Spin up a single node GPU cluster with Minikube
5 minute read
GPU ワークロードをスケジュールおよび実行できる Minikube クラスターで W&B Launch をセットアップします。
このチュートリアルは、複数の GPU を搭載したマシンに直接アクセスできるユーザーを対象としています。クラウドマシンをレンタルしているユーザーは対象としていません。
クラウドマシンに minikube クラスターをセットアップする場合は、クラウドプロバイダーが提供する GPU をサポートする Kubernetes クラスターを作成することをお勧めします。たとえば、AWS、GCP、Azure、Coreweave などのクラウドプロバイダーには、GPU をサポートする Kubernetes クラスターを作成するツールがあります。
単一の GPU を搭載したマシンで GPU のスケジューリングを行うために minikube クラスターをセットアップする場合は、Launch Docker queue を使用することをお勧めします。チュートリアルは、楽しみのために実行することもできますが、GPU のスケジューリングはあまり役に立ちません。
背景
Nvidia container toolkit により、Docker で GPU 対応の ワークフローを簡単に実行できるようになりました。1 つの制限は、ボリュームによる GPU のスケジューリングに対するネイティブサポートがないことです。docker run コマンドで GPU を使用する場合は、ID または存在するすべての GPU で特定の GPU を要求する必要があります。これにより、多くの分散 GPU 対応ワークロードが非現実的になります。Kubernetes はボリュームリクエストによるスケジューリングをサポートしていますが、GPU スケジューリングを備えたローカル Kubernetes クラスターのセットアップには、最近までかなりの時間と労力がかかりました。シングルノード Kubernetes クラスターを実行するための最も一般的なツールの 1 つである Minikube は、最近 GPU スケジューリングのサポート をリリースしました 🎉 このチュートリアルでは、マルチ GPU マシンに Minikube クラスターを作成し、W&B Launch 🚀 を使用して同時 Stable Diffusion 推論ジョブをクラスターに Launch します。
前提条件
開始する前に、以下が必要です。
- W&B アカウント。
- 以下がインストールされ、実行されている Linux マシン:
- Docker ランタイム
- 使用する GPU のドライバー
- Nvidia container toolkit
n1-standard-16 Google Cloud Compute Engine インスタンスを使用しました。Launch ジョブのキューを作成する
まず、Launch ジョブの Launch キューを作成します。
- wandb.ai/launch(または、プライベート W&B サーバーを使用している場合は
<your-wandb-url>/launch)に移動します。 - 画面の右上隅にある青色の Create a queue ボタンをクリックします。キュー作成ドロワーが画面の右側からスライドして表示されます。
- エンティティを選択し、名前を入力して、キューのタイプとして Kubernetes を選択します。
- ドロワーの Config セクションでは、Launch キューの Kubernetes ジョブ仕様 を入力します。このキューから Launch された Run は、このジョブ仕様を使用して作成されるため、必要に応じてこの設定を変更してジョブをカスタマイズできます。このチュートリアルでは、以下のサンプル設定を YAML または JSON としてキュー設定にコピーして貼り付けることができます。
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: '{{gpus}}'
restartPolicy: Never
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
}
}
}
],
"restartPolicy": "Never"
}
},
"backoffLimit": 0
}
}
キュー構成の詳細については、Set up Launch on Kubernetes および Advanced queue setup guide を参照してください。
