Pytorch torchtune
3 minute read
torchtune 은 대규모 언어 모델 (LLM) 의 작성, 미세 조정 및 실험 프로세스를 간소화하도록 설계된 PyTorch 기반 라이브러리입니다. 또한 torchtune 은 W&B 로깅을 기본적으로 지원하여 트레이닝 프로세스의 추적 및 시각화를 향상시킵니다.
torchtune 을 사용한 Mistral 7B 미세 조정에 대한 W&B 블로그 게시물을 확인하세요.
간편한 W&B 로깅
실행 시 커맨드라인 인수를 재정의합니다:
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
metric_logger._component_=torchtune.utils.metric_logging.WandBLogger \
metric_logger.project="llama3_lora" \
log_every_n_steps=5
레시피 구성에서 W&B 로깅을 활성화합니다:
# inside llama3/8B_lora_single_device.yaml
metric_logger:
_component_: torchtune.utils.metric_logging.WandBLogger
project: llama3_lora
log_every_n_steps: 5
W&B 메트릭 로거 사용
metric_logger 섹션을 수정하여 레시피 구성 파일에서 W&B 로깅을 활성화합니다. _component_ 를 torchtune.utils.metric_logging.WandBLogger 클래스로 변경합니다. project 이름과 log_every_n_steps 를 전달하여 로깅 행동을 사용자 정의할 수도 있습니다.
wandb.init 메소드에 전달하는 것처럼 다른 kwargs 를 전달할 수도 있습니다. 예를 들어 팀에서 작업하는 경우 entity 인수를 WandBLogger 클래스에 전달하여 팀 이름을 지정할 수 있습니다.
# inside llama3/8B_lora_single_device.yaml
metric_logger:
_component_: torchtune.utils.metric_logging.WandBLogger
project: llama3_lora
entity: my_project
job_type: lora_finetune_single_device
group: my_awesome_experiments
log_every_n_steps: 5
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
metric_logger._component_=torchtune.utils.metric_logging.WandBLogger \
metric_logger.project="llama3_lora" \
metric_logger.entity="my_project" \
metric_logger.job_type="lora_finetune_single_device" \
metric_logger.group="my_awesome_experiments" \
log_every_n_steps=5
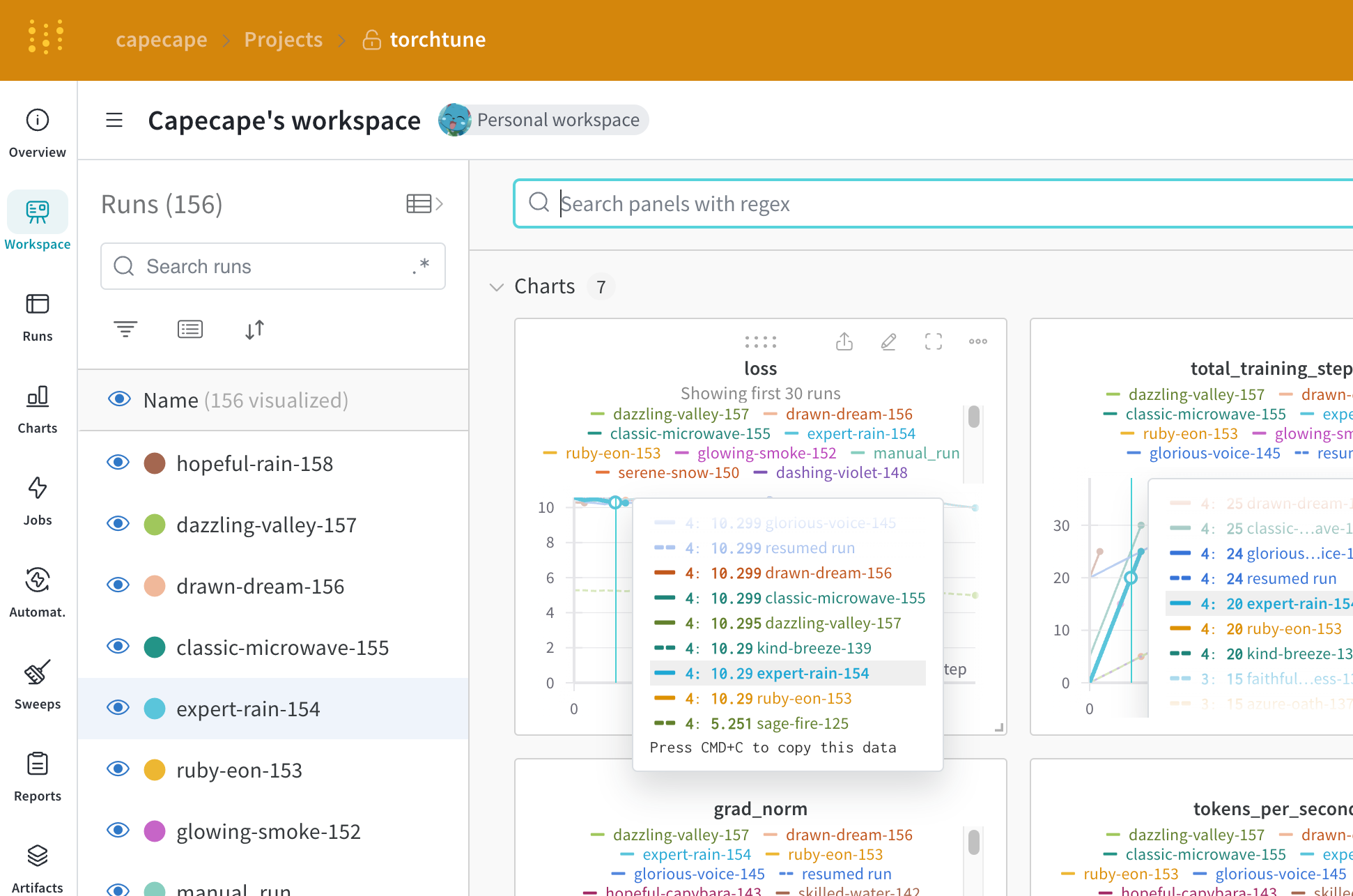
무엇이 로깅되나요?
