Log media and objects
10 minute read
이미지, 비디오, 오디오 등을 지원합니다. 풍부한 미디어를 기록하여 결과물을 살펴보고 run, model, dataset을 시각적으로 비교해 보세요. 예시와 사용 가이드는 아래를 참고하세요.
사전 준비 사항
W&B SDK로 미디어 오브젝트를 기록하려면 추가 종속성을 설치해야 할 수 있습니다. 다음 코맨드를 실행하여 이러한 종속성을 설치할 수 있습니다.
pip install wandb[media]
이미지
이미지를 기록하여 입력, 출력, 필터 가중치, 활성화 등을 추적합니다.

이미지는 NumPy 배열, PIL 이미지 또는 파일 시스템에서 직접 기록할 수 있습니다.
단계별로 이미지를 기록할 때마다 UI에 표시되도록 저장됩니다. 이미지 패널을 확장하고 스텝 슬라이더를 사용하여 다른 스텝의 이미지를 확인합니다. 이렇게 하면 트레이닝 중에 모델의 출력이 어떻게 변하는지 쉽게 비교할 수 있습니다.
torchvision의 make_grid를 사용하는 등 이미지를 수동으로 구성할 때 배열을 직접 제공합니다.
배열은 Pillow를 사용하여 png로 변환됩니다.
images = wandb.Image(image_array, caption="Top: Output, Bottom: Input")
wandb.log({"examples": images})
마지막 차원이 1이면 이미지가 회색조, 3이면 RGB, 4이면 RGBA라고 가정합니다. 배열에 float가 포함된 경우 0과 255 사이의 정수로 변환합니다. 이미지를 다르게 정규화하려면 mode를 수동으로 지정하거나 이 패널의 “PIL 이미지 로깅” 탭에 설명된 대로 PIL.Image를 제공하면 됩니다.
배열을 이미지로 변환하는 것을 완벽하게 제어하려면 PIL.Image를 직접 구성하여 제공합니다.
images = [PIL.Image.fromarray(image) for image in image_array]
wandb.log({"examples": [wandb.Image(image) for image in images]})
더욱 완벽하게 제어하려면 원하는 방식으로 이미지를 만들고 디스크에 저장한 다음 파일 경로를 제공합니다.
im = PIL.fromarray(...)
rgb_im = im.convert("RGB")
rgb_im.save("myimage.jpg")
wandb.log({"example": wandb.Image("myimage.jpg")})
이미지 오버레이
W&B UI를 통해 시멘틱 세그멘테이션 마스크를 기록하고 (불투명도 변경, 시간 경과에 따른 변경 사항 보기 등) 상호 작용합니다.

오버레이를 기록하려면 다음 키와 값이 있는 사전을 wandb.Image의 masks 키워드 인수에 제공해야 합니다.
- 이미지 마스크를 나타내는 두 개의 키 중 하나:
"mask_data": 각 픽셀에 대한 정수 클래스 레이블을 포함하는 2D NumPy 배열"path": (문자열) 저장된 이미지 마스크 파일의 경로
"class_labels": (선택 사항) 이미지 마스크의 정수 클래스 레이블을 읽을 수 있는 클래스 이름에 매핑하는 사전
여러 마스크를 기록하려면 아래 코드조각과 같이 여러 키가 있는 마스크 사전을 기록합니다.
mask_data = np.array([[1, 2, 2, ..., 2, 2, 1], ...])
class_labels = {1: "tree", 2: "car", 3: "road"}
mask_img = wandb.Image(
image,
masks={
"predictions": {"mask_data": mask_data, "class_labels": class_labels},
"ground_truth": {
# ...
},
# ...
},
)
이미지와 함께 바운딩 박스를 기록하고 필터와 토글을 사용하여 UI에서 다양한 박스 세트를 동적으로 시각화합니다.
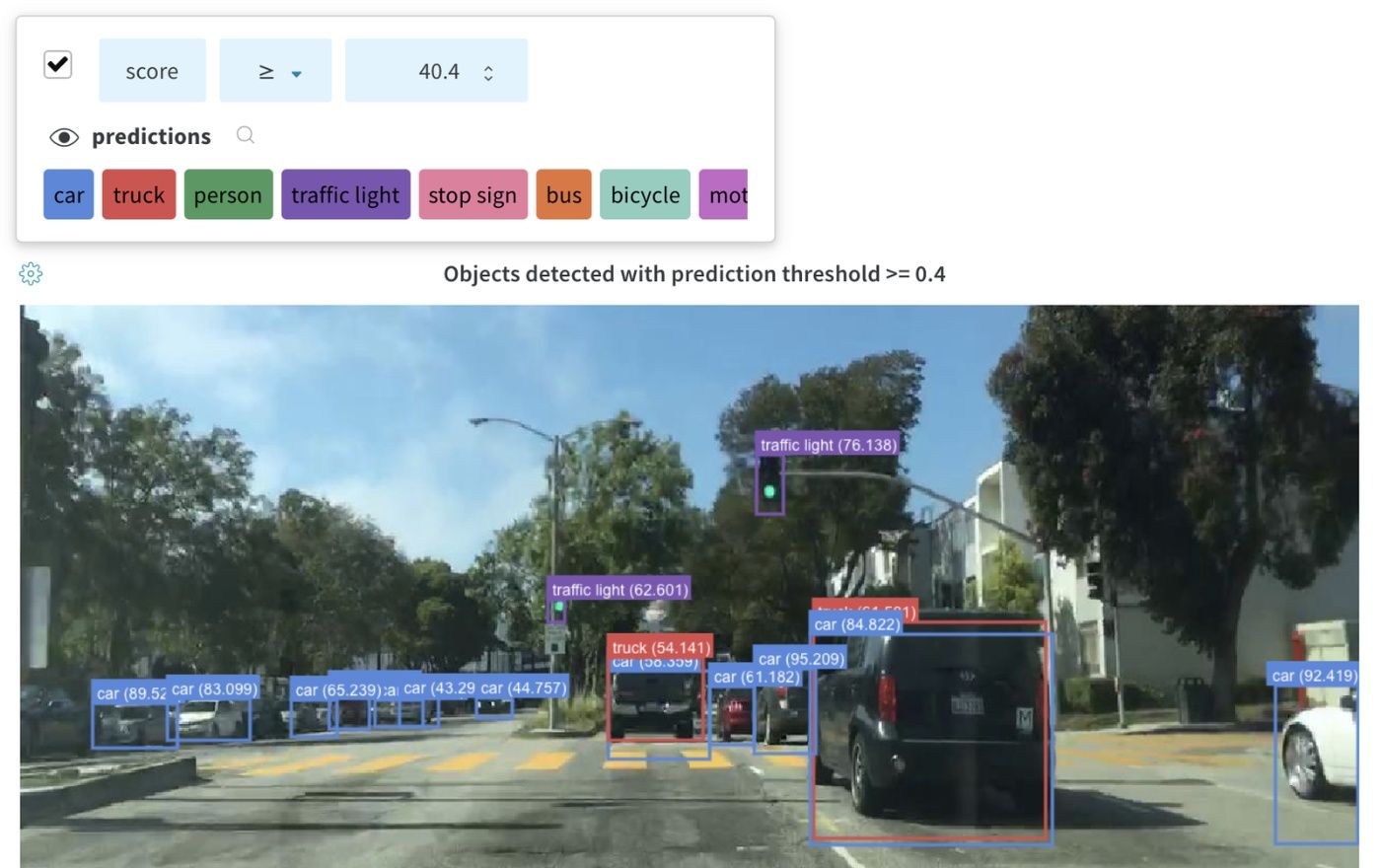
바운딩 박스를 기록하려면 다음 키와 값이 있는 사전을 wandb.Image의 boxes 키워드 인수에 제공해야 합니다.
