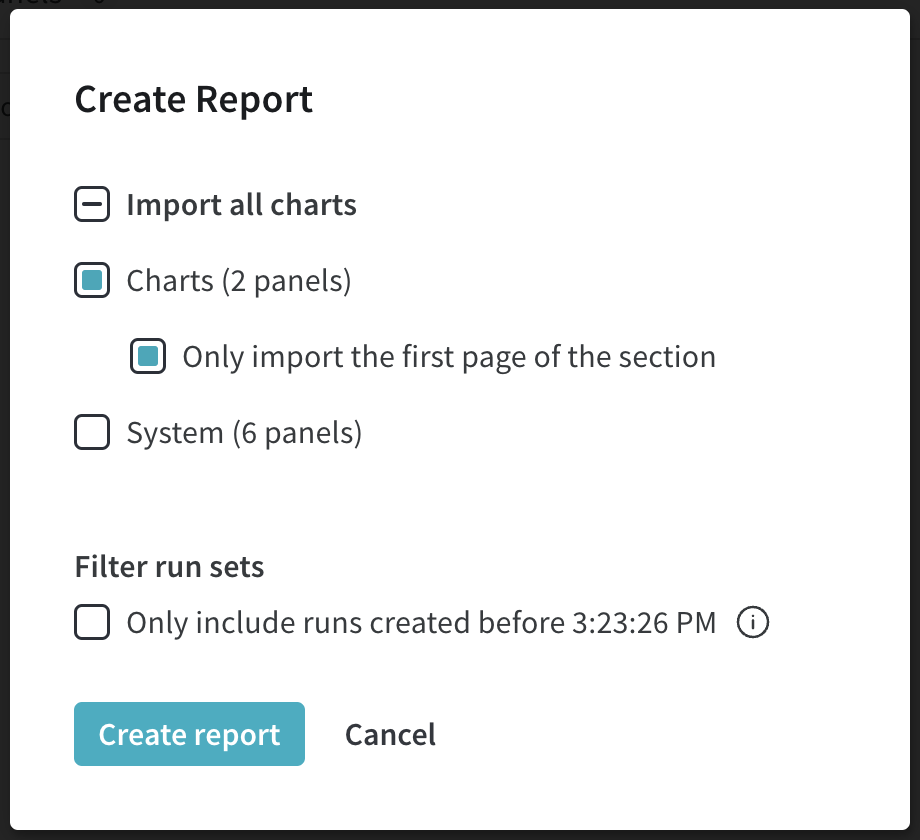
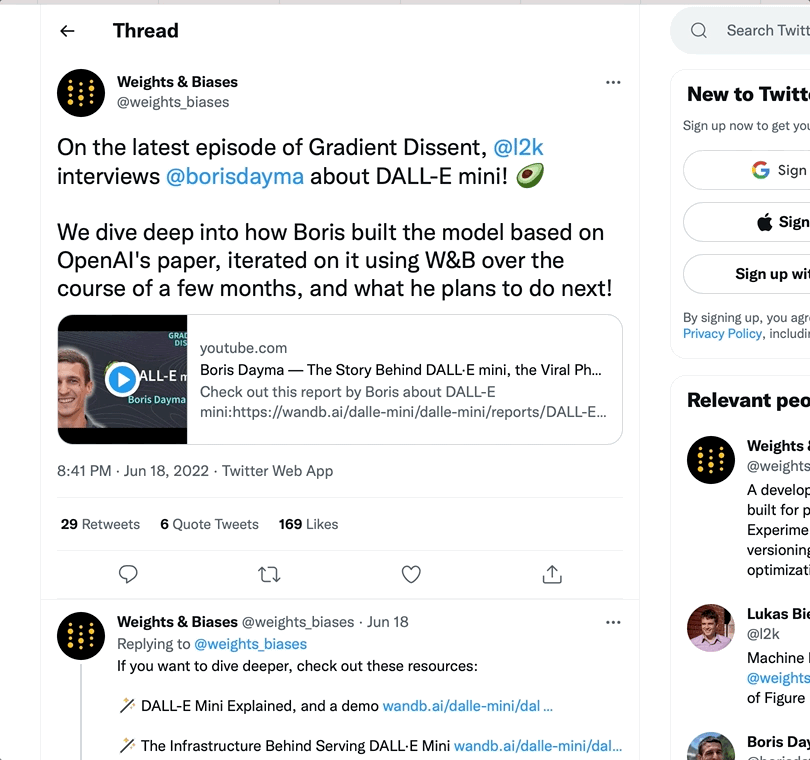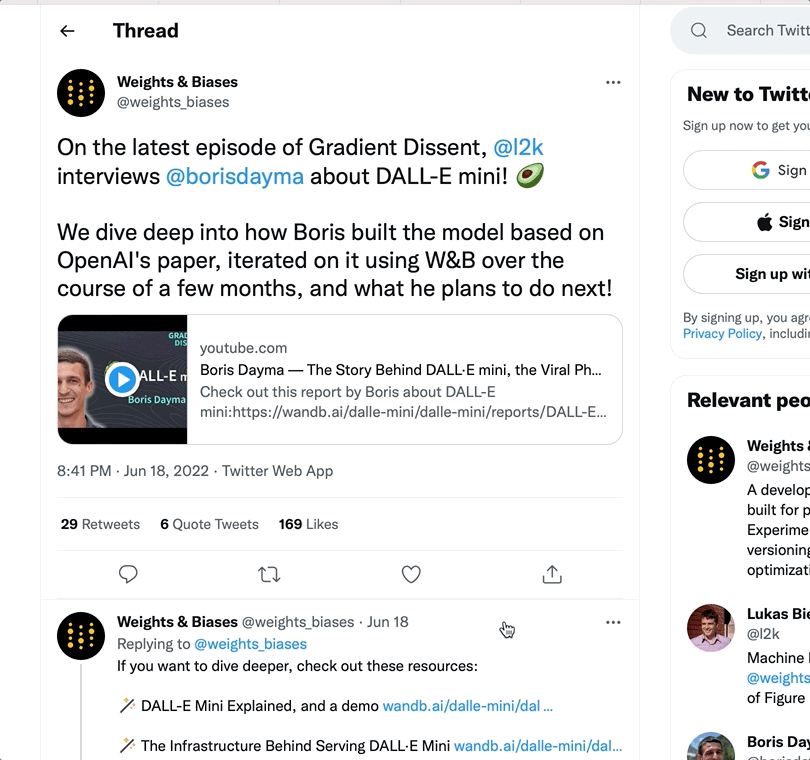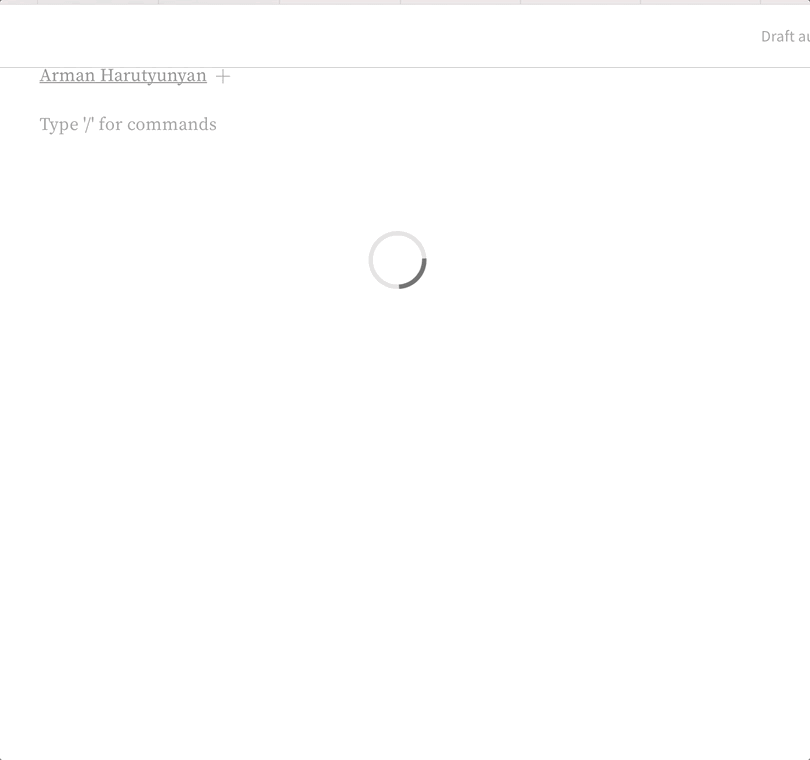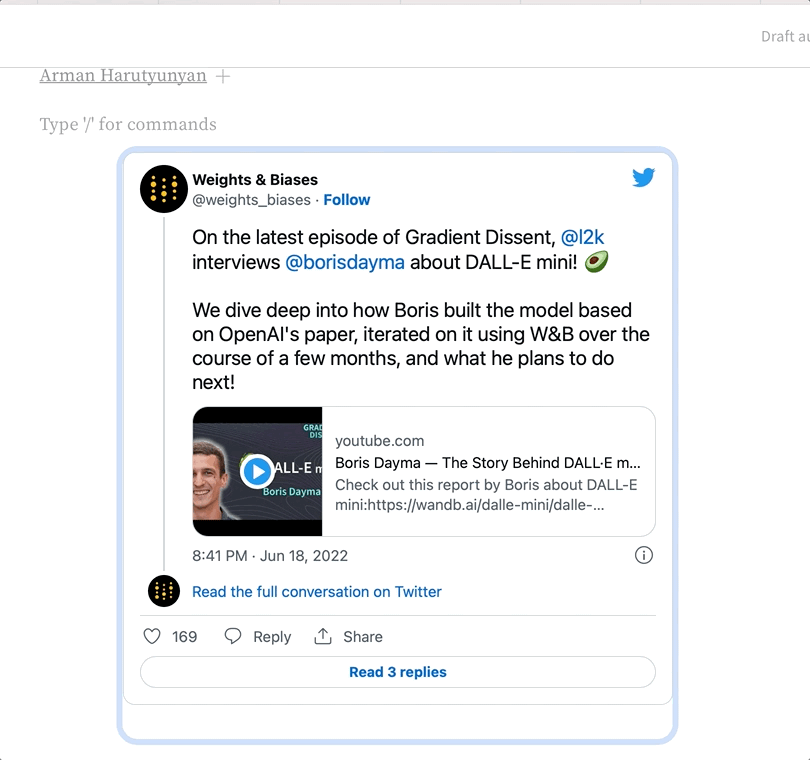
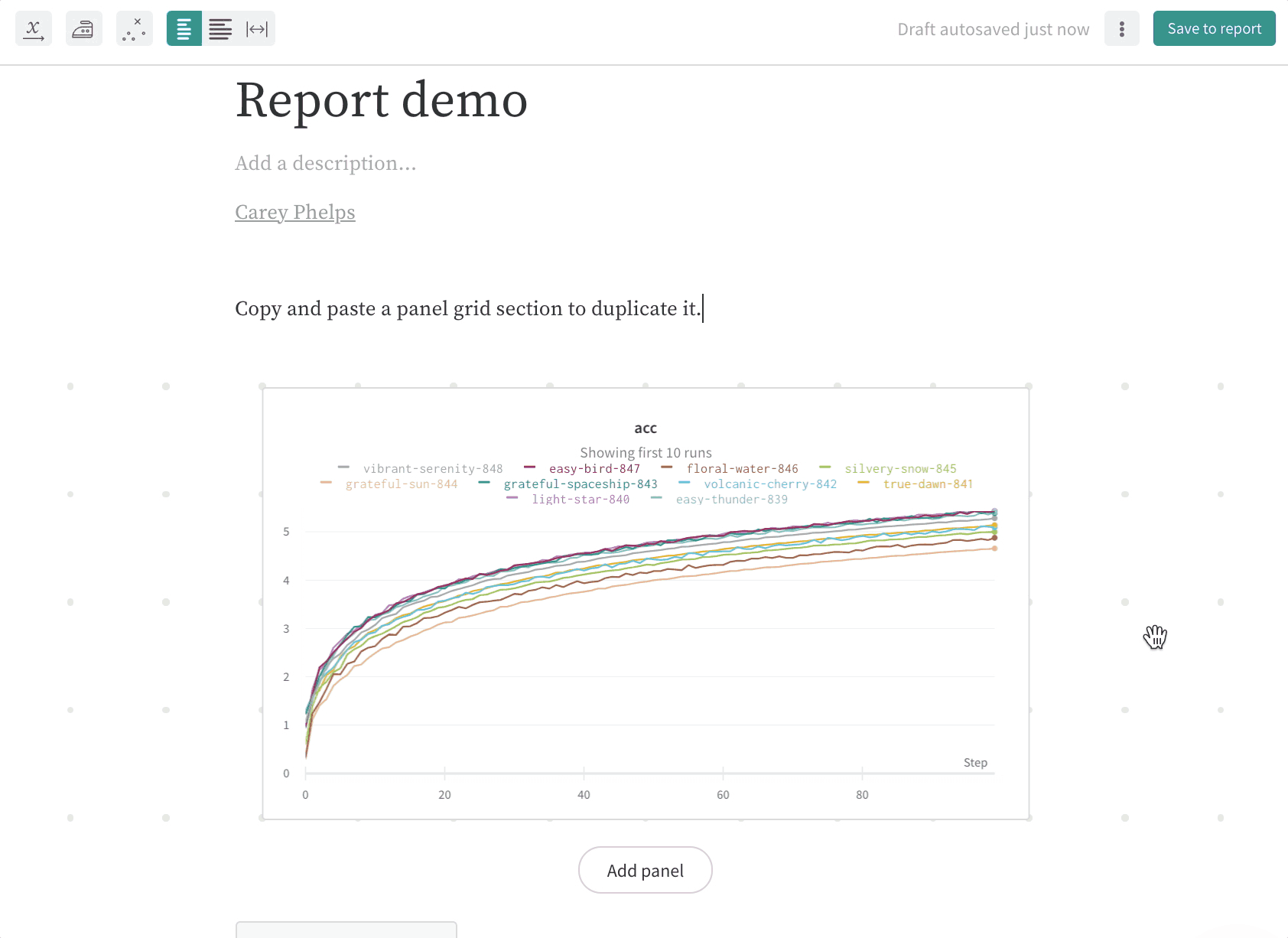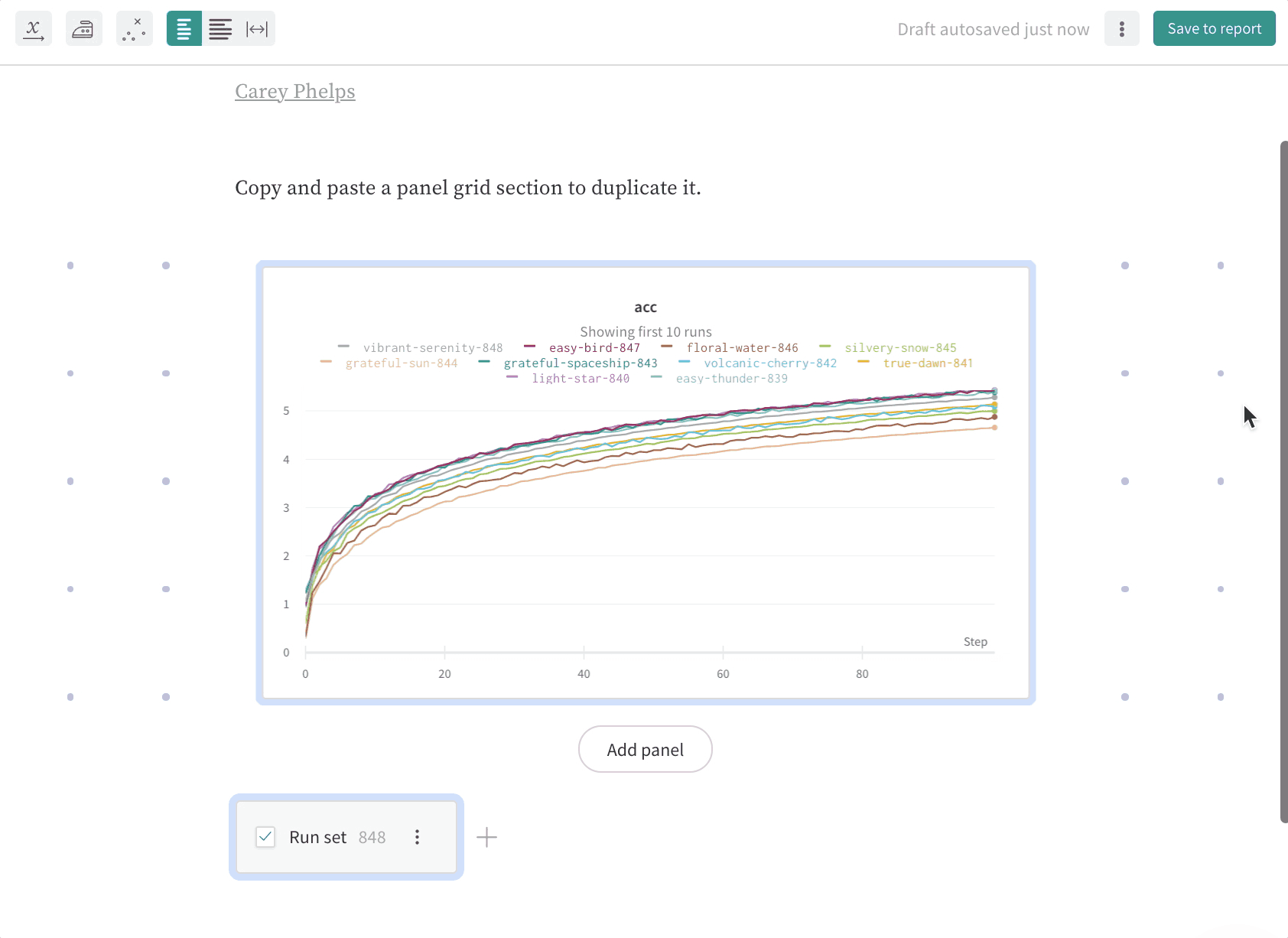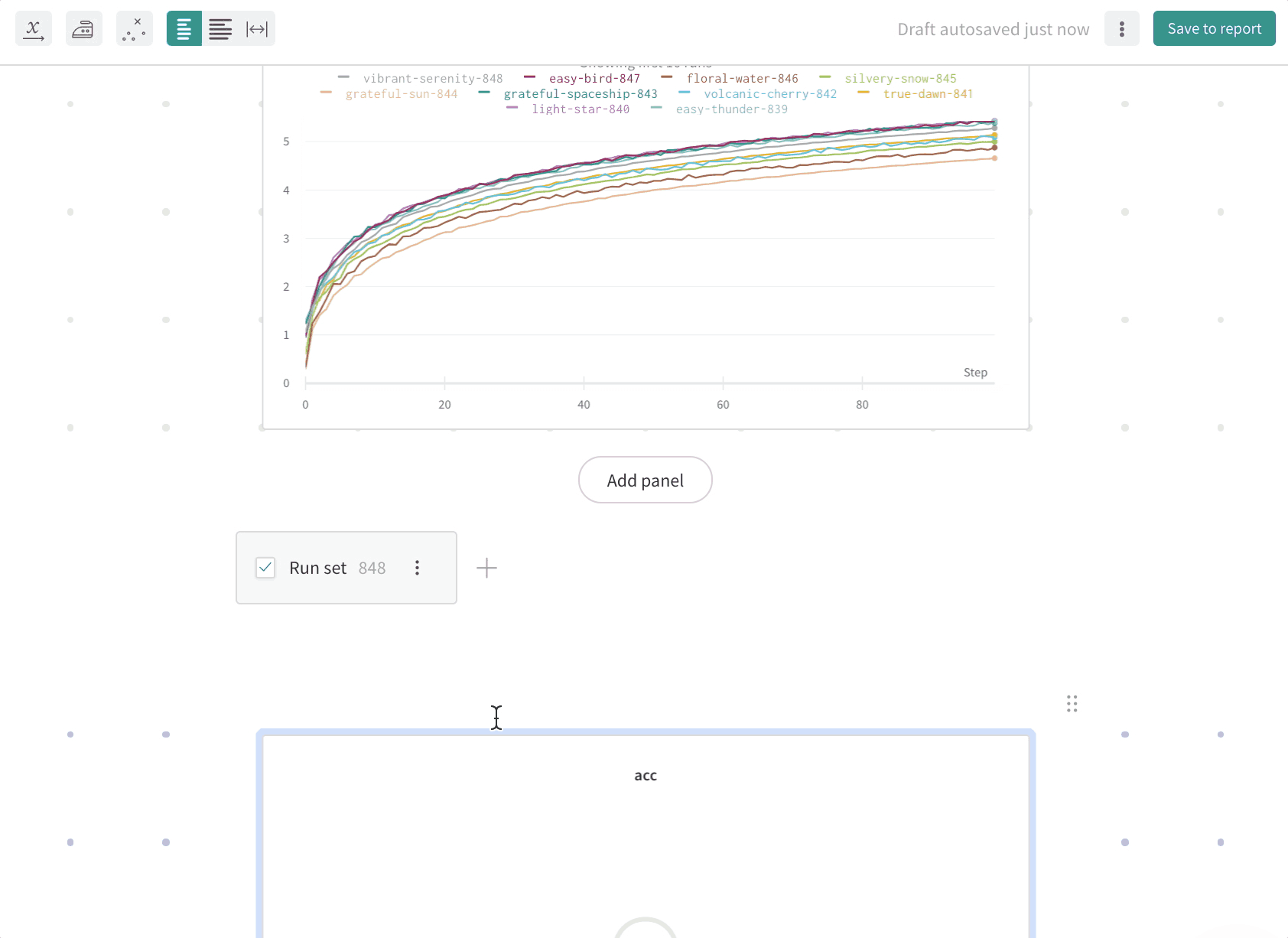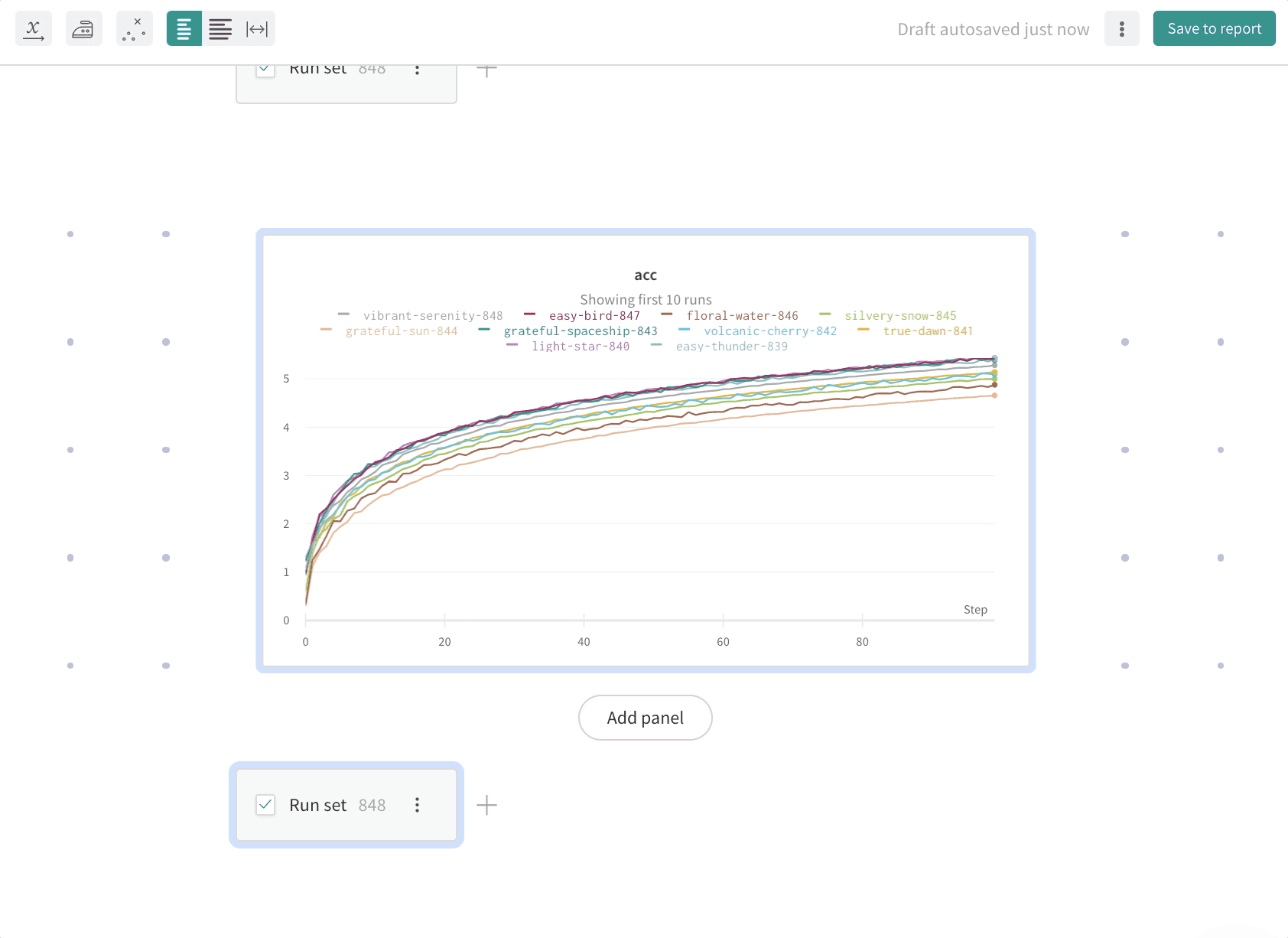
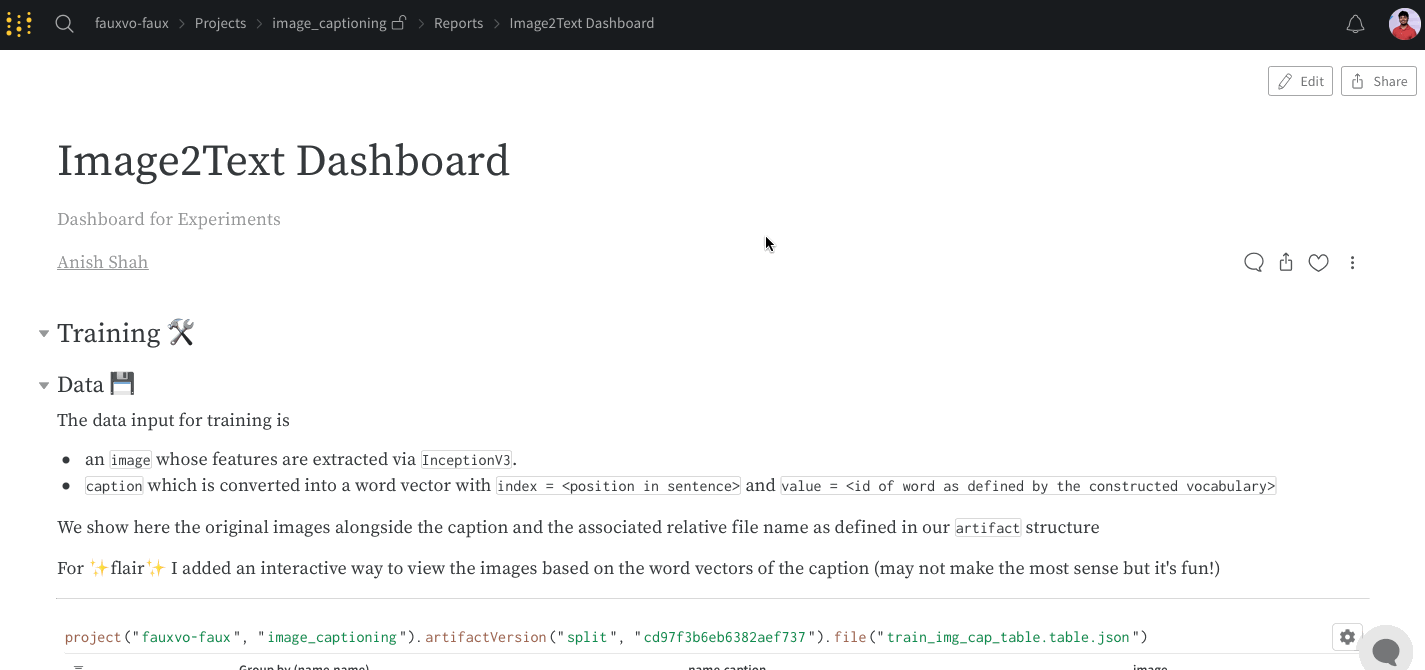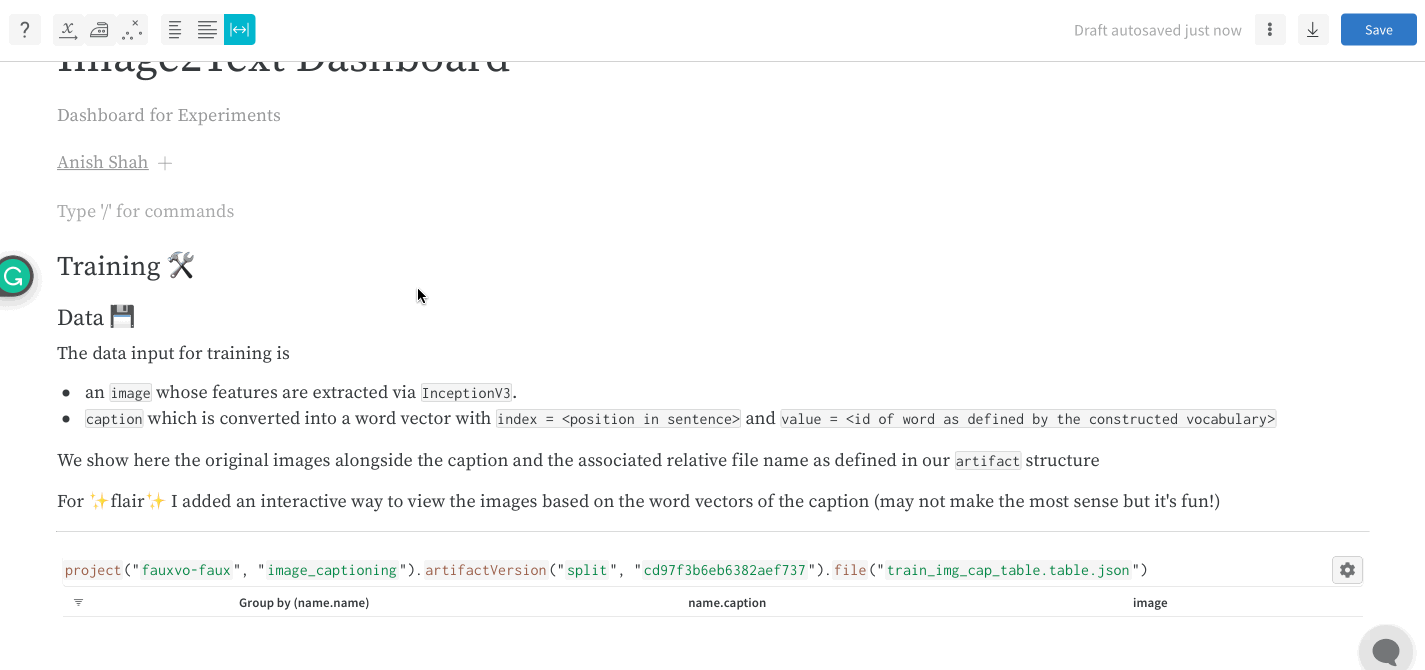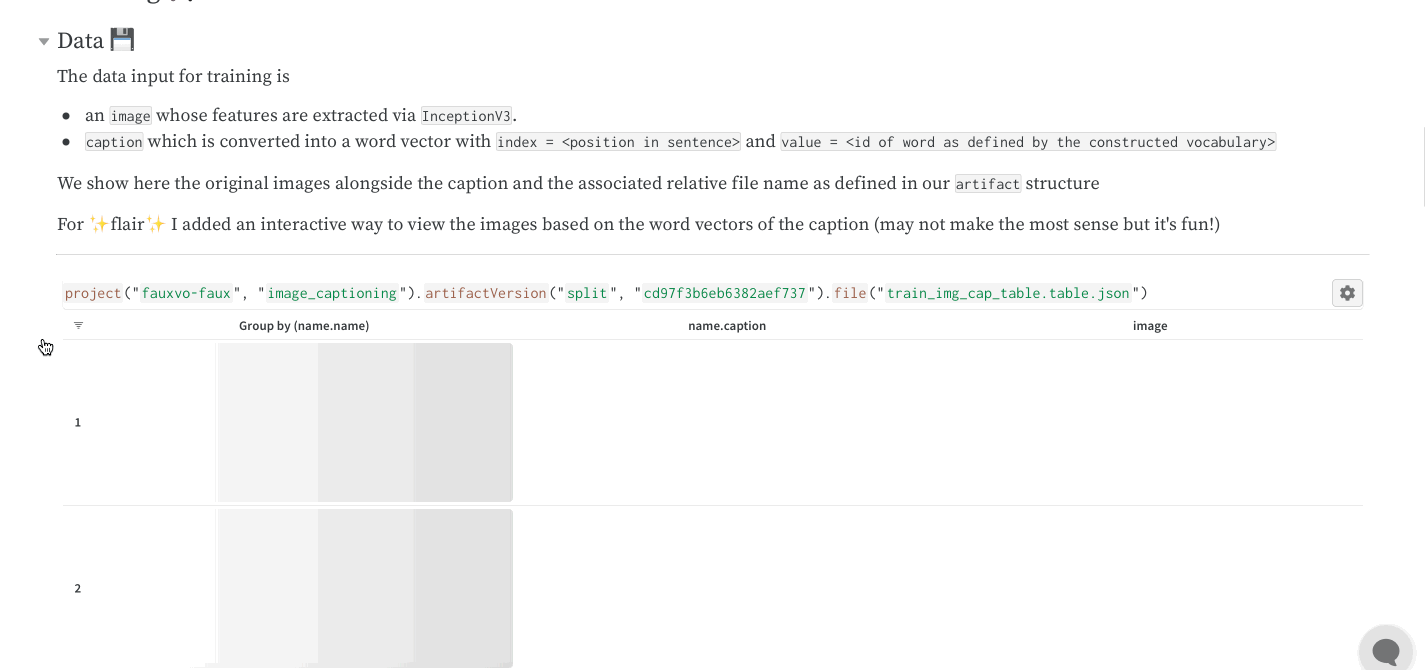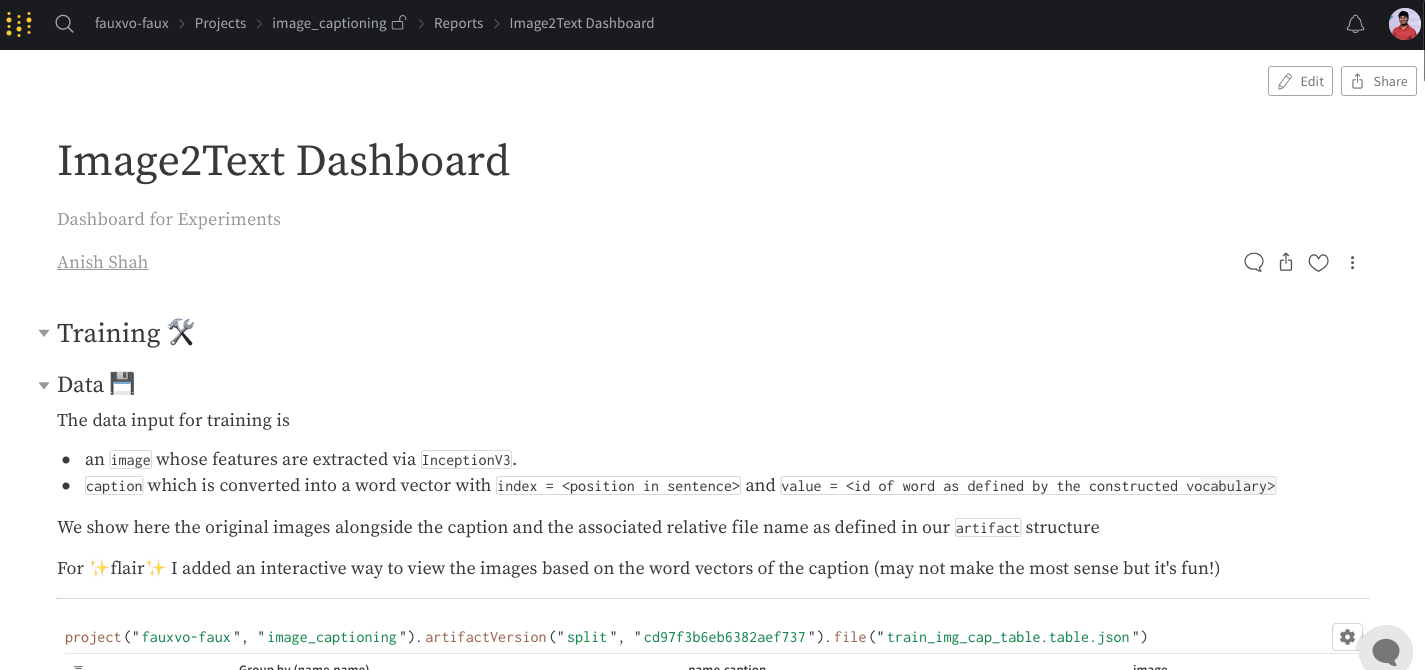
W&B Artifacts를 사용하여 데이터를 W&B Runs의 입력 및 출력으로 추적하고 버전을 관리하세요. 예를 들어, 모델 트레이닝 run은 데이터셋을 입력으로 사용하고 트레이닝된 모델을 출력으로 생성할 수 있습니다. 하이퍼파라미터, 메타데이터, 메트릭을 run에 기록하고, 아티팩트를 사용하여 모델 트레이닝에 사용된 데이터셋을 입력으로, 결과 모델 체크포인트를 출력으로 기록, 추적 및 버전 관리할 수 있습니다.
유스 케이스
runs의 입력 및 출력으로 전체 ML 워크플로우에서 아티팩트를 사용할 수 있습니다. 데이터셋, 모델 또는 기타 아티팩트를 처리 입력으로 사용할 수 있습니다.
Artifacts는 W&B 라이브러리가 처리 방법을 알고 있는 스키마가 URI에 있는 경우 재현성을 위해 체크섬 및 기타 정보를 추적합니다.
add_reference 메소드를 사용하여 외부 URI 참조를 Artifact에 추가합니다. 'uri' 문자열을 자신의 URI로 바꿉니다. 선택적으로 name 파라미터에 대해 Artifact 내에서 원하는 경로를 전달합니다.
# URI 참조 추가artifact.add_reference(uri="uri", name="optional-name")
Artifacts는 현재 다음 URI 스키마를 지원합니다.
http(s)://: HTTP를 통해 액세스할 수 있는 파일의 경로입니다. Artifact는 HTTP 서버가 ETag 및 Content-Length 응답 헤더를 지원하는 경우 etag 형식의 체크섬과 크기 메타데이터를 추적합니다.
s3://: S3의 오브젝트 또는 오브젝트 접두사의 경로입니다. Artifact는 참조된 오브젝트에 대해 체크섬 및 버전 관리 정보(버킷에 오브젝트 버전 관리가 활성화된 경우)를 추적합니다. 오브젝트 접두사는 최대 10,000개의 오브젝트까지 접두사 아래의 오브젝트를 포함하도록 확장됩니다.
gs://: GCS의 오브젝트 또는 오브젝트 접두사의 경로입니다. Artifact는 참조된 오브젝트에 대해 체크섬 및 버전 관리 정보(버킷에 오브젝트 버전 관리가 활성화된 경우)를 추적합니다. 오브젝트 접두사는 최대 10,000개의 오브젝트까지 접두사 아래의 오브젝트를 포함하도록 확장됩니다.
대규모 데이터셋 또는 분산 트레이닝의 경우 여러 병렬 Runs가 단일 Artifact에 기여해야 할 수 있습니다.
import wandb
import time
# 데모 목적으로 ray를 사용하여 Runs를 병렬로 시작합니다.# 원하는 방식으로 병렬 Runs를 오케스트레이션할 수 있습니다.import ray
ray.init()
artifact_type ="dataset"artifact_name ="parallel-artifact"table_name ="distributed_table"parts_path ="parts"num_parallel =5# 병렬 작성기의 각 배치는 자체 고유한 그룹 이름을 가져야 합니다.group_name ="writer-group-{}".format(round(time.time()))
@ray.remotedeftrain(i):
"""
작성기 작업입니다. 각 작성기는 Artifact에 이미지를 하나 추가합니다.
"""with wandb.init(group=group_name) as run:
artifact = wandb.Artifact(name=artifact_name, type=artifact_type)
# 데이터를 wandb 테이블에 추가합니다. 이 경우 예제 데이터를 사용합니다. table = wandb.Table(columns=["a", "b", "c"], data=[[i, i *2, 2**i]])
# Artifact의 폴더에 테이블을 추가합니다. artifact.add(table, "{}/table_{}".format(parts_path, i))
# Artifact를 업서트하면 Artifact에 데이터를 만들거나 추가합니다. run.upsert_artifact(artifact)
# 병렬로 Runs를 시작합니다.result_ids = [train.remote(i) for i in range(num_parallel)]
# 모든 작성기가 완료되었는지 확인하기 위해 모든 작성기에 조인합니다.# Artifact를 완료하기 전에 파일이 추가되었습니다.ray.get(result_ids)
# 모든 작성기가 완료되면 Artifact를 완료합니다.# 준비되었음을 표시합니다.with wandb.init(group=group_name) as run:
artifact = wandb.Artifact(artifact_name, type=artifact_type)
# 테이블 폴더를 가리키는 "PartitionTable"을 만듭니다.# Artifact에 추가합니다. artifact.add(wandb.data_types.PartitionedTable(parts_path), table_name)
# Finish artifact는 Artifact를 완료하고 향후 "upserts"를 허용하지 않습니다.# 이 버전으로. run.finish_artifact(artifact)
1.2 - Download and use artifacts
여러 프로젝트에서 아티팩트 를 다운로드하고 사용하세요.
W&B 서버에 이미 저장된 Artifacts를 다운로드하여 사용하거나, 필요에 따라 중복 제거를 위해 Artifact 오브젝트를 생성하여 전달합니다.
보기 전용 권한을 가진 팀 멤버는 Artifacts를 다운로드할 수 없습니다.
W&B에 저장된 Artifacts 다운로드 및 사용
W&B Run 내부 또는 외부에서 W&B에 저장된 Artifacts를 다운로드하여 사용합니다. W&B에 이미 저장된 데이터를 내보내거나 업데이트하려면 퍼블릭 API (wandb.Api)를 사용하세요. 자세한 내용은 W&B 퍼블릭 API 레퍼런스 가이드를 참조하세요.
이것은 name 경로에 있는 파일만 가져옵니다. 다음과 같은 메서드를 가진 Entry 오브젝트를 반환합니다.
Entry.download: name 경로에 있는 Artifact에서 파일을 다운로드합니다.
Entry.ref: add_reference가 항목을 참조로 저장한 경우 URI를 반환합니다.
W&B가 처리하는 방법을 아는 스키마가 있는 참조는 Artifact 파일처럼 다운로드됩니다. 자세한 내용은 외부 파일 추적을 참조하세요.
먼저 W&B SDK를 임포트합니다. 다음으로 퍼블릭 API 클래스에서 Artifact를 생성합니다. 해당 Artifact와 연결된 엔티티, 프로젝트, Artifact 및 에일리어스를 제공합니다.
import wandb
api = wandb.Api()
artifact = api.artifact("entity/project/artifact:alias")
반환된 오브젝트를 사용하여 Artifact의 내용을 다운로드합니다.
artifact.download()
선택적으로 root 파라미터에 경로를 전달하여 Artifact의 내용을 특정 디렉토리로 다운로드할 수 있습니다. 자세한 내용은 API 레퍼런스 가이드를 참조하세요.
wandb artifact get 코맨드를 사용하여 W&B 서버에서 Artifact를 다운로드합니다.
$ wandb artifact get project/artifact:alias --root mnist/
Artifact 부분 다운로드
선택적으로 접두사를 기반으로 Artifact의 일부를 다운로드할 수 있습니다. path_prefix 파라미터를 사용하면 단일 파일 또는 하위 폴더의 콘텐츠를 다운로드할 수 있습니다.
artifact = run.use_artifact("bike-dataset:latest")
artifact.download(path_prefix="bike.png") # bike.png만 다운로드
또는 특정 디렉토리에서 파일을 다운로드할 수 있습니다.
artifact.download(path_prefix="images/bikes/") # images/bikes 디렉토리의 파일 다운로드
다른 프로젝트의 Artifact 사용
Artifact 이름과 함께 프로젝트 이름을 지정하여 Artifact를 참조합니다. Artifact 이름과 함께 엔티티 이름을 지정하여 엔티티 간에 Artifacts를 참조할 수도 있습니다.
다음 코드 예제는 다른 프로젝트의 Artifact를 현재 W&B run에 대한 입력으로 쿼리하는 방법을 보여줍니다.
import wandb
run = wandb.init(project="<example>", job_type="<job-type>")
# 다른 프로젝트의 Artifact에 대해 W&B를 쿼리하고 다음으로 표시합니다.# 이 run에 대한 입력입니다.artifact = run.use_artifact("my-project/artifact:alias")
# 다른 엔티티의 Artifact를 사용하고 이를 입력으로 표시합니다.# 이 run에.artifact = run.use_artifact("my-entity/my-project/artifact:alias")
Artifact를 동시에 구성하고 사용
Artifact를 동시에 구성하고 사용합니다. Artifact 오브젝트를 생성하고 use_artifact에 전달합니다. 이렇게 하면 아직 존재하지 않는 경우 W&B에 Artifact가 생성됩니다. use_artifact API는 idempotent이므로 원하는 만큼 여러 번 호출할 수 있습니다.
import wandb
run = wandb.init(project="<example>")
api = wandb.Api()
artifact = api.artifact_collection(type="<type-name>", collection="<collection-name>")
artifact.name ="<new-collection-name>"artifact.description ="<This is where you'd describe the purpose of your collection.>"artifact.save()
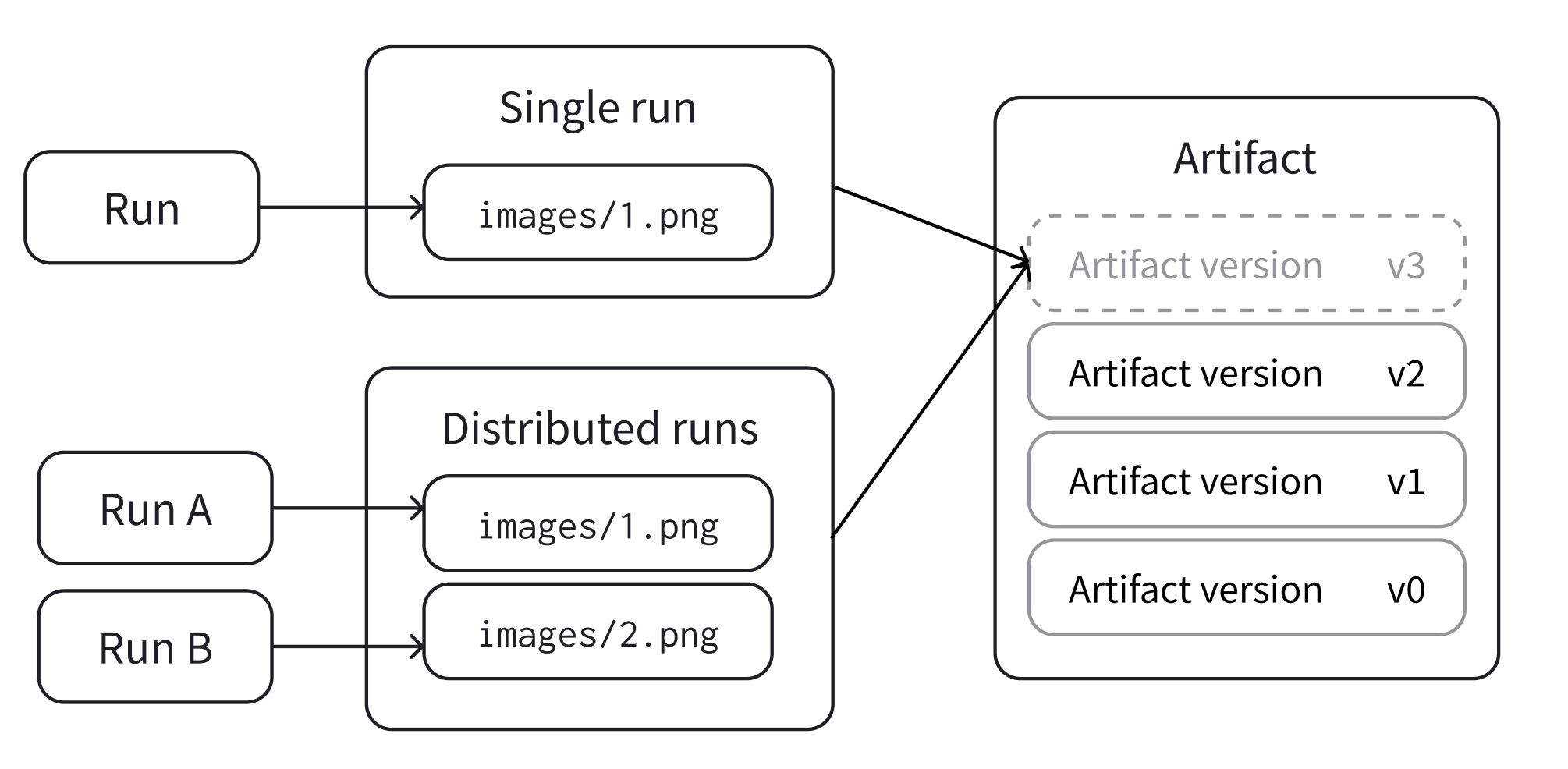
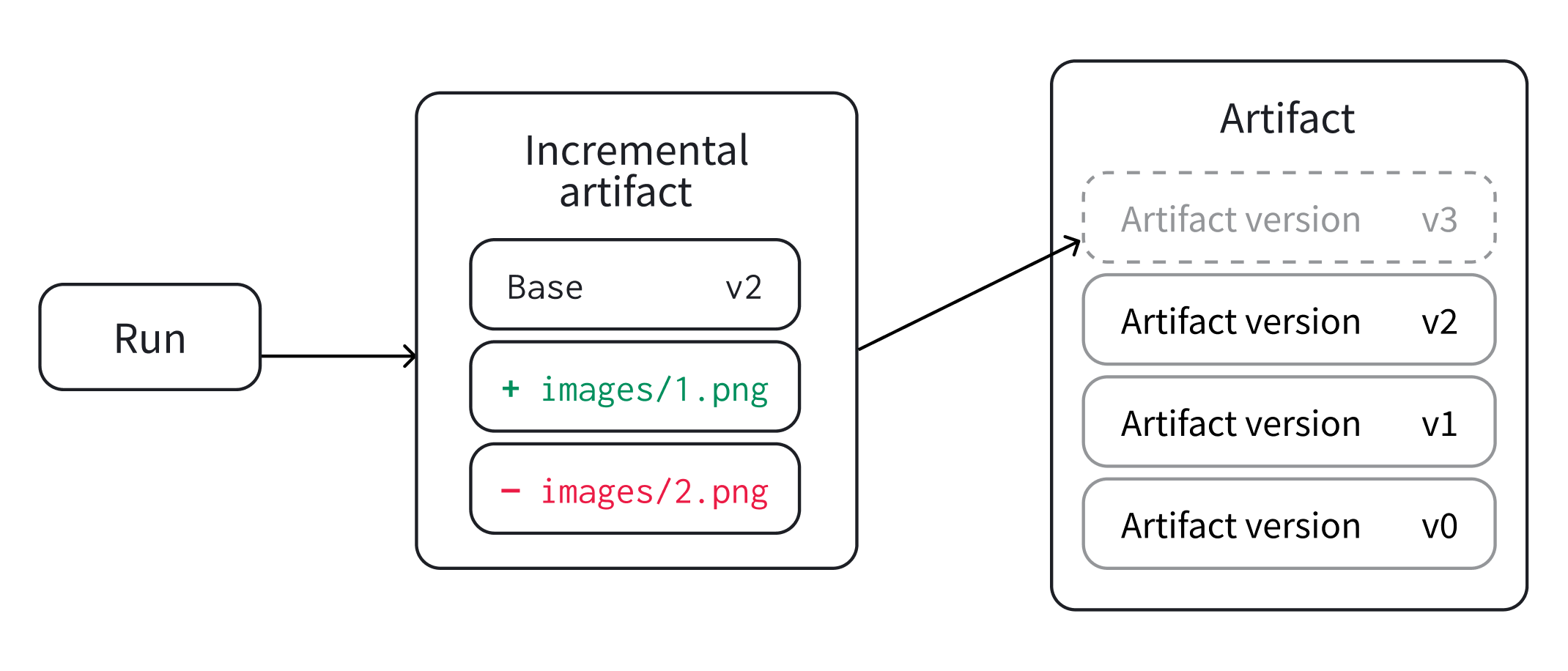
단일 run에서 또는 분산된 run과 협업하여 새로운 아티팩트 버전을 만드세요. 선택적으로 증분 아티팩트라고 알려진 이전 버전에서 새로운 아티팩트 버전을 만들 수 있습니다.
원래 아티팩트의 크기가 상당히 큰 경우 아티팩트에서 파일의 서브셋에 변경 사항을 적용해야 할 때 증분 아티팩트를 만드는 것이 좋습니다.
처음부터 새로운 아티팩트 버전 만들기
새로운 아티팩트 버전을 만드는 방법에는 단일 run에서 만드는 방법과 분산된 run에서 만드는 두 가지 방법이 있습니다. 이들은 다음과 같이 정의됩니다.
단일 run: 단일 run은 새로운 버전에 대한 모든 데이터를 제공합니다. 이것은 가장 일반적인 경우이며, run이 필요한 데이터를 완전히 재 생성할 때 가장 적합합니다. 예를 들어, 분석을 위해 테이블에 저장된 모델 또는 모델 예측값을 출력합니다.
분산된 run: run 집합이 공동으로 새로운 버전에 대한 모든 데이터를 제공합니다. 이것은 여러 run이 데이터를 생성하는 분산 작업에 가장 적합하며, 종종 병렬로 수행됩니다. 예를 들어, 분산 방식으로 모델을 평가하고 예측값을 출력합니다.
W&B는 프로젝트에 존재하지 않는 이름을 wandb.Artifact API에 전달하면 새로운 아티팩트를 생성하고 v0 에일리어스를 할당합니다. 동일한 아티팩트에 다시 로그할 때 W&B는 콘텐츠의 체크섬을 계산합니다. 아티팩트가 변경되면 W&B는 새 버전 v1을 저장합니다.
W&B는 프로젝트에 있는 기존 아티팩트와 일치하는 이름과 아티팩트 유형을 wandb.Artifact API에 전달하면 기존 아티팩트를 검색합니다. 검색된 아티팩트의 버전은 1보다 큽니다.
단일 run
아티팩트의 모든 파일을 생성하는 단일 run으로 Artifact의 새 버전을 기록합니다. 이 경우는 단일 run이 아티팩트의 모든 파일을 생성할 때 발생합니다.
유스 케이스에 따라 아래 탭 중 하나를 선택하여 run 내부 또는 외부에서 새로운 아티팩트 버전을 만드세요.
W&B run 내에서 아티팩트 버전을 만듭니다.
wandb.init으로 run을 만듭니다.
wandb.Artifact로 새로운 아티팩트를 만들거나 기존 아티팩트를 검색합니다.
.add_file로 아티팩트에 파일을 추가합니다.
.log_artifact로 아티팩트를 run에 기록합니다.
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`, `.add_file`, `.add_dir`, and `.add_reference`를 사용하여# 아티팩트에 파일 및 에셋을 추가합니다. artifact.add_file("image1.png")
run.log_artifact(artifact)
W&B run 외부에서 아티팩트 버전을 만듭니다.
wanb.Artifact로 새로운 아티팩트를 만들거나 기존 아티팩트를 검색합니다.
.add_file로 아티팩트에 파일을 추가합니다.
.save로 아티팩트를 저장합니다.
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`, `.add_file`, `.add_dir`, and `.add_reference`를 사용하여# 아티팩트에 파일 및 에셋을 추가합니다.artifact.add_file("image1.png")
artifact.save()
분산된 run
커밋하기 전에 run 컬렉션이 버전에서 공동 작업할 수 있도록 합니다. 이는 하나의 run이 새 버전에 대한 모든 데이터를 제공하는 위에서 설명한 단일 run 모드와 대조됩니다.
컬렉션의 각 run은 동일한 버전에 대해 공동 작업하기 위해 동일한 고유 ID ( distributed_id라고 함)를 인식해야 합니다. 기본적으로 W&B는 있는 경우 wandb.init(group=GROUP)에 의해 설정된 run의 group을 distributed_id로 사용합니다.
해당 상태를 영구적으로 잠그는 버전을 “커밋"하는 최종 run이 있어야 합니다.
협업 아티팩트에 추가하려면 upsert_artifact를 사용하고 커밋을 완료하려면 finish_artifact를 사용하세요.
다음 예제를 고려하십시오. 서로 다른 run (아래에 Run 1, Run 2 및 Run 3으로 표시됨)은 upsert_artifact를 사용하여 동일한 아티팩트에 다른 이미지 파일을 추가합니다.
Run 1:
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`, `.add_file`, `.add_dir`, and `.add_reference`를 사용하여# 아티팩트에 파일 및 에셋을 추가합니다. artifact.add_file("image1.png")
run.upsert_artifact(artifact, distributed_id="my_dist_artifact")
Run 2:
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# `.add`, `.add_file`, `.add_dir`, and `.add_reference`를 사용하여# 아티팩트에 파일 및 에셋을 추가합니다. artifact.add_file("image2.png")
run.upsert_artifact(artifact, distributed_id="my_dist_artifact")
Run 3
Run 1과 Run 2가 완료된 후 실행해야 합니다. finish_artifact를 호출하는 Run은 아티팩트에 파일을 포함할 수 있지만 필요하지는 않습니다.
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# 아티팩트에 파일 및 에셋을 추가합니다.# `.add`, `.add_file`, `.add_dir`, and `.add_reference` artifact.add_file("image3.png")
run.finish_artifact(artifact, distributed_id="my_dist_artifact")
기존 버전에서 새로운 아티팩트 버전 만들기
변경되지 않은 파일을 다시 인덱싱할 필요 없이 이전 아티팩트 버전에서 파일의 서브셋을 추가, 수정 또는 제거합니다. 이전 아티팩트 버전에서 파일의 서브셋을 추가, 수정 또는 제거하면 증분 아티팩트라고 하는 새로운 아티팩트 버전이 생성됩니다.
다음은 발생할 수 있는 각 유형의 증분 변경에 대한 몇 가지 시나리오입니다.
add: 새로운 배치를 수집한 후 데이터셋에 새로운 파일 서브셋을 주기적으로 추가합니다.
remove: 여러 중복 파일을 발견했고 아티팩트에서 제거하고 싶습니다.
update: 파일 서브셋에 대한 주석을 수정했고 이전 파일을 올바른 파일로 바꾸고 싶습니다.
처음부터 아티팩트를 만들어 증분 아티팩트와 동일한 기능을 수행할 수 있습니다. 그러나 처음부터 아티팩트를 만들면 로컬 디스크에 아티팩트의 모든 콘텐츠가 있어야 합니다. 증분 변경을 수행할 때 이전 아티팩트 버전의 파일을 변경하지 않고도 단일 파일을 추가, 제거 또는 수정할 수 있습니다.
마지막으로 변경 사항을 기록하거나 저장합니다. 다음 탭에서는 W&B run 내부 및 외부에서 변경 사항을 저장하는 방법을 보여줍니다. 유스 케이스에 적합한 탭을 선택하세요.
run.log_artifact(draft_artifact)
draft_artifact.save()
모두 합치면 위의 코드 예제는 다음과 같습니다.
with wandb.init(job_type="modify dataset") as run:
saved_artifact = run.use_artifact(
"my_artifact:latest" ) # 아티팩트를 가져와서 run에 입력합니다. draft_artifact = saved_artifact.new_draft() # 초안 버전을 만듭니다.# 초안 버전에서 파일의 서브셋을 수정합니다. draft_artifact.add_file("file_to_add.txt")
draft_artifact.remove("dir_to_remove/")
run.log_artifact(
artifact
) # 변경 사항을 기록하여 새 버전을 만들고 run에 대한 출력으로 표시합니다.
client = wandb.Api()
saved_artifact = client.artifact("my_artifact:latest") # 아티팩트를 로드합니다.draft_artifact = saved_artifact.new_draft() # 초안 버전을 만듭니다.# 초안 버전에서 파일의 서브셋을 수정합니다.draft_artifact.remove("deleted_file.txt")
draft_artifact.add_file("modified_file.txt")
draft_artifact.save() # 초안에 변경 사항을 커밋합니다.
1.6 - Track external files
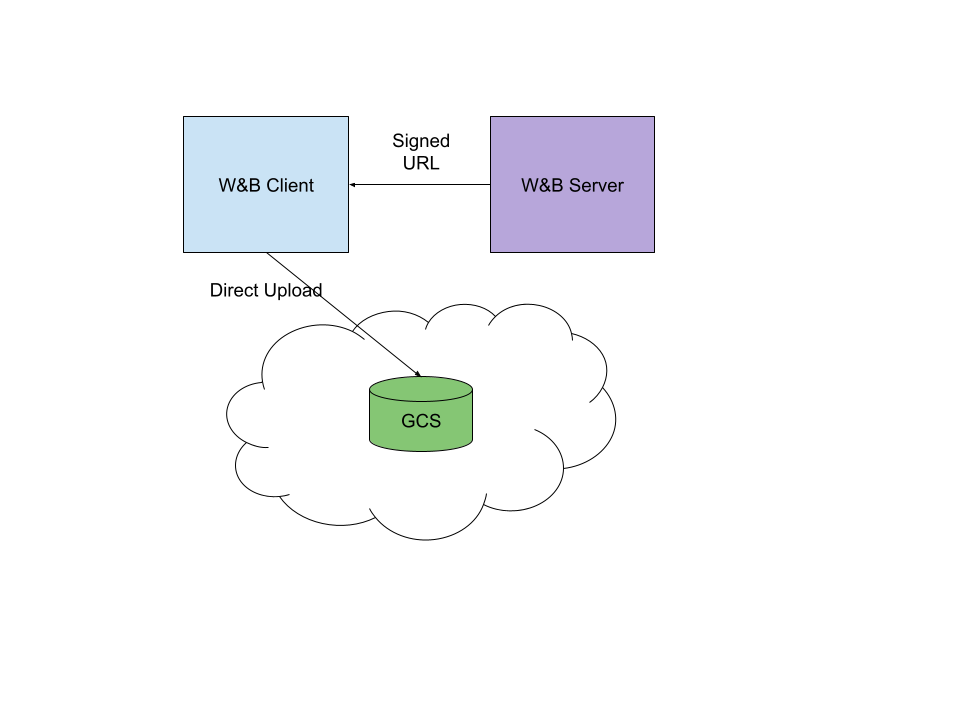
Amazon S3 버킷, GCS 버킷, HTTP 파일 서버 또는 NFS 공유와 같이 W&B 외부에 저장된 파일을 추적합니다.
reference artifacts 를 사용하여 W&B 시스템 외부 (예: Amazon S3 버킷, GCS 버킷, Azure Blob, HTTP 파일 서버 또는 NFS 공유)에 저장된 파일을 추적합니다. W&B CLI를 사용하여 W&B Run 외부에서 아티팩트를 기록합니다.
Run 외부에서 아티팩트 기록
W&B는 run 외부에서 아티팩트를 기록할 때 run을 생성합니다. 각 아티팩트는 run에 속하며, run은 프로젝트에 속합니다. 아티팩트 (버전)는 컬렉션에도 속하며, 유형이 있습니다.
wandb artifact put 코맨드를 사용하여 W&B run 외부의 W&B 서버에 아티팩트를 업로드합니다. 아티팩트가 속할 프로젝트 이름과 아티팩트 이름 (project/artifact_name)을 제공합니다. 선택적으로 유형 (TYPE)을 제공합니다. 아래 코드 조각에서 PATH를 업로드할 아티팩트의 파일 경로로 바꿉니다.
$ wandb artifact put --name project/artifact_name --type TYPE PATH
지정한 프로젝트가 존재하지 않으면 W&B가 새 프로젝트를 생성합니다. 아티팩트 다운로드 방법에 대한 자세한 내용은 아티팩트 다운로드 및 사용을 참조하세요.
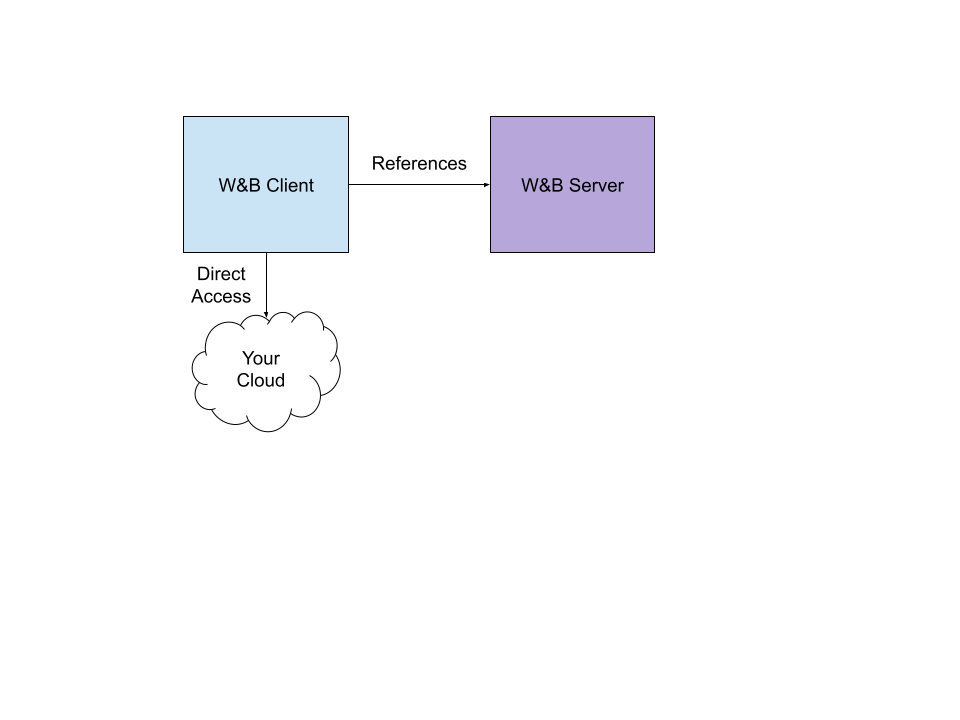
W&B 외부에서 아티팩트 추적
데이터셋 버전 관리 및 모델 이력에 W&B Artifacts를 사용하고, reference artifacts 를 사용하여 W&B 서버 외부에서 저장된 파일을 추적합니다. 이 모드에서 아티팩트는 URL, 크기 및 체크섬과 같은 파일에 대한 메타데이터만 저장합니다. 기본 데이터는 시스템을 벗어나지 않습니다. 파일을 W&B 서버에 저장하는 방법에 대한 자세한 내용은 빠른 시작을 참조하세요.
다음은 reference artifacts 를 구성하는 방법과 이를 워크플로우에 통합하는 가장 좋은 방법을 설명합니다.
Amazon S3 / GCS / Azure Blob Storage 참조
클라우드 스토리지 버킷에서 참조를 추적하기 위해 데이터셋 및 모델 버전 관리에 W&B Artifacts를 사용합니다. 아티팩트 참조를 사용하면 기존 스토리지 레이아웃을 수정하지 않고도 버킷 위에 원활하게 추적 기능을 레이어링할 수 있습니다.
Artifacts는 기본 클라우드 스토리지 공급 업체 (예: AWS, GCP 또는 Azure)를 추상화합니다. 다음 섹션에 설명된 정보는 Amazon S3, Google Cloud Storage 및 Azure Blob Storage에 균일하게 적용됩니다.
W&B Artifacts는 MinIO를 포함한 모든 Amazon S3 호환 인터페이스를 지원합니다. AWS_S3_ENDPOINT_URL 환경 변수를 MinIO 서버를 가리키도록 설정하면 아래 스크립트가 그대로 작동합니다.
기본적으로 W&B는 오브젝트 접두사를 추가할 때 10,000개의 오브젝트 제한을 적용합니다. add_reference 호출에서 max_objects=를 지정하여 이 제한을 조정할 수 있습니다.
새 reference artifact 인 mnist:latest는 일반 아티팩트와 유사하게 보이고 작동합니다. 유일한 차이점은 아티팩트가 ETag, 크기 및 버전 ID (오브젝트 버전 관리가 버킷에서 활성화된 경우)와 같은 S3/GCS/Azure 오브젝트에 대한 메타데이터로만 구성된다는 것입니다.
W&B는 기본 메커니즘을 사용하여 사용하는 클라우드 공급자를 기반으로 자격 증명을 찾습니다. 사용된 자격 증명에 대한 자세한 내용은 클라우드 공급자의 문서를 참조하십시오.
AWS의 경우 버킷이 구성된 사용자의 기본 리전에 있지 않으면 AWS_REGION 환경 변수를 버킷 리전과 일치하도록 설정해야 합니다.
일반 아티팩트와 유사하게 이 아티팩트와 상호 작용합니다. App UI에서 파일 브라우저를 사용하여 reference artifact 의 내용을 살펴보고 전체 종속성 그래프를 탐색하고 아티팩트의 버전 관리된 기록을 스캔할 수 있습니다.
이미지, 오디오, 비디오 및 포인트 클라우드와 같은 풍부한 미디어는 버킷의 CORS 구성에 따라 App UI에서 렌더링되지 않을 수 있습니다. 버킷의 CORS 설정에서 app.wandb.ai 목록을 허용하면 App UI가 이러한 풍부한 미디어를 적절하게 렌더링할 수 있습니다.
개인 버킷의 경우 패널이 App UI에서 렌더링되지 않을 수 있습니다. 회사에 VPN이 있는 경우 VPN 내에서 IP를 허용하도록 버킷의 엑세스 정책을 업데이트할 수 있습니다.
W&B는 아티팩트가 기록될 때 기록된 메타데이터를 사용하여 reference artifact 를 다운로드할 때 기본 버킷에서 파일을 검색합니다. 버킷에서 오브젝트 버전 관리를 활성화한 경우 W&B는 아티팩트가 기록될 당시의 파일 상태에 해당하는 오브젝트 버전을 검색합니다. 즉, 버킷 내용을 발전시키더라도 아티팩트가 트레이닝 당시 버킷의 스냅샷 역할을 하므로 지정된 모델이 트레이닝된 데이터의 정확한 반복을 계속 가리킬 수 있습니다.
워크플로우의 일부로 파일을 덮어쓰는 경우 스토리지 버킷에서 ‘오브젝트 버전 관리’를 활성화하는 것이 좋습니다. 버킷에서 버전 관리를 활성화하면 덮어쓴 파일에 대한 참조가 있는 아티팩트가 이전 오브젝트 버전이 유지되므로 여전히 손상되지 않습니다.
유스 케이스에 따라 오브젝트 버전 관리를 활성화하는 방법에 대한 지침을 읽으십시오. AWS, GCP, Azure.
함께 묶기
다음 코드 예제는 Amazon S3, GCS 또는 Azure에서 트레이닝 작업에 제공되는 데이터셋을 추적하는 데 사용할 수 있는 간단한 워크플로우를 보여줍니다.
import wandb
run = wandb.init()
artifact = wandb.Artifact("mnist", type="dataset")
artifact.add_reference("s3://my-bucket/datasets/mnist")
# 아티팩트를 추적하고# 이 run에 대한 입력으로 표시합니다. 새 아티팩트 버전은# 버킷의 파일이 변경된 경우에만 기록됩니다.run.use_artifact(artifact)
artifact_dir = artifact.download()
# 여기서 트레이닝을 수행합니다...
모델을 추적하기 위해 트레이닝 스크립트가 모델 파일을 버킷에 업로드한 후 모델 아티팩트를 기록할 수 있습니다.
데이터셋에 빠르게 엑세스하기 위한 또 다른 일반적인 패턴은 트레이닝 작업을 실행하는 모든 머신에서 원격 파일 시스템에 대한 NFS 마운트 지점을 노출하는 것입니다. 트레이닝 스크립트의 관점에서 파일이 로컬 파일 시스템에 있는 것처럼 보이기 때문에 클라우드 스토리지 버킷보다 훨씬 더 간단한 솔루션이 될 수 있습니다. 다행히 이러한 사용 편의성은 파일 시스템에 대한 참조를 추적하기 위해 Artifacts를 사용하는 데까지 확장됩니다 (마운트 여부와 관계없이).
다음과 같은 구조로 /mount에 파일 시스템이 마운트되어 있다고 가정합니다.
mount
+-- datasets/
| +-- mnist/
+-- models/
+-- cnn/
기본적으로 W&B는 디렉토리에 대한 참조를 추가할 때 10,000개의 파일 제한을 적용합니다. add_reference 호출에서 max_objects=를 지정하여 이 제한을 조정할 수 있습니다.
URL에서 슬래시가 세 개 있다는 점에 유의하십시오. 첫 번째 구성 요소는 파일 시스템 참조 사용을 나타내는 file:// 접두사입니다. 두 번째는 데이터셋 경로인 /mount/datasets/mnist/입니다.
결과 아티팩트인 mnist:latest는 일반 아티팩트와 마찬가지로 보이고 작동합니다. 유일한 차이점은 아티팩트가 크기 및 MD5 체크섬과 같은 파일에 대한 메타데이터로만 구성된다는 것입니다. 파일 자체는 시스템을 벗어나지 않습니다.
일반 아티팩트와 마찬가지로 이 아티팩트와 상호 작용할 수 있습니다. UI에서 파일 브라우저를 사용하여 reference artifact 의 내용을 찾아보고 전체 종속성 그래프를 탐색하고 아티팩트의 버전 관리된 기록을 스캔할 수 있습니다. 그러나 데이터 자체가 아티팩트에 포함되어 있지 않으므로 UI는 이미지, 오디오 등과 같은 풍부한 미디어를 렌더링할 수 없습니다.
파일 시스템 참조의 경우 download() 작업은 참조된 경로에서 파일을 복사하여 아티팩트 디렉토리를 구성합니다. 위의 예에서 /mount/datasets/mnist의 내용은 artifacts/mnist:v0/ 디렉토리에 복사됩니다. 아티팩트에 덮어쓴 파일에 대한 참조가 포함되어 있는 경우 아티팩트를 더 이상 재구성할 수 없으므로 download()에서 오류가 발생합니다.
모든 것을 함께 놓으면 다음은 마운트된 파일 시스템에서 트레이닝 작업에 제공되는 데이터셋을 추적하는 데 사용할 수 있는 간단한 워크플로우입니다.
import wandb
run = wandb.init()
artifact = wandb.Artifact("mnist", type="dataset")
artifact.add_reference("file:///mount/datasets/mnist/")
# 아티팩트를 추적하고# 이 run에 대한 입력으로 표시합니다. 새 아티팩트 버전은# 디렉토리 아래의 파일이# 변경되었습니다.run.use_artifact(artifact)
artifact_dir = artifact.download()
# 여기서 트레이닝을 수행합니다...
모델을 추적하기 위해 트레이닝 스크립트가 모델 파일을 마운트 지점에 쓴 후 모델 아티팩트를 기록할 수 있습니다.
import wandb
run = wandb.init()
# 여기서 트레이닝을 수행합니다...# 디스크에 모델 쓰기model_artifact = wandb.Artifact("cnn", type="model")
model_artifact.add_reference("file:///mount/cnn/my_model.h5")
run.log_artifact(model_artifact)
1.7 - Manage data
1.7.1 - Delete an artifact
App UI를 통해 대화형으로 또는 W&B SDK를 통해 프로그래밍 방식으로 아티팩트 를 삭제합니다.
