Tune hyperparameters with sweeps
4 minute read
望ましいメトリクス(モデルの精度など)を満たす機械学習モデルを見つけることは、通常、複数の反復を必要とする冗長な作業です。さらに悪いことに、特定のトレーニング run にどの ハイパーパラメーター の組み合わせを使用するか不明確な場合があります。
W&B Sweeps を使用すると、学習率、 バッチサイズ 、隠れ層の数、 オプティマイザー の種類など、 ハイパーパラメーター の値の組み合わせを自動的に検索するための、組織化され効率的な方法を作成し、目的のメトリクスに基づいてモデルを最適化する値を見つけることができます。
このチュートリアルでは、W&B PyTorch インテグレーションを使用して ハイパーパラメーター 探索を作成します。ビデオチュートリアルをご覧ください。
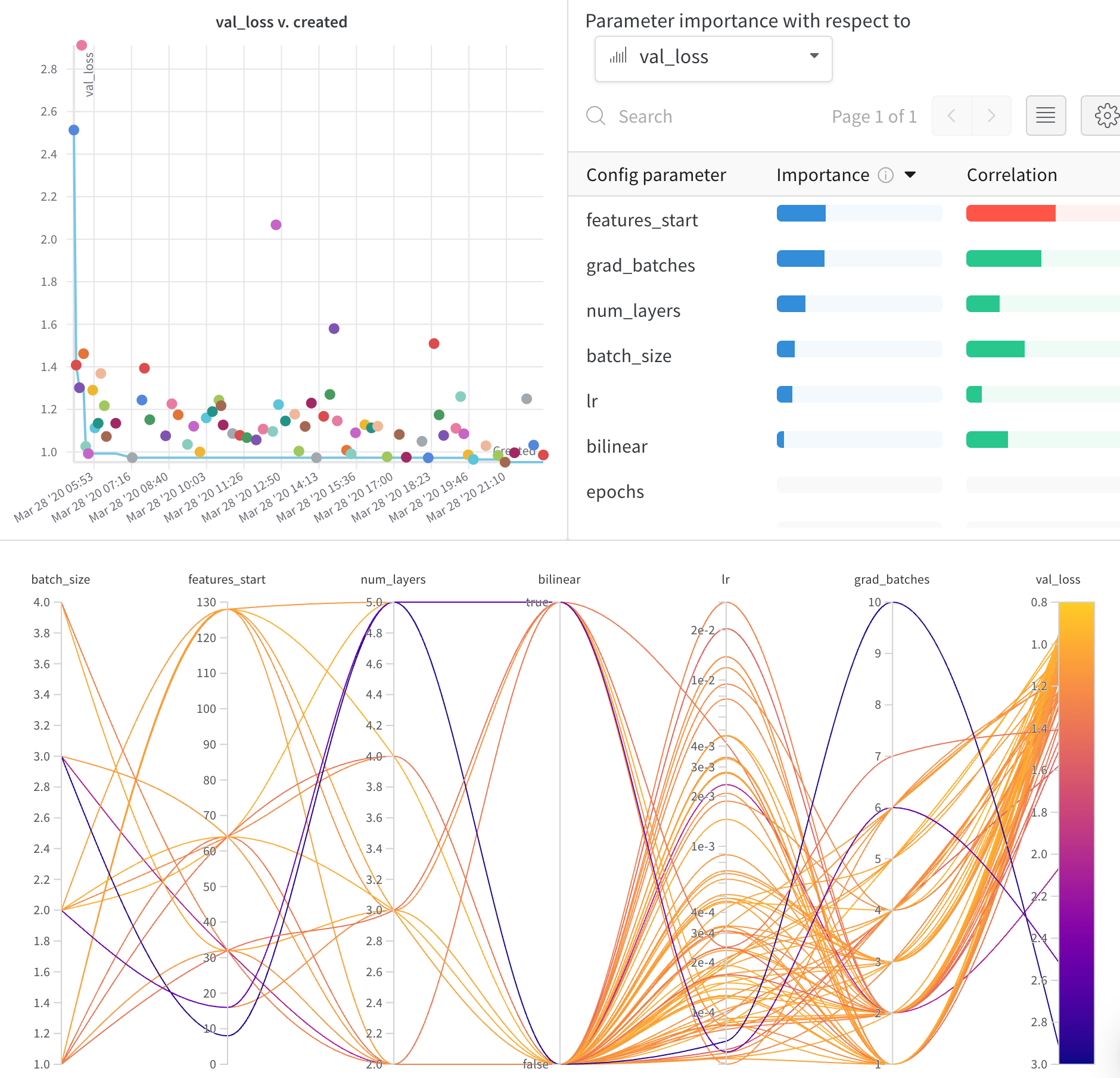
Sweeps:概要
Weights & Biases で ハイパーパラメーター sweep を実行するのは非常に簡単です。簡単な3つのステップがあります。
-
sweep を定義する: 検索する パラメータ 、検索戦略、最適化 メトリクス などを指定する 辞書 または YAML ファイル を作成することにより、これを行います。
-
sweep を初期化する: 1行の コード で sweep を初期化し、sweep 設定の 辞書 を渡します。
sweep_id = wandb.sweep(sweep_config) -
sweep agent を実行する: 1行の コード でも実行でき、
wandb.agent()を呼び出し、実行するsweep_idと、モデル アーキテクチャー を定義してトレーニング する関数を渡します。wandb.agent(sweep_id, function=train)
始める前に
W&B をインストールし、W&B Python SDK を ノートブック にインポートします。
!pip installでインストール:
!pip install wandb -Uq
- W&B をインポート:
import wandb
- W&B にログインし、プロンプトが表示されたら APIキー を入力します。
wandb.login()
ステップ1️:sweep を定義する
W&B Sweep は、多数の ハイパーパラメーター 値を試すための戦略と、それらを評価する コード を組み合わせたものです。 sweep を開始する前に、 sweep 設定 で sweep 戦略を定義する必要があります。
Jupyter Notebook で sweep を開始する場合、sweep 用に作成する sweep 設定は、ネストされた 辞書 にする必要があります。
コマンドライン 内で sweep を実行する場合は、YAML ファイル で sweep 設定を指定する必要があります。
