 名を parameter キーに指定し、value キーに1つ以上の ハイパーパラメーター 値を指定します。
特定の ハイパーパラメーター で検索する値は、調査している ハイパーパラメーター の種類によって異なります。
たとえば、機械学習 オプティマイザー を選択する場合は、Adam オプティマイザー や確率的勾配降下など、1つ以上の有限 オプティマイザー 名を指定する必要があります。
parameters_dict = {
'optimizer': {
'values': ['adam', 'sgd']
},
'fc_layer_size': {
'values': [128, 256, 512]
},
'dropout': {
'values': [0.3, 0.4, 0.5]
},
}
sweep_config['parameters'] = parameters_dict
ハイパーパラメーター を追跡したいが、その値を変更したくない場合があります。この場合、 ハイパーパラメーター を sweep 設定に追加し、使用する正確な値を指定します。たとえば、次の コード セルでは、epochs が1に設定されています。
parameters_dict.update({
'epochs': {
'value': 1}
})
random 検索の場合、
パラメータ のすべての values は、特定の run で選択される可能性が等しくなります。
または、
名前付きの distribution と、その パラメータ (normal 分布の平均 mu や標準偏差 sigma など)を指定できます。
parameters_dict.update({
'learning_rate': {
# 0〜0.1のフラットな分布
'distribution': 'uniform',
'min': 0,
'max': 0.1
},
'batch_size': {
# 32〜256の整数
# 対数が均等に分布
'distribution': 'q_log_uniform_values',
'q': 8,
'min': 32,
'max': 256,
}
})
完了すると、sweep_config はネストされた 辞書 になります。
これは、試してみたい parameters と、それらを試すために使用する method を正確に指定します。
sweep 設定がどのように見えるかを見てみましょう。
import pprint
pprint.pprint(sweep_config)
設定オプションの完全なリストについては、sweep 設定オプション を参照してください。
無限のオプションを持つ可能性のある ハイパーパラメーター の場合、
通常、いくつかの選択された values を試してみるのが理にかなっています。たとえば、前の sweep 設定には、layer_size および dropout パラメータ キーに指定された有限値のリストがあります。
ステップ2️:Sweep を初期化する
検索戦略を定義したら、それを実装するためのものをセットアップします。
W&B は、Sweep Controller を使用して、 クラウド 上またはローカルで1つ以上のマシンにわたって sweep を管理します。このチュートリアルでは、W&B によって管理される sweep コントローラ を使用します。
sweep コントローラ が sweep を管理している間、実際に sweep を実行するコンポーネントは sweep agent と呼ばれます。
デフォルトでは、 sweep コントローラ コンポーネントは W&B の サーバー 上で開始され、 sweep を作成するコンポーネントである sweep agent はローカルマシンでアクティブ化されます。
ノートブック 内では、wandb.sweep メソッドを使用して sweep コントローラ をアクティブ化できます。以前に定義した sweep 設定 辞書 を sweep_config フィールドに渡します。
sweep_id = wandb.sweep(sweep_config, project="pytorch-sweeps-demo")
wandb.sweep 関数は、後で sweep をアクティブ化するために使用する sweep_id を返します。
コマンドライン では、この関数は次のように置き換えられます
ターミナル で W&B Sweeps を作成する方法の詳細については、W&B Sweep チュートリアル を参照してください。
ステップ3:機械学習 コード を定義する
sweep を実行する前に、
試してみたい ハイパーパラメーター 値を使用するトレーニング プロシージャ を定義します。W&B Sweeps をトレーニング コード に統合するための鍵は、各トレーニング 実験 で、トレーニング ロジックが sweep 設定で定義した ハイパーパラメーター 値に アクセス できるようにすることです。
次の コード 例では、ヘルパー関数 build_dataset、build_network、build_optimizer、および train_epoch が sweep ハイパーパラメーター 設定 辞書 に アクセス します。
次の機械学習 トレーニング コード を ノートブック で実行します。これらの関数は、PyTorch で基本的な完全接続 ニューラルネットワーク を定義します。
import torch
import torch.optim as optim
import torch.nn.functional as F
import torch.nn as nn
from torchvision import datasets, transforms
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def train(config=None):
# Initialize a new wandb run
with wandb.init(config=config):
# If called by wandb.agent, as below,
# this config will be set by Sweep Controller
config = wandb.config
loader = build_dataset(config.batch_size)
network = build_network(config.fc_layer_size, config.dropout)
optimizer = build_optimizer(network, config.optimizer, config.learning_rate)
for epoch in range(config.epochs):
avg_loss = train_epoch(network, loader, optimizer)
wandb.log({"loss": avg_loss, "epoch": epoch})
train 関数内では、次の W&B Python SDK メソッドに注意してください。
次のセルは、4つの関数(build_dataset、build_network、build_optimizer、および train_epoch)を定義します。
これらの関数は、基本的な PyTorch パイプライン の標準的な部分であり、
その実装は W&B の使用による影響を受けません。
def build_dataset(batch_size):
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
# download MNIST training dataset
dataset = datasets.MNIST(".", train=True, download=True,
transform=transform)
sub_dataset = torch.utils.data.Subset(
dataset, indices=range(0, len(dataset), 5))
loader = torch.utils.data.DataLoader(sub_dataset, batch_size=batch_size)
return loader
def build_network(fc_layer_size, dropout):
network = nn.Sequential( # fully connected, single hidden layer
nn.Flatten(),
nn.Linear(784, fc_layer_size), nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(fc_layer_size, 10),
nn.LogSoftmax(dim=1))
return network.to(device)
def build_optimizer(network, optimizer, learning_rate):
if optimizer == "sgd":
optimizer = optim.SGD(network.parameters(),
lr=learning_rate, momentum=0.9)
elif optimizer == "adam":
optimizer = optim.Adam(network.parameters(),
lr=learning_rate)
return optimizer
def train_epoch(network, loader, optimizer):
cumu_loss = 0
for _, (data, target) in enumerate(loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# ➡ Forward pass
loss = F.nll_loss(network(data), target)
cumu_loss += loss.item()
# ⬅ Backward pass + weight update
loss.backward()
optimizer.step()
wandb.log({"batch loss": loss.item()})
return cumu_loss / len(loader)
PyTorch で W&B を使用した計測の詳細については、この Colab を参照してください。
ステップ4: sweep agent をアクティブ化する
sweep 設定を定義し、インタラクティブな方法でこれらの ハイパーパラメーター を利用できるトレーニング スクリプト を作成したので、 sweep agent をアクティブ化する準備ができました。 Sweep agent は、 sweep 設定で定義した ハイパーパラメーター 値のセットを使用して 実験 を実行する役割を担います。
wandb.agent メソッドを使用して sweep agent を作成します。以下を指定してください。
- agent が属する sweep (
sweep_id)
- sweep が実行することになっている関数。この例では、 sweep は
train 関数を使用します。
- (オプション) sweep コントローラ に要求する設定の数 (
count)
異なるコンピューティング リソース 上で、同じ sweep_id を持つ複数の sweep agent を開始できます。 sweep コントローラ は、定義した sweep 設定に従って連携するようにします。
次のセルは、トレーニング 関数 (train) を5回実行する sweep agent をアクティブ化します。
wandb.agent(sweep_id, train, count=5)
random 検索方法が sweep 設定で指定されているため、 sweep コントローラ は ランダム に生成された ハイパーパラメーター 値を提供します。
ターミナル で W&B Sweeps を作成する方法の詳細については、W&B Sweep チュートリアル を参照してください。
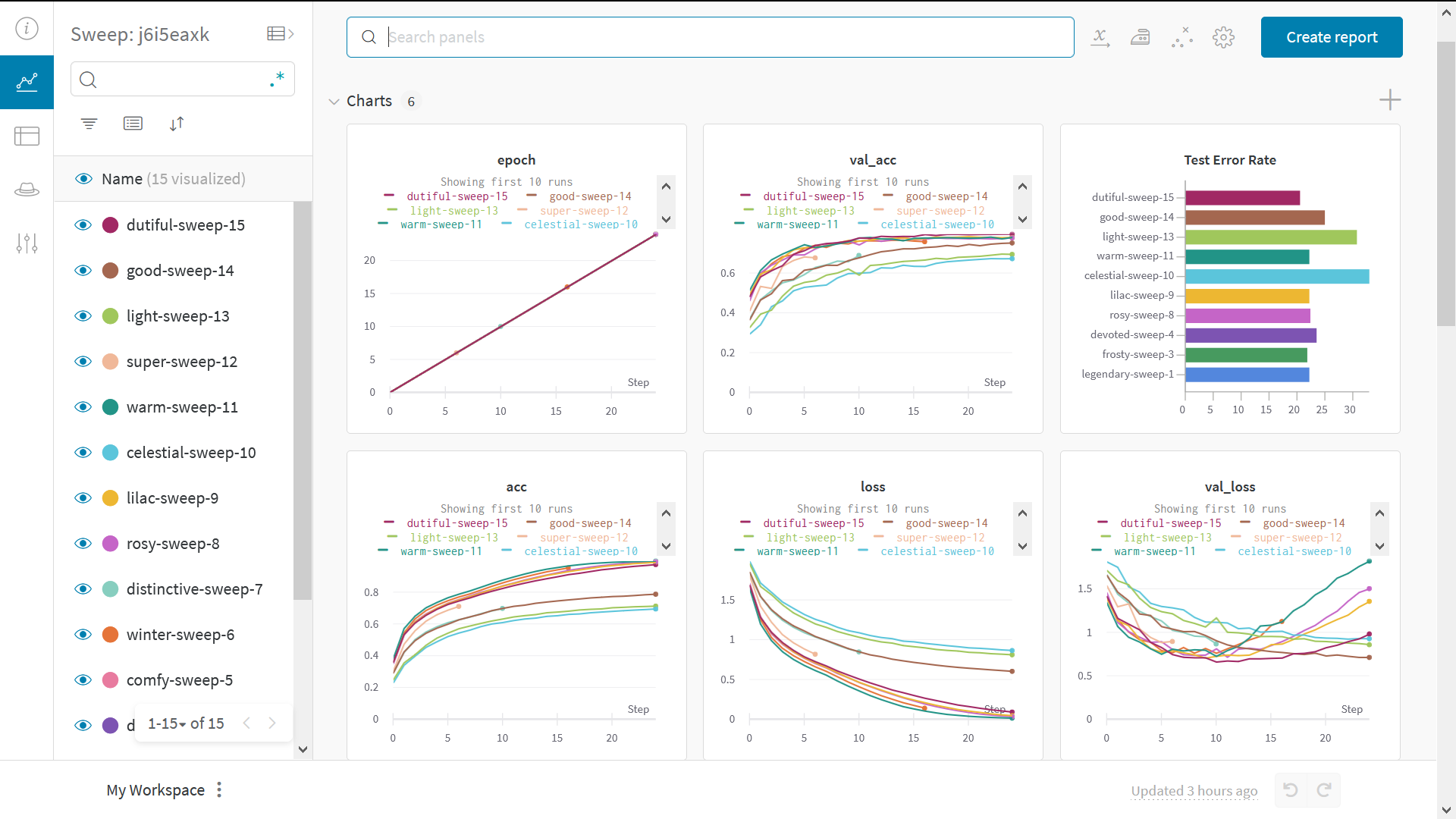
Sweep の結果を 可視化 する
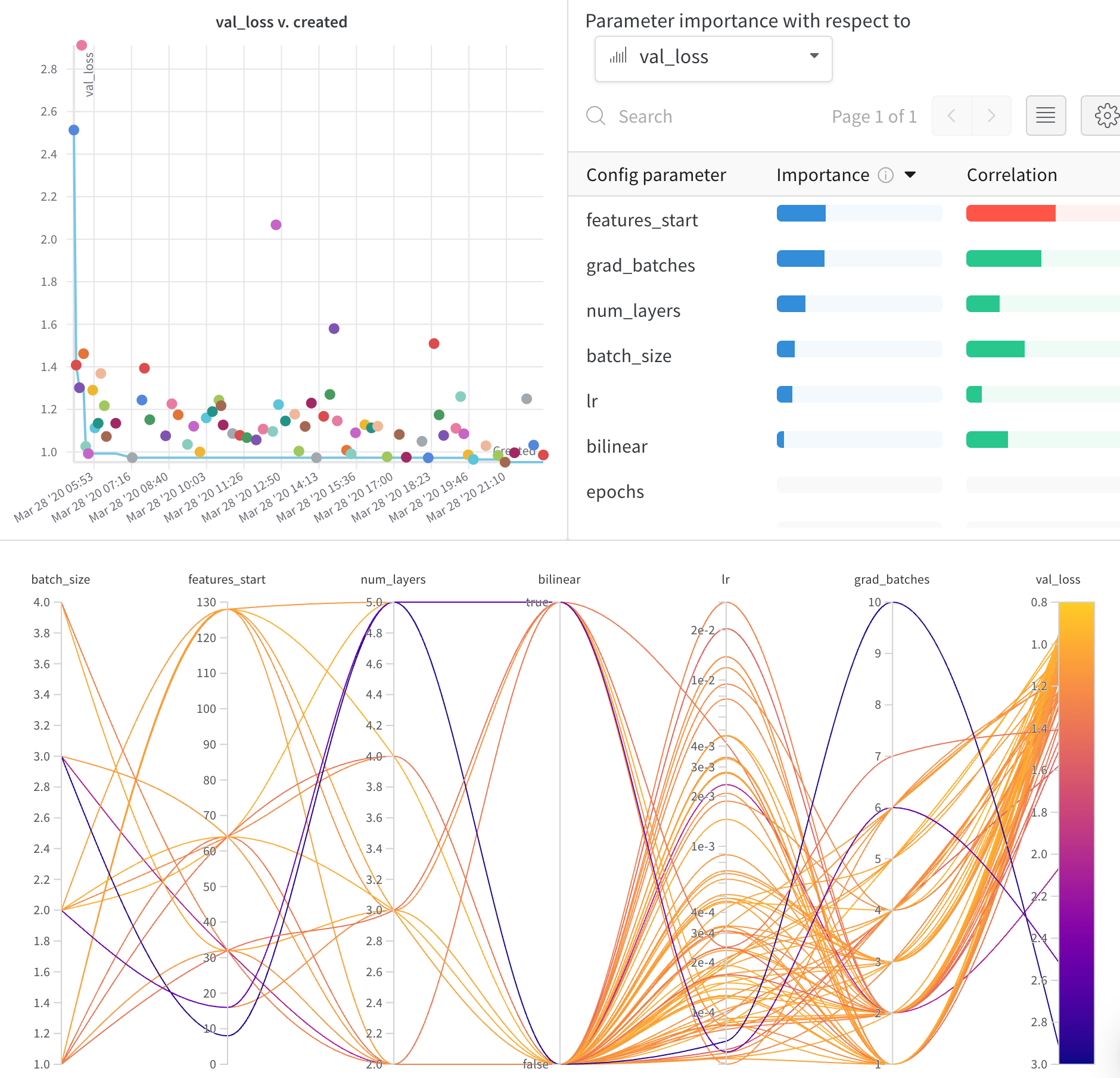
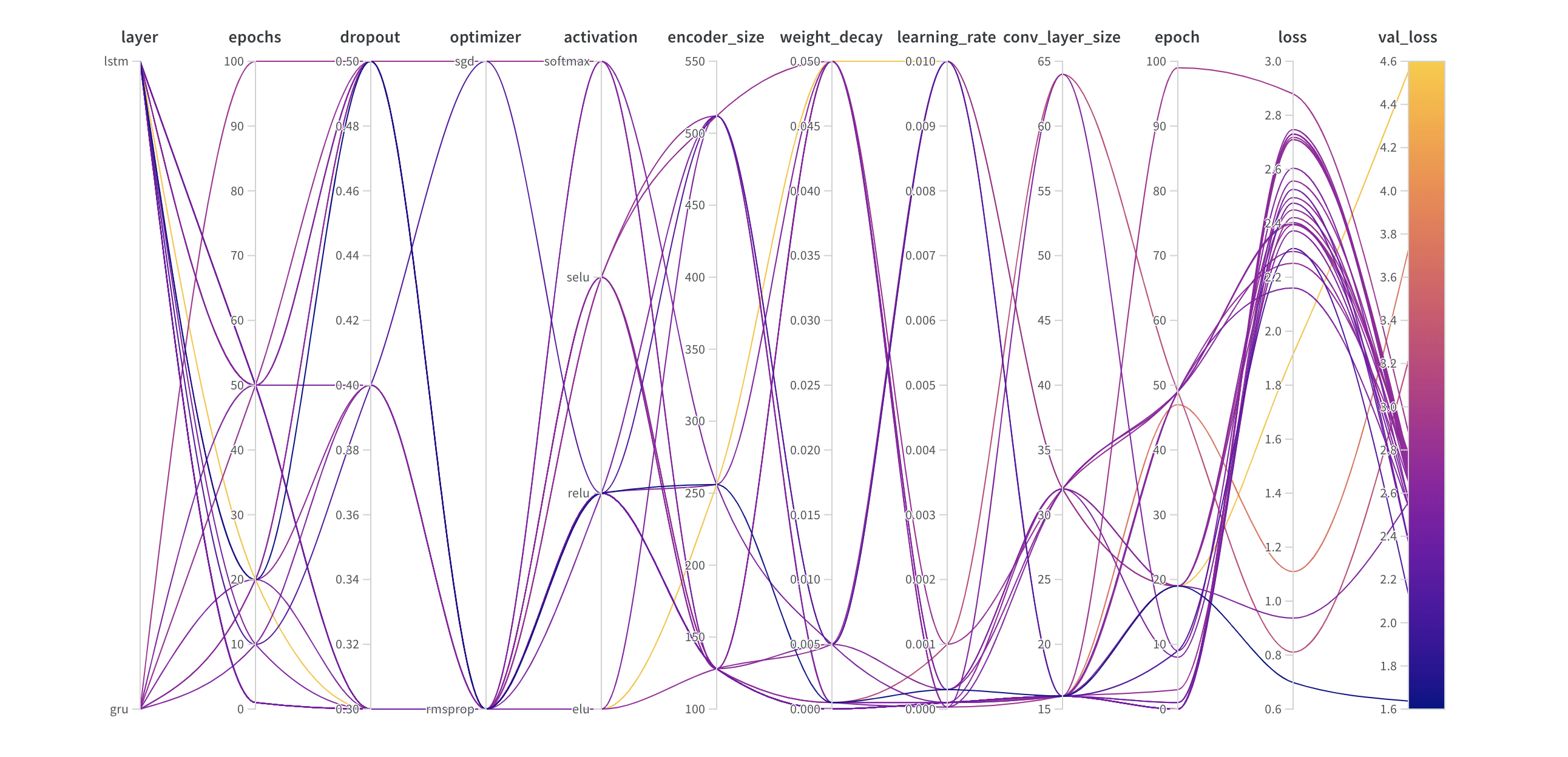
並列座標プロット
このプロットは、 ハイパーパラメーター 値をモデル メトリクス にマッピングします。これは、最高のモデル パフォーマンス につながった ハイパーパラメーター の組み合わせを調整するのに役立ちます。
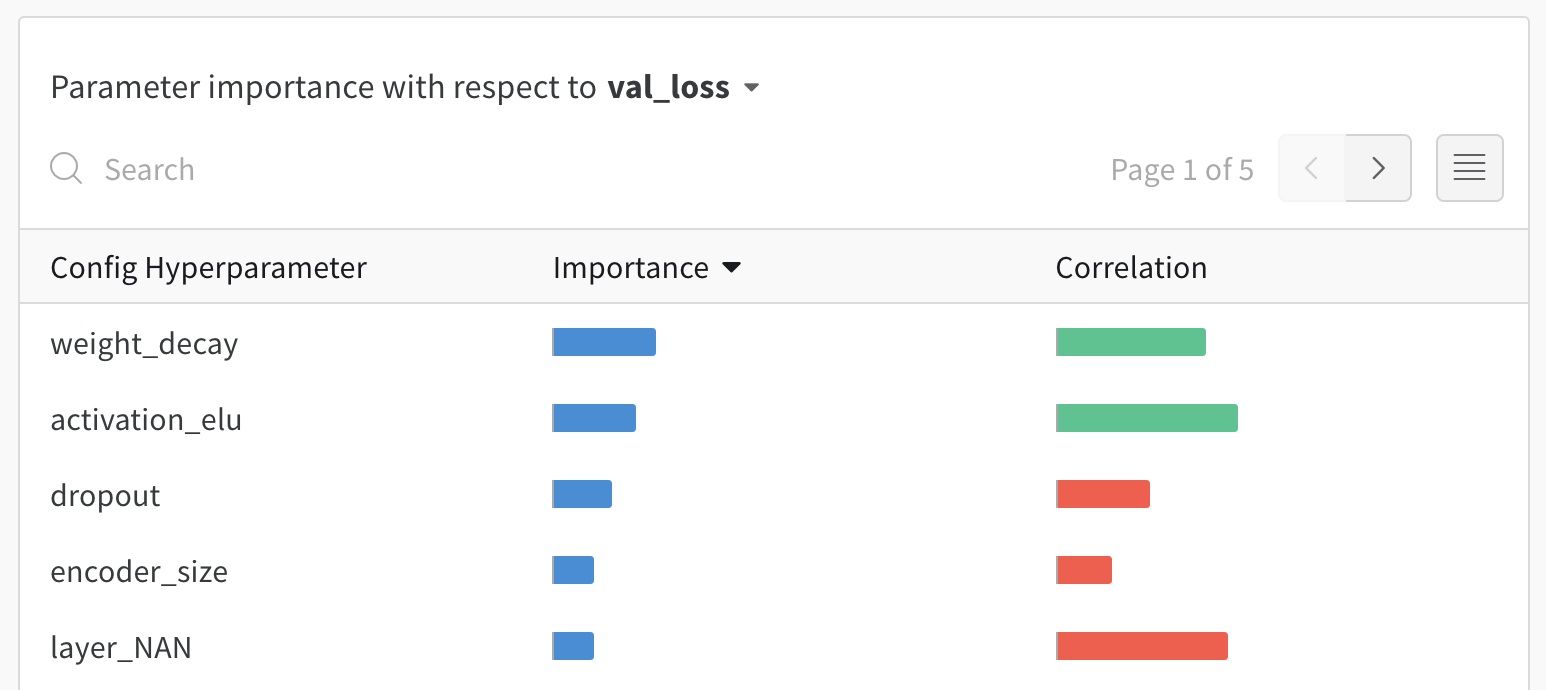
ハイパーパラメーター インポータンスプロット
ハイパーパラメーター インポータンスプロット は、どの ハイパーパラメーター が メトリクス の最良の予測因子であるかを表面化します。
特徴量の重要度( ランダム フォレスト モデル から)と相関関係(暗黙的に線形モデル)を報告します。
これらの 可視化 は、最も重要な パラメータ (および値の範囲)を絞り込むことで、高価な ハイパーパラメーター 最適化を実行する時間とリソースを節約するのに役立ち、それによってさらに調査する価値があります。
W&B Sweeps の詳細
単純なトレーニング スクリプト と、試せる いくつかの種類の sweep 設定 を作成しました。これらを試してみることを強くお勧めします。
その リポジトリ には、ベイズ Hyperband や Hyperopt などの、より高度な sweep 機能を試すのに役立つ例もあります。
4 - Track models and datasets
このノートブックでは、W&B Artifacts を使用して ML 実験パイプラインを追跡する方法を紹介します。
ビデオチュートリアルをご覧ください。
Artifacts について
Artifact は、ギリシャのアンフォラのように、
生成されたオブジェクト、つまりプロセスの出力です。
ML で最も重要な Artifact は、 データセット と モデル です。
そして、コロナドの十字架のように、これらの重要な Artifact は博物館に属します。
つまり、あなた、あなたの Team、そして ML コミュニティ全体がそれらから学ぶことができるように、カタログ化され、整理されるべきです。
結局のところ、トレーニングを追跡しない人は、それを繰り返す運命にあります。
Artifacts API を使用すると、次の図のように、W&B Run の出力として Artifact をログに記録したり、Artifact を Run への入力として使用したりできます。
ここでは、トレーニング run がデータセットを取り込み、モデルを生成します。

1 つの run が別の run の出力を入力として使用できるため、Artifact と Run はまとめて有向グラフ (2 部 DAG) を形成します。Artifact と Run のノードと、Run を消費または生成する Artifact に接続する矢印があります。
Artifacts を使用してモデルとデータセットを追跡する
インストールとインポート
Artifacts は、バージョン 0.9.2 以降の Python ライブラリの一部です。
ML Python スタックのほとんどの部分と同様に、pip 経由で利用できます。
# Compatible with wandb version 0.9.2+
!pip install wandb -qqq
!apt install tree
データセットのログ
まず、いくつかの Artifacts を定義しましょう。
この例は、この PyTorch
“基本的な MNIST の例”
に基づいています。
TensorFlowや他の framework、
または純粋な Python でも簡単に実行できます。
Dataset から始めましょう。
- パラメータを選択するための
train ニング セット
- ハイパーパラメータを選択するための
validation セット
- 最終モデルを評価するための
test ニング セット
以下の最初のセルは、これら 3 つのデータセットを定義します。
import random
import torch
import torchvision
from torch.utils.data import TensorDataset
from tqdm.auto import tqdm
# Ensure deterministic behavior
torch.backends.cudnn.deterministic = True
random.seed(0)
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
# Device configuration
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Data parameters
num_classes = 10
input_shape = (1, 28, 28)
# drop slow mirror from list of MNIST mirrors
torchvision.datasets.MNIST.mirrors = [mirror for mirror in torchvision.datasets.MNIST.mirrors
if not mirror.startswith("http://yann.lecun.com")]
def load(train_size=50_000):
"""
# データのロード
"""
# the data, split between train and test sets
train = torchvision.datasets.MNIST("./", train=True, download=True)
test = torchvision.datasets.MNIST("./", train=False, download=True)
(x_train, y_train), (x_test, y_test) = (train.data, train.targets), (test.data, test.targets)
# split off a validation set for hyperparameter tuning
x_train, x_val = x_train[:train_size], x_train[train_size:]
y_train, y_val = y_train[:train_size], y_train[train_size:]
training_set = TensorDataset(x_train, y_train)
validation_set = TensorDataset(x_val, y_val)
test_set = TensorDataset(x_test, y_test)
datasets = [training_set, validation_set, test_set]
return datasets
これは、この例で繰り返されるパターンを設定します。
Artifact としてデータをログに記録するコードは、データの
生成コードの周りにラップされます。
この場合、データを load するコードは、
データを load_and_log するコードから分離されています。
これは良い習慣です。
これらのデータセットを Artifacts としてログに記録するには、
次の手順が必要です。
wandb.init で Run を作成し (L4)、- データセットの
Artifact を作成し (L10)、
- 関連する
file を保存してログに記録します (L20、L23)。
以下のコードセルの例を確認し、後でセクションを展開して詳細を確認してください。
def load_and_log():
# 🚀 run を開始し、それにラベルを付ける type と、ホームと呼ぶことができる project を指定します
with wandb.init(project="artifacts-example", job_type="load-data") as run:
datasets = load() # データセットをロードするための個別のコード
names = ["training", "validation", "test"]
# 🏺 Artifact を作成
raw_data = wandb.Artifact(
"mnist-raw", type="dataset",
description="Raw MNIST dataset, split into train/val/test",
metadata={"source": "torchvision.datasets.MNIST",
"sizes": [len(dataset) for dataset in datasets]})
for name, data in zip(names, datasets):
# 🐣 Artifact に新しいファイルを保存し、そのコンテンツに何かを書き込みます。
with raw_data.new_file(name + ".pt", mode="wb") as file:
x, y = data.tensors
torch.save((x, y), file)
# ✍️ Artifact を W&B に保存します。
run.log_artifact(raw_data)
load_and_log()
wandb.init
Artifact を生成する Run を作成するときは、
どの project に属するかを明記する必要があります。
workflow によっては、
project は car-that-drives-itself ほど大きくても、
iterative-architecture-experiment-117 ほど小さくてもかまいません。
経験則: 可能であれば、Artifact を共有するすべての Run を
1 つの project 内に保持します。これにより、物事がシンプルになりますが、心配しないでください。Artifact は project 間で移植可能です。
実行する可能性のあるさまざまな種類のジョブをすべて追跡するために、
Run を作成するときに job_type を指定すると便利です。
これにより、Artifact のグラフがすっきりと整理されます。
経験則: job_type は記述的であり、パイプラインの 1 つのステップに対応する必要があります。ここでは、データの load とデータの preprocess を分離しています。
wandb.Artifact
何かを Artifact としてログに記録するには、最初に Artifact オブジェクトを作成する必要があります。
すべての Artifact には name があります。これは、最初の引数で設定されます。
経験則: name は記述的である必要がありますが、覚えやすく、入力しやすい必要があります。
ハイフンで区切られ、コード内の変数名に対応する名前を使用することをお勧めします。
また、type もあります。Run の job_type と同様に、
これは Run と Artifact のグラフを整理するために使用されます。
経験則: type はシンプルにする必要があります。
mnist-data-YYYYMMDD よりも dataset や model に近いものにします。
また、description といくつかの metadata を辞書として添付することもできます。
metadata は、JSON にシリアル化できる必要があります。
経験則: metadata は可能な限り記述的にする必要があります。
artifact.new_file と run.log_artifact
Artifact オブジェクトを作成したら、それにファイルを追加する必要があります。
そのとおりです。ファイル です。
Artifact はディレクトリーのように構造化されており、
ファイルとサブディレクトリーがあります。
経験則: 可能な場合は常に、
Artifact の内容を複数のファイルに分割します。これは、スケーリングするときに役立ちます。
new_file メソッドを使用して、
ファイルを同時に書き込み、Artifact に添付します。
以下では、add_file メソッドを使用します。
これにより、これら 2 つのステップが分離されます。
すべてのファイルを追加したら、wandb.ai に log_artifact する必要があります。
出力に URL がいくつか表示されます。
Run ページの URL も含まれています。
これは、ログに記録された Artifact を含む、Run の結果を表示できる場所です。
以下では、Run ページの他のコンポーネントをより有効に活用する例をいくつか示します。
ログに記録されたデータセット Artifact の使用
博物館の Artifact とは異なり、W&B の Artifact は、
保存されるだけでなく、使用 されるように設計されています。
それがどのようなものかを見てみましょう。
以下のセルは、生のデータセットを受け取るパイプライン ステップを定義します
。これを使用して、preprocess されたデータセットを生成します。
normalize され、正しく整形されています。
wandb とやり取りするコードから、コードの重要な部分である preprocess を分割していることに再び注意してください。
def preprocess(dataset, normalize=True, expand_dims=True):
"""
## データの準備
"""
x, y = dataset.tensors
if normalize:
# Scale images to the [0, 1] range
x = x.type(torch.float32) / 255
if expand_dims:
# Make sure images have shape (1, 28, 28)
x = torch.unsqueeze(x, 1)
return TensorDataset(x, y)
次に、wandb.Artifact ロギングでこの preprocess ステップをインストルメント化するコードを示します。
以下の例では、Artifact を use していること、
これは新しいこと、
そしてそれを log していること、
これは最後のステップと同じであることに注意してください。
Artifact は、Run の入力と出力の両方です。
新しい job_type である preprocess-data を使用して、
これが前のジョブとは異なる種類のジョブであることを明確にします。
def preprocess_and_log(steps):
with wandb.init(project="artifacts-example", job_type="preprocess-data") as run:
processed_data = wandb.Artifact(
"mnist-preprocess", type="dataset",
description="Preprocessed MNIST dataset",
metadata=steps)
# ✔️ 使用する Artifact を宣言します
raw_data_artifact = run.use_artifact('mnist-raw:latest')
# 📥 必要に応じて、Artifact をダウンロードします
raw_dataset = raw_data_artifact.download()
for split in ["training", "validation", "test"]:
raw_split = read(raw_dataset, split)
processed_dataset = preprocess(raw_split, **steps)
with processed_data.new_file(split + ".pt", mode="wb") as file:
x, y = processed_dataset.tensors
torch.save((x, y), file)
run.log_artifact(processed_data)
def read(data_dir, split):
filename = split + ".pt"
x, y = torch.load(os.path.join(data_dir, filename))
return TensorDataset(x, y)
ここで注意すべきことの 1 つは、preprocessing の steps
が preprocessed_data とともに metadata として保存されることです。
実験を再現可能にしようとしている場合は、
多くの metadata をキャプチャすることをお勧めします。
また、データセットが「large artifact」であっても、
download ステップは 1 秒もかからずに完了します。
詳細については、以下の markdown セルを展開してください。
steps = {"normalize": True,
"expand_dims": True}
preprocess_and_log(steps)
run.use_artifact
これらの手順はより簡単です。コンシューマーは、Artifact の name と、もう少しだけ知る必要があります。
その「もう少し」とは、必要な Artifact の特定のバージョンの alias です。
デフォルトでは、最後にアップロードされたバージョンには latest というタグが付けられます。
それ以外の場合は、v0/v1 などを使用して古いバージョンを選択するか、best や jit-script などの独自のエイリアスを指定できます。
Docker Hub タグと同様に、
エイリアスは名前と : で区切られているため、
必要な Artifact は mnist-raw:latest です。
経験則: エイリアスは短く簡潔に保ちます。
Artifact が何らかのプロパティを満たすようにする場合は、latest や best などのカスタム alias を使用します
artifact.download
ここで、download 呼び出しについて心配しているかもしれません。
別のコピーをダウンロードすると、メモリへの負担が 2 倍になるのではないでしょうか。
ご心配なく。実際に何かをダウンロードする前に、
適切なバージョンがローカルで利用可能かどうかを確認します。
これには、torrenting と git によるバージョン管理 の基盤となるのと同じテクノロジーであるハッシュが使用されます。
Artifact が作成されてログに記録されると、
作業ディレクトリー内の artifacts というフォルダー
がサブディレクトリーでいっぱいになり始めます。
これは、各 Artifact に 1 つずつです。
!tree artifacts でその内容を確認してください。
Artifacts ページ
Artifact をログに記録して使用したので、
Run ページの Artifacts タブを確認してみましょう。
wandb 出力の Run ページの URL に移動し、
左側のサイドバーから [Artifacts] タブを選択します
(これはデータベース アイコンが付いたもので、
3 つのホッケー パックが互いに積み重ねられているように見えます)。
[Input Artifacts] テーブルまたは
[Output Artifacts] テーブルのいずれかの行をクリックし、
次にタブ ([Overview]、[Metadata])
をチェックして、Artifact についてログに記録されたすべての内容を確認します。
特に [Graph View] が気に入っています。
デフォルトでは、Artifact の type
と Run の job_type
を 2 種類のノードとして持つグラフが表示され、
矢印は消費と生産を表します。
モデルのログ
これで、Artifact の API の仕組みを理解するのに十分ですが、
この例をパイプラインの最後まで見てみましょう
。Artifact が ML workflow をどのように改善できるかを確認できます。
この最初のセルは、PyTorch で DNN model を構築します。これは、非常に単純な ConvNet です。
最初に model を初期化するだけで、トレーニングは行いません。
そうすることで、他のすべてを一定に保ちながら、トレーニングを繰り返すことができます。
from math import floor
import torch.nn as nn
class ConvNet(nn.Module):
def __init__(self, hidden_layer_sizes=[32, 64],
kernel_sizes=[3],
activation="ReLU",
pool_sizes=[2],
dropout=0.5,
num_classes=num_classes,
input_shape=input_shape):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=input_shape[0], out_channels=hidden_layer_sizes[0], kernel_size=kernel_sizes[0]),
getattr(nn, activation)(),
nn.MaxPool2d(kernel_size=pool_sizes[0])
)
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=hidden_layer_sizes[0], out_channels=hidden_layer_sizes[-1], kernel_size=kernel_sizes[-1]),
getattr(nn, activation)(),
nn.MaxPool2d(kernel_size=pool_sizes[-1])
)
self.layer3 = nn.Sequential(
nn.Flatten(),
nn.Dropout(dropout)
)
fc_input_dims = floor((input_shape[1] - kernel_sizes[0] + 1) / pool_sizes[0]) # layer 1 output size
fc_input_dims = floor((fc_input_dims - kernel_sizes[-1] + 1) / pool_sizes[-1]) # layer 2 output size
fc_input_dims = fc_input_dims*fc_input_dims*hidden_layer_sizes[-1] # layer 3 output size
self.fc = nn.Linear(fc_input_dims, num_classes)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.fc(x)
return x
ここでは、W&B を使用して run を追跡しているため、
wandb.config
オブジェクトを使用して、すべてのハイパーパラメータを格納します。
その config オブジェクトの dict ional バージョンは、非常に役立つ metadata であるため、必ず含めてください。
def build_model_and_log(config):
with wandb.init(project="artifacts-example", job_type="initialize", config=config) as run:
config = wandb.config
model = ConvNet(**config)
model_artifact = wandb.Artifact(
"convnet", type="model",
description="Simple AlexNet style CNN",
metadata=dict(config))
torch.save(model.state_dict(), "initialized_model.pth")
# ➕ Artifact にファイルを追加する別の方法
model_artifact.add_file("initialized_model.pth")
wandb.save("initialized_model.pth")
run.log_artifact(model_artifact)
model_config = {"hidden_layer_sizes": [32, 64],
"kernel_sizes": [3],
"activation": "ReLU",
"pool_sizes": [2],
"dropout": 0.5,
"num_classes": 10}
build_model_and_log(model_config)
artifact.add_file
データセットのログの例のように、
new_file を同時に書き込んで Artifact に追加する代わりに、
1 つのステップでファイルを作成することもできます
(ここでは、torch.save)
してから、別のステップで Artifact に add します。
経験則: 重複を防ぐために、可能な限り new_file を使用します。
ログに記録されたモデル Artifact の使用
dataset で use_artifact を呼び出すことができるのと同様に、
initialized_model で呼び出して、別の Run で使用することができます。
今回は、model を train してみましょう。