W&B 대시보드를 탐색하여 기록된 메트릭을 확인할 수 있습니다. 기본적으로 W&B 는 구성 파일 및 실행 재정의의 모든 하이퍼파라미터를 기록합니다.
W&B 는 Overview 탭에서 확인된 구성을 캡처합니다. W&B 는 또한 YAML 형식으로 파일 탭에 구성을 저장합니다.
로깅된 메트릭
각 레시피에는 자체 트레이닝 루프가 있습니다. 각 개별 레시피를 확인하여 기본적으로 포함되는 로깅된 메트릭을 확인하십시오.
| Metric | Description |
|---|---|
loss |
모델의 손실 |
lr |
학습률 |
tokens_per_second |
모델의 초당 토큰 수 |
grad_norm |
모델의 그레이디언트 norm |
global_step |
트레이닝 루프의 현재 단계를 나타냅니다. 그레이디언트 누적을 고려하며, 기본적으로 옵티마이저 단계가 수행될 때마다 모델이 업데이트되고, 그레이디언트가 누적되며, 모델은 gradient_accumulation_steps 마다 한 번 업데이트됩니다. |
global_step 은 트레이닝 단계 수와 동일하지 않습니다. 트레이닝 루프의 현재 단계를 나타냅니다. 그레이디언트 누적을 고려하며, 기본적으로 옵티마이저 단계가 수행될 때마다 global_step 은 1 씩 증가합니다. 예를 들어 데이터 로더에 10 개의 배치, 그레이디언트 누적 단계가 2 이고 3 에포크 동안 실행되는 경우 옵티마이저는 15 번 단계별로 진행되며, 이 경우 global_step 은 1 에서 15 까지입니다.torchtune 의 간소화된 설계를 통해 사용자 정의 메트릭을 쉽게 추가하거나 기존 메트릭을 수정할 수 있습니다. 예를 들어, 레시피 파일을 수정하여 총 에포크 수의 백분율로 current_epoch 을 계산하여 로깅할 수 있습니다.
# inside `train.py` function in the recipe file
self._metric_logger.log_dict(
{"current_epoch": self.epochs * self.global_step / self._steps_per_epoch},
step=self.global_step,
)
self._metric_logger.* 함수를 호출해야 합니다.체크포인트 저장 및 로드
torchtune 라이브러리는 다양한 체크포인트 형식을 지원합니다. 사용 중인 모델의 출처에 따라 적절한 체크포인터 클래스로 전환해야 합니다.
모델 체크포인트를 W&B Artifacts에 저장하려면 해당 레시피 내에서 save_checkpoint 함수를 재정의하는 것이 가장 간단한 해결책입니다.
다음은 모델 체크포인트를 W&B Artifacts 에 저장하기 위해 save_checkpoint 함수를 재정의하는 방법의 예입니다.
def save_checkpoint(self, epoch: int) -> None:
...
## Let's save the checkpoint to W&B
## depending on the Checkpointer Class the file will be named differently
## Here is an example for the full_finetune case
checkpoint_file = Path.joinpath(
self._checkpointer._output_dir, f"torchtune_model_{epoch}"
).with_suffix(".pt")
wandb_artifact = wandb.Artifact(
name=f"torchtune_model_{epoch}",
type="model",
# description of the model checkpoint
description="Model checkpoint",
# you can add whatever metadata you want as a dict
metadata={
utils.SEED_KEY: self.seed,
utils.EPOCHS_KEY: self.epochs_run,
utils.TOTAL_EPOCHS_KEY: self.total_epochs,
utils.MAX_STEPS_KEY: self.max_steps_per_epoch,
},
)
wandb_artifact.add_file(checkpoint_file)
wandb.log_artifact(wandb_artifact)
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.