TensorFlow Sweeps
4 minute read

W&B Sweeps を 使用して ハイパーパラメーター の 最適化 を 自動化し、インタラクティブな ダッシュボード で モデル の 可能性 を 探ります。
Sweeps を 使用する 理由
- クイックセットアップ: 数行の コード で W&B sweeps を 実行します。
- 透明性: プロジェクト では 使用されている すべての アルゴリズム が 引用されており、 コード は オープンソース です。
- 強力: Sweeps は カスタマイズ オプション を 提供し、複数 の マシン または ラップトップ で 簡単に 実行できます。
詳細については、 Sweep の ドキュメント を 参照してください。
この ノートブック で 説明する 内容
- TensorFlow で W&B Sweep と カスタム トレーニング ループ を 開始する 手順。
- 画像分類タスク に 最適な ハイパーパラメーター を 見つける。
注: Step で 始まる セクション は、 ハイパーパラメーター sweep を 実行するために 必要 な コード を 示しています。残りの 部分 は 簡単 な 例 を 設定します。
インストール、インポート、ログイン
W&B の インストール
pip install wandb
W&B の インポート と ログイン
import tqdm
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import cifar10
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import wandb
from wandb.integration.keras import WandbMetricsLogger
wandb.login()
W&B を 初めて 使用する 場合、または ログイン していない 場合、
wandb.login() を 実行した 後 の リンク は サインアップ / ログイン ページ に 移動します。データセット の 準備
# トレーニングデータセット の 準備
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
x_train = np.reshape(x_train, (-1, 784))
x_test = np.reshape(x_test, (-1, 784))
分類器 MLP の 構築
def Model():
inputs = keras.Input(shape=(784,), name="digits")
x1 = keras.layers.Dense(64, activation="relu")(inputs)
x2 = keras.layers.Dense(64, activation="relu")(x1)
outputs = keras.layers.Dense(10, name="predictions")(x2)
return keras.Model(inputs=inputs, outputs=outputs)
def train_step(x, y, model, optimizer, loss_fn, train_acc_metric):
with tf.GradientTape() as tape:
logits = model(x, training=True)
loss_value = loss_fn(y, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return loss_value
def test_step(x, y, model, loss_fn, val_acc_metric):
val_logits = model(x, training=False)
loss_value = loss_fn(y, val_logits)
val_acc_metric.update_state(y, val_logits)
return loss_value
トレーニング ループ の 作成
def train(
train_dataset,
val_dataset,
model,
optimizer,
loss_fn,
train_acc_metric,
val_acc_metric,
epochs=10,
log_step=200,
val_log_step=50,
):
