TensorFlow Sweeps
4 minute read

W&B Sweeps를 사용하여 하이퍼파라미터 최적화를 자동화하고 대화형 대시보드로 모델 가능성을 탐색하세요.
Sweeps를 사용하는 이유
- 빠른 설정: 몇 줄의 코드로 W&B Sweeps를 실행합니다.
- 투명성: 프로젝트는 사용된 모든 알고리즘을 인용하고, 코드는 오픈 소스입니다.
- 강력한 기능: Sweeps는 사용자 정의 옵션을 제공하며 여러 시스템 또는 랩톱에서 쉽게 실행할 수 있습니다.
자세한 내용은 Sweep documentation을 참조하십시오.
이 노트북에서 다루는 내용
- TensorFlow에서 W&B Sweep 및 사용자 지정 트레이닝 루프로 시작하는 단계.
- 이미지 분류 작업을 위한 최적의 하이퍼파라미터 찾기.
참고: Step 으로 시작하는 섹션은 하이퍼파라미터 스윕을 수행하는 데 필요한 코드를 보여줍니다. 나머지는 간단한 예를 설정합니다.
설치, 임포트 및 로그인
W&B 설치
pip install wandb
W&B 임포트 및 로그인
import tqdm
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import cifar10
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import wandb
from wandb.integration.keras import WandbMetricsLogger
wandb.login()
W&B를 처음 사용하거나 로그인하지 않은 경우
wandb.login()을 실행한 후 링크가 가입/로그인 페이지로 연결됩니다.데이터셋 준비
# 트레이닝 데이터셋 준비
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
x_train = np.reshape(x_train, (-1, 784))
x_test = np.reshape(x_test, (-1, 784))
분류기 MLP 빌드
def Model():
inputs = keras.Input(shape=(784,), name="digits")
x1 = keras.layers.Dense(64, activation="relu")(inputs)
x2 = keras.layers.Dense(64, activation="relu")(x1)
outputs = keras.layers.Dense(10, name="predictions")(x2)
return keras.Model(inputs=inputs, outputs=outputs)
def train_step(x, y, model, optimizer, loss_fn, train_acc_metric):
with tf.GradientTape() as tape:
logits = model(x, training=True)
loss_value = loss_fn(y, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return loss_value
def test_step(x, y, model, loss_fn, val_acc_metric):
val_logits = model(x, training=False)
loss_value = loss_fn(y, val_logits)
val_acc_metric.update_state(y, val_logits)
return loss_value
트레이닝 루프 작성
def train(
train_dataset,
val_dataset,
model,
optimizer,
loss_fn,
train_acc_metric,
val_acc_metric,
epochs=10,
log_step=200,
val_log_step=50,
):
for epoch in range(epochs):
print("\nStart of epoch %d" % (epoch,))
train_loss = []
val_loss = []
# 데이터셋의 배치를 반복합니다.
for step, (x_batch_train, y_batch_train) in tqdm.tqdm(
enumerate(train_dataset), total=len(train_dataset)
):
loss_value = train_step(
x_batch_train,
y_batch_train,
model,
optimizer,
loss_fn,
train_acc_metric,
)
train_loss.append(float(loss_value))
# 각 에포크가 끝날 때 검증 루프를 실행합니다.
for step, (x_batch_val, y_batch_val) in enumerate(val_dataset):
val_loss_value = test_step(
x_batch_val, y_batch_val, model, loss_fn, val_acc_metric
)
val_loss.append(float(val_loss_value))
# 각 에포크가 끝날 때 메트릭을 표시합니다.
train_acc = train_acc_metric.result()
print("Training acc over epoch: %.4f" % (float(train_acc),))
val_acc = val_acc_metric.result()
print("Validation acc: %.4f" % (float(val_acc),))
# 각 에포크가 끝날 때 메트릭을 재설정합니다.
train_acc_metric.reset_states()
val_acc_metric.reset_states()
# 3️⃣ wandb.log를 사용하여 메트릭을 기록합니다.
wandb.log(
{
"epochs": epoch,
"loss": np.mean(train_loss),
"acc": float(train_acc),
"val_loss": np.mean(val_loss),
"val_acc": float(val_acc),
}
)
스윕 구성
스윕을 구성하는 단계:
- 최적화할 하이퍼파라미터 정의
- 최적화 방법 선택:
random,grid또는bayes val_loss최소화와 같이bayes에 대한 목표 및 메트릭 설정- 수행 중인 Runs를 조기에 종료하려면
hyperband를 사용합니다.