${image_uri} および {{gpus}} 文字列は、キュー構成で使用できる 2 種類の変数テンプレートの例です。${image_uri} テンプレートは、エージェントによって Launch しているジョブのイメージ URI に置き換えられます。{{gpus}} テンプレートは、ジョブの送信時に Launch UI、CLI、または SDK からオーバーライドできるテンプレート変数を作成するために使用されます。これらの値はジョブ仕様に配置され、ジョブで使用されるイメージと GPU リソースを制御するために正しいフィールドを変更します。
- Parse configuration ボタンをクリックして、
gpusテンプレート変数のカスタマイズを開始します。 - Type を
Integerに設定し、Default、Min、および Max を選択した値に設定します。 テンプレート変数の制約に違反するこのキューに Run を送信しようとすると、拒否されます。
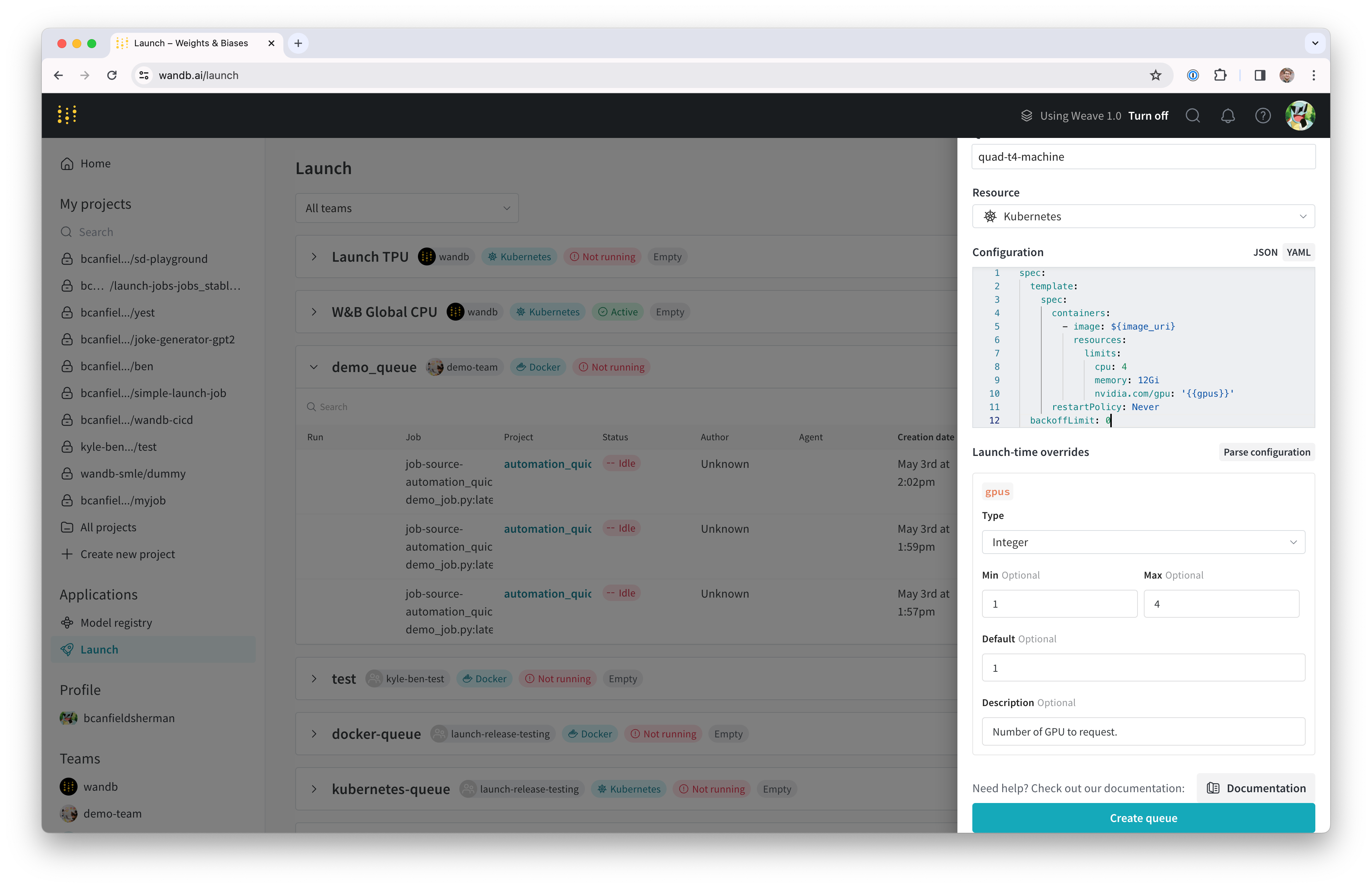
- Create queue をクリックしてキューを作成します。新しいキューのキューページにリダイレクトされます。
次のセクションでは、作成したキューからジョブをプルして実行できるエージェントをセットアップします。
Docker + NVIDIA CTK のセットアップ
Docker と Nvidia container toolkit がマシンに既にセットアップされている場合は、このセクションをスキップできます。
システムでの Docker container エンジンのセットアップ手順については、Docker のドキュメント を参照してください。
Docker をインストールしたら、Nvidia のドキュメントの手順に従って Nvidia container toolkit をインストールします。
コンテナランタイムが GPU にアクセスできることを検証するには、以下を実行します。
docker run --gpus all ubuntu nvidia-smi
マシンに接続されている GPU を記述する nvidia-smi 出力が表示されます。たとえば、セットアップでの出力は次のようになります。
Wed Nov 8 23:25:53 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 Tesla T4 Off | 00000000:00:06.0 Off | 0 |
| N/A 40C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 Tesla T4 Off | 00000000:00:07.0 Off | 0 |
| N/A 39C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Minikube のセットアップ
Minikube の GPU サポートには、バージョン v1.32.0 以降が必要です。最新のインストールヘルプについては、Minikube のインストールドキュメント を参照してください。このチュートリアルでは、次のコマンドを使用して最新の Minikube リリースをインストールしました。
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
次のステップでは、GPU を使用して minikube クラスターを起動します。マシンで、以下を実行します。
minikube start --gpus all
上記のコマンドの出力は、クラスターが正常に作成されたかどうかを示します。
Launch エージェントの起動
新しいクラスターの Launch エージェントは、wandb launch-agent を直接呼び出すか、W&B が管理する helm チャート を使用して Launch エージェントをデプロイすることで起動できます。
このチュートリアルでは、エージェントをホストマシン上で直接実行します。
エージェントをローカルで実行するには、デフォルトの Kubernetes API コンテキストが Minikube クラスターを参照していることを確認してください。次に、以下を実行します。
pip install "wandb[launch]"
エージェントの依存関係をインストールします。エージェントの認証をセットアップするには、wandb login を実行するか、WANDB_API_KEY 環境変数を設定します。
