XGBoost Sweeps
3 minute read

ツリーベースの モデル から最高のパフォーマンスを引き出すには、適切な ハイパーパラメーター を選択する必要があります。
early_stopping_rounds はいくつにするべきでしょうか? ツリーの max_depth はどのくらいにすべきでしょうか?
高次元の ハイパーパラメーター 空間を検索して、最もパフォーマンスの高い モデル を見つけるのは、非常に扱いにくくなる可能性があります。 ハイパーパラメーター Sweeps は、 モデル の バトルロイヤル を実施し、勝者を決定するための、組織的かつ効率的な方法を提供します。 これは、最適な値を見つけるために、 ハイパーパラメーター 値の組み合わせを自動的に検索することによって実現されます。
この チュートリアル では、Weights & Biases を使用して、XGBoost モデル で高度な ハイパーパラメーター Sweeps を 3 つの簡単なステップで実行する方法を説明します。
まず、以下の プロット を確認してください。
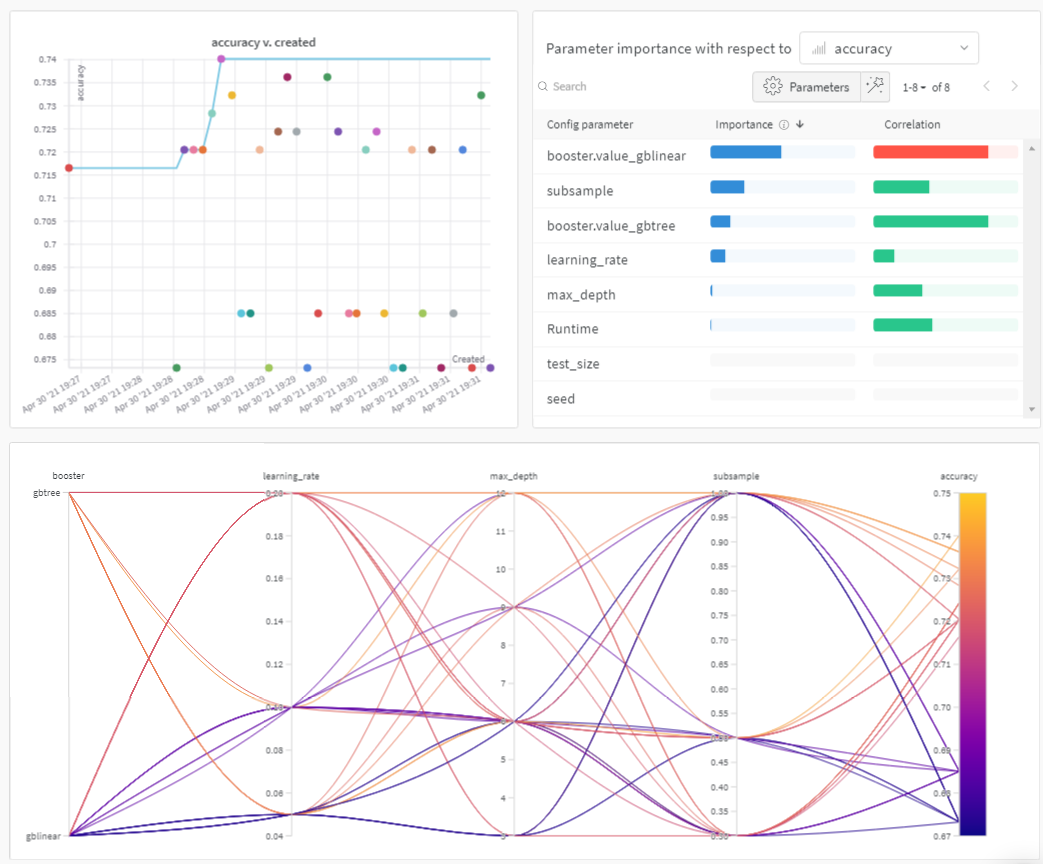
Sweeps: 概要
Weights & Biases で ハイパーパラメーター sweep を実行するのは非常に簡単です。簡単な 3 つのステップがあります。
-
sweep の定義: sweep を指定する 辞書 のような オブジェクト を作成してこれを行います。検索する パラメータ ー、使用する検索戦略、最適化する メトリクス を指定します。
-
sweep の初期化: 1 行の コード で sweep を初期化し、sweep 設定 の 辞書 を渡します。
sweep_id = wandb.sweep(sweep_config) -
sweep agent の実行: これも 1 行の コード で実行できます。
wandb.agent()を呼び出し、sweep_idと モデル の アーキテクチャー を定義して トレーニング する 関数 を渡します。wandb.agent(sweep_id, function=train)
以上が ハイパーパラメーター sweep の実行に必要なすべてです。
以下の ノートブック では、これら 3 つのステップについてさらに詳しく説明します。
この ノートブック をフォークして、 パラメータ ーを調整したり、独自の データセット で モデル を試したりすることを強くお勧めします。
リソース
!pip install wandb -qU
import wandb
wandb.login()
1. Sweep を定義する
Weights & Biases の Sweeps は、わずか数行の コード で、必要な方法で Sweeps を正確に 設定 するための強力な レバー を提供します。sweep の 設定 は、 辞書 または YAML ファイルとして定義できます。