詳細については、次の Colab を参照してください。
W&B を PyTorch でインストルメント化する。
import torch.nn.functional as F
def train(model, train_loader, valid_loader, config):
optimizer = getattr(torch.optim, config.optimizer)(model.parameters())
model.train()
example_ct = 0
for epoch in range(config.epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
example_ct += len(data)
if batch_idx % config.batch_log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0%})]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
batch_idx / len(train_loader), loss.item()))
train_log(loss, example_ct, epoch)
# evaluate the model on the validation set at each epoch
loss, accuracy = test(model, valid_loader)
test_log(loss, accuracy, example_ct, epoch)
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum') # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
return test_loss, accuracy
def train_log(loss, example_ct, epoch):
loss = float(loss)
# where the magic happens
wandb.log({"epoch": epoch, "train/loss": loss}, step=example_ct)
print(f"Loss after " + str(example_ct).zfill(5) + f" examples: {loss:.3f}")
def test_log(loss, accuracy, example_ct, epoch):
loss = float(loss)
accuracy = float(accuracy)
# where the magic happens
wandb.log({"epoch": epoch, "validation/loss": loss, "validation/accuracy": accuracy}, step=example_ct)
print(f"Loss/accuracy after " + str(example_ct).zfill(5) + f" examples: {loss:.3f}/{accuracy:.3f}")
今回は、2 つの別々の Artifact を生成する Run を実行します。
最初の model の train ニングが終了すると、
second は trained-model Artifact
を消費して、test_dataset でそのパフォーマンスを evaluate します。
また、ネットワークが最も混乱する 32 個の例も取り出します。
これは、categorical_crossentropy が最も高い例です。
これは、データセットとモデルの問題を診断するのに適した方法です。
def evaluate(model, test_loader):
"""
## トレーニング済みのモデルの評価
"""
loss, accuracy = test(model, test_loader)
highest_losses, hardest_examples, true_labels, predictions = get_hardest_k_examples(model, test_loader.dataset)
return loss, accuracy, highest_losses, hardest_examples, true_labels, predictions
def get_hardest_k_examples(model, testing_set, k=32):
model.eval()
loader = DataLoader(testing_set, 1, shuffle=False)
# get the losses and predictions for each item in the dataset
losses = None
predictions = None
with torch.no_grad():
for data, target in loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = F.cross_entropy(output, target)
pred = output.argmax(dim=1, keepdim=True)
if losses is None:
losses = loss.view((1, 1))
predictions = pred
else:
losses = torch.cat((losses, loss.view((1, 1))), 0)
predictions = torch.cat((predictions, pred), 0)
argsort_loss = torch.argsort(losses, dim=0)
highest_k_losses = losses[argsort_loss[-k:]]
hardest_k_examples = testing_set[argsort_loss[-k:]][0]
true_labels = testing_set[argsort_loss[-k:]][1]
predicted_labels = predictions[argsort_loss[-k:]]
return highest_k_losses, hardest_k_examples, true_labels, predicted_labels
これらのロギング関数は新しい Artifact 機能を追加しないため、
コメントは付けません。
Artifact を use、download、
および log しているだけです。
from torch.utils.data import DataLoader
def train_and_log(config):
with wandb.init(project="artifacts-example", job_type="train", config=config) as run:
config = wandb.config
data = run.use_artifact('mnist-preprocess:latest')
data_dir = data.download()
training_dataset = read(data_dir, "training")
validation_dataset = read(data_dir, "validation")
train_loader = DataLoader(training_dataset, batch_size=config.batch_size)
validation_loader = DataLoader(validation_dataset, batch_size=config.batch_size)
model_artifact = run.use_artifact("convnet:latest")
model_dir = model_artifact.download()
model_path = os.path.join(model_dir, "initialized_model.pth")
model_config = model_artifact.metadata
config.update(model_config)
model = ConvNet(**model_config)
model.load_state_dict(torch.load(model_path))
model = model.to(device)
train(model, train_loader, validation_loader, config)
model_artifact = wandb.Artifact(
"trained-model", type="model",
description="Trained NN model",
metadata=dict(model_config))
torch.save(model.state_dict(), "trained_model.pth")
model_artifact.add_file("trained_model.pth")
wandb.save("trained_model.pth")
run.log_artifact(model_artifact)
return model
def evaluate_and_log(config=None):
with wandb.init(project="artifacts-example", job_type="report", config=config) as run:
data = run.use_artifact('mnist-preprocess:latest')
data_dir = data.download()
testing_set = read(data_dir, "test")
test_loader = torch.utils.data.DataLoader(testing_set, batch_size=128, shuffle=False)
model_artifact = run.use_artifact("trained-model:latest")
model_dir = model_artifact.download()
model_path = os.path.join(model_dir, "trained_model.pth")
model_config = model_artifact.metadata
model = ConvNet(**model_config)
model.load_state_dict(torch.load(model_path))
model.to(device)
loss, accuracy, highest_losses, hardest_examples, true_labels, preds = evaluate(model, test_loader)
run.summary.update({"loss": loss, "accuracy": accuracy})
wandb.log({"high-loss-examples":
[wandb.Image(hard_example, caption=str(int(pred)) + "," + str(int(label)))
for hard_example, pred, label in zip(hardest_examples, preds, true_labels)]})
train_config = {"batch_size": 128,
"epochs": 5,
"batch_log_interval": 25,
"optimizer": "Adam"}
model = train_and_log(train_config)
evaluate_and_log()
5 - Programmatic Workspaces
Workspacesをプログラムで作成、管理、カスタマイズすることで、機械学習の実験をより効果的に整理し、可視化できます。設定を定義し、パネルレイアウトを設定し、
wandb-workspaces W&B ライブラリでセクションを整理できます。URLで
Workspacesをロードおよび変更したり、式を使用して
Runsをフィルタリングおよびグループ化したり、
Runsの外観をカスタマイズしたりできます。
wandb-workspacesは、W&BのWorkspacesとReportsをプログラムで作成およびカスタマイズするためのPythonライブラリです。
このチュートリアルでは、wandb-workspacesを使用して、設定を定義し、パネルレイアウトを設定し、セクションを整理することで、Workspacesを作成およびカスタマイズする方法を説明します。
ノートブックの使い方
- 各セルを一度に1つずつ実行します。
- セルを実行した後に表示されるURLをコピーして貼り付け、Workspaceに加えられた変更を表示します。
1. 依存関係のインストールとインポート
# 依存関係をインストールする
!pip install wandb wandb-workspaces rich
# 依存関係をインポートする
import os
import wandb
import wandb_workspaces.workspaces as ws
import wandb_workspaces.reports.v2 as wr # パネルを追加するためにReports APIを使用します
# 出力形式を改善する
%load_ext rich
このチュートリアルでは、wandb_workspaces APIを試すことができるように、新しいProjectを作成します。
注:一意のSaved view URLを使用して、既存のWorkspaceをロードできます。これを行う方法については、次のコードブロックを参照してください。
# Weights & Biasesを初期化してログインします
wandb.login()
# 新しいプロジェクトを作成し、サンプルデータを記録する関数
def create_project_and_log_data():
project = "workspace-api-example" # デフォルトのプロジェクト名
# サンプルデータを記録するためにrunを初期化します
with wandb.init(project=project, name="sample_run") as run:
for step in range(100):
wandb.log({
"Step": step,
"val_loss": 1.0 / (step + 1),
"val_accuracy": step / 100.0,
"train_loss": 1.0 / (step + 2),
"train_accuracy": step / 110.0,
"f1_score": step / 100.0,
"recall": step / 120.0,
})
return project
# 新しいプロジェクトを作成し、データを記録します
project = create_project_and_log_data()
entity = wandb.Api().default_entity
新しいProjectを作成する代わりに、独自の既存のProjectとWorkspaceをロードできます。これを行うには、一意のWorkspace URLを見つけて、文字列としてws.Workspace.from_urlに渡します。URLの形式はhttps://wandb.ai/[SOURCE-ENTITY]/[SOURCE-USER]?nw=abcです。
例:
wandb.login()
workspace = ws.Workspace.from_url("https://wandb.ai/[SOURCE-ENTITY]/[SOURCE-USER]?nw=abc").
workspace = ws.Workspace(
entity="NEW-ENTITY",
project=NEW-PROJECT,
name="NEW-SAVED-VIEW-NAME"
)
以下は、プログラムによるWorkspace機能を使用する例です。
# ワークスペース、セクション、およびパネルで利用可能なすべての設定を表示します。
all_settings_objects = [x for x in dir(ws) if isinstance(getattr(ws, x), type)]
all_settings_objects
この例では、新しいWorkspaceを作成し、セクションとパネルを入力する方法を示します。Workspacesは、通常のPythonオブジェクトのように編集でき、柔軟性と使いやすさを提供します。
def sample_workspace_saved_example(entity: str, project: str) -> str:
workspace: ws.Workspace = ws.Workspace(
name="Example W&B Workspace",
entity=entity,
project=project,
sections=[
ws.Section(
name="Validation Metrics",
panels=[
wr.LinePlot(x="Step", y=["val_loss"]),
wr.BarPlot(metrics=["val_accuracy"]),
wr.ScalarChart(metric="f1_score", groupby_aggfunc="mean"),
],
is_open=True,
),
],
)
workspace.save()
print("Sample Workspace saved.")
return workspace.url
workspace_url: str = sample_workspace_saved_example(entity, project)
元の設定に影響を与えることなく、Workspacesを複製してカスタマイズします。これを行うには、既存のWorkspaceをロードし、新しいビューとして保存します。
def save_new_workspace_view_example(url: str) -> None:
workspace: ws.Workspace = ws.Workspace.from_url(url)
workspace.name = "Updated Workspace Name"
workspace.save_as_new_view()
print(f"Workspace saved as new view.")
save_new_workspace_view_example(workspace_url)
Workspaceの名前が「Updated Workspace Name」になっていることに注意してください。
基本設定
次のコードは、Workspaceを作成し、パネル付きのセクションを追加し、Workspace、個々のセクション、およびパネルの設定を構成する方法を示しています。
# カスタム設定でワークスペースを作成および構成する関数
def custom_settings_example(entity: str, project: str) -> None:
workspace: ws.Workspace = ws.Workspace(name="An example workspace", entity=entity, project=project)
workspace.sections = [
ws.Section(
name="Validation",
panels=[
wr.LinePlot(x="Step", y=["val_loss"]),
wr.LinePlot(x="Step", y=["val_accuracy"]),
wr.ScalarChart(metric="f1_score", groupby_aggfunc="mean"),
wr.ScalarChart(metric="recall", groupby_aggfunc="mean"),
],
is_open=True,
),
ws.Section(
name="Training",
panels=[
wr.LinePlot(x="Step", y=["train_loss"]),
wr.LinePlot(x="Step", y=["train_accuracy"]),
],
is_open=False,
),
]
workspace.settings = ws.WorkspaceSettings(
x_axis="Step",
x_min=0,
x_max=75,
smoothing_type="gaussian",
smoothing_weight=20.0,
ignore_outliers=False,
remove_legends_from_panels=False,
tooltip_number_of_runs="default",
tooltip_color_run_names=True,
max_runs=20,
point_visualization_method="bucketing",
auto_expand_panel_search_results=False,
)
section = workspace.sections[0]
section.panel_settings = ws.SectionPanelSettings(
x_min=25,
x_max=50,
smoothing_type="none",
)
panel = section.panels[0]
panel.title = "Validation Loss Custom Title"
panel.title_x = "Custom x-axis title"
workspace.save()
print("Workspace with custom settings saved.")
# 関数を実行してワークスペースを作成および構成します
custom_settings_example(entity, project)
「An example workspace」という別の保存されたビューを表示していることに注意してください。
Runsをカスタマイズする
次のコードセルは、Runsをプログラムでフィルタリング、色の変更、グループ化、および並べ替える方法を示しています。
各例では、一般的なワークフローは、ws.RunsetSettingsの適切なパラメータへの引数として、目的のカスタマイズを指定することです。
Runsをフィルタリングする
Python式と、wandb.logで記録するメトリクス、またはCreated TimestampのようにRunの一部として自動的に記録されるメトリクスを使用してフィルタを作成できます。Name、Tags、またはIDなど、W&B App UIでの表示方法でフィルタを参照することもできます。
次の例は、検証損失の要約、検証精度の要約、および指定された正規表現に基づいてRunsをフィルタリングする方法を示しています。
def advanced_filter_example(entity: str, project: str) -> None:
# プロジェクト内のすべてのRunsを取得します
runs: list = wandb.Api().runs(f"{entity}/{project}")
# 複数のフィルタを適用します:val_loss < 0.1、val_accuracy > 0.8、およびrun名が正規表現パターンと一致します
workspace: ws.Workspace = ws.Workspace(
name="Advanced Filtered Workspace with Regex",
entity=entity,
project=project,
sections=[
ws.Section(
name="Advanced Filtered Section",
panels=[
wr.LinePlot(x="Step", y=["val_loss"]),
wr.LinePlot(x="Step", y=["val_accuracy"]),
],
is_open=True,
),
],
runset_settings=ws.RunsetSettings(
filters=[
(ws.Summary("val_loss") < 0.1), # 'val_loss'サマリーでRunsをフィルタリングします
(ws.Summary("val_accuracy") > 0.8), # 'val_accuracy'サマリーでRunsをフィルタリングします
(ws.Metric("ID").isin([run.id for run in wandb.Api().runs(f"{entity}/{project}")])),
],
regex_query=True,
)
)
# 's'で始まるrun名に一致するように正規表現検索を追加します
workspace.runset_settings.query = "^s"
workspace.runset_settings.regex_query = True
workspace.save()
print("Workspace with advanced filters and regex search saved.")
advanced_filter_example(entity, project)
フィルタ式のリストを渡すと、ブール値の「AND」ロジックが適用されることに注意してください。
この例では、WorkspaceでRunsの色を変更する方法を示します。
def run_color_example(entity: str, project: str) -> None:
# プロジェクト内のすべてのRunsを取得します
runs: list = wandb.Api().runs(f"{entity}/{project}")
# Runsに色を動的に割り当てます
run_colors: list = ['purple', 'orange', 'teal', 'magenta']
run_settings: dict = {}
for i, run in enumerate(runs):
run_settings[run.id] = ws.RunSettings(color=run_colors[i % len(run_colors)])
workspace: ws.Workspace = ws.Workspace(
name="Run Colors Workspace",
entity=entity,
project=project,
sections=[
ws.Section(
name="Run Colors Section",
panels=[
wr.LinePlot(x="Step", y=["val_loss"]),
wr.LinePlot(x="Step", y=["val_accuracy"]),
],
is_open=True,
),
],
runset_settings=ws.RunsetSettings(
run_settings=run_settings
)
)
workspace.save()
print("Workspace with run colors saved.")
run_color_example(entity, project)
この例では、特定のメトリクスでRunsをグループ化する方法を示します。
def grouping_example(entity: str, project: str) -> None:
workspace: ws.Workspace = ws.Workspace(
name="Grouped Runs Workspace",
entity=entity,
project=project,
sections=[
ws.Section(
name="Grouped Runs",
panels=[
wr.LinePlot(x="Step", y=["val_loss"]),
wr.LinePlot(x="Step", y=["val_accuracy"]),
],
is_open=True,
),
],
runset_settings=ws.RunsetSettings(
groupby=[ws.Metric("Name")]
)
)
workspace.save()
print("Workspace with grouped runs saved.")
grouping_example(entity, project)
この例では、検証損失の要約に基づいてRunsをソートする方法を示します。
def sorting_example(entity: str, project: str) -> None:
workspace: ws.Workspace = ws.Workspace(
name="Sorted Runs Workspace",
entity=entity,
project=project,
sections=[
ws.Section(
name="Sorted Runs",
panels=[
wr.LinePlot(x="Step", y=["val_loss"]),
wr.LinePlot(x="Step", y=["val_accuracy"]),
],
is_open=True,
),
],
runset_settings=ws.RunsetSettings(
order=[ws.Ordering(ws.Summary("val_loss"))] # val_lossサマリーを使用して順序付けます
)
)
workspace.save()
print("Workspace with sorted runs saved.")
sorting_example(entity, project)
4. すべてをまとめる:包括的な例
この例では、包括的なWorkspaceを作成し、その設定を構成し、セクションにパネルを追加する方法を示します。
def full_end_to_end_example(entity: str, project: str) -> None:
# プロジェクト内のすべてのRunsを取得します
runs: list = wandb.Api().runs(f"{entity}/{project}")
# Runsに色を動的に割り当て、run設定を作成します
run_colors: list = ['red', 'blue', 'green', 'orange', 'purple', 'teal', 'magenta', '#FAC13C']
run_settings: dict = {}
for i, run in enumerate(runs):
run_settings[run.id] = ws.RunSettings(color=run_colors[i % len(run_colors)], disabled=False)
workspace: ws.Workspace = ws.Workspace(
name="My Workspace Template",
entity=entity,
project=project,
sections=[
ws.Section(
name="Main Metrics",
panels=[
wr.LinePlot(x="Step", y=["val_loss"]),
wr.LinePlot(x="Step", y=["val_accuracy"]),
wr.ScalarChart(metric="f1_score", groupby_aggfunc="mean"),
],
is_open=True,
),
ws.Section(
name="Additional Metrics",
panels=[
wr.ScalarChart(metric="precision", groupby_aggfunc="mean"),
wr.ScalarChart(metric="recall", groupby_aggfunc="mean"),
],
),
],
settings=ws.WorkspaceSettings(
x_axis="Step",
x_min=0,
x_max=100,
smoothing_type="none",
smoothing_weight=0,
ignore_outliers=False,
remove_legends_from_panels=False,
tooltip_number_of_runs="default",
tooltip_color_run_names=True,
max_runs=20,
point_visualization_method="bucketing",
auto_expand_panel_search_results=False,
),
runset_settings=ws.RunsetSettings(
query="",
regex_query=False,
filters=[
ws.Summary("val_loss") < 1,
ws.Metric("Name") == "sample_run",
],
groupby=[ws.Metric("Name")],
order=[ws.Ordering(ws.Summary("Step"), ascending=True)],
run_settings=run_settings
)
)
workspace.save()
print("Workspace created and saved.")
full_end_to_end_example(entity, project)
6 - Integration tutorials
6.1 - PyTorch
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、および プロジェクト の コラボレーションを行います。

この ノートブック の内容
この ノートブック では、 Weights & Biases を PyTorch コード に 統合して、 実験管理 を パイプライン に 追加する方法を紹介します。
# ライブラリをインポート
import wandb
# 新しい 実験 を開始
wandb.init(project="new-sota-model")
# config で ハイパーパラメーター の 辞書 をキャプチャ
wandb.config = {"learning_rate": 0.001, "epochs": 100, "batch_size": 128}
# モデル と データ をセットアップ
model, dataloader = get_model(), get_data()
# オプション: 勾配 を追跡
wandb.watch(model)
for batch in dataloader:
metrics = model.training_step()
# トレーニング ループ 内で メトリクス を ログ に記録して、 モデル の パフォーマンス を視覚化します。
wandb.log(metrics)
# オプション: 最後に モデル を保存
model.to_onnx()
wandb.save("model.onnx")
ビデオ チュートリアルをご覧ください。
注: Step で始まるセクションは、既存の パイプライン に W&B を 統合 するために必要なすべてです。残りの部分は、 データ を ロード し、 モデル を定義するだけです。
インストール、インポート、および ログイン
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from tqdm.auto import tqdm
# 決定論的な 振る舞い を確認
torch.backends.cudnn.deterministic = True
random.seed(hash("setting random seeds") % 2**32 - 1)
np.random.seed(hash("improves reproducibility") % 2**32 - 1)
torch.manual_seed(hash("by removing stochasticity") % 2**32 - 1)
torch.cuda.manual_seed_all(hash("so runs are repeatable") % 2**32 - 1)
# デバイス の 設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# MNIST ミラー の リスト から 低速 ミラー を削除
torchvision.datasets.MNIST.mirrors = [mirror for mirror in torchvision.datasets.MNIST.mirrors
if not mirror.startswith("http://yann.lecun.com")]
Step 0: W&B の インストール
まず、 ライブラリ を取得する必要があります。
wandb は pip を使用して簡単に インストール できます。
!pip install wandb onnx -Uq
Step 1: W&B の インポート と ログイン
データ を Web サービス に ログ に記録するには、 ログイン する必要があります。
W&B を初めて使用する場合は、表示される リンク で 無料 アカウント にサインアップする必要があります。
import wandb
wandb.login()
実験 と パイプライン を定義
wandb.init を使用して メタデータ と ハイパーパラメーター を追跡
プログラムで、最初に行うことは 実験 を定義することです。
ハイパーパラメーター は何ですか? どのような メタデータ がこの run に 関連付けられていますか?
