Hugging Face
2 minute read
 Hugging Face モデルのパフォーマンスを、シームレスな W&B インテグレーションで素早く可視化しましょう。
Hugging Face モデルのパフォーマンスを、シームレスな W&B インテグレーションで素早く可視化しましょう。
モデル間で、ハイパーパラメーター、出力メトリクス、 GPU 使用率などのシステム統計を比較します。
W&B を使うべき理由

- 統合ダッシュボード : すべてのモデルメトリクスと予測の一元的なリポジトリ
- 軽量 : Hugging Face と統合するために必要なコード変更はありません
- アクセス可能 : 個人およびアカデミックチームは無料
- セキュア : デフォルトでは、すべての Projects がプライベートです
- 信頼性 : OpenAI、トヨタ、Lyft などの機械学習チームで使用されています
W&B は、機械学習モデルの GitHub のようなものだと考えてください。機械学習の Experiments をプライベートなホストされたダッシュボードに保存します。スクリプトをどこで実行していても、すべてのバージョンのモデルが保存されるので、安心して迅速に Experiments を行うことができます。
W&B の軽量インテグレーションは、あらゆる Python スクリプトで動作し、モデルのトラッキングと可視化を開始するには、無料の W&B アカウントにサインアップするだけです。
Hugging Face Transformers リポジトリでは、 Trainer に、トレーニングおよび評価メトリクスを各ロギングステップで W&B に自動的にログ記録するように設定しました。
インテグレーションの仕組みの詳細はこちら: Hugging Face + W&B Report。
インストール、インポート、ログイン