エージェントを起動するには、次のコマンドを実行します。
wandb launch-agent -j <max-number-concurrent-jobs> -q <queue-name> -e <queue-entity>
ターミナル内で、Launch エージェントがポーリングメッセージの出力を開始するのを確認できます。
おめでとうございます。Launch キューをポーリングする Launch エージェントができました。ジョブがキューに追加されると、エージェントがそれを取得し、Minikube クラスターで実行するようにスケジュールします。
ジョブの Launch
エージェントにジョブを送信しましょう。W&B アカウントにログインしているターミナルから、次のコマンドで簡単な「hello world」を Launch できます。
wandb launch -d wandb/job_hello_world:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
任意のジョブまたはイメージでテストできますが、クラスターがイメージをプルできることを確認してください。詳細については、Minikube のドキュメント を参照してください。パブリックジョブのいずれかを使用してテスト することもできます。
(オプション) NFS を使用したモデルとデータのキャッシュ
ML ワークロードの場合、多くの場合、複数のジョブが同じデータにアクセスできるようにする必要があります。たとえば、データセットやモデルの重みなどの大きなアセットを繰り返しダウンロードするのを避けるために、共有キャッシュを用意することができます。Kubernetes は、Persistent Volumes と Persistent Volume Claims を通じてこれをサポートします。Persistent Volumes を使用して、Kubernetes ワークロードに volumeMounts を作成し、共有キャッシュへの直接ファイルシステムアクセスを提供できます。
このステップでは、モデルの重みの共有キャッシュとして使用できるネットワークファイルシステム (NFS) サーバーをセットアップします。最初のステップは、NFS をインストールして構成することです。このプロセスはオペレーティングシステムによって異なります。VM は Ubuntu を実行しているため、nfs-kernel-server をインストールし、/srv/nfs/kubedata にエクスポートを構成しました。
sudo apt-get install nfs-kernel-server
sudo mkdir -p /srv/nfs/kubedata
sudo chown nobody:nogroup /srv/nfs/kubedata
sudo sh -c 'echo "/srv/nfs/kubedata *(rw,sync,no_subtree_check,no_root_squash,no_all_squash,insecure)" >> /etc/exports'
sudo exportfs -ra
sudo systemctl restart nfs-kernel-server
ホストファイルシステム内のサーバーのエクスポート場所と、NFS サーバーのローカル IP アドレスをメモしておきます。次のステップでこの情報が必要になります。
次に、この NFS の Persistent Volume と Persistent Volume Claim を作成する必要があります。Persistent Volumes は高度にカスタマイズ可能ですが、ここでは簡単にするために簡単な構成を使用します。
以下の yaml を nfs-persistent-volume.yaml というファイルにコピーし、必要なボリューム容量とクレームリクエストを必ず入力してください。PersistentVolume.spec.capcity.storage フィールドは、基になるボリュームの最大サイズを制御します。PersistentVolumeClaim.spec.resources.requests.stroage を使用して、特定のクレームに割り当てられたボリューム容量を制限できます。ユースケースでは、それぞれに同じ値を使用するのが理にかなっています。
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 100Gi # Set this to your desired capacity.