この 情報 を config 辞書 (または同様の オブジェクト ) に保存し、必要に応じて アクセス するのは非常に一般的な ワークフロー です。
この 例 では、いくつかの ハイパーパラメーター のみを変えることができ、残りは手動で コーディング しています。
ただし、 モデル の 任意の部分を config の一部にすることができます。
また、いくつかの メタデータ も含めます。MNIST データセット と 畳み込み アーキテクチャー を使用しています。たとえば、後で同じ プロジェクト で CIFAR 上の完全に接続された アーキテクチャー を使用する場合、これは run を分離するのに役立ちます。
config = dict(
epochs=5,
classes=10,
kernels=[16, 32],
batch_size=128,
learning_rate=0.005,
dataset="MNIST",
architecture="CNN")
次に、 モデル トレーニング に非常に一般的な 全体的な パイプライン を定義しましょう。
- まず、 モデル 、 関連 データ 、および オプティマイザー を
make し、次に
- モデル をそれに応じて
train し、最後に
test して、 トレーニング の 結果 を確認します。
これらの 関数 を以下に実装します。
def model_pipeline(hyperparameters):
# wandb に 開始 するように指示
with wandb.init(project="pytorch-demo", config=hyperparameters):
# wandb.config を介してすべての HPs に アクセス して、 ログ が 実行 と一致するようにします。
config = wandb.config
# モデル 、 データ 、および 最適化 の 問題 を作成
model, train_loader, test_loader, criterion, optimizer = make(config)
print(model)
# それらを使用して モデル を トレーニング
train(model, train_loader, criterion, optimizer, config)
# 最終的な パフォーマンス を テスト
test(model, test_loader)
return model
標準的な パイプライン との唯一の違いは、それがすべて wandb.init の コンテキスト 内で発生することです。
この 関数 を 呼び出すと、 コード と サーバー 間の 通信回線 が 設定 されます。
config 辞書 を wandb.init に 渡すと、その 情報 がすべてすぐに ログ に記録されるため、 実験 で使用するように 設定 した ハイパーパラメーター の 値 を常に把握できます。
選択および ログ に記録した 値 が モデル で常に使用されるようにするために、 オブジェクト の wandb.config コピー を使用することをお勧めします。
いくつかの 例 を 参照 するには、以下の make の 定義 を確認してください。
サイド ノート: コード を 個別の プロセス で 実行 するように注意してください。これにより、こちら側の 問題 (巨大な海の モンスター が データセンター を攻撃するなど) によって コード が クラッシュ しないようにします。
クラーケン が 深海 に戻るなど、 問題 が解決されたら、 wandb sync で データ を ログ に記録できます。
def make(config):
# データ を作成
train, test = get_data(train=True), get_data(train=False)
train_loader = make_loader(train, batch_size=config.batch_size)
test_loader = make_loader(test, batch_size=config.batch_size)
# モデル を作成
model = ConvNet(config.kernels, config.classes).to(device)
# 損失 と オプティマイザー を作成
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
model.parameters(), lr=config.learning_rate)
return model, train_loader, test_loader, criterion, optimizer
データ の ロード と モデル を定義
次に、 データ の ロード 方法と モデル の 外観を指定する必要があります。
この部分は非常に重要ですが、wandb がなくても同じであるため、詳しく説明しません。
def get_data(slice=5, train=True):
full_dataset = torchvision.datasets.MNIST(root=".",
train=train,
transform=transforms.ToTensor(),
download=True)
# [::slice] で スライス するのと同等
sub_dataset = torch.utils.data.Subset(
full_dataset, indices=range(0, len(full_dataset), slice))
return sub_dataset
def make_loader(dataset, batch_size):
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True, num_workers=2)
return loader
モデル を定義するのは通常楽しい部分です。
しかし、wandb では何も変わらないため、 標準的な ConvNet アーキテクチャー を使用します。
これをいじって 実験 を試すことを恐れないでください。すべての 結果 は wandb.ai に ログ 記録されます。
# 従来の畳み込み ニューラルネットワーク
class ConvNet(nn.Module):
def __init__(self, kernels, classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, kernels[0], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, kernels[1], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * kernels[-1], classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
トレーニング ロジック を定義
model_pipeline で 進めて、train 方法を指定します。
ここでは、2 つの wandb 関数 が 役立ちます。watch と log です。
wandb.watch で 勾配 を追跡し、wandb.log で その他 すべてを追跡
wandb.watch は、 トレーニング のすべての log_freq ステップ で、 モデル の 勾配 と パラメータ を ログ に記録します。
必要なのは、 トレーニング を開始する前にそれを 呼び出すことだけです。
残りの トレーニング コード は同じままです。 エポック と バッチ を 反復処理し、 forward pass と backward pass を 実行 し、オプティマイザー を 適用 します。
def train(model, loader, criterion, optimizer, config):
# モデル が 実行 する 内容 ( 勾配 、 重み など) を wandb に 監視 させる。
wandb.watch(model, criterion, log="all", log_freq=10)
# トレーニング を 実行 し、wandb で 追跡
total_batches = len(loader) * config.epochs
example_ct = 0 # 確認された 例 の 数
batch_ct = 0
for epoch in tqdm(range(config.epochs)):
for _, (images, labels) in enumerate(loader):
loss = train_batch(images, labels, model, optimizer, criterion)
example_ct += len(images)
batch_ct += 1
# 25 回目の バッチ ごとに メトリクス を レポート
if ((batch_ct + 1) % 25) == 0:
train_log(loss, example_ct, epoch)
def train_batch(images, labels, model, optimizer, criterion):
images, labels = images.to(device), labels.to(device)
# Forward pass ➡
outputs = model(images)
loss = criterion(outputs, labels)
# Backward pass ⬅
optimizer.zero_grad()
loss.backward()
# オプティマイザー で ステップ
optimizer.step()
return loss
唯一の違いは ログ コード にあります。以前は ターミナル に 出力 して メトリクス を レポート していた可能性がありますが、 同じ 情報 を wandb.log に 渡すようになりました。
wandb.log は、 キー として 文字列 を持つ 辞書 を想定しています。これらの 文字列 は、 ログ に記録される オブジェクト を識別します。これらが 値 を 構成します。オプションで、 トレーニング のどの step にいるかを ログ に記録することもできます。
サイド ノート: バッチサイズ 全体で 比較 しやすくするために、 モデル が 確認 した 例 の 数を 使用するのが好きですが、 生の ステップ または バッチ カウント を使用できます。より 長い トレーニング run の 場合、エポック ごとに ログ に記録することも 理にかなっています。
def train_log(loss, example_ct, epoch):
# 魔法が起こる場所
wandb.log({"epoch": epoch, "loss": loss}, step=example_ct)
print(f"Loss after {str(example_ct).zfill(5)} examples: {loss:.3f}")
テスト ロジック を定義
モデル の トレーニング が完了したら、それを テスト します。たとえば、 プロダクション からの 新鮮な データ に対して 実行 したり、手作業で キュレーション された 例 に 適用 したりします。
(オプション) wandb.save を 呼び出す
これは、 モデル の アーキテクチャー と 最終的な パラメータ を ディスク に保存する絶好の機会でもあります。最大限の 互換性を得るために、Open Neural Network eXchange (ONNX) 形式で モデル を エクスポート します。
その ファイル名 を wandb.save に 渡すと、 モデル の パラメータ が W&B の サーバー に 保存されます。どの .h5 または .pb がどの トレーニング run に 対応 するかを 追跡 できなくなることはありません。
モデル を保存、 バージョン管理 、および 配布 するための、より 高度な wandb 機能 については、Artifacts ツールを ご覧ください。
def test(model, test_loader):
model.eval()
# いくつかの テスト 例 で モデル を 実行
with torch.no_grad():
correct, total = 0, 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy of the model on the {total} " +
f"test images: {correct / total:%}")
wandb.log({"test_accuracy": correct / total})
# 交換可能な ONNX 形式 で モデル を保存
torch.onnx.export(model, images, "model.onnx")
wandb.save("model.onnx")
トレーニング を 実行 し、wandb.ai で メトリクス を ライブ で 監視
パイプライン 全体を定義し、いくつかの W&B コード を 挿入 したので、完全に 追跡 された 実験 を 実行 する 準備ができました。
ドキュメント、 プロジェクト ページ ( プロジェクト 内のすべての run を 整理します)、および この run の 結果 が 保存される Run ページへの リンク がいくつか レポート されます。
Run ページに 移動 し、これらの タブ を 確認 してください。
- Charts: トレーニング 全体で モデル の 勾配 、 パラメータ 値、および 損失 が ログ に記録されます。
- System: ディスク I/O 使用率、 CPU および GPU メトリクス (温度が急上昇するのを 監視 します) などの さまざまな システム メトリクス が含まれています。
- Logs: トレーニング 中に 標準出力 に プッシュ されたすべてのものの コピー があります。
- Files: トレーニング が完了すると、
model.onnx を クリック して、Netron モデル ビューアーで ネットワーク を 表示 できます。
run が 終了 すると、with wandb.init ブロック が 終了 するときに、 セル の 出力 に 結果 の 概要 も 出力 されます。
# パイプライン を使用して モデル を 構築、 トレーニング 、および 分析
model = model_pipeline(config)
Sweeps で ハイパーパラメーター を テスト
この 例 では、単一の ハイパーパラメーター セット のみを調べました。
しかし、ほとんどの ML ワークフロー の 重要な部分は、多くの ハイパーパラメーター を 反復処理することです。
Weights & Biases Sweeps を使用すると、 ハイパーパラメーター の テスト を 自動化し、 可能な モデル と 最適化 戦略 の スペース を 探索 できます。
Weights & Biases で ハイパーパラメーター sweep を 実行 するのは非常に簡単です。簡単な 3 つの ステップ があります。
-
sweep を定義: 検索 する パラメータ 、 検索 戦略、 最適化 メトリクス などを 指定する 辞書 または YAML ファイル を 作成 して、これを行います。
-
sweep を 初期化:
sweep_id = wandb.sweep(sweep_config)
-
sweep agent を 実行:
wandb.agent(sweep_id, function=train)
これで、 ハイパーパラメーター sweep の 実行 はすべて完了です。
例 ギャラリー
ギャラリー →で W&B で 追跡 および 視覚化 された プロジェクト の 例 を ご覧ください
高度な 設定
- 環境変数: 管理対象 クラスター で トレーニング を 実行 できるように、 環境変数 で APIキー を 設定 します。
- オフライン モード:
dryrun モード を 使用 して オフライン で トレーニング し、後で 結果 を 同期 します。
- オンプレミス: プライベートクラウド または お客様の インフラストラクチャー 内の エアギャップ サーバー に W&B を インストール します。 学術関係者から エンタープライズ チーム まで、あらゆる ユーザー 向けの ローカル インストール があります。
- Sweeps: チューニング 用の 軽量 ツール を 使用 して、 ハイパーパラメーター 検索 を 迅速に 設定 します。
6.2 - PyTorch Lightning
PyTorch Lightning を使用して画像分類のパイプラインを構築します。コードの可読性と再現性を高めるために、こちらの
スタイル ガイド に従います。これに関するわかりやすい説明は、
こちらにあります。
PyTorch Lightning と W&B のセットアップ
このチュートリアルでは、PyTorch Lightning と Weights & Biases が必要です。
pip install lightning -q
pip install wandb -qU
import lightning.pytorch as pl
# お気に入りの 機械学習 トラッキング ツール
from lightning.pytorch.loggers import WandbLogger
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import random_split, DataLoader
from torchmetrics import Accuracy
from torchvision import transforms
from torchvision.datasets import CIFAR10
import wandb
次に、wandb アカウントにログインする必要があります。
wandb.login()
DataModule - 価値のあるデータ パイプライン
DataModule は、データ関連のフックを LightningModule から分離して、データセットに依存しないモデルを開発できるようにする方法です。
データパイプラインを 1 つの共有可能で再利用可能なクラスにまとめます。 datamodule は、PyTorch でのデータ処理に関わる次の 5 つのステップをカプセル化します。
- ダウンロード/トークン化/プロセッシング。
- クリーンアップして、(場合によっては)ディスクに保存します。
- データセット内にロードします。
- 変換(回転、トークン化など)を適用します。
- DataLoader 内にラップします。
datamodule の詳細については、こちらをご覧ください。 Cifar-10 データセット用の datamodule を構築してみましょう。
class CIFAR10DataModule(pl.LightningDataModule):
def __init__(self, batch_size, data_dir: str = './'):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
self.num_classes = 10
def prepare_data(self):
CIFAR10(self.data_dir, train=True, download=True)
CIFAR10(self.data_dir, train=False, download=True)
def setup(self, stage=None):
# dataloader で使用するトレーニング/検証データセットを割り当てます
if stage == 'fit' or stage is None:
cifar_full = CIFAR10(self.data_dir, train=True, transform=self.transform)
self.cifar_train, self.cifar_val = random_split(cifar_full, [45000, 5000])
# dataloader で使用するテストデータセットを割り当てます
if stage == 'test' or stage is None:
self.cifar_test = CIFAR10(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.cifar_train, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.cifar_val, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.cifar_test, batch_size=self.batch_size)
コールバック
callback は、プロジェクト間で再利用できる自己完結型のプログラムです。 PyTorch Lightning には、定期的に使用されるいくつかの 組み込み callbacksが付属しています。
PyTorch Lightning の callbacks の詳細については、こちらをご覧ください。
組み込み Callbacks
このチュートリアルでは、組み込みの Early Stopping と Model Checkpoint の callbacks を使用します。 これらは Trainer に渡すことができます。
カスタム Callbacks
カスタム Keras callback に慣れている場合は、PyTorch パイプラインで同じことができる機能は、まさに嬉しいおまけです。
画像分類を実行しているので、モデルの予測をいくつかの画像のサンプルで視覚化できると役立ちます。 これを callback の形式にすることで、初期段階でモデルをデバッグできます。
class ImagePredictionLogger(pl.callbacks.Callback):
def __init__(self, val_samples, num_samples=32):
super().__init__()
self.num_samples = num_samples
self.val_imgs, self.val_labels = val_samples
def on_validation_epoch_end(self, trainer, pl_module):
# テンソルを CPU に取り込みます
val_imgs = self.val_imgs.to(device=pl_module.device)
val_labels = self.val_labels.to(device=pl_module.device)
# モデルの予測を取得します
logits = pl_module(val_imgs)
preds = torch.argmax(logits, -1)
# 画像を wandb Image として記録します
trainer.logger.experiment.log({
"examples":[wandb.Image(x, caption=f"Pred:{pred}, Label:{y}")
for x, pred, y in zip(val_imgs[:self.num_samples],
preds[:self.num_samples],
val_labels[:self.num_samples])]
})
LightningModule - システムの定義
LightningModule は、モデルではなくシステムを定義します。 ここでは、システムはすべての研究コードを 1 つのクラスにグループ化して、自己完結型にします。 LightningModule は、PyTorch コードを次の 5 つのセクションに整理します。
- 計算 (
__init__)。
- トレーニング ループ (
training_step)
- 検証ループ (
validation_step)
- テスト ループ (
test_step)
- オプティマイザー (
configure_optimizers)
したがって、簡単に共有できるデータセットに依存しないモデルを構築できます。 Cifar-10 分類用のシステムを構築してみましょう。
class LitModel(pl.LightningModule):
def __init__(self, input_shape, num_classes, learning_rate=2e-4):
super().__init__()
# ハイパーパラメータを記録します
self.save_hyperparameters()
self.learning_rate = learning_rate
self.conv1 = nn.Conv2d(3, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 32, 3, 1)
self.conv3 = nn.Conv2d(32, 64, 3, 1)
self.conv4 = nn.Conv2d(64, 64, 3, 1)
self.pool1 = torch.nn.MaxPool2d(2)
self.pool2 = torch.nn.MaxPool2d(2)
n_sizes = self._get_conv_output(input_shape)
self.fc1 = nn.Linear(n_sizes, 512)
self.fc2 = nn.Linear(512, 128)
self.fc3 = nn.Linear(128, num_classes)
self.accuracy = Accuracy(task='multiclass', num_classes=num_classes)
# conv ブロックから Linear レイヤーに入る出力テンソルのサイズを返します。
def _get_conv_output(self, shape):
batch_size = 1
input = torch.autograd.Variable(torch.rand(batch_size, *shape))
output_feat = self._forward_features(input)
n_size = output_feat.data.view(batch_size, -1).size(1)
return n_size
# conv ブロックから特徴テンソルを返します
def _forward_features(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = self.pool2(F.relu(self.conv4(x)))
return x
# 推論中に使用されます
def forward(self, x):
