이 섹션의 다중 페이지 출력 화면임. 여기를 클릭하여 프린트.
Integration tutorials
- 1: PyTorch
- 2: PyTorch Lightning
- 3: Hugging Face
- 4: TensorFlow
- 5: TensorFlow Sweeps
- 6: 3D brain tumor segmentation with MONAI
- 7: Keras
- 8: Keras models
- 9: Keras tables
- 10: XGBoost Sweeps
1 - PyTorch
기계 학습 실험 추적, 데이터셋 버전 관리 및 프로젝트 협업을 위해 Weights & Biases를 사용하세요.

이 노트북에서 다루는 내용
Weights & Biases 와 PyTorch 코드를 통합하여 파이프라인에 실험 추적을 추가하는 방법을 보여줍니다.
# 라이브러리 임포트
import wandb
# 새로운 실험 시작
wandb.init(project="new-sota-model")
# config 로 하이퍼파라미터 사전을 캡처합니다
wandb.config = {"learning_rate": 0.001, "epochs": 100, "batch_size": 128}
# 모델 및 데이터 설정
model, dataloader = get_model(), get_data()
# 선택 사항: 그레이디언트 추적
wandb.watch(model)
for batch in dataloader:
metrics = model.training_step()
# 모델 성능을 시각화하기 위해 트레이닝 루프 내에서 메트릭을 기록합니다
wandb.log(metrics)
# 선택 사항: 마지막에 모델 저장
model.to_onnx()
wandb.save("model.onnx")
비디오 가이드를 따라해보세요.
참고: Step 으로 시작하는 섹션은 기존 파이프라인에 W&B 를 통합하는 데 필요한 전부입니다. 나머지는 데이터를 로드하고 모델을 정의합니다.
설치, 임포트 및 로그인
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from tqdm.auto import tqdm
# 결정론적 동작 보장
torch.backends.cudnn.deterministic = True
random.seed(hash("setting random seeds") % 2**32 - 1)
np.random.seed(hash("improves reproducibility") % 2**32 - 1)
torch.manual_seed(hash("by removing stochasticity") % 2**32 - 1)
torch.cuda.manual_seed_all(hash("so runs are repeatable") % 2**32 - 1)
# 장치 설정
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# MNIST 미러 목록에서 느린 미러 제거
torchvision.datasets.MNIST.mirrors = [mirror for mirror in torchvision.datasets.MNIST.mirrors
if not mirror.startswith("http://yann.lecun.com")]
0단계: W&B 설치
시작하려면 라이브러리를 가져와야 합니다.
wandb 는 pip 를 사용하여 쉽게 설치할 수 있습니다.
!pip install wandb onnx -Uq
1단계: W&B 임포트 및 로그인
웹 서비스에 데이터를 기록하려면 로그인해야 합니다.
W&B 를 처음 사용하는 경우 나타나는 링크에서 무료 계정에 가입해야 합니다.
import wandb
wandb.login()
실험 및 파이프라인 정의
wandb.init 로 메타데이터 및 하이퍼파라미터 추적
프로그래밍 방식으로 가장 먼저 하는 일은 실험을 정의하는 것입니다. 하이퍼파라미터는 무엇입니까? 이 run 과 연결된 메타데이터는 무엇입니까?
이 정보를 config 사전에 저장하는 것은 매우 일반적인 워크플로우입니다
(또는 유사한 오브젝트)
필요에 따라 엑세스합니다.
이 예에서는 몇 가지 하이퍼파라미터만 변경하고
나머지는 수동으로 코딩합니다.
그러나 모델의 모든 부분이 config 의 일부가 될 수 있습니다.
또한 MNIST 데이터셋과 컨볼루션 아키텍처를 사용하고 있다는 메타데이터도 포함합니다. 나중에 동일한 프로젝트에서 CIFAR 에 대한 완전 연결 아키텍처를 사용하는 경우 run 을 분리하는 데 도움이 됩니다.
config = dict(
epochs=5,
classes=10,
kernels=[16, 32],
batch_size=128,
learning_rate=0.005,
dataset="MNIST",
architecture="CNN")
이제 전체 파이프라인을 정의해 보겠습니다. 이는 모델 트레이닝에 매우 일반적입니다.
- 먼저 모델과 관련 데이터 및 옵티마이저를
make한 다음 - 모델을 적절하게
train하고 마지막으로 test하여 트레이닝이 어떻게 진행되었는지 확인합니다.
이러한 함수는 아래에서 구현합니다.
def model_pipeline(hyperparameters):
# wandb 에게 시작하라고 알립니다
with wandb.init(project="pytorch-demo", config=hyperparameters):
# wandb.config 를 통해 모든 HP 에 엑세스하므로 로깅이 실행과 일치합니다.
config = wandb.config
# 모델, 데이터 및 최적화 문제 만들기
model, train_loader, test_loader, criterion, optimizer = make(config)
print(model)
# 모델을 트레이닝하는 데 사용합니다
train(model, train_loader, criterion, optimizer, config)
# 최종 성능 테스트
test(model, test_loader)
return model
표준 파이프라인과의 유일한 차이점은
모두 wandb.init 의 컨텍스트 내에서 발생한다는 것입니다.
이 함수를 호출하면 코드와 서버 간에 통신 라인이 설정됩니다.
config 사전을 wandb.init 에 전달하면
해당 정보가 즉시 기록되므로
실험에서 사용할 하이퍼파라미터 값을 항상 알 수 있습니다.
선택하고 기록한 값이 항상 모델에서 사용되는지 확인하려면
오브젝트의 wandb.config 사본을 사용하는 것이 좋습니다.
몇 가지 예제를 보려면 아래 make 의 정의를 확인하세요.
참고: 코드를 별도의 프로세스에서 실행하도록 주의합니다. 따라서 당사 측의 문제 (예: 거대한 바다 괴물이 데이터 센터를 공격하는 경우) 코드가 충돌하지 않습니다. 크라켄이 심해로 돌아갈 때와 같이 문제가 해결되면
wandb sync로 데이터를 기록할 수 있습니다.
def make(config):
# 데이터 만들기
train, test = get_data(train=True), get_data(train=False)
train_loader = make_loader(train, batch_size=config.batch_size)
test_loader = make_loader(test, batch_size=config.batch_size)
# 모델 만들기
model = ConvNet(config.kernels, config.classes).to(device)
# 손실 및 옵티마이저 만들기
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
model.parameters(), lr=config.learning_rate)
return model, train_loader, test_loader, criterion, optimizer
데이터 로딩 및 모델 정의
이제 데이터를 로드하는 방법과 모델의 모양을 지정해야 합니다.
이 부분은 매우 중요하지만
wandb 가 없으면 달라지지 않으므로
자세히 설명하지 않겠습니다.
def get_data(slice=5, train=True):
full_dataset = torchvision.datasets.MNIST(root=".",
train=train,
transform=transforms.ToTensor(),
download=True)
# [::slice] 로 슬라이싱하는 것과 같습니다
sub_dataset = torch.utils.data.Subset(
full_dataset, indices=range(0, len(full_dataset), slice))
return sub_dataset
def make_loader(dataset, batch_size):
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True, num_workers=2)
return loader
모델을 정의하는 것은 일반적으로 재미있는 부분입니다.
하지만 wandb 에서는 아무것도 변경되지 않으므로
표준 ConvNet 아키텍처를 고수할 것입니다.
이것저것 만지작거리고 실험을 두려워하지 마세요. 모든 결과는 wandb.ai 에 기록됩니다.
# 기존 컨볼루션 신경망
class ConvNet(nn.Module):
def __init__(self, kernels, classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, kernels[0], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, kernels[1], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * kernels[-1], classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
트레이닝 로직 정의
model_pipeline 에서 계속 진행하여 train 방법을 지정할 시간입니다.
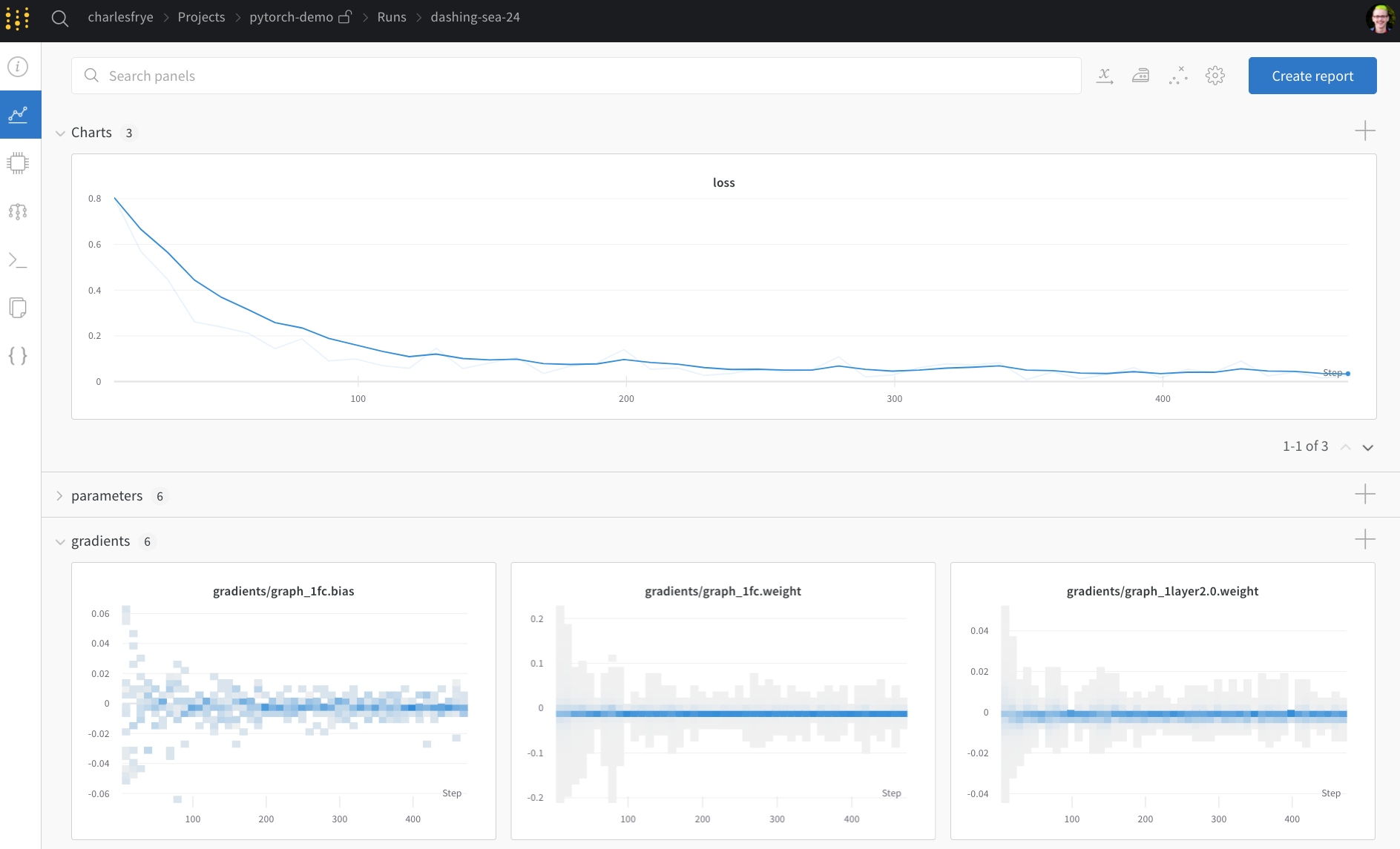
여기서 두 개의 wandb 함수가 사용됩니다. watch 와 log 입니다.
wandb.watch 로 그레이디언트를 추적하고 wandb.log 로 다른 모든 것을 추적합니다
wandb.watch 는 트레이닝의 모든 log_freq 단계에서 모델의 그레이디언트와 파라미터를 기록합니다.
트레이닝을 시작하기 전에 호출하기만 하면 됩니다.
나머지 트레이닝 코드는 동일하게 유지됩니다.
에포크와 배치를 반복하고,
forward 및 backward 패스를 실행하고
옵티마이저 를 적용합니다.
def train(model, loader, criterion, optimizer, config):
# wandb 에게 모델이 무엇을 하는지 (그레이디언트, 가중치 등) 감시하라고 지시합니다.
wandb.watch(model, criterion, log="all", log_freq=10)
# wandb 로 트레이닝을 실행하고 추적합니다
total_batches = len(loader) * config.epochs
example_ct = 0 # 확인된 예제 수
batch_ct = 0
for epoch in tqdm(range(config.epochs)):
for _, (images, labels) in enumerate(loader):
loss = train_batch(images, labels, model, optimizer, criterion)
example_ct += len(images)
batch_ct += 1
# 25번째마다 메트릭 보고
if ((batch_ct + 1) % 25) == 0:
train_log(loss, example_ct, epoch)
def train_batch(images, labels, model, optimizer, criterion):
images, labels = images.to(device), labels.to(device)
# Forward 패스 ➡
outputs = model(images)
loss = criterion(outputs, labels)
# Backward 패스 ⬅
optimizer.zero_grad()
loss.backward()
# 옵티마이저로 단계 진행
optimizer.step()
return loss
유일한 차이점은 로깅 코드에 있습니다.
이전에는 터미널에 인쇄하여 메트릭을 보고했을 수 있지만,
이제 동일한 정보를 wandb.log 에 전달합니다.
wandb.log 는 문자열을 키로 사용하는 사전을 예상합니다.
이러한 문자열은 기록되는 오브젝트를 식별하며, 값을 구성합니다.
선택적으로 트레이닝의 step 을 기록할 수도 있습니다.
참고: 모델이 확인한 예제 수를 사용하는 것을 좋아합니다. 배치 크기 간에 더 쉽게 비교할 수 있기 때문입니다. 하지만 원시 단계 또는 배치 수를 사용할 수 있습니다. 트레이닝 run 이 더 길어지면
에포크로 기록하는 것이 좋습니다.
def train_log(loss, example_ct, epoch):
# 마법이 일어나는 곳
wandb.log({"epoch": epoch, "loss": loss}, step=example_ct)
print(f"Loss after {str(example_ct).zfill(5)} examples: {loss:.3f}")
테스팅 로직 정의
모델 트레이닝이 완료되면 테스트해야 합니다. 프로덕션의 최신 데이터에 대해 실행하거나 수동으로 큐레이팅된 예제에 적용합니다.
(선택 사항) wandb.save 호출
모델 아키텍처를 저장하는 것도 좋은 시기입니다
디스크에 최종 파라미터를 저장합니다.
최대 호환성을 위해 모델을
ONNX (Open Neural Network eXchange) 형식으로 내보냅니다.
해당 파일 이름을 wandb.save 에 전달하면 모델 파라미터가
W&B 서버에 저장됩니다. 더 이상 어떤 .h5 또는 .pb 가
어떤 트레이닝 run 에 해당하는지 추적하지 않아도 됩니다.
모델 저장, 버전 관리 및 배포를 위한 더 고급 wandb 기능은
Artifacts 툴을 확인하세요.
def test(model, test_loader):
model.eval()
# 일부 테스트 예제에서 모델 실행
with torch.no_grad():
correct, total = 0, 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy of the model on the {total} " +
f"test images: {correct / total:%}")
wandb.log({"test_accuracy": correct / total})
# 교환 가능한 ONNX 형식으로 모델 저장
torch.onnx.export(model, images, "model.onnx")
wandb.save("model.onnx")
wandb.ai 에서 트레이닝을 실행하고 메트릭을 실시간으로 확인하세요
전체 파이프라인을 정의하고 몇 줄의 W&B 코드를 추가했으므로 완전히 추적된 실험을 실행할 준비가 되었습니다.
몇 가지 링크를 보고합니다. 당사의 설명서, 프로젝트의 모든 run 을 구성하는 프로젝트 페이지, 이 run 의 결과가 저장될 Run 페이지입니다.
Run 페이지로 이동하여 다음 탭을 확인하세요.
- 차트, 트레이닝 전반에 걸쳐 모델 그레이디언트, 파라미터 값 및 손실이 기록됩니다.
- 시스템, 디스크 I/O 활용률, CPU 및 GPU 메트릭 (온도가 급상승하는 것을 확인하세요) 등을 포함한 다양한 시스템 메트릭이 포함되어 있습니다.
- 로그, 트레이닝 중에 표준 출력으로 푸시된 모든 항목의 사본이 있습니다.
- 파일, 트레이닝이 완료되면
model.onnx를 클릭하여 Netron 모델 뷰어로 네트워크를 볼 수 있습니다.
with wandb.init 블록이 종료될 때 run 이 완료되면
셀 출력에 결과 요약도 인쇄합니다.
# 파이프라인으로 모델 빌드, 트레이닝 및 분석
model = model_pipeline(config)
Sweeps 로 하이퍼파라미터 테스트
이 예에서는 하이퍼파라미터의 단일 세트만 살펴보았습니다. 그러나 대부분의 ML 워크플로우에서 중요한 부분은 여러 하이퍼파라미터를 반복하는 것입니다.
Weights & Biases Sweeps 를 사용하여 하이퍼파라미터 테스팅을 자동화하고 가능한 모델 및 최적화 전략 공간을 탐색할 수 있습니다.
W&B Sweeps 를 사용하여 PyTorch 에서 하이퍼파라미터 최적화 확인
Weights & Biases 로 하이퍼파라미터 스윕을 실행하는 것은 매우 쉽습니다. 다음과 같은 3가지 간단한 단계가 있습니다.
-
스윕 정의: 검색할 파라미터, 검색 전략, 최적화 메트릭 등을 지정하는 사전 또는 YAML 파일을 만들어 이 작업을 수행합니다.
-
스윕 초기화:
sweep_id = wandb.sweep(sweep_config) -
스윕 에이전트 실행:
wandb.agent(sweep_id, function=train)
하이퍼파라미터 스윕을 실행하는 데 필요한 전부입니다.
예제 갤러리
갤러리 →에서 W&B 로 추적 및 시각화된 프로젝트의 예제를 확인하세요
고급 설정
2 - PyTorch Lightning
PyTorch Lightning를 사용하여 이미지 분류 파이프라인을 구축합니다. 코드의 가독성과 재현성을 높이기 위해 이 스타일 가이드를 따릅니다. 이에 대한 멋진 설명은 여기에서 확인할 수 있습니다.PyTorch Lightning 및 W&B 설정
이 튜토리얼에서는 PyTorch Lightning와 Weights & Biases가 필요합니다.
pip install lightning -q
pip install wandb -qU
import lightning.pytorch as pl
# 당신이 가장 선호하는 기계 학습 추적 툴
from lightning.pytorch.loggers import WandbLogger
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import random_split, DataLoader
from torchmetrics import Accuracy
from torchvision import transforms
from torchvision.datasets import CIFAR10
import wandb
이제 wandb 계정에 로그인해야 합니다.
wandb.login()
DataModule - 우리가 원하는 데이터 파이프라인
DataModule은 데이터 관련 훅을 LightningModule에서 분리하여 데이터셋에 구애받지 않는 모델을 개발할 수 있도록 하는 방법입니다.
데이터 파이프라인을 하나의 공유 및 재사용 가능한 클래스로 구성합니다. DataModule은 PyTorch에서 데이터 처리와 관련된 5단계를 캡슐화합니다.
- 다운로드 / 토큰화 / 처리.
- 정리하고 (선택적으로) 디스크에 저장.
- 데이터셋 내부에 로드.
- 변환 적용 (회전, 토큰화 등…).
- DataLoader 내부에 래핑.
DataModule에 대해 자세히 알아보려면 여기를 참조하세요. Cifar-10 데이터셋을 위한 DataModule을 구축해 보겠습니다.
class CIFAR10DataModule(pl.LightningDataModule):
def __init__(self, batch_size, data_dir: str = './'):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
self.num_classes = 10
def prepare_data(self):
CIFAR10(self.data_dir, train=True, download=True)
CIFAR10(self.data_dir, train=False, download=True)
def setup(self, stage=None):
# dataloader에서 사용할 train/val 데이터셋 할당
if stage == 'fit' or stage is None:
cifar_full = CIFAR10(self.data_dir, train=True, transform=self.transform)
self.cifar_train, self.cifar_val = random_split(cifar_full, [45000, 5000])
# dataloader에서 사용할 테스트 데이터셋 할당
if stage == 'test' or stage is None:
self.cifar_test = CIFAR10(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.cifar_train, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.cifar_val, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.cifar_test, batch_size=self.batch_size)
콜백
콜백은 프로젝트 전반에서 재사용할 수 있는 독립적인 프로그램입니다. PyTorch Lightning에는 정기적으로 사용되는 몇 가지 기본 제공 콜백이 함께 제공됩니다. PyTorch Lightning의 콜백에 대해 자세히 알아보려면 여기를 참조하세요.
내장 콜백
이 튜토리얼에서는 Early Stopping 및 Model Checkpoint 내장 콜백을 사용합니다. 이는 Trainer에 전달될 수 있습니다.
사용자 지정 콜백
사용자 지정 Keras 콜백에 익숙하다면 PyTorch 파이프라인에서 동일한 작업을 수행할 수 있다는 것은 금상첨화입니다.