検索方法を選択
まず、設定 辞書 内で ハイパーパラメーター 検索方法を指定します。グリッド、 ランダム 検索、 ベイズ探索 の3つの ハイパーパラメーター 検索戦略から選択できます。
このチュートリアルでは、 ランダム 検索を使用します。 ノートブック 内で、 辞書 を作成し、method キーに random を指定します。
sweep_config = {
'method': 'random'
}
最適化する メトリクス を指定します。 ランダム 検索方法を使用する sweep の メトリクス と目標を指定する必要はありません。ただし、後で参照できるように、sweep の目標を追跡することをお勧めします。
metric = {
'name': 'loss',
'goal': 'minimize'
}
sweep_config['metric'] = metric
検索する ハイパーパラメーター を指定する
これで、sweep 設定で検索方法が指定されたので、検索する ハイパーパラメーター を指定します。
これを行うには、1つ以上の ハイパーパラメーター 名を parameter キーに指定し、value キーに1つ以上の ハイパーパラメーター 値を指定します。
特定の ハイパーパラメーター で検索する値は、調査している ハイパーパラメーター の種類によって異なります。
たとえば、機械学習 オプティマイザー を選択する場合は、Adam オプティマイザー や確率的勾配降下など、1つ以上の有限 オプティマイザー 名を指定する必要があります。
parameters_dict = {
'optimizer': {
'values': ['adam', 'sgd']
},
'fc_layer_size': {
'values': [128, 256, 512]
},
'dropout': {
'values': [0.3, 0.4, 0.5]
},
}
sweep_config['parameters'] = parameters_dict
ハイパーパラメーター を追跡したいが、その値を変更したくない場合があります。この場合、 ハイパーパラメーター を sweep 設定に追加し、使用する正確な値を指定します。たとえば、次の コード セルでは、epochs が1に設定されています。
parameters_dict.update({
'epochs': {
'value': 1}
})
random 検索の場合、
パラメータ のすべての values は、特定の run で選択される可能性が等しくなります。
または、
名前付きの distribution と、その パラメータ (normal 分布の平均 mu や標準偏差 sigma など)を指定できます。
parameters_dict.update({
'learning_rate': {
# 0〜0.1のフラットな分布
'distribution': 'uniform',
'min': 0,