x = self._forward_features(x)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.log_softmax(self.fc3(x), dim=1)
return x
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
# トレーニング メトリクス
preds = torch.argmax(logits, dim=1)
acc = self.accuracy(preds, y)
self.log('train_loss', loss, on_step=True, on_epoch=True, logger=True)
self.log('train_acc', acc, on_step=True, on_epoch=True, logger=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
# 検証メトリクス
preds = torch.argmax(logits, dim=1)
acc = self.accuracy(preds, y)
self.log('val_loss', loss, prog_bar=True)
self.log('val_acc', acc, prog_bar=True)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
# 検証メトリクス
preds = torch.argmax(logits, dim=1)
acc = self.accuracy(preds, y)
self.log('test_loss', loss, prog_bar=True)
self.log('test_acc', acc, prog_bar=True)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
return optimizer
トレーニングと評価
DataModule を使用してデータパイプラインを整理し、LightningModule を使用してモデル アーキテクチャ + トレーニング ループを整理したので、PyTorch Lightning Trainer がそれ以外のすべてを自動化します。
Trainer は以下を自動化します。
- エポックとバッチの反復
optimizer.step()、backward、zero_grad() の呼び出し.eval() の呼び出し、grads の有効化/無効化- 重みの保存とロード
- Weights & Biases ロギング
- 複数 GPU トレーニングのサポート
- TPU サポート
- 16 ビット トレーニングのサポート
dm = CIFAR10DataModule(batch_size=32)
# x_dataloader にアクセスするには、prepare_data と setup を呼び出す必要があります。
dm.prepare_data()
dm.setup()
# 画像予測を記録するためにカスタム ImagePredictionLogger callback で必要なサンプル。
val_samples = next(iter(dm.val_dataloader()))
val_imgs, val_labels = val_samples[0], val_samples[1]
val_imgs.shape, val_labels.shape
model = LitModel((3, 32, 32), dm.num_classes)
# wandb logger を初期化します
wandb_logger = WandbLogger(project='wandb-lightning', job_type='train')
# Callbacks を初期化します
early_stop_callback = pl.callbacks.EarlyStopping(monitor="val_loss")
checkpoint_callback = pl.callbacks.ModelCheckpoint()
# trainer を初期化します
trainer = pl.Trainer(max_epochs=2,
logger=wandb_logger,
callbacks=[early_stop_callback,
ImagePredictionLogger(val_samples),
checkpoint_callback],
)
# モデルをトレーニングします
trainer.fit(model, dm)
# ⚡⚡ 保持されたテスト セットでモデルを評価します
trainer.test(dataloaders=dm.test_dataloader())
# wandb run を閉じます
wandb.finish()
最終的な考え
私は TensorFlow/Keras エコシステム出身で、PyTorch はエレガントなフレームワークですが、少し圧倒されると感じています。 これはあくまで私の個人的な経験です。 PyTorch Lightning を調べているうちに、PyTorch から遠ざかっていた理由のほとんどが解消されていることに気づきました。 私が興奮している点の簡単なまとめを以下に示します。
- 以前: 従来の PyTorch モデルの定義は、あちこちに散らばっていました。 モデルは
model.py スクリプトに、トレーニング ループは train.py ファイルに記述されていました。 パイプラインを理解するには、何度も見返す必要がありました。
- 現在:
LightningModule は、モデルが training_step、validation_step などと共に定義されているシステムとして機能します。 これで、モジュール式になり、共有できるようになりました。
- 以前: TensorFlow/Keras の最も優れている点は、入力データ パイプラインです。 データセット カタログは豊富で、成長を続けています。 PyTorch のデータ パイプラインは、これまでで最大の難点でした。 通常の PyTorch コードでは、データのダウンロード/クリーンアップ/準備は通常、多くのファイルに分散しています。
- 現在: DataModule は、データ パイプラインを 1 つの共有可能で再利用可能なクラスにまとめます。 これは単に、
train_dataloader、val_dataloader(s)、test_dataloader(s) のコレクションであり、必要な変換とデータ プロセッシング/ダウンロードの手順が付属しています。
- 以前: Keras を使用すると、
model.fit を呼び出してモデルをトレーニングし、model.predict を呼び出して推論を実行できます。 model.evaluate は、テストデータに対する古き良き単純な評価を提供しました。 これは PyTorch には当てはまりません。 通常、個別の train.py ファイルと test.py ファイルが見つかります。
- 現在:
LightningModule が導入されたことで、Trainer がすべてを自動化します。 モデルをトレーニングおよび評価するには、trainer.fit と trainer.test を呼び出すだけで済みます。
- 以前: TensorFlow は TPU が大好きですが、PyTorch は…
- 現在: PyTorch Lightning を使用すると、複数の GPU や TPU 上でも同じモデルを簡単にトレーニングできます。
- 以前: 私は Callbacks の大ファンで、カスタム callbacks を記述することを好みます。 Early Stopping のように些細なことでも、従来の PyTorch では議論の対象となっていました。
- 現在: PyTorch Lightning を使用すると、Early Stopping と Model Checkpointing を簡単に使用できます。 カスタム callbacks を記述することもできます。
🎨 まとめとリソース
このレポートがお役に立てば幸いです。 コードを試して、選択したデータセットを使用して画像分類器をトレーニングすることをお勧めします。
PyTorch Lightning の詳細については、次のリソースをご覧ください。
6.3 - Hugging Face
 Hugging Face
Hugging Face モデルのパフォーマンスを、シームレスな
W&B インテグレーションで素早く可視化しましょう。
モデル間で、ハイパーパラメーター、出力メトリクス、 GPU 使用率などのシステム統計を比較します。
W&B を使うべき理由
- 統合ダッシュボード : すべてのモデルメトリクスと予測の一元的なリポジトリ
- 軽量 : Hugging Face と統合するために必要なコード変更はありません
- アクセス可能 : 個人およびアカデミックチームは無料
- セキュア : デフォルトでは、すべての Projects がプライベートです
- 信頼性 : OpenAI、トヨタ、Lyft などの機械学習チームで使用されています
W&B は、機械学習モデルの GitHub のようなものだと考えてください。機械学習の Experiments をプライベートなホストされたダッシュボードに保存します。スクリプトをどこで実行していても、すべてのバージョンのモデルが保存されるので、安心して迅速に Experiments を行うことができます。
W&B の軽量インテグレーションは、あらゆる Python スクリプトで動作し、モデルのトラッキングと可視化を開始するには、無料の W&B アカウントにサインアップするだけです。
Hugging Face Transformers リポジトリでは、 Trainer に、トレーニングおよび評価メトリクスを各ロギングステップで W&B に自動的にログ記録するように設定しました。
インテグレーションの仕組みの詳細はこちら: Hugging Face + W&B Report。
インストール、インポート、ログイン
Hugging Face と Weights & Biases のライブラリ、およびこのチュートリアルの GLUE データセットとトレーニングスクリプトをインストールします。
!pip install datasets wandb evaluate accelerate -qU
!wget https://raw.githubusercontent.com/huggingface/transformers/refs/heads/main/examples/pytorch/text-classification/run_glue.py
# run_glue.py スクリプトには transformers dev が必要です
!pip install -q git+https://github.com/huggingface/transformers
続行する前に、無料アカウントにサインアップ してください。
APIキーを入力
サインアップしたら、次のセルを実行し、リンクをクリックして APIキーを取得し、この notebook を認証します。
import wandb
wandb.login()
オプションで、環境変数を設定して W&B のロギングをカスタマイズできます。詳細については、ドキュメント を参照してください。
# オプション: 勾配とパラメータの両方をログに記録する
%env WANDB_WATCH=all
モデルのトレーニング
次に、ダウンロードしたトレーニングスクリプト run_glue.py を呼び出して、トレーニングが自動的に Weights & Biases ダッシュボードに追跡されることを確認します。このスクリプトは、 Microsoft Research Paraphrase Corpus (意味的に同等かどうかを示す人間の注釈が付いた文のペア) で BERT をファインチューンします。
%env WANDB_PROJECT=huggingface-demo
%env TASK_NAME=MRPC
!python run_glue.py \
--model_name_or_path bert-base-uncased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 256 \
--per_device_train_batch_size 32 \
--learning_rate 2e-4 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir \
--logging_steps 50
ダッシュボードで結果を可視化
上記に出力されたリンクをクリックするか、wandb.ai にアクセスして、結果がライブでストリーミングされるのを確認します。ブラウザで run を表示するためのリンクは、すべての依存関係がロードされた後に表示されます。次の出力を探してください: “wandb: 🚀 View run at [URL to your unique run]”
モデルのパフォーマンスを可視化
多数の Experiments を見渡し、興味深い学びをズームインし、高次元のデータを可視化するのは簡単です。
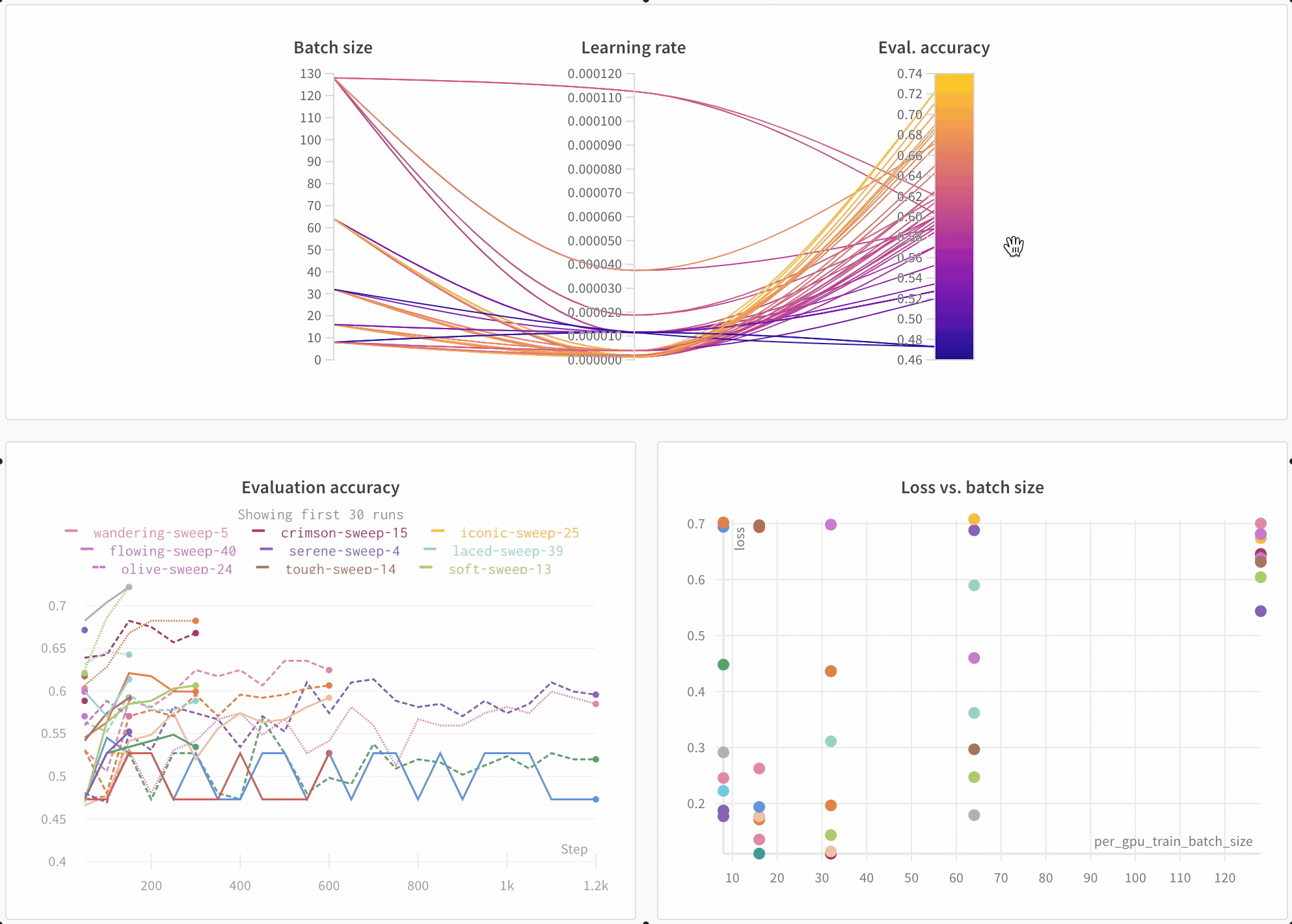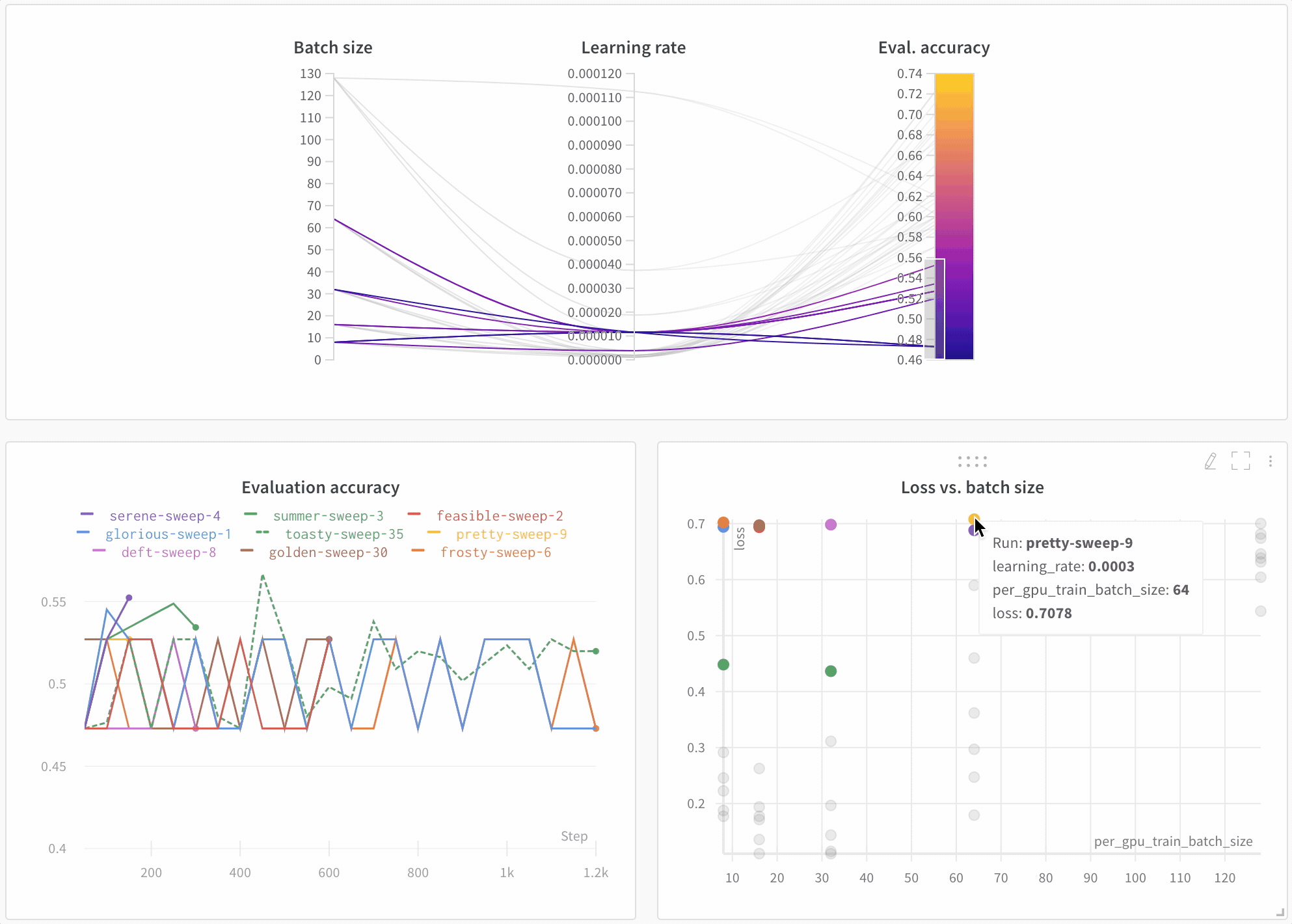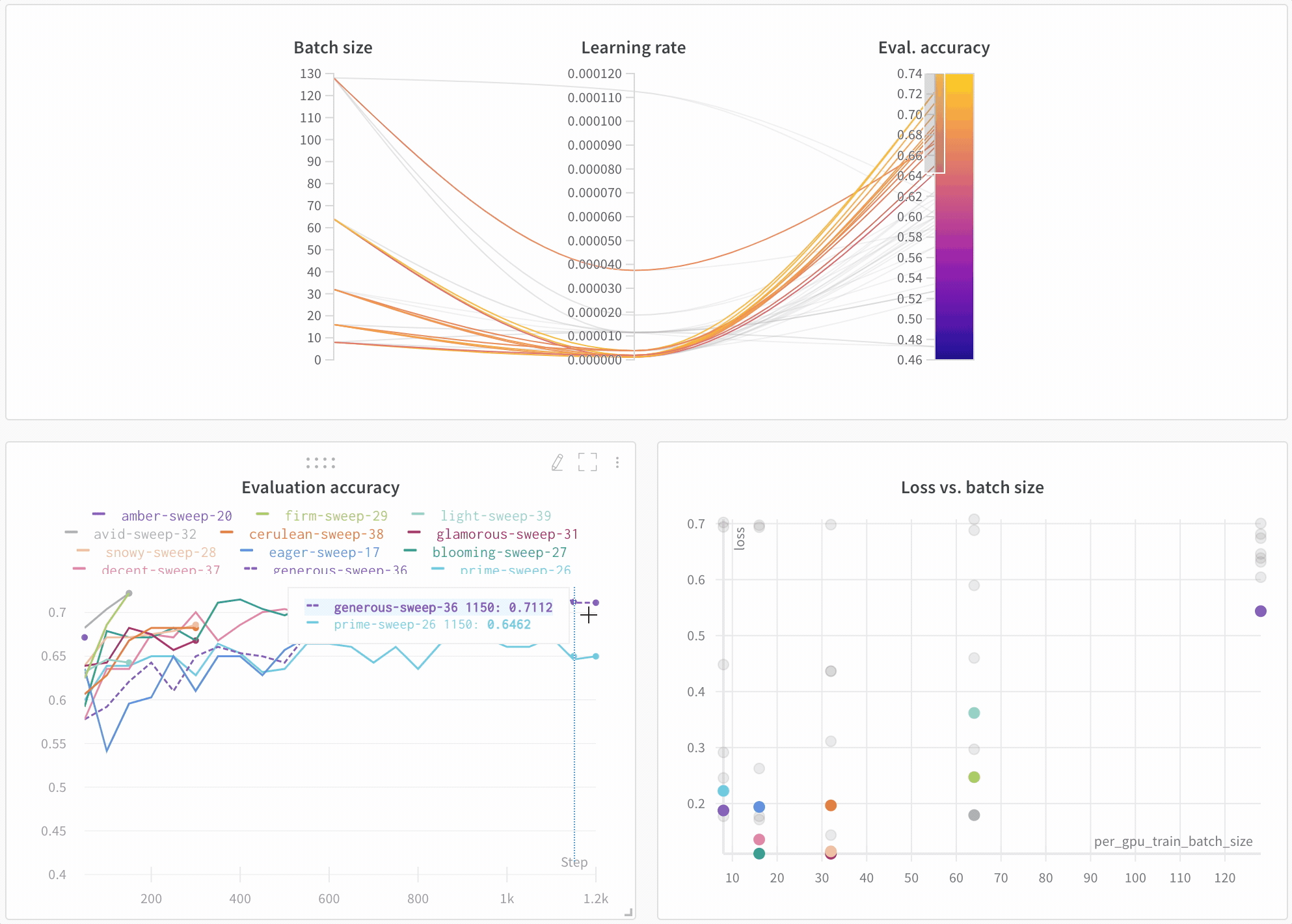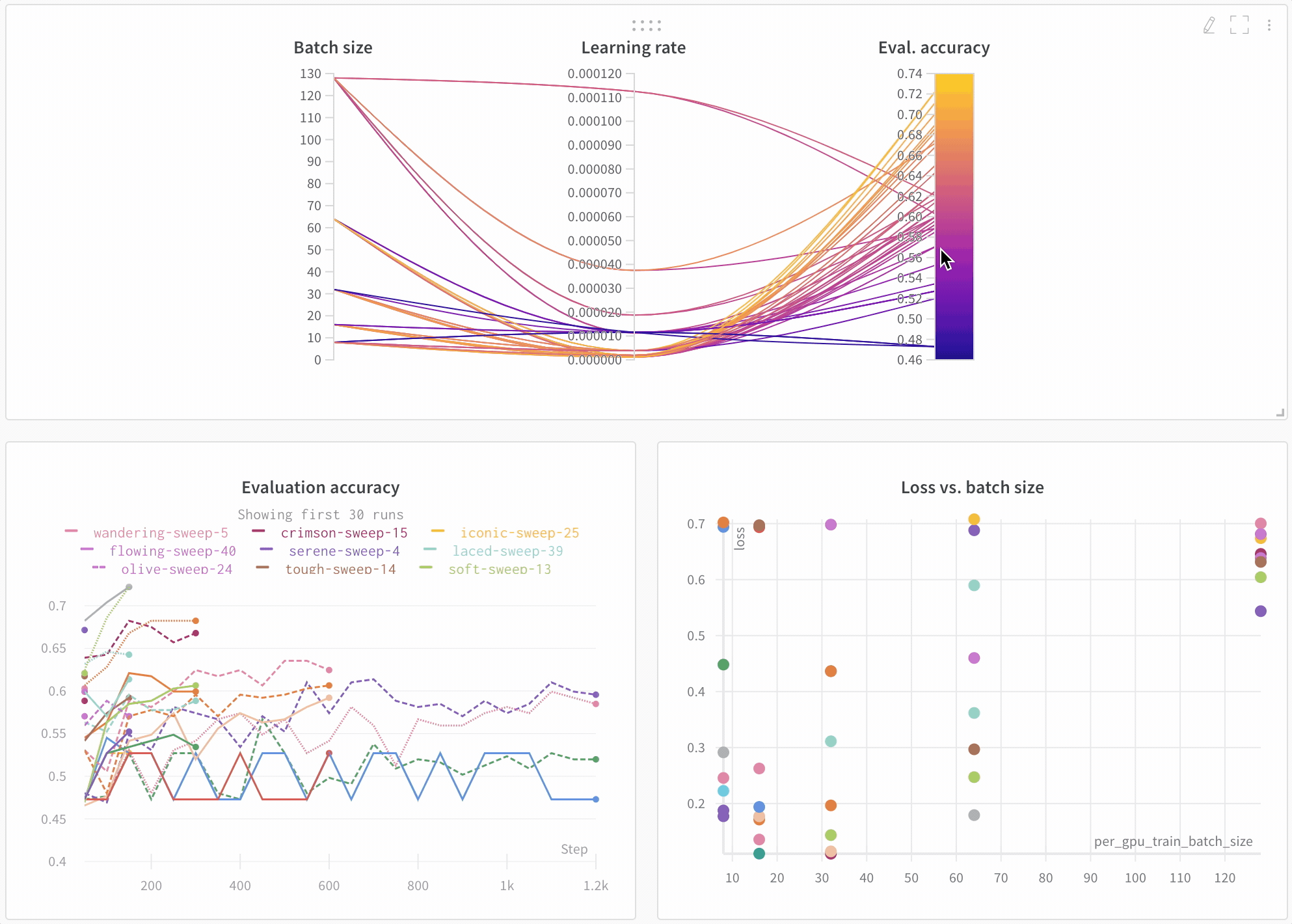
アーキテクチャーの比較
BERT vs DistilBERT を比較した例を次に示します。自動ラインプロットの可視化により、トレーニングを通じて評価精度に異なるアーキテクチャーがどのように影響するかを簡単に確認できます。
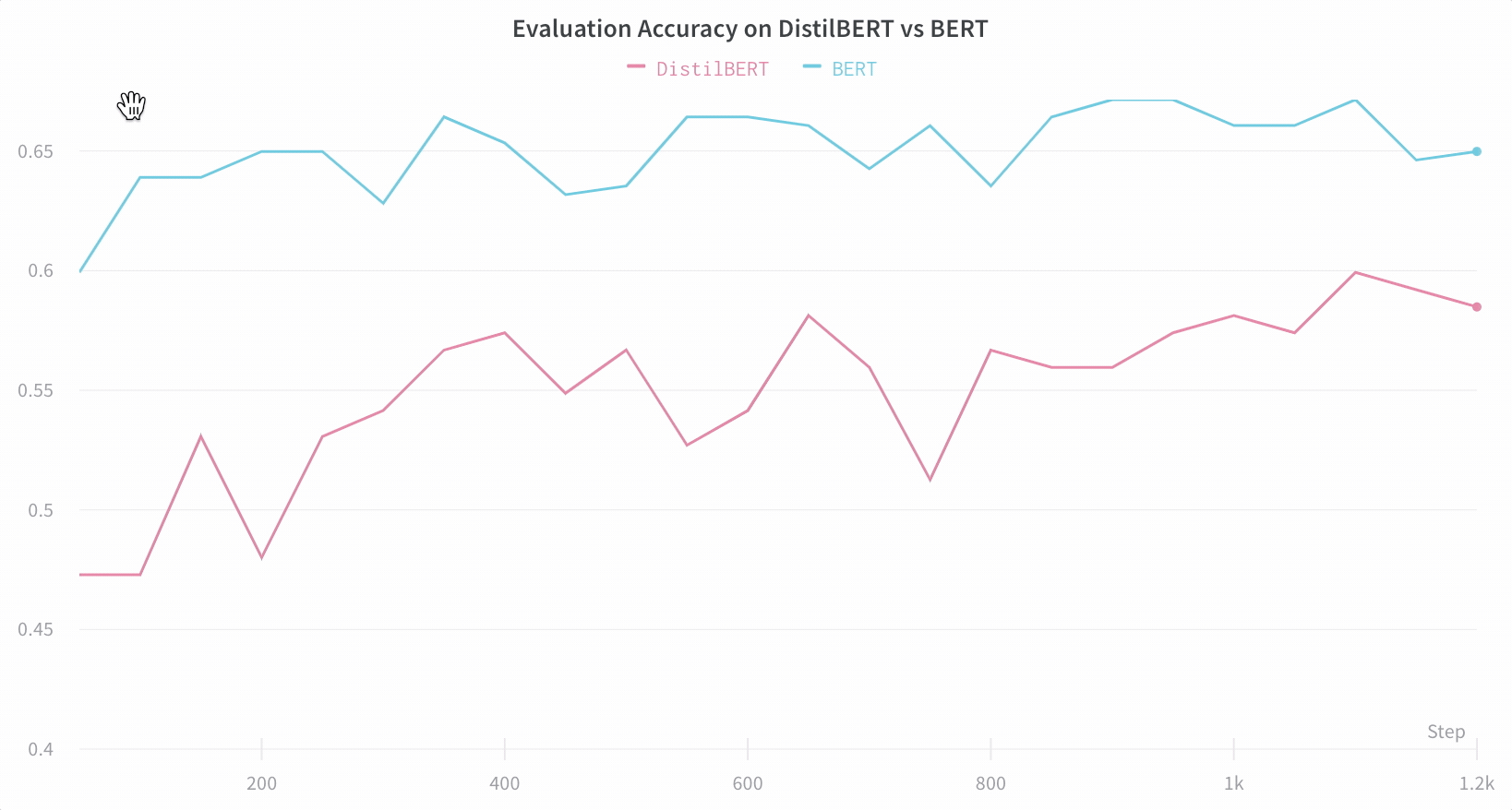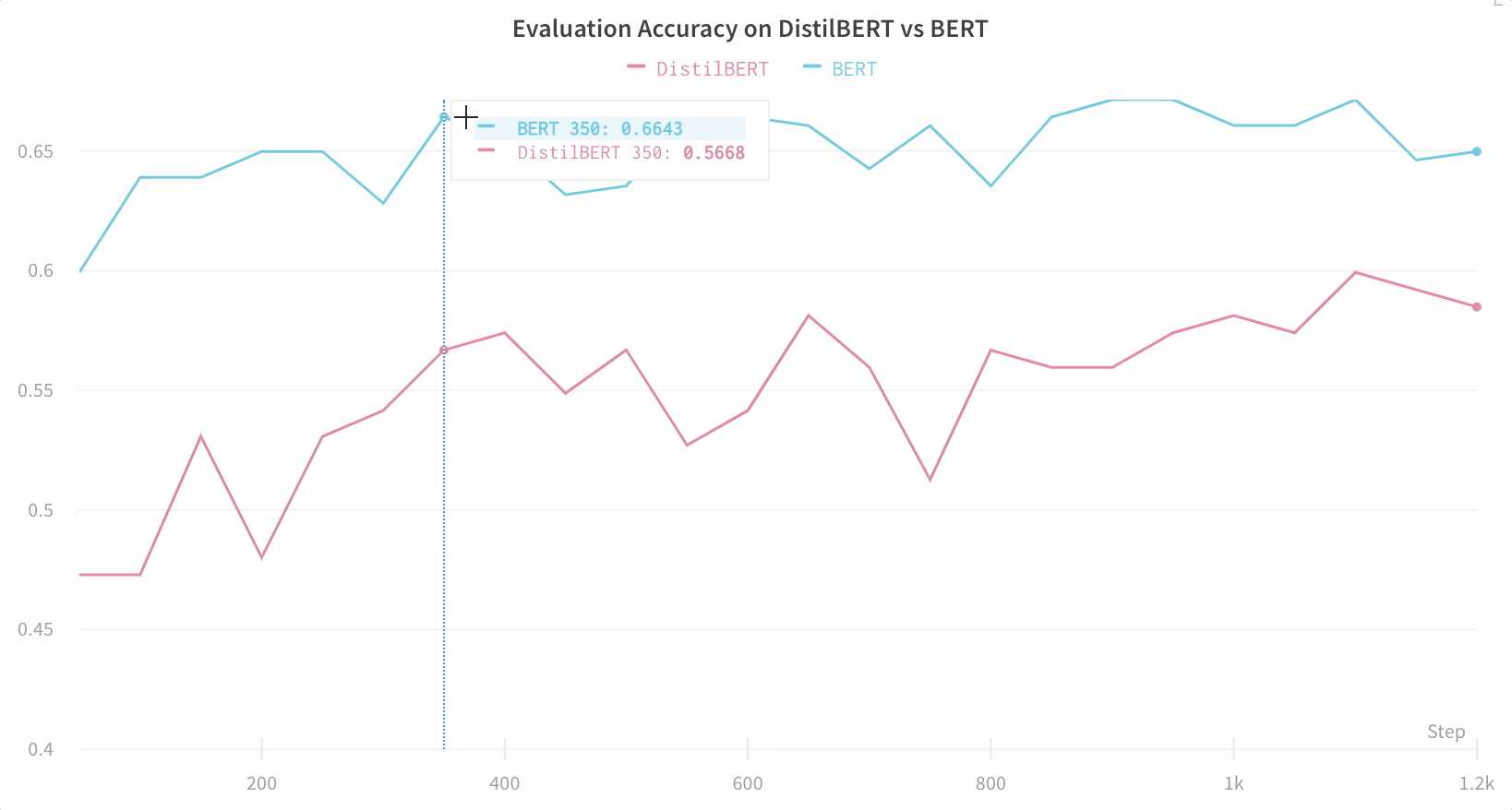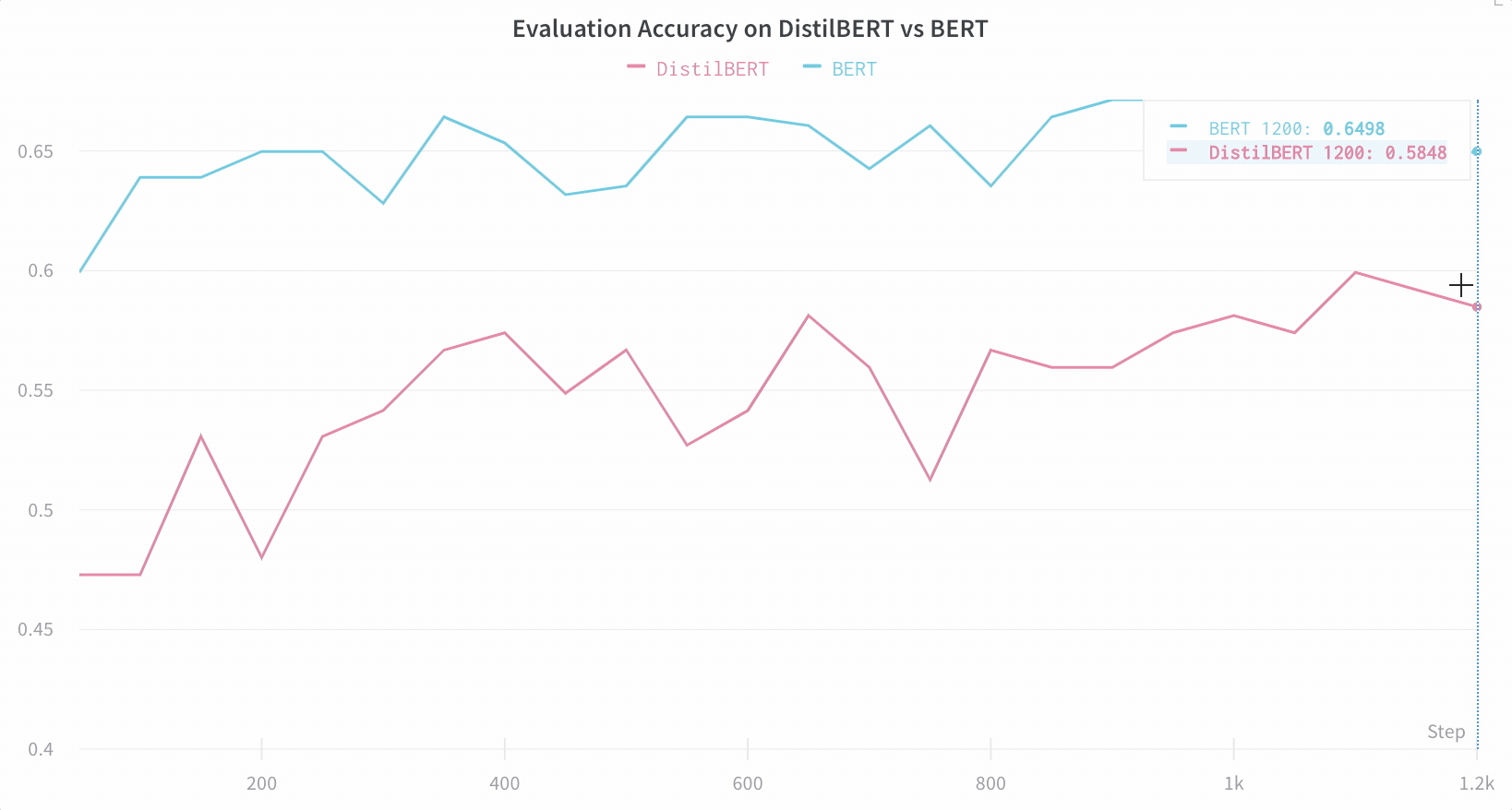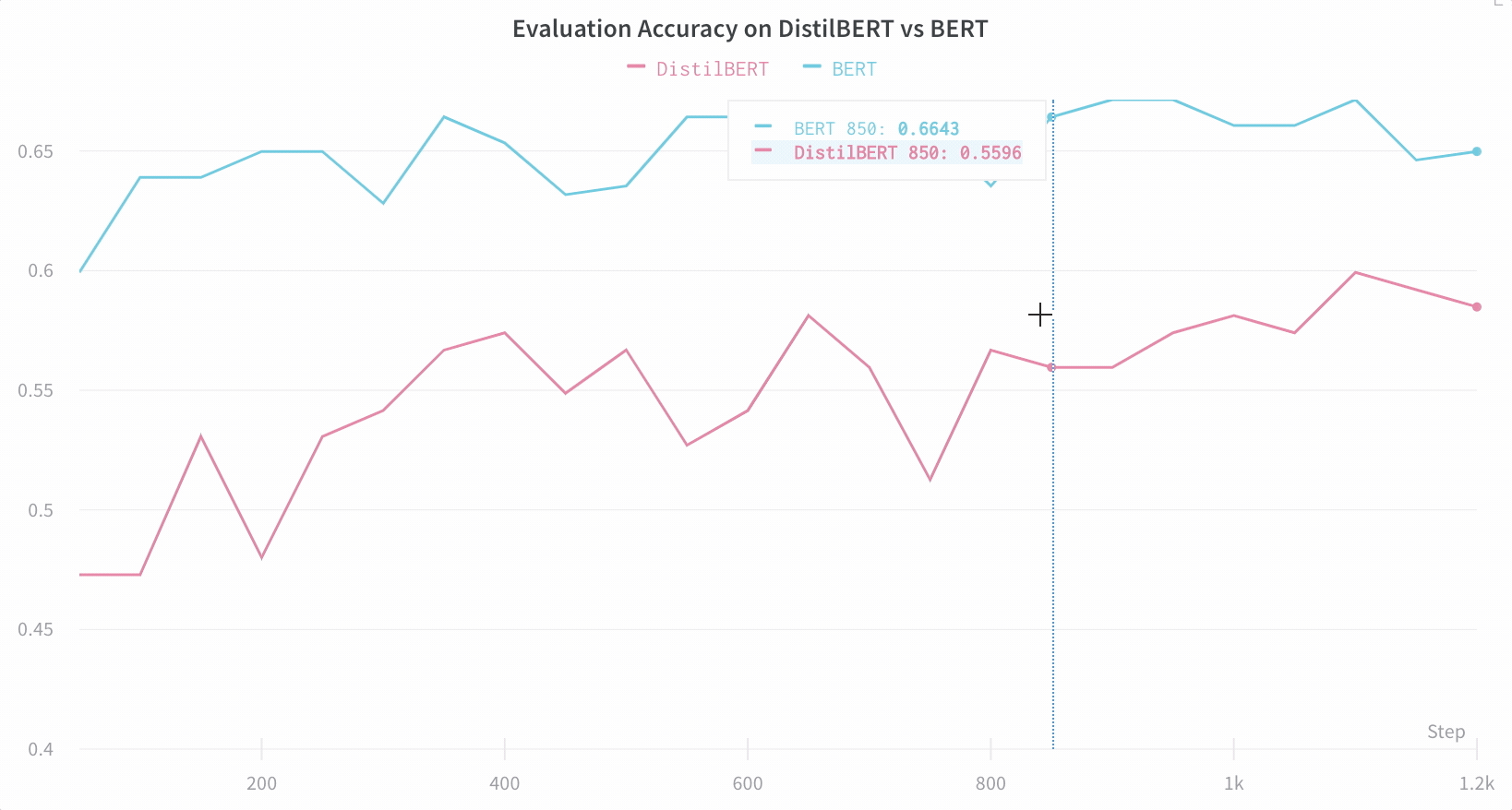
デフォルトで重要な情報を簡単に追跡
Weights & Biases は、 Experiment ごとに新しい run を保存します。デフォルトで保存される情報は次のとおりです。
- ハイパーパラメーター: モデルの Settings は Config に保存されます
- モデルメトリクス: ストリーミングされるメトリクスの時系列データは Log に保存されます
- ターミナルログ: コマンドライン出力が保存され、タブで利用できます
- システムメトリクス: GPU および CPU 使用率、メモリ、温度など
より詳しく知る
- ドキュメント: Weights & Biases と Hugging Face のインテグレーションに関するドキュメント
- ビデオ: チュートリアル、実践者とのインタビュー、および YouTube チャンネルのその他の情報
- お問い合わせ先: ご質問は contact@wandb.com までメッセージをお送りください
6.4 - TensorFlow
このノートブックの内容
- Weights & Biases と TensorFlow パイプラインを簡単に統合して、 実験管理 を行います。
keras.metrics でメトリクスを計算しますwandb.log を使用して、カスタムトレーニングループでこれらのメトリクスを記録します。
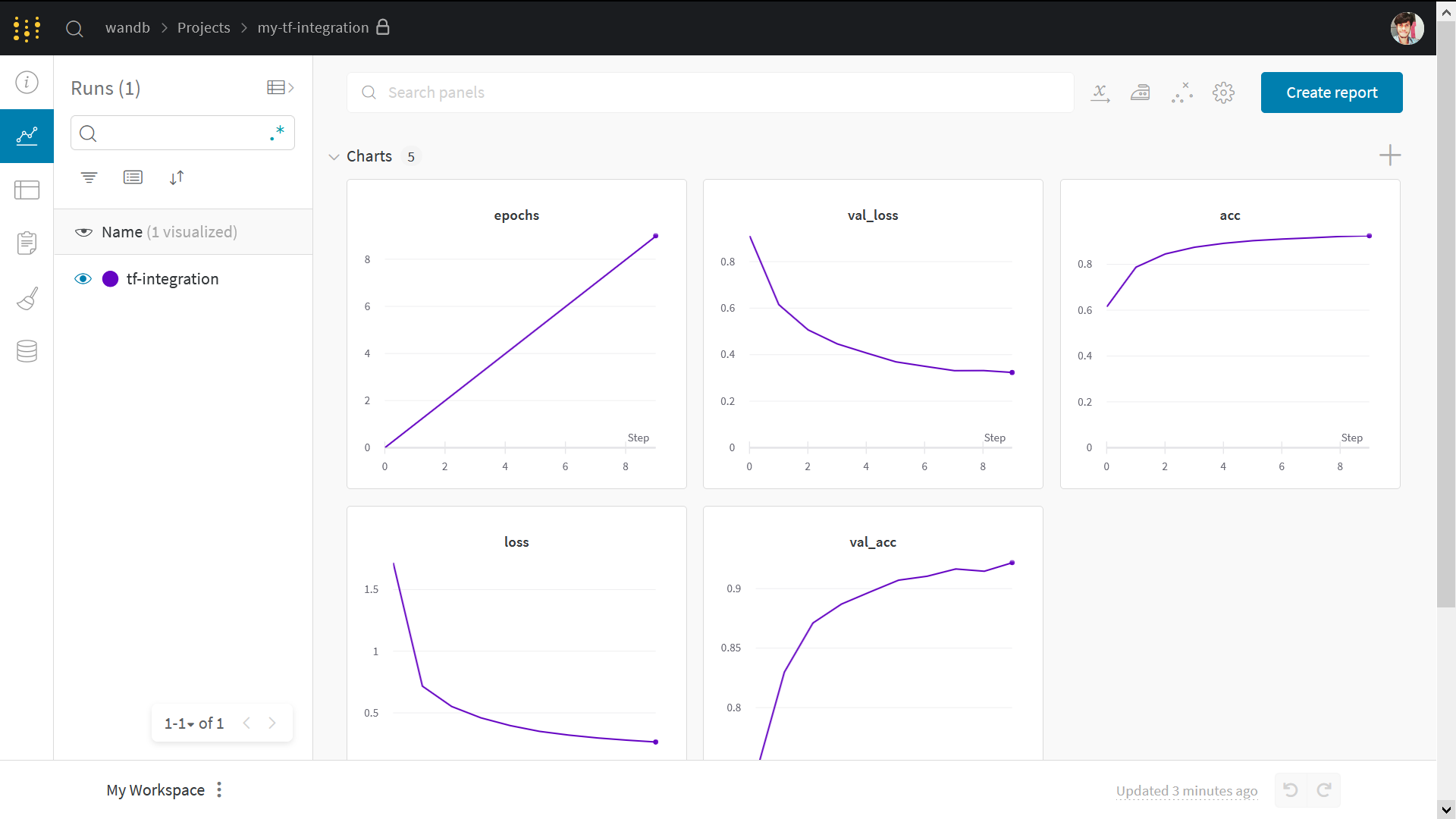
注意: Step で始まるセクションは、既存のコードに W&B を統合するために必要なものです。残りは標準的な MNIST の例です。
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import cifar10
インストール、インポート、ログイン
W&B のインストール
%%capture
!pip install wandb
W&B のインポートとログイン
import wandb
from wandb.integration.keras import WandbMetricsLogger
wandb.login()
補足: W&B を初めて使用する場合、またはログインしていない場合は、wandb.login() の実行後に表示されるリンクからサインアップ/ログインページに移動します。サインアップはワンクリックで簡単に行えます。
データセットの準備
# トレーニングデータセットの準備
BATCH_SIZE = 64
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = np.reshape(x_train, (-1, 784))
x_test = np.reshape(x_test, (-1, 784))
# tf.data を使用して入力パイプラインを構築
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(BATCH_SIZE)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(BATCH_SIZE)
モデルとトレーニングループの定義
def make_model():
inputs = keras.Input(shape=(784,), name="digits")
x1 = keras.layers.Dense(64, activation="relu")(inputs)
x2 = keras.layers.Dense(64, activation="relu")(x1)
outputs = keras.layers.Dense(10, name="predictions")(x2)
return keras.Model(inputs=inputs, outputs=outputs)
def train_step(x, y, model, optimizer, loss_fn, train_acc_metric):
with tf.GradientTape() as tape:
logits = model(x, training=True)
loss_value = loss_fn(y, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return loss_value
def test_step(x, y, model, loss_fn, val_acc_metric):
val_logits = model(x, training=False)
loss_value = loss_fn(y, val_logits)
val_acc_metric.update_state(y, val_logits)
return loss_value
トレーニングループに wandb.log を追加
def train(
train_dataset,
val_dataset,
model,
optimizer,
train_acc_metric,
val_acc_metric,
epochs=10,
log_step=200,
val_log_step=50,
):
for epoch in range(epochs):
print("\nStart of epoch %d" % (epoch,))
train_loss = []
val_loss = []
# データセットのバッチを反復処理します
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
loss_value = train_step(
x_batch_train,
y_batch_train,
model,
optimizer,
loss_fn,
train_acc_metric,
)
train_loss.append(float(loss_value))
# 各エポックの最後に検証ループを実行します
for step, (x_batch_val, y_batch_val) in enumerate(val_dataset):
val_loss_value = test_step(
x_batch_val, y_batch_val, model, loss_fn, val_acc_metric
)
val_loss.append(float(val_loss_value))
# 各エポックの最後にメトリクスを表示します
train_acc = train_acc_metric.result()
print("Training acc over epoch: %.4f" % (float(train_acc),))
val_acc = val_acc_metric.result()
print("Validation acc: %.4f" % (float(val_acc),))
# 各エポックの最後にメトリクスをリセットします
train_acc_metric.reset_states()
val_acc_metric.reset_states()
# ⭐: wandb.log を使用してメトリクスを記録
wandb.log(
{
"epochs": epoch,
"loss": np.mean(train_loss),
"acc": float(train_acc),
"val_loss": np.mean(val_loss),
"val_acc": float(val_acc),
}
)
トレーニングの実行
wandb.init を呼び出して run を開始する
これにより、実験を開始したことが通知され、
固有の ID と ダッシュボード が提供されます。
公式ドキュメントを確認する
# プロジェクト名とオプションで構成を使用して wandb を初期化します。
# 構成値をいろいろ試して、wandb ダッシュボードで結果を確認してください。
config = {
"learning_rate": 0.001,
"epochs": 10,
"batch_size": 64,
"log_step": 200,
"val_log_step": 50,
"architecture": "CNN",
"dataset": "CIFAR-10",
}
run = wandb.init(project='my-tf-integration', config=config)
config = run.config
# モデルを初期化します。
model = make_model()
# モデルをトレーニングするためのオプティマイザーをインスタンス化します。
optimizer = keras.optimizers.SGD(learning_rate=config.learning_rate)
# 損失関数をインスタンス化します。
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# メトリクスを準備します。
train_acc_metric = keras.metrics.SparseCategoricalAccuracy()
val_acc_metric = keras.metrics.SparseCategoricalAccuracy()
train(
train_dataset,
val_dataset,
model,
optimizer,
train_acc_metric,
val_acc_metric,
epochs=config.epochs,
log_step=config.log_step,
val_log_step=config.val_log_step,
)
run.finish() # Jupyter/Colab で、終了したことを知らせます!
結果の可視化
上記の run page リンクをクリックして、ライブ結果を確認してください。
Sweep 101
Weights & Biases Sweeps を使用して、ハイパーパラメーターの最適化を自動化し、可能なモデルの空間を探索します。
W&B Sweeps を使用する利点
- 簡単なセットアップ: 数行のコードだけで W&B sweeps を実行できます。
- 透明性: 使用しているすべてのアルゴリズムを引用し、コードはオープンソースです。
- 強力: sweeps は完全にカスタマイズおよび構成可能です。数十台のマシンで sweep を起動できます。ラップトップで sweep を開始するのと同じくらい簡単です。
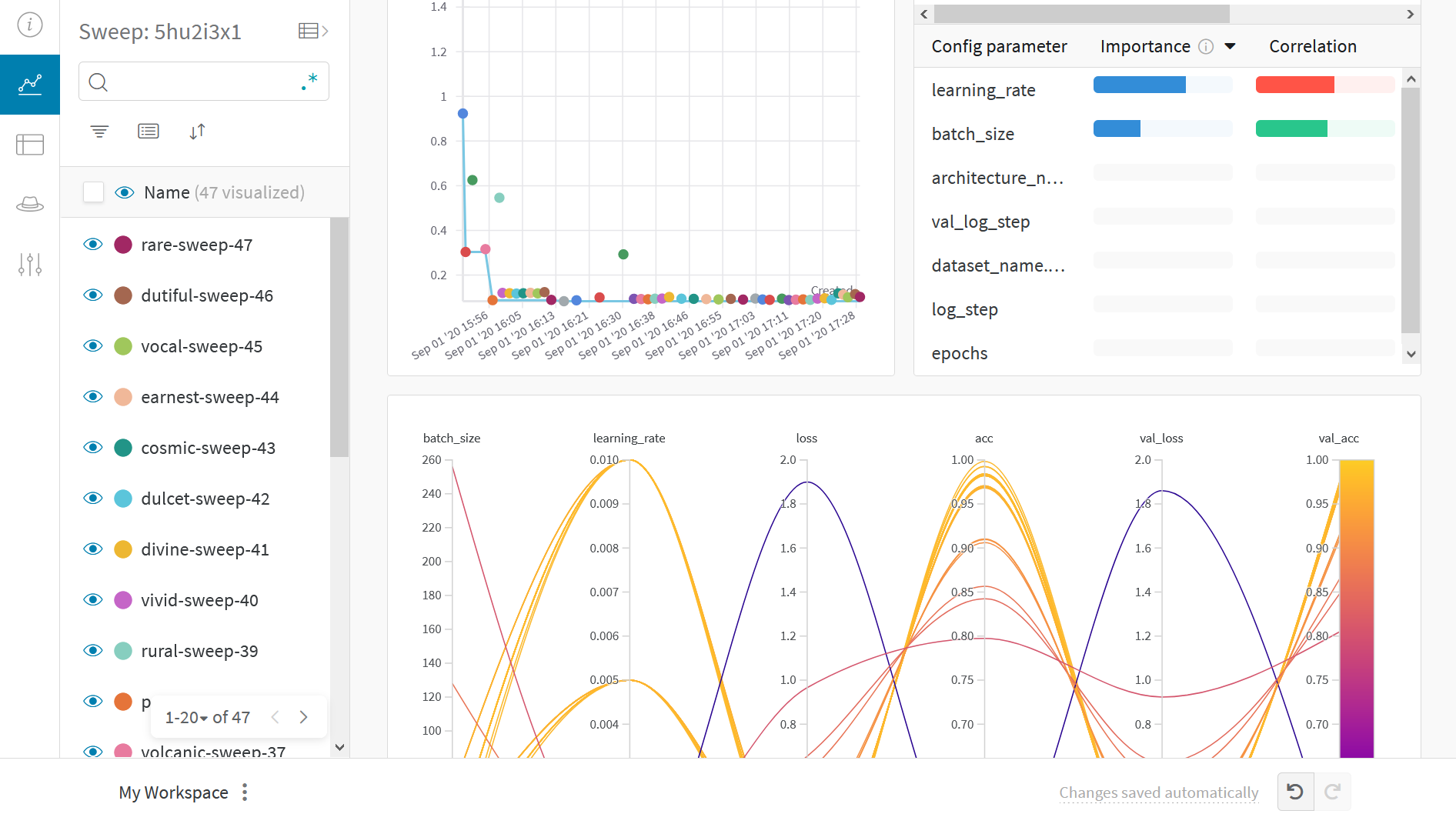
サンプルギャラリー
W&B で追跡および可視化された プロジェクト の例を、サンプルギャラリーでご覧ください。完全接続 →
ベストプラクティス
- Projects: 複数の runs を プロジェクト に記録して比較します。
wandb.init(project="project-name")
- Groups: 複数の プロセス または 交差検証 folds の場合、各 プロセス を runs として記録し、それらをグループ化します。
wandb.init(group="experiment-1")
- Tags: 現在の ベースライン または プロダクション モデル を追跡するために タグ を追加します。
- Notes: テーブルに ノート を入力して、runs 間の変更を追跡します。
- Reports: 同僚と共有するために進捗状況に関する簡単なメモを取り、ML プロジェクト の ダッシュボード と スナップショット を作成します。
高度な設定
- 環境変数: マネージド クラスター で トレーニング を実行できるように、環境変数に APIキー を設定します。
- オフラインモード
- オンプレミス: 独自の インフラストラクチャー で プライベートクラウド または エアギャップ サーバー に W&B をインストールします。学術関係者から エンタープライズ チーム まで、あらゆる人に対応するローカル インストール があります。
- Artifacts: モデル をトレーニング する際に パイプライン ステップ を自動的に取得する方法で、 モデル と データセット を合理的な方法で追跡および バージョン 管理します。
6.5 - TensorFlow Sweeps
機械学習 の 実験管理 、 データセット の バージョン管理 、 プロジェクト の コラボレーション に W&B を 使用します。
W&B Sweeps を 使用して ハイパーパラメーター の 最適化 を 自動化し、インタラクティブな ダッシュボード で モデル の 可能性 を 探ります。
Sweeps を 使用する 理由
- クイックセットアップ: 数行の コード で W&B sweeps を 実行します。