자세한 내용은 W&B Sweeps documentation을 참조하십시오.
sweep_config = {
"method": "random",
"metric": {"name": "val_loss", "goal": "minimize"},
"early_terminate": {"type": "hyperband", "min_iter": 5},
"parameters": {
"batch_size": {"values": [32, 64, 128, 256]},
"learning_rate": {"values": [0.01, 0.005, 0.001, 0.0005, 0.0001]},
},
}
트레이닝 루프 래핑
train을 호출하기 전에 하이퍼파라미터를 설정하기 위해 wandb.config를 사용하는 sweep_train과 같은 함수를 만듭니다.
def sweep_train(config_defaults=None):
# 기본값 설정
config_defaults = {"batch_size": 64, "learning_rate": 0.01}
# 샘플 프로젝트 이름으로 wandb를 초기화합니다.
wandb.init(config=config_defaults) # 이것은 Sweep에서 덮어쓰기됩니다.
# 구성에 대한 다른 하이퍼파라미터를 지정합니다(있는 경우).
wandb.config.epochs = 2
wandb.config.log_step = 20
wandb.config.val_log_step = 50
wandb.config.architecture_name = "MLP"
wandb.config.dataset_name = "MNIST"
# tf.data를 사용하여 입력 파이프라인 구축
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = (
train_dataset.shuffle(buffer_size=1024)
.batch(wandb.config.batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(wandb.config.batch_size).prefetch(
buffer_size=tf.data.AUTOTUNE
)
# 모델 초기화
model = Model()
# 모델을 트레이닝하기 위한 옵티마이저를 인스턴스화합니다.
optimizer = keras.optimizers.SGD(learning_rate=wandb.config.learning_rate)
# 손실 함수를 인스턴스화합니다.
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# 메트릭을 준비합니다.
train_acc_metric = keras.metrics.SparseCategoricalAccuracy()
val_acc_metric = keras.metrics.SparseCategoricalAccuracy()
train(
train_dataset,
val_dataset,
model,
optimizer,
loss_fn,
train_acc_metric,
val_acc_metric,
epochs=wandb.config.epochs,
log_step=wandb.config.log_step,
val_log_step=wandb.config.val_log_step,
)
스윕 초기화 및 개인 디지털 도우미 실행
sweep_id = wandb.sweep(sweep_config, project="sweeps-tensorflow")
count 파라미터로 실행 횟수를 제한합니다. 빠른 실행을 위해 10으로 설정합니다. 필요에 따라 늘립니다.