App UI 또는 W&B SDK를 사용하여 아티팩트를 대화형으로 삭제할 수 있습니다. 아티팩트를 삭제하면 W&B는 해당 아티팩트를 소프트 삭제로 표시합니다. 즉, 아티팩트는 삭제 대상으로 표시되지만 파일은 즉시 스토리지에서 삭제되지 않습니다.
아티팩트의 내용은 정기적으로 실행되는 가비지 수집 프로세스가 삭제 대상으로 표시된 모든 아티팩트를 검토할 때까지 소프트 삭제 또는 삭제 대기 상태로 유지됩니다. 가비지 수집 프로세스는 아티팩트 및 관련 파일이 이전 또는 이후 아티팩트 버전에서 사용되지 않는 경우 스토리지에서 관련 파일을 삭제합니다.
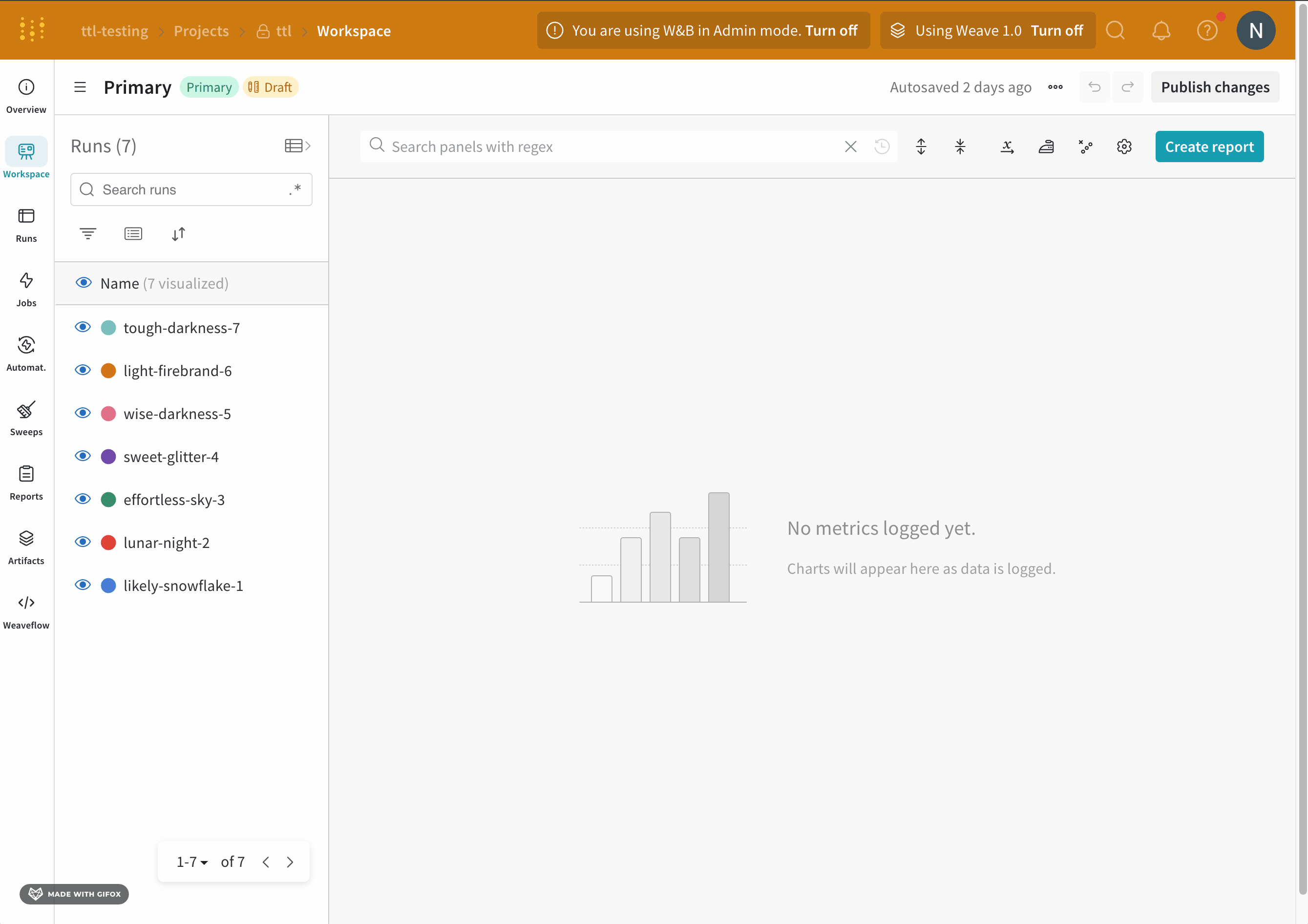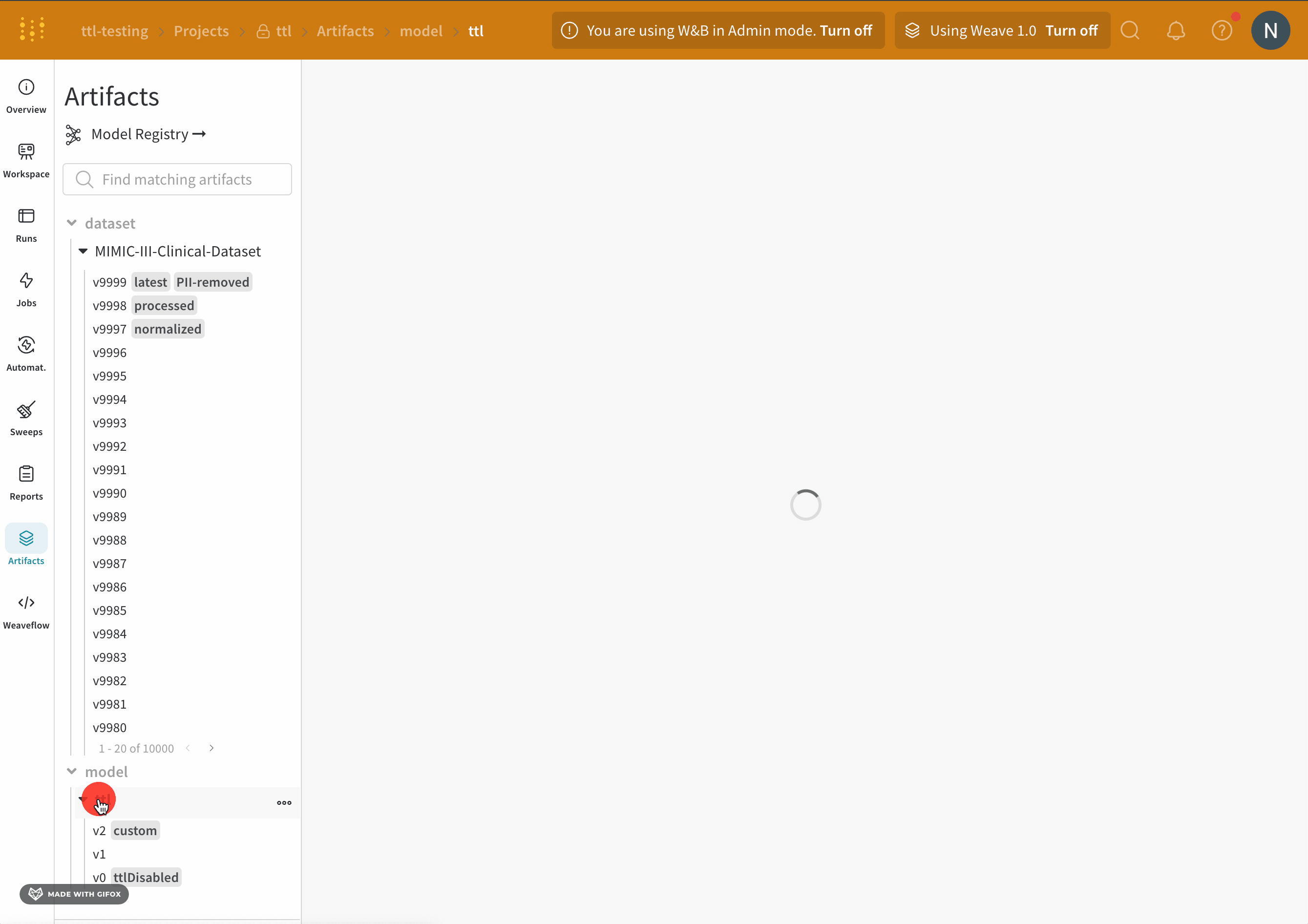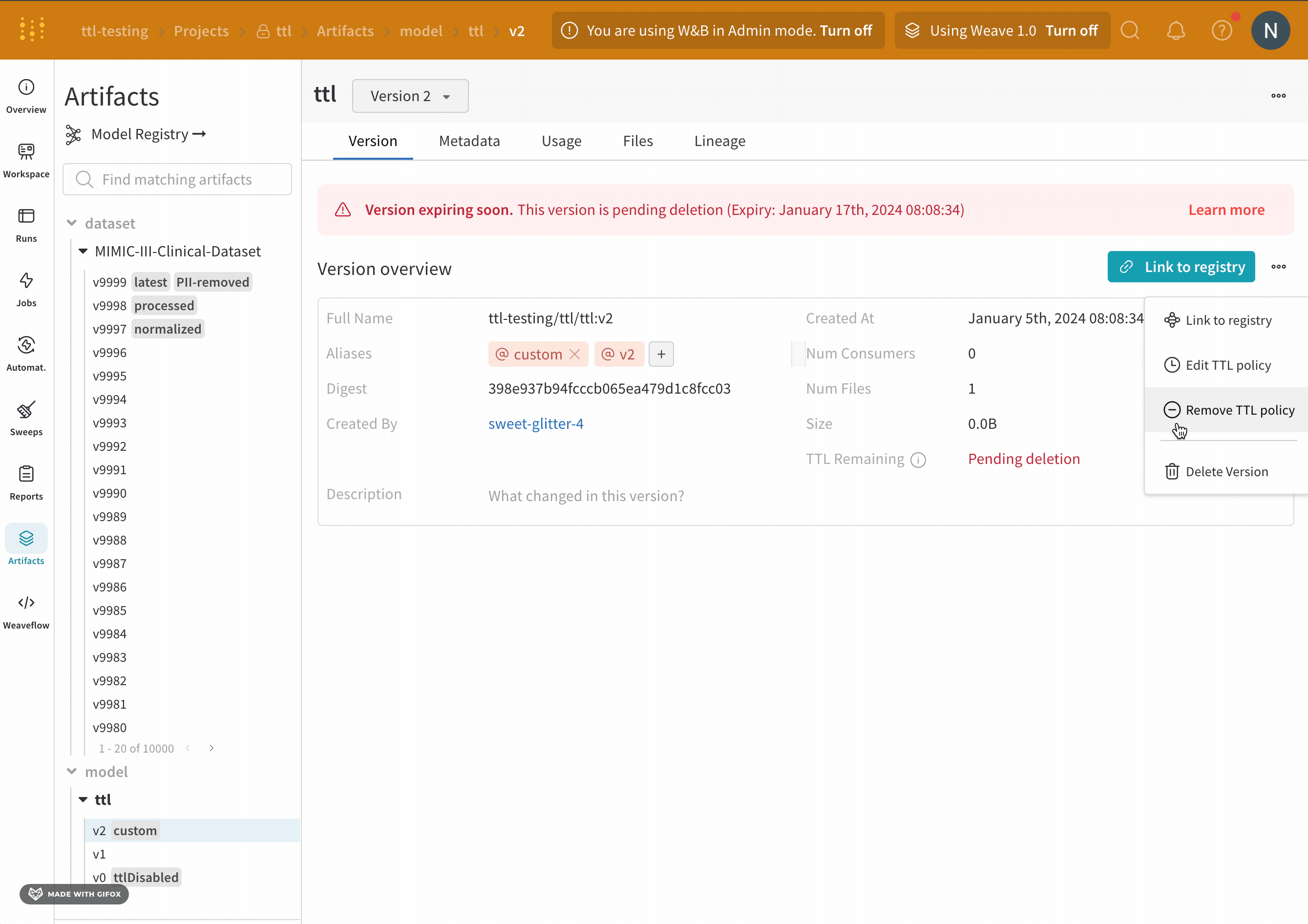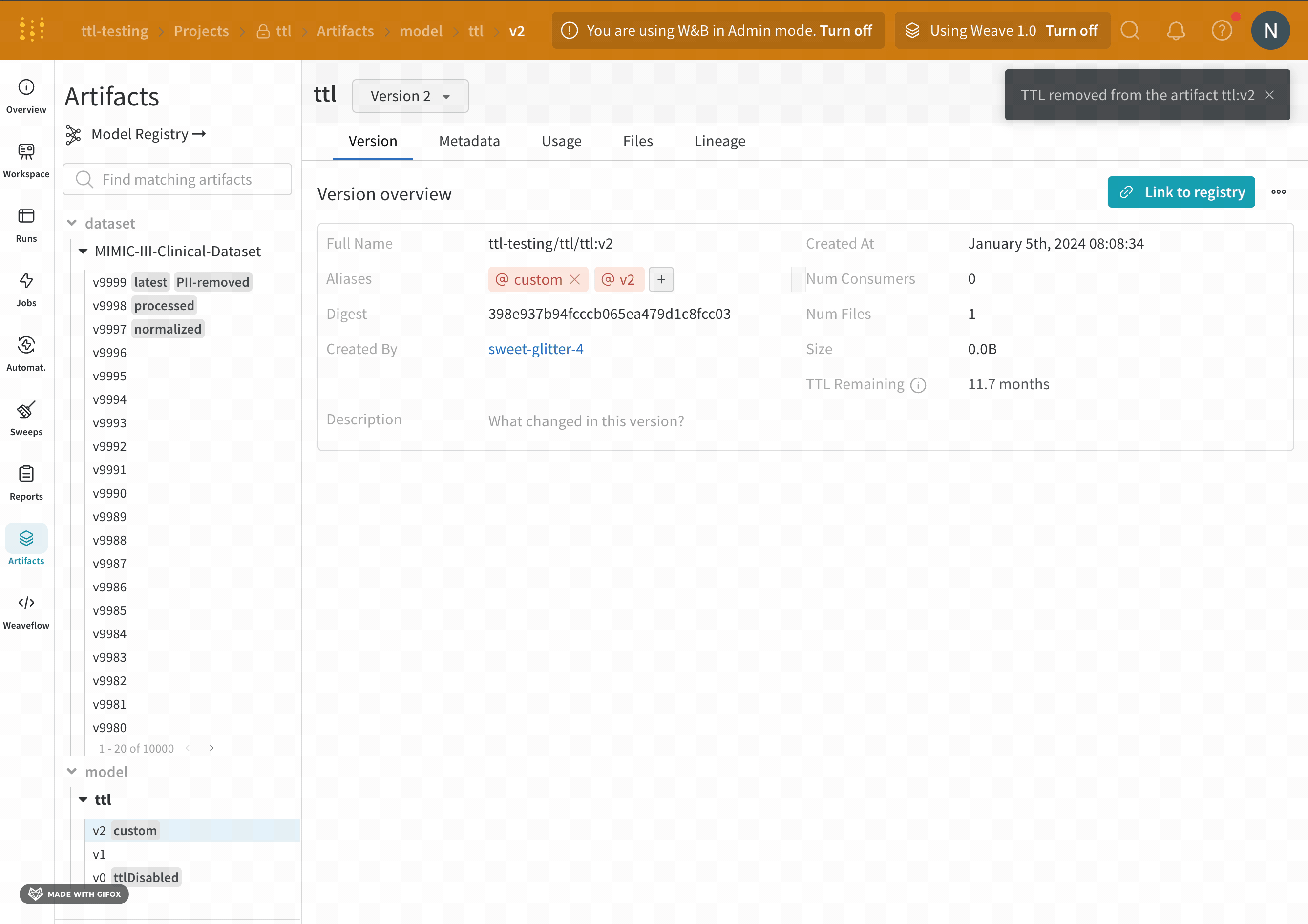
이 페이지의 섹션에서는 특정 아티팩트 버전을 삭제하는 방법, 아티팩트 컬렉션을 삭제하는 방법, 에일리어스가 있거나 없는 아티팩트를 삭제하는 방법 등을 설명합니다. TTL 정책을 사용하여 W&B에서 아티팩트가 삭제되는 시점을 예약할 수 있습니다. 자세한 내용은 아티팩트 TTL 정책으로 데이터 보존 관리을 참조하세요.
TTL 정책으로 삭제 예약된 Artifacts, W&B SDK로 삭제된 Artifacts 또는 W&B App UI로 삭제된 Artifacts는 먼저 소프트 삭제됩니다. 소프트 삭제된 Artifacts는 하드 삭제되기 전에 가비지 수집을 거칩니다.
아티팩트 버전 삭제
아티팩트 버전을 삭제하려면 다음을 수행하세요.
아티팩트 이름을 선택합니다. 그러면 아티팩트 보기가 확장되고 해당 아티팩트와 연결된 모든 아티팩트 버전이 나열됩니다.
아티팩트 목록에서 삭제할 아티팩트 버전을 선택합니다.
워크스페이스 오른쪽에 있는 케밥 드롭다운을 선택합니다.
삭제를 선택합니다.
아티팩트 버전은 delete() 메소드를 통해 프로그래밍 방식으로 삭제할 수도 있습니다. 아래 예시를 참조하세요.
에일리어스가 있는 여러 아티팩트 버전 삭제
다음 코드 예제는 에일리어스가 연결된 아티팩트를 삭제하는 방법을 보여줍니다. 아티팩트를 만든 엔터티, 프로젝트 이름 및 run ID를 제공합니다.
import wandb
run = api.run("entity/project/run_id")
for artifact in run.logged_artifacts():
artifact.delete()
아티팩트에 에일리어스가 하나 이상 있는 경우 delete_aliases 파라미터를 부울 값 True로 설정하여 에일리어스를 삭제합니다.
import wandb
run = api.run("entity/project/run_id")
for artifact in run.logged_artifacts():
# Set delete_aliases=True in order to delete# artifacts with one more aliases artifact.delete(delete_aliases=True)
특정 에일리어스가 있는 여러 아티팩트 버전 삭제
다음 코드는 특정 에일리어스가 있는 여러 아티팩트 버전을 삭제하는 방법을 보여줍니다. 아티팩트를 만든 엔터티, 프로젝트 이름 및 run ID를 제공합니다. 삭제 로직을 직접 작성하세요.
import wandb
runs = api.run("entity/project_name/run_id")
# Delete artifact ith alias 'v3' and 'v4for artifact_version in runs.logged_artifacts():
# Replace with your own deletion logic.if artifact_version.name[-2:] =="v3"or artifact_version.name[-2:] =="v4":
artifact.delete(delete_aliases=True)
에일리어스가 없는 아티팩트의 모든 버전 삭제
다음 코드 조각은 에일리어스가 없는 아티팩트의 모든 버전을 삭제하는 방법을 보여줍니다. wandb.Api의 project 및 entity 키에 대한 프로젝트 및 엔터티 이름을 각각 제공합니다. <>를 아티팩트 이름으로 바꿉니다.
import wandb
# Provide your entity and a project name when you# use wandb.Api methods.api = wandb.Api(overrides={"project": "project", "entity": "entity"})
artifact_type, artifact_name ="<>"# provide type and namefor v in api.artifact_versions(artifact_type, artifact_name):
# Clean up versions that don't have an alias such as 'latest'.# NOTE: You can put whatever deletion logic you want here.if len(v.aliases) ==0:
v.delete()
아티팩트 컬렉션 삭제
아티팩트 컬렉션을 삭제하려면 다음을 수행하세요.
삭제할 아티팩트 컬렉션으로 이동하여 마우스를 올려 놓습니다.
아티팩트 컬렉션 이름 옆에 있는 케밥 드롭다운을 선택합니다.
삭제를 선택합니다.
delete() 메소드를 사용하여 프로그래밍 방식으로 아티팩트 컬렉션을 삭제할 수도 있습니다. wandb.Api의 project 및 entity 키에 대한 프로젝트 및 엔터티 이름을 각각 제공합니다.
import wandb
# Provide your entity and a project name when you# use wandb.Api methods.api = wandb.Api(overrides={"project": "project", "entity": "entity"})
collection = api.artifact_collection(
"<artifact_type>", "entity/project/artifact_collection_name")
collection.delete()
W&B 호스팅 방식에 따라 가비지 수집을 활성화하는 방법
W&B의 공유 클라우드를 사용하는 경우 가비지 수집은 기본적으로 활성화됩니다. W&B를 호스팅하는 방식에 따라 가비지 수집을 활성화하기 위해 추가 단계를 수행해야 할 수 있습니다.
GORILLA_ARTIFACT_GC_ENABLED 환경 변수를 true로 설정합니다. GORILLA_ARTIFACT_GC_ENABLED=true
AWS, GCP 또는 Minio와 같은 다른 스토리지 공급자를 사용하는 경우 버킷 버전 관리를 활성화합니다. Azure를 사용하는 경우 소프트 삭제를 활성화합니다.
Azure의 소프트 삭제는 다른 스토리지 공급자의 버킷 버전 관리와 동일합니다.
다음 표는 배포 유형에 따라 가비지 수집을 활성화하기 위한 요구 사항을 충족하는 방법을 설명합니다.
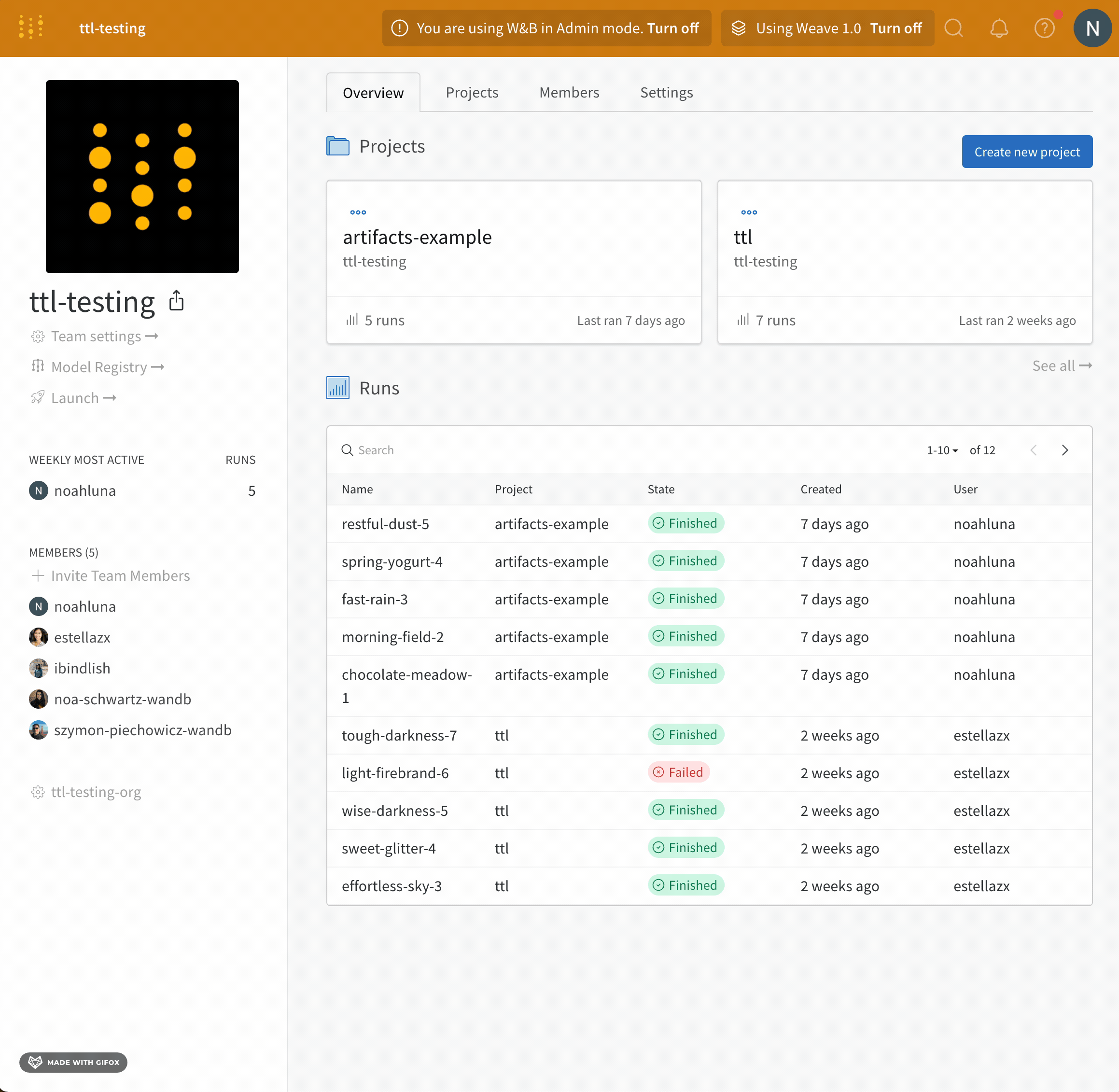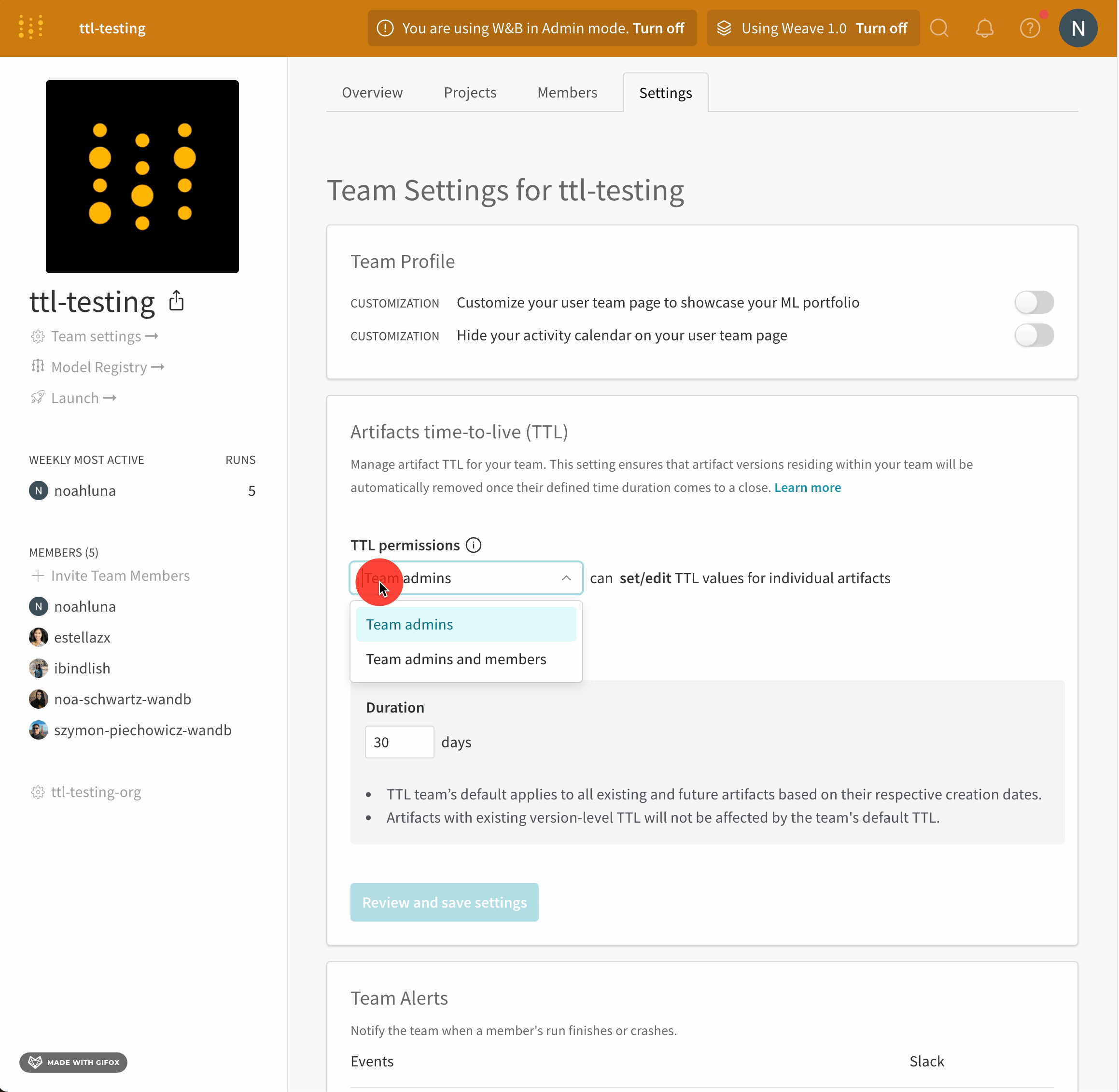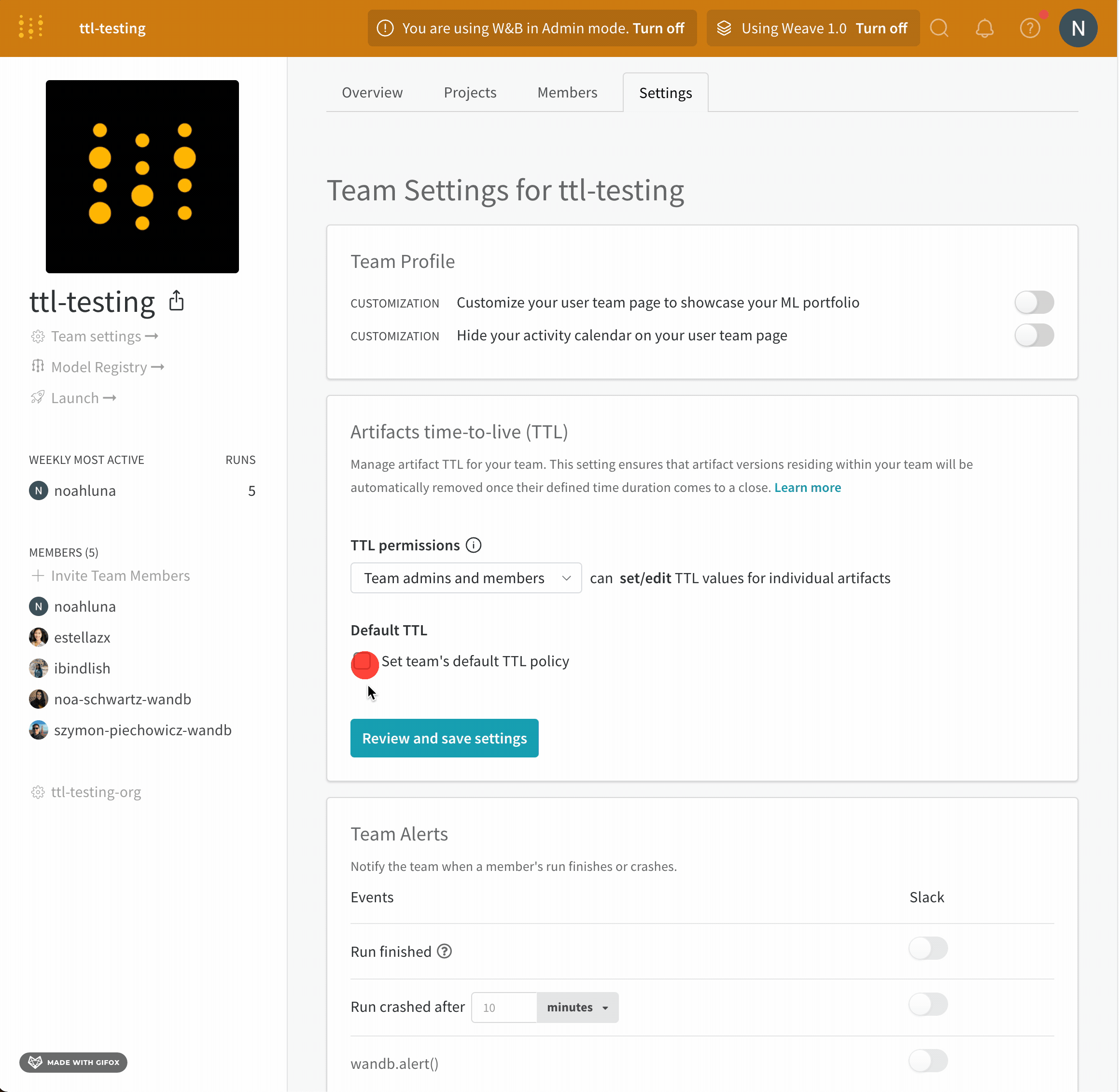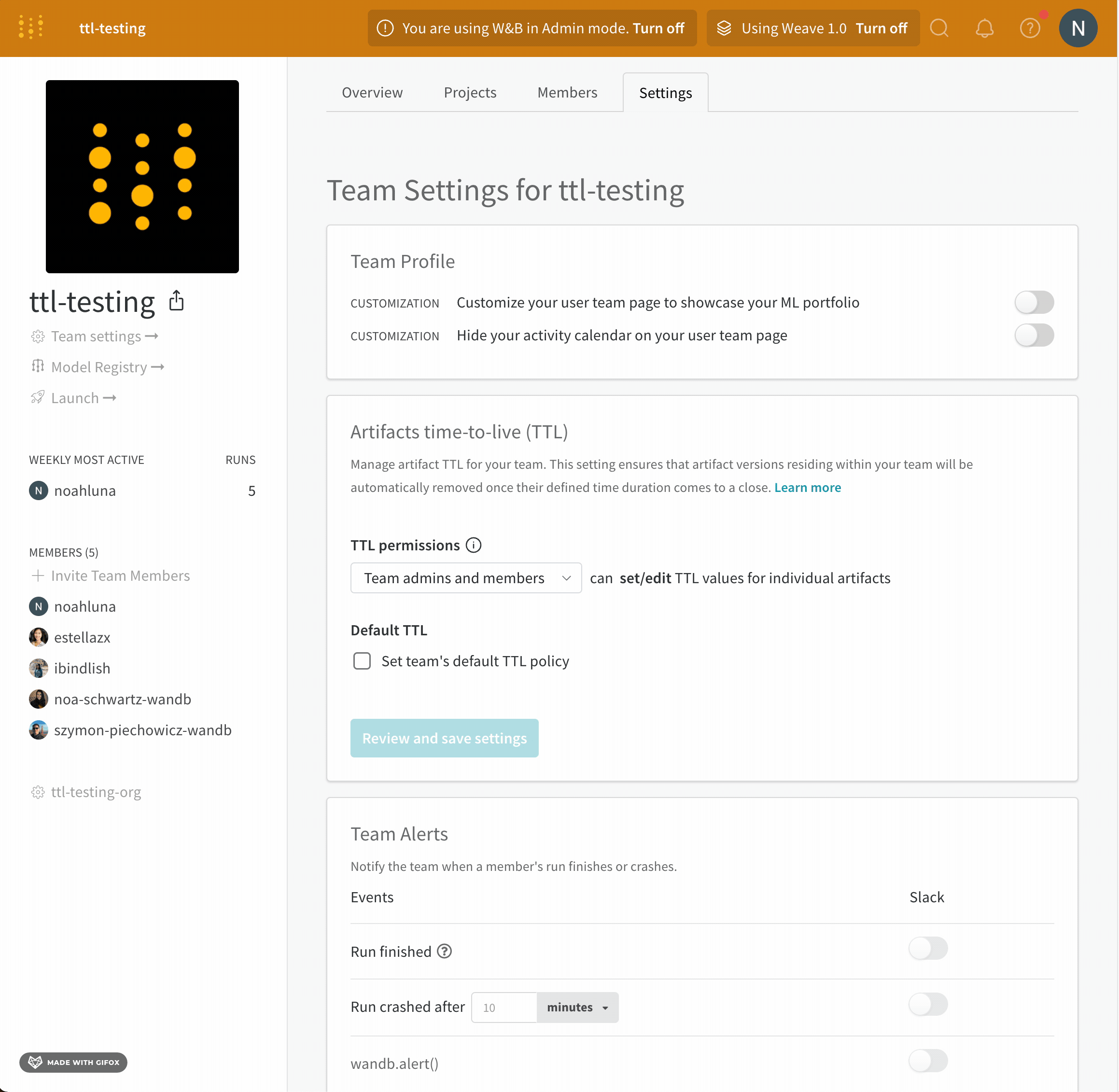
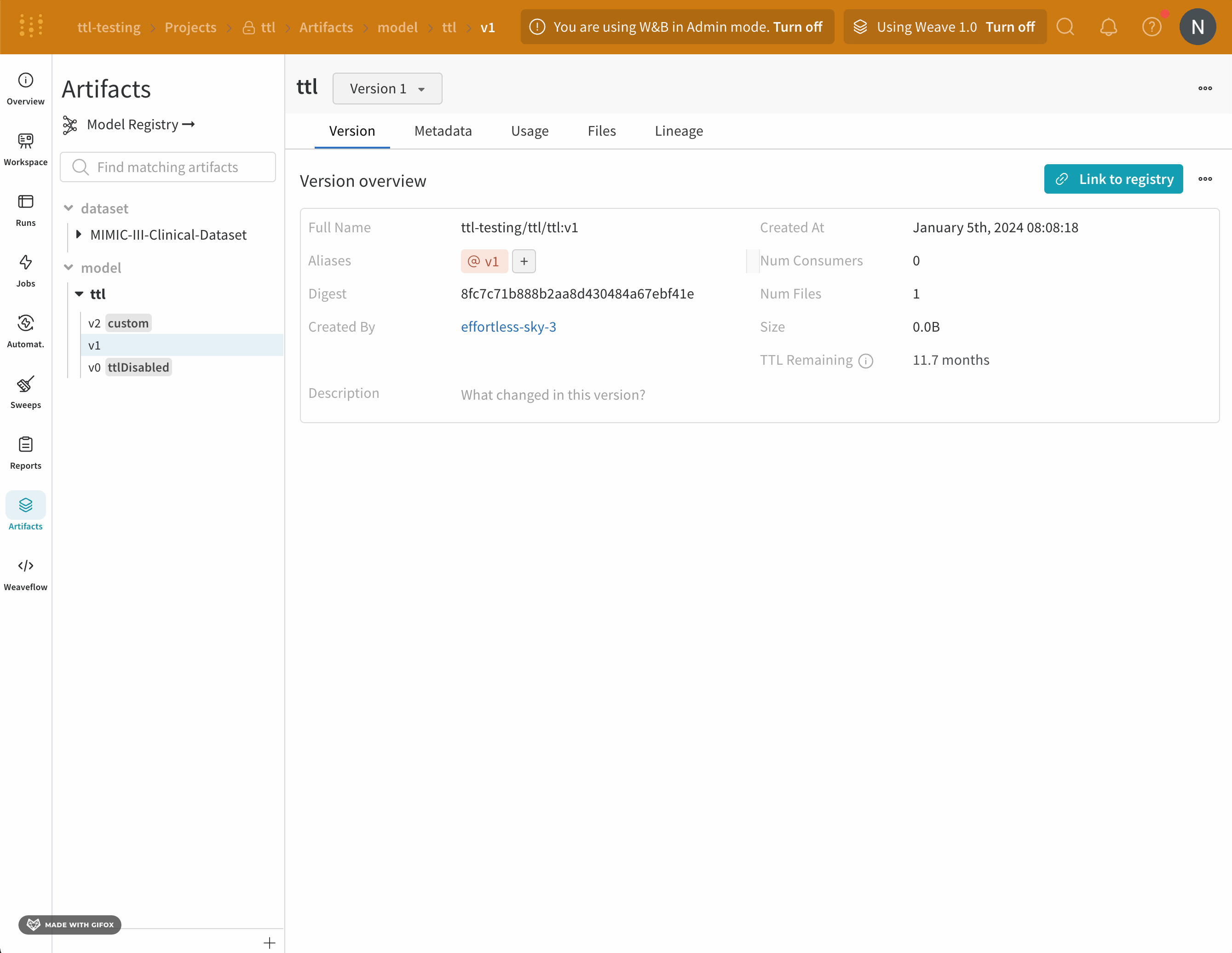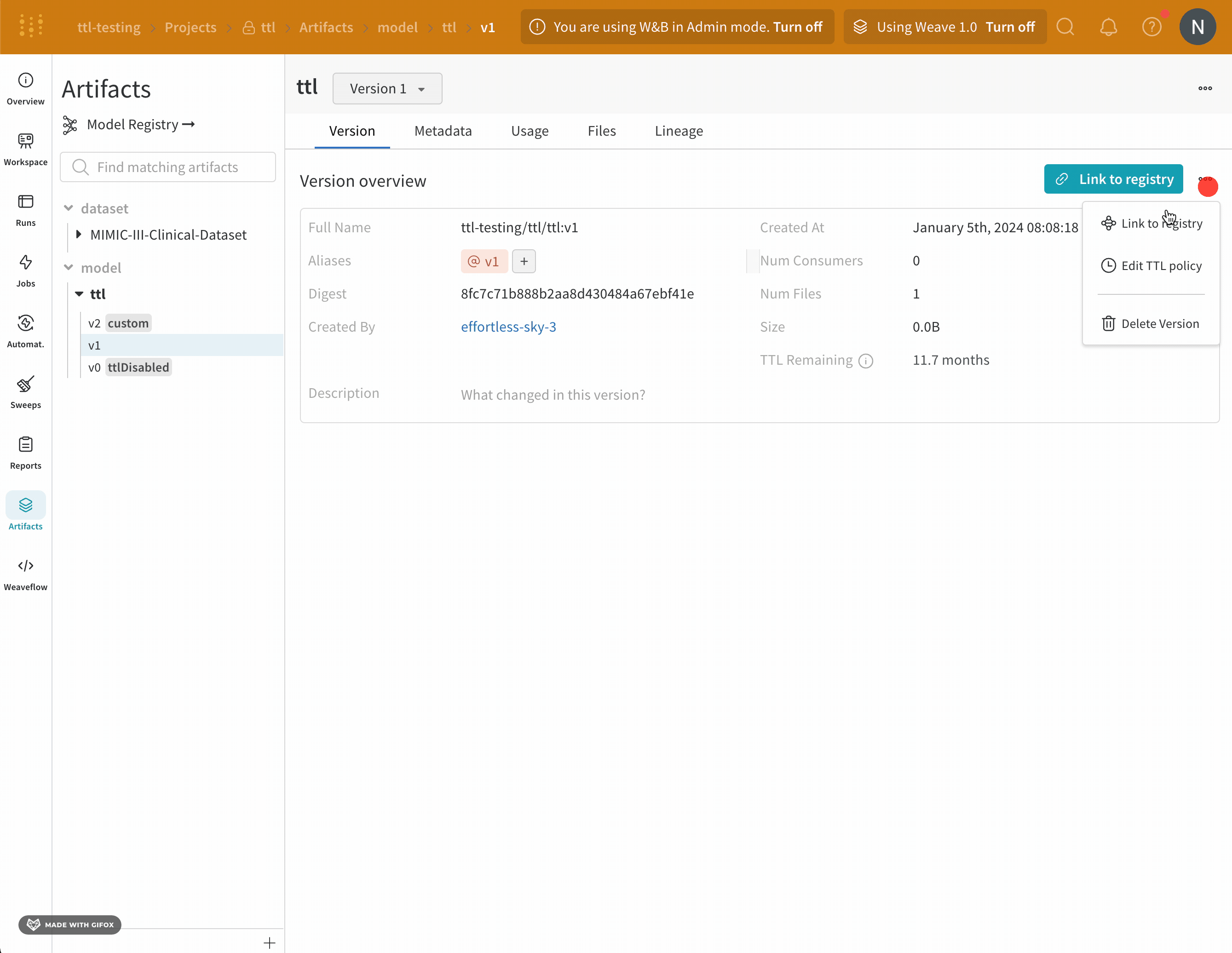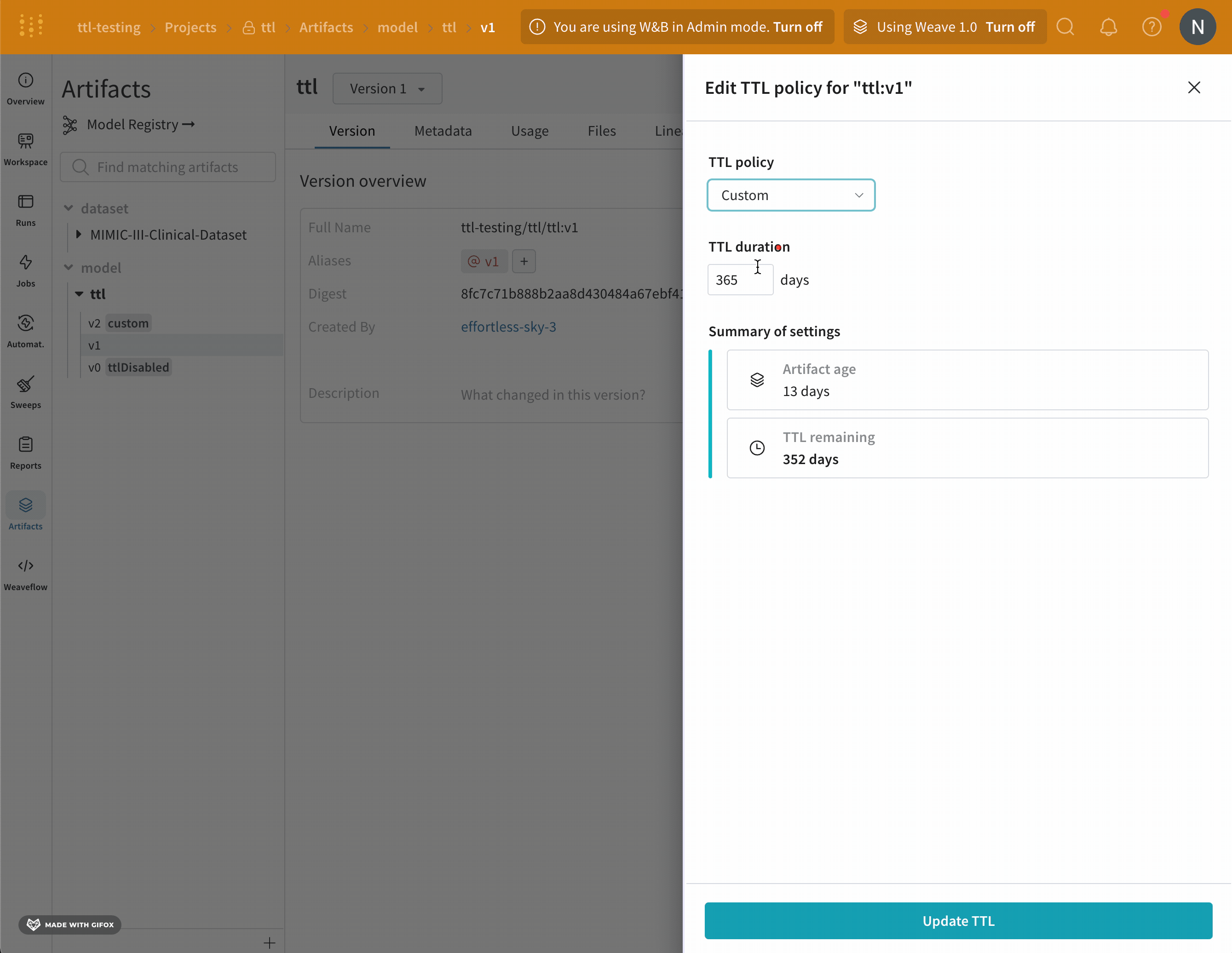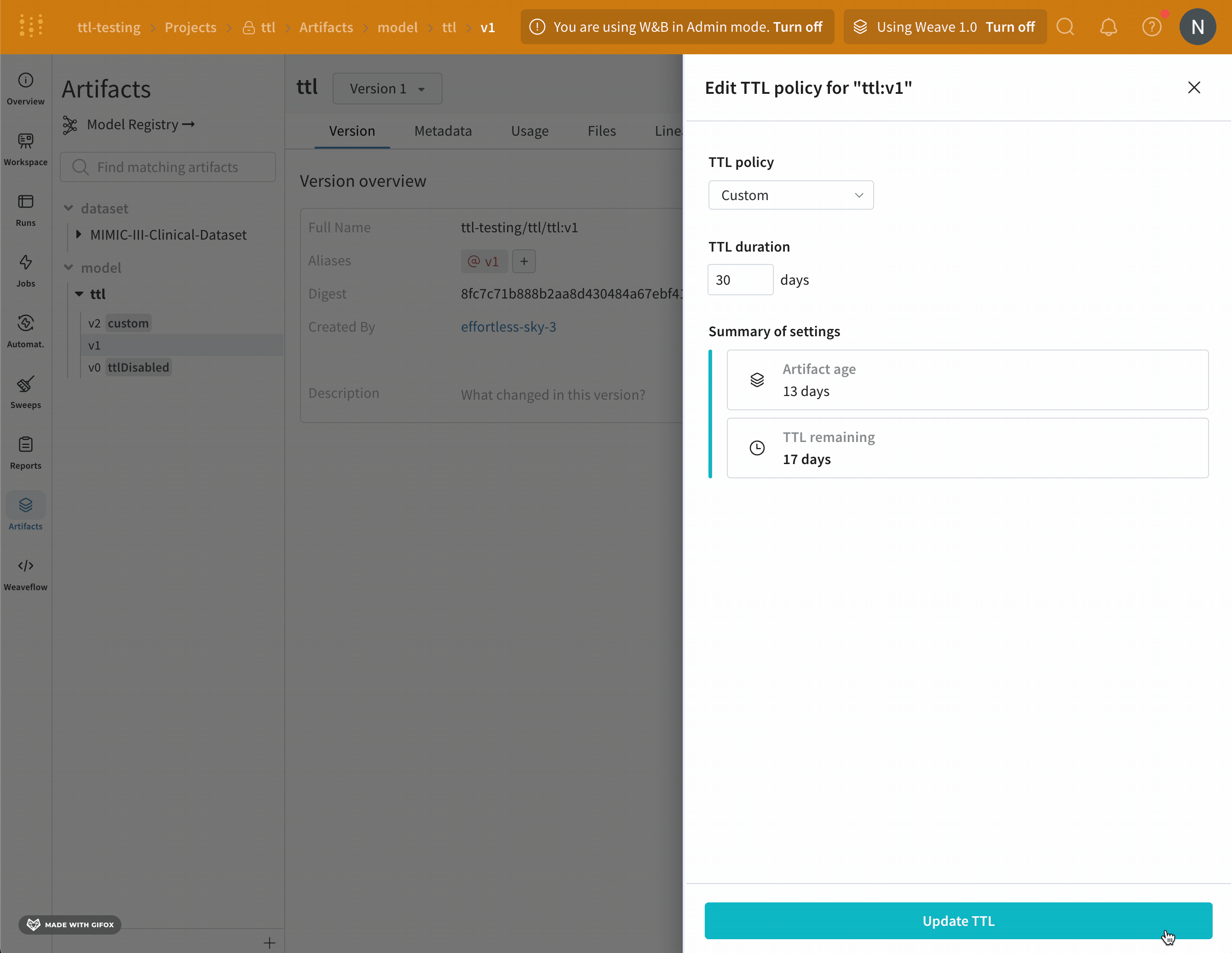
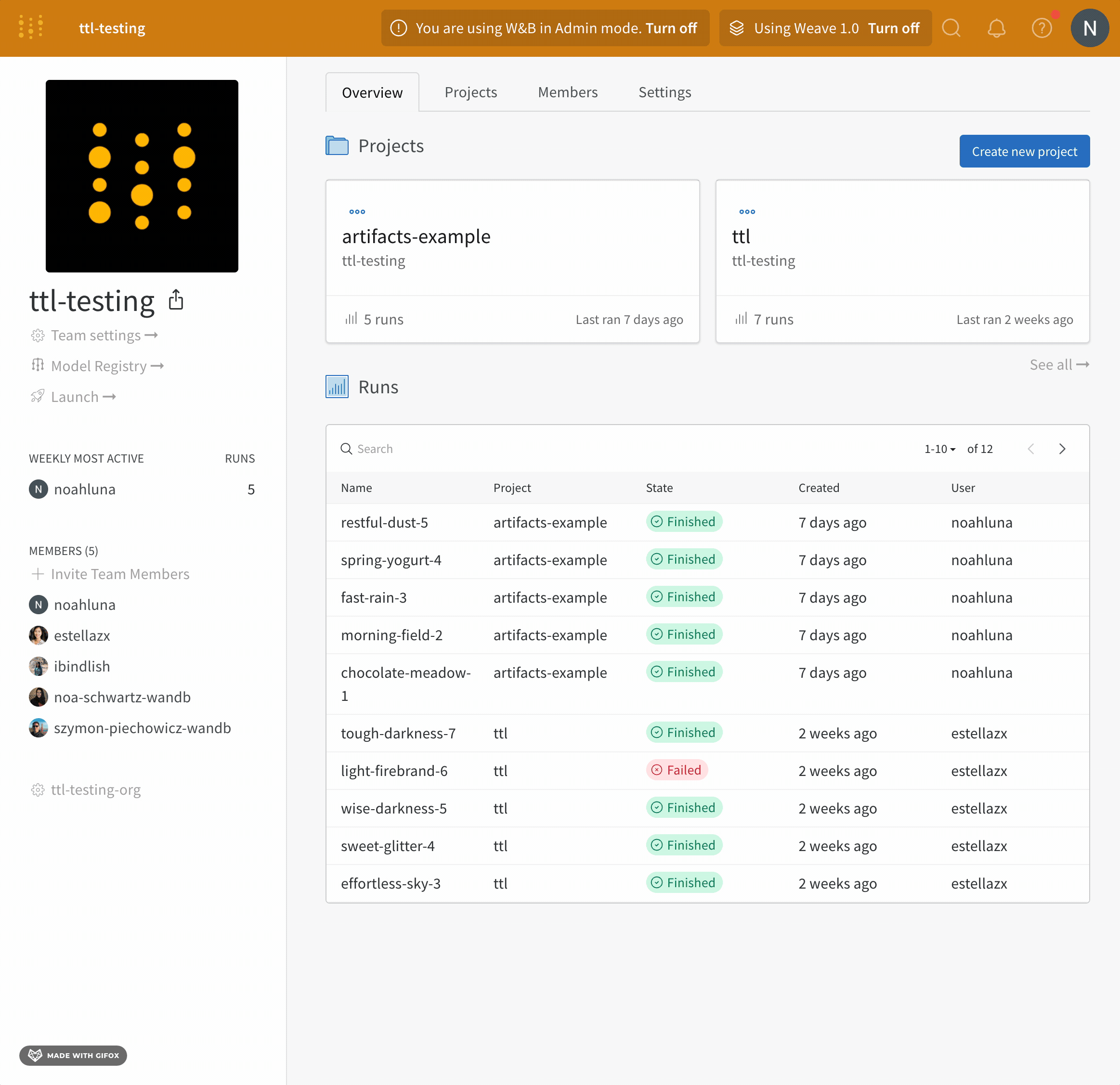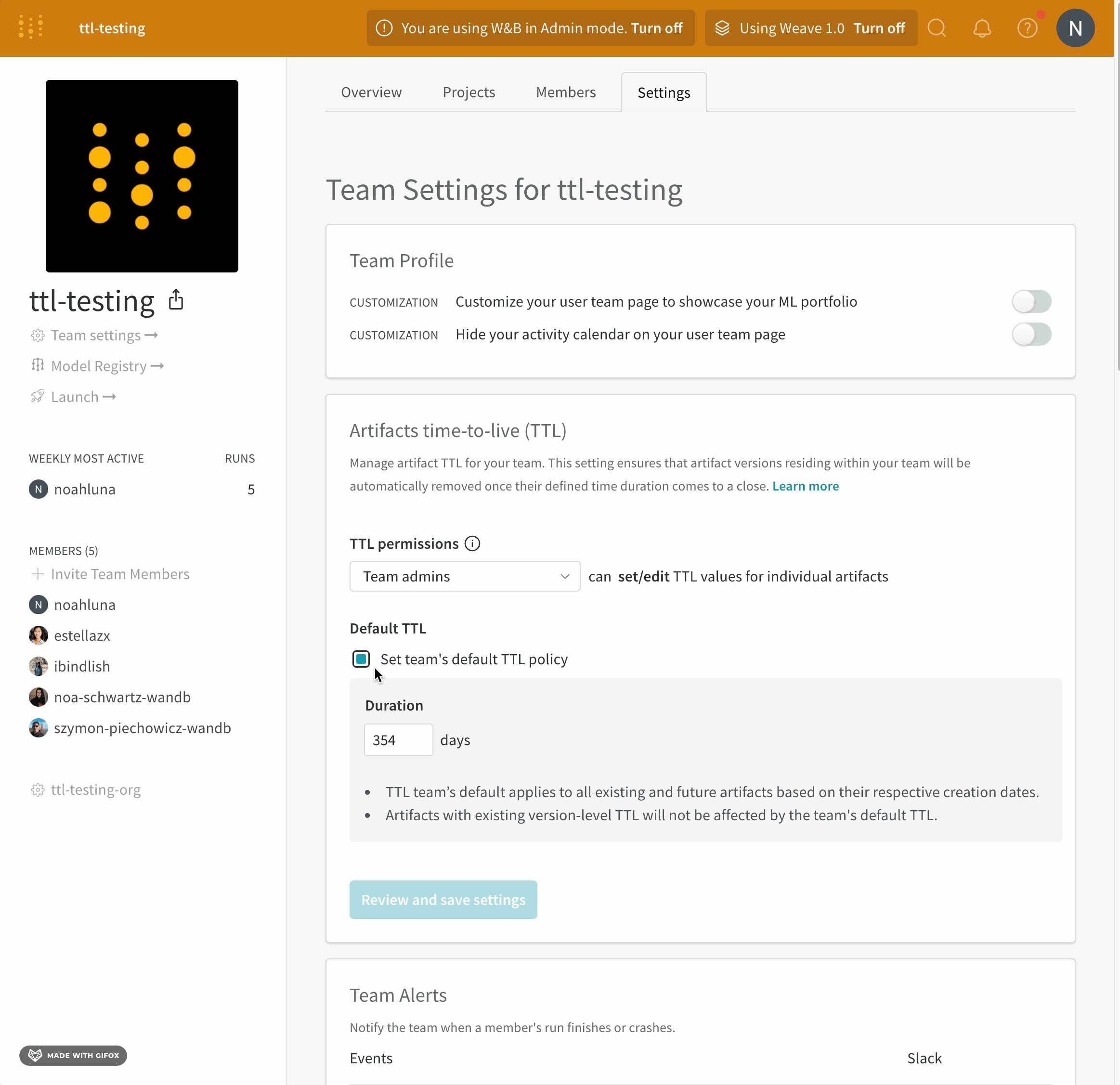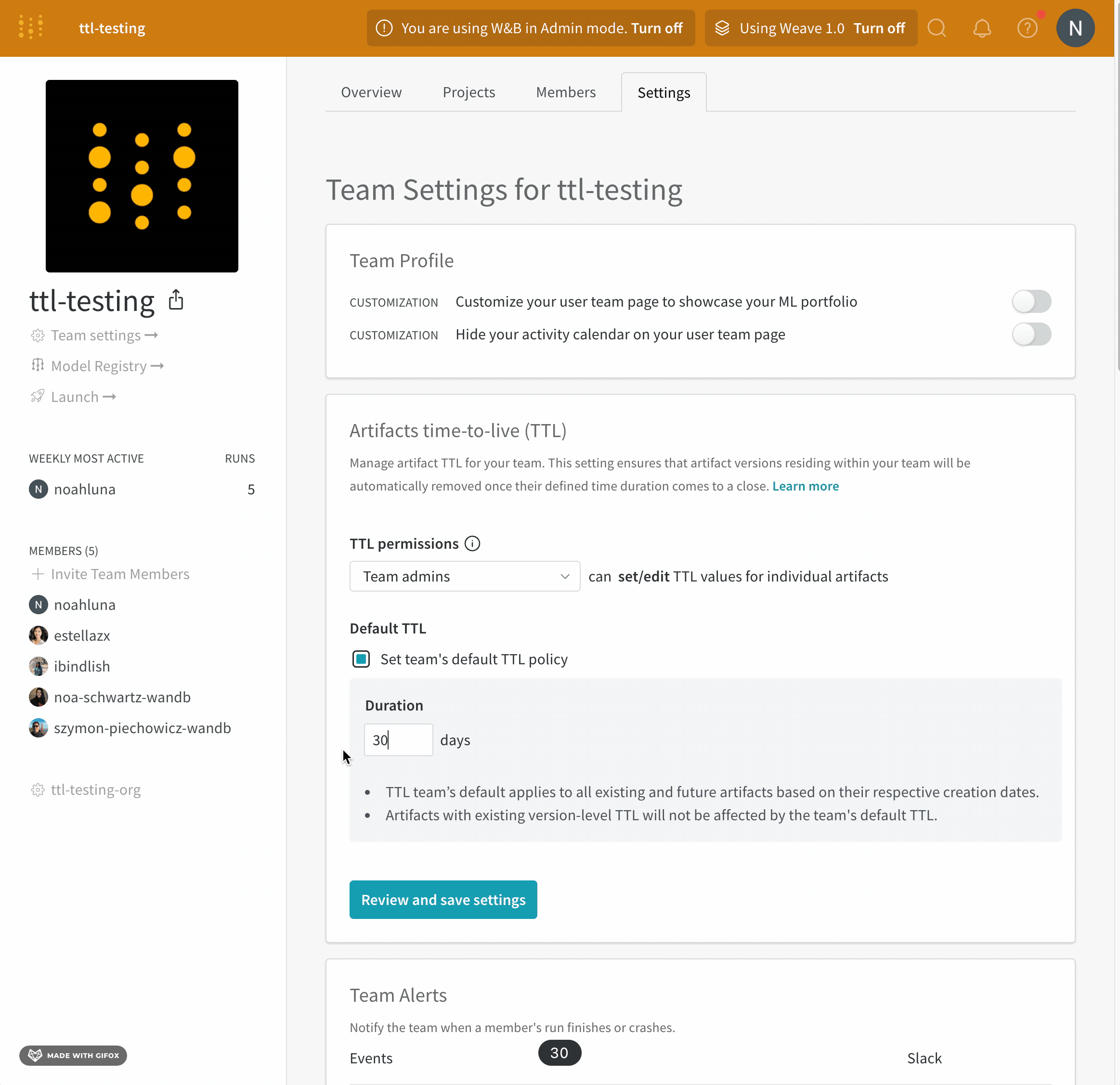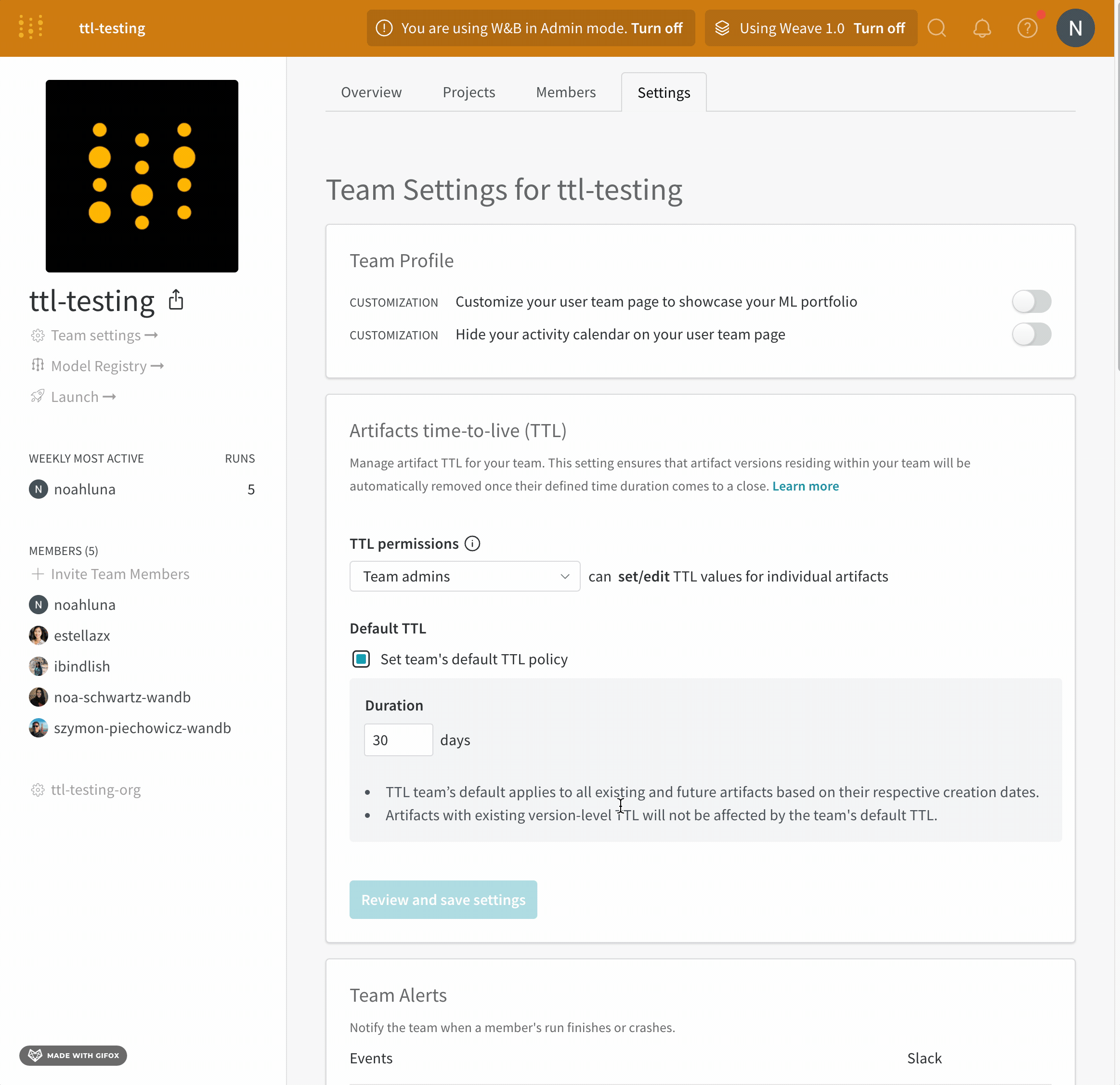
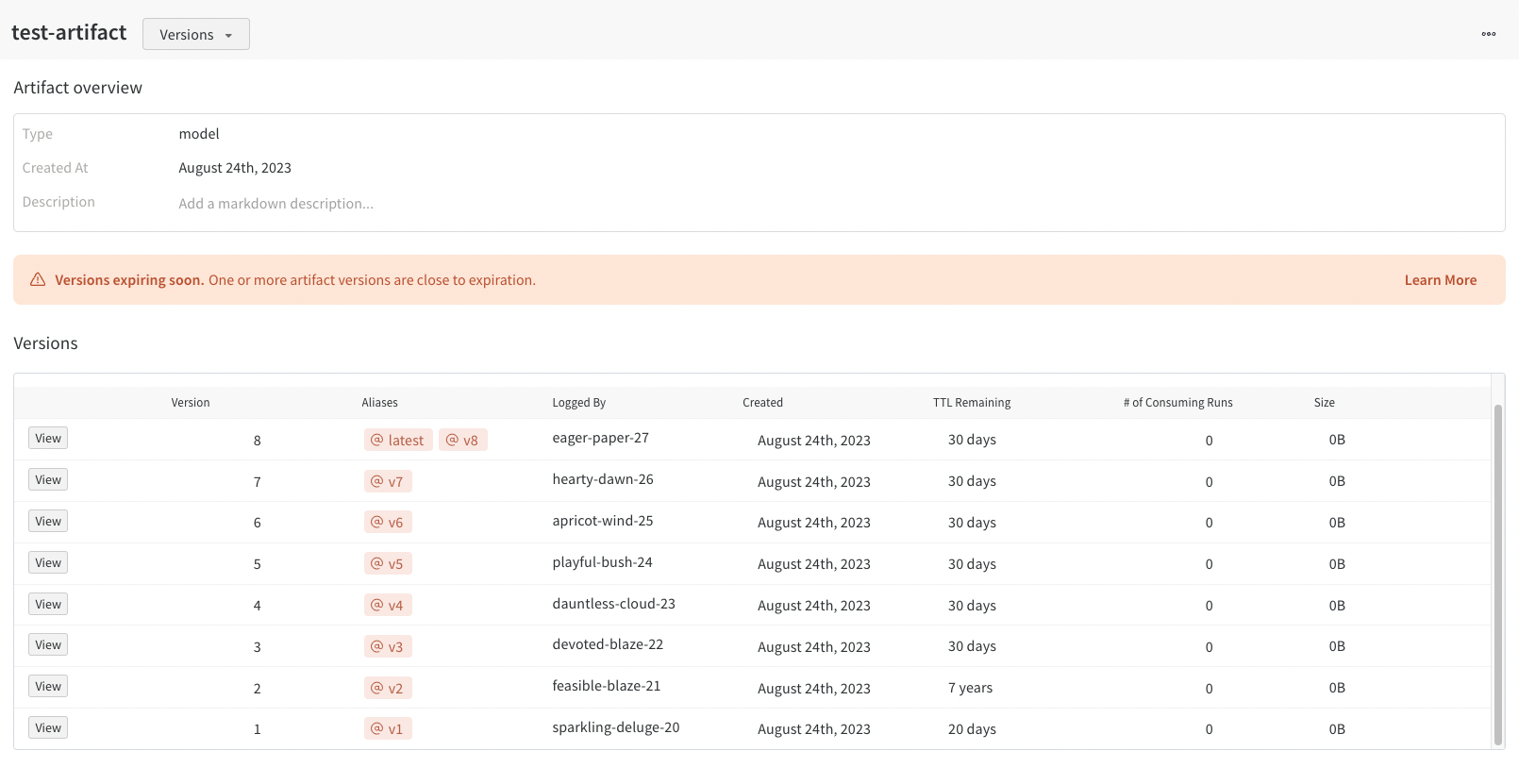
W&B Artifact time-to-live (TTL) 정책을 사용하여 Artifacts가 W&B에서 삭제되는 시점을 예약하세요. 아티팩트를 삭제하면 W&B는 해당 아티팩트를 soft-delete 로 표시합니다. 즉, 아티팩트는 삭제 대상으로 표시되지만 파일은 즉시 스토리지에서 삭제되지 않습니다. W&B에서 아티팩트를 삭제하는 방법에 대한 자세한 내용은 아티팩트 삭제 페이지를 참조하세요.
이 비디오 튜토리얼에서 W&B 앱에서 Artifacts TTL로 데이터 보존을 관리하는 방법을 알아보세요.
W&B는 모델 레지스트리에 연결된 모델 아티팩트에 대한 TTL 정책을 설정하는 옵션을 비활성화합니다. 이는 연결된 모델이 프로덕션 워크플로우에서 사용되는 경우 실수로 만료되지 않도록 하기 위함입니다.
팀 관리자만 팀 설정을 보고 (1) 누가 TTL 정책을 설정하거나 편집할 수 있는지 허용하거나 (2) 팀 기본 TTL을 설정하는 것과 같은 팀 수준 TTL 설정에 엑세스할 수 있습니다.
W&B 앱 UI에서 아티팩트 세부 정보에 TTL 정책을 설정하거나 편집하는 옵션이 표시되지 않거나 프로그래밍 방식으로 TTL을 설정해도 아티팩트의 TTL 속성이 성공적으로 변경되지 않으면 팀 관리자가 해당 권한을 부여하지 않은 것입니다.
자동 생성된 Artifacts
사용자가 생성한 아티팩트만 TTL 정책을 사용할 수 있습니다. W&B에서 자동으로 생성된 아티팩트에는 TTL 정책을 설정할 수 없습니다.
트레이닝 중에 W&B는 로그, 아티팩트 및 설정 파일을 다음 로컬 디렉토리에 로컬로 저장합니다.
파일
기본 위치
기본 위치를 변경하려면 다음을 설정하십시오:
logs
./wandb
wandb.init의 dir 또는 WANDB_DIR 환경 변수를 설정하십시오.
artifacts
~/.cache/wandb
WANDB_CACHE_DIR 환경 변수
configs
~/.config/wandb
WANDB_CONFIG_DIR 환경 변수
업로드를 위한 Staging artifacts
~/.cache/wandb-data/
WANDB_DATA_DIR 환경 변수
다운로드된 artifacts
./artifacts
WANDB_ARTIFACT_DIR 환경 변수
환경 변수를 사용하여 W&B를 구성하는 방법에 대한 전체 가이드는 환경 변수 참조를 참조하십시오.
wandb가 초기화된 머신에 따라 이러한 기본 폴더가 파일 시스템의 쓰기 가능한 부분에 위치하지 않을 수 있습니다. 이로 인해 오류가 발생할 수 있습니다.
로컬 아티팩트 캐시 정리
W&B는 공통 파일을 공유하는 버전 간의 다운로드 속도를 높이기 위해 아티팩트 파일을 캐시합니다. 시간이 지남에 따라 이 캐시 디렉토리가 커질 수 있습니다. wandb artifact cache cleanup 명령을 실행하여 캐시를 정리하고 최근에 사용되지 않은 파일을 제거하십시오.
다음 코드 조각은 캐시 크기를 1GB로 제한하는 방법을 보여줍니다. 코드 조각을 복사하여 터미널에 붙여넣으십시오:
$ wandb artifact cache cleanup 1GB
1.8 - Explore artifact graphs
자동으로 생성된 직접 비순환 W&B Artifact 그래프를 트래버스합니다.
W&B는 주어진 run이 기록한 Artifacts와 주어진 run이 사용하는 Artifacts를 자동으로 추적합니다. 이러한 Artifacts에는 데이터셋, 모델, 평가 결과 등이 포함될 수 있습니다. Artifact의 계보를 탐색하여 기계 학습 라이프사이클 전반에 걸쳐 생성된 다양한 Artifacts를 추적하고 관리할 수 있습니다.
계보
Artifact의 계보를 추적하면 다음과 같은 주요 이점이 있습니다.
재현성: 모든 Artifacts의 계보를 추적함으로써 팀은 실험, 모델 및 결과를 재현할 수 있습니다. 이는 디버깅, 실험 및 기계 학습 모델 검증에 필수적입니다.
버전 관리: Artifact 계보는 Artifacts의 버전 관리와 시간 경과에 따른 변경 사항 추적을 포함합니다. 이를 통해 팀은 필요한 경우 이전 버전의 데이터 또는 모델로 롤백할 수 있습니다.
감사: Artifacts 및 해당 변환에 대한 자세한 기록을 통해 조직은 규제 및 거버넌스 요구 사항을 준수할 수 있습니다.
협업 및 지식 공유: Artifact 계보는 시도에 대한 명확한 기록과 무엇이 작동했고 무엇이 작동하지 않았는지 제공함으로써 팀 멤버 간의 더 나은 협업을 촉진합니다. 이는 노력의 중복을 피하고 개발 프로세스를 가속화하는 데 도움이 됩니다.