Hugging Face と Weights & Biases のライブラリ、およびこのチュートリアルの GLUE データセットとトレーニングスクリプトをインストールします。
- Hugging Face Transformers: 自然言語モデルとデータセット
- Weights & Biases: 実験管理と可視化
- GLUE dataset: 言語理解ベンチマークデータセット
- GLUE script: シーケンス分類用のモデルトレーニングスクリプト
!pip install datasets wandb evaluate accelerate -qU
!wget https://raw.githubusercontent.com/huggingface/transformers/refs/heads/main/examples/pytorch/text-classification/run_glue.py
# run_glue.py スクリプトには transformers dev が必要です
!pip install -q git+https://github.com/huggingface/transformers
続行する前に、無料アカウントにサインアップ してください。
APIキーを入力
サインアップしたら、次のセルを実行し、リンクをクリックして APIキーを取得し、この notebook を認証します。
import wandb
wandb.login()
オプションで、環境変数を設定して W&B のロギングをカスタマイズできます。詳細については、ドキュメント を参照してください。
# オプション: 勾配とパラメータの両方をログに記録する
%env WANDB_WATCH=all
モデルのトレーニング
次に、ダウンロードしたトレーニングスクリプト run_glue.py を呼び出して、トレーニングが自動的に Weights & Biases ダッシュボードに追跡されることを確認します。このスクリプトは、 Microsoft Research Paraphrase Corpus (意味的に同等かどうかを示す人間の注釈が付いた文のペア) で BERT をファインチューンします。
%env WANDB_PROJECT=huggingface-demo
%env TASK_NAME=MRPC
!python run_glue.py \
--model_name_or_path bert-base-uncased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 256 \
--per_device_train_batch_size 32 \
--learning_rate 2e-4 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir \
