TensorFlow
3 minute read
このノートブックの内容
- Weights & Biases と TensorFlow パイプラインを簡単に統合して、 実験管理 を行います。
keras.metricsでメトリクスを計算しますwandb.logを使用して、カスタムトレーニングループでこれらのメトリクスを記録します。
注意: Step で始まるセクションは、既存のコードに W&B を統合するために必要なものです。残りは標準的な MNIST の例です。
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import cifar10
インストール、インポート、ログイン
W&B のインストール
%%capture
!pip install wandb
W&B のインポートとログイン
import wandb
from wandb.integration.keras import WandbMetricsLogger
wandb.login()
補足: W&B を初めて使用する場合、またはログインしていない場合は、
wandb.login()の実行後に表示されるリンクからサインアップ/ログインページに移動します。サインアップはワンクリックで簡単に行えます。
データセットの準備
# トレーニングデータセットの準備
BATCH_SIZE = 64
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = np.reshape(x_train, (-1, 784))
x_test = np.reshape(x_test, (-1, 784))
# tf.data を使用して入力パイプラインを構築
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(BATCH_SIZE)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(BATCH_SIZE)
モデルとトレーニングループの定義
def make_model():
inputs = keras.Input(shape=(784,), name="digits")
x1 = keras.layers.Dense(64, activation="relu")(inputs)
x2 = keras.layers.Dense(64, activation="relu")(x1)
outputs = keras.layers.Dense(10, name="predictions")(x2)
return keras.Model(inputs=inputs, outputs=outputs)
def train_step(x, y, model, optimizer, loss_fn, train_acc_metric):
with tf.GradientTape() as tape:
logits = model(x, training=True)
loss_value = loss_fn(y, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return loss_value
def test_step(x, y, model, loss_fn, val_acc_metric):
val_logits = model(x, training=False)
loss_value = loss_fn(y, val_logits)
val_acc_metric.update_state(y, val_logits)
return loss_value
トレーニングループに wandb.log を追加
def train(
train_dataset,
val_dataset,
model,
optimizer,
train_acc_metric,
val_acc_metric,
epochs=10,
log_step=200,
val_log_step=50,
):
for epoch in range(epochs):
print("\nStart of epoch %d" % (epoch,))
train_loss = []
val_loss = []
# データセットのバッチを反復処理します
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
loss_value = train_step(
x_batch_train,
y_batch_train,
model,
optimizer,
loss_fn,
train_acc_metric,
)
train_loss.append(float(loss_value))
# 各エポックの最後に検証ループを実行します
for step, (x_batch_val, y_batch_val) in enumerate(val_dataset):
val_loss_value = test_step(
x_batch_val, y_batch_val, model, loss_fn, val_acc_metric
)
val_loss.append(float(val_loss_value))
# 各エポックの最後にメトリクスを表示します
train_acc = train_acc_metric.result()
print("Training acc over epoch: %.4f" % (float(train_acc),))
val_acc = val_acc_metric.result()