Artifact의 계보 찾기
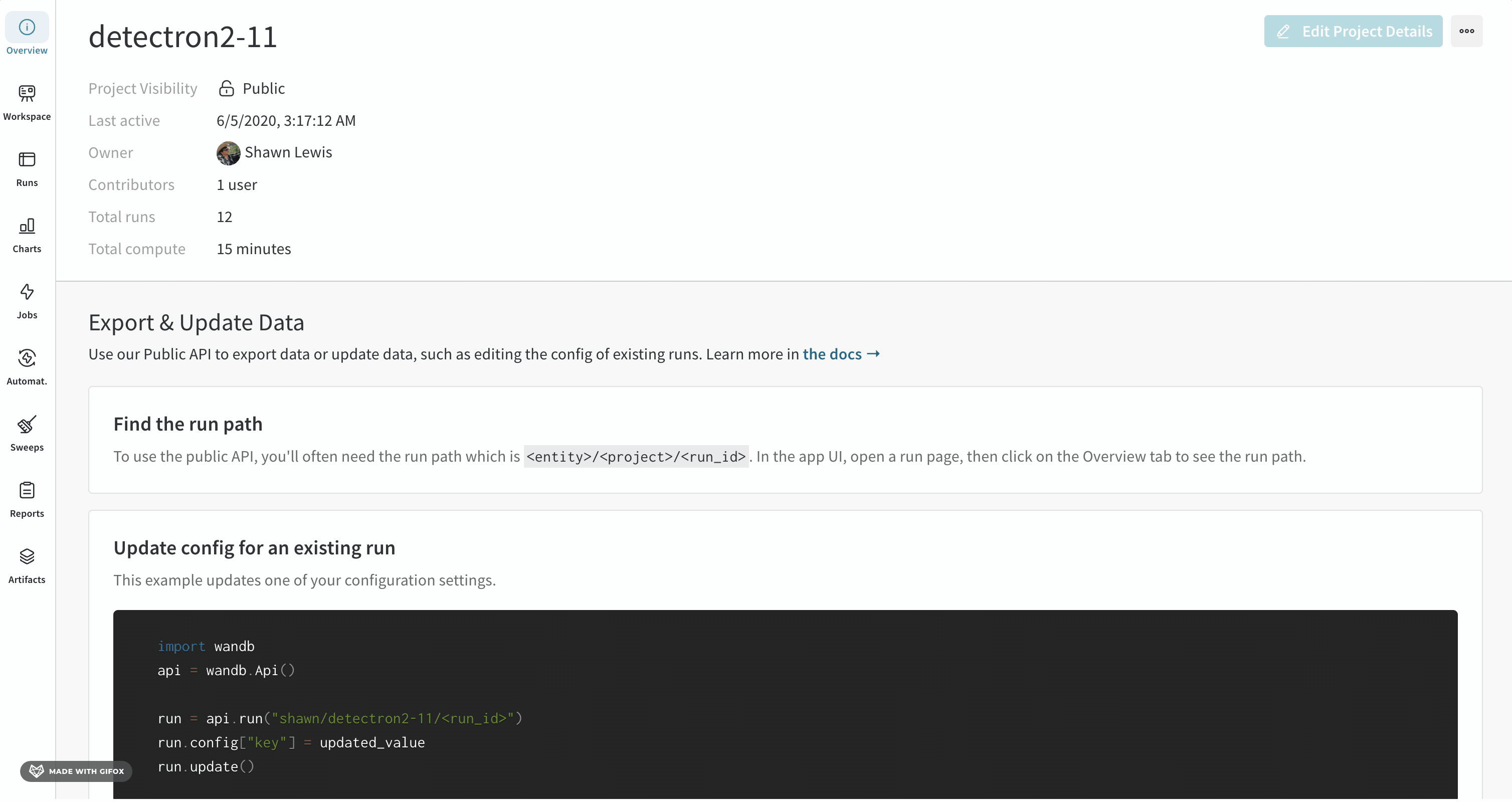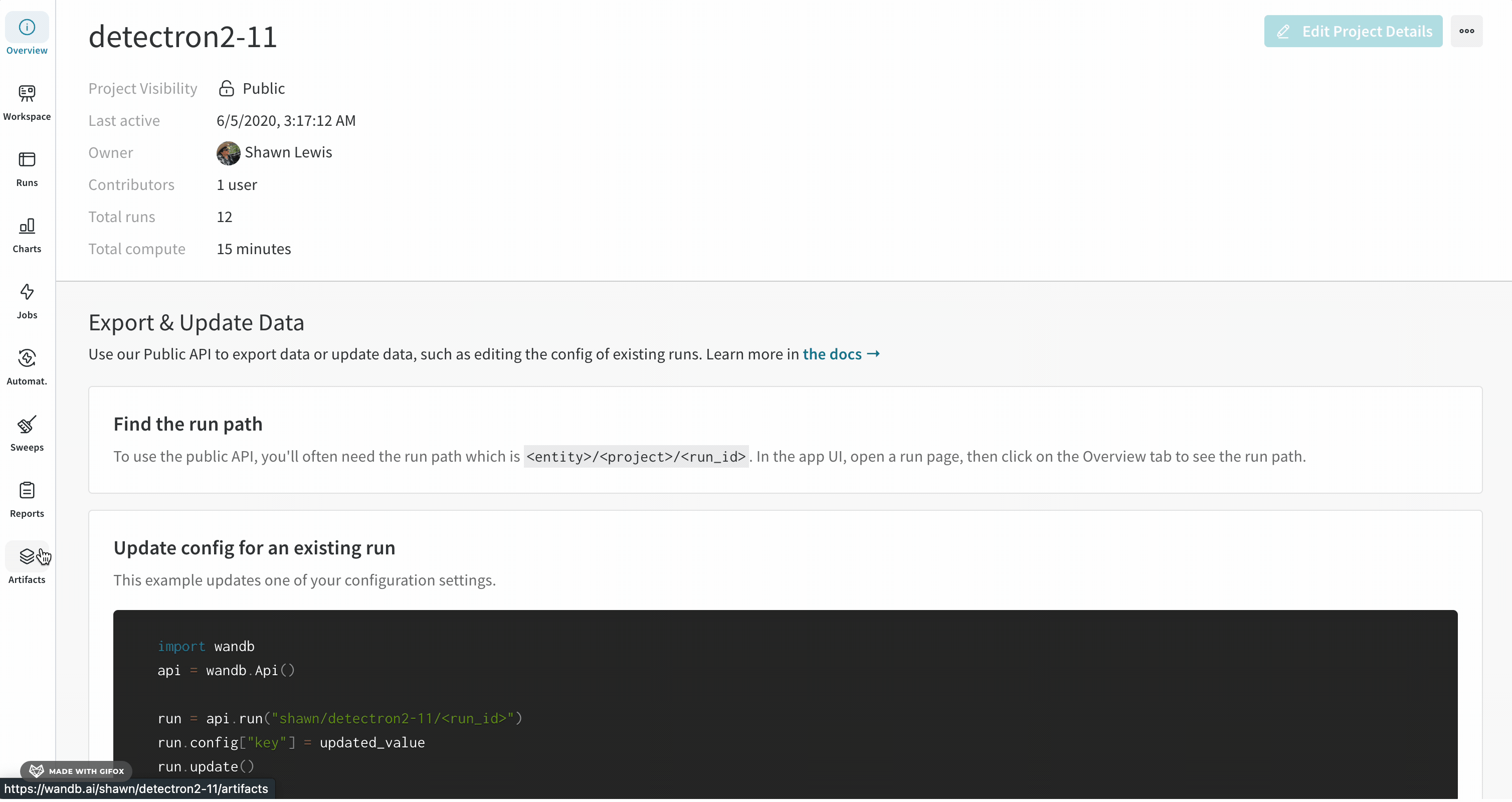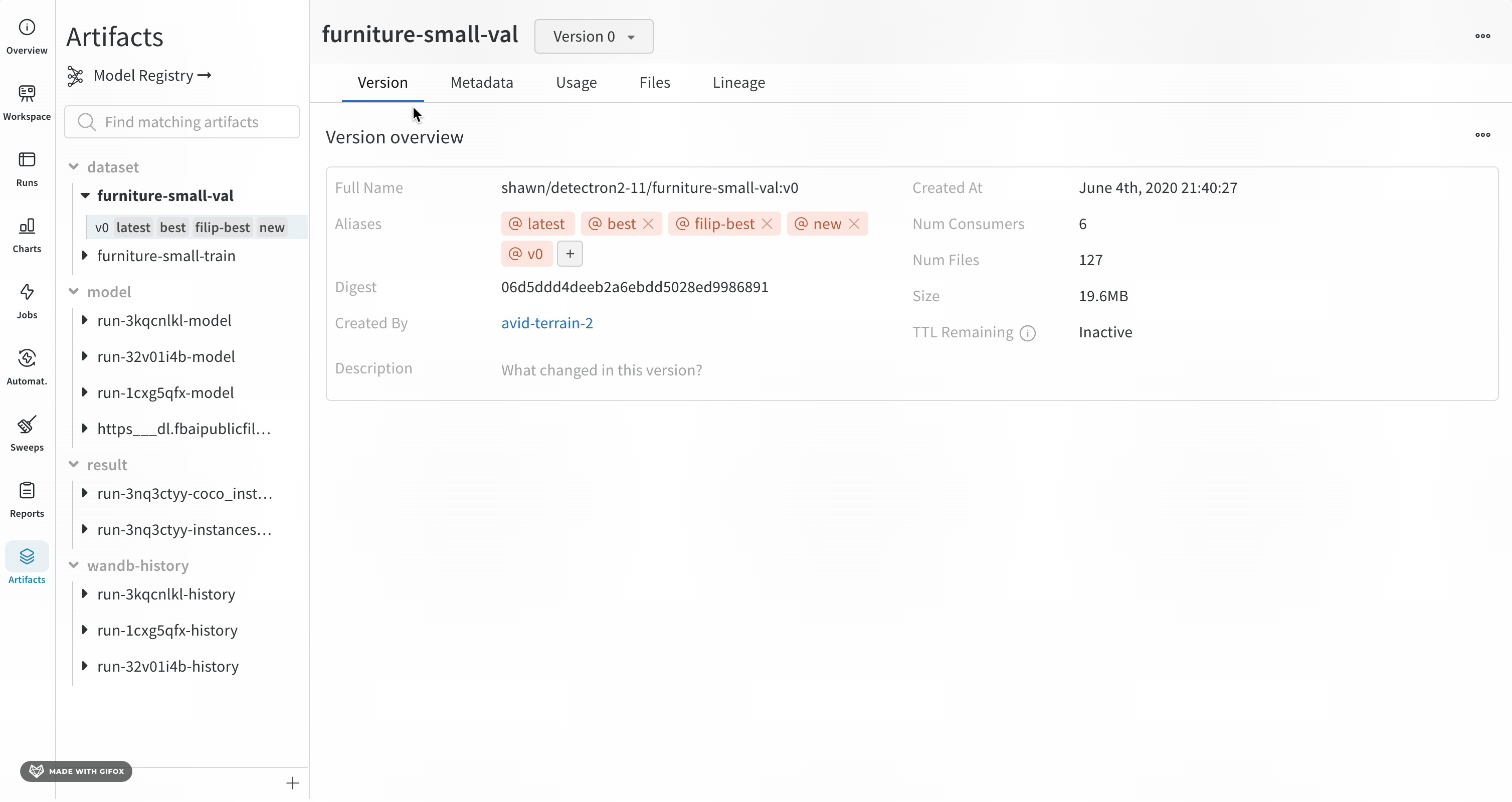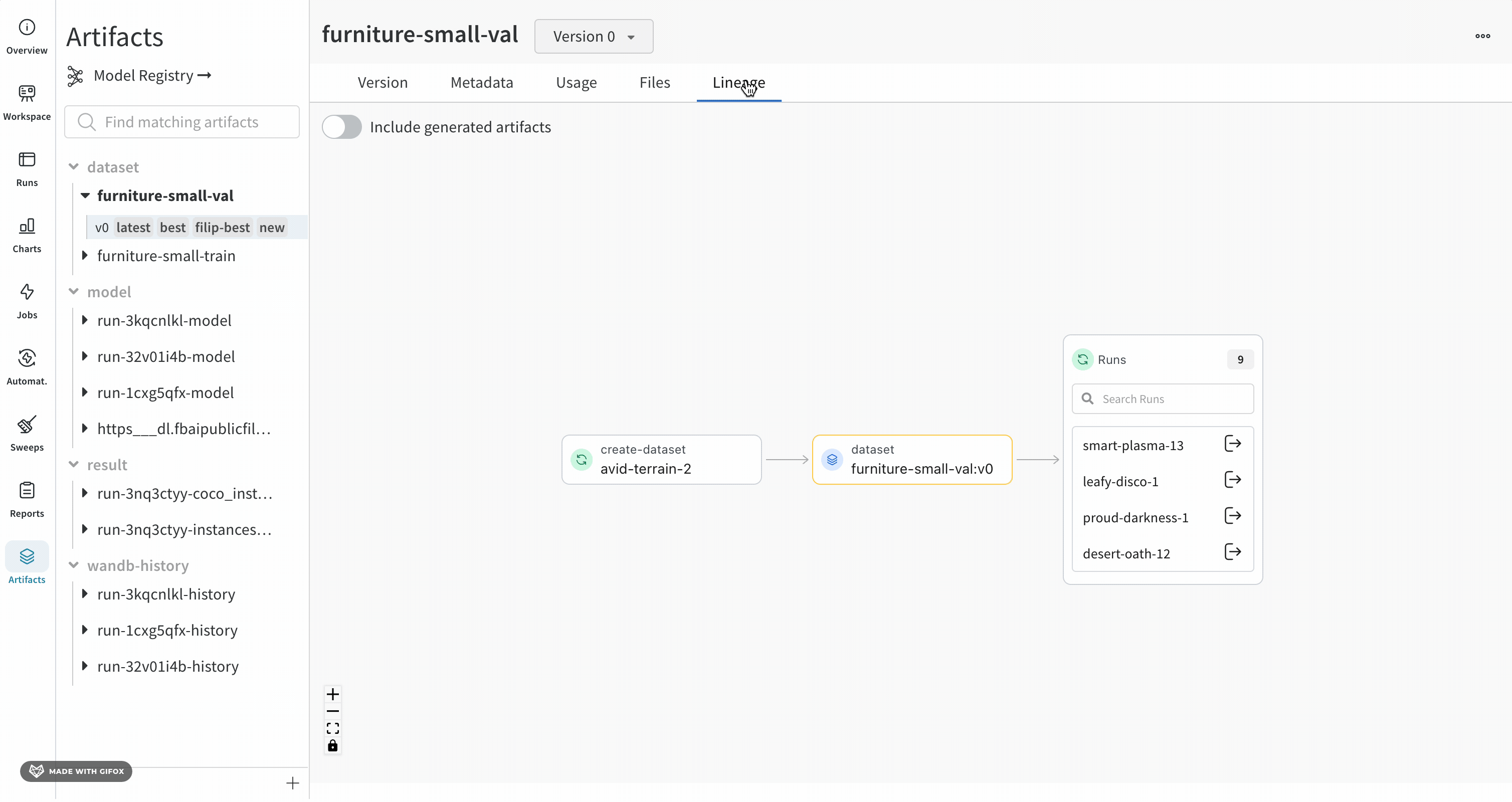
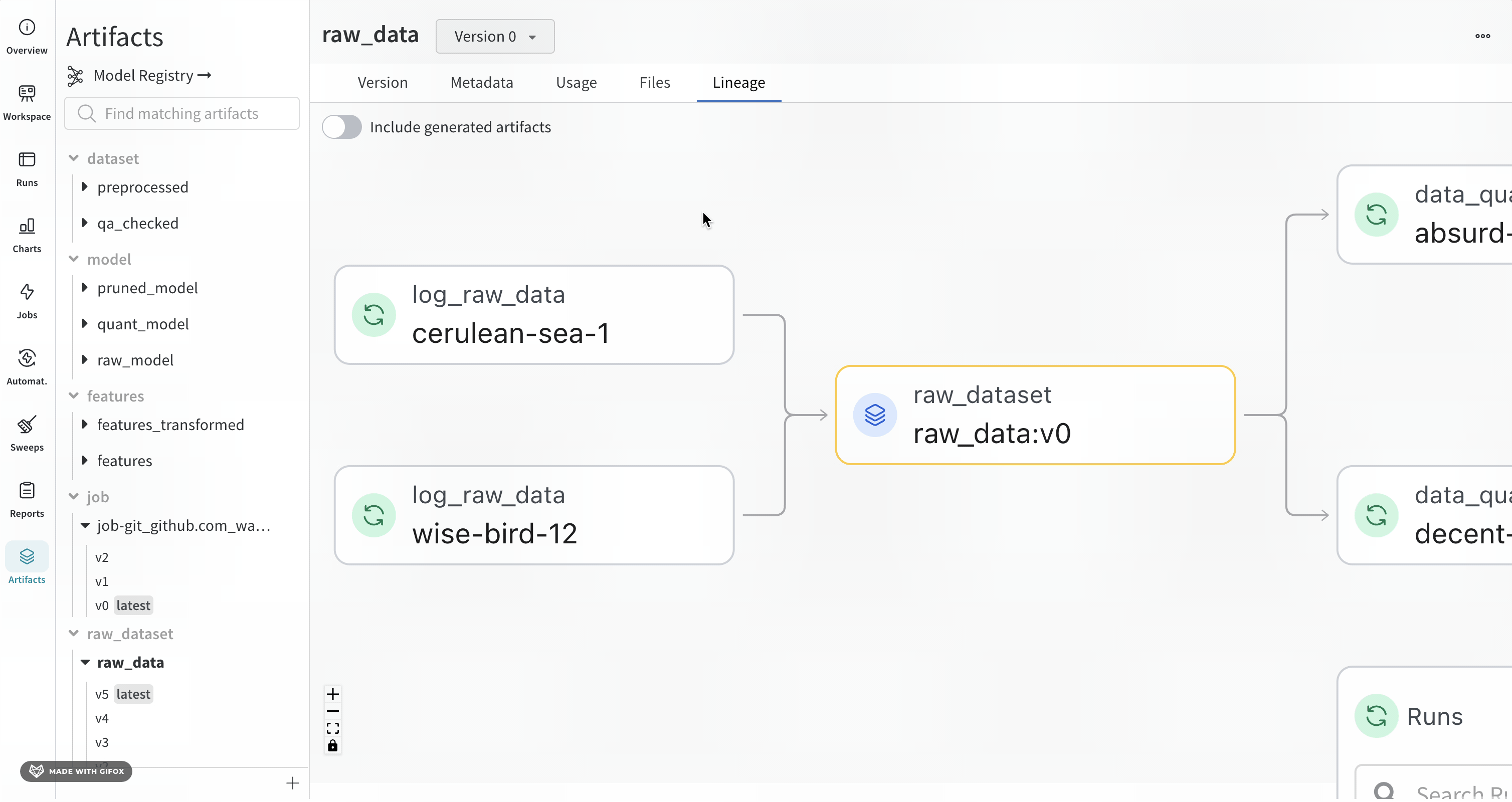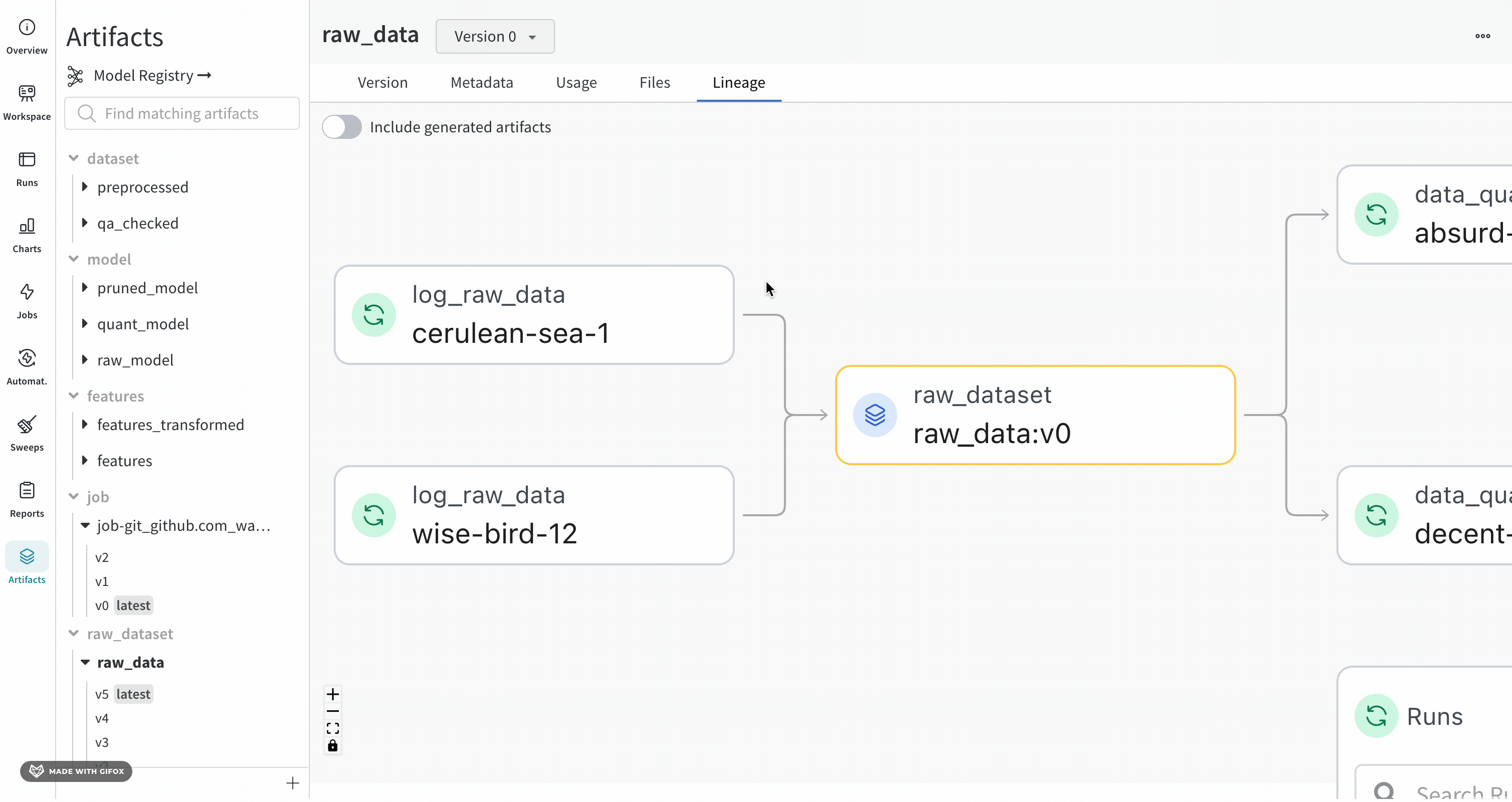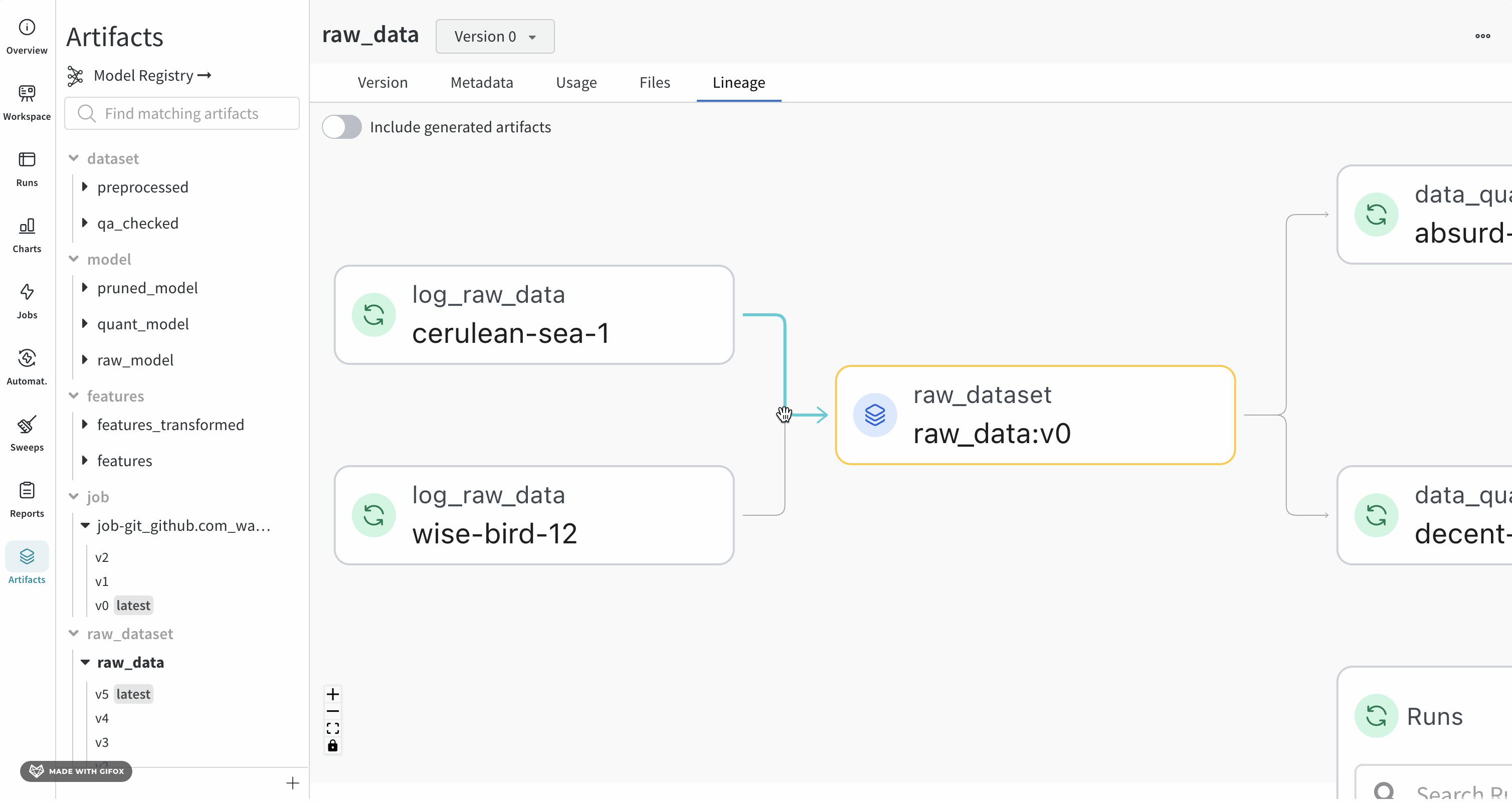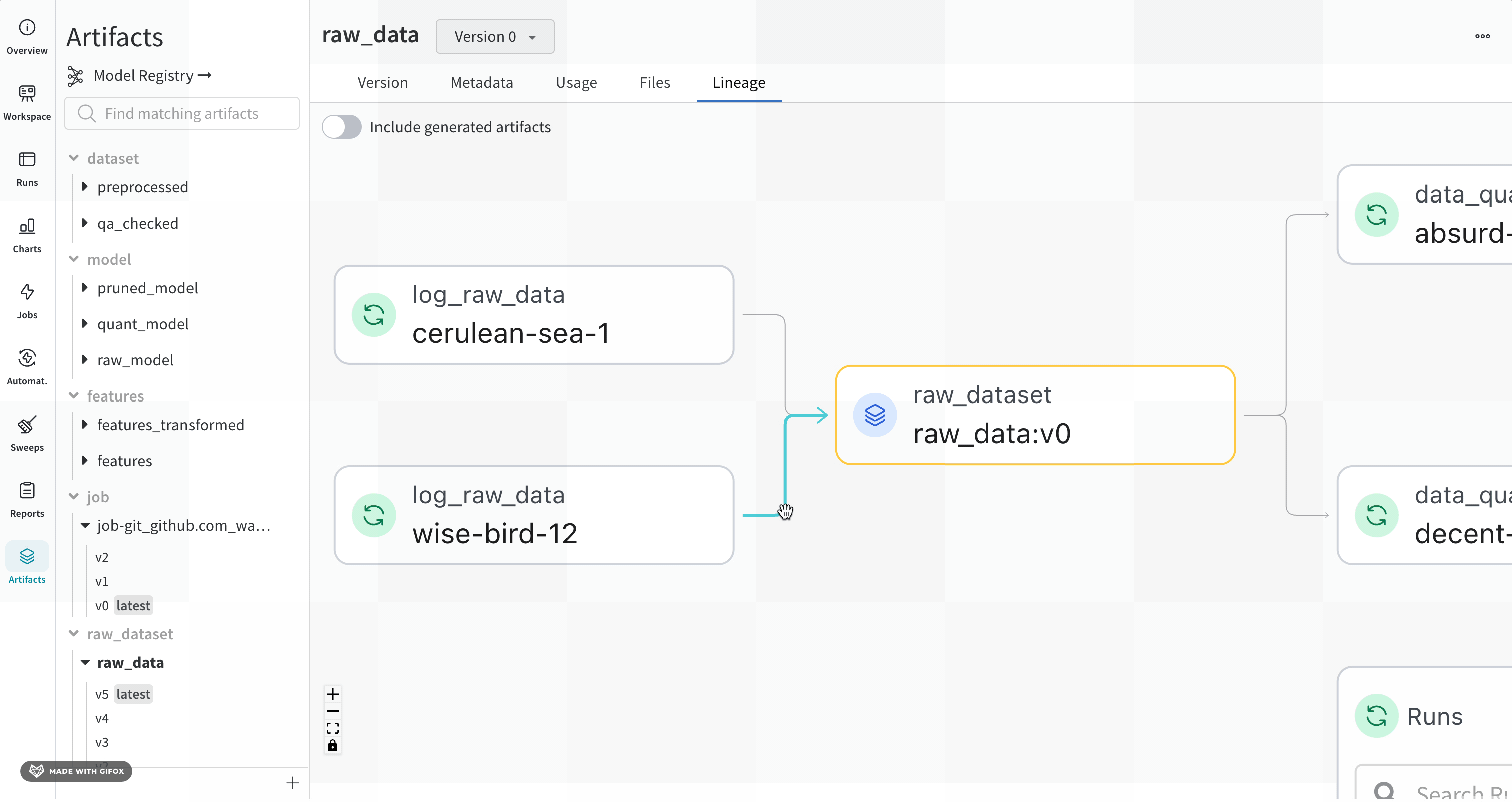
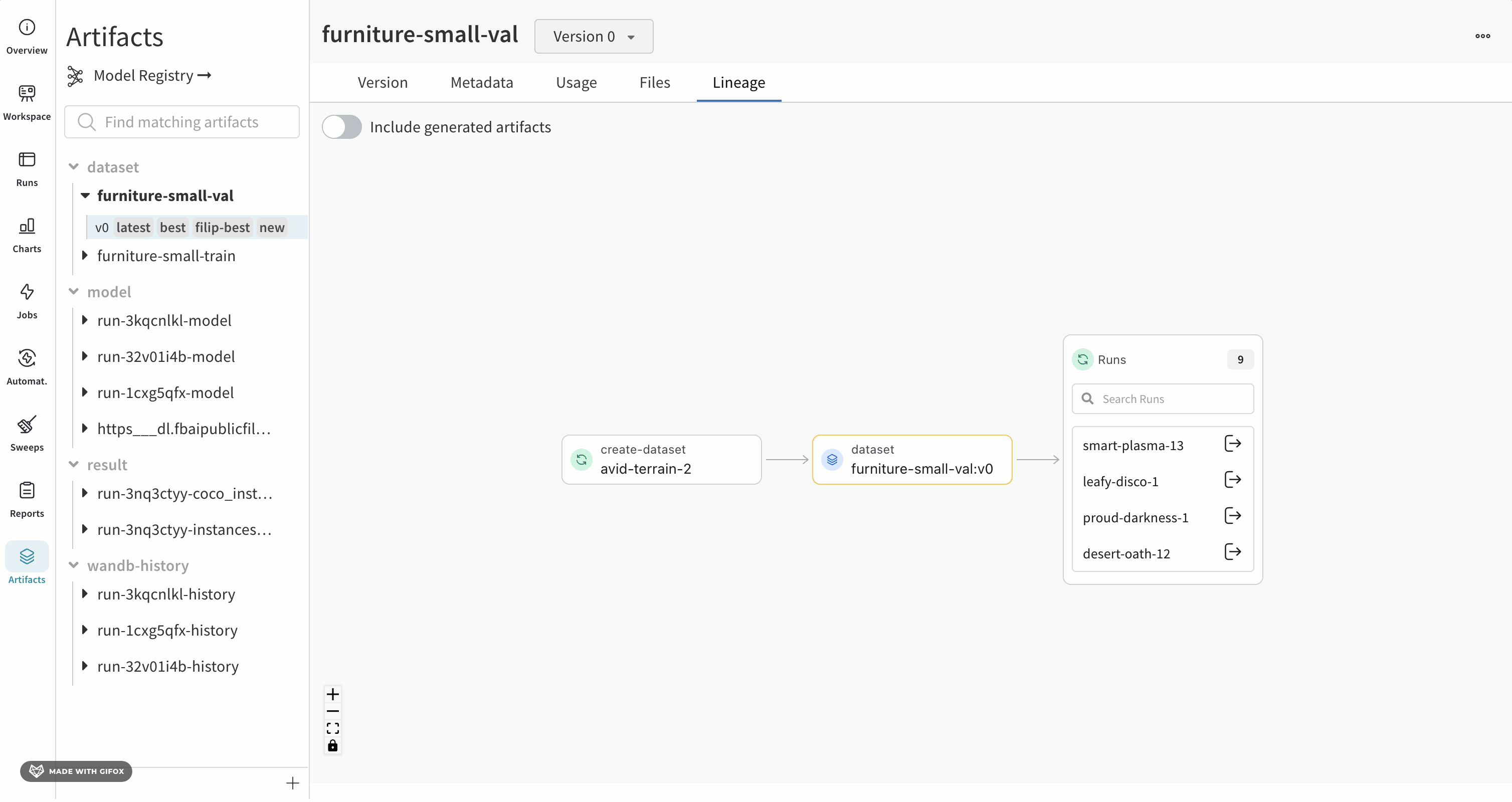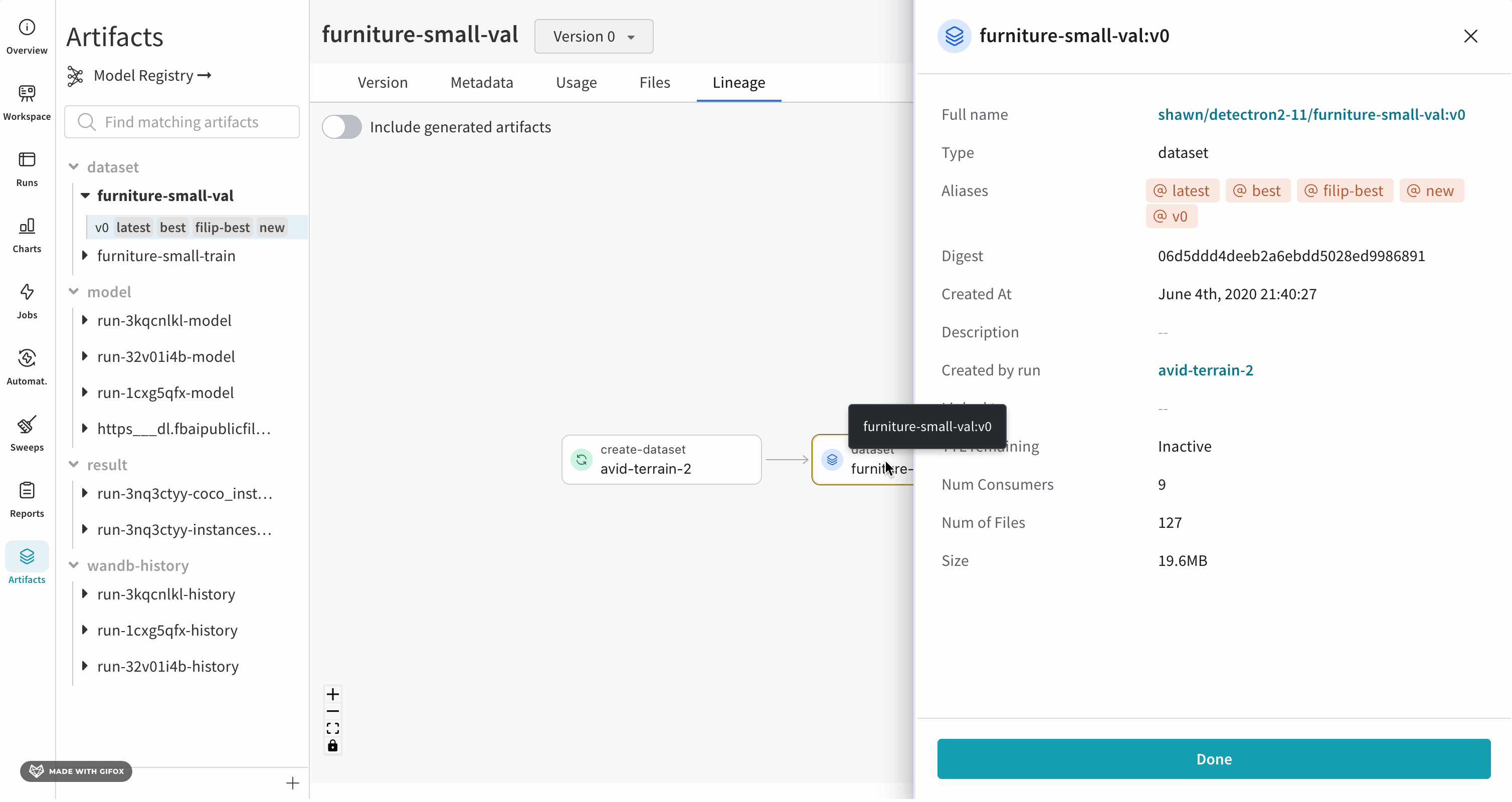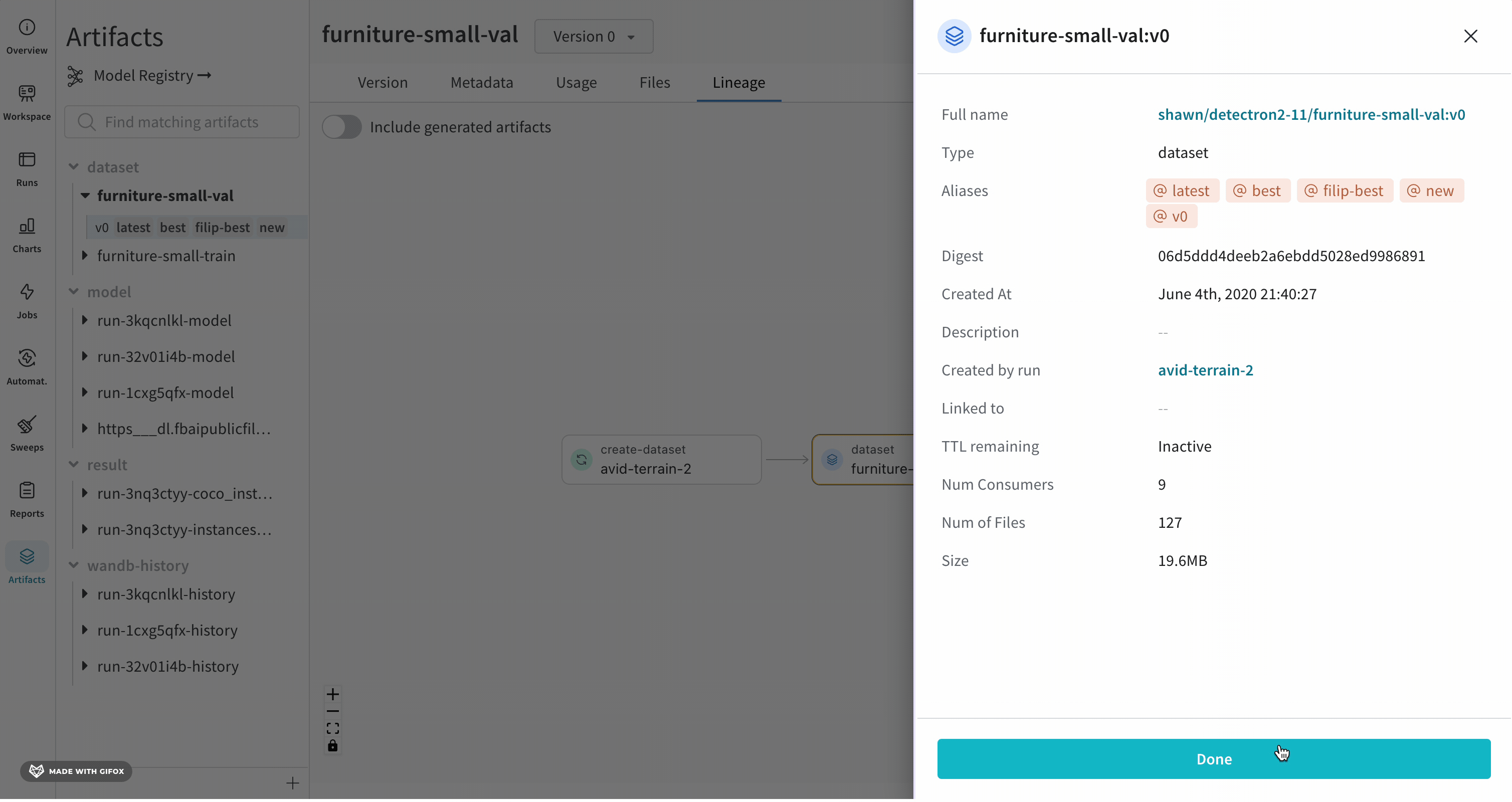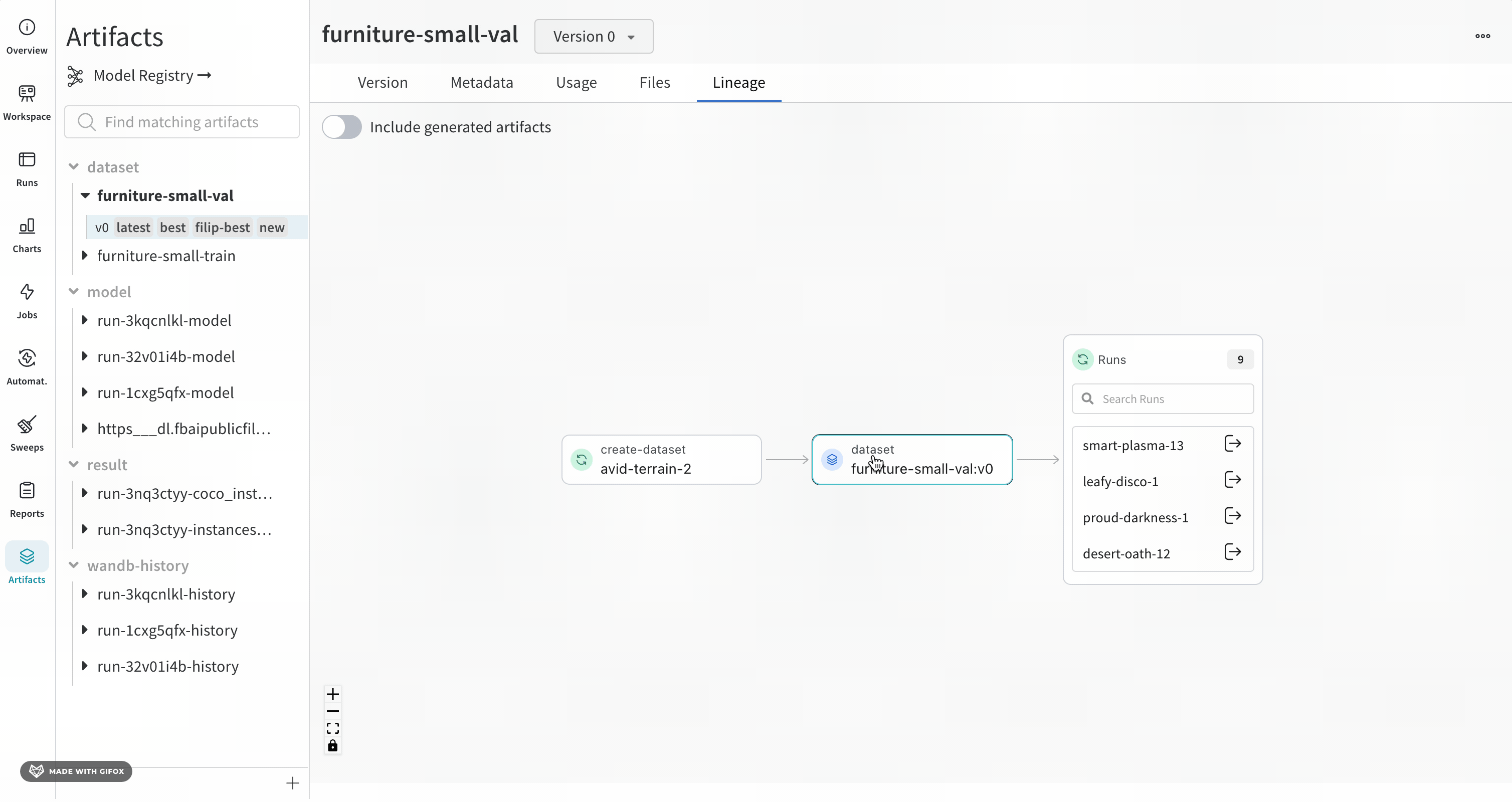
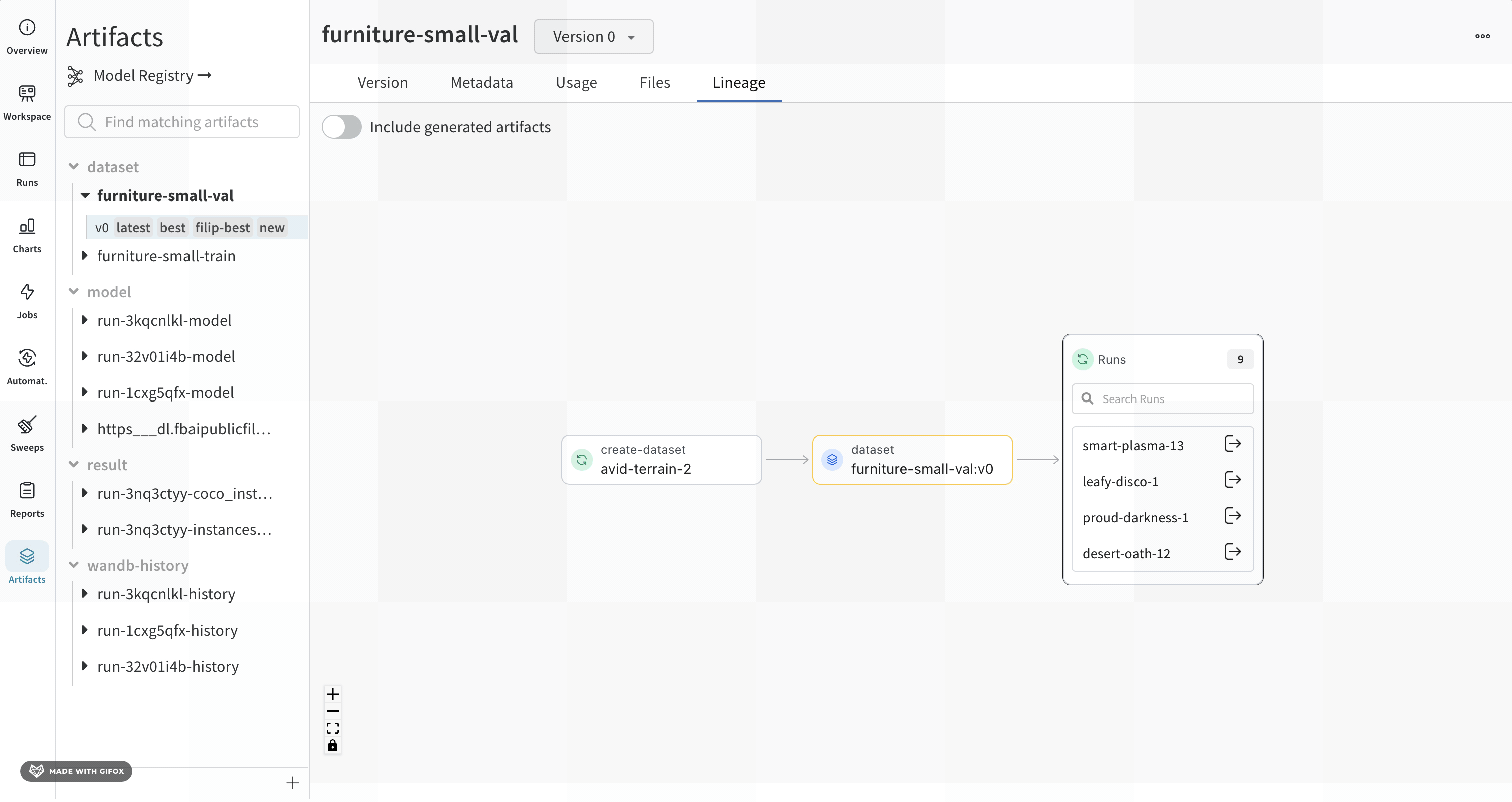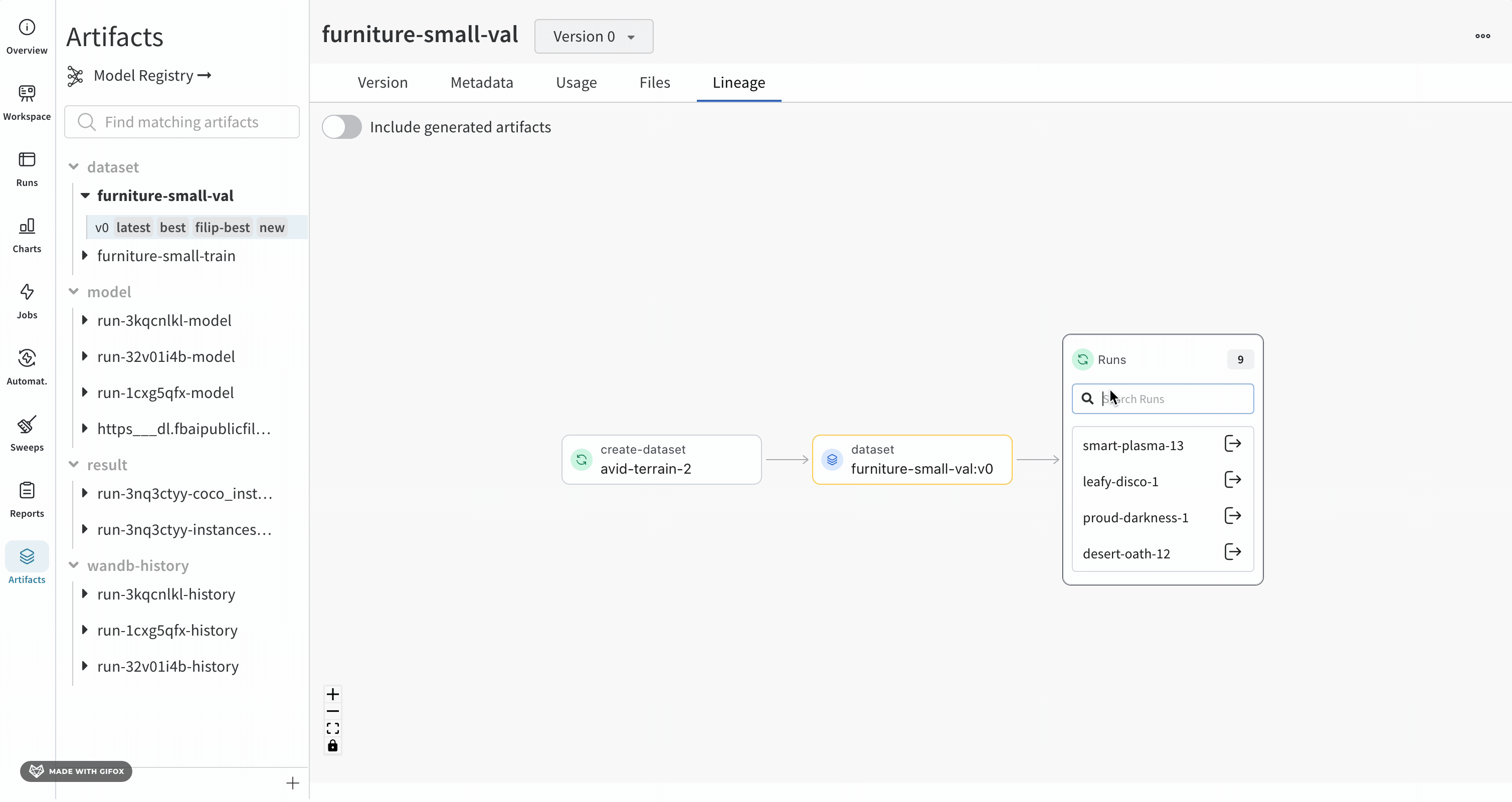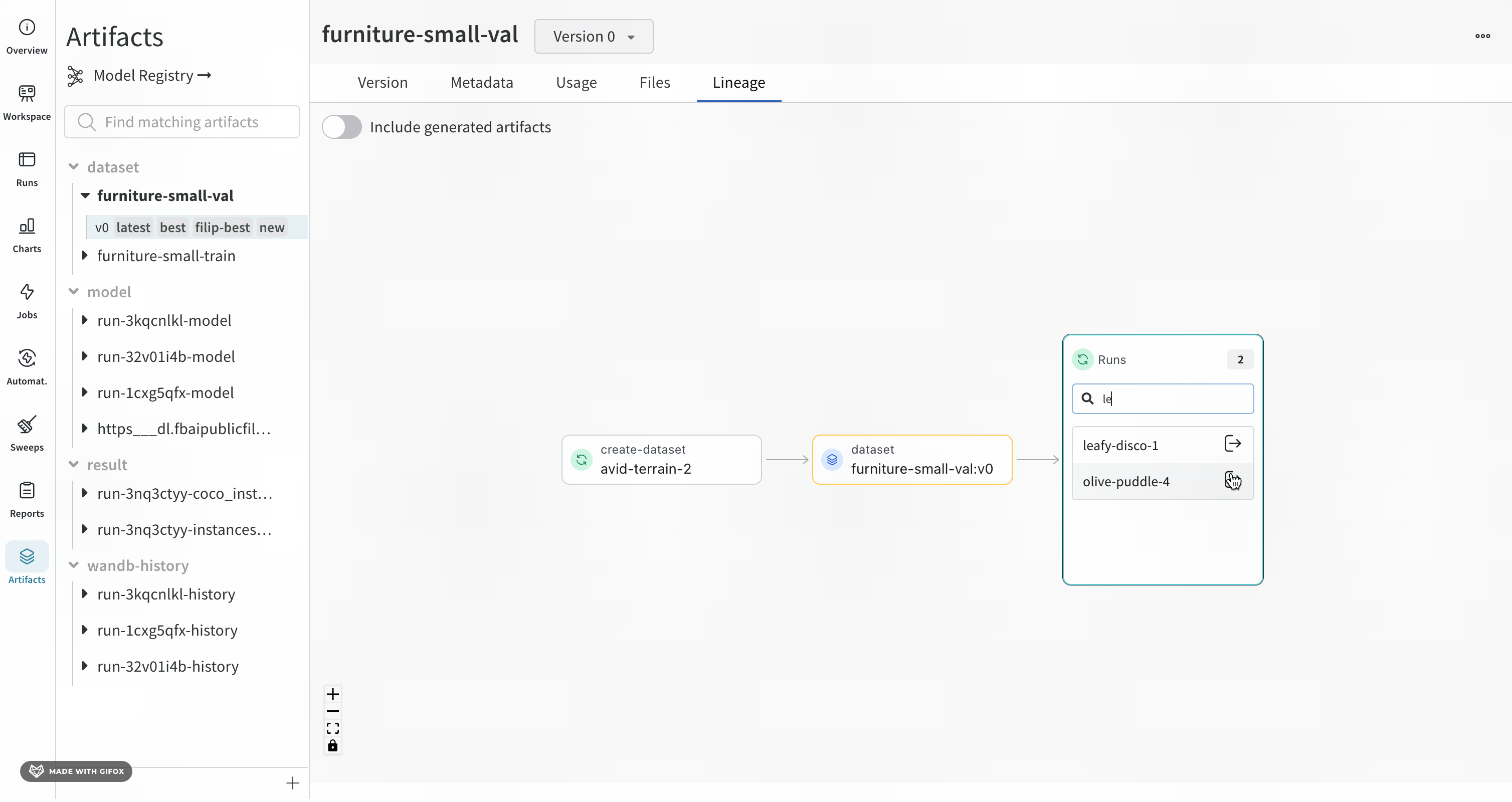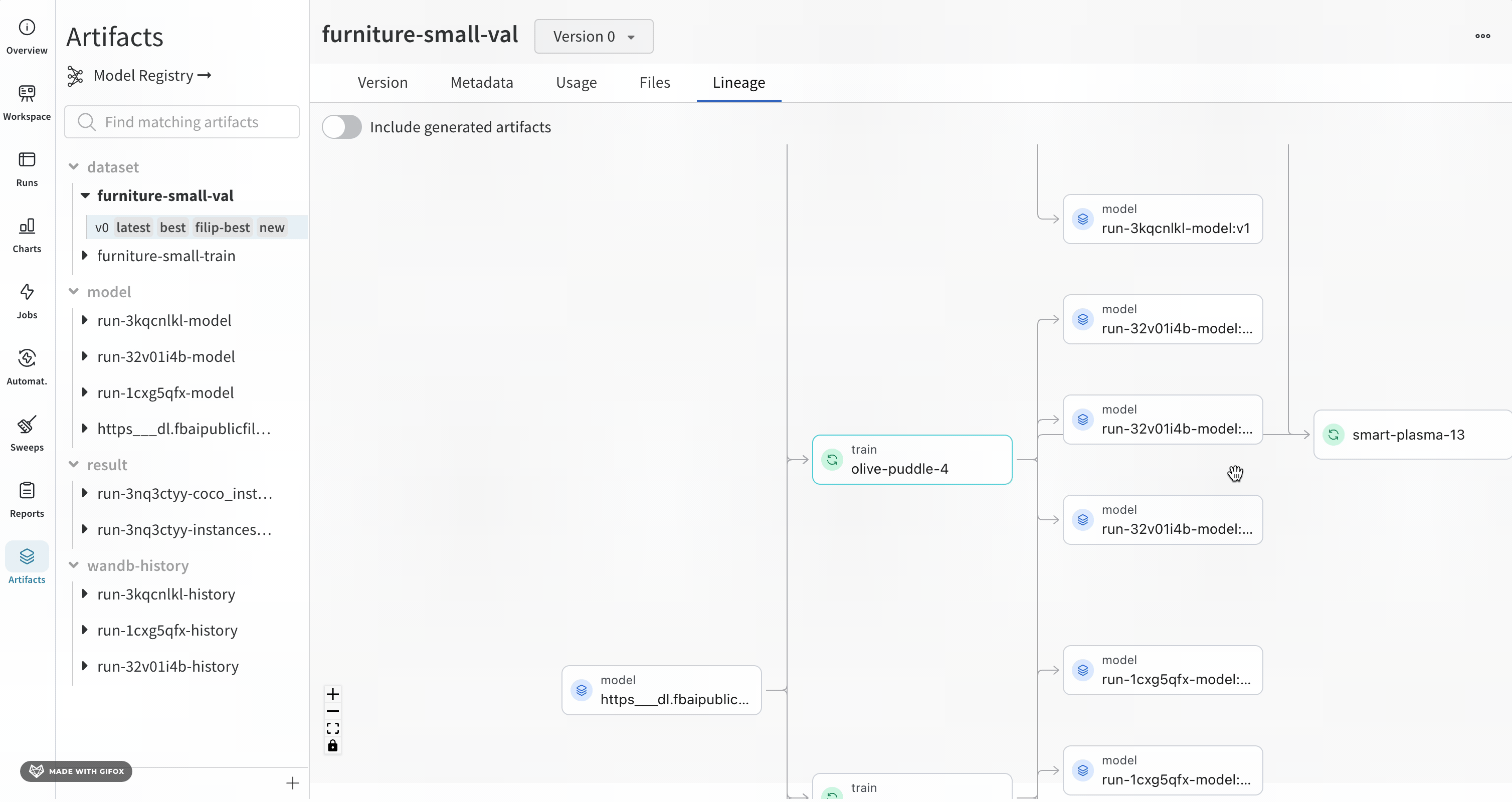
Artifacts 탭에서 Artifact를 선택하면 해당 Artifact의 계보를 볼 수 있습니다. 이 그래프 보기는 파이프라인의 일반적인 개요를 보여줍니다.
Artifact 그래프를 보려면:
W&B App UI에서 프로젝트로 이동합니다.
왼쪽 패널에서 Artifact 아이콘을 선택합니다.
Lineage를 선택합니다.
계보 그래프 탐색
제공하는 Artifact 또는 job 유형은 이름 앞에 표시되며, Artifacts는 파란색 아이콘으로, runs는 녹색 아이콘으로 표시됩니다. 화살표는 그래프에서 run 또는 Artifact의 입력 및 출력을 자세히 설명합니다.
왼쪽 사이드바와 Lineage 탭에서 Artifact의 유형과 이름을 모두 볼 수 있습니다.
더 자세한 보기를 보려면 개별 Artifact 또는 run을 클릭하여 특정 오브젝트에 대한 자세한 정보를 얻으십시오.
Artifact 클러스터
그래프 수준에 5개 이상의 runs 또는 Artifacts가 있는 경우 클러스터가 생성됩니다. 클러스터에는 특정 버전의 runs 또는 Artifacts를 찾기 위한 검색 창이 있으며 클러스터 내부의 노드 계보를 계속 조사하기 위해 클러스터에서 개별 노드를 가져옵니다.
노드를 클릭하면 노드에 대한 개요가 있는 미리보기가 열립니다. 화살표를 클릭하면 개별 run 또는 Artifact가 추출되어 추출된 노드의 계보를 검사할 수 있습니다.
Artifact를 만듭니다. 먼저 wandb.init으로 run을 만듭니다. 그런 다음 wandb.Artifact로 새 Artifact를 만들거나 기존 Artifact를 검색합니다. 다음으로 .add_file로 Artifact에 파일을 추가합니다. 마지막으로 .log_artifact로 Artifact를 run에 기록합니다. 완성된 코드는 다음과 같습니다.
with wandb.init() as run:
artifact = wandb.Artifact("artifact_name", "artifact_type")
# Add Files and Assets to the artifact using# `.add`, `.add_file`, `.add_dir`, and `.add_reference` artifact.add_file("image1.png")
run.log_artifact(artifact)
Artifact 오브젝트의 logged_by 및 used_by 메서드를 사용하여 Artifact에서 그래프를 탐색합니다.
# Walk up and down the graph from an artifact:producer_run = artifact.logged_by()
consumer_runs = artifact.used_by()
W&B 파일이 기본적으로 어디에 저장되는지 알아보세요. 민감한 정보를 저장하고 보관하는 방법을 살펴보세요.
Artifacts를 로깅할 때 파일은 W&B에서 관리하는 Google Cloud 버킷에 업로드됩니다. 버킷의 내용은 저장 시와 전송 중에 모두 암호화됩니다. 아티팩트 파일은 해당 프로젝트에 엑세스 권한이 있는 사용자에게만 표시됩니다.
아티팩트 버전을 삭제하면 데이터베이스에서 소프트 삭제로 표시되고 스토리지 비용에서 제거됩니다. 전체 아티팩트를 삭제하면 영구 삭제 대기열에 추가되고 모든 콘텐츠가 W&B 버킷에서 제거됩니다. 파일 삭제와 관련된 특정 요구 사항이 있는 경우 고객 지원에 문의하십시오.
멀티 테넌트 환경에 상주할 수 없는 중요한 데이터셋의 경우 클라우드 버킷에 연결된 프라이빗 W&B 서버 또는 _reference artifacts_를 사용할 수 있습니다. 레퍼런스 아티팩트는 파일 내용을 W&B로 보내지 않고 프라이빗 버킷에 대한 레퍼런스를 추적합니다. 레퍼런스 아티팩트는 버킷 또는 서버의 파일에 대한 링크를 유지 관리합니다. 즉, W&B는 파일 자체가 아닌 파일과 연결된 메타데이터만 추적합니다.
레퍼런스가 아닌 아티팩트를 만드는 방법과 유사하게 레퍼런스 아티팩트를 만듭니다.
import wandb
run = wandb.init()
artifact = wandb.Artifact("animals", type="dataset")
artifact.add_reference("s3://my-bucket/animals")
다음 코드 예제는 W&B 서버에 기록하고 저장한 Artifact를 사용하는 단계를 보여줍니다.
먼저 **wandb.init()**으로 새 run 오브젝트를 초기화합니다.
둘째, run 오브젝트 use_artifact() 메소드를 사용하여 사용할 Artifact를 W&B에 알립니다. 그러면 Artifact 오브젝트가 반환됩니다.
셋째, Artifact download() 메소드를 사용하여 Artifact의 내용을 다운로드합니다.
# W&B Run을 만듭니다. 여기서는 'training'을 'type'으로 지정합니다.# 이 run을 사용하여 트레이닝을 추적하기 때문입니다.run = wandb.init(project="artifacts-example", job_type="training")
# Artifact에 대해 W&B를 쿼리하고 이 run에 대한 입력으로 표시합니다.artifact = run.use_artifact("bicycle-dataset:latest")
# Artifact의 내용 다운로드artifact_dir = artifact.download()
또는 Public API (wandb.Api)를 사용하여 Run 외부의 W&B에 이미 저장된 데이터를 내보내거나 (또는 업데이트)할 수 있습니다. 자세한 내용은 외부 파일 추적을 참조하십시오.
2 - Secrets
W&B secrets에 대한 개요, 작동 방식, 사용 시작 방법에 대해 설명합니다.
W&B Secret Manager를 사용하면 엑세스 토큰, bearer 토큰, API 키 또는 비밀번호와 같은 중요한 문자열인 _secrets_를 안전하고 중앙 집중식으로 저장, 관리 및 삽입할 수 있습니다. W&B Secret Manager는 중요한 문자열을 코드에 직접 추가하거나 웹 훅의 헤더 또는 페이로드를 구성할 때 불필요하게 만듭니다.
Secrets는 각 팀의 Secret Manager의 팀 설정의 Team secrets 섹션에 저장되고 관리됩니다.
W&B 관리자만 secret을 생성, 편집 또는 삭제할 수 있습니다.
Secrets는 Azure, GCP 또는 AWS에서 호스팅하는 W&B Server 배포를 포함하여 W&B의 핵심 부분으로 포함됩니다. 다른 배포 유형을 사용하는 경우 W&B 계정 팀에 문의하여 W&B에서 secrets를 사용하는 방법에 대해 논의하십시오.
W&B Server에서는 보안 요구 사항을 충족하는 보안 조치를 구성해야 합니다.
W&B는 고급 보안 기능으로 구성된 AWS, GCP 또는 Azure에서 제공하는 클라우드 제공업체의 secrets manager의 W&B 인스턴스에 secrets를 저장하는 것이 좋습니다.
클라우드 secrets manager(AWS, GCP 또는 Azure)의 W&B 인스턴스를 사용할 수 없고 클러스터를 사용하는 경우 발생할 수 있는 보안 취약점을 방지하는 방법을 이해하지 못하는 경우 Kubernetes 클러스터를 secrets 저장소의 백엔드로 사용하지 않는 것이 좋습니다.
secret 추가
secret을 추가하려면:
수신 서비스가 들어오는 웹 훅을 인증하는 데 필요한 경우 필요한 토큰 또는 API 키를 생성합니다. 필요한 경우 비밀번호 관리자와 같이 중요한 문자열을 안전하게 저장합니다.
W&B에 로그인하여 팀의 Settings 페이지로 이동합니다.
Team Secrets 섹션에서 New secret을 클릭합니다.
문자, 숫자 및 밑줄(_)을 사용하여 secret의 이름을 지정합니다.
중요한 문자열을 Secret 필드에 붙여넣습니다.
Add secret을 클릭합니다.
웹 훅을 구성할 때 웹 훅 자동화에 사용할 secrets를 지정합니다. 자세한 내용은 웹 훅 구성 섹션을 참조하십시오.
secret을 생성하면 ${SECRET_NAME} 형식을 사용하여 웹 훅 자동화의 페이로드에서 해당 secret에 엑세스할 수 있습니다.
secret 교체
secret을 교체하고 값을 업데이트하려면:
secret의 행에서 연필 아이콘을 클릭하여 secret의 세부 정보를 엽니다.
Secret을 새 값으로 설정합니다. 선택적으로 Reveal secret을 클릭하여 새 값을 확인합니다.
Add secret을 클릭합니다. secret의 값이 업데이트되고 더 이상 이전 값으로 확인되지 않습니다.
secret을 생성하거나 업데이트한 후에는 더 이상 현재 값을 표시할 수 없습니다. 대신 secret을 새 값으로 교체합니다.
secret 삭제
secret을 삭제하려면:
secret의 행에서 휴지통 아이콘을 클릭합니다.
확인 대화 상자를 읽은 다음 Delete를 클릭합니다. secret이 즉시 영구적으로 삭제됩니다.
secrets에 대한 엑세스 관리
팀의 자동화는 팀의 secrets를 사용할 수 있습니다. secret을 제거하기 전에 secret을 사용하는 자동화가 작동을 멈추지 않도록 업데이트하거나 제거하십시오.