이미지 분류를 수행하므로 이미지 샘플에 대한 모델의 예측을 시각화할 수 있는 기능이 유용할 수 있습니다. 콜백 형태의 이러한 기능은 초기 단계에서 모델을 디버그하는 데 도움이 될 수 있습니다.
class ImagePredictionLogger(pl.callbacks.Callback):
def __init__(self, val_samples, num_samples=32):
super().__init__()
self.num_samples = num_samples
self.val_imgs, self.val_labels = val_samples
def on_validation_epoch_end(self, trainer, pl_module):
# 텐서를 CPU로 가져오기
val_imgs = self.val_imgs.to(device=pl_module.device)
val_labels = self.val_labels.to(device=pl_module.device)
# 모델 예측 가져오기
logits = pl_module(val_imgs)
preds = torch.argmax(logits, -1)
# 이미지를 wandb Image로 기록
trainer.logger.experiment.log({
"examples":[wandb.Image(x, caption=f"Pred:{pred}, Label:{y}")
for x, pred, y in zip(val_imgs[:self.num_samples],
preds[:self.num_samples],
val_labels[:self.num_samples])]
})
LightningModule - 시스템 정의
LightningModule은 모델이 아닌 시스템을 정의합니다. 여기서 시스템은 모든 연구 코드를 단일 클래스로 그룹화하여 독립적으로 만듭니다. LightningModule은 PyTorch 코드를 5개의 섹션으로 구성합니다.
- 계산 (
__init__). - 트레이닝 루프 (
training_step) - 검증 루프 (
validation_step) - 테스트 루프 (
test_step) - 옵티마이저 (
configure_optimizers)
따라서 쉽게 공유할 수 있는 데이터셋에 구애받지 않는 모델을 구축할 수 있습니다. Cifar-10 분류를 위한 시스템을 구축해 보겠습니다.
class LitModel(pl.LightningModule):
def __init__(self, input_shape, num_classes, learning_rate=2e-4):
super().__init__()
# 하이퍼파라미터 기록
self.save_hyperparameters()
self.learning_rate = learning_rate
self.conv1 = nn.Conv2d(3, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 32, 3, 1)
self.conv3 = nn.Conv2d(32, 64, 3, 1)
self.conv4 = nn.Conv2d(64, 64, 3, 1)
self.pool1 = torch.nn.MaxPool2d(2)
self.pool2 = torch.nn.MaxPool2d(2)
n_sizes = self._get_conv_output(input_shape)
self.fc1 = nn.Linear(n_sizes, 512)
self.fc2 = nn.Linear(512, 128)
self.fc3 = nn.Linear(128, num_classes)
self.accuracy = Accuracy(task='multiclass', num_classes=num_classes)
# conv 블록에서 Linear 레이어로 들어가는 출력 텐서의 크기를 반환합니다.
def _get_conv_output(self, shape):
batch_size = 1
input = torch.autograd.Variable(torch.rand(batch_size, *shape))
output_feat = self._forward_features(input)
n_size = output_feat.data.view(batch_size, -1).size(1)
return n_size
# conv 블록에서 특징 텐서를 반환합니다.
def _forward_features(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = self.pool2(F.relu(self.conv4(x)))
return x
# 추론 중에 사용됩니다.
def forward(self, x):
x = self._forward_features(x)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.log_softmax(self.fc3(x), dim=1)
return x
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
# 트레이닝 메트릭
preds = torch.argmax(logits, dim=1)
acc = self.accuracy(preds, y)
self.log('train_loss', loss, on_step=True, on_epoch=True, logger=True)
self.log('train_acc', acc, on_step=True, on_epoch=True, logger=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
# 검증 메트릭
preds = torch.argmax(logits, dim=1)
acc = self.accuracy(preds, y)
self.log('val_loss', loss, prog_bar=True)
self.log('val_acc', acc, prog_bar=True)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
# 검증 메트릭
preds = torch.argmax(logits, dim=1)
acc = self.accuracy(preds, y)
self.log('test_loss', loss, prog_bar=True)
self.log('test_acc', acc, prog_bar=True)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
return optimizer
트레이닝 및 평가
이제 DataModule을 사용하여 데이터 파이프라인을 구성하고 LightningModule을 사용하여 모델 아키텍처 + 트레이닝 루프를 구성했으므로 PyTorch Lightning Trainer가 다른 모든 것을 자동화합니다.
Trainer는 다음을 자동화합니다.
- 에포크 및 배치 반복
optimizer.step(),backward,zero_grad()호출.eval()호출, grads 활성화/비활성화- 가중치 저장 및 로드
- Weights & Biases 로깅
- 다중 GPU 트레이닝 지원
- TPU 지원
- 16비트 트레이닝 지원
dm = CIFAR10DataModule(batch_size=32)
# x_dataloader에 액세스하려면 prepare_data 및 setup을 호출해야 합니다.
dm.prepare_data()
dm.setup()
# 이미지 예측을 기록하기 위해 사용자 지정 ImagePredictionLogger 콜백에 필요한 샘플입니다.
val_samples = next(iter(dm.val_dataloader()))
val_imgs, val_labels = val_samples[0], val_samples[1]
val_imgs.shape, val_labels.shape
model = LitModel((3, 32, 32), dm.num_classes)
# wandb 로거 초기화
wandb_logger = WandbLogger(project='wandb-lightning', job_type='train')
# 콜백 초기화
early_stop_callback = pl.callbacks.EarlyStopping(monitor="val_loss")
checkpoint_callback = pl.callbacks.ModelCheckpoint()
# 트레이너 초기화
trainer = pl.Trainer(max_epochs=2,
logger=wandb_logger,
callbacks=[early_stop_callback,
ImagePredictionLogger(val_samples),
checkpoint_callback],
)
# 모델 트레이닝
trainer.fit(model, dm)
# 보류된 테스트 세트에서 모델 평가 ⚡⚡
trainer.test(dataloaders=dm.test_dataloader())
# wandb run 닫기
wandb.finish()
마지막 생각
저는 TensorFlow/Keras 에코시스템에서 왔으며 PyTorch가 우아한 프레임워크임에도 불구하고 약간 부담스럽다고 생각합니다. 그냥 제 개인적인 경험입니다. PyTorch Lightning를 탐색하면서 저를 PyTorch에서 멀어지게 했던 거의 모든 이유가 해결되었다는 것을 깨달았습니다. 제 흥분에 대한 간략한 요약은 다음과 같습니다.
- 이전: 기존 PyTorch 모델 정의는 모든 곳에 흩어져 있었습니다. 일부
model.py스크립트의 모델과train.py파일의 트레이닝 루프를 사용했습니다. 파이프라인을 이해하기 위해 앞뒤로 많이 살펴봐야 했습니다. - 현재:
LightningModule은 모델이training_step,validation_step등과 함께 정의되는 시스템 역할을 합니다. 이제 모듈화되고 공유 가능합니다. - 이전: TensorFlow/Keras의 가장 좋은 부분은 입력 데이터 파이프라인입니다. 해당 데이터셋 카탈로그는 풍부하고 성장하고 있습니다. PyTorch의 데이터 파이프라인은 가장 큰 문제점이었습니다. 일반적인 PyTorch 코드에서 데이터 다운로드/정리/준비는 일반적으로 여러 파일에 흩어져 있습니다.
- 현재: DataModule은 데이터 파이프라인을 하나의 공유 및 재사용 가능한 클래스로 구성합니다. 이는 필요한 변환 및 데이터 처리/다운로드 단계와 함께
train_dataloader,val_dataloader(s),test_dataloader(s)의 모음일 뿐입니다. - 이전: Keras를 사용하면
model.fit을 호출하여 모델을 트레이닝하고model.predict를 호출하여 추론을 실행할 수 있습니다.model.evaluate는 테스트 데이터에 대한 간단한 평가를 제공했습니다. PyTorch에서는 그렇지 않습니다. 일반적으로 별도의train.py및test.py파일을 찾을 수 있습니다. - 현재:
LightningModule을 사용하면Trainer가 모든 것을 자동화합니다. 모델을 트레이닝하고 평가하려면trainer.fit및trainer.test를 호출하기만 하면 됩니다. - 이전: TensorFlow는 TPU를 좋아하고 PyTorch는…
- 현재: PyTorch Lightning를 사용하면 여러 GPU와 심지어 TPU에서도 동일한 모델을 쉽게 트레이닝할 수 있습니다.
- 이전: 저는 콜백의 큰 팬이며 사용자 지정 콜백을 작성하는 것을 선호합니다. Early Stopping과 같이 사소한 것도 기존 PyTorch와의 논의 대상이었습니다.
- 현재: PyTorch Lightning를 사용하면 Early Stopping 및 Model Checkpointing이 매우 쉽습니다. 사용자 지정 콜백을 작성할 수도 있습니다.
🎨 결론 및 리소스
이 리포트가 도움이 되었기를 바랍니다. 코드를 가지고 놀고 원하는 데이터셋으로 이미지 분류기를 트레이닝하는 것이 좋습니다.
PyTorch Lightning에 대해 자세히 알아볼 수 있는 몇 가지 리소스는 다음과 같습니다.
- 단계별 연습 - 이것은 공식 튜토리얼 중 하나입니다. 해당 문서는 정말 잘 작성되어 있으며 훌륭한 학습 리소스로 적극 권장합니다.
- Weights & Biases와 함께 Pytorch Lightning 사용 - W&B와 함께 PyTorch Lightning를 사용하는 방법에 대해 자세히 알아보기 위해 실행할 수 있는 빠른 colab입니다.
3 - Hugging Face
 원활한 W&B 연동으로 Hugging Face 모델의 성능을 빠르게 시각화하세요.
원활한 W&B 연동으로 Hugging Face 모델의 성능을 빠르게 시각화하세요.
모델 전반에서 하이퍼파라미터, 출력 메트릭, GPU 사용률과 같은 시스템 통계를 비교합니다.
W&B를 사용해야 하는 이유
- 통합 대시보드: 모든 모델 메트릭 및 예측값에 대한 중앙 저장소
- 간편함: Hugging Face와 통합하기 위해 코드 변경이 필요하지 않음
- 접근성: 개인 및 학술 팀에 무료 제공
- 보안: 모든 Projects는 기본적으로 비공개임
- 신뢰성: OpenAI, Toyota, Lyft 등의 기계 학습 팀에서 사용
W&B는 기계 학습 모델을 위한 GitHub와 같습니다. 개인 호스팅 대시보드에 기계 학습 Experiments를 저장하세요. 스크립트를 실행하는 위치에 관계없이 모델의 모든 버전을 저장하므로 안심하고 빠르게 실험할 수 있습니다.
W&B의 간편한 인테그레이션은 모든 Python 스크립트에서 작동하며, 모델 추적 및 시각화를 시작하려면 무료 W&B 계정에 가입하기만 하면 됩니다.
Hugging Face Transformers repo에서 Trainer를 통해 각 로깅 단계에서 트레이닝 및 평가 메트릭을 W&B에 자동으로 기록합니다.
다음은 인테그레이션 작동 방식에 대한 자세한 내용입니다: Hugging Face + W&B Report.
설치, 임포트 및 로그인
Hugging Face 및 Weights & Biases 라이브러리, 그리고 이 튜토리얼의 GLUE 데이터셋 및 트레이닝 스크립트를 설치합니다.
- Hugging Face Transformers: 자연어 모델 및 데이터셋
- Weights & Biases: Experiment 추적 및 시각화
- GLUE dataset: 언어 이해 벤치마크 데이터셋
- GLUE script: 시퀀스 분류를 위한 모델 트레이닝 스크립트
!pip install datasets wandb evaluate accelerate -qU
!wget https://raw.githubusercontent.com/huggingface/transformers/refs/heads/main/examples/pytorch/text-classification/run_glue.py
# run_glue.py 스크립트를 실행하려면 transformers dev가 필요합니다.
!pip install -q git+https://github.com/huggingface/transformers
계속하기 전에 무료 계정에 가입하세요.
API 키 넣기
가입했으면 다음 셀을 실행하고 링크를 클릭하여 API 키를 가져와 이 노트북을 인증합니다.
import wandb
wandb.login()
선택적으로 환경 변수를 설정하여 W&B 로깅을 사용자 정의할 수 있습니다. 설명서를 참조하세요.
# 선택 사항: 그레이디언트와 파라미터를 모두 기록합니다.
%env WANDB_WATCH=all
모델 트레이닝
다음으로 다운로드한 트레이닝 스크립트 run_glue.py를 호출하고 트레이닝이 Weights & Biases 대시보드에서 자동으로 추적되는지 확인합니다. 이 스크립트는 의미상 동등한지 여부를 나타내는 사람 주석이 있는 문장 쌍인 Microsoft Research Paraphrase Corpus에서 BERT를 파인튜닝합니다.
%env WANDB_PROJECT=huggingface-demo
%env TASK_NAME=MRPC
!python run_glue.py \
--model_name_or_path bert-base-uncased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 256 \
--per_device_train_batch_size 32 \
--learning_rate 2e-4 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir \
--logging_steps 50
대시보드에서 결과 시각화
위에 출력된 링크를 클릭하거나 wandb.ai로 이동하여 결과가 실시간으로 스트리밍되는 것을 확인하세요. 브라우저에서 run을 볼 수 있는 링크는 모든 종속성이 로드된 후에 나타납니다. 다음 출력을 찾으세요: “wandb: 🚀 View run at [URL to your unique run]”
모델 성능 시각화 수십 개의 Experiments를 살펴보고, 흥미로운 발견에 집중하고, 고차원 데이터를 시각화하는 것이 쉽습니다.