box_data: 각 박스에 대해 하나씩, 사전의 리스트입니다. 박스 사전 형식은 아래에 설명되어 있습니다.position: 아래에 설명된 두 가지 형식 중 하나로 박스의 위치와 크기를 나타내는 사전입니다. 박스가 모두 동일한 형식을 사용할 필요는 없습니다.- 옵션 1:
{"minX", "maxX", "minY", "maxY"}. 각 박스 차원의 상한 및 하한을 정의하는 좌표 세트를 제공합니다. - 옵션 2:
{"middle", "width", "height"}.middle좌표를[x,y]로 지정하고width와height를 스칼라로 지정하는 좌표 세트를 제공합니다.
- 옵션 1:
class_id: 박스의 클래스 ID를 나타내는 정수입니다. 아래의class_labels키를 참조하세요.scores: 점수에 대한 문자열 레이블과 숫자 값의 사전입니다. UI에서 박스를 필터링하는 데 사용할 수 있습니다.domain: 박스 좌표의 단위/형식을 지정합니다. 박스 좌표가 이미지 크기 범위 내의 정수와 같이 픽셀 공간으로 표현되는 경우 “pixel"로 설정합니다. 기본적으로 도메인은 이미지의 분수/백분율로 간주되며 0과 1 사이의 부동 소수점 숫자로 표현됩니다.box_caption: (선택 사항) 이 박스의 레이블 텍스트로 표시할 문자열입니다.
class_labels: (선택 사항)class_id를 문자열에 매핑하는 사전입니다. 기본적으로class_0,class_1등 클래스 레이블을 생성합니다.
이 예시를 확인해 보세요.