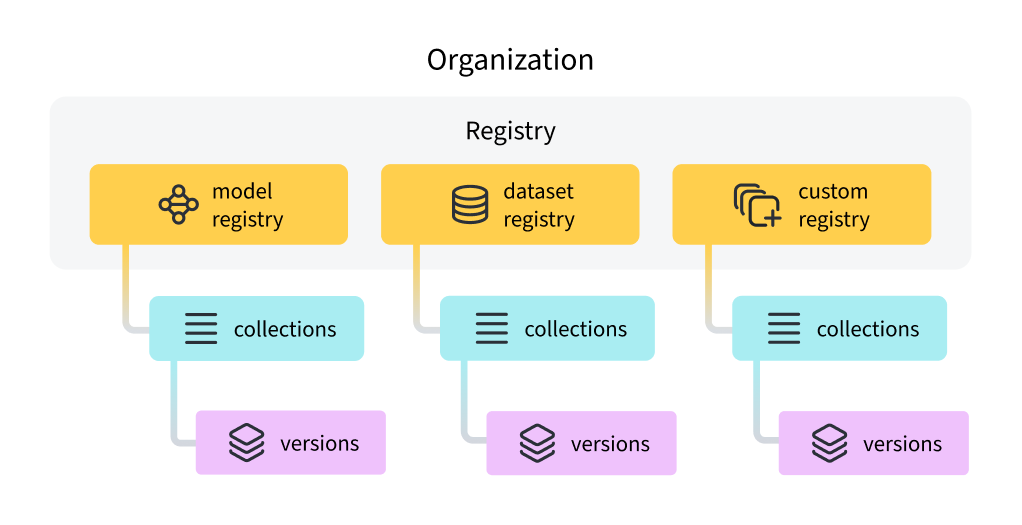
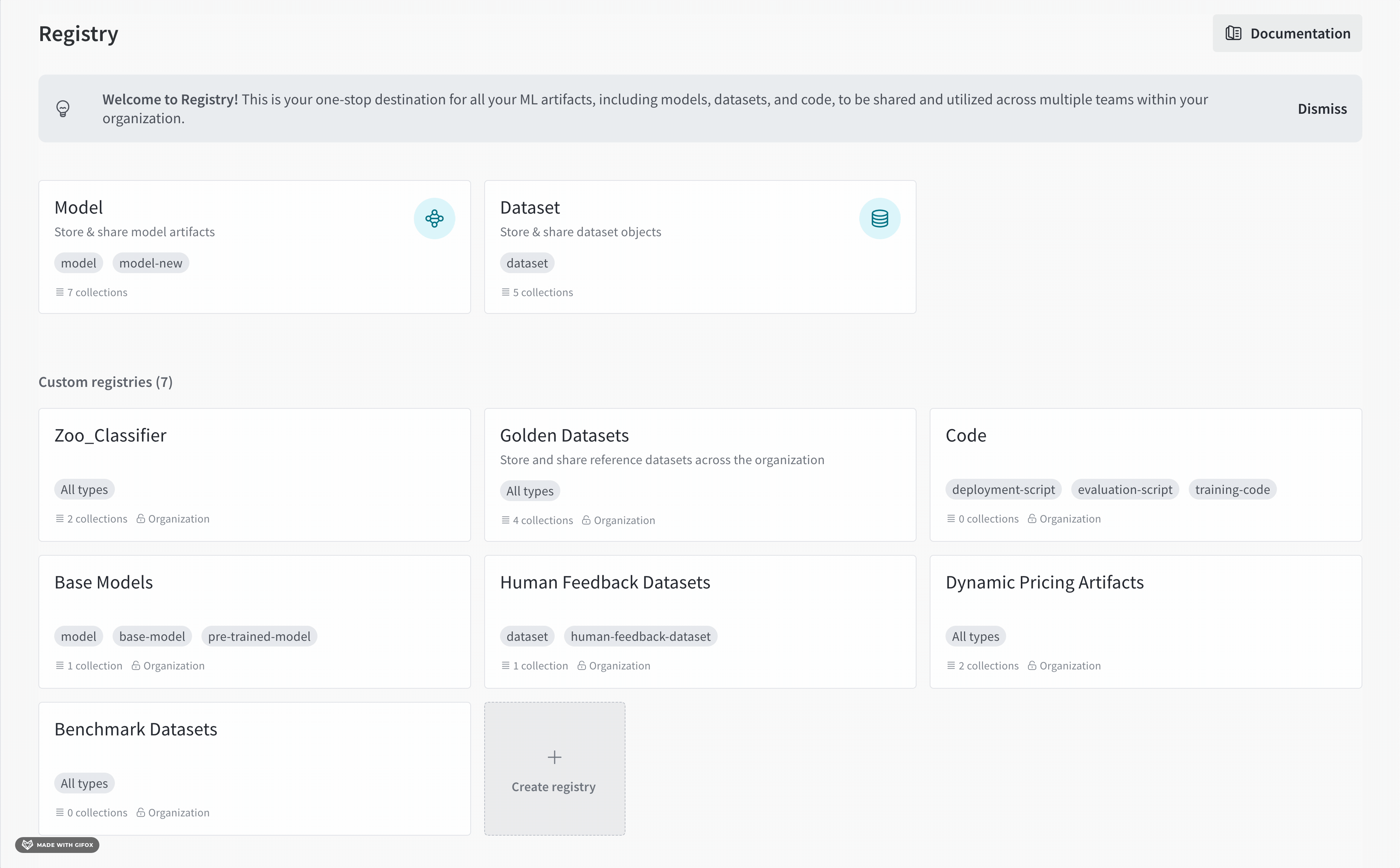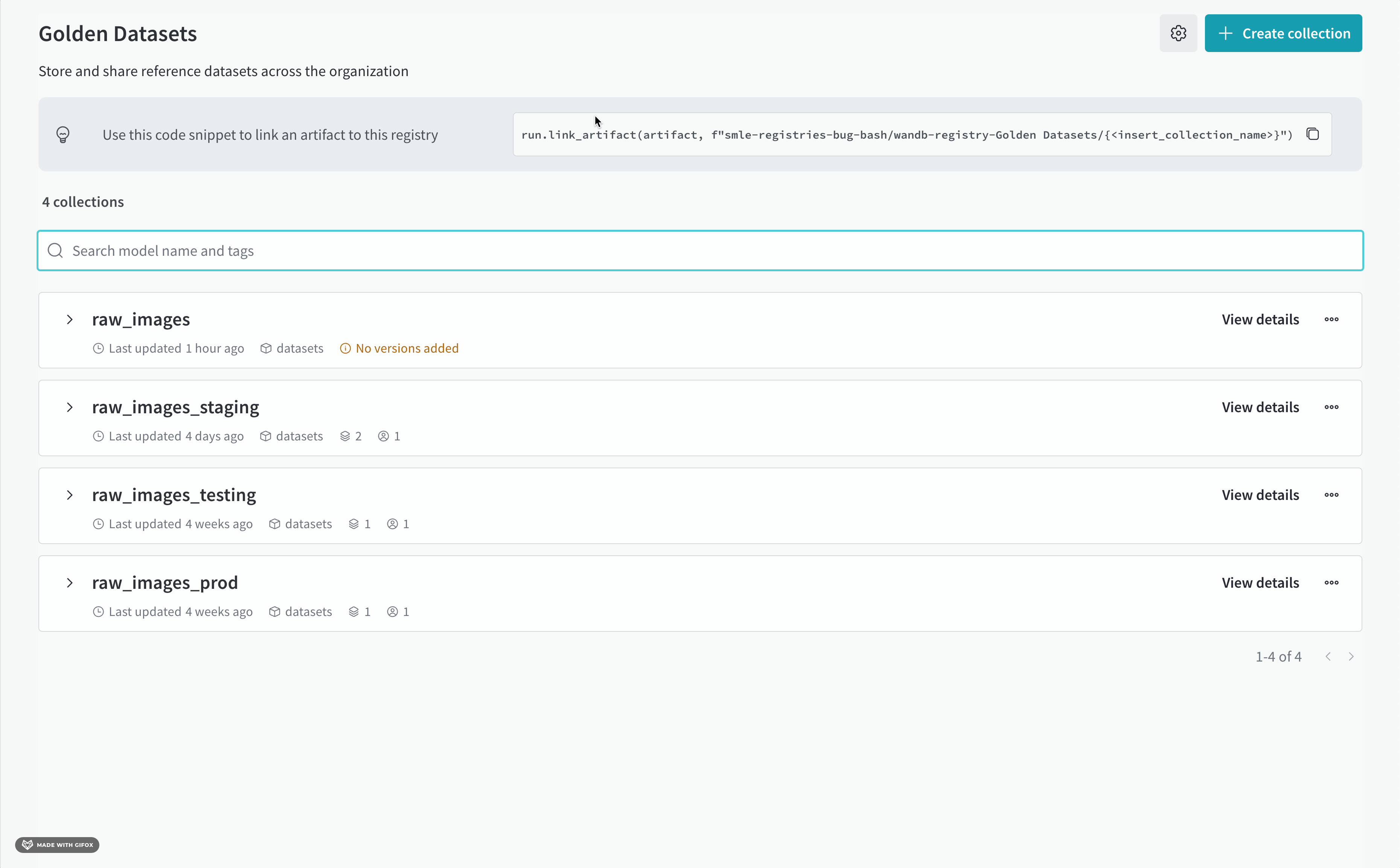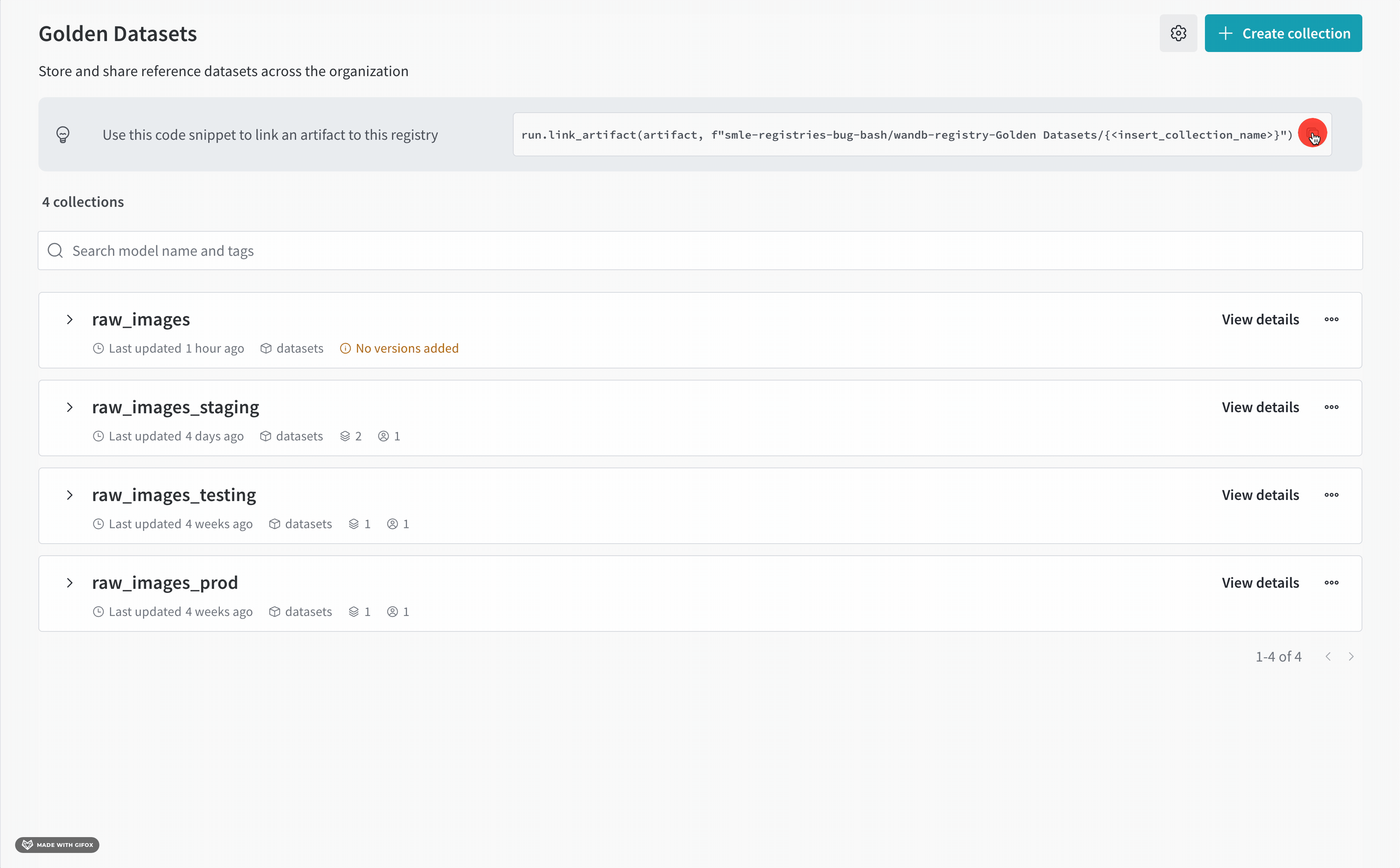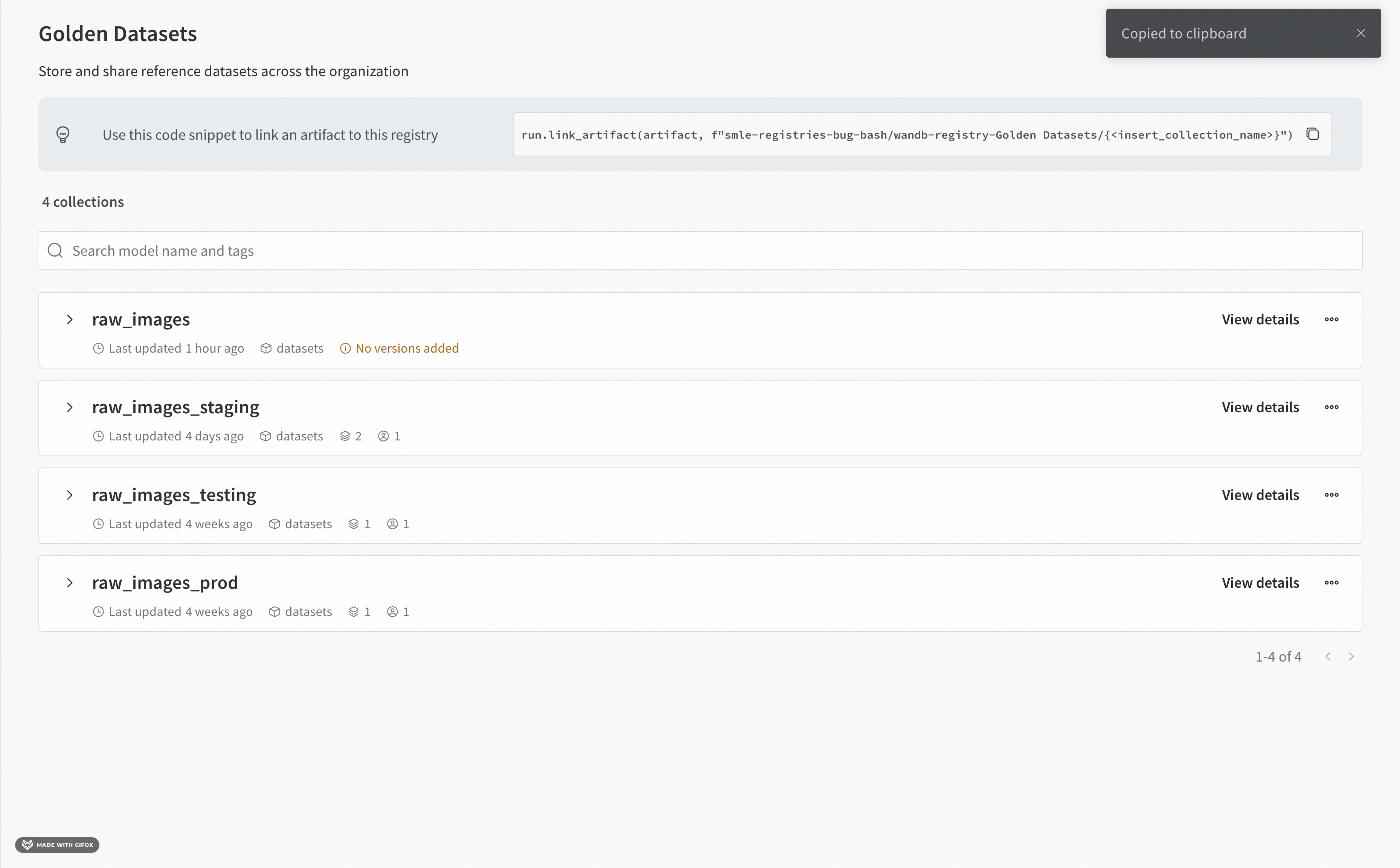
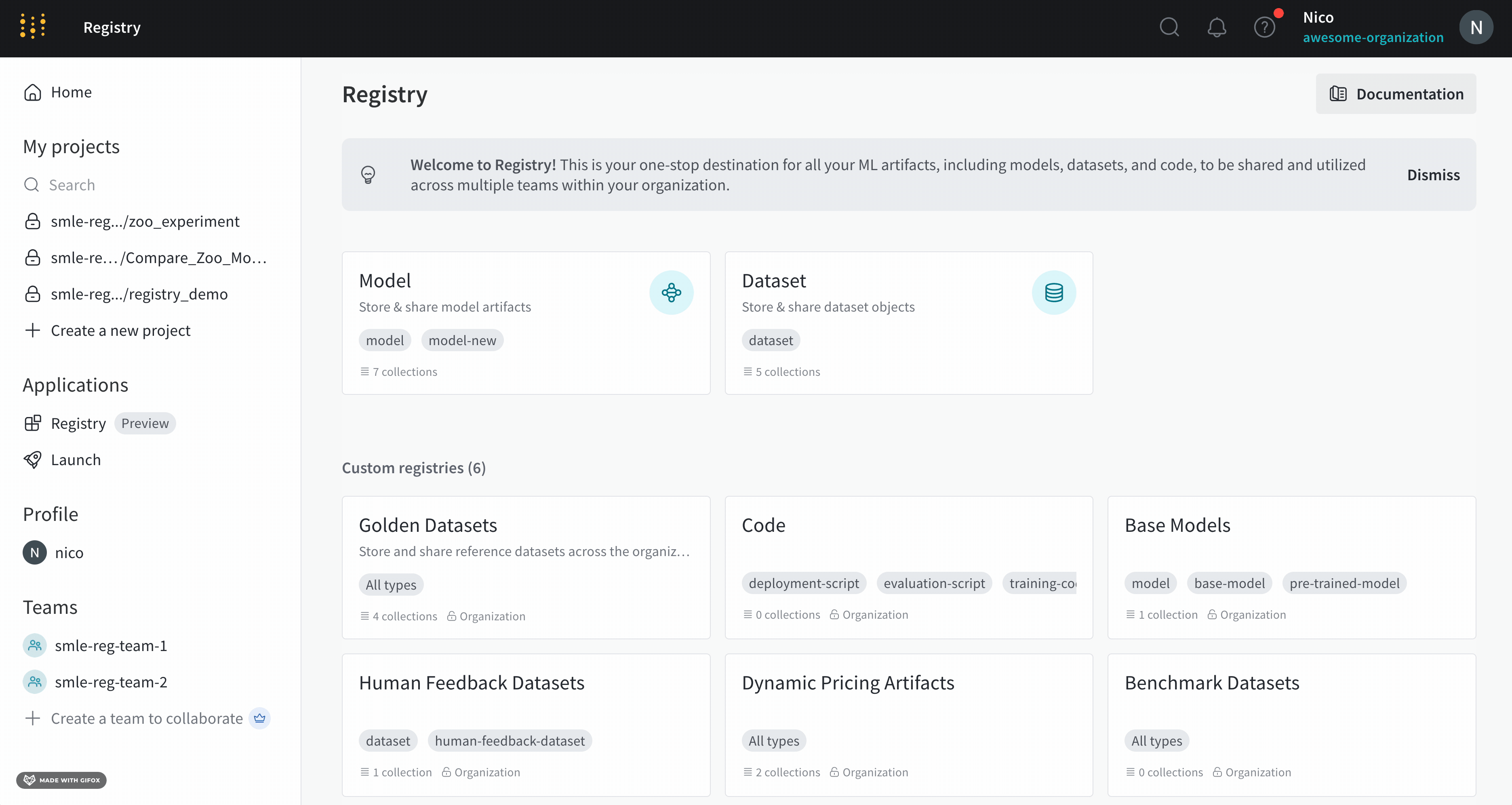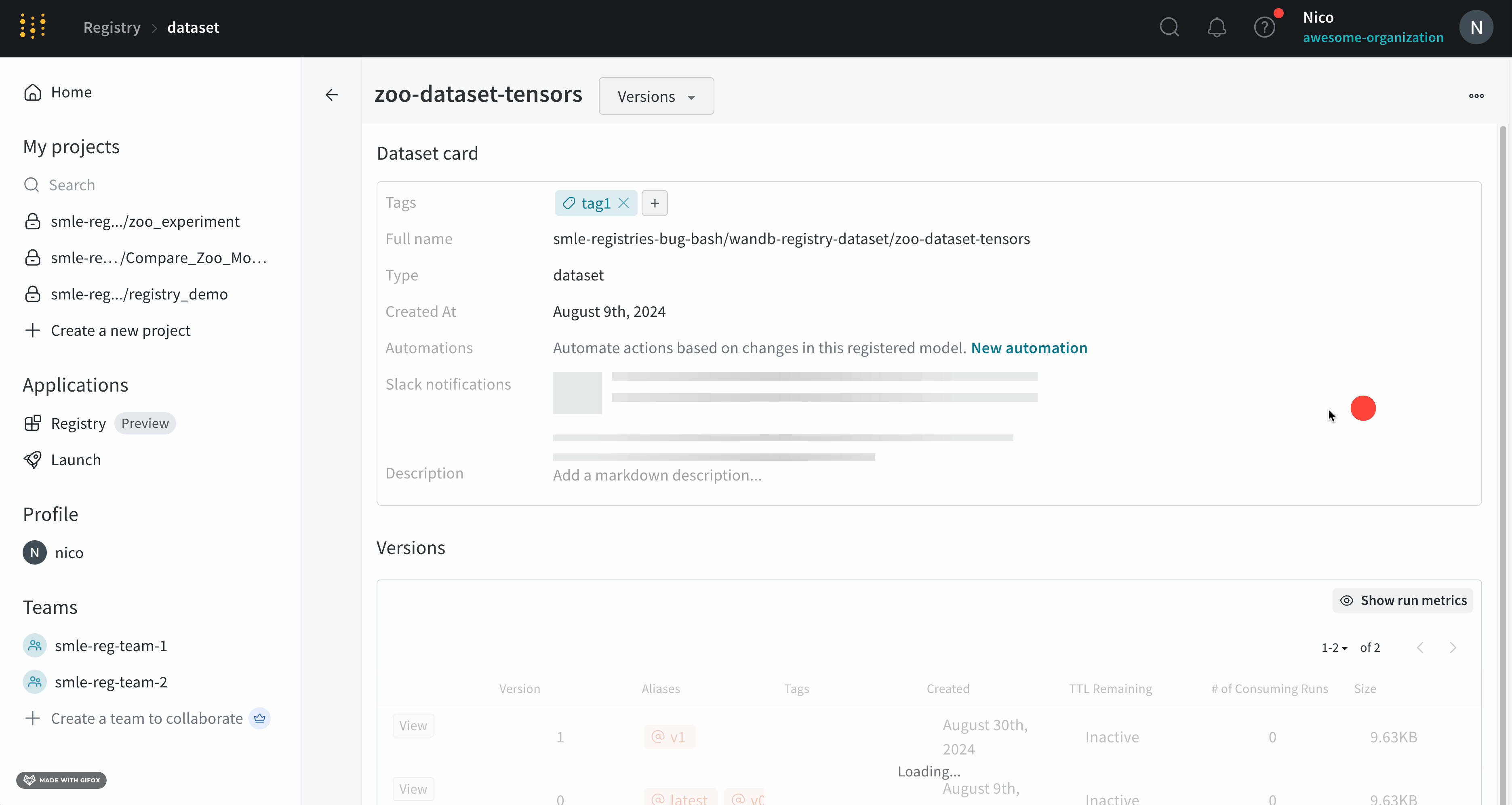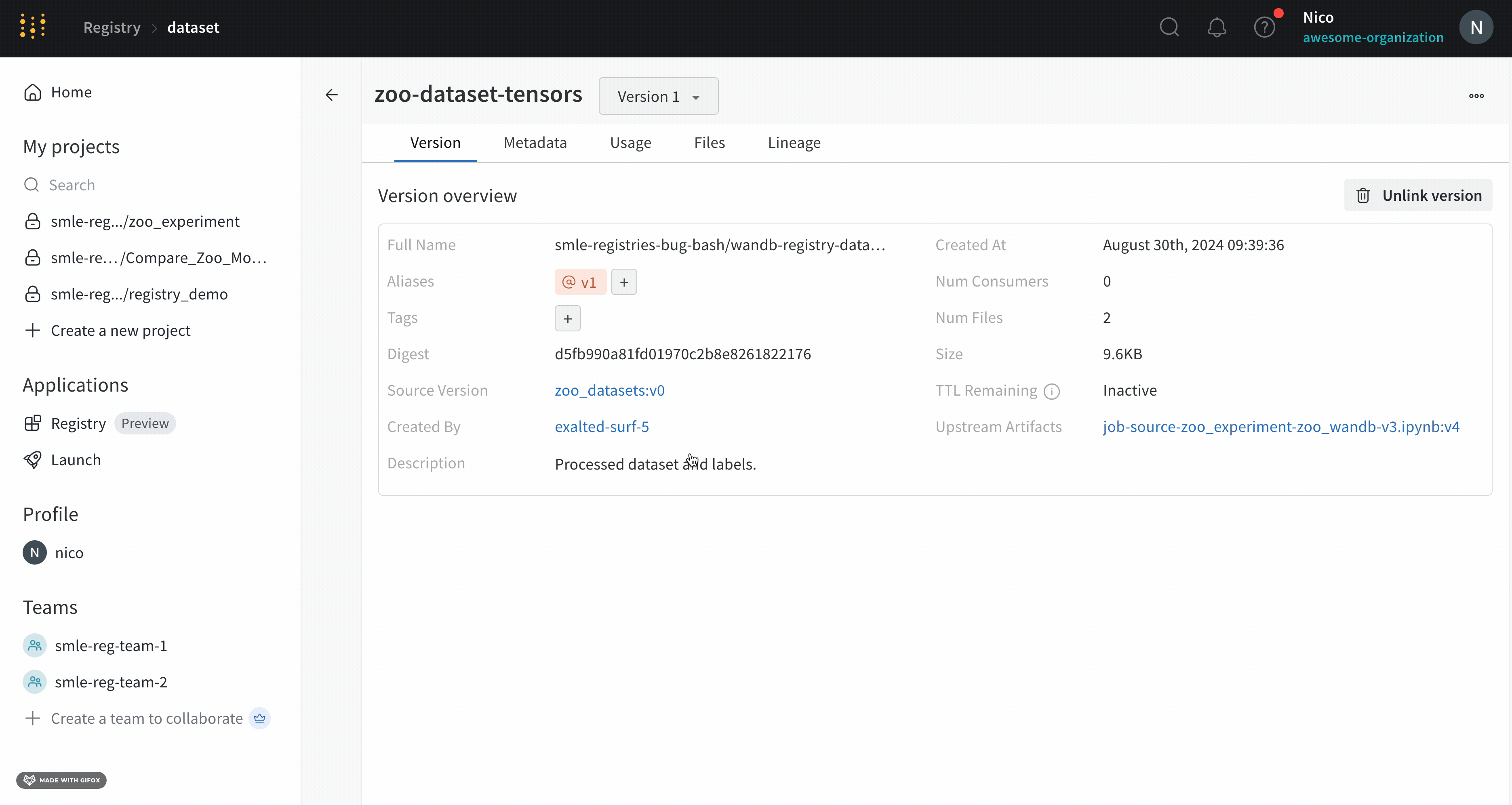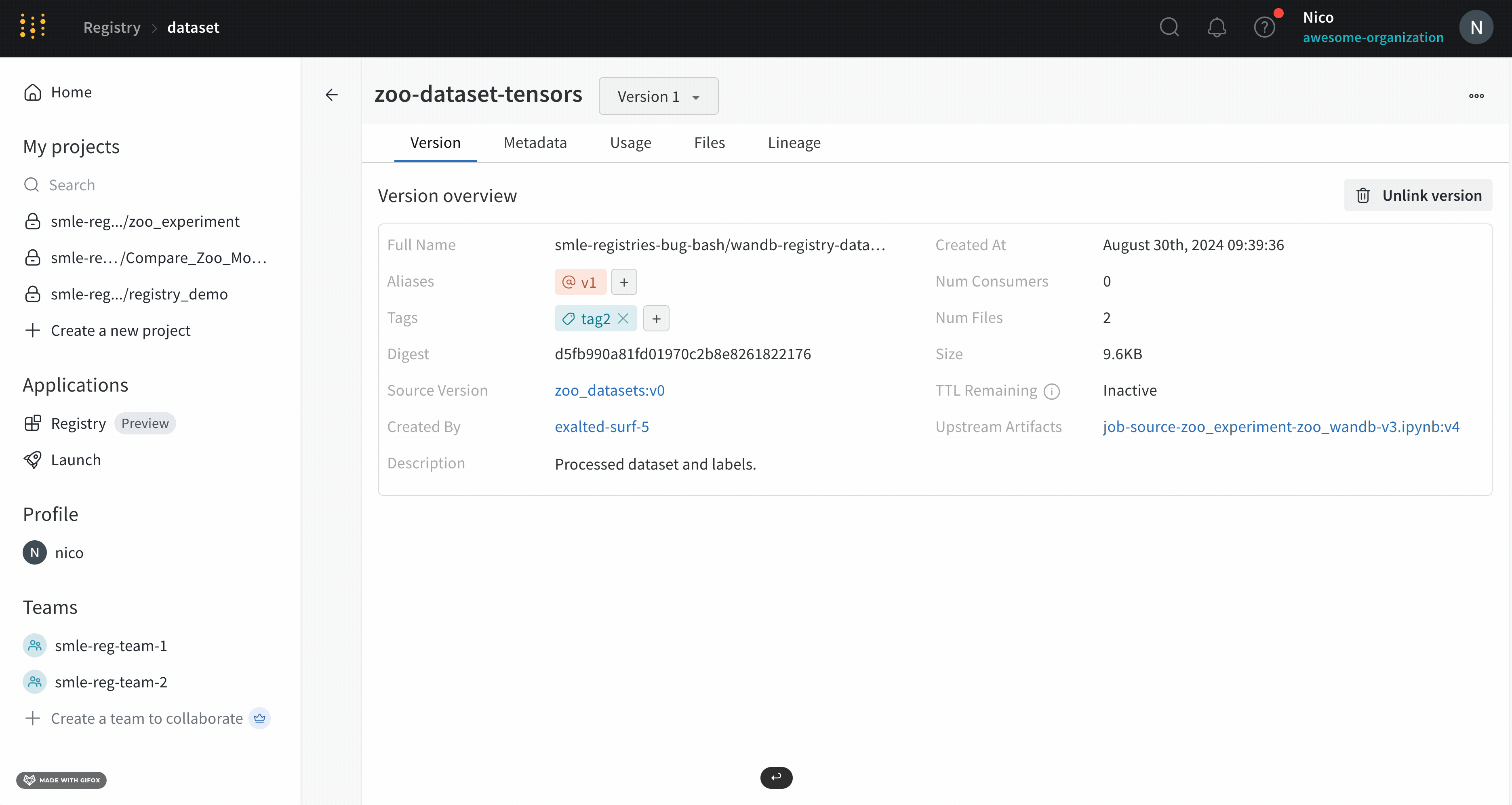
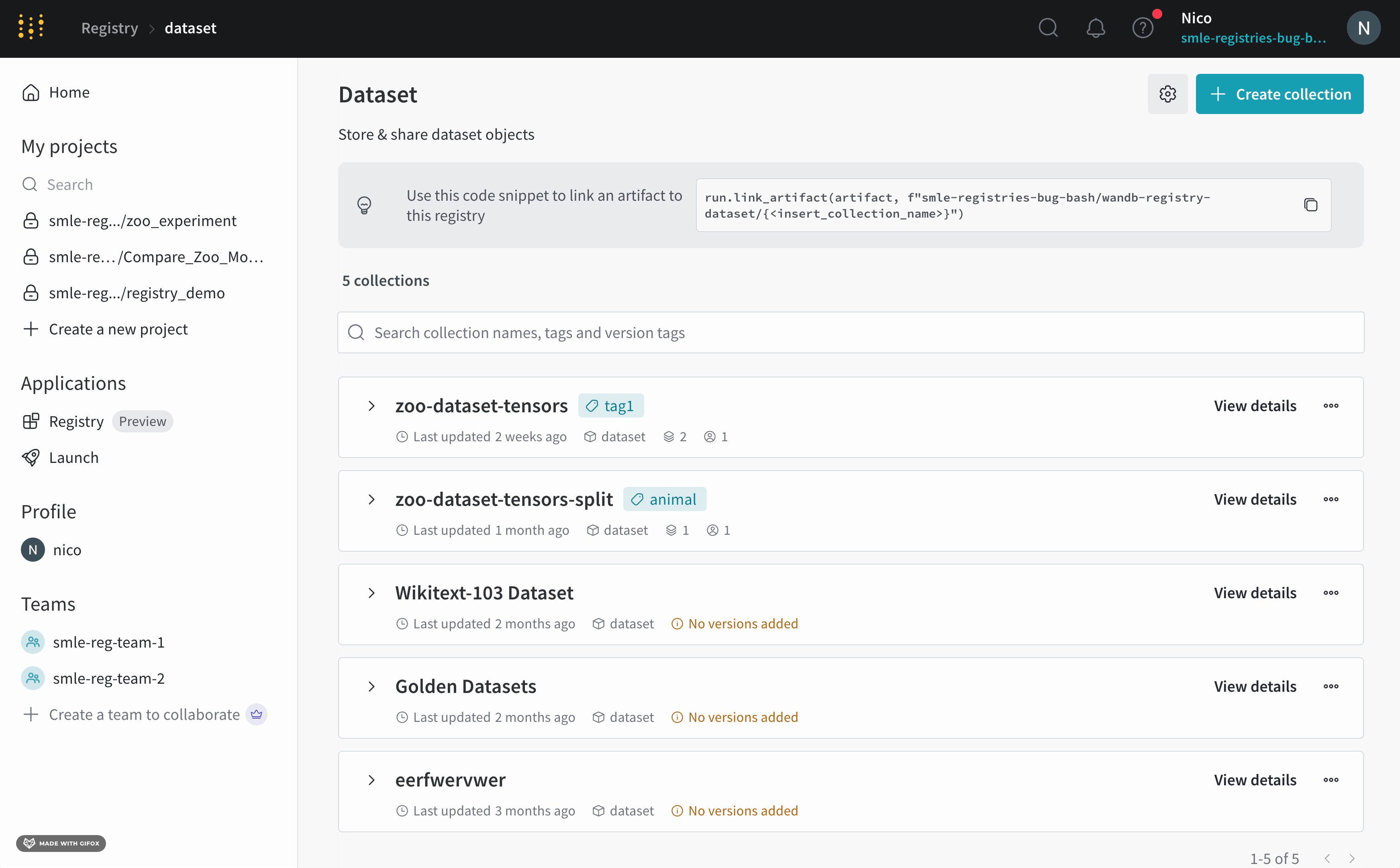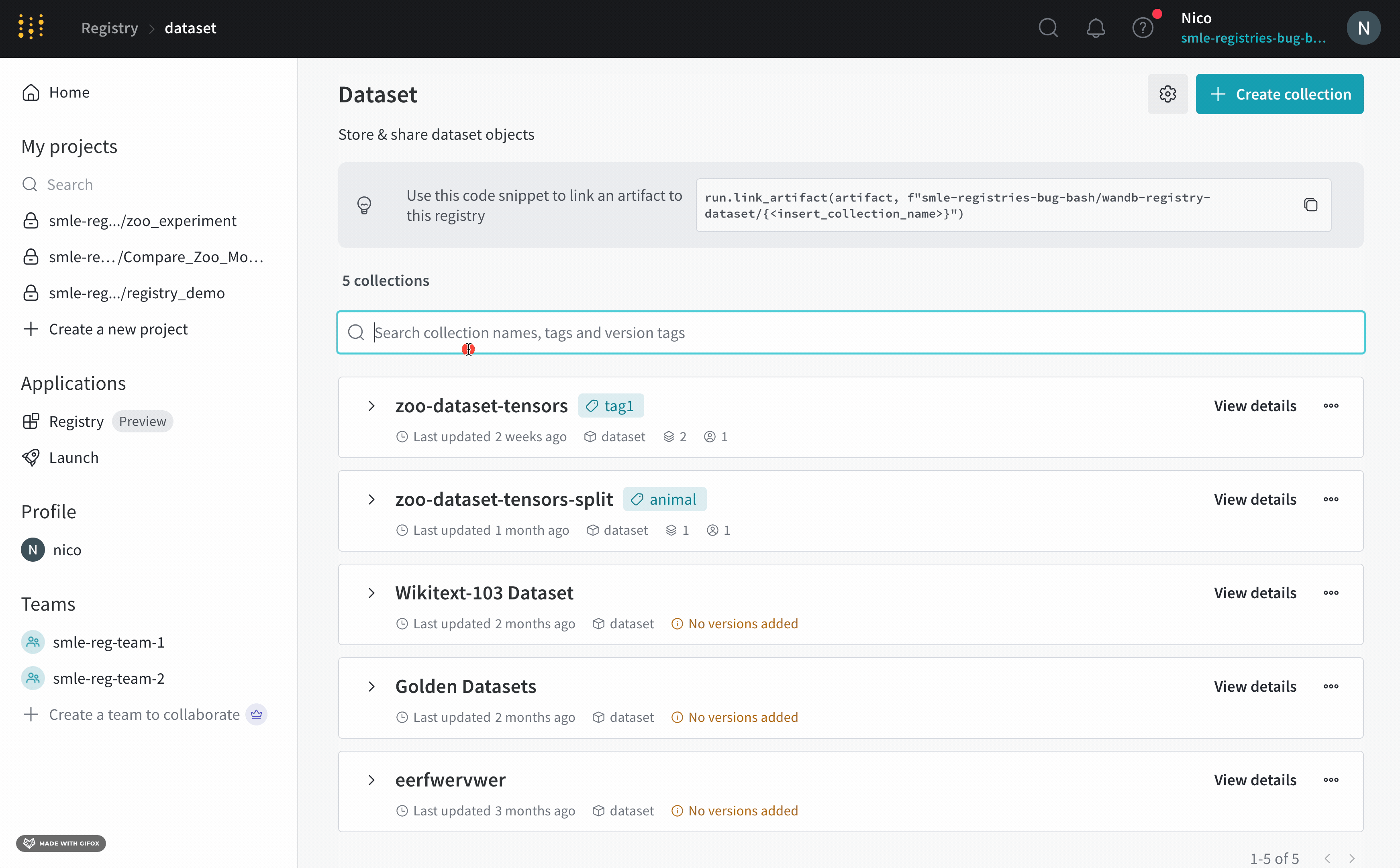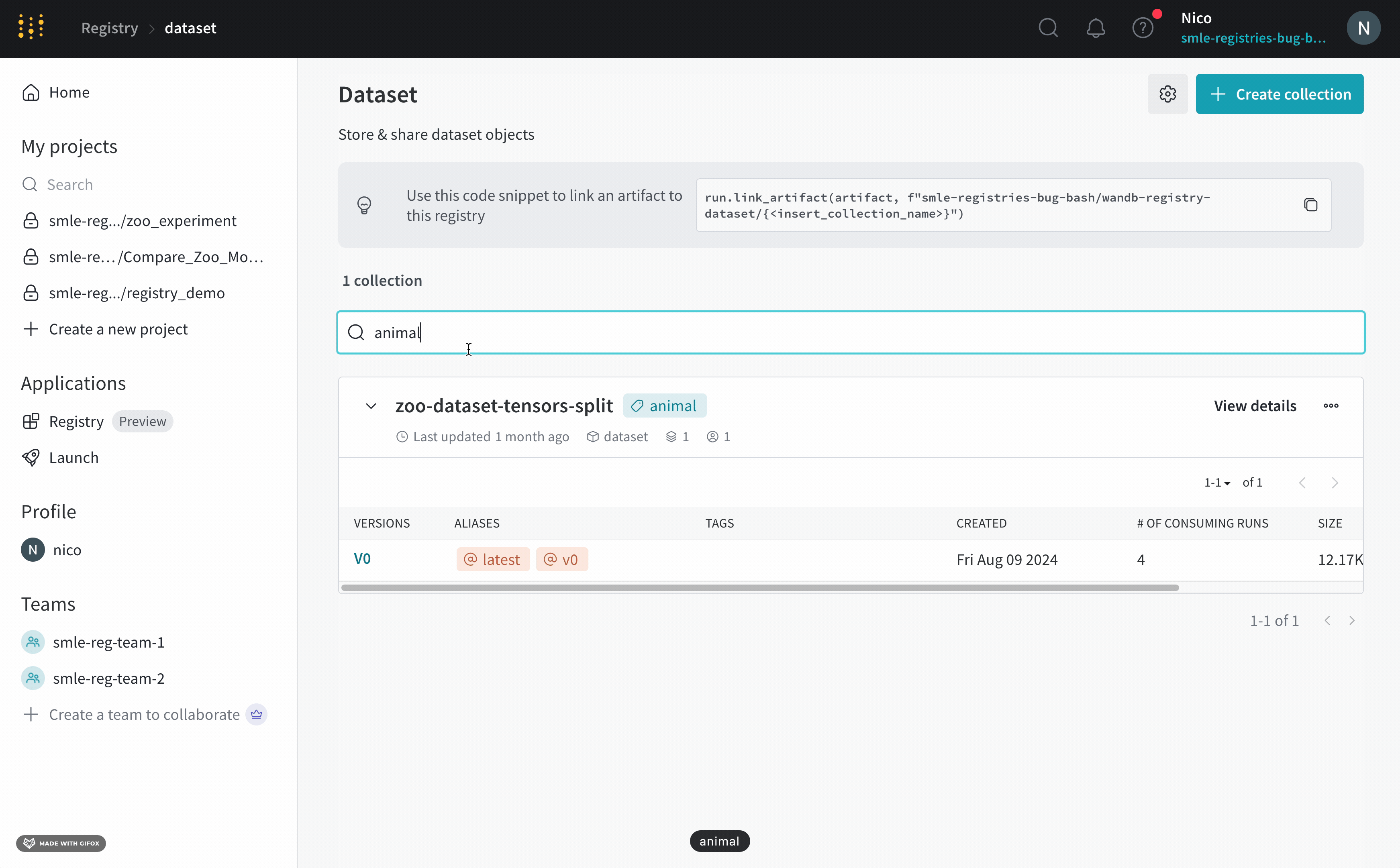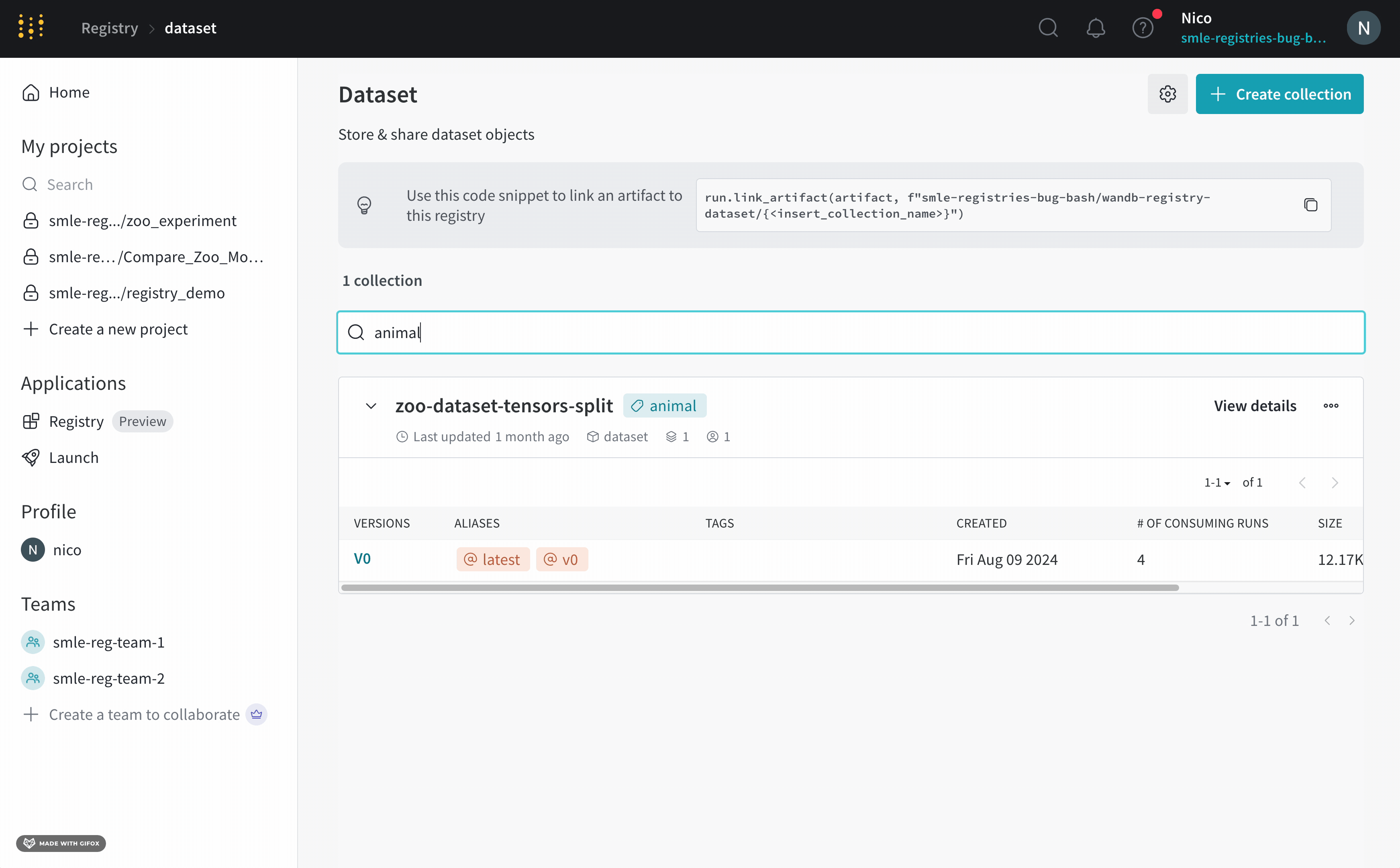
각 registry는 하나 이상의 컬렉션으로 구성됩니다. 각 컬렉션은 고유한 작업 또는 유스 케이스를 나타냅니다.
artifact를 registry에 추가하려면 먼저 특정 artifact 버전을 W&B에 기록합니다. artifact를 기록할 때마다 W&B는 해당 artifact에 버전을 자동으로 할당합니다. artifact 버전은 0부터 인덱싱되므로 첫 번째 버전은 v0, 두 번째 버전은 v1과 같습니다.
artifact를 W&B에 기록한 후에는 해당 특정 artifact 버전을 registry의 컬렉션에 연결할 수 있습니다.
“링크"라는 용어는 W&B가 artifact를 저장하는 위치와 registry에서 artifact에 엑세스할 수 있는 위치를 연결하는 포인터를 나타냅니다. W&B는 artifact를 컬렉션에 연결할 때 artifact를 복제하지 않습니다.
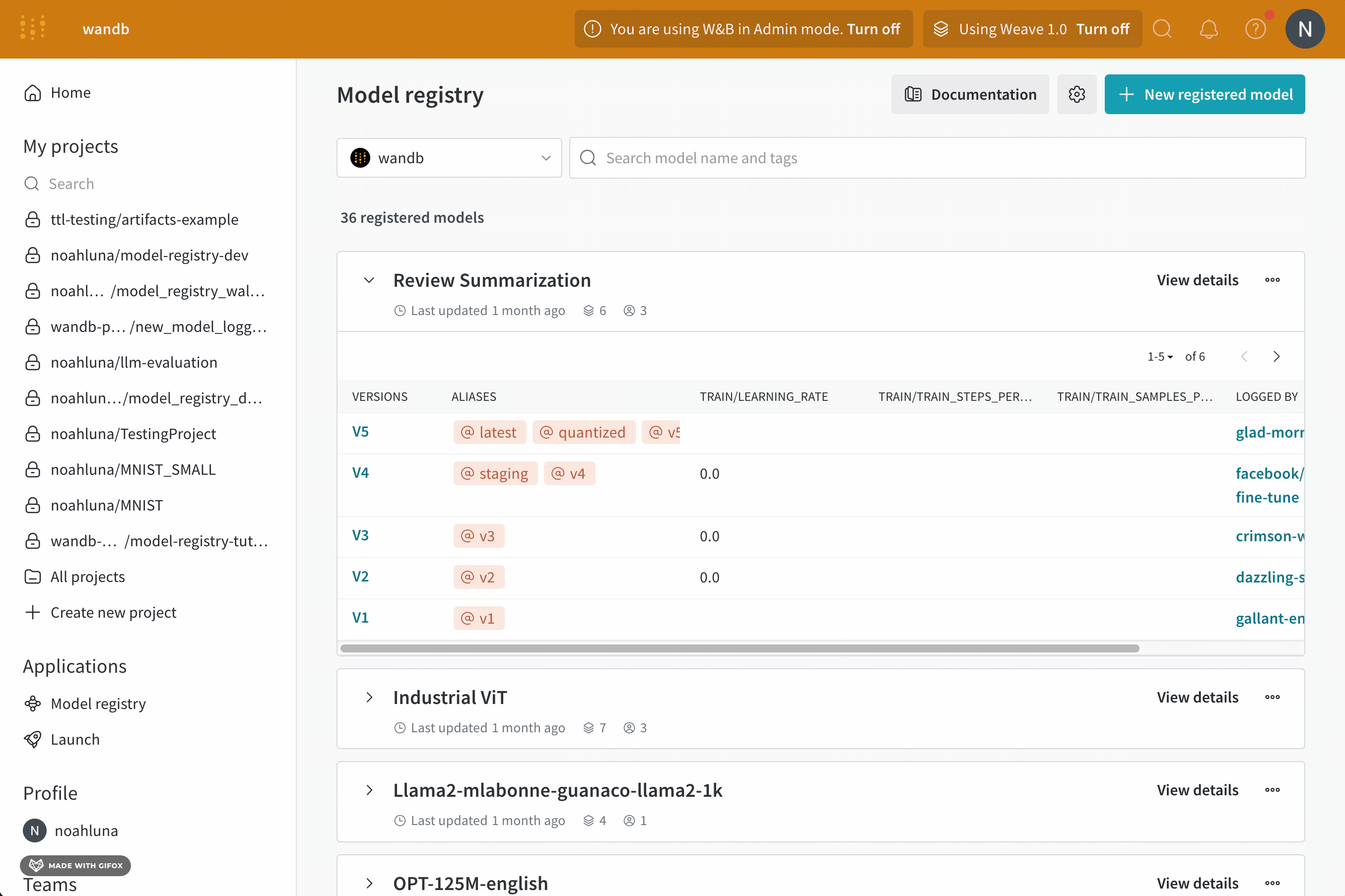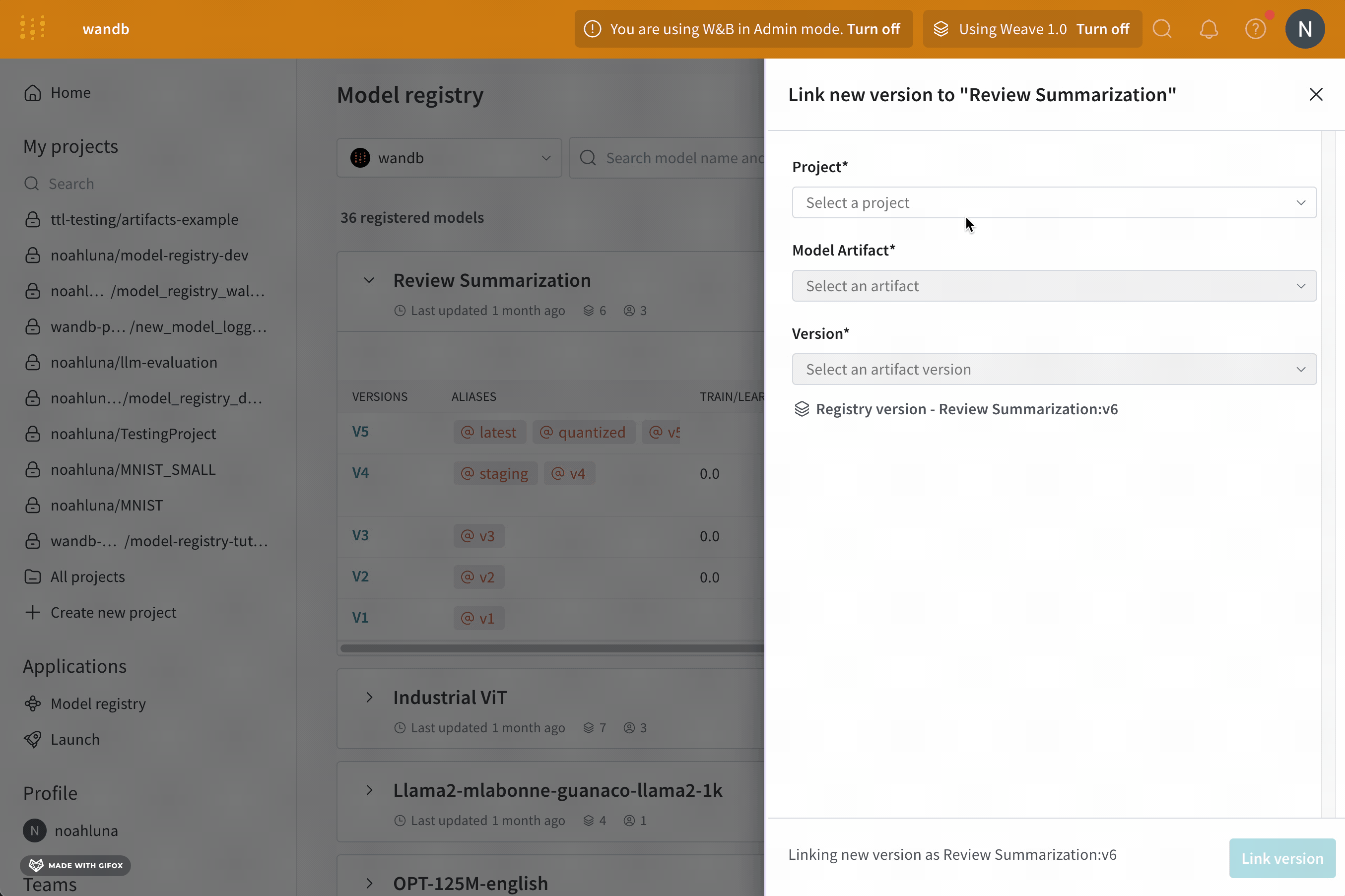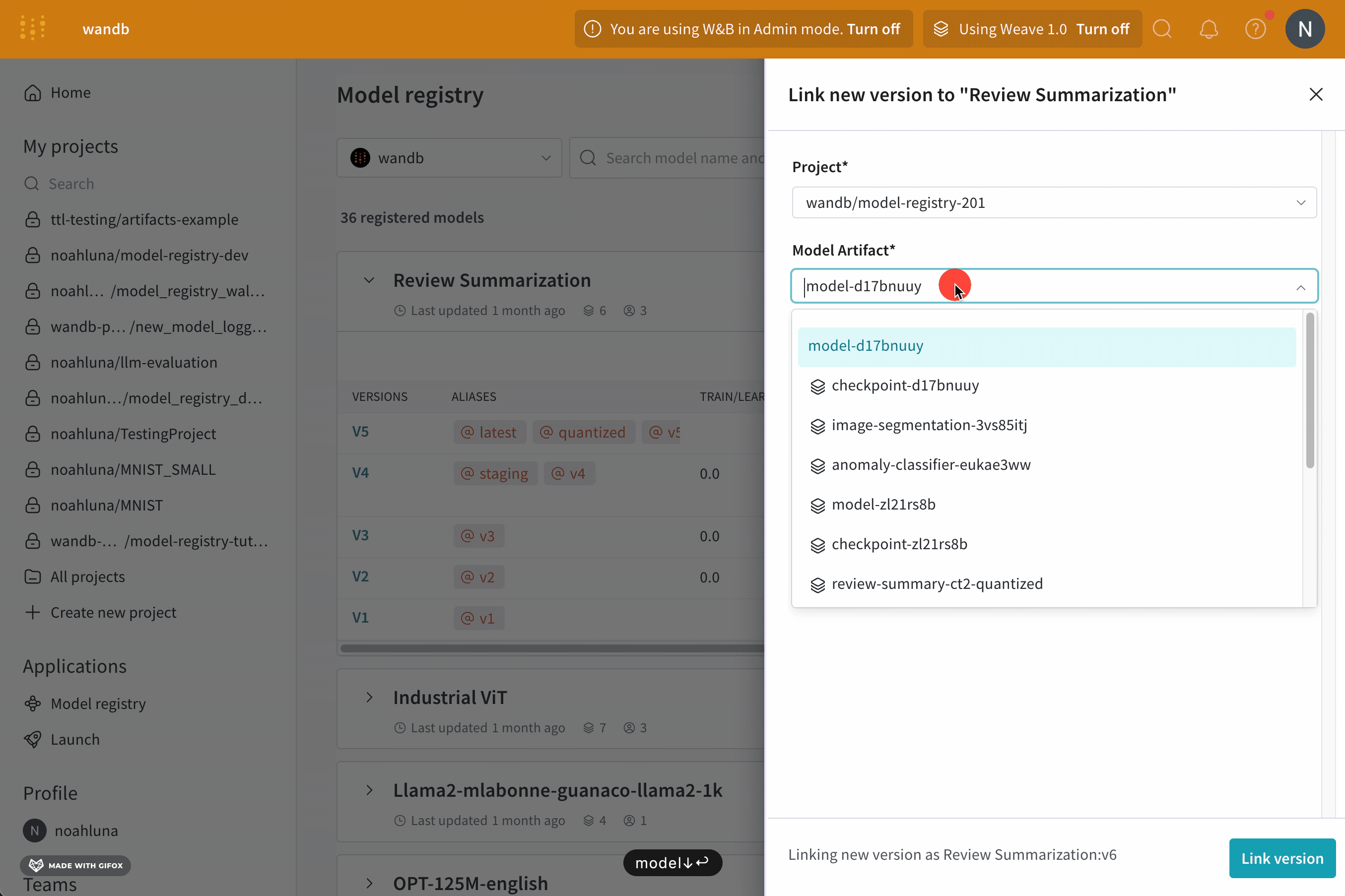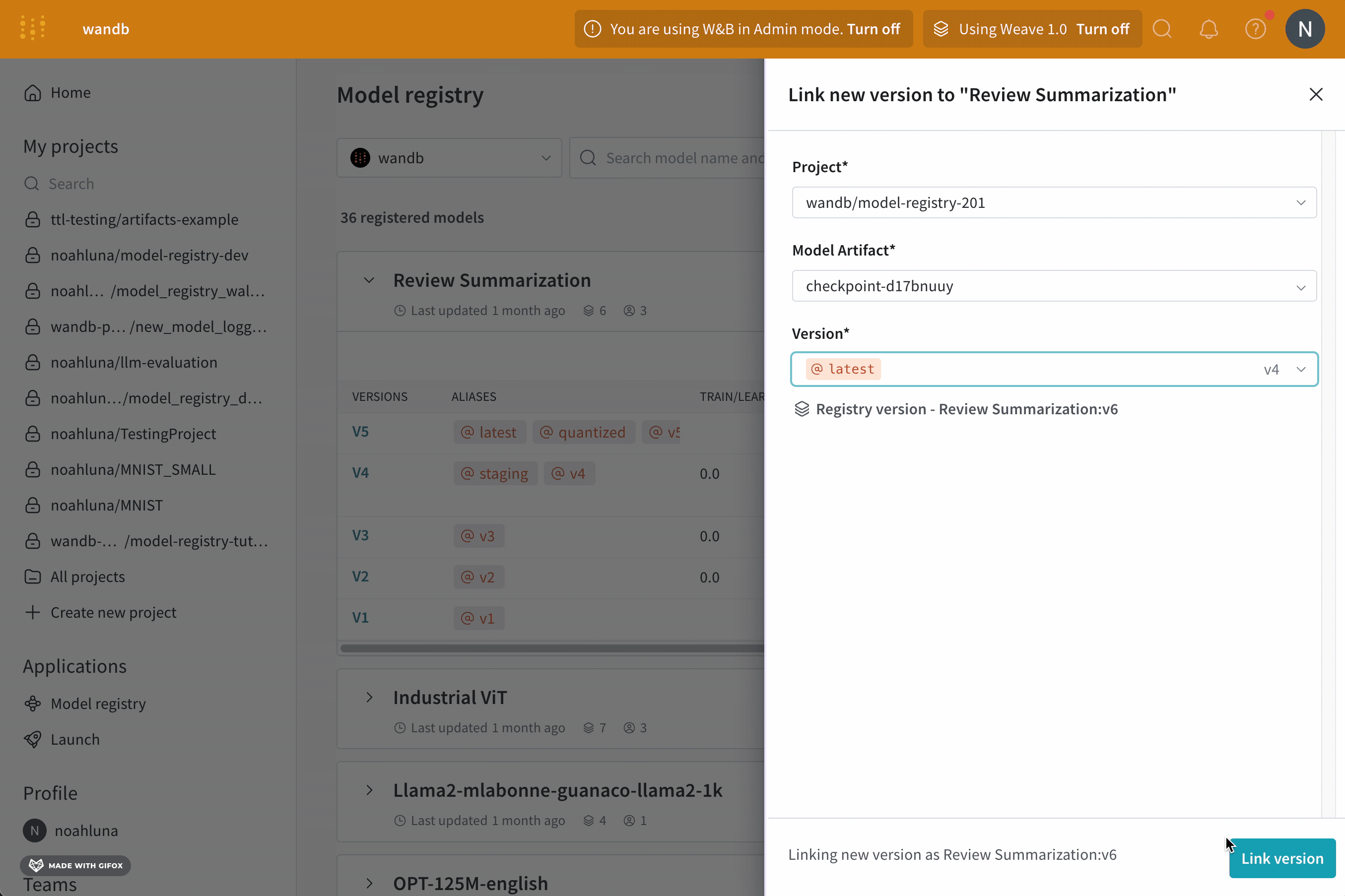
예를 들어, 다음 코드 예제는 “my_model.txt"라는 모델 artifact를 코어 registry의 “first-collection"이라는 컬렉션에 기록하고 연결하는 방법을 보여줍니다.
W&B run을 초기화합니다.
artifact를 W&B에 기록합니다.
artifact 버전을 연결할 컬렉션 및 registry의 이름을 지정합니다.
artifact를 컬렉션에 연결합니다.
이 Python 코드를 스크립트에 저장하고 실행합니다. W&B Python SDK 버전 0.18.6 이상이 필요합니다.
import wandb
import random
# track the artifact를 추적하기 위해 W&B run을 초기화합니다.run = wandb.init(project="registry_quickstart")
# 기록할 수 있도록 시뮬레이션된 모델 파일을 만듭니다.with open("my_model.txt", "w") as f:
f.write("Model: "+ str(random.random()))
# artifact를 W&B에 기록합니다.logged_artifact = run.log_artifact(
artifact_or_path="./my_model.txt",
name="gemma-finetuned",
type="model"# artifact 유형을 지정합니다.)
# artifact를 게시할 컬렉션 및 registry 이름을 지정합니다.COLLECTION_NAME ="first-collection"REGISTRY_NAME ="model"# artifact를 registry에 연결합니다.run.link_artifact(
artifact=logged_artifact,
target_path=f"wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}")
반환된 run 오브젝트의 link_artifact(target_path = "") 메소드에서 지정한 컬렉션이 지정한 registry 내에 없는 경우 W&B는 자동으로 컬렉션을 만듭니다.
터미널에 출력되는 URL은 W&B가 artifact를 저장하는 프로젝트로 연결됩니다.
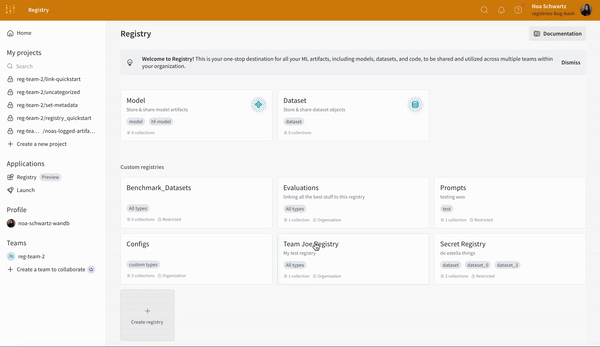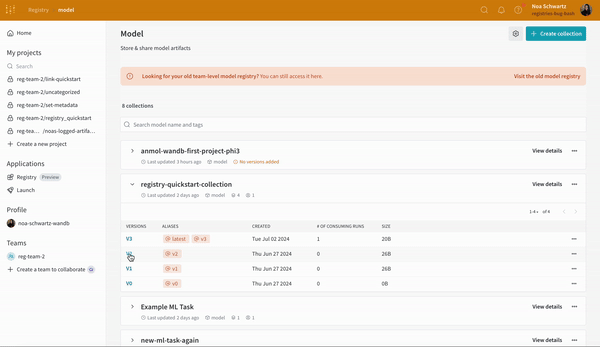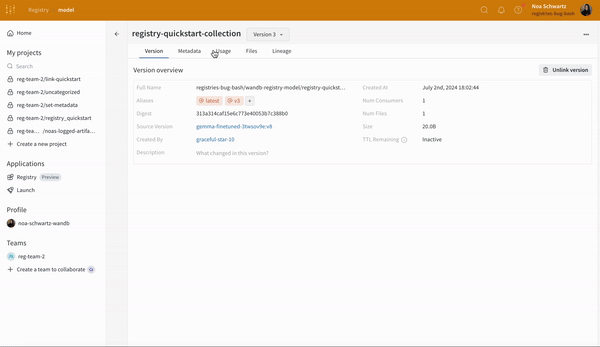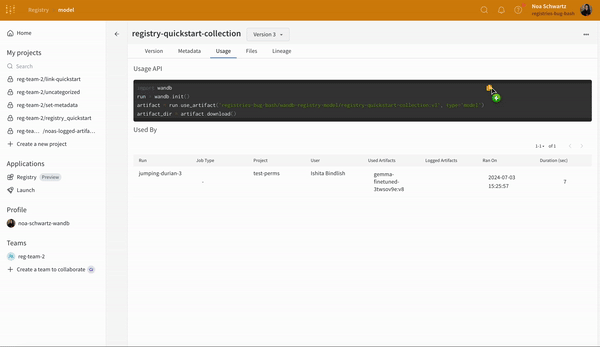
Registry App으로 이동하여 사용자와 조직의 다른 구성원이 게시하는 artifact 버전을 봅니다. 이렇게 하려면 먼저 W&B로 이동합니다. 애플리케이션 아래 왼쪽 사이드바에서 Registry를 선택합니다. “Model” registry를 선택합니다. registry 내에서 연결된 artifact 버전이 있는 “first-collection” 컬렉션을 볼 수 있습니다.
artifact 버전을 registry 내의 컬렉션에 연결하면 조직 구성원은 적절한 권한이 있는 경우 artifact 버전을 보고, 다운로드하고, 관리하고, 다운스트림 자동화를 만들 수 있습니다.
artifact 버전이 (run.log_artifact()를 사용하여) 메트릭을 기록하는 경우 해당 버전의 세부 정보 페이지에서 해당 버전에 대한 메트릭을 볼 수 있으며 컬렉션 페이지에서 artifact 버전 간에 메트릭을 비교할 수 있습니다. registry에서 연결된 artifact 보기를 참조하십시오.
W&B Registry 활성화
배포 유형에 따라 다음 조건을 충족하여 W&B Registry를 활성화합니다.
배포 유형
활성화 방법
Multi-tenant Cloud
별도의 조치가 필요하지 않습니다. W&B Registry는 W&B App에서 사용할 수 있습니다.
Dedicated Cloud
계정 팀에 문의하십시오. SA(Solutions Architect) 팀은 인스턴스의 운영자 콘솔 내에서 W&B Registry를 활성화합니다. 인스턴스가 서버 릴리스 버전 0.59.2 이상인지 확인합니다.
Self-Managed
ENABLE_REGISTRY_UI라는 환경 변수를 활성화합니다. 서버에서 환경 변수를 활성화하는 방법에 대한 자세한 내용은 이 문서를 참조하십시오. 자체 관리형 인스턴스에서는 인프라 관리자가 이 환경 변수를 활성화하고 true로 설정해야 합니다. 인스턴스가 서버 릴리스 버전 0.59.2 이상인지 확인합니다.
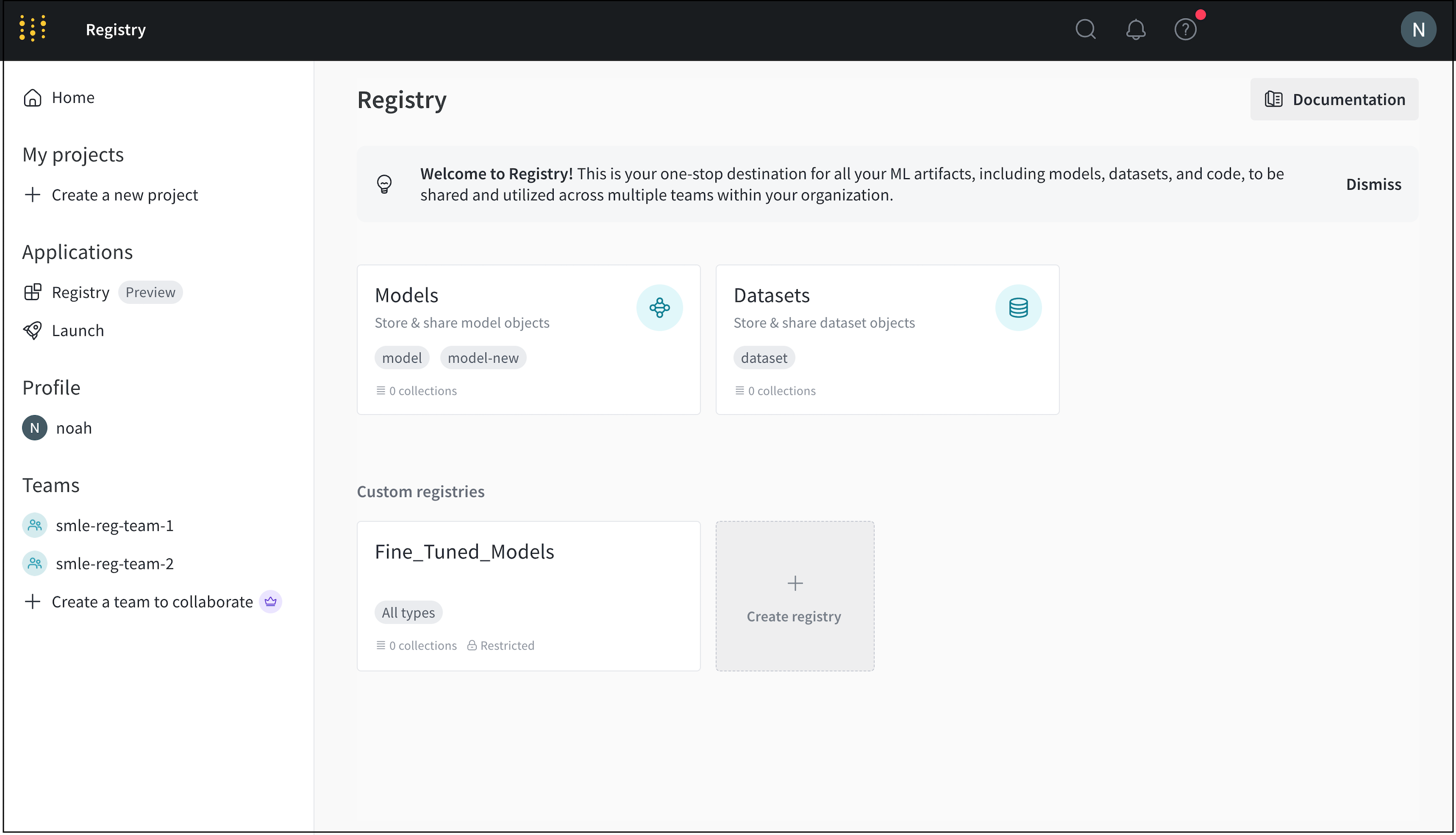
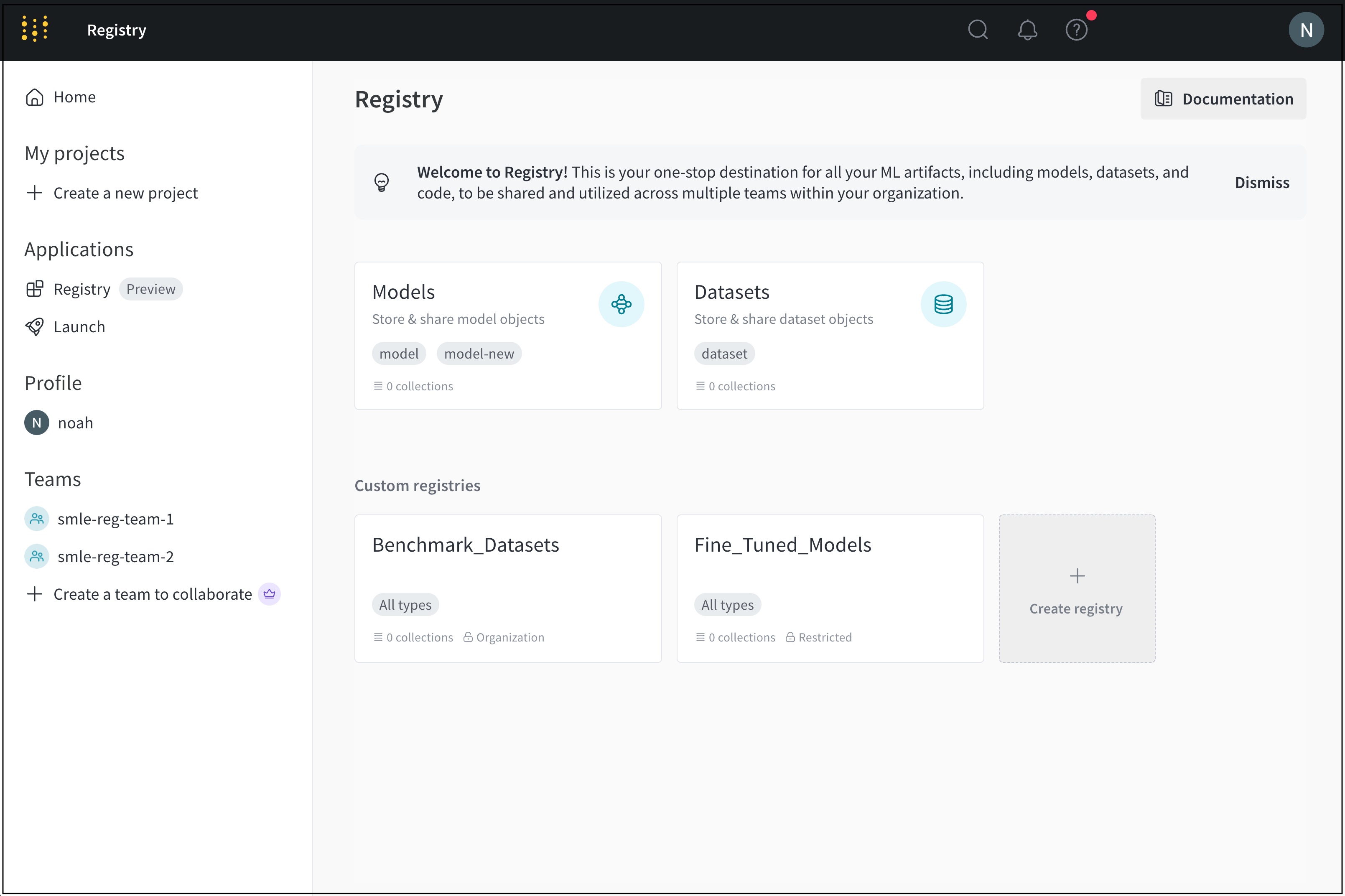
초기 데이터 수집부터 최종 모델 배포까지 기계 학습 파이프라인의 각 단계에 대한 custom registry를 만들 수 있습니다.
예를 들어, 트레이닝된 모델의 성능을 평가하기 위해 선별된 데이터셋을 구성하기 위해 “Benchmark_Datasets"라는 레지스트리를 만들 수 있습니다. 이 레지스트리 내에서 모델이 트레이닝 중에 본 적이 없는 사용자 질문과 해당 전문가 검증 답변 세트가 포함된 “User_Query_Insurance_Answer_Test_Data"라는 컬렉션을 가질 수 있습니다.