'max': 0.1
},
'batch_size': {
# 32〜256の整数
# 対数が均等に分布
'distribution': 'q_log_uniform_values',
'q': 8,
'min': 32,
'max': 256,
}
})
完了すると、sweep_config はネストされた 辞書 になります。
これは、試してみたい parameters と、それらを試すために使用する method を正確に指定します。
sweep 設定がどのように見えるかを見てみましょう。
import pprint
pprint.pprint(sweep_config)
設定オプションの完全なリストについては、sweep 設定オプション を参照してください。
values を試してみるのが理にかなっています。たとえば、前の sweep 設定には、layer_size および dropout パラメータ キーに指定された有限値のリストがあります。ステップ2️:Sweep を初期化する
検索戦略を定義したら、それを実装するためのものをセットアップします。
W&B は、Sweep Controller を使用して、 クラウド 上またはローカルで1つ以上のマシンにわたって sweep を管理します。このチュートリアルでは、W&B によって管理される sweep コントローラ を使用します。
sweep コントローラ が sweep を管理している間、実際に sweep を実行するコンポーネントは sweep agent と呼ばれます。
ノートブック 内では、wandb.sweep メソッドを使用して sweep コントローラ をアクティブ化できます。以前に定義した sweep 設定 辞書 を sweep_config フィールドに渡します。
sweep_id = wandb.sweep(sweep_config, project="pytorch-sweeps-demo")
wandb.sweep 関数は、後で sweep をアクティブ化するために使用する sweep_id を返します。
コマンドライン では、この関数は次のように置き換えられます
wandb sweep config.yaml
ターミナル で W&B Sweeps を作成する方法の詳細については、W&B Sweep チュートリアル を参照してください。
ステップ3:機械学習 コード を定義する
sweep を実行する前に、 試してみたい ハイパーパラメーター 値を使用するトレーニング プロシージャ を定義します。W&B Sweeps をトレーニング コード に統合するための鍵は、各トレーニング 実験 で、トレーニング ロジックが sweep 設定で定義した ハイパーパラメーター 値に アクセス できるようにすることです。
次の コード 例では、ヘルパー関数 build_dataset、build_network、build_optimizer、および train_epoch が sweep ハイパーパラメーター 設定 辞書 に アクセス します。