class_id_to_label = {
1: "car",
2: "road",
3: "building",
# ...
}
img = wandb.Image(
image,
boxes={
"predictions": {
"box_data": [
{
# one box expressed in the default relative/fractional domain
"position": {"minX": 0.1, "maxX": 0.2, "minY": 0.3, "maxY": 0.4},
"class_id": 2,
"box_caption": class_id_to_label[2],
"scores": {"acc": 0.1, "loss": 1.2},
# another box expressed in the pixel domain
# (for illustration purposes only, all boxes are likely
# to be in the same domain/format)
"position": {"middle": [150, 20], "width": 68, "height": 112},
"domain": "pixel",
"class_id": 3,
"box_caption": "a building",
"scores": {"acc": 0.5, "loss": 0.7},
# ...
# Log as many boxes an as needed
}
],
"class_labels": class_id_to_label,
},
# Log each meaningful group of boxes with a unique key name
"ground_truth": {
# ...
},
},
)
wandb.log({"driving_scene": img})
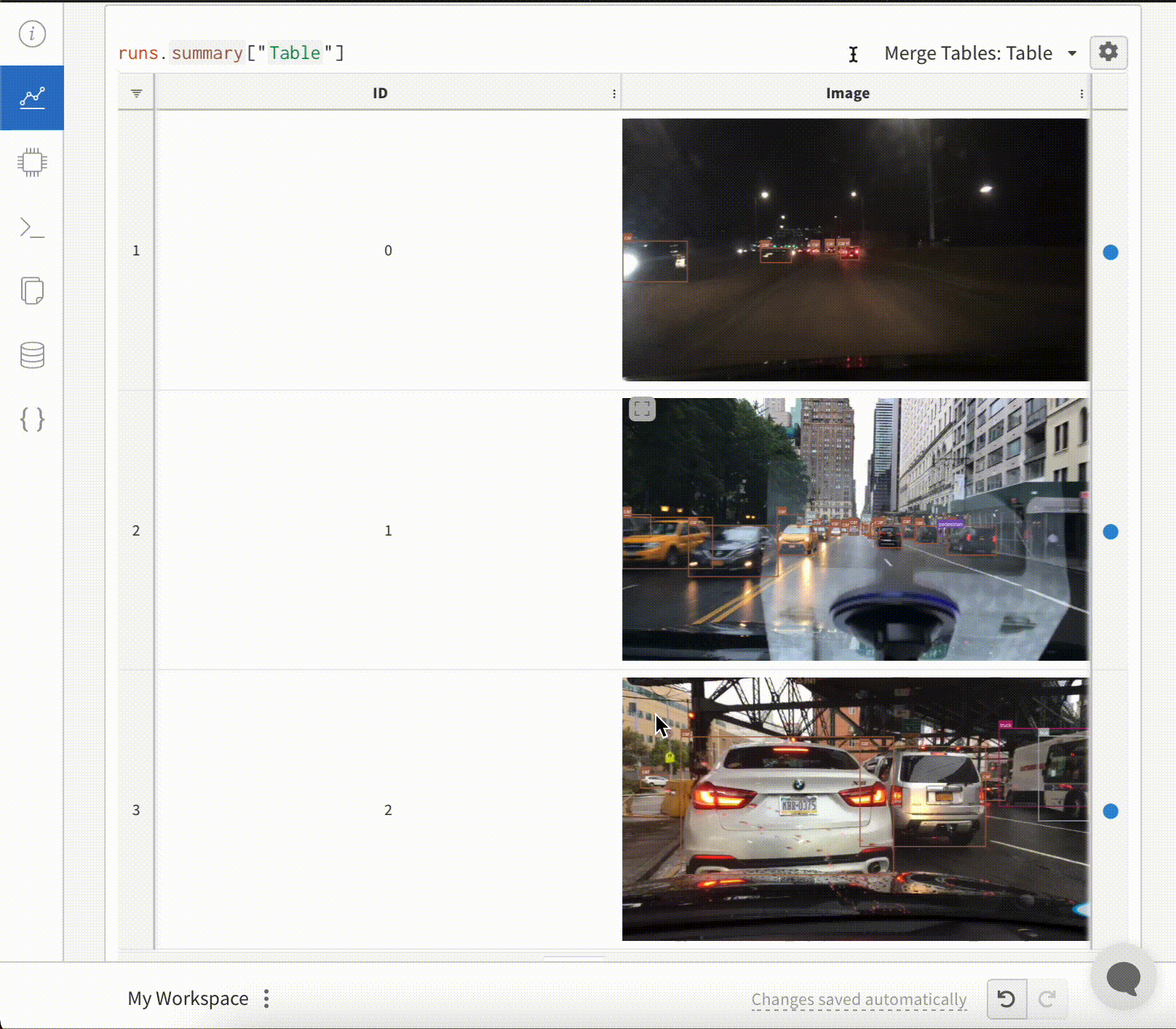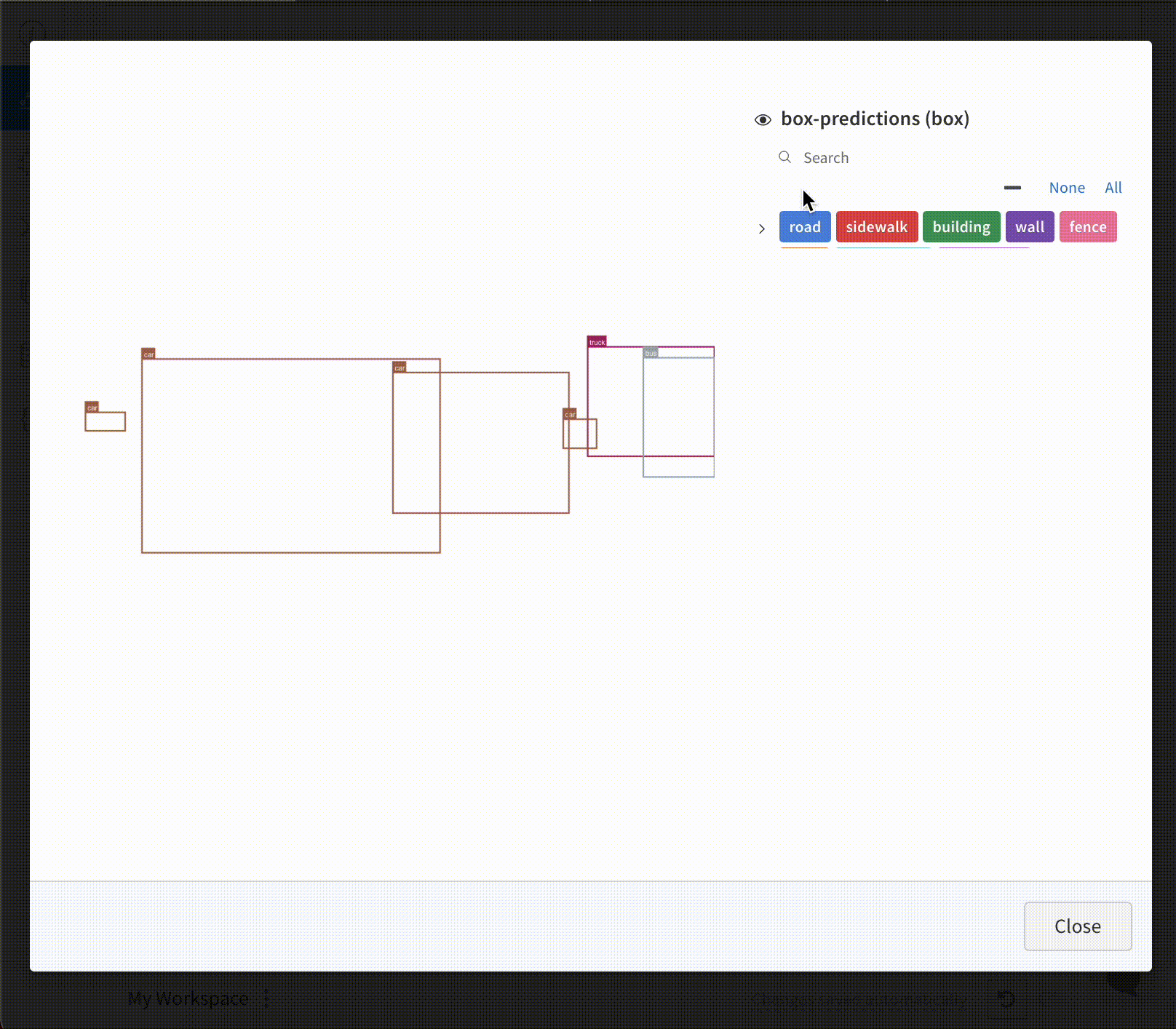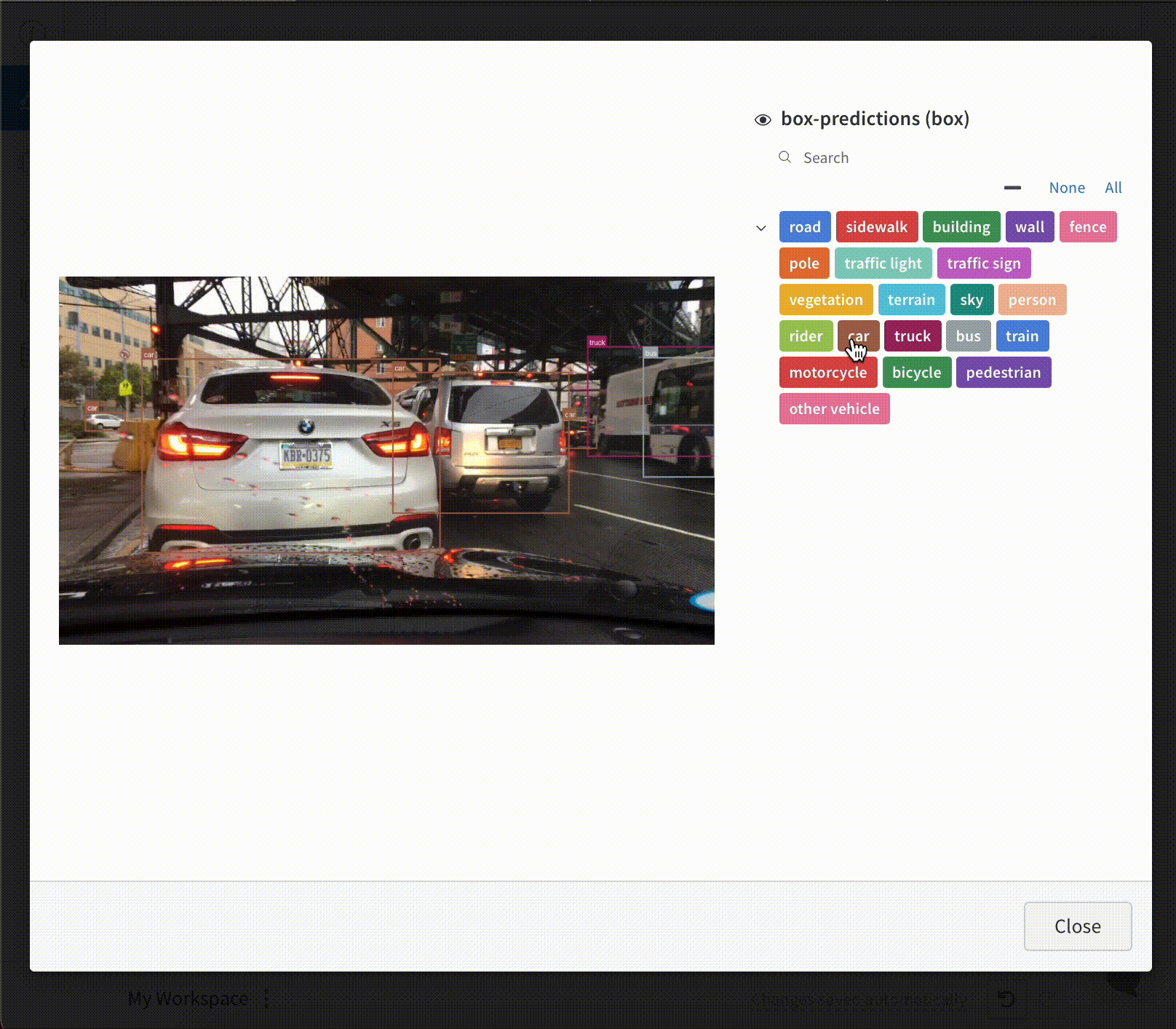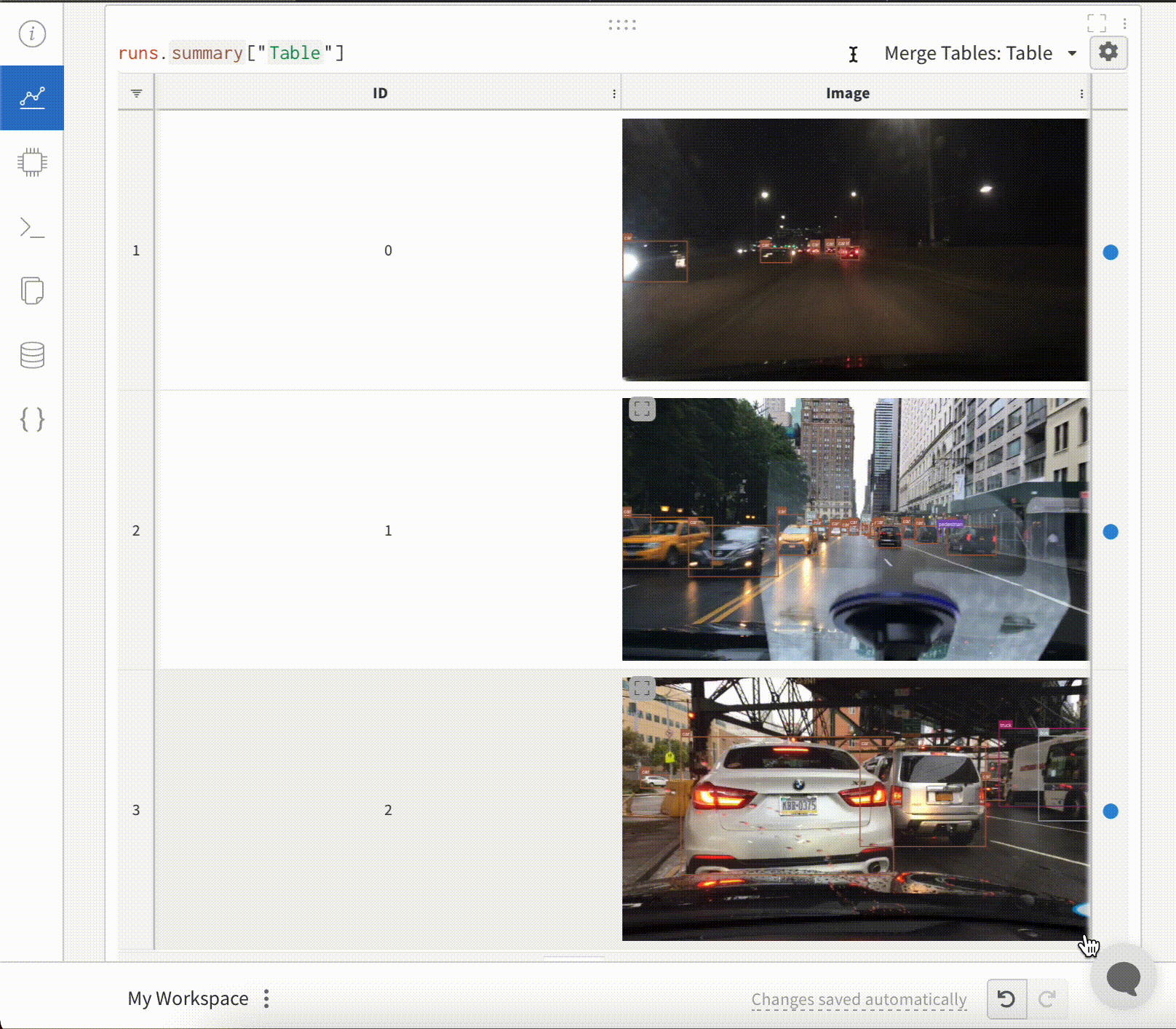
테이블의 이미지 오버레이
테이블에 시멘틱 세그멘테이션 마스크를 기록하려면 테이블의 각 행에 대해 wandb.Image 오브젝트를 제공해야 합니다.
아래 코드조각에 예시가 제공되어 있습니다.
table = wandb.Table(columns=["ID", "Image"])
for id, img, label in zip(ids, images, labels):
mask_img = wandb.Image(
img,
masks={
"prediction": {"mask_data": label, "class_labels": class_labels}
# ...
},
)
table.add_data(id, img)
wandb.log({"Table": table})
