Manage job inputs
5 minute read
Launch의 핵심 경험은 하이퍼파라미터 및 데이터셋과 같은 다양한 작업 입력을 쉽게 실험하고 이러한 작업을 적절한 하드웨어로 라우팅하는 것입니다. 작업이 생성되면 원래 작성자 이외의 사용자도 W&B GUI 또는 CLI를 통해 이러한 입력을 조정할 수 있습니다. CLI 또는 UI에서 Launch할 때 작업 입력을 설정하는 방법에 대한 자세한 내용은 작업 대기열에 추가 가이드를 참조하세요.
이 섹션에서는 작업을 위해 조정할 수 있는 입력을 프로그래밍 방식으로 제어하는 방법에 대해 설명합니다.
기본적으로 W&B 작업은 전체 Run.config를 작업에 대한 입력으로 캡처하지만 Launch SDK는 run config에서 선택한 키를 제어하거나 JSON 또는 YAML 파일을 입력으로 지정하는 기능을 제공합니다.
wandb-core가 필요합니다. 자세한 내용은 wandb-core README를 참조하세요.Run 오브젝트 재구성
작업에서 wandb.init에 의해 반환된 Run 오브젝트는 기본적으로 재구성할 수 있습니다. Launch SDK는 작업을 시작할 때 Run.config 오브젝트의 어떤 부분을 재구성할 수 있는지 사용자 정의하는 방법을 제공합니다.
import wandb
from wandb.sdk import launch
# Required for launch sdk use.
wandb.require("core")
config = {
"trainer": {
"learning_rate": 0.01,
"batch_size": 32,
"model": "resnet",
"dataset": "cifar10",
"private": {
"key": "value",
},
},
"seed": 42,
}
with wandb.init(config=config):
launch.manage_wandb_config(
include=["trainer"],
exclude=["trainer.private"],
)
# Etc.
launch.manage_wandb_config 함수는 Run.config 오브젝트에 대한 입력 값을 허용하도록 작업을 구성합니다. 선택적 include 및 exclude 옵션은 중첩된 config 오브젝트 내에서 경로 접두사를 사용합니다. 예를 들어 작업이 최종 사용자에게 노출하고 싶지 않은 옵션이 있는 라이브러리를 사용하는 경우에 유용할 수 있습니다.
include 접두사가 제공되면 include 접두사와 일치하는 config 내의 경로만 입력 값을 허용합니다. exclude 접두사가 제공되면 exclude 목록과 일치하는 경로는 입력 값에서 필터링되지 않습니다. 경로가 include 및 exclude 접두사와 모두 일치하는 경우 exclude 접두사가 우선합니다.
이전 예에서 ["trainer.private"] 경로는 trainer 오브젝트에서 private 키를 필터링하고 ["trainer"] 경로는 trainer 오브젝트에 속하지 않은 모든 키를 필터링합니다.
\-이스케이프된 .을 사용하여 이름에 .이 있는 키를 필터링합니다.
예를 들어 r"trainer\.private"는 trainer 오브젝트 아래의 private 키 대신 trainer.private 키를 필터링합니다.
위의 r 접두사는 raw 문자열을 나타냅니다.
위의 코드가 패키지되어 작업으로 실행되면 작업의 입력 유형은 다음과 같습니다.
{
"trainer": {
"learning_rate": "float",
"batch_size": "int",
"model": "str",
"dataset": "str",
},
}
W&B CLI 또는 UI에서 작업을 시작할 때 사용자는 4개의 trainer 파라미터만 재정의할 수 있습니다.
Run config 입력 엑세스
Run config 입력으로 시작된 작업은 Run.config를 통해 입력 값에 엑세스할 수 있습니다. 작업 코드에서 wandb.init에 의해 반환된 Run은 입력 값이 자동으로 설정됩니다. 작업 코드의 어디에서든 run config 입력 값을 로드하려면 다음을 사용하십시오.
from wandb.sdk import launch
run_config_overrides = launch.load_wandb_config()
파일 재구성
Launch SDK는 작업 코드의 config 파일에 저장된 입력 값을 관리하는 방법도 제공합니다. 이것은 이 torchtune 예제 또는 이 Axolotl config와 같은 많은 딥러닝 및 대규모 언어 모델 유스 케이스에서 일반적인 패턴입니다.
Run.config 오브젝트를 통해 제어되어야 합니다.launch.manage_config_file 함수를 사용하여 config 파일을 Launch 작업에 대한 입력으로 추가하여 작업을 시작할 때 config 파일 내의 값을 편집할 수 있습니다.
기본적으로 launch.manage_config_file이 사용되면 run config 입력이 캡처되지 않습니다. launch.manage_wandb_config를 호출하면 이 동작이 재정의됩니다.
다음 예를 고려하십시오.
import yaml
import wandb
from wandb.sdk import launch
# Required for launch sdk use.
wandb.require("core")
launch.manage_config_file("config.yaml")
with open("config.yaml", "r") as f:
config = yaml.safe_load(f)
with wandb.init(config=config):
# Etc.
pass
코드가 인접한 파일 config.yaml과 함께 실행된다고 상상해 보십시오.
learning_rate: 0.01
batch_size: 32
model: resnet
dataset: cifar10
launch.manage_config_file을 호출하면 config.yaml 파일이 작업에 대한 입력으로 추가되어 W&B CLI 또는 UI에서 시작할 때 재구성할 수 있습니다.
include 및 exclude 키워드 arugment는 launch.manage_wandb_config와 같은 방식으로 config 파일에 허용되는 입력 키를 필터링하는 데 사용할 수 있습니다.