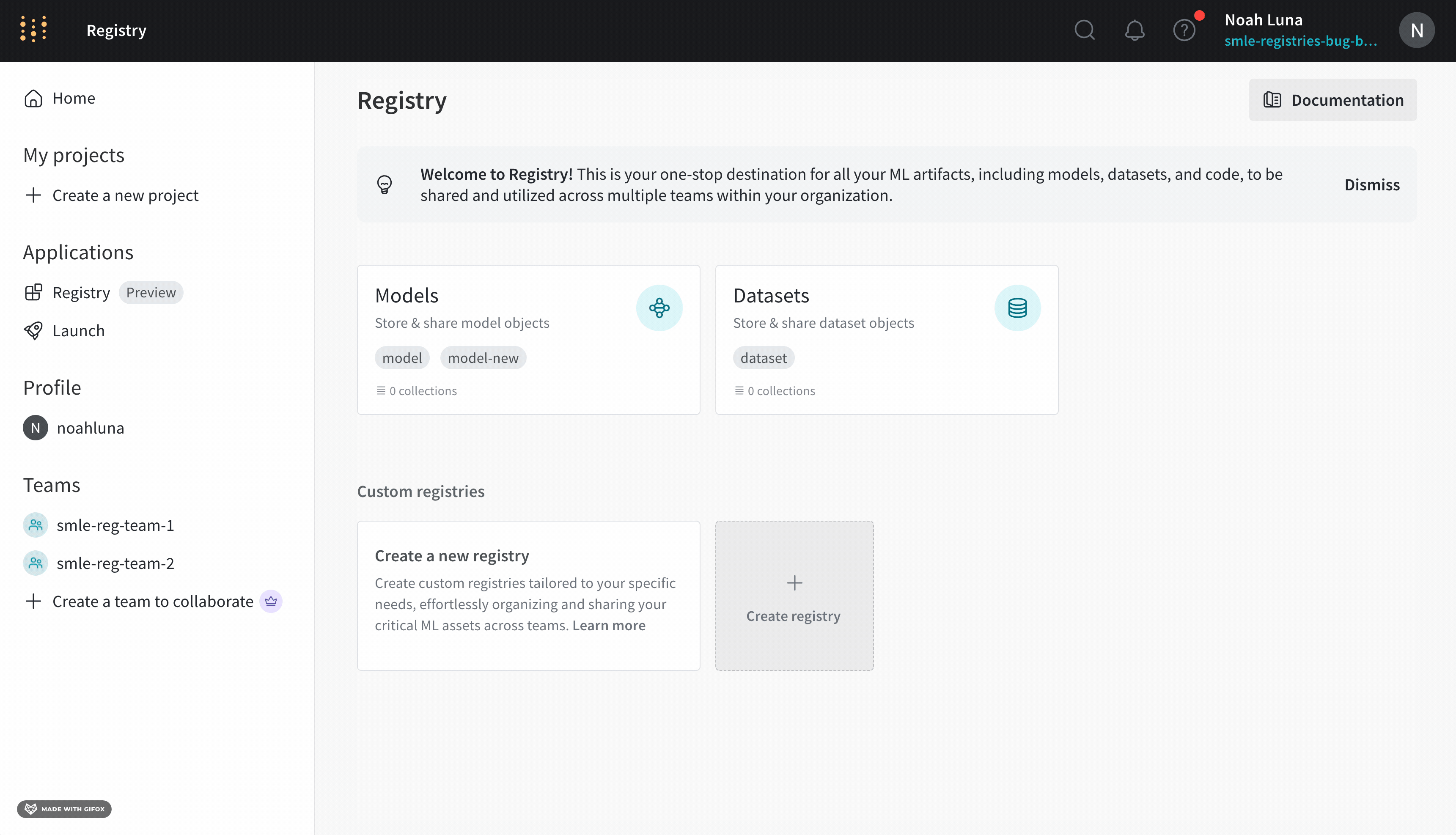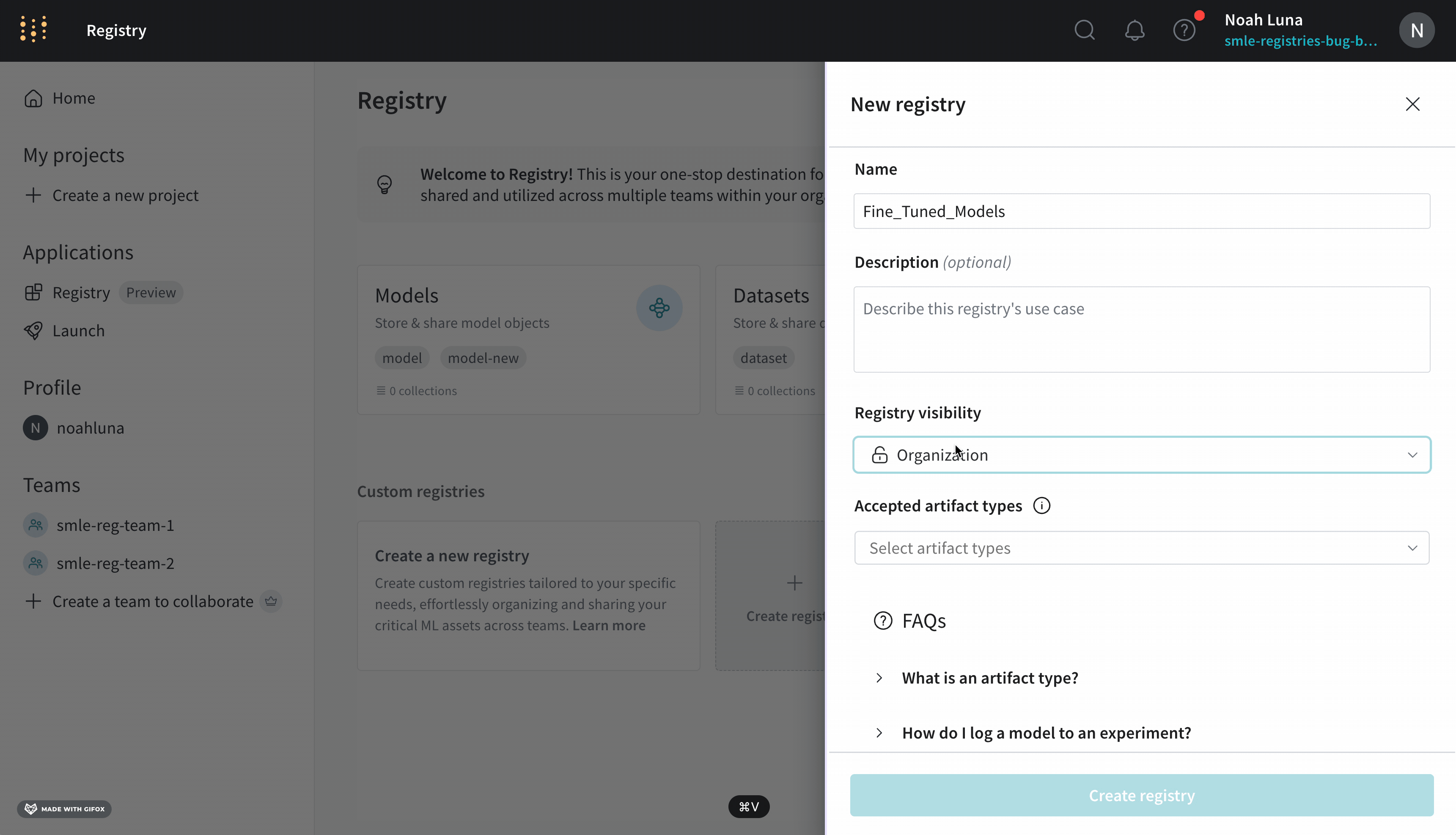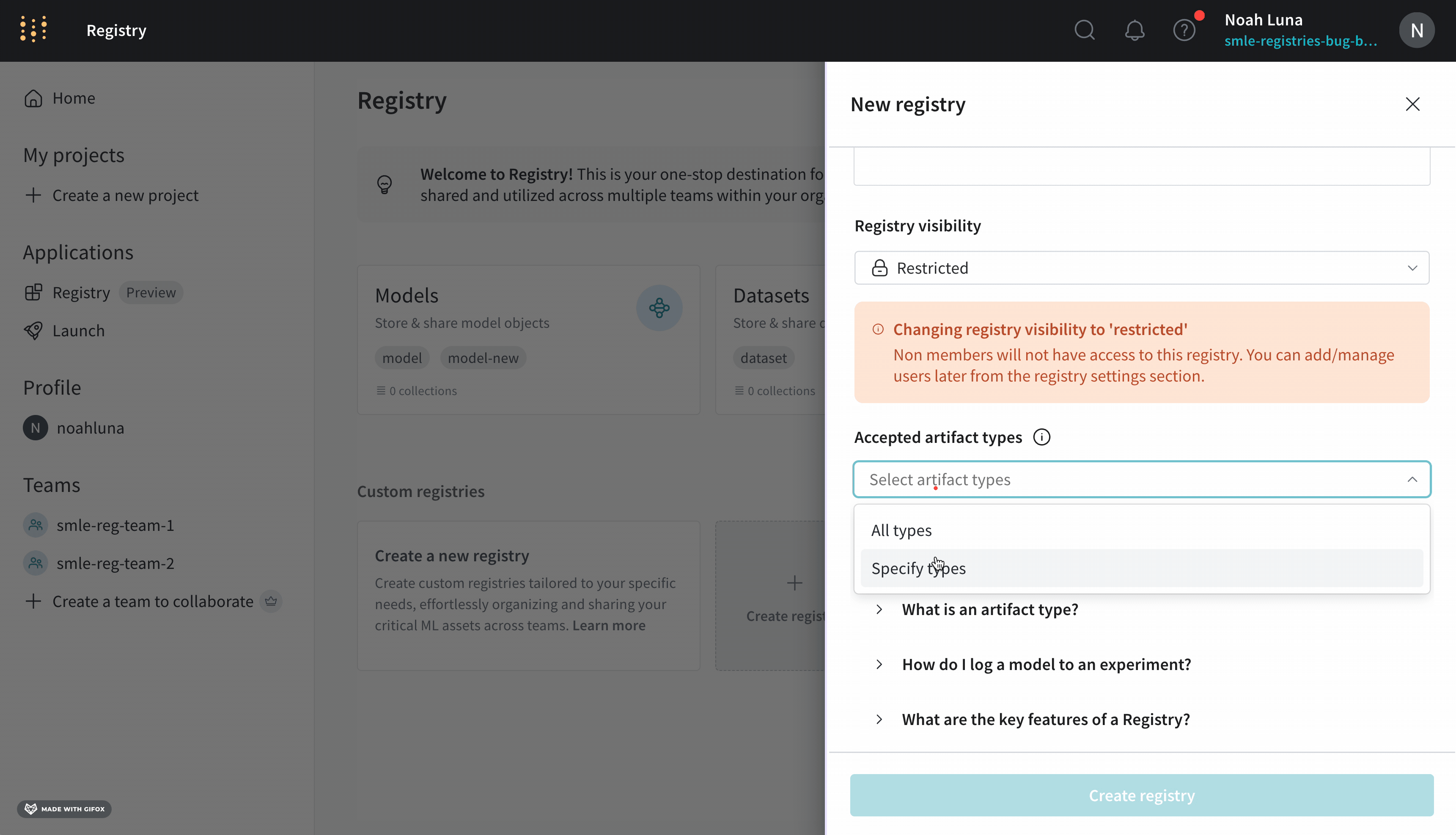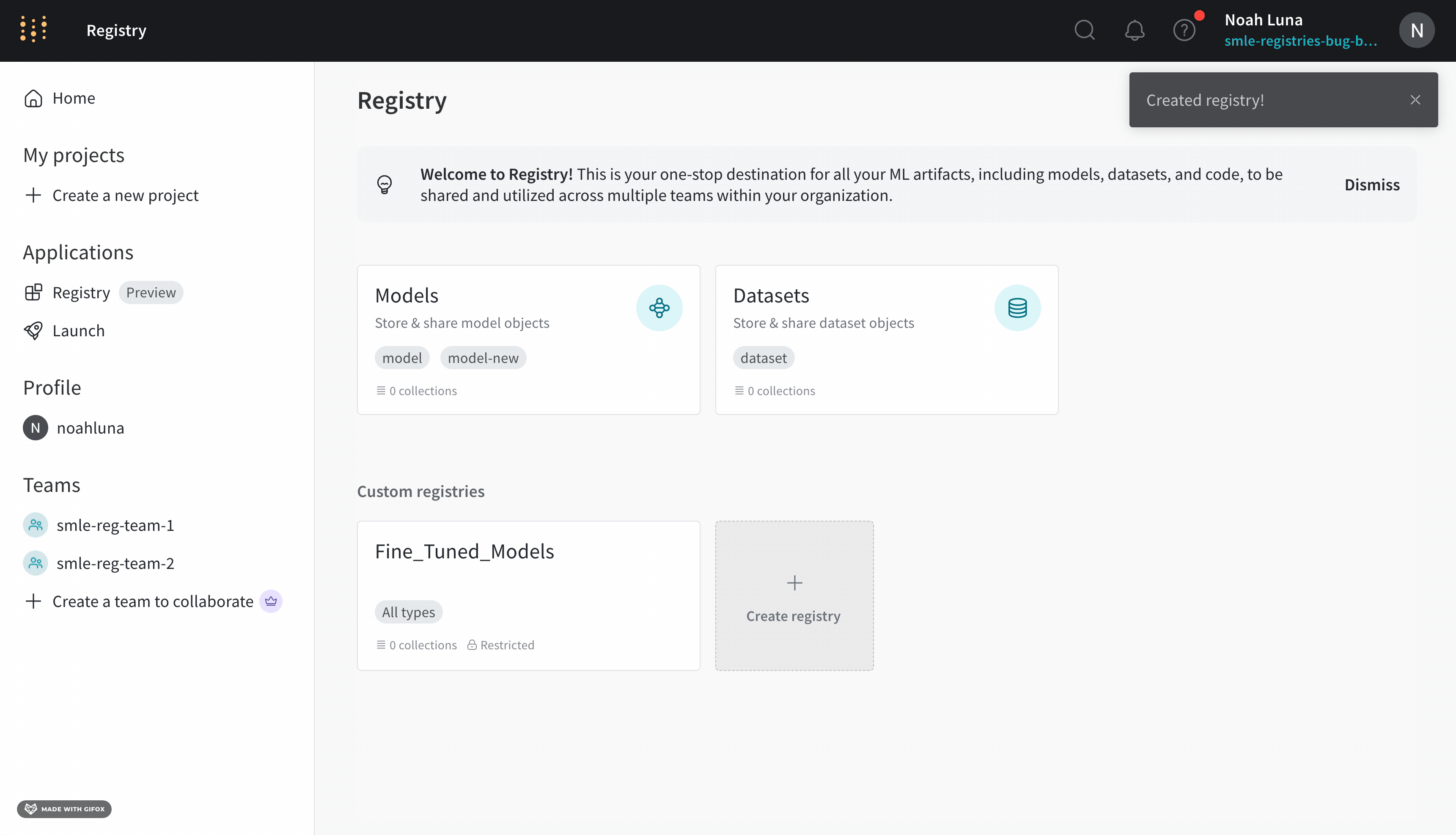
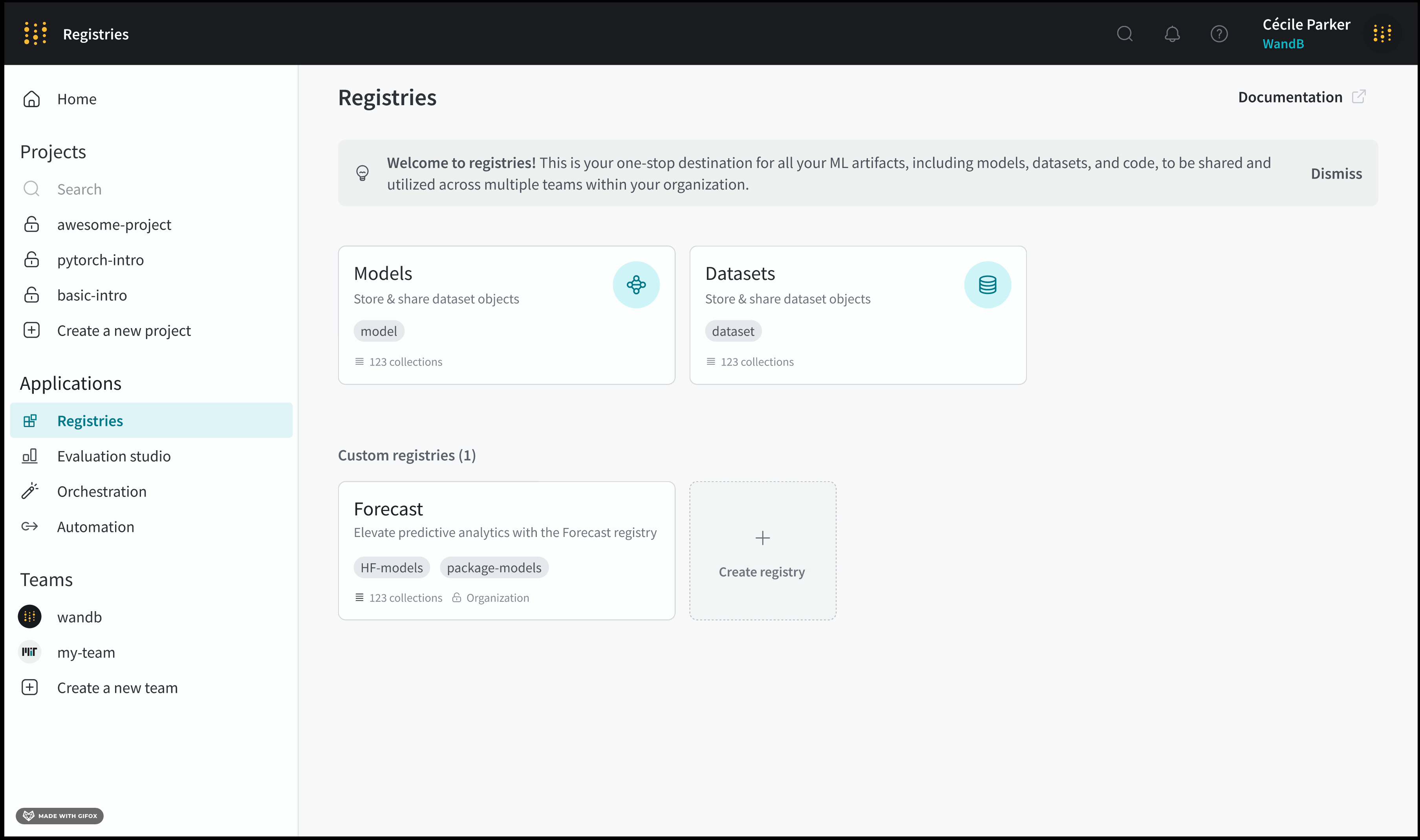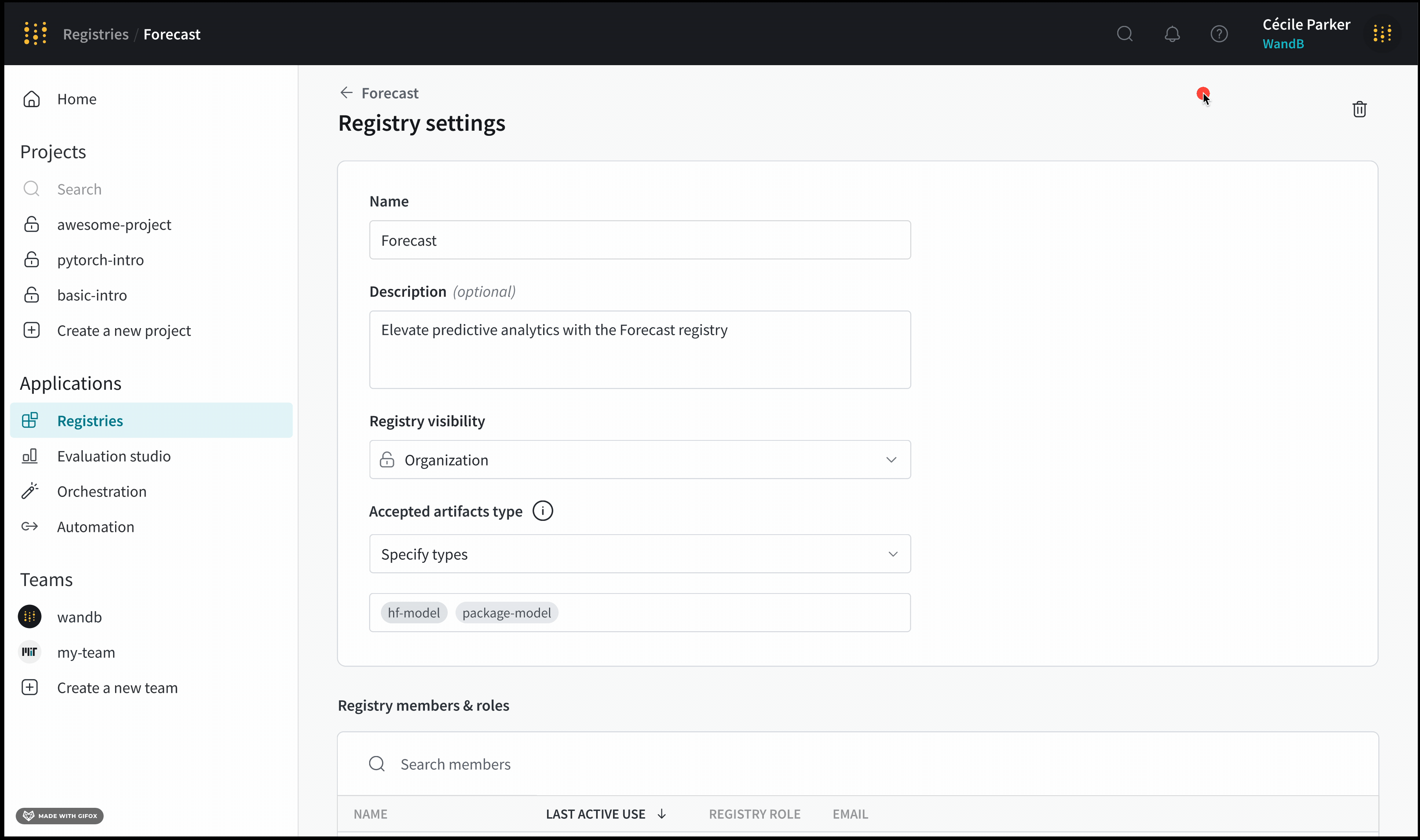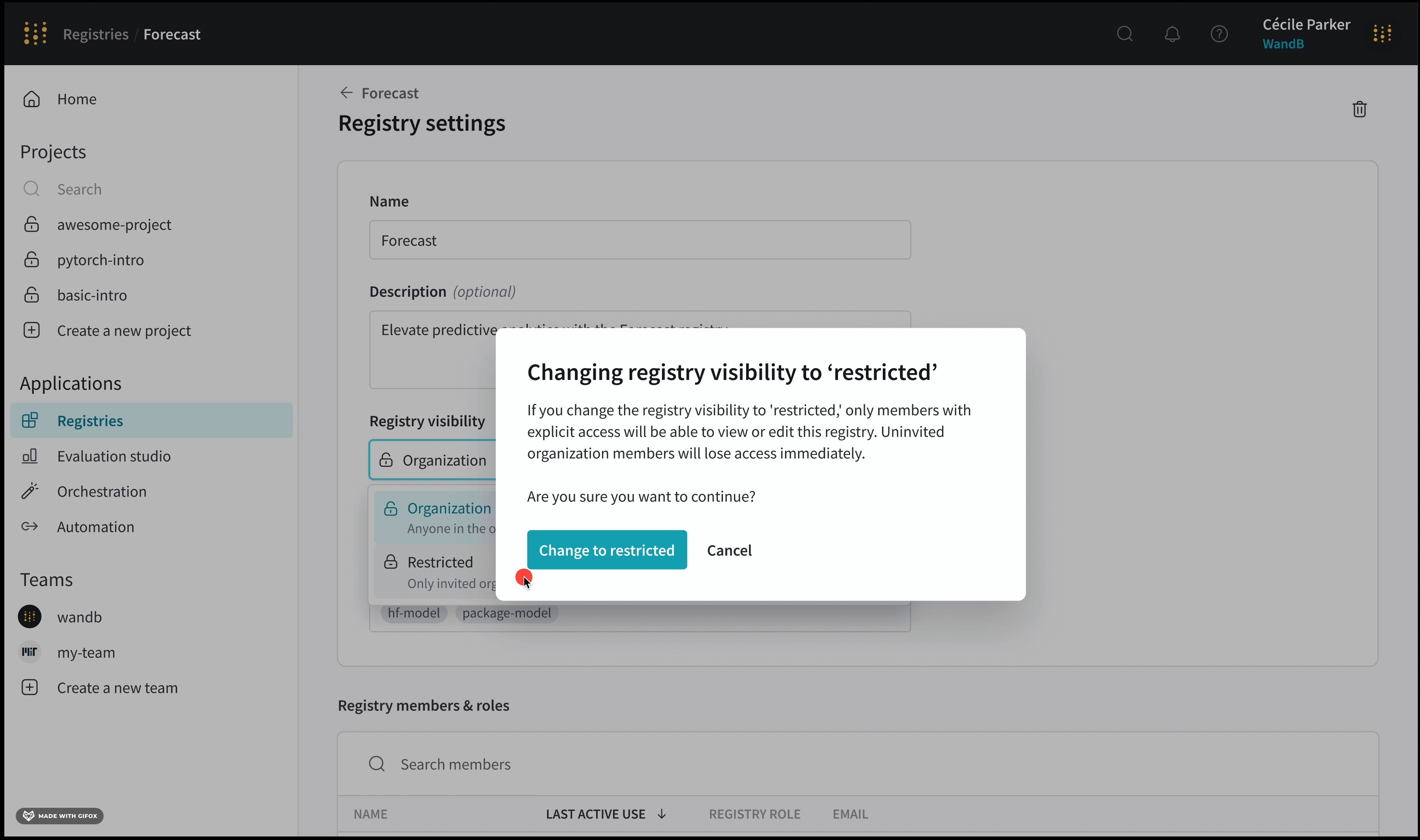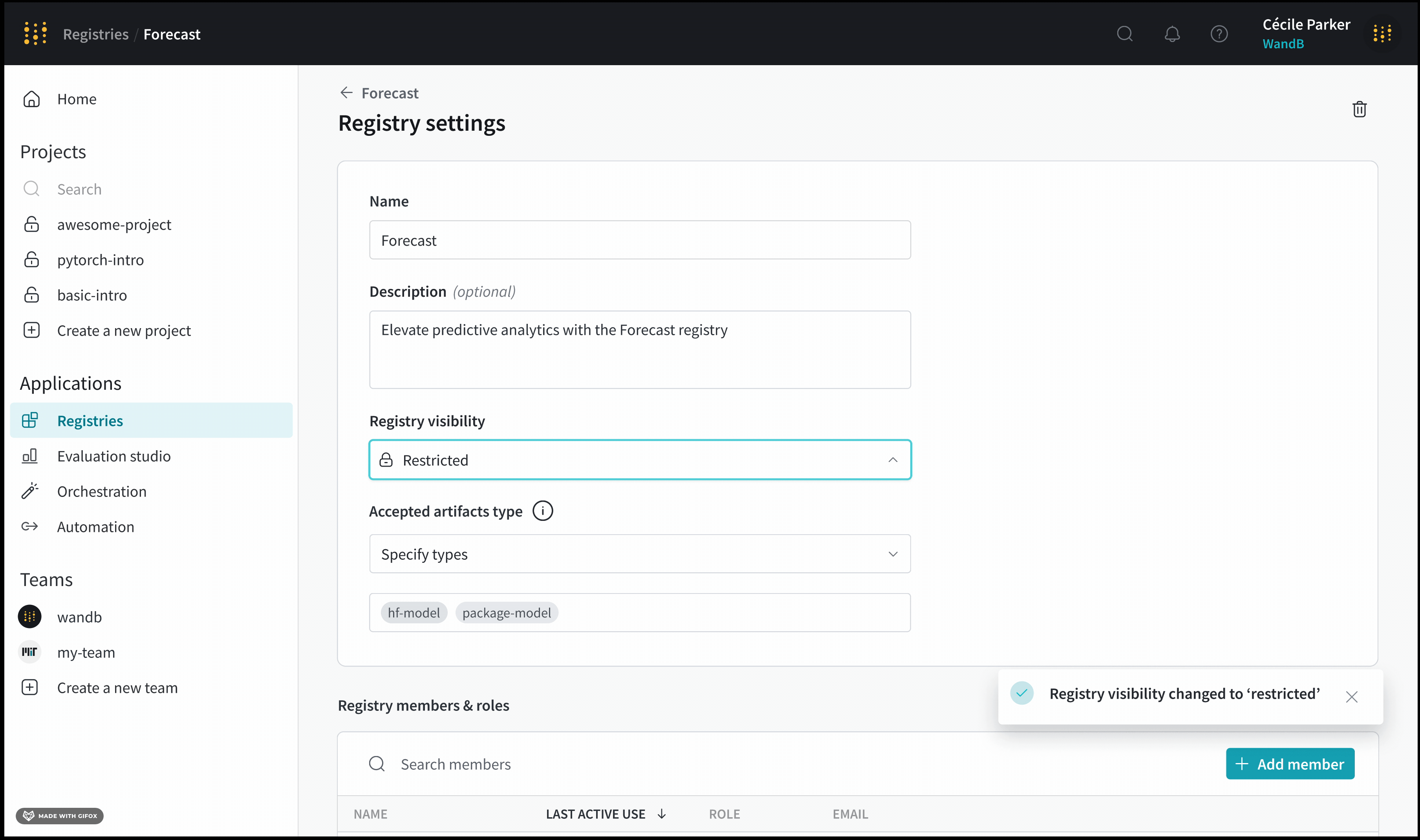
Custom registry는 organization or restricted visibility를 가질 수 있습니다. registry 관리자는 custom registry의 visibility를 organization에서 restricted로 변경할 수 있습니다. 그러나 registry 관리자는 custom registry의 visibility를 restricted에서 organization visibility로 변경할 수 없습니다.
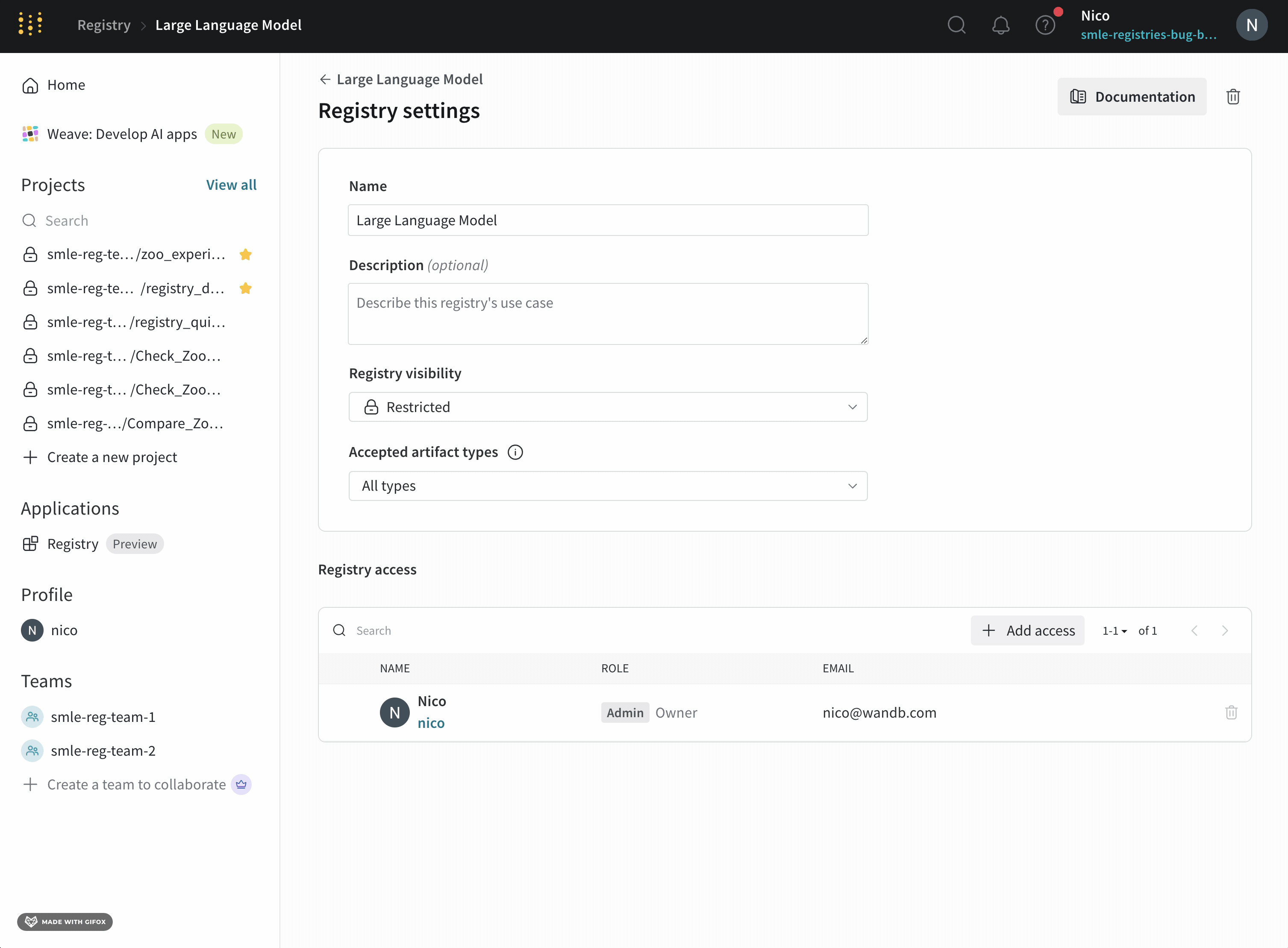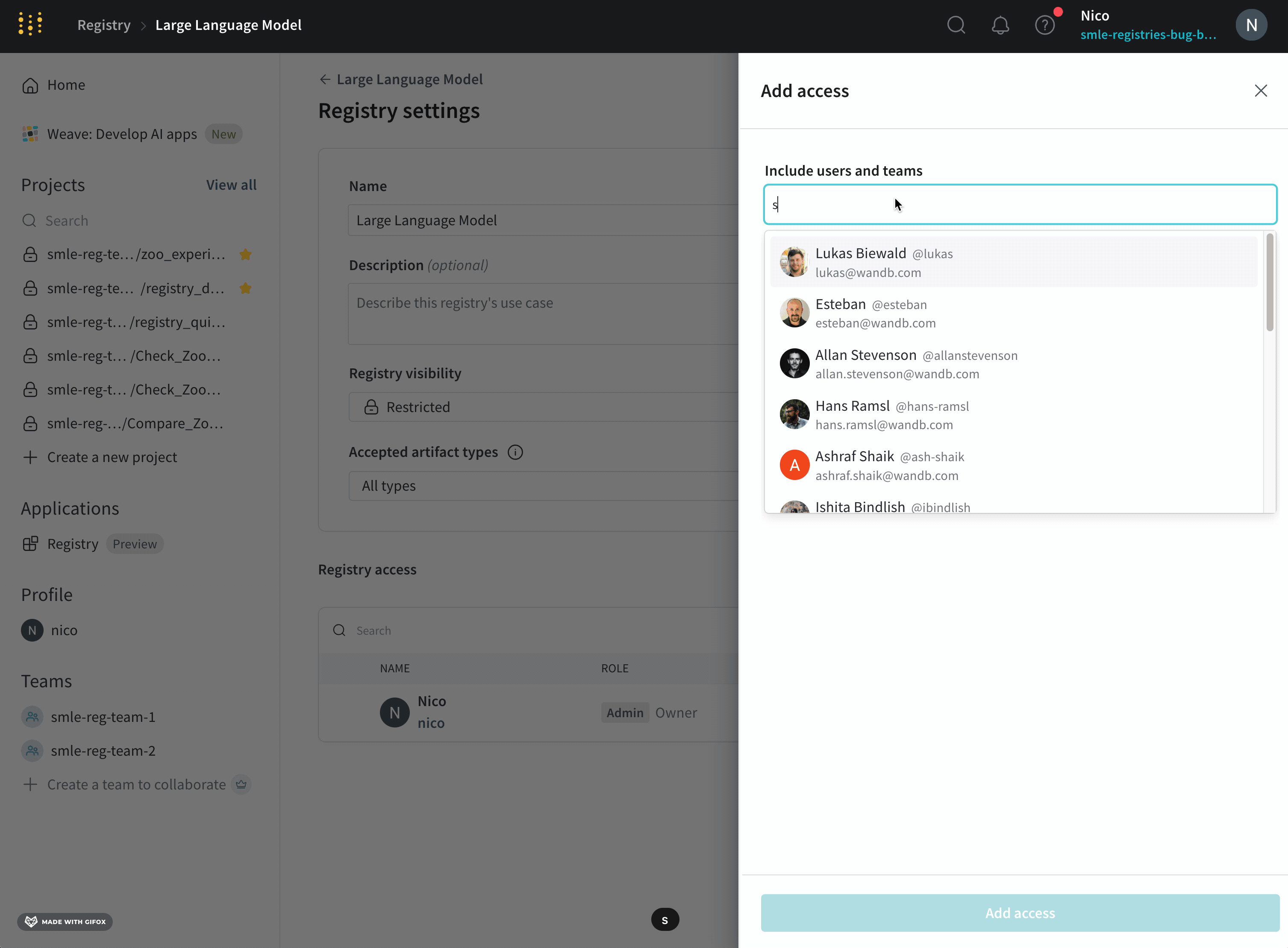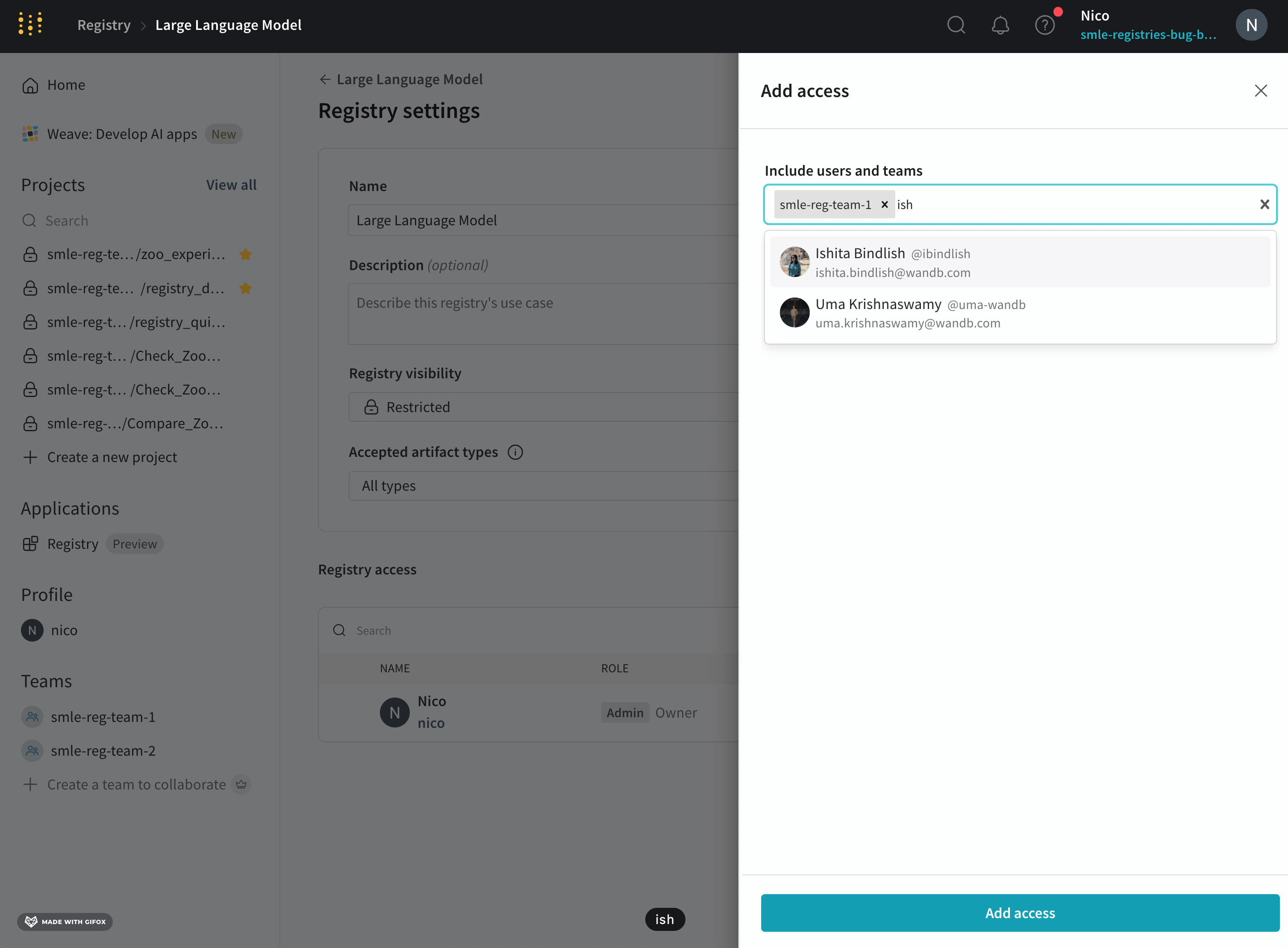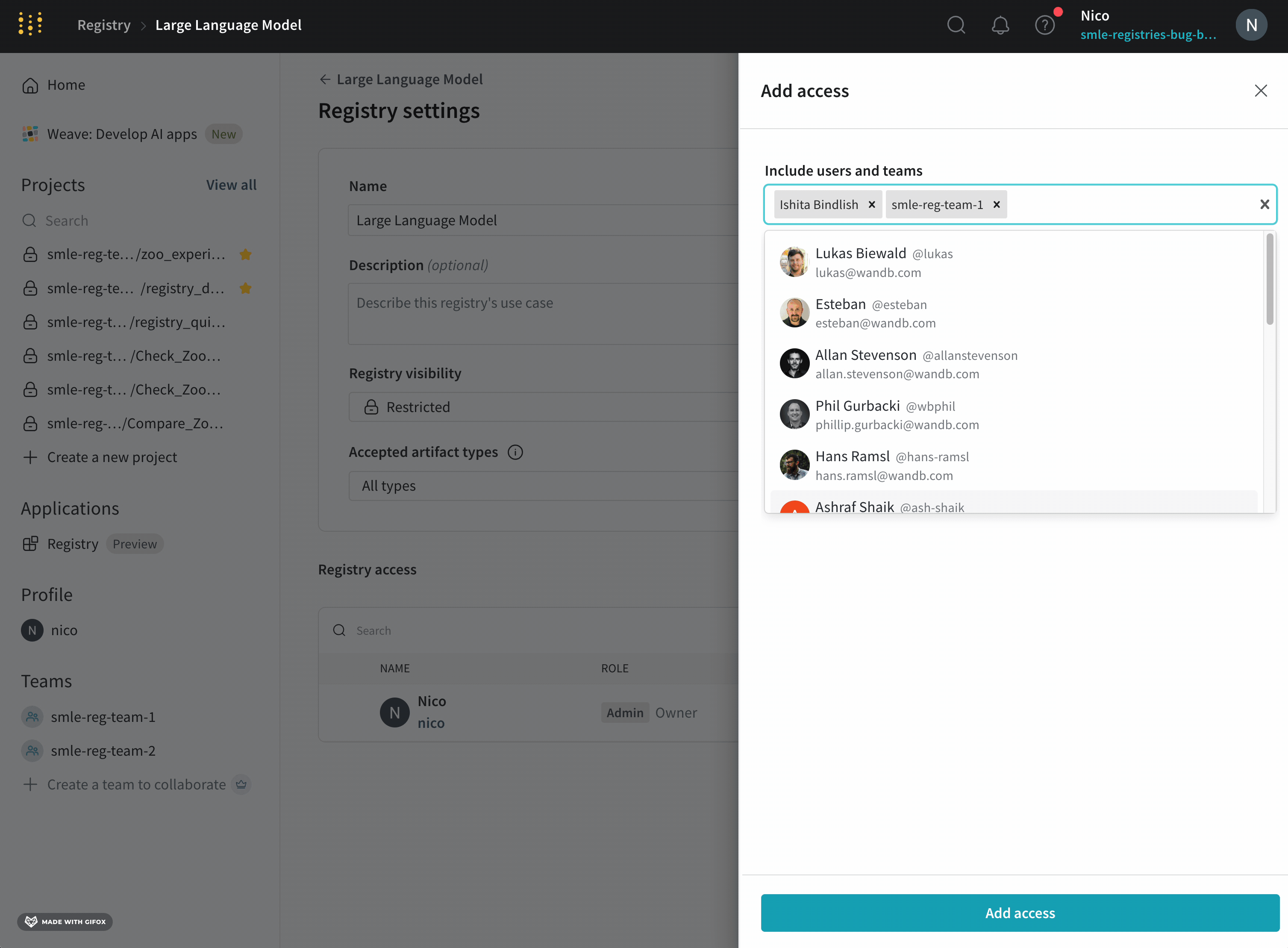
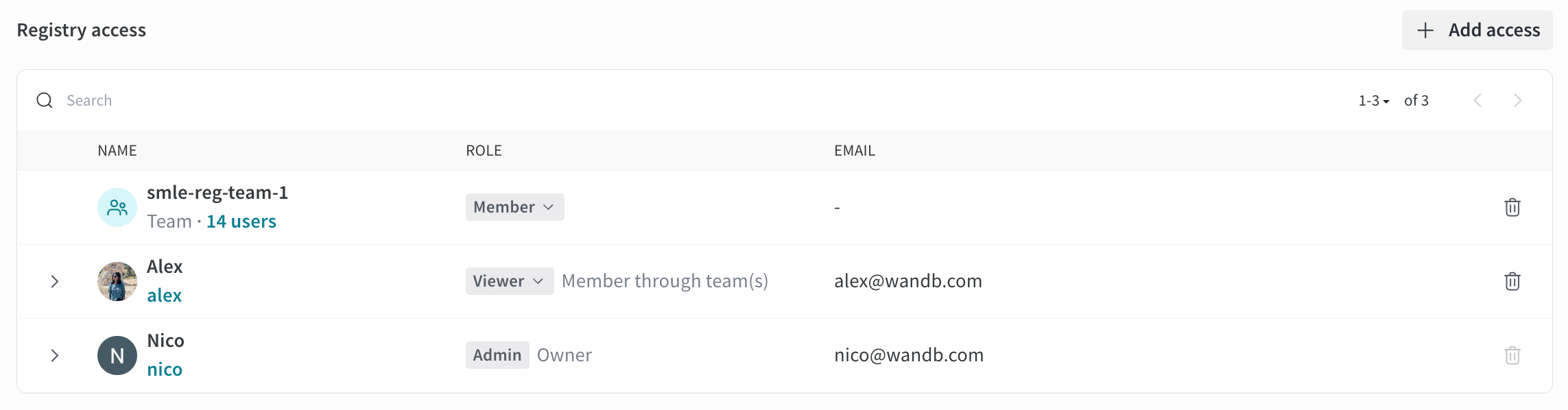
Registry에서 user의 권한은 개별적으로 또는 Team 멤버십에 의해 해당 user에게 할당된 최고 수준의 권한에 따라 달라집니다.
예를 들어, Registry 관리자가 Nico라는 user를 Registry A에 추가하고 Viewer Registry 역할을 할당한다고 가정합니다. 그런 다음 Registry 관리자가 Foundation Model Team이라는 Team을 Registry A에 추가하고 Foundation Model Team에 Member Registry 역할을 할당합니다.
Nico는 Registry의 Member인 Foundation Model Team의 멤버입니다. Member는 Viewer보다 더 많은 권한을 가지고 있기 때문에 W&B는 Nico에게 Member 역할을 부여합니다.
다음 표는 user의 개별 Registry 역할과 해당 멤버인 Team의 Registry 역할 간의 충돌이 발생할 경우 최고 수준의 권한을 보여줍니다.
Team Registry 역할
개별 Registry 역할
상속된 Registry 역할
Viewer
Viewer
Viewer
Member
Viewer
Member
Admin
Viewer
Admin
충돌이 있는 경우 W&B는 user 이름 옆에 최고 수준의 권한을 표시합니다.
예를 들어, 다음 이미지에서 Alex는 smle-reg-team-1 Team의 멤버이기 때문에 Member 역할 권한을 상속받습니다.
컬렉션 은 레지스트리 내에서 연결된 아티팩트 버전들의 집합입니다. 각 컬렉션은 고유한 작업 또는 유스 케이스를 나타냅니다.
예를 들어, 코어 데이터셋 레지스트리 내에 여러 개의 컬렉션을 가질 수 있습니다. 각 컬렉션은 MNIST, CIFAR-10 또는 ImageNet과 같은 서로 다른 데이터셋을 포함합니다.
또 다른 예로, “chatbot"이라는 레지스트리가 있을 수 있으며, 여기에는 모델 Artifacts에 대한 컬렉션, 데이터셋 Artifacts에 대한 또 다른 컬렉션, 그리고 파인튜닝된 모델 Artifacts에 대한 또 다른 컬렉션이 포함될 수 있습니다.
레지스트리와 컬렉션을 구성하는 방법은 사용자에게 달려 있습니다.
W&B 모델 레지스트리에 익숙하신 분은 등록된 모델에 대해 알고 계실 것입니다. 모델 레지스트리의 등록된 모델은 이제 W&B 레지스트리에서 컬렉션이라고 합니다.
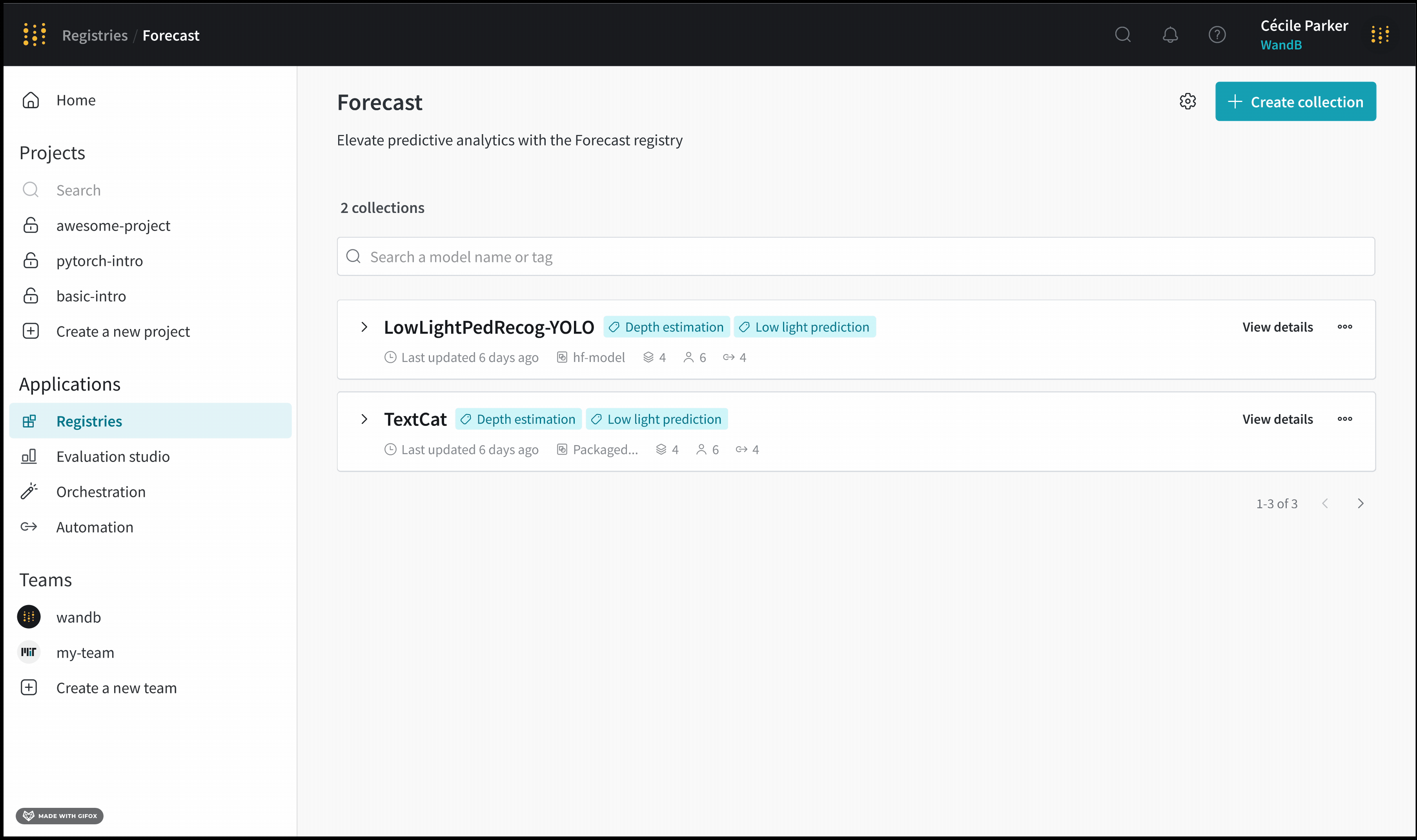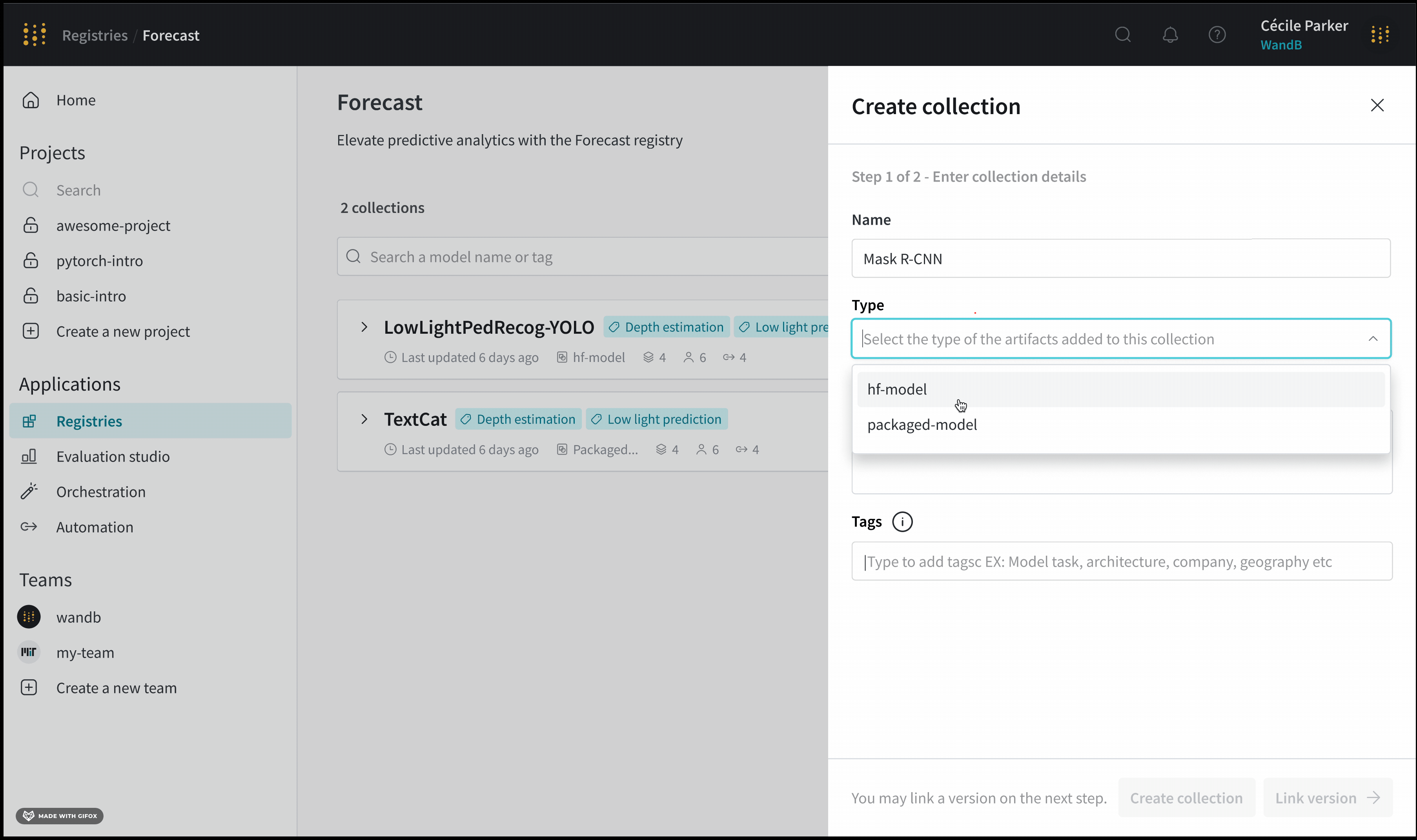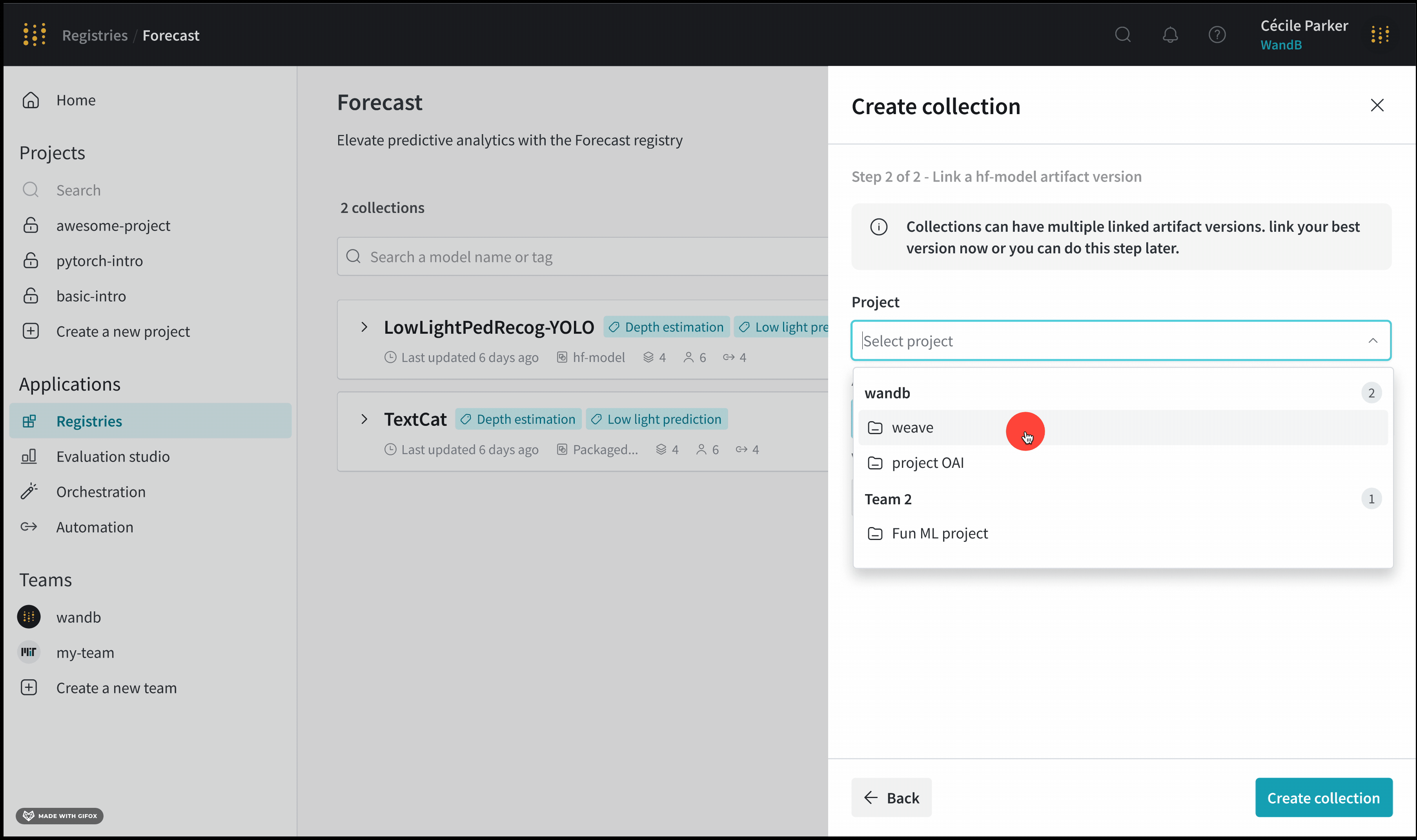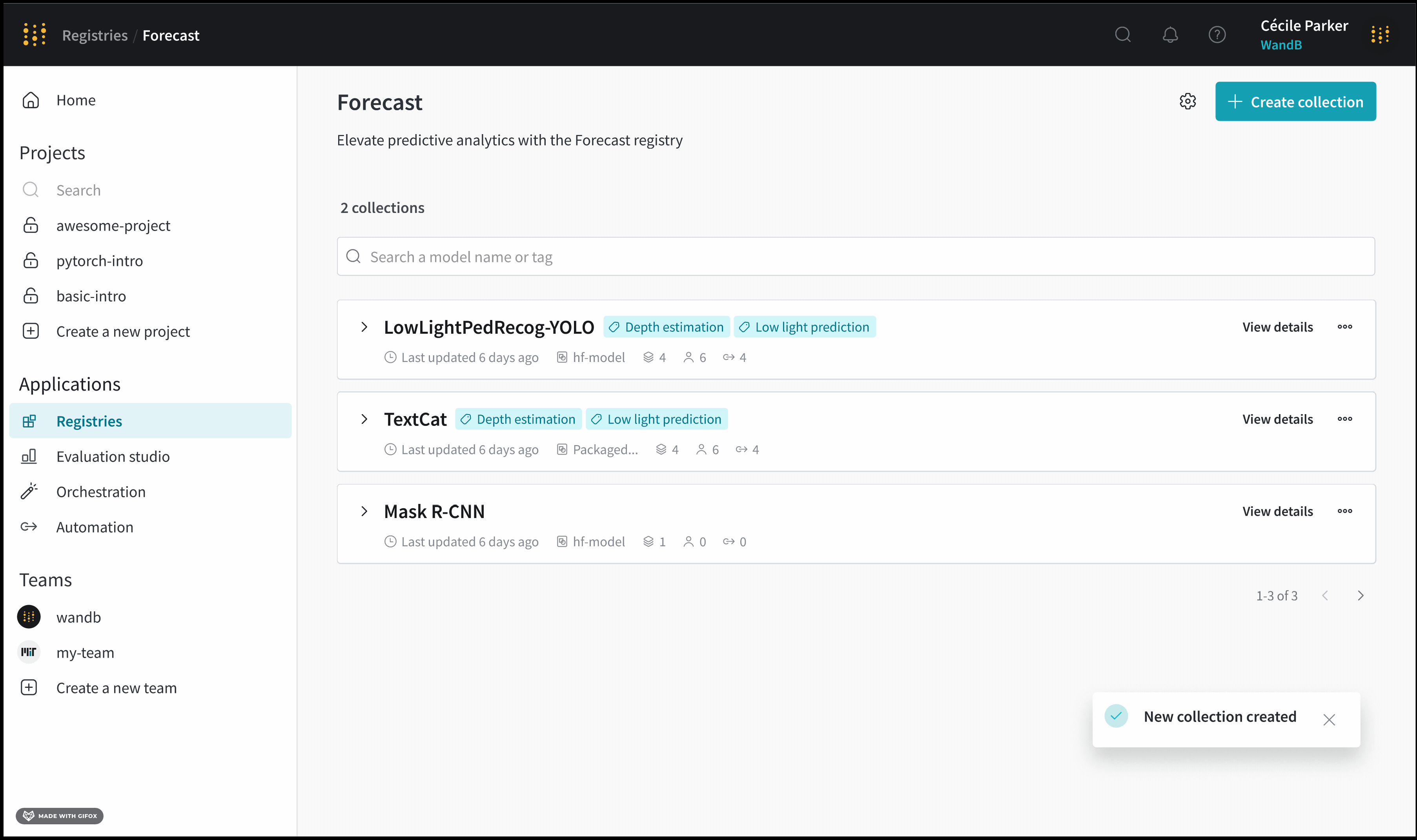
컬렉션 유형
각 컬렉션은 오직 하나의 아티팩트 유형 만을 허용합니다. 지정하는 유형은 사용자와 조직의 다른 구성원이 해당 컬렉션에 연결할 수 있는 Artifacts의 종류를 제한합니다.
아티팩트 유형을 Python과 같은 프로그래밍 언어의 데이터 유형과 유사하게 생각할 수 있습니다. 이 비유에서 컬렉션은 문자열, 정수 또는 부동 소수점을 저장할 수 있지만 이러한 데이터 유형을 혼합하여 저장할 수는 없습니다.
예를 들어, “데이터셋” 아티팩트 유형을 허용하는 컬렉션을 생성한다고 가정합니다. 이는 “데이터셋” 유형을 가진 미래의 Artifacts 버전만 이 컬렉션에 연결할 수 있음을 의미합니다. 마찬가지로, “모델” 아티팩트 유형만 허용하는 컬렉션에는 “모델” 유형의 Artifacts만 연결할 수 있습니다.
아티팩트 오브젝트를 생성할 때 아티팩트의 유형을 지정합니다. wandb.Artifact()의 type 필드를 참고하십시오.
Artifact를 레지스트리에 연결하기 전에 해당 컬렉션에서 허용하는 Artifact 유형을 확인하십시오. 컬렉션 유형에 대한 자세한 내용은 컬렉션 생성 내의 “컬렉션 유형"을 참조하십시오.
유스 케이스에 따라 아래 탭에 설명된 지침을 따르십시오.
Artifact 버전이 메트릭을 기록하는 경우(run.log_artifact() 사용) 해당 버전의 세부 정보 페이지에서 해당 버전에 대한 메트릭을 보고 Artifact 페이지에서 Artifact 버전 간의 메트릭을 비교할 수 있습니다. 레지스트리에서 연결된 Artifact 보기를 참조하십시오.
레지스트리에 연결된 아티팩트를 다운로드하려면 해당 연결된 아티팩트의 경로를 알아야 합니다. 경로는 레지스트리 이름, 컬렉션 이름, 엑세스하려는 아티팩트 버전의 에일리어스 또는 인덱스로 구성됩니다.
레지스트리, 컬렉션, 아티팩트 버전의 에일리어스 또는 인덱스가 있으면 다음 문자열 템플릿을 사용하여 연결된 아티팩트의 경로를 구성할 수 있습니다.
# 버전 인덱스가 지정된 아티팩트 이름f"wandb-registry-{REGISTRY}/{COLLECTION}:v{INDEX}"# 에일리어스가 지정된 아티팩트 이름f"wandb-registry-{REGISTRY}/{COLLECTION}:{ALIAS}"
중괄호 {} 안의 값을 엑세스하려는 레지스트리 이름, 컬렉션 이름, 아티팩트 버전의 에일리어스 또는 인덱스로 바꿉니다.
아티팩트 버전을 핵심 Model registry 또는 핵심 Dataset registry에 연결하려면 model 또는 dataset을 지정하십시오.
연결된 아티팩트의 경로가 있으면 wandb.init.use_artifact 메소드를 사용하여 아티팩트에 엑세스하고 해당 콘텐츠를 다운로드합니다. 다음 코드 조각은 W&B Registry에 연결된 아티팩트를 사용하고 다운로드하는 방법을 보여줍니다. <> 안의 값을 자신의 값으로 바꾸십시오.
다음 코드 예제는 사용자가 Fine-tuned Models 레지스트리의 phi3-finetuned라는 컬렉션에 연결된 아티팩트를 다운로드하는 방법을 보여줍니다. 아티팩트 버전의 에일리어스는 production으로 설정됩니다.
import wandb
TEAM_ENTITY ="product-team-applications"PROJECT_NAME ="user-stories"REGISTRY ="Fine-tuned Models"COLLECTION ="phi3-finetuned"ALIAS ='production'# 지정된 팀 및 프로젝트 내에서 run 초기화run = wandb.init(entity=TEAM_ENTITY, project = PROJECT_NAME)
artifact_name =f"wandb-registry-{REGISTRY}/{COLLECTION}:{ALIAS}"# 아티팩트에 엑세스하고 계보 추적을 위해 run에 대한 입력으로 표시fetched_artifact = run.use_artifact(artifact_or_name = name)
# 아티팩트 다운로드. 다운로드한 콘텐츠의 경로를 반환합니다.downloaded_path = fetched_artifact.download()
여러 조직에 속한 개인 엔터티를 가진 Users는 레지스트리에 연결된 아티팩트에 엑세스할 때 조직 이름을 지정하거나 팀 엔터티를 사용해야 합니다.
import wandb
REGISTRY ="<registry_name>"COLLECTION ="<collection_name>"VERSION ="<version>"# 팀 엔터티를 사용하여 API를 인스턴스화해야 합니다.api = wandb.Api(overrides={"entity": "<team-entity>"})
artifact_name =f"wandb-registry-{REGISTRY}/{COLLECTION}:{VERSION}"artifact = api.artifact(name = artifact_name)
# 경로에 조직 표시 이름 또는 조직 엔터티 사용api = wandb.Api()
artifact_name =f"{ORG_NAME}/wandb-registry-{REGISTRY}/{COLLECTION}:{VERSION}"artifact = api.artifact(name = artifact_name)
여기서 ORG_NAME은 조직의 표시 이름입니다. 멀티 테넌트 SaaS Users는 https://wandb.ai/account-settings/의 조직 설정 페이지에서 조직 이름을 찾을 수 있습니다. Dedicated Cloud 및 Self-Managed Users는 계정 관리자에게 문의하여 조직의 표시 이름을 확인하십시오.
미리 생성된 코드 조각 복사 및 붙여넣기
W&B는 Python 스크립트, 노트북 또는 터미널에 복사하여 붙여넣어 레지스트리에 연결된 아티팩트를 다운로드할 수 있는 코드 조각을 생성합니다.
# 문자열 `model`을 포함하는 모든 registries를 필터링합니다.registry_filters = {
"name": {"$regex": "model"}
}
# 필터와 일치하는 모든 registries의 iterable을 반환합니다.registries = api.registries(filter=registry_filters)
collection 이름에 문자열 yolo를 포함하는 registry에 관계없이 모든 collections을 필터링합니다.
# collection 이름에 문자열 `yolo`를 포함하는 registry에 관계없이# 모든 collections을 필터링합니다.collection_filters = {
"name": {"$regex": "yolo"}
}
# 필터와 일치하는 모든 collections의 iterable을 반환합니다.collections = api.registries().collections(filter=collection_filters)
collection 이름에 문자열 yolo를 포함하고 cnn을 태그로 갖는 registry에 관계없이 모든 collections을 필터링합니다.
# collection 이름에 문자열 `yolo`를 포함하고 `cnn`을 태그로 갖는# registry에 관계없이 모든 collections을 필터링합니다.collection_filters = {
"name": {"$regex": "yolo"},
"tag": "cnn"}
# 필터와 일치하는 모든 collections의 iterable을 반환합니다.collections = api.registries().collections(filter=collection_filters)
문자열 model을 포함하고 태그 image-classification 또는 latest 에일리어스를 갖는 모든 artifact versions을 찾습니다.
# 문자열 `model`을 포함하고# 태그 `image-classification` 또는 `latest` 에일리어스를 갖는 모든 artifact versions을 찾습니다.registry_filters = {
"name": {"$regex": "model"}
}
# 논리적 $or 연산자를 사용하여 artifact versions을 필터링합니다.version_filters = {
"$or": [
{"tag": "image-classification"},
{"alias": "production"}
]
}
# 필터와 일치하는 모든 artifact versions의 iterable을 반환합니다.artifacts = api.registries(filter=registry_filters).collections().versions(filter=version_filters)
이전 코드 조각에서 artifacts iterable의 각 항목은 Artifact 클래스의 인스턴스입니다. 즉, 각 아티팩트의 속성 (예: name, collection, aliases, tags, created_at 등)에 엑세스할 수 있습니다.
for art in artifacts:
print(f"artifact name: {art.name}")
print(f"collection artifact belongs to: { art.collection.name}")
print(f"artifact aliases: {art.aliases}")
print(f"tags attached to artifact: {art.tags}")
print(f"artifact created at: {art.created_at}\n")
아티팩트 오브젝트의 속성 전체 목록은 API Reference 문서의 Artifacts Class를 참조하세요.
2024-01-08과 2025-03-04 13:10 UTC 사이에 생성된 registry 또는 collection에 관계없이 모든 artifact versions을 필터링합니다.
# 2024-01-08과 2025-03-04 13:10 UTC 사이에 생성된 모든 artifact versions을 찾습니다.artifact_filters = {
"alias": "latest",
"created_at" : {"$gte": "2024-01-08", "$lte": "2025-03-04 13:10:00"},
}
# 필터와 일치하는 모든 artifact versions의 iterable을 반환합니다.artifacts = api.registries().collections().versions(filter=artifact_filters)
날짜 및 시간을 YYYY-MM-DD HH:MM:SS 형식으로 지정합니다. 날짜로만 필터링하려면 시간, 분, 초를 생략할 수 있습니다.
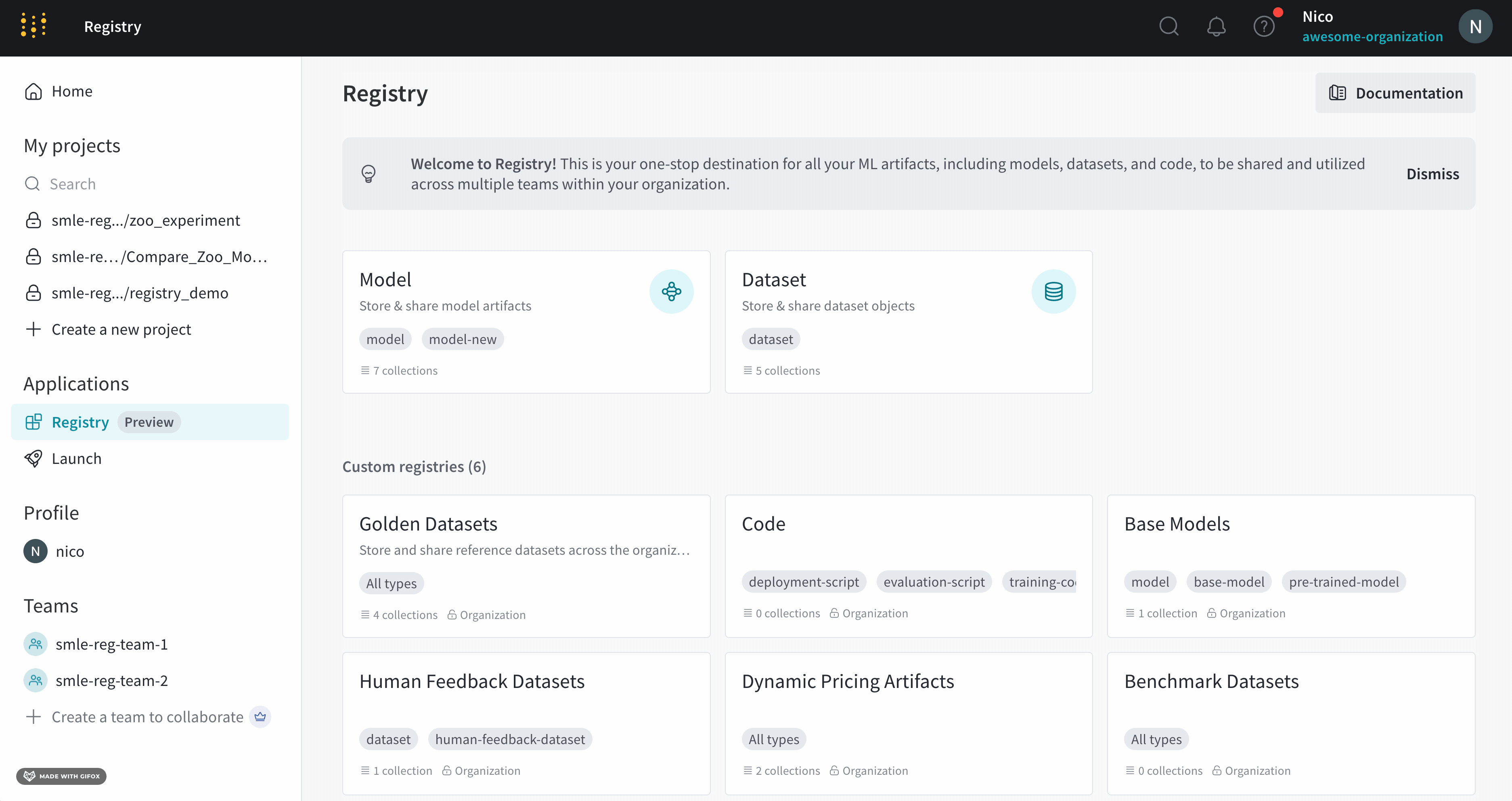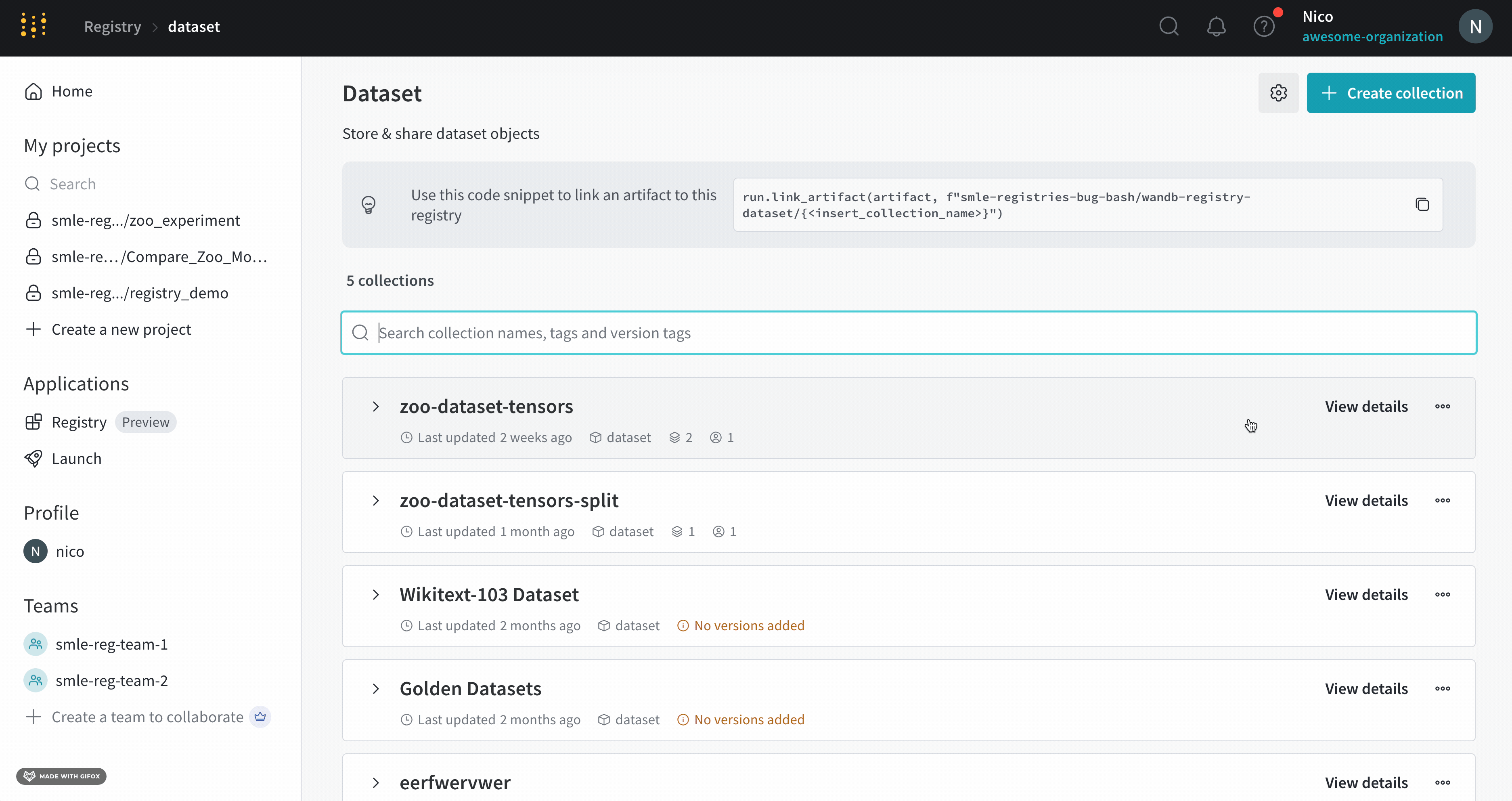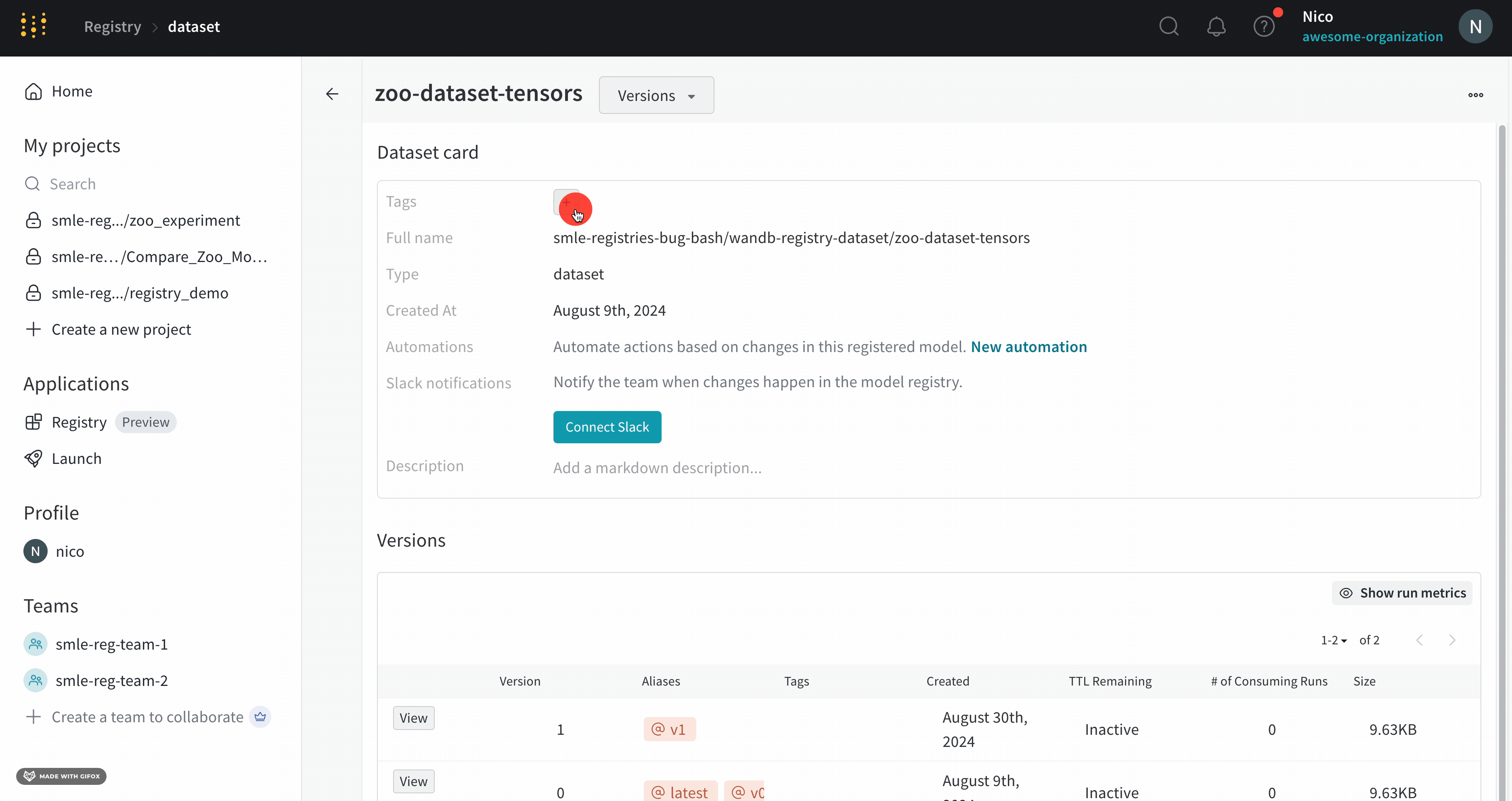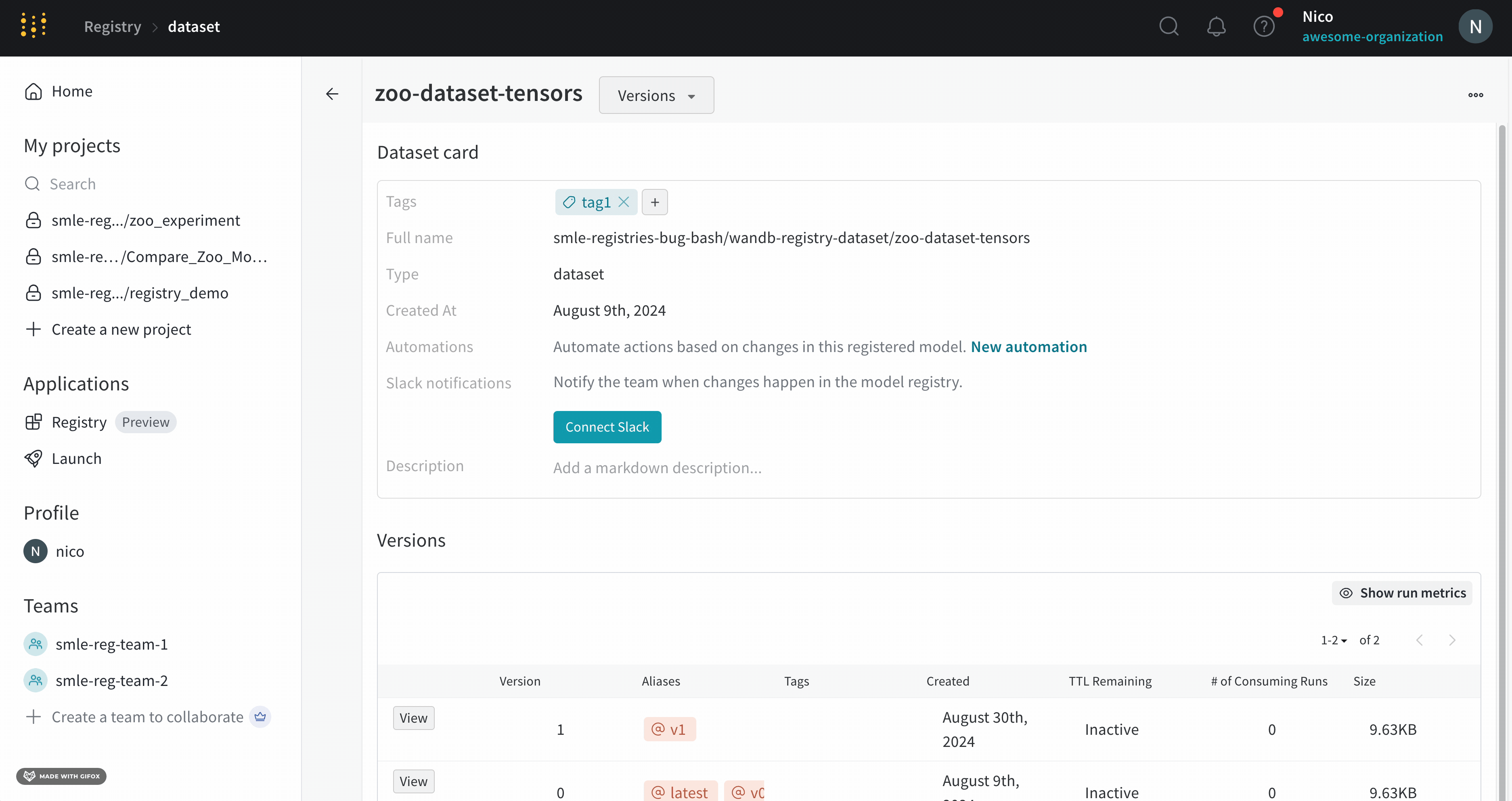
버전 탭 내에서 태그 필드 옆에 있는 더하기 아이콘(+)을 클릭하고 태그 이름을 입력합니다.