一緒にいくつか見ていきましょう。
- メトリクス: これは、Sweeps が最適化しようとしている メトリクス です。メトリクス は、
name(この メトリクス は トレーニング スクリプト によって ログ に記録される必要があります)とgoal(maximizeまたはminimize)を受け取ることができます。 - 検索戦略:
"method"キーを使用して指定します。Sweeps では、いくつかの異なる検索戦略をサポートしています。 - グリッド検索: ハイパーパラメーター 値のすべての組み合わせを反復処理します。
- ランダム検索: ハイパーパラメーター 値のランダムに選択された組み合わせを反復処理します。
- ベイズ探索: ハイパーパラメーター を メトリクス スコア の確率にマッピングする確率 モデル を作成し、 メトリクス を改善する可能性が高い パラメータ ーを選択します。 ベイズ最適化 の目的は、 ハイパーパラメーター 値の選択により多くの時間を費やすことですが、そうすることで、試す ハイパーパラメーター 値を少なくすることです。
- パラメータ ー: ハイパーパラメーター 名、 離散値 、範囲、または各反復でその値を抽出する 分布 を含む 辞書 。
詳細については、すべての sweep 設定 オプション のリストを参照してください。
sweep_config = {
"method": "random", # try grid or random
"metric": {
"name": "accuracy",
"goal": "maximize"
},
"parameters": {
"booster": {
"values": ["gbtree","gblinear"]
},
"max_depth": {
"values": [3, 6, 9, 12]
},
"learning_rate": {
"values": [0.1, 0.05, 0.2]
},
"subsample": {
"values": [1, 0.5, 0.3]
}
}
}
2. Sweep の初期化
wandb.sweep を呼び出すと、Sweep Controller が起動します。これは、クエリを実行するすべての ユーザー に parameters の 設定 を提供し、wandb ログ を介して metrics のパフォーマンスが返されることを期待する集中化された プロセス です。
sweep_id = wandb.sweep(sweep_config, project="XGBoost-sweeps")
トレーニング プロセス を定義する
sweep を実行する前に、 モデル を作成して トレーニング する 関数 を定義する必要があります。これは、 ハイパーパラメーター 値を受け取り、 メトリクス を出力する 関数 です。