Config 파일 입력 엑세스
Launch에서 생성된 Run에서 launch.manage_config_file이 호출되면 launch는 config 파일의 내용을 입력 값으로 패치합니다. 패치된 config 파일은 작업 환경에서 사용할 수 있습니다.
launch.manage_config_file을 호출하십시오.작업의 Launch drawer UI 사용자 정의
작업 입력에 대한 스키마를 정의하면 작업을 시작하기 위한 사용자 정의 UI를 만들 수 있습니다. 작업의 스키마를 정의하려면 launch.manage_wandb_config 또는 launch.manage_config_file 호출에 포함합니다. 스키마는 JSON 스키마 형식의 python dict이거나 Pydantic 모델 클래스일 수 있습니다.
다음 예제는 다음과 같은 속성이 있는 스키마를 보여줍니다.
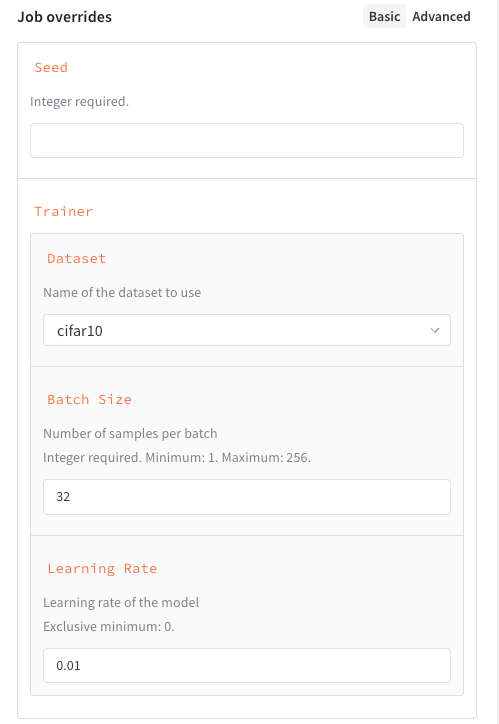
seed, 정수trainer, 지정된 일부 키가 있는 사전:trainer.learning_rate, 0보다 커야 하는 floattrainer.batch_size, 16, 64 또는 256 중 하나여야 하는 정수trainer.dataset,cifar10또는cifar100중 하나여야 하는 문자열
schema = {
"type": "object",
"properties": {
"seed": {
"type": "integer"
}
"trainer": {
"type": "object",
"properties": {
"learning_rate": {
"type": "number",
"description": "Learning rate of the model",
"exclusiveMinimum": 0,
},
"batch_size": {
"type": "integer",
"description": "Number of samples per batch",
"enum": [16, 64, 256]
},
"dataset": {
"type": "string",
"description": "Name of the dataset to use",
"enum": ["cifar10", "cifar100"]
}
}
}
}
}
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=schema,
)
일반적으로 다음 JSON 스키마 속성이 지원됩니다.
| 속성 | 필수 | 메모 |
|---|---|---|
type |
예 | number, integer, string 또는 object 중 하나여야 합니다. |
title |
아니요 | 속성의 표시 이름을 재정의합니다. |
description |
아니요 | 속성 도우미 텍스트를 제공합니다. |
enum |
아니요 | 자유 형식 텍스트 항목 대신 드롭다운 선택을 만듭니다. |
minimum |
아니요 | type이 number 또는 integer인 경우에만 허용됩니다. |
maximum |
아니요 | type이 number 또는 integer인 경우에만 허용됩니다. |
exclusiveMinimum |
아니요 | type이 number 또는 integer인 경우에만 허용됩니다. |
exclusiveMaximum |
아니요 | type이 number 또는 integer인 경우에만 허용됩니다. |
properties |
아니요 | type이 object인 경우 중첩된 구성을 정의하는 데 사용됩니다. |
다음 예제는 다음과 같은 속성이 있는 스키마를 보여줍니다.
seed, 정수trainer, 지정된 일부 하위 속성이 있는 스키마:trainer.learning_rate, 0보다 커야 하는 floattrainer.batch_size, 1에서 256 사이여야 하는 정수(포함)trainer.dataset,cifar10또는cifar100중 하나여야 하는 문자열
class DatasetEnum(str, Enum):
cifar10 = "cifar10"
cifar100 = "cifar100"
class Trainer(BaseModel):
learning_rate: float = Field(gt=0, description="Learning rate of the model")
batch_size: int = Field(ge=1, le=256, description="Number of samples per batch")
dataset: DatasetEnum = Field(title="Dataset", description="Name of the dataset to use")
class Schema(BaseModel):
seed: int
trainer: Trainer
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
schema=Schema,
)
클래스의 인스턴스를 사용할 수도 있습니다.
t = Trainer(learning_rate=0.01, batch_size=32, dataset=DatasetEnum.cifar10)
s = Schema(seed=42, trainer=t)
launch.manage_wandb_config(
include=["seed", "trainer"],
exclude=["trainer.private"],
input_schema=s,
)
작업 입력 스키마를 추가하면 Launch drawer에 구조화된 양식이 만들어져 작업을 더 쉽게 시작할 수 있습니다.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.