키보드에서 Enter 키를 누릅니다.
태그를 추가하거나 업데이트하려는 아티팩트 버전을 가져옵니다. 아티팩트 버전을 가져왔으면 아티팩트 오브젝트의 tag 속성에 액세스하여 해당 아티팩트에 태그를 추가하거나 수정할 수 있습니다. 하나 이상의 태그를 목록으로 아티팩트의 tag 속성에 전달합니다.
다른 Artifacts와 마찬가지로 run을 생성하지 않고도 W&B에서 Artifact를 가져오거나 run을 생성하고 해당 run 내에서 Artifact를 가져올 수 있습니다. 어느 경우든 W&B 서버에서 Artifact를 업데이트하려면 Artifact 오브젝트의 save 메소드를 호출해야 합니다.
아래의 적절한 코드 셀을 복사하여 붙여넣어 아티팩트 버전의 태그를 추가하거나 수정합니다. <> 안의 값을 자신의 값으로 바꿉니다.
다음 코드 조각은 새 run을 생성하지 않고 Artifact를 가져와서 태그를 추가하는 방법을 보여줍니다.
import wandb
ARTIFACT_TYPE ="<TYPE>"ORG_NAME ="<org_name>"REGISTRY_NAME ="<registry_name>"COLLECTION_NAME ="<collection_name>"VERSION ="<artifact_version>"artifact_name =f"{ORG_NAME}/wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}:v{VERSION}"artifact = wandb.Api().artifact(name = artifact_name, type = ARTIFACT_TYPE)
artifact.tags = ["tag2"] # 목록에 하나 이상의 태그 제공artifact.save()
다음 코드 조각은 새 run을 생성하여 Artifact를 가져와서 태그를 추가하는 방법을 보여줍니다.
import wandb
ORG_NAME ="<org_name>"REGISTRY_NAME ="<registry_name>"COLLECTION_NAME ="<collection_name>"VERSION ="<artifact_version>"run = wandb.init(entity ="<entity>", project="<project>")
artifact_name =f"{ORG_NAME}/wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}:v{VERSION}"artifact = run.use_artifact(artifact_or_name = artifact_name)
artifact.tags = ["tag2"] # 목록에 하나 이상의 태그 제공artifact.save()
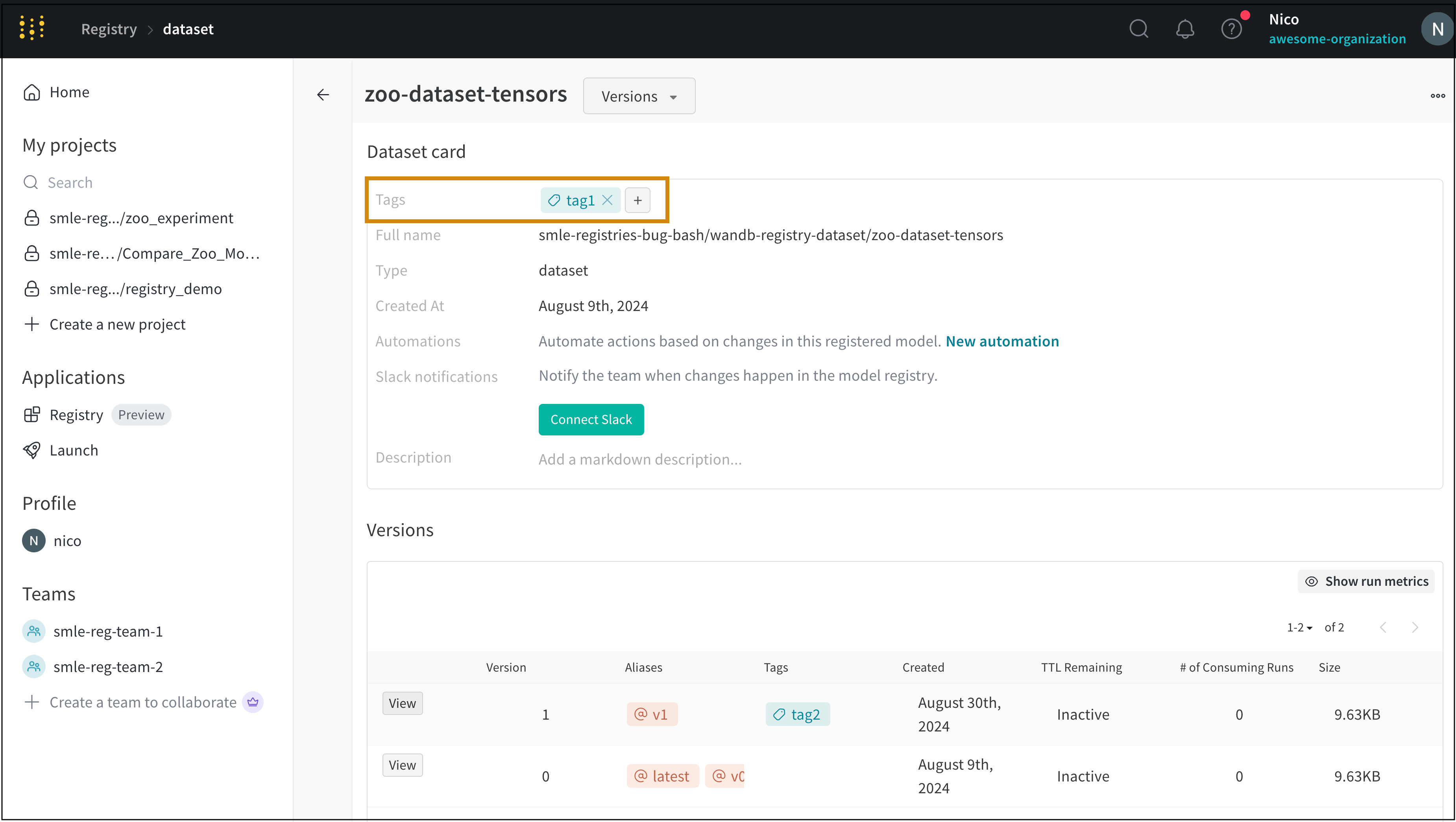
아티팩트 버전에 속한 태그 업데이트
tags 속성을 재할당하거나 변경하여 프로그래밍 방식으로 태그를 업데이트합니다. W&B는 제자리 변경 대신 tags 속성을 재할당하는 것을 권장하며, 이는 좋은 Python 방식입니다.
예를 들어, 다음 코드 조각은 재할당을 통해 목록을 업데이트하는 일반적인 방법을 보여줍니다. 간결성을 위해 아티팩트 버전에 태그 추가 섹션의 코드 예제를 계속합니다.
type_name 파라미터에 컬렉션의 유형을 지정하고 name 파라미터에 컬렉션의 전체 이름을 지정합니다. 컬렉션 이름은 접두사 “wandb-registry”, 레지스트리 이름 및 컬렉션 이름으로 구성되며 슬래시로 구분됩니다.
wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}
다음 코드 조각을 Python 스크립트 또는 노트북에 복사하여 붙여 넣습니다. 꺾쇠 괄호(<>)로 묶인 값을 자신의 값으로 바꿉니다.
import wandb
api = wandb.Api()
collection = api.artifact_collection(
type_name ="<collection_type>",
name ="<collection_name>" )
collection.description ="This is a description."collection.save()
예를 들어 다음 이미지는 모델 아키텍처, 용도, 성능 정보 등을 문서화하는 컬렉션을 보여줍니다.
3.10 - Create and view lineage maps
W&B Registry에서 계보 맵을 만드세요.
W&B 레지스트리의 컬렉션 내에서 ML 실험에서 사용하는 아티팩트의 이력을 볼 수 있습니다. 이 이력을 계보 그래프 라고 합니다.
컬렉션에 속하지 않은 W&B에 기록하는 아티팩트에 대한 계보 그래프를 볼 수도 있습니다.
계보 그래프는 아티팩트를 기록하는 특정 run을 보여줄 수 있습니다. 또한 계보 그래프는 어떤 run이 아티팩트를 입력으로 사용했는지도 보여줄 수 있습니다. 다시 말해, 계보 그래프는 run의 입력과 출력을 보여줄 수 있습니다.
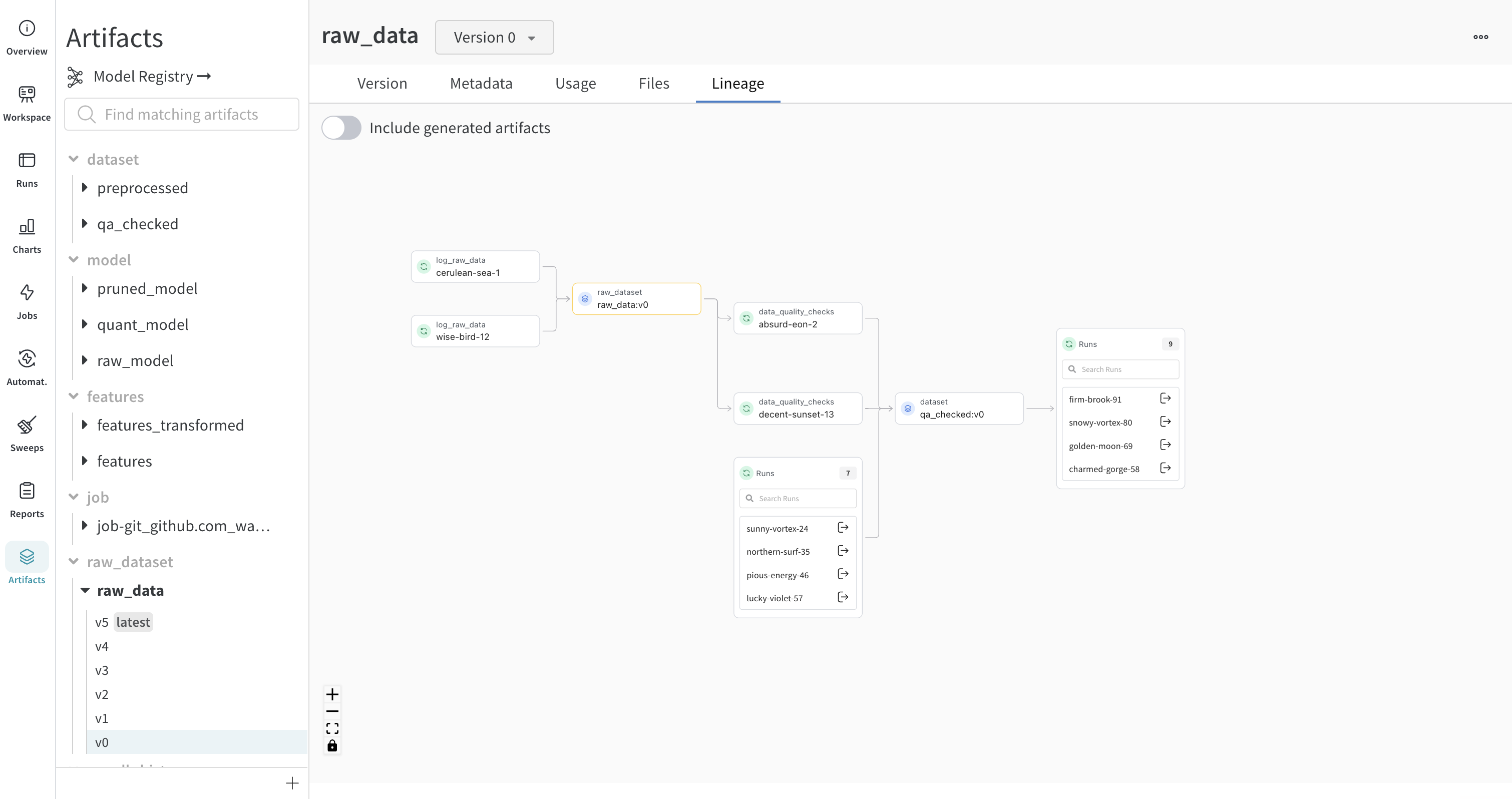
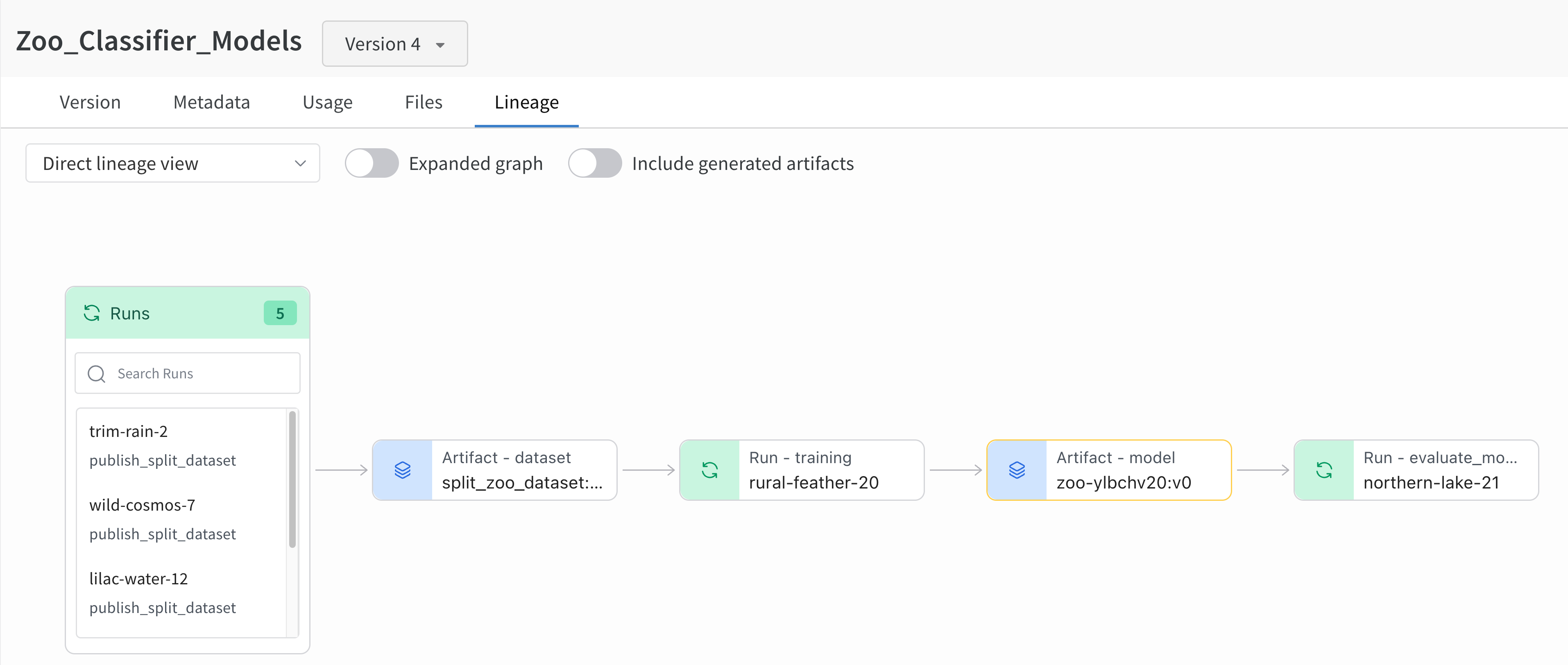
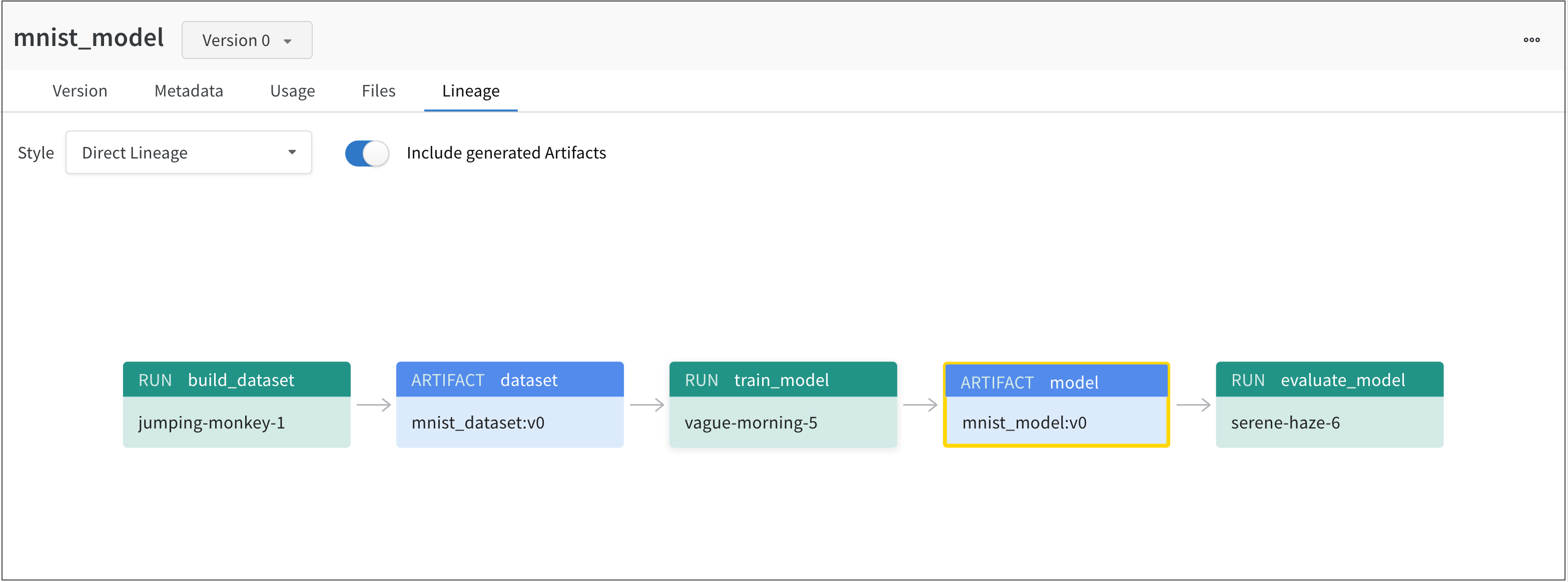
예를 들어, 다음 이미지는 ML 실험 전체에서 생성되고 사용된 아티팩트를 보여줍니다.
왼쪽에서 오른쪽으로 이미지는 다음을 보여줍니다.
여러 개의 run이 split_zoo_dataset:v4 아티팩트를 기록합니다.
“rural-feather-20” run은 트레이닝을 위해 split_zoo_dataset:v4 아티팩트를 사용합니다.
“rural-feather-20” run의 출력은 zoo-ylbchv20:v0이라는 모델 아티팩트입니다.
“northern-lake-21"이라는 run은 모델을 평가하기 위해 모델 아티팩트 zoo-ylbchv20:v0을 사용합니다.
run의 입력 추적
wandb.init.use_artifact API를 사용하여 아티팩트를 run의 입력 또는 종속성으로 표시합니다.
다음 코드 조각은 use_artifact를 사용하는 방법을 보여줍니다. 꺾쇠 괄호(<>)로 묶인 값을 사용자의 값으로 바꿉니다.
아티팩트의 계보 그래프 페이지에 있으면 해당 계보 그래프의 모든 노드에 대한 추가 정보를 볼 수 있습니다.
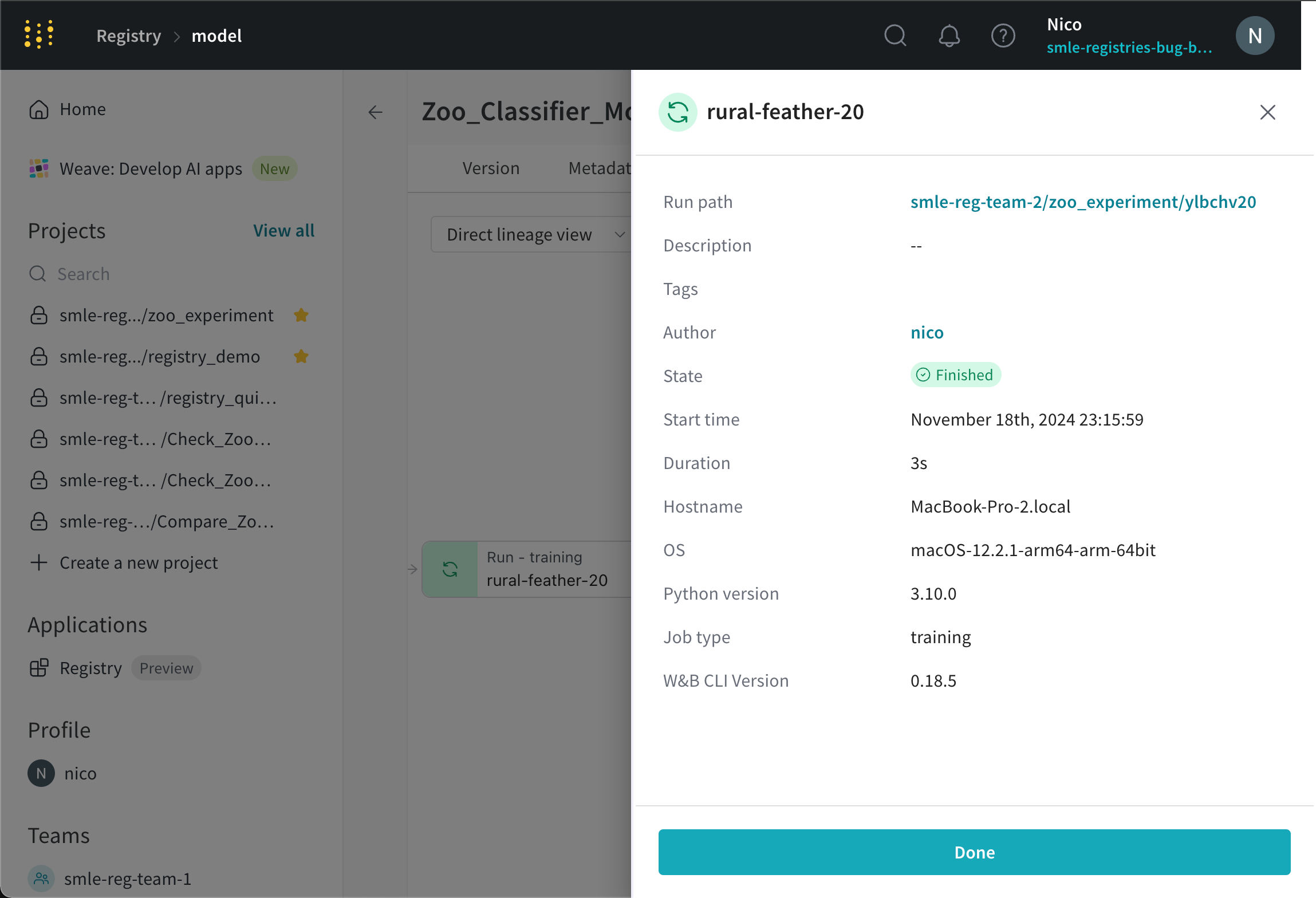
run 노드를 선택하여 run의 ID, run의 이름, run의 상태 등과 같은 run의 세부 정보를 봅니다. 예를 들어, 다음 이미지는 rural-feather-20 run에 대한 정보를 보여줍니다.
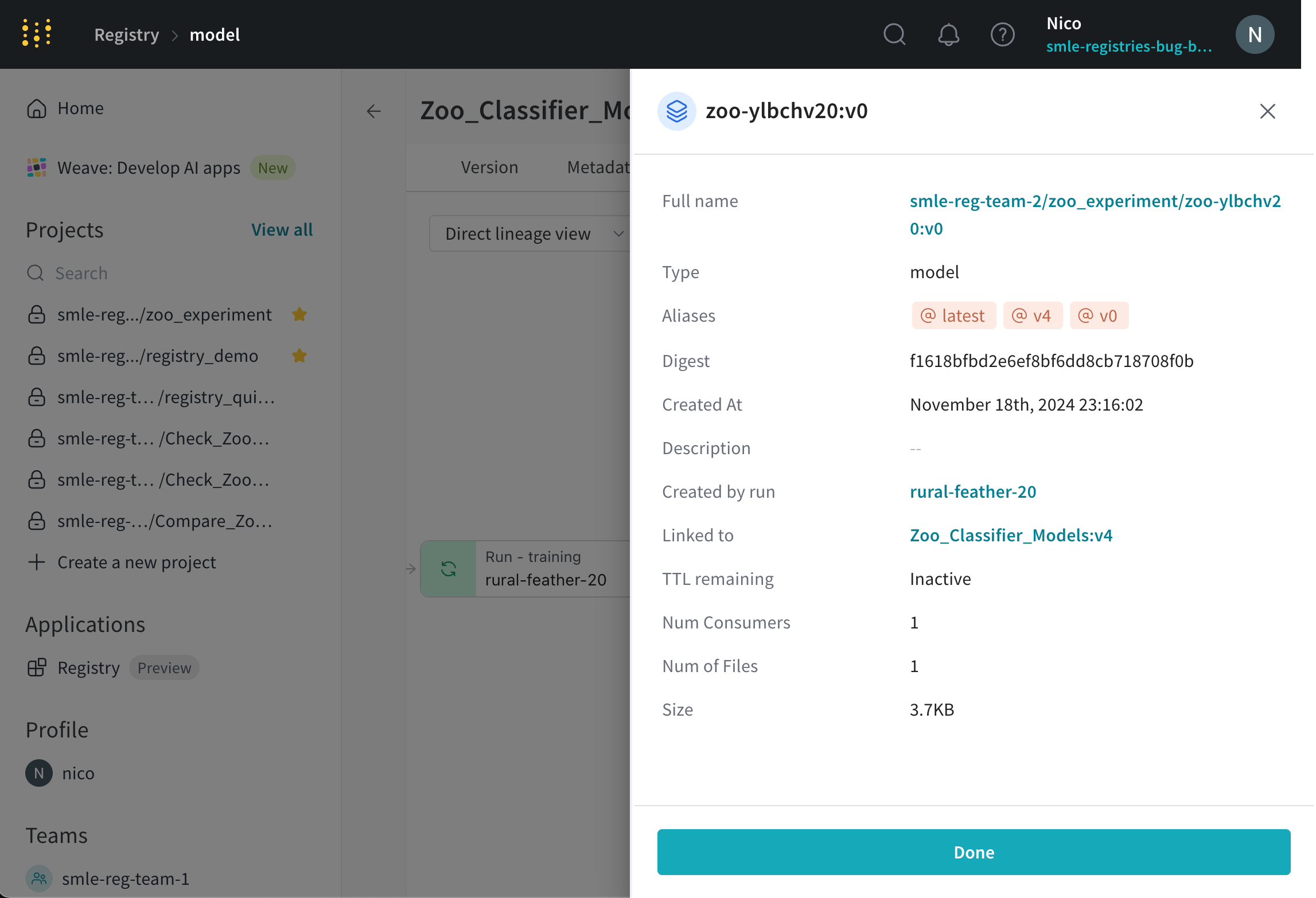
아티팩트 노드를 선택하여 전체 이름, 유형, 생성 시간 및 관련 에일리어스와 같은 해당 아티팩트의 세부 정보를 봅니다.
3.11 - Migrate from legacy Model Registry
W&B는 기존 W&B Model Registry의 자산을 새로운 W&B Registry로 이전할 예정입니다. 이 마이그레이션은 W&B에서 완전히 관리하고 트리거하며, 사용자 의 개입은 필요하지 않습니다. 이 프로세스는 기존 워크플로우의 중단을 최소화하면서 최대한 원활하게 진행되도록 설계되었습니다.
이전은 새로운 W&B Registry에 Model Registry에서 현재 사용할 수 있는 모든 기능이 포함되면 진행됩니다. W&B는 현재 워크플로우, 코드 베이스 및 레퍼런스를 보존하려고 노력할 것입니다.
이 가이드 는 살아있는 문서이며 더 많은 정보를 사용할 수 있게 되면 정기적으로 업데이트됩니다. 질문이나 지원이 필요하면 support@wandb.com으로 문의하십시오.
W&B Registry는 기존 Model Registry와 어떻게 다른가요?
W&B Registry는 모델, 데이터 셋 및 기타 Artifacts 관리 를 위한 보다 강력하고 유연한 환경을 제공하도록 설계된 다양한 새로운 기능과 개선 사항을 제공합니다.
기존 Model Registry 를 보려면 W&B App에서 Model Registry로 이동하십시오. 페이지 상단에 기존 Model Registry App UI를 사용할 수 있도록 하는 배너가 나타납니다.
조직 가시성
기존 Model Registry에 연결된 Artifacts는 팀 수준의 가시성을 갖습니다. 즉, 팀 멤버 만이 기존 W&B Model Registry에서 Artifacts를 볼 수 있습니다. W&B Registry는 조직 수준의 가시성을 갖습니다. 즉, 올바른 권한을 가진 조직 전체의 멤버는 레지스트리에 연결된 Artifacts를 볼 수 있습니다.
레지스트리에 대한 가시성 제한
사용자 정의 레지스트리를 보고 액세스할 수 있는 사용자를 제한합니다. 사용자 정의 레지스트리를 만들 때 또는 사용자 정의 레지스트리를 만든 후에 레지스트리에 대한 가시성을 제한할 수 있습니다. 제한된 레지스트리에서는 선택된 멤버만 콘텐츠에 액세스하여 개인 정보 보호 및 제어를 유지할 수 있습니다. 레지스트리 가시성에 대한 자세한 내용은 레지스트리 가시성 유형을 참조하십시오.
사용자 정의 레지스트리 만들기
기존 Model Registry와 달리 W&B Registry는 Models 또는 데이터셋 레지스트리에만 국한되지 않습니다. 특정 워크플로우 또는 프로젝트 요구 사항에 맞게 조정된 사용자 정의 레지스트리를 만들어 임의의 오브젝트 유형을 담을 수 있습니다. 이러한 유연성을 통해 팀은 고유한 요구 사항에 따라 Artifacts를 구성하고 관리할 수 있습니다. 사용자 정의 레지스트리를 만드는 방법에 대한 자세한 내용은 사용자 정의 레지스트리 만들기를 참조하십시오.
사용자 정의 엑세스 제어
각 레지스트리는 멤버에게 관리자, 멤버 또는 뷰어와 같은 특정 역할을 할당할 수 있는 자세한 엑세스 제어를 지원합니다. 관리자는 멤버 추가 또는 제거, 역할 설정 및 가시성 구성 을 포함하여 레지스트리 설정을 관리할 수 있습니다. 이를 통해 팀은 레지스트리에서 Artifacts를 보고, 관리하고, 상호 작용할 수 있는 사용자를 제어할 수 있습니다.
용어 업데이트
Registered Models는 이제 컬렉션이라고 합니다.
변경 사항 요약
기존 W&B Model Registry
W&B Registry
Artifacts 가시성
팀 멤버 만 Artifacts를 보거나 액세스할 수 있습니다.
조직 내 멤버는 올바른 권한으로 레지스트리에 연결된 Artifacts를 보거나 액세스할 수 있습니다.
사용자 정의 엑세스 제어
사용할 수 없음
사용 가능
사용자 정의 레지스트리
사용할 수 없음
사용 가능
용어 업데이트
모델 버전에 대한 포인터(링크) 집합을 registered models라고 합니다.
아티팩트 버전에 대한 포인터(링크) 집합을 컬렉션이라고 합니다.
wandb.init.link_model
Model Registry 특정 API
현재 기존 모델 레지스트리 와만 호환됩니다.
마이그레이션 준비
W&B는 Registered Models(현재 컬렉션이라고 함) 및 관련 아티팩트 버전을 기존 Model Registry에서 W&B Registry로 마이그레이션합니다. 이 프로세스는 자동으로 수행되며 사용자 의 조치가 필요하지 않습니다.
팀 가시성에서 조직 가시성으로
마이그레이션 후 모델 레지스트리는 조직 수준의 가시성을 갖습니다. 역할 할당을 통해 레지스트리에 액세스할 수 있는 사용자를 제한할 수 있습니다. 이를 통해 특정 멤버만 특정 레지스트리에 액세스할 수 있습니다.
마이그레이션은 기존 W&B Model Registry에서 현재 팀 수준으로 등록된 모델(곧 컬렉션이라고 함)의 기존 권한 경계를 유지합니다. 기존 Model Registry에 현재 정의된 권한은 새 레지스트리에서 보존됩니다. 즉, 현재 특정 팀 멤버 로 제한된 컬렉션은 마이그레이션 중과 후에 보호됩니다.
Artifacts 경로 연속성
현재 필요한 조치는 없습니다.
마이그레이션 중
W&B가 마이그레이션 프로세스를 시작합니다. 마이그레이션은 W&B 서비스의 중단을 최소화하는 시간대에 발생합니다. 마이그레이션이 시작되면 기존 Model Registry는 읽기 전용 상태로 전환되고 참조용으로 액세스할 수 있습니다.
마이그레이션 후
마이그레이션 후 컬렉션, Artifacts 버전 및 관련 속성은 새로운 W&B Registry 내에서 완전히 액세스할 수 있습니다. 현재 워크플로우가 그대로 유지되도록 보장하는 데 중점을 두고 있으며, 변경 사항을 탐색하는 데 도움이 되는 지속적인 지원이 제공됩니다.
새로운 레지스트리 사용
사용자는 W&B Registry에서 사용할 수 있는 새로운 기능과 기능을 탐색하는 것이 좋습니다. 레지스트리는 현재 의존하는 기능을 지원할 뿐만 아니라 사용자 정의 레지스트리, 향상된 가시성 및 유연한 엑세스 제어와 같은 향상된 기능도 제공합니다.
W&B Registry를 조기에 사용해 보거나, 기존 W&B Model Registry가 아닌 레지스트리로 시작하는 것을 선호하는 새로운 사용자를 위해 지원이 제공됩니다. 이 기능을 활성화하려면 support@wandb.com 또는 영업 MLE에 문의하십시오. 초기 마이그레이션은 BETA 버전으로 진행됩니다. W&B Registry의 BETA 버전에는 기존 Model Registry의 모든 기능 또는 특징이 없을 수 있습니다.
자세한 내용과 W&B Registry의 전체 기능 범위에 대해 알아보려면 W&B Registry 가이드를 방문하십시오.
FAQ
W&B가 Model Registry에서 W&B Registry로 자산을 마이그레이션하는 이유는 무엇입니까?
W&B는 새로운 레지스트리를 통해 보다 고급 기능과 기능을 제공하기 위해 플랫폼을 발전시키고 있습니다. 이 마이그레이션은 Models, 데이터 셋 및 기타 Artifacts 관리를 위한 보다 통합되고 강력한 툴 세트를 제공하기 위한 단계입니다.
마이그레이션 전에 수행해야 할 작업은 무엇입니까?
마이그레이션 전에 사용자 의 조치가 필요하지 않습니다. W&B는 워크플로우와 레퍼런스가 보존되도록 전환을 처리합니다.
모델 Artifacts에 대한 액세스 권한이 손실됩니까?
아니요, 모델 Artifacts에 대한 액세스 권한은 마이그레이션 후에도 유지됩니다. 기존 Model Registry는 읽기 전용 상태로 유지되고 모든 관련 데이터는 새 레지스트리로 마이그레이션됩니다.
Artifacts와 관련된 메타데이터가 보존됩니까?
예, Artifacts 생성, 계보 및 기타 속성과 관련된 중요한 메타데이터는 마이그레이션 중에 보존됩니다. 사용자는 마이그레이션 후에도 모든 관련 메타데이터에 계속 액세스할 수 있으므로 Artifacts의 무결성과 추적 가능성이 유지됩니다.
도움이 필요하면 누구에게 연락해야 합니까?
질문이나 우려 사항이 있는 경우 지원을 받을 수 있습니다. 지원이 필요하면 support@wandb.com으로 문의하십시오.
3.12 - Model registry
트레이닝부터 프로덕션까지 모델 생명주기를 관리하는 모델 레지스트리
W&B는 결국 W&B Model Registry에 대한 지원을 중단할 예정입니다. 사용자는 대신 모델 아티팩트 버전을 연결하고 공유하기 위해 W&B Registry를 사용하는 것이 좋습니다. W&B Registry는 기존 W&B Model Registry의 기능을 확장합니다. W&B Registry에 대한 자세한 내용은 Registry 문서를 참조하세요.
W&B는 기존 Model Registry에 연결된 기존 모델 아티팩트를 가까운 시일 내에 새로운 W&B Registry로 마이그레이션할 예정입니다. 마이그레이션 프로세스에 대한 자세한 내용은 기존 Model Registry에서 마이그레이션을 참조하세요.
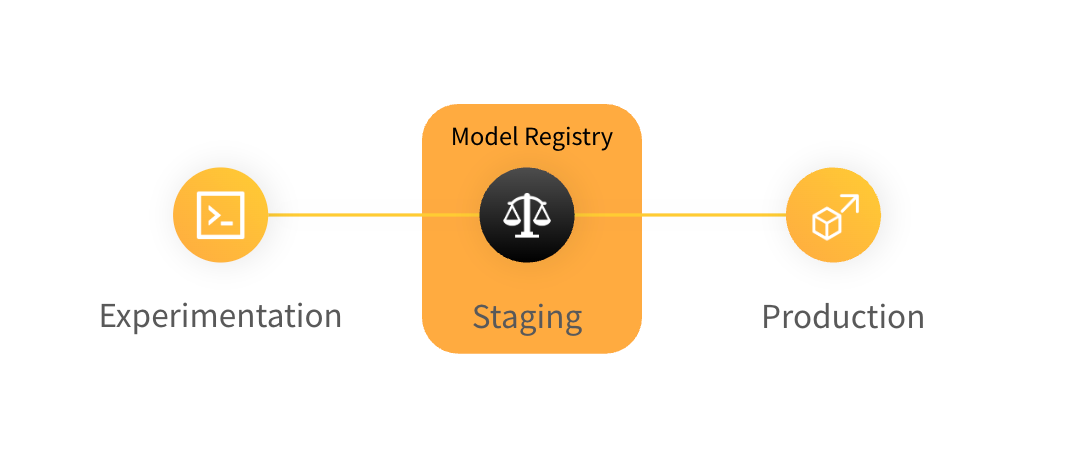
W&B Model Registry는 팀의 트레이닝된 모델을 보관하는 곳으로, ML 전문가가 프로덕션 후보를 게시하여 다운스트림 팀과 이해 관계자가 사용할 수 있습니다. 스테이징된/후보 모델을 보관하고 스테이징과 관련된 워크플로우를 관리하는 데 사용됩니다.
모델 버전 로깅: 트레이닝 스크립트에서 몇 줄의 코드를 추가하여 모델 파일을 아티팩트 로 W&B에 저장합니다.
성능 비교: 라이브 차트를 확인하여 모델 트레이닝 및 유효성 검사에서 메트릭 과 샘플 예측값을 비교합니다. 어떤 모델 버전이 가장 성능이 좋았는지 식별합니다.
레지스트리에 연결: Python에서 프로그래밍 방식으로 또는 W&B UI에서 대화식으로 등록된 모델에 연결하여 최상의 모델 버전을 북마크합니다.
다음 코드 조각은 모델을 Model Registry에 로깅하고 연결하는 방법을 보여줍니다.
import wandb
import random
# Start a new W&B runrun = wandb.init(project="models_quickstart")
# Simulate logging model metricsrun.log({"acc": random.random()})
# Create a simulated model filewith open("my_model.h5", "w") as f:
f.write("Model: "+ str(random.random()))
# Log and link the model to the Model Registryrun.link_model(path="./my_model.h5", registered_model_name="MNIST")
run.finish()
모델 전환을 CI/CD 워크플로우에 연결: 웹훅을 사용하여 워크플로우 단계를 통해 후보 모델을 전환하고 다운스트림 작업 자동화합니다.
W&B Model Registry를 사용하여 모델을 관리 및 버전 관리하고, 계보를 추적하고, 다양한 라이프사이클 단계를 거쳐 모델을 승격합니다.
웹훅을 사용하여 모델 관리 워크플로우를 자동화합니다.
모델 평가, 모니터링 및 배포를 위해 Model Registry가 모델 개발 라이프사이클의 외부 ML 시스템 및 툴 과 어떻게 통합되는지 확인하세요.
3.12.1 - Tutorial: Use W&B for model management
W&B를 사용해 모델 관리를 하는 방법을 알아보세요. (Model Management)
다음 가이드에서는 W&B에 모델을 기록하는 방법을 안내합니다. 이 가이드가 끝나면 다음을 수행할 수 있습니다.
MNIST 데이터셋과 Keras 프레임워크를 사용하여 모델을 만들고 트레이닝합니다.
트레이닝한 모델을 W&B project에 기록합니다.
사용된 데이터셋을 생성한 모델의 종속성으로 표시합니다.
해당 모델을 W&B Registry에 연결합니다.
레지스트리에 연결한 모델의 성능을 평가합니다.
모델 버전을 프로덕션 준비 완료로 표시합니다.
이 가이드에 제시된 순서대로 코드 조각을 복사하세요.
Model Registry에 고유하지 않은 코드는 접을 수 있는 셀에 숨겨져 있습니다.
설정
시작하기 전에 이 가이드에 필요한 Python 종속성을 가져옵니다.
import wandb
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from wandb.integration.keras import WandbMetricsLogger
from sklearn.model_selection import train_test_split
W&B entity를 entity 변수에 제공합니다.
entity ="<entity>"
데이터셋 아티팩트 생성
먼저 데이터셋을 만듭니다. 다음 코드 조각은 MNIST 데이터셋을 다운로드하는 함수를 생성합니다.
다음으로 데이터셋을 W&B에 업로드합니다. 이렇게 하려면 artifact 오브젝트를 생성하고 해당 아티팩트에 데이터셋을 추가합니다.
project ="model-registry-dev"model_use_case_id ="mnist"job_type ="build_dataset"# W&B run 초기화run = wandb.init(entity=entity, project=project, job_type=job_type)
# 트레이닝 데이터를 위한 W&B 테이블 생성train_table = wandb.Table(data=[], columns=[])
train_table.add_column("x_train", x_train)
train_table.add_column("y_train", y_train)
train_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_train"])})
# 평가 데이터를 위한 W&B 테이블 생성eval_table = wandb.Table(data=[], columns=[])
eval_table.add_column("x_eval", x_eval)
eval_table.add_column("y_eval", y_eval)
eval_table.add_computed_columns(lambda ndx, row: {"img": wandb.Image(row["x_eval"])})
# 아티팩트 오브젝트 생성artifact_name ="{}_dataset".format(model_use_case_id)
artifact = wandb.Artifact(name=artifact_name, type="dataset")
# wandb.WBValue obj를 아티팩트에 추가artifact.add(train_table, "train_table")
artifact.add(eval_table, "eval_table")
# 아티팩트에 대한 변경 사항을 유지합니다.artifact.save()
# W&B에 이 run이 완료되었음을 알립니다.run.finish()
아티팩트에 파일(예: 데이터셋)을 저장하는 것은 모델의 종속성을 추적할 수 있으므로 모델 로깅 컨텍스트에서 유용합니다.
모델 트레이닝
이전 단계에서 생성한 아티팩트 데이터셋으로 모델을 트레이닝합니다.
데이터셋 아티팩트를 run에 대한 입력으로 선언
이전 단계에서 생성한 데이터셋 아티팩트를 W&B run에 대한 입력으로 선언합니다. 아티팩트를 run에 대한 입력으로 선언하면 특정 모델을 트레이닝하는 데 사용된 데이터셋(및 데이터셋 버전)을 추적할 수 있으므로 모델 로깅 컨텍스트에서 특히 유용합니다. W&B는 수집된 정보를 사용하여 lineage map을 만듭니다.
use_artifact API를 사용하여 데이터셋 아티팩트를 run의 입력으로 선언하고 아티팩트 자체를 검색합니다.
평가할 W&B의 model version을 다운로드합니다. use_model API를 사용하여 모델에 엑세스하고 다운로드합니다.
alias ="latest"# 에일리어스name ="mnist_model"# 모델 아티팩트 이름# 모델에 엑세스하고 다운로드합니다. 다운로드한 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name=f"{name}:{alias}")
# # 메트릭, 이미지, 테이블 또는 평가에 유용한 모든 데이터를 기록합니다.run.log(data={"loss": (loss, _)})
모델 버전 승격
model alias를 사용하여 기계 학습 워크플로우의 다음 단계를 위해 모델 버전을 준비 완료로 표시합니다. 각 registered model에는 하나 이상의 model alias가 있을 수 있습니다. model alias는 한 번에 하나의 model version에만 속할 수 있습니다.
예를 들어, 모델의 성능을 평가한 후 모델이 프로덕션 준비가 되었다고 확신한다고 가정합니다. 해당 모델 버전을 승격하려면 해당 특정 model version에 production 에일리어스를 추가합니다.
production 에일리어스는 모델을 프로덕션 준비로 표시하는 데 사용되는 가장 일반적인 에일리어스 중 하나입니다.
W&B App UI를 사용하여 대화형으로 또는 Python SDK를 사용하여 프로그래밍 방식으로 model version에 에일리어스를 추가할 수 있습니다. 다음 단계에서는 W&B Model Registry App을 사용하여 에일리어스를 추가하는 방법을 보여줍니다.
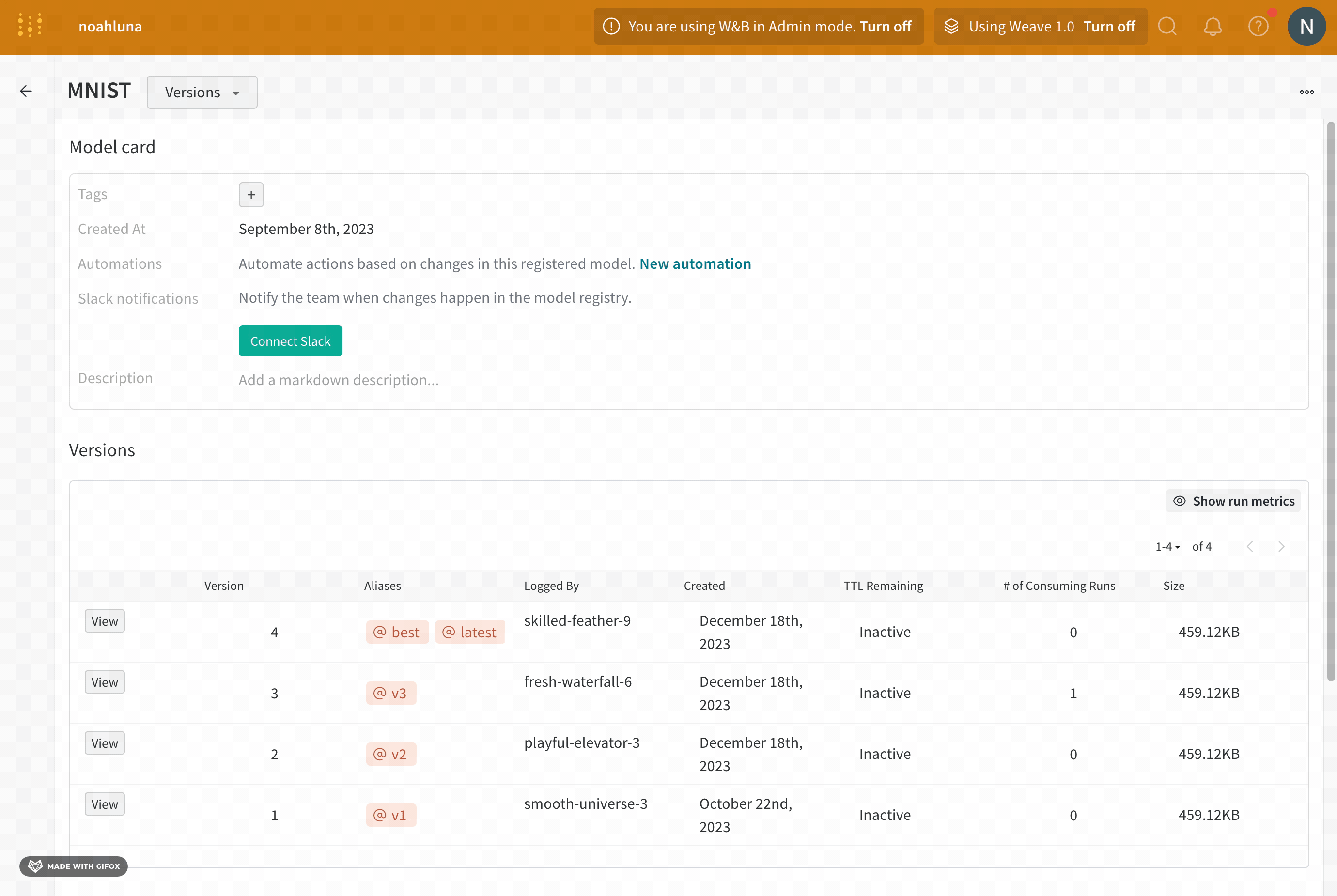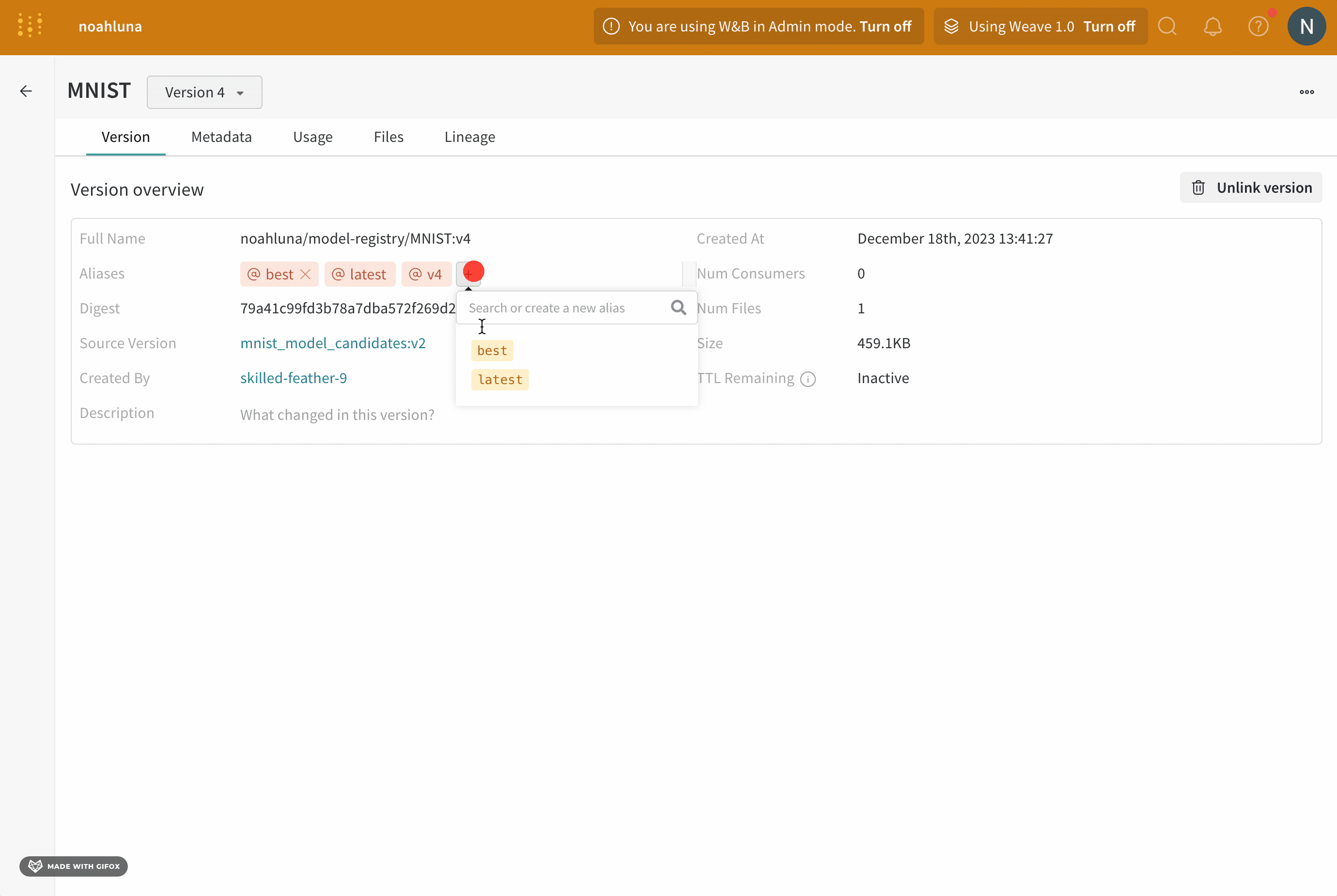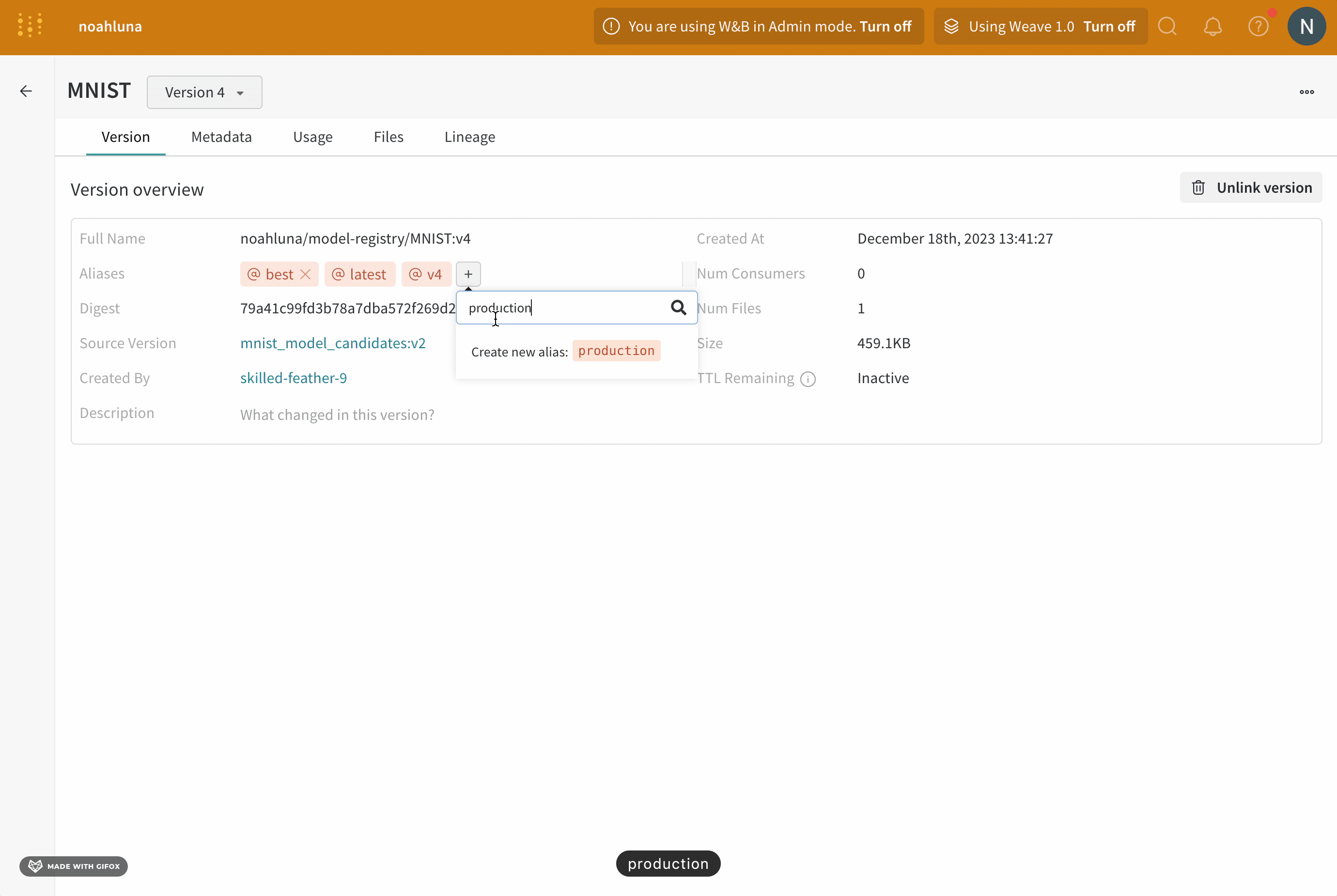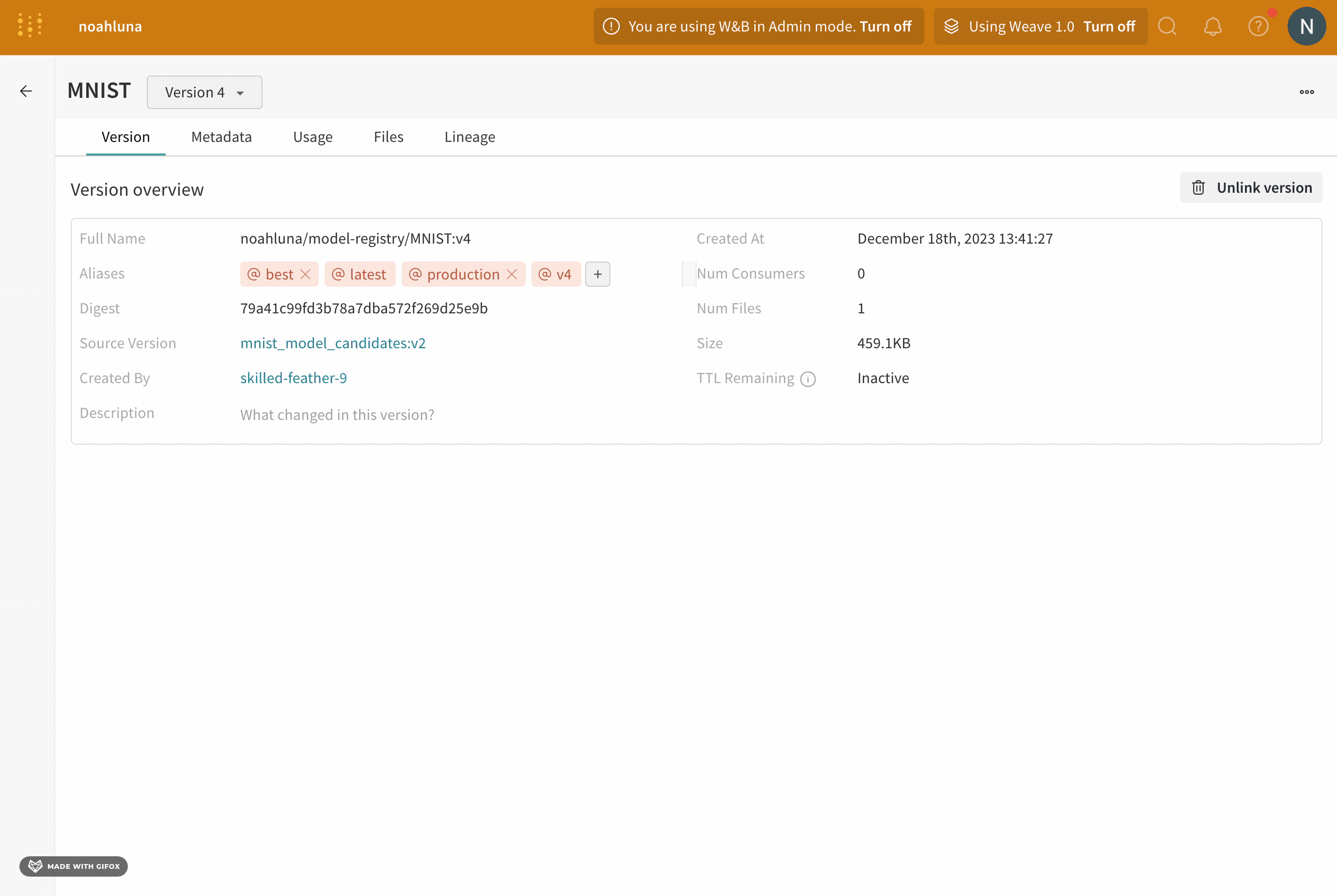
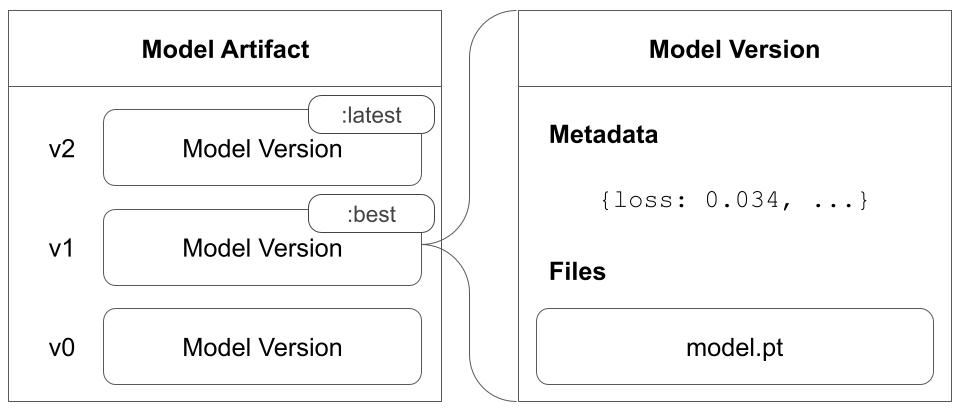
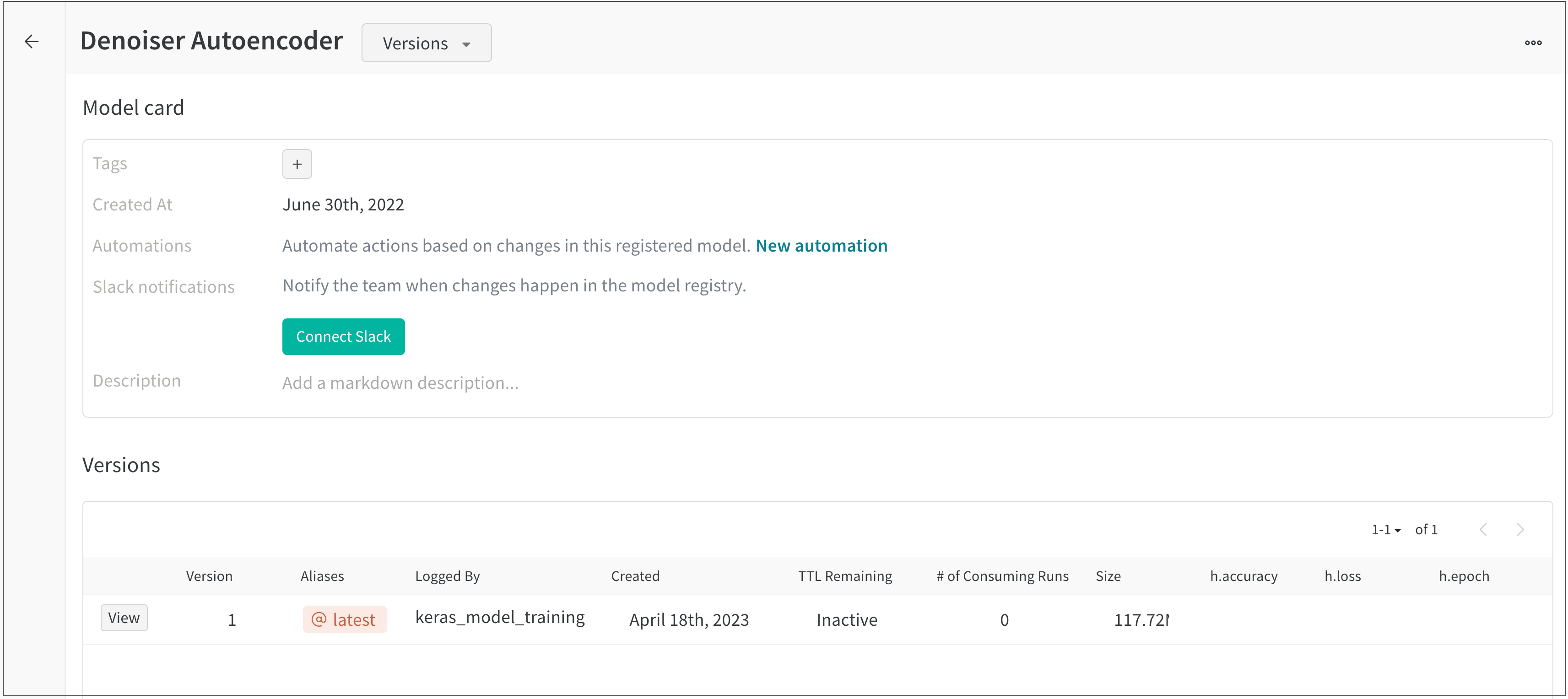
모델 버전은 단일 모델 체크포인트를 나타냅니다. 모델 버전은 실험 내에서 특정 시점의 모델과 해당 파일의 스냅샷입니다.
모델 버전은 학습된 모델을 설명하는 데이터 및 메타데이터의 변경 불가능한 디렉토리입니다. W&B는 모델 아키텍처와 학습된 파라미터를 나중에 저장하고 복원할 수 있도록 모델 버전에 파일을 추가할 것을 제안합니다.
모델 버전은 하나의 model artifact에만 속합니다. 모델 버전은 0개 이상의 registered models에 속할 수 있습니다. 모델 버전은 모델 아티팩트에 기록된 순서대로 모델 아티팩트에 저장됩니다. W&B는 (동일한 model artifact에) 기록하는 모델이 이전 모델 버전과 다른 콘텐츠를 가지고 있음을 감지하면 자동으로 새 모델 버전을 생성합니다.
모델링 라이브러리에서 제공하는 직렬화 프로세스에서 생성된 파일을 모델 버전 내에 저장합니다(예: PyTorch 및 Keras).
Model alias
모델 에일리어스는 등록된 모델에서 모델 버전을 의미적으로 관련된 식별자로 고유하게 식별하거나 참조할 수 있도록 하는 변경 가능한 문자열입니다. 에일리어스는 등록된 모델의 한 버전에만 할당할 수 있습니다. 이는 에일리어스가 프로그래밍 방식으로 사용될 때 고유한 버전을 참조해야 하기 때문입니다. 또한 에일리어스를 사용하여 모델의 상태(챔피언, 후보, production)를 캡처할 수 있습니다.
"best", "latest", "production" 또는 "staging"과 같은 에일리어스를 사용하여 특수 목적을 가진 모델 버전을 표시하는 것이 일반적입니다.
예를 들어 모델을 만들고 "best" 에일리어스를 할당한다고 가정합니다. run.use_model로 특정 모델을 참조할 수 있습니다.
import wandb
run = wandb.init()
name =f"{entity/project/model_artifact_name}:{alias}"run.use_model(name=name)
Model tags
모델 태그는 하나 이상의 registered models에 속하는 키워드 또는 레이블입니다.
모델 태그를 사용하여 registered models를 카테고리로 구성하고 Model Registry의 검색 창에서 해당 카테고리를 검색합니다. 모델 태그는 Registered Model Card 상단에 나타납니다. ML 작업, 소유 팀 또는 우선 순위별로 registered models를 그룹화하는 데 사용할 수 있습니다. 그룹화를 위해 동일한 모델 태그를 여러 registered models에 추가할 수 있습니다.
그룹화 및 검색 가능성을 위해 registered models에 적용되는 레이블인 모델 태그는 model aliases와 다릅니다. 모델 에일리어스는 모델 버전을 프로그래밍 방식으로 가져오는 데 사용하는 고유 식별자 또는 별칭입니다. 태그를 사용하여 Model Registry에서 작업을 구성하는 방법에 대한 자세한 내용은 모델 구성을 참조하세요.
Model artifact
Model artifact는 기록된 model versions의 모음입니다. 모델 버전은 모델 아티팩트에 기록된 순서대로 모델 아티팩트에 저장됩니다.
Model artifact는 하나 이상의 모델 버전을 포함할 수 있습니다. 모델 버전을 기록하지 않으면 Model artifact는 비어 있을 수 있습니다.
예를 들어, Model artifact를 만든다고 가정합니다. 모델 트레이닝 중에 체크포인트 중에 모델을 주기적으로 저장합니다. 각 체크포인트는 자체 model version에 해당합니다. 모델 트레이닝 및 체크포인트 저장 중에 생성된 모든 모델 버전은 트레이닝 스크립트 시작 시 생성한 동일한 Model artifact에 저장됩니다.
다음 이미지는 v0, v1 및 v2의 세 가지 모델 버전을 포함하는 Model artifact를 보여줍니다.
Registered model은 모델 버전에 대한 포인터(링크) 모음입니다. Registered model을 동일한 ML 작업에 대한 후보 모델의 “북마크” 폴더라고 생각할 수 있습니다. Registered model의 각 “북마크"는 model artifact에 속한 model version에 대한 포인터입니다. Model tags를 사용하여 Registered models를 그룹화할 수 있습니다.
Registered models는 종종 단일 모델링 유스 케이스 또는 작업에 대한 후보 모델을 나타냅니다. 예를 들어 사용하는 모델을 기반으로 다양한 이미지 분류 작업에 대해 Registered model을 만들 수 있습니다. ImageClassifier-ResNet50, ImageClassifier-VGG16, DogBreedClassifier-MobileNetV2 등. 모델 버전은 Registered model에 연결된 순서대로 버전 번호가 할당됩니다.
import wandb
run = wandb.init(entity="<entity>", project="<project>")
run.link_model(path="<path-to-model>", registered_model_name="<registered-model-name>")
run.finish()
registered-model-name 파라미터에 지정한 이름이 아직 존재하지 않는 경우, W&B가 등록된 모델을 생성합니다.