--logging_steps 50
ダッシュボードで結果を可視化
上記に出力されたリンクをクリックするか、wandb.ai にアクセスして、結果がライブでストリーミングされるのを確認します。ブラウザで run を表示するためのリンクは、すべての依存関係がロードされた後に表示されます。次の出力を探してください: “wandb: 🚀 View run at [URL to your unique run]”
モデルのパフォーマンスを可視化 多数の Experiments を見渡し、興味深い学びをズームインし、高次元のデータを可視化するのは簡単です。
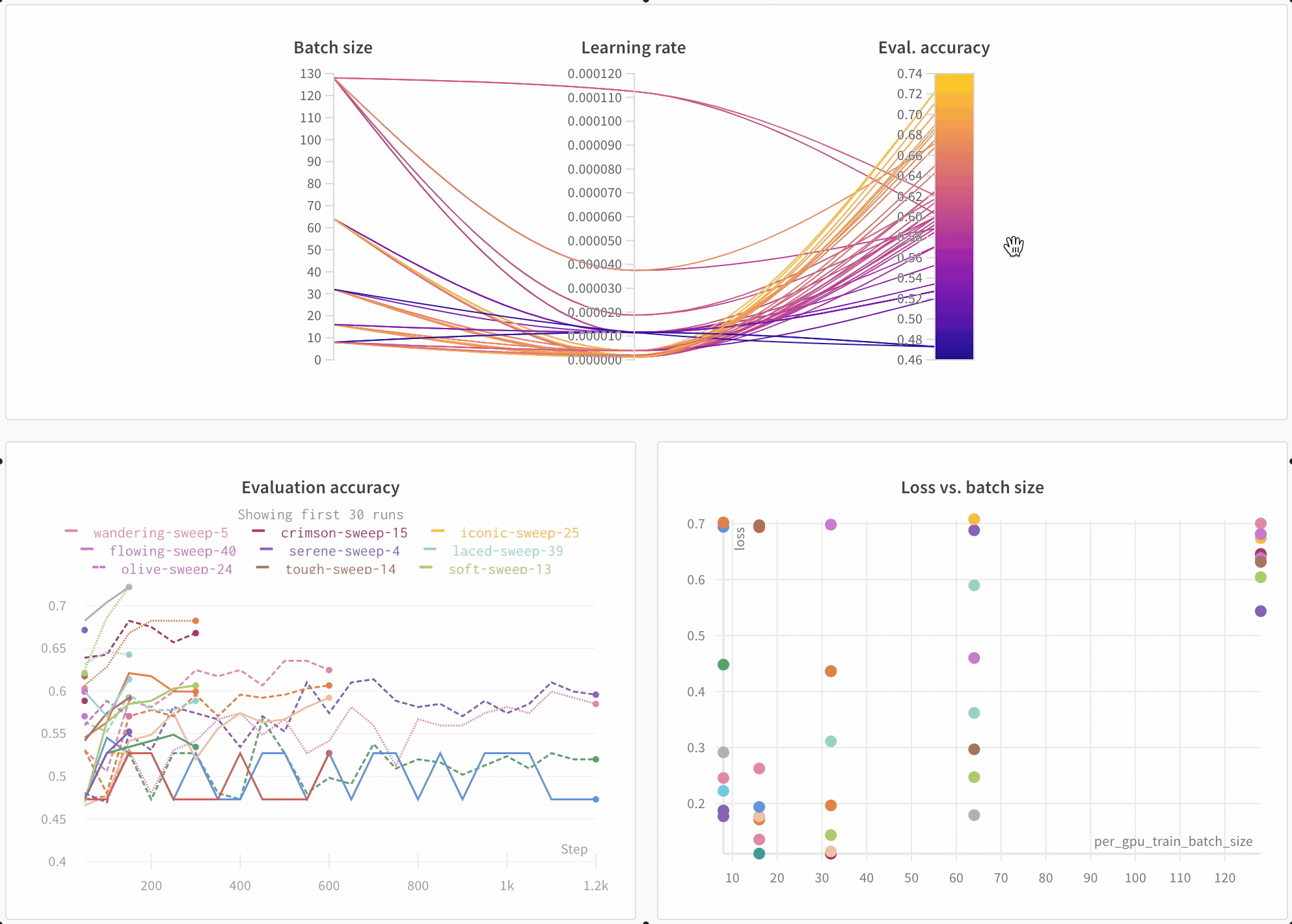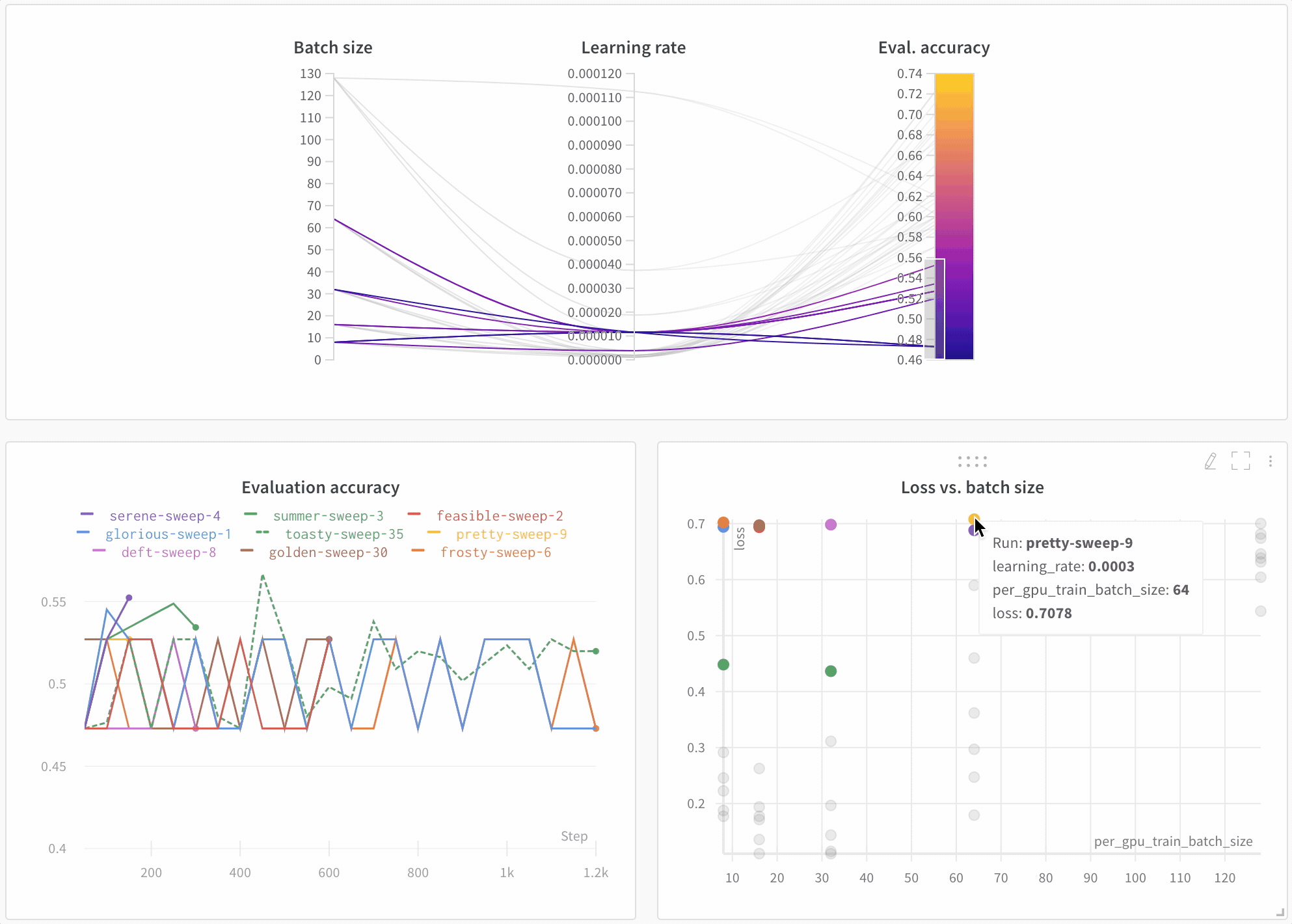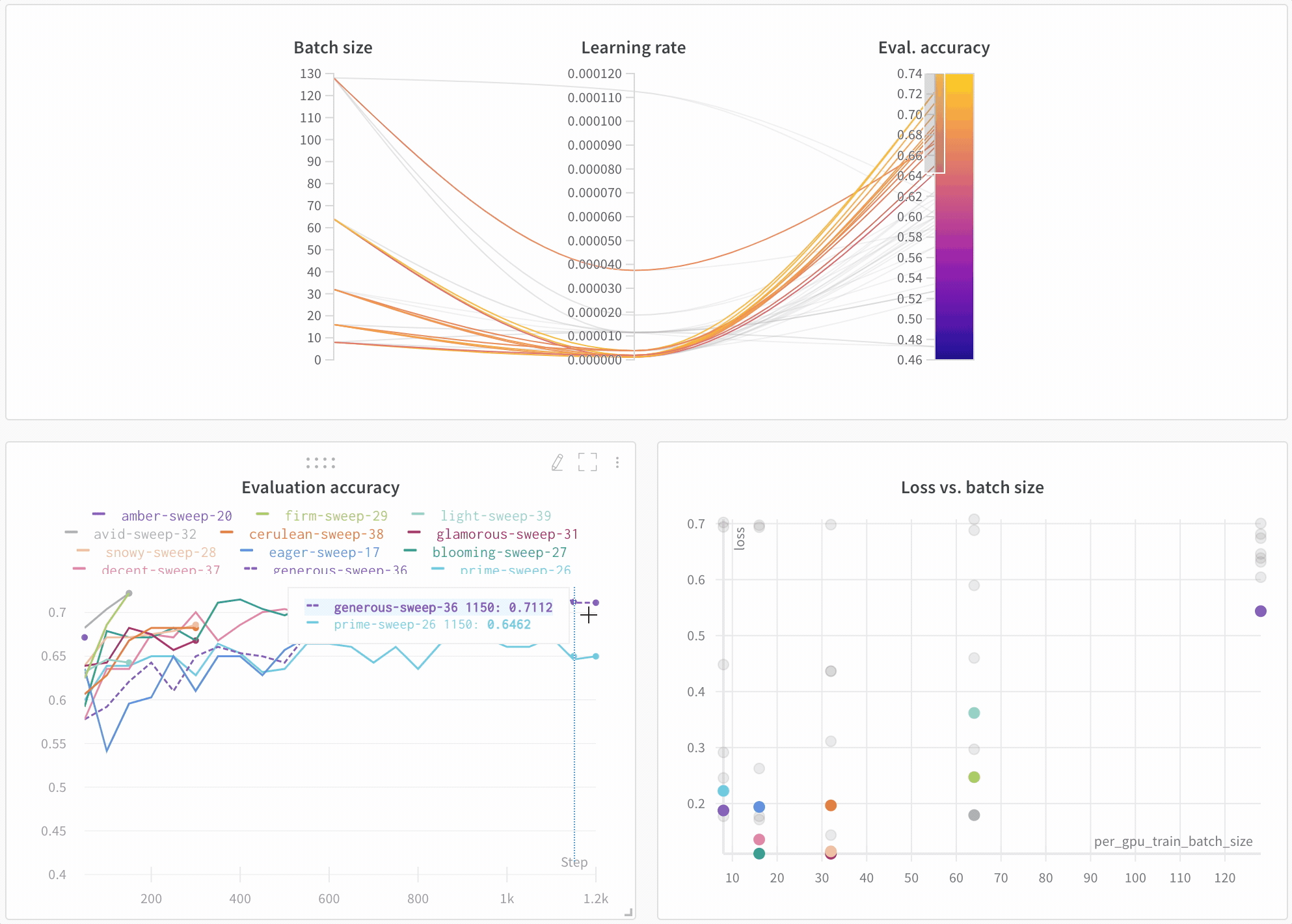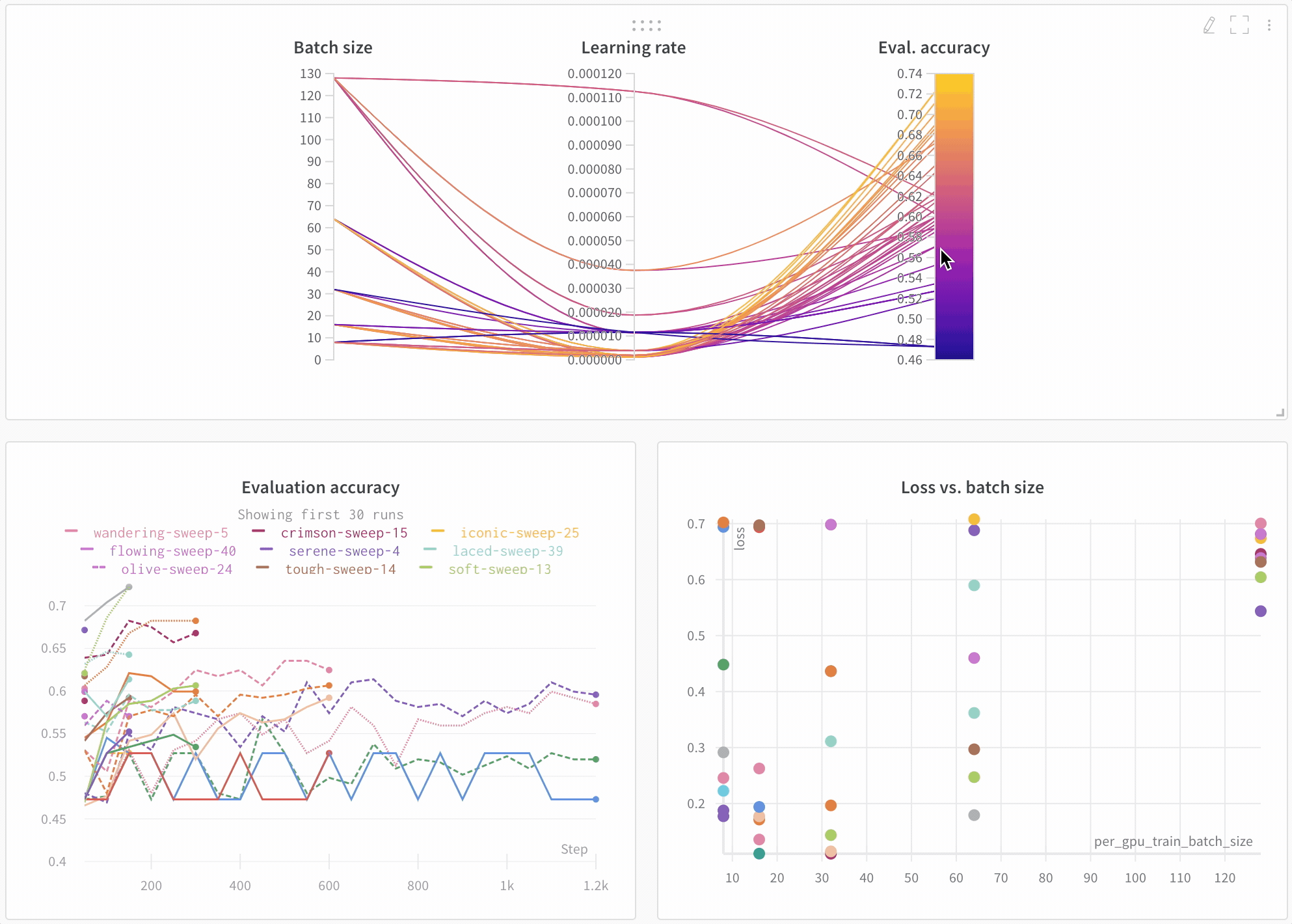