아키텍처 비교 다음은 BERT vs DistilBERT를 비교하는 예입니다. 자동 라인 플롯 시각화를 통해 트레이닝 전반에 걸쳐 다양한 아키텍처가 평가 정확도에 미치는 영향을 쉽게 확인할 수 있습니다.
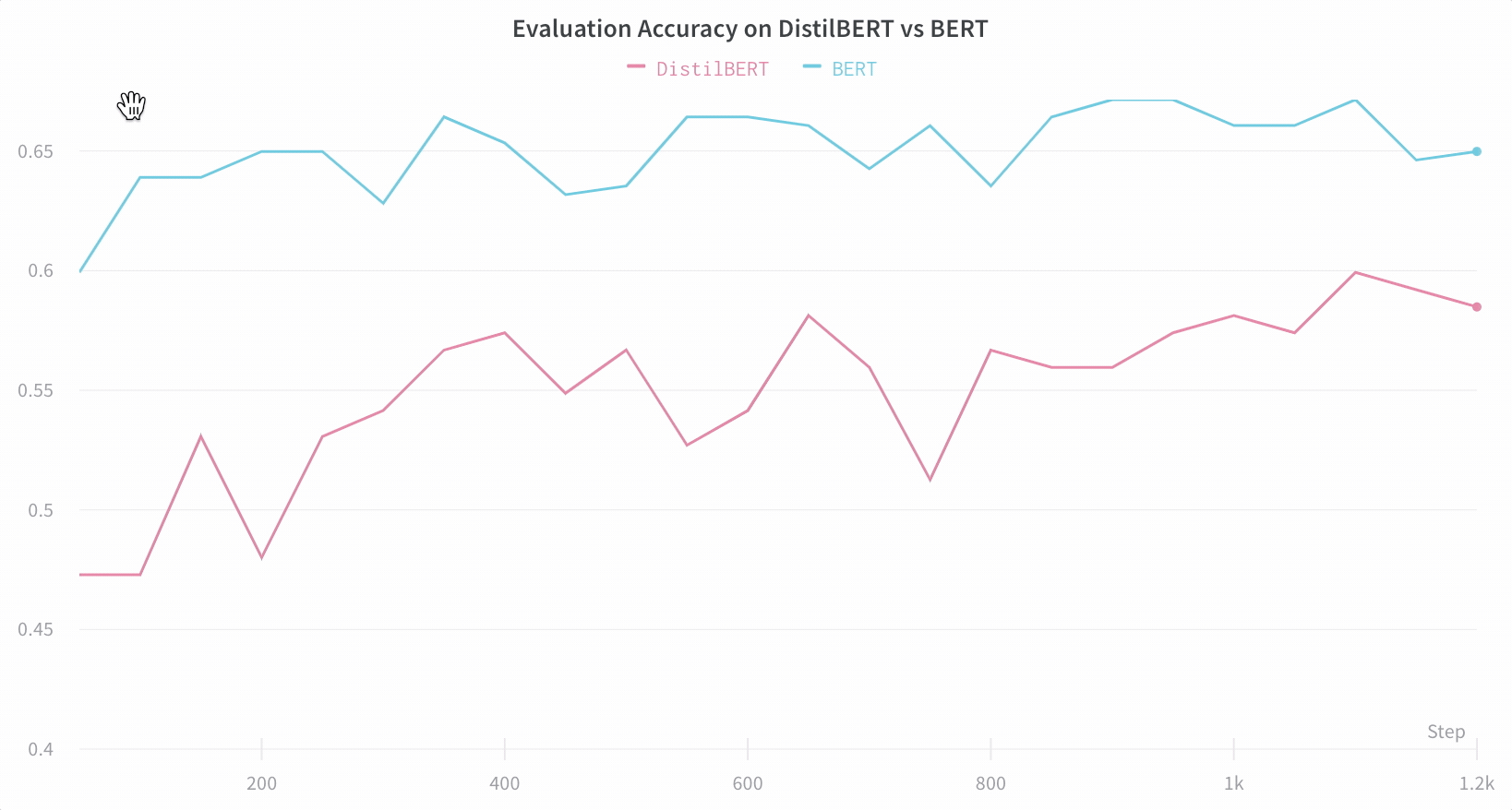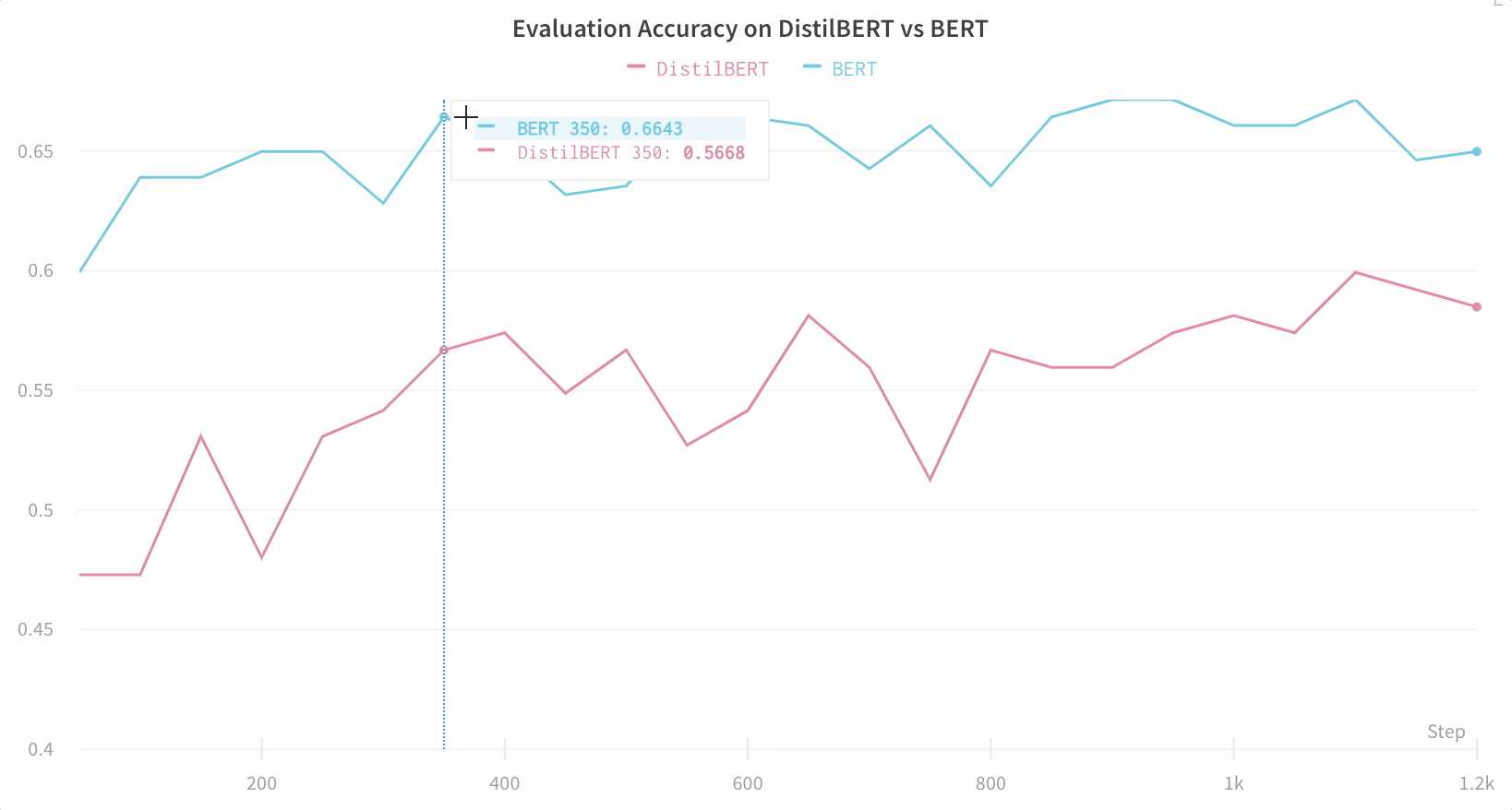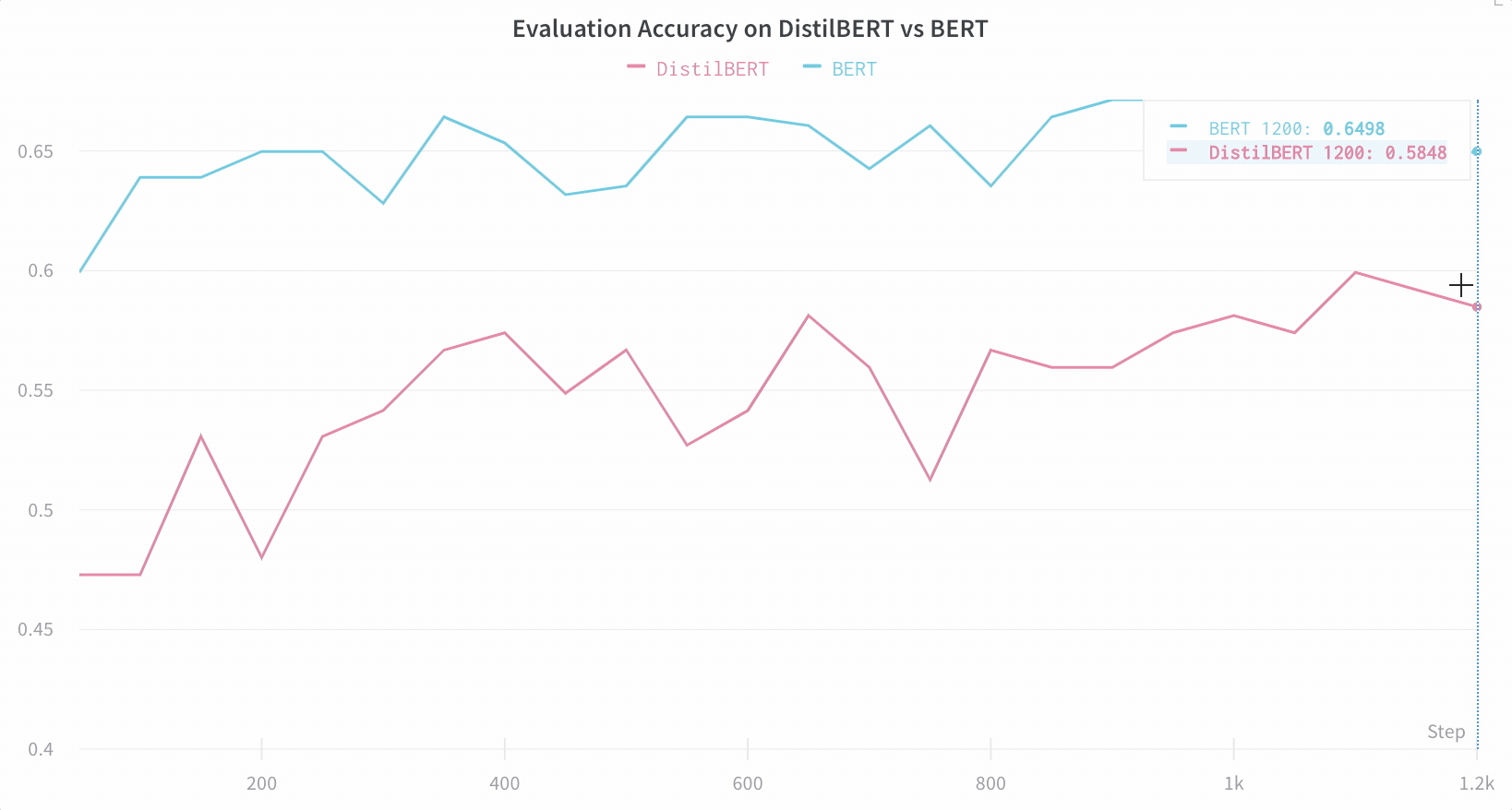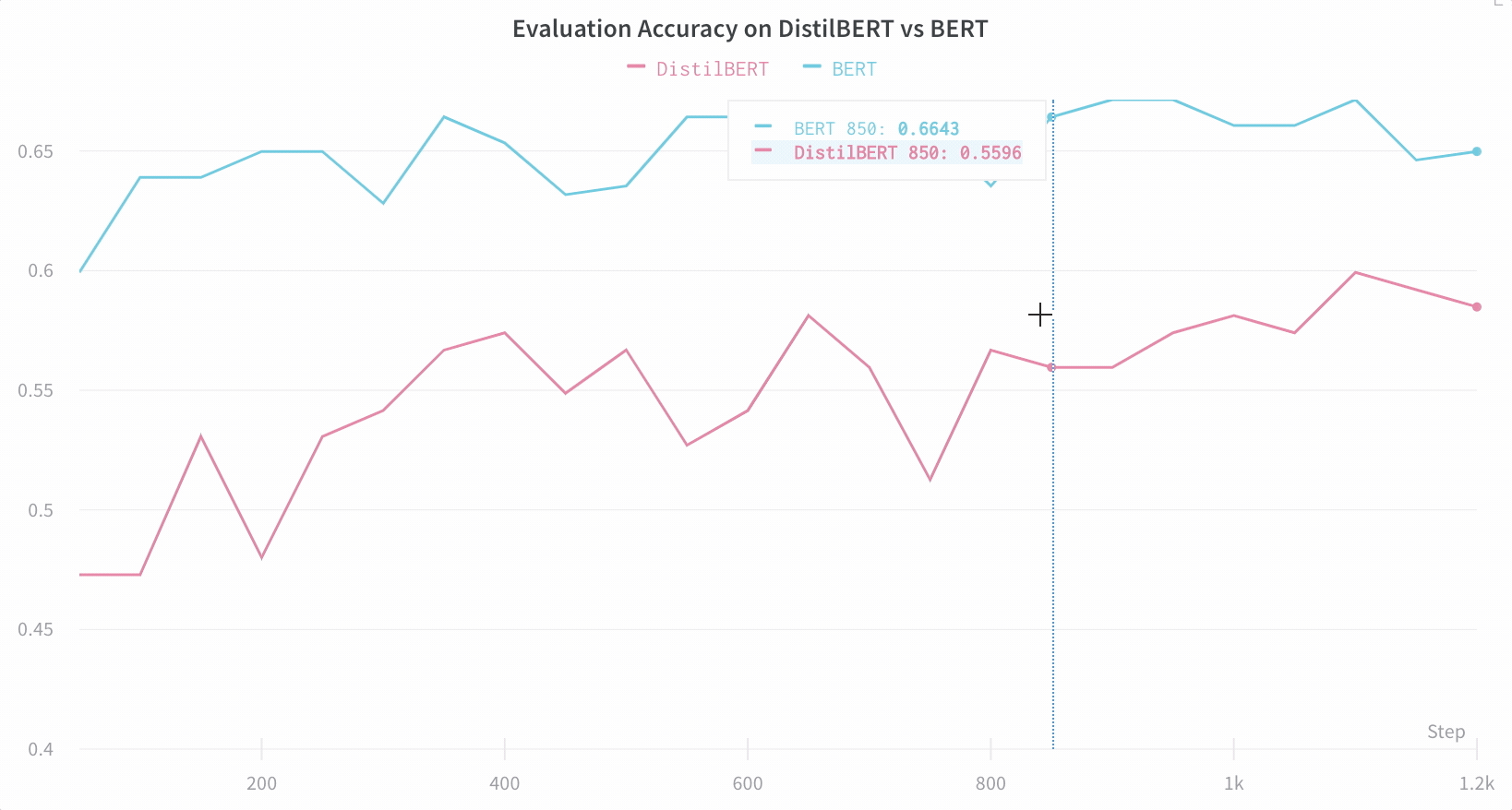
기본적으로 주요 정보를 간편하게 추적
Weights & Biases는 각 Experiment에 대해 새 run을 저장합니다. 다음은 기본적으로 저장되는 정보입니다.
- 하이퍼파라미터: 모델 설정은 Config에 저장됩니다.
- 모델 메트릭: 스트리밍되는 메트릭의 시계열 데이터는 로그에 저장됩니다.
- 터미널 로그: 커맨드라인 출력이 저장되어 탭에서 사용할 수 있습니다.
- 시스템 메트릭: GPU 및 CPU 사용률, 메모리, 온도 등
자세히 알아보기
- 설명서: Weights & Biases 및 Hugging Face 인테그레이션에 대한 문서
- 동영상: YouTube 채널에서 튜토리얼, 실무자와의 인터뷰 등을 시청하세요.
- 문의: 질문이 있는 경우 contact@wandb.com으로 메시지를 보내주세요.
4 - TensorFlow
이 노트북에서 다루는 내용
- 실험 추적을 위해 TensorFlow 파이프라인과 Weights & Biases 의 간편한 통합
keras.metrics를 사용한 메트릭 계산- 사용자 정의 트레이닝 루프에서 해당 메트릭을 기록하기 위해
wandb.log사용
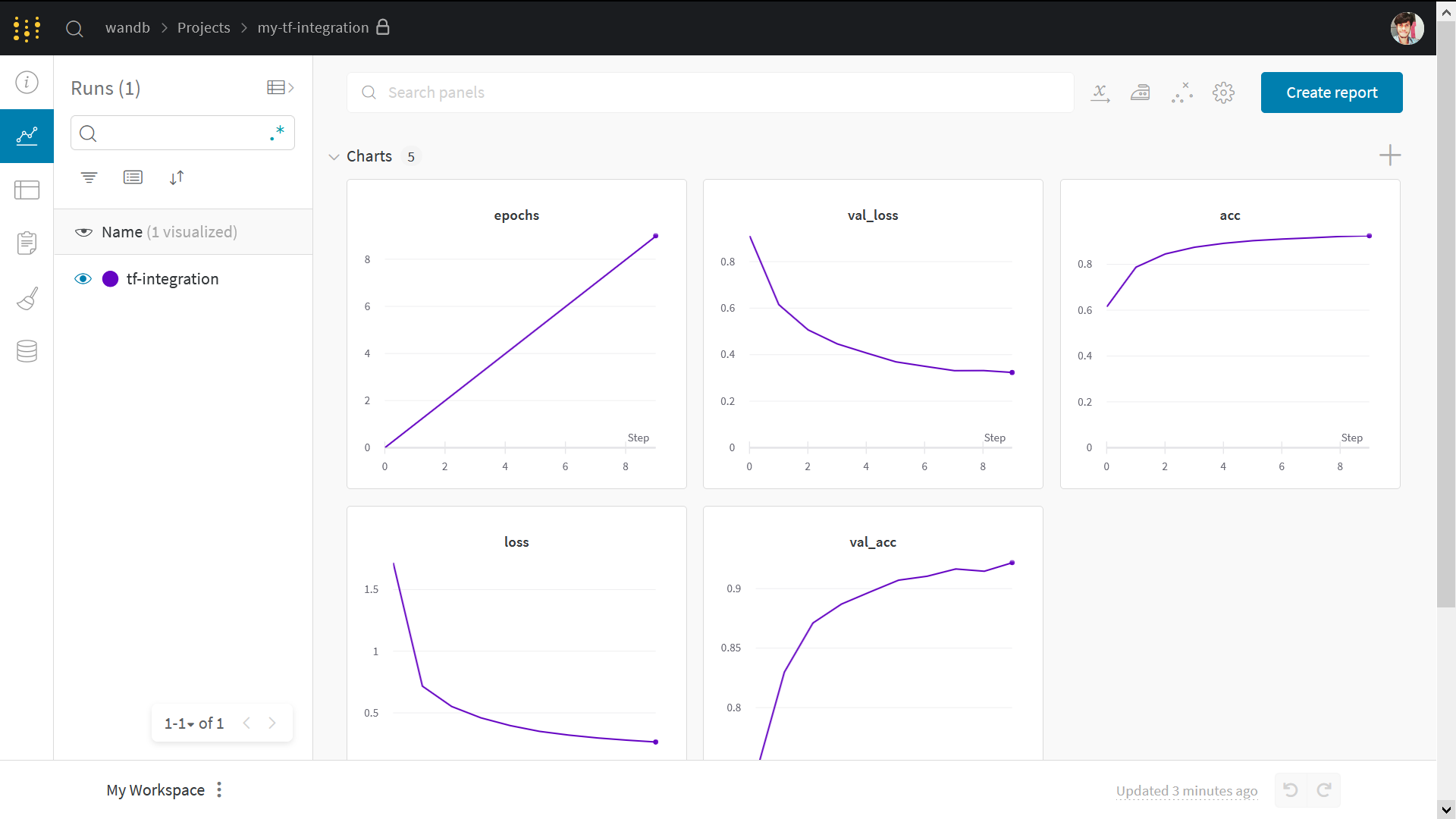
참고: Step 으로 시작하는 섹션은 기존 코드에 W&B 를 통합하는 데 필요한 전부입니다. 나머지는 표준 MNIST 예제입니다.
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import cifar10
설치, 임포트, 로그인
W&B 설치
%%capture
!pip install wandb
W&B 임포트 및 로그인
import wandb
from wandb.integration.keras import WandbMetricsLogger
wandb.login()
참고: W&B 를 처음 사용하거나 로그인하지 않은 경우
wandb.login()실행 후 나타나는 링크를 통해 가입/로그인 페이지로 이동합니다. 가입은 클릭 한 번으로 간단하게 완료할 수 있습니다.
데이터셋 준비
# 트레이닝 데이터셋 준비
BATCH_SIZE = 64
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = np.reshape(x_train, (-1, 784))
x_test = np.reshape(x_test, (-1, 784))
# tf.data를 사용하여 입력 파이프라인 구축
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(BATCH_SIZE)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(BATCH_SIZE)
모델 및 트레이닝 루프 정의
def make_model():
inputs = keras.Input(shape=(784,), name="digits")
x1 = keras.layers.Dense(64, activation="relu")(inputs)
x2 = keras.layers.Dense(64, activation="relu")(x1)
outputs = keras.layers.Dense(10, name="predictions")(x2)
return keras.Model(inputs=inputs, outputs=outputs)
def train_step(x, y, model, optimizer, loss_fn, train_acc_metric):
with tf.GradientTape() as tape:
logits = model(x, training=True)
loss_value = loss_fn(y, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return loss_value
def test_step(x, y, model, loss_fn, val_acc_metric):
val_logits = model(x, training=False)
loss_value = loss_fn(y, val_logits)
val_acc_metric.update_state(y, val_logits)
return loss_value
트레이닝 루프에 wandb.log 추가
def train(
train_dataset,
val_dataset,
model,
optimizer,
train_acc_metric,
val_acc_metric,
epochs=10,
log_step=200,
val_log_step=50,
):
for epoch in range(epochs):
print("\nStart of epoch %d" % (epoch,))
train_loss = []
val_loss = []
# 데이터셋의 배치를 반복합니다.
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
loss_value = train_step(
x_batch_train,
y_batch_train,
model,
optimizer,
loss_fn,
train_acc_metric,
)
train_loss.append(float(loss_value))
# 각 에포크가 끝날 때 검증 루프를 실행합니다.
for step, (x_batch_val, y_batch_val) in enumerate(val_dataset):
val_loss_value = test_step(
x_batch_val, y_batch_val, model, loss_fn, val_acc_metric
)
val_loss.append(float(val_loss_value))
# 각 에포크가 끝날 때 메트릭을 표시합니다.
train_acc = train_acc_metric.result()
print("Training acc over epoch: %.4f" % (float(train_acc),))
val_acc = val_acc_metric.result()
print("Validation acc: %.4f" % (float(val_acc),))
# 각 에포크가 끝날 때 메트릭을 재설정합니다.
train_acc_metric.reset_states()
val_acc_metric.reset_states()
# ⭐: wandb.log를 사용하여 메트릭 기록
wandb.log(
{
"epochs": epoch,
"loss": np.mean(train_loss),
"acc": float(train_acc),
"val_loss": np.mean(val_loss),
"val_acc": float(val_acc),
}
)
트레이닝 실행
wandb.init을 호출하여 run 시작
이를 통해 실험을 시작했음을 알 수 있으며, 고유한 ID와 대시보드를 제공할 수 있습니다.
# 프로젝트 이름과 함께 wandb를 초기화하고 선택적으로 구성을 초기화합니다.
# 구성 값을 변경하고 wandb 대시보드에서 결과를 확인하십시오.
config = {
"learning_rate": 0.001,
"epochs": 10,
"batch_size": 64,
"log_step": 200,
"val_log_step": 50,
"architecture": "CNN",
"dataset": "CIFAR-10",
}
run = wandb.init(project='my-tf-integration', config=config)
config = run.config
# 모델 초기화.
model = make_model()
# 모델을 트레이닝하기 위한 옵티마이저 인스턴스화.
optimizer = keras.optimizers.SGD(learning_rate=config.learning_rate)
# 손실 함수 인스턴스화.
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# 메트릭 준비.
train_acc_metric = keras.metrics.SparseCategoricalAccuracy()
val_acc_metric = keras.metrics.SparseCategoricalAccuracy()
train(
train_dataset,
val_dataset,
model,
optimizer,
train_acc_metric,
val_acc_metric,
epochs=config.epochs,
log_step=config.log_step,
val_log_step=config.val_log_step,
)
run.finish() # Jupyter/Colab에서 완료되었음을 알립니다!
결과 시각화
라이브 결과를 보려면 위의 run page 링크를 클릭하십시오.
Sweep 101
Weights & Biases Sweeps 를 사용하여 하이퍼파라미터 최적화를 자동화하고 가능한 모델 공간을 탐색합니다.
W&B Sweeps 를 사용하여 TensorFlow 에서 하이퍼파라미터 최적화 확인
W&B Sweeps 사용의 이점
- 빠른 설정: 몇 줄의 코드만으로 W&B 스윕을 실행할 수 있습니다.
- 투명성: 사용 중인 모든 알고리즘을 인용하고 코드는 오픈 소스입니다.
- 강력함: 스윕은 완벽하게 사용자 정의하고 구성할 수 있습니다. 수십 대의 장치에서 스윕을 시작할 수 있으며 랩톱에서 스윕을 시작하는 것만큼 쉽습니다.
예제 갤러리
W&B 로 추적하고 시각화한 프로젝트의 예제를 예제 갤러리에서 확인하세요. 완전 연결 →
모범 사례
- Projects: 여러 runs 를 프로젝트에 기록하여 비교합니다.
wandb.init(project="project-name") - Groups: 여러 프로세스 또는 교차 검증 폴드의 경우 각 프로세스를 runs 로 기록하고 함께 그룹화합니다.
wandb.init(group="experiment-1") - Tags: 현재 베이스라인 또는 프로덕션 모델을 추적하기 위해 태그를 추가합니다.
- Notes: 테이블에 노트를 입력하여 runs 간의 변경 사항을 추적합니다.
- Reports: 동료와 공유하고 ML 프로젝트의 대시보드 및 스냅샷을 만들기 위해 진행 상황에 대한 빠른 노트를 작성합니다.
고급 설정
5 - TensorFlow Sweeps
W&B를 사용하여 기계 학습 실험 추적, 데이터셋 버전 관리 및 프로젝트 협업을 수행하세요.
W&B Sweeps를 사용하여 하이퍼파라미터 최적화를 자동화하고 대화형 대시보드로 모델 가능성을 탐색하세요.
Sweeps를 사용하는 이유
- 빠른 설정: 몇 줄의 코드로 W&B Sweeps를 실행합니다.
- 투명성: 프로젝트는 사용된 모든 알고리즘을 인용하고, 코드는 오픈 소스입니다.
- 강력한 기능: Sweeps는 사용자 정의 옵션을 제공하며 여러 시스템 또는 랩톱에서 쉽게 실행할 수 있습니다.
자세한 내용은 Sweep documentation을 참조하십시오.
이 노트북에서 다루는 내용
- TensorFlow에서 W&B Sweep 및 사용자 지정 트레이닝 루프로 시작하는 단계.
- 이미지 분류 작업을 위한 최적의 하이퍼파라미터 찾기.
참고: Step 으로 시작하는 섹션은 하이퍼파라미터 스윕을 수행하는 데 필요한 코드를 보여줍니다. 나머지는 간단한 예를 설정합니다.
설치, 임포트 및 로그인
W&B 설치
pip install wandb
W&B 임포트 및 로그인
import tqdm
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import cifar10
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import wandb
from wandb.integration.keras import WandbMetricsLogger
wandb.login()
wandb.login()을 실행한 후 링크가 가입/로그인 페이지로 연결됩니다.데이터셋 준비
# 트레이닝 데이터셋 준비
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
x_train = np.reshape(x_train, (-1, 784))
x_test = np.reshape(x_test, (-1, 784))
분류기 MLP 빌드
def Model():
inputs = keras.Input(shape=(784,), name="digits")
x1 = keras.layers.Dense(64, activation="relu")(inputs)
x2 = keras.layers.Dense(64, activation="relu")(x1)
outputs = keras.layers.Dense(10, name="predictions")(x2)
return keras.Model(inputs=inputs, outputs=outputs)
def train_step(x, y, model, optimizer, loss_fn, train_acc_metric):
with tf.GradientTape() as tape:
logits = model(x, training=True)
loss_value = loss_fn(y, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return loss_value
def test_step(x, y, model, loss_fn, val_acc_metric):
val_logits = model(x, training=False)
loss_value = loss_fn(y, val_logits)
val_acc_metric.update_state(y, val_logits)
return loss_value
트레이닝 루프 작성
def train(
train_dataset,
val_dataset,
model,
optimizer,
loss_fn,
train_acc_metric,
val_acc_metric,
epochs=10,
log_step=200,
val_log_step=50,
):
for epoch in range(epochs):
print("\nStart of epoch %d" % (epoch,))
train_loss = []
val_loss = []
# 데이터셋의 배치를 반복합니다.
for step, (x_batch_train, y_batch_train) in tqdm.tqdm(
enumerate(train_dataset), total=len(train_dataset)
):
loss_value = train_step(
x_batch_train,
y_batch_train,
model,
optimizer,
loss_fn,
train_acc_metric,
)
train_loss.append(float(loss_value))
# 각 에포크가 끝날 때 검증 루프를 실행합니다.
for step, (x_batch_val, y_batch_val) in enumerate(val_dataset):
val_loss_value = test_step(
x_batch_val, y_batch_val, model, loss_fn, val_acc_metric
)
val_loss.append(float(val_loss_value))
# 각 에포크가 끝날 때 메트릭을 표시합니다.
train_acc = train_acc_metric.result()
print("Training acc over epoch: %.4f" % (float(train_acc),))
val_acc = val_acc_metric.result()
print("Validation acc: %.4f" % (float(val_acc),))
# 각 에포크가 끝날 때 메트릭을 재설정합니다.
train_acc_metric.reset_states()
val_acc_metric.reset_states()
# 3️⃣ wandb.log를 사용하여 메트릭을 기록합니다.
wandb.log(
{
"epochs": epoch,
"loss": np.mean(train_loss),
"acc": float(train_acc),
"val_loss": np.mean(val_loss),
"val_acc": float(val_acc),
}
)
스윕 구성
스윕을 구성하는 단계:
- 최적화할 하이퍼파라미터 정의
- 최적화 방법 선택:
random,grid또는bayes val_loss최소화와 같이bayes에 대한 목표 및 메트릭 설정- 수행 중인 Runs를 조기에 종료하려면
hyperband를 사용합니다.