accessModes:
- ReadWriteMany
nfs:
server: <your-nfs-server-ip> # TODO: Fill this in.
path: '/srv/nfs/kubedata' # Or your custom path
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi # Set this to your desired capacity.
storageClassName: ''
volumeName: nfs-pv
次のコマンドを使用して、クラスター内にリソースを作成します。
kubectl apply -f nfs-persistent-volume.yaml
Run がこのキャッシュを利用できるようにするには、Launch キュー構成に volumes と volumeMounts を追加する必要があります。Launch 構成を編集するには、wandb.ai/launch(または wandb サーバーのユーザーの場合は <your-wandb-url>/launch)に戻り、キューを見つけてキューページをクリックし、Edit config タブをクリックします。元の構成は次のように変更できます。
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: "{{gpus}}"
volumeMounts:
- name: nfs-storage
mountPath: /root/.cache
restartPolicy: Never
volumes:
- name: nfs-storage
persistentVolumeClaim:
claimName: nfs-pvc
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
},
"volumeMounts": [
{
"name": "nfs-storage",
"mountPath": "/root/.cache"
}
]
}
}
],
"restartPolicy": "Never",
"volumes": [
{
"name": "nfs-storage",
"persistentVolumeClaim": {
"claimName": "nfs-pvc"
}
}
]
}
},
"backoffLimit": 0
}
}