예를 들어, Model Registry에 “Fine-Tuned-Review-Autocompletion”(registered-model-name="Fine-Tuned-Review-Autocompletion")이라는 등록된 모델이 이미 있다고 가정합니다. 그리고 몇몇 모델 버전이 연결되어 있다고 가정합니다: v0, v1, v2. 새로운 모델을 프로그램 방식으로 연결하고 동일한 등록된 모델 이름(registered-model-name="Fine-Tuned-Review-Autocompletion")을 사용하면, W&B는 이 모델을 기존 등록된 모델에 연결하고 모델 버전 v3을 할당합니다. 이 이름으로 등록된 모델이 없으면 새로운 등록된 모델이 생성되고 모델 버전 v0을 갖게 됩니다.
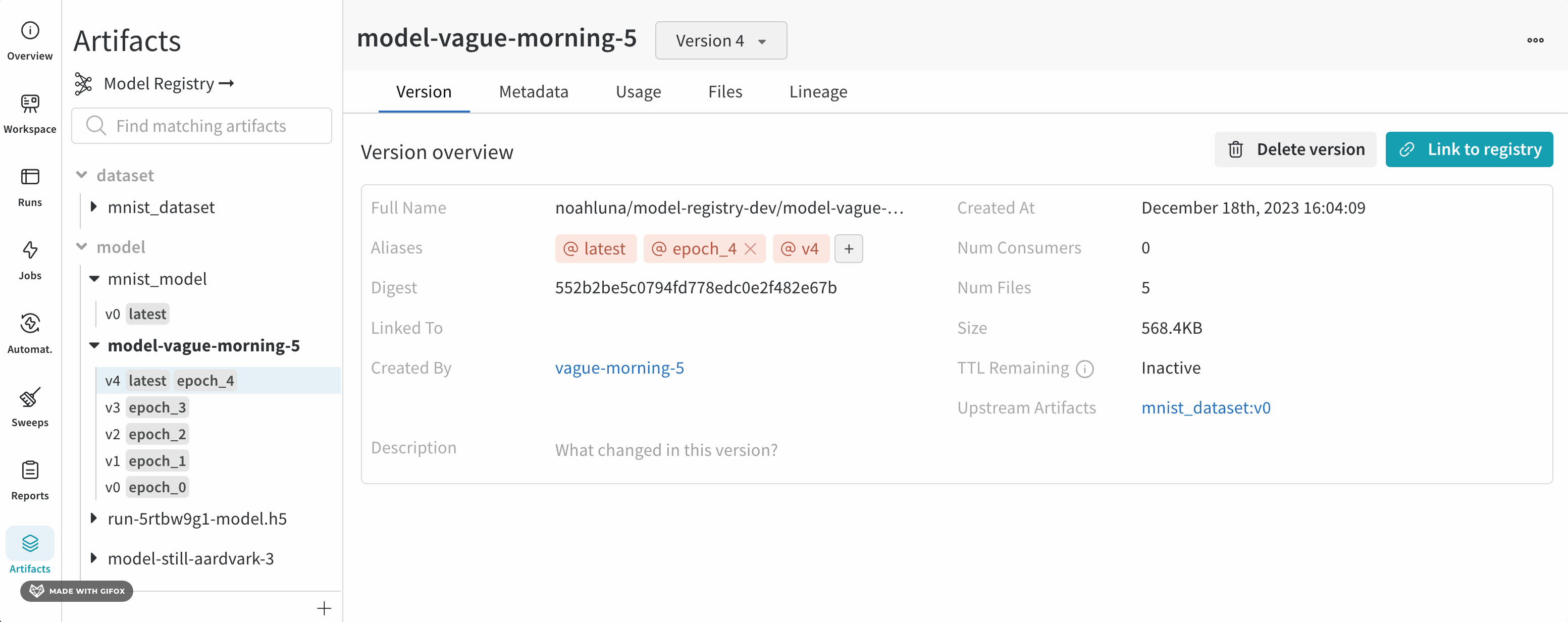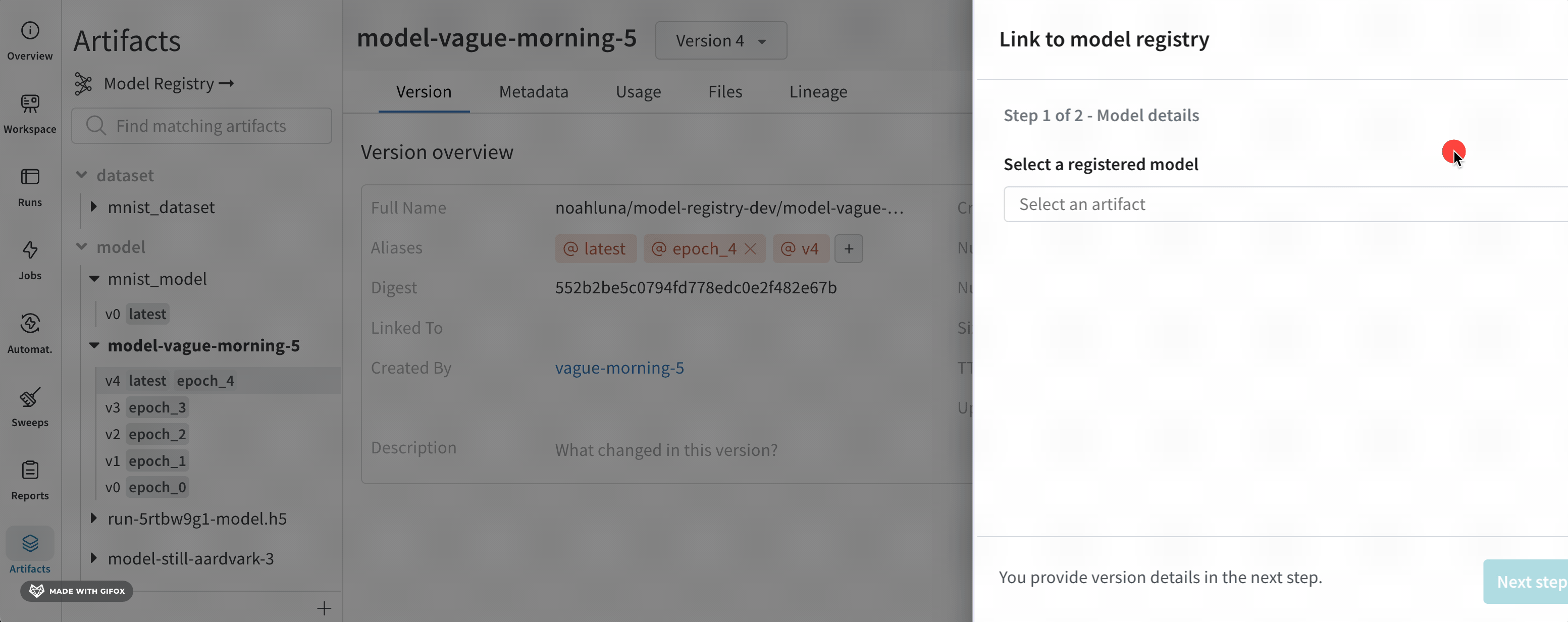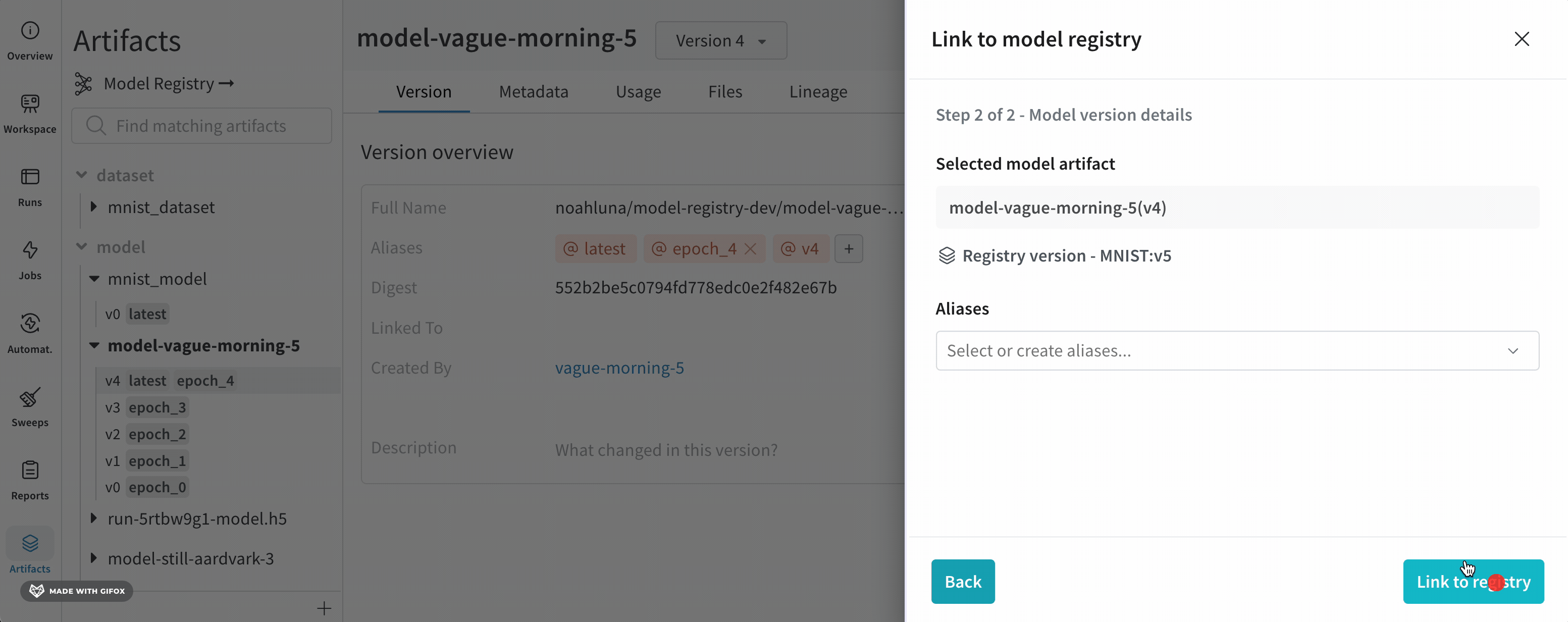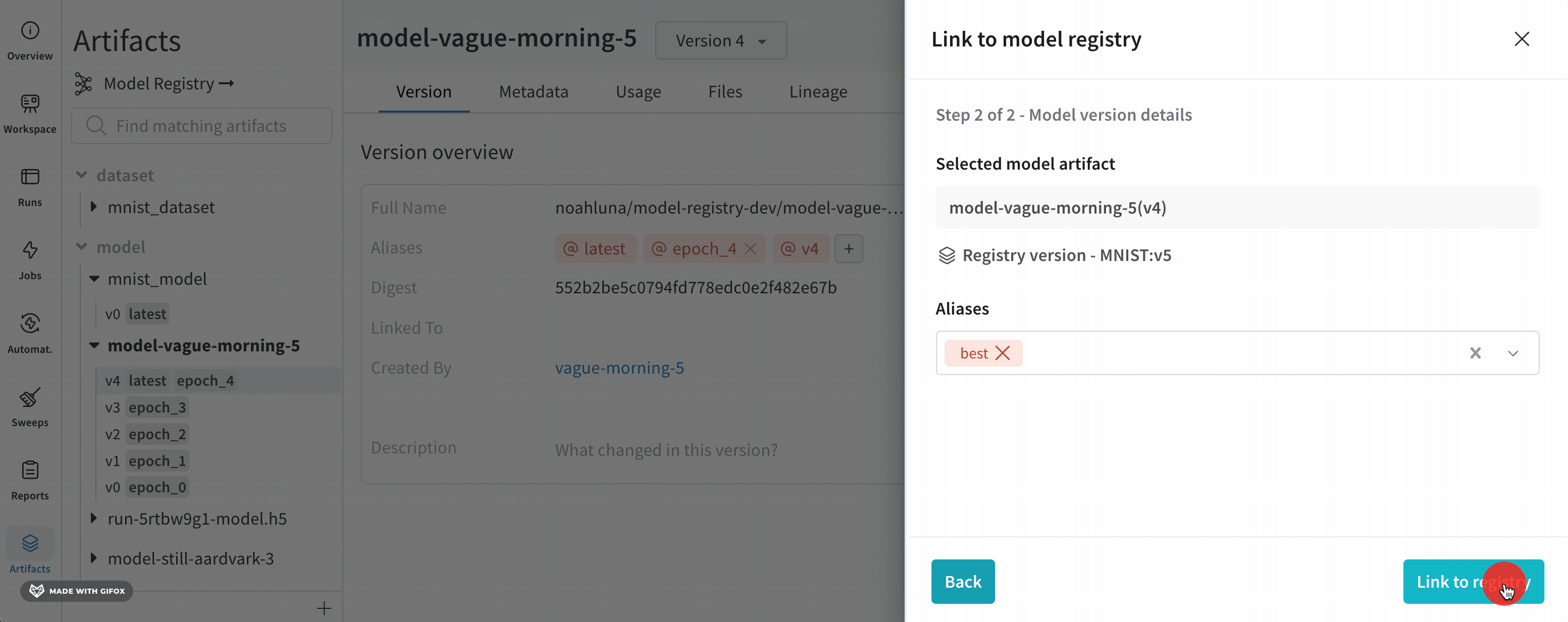
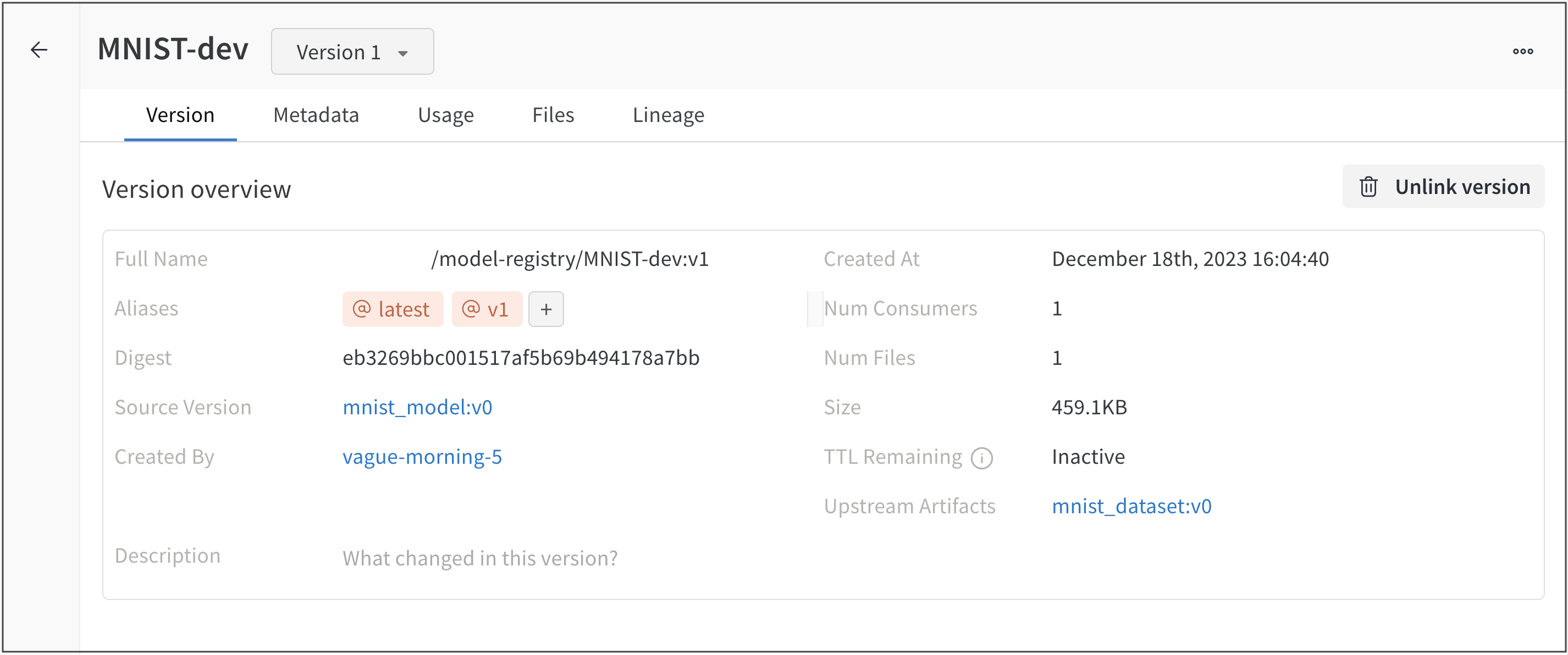
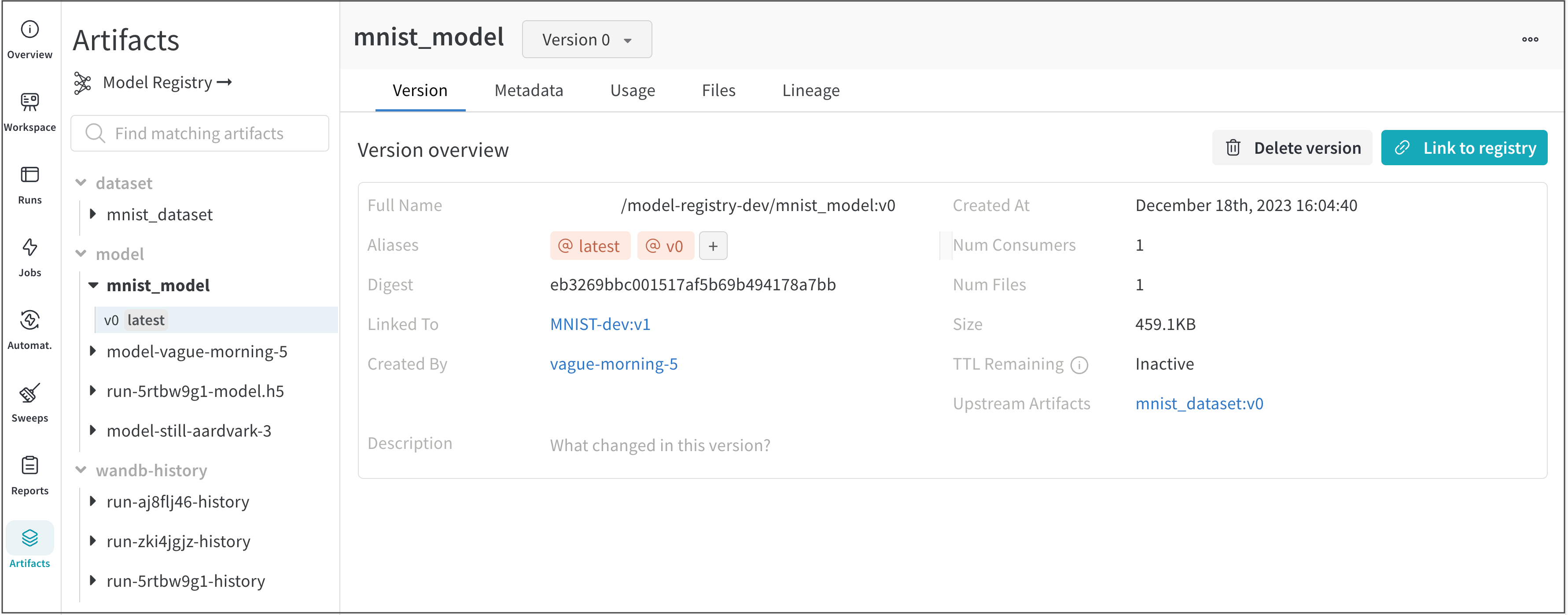
vague-morning-5 W&B run은 mnist_dataset:v0 데이터셋 아티팩트를 사용하여 모델을 트레이닝했습니다. 이 W&B run의 출력은 mnist_model:v0라는 모델 아티팩트였습니다.
serene-haze-6이라는 run은 모델 아티팩트(mnist_model:v0)를 사용하여 모델을 평가했습니다.
아티팩트 종속성 추적
use_artifact API를 사용하여 데이터셋 아티팩트를 W&B run에 대한 입력으로 선언하여 종속성을 추적합니다.
다음 코드 조각은 use_artifact API를 사용하는 방법을 보여줍니다.
# Initialize a runrun = wandb.init(project=project, entity=entity)
# Get artifact, mark it as a dependencyartifact = run.use_artifact(artifact_or_name="name", aliases="<alias>")
아티팩트를 검색한 후에는 해당 아티팩트를 사용하여 (예를 들어) 모델의 성능을 평가할 수 있습니다.
예시: 모델을 트레이닝하고 데이터셋을 모델의 입력으로 추적
job_type ="train_model"config = {
"optimizer": "adam",
"batch_size": 128,
"epochs": 5,
"validation_split": 0.1,
}
run = wandb.init(project=project, job_type=job_type, config=config)
version ="latest"name ="{}:{}".format("{}_dataset".format(model_use_case_id), version)
artifact = run.use_artifact(name)
train_table = artifact.get("train_table")
x_train = train_table.get_column("x_train", convert_to="numpy")
y_train = train_table.get_column("y_train", convert_to="numpy")
# Store values from our config dictionary into variables for easy accessingnum_classes =10input_shape = (28, 28, 1)
loss ="categorical_crossentropy"optimizer = run.config["optimizer"]
metrics = ["accuracy"]
batch_size = run.config["batch_size"]
epochs = run.config["epochs"]
validation_split = run.config["validation_split"]
# Create model architecturemodel = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# Generate labels for training datay_train = keras.utils.to_categorical(y_train, num_classes)
# Create training and test setx_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size=0.33)
# Train the modelmodel.fit(
x=x_t,
y=y_t,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_v, y_v),
callbacks=[WandbCallback(log_weights=True, log_evaluation=True)],
)
# Save model locallypath ="model.h5"model.save(path)
path ="./model.h5"registered_model_name ="MNIST-dev"name ="mnist_model"run.link_model(path=path, registered_model_name=registered_model_name, name=name)
run.finish()
3.12.8 - Document machine learning model
모델 카드에 설명을 추가하여 모델을 문서화하세요.
등록된 모델의 모델 카드에 설명을 추가하여 머신러닝 모델의 여러 측면을 문서화하세요. 문서화할 가치가 있는 몇 가지 주제는 다음과 같습니다.
요약: 모델에 대한 요약입니다. 모델의 목적, 모델이 사용하는 머신러닝 프레임워크 등입니다.
트레이닝 데이터: 사용된 트레이닝 데이터, 트레이닝 데이터 세트에 대해 수행된 처리, 해당 데이터가 저장된 위치 등을 설명합니다.
아키텍처: 모델 아키텍처, 레이어 및 특정 설계 선택에 대한 정보입니다.
모델 역직렬화: 팀 구성원이 모델을 메모리에 로드하는 방법에 대한 정보를 제공합니다.
Task: 머신러닝 모델이 수행하도록 설계된 특정 유형의 Task 또는 문제입니다. 모델의 의도된 기능을 분류한 것입니다.
라이선스: 머신러닝 모델 사용과 관련된 법적 조건 및 권한입니다. 이를 통해 모델 사용자는 모델을 활용할 수 있는 법적 프레임워크를 이해할 수 있습니다.
참조: 관련 연구 논문, 데이터셋 또는 외부 리소스에 대한 인용 또는 참조입니다.
배포: 모델이 배포되는 방식 및 위치에 대한 세부 정보와 워크플로우 오케스트레이션 플랫폼과 같은 다른 엔터프라이즈 시스템에 모델을 통합하는 방법에 대한 지침입니다.
Description 필드 내에 머신러닝 모델에 대한 정보를 제공합니다. Markdown 마크업 언어를 사용하여 모델 카드 내에서 텍스트 서식을 지정합니다.
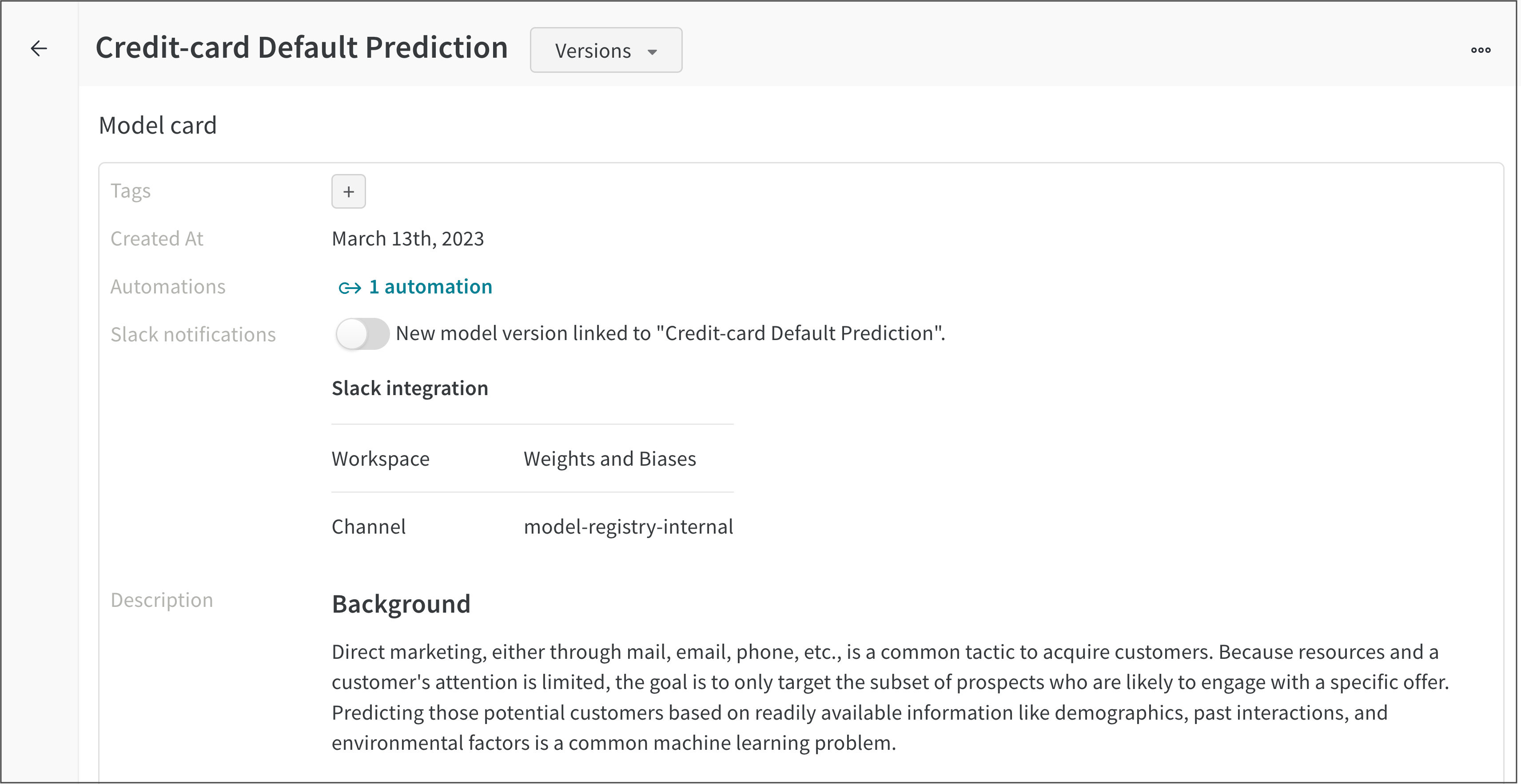
예를 들어 다음 이미지는 신용카드 채무 불이행 예측 등록 모델의 모델 카드를 보여줍니다.
3.12.9 - Download a model version
W&B Python SDK로 모델을 다운로드하는 방법
W&B Python SDK를 사용하여 Model Registry에 연결한 모델 아티팩트를 다운로드합니다.
모델을 재구성하고, 역직렬화하여 사용할 수 있는 형태로 만들려면 추가적인 Python 함수와 API 호출을 제공해야 합니다.
W&B에서는 모델을 메모리에 로드하는 방법에 대한 정보를 모델 카드를 통해 문서화할 것을 권장합니다. 자세한 내용은 기계 학습 모델 문서화 페이지를 참조하세요.
<> 안의 값을 직접 변경하세요:
import wandb
# run 초기화run = wandb.init(project="<project>", entity="<entity>")
# 모델에 엑세스하고 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name="<your-model-name>")
다음 형식 중 하나를 사용하여 모델 버전을 참조하세요:
latest - 가장 최근에 연결된 모델 버전을 지정하려면 latest 에일리어스를 사용합니다.
v# - Registered Model에서 특정 버전을 가져오려면 v0, v1, v2 등을 사용합니다.
alias - 팀에서 모델 버전에 할당한 사용자 지정 에일리어스를 지정합니다.
가능한 파라미터 및 반환 유형에 대한 자세한 내용은 API Reference 가이드의 use_model을 참조하세요.
예시: 기록된 모델 다운로드 및 사용
예를 들어, 다음 코드 조각에서 사용자는 use_model API를 호출했습니다. 가져오려는 모델 아티팩트의 이름을 지정하고 버전/에일리어스도 제공했습니다. 그런 다음 API에서 반환된 경로를 downloaded_model_path 변수에 저장했습니다.
import wandb
entity ="luka"project ="NLP_Experiments"alias ="latest"# 모델 버전에 대한 시맨틱 닉네임 또는 식별자model_artifact_name ="fine-tuned-model"# run 초기화run = wandb.init()
# 모델에 엑세스하고 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name=f"{entity/project/model_artifact_name}:{alias}")
2024년 W&B Model Registry 지원 중단 예정
다음 탭은 곧 지원이 중단될 Model Registry를 사용하여 모델 아티팩트를 사용하는 방법을 보여줍니다.
W&B Registry를 사용하여 모델 아티팩트를 추적, 구성 및 사용합니다. 자세한 내용은 Registry 문서를 참조하세요.
<> 안의 값을 직접 변경하세요:
import wandb
# run 초기화run = wandb.init(project="<project>", entity="<entity>")
# 모델에 엑세스하고 다운로드합니다. 다운로드된 아티팩트의 경로를 반환합니다.downloaded_model_path = run.use_model(name="<your-model-name>")
다음 형식 중 하나를 사용하여 모델 버전을 참조하세요:
latest - 가장 최근에 연결된 모델 버전을 지정하려면 latest 에일리어스를 사용합니다.
v# - Registered Model에서 특정 버전을 가져오려면 v0, v1, v2 등을 사용합니다.
alias - 팀에서 모델 버전에 할당한 사용자 지정 에일리어스를 지정합니다.
가능한 파라미터 및 반환 유형에 대한 자세한 내용은 API Reference 가이드의 use_model을 참조하세요.
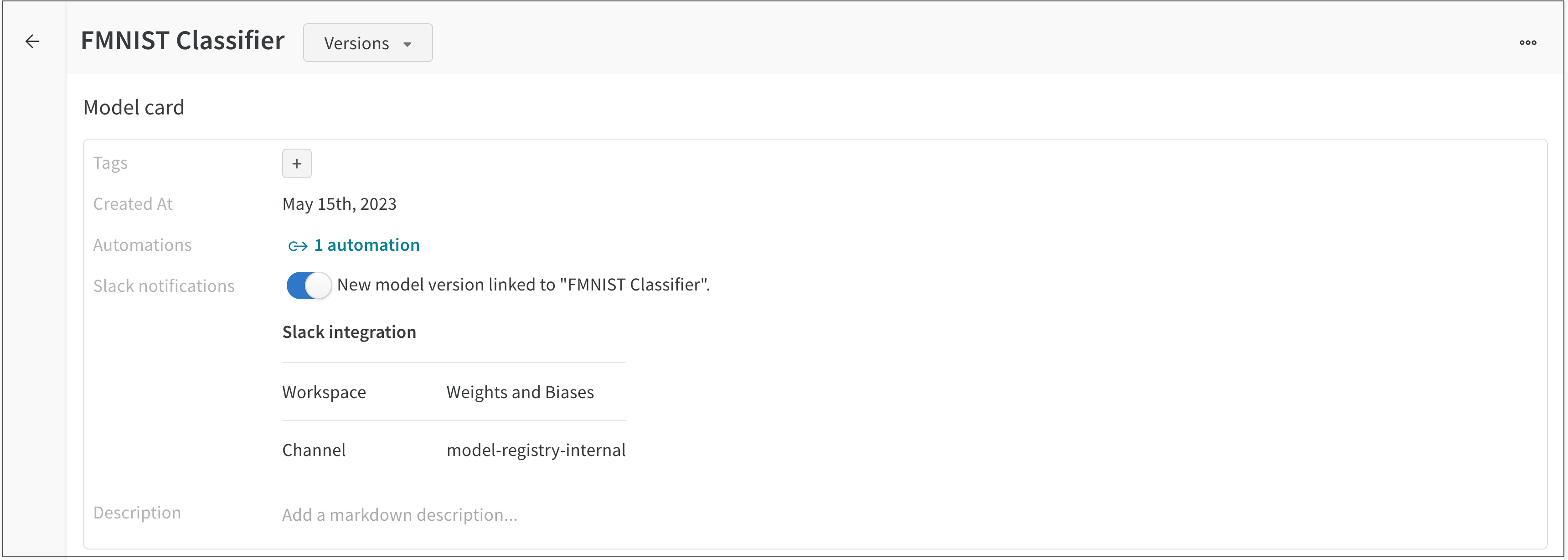
OAuth 페이지에 나타나는 지침에 따라 Slack workspace에서 W&B를 활성화합니다.
팀에 대한 Slack 알림을 구성했으면 알림을 받을 Registered Model을 선택할 수 있습니다.
팀에 대해 Slack 알림을 구성한 경우 Connect Slack 버튼 대신 New model version linked to… 토글이 나타납니다.
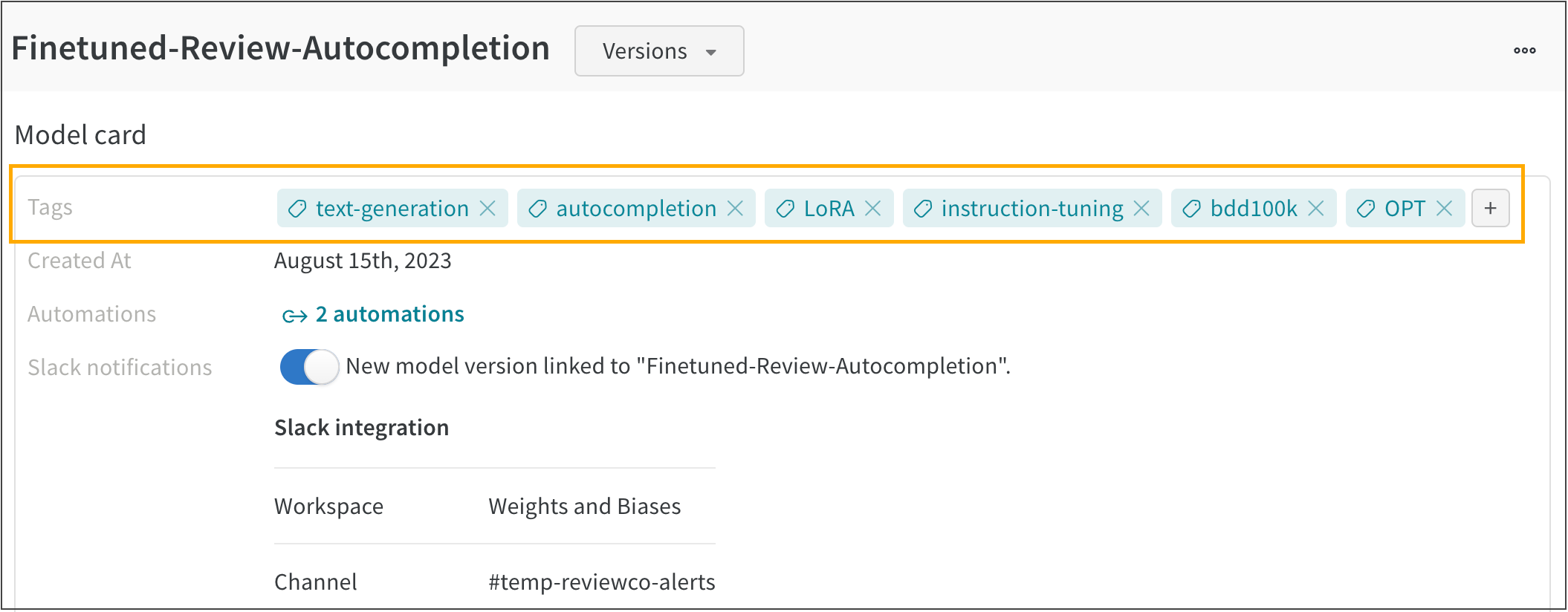
아래 스크린샷은 Slack 알림이 있는 FMNIST 분류기 Registered Model을 보여줍니다.
새로운 모델 버전이 FMNIST 분류기 Registered Model에 연결될 때마다 연결된 Slack 채널에 메시지가 자동으로 게시됩니다.
3.12.11 - Manage data governance and access control
모델 레지스트리 역할 기반 엑세스 제어(RBAC)를 사용하여 보호된 에일리어스를 업데이트할 수 있는 사람을 제어합니다.
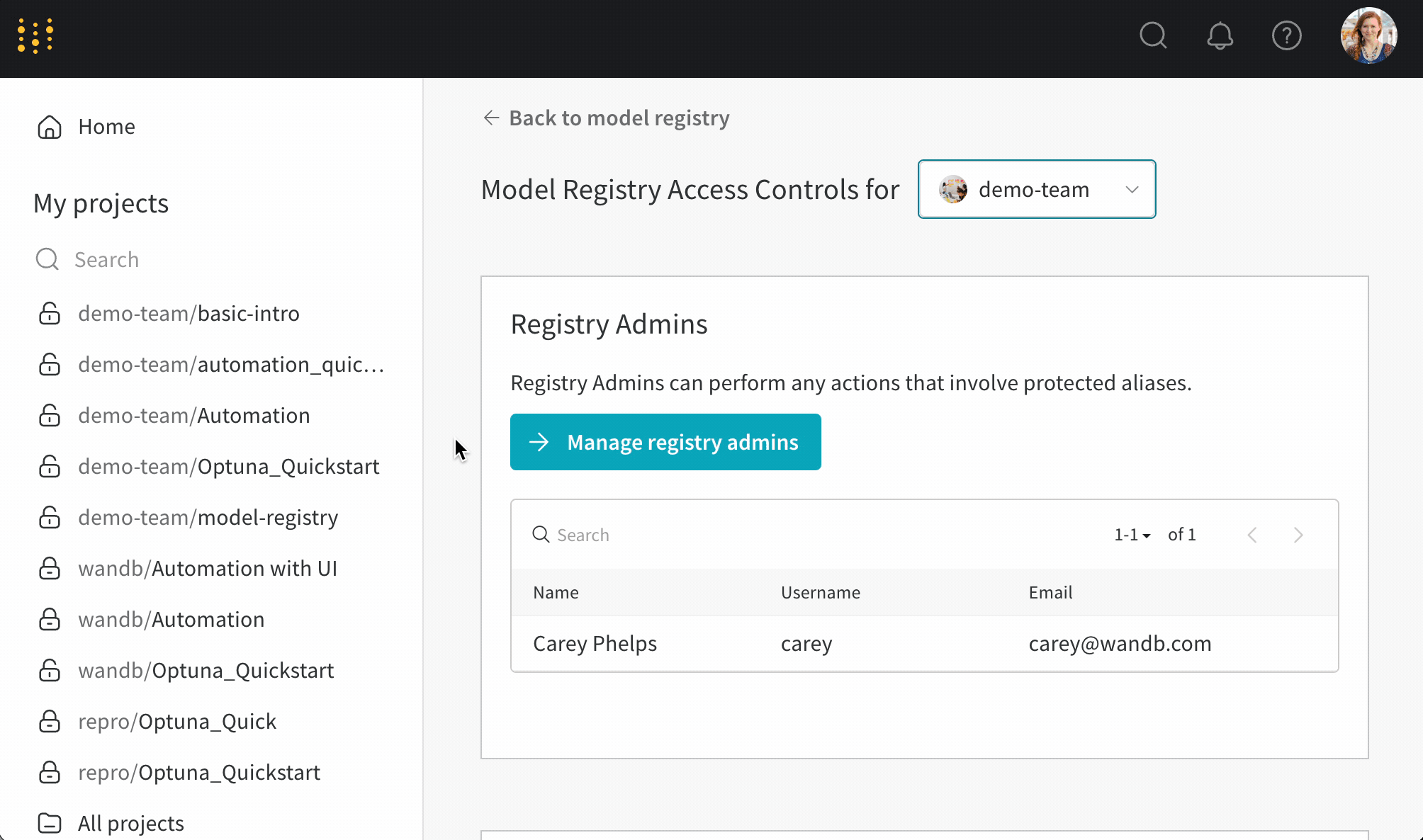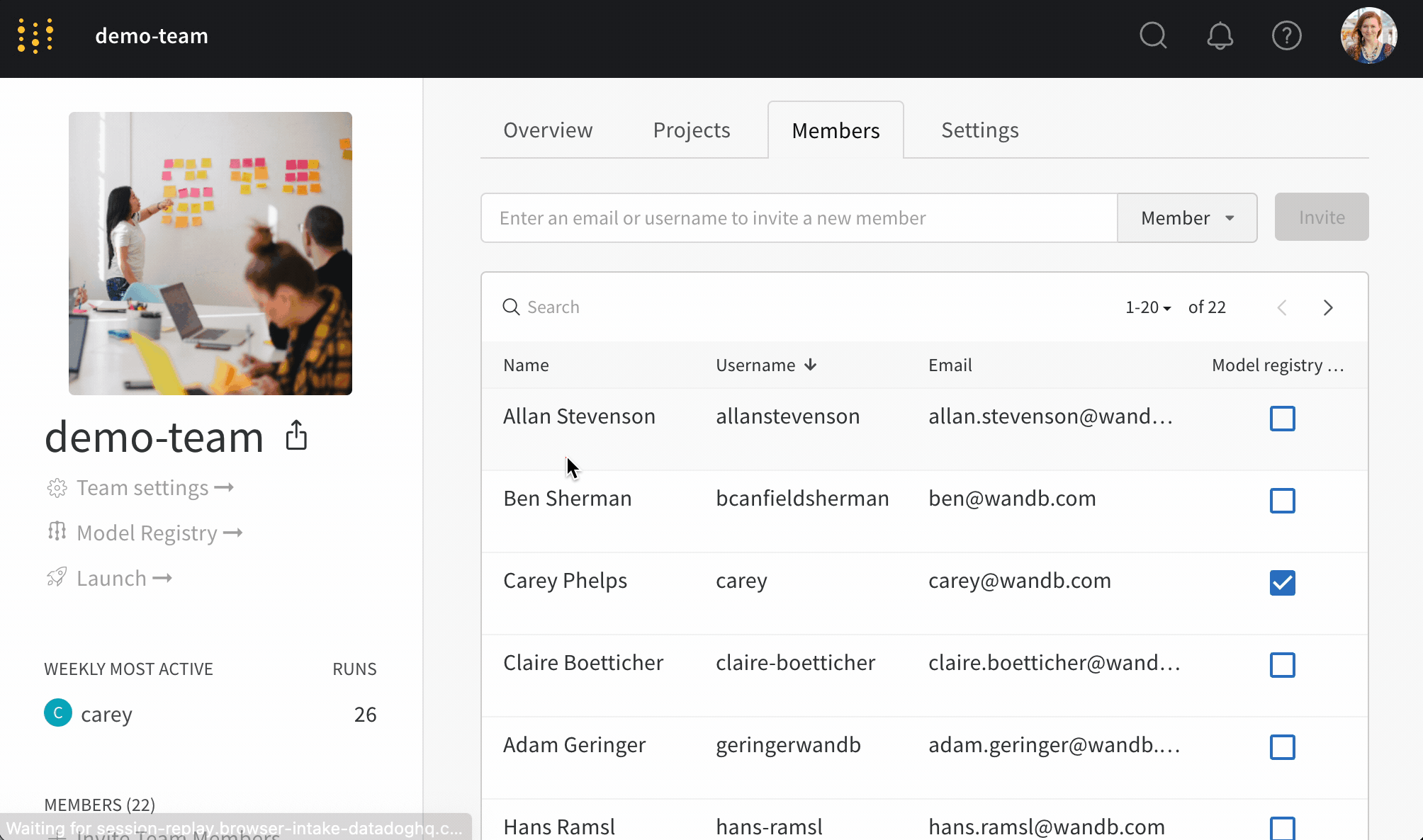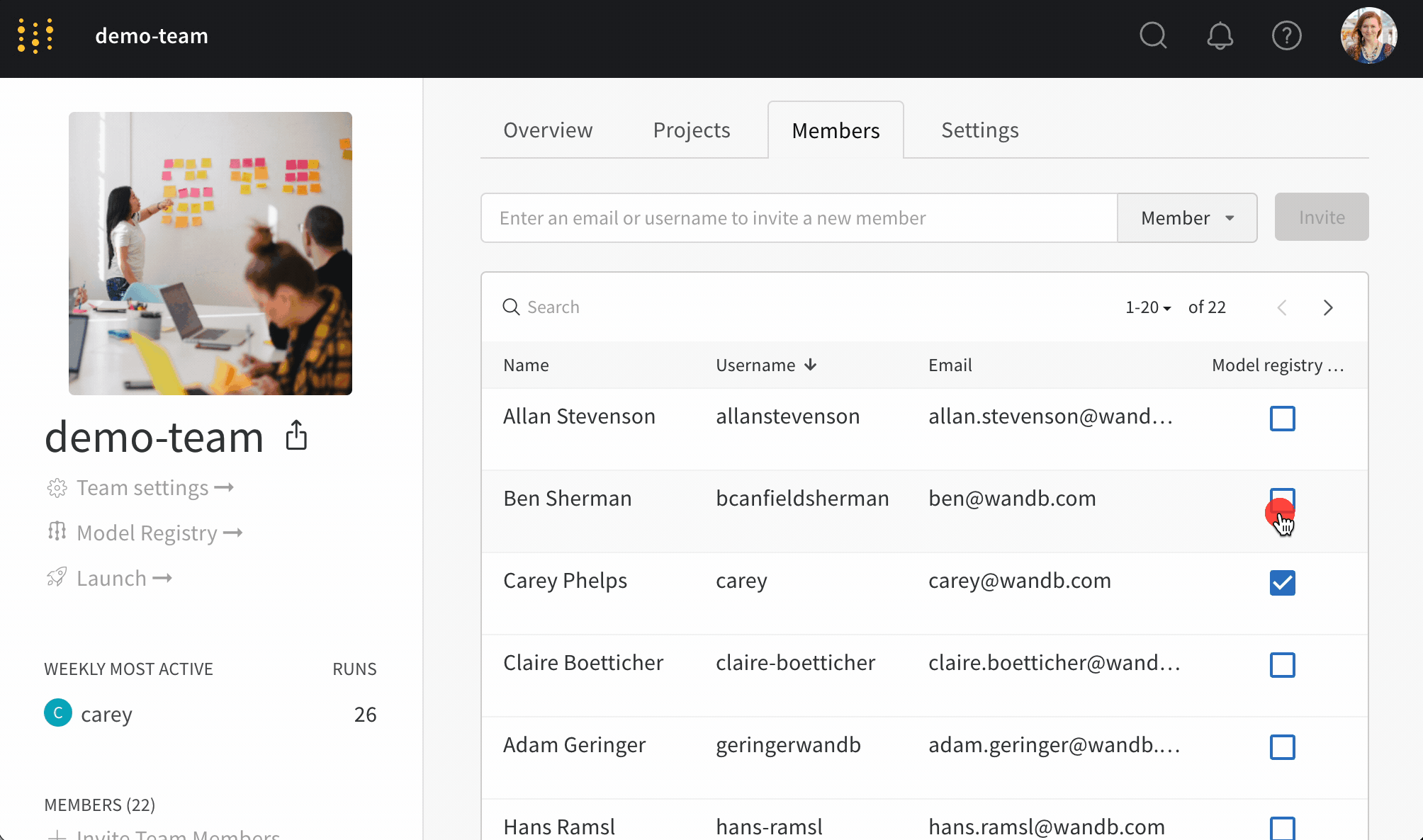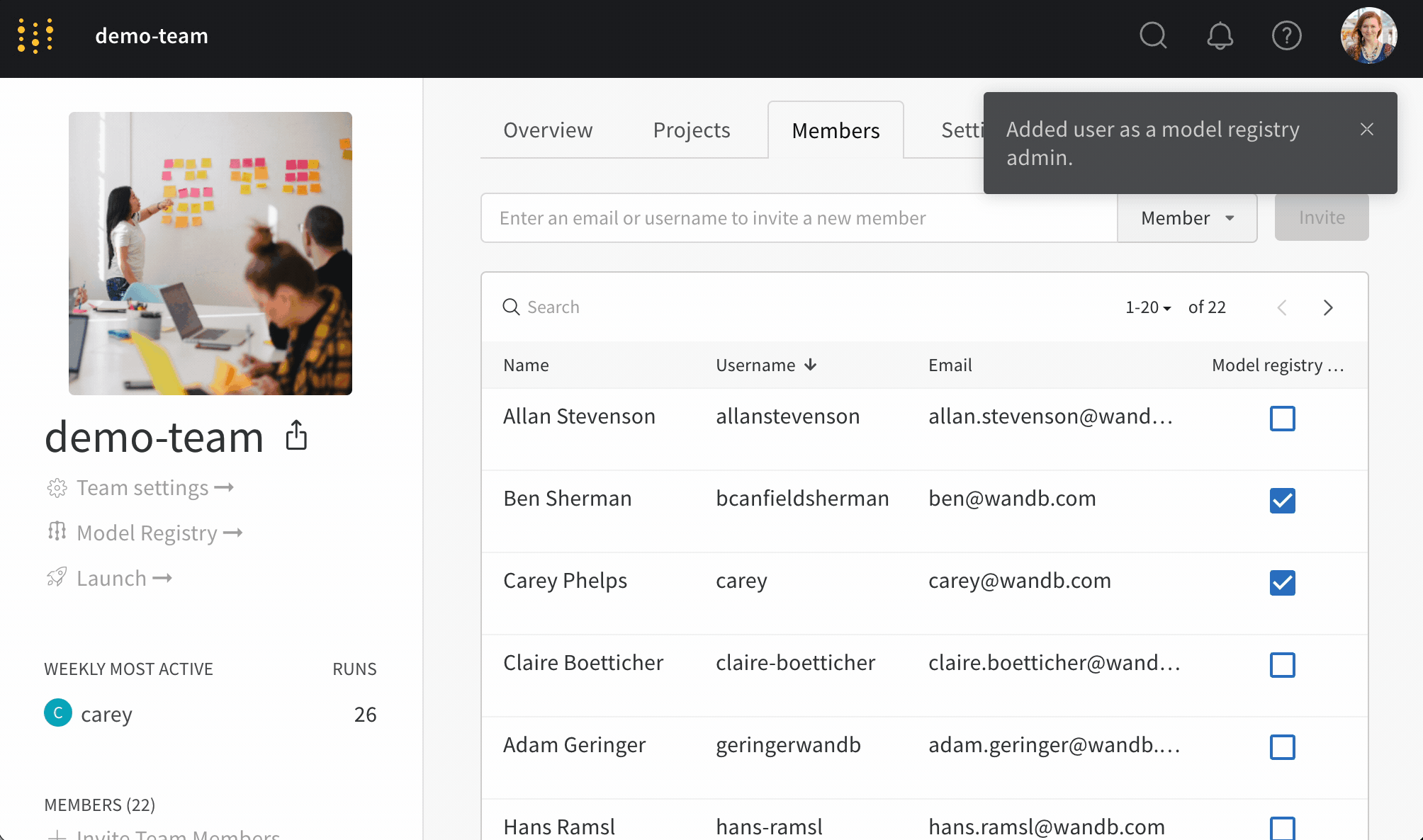
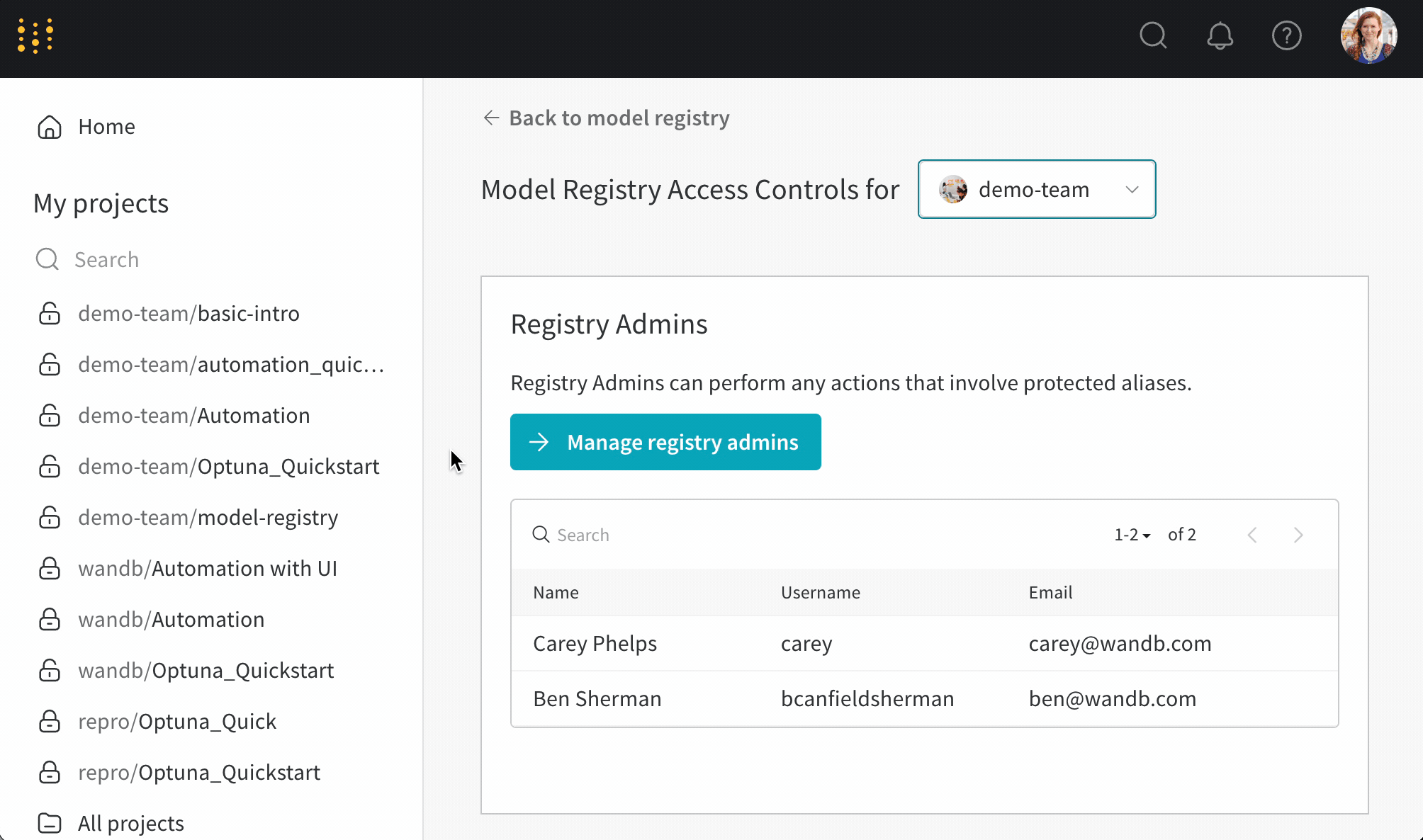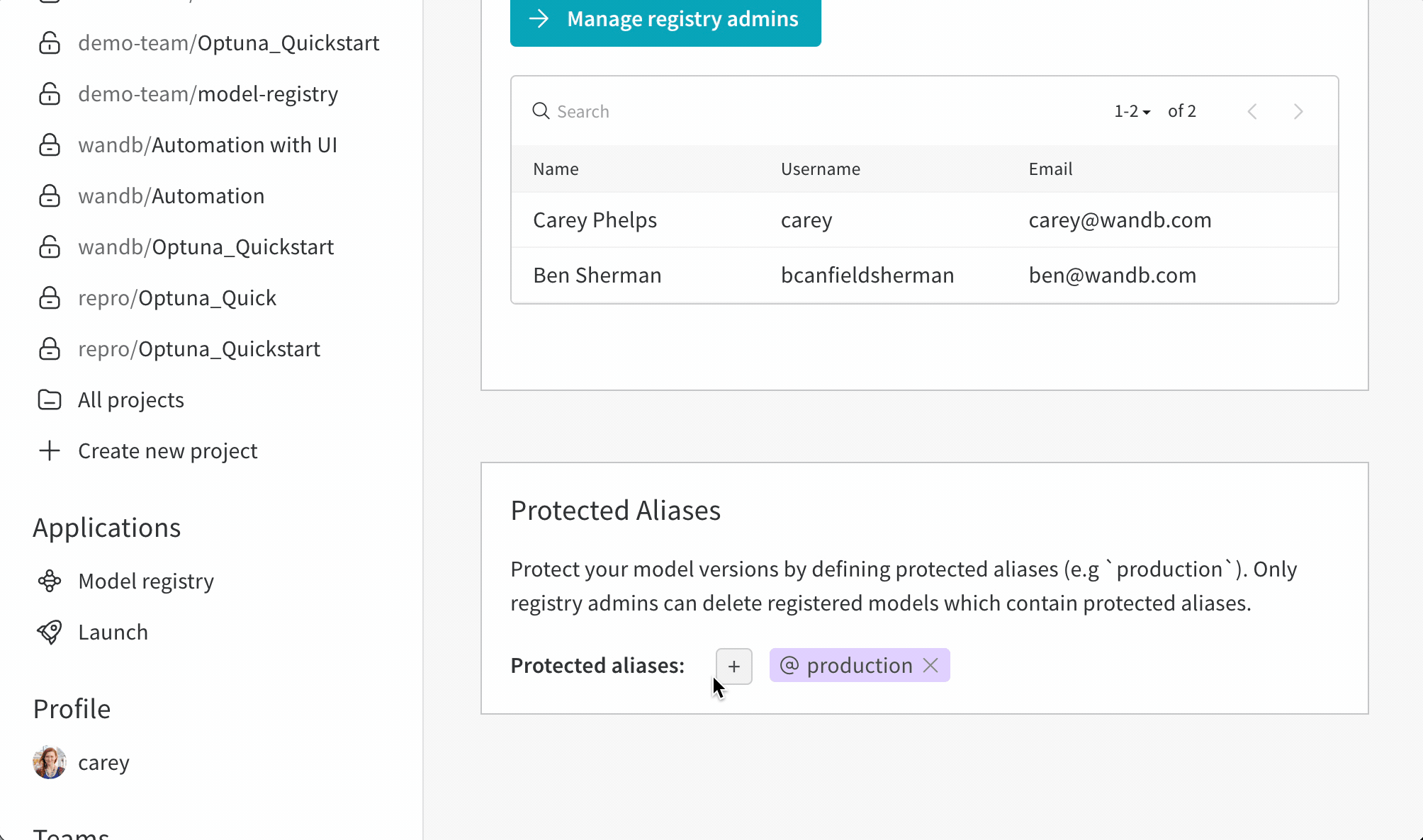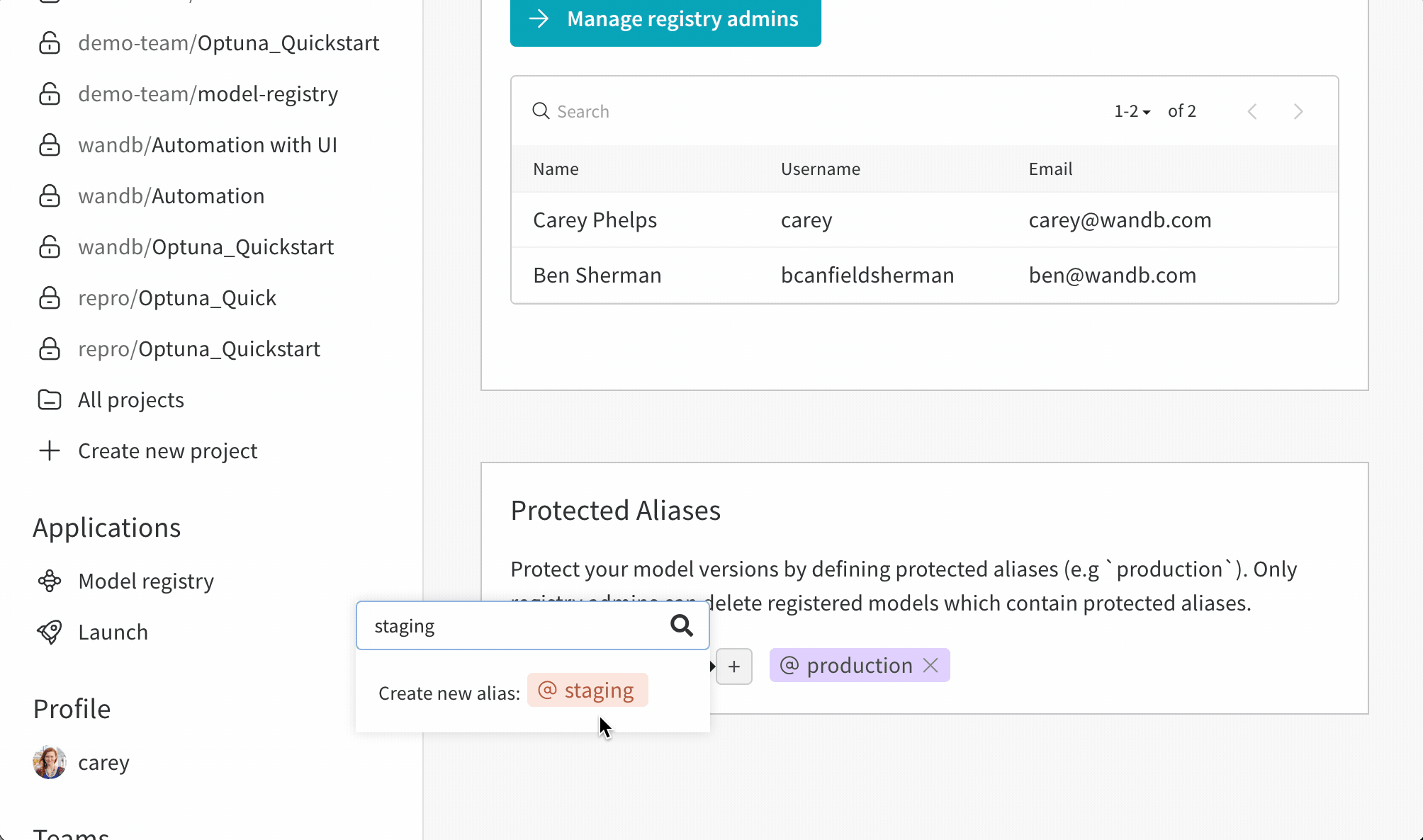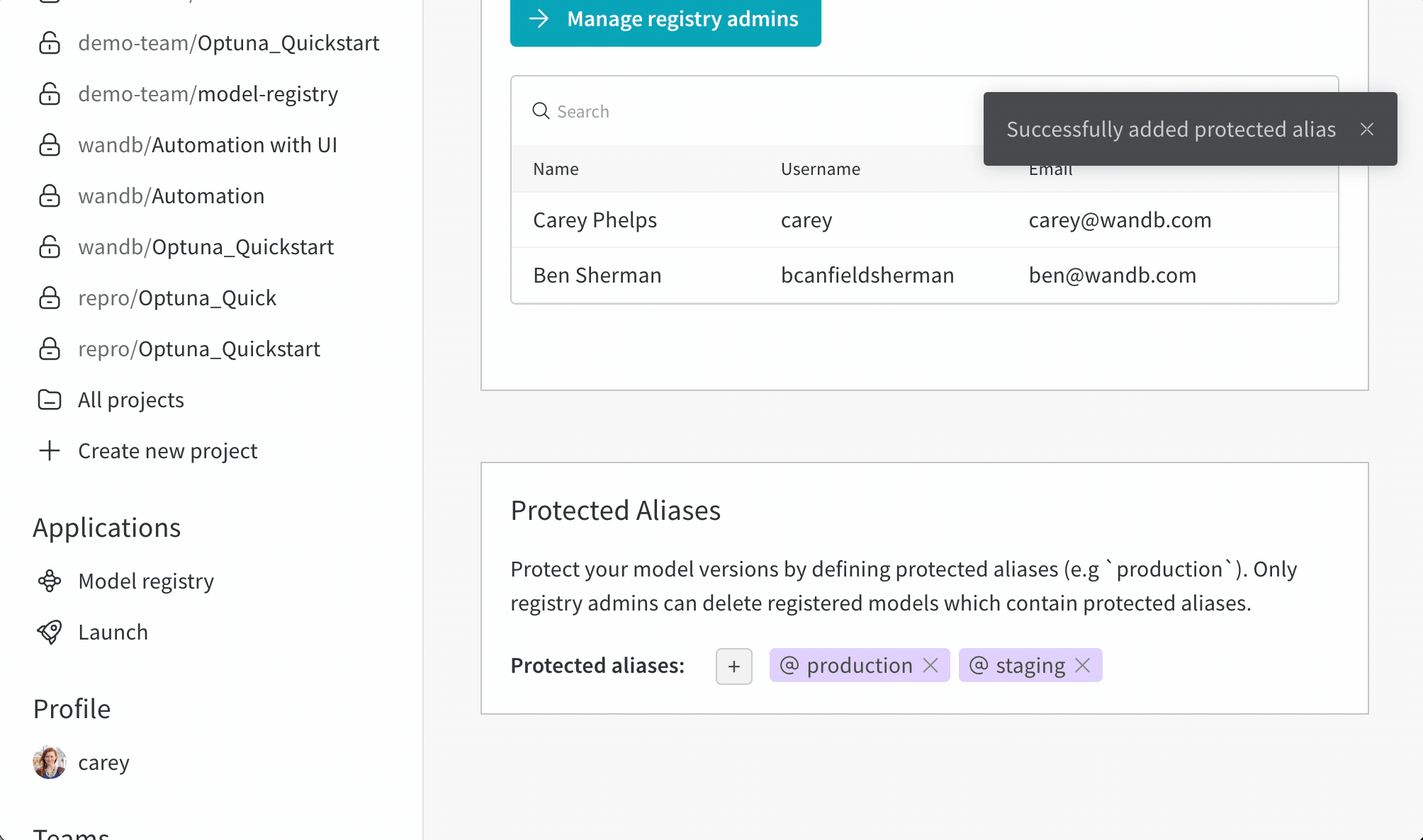
보호된 에일리어스를 사용하여 모델 개발 파이프라인의 주요 단계를 나타냅니다. 모델 레지스트리 관리자 만이 보호된 에일리어스를 추가, 수정 또는 제거할 수 있습니다. 모델 레지스트리 관리자는 보호된 에일리어스를 정의하고 사용할 수 있습니다. W&B는 관리자가 아닌 사용자가 모델 버전에서 보호된 에일리어스를 추가하거나 제거하는 것을 차단합니다.
팀 관리자 또는 현재 레지스트리 관리자만이 레지스트리 관리자 목록을 관리할 수 있습니다.
예를 들어, staging 및 production을 보호된 에일리어스로 설정했다고 가정합니다. 팀의 모든 구성원은 새로운 모델 버전을 추가할 수 있습니다. 그러나 관리자만이 staging 또는 production 에일리어스를 추가할 수 있습니다.
리포트를 프로그래밍 방식으로 편집하려면 W&B Python SDK 외에 wandb-workspaces가 설치되어 있는지 확인하십시오:
pip install wandb wandb-workspaces
플롯 추가
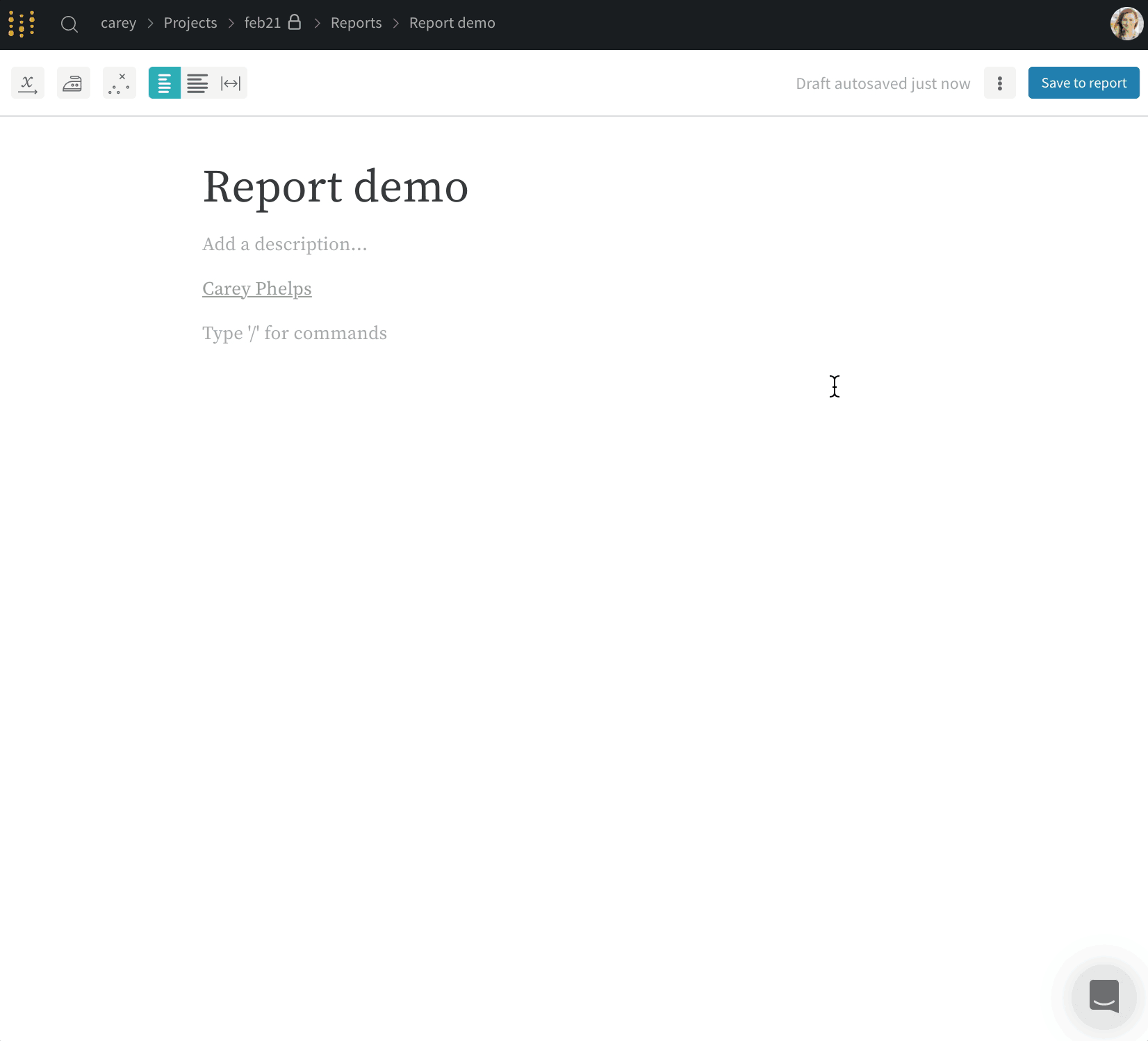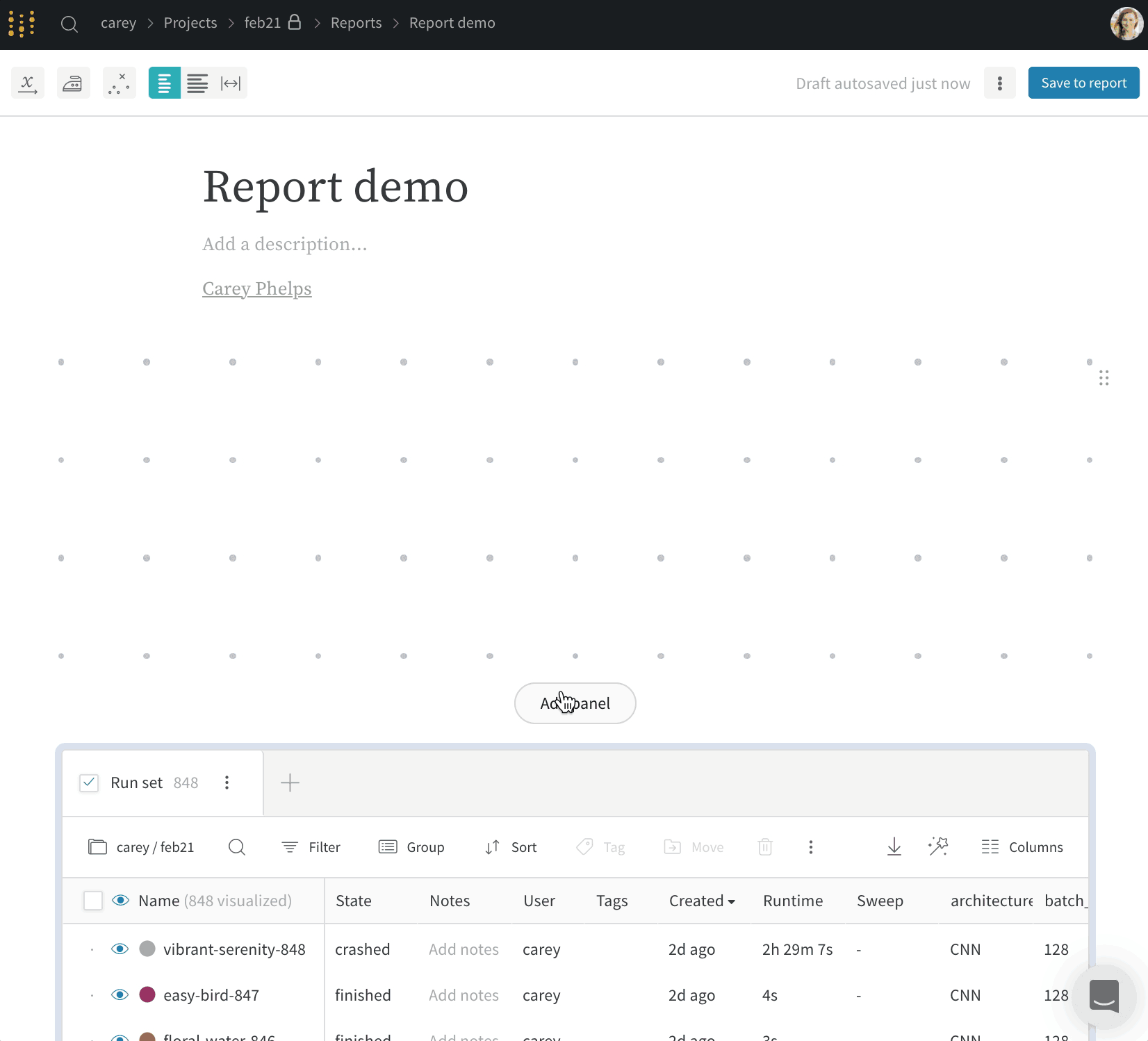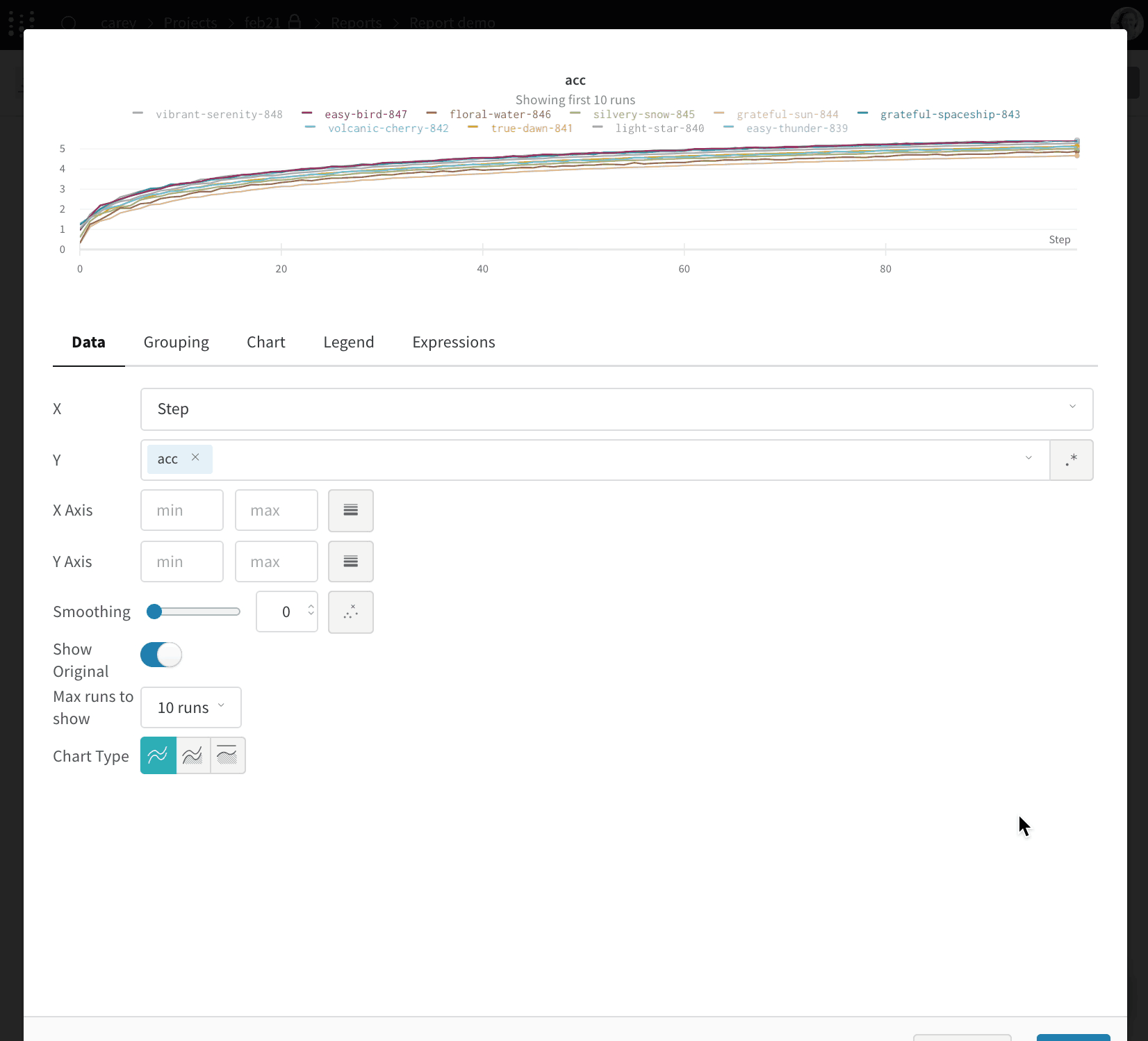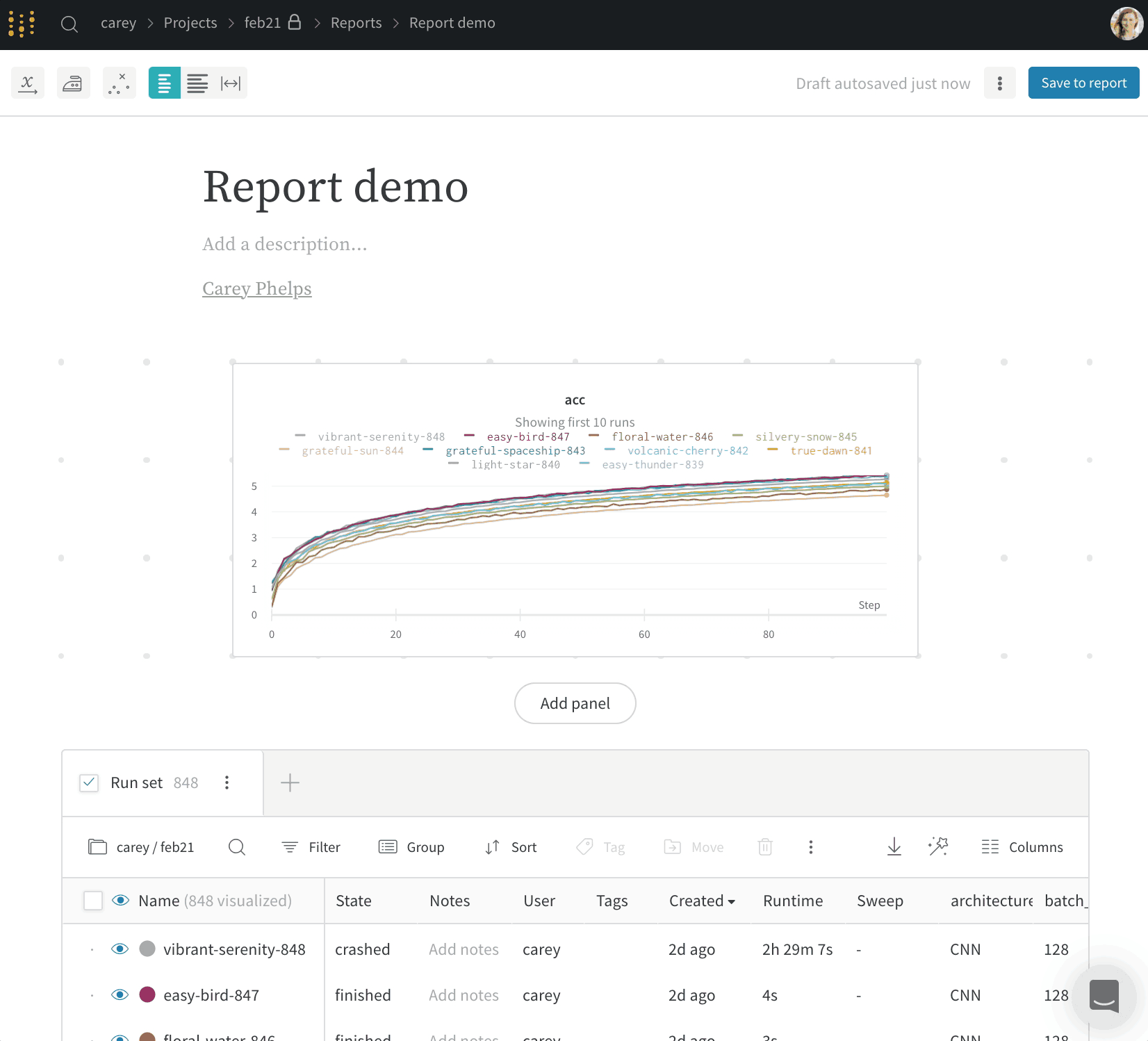
각 패널 그리드에는 run 세트와 패널 세트가 있습니다. 섹션 하단의 run 세트는 그리드의 패널에 표시되는 data를 제어합니다. 서로 다른 run 세트의 data를 가져오는 차트를 추가하려면 새 패널 그리드를 만드십시오.