자세한 내용은 W&B Sweeps documentation을 참조하십시오.
sweep_config = {
"method": "random",
"metric": {"name": "val_loss", "goal": "minimize"},
"early_terminate": {"type": "hyperband", "min_iter": 5},
"parameters": {
"batch_size": {"values": [32, 64, 128, 256]},
"learning_rate": {"values": [0.01, 0.005, 0.001, 0.0005, 0.0001]},
},
}
트레이닝 루프 래핑
train을 호출하기 전에 하이퍼파라미터를 설정하기 위해 wandb.config를 사용하는 sweep_train과 같은 함수를 만듭니다.
def sweep_train(config_defaults=None):
# 기본값 설정
config_defaults = {"batch_size": 64, "learning_rate": 0.01}
# 샘플 프로젝트 이름으로 wandb를 초기화합니다.
wandb.init(config=config_defaults) # 이것은 Sweep에서 덮어쓰기됩니다.
# 구성에 대한 다른 하이퍼파라미터를 지정합니다(있는 경우).
wandb.config.epochs = 2
wandb.config.log_step = 20
wandb.config.val_log_step = 50
wandb.config.architecture_name = "MLP"
wandb.config.dataset_name = "MNIST"
# tf.data를 사용하여 입력 파이프라인 구축
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = (
train_dataset.shuffle(buffer_size=1024)
.batch(wandb.config.batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(wandb.config.batch_size).prefetch(
buffer_size=tf.data.AUTOTUNE
)
# 모델 초기화
model = Model()
# 모델을 트레이닝하기 위한 옵티마이저를 인스턴스화합니다.
optimizer = keras.optimizers.SGD(learning_rate=wandb.config.learning_rate)
# 손실 함수를 인스턴스화합니다.
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# 메트릭을 준비합니다.
train_acc_metric = keras.metrics.SparseCategoricalAccuracy()
val_acc_metric = keras.metrics.SparseCategoricalAccuracy()
train(
train_dataset,
val_dataset,
model,
optimizer,
loss_fn,
train_acc_metric,
val_acc_metric,
epochs=wandb.config.epochs,
log_step=wandb.config.log_step,
val_log_step=wandb.config.val_log_step,
)
스윕 초기화 및 개인 디지털 도우미 실행
sweep_id = wandb.sweep(sweep_config, project="sweeps-tensorflow")
count 파라미터로 실행 횟수를 제한합니다. 빠른 실행을 위해 10으로 설정합니다. 필요에 따라 늘립니다.
wandb.agent(sweep_id, function=sweep_train, count=10)
결과 시각화
라이브 결과를 보려면 앞에 나오는 Sweep URL 링크를 클릭하세요.
예제 갤러리
갤러리에서 W&B로 추적하고 시각화한 프로젝트를 탐색하세요.
모범 사례
- Projects: 여러 Runs를 프로젝트에 기록하여 비교합니다.
wandb.init(project="project-name") - Groups: 각 프로세스를 여러 프로세스 또는 교차 검증 폴드에 대한 Run으로 기록하고 그룹화합니다.
wandb.init(group='experiment-1') - Tags: 태그를 사용하여 베이스라인 또는 프로덕션 모델을 추적합니다.
- Notes: 테이블에 메모를 입력하여 Runs 간의 변경 사항을 추적합니다.
- Reports: Reports를 사용하여 진행 상황 메모, 동료와의 공유, ML 프로젝트 대시보드 및 스냅샷 생성을 수행합니다.
고급 설정
6 - 3D brain tumor segmentation with MONAI
이 튜토리얼에서는 MONAI를 사용하여 다중 레이블 3D 뇌종양 분할 작업의 트레이닝 워크플로우를 구성하고 Weights & Biases의 실험 추적 및 데이터 시각화 기능을 사용하는 방법을 보여줍니다. 이 튜토리얼에는 다음과 같은 기능이 포함되어 있습니다.
- Weights & Biases run을 초기화하고 재현성을 위해 run과 관련된 모든 구성을 동기화합니다.
- MONAI transform API:
- 사전 형식 데이터에 대한 MONAI Transforms.
- MONAI
transformsAPI에 따라 새로운 transform을 정의하는 방법. - 데이터 증강을 위해 강도를 임의로 조정하는 방법.
- 데이터 로딩 및 시각화:
- 메타데이터와 함께
Nifti이미지를 로드하고, 이미지 목록을 로드하고 스택합니다. - 트레이닝 및 유효성 검사를 가속화하기 위해 IO 및 transforms를 캐시합니다.
wandb.Table및 Weights & Biases의 대화형 분할 오버레이를 사용하여 데이터를 시각화합니다.
- 메타데이터와 함께
- 3D
SegResNet모델 트레이닝- MONAI의
networks,losses및metricsAPI를 사용합니다. - PyTorch 트레이닝 루프를 사용하여 3D
SegResNet모델을 트레이닝합니다. - Weights & Biases를 사용하여 트레이닝 실험을 추적합니다.
- Weights & Biases에서 모델 체크포인트를 모델 Artifacts로 로그하고 버전을 관리합니다.
- MONAI의
wandb.Table및 Weights & Biases의 대화형 분할 오버레이를 사용하여 유효성 검사 데이터셋에서 예측을 시각화하고 비교합니다.
설정 및 설치
먼저 MONAI와 Weights & Biases의 최신 버전을 설치합니다.
!python -c "import monai" || pip install -q -U "monai[nibabel, tqdm]"
!python -c "import wandb" || pip install -q -U wandb
import os
import numpy as np
from tqdm.auto import tqdm
import wandb
from monai.apps import DecathlonDataset
from monai.data import DataLoader, decollate_batch
from monai.losses import DiceLoss
from monai.inferers import sliding_window_inference
from monai.metrics import DiceMetric
from monai.networks.nets import SegResNet
from monai.transforms import (
Activations,
AsDiscrete,
Compose,
LoadImaged,
MapTransform,
NormalizeIntensityd,
Orientationd,
RandFlipd,
RandScaleIntensityd,
RandShiftIntensityd,
RandSpatialCropd,
Spacingd,
EnsureTyped,
EnsureChannelFirstd,
)
from monai.utils import set_determinism
import torch
다음으로 W&B를 사용하기 위해 Colab 인스턴스를 인증합니다.
wandb.login()
W&B Run 초기화
새로운 W&B run을 시작하여 실험 추적을 시작합니다.
wandb.init(project="monai-brain-tumor-segmentation")
적절한 구성 시스템을 사용하는 것이 재현 가능한 기계 학습을 위한 권장되는 모범 사례입니다. W&B를 사용하여 모든 실험에 대한 하이퍼파라미터를 추적할 수 있습니다.
config = wandb.config
config.seed = 0
config.roi_size = [224, 224, 144]
config.batch_size = 1
config.num_workers = 4
config.max_train_images_visualized = 20
config.max_val_images_visualized = 20
config.dice_loss_smoothen_numerator = 0
config.dice_loss_smoothen_denominator = 1e-5
config.dice_loss_squared_prediction = True
config.dice_loss_target_onehot = False
config.dice_loss_apply_sigmoid = True
config.initial_learning_rate = 1e-4
config.weight_decay = 1e-5
config.max_train_epochs = 50
config.validation_intervals = 1
config.dataset_dir = "./dataset/"
config.checkpoint_dir = "./checkpoints"
config.inference_roi_size = (128, 128, 64)
config.max_prediction_images_visualized = 20
결정론적 트레이닝을 활성화하거나 끄려면 모듈에 대한 임의 시드도 설정해야 합니다.
set_determinism(seed=config.seed)
# 디렉토리 생성
os.makedirs(config.dataset_dir, exist_ok=True)
os.makedirs(config.checkpoint_dir, exist_ok=True)
데이터 로딩 및 변환
여기서는 monai.transforms API를 사용하여 다중 클래스 레이블을 원-핫 형식의 다중 레이블 분할 작업으로 변환하는 사용자 정의 transform을 만듭니다.
class ConvertToMultiChannelBasedOnBratsClassesd(MapTransform):
"""
brats 클래스를 기반으로 레이블을 다중 채널로 변환합니다:
레이블 1은 종양 주위 부종입니다.
레이블 2는 GD-강화 종양입니다.
레이블 3은 괴사성 및 비강화 종양 코어입니다.
가능한 클래스는 TC(종양 코어), WT(전체 종양) 및 ET(강화 종양)입니다.
참조: https://github.com/Project-MONAI/tutorials/blob/main/3d_segmentation/brats_segmentation_3d.ipynb
"""
def __call__(self, data):
d = dict(data)
for key in self.keys:
result = []
# 레이블 2와 레이블 3을 병합하여 TC를 구성합니다.
result.append(torch.logical_or(d[key] == 2, d[key] == 3))
# 레이블 1, 2 및 3을 병합하여 WT를 구성합니다.
result.append(
torch.logical_or(
torch.logical_or(d[key] == 2, d[key] == 3), d[key] == 1
)
)
# 레이블 2는 ET입니다.
result.append(d[key] == 2)
d[key] = torch.stack(result, axis=0).float()
return d
다음으로 트레이닝 및 유효성 검사 데이터셋에 대한 transforms를 각각 설정합니다.
train_transform = Compose(
[
# 4개의 Nifti 이미지를 로드하고 함께 쌓습니다.
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys="image"),
EnsureTyped(keys=["image", "label"]),
ConvertToMultiChannelBasedOnBratsClassesd(keys="label"),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(
keys=["image", "label"],
pixdim=(1.0, 1.0, 1.0),
mode=("bilinear", "nearest"),
),
RandSpatialCropd(
keys=["image", "label"], roi_size=config.roi_size, random_size=False
),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=0),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=1),
RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=2),
NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True),
RandScaleIntensityd(keys="image", factors=0.1, prob=1.0),
RandShiftIntensityd(keys="image", offsets=0.1, prob=1.0),
]
)
val_transform = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys="image"),
EnsureTyped(keys=["image", "label"]),
ConvertToMultiChannelBasedOnBratsClassesd(keys="label"),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(
keys=["image", "label"],
pixdim=(1.0, 1.0, 1.0),
mode=("bilinear", "nearest"),
),
NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True),
]
)
데이터셋
이 실험에 사용된 데이터셋은 http://medicaldecathlon.com/에서 가져온 것입니다. 다중 모드 다중 사이트 MRI 데이터(FLAIR, T1w, T1gd, T2w)를 사용하여 신경교종, 괴사성/활성 종양 및 부종을 분할합니다. 데이터셋은 750개의 4D 볼륨(484 트레이닝 + 266 테스트)으로 구성됩니다.
DecathlonDataset을 사용하여 데이터셋을 자동으로 다운로드하고 추출합니다. MONAI CacheDataset을 상속하여 cache_num=N을 설정하여 트레이닝을 위해 N개의 항목을 캐시하고 메모리 크기에 따라 유효성 검사를 위해 모든 항목을 캐시하는 기본 인수를 사용할 수 있습니다.
train_dataset = DecathlonDataset(
root_dir=config.dataset_dir,
task="Task01_BrainTumour",
transform=val_transform,
section="training",
download=True,
cache_rate=0.0,
num_workers=4,
)
val_dataset = DecathlonDataset(
root_dir=config.dataset_dir,
task="Task01_BrainTumour",
transform=val_transform,
section="validation",
download=False,
cache_rate=0.0,
num_workers=4,
)
train_dataset에 train_transform을 적용하는 대신 트레이닝 및 유효성 검사 데이터셋 모두에 val_transform을 적용합니다. 이는 트레이닝 전에 데이터셋 분할의 샘플을 시각화하기 때문입니다.데이터셋 시각화
Weights & Biases는 이미지, 비디오, 오디오 등을 지원합니다. 다양한 미디어를 기록하여 결과를 탐색하고 run, 모델 및 데이터셋을 시각적으로 비교할 수 있습니다. 분할 마스크 오버레이 시스템을 사용하여 데이터 볼륨을 시각화합니다. 테이블에서 분할 마스크를 기록하려면 테이블의 각 행에 대해 wandb.Image 오브젝트를 제공해야 합니다.
아래 의사 코드에 예제가 제공되어 있습니다.
table = wandb.Table(columns=["ID", "Image"])
for id, img, label in zip(ids, images, labels):
mask_img = wandb.Image(
img,
masks={
"prediction": {"mask_data": label, "class_labels": class_labels}
# ...
},
)
table.add_data(id, img)
wandb.log({"Table": table})
이제 샘플 이미지, 레이블, wandb.Table 오브젝트 및 일부 관련 메타데이터를 가져와서 Weights & Biases 대시보드에 기록될 테이블의 행을 채우는 간단한 유틸리티 함수를 작성합니다.
def log_data_samples_into_tables(
sample_image: np.array,
sample_label: np.array,
split: str = None,
data_idx: int = None,
table: wandb.Table = None,
):
num_channels, _, _, num_slices = sample_image.shape
with tqdm(total=num_slices, leave=False) as progress_bar:
for slice_idx in range(num_slices):
ground_truth_wandb_images = []
for channel_idx in range(num_channels):
ground_truth_wandb_images.append(
masks = {
"ground-truth/Tumor-Core": {
"mask_data": sample_label[0, :, :, slice_idx],
"class_labels": {0: "background", 1: "Tumor Core"},
},
"ground-truth/Whole-Tumor": {
"mask_data": sample_label[1, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Whole Tumor"},
},
"ground-truth/Enhancing-Tumor": {
"mask_data": sample_label[2, :, :, slice_idx] * 3,
"class_labels": {0: "background", 3: "Enhancing Tumor"},
},
}
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks=masks,
)
)
table.add_data(split, data_idx, slice_idx, *ground_truth_wandb_images)
progress_bar.update(1)
return table
다음으로 wandb.Table 오브젝트와 데이터 시각화로 채울 수 있도록 구성되는 열을 정의합니다.
table = wandb.Table(
columns=[
"Split",
"Data Index",
"Slice Index",
"Image-Channel-0",
"Image-Channel-1",
"Image-Channel-2",
"Image-Channel-3",
]
)
그런 다음 각각 train_dataset 및 val_dataset을 반복하여 데이터 샘플에 대한 시각화를 생성하고 대시보드에 기록할 테이블의 행을 채웁니다.
# train_dataset에 대한 시각화 생성
max_samples = (
min(config.max_train_images_visualized, len(train_dataset))
if config.max_train_images_visualized > 0
else len(train_dataset)
)
progress_bar = tqdm(
enumerate(train_dataset[:max_samples]),
total=max_samples,
desc="Generating Train Dataset Visualizations:",
)
for data_idx, sample in progress_bar:
sample_image = sample["image"].detach().cpu().numpy()
sample_label = sample["label"].detach().cpu().numpy()
table = log_data_samples_into_tables(
sample_image,
sample_label,
split="train",
data_idx=data_idx,
table=table,
)
# val_dataset에 대한 시각화 생성
max_samples = (
min(config.max_val_images_visualized, len(val_dataset))
if config.max_val_images_visualized > 0
else len(val_dataset)
)
progress_bar = tqdm(
enumerate(val_dataset[:max_samples]),
total=max_samples,
desc="Generating Validation Dataset Visualizations:",
)
for data_idx, sample in progress_bar:
sample_image = sample["image"].detach().cpu().numpy()
sample_label = sample["label"].detach().cpu().numpy()
table = log_data_samples_into_tables(
sample_image,
sample_label,
split="val",
data_idx=data_idx,
table=table,
)
# 테이블을 대시보드에 기록
wandb.log({"Tumor-Segmentation-Data": table})
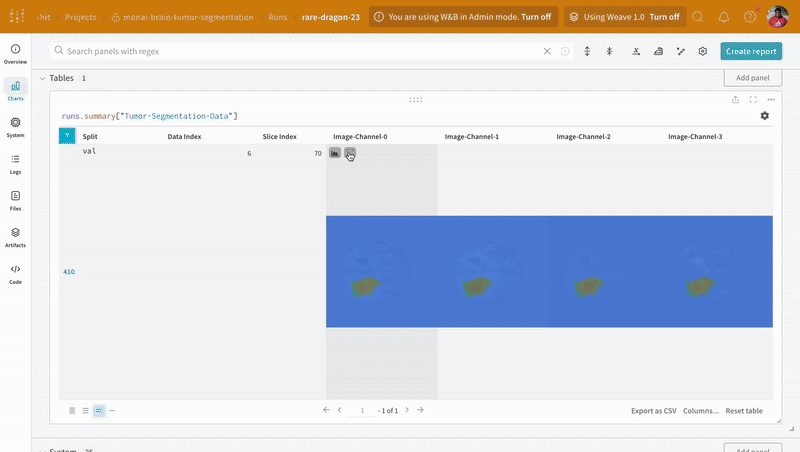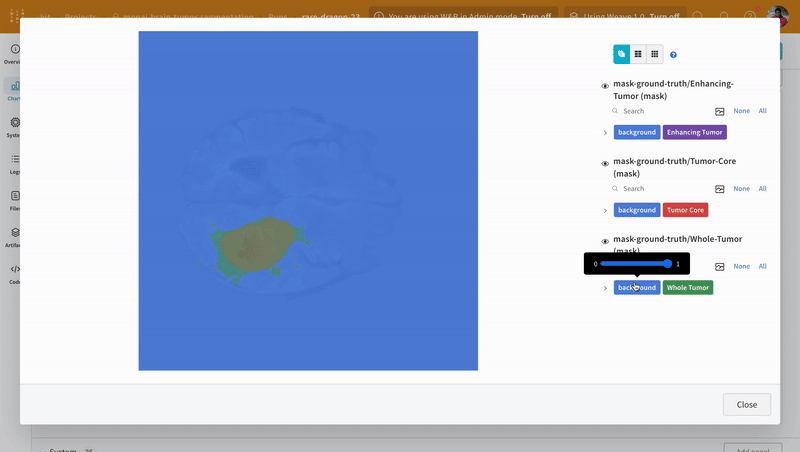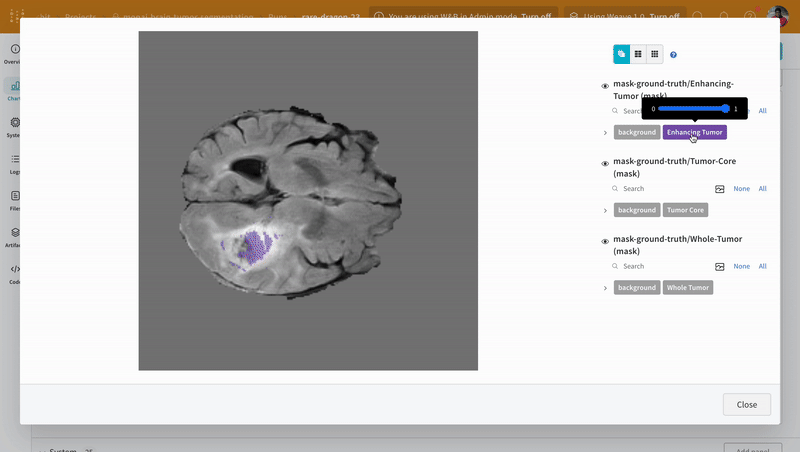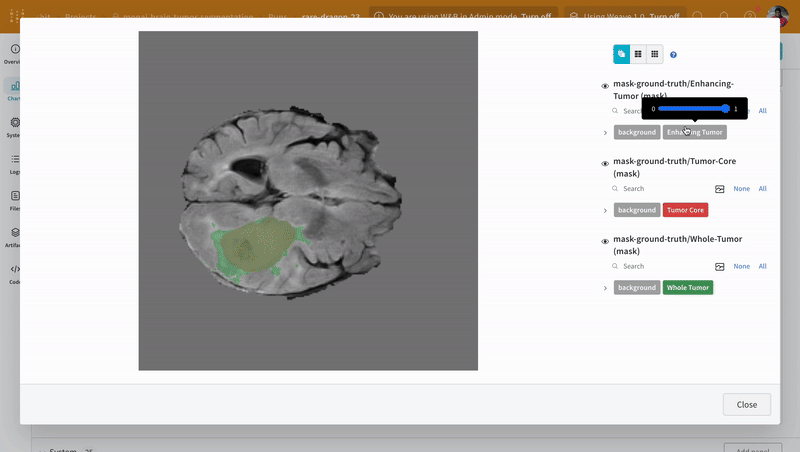
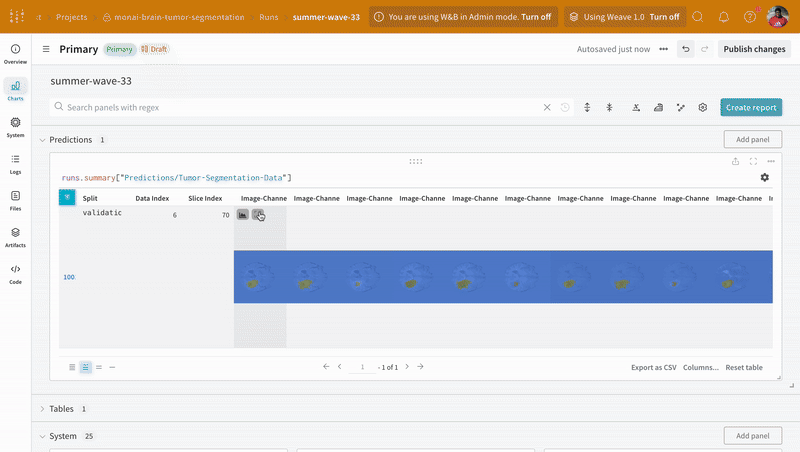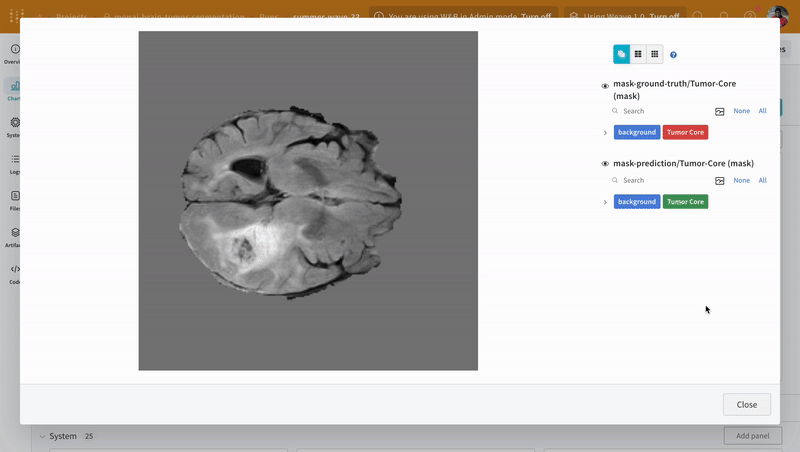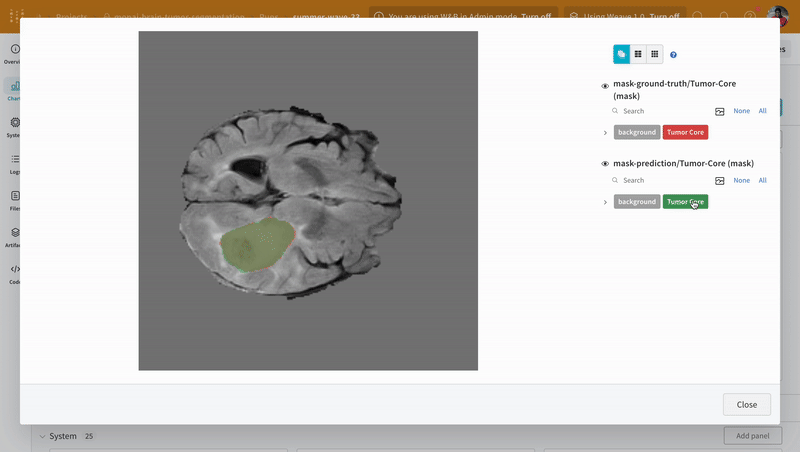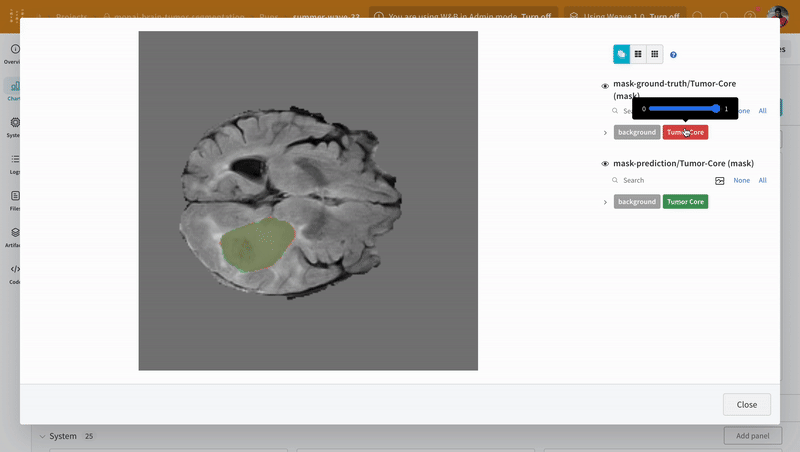
데이터는 대화형 테이블 형식으로 W&B 대시보드에 나타납니다. 각 행에서 데이터 볼륨의 특정 슬라이스의 각 채널이 해당 분할 마스크로 오버레이된 것을 볼 수 있습니다. Weave 쿼리를 작성하여 테이블의 데이터를 필터링하고 특정 행에 집중할 수 있습니다.