- 透明性: プロジェクト では 使用されている すべての アルゴリズム が 引用されており、 コード は オープンソース です。
- 強力: Sweeps は カスタマイズ オプション を 提供し、複数 の マシン または ラップトップ で 簡単に 実行できます。
詳細については、 Sweep の ドキュメント を 参照してください。
この ノートブック で 説明する 内容
- TensorFlow で W&B Sweep と カスタム トレーニング ループ を 開始する 手順。
- 画像分類タスク に 最適な ハイパーパラメーター を 見つける。
注: Step で 始まる セクション は、 ハイパーパラメーター sweep を 実行するために 必要 な コード を 示しています。残りの 部分 は 簡単 な 例 を 設定します。
インストール、インポート、ログイン
W&B の インストール
W&B の インポート と ログイン
import tqdm
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import cifar10
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import wandb
from wandb.integration.keras import WandbMetricsLogger
wandb.login()
W&B を 初めて 使用する 場合、または ログイン していない 場合、wandb.login() を 実行した 後 の リンク は サインアップ / ログイン ページ に 移動します。
データセット の 準備
# トレーニングデータセット の 準備
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
x_train = np.reshape(x_train, (-1, 784))
x_test = np.reshape(x_test, (-1, 784))
分類器 MLP の 構築
def Model():
inputs = keras.Input(shape=(784,), name="digits")
x1 = keras.layers.Dense(64, activation="relu")(inputs)
x2 = keras.layers.Dense(64, activation="relu")(x1)
outputs = keras.layers.Dense(10, name="predictions")(x2)
return keras.Model(inputs=inputs, outputs=outputs)
def train_step(x, y, model, optimizer, loss_fn, train_acc_metric):
with tf.GradientTape() as tape:
logits = model(x, training=True)
loss_value = loss_fn(y, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return loss_value
def test_step(x, y, model, loss_fn, val_acc_metric):
val_logits = model(x, training=False)
loss_value = loss_fn(y, val_logits)
val_acc_metric.update_state(y, val_logits)
return loss_value
トレーニング ループ の 作成
def train(
train_dataset,
val_dataset,
model,
optimizer,
loss_fn,
train_acc_metric,
val_acc_metric,
epochs=10,
log_step=200,
val_log_step=50,
):
for epoch in range(epochs):
print("\nStart of epoch %d" % (epoch,))
train_loss = []
val_loss = []
# データセット の バッチ を 反復処理します
for step, (x_batch_train, y_batch_train) in tqdm.tqdm(
enumerate(train_dataset), total=len(train_dataset)
):
loss_value = train_step(
x_batch_train,
y_batch_train,
model,
optimizer,
loss_fn,
train_acc_metric,
)
train_loss.append(float(loss_value))
# 各 エポック の 最後に 検証 ループ を 実行します
for step, (x_batch_val, y_batch_val) in enumerate(val_dataset):
val_loss_value = test_step(
x_batch_val, y_batch_val, model, loss_fn, val_acc_metric
)
val_loss.append(float(val_loss_value))
# 各 エポック の 最後に メトリクス を 表示します
train_acc = train_acc_metric.result()
print("Training acc over epoch: %.4f" % (float(train_acc),))
val_acc = val_acc_metric.result()
print("Validation acc: %.4f" % (float(val_acc),))
# 各 エポック の 最後に メトリクス を リセットします
train_acc_metric.reset_states()
val_acc_metric.reset_states()
# 3️⃣ wandb.log を 使用して メトリクス を ログ に 記録します
wandb.log(
{
"epochs": epoch,
"loss": np.mean(train_loss),
"acc": float(train_acc),
"val_loss": np.mean(val_loss),
"val_acc": float(val_acc),
}
)
sweep の 設定
sweep を 設定する 手順:
- 最適化する ハイパーパラメーター を 定義します
- 最適化 method を 選択します:
random、grid、または bayes
bayes の 目標 と メトリクス を 設定します (例: val_loss の 最小化)- 実行 を 早期 に 終了させるには、
hyperband を 使用します
詳細については、 W&B Sweeps の ドキュメント を 参照してください。
sweep_config = {
"method": "random",
"metric": {"name": "val_loss", "goal": "minimize"},
"early_terminate": {"type": "hyperband", "min_iter": 5},
"parameters": {
"batch_size": {"values": [32, 64, 128, 256]},
"learning_rate": {"values": [0.01, 0.005, 0.001, 0.0005, 0.0001]},
},
}
トレーニング ループ の ラップ
train を 呼び出す 前 に wandb.config を 使用して ハイパーパラメーター を 設定する sweep_train の よう な 関数 を 作成します。
def sweep_train(config_defaults=None):
# デフォルト値 の 設定
config_defaults = {"batch_size": 64, "learning_rate": 0.01}
# サンプル プロジェクト名 で wandb を 初期化します
wandb.init(config=config_defaults) # これは Sweep で 上書きされます
# 他の ハイパーパラメーター を 設定 (存在する場合)
wandb.config.epochs = 2
wandb.config.log_step = 20
wandb.config.val_log_step = 50
wandb.config.architecture_name = "MLP"
wandb.config.dataset_name = "MNIST"
# tf.data を 使用して 入力 パイプライン を 構築します
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = (
train_dataset.shuffle(buffer_size=1024)
.batch(wandb.config.batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(wandb.config.batch_size).prefetch(
buffer_size=tf.data.AUTOTUNE
)
# モデル の 初期化
model = Model()
# モデル を トレーニング する ため に オプティマイザー を インスタンス化します。
optimizer = keras.optimizers.SGD(learning_rate=wandb.config.learning_rate)
# 損失関数 を インスタンス化します。
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# メトリクス を 準備します。
train_acc_metric = keras.metrics.SparseCategoricalAccuracy()
val_acc_metric = keras.metrics.SparseCategoricalAccuracy()
train(
train_dataset,
val_dataset,
model,
optimizer,
loss_fn,
train_acc_metric,
val_acc_metric,
epochs=wandb.config.epochs,
log_step=wandb.config.log_step,
val_log_step=wandb.config.val_log_step,
)
sweep の 初期化 と パーソナル デジタル アシスタント の 実行
sweep_id = wandb.sweep(sweep_config, project="sweeps-tensorflow")
count パラメータ で 実行 の 数 を 制限します。クイック 実行 の 場合 は 10 に 設定します。必要 に 応じて 増やします。
wandb.agent(sweep_id, function=sweep_train, count=10)
結果 の 可視化
ライブ結果 を 表示する に は、 前 の Sweep URL リンク を クリックします。
例 の ギャラリー
ギャラリー で W&B で トラッキング および 可視化 され た プロジェクト を 探索します。
ベストプラクティス
- Projects: 複数 の run を プロジェクト に 記録して 比較します。
wandb.init(project="project-name")
- Groups: 複数 の プロセス または 交差検証 フォールド の run として 各 プロセス を ログ に 記録し、それら を グループ化します。
wandb.init(group='experiment-1')
- Tags: タグ を 使用して、 ベースライン または プロダクション モデル を 追跡します。
- Notes: テーブル に ノート を 入力して、run 間 の 変更 を 追跡します。
- Reports: Reports を 使用して、進捗状況 の メモ、同僚 と の 共有、ML プロジェクト の ダッシュボード と スナップショット の 作成 を 行います。
高度 な 設定
- 環境変数: 管理対象 クラスター で トレーニング する ため に APIキー を 設定します。
- オフライン モード
- オンプレミス: インフラストラクチャ 内 の プライベートクラウド または エアギャップ サーバー に W&B を インストールします。ローカル インストール は、 学術 チーム と エンタープライズ チーム に 適しています。
6.6 - 3D brain tumor segmentation with MONAI
このチュートリアルでは、MONAI を使用してマルチラベル 3D 脳腫瘍セグメンテーションタスクのトレーニング ワークフローを構築し、Weights & Biases の 実験管理 および データ可視化 機能を使用する方法を説明します。このチュートリアルには、次の機能が含まれています。
- Weights & Biases の run を初期化し、再現性のために run に関連付けられたすべての構成を同期します。
- MONAI transform API:
- 辞書形式のデータに対する MONAI Transforms。
- MONAI
transforms API に従って新しい transform を定義する方法。
- データ拡張のために強度をランダムに調整する方法。
- データのロードと可視化:
- メタデータ付きの
Nifti 画像をロードし、画像のリストをロードしてスタックします。
- トレーニングと検証を高速化するために IO と transform をキャッシュします。
wandb.Table と Weights & Biases 上のインタラクティブなセグメンテーション オーバーレイを使用してデータを可視化します。
- 3D
SegResNet モデルのトレーニング
- MONAI の
networks、losses、および metrics API を使用します。
- PyTorch トレーニング ループを使用して 3D
SegResNet モデルをトレーニングします。
- Weights & Biases を使用してトレーニングの experiment を追跡します。
- モデルの チェックポイント を Weights & Biases 上の モデル Artifacts としてログに記録し、バージョン管理します。
wandb.Table と Weights & Biases 上のインタラクティブなセグメンテーション オーバーレイを使用して、検証データセットの 予測 を可視化して比較します。
セットアップとインストール
まず、MONAI と Weights & Biases の両方の最新バージョンをインストールします。
!python -c "import monai" || pip install -q -U "monai[nibabel, tqdm]"
!python -c "import wandb" || pip install -q -U wandb
import os
import numpy as np
from tqdm.auto import tqdm
import wandb
from monai.apps import DecathlonDataset
from monai.data import DataLoader, decollate_batch
from monai.losses import DiceLoss
from monai.inferers import sliding_window_inference
from monai.metrics import DiceMetric
from monai.networks.nets import SegResNet
from monai.transforms import (
Activations,
AsDiscrete,
Compose,
LoadImaged,
MapTransform,
NormalizeIntensityd,
Orientationd,
RandFlipd,
RandScaleIntensityd,
RandShiftIntensityd,
RandSpatialCropd,
Spacingd,
EnsureTyped,
EnsureChannelFirstd,
)
from monai.utils import set_determinism
import torch
次に、W&B を使用するために Colab インスタンスを認証します。
W&B Run の初期化
新しい W&B run を開始して experiment の追跡を開始します。
wandb.init(project="monai-brain-tumor-segmentation")
適切な構成システムの使用は、再現性のある 機械学習 の推奨されるベスト プラクティスです。W&B を使用して、すべての experiment の ハイパーパラメーター を追跡できます。
config = wandb.config
config.seed = 0
config.roi_size = [224, 224, 144]
config.batch_size = 1
config.num_workers = 4
config.max_train_images_visualized = 20
config.max_val_images_visualized = 20
config.dice_loss_smoothen_numerator = 0
config.dice_loss_smoothen_denominator = 1e-5
config.dice_loss_squared_prediction = True
config.dice_loss_target_onehot = False
config.dice_loss_apply_sigmoid = True
config.initial_learning_rate = 1e-4
config.weight_decay = 1e-5
config.max_train_epochs = 50
config.validation_intervals = 1
config.dataset_dir = "./dataset/"
config.checkpoint_dir = "./checkpoints"
config.inference_roi_size = (128, 128, 64)
config.max_prediction_images_visualized = 20
また、モジュールのランダム シードを設定して、確定的トレーニングを有効または無効にする必要もあります。
set_determinism(seed=config.seed)
# ディレクトリを作成する
os.makedirs(config.dataset_dir, exist_ok=True)
os.makedirs(config.checkpoint_dir, exist_ok=True)
データのロードと変換
ここでは、monai.transforms API を使用して、マルチクラス ラベルを one-hot 形式のマルチラベル セグメンテーション タスクに変換するカスタム transform を作成します。
class ConvertToMultiChannelBasedOnBratsClassesd(MapTransform):
"""
brats クラスに基づいてラベルをマルチ チャンネルに変換します:
label 1 は周囲浮腫です
label 2 は GD 増強腫瘍です
label 3 は壊死性および非増強性腫瘍コアです
可能なクラスは TC (腫瘍コア)、WT (全腫瘍) および ET (増強腫瘍) です。
参考: https://github.com/Project-MONAI/tutorials/blob/main/3d_segmentation/brats_segmentation_3d.ipynb
"""
def __call__(self, data):
d = dict(data)
for key in self.keys:
result = []
# label 2 と label 3 をマージして TC を構築する
result.append(torch.logical_or(d[key] == 2, d[key] == 3))
# labels 1、2、3 をマージして WT を構築する
result.append(
torch.logical_or(
torch.logical_or(d[key] == 2, d[key] == 3), d[key] == 1
)
)
# label 2 は ET です
result.append(d[key] == 2)
d[key] = torch.stack(result, axis=0).float()
return d
次に、トレーニング データセットと検証データセットの transform をそれぞれ設定します。
train_transform = Compose(
[
# 4 つの Nifti 画像をロードして一緒にスタックする
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys="image"),
EnsureTyped(keys=["image", "label"]),
ConvertToMultiChannelBasedOnBratsClassesd(keys="label"),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(
keys=["image", "label"],
pixdim=(1.0, 1.0, 1.0),
mode=("bilinear", "nearest"),
),
RandSpatialCropd(
keys=["image", "label"], roi_size=config.roi_size, random_size=False
),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=0),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=1),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=2),
NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True),
RandScaleIntensityd(keys="image", factors=0.1, prob=1.0),
RandShiftIntensityd(keys="image", offsets=0.1, prob=1.0),
]
)
val_transform = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys="image"),
EnsureTyped(keys=["image", "label"]),
ConvertToMultiChannelBasedOnBratsClassesd(keys="label"),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(
keys=["image", "label"],
pixdim=(1.0, 1.0, 1.0),
mode=("bilinear", "nearest"),
),
NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True),
]
)
データセット
この experiment に使用される データセット は、http://medicaldecathlon.com/ から提供されています。マルチモーダル マルチサイト MRI データ (FLAIR、T1w、T1gd、T2w) を使用して、グリオーマ、壊死/活性腫瘍、および浮腫をセグメント化します。データセット は、750 個の 4D ボリューム (484 トレーニング + 266 テスト) で構成されています。
DecathlonDataset を使用して、 データセット を自動的にダウンロードして抽出します。これは、MONAI CacheDataset を継承しており、cache_num=N を設定してトレーニング用に N 個のアイテムをキャッシュし、メモリ サイズに応じて、デフォルトの 引数 を使用して検証用にすべてのアイテムをキャッシュできます。
train_dataset = DecathlonDataset(
root_dir=config.dataset_dir,
task="Task01_BrainTumour",
transform=val_transform,
section="training",
download=True,
cache_rate=0.0,
num_workers=4,
)
val_dataset = DecathlonDataset(
root_dir=config.dataset_dir,
task="Task01_BrainTumour",
transform=val_transform,
section="validation",
download=False,
cache_rate=0.0,
num_workers=4,
)
注: train_transform を train_dataset に適用する代わりに、val_transform をトレーニング データセット と 検証 データセット の両方に適用します。これは、トレーニングの前に、 データセット の両方の分割から サンプル を 可視化 するためです。
データセット の可視化
Weights & Biases は、画像、ビデオ、オーディオなどをサポートしています。リッチ メディアをログに記録して 結果 を調査し、run、モデル、および データセット を視覚的に比較できます。セグメンテーション マスク オーバーレイ システム を使用して、データ ボリュームを可視化します。Tables でセグメンテーション マスクをログに記録するには、テーブル の各行に wandb.Image オブジェクトを指定する必要があります。
次に、疑似コードの例を示します。
table = wandb.Table(columns=["ID", "Image"])
for id, img, label in zip(ids, images, labels):