次の機械学習 トレーニング コード を ノートブック で実行します。これらの関数は、PyTorch で基本的な完全接続 ニューラルネットワーク を定義します。
import torch
import torch.optim as optim
import torch.nn.functional as F
import torch.nn as nn
from torchvision import datasets, transforms
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def train(config=None):
# Initialize a new wandb run
with wandb.init(config=config):
# If called by wandb.agent, as below,
# this config will be set by Sweep Controller
config = wandb.config
loader = build_dataset(config.batch_size)
network = build_network(config.fc_layer_size, config.dropout)
optimizer = build_optimizer(network, config.optimizer, config.learning_rate)
for epoch in range(config.epochs):
avg_loss = train_epoch(network, loader, optimizer)
wandb.log({"loss": avg_loss, "epoch": epoch})
train 関数内では、次の W&B Python SDK メソッドに注意してください。
wandb.init(): 新しい W&B run を初期化します。各 run は、トレーニング 関数の単一の実行です。wandb.config: 実験する ハイパーパラメーター を使用して sweep 設定を渡します。wandb.log(): 各 エポック のトレーニング 損失を ログ に記録します。
次のセルは、4つの関数(build_dataset、build_network、build_optimizer、および train_epoch)を定義します。
これらの関数は、基本的な PyTorch パイプライン の標準的な部分であり、
その実装は W&B の使用による影響を受けません。
def build_dataset(batch_size):
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