 |
|---|
| 기록된 테이블 데이터의 예. |
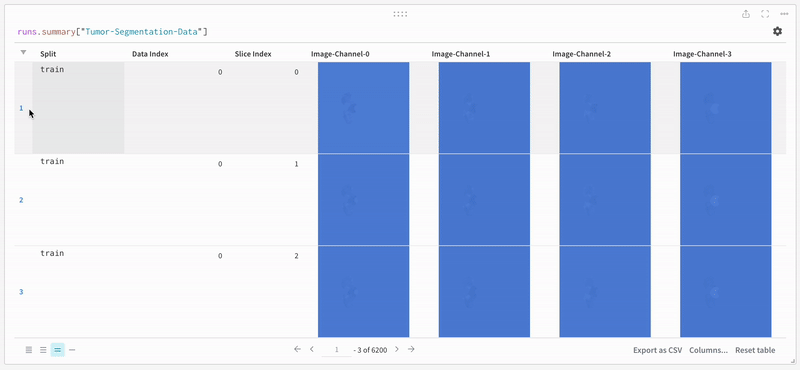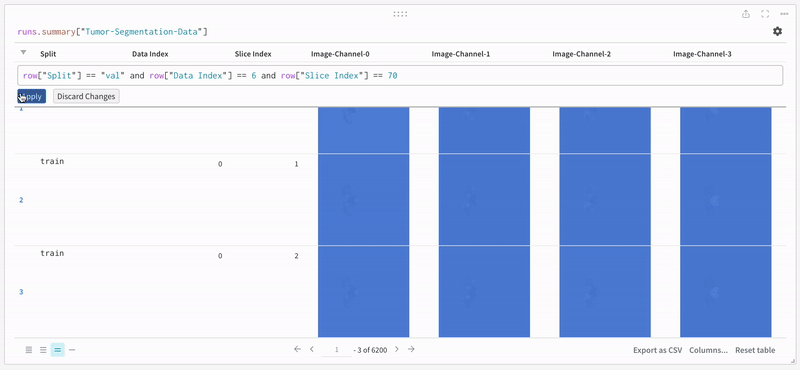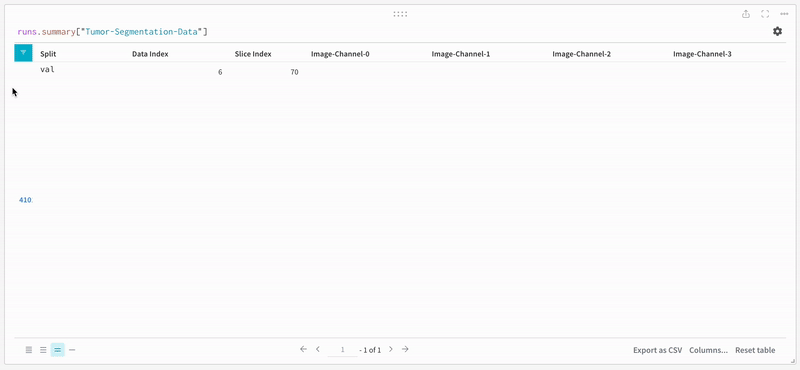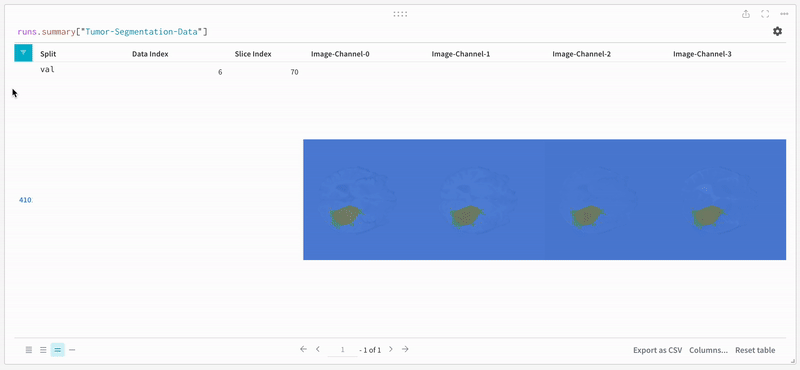
이미지를 열고 대화형 오버레이를 사용하여 각 분할 마스크와 상호 작용하는 방법을 확인합니다.
 |
|---|
| 시각화된 분할 맵의 예. |
데이터 로딩
데이터셋에서 데이터를 로드하기 위한 PyTorch DataLoaders를 만듭니다. DataLoaders를 만들기 전에 트레이닝을 위해 데이터를 사전 처리하고 변환하기 위해 train_dataset에 대한 transform을 train_transform으로 설정합니다.
# 트레이닝 데이터셋에 train_transforms 적용
train_dataset.transform = train_transform
# train_loader 생성
train_loader = DataLoader(
train_dataset,
batch_size=config.batch_size,
shuffle=True,
num_workers=config.num_workers,
)
# val_loader 생성
val_loader = DataLoader(
val_dataset,
batch_size=config.batch_size,
shuffle=False,
num_workers=config.num_workers,
)
모델, 손실 및 옵티마이저 생성
이 튜토리얼에서는 자동 인코더 정규화를 사용한 3D MRI 뇌종양 분할 논문을 기반으로 SegResNet 모델을 만듭니다. SegResNet 모델은 monai.networks API의 일부로 PyTorch 모듈로 구현되었으며 옵티마이저 및 학습률 스케줄러도 함께 제공됩니다.
device = torch.device("cuda:0")
# 모델 생성
model = SegResNet(
blocks_down=[1, 2, 2, 4],
blocks_up=[1, 1, 1],
init_filters=16,
in_channels=4,
out_channels=3,
dropout_prob=0.2,
).to(device)
# 옵티마이저 생성
optimizer = torch.optim.Adam(
model.parameters(),
config.initial_learning_rate,
weight_decay=config.weight_decay,
)
# 학습률 스케줄러 생성
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=config.max_train_epochs
)
monai.losses API를 사용하여 손실을 다중 레이블 DiceLoss로 정의하고 monai.metrics API를 사용하여 해당 주사위 메트릭을 정의합니다.
loss_function = DiceLoss(
smooth_nr=config.dice_loss_smoothen_numerator,
smooth_dr=config.dice_loss_smoothen_denominator,
squared_pred=config.dice_loss_squared_prediction,
to_onehot_y=config.dice_loss_target_onehot,
sigmoid=config.dice_loss_apply_sigmoid,
)
dice_metric = DiceMetric(include_background=True, reduction="mean")
dice_metric_batch = DiceMetric(include_background=True, reduction="mean_batch")
post_trans = Compose([Activations(sigmoid=True), AsDiscrete(threshold=0.5)])
# 자동 혼합 정밀도를 사용하여 트레이닝 가속화
scaler = torch.cuda.amp.GradScaler()
torch.backends.cudnn.benchmark = True
혼합 정밀도 추론을 위한 작은 유틸리티를 정의합니다. 이는 트레이닝 프로세스의 유효성 검사 단계와 트레이닝 후 모델을 실행하려는 경우에 유용합니다.
def inference(model, input):
def _compute(input):
return sliding_window_inference(
inputs=input,
roi_size=(240, 240, 160),
sw_batch_size=1,
predictor=model,
overlap=0.5,
)
with torch.cuda.amp.autocast():
return _compute(input)
트레이닝 및 유효성 검사
트레이닝 전에 트레이닝 및 유효성 검사 실험을 추적하기 위해 나중에 wandb.log()로 기록될 메트릭 속성을 정의합니다.
wandb.define_metric("epoch/epoch_step")
wandb.define_metric("epoch/*", step_metric="epoch/epoch_step")
wandb.define_metric("batch/batch_step")
wandb.define_metric("batch/*", step_metric="batch/batch_step")
wandb.define_metric("validation/validation_step")
wandb.define_metric("validation/*", step_metric="validation/validation_step")
batch_step = 0
validation_step = 0
metric_values = []
metric_values_tumor_core = []
metric_values_whole_tumor = []
metric_values_enhanced_tumor = []
표준 PyTorch 트레이닝 루프 실행
# W&B Artifact 오브젝트 정의
artifact = wandb.Artifact(
name=f"{wandb.run.id}-checkpoint", type="model"
)
epoch_progress_bar = tqdm(range(config.max_train_epochs), desc="Training:")
for epoch in epoch_progress_bar:
model.train()
epoch_loss = 0
total_batch_steps = len(train_dataset) // train_loader.batch_size
batch_progress_bar = tqdm(train_loader, total=total_batch_steps, leave=False)
# 트레이닝 단계
for batch_data in batch_progress_bar:
inputs, labels = (
batch_data["image"].to(device),
batch_data["label"].to(device),
)
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = loss_function(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
epoch_loss += loss.item()
batch_progress_bar.set_description(f"train_loss: {loss.item():.4f}:")
## 배치별 트레이닝 손실을 W&B에 기록
wandb.log({"batch/batch_step": batch_step, "batch/train_loss": loss.item()})
batch_step += 1
lr_scheduler.step()
epoch_loss /= total_batch_steps
## 배치별 트레이닝 손실과 학습률을 W&B에 기록
wandb.log(
{
"epoch/epoch_step": epoch,
"epoch/mean_train_loss": epoch_loss,
"epoch/learning_rate": lr_scheduler.get_last_lr()[0],
}
)
epoch_progress_bar.set_description(f"Training: train_loss: {epoch_loss:.4f}:")
# 유효성 검사 및 모델 체크포인트 단계
if (epoch + 1) % config.validation_intervals == 0:
model.eval()
with torch.no_grad():
for val_data in val_loader:
val_inputs, val_labels = (
val_data["image"].to(device),
val_data["label"].to(device),
)
val_outputs = inference(model, val_inputs)
val_outputs = [post_trans(i) for i in decollate_batch(val_outputs)]
dice_metric(y_pred=val_outputs, y=val_labels)
dice_metric_batch(y_pred=val_outputs, y=val_labels)
metric_values.append(dice_metric.aggregate().item())
metric_batch = dice_metric_batch.aggregate()
metric_values_tumor_core.append(metric_batch[0].item())
metric_values_whole_tumor.append(metric_batch[1].item())
metric_values_enhanced_tumor.append(metric_batch[2].item())
dice_metric.reset()
dice_metric_batch.reset()
checkpoint_path = os.path.join(config.checkpoint_dir, "model.pth")
torch.save(model.state_dict(), checkpoint_path)
# W&B Artifacts를 사용하여 모델 체크포인트를 기록하고 버전 관리합니다.
artifact.add_file(local_path=checkpoint_path)
wandb.log_artifact(artifact, aliases=[f"epoch_{epoch}"])
# 유효성 검사 메트릭을 W&B 대시보드에 기록합니다.
wandb.log(
{
"validation/validation_step": validation_step,
"validation/mean_dice": metric_values[-1],
"validation/mean_dice_tumor_core": metric_values_tumor_core[-1],
"validation/mean_dice_whole_tumor": metric_values_whole_tumor[-1],
"validation/mean_dice_enhanced_tumor": metric_values_enhanced_tumor[-1],
}
)
validation_step += 1
# 이 Artifact가 기록을 마칠 때까지 기다립니다.
artifact.wait()
wandb.log로 코드를 계측하면 트레이닝 및 유효성 검사 프로세스와 관련된 모든 메트릭뿐만 아니라 W&B 대시보드의 모든 시스템 메트릭(이 경우 CPU 및 GPU)을 추적할 수 있습니다.
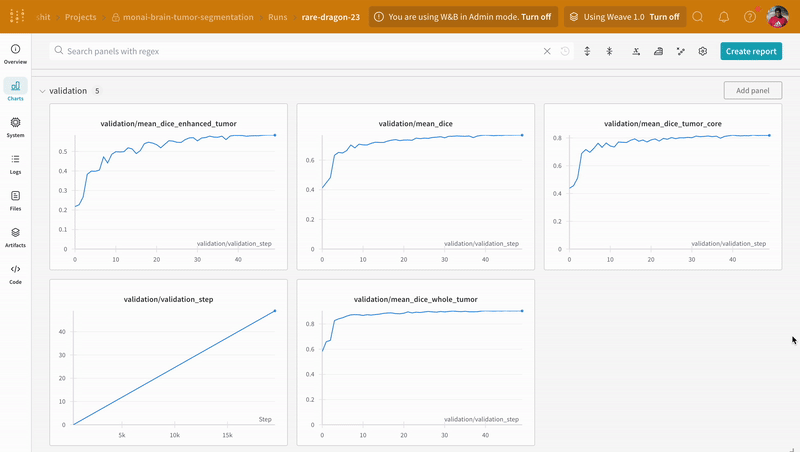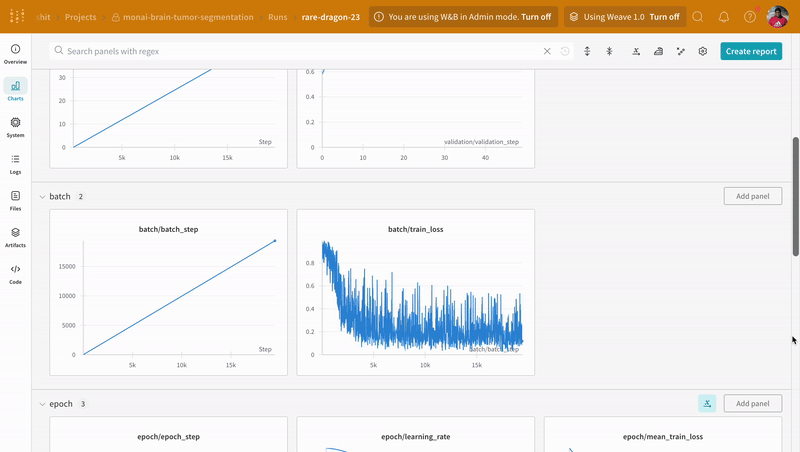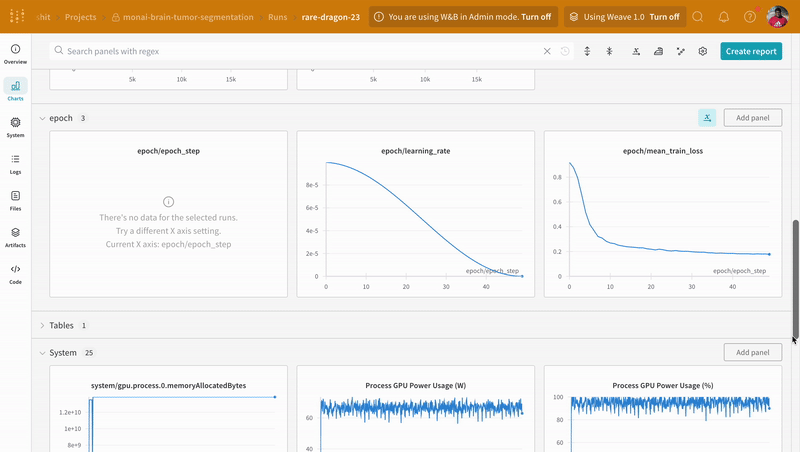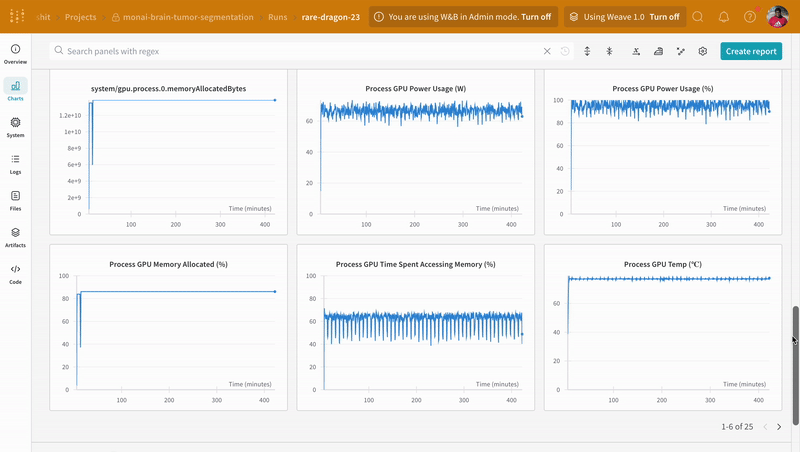 |
|---|
| W&B에서 트레이닝 및 유효성 검사 프로세스 추적의 예. |
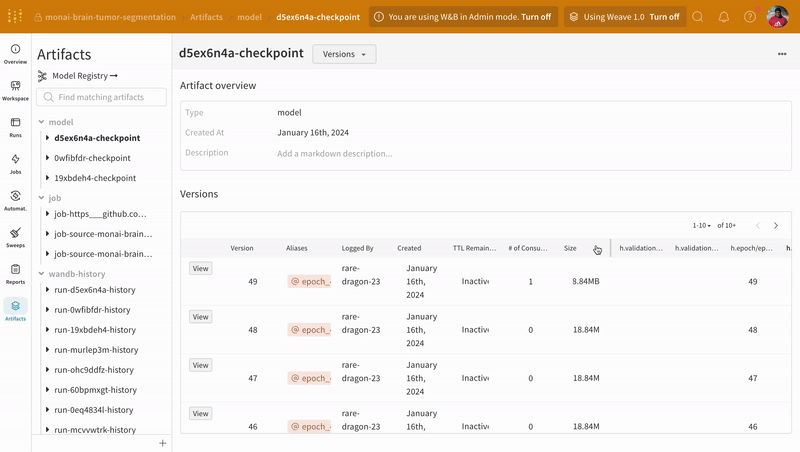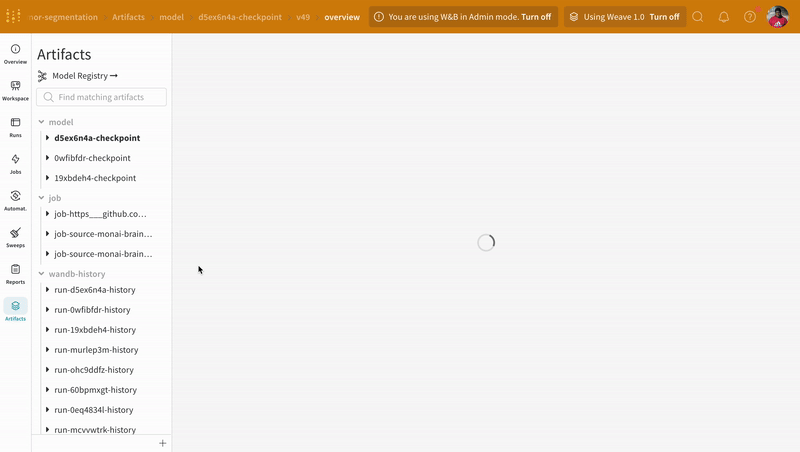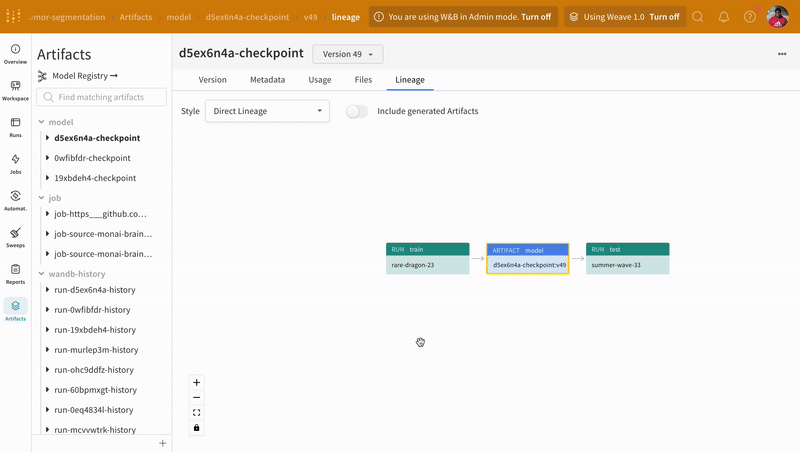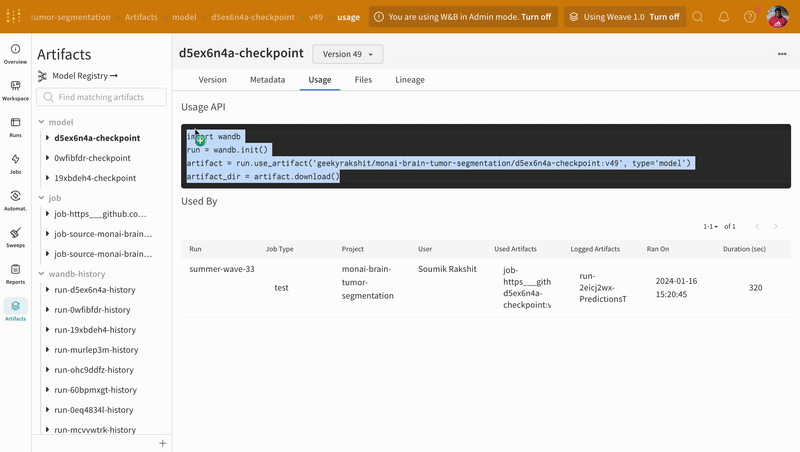
트레이닝 중에 기록된 모델 체크포인트 Artifacts의 다른 버전에 액세스하려면 W&B run 대시보드의 Artifacts 탭으로 이동합니다.