mask_img = wandb.Image(
img,
masks={
"prediction": {"mask_data": label, "class_labels": class_labels}
# ...
},
)
table.add_data(id, img)
wandb.log({"Table": table})
次に、サンプル画像、ラベル、wandb.Table オブジェクト、および関連するメタデータを受け取り、Weights & Biases ダッシュボードにログに記録されるテーブル の行に入力する簡単なユーティリティ関数を作成します。
def log_data_samples_into_tables(
sample_image: np.array,
sample_label: np.array,
split: str = None,
data_idx: int = None,
table: wandb.Table = None,
):
num_channels, _, _, num_slices = sample_image.shape
with tqdm(total=num_slices, leave=False) as progress_bar:
for slice_idx in range(num_slices):
ground_truth_wandb_images = []
for channel_idx in range(num_channels):
ground_truth_wandb_images.append(
masks = {
"ground-truth/Tumor-Core": {
"mask_data": sample_label[0, :, :, slice_idx],
"class_labels": {0: "background", 1: "Tumor Core"},
},
"ground-truth/Whole-Tumor": {
"mask_data": sample_label[1, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Whole Tumor"},
},
"ground-truth/Enhancing-Tumor": {
"mask_data": sample_label[2, :, :, slice_idx] * 3,
"class_labels": {0: "background", 3: "Enhancing Tumor"},
},
}
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks=masks,
)
)
table.add_data(split, data_idx, slice_idx, *ground_truth_wandb_images)
progress_bar.update(1)
return table
次に、wandb.Table オブジェクトと、データ可視化で入力できるようにするために構成される 列 を定義します。
table = wandb.Table(
columns=[
"Split",
"Data Index",
"Slice Index",
"Image-Channel-0",
"Image-Channel-1",
"Image-Channel-2",
"Image-Channel-3",
]
)
次に、train_dataset と val_dataset をそれぞれループして、データ サンプル の 可視化 を生成し、ダッシュボード にログに記録するテーブル の行に入力します。
# train_dataset の 可視化 を生成する
max_samples = (
min(config.max_train_images_visualized, len(train_dataset))
if config.max_train_images_visualized > 0
else len(train_dataset)
)
progress_bar = tqdm(
enumerate(train_dataset[:max_samples]),
total=max_samples,
desc="トレーニング データセット の 可視化 を生成しています:",
)
for data_idx, sample in progress_bar:
sample_image = sample["image"].detach().cpu().numpy()
sample_label = sample["label"].detach().cpu().numpy()
table = log_data_samples_into_tables(
sample_image,
sample_label,
split="train",
data_idx=data_idx,
table=table,
)
# val_dataset の 可視化 を生成する
max_samples = (
min(config.max_val_images_visualized, len(val_dataset))
if config.max_val_images_visualized > 0
else len(val_dataset)
)
progress_bar = tqdm(
enumerate(val_dataset[:max_samples]),
total=max_samples,
desc="検証 データセット の 可視化 を生成しています:",
)
for data_idx, sample in progress_bar:
sample_image = sample["image"].detach().cpu().numpy()
sample_label = sample["label"].detach().cpu().numpy()
table = log_data_samples_into_tables(
sample_image,
sample_label,
split="val",
data_idx=data_idx,
table=table,
)
# テーブル をダッシュボードにログに記録する
wandb.log({"Tumor-Segmentation-Data": table})
データ は、インタラクティブなテーブル形式で W&B ダッシュボード に表示されます。各行にそれぞれのセグメンテーション マスク がオーバーレイされたデータ ボリュームの特定の スライス の各 チャンネル を確認できます。Weave クエリ を記述して、テーブル のデータをフィルタリングし、特定の 1 つの行に焦点を当てることができます。
 |
| ログに記録されたテーブル データの例。 |
画像を開き、インタラクティブなオーバーレイを使用して各セグメンテーション マスク を操作する方法を確認します。
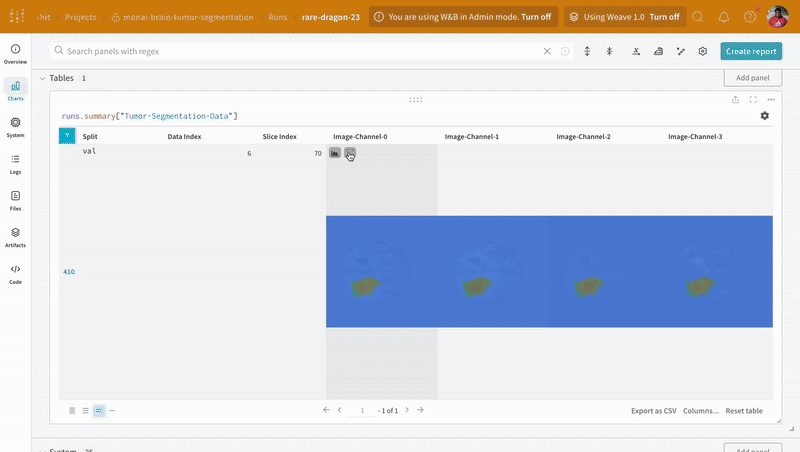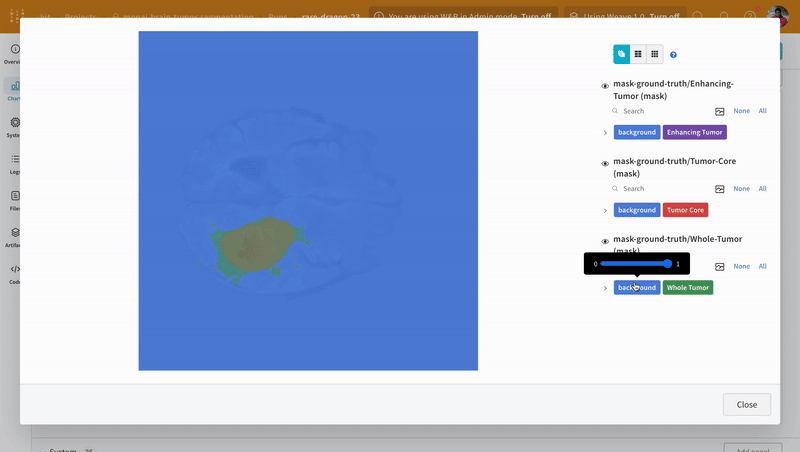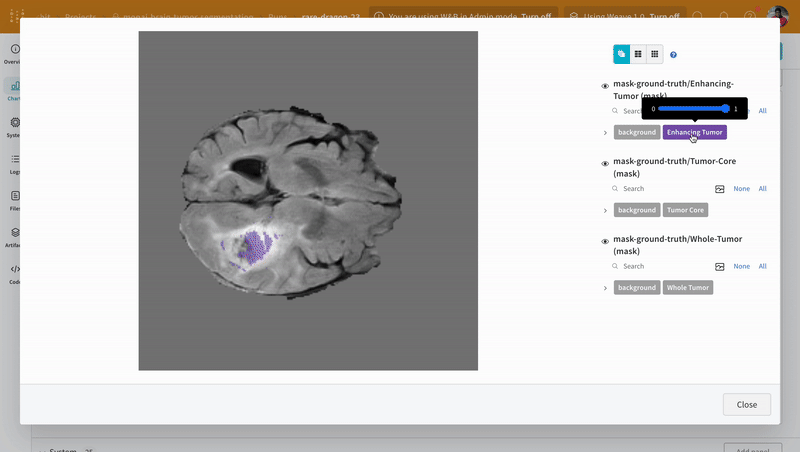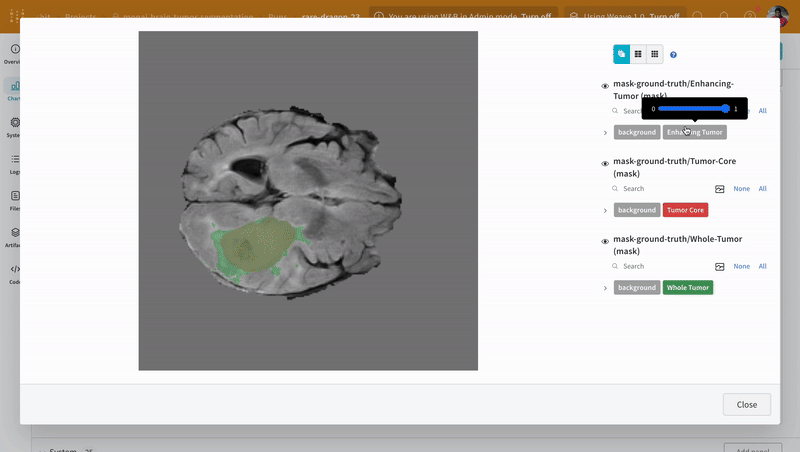 |
| 可視化されたセグメンテーション マップ の例。 |
注: データセット のラベルは、クラス間で重複しないマスクで構成されています。オーバーレイは、ラベルをオーバーレイ内の個別のマスクとしてログに記録します。
データのロード
データセット からデータをロードするために、PyTorch DataLoaders を作成します。DataLoaders を作成する前に、トレーニング用にデータを事前処理および変換するために、train_dataset の transform を train_transform に設定します。
# train_transforms をトレーニング データセット に適用する
train_dataset.transform = train_transform
# train_loader を作成する
train_loader = DataLoader(
train_dataset,
batch_size=config.batch_size,
shuffle=True,
num_workers=config.num_workers,
)
# val_loader を作成する
val_loader = DataLoader(
val_dataset,
batch_size=config.batch_size,
shuffle=False,
num_workers=config.num_workers,
)
モデル、損失、および オプティマイザー の作成
このチュートリアルでは、論文 自動エンコーダー正則化を使用した 3D MRI 脳腫瘍セグメンテーション に基づいて SegResNet モデルを作成します。SegResNet モデルは、monai.networks API の一部として PyTorch モジュールとして実装され、 オプティマイザー と 学習率 スケジューラ も実装されています。
device = torch.device("cuda:0")
# モデルを作成する
model = SegResNet(
blocks_down=[1, 2, 2, 4],
blocks_up=[1, 1, 1],
init_filters=16,
in_channels=4,
out_channels=3,
dropout_prob=0.2,
).to(device)
# オプティマイザー を作成する
optimizer = torch.optim.Adam(
model.parameters(),
config.initial_learning_rate,
weight_decay=config.weight_decay,
)
# 学習率 スケジューラ を作成する
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=config.max_train_epochs
)
monai.losses API を使用して損失をマルチラベル DiceLoss として定義し、monai.metrics API を使用して対応する dice メトリクスを定義します。
loss_function = DiceLoss(
smooth_nr=config.dice_loss_smoothen_numerator,
smooth_dr=config.dice_loss_smoothen_denominator,
squared_pred=config.dice_loss_squared_prediction,
to_onehot_y=config.dice_loss_target_onehot,
sigmoid=config.dice_loss_apply_sigmoid,
)
dice_metric = DiceMetric(include_background=True, reduction="mean")
dice_metric_batch = DiceMetric(include_background=True, reduction="mean_batch")
post_trans = Compose([Activations(sigmoid=True), AsDiscrete(threshold=0.5)])
# 自動混合精度を使用してトレーニングを高速化する
scaler = torch.cuda.amp.GradScaler()
torch.backends.cudnn.benchmark = True
混合精度推論用の小さなユーティリティを定義します。これは、トレーニング プロセスの検証ステップ中、およびトレーニング後にモデルを実行する場合に役立ちます。
def inference(model, input):
def _compute(input):
return sliding_window_inference(
inputs=input,
roi_size=(240, 240, 160),
sw_batch_size=1,
predictor=model,
overlap=0.5,
)
with torch.cuda.amp.autocast():
return _compute(input)
トレーニングと検証
トレーニングの前に、トレーニング および 検証 experiment を追跡するために、後で wandb.log() でログに記録される メトリクス プロパティを定義します。
wandb.define_metric("epoch/epoch_step")
wandb.define_metric("epoch/*", step_metric="epoch/epoch_step")
wandb.define_metric("batch/batch_step")
wandb.define_metric("batch/*", step_metric="batch/batch_step")
wandb.define_metric("validation/validation_step")
wandb.define_metric("validation/*", step_metric="validation/validation_step")
batch_step = 0
validation_step = 0
metric_values = []
metric_values_tumor_core = []
metric_values_whole_tumor = []
metric_values_enhanced_tumor = []
標準的な PyTorch トレーニング ループを実行する
# W&B Artifact オブジェクトを定義する
artifact = wandb.Artifact(
name=f"{wandb.run.id}-checkpoint", type="model"
)
epoch_progress_bar = tqdm(range(config.max_train_epochs), desc="トレーニング:")
for epoch in epoch_progress_bar:
model.train()
epoch_loss = 0
total_batch_steps = len(train_dataset) // train_loader.batch_size
batch_progress_bar = tqdm(train_loader, total=total_batch_steps, leave=False)
# トレーニング ステップ
for batch_data in batch_progress_bar:
inputs, labels = (
batch_data["image"].to(device),
batch_data["label"].to(device),
)
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = loss_function(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
epoch_loss += loss.item()
batch_progress_bar.set_description(f"train_loss: {loss.item():.4f}:")
## バッチごとのトレーニング損失を W&B にログに記録する
wandb.log({"batch/batch_step": batch_step, "batch/train_loss": loss.item()})
batch_step += 1
lr_scheduler.step()
epoch_loss /= total_batch_steps
## バッチごとのトレーニング損失と 学習率 を W&B にログに記録する
wandb.log(
{
"epoch/epoch_step": epoch,
"epoch/mean_train_loss": epoch_loss,
"epoch/learning_rate": lr_scheduler.get_last_lr()[0],
}
)
epoch_progress_bar.set_description(f"トレーニング: train_loss: {epoch_loss:.4f}:")
# 検証と モデル チェックポイント ステップ
if (epoch + 1) % config.validation_intervals == 0:
model.eval()
with torch.no_grad():
for val_data in val_loader:
val_inputs, val_labels = (
val_data["image"].to(device),
val_data["label"].to(device),
)
val_outputs = inference(model, val_inputs)
val_outputs = [post_trans(i) for i in decollate_batch(val_outputs)]
dice_metric(y_pred=val_outputs, y=val_labels)
dice_metric_batch(y_pred=val_outputs, y=val_labels)
metric_values.append(dice_metric.aggregate().item())
metric_batch = dice_metric_batch.aggregate()
metric_values_tumor_core.append(metric_batch[0].item())
metric_values_whole_tumor.append(metric_batch[1].item())
metric_values_enhanced_tumor.append(metric_batch[2].item())
dice_metric.reset()
dice_metric_batch.reset()
checkpoint_path = os.path.join(config.checkpoint_dir, "model.pth")
torch.save(model.state_dict(), checkpoint_path)
# W&B Artifacts を使用して モデル チェックポイント をログに記録し、バージョン管理する。
artifact.add_file(local_path=checkpoint_path)
wandb.log_artifact(artifact, aliases=[f"epoch_{epoch}"])
# 検証 メトリクス を W&B ダッシュボード にログに記録する。
wandb.log(
{
"validation/validation_step": validation_step,
"validation/mean_dice": metric_values[-1],
"validation/mean_dice_tumor_core": metric_values_tumor_core[-1],
"validation/mean_dice_whole_tumor": metric_values_whole_tumor[-1],
"validation/mean_dice_enhanced_tumor": metric_values_enhanced_tumor[-1],
}
)
validation_step += 1
# この Artifact がログ記録を完了するまで待機する
artifact.wait()
wandb.log でコードをインストルメント化すると、トレーニング および 検証 プロセスに関連付けられたすべての メトリクス だけでなく、W&B ダッシュボード 上のすべてのシステム メトリクス (この場合は CPU と GPU) も追跡できます。
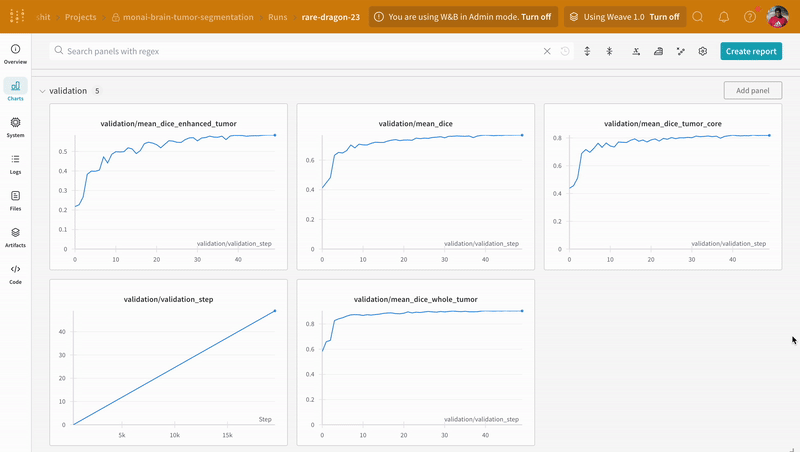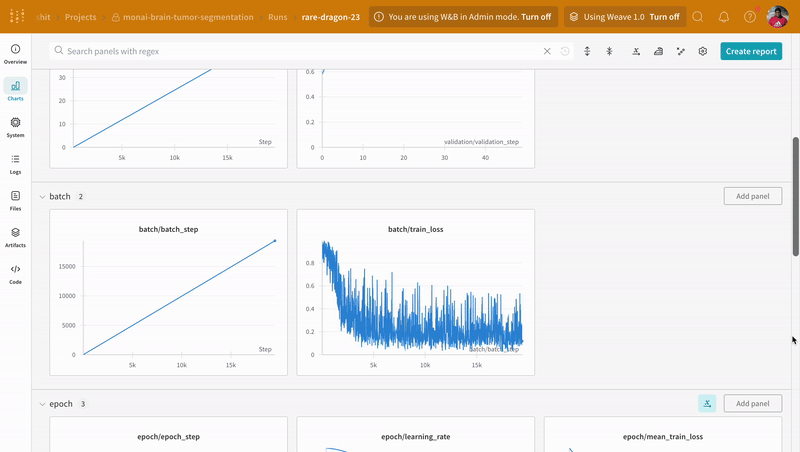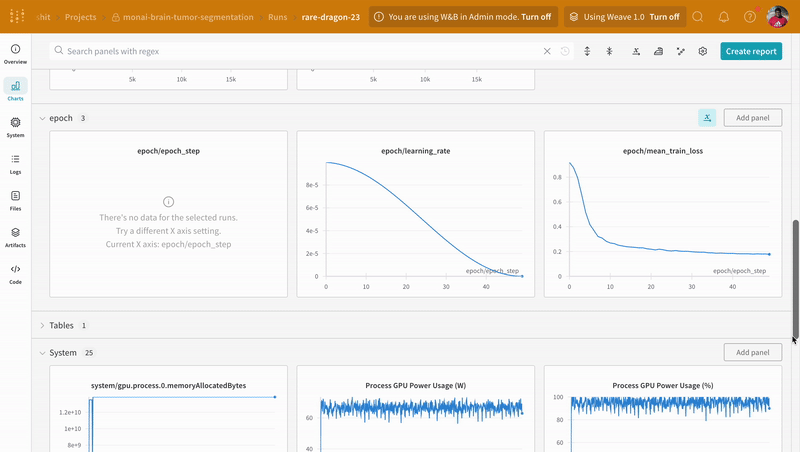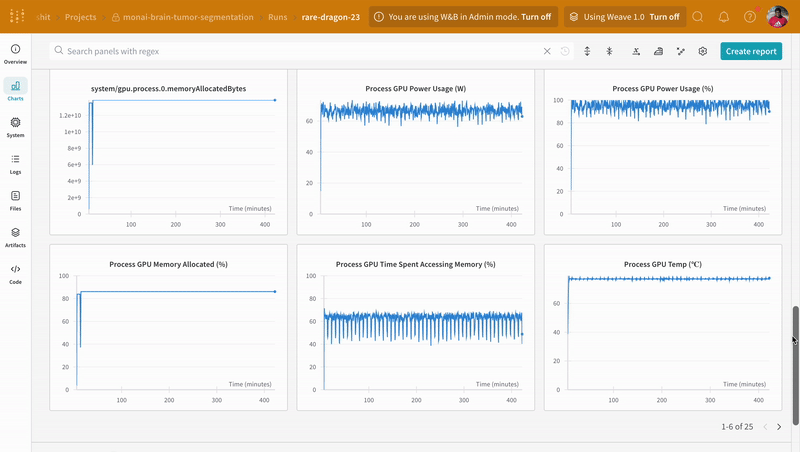 |
| W&B でのトレーニング および 検証 プロセスの追跡の例。 |
W&B run ダッシュボード の Artifacts タブに移動して、トレーニング 中にログに記録された モデル チェックポイント Artifacts のさまざまな バージョン にアクセスします。
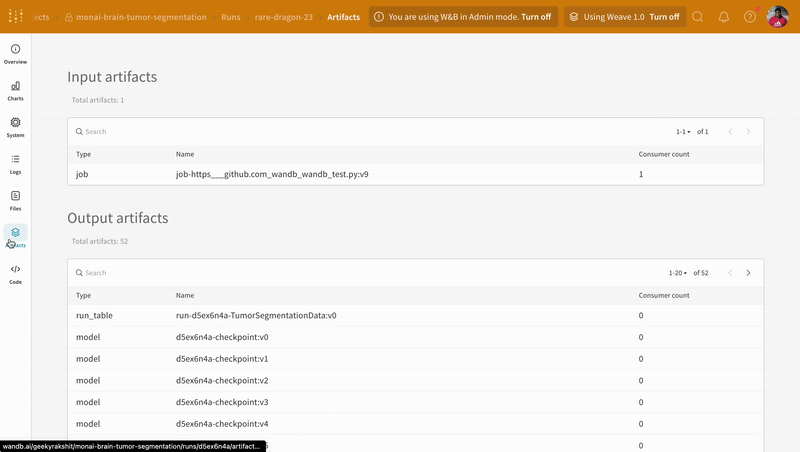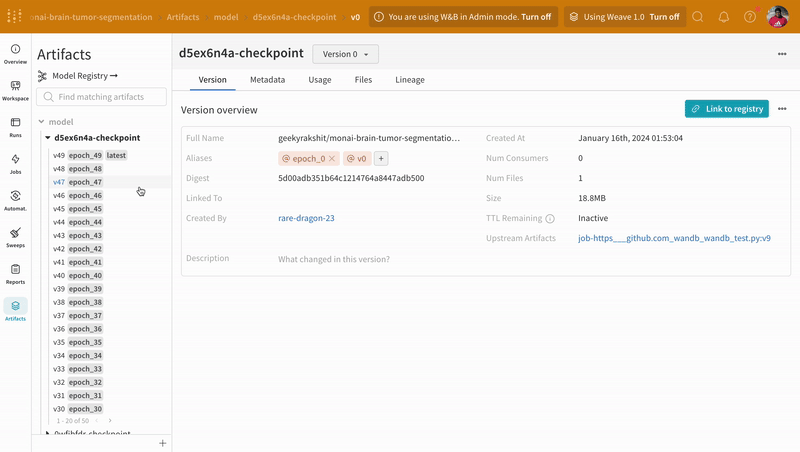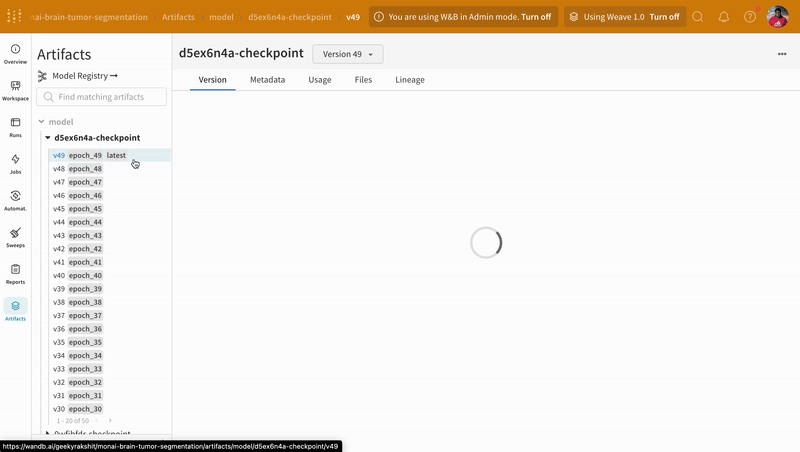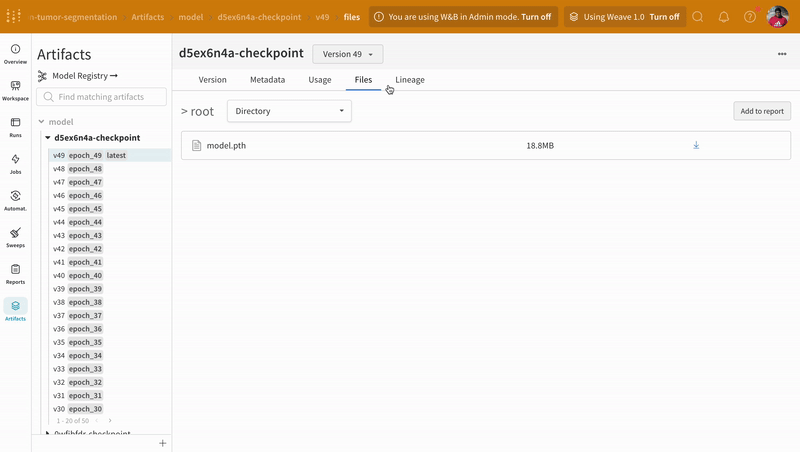 |
| W&B での モデル チェックポイント のログ記録と バージョン管理 の例。 |
推論
Artifacts インターフェイスを使用すると、最適な モデル チェックポイント である Artifact の バージョン を選択できます。この場合、エポックごとの平均トレーニング損失です。Artifact のリネージ全体を調べて、必要な バージョン を使用することもできます。
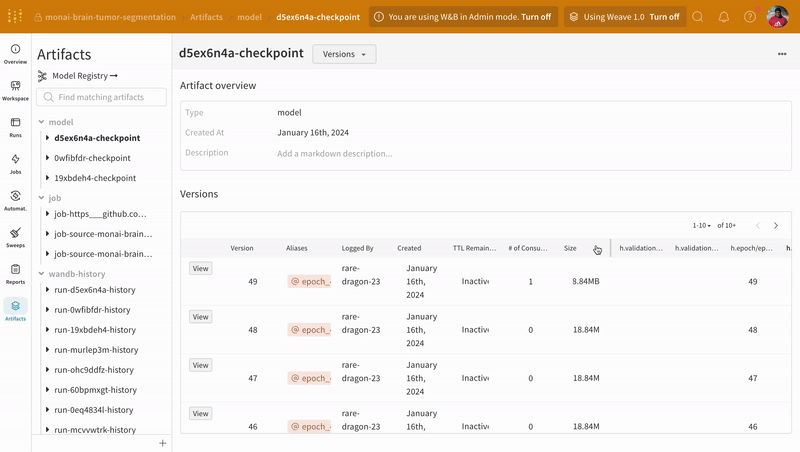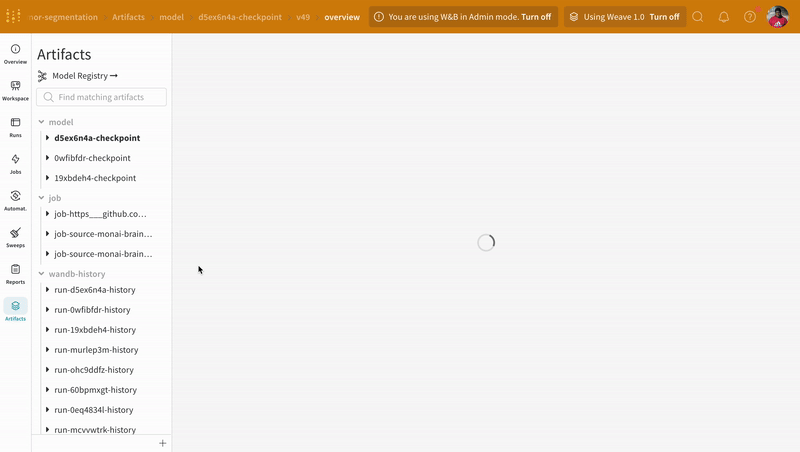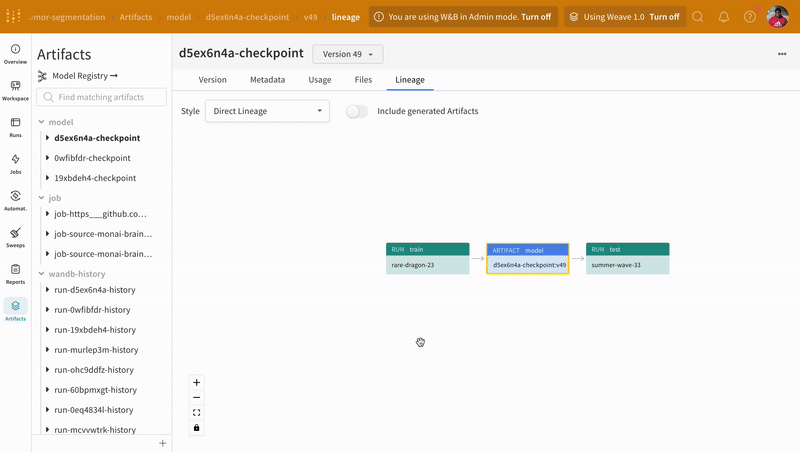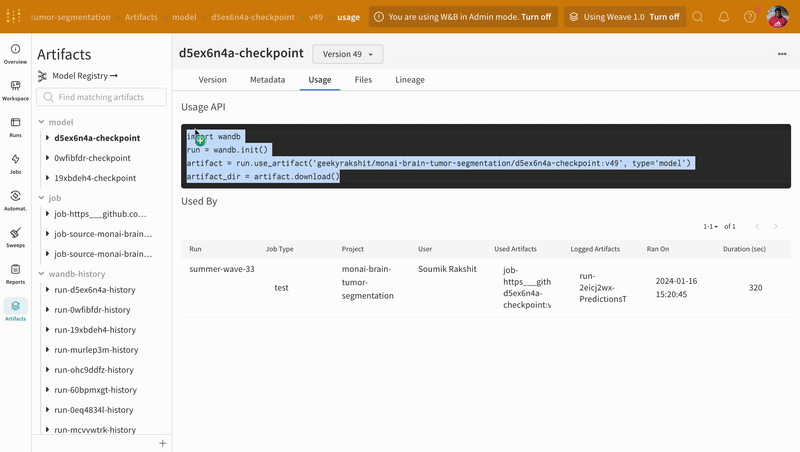 |
| W&B での モデル Artifact の追跡の例。 |
エポックごとの平均トレーニング損失が最適なモデル Artifact の バージョン をフェッチし、チェックポイント 状態 辞書 をモデルにロードします。
model_artifact = wandb.use_artifact(
"geekyrakshit/monai-brain-tumor-segmentation/d5ex6n4a-checkpoint:v49",
type="model",
)
model_artifact_dir = model_artifact.download()
model.load_state_dict(torch.load(os.path.join(model_artifact_dir, "model.pth")))
model.eval()
予測 の可視化と 正解 ラベルとの比較
インタラクティブなセグメンテーション マスク オーバーレイを使用して、学習済み モデル の 予測 を 可視化 し、対応する 正解 セグメンテーション マスク と比較するための別のユーティリティ関数を作成します。
def log_predictions_into_tables(
sample_image: np.array,
sample_label: np.array,
predicted_label: np.array,
split: str = None,
data_idx: int = None,
table: wandb.Table = None,
):
num_channels, _, _, num_slices = sample_image.shape
with tqdm(total=num_slices, leave=False) as progress_bar:
for slice_idx in range(num_slices):
wandb_images = []
for channel_idx in range(num_channels):
wandb_images += [
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks={
"ground-truth/Tumor-Core": {
"mask_data": sample_label[0, :, :, slice_idx],
"class_labels": {0: "background", 1: "Tumor Core"},
},
"prediction/Tumor-Core": {
"mask_data": predicted_label[0, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Tumor Core"},
},
},
),
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks={
"ground-truth/Whole-Tumor": {
"mask_data": sample_label[1, :, :, slice_idx],
"class_labels": {0: "background", 1: "Whole Tumor"},
},
"prediction/Whole-Tumor": {
"mask_data": predicted_label[1, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Whole Tumor"},
},
},
),
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks={
"ground-truth/Enhancing-Tumor": {
"mask_data": sample_label[2, :, :, slice_idx],
"class_labels": {0: "background", 1: "Enhancing Tumor"},
},
"prediction/Enhancing-Tumor": {
"mask_data": predicted_label[2, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Enhancing Tumor"},
},
},
),
]
table.add_data(split, data_idx, slice_idx, *wandb_images)
progress_bar.update(1)
return table
予測 結果を 予測 テーブル にログに記録します。
# 予測 テーブル を作成する
prediction_table = wandb.Table(
columns=[
"Split",
"Data Index",
"Slice Index",
"Image-Channel-0/Tumor-Core",
"Image-Channel-1/Tumor-Core",
"Image-Channel-2/Tumor-Core",
"Image-Channel-3/Tumor-Core",
"Image-Channel-0/Whole-Tumor",
"Image-Channel-1/Whole-Tumor",
"Image-Channel-2/Whole-Tumor",
"Image-Channel-3/Whole-Tumor",
"Image-Channel-0/Enhancing-Tumor",
"Image-Channel-1/Enhancing-Tumor",
"Image-Channel-2/Enhancing-Tumor",
"Image-Channel-3/Enhancing-Tumor",
]
)
# 推論 と 可視化 を実行する
with torch.no_grad():
config.max_prediction_images_visualized
max_samples = (
min(config.max_prediction_images_visualized, len(val_dataset))
if config.max_prediction_images_visualized > 0
else len(val_dataset)
)