# download MNIST training dataset
dataset = datasets.MNIST(".", train=True, download=True,
transform=transform)
sub_dataset = torch.utils.data.Subset(
dataset, indices=range(0, len(dataset), 5))
loader = torch.utils.data.DataLoader(sub_dataset, batch_size=batch_size)
return loader
def build_network(fc_layer_size, dropout):
network = nn.Sequential( # fully connected, single hidden layer
nn.Flatten(),
nn.Linear(784, fc_layer_size), nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(fc_layer_size, 10),
nn.LogSoftmax(dim=1))
return network.to(device)
def build_optimizer(network, optimizer, learning_rate):
if optimizer == "sgd":
optimizer = optim.SGD(network.parameters(),
lr=learning_rate, momentum=0.9)
elif optimizer == "adam":
optimizer = optim.Adam(network.parameters(),
lr=learning_rate)
return optimizer
def train_epoch(network, loader, optimizer):
cumu_loss = 0
for _, (data, target) in enumerate(loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# ➡ Forward pass
loss = F.nll_loss(network(data), target)
cumu_loss += loss.item()
# ⬅ Backward pass + weight update
loss.backward()
optimizer.step()
wandb.log({"batch loss": loss.item()})
return cumu_loss / len(loader)
PyTorch で W&B を使用した計測の詳細については、この Colab を参照してください。
ステップ4: sweep agent をアクティブ化する