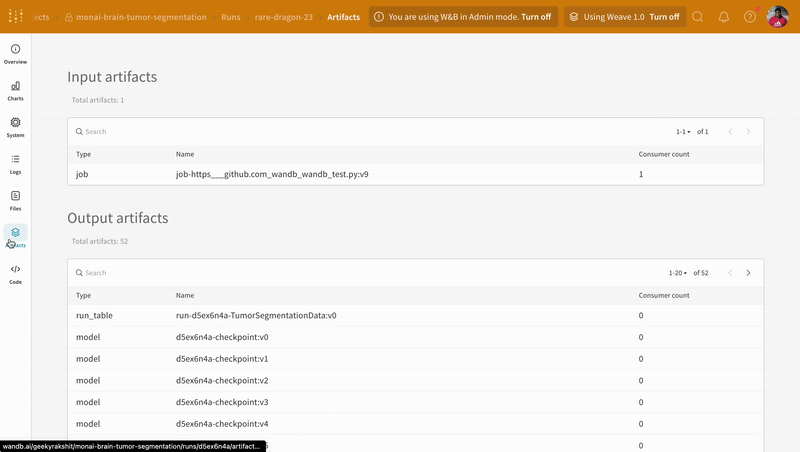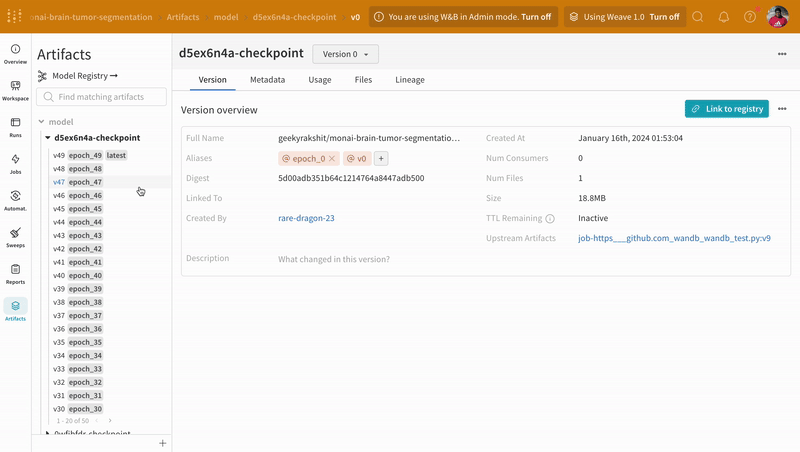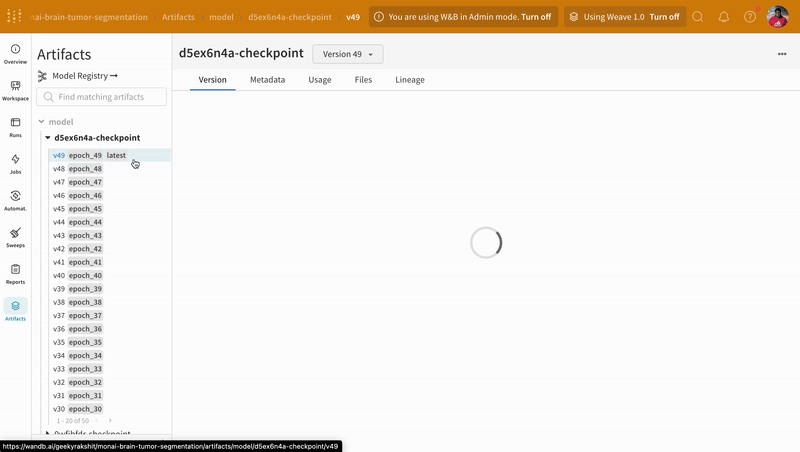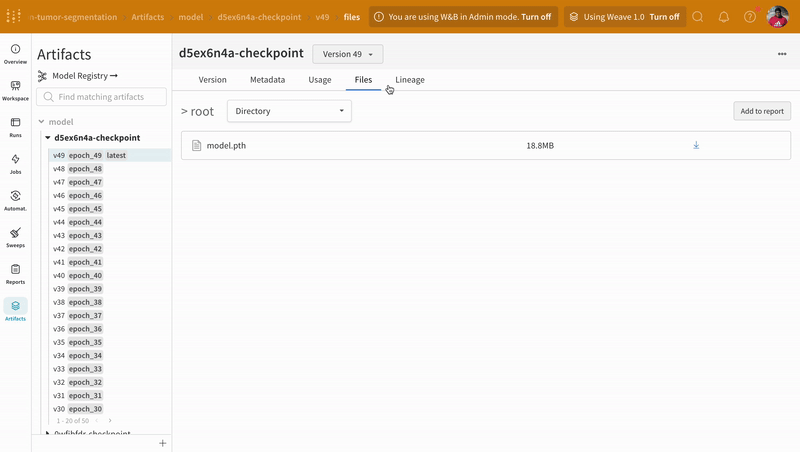 |
|---|
| W&B에서 모델 체크포인트 로깅 및 버전 관리의 예. |
추론
Artifacts 인터페이스를 사용하여 평균 에포크별 트레이닝 손실인 Artifact의 어떤 버전이 가장 적합한 모델 체크포인트인지 선택할 수 있습니다. Artifact의 전체 계보를 탐색하고 필요한 버전을 사용할 수도 있습니다.
 |
|---|
| W&B에서 모델 Artifact 추적의 예. |
최고의 에포크별 평균 트레이닝 손실을 가진 모델 Artifact의 버전을 가져오고 체크포인트 상태 사전을 모델에 로드합니다.
model_artifact = wandb.use_artifact(
"geekyrakshit/monai-brain-tumor-segmentation/d5ex6n4a-checkpoint:v49",
type="model",
)
model_artifact_dir = model_artifact.download()
model.load_state_dict(torch.load(os.path.join(model_artifact_dir, "model.pth")))
model.eval()
예측 시각화 및 그라운드 트루스 레이블과 비교
대화형 분할 마스크 오버레이를 사용하여 사전 트레이닝된 모델의 예측을 시각화하고 해당 그라운드 트루스 분할 마스크와 비교하는 또 다른 유틸리티 함수를 만듭니다.
def log_predictions_into_tables(
sample_image: np.array,
sample_label: np.array,
predicted_label: np.array,
split: str = None,
data_idx: int = None,
table: wandb.Table = None,
):
num_channels, _, _, num_slices = sample_image.shape
with tqdm(total=num_slices, leave=False) as progress_bar:
for slice_idx in range(num_slices):
wandb_images = []
for channel_idx in range(num_channels):
wandb_images += [
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks={
"ground-truth/Tumor-Core": {
"mask_data": sample_label[0, :, :, slice_idx],
"class_labels": {0: "background", 1: "Tumor Core"},
},
"prediction/Tumor-Core": {
"mask_data": predicted_label[0, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Tumor Core"},
},
},
),
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks={
"ground-truth/Whole-Tumor": {
"mask_data": sample_label[1, :, :, slice_idx],
"class_labels": {0: "background", 1: "Whole Tumor"},
},
"prediction/Whole-Tumor": {
"mask_data": predicted_label[1, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Whole Tumor"},
},
},
),
wandb.Image(
sample_image[channel_idx, :, :, slice_idx],
masks={
"ground-truth/Enhancing-Tumor": {
"mask_data": sample_label[2, :, :, slice_idx],
"class_labels": {0: "background", 1: "Enhancing Tumor"},
},
"prediction/Enhancing-Tumor": {
"mask_data": predicted_label[2, :, :, slice_idx] * 2,
"class_labels": {0: "background", 2: "Enhancing Tumor"},
},
},
),
]
table.add_data(split, data_idx, slice_idx, *wandb_images)
progress_bar.update(1)
return table
예측 결과를 예측 테이블에 기록합니다.
# 예측 테이블 생성
prediction_table = wandb.Table(
columns=[
"Split",
"Data Index",
"Slice Index",
"Image-Channel-0/Tumor-Core",
"Image-Channel-1/Tumor-Core",
"Image-Channel-2/Tumor-Core",
"Image-Channel-3/Tumor-Core",
"Image-Channel-0/Whole-Tumor",
"Image-Channel-1/Whole-Tumor",
"Image-Channel-2/Whole-Tumor",
"Image-Channel-3/Whole-Tumor",
"Image-Channel-0/Enhancing-Tumor",
"Image-Channel-1/Enhancing-Tumor",
"Image-Channel-2/Enhancing-Tumor",
"Image-Channel-3/Enhancing-Tumor",
]
)
# 추론 및 시각화 수행
with torch.no_grad():
config.max_prediction_images_visualized
max_samples = (
min(config.max_prediction_images_visualized, len(val_dataset))
if config.max_prediction_images_visualized > 0
else len(val_dataset)
)
progress_bar = tqdm(
enumerate(val_dataset[:max_samples]),
total=max_samples,
desc="Generating Predictions:",
)
for data_idx, sample in progress_bar:
val_input = sample["image"].unsqueeze(0).to(device)
val_output = inference(model, val_input)
val_output = post_trans(val_output[0])
prediction_table = log_predictions_into_tables(
sample_image=sample["image"].cpu().numpy(),
sample_label=sample["label"].cpu().numpy(),
predicted_label=val_output.cpu().numpy(),
data_idx=data_idx,
split="validation",
table=prediction_table,
)
wandb.log({"Predictions/Tumor-Segmentation-Data": prediction_table})
# 실험 종료
wandb.finish()
대화형 분할 마스크 오버레이를 사용하여 각 클래스에 대한 예측된 분할 마스크와 그라운드 트루스 레이블을 분석하고 비교합니다.
 |
|---|
| W&B에서 예측 및 그라운드 트루스 시각화의 예. |
감사의 말씀 및 추가 자료
7 - Keras
Weights & Biases 를 사용하여 기계 학습 실험 추적, 데이터셋 버전 관리 및 프로젝트 협업을 수행하세요.
이 Colab 노트북은 WandbMetricsLogger 콜백을 소개합니다. 이 콜백을 사용하여 실험 추적을 수행하세요. 이 콜백은 트레이닝 및 검증 메트릭과 시스템 메트릭을 Weights & Biases 에 기록합니다.
설정 및 설치
먼저, Weights & Biases 의 최신 버전을 설치해 보겠습니다. 그런 다음 이 Colab 인스턴스를 인증하여 W&B 를 사용합니다.
pip install -qq -U wandb
import os
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow_datasets as tfds
# Weights and Biases 관련 import
import wandb
from wandb.integration.keras import WandbMetricsLogger
W&B 를 처음 사용하거나 로그인하지 않은 경우 wandb.login() 을 실행한 후 나타나는 링크를 통해 가입/로그인 페이지로 이동합니다. 몇 번의 클릭만으로 무료 계정에 가입할 수 있습니다.
wandb.login()
하이퍼파라미터
재현 가능한 기계 학습을 위해서는 적절한 구성 시스템을 사용하는 것이 좋습니다. W&B 를 사용하여 모든 실험에 대한 하이퍼파라미터를 추적할 수 있습니다. 이 Colab 에서는 간단한 Python dict 를 구성 시스템으로 사용합니다.
configs = dict(
num_classes=10,
shuffle_buffer=1024,
batch_size=64,
image_size=28,
image_channels=1,
earlystopping_patience=3,
learning_rate=1e-3,
epochs=10,
)
데이터셋
이 Colab 에서는 TensorFlow 데이터셋 카탈로그의 CIFAR100 데이터셋을 사용합니다. TensorFlow/Keras 를 사용하여 간단한 이미지 분류 파이프라인을 구축하는 것을 목표로 합니다.
train_ds, valid_ds = tfds.load("fashion_mnist", split=["train", "test"])
AUTOTUNE = tf.data.AUTOTUNE
def parse_data(example):
# 이미지 가져오기
image = example["image"]
# image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# 레이블 가져오기
label = example["label"]
label = tf.one_hot(label, depth=configs["num_classes"])
return image, label
def get_dataloader(ds, configs, dataloader_type="train"):
dataloader = ds.map(parse_data, num_parallel_calls=AUTOTUNE)
if dataloader_type == "train":
dataloader = dataloader.shuffle(configs["shuffle_buffer"])
dataloader = dataloader.batch(configs["batch_size"]).prefetch(AUTOTUNE)
return dataloader
trainloader = get_dataloader(train_ds, configs)
validloader = get_dataloader(valid_ds, configs, dataloader_type="valid")
모델
def get_model(configs):
backbone = tf.keras.applications.mobilenet_v2.MobileNetV2(
weights="imagenet", include_top=False
)
backbone.trainable = False
inputs = layers.Input(
shape=(configs["image_size"], configs["image_size"], configs["image_channels"])
)
resize = layers.Resizing(32, 32)(inputs)
neck = layers.Conv2D(3, (3, 3), padding="same")(resize)
preprocess_input = tf.keras.applications.mobilenet.preprocess_input(neck)
x = backbone(preprocess_input)
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(configs["num_classes"], activation="softmax")(x)
return models.Model(inputs=inputs, outputs=outputs)
tf.keras.backend.clear_session()
model = get_model(configs)
model.summary()
모델 컴파일
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=[
"accuracy",
tf.keras.metrics.TopKCategoricalAccuracy(k=5, name="top@5_accuracy"),
],
)
트레이닝
# W&B run 초기화
run = wandb.init(project="intro-keras", config=configs)
# 모델 트레이닝
model.fit(
trainloader,
epochs=configs["epochs"],
validation_data=validloader,
callbacks=[
WandbMetricsLogger(log_freq=10)
], # 여기에서 WandbMetricsLogger 사용에 유의하세요.
)
# W&B run 닫기
run.finish()
8 - Keras models
Weights & Biases 를 사용하여 기계 학습 실험 추적, 데이터셋 버전 관리 및 프로젝트 협업을 수행하세요.
이 Colab 노트북은 WandbModelCheckpoint 콜백을 소개합니다. 이 콜백을 사용하여 모델 체크포인트를 Weight and Biases Artifacts에 기록하세요.
설정 및 설치
먼저 Weights & Biases 의 최신 버전을 설치해 보겠습니다. 그런 다음 이 colab 인스턴스를 인증하여 W&B를 사용합니다.
!pip install -qq -U wandb
import os
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow_datasets as tfds
# Weights and Biases 관련 import
import wandb
from wandb.integration.keras import WandbMetricsLogger
from wandb.integration.keras import WandbModelCheckpoint
W&B를 처음 사용하거나 로그인하지 않은 경우, wandb.login()을 실행한 후 나타나는 링크를 통해 가입/로그인 페이지로 이동할 수 있습니다. 몇 번의 클릭만으로 무료 계정에 가입할 수 있습니다.
wandb.login()
하이퍼파라미터
재현 가능한 기계 학습을 위해서는 적절한 구성 시스템을 사용하는 것이 좋습니다. W&B를 사용하여 모든 실험에 대한 하이퍼파라미터를 추적할 수 있습니다. 이 colab에서는 간단한 Python dict를 구성 시스템으로 사용합니다.
configs = dict(
num_classes = 10,
shuffle_buffer = 1024,
batch_size = 64,
image_size = 28,
image_channels = 1,
earlystopping_patience = 3,
learning_rate = 1e-3,
epochs = 10
)
데이터셋
이 colab에서는 TensorFlow Dataset 카탈로그의 CIFAR100 데이터셋을 사용합니다. TensorFlow/Keras를 사용하여 간단한 이미지 분류 파이프라인을 구축하는 것을 목표로 합니다.
train_ds, valid_ds = tfds.load('fashion_mnist', split=['train', 'test'])
AUTOTUNE = tf.data.AUTOTUNE
def parse_data(example):
# 이미지 가져오기
image = example["image"]
# image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# 레이블 가져오기
label = example["label"]
label = tf.one_hot(label, depth=configs["num_classes"])
return image, label
def get_dataloader(ds, configs, dataloader_type="train"):
dataloader = ds.map(parse_data, num_parallel_calls=AUTOTUNE)
if dataloader_type=="train":
dataloader = dataloader.shuffle(configs["shuffle_buffer"])
dataloader = (
dataloader
.batch(configs["batch_size"])
.prefetch(AUTOTUNE)
)
return dataloader
trainloader = get_dataloader(train_ds, configs)
validloader = get_dataloader(valid_ds, configs, dataloader_type="valid")
모델
def get_model(configs):
backbone = tf.keras.applications.mobilenet_v2.MobileNetV2(weights='imagenet', include_top=False)
backbone.trainable = False
inputs = layers.Input(shape=(configs["image_size"], configs["image_size"], configs["image_channels"]))
resize = layers.Resizing(32, 32)(inputs)
neck = layers.Conv2D(3, (3,3), padding="same")(resize)
preprocess_input = tf.keras.applications.mobilenet.preprocess_input(neck)
x = backbone(preprocess_input)
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(configs["num_classes"], activation="softmax")(x)
return models.Model(inputs=inputs, outputs=outputs)
tf.keras.backend.clear_session()
model = get_model(configs)
model.summary()
모델 컴파일
model.compile(
optimizer = "adam",
loss = "categorical_crossentropy",
metrics = ["accuracy", tf.keras.metrics.TopKCategoricalAccuracy(k=5, name='top@5_accuracy')]
)
학습
# W&B run 초기화
run = wandb.init(
project = "intro-keras",
config = configs
)
# 모델 학습
model.fit(
trainloader,
epochs = configs["epochs"],
validation_data = validloader,
callbacks = [
WandbMetricsLogger(log_freq=10),
WandbModelCheckpoint(filepath="models/") # WandbModelCheckpoint 사용에 주목하세요.
]
)
# W&B run 종료
run.finish()
9 - Keras tables
Weights & Biases를 사용하여 기계 학습 실험 추적, 데이터셋 버전 관리 및 프로젝트 협업을 수행하세요.
이 Colab 노트북은 모델 예측 시각화 및 데이터셋 시각화를 위한 유용한 콜백을 구축하기 위해 상속될 수 있는 추상 콜백인 WandbEvalCallback을 소개합니다.