테이블에 바운딩 박스가 있는 이미지를 기록하려면 테이블의 각 행에 대해 wandb.Image 오브젝트를 제공해야 합니다.
아래 코드조각에 예시가 제공되어 있습니다.
table = wandb.Table(columns=["ID", "Image"])
for id, img, boxes in zip(ids, images, boxes_set):
box_img = wandb.Image(
img,
boxes={
"prediction": {
"box_data": [
{
"position": {
"minX": box["minX"],
"minY": box["minY"],
"maxX": box["maxX"],
"maxY": box["maxY"],
},
"class_id": box["class_id"],
"box_caption": box["caption"],
"domain": "pixel",
}
for box in boxes
],
"class_labels": class_labels,
}
},
)
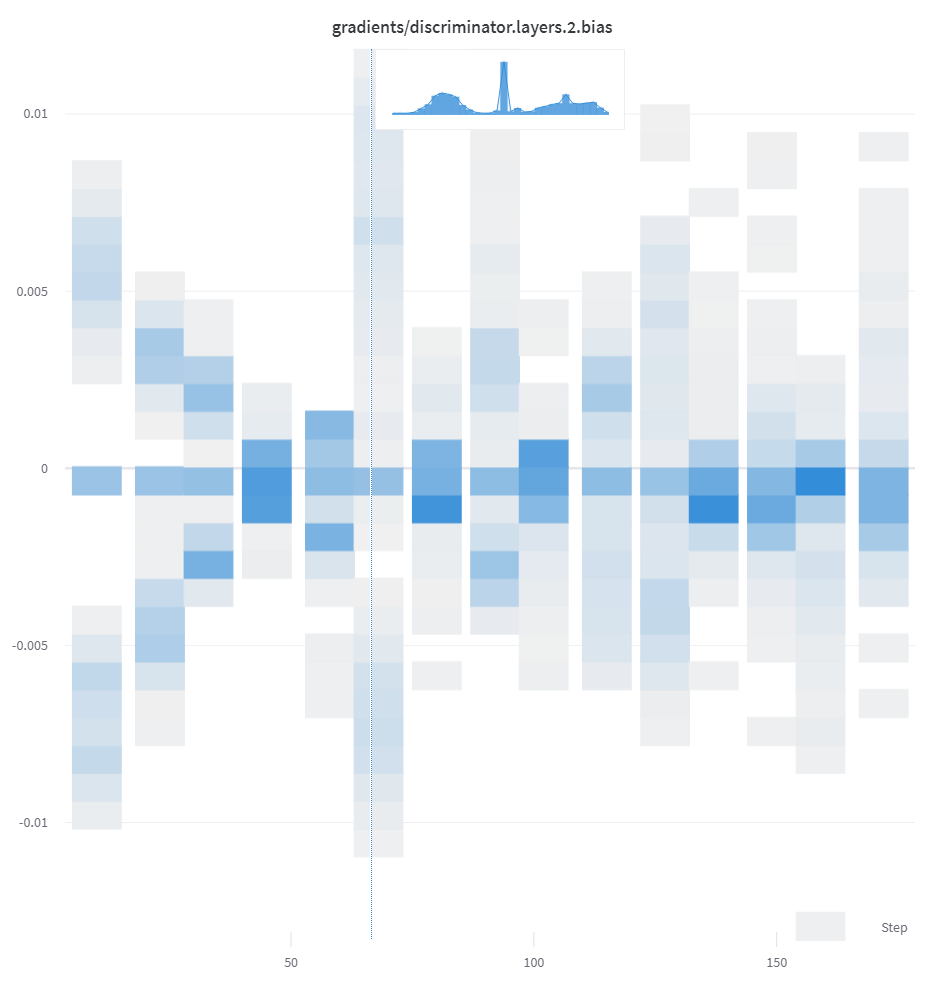
히스토그램
리스트, 배열 또는 텐서와 같은 숫자 시퀀스가 첫 번째 인수로 제공되면 np.histogram을 호출하여 히스토그램이 자동으로 구성됩니다. 모든 배열/텐서는 평면화됩니다. 선택적 num_bins 키워드 인수를 사용하여 기본값인 64개 구간을 재정의할 수 있습니다. 지원되는 최대 구간 수는 512개입니다.