progress_bar = tqdm(
enumerate(val_dataset[:max_samples]),
total=max_samples,
desc="予測 を生成しています:",
)
for data_idx, sample in progress_bar:
val_input = sample["image"].unsqueeze(0).to(device)
val_output = inference(model, val_input)
val_output = post_trans(val_output[0])
prediction_table = log_predictions_into_tables(
sample_image=sample["image"].cpu().numpy(),
sample_label=sample["label"].cpu().numpy(),
predicted_label=val_output.cpu().numpy(),
data_idx=data_idx,
split="validation",
table=prediction_table,
)
wandb.log({"Predictions/Tumor-Segmentation-Data": prediction_table})
# experiment を終了する
wandb.finish()
インタラクティブなセグメンテーション マスク オーバーレイを使用して、各クラスの 予測 されたセグメンテーション マスク と 正解 ラベルを分析および比較します。
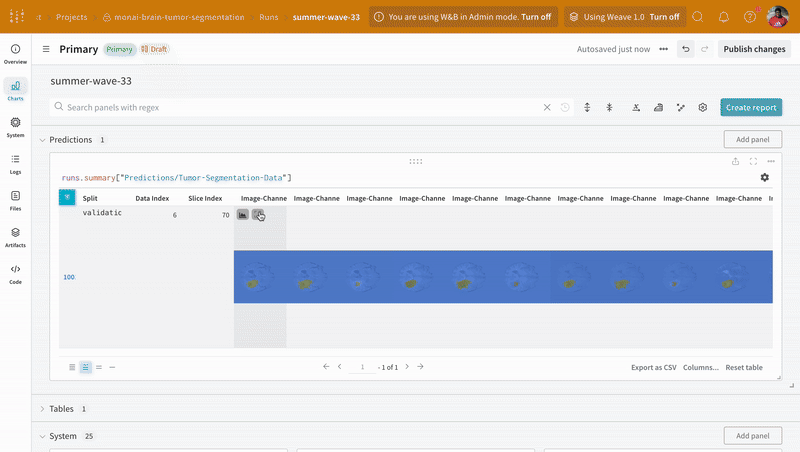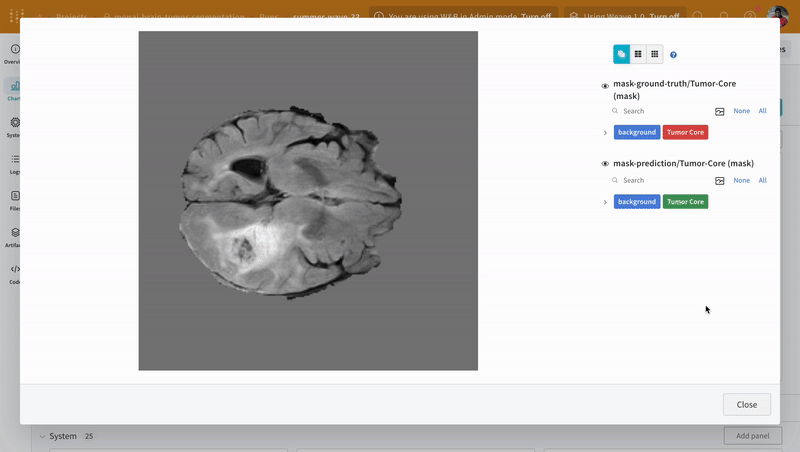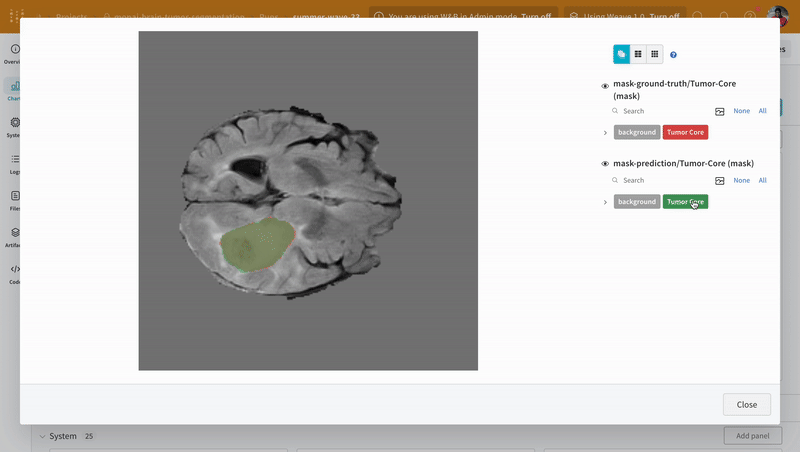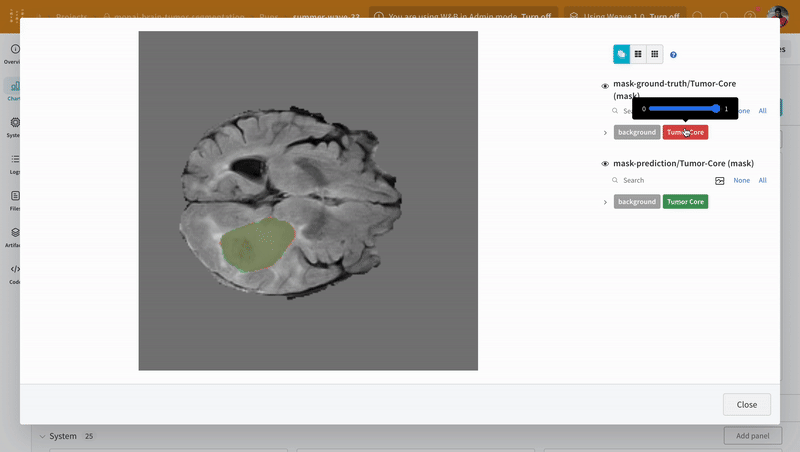 |
| W&B での 予測 と 正解 の 可視化 の例。 |
謝辞とその他のリソース
6.7 - Keras
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、および プロジェクト コラボレーションを行います。
この Colab ノートブック では、WandbMetricsLogger コールバック を紹介します。この コールバック を実験管理に使用します。これは、トレーニング および バリデーション の メトリクス を、システム メトリクス とともに Weights and Biases に ログ します。
セットアップとインストール
まず、Weights and Biases の最新 バージョン をインストールしましょう。次に、この Colab インスタンスを認証して W&B を使用します。
import os
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow_datasets as tfds
# Weights and Biases 関連のインポート
import wandb
from wandb.integration.keras import WandbMetricsLogger
W&B を初めて使用する場合、または ログイン していない場合は、wandb.login() の実行後に表示されるリンクからサインアップ/ログイン ページに移動できます。無料アカウントへのサインアップは、数回クリックするだけで簡単に行えます。
ハイパーパラメータ
適切な config システムを使用することは、再現性のある 機械学習 において推奨されるベスト プラクティスです。W&B を使用して、すべての 実験 の ハイパーパラメータ を追跡できます。この Colab では、シンプルな Python dict を config システムとして使用します。
configs = dict(
num_classes=10,
shuffle_buffer=1024,
batch_size=64,
image_size=28,
image_channels=1,
earlystopping_patience=3,
learning_rate=1e-3,
epochs=10,
)
データセット
この Colab では、TensorFlow Dataset カタログの CIFAR100 データセット を使用します。TensorFlow/Keras を使用して、シンプルな 画像分類 パイプライン を構築することを目指します。
train_ds, valid_ds = tfds.load("fashion_mnist", split=["train", "test"])
AUTOTUNE = tf.data.AUTOTUNE
def parse_data(example):
# 画像を取得
image = example["image"]
# image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# ラベルを取得
label = example["label"]
label = tf.one_hot(label, depth=configs["num_classes"])
return image, label
def get_dataloader(ds, configs, dataloader_type="train"):
dataloader = ds.map(parse_data, num_parallel_calls=AUTOTUNE)
if dataloader_type == "train":
dataloader = dataloader.shuffle(configs["shuffle_buffer"])
dataloader = dataloader.batch(configs["batch_size"]).prefetch(AUTOTUNE)
return dataloader
trainloader = get_dataloader(train_ds, configs)
validloader = get_dataloader(valid_ds, configs, dataloader_type="valid")
モデル
def get_model(configs):
backbone = tf.keras.applications.mobilenet_v2.MobileNetV2(
weights="imagenet", include_top=False
)
backbone.trainable = False
inputs = layers.Input(
shape=(configs["image_size"], configs["image_size"], configs["image_channels"])
)
resize = layers.Resizing(32, 32)(inputs)
neck = layers.Conv2D(3, (3, 3), padding="same")(resize)
preprocess_input = tf.keras.applications.mobilenet.preprocess_input(neck)
x = backbone(preprocess_input)
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(configs["num_classes"], activation="softmax")(x)
return models.Model(inputs=inputs, outputs=outputs)
tf.keras.backend.clear_session()
model = get_model(configs)
model.summary()
モデル の コンパイル
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=[
"accuracy",
tf.keras.metrics.TopKCategoricalAccuracy(k=5, name="top@5_accuracy"),
],
)
トレーニング
# W&B run を初期化
run = wandb.init(project="intro-keras", config=configs)
# モデル をトレーニング
model.fit(
trainloader,
epochs=configs["epochs"],
validation_data=validloader,
callbacks=[
WandbMetricsLogger(log_freq=10)
], # ここで WandbMetricsLogger を使用していることに注意してください
)
# W&B run を閉じる
run.finish()
6.8 - Keras models
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、および プロジェクト の コラボレーションを行います。
この Colab ノートブック では、WandbModelCheckpoint コールバック について紹介します。この コールバック を使用して、モデル の チェックポイント を Weights & Biases Artifacts に ログ 記録します。
セットアップとインストール
まず、Weights & Biases の最新バージョンをインストールしましょう。次に、この Colab インスタンスを認証して W&B を使用します。
!pip install -qq -U wandb
import os
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow_datasets as tfds
# Weights and Biases 関連のインポート
import wandb
from wandb.integration.keras import WandbMetricsLogger
from wandb.integration.keras import WandbModelCheckpoint
W&B を初めて使用する場合、または ログイン していない場合は、wandb.login() の実行後に表示されるリンクからサインアップ/ログイン ページに移動します。無料アカウント へのサインアップは、数回クリックするだけで簡単に行えます。
ハイパーパラメーター
再現性のある 機械学習 のためには、適切な config システムを使用することが推奨されるベストプラクティスです。W&B を使用して、すべての 実験 の ハイパーパラメーター を追跡できます。この Colab では、単純な Python dict を config システムとして使用します。
configs = dict(
num_classes = 10,
shuffle_buffer = 1024,
batch_size = 64,
image_size = 28,
image_channels = 1,
earlystopping_patience = 3,
learning_rate = 1e-3,
epochs = 10
)
データセット
この Colab では、TensorFlow Dataset カタログの CIFAR100 データセット を使用します。TensorFlow/Keras を使用して、単純な 画像分類 パイプライン を構築することを目指します。
train_ds, valid_ds = tfds.load('fashion_mnist', split=['train', 'test'])
AUTOTUNE = tf.data.AUTOTUNE
def parse_data(example):
# 画像を取得
image = example["image"]
# image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# ラベルを取得
label = example["label"]
label = tf.one_hot(label, depth=configs["num_classes"])
return image, label
def get_dataloader(ds, configs, dataloader_type="train"):
dataloader = ds.map(parse_data, num_parallel_calls=AUTOTUNE)
if dataloader_type=="train":
dataloader = dataloader.shuffle(configs["shuffle_buffer"])
dataloader = (
dataloader
.batch(configs["batch_size"])
.prefetch(AUTOTUNE)
)
return dataloader
trainloader = get_dataloader(train_ds, configs)
validloader = get_dataloader(valid_ds, configs, dataloader_type="valid")
モデル
def get_model(configs):
backbone = tf.keras.applications.mobilenet_v2.MobileNetV2(weights='imagenet', include_top=False)
backbone.trainable = False
inputs = layers.Input(shape=(configs["image_size"], configs["image_size"], configs["image_channels"]))
resize = layers.Resizing(32, 32)(inputs)
neck = layers.Conv2D(3, (3,3), padding="same")(resize)
preprocess_input = tf.keras.applications.mobilenet.preprocess_input(neck)
x = backbone(preprocess_input)
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(configs["num_classes"], activation="softmax")(x)
return models.Model(inputs=inputs, outputs=outputs)
tf.keras.backend.clear_session()
model = get_model(configs)
model.summary()
モデルのコンパイル
model.compile(
optimizer = "adam",
loss = "categorical_crossentropy",
metrics = ["accuracy", tf.keras.metrics.TopKCategoricalAccuracy(k=5, name='top@5_accuracy')]
)
学習
# W&B run を初期化
run = wandb.init(
project = "intro-keras",
config = configs
)
# モデルを学習
model.fit(
trainloader,
epochs = configs["epochs"],
validation_data = validloader,
callbacks = [
WandbMetricsLogger(log_freq=10),
WandbModelCheckpoint(filepath="models/") # ここで WandbModelCheckpoint を使用していることに注意してください
]
)
# W&B run を閉じる
run.finish()
6.9 - Keras tables
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、および プロジェクト コラボレーションを行います。
この Colab ノートブック では、モデルの 予測 の 可視化 および データセット の 可視化に役立つ コールバック を構築するために継承できる抽象 コールバック である WandbEvalCallback を紹介します。
セットアップとインストール
まず、Weights & Biases の最新 バージョン をインストールしましょう。次に、この colab インスタンスを 認証 して W&B を使用します。
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow_datasets as tfds
# Weights and Biases related imports
import wandb
from wandb.integration.keras import WandbMetricsLogger
from wandb.integration.keras import WandbModelCheckpoint
from wandb.integration.keras import WandbEvalCallback
W&B を初めて使用する場合、または ログイン していない場合は、wandb.login() の実行後に表示されるリンクからサインアップ/ログイン ページに移動します。無料アカウント へのサインアップは、数回クリックするだけで簡単に行えます。
ハイパーパラメーター
再現性のある 機械学習 には、適切な config システムを使用することをお勧めします。W&B を使用して、すべての 実験 の ハイパーパラメーター を追跡できます。この colab では、単純な Python の dict を config システムとして使用します。
configs = dict(
num_classes=10,
shuffle_buffer=1024,
batch_size=64,
image_size=28,
image_channels=1,
earlystopping_patience=3,
learning_rate=1e-3,
epochs=10,
)
データセット
この colab では、TensorFlow Dataset カタログの CIFAR100 データセット を使用します。TensorFlow/Keras を使用して、単純な 画像分類 パイプライン を構築することを目指します。
train_ds, valid_ds = tfds.load("fashion_mnist", split=["train", "test"])
AUTOTUNE = tf.data.AUTOTUNE
def parse_data(example):
# Get image
image = example["image"]
# image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# Get label
label = example["label"]
label = tf.one_hot(label, depth=configs["num_classes"])
return image, label
def get_dataloader(ds, configs, dataloader_type="train"):
dataloader = ds.map(parse_data, num_parallel_calls=AUTOTUNE)
if dataloader_type=="train":
dataloader = dataloader.shuffle(configs["shuffle_buffer"])
dataloader = (
dataloader
.batch(configs["batch_size"])
.prefetch(AUTOTUNE)
)
return dataloader
trainloader = get_dataloader(train_ds, configs)
validloader = get_dataloader(valid_ds, configs, dataloader_type="valid")
モデル
def get_model(configs):
backbone = tf.keras.applications.mobilenet_v2.MobileNetV2(
weights="imagenet", include_top=False
)
backbone.trainable = False
inputs = layers.Input(
shape=(configs["image_size"], configs["image_size"], configs["image_channels"])
)
resize = layers.Resizing(32, 32)(inputs)
neck = layers.Conv2D(3, (3, 3), padding="same")(resize)
preprocess_input = tf.keras.applications.mobilenet.preprocess_input(neck)
x = backbone(preprocess_input)
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(configs["num_classes"], activation="softmax")(x)
return models.Model(inputs=inputs, outputs=outputs)
tf.keras.backend.clear_session()
model = get_model(configs)
model.summary()
モデルのコンパイル
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=[
"accuracy",
tf.keras.metrics.TopKCategoricalAccuracy(k=5, name="top@5_accuracy"),
],
)
WandbEvalCallback
WandbEvalCallback は、主にモデルの 予測 の 可視化、次に データセット の 可視化のための Keras コールバック を構築するための抽象基本クラスです。
これは、 データセット とタスクに依存しない抽象 コールバック です。これを使用するには、この基本 コールバック クラスから継承し、add_ground_truth および add_model_prediction メソッド を実装します。
WandbEvalCallback は、次のことに役立つ メソッド を提供する ユーティリティ クラスです。
- データ と 予測 の
wandb.Table インスタンスを作成する
- データ と 予測 の テーブル を
wandb.Artifact として ログ に記録する
on_train_begin で データテーブル を ログ に記録するon_epoch_end で 予測 テーブル を ログ に記録する
例として、以下に 画像分類 タスク の WandbClfEvalCallback を実装しました。この コールバック の例:
- 検証 データ (
data_table ) を W&B に ログ 記録します。
- 推論 を実行し、すべての エポック の最後に 予測 (
pred_table ) を W&B に ログ 記録します。
メモリフットプリントを削減する方法
on_train_begin メソッド が呼び出されると、data_table を W&B に ログ 記録します。W&B Artifact としてアップロードされると、data_table_ref クラス変数を使用して アクセス できるこの テーブル への参照を取得します。data_table_ref は、self.data_table_ref[idx][n] のように インデックス を付けることができる 2D リストです。ここで、idx は行番号、n は列番号です。以下の例で使用方法を見てみましょう。
class WandbClfEvalCallback(WandbEvalCallback):
def __init__(
self, validloader, data_table_columns, pred_table_columns, num_samples=100
):
super().__init__(data_table_columns, pred_table_columns)
self.val_data = validloader.unbatch().take(num_samples)
def add_ground_truth(self, logs=None):
for idx, (image, label) in enumerate(self.val_data):
self.data_table.add_data(idx, wandb.Image(image), np.argmax(label, axis=-1))
def add_model_predictions(self, epoch, logs=None):
# Get predictions
preds = self._inference()
table_idxs = self.data_table_ref.get_index()
for idx in table_idxs:
pred = preds[idx]
self.pred_table.add_data(
epoch,
self.data_table_ref.data[idx][0],
self.data_table_ref.data[idx][1],
self.data_table_ref.data[idx][2],
pred,
)
def _inference(self):
preds = []
for image, label in self.val_data:
pred = self.model(tf.expand_dims(image, axis=0))
argmax_pred = tf.argmax(pred, axis=-1).numpy()[0]
preds.append(argmax_pred)
return preds
訓練
# Initialize a W&B run
run = wandb.init(project="intro-keras", config=configs)
# Train your model
model.fit(
trainloader,
epochs=configs["epochs"],
validation_data=validloader,
callbacks=[
WandbMetricsLogger(log_freq=10),
WandbClfEvalCallback(
validloader,
data_table_columns=["idx", "image", "ground_truth"],
pred_table_columns=["epoch", "idx", "image", "ground_truth", "prediction"],
), # Notice the use of WandbEvalCallback here
],
)
# Close the W&B run
run.finish()
6.10 - XGBoost Sweeps
Weights & Biases を使用して、 機械学習 の 実験管理 、 データセット の バージョン管理 、 プロジェクト の コラボレーションを行いましょう。
ツリーベースの モデル から最高のパフォーマンスを引き出すには、適切な ハイパーパラメーター を選択する必要があります。
early_stopping_rounds はいくつにするべきでしょうか? ツリーの max_depth はどのくらいにすべきでしょうか?