sweep 設定を定義し、インタラクティブな方法でこれらの ハイパーパラメーター を利用できるトレーニング スクリプト を作成したので、 sweep agent をアクティブ化する準備ができました。 Sweep agent は、 sweep 設定で定義した ハイパーパラメーター 値のセットを使用して 実験 を実行する役割を担います。
wandb.agent メソッドを使用して sweep agent を作成します。以下を指定してください。
- agent が属する sweep (
sweep_id) - sweep が実行することになっている関数。この例では、 sweep は
train関数を使用します。 - (オプション) sweep コントローラ に要求する設定の数 (
count)
sweep_id を持つ複数の sweep agent を開始できます。 sweep コントローラ は、定義した sweep 設定に従って連携するようにします。次のセルは、トレーニング 関数 (train) を5回実行する sweep agent をアクティブ化します。
wandb.agent(sweep_id, train, count=5)
random 検索方法が sweep 設定で指定されているため、 sweep コントローラ は ランダム に生成された ハイパーパラメーター 値を提供します。ターミナル で W&B Sweeps を作成する方法の詳細については、W&B Sweep チュートリアル を参照してください。
Sweep の結果を 可視化 する
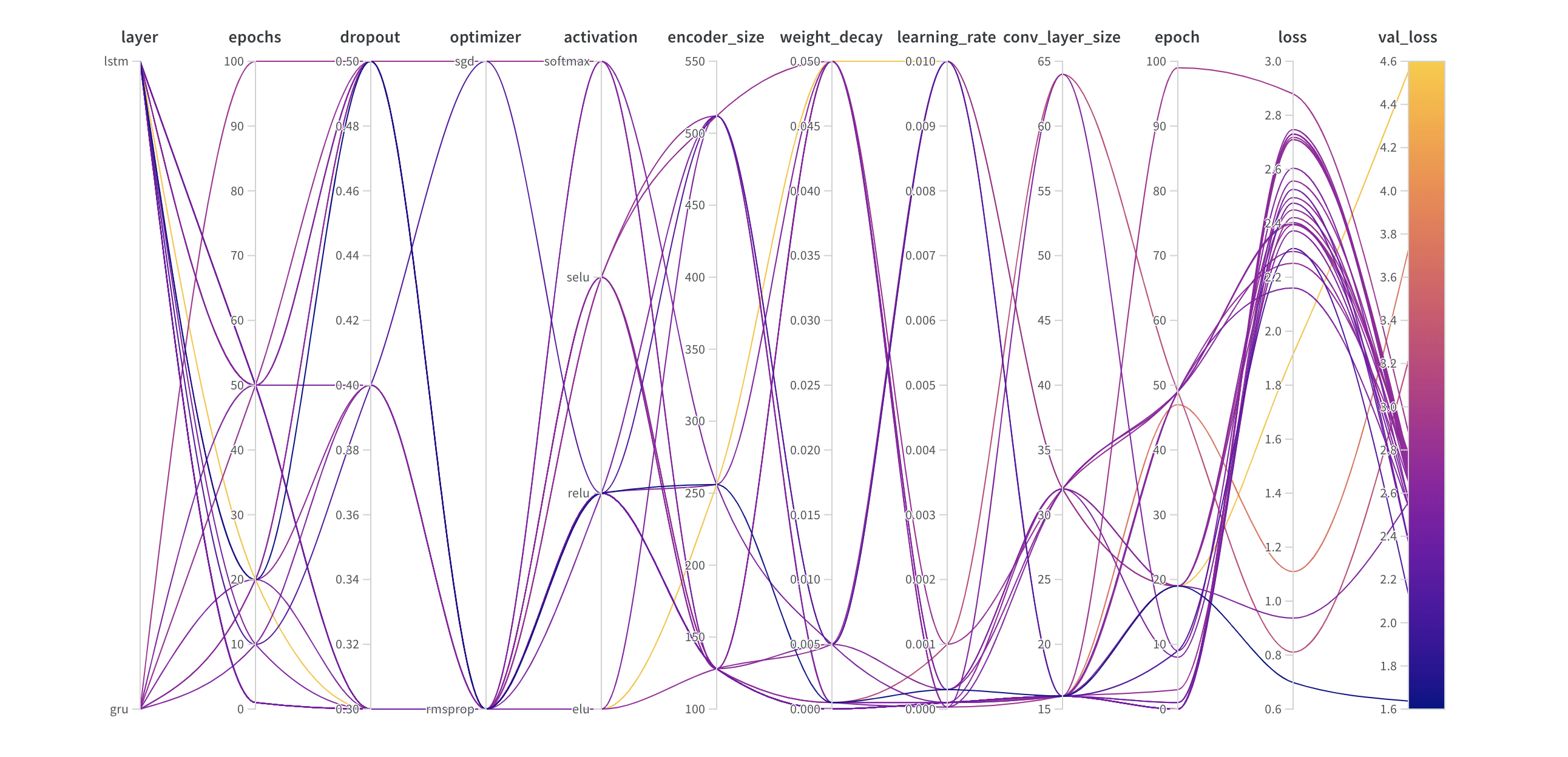
並列座標プロット
このプロットは、 ハイパーパラメーター 値をモデル メトリクス にマッピングします。これは、最高のモデル パフォーマンス につながった ハイパーパラメーター の組み合わせを調整するのに役立ちます。
ハイパーパラメーター インポータンスプロット
ハイパーパラメーター インポータンスプロット は、どの ハイパーパラメーター が メトリクス の最良の予測因子であるかを表面化します。 特徴量の重要度( ランダム フォレスト モデル から)と相関関係(暗黙的に線形モデル)を報告します。
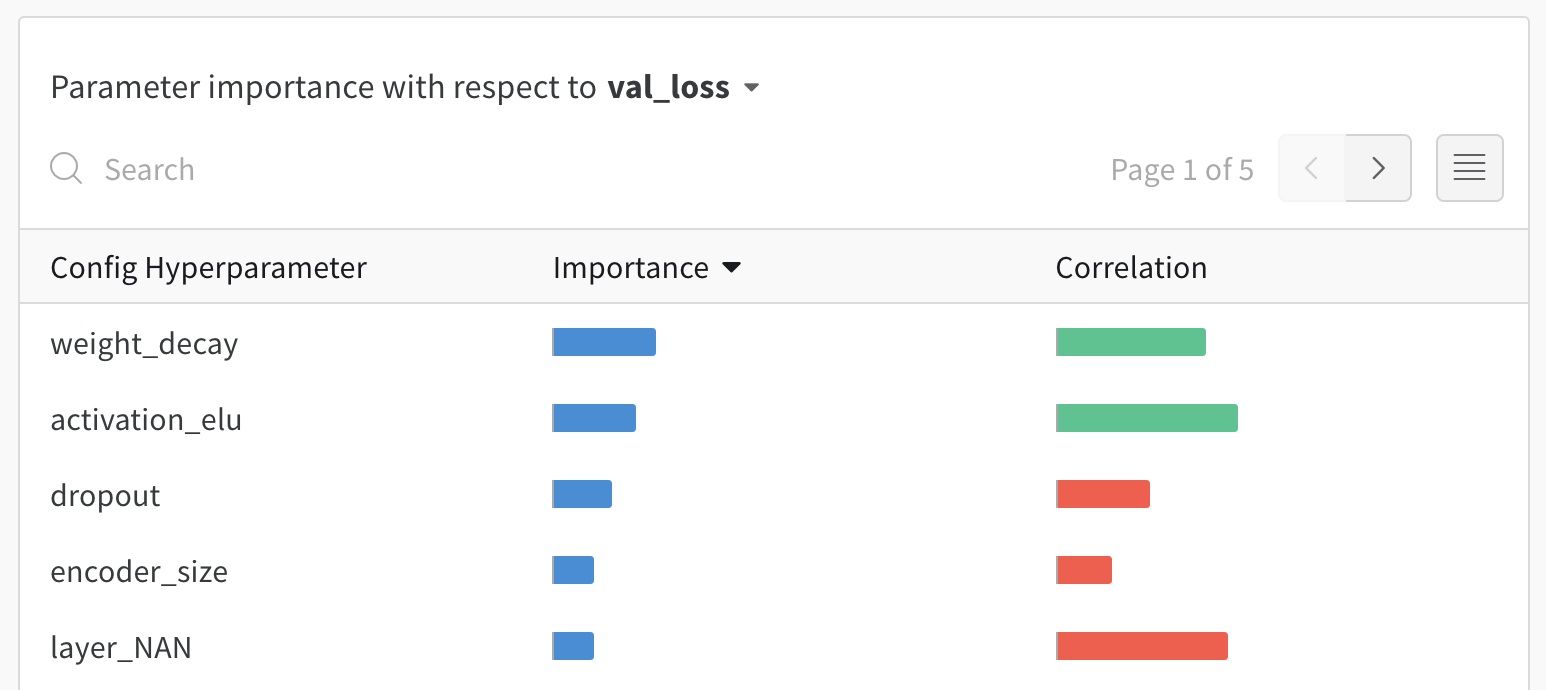
これらの 可視化 は、最も重要な パラメータ (および値の範囲)を絞り込むことで、高価な ハイパーパラメーター 最適化を実行する時間とリソースを節約するのに役立ち、それによってさらに調査する価値があります。
W&B Sweeps の詳細
単純なトレーニング スクリプト と、試せる いくつかの種類の sweep 設定 を作成しました。これらを試してみることを強くお勧めします。
その リポジトリ には、ベイズ Hyperband や Hyperopt などの、より高度な sweep 機能を試すのに役立つ例もあります。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.