UI에서 히스토그램은 x축에 트레이닝 스텝, y축에 메트릭 값, 색상으로 표현되는 개수로 플롯되어 트레이닝 전반에 걸쳐 기록된 히스토그램을 쉽게 비교할 수 있습니다. 일회성 히스토그램 로깅에 대한 자세한 내용은 이 패널의 “요약의 히스토그램” 탭을 참조하세요.
wandb.log({"gradients": wandb.Histogram(grads)})
더 많은 제어를 원하면 np.histogram을 호출하고 반환된 튜플을 np_histogram 키워드 인수에 전달합니다.
np_hist_grads = np.histogram(grads, density=True, range=(0.0, 1.0))
wandb.log({"gradients": wandb.Histogram(np_hist_grads)})
wandb.run.summary.update( # if only in summary, only visible on Overview 탭
{"final_logits": wandb.Histogram(logits)}
)
'obj', 'gltf', 'glb', 'babylon', 'stl', 'pts.json' 형식으로 파일을 기록하면 run이 완료될 때 UI에서 렌더링됩니다.
wandb.log(
{
"generated_samples": [
wandb.Object3D(open("sample.obj")),
wandb.Object3D(open("sample.gltf")),
wandb.Object3D(open("sample.glb")),
]
}
)
히스토그램이 요약에 있으면 Run 페이지의 Overview 탭에 나타납니다. 히스토리가 있으면 차트 탭에서 시간 경과에 따른 구간의 히트맵이 플롯됩니다.
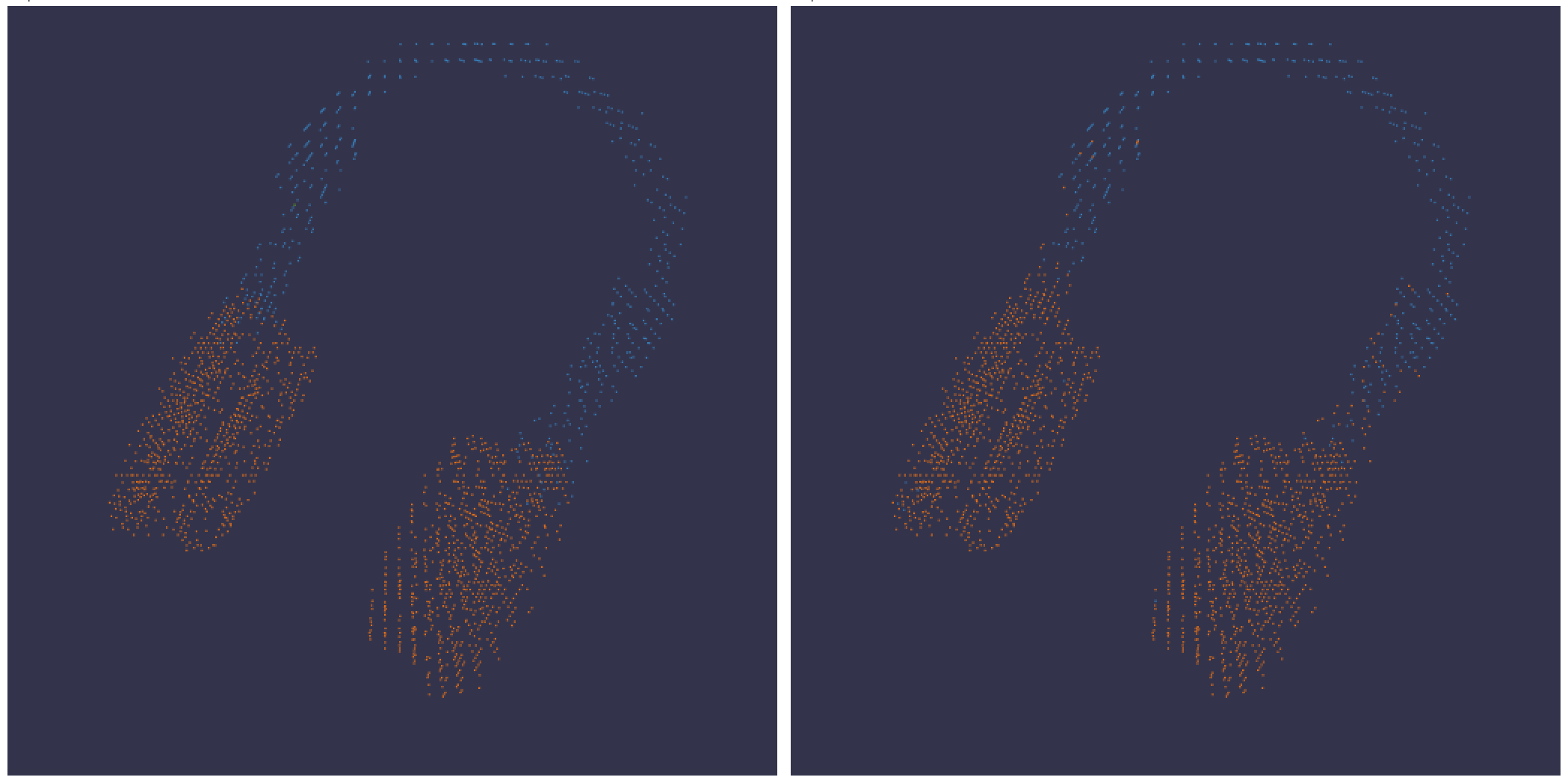
3D 시각화
바운딩 박스가 있는 3D 포인트 클라우드와 Lidar 장면을 기록합니다. 렌더링할 점에 대한 좌표와 색상을 포함하는 NumPy 배열을 전달합니다.
point_cloud = np.array([[0, 0, 0, COLOR]])
wandb.log({"point_cloud": wandb.Object3D(point_cloud)})
:::info W&B UI는 데이터를 300,000개 포인트에서 자릅니다. :::
NumPy 배열 형식
유연한 색 구성표를 위해 세 가지 다른 형식의 NumPy 배열이 지원됩니다.