설정 및 설치
먼저, Weights & Biases의 최신 버전을 설치해 보겠습니다. 그런 다음 이 Colab 인스턴스를 인증하여 W&B를 사용합니다.
pip install -qq -U wandb
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow_datasets as tfds
# Weights and Biases 관련 import
import wandb
from wandb.integration.keras import WandbMetricsLogger
from wandb.integration.keras import WandbModelCheckpoint
from wandb.integration.keras import WandbEvalCallback
W&B를 처음 사용하거나 로그인하지 않은 경우, wandb.login()을 실행한 후 나타나는 링크를 통해 가입/로그인 페이지로 이동합니다. 몇 번의 클릭만으로 무료 계정에 가입할 수 있습니다.
wandb.login()
하이퍼파라미터
재현 가능한 기계 학습을 위해서는 적절한 구성 시스템을 사용하는 것이 좋습니다. W&B를 사용하여 모든 실험에 대한 하이퍼파라미터를 추적할 수 있습니다. 이 Colab에서는 간단한 Python dict를 구성 시스템으로 사용합니다.
configs = dict(
num_classes=10,
shuffle_buffer=1024,
batch_size=64,
image_size=28,
image_channels=1,
earlystopping_patience=3,
learning_rate=1e-3,
epochs=10,
)
데이터셋
이 Colab에서는 TensorFlow 데이터셋 카탈로그의 CIFAR100 데이터셋을 사용합니다. TensorFlow/Keras를 사용하여 간단한 이미지 분류 파이프라인을 구축하는 것을 목표로 합니다.
train_ds, valid_ds = tfds.load("fashion_mnist", split=["train", "test"])
AUTOTUNE = tf.data.AUTOTUNE
def parse_data(example):
# 이미지 가져오기
image = example["image"]
# image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# 레이블 가져오기
label = example["label"]
label = tf.one_hot(label, depth=configs["num_classes"])
return image, label
def get_dataloader(ds, configs, dataloader_type="train"):
dataloader = ds.map(parse_data, num_parallel_calls=AUTOTUNE)
if dataloader_type=="train":
dataloader = dataloader.shuffle(configs["shuffle_buffer"])
dataloader = (
dataloader
.batch(configs["batch_size"])
.prefetch(AUTOTUNE)
)
return dataloader
trainloader = get_dataloader(train_ds, configs)
validloader = get_dataloader(valid_ds, configs, dataloader_type="valid")
모델
def get_model(configs):
backbone = tf.keras.applications.mobilenet_v2.MobileNetV2(
weights="imagenet", include_top=False
)
backbone.trainable = False
inputs = layers.Input(
shape=(configs["image_size"], configs["image_size"], configs["image_channels"])
)
resize = layers.Resizing(32, 32)(inputs)
neck = layers.Conv2D(3, (3, 3), padding="same")(resize)
preprocess_input = tf.keras.applications.mobilenet.preprocess_input(neck)
x = backbone(preprocess_input)
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(configs["num_classes"], activation="softmax")(x)
return models.Model(inputs=inputs, outputs=outputs)
tf.keras.backend.clear_session()
model = get_model(configs)
model.summary()
모델 컴파일
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=[
"accuracy",
tf.keras.metrics.TopKCategoricalAccuracy(k=5, name="top@5_accuracy"),
],
)
WandbEvalCallback
WandbEvalCallback은 주로 모델 예측 시각화를 위해, 부차적으로는 데이터셋 시각화를 위해 Keras 콜백을 구축하는 추상 기본 클래스입니다.
이는 데이터셋 및 작업에 구애받지 않는 추상 콜백입니다. 이를 사용하려면 이 기본 콜백 클래스에서 상속하고 add_ground_truth 및 add_model_prediction 메소드를 구현합니다.
WandbEvalCallback은 다음과 같은 유용한 메소드를 제공하는 유틸리티 클래스입니다.
- 데이터 및 예측
wandb.Table인스턴스 생성, - 데이터 및 예측 Tables를
wandb.Artifact로 기록, - 데이터 테이블을
on_train_begin에 기록, - 예측 테이블을
on_epoch_end에 기록.
예를 들어, 아래에 이미지 분류 작업을 위한 WandbClfEvalCallback을 구현했습니다. 이 예제 콜백은 다음과 같습니다.
- 검증 데이터(
data_table)를 W&B에 기록, - 모든 에포크 종료 시 추론을 수행하고 예측(
pred_table)을 W&B에 기록.
메모리 공간을 줄이는 방법
on_train_begin 메소드가 호출될 때 data_table을 W&B에 기록합니다. W&B Artifact로 업로드되면 data_table_ref 클래스 변수를 사용하여 엑세스할 수 있는 이 테이블에 대한 참조를 얻습니다. data_table_ref는 self.data_table_ref[idx][n]과 같이 인덱싱할 수 있는 2D 목록입니다. 여기서 idx는 행 번호이고 n은 열 번호입니다. 아래 예에서 사용법을 살펴보겠습니다.
class WandbClfEvalCallback(WandbEvalCallback):
def __init__(
self, validloader, data_table_columns, pred_table_columns, num_samples=100
):
super().__init__(data_table_columns, pred_table_columns)
self.val_data = validloader.unbatch().take(num_samples)
def add_ground_truth(self, logs=None):
for idx, (image, label) in enumerate(self.val_data):
self.data_table.add_data(idx, wandb.Image(image), np.argmax(label, axis=-1))
def add_model_predictions(self, epoch, logs=None):
# 예측값 가져오기
preds = self._inference()
table_idxs = self.data_table_ref.get_index()
for idx in table_idxs:
pred = preds[idx]
self.pred_table.add_data(
epoch,
self.data_table_ref.data[idx][0],
self.data_table_ref.data[idx][1],
self.data_table_ref.data[idx][2],
pred,
)
def _inference(self):
preds = []
for image, label in self.val_data:
pred = self.model(tf.expand_dims(image, axis=0))
argmax_pred = tf.argmax(pred, axis=-1).numpy()[0]
preds.append(argmax_pred)
return preds
학습
# W&B run 초기화
run = wandb.init(project="intro-keras", config=configs)
# 모델 학습
model.fit(
trainloader,
epochs=configs["epochs"],
validation_data=validloader,
callbacks=[
WandbMetricsLogger(log_freq=10),
WandbClfEvalCallback(
validloader,
data_table_columns=["idx", "image", "ground_truth"],
pred_table_columns=["epoch", "idx", "image", "ground_truth", "prediction"],
), # 여기에서 WandbEvalCallback 사용에 주목하세요.
],
)
# W&B run 닫기
run.finish()
10 - XGBoost Sweeps
Weights & Biases를 사용하여 기계 학습 실험 추적, 데이터셋 버전 관리 및 프로젝트 협업을 수행하세요.
트리 기반 모델에서 최고의 성능을 짜내려면 적절한 하이퍼파라미터를 선택해야 합니다.
early_stopping_rounds는 몇 번으로 해야 할까요? 트리의 max_depth는 얼마로 설정해야 할까요?
가장 뛰어난 성능의 모델을 찾기 위해 고차원 하이퍼파라미터 공간을 탐색하는 것은 매우 빠르게 복잡해질 수 있습니다. 하이퍼파라미터 Sweeps는 모델 간의 배틀 로얄을 조직적이고 효율적으로 수행하고 승자를 결정하는 방법을 제공합니다. 가장 최적의 값을 찾기 위해 하이퍼파라미터 값의 조합을 자동으로 검색하여 이를 가능하게 합니다.
이 튜토리얼에서는 Weights & Biases를 사용하여 3가지 간단한 단계를 거쳐 XGBoost 모델에서 정교한 하이퍼파라미터 Sweeps를 실행하는 방법을 알아봅니다.
미리 보기를 보려면 아래 그림을 확인하세요.
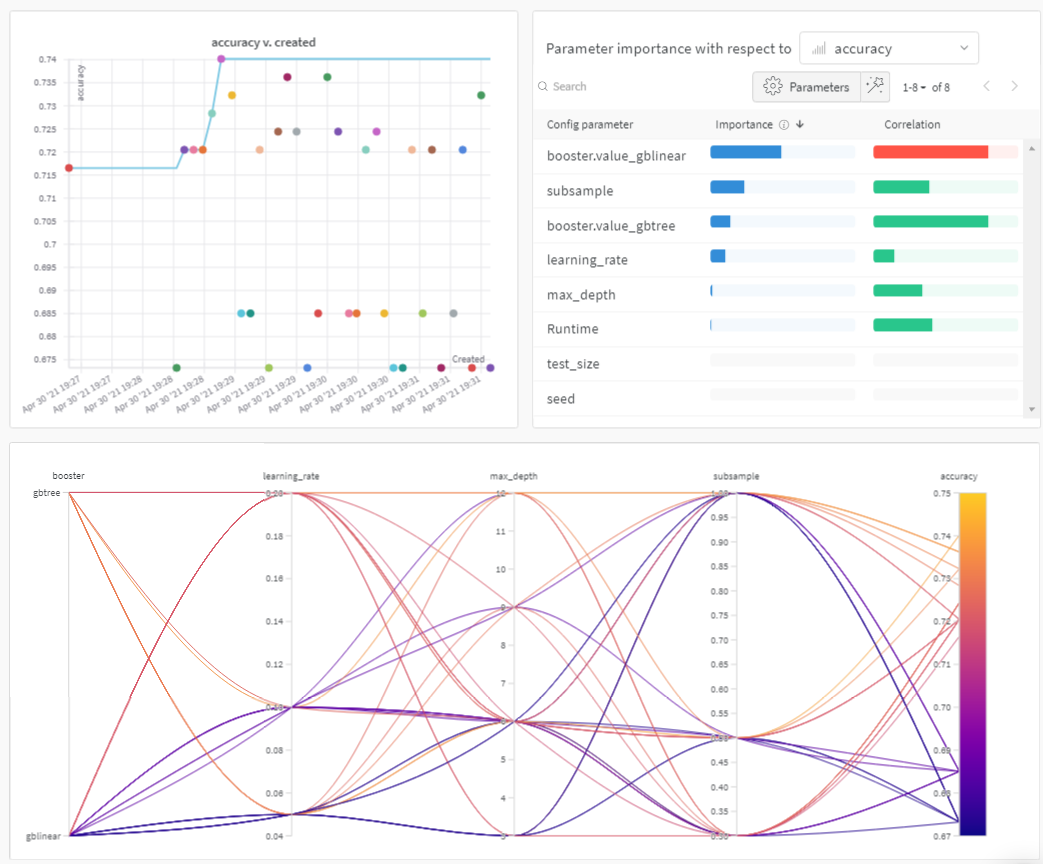
Sweeps: 개요
Weights & Biases로 하이퍼파라미터 스윕을 실행하는 것은 매우 쉽습니다. 3가지 간단한 단계만 거치면 됩니다.
-
스윕 정의: 스윕을 지정하는 사전과 유사한 오브젝트를 생성하여 수행합니다. 검색할 파라미터, 사용할 검색 전략, 최적화할 메트릭을 지정합니다.
-
스윕 초기화: 한 줄의 코드로 스윕을 초기화하고 스윕 구성 사전을 전달합니다.
sweep_id = wandb.sweep(sweep_config) -
스윕 에이전트 실행: 또한 한 줄의 코드로 수행됩니다.
wandb.agent()를 호출하고 모델 아키텍처를 정의하고 트레이닝하는 함수와 함께sweep_id를 전달합니다.wandb.agent(sweep_id, function=train)
하이퍼파라미터 스윕을 실행하는 데 필요한 전부입니다.
아래의 노트북에서는 이러한 3단계를 더 자세히 살펴보겠습니다.
이 노트북을 포크하고, 파라미터를 조정하거나, 자신의 데이터셋으로 모델을 사용해 보는 것이 좋습니다.
참고 자료
!pip install wandb -qU
import wandb
wandb.login()
1. 스윕 정의
Weights & Biases Sweeps는 단 몇 줄의 코드로 원하는 방식으로 스윕을 정확하게 구성할 수 있는 강력한 레버를 제공합니다. 스윕 구성은 사전 또는 YAML 파일로 정의할 수 있습니다.
몇 가지를 함께 살펴보겠습니다.
- 메트릭: 이는 스윕이 최적화하려고 시도하는 메트릭입니다. 메트릭은
name(이 메트릭은 트레이닝 스크립트에 의해 기록되어야 함)과goal(maximize또는minimize)을 사용할 수 있습니다. - 검색 전략:
"method"키를 사용하여 지정합니다. Sweeps를 통해 여러 가지 검색 전략을 지원합니다. - 그리드 검색: 하이퍼파라미터 값의 모든 조합을 반복합니다.
- 랜덤 검색: 하이퍼파라미터 값의 임의로 선택된 조합을 반복합니다.
- 베이지안 탐색: 하이퍼파라미터를 메트릭 점수의 확률에 매핑하는 확률 모델을 생성하고 메트릭을 개선할 가능성이 높은 파라미터를 선택합니다. 베이지안 최적화의 목적은 하이퍼파라미터 값을 선택하는 데 더 많은 시간을 투자하는 것이지만, 그렇게 함으로써 더 적은 수의 하이퍼파라미터 값을 시도하는 것입니다.
- 파라미터: 각 반복에서 값을 가져올 하이퍼파라미터 이름과 불연속 값, 범위 또는 분포를 포함하는 사전입니다.
자세한 내용은 모든 스윕 구성 옵션 목록을 참조하십시오.
sweep_config = {
"method": "random", # try grid or random
"metric": {
"name": "accuracy",
"goal": "maximize"
},
"parameters": {
"booster": {
"values": ["gbtree","gblinear"]
},
"max_depth": {
"values": [3, 6, 9, 12]
},
"learning_rate": {
"values": [0.1, 0.05, 0.2]
},
"subsample": {
"values": [1, 0.5, 0.3]
}
}
}
2. 스윕 초기화
wandb.sweep을 호출하면 스윕 컨트롤러가 시작됩니다. 스윕 컨트롤러는 parameters의 설정을 쿼리하는 모든 사용자에게 제공하고 wandb 로깅을 통해 metrics에 대한 성능을 반환하도록 기대하는 중앙 집중식 프로세스입니다.
sweep_id = wandb.sweep(sweep_config, project="XGBoost-sweeps")
트레이닝 프로세스 정의
스윕을 실행하기 전에 모델을 생성하고 트레이닝하는 함수, 즉 하이퍼파라미터 값을 입력받아 메트릭을 출력하는 함수를 정의해야 합니다.
또한 wandb를 스크립트에 통합해야 합니다.
세 가지 주요 구성 요소가 있습니다.
wandb.init(): 새 W&B run을 초기화합니다. 각 run은 트레이닝 스크립트의 단일 실행입니다.wandb.config: 모든 하이퍼파라미터를 구성 오브젝트에 저장합니다. 이를 통해 저희 앱을 사용하여 하이퍼파라미터 값별로 run을 정렬하고 비교할 수 있습니다.wandb.log(): 이미지, 비디오, 오디오 파일, HTML, 플롯 또는 포인트 클라우드와 같은 메트릭 및 사용자 정의 오브젝트를 기록합니다.
또한 데이터를 다운로드해야 합니다.
!wget https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv
# XGBoost model for Pima Indians dataset
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
def train():
config_defaults = {
"booster": "gbtree",
"max_depth": 3,
"learning_rate": 0.1,
"subsample": 1,
"seed": 117,
"test_size": 0.33,
}
wandb.init(config=config_defaults) # defaults are over-ridden during the sweep
config = wandb.config
# load data and split into predictors and targets
dataset = loadtxt("pima-indians-diabetes.data.csv", delimiter=",")
X, Y = dataset[:, :8], dataset[:, 8]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size=config.test_size,
random_state=config.seed)
# fit model on train
model = XGBClassifier(booster=config.booster, max_depth=config.max_depth,
learning_rate=config.learning_rate, subsample=config.subsample)
model.fit(X_train, y_train)
# make predictions on test
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy:.0%}")
wandb.log({"accuracy": accuracy})
3. 에이전트로 스윕 실행
이제 wandb.agent를 호출하여 스윕을 시작합니다.
다음을 포함하는 W&B에 로그인한 모든 시스템에서 wandb.agent를 호출할 수 있습니다.
sweep_id,- 데이터셋 및
train함수
그러면 해당 시스템이 스윕에 참여합니다.
참고:
random스윕은 기본적으로 영원히 실행되어 새로운 파라미터 조합을 계속 시도합니다. 소가 집으로 돌아올 때까지 또는 앱 UI에서 스윕을 끌 때까지 계속됩니다.agent가 완료하려는 총 runcount를 제공하여 이를 방지할 수 있습니다.
wandb.agent(sweep_id, train, count=25)
결과 시각화
이제 스윕이 완료되었으므로 결과를 살펴볼 차례입니다.
Weights & Biases는 여러 유용한 플롯을 자동으로 생성합니다.