また、wandb を スクリプト に統合する必要があります。
主な コンポーネント は 3 つあります。
wandb.init(): 新しい W&B run を初期化します。各 run は、 トレーニング スクリプト の単一の実行です。wandb.config: すべての ハイパーパラメーター を 設定 オブジェクト に保存します。これにより、アプリを使用して、 ハイパーパラメーター 値で run をソートして比較できます。wandb.log(): メトリクス と、画像、ビデオ、オーディオ ファイル 、HTML、 プロット 、 ポイント クラウド などの カスタム オブジェクト を ログ に記録します。
また、 データ をダウンロードする必要があります。
!wget https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv
# XGBoost model for Pima Indians dataset
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
def train():
config_defaults = {
"booster": "gbtree",
"max_depth": 3,
"learning_rate": 0.1,
"subsample": 1,
"seed": 117,
"test_size": 0.33,
}
wandb.init(config=config_defaults) # defaults are over-ridden during the sweep
config = wandb.config
# load data and split into predictors and targets
dataset = loadtxt("pima-indians-diabetes.data.csv", delimiter=",")
X, Y = dataset[:, :8], dataset[:, 8]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size=config.test_size,
random_state=config.seed)
# fit model on train
model = XGBClassifier(booster=config.booster, max_depth=config.max_depth,
learning_rate=config.learning_rate, subsample=config.subsample)
model.fit(X_train, y_train)
# make predictions on test
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy:.0%}")