高次元の ハイパーパラメーター 空間を検索して、最もパフォーマンスの高い モデル を見つけるのは、非常に扱いにくくなる可能性があります。
ハイパーパラメーター Sweeps は、 モデル の バトルロイヤル を実施し、勝者を決定するための、組織的かつ効率的な方法を提供します。
これは、最適な値を見つけるために、 ハイパーパラメーター 値の組み合わせを自動的に検索することによって実現されます。
この チュートリアル では、Weights & Biases を使用して、XGBoost モデル で高度な ハイパーパラメーター Sweeps を 3 つの簡単なステップで実行する方法を説明します。
まず、以下の プロット を確認してください。
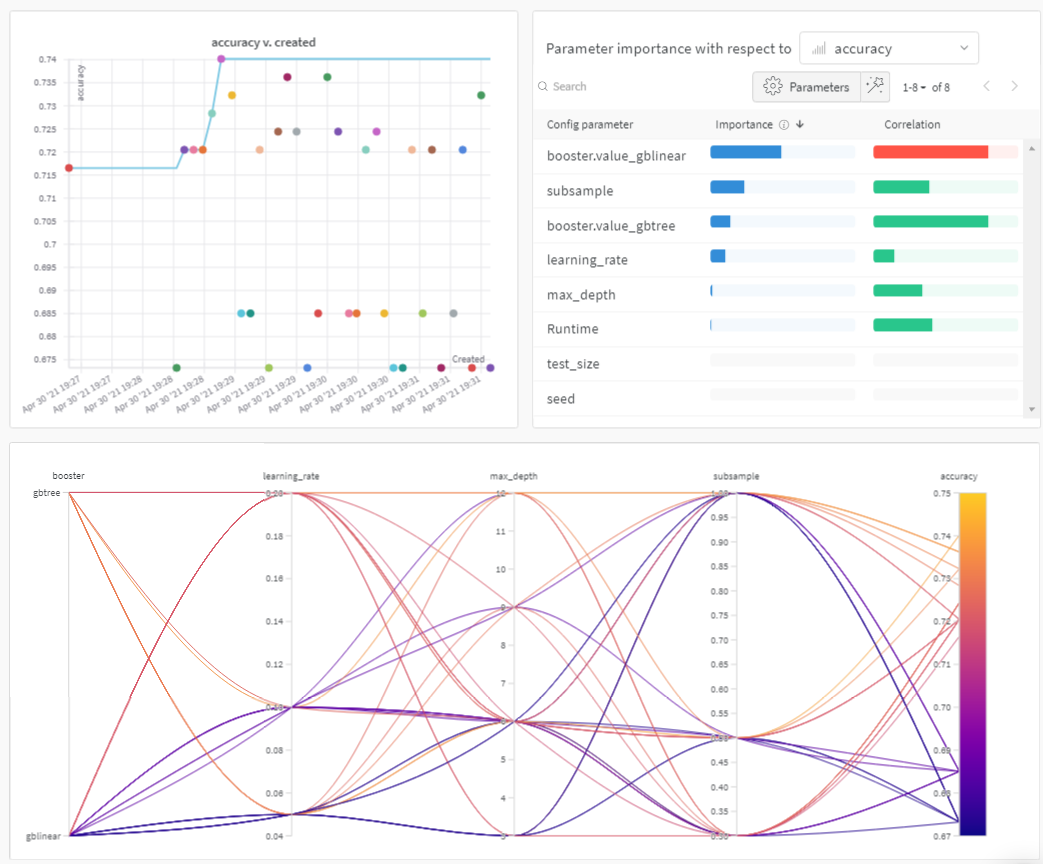
Sweeps: 概要
Weights & Biases で ハイパーパラメーター sweep を実行するのは非常に簡単です。簡単な 3 つのステップがあります。
-
sweep の定義: sweep を指定する 辞書 のような オブジェクト を作成してこれを行います。検索する パラメータ ー、使用する検索戦略、最適化する メトリクス を指定します。
-
sweep の初期化: 1 行の コード で sweep を初期化し、sweep 設定 の 辞書 を渡します。
sweep_id = wandb.sweep(sweep_config)
-
sweep agent の実行: これも 1 行の コード で実行できます。wandb.agent() を呼び出し、sweep_id と モデル の アーキテクチャー を定義して トレーニング する 関数 を渡します。
wandb.agent(sweep_id, function=train)
以上が ハイパーパラメーター sweep の実行に必要なすべてです。
以下の ノートブック では、これら 3 つのステップについてさらに詳しく説明します。
この ノートブック をフォークして、 パラメータ ーを調整したり、独自の データセット で モデル を試したりすることを強くお勧めします。
リソース
import wandb
wandb.login()
1. Sweep を定義する
Weights & Biases の Sweeps は、わずか数行の コード で、必要な方法で Sweeps を正確に 設定 するための強力な レバー を提供します。sweep の 設定 は、 辞書 または YAML ファイルとして定義できます。
一緒にいくつか見ていきましょう。
- メトリクス: これは、Sweeps が最適化しようとしている メトリクス です。メトリクス は、
name(この メトリクス は トレーニング スクリプト によって ログ に記録される必要があります)と goal(maximize または minimize)を受け取ることができます。
- 検索戦略:
"method" キーを使用して指定します。Sweeps では、いくつかの異なる検索戦略をサポートしています。
- グリッド検索: ハイパーパラメーター 値のすべての組み合わせを反復処理します。
- ランダム検索: ハイパーパラメーター 値のランダムに選択された組み合わせを反復処理します。
- ベイズ探索: ハイパーパラメーター を メトリクス スコア の確率にマッピングする確率 モデル を作成し、 メトリクス を改善する可能性が高い パラメータ ーを選択します。 ベイズ最適化 の目的は、 ハイパーパラメーター 値の選択により多くの時間を費やすことですが、そうすることで、試す ハイパーパラメーター 値を少なくすることです。
- パラメータ ー: ハイパーパラメーター 名、 離散値 、範囲、または各反復でその値を抽出する 分布 を含む 辞書 。
詳細については、すべての sweep 設定 オプション のリストを参照してください。
sweep_config = {
"method": "random", # try grid or random
"metric": {
"name": "accuracy",
"goal": "maximize"
},
"parameters": {
"booster": {
"values": ["gbtree","gblinear"]
},
"max_depth": {
"values": [3, 6, 9, 12]
},
"learning_rate": {
"values": [0.1, 0.05, 0.2]
},
"subsample": {
"values": [1, 0.5, 0.3]
}
}
}
2. Sweep の初期化
wandb.sweep を呼び出すと、Sweep Controller が起動します。これは、クエリを実行するすべての ユーザー に parameters の 設定 を提供し、wandb ログ を介して metrics のパフォーマンスが返されることを期待する集中化された プロセス です。
sweep_id = wandb.sweep(sweep_config, project="XGBoost-sweeps")
トレーニング プロセス を定義する
sweep を実行する前に、 モデル を作成して トレーニング する 関数 を定義する必要があります。これは、 ハイパーパラメーター 値を受け取り、 メトリクス を出力する 関数 です。
また、wandb を スクリプト に統合する必要があります。
主な コンポーネント は 3 つあります。
wandb.init(): 新しい W&B run を初期化します。各 run は、 トレーニング スクリプト の単一の実行です。wandb.config: すべての ハイパーパラメーター を 設定 オブジェクト に保存します。これにより、アプリを使用して、 ハイパーパラメーター 値で run をソートして比較できます。wandb.log(): メトリクス と、画像、ビデオ、オーディオ ファイル 、HTML、 プロット 、 ポイント クラウド などの カスタム オブジェクト を ログ に記録します。
また、 データ をダウンロードする必要があります。
!wget https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv
# XGBoost model for Pima Indians dataset
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
def train():
config_defaults = {
"booster": "gbtree",
"max_depth": 3,
"learning_rate": 0.1,
"subsample": 1,
"seed": 117,
"test_size": 0.33,
}
wandb.init(config=config_defaults) # defaults are over-ridden during the sweep
config = wandb.config
# load data and split into predictors and targets
dataset = loadtxt("pima-indians-diabetes.data.csv", delimiter=",")
X, Y = dataset[:, :8], dataset[:, 8]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size=config.test_size,
random_state=config.seed)
# fit model on train
model = XGBClassifier(booster=config.booster, max_depth=config.max_depth,
learning_rate=config.learning_rate, subsample=config.subsample)
model.fit(X_train, y_train)
# make predictions on test
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy:.0%}")
wandb.log({"accuracy": accuracy})
3. agent で Sweep を実行する
次に、wandb.agent を呼び出して sweep を起動します。
W&B に ログイン しているすべての マシン で wandb.agent を呼び出すことができます。
sweep_id、- データセット と
train 関数
があり、その マシン が sweep に参加します。
注: random sweep は、デフォルトで永久に実行され、
牛が家に帰るまで、またはアプリ UI から sweep をオフにするまで、新しい パラメータ ーの組み合わせを試します。
agent が完了する run の合計 count を指定することで、これを防ぐことができます。
wandb.agent(sweep_id, train, count=25)
結果を 可視化 する
sweep が完了したので、結果を見てみましょう。
Weights & Biases は、多くの役立つ プロット を自動的に生成します。
並列座標 プロット
この プロット は、 ハイパーパラメーター 値を モデル メトリクス にマッピングします。これは、最高の モデル パフォーマンスにつながった ハイパーパラメーター の組み合わせを絞り込むのに役立ちます。
この プロット は、学習者としてツリーを使用すると、単純な線形 モデル を学習者として使用するよりもわずかに、
しかし驚くほどではありませんが、
パフォーマンスが向上することを示しているようです。
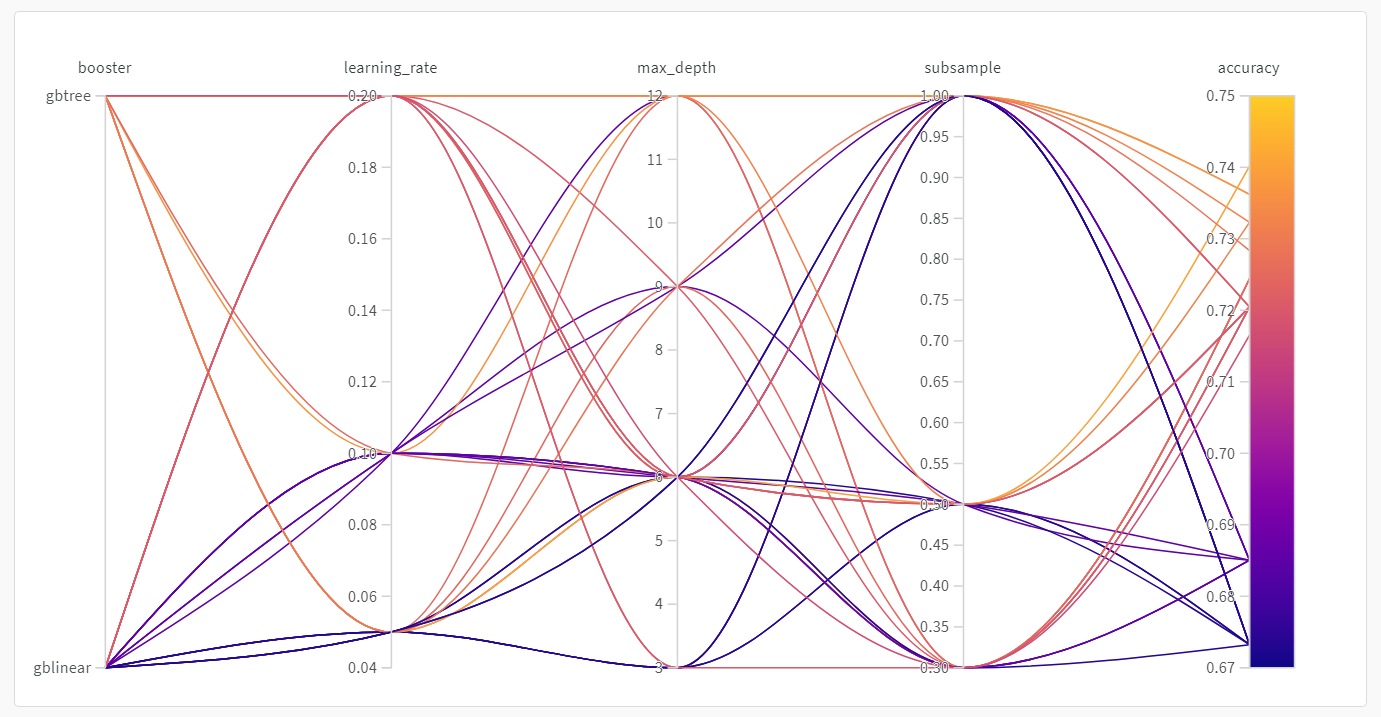
ハイパーパラメーター の インポータンスプロット
ハイパーパラメーター の インポータンスプロット は、どの ハイパーパラメーター 値が メトリクス に最も大きな影響を与えたかを示します。
線形予測子として扱い、相関関係と特徴量の重要度(結果に対して ランダムフォレスト を トレーニング した後)の両方を報告し、どの パラメータ ーが最大の影響を与えたか、
そしてその影響がプラスかマイナスかを確認できるようにします。
この チャート を読むと、上記の並列座標 チャート で気付いた傾向が定量的に確認できます。 検証精度 への最大の影響は、学習者の選択によるものであり、gblinear 学習者は一般的に gbtree 学習者よりも劣っていました。
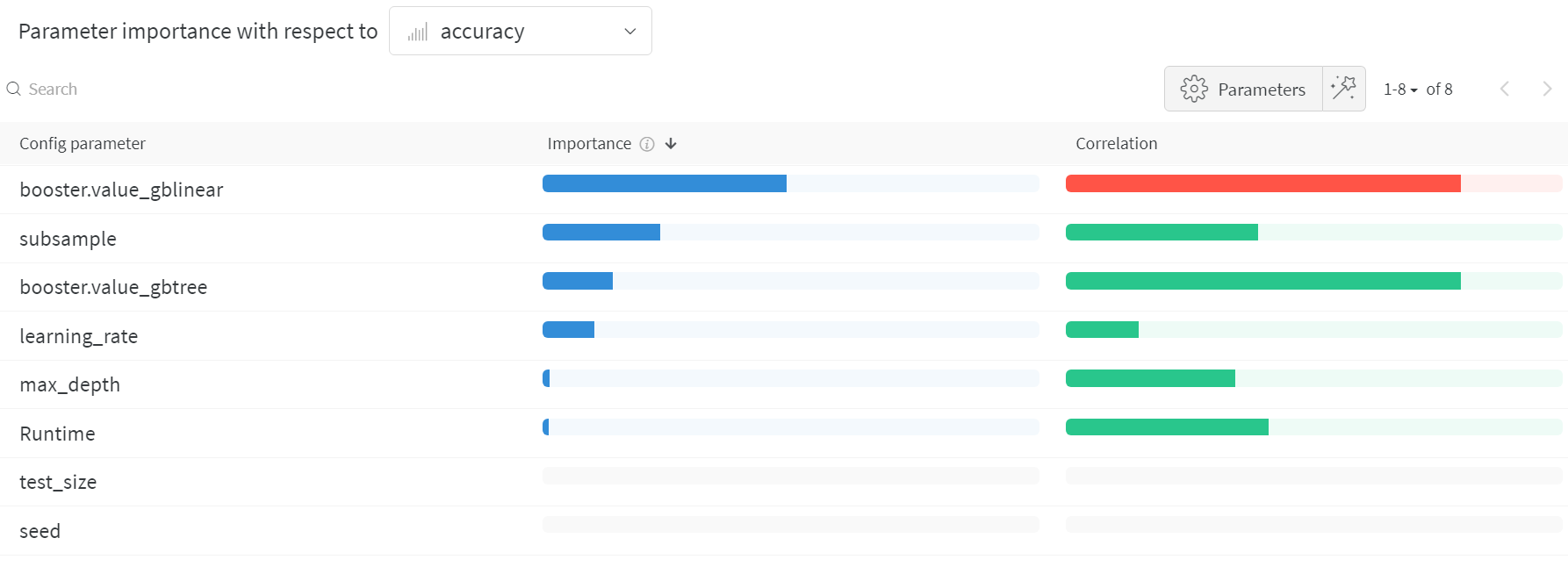
これらの 可視化 は、最も重要な パラメータ ー(および値の範囲)に焦点を当てることで、時間とリソースを節約し、高価な ハイパーパラメーター 最適化 を実行するのに役立ち、それによってさらに調査する価値があります。
7 - Weave and Models integration demo
このノートブックでは、W&B Weave と W&B Models を組み合わせて使用する方法を紹介します。具体的には、この例では 2 つの異なる Teams を考慮します。
- The Model Team: モデル構築 Team は新しいチャット Model (Llama 3.2) をファインチューンし、W&B Models を使用してレジストリに保存します。
- The App Team: アプリ開発 Team はチャット Model を取得して、W&B Weave を使用して新しい RAG チャットボットを作成および評価します。
W&B Models と W&B Weave の両方のパブリック Workspace はこちらにあります。
このワークフローは、次のステップで構成されています。
- W&B Weave で RAG アプリの コードをインストルメント化する
- LLM (Llama 3.2 など。他の LLM に置き換えることもできます) をファインチューンし、W&B Models で追跡する
- ファインチューンされた model を W&B Registry に記録する
- 新しいファインチューンされた model で RAG アプリを実装し、W&B Weave でアプリを評価する
- 結果に満足したら、更新された Rag アプリへの参照を W&B Registry に保存する
注:
以下で参照されている RagModel は、完全な RAG アプリと見なすことができるトップレベルの weave.Model です。これには、ChatModel、ベクター データベース、およびプロンプトが含まれています。ChatModel は別の weave.Model でもあり、W&B Registry から Artifact をダウンロードする コードが含まれており、RagModel の一部として他のチャット model をサポートするように変更できます。詳細については、Weave 上の完全な modelを参照してください。
1. セットアップ
まず、weave と wandb をインストールし、APIキー でログインします。APIキー は https://wandb.ai/settings で作成および表示できます。
import wandb
import weave
import pandas as pd
PROJECT = "weave-cookboook-demo"
ENTITY = "wandb-smle"
wandb.login()
weave.init(ENTITY + "/" + PROJECT)
2. Artifact に基づいて ChatModel を作成する
Registry からファインチューンされたチャット model を取得し、そこから weave.Model を作成して、次のステップで RagModelに直接プラグインします。既存の ChatModel と同じ パラメータ を使用しますが、init と predict のみが変更されます。
pip install unsloth
pip uninstall unsloth -y && pip install --upgrade --no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
モデル Team は、unsloth ライブラリを使用してさまざまな Llama-3.2 model をファインチューンし、高速化しました。したがって、Registry からダウンロードした model をロードするには、アダプターを備えた特別な unsloth.FastLanguageModel または peft.AutoPeftModelForCausalLM model を使用します。「Use」タブからロード コードをコピーして、model_post_init に貼り付けます。
import weave
from pydantic import PrivateAttr
from typing import Any, List, Dict, Optional
from unsloth import FastLanguageModel
import torch
class UnslothLoRAChatModel(weave.Model):
"""
model 名だけでなく、より多くの パラメータ を保存および バージョン 管理するための追加の ChatModel クラスを定義します。
これにより、特定の パラメータ でのファインチューニングが可能になります。
"""
chat_model: str
cm_temperature: float
cm_max_new_tokens: int
cm_quantize: bool
inference_batch_size: int
dtype: Any
device: str
_model: Any = PrivateAttr()
_tokenizer: Any = PrivateAttr()
def model_post_init(self, __context):
# レジストリの「Use」タブからこれを貼り付けます
run = wandb.init(project=PROJECT, job_type="model_download")
artifact = run.use_artifact(f"{self.chat_model}")
model_path = artifact.download()
# unsloth バージョン (ネイティブの 2 倍高速な推論を有効にする)
self._model, self._tokenizer = FastLanguageModel.from_pretrained(
model_name=model_path,
max_seq_length=self.cm_max_new_tokens,
dtype=self.dtype,
load_in_4bit=self.cm_quantize,
)
FastLanguageModel.for_inference(self._model)
@weave.op()
async def predict(self, query: List[str]) -> dict:
# add_generation_prompt = true - 生成用に追加する必要があります
input_ids = self._tokenizer.apply_chat_template(
query,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
).to("cuda")
output_ids = self._model.generate(
input_ids=input_ids,
max_new_tokens=64,
use_cache=True,
temperature=1.5,
min_p=0.1,
)
decoded_outputs = self._tokenizer.batch_decode(
output_ids[0][input_ids.shape[1] :], skip_special_tokens=True
)
return "".join(decoded_outputs).strip()
次に、レジストリからの特定のリンクを使用して新しい model を作成します。
MODEL_REG_URL = "wandb32/wandb-registry-RAG Chat Models/Finetuned Llama-3.2:v3"
max_seq_length = 2048
dtype = None
load_in_4bit = True
new_chat_model = UnslothLoRAChatModel(
name="UnslothLoRAChatModelRag",
chat_model=MODEL_REG_URL,
cm_temperature=1.0,
cm_max_new_tokens=max_seq_length,
cm_quantize=load_in_4bit,
inference_batch_size=max_seq_length,
dtype=dtype,
device="auto",
)
そして最後に、評価を非同期的に実行します。
await new_chat_model.predict(
[{"role": "user", "content": "What is the capital of Germany?"}]
)
3. 新しい ChatModel バージョンを RagModel に統合する
ファインチューンされたチャット model から RAG アプリを構築すると、特に会話型 AI システムのパフォーマンスと汎用性を強化する上で、いくつかの利点が得られます。
次に、既存の Weave プロジェクトから RagModel を取得し (以下の画像に示すように、[use] タブから現在の RagModel の Weave 参照を取得できます)、ChatModel を新しいものに交換します。他の コンポーネント (VDB、プロンプトなど) を変更または再作成する必要はありません。

pip install litellm faiss-gpu
RagModel = weave.ref(
"weave:///wandb-smle/weave-cookboook-demo/object/RagModel:cqRaGKcxutBWXyM0fCGTR1Yk2mISLsNari4wlGTwERo"
).get()
# MAGIC: chat_model を交換して新しい バージョン を公開します (他の RAG コンポーネントを気にする必要はありません)
RagModel.chat_model = new_chat_model
# 最初に新しい バージョン を公開して、予測中に参照されるようにします
PUB_REFERENCE = weave.publish(RagModel, "RagModel")
await RagModel.predict("When was the first conference on climate change?")
4. 既存の Models run に接続する新しい weave.Evaluation を実行する
最後に、既存の weave.Evaluation で新しい RagModel を評価します。統合をできるだけ簡単にするために、次の変更を含めます。
Models の観点から:
- Registry から model を取得すると、チャット model の E2E リネージ の一部である新しい
wandb.run が作成されます
- Trace ID (現在の eval ID を使用) を run config に追加して、モデル Team がリンクをクリックして対応する Weave ページに移動できるようにします
Weave の観点から:
- Artifact / Registry リンクを
ChatModel (つまり RagModel) への入力として保存します
run.id を weave.attributes を使用して トレース の追加の列として保存します
# MAGIC: 評価 データセット とスコアラーを使用して評価を取得し、それらを使用します
WEAVE_EVAL = "weave:///wandb-smle/weave-cookboook-demo/object/climate_rag_eval:ntRX6qn3Tx6w3UEVZXdhIh1BWGh7uXcQpOQnIuvnSgo"
climate_rag_eval = weave.ref(WEAVE_EVAL).get()
with weave.attributes({"wandb-run-id": wandb.run.id}):
# Models に eval トレース を保存するために、結果と呼び出しの両方を取得するために .call 属性を使用します
summary, call = await climate_rag_eval.evaluate.call(climate_rag_eval, ` RagModel `)
5. 新しい RAG model を Registry に保存する
新しい RAG Model を効果的に共有するために、Weave バージョン を エイリアス として追加して、参照 Artifact として Registry にプッシュします。
MODELS_OBJECT_VERSION = PUB_REFERENCE.digest # weave オブジェクト バージョン
MODELS_OBJECT_NAME = PUB_REFERENCE.name # weave オブジェクト名
models_url = f"https://wandb.ai/{ENTITY}/{PROJECT}/weave/objects/{MODELS_OBJECT_NAME}/versions/{MODELS_OBJECT_VERSION}"
models_link = (
f"weave:///{ENTITY}/{PROJECT}/object/{MODELS_OBJECT_NAME}:{MODELS_OBJECT_VERSION}"
)
with wandb.init(project=PROJECT, entity=ENTITY) as run:
# 新しい Artifact を作成します
artifact_model = wandb.Artifact(
name="RagModel",
type="model",
description="Weave の RagModel からの Models リンク",
metadata={"url": models_url},
)
artifact_model.add_reference(models_link, name="model", checksum=False)
# 新しい Artifact を ログ に記録します
run.log_artifact(artifact_model, aliases=[MODELS_OBJECT_VERSION])
# Registry へのリンク
run.link_artifact(
artifact_model, target_path="wandb32/wandb-registry-RAG Models/RAG Model"
)