Stable Baselines 3
W&B를 Stable Baseline 3와 통합하는 방법.
less than a minute
Stable Baselines 3 (SB3)는 PyTorch에서 강화학습 알고리즘을 안정적으로 구현한 것입니다. W&B의 SB3 인테그레이션은 다음과 같습니다:
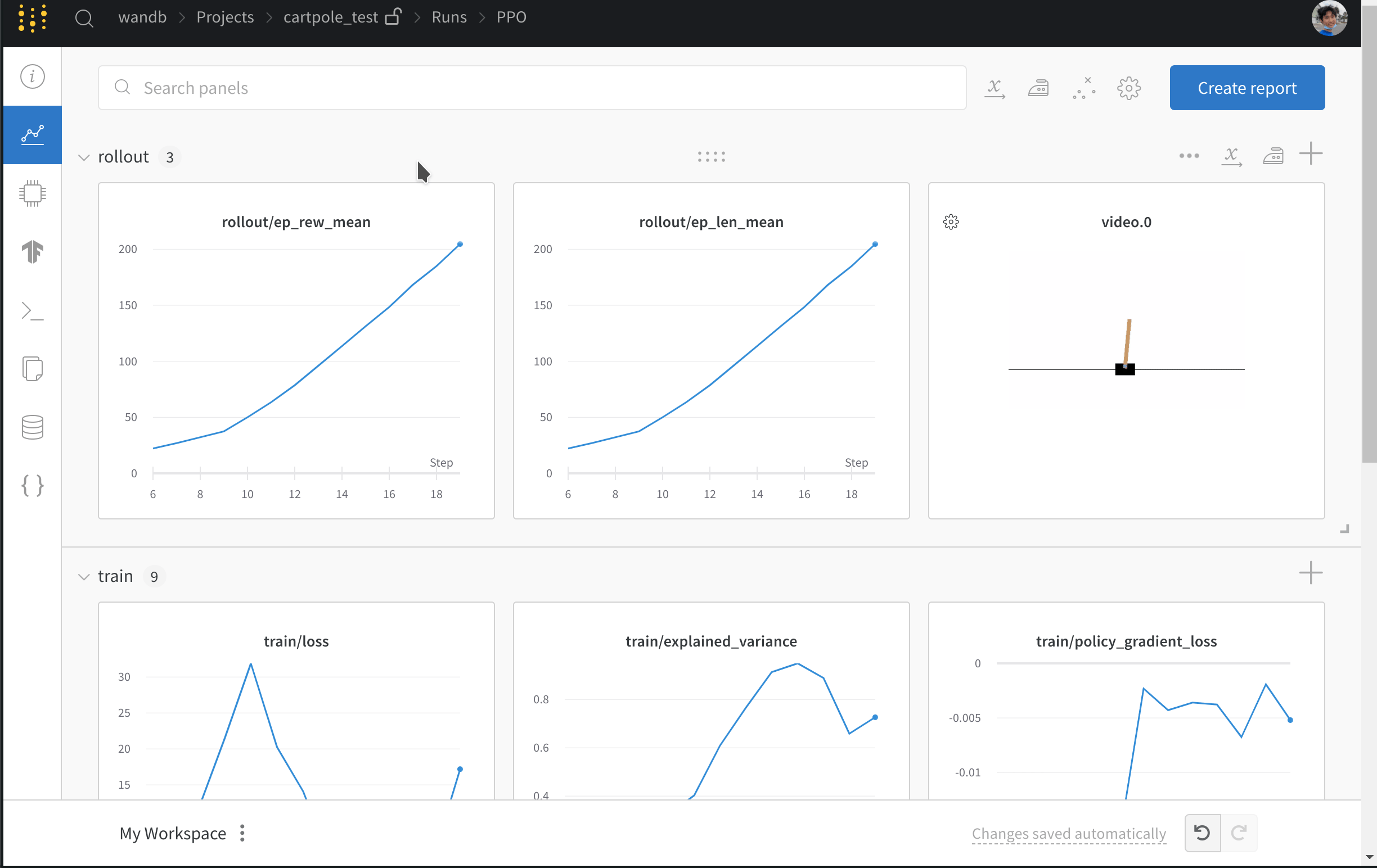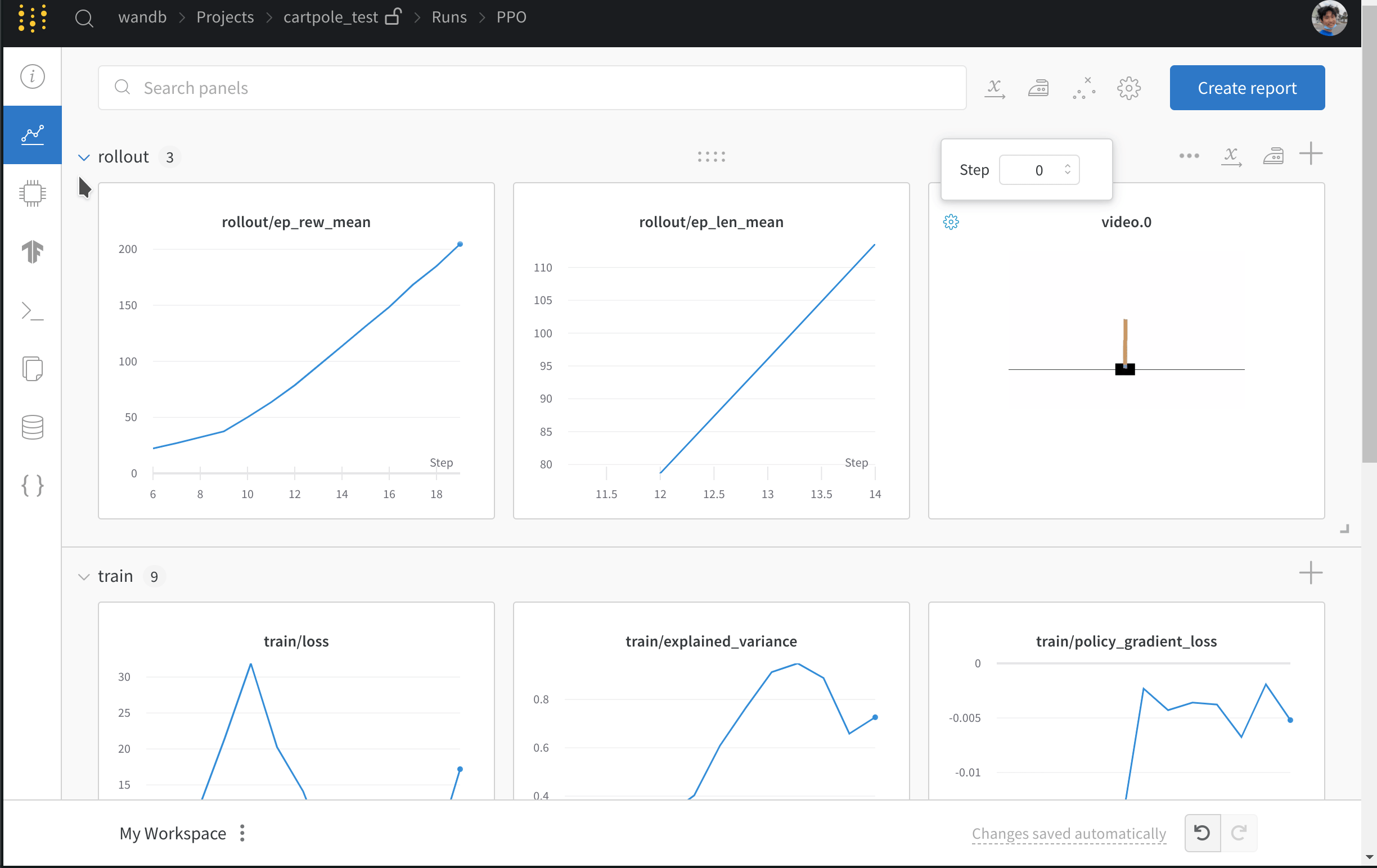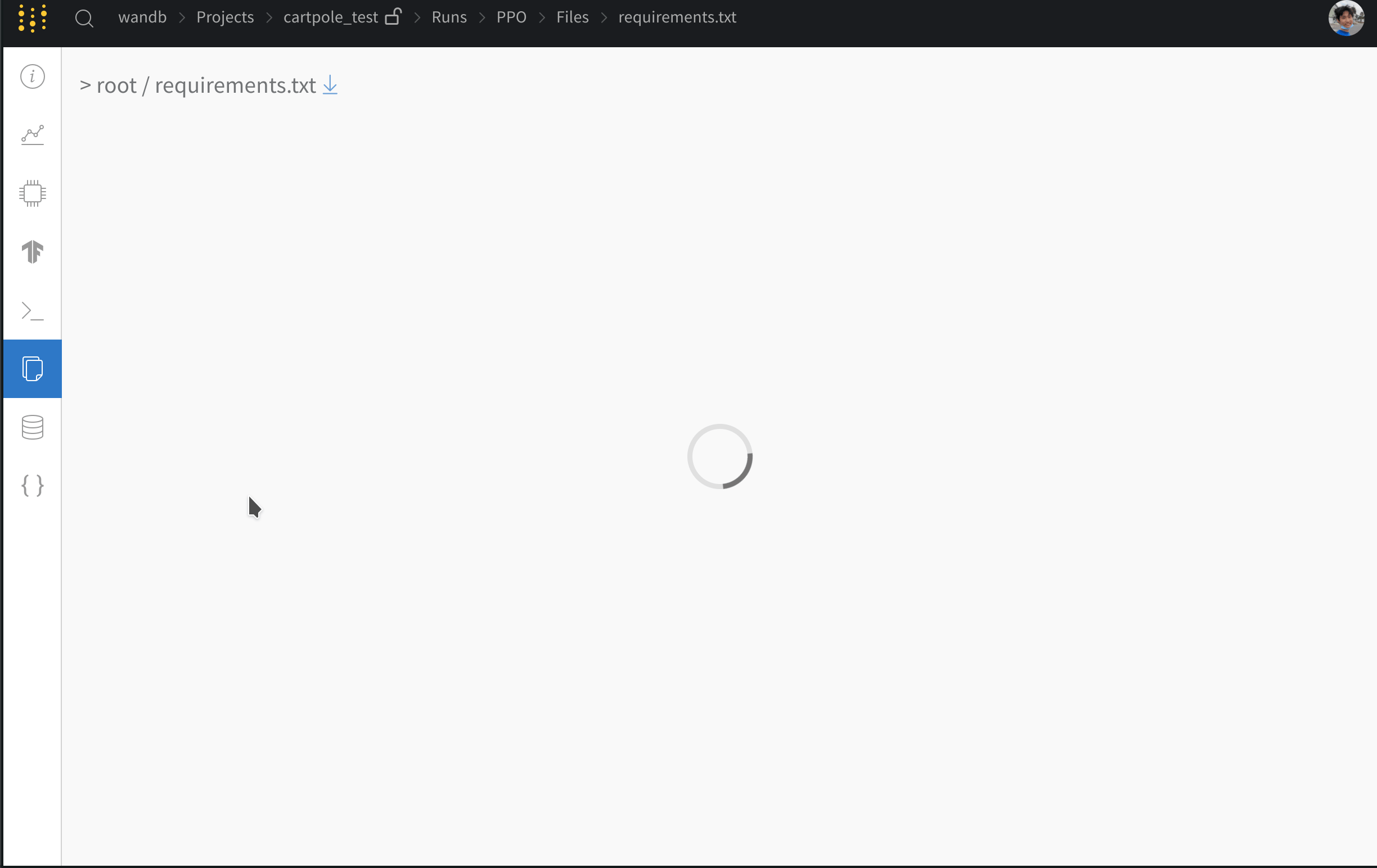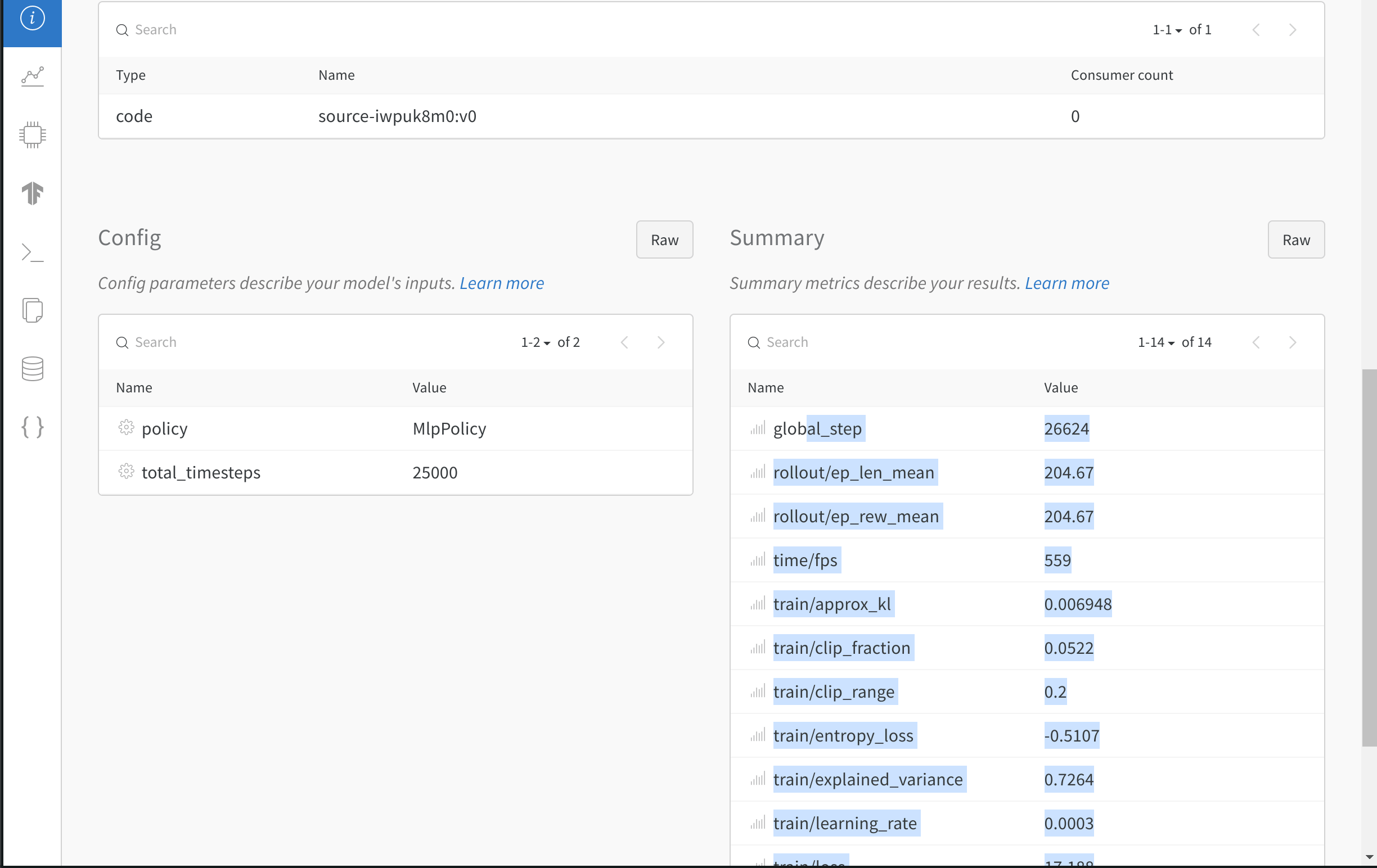
- 손실 및 에피소드별 반환과 같은 메트릭을 기록합니다.
- 에이전트가 게임을 플레이하는 비디오를 업로드합니다.
- 트레이닝된 모델을 저장합니다.
- 모델의 하이퍼파라미터를 기록합니다.
- 모델 그래디언트 히스토그램을 기록합니다.
W&B를 사용한 SB3 트레이닝 run의 예시를 검토하세요.