[[x, y, z], ...]nx3[[x, y, z, c], ...]nx4| c는 카테고리입니다범위[1, 14](세그멘테이션에 유용)[[x, y, z, r, g, b], ...]nx6 | r,g,b는 빨강, 초록 및 파랑 색상 채널에 대한 범위[0,255]의 값입니다.
Python 오브젝트
이 스키마를 사용하면 Python 오브젝트를 정의하고 the from_point_cloud method에 아래와 같이 전달할 수 있습니다.
points는 위에 표시된 단순 포인트 클라우드 렌더러와 동일한 형식을 사용하여 렌더링할 점에 대한 좌표와 색상을 포함하는 NumPy 배열입니다.boxes는 세 가지 속성이 있는 Python 사전의 NumPy 배열입니다.corners- 8개 코너의 리스트label- 박스에 렌더링할 레이블을 나타내는 문자열입니다 (선택 사항)color- 박스의 RGB 값을 나타냅니다score- 바운딩 박스에 표시되며 표시된 바운딩 박스를 필터링하는 데 사용할 수 있는 숫자 값입니다 (예:score>0.75인 바운딩 박스만 표시). (선택 사항)
type은 렌더링할 장면 유형을 나타내는 문자열입니다. 현재 지원되는 유일한 값은lidar/beta입니다.
point_list = [
[
2566.571924017235, # x
746.7817289698219, # y
-15.269245470863748,# z
76.5, # red
127.5, # green
89.46617199365393 # blue
],
[ 2566.592983606823, 746.6791987335685, -15.275803826279521, 76.5, 127.5, 89.45471117247024 ],
[ 2566.616361739416, 746.4903185513501, -15.28628929674075, 76.5, 127.5, 89.41336375503832 ],
[ 2561.706014951675, 744.5349468458361, -14.877496818222781, 76.5, 127.5, 82.21868245418283 ],
[ 2561.5281847916694, 744.2546118233013, -14.867862032341005, 76.5, 127.5, 81.87824684536432 ],
[ 2561.3693562897465, 744.1804761656741, -14.854129178142523, 76.5, 127.5, 81.64137897587152 ],
[ 2561.6093071504515, 744.0287526628543, -14.882135189841177, 76.5, 127.5, 81.89871499537098 ],
# ... and so on
]
run.log({"my_first_point_cloud": wandb.Object3D.from_point_cloud(
points = point_list,
boxes = [{
"corners": [
[ 2601.2765123137915, 767.5669506323393, -17.816764802288663 ],
[ 2599.7259021588347, 769.0082337923552, -17.816764802288663 ],
[ 2599.7259021588347, 769.0082337923552, -19.66876480228866 ],
[ 2601.2765123137915, 767.5669506323393, -19.66876480228866 ],
[ 2604.8684867834395, 771.4313904894723, -17.816764802288663 ],
[ 2603.3178766284827, 772.8726736494882, -17.816764802288663 ],
[ 2603.3178766284827, 772.8726736494882, -19.66876480228866 ],
[ 2604.8684867834395, 771.4313904894723, -19.66876480228866 ]
],
"color": [0, 0, 255], # 바운딩 박스의 RGB 색상
"label": "car", # 바운딩 박스에 표시되는 문자열
"score": 0.6 # 바운딩 박스에 표시되는 숫자
}],
vectors = [
{"start": [0, 0, 0], "end": [0.1, 0.2, 0.5], "color": [255, 0, 0]}, # 색상은 선택 사항입니다.
],
point_cloud_type = "lidar/beta",
)})
포인트 클라우드를 볼 때 control 키를 누른 상태에서 마우스를 사용하여 공간 내부를 이동할 수 있습니다.
포인트 클라우드 파일
the from_file method를 사용하여 포인트 클라우드 데이터로 가득 찬 JSON 파일을 로드할 수 있습니다.
run.log({"my_cloud_from_file": wandb.Object3D.from_file(
"./my_point_cloud.pts.json"
)})
포인트 클라우드 데이터 형식을 지정하는 방법의 예는 아래와 같습니다.
{
"boxes": [
{
"color": [
0,
255,
0
],
"score": 0.35,
"label": "My label",
"corners": [
[
2589.695869075582,
760.7400443552185,
-18.044831294622487
],
[
2590.719039645323,
762.3871153874499,
-18.044831294622487
],
[
2590.719039645323,
762.3871153874499,
-19.54083129462249
],
[
2589.695869075582,
760.7400443552185,
-19.54083129462249
],
[
2594.9666662674313,
757.4657929961453,
-18.044831294622487
],
[
2595.9898368371723,
759.1128640283766,
-18.044831294622487
],
[
2595.9898368371723,
759.1128640283766,
-19.54083129462249
],
[
2594.9666662674313,
757.4657929961453,
-19.54083129462249
]
]
}
],
"points": [
[
2566.571924017235,
746.7817289698219,
-15.269245470863748,
76.5,
127.5,
89.46617199365393
],
[
2566.592983606823,
746.6791987335685,
-15.275803826279521,
76.5,
127.5,
89.45471117247024
],
[
2566.616361739416,
746.4903185513501,
-15.28628929674075,
76.5,
127.5,
89.41336375503832
]
],
"type": "lidar/beta"
}
NumPy 배열
위에서 정의한 것과 동일한 배열 형식을 사용하여 [numpy 배열을 the from_numpy` method와 함께 직접 사용하여 포인트 클라우드를 정의할 수 있습니다.
