Create model lineage map
2 minute read
이 페이지에서는 기존 W&B Model Registry에서 계보 그래프를 생성하는 방법을 설명합니다. W&B Registry의 계보 그래프에 대해 자세히 알아보려면 계보 맵 생성 및 보기를 참조하세요.
W&B는 기존 W&B Model Registry의 자산을 새로운 W&B Registry로 이전할 예정입니다. 이 마이그레이션은 W&B에서 완전히 관리하고 트리거하며, 사용자의 개입이 필요하지 않습니다. 이 프로세스는 기존 워크플로우에 대한 중단을 최소화하면서 최대한 원활하게 진행되도록 설계되었습니다. 기존 Model Registry에서 마이그레이션을 참조하세요.
W&B에 모델 아티팩트를 로깅하는 유용한 기능은 계보 그래프입니다. 계보 그래프는 run에서 로깅한 아티팩트와 특정 run에서 사용한 아티팩트를 보여줍니다.
즉, 모델 아티팩트를 로깅할 때 최소한 모델 아티팩트를 사용하거나 생성한 W&B run을 볼 수 있습니다. 아티팩트 종속성 추적을 통해 모델 아티팩트에서 사용한 입력도 볼 수 있습니다.
예를 들어, 다음 이미지는 ML 실험 전반에 걸쳐 생성 및 사용된 아티팩트를 보여줍니다.
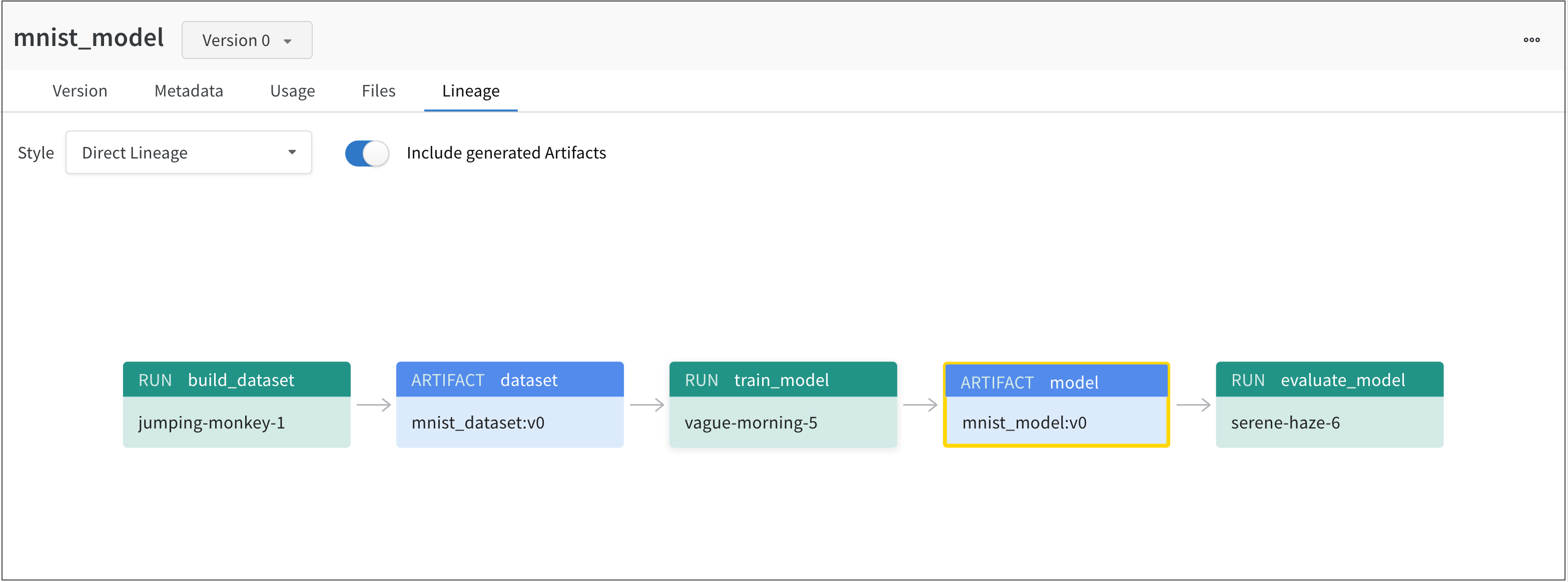
왼쪽에서 오른쪽으로 이미지는 다음을 보여줍니다.
jumping-monkey-1W&B run은mnist_dataset:v0데이터셋 아티팩트를 생성했습니다.vague-morning-5W&B run은mnist_dataset:v0데이터셋 아티팩트를 사용하여 모델을 트레이닝했습니다. 이 W&B run의 출력은mnist_model:v0라는 모델 아티팩트였습니다.serene-haze-6이라는 run은 모델 아티팩트(mnist_model:v0)를 사용하여 모델을 평가했습니다.
아티팩트 종속성 추적
use_artifact API를 사용하여 데이터셋 아티팩트를 W&B run에 대한 입력으로 선언하여 종속성을 추적합니다.
다음 코드 조각은 use_artifact API를 사용하는 방법을 보여줍니다.
# Initialize a run
run = wandb.init(project=project, entity=entity)
# Get artifact, mark it as a dependency
artifact = run.use_artifact(artifact_or_name="name", aliases="<alias>")
아티팩트를 검색한 후에는 해당 아티팩트를 사용하여 (예를 들어) 모델의 성능을 평가할 수 있습니다.
예시: 모델을 트레이닝하고 데이터셋을 모델의 입력으로 추적
job_type = "train_model"
config = {
"optimizer": "adam",
"batch_size": 128,
"epochs": 5,
"validation_split": 0.1,
}
run = wandb.init(project=project, job_type=job_type, config=config)
version = "latest"
name = "{}:{}".format("{}_dataset".format(model_use_case_id), version)
artifact = run.use_artifact(name)
train_table = artifact.get("train_table")
x_train = train_table.get_column("x_train", convert_to="numpy")
y_train = train_table.get_column("y_train", convert_to="numpy")
# Store values from our config dictionary into variables for easy accessing
num_classes = 10
input_shape = (28, 28, 1)
loss = "categorical_crossentropy"
optimizer = run.config["optimizer"]
metrics = ["accuracy"]
batch_size = run.config["batch_size"]
epochs = run.config["epochs"]
validation_split = run.config["validation_split"]
# Create model architecture
model = keras.Sequential(
[
layers.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.compile(loss=loss, optimizer=optimizer, metrics=metrics)
# Generate labels for training data
y_train = keras.utils.to_categorical(y_train, num_classes)
# Create training and test set
x_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size=0.33)
# Train the model
model.fit(
x=x_t,
y=y_t,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_v, y_v),
callbacks=[WandbCallback(log_weights=True, log_evaluation=True)],
)
# Save model locally
path = "model.h5"
model.save(path)
path = "./model.h5"
registered_model_name = "MNIST-dev"
name = "mnist_model"
run.link_model(path=path, registered_model_name=registered_model_name, name=name)
run.finish()
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.