これで、NFS はジョブを実行しているコンテナ内の /root/.cache にマウントされます。コンテナが root 以外のユーザーとして実行されている場合、マウントパスを調整する必要があります。Huggingface のライブラリと W&B Artifacts はどちらもデフォルトで $HOME/.cache/ を使用するため、ダウンロードは 1 回だけ行う必要があります。
Stable Diffusion を使用する
新しいシステムをテストするために、Stable Diffusion の推論パラメーターを試してみます。 デフォルトのプロンプトと適切なパラメーターを使用して、単純な Stable Diffusion 推論ジョブを実行するには、以下を実行します。
wandb launch -d wandb/job_stable_diffusion_inference:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
上記のコマンドは、コンテナイメージ wandb/job_stable_diffusion_inference:main をキューに送信します。
エージェントがジョブを取得してクラスターで実行するようにスケジュールすると、
接続によっては、イメージのプルに時間がかかる場合があります。
wandb.ai/launch(または wandb サーバーのユーザーの場合は <your-wandb-url>/launch)のキューページでジョブのステータスを確認できます。
Run が完了すると、指定したプロジェクトにジョブ Artifact が作成されます。
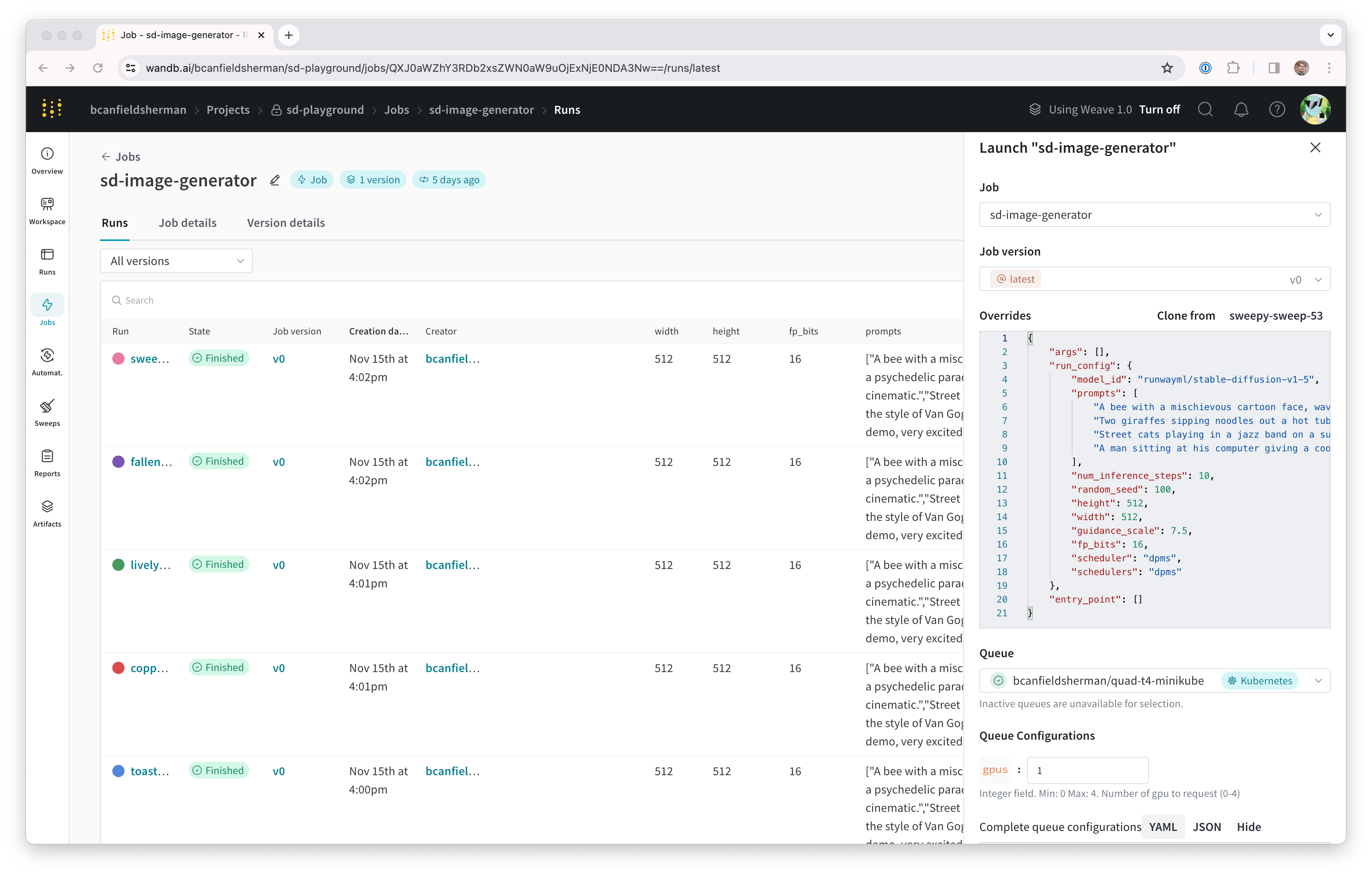
プロジェクトのジョブページ(<project-url>/jobs)を確認して、ジョブ Artifact を見つけることができます。そのデフォルト名は job-wandb_job_stable_diffusion_inference である必要がありますが、ジョブの名前の横にある鉛筆アイコンをクリックして、ジョブのページで好きな名前に変更できます。
これで、このジョブを使用して、クラスターでより多くの Stable Diffusion 推論を実行できます。 ジョブページから、右上隅にある Launch ボタンをクリックして、 新しい推論ジョブを構成し、キューに送信できます。ジョブ構成ページには、元の Run のパラメーターがあらかじめ入力されていますが、Launch ドロワーの Overrides セクションで値を変更することで、好きなように変更できます。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.