アーキテクチャーの比較 BERT vs DistilBERT を比較した例を次に示します。自動ラインプロットの可視化により、トレーニングを通じて評価精度に異なるアーキテクチャーがどのように影響するかを簡単に確認できます。
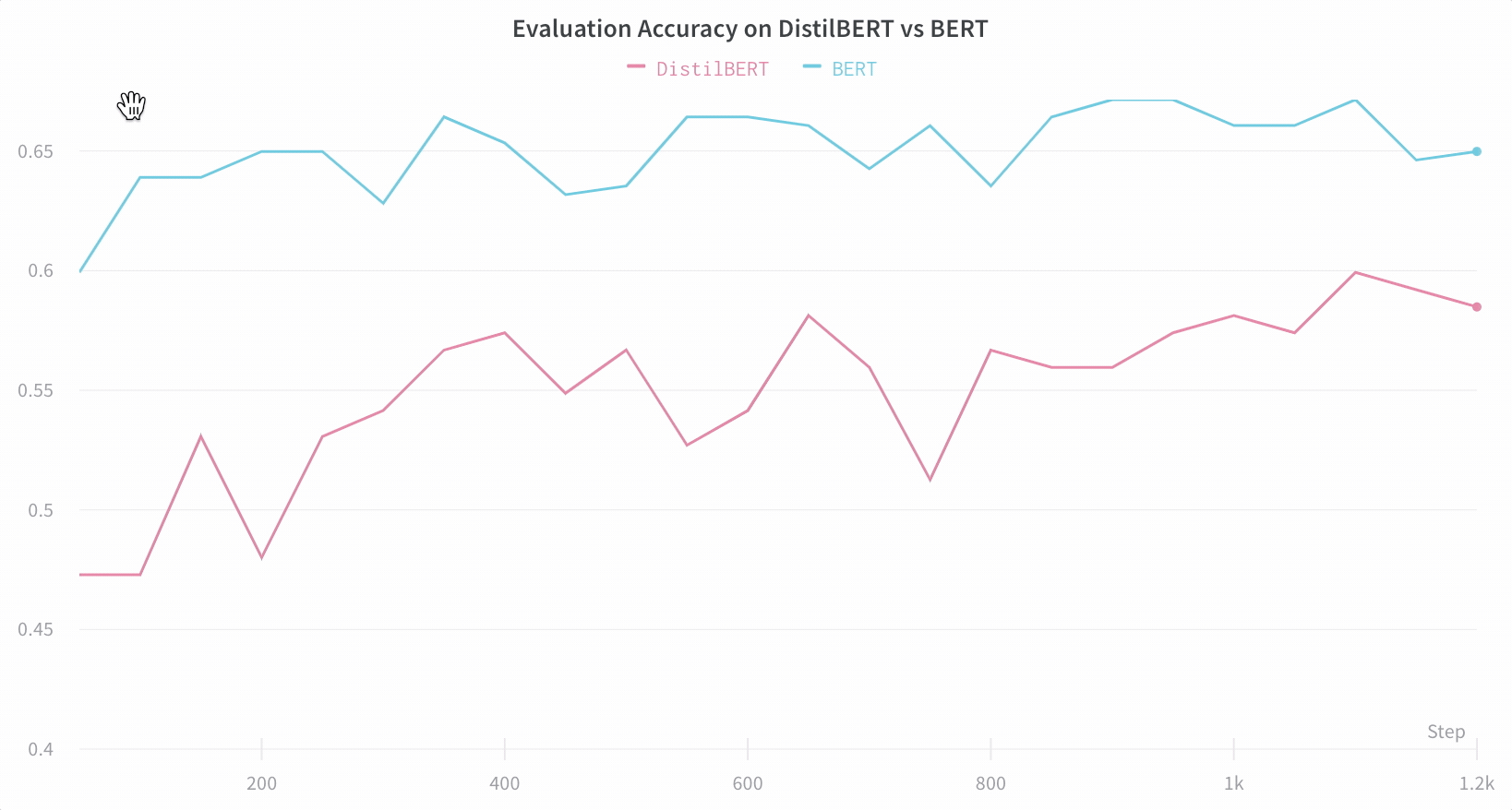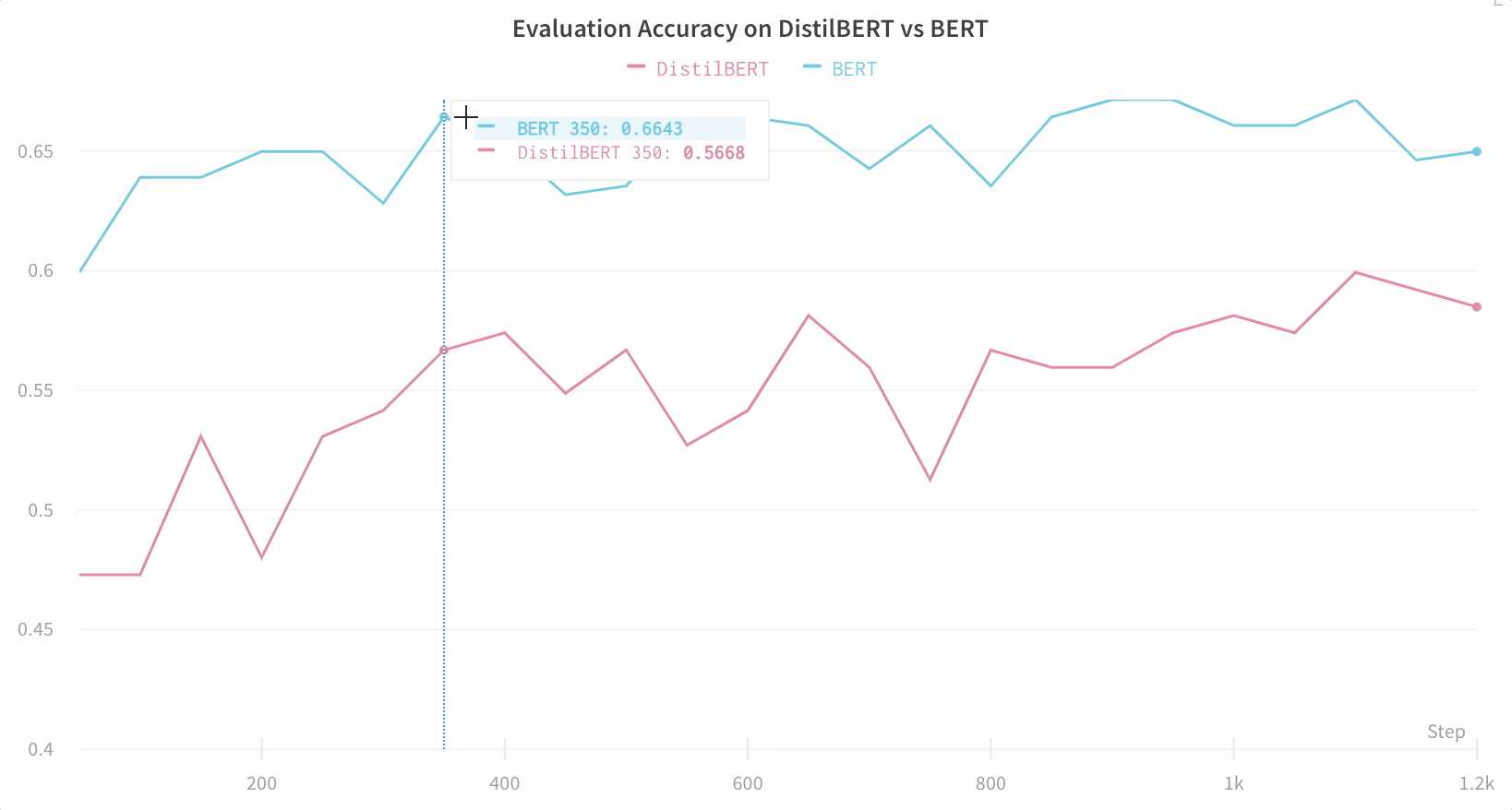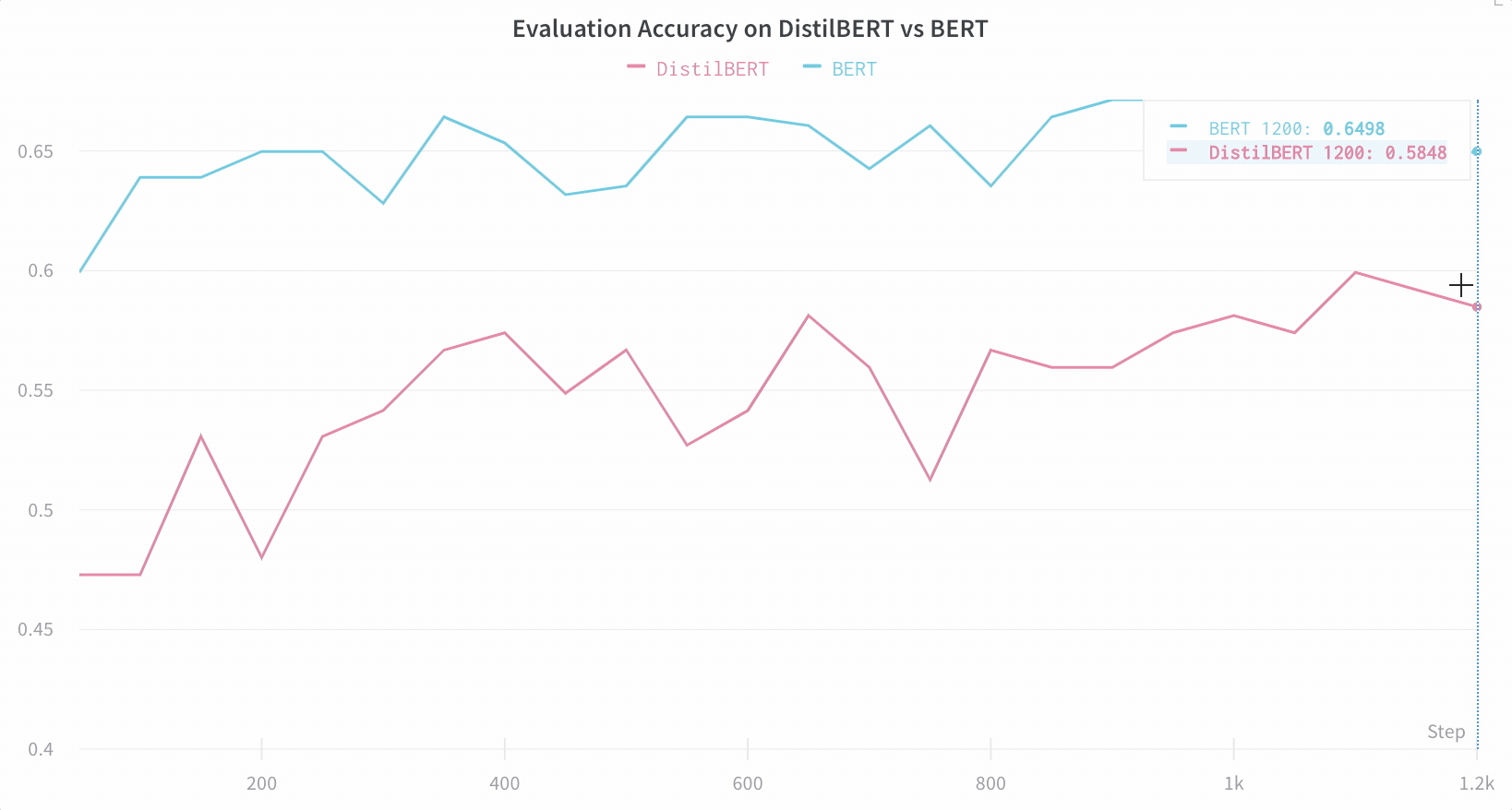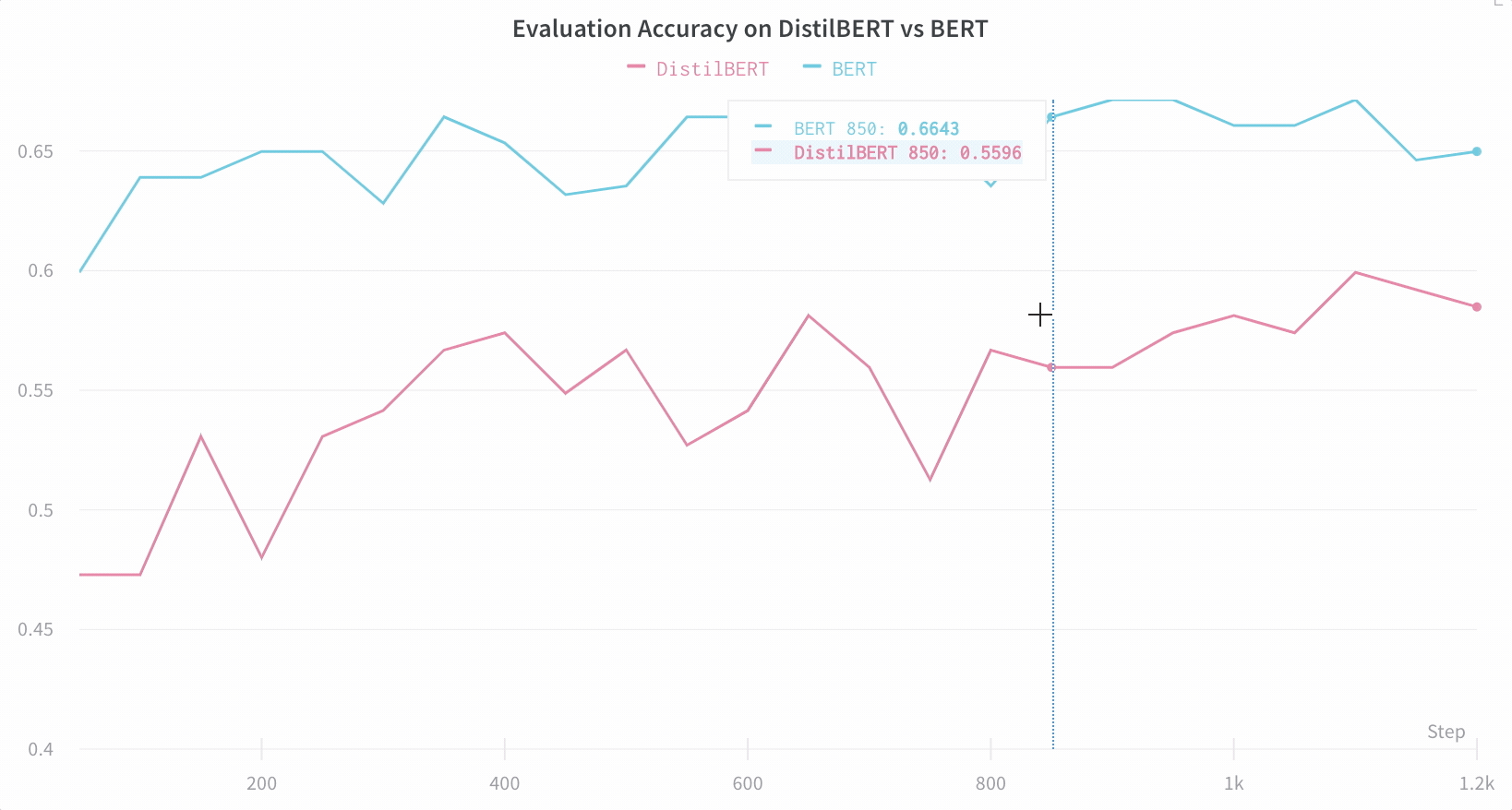
デフォルトで重要な情報を簡単に追跡
Weights & Biases は、 Experiment ごとに新しい run を保存します。デフォルトで保存される情報は次のとおりです。
- ハイパーパラメーター: モデルの Settings は Config に保存されます
- モデルメトリクス: ストリーミングされるメトリクスの時系列データは Log に保存されます
- ターミナルログ: コマンドライン出力が保存され、タブで利用できます
- システムメトリクス: GPU および CPU 使用率、メモリ、温度など
より詳しく知る
- ドキュメント: Weights & Biases と Hugging Face のインテグレーションに関するドキュメント
- ビデオ: チュートリアル、実践者とのインタビュー、および YouTube チャンネルのその他の情報
- お問い合わせ先: ご質問は contact@wandb.com までメッセージをお送りください
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.