wandb.log({"accuracy": accuracy})
3. agent で Sweep を実行する
次に、wandb.agent を呼び出して sweep を起動します。
W&B に ログイン しているすべての マシン で wandb.agent を呼び出すことができます。
sweep_id、- データセット と
train関数
があり、その マシン が sweep に参加します。
注:
randomsweep は、デフォルトで永久に実行され、 牛が家に帰るまで、またはアプリ UI から sweep をオフにするまで、新しい パラメータ ーの組み合わせを試します。agentが完了する run の合計countを指定することで、これを防ぐことができます。
wandb.agent(sweep_id, train, count=25)
結果を 可視化 する
sweep が完了したので、結果を見てみましょう。
Weights & Biases は、多くの役立つ プロット を自動的に生成します。
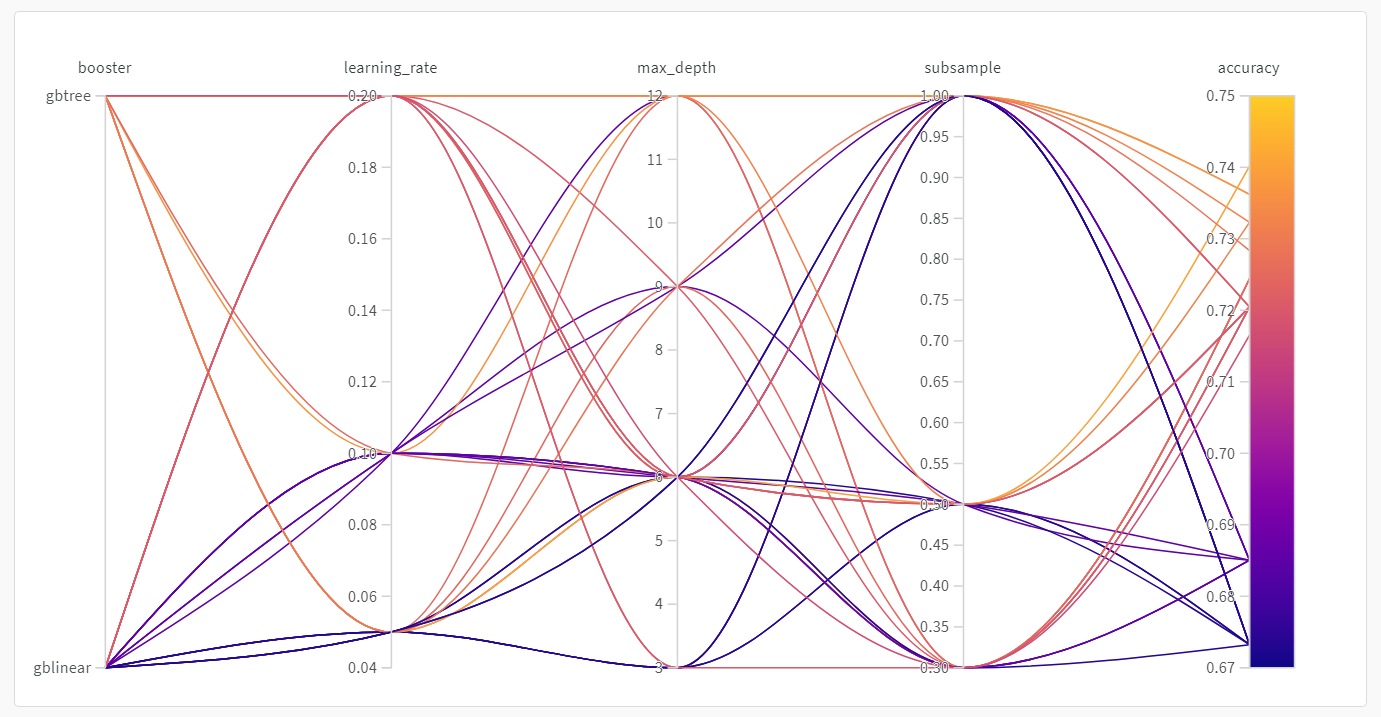
並列座標 プロット
この プロット は、 ハイパーパラメーター 値を モデル メトリクス にマッピングします。これは、最高の モデル パフォーマンスにつながった ハイパーパラメーター の組み合わせを絞り込むのに役立ちます。
この プロット は、学習者としてツリーを使用すると、単純な線形 モデル を学習者として使用するよりもわずかに、 しかし驚くほどではありませんが、 パフォーマンスが向上することを示しているようです。
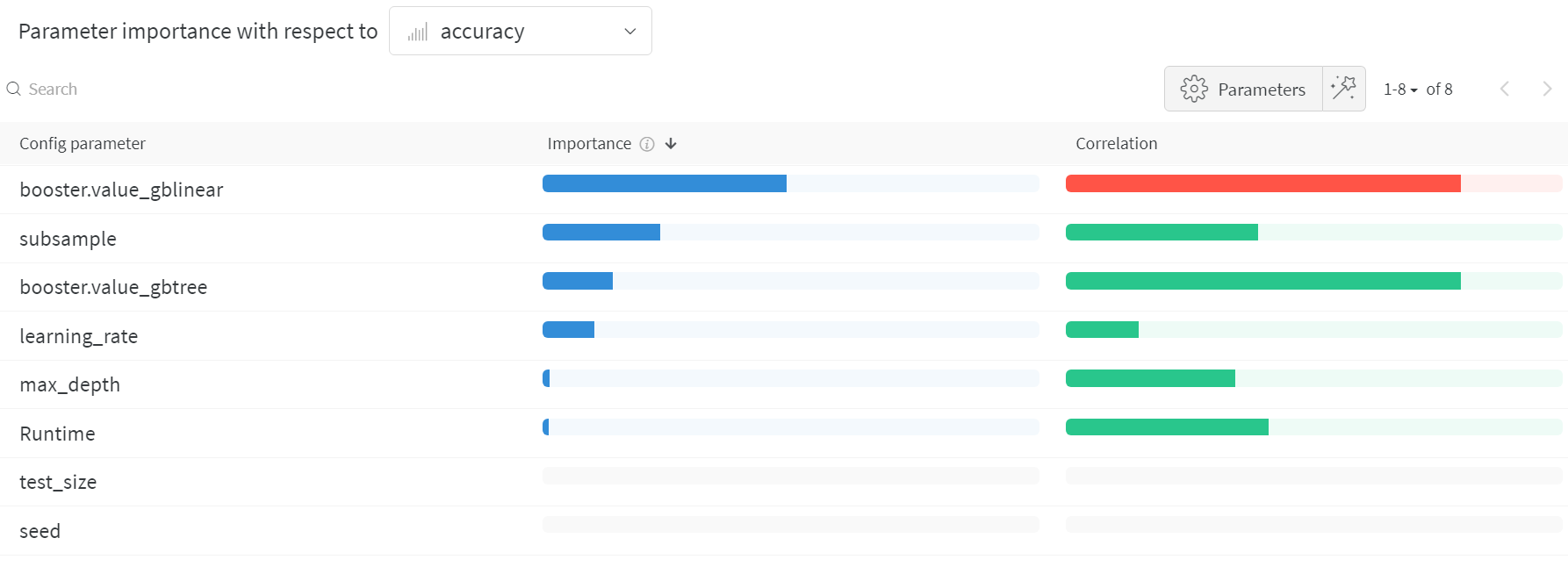
ハイパーパラメーター の インポータンスプロット
ハイパーパラメーター の インポータンスプロット は、どの ハイパーパラメーター 値が メトリクス に最も大きな影響を与えたかを示します。
線形予測子として扱い、相関関係と特徴量の重要度(結果に対して ランダムフォレスト を トレーニング した後)の両方を報告し、どの パラメータ ーが最大の影響を与えたか、 そしてその影響がプラスかマイナスかを確認できるようにします。
この チャート を読むと、上記の並列座標 チャート で気付いた傾向が定量的に確認できます。 検証精度 への最大の影響は、学習者の選択によるものであり、gblinear 学習者は一般的に gbtree 学習者よりも劣っていました。
これらの 可視化 は、最も重要な パラメータ ー(および値の範囲)に焦点を当てることで、時間とリソースを節約し、高価な ハイパーパラメーター 最適化 を実行するのに役立ち、それによってさらに調査する価値があります。
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.