for epoch in range(epochs):
print("\nStart of epoch %d" % (epoch,))
train_loss = []
val_loss = []
# データセット の バッチ を 反復処理します
for step, (x_batch_train, y_batch_train) in tqdm.tqdm(
enumerate(train_dataset), total=len(train_dataset)
):
loss_value = train_step(
x_batch_train,
y_batch_train,
model,
optimizer,
loss_fn,
train_acc_metric,
)
train_loss.append(float(loss_value))
# 各 エポック の 最後に 検証 ループ を 実行します
for step, (x_batch_val, y_batch_val) in enumerate(val_dataset):
val_loss_value = test_step(
x_batch_val, y_batch_val, model, loss_fn, val_acc_metric
)
val_loss.append(float(val_loss_value))
# 各 エポック の 最後に メトリクス を 表示します
train_acc = train_acc_metric.result()
print("Training acc over epoch: %.4f" % (float(train_acc),))
val_acc = val_acc_metric.result()
print("Validation acc: %.4f" % (float(val_acc),))
# 各 エポック の 最後に メトリクス を リセットします
train_acc_metric.reset_states()
val_acc_metric.reset_states()
# 3️⃣ wandb.log を 使用して メトリクス を ログ に 記録します
wandb.log(
{
"epochs": epoch,
"loss": np.mean(train_loss),
"acc": float(train_acc),
"val_loss": np.mean(val_loss),
"val_acc": float(val_acc),
}
)
sweep の 設定
sweep を 設定する 手順:
- 最適化する ハイパーパラメーター を 定義します
- 最適化 method を 選択します:
random、grid、またはbayes bayesの 目標 と メトリクス を 設定します (例:val_lossの 最小化)- 実行 を 早期 に 終了させるには、
hyperbandを 使用します
詳細については、 W&B Sweeps の ドキュメント を 参照してください。
sweep_config = {
"method": "random",
"metric": {"name": "val_loss", "goal": "minimize"},
"early_terminate": {"type": "hyperband", "min_iter": 5},
"parameters": {
"batch_size": {"values": [32, 64, 128, 256]},
"learning_rate": {"values": [0.01, 0.005, 0.001, 0.0005, 0.0001]},
},
}
トレーニング ループ の ラップ
train を 呼び出す 前 に wandb.config を 使用して ハイパーパラメーター を 設定する sweep_train の よう な 関数 を 作成します。
def sweep_train(config_defaults=None):
# デフォルト値 の 設定
config_defaults = {"batch_size": 64, "learning_rate": 0.01}
# サンプル プロジェクト名 で wandb を 初期化します
wandb.init(config=config_defaults) # これは Sweep で 上書きされます
# 他の ハイパーパラメーター を 設定 (存在する場合)
wandb.config.epochs = 2
wandb.config.log_step = 20