print("Validation acc: %.4f" % (float(val_acc),))
# 各エポックの最後にメトリクスをリセットします
train_acc_metric.reset_states()
val_acc_metric.reset_states()
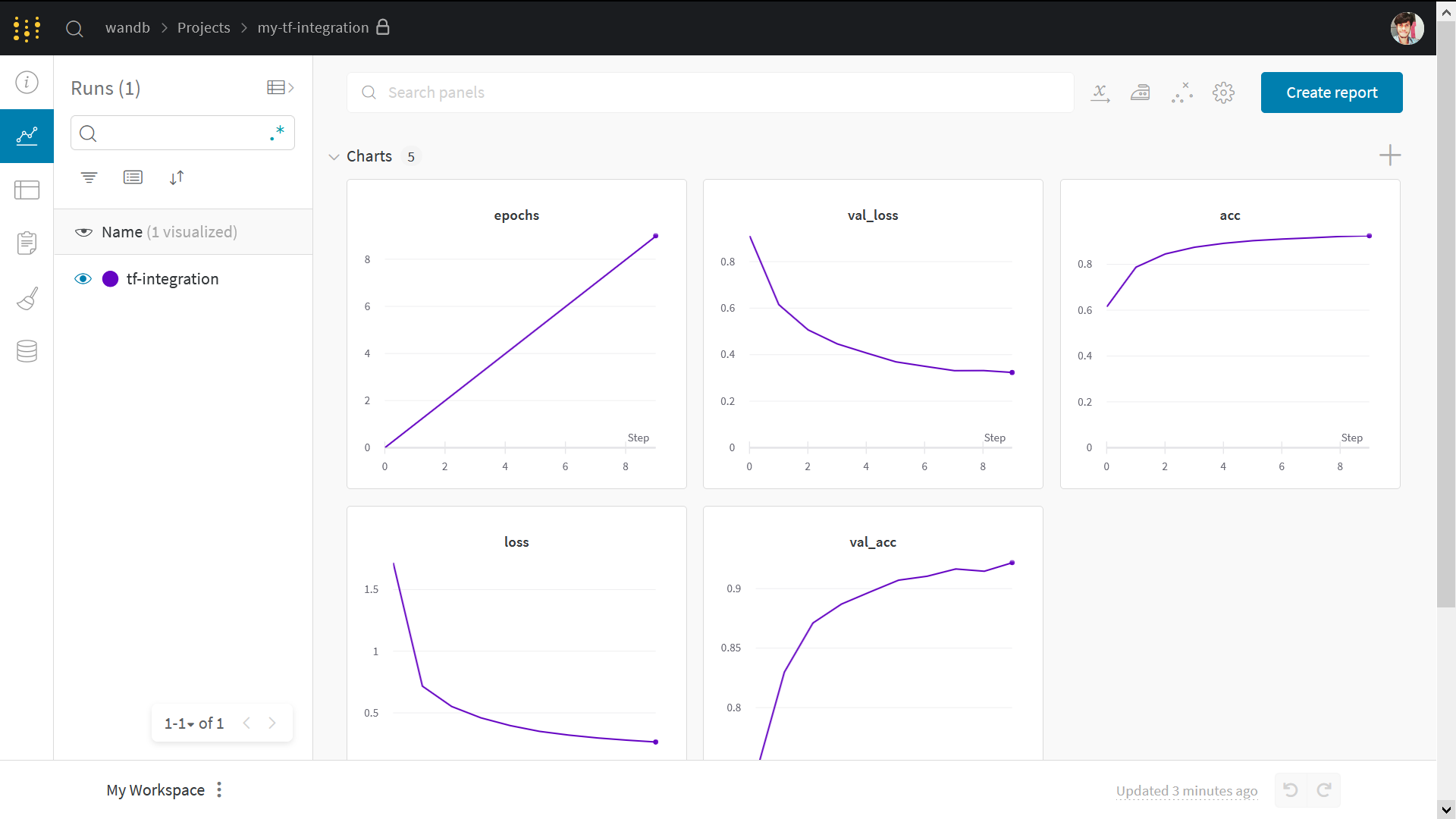
# ⭐: wandb.log を使用してメトリクスを記録
wandb.log(
{
"epochs": epoch,
"loss": np.mean(train_loss),
"acc": float(train_acc),
"val_loss": np.mean(val_loss),
"val_acc": float(val_acc),
}
)
トレーニングの実行
wandb.init を呼び出して run を開始する
これにより、実験を開始したことが通知され、 固有の ID と ダッシュボード が提供されます。
# プロジェクト名とオプションで構成を使用して wandb を初期化します。
# 構成値をいろいろ試して、wandb ダッシュボードで結果を確認してください。
config = {
"learning_rate": 0.001,
"epochs": 10,
"batch_size": 64,
"log_step": 200,
"val_log_step": 50,
"architecture": "CNN",
"dataset": "CIFAR-10",
}
run = wandb.init(project='my-tf-integration', config=config)
config = run.config
# モデルを初期化します。
model = make_model()
# モデルをトレーニングするためのオプティマイザーをインスタンス化します。
optimizer = keras.optimizers.SGD(learning_rate=config.learning_rate)
# 損失関数をインスタンス化します。
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# メトリクスを準備します。
train_acc_metric = keras.metrics.SparseCategoricalAccuracy()
val_acc_metric = keras.metrics.SparseCategoricalAccuracy()
train(
train_dataset,
val_dataset,
model,
optimizer,
train_acc_metric,
val_acc_metric,
epochs=config.epochs,
log_step=config.log_step,
val_log_step=config.val_log_step,
)
run.finish() # Jupyter/Colab で、終了したことを知らせます!
結果の可視化
上記の run page リンクをクリックして、ライブ結果を確認してください。
Sweep 101
Weights & Biases Sweeps を使用して、ハイパーパラメーターの最適化を自動化し、可能なモデルの空間を探索します。
W&B Sweeps を使用した TensorFlow でのハイパーパラメーター最適化を確認する
W&B Sweeps を使用する利点
- 簡単なセットアップ: 数行のコードだけで W&B sweeps を実行できます。
- 透明性: 使用しているすべてのアルゴリズムを引用し、コードはオープンソースです。
- 強力: sweeps は完全にカスタマイズおよび構成可能です。数十台のマシンで sweep を起動できます。ラップトップで sweep を開始するのと同じくらい簡単です。
サンプルギャラリー
W&B で追跡および可視化された プロジェクト の例を、サンプルギャラリーでご覧ください。完全接続 →
ベストプラクティス
- Projects: 複数の runs を プロジェクト に記録して比較します。
wandb.init(project="project-name") - Groups: 複数の プロセス または 交差検証 folds の場合、各 プロセス を runs として記録し、それらをグループ化します。
wandb.init(group="experiment-1") - Tags: 現在の ベースライン または プロダクション モデル を追跡するために タグ を追加します。
- Notes: テーブルに ノート を入力して、runs 間の変更を追跡します。
- Reports: 同僚と共有するために進捗状況に関する簡単なメモを取り、ML プロジェクト の ダッシュボード と スナップショット を作成します。
高度な設定
- 環境変数: マネージド クラスター で トレーニング を実行できるように、環境変数に APIキー を設定します。
- オフラインモード
- オンプレミス: 独自の インフラストラクチャー で プライベートクラウド または エアギャップ サーバー に W&B をインストールします。学術関係者から エンタープライズ チーム まで、あらゆる人に対応するローカル インストール があります。
- Artifacts: モデル をトレーニング する際に パイプライン ステップ を自動的に取得する方法で、 モデル と データセット を合理的な方法で追跡および バージョン 管理します。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.