SB3 Experiments 기록
from wandb.integration.sb3 import WandbCallback
model.learn(..., callback=WandbCallback())
WandbCallback 인수
| 인수 | 사용법 |
|---|---|
verbose |
sb3 출력의 상세 정도 |
model_save_path |
모델이 저장될 폴더 경로. 기본값은 `None`이며, 모델은 기록되지 않습니다 |
model_save_freq |
모델 저장 빈도 |
gradient_save_freq |
그래디언트를 기록하는 빈도. 기본값은 0이며, 그래디언트는 기록되지 않습니다 |
기본 예제
W&B SB3 인테그레이션은 TensorBoard에서 출력된 로그를 사용하여 메트릭을 기록합니다.
import gym
from stable_baselines3 import PPO
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.vec_env import DummyVecEnv, VecVideoRecorder
import wandb
from wandb.integration.sb3 import WandbCallback
config = {
"policy_type": "MlpPolicy",
"total_timesteps": 25000,
"env_name": "CartPole-v1",
}
run = wandb.init(
project="sb3",
config=config,
sync_tensorboard=True, # auto-upload sb3's tensorboard metrics
monitor_gym=True, # auto-upload the videos of agents playing the game
save_code=True, # optional
)
def make_env():
env = gym.make(config["env_name"])
env = Monitor(env) # record stats such as returns
return env
env = DummyVecEnv([make_env])
env = VecVideoRecorder(
env,
f"videos/{run.id}",
record_video_trigger=lambda x: x % 2000 == 0,
video_length=200,
)
model = PPO(config["policy_type"], env, verbose=1, tensorboard_log=f"runs/{run.id}")
model.learn(
total_timesteps=config["total_timesteps"],
callback=WandbCallback(
gradient_save_freq=100,
model_save_path=f"models/{run.id}",
verbose=2,
),
)
run.finish()
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.