run.log({"my_cloud_from_numpy_xyz": wandb.Object3D.from_numpy(
np.array(
[
[0.4, 1, 1.3], # x, y, z
[1, 1, 1],
[1.2, 1, 1.2]
]
)
)})
run.log({"my_cloud_from_numpy_cat": wandb.Object3D.from_numpy(
np.array(
[
[0.4, 1, 1.3, 1], # x, y, z, 카테고리
[1, 1, 1, 1],
[1.2, 1, 1.2, 12],
[1.2, 1, 1.3, 12],
[1.2, 1, 1.4, 12],
[1.2, 1, 1.5, 12],
[1.2, 1, 1.6, 11],
[1.2, 1, 1.7, 11],
]
)
)})
run.log({"my_cloud_from_numpy_rgb": wandb.Object3D.from_numpy(
np.array(
[
[0.4, 1, 1.3, 255, 0, 0], # x, y, z, r, g, b
[1, 1, 1, 0, 255, 0],
[1.2, 1, 1.3, 0, 255, 255],
[1.2, 1, 1.4, 0, 255, 255],
[1.2, 1, 1.5, 0, 0, 255],
[1.2, 1, 1.1, 0, 0, 255],
[1.2, 1, 0.9, 0, 0, 255],
]
)
)})
wandb.log({"protein": wandb.Molecule("6lu7.pdb")})
10가지 파일 형식(pdb, pqr, mmcif, mcif, cif, sdf, sd, gro, mol2 또는 mmtf)으로 분자 데이터를 기록합니다.
또한 W&B는 SMILES 문자열, rdkit mol 파일 및 rdkit.Chem.rdchem.Mol 오브젝트에서 분자 데이터 로깅을 지원합니다.
resveratrol = rdkit.Chem.MolFromSmiles("Oc1ccc(cc1)C=Cc1cc(O)cc(c1)O")
wandb.log(
{
"resveratrol": wandb.Molecule.from_rdkit(resveratrol),
"green fluorescent protein": wandb.Molecule.from_rdkit("2b3p.mol"),
"acetaminophen": wandb.Molecule.from_smiles("CC(=O)Nc1ccc(O)cc1"),
}
)
run이 완료되면 UI에서 분자의 3D 시각화와 상호 작용할 수 있습니다.
PNG 이미지
wandb.Image는 numpy 배열 또는 PILImage 인스턴스를 기본적으로 PNG로 변환합니다.
wandb.log({"example": wandb.Image(...)})
# 또는 여러 이미지
wandb.log({"example": [wandb.Image(...) for img in images]})
비디오
비디오는 wandb.Video 데이터 유형을 사용하여 기록됩니다.
wandb.log({"example": wandb.Video("myvideo.mp4")})
이제 미디어 브라우저에서 비디오를 볼 수 있습니다. 프로젝트 워크스페이스, run 워크스페이스 또는 리포트로 이동하여 시각화 추가를 클릭하여 풍부한 미디어 패널을 추가합니다.
분자의 2D 보기
wandb.Image 데이터 유형과 rdkit을 사용하여 분자의 2D 보기를 기록할 수 있습니다.
molecule = rdkit.Chem.MolFromSmiles("CC(=O)O")
rdkit.Chem.AllChem.Compute2DCoords(molecule)
rdkit.Chem.AllChem.GenerateDepictionMatching2DStructure(molecule, molecule)
pil_image = rdkit.Chem.Draw.MolToImage(molecule, size=(300, 300))
wandb.log({"acetic_acid": wandb.Image(pil_image)})
기타 미디어
W&B는 다양한 다른 미디어 유형의 로깅도 지원합니다.
오디오
wandb.log({"whale songs": wandb.Audio(np_array, caption="OooOoo", sample_rate=32)})
스텝당 최대 100개의 오디오 클립을 기록할 수 있습니다. 자세한 사용 정보는 audio-file을 참조하세요.
비디오
wandb.log({"video": wandb.Video(numpy_array_or_path_to_video, fps=4, format="gif")})
numpy 배열이 제공되면 차원은 시간, 채널, 너비, 높이 순서라고 가정합니다. 기본적으로 4fps gif 이미지를 만듭니다 (ffmpeg 및 moviepy python 라이브러리는 numpy 오브젝트를 전달할 때 필요합니다). 지원되는 형식은 "gif", "mp4", "webm" 및 "ogg"입니다. 문자열을 wandb.Video에 전달하면 파일을 업로드하기 전에 파일이 존재하고 지원되는 형식인지 확인합니다. BytesIO 오브젝트를 전달하면 지정된 형식을 확장자로 사용하여 임시 파일이 생성됩니다.
W&B Run 및 Project 페이지에서 미디어 섹션에 비디오가 표시됩니다.
자세한 사용 정보는 video-file을 참조하세요.
텍스트
UI에 표시되도록 테이블에 텍스트를 기록하려면 wandb.Table을 사용합니다. 기본적으로 열 헤더는 ["Input", "Output", "Expected"]입니다. 최적의 UI 성능을 보장하기 위해 기본 최대 행 수는 10,000으로 설정됩니다. 그러나 사용자는 wandb.Table.MAX_ROWS = {DESIRED_MAX}를 사용하여 최대값을 명시적으로 재정의할 수 있습니다.
columns = ["Text", "Predicted Sentiment", "True Sentiment"]
# Method 1
data = [["I love my phone", "1", "1"], ["My phone sucks", "0", "-1"]]
table = wandb.Table(data=data, columns=columns)
wandb.log({"examples": table})
# Method 2
table = wandb.Table(columns=columns)
table.add_data("I love my phone", "1", "1")
table.add_data("My phone sucks", "0", "-1")
wandb.log({"examples": table})
pandas DataFrame 오브젝트를 전달할 수도 있습니다.
table = wandb.Table(dataframe=my_dataframe)
자세한 사용 정보는 string을 참조하세요.
HTML
wandb.log({"custom_file": wandb.Html(open("some.html"))})
wandb.log({"custom_string": wandb.Html('<a href="https://mysite">Link</a>')})
사용자 지정 HTML은 임의의 키로 기록할 수 있으며, 이는 run 페이지에서 HTML 패널을 노출합니다. 기본적으로 기본 스타일을 삽입합니다. inject=False를 전달하여 기본 스타일을 해제할 수 있습니다.
wandb.log({"custom_file": wandb.Html(open("some.html"), inject=False)})
자세한 사용 정보는 html-file을 참조하세요.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.