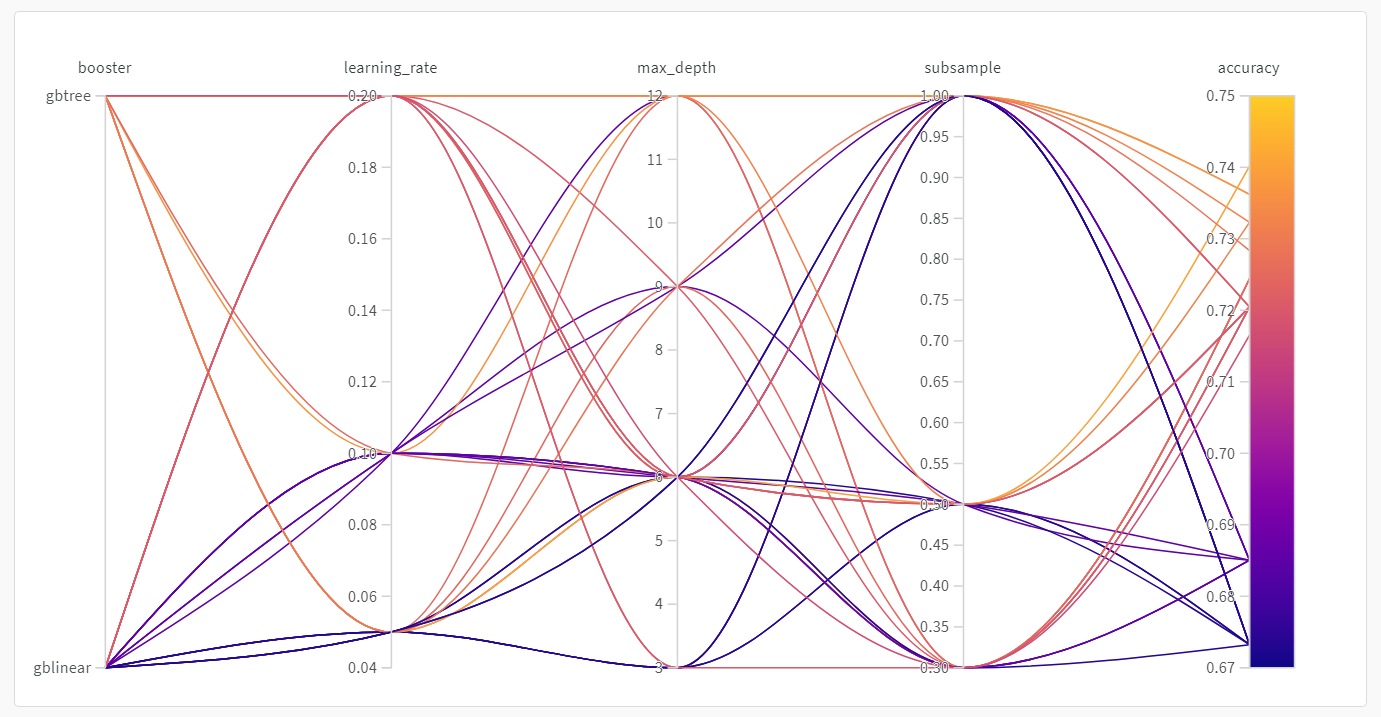
병렬 좌표 플롯
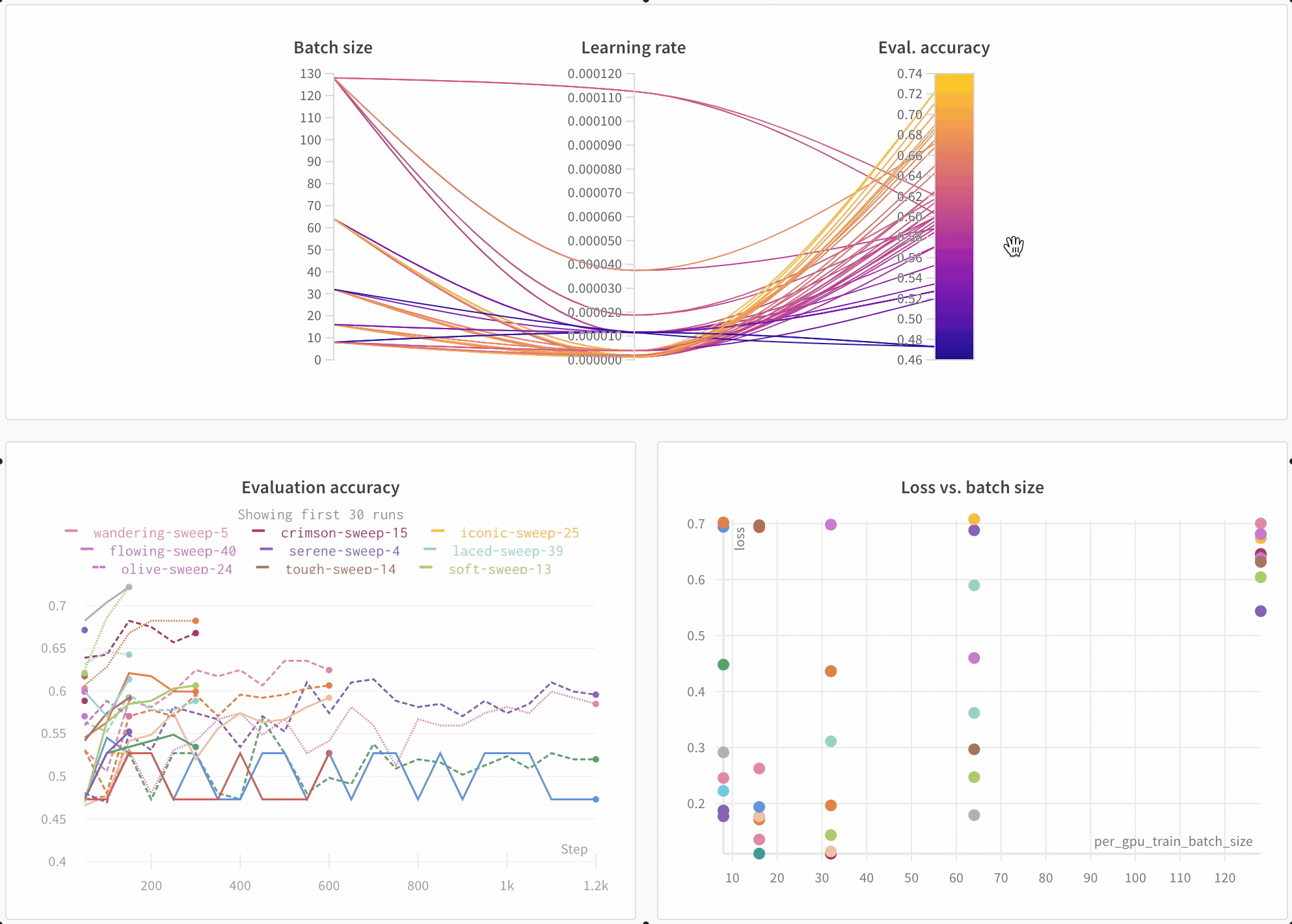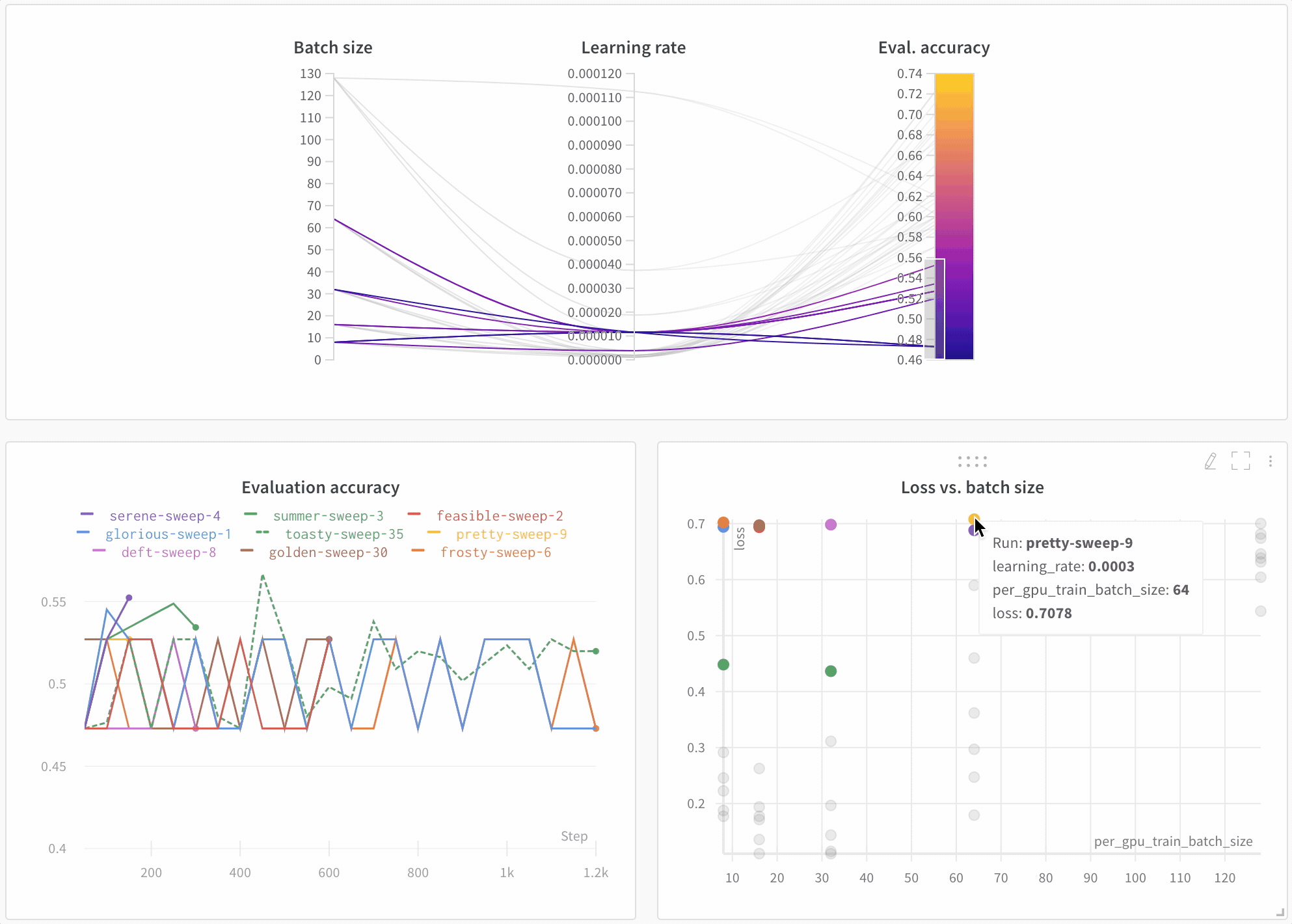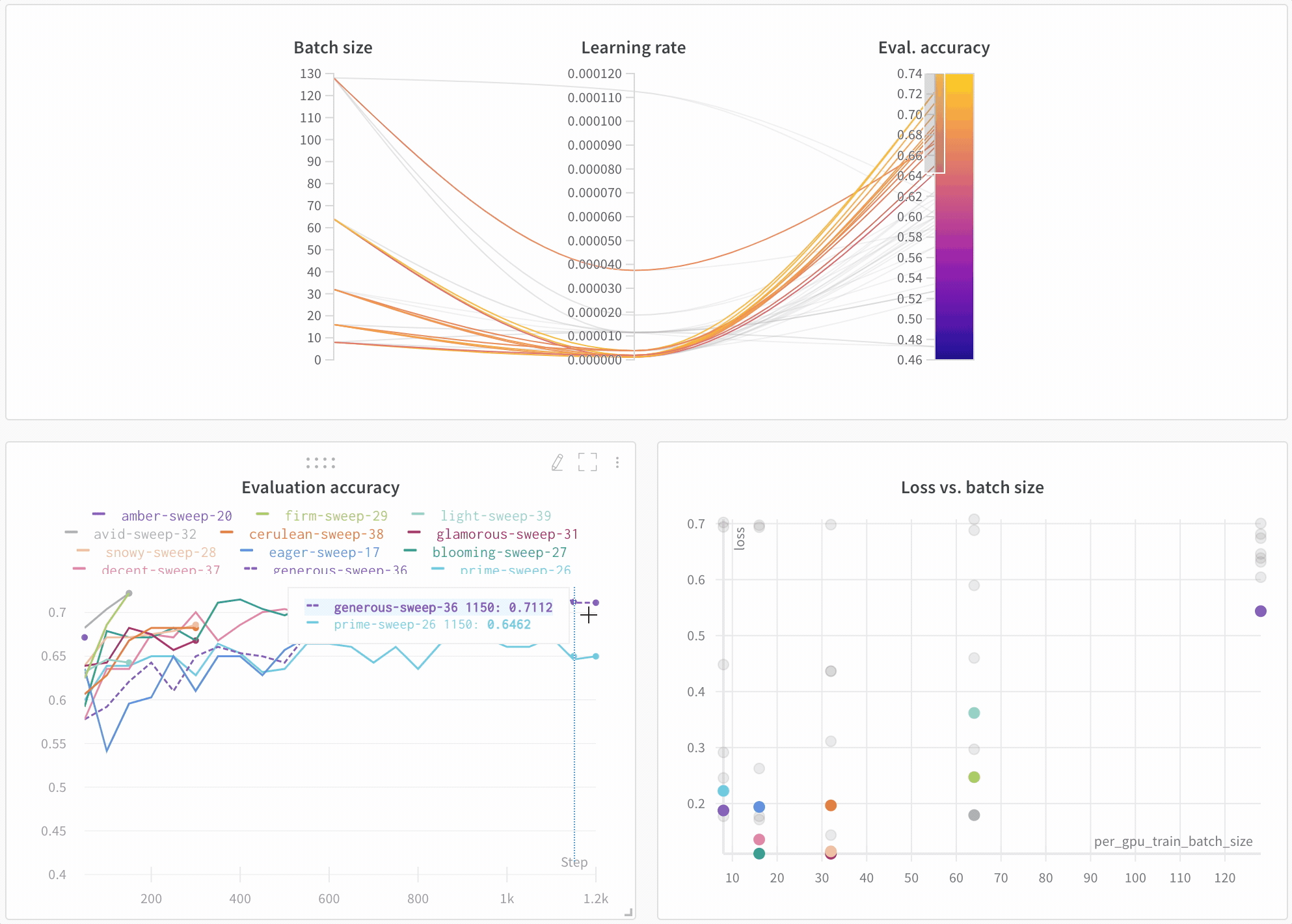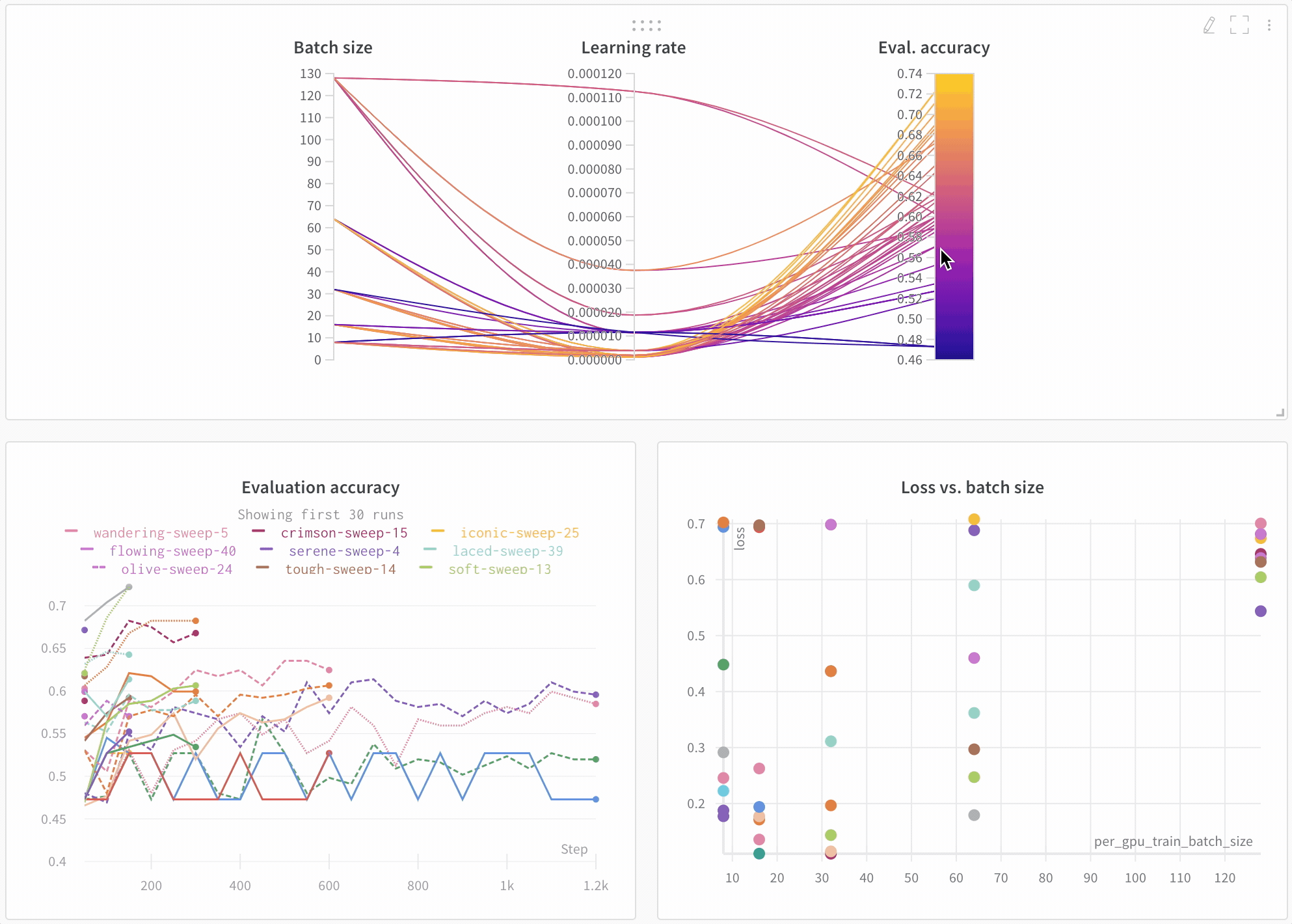
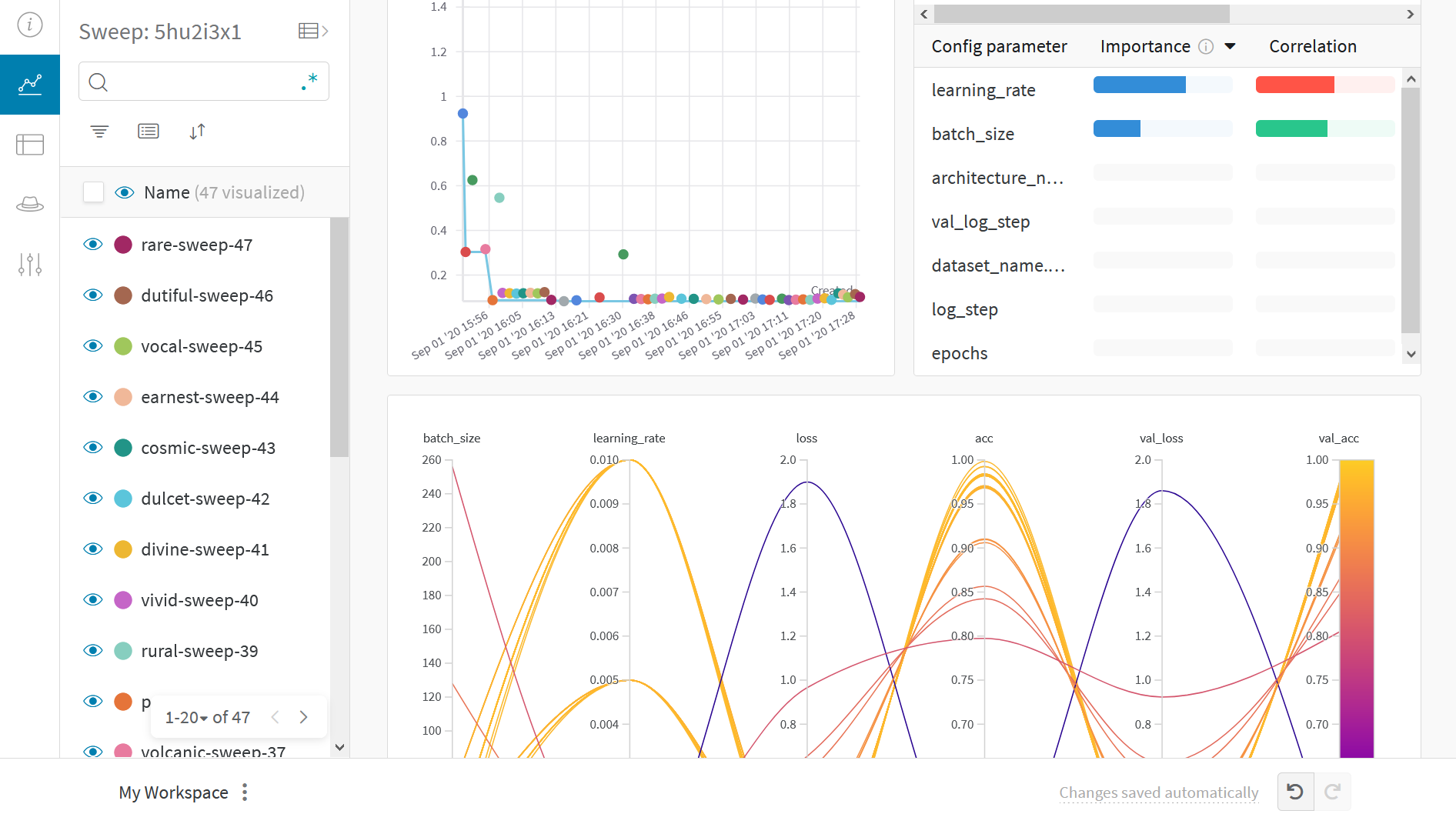
이 플롯은 하이퍼파라미터 값을 모델 메트릭에 매핑합니다. 최고의 모델 성능을 이끌어낸 하이퍼파라미터 조합을 파악하는 데 유용합니다.
이 플롯은 학습기로 트리를 사용하는 것이 학습기로 간단한 선형 모델을 사용하는 것보다 약간 더 나은 성능을 보이지만, 획기적인 수준은 아닌 것으로 보입니다.
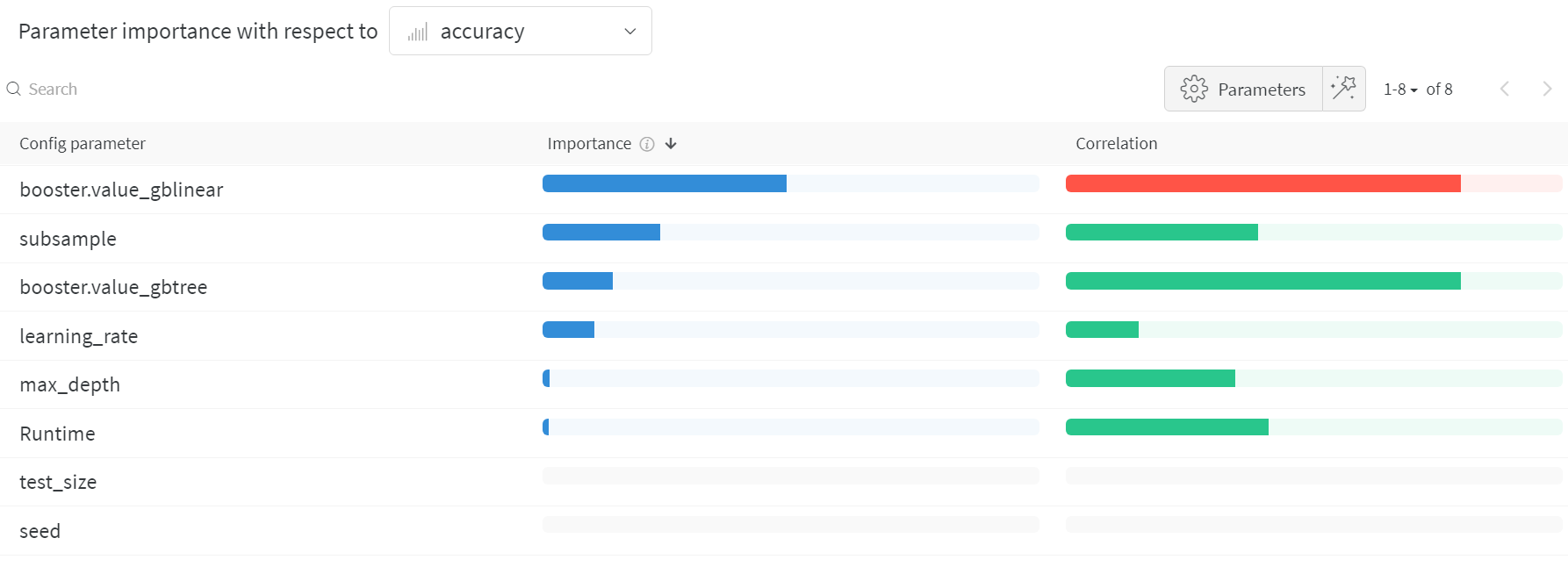
하이퍼파라미터 중요도 플롯
하이퍼파라미터 중요도 플롯은 어떤 하이퍼파라미터 값이 메트릭에 가장 큰 영향을 미쳤는지 보여줍니다.
선형 예측기로 취급하는 상관 관계와 결과에 대한 랜덤 포레스트를 트레이닝한 후의 특징 중요도를 모두 보고하므로 어떤 파라미터가 가장 큰 영향을 미쳤는지, 그리고 그 영향이 긍정적인지 부정적인지 확인할 수 있습니다.
이 차트를 보면 위에서 병렬 좌표 차트에서 발견한 추세를 정량적으로 확인할 수 있습니다. 검증 정확도에 가장 큰 영향을 미친 것은 학습기 선택이었고, gblinear 학습기는 일반적으로 gbtree 학습기보다 성능이 좋지 않았습니다.
이러한 시각화는 가장 중요하고 따라서 더 자세히 탐구할 가치가 있는 파라미터(및 값 범위)에 집중하여 비용이 많이 드는 하이퍼파라미터 최적화를 실행하는 데 드는 시간과 리소스를 절약하는 데 도움이 될 수 있습니다.