wandb.agent(sweep_id, function=sweep_train, count=10)
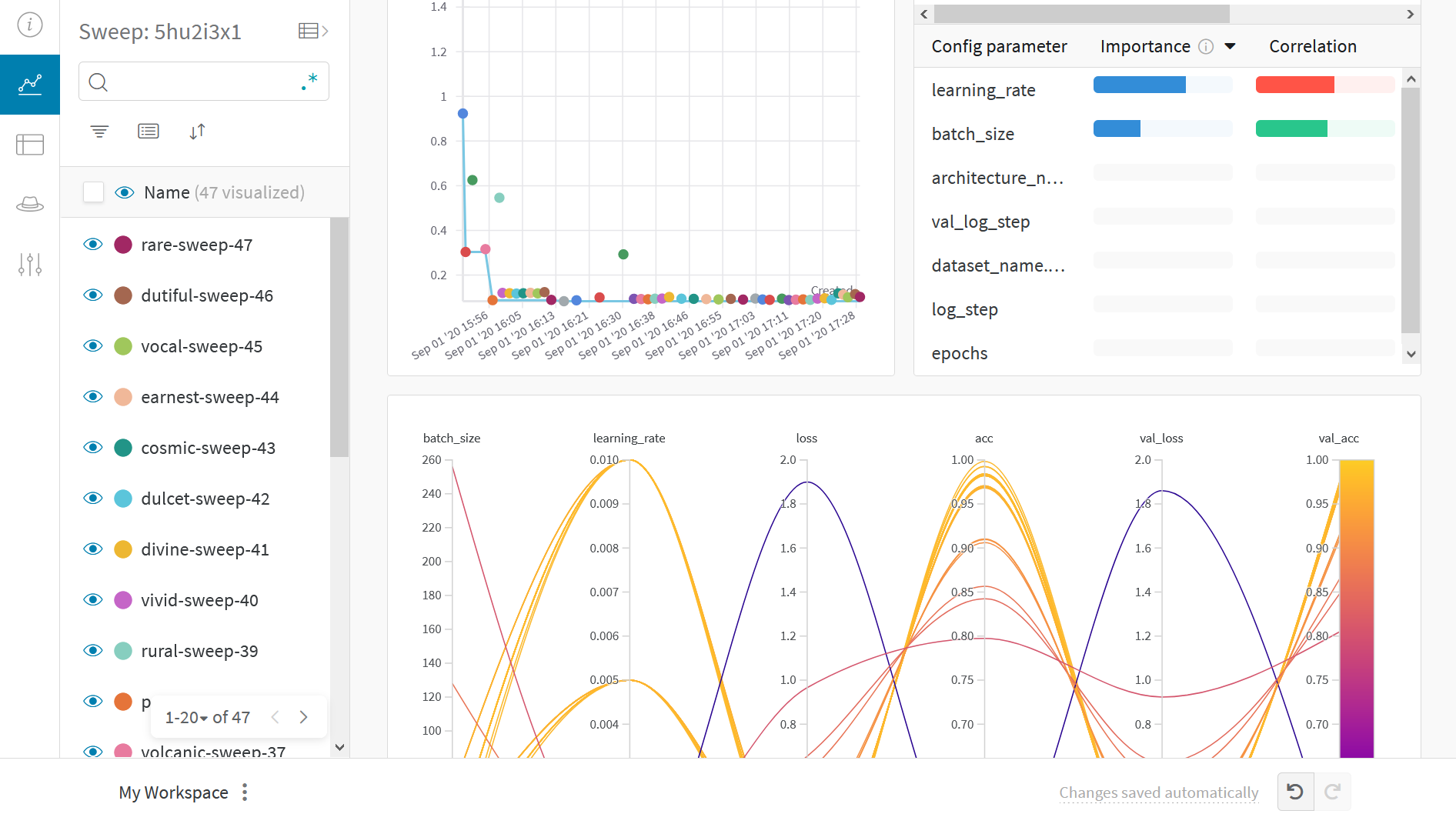
결과 시각화
라이브 결과를 보려면 앞에 나오는 Sweep URL 링크를 클릭하세요.
예제 갤러리
갤러리에서 W&B로 추적하고 시각화한 프로젝트를 탐색하세요.
모범 사례
- Projects: 여러 Runs를 프로젝트에 기록하여 비교합니다.
wandb.init(project="project-name") - Groups: 각 프로세스를 여러 프로세스 또는 교차 검증 폴드에 대한 Run으로 기록하고 그룹화합니다.
wandb.init(group='experiment-1') - Tags: 태그를 사용하여 베이스라인 또는 프로덕션 모델을 추적합니다.
- Notes: 테이블에 메모를 입력하여 Runs 간의 변경 사항을 추적합니다.
- Reports: Reports를 사용하여 진행 상황 메모, 동료와의 공유, ML 프로젝트 대시보드 및 스냅샷 생성을 수행합니다.
고급 설정
- 환경 변수: 관리형 클러스터에서 트레이닝하기 위한 API 키를 설정합니다.
- 오프라인 모드
- On-prem: 인프라의 프라이빗 클라우드 또는 에어 갭 서버에 W&B를 설치합니다. 로컬 설치는 학계 및 엔터프라이즈 팀에 적합합니다.
[i18n] feedback_title
[i18n] feedback_question
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.