wandb.config.val_log_step = 50
wandb.config.architecture_name = "MLP"
wandb.config.dataset_name = "MNIST"
# tf.data を 使用して 入力 パイプライン を 構築します
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = (
train_dataset.shuffle(buffer_size=1024)
.batch(wandb.config.batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(wandb.config.batch_size).prefetch(
buffer_size=tf.data.AUTOTUNE
)
# モデル の 初期化
model = Model()
# モデル を トレーニング する ため に オプティマイザー を インスタンス化します。
optimizer = keras.optimizers.SGD(learning_rate=wandb.config.learning_rate)
# 損失関数 を インスタンス化します。
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# メトリクス を 準備します。
train_acc_metric = keras.metrics.SparseCategoricalAccuracy()
val_acc_metric = keras.metrics.SparseCategoricalAccuracy()
train(
train_dataset,
val_dataset,
model,
optimizer,
loss_fn,
train_acc_metric,
val_acc_metric,
epochs=wandb.config.epochs,
log_step=wandb.config.log_step,
val_log_step=wandb.config.val_log_step,
)
sweep の 初期化 と パーソナル デジタル アシスタント の 実行
sweep_id = wandb.sweep(sweep_config, project="sweeps-tensorflow")
count パラメータ で 実行 の 数 を 制限します。クイック 実行 の 場合 は 10 に 設定します。必要 に 応じて 増やします。
wandb.agent(sweep_id, function=sweep_train, count=10)
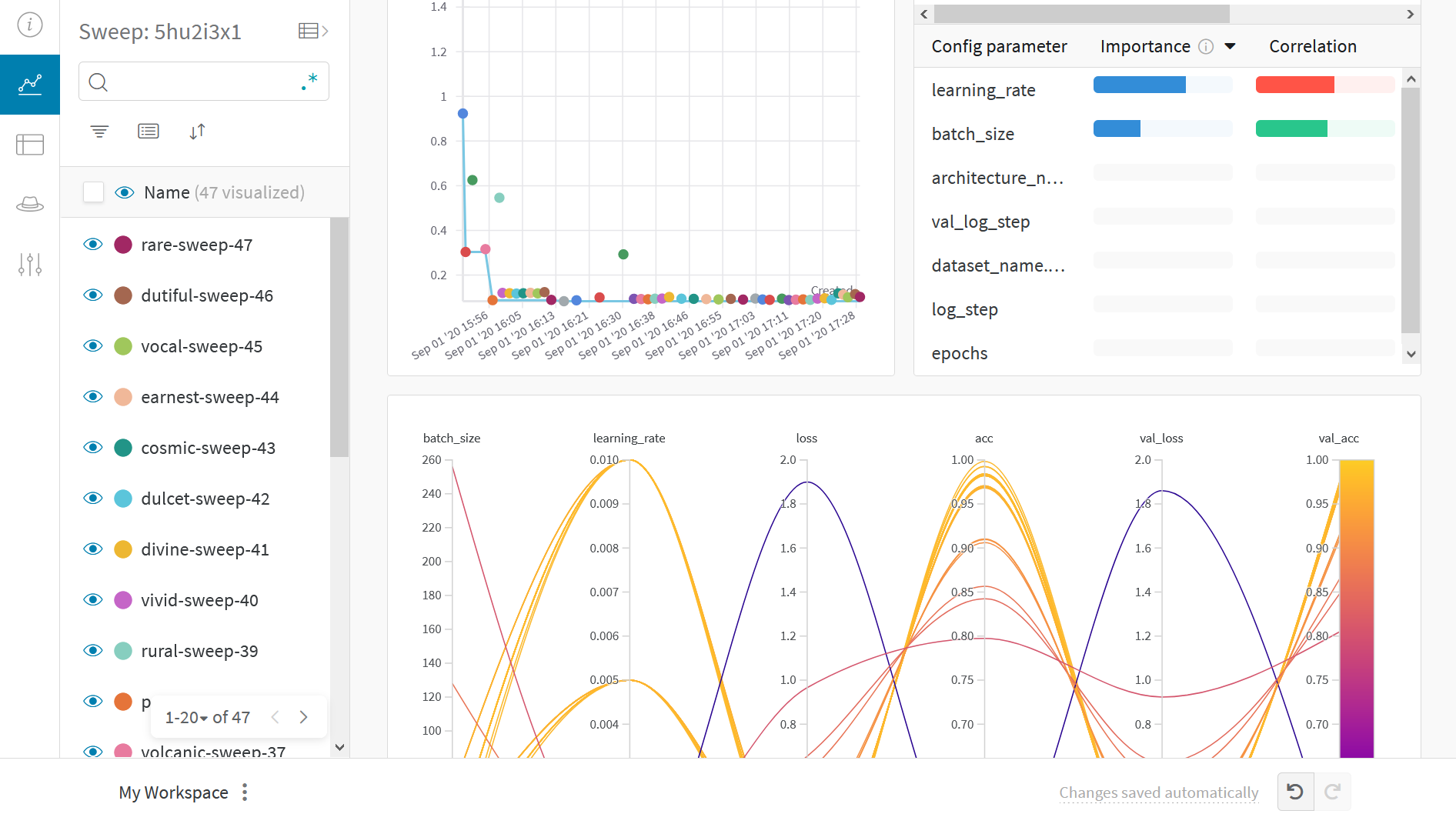
結果 の 可視化
ライブ結果 を 表示する に は、 前 の Sweep URL リンク を クリックします。
例 の ギャラリー
ギャラリー で W&B で トラッキング および 可視化 され た プロジェクト を 探索します。
ベストプラクティス
- Projects: 複数 の run を プロジェクト に 記録して 比較します。
wandb.init(project="project-name") - Groups: 複数 の プロセス または 交差検証 フォールド の run として 各 プロセス を ログ に 記録し、それら を グループ化します。
wandb.init(group='experiment-1') - Tags: タグ を 使用して、 ベースライン または プロダクション モデル を 追跡します。
- Notes: テーブル に ノート を 入力して、run 間 の 変更 を 追跡します。
- Reports: Reports を 使用して、進捗状況 の メモ、同僚 と の 共有、ML プロジェクト の ダッシュボード と スナップショット の 作成 を 行います。
高度 な 設定
- 環境変数: 管理対象 クラスター で トレーニング する ため に APIキー を 設定します。
- オフライン モード
- オンプレミス: インフラストラクチャ 内 の プライベートクラウド または エアギャップ サーバー に W&B を インストールします。ローカル インストール は、 学術 チーム と エンタープライズ チーム に 適しています。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.