리포트에 슬래시(/)를 입력하여 드롭다운 메뉴를 표시합니다. 패널 추가 를 선택하여 패널을 추가합니다. 라인 플롯, 산점도 또는 병렬 좌표 차트를 포함하여 W&B에서 지원하는 모든 패널을 추가할 수 있습니다.
SDK를 사용하여 프로그래밍 방식으로 리포트에 플롯을 추가합니다. 하나 이상의 플롯 또는 차트 오브젝트 목록을 PanelGrid Public API Class의 panels 파라미터에 전달합니다. 관련 Python Class를 사용하여 플롯 또는 차트 오브젝트를 생성합니다.
URL을 복사하여 리포트에 붙여넣어 리포트 내에 리치 미디어를 임베드합니다. 다음 애니메이션은 Twitter, YouTube 및 SoundCloud에서 URL을 복사하여 붙여넣는 방법을 보여줍니다.
Twitter
트윗 링크 URL을 복사하여 리포트에 붙여넣어 리포트 내에서 트윗을 봅니다.
Youtube
YouTube 비디오 URL 링크를 복사하여 리포트에 붙여넣어 리포트에 비디오를 임베드합니다.
SoundCloud
SoundCloud 링크를 복사하여 리포트에 붙여넣어 리포트에 오디오 파일을 임베드합니다.
하나 이상의 임베디드 미디어 오브젝트 목록을 wandb.apis.reports.blocks 속성에 전달합니다. 다음 예제는 비디오 및 Twitter 미디어를 리포트에 임베드하는 방법을 보여줍니다.
import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(project="report-editing")
report.blocks = [
wr.Video(url="https://www.youtube.com/embed/6riDJMI-Y8U"),
wr.Twitter(
embed_html='<blockquote class="twitter-tweet"><p lang="en" dir="ltr">The voice of an angel, truly. <a href="https://twitter.com/hashtag/MassEffect?src=hash&ref_src=twsrc%5Etfw">#MassEffect</a> <a href="https://t.co/nMev97Uw7F">pic.twitter.com/nMev97Uw7F</a></p>— Mass Effect (@masseffect) <a href="https://twitter.com/masseffect/status/1428748886655569924?ref_src=twsrc%5Etfw">August 20, 2021</a></blockquote>\n' ),
]
report.save()
패널 그리드 복제 및 삭제
재사용하려는 레이아웃이 있는 경우 패널 그리드를 선택하고 복사하여 붙여넣어 동일한 리포트에서 복제하거나 다른 리포트에 붙여넣을 수도 있습니다.
오른쪽 상단 모서리에 있는 드래그 핸들을 선택하여 전체 패널 그리드 섹션을 강조 표시합니다. 클릭하고 드래그하여 패널 그리드, 텍스트 및 제목과 같은 리포트의 영역을 강조 표시하고 선택합니다.
패널 그리드를 선택하고 키보드에서 delete를 눌러 패널 그리드를 삭제합니다.
헤더를 축소하여 Reports 구성
Report에서 헤더를 축소하여 텍스트 블록 내의 콘텐츠를 숨깁니다. 리포트가 로드되면 확장된 헤더만 콘텐츠를 표시합니다. 리포트에서 헤더를 축소하면 콘텐츠를 구성하고 과도한 data 로드를 방지하는 데 도움이 될 수 있습니다. 다음 gif는 해당 프로세스를 보여줍니다.
여러 차원에 걸쳐 관계 시각화
여러 차원에 걸쳐 관계를 효과적으로 시각화하려면 색상 그레이디언트를 사용하여 변수 중 하나를 나타냅니다. 이렇게 하면 명확성이 향상되고 패턴을 더 쉽게 해석할 수 있습니다.
색상 그레이디언트로 나타낼 변수를 선택합니다(예: 페널티 점수, 학습률 등). 이렇게 하면 트레이닝 시간(x축)에 따라 보상/부작용(y축)과 페널티(색상)가 상호 작용하는 방식을 더 명확하게 이해할 수 있습니다.
주요 추세를 강조 표시합니다. 특정 run 그룹 위에 마우스를 올리면 시각화에서 해당 run이 강조 표시됩니다.
4.3 - Collaborate on reports
W&B 리포트 를 동료, 동료 직원 및 팀과 협업하고 공유하세요.
리포트를 저장한 후 공유 버튼을 선택하여 협업할 수 있습니다. 편집 버튼을 선택하면 리포트의 초안 사본이 생성됩니다. 초안 리포트는 자동 저장됩니다. 변경 사항을 공유 리포트에 게시하려면 리포트에 저장을 선택하세요.
편집 충돌이 발생하면 경고 알림이 나타납니다. 이는 사용자와 다른 협업자가 동시에 동일한 리포트를 편집하는 경우에 발생할 수 있습니다. 경고 알림은 잠재적인 편집 충돌을 해결하는 데 도움이 됩니다.
리포트에 댓글 달기
리포트의 패널에 댓글을 직접 추가하려면 해당 패널에서 댓글 버튼을 클릭하세요.
4.4 - Clone and export reports
W&B 리포트 를 PDF 또는 LaTeX로 내보내세요.
Reports 내보내기
리포트를 PDF 또는 LaTeX로 내보냅니다. 리포트 내에서 케밥 아이콘을 선택하여 드롭다운 메뉴를 확장합니다. 다운로드를 선택하고 PDF 또는 LaTeX 출력 형식을 선택합니다.
Reports 복제
리포트 내에서 케밥 아이콘을 선택하여 드롭다운 메뉴를 확장합니다. 이 리포트 복제 버튼을 선택합니다. 모달에서 복제된 리포트의 대상을 선택합니다. 리포트 복제를 선택합니다.
프로젝트의 템플릿과 형식을 재사용하기 위해 리포트를 복제합니다. 팀 계정 내에서 프로젝트를 복제하면 복제된 프로젝트가 팀에 표시됩니다. 개인 계정 내에서 복제된 프로젝트는 해당 사용자에게만 표시됩니다.
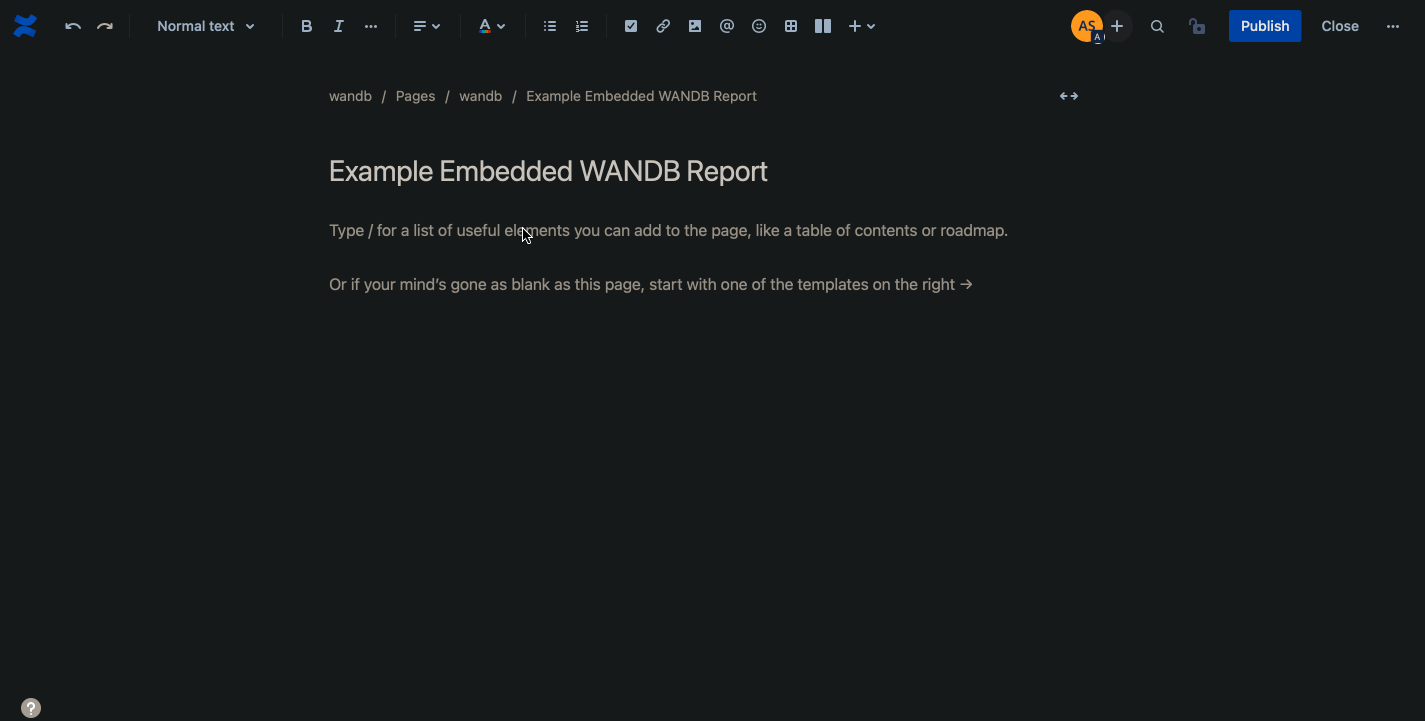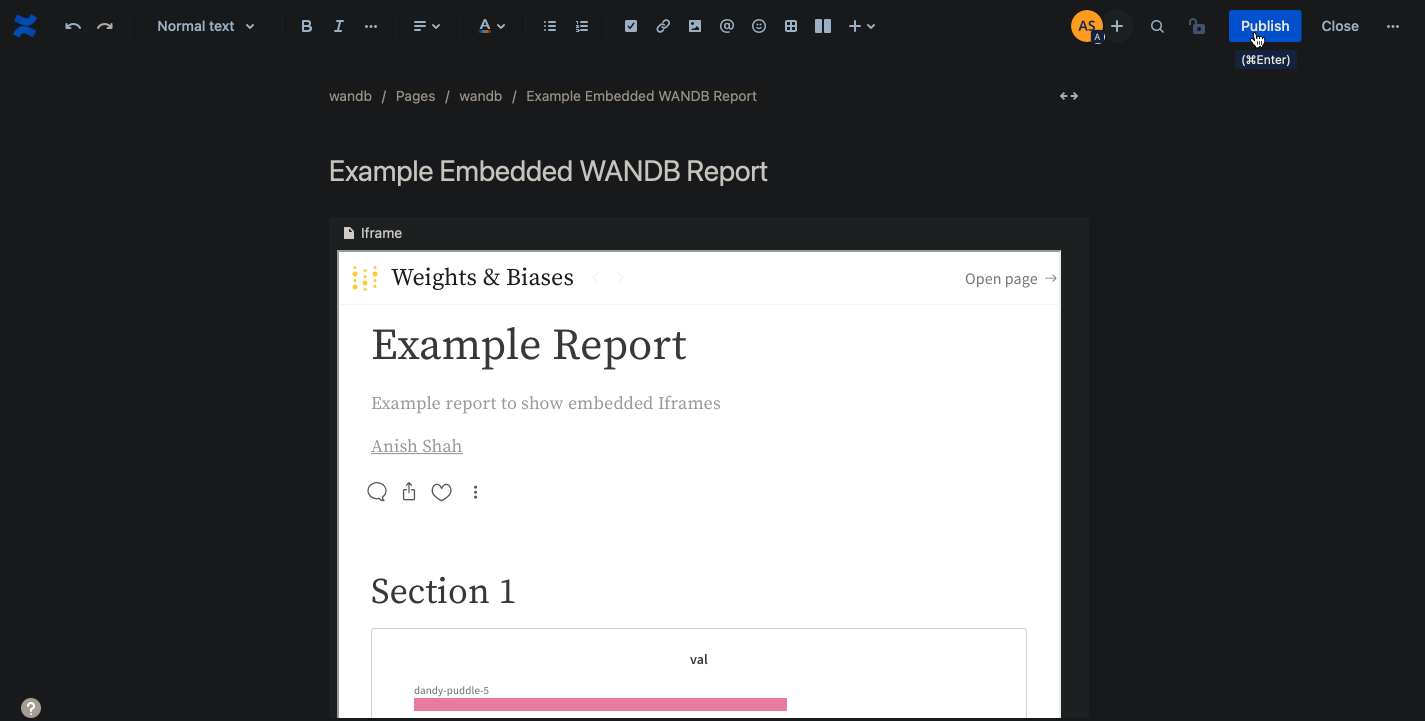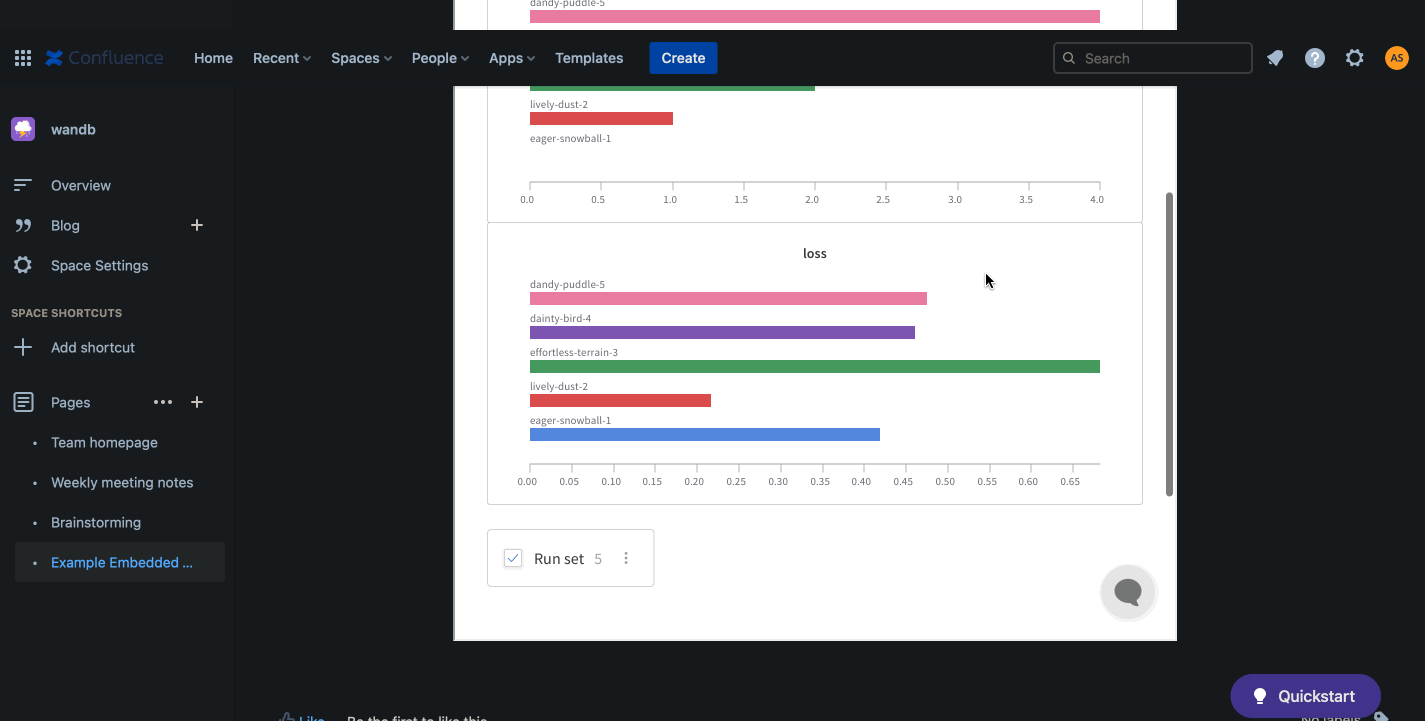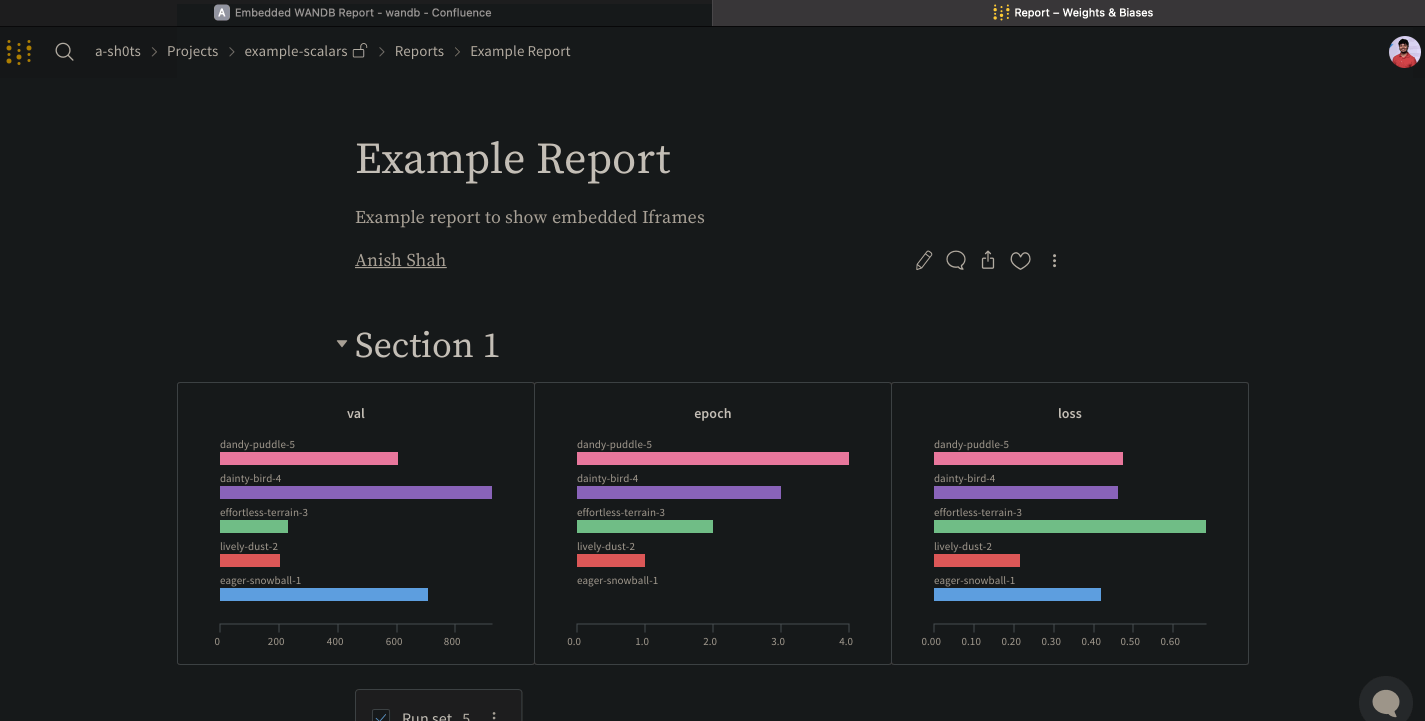
W&B 리포트 를 Notion에 직접 삽입하거나 HTML IFrame 요소를 사용하여 삽입하세요.
HTML iframe 요소
리포트의 오른쪽 상단 모서리에 있는 Share 버튼을 선택합니다. 모달 창이 나타납니다. 모달 창에서 Copy embed code를 선택합니다. 복사된 코드는 Inline Frame (IFrame) HTML 요소 내에서 렌더링됩니다. 복사된 코드를 원하는 iframe HTML 요소에 붙여넣습니다.
공개 리포트만 임베드되었을 때 볼 수 있습니다.
Confluence
다음 애니메이션은 Confluence의 IFrame 셀 내에 리포트에 대한 직접 링크를 삽입하는 방법을 보여줍니다.
Notion
다음 애니메이션은 Notion의 Embed 블록과 리포트의 임베디드 코드를 사용하여 리포트를 Notion 문서에 삽입하는 방법을 보여줍니다.
Gradio
gr.HTML 요소를 사용하여 Gradio 앱 내에 W&B Reports를 임베드하고 Hugging Face Spaces 내에서 사용할 수 있습니다.
import gradio as gr
defwandb_report(url):
iframe =f'<iframe src={url} style="border:none;height:1024px;width:100%">'return gr.HTML(iframe)
with gr.Blocks() as demo:
report = wandb_report(
"https://wandb.ai/_scott/pytorch-sweeps-demo/reports/loss-22-10-07-16-00-17---VmlldzoyNzU2NzAx" )
demo.launch()
프로젝트 간 리포트를 사용하여 서로 다른 두 프로젝트의 run을 비교하세요. run 세트 테이블에서 프로젝트 선택기를 사용하여 프로젝트를 선택합니다.
섹션의 시각화는 첫 번째 활성 runset에서 열을 가져옵니다. 라인 플롯에서 찾고 있는 메트릭이 보이지 않으면 섹션에서 첫 번째로 선택한 run 세트에 해당 열이 있는지 확인하세요.
이 기능은 시계열 라인의 기록 데이터를 지원하지만, 서로 다른 프로젝트에서 서로 다른 요약 메트릭을 가져오는 것은 지원하지 않습니다. 즉, 다른 프로젝트에만 기록된 열에서 산점도를 만들 수 없습니다.
두 프로젝트의 run을 비교해야 하는데 열이 작동하지 않으면, 한 프로젝트의 run에 태그를 추가한 다음 해당 run을 다른 프로젝트로 이동하세요. 각 프로젝트의 run만 필터링할 수 있지만, 리포트에는 두 세트의 run에 대한 모든 열이 포함됩니다.
보기 전용 리포트 링크
비공개 프로젝트 또는 팀 프로젝트에 있는 리포트에 대한 보기 전용 링크를 공유하세요.
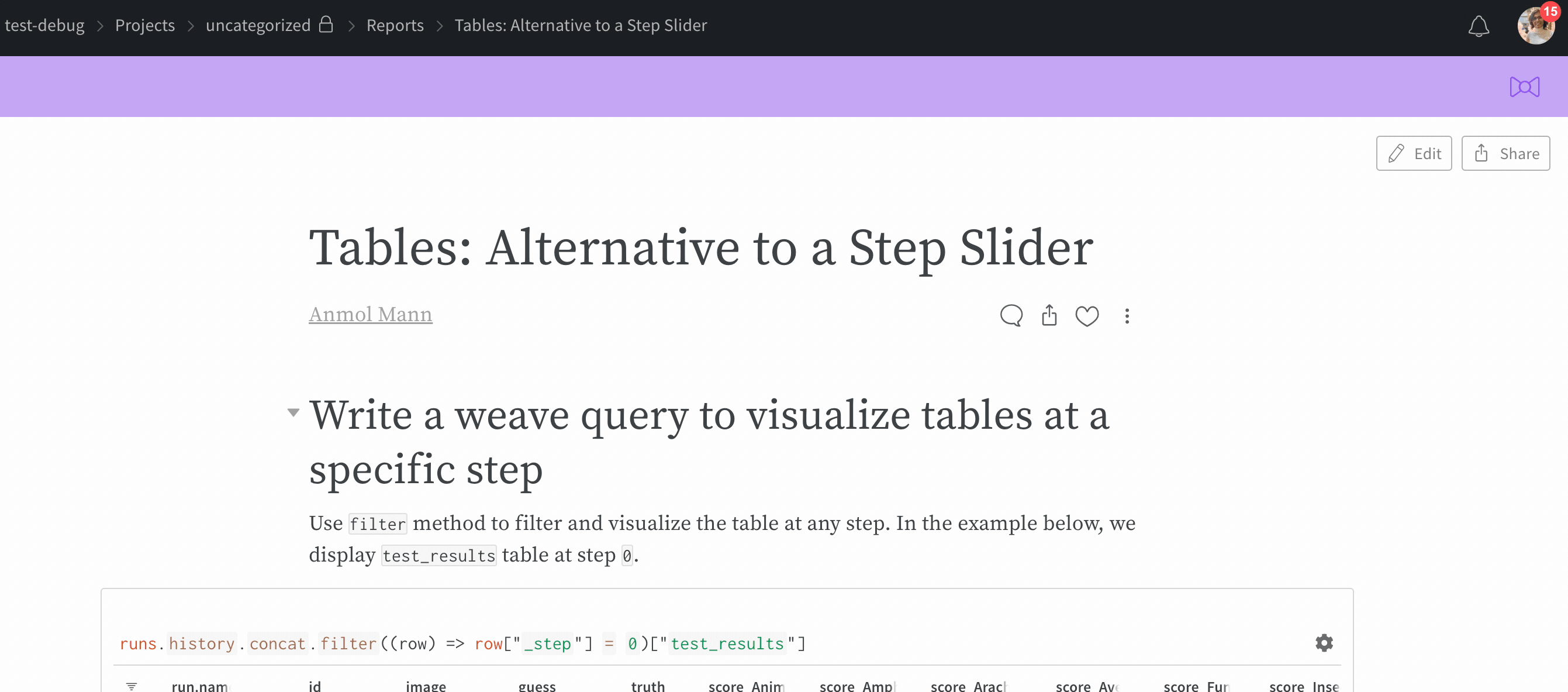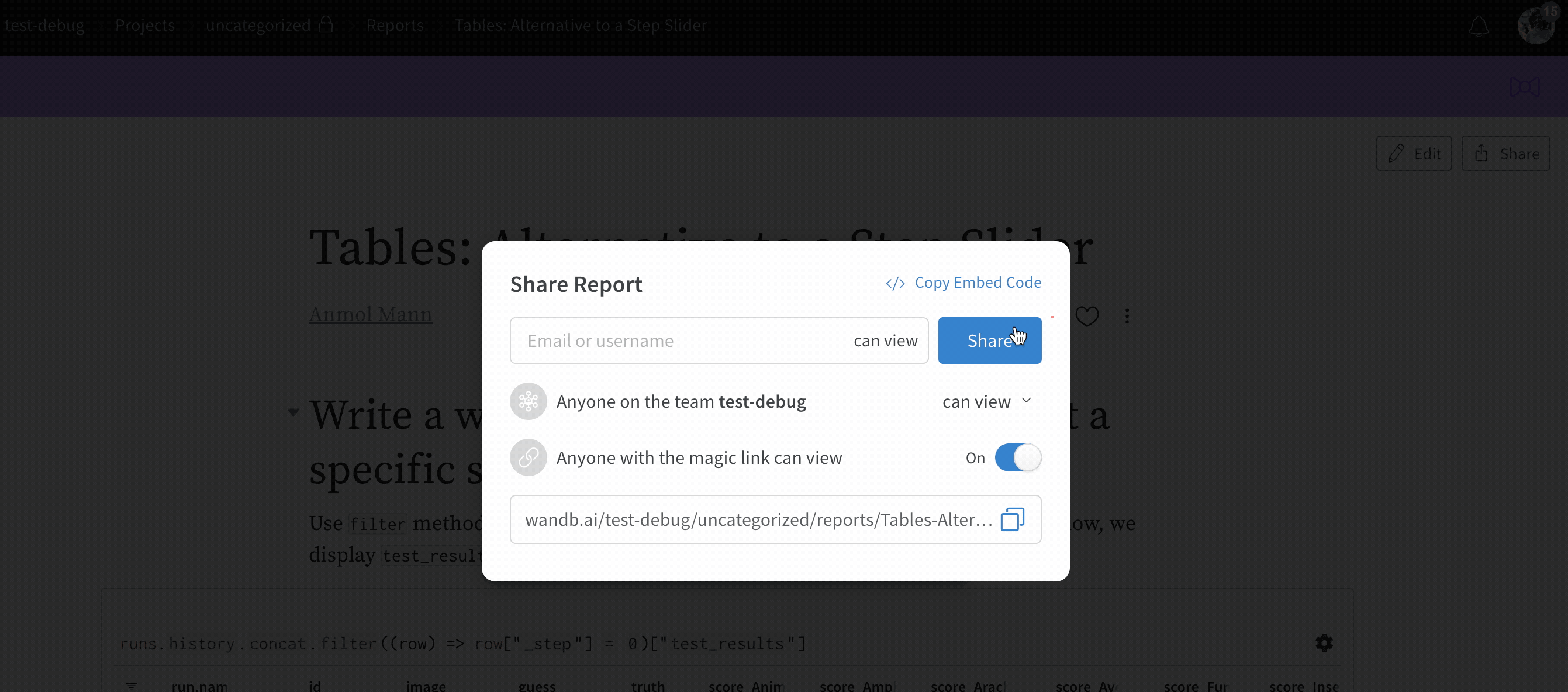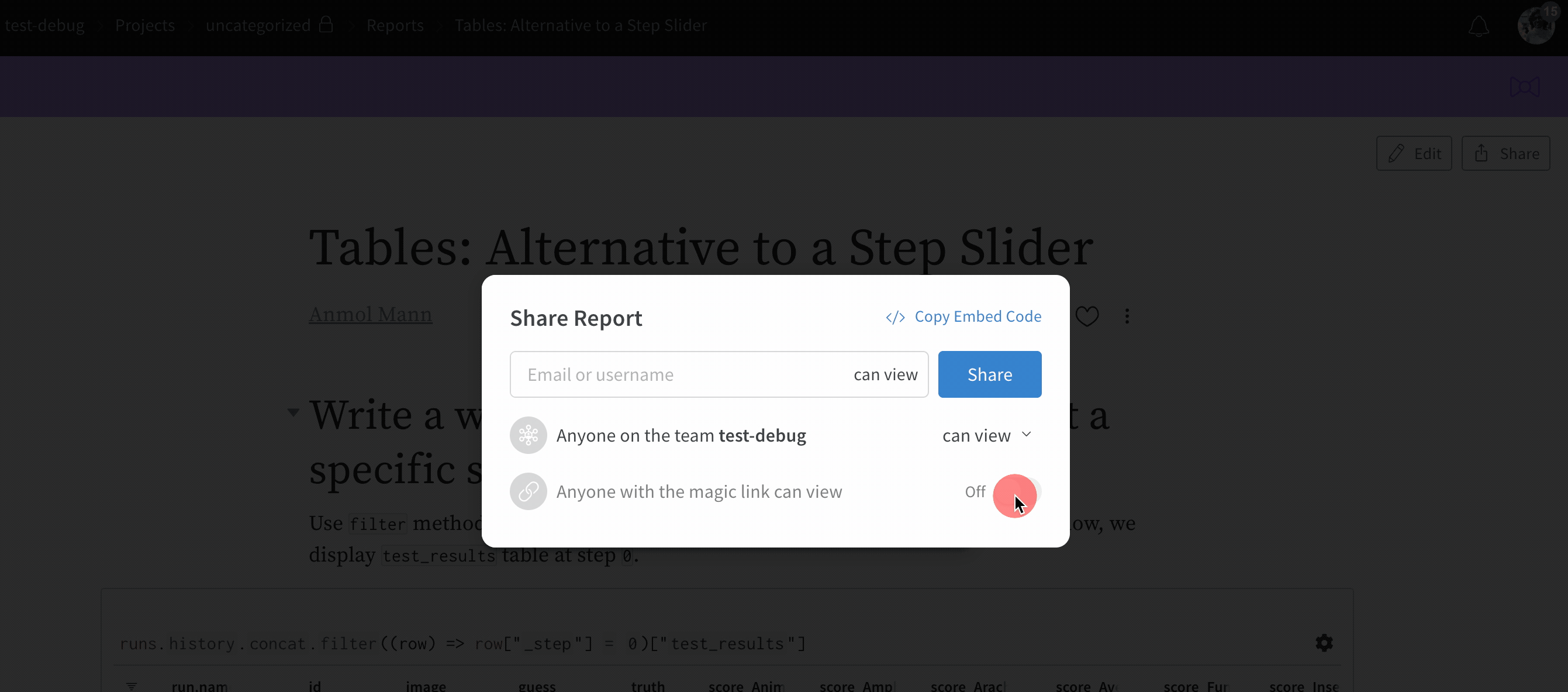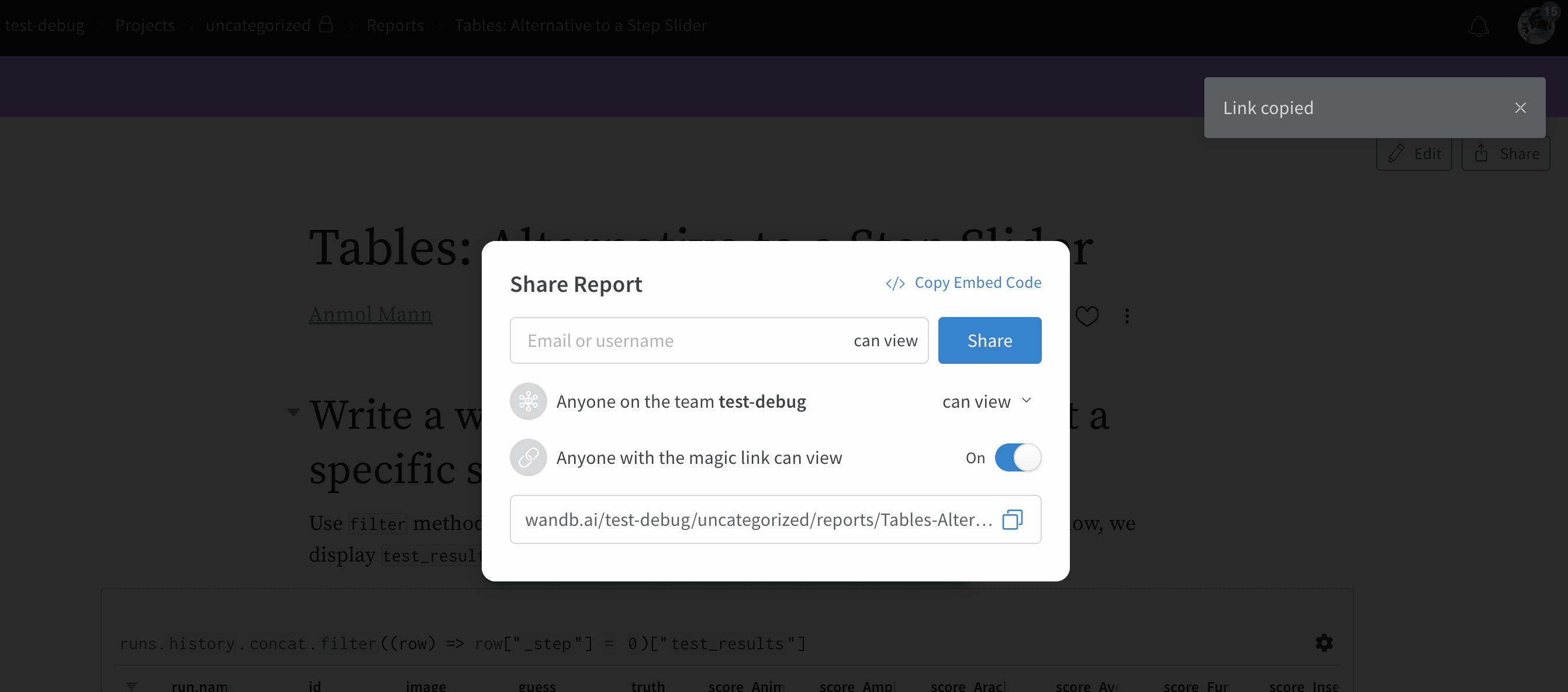
보기 전용 리포트 링크는 URL에 비밀 엑세스 토큰을 추가하므로, 링크를 여는 모든 사람이 페이지를 볼 수 있습니다. 누구나 매직 링크를 사용하여 먼저 로그인하지 않고도 리포트를 볼 수 있습니다. W&B Local 프라이빗 클라우드 설치를 사용하는 고객의 경우, 이러한 링크는 방화벽 내에 유지되므로 팀 구성원 중 프라이빗 인스턴스에 대한 엑세스 권한과 보기 전용 링크에 대한 엑세스 권한이 있는 사람만 리포트를 볼 수 있습니다.
보기 전용 모드에서는 로그인하지 않은 사람도 차트를 보고 마우스를 올려 값의 툴팁을 보고, 차트를 확대/축소하고, 테이블에서 열을 스크롤할 수 있습니다. 보기 모드에서는 데이터를 탐색하기 위해 새 차트 또는 새 테이블 쿼리를 만들 수 없습니다. 리포트 링크의 보기 전용 방문자는 run을 클릭하여 run 페이지로 이동할 수 없습니다. 또한 보기 전용 방문자는 공유 모달을 볼 수 없고 대신 마우스를 올리면 보기 전용 엑세스에는 공유를 사용할 수 없습니다라는 툴팁이 표시됩니다.
매직 링크는 “비공개” 및 “팀” 프로젝트에서만 사용할 수 있습니다. “공개”(누구나 볼 수 있음) 또는 “개방형”(누구나 run을 보고 기여할 수 있음) 프로젝트의 경우, 이 프로젝트는 공개되어 링크가 있는 모든 사람이 이미 사용할 수 있음을 의미하므로 링크를 켜거나 끌 수 없습니다.
그래프를 리포트로 보내기
진행 상황을 추적하기 위해 워크스페이스에서 리포트로 그래프를 보냅니다. 리포트에 복사할 차트 또는 패널의 드롭다운 메뉴를 클릭하고 리포트에 추가를 클릭하여 대상 리포트를 선택합니다.
4.7 - Example reports
Reports 갤러리
노트: 빠른 요약과 함께 시각화 추가
프로젝트 개발에서 중요한 관찰 내용, 향후 작업 아이디어 또는 달성한 이정표를 캡처합니다. 리포트의 모든 실험 run은 해당 파라미터, 메트릭, 로그 및 코드로 연결되므로 작업의 전체 컨텍스트를 저장할 수 있습니다.
복잡한 코드베이스에서 가장 좋은 예제를 저장하여 쉽게 참조하고 향후 상호 작용할 수 있습니다. Lyft 데이터 세트의 LIDAR 포인트 클라우드를 시각화하고 3D 경계 상자로 주석을 추가하는 방법에 대한 예는 LIDAR 포인트 클라우드 W&B Report를 참조하십시오.
협업: 동료와 발견한 내용 공유
프로젝트 시작 방법, 지금까지 관찰한 내용 공유, 최신 findings 종합 방법을 설명합니다. 동료는 패널에서 또는 리포트 끝에 있는 댓글을 사용하여 제안하거나 세부 사항을 논의할 수 있습니다.
동료가 직접 탐색하고 추가 통찰력을 얻고 다음 단계를 더 잘 계획할 수 있도록 동적 설정을 포함합니다. 이 예에서는 세 가지 유형의 Experiments를 독립적으로 시각화, 비교 또는 평균화할 수 있습니다.
Experiments에 대한 생각, findings, 주의 사항 및 다음 단계를 프로젝트를 진행하면서 기록하여 모든 것을 한 곳에서 체계적으로 관리합니다. 이를 통해 스크립트 외에 중요한 모든 부분을 “문서화"할 수 있습니다. findings를 보고하는 방법에 대한 예는 누가 그들인가? 변환기를 사용한 텍스트 명확성 W&B Report를 참조하십시오.
프로젝트의 스토리를 전달하면 귀하와 다른 사람들이 나중에 참조하여 model이 개발된 방법과 이유를 이해할 수 있습니다. findings를 보고하는 방법에 대한 내용은 운전석에서 바라본 시각 W&B Report를 참조하십시오.
OpenAI Robotics 팀이 대규모 기계 학습 프로젝트를 실행하기 위해 W&B Reports를 사용한 방법을 탐색하기 위해 W&B Reports가 사용된 방법에 대한 예는 W&B Reports를 사용하여 엔드투엔드 손재주 학습을 참조하십시오.
필요한 경우, 엑세스 토큰, 비밀번호 또는 민감한 구성 세부 정보와 같이 자동화에 필요한 민감한 문자열에 대한 secrets를 구성합니다. Secrets는 Team Settings에서 정의됩니다. Secrets는 일반적으로 훅 자동화에서 자격 증명 또는 토큰을 일반 텍스트로 노출하거나 훅의 페이로드에 하드 코딩하지 않고 훅의 외부 서비스에 안전하게 전달하는 데 사용됩니다.
W&B가 Slack에 게시하거나 사용자를 대신하여 훅을 실행할 수 있도록 훅 또는 Slack 알림을 구성합니다. 단일 자동화 작업(훅 또는 Slack 알림)은 여러 자동화에서 사용할 수 있습니다. 이러한 작업은 Team Settings에서 정의됩니다.
W&B 팀을 Slack에 연결한 후 Registry 또는 Project를 선택한 다음 다음 단계에 따라 Slack 채널에 알림을 보내는 자동화를 만듭니다.
Registry 관리자는 해당 Registry에서 자동화를 생성할 수 있습니다.
W&B에 로그인합니다.
Registry 이름을 클릭하여 세부 정보를 봅니다.
Registry 범위로 자동화를 생성하려면 Automations 탭을 클릭한 다음 자동화 생성을 클릭합니다. Registry 범위로 지정된 자동화는 해당 컬렉션(향후 생성된 컬렉션 포함) 모두에 자동으로 적용됩니다.
Registry에서 특정 컬렉션에만 범위가 지정된 자동화를 생성하려면 컬렉션 작업 ... 메뉴를 클릭한 다음 자동화 생성을 클릭합니다. 또는 컬렉션을 보는 동안 컬렉션 세부 정보 페이지의 Automations 섹션에서 자동화 생성 버튼을 사용하여 컬렉션에 대한 자동화를 만듭니다.
이 페이지에서는 webhook 자동화를 만드는 방법을 보여줍니다. Slack 자동화를 만들려면 Slack 자동화 만들기를 참조하세요.
개략적으로 webhook 자동화를 만들려면 다음 단계를 수행합니다.
필요한 경우 액세스 토큰, 비밀번호 또는 SSH 키와 같이 자동화에 필요한 각 민감한 문자열에 대해 W&B secret 만들기를 수행합니다. secret은 팀 설정에 정의되어 있습니다.
webhook 만들기를 수행하여 엔드포인트 및 인증 세부 정보를 정의하고 통합에 필요한 secret에 대한 엑세스 권한을 부여합니다.
자동화 만들기를 수행하여 감시할 이벤트와 W&B가 보낼 페이로드를 정의합니다. 페이로드에 필요한 secret에 대한 자동화 엑세스 권한을 부여합니다.
webhook 만들기
팀 관리자는 팀에 대한 webhook을 추가할 수 있습니다.
webhook에 Bearer 토큰이 필요하거나 페이로드에 민감한 문자열이 필요한 경우 webhook을 만들기 전에 해당 문자열을 포함하는 secret을 만드세요. webhook에 대해 최대 하나의 엑세스 토큰과 다른 하나의 secret을 구성할 수 있습니다. webhook의 인증 및 권한 부여 요구 사항은 webhook의 서비스에 의해 결정됩니다.
W&B에 로그인하고 팀 설정 페이지로 이동합니다.
Webhooks 섹션에서 New webhook을 클릭합니다.
webhook의 이름을 입력합니다.
webhook의 엔드포인트 URL을 입력합니다.
webhook에 Bearer 토큰이 필요한 경우 Access token을 해당 토큰을 포함하는 secret으로 설정합니다. webhook 자동화를 사용할 때 W&B는 Authorization: Bearer HTTP 헤더를 엑세스 토큰으로 설정하고 ${ACCESS_TOKEN}페이로드 변수에서 토큰에 엑세스할 수 있습니다.
webhook의 페이로드에 비밀번호 또는 기타 민감한 문자열이 필요한 경우 Secret을 해당 문자열을 포함하는 secret으로 설정합니다. webhook을 사용하는 자동화를 구성할 때 이름 앞에 $를 붙여 페이로드 변수로 secret에 엑세스할 수 있습니다.
webhook의 엑세스 토큰이 secret에 저장된 경우 secret을 엑세스 토큰으로 지정하려면 또한 다음 단계를 완료해야 합니다.
W&B가 엔드포인트에 연결하고 인증할 수 있는지 확인하려면:
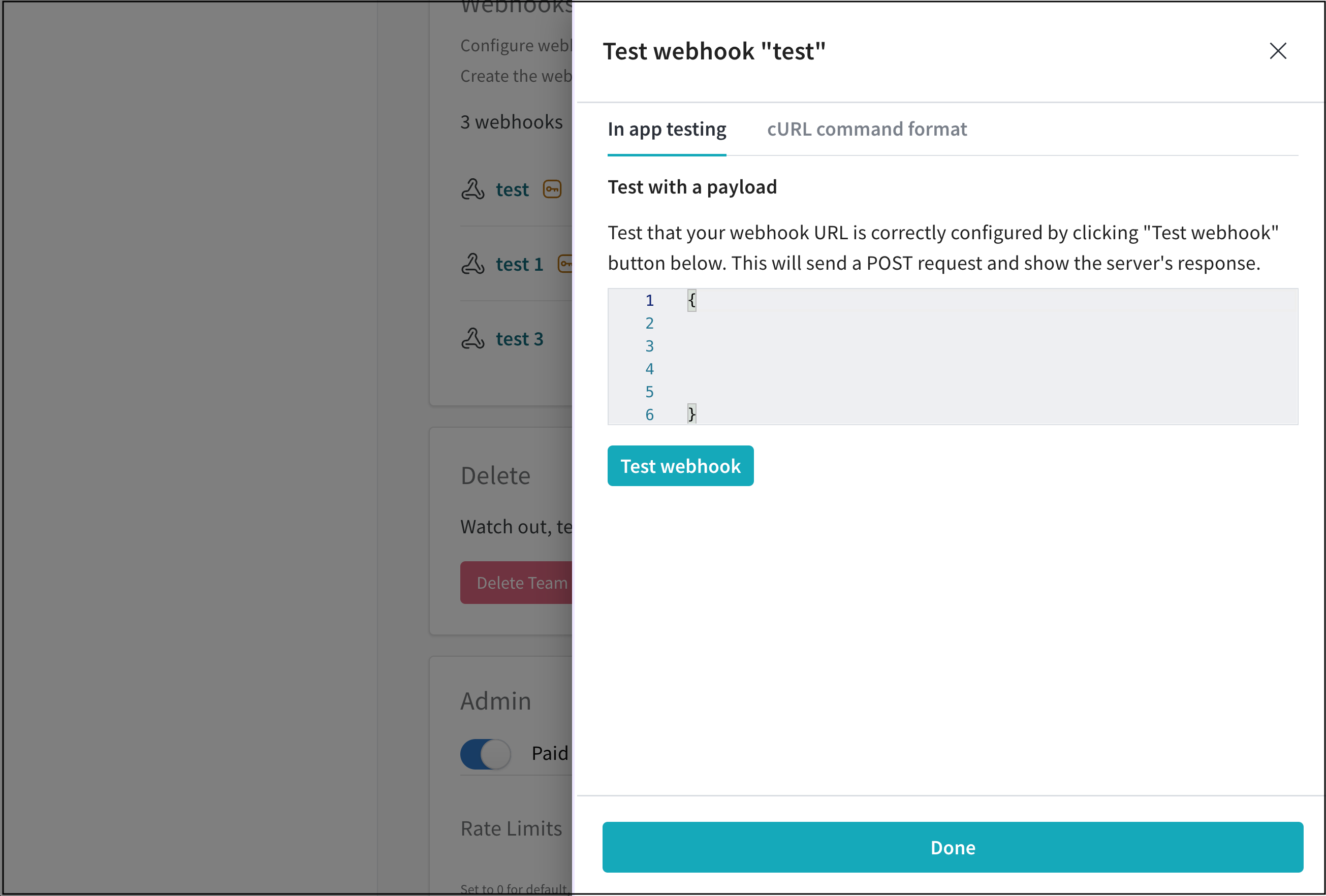
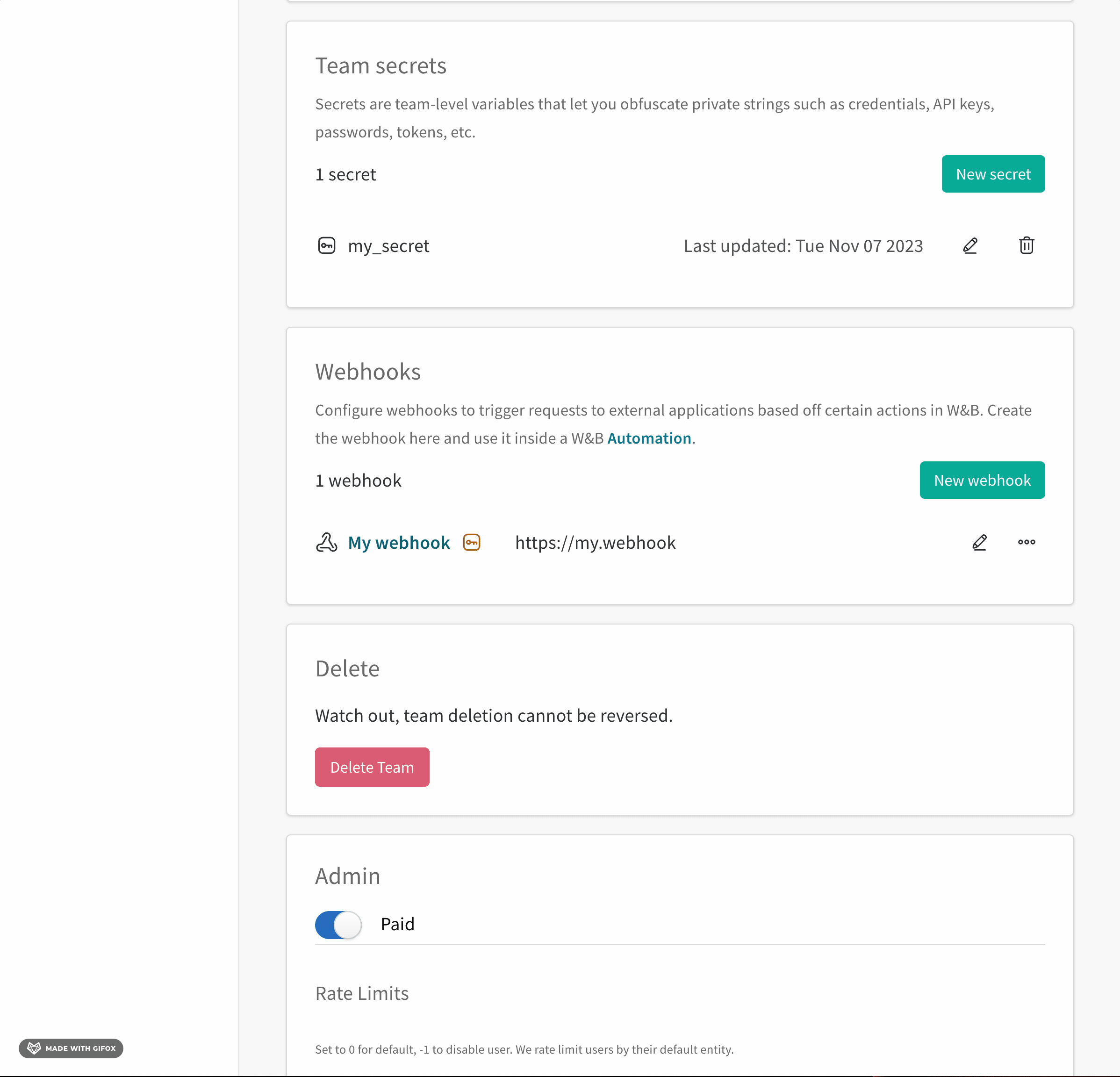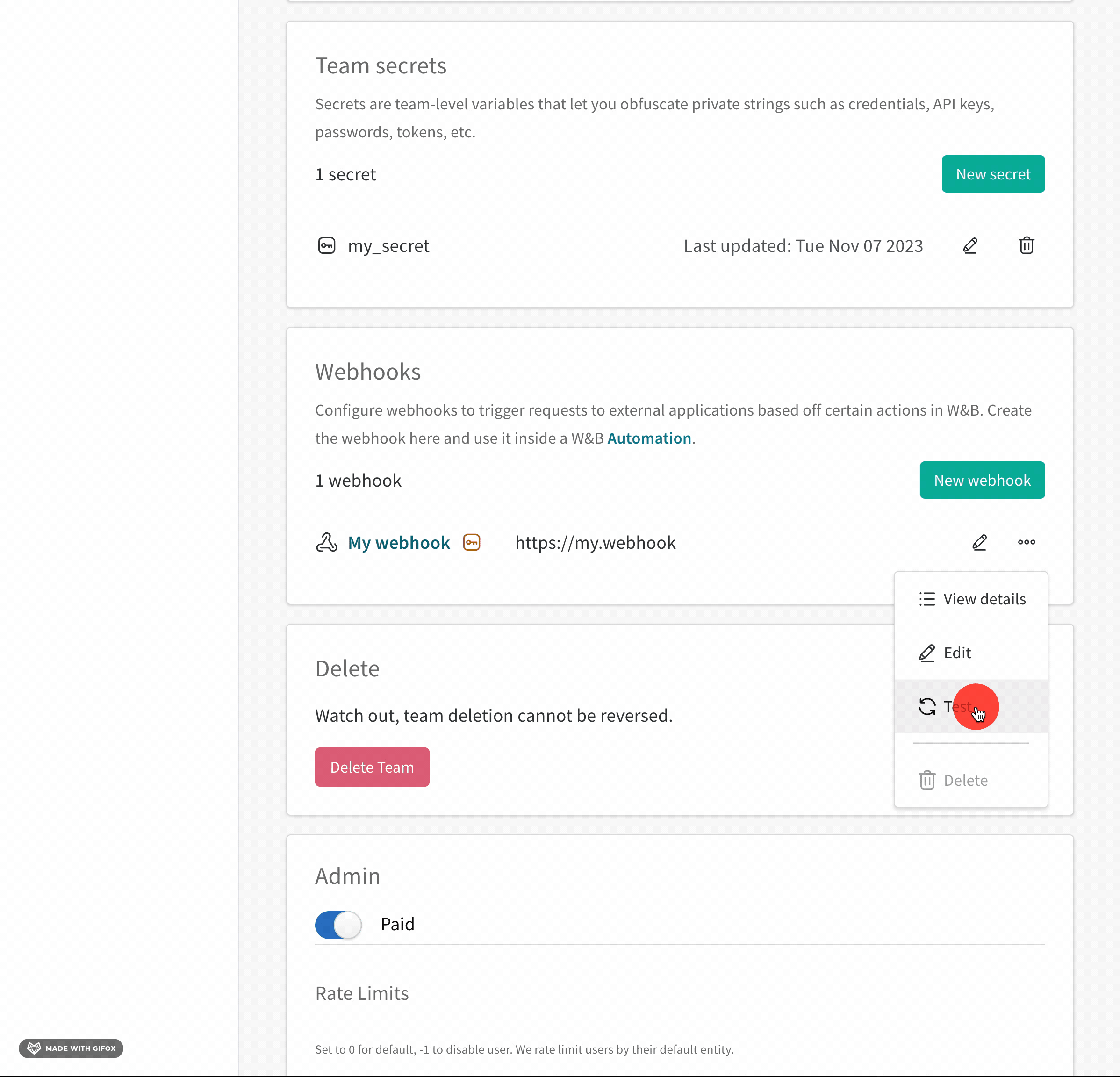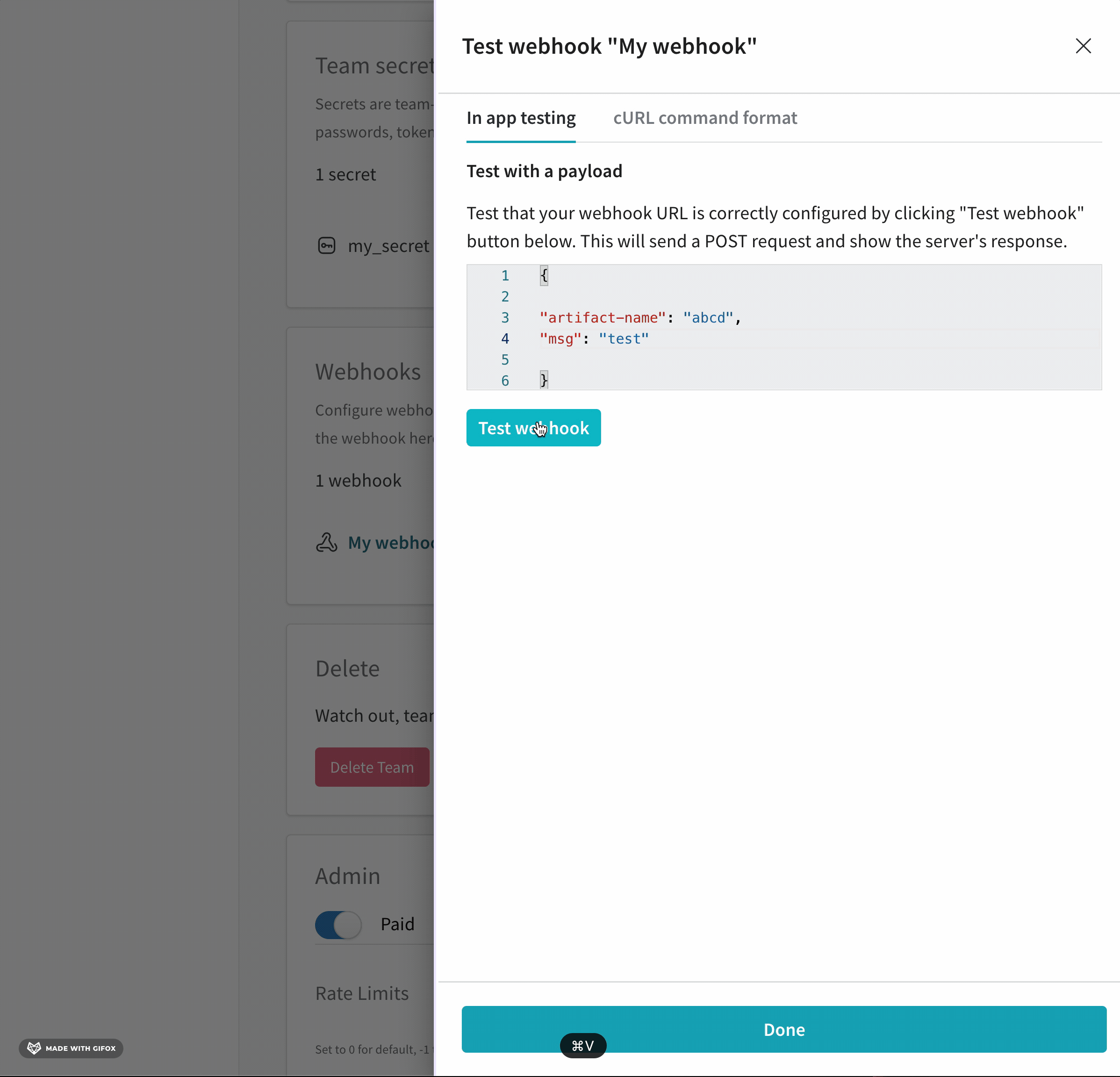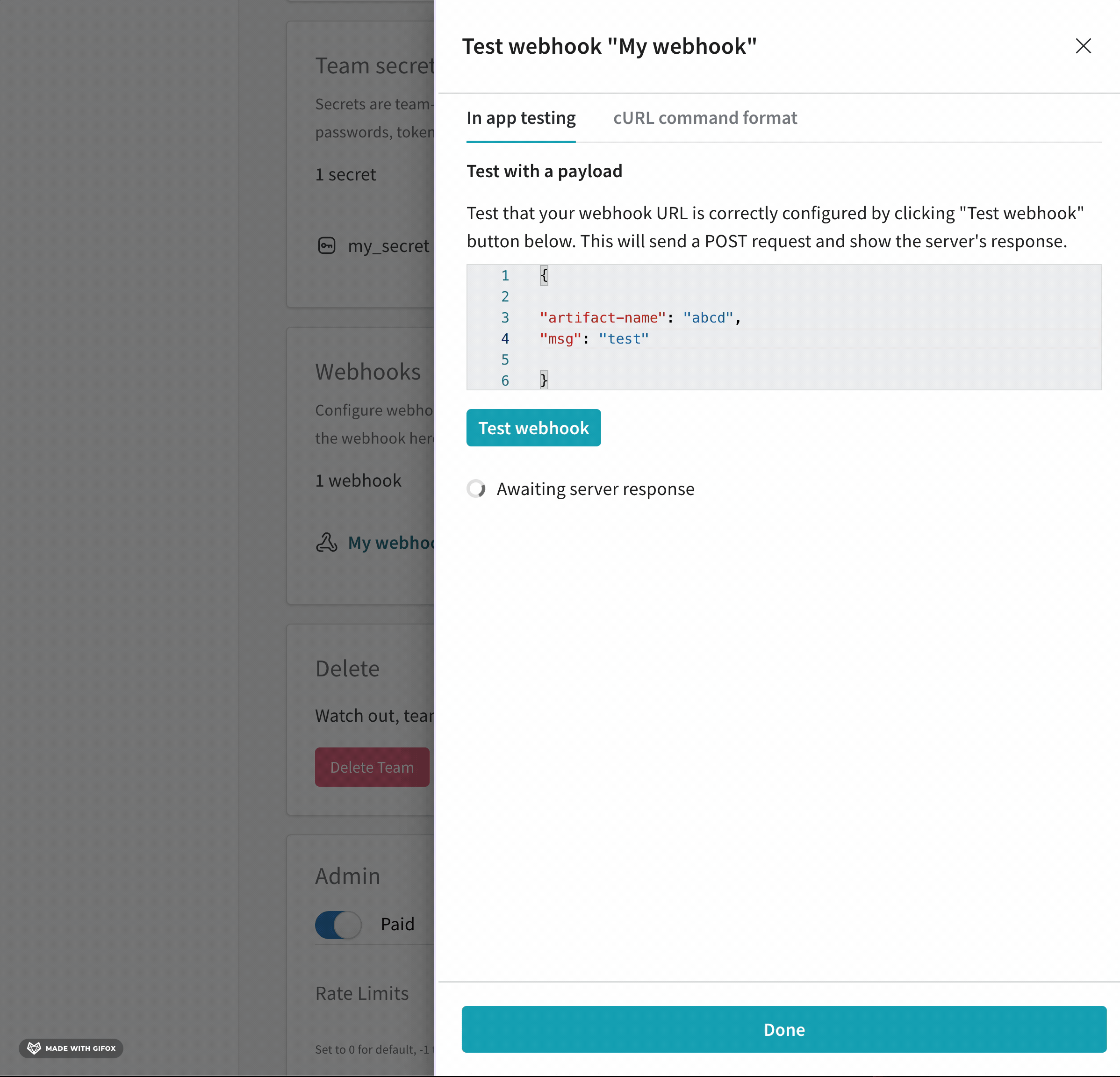
선택적으로 테스트할 페이로드를 제공합니다. 페이로드에서 webhook이 엑세스할 수 있는 secret을 참조하려면 이름 앞에 $를 붙입니다. 이 페이로드는 테스트에만 사용되며 저장되지 않습니다. 자동화를 만들 때 자동화의 페이로드를 구성합니다. secret과 엑세스 토큰이 POST 요청에 지정된 위치를 보려면 webhook 문제 해결을 참조하세요.
Test를 클릭합니다. W&B는 구성한 자격 증명을 사용하여 webhook의 엔드포인트에 연결을 시도합니다. 페이로드를 제공한 경우 W&B는 해당 페이로드를 보냅니다.
테스트가 성공하지 못하면 webhook의 구성을 확인하고 다시 시도하세요. 필요한 경우 webhook 문제 해결을 참조하세요.
webhook을 구성한 후 Registry 또는 Project를 선택한 다음 다음 단계에 따라 webhook을 트리거하는 자동화를 만듭니다.
Registry 관리자는 해당 Registry에서 자동화를 만들 수 있습니다. Registry 자동화는 향후 추가되는 자동화를 포함하여 Registry의 모든 컬렉션에 적용됩니다.
W&B에 로그인합니다.
Registry 이름을 클릭하여 세부 정보를 확인합니다.
Registry로 범위가 지정된 자동화를 만들려면 Automations 탭을 클릭한 다음 Create automation을 클릭합니다. Registry로 범위가 지정된 자동화는 향후 생성되는 컬렉션을 포함하여 모든 컬렉션에 자동으로 적용됩니다.
Registry의 특정 컬렉션으로만 범위가 지정된 자동화를 만들려면 컬렉션의 액션 ... 메뉴를 클릭한 다음 Create automation을 클릭합니다. 또는 컬렉션을 보는 동안 컬렉션 세부 정보 페이지의 Automations 섹션에 있는 Create automation 버튼을 사용하여 컬렉션에 대한 자동화를 만듭니다.
감시할 Event를 선택합니다. 이벤트에 따라 표시되는 추가 필드를 작성합니다. 예를 들어 An artifact alias is added를 선택한 경우 Alias regex를 지정해야 합니다. Next step을 클릭합니다.
webhook에 대해 엑세스 토큰을 구성한 경우 ${ACCESS_TOKEN}페이로드 변수에서 토큰에 엑세스할 수 있습니다. webhook에 대해 secret을 구성한 경우 이름 앞에 $를 붙여 페이로드에서 해당 secret에 엑세스할 수 있습니다. webhook의 요구 사항은 webhook의 서비스에 의해 결정됩니다.
Next step을 클릭합니다.
자동화 이름을 입력합니다. 선택적으로 설명을 제공합니다. Create automation을 클릭합니다.
webhook에 페이로드가 필요한 경우 페이로드를 구성하여 Payload 필드에 붙여넣습니다. webhook에 대해 엑세스 토큰을 구성한 경우 ${ACCESS_TOKEN}페이로드 변수에서 토큰에 엑세스할 수 있습니다. webhook에 대해 secret을 구성한 경우 이름 앞에 $를 붙여 페이로드에서 해당 secret에 엑세스할 수 있습니다. webhook의 요구 사항은 webhook의 서비스에 의해 결정됩니다.
Next step을 클릭합니다.
자동화 이름을 입력합니다. 선택적으로 설명을 제공합니다. Create automation을 클릭합니다.
자동화 보기 및 관리
Registry의 Automations 탭에서 Registry의 자동화를 관리합니다.
컬렉션 세부 정보 페이지의 Automations 섹션에서 컬렉션의 자동화를 관리합니다.
이러한 페이지에서 Registry 관리자는 기존 자동화를 관리할 수 있습니다.
자동화 세부 정보를 보려면 이름을 클릭합니다.
자동화를 편집하려면 해당 액션 ... 메뉴를 클릭한 다음 Edit automation을 클릭합니다.
자동화를 삭제하려면 해당 액션 ... 메뉴를 클릭한 다음 Delete automation을 클릭합니다. 확인이 필요합니다.
W&B 관리자는 Project의 Automations 탭에서 Project의 자동화를 보고 관리할 수 있습니다.
자동화 세부 정보를 보려면 이름을 클릭합니다.
자동화를 편집하려면 해당 액션 ... 메뉴를 클릭한 다음 Edit automation을 클릭합니다.
자동화를 삭제하려면 해당 액션 ... 메뉴를 클릭한 다음 Delete automation을 클릭합니다. 확인이 필요합니다.
페이로드 참조
이 섹션을 사용하여 webhook의 페이로드를 구성합니다. webhook 및 해당 페이로드 테스트에 대한 자세한 내용은 webhook 문제 해결을 참조하세요.
페이로드 변수
이 섹션에서는 webhook의 페이로드를 구성하는 데 사용할 수 있는 변수에 대해 설명합니다.
변수
세부 정보
${project_name}
액션을 트리거한 변경을 소유한 Project의 이름입니다.
${entity_name}
액션을 트리거한 변경을 소유한 엔터티 또는 팀의 이름입니다.
${event_type}
액션을 트리거한 이벤트 유형입니다.
${event_author}
액션을 트리거한 사용자입니다.
${artifact_collection_name}
아티팩트 버전이 연결된 아티팩트 컬렉션의 이름입니다.
${artifact_metadata.<KEY>}
액션을 트리거한 아티팩트 버전의 임의의 최상위 메타데이터 키의 값입니다. <KEY>를 최상위 메타데이터 키의 이름으로 바꿉니다. 최상위 메타데이터 키만 webhook의 페이로드에서 사용할 수 있습니다.
Project 수준: 자동화는 project 의 모든 컬렉션에서 발생하는 이벤트를 감시합니다.
컬렉션 수준: 지정한 필터와 일치하는 project 의 모든 컬렉션.
Events
Project 자동화는 다음 이벤트를 감시할 수 있습니다.
아티팩트의 새 버전이 컬렉션에 생성됨: 아티팩트의 각 버전에 반복 작업을 적용합니다. 컬렉션 지정은 선택 사항입니다. 예를 들어, 새로운 Dataset 아티팩트 버전이 생성되면 트레이닝 작업을 시작합니다.
아티팩트 에일리어스가 추가됨: project 또는 컬렉션의 새로운 아티팩트 버전에 특정 에일리어스가 적용될 때 워크플로우의 특정 단계를 트리거합니다. 예를 들어, 아티팩트에 test-set-quality-check 에일리어스가 적용되면 일련의 다운스트림 처리 단계를 실행합니다.